
arxiv_id
stringlengths 11
13
| markdown
stringlengths 2.09k
423k
| paper_doi
stringlengths 13
47
⌀ | paper_authors
sequencelengths 1
1.37k
| paper_published_date
stringdate 2014-06-03 19:36:41
2024-08-02 10:23:00
| paper_updated_date
stringdate 2014-06-27 01:00:59
2025-04-23 08:12:32
| categories
sequencelengths 1
7
| title
stringlengths 16
236
| summary
stringlengths 57
2.54k
|
|---|---|---|---|---|---|---|---|---|
1408.0001v1 | ## The Bones of the Milky Way
Alyssa A. Goodman
Harvard-Smithsonian Center for Astrophysics, Cambridge, MA 02138
Jo˜ ao Alves
University of Vienna, 1180 Vienna, Austria
Christopher N. Beaumont Harvard-Smithsonian Center for Astrophysics, Cambridge, MA 02138
Robert A. Benjamin University of Wisconsin-Whitewater, Whitewater, WI 53190
Michelle A. Borkin Harvard University, Cambridge, MA 02138
Andreas Burkert University of Munich, Munich, Germany
Thomas M. Dame
Smithsonian Astrophysical Observatory, Cambridge, MA 02138
James Jackson Boston University, Boston, MA 02215
Jens Kauffmann California Institute of Technology, Pasadena, CA 91125
Thomas Robitaille Max Planck Institute for Astronomy, Heidelberg, Germany
Institut f¨r Theoretische Astrophysik, Zentrum f¨r Astronomie der Universi¨t Heidelberg,
Rowan J. Smith u u a Heidelberg, Germany
Received
;
accepted
To appear in The Astrophysical Journal (ApJ)
## ABSTRACT
The very long and thin infrared dark cloud 'Nessie' is even longer than had been previously claimed, and an analysis of its Galactic location suggests that it lies directly in the Milky Way's mid-plane, tracing out a highly elongated bonelike feature within the prominent Scutum-Centaurus spiral arm. Re-analysis of mid-infrared imagery from the Spitzer Space Telescope shows that this IRDC is at least 2, and possibly as many as 5 times longer than had originally been claimed by Nessie's discoverers, Jackson et al. (2010); its aspect ratio is therefore at least 300:1, and possibly as large as 800:1. A careful accounting for both the Sun's offset from the Galactic plane ( ∼ 25 pc) and the Galactic center's offset from the ( l II , b II ) = (0 0) position shows that the latitude of the true Galactic , mid-plane at the 3.1 kpc distance to the Scutum-Centaurus Arm is not b = 0, but instead closer to b = -0 4, which is the latitude of Nessie to within a few pc. . An analysis of the radial velocities of low-density (CO) and high-density (NH ) 3 gas associated with the Nessie dust feature suggests that Nessie runs along the Scutum-Centaurus Arm in position-position-velocity space, which means it likely forms a dense 'spine' of the arm in real space as well. The Scutum-Centaurus arm is the closest major spiral arm to the Sun toward the inner Galaxy, and, at the longitude of Nessie, it is almost perpendicular to our line of sight, making Nessie the easiest feature to see as a shadow elongated along the Galactic Plane from our location. Future high-resolution dust mapping and molecular line observations of the harder-to-find Galactic 'bones' should allow us to exploit the Sun's position above the plane to gain a (very foreshortened) view 'from above' of the Milky Way's structure.
## 1. Introduction
Determining the structure of the Milky Way, from our vantage point within it, is a perpetual challenge for astronomers. We know the Galaxy has spiral arms, but it remains unclear exactly how many (cf. Vall´e 2008). e Recent observations of maser proper motions give unprecedented accuracy in determining the three-dimensional position of the Galaxy's center and rotation speed (Reid et al. 2009; Brunthaler et al. 2011). But, to date, we still do not have a definitive picture of the Milky Way's three dimensional structure.
The analysis offered in this paper suggests that some Infrared Dark Clouds -in 1 particular very long, very dark, clouds-appear to delineate major features of our Galaxy as would be seen from outside of it. In particular, we study a > 3 -long cloud associated ◦ with the IRDC called 'Nessie' (Jackson et al. 2010), and we show that it appears to lie parallel to, and no more than just a few pc from, the true Galactic Plane.
Our analysis uses diverse data sets, but it hinges on combining those data sets with a modern understanding of the meaning of Galactic coordinates. When, in 1959, the IAU established the current system of Galactic ( l, b ) coordinates (Blaauw et al. 1959), the positions of the Sun with respect to the 'true' Galactic disk, and of the Galactic Center, were not as well determined as they are now. As a result, the Galactic Plane is typically not at b = 0, as projected onto the sky. The exact offset from b = 0 depends on distance, as we explain in § 3.1. Taking these offsets into account, one can profitably re-examine data relevant to the Milky Way's 3D structure. The Sun's vantage point slightly 'above' the plane of the Milky Way offers useful perspective.
'IRDCs' are loosely defined as clouds with column densities high enough to be obvious
1 The term 'Infrared Dark Cloud' or 'IRDC' typically refers to any cloud which is opaque in the mid-infrared.
as patches of significant extinction against the diffuse galactic background at mid-infrared wavelengths. Peretto & Fuller (2009) set the boundaries of IRDCs at an optical depth of 0.35 at 8 µ m wavelength, equivalent to an H 2 column density ≈ 10 22 cm -2 . In the Peretto & Fuller (2010) sample, clouds have average column densities of a few 10 22 cm -2 . Some IRDCs actively form high-mass stars (e.g., Pillai et al. 2006 and Rathborne et al. 2007). Kauffmann & Pillai (2010) explain that while some 'starless' IRDCs are potential sites of future high-mass star formation, and the few hundred densest and the most massive, IRDCs may very well contain a large fraction of the star-forming gas in the Milky Way, it is still true that most IRDCs are not massive and dense enough to form high-mass stars. Thus, a small number of very dense and massive IRDCs may be responsible for a large fraction of the galactic star formation rate, and an extragalactic observer of the Milky Way might 'see' IRDCs not unlike Nessie hosting young massive stars as the predominant mode of star formation here.
The traditional ISM-based probes of the Milky Way's structure have been HI and CO. Emission in these tracers gives line intensity as a function of velocity, so the positionposition-velocity data resulting from HI and CO observations can give three dimensional views of the Galaxy, if a rotation curve is used to translate line-of-sight velocity into a distance. Unfortunately, though, the Galaxy is filled with HI and CO, so it is very hard to disentangle features when they overlap in velocity along the line of sight. Nonetheless, much of the basic understanding of the Milky Way's spiral structure we have now comes from HI and CO observations of the Galaxy, much of it from the compilation of CO data presented by Dame et al. (2001).
Recently, several groups have targeted high-mass star-forming regions in the plane of the Milky Way for high-resolution observation. In their BeSSeL Survey, Reid et al. are using hundreds of hours of VLBA time to observe hundreds of regions for maser emission,
which can give both distance and kinematic information for very high-density ( n > 10 8 cm -3 ) gas (Reid et al. 2009; Brunthaler et al. 2011). In the HOPS Survey, hundreds of positions associated with the dense peaks of infrared dark clouds have now been surveyed for NH emission (Purcell et al. 2012), yielding high-spectral resolution velocity measurements 3 towards gas whose density typically exceeds 10 4 cm -3 . In follow-up spectral-line surveys to the ATLASGAL (Beuther et al. 2012) dust-based survey of the Galactic Plane, Wienen et al. (2012) have measured NH 3 emission in nearly 1000 locations. The ThrUMMs Survey aims to map the entire fourth quadrant of the Milky Way in CO and higher-density tracers (Barnes et al. 2010), and it should yield additional high-resolution velocity measurements.
Targets in high-resolution (e.g. BeSSeL) studies are usually identified based on continuum surveys, which show the locations of the highest column-density regions, either as extinction features ('dark clouds' in the optical, 'IRDCs' in the infrared), as dust emission features (in surveys of the thermal infrared), or as gas emission features (e.g. HII regions).
Great power lies in the careful combination of continuum and spectral-line data when one wants to understand the structure of the ISM in three-dimensions. Thus, there have already been several efforts to combine dust maps with spectral-line data, whose goal is often the assignment of more accurate distances to particular clouds or regions (e.g. Foster et al. 2012). These improved distances allow for more reliable conversion of measured quantities (e.g. fluxes) to physical ones (e.g. mass).
In this study, our aim is to combine morphological information from large-scale mid-infrared continuum 'dust' maps of the Galactic Plane with spectral-line data, so as to understand the nature of very long infrared dark clouds that appear parallel to the Galactic Plane. We focus in particular on the IRDC named 'Nessie' in the study presented by Jackson et al. (2010). In that 2010 paper, Nessie is shown to be a highly elongated
filamentary cloud (see Figure 1) exhibiting the after-effects of a sausage instability that led to several massive-star-forming peaks spaced at regular intervals. We extend the work of Jackson et al. by first by literally 'extending' the cloud, to a length of at least 3 degrees ( § 2). In § 3, we show that a careful accounting for the modern measures of the Sun's height off of the Galactic mid-plane and of the true position of the Galactic Center imply that Nessie lies not just parallel to the Galactic Plane, but in the Galactic Plane. We consider what velocity-resolved measures of the material associated with Nessie tell us about its three-dimensional position in the Galaxy, and we conclude, in § 4.1 that Nessie likely marks the 'spine' of the Scutum-Centaurus arm of the Milky Way in which it lies. In § 4.2, we consider the likelihood of finding more 'Nessie-like' structures in the future, and of using them, in conjunction with the Sun's vantage point just above the mid-plane of the Milky Way, to map out the skeleton of our Galaxy.
## 2. Nessie is Longer than We Thought
Nessie was discovered and named using Spitzer Space Telescope images that show the cloud as a very clear absorption feature at mid-infrared wavelengths Jackson et al. (2010). Using observations of the dense-gas tracer HNC, Jackson et al. (2010) further show that the section of the cloud from l =337.85 to 339.1 (labelled 'Nessie Classic' in Figure 1) exhibits very similar line-of-sight velocities, ranging over -40 < v LSR < -36 km s -1 . The similarities of these line-of-sight velocities (cf. Figure 7) is taken to mean that the cloud is a coherent, long structure, and not a chance plane-of-the-sky projection of disconnected features. Thus, 'Nessie Classic' is shown to be a dense, long ( ∼ 1 ), narrow ( ◦ ∼ 0 01 ), . ◦ filament, and Jackson et al. (2010) ultimately conclude that it is undergoing a sausage instability leading to density peaks hosting active sites of massive star formation.
Our purpose in looking at Nessie again here is not to further analyze the star-forming
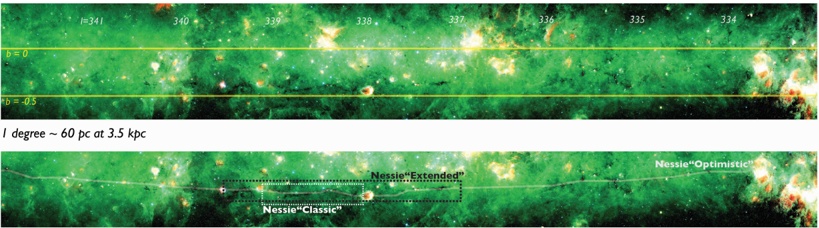
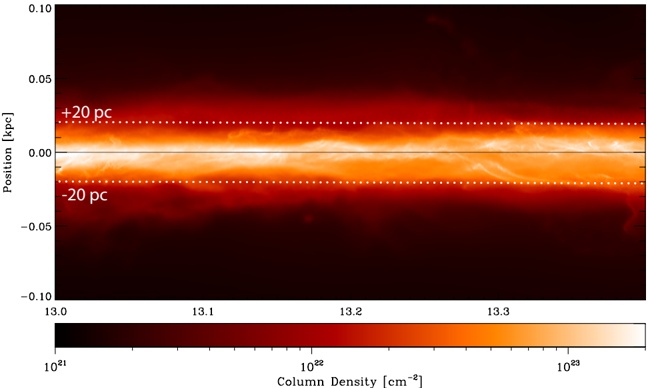
Fig. 1.Nessie 'Classic,' 'Extended,' and 'Optimistic.' It is recommended that this high resolution figure be viewed electronically, as zooming and panning are necessary to reveal the structures discussed. Background imagery is a three-color image constructed from Spitzer where red shows MIPS 24 µ m, green IRAC 8.0 µ m, and blue IRAC 5.8 µ m. Image (brightness/contrast) adjustment used emphasizes Nessie and also makes the image look a bit greener than is 'natural.' Yellow horizontal lines show b = 0 ◦ and b = -0 5 . . ◦ Small white numbers show galactic longitude ( ) in degrees. l Full size version of this figure is available at this link (submit to Journal). A non-annotated high-dynamic-range view of this Spitzer image is available as a supplement to this paper at http://hdl.handle.net/1902.1/22050. (Note that related figures below show less exaggerated contrast, and zoom in on the central portions of Nessie.)
nature of this cloud. Instead, our focus is on how long the full Nessie feature might be, and on what that length combined with Nessie's special position in the Galaxy imply about how similar structures can be used to chart the structure of the Galaxy. Casual inspection of Spitzer imagery given in Figure 1 suggests that Nessie is at least two or three times longer than 'Nessie Classic,' measuring at least 3 ◦ long ('Nessie-Extended'). Very careful inspection (pan and zoom Figure 1) of the Spitzer images suggests that Nessie could be even longer. If one optimistically connects what appear to be all the relevant pieces then 'Nessie Optimistic' could be as much as 8 ◦ long (light white chalk line in Figure 1). The optimism
involved in seeing the longest extent for Nessie could be warranted if bright star-forming regions have broken up the continuous extinction feature, and/or if the background emission fluctuates enough to make the extinction hard to detect.
Determining the physical, three-dimensional, nature of extensions to the Nessie cloud requires a detailed analysis of the velocity of the gas associated with the dust responsible for mid-IR extinction. We offer such an analysis below ( § 3), but here we note that if Nessie (as is nearly certain given its velocity range) lies in or near the Scutum-Centaurus Arm of the Milky Way, then its distance is roughly 3.1 kpc (cf. Jackson et al. 2010). At that distance, Nessie Classic is roughly 80 pc long, Nessie Extended is 160 pc long, and Nessie Optimistic is 430 pc long. For any of these lengths, the dark filament's width is of order 0.01 degrees (0.5 pc), according to Jackson et al.'s (2010) analysis of the Spitzer imagery. Thus, clouds's axial ratio is about 150 for Nessie Classic, 300 for Nessie Extended, and nearly three times more, 800, for Nessie Optimistic. (These calculations are based on Table 1 a publicly-available interactive spreadsheet, at this link, a snapshot of which is shown as Figure 2.)
## 3. The Three-Dimensional Position of Nessie within the Milky Way
## 3.1. Looking 'Down' on the Galaxy
Astronomers would love to leave the Milky Way, so that we could observe its spiral pattern face-on, as we do for other galaxies. But our Sun is so entrenched in the Milky Way's plane that an 'overhead view' of the Milky Way's structure is impossible. Or is it? What if the Sun were just far enough above the Galactic Plane that we could use its height to give ourselves a tiny bit of perspective on the Galactic Plane that would spatially separate long skinny in-plane features located at different distances to be at different
7DEOHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=29,font=/NEXZBU+Georgia>glyph<c=3,font=/NEXZBU+Georgia>(VWLPDWHVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=10,font=/NEXZBU+Georgia>Vglyph<c=3,font=/NEXZBU+Georgia>'HQVLW\glyph<c=3,font=/NEXZBU+Georgia>DQGglyph<c=3,font=/NEXZBU+Georgia>0DVV
| $VVXPSWLRQVglyph<c=29,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | %DU\RQLFglyph<c=3,font=/NEXZBU+Georgia>PDVVglyph<c=3,font=/NEXZBU+Georgia>RIglyph<c=3,font=/NEXZBU+Georgia>0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\glyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>0VXQVglyph<c=12,font=/NEXZBU+Georgia> 'LVWDQFHglyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>glyph<c=11,font=/NEXZBU+Georgia>SFglyph<c=12,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> glyph<c=22,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
|---------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1LFNQDPH | /HQJWK GHJ | 5DGLXV GHJ | /HQJWK SF | 5DGLXV SF | $YHUDJH GHQVLW\ FPAglyph<c=16,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | +glyph<c=21,font=/NEXZBU+Georgia>glyph<c=3,font=/NEXZBU+Georgia>FROXPQ GHQVLW\ FPAglyph<c=16,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | (TXLYglyph<c=17,font=/NEXZBU+Georgia> $Y PDJ | 0DVV 0VXQV | 0DVVglyph<c=3,font=/NEXZBU+Georgia>SHU XQLW OHQJWK 0VXQVglyph<c=18,font=/NEXZBU+Georgia>SF | glyph<c=6,font=/NEXZBU+Georgia>glyph<c=3,font=/NEXZBU+Georgia>WRglyph<c=3,font=/NEXZBU+Georgia>HTXDO PDVVglyph<c=3,font=/NEXZBU+Georgia>RI 0LON\glyph<c=3,font=/NEXZBU+Georgia>:D\ | DVSHFW UDWLR |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>&ODVVLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>([WHQGHGglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>2SWLPLVWLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=15,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>&ODVVLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=26,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>([WHQGHGglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=26,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=20,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=25,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
| glyph<c=5,font=/NEXZBU+Georgia>1HVVLHglyph<c=3,font=/NEXZBU+Georgia>2SWLPLVWLFglyph<c=5,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia> | glyph<c=19,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>glyph<c=22,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=21,font=/NEXZBU+Georgia>glyph<c=17,font=/NEXZBU+Georgia>glyph<c=26,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=21,font=/NEXZBU+Georgia>glyph<c=20,font=/NEXZBU+Georgia> | glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=22,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=25,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia>glyph<c=23,font=/NEXZBU+Georgia> | glyph<c=24,font=/NEXZBU+Georgia>(glyph<c=14,font=/NEXZBU+Georgia>glyph<c=24,font=/NEXZBU+Georgia> | glyph<c=27,font=/NEXZBU+Georgia>glyph<c=19,font=/NEXZBU+Georgia> |
Fig. 2.- Estimates for the density and mass of Nessie, under various assumptions about its length. The top set of values shows estimates for a cylinder with radius, length, and average density appropriate to the Spitzer 'shadow' shown in Figure 1. The average density is set to 10 5 cm -3 so as to achieve a visual extinction of ∼ 100 magnitudes, consistent with the typical extinction on tenths of pc scales in an IRDC. The lower set of values is different only in that a density of 500 cm -3 is used, as an estimate of the typical density of the region seen to emit in HNC by Jackson et al. 2010. Readers can test alternative assumptions for the calculations shown here in the interactive version of this table at http://tinyurl.com/nessietable.
projected latitudes? Turns out we are lucky in this way-the Sun is apparently located a bit above the Plane (see below), and we can use that vantage point to out advantage.
To understand why most modern astronomers do not typically think about the possibility or value of an overhead view, we need to consider the origin of our current Galactic coordinate system, and our current understanding of the Sun's and the Galactic Center's 3D positions. Writing in 1959 on behalf of the International Astronomical Union's (IAU's) sub-commission 33b, Blaauw et al. wrote:
The equatorial plane of the new co-ordinate system must of necessity pass through the sun. It is a fortunate circumstance that, within the observational uncertainty, both the sun and Sagittarius A lie in the mean plane of the Galaxy as determined from hydrogen observations. If the sun had not been so placed, points in the mean plane would not lie on the galactic equator.
In a further explanation of the IAU system in 1960, Blaauw et al. explain that stellar observations did, at that time, indicate the Sun to be at z Sun = 22 ± 2 (22 pc above the plane), but the authors then discount those observations as too dangerously affected by hard-to-correct-for extinction in and near the Galactic Plane (Blaauw et al. 1960). Instead, the 1959 IAU system relies on the 1950s measurements of HI, which showed the Sun to be at z Sun = 4 ± 12 pc off the Plane, consistent with the Sun being directly in the Plane ( z Sun = 0). Interestingly, since the 1950s, the Milky Way's HI layer has been shown to have corrugations on the scale of 10's of pc (Malhotra 1995), and there may be similar fluctuations in the mid-plane of the H 2 (Malhotra 1994), so it is still tricky to use gas measurements to determine the Sun's height off the plane. Although the Sun's ( ∼ 25 pc) offset from the Galactic plane is not large in comparison with the half-thickness of the plane as traced by Population I objects such as GMCs and HII regions ( ∼ 200 pc; Rix & Bovy (2013)), it is much larger than the thickness of an extremely thin gas layer that may, as we argue in § 4.1, be traced out by Nessie-like 'bones' of the Milky Way.
Astronomers today are still using the ( l II , b II ) Galactic coordinate system defined by Blaauw et al. (1959), but it is not still the case, within observational uncertainty, that the Sun is in the mean plane of the Galaxy, and the true position of the Galactic Center is no longer at ( l II = 0 , b II = 0). Instead, a variety of lines of evidence (Chen et al. 2001; Ma´ ız-Apell´niz 2001; Juri´ et al. 2008) show that the Sun is approximately 25 pc above the a c stellar Galactic mid-plane, and VLBA proper motion observations of masers show that the
Galactic Center is about 7 pc below where the ( l II , b II ) system would put it, at b = -0 046 . ◦ (Reid & Brunthaler 2004). After analysis of the spatial distribution of dense gas revealed in the ATLASGAL survey showed a mean at negative latitude, Beuther et al. (2012) noted that their observations are indicative of a real global offset of the Galactic mid-plane from its conventional position where the axis between the Sun and the Galactic center is located at b = 0 deg.
The offsets of the Sun and the Galactic Center from their IAU ' b = 0' positions, as anticipated by Blaauw et al., imply that 'points in the mean plane [do] not lie on the galactic equator.'
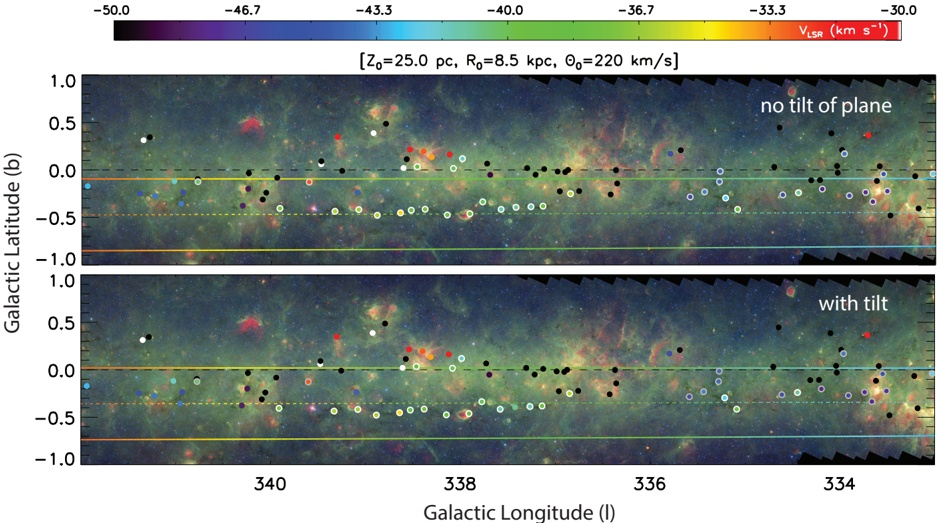
Figure 3 shows a schematic (not-to-scale) diagram of the effect of the Sun's and the Galactic Center's offsets from the mid-plane defined by the IAU in 1959 (and still in use as ( l II , b II ) today). The tilt of the the true, physical, Galactic mid-plane to the presently IAU-defined plane means that, within about 12 kpc of Sun 2 any feature that is truly 'in' the Galactic mid-plane will appear on the Sky at negative b II . Figure 5 shows an example of this effect, where the rainbow-colored dashed line indicates the sky position of the physical Galactic mid-plane at a Nessie-like distance of 3.1 kpc (assuming the the Sun is 25 pc off the plane, a distance to Sgr A** of 8.5 kpc, a rotation speed for the Milky Way of 220 km s -1 , and (U,V,W) motion for the Sun of 11.1, 12.4, and 7.2 km s -1 , respectively).
2 12 kpc is the approximate distance where the physical and IAU planes cross, on a line toward the Galactic Center. Along other directions toward the Inner Galaxy, as shown in the lower panel of Figure 4, it will be further to the crossing point, and toward the Outer Galaxy, for a 'flat' disk, the mid-plane will always appear at negative latitudes.
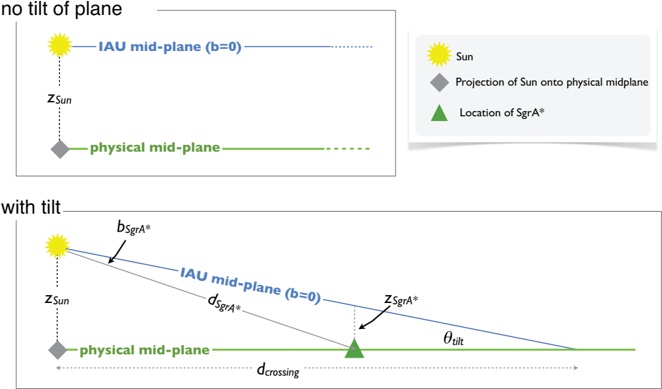
Fig. 3.- . Schematic side-views of the of the physical mid-plane of the Galaxy with respect to the IAU-defined mid-plane. The drawings are not to scale . In both panels, z Sun represents the height of the Sun above the Galactic mid-plane. In the upper panel , and in figures labeled 'no tilt of plane' below, we consider only the Sun's offset from the plane in calculating the observed coordinates of the true 'physical' mid-plane. In the lower panel , and in figures labeled 'with tilt' below, we also take the offset, z SgrA ∗ , of the Galactic Center (Sgr A*) into account. For reference, if the distance to SgrA*, d SgrA ∗ , is 8.5 kpc and z Sun =25 pc and z SgrA ∗ = 7 pc (based on b = -0 046 . ◦ for SgrA*) then the angle by which the IAU mid-plane is tilted with respect to the physical plane is θ tilt = 0 12 . ◦ and the distance from the Sun to where the two planes cross is d crossing = 12 kpc.
## 3.2. Using Rotation Curves and Velocity Measurements to Place Nessie in 3D
Ever since velocity-resolved observations of stars and gas have been possible, astronomers have been modeling the rotation pattern of the Milky Way. Using a measured rotation curve for the Milky Way's gas (e.g. McClureGriffiths & Dickey 2007), one can translate observed LSR velocities to a unique distance in the Outer Galaxy, and to one of two possible ('Near' or 'Far') distances toward the Inner Galaxy. Figure 4 shows isov LSR contours toward the Inner Galaxy, around the longitude range of Nessie, superimposed on the data-driven cartoon of our current understanding of the Milky Way's structure. Notice that velocities associated with the near-side of the Scutum-Centaurus Arm in Nessie's longitude range should be near 40 km s -1 .
Combining a modern estimate for the Sun's height above the plane ( z Sun ∼ 25 pc), with the IAU Galactic coordinate definitions, we can determine where the physical mid-Plane of the Galaxy should appear in the ( l II , b II ) system at any particular distance from the Sun. Figure 5 shows where the Scutum-Centaurus Arm would appear on the Sky (for a distance to Sgr A** of 8.5 kpc, a rotation speed for the Milky Way of 220 km s -1 , and (U,V,W) motion for the Sun of 11.1, 12.4, and 7.2 km s -1 , respectively). As its caption explains in detail, Figure 5's colored lines are associated with the near part of the Scutum-Centaurus Arm. Two versions of this plane-of-the-Sky view are shown, one only accounting for the offset of the Sun, and the other also accounting for the tilt of the coordinate system caused by the Galactic Center also not lying in the IAU plane (see Figure 3).
The dashed colored lines in Figure 5, indicating the predicted position of the Galactic Plane on the Sky at the distance to the near side of the Scutum-Centaurus Arm, pass almost directly through Nessie, regardless of whether or not one considers the 'tilt' of the coordinate system caused by SgrA*'s offset. Solid colored lines show 20 pc above and below the Plane at the distance to the Scutum-Centaurus Arm, so Figure 5 makes it is very clear
that Nessie lies within just a few pc of the Plane, along its entire length. This is either an extremely fortuitous coincidence, or an indication that Nessie is tracing a significant feature that effectively marks the mean location of the Galactic Plane. Given the waviness of the plane on 10 pc scales (see above, (Malhotra 1994)), the location at even less than 10 pc from the mean plane may be fortuitous-but the location so close to the mean is not.
## 3.2.1. CO Velocities
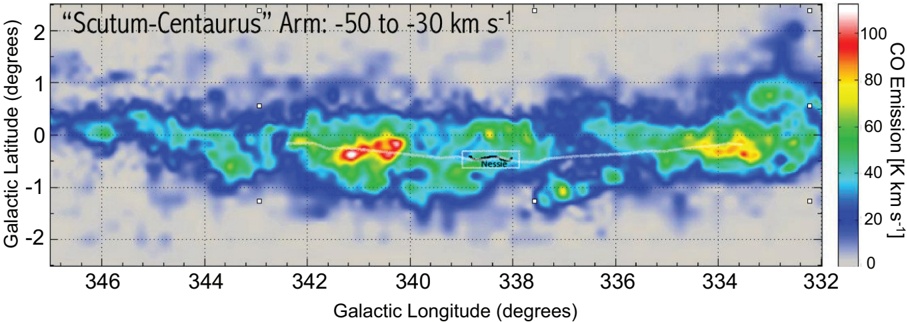
CO observations trace gas with mean density around 100 cm -3 . CO emission associated with the Scutum-Centaurus Arm of the Milky Way (Dame et al. 2001; Dame & Thaddeus 2011) is shown in Figure 6, which presents a plane-of-the-sky map integrated over -50 < v LSR < -30 km s -1 . The velocity range is centered on -40 km s -1 , the average velocity of the Scutum-Centaurus Arm in Nessie's longitude range (see Figures 4 and 5). The white chalk line superimposed on Figure 6 is the same tracing of 'Nessie Optimistic' shown in Figure 1. The black feature labeled 'Nessie' refers to 'Nessie Classic.'
Judging by-eye, the vertical (latitude) centroid of the CO emission in Figure 6 appears to follow Nessie remarkably well, even out to the full 8 ◦ (430 pc) extent of Nessie Optimistic. We have also calculated a curve representing the locus of latitude centroids for CO in this velocity range, and even at this coarse resolution, a curve following Nessie's shape is clearly a better fit than a straight line passing through the CO centroids.
Table 1 estimates that the Nessie IRDC has a typical H 2 column density of ∼ 10 23 cm -2 and a typical volume density of ∼ 10 5 cm -3 . Thus, the plane-of-the-sky coincidence of the line-of-sight-velocity-selected 'Scutum-Centaurus' CO emission and the mid-IR extinction suggests that the Nessie IRDC may be a kind of dense 'spine' or 'bone' of this section of the Scutum-Centaurus Arm, as traced by much-less-dense ( ∼ 100 cm -3 ) CO-traced gas.
no tilt of plane
Galactic Center
Scutum Centaurus Arm l=340 deg
330 deg
-50
-40
-30 km/s
-0.4 deg
-0.3 deg
Sun
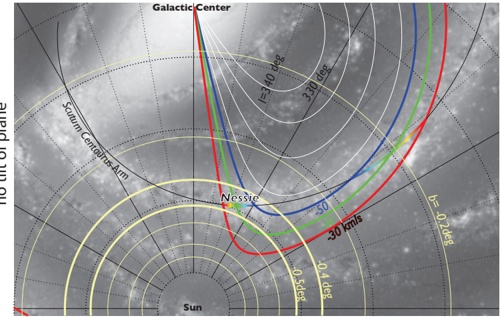
Fig. 4.For the fourth quadrant of the Milky Way, contours of constant LSR velocity of -30,-40,and-50 km s -1 (using a rotation curve from McClureGriffiths & Dickey 2007, ) are superimposed on a cartoon model of the Milky Way. CO and dense gas observations (see below) give LSR velocities associated with Nessie (shown here as rainbow curve) near -40 km -1 , placing Nessie in the Scutum-Centaurus arm (highlighted in black), about 3.1 kpc from the Sun. Yellow-highlighted curves show positions in the Galaxy that would have the labeled value of Galactic Latitude ( b ) when viewed from the Sun. In the top panel , only the height of the Sun off the plane (taken to be 25 pc in this example) is considered in drawing the iso-b curves, and in the bottom panel , a 7 pc offset of the Galactic Center (see text), which causes an overall tilt of 0 12 . ◦ is also taken into account.
with tilt
Nessie b=-0.1 deg
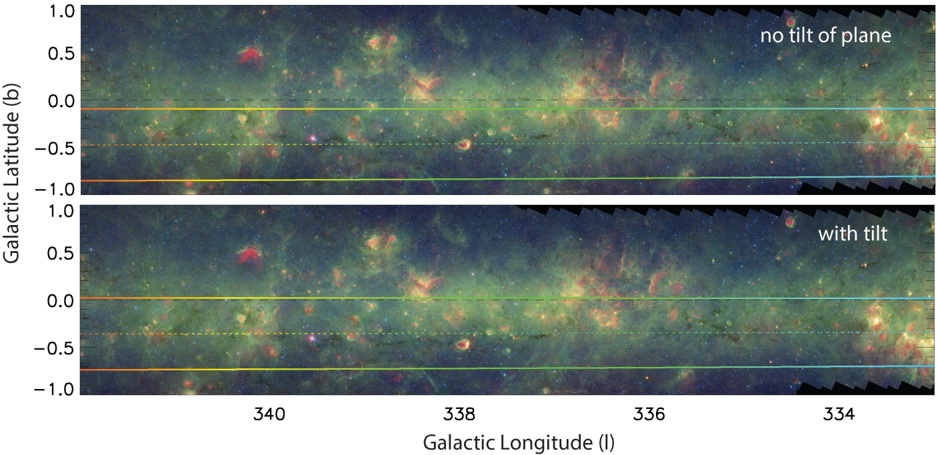
Fig. 5.- . Predicted Sky Position and Radial Velocities for the Scutum-Centaurus Arm of the Milky Way. In both panels, the colored lines are color-coded by velocity, given in the color bar at the top. The colored dashed line shows the predicted position for the Galactic Plane for the near side of the Scutum-Centaurus Arm (roughly 3.1 kpc from the Sun). The solid colored lines show ± 20 pc from the mid-Plane at the same ( ∼ 3 1 kpc) distance. . These lines and colors are calculated using a model of a (flat) Milky Way described by the parameters shown below the color bar. Background imagery is from Spitzer, as in Figure 1. A black dashed line emphasizes the position of b = 0. As in Figure 4: in the top panel , only a 25 pc offset of the Sun above is taken into account; and in the bottom panel , a 7 pc offset for the Galactic Center is also used in the calculation.
But, the spatial resolution of the CO map is too low (8 ), and the 20 km s ′ -1 velocity range associated with the Arm in CO is too broad to decide based on this evidence alone whether Nessie is a well-centered 'spine' or just a long skinny feature associated with, but
potentially significantly inclined to, the Scutum-Centaurus Arm.
Fig. 6.CO emission, integrated between -50 and -30 km s -1 , as projected on the sky, based on data from (Dame et al. 2001), with trace of Nessie Optimistic (light white line) from Figure 1 superimposed. The dark black squiggle labeled 'Nessie' (surrounded by a light white box) marks the position of Nessie Classic.
## 3.2.2. NH 3 Velocities
To estimate the 3D orientation of Nessie more precisely, we need to employ a gas tracer whose emission is sparser than CO's, and more associated with high-density gas, in position-position-velocity space. Many recent studies have shown that IRDCs typically host over-dense blobs of gas (often called 'clumps' or 'cores') that provide the gaseous reservoirs for the formation of massive stars. Thus, several studies have been undertaken to survey IRDCs and their ilk for emission in molecular lines that trace high-density ( glyph[greatermuch] 10 3 cm -3 ), potentially star-forming, gas.
The H O Southern Galactic Plane (HOPS) Survey (Purcell et al. 2012) has surveyed 2
hundreds of sites of massive star formation visible from the Southern Hemisphere for NH 3 emission, which traces gas at densities n glyph[greaterorsimilar] 10 4 cm -3 . The HOPS targets were selected based on H O maser emission, thermal molecular emission, and radio recombination lines, 2 so as to include nearly all known regions of massive star formation within the surveyed area. These 'massive-star-forming region' selection criteria mean that the HOPS database includes NH 3 spectra for dozens of positions within the longitude range covered by Nessie.
Figure 7 adds an overlay of HOPS sources' NH -determined LSR velocities to the 3 information presented in Figure 5, which illustrates how well Nessie fits the prediction of where the Scutum-Centaurus' arm's center would be in position-position-velocity space. The (color-coded) velocities of the HOPS sources, for both Nessie Classic, and Nessie Extended (see Figure 1), agree remarkably well with what is predicted for the Scutum-Centaurus Arm (color-coded lines). Note that agreement of the NH 3 and predicted velocity to better than 5 km s -1 is indicated by grey circles around the HOPS symbol. White circles, indicating agreement to within 2.5 km s -1 , surround all of the Nessie Extended sources, which are also shown in Figure 8, below. Most of the HOPS sources coincident with Nessie Optimistic, especially at the lower longitudes, also appear likely to be associated with the Scutum-Centaurus arm, based on their agreement with arm velocities to within 5 km s -1 , as indicated by grey circles. The velocities of sources at latitudes much different from Nessie's within this longitude range largely do not agree, and those sources are unlikely to be associated with the near-side of the Scutum-Centaurus Arm. For reference, the typical velocity dispersion within molecular gas (with density ∼ 50 cm -3 ) is about 5 km s -1 (Larson 1981), so any white or grey outlined point in Figure 7 is plausibly associated with a structure whose systemic velocity is typical of the near side of the Scutum-Centaurus Arm.
For Nessie Classic, Jackson et al. (2010) had already noted a very narrow velocity range for dense gas associated with the IRDC, based on HNC observations. What is new here
is the three-dimensional (latitude, longitude, and velocity) association of a longer Nessie's dense gas with predictions for where the centroid of the Milky Way's Scutum-Centaurus Arm's 'middle' would lie.
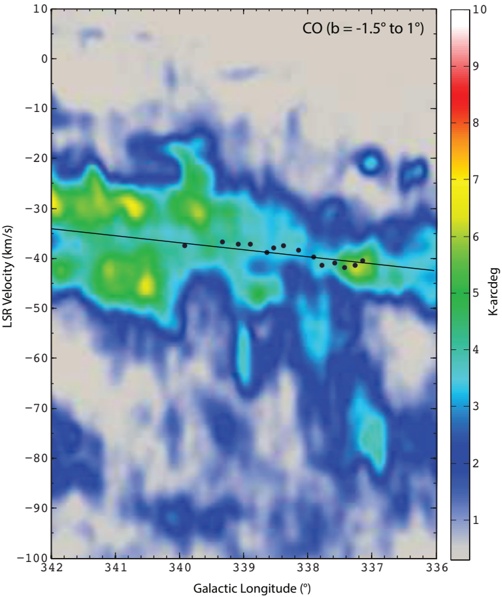
Figure 8, which offers a position-velocity diagram of CO (color) and NH 3 emission (black dots) together, shows the association of the Nessie-HOPS sources with the Scutum Centaurus Arm most clearly. What is most remarkable about Figure 8 is that the black line sloping through the figure is not a fit to the black dots representing the HOPS sources. Instead, that line indicates the position-velocity trace of the Scutum-Centaurus Arm based on (Dame & Thaddeus 2011) data for the full Galaxy, not just this small longitude range. Figure 8 implies that Nessie goes right down the 'spine' of the Scutum-Centaurus Arm, as best we can measure its position in CO position-velocity space.
## 4. What is the Significance of Nessie-like structures within a Spiral Galaxy?
## 4.1. A Bone of the Galaxy
All the evidence presented in this paper, taken together, strongly suggests that Nessie forms a bone-like feature that closely follows the center of the Scutum-Centaurus Arm of the Milky Way. How did it get there? Is it the crest of a classic spiral density wave (Lin & Shu 1964), or does it have some other cause? One would na¨ ıevely expect that any feature this long and skinny that is not controlled by Galactic-scale forces will be subject to a variety of instabilities, and would not last long.
Until very recently, no numerical simulation of gas in a Milky Way-like galaxy had sufficient resolution to reveal features as thin as Nessie. As of 2013, state-of-the-art simulations by Dobbs & Pringle (2013) showed many elongated features along and between
Fig. 7.Superposition of HOPS Sources, color-coded by NH -determined LSR velocity. 3 Colored lines have the same meaning (predicted LSR velocity) as in Figure 5, so the colorful dashed lines at b ∼ -0 5 , . ◦ in both panels, represent the physical Galactic mid-plane, and the solid colorful lines indicate 20 pc above and below the plane. Agreement of the NH 3 and predicted LSR velocity (color) to within 2.5 km s -1 is indicated by a white circle around the HOPS symbol, and grey circles indicate agreement to within 5 km s -1 . As in Figures 4 and 5: in the top panel , only a 25 pc offset of the Sun above is taken into account; and in the bottom panel , a 7 pc offset for the Galactic Center is also used in the calculations.
arms, 3 but the thickness of the features was ∼ 10 pc, an order of magnitude too coarse.
Figures 9 and 10 offer top-down and edge-on snapshots of a brand-new numerical simulation of the gas in a Milky Way-like spiral galaxy from Smith et al. (2014), and this
3 Simulation video online at http://empslocal.ex.ac.uk/people/staff/cld214/movies.htm.
Global Sct-Cen fi
t (Dame & Thaddeus 2011)
HOPS sources ('Nessie Extended')
Fig. 8.- Position-velocity diagram of CO and NH . Colored background shows CO emission 3 integrated over -1 5 . < b < 1 . ◦ Black dots show HOPS sources coincident with Nessie Extended, also shown in Figure 7 as white-circle-highlighted colored points. The dots are plotted at the longitudes given in Figure 7, and the LSR velocities given by the centroid of the NH 3 emission for each HOPS source. The black line shown is not a fit to the HOPS or the CO data shown: it is a segment of a global log-spiral fit to CO data for the entire Scutum-Centaurus Arm, extending almost 360 ◦ around the Galaxy (taken from Fig. 4 of Dame & Thaddeus (2011).
simulation is the first to offer resolution high enough to see potentially Nessie-like features. The AREPO moving mesh code used in these new simulations provides resolution ∼ 0 3 . pc resolution in regions where the gas density n > 10 3 cm -3 , and slightly better in the highest-density cells. The high-resolution views of the simulation in the inset in Figure 9 and in Figure 10 exhibit many spatial features that are as long and thin as Nessie. The overlain lines in Figure 10 additionally show that the Nessie-like high-contrast filamentary structures like centered in the 'Galactic Plane' of the simulation, and that they have vertical extent not unlike Nessie (cf. Figure 5). So as not to over-emphasize the apparently remarkable agreement of the Smith et al. (2014) simulations and Nessie-like structure, we should point out that the simulations do not include the results of feedback from stars and HII Regions, nor do they include magnetic fields. Including these effects in future simulations will likely cause disruption of some filaments, and changes in topology and/or filament orientation where magnetic energy is significant. For reference, the half-thickness of the Milky Way's plane as traced by Population I objects such as GMCs and HII regions is estimated to be ∼ 200 pc (Rix & Bovy 2013), which is the starting thickness of the evolving torus in the Smith et al. (2014) simulation. For now, we offer these simulations as the first evidence that gas in a spiral galaxy is very likely to contain very high-contrast, extraordinarily long and thin, filamentary structure marking out what we call the galaxy's 'skeleton.'
Many of the features that appear to be trailing off from the major spiral arms apparent in Figure 9 are similar to the 'spurs' and 'feathers' that have been previously simulated and observed by E. Ostriker and colleagues (Shetty & Ostriker 2006; La Vigne et al. 2008; Corder et al. 2008) and seen in the simulations of Dobbs & Pringle (2013). Figure 11 shows a recent infrared (WISE) image of the galaxy IC342 (Jarrett et al. 2013), and it is clear from that image that some 'spiral' galaxies also exhibit inter-arm filaments that are even more pronounced than the simulated spurs and feathers. Thus, both simulations and
observations show long, filamentary, structures within, and between arms.
The highest-resolution simulations (Smith et al. 2014) suggest that the highest-contrast filaments tend to largely be found in the plane of a spiral galaxy (Figure 10) associated with arms, rather than inter-arm regions (Figure 9). But, high-density contrast alone does not imply that a filament lies along a spiral arm rather than between arms. The existence of many dense cores within Nessie (see § 3.2.2) implies an over-density of at least 10 3 (comparing NH 3 gas and CO-emitting gas) at many positions along the filament. Similar over-densities, and strings of dense cores, are seen in many IRDCs. Battersby & Bally (2014) identified G32.02+0.06 as a sinuous, long, thin, 80-pc long 'Massive Molecular Filament' near (but not quite in) the Galactic plane, and in very recent work, Ragan et al. (2014) added seven more 'Giant Molecular Filaments' almost as long and thin as Nessie to the list of very long-thin ∼ 10 5 M glyph[circledot] filamentary IRDCs known in the Milky Way.
In using observations to judge whether a specific highly-elongated filamentary cloud lies along (within) an arm, or is highly inclined to an arm, the velocity of the associated gas offers the most relevant evidence. In the case of Nessie, the analysis of the HOPS NH 3 data presented in § 3.2.2, showing agreement with spiral arm line-of-sight velocities, and its location at what is predicted to be the vertical center of the Scutum-Centaurus arm, argues very strongly that Nessie is, three-dimensionally, a spine-like 'bone' of the Scutum-Centaurus Arm.
Estimates for the mass of Nessie under various assumptions are given in Table 1. Jackson et al. 2010 model Nessie as a(n unmagnetized) self-gravitating fluid cylinder supported against collapse by a 'turbulent' analog of thermal pressure, undergoing the sausage instability discussed in Chandrasekhar & Fermi (1953). For the observed line width of HNC, the theoretical critical mass per unit length, m l , is 525 M glyph[circledot] pc -1 for Nessie. But, if, as Jackson et al. explain, one estimates m l using HNC emission itself and (uncertain)
abundance values for HNC, then 110 < m < l 5 × 10 4 M glyph[circledot] pc -1 . Given that the low end of this range (110 M glyph[circledot] pc -1 , favored by Jackson et al.) gives a very low value for extinction toward Nessie ( A V ∼ 4 mag), we favor higher values of m l , needed to be consistent with the observed IR extinction. Recent LABOCA observations of dust continuum emission from pieces of Nessie (Kauffmann, private communication), suggest that m l glyph[greaterorsimilar] 10 3 in the mid-IR-opaque portions of Nessie. So, at present, it would appear that there is at least an order-of-magnitude uncertainty in m l . Some of this uncertainty is caused by the definition of Nessie's shape, which makes it unclear which 'mass' to measure in calculating m l , but more is due to the vagaries of converting molecular line emission and/or dust continuum to true masses.
What most interests us here is not Nessie's exact mass, mass per unit length, or density profile, but instead its total mass as a fraction of the Galaxy's mass, so that we can use that estimate in assessing how many Nessie-like structures may be findable in the Milky Way. To begin that assessment, we only need estimate Nessie's total mass. Toward that end, Table 1 offers very simple estimates of the mass of cylinders, whose (constant) average density is set so that the typical extinctions associated with Nessie's IR-dark ( A v ∼ 100 mag) and HNC bright ( A V glyph[greaterorsimilar] a few mag) radii are sensible. Using HNC emission directly to calculate mass is dangerous, because, as mentioned above (Jackson et al. 2010), the fractional abundance of HNC is uncertain by as much as three orders of magnitude. Calculating masses using a filament diameter of 0 01 pc and a characteristic column density . A V = 80 mag (corresponding a a volume density of 10 5 cm -3 ), Nessie Classic is 1 × 10 5 M , glyph[circledot] Nessie Extended is 2 × 10 5 M glyph[circledot] and Nessie Optimistic is 5 × 10 5 M . If one assumes that glyph[circledot] the envelope traced by the HNC observations of Jackson et al. (2010) for Nessie Classic continues along Nessie's length, then the mass of an n ∼ 500 cm -3 cylinder with diameter 0.1 pc (see Table 1) associated with Nessie would be 5 × 10 4 M glyph[circledot] for Classic and 3 × 10 5 M glyph[circledot] for Optimistic. For the Optimistic case, this mass amounts to 2 millionths of the total gas
mass (assuming ∼ 10 11 M glyph[circledot] total) of the Milky Way.
Most of the mass in molecular clouds, which typically follows a log-normal distribution (cf. Goodman et al. 2009, and references therein), is at densities substantially lower than the 500 cm -3 we have used for Nessie's outer HNC-emitting regions. For example, Battisti & Heyer (2014) find that the Dense Gas Mass Fraction (DGMF) in molecular clouds is of order 10 percent, using the mass in sub-mm-emitting dense dusty cores (from the BGPS Survey, Rosolowsky et al. 2010) as the numerator and the full mass of 13 CO-emitting clouds (from the GRS Survey, Jackson et al. 2006) as the denominator. Emission from 13 CO typically traces of order 10 percent of the total molecular mass (cf. Pineda et al. 2008, and references therein). So, correcting for a a 10% DGMF and 13 CO tracing at most 10% of the total H , in the limiting case that 2 all dense gas were in Nessie-like structures, the total number of 'Nessie Optimistics' that one could find in the Milky Way is at least 100 times less than the 500,000 listed in Table 1 under 'number to equal mass of Milky Way.' By-eye inspection of Figures 9 and 10 gives the impression that roughly 20% of the very high column density ( A V ∼ 100 mag) gas will be in easy-to-identify long, straight structures. So, a coarse estimate of 'how many Nessies' are detectable in the Milky Way can be based on the ratio ( ∼ 500 000) of the Milky Way's gas mass divided by Nessie's mass traced by , HNC, reduced by × ∼ 0 1 to account for the dense gas mass fraction, another . × ∼ 0 1 to . account for the ratio of total molecular to 13 CO-emitting gas, and another at best × ∼ 0 2 . to account for the topology in evidence in the Smith et al. simulations. That leaves us with an estimate that of order many hundreds to thousands of additional Nessie-like features that should be discoverable in the Milky Way. And, of course, features nearer to us, and oriented more perpendicular to our line of sight, as Nessie is, will be the easiest to find.
To make more robust estimates of how discoverable our Galaxy's bones will be, future work should use simulated observations of galaxy simulations like those presented in
Smith et al. (2014), and/or high-resolution extragalactic observations of spiral galaxies, to statistically model what structures could be observable. For reference, the 40 pc resolution of the interferometric state-of-the-art PAWS Survey of CO in the nearby spiral M51 (Schinnerer et al. 2013) is not high enough to find Nessie-like structures. Future ALMA observations with resolution of several pc may be able to find evidence for bones by finding their 'envelopes,' as traced, for example, by the HNC observations in Jackson et al. (2010).
## 4.2. Can We Map the Full Skeleton of the Milky Way?
We have long thought that generating an outside-in view of the Milky Way is impossible, almost as inhabitants of Edwin A. Abbott's Flatland (Abbott 1884) residents cannot envision a 3D view of their 2D world. But, we can escape flatland by realizing that the tiny offset of the Sun above the Milky Way's midplane can give us a tiny, but useful, bit of perspective on the 3D structure of the Milky Way . This view is only useful for mapping structure using very high-contrast, very narrow, features like Nessie, because puffier features will overlap too much to be identifiable in such a foreshortened view. The identification of Nessie as a bone-like feature implies that modern observations are good enough, and features are sharp enough, to identify at least some of our Galaxy's skeleton.
It turns out that Nessie is located in a place where seeing a very long IRDC projected parallel to the Galactic Plane should be easiest. Look again at Figure 4, and consider Nessie's placement there. According to the current (data-based cartoon) view of the Milky Way shown in Figure 4, Nessie is in the closest major spiral arm (Scutum-Centaurus) to us, along a direction toward, but not exactly toward, the (confusing) Galactic Center. Nessie's placement there means that it will have a bright background illumination as seen from further out in the Galaxy (e.g. from the Sun), and that it will have a long extent on the Sky as compared with more distant or less perpendicular-to-our-line-of-sight objects. It is
Fig. 9.Top-down view of the total column density in a simulation of structures forming within a spiral galaxy based on Smith et al. (2014). The main bright curving features show spiral arm structures. Note the 100 pc scale bar within the zoom box, which shows that the simulation's resolution is very close to high enough to compare directly with structures with 'Nessie,' whose width is just under 1 pc.
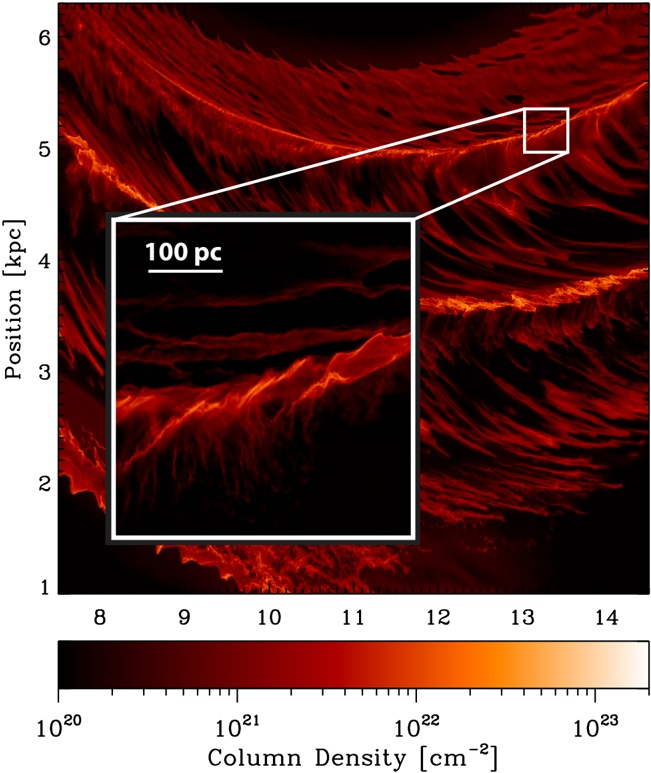
Fig. 10.Edge-on view of the total column density in a simulation of structures forming within a spiral galaxy based on Smith et al. (2014). Note the white dotted lines drawn at 20 pc above and below the Galactic Plane (black line), and, by comparing with Figure 5, notice how the scale of the highly-elongated whitest high-density features in this simulation is approximately comparable to Nessie.
always good when one finds what should be the easiest-to-see example of a new phenomenon first, so we are reassured that Nessie was the first 'Bone' of the Milky Way found. Now, though, we need to think about how to find Bones not as prominent as Nessie. There are essentially two approaches.
In one approach, one can conduct a strategic search for long thin clouds, or broken pieces of such, in places on the Sky where they 'should' occur according to our current understanding of the Milky Way's spatial and velocity structure. Specifically, using current estimates for the Milky Way's arm's 3D locations, one can draw more velocity-encoded traces like the ones shown in Figure 5 on the 2D Sky, showing where arms should appear.
With such predictions in hand, one can design algorithms to look for dust clouds elongated
(roughly) along those lines, and then examine the velocity structure of the elongated features, as we do in § 3, above. Of course, one need be flexible about which features one accepts as possible 'bones,' remembering that the model used to draw the expected features on the Sky is the same one being refined! It is likely that an iterative approach, using the extant Milky Way model as a prior, will succeed in this way.
Taking a less targeted survey approach, one can search the Sky for long, thin, dense clouds, and assess their relationship to Galactic structure after the fact. This blind search approach has recently been taken by Ragan et al. (2014) in the first quadrant of the Milky Way, using near and mid-infrared images. Of the seven new clouds (dubbed 'Giant Molecular Filaments') identified by Ragan et al. (2014) none appears to be tracing spiral arm structures like Nessie. One cloud, GMF 20.0-17.9, appears to be a spur off of the Scutum-Centaurus Arm. Ragan et al. (2014) confirm our claim that Nessie lies in the middle of the Scutum-Centaurus Arm, and they speculate that perhaps identifying bone-like features in the first quadrant is more difficult than in the fourth, where Nessie lies. Examining Figure 4, it is clear that Nessie and other clouds in the Scutum-Centaurus arm would be much more perpendicular to our line of sight, and thus easier-to-detect, in the fourth quadrant than in the first, so we agree with Ragan et al.'s speculation.
In a related approach, a 'connect the dots,' strategy for finding long features is also possible. Using the output of exhaustive (automated) searches for high-density peaks, once can look for non-random, long, straightish, patterns in the distribution of those peaks. For example, in plotting out the Peretto & Fuller (2009) catalog of the positions of 11,000 roundish high-density peaks on the Sky, long thin IRDCs appear to the eye as strings of easy-to-connect sources. Nessie itself is comprised of ∼ 100 Peretto & Fuller sources superimposed on a slightly-lower-density connecting structure. It may be possible to use automated structure-finding algorithms, such as Minimum Spanning Trees, to
connect-the-peaks in efforts to identify additional bones of the Milky Way.
Prior to our work on assessing the role of (a lengthened) Nessie in Galactic structure, and Ragan et al.'s 2014 survey, at least two other exceptionally long molecular clouds near the Galactic plane were presented in the literature. The so-called 'Massive Molecular Filament' G32.02+0.06, studied by Battersby & Bally (2014), does not appear to be tracing an arm structure. And the 500-pc long molecular 'wisp' discussed by Li et al. (2013) also does not presently appear directly related to Galactic structure, although it is interesting to think about its past. As we discuss in § 4.1, it will likely prove important to model the effects of feedback on the evolution of bone-like star-forming molecular clouds. None of the other long, thin, dense clouds discovered to date are as elongated and straight as Nessie. Intuitively, one can guess that over very long time scales, the star formation going on with clouds like Nessie will re-shape them and break them into pieces very hard to recognize as ever having been bone-like.
As extinction, dust emission, and molecular spectral-line maps cover more and more of the sky at ever-improving resolution and sensitivity, it should be possible to map more and more of the Milky Way's skeleton. New wide-field extinction-based efforts based at first on Pan-Starrs (e.g. Green et al. 2014), and ultimately on Gaia, will be tremendously helpful in these efforts in the coming decade. Once enough features are identified on the Sky and in 3D space using dust maps, and in position-position-velocity space (using information from spectral-line observations), it should be possible to fit features together into a skeletal pattern of arms, spurs, and more, in much the same way one solves a jigsaw puzzle by finding the most obvious connections first. Ultimately, we may have enough examples of 'bones' to apply a machine-learning algorithm that would search for additional pieces of the Milky Way's skeleton based on known examples, in much the same way that Beaumont et al. (2011) used the output of the Milky Way Project's citizen science effort as
input to a Support Vector Machine algorithm that quantifies estimates of the density and characteristics of bubble-like features in the interstellar medium.
While many long, thin, IRDCs will likely be identified in the coming years as 'bones' of the Milky Way, it is important to point out that not every long-thin IRDC should be expected to trace a spiral arm. The image of IC342 in Figure 11 and the simulation in Figure 9 illustrate that spiral galaxies' structure can include much more than arm-like high-contrast structures, and we can predict that shear and feedback disrupt long features over time. This complexity will make piecing together the Milky Way's skeleton from its bones very challenging, but it should be an achievable goal.
## 5. Contributions and Facilities
## 5.1. Contributions
This paper was a truly a group effort, and the author list includes only some of the many people who have contributed to it. The entire project was inspired by a question: 'Is Nessie parallel to the Galactic Plane?,' asked by Andi Burkert at the 2012 Early Phases of Star Formation (EPoS) meeting at the Max Planck Society's Ringberg Castle in Bavaria. Three EPoS attendees beyond the author list contributed significant ideas and data to this work, most notably Steven Longmore, Eli Bressert, and Henrik Beuther. We are grateful to Cormac Purcell for giving us advance online access to the HOPS data, and to Mark Reid for generously sharing his expertise on Galactic structure. The text here was largely written by Alyssa Goodman; the theoretical ideas come primarily from Andi Burkert and Rowan Smith; and much of the geometrical analysis was carried out by Christopher Beaumont, Bob Benjamin, and Tom Robitaille. Tom Dame and Bob Benjamin provided expertise on Galactic structure, and they created several of the figures shown here. Jens Kauffmann
Fig. 11.- . IC342 as seen by WISE, reproduced from Jarrett et al. 2013. The colors correspond to WISE bands: 3.4 µ m (blue), 4.6 µ m (cyan/green), 12.0 µ m (orange), 22 µ m (red).

provided expertise on IRDCs, and also was first to point out the potential relevance of the Sun's non-zero height above the Galactic Plane. Joao Alves provided expertise on the
potential for using extinction maps to find more Nessie-like features, and Michelle Borkin was instrumental in early visualization work that led to our present proposals for using the Sun's 'high' vantage point to map out the Milky Way. Jim Jackson contributed critical expertise on the Nessie IRDC, based both on the 2010 study he led and on unpublished work since. During revisions to this manuscript, Rowan Smith provided the new simulations referenced here as Smith et al. (2014).
The article you are reading now was the first to be prepared using a collaborative authoring system called Authorea. The early drafts of the paper, as well as the (preprint) submitted version, were, and will remain, open to the public, at this link. We thank Authorea's founders Alberto Pepe and Nathan Jenkins, and advisors Eli Bressert and Matteo Cantiello, for assistance as the work proceeded.
The final version of this paper benefitted significantly from responses to the comments of an usually thorough referee, to whom we are grateful.
A.B. acknowledges support from the Cluster of Excellence 'Origin and Structure of the Universe.' A.G. and C.B. thank Microsoft Research, the National Science Foundation (AST-0908159) and NASA (ADAP NNX12AE11G) for their support. M.B. was supported by the Department of Defense through the National Defense Science & Engineering Graduate Fellowship (NDSEG) Program. R.B. acknowledges NASA grant NNX10AI70G.
## 5.2. Facilities
Data in this paper were taken with the following telescopes. The CO Survey of the Milky Way data Dame & Thaddeus (2011) are from the 1.2-Meter Millimeter-Wave Telescope in Cambridge, Massachusetts, USA. NH 3 observations of cores Purcell et al. (2012) in and near Nessie are from the Mopra 22-meter telescope near Coonabarabran,
Australia. The mid-infrared images of the Galactic Plane used to define Nessie are from NASA's Spitzer Space Telescope, and they were made as part of the GLIMPSE (Benjamin et al. 2003; Churchwell et al. 2009) and MIPSGAL (Carey et al. 2009) Surveys of the Galactic Plane.
## REFERENCES
Abbott, E. A. 1884, Flatland: A Romance of Many Dimensions (London: Seely), 103
Barnes, P., Lo, N., Muller, E., et al. 2010, ATNF proposal M566
Battersby, C., & Bally, J. 2014, in Astrophysics and Space Science Proceedings, ed. D. Stamatellos, S. Goodwin, & D. Ward-Thompson, Vol. 36, 417
Battisti, A. J., & Heyer, M. H. 2014, ApJ, 780, 173
Beaumont, C. N., Williams, J. P., & Goodman, A. A. 2011, 741, 14
Benjamin, R. A., Churchwell, E., Babler, B. L., et al. 2003, PASP, 115, 953
Beuther, H., Tackenberg, J., Linz, H., et al. 2012, ApJ, 747, 43
Blaauw, A., Gum, C. S., Pawsey, J. L., & Westerhout, G. 1959, ApJ, 130, 702
Blaauw, A., Gum, C. S., Pawsey, J. L., & Westerhout, G. 1960, MNRAS, 121, 123
Brunthaler, A., Reid, M., Menten, K., et al. 2011, Astronomische Nachrichten, 332, 461
Carey, S. J., Noriega-Crespo, A., Mizuno, D. R., et al. 2009, PASP, 121, 76
Chandrasekhar, S., & Fermi, E. 1953, ApJ, 118, 116
Chen, B., Stoughton, C., Smith, J. A., et al. 2001, ApJ, 553, 184
Churchwell, E., Babler, B. L., Meade, M. R., et al. 2009, PASP, 121, 213
Corder, S., Sheth, K., Scoville, N. Z., et al. 2008, ApJ, 689, 148
Dame, T. M., Hartmann, D., & Thaddeus, P. 2001, ApJ, 547, 792
Dame, T. M., & Thaddeus, P. 2011, ApJ, 734, L24
Dobbs, C. L., & Pringle, J. E. 2013, MNRAS, 432, 653
Foster, J. B., Stead, J. J., Benjamin, R. A., Hoare, M. G., & Jackson, J. M. 2012, ApJ, 751, 157
Goodman, A. A., Pineda, J. E., & Schnee, S. L. 2009, The Astrophysical Journal, 692, 91
Green, G. M., Schlafly, E. F., Finkbeiner, D. P., et al. 2014, The Astrophysical Journal, 783, 114
Jackson, J. M., Finn, S. C., Chambers, E. T., Rathborne, J. M., & Simon, R. 2010, ApJ, 719, L185
Jackson, J. M., Rathborne, J. M., Shah, R. Y., et al. 2006, The Astrophysical Journal Supplement Series, 163, 145
Jarrett, T. H., Masci, F., Tsai, C. W., et al. 2013, AJ, 145, 6
Juri´, M., Ivezi´, v., Brooks, A., et al. 2008, ApJ, 673, 864 c c
Kauffmann, J., & Pillai, T. 2010, ApJ, 723, L7
La Vigne, M., Vogel, S., & Ostriker, E. 2008, ApJ, 818
Larson, R. B. 1981, MNRAS, 194, 809
Li, G.-X., Wyrowski, F., Menten, K., & Belloche, A. 2013, A&A, 559, A34
Lin, C. C., & Shu, F. H. 1964, ApJ, 140, 646
Ma´ ız-Apell´niz, J. 2001, AJ, 121, 2737 a
Malhotra, S. 1994, ApJ, 433, 687
Malhotra, S. 1995, ApJ, 448, 138
McClureGriffiths, N. M., & Dickey, J. M. 2007, ApJ, 671, 427
Peretto, N., & Fuller, G. A. 2009, A&A, 505, 405 Peretto, N., & Fuller, G. A. 2010, ApJ, 723, 555 Pillai, T., Wyrowski, F., Menten, K. M., & Krugel, E. 2006, A&A, 447, 929 Pineda, J. E., Caselli, P., & Goodman, A. A. 2008, The Astrophysical Journal, 679, 481 Purcell, C. R., Longmore, S. N., Walsh, A. J., et al. 2012, MNRAS, 426, 1972 Ragan, S. E., Henning, T., Tackenberg, J., et al. 2014, ArXiv e-prints, arXiv:1403.1450 Rathborne, J. M., Simon, R., & Jackson, J. M. 2007, ApJ, 662, 1082 Reid, M. J., & Brunthaler, A. 2004, ApJ, 616, 872 Reid, M. J., Menten, K. M., Zheng, X. W., et al. 2009, ApJ, 700, 137 Rix, H.-W., & Bovy, J. 2013, A&A Rev., 21, 61 Rosolowsky, E., Dunham, M. K., Ginsburg, A., et al. 2010, The Astrophysical Journal Supplement Series, 188, 123 Schinnerer, E., Meidt, S. E., Pety, J., et al. 2013, The Astrophysical Journal, 779, 42 Shetty, R., & Ostriker, E. C. 2006, ApJ, 647, 997 Smith, R. J., Glover, S. C. O., Clark, P. C., Klessen, R. S., & Springel, V. 2014, MNRAS, 441, 1628 Vall´e, J. P. 2008, AJ, 135, 1301 e
Wienen, M., Wyrowski, F., Schuller, F., et al. 2012, A&A, 544, A146
This manuscript was prepared with the AAS LT E X macros v5.2. A | 10.1088/0004-637X/797/1/53 | [
"Alyssa A. Goodman",
"Joao Alves",
"Christopher N. Beaumont",
"Robert A. Benjamin",
"Michelle A. Borkin",
"Andreas Burkert",
"Thomas M. Dame",
"James Jackson",
"Jens Kauffmann",
"Thomas Robitaille",
"Rowan J. Smith"
] | 2014-07-31T15:03:52+00:00 | 2014-07-31T15:03:52+00:00 | [
"astro-ph.GA"
] | The Bones of the Milky Way | The very long and thin infrared dark cloud "Nessie" is even longer than had
been previously claimed, and an analysis of its Galactic location suggests that
it lies directly in the Milky Way's mid-plane, tracing out a highly elongated
bone-like feature within the prominent Scutum-Centaurus spiral arm. Re-analysis
of mid-infrared imagery from the Spitzer Space Telescope shows that this IRDC
is at least 2, and possibly as many as 5 times longer than had originally been
claimed by Nessie's discoverers (Jackson et al. 2010); its aspect ratio is
therefore at least 300:1, and possibly as large as 800:1. A careful accounting
for both the Sun's offset from the Galactic plane ($\sim 25$ pc) and the
Galactic center's offset from the $(l^{II},b^{II})=(0,0)$ position shows that
the latitude of the true Galactic mid-plane at the 3.1 kpc distance to the
Scutum-Centaurus Arm is not $b=0$, but instead closer to $b=-0.4$, which is the
latitude of Nessie to within a few pc. An analysis of the radial velocities of
low-density (CO) and high-density (${\rm NH}_3$) gas associated with the Nessie
dust feature suggests that Nessie runs along the Scutum-Centaurus Arm in
position-position-velocity space, which means it likely forms a dense `spine'
of the arm in real space as well. The Scutum-Centaurus arm is the closest major
spiral arm to the Sun toward the inner Galaxy, and, at the longitude of Nessie,
it is almost perpendicular to our line of sight, making Nessie the easiest
feature to see as a shadow elongated along the Galactic Plane from our
location. Future high-resolution dust mapping and molecular line observations
of the harder-to-find Galactic "bones" should allow us to exploit the Sun's
position above the plane to gain a (very foreshortened) view "from above" of
the Milky Way's structure. |
1408.0002v2 | ## DWARF GALAXY ANNIHILATION AND DECAY EMISSION PROFILES FOR DARK MATTER EXPERIMENTS
ALEX GERINGER-SAMETH 1 , SAVVAS M. KOUSHIAPPAS 2 , AND MATTHEW WALKER 3
Draft version March 12, 2015
## ABSTRACT
Gamma-ray searches for dark matter annihilation and decay in dwarf galaxies rely on an understanding of the dark matter density profiles of these systems. Conversely, uncertainties in these density profiles propagate into the derived particle physics limits as systematic errors. In this paper we quantify the expected dark matter signal from 20 Milky Way dwarfs using a uniform analysis of the most recent stellar-kinematic data available. Assuming that the observed stellar populations are equilibrium tracers of spherically-symmetric gravitational potentials that are dominated by dark matter, we find that current stellar-kinematic data can predict the amplitudes of annihilation signals to within a factor of a few for the ultra-faint dwarfs of greatest interest. On the other hand, the expected signal from several classical dwarfs (with high-quality observations of large numbers of member stars) can be localized to the ∼ 20% level. These results are important for designing maximally sensitive searches in current and future experiments using space and ground-based instruments.
Keywords: dark matter - galaxies: dwarf - galaxies: fundamental parameters - galaxies: kinematics and dynamics
## 1. INTRODUCTION
The search for cosmological dark matter annihilation or decay is a major effort in contemporary astrophysics. Educing the dark matter particle physics from observations requires a detailed understanding of the dark matter distribution in the systems under study. A productive avenue of approach has been to search for gamma-rays generated by dark matter annihilation in Milky Way dwarf spheroidal galaxies (e.g. Scott et al. 2010; Essig et al. 2010; Aleksi´ c et al. 2011; Geringer-Sameth & Koushiappas 2011; Ackermann et al. 2011; Geringer-Sameth & Koushiappas 2012; Aliu et al. 2012; Ackermann et al. 2014; Geringer-Sameth et al. 2014). Such systems are nearby, dark matter-dominated, and contain no conventional sources of astrophysical backgrounds (e.g. cosmic ray generation and propagation through interstellar gas). Many such dwarf galaxies have been discovered in recent years (Willman et al. 2005; Zucker et al. 2006b,a; Walsh et al. 2007; Belokurov et al. 2007, 2008; Belokurov et al. 2009, 2010) with the prospect of more discoveries from ongoing and future sky surveys like Pan-Starrs (Kaiser et al. 2002), the Vista Hemisphere Survey (Ashby et al. 2013, 2014), the Dark Energy Survey (Flaugher 2005), and eventually the Large Synoptic Survey Telescope (Tyson et al. 2003).
Previous studies of dwarf galaxies have begun to constrain the physical properties of dark matter (Geringer-Sameth & Koushiappas 2011; Ackermann et al. 2011, 2014; GeringerSameth et al. 2014). The lack of any significant gamma-ray excess lead to the exclusion of generic dark matter candidates with annihilation cross sections on the order of the benchmark value for a thermal relic ( ∼ 3 × 10 -26 cm 3 s -1 ) and with masses less than a few tens of GeV. Despite current non-detections, dwarf galaxies-and their lack of astrophysical contaminating sources-offer the cleanest possible signature of dark matter
- 1 Department of Physics, Brown University, Providence, RI 02912 and McWilliams Center for Cosmology, Department of Physics, Carnegie Mellon University, Pittsburgh, PA 15213; [email protected]
- 2 Department of Physics, Brown University, Providence, RI 02912; [email protected]
- 3 McWilliams Center for Cosmology, Department of Physics, Carnegie Mellon University, Pittsburgh, PA 15213; [email protected]
annihilation or decay compared with other targets. This is especially interesting in the context of recent claims of a Galactic center gamma-ray excess and associated dark matter interpretation (e.g. Hooper & Goodenough 2011; Boyarsky et al. 2011; Abazajian & Kaplinghat 2012, 2013; Abazajian et al. 2014; Daylan et al. 2014). Observations of dwarf galaxies have the potential to either confirm or rule out such an interpretation.
The dark matter distribution within a target system is a necessary ingredient for placing constraints on any particle theory that predicts dark matter annihilation or decay. Knowledge of the relative signal strengths amongst different targets as well as the spatial distribution of the emission is required for designing maximally sensitive searches in current and future experiments. The overall emission rate from annihilation is described by the ' J value', the integral along the line-ofsight and over an aperture of the square of the dark matter density. The amplitude of J helps to identify which dwarfs are the most promising for searches (i.e. are the 'brightest').
Different groups have devised various methods for estimating dark matter distributions (and uncertainties) using observations of line-of-sight velocities of dwarf galaxy member stars. Some authors use the kinematic data to fit for the mass and/or concentration of dark matter density profiles that are assumed to follow an analytic form typically used to describe low-mass 'subhalos' (virial mass ∼ 10 9 -10 M glyph[circledot] ) that form around Milky-Way-like galaxies in dissipationless cosmological simulations based on cold dark matter (e.g. Strigari et al. 2007; Martinez et al. 2009; Martinez 2013). Some studies make an explicit assumption of a cored profile (Cholis & Salucci 2012; Salucci et al. 2012), while others take a more agnostic approach, fitting relatively flexible density profiles that are not restricted to the form used to describe simulated halos (e.g. Charbonnier et al. 2011).
In addition, different groups use different techniques for propagating the uncertainties in those dark matter distributions when incorporating gamma-ray non-detections to derive limits on the annihilation cross section as a function of particle mass. For example, in their joint analysis of stellarkinematic and gamma-ray data for several dwarfs, Ackermann
et al. (2011) take the uncertainty in J to be described by a lognormal distribution that is subsequently folded into a likelihood for a given particle physics model. Working with similar data, Geringer-Sameth & Koushiappas (2011) separated that same log-normal distribution for J from statistical uncertainties in the gamma-ray data, allowing this systematic J uncertainty to be compared with the derived cross section limits. The results shown by Geringer-Sameth & Koushiappas (2011) are alarming: the uncertainty in J can affect limits on the cross section by a factor of 10; nevertheless, the conservative edge of the 95% systematic band still rules out light dark matter with the benchmark thermal cross section (see Fig. 2 in Geringer-Sameth & Koushiappas (2011)).
Building on these previous works, we have devised a novel statistical approach that operates on stellar-kinematic and gamma-ray data in order to maximize sensitivity to annihilation/decay signals. We present results in a pair of papers. Here (Paper I), we use published stellar-kinematic data to estimate the dark matter density profiles of 20 Milky Way dwarfs. These systems lie at heliocentric distances 23 glyph[lessorsimilar] D / kpc glyph[lessorsimilar] 250 and span a range in luminosity 3 glyph[lessorsimilar] log 10 [ L L / glyph[circledot] ] glyph[lessorsimilar] 7 (McConnachie 2012, and references therein). The primary goal of this work is to quantify uncertainties in the dark matter density profiles-and hence in the J values-that reflect statistical errors due to finite data as well as uncertainties regarding the shapes of dark matter density profiles. We adopt the relatively agnostic modeling approach of Charbonnier et al. (2011) and extend it to the least luminous of the Milky Way's dwarf satellites, where statistical uncertainties can become dominant over systematics; for a thorough examination of the behaviors of random and systematic errors that are inherent to this analysis, we refer the reader to the recent study by Bonnivard et al. (2015). In Paper II, we present a new analysis of gamma-ray data from the Fermi Large Area Telescope (LAT) that, in combination with the estimates of J values presented here, places new limits on dark matter particle interactions.
This paper is structured as follows. In Sec. 2 we introduce the quantities we seek to constrain by briefly reviewing the physics of dark matter annihilation and decay. Sec. 3 describes the parameterization of the density profile and the equations relating this profile to astronomical observables. Sec. 4 introduces the observational datasets used in this analysis and Sec. 5 describes the fitting procedure. We discuss some physical considerations and the importance of truncating the dark matter potentials in Sec. 6. The results of the analysis are presented in Sec. 7. We discuss their relevance in the context of previous work in Sec. 8 and conclude in Sec. 9. Appendix A presents constraints on integrated emission profiles and containment fractions for each dwarf, which are also provided in machine-readable form.
## 2. DARK MATTER SIGNAL
The distribution of dark matter within a system determines the flux of photons and other products of dark matter annihilation and decay. The annihilation rate per volume per time is given by
$$R _ { \text{ann} } = \frac { 1 } { 2 } n ^ { 2 } \langle \sigma v \rangle, \quad \quad \quad ( 1 ) \quad \begin{array} { c } \sin \\ e \vdots \\ \sin \end{array}$$
where n is the number density of dark matter particles and 〈 σ v 〉 is the velocity-averaged annihilation cross section (e.g. Jungman et al. 1996; Gondolo & Gelmini 1991). (Note that n represents the total number density of dark matter irrespective of particle vs. antiparticle; an additional factor of 1 2 appears if particles and antiparticles each constitute half the total abundance.) As dynamical observations offer a handle on the mass density of dark matter but not its number density, it is convenient to write n = ρ/ M χ , where ρ is the mass density and M χ is the mass of a single dark matter particle.
If dark matter decays, the decay rate per volume is given by
$$R _ { \text{dec} } = n \Gamma,$$
where Γ is the decay rate of an individual dark matter particle.
Each annihilation (or decay) gives rise to photons described by the spectrum dN γ ( E ) / dE : the number of photons per energy produced per annihilation (or decay). Photons produced in annihilation or decay travel along straight lines and so the expected flux of photons is determined by dark matter annihilation (or decay) taking place along the entire line of sight in a certain direction. The number of photons per solid angle per energy, area, and time coming from sky-direction ˆ n , in the case of annihilation, is given by
$$\frac { d F ( \hat { \mathbf n }, E ) } { d \Omega d E } = \frac { \langle \sigma v \rangle } { 8 \pi M _ { \chi } ^ { 2 } } \frac { d N _ { \gamma } ( E ) } { d E } \int _ { \ell = 0 } ^ { \infty } d \ell \left [ \rho ( \ell \hat { \mathbf n } ) \right ] ^ { 2 }, \quad ( 3 )$$
while for decay it is given by
$$\frac { d F ( \hat { \mathbf n }, E ) } { d \Omega d E } = \frac { \Gamma } { 4 \pi M _ { \chi } } \frac { d N _ { \gamma } ( E ) } { d E } \int _ { \ell = 0 } ^ { \infty } d \ell \, \rho ( \ell \hat { \mathbf n } ). \quad \ ( 4 )$$
Here, F has the units of photons per area per time, glyph[lscript] is the line of sight distance from Earth and ρ glyph[lscript] ( ˆ n ) is the dark matter mass density at location glyph[lscript] ˆ n . The integrals over the line of sight should be thought of as including the units of [solid angle] -1 . For the case of dark matter annihilation, we define the J -profile to be
$$\frac { d J ( \hat { \mathbf n } ) } { d \Omega } = \int _ { \ell = 0 } ^ { \infty } d \ell \left [ \rho ( \ell \hat { \mathbf n } ) \right ] ^ { 2 }.$$
The corresponding quantity in the case of dark matter decay is the projected mass density along the line of sight:
$$\frac { d J _ { \text{decay} } ( \hat { \mathbf n } ) } { d \Omega } = \int _ { \ell = 0 } ^ { \infty } d \ell \, \rho ( \ell \hat { \mathbf n } ). \quad \quad ( 6 )$$
The terms before the integrals in Eqs. (3) and (4) describe the microscopic physics of dark matter while the J -profile reflects its distribution on large scales. The goal of indirect detection is to use knowledge of dJ / d Ω (or dJ decay / d Ω ) along with observations of photons ( dF / d Ω dE ) to learn something about dark matter particle physics { M χ , 〈 σ v 〉 , Γ } . In the following we will present results for both annihilation and decay.
We consider spherically symmetric density profiles and so dJ / d Ω is a function only of θ , the angular separation between the line of sight ˆ n and the direction towards the center of the dwarf galaxy. The integration in Eqs. (5) and (6) along the line of sight is carried out numerically for every value of θ . We let the variable x denote the distance, along the line of sight, from the point where the line of sight makes its closest approach to the center of the dwarf. That is, the line of sight corresponding to an angular separation θ has an impact parameter b = D sin( θ ), where D is the distance from Earth to the center of the dwarf. The limits of integration in Eqs. (5) and (6) are x = -∞ and x = + ∞ √ , and dx = d glyph[lscript] . The dark matter density is a function of r = b 2 + x 2 , the distance from the center of the dwarf, so that ρ glyph[lscript] ( ˆ n ) is given by ρ ( √ b 2 + x 2 ).
## 3. RECONSTRUCTING THE DARK MATTER POTENTIAL WITH STELLAR KINEMATICS
## 3.1. Dark matter density
In order to accurately quantify uncertainties in the spatial distribution of dark matter it is necessary to use a suitably flexible functional form for the density profile (Bonnivard et al. 2015). Following Charbonnier et al. (2011), we adopt the functional form introduced by Zhao (1996) to generalize the Hernquist (1990) profile. In this spherically symmetric model, the density of dark matter at halo-centric radius r is
$$\rho ( r ) = \frac { \rho _ { s } } { \left ( r / r _ { s } \right ) ^ { \gamma } \left [ 1 + \left ( r / r _ { s } \right ) ^ { \alpha } \right ] ^ { ( \beta - \gamma ) / \alpha } }. \quad \quad ( 7 )$$
This five-parameter profile, normalized by the scale density ρ s , describes a split power law with inner logarithmic slope d log ρ/ d log r | r glyph[lessmuch] rs = -γ and outer logarithmic slope d log ρ/ d log r | r glyph[greatermuch] rs = -β . The transition happens near the scale radius rs , with α specifying its sharpness. For ( α,β,γ ) = (1 3 1) , , one recovers the two-parameter NFW profile that characterizes cold dark matter (CDM) halos formed in dissipationless numerical simulations (Navarro et al. 1997). However, the profile can also describe halos with even steeper central 'cusps' ( γ > 1), or halos with 'cores' of uniform central density ( γ ∼ 0), as are usually inferred from observations of real galaxies (de Blok 2010, and references therein; Walker et al. 2011; Donato et al. 2009). This flexibility lets us explore a wide range of physically plausible dark matter profiles.
## 3.2. Estimation of dark matter profile parameters
From Eq. (3), the flux of annihilation by-products depends on the density of dark matter particles within the source, and thus on the source's gravitational potential. For collisionless stellar systems like dwarf galaxies, the gravitational potential is related fundamentally to the phase-space density of stars f ( r u , ), defined such that f ( r u , ) d 3 r d 3 u gives the expected number of stars lying within the phase-space volume d 3 r d 3 u centered on ( r u , ). However, dwarf galaxies are sufficiently far away that current instrumentation resolves only the projection of their internal phase-space distributions, effectively providing information in just three dimensions: position as projected onto the plane perpendicular to the line of sight, and velocity along the line of sight (from Doppler redshift). Given these limitations, it is common to infer the gravitational potential Φ by considering its relation to moments of the phase-space distribution: the stellar density profile,
$$\nu ( r ) \equiv \int f ( { \mathbf r }, { \mathbf u } ) \, d ^ { 3 } { \mathbf u },$$
and the stellar velocity dispersion profile,
$$\overline { u ^ { 2 } } ( r ) = \overline { u _ { r } ^ { 2 } } ( r ) + \overline { u _ { \theta } ^ { 2 } } ( r ) + \overline { u _ { \phi } ^ { 2 } } ( r ) \quad \quad ( 9 ) \quad R \epsilon$$
$$= \frac { 1 } { \nu ( r ) } \int u ^ { 2 } f ( { \mathbf r }, { \mathbf u } ) \, d ^ { 3 } { \mathbf u }. \quad \quad ( 1 0 ) \quad \frac { \mathbf a } { \mathbf w }$$
Assuming dynamic equilibrium and spherical symmetry, these quantities are related according to the spherical Jeans equation (Binney & Tremaine 2008),
$$\frac { 1 } { \nu ( r ) } \frac { d } { d r } [ \nu ( r ) \overline { u _ { r } ^ { 2 } } ( r ) ] + 2 \frac { \beta _ { a } ( r ) \overline { u _ { r } ^ { 2 } } ( r ) } { r } = - \frac { d \Phi } { d r } = - \frac { G M ( r ) } { r ^ { 2 } }, \ \ ( 1 1 ) \quad \text{recer}$$
where
$$\beta _ { a } ( r ) \equiv 1 - \frac { \overline { 2 u _ { \theta } ^ { 2 } } ( r ) } { \overline { u _ { r } ^ { 2 } } ( r ) }$$
characterizes the orbital anisotropy and the enclosed mass profile
$$M ( r ) = 4 \pi \int _ { 0 } ^ { r } s ^ { 2 } \rho ( s ) d s$$
includes contributions from the dark matter halo.
Equation 11 has the general solution (van der Marel 1994; Mamon & Łokas 2005)
$$\nu ( r ) \overline { u _ { r } ^ { 2 } } ( r ) = \frac { 1 } { f ( r ) } \int _ { r } ^ { \infty } f ( s ) \, \nu ( s ) \, \frac { G M ( s ) } { s ^ { 2 } } \, d s, \quad ( 1 4 )$$
where
$$f ( r ) = 2 \, f ( r _ { 1 } ) \, \exp \left [ \int _ { r _ { 1 } } ^ { r } \beta _ { a } ( s ) s ^ { - 1 } \, d s \right ] \,. \quad \ \ ( 1 5 )$$
Projecting along the line of sight, the mass profile relates to observable profiles, the projected stellar density Σ ( R ), and line-of-sight velocity dispersion σ ( R ), according to (Binney &Tremaine 2008)
$$\int _ { 0 } ^ { \shortmid } \int _ { 0 } ^ { \longmid } \left ( 1 - \beta _ { a } ( r ) \frac { R ^ { 2 } } { r ^ { 2 } } \right ) \frac { \nu ( r ) \overline { u _ { r } ^ { 2 } } ( r ) \ r } { \sqrt { r ^ { 2 } - R ^ { 2 } } } \, d r. \quad ( 1 6 )$$
We use Eq. (16) to fit models for ρ ( r ) and β a ( r ) to observed velocity dispersion and surface brightness profiles under the following assumptions:
- · dynamic equilibrium and spherical symmetry, both implicit in the use of Eq. (11);
- · the stars are distributed according to a Plummer (1911) profile,
$$\nu ( r ) = \frac { 3 L } { 4 \pi R _ { e } ^ { 3 } } \frac { 1 } { ( 1 + R ^ { 2 } / R _ { e } ^ { 2 } ) ^ { 5 / 2 } }, \quad \quad ( 1 7 )$$
implying surface brightness profiles of the form
$$\Sigma ( R ) = \frac { L } { \pi R _ { e } ^ { 2 } } \, \frac { 1 } { ( 1 + R ^ { 2 } / R _ { e } ^ { 2 } ) ^ { 2 } },$$
where L is the total luminosity and Re is the projected halflight radius;
- · the stars contribute negligibly to the gravitational potential, such that Re is the only meaningful parameter in ν ( r ) and Σ ( R );
- · β a = constant;
- · the distribution of stellar velocities is not significantly influenced by the presence of binary stars.
Real galaxies violate all of these assumptions at some level and it is important to consider that the error distributions that we derive for J values will not include the resulting systematic errors. For the present work, we are concerned primarily with quantifying statistical uncertainties that arise from finite sizes of stellar-kinematic samples. For a thorough study of systematic errors that can arise due to different stellar density profiles, non-spherical symmetry, and more complicated behaviors of the velocity anisotropy, we refer the reader to the recent study by Bonnivard et al. (2015).
## 4. OBSERVATIONS
## 4.1. Classical dwarfs
For the Milky Way's eight most luminous 'classical' dwarf galaxies, we adopt projected halflight radii listed in Table 1 of Walker, Mateo & Olszewski (2009, original source is Irwin & Hatzidimitriou 1995). We use the stellar-kinematic data published by Mateo et al. (2008) for Leo I, and by Walker, Mateo & Olszewski (2009) for Carina, Fornax, Sculptor and Sextans.
For Draco, Leo II, and Ursa Minor we use stellar-kinematic data acquired with the Hectochelle spectrograph at the 6.5-m MMT. These data have previously been analyzed by Walker et al. (2009b) and Charbonnier et al. (2011), and will soon be made public (Walker, Olszewski & Mateo, in preparation).
## 4.2. Ultra-faint satellites
For the Milky Way's less luminous 'ultra-faint' satellites discovered over the past seven years (e.g., Willman et al. 2005; Zucker et al. 2006b; Belokurov et al. 2007, 2008; Belokurov et al. 2009), we make use of published data from a variety of sources. We adopt projected halflight radii from the review of McConnachie (2012). Original sources are Martin et al. (2008) and/or discovery papers for satellites discovered after that work (Belokurov et al. 2008; Belokurov et al. 2009).
For Coma Berenices, Canes Venatici I, Canes Venatici II, Leo IV, Leo T, Ursa Major I and Ursa Major II, we utilize the Keck/Deimos velocity data of Simon & Geha (2007), generously provided by Marla Geha (private communication).
For Hercules we adopt the stellar-kinematic data published by Adén et al. (2009b). After using Stromgren photometry to identify and remove foreground contamination independently of velocity, Adén et al. (2009a) use these data to measure a global velocity dispersion of 3 7 . ± 0 9 km s . -1 , slightly smaller than the earlier estimate of 5 1 . ± 0 9 km s . -1 by Simon & Geha (2007). In the interest of deriving conservative estimates on the dark matter density (and ultimately the exclusion limits for particle models), we adopt the Hercules data of Adén et al. (2009b).
For Boötes I, we adopt the stellar-kinematic data published by Koposov et al. (2011). The observing strategy of Koposov et al. (2011) provided ∼ 10 independent velocity measurements of each star over the course of one month, thereby enabling a direct examination of intrinsic velocity variability (e.g., due to unresolved binary stars) that can potentially inflate observed velocity dispersions (and hence the inferred dark matter density) above the values attributable to the galaxy's gravitational potential (McConnachie & Côté 2010). Koposov et al. (2011) directly resolve velocity variability-including near-constant accelerations of ∼ 10 km s -1 month -1 -for ∼ 10% of the stars in their sample. In order to obtain conservative estimates of the dark matter density, we adopt the most restrictive sample of Boötes I members identified by Koposov et al. (2011, marked with a 'B' in their Table 1), which includes only the 37 stars that show no evidence for velocity variability and have small ( ≤ 2 5 km s . -1 ) velocity measurement errors.
For Leo V, we adopt the stellar-kinematic data published by Walker et al. (2009a). These include seven stars identified as likely members. However, while five of these stars lie within three times the projected half-light radius of Leo V ( rh ∼ 40 pc; Belokurov et al. 2008), the other two lie glyph[greaterorsimilar] 10 rh ∼ 400pc away from Leo V's center and in the direction toward Leo IV, which itself lies only ∼ 20 kpc from Leo V. This configuration is highly improbable for a dynamically relaxed system-even given the small number of stars-fueling speculation that Leo IV and Leo V are interacting gravitationally. In that case, the two outermost stars in the Leo V sample may trace a stellar 'bridge' of low surface brightness. However, deep photometric studies have not yielded unambiguous evidence for such a structure (de Jong et al. 2010; Jin et al. 2012; Sand et al. 2010, 2012). In any case, once again in the interest of conservatism, we consider only the five innermost members in the analysis of Leo V.
For Segue 1, we adopt the stellar-kinematic data published by Simon et al. (2011). These data include repeat measurements for tens of stars with velocities originally measured by Geha et al. (2009), enabling an analysis of velocity variability. Martinez et al. (2011) perform a Bayesian analysis and conclude that the presence of unresolved binary stars is likely to have only mild (a ∼ 10% effect) influence on estimates of Segue 1's intrinsic velocity dispersion. Along with velocity measurements, we adopt the 'Bayesian' membership probabilities listed for individual stars in Table 3 of Simon et al. (2011).
For Segue 2, we adopt the stellar-kinematic data published by Kirby et al. (2013) for 25 member stars. These measurements do not resolve Segue 2's internal velocity dispersion, instead placing a 95% upper limit of σ < 2 6 km s . -1 . Aprevious study by Belokurov et al. (2009) reported a velocity dispersion of σ ∼ 3 5 km s . -1 , based on a sample of ∼ 5 member stars that they cautioned might be contaminated by members of a dynamically hotter stream in the same vicinity. Again in the interest of placing conservative limits on the expected dark matter signal, we adopt the sample of Kirby et al. (2013)-not only because it implies a smaller velocity dispersion, but also because it provides a larger number of member stars. While the small velocity dispersion estimated by Kirby et al. (2013) does not, by itself, require that Segue 2 is embedded within a dark matter halo, Kirby et al. (2013) argue that the variance in metallicity among Segue 2's stars constitutes indirect evidence for a dark matter halo (whose deeper potential would help to retain chemically-enriched gas despite strong winds generated by star formation).
Finally, we note that while high-quality stellar-kinematic data sets are available for the Milky-Way satellites Sagittarius and Willman 1, these objects show strong evidence for tidal disruption and/or non-equilibrium kinematics (Ibata et al. 1997; Willman et al. 2011). Since any mass inference based on the Jeans equation relies fundamentally on the assumption of dynamic equilibrium, we do not consider these objects here.
Table 1 lists central coordinates, distances (from the Sun), absolute V-band magnitudes, and projected halflight radii for the Milky Way satellites we consider here. The last column gives the number of member stars with velocity measurements available for the kinematic analysis. Figures 1 and 2 display projected velocity dispersion profiles for each dwarf. These binned profiles are included only for the purpose of display; the fitting that we describe below uses the unbinned data directly.
## 5. FITTING PROCEDURE
Given the available kinematic data and adopted estimates of Re (which fixes Σ ( R ) under the assumption of Plummer profiles), we fit models for ρ ( r ) and β a ( r ) (see Sec. 3) following the procedure of Strigari et al. (2007). Specifically, we assume that the velocity data sample a line-of-sight velocity
Figure 1. Line-of-sight stellar velocity dispersion profiles observed for the Milky Way's eight classical dwarf spheroidal satellites, adopted from Walker et al. (2009b). Solid curves indicate, at each projected radius, the median velocity dispersion of models sampled in the Markov-Chain Monte Carlo analysis. Dashed and dotted curves enclose the central 68% and 95% of velocity dispersion values from the sampled models. The model profiles are fit to the unbinned kinematic data, but clearly show good agreement with the binned data plotted here.
distribution that is Gaussian 4 . Thus we adopt the likelihood function in Charbonnier et al. (2011)) over the following ranges:
$$L = \prod _ { i = 1 } ^ { N } \frac { 1 } { ( 2 \pi ) ^ { 1 / 2 } \left [ \delta _ { u, i } ^ { 2 } + \sigma ^ { 2 } ( R _ { i } ) \right ] ^ { 1 / 2 } } \exp \left [ - \frac { 1 } { 2 } \frac { ( u _ { i } - \langle u \rangle ) ^ { 2 } } { \delta _ { u, i } ^ { 2 } + \sigma ^ { 2 } ( R _ { i } ) } \right ], \ ( 1 9 ) \quad \quad \quad$$
where ui and Ri are the line-of-sight velocity and magnitude of the projected position vector (with respect to the center of the dwarf) of the i th star in the kinematic data set, δ u i , is the observational error in the velocity, and σ ( R ) is the velocity dispersion at projected position R , as specified by model parameters and calculated from Eq. (16). We consider only stars for which published probabilities of membership are greater than 0.95. The bulk velocity of the system 〈 u 〉 is a nuisance parameter that we marginalize over with a flat prior. Besides 〈 u 〉 , the model has six free parameters and we adopt uniform priors (as
4 Given that we allow models with anisotropic and inherently nonGuassian velocity dispersions, this assumption of Gaussianity introduces an internal inconsistency. However, by enabling the simple likelihood function given by Eq. (19), it avoids problems (e.g., arbitrariness of bin boundaries, unresolved dispersions) associated with analyses of binned profiles. A more rigorous treatment would generate the likelihood function directly from a 6-D phase-space distribution function (M. Wilkinson, in preparation).
- · -1 ≤ -log 10 [1 -β a ] ≤ + 1;
- · -4 ≤ log 10 [ ρ / s ( M glyph[circledot] pc -3 )] ≤ + 4;
- · 0 ≤ log 10 [ rs / pc] ≤ + 5;
- · 0 5 . ≤ α ≤ 3;
- · 3 ≤ β ≤ 10;
- · 0 ≤ γ ≤ 1 2. .
In order to sample the parameter space efficiently, we use the nested-sampling Monte Carlo algorithm introduced by Skilling (2004) and implemented in the software package MultiNest (Feroz & Hobson 2008; Feroz et al. 2009), which outputs samples from the model's posterior probability distribution function (PDF).
## 6. PHYSICAL CONSIDERATIONS AND TRUNCATION OF HALO PROFILES
Figure 3 displays samples from the posterior PDFs returned by MultiNest for Fornax and Segue 1-the most luminous
Figure 2. Same as Figure 1, but for the Milky Way's ultra-faint satellites. In many bins the estimated velocity dispersion is zero because the actual dispersion is unresolved by the available data. As in Fig. 1 the points with error bars are for illustration; binned velocity dispersion estimates are not used in the fitting procedure.
classical dwarf and one of the least luminous ultra-faints, respectively. As the model that we adopt for the halo density profile is free (and unconstrained by, e.g., N-body considerations) the kinematic data of each dwarf is compatible with a wide range of profiles. Therefore, we apply three additional filters to the kinematically-allowed dark matter density profiles. The first two involve identifying an outer boundary for a given halo, while the third is a requirement that the halo formed in a cosmologically plausible way.
## 6.1. Halo truncation
tant consequences for the expected dark matter signal from a dwarf galaxy. The data for nearly all dwarf galaxies are consistent with density profiles described by single power laws with logarithmic slopes d log ρ/ d log r > -3 - indeed, despite its unphysically infinite mass, the 'isothermal sphere', characterized by ρ ( r ) ∝ r -2 , has long been used to model kinematics of spheroidal galaxies (Binney & Tremaine 2008). It is therefore important to define some means for preventing the outer parts of a halo - i.e., regions outside the orbits of the observed stellar populations - from dominating the integral used to calculate the J -profile (Eq. (5)).
Given the form of Eq. (7), the annihilation rate will drop rapidly at galactocentric distances r glyph[greatermuch] rs where the density profile is steeply falling ( β > 3). However, within rs the radial distribution of the emission is determined by the slope of the inner density profile γ . For sufficiently cuspy profiles ( γ > 1) the emission is dominated by annihilation near the halo center. For γ ∼ 1 the annihilation rate receives approximately equal contributions from all radii and for γ < 1 the emission comes primarily from the largest radii within rs .
Unfortunately, the current data sets - even for the classical dwarfs - do not place strong upper bounds on rs , thereby allowing emission that extends to an arbitrarily large radius 5 . Therefore, the question of where the halo ends has impor-
5 For spherically symmetric halos the mass exterior to a star's orbit exerts zero net force on that star (Newton 1687); thus stellar kinematics in general carry no information about the mass distribution beyond the orbits of the stars.
## 6.2. Truncating at the outermost observed star
An obvious choice for a conservative truncation radius is that of the outermost member star used to estimate the velocity dispersion profile. For stars well beyond the luminous scale radius Re , the projected distances that we observe are likely to be similar to the de-projected distances r . However, if we observe enough stars close to the center it becomes likely that some of these stars lie at large galactocentric distances. Therefore, we use the entire distribution of projected radii of the kinematic sample to estimate the maximum galactocentric distance r max among those stars.
We estimate r max in the following way. Given spherical symmetry, it is straightforward to find the probability distribution for the unprojected distance to the outermost observed star given the projected distances to the observed stars. We start by considering an individual star. Given its projected
Table 1 Properties of Milky Way Satellites * and Stellar-Kinematic Samples
| object | RA (J2000) [hh:mm:ss] | Dec. (J2000) [dd:mm:ss] | Distance [kpc] | M V [mag] | R half [pc] | N sample | r max [pc] |
|-------------------|-------------------------|---------------------------|------------------|------------------|---------------|------------|--------------------|
| Carina | 06:41:36.7 | - 50:57:58 | 105 ± 6 | - 9 . 1 ± 0 . 5 | 250 ± 39 | 774 | 2224 + 885 - 441 |
| Draco | 17:20:12.4 | +57:54:55 | 76 ± 6 | - 8 . 8 ± 0 . 3 | 221 ± 19 | 292 | 1866 + 715 - 317 |
| Fornax | 02:39:59.3 | - 34:26:57 | 147 ± 12 | - 13 . 4 ± 0 . 3 | 710 ± 77 | 2483 | 6272 + 2616 - 1366 |
| Leo I | 10:08:28.1 | +12:18:23 | 254 ± 15 | - 12 . 0 ± 0 . 3 | 251 ± 27 | 267 | 1948 + 794 - 407 |
| Leo II | 11:13:28.8 | +22:09:06 | 233 ± 14 | - 9 . 8 ± 0 . 3 | 176 ± 42 | 126 | 824 + 345 - 178 |
| Sculptor | 01:00:09.4 | - 33:42:33 | 86 ± 6 | - 11 . 1 ± 0 . 5 | 283 ± 45 | 1365 | 2673 + 1099 - 569 |
| Sextans | 10:13:03.0 | - 01:36:53 | 86 ± 4 | - 9 . 3 ± 0 . 5 | 695 ± 44 | 441 | 2544 + 1109 - 587 |
| Ursa Minor | 15:09:08.5 | +67:13:21 | 76 ± 3 | - 8 . 8 ± 0 . 5 | 181 ± 27 | 313 | 1580 + 626 - 312 |
| Bootes I | 14:00:06.0 | +14:30:00 | 66 ± 2 | - 6 . 3 ± 0 . 2 | 242 ± 21 | 37 | 544 + 252 - 135 |
| Canes Venatici I | 13:28:03.5 | +33:33:21 | 218 ± 10 | - 8 . 6 ± 0 . 2 | 564 ± 36 | 214 | 2030 + 884 - 468 |
| Canes Venatici II | 12:57:10.0 | +34:19:15 | 160 ± 4 | - 4 . 9 ± 0 . 5 | 74 ± 14 | 25 | 352 + 105 - 28 |
| Coma Berenices | 12:26:59.0 | +23:54:15 | 44 ± 4 | - 4 . 1 ± 0 . 5 | 77 ± 10 | 59 | 238 + 103 - 53 |
| Hercules | 16:31:02.0 | +12:47:30 | 132 ± 12 | - 6 . 6 ± 0 . 4 | 330 + 75 - 52 | 30 | 638 + 295 - 147 |
| Leo IV | 11:32:57.0 | - 00:32:00 | 154 ± 6 | - 5 . 8 ± 0 . 4 | 206 ± 37 | 18 | 443 + 197 - 95 |
| Leo V | 11:31:09.6 | +02:13:12 | 178 ± 10 | - 5 . 2 ± 0 . 4 | 135 ± 32 | 5 | 201 + 95 - 43 |
| Leo T | 09:34:53.4 | +17:03:05 | 417 ± 19 | - 8 . 0 ± 0 . 5 | 120 ± 9 | 19 | 534 + 183 - 60 |
| Segue 1 | 10:07:04.0 | +16:04:55 | 23 ± 2 | - 1 . 5 ± 0 . 8 | 29 + 8 - 5 | 70 | 139 + 56 - 28 |
| Segue 2 | 02:19:16.0 | +20:10:31 | 35 ± 2 | - 2 . 5 ± 0 . 3 | 35 ± 3 | 25 | 119 + 45 - 18 |
| Ursa Major I | 10:34:52.8 | +51:55:12 | 97 ± 4 | - 5 . 5 ± 0 . 3 | 319 ± 50 | 39 | 732 + 338 - 181 |
| Ursa Major II | 08:51:30.0 | +63:07:48 | 32 ± 4 | - 4 . 2 ± 0 . 6 | 149 ± 21 | 20 | 294 + 139 - 74 |
* Central coordinates, distances, absolute magnitudes and projected half-light radii are adopted from the review of McConnachie (2012, see references to original sources therein).
distance R we take the probability of its line of sight distance z (relative to the halo center) to be proportional to the (deprojected) Plummer density profile:
$$P ( z | R ) \infty \left ( 1 + \frac { z ^ { 2 } + R ^ { 2 } } { R _ { e } ^ { 2 } } \right ) ^ { - 5 / 2 }, \quad \quad ( 2 0 ) \quad \text{ an}$$
where Re is the projected halflight radius (Sec. 3). Once the above probability has been normalized (by integrating over z ) we can construct the probability distribution for the unprojected distance r given the projected distance R :
$$P ( r | R ) = \underset { z } { \int } P ( r | z, R ) \, P ( z | R ) \, d z. \quad \quad ( 2 1 ) \quad \text{cai} \\ \text{sta} _ { | }$$
In the above P( r z | , R ) is simply the Dirac delta function δ ( r -√ z 2 + R 2 ). Note that the above integral is zero unless r > R , in which case the delta function picks out two values of z. The result we will need is the cumulative distribution function (CDF) of r given R :
$$C D F ( r | R ) = \int _ { 0 } ^ { r } P ( r ^ { \prime } | R ) d r ^ { \prime } = \frac { \left ( r ^ { 2 } - R ^ { 2 } \right ) ^ { 1 / 2 } \left ( r ^ { 2 } + \frac { 1 } { 2 } ( 3 R _ { h } ^ { 2 } + R ^ { 2 } ) \right ) } { \left ( r ^ { 2 } + R _ { h } ^ { 2 } \right ) ^ { 3 / 2 } }, \quad \text{sensi} \\ \text{for } r > R \text{ and CDF} ( r | R ) = 0 \text{ for } r < R \text{ } \text{ } \text{$$
for r > R and CDF( r R | ) = 0 for r < R .
To find the CDF for the distance to the outermost of n observed stars we simply multiply the CDFs for each of the n stars:
$$\mu _ { 0 } \text{ CDF} _ { \max } ( r | R _ { 1 }, \dots, R _ { n } ) = \text{ CDF} ( r | R _ { 1 } ) \cdots \text{ CDF} ( r | R _ { n } ), \quad ( 2 3 )$$
where each term on the right-hand side is given by Eq. (22) and Ri is the measured projected distance to the i th member star.
For each dwarf, Eq. (23) can be used to estimate the distance to the outermost star used in the Jeans analysis. The median estimate and ± 1 σ confidence intervals for the distance to the outermost member star for each dwarf are shown in the last column of Table 1. When computing J -profiles we truncate all halo profiles obtained from the Jeans/MultiNest sampling analysis at the median estimate to the outermost member star.
Note that this truncation is not imposed on the mass profile in Eq. (14) when calculating the integral in Eq. (16) during the Jeans/MultiNest sampling. However, the integral in Eq. (16) is dominated by the contribution from radii r < Re , such that as long as the truncation radius is larger than the luminous effective radius (as it is for every dwarf galaxy we consider), the result from the Jeans/MultiNest analysis is insensitive to whether or not we truncate the halo density profile at the outermost star in the kinematic sample. We have verified this argument by a controlled experiment and found that the significant effect of truncation is on the subsequent integration over the density profile that enters the calculation of the annihilation signal (see Eq. (5)). For the purpose of this work (quantifying the expected dark matter flux from a
Figure 3. Samples from the posterior probability distribution functions of dark matter halo density profile and velocity anisotropy parameters for Segue 1 (black) and Fornax (red).
dwarf) this particular choice of truncation is a conservative one. A spherical Jeans analysis cannot, in principle, constrain the mass distribution far beyond the outermost member stars and we therefore set the density to zero at these distances.
## 6.3. Tidal radius
nal and external potentials (i.e., those of the dwarf and Milky Way, respectively), the orbit of the dwarf, and on the orbital configuration within the dwarf (orbits that are prograde with respect to the dwarf's orbit are more easily stripped than those that are retrograde; Read et al. 2006).
For some allowed models, however, the halo density at the galactocentric radius of the outermost star is far smaller than that expected for the Milky Way halo at the same location. This situation would be inconsistent, as the outermost star (and dark matter particles) would likely be lost due to tides. Therefore we impose an additional, physically-motivated filter by requiring that the tidal radius of any acceptable halo be larger than the distance to the outermost star.
The magnitude of the tidal radius rt depends on the inter-
For each kinematically allowed halo profile we follow von Hoerner (1957) and King (1962) and estimate a tidal radius rt by solving
$$\text{ar} \\ \text{is.} \quad \ r _ { t } ^ { 3 } - D ^ { 3 } \frac { M ( r _ { t } ) } { M _ { \text{MW} } ( D ) } \left [ 2 + \frac { \omega ^ { 2 } D ^ { 3 } } { G M _ { \text{MW} } ( D ) } - \frac { d \ln M _ { \text{MW} } } { d \ln r } \Big | _ { r = D } \right ] ^ { - 1 } = 0. \\ \text{before} \ \ D \text{is the distance between the Millvarpoonright with your center and the}$$
Here, D is the distance between the Milky Way center and the dwarf, M rt ( ) is the mass within the tidal radius of the dwarf
galaxy, M MW( ) is the mass enclosed within radius r r in the Milky Way, and ω is the angular speed of the dwarf about the Galactic center (which we take to be a linear speed of 200 km/s divided by the distance from the dwarf to the Galactic center). The Milky Way mass model is taken to be an NFW profile with virial mass M MW = 10 12 M glyph[circledot] , a scale radius rs , MW = 21 5kpc, and a concentration . c MW = 12 (Klypin et al. 2002) (for a more recent treatment of the subject see, e.g., Nesti & Salucci 2013; the results are not sensitive to the uncertainties in the Milky Way mass model).
The expression in Eq. (24) should be taken as a crude approximation for several reasons (see, for example, discussions in Binney & Tremaine (2008); Mo et al. (2010)). First, it makes the assumption that the dwarf galaxy is on a circular orbit (tidal radii for systems with eccentric orbits are not well defined). Second, the three dimensional tidal surface is not of constant radius and thus does not correspond to one unique value for rt . Third, Eq. (24) does not include the effect of orbital dynamics of the particles within the dwarf galaxy itself (manifested as some variance about the angular velocity ω ). Nevertheless, the utility of this prescription has been thoroughly explored in studies of globular clusters, dark matter substructure, and dwarf galaxies (Johnston 1998; Johnston et al. 2001; Taylor & Babul 2001, 2004; Zentner & Bullock 2002, 2003), and gives a reasonably intuitive definition of 'tidal radius'.
Therefore, we reject any halo profiles for which this estimate of the tidal radius is smaller than the radius we estimate for the outermost member in the kinematic samples 6 . This consistency condition turns out to affect only two dwarfs, the ultra-faints Segue 2 and Leo IV, removing profiles with small values of both ρ s and rs (i.e. profiles that do not lie on the typical ρ s vs. rs constraint seen in Fig. 3).
## 6.4. Cosmological considerations
As a final filter, we reject halo profiles that would be cosmologically 'implausible' in the sense that their formation would have required extremely rare peaks in the primordial matter density field. We estimate the rareness of a candidate halo in the following way. Cosmological simulations show that the density profile near the center of a dark matter halo is more or less set at the time of its formation (modulo feedback effects from baryon-physical processes). The outer profile then evolves as mass is accumulated by accretion in a hierarchical scenario (see e.g., Navarro et al. (1997); Wechsler et al. (2006); Gao et al. (2008)). To a first approximation, then, the primordial mass of a halo (the virial mass of the collapsing overdensity) is greater (or on the order of) the mass M within rs today. In addition, the density of the inner parts of a halo is also roughly set at the time of formation, following a distribution in concentration, c ≡ R vir / rs , where R vir is the radius of the virialized region (Navarro et al. 1996).
For example, the scale density of an NFW profile is ρ s = δ ρ c crit f ( c v), where δ c is the characteristic overdensity of a collapsed object and ρ crit (scaling as (1 + z ) 3 in the matterdominated era) is the critical density of the Universe at the time of collapse (e.g. Gao et al. 2008). The function f ( c v) = ln(1 + c v) + c v / (1 + c v) is a function of order unity. There is thus an approximately one-to-one mapping between the collapse redshift and the scale density ρ s of a halo (ignoring the in-
6 We use the minimum possible distance to the outermost star: the largest projected distance to any of the members. This has a conservative impact in the resulting J values.
trinsic variation in concentration Wechsler et al. (2006); Gao et al. (2008)). For simplicity, and due to a lack of knowledge of the initial conditions that give rise to the intrinsic properties of the dwarf galaxies at their formation time, we use the approximation (Navarro et al. 1996)
$$\frac { 1 + z _ { \text{col} } } { 2 0 } & \gtrsim \left ( \frac { \rho _ { s } } { M _ { \odot } p c ^ { - 3 } } \right ) ^ { 1 / 3 }. \\ \text{$r$ limit on the value of the characteristic distance and} \text{$of$}$$
as an upper limit on the value of the characteristic density of each halo in the chains.
The collapse redshift, along with an estimate of a halo's mass at collapse M , can be used to quantify the rarity of the density perturbation that collapsed to form the halo. In order to estimate the mass of the collapsed perturbation we use the conventional theory of spherical collapse. A region of space has collapsed and virialized when its average overdensity (with respect to the background as computed in linear perturbation theory) is δ collapse ∼ 1 686. . The overdensity at redshift z , averaged over a region of mass M , is a Gaussian random variable with mean 0 and standard deviation σ ( M ) D ( z ), where σ ( M ) = 〈 δ 2 M 〉 1 2 / is the standard deviation of the overdensity today when smoothed over a region of mass M and D ( z ), the growth function, quantifies the linear growth of perturbations such that D ( z = 0) = 1. Therefore, the rarity (in standard deviations) of a region of mass M collapsing at redshift z is given by (see e.g. Bond et al. (1991); Bower (1991); Lacey & Cole (1993)),
$$\nu ( M, z ) = \frac { \delta _ { \text{collapse} } } { \sigma ( M ) \mathcal { D } ( z ) }.$$
The probability that such a region has collapsed by redshift z is the tail probability of a standard normal distribution to the right of ν . We can make a rough estimate of the probability that the Milky Way contains any objects of mass M which formed at (or before) a redshift z by incorporating a trials factor which counts the number of 'independent' regions of the Universe of mass M that eventually make up the Milky Way today. We estimate this quantity simply as M MW / M , where M MW = 10 12 M glyph[circledot] is the mass of the Milky Way. We take the mass M of a halo to be the lesser of the mass within rs and the mass within the outermost star. For the halos generated by the Monte Carlo sampling the masses range from about 10 5 to 10 7 M glyph[circledot] . This leads to trials factors between 10 5 and 10 7 . The probability that the Milky Way contains a halo that collapsed with mass M by redshift z is then
$$\mathsf P ( M, z ) = 1 - \Phi \left [ \nu ( M, z ) \right ] ^ { M _ { M W } / M }, \text{ \quad \ \ } ( 2 7 )$$
where Φ ( x ) is the cumulative distribution function of a standard normal distribution and ν ( M z , ) is given by Eq. (26). We apply the constraint by demanding that the Milky Way is 'typical' at the 3 σ level, i.e. we reject a halo if P( M z , ) < . 0 003. For a trials factor of 10 6 this constraint is equivalent to demanding that ν glyph[lessorsimilar] 6. The results are insensitive to the threshold value for P( M z , ) - the probability of the Milky Way containing a halo goes to zero extremely rapidly as the halo's ν value increases beyond about ν ≈ 6.
In applying this cosmological argument a posteriori on the chains we find that in the case of classical dwarfs (for which we have a large number of gravitational stellar tracers) stellar kinematics alone does not allow for rare peaks and this filter essentially has no effect. However for the ultra-faint dwarfs the stellar kinematic data allow dark matter halos that appear
to be extremely rare, suggesting that the origin of such rare peaks is due to the small size of kinematic samples available compared with the classical dwarfs. In practice, the halos which are eliminated are those with ρ s glyph[greaterorsimilar] 1 M glyph[circledot] / pc 3 .
## 7. RESULTS
## 7.1. J-profiles for annihilation and decay
The gamma-ray flux from dark matter annihilation is fully described by the function dJ ( θ / ) d Ω and any dark matter search is properly conducted using this function (e.g. Geringer-Sameth et al. (2014)). However, it is useful to explore the dark matter distributions in dwarfs using summary quantities based on the J -profiles.
Concerning indirect detection, the most important properties of the dwarf galaxies are the amplitude and spatial extent of the J -profile. The amplitude is often given as the integral of dJ ( θ / ) d Ω over some solid angle; i.e. we define
$$J ( \theta ) \equiv \int _ { 0 } ^ { \theta } \frac { d J ( \theta ^ { \prime } ) } { d \Omega } 2 \pi \sin ( \theta ^ { \prime } ) d \theta ^ { \prime }, \quad \ \ ( 2 8 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
with an analogous definition for J decay ( θ ). A detectorindependent amplitude is the J -profile integrated out to the truncation radius of the halo. This corresponds to integrating dJ ( θ / ) d Ω out to an angle θ max = arcsin( r max / D ), where r max is the distance from the center of the dwarf to the outermost member star (Sec. 6.2) and D is the distance from Earth to the dwarf. Integrating the J -profile within θ max gives the total dark matter flux expected from a halo . We use J or J decay to denote this scalar quantity when there is no confusion.
Using the kinematic data discussed in Sec. 4, and applying the formalism described in Secs. 3, 5, and 6, we apply equations (5) and (6) to estimate the kinematically allowed values of J and J decay . Figures 4 and 5 along with Table 2 show the main results of this work.
Figure 4 shows the derived J values for all of the dwarf galaxies considered in this analysis. Error bars represent the 1 σ uncertainty in the value of J (e.g. the 16 th and 84 th percentiles of the posterior distriution). There are many interesting features of this distribution of J values among the dwarf galaxies. Concerning the overall amplitude of an annihilation signal, we find that among the classical dwarfs Draco and Ursa Minor have the largest expected flux. However, Sculptor and, to a lesser extent, Fornax and Carina have the most constraining kinematic sample, giving a very small range of allowed values for J and thus the smallest uncertainties (in agreement with the analysis of Charbonnier et al. 2011). Among the ultra-faint dwarf galaxies, Segue 1 and Ursa Major II have central J values that are higher then those of any of the classical dwarfs. However, the uncertainties in these values are also larger than those of all the classical dwarfs. Of all the dwarf galaxies in this sample, Sculptor has the smallest uncertainty in its total J value (about 15%). On the other hand, all ultra-faint dwarf galaxies exhibit 1 σ errors that are about an order of magnitude (in some cases several orders of magnitude - e.g., Leo IV). This is an outcome of the limited size of the kinematic samples available to date. From the entire ultra-faint sample, Segue 1, Coma Berenices, and Ursa Major II exhibit well-constrained (less than an order of magnitude) J values, and due to their overall high amplitude they should be considered for current and future annihilation searches.
Figure 5 shows the corresponding J decay values for the twenty dwarf galaxies analyzed. As in Fig. 4, error bars represent the 1 σ range in the value of J decay . In the case of dark mat- ter decay scenarios, the emission profile is set by the amount of mass along the line of sight (Eq. (4)) and is less sensitive to the inner slope of the density profile. As a result, the preferential ordering of dwarfs according to their emission amplitude is different than when searching for annihilation products. In the case of decay, the kinematic analysis shows that Draco, and to a lesser extent, Sextans and Sculptor are the sources with the largest expected emission. As in the annihilation case, Fornax and Sculptor have the least systematic uncertainty in their emission amplitudes compared with the rest of the dwarfs.
Many of the ultra-faint dwarfs do not appear to be as promising targets as several of the classical dwarfs. This is due to the conservative way we chose to truncate the halos when computing J and J decay . The outermost observed member stars of the ultra-faints are much closer in than those in the classical dwarfs (see the θ max values along the bottom of Figs. 4 and 5 and the last column of Table 1). Therefore, we simply do not allow the ultra-faint halos to be as extended as those of the classical dwarfs. Since the emission profile from decay is more sensitive to the total mass of the halo, whereas the annihilation profile is more sensitive to the inner slope, the effect of the truncation has different effects when considering annihilation and decay. Whether this truncation is conservative or if it truly reflects the physical sizes of the ultra-faints' dark matter halos is unknown.
It is important to note that the ranking of the various J values implies a consistency check for any detection claim. First, it is likely that if a signal is seen, it will be seen in multiple dwarfs. Consider the pairs Draco/Ursa Minor (classical) and Segue 1/Ursa Major II (ultra-faint). The similar J values among the members of a pair imply that if an annihilation signal is detected in any of these dwarfs there should be a detection of similar amplitude in the other member of the pair (modulo differences in the diffuse gamma-ray background between the dwarfs).
In the farther future, this argument may be turned around to provide an example of 'dark matter particle astronomy': the relative annihilation fluxes measured in multiple dwarfs can be used to constrain the dark matter distributions in their halos. For example, the detection of a signal in a highly constrained dwarf like Sculptor, Draco, or Ursa Minor would immediately tell us something about the dark matter distribution in Segue 1, an object less luminous by 3 orders of magnitude.
## 7.2. Spatial extent
The question of whether a dark matter halo will appear as an extended source for a gamma-ray instrument is important as the additional information available from the angular distribution of emission can be used to increase the signal-to-noise ratio. More point-like sources of emission are more straightforward to detect. However, the detection of a spatially varying annihilation signal immediately reveals properties of the dark matter halo.
Figure 6 shows the constraints on the emission profiles for two benchmark dwarf galaxies: the classical dwarf Draco and the ultra-faint dwarf Segue 1. The envelopes show the ± 1 σ and median values of the emission profiles as a function of the angular separation from the center of the dwarf. It is important to emphasize that none of the curves in the figure correspond to an individual dark matter profile. Rather, the envelope should be thought of as constraining the value of dJ / d Ω or dJ decay / d Ω at a given angular separation. In the lower panels we show the emission profiles integrated over solid an-
Figure 4. Annihilation J -profiles integrated out to θ max for all dwarf galaxies. The error bars show the 1 σ allowed range in the value of J based on the kinematic analysis described in the text. The most prominent dwarf galaxies for annihilation studies are Draco and Ursa Minor (classical) and Coma Berenices, Segue 1, and Ursa Major II (ultra-faint). Numerical values are provided in Table 2 and in machine-readable form as described in Appendix A.
Figure 5. Same as Fig. 4 for but for dark matter decay ( J decay ). The most prominent dwarf galaxy for decay studies is Draco, with Sculptor and Sextans both a factor of about 3 fainter. Numerical values are provided in Table 2 and in machine-readable form as described in Appendix A.
Table 2 J values for annihilation and decay in dwarf galaxies *
| Dwarf | θ max [deg] | θ 0 . 5 [deg] | θ 0 . 5decay [deg] | log 10 J ( θ max ) [GeV 2 cm - 5 ] | log 10 J (0 . 5 ◦ ) [GeV 2 cm - 5 ] | log 10 J decay ( θ max ) [GeVcm - 2 ] | log 10 J decay (0 . 5 ◦ ) [GeVcm - 2 ] |
|---------------|---------------|--------------------------|--------------------------|--------------------------------------|---------------------------------------|-----------------------------------------|------------------------------------------|
| Carina | 1 . 26 | 0 . 15 + 0 . 15 - 0 . 07 | 0 . 46 + 0 . 16 - 0 . 12 | 17 . 92 + 0 . 19 - 0 . 11 | 17 . 87 + 0 . 10 - 0 . 09 | 18 . 15 + 0 . 34 - 0 . 25 | 17 . 90 + 0 . 17 - 0 . 16 |
| Draco | 1 . 30 | 0 . 40 + 0 . 16 - 0 . 15 | 0 . 64 + 0 . 06 - 0 . 14 | 19 . 05 + 0 . 22 - 0 . 21 | 18 . 84 + 0 . 12 - 0 . 13 | 18 . 97 + 0 . 17 - 0 . 24 | 18 . 53 + 0 . 10 - 0 . 12 |
| Fornax | 2 . 61 | 0 . 13 + 0 . 04 - 0 . 05 | 0 . 31 + 0 . 08 - 0 . 05 | 17 . 84 + 0 . 11 - 0 . 06 | 17 . 83 + 0 . 12 - 0 . 06 | 17 . 99 + 0 . 11 - 0 . 08 | 17 . 86 + 0 . 04 - 0 . 05 |
| Leo I | 0 . 45 | 0 . 13 + 0 . 05 - 0 . 05 | 0 . 22 + 0 . 02 - 0 . 04 | 17 . 84 + 0 . 20 - 0 . 16 | 17 . 84 + 0 . 20 - 0 . 16 | 17 . 91 + 0 . 15 - 0 . 20 | 17 . 91 + 0 . 15 - 0 . 20 |
| Leo II | 0 . 23 | 0 . 04 + 0 . 05 - 0 . 02 | 0 . 09 + 0 . 03 - 0 . 05 | 17 . 97 + 0 . 20 - 0 . 18 | 17 . 97 + 0 . 20 - 0 . 18 | 17 . 24 + 0 . 35 - 0 . 48 | 17 . 24 + 0 . 35 - 0 . 48 |
| Sculptor | 1 . 94 | 0 . 15 + 0 . 05 - 0 . 05 | 0 . 48 + 0 . 14 - 0 . 11 | 18 . 57 + 0 . 07 - 0 . 05 | 18 . 54 + 0 . 06 - 0 . 05 | 18 . 47 + 0 . 16 - 0 . 14 | 18 . 19 + 0 . 07 - 0 . 06 |
| Sextans | 1 . 70 | 0 . 58 + 0 . 32 - 0 . 47 | 0 . 87 + 0 . 10 - 0 . 53 | 17 . 92 + 0 . 35 - 0 . 29 | 17 . 52 + 0 . 28 - 0 . 18 | 18 . 56 + 0 . 25 - 0 . 73 | 17 . 89 + 0 . 13 - 0 . 23 |
| Ursa Minor | 1 . 37 | 0 . 06 + 0 . 07 - 0 . 03 | 0 . 25 + 0 . 14 - 0 . 09 | 18 . 95 + 0 . 26 - 0 . 18 | 18 . 93 + 0 . 27 - 0 . 19 | 18 . 13 + 0 . 26 - 0 . 18 | 18 . 03 + 0 . 16 - 0 . 13 |
| Boötes I | 0 . 47 | 0 . 22 + 0 . 05 - 0 . 10 | 0 . 26 + 0 . 02 - 0 . 04 | 18 . 24 + 0 . 40 - 0 . 37 | 18 . 24 + 0 . 40 - 0 . 37 | 17 . 90 + 0 . 23 - 0 . 26 | 17 . 90 + 0 . 23 - 0 . 26 |
| Coma | 0 . 31 | 0 . 16 + 0 . 02 - 0 . 05 | 0 . 17 + 0 . 01 - 0 . 02 | 19 . 02 + 0 . 37 - 0 . 41 | 19 . 02 + 0 . 37 - 0 . 41 | 17 . 96 + 0 . 20 - 0 . 25 | 17 . 96 + 0 . 20 - 0 . 25 |
| CVnI | 0 . 53 | 0 . 11 + 0 . 15 - 0 . 09 | 0 . 23 + 0 . 07 - 0 . 17 | 17 . 44 + 0 . 37 - 0 . 28 | 17 . 43 + 0 . 37 - 0 . 28 | 17 . 57 + 0 . 37 - 0 . 73 | 17 . 57 + 0 . 36 - 0 . 72 |
| CVnII | 0 . 13 | 0 . 07 + 0 . 01 - 0 . 02 | 0 . 07 + 0 . 00 - 0 . 01 | 17 . 65 + 0 . 45 - 0 . 43 | 17 . 65 + 0 . 45 - 0 . 43 | 16 . 97 + 0 . 24 - 0 . 23 | 16 . 97 + 0 . 24 - 0 . 23 |
| Hercules | 0 . 28 | 0 . 07 + 0 . 08 - 0 . 06 | 0 . 12 + 0 . 03 - 0 . 09 | 16 . 86 + 0 . 74 - 0 . 68 | 16 . 86 + 0 . 74 - 0 . 68 | 16 . 66 + 0 . 42 - 0 . 40 | 16 . 66 + 0 . 42 - 0 . 40 |
| Leo IV | 0 . 16 | 0 . 05 + 0 . 03 - 0 . 04 | 0 . 08 + 0 . 01 - 0 . 06 | 16 . 32 + 1 . 06 - 1 . 69 | 16 . 32 + 1 . 06 - 1 . 69 | 16 . 12 + 0 . 71 - 1 . 14 | 16 . 12 + 0 . 71 - 1 . 14 |
| Leo V | 0 . 07 | 0 . 03 + 0 . 01 - 0 . 02 | 0 . 04 + 0 . 00 - 0 . 01 | 16 . 37 + 0 . 94 - 0 . 87 | 16 . 37 + 0 . 94 - 0 . 87 | 15 . 86 + 0 . 46 - 0 . 47 | 15 . 86 + 0 . 46 - 0 . 47 |
| Leo T | 0 . 08 | 0 . 03 + 0 . 01 - 0 . 02 | 0 . 04 + 0 . 00 - 0 . 01 | 17 . 11 + 0 . 44 - 0 . 39 | 17 . 11 + 0 . 44 - 0 . 39 | 16 . 48 + 0 . 22 - 0 . 25 | 16 . 48 + 0 . 22 - 0 . 25 |
| Segue 1 | 0 . 35 | 0 . 13 + 0 . 05 - 0 . 07 | 0 . 18 + 0 . 01 - 0 . 05 | 19 . 36 + 0 . 32 - 0 . 35 | 19 . 36 + 0 . 32 - 0 . 35 | 17 . 99 + 0 . 20 - 0 . 31 | 17 . 99 + 0 . 20 - 0 . 31 |
| Segue 2 | 0 . 19 | 0 . 07 + 0 . 03 - 0 . 05 | 0 . 10 + 0 . 01 - 0 . 05 | 16 . 21 + 1 . 06 - 0 . 98 | 16 . 21 + 1 . 06 - 0 . 98 | 15 . 89 + 0 . 56 - 0 . 37 | 15 . 89 + 0 . 56 - 0 . 37 |
| Ursa Major I | 0 . 43 | 0 . 15 + 0 . 08 - 0 . 12 | 0 . 22 + 0 . 03 - 0 . 14 | 17 . 87 + 0 . 56 - 0 . 33 | 17 . 87 + 0 . 56 - 0 . 33 | 17 . 61 + 0 . 20 - 0 . 38 | 17 . 61 + 0 . 20 - 0 . 38 |
| Ursa Major II | 0 . 53 | 0 . 24 + 0 . 06 - 0 . 11 | 0 . 29 + 0 . 02 - 0 . 04 | 19 . 42 + 0 . 44 - 0 . 42 | 19 . 42 + 0 . 44 - 0 . 42 | 18 . 39 + 0 . 25 - 0 . 27 | 18 . 38 + 0 . 25 - 0 . 27 |
* Errors correspond to the 1 σ range of the kinematic analysis (i.e. the 16 th and 84 th percentiles). J ( θ ) is the J -profile (Eq. (5)) integrated over a cone with radius θ (Eq. (28)); θ 0 5 . is the 'half-light radius' for dark matter emission (i.e. the angle containing 50% of the total emission: J ( θ 0 5 . ) = 0 5 . × J ( θ max), see Sec. 7.2). Analogous definitions apply for dark matter decay. Halos are truncated at a radius corresponding to θ max (Sec. 6.2).
Figure 6. Expected emission profiles for annihilation (purple) and decay (green) for Draco and Segue 1. At each angle the solid and dashed lines show the median profiles and the shaded band corresponds to the ± 1 σ distribution as derived in the kinematic analysis. The top panels show log 10 dJ ( θ ) / d Ω (purple), and log 10 J decay ( θ ) / d Ω (green) (see Eqs. (5) and (6)) in units of GeV 2 cm -5 and GeVcm -2 respectively. The lower panels show these quantities integrated over a solid angle of radius θ (Eq. (28)). These envelopes should be thought of as giving the uncertainty in the J -profile and integrated J -profile at each value of θ . (Integrated J vs. θ and J decay vs. θ constraints for all the dwarfs are available in machine-readable form as described in Appendix A.)
gle out to an angular separation θ (Eq. (28)). For Draco we see a familiar result: there is a particular radius at which the differential flux profile is most tightly constrained, and another (slightly larger) angle within which the total annihilation flux is best constrained (Walker et al. 2011; Charbonnier et al. 2011; Bonnivard et al. 2015). The uncertainty in the flux within 0 01 . ◦ is about a factor of 5 and decreases to about 20% when integrating within about 0 3 . ◦ , an angle corresponding to twice the projected half-light radius. For Segue 1, however, the situation is somewhat different. While the integrated J value within 0 01 . ◦ can be inferred to within a factor of 6, similar to the case of Draco, and the minimum uncertainty again occurs when integrating within about twice the halflight radius ( θ ≈ 0 15 . ◦ ), even there J can only be determined to within a factor of 3.5. We do not see the drastic decrease in the uncertainty of Segue 1's expected emission that we see with most of the classical dwarfs. The larger uncertainty for Segue 1 is a direct consequence of the relatively small size of its available kinematic sample.
We can quantify the extent to which halos can be spatially resolved in gamma-ray telescopes by comparing the derived emission profiles for either annihilation or decay with the point spread function (PSF) of specific instruments.
Figures 7 and 8 show the angular distribution of dark matter annihilation and decay. The bands show constraints on the 'containment fraction' curves for the different dwarfs. The containment fraction, at angle θ , is defined simply as J ( θ / ) J ( θ max), where J ( θ ) is given by Eq. (28). Each halo profile gives rise to a containment fraction curve and the dotted line corresponds to the median value of the containment fraction among all the allowed halos, computed at each θ . The shaded band corresponds to the 16 th and 84 th percentiles. For example, the constraint on the 'half-light radius' of the dark matter emission profile is the intersection of the horizontal line y = 0 5 with the shaded band. We use . θ 0 5 . and θ 0 5decay . to denote the half-light radii for J - and J decay -profiles and tabulate them in Table 2.
The curves in Figs. 7 and 8 illustrate the point spread functions (PSFs) of two gamma-ray experiments. The containment fraction of a PSF is simply the probability that a gammaray will be reconstructed within an angle θ of its true origin. The solid blue, magenta, red, and green lines correspond to the PSF of the Fermi-LAT at photon energies of 0.5, 1, 2, and 10 GeV (computed using gtpsf - see software and documentation at the Fermi Science Support Center 7 ). The dashed orange line corresponds to a 2-dimensional Gaussian PSF with a 68% containment angle of 0 1 . ◦ (e.g. a Rayleigh distribution with a mean of 0 083 . ◦ ). This corresponds to the benchmark PSF of current-generation Atmospheric Cerenkov ˇ Telescopes (ACTs). Figure 8 is identical to Fig. 7 but shows the containment fractions for J decay .
We find that for many of the classical dwarfs (Carina, Draco, Fornax, Leo I, Sculptor, Sextans) ACTs should be able to detect extended emission from dark matter annihilation (if the emission can be detected at all) and similarly for some of the ultra-faint dwarfs (Boötes I, Coma Berenices, and Ursa Major II). Regarding Fermi-LAT, at the highest energies ( > 10 GeV) only Draco and, perhaps, Ursa Major II appear to be extended enough to be detected, and therefore any limits derived using Fermi-LAT data will not be affected significantly by the assumption of point sources when it comes to dwarf galaxies (in agreement with Ackermann et al. (2014)).
## 8. COMPARISON WITH OTHER WORK
In order to compare the expected signals derived in this paper with the predictions from other work, Figure 9 shows the distributions of the J -profile integrated within a cone of radius 0 5 . ◦ for all the dwarf galaxies in the sample. In this figure, the green diamonds are the median values of J from the sampled halos in this work with ± 1 σ error bars. The red and blue points show the J values integrated within 0 5 . ◦ reported by Ackermann et al. (2011) and Ackermann et al. (2014, NFW profiles) respectively. The J values in the latter study come from Martinez (2013). The error bars on these points correspond to the 1 σ errors quoted in those studies.
We find that to within an order of magnitude the constraints on J values are consistent with those derived by Ackermann
θ
[deg]
Figure 7. The containment fraction for annihilation as a function of angular distance from the center of each dwarf. The x -axis is in degrees up to θ max for each dwarf. The containment fraction is defined as J ( θ ) / J ( θ max). The dotted line shows the median value of the containment fraction while the shaded band corresponds to its 16 th and 84 th percentiles at each angle. The solid blue, magenta, red, and green lines show the containment fraction of the Fermi-LAT PSF at 0.5, 1, 2 & 10 GeV respectively. The dashed orange line corresponds to the PSF of a typical ACT (68% containment of 0 1 . ◦ ). This figure together with Fig. 4 can be used to estimate the proper normalization of the expected emission within any aperture for each dwarf. The data used to construct this figure and Fig. 8 are available in machine-readable form as described in Appendix A.
et al. (2011) and Ackermann et al. (2014); Martinez (2013). The differences, however, appear to be systematic and not random. In particular, for the ultra-faint dwarfs the central J values from Ackermann et al. (2014); Martinez (2013) are almost always larger than those we find. Of the eight classical dwarfs, which are the least dependent on priors in the analysis presented here, the results are inconsistent by more than 1 σ for Fornax, Leo II, and Sextans when compared to Ackermann et al. (2014). For Fornax and Ursa Minor the results of Ackermann et al. (2011) also disagree at similar significance.
Martinez (2013) introduced a new analysis that effectively models the entire population of Milky Way dwarfs simultaneously. As with the study of Ackermann et al. (2011), all halos are assumed to follow the NFW form, but the (assumed linear) relationship between log v max and log r max is modeled simultaneously with an (assumed linear) relationship between log L and log v max, where L is optical luminosity. Empirical information about kinematics enters only in the form of published estimates of masses enclosed within dwarf half-light radii, which are determined given v max and r max. With respect to the J values estimated by Martinez (2013), the analysis presented here yields tighter constraints for the classical dwarfs and looser constraints for ultra-faints. The former makes intuitive sense as the analysis presented here uses the greater amount of information that is available in the larger, unbinned kinematic data sets that are available for classical dwarfs (e.g. using velocity dispersion as a function of radius). We suspect that the discrepency for the ultra-faints results from the assumption by Martinez (2013) that the scatter about the linear relation between log L and log v max is independent of luminosity and that between log v max and log r max is independent of log v max. Given the hierarchical nature of the model, this assumption enables 'sharing' of information among classical and ultra-faint dwarfs. That is, the model is constrained primarily by the better-sampled classical dwarfs, but because scatter about the modeled relations is assumed to be independent of luminosity, it is impossible for the inferred constraints for ultra-faints to be looser than those inferred at the luminous end (notice the uniformity of error bars among nearly all the blue points in Figure 9, especially for the ultra-faints). Thus, it may be possible that the error bars obtained by Martinez (2013) for the ultra-faint dwarfs are suppressed by the unduly restrictive hierarchical model priors.
θ
[deg]
Figure 8. Same as Fig. 7 but for dark matter decay.
## 9. CONCLUSION
Dwarf galaxies represent the cleanest laboratory in which to search for a signal from dark matter annihilation and decay. Understanding the dark matter distribution in these systems is therefore of paramount importance.
Using the latest kinematic observations from 20 dwarf galaxies, we have presented a thorough study of the dark matter content and distribution in these systems. We have shown that, owing to the quality and size of available data sets, the classical dwarf galaxies are better constrained than ultra-faint dwarfs. Relevant to dark matter annihilation searches, Draco and Ursa Minor are the most promising dwarfs, with Sculptor being only a factor 3 fainter but with the smallest uncertainty in its emission. From the ultra-faint dwarf sample, Segue 1, Ursa Major II, and Coma Berenices are by far the brightest dwarf galaxies, albeit with significantly larger systematic uncertainties. Relevant to dark matter decay studies, Draco is the brightest dwarf galaxy in the sample, with Sculptor, Sextans and Ursa Major II a factor of roughly 3 fainter.
In addition, we have explored the angular distribution of annihilation and decay emission from these dwarfs, and show that Atmospheric Cerenkov Telescopes have the necessary anˇ gular resolution to detect extended emission from many of the classical and ultra-faint dwarf galaxies. With the future of gamma-ray astronomy efforts focused on the construction of the Cherenkov Telescope Array (CTA) (Actis et al. 2011), this work provides the necessary ingredients that can be used to derive the expected reach of CTA in the context of dark matter searches.
In summary, the results presented here provide one of the key pieces of information required to test hypotheses about dark matter annihilation and decay using dwarf galaxies. Such searches are currently even more important in light of the recent claims of dark matter annihilation evidence from the Galactic center region. Dwarf galaxies are the most reliable sources where these claims can be tested. This shall be the focus of Paper II.
We acknowledge useful conversations with Gordon Blackadder, Vincent Bonnivard, Celine Combet, David Maurin, Justin Read, Louie Strigari, Mark Wilkinson, and Andrew Zentner. SMK is supported by DOE DE-SC0010010, NSF PHYS-1417505 and NASA NNX13AO94G. MGW acknowledges support from NSF grant AST-1313045. SMK and MGW thank the Aspen Center for Physics for hospitality where part of this work was completed.
Figure 9. J -profiles integrated within 0 5 . ◦ for all the dwarf galaxies. The green diamonds with error bars show the range of J values derived in this work with 1 σ error bars. The red and blue points are the integrated J values for NFW profiles reported in Ackermann et al. (2011) and Ackermann et al. (2014), respectively, with error bars corresponding to the 1 σ uncertainties.
## APPENDIX
## A. TABULATED CONSTRAINTS FOR INDIVIDUAL DWARFS
In this appendix we present an additional table with integrated J -profiles and containment fractions for each dwarf as a function of θ . The data in this tables can be used to reconstruct Figs. 4, 5, 7, 8, 9, the lower panels of Fig. 6, and Table 2.
The first few lines of the table are shown in Table 3. The full table, containing all the dwarfs, is available in machine-readable format as an ancillary file. For each value of θ there are four constrained quantities: the integrated J -profiles J ( θ ) and J decay ( θ ), and the containment fractions J ( θ / ) J ( θ max) and J decay ( θ / ) J decay ( θ max). The columns labeled -2 σ, -1 σ,..., + 2 σ correspond to quantiles of the distribution of a quantity among the Monte Carlo realizations of halos. For example, for each halo realization we find the value of J (0 5 . ◦ ). The 2 3 16 50 84, and 97 7 percentiles of this collection of . , , , . J (0 5 . ◦ )'s are listed in columns 3-7 of the row corresponding to θ = 0 5 . ◦ . The table has 50 rows per dwarf, corresponding to log-spaced angles between 0 01 . ◦ and 2 6 . ◦ (the largest θ max of any of the dwarfs).
## B. HALO PROFILE PARAMETER CONSTRAINTS
In order to facilitate the reproducibility of these results we also provide constraints on the individual halo profile parameters for each dwarf. For each of the parameters ρ , s rs , α, β, γ, and β a (see Eqs. 7 and 12), we provide the -2 σ, -1 σ , median, + 1 σ , and + 2 σ quantiles of the posterior distribution (marginalized over the other parameters). The consistency conditions described in Secs. 6.3 and 6.4 have been applied to the posterior samples. Table 4 shows the constraints for the first few dwarfs. The full table is available in machine-readable format as an ancillary file.
Table 3 Integrated J-profiles and Containment Fractions *
| Name | θ [deg] | log 10 J ( θ ) [GeV 2 cm - 5 ] | log 10 J ( θ ) [GeV 2 cm - 5 ] | log 10 J ( θ ) [GeV 2 cm - 5 ] | | | | | | | J ( θ ) / J ( θ max ) - | J ( θ ) / J ( θ max ) - | J ( θ ) / J ( θ max ) - | J ( θ ) / J ( θ max ) - | J decay ( θ ) / J decay | J decay ( θ ) / J decay | J decay ( θ ) / J decay | J decay ( θ ) / J decay | J decay ( θ ) / J decay |
|--------------|-------------|----------------------------------|----------------------------------|----------------------------------|-------|-------|-----------------|-------|---------|---------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|---------------------------|
| Name | - | 2 σ - 1 σ | median | + 1 σ + 2 σ | - 2 σ | - 1 σ | [GeVcm - median | ] + 1 | σ + 2 σ | - 2 σ | - 1 σ | median | + 1 σ | + 2 σ | - 2 σ | - 1 σ | - median + 1 σ | + 2 σ | |
| Carina 0.010 | 15.38 | 15.88 | 16.52 | 16.93 17.33 | 14.98 | 15.09 | 15.23 | 15.32 | 15.44 | 2.3e-03 | 8.8e-03 | 3.8e-02 | 1.0e-01 | 2.3e-01 | 3.2e-04 | 5.4e-04 | 1.1e-03 2.3e-03 | 4.6e-03 | |
| Carina | 0.011 15.47 | 15.96 | 16.57 | 16.97 17.37 | 15.08 | 15.19 | 15.32 | 15.41 | 15.52 | 2.8e-03 | 1.0e-02 | 4.2e-02 | 1.1e-01 | 2.5e-01 | 4.0e-04 | 6.7e-04 | 1.3e-03 2.8e-03 | 5.6e-03 | |
| Carina 0.013 | 15.57 | 16.03 | 16.62 | 17.01 17.40 | 15.17 | 15.28 | 15.41 | 15.49 | 15.60 | 3.5e-03 | 1.2e-02 | 4.7e-02 | 1.3e-01 | 2.7e-01 | 5.0e-04 | 8.2e-04 | 1.6e-03 3.4e-03 | 6.7e-03 | |
| Carina 0.014 | 15.66 | 16.11 | 16.67 | 17.04 17.44 | 15.27 | 15.38 | 15.49 | 15.57 | 15.68 | 4.3e-03 | 1.5e-02 | 5.3e-02 | 1.4e-01 | 2.9e-01 | 6.2e-04 | 1.0e-03 | 2.0e-03 4.2e-03 | 8.1e-03 | |
| Carina 0.016 | 15.75 | 16.19 | 16.72 | 17.08 17.47 | 15.37 | 15.47 | 15.58 | 15.66 | 15.76 | 5.3e-03 | 1.7e-02 | 6.0e-02 | 1.5e-01 | 3.1e-01 | 7.6e-04 | 1.2e-03 | 2.5e-03 5.1e-03 | 9.8e-03 | |
| Carina 0.018 | | 15.84 16.26 | 16.77 | 17.11 17.50 | 15.46 | 15.56 | 15.67 | 15.74 | 15.84 | 6.4e-03 | 2.1e-02 | 6.7e-02 | 1.6e-01 | 3.3e-01 | 9.5e-04 | 1.5e-03 | 3.0e-03 6.2e-03 | 1.2e-02 | |
| Carina | 0.020 | 15.93 16.34 | 16.82 | 17.15 17.53 | 15.56 | 15.66 | 15.76 | 15.83 | 15.92 | 7.7e-03 | 2.4e-02 | 7.5e-02 | 1.8e-01 | 3.6e-01 | 1.2e-03 | 1.9e-03 | 3.7e-03 7.5e-03 | 1.4e-02 | |
*
This table is published in its entirety in the electronic edition of the Astrophysical Journal. A portion is shown here for guidance regarding its form and content.
Table 4 *
## Halo Profile Parameter Constraints
| Name - | log 10 ρ s [M glyph[circledot] pc - 3 ] - 2 σ - 1 σ median + 1 σ + 2 σ - 2 σ | log 10 r s [pc] - 1 σ median + 1 σ + 2 σ | α - - 2 σ | - 1 σ | median + 1 σ + 2 σ - 2 σ | median + 1 σ + 2 σ - 2 σ | β - - 1 σ | median | + 1 σ + 2 σ - 2 σ - 1 σ | γ - median + 1 σ + 2 σ - 2 σ | γ - median + 1 σ + 2 σ - 2 σ | - log 10 (1 - - - 1 σ median | β a ) + 1 σ + 2 σ | |
|----------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------|----------------------------------------------------------------------------|--------------------------|----------------------------|---------------------------------------------------|--------------------------|--------------------------|-----------------------------------------------------------------------------------------------------|--------------------------------|------------------------------------------------------------------------------------|--------------------------------|---------------------------------------------------|----|
| Carina Draco Fornax Leo I Leo II . . . | -3.74 -2.86 -1.96 -1.28 -0.73 2.61 -3.36 -2.66 -1.74 -1.09 -0.78 2.85 -2.11 -1.83 -1.49 -1.20 -0.76 2.73 -3.69 -3.08 -2.18 -1.38 -0.92 2.91 -3.24 -2.31 -0.92 -0.03 0.47 1.95 | 2.90 3.31 3.11 3.57 2.93 3.09 3.23 3.80 2.29 2.89 | 3.96 4.63 0.62 4.34 4.83 0.75 3.25 3.51 0.86 4.55 4.91 0.71 4.03 4.77 0.64 | 0.87 1.18 1.39 1.12 1.01 | 1.47 2.01 2.13 1.93 1.76 | 2.89 3.12 2.95 3.19 2.96 3.30 2.94 3.16 2.90 3.16 | 3.75 4.16 4.54 3.99 3.89 | 5.60 6.34 6.97 6.15 5.95 | 8.36 9.71 0.13 0.54 8.69 9.74 0.06 0.29 9.02 9.84 0.03 0.19 8.70 9.76 0.09 0.41 8.56 9.73 0.08 0.35 | 0.95 0.71 0.61 0.84 0.82 | 1.19 -0.41 -0.23 1.16 0.01 0.25 1.17 -0.25 -0.15 1.18 -0.20 -0.03 1.18 -0.88 -0.51 | -0.07 0.54 -0.06 0.14 -0.01 | 0.08 0.25 0.81 0.97 0.02 0.09 0.37 0.72 0.51 0.88 | |
* This table is published in its entirety in the electronic edition of the Astrophysical Journal. A portion is shown here for guidance regarding its form and content.
## REFERENCES
| Abazajian, K. N., Canac, N., Horiuchi, S., &Kaplinghat, M. 2014, Phys. Rev. D, 90, 023526 Abazajian, K. N., &Kaplinghat, M. 2012, Phys. Rev. D, 86, |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 083511 -. 2013, Phys. Rev. D, 87, 129902 Ackermann, M., Ajello, M., Albert, A., et al. 2011, Physical Review |
| Letters, 107, 241302 M., Albert, A., Anderson, B., et al. 2014, Phys. Rev. D, 89, |
| Ackermann, 042001 |
| Actis, M., Agnetta, G., Aharonian, F., et al. 2011, Experimental Astronomy, 32, 193 D., Wilkinson, M. I., Read, J. I., et al. 2009a, ApJ, 706, L150 |
| Adén, Adén, D., Feltzing, S., Koch, A., et al. 2009b, A&A, 506, 1147 |
| Aleksi´, c J., Alvarez, E. A., Antonelli, L. A., et al. 2011, J. Cosmology Astropart. Phys., 6, 35 Aliu, E., Archambault, S., Arlen, T., et al. 2012, Phys. Rev. D, 85, 062001 |
| Ashby, M. L. N., Stanford, S. A., Brodwin, M., et al. 2013, ApJS, 209, 22 -. 2014, ApJS, 212, 16 Belokurov, V., Walker, M. G., Evans, N. W., et al. 2009, MNRAS, 397, |
| 1748 -. 2010, ApJ, 712, L103 |
| Belokurov et al. 2007, ApJ, 654, 897 -. 2008, ApJ, 686, L83 |
| Binney, J., &Tremaine, S. 2008, Galactic Dynamics: Second Edition (Princeton University Press) Bond, J. R., Cole, S., Efstathiou, G., &Kaiser, N. 1991, ApJ, 379, 440 |
| Bonnivard, V., Combet, C., Maurin, D., &Walker, M. G. 2015, MNRAS, 446, 3002 |
| Bower, R. G. 1991, MNRAS, 248, 332 Boyarsky, A., Malyshev, D., &Ruchayskiy, O. 2011, Physics Letters 705, 165 |
| B, Charbonnier, A., Combet, C., Daniel, M., et al. 2011, MNRAS, 418, 1526 |
| Cholis, I., &Salucci, P. 2012, Phys. Rev. D, 86, 023528 Daylan, T., Finkbeiner, D. P., Hooper, D., et al. 2014, ArXiv e-prints, arXiv:1402.6703 |
| de Blok, W. J. G. 2010, Advances in Astronomy, 2010, 789293 |
| de Jong, J. T. A., Martin, N. F., Rix, H.-W., et al. 2010, ApJ, 710, 1664 Donato, F., Gentile, G., Salucci, P., et al. 2009, MNRAS, 397, 1169 Essig, R., Sehgal, N., Strigari, L. E., Geha, M., &Simon, J. D. 2010, |
| Phys. Rev. D, 82, 123503 |
| Feroz, F., &Hobson, M. P. 2008, MNRAS, 384, 449 |
| Feroz, F., Hobson, M. P., &Bridges, M. 2009, MNRAS, 398, |
| 1601 Flaugher, B. 2005, International Journal of Modern Physics A, 20, 3121 |
| Gao, L., Navarro, J. F., Cole, S., et al. 2008, MNRAS, 387, 536 |
| Geha, M., Willman, B., Simon, J. D., et al. 2009, ApJ, 692, |
| 1464 Geringer-Sameth, A., &Koushiappas, S. M. 2011, Physical 107, 241303 |
| Review Letters, -. 2012, Phys. Rev. D, 86, 021302 |
| Geringer-Sameth, A., Koushiappas, S. M., &Walker, M. G. 2014, ArXiv e-prints, arXiv:1410.2242 |
| Gondolo, P., &Gelmini, G. 1991, Nuclear Physics B, 360, 145 |
| Hernquist, L. 1990, ApJ, 356, 359 Hooper, D., &Goodenough, L. 2011, Physics Letters B, 697, 412 Ibata, R. A., Wyse, R. F. G., Gilmore, G., Irwin, M. J., &Suntzeff, |
| N. 1997, AJ, 113, 634 |
| B. Irwin, M., &Hatzidimitriou, D. 1995, MNRAS, 277, 1354 |
| Jin, S., Martin, N., de Jong, J., et al. 2012, in Astronomical Society of Pacific Conference Series, Vol. 458, Galactic Archaeology: |
| Cosmology and the Formation of the Milky Way, ed. W. Aoki, |
| the Near-Field M. Ishigaki, T. Suda, T. Tsujimoto, &N. Arimoto, 153 |
| K. V. 1998, ApJ, 495, 297 |
| Johnston, Johnston, K. V., Sackett, P. D., &Bullock, J. S. 2001, ApJ, 557, 137 |
| G., Kamionkowski, M., &Griest, K. 1996, Phys. Rep., 267, 195 |
| Jungman, |
Kaiser, N., Aussel, H., Burke, B. E., et al. 2002, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, Vol. 4836, Survey and Other Telescope Technologies and Discoveries, ed. J. A. Tyson & S. Wolff, 154-164
King, I. 1962, AJ, 67, 471
Kirby, E. N., Boylan-Kolchin, M., Cohen, J. G., et al. 2013, ApJ, 770, 16
Klypin, A., Zhao, H., & Somerville, R. S. 2002, ApJ, 573, 597
Koposov, S. E., Gilmore, G., Walker, M. G., et al. 2011, ApJ, 736, 146
Lacey, C., & Cole, S. 1993, MNRAS, 262, 627
Mamon, G. A., & Łokas, E. L. 2005, MNRAS, 363, 705
Martin, N. F., de Jong, J. T. A., & Rix, H.-W. 2008, ApJ, 684, 1075
Martinez, G. D. 2013, ArXiv e-prints, arXiv:1309.2641
Martinez, G. D., Bullock, J. S., Kaplinghat, M., Strigari, L. E., & Trotta, R.
2009, J. Cosmology Astropart. Phys., 6, 14
Martinez, G. D., Minor, Q. E., Bullock, J., et al. 2011, ApJ, 738, 55
Mateo, M., Olszewski, E. W., & Walker, M. G. 2008, ApJ, 675, 201
McConnachie, A. W. 2012, AJ, 144, 4
- McConnachie, A. W., & Côté, P. 2010, ApJ, 722, L209
- Mo, H., van den Bosch, F. C., & White, S. 2010, Galaxy Formation and Evolution (Cambridge: Cambridge University Press)
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 -. 1997, ApJ, 490, 493
- Nesti, F., & Salucci, P. 2013, J. Cosmology Astropart. Phys., 7, 16
- Newton, I. 1687, Philosophiae naturalis principia mathematica (London: Royal Society Press)
Plummer, H. C. 1911, MNRAS, 71, 460
- Read, J. I., Wilkinson, M. I., Evans, N. W., Gilmore, G., & Kleyna, J. T. 2006, MNRAS, 366, 429
Salucci, P., Wilkinson, M. I., Walker, M. G., et al. 2012, MNRAS, 420, 2034
Sand, D. J., Seth, A., Olszewski, E. W., et al. 2010, ApJ, 718, 530
Sand, D. J., Strader, J., Willman, B., et al. 2012, ApJ, 756, 79
- Scott, P., Conrad, J., Edsjö, J., et al. 2010, J. Cosmology Astropart. Phys., 1, 31
- Simon, J. D., & Geha, M. 2007, ApJ, 670, 313
- Simon, J. D., Geha, M., Minor, Q. E., et al. 2011, ApJ, 733, 46
- Skilling, J. 2004, in American Institute of Physics Conference Series, Vol. 735, Bayesian Inference and Maximum Entropy Methods in Science and Engineering, ed. R. Fischer, R. Preuss, & U. V. Toussaint, 395-405 Strigari, L. E., Koushiappas, S. M., Bullock, J. S., & Kaplinghat, M. 2007, Phys. Rev. D, 75, 083526
- Taylor, J. E., & Babul, A. 2001, ApJ, 559, 716
- -. 2004, MNRAS, 348, 811
Tyson, J. A., Wittman, D. M., Hennawi, J. F., & Spergel, D. N. 2003,
Nuclear Physics B Proceedings Supplements, 124, 21
van der Marel, R. P. 1994, MNRAS, 270, 271
- von Hoerner, S. 1957, ApJ, 125, 451
- Walker, M. G., Belokurov, V., Evans, N. W., et al. 2009a, ApJ, 694, L144
- Walker, M. G., Combet, C., Hinton, J. A., Maurin, D., & Wilkinson, M. I. 2011, ApJ, 733, L46+
- Walker, M. G., Mateo, M., Olszewski, E. W., et al. 2009b, ApJ, 704, 1274 Walker, Mateo & Olszewski. 2009, AJ, 137, 3100
- Walsh, S. M., Jerjen, H., & Willman, B. 2007, ApJ, 662, L83
- Wechsler, R. H., Zentner, A. R., Bullock, J. S., Kravtsov, A. V., & Allgood, B. 2006, ApJ, 652, 71
Willman, B., Geha, M., Strader, J., et al. 2011, AJ, 142, 128
Willman et al. 2005, ApJ, 626, L85
Zentner, A. R., & Bullock, J. S. 2002, Phys. Rev. D, 66, 043003
- -. 2003, ApJ, 598, 49
Zhao, H. 1996, MNRAS, 278, 488
Zucker et al. 2006a, ApJ, 650, L41
- -. 2006b, ApJ, 643, L103 | 10.1088/0004-637X/801/2/74 | [
"Alex Geringer-Sameth",
"Savvas M. Koushiappas",
"Matthew Walker"
] | 2014-07-31T20:00:00+00:00 | 2015-03-11T18:52:54+00:00 | [
"astro-ph.CO",
"astro-ph.GA",
"astro-ph.HE"
] | Dwarf galaxy annihilation and decay emission profiles for dark matter experiments | Gamma-ray searches for dark matter annihilation and decay in dwarf galaxies
rely on an understanding of the dark matter density profiles of these systems.
Conversely, uncertainties in these density profiles propagate into the derived
particle physics limits as systematic errors. In this paper we quantify the
expected dark matter signal from 20 Milky Way dwarfs using a uniform analysis
of the most recent stellar-kinematic data available. Assuming that the observed
stellar populations are equilibrium tracers of spherically-symmetric
gravitational potentials that are dominated by dark matter, we find that
current stellar-kinematic data can predict the amplitudes of annihilation
signals to within a factor of a few for the ultra-faint dwarfs of greatest
interest. On the other hand, the expected signal from several classical dwarfs
(with high-quality observations of large numbers of member stars) can be
localized to the ~20% level. These results are important for designing
maximally sensitive searches in current and future experiments using space and
ground-based instruments. |
1408.0003v1 | ## New physics in resonant production of Higgs boson pairs
Vernon Barger , Lisa L. Everett a a , C. B. Jackson , Andrea Peterson b a , Gabe Shaughnessy a a Department of Physics, University of Wisconsin, Madison, WI 53706, USA b Department of Physics, University of Texas at Arlington, Arlington, TX 76019, USA (Dated: August 4, 2014)
We advocate a search for an extended scalar sector at the LHC via hh production, where h is the 125 GeV Higgs boson. A resonance feature in the hh invariant mass is a smoking gun of an s -channel heavy Higgs resonance, H . With one h decaying to two photons and the other decaying to b -quarks, the resonant signal may be discoverable above the hh continuum background for M H < 1 TeV. The product of the scalar and top Yukawa couplings can be measured to better than 10 -20% accuracy, and its sign can be inferred from the hh lineshape via interference effects.
PACS numbers: 14.80.Ec, 12.60.Fr
Introduction. The discovery of the 125 GeV Higgs boson at the LHC marks the successful completion of the long quest to validate the spontaneous breaking of the Standard Model (SM) gauge symmetry. The discovery intensifies the search for new physics at the TeV scale using this Higgs particle as a probe. The Higgs branching fractions have been measured in many channels, with the best determinations in h → γγ , h → ZZ ∗ → glyph[lscript] + glyph[lscript] -glyph[lscript] + glyph[lscript] -, h → WW ∗ → glyph[lscript] + νglyph[lscript] -¯, ν and (to a lesser extent) in h → bb, τ ¯ + τ -[1, 2]. The h couplings to tt ¯ and gg have been inferred from the cross sections and the total Higgs width has been bounded above the SM prediction. [1-5].
Although all evidence to date is consistent with the SM Higgs sector, LHC14 is quickly approaching. The precision of Higgs coupling measurements may reach a level at which the presence of new physics contributions is evident, and an International Linear Collider could provide still greater precision [4, 5]. However, new physics may be difficult to detect in single Higgs production, for example in the decoupling limit of an extended scalar sector. Indeed, analyses have been done with LHC8 data [6]. Whether or not this occurs, the measurement of the M hh distribution in double Higgs production at LHC14 and its model independent interpretation could give an important new way to determine whether just the SM Higgs is the whole story. This is the aim of this study.
Double Higgs production is potentially discoverable in several final states, of which the most promising is hh → bbγγ ¯ , allowing a measurement of λ hhh to O (50%) from the moderate M bbγγ ¯ region [7, 8]. The presence of γγ allows severe rejection of background, but with an attendant high cost to the signal rate. The branching fraction of hh → bbγγ ¯ is only 0.28% in the SM, and thus the identification of the SM signal above the continuum background is challenging. The hh → bbτ ¯ + τ -signal is rendered unfeasible by the reducible background of bbjj ¯ where both light flavored jets fake a τ . The bbW ¯ + W -channel has only a small significance in the SM [9].
The small SM hh cross section provides an opportunity to search for new physics in this channel. In models with two (or more) Higgs doublets, the hh cross-section may be enhanced significantly above the SM by way of an s -channel Higgs boson resonance, H , dramatically improving the opportunity for a new physics discovery at the LHC. Measurements of the scalar mass and couplings can lead to a deeper understanding of the scalar sector with implications, for instance, in vacuum (meta)stability [10].
Higgs Pair Production. The Higgs pair is dominantly produced through two classes of amplitudes [11-13]: ( ) i the triangle diagram in which an s -channel J CP = 0 + particle mediates the gluon-gluon transition to two Higgs bosons and ( ii ) the box diagram in which the annihilation of two gluons through a loop produces the Higgs boson pair, as shown in Fig. (1). These amplitudes with generic internal/external Higgs bosons (and generic heavy quarks) were first computed in [14], to which we refer readers interested in the details.
The differential cross section at the parton level is
$$\begin{array} { c c c c c } \nu & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ^ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & 0 & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & b & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
FIG. 1: Representative processes that contribute to Higgs boson pair production. The final state requires a 0 + resonance.
in which the C 's are coupling form factors, the F 's and G 's are gauge invariant form factors arising from orthogonal gluonic tensor structures, and the NLO+NNLL Kfactor is K = 2 27 at 14 TeV [15-20]. . Resonant production can shift the overall K-factor, as σ NLO + NNLL /σ LO can be √ ˆ dependent. s However, since the K-factor has not been calculated for the resonant process, we adopt the SM value under the reasonable assumption that any change in its value due to the H resonance is small.
The s -channel diagram in Fig. 1 contains the h and H exchanges, where H is the heavy resonance that must be a 0 + state. Note that the particle(s) that couple to the SM doublet Φ need not carry quantum numbers, and can couple to quarks via mixing. We denote the coupling of the H to the hh pair as
$$\mathcal { L } \supset - \lambda ^ { h h H } H \Phi ^ { \dagger } \Phi. \quad \quad ( 2 ) \quad \ \ M _ { i } \\ \quad \ \ t i o n$$
The SM tri-scalar coupling has the form λ hhh SM = 3 M /v 2 h . The coupling combination λ hhH y H t , where y H t is the t -quark Yukawa coupling to H , is the prefactor in the s -channel H amplitude. The hh cross section is shown in Fig. 2 for LHC14. The enhancement from the resonance is typically over 100 fb, well above the SM value of σ SM pp → hh = 43 fb [18]. For a sufficiently heavy H , the λ hhh uncertainty is approximated to be the SM uncertainty [8]; there is a strong dependence of the coupling uncertainty at low M hh , where the SM signal is strong.
FIG. 2: Higgs pair production cross section at LHC14 with Γ H /M H = 1%. σ SM pp → hh = 43 fb (with a NLO+NNLL Kfactor).
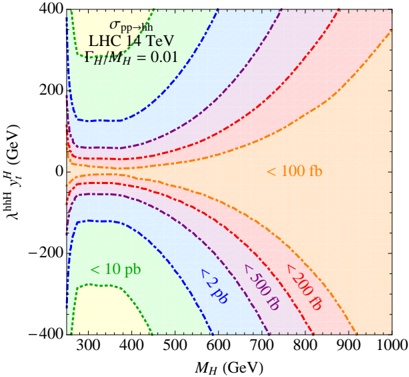
Measuring the hh lineshape. In the bbγγ ¯ channel, the dominant irreducible background is the continuum pp → bbγγ ¯ process. We also include the additional processes listed in [8] and adopt their tagging efficiencies, mis-tag rates, threshold requirements and momentum smearing. We simulate the resonant production of hh → bbγγ ¯ and as minimal cuts, require two b -tags, two γ tags and | M bb -m h | < 20 GeV and | M γγ -m h | < 10 GeV. Additional details on the acceptance criteria are given in [21].
We first study resonant production alone, which serves to determine the response of the detector simulation to an injection of hh states at a given √ ˆ, s greatly simplifying the subsequent analysis. The analytic differential distributions are Gaussian smeared according to the resonant shape after event simulation including particle identification and isolation. In the range of masses we consider, M H = 200 -1000 GeV, the energy resolution of the reconstructed bbγγ ¯ resonance is found to vary with increasing M H between 5 -25 GeV. The acceptance is computed for each resonant mass, which ranges from 6-11%.
To determine how well the H → hh resonance signal can be measured at LHC14, we perform a ∆ χ 2 fit of the M hh distribution to the expected SM pp → hh distribution that does not contain a resonance. We also include the effect of increased uncertainty via background subtraction by inflating the Poisson uncertainty according to the continuum bbγγ ¯ background distribution, and assume a 100% background normalization uncertainty.
The differential event rate is computed via
$$\underset { \text{$the} \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text#\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text}$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text'$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text`$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text.$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text<$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text51$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{#\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$$$
$$\int \stackrel { \cdot \cdot } { d M ^ { \prime } G ( M ^ { \prime }, M _ { b \bar { b } \gamma \gamma } ) } \frac { d \sigma _ { g g \to h h } } { d M ^ { \prime } } \int _ { ( M ^ { \prime } ) ^ { 2 } / s } ^ { 1 } d \tau \frac { d \mathcal { L } _ { g g } } { d \tau },$$
where A M ( bbγγ ¯ ) is the signal acceptance with the resonance at M H = M bbγγ ¯ , the Gaussian kernel with energy resolution σ is G E ,E ( ′ ) = ( √ 2 πσ ) -1 e -( E ′ -E ) 2 2 σ 2 , and d L gg /dτ is the parton luminosity for gg collisions.
In addition to λ hhh , the two free parameters that determine the differential distribution are M H and λ hhH y H t . In Fig. 3, we show the differential distributions for M H = 500 (800) GeV with Γ H /M H = 1% (10%) for λ hhH y H t = ± 100 GeV. The total width of H can vary considerably depending on λ hhH and its coupling to gauge bosons. Since the only measurable quantity is λ hhH y H t , the production rate can be taken to be independent of the total width, and therefore we just take the two cases.
In Fig. 4, we see that with ∫ L dt = 300 fb -1 , LHC14 can constrain | λ hhH y H t | glyph[greaterorsimilar] 100 (500) GeV over most of the mass range up to 1 TeV for a 1% (10%) total width. The decrease in the reach for low M H is mainly due to the continuum bbγγ ¯ background at low M bbγγ ¯ and (to a lesser extent) the reduced phase space near threshold.
The sign of λ hhH y H t can also be determined from the interference of the resonant and continuum amplitudes. This is seen in Fig. 3 where, even with momentum smearing, the interference effect is clearly visible. For λ hhH y H t > 0, an excess of events occurs below resonance and a deficit above resonance (and vice-versa for λ hhH y H t < 0). In Fig. 5, we show regions over which the sign of λ hhH y H t can be distinguished via the hh lineshape.
FIG. 3: The dN/dM bbγγ ¯ distribution for M H = 500 800 GeV , and λ hhH y H t = ± 100 GeV, for Γ H /M H = 1% (top) and Γ H /M H = 10% (bottom). The SM bbγγ ¯ continuum background (gray shaded) peaks at low invariant mass while the SM hh continuum is denoted by the black curve. Even with momentum smearing, the sign of λ hhH y H t can be resolved.
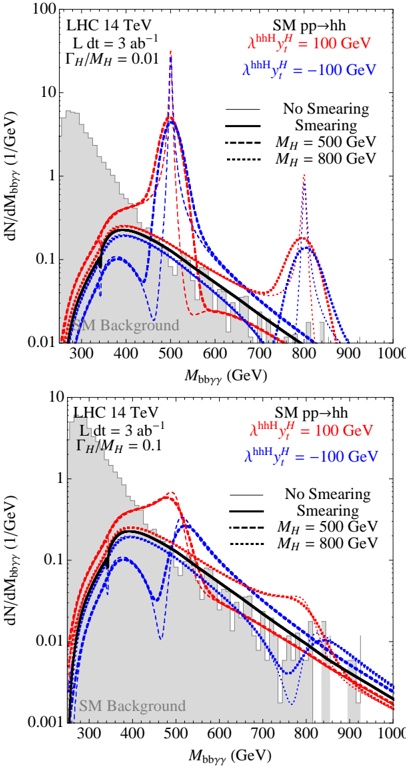
We perform a ∆ χ 2 fit to approximately 1500 points in the M H -λ hhH y H t plane for Γ H /M H = 0 01(0.1), varying . M H , Γ H , λ hhH y H t , and λ hhh simultaneously and restricting the luminosity to L dt = 3 ab -1 . We find that M H can be measured to 0.5% or better and the total width to 20% or better over most of the parameter space. For an intrinsically broader Higgs width with Γ H /M H = 0 1, . the fit is degraded for the Higgs mass measurement, but the fit uncertainty in Γ H /M H is not that different.
In Fig. 6, we show the 1 σ uncertainty of λ hhH y H t , which can be probed to a remarkably sensitive level over most of the parameter space and in some cases to less than 2%. This sensitivity degrades somewhat as the total width is increased, but the uncertainty remains low. For a particular model of Yukawa couplings, the scalar coupling can
FIG. 4: LHC14 reach of the H resonance in the M H and coupling plane with ∫ L dt = 300 fb -1 for Γ H /M H = 1% (top) and Γ H /M H = 10% (bottom). The asymmetry in the contours is due to the SM continuum contribution.
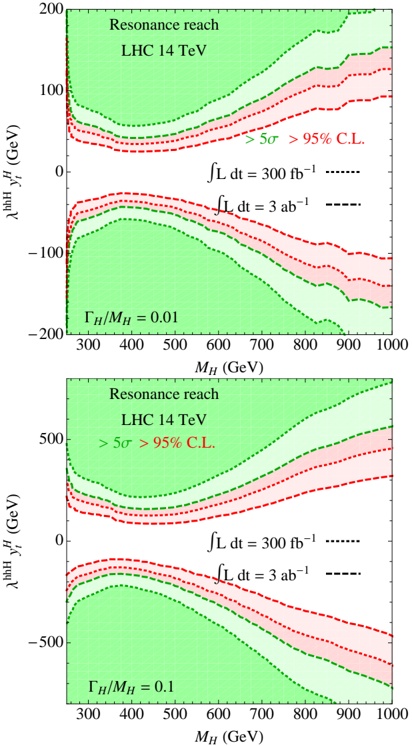
be accurately deduced. Even better, with an independent measurement of the H coupling to the quark sector, the scalar coupling can be uniquely determined.
Conclusions. We studied resonant pair production of the 125 GeV Higgs h for the final state in which one h decays to γγ and the other to bb ¯ . In new physics models with a heavy CP-even Higgs H , the s -channel resonance amplitude of the H interferes with the SM amplitudes. We find that LHC14 sensitivity to the H → hh channel is possible if the magnitude of the product of the scalar and top quark Yukawa couplings λ hhH y H t is O (100 GeV) or larger (for M H ≤ 1 TeV) and its sign can be inferred from the hh lineshape via interference effects. λ hhH y H t can be measured to greater than 10 -20% accuracy over a broad range of M H ≤ 1 TeV. Using the resonant enhancement of hh production, the scalar coupling can be deduced or directly measured, yielding a deeper understanding of the scalar sector with potentially profound implications.
FIG. 5: LHC14 sensitivity to the sign of λ hhH y H t from the interference between the SM and H resonant diagrams for Γ H /M H = 1% (top) and Γ H /M H = 10% (bottom).
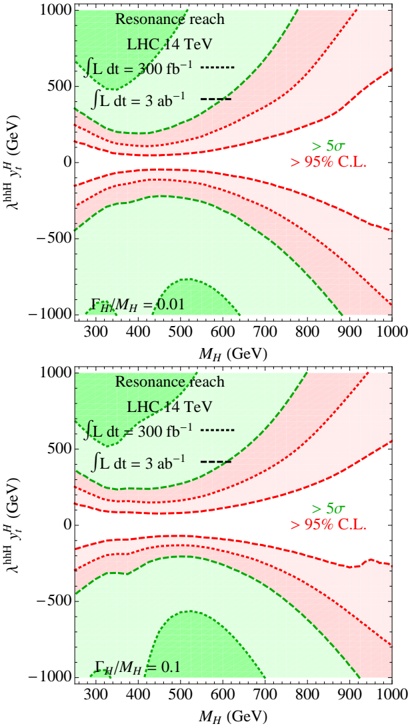
Acknowledgements. V. B., L. L. E, A. P. and G. S. are supported by the U. S. Department of Energy under the contract DE-FG-02-95ER40896.
- [1] The ATLAS collaboration, ATLAS-CONF-2014-009.
- [2] The CMS Collaboration, CMS-PAS-HIG-14-009.
- [3] V. Barger, M. Ishida and W. -Y. Keung, Phys. Rev. Lett. 108 , 261801 (2012) [arXiv:1203.3456 [hep-ph]].
- [4] S. Dawson, A. Gritsan, H. Logan, J. Qian, C. Tully, R. Van Kooten, A. Ajaib and A. Anastassov et al. , arXiv:1310.8361 [hep-ex].
- [5] V. Barger, L. L. Everett, H. E. Logan and G. Shaughnessy, Phys. Rev. D 88 , 115003 (2013) [arXiv:1308.0052 [hep-ph]].
- [6] The CMS Collaboration, CMS-PAS-HIG-13-032.
- [7] W. Yao, arXiv:1308.6302 [hep-ph].
- [8] V. Barger, L. L. Everett, C. B. Jackson and G. Shaughnessy, Phys. Lett. B 728 , 433 (2014) [arXiv:1311.2931
FIG. 6: Fit uncertainties at the 1 σ level for λ hhH y H t for Γ H /M H = 0.01 (top) and 0.1 (bottom) with ∫ L dt = 3 ab -1 .
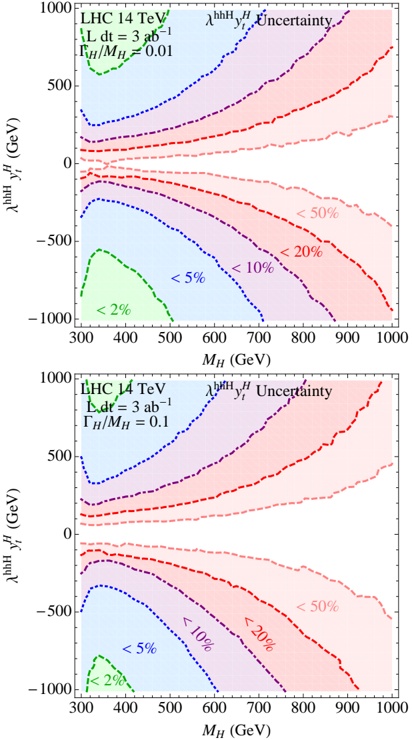
[hep-ph]].
- [9] J. Baglio, A. Djouadi, R. Gro¨ber, M. M. M¨hlleitner, o u J. Quevillon and M. Spira, JHEP 1304 , 151 (2013) [arXiv:1212.5581 [hep-ph]].
- [10] G. Degrassi, S. Di Vita, J. Elias-Miro, J. R. Espinosa, G. F. Giudice, G. Isidori and A. Strumia, JHEP 1208 , 098 (2012) [arXiv:1205.6497 [hep-ph]].
- [11] O. J. P. Eboli, G. C. Marques, S. F. Novaes and A. A. Natale, Phys. Lett. B 197 , 269 (1987).
- [12] E. W. N. Glover and J. J. van der Bij, Nucl. Phys. B 309 , 282 (1988).
- [13] D. A. Dicus, C. Kao and S. S. D. Willenbrock, Phys. Lett. B 203 , 457 (1988).
- [14] T. Plehn, M. Spira and P. M. Zerwas, Nucl. Phys. B 479 , 46 (1996) [Erratum-ibid. B 531 , 655 (1998)] [hepph/9603205].
- [15] S. Dawson, S. Dittmaier and M. Spira, Phys. Rev. D 58 , 115012 (1998) [hep-ph/9805244].
- [16] S. Dittmaier et al. arXiv:1101.0593 [hep-ph].
- [17] G. C. Branco et al, Phys. Rept. 516 , 1 (2012) [arXiv:1106.0034 [hep-ph]].
- [18] D. Y. Shao, C. S. Li, H. T. Li and J. Wang,
arXiv:1301.1245 [hep-ph].
- [19] D. de Florian and J. Mazzitelli, Phys. Lett. B 724 , 306 (2013) [arXiv:1305.5206 [hep-ph]].
- [20] D. de Florian and J. Mazzitelli, Phys. Rev. Lett. 111 ,
201801 (2013) [arXiv:1309.6594 [hep-ph]].
- [21] V. Barger, L. L. Everett, C. B. Jackson, A. Peterson and G. Shaughnessy, in preparation. | 10.1103/PhysRevLett.114.011801 | [
"Vernon Barger",
"Lisa L. Everett",
"C. B. Jackson",
"Andrea Peterson",
"Gabe Shaughnessy"
] | 2014-07-31T20:00:00+00:00 | 2014-07-31T20:00:00+00:00 | [
"hep-ph",
"hep-ex"
] | New physics in resonant production of Higgs boson pairs | We advocate a search for an extended scalar sector at the LHC via $hh$
production, where $h$ is the 125 GeV Higgs boson. A resonance feature in the
$hh$ invariant mass is a smoking gun of an $s$-channel heavy Higgs resonance,
$H$. With one $h$ decaying to two photons and the other decaying to $b$-quarks,
the resonant signal may be discoverable above the $hh$ continuum background for
$M_H<$ 1 TeV. The product of the scalar and top Yukawa couplings can be
measured to better than $10-20\%$ accuracy, and its sign can be inferred from
the $hh$ lineshape via interference effects. |
1408.0004v1 | ## Biharmonic Split Ring Resonator Metamaterial: Artificially dispersive effective density in thin periodically perforated plates
Mohamed Farhat, 1, 2 Stefan Enoch, 3 and Sebastien Guenneau 3
1 Institute of Condensed Matter Theory and Solid State Optics, Abbe Center of Photonics, Friedrich-Schiller-Universit¨t Jena, D-07743 Jena, Germany a 2 Division of Computer, Electrical, and Mathematical Sciences and Engineering, 4700 King Abdullah University of Science and Technology, Thuwal 23955-6900, Saudi Arabia 3 Aix-Marseille Universit´, CNRS, Centrale Marseille, Institut Fresnel, e Campus universitaire de Saint-J´rˆme, 13013 Marseille, France e o
(Dated: August 4, 2014)
## Abstract
We present in this paper a theoretical and numerical analysis of bending waves localized on the boundary of a platonic crystal whose building blocks are split ring resonators (SRR). We first derive the homogenized parameters of the structured plate using a three-scale asymptotic expansion in the linearized biharmonic equation. In the limit when the wavelength of the bending wave is much larger than the typical heterogeneity size of the platonic crystal, we show that it behaves as an artificial plate with an anisotropic effective Young modulus and a dispersive effective mass density. We then analyze dispersion diagrams associated with bending waves propagating within an infinite array of SRR, for which eigen-solutions are sought in the form of Floquet-Bloch waves. We finally demonstrate that this structure displays the hallmarks of All-Angle-Negative-Refraction(AANR) and it leads to superlensing and ultrarefraction effects, interpreted thanks to our homogenization model as a consequence of negative and vanishing effective density, respectively.
PACS numbers: 43.40.+s, 46.40.Cd, 62.30.+d, 81.05.Xj
## I. INTRODUCTION
Left Handed Materials (LHM) are a new kind of materials which were theoretically envisionned by Veselago 1 as early as in 1967. Such materials have simultaneously negative relative permittivity ( ε r ) and negative relative permeability ( µ r ). This theoretical curiosity became a real field of research in 2000 after Pendry showed the potential of LHM to overcome the diffraction limit 2 and Smith et al. 3 proposed a first realization for such extra-ordinary materials based on periodic lattices combining Split Ring Resonators (SRR: Concentric annular rings with splits) and wires. The latter work can be considered as the experimental foundation of LHM (as the first experimental evidence of negative refraction) and it is based on a theoretical study by Pendry et al. which shows that negative permittivity could be obtained by a periodic arrangement of parallel wires and that a periodic lattice of SRR had a negative magnetic response around its resonance frequency . 4
In the recent years, there has been a keen interest in wave propagation in periodically structured media . 5 Investigation of photonic crystals has paved the way to the theoretical prediction and experimental realization of photonic band gaps 6-12 i.e. ranges of frequencies for which light, or a light polarization, is disallowed to propagate. Soon after, the focus has been extended to the study of acoustic waves in periodic media, and the existence of phononic band gaps has been verified both theoretically and experimentally 13-18 . Recently, the interest was even extended to the study of different types of waves, e.g. liquid surface waves 19-23 or biharmonic waves 24-28 in perforated thin plates. It has been shown that complete bandgaps also exist for these waves when propagating through a periodic lattice of vertically standing rods or over a periodically perforated thin plate 22,26 . In addition, many interesting phenomena have been reported, including negative refraction 1,29-33 , the superlensing effect and cloaking 34-38 . The essential condition for the AANR effect is that the constant frequency surfaces (EFS: equifrequency surfaces) should become convex everywhere about some point in the reciprocal space, and the size of these EFS should shrink with increasing frequency 9-11 .
In this paper, we focus on the application of split ring resonator (SRR) structures 4,39,40 to the domain of elastic waves. We first derive the homogenized governing equations of bending waves propagating within a thin-plate with a doubly periodic square array of freely
vibrating holes shaped as SRR, from the generalized biharmonic equation, and an asymptotic analysis involving three scales (one for the thickness of the thin-cut of each SRR, one for the array-pitch, and one for the wave wavelength). We then present an analysis of dispersion curves. To do this, we set the spectral problem for the biharmonic operator within a doubly periodic square array of SRR, homogeneous stress-free boundary conditions are prescribed on the contour of each resonator and the standard Floquet-Bloch conditions are set on the boundary of an elementary cell of the periodic structure. Such a structure presents an elastic bandgap at low frequencies. It turns out that the asymptotic analysis of our structure allows us to get analytically the frequency of the first localized mode and then the frequency of the first band gap. The aim of our work is actually to demonstrate the AANR effect at low frequencies for elastic thin perforated plates as well as their superlensing properties. Ultrarefraction is also considered and shows the versatility and power of using such structured media to realize new functionalities for surface elastic waves.
## II. HOMOGENIZATION OF A THIN-PLATE WITH AN ARRAY OF STRESSFREE SRR INCLUSIONS NEAR RESONANCE
The equations for bending of plates can be found in many textbooks 41,42 . The wavelength λ is supposed to be large enough compared to the thickness of the plate H and small compared to its in-plane dimension L , i.e. H /lessmuch λ /lessmuch L . In this case we can adopt the hypothesis of the theory of Von-Karman 41,42 . In this way, the mathematical setup is essentially two-dimensional, the thickness H of the plate appearing simply as a parameter in the governing equation.
We would like to homogenize a periodically structured thin-plate involving resonant elements. The resonances are associated with fast-oscillating displacement fields in thin-bridges of perforations shaped as split ring resonators (SRR), and we filter these oscillations by introducing a third scale in the usual two-scale expansion. We start with the Kirchhoff-Love equation and we consider an open bounded region Ω f ∈ R 2 . This region is e.g. a slab lens consisting of a square array of SRR shaped as the letter C .
When the bending wave penetrates the structured area Ω f of the plate whose geometry is shown in Figs. 1(c)-(d), it undergoes fast periodic oscillations. To filter these oscillations, we consider an asymptotic expansion of the associated vertical displacement U η solution of the
FIG. 1: (a) Geometry of a split ring resonator C consisting of a disc Σ connected to a thin ligament Π η of length l and thickness ηh where 0 < η /lessmuch 1 in a unit cell Y; (b) Helmholtz resonator consisting of a mass connected to a wall via a spring which models resonances of SRR in (a); (c) Doubly periodic square lattice of SRR with the first Brillouin zone ΓXM in reciprocal space; (d) Geometry of the thin plate of thickness H , with a source on the left side of a platonic crystal (PC) slab occupying the region Ω f .
biharmonic equation given in (1) in terms of a macroscopic (or slow) variable x = ( x , x 1 2 ) and a microscopic (or fast) variable x η = x /η , where η is a small positive real parameter. With all the above assumptions, the out-of-plane displacement u η = (0 0 , , U η ( x , x 1 2 )) in the x 3 -direction (along the vertical axis) is solution of (assuming a time-harmonic dependence
exp( -iωt ) with ω the angular wave frequency):
$$\begin{array} { c } \nu _ { \eta } \, \max \, \nu \, \max \, \nu \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \, \nu _ { \eta } \, \max \\ + \frac { \partial ^ { 2 } } { \partial x _ { 2 } \partial x _ { 2 } } \left ( D _ { \eta } \left ( \frac { \partial ^ { 2 } } { \partial x _ { 2 } \partial x _ { 2 } } + \nu _ { \eta } \frac { \partial ^ { 2 } } { \partial x _ { 1 } \partial x _ { 1 } } \right ) \right ) U _ { \eta } \\ + 2 \frac { \partial ^ { 2 } } { \partial x _ { 1 } \partial x _ { 2 } } \left ( D _ { \eta } \left ( 1 - \nu _ { \eta } \right ) \frac { \partial ^ { 2 } } { \partial x _ { 1 } \partial x _ { 2 } } \right ) U _ { \eta } - \, \beta _ { \eta } ^ { 4 } U _ { \eta } = 0 \,, \\ \text{he heterogeneous isotropic region } \Omega _ { f } \left ( \text{the platonic crystal, PC, in Fig. } 1 ( d ) \right ), \text{where} \end{array}$$
inside the heterogeneous isotropic region Ω f (the platonic crystal, PC, in Fig. 1(d)), where
$$D _ { \eta } = D ( \frac { \mathbf x } { \eta } ) \, \ \nu _ { \eta } = \nu ( \frac { \mathbf x } { \eta } ) \ \text{ and } \ \beta _ { \eta } ^ { 4 } = \beta _ { 0 } ^ { 4 } \rho ( \frac { \mathbf x } { \eta } )$$
are nondimensionalized spatially varying parameters related to the flexural rigidity of the plate, its Poisson ratio and the wave frequency, respectively. In most cases, D and ν take piecewise constant values, with D > 0 and -1 / 2 < ν < 1 / 2. Note that β 2 0 = ω √ ρ H/D 0 0 , where D 0 is the flexural rigidity of the plate outside the platonic crystal, ρ 0 its density and H its thickness.
Remark that (1) is written in weak form and we notably retrieve the classical boundary conditions for a homogeneous plate with stress-free inclusions (vanishing of bending moments and shearing stress for vanishing D η and ν η in the soft phase) 42 . Since there is only one phase in the problem which we consider (homogeneous medium outside freely-vibrating inclusions), it is also possible to recast (1) as
$$( \sqrt { D _ { \eta } } \nabla ^ { 2 } U _ { \eta } + \beta _ { \eta } ^ { 2 } ) ( \sqrt { D _ { \eta } } \nabla ^ { 2 } U _ { \eta } - \beta _ { \eta } ^ { 2 } ) U _ { \eta } = 0 \, \ \text{in} \ \Omega _ { f } \ \, \overline { \Theta } _ { \eta } \, \\ \intertext { e D _ { \ } v a n i s h e s i n s i d e t h e i n c i s i n s o n s o n } \Theta _ { \ } = 1 1.. \in \{ n ( i + C \), \, \text{and} \, i t i s a \, \text{constant in the} }$$
$$& \text{at} \left ( ( 1 + \nu _ { \eta } ) \left ( \frac { \partial ^ { 2 } } { \partial x _ { 1 } ^ { 2 } } + \frac { \partial ^ { 2 } } { \partial x _ { 2 } ^ { 2 } } \right ) + 2 ( 1 - \nu _ { \eta } ) \left ( \frac { \partial ^ { 2 } } { \partial x _ { 1 } \partial x _ { 2 } } \right ) \right ) U _ { \eta } = 0 \, \\ & \left ( ( 3 - \nu _ { \eta } ) \left ( \frac { \partial ^ { 3 } } { \partial x _ { 1 } ^ { 3 } } + \frac { \partial ^ { 3 } } { \partial x _ { 2 } ^ { 3 } } \right ) + ( 1 + \nu _ { \eta } ) \left ( \frac { \partial ^ { 3 } } { \partial x _ { 1 } ^ { 2 } \partial x _ { 2 } } + \frac { \partial ^ { 3 } } { \partial x _ { 1 } \partial x _ { 2 } ^ { 2 } } \right ) \right ) U _ { \eta } = 0 \, \\ ; & \text{the boundary } \partial \Theta _ { \eta } \text{ of } \Theta _ { \eta }, \text{ which is consistent with our former work on thin perforated}$$
since D η vanishes inside the inclusions Θ η = ⋃ i ∈ Z 2 { η i ( + C ) } and it is a constant in the matrix. Bear in mind that the number of SRR in Ω f is an integer which scales as η -2 . Note also that the vanishing of bending moment and shearing stress deduced from (1) requires that
At the boundary ∂ Θ η of Θ , which is consistent with our former work on thin perforated η plates 27 .
In the present case, perforations are shaped as split ring resonators, and each SRR C can be modeled as
$$C = \{ a < \sqrt { x _ { 1 } ^ { 2 } + x _ { 2 } ^ { 2 } } < b \} \, \langle \, \overline { \Pi _ { \eta } } \, \\ \, \rangle$$
where a and b are functions of variables x , x 1 2 , unless the ring is circular and
$$\Pi _ { \eta } = \left \{ ( x _ { 1 }, x _ { 2 } ) \, \colon 0 < x _ { 1 } < l \,, \, | \, x _ { 2 } \, | < \eta h / 2 \right \}, \, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \Pi _ { \eta } = \left \} & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & 0 & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ^ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & b & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & | & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
is a thin ligament of length l = b -a between the ends of the letter C , see Fig. 1(a).
Our aim is to show that the homogenized multi-structured platonic structure within Ω f is characterized by an effective density which can take negative values near the fundamental resonance of the SRR. To do this, we need to perform a homogenization of a periodic structure involving resonant elements. The resonances are associated with fast-oscillating fields in thin-bridges of SRR perforations of the plate, and we filter these oscillations by introducing a third scale in the usual two-scale expansion:
$$\forall \mathbf x \in \Omega _ { f }, \ U _ { \eta } ( \mathbf x ) \, = \, & U _ { 0 } ( \mathbf x, \frac { \mathbf x } { \eta }, \frac { x _ { 2 } } { \eta ^ { 2 } } ) + \eta U _ { 1 } ( \mathbf x, \frac { \mathbf x } { \eta }, \frac { x _ { 2 } } { \eta ^ { 2 } } ) \\ & + \eta ^ { 2 } U _ { 2 } ( \mathbf x, \frac { \mathbf x } { \eta }, \frac { x _ { 2 } } { \eta ^ { 2 } } ) + \dots \\ \wedge \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd�$$
↦
where U i : Ω f × Y × -[ h/ , h/ 2 2] -→ C is a smooth function of variables ( x y , , ξ ) = ( x , x , y 1 2 1 , y 2 , ξ ), independent of η , such that ∀ x ∈ Ω f , φ i ( x , · , ξ ) is Y -periodic, and h denotes the thickness of the thin-cut of the SRR.
The differential operator is rescaled accordingly as ∇ = ∇ x + 1 η ∇ y + 1 η 2 ∇ ξ , so that Eq. (2) can be reexpressed as
$$\ a n \ v o c \colon \ e q p e s c u a s & \quad \\ & \left \{ \sqrt { D _ { \eta } } \left ( \nabla _ { x } + \frac { 1 } { \eta } \nabla _ { y } + \frac { 1 } { \eta ^ { 2 } } \nabla _ { \xi } \right ) \cdot \left ( \nabla _ { x } + \frac { 1 } { \eta } \nabla _ { y } + \frac { 1 } { \eta ^ { 2 } } \nabla _ { \xi } \right ) + \beta _ { \eta } ^ { 2 } \right \} \\ & \times \left \{ \sqrt { D _ { \eta } } \left ( \nabla _ { x } + \frac { 1 } { \eta } \nabla _ { y } + \frac { 1 } { \eta ^ { 2 } } \nabla _ { \xi } \right ) \cdot \left ( \nabla _ { x } + \frac { 1 } { \eta } \nabla _ { y } + \frac { 1 } { \eta ^ { 2 } } \nabla _ { \xi } \right ) - \beta _ { \eta } ^ { 2 } \right \} \\ & \left \{ \sum _ { i = 0 } ^ { \infty } \eta ^ { i U _ { i } ( x, \frac { x } { \eta }, \frac { x _ { 2 } } { \eta } ) } \right \} = 0 \, \\ & \text{ith the notations } \nabla _ { x } = ( \frac { \partial } { \partial x _ { i } }, \frac { \partial } { \partial x _ { i } } ), \nabla _ { y } = ( \frac { \partial } { \partial u }, \frac { \partial } { \partial u _ { n } } ) \text{ and } \nabla _ { \xi } = ( 0, \frac { \partial } { \partial \xi } ).$$
with the notations ∇ x = ( ∂ ∂x 1 , ∂ ∂x 2 ), ∇ y = ( ∂ ∂y 1 , ∂ ∂y 2 ) and ∇ ξ = (0 , ∂ ∂ξ ). Collecting terms of same power of η in Eq. (7), we obtain the homogenized problem 43 ,
$$( \sqrt { D _ { h o m } } \nabla ^ { 2 } U _ { \eta } + \beta _ { 0 } ^ { 2 } \sqrt { \rho _ { h o m } } ) ( \sqrt { D _ { h o m } } \nabla ^ { 2 } U _ { \eta } - \beta _ { 0 } ^ { 2 } \sqrt { \rho _ { h o m } } ) U _ { \eta } = 0 \, \ \text{in} \ \Omega _ { f } \ \langle \overline { \Theta _ { \eta } } \, \quad \quad ( 8 ) \\ \text{in the limit when $n$ tends to zero. in the natonic crystal $\Omega_{\cdot}$ This is the homoserized}$$
in the limit when η tends to zero, in the platonic crystal Ω . f This is the homogenized biharmonic equation with the homogenized plate rigidity D hom = ( ∫ Y ∗ D -1 ( y , y 1 2 ) dy dy 1 2 ) -1 where Y ∗ = Y \ ¯ . C We point out that the circular geometry of SRR is essential, if one would take elliptical SRR, then D hom would be a rank-2 anisotropic tensor.
The homogenized density ρ hom is given in the form
$$\sqrt { \rho _ { h o m } } ( \beta ) = 1 - \sum _ { m = 1 } ^ { \infty } \frac { \beta ^ { 2 } } { \beta ^ { 2 } - \beta _ { m } ^ { 2 } } \| V _ { m } \| _ { L ^ { 2 } ( 0, l ) } ^ { 2 } \,, \\ \intertext { m a t i n d } \lambda \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \colon \end{matrix}$$
where the eigen-solutions V m correspond to longitudinal vibrations of the thin cut Π η within the split ring resonator.
It is clear from Eq. (9) that √ ρ hom ( β ) takes negative values near resonances β 2 = β 2 m . For our purpose, it is enough to look at the first few resonant frequencies β 2 m (the higher the frequency the worse the asymptotic approximation). These frequencies are associated with vibrations V m of the thin domain Π η 39 :
$$V _ { m } ^ { \prime \prime } ( x _ { 1 } ) + \beta _ { m } ^ { \ 2 } V _ { m } ( x _ { 1 } ) \, = \, 0 \,, \, 0 < x _ { 1 } < l \,,$$
$$V _ { m } ( 0 ) \, = \, 0$$
$$\eta h V _ { m } ^ { \prime } ( l ) \, = \, \text{area} ( \Xi ) \beta _ { m } ^ { \, 2 } V _ { m } ( l ) \,,$$
where ηh and l are the thickness and the length of the thin ligament Π , and Ξ is the central η disc within the SRR. The ligament Π η is connected to Ξ, hence V ( ) = l V , where V is the vibration of the stress-free air cavity Ξ. Note that the derivation of Eq. (12) required a boundary layer analysis, and we refer to 44 for more details.
The solution of the problem (10)-(12) has the form
$$V _ { m } ( x _ { 1 } ) = A \sin ( \beta _ { m } x _ { 1 } )$$
where β m (square root of frequency) is given as the solution of the following equation
$$\eta h \cot ( \beta _ { m } l ) = \text{area} ( \Xi ) \beta _ { m } \.$$
Note also that a similar problem to Eqs. (10)-(12) is deduced from Eq. (7) with a minus sign in (10), which leads to a sinh function in (14), but this does not give any additional resonant frequencies. The resonant frequencies of √ ρ hom also lead to negative values of ρ hom , in the same way that a product of two simultaneously negative square roots give a negative refractive index in the metamaterial's literature 1,33 .
In the sequel, we focus our analysis on the Floquet-Bloch bending wave problem and give some numerical results and comparisons with the homogenization theory.
## III. NUMERICAL ANALYSIS OF SRR PLATONIC CRYSTALS
## A. Dispersive properties
FIG. 2: (a) Band diagram for the doubly periodic square lattice representing the normalized frequency β 2 versus the Bloch vector k in the first Brillouin zone ΓXM. (b) Map of the eigen-mode corresponding to the eigen-frequency β 2 = 2 95 in a unit cell for a SRR with an outer radius 0 48 . . d and inner radius 0 1 . d and thickness of the thin ligament equal to 0 05 . d .
To investigate numerically the stop-band properties for out-of-plane bending waves propagating within the array of SRR, we use the Finite Element Method (by implementing the weak form of (2) in the commercial software COMSOL and its corresponding Floquet-Bloch boundary conditions as well as the PMLs: perfectly matched layers).
In Fig. 2(a), we give the band diagram for normalized eigen-frequencies β 2 as a function of the projection of the Bloch vector k on the first Brillouin zone ΓXM. We consider a square array of normalized pitch d =1 (take for example d = 1cm for comparisons with feasible experiments) with embedded SRR of inner radius 0 1 . d and outer radius 0 48 . d with a thin cut (ligament) of thickness 0 05 . d .
This figure displays two full platonic band gaps for the range of normalized frequencies [2 39 . , 2 92] and [4 23 . . , 24 32]. . As depicted in a previous study 39 , the low frequency band gap (the first one) is associated with the resonant modes of a single SRR (microscopic structure),
FIG. 3: (a) Band diagram of surface mode along the ΓX direction. (b) 1D profile along the x 2 direction of the mode. (c) Supercell showing the configuration where the plasmon mode was excited from the top layer with PMLs in the bottom layer to avoid any reflection and Floquet-Bloch boundary conditions on the left and right sides to account for the infinite array in x 1 direction.
while the second one is due to a Bragg scattering phenomenon (macroscopic structure). We also plot in Fig. 2(b) the corresponding localized eigen-function (the first eigen-mode) which corresponds in the context of continuum mechanics, to oscillations of the central region of the SRR as a rigid solid connected by the thin cut Π ε to the fixed rigid region around it 44 . In our context of bending waves, this can be interpreted as a collective vibration of the plate elements together, up and down in each SRR.
The transcendental equation (14) can be further simplified if we look at the first low
frequency, for which we deduce the explicit asymptotic approximation
$$\beta _ { 1 } ^ { 2 } \sim \frac { \eta h } { \text{area} ( \Xi ) l } \.$$
Our numerical estimate is
$$\psi _ { 1 } ^ { 2 } \sim \frac { 0. 0 5 } { 0. 3 8 } \frac { 1 } { \pi 0. 1 ^ { 2 } } = 4. 1 9$$
which is in excellent agreement with the finite element value for the plasmon frequency β 2 = 4 23 occurring at the . M point when k = ( π, π ).
It is interesting to also analyze the dispersive properties of surface elastic modes (waves exponentially localized at the interface of a platonic crystal). These modes originate from interference effect in phononic or platonic crystals and are important, for example, for superlensing effect. The dispersion diagram of these modes is shown in Fig. 3(a), where the frequency is plotted versus Bloch vector in the ΓM direction. The red dotted-dashed line reprsents the surface mode's dispersion and shows that's standing in the elastic bandgap (between the first and the second propagating modes). This means, for instance, that this mode is of evanescent nature. Figure 3(b) shows the flexural displacement at the interface between the platonic crystal and free-space [Fig. 3(c)], validating the decaying nature of the mode.
## B. (Super-)Lensing effect via negative effective density of a platonic crystal
We then consider a 2D finite platonic crystal perforating a thin elastic plate. The crystal consists of 230 holes with a C-shaped cross-section with identical parameters as those of Fig. 2(b). The crystal has a four-fold (square) symmetry with pitch d = 1. A flexural waves source of wavenumber β = 1 98 is located at a distance 0 1 . . d above the top of the crystal. The field-maps in Fig. 4 (a) show the existence of an image of the source, located twice the width of the crystal away in the lower side. As we can see in Fig. 4 (a), the amplitude of the field is the highest near the thin ligaments Π ε of the SRR. Formula (9) shows that the resonance of the field with the microscopic structure of SRR is responsible for the appearance of negative refraction through negative effective density ρ hom . Finally, the resolution of the image δ is enhanced compared to that obtained using an array of perforations with a circular or square cross-section, as demonstrated in Fig. 4(b), (c), whereby the full width at half maximum of the image point δ ≈ λ/ 3.
FIG. 4: (a) Pattern of the energy of the bending wave at the frequency β = 1 98 where AANR . occurs. (b) and (c) give respectively the profile of the energy along the dotted white line at the source (red curve) and the image (green curve) axis, respectively.
We note that at the plasmon frequency, the vibration of the thin ligaments is enhanced, which is in accordance with the behavior of the field as observed on Fig. 4. It is therefore important to incorporate the resonances within the thin-bridges as we did, to model the frequency at which negative refraction occurs.
## C. Gaussian beam at oblique incidence on a platonic crystal
The interaction of a Gaussian beam (GB) with the platonic crystal around the AANR is considered in this section. Refraction of GB (whose size is in the order of the wavelength) obliquely incident on the SRR platonic crystal is demonstrated to be negative.
As known, considering the interaction of a GB with any optical or mechanical media, reveals much of their propagating and scattering properties 45,46 . These are paraxial solutions of the biharmonic scalar wave equation (∆ 2 -β 4 ) W = 0, and thus have the form
$$U ( x, y ) = u ( x, y ) e ^ { - j \beta x } + n. p.$$
FIG. 5: Bending displacement when the platonic crystal is excited by a gaussian beam at an incidence angle θ inc = 25 degrees. (b) Snapshot of the bending wave in the presence of an effective medium with negative elastic index n e = -1 5 + 10 . -3 j , with n e = √ 12 ρ (1 -ν 2 ) / EH ( 2 ).
9 with the wavenumber β , the coefficient u x ( = 0 , y ) has the well know Gaussian distribution in the x -y plane. n.p. denotes a non propagating contribution due to the fourth order nature of the biharmonic equation. It could be neglected in the real implementation. The expression of the obtained elastic beam is thus
$$u ( x, y ) = u _ { 0 } \frac { \omega _ { 0 } } { \omega ( x ) } e ^ { \left ( - \frac { y ^ { 2 } } { \omega ^ { 2 } ( x ) } - i k \frac { y ^ { 2 } } { 2 R ( x ) } + i \zeta ( x ) \right ) } \,,$$
with ω x ( ) = ω 0 √ 1 + ( x x R ) 2 , x R = πω 2 0 λ and ω 0 is called the waist of the beam. The radius of the curvature is given by R x ( ) = x [ 1 + ( x R x ) 2 ] and the Gouy phase shift is ζ ( x ) = atan x x R . Figure 5 gives the snapshot of the displacement field U in the presence of the platonic crystal at oblique incidence with angle θ inc = 25 degrees; a reflected beam could be distinguished as well as a refracted one which turns out to be in the negative refraction regime. To further verify this claim, another simulation using, now, an homogeneous effective slab of the same size, with negative elastic index n e = ω/β 2 = √ 12 ρ (1 -ν 2 ) / EH ( 2 ), is shown in Fig. 5(b). The patterns of the wave are identical in 5(a) and 5(b) and show that the elastic index of
the SRR crystal could be described as negative: n e = -1 5 + 10 . -3 j . The robustness of the AANR was further verified by changing the angle of incidence θ inc and the wavelength of operation around their main values, and the effect still could be observed.
## D. Ultrarefraction effect via vanishing effective density of a platonic crystal
FIG. 6: Pattern of the elastic displacement (a) and energy of the bending wave (b) at the frequency where ultrarefraction occurs when a point source is located at the center of the platonic crystal.
To conclude this section, let us consider another anomalous refractive effect, namely, the ultra-refraction of bending waves. This phenomenon generally occurs when the effective elastic index n e defined above, tends to zero or equally speaking the group velocity v g ≈ 0. In this case, independently of the angle of incidence of an incident ray, propagating towards the crystal, it will be refracted normally to it (parallel to the normal). And the operation point could be easily deduced from the dispersion diagram by picking a point where the mode's dispersion curve becomes flat ( ∇ k β 2 ≈ 0). This allows us to build an elastic antenna (for instance by placing a cylindrical source of flexural waves in the center of the crystal). The wave will be then refracted along the normal to the crystal, permitting thus highly directive beam as could be seen from Fig. 6(a) and (b) where the displacement snapshot and its energy are respectively plotted around a wavelength λ = 2 π/β ≈ 3. This corresponds
as previously stated to the M point in the diagram of Fig. 2(a) at the maximum. Using formula (9), one can indeed achieve ultrarefraction when the effective density of the platonic crystal ρ hom is close to zero, which happens for β 2 2 ∼ 4 37. . To get this estimate, one need replace the boundary condition (11) by V m (0) = -area(Σ) / area(Y -C) which amounts to assuming that the field takes the same non zero values on the opposite edges of the basic cell. This leads to the new frequency estimate
$$\beta _ { 2 } ^ { 2 } & \sim \frac { \eta h } { \text{area} ( \Xi ) l } \left ( 1 + \frac { \text{area} ( \Sigma ) } { \text{area} ( Y - C ) } \right ) \,, \\. \quad \tilde { \lambda } \, \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \tilde { \lambda } \, \quad \ t \, \end{$$
which is a refinement of (15). The numerical result β 2 2 ∼ 4 37 is in . good agreement with finite element computations (4.385).
## IV. CONCLUDING REMARKS
In conclusion, we have proposed an original route towards elastic negative refraction (superlensing) and ultrarefraction based on excitation of flexural surface modes. To analyze these effects, we have derived the homogenized biharmonic equation using a multi-scale asymptotic approach. We found that the homogenized elastic parameters are described by a scalar flexural plate rigidity (since the perforations have a circular geometry owing to the fact that thin-bridges come unseen in the second scale asymptotics) and a scalar density, the latter taking negative values near thin-bridges resonances (unveiled by the third scale). We then performed numerical computations based on the finite element method which confirmed that the asymptotic model gives accurate predictions on dispersive properties of the elastic Lamb modes.
We believe that such a micro-structured plate could be manufactured easily, having in mind some potential applications in superlensing or directive elastic antennas. The range of industrial applications is vast, and our proof of concept should foster research efforts in this emerging area of acoustic and seismic metamaterials.
## Acknowledgments
S.G. would like to acknowledge a funding of the European Research Council through ERC grant ANAMORPHISM.
- 1 V. G. Veselago, Usp. Fiz. Nauk 92 , 517 (1967); V. G. Veselago, Sov. Phys. Usp. 10 , 509 (1968).
- 2 J.B. Pendry, Phys. Rev. Lett. 86 , 3966-3969 (2000).
- 3 D.R. Smith and N. Kroll, Phys. Rev. Lett. 85 , 2933 (2000).
- 4 J.B. Pendry, A.J. Holden, D.J. Robbins, W.J. Stewart, IEEE Trans. Microwave Theory Tech. 47 , 2075 (1999).
- 5 S. Datta, Classical Wave Propagation in Periodic and Random Media (Iowa State University, 1994).
- 6 E. Yablonovitch, Phys. Rev. Lett. 58 , 2059 (1987).
- 7 S. John, Phys. Rev. Lett. 58 , 2486 (1987).
- 8 T. F. Krauss, R. M. DeLaRue, and S. Brand, Nature 383 , 6602 (1996).
- 9 R. Zengerle, J. Mod. Opt. 34 , 1589 (1987).
- 10 B. Gralak, S. Enoch, and G. Tayeb, J. Opt. Soc. Am. A 17 , 1012 (2000).
- 11 M. Notomi, Opt. Quantum Electron. 34 , 133 (2002).
- 12 C. Luo, S. G. Johnson, J. D. Joannopoulos, and J. B. Pendry, Phys. Rev. B 65 , 201104(R) (2002).
- 13 C.G. Poulton, A.B. Movchan, R.C. McPhedran, N.A. Nicorovici, and Y.A. Antipov, Proc. R. Soc. London, Ser. A 456 , 2543-2559 (2000).
- 14 C.G. Poulton, R.C. McPhedran,N.A. Nicorovici, L.C. Botten, and A.B. Movchan, IUTAM Symposium on Mechanical and Eelectromagnetic Waves in Structured Media, (2001).
- 15 L. Feng, X. Liu, Y. Chen, Z. Huang, Y. Mao, Y. Chen, J. Z, and Y. Zhu, Phys. Rev. B 72 , 033108 (2005).
- 16 X. Zhang and Z. Liu, Appl. Phys. Lett. 85 , 341 (2004).
- 17 X. Hu, Y. Shu, X. Liu, R. Fu, and J. Zi, Phys. Rev. E 69 , 030201(R) (2004).
- 18 L. Feng, X. P. Liu, M. H. Lu, Y. B. Chen, Y. F. Chen, Y. W. Mao, J. Zi, Y. Y. Zhu, S. N. Zhu, and N. B. Ming, Phys. Rev. B 73 , 193101 (2006).
- 19 T. Chou, Phys. Rev. Lett. 79 , 4802 (1997).
- 20 T. Chou, J. Fluid Mech. 369 , 333 (1998).
- 21 P. McIver, J. Fluid Mech. 424 , 101 (2000).
- 22 M. Torres, J. P. Adrados, F. R. Montero de Espinosa, D. Garcia-Pablos, and J. Fayos, Phys. Rev. E 63 , 011204 (2000).
- 23 X. Hu, Y. Shen, X. Liu, R. Fu, J. Zi, X. Jiang, and S. Feng, Phys. Rev. E 68 , 037301 (2003).
- 24 N.V. Movchan, R.C. McPhedran, A.B. Movchan, G.G. Poulton, Proc. R. Soc. A-Math. Phys. Eng. Sci. 465 , 3383-3400 (2009).
- 25 A.B. Movchan, N.V. Movchan, R.C. McPhedran, Proc. R. Soc. A-Math. Phys. Eng. Sci. 463 , 2505-2518 (2007).
- 26 M. Farhat, S. Guenneau, S. Enoch, A.B. Movchan, and G. Petursson, Appl. Phys. Lett. 96 , 081909 (2010).
- 27 M. Farhat, S. Guenneau, S. Enoch, and A.B. Movchan, EPL-Europhys. Lett. 91 , 54003 (2010).
- 28 M. Farhat, S.Guenneau, and S. Enoch, Phys. Rev. Lett. 103 , 024301 (2009).
- 29 J. B. Pendry, Phys. Rev. Lett. 85 , 3966 (2000).
- 30 D. Maystre and S. Enoch, J. Opt. Soc. Am. 21 , 122 (2004).
- 31 S. Guenneau, A. C. Vutha, and S. A. Ramakrishna, New J. Phys. 7 , 164 (2005).
- 32 D. R. Smith, W. J. Padilla, D. C. Vier, S. C. Nemat-Nasser, and S. Schultz, Phys. Rev. Lett. 84 , 4184 (2000).
- 33 S. A. Ramakrishna, Rep. Prog. Phys. 68 , 449 (2005).
- 34 S.A. Cummer, D. Schurig, New J. Phys. 9 , 45 (2007).
- 35 A.N. Norris, Proc. R. Soc. Lond. A 464 2411 (2008).
- 36 M. Farhat, S. Enoch, S. Guenneau, and A. B. Movchan, Phys. Rev. Lett. 101 , 134501 (2008).
- 37 G. Dupont, M. Farhat, A. Diatta, S. Guenneau, and S. Enoch, Wave Motion 48 , 483-496 (2011).
- 38 M. Farhat, S. Guenneau, S. Enoch, G. Tayeb, A. B. Movchan, and N. V. Movchan, Phys. Rev. E 77 , 046308 (2008).
- 39 A.B. Movchan, S. Guenneau, Phys. Rev. B 70 , 125116 (2004).
- 40 S. Guenneau, A.B. Movchan, N.V. Movchan, Physica B 394 , 301648 (2006).
- 41 S. Timoshenko, Theory of plates and shells (McGraw-Hill, New York, 1940).
- 42 K.F. Graff, Wave motion in elastic solids (Dover, New York, 1975).
- 43 V.V. Jikhov, S.M. Kozlov, and O. A. Oleinik, Homogenization of Differential Operators and
Integral Functionals (Springer Verlag, New York, 1994).
- 44 V. Kozlov, V. Mazya, and A. B. Movchan, Fields in Multistructures. Asymptotic Analysis (Oxford University Press, Oxford, 1999).
- 45 R.W. Ziolkowski, Opt. Express 11 , 662-681 (2003).
- 46 L.W. Cai and J. Sanchez-Dehesa, New J. Phys. 9 , 450 (2007). | 10.1209/0295-5075/107/44002 | [
"M. Farhat",
"S. Enoch",
"S. Guenneau"
] | 2014-07-28T15:53:22+00:00 | 2014-07-28T15:53:22+00:00 | [
"cond-mat.mtrl-sci"
] | Biharmonic Split Ring Resonator Metamaterial: Artificially dispersive effective density in thin periodically perforated plates | We present in this paper a theoretical and numerical analysis of bending
waves localized on the boundary of a platonic crystal whose building blocks are
split ring resonators (SRR). We first derive the homogenized parameters of the
structured plate using a three-scale asymptotic expansion in the linearized
biharmonic equation. In the limit when the wavelength of the bending wave is
much larger than the typical heterogeneity size of the platonic crystal, we
show that it behaves as an artificial plate with an anisotropic effective Young
modulus and a dispersive effective mass density. We then analyze dispersion
diagrams associated with bending waves propagating within an infinite array of
SRR, for which eigen-solutions are sought in the form of Floquet-Bloch waves.
We finally demonstrate that this structure displays the hallmarks of
All-Angle-Negative-Refraction(AANR) and it leads to superlensing and
ultrarefraction effects, interpreted thanks to our homogenization model as a
consequence of negative and vanishing effective density, respectively. |
1408.0005v1 | ## Star Formation in the vicinity of Nuclear Black Holes: Young Stellar Objects close to Sgr A*
Jalali, B. 1 glyph[star] , Pelupessy, F. I. , Eckart, A. 2 1 3 , , Portegies Zwart, S. , Sabha, N. 2 1 3 , , Borkar, A. 1 3 , , Moultaka, J. , Muˇi´, K. , Moser, L. 4 z c 5 1
- 1 I. Physikalisches Institut, Universit¨t zu K¨ln, Z¨lpicher Stra a o u β e 77, D-50937 K¨ln, Germany o
- 2 Leiden Observatory, Leiden University, PO Box 9513, 2300 RA, Leiden, The Netherlands
- 3 Max-Planck-Institut f¨r Radioastronomie, Auf dem H¨gel 69, 53121 Bonn, Germany u u
- 4 IRAP, Observatoire Midi-Pyr´n´es, CNRS, Universit´ Toulouse III, 14 avenue Edouard Belin, 31000 Toulouse, France e e e
- 5 European Southern Observatory, Alonso de C´rdova 3107, Casilla 19, Santiago, Chile o
Accepted 2014 July 23. Received 2014 July 23; in original form 2013 October 01
## ABSTRACT
It is often assumed that the strong gravitational field of a super-massive black hole disrupts an adjacent molecular cloud preventing classical star formation in the deep potential well of the black hole. Yet, young stars have been observed across the entire nuclear star cluster of the Milky Way including the region close ( < 0.5 pc) to the central black hole, Sgr A*.
Here, we focus particularly on small groups of young stars, such as IRS 13N located 0.1 pc away from Sgr A*, which is suggested to contain about five embedded massive young stellar objects ( < 1 Myr). We perform three dimensional hydrodynamical simulations to follow the evolution of molecular clumps orbiting about a 4 × 10 6 M glyph[circledot] black hole, to constrain the formation and the physical conditions of such groups.
The molecular clumps in our models assumed to be isothermal containing 100 M glyph[circledot] in < 0.2 pc radius. Such molecular clumps exist in the circumnuclear disk of the Galaxy.
In our highly eccentrically orbiting clump, the strong orbital compression of the clump along the orbital radius vector and perpendicular to the orbital plane causes the gas densities to increase to values higher than the tidal density of Sgr A*, which are required for star formation.
Additionally, we speculate that the infrared excess source G2/DSO approaching Sgr A* on a highly eccentric orbit could be associated with a dust enshrouded star that may have been formed recently through the mechanism supported by our models.
Key words: Star Formation: IRS 13N association, ISM - Galactic centre, Black Holes: Sgr A* - Methods: Numerical, SPH simulations, AMUSE
## 1 INTRODUCTION
Our observational and theoretical knowledge about supermassive black holes (SMBHs), including the mechanisms by which the surrounding stars and gas interact with them, are continuously increasing (some examples are: Yu & Tremaine 2002; Gualandris, Portegies Zwart & Sipior 2005; Portegies Zwart et al. 2006; G¨ltekin et al. 2009; Hopkins & Quataert u 2010; Combes 2012; Kormendy & Ho 2013). Nuclear star clusters surrounding nuclear black holes have been observed over the last decade for a variety of galaxies (Seth et al.
2008). These clusters contain two distinct stellar populations that contribute significantly to their luminosities, one very old (several Gyr) and the other relatively young (a few to 100 Myr) indicating that star formation is ongoing in such systems (B¨ker 2010). o
glyph[star] E-mail: [email protected]
However, current instruments do not allow us to resolve the spatial distribution of young stars very close to the central black holes even for the nearest (about 5-10 Mpc) extra-galactic nuclei. On the other hand, individual stars and young stellar associations can be studied in great detail for the Milky Way central region, at a distance of ∼ 8 kpc from the Sun. The observed stars in the Galactic centre show a wide age range, in the nuclear cluster (including the S-
stars) surrounding the SMBH and in at least one (possibly) warped disk further away, about 0.04-0.4 pc, from Sgr A* (Paumard et al. 2006; Buchholz, Sch¨ odel & Eckart 2009; Pfuhl et al. 2011).
In addition to the disk stars and stellar members of the nuclear star cluster itself, Eckart et al. (2004, 2013), Moultaka et al. (2005) and Muˇi´ et al. (2008) find that there are z c very young red objects, 0.1 pc away from Sgr A*, in a compact group called IRS 13N. The authors propose that these are most probably Young Stellar Objects (YSOs) with 0.11 Myr age spread. The young age is inferred from their colors and dynamical considerations (Muˇ zi´ et al. 2008). Rememc bering that the orbital period at about 1 pc (considering the inner edge of the circumnuclear disk (CND) and orbital eccentricities of molecular clumps) is about 10 4 yr, this is an important evidence demonstrating that star formation in such a harsh environment close to a 4 × 10 6 M glyph[circledot] black hole is probably in situ and frequent. It is worth to mention that IRS 13N is located (in projection) north of the IRS 13E complex. Sch¨del et al. (2005) and Fritz et al. (2010) show o that IRS 13E group contains at least three blue/WR stars. The IRS 13E stellar sources are therefore more evolved stars than those belonging to IRS 13N. In fact, Muˇi´ et al. (2008) z c show that the two groups are dynamically distinct based on proper motions.
There are several numerical models attempting to explain the observed disk stars (Nayakshin & Sunyaev 2005; Nayakshin, Cuadra & Springel 2007; Bonnell & Rice 2008; Mapelli et al. 2012). In the mentioned models, infall of a giant molecular cloud is followed using ∼ 10 4 -5 M glyph[circledot] gas inside ∼ 1 pc radius (15 pc in the case of Mapelli et al. 2012) or the evolution of a gaseous disk (initially surrounding the SMBH) is studied. While many properties of the observed young stars are addressed in these models, none of them could reproduce formation of compact stellar groups very close to Sgr A*.
The focus of our current work is therefore to propose a possible scenario on the star formation in small systems very close to Sgr A*. To reach this goal we study the difference between evolution of orbiting clumps and isolated clumps. We particularly compare our modelling with the IRS 13N YSO candidates observed in the vicinity of Sgr A*. The importance of this modelling is to investigate star formation condition on a clump-scale within CND, as well as constraining the origin of the G2/DSO infrared source, as its highly eccentric orbit and possible stellar origin from the CND is not yet completely clear.
We describe our modelling prescription in Section 2. We present our main results in Section 3 and compare clumps densities and the resulting protostars properties in different orbiting models. In Section 4, we discuss about collisions between clumps in the CND and also propose a scenario for the origin of the G2/DSO source. The conclusions of the paper are listed in Section 5.
## 2 MODELLING APPROACH AND AMUSE APPLICATION
Motivated by the observations mentioned above, in particular Eckart et al. (2004, 2013) and Muˇi´ et al. (2008), we z c follow the evolution of a small molecular clump (MC) con- taining 100 M glyph[circledot] closely orbiting a 4 × 10 6 M glyph[circledot] black hole including a simple prescription for star formation (described in detail in Section 2.1 and 2.2). In this study, we mainly investigate if the interactions between the central SMBH and a small clump can lead the clump densities to higher values than the tidal density of the SMBH.
Figure 1 schematically demonstrates the idea we apply in the present work. This set up is also consistent with the observed configuration of the CND, the mini-spiral, IRS 13E and IRS 13N complexes, shown for example in figure 1.1 of Genzel, Eisenhauer & Gillessen (2010). This approach could be generalized for all the nucleated disk galaxies harboring a star forming molecular disk or ring.
To better visualize the observed central 5 pc of the Galaxy, it is helpful to remind that there are a few (neutral and ionized) streamers around Sgr A* forming what is referred to as the mini-spiral. The mass of the ionized gas in the mini-spiral and neutral gas in the central parsec are estimated to be ∼ 100 and 300 M glyph[circledot] , respectively (Jackson et al. 1993; Christopher et al. 2005). Thus, MCs similar to those we model here are observed in the CND.
There are a few possibilities for the origin of the observed mini-spiral and the small stellar groups. One could be that a massive MC within the CND experiences encounters with other clumps, dissipates orbital energy during that encounter, loses angular momentum and consequently falls in toward the SMBH. We study a simplified version of this scenario. Another case could be that some small clumps separate from a giant molecular cloud while some regions of the parent giant cloud are about to be captured by the SMBH (a scenario often modelled to explain the observed young disk stars). It is also possible that a small MC is a byproduct of a collision between two large molecular clouds or a collision of one molecular cloud with a disk-like structure (the scenario recently modelled in Alig et al. 2013).
We model three families of MCs through this work: a) an isolated clump, b) an orbiting clump in a nearly circular orbit (eccentricity ∼ 0.5) and c) an orbiting clump in highly eccentric orbits (eccentricity ∼ 0.94). The choice of orbital parameters (peri- and apo-centre distances) of the two orbiting families of models are motivated by the size of the CND ( ∼ 1-5 pc). Isolated clumps are our reference models, to contrast our orbiting clumps about a SMBH with, and also to help compare our modelling prescription with other numerical studies.
We design the orbiting clumps mainly to study MC evolution and star formation as a function of different orbital configurations about a SMBH. We compare our results specifically with IRS 13N close to Sgr A* if our current scenario could be one of its possible formation routes.
We use smoothed particle hydrodynamics (SPH) method to simulate the evolution of a MC. We perform this modelling in the AMUSE 1 (Astrophysical Multipurpose Software Environment) framework (Portegies Zwart, McMillan & Harfst 2009; Pelupessy et al. 2013). AMUSE is a python-based framework for astrophysical simulations, and allows combining the existing codes for stellar dynamics, stellar evolution, hydrodynamics and radiative transfer. The evolution of our model clump is followed using Fi (Pelupessy,
1 www.amusecode.org
Figure 1. One modelled orbital set up is displayed for eccentricity ∼ 0 95. The circumnuclear disk (cyan) is a clumpy (yellow) . environment. Red (black) crosses represent massive (less massive) stars. The possible radiation from massive young stars is shown by red arrows. The thin red circle close to the black hole marks a IRS 13N-like configuration. The influence radius of Sgr A* is shown by the black circle at ∼ 2 pc. More detailed structures, such as the disk stars, are not shown for clarity.
van der Werf & Icke 2004; Pelupessy 2005), a 'community code' (Portegies Zwart et al. 2013) integrated in AMUSE. The main physics in the current study is the self-gravity of the gas and the stellar interaction between newly formed stars.
## 2.1 Clump Initial Conditions and Orbital Set up
We model a spherical MC containing 100 M glyph[circledot] within 0.376 pc diameter. To investigate star formation, these values are typical for a small molecular clump (Table 1 in Bergin & Tafalla 2007, on the cloud classification). The clump initially has a uniform density with a random Gaussian divergence free velocity structure, with a power spectrum slope of k = -3 following Bonnell, Bate & Vine (2003).
We assume isothermal thermodynamics with mean molecular mass of 2.46. Two different initial temperatures are tested in our present simulations: 10 and 50 Kelvin. The higher temperature would be a better representative for the Galactic centre environment (Ao et al. 2013 and references therein). We remind that our main goal is to probe whether our model clumps could survive in the strong tidal field of the SMBH close to the peri-centre as the clumps are stretched along the orbits. To reach this goal, assuming isothermal gas is a good first approximation that allows us comparing clumps evolution on different orbits and exploring the role of the tidal field of the SMBH on small-scale model clumps. Mapelli et al. (2012) recently tested isothermal as well as radiative cooling thermodynamics for a similar but larger-scale problem. Their results show little difference between the two approaches in terms of stellar mass function.
We do not follow the higher densities including adiabatic regime. We therefore can not constrain the exact num- ber of protostars as we do not resolve opacity limit. However, limiting our current work with the most straight forward thermodynamics (i.e., isothermal), we can investigate the general behaviour of model clumps depending on orbital configurations and compare the different orbiting models with the isolated models.
The detailed properties of early star formation require dedicated modelling, such as including a more realistic equation of state (e.g. polytropic) and resolving the opacity limit (e.g. Krumholz, Klein & McKee 2007; Bate 2012).
Given our assumed clump mass and the number of particles, our mass resolution is 0.0192 M glyph[circledot] (as we describe in detail in the next section) which is well below brown dwarf mass (0.08 M glyph[circledot] ). So, we can model low to intermediate-mass protostars, typically more massive than 0.5-1 M glyph[circledot] for our case. Clumps properties and orbital parameters are tabulated in Tables 1 and 2. We include here a higher resolution run (using 1 0 . × 10 6 particles) for the highly eccentric model to validate our results. We have also performed simulations with lower resolution, using 2.5 × 10 5 particles, for all models to check our numerical results for convergence.
For the orbiting clumps, we design the orbits (varying eccentricity and peri-centre distance) such that one and a half orbital periods (second peri-centre passage) are about 1.25 times the initial free fall time ( t ff ), ∼ 0.175 Myr. We initiate the orbiting clumps from the orbital apo-centre. The sound timescale of clumps is about 1 Myr. The sound speeds for the 10 and 50 Kelvin clumps are ∼ 184 and 411 m/s, respectively. We integrate the clump evolution for 0.2 Myr. The minimum time step is chosen such that it can resolve the t ff at maximum density, 2 -5 × 10 -5 Myr in practice.
## 2.2 SMBH and Sink Description
Orbiting clumps are set to follow a Keplerian orbit about a 4 × 10 6 M glyph[circledot] black hole close to the mass of Sgr A* (Ghez et al. 2008; Sch¨del, Merritt & Eckart 2009; Gillessen et al. o 2009). Note that the influence radius of such a black hole is about 2 pc (Alexander 2005). We consider a point potential to model the SMBH and exclude the possible effect of the nuclear star cluster on the clump evolution. The gravitational softening length in our models is fixed to r peri -centre / 5, ranging from 0.02 to 0.2 pc depending on the orbital configurations.
Protostars are modelled using a sink approach (Bate, Bonnell & Price 1995; Bonnell, Bate & Vine 2003 and references therein) in such a way that gas particles with densities higher than a certain threshold, ρ thresh , are replaced by point mass particles (sinks) that only interact with the remaining particles via gravity. The ρ thresh is set by the requirement for self gravitating SPH simulations of resolving the local Jeans mass with at least 1 5 . × N neighbours = 96 particles. The importance of this point is discussed in Bate & Burkert (1997).
The initial clump density is 1.45 × 10 5 amu cm / 3 and ρ thresh values are a few 10 9 and a few 10 11 amu cm / 3 for 10 and 50 Kelvin models, respectively. Our ρ thresh values are higher than tidal density of the SMBH, 10 8 amu cm / 3 at 1 pc where the clump spends more time in that region, and about 10 11 amu cm / 3 at about 0.1 pc (Yusef-Zadeh et al. 2013). Sinks will be replaced unless there is already a sink particle within the smoothing kernel of the particle ( ∼ 10-
Table 1. Overview of the clumps initial configuration.
| Clump Mass | N particles | Clump Radius | Temperature | Initial Clump t ff | Accretion/Merging Distance | ρ thresh [ amu cm 3 |
|----------------------------|---------------|----------------|---------------|----------------------|------------------------------|-----------------------|
| 100 [ M glyph[circledot] ] | 0.5 × 10 6 | 0.188 pc | 10 K | 0.135 Myr | 20 AU | 2.69 × 10 9 |
| 100 [ M glyph[circledot] ] | 0.5 × 10 6 | 0.188 pc | 50 K | 0.135 Myr | 20 AU | 3.39 × 10 11 |
| 100 [ M glyph[circledot] ] | 1.0 × 10 6 a | 0.188 pc | 10 K | 0.135 Myr | 20 AU | 1.05 × 10 10 |
a This additional run has been performed with higher resolution to numerically check the highly eccentric model
Table 2. The orbital parameters for orbiting models.
| Semi-major Axis | Eccentricity | Peri-centre | Apo-centre | Orbital Period | 2nd Peri-Passage time |
|-------------------|----------------|---------------|--------------|------------------|-------------------------|
| 1.8 pc | 0.944 | 0.1 pc | 3.5 pc | 0.113 Myr | 0.17 Myr |
| 1.8 pc | 0.5 | 0.9 pc | 2.7 pc | 0.113 Myr | 0.17 Myr |
50 AU for 50 and 10 Kelvin models). We also allow sinks to merge with each other if their distance is less than 20 AU. Sink particles also accrete any dense gas particle within this distance. Thus, for a 100 M glyph[circledot] clump using 0.5 × 10 6 particles, we interpret the sink particles with a mass larger than 0.0192 M glyph[circledot] (or ∼ 20 M Jupiter ) as being protostellar objects, but note that we do not follow any additional fragmentation below our resolution of ∼ 10 AU.
For the scope of this paper, we do not include radiative transfer in our clump evolution. We also do not include stellar feedback in any format (mechanical as well as radiative). Excluding stellar feedback could be a good simplification as we stop integrating the simulations as soon as stars form.
Our chosen clump mass and size as well as our sink accretion threshold distance (20 AU) are conservative assumptions to reproduce IRS 13N-like groups and stellar mass distribution. In other words, choosing larger and more massive clumps, together with larger accretion distance criterion for sinks growth can lead to the formation of higher number of protostars, and a mass function with top-heavy IMF trend.
The maximum gas density in gc10Ke0.5 model (red solid line in Fig. 2) reaches its ρ thresh slightly after the first peri-passage, much earlier than gc50Ke0.5 model (red dashed line). The gc10Ke0.5 clump is constantly compressed to form protostars as the Jeans mass in the 10 K model is lower ( ∼ 1 M glyph[circledot] ) than in the case of the 50 K model ( ∼ 10 M glyph[circledot] ). For the highly eccentric orbit (e=0.944), in both the 10 and 50 K models, the relevant ρ thresh limits are reached just at the half-period and protostars start forming right after the first peri-centre passage. This shows that the SMBH helps to orbitally compress the gas, and the densities rise to the necessary ρ thresh quicker than in the case of isolated clumps or the models with the milder eccentricity. The SMBH plays a supportive role in star formation by causing the the gas densities increase towards the threshold values during the first peri-centre passage.
## 3 RESULTS
## 3.1 Qualitative Description
As the upper panel of Figure 2 shows, the maximum gas densities in all models (except the iso50K model) reach the corresponding ρ thresh values earlier than one free fall time (vertical dashed line at 0.135 Myr). However, for all the orbiting models this happens even earlier than in the case of their counterpart isolated models. The required ρ thresh is reached at around half of the orbital period when the clump is experiencing the first peri-centre passage, feeling the orbital compression (see Appendix). This suggests that the orbital compression of a MC close to the SMBH acts as an external pressure on the clump, and facilitates the formation of stars for the high eccentricity clumps. It is known that the gas densities should be above ∼ 10 8 cm -3 in order for star formation to occur close (within the central 1 pc) to Sgr A* (e.g. Yusef-Zadeh et al. 2013). As it can be seen in Fig. 2, this is in fact the case in our orbiting models, while the initial clump density is just about 10 5 cm -3 .
Figure 2 lower panel, presents the number of formed protostars for each model in terms of time. The stellar numbers are consistent with the gas density evolution. In some models, protostars with a mass above the resolution, ∼ 0 0192 . M glyph[circledot] , appear with a short delay after the threshold densities have been reached. In gc50Ke0.944 model, protostars can still form but are less numerous and more massive compared with the gc10Ke0.944 model because of the higher Jeans masses in the 50 K models. The number of stars in e = 0 5 models are between the isolated and the high eccen-. tric ( e = 0 944) ones. .
The number of protostars varies slightly over time due to merging of sinks or scattering and possibly being ejected from the clump. This effect is more prominent in the highly eccentric models (blue lines) where the clump is more orbitally compressed and the number density of stars inside the clump is higher, consequently stellar encounters as well as merger possibilities are more frequent.
The column density maps of the models at 0.7 to 1.4 times of the initial free fall time are illustrated in Figures 5 to 10.
## 3.2 Stellar Mass Distributions: Isolated versus Orbiting Models
We compute the initial mass function (IMF) and cumulative number of protostars at 1 3 . × t ff , that is about 0.175 Myr for
Figure 2. The maximum gas densities and the number of protostars for each model is plotted as a function of time from the beginning of simulations. Symbols of each models are consistent in both panels. One orbital period is 0.113 Myr (vertical dotted line), one free fall time is 0.135 Myr (vertical dashed line) and the second peri-centre passage is 0.175 Myr (vertical solid line). Orange horizontal lines are ρ thresh values for 10 and 50 Kelvin models, respectively at about 2.69 × 10 9 and 3.39 × 10 11 amu cm 3 . [see the online version for full color information]
Table 3. Summary of star formation properties for 100 M glyph[circledot] clumps, computed at 1.3 × t ff .
| Model Clump | N stars | N BDs | Mean Mass [ M glyph[circledot] ] | Maximum Stellar Mass [ M glyph[circledot] | Total resolved Stellar Mass [ M glyph[circledot] | SFE |
|------------------|-----------|---------|------------------------------------|---------------------------------------------|----------------------------------------------------|-------|
| iso10K | ≥ 92-49 | 49 | 0.27 | 3.51 | 24.9 | 25% |
| iso50K | ≥ 5 | 0 | 3.49 | 6.91 | 17.5 | 18% |
| gc10Ke0.5 | ≥ 122-25 | 25 | 0.24 | 1.24 | 29.18 | 29% |
| gc50Ke0.5 | ≥ 9 | 0 | 0.83 | 1.62 | 7.46 | 7% |
| gc10Ke0.944 | ≥ 147-68 | 68 | 0.33 | 8.56 | 48.8 | 49% |
| gc50Ke0.944 | ≥ 19-3 | 3 | 2.2 | 7.83 | 41.87 | 42% |
| gc10Ke0.944-1M a | ≥ 154-91 | 91 | 0.43 | 7.42 | 66.16 | 66% |
a The additional run with higher resolution to numerically check the highly eccentric model
Figure 3. The cumulative number of protostars and the IMF of all models computed at 1.3 × t ff ∼ 0.175 Myr. This is about 1.55 times the period of orbiting models. The black solid line represents the 10 K isolated model (our reference model). Symbols of all the models for both panels are the same. In the lower panel, there is only one data point for the iso50K (larger black dot) and gc50Ke0.5 (larger red dot) models as there are only a few stars. The Kroupa and Salpeter slopes are overplotted with green and orange lines, respectively. Vertical lines are 0.08 M glyph[circledot] (brown dwarf) and 0.5 M glyph[circledot] limit. [see the online version for full color information]
Table 4. The properties of IRS 13N-like groups in models with e=0.944.
| Model Clump | Time [Myr] | Individual Stellar Mass [ M glyph[circledot] | (x,y,z) [pc] from the SMBH |
|-------------------------|--------------|------------------------------------------------|------------------------------------------------------------|
| gc10Ke0.944 gc10Ke0.944 | 0.163 0.175 | 8.39, 1.26, 5.02, 1.39 6.23, 0.76, 1.03, 1.02 | (-0.09866, -0.07554, -0.0041) (-0.10429, -0.0927, 0.00015) |
| gc50Ke0.944 gc50Ke0.944 | 0.164 | 3.67, 3.20 2.72, 4.42 | (-0.03905, 0.11998, 0.00028) |
| | 0.162 | | (-0.09221, 0.02037, |
| | | | -0.00038) |
| gc50Ke0.944 | 0.171 | 7.80, 2.01, 0.99 | (0.01041, 0.20435, 0.00158) |
| gc10Ke0.944-1M | 0.160 | 6.00, 2.52 | (-0.07851, -0.06054, -0.00092) |
| gc10Ke0.944-1M | 0.170 | 0.84, 1.54, 2.63, 3.76 | (-0.09429, 0.01838, -0.00043) |
| gc10Ke0.944-1M | 0.173 | 7.42, 7.19 | (-0.10787, 0.05193, -0.00141) |
all the models and is equivalent to ∼ 1.55 times the orbital period for orbiting clumps (right after the second peri-centre passage).
In Figure 3, the top panel depicts the cumulative number of protostars. There are generally fewer stars for the 50 K models (dashed lines) than in the 10 K models. The higher Jeans mass ( ∼ 10 M glyph[circledot] ) in the case of 50 K clumps prevents it from collapse and form stars as easily as in the case of 10 K models. However, the few formed protostars in the higher temperature models are normally massive, as can be seen in the dashed concaveness-shape curves in the top panel of Figure 3.
We note that our cumulative fractional number of stars for the isolated 10 K model is consistent with the one of Bate (2009) (although he uses a barotropic equation of state for a 50 M glyph[circledot] clump). This suggests that any difference between the results of our models is due to the presence of the SMBH and the different orbital configurations.
The statistical properties of protostars for different models are listed in Table 3 and summarize the above results. We consider every object more massive than our mass resolution and below 0.08 M glyph[circledot] as brown dwarfs and planetsize objects.
The mass distribution of protostars, i.e. initial mass function (IMF), is displayed in the lower panel of Figure 3. The Kroupa (Kroupa 2001) and Salpeter (Salpeter 1955) slopes are also plotted for comparison. This panel shows that between 0.08 to 0.5 M glyph[circledot] the IMF of all models are relatively comparable to each other, and seem to be consistent (in this mass range) with the Kroupa slope. There is only one data point representing the IMF of the orbiting iso50K model as well as the gc50Ke0.5 model (one larger black and one larger red dot respectively), as there are less than 10 stars forming in these models. The gc50Ke0.944 model shows a top-heavy IMF trend that is also obvious from the concaveness of the dashed blue line in the upper panel of this figure. As we also mentioned in Section 2.1, we can not constrain the exact number of stars especially in the low-mass end, below 0.08 M glyph[circledot] , in which there are observational evidences for a decline in this range. Our current models cannot reproduce this behaviour as our star formation modelling does not include the opacity limit and we run relatively low resolution simulations, but note that this mass range is not the main focus of the current study.
The results of the higher resolution run (using 1 0 . × 10 6 particles) in terms of number of stars and mass distribution are consistent with the main models (Table 3), however, its total stellar mass is larger than the corresponding 10 K model. Currently we cannot exclude that this effect is linked to our simplified sink particle prescription described in Section 2.
It is worth noting that we have low number statistics in the current set of simulations, i.e. about 100 stars in each model and masses are non-uniformly distributed over a range of ∼ 0.01 to 10 M glyph[circledot] . Moreover, we focus on the formation of a relatively small group of (massive) stars. Therefore, care should be taken on interpreting and comparing IMF slopes and mass function trends. To compute the mass function we use adaptive binning such that there is always a fixed number (10) of stars in each bin. So, the relative uncertainty for each data point is constant and is ∼ 0.3.
The Jeans mass distribution of gas particles for all mod- els as a function of distance to the SMBH (centre of the clump for isolated models) at 1.3 × t ff is plotted in Figure 4.
## 3.3 Search for Compact Stellar Systems
To probe if a structure with similar properties to those observed in IRS 13N forms in our models, we look for a group consisting of a few stars in a region as compact as 0.02 pc in radius and 0.1-0.2 pc away from the SMBH. We report detecting such a group if there are more than two massive stars or if there are two very massive stars ( > 2 M glyph[circledot] ). Eckart et al. (2004, 2013) suggest Herbig Ae/Be stars ( ∼ 2-8 M glyph[circledot] ) as a possible origin of IRS 13N sources. In our current modelling, which does not resolve the opacity limit, it is likely that a very massive star actually consists of a few less massive stars. This makes the comparison between model and observations less precise. Clearly, more sophisticated simulations (including polytropic equation of state and radiative transfer) are needed to investigate this effect better. We search over the interval of 1.4-1.6 times the orbital period when the clumps are about to pass the peri-centre for the second time. We do not consider low-mass stars (0 1 . -0 5 . M glyph[circledot] ) in defining the above group.
There are in fact more than one such compact small stellar groups in both the highly eccentric models gc10Ke0.944 and gc50Ke0.944. We list the mass and locations of those stars in Table 4.
We only analyze the orbiting models with eccentricity ∼ 0 944 (i.e., . r min ∼ 0 1 pc) to look for IRS 13N-like associa-. tions, as in less eccentric models ( r min ∼ 0 9 pc) stars are . not close enough to the SMBH as the observed IRS 13N. However, it is interesting to note that there are stars (in 0.5 - 1.2 M glyph[circledot] mass range) in a compact format in the less eccentric model as well, but not as massive as in the case of the highly eccentric models.
## 4 DISCUSSION
In this Section we discuss the rate of clumps collision in the CND and the mechanisms that could cause clumps to lose angular momentum and in-spiral toward Sgr A*. Such mechanisms may also explain the episodic star formation very close to Sgr A*. We also suggest a possible scenario for the origin of the recently observed G2/DSO infrared object towards the central black hole.
## 4.1 Collisions/Encounters of clumps in the CND
An estimate on the number of CND clumps that can be transferred to highly elliptical orbits towards Sgr A* may be calculated via estimating the collisional rate between the clumps and also by comparing the CND versus the minispiral lifetime. We show below that both approaches deliver consistent results.
Following the first approach, observations have shown that the CND is a clumpy environment (e.g. Jackson et al. 1993; Christopher et al. 2005; Liu et al. 2013). There is also strong evidence that shocks and clump-clump collisions are on going within the CND based on the observed H 2 and HCN emissions (Yusef-Zadeh et al. 2001, 2013).
Here, we estimate the rate of clumps collision, Γ, based on the CND structure and properties listed in Table 2 of Christopher et al. (2005) using the following relation:
$$\Gamma \, \sim \, n \cdot \sigma _ { v } \cdot A _ { \text{cross} } \,, \quad \quad ( 1 ) \quad \, _ { u }$$
here n is the clump's number density, σ v is (one sigma) velocity dispersion of clumps with respect to each other, and A cross is the (area) cross section of a typical clump within the CND.
We assume at least 100 clumps each with 0.25 pc diameter are within the CND central 2 pc with average thickness of 0.5 pc. Christopher et al. (2005) mention that they observe numerous clumps, but only consider 26 clumps that are isolated in both position and velocity space in their data. We also estimate, using the above mentioned data, that σ v is about 20 km/s (consistent with Genzel, Eisenhauer & Gillessen 2010) or 2 × 10 -5 pc/yr.
Thus, clumps collision rate can be approximated as:
$$\Gamma \sim ( \frac { 1 0 0 } { 0. 5 \times 2 ^ { 2 } } ) \cdot ( 2 \times 1 0 ^ { - 5 } ) \cdot ( \frac { 0. 2 5 } { 2 } ) ^ { 2 } \, \sim 1 0 ^ { - 5 } \ y r ^ { - 1 }. \quad ( 2 ) \quad \text{the} \, \quad \text{effec}$$
Furthermore, the CND orbital period can be estimated as 10 5 yr, and its lifetime as 10 7 yr (Christopher et al. (2005) and references therein). Based on these timescales and our collision rate estimate we argue that during the CND lifetime about 100 collisions are possible. This shows that the CND is an interacting region, and collisions as well as encounters between clumps are common.
This number of collisions, however, could be in any direction, but to deviating from the disk bulk rotation it is necessary that a clump loses angular momentum to fall in toward the SMBH (possibly with several encounters). Thus we divide the above number of collisions by two (two out of four possible directions, along/opposite the disk rotation and inward/outward in the disk, assuming the CND is flat with respect to the clump cross-section), about 50 collisions/encounters that are suitable to dissipate orbital energy and trigger inward motion of the corresponding clumps. About 30% of those 50 encounters with proper directions will have velocities of more than one-sigma velocity dispersion of the clumps among each other. This leads to about 15 collisions per CND lifetime that efficiently remove angular momentum from clumps and result in highly elliptical clump orbits towards the central SMBH.
As for the second approach, the CND and mini-spiral lifetime also allows us to estimate the number of CND gas and dust entities being transferred onto elliptical orbits. The fact that there are a few streamers (called mini-spiral) in non-circular orbits toward the SMBH is the observational evidence for likely encounters that can lead to this phenomenon. The ratio of the CND lifetime (10 6 - 10 7 yr) over the observed mini-spiral lifetime (10 4 - 10 5 yr) is about 10 to 100. This corresponds to the probability of clump collisions and inward motions. This is in good agreement with our previous estimate of ∼ 15 collisions between clumps during the CND lifetime.
The above scenario is also consistent with the possible transient nature of the CND and indications of star formation in it. Requena-Torres et al. (2012) analyze CO transitions and conclude that the CND has a transient nature and contains warmer and less dense clumps. This study suggests that the CND total mass is a few 10 4 M glyph[circledot] , one order of magnitude smaller than the mass reported in Christopher et al. (2005). This would consequently imply that the CND has a shorter lifetime of ∼ 1 Myr. Recently, Lau et al. (2013) use SOFIA/FORCAST imaging data and conclude on the unstable structure of the inner ring of the CND (they called circumnuclear ring). Their high spatial resolution data confirm the high degree of symmetry of the CND (as in Jackson et al. (1993) results), suggesting that the CND has orbited the Galactic centre several times in its lifetime. In this case the authors report that the present-day clumpy structure of the CND (if transient) is puzzling. Yusef-Zadeh et al. (2008), on the other hand, detect methanol masers in some of the clumps and interpret it as a signature of early massive star formation (few 10 4 yr).
Whether the different tracers provide consistently reliable information on the stable or transient nature of the CND and the early phase of star formation probably needs more investigation. One should also consider other mechanisms such as shocks, collisions and UV radiation as well as the role of orbital compression close to the SMBH as each effect might act as an external pressure on some clumps that could then cause their densities to be high enough to maintain the star formation conditions at least over a specific time interval during the CND lifetime.
## 4.2 Young stars close to Sgr A*: massive binaries and compact groups
We have shown that, under some observationally supported assumptions about the gas reservoir surrounding the SMBH, some molecular clumps (within the CND) could experience encounters and collisions, losing angular momentum and falling towards the SMBH on eccentric orbits. Our model clump, on its e = 0 944 orbit is then a simplified version of a . more complex picture in which multiple encounters together with the orbital compression increase the gas densities above a threshold value at which the cloud collapses and forms stars close to the SMBH. This mechanism may also explain the presence of small stellar groups very close to the SMBH. Such systems will not be stable over one or two complete orbits around the SMBH and will dissolve quickly. The formed groups of stars such as those we tabulated in Table 4, could evolve due to the internal dynamics of the stellar group. Although having formed from a bound orbiting clump they may dissolve due to internal stellar dynamics. However, depending on the central density of the system some groups such as IRS 13E or IRS 13N can survive long enough that the stellar members reach a more evolved phase.
Some very massive YSOs ( > 20 M glyph[circledot] ) recently observed (Yusef-Zadeh et al. 2013) about 0.4 pc away from Sgr A* could be also explained as protostars forming in a way similar to our modelling, but perhaps starting with more massive initial clumps.
Furthermore, we report that some massive stars (1-5 M glyph[circledot] each) formed in our simulations are probably binaries similar to those that were recently detected (Pfuhl et al. 2013) close to Sgr A*. Note that we have used for our present simulations a relatively small and not very massive clump, it is therefore likely that more massive binaries and stellar groups might form if we follow the evolution of a more massive clump.
## 4.3 On the origin of the G2/DSO source
Gillessen et al. (2012) detect an infrared bright object, they called G2, infalling towards Sgr A* on a highly eccentric orbit (Gillessen et al. 2013; Phifer et al. 2013). Eckart et al. (2013) present a NIR K-band identification of the object, and called it Dusty S-cluster Object (DSO). The K-band emission implies that it is due to photospheric emission from an embedded star. The nature of this interesting source is not completely clear, particularly it is yet unknown if the dusty object could survive on its orbit all the way to the vicinity of the SMBH.
There are several models proposed for the nature of G2/DSO. In some it is suggested that a star is necessary to bring the observed small cloud in such a harsh environment close to the SMBH. Eckart et al. (2013) speculate that the DSO is potentially a young stellar object. Murray-Clay & Loeb (2012) explore the possibility of a proto-planetary disc surrounding a low-mass star that scattered out of an outer disk of stars towards the SMBH. Scoville & Burkert (2013) suggest that the (mass-loss) envelope of a young T-Tauri star is possibly the origin of the observed source. Future observations can help distinguishing between different scenarios.
Considering the above observational information, we suggest that some of the stars which form in our highly eccentric models and pass close to the central SMBH could be possible G2/DSO progenitors. Such stars could have been formed at any time while the parent clump is orbiting the SMBH. As it could be seen in the column density maps of the highly eccentric models (in Figs. 7 and 8), there are a few young stars (marked in red) that pass close to the central black hole around the 2nd peri-centre. Additionally, there are also a couple of stars that by possible ejection mechanisms are moving towards the SMBH (last raw in Figs. 7 and 8). Thus, supported by the results of our simulations, we propose that if young stars could form or pass close to the SMBH similar to our models, some of them might be G2/DSO progenitors.
The similar idea of a disrupting star close to Sgr A* as a possible G2/DSO progenitor has been recently proposed, e.g. see figure 1 in Guillochon et al. (2014). Such stars could have formed similar to our proposed scenario i.e., via small clumps originated from the CND. Furthermore, Meyer et al. (2013) recently pointed out that a few other sources similar to G2/DSO have been observed further away from Sgr A*. This could be very interesting in the line of our proposed scenario, as in their Fig 2 (L and K composite image), sources 1 and 3 (similar to G2/DSO) are located north of the IRS 13N group. This suggests that young stars, along with their associated dusty envelopes, could sporadically form and pass in the immediate vicinity of the central black hole. Our simulations support such a scenario.
## 5 SUMMARY AND CONCLUSIONS
Our main results can be summarized as follows:
- 1. In our simulations, highly eccentric model clumps, starting with a moderate density (10 5 cm -3 ), passing very close to the SMBH could evolve to high enough densities
that are higher than the SMBH's tidal densities and are necessary for star formation to occur in our approach. Particularly for the highly eccentric models, orbital compression of the clumps perpendicular to the orbit is the dominant factor while the clump is stretched along the orbit (Figure 2).
- 2. A few massive young stars, some in the form of massive binaries, formed in all the model calculations regardless of the presence of the SMBH. As expected, more massive stars (usually less numerous) form in the case of warmer clumps consistent with the higher Jeans mass criterion (Figure 3 top panel).
- 3. In the case of the two high eccentric models (Table 4) a few compact young stellar groups with similar properties as the observed IRS 13N group form. Thorough modelling is planned to further investigate the formation and properties of such young compact systems. Specifically, including a more realistic equation of state for the molecular clump as well as resolving the opacity limit are necessary for better comparison of the mass and number of protostars with the observations.
- 4. In our present modelling, the mass distributions (IMF) of newly formed stars, in almost all models, are consistent with the Kroupa (2001) IMF (Figure 3 bottom panel).
- 5. The scenario described in this paper provides a model that can explain the ongoing formation of stars and small stellar clusters in the Galactic centre region, in addition to the episodic massive star formation as also explained by Nayakshin & Cuadra (2005).
- 6. We show that clumps could encounter with each other in the CND environment and it is plausible that some clumps, as the one modelled in our simulations, eventually lose angular momentum and fall in towards Sgr A*. The observed streamers in non-circular orbits about the central black hole could be explained by this argument. Collisions of molecular clumps also suggest that external pressure on clumps could help trigger massive star formation within the clumps in situ close to the SMBH (Section 4.1).
- 7. Finally, we propose a scenario for the origin of the newly discovered G2/DSO source falling towards the pericentre point of a highly elliptical orbit around the SMBH. Based on our simulations, we suggest that a few young (embedded) stars could form close to the SMBH within a small star forming molecular clump, such as those highly eccentric clumps modelled in our present work (Section 4.2). Such stars at some point could pass very close to the SMBH on eccentric orbits (e.g., around the second peri-centre in our models). It is then possible that a dusty gaseous part of such a star could be separated (at least temporarily) from its stellar progenitor.
## ACKNOWLEDGMENTS
We acknowledge the anonymous referee for the constructive comments that helped clarifying the manuscript. We thank the regional computing center of the university of cologne (RRZK) for providing computing time on the DFG-funded High Performance Computing (HPC) system CHEOPS. This work was also supported by the Netherlands Research Council NWO (grants #643.000.803 [IsFast], #639.073.803 [VICI], #614.061.608 [AMUSE] and #612.071.305 [LGM]), by the Netherlands Research School for Astronomy (NOVA). B.J. is grateful to Volker Winkelmann kind support at the HPC center, and to Arjen Elteren and Nathan de Vries friendly help on the AMUSE installation and its functionality issues. B.J. thanks Fatemeh Motalebi for helping on Figure 1 visualization to be as informative as possible. We thank Mattew Horrobin for English revision. This work was supported in part by the Deutsche Forschungsgemeinschaft (DFG) via the Cologne Bonn Graduate School (BCGS), and via grant SFB 956, as well as by the Max Planck Society and the University of Cologne through the International Max Planck Research School (IMPRS) for Astronomy and Astrophysics. We had fruitful discussions with members of the European Union funded COST Action MP0905: Black Holes in a violent Universe and the COST Action MP1104: Polarization as a tool to study the Solar System and beyond. We received funding from the European Union Seventh Framework Programme (FP7/2007-2013) under grant agreement No.312789.
## REFERENCES
| Alexander T., 2005, Phys. Rep., 419, 65 |
|----------------------------------------------------------------------------------------------------------------|
| Alig C., Schartmann M., Burkert A., Dolag K., 2013, ApJ, 771, 119 |
| Ao Y. et al., 2013, A&A, 550, A135 |
| Bate M. R., 2009, MNRAS, 392, 1363 |
| Bate M. R., 2012, MNRAS, 419, 3115 |
| Bate M. R., Bonnell I. A., Price N. M., 1995, MNRAS, 277, 362 |
| Bate M. R., Burkert A., 1997, MNRAS, 288, 1060 |
| Bergin E. A., Tafalla M., 2007, ARA&A, 45, 339 |
| B¨ker o T., 2010, in IAU Symposium, Vol. 266, IAU Sympo- sium, de Grijs R., L´pine e J. R. D., eds., pp. 58-63 |
| Bonnell I. A., Bate M. R., Vine S. G., 2003, MNRAS, 343, 413 |
| Bonnell I. A., Rice W. K. M., 2008, Science, 321, 1060 |
| Buchholz R. M., Sch¨del o R., Eckart A., 2009, A&A, 499, 483 |
| Christopher M. H., Scoville N. Z., Stolovy S. R., Yun M. S., 2005, ApJ, 622, 346 |
| Combes F., 2012, Journal of Physics Conference Series, 372, 012041 |
| Eckart A., Moultaka J., Viehmann T., Straubmeier C., Mouawad N., 2004, ApJ, 602, 760 |
| Eckart A. et al., 2013, A&A, 551, A18 |
| Fritz T. K. et al., 2010, ApJ, 721, 395 |
| Genzel R., Eisenhauer F., Gillessen S., 2010, Reviews of Modern Physics, 82, 3121 |
| Ghez A. M. et al., 2008, ApJ, 689, 1044 Gillessen S., Eisenhauer F., Trippe S., Alexander T., |
| Genzel R., Martins F., Ott T., 2009, ApJ, 692, 1075 |
| Gillessen S. et al., 2013, ArXiv e-prints |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Gillessen S. et al., 2012, Nature, 481, 51 Gualandris A., Portegies Zwart S., Sipior M. S., 2005, MN- RAS, 363, 223 |
| Guillochon J., Loeb A., MacLeod M., Ramirez-Ruiz E., 2014, ApJ, 786, L12 G¨ltekin u K. et al., 2009, ApJ, 698, 198 |
| Hopkins P. F., Quataert E., 2010, MNRAS, 407, 1529 Jackson J. M., Geis N., Genzel R., Harris A. I., Madden S., Poglitsch A., Stacey G. J., Townes C. H., 1993, ApJ, 402, 173 |
| Kormendy J., Ho L. C., 2013, ArXiv e-prints Kroupa P., 2001, MNRAS, 322, 231 Krumholz M. R., Klein R. I., McKee C. F., 2007, ApJ, 656, 959 |
| Lau R. M., Herter T. L., Morris M. R., Becklin E. E., Adams J. D., 2013, ArXiv e-prints |
| Liu H. B., Ho P. T. P., Wright M. C. H., Su Y.-N., Hsieh P.-Y., Sun A.-L., Kim S. S., Minh Y. C., 2013, ApJ, 770, 44 |
| Mapelli M., Hayfield T., Mayer L., Wadsley J., 2012, ApJ, 749, 168 |
| Meyer L. et al., 2013, ArXiv e-prints J., Eckart A., Sch¨del o R., Viehmann T., Najarro |
| Moultaka F., 2005, A&A, 443, 163 Murray-Clay R. A., Loeb A., 2012, Nature Communica- |
| Nayakshin S., Cuadra J., 2005, A&A, 437, 437 Nayakshin S., Cuadra J., Springel V., 2007, MNRAS, 379, 21 Nayakshin S., Sunyaev R., 2005, MNRAS, 364, L23 |
| Paumard T. et al., 2006, ApJ, 643, 1011 |
| Pelupessy F. I., 2005, PhD thesis, Leiden Leiden University, P.O. Box 9513, 2300 RA Leiden, |
| Observatory, The Netherlands |
| Pelupessy F. I., van der Werf P. P., Icke V., 2004, 422, 55 Pelupessy F. I., van Elteren A., de Vries N., |
| S. L. W., Drost N., Portegies Zwart S. F., 2013, e-prints Pfuhl O., Alexander T., Gillessen S., Martins F., Genzel Eisenhauer F., Fritz T. K., Ott T., 2013, ArXiv e-prints |
| Pfuhl O. et al., 2011, ApJ, 741, 108 Phifer K. et al., 2013, ArXiv e-prints Portegies Zwart S., McMillan S., Harfst S. e. a., 2009, |
| New Astronomy, 14, 369 Zwart S., McMillan S. L. W., van Elteren E., Pelupessy I., de Vries N., 2013, Computer Physics Com- |
| Portegies munications, 183, 456 Portegies Zwart S. F., Baumgardt H., McMillan S. L. Makino J., Hut P., Ebisuzaki T., 2006, ApJ, 641, 319 |
| Requena-Torres M. A. et al., 2012, A&A, 542, L21 E. E., 1955, ApJ, 121, 161 o R., Eckart A., Iserlohe C., Genzel R., Ott T., 2005, |
| Salpeter Sch¨del ApJ, 625, L111 Sch¨del o R., Merritt D., Eckart A., 2009, A&A, 502, 91 |
| N., Burkert A., 2013, ApJ, 768, 108 A., Ag¨eros u M., Lee D., Basu-Zych A., 2008, |
| Scoville Seth 678, 116 |
| Q., Tremaine S., 2002, MNRAS, 335, 965 |
| ApJ, |
| Yu |
| R., |
| A&A, |
| McMillan ArXiv |
| W., |
Yusef-Zadeh F., Braatz J., Wardle M., Roberts D., 2008, ApJ, 683, L147
Yusef-Zadeh F. et al., 2013, ApJ, 767, L32
Yusef-Zadeh F., Stolovy S. R., Burton M., Wardle M., Ash-
ley M. C. B., 2001, ApJ, 560, 749
## 6 APPENDIX: ORBITAL COMPRESSION
In order to discuss the orbital compression of a source on an elliptical orbit around a black hole we consider a source with diameter ∆ p at a position along the orbit that touches the semi-latus rectum, i.e. the source is at the location of the black hole if one projects its location perpendicular onto the semi-major axis. From there it continues to descend towards the peri-centre. At the semi-latus rectum location we approximate the source volume via
$$V _ { 1 } \cong ( \Delta p ) ^ { 3 } \.$$
In Fig. 11 we show a source with diameter ∆ p at its semi-latus rectum position. The three perpendicular crosssections of the source stretch along the orbit and are compressed along the red and blue thin lines to the thick black, red and blue cross-sections of the orbitally compressed source at the position of the peri-centre r P . Following Kepler's second law we find
$$p \ \Delta p \cong r _ { P } \ \Delta S \. \quad \ \ ( 4 ) \quad \ \ \ s$$
This implies that the object is stretched along the orbit and the size ∆ p turns into
$$\Delta S \cong \frac { p \ \Delta p } { r _ { P } } \. \quad \ \ ( 5 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
The peri-centre distance r P is related to the ellipticity e and the semi-latus rectum distance via
$$r _ { P } = \frac { p } { 1 + e } \. \quad \ \ ( 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Therefore, in the orbital plane a variation of p that corresponds to the diameter of the object ∆ p translates into
$$\Delta r _ { P } = \frac { \Delta p } { 1 + e } \. \quad \quad \quad ( 7 )$$
All particles of the object that are located above and below the principle orbital plane are focused towards an intersection line in this plane centred at the peri-centre location. Therefore we can safely assume ∆ r P to be an upper limit of the source diameter ∆ T perpendicular to the orbital plane at the peri-centre location:
$$\Delta T \leq \Delta r _ { P } \.$$
Hence, the volume of the source at peri-centre can be approximated via
$$V _ { 2 } & \leq \Delta S \, \Delta T \, \Delta r _ { P } = \frac { p \, \Delta p } { r _ { P } } ( \Delta r _ { P } ) ^ { 2 } = \frac { p \, \Delta p ( 1 + e ) ( \Delta p ) ^ { 2 } } { p ( 1 + e ) ^ { 2 } } = \frac { ( \Delta p ) ^ { 3 } } { 1 + e } \. \\ \tau _ { m } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
This has to be compared to the volume V 1 and for e → 1 we find
$$\frac { V _ { 2 } } { V _ { 1 } } \leq \frac { ( \Delta p ) ^ { 3 } } { ( \Delta p ) ^ { 3 } } \frac { 1 } { 1 + e } = \frac { 1 } { 1 + e } < \frac { 1 } { 2 } \. \quad \ ( 1 0 )$$
Figure 11. Schematic structure of a source going under orbital compression close to the peri-centre passage. The filled black point is the central black hole, p and r P are the semi-latus rectum and peri-centre distances. Thin blue and red lines as well as the thin black line at the peri-centre are to guide the reader on stretching the cross-sections of the source along the orbit.
The value of 1 / 2 is an upper limit. The value can be much smaller depending on how much the gas volume can be compressed perpendicular to the orbital plane towards the pericentre. Part of this compression will be balanced by the internal pressure of the cloud or turbulences that will be generated close to peri-centre due to shearing motions in azimuthal direction. Particularly for small sources or small sections of a source with ∆ p << r P the shear effects and possible velocity gradients on the source along the orbit result only in differential effects on the corresponding volume compression.
This paper has been typeset from a T E X/ LT E X file prepared A by the author.
Figure 4. The Jeans mass number density of gas particles versus distance to the SMBH (centre of the clump in the isolated models) is plotted at 1 3 . × t ff (0.175 Myr). The number density of gas particles decrease logarithmically from red to blue as shown with the colour bar. Top to bottom correspond to isolated, orbiting e0.944 and e0.5 models. The higher Jeans mass in the case of 50 Kelvin models (right column) explain the lower number of protostars forming in these models. Note that in the Jeans mass distribution of the high eccentricity models (bottom row) orbital compression of the clump (versus iso50K model) results in the formation of more stars.
(pc)
(pc)
Figure 5. The temporal evolution of column density map for iso10K model. Top left to bottom right correspond to 0.7 to 1.4 times the initial free fall time, ∼ 0.095 to 0.19 Myr. The column densities span logarithmically over ∼ 20.0 to 24.5 amu cm 2 increasing from blue to dark orange. The protostars are also overplotted on the map and marked with red, yellow and green dots, respectively for more massive than 1 M glyph[circledot] , more massive than 0.5 M glyph[circledot] but less than 1 M glyph[circledot] , and less massive than 0.5 M glyph[circledot] . The formation of stars in two compact cores formed at about 1 × t ff is noticeable.
(pc)
(pc)
Figure 6. The temporal evolution of column density map for iso50K model. The temporal snaps, color code of densities and protostars symbols are as in the previous figure. The column densities span logarithmically over ∼ 21.0 to 25.0 amu cm 2 . There is a compact dense core forming in which less numerous protostars form than in the case of 10 K clump as the Jeans mass here is higher.
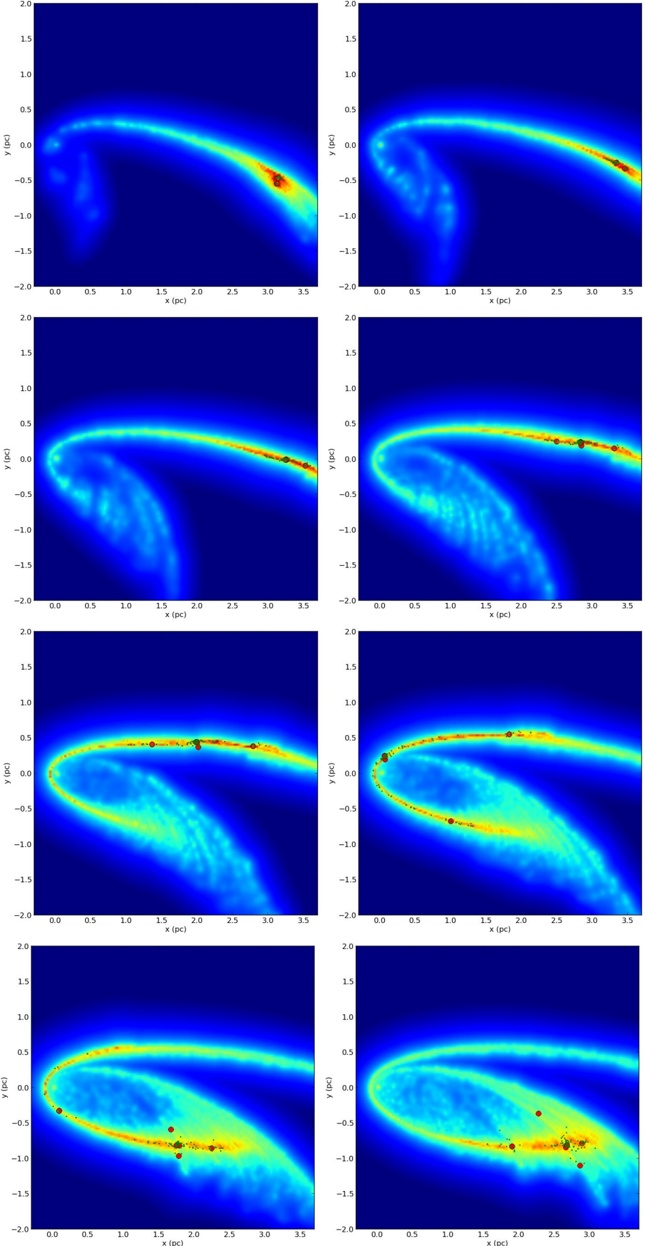
(pC)
Figure 7. The temporal evolution of column density map for gc10Ke0.944 orbiting model. The temporal snaps and color codes are as in figure 5. The clump is rotating anti clockwise. The column densities span logarithmically over ∼ 17.0 to 24.0 amu cm 2 . The orbit is designed such that the second peri-centre passage occurs at ∼ 1 25 . × t ff . Shown above is the beginning of second orbit of the clump from ∼ 3 5 pc . away from the SMBH on the x-axis. After the first peri-centre passage (not shown here) some low-mass protostars have been already formed (caused by the orbital compression), and start accreting more mass toward the second peri-centre passage. A few compact stellar groups (similar to the observed IRS 13N) form around ∼ 1 2 . t ff as discussed in Section 3.3.
Figure 8. The temporal evolution of column density map for gc50Ke0.944 orbiting model. The temporal snaps and color codes are as in figure 5. The column densities span logarithmically over ∼ 17.0 to 24.0 amu cm 2 . The orbital set up is the same for all the orbiting models. Here, the Jeans mass is higher but, the clump feels the strong tidal field of the SMBH and, as addressed in Section 3, some very massive protostars as well as a couple of compact stellar groups form around ∼ 1 2 . t ff .
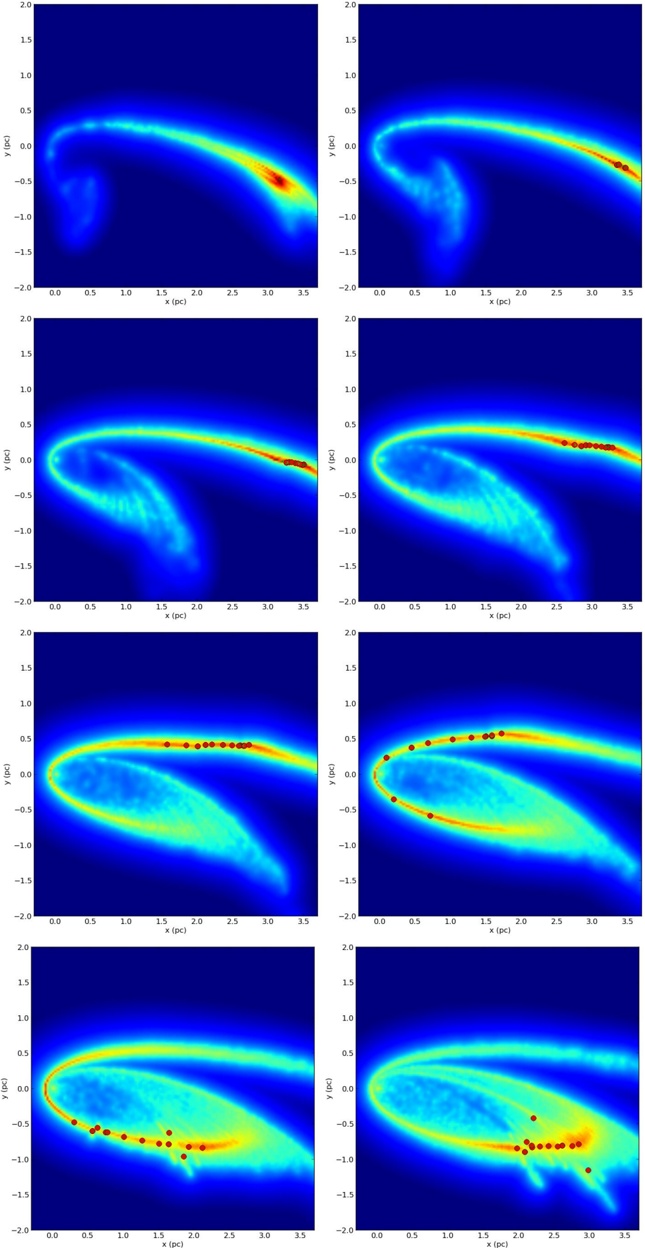
Figure 9. The temporal evolution of column density map for gc10Ke0.5 orbiting model. The temporal snaps and color codes are as in figure 5. The column densities span logarithmically over ∼ 16.5 to 24. amu cm 2 . The orbital set up is the same as all the orbiting models. There are several protostars forming in this model as the Jeans mass is as low as in the other 10 K models, also the clump compression along the orbit might help gas densities reach the ρ thresh limit.
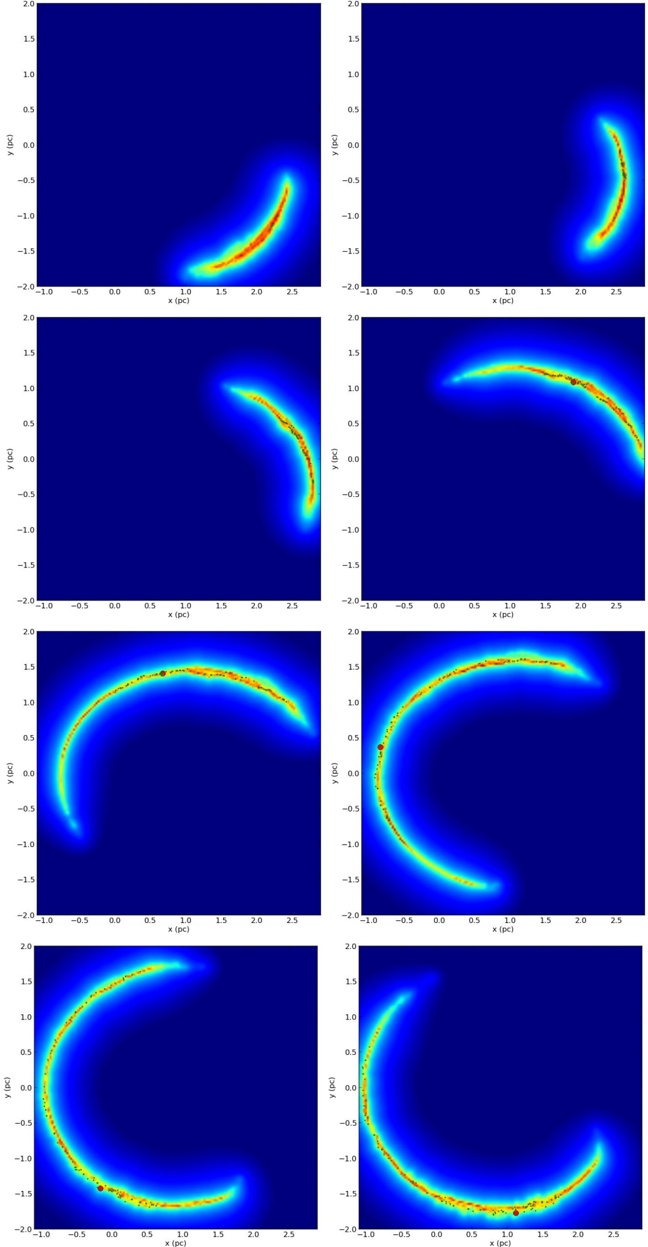
Figure 10. The temporal evolution of column density map for gc50Ke0.5 orbiting model. The temporal snaps and color codes are as in figure 5. The column densities span logarithmically over ∼ 16.5 to 24. amu cm 2 . The orbital set up is the same as all the orbiting models. There are not as many protostars in this model forming as in its colder counterpart model.
 | 10.1093/mnras/stu1483 | [
"B. Jalali",
"F. I. Pelupessy",
"A. Eckart",
"S. Portegies Zwart",
"N. Sabha",
"A. Borkar",
"J. Moultaka",
"K. Mužić",
"L. Moser"
] | 2014-07-31T20:00:08+00:00 | 2014-07-31T20:00:08+00:00 | [
"astro-ph.GA"
] | Star Formation in the vicinity of Nuclear Black Holes: Young Stellar Objects close to Sgr A* | It is often assumed that the strong gravitational field of a super-massive
black hole disrupts an adjacent molecular cloud preventing classical star
formation in the deep potential well of the black hole. Yet, young stars have
been observed across the entire nuclear star cluster of the Milky Way including
the region close ($<$0.5~pc) to the central black hole, Sgr A*. Here, we focus
particularly on small groups of young stars, such as IRS 13N located 0.1 pc
away from Sgr A*, which is suggested to contain about five embedded massive
young stellar objects ($<$1 Myr). We perform three dimensional hydrodynamical
simulations to follow the evolution of molecular clumps orbiting about a
$4\times10^6~M_{\odot}$ black hole, to constrain the formation and the physical
conditions of such groups. The molecular clumps in our models assumed to be
isothermal containing 100 $M_{\odot}$ in $<$0.2 pc radius. Such molecular
clumps exist in the circumnuclear disk of the Galaxy. In our highly
eccentrically orbiting clump, the strong orbital compression of the clump along
the orbital radius vector and perpendicular to the orbital plane causes the gas
densities to increase to values higher than the tidal density of Sgr A*, which
are required for star formation. Additionally, we speculate that the infrared
excess source G2/DSO approaching Sgr A* on a highly eccentric orbit could be
associated with a dust enshrouded star that may have been formed recently
through the mechanism supported by our models. |
1408.0006v2 | ## More on the Matter of 6D SCFTs
Jonathan J. Heckman ∗ 1, 2
1 Department of Physics, University of North Carolina, Chapel Hill, NC 27599, USA 2 Jefferson Physical Laboratory, Harvard University, Cambridge MA, 02138, USA
M5-branes probing an ADE singularity lead to 6D SCFTs with (1 0) supersymmetry. , On the tensor branch, the M5-branes specify domain walls of a 7D Super Yang-Mills theory with gauge group G of ADE-type, thus providing conformal matter for a broad class of generalized quiver theories. Additionally, these theories have G × G flavor symmetry, and a corresponding Higgs branch. In this note we use the F-theory realization of these theories to calculate the scaling dimension of the operator parameterizing seven-brane recombination, i.e. motion of the stack of M5-branes off of the orbifold singularity. In all cases with an interacting fixed point, we find that this operator has scaling dimension more than six, and defines an irrelevant deformation.
## INTRODUCTION
## COLLISIONS AND SCALING DIMENSIONS
An open question in the study of 6D superconformal field theories (SCFTs) is to determine the spectrum of operators and their scaling dimensions. In recent work, a number of new 6D SCFTs have been constructed by compactifying F-theory on non-compact singular elliptically fibered Calabi-Yau threefolds. This has already led to a classification of (1 , 0) theories without a Higgs branch [1], and has also been extended to specific theories with a Higgs branch [2] (see also [3]). For earlier work on the construction of (1 , 0) theories see e.g. [4-12]. The Ftheory realization in particular provides a powerful way to characterize many aspects of these theories.
In this note we extract the scaling dimension of certain operators in the T ( G,N ) theories of reference [2]. These theories are given by a stack of N M5-branes probing an ADE singularity C 2 / Γ G with Γ G a finite ADE subgroup of SU (2). Separating the M5-branes along the line transverse to this singularity, we see that each M5-brane specifies a domain wall in the 7D Super Yang-Mills theory defined by the ADE singularity [2]. Here, the flavor symmetry of the system is G L × G R , with both factors isomorphic to G , the corresponding ADE-type Lie group.
Our aim will be to extract the dimension of the operator parameterizing motion of the M5-branes off of the orbifold singularity. In the F-theory realization of these SCFTs, this corresponds to a brane recombination operation, and we shall refer to it as such. We use the holomorphic geometry of F-theory to extract data about this branch of the theory.
Note Added 07/14/20: The original version of this paper actually performs a computation in a 5D Kaluza-Klein (KK) regulated theory. This result must then be lifted back to six dimensions to extract the corresponding scaling dimensions in 6D SCFTs.
∗ e-mail: [email protected]
We consider the collision of two singularities in an Ftheory compactification, each supporting an ADE-type gauge group G . At the intersection, we have a superconformal matter sector. We would like to know the scaling dimension of the operator associated with Higgsing the flavor symmetry by brane recombination. So, to begin, we consider the local geometries for such collisions:
$$( E _ { 8 }, E _ { 8 } ) \colon y ^ { 2 } = x ^ { 3 } + ( u v ) ^ { 5 } \, \text{ \quad \ \ } ( 1 )$$
$$( E _ { 7 }, E _ { 7 } ) \colon y ^ { 2 } = x ^ { 3 } + ( u v ) ^ { 3 } x$$
$$( E _ { 6 }, E _ { 6 } ) \colon y ^ { 2 } = x ^ { 3 } + ( u v ) ^ { 4 }$$
$$( D _ { p }, D _ { p } ) \colon y ^ { 2 } = ( u v ) x ^ { 2 } + ( u v ) ^ { p - 1 } \quad \ \ ( 4 )$$
$$( A _ { k }, A _ { k } ) \colon y ^ { 2 } = x ^ { 2 } + ( u v ) ^ { k + 1 }, \text{ \quad \ \ } ( 5 )$$
where u and v are local coordinates of the base. In all cases but the A-type, the collision leads to a singular geometry requiring further blowups in the base. Performing such a blowup, we get at least one additional exceptional curve, which can be wrapped by a D3-brane. When this curve collapses to zero size, we get a tensionless string.
Now, this string is a BPS object, so its tension is given by the exact formula:
$$\text{tension} = \int _ { \Sigma } J, \text{ \quad \ \ } ( 6 )$$
with J the K¨hler form of the Calabi-Yau. On the other a hand, the Calabi-Yau geometry tells us that the scaling of the holomorphic three-form Ω is related to the K¨hler a form via J ∧ J ∧ J ∼ Ω ∧ Ω. So, we learn that the holomorphic three-form scales with mass as:
$$[ \Omega ] \sim \text{tension} ^ { 3 / 2 } \sim \text{mass} ^ { 3 }. \text{ \quad \ \ } ( 7 )$$
Our plan will be to use this to extract operator scaling dimensions for our system.
Observe that to really state a relation between the K¨ ahler form and the threefold, we need to allow the volume modulus of the elliptic curve to be a physical mode. This in turn means that we are really working on the Ftheory background S 1 × CY 3 and we are actually dealing
with a 5D Kaluza-Klein (KK) theory. Our answers are therefore obtained with respect to this 5D KK theory, and to extract scaling dimensions in the 6D SCFT we will need to use the relation:
$$\Delta _ { 6 D } = \frac { 4 } { 3 } \Delta _ { 5 D, K K }, \quad \quad \left ( 8 \right ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where the constant of proportionality follows from inspection of a free hypermultiplet in 6D and 5D.
The argument we will give is well-known in the context of lower-dimensional systems, and has been used to extract the scaling dimension of the Coulomb branch parameter for N = 2 SCFTs in four dimensions, as in reference [13]. In four dimensions, the homogeneity argument continues to work for N = 1 systems in four dimensions which have a Coulomb branch [14], but the absolute scaling must be determined via a-maximization [15]. Here, the novelty is that the Calabi-Yau geometry informs us of the Higgs branch, and that we are extending this analysis to higher-dimensional field theories.
As just mentioned, the next step in our analysis will involve relating the scaling dimension of the holomorphic three-form back to the scaling dimension of operators in the SCFT. To this end, let us recall that the brane recombination operation is controlled by activating vevs for operators. In the M-theory description, this corresponds to moving the M5-branes off of the orbifold singularity. This breaks the G L × G R global symmetry down to the diagonal subgroup G diag . In all the cases above, this amounts to the substitution:
↦
$$u v \mapsto u v + r.$$
One should view the parameter r as the vev of a singlet of G diag which is built from an operator O rec of the original CFT. It is natural to expect that just as in the weakly coupled setting, O rec transforms in the adj L ⊗ adj R representation of G L × G R . However, determining this representation is not crucial for our present considerations; All that matters is that the decomposition of O rec into irreducible representations of G diag contains a singlet.
Further support for this picture comes from the BPS equations of motion for the flavor branes, which are controlled by the Hitchin system coupled to defects [16]:
$$F + \left [ \Phi, \Phi ^ { \dagger } \right ] = \mu _ { \mathbb { R } } \delta _ { p } \quad \text{and} \quad \overline { \partial } _ { A } \Phi = \mu _ { \mathbb { C } } \delta _ { p }, \quad ( 1 0 ) \quad \text{nothi} \\ \text{where $n$ denotes the collision of $n=0$ and $n=0$ in the} \quad \mathbb { P } ^ { 1 $ a }$$
where p denotes the collision of u = 0 and v = 0 in the base. Vevs of operators in the CFT translate to moment maps in the Hitchin system, which in turn translate to complex structure deformations. This in turn leads to deformations such as the brane recombination operation of line (9).
Now, in the configuration of F-theory collisions, it follows from the symmetry of the system that the coordinates u and v have the same scaling dimension. Further, we see that r , and thus O rec has twice the scaling dimension of u .
But this can be determined directly from the geometry! To see how to extract this, observe that the holomorphic three-form is given by:
$$\Omega = \frac { d x } { y } \wedge d u \wedge d v.$$
So, once we fix the relative scaling dimensions for the coordinates of the threefold, the absolute scaling of Ω will allow us to extract the scaling dimension of the brane recombination operators.
Let us now proceed to the various collisions. Consider first the geometries:
$$y ^ { 2 } = x ^ { 3 } + ( u v ) ^ { k } \text{ \quad \ \ } \text{(1)}$$
for k = 3 4 5, which respectively covers , , D ,E 4 6 and E 8 . Homogeneity yields the scaling relations:
$$y \sim L ^ { 3 }, \ x \sim L ^ { 2 }, \ r \sim ( u v ) \sim L ^ { 6 / k }, \quad ( 1 3 )$$
for some scaling parameter L . Relating this back to the scaling of the holomorphic three-form, we find:
$$( E _ { 8 }, E _ { 8 } ) \, \colon \dim r _ { K K } = 1 8 \, \text{ \quad \ \ } ( 1 4 )$$
$$( E _ { 6 }, E _ { 6 } ) \, \colon \dim r _ { K K } = 9 \, \text{ \quad \ \ } ( 1 5 )$$
$$( D _ { 4 }, D _ { 4 } ) \, \colon \dim r _ { K K } = 6, \text{ \quad \ \ } ( 1 6 )$$
where dim r KK refers to the scaling dimension in the 5D KK theory. By a similar token, for the cases:
$$y ^ { 2 } = x ^ { 3 } + ( u v ) ^ { l } x, \text{ \quad \ \ } ( 1 7 )$$
we learn, for l = 3 (i.e. E 7 ) and l = 2 (i.e. D 4 ):
$$( E _ { 7 }, E _ { 7 } ) \, \colon \dim r _ { K K } = 1 2 \, \text{ \quad \ \ } ( 1 8 )$$
$$( D _ { 4 }, D _ { 4 } ) \, \colon \dim r _ { K K } = 6, \text{ \quad \ \ } ( 1 9 )$$
And in the case of colliding D-type singularities, we get:
$$( D _ { p }, D _ { p } ) \colon \dim r _ { K K } = 6. \text{ \quad \ \ } ( 2 0 )$$
Finally, in the case of colliding A-type singularities, our method is not really valid. The reason is that the fiber at the collision is still in Kodaira-Tate form, so there is nothing to blow up. This means we have no physical string coming from a D3-brane wrapped on a collapsing P 1 , and consequently, no way to fix the absolute scaling of the holomorphic three-form. Indeed, there is not even an interacting fixed point in this case.
↦
Next, we proceed to all of the T ( G,N ) theories. This is obtained by starting with the collision of two G -type singularities and performing a further quotient by ( u, v ) → ( ζu, ζ -1 v ) for ζ = exp(2 πi/N ). This leads to an additional singularity at the point u = v = 0 in the base of the F-theory geometry. Now, the important point for us is that the coordinates u and v are no longer valid in the quotient geometry, but u N and v N are. This means
that a full brane recombination amounts to the substitution:
↦
$$u v \mapsto \left ( u v \right ) ^ { N } + r _ { ( N ) }, \quad \ \ ( 2 1 ) \quad \ m e$$
where r ( N ) is the vev of our new brane recombination operator. By homogeneity, a similar scaling analysis now reveals:
$$\dim r _ { ( N ) } = N \cdot \dim r _ { ( N = 1 ) }. \quad \ \ ( 2 2 ) \quad \ \ t h a$$
Another way to see this same scaling behavior is to consider a resolution of the C 2 / Z N singularity. When we do this, we partially move onto the tensor branch of the theory, reaching our generalized quiver theory with ( G,G ) conformal matter between each symmetry factor. The singularity resolves to N -1 compact P 1 's, each of which supports a seven-brane with gauge group G . So for each such curve (and the non-compact ones as well), introduce homogeneous coordinates [ u , v i i ] for i = 1 , ..., N +1. The patch u i = 1 indicates the north pole, and v i = 1 indicates the south pole. Here, i = 1 (resp. N +1) denotes the curve for G L (resp. G R ). For example, in the case of E 8 singularities, each local collision will look like:
$$y ^ { 2 } = x ^ { 3 } + ( u _ { i } v _ { i + 1 } ) ^ { 5 } \quad \quad \ \ ( 2 3 ) \quad \ \ \ _ { t o }$$
for i = 1 , ..., N . The local recombination operation for each pair is:
↦
$$u _ { i } v _ { i + 1 } \mapsto u _ { i } v _ { i + 1 } + r _ { i, i + 1 }. \quad \quad ( 2 4 ) \quad \ \$$
Performing one such recombination corresponds to moving that particular M5-brane off of the ADE singularity. In the M-theory picture, the number of domain walls in the 7D SYM theory defined by the ADE singularity goes down by one, and in the F-theory picture the number of compact P 1 's goes down by one. The recombination vev of equation (21) is now given by the product r ( N ) ∼ r 1 2 , · · · r N,N +1 . Based on this, it is tempting to view the aggregate recombination operator as the composite O ( N ) = O 1 2 , · · · O N,N +1 , in the obvious notation. Note that for N > 1, the operator O i,i +1 is not gauge invariant, though its Casimirs will be.
Summarizing, the scaling dimension of the brane recombination operator is given by:
| | ( E 8 , E 8 ) | ( E 7 , E 7 ) | ( E 6 , E 6 ) | ( D p , D p ) | ( A k , A k ) |
|-------------|-----------------|-----------------|-----------------|-----------------|-----------------|
| dim r ( N ) | 24 N | 16 N | 12 N | 8 N | 4 N |
| | | | | | (25) |
,
where here, we have listed the scaling dimensions in the 6D SCFT (see equation (8)). Here, N ≥ 1 for all entries but the A-type case, where N ≥ 2. Indeed, as we already mentioned, we need at least one collapsing P 1 to apply our scaling argument.
Interestingly, in all cases where our analysis applies, we expect to have an interacting conformal fixed point in which the scaling dimension of this operator is greater than six.
Acknowledgements: JJH thanks M. Del Zotto, A. Tomasiello, D.R. Morrison and C. Vafa for helpful discussions and collaboration on related work. JJH also thanks M. Del Zotto, T. Dumitrescu, A. Tomasiello, and C. Vafa for comments on an earlier draft. JJH thanks the organizers of the workshop 'Frontiers in String Phenomenology' for kind hospitality at Schloss Ringberg during the completion of this work. The work of JJH was supported in part by NSF grant PHY-1067976.
- [1] J. J. Heckman, D. R. Morrison and C. Vafa, JHEP 1405 , 028 (2014) [arXiv:1312.5746 [hep-th]].
- [2] M. Del Zotto, J. J. Heckman, A. Tomasiello and C. Vafa, [arXiv:1407.6359 [hep-th]].
- [3] D. Gaiotto and A. Tomasiello, [arXiv:1404.0711 [hep-th]].
- [4] E. Witten, Nucl. Phys. B 460 , 541 (1996) [arXiv:hep-th/9511030].
- [5] O. J. Ganor and A. Hanany, Nucl. Phys. B 474 , 122 (1996) [arXiv:hep-th/9602120].
- [6] N. Seiberg and E. Witten, Nucl. Phys. B 471 , 121 (1996) [arXiv:hep-th/9603003].
- [7] M. Bershadsky and A. Johansen, Nucl. Phys. B 489 , 122 (1997) [arXiv:hep-th/9610111].
- [8] K. A. Intriligator, Nucl. Phys. B 496 , 177 (1997) [arXiv:hep-th/9702038].
- [9] J. D. Blum and K. A. Intriligator, Nucl. Phys. B 506 , 199 (1997) [arXiv:hep-th/9705044].
- [10] K. A. Intriligator, Adv. Theor. Math. Phys. 1 , 271 (1998) [arXiv:hep-th/9708117].
- [11] I. Brunner and A. Karch, JHEP 9803 , 003 (1998) [arXiv:hep-th/9712143].
- [12] A. Hanany and A. Zaffaroni, Nucl. Phys. B 529 , 180 (1998) [arXiv:hep-th/9712145].
- [13] P. C. Argyres, M. R. Plesser, N. Seiberg and E. Witten, Nucl. Phys. B 461 , 71 (1996) [arXiv:hep-th/9511154].
- [14] J. J. Heckman, Y. Tachikawa, C. Vafa and B. Wecht, JHEP 1011 , 132 (2010) [arXiv:1009.0017 [hep-th]].
- [15] K. A. Intriligator and B. Wecht, Nucl. Phys. B 667 , 183 (2003) [arXiv:hep-th/0304128].
- [16] C. Beasley, J. J. Heckman and C. Vafa, JHEP 0901 , 058 (2009) [arXiv:0802.3391 [hep-th]]. | null | [
"Jonathan J. Heckman"
] | 2014-07-31T20:00:09+00:00 | 2020-07-14T18:09:07+00:00 | [
"hep-th"
] | More on the Matter of 6D SCFTs | M5-branes probing an ADE singularity lead to 6D SCFTs with (1,0)
supersymmetry. On the tensor branch, the M5-branes specify domain walls of a 7D
Super Yang-Mills theory with gauge group G of ADE-type, thus providing
conformal matter for a broad class of generalized quiver theories.
Additionally, these theories have G x G flavor symmetry, and a corresponding
Higgs branch. In this note we use the F-theory realization of these theories to
calculate the scaling dimension of the operator parameterizing seven-brane
recombination, i.e. motion of the stack of M5-branes off of the orbifold
singularity. In all cases with an interacting fixed point, we find that this
operator has scaling dimension at least six, and defines a marginal irrelevant
deformation. |
1408.0007v1 | ## On the equilibrium of rotating filaments
## S. Recchi 1 /star , A. Hacar 1 † and A. Palestini 2 ‡
- Department of Astrophysics, Vienna University, T¨rkenschanzstrasse 17, A-1180, Vienna, Austria u
- MEMOTEF, Sapienza University of Rome Via del Castro Laurenziano 9, 00161 Rome, Italy
1 2
Received; accepted
## ABSTRACT
The physical properties of the so-called Ostriker isothermal, non-rotating filament have been classically used as benchmark to interpret the stability of the filaments observed in nearby clouds. However, such static picture seems to contrast with the more dynamical state observed in different filaments. In order to explore the physical conditions of filaments under realistic conditions, in this work we theoretically investigate how the equilibrium structure of a filament changes in a rotating configuration. To do so, we solve the hydrostatic equilibrium equation assuming both uniform and differential rotations independently. We obtain a new set of equilibrium solutions for rotating and pressure truncated filaments. These new equilibrium solutions are found to present both radial and projected column density profiles shallower than their Ostriker-like counterparts. Moreover, and for rotational periods similar to those found in the observations, the centrifugal forces present in these filaments are also able to sustain large amounts of mass (larger than the mass attained by the Ostriker filament) without being necessary unstable. Our results indicate that further analysis on the physical state of star-forming filaments should take into account rotational effects as stabilizing agents against gravity
Key words: stars: formation - ISM: clouds - ISM: kinematics and dynamics - ISM: structure
## 1 INTRODUCTION
Although the observations of filaments within molecular clouds have been reported since decades (e.g. Schneider & Elmegreen 1979), only recently their presence has been recognized as a unique characteristic of the star-formation process. The latest Herschel results have revealed the direct connection between the filaments, dense cores and stars in all kinds of environments along the Milky Way, from low-mass and nearby clouds (Andr´ e et al. 2010) to most distant and high-mass star-forming regions (Molinari et al. 2010). As a consequence, characterizing the physical properties of these filaments has been revealed as key to our understanding of the origin of the stars within molecular clouds.
The large majority of observational papers (Arzoumanian et al. 2011; Palmeirim et al. 2013; Hacar et al. 2013) use the classical 'Ostriker' profile (Ostriker 1964) as a benchmark to interpret observations. More specifically, if the estimated linear mass of an observed filament is larger than the value obtained for the Ostriker filament ( /similarequal 16.6 M /circledot pc -1 for T=10 K), it is assumed that the filament is unsta-
- /star [email protected]
- † [email protected]
- ‡ [email protected]
ble. Analogously, density profiles flatter than the Ostriker profile are generally interpreted as a a sign of collapse. However, it is worth recalling the assumptions and limitations of this model: ( ) filaments are assumed to be isothermal, i ( ii ) they are not rotating, ( iii ) they are isolated, ( iv ) they can be modeled as cylindrical structures with infinite length, ( v ) their support against gravity comes solely from thermal pressure. An increasing number of observational results suggest however that none of the above assumptions can be considered as strictly valid. In a first paper (Recchi et al. 2013, hereafter Paper I) we have relaxed the hypothesis ( ) i and we have considered equilibrium structures of non-isothermal filaments. Concerning hypothesis ( ii ), and after the pioneering work of Robe (1968), there has been a number of publications devoted to the study of equilibrium and stability of rotating filaments (see e.g. Hansen et al. 1976; Inagaki & Hachisu 1978; Robe 1979; Simon et al. 1981; Veugelen 1985; Horedt 2004; Kaur et al. 2006; Oproiu & Horedt 2008). However, this body of knowledge has not been recently used to constrain properties of observed filaments in molecular clouds. In this work we aim to explore the effects of rotation on the interpretation of the physical state of filaments during the formation of dense cores and stars. Moreover, we emphasize the role of envelopes on the
determination of density profiles, an aspect often overlooked in the recent literature.
The paper is organised as follows. In Sect. 2 we review the observational evidences suggesting that star-forming filaments are rotating. In Sect. 3 we study the equilibrium configuration of rotating filaments and the results of our calculations are discussed and compared with available observations. Finally, in Sect. 4 some conclusions are drawn.
## 2 OBSERVATIONAL SIGNS OF ROTATION IN FILAMENTS
Since the first millimeter studies in nearby clouds it is well known that star-forming filaments present complex motions both parallel and perpendicular to their main axis (e.g. Loren 1989; Uchida et al. 1991). Recently, Hacar & Tafalla (2011) have shown that the internal dynamical structure of the so-called velocity coherent filaments is dominated by the presence of local motions, typically characterized by velocity gradients of the order of 1.5-2.0 km s -1 pc -1 , similar to those found inside dense cores (e.g. Caselli et al. 2002). Comparing the structure of both density and velocity perturbations along the main axis of different filaments, Hacar & Tafalla (2011) identified the periodicity of different longitudinal modes as the streaming motions leading to the formation of dense cores within these objects. These authors also noticed the presence of distinct and non-parallel components with similar amplitudes than their longitudinal counterparts. Interpreted as rotational modes, these perpendicular motions would correspond to a maximum angular frequency ω of about 6.5 · 10 -14 s -1 . Assuming these values as characteristic defining the rotational frequency in Galactic filaments, the detection of such rotational levels then rises the question on whether they could potentially influence the stability of these objects. 1
To estimate the dynamical relevance of rotation we can take the total kinetic energy per unit length as equal to T = 1 2 ω R M 2 2 c lin , where R c is the external radius of the cylinder and M lin its linear mass. The total gravitational energy per unit mass is W = GM lin 2 , hence the ratio T /W is
$$& \frac { \mathcal { T } } { W } \simeq 0. 6 5 \left ( \frac { \omega } { 6. 5 \cdot 1 0 ^ { - 1 4 } } \right ) ^ { 2 } \left ( \frac { R _ { c } } { 0. 1 5 \, p c } \right ) ^ { 2 } \left ( \frac { M _ { l i n } } { 1 6. 6 \, M _ { \odot } \, p c ^ { - 1 } } \right ) ^ { - 1 }. \quad \text{Corr} \\ & C _ { \text{Loss} } \text{,\ } \text{$even$ median $1$} \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$} \cdot \, D \text{,\ } \text{$even$}$$
Clearly, for nominal values of ω , R c and M lin the total kinetic energy associated to rotation is significant, thus rotation is dynamically important.
## 3 THE EQUILIBRIUM CONFIGURATION OF ROTATING, NON-ISOTHERMAL FILAMENTS
In order to calculate the density distribution of rotating, non-isothermal filaments, we extend the approach already used in Paper I, which we shortly repeat here. The starting
/negationslash
1 It is worth stressing that if the filament forms an angle β = 0 with the plane of the sky, an observed radial velocity gradient ∆ V r ∆ r corresponds to a real gradient that is 1 cos β times larger than that.
Figure 1. Logarithm of the normalized density θ as a function of x for various models of isothermal filaments with different normalized angular frequencies. The model with Ω = 0 corresponds to the Ostriker profile with ρ ∝ r -4 at large radii.
equation is the hydrostatic equilibrium with rotation: ∇ P = ρ g ( + ω r 2 ). We introduce the normalization:
$$\rho = \theta \rho _ { 0 }, \ T = \tau T _ { 0 }, \ r = H x \ \Omega = \sqrt { \frac { 2 } { \pi G \rho _ { 0 } } } \omega. \quad ( 2 )$$
Here, ρ 0 and T 0 are the central density and temperature, respectively, H = √ 2 kT 0 πGρ µm 0 H is a length scale and Ω is a normalized frequency. Simple steps transform the hydrostatic equilibrium equation into:
$$\theta \tau ^ { \prime } + \tau \theta ^ { \prime } = \theta \left ( \Omega ^ { 2 } x - 8 \frac { \int _ { 0 } ^ { x } \tilde { x } \theta d \tilde { x } } { x } \right ). \quad \quad ( 3 )$$
Calling now I = ∫ x 0 ˜ xθdx ˜, then clearly I ′ = θx . Solving the above equation for I , we obtain 8 I = Ω 2 x 2 -τ x ′ -τx θ ′ θ . Upon differentiating this expression with respect to x and rearranging, we obtain:
$$T / W \quad & \theta ^ { \prime \prime } = \frac { ( \theta ^ { \prime } ) ^ { 2 } } { \theta } - \theta ^ { \prime } \left [ \frac { \tau ^ { \prime } } { \tau } + \frac { 1 } { x } \right ] - \frac { \theta } { \tau } \left [ \tau ^ { \prime \prime } + \frac { \tau ^ { \prime } } { x } + 8 \theta - 2 \Omega ^ { 2 } - 2 x \Omega \Omega ^ { \prime } \right ]. \\ \mathbb { U } ^ { - 1 } \quad & \mathcal { C } _ { \text{S-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-sb-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-sl-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-S-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s+s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s+-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-ss-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s- s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-n-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-ns-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-g-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-a-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-x-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-m-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-ds-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-ms-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-gs-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-s-ls-s-s-s-s-s-s$$
Correctly, for Ω = 0 we recover the equation already used in Paper I. This second-order differential equation, together with the boundary conditions θ (0) = 1, θ ′ (0) = -τ ′ (0) (see Paper I) can be integrated numerically to obtain equilibrium configurations of both rotating and non-isothermal filaments independently. This expression is more convenient than classical Lane-Emden type equations (see e.g. Robe 1968; Hansen et al. 1976) for the problem at hand. Notice also that also the normalization of ω differs from the more conventional assumption η 2 = ω / πGρ 2 4 0 (Hansen et al. 1976).
## 3.1 Uniformly rotating filaments
If we set τ, Ω = Const in Eq. 4, we can obtain equilibrium solutions for isothermal, uniformly rotating filaments. We have checked that our numerical results reproduce the main features of this kind of cylinders, already known in the literature, namely:
- · Density inversions take place for Ω 2 > 0 as the centrifugal, gravitational and pressure gradient forces battle to maintain mechanical equilibrium. Density oscillations occur in other equilibrium distributions of polytropes (see Horedt 2004 for a very comprehensive overview). Noticeably, the equilibrium solution of uniformly rotating cylindrical polytropes with polytropic index n = 1 depends on the (oscillating) zeroth-order Bessel function J 0 (Robe 1968; see also Christodoulou & Kazanas 2007). Solutions for rotating cylindrical polytropes with n > 1 maintain this oscillating character although they can not be expressed analytically. As evident in Fig. 1, in the case of isothermal cylinders (corresponding to n →∞ ), the frequency of oscillations is zero for Ω = 0, corresponding to the Ostriker profile. This frequency increases with the angular frequency Ω.
- · For Ω > 2, ρ ′ (0) > 0, due to the fact that, in this case, the effective gravity g + ω r 2 is directed outwards. For Ω < 2, ρ ′ (0) < 0. If Ω = 2, there is perfect equilibrium between centrifugal and gravitational forces (Keplerian rotation) and the density is constant (see also Inagaki & Hachisu 1978).
/negationslash
- · The density tends asymptotically to the value Ω 2 / 4. This implies also that the integrated mass per unit length Π = ∫ ∞ 0 2 πxθ x dx ( ) diverges for Ω 2 > 0. Rotating filaments must be thus pressure truncated. This limit of θ for large values of x is essentially the reason why density oscillations arise for Ω = 2. This limit can not be reached smoothly, i.e. the density gradient can not tend to zero. If the density gradient tends to zero, so does the pressure gradient. In this case there must be asymptotically a perfect equilibrium between gravity and centrifugal force (Keplerian rotation) but, as we have noticed above, this equilibrium is possible only if Ω = 2. Thanks to the density oscillations, ∇ P does not tend to zero and perfect Keplerian rotation is never attained. Notice moreover that the divergence of the linear mass is a consequence of the fact that the centrifugal force diverges, too, for x →∞ .
All these features can be recognized in Fig. 1, where the logarithm of the normalized density θ is plotted as a function of the filament radius x for models with various angular frequencies Ω, ranging from 0 (non-rotating Ostriker filament) to 1. Hansen et al. (1976) performed a stability analysis of uniformly rotating isothermal cylinders, based on a standard linear perturbation of the hydrodynamical equations. They noticed that, beyond the point where the first density inversion occurs, the system behaves differently compared to the non-rotation case. Dynamically unstable oscillation modes appear and the cylinder tends to form spiral structures. Notice that a more extended stability analysis, not limited to isothermal or uniformly rotating cylinders, has been recently performed by Freundlich et al. (2014; see also Breysse et al. 2014).
Even in its simplest form, the inclusion of rotations has interesting consequences in the interpretation of the physical state of filaments. As discussed in Paper I, the properties of the Ostriker filament (Stod´lkiewicz 1963; o Ostriker 1964), in particular its radial profile and linear mass, are classically used to discern the stability of these structures. According to the Ostriker solution, an infinite and isothermal filament in hydrostatic equilibrium presents an internal density distribution that tends to ρ r ( ) ∝ r -4 at large radii and a linear mass M Ost /similarequal 16 6 M . /circledot pc -1 at 10 K. As shown in Fig. 1, and ought to the effects of the centrifugal force, the radial profile of an uniformly rotating filament in equilibrium (Ω > 0) could present much shallower profiles than in the Ostriker-like configuration (i.e. Ω = 0). Such departure from the Ostriker profile is translated into a variation of the linear mass that can be supported by these rotating systems. For comparison, an estimation of the linear masses for different rotating filaments in equilibrium truncated at a normalized radius x=3 and x=10 are presented in Tables 1 and 2, respectively. In these tables, the temperature profile is the linear function τ ( x ) = 1 + Ax . In particular, the case A = 0 refers to isothermal filaments, whereas if A > 0, the temperature is increasing outwards. 2 As can be seen there, the linear mass of a rotating filament could easily exceed the critical linear mass of its Ostriker-like counterpart without being necessary unstable.
It is also instructive to obtain estimations of the above models in physical units in order to interpret observations in nearby clouds. For typical filaments similar to those found in Taurus (Hacar & Tafalla 2011; Palmeirim et al. 2013; Hacar et al. 2013), with central densities of ∼ 5 · 10 4 cm -3 , one obtains Ω /similarequal 0 5 according to Eq. 2. Assuming a tempera-. ture of 10 K, and from Tables 1 and 2 (case A = 0), this rotation level leads to an increase in the linear mass between ∼ 17.4 M /circledot pc -1 if the filament is truncated at radius x=3, and up to ∼ 112 M /circledot pc -1 for truncation radius of x=10. Here, it is worth noticing that a normalized frequency of Ω /similarequal 0 5, . or ω ∼ 6 5 . · 10 -14 s -1 , corresponds to a rotation period of ∼ 3.1 Myr. With probably less than one revolution in their entire lifetimes ( τ ∼ 1-2 Myr), the centrifugal forces inside such slow rotating filaments can then provide a non-negligible support against their gravitational collapse, being able to sustain larger masses than in the case of an isothermal and static Ostriker-like filament.
## 3.2 Differentially rotating filaments
As can be noticed in Fig. 1, a distinct signature of the centrifugal forces acting within rotating filaments is the presence of secondary peaks (i.e. density inversions) in their radial density distribution at large radii. Such density inversions could dynamically detach the outer layers of the filament to its central region, eventually leading to the mechanical breaking of these structures. In Sect. 3.1, we assumed that the filaments present a uniform rotation, similar to solid bodies. However, our limited information concerning the the rotation profiles in real filaments invites to explore other rotation configurations.
For the sake of simplicity, we have investigated the equilibrium configuration of filaments presenting differential rotation, assuming that Ω linearly varies with the filament radius x . For illustrative purposes, we choose two simple laws: Ω ( 1 x ) = x/ 10 and Ω ( 2 x ) = 1 -x/ 10, both attaining the
2 In Paper I, we considered two types of temperature profiles as a function of the filament radius, i.e. τ 1 ( x ) = 1 + Ax and τ 2 ( x ) = [1 + (1 + B x / ) ] (1 + x ), whose constants defined their respective temperature gradients as functions of the normalized radius. Both cases are based on observations. In this paper we will only consider the linear law τ = τ 1 ( x ); results obtained with the asymptotically constant law are qualitatively the same.
Figure 2. Logarithm of the normalized density θ as a function of x for various models of filaments with different rotation laws.
Table 1. Normalized linear masses at x = 3 compared to the Ostriker filament with similar truncation radius, with M Ost ( x /lessorequalslant 3) = 14 9 M . /circledot pc -1 , as a function of Ω and A .
| Ω | A = 0 | A = 0 . 02 | A = 0 . 1 | A = 0 . 5 |
|-----|---------|--------------|-------------|-------------|
| 0.1 | 1.006 | 1.015 | 1.049 | 1.167 |
| 0.5 | 1.166 | 1.176 | 1.213 | 1.33 |
| 0.8 | 1.553 | 1.561 | 1.593 | 1.676 |
| 1 | 2.108 | 2.108 | 2.111 | 2.117 |
typical frequency Ω = 0 5 at . x = 5. The first of these laws presumes that the filament rotates faster at larger radii but presents no rotation at the axis, resembling a shear motion. Opposite to it, the second one assumes that the filament presents its maximum angular speed at the axis and that it radially decreases outwards.
The comparison of the resulting density profiles for these two models presented above are shown in Fig. 2 for normalized radii x /lessorequalslant 10. For comparison, there we also overplot the density profile obtained with a constant frequency Ω = 0 5 (see Sect. 3.1). For these models, we are assuming . A=0, i.e. isothermal configurations. Clearly, the law Ω 1 ( x ) displays a radial profile with even stronger oscillations than the model with uniform rotation. As mentioned above, oscil-
Table 2. Similar to Table 1 but for linear masses at x = 10, with M Ost ( x /lessorequalslant 10) = 16 4 M . /circledot pc -1 .
| Ω | A = 0 | A = 0 . 02 | A = 0 . 1 | A = 0 . 5 |
|-----|---------|--------------|-------------|-------------|
| 0.1 | 1.015 | 1.039 | 1.137 | 1.623 |
| 0.2 | 1.075 | 1.102 | 1.212 | 1.73 |
| 0.3 | 1.287 | 1.309 | 1.415 | 1.951 |
| 0.4 | 2.533 | 2.321 | 2.063 | 2.379 |
| 0.5 | 7.019 | 6.347 | 4.377 | 3.234 |
| 0.6 | 10.37 | 10.53 | 9.398 | 4.988 |
| 0.7 | 12.29 | 12.77 | 13.78 | 8.399 |
| 0.8 | 14.96 | 15.14 | 16.59 | 13.84 |
| 0.9 | 20.05 | 19.39 | 19.43 | 20.22 |
| 1 | 26.22 | 25.7 | 23.71 | 25.95 |
Figure 3. Logarithm of the normalized density θ as a function of x for various models of uniformly rotating filaments with Ω = 0 5 . and different temperature slopes A .
lations are prone to dynamical instabilities. In this case, instabilities start occurring at the minimum of the density distribution, here located at x /similarequal 4 45. Conversely, these density . oscillations are suppressed in rotating filaments that obey a law like Ω 2 ( x ). It is however worth noticing that this last rotational law fails to satisfy the Solberg-Høiland criterion for stability against axisymmetric perturbations (Tassoul 1978; Endal & Sofia 1978; Horedt 2004). Stability can be discussed by evaluating the first order derivative d dx [ x 4 Ω ( 2 2 x )], which is positive for x ∈ (0 20 , / 3) ∪ (10 + , ∞ ) and negative for x ∈ (20 / , 3 10). We must therefore either consider that this filament is unstable at large radii, or we must assume it to be pressure-truncated at radii smaller than x=20/3 /similarequal 6.7. As we mentioned above, we could not exclude the hypothesis that rotation indeed induced instability and fragmentation of the original filament, separating the central part (at radii x < ∼ 4.45 for Ω = Ω ( 1 x ) and x < ∼ 6.7 for Ω = Ω ( 2 x )) from the outer mantel, which might subsequently break into smaller units. This (speculative) picture would be consistent with the bundle of filaments observed in B213 (Hacar et al. 2013). For comparison, the mass per unit length attained by the model with Ω = Ω ( 1 x ) at x < 4 45 (which corresponds . to ∼ 0.2 pc for T = 10 K and n c ∼ 5 · 10 4 cm -3 ) is equal to 0.99 M Ost whereas the mass outside this minimum is equal to 22.7 M Ost , i.e. there is enough mass to form many other filaments.
## 3.3 Non-isothermal and rotating filaments
As demonstrated in Paper I, the presence of internal temperature gradients within filaments could offer an additional support against gravity. Under realistic conditions, these thermal effects should be then considered in combination to different rotational modes in the study of the stability of these objects.
The numerical solutions obtained for the equilibrium configuration of filaments with Ω = 0 5 and various values of . A are plotted in Fig. 3. Notice that Fig. 5 of Palmeirim et al. (2013) suggests a rather shallower dust temperature gradient with a value of A of the order of 0.02 (green curve in Fig.
Figure 4. Column density, as a function of the normalized impact parameter χ , for filaments characterized by three different rotation laws: increasing outwards (Ω = x/ 10), decreasing outwards (Ω = 1 -x/ 10) and constant (Ω = 0 5). The filament is . embedded in a cylindrical molecular cloud, with radius five times the radius of the filament. The column density of the Ostriker filament (case p = 4) and the one obtained for a Plummer-like model with ρ ∼ r -2 (case p = 2) are also shown for comparison.
3). However, as discussed in Paper I, the gas temperature profile could be steeper than the dust one, so it is useful to consider also larger values of A . Fig. 3 shows that the asymptotic behaviour of the solution does not depend on A θ x : ( ) always tends to Ω 2 / 4 for x → ∞ . By looking at Eq. 4, it is clear that the same asymptotic behaviour holds for a wide range of reasonable temperature and frequency profiles. Whenever τ ′′ , τ /x ′ and ΩΩ ′ x tend to zero for x → ∞ , and this condition holds for a linear increasing τ ( x ) and for Ω =constant, the asymptotic value of θ x ( ) is Ω 2 / 4. It is easy to see that also the asymptotically constant law fulfils this condition if the angular frequency is constant.
Figure 3 also shows that density oscillations are damped in the presence of positive temperature gradients. This was expected as more pressure is provided to the external layers to contrast the effect of the centrifugal force. Since density inversions are dynamically unstable, positive temperature gradients must be thus seen as a stabilizing mechanism in filaments. Our numerical calculations indicate in addition that the inclusion of temperature variations also increases the amount of mass that can be supported in rotating filaments. This effect is again quantified in Tables 1 and 2 for truncation radii of x = 3 and x = 10, respectively, compared to the linear mass obtained for an Ostriker profile at the same radius. As can be seen there, the expected linear masses are always larger than in the isothermal and nonrotating filaments, although the exact value depends on the combination of Ω and A due to the variation in the position of the secondary density peaks compared to the truncation radius.
Figure 5. Same as Fig. 4 but for a filament embedded in a slab, with half-thickness five times the radius of the filament.
## 3.4 Derived column densities for non-isothermal, rotating filaments: isolated vs. embedded configurations
In addition to their radial profiles, we also calculated the column density profiles produced by these non-isothermal, rotating filaments in equilibrium presented in previous sections, as a critical parameter to compare with the observations. For the case of isolated filaments, the total column density at different impact parameters χ can be directly calculated integrating (either analytically or numerically) their density profiles along the line of sight. As a general rule, if the volume density ρ is proportional to r -p , then the column density Σ( χ ) is proportional to χ 1 -p . This result holds not only for both Ostriker filaments (see also Appendix A) and more general Plummer-like profiles (e.g. see Eq. 1 in Arzoumanian et al. 2011), but also also for the new rotating, non-isothermal configurations explored in this paper. Recent observations seem to indicate that those filaments typically found in molecular clouds present column density profiles with Σ( χ ) ∼ χ -1 , i.e. p /similarequal 2 (see Arzoumanian et al. 2011; Palmeirim et al. 2013), a value that we use for comparison hereafter.
An aspect often underestimated in the literature is the influence of the filament envelope in the determination of column densities profiles. Particularly if a filament is embedded in (and pressure-truncated by) a large molecular cloud, the line of sight also intercepts some cloud material whose contribution to the column density could be non-negligible (see also Appendix A), as previously suggested by different observational and theoretical studies (e.g. Stepnik et al. 2003; Juvela et al. 2012). In order to quantify the influence of the ambient gas in the determination of the column densities, here we consider two prototypical cases:
- (i) The filament is embedded in a co-axial cylindrical molecular cloud with radius R m .
- (ii) The filament is embedded in a sheet with half-thickness R m .
Note that, if the filament is not located in the plane of the sky, the quantity that enters the calculation of the column
Figure 6. Fractional contribution of filament and envelope to the total column density. The model shown here corresponds to the blue line of Fig. 4: the rotation profile is Ω = 1 -x/ 10 and the filament is surrounded by a cylindrical envelope with R m /R =5. c
density is not R m itself, but R ′ m = R m / cos β , where β is the angle between the axis of the filament and this plane.
Following the results presented in Sect. 3.1-3.3, we have investigated the observational properties of three representative filaments in equilibrium obeying different rotational laws, namely Ω ( 1 x ) = x/ 10, Ω ( 2 x ) = 1 -x/ 10 and Ω ( 3 x ) = 0 5, covering . both differential and uniform rotational patterns. The contribution of the envelope to the observed column densities is obviously determined by its relative depth compared to the truncation radius of the filament as well as the shape of its envelope. To illustrate this behaviour, we have first assumed that these filaments are pressure-truncated at x = 3 (a conservative estimate). Moreover, we have considered these filaments to be embedded into the two different cloud configurations presented before, that is a slab and a cylinder, both with extensions R m corresponding to five times the radius of the filament (i.e. R m /R c = 5). In both cases, we have assumed that the density of the envelope is constant and equal to the filament density at its truncation radius i.e. at x = 3.
The recovered column densities for the models presented above as a function of the impact parameter χ in the case of the two cylindrical and slab geometries are shown in Figs. 4 and 5, respectively. In both cases, the impact parameter χ is measured in units of H . The results obtained there are compared with the expected column densities in the case of two infinite filaments described by an Ostrikerlike profile (case p = 4) and a Plummer-like profile with ρ ∝ r -2 at large radii (case p = 2), as suggested by observations. From these comparisons it is clear that all the explored configurations present shallower profiles than the expected column density for its equivalent Ostriker-like filament. This is due to the constant value of the density in the envelope, which tends to wash out the density gradient present in the filament if the envelope radius is large. Moreover, the column densities expected for embedded filaments described by rotating laws like Ω 1 ( x ) and Ω ( 3 x ) (this last one only if the filament embedded into a slab) exhibit a radial dependency even shallower than these p=2 models at large impact parameters. The relative contribution of filament and envelope is outlined in Fig. 6. The model shown here corresponds to the blue line of Fig. 4: the rotation profile is Ω = 1 -x/ 10 and the filament is surrounded by a cylindrical envelope with R m /R =5. As expected, at larger c projected radii the observed radial profiles are entirely determined by the total column density of the cloud.
Finally, it is important to remark that the expected column density profiles for the models presented above and, particularly, their agreement to these shallow Plummer-like profiles with p=2, significantly depend on the selection of the truncation radius R c and the extent of the filament envelopes R m . This fact is illustrated in Fig. 7 exploring the expected slope of the observed column density profiles for pressure truncated and isothermal filaments following a rotational law like Ω 2 ( x ) = 1 -x/ 10 under different configurations for both their truncation and cloud radii. These results were calculated as the averaged value of the local slope of the column density at impact parameters χ /lessorequalslant R c , that is, where our models are sensitive to the distinct contributions of both filaments and envelopes. As expected, the larger the cloud depth is compared to the filament, the flatter profile is expected. Within the range of values explored in the figure, multiple combinations for both R c and R m parameters present slopes consistent to a power-law like dependency with p=2. Although less prominently, few additional combinations can be also obtained in the case of filaments with rotational laws like Ω 1 ( x ) = x/ 10 or Ω 3 ( x ) = 0 5 (not shown . here). Unless the rotational state of a filament is known and the contribution of the cloud background is properly evaluated, such degeneration between the parameters defining the cloud geometry and the relative weights of both the filament and its envelope makes inconclusive any stability analysis solely based on its mass radial distribution.
## 4 CONCLUSIONS
The results presented this paper have explored whether the inclusion of different rotational patterns affect the stability of gaseous filaments similar to those observed in nearby clouds. Our numerical results show that, even in configurations involving slow rotations, the presence of centrifugal forces have a stabilizing effect, effectively sustaining large amounts of gas against the gravitational collapse of these objects. These centrifugal forces promote however the formation of density inversions that are dynamically unstable at large radii, making the inner parts of these rotating filaments to detach from their outermost layers. To prevent the formation of these instabilities as well as the asymptotical increase of their linear masses at large radii, any equilibrium configuration for these rotating filaments would require them to be pressure truncated at relatively low radii.
In order to have a proper comparison with observations, we have also computed the expected column density profiles for different pressure truncated, rotating filaments in equilibrium. To reproduce their profiles under realistic conditions we have also considered these filaments to be embedded in an homogeneous cloud with different geometries. According to our calculations, the predicted column density profiles for such rotating filaments and their envelopes tend to produce much shallower profiles than those expected
R c
Figure 7. Expected radial dependence for the observed column density profiles (colour coded) of rotating filaments in equilibrium obeying a rotation law like Ω 2 ( x ) = 1 -x/ 10, truncated at a radius R c , and embedded into a cylindrical cloud extending up to a distance R m . R c and R m are displayed in units of the normalized (i.e. x) and truncation (i.e. R m /R ) radii, respectively. The black solid line c highlights those models with a power-law dependence with p=2, similar to the observations. Notice that also the color palette has been chosen in order to emphasize the transition from p < 2 configurations to p > 2 configurations.
for the case of Ostriker-like filaments, resembling the results found in observations of nearby clouds. Unfortunately, we found that different combinations of rotating configurations and envelopes could reproduce these observed of profiles, complicating this comparison.
To conclude, the stability of an observed filament can not be judged by a simple comparison between observations and the predictions of the Ostriker profile. We have shown in this paper that density profiles much flatter than the Ostriker profile and linear masses significantly larger than the canonical value of /similarequal 16.6 M /circledot pc -1 can be obtained for rotating filaments in equilibrium, surrounded by an envelope. Detailed descriptions of the filament kinematics and their rotational state, in addition to the analysis of their projected column densities distributions, are therefore needed to evaluate the stability and physical state in these objects.
## ACKNOWLEDGEMENTS
This publication is supported by the Austrian Science Fund (FWF). We wish to thank the referee, Dr Chanda J. Jog, for the careful reading of the paper and for the very useful report.
## REFERENCES
Andr´ e, P., Men'shchikov, A., Bontemps, S., et al. 2010, A&A, 518, L102
- Arzoumanian, D., Andr´ e, P., Didelon, P., et al. 2011, A&A, 529, L6
Breysse, P. C., Kamionkowski, M., & Benson, A. 2014, MNRAS, 437, 2675
- Caselli, P., Benson, P. J., Myers, P. C., & Tafalla, M. 2002, ApJ, 572, 238
Christodoulou, D. M., & Kazanas, D. 2007, arXiv:0706.3205
- Endal, A. S., & Sofia, S. 1978, ApJ, 220, 279
- Freundlich, J., Jog, C. J., & Combes, F. 2014, A&A, 564, A7
- Hacar, A., & Tafalla, M. 2011, A&A, 533, A34
- Hacar, A., Tafalla, M., Kauffmann, J., & Kovacs, A. 2013, A&A, 554, A55
- Hansen, C. J., Aizenman, M. L., & Ross, R. L. 1976, ApJ, 207, 736
Horedt, G. P. 2004, Polytropes - Applications in Astrophysics and Related Fields, Astrophysics and Space Science Library, 306 Inagaki, S., & Hachisu, I. 1978, PASJ, 30, 39
- Juvela, M., Malinen, J., & Lunttila, T. 2012, A&A, 544, A141
- Kaur, A., Sood, N. K., Singh, L., & Singh, K. D. 2006, Ap&SS, 301, 89
- Loren, R. B. 1989, ApJ, 338, 925
- Molinari, S., Swinyard, B., Bally, J., et al. 2010, A&A, 518, L100
- Oproiu, T., & Horedt, G. P. 2008, ApJ, 688, 1112
Ostriker, J. 1964, ApJ, 140, 1056
- Palmeirim, P., Andr´, P., Kirk, J., et al. 2013, A&A, 550, A38 e Recchi, S., Hacar, A., Palestini, A. 2013, A&A, 558, A27 (Paper I)
- Robe, H. 1968, Annales d'Astrophysique, 31, 549
- Robe, H. 1979, A&A, 75, 14
- Schneider, S., & Elmegreen, B. G. 1979, ApJS, 41, 87
- Simon, S. A., Czysz, M. F., Everett, K., & Field, C. 1981, American Journal of Physics, 49, 662
- Stepnik, B., Abergel, A., Bernard, J.-P., et al. 2003, A&A, 398, 551
- Stod´ olkiewicz, J. S. 1963, Acta Astronomica, 13, 30
Tassoul, J.-L. 1978, Princeton Series in Astrophysics, Princeton:
Figure A1. Section of the filament (with radius R c ), embedded in a (cylindrical, co-axial) molecular cloud with radius R m .
University Press, 1978, Uchida, Y., Fukui, Y., Minoshima, Y., Mizuno, A., & Iwata, T. 1991, Nature, 349, 140 Veugelen, P. 1985, Ap&SS, 109, 45
## APPENDIX A: ON THE COLUMN DENSITY OF FILAMENTS EMBEDDED IN MOLECULAR CLOUDS
In this appendix we derive a formula to calculate the column density of filaments embedded in large molecular clouds. For that, let us assume first the general case of an isothermal filament described by the Ostriker solution θ i ( x ) = [ 1 + x 2 ] -2 . If we call z the (normalized) distance between the plane in the sky where the filament is located and a generic plane, then the distance between the point ( χ, z ) (where χ is the normalized impact parameter) and the axis is simply x = √ χ 2 + z 2 . As it is well known, if we assume that the filament extends until infinite distances, then the column density is:
$$\Sigma ( \chi ) & = \int _ { - \infty } ^ { \infty } \theta _ { i } ( \chi, z ) d z = \int _ { - \infty } ^ { \infty } \frac { d z } { ( 1 + z ^ { 2 } + \chi ^ { 2 } ) ^ { 2 } } \\ & = \frac { 1 } { 2 } \frac { \pi } { ( \chi ^ { 2 } + 1 ) ^ { 3 / 2 } }.$$
However, the cylinder could be embedded in a more extended cloud, with radius R m . If we take for simplicity the cloud aligned with the filament, the situation is shown in Fig. A1.
Based on this figure (and due to the symmetry of the problem), we can write the column density as:
$$\Sigma ( \chi ) & = 2 \int _ { 0 } ^ { z _ { o } } \theta _ { i } ( \chi, z ) d z = 2 \int _ { z _ { o } } ^ { z _ { i } } \theta _ { b } d z + 2 \int _ { 0 } ^ { z _ { i } } \frac { d z } { ( 1 + z ^ { 2 } + \chi ^ { 2 } ) ^ { 2 } }. \\ \mathfrak { U } _ { \infty } \, \infty \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \infty \, \underline { h } \, \incolon$$
Here we have defined (see also Fig. A1):
$$z _ { o } = \sqrt { R _ { m } ^ { 2 } - \chi ^ { 2 } }, \ \ z _ { i } = \sqrt { R _ { c } ^ { 2 } - \chi ^ { 2 } }, \ \theta _ { b } = \theta ( R _ { c } ), \ ( A 3 )$$
and assumed that the density of the molecular cloud is constant and equal to θ R ( c ). The result is:
$$& \text{start and equal to } \theta ( R _ { c } ). \text{The result is: } \\ & \Sigma ( \chi ) = 2 \theta _ { b } ( z _ { o } - z _ { i } ) + \frac { z _ { i } } { ( \chi ^ { 2 } + 1 ) ( R _ { c } ^ { 2 } + 1 ) } + \frac { \tan ^ { - 1 } \sqrt { \frac { R _ { c } ^ { 2 } - \chi ^ { 2 } } { \chi ^ { 2 } + 1 } } } { ( \chi ^ { 2 } + 1 ) ^ { 3 / 2 } }, \\ & \quad = 2 \frac { \sqrt { R _ { m } ^ { 2 } - \chi ^ { 2 } } - \sqrt { R _ { c } ^ { 2 } - \chi ^ { 2 } } } { ( 1 + R _ { c } ^ { 2 } ) ^ { 2 } } + \frac { \sqrt { R _ { c } ^ { 2 } - \chi ^ { 2 } } } { ( \chi ^ { 2 } + 1 ) ( R _ { c } ^ { 2 } + 1 ) } + \\ & \quad + \frac { \tan ^ { - 1 } \sqrt { \frac { R _ { c } ^ { 2 } - \chi ^ { 2 } } { \chi ^ { 2 } + 1 } } } { ( \chi ^ { 2 } + 1 ) ^ { 3 / 2 } }. \\ & \text{It is easy to see that, in the lines for } R _ { c } \left ( \text{and } R _ { m } \right ) \text{tending to}$$
It is easy to see that, in the limes for R c (and R m ) tending to infinity, we recover the column density profile found above for the infinite cylinder.
Another possibility is to assume that the cylinder is immersed in a slab of gas with half thickness R m . The derivation of the column density remains the same and the only difference is that z o is now fix (it is equal to R m ) and does not depend any more on χ as before.
For filaments whose profiles are determined numerically (like the ones found in Sect. 3) the integral:
$$\int _ { 0 } ^ { z _ { i } } \theta ( \chi, z ) d z, \text{ \quad \quad } ( A 5 )$$
(where as usual χ and z are related to x by x = √ χ 2 + z 2 ) must be calculated numerically. The contribution to the column density due to the surrounding molecular cloud remains unaltered. | 10.1093/mnras/stu1566 | [
"S. Recchi",
"A. Hacar",
"A. Palestini"
] | 2014-07-31T20:00:13+00:00 | 2014-07-31T20:00:13+00:00 | [
"astro-ph.GA"
] | On the equilibrium of rotating filaments | The physical properties of the so-called Ostriker isothermal, non-rotating
filament have been classically used as benchmark to interpret the stability of
the filaments observed in nearby clouds. However, such static picture seems to
contrast with the more dynamical state observed in different filaments. In
order to explore the physical conditions of filaments under realistic
conditions, in this work we theoretically investigate how the equilibrium
structure of a filament changes in a rotating configuration. To do so, we solve
the hydrostatic equilibrium equation assuming both uniform and differential
rotations independently. We obtain a new set of equilibrium solutions for
rotating and pressure truncated filaments. These new equilibrium solutions are
found to present both radial and projected column density profiles shallower
than their Ostriker-like counterparts. Moreover, and for rotational periods
similar to those found in the observations, the centrifugal forces present in
these filaments are also able to sustain large amounts of mass (larger than the
mass attained by the Ostriker filament) without being necessary unstable. Our
results indicate that further analysis on the physical state of star-forming
filaments should take into account rotational effects as stabilizing agents
against gravity |
1408.0008v1 | ## Optical investigation of thermoelectric topological crystalline insulator Pb 0 77 . Sn 0 23 . Se
1, ∗ 1 1
Anjan A. Reijnders, Jason Hamilton, Vivian Britto, Jean-Blaise Brubach, 2 Pascale Roy, 2 Quinn D. Gibson, 3 R.J. Cava, 3 and K. S. Burch 4, †
4
1 Department of Physics & Institute for Optical Sciences, University of Toronto, 60 St. George Street, Toronto, ON M5S 1A7, Canada. 2 Synchrotron SOLEIL, L'Orme des Merisiers Saint-Aubin, 91192 Gif-sur-Yvette, France. 3 Department of Chemistry, Princeton University, Princeton, New Jersey 08544, USA Department of Physics, Boston College, 140 Commonwealth Ave, Chestnut Hill, Massachusetts 02467, USA
(Dated: August 4, 2014)
Pb 0 77 . Sn 0 23 . Se is a novel alloy of two promising thermoelectric materials PbSe and SnSe that exhibits a temperature dependent band inversion below 300 K. Recent work has shown that this band inversion also coincides with a trivial to nontrivial topological phase transition. To understand how the properties critical to thermoelectric efficiency are affected by the band inversion, we measured the broadband optical response of Pb 0 77 . Sn 0 23 . Se as a function of temperature. We find clear optical evidence of the band inversion at 160 ± 15 K, and use the extended Drude model to accurately determine a T 3 / 2 dependence of the bulk carrier lifetime, associated with electron-acoustic phonon scattering. Due to the high bulk carrier doping level, no discriminating signatures of the topological surface states are found, although their presence cannot be excluded from our data.
## I. INTRODUCTION
Thermoelectrics are a subject of great interest to industry for their many applications as macro and micro-scale Peltier coolers, their waste-heat energy recycling potential (heat-to-electricity conversion) in industrial and consumer products, and their application as highly sensitive compact and robust sensors. 1-5 An academic interest has also persisted as the optimization of thermoelectric efficiency offers an intriguing challenge in which ostensibly mutually exclusive physical properties must be combined in one material for the greatest performance. This is illustrated by the figure of merit ZT = TS σ 2 κ , where S σ , , and κ are the Seebeck coefficient, the DC conductivity, and the thermal conductivity, respectively. For high thermoelectric efficiency, S and σ must therefore be simultaneously enhanced, while κ is deliberately suppressed. This is a nontrivial task, considering the intimate link between the parameters that define ZT . For example, both σ and κ depend on the carrier lifetime τ , while both S and σ are a function of the band dispersion. Hence, the improvement of each individual quantity could result in an overall decrease of ZT , thus making experimental techniques that can disentangle the common limitations of each quantity highly desirable.
optical investigation of strongly correlated systems, 16-20 the extended Drude model offers some benefits previously unexplored in the context of thermoelectrics. Using this approach grants access not only to the temperature dependence of the carrier lifetime, but also to its frequency dependence, shedding light on the various scattering mechanisms that govern σ and κ . Moreover, with both high temperature and energy resolution, 21 broadband (far infrared through visible) optical spectroscopy provides direct access to the free carrier plasma frequency and band mass, both affecting S and σ , as well as spectral weight transfers and band transitions, useful for studying band gaps and band inversions.
Currently, the primary methods of studying thermoelectrics are by DC transport, optics, thermopower experiments and neutron scattering, 6-15 where the standard Drude model is often employed to extract temperature dependent information about carrier lifetimes. A major shortcoming of the Drude model, however, is the assumption that the carrier lifetime is frequency independent. When analyzing optical data, this often results in poor quality Drude fits, and carrier scattering rates with large uncertainties. A solution to this shortcoming is the application of the extended Drude analysis to a sample's optical response. 16 While commonplace in the
To illustrate the versatility of this approach we've performed our measurements on Pb 0 77 . Sn 0 23 . Se, a compound combining the thermoelectric characteristics of its thoroughly studied binary constituents PbSe and SnSe 9-12,22-24 However, unlike its constituents, previous works on Pb 0 77 . Sn 0 23 . Se crystals have shown evidence of a temperature dependent band inversion, although neither the exact transition temperature, nor the temperature dependence of the gap has been identified conclusively. This is largely a result of limited energy and temperature resolution of the experimental probes that were used, with various reports ranging between 80 K and 200 K. 6,8,9,25-27 Hence, broadband optical spectroscopy provides a unique opportunity to study, in a very controlled manner, how carrier dynamics change throughout the inversion. Moreover, many traditional thermoelectric probes, such as transport and Seebeck measurements, rely on band structure models to extract the scattering rate. Such band structure assumptions are severely complicated by the band inversion, further motivating the investigation of Pb 0 77 . Sn 0 23 . Se by optical spectroscopy as features of the band inversion and the carrier lifetime can be measured independently in a single experiment. This discriminating quality becomes even more evident by considering previous
transport studies of the Pb 1 -x Sn Se x system. While Pb 1 -x Sn Se x alloys have been studied for 50 years, 28 only specially prepared low-carrier extrinsic p-type Pb 0 77 . Sn 0 23 . Se was found to show abrupt changes in the DC transport properties across the band inversion. 8 Interestingly, as-grown n-type crystals showed no clear signatures of the band inversion at all. A recent paper by Liang et al. highlighted this peculiarity and was the first to show evidence of the band inversion in n-type Pb 0 77 . Sn 0 23 . Se, employing Nernst and thermopower experiments. 6 Particularly for device applications, a thorough understanding of the electronic properties of both n and p-type crystals is pivotal. 24
The temperature dependent band inversion of Pb 0 77 . Sn 0 23 . Se has also received significant attention from the topological insulator community. It was recently shown that while PbSe is a trivial insulator, SnSe is a topological crystalline insulator (TCI); a state of matter in which crystal point group symmetry protects the persistence of gapless surface states with a spin polarized Dirac dispersion. 25,27,29,30 Interestingly, in Pb 0 77 . Sn 0 23 . Se we have the unique opportunity to tune between topological and trivial phases by temperature, rather than doping, thus negating the effects of disorder. Moreover, since it is challenging to perform ARPES and STM (the primary methods of studying surface states) at various temperatures, temperature dependent broadband spectroscopy makes a great tool for the investigation of surface states in topological (crystalline) insulators. 24,27,31-39 We note that since band gaps are typically tuned by electron-phonon coupling and anharmonicity, the concurrent band inversion and topological phase transition hints at a more subtle process. Hence, Pb 0 77 . Sn 0 23 . Se can reveal new insights into how anharmonicity, electron-phonon coupling and topology all interplay.
In the present work, we measure the temperature dependent broadband reflectance of Pb 0 77 . Sn 0 23 . Se between 5 K - 292 K, and extract its optical conductivity and dielectric function between 6 meV - 6 eV. Subsequent extended Drude analysis reveals the frequency dependent free carrier scattering rate, and is used for a precise determination of the dominant temperature dependent scattering mechanism. We find clear optical evidence of the band inversion temperature at 160 ± 15 K, by studying the free carrier plasma frequency and direct optical band gap transitions. Interestingly, the temperature dependent free carrier scattering rate shows no signatures of the band inversion, and follows T 3 / 2 behaviour in accordance with electron-acoustic phonon scattering. Finally, we find that the Fermi level lies deep in the conduction band (114 ± 22 meV), obscuring the observation of surface states, 31,40-42 and causing the Seebeck coefficient and power factor to be insensitive to the band inversion.
(a)
FIG. 1. (a) The changing slope in the reflectance below the plasma edge (reflectance minimum) indicates a temperature dependent free carrier scattering rate in Pb 0 77 . Sn 0 23 . Se. (b) The optical conductivity reveals a clear separation ( ω c ) between Drude conductivity below 125 meV, and inter/intraband transitions above 125 meV. (c) The zero-crossing of the real part of the dielectric function ( glyph[epsilon1] 1 ), indicative of the screened plasma frequency, can be used to determine glyph[epsilon1] ∞
## II. EXPERIMENT
Pb 0 77 . Sn 0 23 . Se samples were grown at Princeton University. 6 Prior to the reflectance measurements, samples were freshly cleaved with a razor blade to produce a lustrous surface. Cleaving by tape was also attempted, but proved unsuccessful in producing high quality surfaces. Temperature dependent reflectance measurements were performed in near-normal geometry between 6 meV - 1.5 eV, using a modified Bruker VERTEX 80v and ARS continuous flow cryostat, described in detail elsewhere 31 (Fig. 1a). Reflectance data below 12 meV were corroborated by repeating the measurements using synchrotron radiation and a custom designed sample chamber with a closed cycle Cryomech cryostat at the AILES Beamline of the SOLEIL synchrotron in France. All infrared data were complemented by partially overlapping room temperature ellipsometry measurements between 0.75 meV -
6 eV.
Using RefFit, a simultaneous variational dielectric fit (VDF) of Reflectance and ellipsometry data yielded all Kramers-Kronig consistent optical constants. All measurements were performed on two different crystals from the same sample batch, showing excellent qualitative resemblance (see inset Fig. 1a for the reflectance of sample 2). Hence, data from only one crystal are discussed.
## III. RESULTS AND ANALYSIS
Fig. 1b shows the real part of the optical conductivity σ 1 ( ω ) of Pb 0 77 . Sn 0 23 . Se in the far and mid infrared. The spectra are dominated by a distinct Drude peak below 125 meV, associated with free carrier conductivity, and separated by a cut-off frequency ω c from the interband transitions above 125 meV.
The simplest approach to understanding the spectral range below ω c is to apply the semi-classical Drude model, in which the complex dielectric function for the free carrier response is given by
$$\hat { \epsilon } ( \omega ) = \epsilon _ { \infty } - \frac { \omega _ { p } ^ { 2 } } { \omega ^ { 2 } + i \frac { \omega } { \tau } } \quad \quad ( 1 ) \quad \$$
where ω p is the bare plasma frequency, τ is the transport lifetime, and glyph[epsilon1] ∞ captures all contributions to the dielectric function other than the Drude conductivity (i.e. interband transitions and polarizability of the static background). The bare plasma frequency is defined as ω 2 p = 4 πne /m 2 b , where n is the carrier density and m b is the band mass.
An immediate consequence of this model is the large, low frequency negative contribution to the real part of the dielectric function (ˆ = glyph[epsilon1] glyph[epsilon1] 1 + iglyph[epsilon1] 2 ) due to the free carrier response. Indeed from eq. 1 it can be seen that in the limit ωτ glyph[greatermuch] 1 the zero-crossing of glyph[epsilon1] 1 corresponds to the screened plasma frequency ˜ ω p , which is related to the bare plasma frequency ω p through ω p = ˜ ω p √ glyph[epsilon1] ∞ . Hence, we expect to observe this zero-crossing in glyph[epsilon1] 1 , which can be seen directly in 1c. The temperature dependence of both ω p and glyph[epsilon1] ∞ are discussed next.
Before analyzing the spectra in detail, it is useful to consider what we expect to observe as a result of the band inversion. For compounds in which the chemical potential is located in the bulk gap, a distinct signature of a band inversion would be the spectral weight redistribution from interband transitions to the Drude conductivity. As the gap closes, the onset frequency of the interband transitions (roughly ω c in Fig. 1c) moves to lower energy, until it merges with the Drude when the gap size reduces to zero. However, since stoichiometric Pb 0 77 . Sn 0 23 . Se is naturally n-type (chemical potential in the conduction band, shown in Fig. 2a), we do not expect to observe such obvious behaviour, and therefore perform a more sophisticated analysis to observe the band inversion. Fig. 2b illustrates how the band inver-
FIG. 2. (a) Band structure cartoon before or after the band inversion (left panel), and during the inversion (right panel), illustrating the allowed (in)direct transitions when the chemical potential is in the bulk conduction band (as is the case in as-grown Pb 0 77 . Sn 0 23 . Se). (b) Signatures of this inversion include a changing free carrier lifetime τ ( T, ω ) and plasma frequency ω p (region I), spectral weight change for indirect gap transitions (region II), and changes in the size of the direct gap (region III). (c) The plasma frequency of Pb 0 77 . Sn 0 23 . Se shows a distinct change in temperature dependence around 160 K, deviating from it's expected quadratic temperature dependence. (d) glyph[epsilon1] ∞ also shots an abrupt change in its temperature dependence at 160 K, further corroborating 160 K as the band inversion temperature.
sion could be deduced from signatures in σ 1 ( ω ). Region I is dominated by free carrier behaviour, described by eqn. 1. Hence, as the band dispersion transforms across the band inversion (Fig. 2a), changes in both m b and n can result in an unusual temperature dependence of the plasma frequency (where ω 2 p ∝ spectral weight in σ 1 ( ω )). One might also expect the inversion driven changes in the electronic structure to be reflected in the carrier lifetime. This can be seen from the width of the Lorentzian features (centred at 0), while deviations from the Lorentzian lineshape indicate an energy dependent lifetime. Region III can be used to extract the magnitude of the direct gap transitions E dir shown in Fig. 2a. With the chemical potential ( µ ) in the conduction band, the smallest allowed E dir is offset from the conduction band minimum.
E #
in
I
III
IV
Hence, changes in the band dispersion as well as n are likely to affect E dir , resulting in a shift of the interband transition onset in σ 1 ( ω ), as shown in Fig. 2b. Since glyph[epsilon1] ∞ is a measure of the spectral weight in σ 1 above the free carriers, this quantity too should reveal signatures of the band inversion, similar to E dir . Finally, below E dir , region II is sensitive to temperature dependent changes in indirect gap transitions E in , where E in < E dir , as well as impurity scattering responsible for an extended E dir onset (known as an Urbach tail 43 ).
## A. Bulk plasma frequency and glyph[epsilon1] ∞
The spectral weight of the Drude feature (area under σ 1 ) is a direct measure of the bare plasma frequency squared, ω 2 p , and was determined by integrating σ 1 ( ω ) up to a cut-off point ω c using
$$\omega _ { p } ^ { 2 } = \frac { 1 2 0 \Omega } { \pi } \int _ { 0 } ^ { \omega _ { c } } \sigma _ { 1 } ( \omega ^ { \prime } ) \, \mathrm d \omega ^ { \prime } \, \quad \quad ( 2 ) \quad \text{ has} \, \quad \text{a tc}$$
where ω c separates the Drude contribution to σ 1 ( ω ) from the interband transitions (as indicated in Fig. 1b). 20 The bare plasma frequency was then used to extract glyph[epsilon1] ∞ from the zero-crossing in glyph[epsilon1] 1 ( ω ). We note that an alternative method to find glyph[epsilon1] ∞ (which does not rely on the zerocrossing and is described elsewhere 20 ) was also used, and resulted in similar temperature dependent values differing only by a constant offset of a few percent.
The temperature dependence of ω 2 p and glyph[epsilon1] ∞ are shown in Fig. 2c and 2d, respectively. Starting with ω 2 p , we find a reduction as temperature increases, with a distinct discontinuity in the trend around 160 K. In general, a temperature dependent reduction in ω 2 p is an expected result that can be understood as follows. While semiclassically we have ω 2 p ∝ n/m , quantum mechanically the squared plasma frequency calculated using eqn. 2 corresponds to an integration of the density of states ( N ω,T ( )) multiplied by the Fermi function ( f ( ω, T )), so that ω 2 p ( T ) ∝ ∫ N ω,T f ω,T ( ) ( ) d ω . 44,45 Evaluating this integral using the Sommerfeld expansion yields a temperature independent term equal to ω 2 p at 0 K, and a negative T 2 term as a result of thermal smearing of the Fermi function. Hence, the temperature dependence of the squared plasma frequency is expected to follow
$$\omega _ { p } ^ { 2 } ( T ) \approx \omega _ { p } ^ { 2 } ( T = 0 K ) - B T ^ { 2 } \text{ \quad \ \ } ( 3 ) \text{ \ \ } \text{sur} \text{ }$$
where B depends on N ω,T ( ) at the Fermi energy. 44-46 Interestingly, while a linear decline in ω 2 p vs T 2 is expected, Fig. 2c shows two distinct regimes in its temperature dependence below and above 160 ± 15 K. Since B is a function of the density of states, this is a clear signature of an abrupt change in the band dispersion, associated with the band inversion. Indeed, this critical temperature falls within the 80 K - 200 K temperature range over which the band inversion was previously observed. 6,8,9,25,26,47 This also provides a first indication that despite the Fermi level of n-type Pb 0 77 . Sn 0 23 . Se not being in the gap, discontinuities in its optical properties are a useful probe in the exact determination of its band inversion temperature.
Besides clear signatures of the band inversion in ω 2 p , we also expect to see a change in glyph[epsilon1] ∞ at 160 ± 15 K. Since glyph[epsilon1] ∞ is a measure of the spectral weight of all interband transitions, it is sensitive to temperature dependent changes in the band structure. 48 This is confirmed by (Fig. 2d), revealing a clear change in the temperature dependence around 160 K, and will be discussed in greater in section III C.
## B. Surface States
Besides the Seebeck sensitivity to the band inversion at 160 ± 15 K, this critical temperature is also relevant to the topological phase of Pb 0 77 . Sn 0 23 . Se. Previous studies have shown how the band inversion is accompanied by a topological phase transition, where at low temperature topologically protected surface states persist in the bulk band gap. 6,25,26,29,47,49 In our optical data below 160 K (Fig.1a) we see no evidence of Dirac surface states, such as previously observed in topological insulators Bi 2 Te Se, 2 Bi Se , and (Bi,Sb) Te 2 3 2 3 31-36 This is not surprising since we find a bulk chemical potential of 114 ± 22 meV above the conduction band minimum at 5 K (shown later), consistent with previous studies of Pb 1 -x Sn Se with simix lar stoichiometry 6,25,26,47 Such a high bulk µ causes bulk conductance to dominate the optical properties, which can by understood by considering how the measured reflectance relates to the complex dielectric function, as R = (1 | -√ ˆ) glyph[epsilon1] / (1 + √ ˆ) glyph[epsilon1] | 2 . From Fig. 1c and eqn. 1 it is clear that | 1 ± √ ˆ glyph[epsilon1] | glyph[greatermuch] 1 for all frequencies ω < ω ˜ p , resulting in R > 95% over the full far infrared (FIR) range for most temperatures. Such high FIR reflectance even above the topological phase transitions obscures discriminating surface conductance signatures from the bulk conductivity in R ω ( ). Moreover, with the Fermi level so high in the conduction band, mixing of the surface and bulk bands also blurs other distinguishing features such as the bulk vs surface carrier lifetime. However, to ensure we did not overlook surface state signatures in our reflectance data, we used the Boltzmann transport equation to estimate their expected effect on the measured reflectance. Indeed, the surface state signatures are far below our detection sensitivity, as described in the Appendix, and crystals with a lower bulk carrier concentration are required for further optical investigations of the topological crystalline surface state properties of Pb 0 77 . Sn 0 23 . Se.
## C. Interband transitions
To study how the bulk electronic structure is affected by the band inversion, we turn to the band gap transi-
tions that are visible above ω c in Fig. 1b. With ARPES measurements showing µ in the conduction band for crystals with identical stoichiometry, 25,26,47 the smallest allowed direct gap transition exceeds the direct bandgap (and thus takes place away from the Brillouin Zone centre), as illustrated in Fig. 2a. This effect is known as the Burstein-Moss shift. 11,50 Assuming a parabolic dispersion for both the conduction and valence band, the energy of this transition can be estimated. By adding µ = ¯ h k 2 2 F / 2 m c to the direct band gap energy E g , and to the energy of the valence band electron with respect to valence band maximum of E v = ¯ h k 2 2 F / 2 m v , the total transition energy at zero energy is given by
$$E _ { d i r } \approx E _ { g } + \mu \left ( 1 + \frac { m _ { c } } { m _ { v } } \right ) \quad \quad ( 4 ) \quad \begin{array} { c } \gtrless \\ \tilde { \Xi } \end{array}$$
The magnitude of E dir can be obtained from a linear fit of the squared absorption coefficient, where α 2 = C ω ( -E dir ), as shown in Fig. 3a. 50 The temperature dependence of E dir is shown in Fig. 3b, where a clear maximum of 315 ± 10 meV is observed around 160 K. A previous study of the doping dependent band inversion in the Pb 1 -x Sn Te system also found a change in sign of x dE dir /dT as the bands invert. 14 Interestingly, for composition Pb 0 44 . Sn 0 56 . Te, in which a temperature dependent inversion takes place, a minimum in E dir is observed at the inversion temperature, in contrast to our maximum. Since the direct gap E g is zero at 160 ± 15 K, eqn. 4 suggests that this maximum is either due to an increase in µ , or a change in m /m c v across the transition. Both scenarios are plausible, and require further study specifically addressing the temperature dependent band mass and µ .
We find a minimum direct transition of 280 meV at 5 K, which is larger than the low temperature direct transition of 200-250 meV shown by previous ARPES results. 25,26,47 This difference is expected considering our larger carrier density compared to previous reports, as we show later in section DC Transport . We also note that the sensitivity to surface states in ARPES conceals bulk signatures, complicating the estimation of bulk transition energies.
We now consider the spectral weight below the direct transition energy E dir . This is often explained as an Urbach tail, which results from disorder in the crystal, and has an exponential energy dependence that changes monotonically with temperature. 11,43 While Fig. 3a does show exponential behaviour below E dir ( ∼ 280 meV), a closer look at α T ( ) at various frequencies in Fig. 3c reveals atypical Urbach behavior. Instead of a monotonic temperature dependent change of the exponential behaviour, a distinct minimum is observed at the 160 K band inversion temperature, while at both lower and higher temperatures the spectral weight in the absorption coefficient increases. Although it is not surprising that transitions below the direct gap are sensitive to the band inversion, the exact details of their temperature dependence are not clear and require future theory/experiment.
FIG. 3. (a) Linear fits of the squared absorption coefficient yield the smallest observable direct band transition energy (xintercept). (b) Direct gap transition extracted from the linear fit. (c) Absorption coefficient (log scale) below E dir , revealing a distinct change in temperature dependence, uncharacteristic for an Urbach tail.
Nonetheless, this shows that the absorption/optical conductivity alone could be used to detect the transition.
## D. Extended Drude analysis and scattering rate
To study the bulk carrier lifetime in Pb 0 77 . Sn 0 23 . Se, we now turn to the extended Drude model. From eqn. 1, it can be seen that the free carrier response in the standard Drude model is fully defined by glyph[epsilon1] ∞ , ω p , and τ , where τ is the static transport lifetime resulting from a sum of all scattering processes according to Matthiessen's rule (including impurity, electron-phonon and electron-electron scattering). 51 While the Drude model is frequently used to study scattering mechanisms that can be distinguished by their temperature dependence, the temperature dependent band inversion in Pb 0 77 . Sn 0 23 . Se severely complicates such analysis. Moreover, the standard Drude model does not consider the energy dependence of the lifetime τ ( ω ). Since the carrier lifetime is an important parameter for thermoelectric efficiency 52 we turn to the extended Drude model, in which the lifetime has an energy dependence given by 16
$$\frac { 1 } { \tau ( \omega ) } = - \frac { \omega _ { p } ^ { 2 } } { \omega } \text{Im} \left ( \frac { 1 } { \hat { \epsilon } ( \omega ) - \epsilon _ { \infty } } \right ) \text{ \quad \ \ } ( 5 )$$
Fig. 4 shows the frequency dependent scattering rate obtained using eqn. 5. The black line shows where ω = 1 /τ , below which the quasiparticle transport is considered to
be coherent. 16 To study the nature of the dominant scattering mechanism, the data were fitted (red dotted lines in Fig. 4a) using the empirical relation
$$\frac { 1 } { \tau ( \omega ) } = \frac { 1 } { \tau _ { D C } } + \beta \omega ^ { n } \quad \quad \ \ ( 6 ) \quad \ \underbrace { \widehat { \in } } _ { \mathbb { S } }$$
where 1 /τ DC = αT m + 1 /τ imp . Here, 1 /τ imp accounts for impurity scattering, and α and β are constants that depends on material properties. When n = m = 2, and for certain values of α/β , eqn. 6 resembles the singleparticle scattering rate within Fermi Liquid theory, in which electron-electron scattering dominates the transport properties. 19
Fig. 4b shows 1 /τ DC , obtained from the fits with eqn. 6. As the temperature is raised, T 3 / 2 behavior is observed (dashed red line), associated with electronacoustic phonon scattering in semiconductors. 50,51 This is consistent with most good thermoelectrics, in which electron-acoustic phonon scattering dominates the transport properties. 7,53-55 Perhaps somewhat unexpected, however, is that the band inversion appears to have no bearing on 1 /τ DC . This is contrasted by recent work by L. Wu et al., 36 in which the scattering rate of carriers in (Bi 1 -x In x ) 2 Se 3 was found to diverge going across the topological phase transition as a function of doping.
We note that since we are most sensitive to bulk carriers (with µ high in the conduction band) we don't expect to see such a divergence, but it is worth emphasizing that more resistive Pb 1 -x Sn Se samples (in which the x surface contributions are enhanced) may exhibit similar behaviour. For such samples, the frequency dependent scattering rate may also serve as a novel analytical technique to discriminate surface states from the bulk. Since surface states are protected from backscattering, their lifetimes are expected to exceed the bulk carrier lifetime. This could result in distinct surface and bulk scattering contributions in 1 /τ ( ω ), for which we see no evidence in our samples. From fitting 1 /τ DC , we also find a constant 1 /τ imp = 6 8 . ± 0 3 meV, attributed to impurity scatter-. ing. We note that in metals and degenerate semiconductors such as as-grown Pb 0 77 . Sn 0 23 . Se, the electronic impurity scattering rate 1 /τ σ imp is roughly equal to the thermal impurity scattering lifetime 1 /τ κ imp . 51
Fig. 4c shows the temperature dependence of fitting parameters n and β . Since we were only able to obtain reliable 1 /τ ( ω ) data over a limited range spanning just one decade in energy (as seen in Fig. 4a), we hesitate to attribute much physical meaning to either parameter. Additional measurements at lower frequencies and temperatures beyond the scope of this work, or detailed studies by alternative probes such as high resolution temperature dependent ARPES could offer greater insights. Nevertheless, a considerable discontinuity in both n and β at 160 K, which does not fall within our error bars, does suggest that the frequency dependent scattering rate is tied to the band inversion. Moreover, with n = 2 normally associated with Fermi liquid type electron-electron dominated scattering, 19 this high value of n is quite sur-
(a)
Frequency (cm -1 )
β
FIG. 4. (a) Allometric fits of the frequency dependent scattering rate. The black dashed line corresponds to ω = 1 /τ . (b) A T 3 / 2 fit (red dashed line) of the temperate dependent static scattering rate 1 /τ DC illustrates phonon dominated scattering. (c) While it's difficult to interpret fitting parameters n and β due to the small frequency range over which 1 /τ could be fitted, they both reveal an abrupt change in temperature dependence around the band inversion temperature ∼ 160 K. (d) Comparison of Pb 0 77 . Sn 0 23 . Se resistivity obtained by optical spectroscopy (solid red line), and by standard DC transport methods by Liang et al. 6 (green dotted line), and Dixon et al. 8 (all other data).
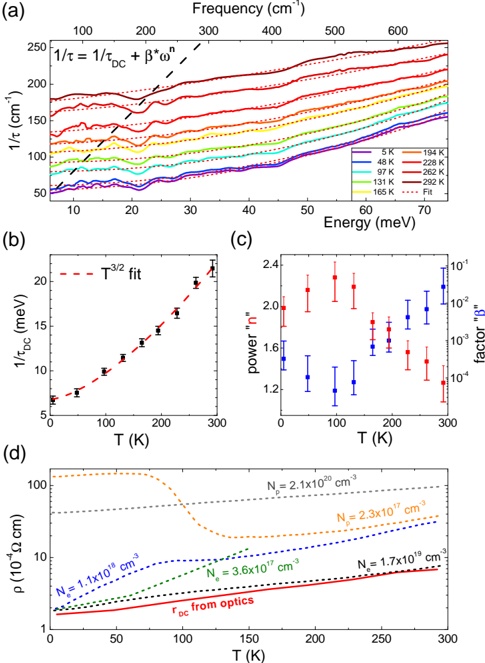
prising considering the relatively high temperatures and frequencies up to which this behavior persists, making it an interesting starting point for followup studies.
## E. DC Transport
For comparison with previous transport studies of Pb 0 77 . Sn 0 23 . Se, we calculate its DC conductivity using σ o = ω τ 2 p DC / 60 and find σ o = 6 2 . × 10 3 Ω -1 cm -1 at 5 K. This low temperature value is in good agreement with previous transport results of n-type samples with identical stoichiometry (6 7 . × 10 3 Ω -1 cm -1 by Dixon et al. 8 and 5 5 . × 10 3 Ω -1 cm -1 by Liang et al. 6 ). A comparison of the resistivity with previously published data
is shown in Fig. 4d, where the dashed lines are digitized data from Liang et al. 6 (green) and Dixon et al. 8 (all other colors). We note that all n-type crystals increase in resistance with temperature, typical for metals and degenerate semiconductors. Only the resistivity of a low carrier p-type sample measured by Dixon et al. 8 shows an anomaly between 75 K and 200 K, possibly associated with the band inversion temperature, while none of the n-type curves reveal such signatures. This further illustrates the utility of optical spectroscopy, which can simultaneously determine ω p and 1 /τ to find σ 0 , while also measuring E F (via direct transitions) and the inversion temperature.
A possible explanation for the difference between ntype and p-type resistivity behavior is the asymmetry of the conduction and valance band, which can be tested by comparing their respective band masses. Using the carrier density of N e = 1 7 . × 10 19 cm -3 (from the resistivity curve most similar to our our results), we find a mobility of 2260 cm 2 V -1 s -1 , and a band mass of m b = 0 076m , . e using σ o = 4 πne τ ω /m 2 ( ) b = neµ . This band mass is smaller than the value of 0.1m e found by Dixon et al. for p-type Pb 0 77 . Sn 0 23 . Se, thus confirming the asymmetry between conduction and valence band. Using eqn. 4 we can now estimate the value of µ ( ≈ E F ), using the low temperature direct gap value of E g = 80 ± 20 meV, consistent with previous studies and calculations. 9,25,26 We find a value for µ of 114 ± 22 meV. To further corroborate this value, we derive an expression for E F using the parabolic band approximation. Starting with E F = ¯ h k 2 2 F / 2 m b , and substituting the 3D carrier density n 3 D = 1 (2 π ) 3 4 3 πk 3 F g g s v , we get
$$E _ { F } = \frac { \hbar { ^ { 2 } } } { 2 m _ { b } } \left ( \frac { 6 \pi ^ { 2 } n } { g _ { s } g _ { v } } \right ) ^ { 2 / 3 }$$
where g s = 2 and g v = 4 are the bulk spin and valley degeneracy, respectively. 6,25 Substituting the plasma frequency in SI units into eqn. 7, where ω 2 p = ne /m glyph[epsilon1] 2 b 0 , we find an expression for E F in [eV] as a function of physical constants, ω 2 p in [rad/s] and n in [m -3 ]:
$$E _ { F } = \frac { \hbar { ^ { 2 } } \omega _ { p } ^ { 2 } \epsilon _ { 0 } } { 2 e ^ { 3 } n ^ { 1 / 3 } } \left ( \frac { 6 \pi ^ { 2 } } { g _ { s } g _ { v } } \right ) ^ { 2 / 3 } \quad \quad ( 8 ) \quad \text{He} \\ \text{at}$$
Eqn. 8 yields a value for E F ( ≈ µ ) of 126 meV at 5 K, which is consistent with our value of µ of 114 ± 22 meV obtained from the direct gap transitions (see section. III C), and further confirms the metallic character of naturally doped n-type Pb 0 77 . Sn 0 23 . Se. As explained in Section III B, this further confirms why surface states are not observed in the Reflectance spectra.
## F. Power Factor
Finally, we relate our obtained values for σ o and µ to the Seebeck coefficient S T ( ) and the power factor
(a)
FIG. 5. (a) Seebeck coefficient in the parabolic band assumption, where all changes in E dir are attributed to changes in E F . (b) The Power Factor indicates minimal (if any) sensitivity to the band inversion at 160 ± 15 K, as a result of the high chemical potential.
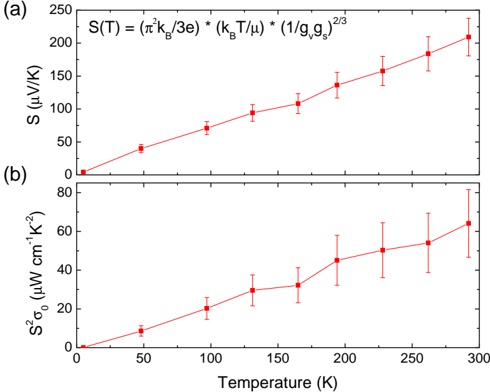
S σ 2 o ( T ). In the parabolic band approximation, the Seebeck coefficient is given by 3 S = 8 π k 2 2 B 3 eh 2 m T b ( π 3 n ) 2 / 3 (where m b is the conduction of valance band mass), which can be expressed as a function of E F (using eqn. 7) as
$$S ( T ) = \left ( \frac { \pi ^ { 2 } k _ { B } } { 3 e } \right ) \left ( \frac { k _ { B } T } { E _ { F } } \right ) \left ( \frac { 1 } { g _ { s } g _ { v } } \right ) ^ { 2 / 3 } \quad ( 9 )$$
Since µ is located high in the conduction band, the direct gap transitions are likely only minimally sensitive to changes in the true band gap E g (and thus m c ) as a function of temperature. This is illustrated in the left and right panel in Fig. 2a, showing a similar band dispersion for high µ despite a dramatic change in the band gap. Hence, we can estimate the maximum change in S T ( ) by attributing the temperature dependence of E dir ( T ) (see eqn. 4) entirely to changes in µ T ( ). The result of this estimation, after substituting µ T ( ) for E F in eqn. 9, is plotted in Fig. 5a, while Fig. 5b shows the associated power factor S σ 2 0 . It is clear that neither S nor S σ 2 0 show distinct signatures of the band inversion at 160 ± 15 K. These results suggests that there is room for optimization of the figure of merit ZT in Pb 1 -x Sn Se compounds where x µ is located deep in the conduction band. Further doping to alter the lattice and suppress phonon contributions will likely only affect the electronic response minimally, as illustrated by its insensitivity to the band inversion and the unaffected power factor.
## IV. CONCLUSION
In conclusion, we have performed broadband optical spectroscopy experiments on as-grown n-type Pb 0 77 . Sn 0 23 . Se and extracted its optical constants over a temperature range between 5 K and 293 K. By studying the plasma frequency and band gap transitions, we find clear signatures of the temperature dependent band inversion at 160 ± 15 K, despite the chemical potential being far in the conduction band. We note that since temperature is an easily controllable variable in optical spectroscopy, in principle this could be used to optically determine band inversion temperatures of conductive samples with extremely high precision. While this band inversion is also associated with a topological phase transition, 6,25-27,29,47,49 we do not see any signatures of surface states, and thus don't comment on the topology of the band structure on either side of the band inversion. This is an expected result, however, as optical modelling suggests that the highly conductive bulk carriers dominate the properties of as-grown Pb 0 77 . Sn 0 23 . Se.
By performing extended Drude analysis, we accurately determine the temperature dependent scattering rate, and find that it follows T 3 / 2 behaviour (associated with electron-acoustic phonon interactions) typical for good thermoelectrics, 53 superimposed on a constant impurity scattering background with 1 /τ = 6 8 . ± 0 3 . meV. The frequency dependence of the scattering rate shows no evidence of different scattering channels below and above the band inversion, but data over a greater energy and temperature range are required for more conclusive results. Moreover, neither the DC resistivity, Seebeck coefficient, or the power factor show any evidence of the band inversion. This result confirms earlier transport studies on similar compounds, 9-12,22,23,28 and emphasizes the utility of optical spectroscopy in the study of thermoelectrics and/or band inversions.
For application of Pb 0 77 . Sn 0 23 . Se as either a topological crystalline insulator or thermoelectric, the high electrical conductivity of bulk states is a major prohibitive factor. Moreover, some of the fundamental physics governing the electronic, thermal, and topological properties are difficult to probe due to the high chemical potential in as-grown Pb 0 77 . Sn 0 23 . Se. Hence, future studies on samples in the Pb 1 -x Sn Se series, in which the carx rier density has been reduced, could lead to new insights
∗ [email protected]
† [email protected]
1 M. Zebarjadi, K. Esfarjani, M. S. Dresselhaus, Z. F. Ren, and G. Chen, Energy & Environmental Science 5 , 5147 (2012).
2 S. B. Riffat and X. Ma, Applied Thermal Engineering 23 , 913 (2003).
into the interplay of phonons, thermal and electronic bulk lifetimes, and the optical and electronic properties of inversion symmetry protected topological surface states.
A reduction of the chemical potential would also enhance the sensitivity of the Seebeck coefficient to the band inversion, which could potentially result in a dramatic enhancement of the figure of merit ZT around the band inversion. Moreover, alternative stoichiometries also offer an interesting avenue, as previous measurements suggest that the band inversion in Pb 1 -x Sn Se x could be pushed to higher temperatures -relevant to many thermoelectric applications- by increasing the Sn content. 8,9,25 Hence, by optimizing Se doping, an ideal Pb 1 -x Sn Se stoichiometry can be determined, in which x ZT peaks around a desired temperature range. Indeed, such doping studies would also allow for the study of the high temperature interplay between the topologically nontrivial phase and thermoelectric efficiency, which is a direction currently unexplored.
With both thermoelectrics and topological (crystalline) insulators offering numerous appealing applications in industry, while presenting nontrivial physical characterization and optimization challenges, a better understanding of fundamental physics governing the figure of merit ZT and the isolation of surface conductance are both of practical and fundamental interest. The Pb 1 -x Sn Se and Pb x 1 -x Sn Te series offer many exciting x opportunities in this pursuit, particularly through optical investigations, by combining several novel physical phenomena into a single temperature tuneable system.
## V. ACKNOWLEDGEMENTS
We acknowledge Young-June Kim for use of an ellipsometer, as well as Luke Sandilands for very helpful discussions. This work has been partially funded by the Ontario Research Fund, the Natural Sciences and Engineering Research council of Canada, Canada Foundation for Innovation, and the Prins Bernhard Cultuurfonds. The crystal growth at Princeton University was supported by grant N6601-11-1-4110.
We also acknowledge the recent optical and Hall-effect study of Pb 0 77 . Sn 0 23 . Se by Anand et al. , 24 which was performed simultaneously, though independently. This study explores the temperature-driven band inversion of p-type Pb 0 77 . Sn 0 23 . Se, which is found to occur around 100 K.
- 3 G. J. Snyder and E. S. Toberer, Nature Materials 7 , 105 (2008).
- 4 F. J. DiSalvo, Science 285 , 703 (1999).
- 5 J. P. Heremans Font, Acta Physica Polonica A 108 , 609 (2006).
- 6 T. Liang, Q. Gibson, J. Xiong, M. Hirschberger, S. P. Koduvayur, R. J. Cava, and N. P. Ong, Nature Communica-
tions 4 , 2696 (2013).
- 7 O. Delaire, J. Ma, K. Marty, A. F. May, M. A. McGuire, M.-H. Du, D. J. Singh, A. Podlesnyak, G. Ehlers, M. D. Lumsden, and B. C. Sales, Nature Materials 10 , 614 (2011).
- 8 J. R. Dixon and G. F. Hoff, Physical Review B 3 , 4299 (1971).
- 9 A. J. Strauss, Physical Review 157 , 608 (1967).
- 10 M. Baleva, T. Georgiev, and G. Lashkarev, Journal of Physics: Condensed Matter 2 , 2935 (1990).
- 11 Z. M. Gibbs, A. LaLonde, and G. J. Snyder, New Journal of Physics 15 , 075020 (2013).
- 12 C. E. Ekuma, D. J. Singh, J. Moreno, and M. Jarrell, Physical Review B 85 , 085205 (2012).
- 13 J. Zhao, C. D. Malliakas, D. Bugaris, N. Appathurai, V. Karlapati, D. Y. Chung, M. G. Kanatzidis, and U. Chatterjee, arXiv (2014), 1404.1807v1.
- 14 S. O. Ferreira, E. Abramof, P. Motisuke, P. H. O. Rappl, H. Closs, A. Y. Ueta, C. Boschetti, and I. N. Bandeira, Brazilian Journal of Physics 29 , 771 (1999).
- 15 Z. M. Gibbs, H. Kim, H. Wang, R. L. White, F. Drymiotis, M. Kaviany, and G. Jeffrey Snyder, Applied Physics Letters 103 , 2109 (2013).
- 16 M. M. Qazilbash, J. J. Hamlin, R. E. Baumbach, L. Zhang, D. J. Singh, M. B. Maple, and D. N. Basov, Nature Physics 5 , 647 (2009).
- 17 D. N. Basov and T. Timusk, Reviews of Modern Physics 77 , 721 (2005).
- 18 D. Basov, R. Averitt, D. van der Marel, M. Dressel, and K. Haule, Reviews of Modern Physics 83 , 471 (2011).
- 19 U. Nagel, T. Uleksin, T. Room, R. P. S. M. Lobo, P. Lejay, C. C. Homes, J. S. Hall, A. W. Kinross, S. K. Purdy, T. Munsie, T. J. Williams, G. M. Luke, and T. Timusk, Proceedings of the National Academy of Sciences 109 , 19161 (2012).
- 20 J. Hwang, T. Timusk, and G. D. Gu, Journal of Physics: Condensed Matter 19 , 5208 (2007).
- 21 S. I. Mirzaei, D. Stricker, J. N. Hancock, C. Berthod, A. Georges, E. Van Heumen, M. K. Chan, X. Zhao, Y. Li, M. Greven, and D. van der Marel, Proceedings of the National Academy of Sciences 110 , 5774 (2013).
- 22 R. K. Shukla, S. K. Shukla, V. K. Pandey, and P. Awasthi, Physics and Chemistry of Liquids 45 , 169 (2007).
- 23 L.-D. Zhao, S.-H. Lo, Y. Zhang, H. Sun, G. Tan, C. Uher, C. Wolverton, V. P. Dravid, and M. G. Kanatzidis, Nature 508 , 373 (2014).
- 24 N. Anand, S. Buvaev, A. F. Hebard, D. B. Tanner, Z. Chen, Z. Li, K. Choudhary, A. B. Sinnott, G. Gu, and C. Martin, arXiv , 1407.5726 (2014).
- 25 P. Dziawa, B. J. Kowalski, K. Dybko, R. Buczko, A. Szczerbakow, M. Szot, E. glyph[suppress] Lusakowska, T. Balasubramanian, B. M. Wojek, M. H. Berntsen, O. Tjernberg, and T. Story, Nature Materials 11 , 1023 (2012).
- 26 B. M. Wojek, R. Buczko, S. Safaei, P. Dziawa, B. J. Kowalski, M. H. Berntsen, T. Balasubramanian, M. Leandersson, A. Szczerbakow, and P. Kacman, Physical Review B 87 , 115106 (2013).
- 27 X. Xi, X.-G. He, F. Guan, Z. Liu, R. D. Zhong, J. A. Schneeloch, T. S. Liu, G. D. Gu, D. Xu, Z. Chen, X. G. Hong, W. Ku, and G. L. Carr, arXiv , 1406.1726 (2014).
- 28 J. F. Butler, A. R. Calawa, and T. C. Harman, Applied Physics Letters 9 , 427 (1966).
- 29 L. Fu, Physical Review Letters 106 , 106802 (2011).
- 30 S.-Y. Xu, C. Liu, N. Alidoust, M. Neupane, D. Qian, I. Be-
- lopolski, J. D. Denlinger, Y. J. Wang, H. Lin, and L. A. Wray, Nature Communications 3 , 1192 (2012).
- 31 A. Reijnders, Y. Tian, L. J. Sandilands, G. Pohl, I. D. Kivlichan, S. Y. Frank Zhao, S. Jia, M. E. Charles, R. J. Cava, N. Alidoust, S. Xu, M. Neupane, M. Z. Hasan, X. Wang, S. W. Cheong, and K. S. Burch, Physical Review B 89 , 075138 (2014).
- 32 R. Vald´ es Aguilar, A. V. Stier, W. Liu, L. S. Bilbro, D. K. George, N. Bansal, L. Wu, J. Cerne, A. G. Markelz, S. Oh, ˇ and N. P. Armitage, Physical Review Letters 108 , 87403 (2012).
- 33 G. S. Jenkins, D. C. Schmadel, A. B. Sushkov, and H. D. Drew, Physical Review B 87 , 155126 (2013).
- 34 P. Di Pietro, M. Ortolani, O. Limaj, A. Di Gaspare, V. Giliberti, F. giorgianni, M. brahlek, N. bansal, N. koirala, S. Oh, P. Calvani, and S. lupi, Nature 8 , 556 (2013).
- 35 B. C. Chapler, M. Liu, K. Post, H. Stinson, M. Goldflam, A. Richardella, J. Lee, A. Reijnders, K. Burch, N. Samarth, and D. Basov, (unpublished) (2014).
- 36 L. Wu, M. Brahlek, R. V. Aguilar, A. V. Stier, C. M. Morris, Y. Lubashevsky, L. S. Bilbro, N. Bansal, S. Oh, and N. P. Armitage, Nature Physics 9 , 410 (2013).
- 37 Z. Li and J. P. Carbotte, Physical Review B 88 , 45414 (2013).
- 38 X. Xi, C. Ma, Z. Liu, Z. Chen, W. Ku, H. Berger, C. Martin, D. B. Tanner, and G. L. Carr, Physical Review Letters 111 , 155701 (2013).
- 39 M. K. Tran, J. Levallois, P. Lerch, J. Teyssier, A. B. Kuzmenko, G. Aut` es, O. V. Yazyev, A. Ubaldini, E. Giannini, D. van der Marel, and A. Akrap, Physical Review Letters 112 , 047402 (2014).
- 40 P. Di Pietro, F. M. Vitucci, D. Nicoletti, L. Baldassarre, P. Calvani, R. Cava, Y. S. Hor, U. SCHADE, and S. lupi, Physical Review B 86 , 045439 (2012).
- 41 A. D. LaForge, A. Frenzel, B. C. Pursley, T. Lin, X. Liu, J. Shi, and D. N. Basov, Physical Review B 81 (2010).
- 42 A. Akrap, M. Tran, A. Ubaldini, J. Teyssier, E. Giannini, D. van der Marel, P. Lerch, and C. C. Homes, Physical Review B 86 , 235207 (2012).
- 43 C. H. Grein and S. John, Physical Review B 39 , 1140 (1989).
- 44 L. Benfatto, S. Sharapov, N. Andrenacci, and H. Beck, Physical Review B 71 , 104511 (2005).
- 45 F. Carbone, A. Kuzmenko, H. Molegraaf, E. van Heumen, E. Giannini, and D. van der Marel, Physical Review B 74 , 024502 (2006).
- 46 M. Ortolani, P. Calvani, and S. Lupi, Physical Review Letters 94 , 67002 (2005).
- 47 A. Gyenis, I. K. Drozdov, S. Nadj-Perge, O. B. Jeong, J. Seo, I. Pletikosic, T. Valla, G. D. Gu, and A. Yazdani, arXiv: 1306.0043 (2013).
- 48 A. B. Kuzmenko, D. van der Marel, F. Carbone, and F. Marsiglio, New Journal of Physics 9 , 229 (2007).
- 49 Y. Okada, M. Serbyn, H. Lin, D. Walkup, W. Zhou, C. Dhital, M. Neupane, S. Xu, Y. J. Wang, R. Sankar, F. Chou, A. Bansil, M. Z. Hasan, S. D. Wilson, L. Fu, and V. Madhavan, Science , 2823 (2013).
- 50 P. Y. Yu and M. Cardona, Fundamentals of Semiconductors , 4th ed. (Springer, 2010).
- 51 J. Singleton, Band Theory and Electronic Properties of Solids (Oxford University Press, 2010).
- 52 M. Jonson and G. D. Mahan, Physical Review B 21 , 4223 (1980).
- 53 Y. Pei, X. Shi, A. LaLonde, H. Wang, L. Chen, and G. J. Snyder, Nature 473 , 66 (2011).
- 54 H. Wang, Y. Pei, A. D. LaLonde, and G. J. Snyder, Advanced Materials 23 , 1366 (2011).
- 55 Y. I. Ravich, B. A. Efimova, and V. I. Tamarchenko, physica status solidi (b) 43 , 11 (1971).
- 56 S. Adam, E. H. Hwang, V. M. Galitski, and S. Das Sarma, in Proceedings of the National Academy of Sciences (2007) pp. 18392-18397.
- 57 J. Liu, W. Duan, and L. Fu, Physical Review B 88 , 241303 (2013).
(a)
FIG. 6. (a) Reflectance of Pb 0 77 . Sn 0 23 . Se at 194 K, and a model of the 194 K Reflectance that included a surface state layer with ω p, 2 D = 0 34 meV cm . 1 / 2 . (b) Ratios of the temperature dependent reflectance above (black), below (green), and across (blue) the topological phase transition. The dotted red line is the ratio of reflectance spectra from (a), illustrating the much larger effect of temperature on R ω ( ) compared to the introduction of surface states below the topological phase transition.
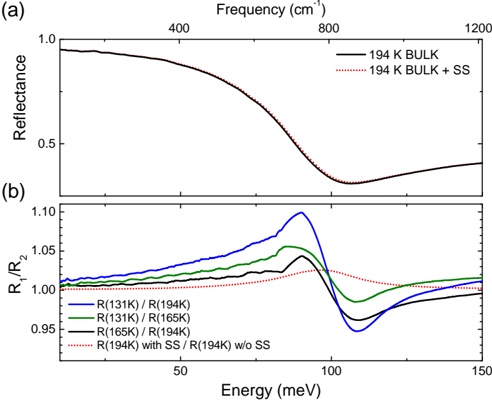
## Appendix A: Expected optical signatures of TCI surface states in Pb 0 77 . Sn 0 23 . Se
To ensure we did not overlook surface state signatures in our reflectance data, we use the Boltzmann transport equation to estimate the expected effect of surface states on the measured reflectance. The 2D surface state plasma frequency can be approximated by ω 2 p, 2 D = ( e /h 2 )2 πk F v F g g s v , where v F and k F are the Fermi velocity and wavevector, and g s and g v are the spin and valley degeneracies. 31,35,56 Ignoring the parabolic correction for the Dirac states, we can use E F = ¯ hk F v F , and express ¯ hω p, 2 D in a convenient form with all SI units
$$\hbar { \omega } _ { p, 2 D } = c \sqrt { e E _ { F } g _ { s } g _ { v } 1 0 ^ { - 5 } } \quad \quad ( A 1 )$$
where c is the speed of light and e is the elementary charge. From previous ARPES measurements, we can estimate a surface Fermi level E ss F around 125 meV. 25 At the risk of overestimating the surface contribution, we can account for sample-to-sample variations by considering an even higher surface state Fermi level of 200 meV. We also note that while g s = 1 and g v = 2 near the Dirac point, additional Dirac states with smaller wavevectors intersect the Fermi surface when the Fermi level crosses the bulk conduction band, thus doubling the surface bands, albeit with different wavevectors. 6,25,49,57 For convenience, we account for these states by setting g v = 4, resulting in a overestimated 2D plasma frequency of 0.34 meV cm 1 / 2 .
Fig. 6a shows the reflectance of Pb 0 77 . Sn 0 23 . Se at 192 K (the topologically trivial regime) as well as a model in which a surface state layer with ¯ hω p, 2 D = 0 34 meV . cm 1 / 2 was added to the 192 K Reflectance. To emphasize the minimal difference, Fig. 6b shows the ratio of both reflectance spectra (red dotted line). The same plot also shows the ratio of reflectance measurements at different temperatures above (black), below (green), and across (blue) the topological phase transition. It is clear that the sharpening bulk plasma edge has a far greater effect on the reflectance, than the surface states. Hence, discriminating surface state signatures are not within our measurement capabilities for samples with such high bulk carrier densities. | 10.1103/PhysRevB.90.235144 | [
"Anjan A. Reijnders",
"Jason Hamilton",
"Vivian Britto",
"Jean-Blaise Brubach",
"Pascale Roy",
"Quinn D. Gibson",
"R. J. Cava",
"K. S. Burch"
] | 2014-07-31T20:00:20+00:00 | 2014-07-31T20:00:20+00:00 | [
"cond-mat.mtrl-sci"
] | Optical investigation of thermoelectric topological crystalline insulator Pb$_{0.77}$Sn$_{0.23}$Se | Pb$_{0.77}$Sn$_{0.23}$Se is a novel alloy of two promising thermoelectric
materials PbSe and SnSe that exhibits a temperature dependent band inversion
below 300 K. Recent work has shown that this band inversion also coincides with
a trivial to nontrivial topological phase transition. To understand how the
properties critical to thermoelectric efficiency are affected by the band
inversion, we measured the broadband optical response of
Pb$_{0.77}$Sn$_{0.23}$Se as a function of temperature. We find clear optical
evidence of the band inversion at $160\pm15$ K, and use the extended Drude
model to accurately determine a $T^{3/2}$ dependence of the bulk carrier
lifetime, associated with electron-acoustic phonon scattering. Due to the high
bulk carrier doping level, no discriminating signatures of the topological
surface states are found, although their presence cannot be excluded from our
data. |
1408.0009v1 | ## The low mass star and sub-stellar populations of the 25 Orionis group
Juan Jos´ e Downes 1 2 , /star , C´ esar Brice˜o, n 1 3 , † , Cecilia Mateu, 1 2 , Jes´s Hern´ndez, u a 1 Anna Katherina Vivas 3 Nuria Calvet 4 Lee Hartmann 4 Monika G. Petr-Gotzens 5 and Lori Allen 6
- 1 Centro de Investigaciones de Astronom´ ıa, AP 264, M´rida 5101-A, Venezuela e
- 2 Instituto de Astronom´ ıa, UNAM, Ensenada, C.P. 22860, Baja California, M´xico e
- 3 Cerro Tololo Interamerican Observatory Casilla 603, La Serena, Chile
- 4 Department of Astronomy, University of Michigan, 825 Dennison Building, 500 Church Street, Ann Arbor, MI 48109, USA
- 5 European Southern Observatory, Karl-Schwarzschild-Str. 2, 85748, Garching bei M¨nchen, Germany u
- 6 National Optical Astronomy Observatoies, 950 N. Cherry Ave. Tucson, AZ 85719, USA
Accepted 2014 -- -. Received 2014 -- -; in original form -- -- -
## ABSTRACT
We present the results of a survey of the low mass star and brown dwarf population of the 25 Orionis group. Using optical photometry from the CIDA Deep Survey of Orion, near IR photometry from the Visible and Infrared Survey Telescope for Astronomy and low resolution spectroscopy obtained with Hectospec at the MMT, we selected 1246 photometric candidates to low mass stars and brown dwarfs with estimated masses within 0 02 . < M/M ∼ /circledot < . ∼ 0 8 and spectroscopically confirmed a sample of 77 low mass stars as new members of the cluster with a mean age of ∼ 7 Myr. We have obtained a system initial mass function of the group that can be well described by either a Kroupa power-law function with indices α 3 = -1 73 . ± 0 31 and . α 2 = 0 68 . ± 0 41 . in the mass ranges 0 03 . /lessorequalslant M/M /circledot /lessorequalslant 0 08 . and 0 08 . /lessorequalslant M/M /circledot /lessorequalslant 0 5 . respectively, or a Scalo log-normal function with coefficients m c = 0 21 . +0 02 . -0 02 . and σ = 0 36 . ± 0 03 in the mass range 0 03 . . /lessorequalslant M/M /circledot /lessorequalslant 0 8. . From the analysis of the spatial distribution of this numerous candidate sample, we have confirmed the EastWest elongation of the 25 Orionis group observed in previous works, and rule out a possible southern extension of the group. We find that the spatial distributions of low mass stars and brown dwarfs in 25 Orionis are statistically indistinguishable. Finally, we found that the fraction of brown dwarfs showing IR excesses is higher than for low mass stars, supporting the scenario in which the evolution of circumstellar discs around the least massive objects could be more prolonged.
Key words: stars: low-mass, brown dwarf, open clusters and associations: individual (25 Orionis)
## 1 INTRODUCTION
Evidence collected over the past several years increasingly supports the general picture that low mass stars (LMS) and brown dwarfs (BDs), likely share a common formation mechanism. However, there are many open questions that remain to be addressed. For example, given typical temperatures and densities within molecular cloud cores (e.g. Padoan & Nordlund 2004), the corresponding classi-
- /star E-mail: [email protected],[email protected]
- † E-mail: [email protected],[email protected]
cal Jeans mass can be much higher than the sub-stellar mass limit ( ∼ 0 072 . M /circledot ; Baraffe et al. 1998), suggesting that forming BDs would be difficult under such conditions. However, we know that not only do LMS and BDs form, but they do so abundantly, being the most numerous objects in the Galaxy (e.g. Padoan & Nordlund 2004; Bastian, Covey & Meyer 2010). Therefore, their formation cannot be explained in terms of a simple-minded model of gravitational collapse alone, which has been an important driver of theoretical and observational efforts looking for the physical processes and conditions that control LMS and BD formation.
Theoretical efforts to explain the formation of LMS and BDs are usually classified in the following models, reviewed by Whitworth et al. (2007): (i) turbulent fragmentation, (ii) gravitational fragmentation (iii) disc fragmentation (iv) premature ejection of protostellar embryos and (v) photo-erosion of cores in HII regions. These processes are not mutually exclusive (Whitworth et al. 2007) in the sense that in a typical star forming region (SFR) all of them could take place simultaneously, resulting in a complex scenario. The relative importance of each model is currently explored in terms of its ability to reproduce observables such as the initial mass function (IMF), the properties of binary and multiple systems, the fraction of LMS and BDs showing circumstellar discs, magnetosferic accretion and/or outflows and studying the kinematic or spatial segregation as a function of stellar mass (e.g. Whitworth et al. 2007). Each model has proven its plausibility of forming LMS and BDs, though only a few of the available simulations offer results directly comparable with observational data, and several assumptions about the initial conditions are still a matter of debate.
Observationally, several SFRs and young clusters have been surveyed looking for their LMS and BD population (e.g. Luhman 2012; Luhman et al. 2010; Boudreault & Bailer-Jones 2009; Bouvier et al. 2008; Lodieu et al. 2007; Caswell 2007; Luhman et al. 2007, and references therein). Some important results are: the continuity of the mass function across the substellar mass limit (e.g. Bastian, Covey & Meyer 2010), the existence of circumstellar discs (e.g. Luhman et al. 2010), accretion phenomena (e.g. Muzerolle et al. 2000; Jayawardhana, Mohanty & Basri 2003) and photometric variability (e.g. Scholz & Eisl¨ffel o 2005) in BDs, which indicate the extension of the T-Tauri behaviour below the sub-stellar mass limit. There is also some initial insight on mass segregation (e.g. Kumar & Schmeja 2007; Boudreault & Bailer-Jones 2009), mass-dependent kinematics (e.g. Joergens 2006) and multiplicity (e.g. McCarthy & Zuckerman 2004; Luhman 2004; Kraus, White & Hillenbrand 2006; Luhman et al. 2009).
Here we present a new, deep optical/near infrared photometric survey of the 25 Orionis group, combined with limited follow-up spectroscopy, to search for and characterise the LMS (0 8 . < M/M ∼ /circledot < . ∼ 0 072) and BD (0 072 . < M/M ∼ /circledot < . ∼ 0 02) members of this population. The relevance of the 25 Orionis group for studies of star/disc formation and early evolution is given by its ∼ 7 Myr old age which roughly corresponds to the time when dissipation of primordial circumstellar discs is expected to have finished ( ∼ 10 Myr; Calvet et al. 2005), as evidenced by the decrease in disc fractions (Hern´ndez et al. 2006, 2007). Ada ditionally, the study of the spatial distribution of members and/or the IMF down to the BD regime at this age, is important to constraint the dynamical evolution of young clusters (e.g. Boudreault & Bailer-Jones 2009).
Other associations of similar age are either too spatially extended because of their vicinity (e.g. TW Hydra, β Pictoris, /epsilon1 Cha; Torres et al. 2008) or too distant (e.g. NGC7160, NGC2169, NGC2362 Kun, Kiss & Balog 2008; Jeffries et al. 2007; Dahm 2008). Lacerta OB1b at a distance of ∼ 400 pc and an estimated age within 12 to 16
Myr, is probably one of the best places to carry out new surveys for young LMS and BD, however, it also spans ∼ 70 deg 2 (Chen & Lee 2008). Another interesting region, also spanning a large area of the sky, is the Upper Scorpius association at a distance between 125 and 165 pc (Luhman & Mamajek 2012), whose last age determination is ∼ 11 Myr old (Pecaut, Mamajek & Bubar 2012). Summarizing, the 25 Orionis group is the most numerous and spatially dense ∼ 7 Myr old population yet known within ∼ 500 pc from the Sun. Its modest angular extent ( < deg ∼ 7 2 ) makes comprehensive studies of its entire population feasible, and being almost free of significant interstellar extinction, it is the ideal place to study slightly more evolved young LMS and BD.
The paper is organized as follows: In Section 2 we summarize previous results on the 25 Orionis group. In Section 3 we describe the observations, data reduction, photometric candidate selection, as well as the spectroscopic confirmation of memberships for a sub-sample of these candidates. In Section 4 we estimate and analyse the visual interstellar extinction affecting each photometric candidate and spectroscopically confirmed member, and estimate the contamination from field stars present in the sample of photometric candidates. In Section 5 we present the derivation of masses and ages, the analysis of the IMF, the analysis of the spatial distribution and infrared excesses as disc indicators and accretion signatures. In Section 6 we summarize our conclusions about the nature of the 25 Orionis group and explore possible implications on predictions from theoretical models for LMS and BD formation.
## 2 THE 25 ORIONIS GROUP
The 25 Orionis group was originally identified by Brice˜o et al. n (2005) as a ∼ 1 ◦ radius overdensity of ∼ 20 pre-main sequence (PMS) stars roughly centred on the Be star 25 Ori located at α J 2000 =05:24:44.8, δ J 2000 =+01:50:47.20. It was recognized on the basis of multi-epoch V and I-band photometry and follow-up optical spectroscopy to confirm memberships. Their initial member sample spanned magnitudes 14 5 . < V ∼ < ∼ 16 5, . corresponding to masses in the range 0 45 . < M/M ∼ /circledot < . ∼ 0 95 1 . Brice˜o et al. n (2005) reported a mean age for the Orion OB1a sub-association, which includes the 25 Orionis overdensity, of ∼ 7 -10 Myr and an inner-disc frequency of ∼ 11 per cent, smaller than the ∼ 23 per cent they had found in the younger ( ∼ 3 6 . Myr) Orion OB1b sub-association. These results were consistent with the decrease in disc fraction with age seen in other regions (Hern´ndez et al. 2008), a and supported the idea that inner discs around low-mass stars dissipate in less than ∼ 10 Myr (Hartmann 2001).
The newly identified 25 Orionis group was also recognized a few months later by Kharchenko et al. (2005) in their extensive survey of new galactic clusters, and listed as cluster ASCC-16. They derive central coordinates α J 2000 =5:24:36, δ J 2000 =+01:48:00, a cluster radius=0 62 . ◦ and core radius=0 25. They estimate a distance of 460 pc . ◦
1 Assuming models from Baraffe et al. (1998), an age of ∼ 7 Myr and distance modulus of 7.78 mag
(V -M V = 8 59), reddening E(B . -V) = 0 09, age . ∼ 8 5 . Myr, and a mean radial velocity of 0 75 . ± 8 75 km/s. How-. ever, the radial velocity comes from only one star, 25 Ori itself, and the age, distance and cluster radius are based on just a small number of stars earlier than K3.
The low-mass population of the 25 Orionis group was later considered by McGehee (2006). His variability-based survey of Orion OB1 using multi-epoch photometry from the Sloan Digital Sky Survey (Abazajian et al. 2005), within a 2 5 wide equatorial strip located roughly 0 6 south of the . ◦ . ◦ star 25 Ori. Based on the spatial distribution of his and Brice˜o et al. n (2005) samples, McGehee (2006) suggested that the 25 Orionis group could extend further south, with a total radius of ∼ 1 4, . ◦ greater than previously reported. McGehee (2006) suggested that the 25 Orionis group is an unbound association and derived a Classical T-Tauri star (CTTS) fraction of ∼ 10 per cent in what he called the 25 Orionis group.
Discs around the low-mass (0 12 . < M/M ∼ /circledot < . ∼ 1 2) members of 25 Orionis were searched for and characterised by Hern´ andez et al. (2007) in their Spitzer IRAC and MIPS imaging study of this group. They found that in the 25 Orionis group, discs around low-mass stars are less frequent ( ∼ 6 per cent) than in the younger ( ∼ 4 Myr) Orion OB1b ( ∼ 13 per cent), and that this frequency seemed to be a function of the spectral type with a maximum around M0. They also determined that disc dissipation takes place faster in the inner region of the discs; as suggested by several disc models (e.g. Weidenschilling 1997; Dullemond & Dominik 2004).
After the initial discovery and first studies, Brice˜o et al. (2007) conducted the most extensive assessn ment so far of the low-mass population (0 3 . < M/M ∼ /circledot < ∼ 1) in the 25 Orionis group. They concluded that not only is 25 Orionis a kinematically distinct entity, but it is also different in velocity space from the widely spread stellar population of Orion OB1a, within which it is located. These results pointed to the idea of the 25 Orionis group as a physical stellar group, akin to structures like the σ Ori cluster. From the spatial distribution of the low-mass members they found a maximum surface density of ∼ 128 stars/ deg 2 with masses M > 0 5 . M /circledot , and derived a cluster radius of ∼ 7 pc. In this work they also redetermined the fraction of Classical TTauri stars (CTTS) using a more numerous sample, and find disc fractions of ∼ 6 per cent in 25 Orionis and ∼ 13 per cent in Ori OB1b, confirming the factor of 2 × decline in the accretor fraction seen by Brice˜o et al. (2005). n
The 25 Orionis group had been also the target for several other works: Using the Spitzer IRAC and MIPS data, Hern´ andez et al. (2006) studied the debris disc fraction in stars with spectral types earlier than F5 in the 25 Orionis group. Biazzo et al. (2011) measured abundances for 8 T Tauri stars with spectral types from K7 to M0 and derived an average metallicity [Fe/H]=-0.05 ± 0.05. Ingleby et al. (2011), have studied the X-ray and far ultraviolet fluxes of 25 Orionis and determined accretion rates for a set of members with spectral types K5 to M5. Most recently, 25 Orionis has been a hunting ground for groups looking for transiting planets among young solar-like stars (van Eyken et al. 2011; Neuh¨user et al. 2011). In Table 1 we summarize the a derived parameters we assume here for the 25 Orionis group, based on the aforementioned studies and the present work. In Figure 1 we show the spatial distribution of candidates and confirmed members from previous surveys.
## 3 OBSERVATIONS, CANDIDATE SELECTION AND MEMBERSHIP DETERMINATION
## 3.1 Optical photometry
Multi-epoch optical V, R, I-band, and H α observations across the entire Orion OB1 association (spanning ∼ 180deg ) were obtained as part of the CVSO (Brice˜o et al. 2 n 2005), being conducted since 1998 with the J¨rgen Stock u 1.0/1.5 Schmidt-type telescope and the 8000 × 8000 pixel QUEST-I CCD Mosaic camera (Baltay et al. 2002), at the National Astronomical Observatory of Venezuela. The instrument is composed of sixteen 2048 × 2048 Loral CCD devices set in a 4 × 4 array covering most of the focal plane of the telescope, and yielding a field of view ∼ 2 3 wide . ◦ in declination. The chips are front illuminated with a pixel size of 15 µ m, which corresponds to a scale of 1.02' per pixel. Each row of four CCDs in the N-S direction can be fitted with a different filter. The system was optimized to operate in drift-scan mode, in which the telescope is fixed at a constant declination and hour angle, and an object moves across each filter as a consequence of sidereal motion, resulting in a survey rate of ∼ 34 deg 2 per hour per filter. The scans for the CVSO were performed along strips centred at declinations -5 , ◦ -3 , ◦ -1 , +1 , +3 ◦ ◦ ◦ and +5 ◦ (for more details of the survey strategy see Brice˜o et al. 2005, 2007; n Downes et al. 2008).
Because the exposure time in the drift-scan mode observations is fixed 2 , this defines the usable magnitude range for each individual observation. At the bright end, our data saturate around magnitude 13 in the V, R and I bands, which corresponds to pre-main sequence (PMS) stars with masses ∼ 1 M /circledot , at the distance and age of the 25 Orionis group (Baraffe et al. 1998). At the faint end, the 3 σ limiting magnitudes for individual scans are V lim ∼ 19 7, . R lim ∼ 19 7, I . lim ∼ 19 5, with completeness magnitude . 3 of V com ∼ 18 7, . R com ∼ 18 7, . I com ∼ 18 2. . Again assuming Baraffe et al. (1998) models, and the age and distance of the 25 Orionis group ( ∼ 7 Myr, ∼ 360 pc from Section 5.1), the substellar limit is located at V sub ∼ 19 8, . R sub ∼ 18 7 . and I sub ∼ 17, which clearly shows that individual scans are not sensitive enough for carrying out a complete study of the least massive BD in the Orion OB1 association.
In order to increase the signal to noise ratio (SNR) and therefore the limiting and completeness magnitudes, so that we could reach well into the substellar regime at the distance of Orion, we coadded the individual observations following the procedure explained in more detail in Downes et al. (2008). Summarizing, the process is based in
2 The exposure time is set by how long it takes the star to cross the entire CCD, which in our instrument is ∼ 140s near the equator.
3 The magnitude for which the logarithm of the number of sources as a function of magnitude departs from linear behaviour
Table 1. General properties of members and candidates for the 25 Orionis group from the present and previous works.
| Reference | Candidates [N] | Members [N] | Mass interval | LMS CTTS [per cent] | LMS Discs [per cent] | D [pc] | Radius [ ◦ ] | Age [Myr] | ¯ AV [mag] |
|---------------------------|------------------|---------------|---------------------------------------|-----------------------|------------------------|----------|----------------|---------------|--------------|
| Brice˜o n et al. (2005) | · · · | 31 | 0 . 45 < ∼ M/M /circledot < ∼ 0 . 95 | ∼ 3 | ∼ 3 | 330 | · · · | 7-10 | 0.28 |
| Kharchenko et al. (2005) | 90 | 29 a | M > 1 . 4 M /circledot b | · · · | · · · | 460 | 0.62 | ∼ 8 . 5 | 0.27 |
| McGehee (2006) | 62 | · · · | 0 . 06 < ∼ M/M /circledot < ∼ 0 . 8 c | ∼ 10 | · · · | 330 | 1.4 | · · · | · · · |
| Hern´ndez a et al. (2007) | 41 | 115 | 0 . 12 < ∼ M/M /circledot < ∼ 1 . 2 | · · · | ∼ 6 | 330 | · · · | · · · | · · · |
| Brice˜o n et al. (2007) | · · · | 124 d | 0 . 3 < ∼ M/M /circledot < ∼ 1 | ∼ 6 | · · · | 330 | 1 | ∼ 7 | 0.29 |
| This work | 1246 | 77 | 0 . 02 < M/M /circledot < 0 . 8 | 3 . 8 ± 0 . 5 | 4 . 1 ± 0 . 4 | 360 | 0.5 | 6 . 1 ± 0 . 8 | 0.30 |
a Considered by Kharchenko et al. (2005) as high probability members.
b The most massive object predicted by Baraffe et al. (1998) models at such age is 1 4 . M /circledot , corresponding to a M V = 4 85 while . the fainter object in the Kharchenko et al. (2005) sample is M V = 4 05. .
c We interpolate into the Baraffe et al. (1998) models the Bessel magnitudes obtained from the SDSS photometry using Davenport et al. (2006) conversions.
d A total of 47 members have kinematic information.
the packages Offline and DQ developed by the QUESTI collaboration (Baltay et al. 2002). In a first step, the QUEST-I data pipeline ( Offline ) automatically processes every single drift-scan considering each CCD of the mosaic as an independent device, corrects the raw images by bias, dark current and flat field, performs the detection of point sources, aperture photometry, and determines detector coordinates for each object. Then the software solves the world coordinate system by computing the astrometric matrices for each CCD of the mosaic, based on the USNOA-2.0 astrometric catalog (Monet 1998).
After the basic processing for every individual scan has been done with the Offline package, the second step is to coadd these reduced single observations, using the package DQ . Using the transformation matrices output by Offline , the DQ package computes the offsets and rotations needed to place images of the same area of the sky, coming from different single drift-scans, in the same reference frame and add them pixel by pixel to produce the final coadded driftscan. The coadded drift-scans used here are listed in Table 2, together with the mean coordinates, filter set, resulting limiting and completeness magnitudes for each photometric band after coadding, average FWHM of point sources, and number of individual scans included in the coadd.
In a third step, photometry and astrometry on the resulting coadded images are performed using an IRAF 4 and IMWCS-based pipeline . The maximum number of detec5 tions at the 3 σ threshold in the I-band images, corresponds to a mean spatial density of ∼ 1 point source per ∼ 340 arcsec square, resulting in a mean distance between nearest sources of about ∼ 22'. Because of this, source crowding is not a problem, and we can safely perform aperture photometry; we used an aperture radius equal to the average FWHM of the coadded images ( ∼ 3'; Table 2).
The zero point calibration of the instrumental photometry in the Cousins system for each coadded drift-scan
4 IRAF is distributed by the National Optical Astronomy Observatories, which are operated by the Association of Universities for Research in Astronomy, Inc., under cooperative agreement with the National Science Foundation.
5 IMWCS is the Image World Coordinate Setting Program described in Mink (2006)
was done by normalizing the instrumental magnitudes to a master catalogue of ∼ 10 5 non-variable stars 6 with calibrated magnitudes. This large set of secondary standards was produced from a set of single drift-scans obtained with the same instrument and filters under photometric conditions, calibrated with Landolt (1992) standard star fields (Mateu et al. 2012). The calibration has an RMS of 0.021, 0.037 and 0.042 magnitudes in the V , R and I bands respectively. The mean positional uncertainty as inferred from the offsets in coordinates between the optical bands is 0.4 ′′ , with a standard deviation of 0.6 ′′ , similar to what we find for the offsets with respect to the infrared datasets we have used in this work ( § 3.2). Therefore, the photometric and astrometric calibration offer adequate accuracy for a reliable selection of LMS and BD candidates.
The catalogues with calibrated photometry for each photometric band from different coadded drift-scans, were finally compiled into a single deep catalog for each band, extracting repetitions and keeping, in such cases, always the measurement showing the highest SNR . We matched our 7 optical source lists using a search radius of 3 ′′ , always keeping the object with the minimum positional difference. We will refer to this collection of four deep catalogs (in the V, R, I passbands and in a narrow band - 10 nm wide - H α filter), as the CIDA Deep Survey of Orion (CDSO, Downes et al. 2014 in preparation). The sources in the CDSO span the region 65 ◦ /lessorequalslant α J2000 /lessorequalslant 100 ◦ and -6 ◦ /lessorequalslant δ J 2000 /lessorequalslant +6 , with ◦ positions and photometry for 8.6 million objects in the Iband, 8.1 million objects in the R-band, 6.9 million objects in the V-band, and 2.4 million objects in the H α filter.
In this contribution we focus on the LMS and BD populations of the 25 Orionis group, therefore we limit our analysis and discussion to drift-scans centred at declinations +1 ◦
6 Since we used individual scans spanning a time baseline of 7 years, we could determine which stars did not show hints of variability above the 0.02 mag level, and use these as secondary standards for our photometric calibration. Because of this, and the large number of stars used, we obtained a very robust calibration.
7 All positional matching between object catalogs throughout this paper was done using routines based on the the Starlink Tables Infrastructure Library Tool Set (STILTS, Taylor 2006) available at http://www.starlink.ac.uk/stilts/
Table 2. Observation log for the coadded drift-scans.
| Drift-Scan | δc J 2000[ ◦ ] | α ini J 2000[ ◦ ] | α end J 2000[ ◦ ] | Filters | FWHM a [ ′′ ] | N b | Vcom c | Rcom | Icom | V lim | R lim | I lim |
|----------------|------------------|---------------------|---------------------|-------------|-----------------|-------|----------|--------|--------|---------|---------|---------|
| Single | +1, +3 | 65 | 99 | All filters | 2.5 | 1 | 18.7 | 19.0 | 18.5 | 20.5 | 20.5 | 20 |
| Coadds 011-012 | +1 | 76.14 | 86.3 | VIIV | 2.6 | 28 | 20.5 | . . . | 20.3 | 22.3 | . . . | 21.8 |
| Coadd 013 | +1 | 77.11 | 82.56 | VIRI | 2.8 | 29 | 20.5 | 20.8 | 20.3 | 22.3 | 22.3 | 21.8 |
| Coadd 940 | +1 | 67 | 98.22 | RH α IV | 2.9 | 13 | 20.1 | 20.4 | 19.9 | 21.9 | 21.9 | 21.4 |
| Coadd 950 | +3 | 71.15 | 89.41 | VRIV | 2.6 | 10 | 19.9 | 20.2 | 19.7 | 21.7 | 21.7 | 21.2 |
- a The mean FWHM is from point sources in the I-band images.
- b The number of added single scans in the I-band.
- c The limiting and completeness magnitudes were computed for a 3 σ detection threshold.
and +3 , in particular within the region 0 35 ◦ . ◦ < δ < ∼ ∼ 3 35 and . ◦ 79 7 . ◦ < α < ∼ ∼ 82 7 shown in Figures 2, which encompasses the . ◦ area expected to be spanned by the 25 Orionis group and its surroundings. In this area the I-band catalog has a limiting I lim ∼ 22 and completeness I com ∼ 19 6, . which is enough to detect objects down to masses ∼ 30 M Jup , assuming Baraffe et al. (1998) models for the assumed age and distance of 25 Orionis. The full analysis of the entire CDSO will be presented in a forthcoming article.
0.6
## 3.2 Infrared photometry
## 3.2.1 Near Infrared Data
As will be explained in Section 3.3, our technique of searching for young BDs and LMS in the extended off-cloud, lowextinction regions of the Orion OB1 association hinges on the combination of deep optical and near-infrared photometry. Ever since its release, the Two Micron All-Sky Survey (2MASS Skrutskie et al. 2006) has been the tool of choice for all large scale studies that required access to near infrared photometry for large numbers of sources over extended areas of the sky, with uniform spatial coverage. However, with limiting magnitudes of J lim ∼ 17 4, H . lim ∼ 16 7, . Ks lim ∼ 16 2 . and completeness magnitudes J com ∼ 16 6, . H com ∼ 15 8, Ks . com ∼ 15 4, the 2MASS catalog is shallow . compared to the deep CDSO data, imposing restrictions on our search for BD in Orion, in particular for the faintest, lowest mass objects. Nevertheless, being at the time of our initial candidate selection the only spatially complete nearIR dataset available, we cross matched our I-band CDSO catalog with 2MASS using a search radius of 3 ′′ , resulting in a master catalog with IJHKs photometry for each source. With this dataset we created the optical-near-IR colourmagnitude diagrams used to select LMS and BD candidates (see § 3.3) for follow-up spectroscopy.
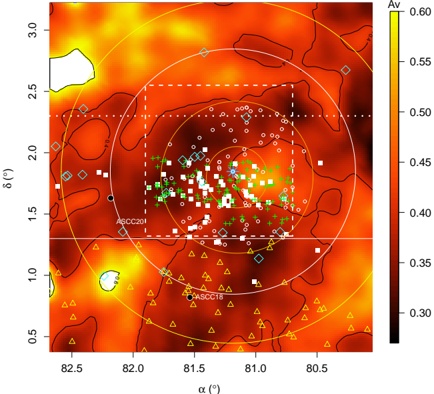
Recently, a new, much deeper near-IR survey has become available. During 2009 a new dedicated 4m survey telescope, the Visible and Infrared Survey Telescope for Astronomy (VISTA), located at ESO's Paranal Observatory, was commissioned by the VISTA consortium (Emerson et al. 2004; Emerson & Sutherland 2010). It is equipped with a 67 × 10 6 pixels camera with a scale of 0.34 ′′ /pix and a field of view of 1 65 in diameter. For the Galactic Science Verifi-. ◦ cation of VISTA, a ∼ 30deg 2 area of the Orion OB1 association, which included the Orion Belt region, part of the Orion A cloud, the 25 Orionis and σ Ori clusters, was imaged in the Z, Y, J, H and Ks filters, during October 16 to Novem-
Figure 1. Spatial distribution of photometric candidates and confirmed members of the 25 Orionis group from previous studies. Solid squares: LMS confirmed as members from Brice˜o et al. n (2005, 2007). The dotted horizontal line indicates the northern limit of the survey from Brice˜o et al. (2005). Small circles: n Photometric and astrometric candidates from Kharchenko et al. (2005). Crosses: members and candidates from Hern´ndez et al. a (2006). Triangles: Photometric candidates from McGehee (2006). The solid horizontal line indicates the northern limit of the survey of McGehee (2006). Diamonds: Eclipsing systems and/or CTTS candidates from van Eyken et al. (2011). Large circles indicate from the centre outward: the core and corona cluster radii (0 . ◦ 25 and 0 62 respectively) . ◦ computed by Kharchenko et al. (2005), the radius suggested by Brice˜o et al. n (2005) ( ∼ 1 ◦ ) and the radius proposed by McGehee (2006) ( ∼ 1 4); the dashed square . ◦ indicates the spatial limits of the IRAC survey. Background: Map of the extinction A V from Schlegel, Finkbeiner & Davis (1998) with scale on the right. The big central asterisk represents the 25 Ori star and the black dots other clusters from Kharchenko et al. (2005).
ber 2, 2009, down to 5 σ limiting magnitudes Z ∼ 22 5, Y . ∼ 21 2, . J ∼ 20 4, . H ∼ 19 4, . Ks ∼ 18 6 . (Petr-Gotzens et al. 2011). The data reduction was performed using a dedicated pipeline, developed within the VISTA Data Flow System, and run by the Cambridge Astronomy Survey Unit in the UK. The pipeline delivers science-ready stacked images and mosaics, as well as photometrically calibrated source cat-
0.6
Figure 2. Spatial distribution of LMS and BD of the 25 Orionis group from the present work. Crosses: LMS and BD photometric candidates ( § 3.3). Circles: LMS confirmed as members ( 3.5). § The dashed circle indicates the field observed with Hectospec ( § 3.4). Other elements are as in Figure 1.
alogs 8 . The final, band-merged Orion OB1 VISTA catalog contains ∼ 3 million sources. The VISTA photometric calibration is based on (but different from) 2MASS. Instrumental magnitudes were converted into apparent calibrated magnitudes on the VISTA system and calibrated via colour equations. This also included the Z and Y bands, following the procedure described in Hodgkin et al. (2009). The point sources detected in the I-band CDSO survey catalog were cross-matched with the VISTA Orion OB1 master catalog, using a 3 ′′ match radius. The resulting IZYJHKs catalog was then matched with our V, R and H α catalogs to add additional measurements in these bands for those objects which had them; however, the VRH α data were not used in the process of selecting LMS and BD candidates. Because VISTA goes much deeper than 2MASS, and since for objects in common the VISTA and 2MASS magnitudes agree within the uncertainties, we adopted the CDSO-VISTA dataset as our final optical-near IR photometry catalog. For objects showing J < 12, H < 12 or Ks < 11 in the VISTA catalogue we adopted J, H and Ks magnitudes from 2MASS in order to avoid possible saturation effects in VISTA data.
## 3.2.2 Mid-infrared Data
In order to identify disc-bearing sources among selected candidate LMS and BDs, we matched our multiband VRH IZYJHKs catalog with our existing Spitzer observaα tions within the 25 Orionis region obtained as part of GO3437 (Hern´ndez et al. 2007) and GO-50360 (Brice˜o et al. a n 2014, in preparation) and also with the recently released
8 More details on the VISTA data processing can be found at http://casu.ast.cam.ac.uk/surveys-projects/vista/technical.
Wide Infrared Survey Explorer (WISE Wright et al. 2010) database. First, a sub-sample of the photometric candidates and of the spectroscopically confirmed members (Sections 3.3 and 3.5), were identified in the object catalogs extracted from our IRAC images. The image reduction, point source detection and photometry for the datasets from Hern´ andez et al. (2007) and Brice˜o et al. (2014, in preparan tion) are analogous and were described in Hern´ndez et al. a (2007). The IRAC observations were performed in the passbands centred at 3.6 µ m, 4.5 µ m, 5.8 µ m and 8.0 µ m with the spatial coverage shown in Figure 1. As a second step, the photometric candidates and spectroscopically confirmed members were identified in the WISE database which offers measurements in four pass-bands, centred at 3.4 µ m, 4.6 µ m, 12 µ m and 22 µ m. Compared to the IRAC observations, WISE is a shallow survey with worse angular resolution, but its spatial coverage is uniform, providing also data for the surroundings of 25 Orionis, where we did not have Spitzer data. The limiting and completeness magnitudes for each VISTA, IRAC and WISE photometric bands are summarized in Table 3 together with the number of photometric candidates and confirmed members from this work with available photometry from these IR surveys.
## 3.3 Selection of photometric candidates
The selection of photometric candidates was performed according to their position in colour-magnitude diagrams which combine optical and near infrared magnitudes. This method has been extensively used and has proved highly successful in identifying LMS and BDs in young clusters and star-forming regions (e.g Brice˜o et al. 2002; Luhman et al. n 2003b; Downes et al. 2008).
We selected as candidates those objects located in what we call the membership locus , simultaneously in the I vs IJ, I vs I-H and I vs I-Ks colour-magnitude diagrams. These loci were defined as regions centred on the isochrone corresponding to the mean age from the Baraffe et al. (1998) models ( ∼ 7 Myr) reported by Brice˜o et al. n (2005, 2007) and a distance of ∼ 360 pc (Brice˜o et al. 2014, in preparan tion). The width of the loci were computed considering the 1 σ uncertainties in age and distance, the mean interstellar extinction throughout the region, unresolved binarity, the 1 σ photometric uncertainties and the expected mean intrinsic photometric variability. The resulting locus for the I vs. I-J diagram is shown in Figure 3. An object was considered as a photometric candidate if it was located within the membership locus in all three diagrams. Using the CDSOVISTA catalog, a total of 1246 photometric candidates were selected inside the region showed in Figure 2, spanning a ∼ 2 5 . ◦ × ∼ 2 5 area covering the previously known population . ◦ of the 25 Orionis group and its surroundings.
The estimated masses of the full candidate sample range from ∼ 0 8 . M /circledot down to ∼ 0 02 . M /circledot according to the models of Baraffe et al. (1998), with an age of ∼ 7 Myr and distance modulus of 7.78 mag. Due to the sensitivity and saturation of the I-band observations, the sample is complete from ∼ 0 8 . M /circledot ( I ∼ 13) down to ∼ 0 03 . M /circledot ( I ∼ 19 6). . In Section 5.1 we present the estimation of ages and masses for each candidate.
We emphasize that colour-magnitude diagrams constructed combining optical and near infrared magnitudes
Table 3. Limiting and completeness magnitudes and the number of candidates and members from VISTA, IRAC and WISE surveys.
| Survey | Band | Completeness | Limiting | Candidates a | Members |
|----------|----------|----------------|------------|----------------|-----------|
| VISTA | Z | 22.5 | 23.5 | 1246 | 77 |
| | Y | 20.8 | 22.5 | 1246 | 77 |
| | J | 20.2 | 21.7 | 1246 | 77 |
| | H | 19.2 | 20.5 | 1246 | 77 |
| | Ks | 18.4 | 19.6 | 1246 | 77 |
| IRAC | 3 . 6 µm | 17.2 | 19.5 | 369 | 72 |
| | 4 . 5 µm | 16.7 | 19 | 388 | 77 |
| | 5 . 8 µm | 15.7 | 18.5 | 365 | 70 |
| | 8 . 0 µm | 14.7 | 17.5 | 358 | 77 |
| WISE | 3 . 4 µm | 16.2 | 17.2 | 1038 | 77 |
| | 4 . 6 µm | 16 | 17 | 1038 | 77 |
| | 12 µm | 12.8 | 13.2 | 1038 | 77 |
| | 22 µm | 9.1 | 9.5 | 1038 | 77 |
- a VISTA and WISE surveys cover the entire region while IRAC survey covers the area shown in Figure 1.
ness bias because BDs at this age and distance are red and very faint, so they drop out quickly in the bluer bands. Second, although our selection is not exempt from contamination by field stars, candidate selection performed in diagrams that include only near infrared data strongly increase the contamination by field dwarfs and by extragalactic sources, because of the limited leverage in colour; in these diagrams the isochrones are almost vertical and piled up, therefore, there is hardly any separation between the PMS locus and the field population. The contamination in our candidate sample by field stars and extragalactic sources is discussed in Section 4.2. The photometric variability in young LMS and BDs affects the optical and near-IR bands in a different way. Because our I-band data is the result from a coadd of images obtained in a period of 15 months, we considered that as the mean I-band magnitudes. The reported amplitudes of the variations in J, H and Ks-bands for LMS and BDs are within 0.2 to 0.5 mag (e.g. Scholz et al. 2009) We add to the width of the membership locus the corresponding change in colors that result from the maximum variation of 0.5 magnitudes in the near-IR bands.
Figure 3. Color-magnitude diagram used as part of the candidate selection, including the objects selected as candidates (empty circles) and those confirmed as new members (big dots). The thick horizontal line indicates the completeness limit. The solid curves indicates evolutionary tracks for 0.8 M /circledot , 0.7 M /circledot , 0.5 M , 0.4 M /circledot /circledot , 0.1 M /circledot , 0.06 M /circledot , 0.05 M /circledot , 0.03 M /circledot , 0.02 M /circledot , 0.01 M /circledot (thin) and 0.072 M /circledot (thick). The thick dashed line indicates the isochrone corresponding to 7 Myr and the thin doted lines enclose the membership locus. Theoretical isochrones and evolutionary tracks are from Baraffe et al. (1998) models, are ploted without extinction correction and assuming m M -= 7 78 magni-. tudes. The dereddening vector for the mean extinction throughout the region ( A V = 0 3) is also indicated. .
yield the best selection of photometric PMS stellar candidates and young sub-stellar objects mainly because of two reasons: first, diagrams based on optical data alone (V, R and I-band magnitudes) suffer from an important complete-
## 3.4 Optical spectroscopy
Even with a refined selection technique, photometric candidate samples suffer from some degree of contamination by non-members like foreground field dwarfs and also by background giant stars and extragalactic objects. Therefore, spectroscopic follow up is necessary to unambiguously confirm membership. Moreover, spectra also provide crucial information necessary to derive fundamental properties, like the object's effective temperature, A V , and hence its luminosity, whether it is accreting from a circumstellar disc, if it has a jet, and so on. Here we have extended in number and to much lower masses the member list discussed by Brice˜o et al. (2005, 2007), by obtaining low resolution n (R ∼ 1000) optical spectra of a sample of 90 photometric candidates of the 25 Orionis group.
The spectra of the sample were obtained during the
night of October 22 2007, during queue mode observations with the Hectospec multi-fiber spectrograph on the 6.5 MMT telescope (Fabricant et al. 2005). We observed a single field centred at α J 2000 =05:25:13, δ J 2000 =+01:39:25 (Figure 2), using one single fiber configuration for which we obtained five consecutive exposures, each 1800 s long. We used the 270 groove mm -1 grating, providing a spectral resolution of R ∼ 1000 with a spectral coverage from 3700 ˚ A to 9150 ˚ . Because of the poor seeing conditions ( A ∼ 2 2 . ′′ ) during the integrations and the diameter of the Hectospec fibers ( ∼ 1 5 . ′′ ), only the brightest candidates ( I < ∼ 17) could be observed with reasonable SNR ( ∼ 15), allowing for an appropriate spectral classification.
The 25 Orionis group is placed far enough from the Orion molecular clouds, so that problems due to the high sky background caused by nebulosity are not present. All the Hectospec spectra were processed, extracted, corrected for sky lines, and wavelength calibrated by S. Tokarz at the CfA Telescope Data Center, using customized IRAF routines and scripts developed by the Hectospec team (see Fabricant et al. 2005). The five individual 1800 s exposures were coadded into a single, deep observation, with a total integration time of 9000 s. Light sources inside the Hectospec fiber positioner, contaminate ∼ 1 3 of the fibers at / wavelengths longer than ∼ 8500 A (N. Caldwell, ˚ private communication), therefore, during the analysis we ignored data at these wavelengths.
Of the 1246 photometric candidates, 277 are placed within our Hectospec field. Because of limitations with the positioning of fibers and the poor seeing conditions we observed a total of 90 candidates out of which 77 were confirmed as new members of the 25 Orionis group for a ∼ 86 per cent efficiency. The remaining 13 candidates were confirmed as field stars. An example of the spectra is shown in Figure 4.
## 3.5 Spectral classification and membership diagnosis
We performed the spectral classification by comparing the equivalent widths of sixteen spectral features typical of M type stars, such as TiO and VO bands, (see Table 3 of Downes et al. 2008), with their corresponding values in a library of standard spectra of field dwarfs from Kirkpatrick et al. (1999), and following the semi-automated scheme of Hern´ndez et al. (2004) a 9 . The differences in surface gravity between the young targets and the field dwarfs used as standards did not affect significantly the spectral classification for objects earlier than M6. We estimate the typical uncertainty resulting from our classification to be ± 0.5 spectral subclass.
We have used several criteria to assign 25 Orionis group membership to each spectroscopically observed candidate. We start by considering the detection of H α in emission. Strong H α in emission is a common feature of chromospherically active young objects, and of objects accreting from a circumstellar disc for the largest equivalent widths (e.g.
9 This procedure was done using the code SPTCLASS, available at http://www.astro.lsa.umich.edu/ ∼ hernandj/SPTclass/sptclass.html
Figure 4. Spectra of a LMS confirmed in this work as a new member of the 25 Orionis group. The top panel shows the complete spectrum obtained by Hectospec and the lower panels the H α emission line, the LiI λ 6708 absorption line and the NaI λ 8183 8195 absorption doublet. Labels indicate the member ID, , the spectral type and the equivalent width of H α . Vertical dashed lines in the lower panels indicate the central wavelength of the H , LiI α λ 6708 and NaI λ 8183 8195. , In the panel for the NaI λ 8183 8195 , absorption doublet we also show the corresponding spectra of a field dwarf (dashed red line; Kirkpatrick et al. (1999)), and a young dwarf from the Chamaeleon I region ( ∼ 2 Myr ; dotted line; Luhman et al. (2005)) of the same spectral type and smoothed to a same spectral resolution of 16 ˚ . The A spectra for the entire sample of new members (see Table 4) are available in the electronic edition.
Muzerolle et al. 2005). Figure 4 shows the H α emission line profile and its corresponding equivalent width for a confirmed member. At the age of the 25 Orionis group ( ∼ 7 Myr), most stars have stopped accreting (at least at significant levels), such that strong H α emission is not necessarily expected (Brice˜o et al. n 2007), and many members could exhibit equivalent widths similar to those measured in active dMe stars. Therefore, as an additional membership indicator we looked at the NaI λ 8183 8195 absorption doublet. , The NaI λ 8183 8195 feature is sensitive to the surface grav-, ity of the star, being very strong (deep) in old field dwarf stars, very weak in late type M giants, and intermediate in late type PMS stars and young BDs which are still contracting down to the main sequence or asymptotically approaching the main sequence in the case of BDs (Luhman et al. 2003a). The NaI λ 8183 8195 absorption doublet of one of , the LMS confirmed as member, superimposed on spectra of field dwarfs from Kirkpatrick et al. (1999), and of young M dwarfs of the same spectra type (from Luhman et al. 2003b) are shown in Figure 4. Given the typical I-J, I-H and I-Ks colours of the LMS and BD candidates considered here and the low visual extinction along the line of sight towards the 25 Orionis group, no reddened late giant stars are expected to contaminate our candidate sample, as we show in Section 4.2.
In addition to the above criteria, the presence of the Li I λ 6708 line in absorption was also considered. This spectral feature is a well-known indicator of youth in late K and Mtype objects (Strom et al. 1989; Brice˜o et al. 1998, 2001), n up to a spectral type ∼ M6.5, which at an age of ∼ 10 Myr corresponds to the mass limit for Li fusion ( M ∼ 0 06 . M /circledot Basri 1998). However, because of the low spectral resolution and SNR in most of our spectra, we could detect the LiI λ 6708 line in only ∼ 60 per cent of the confirmed members. Objects showing Li I λ 6708 line in absorption were selected as members; those without a detection were not discarded as members unless they also failed the Na I criteria explained above.
Summarizing, photometric candidates were classified as members if they showed H α in emission and NaI λ 8183 8195 , in absorption weaker than a field dwarf of the same spectral type. The detection of the Li I λ 6708 line in absorption was only considered as an additional youth indicator, in light of the bias imposed by the low spectral resolution and the SNR in most spectra. Additionally, as a sanity check, we looked at the A V of each star, computed from the observed colours and from the intrinsic colours we obtained from the spectral types and the relations from Luhman et al. (2003b), and noted whether it was consistent with the average A V for the 25 Orionis group (Brice˜o et al. 2007). n
Clearly, the spectral features we have considered above are youth indicators but do not, by themselves, guarantee membership to the 25 Orionis group. The reason is that these same criteria will select young members that belong to other regions of the Orion OB1 association, placed behind the 25 Orionis group. Indeed, we know that 25 Orionis is located in the extended OB1a sub-association, and the much younger OB1b region is a few degrees away. However, as we argue in Section 4.2 the expected number of such possible young contaminants is low and does not affect the general analysis presented here. Additionally, the Hectospec field is centred in the 25 Orionis spatial overdensity we explain in Section 5.2, increasing the probability of these objects being real members of 25 Orionis group.
We confirmed 77 new members of the group whose photometric information and resulting spectral types are listed in Tables 4 and 5. In Figure 5 we show the H-R diagram with the new members.
## 4 INTERSTELLAR EXTINCTION AND CONTAMINATION BY FIELD STARS
One of the problems encountered when carrying out photometric surveys over large areas of the sky is obtaining followup spectroscopy for every single source of interest, thereby making sure one has positively identified every member of the stellar population of interest. Even with the multiplexing capabilities of modern day multi-fiber spectrographs, this can be a daunting task, specially if one needs to use very long exposure times in order to get enough SNR on very faint objects. However, in our case, we can extend our study of the 25 Orionis group beyond the spatial and mass completeness of the spectroscopically confirmed member sample, by a judicious use of the photometric candidate member sample. At the expense of a larger degree of contamination from non-members, the photometric sample has the virtue
Figure 5. H-R diagram for the new members. The isochrones for 1, 3.2, 4.6, 8.5, 11.4 and 100 (dotted) Myr and the evolutionary tracks for 0.8 M /circledot , 0.6 M /circledot , 0.5 M /circledot , 0.3 M /circledot , 0.2 M /circledot , 0.1 M /circledot and 0.072 M /circledot (dashed) from the Baraffe et al. (1998) models are indicated. The top axis indicates the corresponding spectral types from Luhman et al. (2003b).
of providing a spatially complete rendering of the 25 Orionis aggregate, and it also allows us to sample large numbers of objects down to much lower masses. The disadvantage of this approach is that issues like contamination from nonmembers and variable extinction could potentially render any reliable analysis as useless. However, we will show that in the particular case of the 25 Orionis group, conditions are such that a photometric study of the group properties is not only feasible, but quite reliable.
## 4.1 Interstellar extinction
We determined the visual extinction A V for each of the 77 spectroscopically confirmed members, calculated by using the intrinsic I-J colour for the corresponding spectral type proposed by Luhman et al. (2003b), the observed I-J colour, and the Cardelli, Clayton & Mathis (1989) extinction law assuming R V = 3.09. The resulting A V values are in excellent agreement with previous spectroscopic determinations by Brice˜o et al. (2005) for stellar members, as we n show in Figure 6.
The A V for the 1246 photometric candidates were derived using the Schlegel extinction maps (SEM; Schlegel, Finkbeiner & Davis 1998). This approach is valid in this particular region because it has a spatially smooth extinction. Still, estimates from SEM have two main limitations: First, the A V reported in the SEM is the integrated extinction along the line of sight, limited by the sensitivity of the survey and the resulting A V for a nearby object will be overestimated, due to extinction sources behind the object. Second, the low spatial resolution of the SEM could result in an inadequate interpolation for objects placed in regions with abrupt variations of the extinction.
Table 4. Photometric catalog of the new spectroscopically confirmed LMS of the 25 Orionis group. The table is published in its entirety in the electronic edition.
| ID | α J2000 [ ◦ ] | δ J2000 [ ◦ ] | V C | R C | I C | Z | Y | J | H | Ks | 3.6 µ m | 4.5 µ m | 5.8 µ m | 8.0 µ m |
|------|-----------------|-----------------|-------|-------|-------|-------|-------|-------|-------|-------|-----------|-----------|-----------|-----------|
| 1232 | 81.2583 | 1.62249 | 16.25 | 15.18 | 13.69 | 13.35 | 12.95 | 12.36 | 11.71 | 11.5 | 11.45 | 11.24 | 11.38 | 11.18 |
| 1242 | 81.0373 | 1.73113 | 16.11 | 15.09 | 13.66 | 13.18 | 12.68 | 12.07 | 11.57 | 11.39 | 11.17 | 11.11 | 11.07 | 11.10 |
| 1245 | 81.0633 | 1.90166 | 20.61 | 19.24 | 16.9 | 16.32 | 15.56 | 14.98 | 14.51 | 14.16 | 13.77 | 13.72 | 13.67 | 13.65 |
| 1246 | 81.2779 | 1.79876 | 19.16 | 17.83 | 15.65 | 15.12 | 14.46 | 13.89 | 13.4 | 13.11 | 12.69 | 12.64 | 12.57 | 12.54 |
| 1247 | 81.0647 | 1.931 | 17.22 | 16.03 | 14.28 | 13.85 | 13.28 | 12.75 | 12.25 | 11.96 | | | | |
| 1248 | 81.2433 | 1.97599 | 17.45 | 16.38 | 14.73 | 14.33 | 13.86 | 13.36 | 12.77 | 12.56 | | 12.22 | | 12.17 |
| 1252 | 81.2708 | 1.61483 | 16.92 | 15.81 | 14.1 | 13.64 | 13.17 | 12.61 | 12.04 | 11.81 | 11.49 | 11.49 | 11.48 | 11.47 |
| 1253 | 81.1664 | 1.3613 | 15.29 | 14.36 | 13.38 | 12.96 | 12.63 | 12.3 | 11.6 | 11.42 | 11.29 | | 11.25 | |
| 1258 | 81.2161 | 1.54132 | | 18.58 | 16.29 | 15.72 | 14.98 | 14.38 | 13.91 | 13.56 | 13.17 | 13.10 | 13.11 | 13.14 |
| 1261 | 81.0869 | 1.4014 | 15.69 | 14.74 | 13.62 | 13.32 | 13 | 12.47 | 11.77 | 11.65 | 11.47 | | 11.40 | |
Table 5. Spectroscopic catalog of the new confirmed members of the 25 Orionis group. The table is published in its entirety in the electronic edition.
| ID | ST | W[H α ] [ ˚] A | LiI a | Av [mag] |
|---------------------------------------------------|--------------|--------------------------------------|---------------|------------------------|
| 1278 1273 1262 1277 1284 1269 1263 1266 1279 1242 | M4.5 M5 M4.5 | -5.8 -13 -8.4 -4.3 -9.9 -5 -8.9 -8.9 | 0 1 1 1 1 1 1 | 0 0.12 0 0 0 0.46 0.54 |
| | M3.5 | | -1 | |
| | M4.5 | | | |
| | M4.5 | -16.7 | | |
| | M2.5 | | | |
| | M4 | | | 0.06 |
| | M3.5 | | 0 | 0.21 |
| | M3.5 | -6.6 | 1 | 0.79 |
a The flags -1, 0 and 1 indicate respectivelly non detection, uncertain detection and certain detection.
We consider this average ¯ A V as the mean excess extinction added by the SEM. Regarding the issue of limited spatial resolution of the SEM, from Figure 1 it is clear that the background towards the 25 Orionis group is quite smooth, showing no significant spatial variations ( σ A V ∼ 0 2). This . uniformity is also confirmed in our Spitzer-MIPS 24 µ m images of this area (Hern´ndez et al. 2007) and by preliminary a extinction maps performed on the basis of near IR photometry from VISTA (Alves, private communication).
Figure 6. Distribution of the visual extinction A V throughout the 25 Orionis group. Left panel: A V values measured from spectra as explained in the text, from Brice˜o et al. (2005, n 2007) (black), from this work (gray), and the complete sample (white). Right panel: Distribution of the residuals between visual extinctions computed from spectroscopy, and those from the Schlegel, Finkbeiner & Davis (1998) maps, for the same complete sample of the left panel. Solid line indicates the normal distribution which fits the data, with ¯ A V = 0 16 and . σ = 0 39 magni-. tudes after removing the outliers.
In order to assess how much we would overestimate the extinction by using the SEM, we computed a mean excess in A V by comparing the distribution of the residuals between A V computed using spectroscopy for the members confirmed in this work and those from Brice˜o et al. (2005), n and A V from the SEM as we show in Figure 6. Except for a few outliers, the resulting distribution is essentially normal, with a mean ¯ A V = 0 16 and standard deviation . σ A V = 0 39. .
Thus, we estimated the A V for each photometric candidate by interpolating in the SEM and subtracting the ¯ A V estimated from the distribution of residuals. We consider the mean uncertainty of our estimation over the entire sample of candidates as σ A V / √ N = 0 03 magnitudes, where . N = 134 is the number of confirmed members used for the residual distribution.
## 4.2 Contamination of the photometric candidate sample by field stars and extragalactic sources
There are three main possible sources of contamination of a LMS and BD photometric candidate sample from a star forming region: field dwarf and giant stars, unresolved extragalactic sources and, in our case, young stars belonging to other sub-regions such as Orion OB1a. Such contamination could affect estimates of the IMF, the mean age and the spatial distribution of the 25 Orionis group when performed using only photometric candidates. We use a Galactic model to estimate the contamination by Orion non-members to-
wards our field, and since we obtained a large number of spectra, we can verify the predictions from such models.
The number of field stars, of all kinds, in the photometric candidate sample, was estimated from a simulation of the expected galactic stellar population in an area of ∼ 6 4 . deg 2 centred at the 25 Orionis group, performed with the Besan¸ con Galactic model (Robin et al. 2003). This model has been extensively tested and correctly reproduces the luminosity function within the sensitivity limits of the 2MASS survey (Robin et al. 2003). Second, we reproduce in the Besan¸ con data the typical photometric incompleteness from our survey according to the following procedure: First, we ran the model simulation in the range 13 < < I 22 and simulating the photometric errors as function of magnitude, using an exponential function with parameters obtained from fitting our survey data. Second, to estimate the fractional contamination in our photometric survey we need to remove objects from the Besan¸ con model in order to reproduce the fall-off as a function of magnitude observed in our survey. To do this we produced I vs. I-J Hess diagrams for our survey and the simulated sample using 0.1 × 0.1 magnitude bins and randomly discarded simulated objects in each bin until their number matched our observed number. After this correction was applied, a star from the Besan¸on simulation c was considered a contaminant of the photometric candidate sample if it satisfied the selection criteria explained in Section 3.3.
The resulting sample of contaminants is constituted exclusively by 212 low-mass main sequence stars that have an homogeneous spatial distribution with a mean spatial density of ∼ 33 objects per deg 2 , estimated spectral types from K7 to L0 and distances between ∼ 50 pc and ∼ 300 pc. In our spectroscopic sample, every single star rejected as a member turned out to be a field dwarf, several with some degree of emission in H α as seen in dMe stars, but all showing the deep Na I 8183,8195 absorption expected in older, low-mass disc stars. No late type giants were found among the rejected, non-member, spectroscopic sample as suggested by our results from Besan¸ con. In order to estimate the contamination as a function of member's mass, we assume such contaminant field dwarf stars mistaken for members of the 25 Orionis group, and we computed the masses and ages they would have, following the procedure we will explain in Section 5.1, resulting in the distributions we show in Figures 7 and 8.
We compared the observational J vs J-Ks diagram with those obtained from an appropiate simulation with the Besan¸ con Galactic model (Robin et al. 2003) of the expected galactic population in the area covered by the survey (see Section 4.2). We found that the point sources showing JKs¿1.5 are spatially unresolved extragalactic objects that are not predicted by the Besan¸ con galactic model. Then, we applyed to the selected extragalactic sources our criteria for the selection of photometric candidates to members of the 25 Ori group and found that only a negligible number of unresolved extragalactic sources ( ∼ 1 source per deg 2 ) do satisfy our criteria for photometric candidate selection; this means a total of ∼ 7 extragalactic sources is expected in the entire sample of photometric candidates.
Summarizing, we found 1246 member candidates in the 25 Orionis group in the mass range considered here. If we neglect the contamination due to extragalactic sources and
©
c
members from other regions of Orion OB1, from the Besan¸ con model we expect 316 field dwarfs within the sample for a mean density of ∼ 33 contaminants per deg 2 . The total number of candidates expected to be real members of the 25 Orionis group in the mass range considered here is 930 corresponding to a mean spatial density of ∼ 146 members per deg 2 . Thus, our photometric selection has a global efficiency of ∼ 82 per cent which is in good agreement with the 77 new confirmed members which corresponds to the ∼ 86 per cent of our spectroscopic survey because spectra were obtained in the overdensity of candidates explaines in Section 5.2. We emphasize that the contamination shows a dependence with photometric colour which results in the fiducial mass and age distributions shown in Figures 7 and 8, which would be the mass and age distributions resulting from wrongly considering such contaminants as members.
## 5 ANALYSIS AND RESULTS
## 5.1 The mean age and the initial mass function
The masses and ages we derived here for the 25 Orionis lowmass population were obtained through interpolation of the luminosity and effective temperatures in the Baraffe et al. (1998) models, adopting a distance of 360 pc from Brice˜o n et al. (2014, in preparation). For the photometric candidates we interpolated the luminosity and the effective temperature we obtained by interpolation of the I-band magnitude and the I-J photometric colour, both corrected by interstellar extinction as explained in Section 4.1, using the relationships from Luhman et al. (2003b) and Dahn et al. (2002), from which we obtained the effective temperatures and bolometric corrections. For the spectroscopically confirmed members we followed two procedures: First, as we did for the photometric candidates. Second, by interpolation of the measured spectral types in the same relationships. Within the uncertainties, no significant differences were found for masses and ages derived with either procedure for the spectroscopically confirmed member sample. This similarity is not surprising, given the low and smooth interstellar reddening towards this region, and the ∼ 0.5 spectral subclass mean uncertainty in the estimation of spectral types.
We derived the distribution of ages and the systemIMF for the photometric candidates and for the confirmed members in the entire area of our survey and in the spatial overdensity that will be defined in Section 5.2 as the 25 Orionis group overdensity. Figure 7 shows the resulting distribution of ages for photometric candidates and for spectroscopically confirmed members including also the members from Brice˜o et al. n (2005) within the same mass interval. The member sample is still largely incomplete and biased toward the brighter (more massive) objects, but as can be seen in Figure 7, this bias does not strongly affect the estimation of age. The distribution corresponding to photometric candidates was corrected by subtracting the age distribution for the expected contamination by field stars, i.e. the age distribution that results from mistaking the contaminants as members of the 25 Orionis group.
We found a good agreement between the distributions of ages computed from photometric candidates and from
Figure 7. Distribution of ages for the full sample of stellar and sub-stellar candidates and confirmed members in the complete area of the survey (left) and inside a circle with radius 0.5 ◦ centred at the 25 Orionis group overdensity defined in Section 5.2 (right). The distribution corresponding to photometric candidates (crosses) was corrected by subtracting the expected contamination by field stars (gray circles), resulting in the distribution indicated with black dots and the corresponding error bars. The triangles indicate the distribution for the spectroscopically confirmed members from this work and from Brice˜o et al. (2005). The distribution for members n is the same in both plots because the spectroscopic sample covers only the overdensity. Top labels and vertical lines indicate the mode and standard deviation of the distributions from confirmed members (left) and from photometric candidates (right).
Figure 8. The system-IMF for the two samples considered in the Figure 7. The system-IMF from photometric candidates (crosses) was corrected by subtracting the expected contamination by field stars (gray circles), resulting in the system-IMF indicated with black dots and error bars. The empty circles indicate the system-IMF before the completeness correction was applied for objects with masses M < 0 06 . M /circledot . The triangles indicate the system-IMF for the spectroscopically confirmed members, which is still largely incomplete. We compute all the distributions using bins of 0.2 dex. The dotted and solid curves indicate the best-fit to a log-normal distribution and a Kroupa power-law function.
spectroscopically confirmed members. In the complete area of the survey, the derived age of the 25 Orionis group is 7 7 . ± 0 6 Myr from candidates and 6 1 . . ± 0 8 Myr from con-. firmed members. In the spatial overdensity, where the new members were detected, we found a mean age of 8 6 . ± 0 6 . Myr from candidates. All the ages reported correspond to the mode of each distribution. We adopt the age derived from the confirmed members (6 1 . ± 0 8 . Myr) as the age of the 25 Orionis group, although this value is statistically indistinguishable from that obtained from photometric candidates. Therefore we confirm the age derived in previous works by our group ( ∼ 7 Myr ; Brice˜o et al. 2007). In this n new sample we are including several new spectroscopically confirmed members and photometric candidates covering a much wider magnitude range which allows for a more robust estimation of the mean age. Additionally, our result shows that the population within the 25 Orionis group is not distinguishable from the surrounding population in terms of their ages alone.
Figure 8 shows the system-IMF in the LMS and BD regime for the photometric candidates of the 25 Orionis group. Although the photometric completeness of our survey (I=19.6) is equivalent to a completeness mass limit of 0.03 M /circledot assuming the Baraffe et al. (1998) models with an age of 7 Myr old and a distance modulus of m-M=7.78, the width of the membership loci defined in Section 3.3 and the dispersion of the candidates within it, suggest that some objects more massive than 0.03 M /circledot could be located below the photometric completeness. In order to account for such incompleteness in our sample we estimated, per magnitude bin, the number fraction of missing objects as the ratio between the expected and observed number of objects fainter than the completeness magnitude 10 . Figure 8 shows the system-IMF obtained after this completeness correction and the correction for the contamination by field stars were applied.
Because we did not apply any correction to account for unresolved binaries, what we report is the so called system-IMF of the 25 Orionis group (see e.g. Parravano, McKee & Hollenbach 2010, and references therein). Although the system-IMF does not reveal by itself the real number of objects per mass bin, it is useful for comparison with system-IMFs from other SFR and young clusters, assuming that the samples have similar spatial resolution, and that the populations have similar multiplicity properties such as the number fraction of objects belonging to multiple systems, separation and mass ratio distributions.
We describe the derived system-IMF according to a Kroupa power-law function Ψ( m ) = dN/dm ∝ m -α i (Kroupa 2001, 2002), and a Scalo log-normal function (Scalo 1986) in the form Ψ(log m ) = dN/d (log m ) ∝ exp -((log m -log m c ) 2 / σ 2 2 ) (Chabrier et al. 2005). We fitted the mass distributions within the mass range 0 03 . < M/M /circledot < 0 8 . to the log-normal function and within the
10 The observed number counts (for the full catalogue) behave linearly on a log scale up to the completeness magnitude (by definition), after which these start to decline. We extrapolate this linear behaviour for magnitudes fainter than the completeness, and use this fit to compute the expected number counts.
Figure 9. Comparison of the system-IMF obtained for the 25 Orionis group with those from Chabrier (2003b) and Kroupa (2001, 2002). The black solid curve and straight lines correspond to the fit to a log-normal and power-law functions for the entire area of the survey respectively. The gridded area indicates, in the BD regime, the uncertainty in the fit to the log-normal function. The dotted curve and straight lines: fit to a log-normal and power-law functions for the spatial overdensity. The dashed area indicates, in the BD regime, the uncertainty in the fit to the lognormal function. Gray curve: IMF from Chabrier (2003b). Gray solid lines: IMF from Kroupa (2001, 2002).
mass ranges 0 03 . < M/M /circledot < . 0 08 and 0 08 . < M/M /circledot < . 0 5 for the power-law description. As we did for the age estimate, we obtain the system-IMF for the candidates inside the spatial overdensity (see Section 5.2) and for the entire area of the survey. For the latter, the system-IMF for masses in the intervals 0 03 . < M/M /circledot < 0 08 . and 0 08 . < M/M /circledot < 0 5 . follows Kroupa-type functions with α 3 = -1 73 . ± 0 31 and . α 2 = 0 68 . ± 0 41 respectively, and . that in the complete mass interval 0 03 . < M/M /circledot < 0 8 . is well described by a log-normal function with coefficients m c = 0 21 . +0 02 . -0 02 . and σ = 0 36 . ± 0 02. . For the spatial overdensity we found α 3 = -1 97 . ± 0 02, . α 2 = 0 37 . ± 0 04, . m c = 0 22 . +0 02 . -0 02 . and σ = 0 42 . ± 0 05. In Figure 8 and Table . 6 we show the resulting fits and in Figure 9 we compare our derived IMF with other IMFs from the literature in which no correction for binarity was made. Additionally, we computed the distribution of spectral types, which is generally used as a proxy of the IMF which avoids most of the uncertainties related to the computation of masses (e.g. Preibisch 2012). Figure 10 shows the spectral type distributions for confirmed members and photometric candidates. For the later, the spectral types were estimated from the observed I -J colour, dereddened following the procedure explained in Section 4.1, and applying the colour-spectral-type relationship from Luhman et al. (2003b). The distribution of spectral types for candidates peaks around ∼ M . 4 5 and declines for earlier and latter objects, and is consistent with the spectral type distributions reported for confirmed mem-
Table 6. Fit parameters for the system-IMF.
| Population | M interval | α 2 | α 3 | m c | σ | Reference |
|-----------------------------------------------------|----------------------------------------------------------------------------------|---------------------------------------|-------------------------------------------|--------------------------------------------------------|----------------------------------------|--------------------------------------|
| 25 Orionis overdensity 25 Orionis entire area Field | 0 . 03 < M/M /circledot < 0 . 8 0 . 03 < M/M /circledot < 0 . 8 M < M /circledot | 0 . 37 ± 0 . 04 0 . 68 ± 0 . 41 . . . | - 1 . 97 ± 0 . 02 - 1 . 73 ± 0 . 31 . . . | 0 . 22 +0 . 02 - 0 . 02 0 . 21 +0 . 02 - 0 . 02 0 . 22 | 0 . 42 ± 0 . 05 0 . 36 ± 0 . 02 0 . 57 | This work This work Chabrier (2003b) |
Figure 10. The distribution of spectral types in the 25 Orionis group. Triangles: confirmed members from this work and from Brice˜o et al. (2007). Black and empty dots indicate respectively n the candidates in the entire area of the survey and inside the overdensity previously corrected by the expected contamination by field stars.
bers in other regions such as IC348 and Chamaeleon I (e.g Luhman 2012).
The system-IMF, and the spectral type distribution are commonly used as observables to constrain which processes and conditions are preponderant during the formation of LMS and BDs. In the sub-stellar domain some variations have been observed in these quantities, Taurus probably being the most representative case (Brice˜o et al. n 2002). These variations are not well understood and more observations are needed in order to better constraint these phenomenon. What we have presented here is a new photometry-based system-IMF in the mass range 0 03 . < M/M /circledot < 0 8, . obtained for a ∼ 7 Myr old dispersed population in a low-density environment, using a numerous sample with 1246 objects. The peak of the spectral-types distribution and the characteristic mass m c of the log-normal representation of the system-IMF we found for the 25 Orionis group, is consistent with those reported for other SFR and young clusters (e.g. Oliveira, Jeffries & van Loon 2009), which, as mentioned by Oliveira, Jeffries & van Loon (2009), supports the idea of an IMF relatively independent of environmental properties such as density, temperature, metallicity and radiation field, as predicted by the models from Bonnell, Clarke & Bate
(2006) and Elmegreen, Klessen & Wilson (2008). On the other hand, the standard deviation σ from the log-normal fit results to be slightly smaller than is expected from Chabrier (2003b) which is also consistent with the small values for the α 3 coefficients obtained from the fit to a power-law IMF. This suggest that the 25 Orionis population could have a lower number of BDs. Because the fits are strongly dependent on small variations in the number of objects in the least massive bins, more observations are needed in order to better constraint the system-IMF in the sub-stellar domain of the 25 Orionis group and confirm such a trend. A sensitive photometric survey for the detection of a complete sample of BDs down to ∼ 0 01 . M /circledot , and the spectroscopic confirmation of members in the entire mass range (including also M > 0 8 . M /circledot ) of this group are needed to confirm this low number of BD. Also, kinematic information is needed in order to evaluate whether the dynamical evolution of the group could be biasing the result. High spatial resolution imaging intended to detect binary or multiple systems are important in order to establish the effect that such a population of binaries could have on the observed system-IMF. Spectroscopic observations of our least massive candidates and much deeper photometric observations are currently under way.
## 5.2 The spatial distributions
Here we present the first comparative study of the spatial distribution of ∼ 1100 candidate LMS and ∼ 120 candidate BDs within the area covered by the 25 Orionis group and its surroundings. With this deep and spatially complete photometric sample we confirm the 25 Orionis group as the strong overdensity of stellar and sub-stellar candidate and members shown in Figure 11. We compute the number of objects on 3 ′ × 3 ′ bins and smoothed the resulting pattern with a gaussian function with standard deviation of 6 ′ in both spatial directions. The overdensity is centred at ( α, δ ) ∼ (81 2 1 7) . ◦ , . ◦ with a mean radius of ∼ 0 5 and . ◦ a slight elongation approximately in the East-West direction. Its mean density is of ∼ 0.5 objects per 3 ′ × 3 ′ bin ( ∼ 200 obj/deg 2 ), surrounded by a typical mean density of ∼ 0.25 objects per 3 ′ × 3 ′ square ( ∼ 100 obj/deg 2 ). The centre was computed as the position of the maximum density within the overdensity and the mean radius as the distance from the centre at which the density drops to the value of the mean density of the surroundings. Assuming a distance of ∼ 360 pc the angular radius corresponds to a mean linear radius of ∼ 3.14 pc. We note that the 25 Orionis overdensity appears to be superimposed on a low-density diagonal filament indicated in Figure 11, whose mean density is ∼ 0.3 objects per 3 ′ × 3 ′ square.
The overdensities could be intrinsic to the population, a consequence of observational biases or a combination of
both. We consider the detected overdensities as real because: (i) They are not a consequence of interstellar extinction, since the latter does not significantly affect the number of selected candidates and the SEM does not shows a spatial distribution similar with those from candidates, as can be seen in Figure 2. (ii) They cannot be explained as a consequence of contamination by field stars because these follow a smooth spatial distribution which depends on galactic latitude as predicted by the Besan¸ con model. (iii) They are not a consequence of a photometric bias because the completeness and limiting magnitudes in all bands used for the candidate selection are spatially homogeneous in the area where the overdensities were detected and the slight difference in the completeness magnitude within observations centred at δ = 1 ◦ and δ = 3 ◦ (Table 2) cannot produce the detected overdensities. (iv) They are not a consequence of any artifact in the images or inappropriate identification of sources from different catalogues as we concluded from visual inspection of the images.
The East-West elongation of the 25 Orionis overdensity is suggested from the spatial distribution of the members confirmed by Brice˜o et al. n (2005) and also by the spatial distribution of the high mass candidates of Kharchenko et al. (2005) with the highest probability of membership. In this work we confirm this trend with a numerous sample of well characterised candidates covering not only the 25 Orionis group but a reasonable area of its surroundings. Furthermore, our results rule out the idea of a possible extension of the 25 Orionis group to the South as suggested by McGehee (2006). With this new data set, deeper and covering the entire area surrounding the group, we find that the possible southern extension of the group reported by McGehee (2006) is probably part of the filament described above that extends also to the North-East direction, or the cluster ASCC18 from Kharchenko et al. (2005). This conclusion could not have been derived from the data considered by McGehee (2006), which covers only the southern part of the area shown in Figure 1. We note that the southern overdensity detected by McGehee (2006) at ( α, δ ) ∼ (81 2 0 8) is . ◦ , . ◦ also observed in Figures 11 and 12 as part of the southern extension of the filament (note the different scales between our plots and Figure 8 from McGehee (2006)), but its mean low-density and position do not suggest it is part of the overdensity we consider here as the 25 Orionis group.
Results from van den Bergh (2006) show that during their first ∼ 15 Myr, ∼ 20 per cent of galactic clusters and associations have diameters larger than 7 pc, being expanding associations rather than gravitationally bound clusters. Therefore the diameter obtained in this work for the 25 Orionis group (D ∼ 6.3 pc) suggests it could be a bound cluster given its age of about ∼ 7 Myr. Nevertheless, this computation is based on the radius found for the spatial overdensity, but we cannot rule out the cluster is spread over a larger area, since, as noted in Section 5.1, the age distribution and system-IMF are indistinguishable from its surroundings. A formal computation of the virial mass of this cluster is out of the scope of this work, since it depends almost entirely on its massive stars, which are not discussed here.
The panels of Figure 12 show separately the spatial density distribution of ∼ 1100 LMS and ∼ 120 BDs. In order to test whether the observed spatial distributions for
Figure 11. Spatial density distribution of the LMS and BD photometric candidates of the 25 Orionis group and its surroundings. Colored scales and isocontours indicate the mean density computed in bins of 3 ′ × 3 ′ and smoothed with a gaussian with standard deviation of 6 ′ in both directions. The central strong overdensity is the 25 Orionis group and the doted line indicates the filamentary overdensity explained in the text. The circles indicate the radii from the previous works shown also in Figure 1. The contamination from field stars present in the candidate sample is spatially smooth. The central big dot indicates the centre of the group computed in this work, and the big asterisk, the position of the star 25 Ori.
BDs and LMS are drawn from the same parent distribution (null hypothesis), we have computed a two-dimensional twosample Kolmogorov-Smirnov (K-S) test (Press et al. 2007). For the full BD and LMS samples the K-S statistic results in a probability P = 0 30 of the null hypothesis being true, . which means the difference between both spatial distributions is not statistically significant (Press et al. 2007). In order to assess the robustness of this result, we generated 10 3 bootstrap resamples of both the BD and LMS distributions. A single bootstrap sample is made, e.g. for BDs, by randomly sampling with replacement from the BD catalogue, until a new set with the same number of objects (as the original catalogue) is generated. This is a standard technique that allows producing a set of random realizations drawn from the same distribution as the parent populations, which in this case are the BD and VLM samples (see e.g. Wall & Jenkins 2012; Press et al. 2007, for more details). We computed the same K-S test on the 10 3 bootstrap BD and LMS samples and found that only in 12 per cent of the experiments the distributions turned out to be incompatible at the 99 per cent confidence level ( P < 0 01). . This shows it is a robust result, independent on stochastic fluctuations due to sample size, that the spatial distributions observed for BDs and LMS in this 7 Myr old population are statistically indistinguishable.
Although this result is not consistent with the mass segregation predicted by the early premature ejection models from Reipurth & Clarke (2001) subsequent work by
)
°
(
δ
Figure 12. Comparison of the density distributions of LMS candidates ( M > 0 08 . M /circledot , white dots, left) and of BD candidates ( M < 0 08 . M /circledot , white dots, right). The K-S test probability between both distributions is 0.30 which indicates that both distributions are statistically indistinguishable. The big central asterisk represents the 25 Ori star and the black dots clusters from Kharchenko et al. (2005). Other elements are as in Figure 11.
Bate, Bonnell & Bromm (2003) does not predict significantly different velocity dispersions for ejected BDs and stars. Thus, the similar spatial distributions do not necessarily reject the premature ejection scenarios. In any case, what we are presenting here constitutes a new observational evidence supporting the similarity of the spatial distribution of LMS and BDs for a ∼ 7 Myr old population.
## 5.3 Disc indicators and accretion signatures
We computed the number fraction of LMS and BDs showing near IR excesses as an indication of the presence of primordial circumstellar inner-discs. In the left panel of Figure 13 we show a J-H vs. H-Ks colour-colour diagram with the CTTS locus from Meyer, Calvet & Hillenbrand (1997) and its extrapolation to M6 spectral type. We obtained that 3 8 . ± 0 4 . per cent of LMS candidates and 4 5 . ± 0 5 . per cent of spectroscopically confirmed LMS are placed inside the CTTS locus. Both results are in good agreement within the uncertainties and are consistent with those from Brice˜o et al. (2007) ( n ∼ 6 per cent). The fractions reported here for the photometric candidates were computed considering the expected contamination by field stars and the errors were computed according to the binomial distribution.
M9 are more separated, as we show in the right panel of Figure 13. Essentially we define a locus whose lower limit in the I-Ks vs J-H diagram is parallel to the photospheric locus from Luhman et al. (2003b), and which is separated from it by a distance equivalent to a reddening vector corresponding to A V = 0 5, which is slightly larger . than the mean value of the interstellar extinction across the 25 Orionis group, as we have shown in Section 4.1. We found that ∼ 5 6 . ± 0 5 per cent of the candidate LMS and . ∼ 4 1 . ± 0 4 per . cent of the confirmed LMS show excesses. For the substellar regime the number fraction of candidates showing such IR excess is 12 7 . ± 0 5 per cent. Again, the number fraction of . stars showing infrared excesses from inner discs agrees well with previous determinations by Hern´ andez et al. (2006) and Brice˜o et al. n (2007) using Spitzer data. In the substellar regime, our result is the first estimate obtained for the 25 Orionis group.
For objects later than M6, the J-H vs. H-Ks diagram is not a good choice for detecting infrared excesses because the photospheric locus between spectral types M6 and M9 is essentially colinear with the corresponding reddenning vectors, which prevents a reliable measurement of the fraction of objects showing IR excesses as a function of their spectral-types. Because of this limitation, we apply an empirical criterion to detect objects with infrared excesses, using the I-Ks vs J-H diagram, where the photospheric loci and reddening vectors for spectral types between M6 and
Emissions from warm dust in evolved discs or in the external regions of primordial discs, occurs at longer wavelengths. In Figures 14 and 15 we show colour-colour diagrams in the wavelength range from ∼ 2 2 . µ m to ∼ 12 µ m, for confirmed members and photometric candidates with magnitudes from VISTA, IRAC and WISE. The left panel of Figure 14 shows the 3.6 µ m-4.5 µ m vs. 4.5 µ m-5.8 µ m diagram from IRAC data with the excess region defined by Luhman et al. (2005) were 7 8 . ± 0 3 . per cent of the candidates to LMS, 7 5 . ± 0 4 . per cent of the LMS confirmed as members and 18 1 . ± 0 3 . per cent of the candidates to BD show IR excesses. The right panel of Figure 14 shows the IRAC 3.6 µ m-4.5 µ m vs. 5.8 µ m-8.0 µ m diagram showing the CTTS locus defined by Hartmann et al. (2005) and Luhman et al. (2005), were 12 0 . ± 0 4 per cent of the LMS . candidates, 9 4 . ± 0 8 per cent of the LMS confirmed as mem-. bers and 39 2 . ± 0 4 per cent of the BD candidates show IR . excesses.
Figure 13. Optical and near-infrared colour-colour diagrams of spectroscopically confirmed members and photometric candidates. Left panel: J-H vs. H-Ks. Right panel: I-Ks vs. J-H. The dashed lines indicates the photospheric loci from Luhman et al. (2003b) and the shaded areas indicate the excess loci explained in Section 5.3. Empty and filled circles indicate respectively candidates and confirmed LMS. Triangles indicates candidate BDs. Reddening vectors for several spectral types are also indicated for the typical mean visual extinction ( A V ∼ 0 5 mag) through the 25 Orionis group. Number fractions of objects showing IR-excesses are listed in Table 7. .
Table 7. Number fraction of LMS and BDs showing infrared excesses.
| Diagram | LMS members [per cent] | LMS candidates [per cent] | BD candidates [per cent] |
|-----------------------------------|--------------------------|-----------------------------|----------------------------|
| J-H vs. H-Ks | 4 . 5 ± 0 . 5 | 3 . 8 ± 0 . 4 | · · · |
| I-Ks vs. J-H | 4 . 1 ± 0 . 4 | 5 . 6 ± 0 . 5 | 12 . 7 ± 0 . 5 |
| 3.6 µm -4.5 µm vs. 4.5 µm -5.8 µm | 7 . 5 ± 0 . 4 | 7 . 8 ± 0 . 3 | 18 . 1 ± 0 . 3 |
| 3.6 µm -4.5 µm vs. 5.8 µm -8.0 µm | 12 . 0 ± 0 . 4 | 9 . 4 ± 0 . 8 | 39 . 2 ± 0 . 4 |
| Ks-8.0 µm vs. Ks-5.8 µm | 5 . 7 ± 0 . 4 | 7 . 9 ± 0 . 5 | 47 . 0 ± 0 . 5 |
Using the Ks-8 µ m vs. Ks-24 µ m and the Ks-5.8 µ m vs. Ks-24 µ m diagrams based on IRAC and MIPS photometry, Luhman et al. (2010) show the distinction between circumstellar discs at different evolutionary stages. We do not have MIPS observations for the candidates and members considered in this work but we used the Ks-8 µ m and Ks-5.8 µ m colour intervals defined by Luhman et al. (2010) in order to separate objects showing photospheric emissions from those showing primordial discs and those showing transitional or evolved discs. Following this procedure we obtain an estimation of the number fraction of such populations. The left panel of Figure 15 shows the Ks-5.8 µ m vs. Ks-8.0 µ m diagram, where we consider objects with excesses to be those with Ks-5.8 µ m > 1 and Ks-8.0 µ m > 1, resulting in a number fraction of 7 9 . ± 0 5 . per cent of the LMS candidates, 5 7 . ± 0 4 per cent for confirmed LMS and . ∼ 47 0 . ± 0 5 per . cent for the photometric candidates to BD. In the transitional and evolved disc locus, defined as the region between 0 75 . < Ks -8 0 . µm < 1 4 and 0 3 . . < Ks -5 8 . µm < 1, we find 4 LMS members, 5 LMS candidates and 2 BD candidates for number fractions of 7 4 . ± 0 4 per cent, 2 3 . . ± 0 5 per cent . and 15 6 . ± 0 5 per cent respectively. The objects showing IR . excesses indicative of possible transitional or evolved discs are listed in Table 8. In the right panel of Figure 15 we also show the excesses at longer wavelengths, using a Ks-4.6 µ m vs. Ks-12 µ m diagram from WISE data.
The samples of new confirmed members and candidates are not affected by the photometric completeness of the IRAC observations and the reported fractions are not biased towards the objects showing excesses. The number fraction of BD showing IR excesses turns out to be systematically higher in all colour-colour diagrams suggesting that at an age of ∼ 7 Myr the disc fraction among BDs is larger than for LMS which could be an indicator of a slow evolution of discs around BDs. This supports previous results from Luhman & Mamajek (2012) for the Upper Scorpius association which with a estimated age of ∼ 11Myr (Pecaut, Mamajek & Bubar 2012) shows ∼ 25 per cent of objects later than M5 harbouring discs. Our results at a slight younger age support the scenario in which discs around LMS and BD evolve in different time scales in the sense that a higher fraction of BDs could retain their discs for longer periods of time.
Finally, low-resolution spectra provide an appropriate means to look for CTTS emission signatures such as H , the α CaII triplet ( λ 8498, λ 8542 and λ 8662) and
Figure 14. IRAC colour-colour diagrams of spectroscopically confirmed members and photometric candidates. Symbols are as in Figure 13. Left panel: the 3.6 µ m-4.5 µ m vs. 5.8 µ m-8.0 µ m diagram showing the CTTS locus (dashed lines) defined by Hartmann (2005). Right panel: the 3.6 µ m-4.5 µ m vs. 4.5 µ m-5.8 µ m diagrams with the excess region (dashed lines) defined by Luhman et al. (2005). Number fractions of objects showing IR-excesses are listed in Table 7
Figure 15. Color-colour diagram combining photometry from VISTA, IRAC and WISE. Symbols are as in Figure 13. Dashed polygons indicate disc loci and the solid polygon in the left panel encloses the possible transitional or evolved discs from the colour intervals defined by Luhman et al. (2010).
HeI λ 6676. The dividing line between CTTS and weak (non-accreting) T-Tauri stars (WTTS) was first set in terms of the H α emission at W(H ) α = -10 ˚ A by Herbig & Bell (1988). Afterwards, White & Basri (2003) revised this classification and, based on high resolution optical spectra ( R ∼ 33000), redefined the classification considering both the H α equivalent width and the spectral type. Barrado y Navascu´ es & Mart´ ın (2003) using low-resolution optical spectra developed an empirical classification method based on the H α equivalent width and the spectral type. Here we followed the criteria from Barrado y Navascu´ es & Mart´ ın (2003) to classify the confirmed LMS as CTTS or WTTS. Figure 16 shows the resulting classification in the W(H α ) vs. spectral-type plot. We obtained a number fraction of CTTS to WTTS of 3 8 . ± 0 5 . per cent for objects earlier than M6. Our results are consistent with those from the colour-colour diagrams and with previous determinations by Brice˜o et al. n (2005). On the
Table 8. Members and candidates showing possible transitional or evolved discs.
| α ( J 2000) [ ◦ ] | δ ( J 2000) [ ◦ ] | J | I | CH1 | CH2 | CH3 | CH4 | W1 | W2 | W3 | W4 | ST | WHa [ ˚] A | Av Av | Status Status |
|---------------------|---------------------|-------|-------|-------|-------|-------|-------|-------|-------|-------|------|-------|--------------|---------|-----------------|
| 80.7118 | 1.51037 | 15.02 | 16.89 | 13.68 | 13.54 | 13.29 | 12.65 | 13.81 | 13.45 | 11.81 | 8.93 | · · · | · · · | · · · | Candidate |
| 80.8809 | 2.22021 | 13.03 | 14.92 | 11.53 | 11.24 | 11.02 | 10.83 | 11.65 | 11.21 | 10.42 | 8.38 | · · · | · · · | · · · | Candidate |
| 80.883 | 2.17874 | 13.88 | 15.46 | 12.6 | 12.49 | 12.31 | 11.87 | 12.73 | 12.43 | 11.13 | 9.12 | · · · | · · · | · · · | Candidate |
| 80.9344 | 1.69221 | 16.26 | 18.54 | 15 | 14.77 | 14.91 | 14.22 | 15.1 | 14.73 | 11.96 | 8.83 | M1.0 | -3.5 | 6.1 | Member |
| 81.0207 | 2.15769 | 14.48 | 16.47 | 13.1 | 12.87 | 12.59 | 12.06 | 13.33 | 12.85 | 11.54 | 8.31 | · · · | · · · | · · · | Candidate |
| 81.1103 | 1.84858 | 14.81 | 16.55 | 13.59 | 13.5 | 13.39 | 12.82 | 13.76 | 13.57 | 11.72 | 8.76 | M4.0 | -2.1 | 1.1 | Member |
| 81.2452 | 1.42179 | 14.08 | 15.81 | 12.92 | 12.74 | 12.51 | 11.94 | 13.09 | 12.72 | 11.03 | 8.95 | M5.0 | -7.4 | 0.0 | Member |
| 81.3514 | 1.6854 | 13.78 | 15.61 | 12.56 | 12.44 | 12.32 | 11.88 | 12.77 | 12.47 | 10.99 | 8.72 | M5.5 | -15.1 | 0.0 | Member |
| 81.4448 | 1.72511 | 13.15 | 14.54 | 11.97 | 11.9 | 11.72 | 11.08 | 12.1 | 11.84 | 9.91 | 6.74 | M3.5 | -10.1 | 0.0 | Member |
| 81.4683 | 2.36819 | 13.16 | 14.52 | 11.27 | 10.97 | 10.82 | 10.58 | 11.38 | 10.96 | 9.88 | 8.1 | · · · | · · · | · · · | Candidate |
| 81.5062 | 1.54283 | 14.71 | 16.42 | 13.31 | 13.12 | 12.91 | 12.45 | 13.64 | 13.31 | 11.47 | 9.16 | · · · | · · · | · · · | Candidate |
| 81.6042 | 1.87741 | 15.28 | 17.08 | 13.99 | 13.91 | 13.71 | 13.5 | 14.18 | 13.91 | 12.18 | 8.47 | M2.5 | · · · | 2.8 | Member |
| 81.7246 | 2.30153 | 15 | 16.67 | 13.76 | 13.55 | 13.36 | 12.6 | 13.86 | 13.52 | 12.31 | 8.62 | · · · | · · · | · · · | Candidate |
| 81.8506 | 1.63384 | 17.09 | 20.32 | 15.18 | 15.04 | 15.34 | 14.32 | 15.66 | 15.44 | 12.41 | 9.14 | · · · | · · · | · · · | Candidate |
| 82.3184 | 2.15333 | 13.76 | 15.46 | 12.4 | 12.16 | 11.84 | 11.32 | 12.52 | 12.12 | 10.92 | 8.91 | · · · | · · · | · · · | Candidate |
| 82.4414 | 1.95883 | 14.02 | 15.73 | 12.72 | 12.53 | 12.24 | 11.69 | 12.86 | 12.46 | 11.04 | 8.71 | · · · | · · · | · · · | Candidate |
| 82.5921 | 1.64195 | 15.15 | 17.32 | 13.52 | 13.31 | 13.05 | 12.92 | 13.71 | 13.3 | 12.3 | 8.59 | · · · | · · · | · · · | Candidate |
Figure 16. Equivalent width of Hα versus spectral type and effective temperature (upper axis) for the new confirmed LMS members. Dotted lines indicate the limit between CTTS and WTTS according to Barrado y Navascu´ es & Mart´ ın (2003). Circles indicates objects showing equivalent width of Hα consistent with CTTS. Arrows indicate objects with strong Hα emission whose WHα is labelled. We found 3.8 ± 0.5 per cent of the members of 25 Orionis group being CTTS (open circles).
other hand the number fraction of CTTS presented here is larger than the fraction reported by McGehee (2006) ( ∼ 0 1 . per cent) that, as we explained in Section 5.2, most probably does not correspond to the 25 Orionis group.
## 6 SUMMARY AND CONCLUSIONS
We have presented the first extensive study of the lower mass population (0 02 . /lessorequalslant M/M /circledot /lessorequalslant 0 8) of the 25 Ori group . and its surrounding regions. We provide for this mass range the spatial distribution, mean age, IMF, and investigate the presence of circumstellar discs and accretion signatures. In the following we summarize our results:
- · We have obtained a sample of 1246 photometric candidates to LMS and BDs in the 25 Ori group and its surround-
ings with estimated masses within 0 02 . < M/M ∼ /circledot < . ∼ 0 8, as well as 77 new LMS spectroscopically confirmed as members with spectral types in the range ∼ M1 to ∼ M5.
- · We have characterised the possible contamination of our photometric candidate sample using the Besan¸ con Galactic model (Robin et al. 2003). The expected mean contamination was found to be ∼ 33 field dwarf stars from the foreground per deg 2 , which yields an expected average efficiency of ∼ 82 per cent for our photometric candidate selection.
- · From the age distributions of the photometric candidates and confirmed members we find mean ages of 7 7 . ± 0 6 . Myr and 6 1 . ± 0 8 Myr respectively. These results are in good . agreement with those reported by Brice˜o et al. (2005). n
- · We have derived the system-IMF for 25 Ori from a numerous sample of photometric candidate LMS and BDs previously corrected by the contamination from field stars. We have obtained a system-IMF which can be well described by either a Kroupa power-law function with indices α 3 = -1 73 . ± 0 31 and . α 2 = 0 68 . ± 0 41 in the mass . ranges 0 03 . < M/M /circledot < 0 08 and 0 08 . . < M/M /circledot < 0 5 re-. spectively, or a Scalo log-normal function with coefficients m c = 0 21 . +0 02 . -0 02 . and σ = 0 36 . ± 0 02 . in the mass range 0 03 . < M/M /circledot < 0 8. . For the log-normal representation of the IMF we obtained that the characteristic mass is consistent with an IMF independent of environmental properties, although the standard deviation is smaller than the system-IMF from Chabrier (2003a). A sensitive photometric survey for the detection of a complete sample of BD down to ∼ 0 01 . M /circledot , and their spectroscopic counterparts is needed to confirm the slightly lower value of the standard deviation and whether this trend of the system-IMF is a consequence of a real deficit of BDs.
- · From the analysis of the spatial distribution of the photometric candidate sample we find the peak of the 25 Orionis overdensity at ( α, δ ) ∼ (81 2 1 7) with a diameter . ◦ , . ◦ of ∼ 6 3 pc. We have confirmed the East-West elongation . of the 25 Orionis group, also observed in the works from Kharchenko et al. (2005) and Brice˜o et al. (2005), and rule n out the southern extension proposed by McGehee (2006). Additionally we found that the 25 Orionis group is projected over a filament distributed along the south-west to north-east direction. We have also found that the spatial distributions of LMS and BDs in 25 Orionis are statistically indistinguishable.
- · For the LMS we calculated the number fraction of stars
showing IR excess in the J-H vs H-Ks diagram according to the CTTS locus from Meyer, Calvet & Hillenbrand (1997). We found that ∼ 4 per cent of the LMS show the levels of IR excess expected from CTTS with optically thick primordial discs. We found similar fractions for the empirical locus defined in the I -Ks vs J -H colour-colour diagram where we find also that ∼ 12 per cent of the BD show IR excesses indicative of primordial discs.
- · Using VISTA, IRAC and WISE photometry we have also found IR excess at longer wavelengths indicative of discs. Depending on the selected diagram we found that the number fraction of LMS showing IR excesses is between ∼ 7 to ∼ 10 per cent while the number fraction for BDs increases up to ∼ 20 to ∼ 50 per cent.
- · Additionally we found that 11 members and candidates show signs of possible transitional or evolved discs and that 3 8 . ± 0 5 per cent of the LMS members show . Hα emission consistent with a CTTS nature, confirming the CTTS number fraction found by Brice˜o et al. (2007). n
- · Our results show that the fraction of BD showing IR excesses is higher than for LMS, supporting the scenario in which the evolution of circumstellar discs around the least massive stars could occur at larger time scales.
## ACKNOWLEDGMENTS
This work has been supported in part by grant S1200101144 and 200400829 from FONACIT, Venezuela. J. J. Downes, acknowledges support from CIDA, Venezuela and project 152160 from CONACyT, M´ exico. C. Mateu acknowledges the support of the postdoctoral Fellowship of DGAPA-UNAM, M´ exico. We thank Kevin Luhman for useful comments regarding the spectral classification and Susan Tokarz, who is in charge of the reduction and processing of Hectospec spectra.
This work was based on observations collected at the J¨rgen Stock 1-m Schmidt telescope of the National Obseru vatory of Llano del Hato Venezuela (NOV), which is operated by Centro de Investigaciones de Astronom´ ıa (CIDA) for the Ministerio del Poder Popular para Ciencia y Tecnolog´ ıa, Venezuela, and at the MMT Observatory a joint facility of the Smithsonian Institution and the University of Arizona. This work is based [in part] on observations made with the Spitzer Space Telescope, which is operated by the Jet Propulsion Laboratory, California Institute of Technology under a contract with NASA. Support for this work was provided by NASA through an award issued by JPL/Caltech. This publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration. We very much appreciate the great work done by the UK-based VISTA consortium who built and commissioned the VISTA telescope and camera. This work is based on observations made during VISTA science verification, under the program ID 60.A-9285(B).
We thank the assistance of the personnel, observers, telescope operators and technical staff at CIDA and FLWO, who made possible the observations at the J¨rgen u Stock telescope of the Venezuela National Astronomical Observa- tory (OAN) and at the MMT telescope at Fred Lawrence Whipple Observatory (FLWO) of the Smithsonian Institution, especially Perry Berlind, Daniel Cardozo, Orlando Contreras, Franco Della Prugna, Emilio Falco, Freddy Moreno, Hern´ an Ram´ ırez, Carmen Rodr´ ıguez, Richard Rojas, Gregore Rojas, Gerardo S´nchez, Gustavo S´nchez and a a Ubaldo S´ anchez.
This work makes an extensive use of R from the R Development Core Team (2011) available at http://www.R-project.org/ and described in R: A language and environment for statistical computing from R Foundation for Statistical Computing, Vienna, Austria, ISBN 3900051-07-0.
We thank the referee Phil Lucas for useful comments and suggestions to the manuscript.
## REFERENCES
Abazajian K. et al., 2005, AJ, 129, 1755 Baltay C. et al., 2002, PASP, 114, 780 Baraffe I., Chabrier G., Allard F., Hauschildt P. H., 1998, A&A, 337, 403 Barrado y Navascu´ es D., Mart´ ın E. L., 2003, AJ, 126, 2997 Basri G., 1998, in Astronomical Society of the Pacific Conference Series, Vol. 134, Brown Dwarfs and Extrasolar Planets, R. Rebolo, E. L. Martin, & M. R. Zapatero Osorio, pp. 394-+ Bastian N., Covey K. R., Meyer M. R., 2010, ARA&A, 48, 339 Bate M. R., Bonnell I. A., Bromm V., 2003, MNRAS, 339, 577 Biazzo K., Randich S., Palla F., Brice˜o C., 2011, A&A, n 530, A19+ Bonnell I. A., Clarke C. J., Bate M. R., 2006, MNRAS, 368, 1296 Boudreault S., Bailer-Jones C. A. L., 2009, ApJ, 706, 1484 Bouvier J. et al., 2008, A&A, 481, 661 Brice˜o C., Calvet N., Hern´ndez J., Vivas A. K., Hartn a mann L., Downes J. J., Berlind P., 2005, AJ, 129, 907 Brice˜o C., Hartmann L., Hern´ndez J., Calvet N., Vivas n a A. K., Furesz G., Szentgyorgyi A., 2007, ApJ, 661, 1119 Brice˜o C., Hartmann L., Stauffer J., Mart´ ın E., 1998, AJ, n 115, 2074 Brice˜o C., Luhman K. L., Hartmann L., Stauffer J. R., n Kirkpatrick J. D., 2002, ApJ, 580, 317 Brice˜o C. et al., 2001, Science, 291, 93 n Calvet N., Brice˜o C., Hern´ndez J., Hoyer S., Hartmann n a L., Sicilia-Aguilar A., Megeath S. T., D'Alessio P., 2005, AJ, 129, 935 Cardelli J. A., Clayton G. C., Mathis J. S., 1989, ApJ, 345, 245 Caswell J. L., 2007, in IAU Symposium, Vol. 242, IAU Symposium, J. M. Chapman & W. A. Baan, ed., pp. 194199 Chabrier G., 2003a, PASP, 115, 763 Chabrier G., 2003b, ApJL, 586, L133 Chabrier G., Baraffe I., Allard F., Hauschildt P. H., 2005, ArXiv Astrophysics e-prints
Chen W. P., Lee H. T., 2008, arXiv.org, astro-ph, to appear in the Handbook of Star Forming Regions, Vol. I, edited byBo Reipurth
Dahm S. E., 2008, The Young Cluster and Star Forming Region NGC 2264, Reipurth, B., ed., pp. 966-+ Dahn C. C. et al., 2002, AJ, 124, 1170
- Davenport J. R. A., West A. A., Matthiesen C. K., Schmieding M., Kobelski A., 2006, PASP, 118, 1679
- Downes J. J., Brice˜o C., Hern´ndez J., Calvet N., Hartn a mann L., Ponsot Balaguer E., 2008, AJ, 136, 51
- Dullemond C. P., Dominik C., 2004, A&A, 421, 1075
- Elmegreen B. G., Klessen R. S., Wilson C. D., 2008, ApJ, 681, 365
Emerson J. P., Sutherland W. J., 2010, in Society of PhotoOptical Instrumentation Engineers (SPIE) Conference Series, Vol. 7733, Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series
- Emerson J. P., Sutherland W. J., McPherson A. M., Craig S. C., Dalton G. B., Ward A. K., 2004, The Messenger, 117, 27
Fabricant D. et al., 2005, PASP, 117, 1411
Hartmann L., 2001, AJ, 121, 1030
- Hartmann L., 2005, in Astronomical Society of the Pacific Conference Series, Vol. 341, Chondrites and the Protoplanetary Disk, A. N. Krot, E. R. D. Scott, & B. Reipurth, ed., pp. 131-+
- Hartmann L., Megeath S. T., Allen L., Luhman K., Calvet N., D'Alessio P., Franco-Hernandez R., Fazio G., 2005, ApJ, 629, 881
- Herbig G. H., Bell K. R., 1988, Third Catalog of EmissionLine Stars of the Orion Population : 3 : 1988, Herbig, G. H. & Bell, K. R., ed.
- Hern´ andez J., Brice˜o C., Calvet N., Hartmann L., Muzen rolle J., Quintero A., 2006, ApJ, 652, 472
- Hern´ andez J., Calvet N., Brice˜o C., Hartmann L., Berlind n P., 2004, AJ, 127, 1682
- Hern´ andez J. et al., 2007, ApJ, 671, 1784
- Hern´ andez J., Hartmann L., Calvet N., Jeffries R. D., Gutermuth R., Muzerolle J., Stauffer J., 2008, ApJ, 686, 1195
- Hodgkin S. T., Irwin M. J., Hewett P. C., Warren S. J., 2009, MNRAS, 394, 675
- Ingleby L., Calvet N., Hern´ndez J., Brice˜o C., Espaillat a n C., Miller J., Bergin E., Hartmann L., 2011, AJ, 141, 127 Jayawardhana R., Mohanty S., Basri G., 2003, ApJ, 592, 282
- Jeffries R. D., Oliveira J. M., Naylor T., Mayne N. J., Littlefair S. P., 2007, MNRAS, 376, 580
Joergens V., 2006, A&A, 446, 1165
- Kharchenko N. V., Piskunov A. E., R¨ser S., Schilbach E.,
- o Scholz R., 2005, A&A, 440, 403
- Kirkpatrick J. D. et al., 1999, ApJ, 519, 802
- Kraus A. L., White R. J., Hillenbrand L. A., 2006, ApJ, 649, 306
- Kroupa P., 2001, MNRAS, 322, 231
- Kroupa P., 2002, Science, 295, 82
Kumar M. S. N., Schmeja S., 2007, A&A, 471, L33
- Kun M., Kiss Z. T., Balog Z., 2008, Star Forming Regions in Cepheus, Reipurth, B., ed., pp. 136-+
- Landolt A. U., 1992, AJ, 104, 340
- Lodieu N., Hambly N. C., Jameson R. F., Hodgkin S. T., Carraro G., Kendall T. R., 2007, MNRAS, 374, 372
- Luhman K. L., 2004, ApJ, 614, 398
- Luhman K. L., 2012, ARA&A, 50, 65
- Luhman K. L., Allen P. R., Espaillat C., Hartmann L.,
Calvet N., 2010, ApJS, 186, 111
- Luhman K. L., Brice˜o C., Stauffer J. R., Hartmann L., n Barrado y Navascu´ es D., Caldwell N., 2003a, ApJ, 590, 348
- Luhman K. L., Joergens V., Lada C., Muzerolle J., Pascucci I., White R., 2007, Protostars and Planets V, 443 Luhman K. L. et al., 2005, ApJL, 631, L69
- Luhman K. L., Mamajek E. E., 2012, ApJ, 758, 31
- Luhman K. L., Mamajek E. E., Allen P. R., Muench A. A., Finkbeiner D. P., 2009, ApJ, 691, 1265
Luhman K. L., Stauffer J. R., Muench A. A., Rieke G. H., Lada E. A., Bouvier J., Lada C. J., 2003b, ApJ, 593, 1093 Mateu C., Vivas A. K., Downes J. J., Brice˜o C., Zinn R., n Cruz-Diaz G., 2012, MNRAS, 427, 3374
- McCarthy C., Zuckerman B., 2004, AJ, 127, 2871
- McGehee P. M., 2006, AJ, 131, 2959
- Meyer M. R., Calvet N., Hillenbrand L. A., 1997, AJ, 114, 288
Mink D., 2006, in Astronomical Society of the Pacific Conference Series, Vol. 351, Astronomical Data Analysis Software and Systems XV, C. Gabriel, C. Arviset, D. Ponz, & S. Enrique, ed., p. 204
- Monet D. G., 1998, in Bulletin of the American Astronomical Society, Vol. 30, Bulletin of the American Astronomical Society, pp. 1427-+
- Muzerolle J., Brice˜o C., Calvet N., Hartmann L., Hillenn brand L., Gullbring E., 2000, ApJL, 545, L141
- Muzerolle J., Luhman K. L., Brice˜o C., Hartmann L., n Calvet N., 2005, ApJ, 625, 906
- Neuh¨ auser R. et al., 2011, Astronomische Nachrichten, 332, 547
- Oliveira J. M., Jeffries R. D., van Loon J. T., 2009, MNRAS, 392, 1034
- Padoan P., Nordlund ˚ ., 2004, ApJ, 617, 559 A
Parravano A., McKee C. F., Hollenbach D., 2010, 45
- Pecaut M. J., Mamajek E. E., Bubar E. J., 2012, ApJ, 746, 154
Petr-Gotzens M. et al., 2011, The Messenger, 145, 29 Preibisch T., 2012, Research in Astronomy and Astrophysics, 12, 1, provided by the SAO/NASA Astrophysics Data System
- Press W. H., Teukolsky S. A., Vetterling W. T., Flannery B. P., 2007, Numerical recipes in C, Cambridge University Press
Reipurth B., Clarke C., 2001, AJ, 122, 432
- Robin A. C., Reyl´ C., Derri`re S., Picaud S., 2003, A&A, e e 409, 523
Scalo J. M., 1986, FCP, 11, 1
- Schlegel D. J., Finkbeiner D. P., Davis M., 1998, ApJ, 500, 525
- Scholz A., Eisl¨ffel J., 2005, A&A, 429, 1007 o
- Scholz A., Xu X., Jayawardhana R., Wood K., Eisl¨ffel J., o Quinn C., 2009, MNRAS, 398, 873
Skrutskie M. F. et al., 2006, AJ, 131, 1163
- Strom K. M., Wilkin F. P., Strom S. E., Seaman R. L., 1989, AJ, 98, 1444
Taylor M. B., 2006, in Astronomical Society of the Pacific Conference Series, Vol. 351, Astronomical Data Analysis Software and Systems XV, C. Gabriel, C. Arviset, D. Ponz, & S. Enrique, ed., p. 666
- Torres C. A. O., Quast G. R., Melo C. H. F., Sterzik M. F., 2008, Young Nearby Loose Associations, Reipurth, B.,
pp. 757-+ van den Bergh S., 2006, AJ, 131, 1559 van Eyken J. C. et al., 2011, AJ, 142, 60 Wall J. V., Jenkins C. R., 2012, Practical Statistics for Astronomers Weidenschilling S. J., 1997, ICARUS, 127, 290 White R. J., Basri G., 2003, ApJ, 582, 1109 Whitworth A., Bate M. R., Nordlund ˚ ., Reipurth B., ZinA necker H., 2007, Protostars and Planets V, 999, 459 Wright E. L. et al., 2010, AJ, 140, 1868
This paper has been typeset from a T E X/ LT E X file preA pared by the author. | 10.1093/mnras/stu1553 | [
"Juan José Downes",
"César Briceño",
"Cecilia Mateu",
"Jesús Hernández",
"Anna Katherina Vivas",
"Nuria Calvet",
"Lee Hartmann",
"Monika G. Petr-Gotzens",
"Lori Allen"
] | 2014-07-31T20:00:21+00:00 | 2014-07-31T20:00:21+00:00 | [
"astro-ph.SR"
] | The low mass star and sub-stellar populations of the 25 Orionis group | We present the results of a survey of the low mass star and brown dwarf
population of the 25 Orionis group. Using optical photometry from the CIDA Deep
Survey of Orion, near IR photometry from the Visible and Infrared Survey
Telescope for Astronomy and low resolution spectroscopy obtained with Hectospec
at the MMT, we selected 1246 photometric candidates to low mass stars and brown
dwarfs with estimated masses within $0.02 \lesssim M/M_\odot \lesssim 0.8$ and
spectroscopically confirmed a sample of 77 low mass stars as new members of the
cluster with a mean age of $\sim$7 Myr. We have obtained a system initial mass
function of the group that can be well described by either a Kroupa power-law
function with indices $\alpha_3=-1.73\pm0.31$ and $\alpha_2=0.68\pm0.41$ in the
mass ranges $0.03\leq M/M_\odot\leq 0.08$ and $0.08\leq M/M_\odot\leq0.5$
respectively, or a Scalo log-normal function with coefficients
$m_c=0.21^{+0.02}_{-0.02}$ and $\sigma=0.36\pm0.03$ in the mass range $0.03\leq
M/M_\odot\leq0.8$. From the analysis of the spatial distribution of this
numerous candidate sample, we have confirmed the East-West elongation of the 25
Orionis group observed in previous works, and rule out a possible southern
extension of the group. We find that the spatial distributions of low mass
stars and brown dwarfs in 25 Orionis are statistically indistinguishable.
Finally, we found that the fraction of brown dwarfs showing IR excesses is
higher than for low mass stars, supporting the scenario in which the evolution
of circumstellar discs around the least massive objects could be more
prolonged. |
1408.0010v2 | IPHT-T14/088 CRM-3338 RIKEN-MP-90
## Towards U( N M | ) knot invariant from ABJM theory
Bertrand Eynard a,b † and Taro Kimura a,c ‡
a Institut de Physique Th´orique, CEA Saclay, F-91191 Gif-sur-Yvette, France e b Centre de Recherches Math´matiques, Universit´ de Montr´al, Montr´al, QC, Canada, e e e e c Mathematical Physics Laboratory, RIKEN Nishina Center, Saitama 351-0198, Japan
## Abstract
We study U( N M | ) character expectation value with the supermatrix Chern-Simons theory, known as the ABJM matrix model, with emphasis on its connection to the knot invariant. This average just gives the half-BPS circular Wilson loop expectation value in ABJM theory, which shall correspond to the unknot invariant. We derive the determinantal formula, which gives U( N M | ) character expectation values in terms of U(1 1) averages for a particular type of character representations. | This means that the U(1 1) character expectation value is a building block for the U( | N M | ) averages, and also, by an appropriate limit, for the U( N ) invariants. In addition to the original model, we introduce another supermatrix model obtained through the symplectic transform, which is motivated by the torus knot Chern-Simons matrix model. We obtain the Rosso-Jonestype formula and the spectral curve for this case.
† E-mail address: [email protected]
‡
Present address: Department of Physics, Keio University; E-mail address: [email protected] Keywords: knot invariant, ABJM theory, Chern-Simons theory, Matrix model MSC: 81T60, 81T45, 57M27, 14H81
## Contents
| 1 Introduction | 1 Introduction | 1 Introduction | 1 |
|------------------|--------------------------------------------------|-------------------------------------------------------|-----|
| 2 | Unknot matrix model | Unknot matrix model | 4 |
| | 2.1 | U(1 | 1) theory . . . . . . . . . . . . . . . . . . . | 6 |
| | 2.2 | U( N | N ) theory . . . . . . . . . . . . . . . . . . | 7 |
| 3 | Torus knot matrix model | Torus knot matrix model | 9 |
| 4 | U( N | M ) theory | U( N | M ) theory | 11 |
| 5 | Spectral curve | Spectral curve | 14 |
| | 5.1 | Symplectic transformation . . . . . . . . . . . . | 15 |
| | 5.2 | Saddle point analysis . . . . . . . . . . . . . . . | 17 |
| | 5.3 | Asymptotic expansion and topological recursion | 23 |
| 6 | Comments on related topics | Comments on related topics | 23 |
| | 6.1 | Topological A-model . . . . . . . . . . . . . . . | 23 |
| | 6.2 | Topological B-model . . . . . . . . . . . . . . . | 25 |
| | 6.3 | Matrix models . . . . . . . . . . . . . . . . . . | 26 |
| 7 | Discussion | Discussion | 28 |
| A | Mirror of the torus knot ABJM partition function | Mirror of the torus knot ABJM partition function | 31 |
## 1 Introduction
Since it was shown by Witten [1] that a knot invariant is realized by using the Wilson loop operators in Chern-Simons gauge theory, knot theory has been providing various kinds of interesting topics not only for mathematicians, but also for physicists. In particular the most important example of the knot invariant, which is called the Jones polynomial, is obtained from Chern-Simons theory with the Wilson loop in a fundamental representation
$$J ( K ; q ) = \left \langle W _ { \Box } ( K ; q ) \right \rangle / \left \langle W _ { \Box } ( \bigcirc ; q ) \right \rangle,$$
where the Wilson loop in a representation R is given by
$$W _ { R } ( K ; q ) = \text{Tr} _ { R } \, \text{P} \exp \left ( \oint _ { K } A \right ) \,,$$
and its expectation value is taken with respect to Chern-Simons theory with SU(2) gauge symmetry on a three-sphere S 3
$$S _ { \text{CS} } [ A ] = \frac { k } { 4 \pi } \int _ { S ^ { 3 } } \text{Tr} \left ( A \wedge d A + \frac { 2 } { 3 } A \wedge A \wedge A \right ) \,.$$
In this case the parameter q is associated with the level of Chern-Simons theory as q = exp(2 πi/ k ( +2)). This prescription to derive the knot invariant is quite general: when the fundamental representation R = glyph[square] is replaced by a generic representation, one obtains the colored Jones polynomial, and SU( N ) and SO( N / ) Sp( N ) generalizations provide the HOMFLY and Kauffman polynomials, respectively.
The knot polynomial is usually defined by the Skein relation with a proper normalization condition for the unknot invariant. Although it is in principle computable for any knots based on that definition, their expressions get much complicated as the number of crossings in knots increases, or the representation of the knot polynomial becomes highly involved. Thus it is not yet achieved to write down such a knot invariant in a closed form. On the other hand, for a particular class of knots, the unknot and also torus knots, there is a useful integral representation of the knot invariant [2, 3, 4, 5], which is applicable to a generic gauge group and representation. This is based on the matrix integral formula for the partition function of Chern-Simons theory, especially defined on a three-sphere S 3 , and then given as the expectation value of the character in the corresponding group.
In this paper we consider a supergroup character average with the supermatrix ChernSimons theory, known as the ABJM matrix model [6], towards a supersymmetric generalization of the knot invariant. This supermatrix model is derived from N = 6 superconformal Chern-Simons-matter theory with gauge group U( N ) k × U( N ) -k , which is so-called ABJM theory [7], by implementing the localization technique for the path integral. In this theory the circular Wilson loop, in particular the half-BPS operator, is described by a holonomy with a superconnection taking a value in U( N N | ), which is written as a supergroup character [8]. Thus it is expressed in terms of the supersymmetric Schur function [9, 10]. In this sense the average we compute here is expected to be an unknot invariant for U( N N | ) theory.
The knot invariant and the character average have an analogous structure to a matrix integral in the presence of an external field, which is dual to a correlation function of characteristic polynomials. Especially in the case of supermatrix models, the corresponding correlation function is that for the characteristic polynomial ratio. For this correlation function, there is an interesting determinantal formula which consists of a single pair correlation function as a kernel [11, 12, 13]. In this way we shall expect that a similar determinantal structure can be found in U( N N | ) theory, and the U(1 1) expectation value plays a role as | the kernel function there. We will show in this paper such a determinantal formula for the average with a particular type of the character representation.
According to the general scheme of the topological recursion [14], one can determine all order perturbation series for the correlation function from the spectral curve. In the case of the knot invariant, there are basically two kinds of perturbative expansions. The first is based on the spectral curve, which is obtained from the A-polynomial, and its expansion is from the large representation limit [15, 16]. Although this A-polynomial was originally introduced to the Jones polynomial, namely SU(2) Chern-Simons theory, it can be now extended to more
generic theories. See for example [17]. The other expansion comes from the spectral curve arising in the large rank limit of the knot invariant. This kind of spectral curves is quite analogous to that discussed in random matrix theory, because for some kinds of knots we have matrix integral-like expressions for the knot invariant, and in this case the matrix size N corresponds to the rank of Chern-Simons gauge group SU( N ). This large N limit plays an important role in topological string theory, because it describes the geometric transition of the corresponding Calabi-Yau threefold [18]. Such a duality is still available for the situation in the presence of a knot [19], which gives a brane on a proper Lagrangian submanifold of the Calabi-Yau threefold. In the sense of topological strings, the corresponding spectral curve provides the mirror Calabi-Yau threefold. In this paper we will discuss the large N spectral curve for the supermatrix Chern-Simons theories.
The supergroup character average discussed in this paper is based on ABJM theory. As pointed out in [20], it is perturbatively equivalent to Chern-Simons theory on the lens space L (2 , 1) = S / 3 Z 2 ∼ = RP 3 , which is dual to the topological string on the local P 1 × P 1 geometry, and the associated spectral curve becomes a genus-one curve. Therefore the unknot spectral curve is just given by the mirror curve of the local P 1 × P 1 . In the case of the torus knot, the spectral curve is obtained by applying the symplectic transformation of the unknot [5]. As well as the ordinary HOMFLY polynomial for SU( N ) Chern-Simons theory, we will introduce the ( P, Q )-deformed supermatrix model through the symplectic transform of the original matrix model, which is motivated by the torus knot Chern-Simons matrix model. Since the Adams operation works well even for the Schur function associated with the supergroup U( N N | ), we can derive the Rosso-Jones formula for the torus knot average. This means that the torus knot character average can be represented as a linear combination of the fractionally framed unknot averages. We will also derive the spectral curve from the saddle point equations of the ( P, Q )-deformed supermatrix model, and then obtain a consistent result with the symplectic transform of the unknot curve.
This paper is organized as follows. In Sec. 2 we study the supergroup character average with the ABJM matrix model, which is just given as the half-BPS circular Wilson loop operator in ABJM theory. We especially focus on the representation, corresponding to the partition such that the number of its diagonal components is given by N . We will show the determinantal formula factorizing the U( N N | ) character average into the U(1 1) expectation | values. In Sec. 3 we then consider the ( P, Q )-deformation of the supermatrix model, which is obtained by the SL(2 , Z ) transform of the original ABJM matrix model. We will show that the Rosso-Jones formula holds even for the U( N N | ) theoy, and the U(1 1) average plays a | role of a building block for the ( P, Q )-deformed U( N N | ) character expectation value with a particular kind of representations. In Sec. 4 we extend the argument to U( N M | ) theory, and we will see that the determinantal formula for the character average can be derived even in this case. We obtain the expression which interpolates U( N ) and U( N N | ) theories. In Sec. 5 we discuss the spectral curve for the ( P, Q )-deformed matrix model. We show that there
are two consistent ways of obtaining the spectral curve: One is the symplectic transform of the original matrix model and the other is the saddle point analysis of the ( P, Q )-deformed matrix model itself. In Sec. 6 we give some comments on the relations to topological string and random matrix theory. Sec. 7 is devoted to a summary and discussions.
## 2 Unknot matrix model
Let us start with the matrix model description of Chern-Simons theory at level k defined on a three-sphere S 3 . When we take the gauge group G = U( N ), the partition function is given as the matrix model-like integral
$$\mathcal { Z } _ { \text{CS} } ( S ^ { 3 } ; q ) = \frac { 1 } { N! } \int \prod _ { i = 1 } ^ { N } \frac { d x _ { i } } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g _ { s } } x _ { i } ^ { 2 } } \, \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) ^ { 2 } \,,$$
where the parameter q is related to the coupling constant as q = exp g s with
$$g _ { s } & = \frac { 2 \pi i } { k + N } \,.$$
We then consider the expectation value of the circular Wilson loop operator with representation R , which corresponds to the unknot invariant,
$$\left \langle W _ { R } ( \Box ) \right \rangle = \frac { 1 } { \mathcal { Z } _ { \text{CS} } } \frac { 1 } { N! } \int _ { i = 1 } ^ { N } \frac { d x _ { i } } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g s } x _ { i } ^ { 2 } } \, \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) ^ { 2 } \, \text{Tr} _ { R } \, U ( x ) \,. \quad \, ( 2. 3 )$$
The holonomy matrix U x ( ) is given by
$$U ( x ) = \left ( \begin{array} { c c c } e ^ { x _ { 1 } } & & \\ & \ddots & \\ & & e ^ { x _ { N } } \end{array} \right ) \,,$$
and Tr R U is indeed the character of G = U( N ) in the representation R . This character is written as a Schur polynomial with the corresponding partition λ to the representation R
$$\text{Tr} _ { R } U = s _ { \lambda } ( e ^ { x _ { 1 } }, \cdots, e ^ { x _ { N } } ) \,.$$
Although we can deal with only the unknot Wilson loop based on this matrix model, it is possible to obtain the torus knot invariants by applying a slightly different matrix model, as discussed in Sec. 3.
We now consider a supersymmetric extension of this Chern-Simons theory. In this paper we especially apply the supermatrix generalization of the Chern-Simons matrix model (2.1), namely the ABJM matrix model [8]. It was shown in [6] that ABJM theory [7], which is the three-dimensional superconformal Chern-Simons-matter theory with gauge group U( N ) k ×
U( N ) -k , can be similarly reduced to the matrix model-like integral
$$\mathcal { Z } _ { \text{ABJM} } ( S ^ { 3 } ; q ) \ = \ \frac { 1 } { N! ^ { 2 } } \int _ { i = 1 } ^ { N } \frac { d x _ { i } } { 2 \pi } \frac { d y _ { i } } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g _ { s } } ( x _ { i } ^ { 2 } - y _ { i } ^ { 2 } ) } \, \prod _ { i, j } ^ { N } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } \right ) ^ { - 2 } \\ \times \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) ^ { 2 } \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 } \right ) ^ { 2 } \,. \ ( 2. 6 )$$
In this case there is no level shift in the coupling constant
$$g _ { s } & = \frac { 2 \pi i } { k } \,.$$
We can insert the Wilson loop operator into this matrix model as well as Chern-Simons theory with the classical group. Although there are some possibilities for the operators in this case, the relevant choice to this study is the half-BPS circular Wilson loop operator, which is given by a character of the supergroup U( N N | ) [8, 20],
$$\left \langle W _ { R } ( \mathcal { O } ) \right \rangle \ = \ \frac { 1 } { Z _ { \text{ABJM} } } \frac { 1 } { N! ^ { 2 } } \int _ { i = 1 } ^ { N } \frac { d x _ { i } } { 2 \pi } \, \frac { d y _ { i } } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g s } ( x _ { i } ^ { 2 } - y _ { i } ^ { 2 } ) } \, \prod _ { i, j } ^ { N } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } \right ) ^ { - 2 } \\ \times \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) ^ { 2 } \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 } \right ) ^ { 2 } \, \text{Str} _ { R } \, U ( x ; y ) \,, \, ( 2. 8 )$$
where the matrix U x y ( ; ) is of the size 2 N × 2 N
$$U ( x ; y ) = \left ( \begin{array} { c c } U ( x ) & \\ & - U ( y ) \end{array} \right ) \,.$$
Let us call this expectation value the unknot Wilson loop average as an analogy with the knot invariant. The supergroup character for U( N N | ) is obtained by replacing the power sum polynomial Tr U n in the U( N + N ) character with the supertrace Str U n [9].
As well as the U( N ) representation theory, the supergroup character can be also expressed as the Schur polynomial, but with a prescribed symmetry [10]
$$\text{Str} _ { R } U ( x ; y ) = s _ { \lambda } ( e ^ { x } ; e ^ { y } ) \,.$$
For U( N N | ) theory, we have a useful determinantal formula in terms of the Frobenius coordinate of the partition λ = ( α , 1 · · · , α d λ ( ) | β , 1 · · · , β d λ ( ) ) with α i = λ i -i and β i = λ t i -i [21]
$$s _ { \lambda } ( u ; v ) = \det _ { 1 \leq i, j \leq d ( \lambda ) } \left ( \sum _ { k, l = 1 } ^ { N } u _ { k } ^ { \alpha _ { i } } \left ( C ^ { - 1 } \right ) _ { k l } v _ { l } ^ { \beta _ { j } } \right ) \,,$$
where the matrix C -1 is the inverse of the Cauchy matrix
$$C = \left ( \frac { 1 } { u _ { k } + v _ { l } } \right ) _ { 1 \leq k, l \leq N }.$$
Figure 1: The partition λ = (12 9 8 6 5 5 4 3 2 2), , , , , , , , , , which is also represented as λ = (11 7 5 2 0 9 8 5 3 1) in the Frobenius coordinate with , , , , | , , , , d λ ( ) = N (= 5). We obtain sub diagrams µ = (7 4 3 1 0) and , , , , ν t = (5 4 3 2 2) involved in this partition. , , , ,
We remark that the supersymmetric Schur polynomial is identically zero when d λ ( ) > N , or equivalently λ N +1 > N .
The formula (2.11) also implies that it can be written only in terms of the hook representations
$$s _ { \lambda } ( u ; v ) = \det _ { 1 \leq i, j \leq d ( \lambda ) } s _ { ( \alpha _ { i } | \beta _ { j } ) } ( u ; v ) \,.$$
This is just a supersymmetric version of the Giambelli formula. Actually this relation is useful to study the Wilson loop operators with various representations in ABJM theory [22].
Especially for the most generic situation with d λ ( ) = N , on which we focus in this paper, the supersymmetric Schur polynomial is decomposed into the ordinary ones [21]
$$s _ { \lambda } ( u ; v ) \ & = \ \det _ { 1 \leq i, j \leq N } u _ { i } ^ { \alpha _ { j } } \cdot \det _ { 1 \leq i, j \leq N } v _ { i } ^ { \beta _ { j } } \cdot \det _ { 1 \leq i, j \leq N } C _ { i j } ^ { - 1 } \\ & = \ s _ { \mu } ( u ) \ s _ { \nu } ( v ) \prod _ { i, j = 1 } ^ { N } ( u _ { i } + v _ { j } ) \,,$$
where the partitions µ and ν are given by
$$\mu _ { i } = \lambda _ { i } - N \,, \quad \nu _ { i } = \lambda _ { i } ^ { t } - N \,, \quad i = 1, \cdots, N \,,$$
or equivalently, µ t i = λ t i + N , ν t i = λ i + N , as shown in Fig. 1. The determinant of the Cauchy matrix is given by
$$\det C = \Delta ( u ) \Delta ( v ) \prod _ { i, j = 1 } ^ { N } ( u _ { i } + v _ { j } ) ^ { - 1 } \,,$$
with the Vandermonde determinant
$$\Delta ( u ) = \prod _ { i < j } ^ { N } ( u _ { i } - u _ { j } ) \,.$$
## 2.1 U(1 1) | theory
Let us consider the simplest example with the supergroup U(1 1), which plays a fundamental | role in this study. In this case only the hook representation is possible, which is written as
λ = ( α β | ) with the Frobenius coordinate. The corresponding Schur function reads
$$s _ { ( \alpha | \beta ) } ( e ^ { x } ; e ^ { y } ) = ( e ^ { x } + e ^ { y } ) \ e ^ { \alpha x + \beta y } \,.$$
The unknot Wilson loop expectation value is given by
$$\left \langle W _ { ( \alpha | \beta ) } ( \mathcal { O } ) \right \rangle = \frac { 1 } { \mathcal { Z } _ { \text{ABJM} } } \int \frac { d x } { 2 \pi } \frac { d y } { 2 \pi } \, e ^ { \frac { i k } { 3 \pi } ( x ^ { 2 } - y ^ { 2 } ) } \left ( 2 \cosh \frac { x - y } { 2 } \right ) ^ { - 2 } ( e ^ { x } + e ^ { y } ) \, e ^ { \alpha x + \beta y } \,. \quad ( 2. 1 9 )$$
We can compute this integral explicitly by applying the Fourier transform formula
$$\frac { 1 } { 2 \cosh w } = \int \frac { d z } { 2 \pi } \, \frac { e ^ { 2 i w z / \pi } } { \cosh z } \,.$$
Thus we have
$$\int \frac { d x } { 2 \pi } \frac { d y } { 2 \pi } \frac { d z } { 2 \pi } \, \frac { 1 } { \cosh z } \, e ^ { \frac { i k } { 4 \pi } ( x ^ { 2 } - y ^ { 2 } ) + ( \alpha + \frac { 1 } { 2 } ) x + ( \beta + \frac { 1 } { 2 } ) y + \frac { 1 } { \pi } ( x - y ) z } = \frac { 1 } { k } \, \frac { q ^ { \frac { 1 } { 2 } ( \alpha + \beta + 1 ) ( \alpha - \beta ) } } { q ^ { \frac { 1 } { 2 } ( \alpha + \beta + 1 ) } + q ^ { - \frac { 1 } { 2 } ( \alpha + \beta + 1 ) } } \,. \ ( 2. 2 1 )$$
Since the partition function becomes Z ABJM = (4 k ) -1 for N = 1, we obtain the expectation value as follows,
$$\ddot { \ w \sigma }, & \left \langle W _ { ( \alpha | \beta ) } ( \mathrm O ) \right \rangle = \frac { 4 \, q ^ { \frac { 1 } { 2 } ( \alpha + \beta + 1 ) ( \alpha - \beta ) } } { q ^ { \frac { 1 } { 2 } ( \alpha + \beta + 1 ) } + q ^ { - \frac { 1 } { 2 } ( \alpha + \beta + 1 ) } } \,. & & ( 2. 2 2 )$$
This depends only on the total and relative lengths of the partition, given by α + β +1 and α -β , respectively. We will see that the numerator can be seen as the framing factor in the following section.
## 2.2 U( N N | ) theory
We then consider the character expectation value for U( N N | ) theory, in particular with a representation with d λ ( ) = N , λ = ( α , 1 · · · , α N | β , 1 · · · , β N ). Let us first rewrite the partition function (2.6)
$$\mathcal { Z } _ { \text{ABJM} } ( S ^ { 3 } ; q ) = \frac { 1 } { N! ^ { 2 } } \int [ d x ] ^ { N } [ d y ] ^ { N } \, \det \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } } \right ) ^ { 2 } \,,$$
with shorthand notations
$$[ d x ] = \frac { d x } { 2 \pi } \, e ^ { - \frac { 1 } { g _ { s } } x ^ { 2 } } \,, \quad [ d y ] = \frac { d y } { 2 \pi } \, e ^ { \frac { 1 } { g _ { s } } y ^ { 2 } } \,,$$
where we have used the Cauchy formula
$$\det _ { 1 \leq i, j \leq N } \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } } \right ) = \prod _ { i, j = 1 } ^ { N } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } \right ) ^ { - 1 } \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 } \right ) \,.$$
In this case the Schur function has a simple expression as shown in (2.14). Therefore the unnormalized unknot expectation value is now given by
$$\left \langle W _ { R } ( \bigcirc ) \right \rangle = \int [ d x ] ^ { N } [ d y ] ^ { N } \det _ { N } \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } } \right ) \det _ { N } e ^ { x _ { i } \xi _ { j } } \det _ { N } e ^ { y _ { i } \eta _ { j } } \,,$$
where the parameters ξ i and η i , defined as ξ i = λ i -i +1 2 = / α i +1 2 and / η i = λ t i -i +1 2 = / β i +1 2, play a similar role to external fields in matrix models, as discussed in Sec. 6. / Since all the x i and y i are not distinguishable, this integral can be expressed as a size N determinant
$$\det _ { 1 \leq i, j \leq N } \left [ \int \frac { d x } { 2 \pi } \frac { d y } { 2 \pi } \, e ^ { \frac { i k } { 4 \pi } ( x ^ { 2 } - y ^ { 2 } ) + x \xi _ { i } + y m _ { j } } \left ( 2 \cosh \frac { x - y } { 2 } \right ) ^ { - 1 } \right ] \,.$$
At this moment the computation is almost reduced to that for U(1 1) theory. | Again using the formula (2.20), we obtain the determinantal formula for the character expectation value
$$\left \langle W _ { R } ( \bigcirc ) \right \rangle = k ^ { - N } \prod _ { i = 1 } ^ { N } q ^ { \frac { 1 } { 2 } ( \xi _ { i } ^ { 2 } - \eta _ { i } ^ { 2 } ) } \det _ { 1 \leq i, j \leq N } \left ( \frac { 1 } { q ^ { \frac { 1 } { 2 } ( \xi _ { i } + \eta _ { j } ) } + q ^ { - \frac { 1 } { 2 } ( \xi _ { i } + \eta _ { j } ) } } \right ) \,.$$
This shows that the U( N N | ) unknot character average is factorized into that for U(1 1) | theory (2.22), and thus the measure of this matrix integral is Giambelli compatible in the sense of [12].
To see that the U( N N | ) theory contains the U( N ) knot invariant, it is convenient to rewrite the expression (2.28) by applying the Cauchy formula,
$$\left \langle W _ { R } ( \bigcirc ) \right \rangle = k ^ { - N } q ^ { \frac { 1 } { 2 } ( C _ { 2 } ( \mu ) - C _ { 2 } ( \nu ) ) } \prod _ { i, j = 1 } ^ { N } \left ( q ^ { \frac { 1 } { 2 } ( \alpha _ { i } + \beta _ { j } + 1 ) } + q ^ { - \frac { 1 } { 2 } ( \alpha _ { i } + \beta _ { j } + 1 ) } \right ) ^ { - 1 } \\ \times \prod _ { i < j } ^ { N } \left ( q ^ { \frac { 1 } { 2 } ( \alpha _ { i } - \alpha _ { j } ) } - q ^ { - \frac { 1 } { 2 } ( \alpha _ { i } - \alpha _ { j } ) } \right ) \left ( q ^ { \frac { 1 } { 2 } ( \beta _ { i } - \beta _ { j } ) } - q ^ { - \frac { 1 } { 2 } ( \beta _ { i } - \beta _ { j } ) } \right ). \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where the 2nd Casimir operator is defined by
$$C _ { 2 } ( \lambda ) = \sum _ { i = 1 } ^ { \infty } \left ( \left ( \lambda _ { i } - i + \frac { 1 } { 2 } \right ) ^ { 2 } - \left ( - i + \frac { 1 } { 2 } \right ) ^ { 2 } \right ) \,.$$
Thus in this case we see that the standard framing factor is given by q 1 2 ( C 2 ( µ ) -C 2 ( ν )) . Up to the normalization constants, the factors in the second line coincide with the Wilson loop expectation value for U( N ) theory, which is given by the quantum dimension of the representation R ,
$$\left \langle W _ { R } ( \bigcirc ) \right \rangle _ { \mathrm U ( N ) } \ & = \ \prod _ { i < j } ^ { N } \frac { [ \lambda _ { i } - \lambda _ { j } - i + j ] _ { q } } { [ - i + j ] _ { q } } \\ & \equiv \ \dim _ { q } R \,,$$
with
$$[ x ] _ { q } = q ^ { x / 2 } - q ^ { - x / 2 } \,.$$
The denominator in (2.31) corresponds to the partition function of U( N ) Chern-Simons theory
$$\overset { \nu J } { \mathcal { Z } } _ { \text{CS} } ( S ^ { 3 } ; q ) = \frac { e ^ { \frac { \pi i } { 8 } N ( N - 1 ) } } { N ^ { \frac {$$
Let us now comment on the situation such that the representation of the character obeys d λ ( ) < N . In this case we do not obtain a simple determinantal formula, since the Schur function with such a representation is not simply factorized any more. For example, the character expectation value for the hook representation, corresponding to the simplest situation d λ ( ) = 1, is given by
$$\left \langle W _ { ( \alpha | \beta ) } ( \mathcal { O } ) \right \rangle = \frac { 1 } { \mathcal { Z } _ { \text{ABJM} } } \frac { 1 } { N! ^ { 2 }$$
where we have
$$\tilde { C } = \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } } \right ) _ { 1 \leq i, j \leq N }. \quad \quad \quad$$
Although it is difficult to find an explicit formula for this integral, we expect that its asymptotic behavior is obtained from the determinantal formula (2.28) by taking the limit of α , β 1 1 →∞ . Nevertheless, let us comment that we can apply the Fermi gas method even to this case. Actually if we consider the grand canonical partition function, it turns out to be written as a Fredholm determinant, due to the Giambelli formula. See, for example, [22].
## 3 Torus knot matrix model
In addition to the unknot invariant, there is a similar integral formula for the torus knot Wilson loop based on Chern-Simons theory [2, 3, 4, 5],
$$\left \langle W _ { R } ( K _ { P, Q } ) \right \rangle = \frac { 1 } { \mathcal { Z } _ { \text{CS} } ^ { ( P, Q ) } } \frac { 1 } { N! } \int$$
where the coupling constant is now rescaled ˆ g s = PQg s , and the corresponding partition function is then given by
$$\mathcal { Z } _ { \text{CS} } ^ { ( P, Q ) } ( S ^ { 3 } ; q ) = \frac { 1 } { N! } \int \prod _ { i = 1 } ^ { N } \frac { d x _ { i }$$
This is obtained from the ordinary matrix model by applying the SL(2 , Z ) transformation [5]. Note that it is also seen as the biorthogonal generalization of the Chern-Simons matrix model [23].
For the torus knot invariant there is a useful formula, which is called the Rosso-Jones formula [24]
$$\left \langle W _ { R } ( K _ { P, Q } ) \right \rangle = \sum _ { V } c _ { R, Q } ^ { V } \left \langle W _ { V } ( K _ { 1, f } ) \right \rangle,$$
with f = P/Q . This means that the ( P, Q ) torus knot invariant can be expressed as a linear combination of the fractionally framed unknot invariant. This formula is easily derived from the integral formula (3.1) by using the Adams operation
$$s _ { \lambda } ( u ^ { Q } ) = \sum _ { \mu } c _ { \lambda, Q } ^ { \mu } \, s _ { \mu } ( u ) \,.$$
The coefficient c µ λ,Q can be determined by the Frobenius formula for the Schur and power sum polynomials,
$$s _ { \lambda } = \sum _ { \mu } \frac { 1 } { z _ { \mu } } \chi _ { \lambda } ( C _ { \mu } ) \, p _ { \mu } \,, \quad p _ { \mu } = \sum _ { \nu } \chi _ { \nu } ( C _ { \mu } ) \, s _ { \nu } \,,$$
where χ λ and C µ are the character and the conjugacy class for the symmetric group, and the coefficient z µ is given by z µ = ∏ j µ j ! j µ j . Thus we have
$$c _ { \lambda, Q } ^ { \mu } = \sum _ { \nu } \frac { 1 } { z _ { \nu } } \chi _ { \lambda } ( C _ { \nu } ) \chi _ { \mu } ( C _ { Q \nu } ) \,.$$
Since the Rosso-Jones formula (3.3) is obtained from the representation theoretical point of view, it is natural to think that there is a similar formula even for supergroup theories. Actually supersymmetric polynomials obey the same Frobenius formula (3.5) by definition [9]: Let U( x, y ) be a diagonal U( N + M ) matrix, and given an expansion of the U( N + M ) character in terms of the power sum polynomial Tr U x,y ( ) n as
$$\text{Tr} _ { R } U ( x, y ) = \sum _ { R ^ { \prime } } C _ { R } ^ { R ^ { \prime } } \prod _ { i = 1 } ^ { \ell ( R ^ { \prime } ) } \text{Tr} U ( x, y ) ^ { R ^ { \prime } _ { i } }$$
with glyph[lscript] ( R ) to be the number of non-zero entries in the Young diagram R , the supergroup character is just obtained by replacing Tr U x,y ( ) with Str U x y ( ; ),
$$\text{Str} _ { R } U ( x ; y ) = \sum _ { R ^ { \prime } } C _ { R } ^ { R ^ { \prime } } \prod _ { i = 1 } ^ { \ell ( R ^ { \prime } ) } \text{Str} U ( x ; y ) ^ { R ^ { \prime } _ { i } }$$
Therefore we obtain the Adams operation for U( N M | ) theory with the same coefficient (3.6),
$$s _ { \lambda } ( u ^ { Q } ; v ^ { Q } ) = \sum _ { \mu } c _ { \lambda, Q } ^ { \mu } \, s _ { \mu } ( u ; v ) \,.$$
Following the above discussions, we now introduce a supermatrix version of the torus knot matrix model (3.2)
$$\mathcal { Z } _ { \text{ABJM} } ^ { ( P, Q ) } = \frac { 1 } { N! ^ { 2 } } \int [ d x ] ^ { N } [ d y ] ^ { N } \, \det \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 P } } \right ) \det \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 Q } } \right ) \,,$$
with the rescaled coupling constant ˆ g s = PQg s . 1 Then we consider the character expectation value with respect to this partition function
$$\left \langle W _ { R } ( K _ { P, Q } ) \right \rangle = \frac { 1 } { Z _ { \text{ABJM} } ^ { ( P, Q ) } } \, \frac { 1 } { N! ^ { 2 } } \int [ d x ] ^ { N } [ d y ] ^ { N } \, \det \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 P } } \right ) \det \left ( \frac { 1 } { 2 \cosh \frac { x _ { i } - y _ { j } } { 2 Q } } \right ) \, s _ { \lambda } ( e ^ { x } ; e ^ { y } ) \,.$$
Let us call this expectation value the torus knot character average. We can easily show that this ( P, Q )-deformed U( N N | ) character average also satisfies the Rosso-Jones formula
1 We can derive the so-called mirror description for this partition function, as well as the ordinary ABJM matrix model [25]. It depends on the parameters ( P, Q ) in a trivial way (A.3). See Appendix A for details.
(3.3) by applying the Adams operation for U( N N | ) theory (3.9). In this sense it is enough to compute the framed unknot average to obtain the torus knot average. In fact, when we start with a generic partition λ = ( α , 1 · · · , α N | β , 1 · · · , β N ) for a particular torus knot, representations appearing in the expansion (3.3) only provide partitions satisfying d λ ( ) = N . 2 Therefore we now focus on the torus knot and framed unknot with a representation with d λ ( ) = N . In this case we can show that the framed unknot average has the same expression as (2.29), up to the framing factor,
$$& \text{(2.29), up to the training factor,} \\ & \left \langle W _ { R } ( K _ { 1, f } ) \right \rangle = \frac { k ^ { - N } } { \mathcal { Z } ^ { ( 1, 1 ) } \text{$q^{frac{f}{2}(C_{2}(\mu)-C_{2}(\nu))$} } } \det _ { 1 \leq i, j \leq N } \left ( \frac { 1 } { q ^ { \frac { 1 } { 2 } ( \alpha _ { i } + \beta _ { j } + 1 ) } + q ^ { - \frac { 1 } { 2 } ( \alpha _ { i } + \beta _ { j } + 1 ) } } \right ) \\ & \quad = \frac { k ^ { - N } } { \mathcal { Z } ^ { ( 1, 1 ) } \text{$q^{frac{f}{2}(C_{2}(\mu)-C_{2}(\nu))$} } } \prod _ { i, j = 1 } ^ { N } \left ( q ^ { \frac { 1 } { 2 } ( \alpha _ { i } + \beta _ { j } + 1 ) } + q ^ { - \frac { 1 } { 2 } ( \alpha _ { i } + \beta _ { j } + 1 ) } \right ) ^ { - 1 } \\ & \quad \times \prod _ { i < j } ^ { N } \left ( q ^ { \frac { 1 } { 2 } ( \alpha _ { i } - \alpha _ { j } ) } - q ^ { - \frac { 1 } { 2 } ( \alpha _ { i } - \alpha _ { j } ) } \right ) \left ( q ^ { \frac { 1 } { 2 } ( \beta _ { i } - \beta _ { j } ) } - q ^ { - \frac { 1 } { 2 } ( \beta _ { i } - \beta _ { j } ) } \right ) \,. \quad ( 3. 1 2 ) \\ & \text{This means that the II/1/1)\,execution value nlavs a role of the building block for the terms}$$
This means that the U(1 1) expectation value plays a role of the building block for the torus | knot average at least with this kind of representations.
For U(1 1) theory we can compute the character expectation value (3.11) explicitly, as | well as the unknot average (2.22). In this case we have
$$\left \langle W _ { R } ( K _ { P, Q } ) \right \rangle = \frac { 4 \, q ^ { \frac { P Q } { 2 } } ( \alpha + \beta + 1 ) ( \alpha - \beta ) \left ( q ^ { \frac { P Q } { 2 } } ( \alpha + \beta + 1 ) + q ^ { - \frac { P Q } { 2 } } ( \alpha + \beta + 1 ) \right ) } { \left ( q ^ { \frac { P } { 2 } } ( \alpha + \beta + 1 ) + q ^ { - \frac { P } { 2 } } ( \alpha + \beta + 1 ) \right ) } \left ( q ^ { \frac { Q } { 2 } } ( \alpha + \beta + 1 ) + q ^ { - \frac { Q } { 2 } } ( \alpha + \beta + 1 ) \right ) } \,. \quad \text{ (3.13)}$$
Then we obtain 'U(1 1) knot invariant' for the torus knot from this expectation value by | implementing the normalization with the unknot contribution (2.22), as shown in (1.1). Removing the framing factor, we have
$$J _ { R } ( K _ { P, Q } ) = \frac { \left ( q ^ { \frac { 1 } { 2 } ( \alpha + \beta + 1 ) } + q ^ { - \frac { 1 } { 2 } ( \alpha + \beta + 1 ) } \right ) \left ( q ^ { \frac { P Q } { 2 } ( \alpha + \beta + 1 ) } + q ^ { - \frac { P Q } { 2 } ( \alpha + \beta + 1 ) } \right ) } { \left ( q ^ { \frac { P } { 2 } ( \alpha + \beta + 1 ) } + q ^ { - \frac { P } { 2 } ( \alpha + \beta + 1 ) } \right ) \left ( q ^ { \frac { Q } { 2 } ( \alpha + \beta + 1 ) } + q ^ { - \frac { Q } { 2 } ( \alpha + \beta + 1 ) } \right ) } \,.$$
This is a generic formula for the ( P, Q ) torus knot with the representation λ = ( α β | ). This expression is not a polynomial of q and q -1 in general, but it is manifestly invariant under the exchange of P ↔ Q , and also the inversion q ↔ q -1 .
## 4 U( N M | ) theory
The argument shown above can be straightforwardly extended to U( N M | ) theory. The U( N M | ) supermatrix Chern-Simons model is obtained from the Chern-Simons-matter the-
2 Although we do not have an explicit proof of this statement, we check it with a number of examples by numerical calculations.
Figure 2: The partition λ = (14 11 11 9 8 6 5 5 4 3 2 2) satisfying , , , , , , , , , , , λ N ≥ M with N = 7 and M = 5, which includes µ = (9 6 6 4 3 1 0) and , , , , , , ν t = (5 4 3 2 2). , , , ,
ory with gauge group U( N ) k × U( M ) -k , which is called ABJ theory [26],
$$\mathcal { Z } _ { \text{ABJ} } ( S ^ { 3 } ; q ) = \frac { 1 } { N! M! } \int _ { \real & 1 \, j = 1 } & [ d x ] ^ { N } [ d y ] ^ { M } \prod _ { i = 1 \, j = 1 } ^ { N } \int _ { \real & 1 \, j = 1 } ^ { M } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } \right ) ^ { - 2 } \\ & \times \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) ^ { 2 } \prod _ { i < j } ^ { M } \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 } \right ) ^ { 2 }. \\ - \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
The matrix measure in this model can be also expressed as a determinant using the generalized Cauchy determinant formula [27]
$$\Delta _ { N } ( u ) \Delta _ { M } ( v ) \prod _ { i = 1 } ^ { N } \prod _ { j = 1 } ^ { M } ( u _ { i } + v _ { j } ) ^ { - 1 } = \det \left ( \begin{array} { c } u _ { i } ^ { k - 1 } \\ ( u _ { i } + v _ { j } ) ^ { - 1 } \end{array} \right ) \,,$$
where we assume N ≥ M , and the indices run as i = 1 , · · · , N , j = 1 , · · · , M and k = 1 , · · · , N -M . Thus we have
$$& \prod _ { i = 1 } ^ { N } \prod _ { j = 1 } ^ { M } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 } \right ) ^ { - 1 } \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) \prod _ { i < j } ^ { M } \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 } \right ) \\ & = \prod _ { i = 1 } ^ { N } e ^ { \frac { - N + M + 1 } { 2 } x _ { i } } \prod _ { j = 1 } ^ { M } e ^ { \frac { N - M + 1 } { 2 } y _ { j } } \det \left ( \begin{array} { c } e ^ { x _ { i } ( k - 1 ) } \\ ( e ^ { x _ { i } } + e ^ { y _ { j } } ) ^ { - 1 } \end{array} \right ).$$
We then consider the expectation value of the Wilson loop operator with respect to this partition function. As in the case of U( N N | ) theory, if the partition, corresponding to the representation of the Wilson loop, satisfies λ N ≥ M as shown in Fig. 2, the Schur function is factorized into the ordinary ones [21]
$$s _ { \lambda } ( u ; v ) & = s _ { \mu } ( u ) \, s _ { \nu } ( v ) \prod _ { i = 1 } ^ { N } \prod _ { j = 1 } ^ { M } ( u _ { i } + v _ { j } ) \\ & = \prod _ { i = 1 } ^ { N } u _ { i } ^ { \lambda _ { i } + N - M - i } \prod _ { j = 1 } ^ { M } v _ { j } ^ { \lambda _ { j } ^ { t } + M - N - j } \det \left ( \begin{array} { c } u _ { i } ^ { k - 1 } \\ ( u _ { i } + v _ { j } ) ^ { - 1 } \end{array} \right ) \,,$$
where the partitions µ and ν are defined as µ i = λ i -M for i = 1 , · · · , N and ν j = λ t j -N for j = 1 , · · · , M , or equivalently µ t i = λ t i + M and ν t j = λ j + N . Therefore the unknot character expectation value is now given by
$$& \exp e c { \text{aauon your way is now given } } \upsilon y \\ & \left \langle W _ { R } ( \bigcirc ) \right \rangle = \frac { 1 } { Z _ { \text{ABJ} } } \frac { 1 } { N! M! } \int [ d x ] ^ { N } [ d y ] ^ { M } \det \left ( \begin{array} { c } e ^ { x _ { i } ( k - 1 ) } \\ ( e ^ { x _ { i } } + e ^ { y _ { j } } ) ^ { - 1 } \end{array} \right ) \det e ^ { x _ { i } ( \lambda _ { j } - j + 1 ) } \det e ^ { y _ { i } ( \lambda _ { j } ^ { t } - j + 1 ) } \\ & \quad = \frac { 1 } { Z _ { \text{ABJ} } } \det \left ( \begin{array} { c } \int \frac { d x } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g _ { s } } x ^ { 2 } + x ( \xi _ { i } + k - \frac { 1 } { 2 } ) } \\ \int \frac { d x } { 2 \pi } \, d y \\ \int \frac { d x } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g _ { s } } ( x ^ { 2 } - y ^ { 2 } ) + x \xi _ { i } + y _ { n j } } \left ( 2 \cosh \frac { x - y } { 2 } \right ) ^ { - 1 } \end{array} \right ), \quad ( 4. 5 ) \\ \quad \det \psi _ { \ } c. = \, \vee. \quad \psi _ { \ } t + 1 \, \frac { \epsilon _ { \ } w } { \epsilon _ { \ } w } \, \colon = 1 \, \det \pi _ { \ } w \, \colon = 1 \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \, \det \pi _ { \ } t \end{array}$$
with ξ i = λ i -i + 1 2 for i = 1 , · · · , N and η j = λ t j -j + 1 2 for j = 1 , · · · , M . This yields the determinantal formula for U( N M | ) theory
$$\left \langle W _ { R } ( \bigcirc ) \right \rangle = \frac { 1 } { Z _ { \text{ABJ} } } \frac { i \frac { N - M } { 2 } } { k \frac { N + M } { 2 } } \prod _ { i = 1 } ^ { N } q ^ { \frac { 1 } { 2 } ( \epsilon _ { i } ^ { 2 } + \xi _ { i } ) } \prod _ { j = 1 } ^ { M } q ^ { \frac { 1 } { 2 } ( - \eta _ { j } ^ { 2 } + \eta _ { j } ) } \prod _ { k = 1 } ^ { N - M } q ^ { \frac { 1 } { 2 } ( k - \frac { 1 } { 2 } ) ^ { 2 } } \det \left ( \begin{array} { c } q ^ { \xi _ { i } ( k - 1 ) } \\ ( q ^ { \xi _ { i } } + q ^ { \eta _ { j } } ) ^ { - 1 } \end{array} \right ).$$
This formula is also represented as follows,
$$& \text{This formula is also represented as follows,} \\ & \left \langle W _ { R } ( \mathcal { O } ) \right \rangle \\ & = \frac { 1 } { \mathcal { Z } _ { A B J } } \frac { \frac { N - M } { 2 } } { \frac { N + M } { 2 } q ^ { \frac { 1 } { 6 } } ( N - M ) ( N - M + \frac { 1 } { 2 } ) ( N - M - \frac { 1 } { 2 } ) } \prod _ { i = 1 } ^ { N } q ^ { \frac { 1 } { 6 } } ( \mathcal { E } _ { i } ^ { 2 } + ( N - M ) \xi _ { i } ) } \prod _ { j = 1 } ^ { M } q ^ { - \frac { 1 } { 6 } } ( \mathcal { E } _ { j } ^ { 2 } + ( N - M ) \eta _ { j } ) \\ & \times \prod _ { i < j } \left ( q ^ { \frac { 1 } { 6 } ( \xi _ { i } - \xi _ { j } ) } - q ^ { - \frac { 1 } { 6 } ( \xi _ { i } - \xi _ { j } ) } \right ) \prod _ { i < j } ^ { M } \left ( q ^ { \frac { 1 } { 6 } ( \eta _ { i } - \eta _ { j } ) } - q ^ { - \frac { 1 } { 6 } ( \eta _ { i } - \eta _ { j } ) } \right ) \prod _ { i = 1 } ^ { M } \prod _ { j = 1 } ^ { M } \left ( q ^ { \frac { 1 } { 6 } ( \xi _ { i } + \eta _ { j } ) } + q ^ { - \frac { 1 } { 6 } ( \xi _ { i } + \eta _ { j } ) } \right ) ^ { - 1 }. \\ & \text{It is easy to see that this expression is reduced to the U ( N | N ) average (2.29) and the U ( N )$$
It is easy to see that this expression is reduced to the U( N N | ) average (2.29) and the U( N ) invariant (2.31) by taking N = M and M = 0, respectively.
We can similarly introduce the U( N M | ) supermatrix model for torus knots
$$\text{we can similarly introduce use } \cup ( \text{v} | \text{$m$} ) \sup e m a l i x { \text{in} \colon } \text{for two two} } \\ \mathcal { Z } _ { \text{ABJ} } ^ { ( P, Q ) } ( S ^ { 3 } ; q ) & = \frac { 1 } { N! M! } \int [ d x ] ^ { N } [ d y ] ^ { M } \prod _ { i = 1 } ^ { N } \prod _ { j = 1 } ^ { M } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 P } \right ) ^ { - 1 } \left ( 2 \cosh \frac { x _ { i } - y _ { j } } { 2 Q } \right ) ^ { - 1 } \\ & \quad \times \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 P } \right ) \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 Q } \right ) \prod _ { i < j } ^ { M } \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 P } \right ) \left ( 2 \sinh \frac { y _ { i } - y _ { j } } { 2 Q } \right ). \\ \text{$m$} \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \text{$m$} / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / n / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m /m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / s / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / M / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / k / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / l m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m / m.$$
The torus knot average is obtained from this matrix model by inserting the U( N M | ) character, and thus satisfies the Rosso-Jones formula (3.3) thanks to the Adams operation (3.9). We remark that in the limit M → 0 this matrix model reproduces the integral formula for the ordinary U( N ) torus knot invariant, which is the HOMFLY polynomial [2, 3, 4, 5]. This supports a topological nature of the matrix model presented here.
In the next section we will discuss the spectral curve of the matrix model (4.8) arising in the large N limit.
Figure 3: Two ways of obtaining the ( P, Q ) torus knot ABJM (supermatrix) model.
## 5 Spectral curve
We then provide the spectral curve for the ABJ(M) matrix model for ( P, Q ) torus knots, which has been introduced in Sec. 3 and Sec. 4. In order to obtain the spectral curve, we have to solve the saddle point equations arising in the large N limit of the corresponding matrix model. It is well known that the ABJM matrix model is perturbatively equivalent to the Chern-Simons theory on the lens space L (2 1) = , S / 3 Z 2 ∼ = RP 3 , which is regarded as the two-cut solution of the Chern-Simons matrix model [20]. As well as the ordinary ABJM matrix model, we can obtain the spectral curve for the torus knot ABJM model from the ( P, Q )-modified Chern-Simons theory on the lens space L (2 , 1)
$$\Lambda ^ { - 1 } \, \infty / \, \cfrac { \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \end{array}$$
This is interpreted as the two-cut matrix model of the original Chern-Simons torus knot model (3.2), whose gauge symmetry is broken as as U( N + N ) → U( N ) × U( N ), or in general, U( N + M ) → U( N ) × U( M ).
As shown in Fig. 3, we have two ways of obtaining the spectral curve for the torus knot ABJM matrix model. The first is to apply the SL(2 , Z ) transformation to the spectral curve for ABJM theory, which is given by that for the lens space Chern-Simons theory, through the analytic continuation [28, 29]. We note that this kind of symplectic transformation is
considered to discuss the knot invariant for the lens space [30, 31]. The second is directly solving the saddle point equation for the matrix model (5.1). In this case its saddle point analysis is similar to the ordinary one-cut solution, which is discussed in [5]. We will show that these two methods provide a consistent result.
## 5.1 Symplectic transformation
Let us start with the spectral curve for the Chern-Simons theory on the lens space S / 3 Z 2 ∼ = RP 3 , which is essentially equivalent to that for ABJM theory. The spectral curve C is defined as the zero locus of the two-parameter function
$$\mathcal { C } = \left \{ ( U, V ) \in \mathbb { C } ^ { * } \times \mathbb { C } ^ { * } \, \Big | \, H ( U, V ) = 0 \right \},$$
where the function H U,V ( ) for the lens space L (2 1) is now given by [29] ,
$$H ( U, V ) = c \left ( U + \frac { V ^ { 2 } } { U } \right ) - V ^ { 2 } + \zeta V - 1 \,.$$
The parameter ζ is to be determined, and c is related to the 't Hooft coupling constant as c = exp g s ( N + M / ) 2 for the two-cut model with U( N ) × U( M ) symmetry. 3
Although the algebraic curve characterized by the function (5.3) is naturally obtained from the saddle point analysis of the matrix model, we replace the variable ( U, V ) → ( U , c 2 -1 2 U 1 2 V ) to obtain a homogeneous expression in U and V ,
$$H ( U, V ) = c U ^ { 2 } + V ^ { 2 } - c ^ { - 1 } V ^ { 2 } U ^ { 2 } + c ^ { - \frac { 1 } { 2 } } \zeta V U - 1 = 0 \,.$$
This solves
$$V = \frac { 1 } { 1 - c ^ { - 1 } U ^ { 2 } } \left ( - \frac { \zeta } { 2 c ^ { \frac { 1 } { 2 } } } U \pm \sqrt { \frac { \zeta ^ { 2 } } { 4 c } U ^ { 2 } + ( 1 - c U ^ { 2 } ) ( 1 - c ^ { - 1 } U ^ { 2 } ) } \right ) \,,$$
which is a more convenient expression to perform the contour integral as discussed later. By taking the limit ζ → 0, this solution is just reduced to the one-cut solution, which reproduces the previous result [5], up to a proper replacement of the variable V → V 2 ,
$$V \ \stackrel { \zeta \to 0 } { \longrightarrow } \ \frac { 1 - c U ^ { 2 } } { 1 - c ^ { - 1 } U ^ { 2 } } \,.$$
3 The spectral curve for Chern-Simons theory on the lens space L r, ( 1) = S / 3 Z r (the r -cut Chern-Simons matrix model) is given by [29]
$$\Phi _ { \Phi _ { 1 } \Re \nu _ { 1 } } \\ H ( U, V ) = c \left ( U + \frac { V ^ { r } } { U } \right ) - p _ { r } ( V ) = 0 \,,$$
where p r ( V ) is a degree r polynomial such that the coefficients of V r and V 0 are given by one, p r ( V ) = V r + · · · +1. When the Chern-Simons gauge group is broken as U( N 1 + · · · + N r ) → U( N 1 ) ×··· × U( N r ), the parameter c corresponds to the total 't Hooft coupling c = exp g s ( N 1 + · · · + N r ) / 2. Since the polynomial p r ( V ) has r -1 parameters, the total number of the parameters becomes 1 + ( r -1) = r , which is consistent with that of the subgroups, U( N i ) with i = 1 , · · · , r .
If we write the discriminant of (5.6) as
$$\frac { \zeta ^ { 2 } } { 4 c } U ^ { 2 } + ( 1 - c U ^ { 2 } ) ( 1 - c ^ { - 1 } U ^ { 2 } ) = \left ( U ^ { 2 } - \alpha \right ) \left ( U ^ { 2 } - \frac { 1 } { \alpha } \right ),$$
the end point of the cut is determined by
$$\alpha + \frac { 1 } { \alpha } = c + \frac { 1 } { c } - \frac { \zeta ^ { 2 } } { 4 c } \,.$$
Thus the parameter ζ is seen as the blow-up parameter for the spectral curve, which is determined by requiring that the filling fractions of the cuts are:
$$\frac { 1 } { 2 \pi i } \oint _ { [ \alpha ^ { - 1 / 2 }, \alpha ^ { 1 / 2 } ] } \log V \, \frac { d U } { U } = g _ { s } N \,,$$
$$\frac { 1 } { 2 \pi i } \oint _ { [ - \alpha ^ { 1 / 2 }, - \alpha ^ { - 1 / 2 } ] } ^ { \cdot } \log V \, \frac { d U } { U } = g _ { s } M \,,$$
for U( N ) × U( M ) theory where the integration contour surrounds the corresponding segments counterclockwise.
We can obtain the spectral curve for the ( P, Q ) torus knot from (5.6) through the symplectic transformation, which is characterized by the SL(2 , Z ) matrix [5]
$$M _ { P, Q } = \left ( \begin{array} { c c } Q & P \\ \gamma & \delta \end{array} \right ) \,,$$
where these integer entries satisfy the condition
$$Q \delta - P \gamma = 1 \,.$$
We then apply the following choice of variables corresponding to the matrix (5.12),
$$X & = U ^ { Q } V ^ { P } \,,$$
$$Y = U ^ { \gamma } V ^ { \delta } \,.$$
In this case by substituting the original expression (5.6) and rescaling the variable U 2 → c P Q U 2 , we obtain the spectral curve for the ( P, Q ) torus knot Chern-Simons theory on the lens space
$$X = \frac { U ^ { Q } } { \left ( 1 - c ^ { \frac { P } { Q } - 1 } U ^ { 2 } \right ) ^ { P } } \left ( - \frac { \zeta } { 2 } c ^ { ( \frac { P } { Q } - 1 ) / 2 } U \pm \sqrt { \frac { \zeta ^ { 2 } } { 4 } c ^ { \frac { P } { Q } - 1 } U ^ { 2 } + \left ( 1 - c ^ { \frac { P } { Q } - 1 } U ^ { 2 } \right ) \left ( 1 - c ^ { \frac { P } { Q } + 1 } U ^ { 2 } \right ) } \right ) ^ { P } \,,$$
(5.16)
$$V = \frac { 1 } { 1 - c ^ { \frac { P } { Q } - 1 } U ^ { 2 } } \left ( - \frac { \zeta } { 2 } c ^ { ( \frac { P } { Q } - 1 ) / 2 } U \pm \sqrt { \frac { \zeta ^ { 2 } } { 4 } c ^ { \frac { P } { Q } - 1 } U ^ { 2 } + \left ( 1 - c ^ { \frac { P } { Q } - 1 } U ^ { 2 } \right ) \left ( 1 - c ^ { \frac { P } { Q } + 1 } U ^ { 2 } \right ) } \right ) \,.$$
$$( 5. 1 7 )$$
It is shown in [30, 31] that the new curve obtained through this kind of symplectic transformation gives the topological invariants for torus knots in the lens space S / 3 Z 2 , which is dual to the topological string on the local P 1 × P 1 geometry.
## 5.2 Saddle point analysis
We study the torus knot spectral curve from the large N limit of the matrix model (5.1), and then check its consistency with the result obtained through the symplectic transformation, (5.16) and (5.17). We now rewrite the matrix integral (5.1) with another set of variables, u i = e x / PQ i ( ) and v i = e y / PQ i ( ) ,
$$u _ { i } = e ^ { x _ { i } / ( r \varPsi ) } \text{ and } v _ { i } = e ^ { y _ { i } / ( r \varPsi ) }, \\ \mathcal { Z } _ { \text{CS} } ^ { ( P, Q ) } ( L ( 2, 1 ) ; q ) & = \frac { 1 } { N! ^ { 2 } } \int \frac { d ^ { N } u } { ( 2 \pi ) ^ { N } } \frac { d ^ { N } v } { ( 2 \pi ) ^ { N } } \exp \left [ \sum _ { i, j = 1 } ^ { N } \left ( \log ( u _ { i } ^ { P } + v _ { j } ^ { P } ) + \log ( u _ { i } ^ { Q } + v _ { j } ^ { Q } ) \right ) \\ & \quad + \sum _ { i < j } ^ { N } \left ( \log ( u _ { i } ^ { P } - u _ { j } ^ { P } ) + \log ( u _ { i } ^ { Q } - u _ { j } ^ { Q } ) + \log ( v _ { i } ^ { P } - v _ { j } ^ { P } ) + \log ( v _ { i } ^ { Q } - v _ { j } ^ { Q } ) \right ) \\ & \quad - \sum _ { i = 1 } ^ { N } \left ( \frac { P Q } { 2 g _ { s } } \left ( \log ^ { 2 } u _ { i } + \log ^ { 2 } v _ { i } \right ) + \left ( \frac { P + Q } { 2 } ( 2 N - 1 ) + 1 \right ) \left ( \log u _ { i } + \log v _ { i } \right ) \right ) \right ]. \\ \text{The matrix integral has a convex notential (see [32]\). and this implies that the integrand has}$$
The matrix integral has a convex potential (see [32]), and this implies that the integrand has a unique minimum.
In this case we have two saddle point equations with u i and v i variables, glyph[negationslash]
$$\sum _ { j ( \ne i ) } ^ { N } \left [ \frac { P u _ { i } ^ { P } } { u _ { i } ^ { P } - u _ { j } ^ { P } } + \frac { Q u _ { i } ^ { Q } } { u _ { i } ^ { Q } - u _ { j } ^ { Q } } \right ] + \sum _ { j = 1 } ^ { N } \left [ \frac { P u _ { i } ^ { P } } { u _ { i } ^ { P } + v _ { j } ^ { P } } + \frac { Q u _ { i } ^ { Q } } { u _ { i } ^ { Q } + v _ { j } ^ { Q } } \right ] = \frac { P Q } { g _ { s } } \log u _ { i } + \frac { P + Q } { 2 } ( 2 N - 1 ) + 1 \,, \\ \dots \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, -$$
glyph[negationslash]
$$\sum _ { j ( \ne i ) } ^ { N } \left [ \frac { P v _ { i } ^ { P } } { v _ { i } ^ { P } - v _ { j } ^ { P } } + \frac { Q v _ { i } ^ { Q } } { v _ { i } ^ { Q } - v _ { j } ^ { Q } } \right ] + \sum _ { j = 1 } ^ { N } \left [ \frac { P v _ { i } ^ { P } } { v _ { i } ^ { P } + u _ { j } ^ { P } } + \frac { Q v _ { i } ^ { Q } } { v _ { i } ^ { Q } + u _ { j } ^ { Q } } \right ] = \frac { P Q } { g _ { s } } \log v _ { i } + \frac { P + Q } { 2 } ( 2 N - 1 ) + 1 \,.$$
Let us now rewrite these equations in terms of the resolvent [5]. Using the formula
$$\frac { P x ^ { P - 1 } } { x ^ { P } - y ^ { P } } = \sum _ { \substack { k = 0 \\ \sim \. } } ^ { P - 1 } \frac { 1 } { x - \omega ^ { - k Q } y } \,,$$
$$\frac { P x ^ { P - 1 } } { x ^ { P } + y ^ { P } } = \sum _ { k = 0 } ^ { p - 1 } \frac { 1 } { x - \omega ^ { - ( k + \frac { 1 } { 2 } ) Q } y } \,,$$
with the primitive PQ -th root of unity ω = exp2 πi/ PQ ( ), we have glyph[negationslash]
glyph[negationslash]
$$& \sum _ { j ( \neq i ) } ^ { N } \frac { P u _ { i } ^ { P } } { u _ { i } ^ { P } - u _ { j } ^ { P } } + \sum _ { j = 1 } ^ { N } \frac { P u _ { i } ^ { P } } { u _ { i } ^ { P } + v _ { j } ^ { P } } \\ & = \sum _ { j ( \neq i ) } ^ { N } \frac { u _ { i } } { u _ { i } - u _ { j } } + \sum _ { k = 1 } ^ { P - 1 } \left ( \frac { 1 } { g _ { s } } W _ { 0 } ^ { ( 1 ) } ( u _ { i } \omega ^ { k Q } ) - \frac { 1 } { 1 - \omega ^ { - k Q } } \right ) + \sum _ { k = 0 } ^ { P - 1 } \frac { 1 } { g _ { s } } W _ { 0 } ^ { ( 2 ) } ( u _ { i } \omega ^ { ( k + \frac { 1 } { 2 } ) Q ) } ) \,, \quad ( 5. 2 3 )$$
where W ( ) i 0 ( u ) is the leading contribution to the resolvents
$$W ^ { ( 1 ) } ( u ) = \left \langle g _ { s } \sum _ { i = 1 } ^ { N } \frac { u } { u - u _ { i } } \right \rangle = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 1 } W _ { g } ^ { ( 1 ) } ( u ) \,,$$
$$W ^ { ( 2 ) } ( u ) = \left \langle g _ { s } \sum _ { i = 1 } ^ { N } \frac { u } { u - v _ { i } } \right \rangle = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 1 } W _ { g } ^ { ( 2 ) } ( u ) \,.$$
These resolvents are analytic in the complex plane except for a finite set of cuts. We now assume that each resolvent has only one cut in the complex plane C ∗ . We can check later that this assumption is correct, using unicity of the extremum guaranteed by [32].
We introduce the 't Hooft coupling constants for this matrix model. If we consider a generic situation with the gauge group U( N 1 + N 2 ) → U( N 1 ) × U( N 2 ), we have two constants
$$t ^ { ( i ) } = g _ { s } N _ { i } \,, \quad i = 1, \, 2 \,.$$
The summation of them is denoted by t = t (1) + t (2) . ABJM theory corresponds to the situation such that N 2 is analytically continuated as N 2 →-N 2 , and then the gauge group ranks are chosen to be N 1 2 , → N . This means that the total 't Hooft coupling becomes zero t = 0. Then the boundary conditions for the resolvents are given by
$$W _ { 0 } ^ { ( i ) } ( u ) \ & \longrightarrow \ \begin{cases} 0 & ( u \to 0 ) \\ t ^ { ( i ) } & ( u \to \infty ) \end{cases},$$
and the saddle point equations in the 't Hooft limit with N →∞ and g s → 0 yield
$$P Q \log u + \frac { P + Q } { 2 } t = W _ { 0 } ^ { ( 1 ) } ( u + i 0 ) + W _ { 0 } ^ { ( 1 ) } ( u - i 0 ) + \sum _ { k = 1 } ^ { P - 1 } W _ { 0 } ^ { ( 1 ) } ( u \omega ^ { k Q } ) + \sum _ { k = 1 } ^ { Q - 1 } W _ { 0 } ^ { ( 1 ) } ( u \omega ^ { k P } ) \\ + \sum _ { k = 0 } ^ { P - 1 } W _ { 0 } ^ { ( 2 ) } ( u \omega ^ { ( k + \frac { 1 } { 2 } ) Q } ) + \sum _ { k = 0 } ^ { Q - 1 } W _ { 0 } ^ { ( 2 ) } ( u \omega ^ { ( k + \frac { 1 } { 2 } ) P } ) \,,$$
$$P Q \log u + \frac { P + Q } { 2 } t = W _ { 0 } ^ { ( 2 ) } ( u + i 0 ) + W _ { 0 } ^ { ( 2 ) } ( u - i 0 ) + \sum _ { k = 1 } ^ { P - 1 } W _ { 0 } ^ { ( 2 ) } ( u \omega ^ { k Q } ) + \sum _ { k = 1 } ^ { Q - 1 } W _ { 0 } ^ { ( 2 ) } ( u \omega ^ { k P } ) \\ + \sum _ { k = 0 } ^ { P - 1 } W _ { 0 } ^ { ( 1 ) } ( u \omega ^ { ( k + \frac { 1 } { 2 } ) Q } ) + \sum _ { k = 0 } ^ { Q - 1 } W _ { 0 } ^ { ( 1 ) } ( u \omega ^ { ( k + \frac { 1 } { 2 } ) P } ) \,. \quad \quad ( 5. 2 9 ) \\ \cdot \quad \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \end{cases}$$
In order to deal with these equations, it is convenient to introduce the exponentiated resolvents
$$y ^ { ( a ) } ( u ) = - u \exp \frac { P + Q } { P Q } \left ( \frac { t } { 2 } - W _ { 0 } ^ { ( 1 ) } ( u ) - W _ { 0 } ^ { ( 2 ) } ( u \, \omega ^ { \frac { 1 } { 2 } Q } ) \right ) \,,$$
$$y ^ { ( b ) } ( u ) = - u \exp \frac { P + Q } { P Q } \left ( \frac { t } { 2 } - W _ { 0 } ^ { ( 1 ) } ( u ) - W _ { 0 } ^ { ( 2 ) } ( u \, \omega ^ { \frac { 1 } { 2 } \, P } ) \right ) \,,$$
′
1
| F 0 | F 1 | F 2 | F 3 | F 4 |
|---------------|---------------------|---------------------|-------------------------------|-------------------------------|
| F F ′ 3 F ′ 4 | F 3 F 4 F ′ 3 F ′ 4 | F 3 F 4 F 3 F ′ 4 | F 0 F 1 F 2 F ′ 0 F ′ 1 F ′ 2 | F 0 F 1 F 2 F ′ 0 F F ′ 2 |
| F ′ 0 | F ′ 1 | F ′ 2 | F ′ 3 | F ′ 4 |
| F ′ 4 F 3 F 4 | F ′ 4 F ′ 3 F 3 F 4 | F ′ 4 F ′ 3 F 3 F 4 | F ′ 2 F ′ 0 F ′ 1 F 0 F 1 F 2 | F ′ 2 F ′ 0 F ′ 1 F 0 F 1 F 2 |
Table 1: The cuts of the functions F k ( u ) and F Q l + ( u ) for ( P, Q ) = (2 , 3), where F k = F k ( u ), F ′ k = F k ( uω 1 2 ( P -Q ) ) and F ′ Q l + = F Q l + ( uω 1 2 ( Q P -) ). The solid and dotted lines correspond to the cuts from the first resolvent W (1) ( u ) and the second resolvent W (2) ( u ). For example, we can see F 0 = F 3 , F 4 under crossing the corresponding cut of W (1) ( u ), and F 0 = F ′ 3 , F ′ 4 through the cut from W (2) ( u ).
with the boundary behavior
$$y ^ { ( a, b ) } ( u ) \ \longrightarrow \ \begin{cases} - u \, e ^ { \frac { P + Q } { 2 P Q } t } & ( u \to 0 ) \\ - u \, e ^ { - \frac { P + Q } { 2 P Q } t } & ( u \to \infty ) \end{cases}.$$
The saddle point equations are now written as follows,
$$y ^ { ( a ) } ( u + i 0 ) y ^ { ( b ) } ( u - i 0 ) \prod _ { k = 1 } ^ { P - 1 } y ^ { ( a ) } ( u \, \omega ^ { k Q } ) \prod _ { k = 1 } ^ { Q - 1 } y ^ { ( b ) } ( u \, \omega ^ { k P } ) = 1 \,, \quad ( 5. 3 3 )$$
$$y ^ { ( a ) } ( ( u + i 0 ) \omega ^ { \frac { 1 } { 2 } Q } ) y ^ { ( b ) } ( ( u - i 0 ) \omega ^ { \frac { 1 } { 2 } P } ) \prod _ { k = 1 } ^ { P - 1 } y ^ { ( a ) } ( u \omega ^ { ( k + \frac { 1 } { 2 } ) Q } ) \prod _ { k = 1 } ^ { Q - 1 } y ^ { ( b ) } ( u \omega ^ { ( k + \frac { 1 } { 2 } ) P } ) = 1 \,. \quad ( 5. 3 4 )$$
Because it is converted to each other under the exchange of W (1) ( u ) and W (2) ( u ), these equations imply an equivalent condition for the resolvents, which is essentially the same as the one-cut Chern-Simons matrix model for the ( P, Q ) torus knot [5]. Thus we can apply a similar approach to solve these equations.
We consider the products of the resolvents
$$F _ { k } ( u ) = \prod _ { \substack { l = 0 \\ \wedge \,. } } ^ { P - 1 } y ^ { ( a ) } ( u \omega ^ { k P + l Q } ) \,, \quad 0 \leq k \leq Q - 1 \,,$$
$$F _ { Q + l } ( u ) = \prod _ { k = 0 } ^ { Q - 1 } \frac { 1 } { y ^ { ( b ) } ( u \omega ^ { k P + l Q } ) } \,, \quad 0 \leq l \leq P - 1 \,.$$
Since we have assumed that the original resolvents W ( ) i ( u ) have a single cut, these functions F k ( u ) and F Q l + ( u ) have 2 P and 2 Q cuts, obtained by rotating the original one with integer multiple angles of 2 π/ PQ ( ). The total number of the cuts is thus 2 PQ . Due to the saddle point equations they satisfy
$$F _ { k } ( u - i 0 ) \ & = \ \ F _ { Q + l } ( u + i 0 ) \quad \text{ for } \ W ^ { ( 1 ) } ( u ) \,, \\ F _ { k } ( u - i 0 ) \ & = \ \ F _ { Q + l } ( ( u + i 0 ) \omega ^ { \frac { 1 } { 2 } ( Q - P ) } ) \quad \text{for } \ W ^ { ( 2 ) } ( u ) \,, \\ F _ { k } ( ( u - i 0 ) \omega ^ { \frac { 1 } { 2 } ( P - Q ) } ) \ & = \ \ F _ { Q + l } ( ( u + i 0 ) \omega ^ { \frac { 1 } { 2 } ( Q - P ) } ) \quad \text{for } \ W ^ { ( 1 ) } ( u ) \,, \\ F _ { k } ( ( u - i 0 ) \omega ^ { \frac { 1 } { 2 } ( P - Q ) } ) \ & = \ \ F _ { Q + l } ( u + i 0 ) \quad \text{for } \ W ^ { ( 2 ) } ( u ) \,.$$
This means that F k ( u -i 0) = F Q l + ( u + 0) under crossing the cut from the first resolvent i W (1) ( u ), F k ( u -i 0) = F Q l + (( u + 0) i ω 1 2 ( Q P -) ) for the cut from the second W (2) ( u ), and so on. See Table 1 for the case with ( P, Q ) = (2 , 3).
Using these functions we define a function
$$\mathcal { S } ( u, f ) = \mathcal { S } _ { 1 } ( u, f ) \, \mathcal { S } _ { 2 } ( u, f ) \,,$$
where
$$\mathcal { S } _ { 1 } ( u, f ) = \prod _ { \underset { \sim } { \overset { Q - 1 } { \wedge } } } ^ { Q - 1 } \left ( f - F _ { k } ( u ) \right ) \prod _ { l = 0 } ^ { P - 1 } \left ( f - F _ { Q + l } ( u ) \right ),$$
$$\mathcal { S } _ { 2 } ( u, f ) = \prod _ { k = 0 } ^ { Q - 1 } \left ( f - F _ { k } ( u \omega ^ { \frac { 1 } { 2 } ( P - Q ) } ) \right ) \prod _ { l = 0 } ^ { P - 1 } \left ( f - F _ { Q + l } ( u \omega ^ { \frac { 1 } { 2 } ( Q - P ) } ) \right ) \,. \quad \quad ( 5. 4 0 )$$
This function has no cut in the complex plane
$$\mathcal { S } ( u - i 0, f ) = \mathcal { S } ( u + i 0, f ) \,,$$
and the only singularities at u = 0 or u = ∞ as poles. This implies that S u, f ( ) is an entire function of u in C ∗ with polynomial behavior at 0 and at ∞ , therefore it must be a Laurent polynomial of u . Moreover since this function satisfies S ( u, f ) = S ( uω,f ), it depends only on u PQ , and must be a Laurent polynomial of u PQ . We remark that S 1 ( u, f ) and S 2 ( u, f ) still have the cuts, and thus they are not analytic functions.
By definition, S ( u, f ) vanishes when f = F k ( u ), and thus the spectral curve is the algebraic equation:
$$\mathcal { S } ( u, f ) = 0 \,.$$
As shown in [5] we can determine coefficients of the polynomial S ( u, f ) by the asymptotic behavior of F k ( u ) and F Q l + ( u ),
$$F _ { k } ( u ) \, \longrightarrow \, \begin{cases} - \omega ^ { k P ^ { 2 } } \, e ^ { \frac { ( P + Q ) } { 2 Q } t } \, u ^ { P } & ( u \to 0 ) \\ - \omega ^ { k P ^ { 2 } } \, e ^ { - \frac { ( P + Q ) } { 2 Q } t } \, u ^ { P } & ( u \to \infty ) \end{cases},$$
$$F _ { Q + l } ( u ) \, \longrightarrow \, \begin{cases} - \omega ^ { - l Q ^ { 2 } } \, e ^ { - \frac { ( P + Q ) } { 2 P } t } \, u ^ { - Q } & ( u \to 0 ) \\ - \omega ^ { - l Q ^ { 2 } } \, e ^ { \frac { ( P + Q ) } { 2 P } t } \, u ^ { - Q } & ( u \to \infty ) \end{cases}.$$
$$\i e \\ \mathcal { S } _ { i } ( u, f ) = \sum _ { k = 0 } ^ { P + Q } ( - 1 ) ^ { k } \mathcal { S } _ { i, k } ( u ) \, f ^ { P + Q - k } \,, \ \ i = 1, \, 2 \,,$$
this behavior implies
$$\text{ins oceanive} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text
} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text { } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text` \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text
}$$
$$\begin{cases} \mathcal { S } _ { i, k } ( u ) = \mathcal { O } ( u ^ { k P } ) \,, & 1 \leq k \leq Q - 1 \,, \\ \mathcal { S } _ { 1, k } ( u ) = ( - 1 ) ^ { P + Q + P Q } e ^ { - \frac { P + Q } { 2 } t } u ^ { P Q } \left ( 1 + \mathcal { O } ( 1 / u ) \right ) \,, & k = Q \,, \\ \mathcal { S } _ { 2, k } ( u ) = ( - 1 ) ^ { P Q } e ^ { - \frac { P + Q } { 2 } t } u ^ { P Q } \left ( 1 + \mathcal { O } ( 1 / u ) \right ) \,, & k = Q \,, \\ \mathcal { S } _ { i, k } ( u ) = \mathcal { O } ( u ^ { P Q } u ^ { - ( k - Q ) Q } ) \,, & Q + 1 \leq k \leq P + Q - 1 \,, \end{cases}$$
(5.47)
Thus we obtain that S ( u, f ) is a polynomial of f and of u PQ
$$\mathcal { S } ( u, f ) = f ^ { 2 ( P + Q ) } + 1 + ( - 1 ) ^ { P + Q } e ^ { - ( P + Q ) t } \left ( u ^ { - 2 P Q } f ^ { 2 Q } + u ^ { 2 P Q } f ^ { 2 P } \right ) + \cdots.$$
where · · · means terms within the Newton polygon, and which are not determined by asymptotic behaviors. The spectral curve for the two-cut matrix model is now given by the following polynomial relation,
$$\mathcal { S } ( u, f ) = 0 \,.$$
It is shown in [32, 33] that if the potential has convexity property, then the solution of the saddle point analysis is unique. This is the case here. We are looking for a two-cut solution, i.e. a genus-one spectral curve. A generic S ( u, f ) with the given Newton's polygon (5.48), would have genus the number of interior points of the Newton's polygon, i.e. 4( P + Q ) -3. However we are here looking for a genus-one curve, which implies that all but one coefficient
If we write
X
2
1
Figure 4: Newton's polygons for the spectral curve. The polygon in the left panel corresponds to the curve (5.53). There are cetain lattice points inside the polygon, which are fixed by the condition that the curve should have genus-one, and by the filling fraction condition. The right panel shows its singular limit, where the two resolvents W (1) ( u ) and W (2) ( u ) coincide with each other. In this case there is no lattice point inside the polygon.
of S ( u, f ) must be fixed by vanishing of some discriminants. The last coefficient is fixed by the filling fraction condition for U( N M | ), corresponding to (5.10) and (5.11):
$$\frac { 1 } { 2 \pi i } \oint _ { \mathcal { A } } W ( u ) \, d u = g _ { s } N \,, \quad \frac { 1 } { 2 \pi i } \oint _ { \mathcal { B } } W ( u ) \, d u = g _ { s } M \,,$$
where W u ( ) is the sum of the resolvents, and A and B are contours around the first cut and the second cut. One could determine S ( u, f ) by solving all vanishing discriminant equations, so as to impose that the curve have genus-one. However there is a short-cut: one can exhibit an S ( u, f ) with the correct Newton's polygon, the correct filling fraction condition and the correct asymptotic behaviors at 0 and ∞ and which is guaranteed to be genus-one. By unicity according to [32, 33] it must be the correct spectral curve.
The S ( u, f ) which has genus-one and the correct asymptotic behavior is simply the symplectic transform of the unknot of section 5.1, which we write parametrically as [5]
$$f = \frac { V } { U } \,, \quad u ^ { - P Q } = X = U ^ { Q } V ^ { P } \,,$$
we obtain another expression of the spectral curve (5.49) in terms of U and V ,
$$\mathcal { S } ( U, V ) = U ^ { 2 ( P + Q ) } + V ^ { 2 ( P + Q ) } + ( - 1 ) ^ { P + Q } e ^ { - ( P + Q ) t } ( U V ) ^ { 2 ( P + Q ) } + ( - 1 ) ^ { P + Q } e ^ { - ( P + Q ) t } + \cdots = 0 \,,$$
which is equivalent to
$$\mathcal { S } ( X, V ) = V ^ { 2 ( P + Q ) } + X ^ { 2 } + ( - 1 ) ^ { P Q } e ^ { - ( P + Q ) t } X ^ { 2 } V ^ { 2 Q } + ( - 1 ) ^ { P Q } e ^ { - ( P + Q ) t } V ^ { 2 P } + \cdots = 0 \,. \, \text{ (5.53)}$$
P
+
Q
Q
P
V
2
We depict the Newton's polygon for this spectral curve in Fig. 4.
Let us then comment on the singular limit of the spectral curve (5.53), which is realized when the two resolvents W (1) ( u ) and W (2) ( u ) coincide with each other. In this case the analytic function obeys S ( u, f ) = S ( uω ,f 1 2 ). This implies it depends only on u 2 PQ . Therefore the spectral curve (5.53) has to be written only in terms of X 2 and V 2 . The Newton's polygon corresponding to this situation is shown in the right panel of Fig. 4. Since there is no lattice point inside the polygon, the spectral curve has no free parameter. This means that it is just reduced to the genus-zero curve, which corresponds to the limit ζ → 0 of the curve (5.3).
## 5.3 Asymptotic expansion and topological recursion
The matrix integral (3.10) is of the type discussed in [32], therefore it guarantees that it has an asymptotic expansion of the type
$$\log \mathcal { Z } _ { \text{ABJM} } ^ { ( P, Q ) } = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 2 } F _ { g }$$
which obeys the topological recursion of [14], i.e. F g is the g th symplectic invariant of the spectral curve as defined by the topological recursion [14]. Similarly, all expectation values have a g s -expansion, whose coefficients are given by the topological recursion.
The character expectation values 〈 Tr R U 〉 can be decomposed on the basis of power sums. We have:
$$\left \langle \prod _ { i = 1 } ^ { n } \text{Tr} \, U ^ { p _ { i } } \right \rangle = \text{Res} _ { x _ { 1 } \rightarrow 0 } \dots \text{Res} _ { x _ { n } \rightarrow 0 } W _ { n } ( x _ { 1 }, \dots, x _ { n } ) \, x _ { 1 } ^ { p _ { 1 } } \dots x _ { n } ^ { p _ { n } } \prod _ { i = 1 } ^ { n } \frac { d x _ { i } } { x _ { i } } \, \quad \ \ ( 5. 5 5 )$$
and W n has a topological expansion:
$$W _ { n } ( x _ { 1 }, \dots, x _ { n } ) = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 2 + n } W _ { g, n } ( x _ { 1 }, \dots, x _ { n } )$$
and W g,n is computed by the topological recursion.
## 6 Comments on related topics
## 6.1 Topological A-model
Let us comment on the realization of the knot invariant in topological string theory, especially in the topological A-model. It was shown in [19] that the knot invariant for K is obtained in the topological string by adding a brane with a proper Lagrangian submanifold of the Calabi-Yau threefold L K . This insertion of a brane gives rise to the expectation value of the
characteristic polynomial with respect to Chern-Simons theory
$$\mathcal { Z } _ { \text{top} } ( K ; x ) & = \left \langle \det \left ( 1 \otimes 1 - U \otimes e ^ { - x } \right ) \right \rangle _ { \text{CS} } \\ & = \sum _ { n = 0 } ^ { \infty } \left \langle \text{Tr} _ { R _ { n } } U \right \rangle _ { \text{CS} } e ^ { - n x } \,,$$
where the matrix U is the holonomy along the knot K U , = Pexp (∮ K A ) , and R n is the totally symmetric representation with n boxes. This means that this topological string partition function is the discrete Fourier (Laplace) transform of the HOMFLY polynomial, since the expectation value of the holonomy 〈 Tr R n U 〉 just gives the knot invariant. If we consider a multi-point correlator of the characteristic polynomials, the knot invariant with more generic representations is obtained. Note that this knot invariant is analogous to the matrix integral with the external source, as discussed in Sec. 6.3. This kind of relation between the characteristic polynomial and the external source is naturally interpreted from the viewpoint of the topological expansion of spectral curves.
In our case it is natural to consider a supermatrix version of the partition function (6.1), corresponding to ABJM theory
$$\mathcal { Z } _ { \text{top} } ( K ; x, y ) = \left \langle \text{Sdet} \left ( 1 \otimes 1 - U \otimes \left ( \begin{array} { c c } e ^ { - x } \\ & e ^ { - y } \end{array} \right ) \right ) \right \rangle _ { \text{ABJM} } \,.$$
Actually one can obtain this partition function by applying both of bosonic and fermionic modes, describing strings stretching between the three-sphere S 3 and the Lagrangian L K
$$\mathcal { Z } _ { \text{top} } ( K ; x, y ) = \left \langle \frac { \det \left ( 1 \otimes 1 - U ^ { \prime } \otimes e ^ { - x } \right ) } { \det \left ( 1 \otimes 1 - U ^ { \prime \prime } \otimes e ^ { - y } \right ) } \right \rangle$$
where U = diag( U , U ′ ′′ ). Whether it comes in denominator (bosonic) or numerator (fermionic) depends on the relative orientation of S 3 and L K [34]. See also the argument on the characteristic polynomial ratio presented in Sec. 6.3.
We can similarly expand (6.2) with the corresponding expectation value 〈 Str R n U 〉 ABJM . This partition function is also expanded with the string coupling constant in the sense of the WKB expansion [19]. Using the identity
$$\text{Sdet} \left ( 1 \otimes 1 - U \otimes \left ( \begin{array} { c } e ^ { - x } \\ & e ^ { - y } \end{array} \right ) \right ) = \exp \left [ \text{Str log} \left ( 1 \otimes 1 - U \otimes \left ( \begin{array} { c } e ^ { - x } \\ & e ^ { - y } \end{array} \right ) \right ) \right ] \,,$$
we have
$$\mathcal { Z } _ { \text{top} } ( K ; x, y ) \, \sim \, \exp \left ( \frac { 1 } { g _ { s } } \int _ { y } ^ { x } p ( x ) d x \right ) \,,$$
where the integrand is given by
$$p ( x ) = \lim _ { g _ { s } \to 0 } \sum _ { n = 0 } ^ { \infty } g _ { s } \left \langle \text{Str} \, U ^ { n } \right \rangle _ { \text{ABJM} } e ^ { - n x } \,.$$
In this way we can show that its leading contribution is given by the disc amplitude as well as the ordinary knot invariant. In this case, since the ABJM matrix model is obtained from Chern-Simons theory on the lens space L (2 1) through the analytic continuation, the , mirror curve, on which the one-form is defined, is replaced with that for the local P 1 × P 1 geometry. Actually the Wilson loop expectation value is evaluated based on this spectral curve [20, 35]. Furthermore, in (6.5), both of the initial and end points of the integral have physical meanings, as positions of brane and anti-brane. Thus the partition function describes pair creation of branes in the topological string. If we take the limit y → ∞ , it goes back to the usual one, including either of bosonic or fermionic modes.
## 6.2 Topological B-model
In the B-model description of the topological strings, the n -point function defined in (5.56) plays an important role. As well as the one-point function W 1 = W which is given as the resolvent, we also have a series expansion of the multi-point function with respect to the coupling constant. If once a spectral curve is obtained, one can determine higher order terms by using the topological recursion [14]. In this study the spectral curve is given by the genus-one mirror curve for the local P 1 × P 1 geometry and its symplectic transform. Indeed this expansion has a natural interpretation in terms of the B-model topological strings. The multi-point correlation function corresponds to multiple insertion of the Wilson loop operators into the Chern-Simons matrix model. Thus a set of variables in the multi-point function (5.56) provides the boundary condition for topological strings. This implies that it computes the open string sector of the B-model, and we can obtain the corresponding open Gromov-Witten invariants based on the mirror symmetry in a perturbative way [36, 37, 38].
As in the case of the topological A-model, the knot invariant can be investigated also in the B-model through the mirror symmetry. In addition to the unknot invariants [39, 40], the torus knot invariant is formulated by using the symplectic transformation acting on the Bmodel open string moduli [5]. 4 Moreover this prescription for giving the torus knot invariant is now applied to the knot invariant not only in the three-sphere S 3 , but also in the lens space L (2 , 1) [30, 31]. Since the ABJM matrix model is perturbatively equivalent to Chern-Simons theory on the lens space L (2 1), the perturbative analysis of the knot invariant for , L (2 1), , which is based on the topological recursion, is apparently relevant to our supermatrix model for the torus knot introduced in Sec. 3. Although we can obtain a systematic expansion of the correlation functions, we have to also take into account non-perturbative contributions, which play an important role in knot theory [15, 16] and ABJM theory [42]. The study of such a non-perturbative effect on the torus knots is an interesting and important issue to be clarified in the future.
4 Let us note that another kind of approach to the B-model description, which is in principle applicable to any knots, is discussed based on the A-polynomial [41].
## 6.3 Matrix models
We comment on the idea underlying this work, which comes from random matrices. In random matrix theory, the wave functions are expectation values of characteristic polynomials
$$\psi ( x ) = \left \langle \det ( x - M ) \right \rangle,$$
where the expectation value is taken with respect to a certain measure, which is specified later. The Hamiltonian associated with this wave function is given by the non-commutative Riemann surface, which is obtained through quantization of the spectral curve. In fact, a more important object is the kernel
$$\mathcal { K } ( x ; y ) = \frac { 1 } { y - x } \left \langle \frac { \det ( x - M ) } { \det ( y - M ) } \right \rangle \,.$$
Out of that kernel one can reconstruct every other observables. For instance, if the matrix size is given by N , the wave function is obtained by sending y →∞ ,
$$\psi ( x ) = \lim _ { y \to \infty } y ^ { N + 1 } \, \mathcal { K } ( x ; y ) \,.$$
Every other correlations of characteristic polynomials is obtained by the Fay identity [11] (See also [12, 13])
$$\left \langle \prod _ { i = 1 } ^ { k } \frac { \det ( x _ { i } - M ) } { \det ( y _ { i } - M ) } \right \rangle = \frac { \prod _ { i, j } ( y _ { i } - x _ { j } ) } { \prod _ { i < j } ( x _ { i } - x _ { j } ) \, ( y _ { i } - y _ { j } ) } \, \det _ { 1 \leq i, j \leq k } \mathcal { K } ( x _ { i } ; y _ { j } ) \,,$$
which is also seen as Pl¨cker or Hirota equation. u The factor in front of the determinant of the kernel can be written as the Cauchy determinant (2.16).
Wave functions and kernels can be seen themselves as partition functions. Indeed let
$$\mathcal { Z } = \int d \mu ( M )$$
be a matrix integral with some measure dµ M ( ) depending on a coupling constant g s . In many cases, there is a small g s expansion of the type
$$\log \mathcal { Z } = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 2 } \, F _ { g } ( \mathcal { C } )$$
where C is the spectral curve associated to the measure dµ , i.e. the g s → 0 limit of the eigenvalue distribution.
An expectation value of characteristic polynomials can be written
$$\mathcal { K } ( x _ { 1 }, \dots, x _ { k } ; y _ { 1 }, \dots, y _ { k } ) = \frac { 1 } { \mathcal { Z } } \int d \mu ( M ) \prod _ { i = 1 } ^ { k } \frac { \det ( x _ { i } - M ) } { \det ( y _ { i } - M ) } \,,$$
i.e. it is the partition function with a new measure
$$d \mu _ { x ; y } ( M ) = \exp \sum _ { i = 1 } ^ { k } \left ( \, \text{Tr} \log ( x _ { i } - M ) - \text{Tr} \log ( y _ { i } - M ) \right ) d \mu ( M ) \,. \quad \quad \, ( 6. 1 4 )$$
There is also a g s expansion with a new spectral curve
$$\log \mathcal { K } ( x _ { 1 }, \dots, x _ { k } ; y _ { 1 }, \dots, y _ { k } ) = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 2 } \left ( F _ { g } ( \mathcal { C } _ { x ; y } ) - F _ { g } ( \mathcal { C } ) \right ).$$
The way to find the new spectral curve is as follows. The spectral curve C is a Riemann surface equipped with two analytic functions u and v as C = { ( u, v ) ∈ C × C | H u,v ( ) = 0 } . The new spectral curve C x y ; is a Riemann surface such that vdu has additional simple poles at the x i 's (residue +1) and at the y i 's (residue -1).
Instead of characteristic polynomials one may also be interested in external fields interactions
$$\langle \mathrm e ^ { \text{Tr} \, M A } \rangle = \frac { 1 } { \mathcal { Z } } \int d \tilde { \mu } ( M ) \, \mathrm e ^ { \text{Tr} \, M A } \,.$$
Again, this has (under some assumptions) a g s expansion with a new spectral curve C A
$$\log \left \langle e ^ { \text{Tr} \, M A } \right \rangle = \sum _ { g = 0 } ^ { \infty } g _ { s } ^ { 2 g - 2 } \, \left ( F _ { g } ( \mathcal { C } _ { A } ) - F _ { g } ( \mathcal { C } ) \right ) \,.$$
The way to find the new spectral curve is as follows. The spectral curve C is a Riemann surface equipped with two analytic functions u and v . The new spectral curve C A is a Riemann surface such that udv has additional simple poles at the a i 's (the eigenvalues of A ) with a residue equal to the multiplicity of a i .
We see that under the exchange u ↔ v and by identifying the a i 's with the x i 's (multiplicity α i = 1) and the y i 's (multiplicity α i = -1), this would be the same spectral curve and thus
$$\left \langle e ^ { \text{Tr} \, M A } \right \rangle _ { \tilde { \mu } } \in \left \langle \prod _ { i = 1 } ^ { k } \det ( x _ { i } - M ) ^ { \alpha _ { i } } \right \rangle _ { \mu }$$
where the measures µ and ˜ are obtained by exchanging the role of µ u and v in the spectral curves, and A is a matrix with eigenvalues x i with multiplicity α i [14, 43, 44, 45, 46]. This raises the question of how can a multiplicity be negative? This is why supermatrix models are needed. Negative multiplicities correspond to the fermionic side of the supermatrix [47]. This duality between external field and expectation values of characteristic polynomials appeared in [48].
As shown in (2.26), the half-BPS Wilson loop expectation value in ABJM theory has a quite similar expression to that of matrix integral with the external source. The Gaussian matrix model with the external source is given as follows,
$$\left \langle e ^ { \text{Tr} \, M A } \right \rangle & = \frac { 1 } { \mathcal { Z } } \int d M \, e ^ { - \frac { 1 } { 2 g _ { s } } \, \text{Tr} \, M ^ { 2 } + \text{Tr} \, M A } \\ & = \frac { 1 } { \mathcal { Z } } \frac { 1 } { \Delta ( a ) } \int \prod _ { i = 1 } ^ { N } \frac { d x _ { i } } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g _ { s } } x _ { i } ^ { 2 } } \det _ { 1 \leq i, j \leq N } e ^ { x _ { i } a _ { j } } \prod _ { i < j } ^ { N } ( x _ { i } - x _ { j } ) \,,$$
where the U( N ) part is integrated out using the Harish-Chandra-Itzykson-Zuber formula [49, 50]. Writing the U( N ) character in terms of the Schur function
$$s _ { \lambda } ( e ^ { x } ) = \frac { 1 } { \Delta ( e ^ { x } ) } \det _ { 1 \leq i, j \leq N } e ^ { x _ { i } ( \lambda _ { j } + N - j ) } \,,$$
we obtain the Wilson loop expectation value with respect to the U( N ) Chern-Simons theory
$$\left \langle W _ { R } ( \mathcal { O } ) \right \rangle _ { \mathrm U ( N ) } = \frac { 1 } { \mathcal { Z } _ { \mathrm C S } } \int \prod _ { i = 1 } ^ { N } \frac { d x _ { i } } { 2 \pi } \, e ^ { - \frac { 1 } { 2 g _ { s } } x _ { i } ^ { 2 } } \det _ { 1 \leq i, j \leq N } e ^ { x _ { i } \tilde { \xi } _ { j } } \prod _ { i < j } ^ { N } \left ( 2 \sinh \frac { x _ { i } - x _ { j } } { 2 } \right ) \,,$$
with ˜ ξ i = λ i -i + N +1 2 . In this sense insertion of the Wilson loop operator corresponds to the external fields for the matrix integral.
This kind of interpretation can be possible even for the supergroup character average (2.26), at least as long as the partition λ , corresponding to the representation R , satisfies d λ ( ) = N . 5 All this means that characters of U( N N | ) are dual to expectation values of characteristic polynomials of another matrix model with some measure µ ,
$$\left \langle W _ { R } ( K ) \right \rangle _ { U ( N | N ) } = \left \langle \prod _ { i = 1 } ^ { N } \frac { \det ( \alpha _ { i } - M ) } { \det ( \beta _ { i } - M ) } \right \rangle _ { \mu } \,,$$
and where α , β i i are the Frobenius coordinates for the representation R . Then the Fay identity says that
$$\left \langle W _ { R } ( K ) \right \rangle _ { U ( N | N ) } = \det _ { 1 \leq i, j \leq N } \left \langle W _ { ( \alpha _ { i } | \beta _ { j } ) } ( K ) \right \rangle _ { U ( 1 | 1 ) }.$$
This is what we have checked in this article, especially as the determinantal formula for the unknot average shown in (2.28). This means that those supergroup character expectation values are Giambelli compatible [12].
## 7 Discussion
In this paper we have considered the supergroup character expectation value based on the ABJM matrix model as the supermatrix Chern-Simons theory, with emphasis on its connection to the knot invariant. We have explicitly computed the U(1 1) expectation value for |
5 When the representation does not satisfy this condition, there is no simple analogy between the matrix integral with the external fields and the Wilson loop average (2.34), because such an external field has to consist of N + N parameters for U( N N | ) theory. On the other hand, this analogy holds for arbitrary representations in the ordinary U( N ) Chern-Simons theory as (6.21). It is because even if the number of non-zero elements in the partition is less than N at the first place, it can be made N by the constant shift, since the average (2.31) is invariant under the shift of the partition
$$( \lambda _ { 1 }, \lambda _ { 2 }, \cdots, \lambda _ { N } ) \ \longrightarrow \ ( \lambda _ { 1 } + c, \lambda _ { 2 } + c, \cdots, \lambda _ { N } + c ) \,.$$
It is obvious that the U( N N | ) invariant (2.26) is not invariant under such a constant shift of the partition, since the corresponding external field is characterized by the Frobenius coordinates of the partition.
the unknot and torus knot matrix models. We have obtained the determinantal formula, where the U(1 1) average plays a role of a building block for U( | N N | ) theory, and shown the Rosso-Jones-type formula for the supergroup character average. We have also discussed the U( N M | ) theory, and found its determinantal formula which interpolates U( N N | ) and U( N ) theories. We have derived the spectral curve for the torus knot as the symplectic transform of the unknot curve, and by analyzing the saddle point equations for the torus knot matrix model itself. We have shown these two methods to obtain the spectral curve are consistent with each other. We have then commented on how to realize the knot invariant in topological string theory, and the underlying idea coming from random matrix theory.
Let us comment on some open issues to be investigated in the future. The most attractive one is to check whether the supergroup character average can be a knot invariant or not. We have certain evidence on this point. First of all, the U( N N | ) character expectation value contains U( N ) part as shown for the unknot Wilson loop (2.29). Furthermore, in the limit M → 0, the U( N M | ) matrix model (4.8) is explicitly reduced to the U( N ) torus knot matrix model, which is proven to be a topological invariant of the torus knot. This implies that, at least for the torus knot, the U( N M | ) average would play a role of the knot invariant which contains much information than the ordinary U( N ) invariant.
Secondly the ABJM matrix model is obtained from the lens space Chern-Simons theory through the analytic continuation. Since the knot invariant in the lens space is given as the character average with the corresponding matrix model, we can expect the character expectation value with the supermatrix model is also a knot invariant, at least up to some non-perturbative contributions. Moreover, the construction of the knot invariant shown in Sec. 6.1 seems natural from the viewpoint of topological string, and possibly applied to an arbitrary knot. These supporting facts suggest that we can obtain a knot invariant from ABJM theory. For this purpose, for example, it is interesting to see whether the torus knot supermatrix model can be directly obtained from ABJM theory. In the case of classical group theory, it is shown by [51] that the torus knot matrix model is obtained from N = 2 Chern-Simons theory on the ellipsoid-type squashed three-sphere S 3 b . This suggests that the supergroup torus knot character average is given by the half-BPS Wilson loop for the N = 6 ABJM theory on S 3 b . However the integral formula (3.10) is not obtained naively using the localization method for S 3 b , because the matter contribution cannot be written as a simple cosh function for such a case [52]. In addition, the mirror description of the torus knot model (3.10), presented in (A.3), is different from that on S 3 b . Although it is not yet obvious that such a way to obtain the torus knot invariant using the ellipsoid S 3 b is applicable to the present case, this discrepancy would reflect that ABJM theory itself is not topological, and we may need to consider, for example, topological twist to obtain the knot invariant for the Seifert manifold [2, 3, 4, 5]. We will return to this issue in the future.
If we can have the supergroup knot invariant, it is also interesting to provide another definition of the U( N N | ) knot invariant, for example, based on the Skein relation, which
enable us to compute the invariant for any knots in principle. It is naively expected that such a relation can be related to the supergroup WZW model. However, it is known that the U(1 1) WZW model describes the Skein relation for the Alexander-Conway polynomial [53, | 54, 55], while the torus knot average obtained in this paper (3.14) is not consistent with that. This reflects the fact that ABJM theory is not just Chern-Simons theory with the supergroup. We have to explore other possibility of the two-dimensional conformal field theory model, which shall live on the boundary of ABJM theory, if it exists. Furthermore, as the recent progress in knot theory, it is definitely interesting to study the volume conjecture and its generalization [56, 57, 58], the AJ conjecture [59], and also the knot homology [ ? , 60, 61, 62, 63] corresponding to the supergroup knot invariant. In order to discuss the volume conjecture, we have to deal with the hyperbolic knot and the volume of its complement in S 3 . Therefore our construction, which is so far available only for the unknot and torus knots, is not yet enough to study this conjecture. Also from this point of view, the definition of the knot invariant based on the Skein relation is highly desirable, as commented above. The AJ conjecture claims that the knot invariant satisfies some integrable equations, which are obtained through quantization of the A-polynomial. In other words, this implies that the knot invariant is associated with the corresponding τ -function. As pointed out in Sec. 6, the knot invariant is closely related to the matrix integral with the external fields, which can be seen as a certain τ -function. For example, the determinantal formula for the character expectation value given in this paper can be one of the supporting results for such a suggestive relation. The determinantal formula also gives an insight into the knot homology. Using the Jacobi identity for determinants, one can obtain some relations between the knot invariants for different rank groups. Such a relation could provide a natural differential on the knot homology.
## Acknowledgements
We would like to thank G. Borot and M. Mari˜o for fruitful discussions. We are also graten ful to A. Brini for carefully reading the manuscript and giving useful comments. BE thanks Centre de Recherches Math´ ematiques de Montr´al, the FQRNT grant from the Qu´bec gove e ernment, Piotr Suglyph[suppress]kowski l and the ERC starting grant Fields-Knots. The work of TK is supported in part by Keio Gijuku Academic Development Funds, MEXT-Supported Program for the Strategic Research Foundation at Private Universities 'Topological Science' (No. S1511006), and JSPS Grant-in-Aid for Scientific Research on Innovative Areas 'Topological Materials Science' (No. JP15H05855).
## A Mirror of the torus knot ABJM partition function
In this appendix we derive the mirror description of the torus knot ABJM partition function [25]. We first expand the determinants in (3.10) as summation over permutations
$$\mathcal { Z } _ { \text{ABJM} } ^ { ( P, Q ) } = \sum _ { \sigma, \sigma ^ { \prime } \in \mathfrak { S } _ { N } } ( - 1 ) ^ { \sigma + \sigma ^ { \prime } } \frac { 1 } { N! ^ { 2 } } \int _ { [ d x ] ^ { N } [ d y ] ^ { N } } \prod _ { i = 1 } ^ { N } \left ( 2 \cosh \frac { x _ { i } - y _ { \sigma ( i ) } } { 2 P } \, 2 \cosh \frac { x _ { i } - y _ { \sigma ^ { \prime } ( i ) } } { 2 Q } \right ) ^ { - 1 }.$$
Applying the formula (2.20), we have
$$\text{pying use formula } ( z _ { \sigma } \varnothing ), \, \text{we move} \\ \sum _ { \sigma, \sigma ^ { \prime } \in \mathfrak { S } _ { N } } ( - 1 ) ^ { \sigma + \sigma ^ { \prime } } \frac { 1 } { N! ^ { 2 } } \int _ { \frac { d ^ { N } x } { ( 2 \pi ) ^ { N } } } \frac { d ^ { N } y } { ( 2 \pi ) ^ { N } } \frac { d ^ { N } z } { ( 2 \pi ) ^ { N } } \, \frac { d ^ { N } w } { ( 2 \pi ) ^ { N } } \, \prod _ { i = 1 } ^ { N } \left ( \cosh z _ { i } \, \cosh w _ { i } \right ) ^ { - 1 } \\ \times \exp \left [ \frac { i k } { 4 P Q \pi } \sum _ { i = 1 } ^ { N } ( x _ { i } ^ { 2 } - y _ { i } ^ { 2 } ) + \frac { i } { \pi } \sum _ { i = 1 } ^ { N } \left ( x _ { i } \left ( \frac { z _ { i } } { P } + \frac { w _ { i } } { Q } \right ) - y _ { i } \left ( \frac { z _ { \sigma } - 1 ( i ) } { P } + \frac { w _ { \sigma ^ { \prime } - 1 ( i ) } } { Q } \right ) \right ) \right ] \\ = \sum _ { \sigma, \sigma ^ { \prime } \in \mathfrak { S } _ { N } } ( - 1 ) ^ { \sigma + \sigma ^ { \prime } } \frac { ( P Q ) ^ { N } } { N! ^ { 2 } \, k ^ { N } } \int _ { \frac { d ^ { N } z } { ( 2 \pi ) ^ { N } } } \frac { d ^ { N } w } { ( 2 \pi ) ^ { N } } \prod _ { i = 1 } ^ { N } \frac { \exp \left [ - \frac { 2 i } { k \pi } \left ( z _ { i } w _ { i } - z _ { \sigma } - 1 ( i ) w _ { \sigma ^ { \prime } - 1 ( i ) } \right ) \right ] } { \cosh z _ { i } \, \cosh w _ { i } } \,. \ \ ( A. 2 )$$
At this moment it is obvious that the partition function depends only on the composition of permutations σ · σ ′-1 . Thus, by fixing either of them σ ′ as the trivial permutation, we obtain
$$\text{ obtain} \\ \mathcal { Z } _ { \text{ABJM} } ^ { ( P Q ) } & = \sum _ { \sigma \in \mathfrak { S } _ { N } } ( - 1 ) ^ { N } \frac { ( P Q ) ^ { N } } { N! k ^ { N } } \int _ { \frac { d ^ { N } z } { ( 2 \pi ) ^ { N } } } \frac { d ^ { N } w } { ( 2 \pi ) ^ { N } } \prod _ { i = 1 } ^ { N } \frac { \exp \left [ \frac { - \frac { 2 i } { k \pi } } { \left ( z _ { i } - z _ { \sigma ( i ) } \right ) w _ { i } } \right ] } { \cosh z _ { i } \cosh w _ { i } } \\ & = \sum _ { \sigma \in \mathfrak { S } _ { N } } ( - 1 ) ^ { N } \frac { ( P Q ) ^ { N } } { N! k ^ { N } } \int _ { \frac { d ^ { N } z } { ( 2 \pi ) ^ { N } } } \prod _ { i = 1 } ^ { N } \left ( \cosh z _ { i } \cdot 2 \cosh \frac { z _ { i } - z _ { \sigma ( i ) } } { k } \right ) ^ { - 1 } \\ & = \frac { ( P Q ) ^ { N } } { N! ( 2 k ) ^ { N } } \int _ { \frac { d ^ { N } z } { ( 2 \pi ) ^ { N } } } \prod _ { i < j } ^ { N } \left ( \tanh \frac { z _ { i } - z _ { j } } { 2 k } \right ) ^ { 2 } \prod _ { i = 1 } ^ { N } \left ( 2 \cosh \frac { z _ { i } } { 2 } \right ) ^ { - 1 } \\ & = ( P Q ) ^ { N } \mathcal { Z } _ { \text{ABJM} } ^ { ( 1, 1 ) } \cdot \\ \text{This is the mirror expression of the partition function (3.10). Especially for $k=1$, the mirror}$$
This is the mirror expression of the partition function (3.10). Especially for k = 1, the mirror theory turns out to be N = 4 SYM theory with a single fundamental and a single adjoint hypermultiplet. The dependence on the parameters ( P, Q ) becomes trivial in this mirror representation.
## References
- [1] E. Witten, 'Quantum field theory and the Jones polynomial,' Commun. Math. Phys. 121 (1989) 351-399.
- [2] R. Lawrence and L. Rozansky, 'Witten-Reshetikhin-Turaev Invariants of Seifert Manifolds,' Commun. Math. Phys. 205 (1999) 287-314.
| [3] | C. Beasley, 'Localization for Wilson Loops in Chern-Simons Theory,' Adv. Theor. Math. Phys. 17 (2013) 1-240, arXiv:0911.2687 [hep-th] . |
|-------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [4] | J. K¨ll´n, a e 'Cohomological localization of Chern-Simons theory,' JHEP 1108 (2011) 008, arXiv:1104.5353 [hep-th] . |
| [5] | A. Brini, B. Eynard, and M. Mari˜o, n 'Torus knots and mirror symmetry,' Ann. Henri Poincar´ e 13 (2012) 1873-1910, arXiv:1105.2012 [hep-th] . |
| [6] | A. Kapustin, B. Willett, and I. Yaakov, 'Exact Results for Wilson Loops in Superconformal Chern-Simons Theories with Matter,' JHEP 1003 (2010) 089, arXiv:0909.4559 [hep-th] . |
| [7] | O. Aharony, O. Bergman, D. L. Jafferis, and J. Maldacena, ' N = 6 superconformal Chern-Simons-matter theories, M2-branes and their gravity duals,' JHEP 0810 (2008) 091, arXiv:0806.1218 [hep-th] . |
| [8] | N. Drukker and D. Trancanelli, 'A Supermatrix model for N = 6 super Chern-Simons-matter theory,' JHEP 1002 (2010) 058, arXiv:0912.3006 [hep-th] . |
| [9] | I. Bars, 'Supergroups and Their Representations,' Lectures Appl. Math. 21 (1983) 17. |
| [10] | A. Berele and A. Regev, 'Hook Young-diagrams with applications to combinatorics and to representations of Lie superalgebras,' Adv. Math. 64 (1987) 118-175. |
| [11] | J. D. Fay, Theta Functions on Riemann Surfaces , vol. 352 of Lecture Notes in Mathematics . Springer Berlin Heidelberg, 1973. |
| [12] | A. Borodin, G. Olshanski, and E. Strahov, 'Giambelli compatible point processes,' Adv. Appl. Math. 37 (2006) 209-248, arXiv:math-ph/0505021 . |
| [13] | M. Berg`re e and B. Eynard, 'Determinantal formulae and loop equations,' arXiv:0901.3273 [math-ph] . |
| [14] | B. Eynard and N. Orantin, 'Invariants of algebraic curves and topological expansion,' Commun. Num. Theor. Phys. 1 (2007) 347-452, arXiv:math-ph/0702045 [math-ph] |
| [15] | R. Dijkgraaf, H. Fuji, and M. Manabe, 'The Volume Conjecture, Perturbative Knot Invariants, and Recursion Relations for Topological Strings,' Nucl. Phys. B849 (2011) 166-211, arXiv:1010.4542 [hep-th] . |
| [16] | G. Borot and B. Eynard, 'All-order asymptotics of hyperbolic knot invariants from non-perturbative topological recursion of A-polynomials,' Quantum Top. 6 (2015) 39-138, arXiv:1205.2261 [math-ph] . |
| [17] | S. Gukov and I. Saberi, 'Lectures on Knot Homology and Quantum Curves,' arXiv:1211.6075 [hep-th] . |
|--------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|
| [18] | R. Gopakumar and C. Vafa, 'On the gauge theory/geometry correspondence,' Adv. Theor. Math. Phys. 3 (1999) 1415-1443, arXiv:hep-th/9811131 [hep-th] . |
| [19] | H. Ooguri and C. Vafa, 'Knot invariants and topological strings,' Nucl. Phys. B577 (2000) 419-438, arXiv:hep-th/9912123 [hep-th] . |
| [20] | M. Mari˜o n and P. Putrov, 'Exact Results in ABJM Theory from Topological Strings,' JHEP 1006 (2010) 011, arXiv:0912.3074 [hep-th] . |
| [21] | E. Moens and J. Van der Jeugt, 'A Determinantal Formula for Supersymmetric Schur Polynomials,' J. Alg. Comb. 17 (2003) 283-307. |
| [22] | Y. Hatsuda, M. Honda, S. Moriyama, and K. Okuyama, 'ABJM Wilson Loops in Arbitrary Representations,' JHEP 1310 (2013) 168, arXiv:1306.4297 [hep-th] . |
| [23] | Y. Dolivet and M. Tierz, 'Chern-Simons matrix models and Stieltjes-Wigert polynomials,' J. Math. Phys. 48 (2007) 023507, arXiv:hep-th/0609167 [hep-th] . |
| [24] | M. Rosso and V. Jones, 'On the invariants of torus knots derived from quantum groups,' J. Knot Theory Ramifications 2 (1993) 97-112. |
| [25] | A. Kapustin, B. Willett, and I. Yaakov, 'Nonperturbative Tests of Three-Dimensional Dualities,' JHEP 1010 (2010) 013, arXiv:1003.5694 [hep-th] . |
| [26] | O. Aharony, O. Bergman, and D. L. Jafferis, 'Fractional M2-branes,' JHEP 0811 (2008) 043, arXiv:0807.4924 [hep-th] . |
| [27] | E. L. Basor and P. J. Forrester, 'Formulas for the Evaluation of Toeplitz Determinants with Rational Generating Functions,' Math. Nachr. 170 (1994) 5-18. |
| [28] | M. Aganagic, A. Klemm, M. Mari˜o, n and C. Vafa, 'Matrix model as a mirror of Chern-Simons theory,' JHEP 0402 (2004) 010, hep-th/0211098 . |
| [29] | N. Halmagyi and V. Yasnov, 'The spectral curve of the lens space matrix model,' JHEP 0911 (2009) 104, arXiv:hep-th/0311117 . |
| [30] | H. Jockers, A. Klemm, and M. Soroush, 'Torus Knots and the Topological Vertex,' Lett. Math. Phys. 104 (2014) 953-989, arXiv:1212.0321 [hep-th] . |
| [31] | S. Stevan, 'Torus Knots in Lens Spaces and Topological Strings,' Ann. Henri Poincar´ e 16 (2015) 1937-1967, arXiv:1308.5509 [hep-th] . |
| [32] | G. Borot, B. Eynard, and N. Orantin, 'Abstract loop equations, topological recursion and new applications,' Commun. Num. Theor. Phys. 9 (2015) 51-187, arXiv:1303.5808 [math-ph] . |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [33] | G. Borot, A. Guionnet, and K. K. Kozlowski, 'Large- N asymptotic expansion for mean field models with Coulomb gas interaction,' Int. Math. Res. Not. 2015 (2015) 10451-10524, arXiv:1312.6664 [math-ph] . |
| [34] | M. Aganagic, A. Klemm, M. Marino, and C. Vafa, 'The Topological vertex,' Commun. Math. Phys. 254 (2005) 425-478, arXiv:hep-th/0305132 [hep-th] . |
| [35] | A. Klemm, M. Mari˜o, n M. Schiereck, and M. Soroush, 'ABJM Wilson loops in the Fermi gas approach,' Z. Naturforsch. A68 (2013) 178-209, arXiv:1207.0611 [hep-th] . |
| [36] | M. Mari˜o, n 'Open string amplitudes and large order behavior in topological string theory,' JHEP 0803 (2008) 060, arXiv:hep-th/0612127 [hep-th] . |
| [37] | V. Bouchard, A. Klemm, M. Mari˜o, n and S. Pasquetti, 'Remodeling the B-model,' Commun. Math. Phys. 287 (2009) 117-178, arXiv:0709.1453 [hep-th] . |
| [38] | B. Eynard and N. Orantin, 'Computation of open Gromov-Witten invariants for toric Calabi-Yau 3-folds by topological recursion, a proof of the BKMP conjecture,' Commun. Math. Phys. 337 (2015) 483-567, arXiv:1205.1103 [math-ph] . |
| [39] | M. Aganagic and C. Vafa, 'Mirror symmetry, D-branes and counting holomorphic discs,' arXiv:hep-th/0012041 [hep-th] . |
| [40] | M. Aganagic, A. Klemm, and C. Vafa, 'Disk instantons, mirror symmetry and the duality web,' Z. Naturforsch. A57 (2002) 1-28, arXiv:hep-th/0105045 [hep-th] . |
| [41] | M. Aganagic and C. Vafa, 'Large N Duality, Mirror Symmetry, and a Q-deformed A-polynomial for Knots,' arXiv:1204.4709 [hep-th] . |
| [42] | Y. Hatsuda, M. Mari˜o, n S. Moriyama, and K. Okuyama, 'Non-perturbative effects and the refined topological string,' JHEP 1409 (2014) 168, arXiv:1306.1734 [hep-th] . |
| [43] | B. Eynard and N. Orantin, 'Topological expansion of mixed correlations in the Hermitian 2-matrix model and x - y symmetry of the F g invariants,' J. Phys. A41 (2008) 015203, arXiv:0705.0958 [math-ph] . |
| [44] | B. Eynard and N. Orantin, 'About the x - y symmetry of the F g algebraic invariants,' arXiv:1311.4993 [math-ph] . |
| [45] | T. Kimura, 'Note on a duality of topological branes,' PTEP 2014 (2014) 103B04, arXiv:1401.0956 [hep-th] . |
| [46] | T. Kimura, 'Duality and integrability of a supermatrix model with an external source,' PTEP 2014 (2014) 123A01, arXiv:1410.0680 [math-ph] . |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [47] | P. Desrosiers and B. Eynard, 'Supermatrix models, loop equations, and duality,' J. Math. Phys. 51 (2010) 123304, arXiv:0911.1762 [math-ph] . |
| [48] | E. Br´zin e and S. Hikami, 'Characteristic Polynomials of Random Matrices,' Commun. Math. Phys. 214 (2000) 111-135, arXiv:math-ph/9910005 . |
| [49] | Harish-Chandra, 'Differential Operators on a Semisimple Lie Algebra,' Amer. J. Math. 79 (1957) 87-120. |
| [50] | C. Itzykson and J.-B. Zuber, 'The Planar Approximation. II,' J. Math. Phys. 21 (1980) 411-421. |
| [51] | A. Tanaka, 'Comments on knotted 1/2 BPS Wilson loops,' JHEP 1207 (2012) 097, arXiv:1204.5975 [hep-th] . |
| [52] | N. Hama, K. Hosomichi, and S. Lee, 'SUSY Gauge Theories on Squashed Three-Spheres,' JHEP 1105 (2011) 014, arXiv:1102.4716 [hep-th] . |
| [53] | T. Deguchi and Y. Akutsu, 'Graded Solutions of the Yang-Baxter Relation and Link Polynomials,' J. Phys. A23 (1990) 1861-1876. |
| [54] | L. H. Kauffman and H. Saleur, 'Free fermions and the Alexander-Conway polynomial,' Commun. Math. Phys. 141 (1991) 293-327. |
| [55] | L. Rozansky and H. Saleur, ' S and T matrices for the super U(1,1) WZW model: Application to surgery and three manifolds invariants based on the Alexander-Conway polynomial,' Nucl. Phys. B389 (1993) 365-423, arXiv:hep-th/9203069 [hep-th] . |
| [56] | R. M. Kashaev, 'The Hyperbolic volume of knots from quantum dilogarithm,' Lett. Math. Phys. 39 (1997) 269-275, arXiv:q-alg/9601025 [math.QA] . |
| [57] | H. Murakami and J. Murakami, 'The colored Jones polynomials and the simplicial volume of a knot,' Acta Math. 186 (2001) 85-104, arXiv:math/9905075 [math.GT] |
| [58] | S. Gukov, 'Three-dimensional quantum gravity, Chern-Simons theory, and the A-polynomial,' Commun. Math. Phys. 255 (2005) 577-627, arXiv:hep-th/0306165 [hep-th] . |
| [59] | S. Garoufalidis, 'On the characteristic and deformation varieties of a knot,' Geom. Topol. Monogr. 7 (2004) 291-309, arXiv:math/0306230 [math.GT] . |
| [60] | M. Khovanov and L. Rozansky, 'Matrix factorizations and link homology,' Fund. Math. 199 (2008) 1-91, arXiv:math/0401268 [math.QA] . |
- [61] M. Khovanov and L. Rozansky, 'Matrix factorizations and link homology II,' Geom. Topol. 12 (2008) 1387-1425, arXiv:math/0505056 [math.QA] .
- [62] S. Gukov, A. S. Schwarz, and C. Vafa, 'Khovanov-Rozansky homology and topological strings,' Lett. Math. Phys. 74 (2005) 53-74, arXiv:hep-th/0412243 [hep-th] .
- [63] N. M. Dunfield, S. Gukov, and J. Rasmussen, 'The Superpolynomial for Knot Homologies,' Experimental Math. 15 (2006) 129-159, arXiv:math/0505662 [math.GT] . | 10.1007/s11005-017-0936-0 | [
"Bertrand Eynard",
"Taro Kimura"
] | 2014-07-31T20:00:22+00:00 | 2016-12-05T05:12:41+00:00 | [
"hep-th",
"math-ph",
"math.GT",
"math.MP",
"81T60, 81T45, 57M27, 14H81"
] | Towards U(N|M) knot invariant from ABJM theory | We study U(N|M) character expectation value with the supermatrix Chern-Simons
theory, known as the ABJM matrix model, with emphasis on its connection to the
knot invariant. This average just gives the half BPS circular Wilson loop
expectation value in ABJM theory, which shall correspond to the unknot
invariant. We derive the determinantal formula, which gives U(N|M) character
expectation values in terms of U(1|1) averages for a particular type of
character representations. This means that the U(1|1) character expectation
value is a building block for all the U(N|M) averages, and in particular, by an
appropriate limit, for the U(N) invariants. In addition to the original model,
we introduce another supermatrix model obtained through the symplectic
transform, which is motivated by the torus knot Chern-Simons matrix model. We
obtain the Rosso-Jones-type formula and the spectral curve for this case. |
1408.0011v2 | ## Erratum: Bounds on Invisible Higgs boson Decays from ttH ¯ Production
Ning Zhou, 1 Zepyoor Khechadoorian, 1 Daniel Whiteson, 1 and Tim M.P. Tait 1 1 Department of Physics and Astronomy, University of California, Irvine, CA 92697
Bounds on invisible decays of the Higgs boson from ttH ¯ production were inferred from a CMS search for stop quarks decaying to tt ¯ + E miss T . Limits on the production of ttH ¯ relied on the efficiency of the CMS selection for ttH ¯ , as measured in a simulated sample. An error in the generation of the simulated sample lead to a significant overestimate of the selection efficiency. Corrected results are presented.
PACS numbers:
In a recent Letter [1], we recast a CMS search for supersummetric stop quarks ( ˜ t → bW + E miss T ) [2] to set bounds on ttH ¯ production where the Higgs boson decays invisibly.
The result relies on the measurement of the efficiency of the CMS selection for ttH ¯ events, as measured in simulated samples generated with Madgraph5 [3], showering and hadronization with Pythia [4] and detector response simulated by Delphes [5]. The event generation used a model which included a Hχχ ¯ vertex to describe the invisible decay H → χχ ¯. Inadvertantly, the contribution from diagrams containing a ggH effective vertex was overestimated. These diagrams tend to give larger transverse momentum to the Higgs boson, leading to larger measured E miss T and a significant overestimate of the selection efficiency. Figure 1 shows a comparison of the original flawed sample and a new, correct sample. Figure 2 shows a comparison of the kinematics of the corrected ttH ¯ sample to the primary sources of background, top quark pair production.
For the corrected sample, we again apply the results of the CMS ˜ search to invisible Higgs boson det cays by calculating the expected yield of ttH ¯ in each
FIG. 1: Distribution of missing transverse momentum ttH ¯ with H → invisible for the simulated sample in the original paper as well as the corrected simulated sample. Distributions are shown after requiring exactly one lepton, at least four jets and one b -tag.
FIG. 2: Kinematics of ttH ¯ with H → invisible and all tt ¯ decay modes, compared to the two dominant backgrounds, SM top quark production with either single lepton ( glyph[lscript]ν bqq b ′ ) or di-lepton ( glyph[lscript]ν bglyph[lscript] ′ νb ) decay modes. Distributions are shown of M T , the transverse mass; M W T 2 , as defined in Ref. [10]; χ 2 had , the consistency of the jjb system with a top quark hadronic decay; and min(∆ φ [MET, jet]), the minimum angle between the E miss T and any jet . Distributions are shown after requiring exactly one lepton, at least four jets and one b -tag.
of the signal regions. We calculate upper bounds on σ ttH ( ¯ ) × BF H ( → inv.) using a one-sided profile likelihood and the CLs technique [6, 7], evaluated using the asymptotic approximation [8]. For each of the sixteen signal regions, we calculate the median expected limit on σ ttH ( ¯ ) × BF H ( → inv.). As with the original sample, the region with the strongest expected limit is that targeting ˜ t → tχ ˜ in the high-∆ M regime, with E miss T > 250 GeV. This region has the additional requirements of min(∆ φ E [ miss T , j ]) > 0 8, . M W T 2 > 200 GeV and χ 2 had < 5 0. . The expected background is reported to be 9 5 . ± 2 8. . With our simulated sample, we calculate an expected ttH ¯ yield of 2.1 events if BF( H → inv.) = 1 0 . (compare to 11.4 events for the incorrect sample). The
H
FIG. 3: Top pane gives 95% CL upper limits on σ ttH ( ¯ ) × BF H ( → inv.), including both expected and observed limits. Also shown is the SM rate of σ ttH ( ¯ ) [9]. The bottom pane shows the ratio of the constraint to the SM σ ttH ( ¯ ) cross section.
efficiency of this selection for ttH ¯ → ttχχ ¯ ¯ events with m H = 125 GeV is 0.085% (compare to 0.45% for the incorrect sample).
In this particular signal region, the data have fluctuated quite low, N obs = 3 events, giving an observed upper bound considerably stronger than the median expected results; see Fig. 3. Dividing by the predicted rate of ttH ¯ production in the SM [9] gives a limit on BF( H → inv); the observed (expected) result is < 1 9 (3 0) at 95% CL . . for m H = 125 GeV.
This result is significantly weaker than the previous. For this reason, we do not perform a combination with other channels nor provide an interpretation in terms of the Higgs portal model.
- [1] N. Zhou, Z. Khechadoorian, D. Whiteson, and T. M. Tait, Phys.Rev.Lett. 113 , 151801 (2014), 1408.0011.
- [2] S. Chatrchyan et al. (CMS Collaboration), Eur.Phys.J. C73 , 2677 (2013), 1308.1586.
- [3] J. Alwall, M. Herquet, F. Maltoni, O. Mattelaer, and T. Stelzer, JHEP 1106 , 128 (2011), 1106.0522.
- [4] T. Sjostrand, S. Mrenna, and P. Z. Skands, JHEP 0605 , 026 (2006), hep-ph/0603175.
- [5] J. de Favereau et al. (DELPHES 3), JHEP 1402 , 057 (2014), 1307.6346.
- [6] A. L. Read, J.Phys. G28 , 2693 (2002).
- [7] T. Junk, Nucl.Instrum.Meth. A434 , 435 (1999), hepex/9902006.
- [8] G. Cowan, K. Cranmer, E. Gross, and O. Vitells, Eur.Phys.J. C71 , 1554 (2011), 1007.1727.
- [9] S. Heinemeyer et al. (LHC Higgs Cross Section Working Group) (2013), 1307.1347.
- [10] Y. Bai, H.-C. Cheng, J. Gallicchio, and J. Gu, JHEP 1207 , 110 (2012), 1203.4813. | 10.1103/PhysRevLett.113.151801 | [
"Ning Zhou",
"Zepyoor Khechadoorian",
"Daniel Whiteson",
"Tim Tait"
] | 2014-07-31T20:00:23+00:00 | 2015-04-17T16:57:29+00:00 | [
"hep-ph"
] | Erratum: Bounds on Invisible Higgs boson Decays from $t\bar{t}H$ Production | Bounds on invisible decays of the Higgs boson from $t\bar{t}H$ production
were inferred from a CMS search for stop quarks decaying to $t\bar{t}$ and
missing transverse momentum. Limits on the production of $t\bar{t}H$ relied on
the efficiency of the CMS selection for $t\bar{t}H$, as measured in a simulated
sample. An error in the generation of the simulated sample lead to a
significant overestimate of the selection efficiency. Corrected results are
presented. |
1408.0012v2 | ## Real-Time Feynman Path Integral Realization of Instantons
Aleksey Cherman 1, ∗ and Mithat Unsal ¨ 2, †
1 Fine Theoretical Physics Institute,
Department of Physics, University of Minnesota, Minnesota, MN 55455, USA
2 Department of Physics, North Carolina State University, Raleigh, NC, 27695
In Euclidean path integrals, quantum mechanical tunneling amplitudes are associated with instanton configurations. We explain how tunneling amplitudes are encoded in real-time Feynman path integrals. The essential steps are borrowed from Picard-Lefschetz theory and resurgence theory.
Introduction -The real-time Feynman path integral[1] is one of the several equivalent formulations of quantum mechanics (QM) and quantum field theory (QFT). The amplitude of an event is found by summing over all path histories with the contribution of each path γ weighed by its action S γ [ ] via the factor e iS γ / [ ] glyph[planckover2pi1] . For real paths, this is a sum over pure phases. The real-time path integral formulation is very useful in many settings, and yields beautiful explanations of many quantum phenomena, such as the interference patterns seen in double-slit experiments and the Aharonov-Bohm effect. Yet surprisingly, some very basic quantum phenomena do not have a known description in the real-time path integral. For instance, tunneling phenomena, which are well-understood in the operator (Hamiltonian) formalism, as well as in the Euclidean-time path integral formulation, are not yet understood in the real-time Feynman path integral formulation[2].
We focus on a particle in a symmetric double-well potential as a paradigmatic example. The level splitting between the ground state and first excited state is given by a non-perturbative factor, ∼ exp[ -A/ g ( 2 glyph[planckover2pi1] )] where A is a pure number and g is a parameter controlling the depth of the wells. It is a consequence of tunneling in the operator formalism or instanton saddles[3] in the Euclidean path integral formulation, but its origin is mysterious in the Feynman path integral.
Understanding such non-perturbative phenomena directly in real-time path integrals is likely to be very important. Euclidean path integrals give deep insights into the non-perturbative properties of QM and QFT, but there is a huge range of problems for which they are not useful, such as calculations of scattering amplitudes or non-equilibrium observables. These questions are more naturally handled using real-time path integrals. Yet the current understanding of real-time path integrals beyond the perturbative level is extremely rudimentary, as is highlighted by the fact that even tunneling phenomena are not understood in the framework. Our results are a step toward developing a non-perturbative understanding of real-time path integrals.
Euclidean-time instantons -To set notation we review the standard path integral treatment of tunneling in QM. The real-time Feynman path integral representation of the amplitude A for a particle initially at position x i at time t i to end up at position x f at time t f is
$$\mathcal { A } _ { x _ { i }, t _ { i } } ^ { x _ { f }, t _ { i } } = \int _ { x ( t _ { i } ) = x _ { i } } ^ { x ( t _ { f } ) = x _ { f } } d [ x ( t ) ] \, e ^ { \frac { i } { h } S [ x ] } \, \quad \quad ( 1 )$$
where S is the classical action. For a non-relativistic bosonic particle moving in a symmetric double-well potential the action can be written as
$$S [ x ] = \frac { 1 } { 2 g ^ { 2 } } \int _ { t _ { i } } ^ { t _ { f } } d t \left [ ( \partial _ { t } x ) ^ { 2 } - ( x ^ { 2 } - 1 ) ^ { 2 } \right ] \quad ( 2 )$$
Our semiclassical treatment of tunneling will be justified if g glyph[lessmuch] 1. If the particle is initially near e.g. x = -1 at t = t i the amplitude for it to end up near x = +1 will be zero to any order in a perturbative expansion in g .
Let us now focus on the tunneling amplitude from x i = -1 at t i = -∞ to x f = +1 at t f = + ∞ . The standard way to compute this amplitude using path integrals involves moving to Euclidean time by a Wick rotation t →-iτ, x ( ) t → x τ ( ). The Euclidean action
$$S _ { E } = \frac { 1 } { 2 g ^ { 2 } } \int _ { - \infty } ^ { \infty } d \tau \left [ ( \partial _ { \tau } x ) ^ { 2 } + ( x ^ { 2 } - 1 ) ^ { 2 } \right ]. \quad ( 3 )$$
is then positive semi-definite and enters the path integral as e -S E . The Euclidean equation of motion ∂ x τ 2 τ ( ) = 2 x τ ( ) ( x τ ( ) 2 -1 ) has two finite-action solutions, the instanton x + I and anti-instanton x -I :
$$x _ { I } ^ { \pm } ( \tau ) = \pm \tanh ( \tau - \tau _ { 0 } ), \text{ \quad \ \ } ( 4 )$$
where τ 0 is a zero mode parameter. These solutions interpolate from x = ∓ 1 to x = ± 1 as τ goes from -∞ to + ∞ . In what follows we will focus on x + I and will drop the superscript. The Euclidean action of (4) is S I = 4 3 g 2 , so that (4) is a saddle-point of the Euclidean path integral, with contributions weighed by e -4 3 g 2 . For g glyph[lessmuch] 1 the desired tunneling amplitude can be computed using a steepest-descent approximation, and is given by
$$\mathcal { A } = \sqrt { \frac { 3 2 } { \pi g ^ { 2 } } } e ^ { - \frac { 4 } { 3 g ^ { 2 } h } }$$
where the prefactor is obtained by integrating over Gaussian and zero mode fluctuations around x = x I ( τ ).
Real-time instantons -The Euclidean-time derivation is not fully satisfying, as physics happens in real time.
FIG. 1. (Color Online.) The complexified instanton configuration (9). Left column: α = π/ 2 (Euclidean instanton). Center column: α = π/ 4. Right column: α = π/ 8. The top row shows the trajectories of (9) for τ ∈ -∞ ( , + ∞ ), while the bottom row shows the real and imaginary parts of (9) as a function of τ .
Yet there is a good reason that instantons were never formulated in the real-time Feynman path integral. A natural attempt to do this involves looking for finiteaction solutions of the real-time equation of motion
$$- \partial _ { t } ^ { 2 } x ( t ) = 2 x ( t ) \left ( x ( t ) ^ { 2 } - 1 \right ). \quad \quad ( 6 ) \quad \text{$\mathfrak { a }$}$$
Since we are looking for an answer of the form e iS/ glyph[planckover2pi1] = e -A g 2 glyph[planckover2pi1] the action of the solution would have to be imaginary. That means that a 'real-time instanton' configuration has to be complex. Such a notion raises major conceptual issues:
- (A) If the field space is complexified, how do we avoid an undesired doubling of degrees of freedom in the complexified path integral?
- (B) Relatedly, how do we avoid including pathological directions in the complex field space which may yield exponentially large contributions? Over what sub-space of fields (complex paths) should one integrate over?
Setting these important questions aside for the moment, we note that it is tempting to guess that the desired saddle field configurations might be given by the Wick rotation of the Euclidean instanton back to real time. Indeed, (6) does have the formal solution
$$x ( t ) = i \tan ( t - t _ { 0 } ) \quad \quad \ ( 7 ) \quad \text{an}$$
which is a Wick rotation of (4). But (7) looks nonsensical, for many reasons:
(i) It is pure-imaginary-valued, so it cannot possibly give a contribution like e iS/ glyph[planckover2pi1] = e -A g 2 glyph[planckover2pi1] , and cannot describe a path interpolating from x = -1 to +1.
(ii) It does not appear to have anything to do with tunneling from x = -1 to +1, since it is never localized near the bottoms of the wells.
(iii) It has singularities at t = (2 n +1) π/ , n 2 ∈ Z , and these singularities are not integrable, so that the action is not well-defined.
Until fairly recently this is where an analysis would have had to stop. Fortunately, there has recently been major progress in the understanding the complexification of functional integrals [4-6] and the structure of the semiclassical expansion of path integrals in QM [7] and QFT [8] via resurgence theory[9]. Motivated by these developments, let us see what happens if we do not insist on working in either purely real or imaginary time.
Specifically, let us start in real time t and do a complex Wick rotation t → τe -iα , φ ( ) t → φ τ ( ). In contrast to purely real or purely imaginary time, now the action itself becomes complex:
$$\stackrel { \dots } { \text{of} } \\ \alpha = 0$$
Hence issues (A) and (B) with the complexification of configuration space in path integrals must be deal with, and we do so below. For small α , τ ≈ t and S α ≈ S , while for α = π/ 2 τ becomes the standard Euclidean time coordinate and iS π/ 2 = -S E . It turns out that an infinitesimal α acts as a crucial regulator which is necessary to make sense of real-time instantons.
The α -dependent equation of motion -e 2 iα ∂ x τ 2 τ ( ) = 2 x τ ( ) ( x τ ( ) 2 -1 ) has the solutions
$$x _ { I } ( \tau ) = \pm \tanh \left [ ( \tau - \tau _ { 0 } ) e ^ { - i ( \alpha - \pi / 2 ) } \right ] \quad ( 9 )$$
To make (9) a legitimate solution one must complexify the space of path histories from x : R → R to
FIG. 2. (Color Online.) Upper-left: trajectory of (9) for α = 4 × 10 -2 × π 2 in complex configuration space. Upper-right: real and imaginary parts of (9) for α = 1 × 10 -2 × π 2 , with a green α = π/ 2 trajectory shown for comparison. Lower-left: illustration of the manner in which the imaginary part of (9) approaches the singular configuration (7) for small α (here α = 1 × 10 -2 × π 2 ), while the real part approaches to a distribution, a signed Dirac comb. Lower-right: the trajectory for α = 1 × 10 -3 × π 2 , with red dots marking the centers of the wells x = ± 1. In the real-time limit the real-time instanton appears to become a space-filling curve in complexified configuration space.
x : R e -iα → C . While (9) looks like a simple analytic continuation of (4), the conceptual issues raised by allowing such an continuation are quite complex.
Naively, precisely at α = 0 (9) reduces to (7), although we are about to see that the limit is subtle. Consider the situation for 0 < α ≤ π/ 2 [10]. Remarkably, the imaginary parts of the complex instanton solution (9) vanish for large | τ | , and x I approaches ∓ 1 as τ →∓∞ ! The behavior of the complexified instanton at generic α values is summarized in Fig. 1 and Fig. 2. For generic 0 < α ≤ π/ 2 field starts at x = -1 at τ = -∞ , whips around in the left half of complexx plane for τ < τ 0 , then crosses to the right half of the plane at τ = τ 0 , whips around x = +1 for τ > τ 0 , and then settles down at x = +1 at τ = + ∞ .
illustrated in Fig. 2. The Re x < 0 and Re x > 0 halfplanes form two basins of attraction for the repulsive and attractive fixed points x = -1 and x = +1 respectively. After starting at x = -1 at τ = -∞ , as α → 0 the instanton spends more and more time whipping around in the Re x < 0 region in a huge number of more and more tightly spaced increasingly large arcs for τ < τ 0 , then jumps over to the Re x > 0 region and winds closer and closer to x = +1 in the same manner, until settling at x = +1 at τ = + ∞ . From the bottom-right plot in Fig. 2, the complex instanton trajectory appears to become a space-filling curve in the real-time limit.
glyph[negationslash]
The instanton remains smooth for any α = 0, but the behavior in the real time limit α → 0 is singular, as
In the strict α = 0 limit, the imaginary part of the instanton solution is given by (7), while the real part
approaches to a distribution, given by
$$\text{Re} \, x = \pi \text{sign} ( t - t _ { 0 } ) \sum _ { k = - \infty } ^ { \infty } \delta ( t - t _ { 0 } - \frac { \pi } { 2 } ( 2 k - 1 ) ) \ \ ( 1 0 ) \quad \text{integr} \quad \text{cls de} \quad \text{that} \ \ ;$$
which is a signed Dirac comb. The time average of 〈 Re x 〉 T and 〈 Im x 〉 T (which we define as 〈·〉 T = 1 T ∫ T τ 0 · dτ with T = πk + τ 0 , k ∈ Z ) for any α , including α = 0, essentially follows the pattern of a Euclidean instanton,
$$\langle \text{Re} \, x \rangle _ { T } & = \begin{cases} \, + 1, \quad & \tau > \tau _ { 0 } & \quad & \text{th} \\ \, - 1, \quad & \tau < \tau _ { 0 } & \quad & \text{the} \end{cases} \\ \langle \text{Im} \, x \rangle _ { T } & = 0 & \quad & \quad & \text{(11)}$$
as illustrated by Fig. 2.
Next, we show that the action -iS α of the instanton is always precisely 4 / (3 g 2 ) for any α , with the action at α = 0 defined by continuation from | α | > 0. The Lagrangian evaluated on (9) oscillates wildly through the complex plane as α → 0. Nevertheless, -iS α [ x I ] turns out to be independent of α . To show this we rewrite
$$S _ { \alpha } ( x ) = \frac { e ^ { - i \alpha } } { 2 g ^ { 2 } } \int _ { - \infty } ^ { + \infty } d \tau \left ( \left [ e ^ { + i \alpha } \dot { x } - W ^ { \prime } ( x ) \right ] ^ { 2 } + 2 e ^ { + i \alpha } \dot { x } W ^ { \prime } \right ) \int _ { \frac { \partial \ell } { A } } ^ { \nu \omega \nu }$$
where ′ ≡ ∂ , x ˙ ≡ ∂ τ , and ( W ′ ) 2 = V ( x ). But (9) satisfies the first-order equation e + iα ˙ x -W x ′ ( ) = 0, so
$$- i S ( x _ { I } ) = \frac { 1 } { g ^ { 2 } } \int _ { - \infty } ^ { + \infty } d \tau \dot { x } _ { I } W ^ { \prime } ( x _ { I } ) = \frac { 4 } { 3 g ^ { 2 } } \quad ( 1 2 ) \quad \text{ simple}$$
We conjecture that the solution with minimal non-zero action is (9) for any α . This is obvious at α = π/ 2, while at α = 0, resurgence theory implies that the minimumaction saddle must have action -iS x ( I ) due to the largeorder structure of perturbation theory. We leave a detailed exploration of this conjecture to future work.
The question of whether singular but finite-action field configurations contribute to path integrals is controversial[11]. Our results support the notion that such configurations do contribute, since (9) is a finite action configuration whichis associated with a dramatic physical effect of level splitting. Hence it is physically clear that it must be included it in the evaluation of the path integral, even though it becomes singular and discontinuous in the strict α = 0 limit.
Lefshetz thimbles -To find the contribution of the complex instantons to observables in the real time limit, it is necessary to take into account fluctuations around the instanton saddle points. As we already noted this is a subtle problem due to the complexification of the field space, and involves understanding the analytic continuation of path integrals. A program to study this issue was recently initiated in [5].
A sensible complexification of the integration cycle of an integral which initially has a real domain of integration must not double the number of degrees of freedom. A full understanding of the analytic continuation of the integral thus involves finding a basis of convergent middle-dimensional integration cycles in the complexified integral, and then working out how the original real cycle decomposes into the complex cycles. Ref. [5] showed that in favorable circumstances, this can be done by using Picard-Lefshetz theory[12]. Every finite-action saddle point of the path integral is associated to a convergent integration cycle called a 'Lefshetz thimble' - a multidimensional generalization of a steepest-descent path. The thimbles are solutions of the downward flow equations for the Morse function Re [ iS ]. For us, the flow equation is
$$\frac { \partial x } { \partial s } = - \frac { e ^ { + i \left ( \alpha - \pi / 2 \right ) } } { \overline { g ^ { 2 } } } \left [ e ^ { - 2 i \alpha } \partial _ { \tau } ^ { 2 } \bar { x } + 2 \bar { x } \left ( \bar { x } ^ { 2 } - 1 \right ) \right ] \quad ( 1 3 )$$
where x is complex and s is the flow 'time' along the thimble. The fluctuations around x I are described by the solutions of (13) with the initial condition x s ( →-∞ , τ ) = x I ( τ ). The structure of the Gaussian fluctuations can be determined by writing x s, τ ( ) = x I ( τ ) + δx s, τ ( ) with δx s ( →-∞ , τ ) = 0 and expanding (13) to O ( δx ):
$$\Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big \| _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _{ \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \outline } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty } \Big | _ { \infty }$$
The existence of the flow equations means that it is possible to choose sensible integration cycles in the complexified path integral, and in the Gaussian-fluctuation limit the determination of our desired cycle reduces to finding the solution of (14). By moving to the variable τ ′ = τ exp[ -i ( α -π/ 2)] and rescaling δx one can map (14) to the Euclidean flow equation. This implies that integrating over the thimble amounts to calculating the standard fluctuation determinant (see [6] for a nice discussion of this) multiplying e -4 / g 3 2 , and reproduces (5).
Conclusions -We have shown how to compute tunneling amplitudes between low-lying states, a hallmark non-perturbative feature of quantum mechanics, directly from a real-time Feynman path integral. The amplitude is given by a real-time instanton saddle point, which requires a complexification of the space of paths and the addition an infinitesimal imaginary part to the time coordinate as a regulator for its definition as a smooth configuration. In the real-time limit the instanton trajectory takes a wild ride through complex configuration space on its way between the minima of the potential, with the path resembling a space-filling curve. Yet its action remains equal to that of the Euclidean instanton. Our results are a step toward developing a non-perturbative understanding of physics using the real-time Feynman path integral formalism.
Acknowledgements: We are very grateful to Y. Tanizaki, G. Ba¸ sar, D. Dorigoni, G. Dunne, A. Joseph, and M. Shifman for discussions. A. C. acknowledges the partial support of the US DOE under grant number DE-SC0011842.
- ∗ [email protected]
- † [email protected]
- [1] R. P. Feynman, Rev. Mod. Phys. 20 , 367 (1948); R. Feynman and A. Hibbs, Quantum mechanics and path integrals , International series in pure and applied physics (McGraw-Hill, 1965).
- [2] For an earlier attempt at grappling with instantons in real time see e.g. [13].
- [3] A. Belavin, A. M. Polyakov, A. Schwartz, and Y. Tyupkin, Phys.Lett. B59 , 85 (1975).
- [4] F. Pham, Proc. Symp. Pure Math. 2 , 319 (1983).
- [5] E. Witten, preprint , 347 (2010), arXiv:1001.2933 [hepth]; preprint (2010), arXiv:1009.6032 [hep-th].
- [6] Y. Tanizaki and T. Koike, (2014), arXiv:1406.2386 [math-ph].
- [7] E. Bogomolny, Phys.Lett. B91 , 431 (1980); J. ZinnJustin, Nucl.Phys. B192 , 125 (1981); G. V. Dunne and M. Unsal, preprint (2014), arXiv:1401.5202 [hep-th].
- [8] P. Argyres and M. Unsal, Phys.Rev.Lett. 109 , 121601 (2012), arXiv:1204.1661 [hep-th]; P. C. Argyres and M. Unsal, JHEP 1208 , 063 (2012), arXiv:1206.1890 [hep-th]; G. V. Dunne and M. Unsal, JHEP 1211 , 170 (2012), arXiv:1210.2423 [hep-th]; Phys.Rev. D87 , 025015 (2013), arXiv:1210.3646 [hep-th]; A. Cherman, D. Dorigoni, G. V. Dunne, and M. Unsal, Phys.Rev.Lett. 112 , 021601 (2014), arXiv:1308.0127 [hep-th]; G. Basar,
- G. V. Dunne, and M. Unsal, JHEP 1310 , 041 (2013), arXiv:1308.1108 [hep-th]; A. Cherman, D. Dorigoni, and M. Unsal, (2014), arXiv:1403.1277 [hep-th]; T. Misumi, M. Nitta, and N. Sakai, JHEP 1406 , 164 (2014), arXiv:1404.7225 [hep-th]; T. Misumi and T. Kanazawa, JHEP 1406 , 181 (2014), arXiv:1405.3113 [hep-ph].
- [9] There are also related developments in string theory, see e.g. [14].
- [10] The instanton and anti-instanton get interchanged if -π/ 2 ≤ α < 0.
- [11] D. Harlow, J. Maltz, and E. Witten, JHEP 1112 , 071 (2011), arXiv:1108.4417 [hep-th].
- [12] How to carry out this program completely for configuration-space path integrals is an open problem, but the present understanding is already sufficient for our Gaussian analysis.
- [13] D. Levkov and S. Sibiryakov, JETP Lett. 81 , 53 (2005), arXiv:hep-th/0412253 [hep-th].
- [14] M. Marino, R. Schiappa, and M. Weiss, Commun.Num.Theor.Phys. 2 , 349 (2008), arXiv:0711.1954 [hep-th]; M. Marino, JHEP 0812 , 114 (2008), arXiv:0805.3033 [hep-th]; M. Marino, R. Schiappa, and M. Weiss, J.Math.Phys. 50 , 052301 (2009), arXiv:0809.2619 [hep-th]; I. Aniceto, R. Schiappa, and M. Vonk, 6 , 339 (2012), arXiv:1106.5922 [hep-th]; R. Schiappa and R. Vaz, Commun.Math.Phys. 330 , 655 (2014), arXiv:1302.5138 [hep-th]. | null | [
"Aleksey Cherman",
"Mithat Unsal"
] | 2014-07-31T20:00:35+00:00 | 2014-08-19T17:06:34+00:00 | [
"hep-th"
] | Real-Time Feynman Path Integral Realization of Instantons | In Euclidean path integrals, quantum mechanical tunneling amplitudes are
associated with instanton configurations. We explain how tunneling amplitudes
are encoded in real-time Feynman path integrals. The essential steps are
borrowed from Picard-Lefschetz theory and resurgence theory. |
1408.0013v1 | ## GRAVITATIONAL WAVES FROM MASSIVE MAGNETARS FORMED IN BINARY NEUTRON STAR MERGERS
SIMONE DALL'OSSO 1 , BRUNO GIACOMAZZO 2,3 , ROSALBA PERNA 4 , LUIGI STELLA 5 1. Theoretical Astrophysics, University of Tübingen, auf der Morgenstelle 10, 72076, Germany 2. Physics Department, University of Trento, via Sommarive 14, I-38123 Trento, Italy 3. INFN-TIFPA, Trento Institute for Fundamental Physics and Applications, via Sommarive 14, I-38123 Trento, Italy 4. Department of Physics and Astronomy, Stony Brook University, Stony Brook, NY, 11794,USA and 5. INAF-Osservatorio Astronomico di Roma, via di Frascati 33, 00040, Monteporzio Catone, Roma, Italy
Draft version August 4, 2014
## ABSTRACT
Binary neutron star (NS) mergers are among the most promising sources of gravitational waves (GWs), as well as candidate progenitors for short Gamma-Ray Bursts (SGRBs). Depending on the total initial mass of the system, and the NS equation of state, the post-merger phase can be characterized by a prompt collapse to a black hole, or by the formation of a supramassive NS, or even a stable NS. In the latter cases of post-merger NS (PMNS) formation, magnetic field amplification during the merger will produce a magnetar and induce a mass quadrupole moment in the newly formed NS. If the timescale for orthogonalization of the magnetic symmetry axis with the spin axis is smaller than the spindown time, the NS will radiate its spin down energy primarily via GWs. Here we study this scenario for the various outcomes of NS formation: we generalize the set of equilibrium states for a twisted torus magnetic configuration to include solutions that, for the same external dipolar field, carry a larger magnetic energy reservoir; we hence compute the magnetic ellipticity for such configurations, and the corresponding strength of the expected GW signal as a function of the relative magnitude of the dipolar and toroidal field components. The relative number of GW detections from PMNSs and from binary NSs is a very strong function of the NS equation of state (EOS), being higher ( ∼ 1%) for the stiffest EOSs and negligibly small for the softest ones. For intermediate-stiffness EOSs, such as the n = 4 / 7 polytrope recently used by Giacomazzo & Perna or the GM1 used by Lasky et al., the relative fraction is ∼ 0 3%; cor-. respondingly we estimate a GW detection rate from stable PMNSs of ∼ 0 1 . -1 yr -1 with Advanced detectors, and of ∼ 100 -1000 yr -1 with detectors of third generation such as the Einstein Telescope. Measurement of such GW signal would provide constraints on the NS equation of state and, in connection with a SGRB, on the nature of the binary progenitors giving rise to these events. Subject headings:
## 1. INTRODUCTION
Binary neutron star (BNS) mergers are among the most powerful sources of gravitational waves (GWs) that are expected to be detected in the next few years by ground-based detectors, such as advanced LIGO and Virgo (Abadie et al 2010). BNSs are also the focus of theoretical modeling of short gamma-ray bursts (SGRBs) since their merger can lead to the production of relativistic jets and hence generate powerful gamma-ray emissions (e.g., see Berger 2013 for a recent review). One of the main scenarios of BNS mergers predicts the formation of a spinning black hole (BH) surrounded by an accretion torus soon after the merger, i.e., in less than one second approximately (see Faber and Rasio 2012 for a recent review of BNS merger simulations).
& Perna 2013), even a stable PMNS that will not collapse to a BH independently of its rotation.
It is however known that the total mass of the binary, together with the NS equation of state (EOS), can lead to different dynamics in the post-merger phase (e.g, see Baiotti et al 2008; Hotokezaka et al 2011; Bauswein et al 2013; Andersson et al 2013). Depending on the initial mass of the system, and going from high-mass to low-mass BNSs, the end result of the merger could be a prompt collapse to BH (e.g., Rezzolla et al 2010) or the formation of a post-merger NS (PMNS). The latter could be an hypermassive PMNS(i.e., supported by strong differential rotation) which will collapse in less than one second (e.g., Baiotti et al 2008), a supramassive PMNS(i.e., supported by rapid and uniform rotation) and, if the masses are sufficiently low (e.g., ∼ 1 22 . M glyph[circledot] in the case of Giacomazzo
1 contact address: [email protected]
The discovery of two NSs of ∼ 2 M glyph[circledot] (Demorest et al. 2010; Antoniadis et al. 2013) has opened the possibility that indeed a supramassive, or a stable NS, may be the end result in a significant number of BNS mergers. Moreover, recent observations of X-ray plateaus in SGRBs could support the possibility, that at least in some SGRBs, a supramassive or a stable NS with a strong magnetic field was formed after merger (Rowlinson et al 2013; see also Metzger et al. 2008, Dall'Osso et al. 2011). The recent discovery of fast radio bursts (Lorimer et al. 2007; Thornton et al. 2013) has also been interpreted as the final signal of a supramassive rotating NS that collapses to a black hole due to magnetic braking (Falcke & Rezzolla 2014; cf. Ravi & Lasky 2014). Recent numerical simulations of BNS mergers followed the formation of a stable PMNS with a large mass ( glyph[lessorsimilar] 2 36 M . glyph[circledot] ), a relatively large radius ( ≈ 15 km), a spin close to break up and a large degree of differential rotation (Giacomazzo & Perna 2013). Due to the combined effect of Kelvin-Helmholtz instabilities and dynamo action, a strong amplification of the internal magnetic field occurs promptly and the PMNS settles into uniform rotation, with millisecond spin and a strongly twisted interior magnetic field. The resulting picture is reminiscent of the so-called 'standard" magnetar formation scenario (Duncan & Thompson 1992), in which an ultramagnetized NS is formed in the core-collapse of a massive star by tapping a fraction of the energy in differential rotation of a fast-spinning proto-NS.
Such a scenario would have a very important role as, along
with explaining some electromagnetic observations, the millisecond spinning, ultramagnetized PMNS could provide a long-lasting GW signal, extremely valuable for studying the EOS of NS matter (e.g., Takami et al 2014), in analogy with what was proposed for magnetars born in the core-collapse of massive stars (Duncan & Thompson 1994; Zhang & Meszaros 2001; Cutler 2002; Stella et al. 2005; Bucciantini et al. 2006; Dall'Osso & Stella 2007; Bucciantini et al. 2008; Dall'Osso et al. 2009; Metzger et al. 2011).
In this work we address the possible long-lasting GW signal following the BNS merger due to the spindown of a magnetically deformed PMNS, based on the picture studied by Cutler (2002), Stella et al. (2005) and Dall'Osso et al. (2009). In § 2 we analyse the main steps that characterise this picture, and introduce a physical model to calculate the properties of the strongly magnetised PMNS. In § 3 we address the role of the NS EOS in determining the possible outcome of a merger, and compare expectations with available data from known BNSs. In § 4 we calculate the strength of the expected GWsignals and, based on the inferred properties of the BNS population, estimate the rate at which stable or supramassive PMNSs could be detected, relative to the total population of BNS mergers, by the forthcoming generation of detectors.
## 2. A GENERIC SCENARIO FOR GW EMISSION
The general scenario for efficient GW emission from the newly formed, millisecond spinning and strongly magnetised PMNS can be summarised as follows (cf. Cutler 2002):
- · The mechanism for field amplification at the merger implies that the axis of symmetry of the strongly twisted magnetic field will start almost aligned with the spin axis.
- · The NS is distorted into an ellipsoidal shape by the anisotropic magnetic stress. Free body precession will be excited by even a small misalignement between the magnetic symmetry axis and the spin axis. We indicate the tilt angle with χ from here on.
- · Strictly speaking, the largest deformation of the PMNS shape is caused by its fast rotation at ∼ kHz frequency. The rotationally-induced distortion is, however, always aligned with the instantaneous spin axis and thus plays no role in the dynamics of free body precession (see Cutler 2002 for a detailed discussion of this point). This is why we only consider the magnetically-induced distortion.
- · The energy of freebody precession is viscously dissipated and the conserved angular momentum is redistributed in the stellar interior. As a result, the PMNS ends up rotating around an axis that corresponds to its largest moment of inertia, so as to minimize spin energy at constant angular momentum.
- · A toroidal magnetic field produces a prolate ellipsoid, i.e. , one in which the smallest moment of inertia is the one relative to the axis of symmetry of the magnetic field.
- · For a prolate ellipsoid, viscous dissipation implies that the magnetic symmetry axis is driven orthogonal to the spin axis. This maximises the time-varying quadrupole moment of the rotating top, hence its GW emission efficiency.
After this sequence of events the PMNS becomes a potential source of GWs. The strength of the emitted signal will be determined by the strength of the GW-induced spindown torque, and by the competition with the additional torque due to magnetic dipole braking (see § 2.3).
## 2.1. Growth of the internal field: theoretical and observational support
General relativistic MHD simulations of BNS mergers show that a strong toroidal field is always produced during the merger (Giacomazzo et al 2011), even starting with a purely poloidal magnetic field. For the specific choice of an initial dipole ∼ 10 12 G, Giacomazzo & Perna (2013) showed that hydrodynamical instabilities during the merger can generate poloidal and toroidal components of at least ∼ 10 13 G; further amplification was seen while following the remnant's evolution for tens of milliseconds after the merger, with the energy in the toroidal field becoming larger than the poloidal energy by at least one order of magnitude. It is expected that the interior field can grow even stronger in the subsequent evolution, up to glyph[greaterorsimilar] 10 16 G, as suggested by recent local simulations at very high resolution (Zrake and MacFadyen 2013; Giacomazzo et al. 2014).
The timing and X-ray emission properties of the galactic population of magnetars suggest the presence of internal fields much stronger than the external dipoles (e.g. Dall'Osso et al. 2012). Internal magnetic fields of ∼ 10 15 G are also derived by energy arguments, in particular based on the 2004 Giant Flare from SGR 1806 (Stella et al. 2005). Recent observations (Rea et al. 2010, 2012, 2013) have revealed outbursting behaviour and enhanced quiescent X-ray luminosity in a few NSs with dipolar fields in the 5 × 10 12 -5 × 10 13 Grange, well below the few × 10 14 G strength believed necessary to cause crustal fractures, trigger magnetic outbursts and enhance the NS quiescent X-ray luminosity. By means of magnetothermal simulations of the NS crust it was shown (Perna & Pons 2011; Pons & Perna 2011; Viganò et al. 2013) that magnetic stresses can fracture the crust even in NSs with relatively low external dipoles, as long as the internal toroidal field is very strong ( glyph[greaterorsimilar] a few × 10 15 G), thus accounting for the outbursts of 'lowB ' field NSs.
## 2.2. The twisted-torus magnetic configuration
The magnetic field of the PMNS at the end of the merger phase is expected to quickly settle into an equilibrium state, driven by the growth of magnetic instabilities on very short timescales.
A general equilibrium configuration for a wide range of initial conditions was found by means of extensive numerical simulations (Braithwaite & Nordlund 2006, Braithwaite 2009) in the form of the so-called twisted-torus, i.e. a linked toroidal-poloidal magnetic field. The poloidal component contains an inner bundle of field lines that close inside the NS and therefore do not contribute to the exterior field.
We consider here such a configuration and, following the existing literature, restrict attention to the case where the toroidal field does not reach the exterior, which requires that it remains confined within the close-field-line region. While only a part of the poloidal flux extending beyond the NS surface contributes to the exterior dipolar field, both closed and open poloidal field lines contribute to the total poloidal energy. The latter will thus depend explicitly on the size of the closed field line region, and might exceed the energy of the (exterior) dipole even by a large factor.
*
FIG. 1.- Representation of magnetic field lines in the chosen configuration. The NS surface is indicated by the thick gray dashed circle. A mixed toroidalpoloidal field in the NS interior is matched to a pure dipole in the exterior with no surface currents. The toroidal field is confined within the region of closed poloidal field lines, the boundary of which is indicated by the thick closed curve. The extension of this region can be adjusted freely at a fixed strength of the exterior dipole, Bdip . This adjustment induces: i) a change in the total poloidal field energy, without changing Bdip ; ii) a change in the total NS ellipticity, glyph[epsilon1] B, at fixed values of Bdip and ET (see § 2.2.1); iii) a change in the stability threshold for the toroidal-to-poloidal field ratio (see § 2.2.2).
In order to derive the relevant physical properties of a magnetised PMNS we have slightly generalised previous treatments of the twisted-torus (Mastrano et al. 2011, 2012) to allow for an arbitrary size of the closed-field-line region, according to the prescription of Agkün et al. (2013). Details of this generalization are provided in Appendix A1. We have then chosen a specific configuration of the magnetic field within a class of solutions that, compared to previous studies of the twisted torus, allow for i) a larger magnetic energy reservoir in the NS interior and ii) stabilisation of a stronger toroidal field, for the same strength of the exterior dipole . While our procedure is valid in general, the specific choice of the magnetic field geometry determines all numerical estimates. A detailed study of how these change according to the size of the closed-field-line region will appear in a separate work (in preparation).
## 2.2.1. Magnetic ellipticity
The anisotropic stress due to the interior magnetic field will induce a distortion of the PMNS shape, hence a mass quadrupole moment Q ∼ I 0 glyph[epsilon1] B that is best expressed in terms of the moment of inertia of the unperturbed star, I 0, and its total magnetic ellipticity, glyph[epsilon1] B. The latter can be formally defined as the fractional difference between two main eigenvalues of the moment of inertia tensor. Let the axis of symmetry of the internal field be the z -axis, and the x and y -axes lie in a plane perpendicular to it, then glyph[epsilon1] B ≡ ( I zz -I xx ) / I 0. To calculate the magnetically-induced ellipticity we followed Mastrano et al. (2011), adjusting the calculations to our different choice for the interior field configuration. More details about our procedure are given in Appendix A2.
Our main result is the following numerical expression,
$$\epsilon _ { B } \simeq 2. 7 2 5 \times 1 0 ^ { - 6 } \left ( \frac { B _ { \text{dip} } } { 1 0 ^ { 1 4 } \, G } \right ) ^ { 2 } \left ( \frac { R _ { * } } { 1 5 \, \text{km} } \right ) ^ { 4 } \quad ( 1 ) \quad \frac { k _ { \text{hyd} } } { 2 } \quad \frac { k _ { \text{hyd} } } { \dots }$$
$$\times \left ( \frac { M _ { * } } { 2. 3 6 \, M _ { \odot } } \right ) ^ { - 2 } \left ( 1 - 0. 7 3 \, \frac { E _ { T } } { E _ { \text{pol} } } \right ), \quad \quad ( 2 ) \quad \text{ term}$$
where the (positive) contribution of the poloidal component and the (negative) contribution of the toroidal component are consistently accounted for . 2
## 2.2.2. Interior magnetic field vs. exterior dipole
Stability considerations set a maximum to the allowed toroidal-to-poloidal field ratio. Stable stratification of NS matter allows for much larger values of such ratio than previously thought (Reisenegger 2009; Akgün et al. 2013). We derived the maximum allowed ratio for the specific magnetic configuration represented in Fig. 1, by following the procedure of Akgün et al. (2013). Since our discussion here is necessarily limited in scope, we refer the reader to that paper for a thorough derivation. A generalisation of our calculations to arbitrary magnetic fields is postponed to a forthcoming paper. Adopting the general expression of the NS field given in § .1, we integrate its two components within their respective domains (see § 2.2) and obtain the total energies
$$\colon \ e l u \quad \ e _ { \text{pol} } \simeq 6 4. 6 7 5 \, \eta _ { \text{pol} } ^ { 2 } B _ { 0 } ^ { 2 } R _ { \text{ns} } ^ { 3 }$$
$$\overset { \cdot } { s } \\ \overset { \cdot } { s } \\ = 0. 0 0 5 5 \, b _ { \text{pol} } ^ { 2 } B _ { 0 } ^ { 2 } R _ { \text{ns} } ^ { 3 } \simeq 5. 5 \times 1 0 ^ { 4 7 } \left ( \frac { B _ { \text{dip} } } { 1 0 ^ { 1 4 } \, G } \right ) ^ { 2 } \left ( \frac { R _ { \text{ns} } } { 1 5 \text{km} } \right ) ^ { 3 } \, \text{erg}$$
$$\underset { \text{$a$s$ of} } { \text{$me$} } \underset { \text{$f$ the} } { \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text#\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text}$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text'$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text`$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text.$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text<$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text1$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test}$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$$$
where η pol T , are dimensionless constants measuring the relative strength of the two field components, B 0 is the field normalisation, Bdip = 2 η pol B 0 and the following definitions holds: B (max) pol ≡ b pol B 0, B (max) T ≡ b B T 0, B (max) indicating the maximum value of either field component inside the NS volume.
With these expressions, and after calculating the parameters k hydro , k pol and k T defined in Eqs. (79)-(82) of Akgün et al.
2 Mastrano et al. (2011, 2012) give glyph[epsilon1] B vs. Λ = Epol / (Epol + ET). The latter goes from 0 (for a purely toroidal field) to 1 (for a purely poloidal field). In terms of Λ , Eq. (1) becomes glyph[epsilon1] B glyph[similarequal] 4 7 . × 10 -6 ( Bdip / 10 14 G ) 2 ( 1 -0 422 . / Λ ) , omitting R ∗ and M ∗ .
(2013), we derived the condition for stability of the magnetic field in terms of the energy ratio between its components (cf. Eq. (83) of Akgün et al. 2013)
$$\frac { E _ { \text{pol} } } { E _ { \text{T} } } \gtrsim 0. 0 0 8 9 4 \, \frac { b _ { \text{T} } ^ { 2 } } { \left ( \Gamma / \gamma - 1 \right ) p } \,, \quad \quad \ \ ( 5 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where Γ = 1 + 1 / n for a polytrope with index n , γ is the adiabatic index of the NS fluid 3 , and p = 8 π Pc / B 2 0 , with Pc the NS central pressure. The ratio b 2 T / p is derived by inverting
$$\frac { E _ { T } } { E _ { G } } \simeq 0. 1 0 9 8 \, \frac { b _ { T } ^ { 2 } } { p } \,, \quad \quad \ \ ( 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where EG = 3 5 -n GM 2 R is the NS binding energy. Combining Eqs. (5) and (6) we finally get
$$\frac { E _ { \text{pol} } } { E _ { T } } \gtrsim \frac { 0. 0 8 1 4 } { ( \Gamma / \gamma - 1 ) } \frac { E _ { \text{tor} } } { E _ { G } } \,. \quad \quad \ ( 7 ) \quad \ w$$
Assuming f p glyph[similarequal] 0 05 (Reisenegger & Goldreich 1992) the co-. efficient Γ /γ -1 glyph[similarequal] 0 02, hence the stability condition reads .
$$& \left ( \frac { E _ { T } } { 1 0 ^ { 5 0 } \arg } \right ) \lesssim 3 \left ( \frac { B _ { \text{dip} } } { 1 0 ^ { 1 4 } \, G } \right ) \left ( \frac { \Gamma / \gamma - 1 } { 0. 0 2 } \right ) \left ( \frac { R _ { * } } { 1 5 \, \text{km} } \right ) \left ( \frac { M _ { * } } { 2. 3 6 \, M _ { \odot } } \right ) \cdot \text{ the evolu} \\ & \quad T h i c e n c a c t e \, \text{ that at the and of the amount of use acc}$$
This suggests that, at the end of the amplification process, a massive magnetar can be formed with a stable mixed field dominated by the toroidal component. The latter can in principle tap the energy glyph[greaterorsimilar] 10 50 erg that was originally in differential rotation, e.g., for the magnetic configuration of Fig. 1. The strength of the exterior dipole will be determined by the total energy in the poloidal field and by the size of the closedfield-line region.
Finally, by adopting the scalings of Eq. (3) we can write the stability condition (8) as
$$\frac { E _ { T } } { E _ { \text{pol} } } \lesssim 5 4 5 \left ( \frac { B _ { \text{dip} } } { 1 0 ^ { 1 4 } \, G } \right ) ^ { - 1 } \left ( \frac { M } { 2. 3 6 \, M _ { \odot } } \right ) \left ( \frac { R _ { * } } { 1 5 \, k m } \right ) ^ { - 2 } \left ( \frac { \Gamma / \gamma - 1 } { 0. 0 2 } \right ) \cdot \begin{array} { c } \text{ be short} \end{array} \\ \text{ the initia} \\ \text{GW emi} \\ \text{Daily} C \end{array}$$
## 2.3. Spindown of the newly formed NS
A rotating ellipsoid with the symmetry axis tilted with respect to the spin axis by an angle χ has a GW-induced spindown luminosity (Cutler & Jones 2001 and references therein)
$$\dot { E } _ { G W } = - \frac { 2 } { 5 } \frac { G ( I \epsilon _ { B } ) ^ { 2 } } { c ^ { 5 } } \, \omega _ { s } ^ { 6 } \sin ^ { 2 } \chi ( 1 + 1 5 \sin ^ { 2 } \chi ) \quad ( 1 0 ) \quad \begin{pmatrix} \stackrel { \cdots } { \text{tion} } \\ \text{the} \\ \text{eter} \end{pmatrix}$$
where ν s is the spin frequency and ω s = 2 πν s .
Once the prolate ellipsoid has become an orthogonal rotator the GW-induced spindown is maximised and the resulting spindown formula becomes
$$\dot { E } _ { G W } = - \frac { 3 2 } { 5 } \frac { G ( I \epsilon _ { \text{B} } ) ^ { 2 } } { c ^ { 5 } } \, \omega _ { s } ^ { 6 }, \quad \quad ( 1 1 ) \quad \quad \ w _ { \text{.} }$$
which we will use throughout this work.
When the additional torque due to the dipole magnetic field is included, the total spin down of the PMNS becomes
$$\dot { \omega } _ { s } = - \frac { B _ { \text{dip} } ^ { 2 } R ^ { 6 } } { 6 I c ^ { 3 } } \omega _ { s } ^ { 3 } - \frac { 3 2 } { 5 } \frac { G I \epsilon _ { \text{B} } ^ { 2 } } { c ^ { 5 } } \omega _ { s } ^ { 5 } \,, \quad \quad ( 1 2 ) \quad \text{EQ}$$
3 The factor ( Γ / γ -1) ∼ f p / 2 glyph[similarequal] a few % in a NS core, where f p is the charged particle fraction (Reisenegger & Goldreich 1992).
.
where Bdip is the dipole field at the NS pole 4 and R the PMNS radius.
In Fig. 2 we plot the solution of Eq. (12) in two representative cases, showing the critical role of the ratio between the interior toroidal field and the exterior dipole in setting the intensity and duration of the spindown-induced GW signal. When GW emission initially dominates the spindown, it will do so only for a limited time after which magnetic dipole takes over. If magnetic dipole braking dominates at birth, on the other hand, it will do so even at later times due to its weaker dependence on ω . In this case the PMNS spin energy is released electromagnetically and could produce observables like, e.g. plateaus in short GRBs (Rowlinson et al. 2013; cf. Dall'Osso et al. 2011 for long GRBs).
In this paper we will only be concerned with the GW signal, thus we aim at determining the conditions under which the GW torque dominates the PMNS spindown. However, we will be interested in tracking the spindown for as long as possible since the population of potential sources, stable and supramassive PMNSs, will display distinctive features in the evolution of their signals. The GW signal emitted by a stable PMNS will be characterised by steadily decreasing frequency and amplitude, with dipole braking significantly accelerating the evolution at late time. On the other hand, the collapse of the supramassive object will truncate the signal thus leaving a very specific signature.
## 2.4. Orthogonalization timescale
Given the near alignment implied by the initial conditions, significant GW emission will ensue only after the tilt angle χ has become large. During this very early phase the PMNS is however subject to magnetic dipole braking, with a spindown time τ em i , = ω / i (2 ˙ ω i ) glyph[similarequal] 1 day B 2 dip 14 , P 2 i , ms . A necessary condition for the PMNS to be able to radiate its huge spin energy reservoir via GWs is that the growth time of the tilt angle, τ χ , be shorter than τ em i , . In the opposite case, a bright electromagnetic transient of duration ∼ τ em i , would carry away much of the initial spin energy, leaving much less energy available for GWemission once χ has grown significantly.
Dall'Osso et al. (2009) derived the expression τ χ ∼ 13 ET 50P 2 , ms T -6 10 s, where the strong temperature dependence is due to bulk viscosity being the most important dissipation mechanism. Using this expression, they calculated the time for the tilt angle to grow to, e.g. π/ 3 rad, explicitly accounting for the fact that the very efficient modified-URCA reactions cause the NS temperature to change significantly during the process. They concluded that, for the region of parameter space where GW spindown wins over magnetic dipole braking, orthogonalisation is always achieved in a time significantly shorter than τ em i . .
## 3. STABLE VS. UNSTABLE MAGNETARS: DIFFERENT EOS AND TIME OF COLLAPSE
Whether a merger forms a stable or a supramassive PMNS will depend on the mass of the binary components and on the maximum mass (Mmax) allowed by the NS EOS. A stable PMNS can be formed in the merger of a relatively low-mass BNS (Giacomazzo & Perna 2013), for a sufficiently stiff EOS that allows a maximum NS mass Mmax glyph[greaterorsimilar] 2 3 M . glyph[circledot] . For a given EOS, fast rotation 5 provides additional support against collapse, increasing the mass limit by up to ∼ 20% when break-
4 The magnetic dipole moment is µ d = Bdip R 3 / 2.
5 We only consider uniform rotation here.
FIG. 2.- The spindown of a PMNS born with a spin period of 1 ms, in two representative cases: Left Panel: initially the GW-induced torque dominates and a strong GW signal can be emitted. The dipole magnetic field is Bdip glyph[similarequal] 10 14 G and the interior toroidal field energy corresponds to glyph[epsilon1] B glyph[similarequal] 10 -3 . As the spin frequency decreases the electromagnetic torque progressively kicks in, while the amplitude and frequency of the GW signal both decay faster than they would if only GW emission were effective. Right Panel: the spindown is dominated since the beginning by the electromagnetic torque. Here Bdip glyph[similarequal] 3 × 10 14 G and the same glyph[epsilon1] B glyph[similarequal] 10 -3 . No strong GW signal is expected in this case, but a bright electromagnetic transient, e.g., a short GRB extended emission or plateau, could result.
up speed is approached (Lyford et al. 2003). Supramassive PMNSs could thus be formed in a wider range of conditions and may well represent a large fraction of the whole population, especially when considering the softer EOS among those consistent with the observational constraint Mmax > . 2 1 M glyph[circledot] .
NS masses generally refer to the gravitational mass, Mg , the corresponding rest-mass being approximately 6 (Timmes et al. 1996)
$$M _ { r } = M _ { g } + 0. 0 7 5 M _ { g } ^ { 2 } \,. \quad \quad ( 1 3 ) \quad \, 3.$$
For a given EOS the equilibrium mass of a NS is a function of the central density, ˆ Mg ( ρ c ), and the maximum mass M g , max indicates the peak in this function. Models with Mg > M max g , are unstable and immediately collapse to BHs when rotation is negligible.
30000 that well approximates the behaviour at high density of the EOS by Shen et al. 1998 (see Oechslin et al. 2007). This polytropic EOS has a maximum mass M g , max ∼ 2 43 . M glyph[circledot] (and radius ∼ 12 km) for a nonrotating NS, while the maximally rotating model 8 has a maximum M g , max( P min) ∼ 2 95 . M glyph[circledot] (see Giacomazzo & Perna 2013 for more details). Finally, a relatively softer EOS which is widely used is the APR (Akmal et al. 1998) with M g , max = 2 2 M . glyph[circledot] , R max = 10 km, α = 3 03 . × 10 -11 and β = 2 95 (Lasky et al. . 2014). With these figures we get P min glyph[similarequal] 0 51 ms and M . g , max( P min) glyph[similarequal] 2 54 M . glyph[circledot] .
When rotation is included one can formally write the equilibrium mass as a function of the spin period P , or of the rotation rate Ω , as (Lasky et al. 2014; Ravi & Lasky 2014)
$$\hat { M } _ { g } ( P ; \rho _ { c } ) = \hat { M } _ { g } ( \rho _ { c } ) + \Delta M ( P ; \rho _ { c } ) = \hat { M } _ { g } ( \rho _ { c } ) ( 1 + \alpha P ^ { - \beta } ) \,, \ \ ( 1 4 ) \quad \underset { 1 \text{area} } { \text{sugg} }$$
where both coefficients α and β depend on the star's EOS 7 . The maximum mass, M g , max( P min), now depends explicitly on the maximum allowed rotation rate, i.e. the mass-shedding limit Ω max or the corresponding minimum period Pmin. The latter is given, to an accuracy of a few percent, by (Stergioulas 2003 and references therein)
$$\Omega _ { \max } = \mathcal { C } ( \chi _ { s } ) \sqrt { G M _ { g, \max } / R _ { \max } ^ { 3 } } \,, \quad \quad ( 1 5 ) \quad \ p o _ { \lambda \lambda }$$
where M g , max and R max are the mass and radius of the maximum mass nonrotating model, χ s = 2 G M max g , / ( c R 2 max) its compactness, and the function C ( χ s ) = 0 468 . + 0 378 . χ s . Comparing with, e.g. the numerical results of Lasky et al. (2014) for three selected EOS, gives indeed a very good agreement.
The EOS GM1 used by Lasky et al. (2014) has M g , max = 2 37 M . glyph[circledot] and R max = 12 km, corresponding to χ s glyph[similarequal] 0 586 and . Ω max glyph[similarequal] 9 3 . × 10 3 rad s -1 ( P min glyph[similarequal] 0 67 ms). . For this EOS, α = 1 58 . × 10 -10 and β = 2 84 (Lasky et al. . 2014), giving M max( g , P min) glyph[similarequal] 2 77 M . glyph[circledot] . For comparison, Giacomazzo & Perna (2013) adopted a polytropic EOS with n = 4 / 7 and K =
6 This accounts for the NS binding energy, including leading-order relativistic corrections as well as finite entropy effects.
7 This is true for relativistic models, while in Newtonian models β = 2 and only α depends on the stellar structure.
Based on the measured masses of 9 BNSs, the mass distribution of NSs in binaries was found to be peaked at 〈 M g 〉 glyph[similarequal] (1 32 . ± 0 11) M . glyph[circledot] (Kiziltan et al. 2013) which corresponds to 〈 M r 〉 glyph[similarequal] (1 45 . ± 0 13) M . glyph[circledot] , with the errors indicating a 68% probability interval. A 'typical" equal-mass binary would have Mr = (2 91 . ± 0 18) M . glyph[circledot] , or Mg = (2 45 . ± 0 13) M . glyph[circledot] , close to the maximum for the n =4 7 polytrope described above but / uncomfortably large for, e.g. the APR EOS. Such numbers suggest that, for the n = 4 / 7 EOS (or, possibly, the GM1), a large majority of BNS mergers would produce either a supramassive or a stable PMNS, with the latter potentially representing a sizeable fraction. A BH would be the most likely result for softer EOS, possibly with a small fraction of supramassive PMNSs rotating close to break-up.
To further clarify this point we plot in Fig. 3 the measured NS masses in 9 BNSs (Kiziltan et al. 2013, their Tab.1) along with lines indicating M g , max for the EOS GM1 and the n = 4 / 7 polytrope. These lines assume that the total rest-mass is conserved in the merger: any loss of rest-mass due to, e.g mass ejection or the formation of a disk/torus around the remnant, would shift them upwards in the plot. For three systems only the total gravitational mass is well determined, hence we plot them separately showing the 68% probability range for the total mass in the right panel of Fig. 3.
## 4. SOURCE DETECTION
Three main factors determine the rate at which GW signals of massive magnetars formed in BNS mergers can be revealed with advanced detectors: i) the total rate of BNS mergers, ˙ N , and the fraction of such events that will form a massive PMNS, call it p ns ; ii) the intrinsic signal strength as a function
8 The formulae for rotating models give Ω max glyph[similarequal] 9 52 . × 10 3 rad s -1 (Pmin glyph[similarequal] 0 66 ms). .
FIG. 3.Left Panel: Measured gravitational masses for NSs in BNSs (Kiziltan et al. 2013). Points below the diagonal lines indicate systems that will potentially form a stable PMNS, i.e. Mg < M max, for two different EOS: g , a) a polytrope with n = 4 / 7 and K = 30000, that well approximates the nuclear EOS by Shen et al. 1998 (dashed line); b) GM1 from Lasky et al. 2014 (dotted line). The two lines are obtained assuming conservation of rest-mass in the merger and an approximate Mr -Mg relation (see text). Mass-loss shifts the lines upwards. For example, the two lines are separated by a rest-mass difference of glyph[similarequal] 0 04 M . glyph[circledot] . Right Panel: For 3 BNSs individual masses are loosely constrained and only the total gravitational mass is well determined. The 1 σ error ranges (Kiziltan et al. 2013) are plotted: PSR J1829+2456 falls between the two lines. Conclusions are uncertain for the remaining systems.
of the physical properties of the sources; iii) the detector's properties.
## 4.2. The detector's 'range" R
## 4.1. Signal-to-noise ratio
The maximum strain received from an ideally-oriented 9 NS spinning at frequency ν s and at a distance D is
$$h ( f ) = \frac { 4 \pi ^ { 2 } G I \epsilon _ { \text{B} } } { c ^ { 4 } D } \ f ^ { 2 } \,, \quad \quad \ \ ( 1 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where f = 2 ν s is the frequency of the GW signal.
As the detector collects the signal, the NS spins down and both frequency and strain decrease. The signal-to-noise ratio for an ideal matched-filter search is thus defined as
$$S / N = 2 \left [ \int _ { f _ { i } } ^ { f _ { f } } d f \frac { | \tilde { h } ( f ) | ^ { 2 } } { S _ { h } ( f ) } \right ] ^ { 1 / 2 }, \quad \quad ( 1 7 ) \quad \text{nc} \\ \text{so} \quad \text{ori}$$
where Sh ( f ) is the detector's (one-sided) noise spectral density and ˜ ( h f ) is the Fourier transform of h f [ ( )]. t The latter will depend on the frequency spindown (see Sathyaprakash & Schutz 2009), hence on both Bdip and glyph[epsilon1] B in general (cf. Dall'Osso et al. 2009). It is useful for our purposes to write it in the limit where d f / f t is only due to GW emission
$$\left ( \frac { S } { N } \right ) _ { G W } \simeq & \ 1 0 \left ( \frac { D } { 3 3. 5 M p c } \right ) ^ { - 1 } \left ( \frac { R } { 1 5 k m } \right ) \left ( \frac { M } { 2. 3 6 M _ { \odot } } \right ) ^ { 1 / 2 } \quad \begin{array} { c } \text{To} \\ \text{to de} \\ \text{signi} \\ \end{array} \right ) \\ & \times \left [ \left ( \frac { f _ { f } } { k H z } \right ) ^ { - 2 } - \left ( \frac { f _ { i } } { k H z } \right ) ^ { - 2 } \right ] ^ { 1 / 2 }. \quad \begin{array} { c } \text{To} \\ \text{new} \\ \text{case} \\ \text{may} \end{array} \right )$$
The choice of the low end of the frequency range, f f , can be very important for the value of S/N, while f i has a marginal role as long as it is not too close to f f . This will be a crucial point in the next section, where we aim at assessing the effective detectability of our sources.
9 Ideal orientation to the detector's arms and optimal angle between spin and line of sight.
The intensity of a received GW signal also depends on the source's direction, and on the orientation of its spin axis with respect to the line-of-sight. At a fixed detection threshold, favourably oriented sources are detectable out to much larger distances than badly oriented, yet identical, ones. A proper average of these orientation-dependent horizons, which accounts for the probability of different sources making different angles with respect to the detector's arms and having different angles between their spin axis and the line of sight, is the detector's 'range", R (Finn & Chernoff 1993). This allows to write the total rate of detectable events simply as 10
$$\dot { N } _ { \text{det} } = \frac { 4 } { 3 } \pi \dot { N } p _ { \text{ns} } \mathcal { R } ^ { 3 } \,.$$
Note that not all detected sources will actually be within R : some will be farther away but with a particularly favourable orientation while others, that are well within R , will go undetected being unfavourably oriented 11 .
If we define the optimal horizon Dopt as the maximum distance at which an optimally oriented source can be detected with an ideal matched-filter search made using one single interferometer, then the range is simply obtained as R = Dopt / 2 26 (see sec. 4.3 in Finn & Chernoff 1993). .
For a single-detector search we set for simplicity the detection threshold at S/N=8 (Abadie et al. 2010). We don't need to determine it more accurately at this stage, in view of the significant improvement in sensitivity that the operation of a network of detectors will guarantee over the single-detector case (Schutz 2011). For this reason, the estimates that follow may well be regarded as conservative ones.
The maximum distance at which S/N is above threshold, Dopt, can only be obtained as a function of source parameters. In particular, given the dependence of S/N on f f (Eq. 18), we will consider stable and supramassive NSs separately. Indeed,
10 We just added the factor p ns to the formula given by Finn & Chernoff (1993).
11 The fraction of detected sources that will be beyond a given distance can also be estimated (Finn & Chernoff 1993).
FIG. 4.- Contours of the optimal signal-to-noise ratio in the Bd vs. ET plane, for a single detector search and an ideally oriented source at a distance of 75 Mpc. We define this, somewhat arbitrarily, as the maximum distance at which S/N is above threshold in a sufficiently large region of the parameter space (about half). Following Abadie et al. (2010), the threshold for detectability is set at S/N = 8. No NS can be found in the instability region defined by inequality (8).
while f f for the former is determined by spindown causing a decrease of the signal amplitude (Fig. 2), for the latter it is determined by the collapse of the NS which, in general, occurs much earlier (see below).
## 4.2.1. Stable PMNS
If a stable PMNS is formed in the merger, a strong GW signal starts within a few tens of minutes, once the angle between the rotation axis and the symmetry axis of the toroidal field has grown sufficiently. The initial frequency is f i = 2 ν , s i and GWs should dominate the spindown, initially, in order for the signal to be detectable at all. As the PMNS spin frequency decreases, the magnetic dipole torque becomes relatively more important (cfr. Eq. 12), the signal amplitude and frequency decay progressively faster than they would under pure GW emission, and GW emission eventually fades away once the spin down is dominated by the magnetic dipole. This determines the lower end of the frequency interval, f f .
We have calculated S/N according to Eq. (17) including self-consistently both torques in the expression for the spindown. Since S/N depends on two parameters (Bdip, EB), the distance up to which it remains above threshold is not unequivocally determined. We choose as our horizon a distance at which S/N ≥ 8 for approximately half of the parameter space of interest, which turns out to be Dopt glyph[similarequal] 75 Mpc for a PMNS with M=2.36 M glyph[circledot] , R=15 km and ν , s i = 1 kHz (cf. Giacomazzo & Perna 2013), translating to Rglyph[similarequal] 33 5 Mpc. The . S/N contours in the Bd vs. EB plane for this specific configuration are shown in Fig. 4, where the range of the two magnetic field components was chosen appropriately for our case.
## 4.2.2. Supramassive PMNS
The collapse of a supramassive PMNS sets the frequency = f coll . It occurs when the star's mass, Mns, equals the maximum mass at a given spin period, M g , max( P min). By inverting the definition of ˆ Mg P ( ; ρ c ) of § 3 we can write (Lasky et al. 2014)
$$f _ { \text{coll} } = 2 \left ( \frac { M _ { n s } - M _ { g, \max } } { \alpha M _ { g, \max } } \right ) ^ { 1 / \beta }, \quad \quad ( 2 0 ) \quad \overset { \infty } { m i } \\ \ m \dot { \alpha }$$
the solution of which is plotted in Fig. 5, as a function of Mns, for the three selected EOS discussed in § 3. In general, the frequency at collapse decreases with the mass and becomes lower than 1 kHz only if Mns lies in an extremely narrow range
FIG. 5.- The signal frequency at which a supramassive PMNS collapses, f coll = 2 ν s , coll vs. the initial mass, for the three selected EOS discussed in § 3. The red dashed lines indicate the initial mass at which f coll = 1 kHz (spin period of 2 ms), with only lower initial masses collapsing at lower frequencies, implying a narrow range of allowed masses ∆ M glyph[similarequal] 0.02 M glyph[circledot] for the n = 4 / 7 and GM1 EOS. For the APR EOS the allowed range is ∆ M < . 0 01 M glyph[circledot] .
just above M g , max. A much lower S/N than for stable PMNSs is thus expected, which implies a smaller horizon and a much smaller number of events. One must restrict attention to the smallest masses in order to get the strongest signals, visibile to the largest distances. However, this reduces drastically the number of possible targets.
For an approximately Gaussian distribution of remnant masses peaked at 2.45 M glyph[circledot] and with σ M = 0 13 M . glyph[circledot] (see § 3), only ∼ 5 % and 6% of them would lie between M g , max and (M g , max + 0 02) M . glyph[circledot] , for the GM1 and the n = 4 / 7 EOS, respectively. This fraction becomes quickly negligible for softer EOS, while for stiffer EOS most mergers would produce stable PMNSs given that M g , max is above the Gaussian peak. For illustration we have considered a 2.45 M glyph[circledot] remnant with R=15 km and initially spinning at break up, ν , s i glyph[similarequal] 1500 Hz for the n =4 7 polytrope. According to Eq. (20) it will collapse when / f coll glyph[similarequal] 1 kHz, or the spin period glyph[similarequal] 2 ms. We derived the optimal horizon for this relatively favourable case as was done in the previous section. The result is shown in Fig. 6 with Dopt = 35 Mpc, corresponding to Rglyph[similarequal] 16 Mpc. This considerably smaller horizon compared to the stable PMNSs causes a factor 10 reduction in the sampling volume. Together with the small fraction of objects that fall in this favourable mass range, it implies that a number ∼ 100-200 times smaller of such events can be detected compared to the stable PMNSs.
## 4.3. The expected event rate
In light of the above findings, the number of PMNSs that can be revealed with the forthcoming generation of GW detectors will be dominated by stable PMNSs, and will strongly depend on the NS EOS. The discussion of § 3, summarised in Fig. 3, suggests that a sizeable fraction, p ns ∼ 0 2 . -0 5, of the . whole population of BNS mergers could result in a stable or marginally supramassive PMNS for the GM1 or the n = 4 / 7 polytropic EOS. This fraction grows to ∼ unity for harder EOS's, in particular those with M g , max ≥ 2 5 M . glyph[circledot] . For relatively softer EOS's like, e.g. the APR, on the other hand, the maximum mass becomes quickly too low and essentially all mergers would immediately produce a BH. The detection of a ∼ kHz frequency GW signal with hour-long spindown following a BNS merger, as discussed here, would thus provide a very interesting constrain on the EOS of NS matter. This would be especially valuable when combined with an inde-
,50
FIG. 6.- Contours of the optimal signal-to-noise ratio in the Bd vs. ET plane, for a single detector search and an ideally oriented supramassive PMNS at Dopt =35 Mpc. We chose M g = 2.45 M glyph[circledot] , R=15 km and an n = 4 / 7 ( K =3000) polytropic EOS, for which the breakup frequency is 1500 Hz, and the collapse frequency f coll glyph[similarequal] 1 kHz. With the initial spin frequency taken to be at breakup, we have f i = 3 kHz and = f coll glyph[similarequal] 1 kHz. We define Dopt, somewhat arbitrarily, as the maximum distance at which the S/N is above threshold in a sufficiently large region of the relevant parameter space. No NS can be found in the instability region defined by (8).
pendent determination of the total population of BNS, which could provide a direct measure of the fraction p ns .
Since Ndet ˙ ∝ N ˙ (cf. Eq. 19), we can express the rate of detection of PMNS signals relative to the rate of detection of BNS mergers with Advanced detectors as
$$\frac { \dot { N } _ { \text{det} } } { \dot { \mathcal { N } } } \sim p _ { \text{ns} } \left ( \frac { \mathcal { R } _ { \text{PMNS} } } { \mathcal { R } _ { \text{BNS} } } \right ) ^ { 3 } \sim 0. 0 0 3 \,, \quad \ \ ( 2 1 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where R BNS ∼ 170 Mpc (Abadie et al. 2010) and we assumed p ns ∼ 0 3 (thus excluding EOSs softer than the GM1). In this . case, the small fraction mostly reflects the difference in the sampling volume for the two different types of signals.
'Realistic" estimates of the detection rates of BNS mergers with Advanced detectors range from 40 to 400 events per year (Abadie et al. 2010), and were derived phenomenologically based on a statistical study of the population of known BNS in the Galaxy (Kalogera et al. 2004). By adopting these numbers, we conclude that stable PMNSs may be detectable at a rate Nset ˙ ∼ (0 1 . -1) yr -1 with Advanced detectors, for the GM1 or the n = 4 / 7 polytropic EOS. For stiffer EOS, with M max g , glyph[greaterorsimilar] 2 5 M . glyph[circledot] , nearly all mergers would produce a PMNS, thus the detection rate could be higher by a factor ≈ 3. For softer EOS, on the other hand, these figures drop significantly following the drop in the coefficient p ns .
We finally note that third generation detectors, such as the Einstein Telescope, will have a higher sensitivity by up to a factor ∼ 10 (Punturo et al 2010). This will increase the detector's range, R by the same factor, making stable PMNSs detectable up to R glyph[greaterorsimilar] 300 Mpc, and even supramassive ones up to R glyph[greaterorsimilar] 150 Mpc. The detection rate will thus increase by a very large factor, ∼ 10 3 , which is extremely important in particular for supramassive PMNSs. Indeed, with Advanced detectors these objects will also become interesting sources, with a likely rate of detection of a few events per year.
## 5. SUMMARY AND DISCUSSION
The GW signatures of a newly born NS are very sensitive to the equation of state. Intense GW emission is expected under the presence of a strong toroidal magnetic field, as a result of the star's prolate ellipsoidal shape. In such a configuration, viscous dissipation drives the magnetic symmetry axis orthogonal to the spin axis, hence maximizing the strength of the emitted GW radiation.
GWs from highly magnetized NSs newly born in core collapse supernovae have been studied in a number of works. Here, motivated by recent numerical simulations of binary NS mergers which show magnetic field amplification, we have studied the conditions under which strong GW emission is expected in the post-merger phase, if this is characterized by the presence of a short-lived, or stable, highly magnetized NS. To this aim, we have extended the set of equilibrium states for a twisted torus magnetic configuration to include solutions that, for a given external dipolar field, carry a larger magnetic energy reservoir. We have then computed the magnetic ellipticity for such configurations, hence the strength of the GW signal, once the system has orthogonalized.
We find that the strength of the signal, and hence its detectability, is mainly dependent by the NS EOS. The dependence is twofold. Firstly, whether the merger of two NSs leads to a supramassive NS (which eventually collapses to a BH) or to a stable NS, is highly dependent on the NS EOS. For a given distribution of remnant masses, stiffer EOSs yield a higher fraction of stable NSs. Second, the GW signal itself, and in particular the two distinct and robust spectral features which characterize the postmerger emission, are very sensitive to the NS EOS (e.g. Takami et al. 2014). For an intermediate EOS, such as the n = 4 / 7 polytrope, or the GM1 used by Lasky et al. (2014), we estimate that we expect GW emission from PMNSs in about 0.3% of all GW detections from BNS mergers. Correspondingly, we expect a detection rate of about 0.1-1 event per year with Advanced detectors; this rate would increase by a factor of ∼ 10 3 with third generation detectors, such as the Einstein Telescope, which will have a higher S/N by up to a factor of 10. These detectors would be able to observe even the weaker emission from the unstable PMNSs, albeit with lower rates.
GWs from highly magnetized PMNSs produced in mergers would be especially interesting if detected in connection with a short GRB. In fact, while there is plenty of circumstantial evidence that these events are produced by a merger, whether the final product is a stable (or unstable) NS, or a promptly-formed BH is still a subject of investigation. Extended emission, occasionally in the form a plateau, has been seen in about half of Swift SGRBs. In some cases, this emission ends abruptly (possibly indicating the collapse of a hypermassive NS to a BH), while in some other cases it declines with a powerlaw, possibly indicating the presence of a stable NS (Rowlinson et al. 2013). Detection of GWs from the postmerger NS would allow to discern its identity, and hence shed light on the nature of the binary progenitors of SGRBs. In addition, contemporary detection of a SGRB and GWs would further constrain the NS EOS (e.g. Giacomazzo et al. 2013).
For this work S.D. was supported by the SFB/Transregio 7, funded by the Deutsche Forschungsgemeinschaft (DFG). B.G. acknowledges support from MIUR FIR Grant No. RBFR13QJYF, and R.P. from NSF grant No. AST 1009396 and NASA grant No. NNX12AO67G.
## REFERENCES
Akmal, A., Pandharipande, V. R., & Ravenhall, D. G. 1998, Phys. Rev. C, 58, 1804
Andersson, N., Baker, J., Belczynski, K., et al. 2013, Classical and Quantum Gravity, 30, 193002
Antoniadis, J., Freire, P. C. C., Wex, N., et al. 2013, Science, 340, 448
Baiotti, L., Giacomazzo, B., & Rezzolla, L. 2008, Phys. Rev. D, 78, 084033
Bauswein, A., Baumgarte, T. W., & Janka, H.-T. 2013, Physical Review Letters, 111, 131101
Berger, E. 2013, arXiv:1311.2603
Braithwaite, J., & Nordlund, Å. 2006, A&A, 450, 1077
Braithwaite, J. 2009, MNRAS, 397, 763
Bucciantini, N., Thompson, T. A., Arons, J., Quataert, E., & Del Zanna, L. 2006, MNRAS, 368, 1717
Bucciantini, N., Quataert, E., Arons, J., Metzger, B. D., & Thompson, T. A. 2008, MNRAS, 383, L25
Cutler, C., & Jones, D. I. 2001, Phys. Rev. D, 63, 024002
Cutler, C. 2002, Phys. Rev. D, 66, 084025
Dall'Osso, S., & Stella, L. 2007, Ap&SS, 308, 119
Dall'Osso, S., Shore, S. N., & Stella, L. 2009, MNRAS, 398, 1869
Dall'Osso, S., Stratta, G., Guetta, D., et al. 2011, A&A, 526, A121
Dall'Osso, S., Granot, J., & Piran, T. 2012, MNRAS, 422, 2878
- Demorest, P. B., Pennucci, T., Ransom, S. M., Roberts, M. S. E., & Hessels, J. W. T. 2010, Nature, 467, 1081
Duncan, R. C., & Thompson, C. 1992, ApJ, 392, L9
Faber, J. A., & Rasio, F. A. 2012, Living Reviews in Relativity, 15, 8
Falcke, H., & Rezzolla, L. 2014, A&A, 562, 137
Finn, L. S., & Chernoff, D. F. 1993, Phys. Rev. D, 47, 2198
Giacomazzo, B., Rezzolla, L., & Baiotti, L. 2011, Phys. Rev. D, 83, 044014
Giacomazzo, B., & Perna, R. 2013, ApJ, 771, L26
Giacomazzo, B., Perna, R., Rezzolla, L., Troja, E., Lazzati, D. 2013, ApJ, 762, L18
Hotokezaka, K., Kyutoku, K., Okawa, H., Shibata, M., & Kiuchi, K. 2011, Phys. Rev. D, 83, 124008
Kalogera, V., Kim, C., Lorimer, D. R., et al. 2004, ApJ, 601, L179
Kiziltan, B., Kottas, A., De Yoreo, M., & Thorsett, S. E. 2013, ApJ, 778, 66 Lasky, P. D., Haskell, B., Ravi, V., Howell, E. J., & Coward, D. M. 2014,
Phys. Rev. D, 89, 047302
Lorimer, D. R., Bailes, M., McLaughlin, M. A., Narkevic, D. J., Crawford, F.
2007, Science, 318, 777
## APPENDIX
## A1: The twisted-torus configuration
In spherical coordinates, the interior poloidal field is
$$B _ { \text{pool} } ( \hat { r }, \theta ) & = B _ { 0 } \, \left [ \eta _ { \text{pool} } \nabla \hat { \alpha } ( \hat { r }, \theta ) \times \nabla \hat { \phi } + \eta _ { \text{T} } \hat { \beta } ( \hat { r }, \theta ) \nabla \hat { \phi } \right ] \,,$$
where ˆ r = r / R ns is the dimensionless radial coordinate and ∇ ˆ φ = ˆ φ/ ( ˆ r sin θ ), with ˆ φ the unit vector in the φ -direction. B 0 is a normalisation (in Gauss), ˆ α the (adimensional) flux function, i.e. the poloidal magnetic flux threading a polar cap of radius ˜ ω = R r ∗ ˆ sin θ , η pol and η T are dimensionless constants measuring the relative strength of the two field components and the 'current function" ˆ β ≡ ˆ ˆ β α ( ), as required by axysimmetry. Since no currents exist in the exterior, this implies that electrical currents can only flow on poloidal field lines that close inside the NS, hence the bounding region for BT. In particular, ˆ β = ( ˆ α -1) n is usually assumed, with n > 1 to ensure regularity of the supporting currents at the boundary of the toroidal field region. Finally, the exterior dipole field is matched at the NS surface to the interior field by taking the flux function ˆ ˆ α ( r , θ ) = f ( ˆ r ) sin 2 θ .
Th function f is determined 12 by first imposing the magnetic force and current density to remain finite everywhere inside the NS. For a trial form f ( ˆ r ) ∝ ˆ r p this implies either p = 2 or p > 3, suggesting to seek a polynomial solution for f . Smoothly matching the interior and exterior fields requires continuity of the magnetic field at the NS surface, and that no surface currents exist. To satisfy this at least three terms in the polynomial are needed, therefore the 'simplest" solution is f ( ˆ r ) = c r 2 ˆ 2 + c r 4 ˆ 4 + c r 5 ˆ 5 . The coefficients are determined by normalisation of f ( ˆ r ), thus fixing the field shape. Different choices for the polynomial terms are however possible, which affect the shape and size of the closed-field-line region. For the purpose of this work we have chosen the configuration represented in Fig. 1, which corresponds to f ( ˆ r ) = (435 / 8) ˆ r 2 -(1221 / 4) ˆ r 4 + 400 ˆ r 5 -(1185 / 8) ˆ r 6 and ˆ β = ( ˆ α -1) . 2
## A2: Magnetic ellipticity
The two components of the inertia tensor I zz and I xx are obtained through the magnetically-induced density perturbation by (Mastrano et al. 2011)
$$I _ { j k } = R _ { * } ^ { 5 } \, \int d \mathcal { N } \, [ \rho ( \hat { r } ) + \delta \rho ( \hat { r }, \theta ) ] \, ( \hat { r } ^ { 2 } \delta _ { j k } - \hat { x } _ { j k } ^ { 2 } ) \,.$$
12 A full derivation is given by Akgün et al. (2013).
Lyford, N. D., Baumgarte, T. W., & Shapiro, S. L. 2003, ApJ, 583, 410 Mastrano, A., Melatos, A., Reisenegger, A., & Akgün, T. 2011, MNRAS, 417, 2288
Mastrano, A., & Melatos, A. 2012, MNRAS, 421, 760
- Metzger, B. D., Quataert, E., & Thompson, T. A. 2008, MNRAS, 385, 1455
Metzger, B. D., Giannios, D., Thompson, T. A., Bucciantini, N., & Quataert,
E. 2011, MNRAS, 413, 2031
Oechslin, R., Janka, H.-T., & Marek, A. 2007, A&A, 467, 395
Perna, R., & Pons, J. A. 2011, ApJ, 727, L51
Pons, J. A., & Perna, R. 2011, ApJ, 741, 123
Punturo, M., Abernathy, M., Acernese, F., et al. 2010, Classical and Quantum Gravity, 27, 194002
Ravi, V., & Lasky, P. D. 2014, MNRAS, 441, 2433
Rea, N., Esposito, P., Turolla, R., et al. 2010, Science, 330, 944
Rea, N., Israel, G. L., Esposito, P., et al. 2012, ApJ, 754, 27
Rea, N., Israel, G. L., Pons, J. A., et al. 2013, ApJ, 770, 65
Reisenegger, A., & Goldreich, P. 1992, ApJ, 395, 240
Reisenegger, A. 2009, A&A, 499, 557
Rezzolla, L., Baiotti, L., Giacomazzo, B., Link, D., & Font, J. A. 2010, Classical and Quantum Gravity, 27, 114105
Rowlinson, A., O'Brien, P. T., Metzger, B. D., Tanvir, N. R., & Levan, A. J. 2013, MNRAS, 430, 1061
- Sathyaprakash, B. S., & Schutz, B. F. 2009, Living Reviews in Relativity, 12, 2
Schutz, B. F. 2011, Classical and Quantum Gravity, 28, 125023
- Shen, H., Toki, H., Oyamatsu, K., & Sumiyoshi, K. 1998, Nuclear Physics A, 637, 435
- Stella, L., Dall'Osso, S., Israel, G. L., & Vecchio, A. 2005, ApJ, 634, L165 Stergioulas, N. 2003, Living Reviews in Relativity, 6, 3
Takami, K., Rezzolla, L., & Baiotti, L. 2014, arXiv:1403.5672
Timmes, F. X., Woosley, S. E., & Weaver, T. A. 1996, ApJ, 457, 834
Thornton, D. et al.
2013, Science, 341, 53
Viganò, D., Rea, N., Pons, J. A., Perna, R., Aguilera, D. N., Miralles, J. A.
2013, MNRAS, 434, 123
Zhang, B., & Mészáros, P. 2001, ApJ, 552, L35
Zrake, J., & MacFadyen, A. I. 2013, ApJ, 769, L29
With these definitions the total ellipticity is eventually expressed as
$$\epsilon _ { B } = \frac { \pi R _ { * } ^ { 5 } } { I _ { 0 } } \int d \theta d \hat { r } \, \delta \rho ( \hat { r }, \theta ) \, \hat { r } ^ { 4 } \, \sin \theta ( 1 - 3 \cos ^ { 2 } \theta ) \,,$$
hence the relation between the magnetic field structure and the induced ellipticity of the NS is obtained directly from δρ ( ˆ r , θ ). To calculate the latter we follow the steps described by Mastrano et al. (2011), who write the equation of hydrostatic equilibrium to first order in the magnetic perturbation in the Cowling approximation,
$$- \frac { B _ { 0 } ^ { 2 } } { \hat { r } ^ { 2 } \sin ^ { 2 } \theta } \left ( \eta _ { \text{pol} } ^ { 2 } \nabla \hat { \alpha } \hat { \Delta } \hat { \alpha } + \eta _ { \text{i} } ^ { 2 } \hat { \beta } \nabla \hat { \beta } \right ) = \nabla \delta p + \delta \rho \nabla \Phi \,.$$
Here δ p is the magnetically-induced pressure perturbation, Φ the unperturbed gravitational potential and the Grad-Shafranov operator is ˆ ∆ = ∂ 2 r + ( sin θ/ ˆ r 2 ) ∂ θ [ (sin θ ) -1 ∂ θ ] . The θ -component of Eq. (4) relates the magnetic term to δ p alone. Feeding the latter in the ˆ r -component gives the density perturbation inside the NS as a function of ˆ α , ˆ r , θ and the parameters ( B 0 , η T, η pol ). The poloidal and toroidal field contribute with opposite signs to δρ ( ˆ r , θ ), hence the ellipticity due to the poloidal field is positive according to our definition, while the toroidal field produces a negative glyph[epsilon1] B. Solving eq. 4 for δρ ( ˆ r , θ ) with our chosen ˆ ˆ α ( r , θ ), we plug it into eq. 3 to eventually obtain the total magnetic ellipticity of the NS reported in Eq. (1). | 10.1088/0004-637X/798/1/25 | [
"Simone Dall'Osso",
"Bruno Giacomazzo",
"Rosalba Perna",
"Luigi Stella"
] | 2014-07-31T20:01:28+00:00 | 2014-07-31T20:01:28+00:00 | [
"astro-ph.HE",
"gr-qc"
] | Gravitational waves from massive magnetars formed in binary neutron star mergers | Binary neutron star (NS) mergers are among the most promising sources of
gravitational waves (GWs), as well as candidate progenitors for short Gamma-Ray
Bursts (SGRBs). Depending on the total initial mass of the system, and the NS
equation of state (EOS), the post-merger phase can see a prompt collapse to a
black hole, or the formation of a supramassive NS, or even a stable NS. In the
case of post-merger NS (PMNS) formation, magnetic field amplification during
the merger will produce a magnetar with a large induced mass quadrupole moment,
and millisecond spin. If the timescale for orthogonalization of the magnetic
symmetry axis with the spin axis is sufficiently short the NS will radiate its
spin down energy primarily via GWs. Here we study this scenario for various
outcomes of NS formation: we generalise the set of equilibrium states for a
twisted torus magnetic configuration to include solutions that, at a fixed
exterior dipole field, carry a larger magnetic energy reservoir; we hence
compute their magnetic ellipticity and the strength of the expected GW signal
as a function of the magnitude of the dipole and toroidal field. The relative
number of GW detections from PMNSs and from binary NSs is a strong function of
the NS equation of state (EOS), being higher (~ 1%) for the stiffest EOSs and
negligibly small for the softest ones. For intermediate-stiffness EOSs, such as
the n=4/7 polytrope recently used by Giacomazzo \& Perna or the GM1 used by
Lasky et al., the relative fraction is ~0.3%; correspondingly we estimate a GW
detection rate from stable PMNSs of ~ (0.1-1) yr$^{-1}$ with Advanced
detectors, and of ~ (100-1000) yr$^{-1}$ with third generation detectors such
as the Einstein Telescope. Measurement of such GW signal would provide strong
constraints on the NS EOS and on the nature of the binary progenitors giving
rise to SGRBs. |
1408.0014v2 | ## Ground State Degeneracy of Topological Phases on Open Surfaces
Ling-Yan Hung 1, 2, ∗ and Yidun Wan 3, †
1 Department of Physics and Center for Field Theory and Particle Physics, Fudan University, Shanghai 200433, China 2 Department of Physics, Harvard University, Cambridge MA 02138, USA 3 Perimeter Institute for Theoretical Physics, Waterloo, ON N2L 2Y5, Canada
We relate the ground state degeneracy (GSD) of a non-Abelian topological phase on a surface with boundaries to the anyon condensates that break the topological phase to a trivial phase. Specifically, we propose that gapped boundary conditions of the surface are in one-to-one correspondence to the sets of condensates, each being able to completely break the phase, and we substantiate this by examples. The GSD resulting from a particular boundary condition coincides with the number of confined topological sectors due to the corresponding condensation. These lead to a generalization of the Laughlin-Tao-Wu (LTW) charge-pumping argument for Abelian fractional quantum Hall states (FQHS) to encompass non-Abelian topological phases, in the sense that an anyon loop of a confined anyon winding a non-trivial cycle can pump a condensed anyon from one boundary to another. Such generalized pumping may find applications in quantum control of anyons, eventually realizing topological quantum computation.
PACS numbers: 11.15.-q, 71.10.-w, 05.30.Pr, 71.10.Hf, 02.10.Kn, 02.20.Uw
## I. INTRODUCTION
## vacuum by the folding trick.
A key feature of intrinsic topological orders is the existence of protected GSD. On closed spatial 2-surfaces, its genus number and the fusion rules between anyon excitations determine the GSD 1-8 . Protected GSD is vital to topological quantum computation, and yet realizing GSD on high genus closed surfaces is unfeasible in experiments. Obviously it is much more natural to build finite open systems. Yet, it is necessary that any boundary massless modes that often appear can be gapped to have a well defined GSD. The gapping conditions of Abelian phases have recently been understood in terms of the concept of Lagrangian subsets 9-14 , and subsequently the GSDs of these Abelian phases on open surfaces with multiple boundaries were computed 13,15 , based on the idea of anyon transport across boundaries. Experiments detecting and applying the topological degeneracy with gapped boundaries were proposed in 16,17 . Nevertheless, non-Abelian phases bear much richer sets of degenerate ground states, and the braiding of non-Abelian anyons serves as the best known candidate that may realize universal topological quantum computing. It is also hopeful to realize or simulate non-Abelian anyons 18 . Despite the importance of understanding non-Abelian phases on open surfaces, it remains a big open problem, a problem we shall solve here via the method of anyon condensation. Summarizing our main results:
- · We find the condition for gapped boundaries of non-chiral non-Abelian phases by identifying each such boundary to a set of anyon condensate; the condition allows one to classify all gapped boundaries for the given phase. Our results also encompass situations in which a defect/phase boundary separates arbitrary phases because any such system can always be mapped back to one where a phase ends on the trivial
- · for any given boundary conditions on some arbitrary open system, we describe the computation of the GSD, dictated by a reduced set of conserved topological sectors-the set of confined anyons -anyons mutually non-local with the boundary condensate. Typically, on a cylinder,
$$G S D = \# \text{confined anyons.}$$
We show an explicit non-trivial example of a GSD counting on a cylinder whose two ends have distinct boundary conditions. Note that such reduction in the number of conserved anyons suggests a novel way to engineer desired conserved bulk anyons suitable for specific quantum computations; Our method is corroborated using the correspondence between a generic non-Abelian phase A and its double A×A ¯ via the folding trick.
- · we find connections between our counting and prior works on Abelian phases that make use of charge transport. This generalizes the LTW charge-pump argument in Abelian FQHS 1,19 to generic anyonpump in non-Abelian phases, hinting at novel ways of braiding and controlling non-Abelian anyons. Such anyon transport may also help experimentally discern different topological phases 16,17 ;
We shall make heavy use of the technologies studying anyon condensation 20-22 . The basic premise of anyon condensation is that certain types of anyons cease to have conserved particle number across a phase transition; they thus effectively condense, exactly as how Cooper pairs condense, in the process breaking some symmetry. As in usual Bose condensation, the condensable anyons should have bosonic self-statistics. There are various constraints that determine the properties of the condensed phase, such as the types of anyons that remain conserved and
their fusion rules. We shall refer the reader to the original references for details. Some prior attempts on nonAbelian phases are found in 23,24 .
## II. GSD OF THE Z 2 TORIC CODE ON OPEN SURFACES REVISITED
To explain the generalization of Lagrangian subsets and the subsequent GSD counting in Abelian phases, we revisit these concepts from the perspective of anyon condensation by taking the Z 2 toric code as an example. Recall that the Z 2 toric code has four topological sectors { 1 , e, m, f } , where e, m are self-bosons, and f a fermion. Any two distinct nontrivial anyons are mutual-fermions. The nontrivial fusion rules are e 2 = m 2 = f 2 = 1 and e × m = f . Each boundary of the system admits two distinct gapping conditions, respectively characterized by the two Lagrangian subsets :
$$L _ { e } = \{ 1, e \}, \ L _ { m } = \{ 1, m \}. \text{ \quad \ \ } ( 2 )$$
A Lagrangian subset L is a maximal collection of anyons that are self-bosons with trivial mutual statistics and that all remaining anyons excluded from the set are non-local wrt at least one member of L 9-12 . This is clearly satisfied by both sets in (2). One crucial observation 9,10,13,20-22,25,26 is that for the boundary condition characterized by a set L i , an anyon in the set ceases to be conserved and can be either created or annihilated at the boundary. Therefore, a gapped boundary condition L i is equivalent to the condensation of the anyons in L i right at the boundary. Any anyon not in a condensed L i would be confined at the boundary 20-22,25-27 . For example, m and f are confined in L e condensate and thus are mobile in the bulk but fail to cross the boundary into the vacuum. Equally importantly, in the vicinity of the L e condensate, m and f are indistinguishable, like 1 and e become identified, by fusion with any number of e 's freely supplied by the boundary condensate 20-22,25-27 . This leads to an easy GSD counting. Consider a cylinder with both boundaries characterized by L e . A convenient basis for ground states consists of uncontractible anyon loops winding the cylinder. For the L e boundaries, only two distinct anyon loops exist: 1 and m . One then infers that
$$\ G S D _ { \mathbb { Z } _ { 2 } \text{toric code} } ^ { L _ { e } \text{boundaries on cylinder} } = 2, \quad \ \ ( 3 ) \quad \sin \text{sist}.$$
in accord with the result of 13 . This is illustrated in Fig. 1. The LTW charge-pump argument for FQHS 1,19 applies here: If one threads a magnetic flux loop around the cylinder and adiabatically increase it from zero to a unit m flux, a charge e can be pumped from one boundary to the other of the cylinder, as depicted in Fig. 1.
To deal with more boundaries potentially characterized by different L i 's, we need only to work out the remaining conserved (i.e. confined) distinct uncontractible anyon loops, and the anyon loops around different cycles must
FIG. 1. Ground state basis specified by a conserved anyon line m winding the cylinder where the boundaries are characterized by the L e condensate. A unit of e is transferred across the boundaries via the LTW charge pumping mechanism if the unit m line can be changed to two units adiabatically.
admit at least a fusion channel. We now generalize the procedure described above to non-Abelian phases.
## III. GSD OF NON-ABELIAN PHASES ON OPEN SURFACES
We now lay down the general procedure to obtain the GSD of a generic non-Abelian topological order with boundaries. We will illustrate each step with the example of the doubled Fibonnacci model. To avoid clutter, the topological data of the doubled Fibonnacci model and notations are reviewed in the supplemental material.
Defining boundary conditions. First we have to decide upon the boundary condition on each boundary. Each boundary whose edge modes could be completely gapped is characterized by a generalized Lagrangian subset L , which is a collection of anyons that could condense simultaneously at the boundary, and that the resultant phase after the condensation T L contains only confined anyons as well as the trivial sector. As reviewed in the supplemental material, in the case of Fibo × Fibo, it has L ττ ¯ = { 1 , τ τ ¯ , } leading to T L ττ ¯ = { 1 , χ } , where χ behaves like a Fibonacci anyon τ except for its lack of a well-defined topological spin.
Counting GSD via confined charges. If all the boundaries are characterized by the same L , the GSD is obtained as follows. We first find out the fusion rules of all the confined anyons in T L . Then we count all possible basis states constructed from loops of confined anyons winding nontrivial cycles. This is subjected to the consistency condition on anyons wrapping cycles that merge have to fuse to the anyon wrapping the resultant merged cycle. This is to ensure no net charge exists in the bulk.
Consider for example Fibo × Fibo on a cylinder, where both boundaries must be characterized by L ττ ¯ . As a result, the only conserved nontrivial topological sector must be the confined χ ∈ T L ττ ¯ , as it cannot leak through the boundaries into the vacuum. We conclude that the 2 distinct sectors in T L implies that
$$\ G S D _ { \text{Fibo} \times \overline { \text{Fibo} } } ^ { \text{cylinder} } = | \mathcal { T } _ { L _ { \tau \neq } } | = 2, \text{ \quad \ \ } ( 4 )$$
To check our claims, note that it is expected that
$$\ G S D _ { \ F i b o \times \overline { \ F i b o } } ^ { \text{cylinder} } = \ G S D _ { \ F i b o } ^ { \text{torus} }. \quad \ \ ( 5 ) \quad \ \ \ c e d \\ \quad \ \ \ \ c o n$$
This is because Fibo × Fibo ending at a boundary can be thought of as folding up a Fibonacci phase characterized by single copy of the anyons { 1 , τ } . Thus the Fibo × Fibo on a cylinder is in fact equivalent to the Fibonacci phase itself residing on two different cylinders, yet joined at both boundaries because of the gapped boundary condition we imposed on Fibo × Fibo. That is, we have in fact Fibo on a torus. Similarly, we can consider placing
FIG. 2. (a) Fibo × Fibo on a cylinder with both boundaries characterized by the Lagrangian subset { 1 , τ τ ¯ . } (b) Single Fibonacci phase on a torus. The two systems are equivalent.
the Fibo × Fibo on a surface with three holes, or the 'pants diagram' (a special case of Fig. 3(a)). The three boundaries must again be characterized by L ττ ¯ . On this surface, when two confined anyon loops a and b respectively winding two of the three cycles (holes) merge to an anyon loop c winding the third cycle, the three loops of anyons must admit a fusion channel. The GSD counting in this scenario then boils down to the formula:
$$\ G S D _ { \text{Fibo} \times \overline { \text{Fibo} } } ^ { \text{pants} } = \sum _ { a, b, c \in \mathcal { T } _ { L _ { \tau \bar { \tau } } } } N _ { a b } ^ { c } = 5, \quad \ ( 6 ) \quad \ e r i n | _ { \text{to c} } \, \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where for a given c , the fusion matrix element N c ab is the multiplicity of c in the fusion product of a and b . This again agrees with the expected result following from
$$\ G S D _ { \text{Fibo} \times \overline { \text{Fibo} } } ^ { \text{pants} } = \ G S D _ { \text{Fibo} } ^ { \text{genus-2 torus} }. \quad \ ( 7 ) \quad \text{Speq}$$
We note that such a correspondence between a 'doubled phase' on a surface with gapped boundaries characterized by condensates of all the diagonal pair-the analogues of ττ ¯-and the undoubled phase on a closed surface is in fact generic. This correspondence offers a non-trivial check of our methods in large classes of nonAbelian phases expressible as a doubled phase using wellknown results of GSD of phases on closed surfaces, and by which we find perfect agreement.
More generically, the boundaries could also be characterized by different L i 's, which would contain anyons not mutually local. One would have to work out the condensed phase T L i at each boundary, and then further reduce the number of conserved anyons, which correspond roughly to finding an intersection of the T L i 's. The fusion between the remaining conserved anyons again determine the GSD. There is not to date a fully systematic procedure dealing with multiple sets of non-mutually local condensates, but we will exemplify how this is to work by a non-trivial example in the next section. In summary (Fig. 3), assuming that there are M > 3 boundaries, respectively characterized by (potentially identical) Lagrangian subsets L i 's,
$$\inf _ { \text{ing} } \quad \ G S D _ { \{ L _ { i } \} } = \sum _ { \{ a _ { i }, b _ { i } \} } N _ { a _ { 1 } a _ { 2 } } ^ { b _ { 1 } } \prod _ { i = 1 } ^ { M - 4 } N _ { a _ { i + 2 } b _ { i } } ^ { b _ { i + 1 } } N _ { a _ { M - 1 } b _ { M - 3 } } ^ { \bar { a } _ { M } }, \quad ( 8 )$$
where {T L i } := ∩ M i =1 T L i , b i 's are the intermediate fusion channels, and { a , b i i } refers to summing over {T L i } . Note that the product term exists only for M ≥ 5.
FIG. 3. (a) An open surface with M > 3 boundaries. (b) A genus-( M -1) torus.

Counting GSD via charge transport. As alluded to at the beginning and also in the discussion of Abelian phases, we can alternatively count the GSD by considering charge transport across boundaries. This amounts to counting the fusion channels to the trivial sector, between anyons across Lagrangian subsets L i 's characterizing the boundaries. Recall that Fibo × Fibo on a cylinder has a GSD given in (4). The same result can be obtained by counting the fusion channels between condensed anyons on the two boundaries to the trivial sector. Specifically, since there is only one trivial fusion channel in ττ ¯ × ττ ¯ = 1 + 1¯ + τ τ ¯ + 1 ττ ¯, together with the obvious trivial fusion channel 1 × 1 = 1, there are exactly 2 trivial fusion channels. Such an agreement between the two different ways of counting the GSD shouts for a generalization of the aforementioned LTW argument for FQHS to the case of non-Abelian topological phases. i.e. In a non-Abelian (gauge) theory, there should exist some adiabatically changing Wilson (anyon) loop, e.g., χ around the cylinder, which pumps a unit of the condensed ττ ¯ from one boundary to the other (Fig. 2(a)).
To be seen in the next section, such a flux-charge correspondence would work only if each L i also includes the multiplicity data of a condensed anyon-the number of condensed sectors contained in each anyon in L i that splits under condensation. This extra twist in the story makes GSD counting by confined anyons more natural.
## IV. Z 3 2 TWISTED QUANTUM DOUBLE
/negationslash
We now present here a fascinating example-the Z 3 2 twisted quantum double (TQD) 28-30 -that bears more than one set of nontrivial gapped boundary conditions. As a twisted version of the G = Z 3 2 Kitaev model, this model contains 22 distinct anyons. As in other gauge theories, the electric charges are representations of the gauge group G , and as such they come in 8 distinct types. We can denote them by E e 1 e 2 e 3 , where e i ∈ { 0 1 , } , corresponding to the trivial and nontrivial one dimensional representations of each of the three Z 2 groups in G . The rest of the anyons are 14 non-Abelian dyons all with quantum dimension 2, denoted by D ± m m m 1 2 3 , where m i ∈ { 0 1 , } , and m m m 1 2 3 = 000. Their properties, such as fusion rules, are detailed in the supplemental material. We focus on two distinct admissible Lagrangian subsets, L E and L D . Set L E = { E e 1 e 2 e 3 } contains all the electric charges. As explained in the supplemental material, the condensed phase T E contains the new trivial sector and 7 non-trivial confined anyons that descend from the dyons, where D ± m m m 1 2 3 → 2 d m m m 1 2 3 . This gives, on a cylinder with both boundaries characterized by L E
$$\ G S D _ { \mathbb { Z } _ { 2 } ^ { 3 } T Q D } ^ { L _ { E } \text{ boundaries on cylinder} } = 8. \quad \quad ( 9 )$$
This immediately agrees with the result obtained by considering allowed charge transport across the boundaries, i.e. the number of fusion channels between the condensed anyons in the top and bottom boundary that fuse to the trivial sector. More interesting is the boundary characterized by L D , where
$$L _ { \mathbb { D } } = \{ 2 D _ { 1 0 0 } ^ { + }, E _ { 0 e _ { 2 } e _ { 3 } } \}. \quad \quad ( 1 0 ) \quad \text{the}$$
The resultant condensed phase T D contains again 8 distinct sectors, 7 of which confined and descended from the other dyons and electric charges of the form E 0 e 2 e 3 . A very special thing arises here: The condensed anyon D + 100 → 1 + 1 splits into two copies of the vacuum in the condensed phase T D . This is unlike the examples encountered above, where each sector appearing in the condensate only splits into the trivial sector once! To make that information explicit, we have included the dyon D + 100 twice in defining the set L D above. Now the number of confined sectors in T D would indicate that on a cylinder,
$$\ G S D _ { \mathbb { Z } _ { 2 } ^ { 3 } T Q D } ^ { L _ { D } } \text{boundaries on cylinder} = 8. \quad \ \ ( 1 1 ) \quad \text{and}$$
again. However, a naive count of allowed charge transport across the boundaries gives only 5 channels, if we count D + 100 only once. The only way to recover a match between these two ways of counting is to take D + 100 literally as appearing twice, so that they alone contribute 2 2 = 4 fusion channels between the top and bottom boundaries to the trivial sector, instead of only one as in the naive count. Then we recover a GSD =4+4 = 8. We therefore postulate that the generalization of the
Lagrangian subset in non-Abelian phases must include specifying the multiplicity of a condensed anyon-the number of condensates that is actually contained in the splitting of the anyon after anyon condensation. We have tested this postulate in this model in surfaces with more boundaries and found that the counting via charge-transport across boundaries continue to match the analysis via confined sectors in the condensed phase. We have also checked our postulate in the quantum double model with group G = D 3 . The GSD due to a condensate involving multiplicities greater than 1 again supports our postulate.
To end the section, we return to the Z 3 2 TQD model on a cylinder, with, now, the left boundary characterized by L E and the right by L D . The two sets of anyons have exactly 4 fusion channels that can fuse to one, namely the fusion of the four shared electric charges. So the charge transport reasoning leads to the interesting result:
$$\ G S D _ { \mathbb { Z } _ { 2 } ^ { 3 } T Q D } ^ { L _ { E } \text{ left, } L _ { D } \text{ right} } = 4. \text{ \quad \ \ } ( 1 2 )$$
The same result can be obtained via counting the confined sectors, as depicted in Fig. 4. As aforementioned
FIG. 4. Z 3 2 twisted quantum double on a cylinder with the left boundary characterized by electric condensation L E and the right one by dyonic condensation L D . GSD = | T E ∩ T D | .

and detailed in the supplemental material , T D has 8 sectors, conveniently denoted by
/negationslash
$$\{ 1, d _ { m _ { 2 } m _ { 3 } } ^ { 1, 2 }, d | m _ { 2 } m _ { 3 } \neq 0 0 \}, \quad \quad ( 1 3 )$$
satisfying the following important fusion rule
$$d _ { m _ { 2 } m _ { 3 } } ^ { 1 ( 2 ) } \otimes d = d _ { m _ { 2 } m _ { 3 } } ^ { 2 ( 1 ) }. \text{ \quad \ \ } ( 1 4 )$$
Since d descends from E 1 e 1 e 2 , it is is no longer conserved in the other boundary where all electric charges are in L E and condense. Hence, d ± m m 2 3 becomes indistinguishable, and the GSD is determined by the following four states each with an anyon line winding the non-trivial cycle
$$\{ | 1 \rangle, | d _ { 0 1 } \rangle, | d _ { 1 0 } \rangle, | d _ { 1 1 } \rangle \}, \quad \quad ( 1 5 )$$
leading again to a precise match. This is the first example to date of a non-Abelian phase whose GSD on an open surface with multiple boundary conditions is computed.
Conclusion: We have achieved the long sought goal to count the GSD of a generic non-chiral non-Abelian topological order with boundaries, making use of insights and techniques developed in the past 9,13,20-22,25,26,31 .
We note that very much analogous to prior analysis of gapped boundary conditions via the introduction of explicit boundary gapping terms, one could imagine that such an analysis is also possible for non-Abelian phases. Some preliminary work has been done for example in 32 , in which explicit terms can be written down, whenever the bulk non-Abelian phase adopts a simple construction based on orbifolding Abelian ones. It would be useful to generalize these studies to other non-Abelian phases. Given the importance of robust GSD as a resource in TQC, our new understanding will be crucial towards finding experimental realizations and applications of topological orders.
## ACKNOWLEDGMENTS
We thank Juven Wang for explaining his work on Abelian phases to us, and William Witczak-Krempa for his comments on the manuscript. YW appreciates his mentor, Xiao-gang Wen, for his constant support and inspiring conversations. YW is grateful to Yong-Shi Wu for his hospitality at Fudan University, where the work was done, and for his insightful comments on the manuscript. YW also thanks his cousin, Wanxing Wang, who helped drawing the figures. LYH is supported by the Croucher Fellowship. Research at Perimeter Institute is supported by the Government of Canada through Industry Canada and by the Province of Ontario through the Ministry of Economic Development & Innovation.
Note added .-Recently we became aware of a related work by Lan, Wang, and Wen 33 .
## Appendix A: The doubled Fibonacci Phase
We review the topological data of the doubled Fibonacci Phase here.
Consider the doubled Fibonacci system, Fibo × Fibo, which has four anyons { 1 , τ τ , ¯ 1¯ τ, τ ¯ 1 } of quantum dimensions d 1 = 1 , d ττ ¯ = 1 + d τ , and d 1¯ τ = d τ ¯ 1 = d τ , with d τ = 1+ √ 5 2 . Their self statistics are θ 1 = 1 , θ ττ ¯ = 1 , θ 1¯ τ = exp( -2 πi/ 10) = θ τ ¯ 1 . Since θ ττ ¯ = 1, ττ ¯ is the only nontrivial anyon that may condense. Thus, the only admissible non-Abelian Lagrangian subset would be L ττ ¯ = { 1 , τ τ ¯ . } Moreover, because d ττ ¯ > 1, ττ ¯ must split in order to condense 20-22,25-27 : ττ ¯ = 1 + χ , where the trivial part 1 is the actual condensate, and χ with d χ = d τ is some topological sector in the phase T L ττ ¯ after the condensation of L ττ ¯ . It is easy to check that in T L ττ ¯ all nontrivial anyons are confined and that χ , 1¯, τ and τ ¯ are indistinguishable. Namely, 1 T L ττ ¯ = { 1 , χ } with χ × χ = 1 + χ , behaving just like the Fibonacci anyon τ .
## Appendix B: The Z 3 2 Twisted Quantum Double
We review the details of the Z 3 2 TQD model here, which is characterized by the 3-cocycle ω ∈ H 3 ( Z 2 × Z 2 × Z 2 , U (1)),
$$\omega ( x, y, z ) = e ^ { i \pi x _ { 1 } y _ { 2 } z _ { 3 } }, \text{ \quad \ \ } ( B 1 )$$
where each of x, y, z is a three component vector, and each of its component takes values in { 0 1 , } .
The anyons in this theory fall into two categories: pure charges and dyons. Each pure charge is labelled by a three component vector E = ( e , e 1 2 , e 3 ), where e i ∈ { 0 1 , } . The dyons are each two dimensional irreducible projective presentation of Z 2 × Z 2 × Z 2 . A dyon is labeled by a 3-vector M = ( m ,m ,m 1 2 3 ) ∈ Z 2 × Z 2 × Z 2 , and for each M there are two corresponding distinct representations, labeled ± , which can be taken as the charge label. The table summarises the distinct topological sectors in the theory and their self-statistics 28 .
/negationslash
TABLE I. Different topological sectors of D ω ( Z 2 × Z 2 × Z 2 )
| Top. Sector | Self-statistics | q.d.= d a |
|--------------------------------------------------|-------------------|-------------|
| E E =( e 1 ,e 2 ,e 3 ) | 1 | 1 |
| D ± M | [ M =( m 1 ,m 2 ,m 3 ) , M =(0 , 0 , 0)] | ± 1 | 2 |
| D ± M | [ M =(1 , 1 , 1)] | ± i | 2 |
We will explore two boundary conditions characterized by two different generalized Lagrangian subsets and work out the corresponding condensed phase for each of them. We shall not need to make use of the entire fusion algebra of the anyons of this model, for which we refer the reader to Eqs. (2.5.28) and (2.8.14) through (2.8.17) in 28 . The relevant fusion rules will be shown explicitly where they are used in the subsequent discussion.
## 1. Electric condensate
This is the simplest scenario, in which
$$L _ { \text{E} } = \{ E _ { e _ { 1 } e _ { 2 } e _ { 3 } } \},$$
meaning that the boundary is characterized by the simultaneous condensation of all the electric charges, all having trivial self statistics and mutual statistics among themselves.
All members in L E have quantum dimension unity, so they do not split any further in the condensed phase T E . The dyonic anyons have quantum dimension 2, and might potentially split into two pieces.
Let us assume that
$$D _ { M } ^ { \pm } = d _ { M } ^ { \pm, 1 } \oplus d _ { M } ^ { \pm, 2 }.$$
Now using the fusion rules
$$D _ { M } ^ { \pm } \otimes E _ { e _ { 1 } e _ { 2 } e _ { 3 } } = D _ { M } ^ { \pm ( - 1 ) ^ { e _ { 1 } + e _ { 2 } + e _ { 3 } + 1 } }. \quad \text{(B4)}$$
Replacing these anyons by their decomposition in T E immediately implies that d + ,i M = d -,i M ≡ d i M . Now recall that D + M and D -M i have different topological spins (Table I), implying that d M , descended from both sectors, have ill-defined statistics, and thus must be confined in the condensate. This is a proof that the choice of the set of condensate L E leads to complete confinement of the phase, and thus a gapped boundary. Now,
$$D _ { m _ { 1 } m _ { 2 } m _ { 3 } } ^ { \pm } \otimes D _ { m _ { 1 } m _ { 2 } m _ { 3 } } ^ { \pm } = E _ { E _ { 1 } } + E _ { E _ { 2 } } + E _ { E _ { 3 } } + E _ { E _ { 4 } }, \ ( B 5 )$$
where the precise value of E i depends on the vectors { m ,m ,m 1 2 3 } . What is important however is that as soon as we replace it by their decompositions, one concludes that
$$d _ { M } ^ { i } \otimes d _ { M } ^ { i } = 1 = d _ { M } ^ { 1 } \otimes d _ { M } ^ { 2 }. \text{ \quad \ \ } ( \mathbb { B } 6 )$$
For a unitary theory in which the conjugate of an anyon is unique, this implies that
$$d _ { M } ^ { 1 } = d _ { M } ^ { 2 } = d _ { M }.$$
We therefore end up with exactly 8 distinct sectors in T E .
## 2. Dyonic condensate
Now we move on to the more interesting gapped boundary condition characterized by a dyonic condensate L D .
To begin with we would like to pick D + 100 as a condensate. This has to split into two parts:
$$D _ { 1 0 0 } ^ { + } \to 1 \oplus c. \quad \quad \ ( B 8 ) \quad _ { \text{lex} }$$
Taking into account that other dyons also potentially split into two pieces, we write
$$D _ { M } ^ { \pm } \rightarrow c _ { 1 } ^ { M, \pm } \oplus c _ { 2 } ^ { M, \pm }. \quad \quad \text{(B9)} \quad d _ { m } ^ { a }$$
As we will conclude below, D ± M should split if T D remains unitary, such that each anyon and its conjugate only fuse to the trivial sector once.
Using the fusion relations
$$D _ { 1 0 0 } ^ { + } \otimes E _ { 0 e _ { 2 } e _ { 3 } } = D _ { 1 0 0 } ^ { + },$$
$$D _ { 1 0 0 } ^ { + } \otimes D _ { 1 0 0 } ^ { + } = \sum _ { e _ { 2 }, e _ { 3 } } E _ { 0 e _ { 2 } e _ { 3 } }, \quad \quad ( B 1 1 )$$
one can conclude that
$$E _ { 0 e _ { 2 } e _ { 3 } } \rightarrow 1, \ c = 1. \quad \quad ( B 1 2 ) \quad \text{fin}$$
Then the following fusion rules
$$D _ { 1 0 0 } ^ { + } \otimes D _ { 1 0 0 } ^ { - } = \sum _ { e _ { 2 }, e _ { 3 } } E _ { 1 e _ { 2 } e _ { 3 } }, \quad \quad ( B 1 3 )$$
$$D _ { 1 0 0 } ^ { + } \otimes E _ { 1 e _ { 2 } e _ { 3 } } = D _ { 1 0 0 } ^ { - },$$
$$D _ { 1 0 0 } ^ { - } \otimes D _ { 1 0 0 } ^ { - } = \sum _ { e _ { 2 }, e _ { 3 } } E _ { 0 e _ { 2 } e _ { 3 } }, \quad \quad ( B 1 5 )$$
immediately imply that
$$E _ { 1 e _ { 2 } e _ { 3 } } \rightarrow d,$$
$$D _ { 1 0 0 } ^ { - } \rightarrow c _ { 1 } ^ { 1 0 0, - } \oplus c _ { 2 } ^ { 1 0 0, - } = 2 d, \quad \ ( B 1 7 )$$
$$d \otimes d \, = \, 1,$$
the last equality following also from E 2 1 e 2 e 3 = 1. This immediately suggests that E 1 e 2 e 3 and D -100 are confined because they have different topological spins and yet decompose to the same anyon. Next we have
$$D _ { 0 m _ { 2 } m _ { 3 } } ^ { \pm } \otimes E _ { 0 e _ { 2 } e _ { 3 } } = D _ { 0 m _ { 2 } m _ { 3 } } ^ { \mp ( - ) ^ { \gamma _ { 1 } + \gamma _ { 2 } } }, \quad \ \ ( B 1 9 )$$
$$\gamma _ { i } = \frac { ( 2 m _ { i } - 1 ) ( 2 e _ { i } - 1 ) + 1 } { 2 }. \quad ( B 2 0 )$$
This implies that
$$c _ { 1 } ^ { M, + } \oplus c _ { 2 } ^ { M, + } = c _ { 1 } ^ { M, - } \oplus c _ { 2 } ^ { M, - },$$
$$M \in \{ ( 1 ( 0 ), m _ { 2 }, m _ { 3 } ) \} | _ { \text{excluding} \ m _ { 2 } = m _ { 3 } = 0 }. \ \ ( B 2 2 )$$
Therefore, we are identifying
$$c _ { i } ^ { M, + } = c _ { i } ^ { M, - }, \text{ \quad \quad } \text{(B23)}$$
and again these anyons become confined. This implies that all non-trivial sectors are confined in the condensate, and
$$L _ { \mathbb { D } } = \{ 2 D _ { 1 0 0 } ^ { + }, E _ { 0 e _ { 2 } e _ { 3 } } \} \quad \quad \quad ( B 2 4 )$$
satisfies the desired condition of a generalized Lagrangian subset.
Now
$$D _ { 1 0 0 } ^ { + } \otimes D _ { 0 m _ { 2 } m _ { 3 } } ^ { \pm } = D _ { 1 m _ { 2 } m _ { 3 } } ^ { + } \oplus D _ { 1 m _ { 2 } m _ { 3 } } ^ { - }, \quad ( B 2 5 )$$
leading to identifying c 0 m m , 2 3 ± i = c 1 m m , 2 3 ± i ≡ d i m m 2 3 , (excluding m 2 = m 3 = 0) . (B26)
where we further simplify notations by introducing d i m m 2 3 . Using
$$D _ { 0 m _ { 2 } m _ { 3 } } ^ { + } \otimes E _ { 1 e _ { 2 } e _ { 3 } } = D _ { 0 m _ { 2 } m _ { 3 } } ^ { + ( - 1 ) ^ { \gamma _ { 1 } + \gamma _ { 2 } } }, \quad ( { \mathrm B } 2 7 )$$
D
+
+
0
m m
2
3
⊗
D
0
m m
2
3
$$= \sum _ { e _ { 1 } } E _ { e _ { 1 } 0 0 } + E _ { e _ { 1 } m _ { 3 } m _ { 2 } },$$
one concludes that
$$( d _ { m _ { 2 } m _ { 3 } } ^ { i } ) ^ { 2 } = 1, \ d _ { m _ { 2 } m _ { 3 } } ^ { 1 } \otimes d _ { m _ { 2 } m _ { 3 } } ^ { 2 } = d, \quad ( { \mathrm B } 2 9 )$$
$$d _ { m _ { 2 } m _ { 3 } } ^ { 1 } \otimes d = d _ { m _ { 2 } m _ { 3 } } ^ { 2 },$$
$$d _ { m _ { 2 } m _ { 3 } } ^ { i } \otimes d _ { m _ { 2 } ^ { \prime } m _ { 4 } ^ { \prime } } ^ { i } = d _ { ( m _ { 2 } + m _ { 2 } ^ { \prime } ) ( m _ { 3 } + m _ { 3 } ^ { \prime } ) } ^ { 1 }, \quad ( B 3 1 )$$
$$d _ { m _ { 2 } m _ { 3 } } ^ { 1 } \otimes d _ { m _ { 2 } ^ { \prime } m _ { 3 } ^ { \prime } } ^ { 2 } = d _ { ( m _ { 2 } + m _ { 2 } ^ { \prime } ) ( m _ { 3 } + m _ { 3 } ^ { \prime } ) } ^ { 2 }, \quad ( B 3 2 )$$
where the addition appearing in the subscripts are defined only modulo 2.
- ∗ [email protected]
- † [email protected]
- 1 R. Tao and Y.-S. Wu, Phys. Rev. B 30 , 1097 (1984).
- 2 Q. Niu, D. Thouless, and Y.-S. Wu, Phys. Rev. B 31 , 3372 (1985).
- 3 X.-G. Wen, Phys. Rev. B 40 , 7387 (1989).
- 4 X.-G. Wen and A. Zee, Nucl. Phys. B - Proc. Suppl. 15 , 135 (1990).
- 5 X.-G. Wen and Q. Niu, Phys. Rev. B 41 , 9377 (1990).
- 6 X.-G. Wen, Int. J. Mod. Phys. B 5 , 1641 (1991).
- 7 X.-G. Wen, Int. J. Mod. Phys. B 04 , 239 (1990).
- 8 C. Nayak, A. Stern, M. Freedman, and S. Das Sarma, Rev. Mod. Phys. 80 , 1083 (2008).
- 9 A. Kitaev and L. Kong, Commun. Math. Phys. 313 , 351 (2012).
- 10 M. Levin, Phys. Rev. X 3 , 021009 (2013), 1301.7355.
- 11 M. Barkeshli, C.-m. Jian, and X.-l. Qi, Phys. Rev. B 88 , 241103 (2013), arXiv:1304.7579v1.
- 12 M. Barkeshli, C.-M. Jian, and X.-L. Qi, Phys. Rev. B 88 , 235103 (2013).
- 13 J. Wang and X.-G. Wen, p. 4 (2012), 1212.4863.
- 14 L.-Y. Hung and Y. Wan, Phys. Rev. B 87 , 195103 (2013).
- 15 T. Iadecola, T. Neupert, C. Chamon, and C. Mudry, p. 11 (2014), 1407.4129.
- 16 M. Barkeshli, Y. Oreg, and X.-L. Qi, p. 5 (2014), 1401.3750.
- 17 M. Barkeshli, E. Berg, and S. Kivelson, p. 5 (2014), 1402.6321.
- 18 I. Lesanovsky and H. Katsura, Phys. Rev. A 86 , 041601 (2012).
- 19 R. B. Laughlin, Phys. Rev. Lett. 50 , 1395 (1983).
- 20 F. A. Bais, B. Schroers, and J. Slingerland, Phys. Rev. Lett. 89 , 181601 (2002).
- 21 F. A. Bais, J. Slingerland, and S. Haaker, Phys. Rev. Lett. 102 , 220403 (2009), arXiv:0812.4596v1.
- 22 F. A. Bais and J. Slingerland, Phys. Rev. B 79 , 045316 (2009).
- 23 H. Bombin and M. Martin-Delgado, Phys. Rev. B 78 , 115421 (2008).
- 24 H. Bombin and M. a. Martin-Delgado, New J. Phys. 13 , 125001 (2011).
- 25 L.-Y. Hung and Y. Wan, Int. J. Mod. Phys. B 28 , 1450172 (2014), Highlighted as Editors Suggestion.
- 26 Y. Gu, L.-Y. Hung, and Y. Wan, Phys. Rev. B 90 , 245125 (2014), 1402.3356.
- 27 F. A. Bais and S. M. Haaker (2014), 1407.5790.
- 28 M. Propitius, Ph.D. thesis, University of Amsterdam (1995), 9511195v1.
- 29 Y. Hu, Y. Wan, and Y.-S. Wu, Phys. Rev. B 87 , 125114 (2013), 1211.3695.
- 30 A. Mesaros and Y. Ran, Phys. Rev. B 87 , 155115 (2013), 1212.0835.
- 31 X.-G. Wen, Phys. Rev. B 41 , 12838 (1990).
- 32 A. Cappelli and E. Randellini, p. 31 (2014), 1407.0582.
- 33 T. Lan, J. C. Wang, and X.-G. Wen, Phys. Rev. Lett. 114 , 9 (2015), 1408.6514. | 10.1103/PhysRevLett.114.076401 | [
"Ling-Yan Hung",
"Yidun Wan"
] | 2014-07-31T20:03:01+00:00 | 2015-02-22T04:47:07+00:00 | [
"cond-mat.str-el",
"hep-th",
"math-ph",
"math.MP"
] | Ground State Degeneracy of Topological Phases on Open Surfaces | We relate the ground state degeneracy (GSD) of a non-Abelian topological
phase on a surface with boundaries to the anyon condensates that break the
topological phase to a trivial phase. Specifically, we propose that gapped
boundary conditions of the surface are in one-to-one correspondence to the sets
of condensates, each being able to completely break the phase, and we
substantiate this by examples. The GSD resulting from a particular boundary
condition coincides with the number of confined topological sectors due to the
corresponding condensation. These lead to a generalization of the
Laughlin-Wu-Tao (LWT) charge-pumping argument for Abelian fractional quantum
Hall states (FQHS) to encompass non-Abelian topological phases, in the sense
that an anyon loop of a confined anyon winding a non-trivial cycle can pump a
condensate from one boundary to another. Such generalized pumping may find
applications in quantum control of anyons, eventually realizing topological
quantum computation. |
1408.0015v1 | ## Quasi-periodicities of the BL Lac Object PKS 2155-304
## A. Sandrinelli
Universit` degli Studi del a l ′ Insubria, Via Valleggio 11, I-22100 Como, Italy INAF - Osservatorio Astronomico di Brera, Via Emilio Bianchi 46, I-23807 Merate, Italy. INFN - Istituto Nazionale di Fisica Nucleare, Sezione Milano Bicocca, Dipartimento di Fisica G. Occhialini, Piazza della Scienza 3, I-20126 Milano, Italy
## [email protected]
## S. Covino
INAF - Osservatorio Astronomico di Brera, Via Emilio Bianchi 46, I-23807 Merate, Italy
## A. Treves
Universit` degli Studi del a l ′ Insubria, Via Valleggio 11, I-22100 Como, Italy INAF - Osservatorio Astronomico di Brera, Via Emilio Bianchi 46, I-23807 Merate, Italy INFN - Istituto Nazionale di Fisica Nucleare, Sezione Milano Bicocca, Dipartimento di Fisica G. Occhialini, Piazza della Scienza 3, I-20126 Milano, Italy
Received
;
accepted
Not to appear in Nonlearned J., 45.
## ABSTRACT
We have searched for periodicities in our VRIJHK photometry of PKS 2155304, which covers the years 2005-2012. A peak of the Fourier spectrum with high significance is found at T ∼ 315 days, confirming the recent findings by Zhang et al. (2014). The examination of the gamma-ray light curves from the Fermi archives yields a significant signal at ∼ 2T, which, while nominally significant, involves data spanning only ∼ 6T. Assuming a black hole mass of 10 9 M /circledot the Keplerian distance corresponding to the quasi-period T is ∼ 10 16 cm, about 50 Schwarzschild radii.
Subject headings: BL Lacertae objects: general -BL Lacertae objects: individual (PKS 2155-304) -galaxies: active -method: statistical
## 1. Introduction
Variability is one of the main tools for constraining models of BL Lac objects. The time scales can be so short (e.g. hours, minutes) that, even taking into account relativistic beaming effects, they can shed light on sizes comparable with the gravitational radius of the black hole that is supposed to lie at their center (e.g. Urry & Padovani 1991). Variability on month/year time scale is a probe of the relativistic jet structure indicating for instance a global helicoidal pattern, and a possible stratification in the direction perpendicular to the jet axis (e.g. Marscher et al. 2008). This kind of variability is essentially non periodic, describing turbulent mechanisms that may ultimately have been triggered by some instability in the accretion process (e.g. Ulrich et al. 1997).
Up to now the only strong claim of periodicity in emission of a BL Lac object was raised in the case of OJ 287 where, on the basis of optical records extending for a century, a period of 12 years was suggested (Sillanpaa et al. 1988). It may be interpreted as a Keplerian period of a system of two black holes of masses 1.7 x 10 10 M /circledot and 1.4 x 10 8 M /circledot and orbital semi-major axis of 0.056 pc (Lehto & Valtonen 1996). Note, however, that this periodicity is still widely discussed (e.g. Hudec et al. 2013).
In this letter we concentrate on the case of the BL Lac object PKS 2155-304 (z=0.116, V ∼ 13), which is a prototype of the class, and one of the most intensely observed objects, since its discovery in the seventies. It is a highly variable source, and numerous multifrequency observations from radio to TeV are now available (e.g. Aharonian et al. 2007; Foschini et al. 2008, and references therein). Possible quasi-periodicities on various time scales have been reported. Urry et al. (1993) found a repetition time scale of 0.7 days in ultraviolet and optical bands in a campaign lasting about one month. Lachowicz et al. (2009) using few days of data from XMMNewton proposed a quasi-periodicity of 4.6 h, with a rather convincing sinusoidal folded light curve. Fan & Lin (2000) collected a
miscellaneous set of data from ∼ 17 years of UBVRI observations, and found evidence of quasi-periodicity at 4 and 7 years.
More recently Zhang et al. (2014) made a collection of rather inhomogeneous optical data over the last 35 years. In particular they produced an R-band light curve with ∼ 8000 points deriving from the photometrical data of 25 different astronomical groups. This light curve was searched for periodicity with various procedures, namely, epoch-folding (Leahy et al. 1983), the Jurkevich method (Jurkevich 1971) and the discrete correlation function (Edelson & Krolik 1988), that yielded, with high significance, a quasi-period T ∼ 317 days.
In Section 2 we consider for periodicities our homogeneous optical-NIR photometry of PKS 2155-304 (Sandrinelli et al. 2014), which was not included in Zhang et al. (2014) data collection. We then examine the archived Fermi γ -ray curves (Section 3). Conclusions are drawn in Section 4.
## 2. REM data
Our photometric study of PKS 2155-304 was obtained with the Rapid Eye Mounting Telescope (REM, 60 cm, Zerbi et al. 2004; Covino et al. 2004) in the VRIJHK bands from 2005/05/18 (MJD 53508) to 2012/05/29 (MJD 56076). Results and details about reduction and analysis procedures are thoroughly discussed in Sandrinelli et al. (2014). Instrumental magnitudes were obtained via aperture photometry. Calibration was performed by means of comparison stars in the field reported in Two Micron All Sky Survey Catalog 1 (2MASS, Skrutskie et al. 2006) for NIR images and in Hamuy & Maza (1989) for the optical. Check stars were used in all CCD frames. Though the photometry is fully automatized, a direct
1 http://www.ipac.caltech.edu/2mass/
eye check of the data was performed. Several frames were excluded, because the target or the reference stars were at the border, or other obvious problems were apparent.
Since we are interested in a long periodicity, we considered light curves based on nightly averages. We searched for periodicity using the Date Compensated Discrete Fourier Transform (DC DFT, Ferraz-Mello 1981; Foster 1995) and the Lomb-Scargle (LS) algorithms (Scargle 1982). Results are reported in Table 1 and in Figure 1. The Fourier spectra of the photometry in the VIJK filters are very similar to those in R and H, and are not reported in the Figure.
Our most prominent peaks are in the T 1 = 306-319 days range and their significance is high. In the NIR Fourier spectra other noticeable peaks appear at ∼ 461 days and at ∼ 1270 days ( ∼ 4 · T 1 ). Folded light curves based on DC-DFT 2 periods are shown in Figure 1, where data are divided in T / 1 6 width bins. The folded light curves are clearly sinusoidal, with an amplitude of ∼ 0.6 mag. Therefore we basically confirm the results of Zhang et al. (2014) with completely independent optical and NIR data.
## 3. Fermi data
PKS 2155-304 is a well known γ -ray emitter (average photon flux f 1 -100 GeV = 2 35 . ± 0 06 . · 10 -8 photon cm -2 s -1 and photon index Γ 100 MeV -100 GeV = 1 84 . ± 0 02, . Nolan et al. 2012). We considered the Fermi 3 light curves as provided by the automatic standard analysis procedure. Light curves cover the interval 2008/08/06 (54684 MJD) to 2014/06/09 (56817 MJD). We took one week integrations and selected the two energy ranges 100 MeV - 300 GeV and 300 MeV - 1 GeV. The data were searched again with LS
2 http://www.aavso.org
3 http://fermi.gsfc.nasa.gov/ssc/data/access/lat/msl lc/
Table 1: Period analysis.
| | | | LS | LS | LS | DC-DFT | DC-DFT | DC-DFT | DC-DFT |
|-------------------|-------|---------|------------|-------|----------------|------------|----------|-----------|----------------|
| Band | N obs | N night | T | Power | p-value | T | Power | A | p-value |
| (a) | (b) | (c) | [days] (d) | (e) | (f) | [days] (g) | (h) | [mag] (i) | (j) |
| V | 1938 | 275 | 306 | 75.42 | < 5 · 10 - 7 | 309 | 81.15 | 0.65 | < 1 · 10 - 6 |
| R | 1903 | 297 | 309 | 74.54 | < 5 · 10 - 7 | 314 | 78.14 | 0.60 | < 1 · 10 - 6 |
| I | 1743 | 281 | 315 | 77.85 | < 5 · 10 - 7 | 316 | 76.24 | 0.58 | < 1 · 10 - 6 |
| J | 547 | 274 | 317 | 62.21 | < 5 · 10 - 7 | 316 | 62.99 | 0.65 | < 1 · 10 - 6 |
| H | 646 | 258 | 314 | 62.32 | < 5 · 10 - 7 | 319 | 60.50 | 0.64 | < 1 · 10 - 6 |
| K | 455 | 243 | 318 | 61.09 | < 5 · 10 - 7 | 317 | 62.03 | 0.71 | < 1 · 10 - 6 |
| 100 MeV - 300 GeV | - | 305 | 650 | 22.02 | 8 . 4 · 10 - 7 | 659 | 21.67 | 0.30 | 1 . 6 · 10 - 5 |
| 300 MeV -1 GeV | - | 295 | 625 | 12.28 | 1 . 4 · 10 - 2 | 621 | 12.26 | 0.16 | 5 . 7 · 10 - 5 |
Notes: (a) Band or range of energy. (b) Number of observations. (c) Number of night-average photometric points, or one-week integrations for γ -rays. (d) Period corresponding to the maximum frequency in LS periodogram. (e) Power of maximum frequency in LS periodogram. (f) LS p-value. (g) Period corresponding to the maximum frequency in DC-DFT technique. (h) Power of maximum frequency in DC-DFT technique. (i) Amplitude. (j) DC-DFT p-value.
Fig. 1.Left panels: Power spectra, computed with the DC DFT approach, in R and H bands and in 100 MeV - 300 GeV range. Periods in days corresponding to the prominent peaks are marked. Right panels: Folded light curves. Error bars are the standard errors of the average. Flux f is in photon cm -2 s -1 . The initial time for folding cycles is the same for all the curves (2009/07/28, 55040 MJD).
and DC-DFT (Table 1 and Figure 1). It is apparent that the periodicity peaks at T 2 ∼ 630-640 days, which is consistent with twice the optical/NIR period T 1 . Note, however, that the folded light curves cover a time interval of only ∼ 3 · T 2 , so this must be considered a tentative result at this time. Moreover the present data do not allow to comment about a possible phase shift of optical and γ -ray bands
## 4. Discussion
The simple fact that we recover the T 1 ∼ 317 days period of Zhang et al. (2014) on independent data, though with an overlap of the observing time interval, makes their claim of this quasi-periodicity more robust. The discovery of a possible quasi-periodicity at T 2 ∼ 2 T 1 in γ -rays, is intriguing, and per se an indirect confirmation of T . 1 At this stage, because of the limited number of monitored periods, it is impossible to discriminate between a quasi-periodicity and a real period. Note that Fermi satellite follows this source with no interaction with Sun constraints so that the light curve is not annually biased. For the optical-NIR data, T 1 ∼ 317 days can be distinguished from 1 yr period, given the length of our data-train and this distinction is even stronger for the data collected by Zhang et al. (2014). In fact in our Fourier spectra (Figure 1, top and central panels on the left) the power associated to a 1 yr periodicity is significantly lower than that at T 1 . In principle, it is also possible that T 1 is a beat frequency for instance with a 1 yr period. In this case the true period could be ∼ 168 days (0.46 yr) or ∼ 2246 days ( 6.15 yr). The former period does not appear in our power spectra, while the latter is comparable with the duration of our optical observations. Further information on the quasi-periodicity may come from unpublished archived observations, which we expect to be numerous since the source is a rather common target. Additional Fermi data will show whether our tentative quasi-periodicity in γ -rays holds up long enough to be fully convincing. Of interest would also be a detailed study of
the X-ray light curves beyond that performed by Lachowicz et al. (2009). This will be a delicate business. In fact because of the nature of most X-ray observations, a combination of data from numerous different instruments is required.
One can assume a mass of the black hole in PKS 2155-304 ∼ 10 9 M /circledot , as proposed by Falomo et al. (1991) and Kotilainen et al. (1998) on the basis of the absolute magnitude of the host galaxy. If T 1 ( T 2 ) were a real periodicity one could consider a Keplerian frame which yields an orbital radius of 1 3 . · 10 16 cm (2 · 10 16 cm), ∼ 40 (70) Schwarzschild radii. The tidal effects on a star orbiting the supermassive black hole at such radius would be very relevant, a subject which deserves further investigations.
We thank the referee for her/his prompt and competent report which enabled us to improve this letter.
We acknowledge the support of the Italian Ministry of Education (grant PRIN-MIUR 2009, 2010, 2011). This work has also been supported by ASI grant I/004/11/0.
## REFERENCES
```
1
0 2 3 4 6 7 8 9 10 5 11 13 19 17 18 16
```
Scargle J. D., 1982, ApJ, 263, 835
Sillanpaa, A., Haarala, S., Valtonen, M. J., Sundelius, B., & Byrd, G. G. 1988, ApJ, 325, 628
Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163
Ulrich, M.-H., Maraschi, L., & Urry, C. M. 1997, ARA&A, 35, 445
Urry, C. M., & Padovani, P. 1991, ApJ, 371, 60
Urry, C. M., Maraschi, L., Edelson, R., et al. 1993, ApJ, 411, 614
Zhang, B.-K., Zhao, X.-Y., Wang, C.-X., & Dai, B.-Z. 2014, Res. in Astronomy and Astrophysics, in press (arXiv:1405.6858)
Zerbi, F. M., Chincarini, G., Ghisellini, G., et al. 2004, Proc. SPIE, 5492, 1590
This manuscript was prepared with the AAS LT E X macros v5.2. A | 10.1088/2041-8205/793/1/L1 | [
"Angela Sandrinelli",
"Stefano Covino",
"Aldo Treves"
] | 2014-07-31T20:06:10+00:00 | 2014-07-31T20:06:10+00:00 | [
"astro-ph.HE",
"astro-ph.GA"
] | Quasi-periodicities of PKS 2155-304 | We have searched for periodicities in our VRIJHK photometry of PKS 2155-304,
which covers the years 2005-2012. A peak of the Fourier spectrum with high
significance is found at T$\sim$315 days, confirming the recent findings by
\cite{Zhang2014}. The examination of the gamma-ray light curves from
the\textit{ Fermi} archives yields a significant signal at $\sim$ 2T, which,
while nominally significant, involves data spanning only $\sim$ 6T. Assuming a
black hole mass of $10^{9}\ M_{\odot}$ the Keplerian distance corresponding to
the quasi-period T is $\sim10^{16}$ cm, about 50 Schwarzschild radii. |
1408.0016v1 | ## Architecture of a Web-based Predictive Editor for Controlled Natural Language Processing
Stephen Guy and Rolf Schwitter
Department of Computing Macquarie University Sydney, 2109 NSW, Australia {Stephen.Guy|Rolf.Schwitter}@mq.edu.au
Abstract. In this paper, we describe the architecture of a web-based predictive text editor being developed for the controlled natural language PENG ASP . This controlled language can be used to write non-monotonic specifications that have the same expressive power as Answer Set Programs. In order to support the writing process of these specifications, the predictive text editor communicates asynchronously with the controlled natural language processor that generates lookahead categories and additional auxiliary information for the author of a specification text. The text editor can display multiple sets of lookahead categories simultaneously for different possible sentence completions, anaphoric expressions, and supports the addition of new content words to the lexicon.
Keywords: controlled natural language processing, predictive editor, web-based authoring tools, answer set programming
## 1 Introduction
Writing a specification in a controlled natural language without any tool support is a difficult task since the author needs to learn and remember the restrictions of the controlled language. Over the last decade, a number of different techniques and tools [3,5,12,13] have been proposed and implemented to minimise the learning effort and to support the writing process of controlled natural languages. The most promising approach to alleviate these habitability problems is the use of a predictive text editor [13,17] that constrains what the author can write and provides predictive feedback that guides the writing process of the author. In this paper, we present the architecture of a web-based predictive text editor being developed for the controlled natural language PENG ASP [15]. The text editor uses an event-driven Model-View-Controller based architecture to satisfy a number of user entry and display requirements. These requirements include the display of multiple sets of lookahead categories for different sentence completions, the deletion of typed words, the addition of new content words to the lexicon and the handling of anaphoric expressions. Additionally, the text editor displays a paraphrase for each input sentence and displays the evolving Answer Set Program [11].
## 2 Overview of the PENG ASP System
## 2.1 Client-Server Architecture
The PENG ASP system is based on a client-server architecture where the predictive editor runs in a web browser and communicates via an HTTP server with the controlled natural language processor; the language processor uses in our case an Answer Set Programming (ASP) tool as reasoning service (Fig. 1):
Fig. 1. Client-Server Architecture of the PENG ASP System
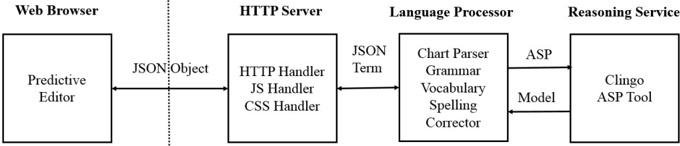
The communication between the predictive editor and the HTTP server occurs asynchronously with the help of AJAX technologies and by means of JSON 1 objects. The predictive editor is implemented in JavaScript 2 and JQuery . The 3 HTTP server as well as the controlled natural language processor are implemented in SWI Prolog . The Prolog server translates JSON objects into JSON 4 terms and vice versa so that these terms can be processed directly by the language processor. The language processor incrementally translates the controlled language input via discourse representation structures [8] into an ASP program and sends this ASP program to the ASP tool clingo [6,7] that tries to generate one or more satisfiable answer sets for the program.
## 2.2 HTTP Server
SWI-Prolog provides a series of libraries for implementing HTTP server capabilities. Our server is based on this technology and can be operated as a stand-alone server on all platforms that are supported by SWI-Prolog. The following code fragment illustrates how an HTTP server is created, a port ( 8085 ) specified, and a request ( Request ) dispatched using a handler registration ( http handler/3 ):
server(Port) :-http\_server(http\_dispatch, [port(Port)]). :- http\_handler('/peng/', handle, []). handle(Request) :- ... :- server(8085).
1 http://json.org/
2 http://www.ecmascript.org/
3 http://jquery.com/
4 http://www.swi-prolog.org/
In our case, we can now connect via http://localhost:8085/peng/ from the web browser to the server that uses specific JavaScript and stylesheet handlers to load the predictive editor and to establish the communication between the editor and the controlled language processor.
## 2.3 Predictive Editor
The predictive editor is implemented in JavaScript and JQuery, with the Superfish 5 plug-in providing pull-down menu functionality. These technologies allow the editor to be run in most browsers, which in conjunction with the capabilities of a potentially remote language processor coded in Prolog, provides a highly portable system. Data communication with the server provides for both command functions, such as file saving and loading, as well as data transfer between the language processor and the predictive editor system. The JSON data for parsing sent from the predictive editor to the HTTP server includes the current token of a word form, its position in the relevant sentence and relevant sentence number. For each word form or completed sentence submitted by the predictive editor, the lookahead categories and word forms along with the output of the language processor are returned.
An overview of a typical predictive editor display is presented in Figure 2. Command function menus are presented at the top, below which is the main text input field displaying the current sentence. Lookahead categories for the available sentence completion are highlighted using the pull-down menus. Below these lookahead categories is a display summarising relevant information in the system, at both the client and server. First is a summary of previously entered text at the client side. Second are the generated paraphrases at the server, with any anaphoric references being highlighted (which may also be accessed from the pull-down menus). Third is a summary of the current answer set program for the input, followed by the final section of output from answer set tool clingo .
The editor allows entering text specifications manually by typing in the text entry field, plus using pull-down menus of lookahead categories to enter text into the input field. The reasons for allowing direct input of text include that some users, especially those experienced in the structure of the controlled natural language, can type faster than they can enter via menus, even with some level of auto-completion. Additionally, the system allows entering new content words into the lexicon, via the text field, that do not appear in the displayed lookahead categories.
## 3 Processing and Reasoning in the PENG ASP System
## 3.1 Controlled Natural Language Processor
The controlled natural language processor of the PENG ASP system consists of a chart parser, a unification-based grammar, a lexicon and a spelling corrector.
5 http://users.tpg.com.au/j\_birch/plugins/superfish/
## PREDICTIVE EDITOR FOR CONTROLLED NATURAL LANGUAGE
Fig. 2. Predictive Editor Display
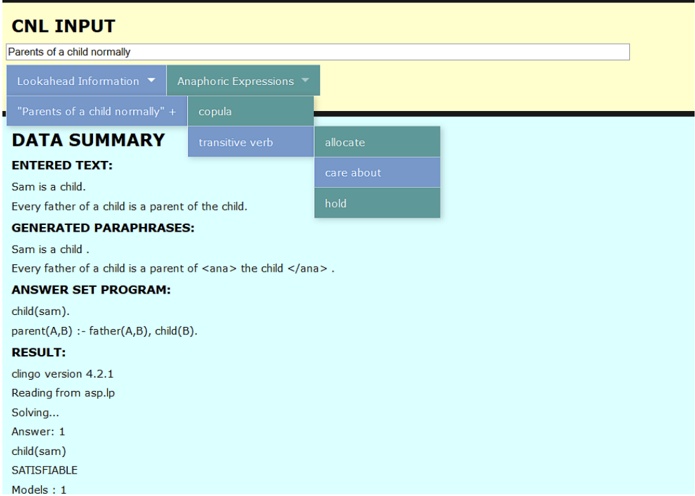
The chart parser is initialised for the first time when the author moves the cursor into the textfield of the predictive editor and reset at the beginning of each new sentence and generates lookahead categories using the grammar and the lexicon of the controlled language processor. These lookahead categories inform the author of a specification how to start a sentence and are generated dynamically for each word form that the author enters into the textfield of the editor. This mechanism guarantees that the author can only input word forms and construct sentences that follow the rules of the controlled language. If a word is misspelled, then the spelling corrector is used to generate a list of candidates that occur in the lexicon. If a content word is not in the lexicon, then the author can add this word to the lexcion during the specification process.
The controlled natural language PENG ASP [15] that the author uses as input language has been designed as a high-level interface language to ASP programs. In certain aspects the language PENG ASP is similar to PENG Light [18] and Attempto Controlled English [5], since it uses a version of discourse representation theory (DRT), in the spirit of [2,8], as intermediate representation language. However, PENG ASP does not rely on full first-order logic (FOL) as target lan-
guage as the use of DRT would suggest but on the language for ASP programs. The language of FOL is in some respects more expressive than the language of ASP but unfortunately FOL is not adequate for representing commonsense knowledge, because FOL cannot deal with non-monotonic reasoning. ASP, on the other hand, allows us to represent and process commonsense knowledge because of its unique connectives and non-monotonic entailment relation. Beyond that, ASP is still expressive enough to represent function-free FOL formulas of the ∃ ∀ ∗ ∗ prefix class in form of a logic program [10]. Below is an example specification in PENG ASP that uses a default rule in (5), a cancellation axiom in (6), and sentence with strong negation in (7):
- 1. Sam is a child.
- 2. John is the father of Sam and Alice is the mother of Sam.
- 3. Every father of a child is a parent of the child.
- 4. Every mother of a child is a parent of the child.
- 5. Parents of a child normally care about the child.
- 6. If a parent of a child is provably absent then the parent abnormally cares about the child.
- 7. John does not care about Sam.
- 8. Alice is absent.
Of course, the specific features of the ASP language have an impact on what we can express on the level of the controlled natural language and therefore rely on the support of the predictive editor.
## 3.2 Reasoning Service
Since we are interested in specifying commonsense theories in PENG ASP , we need a non-monotonic reasoning service. ASP is a relatively novel logic-based knowledge representation formalism that has its roots in logic programming with negation, deductive databases, non-monotonic reasoning and constraint solving [1,7]. An ASP program consists of a set of rules of the following form:
$$L _ { 0 } \ ; \, \dots \ ; \, L _ { k } \, \colon - \, L _ { k + 1 }, \, \dots, \, L _ { m }, \, \text{not} \, L _ { m + 1 }, \, \dots, \, \text{not} \, L _ { n }.$$
where all L i 's are literals. A literal is an atom or its negation. A positive atom has the form p(t , 1 ..., t n ) where p is a predicate symbol of arity n and t , 1 ..., t n are object constants or variables. A negative atom has the form -p(t , 1 ..., t n ) where the symbol -denotes strong negation. The symbol :-stands for an implication. The expression on the left-hand side of the implication is called the head of the rule and the expression on the right-hand side is called the body of the rule. The head may consist of an epistemic disjunction of literals denoted by the symbol ; . Literals in the body may be preceded by negation as failure denoted by the symbol not . The head or the body of a rule can be empty. A rule with an empty head is called an integrity constraint and a rule with an empty body is called a fact . For instance, the example specification in Section 3.1 is translated automatically via discourse representation structures in the subsequent ASP program:
- 6 Stephen Guy, Rolf Schwitter
```
<_Erlang_>
```
## 4 Predictive Editor Requirements
In addition to the generic requirements outlined in Section 2.3, a number of detailed user input and system display requirements for the lookahead categories are determined to aid in the design of the predictive editor architecture. The main requirements are that the system should allow appropriate editing of information already entered, that the lookahead categories for a particular sentence position are displayed until all possibilities are no longer possible and that the lookahead categories for the next sentence position are displayed as soon as the relevant options are possible. These requirements are presented in detail in the following sections.
## 4.1 User and System Requirements
## User Entry Requirements
Requirement E.1.1: The system will allow deletion of characters or words already typed, or all or part of a sentence not yet submitted . (This deletion will be referred to as backward editing ).
Requirement E.2.1: A new sentence is not commenced (via the chart parser being reset) until a submit or an enter event or a beginning of sentence character/word occurs after an end-of-sentence marker (full stop or question mark). A new sentence being commenced means that the previous sentence has been submitted .
Requirement E.3.1: A user is allowed to enter a content word not in the lexicon and force its submission to the language processor as the next content word.
Requirement E.3.2: A user may enter a misspelt word that is yet to be completed with the word still subject to backward editing .
Requirement E.4.1: Aword is completed if it followed by a space or directly by a valid punctuation character which in turn is followed by a space or sentence submission . This latter requirement of a space after the punctuation allows the system to distinguish the state from the case of an incomplete misspelt word with an erroneous punctuation character at the end.
## System Display Requirements
Requirement D.1.1: Before and whilst a word is being entered at position A (or for a new sentence commencing at position A), the system should display all the lookahead categories for position A until all of those categories are no longer possible.
Assertion D.1.1: All lookahead categories for position A are no longer possible if the next non-punctuation word at position A+1 has commenced, or a word is completed according to Requirement E.4.1.
Requirement D.2.1: The system should display the lookahead categories for position A+1 when a word entered at position A matches the lookahead categories for position A.
Note that in terms of displaying one set of lookahead categories for a particular word, requirements D.1.1 and D.2.1 are not mutually exclusive, that is there occur system states where the lookahead categories at position A and position A+1 need to be displayed concurrently.
Assertion D.2.1: If a word at position A matches the lookahead categories for position A, then other lookahead categories for position A may still be possible.
## 4.2 Display of Multiple Sentence Completions
Some examples are presented to help clarify the requirements detailed above. The two main cases which are catered for are the existence of subsets within the lookahead categories for one sentence position and the allowed juxtaposition of punctuation directly after a word without an intervening space.
For the case of subsets in lookahead categories, consider the commencement of a sentence and the above two display requirements D.1.1 and D.2.1. Initial lookahead categories may include 'The', 'There is', 'A', 'Thelma', 'John' and 'Johnathan' for example, which according to D.1.1 should all be displayed by the system. A user entering the characters 'The' would then satisfy requirement D.2.1, whereby the lookahead categories for the next position would be displayed. If these categories included the word 'child', the user could enter this word and the entered text would be 'The child', illustrating that a display of this sentence completion option was necessary. However, the original situation of the user entering the characters 'The' may have been the precursor to the entry of the words 'There is' or even 'Thelma'. Thus even though requirement D.2.1 is satisfied after the entry of 'The', requirement D.1.1 still holds for the presentation of the original lookahead categories whilst the user completes this entry, thus illustrating assertion D.2.1. Whether the user has entered 'Thelma' or 'The' without a subsequent character, requirement E.4.1 has not been satisfied, so a user may backward edit from the word 'Thelma' back to 'The' or 'Thelma'/'The' back to 'A'.
For the case of juxtaposition of word forms with punctuation and requirements E.4.1 and D.2.1, the lexicon and grammar allows phrases such as 'John, Thelma and Pete are parents.'. Here, a word is followed directly by punctuation, so that once the characters 'John' are entered, according to requirement D.2.1, the system must display the options for the next lookahead categories which include the comma which could be clicked or typed directly. Alternatively, a user may have been intending to type 'Johnathan', so as for the case of subsets must see the original set of lookahead categories. If a user accidentally hit the comma on the fifth character, leaving 'John,' (John comma), as the current word, the system should still display the original lookahead categories, including 'Johnathan', as the word has not been completed according to requirement E.4.1.
## 5 Architecture of the Predictive Editor
The predictive editor is designed to meet the requirements of the PENG ASP system, the asynchronous client-server communications, the different modes of the editor input as well as user entry and system display requirements.
## 5.1 Model-View-Controller Architecture
The architecture of the predictive editor is based approximately on that of a Model-View-Controller (MVC) system [4,16] in terms of separation and independence.
The Model includes the currently active sentence, including that entered by the user and that submitted to the HTTP server, all previously entered sentences and all data (including lookahead categories) received from the language processor via the HTTP server. The model also stores all variables relevant to determining the state of the system.
The View includes the events-triggered input text field, the pull-down menu display of lookahead categories and the input of word forms via mouseover selection. It also displays the overall model of entered sentences and the ASP model generated by the language processor.
The Controller synchronises all functions, and importantly monitors for the need of a state change in the Model , such as when the user has input data that is different from the currently active sentence and if so, whether to submit new data to the server or not. Additionally, the Controller co-ordinates loading of all the returned lookahead categories into data structures and determines which of these lookahead categories are displayed to the user as dependent on the current state of the system.
## 5.2 Event-Triggered Implementation
A key issue with the implementation of the MVC architecture is the requirement to have event-driven data processing and control to be compatible with
the asynchronous AJAX communication between the predictive editor and the HTTP server and events-triggered predictive editor input. When content words are submitted to the HTTP server via JSON data, the predictive editor system must wait until corresponding lookahead data is returned by the server.
Once this information is received, it may then be stored in the model and only then can the Controller process this model data to determine if the model state variables should be changed and update the display if necessary. To implement this, the Controller organises run-time execution of events in a pipe and filter architecture, where each element of the pipe is a data structure containing the relevant primary data for that event, the relevant processing function and an optional link to the next data structure in the pipe.
Whilst this may not be a classical MVC implementation, it provides a robust method of ensuring model data is in a consistent state for process control. Thus for the above example of sending a new content word to the server, the AJAX send/receive routine will trigger the return data storage event, which when complete will trigger the model state change assessment functionality, which when complete may cause a trigger of the display of the next lookahead categories to the display.
Any multi-stage data processing may also be organised as a pipe and filter structure using the above data structures, with the next stage of the processing function only allowed once the model data from the previous processing function becomes stable.
## 5.3 Data Structures
As with many client-server systems, some model data is stored and processed at the predictive editor client side to allow for optimal processing and control. The model data is stored in objects defined by JavaScript functions, with appropriate object methods declared to allow for this data to be processed conveniently and allowing functionality beyond the capabilities of using raw JSON objects for storage. For example, the model data includes stack objects (containing stacks of anything from word forms to whole sentences), individual send and received objects plus a single object of correlated send and receive data. Methods can detect if a beginning or end of sentence token is present, or whether a word form matches a lookahead category and whether it is also a subset of another lookahead category (such as 'The' being a subset of 'There'). Display objects allow storage of different sets of lookahead categories and the ability to switch the display from 'displayed' to 'hidden' and vice versa.
## 5.4 Predictive Editor Controller
Given the user entry and system display requirements discussed Section 4.1 and generic requirements presented in Section 2.3, the control system for the predictive editor has been designed to allow displaying of multiple lookahead categories for different sentence completions and strict control over when data entered by a user is ultimately committed to the server. The currently active
sentence is stored in two forms, namely from a tokenisation of the user input and from a summary of the data submitted to the server. By comparing a stack of the set of tokens in each sentence, a difference stack is generated to aid the controller in determining a change in the model state. Any newly entered valid words, or changes in the current word are assessed for submission, or alternately earlier submitted tokens/words may be removed and new tokens sent in their place (such as in the case of backward editing ).
As discussed regarding requirement D.2.1 in Section 4.1, if an entered word matches a lookahead category for that position, the controller automatically submits this word to the server and retrieves the next set of lookahead categories for this new token. However, this data transfer is just the predictive editor gathering information and doesn't directly synchronise with the totality of the display to the user. If the controller doesn't detect a word completion, or finds that at least one lookahead category from the previous word is still possible, the previous lookahead categories are not cleared as per assertion D.2.1.
As described in Section 5.3, display data structures allow easy addition and display of data and hiding of data as necessary. As well as automatically submitting a word matching the current lookahead categories, a word matching the previous set of lookahead categories where the previous word is a subset of the new word will also trigger an automatic submission of the token to the HTTP server. This would be the case for 'Thelma' being typed after 'The' has been submitted to the server and lookahead categories already returned for the next sentence position.
## 5.5 Adding Content Words to the Lexicon
Recall from requirement E.3.1 that a user may forcibly submit a word form to the language processor that does not correspond to the lexicon. When this occurs, the language processor may offer a set of spelling suggestions (assuming that an incorrect word has been submitted by mistake) or the predictive editor will offer an option to add this new word to the lexicon in this current context. If the user selects to add a word, then the position in the sentence, the lexical category and the new word form are collected and sent to the server where the new word is added to the lexicon. The new word is then parsed again by the language processor and a new set of lookahead categories is generated and sent to the predictive editor.
## 6 Future Research
The current predictive editor may be extended for multiple users in line with the web-based portability of the system. A user login would allow for a number of features, such as a user-group based lexicon depending on the nature of the specification system for that group (e.g. medical, engineering, automotive, etc.). Additionally, an individual could have their own extended lexicon for any content words added to the lexicon. A user could set a level of knowledge for their
grammar, which would aid in controlling the complexity of the pull-down menus, in that instead of displaying all possible lexical categories, a user with limited knowledge could display a smaller number of less-technial word categories, such as 'function words' instead of individual groups such as 'adjective', 'adverb', 'noun', etc. The user login could be used to set preferences for any further adjustable enhancements.
## 7 Conclusion
In this paper, we introduced the architecture of a web-based predictive text editor developed for the PENG ASP system. This system is suitable for writing non-monotonic specifications that have the expressive power of Answer Set Programs. The web-based predictive editor supports the writing process of these specifications and is based on a portable client-server architecture and is predominantly implemented in JavaScript. An event-driven Model-View-Controller based architecture was used for the editor, allowing strict control of system functionality to satisfy a set of user entry and display requirements that included the display of multiple sets of lookahead categories for different sentence completions. The predictive editor allows for new content words to be added to the lexicon and supports the selection of anaphoric expressions An extension of a user login would allow tailoring of preferences and a user-based lexicon.
## References
- 1. Brewka, G., Eiter, T., Truszczy´ski, M.: Answer Set Programming at a Glance. In: n Communications of the ACM , Vol. 54, No. 12, December (2011)
- 2. van Eijck, J., Kamp, H.: Discourse Representation in Context. In: J. van Benthem and A. ter Meulen (eds.), Handbook of Logic and Language , Second Edition, Elsevier, pp. 181-252 (2011)
- 3. Franconi, E., Guagliardo, P., Trevisan, M., Tessaris S.: Quelo: an ontology-driven query interface. In: Proceedings of the 24th International Workshop on Description Logics (DL 2011) , (2011)
- 4. Freeman, E., Robson, E., Bates, B., Sierra, K.: Head First Design Patterns , O'Reilly, pp. 526-577, (2004)
- 5. Fuchs, N.E., Kaljurand, K., Kuhn, T.: Attempto Controlled English for Knowledge Representation. In: C. Baroglio, P.A. Bonatti, J. Maluszynski, M. Marchiori, A. Polleres, S. Schaffert, (eds.), Reasoning Web , Fourth International Summer School 2008, LNCS 5224, pp. 104-124 (2008)
- 6. Gebser, M., Kaminski, R., Kaufmann, B., Ostrowski, M., Schaub, T., Schneider, M.: Potassco: The Potsdam Answer Set Solving Collection. In: AI Communications , Vol. 24, No. 2, pp. 105-124, (2011)
- 7. Gebser, M., Kaminski, R., Kaufmann, B., Schaub, T.: Answer Set Solving in Practice. In: Synthesis Lectures on Artificial Intelligence and Machine Learning, Vol. 6, No. 3, pp. 1-238 (2012)
- 8. Kamp, H., Reyle, U.: From Discourse to Logic . Kluwer, Dordrecht (1993)
- 9. Kuhn, T., Schwitter, R.: Writing Support for Controlled Natural Languages. In: Proceedings of ALTA , Tasmania, pp. 46-54, (2008)
- 10. Lierler, Y., Lifschitz, V.: Logic Programs vs. First-Order Formulas in Textual Inference. In: Proceedings of the 10th International Conference on Computational Semantics (IWCS 2013) , Potsdam, Germany, pp. 340-346, (2013)
- 11. Lifschitz, V.: What is Answer Set Programming? In: Proceedings of AAAI 2008 , pp. 1594-1597, (2008)
- 12. Power, R.: OWL Simplified English: a finite-state language for ontology editing. In: Kuhn, T. and Fuchs, N.E. (eds): Proceedings of CNL 2012 , Springer, Heidelberg, pp. 44-60, (2012)
- 13. Schwitter, R., Ljungberg, A., Hood, D.: ECOLE: A Look-ahead Editor for a Controlled Language. In: Proceedings of EAMT-CLAW03 , Dublin, pp. 141-150, (2003)
- 14. Schwitter, R.: Controlled Natural Languages for Knowledge Representation. In: Proceedings of COLING 2010 , Beijing, China, pp. 1113-1121, (2010)
- 15. Schwitter, R.: The Jobs Puzzle: Taking on the Challenge via Controlled Natural Language Processing. In: Journal of Theory and Practice of Logic Programming , Vol. 13, Special Issue 4-5, pp. 487-501 (2013)
- 16. Sommerville, I.: In: Software Engineering , International Edition, Ninth Edition, Pearson, pp. 155-164, (2011)
- 17. Tennant, H.R., Ross, K.M., Saenz, R.M., Thompson, C.W., Miller, J. R.: Menubased natural language understanding. In: Proceedings of ACL , pp. 151-158, (1983)
- 18. White, C., Schwitter, R.: An Update on PENG Light. In: L. Pizzato and R. Schwitter (eds.), Proceedings of ALTA 2009 , Sydney, Australia, pp. 80-88, (2009) | null | [
"Stephen Guy",
"Rolf Schwitter"
] | 2014-06-27T01:00:59+00:00 | 2014-06-27T01:00:59+00:00 | [
"cs.CL",
"cs.AI"
] | Architecture of a Web-based Predictive Editor for Controlled Natural Language Processing | In this paper, we describe the architecture of a web-based predictive text
editor being developed for the controlled natural language PENG$^{ASP)$. This
controlled language can be used to write non-monotonic specifications that have
the same expressive power as Answer Set Programs. In order to support the
writing process of these specifications, the predictive text editor
communicates asynchronously with the controlled natural language processor that
generates lookahead categories and additional auxiliary information for the
author of a specification text. The text editor can display multiple sets of
lookahead categories simultaneously for different possible sentence
completions, anaphoric expressions, and supports the addition of new content
words to the lexicon. |
1408.0018v2 | ## LIE ALGEBROIDS GENERATED BY COHOMOLOGY OPERATORS
## Dennise Garc´ ıa-Beltr´n a
Departamento de Matem´ aticas, Universidad de Sonora Blvd. Encinas y Rosales, Edificio 3K-1 Hermosillo, Son 83000, M´xico e
## Jos´ A. Vallejo e
Facultad de Ciencias, Universidad Aut´noma de San Luis Potos´ ı o Lat. Av. Salvador Nava s/n Col. Lomas San Luis Potos´ ı, SLP 78290, M´xico e
## Yurii Vorobiev
Departamento de Matem´ aticas, Universidad de Sonora Blvd. Encinas y Rosales, Edificio 3K-1 Hermosillo, Son 83000, M´xico e
Abstract. By studying the Fr¨licher-Nijenhuis decomposition of cohomology o operators (that is, derivations D of the exterior algebra Ω( M ) with Z -degree 1 and D 2 = 0), we describe new examples of Lie algebroid structures on the tangent bundle TM (and its complexification T C M ) constructed from pre-existing geometric ones such as complex, product or tangent structures. We also describe a class of Lie algebroids on tangent bundles associated to idempotent endomorphisms with nontrivial Nijenhuis torsion.
## 1. Introduction
In this paper, we present an algebraic approach to the study of the relationship between Lie algebroids and cohomology operators which is based on the Fr¨lichero Nijenhuis calculus (various approaches to this issue can be found, for example, in [6, 12, 16, 17]).
Our idea comes from the relation between the exterior differential and the Lie bracket of vector fields on a manifold M . As a first-order differential operator on the (sections of) exterior algebra, Ω( M ) = ΓΛ T ∗ M , the exterior differential can be characterized by giving its action on generators:
$$\begin{cases} \mathrm d f ( X ) = X f, \\ \mathrm d \alpha ( X, Y ) = X \alpha ( Y ) - Y \alpha ( X ) - \alpha ( [ X, Y ] ), \end{cases}$$
where f ∈ C ∞ ( M ,α ) ∈ Ω( M ,X,Y ) ∈ X ( M ) are arbitrary. The action is then extended to the whole of Ω( M ) as a derivation of Z -degree 1. Notice that the cohomology property d 2 = 0 is equivalent to the Jacobi identity for [ , ]. This setup allows us to reverse the definitions. Starting from the exterior differential
1991 Mathematics Subject Classification. Primary: 58F15, 58F17; Secondary: 53C35. Key words and phrases. Lie algebroids, cohomology operators, product structures, complex structures, tangent structures, sprays.
The second author was partially supported by a CONACyT project CB-179115.
d on Ω( M ), we could define the Lie bracket on X ( M ) as follows: given X,Y ∈ X ( M ), their bracket is the unique element [ X,Y ] ∈ X ( M ) such that,
$$\alpha ( [ X, Y ] ) = X \alpha ( Y ) - Y \alpha ( X ) - \mathrm d \alpha ( X, Y ),$$
for any α ∈ Ω ( 1 M ). In particular, if α = d f , for f ∈ C ∞ ( M ), the preceding formula along with d 2 = 0 gives
$$[ X, Y ] f = \mathrm d f ( [ X, Y ] ) = X \mathrm d f ( Y ) - Y \mathrm d f ( X ) = X ( Y f ) - Y ( X f ),$$
so the defined bracket certainly coincides with the Lie one. Again, the Jacobi identity is readily seen to be equivalent to the coboundary condition d 2 = 0.
The correspondence between brackets and cohomology operators can be extended to the setting of Lie algebroids. Recall that a Lie algebroid on a manifold M consists of a vector bundle E over M , together with a vector bundle map q : E → TM over M (called the anchor map), and a Lie bracket on sections [ [ , ] ] : Γ E × Γ E → Γ E satisfying the Leibniz rule
$$[ A, f B ] = f [ A, B ] + q A ( f ) B,$$
for all A,B ∈ Γ E f , ∈ C ∞ ( M ). It can be thought as a replacement of the tangent bundle TM , joint with the Lie bracket on vector fields, by the new bundle E and the bracket [ [ , ] ] on its sections. For a comprehensive reference on Lie algebroids, see [17]. The relevance of Lie algebroids in Mechanics is explained in detail in works such as [23, 4, 18] and references therein.
We first describe a class of Lie algebroids arising from an idempotent endomorphism with nontrivial Nijenhuis torsion, and then construct new examples of Lie algebroids. More precisely, the paper is organized as follows: Section 2 of this paper contains a brief r´sum´ of the Fr¨licher-Nijenhuis calculus for derivations of the e e o exterior algebra over a vector bundle. In section 3 we will recall how, given a Lie algebroid E on M , one can construct a cohomology operator on ΓΛ E ∗ , and study its Fr¨licher-Nijenhuis decomposition. o It turns out that this decomposition can be described within the framework of Lie algebroid connections [10, 17, 2]. In section 4 we will follow the reverse path, constructing Lie algebroids on the tangent bundle E = TM from a given cohomology operator D on Ω( M ). Our main tool here will be again the Fr¨licher-Nijenhuis decomposition of derivations, which we apply in o section 5 to the case of idempotent endomorphisms with nonzero Nijenhuis decomposition of the tangent bundle. In section 6, on the framework of our approach, we discuss Lie algebroids associated to regular foliations. Finally, sections 7 to 9 are devoted to introducing new examples of Lie algebroids canonically associated to a generalized foliation, and to complex, product and tangent manifolds (the latter, with the aid of a connection defined through a semispray).
## 2. The Fr¨ olicher-Nijenhuis decomposition
The proofs of the results stated in this section are slight generalizations of those corresponding to the real case, which can be found, e.g., in [19] or [15].
Let M be a differential manifold with tangent bundle TM . Its complexified bundle is then T M C = TM ⊕ iTM . Complex vector fields are of the form Z = X + iY , with X,Y ∈ Γ TM , and complex 1 -forms are constructed as the duals Ω 1 C ( M ) = Γ ( T ∗ C M ) /similarequal ( Γ T ∗ M ) ⊕ i ( Γ T ∗ M ) /similarequal Ω ( 1 M ) ⊕ i Ω ( 1 M ). By taking exterior products we obtain the complex k -forms Ω k C ( M ) = Γ ( Λ k T ∗ C M ) /similarequal Ω ( k M ) ⊕ i Ω ( k M ),
and tensoring by T M C we get vector-valued complex p -forms, Ω ( p C M TM ; ) = Γ ( Λ p T ∗ C M ⊗ T M C ). We will denote Ω C ( M ) = ∞ ⊕ k =0 Ω ( k C M ).
A derivation of degree l ∈ Z is a C -endomorphism of Ω C ( M ) such that
$$D \colon \Omega _ { \mathbb { C } } ^ { k } ( M ) \rightarrow \Omega _ { \mathbb { C } } ^ { k + l } ( M ),$$
and, for any homogeneous form α and arbitrary β ,
$$D ( \alpha \wedge \beta ) = D ( \alpha ) \wedge \beta +$$
where | α | denotes the degree of α . The vector space (and C ∞ ( M ) -module) of such derivations is denoted Der l Ω ( C M ), and then Der Ω C ( M ) = ⊕ l ∈ Z Der Ω ( l C M ) is a Z -graded Lie algebra endowed with the (graded) commutator of derivations
$$[ D _ { 1 }, D _ { 2 } ] = D _ { 1 } \circ D$$
where | D 1 | , | D 2 | denote the degree of D 1 , D 2 , respectively.
Any complex vector-valued ( k +1) -form K ∈ Ω k +1 C ( M TM ; ), defines a derivation of degree k , called the insertion of K and denoted ı K : if ω ∈ Ω ( p C M ) and Z j ∈ Γ ( TM ⊕ iTM ), with j = 1 , ..., k + , then p
$$\begin{array} {$$
where S k +1 ,p -1 are shuffle permutations and sgn denotes the signature.
A derivation D ∈ DerΩ ( C M ) such that it vanishes on functions, D f ( ) = 0 for all f ∈ Ω ( 0 C M ), is called a tensorial (or algebraic) derivation. They all are insertions.
Proposition 2.1. Let D ∈ Der k Ω ( C M ) be a tensorial derivation. Then, there exists a unique vector-valued complex form K ∈ Ω k +1 C ( M TM ; ) such that
$$D = \imath _ { K }.$$
The K in this proposition can be obtained simply by making D act on complex valued 1 -forms d f . If K ∈ Ω k +1 C ( M TM ; ), L ∈ Ω l +1 C ( M TM ; ), their corresponding insertions are ı K ∈ Der k Ω ( C M ), ı L ∈ Der l (Ω C ( M )), so their graded commutator is again a derivation [ ı K , ı L ] ∈ Der k + l Ω ( C M ). Moreover, this new derivations is obviously tensorial so, applying proposition 2.1, there exists a unique vector-valued complex ( k + +1) l -form determined by it.
Definition 2.2. Given K ∈ Ω k +1 C ( M TM ; ), L ∈ Ω l +1 C ( M TM ; ), their RichardsonNijenhuis bracket is defined as the element [ K,L ] RN ∈ Ω k + +1 l C ( M TM ; ) such that
$$[ \imath _ { K }, \imath _ { L } ] = \imath _$$
The bracket of vector fields on M can be clearly extended by C -linearity to complex vector fields; the same occurs with the exterior differential d, which can be extended by C -linearity to a derivation d ∈ Der 1 Ω ( C M ) (we will use the same notation for d and this extension). Then, given a K ∈ Ω k +1 C ( M TM ; ), as ı K ∈ Der k Ω ( C M ) and d ∈ Der 1 Ω ( C M ), their graded commutator will be again a derivation, called the Lie derivative along K ,
$$\mathcal { L } _ { K } \coloneqq [ \imath _ { K }, \mathrm d ] = \imath _ { K } \circ \mathrm d - ( - 1 ) ^ { k } \mathrm d \circ \imath _ { K }.$$
As a consequence of the Jacobi identity for the graded commutator of derivations, and the nilpotency of d, we get the following.
Proposition 2.3. For any K ∈ Ω ( C M TM ; ) , the graded commutator of the derivations L K and d vanishes.
Thus, there exist tensorial derivations, of type ı K for K ∈ Ω ( k C M TM ; ), and derivations commuting with the exterior differential d, such as Lie derivatives. The Fr¨licher-Nijenhuis decomposition theorem states that any other derivation is a sum o of two of these.
Theorem 2.4 (Fr¨licher-Nijenhuis) o . Let D ∈ Der k Ω ( C M ) . Then, there exists a unique couple ( K,L ) , K ∈ Ω ( k C M TM ; ) and L ∈ Ω k +1 C ( M TM ; ) , such that
$$D = \mathcal { L } _ { K } + \imath _ { L }.$$
A useful consequence is the following result.
Corollary 2.5. Let D ∈ Der k Ω ( C M ) . Then
- (1) D is tensorial if and only if K = 0 .
- (2) D commutes with d if and only if L = 0 .
Example 1. The Fr¨licher-Nijenhuis decomposition of the exterior differential is o
$$d = \mathcal { L } _ { I d },$$
(where Id : TM → TM is the identity morphism) as it should be for a derivation that commutes with d .
If K ∈ Ω ( k C M TM ; ) and L ∈ Ω ( l C M TM ; ), then [ L K , L L ] is again a derivation and it commutes with d, because of the Jacobi identity. Thus, according to Corollary 2.5, it must be of the form L R ∈ Der k + l (Ω C ( M TM ; )) for a unique R ∈ Ω k + l (Ω C ( M TM ; )).
Definition 2.6. Given K ∈ Ω ( k C M TM ; ) and L ∈ Ω ( l C M TM ; ), their Fr¨lichero Nijenhuis bracket is the unique element [ K,L ] FN ∈ Ω k + l C ( M TM ; ) such that
$$[ \mathcal { L } _ { K }, \mathcal { L } _ { L } ] = \mathcal { L } _ { [ K, L ] _ { F N } }.$$
Along with the Fr¨licher-Nijenhuis bracket we have the notion of Nijenhuis toro sion: if N ∈ Ω ( 1 C M TM ; ) is a vector-valued 1 -form, it is defined as the vector-valued 2 -form T N = 1 2 [ N,N ] FN . Explicitly, we have
- (1) T N ( X,Y ) = [ NX,NY ] -N NX,Y [ ] -N X,NY [ ] + N 2 [ X,Y , ] for any X,Y ∈ X ( M ).
- 3. From Lie algebroids to cohomology operators
Suppose that ( E,q, [ [ , ] ]) is a Lie algebroid. Let us define an operator D : Γ ( Λ p E ∗ ) → Γ ( Λ p +1 E ∗ ) by putting
$$\begin{cases} D f ( A ) = q A ( f ) \\ D \alpha ( A, B ) = q A ( \alpha ( B ) ) - q B ( \alpha ( A ) ) - \alpha ( [ A, B ] ), \end{cases}$$
for any f ∈ C ∞ ( M ,α ) ∈ Γ ( Λ 1 E ∗ ) , A, B ∈ Γ E , and extending its action to Γ ( Λ · E ∗ ) as a derivation of Z -degree 1.
Proposition 3.1. D is a cohomology operator, that is,
$$D ^ { 2 } = \frac { 1 } { 2 } [ D, D ] = 0, \\. \quad \, \quad \, \cdots \cdots \cdots$$
where [ , ] denotes the graded commutator of derivations.
This is a very well-known construction (see chapter 7 in [17], for instance), sometimes called the De Rham differential of the Lie algebroid (because one recovers the usual exterior differential d, when E = TM endowed with the Lie bracket on vector fields and the identity as anchor map). The operator D is a derivation of Γ ( Λ · E ∗ ), so it can be decomposed ` la Fr¨licher-Nijenhuis. a o Let us see how this can be done in a particular, but instructive, case.
Example 2. When E = TM , we have a Lie algebroid ( TM,q, [ [ , ] ]) and a derivation D ∈ DerΩ( M ) . Recall (see [11] ) that given a bilinear operation ◦ on the sections of a vector bundle E (such as [ [ , ] ] on Γ TM ), and a bundle endomorphism ϕ (such as q : Γ TM → Γ TM ), the contracted bracket of the operation is given by A ◦ ϕ B = ϕ X ( ) ◦ Y + X ◦ ϕ Y ( ) -ϕ X ( ◦ Y ) , for A,B ∈ E . In our case, the contracted bracket of the Lie bracket of vector fields by the anchor map of the algebroid is
$$[ X, Y ] _ { q } = [ q X, Y ] + [ X, q Y ] - q [ X, Y ].$$
Now, a computation using the Fr¨licher-Nijenhuis o decomposition D = L K + i L , where K ∈ Ω ( 1 M TM ; ) and L ∈ Ω ( 2 M TM ; ) , shows that
$$K = q,$$
and
$$L ( X, Y ) & = [ X, Y ] _ { q } - [ X, Y ].$$
Indeed, we have that K is given by
$$K X ( f ) = D f ( X ) = q X ( f ),$$
for each f ∈ C ∞ ( M ) , X ∈ X ( M ) , and also
$$( 5 ) \quad \ \ ( D - \mathcal { L } _ { q } ) ( \alpha ) ( X, Y ) = ( i _ { L } \alpha ) ( X, Y ) = \alpha ( L ( X, Y ) ).$$
This is enough to characterize i L , as it is determined by its action on 1 -forms (on functions it vanishes by definition): Developing the left-hand side in (5) ,
$$( D \alpha ) ( X, Y ) = q X ( \alpha ( Y ) ) - q Y ( \alpha ( X ) ) - \alpha ( \left [ X, Y \right ] ),$$
and, from the definition of L q α ,
$$( \cdot )$$
$$& ( \mathcal { L } _ { q } \alpha ) ( X, Y ) \\ & = q X ( \alpha ( Y ) ) - \alpha ( [ q X, Y ] ) - q Y ( \alpha ( X ) ) + \alpha ( [ q Y, X ] ) + \alpha ( q [ X, Y ] ) \\ & = q X ( \alpha ( Y ) ) - q Y ( \alpha ( X ) ) - \alpha ( [ q X, Y ] ) - \alpha ( [ X q, Y ] ) + \alpha ( q [ X, Y ] ),$$
thus:
$$\alpha ( L ( X, Y ) ) = \alpha ( [ q X, Y ] + [ X, q Y ] - q [ X, Y ] - [ X, Y ] ).$$
As this is valid for arbitrary α ∈ Ω ( 1 M ) , X,Y ∈ X ( M ) , we get (4) .
The question now is how to obtain an analog result for an arbitrary Lie algebroid ( E,q, [ [ , ] ]), where D ∈ Der Γ ( Λ · E ∗ ) and we do not have a Lie derivative operator at our disposal. We can proceed by choosing a connection ∇ on E ; then, a proof analogous to that of the classical Fr¨licher-Nijenhuis theorem (see [20]), shows that o D must decompose itself as
$$D & = \nabla _ { K } + \imath _ { L }$$
for certain tensor fields K ∈ Γ ( E ∗ ⊗ TM ) and L ∈ Γ ( Λ 2 E ∗ ⊗ E ). We briefly describe the proof of this result here, as we will make use of some of its intermediate steps below.
Theorem 3.2. Let π : F → M be a smooth vector bundle over the differential manifold M . Let D ∈ Der Γ ( Λ F ) , and let ∇ be a linear connection on F ∗ . Then, there exist unique tensor fields K ∈ Γ ( F ⊗ TM ) and L ∈ Γ ( Λ 2 F ⊗ F ∗ ) , such that
$$D & = \nabla _ { K } + \imath _ { L }.$$
Proof. Let α , . . . , α 1 k ∈ Γ( F ∗ ) be smooth sections. The map f → ( Df )( α , . . . , α 1 k ), where f ∈ C ∞ ( M ), is a derivation so it defines a vector field on M , which we denote by K α ,.. . , α ( 1 k ). The map from Γ( F ∗ ) ×··· × Γ( F ∗ ) to X ( M ) defined by ( α , . . . , α 1 k ) → K α ,.. . , α ( 1 k ) is C ∞ ( M ) -linear and skew-symmetric, therefore it defines a section K ∈ Γ(Λ k F ⊗ TM ) that satisfies ∇ K f = Df for every f ∈ C ∞ ( M ). The operator D - ∇ K is a derivation of degree k that acts trivially on C ∞ ( M ); therefore it is a C ∞ ( M ) -linear endomorphism of Γ(Λ F ) which is determined by its action on the sections of degree 1. Then, if s ∈ Γ( F ), the map s → ( D -∇ K ) s defines a morphism from Γ( F ) into Γ(Λ k +1 F ) so there is a section L ∈ Γ(Λ k +1 F ⊗ F ∗ ) such that ( D -∇ K ) s = ı L s . The operator ı L is a derivation of degree k that acts trivially on C ∞ ( M ) and as D -∇ K on the sections of F . Then, D = ∇ K + ı L . /square
The decomposition (6) above follows, of course, taking F = E ∗ . From the proof, we get that K : Γ E → Γ TM is such that, for any A ∈ Γ E and f ∈ C ∞ ( M ),
$$K ( A ) ( f ) = D f ( A ) = q A ( f ),$$
so K = , as before. q
The following result will be useful when doing explicit computations.
Lemma 3.3. Let K : E → TM be a vector bundle morphism, and let ∇ be a connection on E . If α ∈ Γ E ∗ and A,B ∈ Γ E , then,
$$( \nabla _ { K } \alpha ) ( A, B ) = K A ( \alpha ( B ) ) - \alpha ( \nabla _ { K A } B ) - K B ( \alpha ( A ) ) + \alpha ( \nabla _ { K B } A ).$$
Proof. Consider a basis of sections of Γ E , { s a } r a =1 (with r = rank E ), and let { η b } r b =1 be the dual basis. Also, let { ∂ i } m i =1 be a local basis of local vector fields on M (with dim M = m ). Then, we have the local expressions A = A s a a , B = B s b b , and K = K η j c c ⊗ ∂ j . We can write
$$\nabla _ { K } = \nabla _ { K _ { c } ^ { j } \eta ^ { c } \otimes \partial _ { j } } = K _ { c } ^ { j } \eta ^ { c } \wedge \nabla _ { \partial _ { j } },$$
and compute
$$( \nabla _ { K } \alpha ) ( A, B ) = ( K _ { c } ^ { j } \eta ^ { c } \wedge \nabla _ { \partial _ { j } } \alpha ) ( A, B )$$
- = K j c ( η c ( A )( ∇ ∂ j α )( B ) -η c ( B )( ∇ ∂ j α )( A ))
- = K j c ( A c ( ∇ ∂ j ( α B ( )) -α ( ∇ ∂ j B )) -B c ( ∇ ∂ j ( α A ( )) -α ( ∇ ∂ j A )))
- = ∇ K A ∂ j c c j ( α B ( )) -K A α j c c ( ∇ ∂ j B ) -∇ K B ∂ j c c j ( α A ( )) + K B α j c c ( ∇ ∂ j A . )
Notice that KA = K A ∂ j c c j , so we can rearrange the preceding expression, using also the C ∞ ( M ) -linearity of α , as
$$( \nabla _ { K } \alpha ) ( A, B ) & = \nabla _ { K A } ( \alpha ( B ) ) - \alpha ( \nabla _ { K A } B ) - \nabla _ { K B } ( \alpha ( A ) ) - \alpha ( \nabla _ { K B } A ) \\ & = K A ( \alpha ( B ) ) - K B ( \alpha ( A ) ) + \alpha ( \nabla _ { K B } A - \nabla _ { K A } B ). \\ & \quad \square$$
Now, we can find L in the decomposition (6). Let us start with:
$$( D - \nabla _ { q } ) ( \alpha ) ( A, B ) = ( \imath _ { L } \alpha ) ( A, B ) = \alpha ( L ( A, B ) ).$$
Now, on the one hand,
$$( D \alpha ) ( A, B ) = q A ( \alpha ( B ) ) - q B ( \alpha ( A ) ) - \alpha ( \mathbb { [ } A, B \mathbb { ] } ),$$
and on the other, from lemma 3.3
$$\nabla _ { q } \alpha ( A, B ) = q A ( \alpha ( B ) ) - \alpha ( \nabla _ { q A } B ) - q B ( \alpha ( A ) ) + \alpha ( \nabla _ { q B } A ).$$
Thus,
$$\alpha ( L ( A, B ) ) = ( D - \nabla _ { q } ) ( \alpha ) ( A, B ) = \alpha ( \nabla _ { q A } B - \nabla _ { q B } A - [ A, B ] ),$$
hence:
$$L ( A, B ) = \nabla _ { q A } B - \nabla _ { q B } A - [ A, B ].$$
Remark 1. Let ( E,q, [ [ , ] ]) be a Lie algebroid over M . Let V → M another vector bundle over M . An E -connection on V , δ , is an R -bilinear map δ : Γ E × Γ V → Γ V , whose action is denoted δ A, s ( ) = δ A s , such that, for any f ∈ C ∞ ( M ),
$$& \delta _ { f A } s = f \delta _ { A } s \\ & \delta _ { A } ( f s ) = ( q A ) ( f ) s + f \delta _ { A } s.$$
An E -connection is simply an E -connection on E itself (see [10, 17, 2] for references on Lie algebroid connections and their applications). In this case, it is possible to define the torsion of δ as the E -valued 2 -form Tor δ ∈ Ω ( 2 E E ; ) given by the usual expression, but using the Lie algebroid bracket instead of the Lie one:
$$\text{Tor} \, \delta ( A, B ) \coloneqq \delta _ { A } B - \delta _ { B } A - [ A, B ].$$
Notice that each linear connection ∇ on E determines an E -connection δ ∇ . Simply define
$$\delta _ { A } ^ { \nabla } B \coloneqq \nabla _ { q A } B.$$
The torsion of this connection is then
$$\text{Tor} \, \delta ^ { \nabla } ( A, B ) = \nabla _ { q A } B - \nabla _ { q B } A - \left [ A, B \right ],$$
which is precisely our expression (9).
We summarize these calculations in the following result.
Theorem 3.4. Let ( E,q, [ [ , ] ]) be a Lie algebroid and D ∈ Der Γ ( Λ · E ∗ ) be the derivation defined in (2) . Then, given any linear connection ∇ on E , D can be written as
$$D = \nabla _ { q } + \imath _ { L ^ { \nabla } },$$
where L ∇ ∈ Γ ( Λ 2 E ∗ ⊗ E ) , the torsion of the E -connection δ ∇ , is given by
$$L ^ { \nabla } ( A, B ) = \nabla _ { q A } B - \nabla _ { q B } A - [ A, B ],$$
for A,B ∈ Γ E .
An equivalent formulation of this result can be obtained in the particular case of a Lie algebroid on the tangent bundle, which offers an alternative interpretation of the contracted bracket [ X,Y ] q in terms of the torsion of the TM -connection δ ∇ in (10).
Observe that if E = TM , then, given any symmetric linear connection ∇ on TM , the torsion of the corresponding TM -connection δ ∇ is given by
$$\dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta\delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \dots \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \ delta \ delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \dia \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \Delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta \delta
T \text{or} \delta \delta ^ { \nabla } = & L ^ { \nabla } ( X, Y ) \\ = & L ^ { \nabla } _ { q } ( X ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \ nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } ) - \nabla _ { Y } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( \nabla _ { q } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ) ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla } ( Y ^ { \nabla } _ { Y } - \nabla$$
for any X,Y ∈ X ( M ).
Just apply that ∇ is torsionless, and the properties of any covariant derivative.
## 4. From cohomology operators to Lie algebroids
Suppose we have a smooth vector bundle π : E → M , and a derivation D ∈ Der Γ ( Λ E ∗ ) such that D 2 = 0. Then, we can define a mapping q : Γ E → Γ TM as follows,
$$q ( A ) ( f ) \coloneqq D f ( A ),$$
for any f ∈ C ∞ ( M ), A ∈ Γ E .
Let us define also a bracket on the sections of E in the following way: if A,B ∈ Γ E , then their bracket [ [ A,B ] ] is the section of E characterized by
$$\alpha ( \left [ A, B \right ] ) = D ( \alpha ( B ) ) ( A ) - D ( \alpha ( A ) ) ( B ) - D \alpha ( A, B ),$$
for any α ∈ Γ E ∗ . The following result is well-known.
Proposition 4.1. The triple ( E,q, [ [ , ] ]) is a Lie algebroid.
Remark 2. It follows from proposition 3.1 and proposition 4.1, that there exists a one to one correspondence between Lie algebroids on E and cohomology operators in Γ ( Λ E ∗ ), that is, derivation D of degree one on Γ ( Λ E ∗ ) such that D 2 = 0. For various formulations of this results see, for example, [16] and [6].
Let us delve into the structure of this Lie algebroid when E = TM . In this case, last proposition can be reformulated: Let D be a derivation, D ∈ Der Γ ( Λ · T ∗ M ), such that D 2 = 0, then it has a Fr¨licher-Nijenhuis decomposition o D = L K + ı L , where K ∈ Ω ( 1 M TM ; ) and L ∈ Ω ( 2 M TM ; ). Then, the triple ( E,q, [ [ , ] ]) is a Lie algebroid with
$$q = K$$
and
$$( 1 1 ) & & [ X, Y ] = [ X, Y ] _ { K } - L ( X, Y ),$$
where the contracted bracket is given in (3).
Formula (11) can be deduced by observing that D is precisely the operator associated to the Lie algebroid by the construction in the previous section. In particular, that tells us that the distribution Im K is involutive, because (as the anchor map of a Lie algebroid is a Lie algebra morphism) [ KX,KY ] = K X,Y [ [ ] ] ∈ Im K . Notice (see [11]) that when the Nijenhuis torsion of K vanishes, then [ , ] K is a Lie bracket.
Taking the action of K on both sides of (11), we get
$$K L ( X, Y ) = K [ K X, Y ] + K [ X, K Y ] - K ^ { 2 } [ X, Y ] - K [ X, Y ].$$
But, as K = q is a Lie algebroid anchor, it is a Lie algebra morphism, so
$$[ K X, K Y ] - K [ K X, Y ] - K [ X, K Y ] + K ^ { 2 } [ X, Y ] = - K L ( X, Y ),$$
or, more succintly, in terms of the Nijenhuis torsion of K ,
$$T _ { K } ( X, Y ) = - K L ( X, Y ).$$
This expression allows us to prove the following result: Let D ∈ Der Ω( 1 M ) be such that D 2 = 0 and its Fr¨licher-Nijenhuis decomposition has the form o D = L K (i.e, L = 0).
Proposition 4.2. The derivation D = L K induces a Lie algebroid structure on (sections of) TM with anchor map q = K and bracket
$$[ X, Y ] _ { K } = [ K X, Y ] + [ X, K Y ] - K [ X, Y ],$$
if and only if K is integrable (i.e, T K = 0 ).
Proof. The condition T K = 0 follows from (12) above. On the other hand, the sufficiency is guaranteed by the identities D 2 = 1 2 [ D,D ] and [ L K , L L ] = L [ K,L ] FN and by proposition 4.1. /square
Remark 3. The 'if' part of this proposition was given as theorem 3.7 in [12] and as exercise 40 in [5].
/negationslash
Recall that, given a bundle map N : TM → TM , when T N = 0, N is called a Nijenhuis tensor. As every Nijenhuis tensor induce a Lie algebroid, then, any complex structure ( K 2 = -I ), tangent structure ( K 2 = 0) or product structure ( K 2 = I ), defines a Lie algebroid on TM . Let us see what happens when a term L = 0 is non trivial. Still demanding that D = L K + ı L be of square zero; we will do this in two steps, assuming in the first one that K is invertible. If K : Γ TM → Γ TM is an invertible endomorphism, the vector-valued 2 -form L ∈ Ω ( 2 M TM ; ) is determined by
$$\Phi _ { - 1 }$$
(13) L X,Y ( ) := -K T K ( X,Y , ) for any X,Y ∈ Γ TM , and then, the bracket [ [ , ] ] : Γ TM → Γ TM is (14) [ [ X,Y ] ] := [ X,Y ] K + K -1 T K ( X,Y , )
for all X,Y ∈ Γ TM .
Lemma 4.3. The bracket (14) satisfies
$$[ X, Y ] = K ^ { - 1 } [ K X, K Y ].$$
Proof. It is a straightforward computation:
$$r r o o j. \ n i s a s a n g u n u o r w a r c o m p u a u o n \colon & [ X, Y ] = & [ X, Y ] _ { K } + K ^ { - 1 } T _ { K } ( X, Y ) \\ & = & [ K X, Y ] + [ X, K Y ] - K [ X, Y ] \\ & \quad + K ^ { - 1 } ( [ K X, K Y ] - K [ K X, Y ] - K [ X, K Y ] + K ^ { 2 } [ X, Y ] ) \\ & = & K ^ { - 1 } [ K X, K Y ] \\ & \quad & \sqcap$$
/square
Proposition 4.4. The triple ( TM,K, [ [ , ] ]) , with the bracket defined in (14) , is a Lie algebroid.
Proof. That ( Γ TM, [ [ , ] ]) is a Lie algebra is immediate (Jacobi's identity results by applying Lemma 4.3), and K is a morphism of C ∞ ( M ) -modules, so we only need to check the Leibniz rule:
$$\begin{array} { r c l } \text{to check use Lemnz true} \\ [ X, f Y ] & = & [ X, f Y ] _ { K } + K ^ { - 1 } T _ { K } ( f X, Y ) \\ & = & [ K X, f Y ] + [ X, f K Y ] - K [ X, f Y ] + f K ^ { - 1 } T _ { K } ( X, Y ) \\ & = & f [ X, Y ] _ { K } + K X ( f ) Y + X ( f ) K Y - X ( f ) K Y + f K ^ { - 1 } T _ { K } ( X, Y ) \\ & = & f [ X, Y ] + K X ( f ) Y. \end{array}$$
/square
Every Lie algebroid induced by an invertible endomorphism is isomorphic to the trivial Lie algebroid:
Proposition 4.5. The Lie algebroids ( TM,K, [ [ , ] ]) (given by proposition 4.4) and the trivial one ( TM,Id, [ , ]) are isomorphic.
Proof. The desired isomorphism is φ = K -1 : Γ TM → Γ TM , since
$$K \circ \phi = K \circ K ^ { - 1 } = I d \,,$$
and
$$\phi ( [ X, Y ] ) & = K ^ { - 1 } ( [ X, Y ] ) = K ^ { - 1 } ( [ K \circ K ^ { - 1 } ( X ), K \circ K ^ { - 1 } ( Y ) ] ) = [ \phi ( X ), \phi ( Y ) ] \\ & \text{by lemma 4.3.}$$
$$by lemma 4.3.$$
To summarize, we have the following result which, in particular, applies to almost-complex or almost-product structures.
Theorem 4.6. Let K : TM → TM be an invertible bundle endomorphism. Then, a derivation of the form
$$D = \mathcal { L } _ { K } + \imath _ { L } \in \text{Der} ^ { 1 } \Omega ( M ),$$
(with L ∈ Ω ( 2 M TM ; ) ) has vanishing square if and only if
$$L = - K ^ { - 1 } T _ { K }.$$
In this case, the Lie algebroid structure on TM determined by D is isomorphic to the trivial one.
In the next step, we consider the general situation of a derivation of Z -degree 1, D = L K + i L , where K is not necessarily invertible. We ask ourselves under which conditions on K and L , it defines a Lie algebroid structure. From the Fr¨lichero Nijenhuis decomposition D = L K + i L and the general properties of the Fr¨lichero Nijenhuis and Richardson-Nijenhuis brackets (see [15, 19, 21]), we get:
$$\Lambda _ { \Lambda } & = \frac { 1 } { 2 } [ D, D ] = \frac { 1 } { 2 } [ \mathcal { L } _ { K } + \imath _ { L }, \mathcal { L } _ { K } + \imath _ { L } ] \\ & = \frac { 1 } { 2 } \mathcal { L } _ { [ K, K ] _ { F N } } + \imath _ { [ K, L ] _ { F N } } + \mathcal { L } _ { \imath _ { L } K } + \frac { 1 } { 2 } \imath _ { [ L, L ] _ { R N } }, \\ \Lambda \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \cdot \cdot$$
so D 2 = 0 is equivalent to the conditions
$$\infty \, \lambda \, - \infty \, \text{equivalent to one common} \\ ( 1 5 ) & \quad \begin{cases} \frac { 1 } { 2 } [ K, K ] _ { F N } + \imath _ { L } K = 0 \\ [ K, L ] _ { F N } + \frac { 1 } { 2 } [ L, L ] _ { R N } = 0. \end{cases} \\ \text{The first of these is already known, it comes from the imposit} \\ \text{algebroid bracket be of the form } [ X. Y ] = [ X. Y ] _ { K } - L ( X. Y ) \, \text{and}$$
The first of these is already known, it comes from the imposition that the Lie algebroid bracket be of the form [ [ X,Y ] ] = [ X,Y ] K -L X,Y ( ) and is nothing more than equation (12). A straightforward computation shows that, in fact, it is also equivalent to D f 2 = 0, for any f ∈ C ∞ ( M ). The second condition is much more difficult to satisfy. In the following sections we will construct some solutions out of structures on the tangent bundle of a manifold M with geometric relevance.
## 5. Lie algebroids associated to idempotent endomorphisms
Let TM → M be the tangent bundle over the connected manifold M , and let N : TM → TM be an idempotent endomorphism (that is, such that N 2 = N ). Then, N has locally constant rank and ker N , Im N are vector (sub)bundles such that TM = ker N ⊕ Im N (see [14]). We will assume that Im N is an involutive distribution and write down proofs in the real case for simplicity, but the results are valid in the complex case as well.
Lemma 5.1. Under the above assumptions, the following holds:
$$( 1 6 ) & & N [ N X, N Y ] = [ N X, N Y ].$$
Proof. As Im N is involutive, there exists a Z ∈ Γ TM such that [ NX,NY ] = NZ , and by applying N to both sides of this equation,
$$N [ N X, N Y ] = N ^ { 2 } Z = N Z = [ N X, N Y ]$$
Consider now the Nijenhuis torsion of N (1). In our case, it can be rewritten as
$$T _ { N } ( X, Y ) = [ N X, N Y ] - N [ N X, Y ] - N [ X, N Y ] + N [ X, Y ].$$
By applying N to both sides, we get
$$N T _ { N } ( X, Y ) = N [ N X, N Y ] - N ^ { 2 } [ N X, Y ] - N ^ { 2 } [ X, N Y ] + N ^ { 2 } [ X, Y ],$$
and, using lemma 5.1 along with the property N 2 = N ,
$$( 1 7 ) \ N T _ { N } ( X, Y ) = [ N X, N Y ] - N [ N X, Y ] - N [ X, N Y ] + N [ X, Y ] = T _ { N } ( X, Y ).$$
This suggest to define the vector-valued 2 -form
$$L \coloneqq - T _ { N }.$$
The pair ( N,L ) is a solution to equations (15).
Proposition 5.2. Let N : TM → TM be an idempotent endomorphism with Im N involutive, and L ∈ Ω ( 2 M TM ; ) defined by (18) . Then NL = -T N , also
$$\begin{cases} [ N, L ] _ { F N } = 0 \\ [ L, L ] _ { R N } = 0 \end{cases}$$
Proof. The first affirmation is a direct consequence of definition (18). As L = -1 2 [ N,N ] FN , and (Ω ( ∗ M TM , ; ) [ , ] FN ) is a graded Lie algebra (see [19]), we have
$$[ N, L ] _ { F N } = - \frac { 1 } { 2 } [ N, [ N, N ] _ { F N } ] _ { F N } = 0.$$
Moreover, as L ∈ Ω ( 2 M TM ; ), it follows that [ L, L ] RN ∈ Ω ( 3 M TM ; ), i L ∈ Der 1 Ω( M ), and i [ L,L ] RN ∈ Der 2 Ω( M ); thus, i [ L,L ] RN is completely characterized by its action on 0 -forms (smooth functions) and 1 -forms. But i [ L,L ] RN is a tensorial derivation, so it vanishes on C ∞ ( M ). Now, given an α ∈ Ω ( 1 M ) it is
$$i _ { [ L, L ] _ { R N } } \in \Omega ^ { 3 } ( M ) \text{ so, whenever } X, Y, Z \in \Gamma T M,$$
$$\iota _ { N } \in \mathcal { A } ( I \lambda ) \, \text{so, whenever } \Lambda, \, I, \, Z \in \mathcal { A } ( I \lambda ), \\ ( i _ { [ L, L ] _ { R N } } \alpha ) ( X, Y, Z ) & = \alpha ( [ L, L ] _ { R N } ( X, Y, Z ) ) \\ & = 2 i _ { L } ^ { 2 } \alpha ( X, Y, Z ) \\ & = 2 \bigcirc i _ { L } \alpha ( L ( X, Y ), Z ) \\ & = 2 \bigcirc \alpha ( L ( L ( X, Y ), Z ) ) \\ & = 2 \bigcirc \alpha ( T _ { N } ( T _ { N } ( X, Y ), Z ) ) = 0, \\ \Big \rangle \text{ denotes cyclic sum in } ( X. Y. Z ) ) \text{ because}$$
(here /clockwise denotes cyclic sum in ( X,Y,Z )) because
T
N
(
T
N
(
X,Y ,Z
)
)
=[
NT
N
(
X,Y ,NZ
)
]
-
N NT
[
N
(
X,Y ,Z
)
]
-
N T
[
N
(
X,Y ,NZ
)
] +
N
2
[
T
N
(
X,Y ,Z
)
]
=
N NT
[
N
(
X,Y ,NZ
)
]
-
N T
[
N
(
X,Y ,Z
)
]
-
N T
[
N
(
X,Y ,NZ
)
] +
N T
[
N
(
X,Y ,Z
)
]
$$= & N [ T _ { N } ( X, Y ), N Z ] - N [ T _ { N } ( X, Y ), Z ] - N [ T _ { N } ( X, Y ), N Z ] + N [ T _ { N } ( X, Y ), Z ] = 0,$$
where we have used lemma 5.1, equation (17), and the property N 2 = N . /square
Combining (15) with proposition 5.2, we arrive at the following result
Theorem 5.3. Let N ∈ Ω ( 1 M TM ; ) be such that N 2 = N and Im N is involutive. Then, defining L as in (18) , the derivations given by D 1 = L N + ı L , and D 2 = ı L ∈ Der Ω( 1 M ) are cohomology operators, that is, D 2 1 = 0 = D 2 2 .
Note that when N is a Nijenhuis tensor, automatically Im N is involutive, since in this case [ N X ,N Y ( ) ( )] = N N X ,Y ([ ( ) ] + [ X,N Y ( )] -N X,Y ([ ])) for every X,Y ∈ Γ TM . And if it holds that Ker N and Im N are involutive, it follows that N is Nijenhuis tensor.
Corollary 5.4. Let N ∈ Ω ( 1 M TM ; ) be such that N 2 = N and T N = 0 . Then, the derivation given by D = L Id -N ∈ Der Ω( 1 M ) is a cohomology operator, that is, D 2 = 0 .
Proof. First we observe that ( Id -N ) 2 = Id -N , moreover using the identity [ Id, N ] FN = -[ N,Id ] FN , we get
$$\cdot \quad \cdot \quad & \cdot \quad \\ T _ { I d - N } = & [ I d - N, I d - N ] _ { F N } \\ = & [ I d, I d ] _ { F N } - [ N, I d ] _ { F N } - [ I d, N ] _ { F N } + [ N, N ] _ { F N } \\ = & 0$$
Then simply apply theorem 5.3.
/square
Applying formula (11), the Lie algebroid induced by the operator D 1 = L N + ı L of Theorem 5.3 can be explicitly described as follows.
Theorem 5.5. Let N ∈ Ω ( 1 M TM ; ) be such that N 2 = N and Im N is involutive. Then, there exists a Lie algebroid structure ( TM,q, [ | , | ]) with anchor map q = N and bracket
$$| X, Y | = [ X, Y ] _ { N } + T _ { N } ($$
We remark that the bracket on TM constructed this way, is given by the sum of the deformed bracket [ · , · ] N and the torsion T N . Another useful expresion for this bracket is
$$( 2 0 ) \quad \left | X, Y \right | = \left [ N X,$$
## 6. Relation with the foliated exterior differential
Let F be a regular foliation on a manifold M and T F ⊂ TM its tangent bundle. Denote by j : T F → ↪ TM the canonical injection. To any such a foliation we can associate a Lie algebroid in two equivalent ways.
- (a) The space of tangent sections Γ ( T F ) is closed with respect to the Lie bracket of vector fields on M , by the integrability of F , so it carries a natural (foliated) bracket [ · , · ] F which is just the restriction of the Lie bracket to F . Then,
$$( E = T \mathcal { F }, [ \cdot, \cdot ] _ {$$
is a Lie algebroid, called the Lie algebroid of the foliation F (see, for example, [10]). In this case the corresponding cohomology operator is the foliated exterior differential d F : Γ ( Λ p T ∗ F ) → Γ ( Λ p +1 T ∗ F ), which gives rise to the foliated DeRham cohomology.
- (b) Let H be an Ehresmann connection on ( M, F ) complementary to T F , that is, TM = H ⊕F . Denote by γ the associated projection on F , γ : H ⊕F → F , so H = ker γ and F = Im γ . It follows that γ is a vector-valued 1 -form, and then the curvature of the connection is defined as the Nijenhuis torsion
$$R = \frac { 1 } { 2 } [ \gamma, \gamma ] _ { F$$
On the whole TM we can construct the Lie algebroid structure given by Theorem 5.5. In this case, the explicit expression of the bracket can be easily computed from (20):
$$\begin{array} {$$
The anchor map, as we know, is given by q = γ . Obviously, this algebroid structure coincides with the previous one when restricted to Γ ( T F ), independently of the chosen connection γ .
In what follows, we offer an interpretation of the foliated cohomology within the framework described in item (b). The splitting induced by γ , TM = H ⊕ T F , define a bigrading on Ω( M ). A differential form ω on a foliated manifold is said to be of type ( p, q ) if it has degree p + q and ω X ,. . . , X ( 1 p + q ) = 0 whenever the arguments contain more than q vector fields in Γ ( T F ), or more than p in H . According to this bigrading, we have a decomposition of the exterior differential on M ,
$$d & = d _ { 1, 0 } + d _ { 2, - 1 } + d _ { 0, 1 } \,,$$
(see [22]), where d i,j : Ω p,q ( M ) → Ω p + i,q + j .
Remark 4. Denoting by h : Γ ( Λ T ∗ F ) → Γ ( Λ H 0 ) the natural identification, we notice that d 0 1 , is a γ -dependent extension of the foliated exterior differential, that is,
$$\left ( d _ { 0, 1 } \circ h \right ) \omega = \left ( h \circ d _ { \mathcal { F } } \right ) \omega \,,$$
for all ω ∈ Γ ( Λ T ∗ F ).
The Fr¨licher-Nijenhuis decomposition of the operators appearing in the decomo position (21) can be readily computed from the results in section 2:
$$& d _ { 1, 0 } = \, \mathcal { L } _ { \text{Id} - \gamma } + \imath _ { 2 R } \\ & d _ { 0, 1 } = \, \mathcal { L } _ { \gamma } - \imath _ { R } \\ & d _ { 2, - 1 } = \, - \imath _ { R } \,.$$
From (21) and d 2 = 0, it follows that
$$d _ { 0, 1 } ^ { 2 } = 0 = d _ { 2, - 1 } ^ { 2 } \,.$$
Moreover, the derivation d 1 0 , is a cohomology operator if and only if the curvature of the connection γ vanishes.
Theorem 6.1. The cohomology operator associated to the Lie algebroid on TM described in item (b) above, is given by
$$D = d _ { 0, 1 } \,.$$
Moreover, the Lie algebroid of the foliation F and the restriction to T F of the Lie algebroid associated to a connection γ on TM , coincide. Thus, the complexes associated to the cohomology operators d F and d 0 1 , | Γ ( Λ H 0 ) are isomorphic.
Proof. The first statement is just a consequence of Theorem 3.1 and example 2. The second one follows from preceding results, along with remark 4. /square
Remark 5. Notice that, once this equivalence has been established, given the Lie algebroid structure N : TM → TM , with N idempotent, we could define the associated foliated cohomology independently of any regularity condition on F , just using the decomposition
$$d = \mathcal { L } _ { I d } = ( \mathcal { L } _ { I d - \gamma } + 2 \imath _ { R } ) + ( \mathcal { L } _ { \gamma } - \imath _ { R } ) - \imath _ { R } \,.$$
## 7. Complex Lie algebroids associated to complex structures
Recall that an almost-complex structure on a manifold M is a vector-valued 1 -form J ∈ Ω ( 1 M TM ; ) such that J 2 = -Id TM . In order to diagonalize the endomorphism J , we work in the complexified tangent bundle T C M , and extend by C -linearity all real endomorphisms and differential operators on TM (with a little abuse of notation, we will denote these extensions by the same symbols as their real counterparts). The Lie bracket of vector fields can also be extended by C -linearity.
The almost-complex structure J is said to be integrable if its Nijenhuis torsion vanishes, that is, if for every X,Y ∈ X ( M ),
$$T _ { J } ( X, Y ) = \frac { 1 } { 2 } [ J, J ] _ { F N } ( X, Y ) = [ J X, J Y ] - J [ J X, Y ] - J [ X, J Y ] - [ X, Y ] = 0.$$
The Newlander-Nirenberg theorem states that this happens if and only if M has he structure of a complex manifold.
From the condition J 2 = -Id TM , we know that J has the eigenvalues ± i . If we define the projection operators
$$p ^ { \pm } \coloneqq \frac { 1 } { 2 } ( \text{Id} \mp i J ) \, \colon T ^ { \mathbb { C } } M \to T ^ { \mathbb { C } } M,$$
we get the usual properties
$$( p ^ { \pm } ) ^ { 2 } & = p ^ { \pm } \\ p ^ { + } + p ^ { - } & = \text{Id} _ { T ^ { \text{c} } M } \\ p ^ { + } \circ p ^ { - } & = 0 = p ^ { - } \circ p ^ { + } \,,$$
$$\psi$$
which determine the subbundle decomposition T C M = T + M ⊕ T -M , where
$$\Gamma T ^ { \pm } M = \{ Z \in \Gamma T ^ { \mathbb { C } } M \, \colon J Z = \pm i Z \}.$$
The elements of Γ T + M are called holomorphic vector fields, and those of Γ T -M anti-holomorphic. Notice that Im p ± = T ± M , and ker p ± = T ∓ M , and that if Z ∈ Γ T + M , then its complex conjugate ¯ Z ∈ Γ T -M (and vice versa).
We will need the following technical results.
Lemma 7.1. Let J ∈ Ω ( 1 M TM ; ) be an almost-complex structure on M , and let T J be its Nijenhuis torsion. If T J = 0 , then its complex extension also satisfies T J = 0 .
Proof. Let Z = X + iY, W = X ′ + iY ′ . A straightforward computation shows that
$$\mathcal { T } _ { J } ( Z, W ) & = [ J Z, J W ] - J [ J Z, W ] - J [ Z, J W ] - [ Z, W ] \\ & = T _ { J } ( X, X ^ { \prime } ) - T _ { J } ( Y, Y ^ { \prime } ) + i ( T _ { J } ( Y, X ^ { \prime } ) + T _ { J } ( X, Y ^ { \prime } ) ) \\ & \quad \square$$
Proposition 7.2. An almost-complex structure J ∈ Ω ( 1 M TM ; ) is integrable if and only if [ T + M,T + M ] ⊂ T + M , that is, the distribution defined by the holomorphic vector fields is involutive.
Proof. Consider first the case of J ∈ Ω ( 1 M TM ; ) integrable. By the preceding lemma, if T J = 0, then also T J = 0. If Z, W are holomorphic vector fields, we have JZ = iZ and JW = iW , so
$$0 = \mathcal { T } _ { J } ( Z, W ) & = [ i Z, i W ] - J [ i Z, W ] - J [ Z, i W ] - [ Z, W ] \\ & = - [ Z, W ] - i J [ Z, W ] - i J [ Z, W ] - [ Z, W ] \\ & = - 2 ( [ Z, W ] + i J [ Z, W ] ),$$
1
that is J Z, W [ ] = -i [ Z, W ] = i Z, W [ ], so [ Z, W ] is holomorphic. Reciprocally, assume that [ Z, W ] is a holomorphic vector field whenever Z, W are. Given arbitrary vector fields X,Y ∈ Γ TM , we can rewrite them in the form X = Z + ¯ , Z Y = W + ¯ W for some Z, W ∈ Γ T + M . Then, it is readily proved that T J ( Z, W ¯ ) = T J ( ¯ Z,W ) = 0, and
$$T _ { J } ( X, Y ) = \mathcal { T } _ { J } ( Z, W ) + \mathcal { T } _ { J } ( \bar { Z }, \bar { W } ).$$
But for holomorphic vector fields we already know that T J ( Z, W ) = -2([ Z, W ] + iJ Z, W [ ]), and, as [ Z, W ] is holomorphic by assumption, J Z, W [ ] = [ i Z, W ]. Therefore T J ( Z, W ) = -2([ Z, W ] + i 2 [ Z, W ]) = 0. A similar calculation shows that T J ( ¯ Z,W ¯ ) = 0, and we conclude that J is integrable. /square
We are now ready to construct a complex Lie algebroid canonically associated to a complex manifold. Recall (see [24]) that a complex Lie algebroid over the manifold M is given by a complex vector bundle E over M endowed with a complex
Lie algebra structure on its space of sections Γ E , together with a bundle map q : E → T C M (the anchor map) satisfying the Leibniz rule
$$[ A, f B ] = f [ A, B ] + ( q A ) ( f ) B,$$
for any A,B ∈ Γ E , and f : M → C smooth. The main example of a complex Lie algebroid is given by the inclusion q : T + M ↪ → T C M of the subbundle of holomorphic vector fields on a complex manifold. Notice that the vector bundle in this case, E = T + M , is not T C M .
Remark 6. We want to make use of the property ( p + 2 ) = p + of the projection operator p + = 1 2 (Id -iJ ), and the results in section 5 to construct an algebroid where p + will be the anchor map, and the whole T C M the corresponding bundle. However, as Im p + must be involutive, proposition 7.2 forces us to restrict ourselves to complex manifolds.
Our main result is, then, the following.
Theorem 7.3. Let J ∈ Ω ( 1 M TM ; ) be a complex structure on the manifold M . There exists a complex Lie algebroid structure on M , ( T C M,q, [ [ , ] ]) , where the anchor map is q = p + = 1 2 ( Id -iJ ) , and the bracket
$$[ Z, W ] = [ Z, W ] _ { p ^ { + } } = \frac { 1 } { 2 } ( [ Z, W ] - i [ Z, W ] _ { J } ).$$
Proof. First of all, notice that given a complex structure J on M , there is a relation
$$\mathcal { T } _ { p ^ { + } } = - \frac { 1 } { 4 } \mathcal { T } _ { J }, \\ \dots$$
which can be proved by a direct computation. According to the results on section 5, the idempotent endomorphism p + will induce a Lie algebroid T C M → T C M where the anchor map is precisely q = p + , and the bracket [ [ Z, W ] ] = [ Z, W ] p + - T p + . However, the above comment implies that T p + = 0, so the bracket is simply
$$[ Z, W ] = [ Z, W ] _ { p ^ { + } }.$$
A further straightforward computation shows that
$$[ Z, W ] _ { p ^ { + } } = \frac { 1 } { 2 } ( [ Z, W ] - i [ Z, W ] _ { J } ).$$
$$\bar { W } ] _ { p ^ { + } } = \frac { 1 } { 2 } ( [ Z, W ] - i [ Z, W ] _ { J } ).$$
Notice that this Lie algebroid is different to that obtained by applying proposition 4.2, where the resulting bracket would be [ | Z, W | ] = [ Z, W ] J (that is, the C -linear extension of [ , ] J to T C M ).
Remark 7. The proof extends trivially to the case of an endomorphism J ∈ Ω ( 1 M TM ; ) such that J 2 = -/epsilon1 2 Id TM with /epsilon1 ∈ R -{ } 0 .
## 8. Lie algebroids associated to product structures
Consider now an almost-product structure on the manifold M , that is, a vector bundle endomorphism P : TM → TM such that P 2 = Id TM . It has locally constant rank and it defines two projection operators associated to its eigenvalues λ = ± 1, p ± := 1 2 (Id ± P ). We have a decomposition of the tangent bundle analogous to that of the complex case, TM = T + M ⊕ T -M , where, this time, T ± M = Im p ± .
A basic result is that the complementary distributions T ± M are integrable if and only if P is integrable, in the sense of having vanishing Nijenhuis torsion (see [9]),
that is, T ± M are integrable if and only if P is a product structure. In this case, both T ± M are involutive, as we will assume. A simple computation shows that
$$T _ { p ^ { \pm } } = \frac { 1 } { 4 } T _ { P }, \quad \cdot \quad \cdot$$
thus, in the case of a product structure we have T p -= 0.
Of course, given a product structure on M we can construct a Lie algebroid, induced by the operator D = L P , applying proposition 4.2. The bracket is then the contracted one,
$$\left \lfloor X, Y \right \rfloor = [ X, Y ] _ { P }.$$
As we know, the Lie algebroid obtained in this way is isomorphic to the trivial one on TM (recall proposition 4.5). The results in section 5 show that we can define another Lie algebroid structure.
Theorem 8.1. Let P ∈ Ω ( 1 M TM ; ) be a product structure on the manifold M . There exists a Lie algebroid structure on M , ( TM,q, [ [ , ] ]) , where the anchor map is q = p -= 1 2 (Id -P ) , and the bracket
$$[ X, Y ] = [ X, Y ] _ { p - } = \frac { 1 } { 2 } ( [ X, Y ] - [ X, Y ] _ { P } ).$$
Proof. The statement is actually a corollary to theorem 5.3. The last equality is just a trivial computation. /square
Remark 8. The theorem applies also to the case of an operator P ∈ Ω ( 1 M TM ; ) such that P 2 = /epsilon1 2 Id TM , with /epsilon1 ∈ R -{ } 0 .
## 9. The Lie algebroid associated to a tangent structure and a connection
Let us recall some facts about the geometry of the tangent bundle (see [13]). Let π : TM → M be the tangent bundle of a manifold M , and let τ : TTM → TM be the second tangent bundle. Then, we have a short exact sequence of vector bundles
$$0 \longrightarrow T M \times _ { M } T M \stackrel { \iota } { \longrightarrow } T T M \stackrel { j } { \longrightarrow } T M \times _ { M } T M \longrightarrow 0,$$
where
∣ is the natural injection, and j = ( τ, π ). The vertical sub-bundle V TM = ker π ∗ can be expressed in either form
$$\iota ( u, w ) = \frac { \text{d} } { \text{d} t } ( u + t w ) \Big | _ { t = 0 } \\ \text{and} \ j = ( \tau, \pi ). \\ \text{lle} \ \mathcal { V } T M = \ker \pi _ { * } \text{ can be express}$$
$$\text{Im} \iota = \mathcal { V } T M = \ker j,$$
and the vector-valued form J ∈ Ω ( 1 TM TTM ; ) defined by
$$J = \iota \circ j,$$
is called the vertical endomorphism. It is immediate to prove the following properties:
$$2$$
$$\overline { 2 }$$
$$J ^ { 2 } & = 0 \\ \ker J = \mathcal { V } T M = \text{Im} J \\ T _ { J } & = \frac { 1 } { 2 } [ J, J ] _ { F N } = 0.$$
Thus, J defines a (canonical) tangent structure on TM . It has locally constant rank equal to dim M . We also have the (canonical) Liouville vector field on TM , C ∈ X ( TM ), defined as
$$C = \iota \circ \Delta,$$
where ∆ : TM → TM × M TM is the diagonal ∆( v ) = ( v, v ). The Liouville vector field has the property
$$\mathcal { L } _ { C } J = - J.$$
A (nonlinear) connection Γ on TM is a vector-valued form Γ ∈ Ω ( 1 TM TTM ; ) such that
$$J \circ \Gamma = J = - \Gamma \circ J.$$
A basic property of a connection is that it defines an almost product structure on TM , that is,
$$\Gamma ^ { 2 } = \text{Id} _ { T T M },$$
in such a way that the eigenbundle corresponding to the eigenvalue λ = -1 is precisely the vertical distribution. In other words, if we define the projectors
$$\Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \} \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \. \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \ \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \ \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \, \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \, \Phi _ { \mu } \, \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \, \Phi _ { \mu } \quad \Phi _ { \mu } \, \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \ \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \quad \Phi _ { \mu } \ \Phi _ { \mu } \quad \Phi _ { \mu } \quad 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0. \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \, 0 \$$
we have V TM = Im , and v TTM = Im v ⊕ Im . h
Notice that the vertical distribution is integrable (Im v is involutive), while, in general, the horizontal distribution is not (in fact, a necessary and sufficient condition for this is the vanishing of the curvature of the connection). Thus, we expect to be able to apply the results of section 5 in order to construct a Lie algebroid structure where the vector bundle is E = TTM , and the anchor map v .
Theorem 9.1. Let M be a manifold, and J the canonical tangent structure on TM . Let Γ ∈ Ω ( 1 TM TTM ; ) be a connection on TM . Then, there exists a Lie algebroid structure on TM , ( TTM,q, [ [ , ] ]) , where the anchor map is q = v = 1 2 (Id TTM -Γ) and the bracket
$$( 2 2 ) & & [ A, B ] = \frac { 1 } { 2 } \left ( [ A, B ] - [ A, B ] _ { \Gamma } \right ) + \frac { 1 } { 4 } T _ { \Gamma } ( A, B ).$$
Proof. This is just a corollary to theorem 5.3. Simply notice that, as a quick calculation shows,
$$T _ { v } ( A, B ) = \frac { 1 } { 4 } T _ { \Gamma } ( A, B ),$$
for all A,B ∈ X ( TM ), and
$$r \, \text{all} \, A, B \in \mathcal { A } \, ( \mathcal { I } \, M ), \, \text{ana} \\ [ A, B ] _ { v } = & [ v A, B ] + [ A, v B ] - v [ A, B ] \\ = & \frac { 1 } { 2 } ( [ A - \Gamma A, B ] + [ A, B - \Gamma B ] - [ A, B ] + \Gamma [ A, B ] ) \\ = & \frac { 1 } { 2 } ( [ A, B ] - [ \Gamma A, B ] - [ A, \Gamma B ] + \Gamma [ A, B ] ) \\ = & \frac { 1 } { 2 } ( [ A, B ] - [ A, B ] _ { \Gamma } ).$$
The easiest method for obtaining connections on TM is to choose a semispray. A semispray (or a second-order differential equation, see [1]) on M is a vector field on TM S , ∈ X ( TM ), such that it is also a section of the second tangent bundle TTM → TM . Vector fields S ∈ X ( TM ) which are semisprays can be characterized with the aid of the canonical structures on TM as those satisfying
$$J \circ S = C.$$
It is well known (see [1, 9]) that for any semispray S , the endomorphism Γ = -L S J is a connection on TM , with associated projectors
$$\tilde { h } = \frac { 1 } { 2 } ( \text{Id} _ { T T M } - \mathcal { L } _ { S } J ) \\ v = \frac { 1 } { 2 } ( \text{Id} _ { T T M } + \mathcal { L } _ { S } J ). \\ \tilde { \ } \text{mod to non non-zero}$$
Remark 9. This intimate relation between semisprays and connections has been used in Physics to study such topics as the inverse problem for Lagrangian dynamics [7], degenerate Lagrangian systems [3], or the geometry and mechanics of higher order tangent bundles [8].
We have the following result.
Theorem 9.2. Let M be a manifold, and J the canonical tangent structure on TM . Let S ∈ X ( TM ) be a semispray on M . Then, there exists a Lie algebroid structure on TM , ( TTM,q, [ [ , ] ]) , where the anchor map is q = v = 1 2 (Id TTM + L S J ) and the bracket
$$& ( 2 4 ) & & [ A, B ] = \frac { 1 } { 2 } \left ( [ A, B ] - \bigcirc _ { A, B, S } [ A, \mathcal { L } _ { S } B ] _ { J } \right ) + \frac { 1 } { 4 } T _ { \mathcal { L } _ { S } J } ( A, B ). \\ & \nolimits _ { \dots } \tilde { t } \ n \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ & \nolimits _ { \dots } \tilde { t } \ n \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \nu \sim \nu / \tau / \nolimits \nu \infty }$$
Proof. Rewrite (22) taking into account (23) so, for any X ∈ X ( TM ),
$$\mu _ { \begin{array} { c } ( \mathcal { L } _ { S } J ) X \\ = [ S, J X ] - J [ S, X ] \\ = [ S, X ] _ { J } - [ J S, X ] \\ = [ S, X ] _ { J } - [ C, X ]. \\ \end{array} } } \mu _ { \begin{array} { c } ( \mathcal { L } _ { S } J ) X \\ = [ S, J X ] _ { J } - [ C, X ]. \\ \end{array} } } \mu _ { \begin{array} { c } ( \mathcal { L } _ { S } J ) X \\ = [ S, J X ] _ { J } - [ C, X ]. \\ \end{array} } }$$
That is, Γ X = [ C, X ] -[ S, X ] J . A long but otherwise straightforward computation leads to (24). /square
## Acknowledgments
The authors express their gratitude to J. V. Beltr´n and J. Monterde (both at a the Universitat de Val`ncia, Spain), for many useful discussions. e
## References
- [1] W. Ambrose, R. S. Palais and I. M. Singer, Sprays , An. Acad. Bras. Cie. 32 (1960), 163-178. Available from http://vmm.math.uci.edu/PalaisPapers/Sprays(withAmbrose&Singer).pdf .
- [2] A. D. Blaom, Geometric structures as deformed infinitesimal symmetries , Trans. Amer. Math. Soc. 358 (2006), 3651-3671.
- [3] F. Cantrijn, J. Cari˜ena, J. Crampin and L. Ibort, n Reduction of degenerate Lagrangian systems , J. Geom. Phys. 3 (1986) 353-400.
- [4] J. Clemente-Gallardo, Applications of Lie algebroids in mechanics and control theory , in 'Nonlinear control in the Year 2000', Lect. Not. in Control and Inf. Sci. 258 (2001) 299-313.
- [5] M. Crainic and R. L. Fernandes, Lectures on integrability of Lie brackets , Geometry and Topology Monographs, vol 17, (2011), p. 1-107. Available from: http://msp.org/gtm/2011/17/gtm-2011-17-001s.pdf
- [6] M. Crainic and I.Moerdijk, Deformations of Lie brackets: cohomological aspects , preprint, arXiv: math.DG/0403434, (2005). Available from: http://arxiv.org/pdf/math/0403434v2.pdf
- [7] M. Crampin, On the differential geometry of the Euler-Lagrange equations, and the inverse problem of Lagrangian dynamics , J. Phys. A: Math. Gen. 14 (1981) 2567-2575.
- [8] L. De Andr´ es, M. De Le´n and P. R. Rodrigues, o Connections on tangent bundles of higher order associated to regular Lagrangians , Geometriae Dedicata 39 1 (1991) 17-28.
- [9] M. De Le´ on and P. R. Rodrigues, Methods of Differential Geometry in Analytical Mechanics , North-Holland Mathematics Studies 158 , Elsevier, Amsterdam, 1998.
- [10] R. L. Fernandes, Lie Algebroids, Holonomy and Characteristic Classes , Adv. in Math. 170 1 (2002) 119-179.
- [11] J. Grabowski, Courant-Nijenhuis tensors and generalized geometries , in 'Groups, geometry and physics', Monograf´ ıas de la Real Academia de Ciencias de Zaragoza 29 (2006), 101-112. Available from: http://arxiv.org/abs/math/0601761 .
- [12] J. Grabowski, Brackets , Int. J. of Geom. Methods in Mod. Phys. 10 8 (2013) 1360001 (45 pages).
- [13] J. Grifone, Structure presque-tangent et connexions , Ann. Inst. Fourier 22 1 (1972), 287-334. Available from: https://eudml.org/doc/74069 .
- [14] D. Husem¨ oller, M. Joachim, B. Jur˘ co and M. Schottenloher, Basic Bundle Theory and K -Cohomology Invariants , Lecture Notes in Physics 726 , Springer-Verlag, Berlin, 2008.
- [15] I. Kol´˘, P. W. Michor and J. Slov´k, ar a Natural operations in differential geometry , 2nd edition, Springer-Verlag, New York, 1994.
- [16] Y. Kosmann-Schwarzbach and F. Magri, Possion-Nijenhuis structures , Annales de l'I.P.H., section A, vol 53, no 1, Elsevier (1990), p.35-81. Available from:
- http://archive.numdam.org/ARCHIVE/AIHPA/AIHPA\_1990\_\_53\_1/AIHPA\_1990\_\_53\_1\_35\_0/AIHPA\_1990\_\_53\_1\_35\_0.pdf London Math. Soc.
- [17] K. C. H. Mackenzie, General Theory of Lie Groupoids and Lie algebroids , Lec. Notes 213 , Cambridge UP, Cambridge, 2005.
- [18] E. Mart´ ınez, Lie Algebroids in Classical Mechanics and Optimal Control , SIGMA 3 (2007) 050 (17 pages).
- [19] P. W. Michor, Remarks on the Fr¨licher-Nijenhuis bracket o , Proceedings of the Conference on Differential Geometry and its Applications, Brno (1986), Springer-Verlag, Berlin, 1987. Available from: http://www.mat.univie.ac.at/ ~ michor/froe-nij.pdf .
- [20] J. Monterde and A. Montesinos, Integral curves of derivations , Ann. of Global Anal. and Geom. 6 2, (1988), 177-189.
- [21] A. Nijenhuis and R. Richardson, Deformation of Lie algebra structures , J. Math. Mech. 17 (1967), 89-105.
- [22] I. Vaisman, Cohomology and Differential Forms , Marcel Dekker Inc., New York, 1973.
- [23] A. Weinstein, Lagrangian Mechanics and Groupoids , in 'Mechanics Day', Fields Inst. Comm. 7 , AMS Publishing (1996), 207-232. Available from: http://math.berkeley.edu/ ~ alanw/Lagrangian.tex .
- [24] A. Weinstein, The Integration Problem for Complex Lie Algebroids , in 'From Geometry to Quantum Mechanics', Progress in Mathematics 252 , pp 93-109, Birkh¨user, Boston, 2007. a
E-mail address
: [email protected]
E-mail address
: [email protected]
E-mail address : [email protected] | 10.3934/jgm.2015.7.295 | [
"D. García-Beltrán",
"J. A. Vallejo",
"Yu. Vorobiev"
] | 2014-07-31T20:14:58+00:00 | 2014-10-07T04:42:22+00:00 | [
"math.DG",
"math-ph",
"math.MP",
"58F15 (Primary), 58F17, 53C35 (Secondary)"
] | Lie algebroids generated by cohomology operators | By studying the Fr\"olicher-Nijenhuis decomposition of cohomology operators
(that is, derivations $D$ of the exterior algebra $\Omega (M)$ with
$\mathbb{Z}-$degree $1$ and $D^2=0$), we describe new examples of Lie algebroid
structures on the tangent bundle $TM$ (and its complexification
$T^{\mathbb{C}}M$) constructed from pre-existing geometric ones such as
foliations, complex, product or tangent structures. We also describe a class of
Lie algebroids on tangent bundles associated to idempotent endomorphisms with
nontrivial Nijenhuis torsion. |
1408.0019v1 | ## Hidden photons with Kaluza-Klein towers
Joerg Jaeckel , Sabyasachi Roy , Chris J. Wallace 1 2 2
- 1 Institut für theoretische Physik, Universität Heidelberg, Philosophenweg 16, 69120 Heidelberg, Germany
- 2 Institute for Particle Physics Phenomenology, University of Durham, South Road, Durham, DH1 3LE, UK
August 4, 2014
## Abstract
One of the simplest extensions of the Standard Model (SM) is an extra U(1) gauge group under which SM matter does not carry any charge. The associated boson - the hidden photon - then interacts via kinetic mixing with the ordinary photon. Such hidden photons arise naturally in UV extensions such as string theory, often accompanied by the presence of extra spatial dimensions. In this note we investigate a toy scenario where the hidden photon extends into these extra dimensions. Interaction via kinetic mixing is observable only if the hidden photon is massive. In four dimensions this mass needs to be generated via a Higgs or Stueckelberg mechanism. However, in a situation with compactified extra dimensions there automatically exist massive Kaluza-Klein modes which make the interaction observable. We present phenomenological constraints for our toy model. This example demonstrates that the additional particles arising in a more complete theory can have significant effects on the phenomenology.
## 1 Introduction
Extra U(1) gauge groups and the corresponding gauge bosons are a common feature in completions of the Standard Model (SM) [1-17] such as, e.g. string theory. To account for their not having being observed these gauge bosons either have to be very massive or the interactions with SM particles have to be very weak. Here, we are mainly interested in the latter case.
Weakness of the interactions is automatic if SM particles do not carry charge under this new U(1). In this case the only renormalizable interaction is via kinetic mixing of the new U(1) with the photon , 1
$$\frac { \ddot { \nu }, } { \mathcal { L } } = - \frac { 1 } { 4 } F ^ { \mu \nu } F _ { \mu \nu } - \frac { 1 } { 4 } X ^ { \mu \nu } X _ { \mu \nu } - \frac { 1 } { 2 } \chi F ^ { \mu \nu } X _ { \mu \nu } + j ^ { \mu } A _ { \mu }.$$
1 In principle the interaction is via the hypercharge U(1) but after electroweak symmetry breaking the most relevant part for the accessible phenomenology at low energies is the mixing with the photon.
Here F µν is the ordinary photon field strength tensor, X µν is the field strength for the hidden photon field X µ and j µ is the electromagnetic current. In the simplest case where there is no additional matter we do not have such a current interaction with the hidden photon since all SM particles are uncharged under it.
It is straightforward to see that if the Lagrangian above was a complete description of the new gauge boson, no effects would be observable, since the kinetic mixing term can be made to vanish by applying a field redefinition,
$$X _ { \mu } \rightarrow X _ { \mu } - \chi A _ { \mu }.$$
In the presence of a mass term,
$$\mathcal { L } _ { \text{mass} } = \frac { 1 } { 2 } m _ { X } ^ { 2 } X ^ { \mu } X _ { \mu }, \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
this redefinition does not remove all couplings between A and X and the hidden photon is therefore observable.
In four dimensions such a mass term has to be generated by a Higgs or Stueckelberg mechanism. Interestingly, if we have extra compactified spatial dimensions, which are commonly present in string theory, there are automatically massive Kaluza-Klein (KK) modes. If the hidden photon extends into the extra dimensions these modes (and their kinetic mixing with the photon) can facilitate an observable interaction with the SM. We will explicitly show this for a toy model in Sect. 2. In this case there is no need for an additional mass generation mechanism and we focus on this situation.
At the same time the presence of a potentially huge number of observable modes impacts the phenomenology and can impose strong constraints (this may also open new paths for experimental or observational tests). To make a start on this we examine the existing constraints on the parameter space of a single four dimensional hidden photon and investigate their impact in our toy model featuring a KK tower.
We will focus on the case of large, flat extra dimensions (LED) [18,19]. The case of a warped, Randall-Sundrum [20-22] type scenario has been considered in [23,24].
The paper is structured as follows. In Section 2, we present our toy model for a higher dimensional hidden photon field in a braneworld scenario, in the language of effective field theory. In Section 3, we briefly review the existing constraints on 4-dimensional hidden photons, and discuss in general terms features and their relevance for higher dimensional scenarios. We analyze their quantitative impact in Section 4. Further discussion of some issues regarding renormalizability and perturbativity is given in Section 5. Finally, we conclude in Section 6.
## 2 Toy Model
We begin with a D -dimensional bulk of Minkowski space, with the Standard Model confined to a 3-brane within the bulk. Our description is purely a low-energy, effective one; we assume the brane to be infinitely heavy, infinitesimally thin and possessed of no intrinsic dynamics. We allow gravity and an additional U(1) ′ gauge group, which gives rise to a hidden photon, to propagate freely though the whole bulk.
The interaction between the photon and the new 'hidden photon' is introduced through a brane localized mixing term. This is not the most general situation because we have neglected a number of brane localized kinetic and interaction terms. Nevertheless this simplified toy model serves to demonstrate the potentially huge impact the KK tower can have on phenomenology.
Table 1: Limits on the scale of extra dimensions. The d = 1 constraint arises from direct tests of the gravitational inverse square law [25,26]. For d = 2-6 the scale is more strongly constrained by the minimum value of the extra dimensional Planck scale M glyph[star] [27, 28], provided by colliders.
| d | 1 /R = m 0 | M glyph[star] |
|-----|--------------|--------------------------------------|
| 1 | > 200 µ eV | glyph[greaterorsimilar] 3 × 10 5 TeV |
| 2 | > 700 µ eV | glyph[greaterorsimilar] 3 TeV |
| 3 | > 100 eV | glyph[greaterorsimilar] 3 TeV |
| 4 | > 50 keV | glyph[greaterorsimilar] 3 TeV |
| 5 | > 2 MeV | glyph[greaterorsimilar] 3 TeV |
| 6 | > 20 MeV | glyph[greaterorsimilar] 3 TeV |
The effective action describing the above setup then is:
$$S _ { D } = \int \mathrm d ^ { D } x \sqrt { g } \left ( - \, \frac { 1 } { 4 } F ^ { \mu \nu } F _ { \mu \nu } \delta ^ { d } ( \vec { y } ) - \frac { 1 } { 4 } X ^ { M N } X _ { M N } - \frac { 1 } { 2 } \chi _ { D } F ^ { \mu \nu } X _ { \mu \nu } \delta ^ { d } ( \vec { y } ) \right ), \quad ( 2. 1 )$$
The captial roman indices ( M,N ) run over 0 , . . . , D -1 , the lower case greek indices ( µ, ν ) over 0 , . . . , 3 and the coordinate glyph[vector] y represents { x , . . . , x 4 D -1 } .
We compactify the d = D -4 additional spatial dimensions from Minkowski space onto a d -dimensional torus T d = S 1 ×S 1 . . . S 1 , with each torus chosen to be of equal radius R . In this case the 4-dimensional Planck mass, M Pl , is related to the higher dimensional one, M glyph[star] via,
$$M _ { \text{Pl} } ^ { 2 } = M _ { * } ^ { 2 + d } ( 2 \pi R ) ^ { d }.$$
Limits on R arise both from direct tests of the gravitational inverse square law and via limits on M glyph[star] from graviton searches at colliders. They are summarized in Table 1.
For the hidden photon, which lives in the bulk, compactification results in a stack of KaluzaKlein modes corresponding to the Fourier modes of the hidden photon field in the extra spatial dimensions. In the general case the KK mode expansion is,
$$X _ { M } ( x ^ { \mu }, y ^ { a } ) = \frac { 1 } { ( 2 \pi R ) ^ { d / 2 } } \sum _ { | \vec { n } | \geq 0, \sigma } X _ { M } ^ { ( \vec { n }, \sigma ) } ( x ^ { \mu } ) \prod _ { i = 1 } ^ { d } f _ { \sigma _ { i } } ( n _ { i } y _ { i } )$$
where σ = { (+ , . . . , + +) (+ , , , . . . , + , -) , . . . , ( -, . . . , - - } , ) and,
$$\langle \cdot ^ { \prime } \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \cdot \langle \, ^ { \prime } } \\ f _ { s } ( n x ) = \begin{cases} \sqrt { 2 } \cos n x & s = +, & n > 0 \\ \sqrt { 2 } \sin n x & s = -, & n \geq 0 \\ 1 & s = +, & n = 0. \end{cases}$$
For example, in the simplest case of a single extra spatial dimension ( d = 1 ) we have,
$$X _ { M } ( x ^ { \mu }, y ^ { a } ) = \frac { X _ { M } ^ { ( 0 ) } } { ( 2 \pi R ) ^ { 1 / 2 } } + \frac { 1 } { ( \pi R ) ^ { 1 / 2 } } \sum _ { n > 0 } \left ( X _ { M } ^ { ( n, + ) } ( x ^ { \mu } ) \cos \left ( \frac { n y } { R } \right ) + X _ { M } ^ { ( n, - ) } ( x ^ { \mu } ) \sin \left ( \frac { n y } { R } \right ) \right ).$$
By choice, our SM 3-brane is located at glyph[vector] y = 0 . Accordingly, the kinetic mixing operator is also localized at glyph[vector] y = 0 . Therefore only those hidden photon modes that are non-vanishing at this
point can interact with the SM photon. In the expansion for the 5D case, this corresponds to the cosine mode. In the general case all f s factors must be cosines corresponding to σ = (+ , . . . , +) . (Of course, the brane may be located anywhere in the bulk, and shifting it would result in a linear combination of the X + and X -fields interacting, which could be simplified by a field redefinition). The zero mode has no mass, hence its mixing is not observable. Inserting the Fourier transform into the action, we obtain for the D -dimensional case:
$$S _ { \text{eff} } = \int d ^ { 4 } x \left [ & - \frac { 1 } { 4 } F ^ { \mu \nu } F _ { \mu \nu } - \frac { 1 } { 4 } X ^ { \mu \nu ( 0 ) } X ^ { ( 0 ) } _ { \mu \nu } + \sum _ { | \vec { n } | \geq 0, \sigma } \left ( \frac { 1 } { 4 } X ^ { \mu \nu ( \vec { n }, \sigma ) } X ^ { ( \vec { n }, \sigma ) } _ { \mu \nu } + \frac { 1 } { 2 } \frac { n ^ { 2 } } { R ^ { 2 } } X ^ { ( \vec { n }, \sigma ) } _ { \mu } X ^ { \mu ( \vec { n }, \sigma ) } \right ) \\ & + \sum _ { | \vec { n } | \geq 0 } \left ( \frac { 1 } { 2 } \chi _ { 4 } F ^ { \mu \nu } X ^ { ( \vec { n }, + \dots + ) } _ { \mu \nu } \right ) + \dots \right ]$$
Omitted from the Lagrangian are the d massless scalar fields from X 0 a =5 ...D , and the Kaluza-Klein tower associated with d -1 (linear combinations) of the scalars. The modes of the remaining scalar Kaluza-Klein tower are eaten by the respective massless vector in the KK stack, generating a single stack of 4D hidden photons, with masses
$$m _ { \gamma ^ { \prime } } ^ { 2 } = \frac { n ^ { 2 } } { R ^ { 2 } } ( 1 + \mathcal { O } ( \chi ^ { 2 } ) ).$$
In the action (2.1), X M is a D -dimensional field with mass dimension D 2 -1 . When we write the 4-dimensional effective action (2.6), the mass dimension for the KK modes is reduced to 1. The necessary rescaling of the hidden photon field by a volume factor results in the same rescaling of the kinetic mixing parameter (generalizing to the d -dimensional case), glyph[negationslash]
$$\chi _ { 4 } = \frac { \chi _ { D } } { ( \pi R ) ^ { d / 2 } } \prod _ { i = 1 } ^ { d } \eta _ { n _ { i } }, \quad \text{where} \quad \eta _ { n _ { i } } = \begin{cases} \begin{array} { c } 1 / \sqrt { 2 } \end{array} & n _ { i } = 0 \\ 1 \end{cases} & n _ { i } \neq 0 \end{cases},$$
where n i is the component of glyph[vector] n along the i th extra dimension. The sums in Eq. (2.6) run over glyph[vector] n ≥ 0 , representing the fact that (for d > 1 ) massive KK modes arise even if momentum along some of the extra dimensions is zero. In practice, for the scenarios we consider there are very many modes, and few have a zero momentum component compared to the number that do not. For phenomenological purposes, we therefore ignore the product in Eq. (2.8), and use the same equation, χ 4 ∼ χ D / (2 π ) d/ 2 , for all modes.
## 2.1 The particle spectrum
After compacitifcation, the resulting particle spectrum consists of the unmodified SM field quanta, which interact with the hidden sector only through kinetic mixing with a stack of infinitely many additional hidden photons. The mass of the lightest of the hidden photons, m 0 , is determined by the compactification radius, and each subsequent field is m 0 more massive than the last. We have a stack of increasingly massive Kaluza-Klein modes, corresponding to the infinite number of terms in a Fourier decomposition of the original, higher dimensional field along the additional dimensions. We also have a similar stack of scalar fields associated with each extra dimension (one of which is eaten), which decouple from our phenomenology.
## 2.2 Gravity
In a scenario featuring large extra dimensions the fundamental Planck scale can be significantly lowered (see Eq. (2.2)) and the effects of gravity in the bulk can be important.
The interaction of gravity with any theory described by an energy momentum tensor T µν is,
$$\mathcal { L } = - \frac { 1 } { 2 M _ { \text{Pl} } } \sum _ { \vec { k } } \left ( G _ { \mu \nu } ^ { ( \vec { k } ) } T ^ { \mu \nu } + \sqrt { \frac { 2 } { 3 ( d + 2 ) } } \phi ^ { ( \vec { k } ) } T _ { \mu } ^ { \mu } \right ).$$
It is clear than any interaction involving the graviton G µν or dilaton φ is suppressed by the Planck scale. For a compactified theory, the fundamental scale is reduced after a summation over all modes (i.e. when the extra dimension is resolved), but each interaction is still suppressed by M Pl . Since both the gravitational and U(1) ′ field begin as massless and are compactified on the same manifold, their mass spectra are the same, with each mode having mass | k /R | . Thus the same number of graviton and hidden photon modes contribute to a given process, so the analysis for one mode is true in generality, and pure gravitational interactions are important relative to hidden photon interactions only when χ 4 glyph[lessorsimilar] Λ M Pl . , where Λ represents the energy scale at which the relevant process occurs. As we will see, such small values of χ 4 are out of reach of current experiments - even with a stack of KK modes present - and as such we may safely ignore gravitational interactions. We discuss hidden photon decays into gravitons below.
## 2.3 Bulk Interactions
For interactions between gravity and the hidden photon, i.e. those involving only bulk fields, one may ignore the presence of the 3-brane and there is translational invariance along the extra dimensions in the bulk - a symmetry group (generated by the position operator) of which the conserved quantity is momentum. Upon compactification, the extra dimensional momentum conservation translates into conservation of KK mode number. This forbids decays of KK particles of the form X ( k ) → X ( ) l + G ( m ) , where all the products are bulk fields, and k , l and m are the KK mode numbers. Conservation of mode number is encapsulated in the relation | k | ≤ | l + m | and, since any decay can only be to lighter states (recall that the mass of a KK mode is m = n × m 0 , with n the mode number), in the best case the phase space vanishes precisely (at | k | = | l + m | ). Note however, that this is a special feature of the symmetry structure of our toy model.
## 2.4 Brane interactions
The above reasoning holds for interactions occurring purely in the bulk. However, presence of the SM3-brane breaks the translational invariance so that any interaction involving a brane localized (i.e. SM) particle does not conserve KK number, making decays of the form X ( k ) → G ( ) l + γ possible. Nonetheless, the decay is strongly suppressed by the weakness of the gravitational interaction (which is suppressed by the higher dimensional Planck scale M glyph[star] ), and decays of the hidden photon to pure SM states e + e -( m X > 2 m e ), γγγ ( m X < m 2 e ) dominate. The decay to one photon and one graviton is bounded by the case where both decay products are massless, with decay rate,
$$\Gamma ( X ^ { ( k ) } \to G ^ { ( l ) } + \gamma ) < \frac { \chi ^ { 2 } m _ { X } ^ { 3 } } { 1 2 \pi M _ { \text{Pl.} } ^ { 2 } }.$$
After summing over KK modes and using relation (2.2),
$$\Gamma ( X ^ { ( k ) } \to G + \gamma ) _ { \text{total} } & < \Gamma ( X ^ { ( k ) } \to G ^ { ( 0 ) } + \gamma ) \times \int _ { 0 } ^ { m _ { X } / m _ { 0 } } d ^ { d } l \\ & < \frac { 1 } { 2 ^ { d - 1 } \pi ^ { d / 2 } d \Gamma ( d / 2 ) } \frac { \chi ^ { 2 } m _ { X } ^ { d + 3 } } { 1 2 \pi M _ { * } ^ { d + 2 } } \\ \hat { \nu } \quad \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
The case for which decays to G + γ are most likely to be relevant is when d = 2 , which minimises the suppression of the branching ratio with d , combined with the extra dimensional Planck scale M d =2 glyph[star] being 10 -5 times the d = 1 case. Inserting the most extreme value, where m X ∼ M glyph[star] for m 0 very low, the decay rate into KK gravitons plus photons is smaller than, but of the same order as Γ( X → e + e -) for m X > 2 m e . This does not affect the LHC constraints we compute, but could potentially lead to new, novel collider signatures and be suitable for investigation in a more developed (i.e. non-toy) model.
The constraints for which additional decay channels to photons are important (for example the Intergalactic Diffuse Photon Background (IDPB) constraint), all occur at energies where the decay rate to gravitons is negligible.
It is pertinent here to mention that the action (2.1) does not include a brane-localized hidden photon term ∝ -1 4 X µν X µν δ d ( glyph[vector] y ) , which could lead to a different phenomenology owing to additional mixing terms in the effective Lagrangian.
## 3 Canonical constraints on the hidden photon parameter space
Since we will be investigating the whole of the currently accessible hidden photon ( m ,χ X ) parameter space in a new context, it is worthwhile to summarize the existing limits. Here we provide a list of the 'canonical' constraints for the 4D case (see, e.g., [29,30]), where the hidden photon mass is generated by a Higgs or Stueckelberg mechanism. The following bounds involve processes where the hidden photon is produced on-shell, listed in approximate order of increasing energy.
- · Cosmic microwave background. Hidden photons contribute a positive effective neutrino number, causing potential conflict with the number, N eff ν = 3 36 . +0 68 . -0 64 . [31], obtained using measurements of the cosmic microwave background (CMB), large scale structure (LSS) and supernovae [32, 33]. The low mass region bounded by CMB considerations renders it unimportant for the LED model we employ 2 .
- · Big bang nucleosynthesis. A small area of parameter space may be ruled out by considering the hidden photon distortion to big bang nucleosynthesis (BBN) [35,36]. This bound applies only to hidden photons of extremely low mass and is eclipsed by more constraining bounds in our scenario 3 .
- · Light-shining-through-walls. Photon-hidden photon oscillations allow photons to pass through otherwise infinite potential barriers by converting to a hidden photon state that
2 During the final stages of the preparation of this manuscript, some constraints arising from consideration of the CMB and BBN for higher mass hidden photons with extremely weak couplings ('very dark photons') were released [34]. It would be interesting to consider their impact on the LED scenario in future work.
3 Higher mass constraints were recently detailed in [34], see previous footnote.
does not interact with the barrier. Lab experiments searching for this 'light-shiningthrough-walls' (LSW) phenomena put constraints on the parameter space. For a review, see [37]. More recent developments are reported in [38-40]. A lower mass regime was recently probed with a few GHz microwave cavity resonator operating on the same principle as optical LSW experiments [41-44]. In our scenario, these constraints are eclipsed by others.
- · Helioscopes. The CERN-Axion-Solar-Telescope (CAST) operates on the LSW principle, with the sun as the light source [45-47].
- · Stellar evolution. Hidden photons contribute to energy loss from the Sun. Reconciling the existence of a hidden photon with the accepted models of stellar evolution bound large areas of parameter space. Identical arguments can be applied to the evolution of Horizontal Branch stars [45,48-52].
- · Intergalactic-diffuse-photon-background. It is possible that hidden photons produced in the early universe have survived until the present day. Their decays to SM photons would contribute to the intergalactic-diffuse-photon-background (IDPB) [35].
- · Electron fixed target experiments. An electron beam incident on a target emits hidden photons by bremsstrahlung. The hidden photon can then pass through the shielding before decay via SM photon into an e + e -pair, which can be detected [53].
- · SN1987a. Hidden photons contribute to the energy loss in supernovae. If this effect is too large, the supernova may quickly cool preventing the observed neutrino burst. This provides a very strong constraint on hidden photon couplings for a large range of masses [53-55].
- · B factories. The BABAR [56] and DA Φ NE (with the KLOE-2 detector) [57] collaborations produce constraints on the hidden photon parameter space as a byproduct of their e + e -collisions to study Υ , φ and η meson decays. The hidden photon may be produce missing energy or multi-lepton signatures in the minimal model, featuring a Higgs ′ boson [58], which is not present in our model. The search for a hidden photon without an associated Higgs ′ relies upon a peak search , which, in the presence of a KK tower, is not 4 viable in the mass region these facilities can probe, since the mass splitting of the modes is smaller than their width. A full treatment would require simulation of the experimental detector, which is outside the scope of this work, since in the KK scenario the resulting limits are unlikely to improve much on the LHC dilepton search we discuss in Section 4.2.2.
- · LHC. Recently, constraints on hidden photons from the LHC were computed [59]. We consider two signals - monojets and dileptons, finding that the dilepton constraint is everywhere stronger than the monojet. Note that this result changes if the hidden photon mediates interactions to a hidden sector, investigated comprehensively in [60].
Next we have bounds from purely virtual processes, i.e. processes where there is insufficient energy for the hidden photon to be produced on-shell:
4 The alternative is a missing energy signal. Here, in order for the hidden photon to escape the detector, the mixing parameter must be very small, which suppresses production strongly. This is investigated in more detail for the LHC in Section 4.2.2.
- · Planetary magnetic fields. The modification to Maxwell's equations governing electrodynamics caused by the kinetic mixing is detectable in the macroscopic, planetary magnetic fields of Earth and Jupiter. The large distance scales involved allow the probing of small hidden photon masses, m X = (10 -15 -10 -12 ) eV [61], which are irrelevant to the KK scenario, where the minimum mass of a hidden photon mode is 200 µ eV (see Table 1 and the corresponding lines in Fig. 1.)
- · Coulomb potential. A hidden photon modifies the Coulomb potential in a Yukawa like way [1, 50], which can be tested precisely in a lab using a Cavendish experiment (measuring the potential difference between concentric spheres). The philosophy is similar to the planetary magnetic field constraints, with the lab length scales resulting in bounds around m X = 0 1 . µ eV.
- · Atomic-spectra. Transitions between atomic energy levels occur via the emission and absorption of photons. A virtual insertion into this propagator alters the frequency of the transition, changing the atomic spectra [62-64]. There is no real production of hidden photons in this case, which leads to some interesting features in the presence of extra dimensions, discussed in Section 5.
- · Anomalous magnetic moment. A virtual insertion into the photon propagator means that the anomalous magnetic moment of the electron and muon are sensitive to the hidden photon [65].
- · Electroweak precision constraints. The Z-boson mass would receive a contribution from a hidden photon by an insertion into the photon propagator [66]. Being a virtual correction, this exhibits the same features as the anomalous magnetic moment and atomic spectra. The mass region probed by electroweak precision constraints is eclipsed by the LHC bound (Sec. 4.2.2) in the KK scenario, so it is not investigated further.
The constraints discussed above are summarized in Fig. 1. It will turn out that the most important bounds on our parameter space are those from the LHC, HB stars and fixed target experiments, with a small additional area ruled out by consideration of the IDPB. All other constraints are effective only in regions of parameter space already ruled out by these few observations and experiments . 5
We also include a discussion of constraints arising from atomic spectra and anomalous magnetic moments, since they give rise to some interesting considerations regarding the cutoffdependence and perturbativity of the effective theory.
It was noted in Section 2 that the size of extra dimensions are subject to constraints (Table 1). In our scenario, limits on R translate directly to limits on the minimum hidden photon KK mode mass. Fig. 1 shows the minimum masses that are viable for d = 1 . . . 6 extra dimensions, overlaid on the constraints in 4 dimensions. This illustrates the reasoning behind the selection of experiments we use to constrain the KK scenario.
5 The singular exception is the case of SN1987A, which could in principle eclipse the IDPB constraint. However, we think that the existing constraints on hidden photons arising from SN1987A neglect some important plasma effects, so we do not include them here.
Figure 1: Limits on hidden photon parameter space in D = 4 dimensions. Coloured lines indicate the minimum mode mass associated with the constraint on the compactification radius R for each of d = 1 . . . 6 extra dimensions.
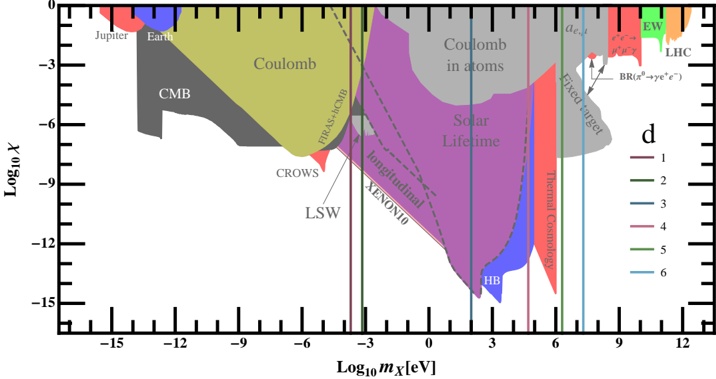
## 4 Experimental and Observational Constraints
Let us start by commenting briefly on some generalities regarding the calculation of observational constraints in the presence of a stack of KK modes. The constraints we present are on the toy model specified in Eq. (2.6), i.e. the hidden photon has a stack of KK modes, each of which interacts with the same kinetic mixing parameter χ 4 . The structure of the stack of KK modes depends on the dimension, and therefore different dimensionalities represent different theories. In this sense constraints on the kinetic mixing should not be compared between models of different dimension.
Processes can now involve a large number of KK modes and we have to sum over all of their contributions. Typically observables will be dominated by KK modes within a certain mass range. If the spacing between different KK modes, m 0 = 1 /R , is sufficiently smaller than this range we can approximate the sum over KK modes by an integral,
$$\sum _ { \vec { n } > 0 } \rightarrow \frac { 1 } { 2 ^ { d } } \int d ^ { d } k,$$
where the prefactor to the integral accounts for it running over the whole space. This already tells us something about the typical shape that we expect for our constraints. Let the contribution of a hidden photon of mass m to a given observable be χ p P ( m ) . Moreover let the dominant contribution arise from masses between M 1 and M 2 . Summing over KK modes (requiring M 1 glyph[greatermuch] m 0 ) the total contribution then reads,
$$\chi ^ { p } \frac { 2 \pi ^ { \frac { d } { 2 } } } { \Gamma ( \frac { d } { 2 } ) } \frac { 1 } { 2 ^ { d } } \int _ { M _ { 1 } / m _ { 0 } } ^ { M _ { 2 } / m _ { 0 } } d k k ^ { d - 1 } \mathcal { P } ( k \, m _ { 0 } ) = \chi ^ { p } \frac { 1 } { m _ { 0 } ^ { d } } \frac { 2 \pi ^ { \frac { d } { 2 } } } { \Gamma ( \frac { d } { 2 } ) } \frac { 1 } { 2 ^ { d } } \int _ { M _ { 1 } } ^ { M _ { 2 } } d M M ^ { d - 1 } \mathcal { P } ( M ). \quad \ ( 4. 2 )$$
The integral on the right hand side is independent of m 0 and χ . Accordingly we can see that
the total contribution scales as
$$\sim \frac { \chi ^ { p } } { m _ { 0 } ^ { d } }.$$
For small m 0 any limit arising from a constraint on this observable then strengthens as,
$$\chi & \sim m _ { 0 } ^ { - \frac { d } { p } }$$
for decreasing m 0 . Small values of m 0 are therefore very tightly constrained.
## 4.1 Astrophysical Constraints
## 4.1.1 Stellar Lifetime
The mixing between photon and hidden photon states allows the production of hidden photons in stellar interiors. Once produced, and if not reabsorbed, the hidden states would contribute to the energy loss of the star. If the energy loss through this channel is greater than the visible luminosity, no stellar model can be constructed in which the properties of the Sun (or star) are consistent with observations. Even if the hidden states never leave the Sun, if their presence is sufficiently great, they can contribute unacceptably large levels of non-local energy transfer. The mass and coupling of a hidden photon must be constrained to be consistent with these considerations [48-52].
For our local star, the Sun, we use the solar model BS05(OP) [67]. We ignore the effects of the less abundant heavier ions, 12 C, 14 N and 16 O, accounting only for the presence of the lighter elements 1 H, 3 He and 4 He. Since stellar energies are relatively low, glyph[lessorsimilar] 0.1 MeV, only a negligible fraction of hidden photons that are massive enough to decay to Standard Model particles could be produced, so the only relevant process is the oscillation of photon and hidden photon states. We assume that any photon to hidden photon oscillation is effectively irreversible and contributes to energy loss or unacceptably large non-local energy transfer.
The same stellar energy loss arguments apply to stars elsewhere in the Milky Way, the best studied of which lie on the horizontal branch (HB). There are two significant differences between HB stars and the Sun. The first is the higher luminosity of the HB stars, L HB ∼ 20 L glyph[circledot] . The second is their structure. HB stars are globular cluster (i.e. low metallicity) stars and are modelled as having two distinct components: the helium dominated core and the hydrogen dominated shell.
The critical feature of both the Sun and horizontal branch stars is the facility for resonant production of hidden photons at a particular energy, which manifests as the sharp peaks in the constraints shown in Fig. 1. The HB star actually features two resonance regions (corresponding to the hydrogen shell and helium core structure), with the lower energy resonance being eclipsed by the constraint from the Sun.
These resonances are particularly effective at enhancing constraints in the presence of the Kaluza-Klein stack. When the hidden photon mode spacing is smaller than the resonance width in the Sun/HB star, at least one mode in the Kaluza-Klein tower will sit in the resonance region. The same scaling is observed as in the other bounds (i.e. the hidden photon effect grows with decreasing mode spacing), but beginning at the peak of the resonance.
Recently, the treatment of [45] of solar and horizontal branch constraints on hidden photons has been improved [51,52]. The longitudinal hidden photon modes, previously ignored, are actually important in the low energy regime: the contribution from transverse modes to production
dies off as m 4 0 , whereas the longitudinal mode contribution dies only as m 2 0 , strengthening the bound into the region probed by light-shining-through-walls experiments. We have included the effect of the longitudinal modes in the constraints for KK towers. The corresponding limits are shown as the yellow and orange regions in Fig. 2.
## 4.1.2 Intergalactic Diffuse Photon Background
The intergalactic diffuse photon background (IDPB) could receive a contribution from hidden photons decaying into standard model photons. Naturally the magnitude of the contribution is dependent on the number of hidden photons produced and their survival until the time at which the CMB decouples.
The biggest contribution to the production of a HP with of a given mass arises when the plasma mass in the Universe agrees with the HP mass, i.e. when there is a resonance. Effective thermal production stops at CMB decoupling when the plasma recombines into atoms. Therefore very low mass modes, corresponding to low temperatures, are not produced en masse . 6 The towers of KK modes (above a certain mass) associated with low m 0 hidden photons would still be thermally produced in the earlier Universe and as such the low masses can still be constrained, but a lower cutoff on the modes that contribute to the constraint applies. In any case, data for the diffuse photon spectrum exists only in the energy region of ∼ 10 4 eV and upwards, so only the effect of modes with masses greater than this contribute to the limit. We can, however, still constrain the kinetic mixing of hidden photons with m 0 below the range for which data exists by observing the effects of the higher mass modes in the KK tower.
The survival of hidden photons depends upon their decay width. If the decay to electrons and positrons is accessible, i.e. when m X > 2 m e , this decay mode dominates, eliminating the contribution to the IDBP. However, for m X below twice the electron mass it is the three-photon decay that dominates. Its rate is given by [35],
$$\Gamma _ { X \to \gamma \gamma \gamma } = \frac { 1 7 \alpha ^ { 4 } \chi ^ { 2 } } { 1 1 6 6 4 0 0 0 \pi ^ { 3 } } \frac { m _ { X } ^ { 9 } } { m _ { e } ^ { 8 } }.$$
In order to leave detectable traces in the IDPB, the hidden photons must survive until after the CMB decoupling time, ∼ 10 12 s after the Big Bang. Therefore we enforce the constraint that to be within reach of IDPB exlusion, τ = Γ -1 X → γγγ > 10 12 s. This provides the upper boundary to the purple IDPB region seen for the d = 1 , 2 cases in Fig. 2. For those hidden photons in the parameter range that can survive as dark matter, the same three-photon decay would certainly contribute to the diffuse intergalactic photon spectrum. We use the formulation of [35], applying the constraint that,
$$\text{v cuda}, \quad \frac { m _ { X } \tau ( m _ { X }, \chi ) } { \text{GeVs} } \lesssim 1 0 ^ { 2 7 } \left ( \frac { \omega } { \text{GeV} } \right ) ^ { 1. 3 } \left ( \frac { \Omega _ { 2 } h ^ { 2 } ( \chi ^ { 2 } ) } { 0. 1 } \right ),$$
i.e. that the photon flux from HP decays is not greater than the total photon flux from the IDPB. In particular, as per [35] (as opposed to [68]), the hidden photon contribution to the relic density is calculated for each point in parameter space, so the final factor in brackets on the r.h.s. of Eq. (4.6) is not unity, but depends on χ 2 (i.e. Ω 2 h 2 ( χ 2 ) is not, de facto equal to 0.1).
6 In fact, there can still be medium-induced resonant effects at lower masses, such as discussed in [69], however, they do not lie in a mass region of interest for the LED scenario: the low mass region is already strongly bounded by the cumulative effect of KK modes being resonant at higher energies.
Solving Eq. (4.6) for χ for each value of m 0 , including the effects of the tower of KK modes results in the plotted constraint (purple region in Fig. 2).
For a given m 0 , many KK modes contribute to the IDPB signal, with the resulting enhancement spread over a wide spectrum of energies. The experimental analysis (see [68]) separates the spectrum into energy bins-the region in Fig. 2 represents constraint from the most constraining bin for each value of m 0 .
## 4.2 Constraints from scattering experiments
## 4.2.1 Fixed Target Constraints
Fixed target, or beam dump, experiments provide very clean testing grounds for new physics, owing in part to the well understood Standard Model backgrounds. Several experiments have previously been used to constrain four dimensional hidden photons [53], with some purposebuilt experiments underway to further explore the parameter space (see, e.g. Section 3 of [70] and references therein). The three fixed target experiments employed here are E137, E141 at Fermilab and E774 at SLAC.
The operating principle of the experiment, in context of a hidden photon search, is that hidden photon bremsstrahlung can propagate through the shielding of the apparatus, before decaying to an electron-positron pair in the vacuum region in front of the detector. The only effect of KK modes on the experiment is to supply additional channels by which the bremsstrahlung can evade the shielded region and we observe a tightening of the constraints at lower masses consistent with this. The slope of the constraint differs from that for the stellar and LHC cases as the kinetic mixing also enters (exponentially) the probability for the hidden photon to decay in the detector region, resulting in a different scaling behavior. It is important to note that this simple strategy applies to searches using event counting. Searches relying on a peak in the invariant mass distribution require a different analysis.
## 4.2.2 LHC
LHC constraints on the hidden photon parameter space in the absence of extra dimensions have been computed [59], but it is worthwhile to reassess the discovery potential of the LHC in light of our modified phenomenology due to the towers of KK modes.
For the range of kinetic mixing parameters typically of interest, χ 4 < 10 -3 say, we can make a narrow width approximation (NWA) for the hidden photon, so that the width does not affect the cross-section and we can factor the kinetic mixing out of the calculation. If the width is extremely small, once produced on-shell in the beam pipe, the HP may not decay within range of the detectors, but instead escape, leaving only missing transverse energy as a 'signal'. The canonical probe of such a phenomenon is the monojet search.
Alternatively, the hidden photon could decay inside the detector region to two leptons (or else mediate this interaction off-shell), so our candidate events are of dilepton plus jets type. We thus investigate two potential LHC signals of hidden photons: monojets + MET and dileptons.
## Monojets
An on-shell hidden photon can be produced in the collision of two protons in s-channel qg → γ q ′ and and t-channel qq ¯ → γ g ′ processes. If such a hidden photon is long lived, i.e. it has a small
kinetic mixing parameter χ that restricts its decays, it can escape the detector region without interacting and contribute to a missing transverse energy (MET) signal, in association with a single jet that balances the (missing) transverse momentum of the hidden photon.
The decay rate of a massive hidden photon into a fermion-antifermion pair is,
$$\Gamma ( X \rightarrow f \bar { f } ) = \frac { \chi ^ { 2 } Q _ { e / m } ^ { 2 } \alpha \, m _ { X } } { 3 } \sqrt { 1 - 4 \frac { m _ { f } ^ { 2 } } { m _ { X } ^ { 2 } } } \left ( 1 + 2 \frac { m _ { f } ^ { 2 } } { m _ { X } ^ { 2 } } \right ).$$
The decay time is then τ = 1 Γ / tot . where Γ tot . must account for all open decay channels (quarks and leptons). We are primarily interested in the LHC for heavy hidden photons, where bounds from other sources are not already strong. Considering for example, a 100 GeV hidden photon, its total width to charged fermions is ∼ 1 χ 2 GeV. In order that it's decay length is at least the radius of the ATLAS detector, ∼ 10 m, we must enforce χ glyph[lessorsimilar] 5 × 10 -9 . This results in a production cross section for a monojet event ∼ 6 × 10 -14 pb, orders of magnitude too small to give a reasonable event rate at the LHC.
However, due to the mixing with the Z a high mass hidden photon has a branching ratio of ∼ 8 %to the three species of SM neutrino when all SM decay modes are available (i.e. when m X > 2 m top ) which could provide an enhanced signal. Using Herwig++ [72] and CheckMATE [73-81], we find that for a single hidden photon the additional signal is insufficient to be distinguishable above background uncertainty, even for kinetic mixings of order unity. This may no longer be the case when the effect of all modes in the KK tower is summed, since this provides many more decay modes to neutrinos. However, any possible constraint arising from this is eclipsed by the constraint from the dilepton channel, for which even a single hidden photon provides a constraint [59]. As such, monojets do not provide a competitive or novel constraint.
## Dileptons
If the hidden photon is produced on-shell and decays into charged leptons, we may search for their tracks. In principle the mediator need not be on-shell, though this provides the dominant contribution to the cross-section, and we assume the resulting dilepton invariant mass distribution to be strongly peaked at the mass of the hidden photon.
We use the result of the ATLAS dilepton search for Z ′ [82], mapping the constraints directly to our model, with cross sections generated by MadGraph 5 [83] from a FeynRules [84] model via the UFO format [85]. The presence of stacks of KK modes complicates matters slightly. We must factor in the larger contribution to the cross-section due to the presence of multiple KK modes in the same experimental energy bin. For a given mode spacing, m 0 , the modes are summed per bin. The limit on χ is calculated for each bin and the tightest constraint arising from this procedure is used as the constraint for a given m X .
There is an additional complication arising from multiple modes. In principle, we can sum over the modes in a bin only when they are separated into distinct peaks. A reasonable measure for this is when the mode spacing is greater than the mode width, ∆ m> Γ( m ,χ X ) . In the high energy region, m 0 ∼ TeV, the mode width is narrow compared to the mass of the modes. Below this scale, there is a region where the mode width is comparable to the mass of the modes. This is shown as a darkened region of the LHC constraint in Fig. 2. Here we cannot ignore interference, which must be calculated at the amplitude level. However, as we will discuss in Section 5, the LHC constraint ends up covering a region of parameter space throughout most
of which a perturbative treatment is not valid, rendering interference effects somewhat a moot point.
## 4.3 Constraints from low energy precision measurements
The previous constraints from astrophysical observations and scattering experiments featured the real production of hidden photons and the associated KK modes. As such, the result is not cutoff dependent, since the maximum energy of the experiment (for example, the temperature in a stellar interior) provided a natural physical upper bound on the masses of KK modes that could be produced. This argument rests upon the hidden photon being produced on-shell, with definite energy and momenta. If the hidden photon were to be produced as an insertion to a propagator, for example in a loop process, the energy available is in principle infinite. This results in a divergence for higher dimensional theories, where the integral over the KK number does not converge. To avoid these divergences, a cutoff must be imposed at some finite energy scale Λ .
In the constraints of this subsection, there is insufficient energy for real hidden photon production, and we are afflicted by the cutoff dependencies discussed above and in Section 5.
## 4.3.1 Atomic Spectral Constraints
The most stringent of the atomic spectral constraints for four dimensional hidden photons is that associated with the 2 s 1 2 / -2 p 1 2 / Lamb shift in atomic hydrogen [62-64], so we will limit our attention to this case. Hidden photons enter the process as a propagator insertion in the Coulomb interaction, which modifies the potential with a Yukawa-like term (in the static limit), δV ( r ) = -( χ Zαe 2 -m r X ) /r where Z is the atomic charge, r is the radius and α the fine structure constant. Comparing the modification to the Coulomb potential against the experimental uncertainty in the measurement of the Lamb shift constrains the region plotted in dark red in Fig. 2, once the effect of the tower of KK modes is accounted for by summation.
The lack of a natural limit to the hidden photon mass in the propagator means that we must artificially impose a cutoff in the sum. In Fig. 2, a finite UV cutoff is used, corresponding to the point at which the mixing parameter χ becomes non-perturbative due to the cumulative effect of many KK modes. See Section 5 for a detailed discussion of cutoff dependency and the related problem of perturbativity.
## 4.3.2 Electron and Muon g -2 Constraints
The electron and muon g -2 are among the most precisely measured of all physical observables. The anomalous magnetic moment, a e µ ( ) = g e µ ( ) -2 2 , arises from the electron (muon) vertex correction and would be sensitive to hidden photon insertions to the photon propagator [65].
The analysis of magnetic dipole moment constraints proceeds very much analogously to the constraints from atomic spectra, and we apply the same cutoff scheme to the results shown in Fig. 2. There is an added feature in the case of magnetic dipole moments that there are two measurements which need to be combined to give a constraint . 7 Both the electron and the muon magnetic moments receive a contribution proportional to χ 2 . However, neither measurement alone provides a constraint since one could adjust α to cancel out the HP contribution.
7 One can also use this method to combine measurements of exotic atomic spectra, but, due to the experimental precision in the measurements, the Lamb shift alone imposes a stronger constraint.
4
c
Log 10
4
c
Log 10
0
-
5
-
10
-
15
-
20
0
-
5
-
10
-
15
-
20
2
Atomic
Spectra
Solar
0
Atomic
Spectra
Solar
HB
4
HB
IDPB
5
Log 10
m
0
(a) d = 1
FT
IDPB
6
Log 10
m
0
@
8
@
eV
eV
FT
D
-
LHC
L =
5 TeV
L =
10
2
LHC
Solar
L =
L =
*
M mX
H
5 TeV
*
M mX
H
12
g
D
(c)
d
= 3
IDPB
Atomic
Spectra
HB
5
Log 10
m
0
@
(b) d = 2
2
g
-
FT
8
Log 10
m
0
@
(d)
d
eV
= 4
LHC
10
Log 10
m
0
@
eV
D
D
(f)
d
= 6
Figure 2: Limits on hidden photon parameter space for d = 1 , . . . , 6 extra dimensions. The mass constrained, m 0 , represents the lowest KK mode mass, i.e. also the spacing between modes. The lowest value of the mass axis is set by constraints on the maximum size, R , of the extra dimensions from graviton searches, see Table 1. The black lines indicate regions (above) where a perturbative treatment fails if a cut off at the indicated scale is employed. Refer to the text for further discussion.
eV
-
g
10
2
L
L
4
c
Log 10
4
c
Log 10
4
c
Log 10
0
-
5
-
10
-
15
-
20
-
25
0
-
5
-
10
-
15
-
20
0
-
5
-
10
-
15
-
20
Solar
0
Atomic
Spectra
HB
IDPB
Atomic
Spectra
8
6
FT
-
g
2
9
FT
D
LHC
10
11
-
g
2
LHC
L =
5 TeV
L =
10
L =
L =
M mX
*
H
5 TeV
*
M mX
H
12
L =
L =
12
5 TeV
*
H
M mX
L
L
L
13
Combining the measurements with the renormalisation procedure described in [64] resolves this ambiguity and also results in the appropriate decoupling behavior in the low mass region. Note, that after summation over KK modes, the bound (pink region in Fig. 2) strengthens as the mass decreases in the LED scenario.
## 4.4 Summary of constraints
The combined constraints on the ( m χ 0 , ) parameter space are shown for each d = 1 , . . . , 6 extra dimensions in Fig. 2. The horizontal axis corresponds to m 0 , the minimum KK mode mass and mass spacing. For each point in the parameter space the effect of all higher mass modes has been included, with the mode spacing set by the mass at the point in the parameter space being probed. The lowest mass in each plot corresponds to the limit from Table 1. There is in principle no upper limit to the parameter space, and indeed the KK stack continues up to an arbitrarily high mass scale. However, no known phenomena operate with sufficiently high energy to produce the higher mass modes, so we can derive no constraints.
## 5 Limits of the effective theory, perturbativity, etc.
When calculating the amplitude for a process involving the hidden photon, we must sum over the Kaluza-Klein modes with masses low enough that they can be produced in the collider, stellar interior or whatever relevant factory. For situations where the hidden photon is produced on-shell, there is a natural cutoff, Λ = E max . , for the maximum mode mass at the energy of the experiment. (We discuss cases where the hidden photon is produced off-shell below).
The higher the cutoff scale, the more Kaluza-Klein modes contribute to a process. The stack of modes all mediate the same force, so each available mode increases an effective coupling (in this case, the kinetic mixing parameter) of the theory. When the effective coupling becomes large, the theory is no-longer weakly coupled and becomes non-perturbative. We can define a region of validity of our perturbative treatment as shown, by enforcing,
$$\chi _ { \text{pert.} } ^ { 2 } = \chi ^ { 2 } \times \int _ { 1 } ^ { \frac { \Lambda } { m _ { 0 } } } d ^ { d } k = \chi ^ { 2 } \times \int _ { 1 } ^ { \frac { \Lambda } { m _ { 0 } } } \frac { 2 \pi ^ { \frac { d } { 2 } } } { \Gamma ( \frac { d } { 2 } ) } k ^ { d - 1 } d k \ll 1.$$
Regions of parameter space outside of this domain are not de facto excluded. It is simply that for some combinations of parameter values (lower masses and higher mixings), the theory is so strongly coupled that our perturbative treatment is not valid, and we cannot make a statement about compatibility of the theory with experiment. These non-perturbative regions are whitedout in Fig. 3.
Amplitudes involving virtual hidden photons do not present us with such a 'natural' maximum energy. The 4-momentum of the virtual HP is integrated over, in principle to infinity. If the amplitude for a process does not decouple sufficiently quickly at high energies, which is the case for many processes in which the hidden photon is off-shell, it can diverge with the log or some power of the energy. To tame this divergence, we must insert by hand a UV cutoff. Any finite cutoff defines a region in which the theory is non-perturbative. We will consider three kinds of cutoff scheme.
Perhaps the simplest scheme is to employ a fixed cutoff at some suitable scale. In Fig. 2 we show the line in parameter space that defines the lower boundary of the non-perturbative region
Figure 3: Limits on hidden photon parameter space for d = 1 4 , extra dimension. Perturbativity limits have been enforced on a bound-by-bound basis, with modes included up to the energy scale of each constraint. Regions where a perturbative treatment is invalid are not shown as constrained (see text for details).
for a cutoff at Λ = 5 TeV (i.e. a little greater than the current minimum scale of extra dimensions from graviton searches in Table 1). This seems to rule out a perturbative treatment of almost all of the experimentally accessible parameter space, but these are very strict requirements to enforce. While it is certainly reasonable to impose this condition on the LHC constraints, it is not strictly necessary to require the theory to be perturbative anywhere above the experimental energy at which it is being probed for our treatment to be valid. Consider the fixed target constraints. In order for our treatment of those to be valid, we must only require perturbativity up to the ∼ GeV scale. This significantly raises the boundary at which perturbativity breaks down.
Another possible choice for Λ is extra dimensional Planck scale M glyph[star] . Using the relationship M 2+ d glyph[star] = M /V 2 Pl d , where V d is the extra dimensional volume, (2 πR ) d , we can see that the cutoff is proportional to the inverse size of the extra dimension to some power. We can phrase this in terms of the lowest KK mode mass as
$$M _ { * } & = \left ( \frac { M _ { \text{P1} } ^ { 2 } } { ( 2 \pi ) ^ { d } } m _ { 0 } ^ { d } \right ) ^ { \frac { 1 } { 2 + d } }.$$
The application of a cutoff represents summing over only a finite number of modes equal to Λ /m 0 . If we choose Λ = M glyph[star] as a cutoff, then both Λ and the number of modes summed over vary with the mode mass, so the cutoff changes for different points in parameter space. As indicated by the dashed line in Fig. 2, this cutoff rules out a perturbative treatment of essentially all the accessible parameter space for d ≥ 4 , and large sections for d = 1 . . . 3 . However, we are working in a low energy regime, using an effective theory that is understood to be a reasonable description only up to some finite energy scale, which could be lower than M glyph[star] .
The second scheme we consider is to cut off the integration at the point at which the effective kinetic mixing parameter becomes large enough that a perturbative treatment is no longer valid. The constraints from atomic spectra and g -2 bounds in Fig. 2 are shown as they arise when only KK modes up to the χ eff . = 1 limit are included. The effect of this cutoff is only significant
in the d = 1 2 , cases, leaving a small corner of parameter space unconstrained by the either g -2 or atomic spectra bounds, but in any case ruled out by solar lifetime (and HB star) bounds. If additional KK modes are included (up to some fixed high scale, say 5 TeV) the upper left corner of parameter space is also excluded by these experiments, but one should not trust a perturbative treatment in such a regime, where the kinetic mixing parameter is non-perturbatively large.
The final cutoff scheme to consider is to cut off the effect of KK modes above the relevant experimental energy. This is equivalent to a fixed cutoff, with the cutoff changing between constraints from different sources. To trust the constraint from horizontal branch stars, for example, we require that the effective kinetic mixing remain small only when summing over modes with masses less than approximately an MeV. Imposing the fixed cutoff at the energy scale of each experiment independently and then whiting out the regions that the cutoff renders non-perturbative generates the plots shown for d = 1 4 , extra dimensions in Fig. 3.
## 6 Conclusions
In UV completions of the Standard Model, in particular string theory, both additional U(1) gauge groups and extra dimensions naturally emerge. Here, we have employed a low energy effective theory for a toy model in order to capture something of the flavour of the phenomenology of such a setup.
The salient feature of the bounds is increasingly tight constraints as the mass of the lightest hidden photon KK mode (i.e. the mode spacing) decreases. This owes to the increasing number of Kaluza-Klein modes available to any given production mechanism as the modes become lighter and more tightly spaced.
We found that, true to the non-renormalizable nature of extra dimensional theories, constraints arising from processes where the hidden photon was not produced on-shell suffered from cutoff dependence. Fixing a cutoff defines a region of the parameter space where the theory is non-perturbative and a perturbative treatment is not sufficient to make any statement about the experimental validity of the theory. The non-perturbative regions can be large and limit our understanding of the behaviour of such theories.
It is clearly unrealistic to draw conclusions about the truth of any given UV completion from such a crude model, but our investigation does highlight that the constraints on the hidden photon mass-kinetic mixing plane do strongly depend on the mechanism of mass generation and that they can also depend on the additional states that a UV completion may provide.
## Acknowledgements
We would like to thank thank Javier Redondo for useful discussions. CJW thanks ITP Heidelberg for generous hospitality while a large portion of this work was carried out.
## References
- [1] L. B. Okun, Sov. Phys. JETP 56 , 502 (1982) [Zh. Eksp. Teor. Fiz. 83 , 892 (1982)].
- [2] P. Galison and A. Manohar, Phys. Lett. B 136 , 279 (1984).
- [3] B. Holdom, Phys. Lett. B 166 (1986) 196.
- [4] K. R. Dienes, C. F. Kolda and J. March-Russell, Nucl. Phys. B 492 (1997) 104 [hep-ph/9610479].
- [5] A. Lukas and K. S. Stelle, JHEP 0001 (2000) 010 [hep-th/9911156].
- [6] S. A. Abel and B. W. Schofield, Nucl. Phys. B 685 (2004) 150 [hep-th/0311051].
- [7] R. Blumenhagen, G. Honecker and T. Weigand, JHEP 0506 (2005) 020 [hep-th/0504232].
- [8] S. A. Abel, J. Jaeckel, V. V. Khoze and A. Ringwald, Phys. Lett. B 666 (2008) 66 [hep-ph/0608248].
- [9] S. A. Abel, M. D. Goodsell, J. Jaeckel, V. V. Khoze and A. Ringwald, JHEP 0807 (2008) 124 [arXiv:0803.1449 [hep-ph]].
- [10] M. Goodsell, arXiv:0912.4206 [hep-th].
- [11] M. Goodsell, J. Jaeckel, J. Redondo and A. Ringwald, JHEP 0911 (2009) 027 [arXiv:0909.0515 [hep-ph]].
- [12] M. Goodsell and A. Ringwald, Fortsch. Phys. 58 (2010) 716 [arXiv:1002.1840 [hep-th]].
- [13] J. J. Heckman and C. Vafa, Phys. Rev. D 83 (2011) 026006 [arXiv:1006.5459 [hep-th]].
- [14] M. Bullimore, J. P. Conlon and L. T. Witkowski, JHEP 1011 (2010) 142 [arXiv:1009.2380 [hep-th]].
- [15] M. Cicoli, M. Goodsell, J. Jaeckel and A. Ringwald, JHEP 1107 (2011) 114 [arXiv:1103.3705 [hep-th]].
- [16] M. Goodsell, S. Ramos-Sanchez and A. Ringwald, JHEP 1201 (2012) 021 [arXiv:1110.6901 [hep-th]].
- [17] M. Ahlers, J. Jaeckel, J. Redondo and A. Ringwald, Phys. Rev. D 78 (2008) 075005 [arXiv:0807.4143 [hep-ph]].
- [18] N. Arkani-Hamed, S. Dimopoulos and G. R. Dvali, Phys. Lett. B 429 (1998) 263 [hep-ph/9803315].
- [19] N. Arkani-Hamed, S. Dimopoulos and G. R. Dvali, Phys. Rev. D 59 (1999) 086004 [hep-ph/9807344].
- [20] L. Randall and R. Sundrum, Nucl. Phys. B 557 (1999) 79 [hep-th/9810155].
- [21] L. Randall and R. Sundrum, Phys. Rev. Lett. 83 (1999) 3370 [hep-ph/9905221].
- [22] L. Randall and R. Sundrum, Phys. Rev. Lett. 83 (1999) 4690 [hep-th/9906064].
- [23] K. L. McDonald and D. E. Morrissey, JHEP 1005 (2010) 056 [arXiv:1002.3361 [hep-ph]].
- [24] K. L. McDonald and D. E. Morrissey, JHEP 1102 (2011) 087 [arXiv:1010.5999 [hep-ph]].
- [25] E. G. Adelberger, B. R. Heckel and A. E. Nelson, Ann. Rev. Nucl. Part. Sci. 53 (2003) 77 [hep-ph/0307284].
- [26] C. D. Hoyle, et al. Phys. Rev. D 70 (2004) 042004 [hep-ph/0405262].
- [27] G. Aad et al. [ATLAS Collaboration], New J. Phys. 15 (2013) 043007 [arXiv:1210.8389 [hep-ex]].
- [28] S. Chatrchyan et al. [CMS Collaboration], JHEP 1209 (2012) 094 [arXiv:1206.5663 [hep-ex]].
- [29] J. Jaeckel and A. Ringwald, Ann. Rev. Nucl. Part. Sci. 60 (2010) 405 [arXiv:1002.0329 [hep-ph]].
- [30] J. Jaeckel, Frascati Phys. Ser. 56 172 [arXiv:1303.1821 [hep-ph]].
- [31] P. A. R. Ade et al. [Planck Collaboration], arXiv:1303.5076 [astro-ph.CO].
- [32] J. Jaeckel, J. Redondo and A. Ringwald, Phys. Rev. Lett. 101 (2008) 131801 [arXiv:0804.4157 [astro-ph]].
- [33] J. Redondo, arXiv:1002.0447 [hep-ph].
- [34] A. Fradette, M. Pospelov, J. Pradler and A. Ritz, arXiv:1407.0993 [hep-ph].
- [35] J. Redondo and M. Postma, JCAP 0902 (2009) 005 [arXiv:0811.0326 [hep-ph]].
- [36] E. W. Kolb and R. J. Scherrer, Phys. Rev. D 25 (1982) 1481.
- [37] J. Redondo and A. Ringwald, Contemp. Phys. 52 (2011) 211 [arXiv:1011.3741 [hep-ph]].
- [38] M. Betz, F. Caspers, M. Gasior and M. Thumm, arXiv:1204.4370 [physics.ins-det].
- [39] B. Döbrich [ for the ALPS-II Collaboration], arXiv:1309.3965 [physics.ins-det].
- [40] B. Döbrich, H. Gies, N. Neitz and F. Karbstein, Phys. Rev. D 87 (2013) 025022 [arXiv:1203.4986 [hep-ph]].
- [41] J. Jaeckel and A. Ringwald, Phys. Lett. B 659 (2008) 509 [arXiv:0707.2063 [hep-ph]].
- [42] S. R. Parker, J. G. Hartnett, R. G. Povey and M. E. Tobar, Phys. Rev. D 88 (2013) 11, 112004.
- [43] M. Betz, F. Caspers, M. Gasior, M. Thumm and S. W. Rieger, Phys. Rev. D 88 (2013) 7, 075014 [arXiv:1310.8098 [physics.ins-det]].
- [44] P. W. Graham, J. Mardon, S. Rajendran and Y. Zhao, arXiv:1407.4806 [hep-ph].
- [45] J. Redondo, JCAP 0807 (2008) 008 [arXiv:0801.1527 [hep-ph]].
- [46] S. N. Gninenko and J. Redondo, Phys. Lett. B 664 (2008) 180 [arXiv:0804.3736 [hep-ex]].
- [47] B. Lakic et al. [CAST Collaboration], J. Phys. Conf. Ser. 375 (2012) 022001.
- [48] J. A. Frieman, S. Dimopoulos and M. S. Turner, Phys. Rev. D 36 (1987) 2201.
- [49] G. G. Raffelt and D. S. P. Dearborn, Phys. Rev. D 37 (1988) 549.
- [50] V. Popov, Tr. J. Phys. 23 (1999) 943.
- [51] H. An, M. Pospelov and J. Pradler, Phys. Lett. B 725 (2013) 190 [arXiv:1302.3884 [hep-ph]].
- [52] J. Redondo and G. Raffelt, JCAP 1308 (2013) 034 [arXiv:1305.2920 [hep-ph]].
- [53] J. D. Bjorken, R. Essig, P. Schuster, and N. Toro, Phys. Rev. D80 , 075018 (2009), arXiv:0906.0580.
- [54] M. S. Turner, Phys. Rev. Lett. 60 (1988) 1797.
- [55] G. Raffelt and D. Seckel, Phys. Rev. Lett. 60 (1988) 1793.
- [56] J. P. Lees et al. [BaBar Collaboration], arXiv:1406.2980 [hep-ex].
- [57] D. Babusci et al. [KLOE-2 Collaboration], Phys. Lett. B 720 (2013) 111 [arXiv:1210.3927 [hep-ex]].
- [58] B. Batell, M. Pospelov and A. Ritz, Phys. Rev. D 79 (2009) 115008 [arXiv:0903.0363 [hep-ph]].
- [59] J. Jaeckel, M. Jankowiak and M. Spannowsky, Phys. Dark Univ. 2 (2013) 111 [arXiv:1212.3620 [hep-ph]].
- [60] M. T. Frandsen, F. Kahlhoefer, A. Preston, S. Sarkar and K. Schmidt-Hoberg, JHEP 1207 (2012) 123 [arXiv:1204.3839 [hep-ph]].
- [61] A. S. Goldhaber and M. M. Nieto, Rev. Mod. Phys. 82 (2010) 939 [arXiv:0809.1003 [hep-ph]].
- [62] S. G. Karshenboim, Phys. Rev. Lett. 104 (2010) 220406 [arXiv:1005.4859 [hep-ph]].
- [63] S. G. Karshenboim, Phys. Rev. D 82 (2010) 073003 [arXiv:1005.4872 [hep-ph]].
- [64] J. Jaeckel and S. Roy, Phys. Rev. D 82 (2010) 125020 [arXiv:1008.3536 [hep-ph]].
- [65] M. Pospelov and A. Ritz, Annals Phys. 318 (2005) 119 [hep-ph/0504231].
- [66] A. Hook, E. Izaguirre and J. G. Wacker, Adv. High Energy Phys. 2011 (2011) 859762 [arXiv:1006.0973 [hep-ph]].
- [67] J. N. Bahcall, A. M. Serenelli and S. Basu, Astrophys. J. 621 (2005) L85 [astro-ph/0412440].
- [68] H. Yuksel and M. D. Kistler, Phys. Rev. D 78 (2008) 023502 [arXiv:0711.2906 [astro-ph]].
- [69] A. Mirizzi, J. Redondo and G. Sigl, JCAP 0903 (2009) 026 [arXiv:0901.0014 [hep-ph]].
- [70] R. Essig, J. A. Jaros, W. Wester, P. H. Adrian, S. Andreas, T. Averett, O. Baker and B. Batell et al. , arXiv:1311.0029 [hep-ph].
- [71] [ATLAS Collaboration], ATLAS-CONF-2012-147.
- [72] M. Bahr, S. Gieseke, M. A. Gigg, D. Grellscheid, K. Hamilton, O. Latunde-Dada, S. Platzer and P. Richardson et al. , Eur. Phys. J. C 58 (2008) 639 [arXiv:0803.0883 [hep-ph]].
- [73] M. Drees, H. Dreiner, D. Schmeier, J. Tattersall and J. S. Kim, arXiv:1312.2591 [hep-ph].
- [74] J. de Favereau et al. [DELPHES 3 Collaboration], JHEP 1402 (2014) 057 [arXiv:1307.6346 [hep-ex]].
- [75] M. Cacciari, G. P. Salam and G. Soyez, Eur. Phys. J. C 72 (2012) 1896 [arXiv:1111.6097 [hep-ph]].
- [76] M. Cacciari and G. P. Salam, Phys. Lett. B 641 (2006) 57 [hep-ph/0512210].
- [77] M. Cacciari, G. P. Salam and G. Soyez, JHEP 0804 (2008) 063 [arXiv:0802.1189 [hep-ph]].
- [78] A. L. Read, J. Phys. G 28 (2002) 2693.
- [79] C. G. Lester and D. J. Summers, Phys. Lett. B 463 (1999) 99 [hep-ph/9906349].
- [80] A. Barr, C. Lester and P. Stephens, J. Phys. G 29 (2003) 2343 [hep-ph/0304226].
- [81] H. -C. Cheng and Z. Han, JHEP 0812 (2008) 063 [arXiv:0810.5178 [hep-ph]].
- [82] [ATLAS Collaboration], ATLAS-CONF-2013-017.
- [83] J. Alwall, M. Herquet, F. Maltoni, O. Mattelaer and T. Stelzer, JHEP 1106 (2011) 128 [arXiv:1106.0522 [hep-ph]].
- [84] A. Alloul, N. D. Christensen, C. Degrande, C. Duhr and B. Fuks, arXiv:1310.1921 [hep-ph].
- [85] Comput. Phys. Commun. 183 (2012) 1201 [arXiv:1108.2040 [hep-ph]]. | null | [
"Joerg Jaeckel",
"Sabyasachi Roy",
"Chris J. Wallace"
] | 2014-07-31T20:15:17+00:00 | 2014-07-31T20:15:17+00:00 | [
"hep-ph"
] | Hidden photons with Kaluza-Klein towers | One of the simplest extensions of the Standard Model (SM) is an extra U(1)
gauge group under which SM matter does not carry any charge. The associated
boson -- the hidden photon -- then interacts via kinetic mixing with the
ordinary photon. Such hidden photons arise naturally in UV extensions such as
string theory, often accompanied by the presence of extra spatial dimensions.
In this note we investigate a toy scenario where the hidden photon extends into
these extra dimensions. Interaction via kinetic mixing is observable only if
the hidden photon is massive. In four dimensions this mass needs to be
generated via a Higgs or Stueckelberg mechanism. However, in a situation with
compactified extra dimensions there automatically exist massive Kaluza-Klein
modes which make the interaction observable. We present phenomenological
constraints for our toy model. This example demonstrates that the additional
particles arising in a more complete theory can have significant effects on the
phenomenology. |
1408.0021v1 | ## Effect of pairing fluctuations on the spin resonance in Fe-based superconductors
Alberto Hinojosa, 1 Andrey V. Chubukov, 1 and Peter W¨ olfle 2
1
Department of Physics, University of Wisconsin, Madison, Wisconsin 53706, USA 2 Institute for Condensed Matter Theory and Institute for Nanotechnology, Karlsruhe Institute of Technology, D-76128 Karlsruhe, Germany
The spin resonance observed in the inelastic neutron scattering data on Fe-based superconductors has played a prominent role in the quest for determining the symmetry of the order parameter in these compounds. Most theoretical studies of the resonance employ an RPA-type approach in the particle-hole channel and associate the resonance in the spin susceptibility χ S ( q , ω ) at momentum Q = ( π, π ) with the spin-exciton of an s + -superconductor, pulled below 2∆ by residual attraction associated with the sign change of the gap between Fermi points connected by Q . Here we explore the effect of fluctuations in the particle-particle channel on the spin resonance. Particle-particle and particle-hole channels are coupled in a superconductor and to what extent the spin resonance can be viewed as a particle-hole exciton needs to be addressed. In the case of purely repulsive interactions we find that the particle-particle channel at total momentum Q (the π channel) contributes little to the resonance. However, if the interband density-density interaction is attractive and the π -resonance is possible on its own, along with spin-exciton, we find a much stronger shift of the resonance frequency from the position of the would-be spin-exciton resonance. We also show that the expected doublepeak structure in this situation does not appear because of the strong coupling between particle-hole and particle-particle channels, and Im χ S ( Q , ω ) displays only a single peak.
## I. INTRODUCTION
The spin resonance, observed by inelastic neutron scattering (INS) experiments first in the cuprates 1 and then in heavy-fermion 2 and Fe-based superconductors (FeSCs) , has been the subject of intense theoretical and 3 experimental studies over the past decade using both metallic 4-6,10 and near-localized strong-coupling scenarios 8 (see Ref. 9 for a review). The theoretical interpretations of the resonance can be broadly split into two classes. The first class of theories assumes that the spin resonance is a magnon, overdamped in the normal state due to the strong decay into low-energy particle-hole pairs, but emerging prominently in the superconducting state due to reduction of scattering at low energies 10,11 . In this line of reasoning the resonance energy Ω res is the magnon energy and as such it is uncorrelated with the superconducting gap ∆. However, the decay of magnons into particle-hole pairs is only suppressed at energies below 2∆, hence the magnons become sharp in a superconductor only if their energy is below 2∆. The symmetry of the superconducting state does not play a crucial role here. It is only relevant that the superconducting gap is finite at the Fermi surface (FS) points connected by the gap momentum Q .
Theories from the second class assume that the resonance does not exist in the normal state and emerges in the superconducting state as a feedback effect from superconductivity, like e.g., the Anderson-Bogolyubov mode in the case of a charge neutral single condensate component, a Leggett mode in the case of several gap components, a wave-like excitation of a spin-triplet order parameter, or a pair vibration mode in the case of a gap parameter possessing internal structure 21 . These 'feedback' theories can be further split into three subclasses. In the first the resonance is viewed as a spin- exciton, i.e., the pole in the dynamical spin susceptibility χ ( q , Ω) dressed by multiple particle-hole bubbles 4-6 . Such χ ( q , Ω) can be obtained by using a computational scheme based on the random-phase approximation (RPA). It was argued that, if the superconducting gap changes sign between FS points connected by Q , the residual attraction pulls the resonance frequency to Ω res < 2∆, where the decay into particle-hole pairs is reduced below T c and vanishes at T = 0. As a result, at T = 0, χ ′′ ( q , Ω) has a δ -functional peak at Ω res . In this respect, if the resonance is an exciton, its existence necessary implies that the superconducting gap changes sign either between patches of the FS connected by Q or between different Fermi pockets again connected by Q . The role of the resonance in allowing to determine the structure of the gap in a number of different superconductors has been highlighted in . 7 Theories of the second subclass explore the fact that in a superconductor the particle-hole and particle-particle channels are mixed and argue that the strongest resonance is in the particleparticle channel and the measurements of the spin susceptibility just reflect the 'leakage' of this resonance into the particle-hole channel. The corresponding resonance has been labeled as the π -exciton 12 , where the π boson is a particle-particle excitation with total momentum Q (a 'pair density-wave' in modern nomenclature 13-15 ). Finally, theories of the third class explore the possibility that the resonance emerges due to coupling between fluctuations in particle-hole and particle-particle channel. Within RPA, such resonance is due to non-diagonal terms in the generalized RPA which includes both particle-hole and particle-particle bubbles. It was called a plasmon 16 to stress the analogy with collective excitations in an electronic liquid.
The interplay between the 'damped spin-wave' scenarios, the spin-exciton π -resonance, and the plasmon sce-
narios for 2D highT c cuprates has been studied in detail in the past decade. The outcome is that near and above optimal doping the resonance is best described as a spinexciton, with relatively weak corrections from coupling to the particle-particle channel 5,17,18 , while in the underdoped regime, where superconductivity emerges from a pre-existing pseudogap phase, both spin-exciton and spin-wave scenarios have been argued to account for the neutron resonance . 9 The situation is more complicated in 3D heavy-fermion systems 11,19 because there the excitonic resonance has a finite width even at T = 0 if the locus of FS points separated by Q intersects a line of gap nodes.
In this work we discuss the interplay between spinexciton, π -resonance, and plasmon scenarios in FeSCs. Previous studies of the resonance in FeSCs 6 focused only on the response in the particle-hole (spin-exciton) channel and neglected the coupling between particle-hole and particle-particle channels. Our goal is to analyze the effect of such coupling.
As we said, the resonance peak has been observed below T c in several families of FeSCs 3 . The spin response above T c in FeSCs is rather featureless away from small doping, which implies that the magnetic excitations in the normal state are highly overdamped and don't behave as damped spin waves. The full analysis of the spin resonance in FeSCs is rather involved as these systems are multi-band materials with four or five FSs, on which the superconducting gap has different amplitudes and phases. Still, the basic conditions for spin-excitonic resonance are the same as in the cuprates and heavy fermion materials: namely, the resonance emerges at momentum Q if the superconducting gap changes sign between FS points connected by Q . This condition holds if the superconducting gap has s + -symmetry, as most researchers believe, and changes sign between at least some hole and electron pockets. An alternative scenario 20 , which we will not discuss in this paper is that the superconducting state has a conventional, sign-preserving s ++ symmetry, and the observed neutron peak is not a resonance but rather a hump at frequencies slightly above 2∆.
In FeSCs that contain both hole and electron pockets, the resonance has been observed at momenta around Q = ( π, π ), which is roughly the distance between hole and electron pockets in the actual (folded) Brillouin zone. To account for the resonance and, at the same time, avoid unnecessary complications, we consider a minimal threeband model (one hole pocket and two electron pockets), and neglect the angular dependence of the interactions along the FSs. Including this dependence and additional hole pockets will complicate the analysis but we don't expect it to lead to any qualitative changes to our results.
We find that for repulsive density-density and pairhopping interactions, the resonance peak is, to a good accuracy, a spin-exciton. The π -resonance does not develop on its own, and the coupling between the resonant spin-exciton channel and the non-resonant π -channel only slightly shifts the energy of the excitonic resonance.
We also considered the case (less justified microscopically) when the interaction in the π channel is attractive, such that both spin-exciton and π resonance develop on their own at frequencies below 2∆. One could expect in this situation that the full dynamical spin susceptibility has two peaks. We found, however, that this happens only if we make the coupling between particle-hole and particle-particle channels artificially small. When we restored the original coupling, we found, in general, only one peak below 2∆. The peak is a mixture of a spinexciton and π -resonance and at least in some range of system parameters its energy is smaller than that of a spin-exciton and a π -resonance. This implies that, when both channels are attractive, the coupling between the two plays a substantial role in determining the position of the true resonance which can, at least partly, be viewed as a plasmon. A somewhat similar result has been obtained earlier for the cuprates 5,16,18 . For some system parameters we did find two peaks in Im χ S ( Q , ω ), but for one of them Im χ S has wrong sign. We verified that this indicates that for such parameters the system is unstable either against condensation of π excitations (i.e., against superconductivity at momentum Q ), or against the development of SDW order in co-existence with superconductivity.
The paper is organized as follows: In the next section we consider the model. In Sec. III we obtain the dynamical spin susceptibility within the generalized RPA scheme, which includes the coupling between particlehole and particle-particle channels. In Sec. IV we analyze the profile of χ S ( Q , ω ) first for purely repulsive densitydensity and pair-hopping interactions, and then for the case when we allow the density-density interaction to become attractive. We summarize our conclusions in Sec. V.
## II. THE MODEL
The FeSCs are multiband metals with two or three hole FS pockets centered around the Γ point (0 0) and , two elliptical electron pockets centered at ( π, π ) in the folded BZ with two iron atoms per unit cell. The electron pockets are elliptical and related by symmetry, while the hole pockets are C 4 -symmetric, but generally differ in size. Since we are only interested in studying the role of the particle-particle channel in the spin response function, for which the non-equivalence between hole pockets is not essential, we consider the case of two hole pockets and assume that they are circular and identical, and also neglect the ellipticity of electron pockets. Under these assumptions our model reduces effectively to only one hole pocket ( c fermions) and one electron pocket ( f fermions). The fact that there are actually two hole and two electron pockets only adds up combinatoric factors.
The free part of the Hamiltonian is
$$H _ { 0 } = \sum _ { { \mathbf k }, \sigma } \left ( \xi _ { { \mathbf k } } ^ { c } c _ { { \mathbf k } \sigma } ^ { \dagger } c _ { { \mathbf k } \sigma } + \xi _ { { \mathbf k } + { \mathbf Q } } ^ { f } f _ { { \mathbf k } + { \mathbf Q } \sigma } ^ { \dagger } f _ { { \mathbf k } + { \mathbf Q } \sigma } \right ), \quad ( 1 ) \quad \text{parti} \\ \text{prod}$$
where
$$\xi _ { \mathbf k } ^ { c } = \mu _ { c } - \frac { k _ { x } ^ { 2 } + k _ { y } ^ { 2 } } { 2 m _ { c } }, \quad \quad \quad ( 2 )$$
$$\xi _ { \mathbf k + \mathbf Q } ^ { f } = - \mu _ { f } + \frac { k _ { x } ^ { 2 } + k _ { y } ^ { 2 } } { 2 m _ { f } } \, \quad \quad ( 3 ) \, \quad$$
We do not study here how superconductivity develops from interactions, as that work has been done elsewhere 22 . Instead, we simply assume that the system reaches a superconducting state with s + -symmetry before it becomes unstable towards magnetism and take the superconducting gaps as inputs. In this state, the free part of the Hamiltonian is
$$H _ { 0 } ^ { S C } = \sum _ { { \mathbf k }, \sigma } \left ( E _ { { \mathbf k } } ^ { c } c _ { { \mathbf k } \sigma } ^ { \dagger } c _ { { \mathbf k } \sigma } + E _ { { \mathbf k } + { \mathbf Q } } ^ { f } f _ { { \mathbf k } + { \mathbf Q } \sigma } ^ { \dagger } f _ { { \mathbf k } + { \mathbf Q } \sigma } \right ), \quad ( 4 ) \quad \text{To m}$$
where the dispersions are E c k = √ ( ξ c k ) 2 +(∆ ) c 2 and E f k + Q = √ ( ξ f k + Q ) 2 +(∆ ) , and ∆ f 2 c = -∆ f ≡ ∆.
Now we consider interactions that contribute to the spin susceptibility. They consist of a density-density interband interaction u 1 and a correlated interband hopping u 3 . Intraband repulsion only affects the chemical potentials but does not otherwise contribute to the spin susceptibility. Interband exchange in principle contributes in the π channel but in renormalization group analysis it flows to small values 26 . In general, u 1 and u 3 depend on the angle in momentum space via coherence factors associated with the transformation from the orbital to the band basis 23 . However, this complication is not essential for our purposes and we take both interactions to be momentum independent. The interaction Hamiltonian is
/negationslash
/negationslash
$$H _ { \text{int} } & = u _ { 1 } \sum _ { [ 1 2 3 4 ], \sigma \neq \sigma ^ { \prime } } c _ { \text{p} _ { 1 } \sigma } ^ { \dagger } f _ { \text{p} _ { 2 } \sigma ^ { \prime } } ^ { \dagger } f _ { \text{p} _ { 3 } \sigma ^ { \prime } } c _ { \text{p} _ { 4 } \sigma } \\ & + u _ { 3 } \sum _ { [ 1 2 3 4 ], \sigma \neq \sigma ^ { \prime } } \left ( c _ { \text{p} _ { 1 } \sigma } ^ { \dagger } c _ { \text{p} _ { 2 } \sigma ^ { \prime } } ^ { \dagger } f _ { \text{p} _ { 3 } \sigma ^ { \prime } } f _ { \text{p} _ { 4 } \sigma } + \text{h.c.} \right ), \quad ( 5 ) \quad \text{//where} \\ & \quad \text{//visual} \\ & \quad \text{//kw.k.}$$
where the sum over momenta obeys momentum conservation as usual ( p 1 + p 2 = p 3 + p 4 ).
Because the interactions in the band basis are linear combinations of Hubbard and Hund interactions in the orbital basis, weighted with orbital coherence factors, the sign of u 1 and u 3 depends on the interplay between intraorbital and inter-orbital interactions 20,24 . The interaction u 3 contributes to the superconducting channel, and for an s + -gap structure must be repulsive. The sign of u 1 is a priori unknown. In most microscopic studies it comes out positive (repulsive), but in principle it can also be negative (attractive). We do not assume a particular sign of u 1 and consider first a case where u 1 is positive and then when it is negative. For the first case we show that a resonance can only originate from the particle-hole channel. For negative u 1 the π channel can produce collective modes as well, and we show that in general the resonant mode is a mix between spin exciton and a π -resonance.
## III. SUSCEPTIBILITIES AND RPA
We focus on susceptibilities at antiferromagnetic momentum Q which separates the centers of hole and electron pockets. Following similar work done on the cuprates , we define spin and 5 π operators as
$$\underset { \text{ take }, \text{ the } } ^ { \prime \text{ be-} } S ^ { z } ( \mathbf Q ) = \frac { 1 } { \sqrt { N } } \sum _ { \mathbf k } \left [ c _ { \mathbf k \alpha } ^ { \dagger } \sigma _ { \alpha \beta } ^ { z } f _ { \mathbf k + \mathbf Q \beta } + f _ { \mathbf k + \mathbf Q \alpha } ^ { \dagger } \sigma _ { \alpha \beta } ^ { z } c _ { \mathbf k \beta } \right ], \ ( 6 )$$
$$\intertext { a } _ { \substack { \pi ( \mathbf Q ) } } = \frac { 1 } { \sqrt { N } } \sum _ { \mathbf k } ^ { \mu \mu } \left [ c _ { \mathbf k \alpha } \sigma _ { \alpha \beta } ^ { x } f _ { \mathbf Q - \mathbf k \beta } \right ].$$
To make a closer connection to , the operator 5 π can be equivalently defined as π = 1 √ N ∑ [ k g k a k α σ x αβ a Q k -β ] , with | g k | = 1 2 and the sign of / g k is chosen so that it is positive near the hole FS and negative near the electron FS ( g k = -g Q k -).
For notational convenience we split S z into two operators such that S z = S c + S f , where
$$S _ { c } ( \mathbf Q ) = \frac { 1 } { \sqrt { N } } \sum _ { \mathbf k } c _ { \mathbf k \alpha } ^ { \dagger } \sigma _ { \alpha \beta } ^ { z } f _ { \mathbf k + \mathbf Q \beta }, \quad \quad ( 8 )$$
$$S _ { f } ( { \mathbf Q } ) = \frac { 1 } { \sqrt { N } } \sum _ { \mathbf k } ^ { \, \, \cdot \, } f _ { \mathbf k + { \mathbf Q } \alpha } ^ { \dagger } \sigma _ { \alpha \beta } ^ { z } c _ { \mathbf k \beta }.$$
We now define the susceptibilities χ ab (Ω m ) in terms of Matsubara frequencies as
$$\varsigma _ { a b } ( \Omega _ { m } ) = \int _ { 0 } ^ { 1 / T } \mathrm d \tau ^ { \prime } e ^ { i \Omega _ { m } \tau ^ { \prime } } \left \langle T _ { \tau } A _ { a } ( \tau ^ { \prime } ) A _ { b } ^ { \dagger } ( 0 ) \right \rangle, \quad ( 1 0 )$$
where A a = ( S , S c f , π, π † ) a . The actual spin susceptibility is given by χ S = χ 11 + χ 12 + χ 21 + χ 22 .
The bare susceptibilities χ 0 ab can be calculated in the usual way in terms of Green's functions and are given by bubbles made out of c and f -fermions, with different Pauli matrices in the vertices. At T = 0 and after performing analytic continuation to real frequency space, the (retarded) susceptibilities have the following form:
$$\begin{array} { c c c c } e & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ^ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & | & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & b & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ( & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
where χ 0 ab , A ab , and B ab are symmetric matrices. The expressions for A ab and B ab are presented in Table I in
Table I: Coefficients of bare susceptibilities. Note: k ′ = k + Q .
| a | b | A ab ( k ) | B ab ( k ) |
|-----|-----|-------------------------------|-------------------------------|
| 1 | 1 | ( v c k u f k ′ ) 2 | ( u c k v f k ′ ) 2 |
| 1 | 2 | - u c k v c k u f k ′ v f k ′ | - u c k v c k u f k ′ v f k ′ |
| 1 | 3 | u c k v c k ( u f k ′ ) 2 | - u c k v c k ( v f k ′ ) 2 |
| 1 | 4 | ( v c k ) 2 u f k ′ v f k ′ | - ( u c k ) 2 u f k ′ v f k ′ |
| 2 | 2 | ( u c k v f k ′ ) 2 | ( v c k u f k ′ ) 2 |
| 2 | 3 | - ( u c k ) 2 u f k ′ v f k ′ | ( v c k ) 2 u f k ′ v f k ′ |
| 2 | 4 | - u c k v c k ( v f k ′ ) 2 | u c k v c k ( u f k ′ ) 2 |
| 3 | 3 | ( u c k u f k ′ ) 2 | ( v c k v f k ′ ) 2 |
| 3 | 4 | u c k v c k u f k ′ v f k ′ | u c k v c k u f k ′ v f k ′ |
| 4 | 4 | ( v c k v f k ′ ) 2 | ( u c k u f k ′ ) 2 |
terms of coherence factors which are given by:
$$u _ { \mathbf k } ^ { c } = \sqrt { \frac { 1 } { 2 } \left ( 1 + \frac { \xi _ { \mathbf k } ^ { c } } { E _ { \mathbf k } ^ { c } } \right ) },$$
$$v _ { \mathbf k } ^ { c } = \sqrt { \frac { 1 } { 2 } \left ( 1 - \frac { \xi _ { \mathbf k } ^ { c } } { E _ { \mathbf k } ^ { c } } \right ) } \, \text{sgn} \, \Delta ^ { c }, \quad \ \ ( 1 3 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
and similar expressions for u f k ′ and v f k ′ .
To obtain the full susceptibilities χ ab we used the generalized RPA approach. Within this approach
$$\chi _ { a b } = ( 1 - \chi ^ { 0 } V ) _ { a c } ^ { - 1 } \chi _ { c b } ^ { 0 }, \text{ \quad \ \ } ( 1 4 )$$
where the sum over repeated indices is implied and V is given by
$$V = \frac { 1 } { 2 } \begin{pmatrix} u _ { 1 } & u _ { 3 } & 0 & 0 \\ u _ { 3 } & u _ { 1 } & 0 & 0 \\ 0 & 0 & - u _ { 1 } & 0 \\ 0 & 0 & 0 & - u _ { 1 } \end{pmatrix}. \quad \quad ( 1 5 ) \quad \text{fig} \\ \text{cpt} \quad \text{$\epsilon$}.$$
The solution for the full spin susceptibility can be written in a simpler form once we note that the matrix χ 0 ab has additional symmetry. Indeed, the functions A ab ( k ) and B ab ( k ) can be separated into parts that are even or odd with respect to ξ c k and ξ f k . If the momentum sums are evaluated only near the FSs, where the integration region can be chosen to be symmetric with respect to positive and negative values of ξ c k and ξ f k , then the odd parts cancel out and χ 0 ab acquires the following form:
$$\chi ^ { 0 } = \begin{pmatrix} a & b & c & - d \\ b & a & d & - c \\ c & d & e & f \\ - d & - c & f & e \end{pmatrix} \quad \quad ( 1 6 )$$
If we rotate the basis of operators from ( S , S c f , π, π † ) to ( S c + S , π f -π , S † c -S , π f + π † ) we find that both V and χ 0 become block diagonal, so the first 2 × 2 system decouples from the second one. In this case, the solution for the subset ( S c + S , π f -π † ) takes the simple form
$$\chi _ { S } = & \frac { \chi _ { S } ^ { 0 } + \delta \chi _ { S } ^ { 0 } } { 1 - u _ { S } ( \chi _ { S } ^ { 0 } + \delta \chi _ { S } ^ { 0 } ) }, \quad \quad ( 1 7 )$$
$$\chi _ { \pi } = & \frac { \chi _ { \pi } ^ { 0 } + \stackrel { \lambda } { \delta } \chi _ { \pi } ^ { 0 } } { 1 - u _ { \pi } ( \chi _ { \pi } ^ { 0 } + \delta \chi _ { \pi } ^ { 0 } ) },$$
$$\delta \chi _ { S } ^ { 0 } = & \frac { u _ { \pi } } { 1 - u _ { \pi } \chi _ { \pi } ^ { 0 } } \left ( \chi _ { S \pi } ^ { 0 } \right ) ^ { 2 }, \quad \quad \left ( 1 9 \right )$$
$$\delta \chi _ { \pi } ^ { 0 } = & \frac { \mu ^ { - n \wedge \pi } } { u _ { S } } \left ( \chi _ { S \pi } ^ { 0 } \right ) ^ { 2 }. \quad \quad \left ( 2 0 \right )$$
and u S = ( u 1 + u 3 ) / 4 and u π = -u / 1 4. The bare susceptibilities in this basis are given by
$$\chi ^ { 0 } _ { S } = \chi ^ { 0 } _ { 1 1 } + \chi ^ { 0 } _ { 1 2 } + \chi ^ { 0 } _ { 2 1 } + \chi ^ { 0 } _ { 2 2 } = 2 ( \chi ^ { 0 } _ { 1 1 } + \chi ^ { 0 } _ { 1 2 } ), \quad ( 2 1 )$$
$$\chi ^ { 0 } _ { \pi } = \chi ^ { 0 } _ { 3 3 } - \chi ^ { 0 } _ { 3 4 } - \chi ^ { 0 } _ { 4 3 } + \chi ^ { 0 } _ { 4 4 } = 2 ( \chi ^ { 0 } _ { 3 3 } - \chi ^ { 0 } _ { 3 4 } ), \quad ( 2 2 )$$
$$\chi ^ { 0 } _ { S \pi } = \chi ^ { 0 } _ { 1 3 } - \chi ^ { 0 } _ { 1 4 } + \chi ^ { 0 } _ { 2 3 } - \chi ^ { 0 } _ { 2 4 } = 2 ( \chi ^ { 0 } _ { 1 3 } - \chi ^ { 0 } _ { 1 4 } ). \quad ( 2 3 )$$
The first two bare susceptibilities contain contributions of products of two normal Green's functions and of two anomalous Green's functions, while χ 0 Sπ is composed of one normal and one anomalous Green's function (see Fig. 1 for some contributions of χ 0 Sπ to the spin response function).
Figure 1: Some mixed-channel contributions to the spin susceptibility and Raman scattering. The solid lines represent f fermions and the dashed lines c fermions, corresponding to quasiparticles from the electron and hole pockets, respectively.
We obtained expressions for the real parts of the bare susceptibilities by replacing the momentum sums by integrals and evaluating them within an energy range from -Λ to Λ about the FSs. They are valid in the range 0 < ω < 2∆ in the limit when the broadening γ → 0.
$$R e \chi _ { S } ^ { 0 } ( \omega ) = & L + \frac { \omega ^ { 2 } } { 4 \Delta ^ { 2 } } R e \chi _ { \pi } ^ { 0 } ( \omega ), \quad \quad \quad ( 2 4 )$$
$$\text{Re} \chi _ { \pi } ^ { 0 } ( \omega ) = & \frac { m } { \pi } \frac { \stackrel { \text{$\mapsto \ell$} } { 4 \Delta ^ { 2 } } } { \omega \sqrt { 4 \Delta ^ { 2 } - \omega ^ { 2 } } } \arctan \left ( \frac { \omega } { \sqrt { 4 \Delta ^ { 2 } - \omega ^ { 2 } } } \right ), \\ \dots$$
$$\tilde { R e } \chi _ { S \pi } ^ { 0 } ( \omega ) = & \frac { \omega } { 2 \Delta } \tilde { R e } \chi _ { \pi } ^ { 0 } ( \omega ), & \cdot & \cdot \\ \pi ^ { \dagger } )$$
where L = m π log(2Λ / ∆) and we have neglected terms of order (∆ / Λ) . 2
where
Figure 2: Real part of the bare spin susceptibilities ( T = 0, units of ∆ -1 ) in the case of perfectly nested circular pockets ( m ≡ m c = m f = 1 100∆ ). In all numerical calculations µ = 10∆ and we include a finite broadening γ = ∆ 200 when / evaluating momentum integrals.
In Fig. 2 we present the results of numerical calculations of the bare susceptibilities in the case of perfectly nested FSs ( µ c = µ f ≡ µ ). The susceptibility χ 0 S would diverge at ω = 0 in the absence of superconductivity, but becomes finite at a finite ∆. Conversely, χ 0 π at ω = 0 would be zero in the absence of superconductivity, but becomes non-zero because of ∆. Note that all three susceptibilities monotonically increase with frequency in the domain 0 ≤ ω ≤ 2∆ and diverge at ω = 2∆. The imaginary parts of the three bare susceptibilities (not shown in the plot) are infinitesimally small and undergo a discontinuous jump at ω = 2∆. If we make the electron pocket elliptical, the divergence in the real part is replaced by a local maximum.
We see that χ 0 S ( ω ) and χ 0 π ( ω ) have finite value at ω = 0. We recall that, in the absence of superconductivity, χ S (0) would diverge and χ π (0) would vanish at perfect nesting. At ω = 2∆ both bare susceptibilities diverge. The cross-susceptibility χ 0 Sπ ( ω ) vanishes at ω = 0 simply because it is composed from one normal and one anomalous Green's function but rapidly increases with ω and becomes comparable to χ S ( ω ) and χ π ( ω ) at ω ≤ 2∆. The cross-susceptibility between particle-hole and particle-particle channels has been recently analyzed for an s + -superconductor in the context of Raman scattering 25 . There, it was computed in the charge channel and was found to be very small due to near-cancellation between contributions from Fermi surfaces with plus and minus values of the superconducting gap. In our case we found that the contributions from hole and electron FSs add up rather than cancel. The difference is that in Raman scattering the side vertices in the susceptibility bubble have the spin structure given by δ α,β , while in our case the spin structure is, say, σ z α,β . For an s + - gap, Raman bubbles from hole and electron pocket have the same vertex structure but differ in the sign of the anomalous Green's function, hence the two contributions to cross-susceptibility have opposite signs, resulting in a cancellation that is complete in the case of perfect nesting and near-complete in the case of one circular and one elliptical pocket. This cancellation does not occur in our case because the σ z structure of the side vertices additionally flips the sign of one of the two diagrams, and the contributions to χ 0 Sπ ( ω ) from hole and electron FSs add constructively.
We next note that the terms δχ 0 S and δχ 0 π are precisely what is neglected when the particle-particle channel is not included in the calculation of the spin susceptibility. Setting these terms to zero reduces the expressions for the full χ S and χ π to the usual RPA results
$$\chi _ { S } = \frac { \chi _ { S } ^ { 0 } } { 1 - u _ { S } \chi _ { S } ^ { 0 } }, \quad \chi _ { \pi } = \frac { \chi _ { \pi } ^ { 0 } } { 1 - u _ { \pi } \chi _ { \pi } ^ { 0 } }. \quad ( 2 7 )$$
The effect of coupling the two channels can be seen more clearly by substituting (19) into (17), which yields
$$\text{lcula} _ { \text{effectly} } \quad \chi _ { S } = & \frac { \chi _ { S } ^ { 0 } ( 1 - u _ { \pi } \chi _ { \pi } ^ { 0 } ) + u _ { \pi } ( \chi _ { S \pi } ^ { 0 } ) ^ { 2 } } { ( 1 - u _ { S } \chi _ { S } ^ { 0 } ) ( 1 - u _ { \pi } \chi _ { \pi } ^ { 0 } ) - u _ { S } u _ { \pi } ( \chi _ { S \pi } ^ { 0 } ) ^ { 2 } } \\ \text{-} \text{-} \text{-} 0 \\ \text{-} \text{-} 0$$
The positions of resonance peaks are given by the zeroes of the denominator in this equation and we can see that the particle-hole and particle-particle channels are coupled through the mixed-channel susceptibility χ 0 Sπ ( ω ).
## IV. THE RESULTS
## A. Purely repulsive interaction, u 1 > 0 , u 3 > 0 .
For repulsive interactions u S > u | π | > 0 and u π < 0. In the absence of χ 0 Sπ the resonance in χ S is present for any u S because the bare susceptibility χ 0 S is positive and diverges at ω = 2∆, hence the equation 1 -u S Re χ 0 S ( ω ) = 0 has a solution for 0 < u S < (Re χ 0 S (0)) -1 . In contrast, the fact that Re χ 0 π > 0 means that no resonance originates from this channel. When χ 0 Sπ is included, we found in our numerical calculations that the effect of the particle-particle channel is that the peak in the imaginary part of the full susceptibility is shifted to a higher frequency (since Re { u S u π ( χ 0 Sπ ) 2 } < 0). We show representative behavior of real and imaginary parts of the full spin susceptibility in Fig. 3
This result is also obtained when we consider an elliptical electron pocket, except that there is a minimum value for u S below which no resonance is observed. This is due to the fact that the bare susceptibilities have a local maximum instead of a divergence at ω = 2∆.
Figure 3: Imaginary part (main plot) and real part (insert) of the full spin susceptibility ( T = 0, units of ∆ -1 ) in the case of repulsive interactions. In this plot u S = 26∆ and u π = -13∆. The solid, black line indicates the full calculation. For comparison, the dashed, blue line indicates a calculation that neglects particle-particle contributions.
## B. Partially attractive interaction, u 1 < ,u 0 3 > 0 .
We now consider an alternative case where the densitydensity interaction u 1 < 0, hence u π = -u / 1 4 > 0. We still assume u 3 > u | 1 | such that u S > 0. For positive u π , the π channel can acquire a resonance on its own since the equation 1 -u π Re χ 0 π ( ω ) = 0 necessarily has a solution at a frequency between 0 and 2∆ if u π < (Re χ 0 π (0)) -1 . We assume that this inequality holds together with u S < (Re χ 0 S (0)) -1 . If any of these two conditions are not satisfied, the system becomes unstable either towards π superconductivity with total momentum of a Cooper pair Q or towards magnetic order. In both cases, the analysis of the spin susceptibility has to be modified to include the new condensates. If the spinexciton and π channels were not coupled (i.e., if χ 0 Sπ ( ω ) was absent), we would find resonances in the spin and π channels at frequencies ω S and ω π , respectively, set by 1 -u S Re χ 0 S ( ω S ) = 0 and 1 -u π Re χ 0 π ( ω π ) = 0. This suggests the possibility that there may be two resonance peaks in the full spin susceptibility χ S ( Q,ω ) once we restore the coupling χ 0 Sπ ( ω ).
However, we found that for all values of u S and u π for which the pure s + -state is stable, there is only a single peak in the spin susceptibility at a frequency lower than both ω S and ω π . We show representative behavior in Fig. 4. The existence of a single peak is due to the fact that χ 0 Sπ is small at small frequencies, hence it does not prevent the increase of the real part of the spin susceptibility with increasing ω (see insert in Fig. 4) and only shifts the position of the lower pole ( ω S or ω π ) to a smaller value ω res . At the same time, at higher frequencies, χ 0 Sπ is no longer small relative to the other bare susceptibilities χ 0 S and χ 0 π . As a result, the denominator in χ S ( Q , ω ) in (28) passes through zero at ω = ω res and then remains negative all the way up to ω = 2∆ and does not cross zero for the second time.
To better understand this, we artificially add a factor /epsilon1 to χ 0 Sπ and consider how the solutions evolve as we progressively increase /epsilon1 between 0 and 1. At small /epsilon1 , the two solutions obviously survive and just further split from each other - the peak that was at a higher frequency shifts to a higher frequency and the other peak shifts to to a lower frequency. As /epsilon1 increases, the peak at a higher frequency rapidly moves towards 2∆. If we keep Im χ 0 ab strictly zero, this peak survives up to /epsilon1 = 1 with exponentially vanishing amplitude. If, however, we keep a small but finite fermionic damping in the computations of χ 0 ab , we find that the functions χ 0 ab ( ω ) increase but do not diverge at 2∆. In this situation, the higher frequency peak in χ S ( Q , ω ) vanishes already at some /epsilon1 < 1.
We also considered the evolution of the two-peak solution with /epsilon1 in a different way: we postulated that the two peaks should be at ω res, 1 and ω res, 2 , both below 2∆ and solved the set of equations for u S and u π which would correspond to such a solution. At small /epsilon1 we indeed found some real u S and u π which satisfy 'boundary conditions' u S χ 0 S < 1 and u χ π 0 π < 1. However this holds only up to some /epsilon1 cr . At higher /epsilon1 the solutions for u s and u π become complex, which implies that the two-peak solution is no longer possible. At even higher /epsilon1 real solutions for u s and u π reappear, but they do not satisfy the boundary conditions. We searched for a range of ω res, 1 and ω res, 2 and for all values that we tested we found /epsilon1 cr < 1, i.e., again there is only a single peak for the actual case of /epsilon1 = 1.
Another way to see that there is only one peak in the full χ S is to substitute the expressions for the real parts of the susceptibilities, Eqs. (24)-(26), into the denominator of Eq. (28) and express the real part of the term D = (1 -u S χ 0 S )(1 -u χ π 0 π ) -u S u π ( χ 0 Sπ ) 2 via χ 0 π = χ 0 π ( ω ). We obtain
$$\stackrel { \sigma \psi \psi } { S _ { \pi } } ( \omega ) \\ \text{and } \pi \\ \text{set by } \\ \text{This } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D } \quad \mathfrak { D }$$
Because (1 -u S L ) and (1 -u χ π 0 π (0)) are required to be positive for the stability of the paramagnetic state, at zero frequency, D is surely positive. At finite ω , the first term in (29) is positive, while the second one is negative and its magnitude monotonically increases with increasing ω . As a result, the denominator crosses zero only once, at some ω < 2∆.
The single resonance peak is a mixture of a spinexciton and π -resonance and for the representative case shown in Fig. 4 its energy is smaller that that of spinexciton and a π -resonance. This implies that, when both channels are attractive, the coupling between the two plays substantial role in determining the position of the true resonance. From this perspective, the resonance at
u 1 < 0 can, at least partly, be viewed as a plasmon. A somewhat similar result has been earlier obtained in the analysis of the resonance in the cuprates in the parameter range where π -resonance is allowed 5,16,18 .
Figure 4: Imaginary part (main plot) and real part (insert) of the full spin susceptibility ( T = 0, units of ∆ -1 ) in the case of u S = 30 5∆ and . u π = 130∆. In the absence of coupling we would observe resonance peaks in the spin and π channels at frequencies ω S ≈ 0 57∆ and . ω π ≈ 1 0∆, respectively, . indicated on the plot.
## V. CONCLUSIONS
We have studied the spin resonance at antiferromagnetic momentum ( π, π ) in an s + -superconducting state
1 J. Rossat-Mignod, L.P. Regnault, C. Vettier, P. Bourges, P. Burlet, J. Bossy, J.Y. Henry, and G. Lapertot, Physica C 185-189 , 86 (1991); H. A. Mook, M. Yethitaj, G. Aeppli, T. E. Mason, and T. Armstrong, Phys. Rev. Lett. 70 , 3490 (1993); H. F. Fong, B. Keimer, P. W. Anderson, D. Reznik, F. Dogan, and I. A. Aksay, Phys. Rev. Lett. 75 , 316 (1995); H.F. Fong et al, Nature 398 , 588 (1999); Ph. Bourges et al, Science 288 1234 (2000); H. He et al, Science 295 , 1045 (2002); G. Yu, Y. Li, E. M. Motoyama, and M. Greven, Nat. Phys. 5 , 873 (2009).
2 N.K. Sato, N. Aso, K. Miyake, R. Shiina, P. Thalmeier, G. Varelogiannis, C. Geibel, F. Steglich, P. Fulde, and T. Komatsubara, Nature 410 , 340 (2001); C. Stock, C. Broholm, J. Hudis, H.J. Kang, and C. Petrovic, Phys. Rev. Lett. 100 , 087001 (2008).
3 A. D. Christianson, E. A. Goremychkin, R. Osborn, S. Rosenkranz, M. D. Lumsden, C. D. Malliakas, I. S. Todorov, H. Claus, D. Y. Chung, M. G. Kanatzidis, R. I. Bewley, and T. Guidi, Nature (London) 456 , 930 (2008); M. D. Lumsden, A. D. Christianson, D. Parshall, M. B.
of FeSCs by including contribution from the particleparticle channel, which in the superconducting state gets mixed with the particle-hole channel. We have shown that for purely repulsive interactions the inclusion of this channel does not qualitatively change the spin resonance, which remains predominantly spin-exciton and only slightly shifts to higher frequencies. For attractive density-density interaction, when both spin-exciton resonance in the particle-hole channel and π -resonance in the particle-particle channel are allowed, we found that strong coupling between the two channels destroys the two-peak structure and only one peak survives, whose frequency is smaller than would be that of a spin-exciton and π -resonance in the absence of the coupling. We argued that strong coupling between the particle-hole and particle-particle channels is peculiar to the spin susceptibility, while for the charge susceptibility, which, e.g., is relevant for Raman scattering, the coupling is much smaller.
We acknowledge useful discussions with R. Fernandes, S. Maiti, and Y. Wang. The work by A. H. and A.V.C. is supported by the DOE grant DE-FG02-ER46900. P. W. thanks the Department of Physics at the University of Wisconsin-Madison for hospitality during a stay as a visiting professor. P. W. also acknowledges partial support through the DFG research unit 'Quantum phase transitions'.
Stone, S. E. Nagler, G. J. MacDougall, H. A. Mook, K. Lokshin, T. McGuire, A. S. Sefat, R. Jin, B. C. Sales, and D. Mandrus, Phys. Rev. Lett. 102 , 107005 (2009); S. Chi, A. Schneidewind, J. Zhao, L. W. Harriger, L. Li, Y. Luo, G. Cao, Z. Xu, M. Loewenhaupt, J. Hu, and P. Dai, Phys. Rev. Lett. 102 , 107006 (2009); S. Li, Y. Chen, S. Chang, J.W. Lynn, L. Li, Y. Luo, G. Cao, Z. Xu, and P. Dai, Phys. Rev. B 79 , 174527 (2009); D.S. Inosov, J.T. Park, P. Bourges, D.L. Sun, Y. Sidis, A. Schneidewind, K. Hradil, D. Haug, C. T. Lin, B. Keimer, V. Hinkov, Nature Phys. 6 , 178 (2010); J.-P. Castellan, S. Rosenkranz, E. A. Goremychkin, D. Y. Chung, I. S. Todorov, M. G. Kanatzidis, I. Eremin, J. Knolle, A. V. Chubukov, S. Maiti, M. R. Norman, F. Weber, H. Claus, T. Guidi, R. I. Bewley, and R. Osborn, arXiv:1106.0771; Y. Qiu, W. Bao, Y. Zhao, C. Broholm, V. Stanev, Z. Tesanovic, Y. C. Gasparovic, S. Chang, J. Hu, B. Qian, M. Fang, and Z. Mao, Phys. Rev. Lett. 103, 067008 (2009); D.N. Argyriou, A. Hiess, A. Akbari, I. Eremin, M.M. Korshunov, J. Hu, B. Qian, Z. Mao, Y. Qiu, C. Broholm, and W. Bao, Phys. Rev. B 81,
- 4 N. Bulut, and D. J. Scalapino, Phys. Rev. B 47 , 3419 (1993); I. Mazin and V. Yakovenko, Phys. Rev. Lett. 75 4134 (1995); D. Z. Liu, Y. Zha, and K. Levin, Phys. Rev. Lett. 75 4130 (1995); N. Bulut and D. Scalapino, Phys. Rev. B 53 , 5149 (1996); A. J. Millis and H. Monien, Phys. Rev. B, 54 , 16172 (1996); D. Manske, I. Eremin, and K. H. Bennemann, Phys. Rev. B 63 , 054517 (2001); M.R. Norman, Phys. Rev. B 61 , 14751 (2000); ibid 63 , 092509 (2001); A. Chubukov, B. Janko and O. Tchernyshov, Phys. Rev. B 63 , 180507(R) (2001); A. Abanov, A. Chubukov, and J. Schmalian, Journal of Electron Spectroscopy and Related Phenomena 117, 129-151 (2001); F. Onufrieva and P. Pfeuty, Phys. Rev. B 65, 054515 (2002); I. Eremin, D.K. Morr, A.V. Chubukov, K.H. Bennemann, and M.R. Norman, Phys. Rev. Lett. 94, 147001 (2005); Ar Abanov, A. Chubukov, and M. Norman, Phys. Rev. B 78, 220507 (2008).
- 5 O. Tchernyshyov, M. R. Norman, and A. V. Chubukov, Phys. Rev. B 63 , 144507 (2001).
- 6 M.M. Korshunov, and I. Eremin, Phys. Rev. B 78 , 140509(R) (2008); T.A. Maier, and D.J. Scalapino, Phys. Rev. B 78 , 020514(R) (2008); T. A. Maier, S. Graser, D. J. Scalapino, and P. Hirschfeld, Phys. Rev. B 79 , 134520 (2009); J. Zhang, R. Sknepnek, and J. Schmalian, Phys. Rev. B 82 , 134527 (2010); S. Maiti, J. Knolle, I. Eremin, and A.V. Chubukov, Phys. Rev. B 84 , 144524 (2011).
- 7 D. J. Scalapino, Rev. Mod. Phys. 84 , 1383 (2012).
- 8 J. Brinckmann, and P. A. Lee, Phys. Rev. Lett. 82 , 2915 (1999); K. Seo, C. Fang, B.A. Bernevig, and J. Hu, Phys. Rev. B 79 , 235207 (2009).
- 9 for a review see M. Eschrig, Adv. Phys. 55 , 47 (2006).
- 10 D. Morr and D. Pines, Phys. Rev. Lett. 81 , 1086 (1998).
- 11 A.V. Chubukov and L.P. Gorkov, Phys. Rev. Lett. 101, 147004 (2008).
- 12 E. Demler, and S.-C. Zhang, Phys. Rev. Lett. 75, 4126 (1995); E. Demler, H. Kohno, and S.-C. Zhang, Phys. Rev. B 58 , 5719 (1998).
- 13 E. Fradkin and S. A. Kivelson, Nature Physics 8 , 865-866 (2012).
- 14 P. A. Lee, arXiv:1401.0519.
- 15 D. Agterberg and M. Kashuap, arXiv:1406.4959.
- 16 W.C. Lee et al, Phys. Rev. B 77, 214518 (2008) W.C. Lee and A.H. MacDonald, Phys. Rev. B 78, 174506 (2008).
- 17 I. Fomin, P. Schmitteckert, and P. W¨lfle, Phys. Rev. Lett. o 69 , 214 (1992).
- 18 Z. Hao and A. Chubukov, Phys. Rev. B 79 , 224513 (2009).
- 19 I. Eremin, G. Zwicknagl, P. Thalmeier, and P. Fulde, Phys. Rev. Lett. 101, 187001 (2008).
- 20 S. Onari and H. Kontani, Phys. Rev. B 84 , 144518 (2011).
- 21 D. Vollhardt and P. W¨lfle, 'The Superfluid Phases of Heo lium 3', Taylor and Francis, London, (1990).
- 22 see e.g., I.I. Mazin and J. Schmalian, Physica C, 469 , 614 (2009); S. Graser, T. A. Maier, P. J. Hirshfeld, D. J. Scalapino, New J. Phys. 11 , 025016 (2009); K. Kuroki, H. Usui, S. Onari, R. Arita, and H. Aoki, Phys. Rev. B 79, 224511 (2009); J-P Paglione and R.L. Greene, Nature Phys. 6 , 645 (2010); D.N. Basov and A.V. Chubukov, Nature Physics 7 , 241 (2011); P.J. Hirschfeld, M.M. Korshunov, and I.I. Mazin, Reports on Progress in Physics 74, 124508 (2011); H.H. Wen and S. Li, Annu. Rev. Condens. Matter Phys., 2 , 121 (2011); A.V. Chubukov, Annual Review of Condensed Matter Physics 3, 57 (2012).
- 23 A.V. Chubukov, M.G. Vavilov, and A.B. Vorontsov, Phys. Rev. B 80, 140515(R) (2009); A. F. Kemper, T. A. Maier, S. Graser, H.-P. Cheng, P. J. Hirschfeld, and D. J. Scalapino New J. Phys. 12 073030 (2010).
- 24 S. Raghu, Xiao-Liang Qi, Chao-Xing Liu, D. Scalapino, and Shou-Cheng Zhang, Phys.Rev.B 77 220503(R) (2008); A. V. Chubukov, D. Efremov, and I. Eremin, Phys. Rev. B 78 , 134512 (2008).
- 25 M. Khodas, A.V. Chubukov, and G. Blumberg, Phys. Rev. B 89 , 245134 (2014).
- 26 A. V. Chubukov, D. Efremov, and I. Eremin, Phys. Rev. B 78 , 134512 (2008). | 10.1103/PhysRevB.90.104509 | [
"Alberto Hinojosa",
"Andrey V. Chubukov",
"Peter Wolfle"
] | 2014-07-31T20:21:30+00:00 | 2014-07-31T20:21:30+00:00 | [
"cond-mat.supr-con"
] | Effect of pairing fluctuations on the spin resonance in Fe-based superconductors | The spin resonance observed in the inelastic neutron scattering data on
Fe-based superconductors has played a prominent role in the quest for
determining the symmetry of the order parameter in these compounds. Most
theoretical studies of the resonance employ an RPA-type approach in the
particle-hole channel and associate the resonance in the spin susceptibility
$\chi_S (\mathbf{q}, \omega)$ at momentum ${\bf Q} = (\pi,\pi)$ with the
spin-exciton of an $s^{+-}$ superconductor, pulled below $2\Delta$ by residual
attraction associated with the sign change of the gap between Fermi points
connected by ${\bf Q}$. Here we explore the effect of fluctuations in the
particle-particle channel on the spin resonance. Particle-particle and
particle-hole channels are coupled in a superconductor and to what extent the
spin resonance can be viewed as a particle-hole exciton needs to be addressed.
In the case of purely repulsive interactions we find that the particle-particle
channel at total momentum ${\bf Q}$ (the $\pi $channel) contributes little to
the resonance. However, if the interband density-density interaction is
attractive and the $\pi-$resonance is possible on its own, along with the
spin-exciton, we find a much stronger shift of the resonance frequency from the
position of the would-be spin-exciton resonance. We also show that the expected
double-peak structure in this situation does not appear because of the strong
coupling between particle-hole and particle-particle channels, and $\mathrm{Im}
\chi_S ({\bf Q}, \omega)$ displays only a single peak. |
1408.0023v1 | ## Strategic Evolution of Adversaries Against Temporal Platform Diversity Active Cyber Defenses
MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA 02421, USA
Michael L. Winterrose and Kevin M. Carter { michael.winterrose, kevin.carter } @ll.mit.edu
Keywords: cyber security, genetic algorithm, moving target, learning
## Abstract
Adversarial dynamics are a critical facet within the cyber security domain, in which there exists a co-evolution between attackers and defenders in any given threat scenario. While defenders leverage capabilities to minimize the potential impact of an attack, the adversary is simultaneously developing countermeasures to the observed defenses. In this study, we develop a set of tools to model the adaptive strategy formulation of an intelligent actor against an active cyber defensive system. We encode strategies as binary chromosomes representing finite state machines that evolve according to Holland's genetic algorithm. We study the strategic considerations including overall actor reward balanced against the complexity of the determined strategies. We present a series of simulation results demonstrating the ability to automatically search a large strategy space for optimal resultant fitness against a variety of counter-strategies. 1
In recent years active cyber defense techniques have been an important area of research and development [2, 3]. A prominent example of a family of active defense techniques that have recently been under development is that of moving target defenses [4, 5], which systematically vary a system's attack surface to diminish the inherent advantages cyber attackers typically enjoy [5]. Temporal platform migration systems [6] are a class of moving target defenses that dynamically change the system interface (e.g. operating system (OS), spam filter, etc.) over time. These techniques work under the assumption that the attacker has limited resources and generally does not have exploits for all platforms at his disposal. As such, migrating between platforms with some frequency reduces the ability for an attacker to maintain persistence on a system. Additionally, it increases the uncertainty for an attacker that aims to expend resources towards countermeasure development.
## 1. INTRODUCTION
Adversarial dynamics are at the heart of many important security challenges. The central issue in this problem class is the existence of an intelligent, adaptable adversary able to actively counter defensive moves. Models developed to increase understanding in these areas must include adaptive learning as a central component if they aim to capture the adversarial dynamics observed to dominate many real-world conflict scenarios [1].
Cyber security researchers, attempting to understand and predictably influence the highly dynamic, noisy, and innovative cyber realm, require tools that shed light on strategic interactions that are often out of equilibrium and driven by adaptive learning. Furthermore, the sought after techniques should be able to account for the limited ability of real world actors to gather and process information and the consequent bounded nature of the rationality that characterizes real world adversarial opponents.
1 This work is sponsored by the Department of Defense under Air Force Contract FA8721-05-C-0002. Opinions, interpretations, conclusions and recommendations are those of the author and are not necessarily endorsed by the United States Government.
Recent studies have examined the optimal scheduling policy for a temporal platform migration moving target defense. According to [7], a uniform random scheduling of active spam filters gave superior performance against an evolving adversary. On the other hand, [8] found that a scheduling policy that maximizes the diversity of the platforms played in each successive round as quantified by a measure of platform similarity was superior. Crucially, the threat model in these studies differed, with [8] modeling a threat that required attacker persistence in the system before a payoff accrued, in contrast to [7] which used a simple attacker model with no requirement for persistence.
The primary aim of this study is not to formulate new moving target defense strategies, but rather to develop a set of modeling tools that facilitate insight into the effect these strategies have on the potential success and strategy evolution of a cyber attacker that is able to observe a system and react adaptively to defensive moves. In this study we demonstrate a tractable approach to the modeling of adaptive strategic learning by boundedly rational agents and apply the scheme for the first time to a resource allocation problem in the cyber security domain.
The modeling approach we employ involves the use of genetic algorithms, which have been used in a number of security applications and in studies of agent strategy formulation. Intrusion detection systems have incorporated genetic algorithms [9, 10, 11, 12]. Genetic algorithms have also been used to create active defense strategies [13] and to generate diverse configurations in a moving target system [14, 15]. In his pioneering work Axelrod [16] used a genetic algorithm to explore strategy evolution in the Iterated Prisoner's Dilemma (IPD). Miller [17] (see below) brought together the ideas of Axelrod with methods from automata theory [18, 19, 20] developed to model the strategic play of boundedly rational agents. The combination of a genetic algorithm and finite state machines allows for the tractable modeling of boundedly rational agents able to learn and adapt in dynamic environments [17].
The major contributions of this work are as follows:
- 1. We present the first use of genetic algorithms to study optimal attacker strategies against temporal platform diversity defenses
- 2. We quantify a strategic complexity measure to balance the cost/benefit within resource investment
- 3. We study the efficacy of different defender strategies against an evolving adversary
The paper proceeds as follows: In Section 2. we formulate the problem and present our techniques and evaluation metrics. In Section 3. we present a series of experiments in which the adaptive attacker interacts with different defender strategies, finally concluding by discussing future work in Section 4.
## 2. PROBLEM AND METHODS 2.1. Attacker/Defender Game Scenario
We study the interaction between the attacker and defender through the dynamics of a two-player game. In our scenario the attacker observes the operating system the defender, utilizing a moving target defense, activates in each round of play. The attacker uses this information to formulate a strategy for resource investment, with the goal to bring exploits (e.g. countermeasures) into existence to most effectively compromise the defender's system and maximize his own gain.
In each match (i.e. round of play), the attacker uses any exploits it has developed against the activated platform. Success for the attacker in a match occurs when he has an available exploit that works against the platform activated by the defender. Intuitively, the attacker gains a reward if they are able to compromise the defender's system during the match, and earns nothing otherwise. One may view this as the ability for the attacker to exfiltrate data, perform reconnaissance, steal credentials, etc.; all attacks that benefit from system access.
Exploits are developed by cumulative attacker investment; in each round of play the attacker invests a single resource to the creation of a chosen exploit. The amount of investment required to bring a given exploit into existence is randomly determined at the beginning of each game. The attacker is not informed a priori of the number of resources that will be required to bring a given exploit into existence, instead discovering this fact only after having successfully created the exploit through the required allocation of resources. This uncertainty matches reality in that a real-world attacker is not in general able to predict a priori the level of effort that will be required to develop new exploits against a given system. Without loss of generality, in this initial version of the game, there exists one possible exploit for each type of platform a defender might utilize.
All exploits in this study are assumed to be zero-day exploits, meaning that they are unobserved by the defender when used against the corresponding operating system. Intuitively, the defender has no detection capability against an attack they have no knowledge of. This has ramifications in the sense that the defender has no means or reason to change their own defensive strategy, and hence will stick to the preassigned strategy.
We note that while the agents in agent-based models typically manifest attributes such as heterogeneity, adaptation, interaction, autonomy, and situatedness [21, 22], our current game scenario focuses primarily on one of these attributes, namely adaptive strategy development. Our intention in this study is to focus on developing a powerful set of tools for modeling adaptive strategy evolution in cyber agent systems. These tools will be incorporated into more complete agent contexts in future studies.
## 2.2. Moore Machine Strategy Encoding
Afinite-state automata or finite-state machine is an abstract machine that takes discrete inputs from an environment and specifies a discrete output in response. An agent modeled by a finite state machine will occupy only one state at any point in time. Such an agent transitions between states based on triggering events. A Moore machine [23] is one kind of finitestate automata in which the output from the machine depends solely on the machine's internal state.
AMoore machine is formally defined by four components, < Q q , 0 , L x , > , where Q is the set of possible internal states, q 0 ∈ Q is the internal state the machine begins in, L is a function mapping the internal states to actions in the game being played, and x is the transition function mapping an internal state of the machine and the observed move of the opponent into the next internal state that will become active. Moore machines provide a simple, yet rich and flexible tool with which to encode and evolve game strategies [17].
Figure 1 shows the transition diagram for a possible strategy for the game studied in this work represented as a Moore machine. Here s marks the state the machine begins a game in. States are labeled by L : Q → Ai ∈ { E 1 , E 2 , ... En } , where En indicates the attacker devotes his zero-day exploit cre-
Figure 1. Transition diagram for a possible attacker strategy. In this example the attacker invests in the creation of platform zero-day vulnerabilities with a frequency proportional to the platforms it observes the defender to activate in the rounds of play.
ation resource in the current round to the creation of an exploit for platform n . The transitions in Fig. 1 are labeled by { P 1 , P 2 , ... Pn } , indicating that the attacker transitions to its next active state based on the platform Pn it observes the defender to have made active in the current round.
To summarize, the attacker makes an initial investment En in the creation of zero-day exploit for platform n , observes the platform type the defender has activated in the current round of its moving target defense, and selects the next investment in exploit creation to make based on this information.
## 2.3. Genetic Algorithm
The central issue this simulation model aims to address is the efficiency and effectiveness with which an adversary learns to counter various moving target defense strategies. Learning and adaptation is modeled here using a genetic algorithm [24]. The genetic algorithm is a robust search method that does not require its objective function to be linear or continuous and has proven itself efficient at searching large fitness landscapes. The algorithm used in this study is outlined in Algorithm 1.
In this initial version of the study the defender chooses one operating system to make active in each round from its supply of two operating systems. We call this initial version of the attacker-defender contest the binary game . We denote the operating systems available to the defender as OS-A and OSB . As stated previously the attacker can create a zero-day exploit effective against each operating system available to the defender. We denote these ZD-A and ZD-B .
The Moore machine is mapped into a binary chromosome according to the scheme described in [17]. We limit the Moore machine representation to 16 states, following [17]. Auxiliary studies show limiting the Moore machines used in the study to 16 states does not strongly affect strategy development in our simple game scenario. Each state of the 16 state Moore machine maps to 9 bits of a binary chromosome. One of the bits specifies the exploit type that will be invested in when the attacker occupies the state. The subsequent 8 bits specifies the two transitions (4 bits for each transition en-
## Algorithm 1 Implemented Genetic Algorithm
- 1) At generation g =1, randomly initialize N strategies, i =1 to N .
- 2) Generate a fitness score Fi g , for each strategy based on its success against the defender.
- 3) Form a new population of N structures.
- a) Create 0 6 . N new strategies.
- i) Select 2 parents using the tournament selection algorithm (with replacement).
- ii) Form 2 children from the two selected parents through crossover.
- iii) Repeat (i) (ii) until 0 6 . N new structures are formed.
- b) Select 0 4 . N strategies from the old population using tournament selection and copy them into the new generation.
- 4) Mutate (see below) the new generation of strategies
- 5) Increment g by 1 (next generation), and iterate (go to Step 2).
coded in a binary representation) the attacker can make out of the state based on its observation of the operating system the defender makes active in the current round. This is depicted in Fig. 2. An additional 4 bits are added to the chromosome to specify the starting state for the machine. These factors together lead to the 148 bit chromosome used in this study to encode the attacker strategy.
This encoding scheme has been previously used to study strategy co-evolution in the Iterated Prisoner's Dilemma (IPD) [17, 25]. To the best of our knowledge, this study marks the first application of this encoding scheme developed in the IPD literature to a resource allocation problem, and its first application to a cyber security problem.
A single-point crossover operation is used in this study. In this operation, a single crossover point z ∈ { 1 2 , , ... 148 } on each of two parent chromosomes is selected at random. The first child combines the first z bits from the first parent with all bits after the z + 1 chromosome position of the second parent to form a new chromosome. The second child takes all bits after the z + 1 chromosome position from the first parent and combines it with the first z bits of parent two's chromosome to form a new strategy.
The mutation operation is implemented here such that each chromosomal position on each of the strategy population members has a low probability of mutation in each generation, with the probability being specified by a mutation rate parameter in the model. The mutation rate is selected in our study such that on average half of the chromosomes experience a single bit flip in each generation.
Figure 2. Chromosomal structure for an attacker strategy consisting of a single state. Chromosome bits are represented by # ∈ { 0 1 , } . Each attacker state is represented in the chromosome by 9 bits, 1 bit for the action specification, and 4 bits each for the two transition states in this example. Binary encoding is used throughout.
## 2.4. Model for Attacker Fitness
Attacker fitness determination takes into account three aspects of the attacker's play against the defender. These are game play success ( G ), exploit creation success ( C ), and strategic complexity costs ( S ). In generation g attacker i has a fitness function of the form,
$$F _ { i, g } = G _ { i, g } + C _ { i, g } - S _ { i, g }. \quad \quad \ \ ( 1 ) \quad \text{nat}$$
Game payoff for attacker i in generation g is expressed in terms of the attacker's success ( F i , j ) in compromising the system with its created zero-day exploits in the course of play against defender j ,
$$G _ { i, g } = \sum _ { j = 1 } ^ { T _ { g } } \Phi _ { i, j }, \quad \quad ( 2 ) \quad \begin{array} { c } \text{a\varepsilon} \\ 2. \end{array}$$
with F i , j set to 1 if the attacker successfully compromises defender j 's system in a given match, and 0 otherwise. Tg is the total number of matches in a given generation between attacker i and defender j . For example, if in a 365-match game the attacker compromises the defender's system for 50 matches, then the Gi g , term is set to 50 in Eqt. 1.
The Ci g , term in Eqt. 1 models the notion that each exploit created brings an intrinsic reward, d , to the attacker, independent of their subsequent use in actual attacks. After examining the effect a range of possible values for d have on attacker strategy, we set d equal to a value of 1 in this study. This value encourages balanced investment by the attacker while directly impacting overall fitness scores minimally. If Zg exploits are created by attacker i in generation g we have,
$$C _ { i, g } = \sum _ { k = 1 } ^ { Z _ { g } } \delta _ { i, k }. \quad \ \ \ ( 3 )$$
As an example, if 2 exploits are created in the course of an attacker-defender game, we have Ci g , = 2 d i = 2, using our chosen d value.
The third fitness criteria is the strategic complexity ( Si g , ) of attacker i 's exploit investment policy. We quantify the complexity cost as,
$$S _ { i, g } = \beta \gamma \tau _ { i, g }.$$
Here t i g , is the number of transitions attacker i makes between Moore machine states in the course of its matches against the defender in a given generation g . This is multiplied by g , the transition-penalty term, which we set to max [ F i , j ] , and the unit strategic complexity b , ranging between 0 and 1. The value of b can be adjusted to emphasize or de-emphasize the importance of strategic complexity in the fitness evaluation. The strategic complexity term in Eqt. 1 is of a similar form to that used in [25] for characterizing complexity costs in the IPD.
A less complex strategy is one with a simpler transition structure [26], i.e. given a certain level of success against the defender, a strategy that causes the Moore machine encoding the attacker strategy to transition less often between states is preferable. We leverage this to imitate the natural cost/benefit analysis that any human actor factors into strategy determination; a slightly less rewarding strategy is often preferable if it is significantly less complex. As a baseline value, we find that setting b = 0 1 biases evolved strategies toward simplic-. ity without causing strong distortions in game play policy. We adopt this value throughout the study. Taking this value for b we find that an attacker that makes 30 transitions between Moore machine states in the course of a 365-match game pays a strategic complexity cost of 3 points, for example.
## 2.5. Investment Bias Metric
We define the Investment Bias , G , the normalized difference between the mean investment in the creation of ZD-A versus ZD-B exploits, as a measure of the inequality in attacker resource investment,
$$\Gamma = \frac { \langle I _ { Z D B } \rangle - \langle I _ { Z D A } \rangle } { \langle I _ { Z D B } \rangle + \langle I _ { Z D A } \rangle },$$
where < IZD > is the average investment in a zero-day exploit ( ZD ) over a population of N attacker strategies and a number of simulation runs carried out to account for stochasticity in the model. Particular emphasis is placed on the investment bias in the analysis below because attacker exploit creation investment patterns directly reflect the learned attacker strategy. Alternative measures of strategy are dependent on factors exogenous to learned attacker strategy such as exploit
Figure 3. Example Gamma distribution parameterizations with µ = 100 and s 2 set as indicated.
creation cost values. Attacker investment bias offers the most direct insight into attacker strategy.
## 3. EXPERIMENTS
## 3.1. Simulation Set-Up
For ease of interpretation, and without loss of generality, we limit the defender to 2 platforms in this study. Each parameterization of the simulation was allowed to evolve for 100 generations, with a single generation consisting of each of the N = 30 attacker strategies in the population playing T = 365 matches against the defender. The 100 generation run was repeated 100 times to account for stochasticity in the model. Simulations were created and run in the NetLogo modeling environment [27].
Recall that the attacker resource investment required to bring a given zero-day exploit into existence is stochastic and unknown to the attacker. We determine this cost by sampling a Gamma distribution parameterized by shape parameter a and rate parameter l . The shape and rate parameters can be written in terms of a mean ( µ ) and variance ( s 2 ) according to the relations,
$$\alpha = \frac { \mu ^ { 2 } } { \sigma ^ { 2 } }, \lambda = \frac { \mu } { \sigma ^ { 2 } }. \quad \quad \ ( 6 ) \quad \ t a c { \ t a c { \ t h i } }$$
The parameterization of the Gamma distribution for zero-day costs is set at the beginning of each generation of genetic algorithm evolution through the choice of a mean and variance value. The effect parameterization choices has on the resulting distribution of exploit creation costs is shown in Fig. 3. For the duration of this study, we set µ = 100 and s 2 = 30 for exploit creation.
## 3.2. The 1-to-1 Game
Wedenote by the 1-to-1 Game a series of contests in which the attacker faces defenders that activate OS-A and OS-B with approximately equal frequency in each contest. We use the term contest and the term game interchangeably to denote a set of T matches that a single attacker plays consecutively against the defender. While within a game the frequency of OS-A and OS-B activation is equal, the distribution of these activations among the T matches differs among defender types within the 1-to-1 defender family.
The SingleFlip-FixedOrder defender activates OS-A in 182 consecutive matches, then switches to OS-B for the next 183 matches. The defender denoted by SingleFlipRandomOrder plays a similar strategy, but instead of predictably playing OS-A for half the matches then switching to OS-B, this defender instead decides uniformly at random at the start of each game whether to begin play with OSA or OS-B. The EachMatchFlip-FixedAlternating defender plays OS-A followed by OS-B, followed by OS-A, then OS-B again, and so on, alternating between activating each operating system on each consecutive match. Finally, the EachMatchFlip-RandomOrder defender chooses at random on each match whether to activate OS-A or OS-B.
Figure 4 shows the mean attacker fitness as well as the strategic complexity cost and game payoff results as a function of the genetic algorithm generation. The attacker is able to evolve more effectively against the SingleFlip defenders in which the defender predictably activates one of the operating systems available to it during each half of match play. Figure 5 shows the investment bias ( G ) (see Section 2.5.) for these 1-to-1 cases. The frequency of defender OS activations within a game strongly influences the investment bias of the attacker's learned strategy, with the 1-to-1 defender strategies causing the attacker to evolve strategies with investment bias clustered around zero, indicating balanced investment in ZDA and ZD-B creation over the course of a game. The deviation from this pattern in G is for the SingleFlip-FixedOrder defender, which causes the attacker to invest more heavily in ZD-A.
Aclearer picture of learned attacker strategy can be gained from understanding the match-level choices the attacker is making. We find that when the defender predictably plays a monolithic OS-B strategy in later rounds of the game the attacker quickly (generationally) learns to predict and exploit this regularity, ignoring the defender's early activations of OS-A and focusing investment on the creation of ZD-B for use in the second half of the game. Note that this learned strategy by the attacker is also taking account for the approximate cost of zero-day exploit creation in that the attacker has learned after a few generations that it needs to begin investing in the creation of ZD-B well before the defender begins activating OS-B in order to gain full benefit from the defender's
Figure 4. Attacker fitness (upper), state transitions (middle), and game payoff (lower) averaged over the 30 agent population and 100 simulation runs for the 4 defenders playing 1-to1 strategies.
predictable behavior. Also note that while the attacker does learn the approximate cost of exploit creation (the mean cost of exploit creation is 100 units in this example), the attacker seems to believe the cost is approximately 182 units, only switching to invest in the creation of ZD-A after the defender transitions from playing OS-A to OS-B at the 182nd round.
Figure 5. Attacker investment bias ( G ) for each of the platform migration policies in the 1-to-1 defender family.
This inability of the attacker to learn to predict the true exploit creation costs was found to be a robust feature of the learning algorithms used for the present game. We believe this observation is related to the fact that the attacker uses all available exploits against the defender's system on each match, which we speculate makes the attacker insensitive to the precise effect the play of each individual exploit is having on the game payoff. This is a topic we plan to revisit in future studies which will look at other variants of evolutionary algorithms and game structure to understand more fully why the current attacker consistently fails to distinguish the true costs of exploit creation from the ratio of defender play of said exploits.
A portion of the superior performance of the attacker against the SingleFlip defenders can be traced to superior game-play strategies for these SingleFlip cases (Fig. 4 (lower)), and a portion can be traced to the ability of the attacker to discover strategies of minimal complexity costs (Fig. 4 (middle)). Future studies will examine the robustness under b variation of strategic complexity cost differences for attackers facing SingleFlip versus EachMatchFlip defenders. In the case shown in Fig. 4 it makes intuitive sense that the attacker requires less strategic complexity to counter a defender that only changes its actions once during match play, as opposed to a defender that is executing migration policies with structure on the scale of a few matches.
It is interesting to note the the attacker performs nearly as well against the SingleFlip-RandomOrder defender, which randomly chooses between two available platform migration policies at the start of each generation, as it does against the more predictable SingleFlip-FixedOrder defender, though the less predictable SingleFlip defender causes a noisier attacker response. Examining the match level structure of the attacker response to the SingleFlip-RandomOrder defender we find that the attacker has learned after a number of generations to observe the defender's move in match 1 of the game and predict all future OS activations by the defender, thus gaining the ability to efficiently counter the defender despite the random element in the defender's policy. This has implications to other active defense techniques, such as Address Space Layout Randomization (ASLR) [28], for which randomization only increases the adversary's initial uncertainty and the entire system can be compromised given a single observation.
It is important to note that these results not only have implications to the attacker, who learns an optimal strategy against a specified defender, but also the defender as well. By evaluating the optimal fitness of an attacker against differing defenders, we also uncover the efficacy of different defensive strategies. If we assume the interaction is a zero-sum game any gains by the attacker are losses by the defender - then the defender's goal should be to minimize the attacker fitness.
## 3.3. The 2-to-1 Game
In the 2-to-1 game the attacker faces a set of defenders that activate OS-A at a 2-to-1 ratio to OS-B. As with the 1-to1 game, in the 2-to-1 case the frequency of OS-A and OSB activation is 2 : 1 over the 365 matches taken as a whole, with the distribution of these activations among the matches differing among defender types.
The evolved attacker responses to these defender policies are shown in Fig.6. Here the SingleFlip-A-FixedOrder defender activates OS-A monolithically for the first 243 matches of a game, then switches to OS-B for the remaining 122 matches. On the other hand, the SingleFlip-B-FixedOrder defender begins match play by activating OS-B for 122 consecutive matches, then switches to OS-A for the remaining 243 matches of the game. In reaction to the different members of the 2-to-1 family of defenders we see two different classes of responses by the attacker. The first, and simpler, type of response has the attacker deciding to essentially only invest in the creation of ZD-A, completely neglecting attacks against the less activated OS-B. The attacker uses this class of strategy against the EachMatchFlip-FixedAlternating and EachMatchFlip-UniformRandom defenders. We note in Fig. 6 that although a priori this might seem a simple response by the attacker to biased defender policies, the strategic complexity cost is not negligible. We hypothesize that variability in the defender's OS activations on the scale of a few matches is an important factor in determining the transition structure (and so the strategic complexity cost) of the evolved attacker machines. This implies that a simple attacker response to a highly dynamic migration policy might entail a greater strategic complexity cost than would be expected from the attacker's simple actions alone. We will return to this question in a future study.
The second class of attacker response has the attacker mak-
Figure 6. Attacker fitness (upper), state transitions (middle), and game payoff (lower) averaged over the 30 agent population and 100 simulation runs for the 5 defenders playing 2-to1 strategies.
ing predictions about future defender activation activity and tuning resource investment accordingly. This prediction strategy is most successful against the SingleFlip-B-FixedOrder defender, where the attacker learns to ignore the activation of OS-B in the first 122 matches of play, investing instead in ZD-A which has been brought into existence by the time the
Figure 7. Attacker investment bias ( G ) for each of the platform migration policies in the 2-to-1 defender family.
defender begins its 243 match run of OS-A activation. The tactical outcome of this attacker strategy bears resemblance to the simpler class of strategies discussed above in that only the ZD-A exploit ends up significantly benefiting the attacker, but the strategy underlying this result is quite different in the present case as evidenced by the distinctive investment bias result for the attacker facing the SingleFlip-B-FixedOrder defender in Fig. 7.
The attacker attempts a similarly intricate investment scheme when facing the SingleFlip-A-FixedOrder defender, but to diminished success due primarily to the earlier noted inability to discern the true costs of exploit creation. When facing the SingleFlip-A-FixedOrder defender the attacker learns to begin with focused investment in ZD-A to capitalize on the defenders early monolithic play of OS-A. The attacker continues investing heavily in ZD-A creation until the defender transitions to playing OS-B late in the game, investing well beyond the resources required to bring ZD-A into existence, resulting in a suboptimal result for the attacker. We speculate again that the learning algorithms underlying the attacker behavior are having difficulties grasping the fact that the attacker does not need to continue investing in an exploit after it has been created in order to benefit from its play against the defender. Again, we will take up this issue in a future study.
The SingleFlip-RandomOrder defender randomly switches between the SingleFlip-A-FixedOrder and the SingleFlip-BFixedOrder policies in each generation. The response to this more variable defender is similar to that in the 1-to-1 case, in which the attacker strategy is wholly defined based on the observations of the initial activation by the defender. The defender's choice of which migration to activate in each round varies randomly between simulation runs, causing the aggregate result shown in Fig. 6 to be noisy (and reflective of the actual strategies being employed by the attacker only in a very approximate sense).
## 4. CONCLUSION
We have developed a model of adaptive strategy formulation and used it to study the choices an attacker learns to make to overcome temporal platform migration moving target defense strategies. The attacker-defender interaction has been modeled as a game in which a non-adaptive defender deploys a temporal platform migration defense. Against this active defense, a population of attackers developed strategies specifying the temporal ordering of resource investments that bring zero-day exploits into existence to compromise the defender's system.
Wenote that in this study, the attacker has often ignored the effects of causality by learning over generations which platforms the defender will play before they are actually played in each game. This actually maps to realistic scenarios, when an attacker is able to perform reconnaissance to learn a strategy before engaging a system. Random strategies do not suffer nearly as strongly as those which are predictable, suggesting that increased uncertainty, even with a defined strategy, improves defender performance.
This work has strong implications in cyber security, as it enables defenders to understand their defensive posture without having to explicitly detail an attacker. The reality is that defenders often do not know their adversaries' strategies, but they do know some of their goals, which can be codified into a fitness function. While we have demonstrated a simple case study in this paper, the framework we have developed is highly extensible and will be used to answer very detailed questions. In future work, we aim to expand this study by including complex defender strategies, numerous platforms, and the ability for adversaries to develop exploits that work against multiple systems.
## ACKNOWLEDGMENTS
We thank William Streilein, Seth Webster, and Neal Wagner of MIT Lincoln Laboratory for helpful discussions.
## REFERENCES
- [1] Bilar, Daniel, George Cybenko, and John Murphy. Adversarial Dynamics: The Conficker Case Study. Moving Target Defense II , 41-71, 2013.
- [2] Colbaugh, Richard and Kristin Glass. Proactive Defense for Evolving Cyber Threats. Sandia Report , SAND201210177, 2012.
- [3] Okhravi, Hamed, Mark Rabe, Travis Mayberry, Thomas Hobson, David Bigelow, William Leonard, and William Streilein, Survey of Cyber Moving Target Techniques.
- MIT Lincoln Laboratory Technical Report , Number 1166, 2013.
- [4] Sushil Jajodiaj, A. Ghosh, V. Swarup, C. Wang, X. S. Wang (Eds). Moving Target Defense: Creating Asymmetric Uncertainty for Cyber Threats . Springer, 2011.
- [5] Sushil Jajodiaj, A. Ghosh, V. Subrahmanian, V. Swarup, C. Wang, X. S. Wang (Eds). Moving Target Defense II: Application of Game Theory and Adversarial Modeling . Springer, 2013.
- [6] H. Okhravi, A. Comella, E. Robinson, and J. Haines. Creating a cyber moving target for critical infrastructure applications using platform diversity. International Journal of Critical Infrastructure Protection , 5(1):30 - 39, 2012.
- [7] Colbaugh, R., and K. Glass. Predictability-Oriented Defense Against Adaptive Adversaries. Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics , 2012.
- [8] Carter, Kevin M., Hamed Okhravi, and James Riordan. Quantitative Analysis of Active Cyber Defenses Based on Temporal Platform Diversity. arXiv: 1401.8255, 2014.
- [9] Crosbie, M. and E. Spafford. Applying Genetic Programming to Intrusion Detection. Working Notes for the AAAI Symposium on Genetic Programming . MIT Press, 1995.
- [10] Dasgupta, D. and F. A. Gonzalez. An Intelligent Decision Support System for Intrusion Detection and Response. Information Assurance in Computer Networks , 1-14, 2001.
- [11] Pillai, M. M., J. H. Eloff, and H. S. Venter. An Approach to Implement a Network Intrusion Detection System Using Genetic Algorithms. Proceedings of the South African Institute of Computer Scientists , 221, 2004.
- [12] Li, Wei. Using Genetic Algorithm for Network Intrusion Detection. Proceedings of the United States Department of Energy Cyber Security Group , 1-8, 2004.
- [13] Caltagirone, S. Evolving Active Cyber Defense Strategies. University of Idaho Technical Report . CSDS-DFTR-05-27, 2005.
- [14] Crouse, M. and E. W. Fulp. A Moving Target Environment for Computer Configurations. IEEE Configuration Analytics and Automation, 4:1-7, 2011.
- [15] Crouse, M., E. W. Fulp, and D. Canas. Improving the Diversity Defense of Genetic Algorithm-Based Moving Target Approaches. Proceedings of the National Symposium on Moving Target Research , 2012.
- [16] Axelrod, R. The Evolution of Strategies in the Iterated Prisoner's Dilemma. Genetic Algorithms and Simulated Annealing , 32-41, 1987.
- [17] Miller, J. H. The Coevolution of Automata in the Repeated Prisoner's Dilemma. Journal of Economic Behavior and Organization , 29:87-112, 1996.
- [18] Aumann, R. J. Survey of Repeated Games. Essays in Game Theory and Mathematical Economics in Honor of Oskar Morgenstern , 11-42, 1981.
- [19] Rubinstein, A. Finite Automata Play the Repeated Prisoner's Dilemma. Journal of Economic Theory , 39: 8396,1986.
- [20] Abreu, D. and A. Rubinstein. The Structure of Nash Equilibrium in Repeated Games with Finite Automata. Econometrica , 56:1259-1281, 1988.
- [21] Tolk, Andreas, and Adelinde M. Uhrmacher. Agents: Agenthood, Agent Architectures, and Agent Taxonomies. Agent-Directed Simulation and Systems Engineering , 75-109, 2009.
- [22] Yilmaz, Levent, and Tuncer I. ¨ ren. O Agent-directed Simulation. Agent-Directed Simulation and Systems Engineering , 111-143, 2009.
- [23] Moore, E. F. Gedanken-experiments on Sequential Machines. Annals of Mathematical Studies . 34:129-153. Princeton University Press, 1956.
- [24] J. H. Holland, Adaptation in Natural and Artificial Systems .The University of Press, 1975.
- [25] Ho, Teck-Hua. Finite automata play repeated prisoner's dilemma with information processing costs. Journal of economic dynamics and control . 20:173-207, 1996.
- [26] Banks, J. and R. Sundara. Repeated games, finite automata and complexity. Games and Economic Behavior , 2:97-117, 1990.
- [27] Wilensky, U. 1999. NetLogo. http://ccl.northwestern. edu/netlogo/. Center for Connected Learning and Computer-Based Modeling, Northwestern University. Evanston, IL.
- [28] Shacham, H. and Page, M. and Pfaff, B. and Goh, E.J. and Modadugu, N. and Boneh, D. On the Effectiveness of Address-Space Randomization. Proceedings of the 11th ACM Conference on Computer and Communications Security , pp. 298-307, 2004. | null | [
"Michael L. Winterrose",
"Kevin M. Carter"
] | 2014-07-31T20:32:09+00:00 | 2014-07-31T20:32:09+00:00 | [
"cs.CR",
"cs.GT"
] | Strategic Evolution of Adversaries Against Temporal Platform Diversity Active Cyber Defenses | Adversarial dynamics are a critical facet within the cyber security domain,
in which there exists a co-evolution between attackers and defenders in any
given threat scenario. While defenders leverage capabilities to minimize the
potential impact of an attack, the adversary is simultaneously developing
countermeasures to the observed defenses. In this study, we develop a set of
tools to model the adaptive strategy formulation of an intelligent actor
against an active cyber defensive system. We encode strategies as binary
chromosomes representing finite state machines that evolve according to
Holland's genetic algorithm. We study the strategic considerations including
overall actor reward balanced against the complexity of the determined
strategies. We present a series of simulation results demonstrating the ability
to automatically search a large strategy space for optimal resultant fitness
against a variety of counter-strategies. |
1408.0024v1 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-4
## Extracting the bulk viscosity of the quark-gluon plasma
Jean-Bernard Rose a , Jean-Francois Paquet , Gabriel S. Denicol , Matthew Luzum a a a,b , Bjoern Schenke c , Sangyong Jeon a , Charles Gale a a Department of Physics, McGill University, 3600 rue University, Montr´ eal, Qu´ ebec H3A 2T8, Canada b Lawrence Berkeley National Laboratory, Berkeley, CA 94720, USA c Physics Department, Brookhaven National Lab, Building 510A, Upton, NY, 11973, USA
## Abstract
We investigate the implications of a nonzero bulk viscosity coe GLYPH<14> cient on the azimuthal momentum anisotropy of ultracentral relativistic heavy ion collisions at the Large Hadron Collider. We find that, with IP-Glasma initial conditions, a finite bulk viscosity coe GLYPH<14> cient leads to a better description of the flow harmonics in ultracentral collisions. We then extract optimal values of bulk and shear viscosity coe GLYPH<14> cients that provide the best agreement with flow harmonic coe GLYPH<14> cients data in this centrality class.
## 1. Introduction
Currently, most fluid-dynamical simulations of relativistic heavy ion collisions take into account only dissipative e GLYPH<11> ects originating from shear viscosity. However, QCD is a nonconformal field theory and in principle there is no a priori reason to neglect the e GLYPH<11> ects of bulk viscous pressure. In this contribution, we explore the phenomenological implications of a nonzero bulk viscosity coe GLYPH<14> cient on the azimuthal momentum anisotropy of ultracentral heavy ion collisions at the Large Hadron Collider (LHC). We then extract optimal values of bulk and shear viscosity coe GLYPH<14> cients that are able to describe the flow harmonic coe GLYPH<14> cients in this centrality class. We find that, with IP-Glasma initial conditions, a finite bulk viscosity coe GLYPH<14> cient improves the description of flow harmonics in ultracentral collisions.
## 2. Fluid-dynamical model of the collision
In this work we simulate ultrarelativistic heavy ion collisions in the 0-1% centrality class at LHC energies. The initial energy density profile is obtained using the IP-Glasma initial condition model, with a thermalization time of GLYPH<28> 0 = 0 4 fm [1]. : The time evolution of this system is determined using relativistic dissipative fluid dynamics, with the main equations of motion being the continuity equation for the energy-momentum tensor, T GLYPH<22>GLYPH<23> , @GLYPH<22> T GLYPH<22>GLYPH<23> = 0, where T GLYPH<22>GLYPH<23> = " u u GLYPH<22> GLYPH<23> GLYPH<0> GLYPH<1> GLYPH<22>GLYPH<23> ( P 0 +GLYPH<5> ) + GLYPH<25> GLYPH<22>GLYPH<23> , with " being the energy density, P 0 the thermodynamic pressure, GLYPH<5> the bulk viscous pressure, and GLYPH<25> GLYPH<22>GLYPH<23> the shear-stress tensor. We further introduced the projection operator GLYPH<1> GLYPH<22>GLYPH<23> = g GLYPH<22>GLYPH<23> GLYPH<0> u u GLYPH<22> GLYPH<23> onto the 3-space orthogonal to the fluid velocity. We assume that the baryon number density and di GLYPH<11> usion are zero at all space-time points and our metric convention is g GLYPH<22>GLYPH<23> = diag( + 1 ; GLYPH<0> 1 GLYPH<0> 1 GLYPH<0> 1).
The conservation laws and equation of state P 0 ( " ) are not enough to determine the time evolution of T GLYPH<22>GLYPH<23> . In order to do so, one still needs to provide the time-evolution or constitutive equations satisfied by GLYPH<5> and GLYPH<25> GLYPH<22>GLYPH<23> . For this purpose, we employ relaxation-time equations derived from kinetic theory [2, 3], solved numerically using the music
hydrodynamic simulation [4, 5]. Explicitly, we solve
$$\tau _ { \Pi } \dot { \Pi } + \Pi \ = \ - \zeta \theta - \delta _ { \Pi \Pi } \Pi \theta + \lambda _ { \Pi \pi } \pi ^ { \mu \nu } \sigma _ { \mu \nu }$$
$$\tau _ { \pi } \dot { \pi } ^ { ( \mu \nu ) } + \pi ^ { \mu \nu } \ = \ 2 \eta \sigma ^ { \mu \nu } + 2 \tau _ { \pi } \pi _ { \alpha } ^ { ( \mu } \omega ^ { \nu ) \alpha } - \delta _ { \pi \pi } \pi ^ { \mu \nu } \theta + \varphi _ { \gamma } \pi _ { \alpha } ^ { ( \mu } \pi ^ { \nu ) \alpha } - \tau _ { \pi \pi } \pi _ { \alpha } ^ { ( \mu } \sigma ^ { \nu ) \alpha } + \lambda _ { \pi \Pi } \Pi \sigma ^ { \mu \nu }.$$
The above equations of motion include nonlinear terms that couple bulk viscous pressure to the shear-stress tensor and vice-versa. Recently, they were shown to be in good agreement with solutions of the 0 + 1 Anderson-Witting equation in the massive limit [6]. The transport coe GLYPH<14> cients GLYPH<28> GLYPH<5> , GLYPH<16> , GLYPH<14> GLYPH<5>GLYPH<5> , GLYPH<21> GLYPH<5> GLYPH<25> , GLYPH<28> GLYPH<25> , GLYPH<17> , GLYPH<14> GLYPH<25>GLYPH<25> , ' 7 , GLYPH<28> GLYPH<25>GLYPH<25> , and GLYPH<21> GLYPH<25> GLYPH<5> are complicated functions of temperature. For strongly coupled fluids, such as the quark-gluon plasma created at the LHC, their values are not known. As a first step, we fix the parametric dependence of all transport coe GLYPH<14> cients on the shear viscosity, GLYPH<17> , and bulk viscosity, GLYPH<16> , using formulas derived from the Boltzmann equation near the conformal limit [3].
The shear viscosity is assumed to be proportional to the entropy density, i.e., GLYPH<17> = as , where the parameter a is fixed by fitting the data. In simulations using IP-Glasma initial conditions that include only dissipative e GLYPH<11> ects from shear viscosity, one usually obtains a = 0 20 : GLYPH<0> 0 22 at LHC energies [7, 8]. The bulk viscosity coe : GLYPH<14> cient is parametrized as [3]
$$\zeta = b \times \eta \left ( \frac { 1 } { 3 } - c _ { s } ^ { 2 } \right ) ^ { 2 },$$
where cs is the velocity of sound and b a parameter that will also be adjusted to fit the data. Of course, the actual temperature dependence of each viscosity coe GLYPH<14> cient is not known for QCD matter. Nevertheless, the aforementioned parametrizations should be able to capture the relevant features of dissipation and will be enough for the purposes of this initial study.
The final state hadrons are produced following the usual Cooper-Frye procedure [9], in the same way as outlined in Ref. [8]. The only di GLYPH<11> erence is that we have to specify the nonequilibrium correction to the hadron momentum distribution function due to bulk viscosity, in addition to the usual correction due to shear viscosity . Here, we employ the distribution derived from the Boltzmann equation using the relaxation time approximation, also used by Bozek et al [10],
$$\delta f _ { \Pi } ^ { i } \ = \ - f _ { 0 \text{k} } ^ { i } \left ( 1 \pm f _ { 0 \text{k} } ^ { i } \right ) \left [ \frac { 1 } { u _ { \mu } k _ { i } ^ { \mu } } \frac { m _ { i } ^ { 2 } } { 3 } - \left ( \frac { 1 } { 3 } - c _ { s } ^ { 2 } \right ) u _ { \mu } k _ { i } ^ { \mu } \right ] \frac { \Pi } { C _ { \Pi } },$$
$$C _ { \Pi } \ = \ \frac { 1 } { 3 } \sum _ { i = 1 } ^ { N } m _ { i } ^ { 2 } g _ { i } \int d K _ { i } \, f _ { 0 \text{k} } ^ { i } \left ( 1 \pm f _ { 0 \text{k} } ^ { i } \right ) \left [ \frac { 1 } { u _ { \mu } k _ { i } ^ { \mu } } \frac { m _ { i } ^ { 2 } } { 3 } - \left ( \frac { 1 } { 3 } - c _ { s } ^ { 2 } \right ) u _ { \mu } k _ { i } ^ { \mu } \right ].$$
Above, k GLYPH<22> i , mi , and gi are the 4-momentum, mass, and degeneracy factor of the i -th hadron species, respectively, N is the number of hadrons considered in the calculation, and f i 0 k is the Fermi-Dirac or Bose-Einstein distribution function.
We note that the IP-Glasma initial conditions used in this work include the e GLYPH<11> ect of nucleon-nucleon correlations in the initial state. Such correlations were recently found to be important when simulating central and ultracentral collisions with the IP-Glasma model [8].
## 3. Results
We calculate the integrated elliptic flow coe GLYPH<14> cient vn f 2 g via the cumulant method. In order to compare with CMSdata [12], we use a lower cut o GLYPH<11> of 0.3 GeV when performing integrals in the transverse momentum, pT . All our calculations were done using the parametrization of the lattice QCD equation of state by Huovinen and Petreczky [11]. The calculations with bulk viscosity were all performed in chemical equilibrium and with a freezeout temperature of TFO = 140 MeV. The calculations with only shear viscosity were performed using the same parameters as in [8], with a chemical freezeout temperature of TCF = 150 MeV and TFO = 103 MeV. In all figures, the shaded bands represent the statistical uncertainty.
In Fig. 1 we show the results for a given shear viscosity, GLYPH<17>= s = 0 15, and several values of : b = 15, 45, and 75. We see that increasing the value of bulk viscosity improves the agreement with the flow harmonics measured by CMS. In Fig. 1(b), we compare a simulation which includes only shear viscosity, with GLYPH<17>= s = 0 22, to another with : GLYPH<17>= s = 0 15 :
Figure 1. (Color online) Comparison of the flow harmonics, vn f 2 , calculated using IP-Glasma initial conditions, with with CMS data for the 0-1% g centrality class and for several values of the parameter b.
and b = 15. Both calculations provide an almost equally good agreement with the flow harmonics measured by CMS, but with rather di GLYPH<11> erent values of shear viscosity. In this case, including bulk viscosity reduced the value of GLYPH<17>= s by 32%, from 0.22 to 0.15.
In Fig. 2(a) we show what happens when the parameter b is fixed as b = 45 and the shear viscosity is varied, taking the values GLYPH<17>= s = 0 12, 0.15, and 0.18. : Note that the parametrization of bulk viscosity used in this work, Eq. (3), is linear in the shear viscosity, so keeping b constant does not imply that the bulk viscosity is kept fixed. In this figure we see that the value of shear viscosity that provides the best overall agreement with the CMS data is GLYPH<17>= s = 0 15, : which was the value already employed in the simulations discussed above.
Figure 2. In the left panel we show the flow harmonics, vn f 2 , calculated using IP-Glasma initial conditions, for g b = 45 and several values of GLYPH<17>= s (left panel). In the right panel we show the e GLYPH<11> ect of GLYPH<14> i f GLYPH<5> on vn f 2 . g
In Fig. 2(b) the results for GLYPH<17>= s = 0 18 and : b = 45 are shown calculated with and without the bulk component of GLYPH<14> f , GLYPH<14> i f GLYPH<5> . In contrast to the shear correction, the bulk correction to the single particle distribution function used in this work lead to an increase in the flow harmonics. Such an increase was systematically stronger for higher harmonics: v 2 f 2 g is increased by 4%, v 3 f 2 g by 8%, v 4 f 2 g by 20%, v 5 f 2 g by 57%, and v 6 f 2 g by 117%. Therefore, in order to properly
describe higher harmonics, it is important to take into account the GLYPH<14> i f GLYPH<5> contribution. However, one should note that di GLYPH<11> erent momentum dependences for this quantity can provide rather di GLYPH<11> erent results.
Finally, we show the e GLYPH<11> ect of bulk viscosity on the mean transverse momentum of pions, h p GLYPH<25> T i , in Fig. 3. Our calculations are compared to ALICE data [13] in the 0-5% centrality class and, for this purpose, we used a lower cut-o GLYPH<11> of 0.12 GeV when performing integrals in transverse momentum. The e GLYPH<11> ect of bulk viscosity on h p GLYPH<25> T i is not small and can be used to further restrict the size of the bulk viscosity coe GLYPH<14> cient. Here, we see that the best description of h p GLYPH<25> T i happens when b = 20-40, for the case where GLYPH<17>= s = 0 15. Note that the : h p GLYPH<25> T i has a strong dependence on GLYPH<14> i f GLYPH<5> , so the optimal values we obtained can be modified if another GLYPH<14> i f GLYPH<5> is used.
Figure 3. (Color online) The mean transverse momentum of pions, h p GLYPH<25> T i , for several values of b compared to the ALICE data [13].
## 4. Conclusions
In this contribution we performed a preliminary study on the e GLYPH<11> ects of bulk viscous pressure in ultracentral relativistic heavy ion collisions at the LHC. We found that bulk viscous pressure can have non-negligible e GLYPH<11> ect on the flow harmonic coe GLYPH<14> cients in this centrality class. Furthermore, we showed that, at least for IP-Glasma initial conditions, the inclusion of bulk viscosity leads to a better description of the data. Although describing the anisotropy distribution of ultracentral events remains a challenge, we expect bulk viscosity to be a key ingredient in understanding such observables.
Acknowledgments: The authors thank H. Niemi and J. Jia for fruitful discussions. This work was supported in part by the Natural Sciences and Engineering Research Council of Canada, and by the U. S. DOE Contract No. DEAC02-98CH10886. G.S. Denicol acknowledges support through a Banting Fellowship of the Natural Sciences and Engineering Research Council of Canada, and C. G. acknowledges support from the Hessian Initiative for Excellence (LOEWE) through the Helmholtz International Center for FAIR (HIC for FAIR).
## References
- [1] B. Schenke, P. Tribedy and R. Venugopalan, Phys. Rev. C 86 , 034908 (2012).
- [2] G. S. Denicol, H. Niemi, E. Molnar and D. H. Rischke, Phys. Rev. D 85 , 114047 (2012).
- [3] G. S. Denicol, S. Jeon and C. Gale, accepted for publication in Phys. Rev. C, arXiv:1403.0962 [nucl-th].
- [4] B. Schenke, S. Jeon and C. Gale, Phys. Rev. C 82 , 014903 (2010).
- [5] H. Marrochio, J. Noronha, G. S. Denicol, M. Luzum, S. Jeon and C. Gale, arXiv:1307.6130 [nucl-th].
- [6] G. S. Denicol, W. Florkowski, R. Ryblewski and M. Strickland, arXiv:1407.4767 [hep-ph].
- [7] C. Gale, S. Jeon, B. Schenke, P. Tribedy and R. Venugopalan, Phys. Rev. Lett. 110 , 012302 (2013).
- [8] G. S. Denicol, C. Gale, S. Jeon, J. -F. Paquet and B. Schenke, arXiv:1406.7792 [nucl-th].
- [9] F. Cooper and G. Frye, Phys. Rev. D 10 , 186 (1974).
- [10] P. Bozek, Phys. Rev. C 81 , 034909 (2010).
- [11] P. Huovinen and P. Petreczky, Nucl. Phys. A 837 , 26 (2010).
- [12] S. Chatrchyan et al. [CMS Collaboration], JHEP 1402 , 088 (2014).
- [13] B. Abelev et al. [ALICE Collaboration], Phys. Rev. C 88 , no. 4, 044910 (2013). | 10.1016/j.nuclphysa.2014.09.044 | [
"J. -B. Rose",
"J. -F. Paquet",
"G. S. Denicol",
"M. Luzum",
"B. Schenke",
"S. Jeon",
"C. Gale"
] | 2014-07-31T20:42:38+00:00 | 2014-07-31T20:42:38+00:00 | [
"nucl-th",
"hep-ph"
] | Extracting the bulk viscosity of the quark-gluon plasma | We investigate the implications of a nonzero bulk viscosity coefficient on
the azimuthal momentum anisotropy of ultracentral relativistic heavy ion
collisions at the Large Hadron Collider. We find that, with IP-Glasma initial
conditions, a finite bulk viscosity coefficient leads to a better description
of the flow harmonics in ultracentral collisions. We then extract optimal
values of bulk and shear viscosity coefficients that provide the best agreement
with flow harmonic coefficients data in this centrality class. |
1408.0025v1 | ## Effects of electron irradiation on resistivity and London penetration depth of Ba 1 -x K Fe As x 2 2 ( x ≤ 0.34) iron - pnictide superconductor
K. Cho, 1 M. Ko´ nczykowski, 2 J. Murphy, 1 H. Kim, 1 M. A. Tanatar, 1
W. E. Straszheim, B. Shen, H. H. Wen, and R. Prozorov
1 3 3 1, ∗
1 The Ames Laboratory and Department of Physics &
Astronomy, Iowa State University, Ames, IA 50011, USA 2 Laboratoire des Solides Irradi´s, e CNRS UMR 7642 & CEA-DSM-IRAMIS,
Ecole Polytechnique, F-91128 Palaiseau cedex, France
3 Center for Superconducting Physics and Materials,
National Laboratory of Solid State Microstructures & Department of Physics, Nanjing University, Nanjing 210093, China (Dated: 28 July 2014)
Irradiation with 2.5 MeV electrons at doses up to 5.2 × 10 19 electrons/cm 2 was used to introduce point-like defects in single crystals of Ba 1 -x K Fe As x 2 2 with x = 0.19 ( T c = 14 K), x = 0.26 ( T c = 32 K) and 0.34 ( T c = 39 K) to study the superconducting gap structure by probing the effect of non-magnetic scattering on electrical resistivity, ρ T ( ), and London penetration depth, λ T ( ). For all compositions, the irradiation suppressed the superconducting transition temperature, T c and increased resistivity. The low - temperature behavior of λ T ( ) is best described by the power - law function, ∆ λ T ( ) = A T/T ( c ) n . While substantial suppression of T c supports s ± pairing mechanism, in samples close to the optimal doping, x = 0.26 and 0.34, the exponent n remained high ( n ≥ 3) indicating robust full superconducting gaps. For the x = 0.19 composition, exhibiting coexistence of superconductivity and long - range magnetism, the suppression of T c was much more rapid and the exponent n decreased toward dirty limit of n = 2. In this sample, the irradiation also suppressed the temperature of structural/magnetic transition, T sm , from 103 K to 98 K consistent with the itinerant nature of the magnetic order. Our results suggest that underdoped compositions, especially in the coexisting regime are most susceptible to non-magnetic scattering and imply that in multi-band Ba 1 -x K Fe As x 2 2 superconductors, the ratio of the inter-band to intra-band pairing strength, and associated gap anisotropy, increases upon the departure from the optimal doping.
PACS numbers: 74.70.Xa,74.20.Rp,74.62.Dh
## INTRODUCTION
Studying the effects of a controlled point -like disorder on superconducting properties is a powerful tool to understand the mechanisms of superconductivity [18]. According to the Anderson's theorem, conventional isotropic s -wave superconductors are not affected by the potential (non-magnetic) scattering, but are sensitive to a spin - flip scattering on magnetic impurities [1]. In high -T c cuprates, both magnetic and non-magnetic impurities were found to cause a rapid suppression of the superconducting transition temperature, T c , strongly supporting d -wave pairing [9]. For an order parameter changing sign between the sheets of the Fermi surface (s ± symmetry), considered the most plausible pairing state in multi-band iron-based superconductors (FeSCs) [10-12], the response to non-magnetic scattering is expected to be significant and formally similar to the magnetic scattering in single band s -wave superconductors [12, 13]. We should note that the multi-band character of superconductivity itself does not lead to the anomalous response to disorder beyond expected smearing of the gap variation on the Fermi surface, including the difference in gap magnitude between the different bands [14]. For example, in a known two - gap s ++ superconductor, MgB , 2 electron irradiation resulted only in a minor change in T c [15]. The sign change of the order parameter either along one sheet of the Fermi surface or between the sheets is what causes the dramatic suppression of T c due to pairbreaking nature of inter-band scattering in this case.
A relatively slow rate of T c suppression with disorder found in several experiments in iron-based superconductors was used as an argument for the s ++ pairing, in line with the expectations of orbital fluctuations mediated superconductivity [16, 17]. In reality, the situation in sign-changing multi-band superconductors is more complicated due to the competition between intra-band and inter-band pairing and, also, band-dependent scattering times and gap anisotropies [6, 11, 12]. Realistic calculations of the effect of point-like disorder on T c within s ± scenario [6] agree very well with the experiment, for example in electron irradiated Ba(Fe 1 -x Ru ) As x 2 2 [7] and BaFe (As 2 1 -x P ) x 2 [8].
Experimentally, it is quite difficult to introduce controlled point - like disorder. Studies of the disorder introduced by chemical substitution [18-20], heavy-ion or particle irradiation produced results that differ significantly from each other as far as the impact on the superconducting and materials properties is concerned [2126]. Chemical substitution changes both crystalline and electronic structure and most particle irradiations introduce correlated disorder, in forms of columnar defects and/or clusters of different spatial extent [27]. The effective scattering potential strength and range (size) of such
defects is very different from point-like scattering. On the other hand, MeV - range electron irradiation is known to produce vacancy/interstitial (Frenkel) pairs, which act as efficient point -like scattering centers [27]. This is consistent with the analysis of the collective pinning in BaFe (As 2 1 -x P ) x 2 and Ba(Fe 1 -x Co ) As x 2 2 [28] as well as penetration depth in BaFe (As 2 1 -x P ) x 2 [8]. In the highT c cuprates, electron irradiation defects are known to be strong unitary scatterers causing significant suppression of T c [29].
In addition to T c , another parameter sensitive to disorder is quasi-particle density, which may be probed, for example, by measuring London penetration depth, λ T ( ). In the case of isotropic single band s -wave or multiband s ++ -wave superconductors, λ T ( ) remains exponential at low temperatures with the addition of nonmagnetic scattering [6, 13, 30], whereas in the case of nodeless s ± pairing it changes from exponential in the clean limit to ∼ T 2 in the dirty limit [6, 13]. Yet, an opposite behavior is observed in superconductors with line nodes where λ ∼ T in the clean limit changing to ∼ T 2 in the dirty limit [3, 31-33]. In the case of pnictide superconductors with accidental nodes, λ T ( ), evolves from linear to exponential and, ultimately, to the T 2 behavior [8]. The details of the evolution from clean to dirty limit also depend on the (usually unknown) scattering potential amplitude and spatial extent. Weak Born scattering approximation, usually valid for normal metals, could not explain the rapid T → T 2 evolution in the cuprates, so the unitary limit was used instead [4, 33]. In iron - based superconductors, the situation is unclear and it seems that intermediate scattering amplitudes (modeled within t -matrix approach) are needed [6, 7, 13]. The spatial extent of the scattering potential affects the predominant scattering Q -vector, and it was suggested as the cause of a notable difference in quasi-particle response and evolution of T c in SrFe 2 (As 1 -x P ) x 2 with natural and artificial disorder [34].
In this paper, we study the effects of electron irradiation on superconducting T c and quasi-particle excitations of hole-doped (Ba 1 -x K )Fe As x 2 2 single crystals by measuring in-plane resistivity, ρ T ( ), and in-plane London penetration depth, ∆ ( λ T ). (Ba 1 -x K )Fe As x 2 2 has the highest T c ≈ 40 K among the 122 family and at the optimal doping reveals extremely robust superconductivity [25, 35, 36]. The superconducting gap structure of (Ba 1 -x K )Fe As x 2 2 varies with composition from full isotropic gap at the optimal doping to the gap with line nodes at x = 1 [37-39]. On the underdoped side of interest here, gap anisotropy increases towards the edge of the superconducting dome, especially in the range of bulk coexistence of superconductivity and long range magnetic order [36, 40]. This might imply that the ratio of the inter-band to intra-band pairing, as well as gap anisotropy, increase upon the departure from the optimal doping.
TABLE I. List of samples measured before and after electron irradiation. 1 C/cm 2 = 6.24 × 10 18 electrons/cm . 2
| x (WDS) | sample label | measurement |
|-----------|------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0.19 | 0.19-A 0.19-A 0.19-A | ρ before irradiation ρ after 1.8 C/cm 2 irradiated ∆ λ after 1.8 C/cm 2 irradiated |
| 0.26 | 0.26-A 0.26-B 0.26-B 0.26-B 0.26-B | ρ before irradiation ∆ λ before irradiation ρ after 1.5 C/cm 2 irradiated ∆ λ after 1.5 C/cm 2 irradiated 2 |
| 0.34 | 0.34-A 0.34-B 0.34-B 0.34-B 0.34-C | ∆ λ after 1.5 + 1.1 C/cm irr. ρ before irradiation ∆ λ before irradiation ρ after 2.0 C/cm 2 irradiated ∆ λ after 2.0 C/cm 2 irradiated ∆ λ before irradiation |
## EXPERIMENTAL
Single crystals of (Ba 1 -x K )Fe As x 2 2 were synthesized using high temperature FeAs flux method [41]. Samples used in this study were cleaved from the inner parts of single crystals and were first extensively characterized using radio-frequency magnetic susceptibility as well as magneto-optical imaging to exclude chemical and spatial inhomogeneity. The composition of each of the samples studied (see Table for the list) was measured with wavelength dispersive spectroscopy (WDS) technique, see Ref. [42] for details. Four - probe measurements of in-plane resistivity were performed in Quantum Design PPMS. Samples for resistivity measurements had typical dimensions of (1-2) × 0.5 × (0.02-0.1) mm . 3 Electrical contacts to samples prior to irradiation were made by soldering 50 µ m silver wires with ultra-pure tin solder, as described in Ref. [43]. The in-plane London penetration depth, ∆ λ T ( ), was measured using a self-oscillating tunnel-diode resonator technique [44, 45]. The samples had typical dimensions of 0.5 × 0.5 × 0.03 mm . 3 Details of the measurements and calibration can be found elsewhere [44]. The 2.5 MeV electron irradiation was performed at the SIRIUS Pelletron facility of the Laboratoire des Solides Irradi´s e (LSI) at the ´ cole E Polytechnique in Palaiseau, France [28]. The dose is conveniently measured in C/cm , 2 where 1 C/cm 2 = 6.24 × 10 18 electrons/cm . 2 The details of the measurements and doses of electron irradiation are summarized in Table I. London penetration depth in samples 0.26-B and 0.34-B was measured in the same samples before and after the irradiation. For these samples, resistivity af-
(300 K)
/
FIG. 1. (Color online) Temperature dependent resistivity normalized by the value at 300 K upon electron irradiation: (a) x = 0.19-A, (b) x = 0.26-A and B, and (c) x = 0.34-A and B. Insets zoom on the superconducting transitions.
ter electron irradiation was measured by gluing the contacts with silver paint to prevent defect annealing during soldering process. Reference samples 0.26-A and 0.34A of the same composition for resistivity measurements were cut from the same initial larger slab. For composition x = 0.19, the sample was prepared for resistivity measurements with soldered contacts. Its temperaturedependent resistivity was measured in pristine and irradiated states, see top panel of Fig. 1. After that, the contacts were removed and London penetration depth was measured.
## RESULTS AND DISCUSSION
Figure 1 shows normalized in-plane resistivity, ρ T ( ) /ρ (300 K ), measured before and after electron irradiation in samples with (a) x = 0.19, (b) x = 0.26 and (c) x = 0.34. Insets zoom on the superconducting transitions. For samples of all three doping levels, the introduction of disorder leads to a notable increase of residual resistivity. Superconducting transition temperature, T c , was determined by linear extrapolation of ρ T ( ) at the transition to ρ =0. Overall, the irradiation doses of 1.5 to 2 C/cm 2 lead to T c decrease by 3 to 5 K, see Fig. 4. Samples with x = 0.26 and x = 0.34 were outside the
FIG. 2. (Color online) Experimental data of T /T c c 0 versus ∆ ( ρ T c ) upon electron irradiation, where ρ T ( c ) is the resistivity right above T c and ∆ ( ρ T c ) is the change of the resistivity after irradiation. Inset shows T /T c c 0 versus dimensionless scattering rate g λ . The classical Abrikosov-Gor'kov theory for an isotropic s -wave superconductor with magnetic impurities is also shown by a solid line [2].
range of the coexisting magnetism and superconductivity. For x = 0.19, in addition to superconductivity, the long - range magnetic order develops simultaneously with orthorhombic distortion below structural/magnetic transition, T sm . This transition is revealed as a small feature in ρ T ( ) marked with the up-arrows in Fig. 1 (a). Irradiation with 1.8 C/cm 2 leads to T sm decrease by 5.1 K, supporting the itinerant nature of antiferromagnetism [46]. A 'bump' in ρ T ( ) above T c developed after the irradiation in the sample with x = 0.34, similar to electron irradiated YBaCuO, where it was interpreted to be due to localization effects [29].
Figure 2 shows the variation of T /T c c 0 versus ∆ ρ T = T c . From these values, we estimated the dimensionless scattering rate ( g λ ) defined in a simple form as [7, 47],
$$g ^ { \lambda } = \frac { \hbar { } } { 2 \pi k _ { B } \mu _ { 0 } } \frac { \Delta \rho ( T _ { c } ) } { T _ { c 0 } \lambda ( 0 ) ^ { 2 } } \, \text{ \quad \ \ } ( 1 )$$
where ∆ ρ T ( c ) is the change in resistivity at T c after the irradiation. Zero - temperature London penetration depth, λ (0), was estimated from the Homes scaling [48], which takes into account both, the doping dependence and the change with pair-breaking scattering [33], see Fig. 4 and the corresponding text. The g λ estimated from equation (1) was plotted in the inset in Fig. 2. The largest variation of d T /T ( c c 0 ) /dg λ = -1 94 was obtained for . x = 0.19 while the smallest change of d T /T ( c c 0 ) /dg λ = - 0.76 for x = 0.34. This indicates that the electron irradiation is
/
FIG. 3. (Color online) Variation of normalized in-plane penetration depth, ∆ λ T ( ) / ∆ ( λ T c ), before and after electron irradiation, see Table I for the details of the samples.
more efficient for under-doped compounds which have a fragile superconductivity competing with long-range magnetism.
Figure 3 shows the normalized variation of the London penetration depth, ∆ λ T ( ), measured down to ∼ 450 mK before and after electron irradiation for all three compositions. Magnetic superconducting transition temperature, T c , was defined at a point of 50% of the total change at the phase transition and was consistent with the transport measurements shown in Fig. 1. The superconducting phase transition remained sharp even at the highest dose of 8.3 C/cm 2 that caused T c to decrease by 11.2 K for x = 0.34 sample. Figure 4 summarizes the reduced T c / T c 0 obtained from resistivity (open symbols) and penetration depth (full symbols) data plotted versus electron irradiation dose, where T c 0 is the T c before irradiation. The variation of T c / T c 0 for x = 0.34 and x = 0.26 samples was about ∆ T /T c c 0 glyph[similarequal] -0.04 per C/cm , 2 whereas for the most underdoped sample with x = 0.19 we find a five times larger value of ∆ T /T c c 0 glyph[similarequal] -0.2 per C/cm . Quantitatively the observed doping dependence 2 of the effect of electron irradiation on T c is similar to electron - doped Ba(Fe 1 -x Co )As x 2 [28].
To quantify the evolution of the superconducting gap structure, we analyzed the low temperature part of ∆ ( λ T ) as shown in Fig. 5. The absolute change ∆ λ T ( ) = λ (0 3 . T/T c ) -λ T ( min /T c ) clearly increases after the irradiation indicating enhanced pair-breaking upon introduction of additional disorder. However, the low temperature ∆ λ T ( ) of the two closest to the optimal doping level samples, x = 0.34-B and 0.34-C still clearly show exponential saturation below 0.2 T/T c even after the irradiation. This result suggests that the optimally - doped
2
FIG. 4. (Color online) Variation of the reduced critical temperature, T /T c c 0 , with the dose of electron irradiation for samples x = 0.19 (green squares), x = 0.26 (blue triangles) and x = 0.34 (red diamonds).
compositions with isotropic superconducting gaps are extremely robust against electron irradiation, even at the very large dose of 8.3 C/cm 2 which caused suppression of T c by 11.2 K or ∆ T c ≈ 0 3 . T c 0 . The situation is similar in a slightly under-doped sample at x = 0.26 in which the low temperature saturation is seen below 0.1 T/T c . In a stark contrast, in the most underdoped sample with x = 0.19, where superconductivity and magnetism coexist, the saturating behaviour disappears after the irradiation.
These observations become more apparent when the low-temperature ∆ λ T ( ) is fitted using a power - law function, ∆ λ = A T/T ( c ) n . The results are plotted in Fig. 5 (e-h). To eliminate the uncertainty related to the upper fitting limit, we performed several fitting runs with a variable high-temperature end of the fitting range, T up /T c , from 0.1 to 0.3, while keeping the lower limit at the base temperature. The strong saturation behavior of the higher - doping samples is apparent from the large exponent values, n > 3, even for the very large irradiation dose of 8.3 C/cm . 2 For x = 0.26 sample, n increases as the T up /T c decreases. This implies that the gap remains nodeless, but develops anisotropy with a minimum value about 2 times smaller than in the case of a x = 0.34 sample. For the most under-doped sample, x = 0.19, there is a clear evolution toward the dirty T 2 limit. In the pristine state, the exponent n varied from n ≈ 2.3 at the widest range to 2.6 - 2.8 at the narrowest T up /T c range. However, after the irradiation, this tendency reverses. As the T up /T c decreases, n starts to decrease toward n = 2.
30
upper limit of the fitting range ( T up / T c )
FIG. 5. (Color online) The low temperature part of ∆ λ T ( ) before and after electron irradiation of sample x = 0.19 (a), x = 0.26 (b), and x = 0.34 (c) and (d). The data were analyzed with a power-law function, ∆ λ = A T/T ( c ) n , over a variable temperature range from base temperature to a temperature T up . The corresponding results of the analysis are summarized in the bottom raw of panels (e-h).
(nm)
FIG. 6. (Color online) The low temperature part of ∆ λ of sample x = 0.19 before and after electron irradiation plotted as a function of ( T/T c ) 2 . The straight lines are the guides for the pure T 2 behavior.
This is clearly shown in Fig. 6 where ∆ λ is plotted vs. ( T/T c ) 2 . While the data before the irradiation show an upward deviation from T 2 , the post-irradiated curve is a clean T 2 line.
Another way to analyze the data is to compare the normalized superfluid density, ρ s ( T ) = λ 2 (0) /λ 2 ( T ). Fig- ure 7 shows ρ s ( T ) before and after electron irradiation. Since the values of λ (0) are not known, we first used the literature value of λ (0) = 200 nm found for unirradiated optimally doped samples, x = 0.34 [49-52]. Then, we used the Homes scaling, λ (0) ∝ ρ T ( c ) /T c [48]. Here ρ T ( c ) is the resistivity at T c . The estimated λ (0) = 226 nm and 356 nm for x = 0.26 ( T c = 24.3 K) and x = 0.19 ( T c = 13.2 K) samples, respectively. In addition, the maximum possible increase of λ (0) induced by the irradiation was estimated by correlating the change of T c with the pair-breaking scattering and relating it to the expected change of λ (0) [33]. For example, for x = 0.34C sample, ∆ T c = - 11.2 K after 8.3 C/cm 2 irradiation, so the estimate of λ (0) is about 232 nm. Following these two - step procedures, we estimated doping and irradiation dependence of λ (0). All values are shown in the labels of Fig. 7.
The superfluid density, ρ s ( T/T c ), is compared in Fig.7 and it is quite different for samples with different x . For x = 0.34, panels (c-d), the overall behavior follows the expectations for an s -wave type pairing. Despite the change of T c , the irradiation did not change the functional form of ρ s ( T/T c ) much. For the more underdoped x = 0.26 sample, the region of saturation shrinks, but still exists at the lowest temperatures, below 0.1 T/T c . This small saturation region remains almost intact upon 2.6 C/cm 2 irradiation. In contrast, the superfluid density shows the largest change in the most under-doped sample, x = 0.19, where even minor signs of saturation in the pre-irradiated sample disappear after the irradiation. This suggests that the superconducting gap is very anisotropic in heavily under-doped samples and, therefore, is most susceptible to the defects induced by electron irradiation. This result is also consistent with the observation that the largest T c suppression is found in the most under-doped sample, see Fig. 4. Overall, the full temperature - range shape of ρ s ( T ) is close to a full gap s -wave behavior in the optimally doped sample and to a line - nodal curve for the most underdoped sample, x = 0.19.
## CONCLUSIONS
To summarize, the effects of electron irradiation on the in-plane resistivity and London penetration depth were studied in single crystals of hole-doped (Ba 1 -x ,K )Fe As x 2 2 superconductor. The irradiation leads to the suppression of the superconducting T c and of the temperature of the structural/magnetic transition, T sm . The suppression of T c is much more rapid in the underdoped sample with x = 0.19, in which superconductivity coexists with the long range magnetic order. This is consistent with the development of significant gap anisotropy in the coexisting phase. In the coexisting phase, the irradiation might even induce gapless super-
FIG. 7. (Color online) Normalized superfluid density, ρ s = ( λ (0) /λ T ( )) 2 , before and after electron irradiation: for (a) x = 0.19, (b) x = 0.26, and (c-d) x = 0.34. Doping dependent λ (0) was estimated considering resistivity right above T c (Homes scaling) and irradiation-induced T c decrease, see text for details.
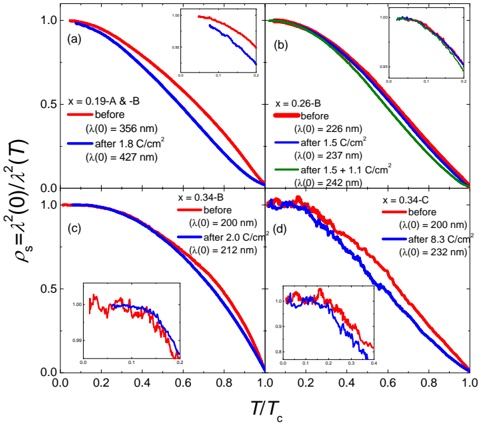
conductivity. Considering our previous study [36] and the prediction for the rate of suppression of T c in the extended s ± model [6], we suggest that the interband to the intraband pairing ratio increases when moving away from the optimal concentration.
## ACKNOWLEDGMENTS
We thank A. Chubukov, P. Hirschfeld, V. Mishra and T. Shibauchi for useful discussions. This work was supported by the U.S. Department of Energy (DOE), Office of Science, Basic Energy Sciences, Materials Science and Engineering Division. Ames Laboratory is operated for the U.S. DOE by Iowa State University under contract DE-AC02-07CH11358. We thank the SIRIUS team, B. Boizot, V. Metayer, and J. Losco, for running electron irradiation at Ecole Polytechnique (supported by EMIR network, proposal 11-11-0121.) Work in China was supported by the Ministry of Science and Technology of China, project 2011CBA00102.
∗ Corresponding author: [email protected]
- [1] P. W. Anderson, J Phys Chem Solids 11 , 26 (1959).
- [2] A. A. Abrikosov and L. P. Gor'kov, Zh. Eksp. Teor. Fiz. [Sov. Phys. JETP 12, 1243 (1961)] 39 , 1781 (1960).
- [3] P. J. Hirschfeld and N. Goldenfeld, Phys. Rev. B 48 , 4219 (1993).
- [4] H. Kim, G. Preosti, and P. Muzikar, Phys. Rev. B 49 , 3544 (1994).
- [5] A. V. Balatsky, I. Vekhter, and J.-X. Zhu, Rev. Mod. Phys. 78 , 373 (2006).
- [6] Y. Wang, A. Kreisel, P. J. Hirschfeld, and V. Mishra, Phys. Rev. B 87 , 094504 (2013).
- [7] R. Prozorov, M. Koczykowski, M. A. Tanatar, A. Thaler, S. L. Bud'ko, P. C. Canfield, V. Mishra, and P. J. Hirschfeld, arXiv:1405.3255 (2014), 1405.3255.
- [8] Y. Mizukami, M. Konczykowski, Y. Kawamoto, S. Kurata, S. Kasahara, K. Hashimoto, V. Mishra, A. Kreisel, Y. Wang, P. J. Hirschfeld, Y. Matsuda, and T. Shibauchi, arXiv:1405.6951 (2014).
- [9] G. Xiao, M. Z. Cieplak, J. Q. Xiao, and C. L. Chien, Phys. Rev. B 42 , 8752 (1990).
- [10] I. Mazin and J. Schmalian, Physica C 469 , 614 (2009).
- [11] P. J. Hirschfeld, M. M. Korshunov, and I. I. Mazin, Rep Prog Phys 74 , 124508 (2011).
- [12] A. Chubukov, Ann. Rev. Cond. Matt. Phys. 3 , 13 (2012).
- [13] V. Mishra, G. Boyd, S. Graser, T. Maier, P. J. Hirschfeld, and D. J. Scalapino, Phys. Rev. B 79 , 094512 (2009).
- [14] A. A. Golubov and I. I. Mazin, Phys. Rev. B 55 , 15146 (1997).
- [15] T. Klein, R. Marlaud, C. Marcenat, H. Cercellier, M. Konczykowski, C. J. van der Beek, V. Mosser, H. S. Lee, and S. I. Lee, Phys Rev Lett 105 , 047001 (2010).
- [16] Y. Senga and H. Kontani, J. Phys. Soc. Jpn. 77 , 113710 (2008).
- [17] S. Onari and H. Kontani, Phys Rev Lett 103 , 177001 (2009).
- [18] P. Cheng, B. Shen, J. Hu, and H.-H. Wen, Phys. Rev. B 81 , 174529 (2010).
- [19] J. Li, Y. Guo, S. Zhang, S. Yu, Y. Tsujimoto, H. Kontani, K. Yamaura, and E. Takayama-Muromachi, Phys. Rev. B 84 , 020513 (2011).
- [20] J. Li, Y. F. Guo, S. B. Zhang, J. Yuan, Y. Tsujimoto, X. Wang, C. I. Sathish, Y. Sun, S. Yu, W. Yi, K. Yamaura, E. Takayama-Muromachiu, Y. Shirako, M. Akaogi, and H. Kontani, Phys. Rev. B 85 , 214509 (2012).
- [21] H. Kim, R. T. Gordon, M. A. Tanatar, J. Hua, U. Welp, W. K. Kwok, N. Ni, S. L. Bud'ko, P. C. Canfield, A. B. Vorontsov, and R. Prozorov, Phys. Rev. B 82 , 060518 (2010).
- [22] C. Tarantini, M. Putti, A. Gurevich, Y. Shen, R. K. Singh, J. M. Rowell, N. Newman, D. C. Larbalestier, P. Cheng, Y. Jia, and H.-H. Wen, Phys Rev Lett 104 , 087002 (2010).
- [23] Y. Nakajima, T. Taen, Y. Tsuchiya, T. Tamegai, H. Kitamura, and T. Murakami, Phys. Rev. B 82 , 220504 (2010).
- [24] J. Murphy, M. A. Tanatar, H. Kim, W. Kwok, U. Welp, D. Graf, J. S. Brooks, S. L. Bud'ko, P. C. Canfield, and R. Prozorov, Phys. Rev. B 88 , 054514 (2013).
- [25] N. W. Salovich, H. Kim, A. K. Ghosh, R. W. Giannetta, W. Kwok, U. Welp, B. Shen, S. Zhu, H.-H. Wen, M. A. Tanatar, and R. Prozorov, Phys. Rev. B 87 , 180502 (2013).
- [26] T. Taen, F. Ohtake, H. Akiyama, H. Inoue, Y. Sun, S. Pyon, T. Tamegai, and H. Kitamura, Phys. Rev. B 88 , 224514 (2013).
- [27] A. C. Damask and G. J. Dienes, Point Defects in Metals (Gordon and Breach Science Publishers Ltd, 1963).
- [28] C. J. van der Beek, S. Demirdis, D. Colson, F. RullierAlbenque, Y. Fasano, T. Shibauchi, Y. Matsuda, S. Kasahara, P. Gierlowski, and M. Konczykowski, Journal of Physics: Conference Series 449 , 012023 (2013).
- [29] F. Rullier-Albenque, H. Alloul, and R. Tourbot, Phys Rev Lett 91 , 047001 (2003).
- [30] M. Tinkham, Introduction to Superconductivity , 2nd ed., Dover Books on Physics (Dover Publications, 2004).
- [31] S. K. Yip and J. A. Sauls, Phys Rev Lett 69 , 2264 (1992).
- [32] D. Xu, S. K. Yip, and J. A. Sauls, Phys. Rev. B 51 , 16233 (1995).
- [33] V. G. Kogan, R. Prozorov, and V. Mishra, Phys. Rev. B 88 , 224508 (2013).
- [34] C. P. Strehlow, M. Ko´ nczykowski, J. A. Murphy, S. Teknowijoyo, K. Cho, M. A. Tanatar, T. Kobayashi, S. Miyasaka, S. Tajima, and R. Prozorov, Phys. Rev. B 90 , 020508 (2014).
- [35] J.-P. Reid, A. Juneau-Fecteau, R. T. Gordon, S. R. de Cotret, N. Doiron-Leyraud, X. G. Luo, H. Shakeripour, J. Chang, M. A. Tanatar, H. Kim, R. Prozorov, T. Saito, H. Fukazawa, Y. Kohori, K. Kihou, C. H. Lee, A. Iyo, H. Eisaki, B. Shen, H.-H. Wen, and L. Taillefer, Superconductor Science and Technology 25 , 084013 (2012).
- [36] H. Kim, M. A. Tanatar, W. E. Straszheim, K. Cho, J. Murphy, N. Spyrison, J.-P. Reid, B. Shen, H.-H. Wen, R. M. Fernandes, and R. Prozorov, Phys. Rev. B 90 , 014517 (2014).
- [37] H. Fukazawa, Y. Yamada, K. Kondo, T. Saito, Y. Kohori, K. Kuga, Y. Matsumoto, S. Nakatsuji, H. Kito, P. M. Shirage, K. Kihou, N. Takeshita, C.-H. Lee, A. Iyo, and H. Eisaki, Journal of the Physical Society of Japan 78 , 083712 (2009).
- [38] K. Okazaki, Y. Ota, Y. Kotani, W. Malaeb, Y. Ishida, T. Shimojima, T. Kiss, S. Watanabe, C.-T. Chen, K. Kihou, C. H. Lee, A. Iyo, H. Eisaki, T. Saito, H. Fukazawa, Y. Kohori, K. Hashimoto, T. Shibauchi, Y. Matsuda, H. Ikeda, H. Miyahara, R. Arita, A. Chainani, and S. Shin, Science 337 , 1314 (2012).
- [39] J.-P. Reid, M. A. Tanatar, A. Juneau-Fecteau, R. T. Gordon, S. R. de Cotret, N. Doiron-Leyraud, T. Saito,
- H. Fukazawa, Y. Kohori, K. Kihou, C. H. Lee, A. Iyo, H. Eisaki, R. Prozorov, and L. Taillefer, Phys. Rev. Lett. 109 , 087001 (2012).
- [40] Z. Li, R. Zhou, Y. Liu, D. L. Sun, J. Yang, C. T. Lin, and G.-q. Zheng, Phys. Rev. B 86 , 180501 (2012).
- [41] H. Luo, Z. Wang, H. Yang, P. Cheng, X. Zhu, and H.-H. Wen, Supercond. Sci. Technol. 21 , 125014 (2008).
- [42] M. A. Tanatar, W. E. Straszheim, H. Kim, J. Murphy, N. Spyrison, E. C. Blomberg, K. Cho, J.-P. Reid, B. Shen, L. Taillefer, H.-H. Wen, and R. Prozorov, Phys. Rev. B 89 , 144514 (2014).
- [43] M. A. Tanatar, N. Ni, S. L. Budko, P. C. Canfield, and R. Prozorov, Supercond. Sci. Technol. 23 , 054002 (2010).
- [44] R. Prozorov and R. W. Giannetta, Supercond. Sci. Technol. 19 , R41 (2006).
- [45] R. Prozorov, R. W. Giannetta, A. Carrington, and F. M. Araujo-Moreira, Phys. Rev. B 62 , 115 (2000).
- [46] R. M. Fernandes, M. G. Vavilov, and A. V. Chubukov, Phys. Rev. B 85 , 140512 (2012).
- [47] V. G. Kogan, Phys. Rev. B 80 , 214532 (2009).
- [48] C. C. Homes, S. V. Dordevic, M. Strongin, D. A. Bonn, R. Liang, W. N. Hardy, S. Komiya, Y. Ando, G. Yu, N. Kaneko, X. Zhao, M. Greven, D. N. Basov, and T. Timusk, Nature 430 , 539 (2004).
- [49] C. Martin, R. T. Gordon, M. A. Tanatar, H. Kim, N. Ni, S. L. Bud'ko, P. C. Canfield, H. Luo, H. H. Wen, Z. Wang, A. B. Vorontsov, V. G. Kogan, and R. Prozorov, Phys. Rev. B 80 , 020501 (2009).
- [50] C. Ren, Z.-S. Wang, H.-Q. Luo, H. Yang, L. Shan, and H.-H. Wen, Phys Rev Lett 101 , 257006 (2008).
- [51] G. Li, W. Z. Hu, J. Dong, Z. Li, P. Zheng, G. F. Chen, J. L. Luo, and N. L. Wang, Phys Rev Lett 101 , 107004 (2008).
- [52] D. V. Evtushinsky, D. S. Inosov, V. B. Zabolotnyy, M. S. Viazovska, R. Khasanov, A. Amato, H.-H. Klauss, H. Luetkens, C. Niedermayer, G. L. Sun, V. Hinkov, C. T. Lin, A. Varykhalov, A. Koitzsch, M. Knupfer, B. Buchner, A. A. Kordyuk, and S. V. Borisenko, New J. Phys. 11 , 055069 (2009). | 10.1103/PhysRevB.90.104514 | [
"K. Cho",
"M. Konczykowski",
"J. Murphy",
"H. Kim",
"M. A. Tanatar",
"W. E. Straszheim",
"B. Shen",
"H. H. Wen",
"R. Prozorov"
] | 2014-07-31T20:46:17+00:00 | 2014-07-31T20:46:17+00:00 | [
"cond-mat.supr-con"
] | Effects of electron irradiation on resistivity and London penetration depth of Ba$_{1-x}$K$_x$Fe$_2$As$_2$ ($x \leq$ 0.34) iron - pnictide superconductor | Irradiation with 2.5 MeV electrons at doses up to 5.2 $\times$10$^{19}$
electrons/cm$^2$ was used to introduce point-like defects in single crystals of
Ba$_{1-x}$K$_x$Fe$_2$As$_2$ with $x=$ 0.19 ($T_c=$ 14 K), $x=$ 0.26 ($T_c=$ 32
K) and 0.34 ($T_c=$ 39 K) to study the superconducting gap structure by probing
the effect of non-magnetic scattering on electrical resistivity, $\rho(T)$, and
London penetration depth, $ \lambda (T)$. For all compositions, the irradiation
suppressed the superconducting transition temperature, $T_c$ and increased
resistivity. The low - temperature behavior of $\lambda (T)$ is best described
by the power - law function, $\Delta \lambda (T) = A(T/T_c)^n$. While
substantial suppression of $T_c$ supports $s_{\pm}$ pairing mechanism, in
samples close to the optimal doping, $x=$ 0.26 and 0.34, the exponent $n$
remained high ($n \geq 3$) indicating robust full superconducting gaps. For the
$x=$ 0.19 composition, exhibiting coexistence of superconductivity and long -
range magnetism, the suppression of $T_c$ was much more rapid and the exponent
$n$ decreased toward dirty limit of $n$ = 2. In this sample, the irradiation
also suppressed the temperature of structural/magnetic transition, $T_{sm}$,
from 103 K to 98 K consistent with the itinerant nature of the magnetic order.
Our results suggest that underdoped compositions, especially in the coexisting
regime are most susceptible to non-magnetic scattering and imply that in
multi-band Ba$_{1-x}$K$_x$Fe$_2$As$_2$ superconductors, the ratio of the
inter-band to intra-band pairing strength, and associated gap anisotropy,
increases upon the departure from the optimal doping. |
1408.0026v1 | ## Invariant Measures for Hybrid Stochastic Systems
| Xavier Garcia ∗ | Jennifer Kunze † | Thomas Rudelius ‡ |
|-------------------|------------------------------|---------------------|
| Anthony Sanchez § | Sijing Shao ¶ Chad Vidden ∗∗ | Emily Speranza ‖ |
| August 4, 2014 | | |
## Abstract
In this paper, we seek to understand the behavior of dynamical systems that are perturbed by a parameter that changes discretely in time. If we impose certain conditions, we can study certain embedded systems within a hybrid system as time-homogeneous Markov processes. In particular, we prove the existence of invariant measures for each embedded system and relate the invariant measures for the various systems through the flow. We calculate these invariant measures explicitly in several illustrative examples.
Keywords: Dynamical Systems; Markov processes; Markov chains; stochastic modeling
## 1 Introduction
An understanding of dynamical systems allows one to analyze the way processes evolve through time. Usually, such systems are given by differential equations that model real world phenomena. Unfortunately, these models are limited in that they cannot account for random events that may occur in application. These stochastic developments, however, may sometimes be modeled with Markov processes, and in particular with Markov chains.
∗ Department of Mathematics, University of Minnesota - Twin Cities, Minneapolis, MN 55455, USA ([email protected]). Research supported by DMS 0750986 and DMS 0502354
† Department of Mathematics, Saint Mary's College of Maryland, St Marys City, MD 20686, USA ([email protected]). Research supported by DMS 0750986
‡ Department of Mathematics, Cornell University, Ithaca, NY 14850, USA ([email protected]). Research supported by DMS 0750986
§ Department of Mathematics, Arizona State University, Tempe, AZ 85281, USA ([email protected]). Research supported by DMS 0750986 and DMS 0502354
¶ Department of Mathematics, Iowa State University, Ames, IA 50014, USA ([email protected]). Research supported by Iowa State University
‖ Department of Mathematics, Carroll College, Helena, MT 59625, USA ([email protected]). Research supported by DMS 0750986
∗∗ Department of Mathematics, Iowa State University, Ames, IA 50014, USA ([email protected]). Research supported by Iowa State University.
We can unite the two models in order to see how these dynamical systems behave with the perturbation induced by the Markov processes, creating a hybrid system consisting of the two components. Complicating matters, these hybrid systems can be described in either continuous or discrete time.
The focus of this paper is studying the way these hybrid systems behave as they evolve. We begin by defining limit sets for a dynamical system and stochastic processes. We next examine the limit sets of these hybrid systems and what happens as they approach the limit sets. Concurrently, we define invariant measures and prove their existence for hybrid systems while relating these measures to the flow. In addition, we supply examples with visuals that provide insight to the behavior of hybrid systems.
## 2 The Stochastic Hybrid System
In this section, we define a hybrid system.
Definition 1. A Markov process X t is called time-homogeneous on T if, for all t 1 , t 2 , k ∈ T and for any sets A , A 1 2 ∈ S ,
$$P ( X _ { t _ { 1 } + k } \in A _ { 1 } | X _ { t _ { 1 } } \in A _ { 2 } ) = P ( X _ { t _ { 2 } + k } \in A _ { 1 } | X _ { t _ { 2 } } \in A _ { 2 } ).$$
Otherwise, it is called time-inhomogeneous.
Definition 2. A Markov chain X n is a Markov process for which perturbations occur on a discrete time set T and finite state space S .
For a Markov chain on the finite state space S with cardinality | S | , it is useful to describe the probabilities of transitioning from one state to another with a transition matrix
$$Q \equiv \left ( \begin{array} { c c c c c } P _ { 1 \to 1 } &. &. &. & P _ { 1 \to | S | } \\. & & &. \\. & & &. \\ P _ { | S | \to 1 } &. &. & P _ { | S | \to | S | } \end{array} \right ) \\. &. &. &. &. &. &. \end{array} \right )$$
where P i → j is the probability of transitioning from state s i ∈ S to state s j ∈ S .
Also, for the purposes of this paper, we suppose that our Markov chain transitions occur regularly at times t = nh for some length of time h ∈ R + and for all n ∈ N .
Definition 3. Let { X n } , for X n ∈ S and n ∈ N , be a sequence of states determined by a Markov chain.
+
- h h
For t ∈ R , define the Markov chain perturbation Z t = X glyph[floorleft] t h glyph[floorright] , where ⌊ t ⌋ is the greatest integer less than or equal to t .
Note that Z t , instead of being defined only on discrete time values like a Markov chain, is instead a stepwise function defined on continuous time.
Definition 4. Given a metric space M and state space S as above, define a dynamical system ϕ with random perturbation function Z t , as given in Definition 3, by
$$\varphi \colon \mathbb { R } ^ { + } \times M \times S \rightarrow M$$
with
$$\varphi ( t, x _ { 0 }, Z _ { 0 } ) = \varphi _ { Z _ { t } } ( t - n h, \varphi _ { Z _ { n h } } ( h, \dots \varphi _ { Z _ { 2 h } } ( h, \varphi _ { Z _ { h } } ( h, \varphi _ { Z _ { 0 } } ( h, x _ { 0 } ) ) ) ) )$$
where ϕ Z k represents the deterministic dynamical system ϕ evaluated in state Z k and nh is the largest multiple of h less than t .
For ease of notation, let
$$x _ { t } = \varphi ( t, x _ { 0 }, Z _ { 0 } ) \in M$$
represent the position of the system at time t .
Definition 5. Let
$$Y _ { t } = \left ( \begin{array} { c } x _ { t } \\ Z _ { t } \end{array} \right )$$
define the hybrid system at time t . In other words, the hybrid system consists of both a position x t = ϕ t, x ( 0 , Z 0 ) ∈ M and a state Z t ∈ S .
The ω -limit set has the following generalization in a hybrid system.
Definition 6. The stochastic limit set C x ( ) for an element of our state space x ∈ M and the hybrid system given above is the subset of M with the following three properties:
- 1. Given y ∈ M and t k →∞ such that x t k → y , P y ( ∈ C x ( )) = 1 .
- 2. C x ( ) is closed.
- 3. C x ( ) is minimal: if some set C ′ ( x ) has properties 1 and 2, then C ⊆ C ′ .
## 3 The Hybrid System as a Markov Process
Lemma 7. Each of the following is a Markov process:
(i) any deterministic dynamical system ϕ t, x ( 0 ) , as in Definition ?? . (ii) any Markov chain perturbation Z t , as in Definition 3. (iii) the corresponding hybrid system Y t , as in Definition 5.
Proof. (i) Any deterministic system is trivially a Markov process, since ϕ t, x ( 0 ) is uniquely determined by ϕ τ, x ( 0 ) at any single past time τ ∈ R + .
(ii) By definition, a Markov chain is a Markov process. However, the Markov chain perturbation Z t is not exactly a Markov chain. A Markov chain exists on a discrete time set, in our case given by T = { t ∈ R + | t = nh for some n ∈ N } ; conversely, the time set of Z t is R + , with transitions between states ocurring on the previous time set (that is, at t ≡ 0 mod h ). Despite this difference, Z t maintains the Markov property: we can compute P Z ( t ∈ A ) for any set A based solely on Z τ 1 and the values of the times t and τ 1 . Explicitly, the probability that Z t will be in state s i at time t is given by
$$P ( Z _ { t } = s _ { i } ) = \left ( ( Q ^ { T } ) ^ { n } \right ) _ { i j }$$
where n is the number of integer multiples of h (i.e. the number of transitions that occur) between t and τ 1 . Clearly, this is independent of the states Z τ i for i > 1, so that the random perturbation is indeed a Markov process.
(iii) Now, keeping in mind that the hybrid system Y t consists of both a location x t ∈ M in the state space and a value Z t ∈ S of the random component, we can combine (i) and (ii) to see that the entire system is also a Markov process. We see from (ii) that Z t follows a Markov process. Furthermore, P x ( t ∈ A x ) at time t depends solely on the location x τ 1 at any time τ 1 < t and the states of the random perturbation sequence Z between t and τ 1 , regardless of any past behavior of the system. Hence, for any collection of sets A α , α ∈ N ,
P Z ( t ∈ A Z z | τ 1 ∈ A z 1 , Z τ 2 ∈ A z 2 , ..., Z τ n ∈ A z n ) = P Z ( t ∈ A Z z | τ 1 ∈ A z 1 ) and
P x ( t ∈ A x | x τ 1 ∈ A x 1 , x τ 2 ∈ A x 2 , ..., x τ n ∈ A x n ) = P x ( t ∈ A x | x τ 1 ∈ A x 1 ) . So,
$$P ( Y _ { t } \in A _ { y } | Y _ { \tau _ { 1 } } \in A _ { y _ { 1 } }, Y _ { \tau _ { 2 } } \in A _ { y _ { 2 } }, \dots, Y _ { \tau _ { n } } \in A _ { y _ { n } } ) = P ( Y _ { t } \in A _ { y } | Y _ { \tau _ { 1 } } \in A _ { y _ { 1 } } ).$$
Thus, the hybrid system is a Markov process.
Unfortunately, the hybrid system is not time-homogeneous. Recall that state transitions of Z t occur at times t = nh for n ∈ N . So, the state of the system at time h 4 uniquely determines the system at 3 h 4 , since there is no transition in this interval. However, the system at time 5 h 4 is not determined uniquely by the system at 3 h 4 , since a stochastic transition occurs at t = h ∈ [ 3 4 , 5 4 ]. Therefore, with t 1 = h 4 , t 2 = 3 h 4 , and k = 1 2 , glyph[negationslash]
$$P ( Y _ { \frac { h } { 4 } + \frac { 1 } { 2 } } \in A | Y _ { \frac { h } { 4 } } \in A _ { 0 } ) \ne P ( Y _ { \frac { 3 h } { 4 } + \frac { 1 } { 2 } } \in A | Y _ { \frac { 3 h } { 4 } } \in A _ { 0 } ),$$
violating Definition 1. However, in order to satisfy the hypotheses of the Krylov-Bogolyubov theorem [5, 6] found in Theorem 14, the hybrid system must be time-homogeneous.
To create a time-homogeneous system, we restrict the time set on which our Markov process is defined. Instead of allowing our time set { t, τ 1 , τ 2 , τ 3 , ..., τ n } ⊂ R + to be any decreasing sequence of real numbers, we create time sets t 0 + nh for each t 0 ∈ [0 , h ) and n ∈ N . In other words, we define a different time set for each value t 0 < h with
{ t ∈ R + | t = t 0 + nh for some n ∈ N } .
We call the hybrid system on these multiple, restricted time sets the discrete system.
Proposition 8. The discrete hybrid system above is a time-homogeneous Markov process.
Proof. First, we must show that the discrete hybrid system is a Markov process at all. This follows immediately from the proof that our original hybrid system is a Markov process. Since the Markov property (Definition ?? ) holds for all t, τ 1 , τ 2 , ..., τ n ∈ R + , it must necessarily hold for the specific time sets
$$\{ t \in \mathbb { R } ^ { + } | \exists n \in \mathbb { N } \text{ such that } t = t _ { 0 } + n h \}$$
for each t 0 < h .
Now, it remains to show that this system is time-homogeneous. Recall that the time-continuous hybrid system failed to be time-homogeneous because its Z t component was not time-homogeneous. Although transitions occurred only at regular, discrete time values, a test interval could be of any length; an interval of size h 2 , for example, might contain either 0 or 1 transitions. However, because our discrete system creates separate time sets, any time interval - starting and ending within the same time set - must be of length nh for some n ∈ N , and thus will contain precisely n potential transitions. So, taking t 1 , t 2 ∈ R + , we know
$$P ( Y _ { t _ { 1 } + n h } \in A | Y _ { t _ { 1 } } \in A _ { 0 } ) = P ( Y _ { t _ { 2 } + n h } \in A | Y _ { t _ { 2 } } \in A _ { 0 } ).$$
Note that the first component of the hybrid system, x t , is also timehomogeneous under the discrete time system. Given Z t , it can be treated as a deterministic system, and therefore time-homogeneous. Thus, the discrete hybrid system is time-homogeneous.
## 4 Invariant Measures for the Hybrid System
We now introduce several definitions that will lead to the main results of this paper.
Definition 9. Consider a hybrid system Y t and a σ -algebra Σ on the space M . A measure µ on M is invariant if, for all sets A ∈ Σ and all times t ∈ R + ,
$$\mu ( A ) = \int _ { x _ { 0 } \in M } P ( x _ { t } \in A ) \mu ( d x ).$$
Definition 10. Let ( M, T ) be a topological space, and let Σ be a σ -algebra on M that contains the topology T . Let M be a collection of probability measures defined on Σ . The collection M is called tight if, for any glyph[epsilon1] > 0 , there is a compact subset K glyph[epsilon1] of M such that, for any measure µ in M ,
$$\mu ( M \nabla K _ { \epsilon } ) < \epsilon.$$
Note that, since µ is a probability measure, it is equivalent to say µ K ( glyph[epsilon1] ) > 1 -glyph[epsilon1] .
The following definitions are from [5].
Definition 11. Let ( M,ρ ) be a separable metric space. Let {P ( M ) } denote the collection of all probability measures defined on M (with its Borel σ -algebra). A collection K ⊂ {P ( M ) } of probability measures is tight if and only if K is sequentially compact in the space equipped with the topology of weak convergence.
Definition 12. Consider M with σ -algebra Σ . Let C 0 ( M, R ) denote the set of continuous functions from M to R . The probability measure P ( t, x, · ) on Σ induces a map
$$\mathcal { P } _ { t } ( x ) \colon C ^ { 0 } ( M, \mathbb { R } ) \rightarrow \mathbb { R }$$
with
$$\mathcal { P } _ { t } ( x ) ( f ) = \int _ { y \in M } f ( y ) \mathcal { P } ( t, x, d y ).$$
P t is called a Markov operator.
↦
Definition 13. A Markov operator P is Feller if P ϕ is continuous for every continuous bounded function ϕ : X → R . In other words, it is Feller if and only if the map x → P ( x, · ) is continuous in the topology of weak convergence.
We state the Krylov-Bogolyubov Theorem without proof.
Theorem 14. (Krylov-Bogolyubov) Let P be a Feller Markov operator over a complete and separable space X. Assume that there exists x 0 ∈ X such that the sequence P n ( x , 0 · ) is tight. Then, there exists at least one invariant probability measure for P .
We now show that the conditions of the theorem are satisfied by the discrete hybrid system, yielding the existence of invariant measures as a corollary.
Lemma 15. Given t 0 ∈ [0 , h ) , the discrete hybrid system Markov operators P n for n ∈ N given by
$$\mathcal { P } _ { n } f ( Y ) \equiv \int _ { M \times S } f ( Y _ { 1 } ) \mathcal { P } ( n h, Y, d Y _ { 1 } )$$
are Feller.
Proof. We begin by showing that P 1 is Feller. By induction, it follows that P n is Feller for all n ∈ N . It is clear that there are only finitely many possible outcomes of running the hybrid system for time h . Namely, there are at most | S | possible outcomes, where | S | denotes the cardinality of S . Given
$$Y _ { 0 } = \left ( \begin{array} { c } x _ { 0 } \\ Z _ { 0 } = s _ { i } \end{array} \right ) \in M \times S,$$
the only possible outcomes at time t = 1 are
$$Y _ { 1 } ^ { j } = \left ( \begin{array} { c } \varphi _ { j } ( t _ { 0 }, \varphi _ { i } ( h - t _ { 0 }, x ) ) \\ s _ { j } \end{array} \right )$$
for j ∈ { 1 , ..., | S |} where ϕ , ϕ i j are the flows of the dynamical systems corresponding to states s i and s j , respectively. The probability of the j th outcome is given by P i → j , the probability of transitioning from state s i to state s j . Therefore,
$$\mathcal { P } _ { 1 } f ( Y ) = \int _ { M \times S } f ( Y _ { 1 } ) \mathcal { P } ( h, Y, d Y _ { 1 } ) = \sum _ { j = 1 } ^ { | S | } P _ { i \rightarrow j } f ( Y _ { 1 } ^ { j } )$$
Each ϕ i is continuous under the assumption that each flow is continuous with respect to its initial conditions. The map from s i to s j is continuous since S is finite, so every set is open and hence the inverse image of any open set is open. The function f is continuous by hypothesis, and any finite sum of continuous functions is also continuous. Therefore P 1 f is also continuous, and hence P 1 is Feller.
We see now that the conditions of the Krylov-Bogolyubov Theorem (14) hold. Namely, because M and S are compact (the former by assumption, the latter since it is finite), M × S is compact. Thus, any collection of measures is automatically tight, since we can take K glyph[epsilon1] = X . It is wellknown that any compact metric space is also complete and separable. Applying Theorem 14, then, gives the following corollary, which is one of the primary results of the paper.
Corollary 16. The discrete hybrid system has an invariant measure for each t 0 ∈ [0 , h ) .
So, rather than speaking of an invariant measure for the time-continuous hybrid system, we can instead imagine a periodic invariant measure cycling continuously through h . That is, for each time t 0 ∈ [0 , h ), there exists a measure µ t 0 such that for t ≡ 0 (mod h ),
$$\mu _ { t _ { 0 } } ( A ) = \int _ { Y \in M \times S } \mathcal { P } ( t, Y, A ) d \mu _ { t _ { 0 } }.$$
The measure µ t 0 above is a measure on the product space M × S , since this is where the hybrid system lives. However, what we are really after is an invariant measure on just M , the space where the dynamical system part of the hybrid system lives. Fortunately, we can define a measure on M by the following construction.
Proposition 17. Given µ t , an invariant probability measure on M × S , the function
$$\tilde { \mu } _ { t } ( A ) \equiv \mu _ { t } ( A, S )$$
where A ⊆ M is an invariant probability measure on M .
Proof. The fact that ˜ µ t is a probability measure follows almost immediately from the fact that µ t is a probability measure. The probability that x t ∈ ∅ is 0, so ˜ ( µ t ∅ ) = 0. The probability that x t ∈ M is 1, so ˜ ( µ t M ) = 1. Countable additivity of ˜ µ t follows from countable additivity of µ t . Therefore, ˜ µ t is a probability measure on M .
Thus far, we have proven the existence of a measure µ t 0 for t 0 ∈ [0 , h ) such that for t ≡ 0 (mod h ),
$$\mu _ { t _ { 0 } } ( A ) = \int _ { x _ { 0 } \in M, s \in S } P ( \varphi ( t, x _ { 0 }, s ) \in A ) d \mu _ { t _ { 0 } }.$$
The following theorem relates the collection of invariant measures { ˜ µ t 0 } using the flow ϕ . This is the main result of the paper.
Theorem 18. Given invariant measure µ 0 , the measure µ t defined by
$$\mu _ { t } ( A ) = \sum _ { s \in S } \int _ { x _ { 0 } \in M } P ( \varphi ( t, x _ { 0 }, s ) \in A ) d \mu _ { 0 }$$
is also invariant in the sense that µ t = µ t + nh for n ∈ N .
Proof. We will show that µ t = µ t + h . By induction, this implies that µ t = µ t + nh for all n ∈ N . We have
$$\mu _ { t + h } ( A ) = \sum _ { s \in S } \int _ { x _ { 0 } \in M } P ( \varphi ( t + h, x _ { 0 }, s ) \in A ) d \mu _ { 0 }.$$
Applying the definition of conditional probability,
$$\sum _ { s \in S } \int _ { x _ { 0 } \in M } P ( \varphi ( t + h, x _ { 0 }, s ) \in A ) d \mu _ { 0 } =$$
$$\sum _ { r \in S } \int _ { y \in M } \left [ P ( \varphi ( t, y, r ) \in A ) \sum _ { s \in S } \int _ { x _ { 0 } \in M } P ( \varphi ( h, x _ { 0 }, s ) \in d y \times \{ r \} ) d \mu _ { 0 } \right ].$$
Loosely speaking, the probability that a trajectory beginning at ( x, s ) will end in a set A after a time t + h is the product of the probability that a trajectory beginning at ( y, r ) will end in A after a time t multiplied by the probability that a trajectory beginning at ( x, s ) will end at ( y, r ) after a time h , integrating over all possible pairs ( y, r ). Here, we have implicitly used the fact that the hybrid system is a Markov process to ensure that the state of the system at time t + h given the state at time h is independent of the initial state, and we have avoided the problem of time-inhomogeneity by considering trajectories that only begin at times congruent to 0 (mod h ).
Furthermore, we have that
$$\mu _ { h } ( d y \times \{ r \} ) = \sum _ { s \in S } \int _ { x _ { 0 } \in M } P ( \varphi ( h, x _ { 0 }, s ) \in d y \times \{ r \} ) d \mu _ { 0 }$$
and so,
$$\mu _ { t + h } ( A ) = \sum _ { r \in S } \int _ { y \in M } P ( \varphi ( t, y, r ) \in A ) d \mu _ { h }.$$
Since µ 0 is invariant by assumption, µ 0 = µ h . Therefore,
$$\mu _ { t + h } ( A ) = \sum _ { r \in S } \int _ { y \in M } P ( \varphi ( t, y, r ) \in A ) d \mu _ { 0 } = \mu _ { t } ( A ).$$
## 5 Examples
Some examples of hybrid systems can be found in [3, 4]. Here, we will examine two simple cases to illustrate the theory developed above.
$$\mu _ { h } ( d y \times \{ r \} ) = d \mu _ { h } ( y, r ) ;$$
## 5.1 A 1-D Hybrid System
We begin with a 1-dimensional linear dynamical system with a stochastic perturbation:
$$\dot { x } = - x + Z _ { t }$$
where Z t ∈ {-1 1 , } . Both components of this system have a single, attractive equilibrium point: for Z t = 1, this is x = 1, and for Z t = -1, x = -1. At timesteps of length h = 1, Z t is perturbed by a Markov chain given by the transition matrix Q . Q is therefore a 2 × 2 matrix of nonnegative entries,
$$Q = \left ( \begin{array} { c c } P _ { 1 \rightarrow 1 } & P _ { 1 \rightarrow - 1 } \\ P _ { - 1 \rightarrow 1 } & P _ { - 1 \rightarrow - 1 } \end{array} \right ),$$
where P i → j gives the probability of the equilibrium point transitioning from i to j at each integer time step. Since the total probability measure must equal 1,
$$\sum _ { j } P _ { i \rightarrow j } = 1, \ i, j \in \{ 1, - 1 \}.$$
glyph[negationslash]
Furthermore, to avoid the deterministic case, we take P i → j = 0 for all i, j . Proposition 19. The stochastic limit set C x ( 0 ) = [ -1 1] , for all x 0 ∈ R .
Proof. We begin by showing that C x ( ) ⊂ [ -1 1]: , that is, that every possible trajectory in our system will eventually enter and never leave [ -1 1], , meaning that no it is only possible to have t ∗ → ∞ such that x ∗ = y for y ∈ [ -1 1]. , First, consider x 0 ∈ [ -1 1]. , If we are in state Z t = 1, then the trajectory is attracted upwards and bounded above by x = 1; in state Z t = -1, the trajectory is attracted downwards and bounded below by x = -1. In both cases, the trajectory cannot move above 1 or below -1, and so will remain in [ -1 1] for all time. ,
Now, consider x 0 / ∈ [ -1 1]. , If the trajectory ever enters [ -1 1], , by similar argument as above, it will remain in that region for all time. So, it remains to show that ϕ t, x ( 0 , Z 0 ) ∈ -[ 1 1] for some , t ∈ R . First, take x 0 > 1. In either state, the trajectory will be attracted downward, and will eventually enter [1 , 2] at time t 2 . Once there, at the first timestep in which Z t = -1 it will cross x = 1 and enter [ -1 1]. , And since we have taken all entries of the transition probability matrix Q to be nonzero, there almost surely exists a time t 3 > t 2 for which the state is Z t = -1; then, the trajectory will enter [ -1 1] and never leave. By similar argument, any , trajectory starting at x 0 < -1 will enter and never leave [ -1 1]. , Thus, C x ( ) ⊂ -[ 1 1]. ,
Now, we must show that [ -1 1] , ∈ C x ( ): that is, that for every trajectory ϕ t, x ( 0 , Z 0 ) and every point y ∈ -[ 1 1] there is , t ∗ →∞ such that ϕ t ( ∗ , x 0 , Z 0 ) → y . To do this, we really only need to show that given any point x 0 ∈ -[ 1 1] and any transition matrix , Q , there almost surely exists some time t ∗ with ϕ t ( ∗ , x 0 , Z 0 ) = x ∗ . If one such time t ∗ is guaranteed to exist, then we can iterate the process for a solution beginning at ( t ∗ , x ∗ ) to produce an infinite sequence of times. To show that t ∗ exists, we calculate a lower bound on the probability that ϕ t ( n , x 0 , Z 0 ) = x ∗ .
Without loss of generality, suppose that x 0 > x ∗ . We have already shown that any solution will enter [ -1 1], so take sup( , x 0 ) = 1. From here,
we can calculate the minimum number of necessary consecutive periods, k , for which Z n = -1 in order for a solution with x 0 = 1 to decay to x ∗ . The probability of this sequence of k consecutive periods occurring is given by
$$P _ { 1 } ( k ) = ( P _ { 1 \rightarrow - 1 } ) ( P _ { - 1 \rightarrow - 1 } ) ^ { k - 1 }$$
if Z 0 = 1 and
$$P _ { - 1 } ( k ) = \left ( P _ { - 1 \rightarrow - 1 } \right ) ^ { k }$$
if Z 0 = -1. Thus, for some t ∗ ∈ [0 , k ],
$$P ( \varphi ( t ^ { * }, x _ { 0 }, Z _ { 0 } ) = x ^ { * } ) \geq \min ( P _ { 1 } ( k ), P _ { - 1 } ( k ) ) > 0$$
since P i → j > 0. So,
$$P ( t ^ { * } \notin [ 0, k ] ) \leq 1 - P ( x ^ { * } ) < 1$$
and
$$P ( t ^ { * } \notin [ 0, m k ] ) \leq ( 1 - P ( x ^ { * } ) ) ^ { m }.$$
As m → ∞ , (1 -P x ( ∗ )) m → 0. So, with probability 1, there exists t ∗ with ϕ t ( ∗ , x 0 , Z 0 ) = x ∗ .
By similar argument, for x 0 < x ∗ and all x ∗ ∈ ( -1 1), we can find a , time sequence { t n } such that ϕ t ( n , x 0 , Z 0 ) = x ∗ . So, we know that for all x ∗ ∈ -( 1 1), , x ∗ ∈ C x ( ).
So, we have proven that [ -1 1] , ⊆ C x ( ) and ( -1 1) , ⊆ C x ( ). Since C x ( ) must by definition be closed, C x ( ) = [ -1 1]. ,
We can study the behavior of this system numerically. Figure 1 (left) depicts a solution calculated for the transition matrix
$$Q _ { 1 } = \left ( \begin{array} { c c }. 4 &. 6 \\. 5 &. 5 \end{array} \right )$$
with initial values x 0 = 2, Z 0 = 1.
As expected, the trajectory enters the interval ( -1 1) and stays there , for all time, oscillating between x = -1 and x = 1. Intuitively, it seems that the trajectory will cross any x ∗ in this interval repeatedly, so that indeed C x ( ) = [ -1 1]. , This is not quite so clear for the transition matrix
$$Q _ { 2 } = \left ( \begin{array} { c c }. 1 &. 9 \\. 1 &. 9 \end{array} \right )$$
which yields the trajectory shown in Figure 1 (right) for x 0 = 2, Z 0 = 1.
Trajectory Calculated
Trajectory Calculated
Figure 1. A sample trajectory for a hybrid system with transition matrix Q 1 (left) and Q 2 (right).
It may appear that some set of points near x = 1 might be crossed by our path only a finite number of times. But, as proven above, any point in ( -1 1) will almost surely be reached infinitely many times as , t →∞ , so C x ( ) = [ -1 1]. ,
Now, we consider the eigenvalues and eigenvectors of the transition matrices. The eigenvector of Q T 1 with eigenvalue 1 is
$$\vec { v } = \left ( \begin{array} { c } \frac { 5 } { 1 1 } \\ \frac { 6 } { 1 1 } \end{array} \right ),$$
and the eigenvector of Q T 2 with eigenvalue 1 is
$$\vec { v } \, ^ { \prime } = \left ( \begin{array} { c } \frac { 9 } { 1 0 } \\ \frac { 1 } { 1 0 } \end{array} \right ).$$
These eigenvectors give the invariant measures on the state space S . We know from Proposition 17 that there also exists an invariant measure on M . Here, since any trajectory in M will almost surely enter C x ( ) = [ -1 1], the support of the invariant measure must be contained in , C x ( ). It is not difficult to see that this invariant measure cannot be constant for all t ∈ R + . Given any point x 0 ∈ -[ 1 1], we know that at , t = 1, one of two things will have happened to the trajectory:
- (i) it will have decayed exponentially toward x = 1, if Z 1 = 1, or
- (ii) it will have decayed exponentially toward x = -1, if Z = -1.
1 In case (i), if a solution begins at x 0 = -1 for t = 0, then the solution will have decayed to a value of 1 -(2 e -1 ) ≈ 0 264 by . t = 1 . In case (ii) a solution beginning at x 0 = 1 for t = 0 will decay to a value of -1 + 2 e -1 ≈ -0 264. . Thus, if we are in case (i), all trajectories in [ -1 1] , at t = n will be located in [0 264 . , 1] at t = n +1. If we are in case (ii), all will be in [ -1 , -0 264]. . It is not possible for any trajectory to be located in [ -0 264 0 264] at an integer time value. . , . But, clearly, some solutions will cross into this region, as depicted in Figure 2. Therefore, no probability distribution will remain constant for all t in the timeset R + .
Figure 2. A spider plot showing all possible trajectories starting at x 0 = 0.
However, as Figure 2 suggests, there is some distribution that is invariant under t → t + n for n ∈ N . Approximations of the invariant measures at t ∈ [0 , 1] for transition matrix Q 1 are shown in Figure 3.
Figure 3. The invariant measure ˜ µ 0 for a hybrid system with transition matrix Q 1 .
## 5.2 A 2-D Hybrid System
Our second example is a two-dimensional system used to model the kinetics of chemical reactors. The general system f ( x , x 1 2 ) is given by
$$\dot { x _ { 1 } } = - \lambda x _ { 1 } - \beta ( x _ { 1 } - x _ { c } ) + B D a f ( x _ { 1 }, x _ { 2 } ) \\ \dot { x _ { 2 } } = - \lambda x _ { 2 } + D a f ( x _ { 1 }, x _ { 2 } ).$$
[7]
Here, we use the following simplified application of the system:
$$\dot { x _ { 1 } } = - x _ { 1 } -. 1 5 ( x _ { 1 } - 1 ) +. 3 5 ( 1 - x _ { 2 } ) e ^ { x _ { 1 } } + Z _ { t } ( 1 - x _ { 1 } ) \\ \dot { x _ { 2 } } = - x _ { 2 } +. 0 5 ( 1 - x _ { 2 } ) e ^ { x _ { 1 } }.$$
This system is used to describe a Continuous Stirred Tank Reactor (CSTR). This type of reactor is used to control chemical reactions that require a continuous flow of reactants and products and are easy to control the temperature with. They are also useful for reactions that require working with two phases of chemicals.
To understand the behavior of this system mathematically, we set our stochastic variable Z t = 0 and treat it as a deterministic system. This system has three fixed points, approximately at ( 67 . , . 09), (2 64 . , . 41), and (5 90 . , . 95); the former and latter are attractor points, while the middle is a saddle point, as shown in Figure 4. The saddle point (2 64 . , . 41) creates a separatrix, a repelling equilibrium line between the two attracting fixed points. These points, ( 67 . , . 09) and (5 90 . , . 95), comprise the ω -limit set of our state space.
y
x ' = - x - 0.15 (x - 1) + 0.35 (1 - y) e
x
e = 2.71828
y ' = - y + 0.05 (1 - y) e
x
1.2
0.8
0.6
0.4
0.2
x
Figure 4. Phase plane of the deterministic system, Z n = 0.
With this information, we proceed to analyze the stochastic system. As discussed above, the random variable here is Z t , which in applications can take values between -. 15 and . 15. To understand the full variability of this system, we take
$$Z _ { t } \in \{ -. 1 5, 0,. 1 5 \}$$
with the transition matrix
$$\left ( \begin{array} { c c c }. 3 &. 3 &. 4 \\. 3 &. 3 &. 4 \\. 3 &. 3 &. 4 \end{array} \right ),$$
yielding the phase plane in Figure 5. We use red to indicate state 1 ( Z t = -. 15), blue to indicate state 2 ( Z t = 0), and green to indicate state 3 ( Z t = 15) for the corresponding fixed points, separatrices, and portions . of trajectories.
Figure 5. Phase plane with randomness.
We see that, for x 0 away from the separatrices, ϕ t, x ( 0 , Z 0 ) behaves similarly to ϕ t, x ( 0 ). Although state changes create some variability in a given trajectory, these paths move toward the groups of associated attracting fixed points, which define the stochastic limit sets for this system. However, ϕ t, x ( 0 , Z 0 ) for x 0 between the red and green separatrices is unpredictable; depending on the sequence of state changes for a given trajectory, it might move either to the right or the left of the region defined by the separatrices. This area is the bistable region , because a trajectory beginning within it has two separate stochastic limit sets.
For example, we have in Figure 6 a spider plot beginning in the bistable region at (3 5 . , 0 75). . A spider plot shows all possible trajectories starting from a single point in a hybrid system by, at each time step, taking every possible state. Our previous coloring scheme still applies.
Figure 6. Spider plot.
Thus, we see that the introduction of a stochastic element to a deterministic system can grossly affect the outcome of the system, as a trajectory can now cross any of the separatrices by being in a different state.
The stochastic element also affects the behavior of the hybrid system around the invariant region. In Figure 7, we show the path of a single trajectory in the invariant region defined by the fixed points near ( 67 . , 0 9). . Plotting this trajectory for a long period of time approximates the invariant region that would appear if we ran a spider plot from the same point, but much more clearly.
0.76
Figure 7. Random trajectory.
As we saw in the 1-dimensional system, considering the counts taken at specific times in the interval between two state changes, h = 1 (since our state transitions occur on N ), yields a periodic set of invariant measures. Similarly to Figure 3, Figure 8 shows the positions of our random trajectory in the invariant region at time t , mod h .
A denser series of count images would show more clearly that the invariant measure at t mod h cycles continuously.
## 6 Conclusion
We have studied hybrid systems consisting of a finite set S of dynamical systems over a compact space M with a Markov chain on S acting at discrete time intervals. Such a hybrid system is a Markov process, which can be made time-homogeneous by discretizing the system. Then, there
exists a family of invariant measures on the product space M × S , which can be projected onto a family of measures on M . We have demonstrated a relation between the members of this family.
We have studied both a one-dimensional and a two-dimensional example of a hybrid system. These examples provide insight into the stochastic equivalent of ω -limit sets and yield graphical representations of the invariant measures on these sets.
## 7 Acknowledgements
We wish to recognize Kimberly Ayers for her helpful discussions and Professor Wolfgang Kliemann for his instruction and guidance. We would like to thank the Department of Mathematics at Iowa State University for their hospitality during the completion of this work. In addition, we would like to thank Iowa State University, Alliance, and the National Science Foundation for their support of this research. Figure 4 was drawn using the 'pplane8.m' MATLAB program.
## References
- [1] Ackerman, J., K. Ayers, E. J. Beltran, J. Bonet, and D. Lu. A Behavioral Characterization of Discrete Time Dynamical Systems using Directed Graphs . Iowa State University, Ames, 2011.
- [2] Ayala-Hoffmann, J., P. Corbin, K. McConville, F. Colonius, W. Kliemann, J. Peters. Morse Decompositions, Attractors and Chain Recurrence . Iowa State University, Ames, 2007.
- [3] Ayers, K.D. Stochastic Perturbations of the Fitzhugh-Nagurno Equations . Bowdoin College, Maine, 2010.
- [4] Baldwin, M.C. Stochastic Analysis of Marotzke and Stone climate model . Iowa State University, Ames, 2007.
- [5] Hairer, M. Convergence of Markov Processes . University of Warwick, Coventry, UK, 2010.
- [6] Hairer, M. Ergodic Properties of Markov Processes . University of Warwick, Coventry, UK, 2006.
- [7] Poore, A. B. A Model Equation Arising from Chemical Reactor Theory . Arch. Rational Mech. Anal. 52 (1974), pp 358-388.
- [8] Van Zanten, H. An Introduction to Stochastic Processes in Continuous Time . Eindhoven University of Technology, Centrum, NL, 2010. | 10.2140/involve.2014.7.565 | [
"Xavier Garcia",
"Jennifer Kunze",
"Thomas Rudelius",
"Anthony Sanchez",
"Sijing Shao",
"Emily Speranza",
"Chad Vidden"
] | 2014-07-31T20:48:53+00:00 | 2014-07-31T20:48:53+00:00 | [
"math.DS",
"math.PR"
] | Invariant Measures for Hybrid Stochastic Systems | In this paper, we seek to understand the behavior of dynamical systems that
are perturbed by a parameter that changes discretely in time. If we impose
certain conditions, we can study certain embedded systems within a hybrid
system as time-homogeneous Markov processes. In particular, we prove the
existence of invariant measures for each embedded system and relate the
invariant measures for the various systems through the flow. We calculate these
invariant measures explicitly in several illustrative examples. |
1408.0027v2 | ## The power spectrum and bispectrum of SDSS DR11 BOSS galaxies II: cosmological interpretation
H´ ector Gil-Mar´ ın 1 glyph[star] , Licia Verde 2 3 4 , , , Jorge Nore˜a n 2 5 , , Antonio J. Cuesta 2 , Lado Samushia , Will J. Percival , Christian Wagner , Marc Manera , 1 1 6 7 8 9 ,
## Donald P. Schneider
- 1 Institute of Cosmology & Gravitation, University of Portsmouth, Dennis Sciama Building, Portsmouth PO1 3FX, UK
- 2 Institut de Ci`ncies del Cosmos, Universitat de Barcelona, IEEC-UB, Mart´ ı i Franqu`s 1, 08028, Barcelona, Spain e e
- 3 ICREA (Instituci´ Catalana de Recerca i Estudis Avan¸ cats), Passeig Llu´ ıs Companys, 23 08010 Barcelona - Spain o
- 4 Institute of Theoretical Astrophysics, University of Oslo, Norway
- 5 Department of Theoretical Physics and Center for Astroparticle Physics (CAP), 24 quai E. Ansermet, CH-1211 Geneva 4, CH
- 6 Max-Planck-Institut f¨r Astrophysik, Karl-Schwarzschild Str. 1, 85741 Garching, Germany u
- 7 University College London, Gower Street, London WC1E 6BT, UK
- 8 Department of Astronomy and Astrophysics, The Pennsylvania State University, University Park, PA 16802, USA
- 9 Institute for Gravitation and the Cosmos, The Pennsylvania State University, University Park, PA 16802, USA
18 June 2015
## ABSTRACT
We examine the cosmological implications of the measurements of the linear growth rate of cosmological structure obtained in a companion paper from the power spectrum and bispectrum monopoles of the Sloan Digital Sky Survey III Baryon Oscillation Spectroscopic Survey Data, Release 11, CMASS galaxies. This measurement was of f 0 43 . σ 8 , where σ 8 is the amplitude of dark matter density fluctuations, and f is the linear growth rate, at the effective redshift of the survey, z eff = 0 57. In conjunction with . Cosmic Microwave Background (CMB) data, interesting constraints can be placed on models with non-standard neutrino properties and models where gravity deviates from general relativity on cosmological scales. In particular, the sum of the masses of the three species of the neutrinos is constrained to m < . ν 0 49 eV (at 95% confidence level) when the f 0 43 . σ 8 measurement is combined with state-of-the-art CMB measurements. Allowing the effective number of neutrinos to vary as a free parameter does not significantly change these results. When we combine the measurement of f 0 43 . σ 8 with the complementary measurement of fσ 8 from the monopole and quadrupole of the twopoint correlation function we are able to obtain an independent measurements of f and σ 8 . We obtain f = 0 63 . ± 0 16 and . σ 8 = 0 710 . ± 0 086 (68% confidence level). This . is the first time when these parameters have been able to be measured independently using the redshift-space power spectrum and bispectrum measurements from galaxy clustering data only.
Key words: cosmology: theory - cosmology: cosmological parameters - cosmology: large-scale structure of Universe - galaxies: haloes
## 1 INTRODUCTION
Direct and model-independent constraints on the growth of cosmological structure are particularly important in cosmology. Measurements of the expansion history of the Universe (via standard candles or standard rulers) have clearly indicated an accelerated expansion since redshift z ∼ 0 3, . but
- glyph[star] [email protected]
are insufficient to identify the physics causing it; information on the growth of structure is key (for a review of the state of the field and general introduction to it see e.g., Albrecht et al. (2006); Amendola et al. (2013); Feng et al. (2014) and references therein). In particular, while the cosmological constant remains at the core of the standard cosmological model, and is the most popular explanation for the accelerated expansion, it raises several problems from its smallness (the cosmological constant problem) to its fine tuning (the
coincidence problem). This situation has led many scientists to investigate alternatives to vacuum energy (dark energy) or to challenge one of the basic tenets of cosmology, namely General Relativity (GR). After all, precision tests of GR have been performed on solar system scales, but more than 10 orders of magnitude extrapolation is required to apply it on cosmological scales. Should GR be modified on cosmological scales, it could still mimic the ΛCDM expansion history but the growth of structure would be affected.
Most of the information we can gather about clustering and large scale structure, which on large scales would trace the linear growth of perturbations, come from galaxies. It is well known that different kinds of galaxies show different clustering properties, and thus not all objects can be faithful tracers of the underlying mass distribution; this feature is called galaxy bias. There are two notable observational techniques that avoid this limitation: gravitational lensing and redshift-space distortions. Gravitational lensing is an extremely promising approach which, however, at present reaches limited signal-to-noise ratio in the linear or mildly non-linear regime. The study of redshift-space distortions observed in galaxy redshift surveys uses galaxies as test particles in the velocity field and thus this technique is relatively insensitive to galaxy bias 1 .
A third approach is to use higher-order correlations to disentangle the effects of gravity from those of galaxy bias (e.g., Fry 1994). This is the approach recently pursued in Gil-Mar´ ın et al. (2014) where, by performing a joint analysis of the monopole power spectrum and bispectrum of the CMASS sample of the Baryon Oscillation Spectroscopic Survey Data Release 11 (BOSS DR11 SDSSIII) survey (Gunn et al. 1998, 2006; Eisenstein et al. 2011; Bolton et al. 2012; Dawson et al. 2013; Smee et al. 2013), constraints on both galaxy bias and growth of structures at the effective redshift of the survey z = 0 57 were obtained. .
Here we investigate the cosmological implications of the measurement of the quantity f 0 43 . σ 8 at z = 0 57 (hereafter . f 0 43 . σ 8 | z =0 57 . ) obtained in Gil-Mar´ ın et al. (2014) (hereafter Paper I). The parameter f quantifies the linear growth rate of structures: f = d ln δ/d ln a , where a is the scale factor and δ the (linear) matter overdensity fluctuation; σ 8 is the rms of the (linear) matter over density field extrapolated at z = 0 and smoothed on scales of 8 h -1 Mpc. Paper I reported f 0 43 . σ 8 | z =0 57 . = 0 582 . ± 0 084 . (0 584 . ± 0 051); . where the first result correspond to the conservative analysis while the second to the more optimistic analysis (see Gil-Mar´ ın et al. (2014) for details). Hereafter we report in parenthesis the results corresponding to the optimistic analysis. The difference in the central values is negligible at all effects thus we will only report the error-bars corresponding to the optimistic analysis. This 14% (9%) error on the quantity f 0 43 . σ 8 | z =0 57 . is comparable to that obtained in the quantity fσ 8 from the study of redshift-space distortions of the power spectrum of the same survey (e.g., Beutler et al. 2013; Chuang et al. 2013; Samushia et al. 2014 and S´nchez et al. 2014), which a have error-bars of typically 10%. While not being statisti-
1 This technique would be sensitive, of course, to a velocity bias if tracers did not to statistically represent the distribution of velocities of dark matter. Such a velocity bias is not expected on large-scales.
cally independent (the survey is the same), the method is complementary and the measurement relies on a different physical effect, harvesting the power of higher-order correlations rather than the anisotropy of clustering induced by the redshift-space distortions. This paper is organised as follows: in § 2 we present the data sets we use and the methodology and the consistency of the measurement with the ΛCDM model with GR. § 3 presents tests constraining several extensions of this model which involve changes in the composition (i.e., neutrino properties) or background (i.e., dark energy models and geometry) or deviations from GR. We explore the potential of combining the bispectrum monopole with anisotropic clustering of the two point function in § 4 and conclude in § 5.
## 2 METHODS AND DATA SETS
In Paper I we have analysed the anisotropic clustering of the Baryon Oscillation Spectroscopic Survey (BOSS) CMASS Data Release 11 sample, composed of 690827 galaxies in the redshift range of 0 43 . < z < 0 70. . This surveys covers an angular area of 8498 deg 2 , which corresponds to an effective volume of ∼ 6 Gpc . 3 We have measured the corresponding redshift-space galaxy power spectrum and bispectrum monopoles, providing a measurement of the linear growth rate, f , in combination with the amplitude of matter density fluctuations, σ 8 , f 0 43 . σ 8 = 0 582 . ± 0 084 (0 584 . . ± 0 051) . at the effective redshift of the survey, z eff = 0 57. The op-. timistic estimate is obtained by pushing slightly more into the mildly non-linear regime and thus including significantly more modes. For this particular combination of f and σ 8 , close to the maximum likelihood solution the likelihood surface is much closer to that of Gaussian distribution than in the individual parameters. In addition, this measurement is insensitive to the fiducial cosmology assumed in the analysis. Our measurements are supported by a series of tests performed on dark matter N-body simulations, halo catalogues (obtained both from PThalos and N-body simulations) and mock galaxy catalgoues (see § 5 in Paper I for an extensive list of tests to check for systematic errors and to asses the performance of the different approximations adopted). These tests are used to identify the regime of validity of the adopted modelling, which occurs when all the k -modes of the bispectrum triangles are larger than 0 03 . h Mpc -1 and less than 0 17 . h Mpc -1 (with the conservative analysis) or less than 0 20 . h Mpc -1 being more optimistic. We have also accounted for real world effects such as the survey window and systematic weighting of objects. We have opted to add in quadrature the statistical error and half of the systematic shift in order to account for the uncertainty in the systematics correction. Because the bispectrum calculation is computationally intensive, we have only considered a subset of all possible bispectrum shapes: k /k 2 1 = 1 and k /k 2 1 = 2. The statistical error on f 0 43 . σ 8 | z =0 57 . has been obtained from the scatter among 600 mock catalogs. Our cosmologically interesting parameters are: the linear matter clustering amplitude σ 8 and the growth rate of fluctuations f = d ln δ/d ln a . In Paper I we showed that even jointly, the power spectrum and bispectrum monopole cannot measure these two parameter separately, but do constrains on the f 0 43 . σ 8 | z =0 57 . . In this variable, the distribution of the best-fit parameters for
Figure 1. Constraints in the f σ -8 plane where both quantities are at the effective redshift of the BOSS CMASS DR11 galaxies z = 0 57. The ellipses represent the . Planck CMB inferred constraints (68 and 95% confidence) when assuming GR and a ΛCDM model. The dot-dashed line represents the best-fitting value for the measurements of Paper I, which uses the monopole power spectrum and bispectrum of the BOSS CMASS DR11 galaxies. The solid and dashed lines represent the 68% confidence region corresponding to the conservative and optimistic analysis respectively. The dotted lines are the 68% constraints obtained from the monopole and quadrupole of the two-point function from the same galaxy catalog (Samushia et al. 2014).
the galaxy mock catalogues is much closer to a Gaussian distribution than in the separate σ 8 and f parameters.
We combine the f 0 43 . σ 8 | z =0 57 . measurement with the constraints from Cosmic Microwave Background (CMB) observations acquired by the Planck satellite (Planck Collaboration et al. 2011, 2013a,b). In many cases we use the outputs of their Monte Carlo Markov Chains for importance sampling; when specified we run new Markov chains. We use either the Planck +WP data Planck primary temperature data with the Wilkinson Microwave Anisotropy Probe WMAP (Bennett et al. 2003) polarisation data (Bennett et al. 2012; Hinshaw et al. 2012) at low multipolesor Planck +WP+highL - the above data with the addition of high multipoles temperature observations from the Atacama Cosmology Telescope (Das et al. 2013) and the South Pole telescope (Reichardt et al. 2012). The Planck maps have also been analysed to extract the weak gravitational lensing signal arising from intervening large scale structure (Planck Collaboration et al. 2013c). This task is done through the four point function of the temperature maps; when including this information we refer to it as lensing . In some cases the CMB constraints are improved by the addition of information on the expansion history via Baryon Acoustic Oscillation (BAO) measurements (Beutler et al. 2011; Blake et al. 2011; Padmanabhan et al. 2012; Anderson et al. 2013; Percival et al. 2010).
We investigate whether the f 0 43 . σ 8 | z =0 57 . measurement is consistent with the ΛCDM+GR model prediction when the model parameters are constrained by CMB observations. Assuming GR, the expansion history uniquely predicts the linear growth rate. In a ΛCDM+GR model, observations of the CMB impose tight constraints on the expansion history and therefore on the growth of structure.
Fig. 1 presents the constraints on the f -σ 8 -plane, at z = 0 57, obtained from the . Planck+WP CMB observations extrapolated assuming GR and a flat-ΛCDM model, from the direct measurement of Paper I and, for completeness, from the BOSS CMASS galaxies anisotropic clustering (Samushia et al. 2014): fσ 8 = 0 441 . ± 0 044, at . z = 0 57. The galaxy . clustering measurements are individually in agreement with the standard ΛCDM cosmological paradigm within ∼ 1 σ .
As the two measurements constrain different combinations of f and σ 8 , they can be measured separately from a combined analysis. We explore this prospect in § 4.
Although there is no evidence for significant tensions between the CMB and the lower redshift measurements (in particular the f 0 43 . σ 8 | z =0 57 . measurement of Gil-Mar´ ın et al. (2014)), we consider standard ΛCDM model extensions, where one or more extra cosmological parameters are allowed to vary. We then consider direct constraints on modifications of GR.
In § 4 we also consider the measurement of the combination fσ 8 from Samushia et al. (2014). This reference uses the same data set as Paper I but exploits the fact that redshift-space distortions cause an isotropic two-point correlation function become anisotropic. The magnitude of the large-scale velocity field traced by galaxies depends on the nature of gravitational interactions, thus the angular dependence of the two-point function can be used to measure the combination fσ 8 . For more details see Reid et al. (2012); Samushia et al. (2014) and references therein.
## 3 RESULTS
In this section we present the constrains that the f 0 43 . σ 8 | z =0 57 . measurement provide on different extensions of ΛCDM+GR such as, i) neutrino mass properties, ii) changes in the dark energy equation of state, iii) deviations from GR.
## 3.1 Neutrino mass constraints
Among possible ΛCDM model extensions, which still assume GR, we expect the f 0 43 . σ 8 | z =0 57 . measurement to provide significant improvement over CMB data alone for the cases of where significant evolution in the growth rate to low redshift is expected. This is the case for massive neutrinos and for models where dark energy deviates from a cosmological constant and where more than one evolution-affecting parameter is added to the 'base' ΛCDM model. In other model extensions, the addition of the growth constraints only reduces the CMB error-bars by few percent. In these cases therefore, this combination offers a test of consistency rather than a technique of reducing parameter degeneracies and improving cosmological constraints.
Massive neutrinos affect the growth of cosmological structure by suppressing clustering below their free streaming length; as a result in models with massive neutrinos the power spectrum amplitude at large-scale structure scales is lower than that at CMB scales. If we allow the three standard-model neutrinos to have a non-zero mass and the sum of the masses m ν to be the parameter to be constrained,
Figure 2. Constraints in the σ 8 -m ν plane. In both panels the blue, dashed contours are the (joint) 68 and 95% confidence regions for Planck . On the top panel Planck temperature data and WMAP low glyph[lscript] polarisation are used ( Planck +WP ), while on the bottom panel also the highL data are included ( Planck +WP+highL ). The solid contours show how constraints improve by including f 0 43 . σ 8 | z =0 57 . : thick, purple lines correspond to the conservative estimate and thin, black lines to the optimistic one.
the Planck+WP data constraints are m < . ν 1 31 eV at 95% confidence, which become m ν < 0 66 eV . when the highL data are considered. Including the f 0 43 . σ 8 | z =0 57 . measurement produces m < . ν 0 68(0 47) eV and . m < . ν 0 49(0 38) eV, . respectively, always at 95% confidence, which represent a factor 2 (2.8) and 1.3 (1.7) improvement, respectively. When the information about lensing is included (through the four point function of the CMB temperature) in the CMB analysis the constraint on neutrino masses relaxes to, m ν < 0 85 eV . (95% confidence) . 2 Including f 0 43 . σ 8 | z =0 57 . brings back the upper limit to m < . ν 0 67(0 50) eV. Fig. 2 presents . the constraints in the σ 8 -m ν plane and illustrates the above features. Basically the f 0 43 . σ 8 | z =0 57 . measurement, by effectively constraining σ 8 , breaks the m ν -σ 8 degeneracy.
2 This point is discussed at length in the literature and in Planck Collaboration et al. (2013b) and is possibly due to a mild tension between the CMB damping tail and the four-point function constraints on the magnitude of the lensing signal.
Figure 3. Constraints in the total neutrino mass m ν , number of effective neutrino species N eff from Planck+WP in (light) blue, dashed lines indicating 68% and 95% and with the addition of the f 0 43 . σ 8 | z =0 57 . constraints in solid thick purple (solid thin black) contours. As above the tighter constraints are obtained with the optimistic measurement. For m ν (marginalised over N eff ) we obtain that the CMB constraint m < . ν 0 85 eV (at 95% confidence) becomes m < . ν 0 63(0 46) eV (at 95% confidence). .
Aslightly more general extension of the ΛCDM model is the case where both the number of effective neutrino species N eff and the neutrino mass m ν are treated as free parameters. Also in this case the f 0 43 . σ 8 | z =0 57 . measurement improves the constraints, especially on the sum of neutrino masses. This behaviour is illustrated in Fig. 3, where the blue, dashed contours are for Planck+WP and the solid, thick purple (thin, black) contours are in combination with the f 0 43 . σ 8 | z =0 57 . measurement. For m ν (marginalised over N eff ) the CMB constraint m < . ν 0 85 eV (at 95% confidence) becomes m < . ν 0 63(0 46) eV (at 95% confidence). .
Qualitatively similar results are also obtained for the massive sterile neutrino case, where the extra sterile neutrinos are made massive rather than having the mass being equally distributed among all neutrino families: m ν < 0 51(0 42) eV at 95% confidence when we impose a limit to . . the physical thermal mass for the sterile neutrino < 10 eV, for which the particles are distinct from cold or warm dark matter (see Table 1 for details). Some large-scale structure datasets, including the cluster abundance from the Planck Sunyaev-Zeldovich clusters (Planck Collaboration et al. 2013d), yield a much lower value for σ 8 ( z = 0) than that inferred from the CMB assuming a standard ΛCDM-model with near massless neutrinos. This mismatch has been interpreted as an evidence of non-zero neutrino mass with m ν ∼ 0 45 eV. In particular the joint analysis of . Planck temperature data with the cluster abundance from the Planck Sunyaev-Zeldovich clusters (Planck Collaboration et al. 2013d) yields a tentative detection of neutrino masses m ν = 0 45 . -0 58 . ± 0 21 eV depending on assump-. tions about the calibration of the mass-observable relation. The f 0 43 . σ 8 | z =0 57 . measurement seems to disfavour the 'new physics in the neutrino sector' interpretation of the σ 8 mismatch. These results are summarised in Table 1.
Table 1. Constraints (95% limits) on the sum of neutrino masses for several models and data set combinations. The m ν -ΛCDM model is a spatially flat power law ΛCDM model where the sum of neutrino masses is an extra parameter. The N eff -m ν -ΛCDM model is a spatially flat power law ΛCDM model where both the effective number of neutrino species and the total neutrino mass are extra parameters. The N eff -m sterile eff -ΛCDM model is similar to N eff -m ν -ΛCDM, but where the massive neutrinos are only the sterile ones. To calculate the constraints we have imposed a physical thermal mass for the sterile neutrino < 10 eV, which defines the region (for the CMB) where the particles are distinct from cold or warm dark matter.
| | m ν - ΛCDM | m ν - ΛCDM | N eff - m ν - ΛCDM | N eff - m sterile eff - ΛCDM |
|-----------------|-------------------------------------------------------------------------------------|------------------------------------------------------------|--------------------------------------------------------------|------------------------------------------------------------|
| | Planck +WP Planck +WP+highL m ν < 1 . 31 eV m ν < | Planck +WP+highL+lensing m ν < 0 . 85 eV | Planck+WP m ν < 0 . 85 eV | Planck +WP+highL m ν < 0 . 59 eV |
| conserv. optim. | + f 0 . 43 σ 8 | z =0 . 57 + f 0 . 43 σ m ν < 0 . 68 eV m ν < m ν < 0 . 46 eV m ν < | + f 0 . 43 σ 8 | z =0 . 57 m ν < 0 . 67 eV m ν < 0 . 50 eV | + f 0 . 43 σ 8 | z =0 . 57 m ν < 0 . 63 , eV m ν < 0 . 46 eV | + f 0 . 43 σ 8 | z =0 . 57 m ν < 0 . 51 eV m ν < 0 . 42 eV |
Figure 4. Constraints obtained from Planck+WP in combination with the f 0 43 . σ 8 | z =0 57 . measurement for the following models. In the left panel constraints in the Ω k -w plane for a non-flat Universe where the dark energy equation of state is constant but not necessarily -1; in the middle panel constraints in the w w -a plane for a flat model where the dark energy equation of state parameter changes with the scale factor a as w a ( ) = w + w a (1 -a ). The right panel is the same as the middle panel but where the spatial flatness assumption is relaxed. In this case -0 076 . < Ω k < 0 009 (95% confidence), respectively. The contour lines represent the 68% and the 95% confidence . regions. The saturation of the colour is proportional to the posterior likelihood.
## 3.2 Dark energy equation of state constraints
In the case of a non-flat model where the dark energy equation of state parameter w is constant, but not necessarily equal to -1 ow CDM-, the combination of Planck+WP and f 0 43 . σ 8 | z =0 57 . measurements constrain w to be -2 10 . < w < -0 33 . ( -1 94 . < w < -0 62) . at 95% confidence and the curvature to be -0 093 . < Ω k < +0 008 ( . -0 076 . < Ω k < +0 007), . also at 95% confidence. The joint constraints in the Ω k -w plane are displayed in the left panel of Fig. 4.
Conversely, if we assume flat geometry, but allow the dark energy equation of state to change with the scalefactor a (according to Chevallier & Polarski 2001 and Linder 2003) as w a ( ) = w + w a (1 -a ) -ww a CDM-, we obtain the constraints presented in the middle panel of Fig. 4. The single parameter constraints are: -2 03 . < w < -0 06 . ( -1 80 . < w < -0 16) and . w a < 1 27(1 08) (at 95% confi-. . dence). These constraints do not degrade significantly if flatness is relaxed oww a CDM-, as shown in the right panel of Fig. 4. In this case the constraint on the geometry becomes -0 083 . < Ω k < 0 007( . -0 074 . < Ω k < 0 007) at 95% confi-. dence and for the dark energy parameters -2 38 . < w < 0 39 . ( -2 20 . < w < -0 01) . and w a < 1 64(1 60) . . (95% confi- dence). For all these cases, we ran new Markov Chains rather than importance sampling existing ones. We conclude that a dark energy component is needed and is dominant even in non-flat models where the dark energy equation of state parameter is not necessarily constant. The density of dark energy in units of the critical density Ω dark energy at 68% confidence is 0 61 . ± 0 13 (0 637 . . ± 0 090) in the . ow CDM model, 0 742 . ± 0 071 (0 728 . . ± 0 055) in the . ww a CDM model and 0 62 . ± 0 12 (0 639 . . ± 0 086) in the . oww a CDM model. These constraints are obtained using only data at z glyph[greaterorequalslant] 0 57 (i.e., . f 0 43 . σ 8 | z =0 57 . and CMB). Any more 'local' explanation for dark energy is therefore disfavoured.
## 3.3 Modifications of GR
In modern cosmology the rationale behind introducing modifications of GR is to explain the late-time cosmological acceleration. Therefore, the most popular modifications of GR mimic the effects of the cosmological constant on the expansion history and become important only at low redshifts. If we allow gravity to deviate from GR, the CMB offers only weak constrains on the late-time growth of structures, via the Integrated Sachs-Wolfe (ISW) effect and lensing. A pop-
ular parametrisation for deviations from GR growth is given by,
$$f ( z ) = \Omega _ { m } ( z ) ^ { \gamma }. \quad \quad ( 1 ) \quad,$$
For ΛCDM+GR γ | ΛCDM glyph[similarequal] 0 56; . for dark energy models with an equation of state parameter different from w = -1, γ acquires a weak redshift dependence and its value does not deviate significantly from γ | ΛCDM . Since we have a measurement at a given redshift we consider γ to be constant. We also assume that this modification affects the late-time Universe and not the CMB. This assumption is reasonable as in this parametrisation, as Ω m ( z ) -→ 1 (i.e., for most cosmologies at z glyph[greatermuch] 1) the growth becomes that of an EinsteinDe-Sitter Universe for any value of γ .
For this extension to the base model we assume that the background expansion history is given by that of the ΛCDMmodel as constrained by Planck+WP (using Planck+WP+ highL +BAO does not change the results significantly). The constraints on the growth rate reduce to γ = 0 40 . +0 50 . -0 42 . ( +0 28 . -0 26 . ) at 68% confidence and γ < 0 87 (0 80) at 95% confi-. . dence.
For coupled dark energy-dark matter models the growth can be parametrised as (e.g., di Porto & Amendola (2008) and references therein),
$$f ( z ) = \Omega _ { m } ( z ) ^ { 0. 5 6 } ( 1 + \eta ). \quad \quad ( 2 ) \quad r \varepsilon$$
Using this equation we obtain η = 0 055 . ± 0 145 ( . ± 0 090) . at 68% confidence. For the coupled dark energy-dark matter models, η is related to the coupling constant β c . These models have a non-negligible amount of dark energy at early times, so they can be constrained by the CMB. Nevertheless, the η constraint can be re-interpreted as a limit on the coupling constant β c < 0 34 ( . < 0 28) at 95% confidence at . the effective survey redshift z = 0 57; as expected this con-. straint is much weaker than that obtained from the CMB by Pettorino et al. (2012) assuming a constant coupling.
Inspired by Acquaviva et al. (2008), who introduced the quantity glyph[epsilon1] = f/f | ΛCDM -1, we can define
$$\epsilon ^ { \prime } \equiv \frac { f ^ { 0. 4 3 } \sigma _ { 8 } } { f ^ { 0. 4 3 } \sigma _ { 8 } | _ { \Lambda C D M } } - 1, \quad \quad ( 3 ) \quad \text{ is} \\ \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text
} $ . - + ) , " ( ' ; : <$$
which is a more model-independent approach than the γ -parameterisation of Eq. 1 or the η -parameterisation of Eq. 2. Eq. 3 also enables one to quantify possibly early times deviations from GR . Note that since 3 σ 8 ( z /σ ) 8 ( z ) | ΛCDM = D z /D z ( ) ( ) | ΛCDM , where D z ( ) is the linear growth factor, Eq. 3 parametrizes deviations on the f 0 43 . σ 8 | z =0 57 . (or on the f 0 43 . D | 0 57 . ) produced by changes in the theory of gravity on f and D , whereas Eq. 2 only accounts for changes on f . This quantity, which is identical to zero for ΛCDM and exceedingly close to zero for minimally coupled quintessencetype models, is redshift dependent and can, in principle, be also scale dependent when departures from GR are present. Here we assume glyph[epsilon1] ′ is scale-independent over the scales probed and we compute its value at the effective survey redshift. For f 0 43 . σ 8 ΛCDM | we take the range predicted by the Planck+WP combination and obtain, at 68% confidence,
$$\epsilon ^ { \prime } ( z = 0. 5 7 ) = 0. 0 4 \pm 0. 1 5 ( \pm 0. 1 0 ) \,, \quad \ \ ( 4 ) \quad \ \ _ { t \omega } ^ { \text{er} }.$$
3 In the γ parameterisation the standard growth is recovered for all values of γ at z > 0 5, when Ω . m → 1.
in agreement with the GR value of zero.
## 4 BREAKING THE f -σ 8 DEGENERACY
As displayed in Fig. 1, the constraints in the f -σ 8 plane produced by the redshift-space distortions of the anisotropic redshift-space correlation function and those produced by the monopole of the power spectrum and bispectrum are highly complementary.
A joint analysis combining the two-point anisotropic clustering and the bispectrum monopole is able to break the degeneracy between f and σ 8 , enabling the measurement of both quantities separately. Here we do not attempt a full, combined analysis of the power spectrum monopole, quadrupole and the bispectrum monopole, which would yield the combined constraint of multiples parameters, including bias if a single consistent bias model were adopted. We will consider such analysis in a future work.
Instead, we perform a combined, a posteriori , analysis between the measurements of fσ 8 | z =0 57 . obtained by Samushia et al. (2014), when the background expansion is fixed to the one predicted by Planck, and of f 0 43 . σ 8 | z =0 57 . obtained in Paper I. Although the measurements were carried out independently, and one is performed in configuration space while the other in Fourier space, they share the information related to the monopole of the two-point statistics, and therefore they are expected to be moderately correlated. Using measurements based on the same set of mocks (Manera et al. 2013) we compute the correlation and errors from their dispersion (see § 3.9 in Paper I for details of the method). We consider the measurement of [ fσ 8 ] i and [ f 0 43 . σ 8 ] i for each single i -mock, and combining them we extract the corresponding values:
$$\text{MB} \quad [ f ] _ { i } \ = \ \left \{ [ f \sigma _ { 8 } ] _ { i } / [ f ^ { 0. 4 3 } \sigma _ { 8 } ] _ { i } \right \} ^ { 1 / 0. 5 7 },$$
$$\stackrel { \varkappa } { 1 } \text{ the } \quad [ \sigma _ { 8 } ] _ { i } \ = \ [ f \sigma _ { 8 } ] _ { i } / [ f ] _ { i }.$$
The errors on f and σ 8 are estimated from the dispersion of [ f ] i and [ σ 8 ] i among all the mocks, respectively. This result is illustrated in Fig. 5, where the blue dots represent the obtained values of [ f ] i and [ σ 8 ] i for the 600 realisations of the galaxy mocks: i = 1 2 , , . . . , 600.
The combined constraints in the f -σ 8 plane are displayed in Fig. 5, which illustrates the constraints on fσ 8 and f 0 43 . σ 8 from Samushia et al. (2014) and Paper I, respectively, using the same line-notation as in Fig. 1. Blue dots represent the best-fit values for the mocks and the red cross shows the best-fit value for the DR11 CMASS dataset. The green dashed ellipses represent the Planck CMB inferred constraints (68 and 95% confidence) when assuming GR and a ΛCDM model. The red contours correspond to the (joint) 68% (solid lines) and 95% (dashed lines) confidence levels extracted from the mocks and centered on the data, where the mild prior 0 < f < 2 has been used.
Originally the constrains on fσ 8 and f 0 43 . σ 8 were: fσ 8 | z =0 57 . = 0 447 . ± 0 028 . and f 0 43 . σ 8 | z =0 57 . = 0 582 . ± 0 084 (0 051). After combining the measurements the degen-. . eracy between f and σ 8 is broken, although the two parameters remain significantly (anti)correlated, with a correlation coefficient of ∼ -0 9. . From the joint distribution we can now obtain marginalised constraints on each of the parameters: f ( z eff ) = 0 63 . ± 0 16(0 13) . . (marginalised over σ 8 ),
Figure 5. Constraints in the f -σ 8 plane where both quantities are at the effective redshift of the BOSS CMASS DR11 galaxies z = 0 57. In this figure, for . f 0 43 . σ 8 | z =0 57 . we consider the conservative measurement only. The blue dots represent the best-fitting values for 600 mocks when the results from Samushia et al. (2014) (short dashed line) and Paper I (dot-dashed line) are combined (see text for details). The black dotted and dashed lines show the 1 σ errors, respectively. The contours correspond to the 68 and 95% confidence regions (solid and dashed lines, respectively) estimated from the dispersion of the mocks. The green dashed ellipses represent the Planck CMB inferred constraints (68 and 95% confidence) when assuming GR and a ΛCDM model. The red cross represents the best-fitting value for the BOSS CMASS DR11 data. The best-fitting values of the galaxy mocks, as well as the contours, have been displaced in the logarithmic space to be centered on the measurement from the data.
σ 8 ( z eff ) = 0 710 . ± 0 086(0 069) (marginalised over . . f ), where all the reported errors are at the 68% confidence level. These values represent a 12(10)% and 25(20)% relative error for σ 8 ( z eff ) and f ( z eff ), respectively.
Previous works in the literature have used bispectrum alone or in combination with the power spectrum of galaxies to break degeneracies present in the power spectrum analysis. Scoccimarro et al. (2001); Verde et al. (2002); Nishimichi et al. (2007); McBride et al. (2011); Chiang et al. (2015) constrain the bias parameters b 1 and b 2 with the bisectrum (or equivalent observables), the derived b 1 parameter can then be used in combination with the power spectrum-derived β ∼ f/b 1 to constrain f . Mar´ ın et al. (2013) use the bispectrum to constrain the amplitude of primodrial fluctuations σ 8 when other cosmological parameters (such as f ) were fixed to fiducial (ΛCDM, GR) values. However, this is the first time that these two quantities f and σ 8 have been separately determined from galaxy clustering using the power spectrum and bispectrum measurements.
The resulting values for f and σ 8 are in broad agreement with the CMB-inferred values. This can be appreciated in Fig. 5, where the green dashed ellipses are in general agreement with the red contours of the data. We have also computed the tension T as introduced in Verde, Protopapas & Jimenez (2013), which quantifies whether multi-dimensional cosmological parameters constraints from two different ex- periments are in agreement or not. We find that the tension is not significant, ln T < 1, i.e., the two measurements are in agreement.
We have repeated the analysis of § 3.1 and 3.2 using these new constraints, but we find that the constraints on the cosmological parameters do not change in any significant way. At the current size of the error-bars of f 0 43 . σ 8 | z =0 57 . , the fσ 8 degeneracy is being cut for high values of σ 8 , but has a tail for low values of σ 8 , as it is shown in Fig. 5. Therefore, breaking the fσ 8 degeneracy in this way (in combination with Planck data) does not improve significantly the errorbars in the studied parameters. We expect that this will improve with the forthcoming analysis of DR12, where a joint analysis of power spectrum monopole, quadrupole and bispectrum monopole will be performed.
When the measurements obtained on f are applied to the parameters of Eq. 1 the constraints on γ become γ = 0 40 . ± 0 43(0 35) (68% confidence). We can now con-. . sider the variable glyph[epsilon1] introduced by Acquaviva et al. (2008), obtaining glyph[epsilon1] = -0 21 . ± 0 56(0 45), . . also at 68% confidence. Both measurements should be considered at z eff = 0 57 at . scales of k glyph[similarequal] 0 1 . h Mpc -1 . In order to be able to use these measurements to distinguish between GR and popular and viable modifications of gravity that match the ΛCDM model expansion history, error-bars would have to be reduced by a factor of few.
In this paper we only have considered to combine the results obtained from the power spectrum and bispectrum monopole analysis, with those from the anisotropic twopoint correlation function Samushia et al. (2014) . Moreover we only consider constraints on the parameters describing the growth of perturbations and not the expansion history. The expansion history can be probed with the power spectrum (both monople and quadrupole) via the parameters D /r V s and F as it has been done by the same collaboration (Samushia et al. 2014). But exploring the effect of adding the bispectrum information to e.g. break the degeneracy between F and fσ 8 goes beyond the scope of this paper.
It may seem disappointing at first sight that the time consuming and challenging analysis of the galaxy bispectrum does not seem to improve dramatically the cosmological constraints on parameters such as γ . However, is important to keep in mind that the bispectrum is a different statistic from the monopole and quadrupole of the power spectrum, which relies on different modelling, different physical effects and is affected by different systematics. It adds some additional information to the power spectrum analysis which goes beyond the size of the error-bars on some cosmological parameters. It offers a consistency check. It gives insights on the behaviour and amplitude of the galaxy bias, it serves as a test of our modelling of mild non-linearities and non-linear redshift space distortions.
We have shown for example that adding our bispectrum result on f 0 43 . σ 8 to Planck data, constrains neutrino mass as much as adding the ' highL ' and ' highL ' combined with Planck lensing .
Moreover, it has been proposed that the bispectrum in combination with the power spectrum could be used to constrain not just gravity and bias, but also the nature of the initial conditions (primordial non-Gaussianity) from future surveys. It is important to start exploring the challenges and
opportunities that a combined power spectrum and bispectrum analysis offer.
## 5 CONCLUSIONS
We have examined the cosmological implications of the constraints on the quantity f 0 43 . σ 8 at z eff = 0 57, which of-. fers a direct cosmological and model-independent probe of the growth of structure. This constraint has been obtained from the measurement of the power spectrum and bispectrum monopoles of the SDSSIII BOSS DR11 CMASS galaxies and has been recently presented in a companion paper (Gil-Mar´ ın et al. 2014) (Paper I).
We have combined this result with recent state-of-the art CMB constraints for several underlying cosmological models. We find agreement in the standard ΛCDM cosmological paradigm between the growth of structure predicted by CMB observations and the direct measurement from galaxy clustering.
When considering popular ΛCDM model extensions, which still rely on GR, we find that this new measurement is useful to improve the CMB constraints on cosmological parameters only for model extensions that involve massive neutrinos or for models where dark energy deviates from a cosmological constant and where more than one parameter is added. The f 0 43 . σ 8 | z =0 57 . measurement improves CMB neutrino mass constraints by at least 30% and in some cases by as much as factor 2 to 2.8. (see Table 1 for details). There is no evidence for non-standard neutrino properties when considering CMB and f 0 43 . σ 8 | z =0 57 . measurements.
For dark energy models where the equation of state parameter of dark energy is not constant, or for models where it is constant but not equal to -1 and the geometry of the Universe is not constrained to be flat, we can obtain interesting constraints. Curvature is constrained at the 8% level (95% confidence). We find no evidence for any deviations from a cosmological constant, but dark energy is needed as a dominant component of the Universe, even for non-flat, non-ΛCDM cosmologies. This conclusion is reached using only data at z glyph[greaterorequalslant] 0 57, . thus disfavouring 'local' explanations of dark energy.
We have also examined the constraints that the measurement of f 0 43 . σ 8 | z =0 57 . , in combination with data on the Universe's geometry and expansion history, provide on modifications of GR. We have examined different phenomenological parametrisations of how the growth of structure is modified when we relax the assumption of GR. We do not observe any significant tension between these measurements and GR predictions, in particular we find that γ = 0 40 . +0 50 . -0 45 . ( +0 28 . -0 26 . ) (68% confidence), where f ( z ) = Ω m ( z ) γ .
Finally, we have presented how the measurement of f 0 43 . σ 8 | z =0 57 . can be combined with the measurement of fσ 8 | z =0 57 . from the same galaxy sample to break the degeneracy between f and σ 8 . This is the first time that a separate measurement of f and σ 8 has been obtained using power spectrum and bispectrum measurements from galaxy clustering: f = 0 63 . ± 0 16 and . σ 8 = 0 710 . ± 0 086, . both at z = 0 57. The size of errors already provides an insight . on how powerful a fully and optimal joint analysis can be. We find that f can be measured with a relative precision of ∼ 25%, and σ 8 with ∼ 10% at 68% confidence level. We expect that the size of these error-bars can be reduced if the power spectrum multipoles and bispectrum monopole are combined prior to obtain the f and σ 8 best-fitting values. Further testing for potential systematics would also be of benefit for such novel analysis.
While the f -σ 8 degeneracy could also be broken using measurements at several different redshifts, or resorting to weak lensing data or cross correlation with the weak lensing signal of the CMB, the approach described in this paper provides a complementary and self-contained approach to achieve the same goal relying on galaxy redshift surveys alone, without the need of wide redshift coverage.
## ACKNOWLEDGEMENTS
HGM is grateful for support from the UK Science and Technology Facilities Council through the grant ST/I001204/1. LV is supported by the European Research Council under the European Community's Seventh Framework Programme grant FP7-IDEAS-Phys.LSS and acknowledges Mineco grant FPA2011-29678- C02-02. JN is supported in part by ERC grant FP7-IDEAS-Phys.LSS. AC is supported by the European Research Council under the European Community's Seventh Framework Programme grant FP7IDEAS-Phys.LSS. WJP is grateful for support from the UK Science and Technology Facilities Research Council through the grant ST/I001204/1, and the European Research Council through the grant 'Darksurvey'.
Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/.
SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSSIII Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, University of Cambridge, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University. This research used resources of the National Energy Research Scientific Computing Center, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC02-05CH11231.
Results are based on observations obtained with Planck (http://www.esa.int/Planck), an ESA science mission with instruments and contributions directly funded by ESA Member States, NASA, and Canada.
Numerical computations were done on Hipatia ICC-UB BULLx High Performance Computing Cluster at the University of Barcelona.
## REFERENCES
| Acquaviva V., Hajian A., Spergel D. N., Das S., 2008, Phys. Rev. D , 78, 043514 |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Albrecht A. et al., 2006, ArXiv Astrophysics e-prints Amendola L. et al., 2013, Living Reviews in Relativity, 16, |
| 6 Anderson L., Aubourg E., Bailey S., Bizyaev D., Blanton M., et al., 2013, Mon.Not.Roy.Astron.Soc., 427, 3435 Bennett C., Larson D., Weiland J., Jarosik N., Hinshaw G., et al., 2012 |
| Bennett C. L. et al., 2003, ApJS , 148, 1 Beutler F., Blake C., Colless M., Jones D. H., Smith L., et al., 2011, Mon.Not.Roy.Astron.Soc., |
| Staveley- 416, 3017 |
| Beutler F. et al., 2013, ArXiv e-prints Blake C., Kazin E., Beutler F., Davis T., Parkinson D., et al., 2011, Mon.Not.Roy.Astron.Soc., 418, 1707 Bolton A. S. et al., 2012, AJ , 144, 144 |
| Chevallier M., Polarski D., 2001, International Journal of Modern Physics D, 10, 213 C.-T., Wagner C., S´nchez a A. G., Schmidt F., Ko- matsu E., 2015, ArXiv e-prints |
| Chiang Chuang C.-H. et al., 2013, MNRAS , 433, 3559 |
| Das S., Louis T., Nolta M. R., Addison G. E., Battistelli E. S., et al., 2013 K. S. et al., 2013, AJ , 145, 10 |
| Dawson di Porto C., Amendola L., 2008, Phys. Rev. D , 77, 083508 Eisenstein D. J. et al., 2011, AJ , 142, 72 |
| Feng J. L. et al., 2014, ArXiv e-prints J. N., 1994, Physical Review Letters, 73, 215 ı H., Nore˜a n J., Verde L., Percival W. J., Wagner C., Manera M., Schneider D. P., 2014, ArXiv e-prints J. E. et al., 1998, AJ , 116, 3040 |
| Fry Gil-Mar´n Gunn Gunn J. E. et al., 2006, AJ , 131, 2332 |
| Hinshaw G., et al., 2012 Linder E. V., 2003, Physical Review Letters, 90, 091301 Manera M. et al., 2013, MNRAS , 428, 1036 |
| Mar´n ı F. A. et al., 2013, MNRAS , 432, 2654 |
| McBride C. K., Connolly A. J., Gardner J. P., Scranton Scoccimarro R., Berlind A. A., Mar´n ı F., Schneider D. |
| R., P., 2011, ApJ , 739, 85 |
| Nishimichi T., Kayo I., Hikage C., Yahata K., Taruya A., Jing Y. P., Sheth R. K., Suto Y., 2007, PASJ , 59, 93 |
| Padmanabhan N., Xu X., Eisenstein D. J., Scalzo R., Cuesta A. J., et al., 2012 |
| Percival W. J., et al., 2010, Mon.Not.Roy.Astron.Soc., 401, 2148 Quercellini C., |
| Pettorino V., Amendola L., Baccigalupi C., 2012, Phys. Rev. D , 86, 103507 Planck Collaboration et al., 2013a, ArXiv e-prints |
| Planck Collaboration et al., 2013b, ArXiv e-prints Planck Collaboration et al., 2013c, ArXiv e-prints |
| Planck Collaboration et al., 2013d, ArXiv |
| e-prints Planck Collaboration et al., 2011, A&A , 536, A1 |
| Reichardt C., Shaw L., Zahn O., Aird K., Benson B., et al., 2012, Astrophys.J., 755, 70 |
| Reid B. A. et al., 2012, MNRAS , 426, 2719 |
| Samushia L. et al., 2014, MNRAS , 439, 3504 S´nchez a A. G. et al., 2014, MNRAS , 440, 2692 |
| Scoccimarro R., Feldman H. A., Fry J. N., |
| J. A., 2001, ApJ , 546, 652 |
| Frieman |
Smee S. A. et al., 2013, AJ , 146, 32
Verde L. et al., 2002, MNRAS , 335, 432
Verde L., Protopapas P., Jimenez R., 2013, Physics of the Dark Universe, 2, 166 | 10.1093/mnras/stv1359 | [
"Héctor Gil-Marín",
"Licia Verde",
"Jorge Noreña",
"Antonio J. Cuesta",
"Lado Samushia",
"Will J. Percival",
"Christian Wagner",
"Marc Manera",
"Donald P. Schneider"
] | 2014-07-31T20:59:16+00:00 | 2015-06-17T18:05:05+00:00 | [
"astro-ph.CO",
"astro-ph.GA"
] | The power spectrum and bispectrum of SDSS DR11 BOSS galaxies II: cosmological interpretation | We examine the cosmological implications of the measurements of the linear
growth rate of cosmological structure obtained in a companion paper from the
power spectrum and bispectrum monopoles of the Sloan Digital Sky Survey III
Baryon Oscillation Spectroscopic Survey Data, Release 11, CMASS galaxies. This
measurement was of $f^{0.43}\sigma_8$, where $\sigma_8$ is the amplitude of
dark matter density fluctuations, and $f$ is the linear growth rate, at the
effective redshift of the survey, $z_{\rm eff}=0.57$. In conjunction with
Cosmic Microwave Background (CMB) data, interesting constraints can be placed
on models with non-standard neutrino properties and models where gravity
deviates from general relativity on cosmological scales. In particular, the sum
of the masses of the three species of the neutrinos is constrained to
$m_\nu<0.49\,{\rm eV}$ (at 95\% confidence level) when the $f^{0.43}\sigma_8$
measurement is combined with state-of-the-art CMB measurements. Allowing the
effective number of neutrinos to vary as a free parameter does not
significantly change these results. When we combine the measurement of
$f^{0.43}\sigma_8$ with the complementary measurement of $f\sigma_8$ from the
monopole and quadrupole of the two-point correlation function we are able to
obtain an independent measurements of $f$ and $\sigma_8$. We obtain
$f=0.63\pm0.16$ and $\sigma_8=0.710\pm0.086$ (68\% confidence level). This is
the first time when these parameters have been able to be measured
independently using the redshift-space power spectrum and bispectrum
measurements from galaxy clustering data only. |
1408.0028v1 | ## MONADICITY THEOREM AND WEIGHTED PROJECTIVE LINES OF TUBULAR TYPE
JIANMIN CHEN, XIAO-WU CHEN , ZHENQIANG ZHOU ∗
Abstract. We formulate a version of Beck's monadicity theorem for abelian categories, which is applied to the equivariantization of abelian categories with respect to a finite group action. We prove that the equivariantization is compatible with the construction of quotient abelian categories by Serre subcategories. We prove that the equivariantization of the graded module category over a graded ring is equivalent to the graded module category over the same ring but with a different grading. We deduce from these results two equivalences between the category of (equivariant) coherent sheaves on a weighted projective line of tubular type and that on an elliptic curve, where the acting groups are cyclic and the two equivalences are somehow adjoint to each other.
## 1. Introduction
The close relationship between weighted projective lines of tubular type and elliptic curves is known to experts since the creation of weighted projective lines in [9]. Roughly speaking, the category of coherent sheaves on a weighted projective line of tubular type is equivalent to the category of equivariant coherent sheaves on an elliptic curve with respect to a finite abelian group action. This result is implicitly exploited in [19] using ramified elliptic Galois coverings over the field of complex numbers; compare [18]. Moreover, the somehow converse result holds true by [14, 15]: the category of coherent sheaves on an elliptic curve is equivalent to the category of equivariant coherent sheaves on a weighted projective line of tubular type with respect to a different finite abelian group action, which contains the action given by the Auslander-Reiten translation.
The goal of this paper is to re-exploit the above mentioned equivalences in an explicit form. We emphasize that our treatment of the four tubular types is in a uniform manner, and that we deduce these equivalences from general results on the equivariantization of abelian categories. These general results are direct applications of the famous Beck's monadicity theorem which characterizes the module category over a monad; see [16, Chapter VI]. We mention that monads appear naturally, since the category of equivariant objects is isomorphic to the module category over a certain monad; see [4, 7].
Let us describe the content of this paper. In Section 2, we collect some basic facts on monads and modules over monads. We formulate a version of Beck's monadicity theorem for abelian categories, which is convenient for applications; see Theorem 2.1. We give a self-contained proof to Theorem 2.1. In Section 3, we recall the notions of a group action on a category and the category of equivariant objects. The observation we need is that the category of equivariant objects is isomorphic to the category of modules over a certain monad; see Proposition 3.1. In Section 4,
Date : August 4, 2014.
2010 Mathematics Subject Classification. 16W50, 14A22, 14H52.
Key words and phrases. weighted projective line, elliptic curve, equivariantization, monad, graded ring.
∗ the corresponding author.
we apply Theorem 2.1 to prove that the equivariantization of an abelian category is compatible with quotient abelian categories by Serre subcategories; indeed, a slightly more general result on the category of modules over an exact monad is obtained; see Proposition 4.3 and Corollary 4.4. In Section 5, we prove that the equivarianzation of the graded module category over a graded ring with respect to a degree-shift action is equivalent to the graded module category over the same ring but with a coarser grading; see Proposition 5.2. This enables us to recover [17, Theorem 6.4.1] on the graded module category over the corresponding graded group ring; see Corollary 5.5. For the case that the acting group is finite abelian, we generalize slightly a result in [14] and prove that the equivariantization of the graded module category over a graded ring with respect to a twisting action is equivalent to the graded module category over the same ring but with a refined grading; see Proposition 5.7.
In Section 6, we recall some basic facts on the homogeneous coordinate algebra of a weighted projective line. We prove that the quotient graded module category over a restriction subalgebra of the homogeneous coordinate algebra is equivalent to a quotient of the category of coherent sheaves on the weighted projective line by a certain Serre subcategory; see Proposition 6.6. This motivates the notion of an effective subgroup of the grading group for the homogeneous coordinate algebra; see Definition 6.5. For these subgroups, Proposition 6.6 claims an equivalence between the quotient graded module category over the restriction subalgebra and the category of coherent sheaves on the weighted projective line.
The final section is devoted to the study of the relationship between weighted projective lines of tubular type and elliptic plane curves. We prove that the homogeneous coordinate algebra of an elliptic plane curve is isomorphic to the restriction subalgebra of the homogeneous coordinate algebra of the weighted projective line with respect to a suitable effective subgroup; see Theorem 7.4. Applying Theorem 7.4 and the results in Sections 4 and 5, we prove the main result: the equivariantization of the category of coherent sheaves on a weighted projective line of tubular type with respect to a certain degree-shift action is equivalent to the category of coherent sheaves on an elliptic plane curve; the equivariantization of the category of coherent sheaves on an elliptic plane curve with respect to a certain twisting action is equivalent to the category of coherent sheaves on a weighted projective line of tubular type; see Theorem 7.7. We mention that here the acting groups are cyclic, and that we need two different kinds of group actions to have these two equivalences. On the other hand, the two equivalences obtained are somehow adjoint to each other; see Remark 7.8(1).
We emphasize that the two equivalences in Theorem 7.7 are contained in [9] and [14, 15], which are presented in a slightly different form with sketched proofs; compare [12] and Remark 7.8(3). As pointed out in [9], these equivalences link the classification of indecomposable coherent sheaves on elliptic curves in [1] with the classification of indecomposable modules of tubular algebras in [22].
## 2. Modules over monads
In this section, we recall some basic facts from [16, Chapter VI] on monads and modules over monads. We formulate a version of Beck's monadicity theorem for abelian categories, for which we provide a self-contained proof.
Let C be a category. Recall that a monad on C is a triple ( M,η,µ ) consisting of an endofunctor M : C → C and two natural transformations, the unit η : Id C → M and the multiplication µ : M 2 → M , subject to the relations µ ◦ Mµ = µ ◦ µM and µ ◦ Mη = Id M = µ ◦ ηM . We sometimes suppress the unit and the multiplication, and denote the monad simply by M .
Monads arise naturally in adjoint pairs. Assume that F : C → D is a functor which admits a right adjoint U : D → C . We denote by η : Id C → UF the unit and /epsilon1 : FU → Id D the counit; they satisfy /epsilon1F ◦ Fη = Id F and U/epsilon1 ◦ ηU = Id U . We denote this adjoint pair on C and D by the quadruple ( F, U ; η, /epsilon1 ). We suppress the unit and the counit when they are clear from the context.
Each adjoint pair ( F, U ; η, /epsilon1 ) on two categories C and D defines a monad ( M,η,µ ) on C , where M = UF : C → C and µ = U/epsilon1F : M 2 = UFUF → U Id D F = M . The resulting monad ( M,η,µ ) on C is said to be defined by the adjoint pair ( F, U ; η, /epsilon1 ). Indeed, as recalled now every monad is defined by some adjoint pair.
For a monad ( M,η,µ ) on C , an M -module is a pair ( X,λ ) consisting of an object X in C and a morphism λ : M X ( ) → X subject to the conditions λ ◦ Mλ = λ ◦ µ X and λ ◦ η X = Id X ; the object X is said to be the underlying object of the module. A morphism f : ( X,λ ) → ( X , λ ′ ′ ) between two M -modules is a morphism f : X → X ′ in C satisfying f ◦ λ = λ ′ ◦ M f ( ). This gives rise to the category M -Mod C of M -modules; moreover, we have the forgetful functor U M : M -Mod C →C . The functor U M is faithful.
We observe that each object X in C yields an M -module F M ( X ) = ( M X ,µ ( ) X ), the free M -module generated by X . Indeed, this gives rise to the free module functor F M : C → M -Mod C sending X to the free module F M ( X ), and a morphism f : X → Y to the morphism M f ( ): F M ( X ) → F M ( Y ).
We have the adjoint pair ( F M , U M ; η, /epsilon1 M ) on C and M -Mod , where for an C M -module ( X,λ ), the counit /epsilon1 M is given such that
$$( \epsilon _ { M } ) _ { ( X, \lambda ) } = \lambda \colon F _ { M } U _ { M } ( X, \lambda ) = ( M ( X ), \mu _ { X } ) \longrightarrow ( X, \lambda ).$$
We observe that this adjoint pair ( F M , U M ; η, /epsilon1 M ) defines the given monad ( M,η,µ ). The above adjoint pair ( F M , U M ; η, /epsilon1 M ) enjoys the following universal property: for any adjoint pair ( F, U ; η, /epsilon1 ) on C and D that defines the monad M , there is a unique functor
$$K \colon \mathcal { D } \longrightarrow M \text{-Mod} \mathcal { C }$$
satisfying KF = F M and U M K = U ; see [16, VI.3]. This unique functor K will be referred as the comparison functor associated to the adjoint pair ( F, U ; η, /epsilon1 ). For its construction, we have
$$( 2. 1 ) & K ( D ) = ( U ( D ), U \epsilon _ { D } ), \ \ K ( f ) = U ( f )$$
for an object D and a morphism f in D . Here, we observe that M = UF and that ( U D ,U/epsilon1 ( ) D ) is an M -module.
Following [16, VI.3] the adjoint pair ( F, U ) is monadic ( resp. strictly monadic ) provided that the associated comparison functor K : D → M -Mod C is an equivalence ( resp. an isomorphism). In these cases, we might identify D with M -Mod . C
The famous monadicity theorem of Beck gives intrinsic characterizations on (strictly) monadic adjoint pairs; see [16, VI.7]. However, the conditions in Beck's monadicity theorem on coequalizers seem rather technical.
In the following result, we formulate a version of Beck's monadicity theorem for abelian categories, which is quite convenient for applications.
Theorem 2.1. Let F : A → B be an additive functor on two abelian categories. Assume that F admits a right adjoint U : B → A which is exact. Denote by M the defined monad on A . Then the comparison functor K : B → M -Mod A is an equivalence if and only if the functor U : B → A is faithful.
The 'only if' part of Theorem 2.1 is trivial, since U = U M K and the forgetful functor U M is faithful. We will present two proofs for the 'if' part. The first one is an application of the original version of Beck's monadicity theorem, while the second one is more self-contained and seems to be of independent interest.
The following observation is well known.
Lemma 2.2. Let F : A → B be an exact functor on two abelian categories, which is faithful. Then F preserves and reflects cokernels, that is, for two morphisms f : X → Y and c : Y → C in A , c is a cokernel of f if and only if F c ( ) is a cokernel of F f ( ) .
Proof. The 'only if' part follows from the right exactness of F .
For the 'if' part, we assume that F c ( ) is a cokernel of F f ( ). In particular, F c ( ◦ f ) = 0, and thus c ◦ f = 0 since F is faithful. By the exactness of F , we have the following fact: for any complex ξ : X → Y → Z in A with cohomology H at Y , the complex F ξ ( ): F X ( ) → F Y ( ) → F Z ( ) in B has cohomology F H ( ) at F Y ( ). Since F is faithful, we infer that the complex F ξ ( ) is exact at F Y ( ), that is, F H ( ) /similarequal 0, if and only if H /similarequal 0, that is, the complex ξ is exact at Y . We apply this fact to the complexes X f → Y c → C and Y c → C → 0. We infer that c is a cokernel of f . /square
The first proof of the 'if' part of Theorem 2.1. Recall that a coequalizer of two parallel morphisms in an additive category equals a cokernel of their difference. Then we apply Lemma 2.2 to the functor U , and infer that U preserves and reflects coequalizers. Then the comparison functor K is an equivalence by the 'equivalence' version of Beck's monadicity theorem; see [16, VI.7, Exercise 6]. /square
The second proof is an application of a slightly more general result, which seems to be standard in relative homological algebra.
Let X be a full subcategory of a category C . Let C be an object in C . Recall that a right X -approximation of C is a morphism f : X → C with X ∈ X such that any morphism t : T → C with T ∈ X factors through f , that is, there exists a morphism t ′ : T → X with t = f ◦ t ′ ; compare [2, Section 3]. In case that C is abelian, an X -presentation of C means an exact sequence X 1 g → X 0 f → C → 0 such that f is a right X -approximation of C and that the induced morphism ¯: g X 1 → Ker f is a right X -approximation of Ker f .
For a functor F : C → D and a full subcategory X ⊆ C , we denote by F ( X ) the full subcategory of D consisting of objects that are isomorphic to F X ( ) for some object X in X . In particular, we write Im F = F ( C ), the essential image of F .
Example 2.3. Let ( F, U ; η, /epsilon1 ) be an adjoint pair on two categories C and D . Then for any object D in D , the counit /epsilon1 D : FU D ( ) → D is a right Im F -approximation. Indeed, any morphism t : F C ( ) → D factors through /epsilon1 D as t = /epsilon1 D ◦ F U t ( ( ) ◦ η C ) .
Let us state a special case explicitly. For a monad M = ( M,η,µ ) on C , we apply the above to the adjoint pair ( F M , U M ; η, /epsilon1 M ) . Then for any M -module ( X,λ ) , the counit
- ( /epsilon1 M ) ( X,λ ) = λ : F M U M ( X,λ ) = ( M X ,µ ( ) X ) -→ ( X,λ ) (2.2)
is a right Im F M -approximation of ( X,λ ) in M -Mod C ; it is an epimorphism, since λ ◦ η X = Id X .
The following general result seems to be standard in relative homological algebra, whose proof is also standard.
Proposition 2.4. Let F : A → B be a right exact functor on two abelian categories. Let X be a full subcategory of A . We assume that the following conditions are satisfied.
- (i) For any object C in A , there exists an epimorphism f : X → C which is a right X -approximation such that F f ( ) is a right F ( X ) -approximation of F C ( ) .
- (ii) The restricted functor F | : X → B is fully faithful.
F : A → B is fully faithful. Assume that in addition the following
- X Then the functor condition is satisfied.
- (iii) For any object B in B , there is an epimorphism F A ( ) → B for some object A in A .
Then the functor F : A → B is an equivalence.
Proof. Let A,A ′ be two objects in A . By the right exactness of F and (i), we have two X -presentations ξ : X 1 d → X 0 p → A → 0 and ξ ′ : X ′ 1 d ′ → X ′ 0 p ′ → A ′ → 0 such that F ξ ( ) and F ξ ( ′ ) are F ( X )-presentations of F A ( ) and F A ( ′ ), respectively. To show that F is full, take a morphism t : F A ( ) → F A ( ′ ). Since F ξ ( ′ ) is an F ( X )-presentation, we have the following commutative diagram
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d47
$$\begin{array} { c } F ( X _ { 1 } ) \xrightarrow { F ( d ) } F ( X _ { 0 } ) \xrightarrow { F ( p ) } F ( A ) \xrightarrow { 0 } \\ \vdots t _ { 1 } & \ddots & \ddots t _ { 0 } \\ F ( X _ { 1 } ^ { \prime } ) \xrightarrow { F ( d ^ { \prime } ) } F ( X _ { 0 } ^ { \prime } ) \xrightarrow { F ( p ^ { \prime } ) } F ( A ^ { \prime } ) \xrightarrow { 0 } \\ \vdots & \vdots & \vdots \\ \end{array}$$
/d47
/d47
/d47
/d47
/d47
By (ii), there exist morphisms s i : X i → X ′ i such that F s ( i ) = t i and s 0 ◦ d = d ′ ◦ s 1 . The identity s 0 ◦ d = d ′ ◦ s 1 implies the existence of a morphism s : A → A ′ such that s ◦ p = p ′ ◦ s 0 . It follows that F s ( ) = t by comparing commutative diagrams.
The faithfulness of F follows by a converse argument. Indeed, given a morphism s : A → A ′ with F s ( ) = 0, we have morphisms s i : X i → X ′ i such that s ◦ p = p ′ ◦ s 0 and s 0 ◦ d = d ′ ◦ s 1 ; here, we use the X -presentation ξ ′ . Then in the above diagram, t = F s ( ) = 0 and thus t 0 = F s ( 0 ) factors through F d ( ′ ). By (ii), s 0 factors through d ′ , and thus s ◦ p = p ′ ◦ s 0 = 0. We infer that s = 0, since p is epic.
We assume that (iii) is satisfied. Then any object B fits into an exact sequence F A ( ′ ) g → F A ( ) → B → 0. By the fully faithfulness of F , there exists a morphism s : A ′ → A satisfying F s ( ) = g . It follows that F (Cok s ) /similarequal B . This proves the denseness of F , and thus F is an equivalence. /square
The second proof of the 'if' part of Theorem 2.1. Since F has a right adjoint, it is right exact. Then the endofunctor M = UF on A is right exact. It follows that the category M -Mod A is abelian; indeed, a sequence of M -modules is exact if and only if the corresponding sequence of the underlying objects in A is exact.
Recall from (2.1) that K B ( ) = ( U B ,U/epsilon1 ( ) B ) and that K f ( ) = U f ( ) for an object B and a morphism f in B . Since the functor U is exact and faithful, it follows that the comparison functor K : B → M -Mod A is exact and faithful. Consider X = Im F as a full subcategory of B . We claim that the pair K and X satisfy the three conditions in Proposition 2.4. Then we infer that K is an equivalence.
For the claim, we verify the conditions (i)-(iii). For (i), take any object B in B and consider the counit /epsilon1 B : FU B ( ) → B , which is a right X -approximation by Example 2.3. We observe that K /epsilon1 ( B ) equals ( /epsilon1 M K B ) ( ) , the counit /epsilon1 M applied on the M -module K B ( ). In particular, by Example 2.3 K /epsilon1 ( B ) is a right Im F M -approximation of K B ( ) in M -Mod A , which is an epimorphism. Recall that F M = KF and thus Im F M = K ( X ). Hence, the epimorphism K /epsilon1 ( B ) is a right K ( X )-approximation of K B ( ). By Lemma 2.2 the functor K reflects epimorphisms. It follows that /epsilon1 B is an epimorphism. This is the required morphism in (i).
The condition (ii) is well known, since the restriction of K on X = Im F is fully faithful; see [4, Lemma 3.3] and compare [16, VI.3 and VI.5]. The condition (iii) follows from the epimorphism (2.2) for any M -module ( X,λ ), since F M U M =
KFU M and thus ( M X ,µ ( ) X ) = KF X ( ). Set B = F X ( ). In particular, we have by (2.2) a required epimorphism K B ( ) → ( X,λ . ) /square
## 3. Equivariant objects as modules
In this section, we recall the notions of a group action on a category and the category of equivariant objects. We give a direct proof of the fact that in the additive case, the category of equivariant objects is isomorphic to the category of modules over a certain monad.
Let G be an arbitrary group. We write G multiplicatively and denote its unit by e . Let C be an arbitrary category.
The notion of a group action on a category is well known; compare [5, 20, 6]. An action of G on C consists of the data { F , ε g g,h | g, h ∈ G } , where each F g : C → C is an auto-equivalence and each ε g,h : F F g h → F gh is a natural isomorphism such that a 2-cocycle condition holds, that is,
$$\varepsilon _ { g h, k } \circ \varepsilon _ { g, h } F _ { k } = \varepsilon _ { g, h k } \circ F _ { g } \varepsilon _ { h, k }$$
for all g, h, k ∈ G . We observe that there exists a unique natural isomorphism u : F e → Id C , called the unit of the action, satisfying ε e,e = F u e ; moreover, we have F u e = uF e by (3.1).
The given action is strict provided that each F g is an automorphism and each isomorphism ε g,h is the identity, in which case the unit is also the identity. Therefore, a strict action coincides with a group homomorphism from G to the automorphism group of C .
Let G act on C . A G -equivariant object in C is a pair ( X,α ), where X is an object in C and α assigns for each g ∈ G an isomorphism α g : X → F g ( X ) subject to the relations
$$\alpha _ { g g ^ { \prime } } & = ( \varepsilon _ { g, g ^ { \prime } } ) _ { X } \circ F _ { g } ( \alpha _ { g ^ { \prime } } ) \circ \alpha _ { g }.$$
These relations imply that α e = u -1 X . A morphism θ : ( X,α ) → ( Y, β ) between two G -equivariant objects is a morphism θ : X → Y in C such that β g ◦ θ = F g ( θ ) ◦ α g for all g ∈ G . This gives rise to the category C G of G -equivariant objects, and the forgetful functor U : C G → C defined by U X,α ( ) = X . The process forming the category C G of equivariant objects is known as the equivariantization with respect to the group action; see [6].
In what follows, we assume that the group G is finite and that C is an additive category. In this case the forgetful functor U admits a left adjoint F : C → C G , which is known as the induction functor ; see [6, Lemma 4.6]. The functor F is defined as follows: for an object X , set F X ( ) = ( ⊕ h ∈ G F h ( X ,ε ) ), where for each g ∈ G , the isomorphism ε g : ⊕ h ∈ G F h ( X ) → F g ( ⊕ h ∈ G F h ( X )) is diagonally induced by the isomorphism ( ε g,g -1 h X ) -1 : F h ( X ) → F g ( F g -1 h ( X )). Here, to verify that F X ( ) is indeed an equivariant object, we need the 2-cocycle condition (3.1). The functor F sends a morphism θ : X → Y to F θ ( ) = ⊕ h ∈ G F h ( θ ): F X ( ) → F Y ( ).
For an object X in C and an object ( Y, β ) in C G , a morphism F X ( ) → ( Y, β ) is of the form ∑ h ∈ G θ h : ⊕ h ∈ G F h ( X ) → Y satisfying F g ( θ h ) = β g ◦ θ gh ◦ ( ε g,h ) X for any g, h ∈ G . The adjunction of ( F, U ) is given by the following natural isomorphism
$$\text{Hom} _ { \mathcal { C } ^ { G } } ( F ( X ), ( Y, \beta ) ) \stackrel { \sim } { \longrightarrow } \text{Hom} _ { \mathcal { C } } ( X, U ( Y, \beta ) )$$
sending ∑ h ∈ G θ h to θ e ◦ u -1 X . The corresponding unit η : Id C → UF is given such that η X = ( u -1 X , 0 , · · · , 0) , t where 't' denotes the transpose; the counit /epsilon1 : FU → Id C G is given such that /epsilon1 ( Y,β ) = ∑ h ∈ G β -1 h .
Let us compute the monad M = ( UF,η,µ ) defined by the adjoint pair ( F, U ; η, /epsilon1 ). This monad is said to be defined by the group action. The endofunctor M : C → C
MONADICITY THEOREM AND WEIGHTED PROJECTIVE LINES OF TUBULAR TYPE 7
is given by M X ( ) = ⊕ h ∈ G F h ( X ) and M θ ( ) = ⊕ h ∈ G F h ( θ ) for a morphism θ in C . The multiplication µ : M 2 → M is given by
$$\mu _ { X } = U \epsilon _ { F ( X ) } \colon M ^ { 2 } ( X ) = \oplus _ { h, g \in G } F _ { h } F _ { g } ( X ) \longrightarrow M ( X ) = \oplus _ { h \in G } F _ { h } ( X )$$
with the property that the corresponding entry F F h g ( X ) → F h ′ ( X ) is δ hg,h ′ ( ε h,g ) X ; here, δ is the Kronecker symbol.
The following result shows that the category of equivariant objects is isomorphic to the category of M -modules. Roughly speaking, equivariant objects are modules. We mention that the result is an immediate consequence of Beck's monadicity theorem in [16, VI.7]; see also [4, Lemma 4.3] and compare [7, Proposition 3.10]. We provide a direct proof for completeness.
Proposition 3.1. Let C be an additive category and G be a finite group acting on C . Keep the notation as above. Then the adjoint pair ( F, U ; η, /epsilon1 ) is strictly monadic, that is, the associated comparison functor K : C G → M -Mod C is an isomorphism of categories.
Proof. We have just computed explicitly the monad M . Let us take a closer look at M -modules. An M -module is a pair ( X,λ ) with λ = ∑ h ∈ G λ h : M X ( ) = ⊕ h ∈ G F h ( X ) → X . The condition λ ◦ η X = Id X is equivalent to λ e = u X , and λ ◦ M λ ( ) = λ ◦ µ X is equivalent to λ hg ◦ ε h,g = λ h ◦ F h ( λ g ) for any h, g ∈ G . Hence, if we set α h : X → F h ( X ) to be ( λ h ) -1 and compare (3.2), we obtain an object ( X,α ) ∈ C G . Roughly speaking, the maps λ h 's carry the same information as α h 's.
Recall from (2.1) that the associated comparison functor K : C G → M -Mod C is constructed such that K X,α ( ) = ( U X,α ,U/epsilon1 ( ) ( X,α ) ), which equals the M -module ( X,λ ) with λ h = ( α h ) -1 by the explicit form of the counit /epsilon1 . It follows immediately that K induces a bijection on objects, and is fully faithful. We infer that K is an isomorphism of categories. /square
Remark 3.2. Proposition 3.1 can be extended slightly. Let G be a group whose cardinality | G | might be infinite. Assume that the additive category C has coproducts with any index set of cardinality less or equal to | G | . For a G -action on C , we define the induction functor F and the monad M as above by replacing finite coproducts by coproducts indexed by a possibly infinite index set. The same argument proves that the comparison functor K : C G → M -Mod C is an isomorphism of categories.
## 4. Exact monads and quotient abelian categories
In this section, we give the first application of Theorem 2.1, which states that the formation of the module category of an exact monad is compatible with quotient abelian categories by Serre subcategories. This result applies to the category of equivariant objects in an abelian category.
- 4.1. Let A be an abelian category. A Serre subcategory N of A is by definition a full subcategory which is closed under subobjects, quotient objects and extensions. In other words, for an exact sequence 0 → X → Y → Z → 0 in A , Y lies in N if and only if both X and Z lie in N . It follows that a Serre subcategory N is abelian and the inclusion functor N → A is exact.
For a Serre subcategory N of A , we denote by A N / the quotient abelian category ; see [8]. The objects of A N / are the same as A , and for two objects X and Y , a morphism in A N / is represented by a morphism X ′ → Y/Y ′ , where X ′ ⊆ X and Y ′ ⊆ Y are subobjects with both X/X ′ and Y ′ in N . The quotient functor q : A → A N / sends an object X to X , a morphism f : X → Y to the morphism q f ( ), which is represented by f : X → Y ; here, the corresponding X ′ and Y ′ are X
and 0, respectively. The functor q is exact with its essential kernel Ker q = N . In particular, for a morphism f : X → Y in A , q f ( ) = 0 if and only if its image Im f lies in N .
- Let F : A → A ′ be an exact functor. Then the essential kernel Ker F is a Serre subcategory of A , and F induces a unique exact functor F ′ : A / Ker F → A ′ . We say that F is a quotient functor provided that F ′ is an equivalence.
Let F : A → A ′ be an exact functor. Assume that N ⊆ A and N ′ ⊆ A ′ are Serre subcategories such that F ( N ⊆ N ) ′ . Then there is a uniquely induced exact functor ¯ : F A N → A / ′ / N ′ .
Lemma 4.1. Keep the notation as above. Assume that F : A → A ′ is a quotient functor. Then the induced functor ¯ : F A N → A / ′ / N ′ is also a quotient functor.
Proof. Denote by C the inverse image of N ′ under F . Then C is a Serre subcategory of A containing N and Ker F . The essential kernel Ker ¯ of F ¯ equals F C / N .
We observe the following isomorphisms of abelian categories
( A N / ) / ( C / N /similarequal ) A C /similarequal / ( A / Ker F / ) ( C / Ker F . )
By the assumption, we have the equivalence F ′ : A / Ker F ∼ -→ A ′ , which induces an equivalence ( A / Ker F / ) ( C / Ker F ) ∼ -→ A ′ / N ′ . Consequently, we have the required equivalence ( A N / ) / Ker ¯ F ∼ -→ A ′ / N ′ . /square
Let M : A → A be an exact monad on A , that is, M = ( M,η,µ ) is a monad on A and the endofunctor M is exact. Recall that the category M -Mod A of M -modules is abelian, where a sequence of M -modules is exact if and only if the corresponding sequence of underlying objects in A is exact. It follows that both the free module functor F M : A → M -Mod A and the forgetful functor U M : M -Mod A → A are exact.
Let N ⊆ A be a Serre subcategory such that M ( N ) ⊆ N . Then we have the induced endofunctor ¯ : M A N → A N / / ; moreover, the natural transformations η and µ induce natural transformations ¯: Id η A N / → ¯ M and ¯: µ ¯ M 2 → ¯ . M Indeed, we obtain a monad ¯ M = ( ¯ M,η,µ ¯ ¯) on A N / , called the induced monad of M .
We will need the following standard fact.
Lemma 4.2. Let F : A → A ′ be an exact functor between two abelian categories, which has an exact right adjoint U : A → A ′ . Assume that N ⊆ A and N ⊆ A ′ ′ are Serre subcategories such that F ( N ⊆ N ) ′ and U ( N ′ ) ⊆ N . Then the following statements hold.
- (1) The induced functor ¯ : F A N → A / ′ / N ′ is left adjoint to the induced functor ¯ : U A N → A N ′ / ′ / .
- (2) The monad on A N / defined by the adjoint pair ( ¯ F,U ¯ ) coincides with the induced monad of the one on A defined by the adjoint pair ( F, U ) .
- (3) Denote by U -1 ( N ) the inverse image of N . Assume that U -1 ( N ) = N ′ . Then the induced functor ¯ U is faithful.
Proof. Denote the given adjoint pair by ( F, U ; η, /epsilon1 ) and its defined monad by ( M = UF,η,µ ). We observe that the unit η ( resp. , the counit /epsilon1 ) induces naturally a natural transformation ¯: Id η A N / → ¯ ¯ UF ( resp. , ¯: /epsilon1 ¯ ¯ FU → Id A ′ / N ′ ). Then we apply [16, IV.1, Theorem 2(v)] to deduce the adjoint pair ( ¯ F,U η,/epsilon1 ¯ ; ¯ ¯). It follows that the monad defined by this adjoint pair coincides with ( ¯ M,η,µ ¯ ¯), the induced monad of M .
For (3), take any morphism θ : X → Y in A N ′ / ′ with ¯ ( U θ ) = 0. We assume that θ is represented by a morphism f : X ′ → Y/Y ′ , where X ′ ⊆ X and Y ′ ⊆ Y are subobjects satisfying that both X/X ′ and Y ′ lie in N ′ . Then ¯ ( U θ ) is represented by U f ( ): U X ( ′ ) → U Y/Y ( ′ ), and thus q U f ( ( )) = 0 in A N / , or equivalently, the
image Im U f ( ) lies in N . We observe that Im U f ( ) /similarequal U (Im f ) and then Im f lies in N ′ , since U -1 ( N ) = N ′ . We infer that θ equals zero in A N ′ / ′ . We are done. /square
- 4.2. Let A be an abelian category, and M : A → A be an exact monad. We will apply Lemma 4.2 to the adjoint pair ( F M , U M ).
Let N ⊆ A be a Serre subcategory with M ( N ⊆ N ) . Then we have the restricted exact monad M : N → N and the category M -Mod N of M -modules in N . We view M -Mod N as a full subcategory of M -Mod A , in other words, an M -module ( X,λ ) lies in M -Mod N if and only if the underlying object X lies in N . We observe that M -Mod N ⊆ M -Mod A is a Serre subcategory.
Consider the induced monad ¯ M on A N / . We observe that an M -module ( X,λ ) yields an ¯ -module ( M X,q λ ( )) on A N / , where q λ ( ): ¯ ( M X ) = qM X ( ) → X . This gives rise to an exact functor
↦
$$\Phi \colon M \text{-Mod} _ { \mathcal { A } } \longrightarrow \bar { M } \text{-Mod} _ { \mathcal { A } / \mathcal { N } }, \ \ ( X, \lambda ) \mapsto ( X, q ( \lambda ) ).$$
The functor Φ sends a morphism θ to q θ ( ). We observe that Φ vanishes on the Serre subcategory M -Mod N , and induces an exact functor Φ: ¯ M -Mod A /M -Mod N → ¯ -Mod M A N / .
Proposition 4.3. Let M : A → A be an exact monad on an abelian category A , and let N ⊆ A be a Serre subcategory satisfying M ( N ⊆ N ) . Keep the notation as above. Then the induced functor
$$\bar { \Phi } \colon M \text{-Mod} _ { \mathcal { A } } / M \text{-Mod} _ { \mathcal { N } } \stackrel { \sim } { \longrightarrow } \bar { M } \text{-Mod} _ { \mathcal { A } / \mathcal { N } }$$
is an equivalence of categories.
Proof. Consider the free module functor F M : A → M -Mod A and the forgetful functor U M : M -Mod A →A , both of which are exact. We observe that F M ( N ) ⊆ M -Mod N , and U -1 M ( N ) = M -Mod N . We apply Lemma 4.2(1) and (3), and obtain the adjoint pair F M and U M between quotient abelian categories A N / and M -Mod A /M -Mod N , where U M is faithful. Moreover, by Lemma 4.2(2) the monad defined by this adjoint pair coincides with the induced monad ¯ M of M . We apply Theorem 2.1 to the adjoint pair ( F M , U M ) and infer that the associated comparison functor
$$K \colon M \text{-Mod} _ { \mathcal { A } } / M \text{-Mod} _ { \mathcal { N } } \longrightarrow \bar { M } \text{-Mod} _ { \mathcal { A } / \mathcal { N } }$$
is an equivalence.
It remains to observe that K = ¯ . Φ Indeed, by (2.1) the comparison functor K sends an M -module ( X,λ ) to an ¯ -module ( M U M ( X,λ , U ) M (¯ /epsilon1 M ) ( X,λ ) ), which equals ( X,q λ ( )). Hence, the functors K and Φ agree on objects. ¯ For the same reason, they agree on morphisms. /square
We now apply Proposition 4.3 to the category of equivariant objects. Let G be a finite group which acts on an abelian category A by the data { F , ε g g,h | g, h ∈ G } . Then the category A G of G -equivariant objects is abelian; indeed, a sequence of equivariant objects is exact if and only if the corresponding sequence of the underlying objects in A is exact.
Let N ⊆ A be a Serre subcategory which is invariant under this action, that is, F g ( N ) ⊆ N for any g ∈ G . Then the quotient category A N / inherits a G -action, which is given by the data { ¯ F , ε g ¯ g,h | g, h ∈ G } . The quotient functor q : A → A N / induces an exact functor
$$\Psi \colon \mathcal { A } ^ { G } \longrightarrow ( \mathcal { A } / \mathcal { N } ) ^ { G }.$$
More precisely, Ψ sends a G -equivariant object ( X,α ) to ( X,q α ( )), where q α ( ) g = q α ( g ): X → ¯ ( F g X ) = qF g ( X ) for each g ∈ G , and Ψ sends a morphism θ : ( X,α ) → ( Y, β ) to q θ ( ): ( X,q α ( )) → ( Y, q ( β )). We observe that the functor Ψ is exact
and that its essential kernel equals N G . Therefore, we have the induced functor ¯ : Ψ A G / N G → A N ( / ) G .
Corollary 4.4. Let G be a finite group acting on an abelian category A , and let N ⊆ A be a Serre subcategory which is invariant under the action. Keep the notation as above. Then the induced functor
$$\bar { \Psi } \colon \mathcal { A } ^ { G } / \mathcal { N } ^ { G } \stackrel { \sim } { \longrightarrow } ( \mathcal { A } / \mathcal { N } ) ^ { G }$$
is an equivalence of categories.
Proof. Denote by M the monad on A that is defined by the group action. Then M is exact and by the invariance of N , we have M ( N ) ⊆ N . We observe that the induced monad ¯ M on A N / coincides with the monad defined by the induced G -action on A N / .
By Proposition 3.1 we identify A G with M -Mod A , and ( A N / ) G with ¯ -Mod M A N / . Then the equivalence follows from Proposition 4.3. Here, one observes that the functor Φ in Proposition 4.3 corresponds to the functor Ψ. ¯ ¯ /square
## 5. Graded module categories and graded group rings
In this section, we give the second application of Theorem 2.1, and prove that the equivarianzation of the graded module category over a graded ring with respect to a certain degree-shift action is equivalent to the graded module category over the same ring but with a coarser grading; this result is essentially due to [17, Theorem 6.4.1] in a different setup. On the other hand, we prove that the equivariantization of the graded module category over a graded ring with respect to a certain twisting action is equivalent to the graded module category over the same ring but with a refined grading. All modules are right modules.
- 5.1. Let G be an arbitrary group. Let R = ⊕ g ∈ G R g be a G -graded ring with a unit. Here, the unit 1 R lies in R e , and the subgroups R g of R are called the homogeneous components of degree g .
/negationslash
- A G -graded R -module X is an R -module with a decomposition X = ⊕ g ∈ G X g into homogeneous components X g such that X .R g g ′ ⊆ X gg ′ , where the dot '.' means the right action. An element x in X g is said to be homogeneous of degree g , denoted by | x | = g or deg x = g . The grading support of X is by definition gsupp( X ) = { g ∈ G | X g = 0 , which is a subset of } G .
We denote by Mod G -R the abelian category of G -graded R -modules, where the homomorphism between graded modules are module homomorphisms that preserve the degrees. More precisely, a homomorphism f : X → X ′ is an R -module homomorphism satisfying f ( X g ) ⊆ X ′ g , and we denote by f g : X g → X ′ g its restriction to the corresponding homogeneous component. We denote by mod G -R the full subcategory formed by finitely presented graded modules.
For a G -graded R -module X and g ′ ∈ G , the shifted module X g ( ′ ) is defined such that X g ( ′ ) = X as an ungraded R -module and that its grading is given by X g ( ′ ) g = X g g ′ for each g ∈ G . This gives rise to an automorphism ( g ′ ): Mod G -R → Mod G -R , called the degree-shift functor . For example, we consider R g ( ′ ) as a G -graded R -module with 1 R having degree g ′-1 . Indeed, the set { R g ( ) | g ∈ G } is a set of projective generators in the category Mod G -R .
Each subgroup G ′ ⊆ G has a strict action on Mod G -R by assigning to each g ′ ∈ G ′ the automorphism F g ′ = ( g ′-1 ). Such a G ′ -action on Mod G -R is referred as a degree-shift action ; in this case, G ′ acts also on mod G -R .
Let π : G → H be a homomorphism of groups. We define an H -graded ring π ∗ ( R ) as follows: as an ungraded ring π ∗ ( R ) = R , while its homogeneous component is
given by π ∗ ( R ) h = ⊕ g ∈ π -1 ( h ) R g for each h ∈ H ; compare [17, Subsection 1.2]. Then we have the abelian category Mod H -π ∗ ( R ) of H -graded π ∗ ( R )-modules and its full subcategory mod H -π ∗ ( R ) consisting of finitely presented modules, both of which carry a natural strict H -action by degree-shift.
The functor π ∗ has a right adjoint π ∗ : Mod H -π ∗ ( R ) → Mod G -R , which is defined as follows. For an H -graded π ∗ ( R )-module Y = ⊕ h ∈ H Y h , we define a G -graded abelian group π ∗ ( Y ) such that its homogeneous component π ∗ ( Y ) g = Y π g ( ) for each g ∈ G . A homogeneous element r ∈ R g ′ acts on an element y ∈ π ∗ ( Y ) g as the given action y.r on Y , where the resulting element y.r ∈ Y π g g ( ′ ) is viewed now as an element in π ∗ ( Y ) gg ′ . This defines a G -graded R -module π ∗ ( Y ). For an H -graded π ∗ ( R )-module homomorphism f : Y → Y ′ , the corresponding homomorphism π ∗ ( f ): π ∗ ( Y ) → π ∗ ( Y ′ ) sends an element y ∈ π ∗ ( Y ) g = Y π g ( ) to f ( y ) ∈ Y ′ π g ( ) = π ∗ ( Y ′ ) g for each g ∈ G . We observe that the functor π ∗ is exact.
We define a functor π ∗ : Mod G -R → Mod H -π ∗ ( R ) as follows: for a G -graded R -module X = ⊕ g ∈ G X g , we assign an H -graded π ∗ ( R )-module π ∗ ( X ) such that π ∗ ( X ) = X as an ungraded R -module and that its homogeneous component is given by π ∗ ( X ) h = ⊕ g ∈ π -1 ( h ) X g . The functor π ∗ acts on homomorphisms by the identity. We observe that π ∗ sends R to π ∗ ( R ), and more generally, π ∗ sends R g ( ) to π ∗ ( R )( h ) for each g ∈ G and h = π g ( ). We observe also that the functor π ∗ is exact.
The adjoint pair ( π , π ∗ ∗ ) is given by the following natural isomorphism
$$\text{Hom} _ { \text{Mod} ^ { H } - \pi _ { * } ( R ) } ( \pi _ { * } ( X ), Y ) \stackrel { \sim } { \longrightarrow } \text{Hom} _ { \text{Mod} ^ { G } - R } ( X, \pi ^ { * } ( Y ) )$$
which sends f : π ∗ ( X ) → Y to f ′ : X → π ∗ ( Y ) such that f ′ g : X g → π ∗ ( Y ) g = Y π g ( ) is the restriction of f π g ( ) : π ∗ ( X ) π g ( ) → Y π g ( ) to the direct summand X g . It follows that the unit η : Id Mod G -R → π π ∗ ∗ is given such that ( η X g ) : X g → π π ∗ ∗ ( X ) g = ⊕ g ′ ∈ π -1 ( π g ( )) X g ′ is the inclusion of X g . The counit /epsilon1 : π π ∗ ∗ → Id Mod H -π ∗ ( R ) is given such that ( /epsilon1 Y ) h : π π ∗ ∗ ( Y ) h = ⊕ g ∈ π -1 ( h ) Y π g ( ) → Y h maps each direct summand Y π g ( ) identically to Y h if h ∈ π G ( ), and that ( /epsilon1 Y ) h = 0 otherwise.
Lemma 5.1. Let N be the kernel of π : G → H . Then the monad defined by the adjoint pair ( π , π ∗ ∗ ; η, /epsilon1 ) coincides with the monad defined by the degree-shift action of N on Mod G -R .
Proof. Denote by ( M,η ,µ ′ ) the monad that is defined by the degree-shift action of N on Mod G -R . As we computed above, π π ∗ ∗ ( X ) g = ⊕ g ′ ∈ π -1 ( π g ( )) X g ′ = ⊕ n ∈ N X n ( -1 ) g for each g ∈ G . Indeed, this proves that the endofunctor π π ∗ ∗ equals M , which is by definition ⊕ n ∈ N F n = ⊕ n ∈ N ( n -1 ). It is direct to verify that η = η ′ and µ = π /epsilon1π ∗ ∗ . /square
We consider the degree-shift action of N on Mod G -R , and thus the category (Mod G -R ) N of N -equivariant objects. Consider the following functor
$$\Theta \colon \text{Mod} ^ { H } \text{-} \pi _ { * } ( R ) \longrightarrow ( \text{Mod} ^ { G } \text{-} R ) ^ { N }$$
sending Y to Θ( Y ) = ( π ∗ ( Y ) , Id), where Id n : π ∗ ( Y ) → π ∗ ( Y )( n -1 ) is the identity for each n ∈ N ; here, we observe that π ∗ ( Y )( n -1 ) = π ∗ ( Y ). The functor Θ sends a homomorphism f to π ∗ ( f ).
The main observation is as follows. We mention that it is implicitly due to [17, Theorem 6.4.1]; see Corollary 5.5.
Proposition 5.2. Keep the notation as above. Then the functor Θ is an equivalence if and only if π : G → H is surjective. In this case, if in addition N is finite, the equivalence Θ restricts to an equivalence
$$\Theta \colon \bmod ^ { H } \psi _ { * } ( R ) \stackrel { \sim } { \longrightarrow } ( \bmod ^ { G } \psi _ { R } ) ^ { N }.$$
Proof. We claim that the functor π ∗ is faithful if and only if π is surjective. Recall that π ∗ ( Y ) g = Y π g ( ) for each g ∈ G , and that for a morphism f : Y → Y ′ , π ∗ ( f ) g = f π g ( ) . In particular, π ∗ ( f ) = 0 if and only if f h = 0 for all h ∈ π G ( ). This proves the 'if' part of the claim. On the other hand, if π is not surjective, we take h ∈ H that is not contained in π G ( ). Consider Y = π ∗ ( R )( h ) in Mod H -π ∗ ( R ). Then π ∗ ( Y ) = 0, or equivalently, π ∗ (Id Y ) = 0. This shows that π ∗ is not faithful in this case.
Set A = Mod G R . Denote by M the monad on A defined by the adjoint pair ( π , π ∗ ∗ ). We consider the associated comparison functor K : Mod H -π ∗ ( R ) → M -Mod A . By Lemma 5.1, Proposition 3.1 and Remark 3.2, we identify M -Mod A with A N , with which the functor Θ is identified with this comparison functor K . Here, one compares the definition of Θ in (5.1) with the construction of K in (2.1). Recall that the functor π ∗ is exact. Then we apply Theorem 2.1 to the adjoint pair ( π , π ∗ ∗ ), and infer that Θ is an equivalence if and only if π ∗ is faithful, which by the above claim is equivalent to the surjectivity of π .
The restricted equivalence follows from Lemma 5.3(2).
/square
The following fact is well known.
Lemma 5.3. Assume that the homomorphism π : G → H is surjective with its kernel N finite. Let X be a G -graded R -module and Y an H -graded π ∗ ( R ) -module. Keep the notation as above. Then the following statements hold.
- (1) The G -graded R -module X is finitely presented if and only if so is π ∗ ( X ) .
- (2) The H -graded π ∗ ( R ) -module Y is finitely presented if and only if so is π ∗ ( Y ) .
Proof. Recall that π ∗ ( R g ( )) = π ∗ ( R )( h ) for each g ∈ G and h = π g ( ). Thus the exact functor π ∗ preserves finitely generated projective modules. Then the 'only if' part of (1) follows.
We observe that π ∗ ( π ∗ ( R )( h )) /similarequal ⊕ n ∈ N R ng ( ) for h = π g ( ), and that N is finite. It follows that the exact functor π ∗ preserves finitely generated projective modules. The 'only if' part of (2) follows.
For the 'if' part of (1), we assume that π ∗ ( X ) is finitely presented, and thus so is π π ∗ ∗ ( X ). The unit η X : X → π π ∗ ∗ ( X ) is a split monomorphism. It follows that X is finitely presented.
It remains to prove the 'if' part of (2). We claim that for each H -graded π ∗ ( R )-module Z , if π ∗ ( Z ) is finitely generated, so is Z . Indeed, we recall that the exact functor π ∗ preserves finitely generated projective modules. It follows that π π ∗ ∗ ( Z ) is finitely generated. Since the counit /epsilon1 Z : π π ∗ ∗ ( Z ) → Z is surjective, we infer that Z is finitely generated. Here, for the surjectivity of /epsilon1 Z we use the surjectivity of the homomorphism π : G → H .
We assume that π ∗ ( Y ) is finitely presented. By the claim Y is finitely generated. Take an exact sequence 0 → K → P → Y → 0 in Mod H -π ∗ ( R ) with P finitely generated projective. Applying the exact functor π ∗ and the fact that π ∗ ( P ) is finitely generated projective, we infer that π ∗ ( K ) is finitely generated. By the claim again, we have that K is finitely generated. This shows that Y is finitely presented. /square
5.2. We will relate Proposition 5.2 to [17, Theorem 6.4.1].
Let N be a normal subgroup of a group G . Let R = ⊕ g ∈ G R g be a G -graded ring. The graded group ring R gr [ N ] is defined as follows: R gr [ N ] = ⊕ n ∈ N Ru n is a free left R -module with a basis { u n | n ∈ N } , which is G -graded by means of | ru n | = | r | · n for a homogeneous element r in R ; the multiplication is given as
follows
$$( r u _ { n } ) ( r ^ { \prime } u _ { n ^ { \prime } } ) = r r ^ { \prime } u _ { ( | r ^ { \prime } | ^ { - 1 } \cdot n \cdot | r | ^ { \prime } ) n ^ { \prime } }.$$
We mention that the elements u n are invertible.
We observe that R gr [ N ] is a G -graded ring, and that the canonical map R → R gr [ N ], sending r to ru e , identifies R as a G -graded subring of R gr [ N ]. We refer for the details to [17, Subsection 6.1].
The following result establishes the link between the graded group ring R gr [ N ] and the category of N -equivariant objects in Mod G -R . We emphasize that here we consider the degree-shift action of N on Mod G -R .
Proposition 5.4. Keep the notation as above. Then there is an isomorphism of categories
$$( \text{Mod} ^ { G } \text{-} R ) ^ { N } \stackrel { \sim } { \longrightarrow } \text{Mod} ^ { G } \text{-} ( R ^ { g r } [ N ] ).$$
Proof. Recall that an N -equivariant object ( X,α ) is a G -graded R -module X with isomorphisms α n : X → F X n = X n ( -1 ) in Mod G -R , subject to the relations F n ( α n ′ ) ◦ α n = α nn ′ . We also view α n as an automorphism on X of degree n -1 .
We define a functor ∆: (Mod G -R ) N ∼ -→ Mod G -( R gr [ N ]) as follows. To an N -equivariant object ( X,α ), we associate a G -graded R gr [ N ]-module ∆( X,α ) = X such that the R -action is the same as X and that
$$x. u _ { n } = ( \alpha _ { | x | \cdot n \cdot | x | ^ { - 1 } } ) ^ { - 1 } ( x )$$
for each homogeneous element x in X and n ∈ N . It is rountine to verify that this defines a G -graded R gr [ N ]-module structure on X . The functor ∆ acts by the identity on morphisms. Roughly speaking, the functor ∆ rearranges the isomorphisms α n 's into the action of the invertible elements u n 's.
The inverse functor of ∆ associates to a G -graded R gr [ N ]-module Y the N -equivaraint object ( Y, β ), where the isomorphism β n : Y → Y ( n -1 ) is given by β n ( y ) = y. u ( | y | -1 · n -1 ·| y | ) for each homogeneous element y ∈ Y . /square
We combine Propositions 5.2 and 5.4 to recover the following result.
Corollary 5.5. ([17, Theorem 6.4.1]) Let R = ⊕ g ∈ G R g be a G -graded ring and let N ⊆ G be a normal subgroup. Consider the canonical projection π : G → G/N . Then there is an equivalence of categories
$$\text{Mod} ^ { G / N } \text{-} \pi _ { * } ( R ) \xrightarrow { \sim } \text{Mod} ^ { G } \text{-} ( R ^ { g r } [ N ] ).$$
- 5.3. We will show that in the case that N is a finite abelian group which is a direct summand of G , one might recover the category of G -graded R -modules from the category of G/N -graded π ∗ ( R )-modules via the equivariantization with respect to a certain twisting action; see Proposition 5.7.
Throughout this subsection, we assume that A is a finite abelian group. Let k be a splitting field of A . In other words, the group algebra kA is isomorphic to a direct product of copies of k ; in particular, the characteristic of the field k does not divide the order of A . Denote by ̂ A the character group of A , that is, the group of linear characters of A over k .
Let V be a vector space over k . By a linear ̂ A -action on V we mean a group homomorphism from ̂ A to the general linear group of V . By an A -gradation on V , we mean a decomposition V = ⊕ a ∈ A V a into subspaces indexed by A . We have the following well-known one-to-one correspondence:
$$& \{ A \text{-gradations on } V \} \longleftrightarrow \{ \text{linear } \widehat { A } \text{-actions on } V \}. \\ & \text{R} \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \dots \quad \delta \quad \dots \quad \delta \quad \dots \quad \delta \quad \dots \quad \delta \quad \dots \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dots \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dots \quad \delta \quad \dots \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dots \quad \delta \quad \delta \quad \delta \quad \dots \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dia \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dia \quad \delta \quad \delta \quad \delta \quad \dia \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dia \quad \delta \quad \delta \quad \delta \quad \d� \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \d� \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \d� \quad \delta \quad \delta \quad \delta \quad \d� \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dia \quad \delta \quad \delta \quad \delta \quad \dag \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dag \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \dag \quad \delta \quad \delta \quad \delta \quad \dag \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \delta \quad \d� \quad \delta \quad \delta \quad \delta \quad \dag \quad \delta \quad \delta \quad \dag \quad \dag \quad \dag \quad \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \ dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag \dag$$
The correspondence identifies an A -gradation V = ⊕ a ∈ A V a with the linear ̂ A -action given by χ.v = χ a v ( ) for any χ ∈ ̂ A and v ∈ V a . Here, χ.v denotes the left action of χ on v .
We will consider a restriction of this correspondence. Let H be an arbitrary group and let R = ⊕ h ∈ H R h be an H -graded algebra over k . By an ̂ A -action as graded automorphisms on R we mean a group homomorphism from ̂ A to the automorphism group of R as an H -graded algebra.
Consider the canonical projection π : H × A → H which sends ( h, a ) to h . An A -refinement of R means an ( H × A )-graded algebra ¯ R such that π ∗ ( ¯ ) R = R , or equivalently, each homogeneous component R h = ⊕ a ∈ A ¯ R ( h,a ) has an A -gradation such that rr ′ ∈ ¯ R ( hh ,aa ′ ′ ) for any elements r ∈ ¯ R ( h,a ) and r ′ ∈ ¯ R ( h ,a ′ ′ ) .
The following result is well known; compare [17, Proposition 1.3.13 and Remarks 1.3.14].
Lemma 5.6. Let R be an H -graded algebra. Then there is a one-to-one correspondence
- { A -refinements of R } ←→ { ̂ A -actions as graded automorphisms on R , } (5.3)
Proof. We apply the correspondence (5.2) to the homogeneous component R h for each h ∈ H . It suffices to show that the decomposition R = ⊕ ( h,a ) ∈ H × A ¯ R ( h,a ) makes R = ¯ an ( R H × A )-graded algebra if and only if the corresponding ̂ A -action on R is given by H -graded algebra automorphisms. Take the 'only if' part for example. For any two elements r ∈ ¯ R ( h,a ) ⊆ R h and r ∈ ¯ R ( h ,a ′ ′ ) ⊆ R h ′ , we have which identifies an A -refinement ¯ R with the ̂ A -action given by χ.r = χ a r ( ) for χ ∈ ̂ A and r ∈ ¯ R ( h,a ) .
$$\chi. ( r r ^ { \prime } ) = \chi ( a a ^ { \prime } ) r r ^ { \prime } = ( \chi ( a ) r ) ( \chi ( a ^ { \prime } ) r ^ { \prime } ) = ( \chi. r ) ( \chi. r ^ { \prime } ),$$
where the leftmost equality uses the ( H × A )-gradation on R = ¯ . R This proves that χ acts on R by an H -graded algebra automorphism. /square
Let σ : R → R be an automorphism as an H -graded algebra. For each X ∈ Mod H -R , the twisted module X σ is defined such that X σ = X as an H -graded space and that it has a new R -action ' ◦ ' given by x r ◦ = x.σ r ( ). This gives rise to an automorphism ( -) σ : Mod H -R → Mod H -R . In this way, each subgroup G ′ of the automorphism group of R as an H -graded algebra has a strict action on Mod H -R by assigning to each g ∈ G ′ the automorphism F g = ( -) g -1 . Such an action is referred as a twisting action of G ′ on Mod H -R .
By Proposition 5.2 there is an equivalence of categories
Let A be a finite abelian group. Consider an A -refinement ¯ R of R , and the corresponding ̂ A -action on R . Then there is a strict ̂ A -action on Mod H -R by assigning to each χ ∈ ̂ A the automorphism F χ = ( -) χ -1 ; here, we identify χ as an element in the automorphism group of R . We refer to this action as the twisting action of ̂ A on Mod H -R that corresponds to the A -refinement ¯ . R We will consider the category (Mod H -R ) ̂ A of ̂ A -equivariant objects in Mod H -R .
$$\Theta \colon \text{Mod} ^ { H } \text{-} R \stackrel { \sim } { \longrightarrow } ( \text{Mod} ^ { ( H \times A ) } \text{-} \bar { R } ) ^ { A }$$
where we consider the degree-shift action of A on Mod ( H × A ) -¯ . R The following is a different equivalence, which is somehow adjoint to (5.4); see Remark 5.8.
Recall that the canonical projection π : H × A → H satisfies π ∗ ( ¯ ) R = R . We define the following functor
$$\Gamma \colon \text{Mod} ^ { ( H \times A ) } \text{ } \bar { R } \longrightarrow \left ( \text{Mod} ^ { H } \text{ } \text{ } R \right ) ^ { \widehat { A } }$$
which sends an ( H × A )-graded ¯ -module R ¯ X to Γ( ¯ ) X = ( π ∗ ( ¯ ) X ,γ ), where each isomorphism γ χ : π ∗ ( ¯ ) X → F χ ( π ∗ ( ¯ )) X = π ∗ ( ¯ ) X χ -1 is given by γ χ ( x ) = χ -1 ( a x ) for x ∈ ¯ X ( h,a ) ⊆ π ∗ ( ¯ ) X h . The action of Γ on morphisms is given by π ∗ .
The following result generalizes slightly a result in [14].
Proposition 5.7. Let R be an H -graded algebra over k , and let A be a finite abelian group such that k is a splitting field of A . Consider an A -refinement ¯ R of R and the corresponding twisting action of ̂ A on Mod H -R . Then the above functor Γ is an isomorphism of categories. Moreover, we have a restricted isomorphism
$$\Gamma \colon \bmod ^ { ( H \times A ) } \psi _ { \psi } \bar { R } \stackrel { \sim } { \longrightarrow } ( \bmod ^ { H } \psi _ { \psi } R ) ^ { \widehat { A } }.$$
↦
Proof. Let us indicate the inverse of Γ. For an ̂ A -equivariant object ( X,α ) in Mod H -R , we have for each χ ∈ ̂ A the isomorphism α χ : X → F χ ( X ) = X χ -1 in Mod H -R ; in particular, α χ induces a k -linear automorphism on each homogeneous component X h for each h ∈ H . In view of (3.2), we observe that these isomorphisms ( α χ ) -1 = α χ -1 induce a linear ̂ A -action on X h . By the correspondence (5.2) each homogeneous component X h has an A -gradation X h = ⊕ a ∈ A ¯ X ( h,a ) such that α χ -1 ( x ) = χ a x ( ) for x ∈ ¯ X ( h,a ) . This makes ¯ X = X = ⊕ ( h,a ) ∈ H × A ¯ X ( h,a ) an ( H × A )-graded ¯ -module; moreover, we have R α χ = γ χ for each χ ∈ ̂ A . In other words, ( X,α ) = Γ( ¯ ). X Then the assignment ( X,α ) → ¯ defines the inverse functor X of Γ.
The restricted isomorphism follows from Lemma 5.3(1).
$$\Box$$
Remark 5.8. We mention that one might infer the equivalence (5.4) from Proposition 5.7 and a general result [7, Theorem 7.2]. Here, we identify A with the character group of ̂ A . In other words, these two equivalences are somehow adjoint to each other. We thank Helmut Lenzing for this remark.
## 6. Weighted projective lines and quotient abelian categories
In this section, we recall from [9, 10] some basic facts on weighted projective lines. For a weighted projective line, we study the relationship between the restriction subalgebras of its homogeneous coordinate algebra and certain quotient categories of the category of coherent sheaves on it. Here, we work on an arbitrary field k .
- 6.1. Let t ≥ 1 be an integer. A weight sequence p = ( p , p 1 2 , · · · , p t ) with t weights consists of t positive integers satisfying p i ≥ 2. We will assume that p 1 ≥ p 2 ≥ · · · ≥ p t .
The string group L ( p ) associated to a weight sequence p is an abelian group with generators /vector x , /vector 1 x , 2 · · · , /vector x t subject to the relations p /vector 1 x 1 = p /vector 2 x 2 = · · · = p /vector t x t . This common element is denoted by /vector c , called the canonical element . The abelian group L ( p ) is of rank one, where the canonical element /vector c has infinite order. We observe an isomorphism L ( p ) / Z /vector c /similarequal ∏ t i =1 Z /p i Z of abelian groups. From these facts, we infer that each element /vector x in L ( p ) is uniquely expressed in its normal form
$$\vec { x } = l \vec { c } + \sum _ { i = 1 } ^ { t } l _ { i } \vec { x } _ { i }$$
with l ∈ Z and 0 ≤ l i < p i . Set φ /vector ( x ) = l ; this gives rise to a map φ : L ( p ) → Z . For each 1 ≤ i ≤ t , we define a homomorphism π i : L ( p ) → Z /p i Z such that π i ( /vector x j ) = δ i,j ¯ ; 1 it is surjective.
We denote by N = { 0 1 2 , , · · · } the set of natural numbers. Define the following map
$$\text{mult} \colon L ( \mathbf p ) \longrightarrow \mathbb { N }, \ \vec { x } \mapsto \max \{ \phi ( \vec { x } ) + 1, 0 \}.$$
↦
We set p = lcm( p ) = lcm( p , p 1 2 , · · · , p t ) to be the least common multiple of p . The following homomorphism of abelian groups, called the degree map , is well
defined
↦
$$\delta \colon L ( { \mathbf p } ) \longrightarrow \mathbb { Z }, \ \vec { x } _ { i } \mapsto \frac { p } { p _ { i } }.$$
The degree map is surjective and its kernel coincides with the torsion subgroup of L ( p ). We observe that δ /vector ( c ) = p .
The string group L ( p ) is partially ordered such that /vector x ≤ /vector y if and only if /vector y -/vector x ∈ N { /vector x , /vector 1 x , 2 · · · , /vector x t } , which is further equivalent to φ /vector ( y -/vector x ) ≥ 0. Here, for a subset S of an abelian group A , we denote by N S the submonoid of A generated by S . We denote by L ( p ) + the positive cone of L ( p ), which by definition equals the submonoid N { /vector x , /vector 1 x , 2 · · · , /vector x t } .
Recall that the dualizing element /vector ω in L ( p ) is defined as /vector ω = ( t -2) /vector c -∑ t i =1 /vector x i ; its normal form is /vector ω = -2 /vector c + ∑ t i =1 ( p i -1) /vector x i . One computes that δ /vector ( ω ) = p (( t -2) -∑ t i =1 1 p i ).
- 6.2. Let k be an arbitrary field. A weighted projective line X = X ( p , λ ) is given by a parameter sequence λ = ( λ , λ 1 2 , · · · , λ t ), that is, a collection of pairwise distinct rational points on the projective line P 1 k , together with a weight sequence p = ( p , p 1 2 , · · · , p t ). We will assume that the parameter sequence λ is normalized such that λ 1 = ∞ , λ 2 = 0 and λ 3 = 1.
The homogeneous coordinate algebra S = S ( p , λ ) of a weighted projective line X is by definition k X , X , [ 1 2 · · · , X t ] /I , where I is the ideal generated by X p i i -( X p 2 2 -λ X i p 1 1 ) , 3 ≤ i ≤ t . We write x i = X i + I in S .
/negationslash
The algebra S is L ( p )-graded by means of deg x i = /vector x i . Hence, S = ⊕ /vector x ∈ L ( p ) S /vector x , where S /vector x is the homogeneous component of degree /vector x . We observe that S /vector x = 0 if and only if /vector x ≥ /vector 0; in this case, if /vector x = l/vector c + ∑ t i =1 l i /vector x i is in its normal form, then the subset { x ap 1 1 x bp 2 2 x l 1 1 x l 2 2 · · · x l t t | a + b = l, a, b ≥ 0 } is a basis of S /vector x . We infer that
$$\dim _ { k } S _ { \vec { x } } = \text{mult} ( \vec { x } )$$
for any /vector x ∈ L ( p ).
/negationslash
For an irreducible monic polynomial f ( X ) ∈ k X [ ], we define its homogenization f h ( X,Y ) = X f Y/X d ( ) ∈ k X, Y [ ], where d is the degree of f . The set of all homogeneous prime ideals of S is given by Spec L ( p ) ( S ) = { (0) , ( x i ) , ( f h ( x p 1 1 , x p 2 2 )) , m = ( x , x 1 2 , · · · , x t ) | f = X -λ , i 1 ≤ i ≤ } t ; compare [9, Proposition 1.3]. Here, m is the unique homogeneous maximal ideal of S .
The following observation is direct. Recall that for an L ( p )-graded S -module X , we denote by gsupp( X ) its grading support; see Subsection 5.1.
Lemma 6.1. Consider the graded S -modules S/ p ( /vector x ) for p ∈ Spec L ( p ) ( S ) and /vector x ∈ L ( p ) . Write /vector x = l/vector c + ∑ t j =1 l j /vector x j in its normal form. Then the following statements hold.
- (1) Assume that p = (0) or ( f h ( x p 1 1 , x p 2 2 )) . Then gsupp S/ p ( /vector x ) = L ( p ) + -/vector x . In particular, N ( m /vector 0 c ) ⊆ gsupp S/ p ( /vector x ) for sufficiently large m > 0 0 .
/negationslash
- (3) Assume that p = m . Then gsupp S/ p ( /vector x ) = {- } /vector x .
- (2) Assume that p = ( x i ) . Then gsupp S/ p ( /vector x ) = ∑ j = i N /vector x j -/vector x . In particular, N ( m /vector 0 c ) -l i /vector x i ⊆ gsupp S/ p ( /vector x ) ⊆ π -1 i ( -¯ ) l i for sufficiently large m > 0 0 .
/negationslash
Proof. We use the facts that gsupp( X /vector ( x )) = gsupp( X ) -/vector x , and that the quotient algebra S/ p is a graded domain which is generated as an algebra by x i 's that are not contained in p . It follows that gsupp( S/ p ) = L ( p ) + for p = (0) or ( f h ( x p 1 1 , x p 2 2 )), and that gsupp( S/ x ( i )) = ∑ j = i N /vector x j . The remaining statements are evident. /square
Let H ⊆ L ( p ) be an infinite subgroup. Consider the restriction subalgebra S H = ⊕ /vector x ∈ H S /vector x of S , which will be viewed as an H -graded algebra. For example,
S Z /vector c is isomorphic to the polynomial algebra k X, Y [ ] by identifying X with x p 1 1 and Y with x p 2 2 . More generally, for m ≥ 1 the restriction subalgebra S Z ( m/vector c ) is isomorphic to the subalgebra of k X, Y [ ] generated by monomials of degree m .
Lemma 6.2. Let H ⊆ L ( p ) be an infinite subgroup. Then the restriction subalgebra S H is a finitely generated k -algebra, and as an S H -module, S is finitely generated.
Proof. Assume that H ∩ Z /vector c = Z ( m/vector c ) for some m ≥ 1. Recall from [9, Proposition 1.3] that S is a finitely generated S Z /vector c -module, and thus a finitely generated S Z ( m/vector c ) -module. Since the algebra S Z ( m/vector c ) is noetherian, the algebra S H , viewed as an S Z ( m/vector c ) -submodule of S , is finitely generated. Then the statements follow immediately. /square
Recall that mod L ( p ) -S denotes the abelian category of finitely presented L ( p )-graded S -modules. Consider the restriction functor
$$\text{res} \colon \text{mod} ^ { L ( \mathbf p ) } \text{-} S \rightarrow \text{mod} ^ { H } \text{-} S _ { H },$$
which sends an L ( p )-graded S -module X to X H = ⊕ h ∈ H X h , which is naturally an H -graded S H -module. The functor 'res' is well defined by the following fact.
Lemma 6.3. Let H ⊆ L ( p ) be an infinite subgroup, and let X be a finitely generated L ( p ) -graded S -module. Then the H -graded S H -module X H is finitely generated.
Proof. Assume that H ∩ Z /vector c = Z ( m/vector c ) for some m ≥ 1. We observe that X , viewed as an S Z ( m/vector c ) -module, is finitely generated. Thus as its submodule, X H is a finitely generated S Z ( m/vector c ) -module. In particular, X H is a finitely generated S H -module. /square
The following fact is well known.
Lemma 6.4. Let H ⊆ L ( p ) be an infinite subgroup. Then the restriction functor res: mod L ( p ) -S → mod H -S H is a quotient functor.
Proof. Indeed, the functor 'res' admits a left adjoint S ⊗ S H -: mod H -S H → mod L ( p ) -S . Moreover, the counit res ◦ S ⊗ S H - -→ Id mod H -S H is an isomorphism. It follows from [11, 1.3 Proposition (iii)] that the restriction functor is a quotient functor. /square
- 6.3. Let S = S ( p , λ ) be the homogenous coordinate algebra of a weighted projective line X = X ( p , λ ). Set L = L ( p ). Denote by mod L 0 -S the full subcategory of mod L -S consisting of finite dimensional modules; it is a Serre subcategory. The corresponding quotient category is denoted by qmod L -S = mod L S/ mod L 0 S , and the quotient functor is denoted by q : mod L S → qmod L S .
We mention that the quotient category qmod L -S is equivalent to the category cohX of coherent sheaves on X , and the object S i corresponds to a simple sheaf concentrated at the homogeneous prime ideal ( x i ); see [9, Subsections 1.8 and 1.7].
For each /vector x ∈ L , the degree-shift functor ( /vector x ) on mod L -S induces an automorphism on the quotient category qmod L -S , which is also denoted by ( /vector x ). Consequently, each subgroup of L has a strict action on qmod L -S . Set S i = ( q S/ x ( i )) for 1 ≤ i ≤ t .
Let H ⊆ L be an infinite subgroup. Consider the H -graded restriction subalgebra S H . We have the quotient category qmod H -S H = mod H -S H / mod H 0 -S H . The restriction functor res: mod L -S → mod H -S H induces the corresponding functor betwen the quotient categories res: qmod L -S → qmod H -S H ,
which will also be referred as the restriction functor . L
We will consider the following Serre subcategory of qmod -S
N H = 〈S i ( l/vector x i ) | 1 ≤ i ≤ t, 0 ≤ l ≤ p i -1 with -¯ l / π ∈ i ( H ) 〉 .
That is, N H is the Serre subcategory generated by these simple sheaves S i ( l/vector x i ).
Recall that for each 1 ≤ i ≤ t , the surjective homomorphism π i : L → Z /p i Z is defined by π i ( /vector x j ) = δ i,j ¯ . 1 The following concept is related to the general notion of a wide subcategory of the category formed by all the line bundles on a weighted projective line in [13].
Definition 6.5. Let p be a weight sequence and L ( p ) be the string group. An infinite subgroup H ⊆ L ( p ) is said to be effective provided that for each 1 ≤ i ≤ t , π i ( H ) = Z /p i Z , or equivalently, ¯ lies in 1 π i ( H ).
For example, any infinite subgroup of L ( p ) containing the dualizing element /vector ω is effective, while the subgroup Z /vector c generated by /vector c is not effective for t ≥ 1.
The following result justifies the terminology 'effective subgroup'. We mention that in spirit it is close to [10, Proposition 8.5]; compare the argument in [9, Example 5.8]. The equivalence part of the following proposition is contained in a more general result in [13].
Proposition 6.6. Let L = L ( p ) . Keep the notation as above. Then the restriction functor res: qmod L -S → qmod H -S H induces an equivalence of categories
$$\ q m o d ^ { L } \text{-} S / \mathcal { N } _ { H } \stackrel { \sim } { \longrightarrow } \ q m o d ^ { H } \text{-} S _ { H }.$$
In particular, the restriction functor res: qmod L -S → qmod H -S H is an equivalence if and only if the subgroup H ⊆ L is effective.
Proof. The restriction functor res: mod L -S → mod H -S H is a quotient functor by Lemma 6.4. Then by Lemma 4.1 the induced functor res: qmod L -S → qmod H -S H is also a quotient functor. It suffices to calculate its essential kernel. Instead, we will compute the essential kernel of the composite F : mod L S q → qmod L S res → qmod H -S H . Indeed, for an L -graded S -module X F X , ( ) = 0 if and only if X H is a finite dimensional S H -module, which is equivalent to the condition that gsupp( X ) ∩ H is a finite set.
We observe that Z ( m/vector c ) ⊆ H for a sufficiently large m> 0. Let /vector x = l/vector c + ∑ t i =1 l i /vector x i an arbitrary element in L that is written in its normal form. It follows from Lemma 6.1 that gsupp( S/ p ( /vector x )) ∩ H is finite if and only if p = m , or p = ( x i ) and -¯ l i / π ∈ i ( H ).
Recall that a finitely generated L -graded S -module X has a finite filtration with factors isomorphic to S/ p ( /vector x ) for some p ∈ Spec L ( S ) and /vector x ∈ L . Recall that Ker F is a Serre subcategory of mod L -S . It follows that
Ker F = 〈 S/ m ( /vector y , S/ x ) ( i )( /vector x ) | /vector y ∈ L, 1 ≤ i ≤ t, /vector x satisfying that -¯ l i / π ∈ i ( H ) 〉 .
Then we are done by using the fact that the essential kernel of 'res' equals q (Ker F ), which equals N H . Here, we recall from [9, Subsection 1.6] the well-known fact that S i ( /vector x ) = S i ( l i /vector x i ) for each 1 ≤ i ≤ t . /square
## 7. Weighted projective lines of tubular type
In this section, we study weighted projective lines of tubular type. They are explicitly related to elliptic plane curves via two different equivariantizations. We emphasize that the idea goes back to [9, Example 5.8] and more explicitly to [14, 15]; compare [19, 12, 18].
7.1. We recall that a weight sequence p = ( p , p 1 2 , · · · , p t ) is of tubular type provided that the dualizing element /vector ω in L ( p ) is torsion, or equivalently, δ /vector ( ω ) = 0. An elementary calculation yields a complete list of weight sequences of tubular type: (2 , 2 2 2), (3 , , , 3 3), (4 , , 4 2) and (6 3 2). , , , We observe that in each case the order of /vector ω equals p = lcm( p ), which further equals p 1 .
We have the following easy observation.
Lemma 7.1. Let p be a weight sequence of tubular type and let n ≥ 1 . Recall that p = lcm( p ) . Then the following equation holds
$$\sum _ { j = 0 } ^ { p - 1 } \text{mult} ( n \vec { x } _ { 1 } + j \vec { \omega } ) = n.$$
Proof. We observe that mult( /vector x + ) = mult( /vector c /vector x ) + 1 provided that φ /vector ( x ) ≥ -1. For a weight sequence p of tubular type, we recall that p = p 1 and thus p/vector x 1 = . We /vector c observe that φ n/vector ( x 1 + j/vector ω ) ≥ -1 for each n ≥ 1 and 0 ≤ j < p -1. Denote the left hand side of the equation by f ( n ). It follows that f ( n + ) = p f ( n ) + p for each n ≥ 1.
Therefore, to show the required equation, it suffices to prove that f ( ) = i i for 1 ≤ i ≤ p . These p equations are easy to verify for each of the four cases. Take the case p = (6 3 2) for example. , , We have that f (4) = ∑ 5 j =0 mult(4 /vector x 1 + j/vector ω ) = 1+0+1+1+1+0= 4 and that f (5) = ∑ 5 j =0 mult(5 /vector x 1 + j/vector ω ) = 1+0+1+1+1+1 = 5. We omit the details. /square
The following consideration is inspired by [9, Example 5.8]. Let p be a weight sequence of tubular type. We consider the subgroup H ( p ) = Z (3 /vector x 1 ) ⊕ Z /vector ω of L ( p ) generated by 3 /vector x 1 and /vector ω . It inherits the partial order from L ( p ) such that its positive cone equals H ( p ) + = H ( p ) ∩ L ( p ) + , which is a submonoid of H ( p ). We consider the subset 3 /vector x 1 + Z /vector ω = { 3 /vector x 1 + j/vector ω | j = 0 1 , , · · · , p - } 1 of H ( p ). We list in Table 1 all the positive elements in 3 /vector x 1 + Z /vector ω explicitly.
Table 1. The list of generators of H ( p ) +
| the weight sequence p | the elements in (3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + | the elements in (3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + | the elements in (3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + |
|-------------------------|--------------------------------------------------------------|----------------------------------------------------------------------|----------------------------------------------------------------------|
| (2 , 2 , 2 , 2) | 3 /vector x 1 | 3 /vector x 1 + /vector ω = /vector x 2 + /vector x 3 + /vector x 4 | 3 /vector x 1 + /vector ω = /vector x 2 + /vector x 3 + /vector x 4 |
| (3 , 3 , 3) | 3 /vector x 1 | 3 /vector x 1 +2 /vector ω = /vector x 1 + /vector x 2 + /vector x 3 | 3 /vector x 1 +2 /vector ω = /vector x 1 + /vector x 2 + /vector x 3 |
| (4 , 4 , 2) | 3 /vector x 1 | 3 /vector x 1 +2 /vector ω = /vector x 1 +2 /vector x 2 | 3 /vector x 1 +3 /vector ω = /vector x 2 + /vector x 3 |
| (6 , 3 , 2) | 3 /vector x 1 | 3 /vector x 1 +2 /vector ω = /vector x 1 + /vector x 2 | 3 /vector x 1 +3 /vector ω = /vector x 3 |
We have the following elementary observation, for which we include an elementary proof here. For a conceptual reasoning, we refer to Remark 7.5.
Lemma 7.2. Let p be a weight sequence of tubular type. Then we have
$$H ( { \mathbf p } ) _ { + } = \mathbb { N } ( ( 3 \vec { x } _ { 1 } + \mathbb { Z } \vec { \omega } ) \cap H ( { \mathbf p } ) _ { + } ).$$
In other words, the monoid H ( p ) + is generated by the subset (3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + .
Proof. Recall that p = lcm( p ) = p 1 equals the order of /vector ω . For each 0 ≤ j ≤ p -1, we define m j ( ) to be the least natural number m such that m (3 /vector x 1 ) + j/vector ω ≥ /vector 0. We observe that m (0) = 0 and m j ( ) ≥ 1 for j = 0.
/negationslash
We claim that m j ( )(3 /vector x 1 ) + j/vector ω lies in N ((3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + ) for each 0 ≤ j ≤ p -1. Then we are done. Indeed, for any positive element /vector x = m (3 /vector x 1 ) + j/vector ω , we have m ≥ m j ( ), and thus /vector x = ( m -m j ( ))(3 /vector x 1 ) + ( m j ( )(3 /vector x 1 ) + j/vector ω ), which lies in N ((3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + ).
The claim is easily verified case by case.
/square
7.2. We recall that a weighted projective line X = X ( p , λ ) over a field k is of tubular type provided that the weight sequence p is of tubular type. Recall that S = S ( p , λ ) is the homogeneous coordinate algebra of X .
/negationslash
We fix the notation for S in the four tubular types. For the weight type (2 , 2 2 2), , , there exists a parameter λ = 0 1 in the presentation of the corresponding homoge-, neous coordinate algebra S . In other three cases, we omit the normalized parameter
sequences. Hence, we refer to (2 , 2 2 2; , , λ ), (3 , 3 3), (4 , , 4 2) and (6 , , 3 2) as the , type of S . We emphasize that λ ∈ k , which is not equal to 0 or 1.
We list the homogeneous coordinate algebras S explicitly, according to their types. We define the associated Z -graded algebras R of the same type on the right hand side, where all the variables are of degree one.
$$S ( 2, 2, 2 ; \lambda ) & = \frac { k [ X _ { 1 }, X _ { 2 }, X _ { 3 }, X _ { 4 } ] } { ( X _ { 3 } ^ { 2 } - ( X _ { 2 } ^ { 2 } - X _ { 1 } ^ { 2 } ), X _ { 4 } ^ { 2 } - ( X _ { 2 } ^ { 2 } - \lambda X _ { 1 } ^ { 2 } ) ) }, \quad R ( 2, 2, 2 ; \lambda ) & = \frac { k [ X, Y, Z ] } { ( Y ^ { 2 } Z - X ( X - Z ) ( X - \lambda Z ) ) } ; \\ S ( 3, 3, 3 ) & = \frac { k [ X _ { 1 }, X _ { 2 }, X _ { 3 } ] } { ( X _ { 3 } ^ { 3 } - ( X _ { 3 } ^ { 2 } - X _ { 1 } ^ { 3 } ) ) }, \quad R ( 3, 3, 3 ) & = \frac { k [ X, Y, Z ] } { ( X ^ { 3 } - ( Y ^ { 2 } Z - Z ^ { 2 } Y ) ) } ; \\ S ( 4, 4, 2 ) & = \frac { k [ X _ { 1 }, X _ { 2 }, X _ { 3 } ] } { ( X _ { 3 } ^ { 2 } - ( X _ { 4 } ^ { 4 } - X _ { 4 } ^ { 4 } ) ) }, \quad R ( 4, 4, 2 ) & = \frac { k [ X, Y, Z ] } { ( Y ^ { 2 } Z - X ( X - Z ) ( X + Z ) ) } ; \\ S ( 6, 3, 2 ) & = \frac { k [ X _ { 1 }, X _ { 2 }, X _ { 3 } ] } { ( X _ { 3 } ^ { 2 } - ( X _ { 2 } ^ { 2 } - X _ { 1 } ^ { 6 } ) ) }, \quad R ( 6, 3, 2 ) & = \frac { k [ X, Y, Z ] } { ( Y ^ { 2 } Z - ( X ^ { 3 } - Z ^ { 3 } ) ) }. \\ & \, \begin{matrix} \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \, \\ \end{matrix}$$
We denote by E the projective plane curve defined by R . By Serre's theorem, there is an equivalence between the category cohE of coherent sheaves on E and the quotient category qmod Z -R of mod Z -R by the Serre subcategory mod Z 0 -R consisting of finite dimensional modules.
/negationslash
/negationslash
/negationslash
/negationslash
Remark 7.3. We mention that E (2 , 2 2 2; , , λ ) is an elliptic curve for λ = 0 1. For , other types, we have requirement on the characteristic of the field k ; see also [14]. If char k = 3, E (3 , 3 3) is an elliptic curve with , j -invariant 0; if char k = 2, E (4 , 4 2) , is an elliptic curve with j -invariant 1728; if char k = 2 3, , E (6 , 3 2) is an elliptic , curve with j -invariant 0.
We define three homogeneous elements x , y and z in S according to Table 2. By comparing with Table 1, all their degrees lie in (3 /vector x 1 + Z /vector ω ) ∩ H ( p ) + . For an explanation of the term 'extra degree' in Table 2, we refer to Remark 7.6.
Table 2. The elements x , y and z in S and their extra degrees
| the types of S and R | x | y | z | deg x | deg y | deg z |
|------------------------|-------------|-------------|-------|-----------|-----------|-----------|
| (2 , 2 , 2 , 2; λ ) | x 1 x 2 2 | x 2 x 3 x 4 | x 3 1 | (1 , ¯ 0) | (1 , ¯ 1) | (1 , ¯ 0) |
| (3 , 3 , 3) | x 1 x 2 x 3 | x 3 2 | x 3 1 | (1 , ¯ 2) | (1 , ¯ 0) | (1 , ¯ 0) |
| (4 , 4 , 2) | x 1 x 2 2 | x 2 x 3 | x 3 1 | (1 , ¯ 2) | (1 , ¯ 3) | (1 , ¯ 0) |
| (6 , 3 , 2) | x 1 x 2 | x 3 | x 3 1 | (1 , ¯ 2) | (1 , ¯ 3) | (1 , ¯ 0) |
We consider the subalgebra k x, y, z [ ] of S generated by x , y and z . We observe that k x, y, z [ ] ⊆ S H ( p ) . Consider the surjective homomorphism π : H ( p ) → Z defined by π (3 /vector x 1 ) = 1 and π /vector ( ω ) = 0.
The central technical result of this section is as follows.
Theorem 7.4. Let S be the homogeneous coordinate algebra of a weighted projective line X of tubular type and let R be the associated Z -graded algebra of the same type. Let H = H ( p ) . Keep the above notation. Then we have k x, y, z [ ] = S H , and that there is an isomorphism of Z -graded algebras
$$R \stackrel { \sim } { \longrightarrow } \pi _ { * } ( S _ { H } ).$$
Proof. We claim that k x, y, z [ ] ⊆ S is an integral extension. Recall that an integral extension preserves Krull dimensions and that the Krull dimension of the algebra S is two. Hence the Krull dimension of k x, y, z [ ] is also two.
Recall that S Z /vector c = k x [ p 1 1 , x p 2 2 ] and that S is a finitely generated S Z /vector c -module. Hence S is integral over S Z /vector c and thus over the subalgebra k x , x [ 1 2 ]. For the claim, it suffices to show that both x 1 and x 2 are integral over k x, y, z [ ]. Since x 3 1 = z , the element x 1 is integral over k x, y, z [ ].
We consider the element x 2 case by case. We take p = (2 2 2 2) for example, , , , while other cases are similar and even easier. Observe in Table 2 that y 2 = x 2 2 ( x 2 2 -x 2 1 )( x 2 2 -λx 2 1 ). This implies that x 2 is integral over k x, y, z, x [ 1 ] and thus over k x, y, z [ ]. We are done with the claim.
We define a homomorphism θ : R → S of algebras by sending X to x , Y to y and Z to z ; see Table 2. The relation of R is satisfied by an elementary calculation. The image of θ is k x, y, z [ ]. Recall that R is an integral domain of Krull dimension two. Comparing the Krull dimensions of R and the image of θ , we infer that θ is injective. Consequently, we have an injective homomorphism of Z -graded algebras θ : R → π ∗ ( S H ). Here, we recall that k x, y, z [ ] ⊆ S H .
We claim that the injective homomorphism θ : R → π ∗ ( S H ) is an isomorphism. Then the two required statements follow. Indeed, it suffices to show that for each n ≥ 1, dim k R n = dim k π ∗ ( S H n ) . Recall that π ∗ ( S H n ) = ⊕ p -1 j =0 S 3 n/vector x 1 + j/vector ω , and thus has dimension ∑ p -1 j =0 mult(3 n/vector x 1 + j/vector ω ); see (6.2). By Lemma 7.1 we have dim k π ∗ ( S H n ) = 3 n . On the other hand, it is well known that dim k R n = 3 n . Then we are done. /square
/negationslash
Remark 7.5. Recall that /vector x ∈ H ( p ) is positive if and only if ( S H ( p ) ) /vector x = S /vector x = 0. We deduce from the equality k x, y, z [ ] = S H ( p ) that each /vector x ∈ H ( p ) + lies in the submonoid generated by the degrees of x , y and z . This gives another proof of Lemma 7.2.
Remark 7.6. We now explain the 'extra degrees' of x , y and z in S H ( p ) . We recall that p = lcm( p ) equals the order of /vector ω . So we have the following isomorphism of abelian groups
$$\psi \colon H ( \mathbf p ) = \mathbb { Z } ( 3 \vec { x } _ { 1 } ) \oplus \mathbb { Z } \vec { \omega } \xrightarrow { \sim } \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z }$$
such that ψ (3 /vector x 1 ) = (1 , ¯ ) and 0 ψ /vector ( ω ) = (0 , ¯ ). 1 By this isomorphism, the H ( p )-graded algebra S H ( p ) is Z × Z /p Z -graded. This yields the extra degrees of x y , and z , which are computed by applying ψ to the degrees of x , y and z ; compare Table 1.
We observe that the algebras R are naturally Z × Z /p Z -graded according to the degrees in Table 2; here, we abuse X Y , , Z with x y , and z , respectively. We denote the resulting Z × Z /p Z -graded algebras by ¯ ; R it is a Z /p Z -refinement of R .
Then the isomorphism θ in the above proof, which is given according to Table 2, yields an isomorphism of Z × Z /p Z -algebras
$$\theta \colon \bar { R } \stackrel { \sim } { \longrightarrow } S _ { H ( \mathbf p ) }.$$
Let p be a weight sequence of tubular type. Recall that p = lcm( p ). Denote by C p = 〈 g | g p = 1 〉 the cyclic group of order p .
We assume that k is a splitting field of C p . Equivalently, p is invertible in k which contains a primitive p -th root of unity. Fix ω ∈ k a primitive p -th root of unity. For example, if p = (2 2 2 2), then the characteristic of , , , k is not equal to 2 and ω = -1.
We identify C p with the character group ̂Z Z /p of Z /p Z such that g ( ¯ ) 1 = ω . Applying the correspondence (5.3) to the above Z /p Z -refinement ¯ of the R Z -graded algebra R , we obtain in Table 3 the corresponding C p -action on R as Z -graded algebra automorphisms.
We mention that the cyclic group action on R corresponds to a ramified Galois covering from the elliptic curve E to the projective line P 1 k , where the Galois group is isomorphic to the acting cyclic group; compare [19, Subsection 1.3].
Table 3. The cyclic group action on R
| the types of R | the action of C p = 〈 g | g p = 1 〉 on generators | the order of ω ∈ k |
|---------------------|-------------------------------------------------------|----------------------|
| (2 , 2 , 2 , 2; λ ) | g.x = x, g.y = ωy, g.z = z | 2 |
| (3 , 3 , 3) | g.x = ω 2 x, g.y = y, g.z = z | 3 |
| (4 , 4 , 2) | g.x = ω 2 x, g.y = ω 3 y, g.z = z | 4 |
| (6 , 3 , 2) | g.x = ω 2 x, g.y = ω 3 y, g.z = z | 6 |
- 7.3. We will formulate the main result of this paper. As mentioned earlier, the result is implicitly contained in [9, Example 5.8] and later explicitly in [14] with more details; see also [15]. The treatment here is slightly different from [14, 15], and we strengthen slightly the results therein; compare Remark 7.8(3). We mention that related results appear in [12].
Let k be an arbitrary field. Let S be the homogeneous coordinate algebra of a weighted projective line X of tubular type, and R be the associated Z -graded algebra of the same type. Let p be the weight sequence and denote p = lcm( p ). Recall that the dualizing element /vector ω in L = L ( p ) has order p . The subgroup Z /vector ω acts on mod L -S by the degree-shift action, which induces the degree-shift action of Z /vector ω on qmod L -S . We consider the category (qmod L -S ) Z /vector ω of equivariant objects.
Assume that k is a splitting field of the cyclic group C p of order p . Consider the C p -action on R as Z -graded algebra automorphisms in Table 3. Such an action induces the twisting action of C p on mod Z R , which further induces the twisting action of C p on qmod Z R . We consider the category (qmod Z -R ) C p of equivariant objects.
Theorem 7.7. (Lenzing-Meltzer) Let k be a field. Let S be the homogeneous coordinate algebra of a weighted projective line X of tubular type, and let R be the associated Z -graded algebra of the same type, where we keep the notation as above. Then the following statements hold.
- (1) There is an equivalence of categories
$$( q \bmod { ^ { L } } _ { \mu } S ) ^ { \mathbb { Z } \vec { \omega } } \stackrel { \sim } { \longrightarrow } q \bmod { ^ { Z } } _ { \mu } R.$$
- (2) Assume that k is a splitting field of C p . Then there is an equivalence of categories
$$\ q { \bmod { ^ { L } } } _ { \bullet } S \stackrel { \sim } { \longrightarrow } ( \ q { \bmod { ^ { Z } } } _ { \bullet } R ) ^ { C _ { p } }.$$
Proof. Recall the subgroup H = H ( p ) = Z (3 /vector x 1 ) ⊕ Z /vector ω of L from Subsection 7.1; it is an effective subgroup in the sense of Definition 6.5. By Proposition 6.6 the restriction functor is an equivalence
$$\text{res} \colon q { \bmod } ^ { L } { - S } \stackrel { \sim } { \longrightarrow } q { \bmod } ^ { H } { - S } _ { H }.$$
Recall from Remark 7.6 the Z /p Z -refinement ¯ of the R Z -graded algebra R . By the isomorphism θ in (7.2) we have an isomorphism of categories
$$\theta ^ { * } \colon q { \bmod } ^ { H } { - S _ { H } } \stackrel { \sim } { \longrightarrow } q { \bmod } ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } { - \bar { R } }.$$
Consider the following composite equivalence
$$\theta ^ { * } \circ \text{res} \colon \text{qmod} ^ { L } \text{-} S \xrightarrow { \sim } \text{qmod} ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } \text{-} \bar { R }.$$
We observe that this equivalence transfers the degree-shift action of Z /vector ω on qmod L -S to the degree-shift action of Z /p Z on qmod ( Z × Z /p Z ) - ¯ . R Consequently, this equivalence induces an equivalence of categories
$$( 7. 4 ) & & ( \text{qmod} ^ { L } \text{-} S ) ^ { \mathbb { Z } \vec { w } } \stackrel { \sim } { \longrightarrow } ( \text{qmod} ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } \text{-} \bar { R } ) ^ { \mathbb { Z } / p \mathbb { Z } }.$$
By Proposition 5.2 we have an equivalence of categories
$$( \mod ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } _ { \text{-} } \bar { R } ) ^ { \mathbb { Z } / p \mathbb { Z } } \stackrel { \sim } { \longrightarrow } \mod ^ { \mathbb { Z } } _ { \text{-} } R,$$
which restricts to an equivalence (mod ( Z × Z /p Z ) 0 - ¯ ) R Z /p Z ∼ -→ mod Z 0 R of full subcategories consisting of finite dimensional modules. Applying Corollary 4.4, we have an equivalence of categories
$$( \text{qmod} ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } \bar { R } ) ^ { \mathbb { Z } / p \mathbb { Z } } \stackrel { \sim } { \longrightarrow } \text{qmod} ^ { \mathbb { Z } } \text{-} R.$$
We combine this equivalence with (7.4) to obtain (1).
For (2), we assume that k is a splitting field of C p . Recall that C p is identified with the character group of Z /p Z . By Proposition 5.7 we have an isomorphism of categories
$$\mod ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } \bar { R } \stackrel { \sim } { \longrightarrow } ( \mod ^ { \mathbb { Z } } \bar { \ } R ) ^ { C _ { p } },$$
which restricts to an isomorphism mod ( Z × Z /p Z ) 0 - ¯ R ∼ -→ (mod Z 0 R ) C p of full subcategories consisting of finite dimensional modules. Applying Corollary 4.4, we have an equivalence of categories
$$\ q { \bmod } ^ { ( \mathbb { Z } \times \mathbb { Z } / p \mathbb { Z } ) } \bar { R } \stackrel { \sim } { \longrightarrow } ( \ q { \bmod } ^ { \mathbb { Z } } \text{-} R ) ^ { C _ { p } }.$$
We combine this equivalence with (7.3) to obtain (2).
/square
Remark 7.8. (1) We recall that X is the weighted projective line defined by S and that E is the projective plane curve defined by R . If k is a splitting field of C p , then E is an elliptic plane curve. Then Theorem 7.7 relates the categories of coherent sheaves on X and E via two equivariantizations.
↦
We emphasize that the two group actions on relevant categories are completely different: one is the degree-shift action and another is the twisting action. However, as in Remark 5.8 the two equivalences obtained in Theorem 7.7 are somehow adjoint to each other. We mention that by Remark 7.3 the assignment X → E is not a bijection up to isomorphism; see also [15].
(2) For the L -graded algebra S and the associated Z -graded R one might consider the quotient categories 'QMod' of arbitrary graded modules, which are equivalent to the categories of quasi-coherent sheaves on X and E , respectively. Then a similar result as Theorem 7.7 holds for theses two quotient categories 'QMod'.
(3) Let us mention the version of Theorem 7.7 in [15].
Consider the degree map δ : L → Z whose kernel equals the torsion subgroup tor( L ) of L ; moreover, we have a decomposition L = tor( L ) ⊕ Z /vector x 1 . Consider the Z -graded algebra S = δ ∗ ( S ); see Subsection 5.1. We view the L -graded algebra S as a tor( L )-refinement of S . Observe that Z /vector ω ⊆ tor( L ).
If the field k is a splitting field of C p , then it is also a splitting field of tor( L ). In this case, we denote by A the character group of tor( L ). Then A acts on S as Z -graded algebra automorphisms by Lemma 5.6. We consider the degree-shift action of tor( L ) on qmod L -S , and the twisting action of A on qmod Z S . Then under the same assumptions as Theorem 7.7, the same argument yields the following two adjoint equivalences:
$$( 7. 5 ) \quad ( q \text{mod} ^ { L } \text{-} S ) ^ { \text{tor} ( L ) } \stackrel { \sim } { \longrightarrow } q \text{mod} ^ { Z } \text{-} S, \quad q \text{mod} ^ { L } \text{-} S \stackrel { \sim } { \longrightarrow } ( q \text{mod} ^ { Z } \text{-} S ) ^ { A }.$$
Indeed, the argument here is easier since it does not rely on Proposition 6.6 and Theorem 7.4.
The major difference between the two equivalences (7.5) and the ones in Theorem 7.7 is the fact that the acting groups in (7.5) are not cyclic except the case p = (6 , 3 2), while all the acting groups in Theorem 7.7 are cyclic. ,
We mention that for the cases p = (4 4 2) and (6 3 2), the variables of the , , , , Z -graded algebra S are not all of degree one. Therefore, to verify that qmod Z -S is
equivalent to the category of coherent sheaves on an elliptic curve, one might need the general fact on Veronese subalgebras [3, Proposition 5.10], or the axiomatic description of the category of coherent sheaves on an elliptic curve in [21, Theorem C]. If the characteristic of k is not equal to 2, the Z -graded algebra S for the case p = (2 2 2 2) defines an elliptic space curve in its Jacobi form. , , , If the characteristic of k is not equal to 3, the Z -graded algebra S for the case p = (3 3 3) defines an , , elliptic curve as a Fermat curve of degree 3.
Acknowledgements J. Chen is very grateful to Helmut Lenzing for giving her the manuscript [14] during his visit at Xiamen University in 2011. The authors thank Helmut Lenzing very much for enlightening and helpful discussions. The authors are grateful to Henning Krause and Hagen Meltzer for helpful comments.
- J. Chen and Z. Zhou are supported by National Natural Science Foundation of China (No. 11201386) and Natural Science Foundation of Fujian Province (No. 2012J05009); X.W. Chen is supported by NCET-12-0507, National Natural Science Foundation of China (No. 11201446) and the Alexander von Humboldt Stiftung.
## References
- [1] M.F. Atiyah , Vector bundles over an elliptic curve , Proc. London Math. Soc. 7 (1957), 414-452.
- [2] M. Auslander, and S.O. Smalø, Preprojective modules over artin algebras , J. Algebra 66 (1980), 61-122.
- [3] M. Artin, and J.J. Zhang , Noncommutative projective schemes , Adv. Math. 109 (1994), 228-287.
- [4] X.W. Chen , A note on separable functors and monads with an application to equivariant derived categories , arXiv:1403.1332.
- [5] P. Deligne , Action du groupe des tresses sur une cat´gorie e , Invent. Math. 128 (1997), 159-175.
- [6] V. Drinfeld, S. Gelaki, D. Nikshych, and V. Ostrik , On braided fusion categories, I , Sel. Math. New Ser. 16 (2010), 1-119.
- [7] A.D. Elagin , On equivariant triangulated categories , arXiv:1403.7027.
- [8] P. Gabriel , Des cat´gories ab´liennes e e , Bull. Soc. Math. France 90 (1962), 323-448.
- [9] W. Geigle, and H. Lenzing, A class of weighted projective curves arising in representation theory of finite dimensional algebras , in: Singularities, representations of algebras and vector bundles, Lecture Notes in Math. 1273 , 265-297, Springer, 1987.
- [10] W. Geigle, and H. Lenzing, Perpendicular categories with applications to representations and sheaves , J. Algebra 144 (1991), 273-343.
- [11] P. Gabriel, and M. Zisman , Calculus of Fractions and Homotopy Theory, Springer-Verlag, New York, Inc., New York, 1967.
- [12] L. Hille , Weighted projective spaces, Calabi-Yau categories and reflexive polytopes , a talk presented in 'Representations of Algebras and their Geometry', Paderborn, 2006.
- [13] D. Kussin, H. Lenzing, and H. Meltzer , Invariant flags for nilpotent operators and weighted projective lines , in preparation, 2014.
- [14] H. Lenzing , Tubular and elliptic curves , an unpublished note on joint work with H. Meltzer, Paderborn, 2004.
- [15] H. Lenzing , Tubular and elliptic curves , a slide talk on joint work with H. Meltzer, ICRA XI, Patzcuaro, 2004.
- [16] S. Mac Lane , Categories for the Working Mathematician, Grad. Texts in Math. 5 , Springer-Verlag, New York, 1998.
- [17] C. Nastasescu, and F. Van Oystaeyen , Methods of Graded Rings, Lecture Notes Math. 1836 , Springer-Verlag, Berlin Heidelberg, 2004.
- [18] D. Ploog , Weighted projective lines as quotient stacks , a draft, Hannover, 2009.
- [19] A. Polishchuk , Holomorphic bundles on 2 -dimensional noncommutative toric orbifolds , in: Noncommutative Geometry and Number Theory, Ed. by C. Consani and M. Marcolli, 341-359, Vieweg, 2006.
- [20] I. Reiten, and Ch. Riedtmann, Skew group algebras in the representation theory of artin algebras , J. Algebra 92 (1985), 224-282.
## MONADICITY THEOREM AND WEIGHTED PROJECTIVE LINES OF TUBULAR TYPE 25
- [21] I. Reiten, and M. Van den Bergh, Noetherian hereditary abelian categories satisfying Serre duality , J. Amer. Math. Soc. 15 (2002), 295-366.
- [22] C.M. Ringel , Tame Algebras and Integral Quadratic Forms, Lecture Notes Math. 1099 , Springer-Verlag, Berlin, 1984.
Jianmin Chen, and Zhenqiang Zhou
School of Mathematical Sciences,
Xiamen University, Xiamen, 361005, Fujian, PR China.
E-mail: [email protected], [email protected].
Xiao-Wu Chen
School of Mathematical Sciences,
University of Science and Technology of China, Hefei 230026, Anhui, PR China
Wu Wen-Tsun Key Laboratory of Mathematics,
USTC, Chinese Academy of Sciences, Hefei 230026, Anhui, PR China.
E-mail: [email protected], URL: http://home.ustc.edu.cn/ ∼ xwchen. | null | [
"Jianmin Chen",
"Xiao-Wu Chen",
"Zhenqiang Zhou"
] | 2014-07-31T21:07:31+00:00 | 2014-07-31T21:07:31+00:00 | [
"math.RA",
"math.AG",
"math.RT",
"16W50, 14A22, 14H52"
] | Monadicity theorem and weighted projective lines of tubular type | We formulate a version of Beck's monadicity theorem for abelian categories,
which is applied to the equivariantization of abelian categories with respect
to a finite group action. We prove that the equivariantization is compatible
with the construction of quotient abelian categories by Serre subcategories. We
prove that the equivariantization of the graded module category over a graded
ring is equivalent to the graded module category over the same ring but with a
different grading. We deduce from these results two equivalences between the
category of (equivariant) coherent sheaves on a weighted projective line of
tubular type and that on an elliptic curve, where the acting groups are cyclic
and the two equivalences are somehow adjoint to each other. |
1408.0029v1 | New windows on massive stars: asteroseismology, interferometry,
and spectropolarimetry
Proceedings IAU Symposium No. 307, 2014
G. Meynet, C. Georgy, J.H. Groh & Ph. Stee, eds.
c © 2014 International Astronomical Union DOI: 00.0000/X000000000000000X
## Beam me up, Spotty: Toward a new understanding of the physics of massive star photospheres
Alexandre David-Uraz , Gregg Wade 1 2 and Stan Owocki 3
1 Queen's University, Canada email: [email protected] 2 Royal Military College, Canada 3 University of Delaware, USA
Abstract. For 30 years, cyclical wind variability in OB stars has puzzled the astronomical community. Phenomenological models involving co-rotating bright spots provide a potential explanation for the observed variations, but the underlying physics remains unknown. We present recent results from hydrodynamical simulations constraining bright spot properties and compare them to what can be inferred from space-based photometry. We also explore the possibility that these spots are caused by magnetic fields and discuss the detectability of such fields.
Keywords. Hydrodynamics, methods: numerical, stars: winds, outflows
## 1. Introduction
Massive stars exhibit cyclical spectral variability on timescales of hours to days. One seemingly ubiquitous manifestation of these variations is the presence of so-called 'discrete absorption components' (DACs, Howarth & Prinja 1989): additional absorption features within the P Cygni absorption troughs of wind-sensitive UV resonance lines which progress from low to near-terminal velocity. They are believed to be rotationally modulated. The generally-accepted hypothesis which explains their formation is the 'corotating interaction regions' model (CIR, Mullan 1986). Bright spots on the surface of the star locally drive an enhanced wind, leading to spiral-like structures (Cranmer & Owocki 1996, henceforth referred to as CO96). The most important feature of this model is the presence of 'velocity kinks' in the wind; the driving of extra material by the bright spots cannot be sustained (the wind is overloaded) and that material eventually decelerates, which results in a velocity plateau, thus leading to an accumulation of matter at a given velocity which causes the extra absorption associated with DACs.
## 2. Modern constraints and revisited model
CO96 provide a phenomenological explanation for the DAC phenomenon. Consequently, the presence of bright spots was not a priori physically motivated (nor constrained). However, with the advent of space-based photometry (e.g. the MOST space telescope), the precisely-determined amplitude of light-curve variations places very strong constraints on the size and contrast of putative spots on the surface of the star.
Ramiaramanantsoa et al. (2014) find a 10 mmag amplitude for ξ Per, constraining any spots present to be much more modest than those used by CO96. It is unclear whether velocity kinks can be formed with such modest spots. One possible way to facilitate kink formation is by including ionization effects, which were not taken into account by CO96.
Following up on that work, we aim to study the effects of adding the ionization correction ( δ ) in hydrodynamic wind simulations, using the VH-1 package. 1D simulations show that for high values of the δ parameter (Abbott 1982), the wind becomes overloaded and we obtain a coasting solution, even without spots. While this work is quite preliminary, 2D hydrodynamical simulations based on realistic stellar parameters (in this case, ξ Per, with 10 ◦ spots and a 33% brightness enhancement) and including additional wind physics (ionization effect, finite disk correction) show that we can reproduce CIRs and even obtain the desired velocity kinks (see Fig. 1).
## 3. The role of magnetic fields
Magnetic fields constitute a popular hypothesis to explain the surface nonuniformities apparently needed to form CIRs. While only a small fraction of OB stars are known to host detectable fields (about 7%, Wade et al. 2013), most known magnetic massive stars have a large scale, essentially dipolar field. However, David-Uraz et al. (2014) effectively rule out large-scale magnetic fields as the physical cause of DACs. Recent models (e.g. Cantiello et al. 2009) suggest the existence of a sub-surface convection layer in massive stars which could produce small-scale surface magnetic fields. Kochukhov & Sudnik (2013) have characterized the detectability of randomly distributed magnetic spots. For v sin i < 50 km/s, one would expect to detect 10 ◦ magnetic spots with a field strength of over 100 G (with a 0.5 filling factor); to produce a 10 mmag photometric variation, such a spot should have a field strength of about 330 G (using the formula of David-Uraz et al. 2014), which should therefore be detectable with current instrumentation. Further work on both the numerical and observational fronts will be required to better understand and constrain the role of small-scale magnetic fields in producing DACs.
## References
Abbott, D. C. 1982, ApJ 259, 282
Cantiello, M., Langer, N., Brott, I., et al. 2009, A&A 499, 279
Cranmer, S. R. & Owocki, S. P. 1996, ApJ 462, 469
David-Uraz, A., Wade, G. A., Petit, V., et al. 2014, ArXiv e-prints
Howarth, I. D. & Prinja, R. K. 1989, ApJS 69, 527
Kochukhov, O. & Sudnik, N. 2013, A&A 554, A93
Mullan, D. J. 1986, A&A 165, 157
Ramiaramanantsoa, T., Moffat, A. F. J., Chen´, A.-N., et al. 2014, e MNRAS 441, 910
Wade, G. A., Grunhut, J., Alecian, E., et al. 2013, ArXiv e-prints
Figure 1. Preliminary 2D hydrodynamic models show that four spots with 10 ◦ radius and 33% brightness enhancement allow us to qualitatively reproduce the conditions necessary to obtain DACs. From left to right: density profile, radial velocity profile, density divided by the radial velocity gradient (this proxy variable acts like the optical depth and the bright trailing edges indicate the presence of velocity kinks).
 | 10.1017/S1743921314007121 | [
"Alexandre David-Uraz",
"Gregg Wade",
"Stan Owocki"
] | 2014-07-31T21:15:06+00:00 | 2014-07-31T21:15:06+00:00 | [
"astro-ph.SR"
] | Beam me up, Spotty: Toward a new understanding of the physics of massive star photospheres | For 30 years, cyclical wind variability in OB stars has puzzled the
astronomical community. Phenomenological models involving co-rotating bright
spots provide a potential explanation for the observed variations, but the
underlying physics remains unknown. We present recent results from
hydrodynamical simulations constraining bright spot properties and compare them
to what can be inferred from space-based photometry. We also explore the
possibility that these spots are caused by magnetic fields and discuss the
detectability of such fields. |
1408.0032v2 | ## Calculating Ultra-Strong and Extended Solutions for Nine Men's Morris, Morabaraba, and Lasker Morris
Gábor E. Gévay, and Gábor Danner
Abstract -The strong solutions of Nine Men's Morris and its variant, Lasker Morris are well-known results (the starting positions are draws). We re-examined both of these games, and calculated extended strong solutions for them. By this we mean the game-theoretic values of all possible game states that could be reached from certain starting positions where the number of stones to be placed by the players is different from the standard rules. These were also calculated for a previously unsolved third variant, Morabaraba, with interesting results: most of the starting positions where the players can place an equal number of stones (including the standard starting position) are wins for the first player (as opposed to the above games, where these are usually draws). We also developed a multi-valued retrograde analysis, and used it as a basis for an algorithm for solving these games ultra-strongly. This means that when our program is playing against a fallible opponent, it has a greater chance of achieving a better result than the game-theoretic value, compared to randomly selecting between 'just strongly' optimal moves. Previous attempts on ultra-strong solutions used local heuristics or learning during games, but we incorporated our algorithm into the retrograde analysis.
## I. INTRODUCTION
Nine Men's Morris and its variants are two-player, sequential, perfect information, deterministic, finite, zero-sum games, and there are three possible outcomes: win, draw, loss (these are given from the point of view of a specific player).
## A. Solving games
Solving games is possible on several levels [1]:
- · Ultra-weakly solved: the game-theoretic value of the starting position was obtained by a possibly non-constructive proof, which does not give us any actual strategy to achieve the proven value.
- · Weakly solved: the game-theoretic value of the starting position is known, and we also have a strategy to achieve that. (This might require a database with the gametheoretic values for a large subset of the game states.) Checkers, for example, was solved in this sense [2].
- · Strongly solved: a strategy is known that achieves the game-theoretic value starting from any game state that can be reached from the starting position. This has the effect that it can play perfectly even if mistakes were made on one or both sides.
Gábor E. Gévay is with the Eötvös Loránd University, email: [email protected].
Gábor Danner is with the University of Szeged, email: [email protected].
- · Ultra-strongly solved [3]: a strategy is known which increases our chances to achieve more than the gametheoretic value when faced with a fallible opponent (i.e. a player who is not playing perfectly).
- · Extended strong solution: We define this as a strong solution for an extended state space, namely, for all the positions reachable from a set of alternative starting positions. This can provide further insight into the game. In this paper, we examined the positions that can be obtained from the usual starting position by modifying the number of pieces to be placed by the players.
The standard method for strongly solving games is to use retrograde analysis (that is, to propagate values from end states using the minimax principle) to calculate a database containing the game-theoretic values of all the game states [4]. (See Section III for details.) A game-playing program can use this database at every move by looking ahead one move, and maximizing the game-theoretic value of the state (from its perspective) after its move. But if there are cycles in the state space graph, then this algorithm does not ensure winning. This might happen when we reach a game state during a game that has already occurred: if we choose our moves deterministically, then the game might never end, thus we cannot realize the game-theoretic value. Choosing randomly does not really solve this problem, because that way the games might stretch out too long.
The standard solution to this problem is to also calculate a depth to win value for all (not draw) game states. This value gives the number of moves that will happen until the end of the game if both players play optimally, not just regarding the game-theoretic values, but also in minimizing or maximizing the number of moves to the end, based on whether they are winning or losing. This way, it cannot happen that we move away from the winning end state from time to time.
We used this method to calculate the extended strong solutions for standard Nine Men's Morris, and its variants, Lasker Morris, and Morabaraba.
Strong solutions have an important property. Many of the positions among the theoretical draw positions are weak for one of the players for practical purposes (if he is not a perfect player), meaning that the player is just one small mistake away from getting into a theoretical losing position. In these cases the opponent is usually in an easier situation, because his small mistakes do not affect the game-theoretical value of the position. The program based only on the strong solution completely disregards this phenomenon, and tends to get to these weak positions. In the case of standard Nine Men's Morris and Lasker Morris, this results in lots of draws, even
against novice players. Gasser mentions this problem in his PhD dissertation [5].
To solve this problem we developed a variant of retrograde analysis to classify the draws and used it to calculate ultrastrong solutions for all three variants.
## B. Rules
For the rules of Nine Men's Morris, see for example Gasser's work [6]. There are two points in the rules, for which there is no consensus. The first question is what should happen when two mills are closed with one move. The second is whether a player should be allowed to take a stone from a mill, when all the opponent's stones are in mills. Our implementation followed Gasser's decisions: mill closure is always followed by taking exactly one stone. Moreover, we regard position repetitions as draws.
The main difference between Lasker Morris [7] and the standard variant is that there are no distinct placement and movement phases, i.e. the players can decide at every move whether they want to place a stone on the board or move one of their stones (as long as they have remaining stones to place). The other difference is that players can place 10 stones instead of 9.
Morabaraba differs from the standard variant in the graph of the game board (see Fig. 3 and Fig. 4), and in the number of stones the players can place, which is 12. There is also a special rule: if the board becomes full (because neither player closed a mill during the opening), the game ends in a draw. There is no consensus about whether to use the rule or not, so we implemented both versions. The state space of Morabaraba is about four times bigger than that of the standard variant.
## C. Related work
Ralph Gasser calculated a strong solution for the moving phase of the standard Nine Men's Morris, and established the game-theoretic value of the game to be a draw [6]. One reason of the importance of Gasser's work, is that he provided a perfect, and almost minimal hash function that takes the symmetries of the board into account, which allows an almost 16-fold reduction of the state space. Peter Stahlhacke calculated a strong solution for Lasker Morris [8]. To our knowledge, there were no solution attempts for Morabaraba.
There are several approaches for achieving better results than the game-theoretic value against a fallible opponent. A simple method is to combine the perfect program with an AI that uses α β -search, by having the latter choose only from the perfect moves [5]. Other local heuristics use the information in the solution database about the game states which are at most a few moves away from the current position. For example, one can look at the ratio of optimal moves to all the moves in a position. The DTW (depth-to-win) of the non-draw states can also be relevant, because a model of a fallible opponent might assume that it is using shallow searches on the game-tree. These heuristics can be combined recursively by multiplying probabilities of making an optimal move along the considered paths [9], [10]. Schaeffer [11, p. 258, 331] used small searches in positions recognized as draws by the endgame databases in his heuristic ( α β -) Checkers playing program Chinook. Other approaches are to learn desirability values about individual positions during games [12], or learn a model of the opponent [13].
Our approach is different, because we modified the retrograde analysis to calculate additional information about the game states, and developed a global 1 heuristic to increase our chances of achieving more than the game-theoretic value.
ˇ ermák et al. studied [14] the performance of refinements C of Nash Equilibria in smaller, imperfect-information games against fallible opponents. Their methods are computationally significantly more expensive, so they could not be used for Nine Men's Morris.
A variation of retrograde analysis which can handle more than three outcomes was described by Lincke [15] for use with Awari, but that algorithm is quite different from ours. It uses less memory (but it is also slower), because it stores only two bits per positions, and does not calculate DTWs.
## D. The structure of the paper
Although retrograde analysis is a well-known algorithm, implementations often differ in important details, because they are tailored to the actual problem. For example, an important point to note for Nine Men's Morris and its variants is that there is a natural subdivision of the state space. In the next Sections we describe this partitioning, then briefly describe the basic retrograde analysis algorithm, which is followed by some implementation details along with a pseudocode.
Then we give a modified version of retrograde analysis which is able to handle more outcomes than win/draw/loss, and we use this as a basis for a new algorithm to classify draws into subclasses and achieve an ultra-strong solution. Finally, we present the results of the computations and then outline an extension and generalization of the algorithm.
## II. PARTITIONING THE STATE SPACE
Without partitioning the state space, retrograde analysis would require holding some information about every game state in memory, because random access disk I/O is very slow. Anatural way to partition the state space of Nine Men's Morris and its variants is to specify a subspace by four integers: the number of stones on the board for the first and second players, and the number of stones to be placed by the first and second players. The largest subspace has 603,332,730 game states (using Gasser's hash function to take symmetries into account [5]).
Notice that if we swap the white and black stones and change the player to move in a particular position, then we get a game state which has the same game-theoretic value as the original (given from the point of view of the player to move). There are multiple ways to use this to achieve a 2-fold reduction of the state space. What we did is to drop every position where Black is to move. When we need the value
1 Global in the sense that the evaluation of a game state calculated by our algorithm takes into account the heuristic values of all states reachable from that state.
of a position which was dropped, then we use the swapped position instead.
An unfortunate consequence of this is that the dependency graph 2 of the subspaces ceases to be acyclic, since in the moving phase, we no longer have to take a stone from the board to leave a subspace. Rather, every sliding move in a subspace where the number of stones on the board (or the number of stones to be placed) for the two players are different, moves into the subspace where the first two and the last two identifying numbers are swapped (we call this operation negating a subspace ). So, for example, there are edges in both directions between the subspaces 5,7,0,0, and 7,5,0,0 (another example, which can occur only in Lasker Morris, is 5,7,2,1, and 7,5,1,2). The only cycles introduced this way are back and forth edges between subspaces, and a subspace can only be part of at most one cycle. We regard such subspace pairs (and also individual subspaces which are not part of a cycle) as work units , because the retrograde analysis has to work with both of them at the same time. Let us call a work unit transient , if every move in every position in it leaves the work unit. Notice that a transient work unit can contain only one subspace, which we call a transient subspace . Let us call a subspace ESC (Equal Stone Count) if both players have the same number of stones both on the board and to be placed.
Calculating the values of the positions in a work unit involves the one or two subspaces in the work unit (we call these primary subspaces ) and those other subspaces on which the primary subspaces directly depend, i.e. those for which there is a move from a position in a primary subspace that leads to a position in them (we call these secondary subspaces ). Information is propagated from secondary and primary subspaces to primary subspaces.
Another advantage of partitioning the state space is that pairs of work units which does not have a directed path between them in the dependency graph can be easily worked on in parallel. The scope of this is determined by the available memory (apart from the number of processor cores we have), because working on one of the larger work units requires multiple gigabytes of memory. The speed of the memory is also an important factor, since the frequency of memory accesses increases with more parallelism.
## III. RETROGRADE ANALYSIS
## A. The basic algorithm
Retrograde analysis works from the ending positions backwards by calculating values according to the minimax principle [16]. To have an algorithm that can handle cycles in the state graph, we have to notice that in order to establish a position to be a win, we do not need the values of all the successors of the position. Rather, it is enough if we know that at least one of the successors is a loss (from now on, we are thinking as in negamax: position values are understood from the point of view of the player to move). To also correctly determine the
2 We can construct the following dependency graph of the subspaces: each subspace corresponds to a node, and there is an arc from u to v , if there is a state in u from which we can go to a state in v with one move.
DTW values when making use of the above point, we have to process positions in increasing order of DTW. Here, processing positions means repeatedly picking a position of which the final value is already known, and updating the knowledge we have about its predecessors.
Two kinds of information are kept for a position: count means the number of successors that we have not processed yet, and value means the game-theoretic value of the position (with DTW). The algorithm can be organized in such a way that these are not needed at the same time, and when we have a value for a position, then it is already final. We say that a position is count-state if the information currently recorded for it is a count , and similarly for value-state . If a position is still a count-state after no position remains to be processed, then it is a draw.
See figures 1 and 2 for the pseudocode.
## B. Implementation for a partitioned state space
The question arises that how to pick positions to be processed. Gasser repeatedly scanned the entire file for positions that are done, and thus can be processed [5]. We decided to use a queue instead, for efficiency reasons. When a position becomes value-state, we push it into the queue. Picking a position to process is done by popping the queue. (This ensures the right order, because the DTW values always increase by one.)
There is some difficulty with this when the state space is partitioned: the range of DTW values can overlap between subspaces, so it would be inconvenient to process positions globally in the order of DTW. This means that sometimes we process a position that has a greater DTW value earlier than some positions that have lower DTW values. Notice that this is not a real problem: we only wanted to process the positions in increasing DTW order, to avoid the situation when processing some position affects our knowledge about some already processed positions (which would obviously create inconsistencies in the database). But if we keep the order locally, i.e. during the processing of one work unit, then this problematic situation does not occur. The reason is that the only case when we process a position v with smaller DTW later than a position u with larger DTW, is when the work unit of v is processed later than the work unit of u , in which case the value of v cannot possibly have an effect on the value of u , since a path in the state graph does not exist from u to v .
Thus we have to make sure that every one of the valuestates in the secondary subspaces (which have a wide range of DTW values) gets processed at the right time, that is, when the processing of positions in the primary subspaces reaches the same DTW value. Theoretically thinking, this could be achieved by using a priority queue with DTW as the key instead of a regular queue, but a faster way in practice is to use two queues 3 and continuously merge them when popping: one of the queues contains non-draw positions from the secondary
3 Note that if we calculated the depths to the taking of the next piece instead of the DTW, then the problem would be trivially solved with only one queue, because then all the states in the secondary subspaces would come before all the states in the primary ones.
## 1. Initialization
for all positions p do if p is a win end-state then R p [ ] ← value (win in 0) Push p into the priority queue else if p is a loss end-state then R p [ ] ← value (loss in 0) Push p into the priority queue else if p is a draw end-state then R p [ ] ← count (0) else R p [ ] ← count (number of possible moves in p ) end if
end for
2.
Processing the priority queue while the priority queue is not empty do
Pop a position e from the priority queue for all predecessors p of e do
if R p [ ] is count then if R e [ ] is a win then
Decrement R p .count [ ]
if
R p .count
[
]
= 0
then
R p [ ] ← value (loss in 1 + R e .value.DTW [ ] )
Push p into the priority queue end if
else
R p
[
]
←
value
(win in
1 +
R e .value.DTW
[
]
Push p into the priority queue end if
end if end for
end while
Fig. 1: Pseudocode of retrograde analysis. Recall that the kinds of information recorded for a position (in the array R ) are count ( n ) and value (win/loss in n ), but only one of these is stored at a time (union type). (Also, in Nine Men's Morris and its variants, win/loss can be determined by the parity of DTW.) The priority queue is keyed with DTW, and in the simplest case, it can be implemented with a simple queue, because states are processed monotonically. But when end states can have different DTWs (because we take into account the partitioning of the state space, see Fig. 2), then the method of two queues can be used as described at the end of Subsection III-B. Note that states in secondary subspaces are treated as end states. Also note that e can be in either a primary or a secondary subspace, but the predecessors are restricted to the primary subspaces.
)
```
1. Pre-initialization of primary subspaces
for all positions e in primary subspaces do
if we can close a mill in e and the opp. has 3 stones then
R[e] <- value(win in 1)
else
R[e] <- count(0)
end if
end for
```
- then end for 2. Setting count s to the number of successors and pushing value-states for all positions e in primary and secondary subspaces do for all predecessors p of e do if p is in a primary subspace and R p [ ] is count then Increment R p .count [ ] end if end for if R e [ ] is value then Push e into the priority queue end if end for 3. Handling blocked states for all positions e in primary subspaces do if R e [ ] = count (0) then R e [ ] ← value (loss in 0) Push e into the priority queue end if end for
Fig. 2: Initialization of retrograde analysis tailored to Nine Men's Morris and to the partitioning of the state space. This replaces Step 1 in Fig. 1.
subspaces (and end states from the primary ones) and is initialized at the start of processing the work unit, and the other is populated by positions from the primary subspaces as they become ready. We call the former the secondary queue .
Initializing the secondary queue involves sorting the positions of several (in our case, up to six) subspaces, which might not fit into memory, so we used a bucket sort on disk to do this. The primary queue could be implemented on disk with only sequential accesses, but we stored it in main memory for simplicity and reducing disk I/O (for better parallelism).
The time complexity of the algorithm is O ( E + V D + SB ) , where V is the number of positions, E is the number of edges between these, D is the maximal in-degree of a node of the subspace graph, S is the number of subspaces, and B is the maximal DTW. The factor B comes from the bucket sort. V D comes from reprocessing positions multiple times as part of secondary subspaces. We assumed that the complexity of generating predecessors of a position is the number of predecessors that are in primary subspaces (without this assumption, the complexity would be O ( ED + E + V D + SB ) ).
## C. Handling more than three outcomes
We now modify the general algorithm described in the previous section to more than three outcomes. We assume that
outcomes range from -w to w . Our algorithm proceeds from more extreme outcomes to more drawish outcomes: we start by determining the positions that have values -w and w , then -w + 1 and w -1 , and so on. While we are determining positions with absolute value c , the positions with absolute values smaller than c have the same role as draws in the basic algorithm, and the positions with values -c and c will behave like losses and wins. The zeros are not processed.
At the beginning of the algorithm, non-zero end states are inserted into the secondary queue in the appropriate order (the first key of the ordering is the negated absolute value, and the second one is the DTW). Popping them at the right times can be achieved by the merging method we mentioned earlier.
In the basic algorithm, we made use of the fact that when one successor of a position u becomes a loss, we know that u is a win. There is a similar fact here, which points out the importance of going from larger absolute values towards smaller ones.
Assume that we are processing positions with absolute value v . If we discover a position with value -v among the successors of a position s , then we immediately know that the value of s is v . We will not find a successor b later with value smaller than -v , because b should have already been processed earlier. Furthermore, in the moment when we have processed all successors of a position s , then if none of them had negative values, then we know that the value of s is -v because so far we only processed nodes that have absolute values of at least v .
What we have showed in the previous paragraph is that when we write a value for a position, then it is indeed the correct final value of it. What remains to be proven is that we cannot have the situation that we should have already written a value for a particular position, but we have not. When we have finished writing the values of the positions with absolute values of v , then the absolute values of the positions that we have not yet written must really be v -1 at most, since it is not possible that all the successors of such a position has at least the value of v , or that it has a successor that has at most the value of -v .
The above algorithm also minimizes DTW values in 'winning' (positive valued) states, and maximizes in 'losing' (negative valued) states. Positions that remain count-states do not have DTW information. (Note that these can be viewed as implicitly having the value of 0.)
The pseudocode in the previous subsection can be adapted for this algorithm with small modifications:
- · The comparison operator used by the queue operations has to use the negated absolute values of the states as a first key, and the DTW should only be the second key. Thus we process the positions with the same absolute values in the order of DTW.
- · Propagating a value to a predecessor now involves negating the game-theoretical value.
The time complexity changes a bit because of the extended range the bucket sort has to deal with: O ( E + V D + SRB ) , where R is the range of the first key.
This algorithm can be used for any game with the properties described at the beginning of the introduction, but with more than three possible outcomes, e.g. Awari or Othello.
## IV. THE ULTRA-STRONG SOLUTION
The ultra-strong solution means that our program has a better chance to achieve a better result than the game-theoretic value against a non-perfect opponent, compared to a program which is based only on the strong solution. The outcome of a Nine Men's Morris game (and its variants) can be win, draw, or loss. In (game-theoretically) winning states we are already in the best possible position (we are going to win, because we play perfectly). In losing states, maximizing DTW is already a good heuristic to lead the game into positions which are hard for the opponent to win. Therefore we designed an algorithm to classify draws into subclasses.
We need the notion of stable draw for this: a draw is stable if there exists an optimal sequence of moves which does not leave the current work unit. (Not all draws are stable: positions in work units where the players have remaining stones to place are obviously not stable; furthermore, there are lots of positions in other work units where the only way for both players to keep the draw is to attack and close mills. Also notice that not all stable states are part of a cycle in the subgraph of optimal moves.)
Our method for distinguishing draws is based on the following goal: if we do not see a winning move, then at least try to go in the direction of stable draws where our opponent is in a (heuristically) difficult situation. Furthermore, it also seems reasonable to assume that when aiming for such draws, our opponent will 'have a hard time' finding the moves that keep up the draw even before reaching the stable draw. Our results show that this is indeed the case: for example, in the standard variant, after our program has already managed to get to a game state from which optimal play leads to the subspace 6,3,0,0, our opponent almost always makes a mistake before even reaching the final work unit, and we win the game.
So we need a heuristic which can assign values to stable states, and then an algorithm which assigns different values to draws based on the value of the stable state that will be reached by optimal play. Notice that the algorithm cannot just pick the stable states at the beginning, use the heuristic to assign values to them, and then propagate these with standard multi-valued retrograde analysis, because we do not know in advance which states are stable, as this depends on the values of lots of other states. (Also notice that what was a stable state before we distinguished the draws is not necessarily stable now, so we also cannot just use these as a starting point.)
## A. The heuristic for assigning values to stable states
First, we describe the heuristic that is used to assign values to stable states. Actually, we assigned values to subspaces, and the value of a stable state is the same as the subspace in which it lies. A natural idea is to use the difference of the number of stones of the players.
We focused on another heuristic, where we used information from the already calculated databases: if the ratio of wins in a subspace is high, then it is obviously a good subspace for us (at least when the subspace is not ESC). The ratio of
draws can also be relevant. If there is another subspace in the work unit, then a large ratio of losses in that subspace is also good for us (note that values in the other subspace are understood from the point of view of the opponent). Thus a pair of subspaces ( s, -s ) in a non-transient work unit is in a symmetrical relationship (the members of the pair need not be different from each other). In Section IV-B it is shown that the algorithm works correctly only if the assigned values of these pairs are opposites of each other. So the heuristic formula we used takes both subspaces of the pair into account:
$$\ v a l _ { s } = ( W _ { s } + L _ { - s } + D _ { s } / 2 + D _ { - s } / 2 ) / ( T _ { s } + T _ { - s } ) \quad \stackrel { \infty } { \mathfrak t }$$
where W s , L s , D s are the numbers of wins, losses, and draws, respectively, and T s is the total number of states in the subspace. For subspaces in transient work units we use the following formula:
$$\ v a l _ { s } = ( W _ { s } + D _ { s } / 2 ) / T _ { s }$$
Using floating point numbers for subspace values during the computation would require too much memory, so we assigned ranks to subspaces instead: we ordered them based on the above values and used their place in the ordering. These ranks are centered around 0, and there is a correction to make: we have to make sure that the ranks of subspaces in a nontransient work unit are the negations of each other (for nontransient ESC subspaces, this means that they have to have the rank of 0). This correction results in holes in the range of ranks.
After using the ranking method described above, the rank of the subspace 8,9,0,0 seemed too high. For example, the program wanted to go to this subspace more than to 6,3,0,0. So we manually lowered the rank of this subspace, and the program got stronger (achieved more wins).
Wins and losses receive values just outside the range of the values calculated by the above ranking method. In the remaining part of the paper, game-theoretic values of states come from this extended range.
## B. A new variant of retrograde analysis to classify draws
This algorithm uses the heuristic of the previous section and is based on the multi-valued retrograde analysis described in Section III-C. Recall that the value of a position now consists of two parts: the game-theoretic value and the DTW. We refer to these here as first and second keys, respectively. (Note that these keys are not directly the keys of an ordering.)
1) Storing relative values: The difficulty lies in the fact that with the algorithm described in Subsection III-C, the stable states can only be count-states (which can be viewed as implicitly having the value of 0 as the first key), but now we would need to assign different game-theoretic values to these. This is achieved by storing relative values in the first key: how much better (or worse) subspace than the current one we end up in with optimal play. This way, stable states look like having the appropriate first keys from the absolute viewpoint. For this, we need to adjust the first keys when propagating between subspaces: first, to the absolute viewpoint, then do the usual negation, then adjust to the value of the subspace that we are propagating to. Count-states are treated as if they had 0 as first key when making adjustments, and if the first key of a value-state is adjusted to 0, then it is treated as a count-state (the actual count is not important in this case, since this can only happen in a secondary subspace, so we never propagate into it).
This can be implemented by already making all the adjustments while loading the secondary subspaces into memory (by adding the sum of the values of the two subspaces), because every state is propagated to only one primary subspace in Nine Men's Morris 4 . The ordering of the queue has to be based on the values adjusted this way. Also notice that no adjustment is needed when propagating between primary subspaces, because the subspace values were constructed such that the sum of the values of the members of a non-transient work unit is 0.
2) Generalizing depth-to-win: It is not apparent how to extend the definition of DTW to draws, since it is not immediately clear that who should maximize or minimize it, and when. To determine this, we have to recall the intent of the players with minimizing and maximizing DTW. In the basic retrograde analysis, the winning player has to minimize DTW in order to avoid the situation where we are in a winning state, but cannot realize this, because we move away from it from time to time. When someone is losing against a perfect player, there is no point in maximizing DTW. Yet, we have to assume that he does that, because from the point of view of the winning player we have to 'prepare for the worst'. In other words, for the minimization of DTW to work, we must do the opposite for the other player, because a minimax-based approach can only optimize for symmetric (zero-sum) utility functions.
Now the question is, should we be maximizing or minimizing when the state is a draw so there is no clear winning or losing player? As we mentioned earlier, we are seeking good valued stable states not just because being in the final subspace will be good for us, but we hope that the opponent will make a mistake on the way to reach it. Thus how much time we spend in good valued subspaces even before reaching the final subspace is of importance. We would like to use the DTW to optimize for spending as much time (before reaching a stable state) as possible in subspaces which are better than the final one (cf. DTW in losing states). In order for this to make sense, we should optimize for spending as little time as possible in a subspace that has a worse value than the final one (and also to avoid the situation that we do not progress into a better subspace).
This is a multi-objective optimization task which we solve by linear scalarization: we maximize the (signed) difference between the number of moves taken in subspaces that are better than the final one and the number of moves taken in subspaces that are worse than the final one. (Note that this is symmetric (zero-sum) for the players.) (Also note that it might very well happen that the optimal sequence of moves leads through better and worse subspaces then the final destination.)
This can be implemented in the following way:
4 For other games, this can be achieved by the method described in Section VII-A.
- · we increment DTW upon propagation as usual;
- · when we are comparing two values with equal first keys, we decide on minimizing or maximizing the second one (DTW) based on the sign of the first key (which reflects the relation between the values of the current and final subspaces) (minimize when negative);
- · when a first key changes sign during an adjustment (see Subsection IV-B1), we negate the second one. This way, the steps of the optimal path which are taken in oppositely optimized subspaces are reflected in DTW with opposite signs .
Note that the first two items correspond to the way the algorithm in Subsection III-C manages DTWs. The third item is not needed in that algorithm, because the values stored there are not relative (cf. Subsection IV-B1).
Also note that this is equivalent with the following implementation: we always maximize DTW, but we increment or decrement it based on the sign of the first key (increment when negative) and we negate the DTW at every move 5 . This way DTW always equals the aforementioned utility function (while in the other implementation it is the negated utility function when the first key is positive).
Also note that the traditional DTW can be viewed as a special case of the above if we consider the values of the subspaces of non-terminal states to be 0. (End-states can be considered to be in a virtual subspace: there is a virtual lose subspace and a virtual win subspace.) In this case, one of the terms of the aforementioned utility function is always 0 (depending on the sign of the first key).
A limitation of the algorithm is that if the optimal path goes through an s 2 subspace which has the same v value as the final s 1 subspace, then DTWs only take into account the part of the path before s 2 . This happens because states in s 2 that have v as first keys from an absolute point of view are considered count-states, so we lose the DTW information coming from secondary subspaces. Nevertheless, this does not seem to be a big problem.
The following equality holds for the DTWs calculated by the above algorithm:
$$d ( g ) = \text{sgn} ( k 1 ( g ) ) \sum _ { i = 0 } ^ { n - 1 } \text{sgn} ( k 1 _ { g } ( g _ { i } ) ),$$
where g i are the positions of the optimal path starting from g , n is the number of the first count-state or end state on the optimal path, k 1 gives the relative first key of a state, and k 1 g negates this, if the player to move is not the same as in g .
If we do not assume that the optimal path is known, then the above formula can be written in the following form:
$$d ( g ) = s g n ( k 1 ( g ) ) \min _ { p \in P _ { g } } \sum _ { v \in p } s g n ( k 1 _ { g } ( v ) ),$$
where P g denotes the set of optimal paths (by the first key from the absolute viewpoint) up until the first count-state or end state, and v is a state on a path.
5 We can choose the order of the negation and incrementation/decrementation operations either way, but we have to make sure that the negation of the first key happens together with the negation of the DTW.
The heuristic could be enhanced a little if we would not increment DTW by only 1, but by a number that is dependent on how much better subspace we are in, than the final one. But the values of subspaces are on an ordinal scale (mainly because of practical reasons), which does not fit well to this, so we did not implement it.
## V. RESULTS
The computed databases for the ultra-strong solutions, and other resources 6 are available at our website: http://compalg.inf.elte.hu/~ggevay/mills/ .
Table I shows some statistics about the variants. Note that the numbers for Lasker Morris are different from what Stahlhacke gave [8], because he used slightly different rules.
Some of the databases were computed on an Intel Core i72630QM (2 GHz) machine with 16 GB of memory. Strongly solving Morabaraba took approximately 2 days, ultra-strongly solving the standard variant took one and a half days. Computing the extended solution of Lasker Morris took the most time, about 9 days on the same machine. Calculating the extended solution of Morabaraba took about 5 days on an AMD Phenom II X4 955 (3.2 GHz) machine with 20 GB memory. (The memories were larger than that of average computers to allow greater parallelism.) Note that in the case of Lasker Morris, not only the state space is larger, but the average number of possible moves in a position is also larger.
## A. Morabaraba
The game-theoretic value of Morabaraba is win in 49. This is in contrast with the other two variants, which are draws. Fig. 3 shows the values of all possible first moves of Morabaraba. Because of the board symmetries, actually only four of these moves are different. Two of them result in a draw, and the other two are wins in 49 and 69 moves.
Fig. 5 shows the distribution of DTWs in Morabaraba, and Fig. 6 shows a game played optimally. Fig. 7 shows the position with the maximal DTW (124).
## B. Extended solutions
Tables II, III, and IV show the game-theoretic values of the various starting positions involved in the extended solutions of the three variants. Uiterwijk and van den Herik investigated [17] the advantage of the initiative (i.e. having the right to move first) in mnk -games and domineering on various board sizes. The extended solution tables for Nine Men's Morris and its variants can also be examined in this respect.
6 The programs that can compute and use the databases, and the heuristic α β -program that we used for testing are also available with their sources.
TABLE I: Number of states (also for extended solutions), win/draw/loss ratios, and maximal DTW for the three variants
| Variant | #states (extended) | W/D/L % | max. DTW |
|---------------|----------------------|--------------------------|------------|
| Standard | 27bn (284bn) | 53 . 6 / 22 . 3 / 24 . 1 | 206 |
| Lasker Morris | 133bn (398bn) | 52 . 5 / 14 . 3 / 33 . 2 | 214 |
| Morabaraba | 112bn (284bn) | 60 . 7 / 4 . 6 / 34 . 7 | 124 |
Fig. 3: Game-theoretic values with DTWs of all possible moves in the starting position of Morabaraba. The optimal moves are marked with an '!'.
Fig. 4: A game-theoretical draw position in the standard or Lasker variant. White to move. Although White can preserve his material advantage, he cannot win. This is one of the only two such positions in the subspace of 8 white and 3 black stones. The only move here that can keep this stone count indefinitely is marked with an arrow.
Fig. 5: Distribution of DTWs in Morabaraba. The very first bar shows the number of draws. Note that every second bar corresponds to an even depth, which means that it represents the number of losses with that depth. These are usually smaller than neighbouring bars, because it is an advantage to have the right to move first.
f2, f6; b6, b2; a1, c5; g1, e3; d1xf6, f6; g7, g4; a7, e4; e5, f4xe5; a4xe3, e3; e5, c3; d3, c4xd3; d3, d2; a7-d7, c4-b4; d7-a7xc5, f6-d6; g7-f6, g4-g7; g1-g4, c3-c4; a7-d7, c4-c3; g4-g1xg7, f4-g4; f6-f4, d6-d5; b6-a7xg4, d5-d6; e5-f6xd6, b4-c4; f6-g7xe3, c4-b4; g7-f6xe4, b4-b6; f6-g7xb2, c3-e5; f4-g4xd2
Fig. 6: A game of Morabaraba played optimally (using the standard notation for moves)
The main diagonals divide the tables into positions where either White or Black has more stones to be placed. First, let us focus our attention to the cells not on the main diagonals. It is clear that having one more stone to be placed is a substantial advantage, since it completely outweighs the advantage of the initiative in all three variants: there are no wins for White if he can place fewer stones than Black, and these are even all losses above 5-6 stones to be placed.
However, if we also consider the DTWs in these cells,
Fig. 7: The Morabaraba position with the maximal DTW (124 plies). Both players have 7-7 pieces left to place.
TABLE II: Game-theoretic values and DTWs of different starting positions of the standard Nine Men's Morris. The first numbers of the rows and columns show the number of stones to be placed by White and Black, respectively. The position marked with an '*' becomes a draw, if we use the rule that a full board results in a draw. (This is the only case across all three variants where this rule makes a difference in the value of a starting position.)
| | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|----|-----|-----|-----|-----|-----|-----|-----|------|------|------|
| 3 | W23 | D | D | L12 | L12 | L12 | L12 | L12 | L12 | L12 |
| 4 | D | D | D | D | L20 | L16 | L16 | L16 | L16 | L16 |
| 5 | W9 | D | D | D | L24 | L22 | L20 | L20 | L20 | L20 |
| 6 | W9 | D | D | D | L34 | L26 | L24 | L24 | L22 | L22 |
| 7 | W9 | W17 | W25 | W33 | D | L36 | L28 | L26 | L26 | L24 |
| 8 | W9 | W15 | W21 | W25 | W33 | D | L36 | L30 | L28 | L26 |
| 9 | W9 | W15 | W19 | W23 | W27 | W35 | D | L36 | L32 | L28 |
| 10 | W9 | W15 | W19 | W23 | W25 | W29 | W35 | D | L36 | L28 |
| 11 | W9 | W15 | W19 | W21 | W25 | W27 | W29 | W31 | L44 | L28 |
| 12 | W9 | W15 | W19 | W21 | W23 | W25 | W27 | W27 | W27 | *L26 |
we can see a more fine-grained picture: almost all the wins for White below the main diagonals are quicker wins than the corresponding symmetrical positions for Black, so having the initiative means some advantage after all. (Note that this advantage is more pronounced in the non-standard variants.)
The diagonals show game-theoretic values of positions where the players can place an equal number of stones. These are all draws in Lasker Morris (except the 3-3 stones), and all wins in Morabaraba above 6-6 stones to be placed. However, in the standard variant, the values of the positions where the players can place 11 or 12 stones are losses for White!
We can conjecture about the reason for this surprising result. When we are placing a stone on the board, we can place it anywhere, but when we can only slide a stone, then our options are much more limited. This means that after Black places his last stone on the board, White can respond to the situation created by Black with (generally) less powerful moves. Also notice that after 22 (or 24) stones have been placed on the board, there is very little room left to slide pieces around (especially if one of the players played defensively during the opening), so there is a high chance that someone loses the game because of being unable to make a move. These two observations complement each other: Black has an advantage right when there is a high chance to end the game.
The role of the sometimes used rule that a full board results in a draw (rather than a loss for White) can also be examined. The only cells in the tables where it has a chance to make a difference are the bottom right cells. However, Morabaraba is a win for White, so this cannot possibly be affected by this rule. We found that this starting position is a draw with or without this rule in Lasker Morris, but in the standard variant this position changes into a draw from a loss upon introducing the rule.
There are a few places in the tables where one more stone for White results in a worse value. These are 3,3 and 11,12 for the standard variant, 3,3 for Lasker Morris, and 10,7 for Morabaraba. A similar place is 7,11 in Morabaraba where one more stone for Black results in a deeper loss for White.
Table V shows the win/draw/loss percentages for the (ex-
TABLE III: Game-theoretic values and DTWs of different starting positions of Lasker Morris
| 3 | 4 | 5 | 6 | | 7 | 8 9 | 10 | 11 | 12 |
|-----|-----|-----|-----|-----|-----|-------|------|------|------|
| W23 | D | D | L12 | L12 | L12 | L12 | L12 | L12 | L12 |
| D | D | D | L24 | L16 | L16 | L16 | L16 | L16 | L16 |
| W9 | D | D | D | L24 | L20 | L20 | L20 | L20 | L20 |
| W9 | W19 | D | D | L40 | L26 | L24 | L22 | L22 | L22 |
| W9 | W15 | W21 | W39 | D | L40 | L30 | L28 | L26 | L26 |
| W9 | W15 | W19 | W25 | W33 | D | L44 | L34 | L32 | L30 |
| W9 | W15 | W17 | W23 | W29 | W35 | D | L46 | L36 | L34 |
| W9 | W15 | W17 | W21 | W25 | W31 | W37 | D | L44 | L38 |
| W9 | W15 | W17 | W21 | W25 | W29 | W33 | W39 | D | L46 |
| W9 | W15 | W17 | W21 | W25 | W29 | W31 | W35 | W41 | D |
TABLE IV: Game-theoretic values and DTWs of different starting positions of Morabaraba
| | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|----|-----|-----|-----|-----|-----|-----|-----|------|------|------|
| 3 | W9 | D | L12 | L12 | L12 | L12 | L12 | L12 | L12 | L12 |
| 4 | W9 | D | D | L20 | L18 | L16 | L16 | L16 | L16 | L16 |
| 5 | W9 | D | D | L22 | L20 | L20 | L18 | L18 | L18 | L18 |
| 6 | W9 | W17 | W23 | D | L26 | L26 | L24 | L24 | L22 | L22 |
| 7 | W9 | W13 | W19 | W25 | W45 | L32 | L30 | L26 | L26 | L28 |
| 8 | W9 | W13 | W19 | W21 | W27 | W53 | L50 | L34 | L32 | L30 |
| 9 | W9 | W13 | W17 | W21 | W25 | W31 | W43 | L56 | L40 | L36 |
| 10 | W9 | W13 | W17 | W21 | W23 | W29 | W37 | W51 | L54 | L40 |
| 11 | W9 | W13 | W17 | W21 | W25 | W27 | W33 | W39 | W45 | L52 |
| 12 | W9 | W13 | W17 | W21 | W25 | W27 | W31 | W33 | W37 | W49 |
tended) standard and Lasker Morris variants for subspaces where all stones have been placed. Table VI shows the same for Morabaraba. A notable fact is that in Morabaraba there are no draws at all in the 3,3 subspace, as opposed to the standard and Lasker Morris variants where the ratio of the draws is 0.16%.
Tables VII and VIII shows the maximal depth-to-win values in subspaces where all stones have been placed.
## C. Ultra-strong solutions
We examined two heuristics for the values of stable states (see Subsection IV-A): one is based on stone difference and the other is based on win/draw/loss ratios in the work unit. In the following paragraphs we discuss the latter, except where noted otherwise.
Recall that in the databases for the ultra-strong solutions, the subspace which we end up in via optimal play determines the value of a draw. Table X shows the frequencies of these values (adjusted to absolute viewpoint) for the three variants.
TABLE VII: Maximal depth-to-win values for the (extended) standard variant for subspaces where no stones are left to be placed (White to move). This table is the same for Lasker Morris.
| | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|----|-----|-----|-----|-----|-----|-----|-----|------|------|------|
| 3 | 26 | 33 | 31 | 6 | 30 | 34 | 30 | 16 | 14 | 12 |
| 4 | 32 | 9 | 28 | 156 | 112 | 112 | 110 | 26 | 20 | 18 |
| 5 | 3 | 29 | 57 | 162 | 160 | 160 | 114 | 114 | 54 | 34 |
| 6 | 7 | 157 | 163 | 167 | 184 | 186 | 173 | 169 | 169 | 135 |
| 7 | 31 | 111 | 159 | 185 | 181 | 204 | 202 | 180 | 152 | 134 |
| 8 | 33 | 111 | 153 | 185 | 203 | 196 | 202 | 202 | 180 | 162 |
| 9 | 25 | 103 | 113 | 172 | 201 | 201 | 191 | 191 | 186 | 180 |
| 10 | 15 | 19 | 113 | 168 | 179 | 181 | 189 | 192 | 193 | 176 |
| 11 | 13 | 17 | 33 | 134 | 151 | 179 | 185 | 185 | 185 | 148 |
| 12 | 11 | 15 | 31 | 128 | 125 | 161 | 161 | 175 | 147 | 0 |
| | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|----|---------------|-----------------|--------------------|-----------------|-----------------|--------------------------|-----------------|-----------------|-----------------|-----------------|
| 3 | 83 / 0 + / 17 | 13 / 87 / 0 | 0 + / 99 / 0 + 0 / | 97 / 3 0 / | 53 / 47 | 0 / 9 / 91 0 / 0 + / 100 | 0 | / 0 / 100 | 0 / 0 / 100 | 0 / 0 / 100 |
| 4 | 10 / 90 / 0 + | 0 + / 100 / 0 + | 0 + / 100 / 0 + | 0 + / 94 / 6 | 0 + / 27 / 73 | 0 + / 7 / 93 | 0 + / 0 + / 100 | 0 + / 0 / 100 | 0 + / 0 / 100 | 0 + / 0 / 100 |
| 5 | 23 / 77 / 0 | 0 + / 100 / 0 + | 0 + / 100 / 0 + | 0 + / 93 / 7 | 0 + / 40 / 60 | 0 + / 12 / 88 | 0 + / 2 / 98 | 0 + / 0 + / 100 | 0 + / 0 + / 100 | 0 + / 0 + / 100 |
| 6 | 40 / 60 / 0 | 23 / 77 / 0 + | 24 / 76 / 0 + | 15 / 82 / 3 | 7 / 56 / 37 | 2 / 27 / 70 | 1 / 6 / 94 | 0 + / 1 / 99 | 0 + / 0 + / 100 | 0 + / 0 + / 100 |
| 7 | 91 / 9 / 0 | 92 / 8 / 0 + | 88 / 12 / 0 + | 74 / 25 / 1 | 47 / 38 / 15 | 21 / 37 / 42 | 8 / 16 / 76 | 3 / 4 / 93 | 2 / 1 / 98 | 1 / 0 + / 99 |
| 8 | 100 / 0 + / 0 | 99 / 1 / 0 + | 98 / 2 / 0 + | 94 / 6 / 0 + | 80 / 16 / 4 | 54 / 28 / 18 | 28 / 24 / 47 | 13 / 11 / 75 | 7 / 3 / 90 | 5 / 1 / 94 |
| 9 | 100 / 0 + / 0 | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 99 / 1 / 0 + | 96 / 3 / 1 | 83 / 11 / 7 | 59 / 19 / 22 | 36 / 15 / 49 | 23 / 7 / 70 | 18 / 3 / 80 |
| 10 | 100 / 0 / 0 | 100 / 0 / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 99 / 0 + / 0 + | 95 / 3 / 2 | 82 / 8 / 10 | 62 / 11 / 27 | 46 / 7 / 47 | 39 / 2 / 59 |
| 11 | 100 / 0 / 0 | 100 / 0 / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 98 / 1 / 1 | 92 / 3 / 6 | 78 / 4 / 17 | 64 / 3 / 33 | 53 / 0 + / 47 |
| 12 | 100 / 0 / 0 | 100 / 0 / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 99 / 0 + / 1 | 94 / 1 / 5 | 83 / 1 / 16 | 64 / 0 + / 36 | 0 / 0 / 100 |
TABLE V: Win/draw/loss percentages (rounded) in the (extended) standard variant for subspaces where no stones are left to be placed (White to move). The first numbers of the rows and columns show the number of stones on the board for White and Black, respectively. This table is the same for Lasker Morris.
TABLE VI: Win/draw/loss percentages (rounded) in Morabaraba for subspaces where no stones are left to be placed (White to move). (Note that the bottom right entry depends on whether we use the rule that a full board results in a draw.)
| | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|----|---------------|---------------|------------------|------------------|-----------------|---------------------------|-----------------|-----------------|-----------------|-----------------|
| 3 | 83 / 0 / 17 | 20 / 78 / 2 | 3 / 92 / 5 0 + / | 60 / 40 0 / 17 / | 83 | 0 / 0 + / 100 0 / 0 / 100 | 0 | / 0 / 100 | 0 / 0 / 100 | 0 / 0 / 100 |
| 4 | 21 / 78 / 1 | 6 / 93 / 1 | 1 / 95 / 4 | 0 + / 36 / 64 | 0 / 8 / 92 | 0 / 0 + / 100 | 0 / 0 / 100 | 0 / 0 / 100 | 0 / 0 / 100 | 0 / 0 / 100 |
| 5 | 43 / 57 / 0 + | 12 / 88 / 0 + | 9 / 89 / 2 | 3 / 53 / 44 | 1 / 18 / 82 | 0 + / 2 / 98 | 0 + / 0 + / 100 | 0 + / 0 + / 100 | 0 + / 0 + / 100 | 0 + / 0 / 100 |
| 6 | 88 / 12 / 0 | 90 / 10 / 0 + | 82 / 18 / 0 + | 52 / 33 / 15 | 19 / 35 / 46 | 3 / 9 / 88 | 0 + / 1 / 98 | 0 + / 0 + / 100 | 0 + / 0 + / 100 | 0 + / 0 + / 100 |
| 7 | 99 / 1 / 0 | 99 / 1 / 0 | 98 / 2 / 0 + | 88 / 10 / 2 | 60 / 24 / 16 | 25 / 24 / 51 | 6 / 8 / 87 | 1 / 1 / 98 | 0 + / 0 + / 100 | 0 + / 0 + / 100 |
| 8 | 100 / 0 + / 0 | 100 / 0 + / 0 | 100 / 0 + / 0 + | 99 / 1 / 0 + | 91 / 6 / 3 | 67 / 15 / 18 | 32 / 15 / 53 | 10 / 6 / 84 | 2 / 1 / 96 | 1 / 0 + / 99 |
| 9 | 100 / 0 / 0 | 100 / 0 / 0 | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 99 / 1 / 0 + | 92 / 4 / 4 | 70 / 10 / 21 | 39 / 9 / 52 | 17 / 4 / 79 | 9 / 1 / 90 |
| 10 | 100 / 0 / 0 | 100 / 0 / 0 | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 99 / 1 / 1 | 91 / 3 / 7 | 70 / 6 / 24 | 45 / 5 / 50 | 31 / 2 / 67 |
| 11 | 100 / 0 / 0 | 100 / 0 / 0 | 100 / 0 / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 97 / 1 / 2 | 87 / 2 / 11 | 68 / 3 / 29 | 56 / 0 + / 44 |
| 12 | 100 / 0 / 0 | 100 / 0 / 0 | 100 / 0 / 0 | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 100 / 0 + / 0 + | 98 / 0 + / 1 | 91 / 1 / 8 | 75 / 0 + / 25 | 0 / 100 / 0 |
TABLE VIII: Maximal depth-to-win values for Morabaraba for subspaces where no stones are left to be placed (White to move)
| 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|------|-----|----|-----|-----|-----|-----|-----|------|------|------|
| 3 16 | 23 | 27 | 32 | 34 | | 34 | 16 | 8 | 8 | 8 |
| 4 22 | 19 | 34 | | 46 | 42 | 38 | 20 | 12 | 12 | 10 |
| 5 26 | 35 | 33 | | 56 | 60 | 56 | 54 | 38 | 27 | 27 |
| 6 33 | | 45 | 57 | 81 | 86 | 86 | 78 | 56 | 48 | 39 |
| 7 33 | | 41 | 59 | 87 | 101 | 102 | 96 | 96 | 85 | 69 |
| 8 33 | | 31 | 55 | 83 | 101 | 103 | 102 | 106 | 108 | 94 |
| 9 9 | 13 | | 43 | 77 | 95 | 103 | 105 | 108 | 110 | 108 |
| 10 7 | 11 | 25 | 53 | | 93 | 107 | 109 | 111 | 112 | 114 |
| 11 7 | 11 | 26 | 46 | | 68 | 94 | 109 | 113 | 103 | 96 |
| 12 7 | 9 | 13 | 34 | | 51 | 93 | 106 | 106 | 90 | N/A |
| | 0 . 1 - 0 . 2 | 0 . 2 - 0 . 4 | 0 . 4 - 0 . 8 | 0 . 8 - 1 . 6 |
|--------------------------------|-----------------|-----------------|-----------------|-----------------|
| Ultra-str. (W/D/L rat. heur.) | 57% | 42% | 28% | 25% |
| Ultra-str. (stone diff. heur.) | 52% | 51% | 36% | 32% |
| Strong | 17% | 21% | 17% | 12% |
Unfortunately, 64.21% and 55.66% of the draw positions has the value of 0 in the standard variant and Lasker Morris, respectively. Table XI shows the same for the stone difference heuristic.
In the standard variant, the value of the starting position is also 0. This results in that lots of games still end with a draw (often in a 0-ranked subspace) even with our ultra-strong solution. However, the number of these games is substantially less than without distinguishing the draws.
The ultra-strong solution works better for Lasker Morris: here, the value of the starting position is 399. This means that when the program is the first player, it starts from a substantial advantage, and the opponent is just a small mistake away from losing the game.
To actually test the effectiveness of the ultra-strong solutions, we ran matches of the standard variant against a non-
TABLE IX: Win ratios of the strong and the two ultra-strong solutions in the standard variant against the heuristic ( α β -) opponent with different node count settings: the numbers in the header give the number of nodes (in millions) searched by the heuristic program before each move (uniform random in the given interval, to provide greater variety to the games). Each match consisted of at least 200 games. (The sides were switched after each game.)
perfect program that uses α β -search 7 . The ultra-strong solutions performed significantly better than the strong solution. We also compared the two heuristics for assigning values to stable states. We expected the win/draw/loss ratio based heuristic to be better, but the results have not confirmed this. The win ratios can be seen in Table IX. In all our test games, the game was considered a draw if 50 consecutive moves happened without placing or taking a stone.
We also did some testing at a website ( flyordie.com ) where usually humans play against each other. With the standard variant, the ultra-strong program played 36 games against players titled 'master' in the website's scoring system, and was able to win 18 of these (50%). The strong program played 47 games against masters, and won only 11 (23%). The ultra-strong program also played 19 games with the
7 The program uses iterative deepening, transposition table, enhanced transposition cutoff, and killer move heuristic. It examines about 2-4 million nodes per second, and achieves ∼ 9-21 plies. The evaluation function takes into account the stone ratio, the number of available stone-sliding moves, and the possession of the points of the board that have four neighbors.
d7, d6; d2, f4; b6, b4; e4, c3; c4, d3; e3, e5; f2, d1; g7, a7? (the value becomes the value of the 8,9,0,0 subspace; the only move that would have kept the value 0 is c5 ; ) b2xb4, b4; g7-g4, e5-d5; e4-e5, d1-a1; e3-e4, b4-a4xd7? (now we are heading for the 3,6,0,0 subspace; the only move that would have kept the value is a1-d1 ; ) c4-b4xd6, a1-d1; b4-c4, a4-b4; g4-g7, a7-d7; e4-e3, d5-d6? (the value of the position after this move is win in 75 moves) ; e5-d5, d7-a7; g7-d7, d1-a1; e3-e4, d3-e3 (win in 21 moves) ; d2-d1, b4-a4xd7; c4-b4xf4, a7-d7; d1-d2xa1, Black resigns
Fig. 8: A won game of standard Nine Men's Morris against a strong master player at the flyordie.com website. Moves that do not keep the game-theoretic value (in the ultra-strong solution sense) are marked with a '?'. Our program played as White.
f4, b4; a4, d2; f6, f2; b2, d7; d1, g7; a7, a1; d5, g4; g1, c3; e3, c5; f6-d6, d2-d3; f4-e4, b4-c4xd5?; d6-d5, g4-f4; d5-e5xa1, c4-b4; e5-d5, b4-c4xd5; b2-b4, d3-d2; a4-a1xf4, g7-g4; e4-f4, c3-d3;
b4-a4xc4, Black resigns
Fig. 9: A won game of standard Nine Men's Morris against the strongest player at the flyordie.com website. Our program played as White. The crucial mistake is made at the move marked with a '?'. The position after this move is a win in 41 moves. b4-c4xe3 would have kept the draw (in a 0 valued subspace).
strongest player on the website (among thousands), of which our program was able to win 6 (32%). Two of the games played against strong humans can be seen on Figs. 8 and 9. (The α β -program is just below master level on the same website.)
In Lasker Morris, there were not enough strong players at the website to carry out proper testing, but the ultra-strong version seemed to be stronger here as well. In Lasker Morris, draws are much less frequent than in the standard variant (even with the strong solution). Recall, that according to our algorithm, the value of the starting position of Lasker Morris is quite high. The correctness of this is somewhat corroborated by the fact, that we won every one of the 16 games that the ultra-strong program played as the first player (often by the opponent making a fatal mistake in the first few moves), but there were two draws among the 17 games when playing as the second one.
We had the same problem with Morabaraba (not enough strong players). Additionally, when the ultra-strong program played Morabaraba as the second player, it usually either lost the game or the game transitioned directly from a losing position into a winning position. Unfortunately, this means that our ultra-strong solution did not help in these games, as only the draw-valued positions are treated differently from that of the strong solution. (In non-draw positions both optimize for DTW.)
We also experimented with some local heuristics to choose between the moves that the database says to be optimal, but these did not have a significant effect on the results. (For example, minimizing the number of optimal moves in the position that results from our move.)
TABLE X: Distribution of first keys (adjusted to absolute viewpoint) among draws when draws are distinguished for standard Nine Men's Morris (a), Lasker Morris (b), and Morabaraba (c)
| Subspace | Rank | % | Subspace | Rank | % |
|------------|--------|-----------|------------|--------|-----------|
| N/A | 0 | 64 . 21 % | N/A | 0 | 55 . 66 % |
| 6,3,0,0 | 112 | 15 . 6 % | 6,3,0,0 | 231 | 13 . 78 % |
| 3,6,0,0 | -112 | 12 . 34 % | 3,6,0,0 | -231 | 12 . 67 % |
| 3,5,0,0 | -60 | 1 . 3 % | 4,3,0,1 | -88 | 2 . 96 % |
| 5,3,0,0 | 60 | 1 . 19 % | 3,4,1,0 | 88 | 2 . 59 % |
| 5,4,0,0 | 29 | 0 . 78 % | 5,3,0,0 | 184 | 1 . 23 % |
| 9,8,0,0 | 59 | 0 . 72 % | 3,5,0,0 | -184 | 1 . 16 % |
| 8,7,0,0 | 113 | 0 . 65 % | 9,8,0,0 | 354 | 0 . 96 % |
| 7,8,0,0 | -113 | 0 . 54 % | 8,7,0,0 | 361 | 0 . 71 % |
| 8,9,0,0 | -59 | 0 . 53 % | 8,9,0,0 | -354 | 0 . 70 % |
| Other | | 2 . 13 % | Other | | 7 . 58 % |
| | (a) | | | (b) | |
| Subspace 3,4,0,0 4,3,0,0 N/A 5,3,0,0 3,5,0,0 5,4,0,0 4,5,0,0 11,10,0,0 10,11,0,0 10,9,0,0 Other | Rank -11 11 0 | % 37 . 86 % 27 . 97 % 11 . 51 % 8 . 38 % 7 . 69 1 . 01 % |
|---------------------------------------------------------------------------------------------------|-----------------|------------------------------------------------------------|
| | 54 | |
| | -54 | % |
| | 28 | |
| | -28 | 0 . 96 % |
| | 86 | 0 . 71 % |
| | -86 | 0 . 65 % |
| | 99 | 0 . 40 % |
| | | 2 . 87 % |
| (c) | (c) | (c) |
TABLE XI: Distribution of first keys (adjusted to absolute viewpoint) among draws when draws are distinguished for standard Nine Men's Morris (a), Lasker Morris (b), and Morabaraba (c) using the stone difference heuristic
| Diff % | Diff | % | Diff | % |
|--------------|--------|-----------|--------|-----------|
| 5 0 % | 5 | 0 . 00 % | 5 | 0 % |
| 4 0 % | 4 | 0 . 01 % | 4 | 0 . 01 % |
| 3 15 . 6 % | 3 | 13 . 85 % | 3 | 0 . 07 % |
| 2 1 . 44 % | 2 | 1 . 90 % | 2 | 8 . 88 % |
| 1 30 . 82 % | 1 | 32 . 31 % | 1 | 30 . 73 % |
| 0 3 . 44 % | 0 | 5 . 93 % | 0 | 11 . 51 % |
| -1 34 . 95 % | -1 | 31 . 62 % | -1 | 40 . 59 % |
| -2 1 . 51 % | -2 | 1 . 66 % | -2 | 8 . 14 % |
| -3 12 . 23 % | -3 | 12 . 73 % | -3 | 0 . 07 % |
| -4 0 . 01 % | -4 | 0 . 01 % | -4 | 0 . 01 % |
| -5 0 % | -5 | 0 . 00 % | -5 | 0 % |
## D. Verification of the calculations
We took the approach of Gasser [5] for the verification of the databases: a separate verifier program went through all the positions, and checked if their values are consistent with the values of their successors (also taking into account DTWs).
## VI. CONCLUSION
We strongly solved Morabaraba, which turned out to be a win for the first player in 49 moves. We also calculated extended strong solutions for Nine Men's Morris, Lasker Morris, and Morabaraba which provided some insights into these games (and also confirmed the result of Stahlhacke [8] that Lasker Morris is a draw).
Furthermore, we developed a multi-valued retrograde analysis. Then we modified this to have an algorithm which can solve these games ultra-strongly. This means that the program has a much higher chance to win a game of Nine Men's Morris or Lasker Morris against a fallible opponent instead of just drawing it, compared to a program which uses only a strong solution. This is important, because when a program is playing Nine Men's Morris based only on the strong solution, it is surprisingly easy for the opponent to achieve a draw. The algorithm classifies draws into subclasses based on a heuristic value of the subspace that can be reached via perfect play. We investigated two heuristics for the subspace values.
We compared our ultra-strong solution to the strong solution by having them play against a heuristic ( α β -) program, and against human players, and found that it achieved wins more often.
## VII. FUTURE WORK
## A. Splitting positions based on the type of the player to move
When we are aiming for the strong solution, the players can be treated identically, but from the point of view of the ultra-strong solution, there is a perfect player, and a fallible one. (For simplicity, we refer to these as computer and human, respectively.) Note that previously we did not specify the type of the player to move in a given position. At the expense of doubling the state space, one can use more refined heuristics. Subspaces get a fifth parameter which specifies the player to move. This way, non-transient work units have exactly two subspaces: one human-to-move and one computer-to-move. Since these subspaces must have the opposite values, it is more convenient to talk about assigning values to work units. These values are the same as the values of the computer-to-move subspaces in the work units.
Now we can use a heuristic that assigns high value to a work unit where most of the computer-to-move positions are wins (and therefore the fallible player can easily wander into a loss), but disregards the values of the human-to-move positions (since the program does not make any mistakes when choosing the human-to-move position to move into). Previously we assigned neutral values to the subspaces of work units with many draws in it, but now we can assign low/high values to the computer/human-to-move subspaces of such work units. The motivation behind this is that a drawish work unit is bad for the perfect player if he wants to get his opponent to make a mistake, and is good for the human, since he can achieve a draw more easily (he cannot hope to win anyway).
Note that this might also solve the problem that too many subspaces had to be assigned the value of 0.
## B. Generalization to other games
Our draw distinguishing algorithm can be used for any game with the properties described at the beginning of the introduction. But to be effective, there should exist a finegrained enough partitioning of the state space, so that the partitions can be assigned meaningful heuristic values, and all cycles are confined to within one partition. In the general case, the splitting of positions to computer-to-move and human-tomove positions described in the previous subsection would be required . The partitions would correspond to the work units, 8 and the subsets where a specific player type is to move would correspond to subspaces.
For example, a checkers playing program could probably benefit from this algorithm. The state space of that game is much larger, so our algorithm could only be used for some endgame databases, but that could still make a difference in some cases.
## ACKNOWLEDGEMENT
We would like to thank the three anonymous reviewers (especially reviewer #2) whose comments helped improve and clarify the paper.
## REFERENCES
- [1] L. V. Allis, 'Searching for solutions in games and artificial intelligence,' Ph.D. dissertation, University of Limburg, 1994.
- [2] J. Schaeffer, N. Burch, Y. Björnsson, A. Kishimoto, M. Müller, R. Lake, P. Lu, and S. Sutphen, 'Checkers is solved,' Science , vol. 317, no. 5844, pp. 1518-1522, 2007.
- [3] J. Schaeffer and R. Lake, 'Solving the game of Checkers,' Games of No Chance , vol. 29, pp. 119-133, 1996.
- [4] K. Thompson, 'Retrograde analysis of certain endgames,' ICCA Journal , vol. 9, no. 3, pp. 131-139, 1986.
- [5] R. U. Gasser, 'Harnessing computational resources for efficient exhaustive search,' Ph.D. dissertation, ETH Zürich, Switzerland, 1995.
- [6] R. Gasser, 'Solving Nine Men's Morris,' Computational Intelligence , vol. 12, no. 1, pp. 24-41, 1996. [Online]. Available: http://dx.doi.org/ 10.1111/j.1467-8640.1996.tb00251.x
- [7] E. Lasker, Brettspiele der Völker, Rätsel und mathematische Spiele . Scherl, 1931.
- [8] P. Stahlhacke, 'The game of Lasker Morris,' FSU Jena, Tech. Rep., 2003. [Online]. Available: http://www.althofer.de/ stahlhacke-lasker-morris-2003.pdf
- [9] P. J. Jansen, 'Using knowledge about the opponent in game-tree search.' DTIC Document, Tech. Rep., 1992.
- [10] T. Lincke, 'Perfect play using Nine Men's Morris as an example,' diploma thesis, ETH Zürich, 1994.
- [11] J. Schaeffer, One jump ahead: computer perfection at checkers , revised ed. Springer, 2008.
- [12] W. Slany, 'Graph ramsey games,' arXiv preprint cs/9911004 , 1999.
- [13] S. C. J. Bakkes, P. H. M. Spronck, and H. J. van den Herik, 'Opponent modelling for case-based adaptive game AI,' Entertainment Computing , vol. 1, no. 1, pp. 27-37, 2009.
- [14] J. ˇ ermák, C B. Bošanský, and V. Lisý, 'Practical performance of refinements of nash equilibria in extensive-form zero-sum games,' in Proceedings of the 21st European Conference on Artificial Intelligence (ECAI) , 2014, pp. 201 - 206, DOI:10.3233/978-1-61499-419-0-201.
- [15] T. R. Lincke, 'Exploring the computational limits of large exhaustive search problems,' Ph.D. dissertation, ETH Zürich, Switzerland, 2002.
- [16] T. Ströhlein, 'Untersuchungen über kombinatorische spiele,' Ph.D. dissertation, Technische Hochschule München, 1970.
- [17] J. W. H. M. Uiterwijk and H. J. van den Herik, 'The advantage of the initiative,' Information Sciences , vol. 122, no. 1, pp. 43-58, 2000.
8 This way, it is also guaranteed that every position in a secondary subspace needs to be adjusted to only a single primary subspace. | null | [
"Gábor E. Gévay",
"Gábor Danner"
] | 2014-07-31T21:38:05+00:00 | 2015-03-15T00:09:41+00:00 | [
"cs.AI",
"I.2.8"
] | Calculating Ultra-Strong and Extended Solutions for Nine Men's Morris, Morabaraba, and Lasker | The strong solutions of Nine Men's Morris and its variant, Lasker Morris are
well-known results (the starting positions are draws). We re-examined both of
these games, and calculated extended strong solutions for them. By this we mean
the game-theoretic values of all possible game states that could be reached
from certain starting positions where the number of stones to be placed by the
players is different from the standard rules. These were also calculated for a
previously unsolved third variant, Morabaraba, with interesting results: most
of the starting positions where the players can place an equal number of stones
(including the standard starting position) are wins for the first player (as
opposed to the above games, where these are usually draws).
We also developed a multi-valued retrograde analysis, and used it as a basis
for an algorithm for solving these games ultra-strongly. This means that when
our program is playing against a fallible opponent, it has a greater chance of
achieving a better result than the game-theoretic value, compared to randomly
selecting between "just strongly" optimal moves. Previous attempts on
ultra-strong solutions used local heuristics or learning during games, but we
incorporated our algorithm into the retrograde analysis. |
1408.0033v2 | ## Intact quasiparticles at an Unconventional Quantum Critical Point
M. L. Sutherland, 1 E. C. T. O'Farrell, 2 W.H. Toews, 3 J. Dunn, 3 K. Kuga, 2 S. Nakatsuji, 2 Y. Machida, 4 K. Izawa, 4 and R.W. Hill 3
1 Cavendish Laboratory, University of Cambridge, JJ Thomson Ave, Cambridge, UK, CB3 0HE 2 Institute for Solid State Physics, University of Tokyo, Kashiwa, Japan 277-8581 3 GWPI and Department of Physics and Astronomy, University of Waterloo, Waterloo, Ontario, Canada, N2L 3G1 4 Department of Physics, Tokyo Institute of Technology, Meguro, Japan 152-8551 (Dated: July 27, 2015)
We report measurements of in-plane electrical and thermal transport properties in the limit T → 0 near the unconventional quantum critical point in the heavy-fermion metal β -YbAlB . 4 The high Kondo temperature T K glyph[similarequal] 200 K in this material allows us to probe transport extremely close to the critical point, at unusually small values of T/T K < 5 × 10 -4 . Here we find that the Wiedemann-Franz law is obeyed at the lowest temperatures, implying that the Landau quasiparticles remain intact in the critical region. At finite temperatures we observe a non-Fermi liquid T-linear dependence of inelastic scattering processes to energies lower than those previously accessed. These processes have a weaker temperature dependence than in comparable heavy fermion quantum critical systems, and suggest a new temperature scale of T ∼ 0 3 . K which signals a sudden change in character of the inelastic scattering.
PACS numbers: 71.27.+a,72.15.Eb, 75.30.Mb
The effect of quantum fluctuations on the properties of matter has become an important area of research motivated by the potential for technological advances through harnessing and manipulating quantum mechanical properties. A quantum critical point (QCP) arises when a continuous transition between competing order occurs at zero temperature. Here, strong quantum fluctuations can drive the formation of new phases of matter [1], and may lead to the breakdown of normal Fermiliquid behaviour in metals. Much of our understanding of QCPs comes from the study of heavy-fermion compounds, which are canonical systems for investigating antiferromagnetic quantum criticality. An important open question in these materials is whether multiple types of QCPs exist, differentiated by their microscopic behaviour in the critical regime.
The standard model of quantum criticality in metals is the Hertz-Moriya-Millis framework [2], where the suppression of itinerant antiferromagnetic order results in a paramagnetic state with heavy quasiparticles formed as a result of the Kondo screening of f -electron moments by electrons in the conduction band. While this works very well in describing many materials, the presence of localized moments, Fermi surface reconstruction, and diverging effective masses at the magnetic transition in YbRh Si 2 2 has been interpreted as evidence for a more exotic type of quantum criticality [3]. Alternate frameworks have been proposed where a new energy scale, the 'effective Kondo temperature', collapses at the QCP leading to the breakdown of the heavy electron metal [4]. At the so-called Kondo-breakdown QCP, the Kondo effect is destroyed and the entire Fermi surface is destabilized.
Distinguishing between these pictures is a challenging experimental task. One promising approach is to search for the breakdown of the Landau quasiparticle picture via thermal transport measurements, which would provide compelling evidence for the existence of less conventional classes of QCPs. In the Kondo-breakdown model for instance, a fractionalised Fermi liquid [5] emerges and the presence of additional entropy carriers (spinons) enhances the thermal conductivity above that expected in the normal heavy-fermion metallic state [6]. This should lead to a T = 0 violation of the Wiedemann-Franz (WF) law which relates the electrical conductivity of a material ( σ ) with its thermal conductivity ( κ ) via the Sommerfeld value of the Lorenz number ( L 0 ):
$$\frac { \kappa } { \sigma T } = \frac { \pi ^ { 2 } k _ { B } ^ { 2 } } { 3 e ^ { 2 } } = L _ { 0 } = 2. 4 5 \times 1 0 ^ { - 8 } \, \text{W} \Omega K ^ { - 2 } \quad ( 1 )$$
In contrast, the quasiparticles near a conventional QCP are expected to remain intact, and the WF law obeyed.
In this letter we report a test of the WF law in the heavy-fermion material β -YbAlB , 4 which has the unusual property of lying almost exactly at a QCP at ambient magnetic field and pressure [7]. Magnetic susceptibility measurements in this material have revealed unusual T/B scaling and an effective mass which diverges as B -1 / 2 [8]. Together with the observation of strong valence fluctuations [9], these properties have led to the suggestion that the QCP in β -YbAlB 4 is unconventional in nature. Our thermal transport measurements directly address the question of whether the quasiparticles remain intact in the critical region, and act as an important test for microscopic theories of unconventional quantum criticality in this and other heavy-fermion compounds.
Figure 1 shows the result of thermal and charge transport measurements at several magnetic fields, with B ‖ c and I ‖ ab . The high quality single crystals used in this work were thin platelets prepared using a flux growth method [10], with typical sample dimensions of 2mm ×
200 µ m × 15 µ m, and the best sample having a residual resistivity ratio (RRR) of ρ (300 K ) /ρ 0 = 300. Contacts with very low electrical resistance ( < 5 mΩ) were prepared by firstly ion milling the surface and then depositing Pt contacts.
The thermal conductivity was measured to T ∼ 70 mK using a two thermometer, one heater steady-state technique, with in-situ thermometer calibrations performed at each field to eliminate the effects of thermometer magnetoresistance. Electrical and thermal transport measurements were taken on the same sample, using the same contacts. In order to compare the charge and heat transport more closely, the thermal conductivity data is converted to thermal resistivity ( w ), in electrical units ( µ Ω cm), using Eq. 1: w = L T/κ 0 . We estimate a relative error between thermal and electrical measurements of 3%, arising mainly from slightly different effective contact separations for heat and charge measurements. Our measurements were repeated in two laboratories using several samples, and we obtain good reproducibility of our results.
In zero field, β -YbAlB 4 lies in a non-Fermi liquid state at low temperatures characterized by an electrical resistivity ρ T ( ) ∼ T 1 5 . , a magnetic susceptibility χ c ∼ T -1 / 2 and an electronic specific heat γ ∼ ln T /T ( 0 ) with T 0 = 200 K, associated with a high-energy valence fluctuation scale [8]. In the cleanest samples, superconductivity is also seen [7].
A fit of B = 0 resistivity data in Fig. 1a to ρ T ( ) = ρ 0 + aT n gives n ∼ 1.5 (which is identical to that reported previously [7]), and ρ 0 ∼ 0.4 µ Ωcm, indicating the high quality of the samples. We observe a clear drop in resistivity at an onset temperature T c = 80 mK, consistent with the presence of superconductivity. A small magnetic field of B = 50 mT completely suppresses superconductivity, consistent with the reported critical field of B c 2 = 25 mT [11]. Increasing the field further increases ρ 0 , (Fig. 1b-f), and the temperature dependence increases its curvature, with ρ T ( ) ∼ T 2 by B ≥ 3 T, indicating a return to a Fermi liquid state. Our observations are consistent with the phase diagram for this material elucidated through earlier transport [7] and magnetization measurements [8].
The thermal conductivity at these low temperatures is taken to be dominated by the electron contribution. In a paramagnetic metal, heat is carried by both electrons ( κ el ) and phonons ( κ ph ), however in the limit T → 0 samples with low residual resistivities ( ρ 0 < 1 µ Ωcm) should have κ el glyph[greatermuch] κ ph , allowing us to ignore the contributions of κ ph below 1 K. This is the case in metallic compounds with comparable values of ρ 0 , for instance YbRh 2 Si 2 [12], CeCoIn 5 [13], CeRhIn 5 [14] and ZrZn 2 [15].
The comparison of the w and ρ curves in Fig. 1 offers a direct test of the WF law. Clearly, all the w and ρ curves converge below T = 200 mK in both zero and applied magnetic fields [16]. From this we conclude that the WF law is robustly obeyed both at the QCP and at all other fields in the phase diagram of β -YbAlB , at 4
FIG. 1. a)-f) In-plane electrical resistivity (lines) and thermal resistivity (open symbols) at various values of applied magnetic field. g) shows the temperature dependence of the Lorenz ratio L/L 0 at each field measured.
least to within our experimental resolution of 3%. A plot of the Lorenz ratio, L/L 0 = κ/σTL 0 , seen in Fig. 1g further emphasizes this point, approaching unity as the temperature falls below 200 mK.
This observation argues against the appearance of a fractionalized Fermi liquid that emerges in some Kondobreakdown models. Specifically, recent theoretical work predicts that a spinon contribution leads to an excess thermal conductivity and a Lorenz ratio that diverges as L T ( ) ∼ ( k B T ) -3 at low temperatures, before being cut off by elastic scattering as T → 0 [17]. This is expected to give a characteristic peak with L/L 0 > 1, which is not observed in β -Y bAlB 4 .
Our results also stand in stark contrast to recent observations in similar materials. At the putative Kondobreakdown QCP in YbRh Si 2 2 for instance, a WF law violation of 10% has been reported [12], with L/L 0 ( T →
FIG. 2. The difference δ T ( ) between thermal ( w ) and electrical ( ρ ) in-plane resistivity measured in quantum critical systems a) β -YbAlB 4 b) CeCoIn 5 [13] and c) YbRh Si 2 2 [12], with fields applied along the c -axis. The scale has been reduced in panel a) to make the date for β -YbAlB 4 more clear. The critical fields for these systems are H c = 0, 5.25 T and 60 mT respectively. The dotted lines in a) show the results of a linearT fit to the B = 0 data in the non-Fermi liquid state, and a T 2 fit to the B = 5T data in the Fermi liquid state. Panel d) shows the data for the three materials with the temperature axis scaled by the respective Kondo temperatures T K and plotted logarithmically.
0) ∼ 0.9 indicating lower than expected heat conduction. However, more recent measurements indicate the WF law is satisfied [18, 19]. At the field-tuned magnetic QCP in CeCoIn , the situation is more complex, showing agree5 ment with the WF law as T → 0 for heat current in one direction but violation in another [13].
In this context, our observations are significant. Despite the signatures of unconventional criticality, we find that the quasiparticles which carry heat and charge in β -YbAlB 4 remain intact at, or near, the unconventional QCP . It directly follows that a theoretical treatment of criticality in this material must be able to account for unconventional magnetic and transport properties while maintaining the basic framework of the quasiparticle picture. One recent model that is consistent with our results is proposed by Ramires et al ., in which a hybridisation gap between conduction and f -electons is strongly k -dependent, and vanishes along a line in which zeroenergy excitations form [20].
Having discussed the T = 0 results, we now consider the temperature evolution of heat and charge transport. Deviations of the ratio L/L 0 from unity give a measure of the ratio of inelastic to elastic scattering. In Fig. 1(g), our data shows that at low temperatures, the ratio of inelastic to elastic scattering processes remains fairly small in β -YbAlB , even at the zero field 4 QCP and in very clean samples. Furthermore, this modest temperature dependence is largely magnetic field independent. We now analyse these basic observations in more detail.
As T is increased, the thermal and electrical resistivities evolve differently, reflecting dissimilarities in how scattering mechanisms affect heat and charge currents. Consider an electron of mass m glyph[star] , wavevector k F and an energy E relative to the Fermi energy. When scattered through an angle θ , the electric current j ρ and thermal current j w are reduced by amounts [21]:
$$\Delta j _ { \rho } = - \frac { e k _ { F } } { m ^ { * } } ( 1 - \cos ( \theta ) ) \text{ \quad \ \ } ( 2 )$$
$$\Delta j _ { w } = - \frac { k _ { F } } { m ^ { * } } [ E ( 1 - \cos \theta ) + \Delta E \cos \theta ] \quad ( 3 )$$
The (1 -cos( θ )) terms in these equations arise from changes in the direction of the wavevector of the electron, and are often referred to as 'horizontal processes', K hor . The second term in Eq. 3 arises due to the fact that the electron may suffer a loss of energy ∆ E in an inelastic collision, which further degrades a heat current. This is often referred to as a 'vertical process', K ver . In the case of elastic scattering ∆ E =0and the WF law is recovered.
In magnetic scattering, a full calculation of the electrical and thermal resistivities involves integrating Eqs. 2 and 3 over the q and ω dependence of the fluctuation spectrum. Horizontal processes are weighted by a factor of q 2 , while vertical processes are weighted by a factor of ω 2 [21, 22]. Comparing heat and charge resitivities directly can thus give access to detailed information about the q and ω dependence of scattering.
Defining δ T ( ) = w T ( ) -ρ T ( ) yields the temperature dependence of the vertical scattering processes, since ρ ∼ K hor and w ∼ K hor + K ver . In Fig. 2, we plot δ T ( ) for β -YbAlB 4 alongside equivalent data for the unconventional quantum critical systems CeCoIn 5 [13] and YbRh Si 2 2 [12]. In zero field, a linear fit to δ T ( ) in β -YbAlB 4 for T < 0 8 . K is shown to describe the data remarkably well,. This T -linear property of inelastic scattering is strikingly different than what is expected in a conventional Fermi-liquid where δ T ( ) ∼ T 2 or δ T ( ) ∼ T 3 + T 5 from electron-electron and electronphonon scattering respectively [22].
A similar linear variation of δ T ( ) was previously observed arising from critical ferromagnetic fluctuations in
the itinerant d -metal ZrZn 2 [23]. The high Wilson ratio R W ∼ 7 in β -YbAlB 4 suggests the presence of ferromagnetic fluctuations in the Yb moments [24]. However, despite evidence that local moments may persist to low temperatures [8], it is unclear how strongly these local fluctuations might couple to the itinerant electrons. Valence fluctuations are another important consideration. X-ray photoemission spectroscopy measurements reveal a mixed valence of Yb +2 75 . in β -YbAlB 4 [9], associated with Yb +3 glyph[harpoonleftright] Yb +2 fluctuations that may play a role in the quantum critical behaviour. Such fluctuating modes have been shown to lead to T -linear electrical resistivity at intermediate temperatures, and T 3 / 2 behaviour at low temperatures [25, 26], similar to that observed in β -YbAlB . 4 Whether such valence fluctuations could also give rise to a linear temperature dependence in δ T ( ) is an open theoretical question.
The magnetic field dependence of δ T ( ) is also interesting. For the most part, the approximately linear-intemperature behaviour is maintained at low field. As the field increases towards 5 T, the curvature increases towards a T 2 dependence, shown by the fit in the figure, and the magnitude at low temperatures is smaller. This is roughly consistent with the electronic specific heat coefficient γ which is reduced by applying a magnetic field at low temperatures [8]. It also consistent with δ T ( ) in other field-driven quantum critical systems. In Fig. 2b for example, applying a magnetic field greater than H c to CeCoIn 5 quenches inelastic scattering, changing δ T ( ) from T -linear at the critical field to δ T ( ) ∼ T 2 by 10 T, where the Fermi liquid state is recovered [27]. The same general trend is true of YbRh Si 2 2 in Fig. 2c. The lowfield curves in YbRh Si 2 2 show a feature below 100 mK that is consistent with the presence of scattering associated with the antiferromagnetic ordering at T N =80 mK, but as the field is increased the temperature dependence reverts to linear for B > 300 mT, approaching quadratic for the highest field ( B = 1 T) [12].
Perhaps the most conspicuous difference in comparing heat transport in these materials is in the magnitude of δ T ( ). This is shown versus the scaled temperature axis of T/T K in Fig. 2d, where T K is the respective characteristic energy scale (Kondo temperature) for each material. The values for T K used are YbRh Si : 2 2 T K ∼ 25 K [28], CeCoIn : 5 T K ∼ 35 K [29] and β -YbAlB : 4 T K ∼ T 0 ∼ 200 K [8]. At the lowest temperatures T/T K < 10 -3 , δ T ( ) → 0, however δ T ( ) increases more slowly with temperature in β -YbAlB 4 indicating a comparatively smaller amount of inelastic scattering in this material. This is not simply due to differences in impurities levels between the systems, as CeCoIn 5 has a much lower residual resistivity ( ρ 0 = 0 1 . µ Ω cm [27]) while for YbRh Si 2 2 the samples have a higher scattering rate ( ρ 0 = 1 6 . µ Ω cm [12]).
Further insight may be gained by subtracting the elastic scattering and looking solely at the temperature dependence of the inelastic scattering channel. Defining the inelastic Lorenz ratio L in = ( δ -δ 0 ) / w ( -w 0 ), where δ 0
FIG. 3. The inelastic Lorenz ratio, L in = ( δ -δ 0 ) / ( w -w 0 ), in β -YbAlB , measured at several fields 4 with B ‖ c . The inelastic ratio, L in , is a measure of the ratio of vertical (energy non-conserving) to horizontal (energy conserving) contributions to inelastic scattering processes. The data for two samples (S1 and S2) at zero field is shown.
and w 0 are the T = 0 values of δ T ( ) and w T ( ), allows access to the relative weighting of vertical to horizontal inelastic scattering processes, as L in ∝ K ver K hor + K ver . In a Fermi liquid, L in glyph[similarequal] 0.4-0.6, indicating the ratio of vertical to horizontal inelastic processes is close to unity and is roughly temperature independent [21, 30]. Fig. 3, however, reveals a remarkable feature of our data. A new energy scale, which is field independent, appears at a temperature of T ∼ 0.3 K below which the inelastic Lorenz number L in falls rapidly [31].
Two conclusions can be drawn from the feature at T ∼ 0.3 K. First, in conjunction with our observations of the magnitude of δ T ( ), the magnitude of L in above T ∼ 0 3 . K indicates that both horizontal and vertical inelastic processes are small compared to that seen in similar quantum critical systems. Second, the decrease in L in indicates a decrease in the ratio of vertical to horizontal inelastic processes as the temperature is lowered. Consequently, either the horizontal scattering processes are increasing, or the vertical processes are reduced, perhaps through a gapping of the fluctuation spectrum. This feature persists through the critical regime, and corresponds roughly to the temperature at which a T 2 Fermi liquid state is recovered in transport measurements [ ? ]. Low temperature inelastic neutron scattering studies would help establish what drives the collapse in L in , and its significance to quantum criticality.
One possible explanation that accounts for these observations is the existence of two types of carriers in β -YbAlB , 4 arising from the two bands that cross the Fermi level [33]. One is relatively fast and light and
dominates transport, with only weak inelastic scattering arising mainly from a largely field independent scattering mechanism. Another carrier is slow and heavy and is strongly scattered by inelastic fluctuations, with a reasonable contribution to specific heat but a limited contribution to transport. There is some experimental support for this picture. The multiband Fermi surface revealed by experimental and theoretical studies [34, 35] shows cyclotron masses ranging from m /m glyph[star] 0 ∼ 3.6 - 13.1, for instance. Also, the entropy associated with the approach to the QCP in β -YbAlB 4 is quite small, with an upturn in ( C/T T ) 0 an order of magnitude smaller than in CeCu 5 9 . Au 0 1 . or YbRh Si 2 2 [8], suggesting that perhaps only some electrons are renormalized in the approach to the critical point. Recent detailed Hall effect measurements [36] are indeed well fit by a two-component model with one high mobility component dominating transport, at least at intermediate temperatures.
Based on our thermal transport observations, there are clearly three issues unique to β -YbAlB 4 that must be
- [1] N. D. Mathur, F. M. Grosche, S. R. Julian, I. R. Walker, D. M. Freye, R. K. W. Haselwimmer, and G. G. Lonzarich, Nature 394 , 39 (1998).
- T. Moriya and A. Kawabata, Journal of the Physical So-
- [2] ciety of Japan 34 , 639 (1973). J. A. Hertz, Phys. Rev. B 14 , 1165 (1976). A. J. Millis, Phys. Rev. B 48 , 7183 (1993).
- [3] P. Gegenwart, Q. Si, and F. Steglich, Nature Physics 4 , 186 (2008).
- [4] Q. Si and S. Paschen, Phys. Status Solidi B 250 , 425 (2013).
- [5] T. Senthil, S. Sachdev, and M. Vojta, Phys. Rev. Lett. 90 , 216403 (2003).
- [6] K.-S. Kim and C. P´ epin, Phys. Rev. Lett. 102 , 156404 (2009).
- [7] S. Nakatsuji, K. Kuga, Y. Machida, T. Tayama, T. Sakakibara, Y. Karaki, H. Ishimoto, S. Yonezawa, Y. Maeno, E. Pearson, et al., Nature Physics 4 , 603 (2008).
- [8] Y. Matsumoto, S. Nakatsuji, K. Kuga, Y. Karaki, N. Horie, Y. Shimura, T. Sakakibara, A. H. Nevidomskyy, and P. Coleman, Science 331 , 316 (2011).
- [9] M. Okawa, M. Matsunami, K. Ishizaka, R. Eguchi, M. Taguchi, A. Chainani, Y. Takata, M. Yabashi, K. Tamasaku, Y. Nishino, et al., Phys. Rev. Lett. 104 , 247201 (2010).
- [10] R. T. Macaluso, S. Nakatsuji, K. Kuga, E. L. Thomas, Y. Machida, Y. Maeno, Z. Fisk, and J. Y. Chan, Chemistry of Materials 19 , 1918 (2007).
- [11] K. Kuga, Y. Karaki, Y. Matsumoto, Y. Machida, and S. Nakatsuji, Phys. Rev. Lett. 101 , 4 (2008).
- [12] H. Pfau, S. Hartmann, U. Stockert, P. Sun, S. Lausberg, M. Brando, S. Friedemann, C. Krellner, C. Geibel, S. Wirth, et al., Nature 484 , 493 (2012).
- [13] M. Tanatar, J. Paglione, C. Petrovic, and L. Taillefer, Science 316 , 1320 (2007).
- [14] J. Paglione, M. A. Tanatar, D. G. Hawthorn, R. Hill,
resolved with theoretical input. The first is the linear temperature dependence of δ T ( ) and its small magnitude in comparison to other field-tuned quantum critical systems, the second is the origin of the energy scale ( 0.3 K) observed in the inelastic scattering channel and the third is the overall insensitivity of these transport phenomena to the applied magnetic field, perhaps arising from the low energy scales T/T K accessed in this system.
## ACKNOWLEDGMENTS
This research was supported by NSERC of Canada, the Royal Society, and the EPSRC. This work was partially supported by Grants-in-Aid (No. 25707030) from the Japanese Society for the Promotion of Science. E.O'F. also acknowledges support from the JSPS. We would like to thank Makariy Tanatar, Malte Grosche, Gil Lonzarich, Sven Friedemann and Mike Smith for useful discussions.
- F. Ronning, M. Sutherland, L. Taillefer, C. Petrovic, and P. C. Canfield, Phys. Rev. Lett. 94 , 216602 (2005).
- [15] R. P. Smith, M. Sutherland, G. G. Lonzarich, S. S. Saxena, N. Kimura, S. Takashima, M. Nohara, and H. Takagi, Nature 455 , 1220 (2008).
- [16] Strictly speaking, the presence of superconductivity in the charge channel excludes any statement on the WF law in zero field in the T = 0 limit. However, in a small magnetic field ( B = 50 mT), the superconducting transition in the resistivity is removed and we recover the WF law within our experimental resolution.
- [17] A. Hackl and R. Thomale, Phys. Rev. B 83 , 235107 (2011).
- [18] Y. Machida, K. Tomokuni, K. Izawa, G. Lapertot, G. Knebel, J. P. Brison, and J. Flouquet, Physical Review Letters 110 , 236402 (2013).
- [19] J.-P. Reid, M. A. Tanatar, R. Daou, R. Hu, C. Petrovic, and L. Taillefer, Phys. Rev. B 89 , 045130 (2014).
- [20] A. Ramires, P. Coleman, A. H. Nevidomskyy, and A. M. Tsvelik, Phys. Rev. Lett. 109 , 176404 (2012).
- [21] J. Schriemp, A. I. Schindler, and D. L. Mills, Phys. Rev. 187 , 959 (1969).
- [22] J. Ziman, Electrons and Phonons (Clarendon Press 1962, Oxford, 1962).
- [23] M. Sutherland, R. Smith, N. Marcano, Y. Zou, F. M. Grosche, N. Kimura, S. M. Hayden, S. Takashima, M. Nohara, and H. Takagi, Phys. Rev. B 85 , 035118 (2012).
- [24] S. Julian, A. Mackenzie, G. Lonzarich, C. Bergemann, R. Haselwimmer, Y. Maeno, S. NishiZaki, A. Tyler, S. Ikeda, and T. Fujita, Physica B 259 , 928 (1999).
- [25] S. Watanabe and K. Miyake, J. Phys.: Condens. Matter 24 , 294208 (2012).
- [26] K. Miyake and S. Watanabe, J. Phys. Soc. Jpn. 83 , 061006 (2014).
- [27] J. Paglione, M. A. Tanatar, D. G. Hawthorn, F. Ronning, R. Hill, M. Sutherland, L. Taillefer, and C. Petro-
- vic, Phys. Rev. Lett. 97 , 106606 (2006).
- [28] J. Sichelschmidt, V. Ivanshin, J. Ferstl, C. Geibel, and F. Steglich, Phys. Rev. Lett. 91 , 156401 (2003).
- [29] S. Nakatsuji, S. Yeo, L. Balicas, Z. Fisk, P. Schlottmann, P. G. Pagliuso, N. O. Moreno, J. L. Sarrao, and J. D. Thompson, Phys. Rev. Lett. 89 , 106402 (2002).
- [30] A. Kaiser, Phys. Rev. B 3 , 2040 (1971).
- [31] We distinguish this from the recently reported energy scale T ∗ found in transport measurements of YbRh Si 2 2 [19]. In that case, T ∗ is determined from the temperature dependence of δ T ( ) and is interpreted as the onset temperature for short-range magnetic correlations, causing δ to vary sub-linearly with temperature. In YbAlB , 4 δ T ( ) is linear to the lowest measured temperatures.
- [32] Y. Matsumoto, K. Kuga, Y. Karaki, Y. Shimura, T. Sakakibara, M. Tokunaga, K. Kindo, and S. Nakatsuji, JPSJ 84 , 024710 (2015).
- [33] D. A. Tompsett, Z. P. Yin, G. G. Lonzarich, and W. E. Pickett, Phys. Rev. B 82 , 235101 (2010).
- [34] E. C. T. O'Farrell, D. A. Tompsett, S. E. Sebastian, N. Harrison, C. Capan, L. Balicas, K. Kuga, A. Matsuo, K. Kindo, M. Tokunaga, et al., Phys. Rev. Lett. 102 , 216402 (2009).
- [35] A. H. Nevidomskyy and P. Coleman, Phys. Rev. Lett. 102 , 077202 (2009).
- [36] E. C. T. O'Farrell, Y. Matsumoto, and S. Nakatsuji, Phys. Rev. Lett. 109 , 176405 (2012). | 10.1103/PhysRevB.92.041114 | [
"M. L. Sutherland",
"E. C. T. O'Farrell",
"W. H. Toews",
"J. Dunn",
"K. Kuga",
"S. Nakatsuji",
"Y. Machida",
"K. Izawa",
"R. W. Hill"
] | 2014-07-31T21:39:18+00:00 | 2015-07-24T11:27:03+00:00 | [
"cond-mat.str-el"
] | Intact Quasiparticles at an Unconventional Quantum Critical Point | We report measurements of in-plane electrical and thermal transport
properties in the limit $T \rightarrow 0$ near the unconventional quantum
critical point in the heavy-fermion metal $\beta$-YbAlB$_4$. The high Kondo
temperature $T_K$ $\simeq$ 200 K in this material allows us to probe transport
extremely close to the critical point, at unusually small values of $T/T_K < 5
\times 10^{-4}$. Here we find that the Wiedemann-Franz law is obeyed at the
lowest temperatures, implying that the Landau quasiparticles remain intact in
the critical region. At finite temperatures we observe a non-Fermi liquid
T-linear dependence of inelastic scattering processes to energies lower than
those previously accessed. These processes have a weaker temperature dependence
than in comparable heavy fermion quantum critical systems, and suggest a new
temperature scale of $T \sim 0.3 K$ which signals a sudden change in character
of the inelastic scattering. |
1408.0035v1 | ## Effects of Meridional Flow Variations on Solar Cycles 23 and 24
## Lisa Upton
Department of Physics &Astronomy, Vanderbilt University, Nashville, TN 37235 USA Center for Space Physics and Aeronomy Research, The University of Alabama in Huntsville, Huntsville, AL 35899 USA
[email protected] [email protected]
## David H. Hathaway
NASA Ames Research Center, Moffett Field, CA 94035
[email protected]
## ABSTRACT
The faster meridional flow that preceded the solar cycle 23/24 minimum is thought to have led to weaker polar field strengths, producing the extended solar minimum and the unusually weak cycle 24. To determine the impact of meridional flow variations on the sunspot cycle, we have simulated the Sun's surface magnetic field evolution with our newly developed surface flux transport model. We investigate three different cases: a constant average meridional flow, the observed time-varying meridional flow, and a time-varying meridional flow in which the observed variations from the average have been doubled. Comparison of these simulations shows that the variations in the meridional flow over cycle 23 have a significant impact ( ∼ 20%) on the polar fields. However, the variations produced polar fields that were stronger than they would have been otherwise. We propose that the primary cause of the extended cycle 23/24 minimum and weak cycle 24 was the weakness of cycle 23 itself - with fewer sunspots, there was insufficient flux to build a big cycle. We also find that any polar counter-cells in the meridional flow (equatorward flow at high latitudes) produce flux concentrations at mid-to-high latitudes that are not consistent with observations.
Subject headings: Sun: dynamo, Sun: surface magnetism
## 1. INTRODUCTION
Activity on the Sun is periodic with the average cycle lasting ∼ 11 years. Babcock (1961) explained this periodic behavior with a phenomenological solar dynamo model. In his model, the Sun's dipolar fields at solar cycle minimum are converted into toroidal fields within the Sun by differential rotation. These toroidal fields emerge at the surface in the form of tilted bipolar active regions. Surface flux transport on the Sun then carries the remnants of the active region flux to the poles where it cancels the original dipole and creates a new poloidal field with the opposite polarity. The strength of this new poloidal field (at solar minimum) is the seed to the next solar cycle. This theory is supported by findings (Schatten et al. 1978; Svalgaard et al. 2005; Mu˜oz-Jaramillo et al. n 2012; Svalgaard & Kamide 2013) that the strength of the Sun's polar fields during solar minimum is well correlated with (and can be used to predict) the amplitude of the following cycle.
The polar field strengths have been measured directly by the Wilcox Solar Observatory for the last three solar cycles. The polar fields during the last solar minimum (cycle 23/24 minimum) were the weakest to date; they were ∼ half the strength
of the prior two cycles. This minimum proved to be exceptionally long and was followed by a cycle (cycle 24, the current solar cycle) that is developing into the weakest solar cycle in the last century. These unusual solar conditions may provide insight as to how magnetic flux transport at the surface regulates the polar field evolution and thus the solar activity cycle.
Surface flux transport on the Sun is achieved via differential rotation, meridional circulation, and the turbulent motions of convection. While the characteristics of the convective motions and differential rotation are fairly constant, the meridional flow varies in two fundamental ways: over the course of a solar cycle and from one cycle to the next (Komm et al. 1993; Hathaway & Rightmire 2010, 2011). The meridional flow is faster at solar cycle minimum and slower at maximum. Furthermore, the meridional flow speeds that preceded the cycle 23/24 minimum were ∼ 20% faster than the meridional flow speeds that preceded the prior minimum. This faster meridional flow may have led to the weaker polar field strengths of cycle 23/24 minimum and thus the subsequent extended solar minimum and a weak cycle 24 (see e.g. Schrijver & Liu 2008; Wang et al. 2009; Hathaway & Rightmire 2010, 2011).
Surface Flux Transport models have long been used to characterize the dynamics of the Sun's magnetic fields. These models (DeVore et al. 1984; Wang et al. 1989; van Ballegooijen et al. 1998; Schrijver & Title 2001; Baumann et al. 2004; Jiang et al. 2010) look exclusively at how magnetic flux moves at the surface, i.e. as a function of latitude and longitude. Surface flux transport evolves the magnetic fields with a given differential rotation, meridional flow, and supergranular diffusion. Most models have been highly parameterized, in particular with respect to the meridional flow and diffusion. The adopted meridional flow profiles (sharply peaked at low latitudes, stopping short of the poles, exaggerated variations around active regions) deviate substantially from the observed profiles. Additionally, these models have typically neglected the variability in the meridional flow all together. Furthermore, virtually all previous models have parameterized the turbulent convection by a diffusivity with widely varying values from model to model.
Recently, Jiang et al. (2010) showed that per- turbations on the meridional flow in the form of superimposed inflows into active regions (a strengthening of the flow on the equatorward side of the active regions and a weakening of the flow on the poleward side of the active regions) could modulate the strength of the polar fields, and thus the amplitude of the next cycle. Cameron & Sch¨ssler u (2012) went on to suggest that these inflows were strong enough to reduce the tilt angle of the active regions and cause cross-equator flows that would enhance the cancellation of leading polarity flux across the equator. Yeates (2014) attempted to use the inflows suggested by Cameron & Sch¨ssler u (2012), but found that this led to a poorer correlation with the observations. This may be explained by the fact that our meridional flow observations indicate that the inflows into active regions are much weaker than suggested by Cameron & Sch¨ ussler (2012). We find that the presence of active regions causes the peak of the meridional flow to drop and move to lower latitudes - giving a relatively faster poleward flow near the equator and a slower poleward flow at higher latitudes. Furthermore, no significant cross-equator flow is seen in the observations.
We have developed a new surface magnetic flux transport model that advects the magnetic flux emerging in active regions using the observed nearsurface flows including evolving convection cells that do not require any parameterizations or free parameters (Upton & Hathaway 2014). Here we use this model with the observed meridional flow variations to investigate the importance of these variations on the polar fields produced by cycle 23 - the ultimate cause of the weak cycle 24 and exceptional cycle 23/24 minimum.
## 2. THE SURFACE FLUX TRANSPORT MODEL
We have created a surface flux transport model to simulate the dynamics of magnetic fields over the entire surface of the Sun. The basis of this flux transport model is the advection equation:
$$\frac { \partial B _ { r } } { \partial t } + \nabla \cdot ( u B _ { r } ) = S ( \lambda, \phi, t ) \text{ \quad \ } ( 1 )$$
where B r is the radial magnetic flux, u is the horizontal velocity vector (which includes the observed axisymmetric flows and the nonaxisymmetric convective flows), and S is an active region magnetic
source term as a function of latitude ( λ ), longitude ( φ ), and time ( ). t
This purely advective model is supported by both theory and observation. The Sun's magnetic field is carried to the boundaries of the convective structures (granules and supergranules) by flows within those convective structures. The field becomes concentrated in the downdrafts as small magnetic elements with radial (vertical) field. These weak magnetic elements are then transported like passive scalars (corks). This has been found in numerous numerical simulations of magneto-convection (c.f. V¨gler et al. 2005) and is o borne out in high time- and space-resolution observations of the Sun (Simon et al. 1988; Roudier et al. 2009).
We have measured the axisymmetric flows (meridional flow and differential rotation) averaged over 27-day rotations of the Sun by using feature tracking (Hathaway & Rightmire 2010, 2011; Rightmire-Upton et al. 2012) on full disk images of the Sun's magnetic field obtained from space by the Solar and Heliospheric Observatory Michelson Doppler Imager (MDI) (Scherrer et al. 1995) and by the Solar Dynamics Observatory Helioseismic and Magnetic Imager (HMI) (Scherrer et al. 2012). These axisymmetric flow profiles were fit with Legendre polynomials up to 5th order in sin( λ ). The polynomial coefficients were smoothed (in time) using a tapered Gaussian with a full width at half maximum of 13 rotations. Figure 1 shows that these polynomial fits fully capture the structure of the flow profiles. These smoothed coefficients were used to update the axisymmetric flow component of the vector velocities for each rotation, thereby including the solar cycle variations inherent in these flows.
The convective flows on the Sun, i.e., granules and supergranules, act not only to disperse magnetic flux, but also to concentrate flux into the magnetic elements of the magnetic network. Schrijver et al. (1996) showed that estimates of the diffusivity coefficient depend on the temporal and spatial scales, i.e. the effects of the convective flows cannot be captured by a single diffusivity alone. They state that '...despite the apparent success of the description of flux dispersal as a diffusion process, there are several notable inconsistencies between that model and observations.' Rather than employing a diffusivity with a Lapla-
Fig. 1.- Legendre polynomial fit to the meridional flow in 2001. The measured meridional flow profile averaged over calendar year 2001 is shown with the thin line. The polynomial fit is shown with the thick smooth line. The filled black circles mark the active region centroid positions for that year. It can be seen that even at cycle maximum that the polynomial fit is a good fit to the data. Any additional superimposed flows must be relatively weak (1-2 m s -1 ).
cian operator, we have chosen to use a supergranule simulation to explicitly model the convective motions. While the simulation is named for the dominant feature in spectrum, the supergranules, the simulation includes flow velocities for convective structures on all resolved scales (in this case, down to cells 6000 km in diameter).
The convective flows have been modeled using vector spherical harmonics as described by Hathaway et al. (2010) to simulate the convective motions on the Sun. A spectrum of complex spherical harmonic coefficients was used to create convective flows that reproduce the observed spectral characteristics. The spectral coefficients were evolved at each time step to give the cells finite lifetimes and to make them move with the observed differential rotation and meridional flow. The convection cells have lifetimes that are proportional to their size, e.g. granules with velocities of 3000 m s -1 , diameters of 1 Mm, have lifetimes of ∼ 10 minutes and supergranules with velocities of 500 m s -1 , diameters of 30 Mm, have lifetimes of ∼ 1 day. The evolving spectral coefficients are used to create a set of vector velocities that realistically simulate the flows observed on the Sun. For the simulations done here, vector velocities were created for
the full Sun at 1024 pixels in longitude, 512 pixels in latitude, and at a 15 minute cadence. These evolving flows automatically give different 'diffusivities' at different spatial and temporal scales.
Outside of active regions, the magnetic fields are weak, the plasma beta is high, and the field elements are carried by the plasma flows. Inside active regions, the plasma beta is low so the flows themselves are modified (quenched) by the strong magnetic fields. To account for this, the supergranule flow velocities are reduced where the magnetic field was strong. While this model allows us to easily quench the velocities in active regions, this is not easily done with a diffusion coefficient. This aspect of the flux transport has not typically been captured in previous models.
The advection equation was solved with explicit finite differencing (first order in time and second order in space) to produce magnetic flux maps of the entire Sun at a cadence of 15 minutes. These synchronic maps represent the Sun's magnetic field over the entire surface at a moment in time. The high convective velocities and high spatial resolution in the model can produce Gibbs phenomenon, i.e., ringing artifacts at sharp edges that can cause the solution to overshoot/undershoot in adjacent pixels. To stabilize the numerical integrations and mitigate this effect, a diffusion term is added so that Equation 1 becomes:
$$\frac { \partial B _ { r } } { \partial t } + \nabla \cdot ( u B _ { r } ) = S ( \lambda, \phi, t ) + \eta \nabla ^ { 2 } B _ { r } \quad ( 2 )$$
where η is a diffusivity. We note that this diffusivity term was strictly for numerical stability. Unlike previous surface flux transport models, the addition of this term has little effect on the flux transport. The convective motions produced explicit random walks for the magnetic elements in this model.
The supergranule simulation far surpasses the realism that can be provided by a diffusion coefficient alone, making it both appropriate and effective for use in surface flux transport models. Figure 2 illustrates the improvements that this supergranule simulation provides. The figure compares surface flux transport that uses a diffusivity coefficient of 250 km 2 s -1 , surface flux transport that uses the supergranule simulation, and surface flux transport as observed on the Sun. The surface flux transport that uses the supergranule simulation provides the closest match to surface flux transport observed on the Sun, in particular the formation of the magnetic network.
Ideally, we would like detailed information on the active regions sources - location and magnetic flux of every sunspot at least once per day. The National Oceanic and Atmospheric Administration (NOAA) Solar Region Summaries provide information about the total sunspot area, location, and longitudinal extent of all the sunspot groups that have been observed since 1977 (cycles 21-24). Active regions emerge and grow over several days or weeks. Flux is constantly emerging and spreading out across the Sun's surface. While previous models have represented active region sources by the addition of a single dipole source on the day of maximum sunspot group area (Sheeley et al. 1985; Wang et al. 1989), we choose to add flux daily as the sunspot group grows. If a sunspot group's area is larger than its previous maximum, then we add the additional flux (in the form of a Gaussian spot pair) centered on the daily position given by the NOAA Solar Region Summaries.
The increase in magnetic flux was calculated as a function of the increase in reported sunspot group area using the relationship described by Sheeley (1966) and by Mosher (1977):
$$\Phi ( A ) = 7. 0 \times 1 0 ^ { 1 9 } A \text{ \quad \ \ } ( 3 )$$
where Φ( A ) is the magnetic flux in Maxwells and A is the total sunspot area in units of micro hemispheres (1 µ Hem = 3 × 10 16 cm ). 2 NOAA also provides the longitudinal extent of each active region from the leading edge of the sunspot group to the trailing edge of the sunspot group. The centers of the Gaussian spot pairs were placed at longitudes on either side of the reported position at ± 0 3 times the given longitudinal extent and at . latitudes given by the longitudinal separations and the average Joy's Law tilt i.e., the angle between the bipolar spots with respect to lines of latitude is equal to one half of the latitude (Hale et al. 1919; Stenflo & Kosovichev 2012).
Ideally we would want to include the emergence, and further development, of active region on the far side of the Sun. Unfortunately, detailed active region information for the far side of the Sun during the time interval we model does not exist. However, the flux we do miss on the far side is somewhat offset by the fact that we do include
Fig. 2.- Flux transport method comparisons. A starting map (a) and a set of maps from one rotation of the Sun later: (b) a map from traditional surface flux transport that uses a diffusivity of 250 km 2 s -1 , (c) a map from our surface flux transport that uses the supergranule simulation, and (d) a map of the observed magnetic field. It is clear from this figure that surface flux transport with the supergranule simulation is more realistic.
active regions as soon as they rotate onto the near side and some of these active regions were already added in during their previous near side disk passage.
## 3. SIMULATIONS
Our surface flux transport model was first used to create what we call a baseline data set. The baseline is created by allowing the model to assimilate (i.e. continually add in observed data weighted by it's noise level) magnetic data from
magnetograms at all available longitudes and latitudes. The data assimilation process provides the closest contact with observations by correcting for any differences between data and model. In regions where data were recently assimilated (the outlined area in Fig. 2a), the baseline is virtually identical to the observations (including an annual signal due to instrumental effects). The baseline was used as a metric for comparison with the simulations in which the meridional flow varied. More detail about the baseline can be found in Upton & Hathaway (2014).
The model was then used in three simulations to determine the impact of the observed meridional flow variations on the sunspot cycle. Each simulation was run from January 1997 through July 2013. All three models used the same average, constant, and North-South symmetric differential rotation, given in terms of latitude ( λ ) by
$$v _ { \phi } ( \lambda ) = [ A + B \sin ^ { 2 } ( \lambda ) + C \sin ^ { 4 } ( \lambda ) ] \cos ( \lambda ) \ \ ( 4 )$$
with
$$A & = 3 9 \ m \ s ^ { - 1 } \\ B & = - 2 4 4 \ m \ s ^ { - 1 } \\ C & = - 3 7 4 \ m \ s ^ { - 1 }$$
The supergranule realizations were virtually identical for all three simulations. The size, lifetimes, and initial locations of the cells were the same. However the latitudinal drift of the convective cells were modulated by the meridional flow applied to each simulation. The meridional flow for each simulation was updated at six month intervals. Figure 3 shows the meridional flow profiles for all three simulations as functions of latitude and time.
The first simulation (hereafter referred to as Sim 1) included an average, constant, North-South antisymmetric meridional flow given by
$$v _ { \theta } ( \lambda ) = [ D \sin + E \sin ^ { 3 } ( \lambda ) + F \sin ^ { 5 } ( \lambda ) ] \cos ( \lambda )$$
(6)
with
$$D & = 2 4 \ m \ s ^ { - 1 } \\ E & = 1 6 \ m \ s ^ { - 1 } \\ F & = - 3 7 \ m \ s ^ { - 1 }$$
$$( 7 )$$
## Constant
Fig. 3.- The meridional flows as functions of latitude and time. (a) The constant North-South antisymmetric meridional flow used in Sim 1. (b) The observed meridional flow used in Sim 2. (c) The meridional flow with amplified variations used in Sim 3. Red is northward flow and blue is southward flow. For reference the contours (black lines) show 0, ± 5, ± 10, and ± 15 m s -1 .
The second simulation (Sim 2) included a meridional flow with the observed North-South structure and variations in time. In the third simulation (Sim 3), the differences between the average meridional flow and the observed meridional flow were doubled to amplify the variations in the meridional flow. The meridional flows in Sim 2 and Sim 3 included additional terms with even powers of sin( λ ) to account for the observed North-South asymmetries - most notably the polar counter-cells observed with MDI.
Figure 3 shows that the observed meridional flow varied in four stages relative to the average meridional flow. At the start of the simulations (1997-1998) the observed flow was similar in strength to the average flow (but with a countercell in the south). Around the time of the maximum of cycle 23 (1999-2002) the observed flow was slower than the average flow. By 2003 the flow speed had increased to become faster than average and it remained faster until 2010. This was then followed by rapid decrease in flow speed and a return to average. Note that the flow speed was average at cycle 22/23 minimum and average again at the maximum of cycle 24. In general, the meridional flow was slow at both the start and at the maximum of cycle 23 when compared to similar phases of cycles 21, 22, and now 24.
## 4. RESULTS
Each simulation produces synchronic maps (magnetic flux maps of the entire Sun) at a cadence of 15 minutes. These maps were used to calculate the axial magnetic dipole moment B p at each time step, where B p is given by
$$B _ { p } = \int _ { 0 } ^ { 2 \pi } \int _ { - \pi / 2 } ^ { \pi / 2 } B _ { r } ( \lambda, \phi ) Y _ { 1 } ^ { 0 } ( \lambda, \phi ) \cos \lambda d \lambda d \phi. \ ( 8 ) \quad \begin{array} { c } 1 \\ 1 \end{array}$$
The axial dipole moments measured for the baseline and each simulation are plotted in Figure 4.
A quick inspection of these axial dipole moments reveals that the dipole moments in the simulations reach amplitudes about twice as strong as the observed axial dipole moment. Given the fact that the relative positions and magnetic flux we added for the active region sources were based on simple statistical relationships, it is not at all surprising that the match is less than perfect. However, the systematic offset suggests that the ac-
Fig. 4.- The evolution of the axial dipole moments with different meridional flow profiles. The baseline axial dipole moment is shown in black (dashed for MDI, solid for HMI). Sim 2 (red, with the observed variations in the meridional flow) produced an axial dipole moment at cycle 23/24 minimum (late 2008) that is approximately 20% stronger than Sim 1 (blue, with the constant average meridional flow profile). Sim 3 (green, with the amplified variations) made the dipole another 20% stronger than in Sim 2.
tive region sources that most influence the axial dipole moment (total flux and/or latitudinal separations) are systematically over-estimated. Remarkably (and despite this) the timing of the cycle 24 reversal (in 2012/2013) is accurate to within about a year. Using observed magnetic flux and its location in active regions might improve the model to the point that the axial dipole moment for an entire solar cycle is reproduced with the observed flows.
Somewhat surprisingly, rather than producing weaker polar fields, the observed meridional flow variations produced a stronger axial dipole moment. Furthermore, this effects was more pronounced with the amplified meridional flow variations (Sim 3), indicating that the flow variations were indeed the source of the difference.
In all three cases, the axial dipole is well matched for the first three years as the dipole steadily and rapidly reverses polarity during the rise to maximum of cycle 23. During this time, the meridional flow was similar in all three simulations and consequently had the same effect on the axial dipole moments.
This dipole reversal is caused by the steadily increasing active region emergence combined with
Joy's Law, Sp¨rer's Law, and the poleward transo port of the following polarity flux. (Joy's Law is the characteristic tilt of bipolar active regions such that the leading polarity is more equatorward than the following polarity and Sp¨rer's Law says o that active region emergence progresses towards the equator over the course of the cycle.) The following polarity of newly emerging active regions cancels and then exceeds the leading polarity of the older active regions at progressively lower latitudes. The excess following polarity flux is transported to poles where it cancels the dipole field established at the previous minimum.
From 2000 to about 2004 the axial dipole moments in the three simulations follow different paths with the dipole moments getting stronger in Sim 2 and stronger yet in Sim 3. We attribute this divergence to the slowdown in the meridional flow in these simulations. By 2000 (cycle 23 maximum) the active regions cover their widest range of latitudes and many active regions emerge close to the equator. The slower meridional flow at this time allows more leading polarity flux to be transported across the equator by the convective motions. This leaves behind a greater excess of following polarity flux which, when transported poleward, increases the axial dipole moment. (Note that it takes a year or two for active region flux to be transported to the polar regions. This gives a similar lag in the response of the axial dipole moment to the variations in the meridional flow.)
After 2004 cycle 23 was in decline and the meridional flow speed increased substantially. With fewer active region sources and less cancellation across the equator it was more difficult to continue building up stronger polar fields. Furthermore, during solar minimum very little flux is emerging in the form of active regions. Without flux to transport, the meridional flow has little to no effect. Instead, turbulent motions slowly erode the flux at the poles and the axial dipole moment gradually decays in all three simulations.
From 2010 to 2012, the cycle 24 field reversal occurs with Sim 3 reversing the fastest and Sim 1 reversing the slowest. While we attribute this to the rapid slow down of the meridional flow around 2010, the active regions are emerging far from the equator and thus it is too early for any crossequatorial flow. We conjecture that the slower meridional flow may simply allow for more cancel- lation in the active latitudes, resulting in less following polarity flux being transport to the poles, and thus the different reversal rates. We note that this is also precisely the time when the countercell in the north disappears. The sudden lack of a counter-cell in the north may cause more following polarity flux to be picked up by the meridional flow and carried to the poles, exacerbating the different reversal rates. After 2012 all three simulations have similar developments since the meridional flow is nearly average in all three.
To provide additional context and information, the magnetic butterfly diagrams of the baseline and each simulation are shown in Figure 5.
A comparison of the simulated magnetic butterfly diagrams with the baseline illustrates the fidelity of this flux transport model. The simulated magnetic butterfly diagrams share details with the baseline in spite of the lack of detail in our active region sources (i.e., total flux, tilt, and longitudinal separation). The mottled pattern produced by active region emergence (i.e. the butterfly 'wings') are well reproduced, with distinct features often visible in both the baseline and the simulations. Poleward streams of both polarities are also observed, often with a one-to-one correspondence between the baseline and the simulations.
The biggest discrepancies between the baseline and the simulations appear at the poles, and in the north in particular. First of all, the amplitude is too strong, further indicating that the sources are being over-estimated. Secondly, we note that the polar concentrations occur at lower latitudes for Sim 2 and Sim 3 when counter-cells are present in the meridional flow (in the south prior to 2000 and in the north from 2000 to 2010). The fact that this is not observed in the baseline, nor with the HMI data, suggests that these polar countercells are not real. The presence of counter-cells in the meridional flow as measured by MDI could be caused by unaccounted for changes in the geometry (e.g., elliptical distortion) of the MDI images.
## 5. CONCLUSIONS
Our innovative surface flux transport model features several advantages over most previous surface flux transport models:
- 1. This model advects the flux with simulated convective motions, rather than invoking a
## -10G ~5G OG +5G +10G
Fig. 5.- Magnetic Butterfly Diagrams. These magnetic butterfly diagram illustrate the evolution of magnetic flux in the baseline and in the three simulations. The baseline is shown on the top left. Sim 1 (top right) used a constant north-south symmetric meridional flow. The observed meridional flow was used in Sim 2 (bottom left). Sim 3 (bottom right) used the observed meridional flow with variations from the average doubled.
diffusion coefficient to account for the turbulent transport.
- 2. This model incorporates the observed meridional flows, whereas previous models have used meridional profiles that deviate significantly from the observations.
- 3. In the Sun, the convective flows are affected by strong magnetic fields (i.e., the flows are quenched in active regions). While this effect is difficult to reproduce with the diffusivity used in prior models, this effect is captured in our model by actually quenching the convective flows where the field is strong.
- 4. While previous models have added a single magnetic flux source on the day of maximum sunspot group area to represent sunspots, our model adds flux daily as it emerges.
These advantages make this model the most realistic surface flux transport model to date.
The simulations presented in this paper show that the variations in the meridional flow over cycle 23 had a significant impact (at least ∼ 20%) on the polar fields. The variable meridional flow produced a stronger axial dipole moment than was produced with a constant meridional flow. We are confident that this is a robust result that would also be obtained with other surface flux transport
models using our meridional flow and its variations. The meridional flow variations (in particular the very slow flow at cycle 23 maximum) appear to have kept the polar fields from becoming even weaker yet. The weak polar fields at cycle 23/24 minimum caused the extended minimum and then went on to produce the weak cycle 24. If the polar fields were even weaker they might have led to a grand, Maunder-type, minimum. This suggests that variations in the meridional flow may provide a possible feedback mechanism for regulating the solar cycle and possibly recovering from a Maunder-type minimum (see e.g. Jiang et al. 2010; Cameron & Sch¨ ussler 2012).
There are two possible ways for producing the observed weak polar fields that modulate the solar cycle: 1) via flux transport or 2) via the active region sources. There is no credible evidence that the diffusion process changes substantially, but there is significant variation in the meridional transport. This experiment suggests that the actual cause of the weak polar fields at the end of cycle 23 was not the meridional flow variations. By eliminating the meridional flow as a cause of the weak polar fields, the active region sources must be the culprit.
Active region sources can modulate the polar field strengths in two ways: 1) via the amount of flux emerging at the surface (i.e., the amplitude of the sunspot cycle) or 2) via the orientation of the active regions (i.e., the latitudinal separation of the opposing polarities). We propose that the most simple and reasonable explanation for the weak polar fields at the end of cycle 23 is the emergence of fewer active region sources. Cycle 23 had a peak sunspot number of ∼ 120 - much smaller that cycle 21 and cycle 22 (which had peaks of ∼ 160). With fewer active region sources to reverse the strong polar fields at cycle 22/23 minimum (in 1996), there was insufficient flux to rebuild a strong polar field.
This conclusion, while simple and supported by observations of cycle 23, is contrary to conclusions by others. In particular, Jiang et al. (2013) concluded that the weakness of the polar fields at the end of cycle 23 could have been produced by an increase in the meridional flow by 55%, or by a decrease in active region tilt by 28% (but with a 1.5 year delay in the polar field reversal relative to what was observed). While they also found that a 40% reduction in the sunspot number could account for the weaker polar fields, they discounted this explanation because it did not produce enough open flux.
There are significant differences between their study and ours, especially in the details of the flux transport itself. They used an idealized meridional flow profile significantly different from the profile we observe (no meridional flow at all above 75 degrees latitude). Additionally, their meridional flow did not include the observed systematic variations (amplitude and latitudinal structure) over the course of the cycle. They parameterized the advection of the magnetic field by the convective motions by a diffusivity (250 km 2 s -1 ) and a Laplacian operator rather than explicitly including those flows. They also used idealized active region sources instead of actual active region sizes and locations. Different values for the meridional flow, the diffusivity, or for the active region sizes and locations would impact their conclusions.
Their conclusions were based on comparisons to their reference model - which produced strong polar fields at the end of cycle 23 (even stronger than those at the end of the much larger previous two cycles). This is inconsistent with the polar fields observed on the Sun for Cycle 23, which were about half as strong as for the prior two cycles. The production of these strong polar fields in their reference model can be traced to two significant differences in their active region sources. First of all, they included changes in Joy's law tilt, with their reference case having 10% more tilt in cycle 23 than in the two preceding cycles. Secondly, they did not use actual data for the sizes and locations of active regions in these cycles. Instead they used the monthly sunspot number as a parameter in a set of empirical relations that generate artificial sizes and locations for active regions. An important difference, evident from comparing butterfly diagrams of active region locations, is the continued emergence in their data of active regions in the north after 2005. This is notably absent in actual cycle 23 data.
While the active region tilt and meridional flow no doubt play a role in modulating the polar fields, as suggested by Jiang et al. (2013), the importance of the amplitude of the cycle may have been masked by other details in their flux transport model. In this paper, we have performed
a fairly simple scientific experiment in which the only variable was the meridional flow. We found that the observed variations in the meridional flow produced a stronger axial dipole moment relative to that produced by the average meridional flow. Based on these results, we conclude that the primary reason the polar fields were weak at the end of cycle 23 is because the active region sources were weak.
Comparison of the magnetic butterfly diagrams showed that polar counter-cells in the meridional flow produce magnetic flux concentrations that are offset to lower latitudes from the poles. This effect was previously noted by Jiang et al. (2009). In the baseline, however, the flux is concentrated precisely at the poles. This is evidence that the polar counter-cells observed in the meridional flow measurements are likely to be artifacts. Furthermore, the full magnetic butterfly diagram history does not contain any offset polar magnetic field concentrations. This indicates that the meridional flow has not had any polar counter-cells during this time period, i.e., from 1973 to present.
The presence of poleward streams of leading polarity flux provides insight into the nature of these streams. In the past, these poleward streams have been attributed to active regions with large variations from Joy's law tilt. However, the current version of the flux transport model uses the average Joy's law tilt for each active region source without any variations. Since these streams can be reproduced without the scatter in the tilt of bipolar active regions, we propose an alternate explanation.
Normally, new active regions emerge slightly equatorward of the older decaying active regions. This causes the following polarity of the new active regions to emerge at similar latitudes to the leading polarity flux in old active regions. The excess following polarity flux is then transported to the poles forming a following polarity poleward stream, while the new leading polarity flux is left to be canceled by future following polarity emergence. However, if a substantial gap or a sudden equatorward shift in active region emergence occurs, there would be nothing to cancel with the leading polarity flux. This leading polarity flux would then be transported (after the following polarity flux) to the poles in the form of a leading polarity poleward stream. Alternatively, the appear- ance of an unusually strong bipolar active region (or progressively weaker active region emergence occurring in the declining phase of the solar cycle) may produce the effect. While active regions with substantial deviations from Joy's law probably do contribute to the production of these streams, this is clearly not the only source.
The fact that all three simulations produced axial dipole moments and polar fields much stronger than observed suggests that our active region sources need revision. Active region flux versus sunspot group area is a crucial component in our model. We suspect that this relationship may be in error. Sheeley (1966) and Mosher (1977) found a linear relationship between these parameters; however this was based on very few data points. Dikpati et al. (2006) found a linear relationship with a nonzero intercept that gives about 7-times as much flux, but argue that only 1/7 th survives immediate cancellation with nearby opposite polarity flux. Further investigation of this this relationship using MDI and HMI data may be needed to improve the predictive capability of this flux transport model. Our surface flux transport model (which can use active region databases to replicate magnetic field emergence) has been shown to accurately predict the polar field evolution for 3-5 years (Upton & Hathaway 2014). Improvements to the active region flux versus area relationship may extend the predictive capability of the model by years. Remarkably, and despite this impairment, the timing of the polar field reversals were accurate to within a year.
The authors were supported by a grant from the NASA Living with a Star Program to Marshall Space Flight Center. The HMI data used are courtesy of the NASA/SDO and the HMI science team. The SOHO/MDI project was supported by NASA grant NAG5-10483 to Stanford University. SOHO is a project of international cooperation between ESA and NASA.
## REFERENCES
| Babcock, H. W. 1961, ApJ, 133, 572 |
|-----------------------------------------------------------------------------------------------------------------------------|
| Baumann, I., Schmitt, D., Sch¨ssler, u M., & Solanki, S. K. 2004, A&A, 426, 1075 |
| Cameron, R. H. & Sch¨ssler, u M. 2012, A&A, 548, A57 |
| DeVore, C. R., Boris, J. P., & Sheeley, Jr., N. R. 1984, Sol. Phys., 92, 1 |
| Dikpati, M., de Toma, G., & Gilman, P. A. 2006, Geophys. Res. Lett., 33, 5102 |
| Hale, G. E., Ellerman, F., Nicholson, S. B., & Joy, A. H. 1919, ApJ, 49, 153 |
| Hathaway, D. H. & Rightmire, L. 2010, Science, 327, 1350 |
| -. 2011, ApJ, 729, 80 |
| Hathaway, D. H., Williams, P. E., Dela Rosa, K., & Cuntz, M. 2010, ApJ, 725, 1082 |
| Jiang, J., Cameron, R., Schmitt, D., & Sch¨ssler, u M. 2009, ApJ, 693, L96 |
| Jiang, J., Cameron, R. H., Schmitt, D., & Sch¨ssler, u M. 2013, Space Sci. Rev., 176, 289 |
| Jiang, J., I¸ik, s E., Cameron, R. H., Schmitt, D., & Sch¨ssler, u M. 2010, ApJ, 717, 597 |
| Komm, R. W., Howard, R. F., & Harvey, J. W. 1993, Sol. Phys., 147, 207 |
| Mosher, J. M. 1977, PhD thesis, California Insti- tute of Technology, Pasadena. |
| Mu˜oz-Jaramillo, n A., Sheeley, N. R., Zhang, J., & DeLuca, E. E. 2012, ApJ, 753, 146 |
| Rightmire-Upton, L., Hathaway, D. H., & Kosak, K. 2012, ApJ, 761, L14 |
| Roudier, T., Rieutord, M., Brito, D., Rincon, F., Malherbe, J. M., Meunier, N., Berger, T., & Frank, Z. 2009, A&A, 495, 945 |
| Schatten, K. H., Scherrer, P. H., Svalgaard, L., & Wilcox, J. M. 1978, Geophys. Res. Lett., 5, 411 |
Scherrer, P. H., Bogart, R. S., Bush, R. I., Hoeksema, J. T., Kosovichev, A. G., Schou, J., Rosenberg, W., Springer, L., Tarbell, T. D., Title, A., Wolfson, C. J., Zayer, I., & MDI Engineering Team. 1995, Sol. Phys., 162, 129
Scherrer, P. H., Schou, J., Bush, R. I., Kosovichev, A. G., Bogart, R. S., Hoeksema, J. T., Liu, Y., Duvall, T. L., Zhao, J., Title, A. M., Schrijver, C. J., Tarbell, T. D., & Tomczyk, S. 2012, Sol. Phys., 275, 207
Schrijver, C. J. & Liu, Y. 2008, Sol. Phys., 252, 19
Schrijver, C. J., Shine, R. A., Hagenaar, H. J., Hurlburt, N. E., Title, A. M., Strous, L. H., Jefferies, S. M., Jones, A. R., Harvey, J. W., & Duvall, Jr., T. L. 1996, ApJ, 468, 921
Schrijver, C. J. & Title, A. M. 2001, ApJ, 551, 1099
Sheeley, Jr., N. R. 1966, ApJ, 144, 723
Sheeley, Jr., N. R., DeVore, C. R., & Boris, J. P. 1985, Sol. Phys., 98, 219
Simon, G. W., Title, A. M., Topka, K. P., Tarbell, T. D., Shine, R. A., Ferguson, S. H., Zirin, H., & SOUP Team. 1988, ApJ, 327, 964
Stenflo, J. O. & Kosovichev, A. G. 2012, ApJ, 745, 129
Svalgaard, L., Cliver, E. W., & Kamide, Y. 2005, Geophys. Res. Lett., 32, 1104
Svalgaard, L. & Kamide, Y. 2013, ApJ, 763, 23
Upton, L. & Hathaway, D. H. 2014, ApJ, 780, 5
van Ballegooijen, A. A., Cartledge, N. P., & Priest, E. R. 1998, ApJ, 501, 866
V¨ ogler, A., Shelyag, S., Sch¨ssler, M., Cattaneo, u F., Emonet, T., & Linde, T. 2005, A&A, 429, 335
Wang, Y.-M., Nash, A. G., & Sheeley, Jr., N. R. 1989, ApJ, 347, 529
Wang, Y.-M., Robbrecht, E., & Sheeley, Jr., N. R. 2009, ApJ, 707, 1372
Yeates, A. R. 2014, Sol. Phys., 289, 631
This 2-column preprint was prepared with the AAS L T E X A macros v5.2. | 10.1088/0004-637X/792/2/142 | [
"Lisa Upton",
"David H. Hathaway"
] | 2014-07-31T21:46:40+00:00 | 2014-07-31T21:46:40+00:00 | [
"astro-ph.SR"
] | Effects of Meridional Flow Variations on Solar Cycles 23 and 24 | The faster meridional flow that preceded the solar cycle 23/24 minimum is
thought to have led to weaker polar field strengths, producing the extended
solar minimum and the unusually weak cycle 24. To determine the impact of
meridional flow variations on the sunspot cycle, we have simulated the Sun's
surface magnetic field evolution with our newly developed surface flux
transport model. We investigate three different cases: a constant average
meridional flow, the observed time-varying meridional flow, and a time-varying
meridional flow in which the observed variations from the average have been
doubled. Comparison of these simulations shows that the variations in the
meridional flow over cycle 23 have a significant impact (~20%) on the polar
fields. However, the variations produced polar fields that were stronger than
they would have been otherwise. We propose that the primary cause of the
extended cycle 23/24 minimum and weak cycle 24 was the weakness of cycle 23
itself - with fewer sunspots, there was insufficient flux to build a big cycle.
We also find that any polar counter-cells in the meridional flow (equatorward
flow at high latitudes) produce flux concentrations at mid-to-high latitudes
that are not consistent with observations. |
1408.0036v1 | ## Discovery of the supernova remnant G351.0-5.4
F. de Gasperin , C. Evoli 1 2 , M.Br¨ uggen 1 , A. Hektor 3 , M. Cardillo 4 , P. Thorman 5 , W.A. Dawson 5 6 ; , and C.B. Morrison 5 7 ;
- 1 Universit¨ at Hamburg, Hamburger Sternwarte, Gojenbergsweg 112, 21029, Hamburg, Germany e-mail: [email protected]
- 2 Institut f¨r Theoretische Physik, Universit¨ at Hamburg, Luruper Chaussee 149, 22761, Hamburg, Germany u
- 3 National Institute of Chemical Physics and Biophysics, Ravala 10, Tallinn, Estonia
- 4 INAF-Osservatorio di Arcetri, Largo Enrico Fermi 5, 50125, Firenze, Italy
- 5 University of California, One Shields Avenue, Davis, CA 95616, USA
- 6 Lawrence Livermore National Lab, 7000 East Avenue, Livermore, CA 94550, USA
- 7 Argelander Institute for Astronomy, University of Bonn, Auf dem H¨ ugel 71, 53121 Bonn, Germany
## ABSTRACT
Context. While searching the NRAO VLA Sky Survey (NVSS) for di GLYPH<11> use radio emission, we have serendipitously discovered extended radio emission close to the Galactic plane. The radio morphology suggests the presence of a previously unknown Galactic supernova remnant. An unclassified GLYPH<13> -ray source detected by EGRET (3EG J1744-3934) is present in the same location and may stem from the interaction between high-speed particles escaping the remnant and the surrounding interstellar medium.
Aims. Our aim is to confirm the presence of a previously unknown supernova remnant and to determine a possible association with the GLYPH<13> -ray emission 3EG J1744-3934.
Methods. We have conducted optical and radio follow-ups of the target using the Dark Energy Camera (DECam) on the Blanco telescope at Cerro Tololo Inter-American Observatory (CTIO) and the Giant Meterwave Radio Telescope (GMRT). We then combined these data with archival radio and GLYPH<13> -ray observations.
Results. While we detected the extended emission in four di GLYPH<11> erent radio bands (325, 1400, 2417, and 4850 MHz), no optical counterpart has been identified. Given its morphology and brightness, it is likely that the radio emission is caused by an old supernova remnant no longer visible in the optical band. Although an unclassified EGRET source is co-located with the supernova remnant, Fermi-LAT data do not show a significant GLYPH<13> -ray excess that is correlated with the radio emission. However, in the radial distribution of the GLYPH<13> -ray events, a spatially extended feature is related with SNR at a confidence level GLYPH<24> 1 5 : GLYPH<27> .
Conclusions. We classify the newly discovered extended emission in the radio band as the old remnant of a previously unknown Galactic supernova: SNR G351.0-5.4.
Key words. ISM: supernova remnant - Radio continuum: ISM - Gamma rays: ISM
## 1. Introduction
Supernova Remnants (SNRs) have a fundamental role inside our Galaxy and in general, inside their host-galaxies. The gravitational collapse of a stellar core causes the ejection of the outer layers of the star at very high velocities ( GLYPH<25> 10 000 km s ; GLYPH<0> 1 ). The interaction between the circumstellar medium and the ejected matter produces shock-waves propagating at a non-negligible fraction of the speed of light ( v GLYPH<25> 0 1 : GLYPH<0> 0 2 c). : In addition, di GLYPH<11> usive shock acceleration (DSA) predicts that shock fronts observed in SNRs are e GLYPH<14> cient accelerators of Galactic Cosmic Rays (GCR). Accelerated protons interact with the protons of the ISM producing a GLYPH<25> 0 meson that then decays into two GLYPH<13> -ray photons (Malkov & Drury 2001, and references therein). At the same time, accelerated electrons will follow a power-law momentum distribution and produce radio non-thermal emission from the SNR. The proton-proton interaction time decreases with the target density enhancement. Consequently, GLYPH<13> -ray emission from SNRs can be more easily seen when the remnant interacts with a target denser than the ISM, such as a molecular cloud, as is the case with S147 (Katsuta et al. 2012), IC443 (Tavani et al. 2010; Ackermann et al. 2013), W28 (Giuliani et al. 2010) and W44 (Ackermann et al. 2013; Cardillo et al. 2014).
and 10 000. However, only ; GLYPH<24> 274 SNRs have been identified (Green 2009, and references therein). Most of the known SNRs are sources of radio-synchrotron emission and radio observations were routinely used to discover new candidates. Images from radio surveys, such as the NRAO VLA Sky Survey (NVSS; Condon et al. 1998), were successfully used in the past to identify new SNR candidates (see e.g., Green 2001, for the case of G353.9-2.0). The NVSS provides polarized images at 1.4 GHz, covering the sky down to a declination of GLYPH<0> 40 , and its data were GLYPH<14> collected with the VLA in D-configuration. Although the survey images are obtained with short snap-shots which may limit the sensitivity on the largest scales, the NVSS is a good starting point to look for extended radio emission, up to scales of GLYPH<24> 16 . 0
It has been predicted (Berkhuijsen 1984; Tammann et al. 1994) that the total number of Galactic SNRs is between 1000
By inspecting NVSS radio maps, we discovered a new candidate SNR which we designated SNR G351.0-5.4. Here we present a radio follow-up at 325 MHz using the GMRT and an optical follow-up using DECam on the CTIO 4 m Blanco telescope. Furthermore, SNR G351.0-5.4 appears to be co-located with the unclassified EGRET GLYPH<13> -ray source 3EG J1744-3934. In order to test the EGRET detection, we have conducted a search for GLYPH<13> -ray emission at the location of SNR G351.0-5.4 with the Large Area Telescope (LAT) on board the Fermi Gamma-Ray Space Telescope.
In Sec. 2 we present the GMRT (Sec. 2.1), DECam (Sec. 2.3) and Fermi (Sec. 2.4) observations and the respective data reductions. The main characteristics of SNR G351.0-5.4 are presented
Table 1: Coordinates and flux densities at 325 MHz of the subtracted point sources
| Source name | RA (J2000) | Dec (J2000) | S 325 (Jy) |
|---------------------|----------------|---------------------------------|--------------|
| NVSS J174802-385754 | 17 h 48 m 01 s | GLYPH<0> 38 GLYPH<14> 57 m 51 s | 0.24 |
| NVSS J174543-392912 | 17 h 45 m 44 s | GLYPH<0> 39 GLYPH<14> 29 m 12 s | 0.15 |
| NVSS J174737-394957 | 17 h 47 m 38 s | GLYPH<0> 39 GLYPH<14> 49 m 59 s | 0.13 |
| NVSS J174122-392935 | 17 h 41 m 22 s | GLYPH<0> 39 GLYPH<14> 29 m 35 s | 0.12 |
in Sec. 3. Discussion and conclusions are in Sec. 4 and Sec. 5, respectively.
## 2. Observations and data reduction
## 2.1. GMRT
Using the GMRT 1 , we observed the radio emission in the direction of SNR G351.0-5.4 with a run of 5 hours. During the night of March 18-19, 2013, visibilities were recorded at 325 MHz in dual-polarization (RR and LL). We used an 8 second integration time, and a 33 MHz bandwidth divided into 512 channels. The (primary) flux and bandpass calibrator 3C 286 was observed at the start and end of each run, while the (secondary) gain calibrator PKS 1827-36 was observed every half an hour for three minutes. The total time-on-target was 135 minutes.
The visibility data was processed using a semi-automated CASA 2 -based data reduction pipeline written in Python. Data were initially flagged through a series of increasingly sensitive runs of the CASA tasks FLAGDATA in the 'rflag' mode. During these cycles a refined bandpass was obtained. 3C 286 was used as the flux and bandpass calibrator. Flags were then reset and, once corrected for the bandpass, AOflagger (O GLYPH<11> ringa et al. 2012) was used to detect and remove radio frequency interference. At the end of the procedure seven antennas (two of which in the core) were manually flagged together with approximately 45% of the remaining data because of interference. After an initial phase and amplitude calibration on 3C 286, bad baselines were identified and removed by inspecting the BLCAL calibration tables, and the phase and amplitude solutions were extended to the target field. Several cycles of phase self-calibration, with subsequent clipping of the outliers, were performed and a final cycle of amplitude self-calibration was eventually made. Calibration in time and amplitude in the direction of the four brightest sources in the field and subsequent subtraction ('peeling', Noordam 2004) was done iteratively after subtracting the best model of the rest of the field. The source to peel is then subtracted and the other sources restored. Location of the peeled sources and flux densities are given in Table 1.
Afinal image was made removing baselines longer than 8 k GLYPH<21> and data were tapered applying a circular Gaussian taper with FWHMat18k GLYPH<21> to reach a resolution of 141 00 GLYPH<2> 89 00 and enhance the extended emission of the target. The resulting primary-beam corrected image has a background noise of 1.5 mJy beam GLYPH<0> 1 and is presented in Fig. 1. The flux densities of the east and west part of the shell are listed in Table 2.
## 2.2. Archival radio data
Amapat 1400 MHz has been extracted from the NVSS (Condon et al. 1998). The image rms is GLYPH<24> 0 5 : mJybeam GLYPH<0> 1 at a reso-
- 1 GMRT: http://gmrt.ncra.tifr.res.in
2 CASA: http://casa.nrao.edu
20
Fig. 1: GMRT radio maps of SNR G351.0-5.4 at 325 MHz. Beam size is shown in the bottom left corner, contours are equally spaced between 2 GLYPH<27> and 20 GLYPH<27> in logarithm space with GLYPH<27> = 1 5 mJy beam : GLYPH<0> 1 . Dashed contours are at GLYPH<0> 2 GLYPH<27> . The dashed circle traces the SNR shell location, while the yellow dot shows the positions of the pulsar PSR J1744-3922 and the red star shows the position of the GLYPH<13> -ray source 3EG J1744-3934. The dotted circle is the 1 GLYPH<27> position error of the GLYPH<13> -ray source.
RA (2000)
Fig. 3: Fractional polarization map obtained from the Parkes 2.4 GHz Survey of the southern Galactic Plane. E-vectors (perpendicular to the magnetic field) are also displayed for every pixel of the original maps. Pixel below 2 GLYPH<27> in the total intensity ( GLYPH<27> = 11 mJybeam GLYPH<0> 1 ) or in the polarized intensity map ( GLYPH<27> = 20 mJy beam GLYPH<0> 1 ) were blanked.
(a) VLA (NVSS) - 1400 MHz
(b) Parkes 64m - 2417 MHz
(c) Parkes 64m (PMN) - 4850 MHz
Fig. 2: Radio maps of SNR G351.0-5.4 at 1400 (NVSS), 2417 (Parkes 64m) and 4850 (PMN) MHz. Beam size is shown in the bottom left corner of every panel, contours are equally spaced between 2 GLYPH<27> and 20 GLYPH<27> in logarithm space with GLYPH<27> 1400 = 0 5 mJy beam : GLYPH<0> 1 , GLYPH<27> 2400 = 11 mJy beam GLYPH<0> 1 , and GLYPH<27> 4850 = 11 mJy beam GLYPH<0> 1 . Dashed contours are at GLYPH<0> 2 GLYPH<27> . Markers and lines are as in Fig. 1.
lution of 45 00 . This high-resolution image of SNR G351.0-5.4 shows the extremely narrow front of the expanding shell towards the east (see Fig. 2a). Although the extension of the SNR is smaller than the largest detectable angular scale for the VLA in D-configuration, flux density measurements are likely to be underestimated due to the poor coverage of the central part of the u v -plane caused by the short observing time. NVSS polarized intensity in the direction of SNR G351.0-5.4 is too weak to provide useful information.
A map at 2417 MHz has been obtained from the Parkes 2.4 GHz Survey of the southern Galactic Plane (Duncan et al. 2012) with an image noise of GLYPH<24> 11 mJybeam GLYPH<0> 1 and a resolution of 10 (see Fig. 2b). The target is detected but it is embedded in a 0 larger-scale emission. Enhanced emission is visible in the corresponding regions of the shell that are detected in the higherresolution maps. Compared to all other radio maps, the Parkes 2.4 GHz map shows entirely the extended structure of the source, having been extracted from a single-dish observation with no filtering applied. Polarized intensity maps from the Parkes 2.4 GHz survey have also been analysed. After applying a cut at 2 GLYPH<27> both in the total intensity and in the polarized intensity maps, a region with a fractional polarization emission of GLYPH<24> 15% has been detected in the north west part of the remnant (see Fig. 3).
We obtained a high-frequency radio map from the ParkesMIT-NRAO (PMN; Gri GLYPH<14> th & Wright 1993) survey at 4850 MHz with an image local noise of GLYPH<24> 11 mJy beam GLYPH<0> 1 and a resolution is of 4 0 : 9 (see Fig. 2c). The SNR G351.0-5.4 is visible even at this higher frequency but the elongated bow structure on the east is broken into two distinct parts. The presence of an extended emission inside the boundary of the SNR is also visible. The PMN survey was optimized for point source detection, consequently a low-pass filter was applied in the data reduction process (Gri GLYPH<14> th & Wright 1993) with the e GLYPH<11> ect to bias the flux densities of detected sources, mostly if extended, towards lower values. We note therefore that also PMN flux densities are likely to be underestimated.
## 2.3. DECam
In order to determine if the di GLYPH<11> use radio emission was a radio relic associated with a merging cluster of galaxies we observed the field in the optical during 4-7 Apr 2013 using DECam
(DePoy et al. 2008) on the CTIO 4 m Blanco telescope. We observed the field in g , r , and i to facilitate star-galaxy separation and potentially select cluster members. Exposures in g , r , and i were 100-200 s, dithered by 90 00 along each axis to cover the chip gaps. The total exposure times were 2000 s in g , 2000 s in r , and 2623 s in i . These correspond to a 5 GLYPH<27> point source AB magnitude depths of 26.6 in g , 26.1 in r , and 25.8 in i . After accounting for Galactic extinction (Schlafly & Finkbeiner 2011) the depths are 24.7 in g , 24.8 in r , and 24.8 in i . Using IRAF, all images were bias subtracted and flat-field corrected using nightly dome flats, then registered using msccmatch for alignment. Residual gradients across the CCDs were removed using imsurfit , and the resulting images were stacked using mscimatch to estimate the relative normalizations. The final image is shown in Fig. 4.
## 2.4. Fermi-LAT
To probe whether SNR G351.0-5.4 is a site of GCR acceleration, we searched for GLYPH<13> -ray emission at its location from the public database of the Fermi-LAT. LAT on board the Fermi Gamma-ray Space Telescope is able to detect GLYPH<13> -rays with energies between 100 MeV and 300 GeV (Atwood et al. 2009). Data used in this work were obtained between 2008 August 4 and 2013 November 3 (Pass 7 Reprocessed Weekly Files), which are available from the Fermi Science Support Center . We used the Fermi Science 3 Tools 'v9r23p1' package to reduce and analyse the data in the vicinity of SNR G351.0-5.4. The region of interest was defined as a square GLYPH<6> 3 GLYPH<14> around the central point of SNR G351.0-5.4. From the Fermi LAT data we extracted the GLYPH<13> -ray events for the region of interest in the energy range from 1 to 500 GeV. To calculate the flux we used the energy dependent point spread function of LAT (Ackermann et al. 2012). We did not considered energy events below 1 GeV due to the very poor angular resolution. The image with the photon count is shown in Fig. 5.
3 http://fermi.gsfc.nasa.gov/ssc/data/analysis/ software/
Table 2: Radio observations
| Telescope | Frequency (MHz) | Resolution | Largest scale (arcmin) | Flux density (mJy) | Flux density (mJy) | Rms (mJy beam GLYPH<0> 1 ) |
|------------------|-------------------|------------------------------|--------------------------|----------------------|----------------------|------------------------------|
| | | | | East | West | |
| GMRT | 325 | 141 00 GLYPH<2> 89 00 | ' 32 | 151 | 280 | 1.5 |
| VLA (NVSS) | 1400 | 45 00 GLYPH<2> 45 00 | ' 16 | 48 | 67 | 0.5 |
| Parkes 64m | 2417 | 10 0 : 23 GLYPH<2> 10 0 : 62 | - | GLYPH<24> 3000 b | GLYPH<24> 3000 b | 11 |
| Parkes 64m (PMN) | 4850 | 4 0 : 9 GLYPH<2> 4 0 : 9 | ' 57 a | 367 | 162 | 11 |
a although the PMN is a single dish survey, a limit on the largest scale is given by the filtering procedure applied during data reduction (Gri GLYPH<14> th & Wright 1993). b The target emission is blended with the surrounding Galactic extended emission.

Fig. 4: DECam optical image ( g , r and i filters) of the target field. In red dashed-line the hypothetical size of the supernova remnant. Contours are from the NVSS survey (1400 MHz) at (2 ; 2 75 3 5 4 25 5) : ; : ; : ; GLYPH<2> GLYPH<27> with GLYPH<27> = 0 5 mJy beam : GLYPH<0> 1 .
## 3. SNR G351.0-5.4
The candidate SNR has a radius of 15 0 : 5 with a centre located at GLYPH<11> = 17 h 45 m 55 s , GLYPH<14> = GLYPH<0> 39 24 m GLYPH<14> 50 s (J2000) or l = 351 06 , : GLYPH<14> b = GLYPH<0> 5 49 (Galactic). : GLYPH<14>
In Fig. 1 and 2 we present the four available radio images (325, 1400, 2417 and 4850 MHz) of SNR G351.0-5.4. In the high-resolution NVSS image the very narrow edge of the expanding shell is visible on the east side. On the west side a more disrupted edge is visible. Hints of emission come also from the north-east side of the shell and are mostly visible in the GMRT and PMN maps. The radio emission is globally not symmetric and mostly located on the expanding shell, features typical of old SNRs where the interaction with the ISM has already modified the symmetry present in the primary expansion stages (see e.g. Green 1986; Leahy & Roger 1998, for IC443 and the Cygnus Loop respectively).
Given the radio morphology, another interpretation could be that the radio emission is a 'double radio relic' generated by merging galaxy clusters producing shocks (Feretti et al. 2012). Relics are typically found in massive and merging systems with a hot intra-cluster medium (10 7 GLYPH<0> 10 8 K) glowing in the X-ray. However, given the typical size of radio relics ( GLYPH<24> 1 Mpc), the cluster should be at z GLYPH<24> 0 05 and should have been detected by :
Fig. 5: Photon count from the Fermi-LAT observation in the energy band 1 GLYPH<0> 500 GeV. The angular resolution (68% containment radius) increases monotonically from GLYPH<24> 1 GLYPH<14> to GLYPH<24> 0.2 GLYPH<14> in the energy range 1-300 GeV (Ackermann et al. 2012). White contours follow the GLYPH<13> -ray emission. Black contours follow the NVSS 1.4 GHz emission (Fig. 2a). Markers and lines are as in Fig. 2a.
the ROSAT all sky survey although it is not. Furthermore, we find no evidence for significant galaxy over density associated with the radio emission in our optical observation (see Sec. 2.3). Given the limiting magnitudes of the optical images and the fact that di GLYPH<11> use cluster radio emission has only been observed in rich massive clusters we can confidently rule out any clusters associated with the radio emission below a redshift of 0.2. Were the radio emission to be associated with a redshift greater then 0.2, the projected physical scale of the emission would be > 16 Mpc. This is > 7 GLYPH<27> larger than the distribution of observed radio relics (Feretti et al. 2012). Thus it is highly unlikely that the di GLYPH<11> use radio emission is a radio relic associated with a merging galaxy cluster.
The extraction of a spectral index value is complicated because of the object's extension which could lower its flux density because of missing short baselines in interferometric observations and filtering in the single-dish case. This is clearly the case for the flux density extracted from the NVSS 1400 MHz map, which in both the east and west side of the source is lower
than the flux density at 325 and 4850 MHz implying a concave spectrum not compatible with synchrotron radiation.
## 4. Discussion
The radio emission of SNR G351.0-5.4 is coincident with an unknown EGRET GLYPH<13> -ray detection (3EG J1744-3934) which could be the consequence of the interaction between the expanding shell and the surrounding medium, e.g. molecular clouds. The GLYPH<13> -ray source 3EG J1744-3934 (Hartman et al. 1999) position, although having large errors ( r = 0 66 : GLYPH<14> is the 95% confidence area), is centred on the west side of SNR G351.0-5.4. The source is marked as a possibly extended multiple source and has a flux / of F ( > 100 MeV) = 17 1 : GLYPH<6> 3 5 : GLYPH<2> 10 GLYPH<0> 8 photon cm GLYPH<0> 2 s GLYPH<0> 1 and a spectral index GLYPH<13> = 2 42. A new map of the : GLYPH<13> -ray emission detected by Fermi-LAT in the energy range 1 GLYPH<0> 500 GeV in the area surrounding the nominal position of SNR G351.0-5.4 is reported in Fig. 5. We found no statistically significant GLYPH<13> -ray excess over the local background associated with SNR G351.0-5.4 in our study. The background is modelled as the averaged flux of region of interest, where the region ( < 1 ) of the SNR and the Fermi LAT GLYPH<14> point sources (Nolan et al. 2012) are excluded. In the region associated with the SNR, the limiting photon flux at energies > 1 GeV is constrained to be F ( > 1 GeV) < 7 9 : GLYPH<2> 10 GLYPH<0> 9 cm GLYPH<0> 2 s GLYPH<0> 1 . However, in the radial distribution of the GLYPH<13> -ray events around the centre of the SNR, a slightly spatially extended feature is detected with a confidence level of GLYPH<24> 1 5 : GLYPH<27> , see Fig. 6.
CO and H i maps obtained by NANTEN telescope do not show any association between the SNR and possible molecular cloud systems (Fukui Y. priv. comm.). If SNR G351.0-5.4 is indeed an old SNR, the GLYPH<13> -ray emission is absent because all CRs have escaped from the source, therefore energetic photons from neutral pion decay cannot be detected. This is in line with an absence of clouds along their path. If there were high density targets in the source surroundings, we could have seen GeV emission due to low-energy CRs (in the case of a target embedded in the source) or to high-energy CRs (in the case of a distant target) as in the case of the SNR W28 (Giuliani et al. 2010).
The pulsar PSR J1744-3922 is at a distance of 3.1 kpc, it was identified as a possible origin of the GLYPH<13> -ray emission for the source 3EG J1744-3934 (Hessels et al. 2005) and it is close to the target SNR ( GLYPH<24> 23 0 from the SNR centre towards west). A subsequent follow up with XMM showed no X-ray emission from the object and the source does not appear to be energetic enough to power the production of GLYPH<13> -rays (Faulkner et al. 2004).
The optical observation made with the DECam does not show any evidence of optical emission in any of the observed bands (see Fig. 4). The non-detection in the optical and in the GLYPH<13> -ray bands, together with the absence of CO and H i emission in the surroundings, the radio morphology and the low surface brightness, support the idea that SNR G351.0-5.4 must be an old SNR.
## 5. Conclusions
Wereport the discovery of an extended radio emission located in the proximity to the Galactic plane (Galactic latitude b = GLYPH<0> 5 5). : The emission is visible in three radio surveys: NVSS at 1400 MHz, Parkes 64m at 2417 MHz, and PMN at 4850 MHz. The source has been also detected by the GMRT at 325 MHz. The source has not been detected in the optical band. Given the source morphology, we classify it as the old shell of a Galactic supernova remnant which no longer emits in the optical and designate it SNR G351.0-5.4.
H L Fig. 6: Radial distribution of GLYPH<13> -ray events ( E > 10 GeV) around the centre of the SNR. The red line denotes the ratio between the signal and the background estimated events (dotted line). Dashed line assumes a point source located at the centre of the SNR. A slightly spatially extended (confidence level GLYPH<24> 1.5 GLYPH<27> ) feature is related with SNR. Also, the two excesses can be seen at 0.5 GLYPH<14> and 1.2 GLYPH<14> from SNR probably related to the two Fermi LAT point sources at those distances (Nolan et al. 2012).
The presence of a SNR at these coordinates could also explain the unclassified EGRET GLYPH<13> -ray source 3EG J1744-3934 that may be the consequence of the interaction between particles escaping the remnant and the surrounding intra-galactic medium. However, deep analysis of the GLYPH<13> -ray data from Fermi-LAT did not show any significant excess in this region, no detection in CO or H i is also reported. In the radial distribution of the GLYPH<13> -ray events around the centre of the SNR, a slightly spatially extended excess is detected with a confidence level of GLYPH<24> 1 5 : GLYPH<27> .
Acknowledgements. We would like to thank Ishwara Chandra C. H. and the sta GLYPH<11> of the GMRT that made these observations possible. Based on observations obtained at Cerro Tololo Inter-American Observatory, a division of the National Optical Astronomy Observatories, which is operated by the Association of Universities for Research in Astronomy, Inc. under cooperative agreement with the National Science Foundation. AH acknowledges the European Social Fund for the grants MTT8, MTT60 and the European Regional Development Fund for the grant TK120.
## References
Ackermann, M., Ajello, M., Albert, A., et al. 2012, The Astrophysical Journal
Supplement Series, 203, 4
- Ackermann, M., Ajello, M., Allafort, A., et al. 2013, Science, 339, 807
- Atwood, W. B., Abdo, A. A., Ackermann, M., et al. 2009, The Astrophysical Journal, 697, 1071
- Berkhuijsen, E. M. 1984, Astronomy and Astrophysics, 140, 431
- Cardillo, M., Tavani, M., Giuliani, A., et al. 2014, eprint arXiv:1403.1250
- Condon, J. J., Cotton, W. D., Greisen, E. W., et al. 1998, The Astronomical Journal, 115, 1693
- DePoy, D. L., Abbott, T., Annis, J., et al. 2008, in Proceeding SPIE, ed. I. S. McLean & M. M. Casali, Vol. 7014, 7014
- Duncan, A. R., Haynes, R. F., Jones, K. L., & Stewart, R. T. 2012, Monthly Notices of the Royal Astronomical Society, 291, 3
- Faulkner, A. J., Stairs, I. H., Kramer, M., et al. 2004, Monthly Notices of the Royal Astronomical Society, 355, 147
- Feretti, L., Giovannini, G., Govoni, F., & Murgia, M. 2012, The Astronomy & Astrophysics Review, 20, 54
- Giuliani, A., Tavani, M., Bulgarelli, A., et al. 2010, Astronomy and Astrophysics, 516, L11
- Green, D. A. 1986, Monthly Notices of the Royal Astronomical Society, 221, 473
- Green, D. A. 2001, Monthly Notices of the Royal Astronomical Society, 326, 283
- Green, D. A. 2009, Bulletin of the Astronomical Society of India, 37, 45 Gri GLYPH<14> th, M. R. & Wright, A. E. 1993, The Astronomical Journal, 105, 1666 Hartman, R. C., Bertsch, D. L., Bloom, S. D., et al. 1999, The Astrophysical Journal Supplement Series, 123, 79
- Hessels, J., Ransom, S., Roberts, M., et al. 2005, in Binary Radio Pulsars, ASP Conference Series, Vol. 328, Vol. 328, 395
- Katsuta, J., Uchiyama, Y., Tanaka, T., et al. 2012, The Astrophysical Journal, 752, 135
Leahy, D. A. & Roger, R. S. 1998, The Astrophysical Journal, 505, 784 Malkov, M. A. & Drury, L. O. 2001, Reports on Progress in Physics, 64, 429 Nolan, P. L., Abdo, A. A., Ackermann, M., et al. 2012, The Astrophysical Journal Supplement Series, 199, 31
- Noordam, J. E. 2004, in Proceedings of SPIE, Vol. 5489 (SPIE), 817-825 O ringa, A. R., van de Gronde, J. J., & Roerdink, J. B. T. M. 2012, Astronomy GLYPH<11> &Astrophysics, 539, A95
Schlafly, E. F. & Finkbeiner, D. P. 2011, The Astrophysical Journal, 737, 103 Tammann, G. A., Loe GLYPH<15> er, W., & Schroeder, A. 1994, The Astrophysical Journal Supplement Series, 92, 487
- Tavani, M., Giuliani, A., Chen, A. W., et al. 2010, The Astrophysical Journal, 710, L151 | 10.1051/0004-6361/201424191 | [
"F. de Gasperin",
"C. Evoli",
"M. Bruggen",
"A. Hektor",
"M. Cardillo",
"P. Thorman",
"W. A. Dawson",
"C. B. Morrison"
] | 2014-07-31T21:57:51+00:00 | 2014-07-31T21:57:51+00:00 | [
"astro-ph.HE"
] | Discovery of the supernova remnant G351.0-5.4 | Context. While searching the NRAO VLA Sky Survey (NVSS) for diffuse radio
emission, we have serendipitously discovered extended radio emission close to
the Galactic plane. The radio morphology suggests the presence of a previously
unknown Galactic supernova remnant. An unclassified {\gamma}-ray source
detected by EGRET (3EG J1744-3934) is present in the same location and may stem
from the interaction between high-speed particles escaping the remnant and the
surrounding interstellar medium.
Aims. Our aim is to confirm the presence of a previously unknown supernova
remnant and to determine a possible association with the {\gamma}-ray emission
3EG J1744-3934.
Methods. We have conducted optical and radio follow-ups of the target using
the Dark Energy Camera (DECam) on the Blanco telescope at Cerro Tololo
Inter-American Observatory (CTIO) and the Giant Meterwave Radio Telescope
(GMRT). We then combined these data with archival radio and {\gamma}-ray
observations.
Results. While we detected the extended emission in four different radio
bands (325, 1400, 2417, and 4850 MHz), no optical counterpart has been
identified. Given its morphology and brightness, it is likely that the radio
emission is caused by an old supernova remnant no longer visible in the optical
band. Although an unclassified EGRET source is co-located with the supernova
remnant, Fermi-LAT data do not show a significant {\gamma}-ray excess that is
correlated with the radio emission. However, in the radial distribution of the
{\gamma}-ray events, a spatially extended feature is related with SNR at a
confidence level $\sim 1.5$ {\sigma}.
Conclusions. We classify the newly discovered extended emission in the radio
band as the old remnant of a previously unknown Galactic supernova: SNR
G351.0-5.4. |
1408.0037v2 | ## MODULI OF MORPHISMS OF LOGARITHMIC SCHEMES
## JONATHAN WISE
Abstract. We show that there is a logarithmic algebraic space parameterizing logarithmic morphisms between fixed logarithmic schemes when those logarithmic schemes satisfy natural hypotheses. As a corollary, we obtain the representability of the stack of stable logarithmic maps from logarithmic curves to a fixed target without restriction on the logarithmic structure of the target.
An intermediate step requires a left adjoint to pullback of ´tale e sheaves, whose construction appears to be new in the generality considered here, and which may be of independent interest.
## Contents
| 1. | Introduction | Introduction | 1 |
|-------------|--------------------------------------------------|--------------------------------------------------|-----|
| 2. | Algebraicity relative to the category of schemes | Algebraicity relative to the category of schemes | 6 |
| 3. | Local minimality | Local minimality | 9 |
| 4. | Global minimality | Global minimality | 17 |
| 5. | Automorphisms of minimal logarithmic structures | Automorphisms of minimal logarithmic structures | 29 |
| Appendix A. | Appendix A. | Integral morphisms of monoids | 31 |
| Appendix B. | Appendix B. | Minimality | 31 |
| Appendix C. | Appendix C. | Explicit formulas: by Sam Molcho | 34 |
| References | References | References | 44 |
## 1. Introduction
Let X and Y be logarithmic algebraic spaces over a logarithmic scheme S . Consider the functor Hom LogSch /S ( X,Y ) 1 whose value on a logarithmic S -scheme S ′ the set of logarithmic morphisms X ′ → Y ′ , where X ′ = X × S S ′ and Y ′ = Y × S S ′ . Under reasonable hypotheses
Date : November 9, 2015.
2010 Mathematics Subject Classification. 14H10, 14D23, 14A20 .
Wise is supported by an NSA Young Investigator's Grant, Award #H98230-141-0107.
1 See Section 1.3 for our conventions on notation.
on these data, we show that Hom LogSch /S ( X,Y ) is representable by a logarithmic algebraic space over S .
Our strategy is to work relative to the space Hom LogSch /S ( X,Y ) parameterizing morphisms of the underlying algebraic spaces X and Y of X and Y , respectively. More precisely, Hom LogSch /S ( X,Y )( S ′ ) is the set of morphisms of schemes X × S S ′ → Y × S S ′ . In order to guarantee that a morphism
$$\text{Hom} _ { \text{LogSch} / S } ( X, Y ) \rightarrow \text{Hom} _ { \text{LogSch} / S } ( \underline { X }, \underline { Y } )$$
exists, we need to assume that the morphism of logarithmic spaces π : X → S is integral, meaning π M ∗ S → M X is an integral morphism of sheaves of monoids.
Theorem 1.1. Let π : X → S be a proper, flat, finite presentation, geometrically reduced, integral morphism of fine logarithmic algebraic spaces. Let Y be a logarithmic stack 2 over S . Then the morphism
$$\text{Hom} _ { \text{LogSch} / S } ( X, Y ) \rightarrow \text{Hom} _ { \text{LogSch} / S } ( \underline { X }, \underline { Y } )$$
is representable by logarithmic algebraic spaces.
Combining the theorem with already known criteria for the algebraicity of Hom LogSch /S ( X,Y ) such as [HR14, Theorem 1.2], we obtain
Corollary 1.1.1. In addition to the assumptions of Theorem 1.1, assume as well that Y is an algebraic stack over S that is locally of finite presentation with quasi-compact and quasi-separated diagonal and affine stabilizers and that X → S is of finite presentation. Then Hom LogSch /S ( X,Y ) is representable by a logarithmic algebraic stack.
One application is to the construction of the stack of pre-stable logarithmic maps. Let M denote the logarithmic stack of logarithmic curves. The algebraicity of M may be verified in a variety of ways, e.g., [GS13, Proposition A.3]. For a logarithmic algebraic stack Y over S , we write M ( Y/S ) for the logarithmic stack whose T -points are logarithmically commutative diagrams
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
in which C is a logarithmic curve over T .
Taking X to be the universal curve over M in the previous corollary yields
2 It is not necessary for Y to be algebraic.
Corollary 1.1.2. Suppose that Y → S is a morphism of logarithmic algebraic stacks with quasi-finite and separated relative diagonal. Then M ( Y/S ) is representable by a logarithmic algebraic stack.
This improves on several previous results:
- (1) [Che10] required Y to have a rank 1 Deligne-Faltings logarithmic structure,
- (2) [AC11] required Y to have a generalized Deligne-Faltings logarithmic structure, and
- (3) [GS13] required Y to have a Zariski logarithmic structure.
The evaluation space for stable logarithmic maps can also be constructed using Theorem 1.1. Recall that the standard logarithmic point P is defined by restricting the divisorial logarithmic structure of A 1 to the origin. A family of standard logarithmic points in Y parameterized by a logarithmic scheme S is a morphism of logarithmic algebraic stacks S × P → Y . Following [ACGM10], we define ∧ Y to be the fibered category of standard logarithmic points of Y .
Corollary 1.1.3 ([ACGM10, Theorem 1.1.1]) . If Y is a logarithmic algebraic stack with quasi-finite and quasi-separated diagonal then ∧ Y is representable by an algebraic stack with logarithmic structure.
- 1.1. Outline of the proof. Working relative to Hom LogSch /S ( X,Y ), the question of the algebraicity of Hom LogSch /S ( X,Y ) is reduced to showing that, given a logarithmic algebraic space X and a logarithmic algebraic stack Y , both over S , as well as a commutative triangle of algebraic stacks,
/d47
/d47
/d31
/d31
/d0
/d0
the lifts of f to an S -morphism of logarithmic algebraic stacks making the triangle commute are representable by a logarithmic algebraic stack.
This problem reduces immediately to the verification that morphisms of logarithmic structures f ∗ M Y → M X compatible with the maps from π M ∗ S are representable by a logarithmic algebraic space over S . We may therefore eliminate Y from our consideration by setting M = f ∗ M Y and restricting our attention to the functor Hom LogSch /S ( M,M X ) that parameterizes morphisms of logarithmic structures M → M X .
Stated precisely, the S ′ -points of Hom LogSch /S ( M,M X ) are the morphisms of logarithmic structures M ′ → M ′ X , where M ′ and M ′ X are the
logarithmic structures deduced by base change on X ′ = X × S S ′ , that fit into a commutative triangle:
/d123
/d123
/d35
/d35
/d47
/d47
As is typical for logarithmic moduli problems, we now separate the question of the representability of Hom LogSch /S ( M,M X ) by a logarithmic algebraic stack into a question about the representability of a larger stack Log (Hom LogSch /S ( M,M X )) = Hom Sch / Log ( S ) ( M,M X ) over schemes (not logarithmic schemes), followed by the identification of an open substack of minimal objects within Log (Hom LogSch /S ( M,M X )) that represents Hom LogSch /S ( M,M X ).
When Log (Hom LogSch /S ( M,M X )) is viewed as a category, its objects are the same as the objects of Hom LogSch /S ( M,M X ). Its fiber over a scheme T therefore consists of tuples ( M ,f,α T ) where
- (i) M T is a logarithmic structure on T ,
- (ii) f : ( T, M T ) → S is a morphism of logarithmic schemes, and
- (iii) α : f ∗ M → f ∗ M X is a morphism of logarithmic structures on X × S T that is compatible with the maps from M T .
The distinction between the categories Log (Hom LogSch /S ( M,M X )) and Hom LogSch /S ( M,M X ) is that morphisms in the former are required to be cartesian over the category of schemes, while in the latter they are only required to be cartesian over the category of logarithmic schemes. That is, ( T, M T , f, α ) → ( T , M ′ T ′ , f ′ , α ′ ) in Hom LogSch /S ( M,M X ) lies in Log (Hom LogSch /S ( M,M X )) only if the map ( T, M T ) → ( T , M ′ T ′ ) is strict.
Weshow in Section 2 that Log (Hom LogSch /S ( M,M X )) is representable by an algebraic space relative to Log ( S ). As Olsson has proved that Log ( S ) is algebraic, the representability of Log (Hom LogSch /S ( M,M X )) by an algebraic stack follows.
In Sections 3 and 4 we use Gillam's criterion (Section B) to prove that the fibered category Hom LogSch /S ( M,M X ) over logarithmic schemes is induced from a fibered category over schemes with a logarithmic structure. Section 3 treats the case where X = S by adapting methods from homological algebra to commutative monoids. In Section 4, we transform the local minimal object of Section 3 to a global minimal object by means of a left adjoint to pullback for ´tale sheaves (constructed, e under suitable hypotheses, in Section 4.1), whose existence appears to be a new observation.
Gillam's criterion characterizes the fibered category over schemes inducing the fibered category Hom LogSch /S ( M,M X ) over logarithmic schemes: it is the substack of minimal objects of Hom LogSch /S ( M,M X ). A slight augmentation of that criterion (described in Section B) implies that the substack of minimal objects is open in Log (Hom LogSch /S ( M,M X )). Combined with the algebraicity of Log (Hom LogSch /S ( M,M X )) proved in Section 2, the verification of Gillam's criteria in Sections 3 and 4 implies that Hom LogSch /S ( M,M X ) is representable by a logarithmic algebraic stack . A direct analysis of the stabilizers of logarithmic maps in Section 5 then implies that Hom LogSch /S ( M,M X ) is representable by an algebraic space .
- 1.2. Remarks on hypotheses. It is far from clear that all of the hypotheses of Theorem 1.1 are essential. We summarize how they are used in the proof: Integrality of X over S is used to guarantee the existence of a morphism Hom LogSch /S ( X,Y ) → Hom LogSch /S ( X,Y ); it is also used in the construction of minimal objects. Properness and finite presentation are used to guarantee the representability of Log (Hom LogSch /S ( M,M X )) by an algebraic stack. Flatness, finite presentation, and geometrically reduced fibers are used to guarantee the existence of a left adjoint to pullback of ´ etale sheaves, used in the construction of global minimal objects from local ones.
- 1.3. Conventions. We generally follow the notation of [Kat89a] concerning logarithmic structures, except that we write X for the scheme (or fibered category) underlying a logarithmic scheme (or fibered category) X . The logarithmic structures that appear in this paper will all be fine, although we will usually point this out in context. If M is a logarithmic structure on X , we write exp : M →O X for the structural morphism and log : O ∗ X → M for the reverse inclusion.
It is occasionally convenient to pass only part of the way from a chart for a logarithmic structure to its associated logarithmic structure. We formalize this in the following definition:
Definition 1.2. A quasi-logarithmic structure on an scheme X is an extension N of an ´ etale sheaf of integral 3 monoids N by O ∗ X and a morphism N →O X compatible with the inclusions of O ∗ X . We will say that a quasi-logarithmic structure is coherent if its associated logarithmic structure is coherent. If f : X ′ → X is a morphism of schemes, the
3 The integrality assumption is not necessary in the definition. It is included to avoid qualifying every quasi-logarithmic structure that appears below with the adjective 'integral'.
pullback f ∗ N of N to X ′ is obtained by pushout via f -1 O ∗ X → O X ′ from the pulled back extension f -1 N :
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
We write Hom( A, B ) for the set of morphisms between two objects of the same type. When A and B and the morphisms between them may reasonably be construed to vary with objects of a category C , we write Hom ( C A, B ) for the functor or fibered category of morphisms between A and B . Occasionally, we also employ a subscript on Hom to indicate restrict to homomorphisms preserving some additional structure. We rely on context to keep the two meanings of these decorations distinct.
- 1.4. Acknowledgements. The central construction of this paper was inspired by the construction of basic logarithmic maps in [GS13]. I am very grateful to Qile Chen and Steffen Marcus for their comments on an early draft, and to Dan Abramovich for his many detailed comments and his encouragement that I present these results in their natural generality. Samouil Molcho discovered an error in my original presentation of the main construction. I am very grateful to him for that correction, as well as for the attached Appendix C, which translates the results of this paper into explicit formulas.
This work was supported by an NSA Young Investigator's grant, award number H98230-14-1-0107.
## 2. Algebraicity relative to the category of schemes
We show that the morphism
$$\text{(2.1)} & & \text{Log(Hom} _ { \text{LogSch/S} } ( M, M _ { X } ) ) \rightarrow \text{Log(S)}$$
is representable by algebraic spaces. Combined with the algebraicity of Log ( S ) [Ols03, Theorem 1.1], this implies Log (Hom LogSch /S ( M,M X )) is representable by an algebraic stack.
Proposition 2.1. Let S = ( S, M S ) be a logarithmic scheme, X a proper S -scheme with π : X → S denoting the projection. Assume given logarithmic structures M and M X on X with morphisms of logarithmic structures π M ∗ S → M and π M ∗ S → M X . Assume as well that M S , M X , and M are all coherent. Then the morphism (2.1) is representable by algebraic spaces.
We divide this into a local problem in which X = S and then pass to the general case.
Theorem 2.2 ([GS13, Proposition 2.9]) . Suppose that P and Q are coherent logarithmic structures on a scheme X . Then Hom Sch /X ( P, Q ) is representable by an algebraic space over X .
For isomorphisms, this is [Ols03, Corollary 3.4].
Proof. The question of the algebraicity of Hom Sch /X ( P, Q ) may be separated into one about the algebraicity of Hom Sch /X ( P, Q ) and another about the relative algebraicity of the map
$$& ( 2. 2 ) & & \text{Hom} _ { \text{Sch} / X } ( P, Q ) \to \text{Hom} _ { \text{Sch} / X } ( \overline { P }, \overline { Q } ).$$
Lemma 2.2.1. The functor Hom Sch /X ( P, Q ) is representable by an ´ etale algebraic space over X .
Proof. Because P and Q are constructible, the natural map
$$f ^ { * } \text{Hom} _ { \acute { e t } ( X ) } ( \overline { P }, \overline { Q } ) \to \text{Hom} _ { \acute { e t } ( X ^ { \prime } ) } ( f ^ { * } \overline { P }, f ^ { * } \overline { Q } )$$
is an isomorphism for any morphism f : X ′ → X . Therefore we may represent Hom Sch /X ( P, Q ) with the espace ´tal´ of Hom e e ´ et( X ) ( P, Q ). /square
The relative algebraicity of (2.2) is equivalent to the following lemma:
Lemma 2.2.2 ([GS13, Lemma 2.12]) . Let Q be a logarithmic structure on a scheme X and let P be a coherent quasi-logarithmic structure on X . Fix a morphism u : P → Q . The lifts of u to a morphism of quasilogarithmic structures u : P → Q are parameterized by a relatively affine scheme over X .
Our proof of this lemma only differs from that of loc. cit. superficially, but is nevertheless included for the sake of completeness. It is also possible to deduce Lemma 2.2.2 from Lemma 2.2.1 and [Ols03, Corollary 3.4].
Proof. This is a local question in X , so we may freely pass to an ´tale e cover. Furthermore, replacing P with a quasi-logarithmic structure P 0 that has the same associated logarithmic structure does not change the morphisms to Q , by the universal property of the associated logarithmic structure. Since the logarithmic structure associated to P admits a chart ´tale locally, we can therefore select e P 0 to be a quasi-logarithmic structure whose sheaf of characteristic monoids P 0 is constant. Replacing P with P 0 , we can assume that the characteristic monoid of P is constant.
We wish to construct the space of completions of the diagram below (in which u is also required to be compatible with the maps exp : P → O X and exp : Q →O X ):
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
Replacing Q with u -1 Q , we can assume that P = Q and u = id P . 4 Let H be the moduli space of maps u : P → Q that are compatible with u = id P , ignoring the maps to O X . Locally such a map exists because P and Q are both extensions of P by G m and P is generated by a finite collection of global sections. Indeed, this implies that P and Q are each determined by a finite collection of G m -torsors on X , all of which can be trivialized after passage to a suitable open cover of X . It follows that H is a torsor on X under Hom Sch /X ( P, G m ) and in particular is representable by an affine scheme over X .
We may now work relative to H and assume that the map u : P → Q has already been specified. We argue that the locus where the diagram
/d15
/d32
/d32
/d15
/d47
/d47
commutes is closed. In effect, we are looking at the locus where two G m -equivariant maps P → A 1 agree. But P is generated as a monoid with G m -action by a finite collection of sections, hence the agreement of the two maps P → A 1 corresponds to the agreement of a finite collection of pairs of sections of A 1 . But A 1 is separated, so this is representable by a closed subscheme. /square
This completes the proof of Theorem 2.2. /square
We can now obtain a global variant:
Corollary 2.2.3. Let X be a proper, flat, finite presentation algebraic space over S and let P and Q be logarithmic structures on X with P coherent. Then Hom Sch /S ( P, Q ) is representable by an algebraic space over S .
4 At this point a morphism P → Q covering u must be an isomorphism so we could complete the proof using [Ols03, Corollary 3.4].
Proof. Let π : X → S be the projection. Then we have
$$\text{Hom} _ { \text{Sch} / S } ( P, Q ) = \pi _ { * } \text{Hom} _ { \text{Sch} / X } ( P, Q ).$$
We have already seen in Theorem 2.2 that Hom Sch /X ( P, Q ) is representable by an algebraic space over X that is quasi-compact, quasiseparated, and locally of finite presentation. We may therefore apply [HR14, Theorem 1.2] (or any of a number of other representability results for schemes of morphisms) to deduce the algebraicity of π ∗ Hom Sch /X ( P, Q ). /square
Corollary 2.2.4. Let X and S be as in the last corollary. Suppose that P , Q , and R are logarithmic structures on X with P and Q coherent and morphisms α : P → Q and β : P → R have been specified. Then there is an algebraic space over S parameterizing the commutative triangles shown below:
/d15
$$\stackrel { P } { \alpha } \Big \downarrow _ { Q \longrightarrow R } ^ { \beta }$$
/d15
/d31
/d31
/d47
/d47
Proof. We recognize this functor as a fiber product:
$$\text{Hom} _ { \text{Sch} / S } ( Q, R ) \times _ { \text{Hom} _ { \text{Sch} / S } ( P, R ) } \{ \beta \}$$
$$\Box$$
Proposition 2.1 is an immediate consequence of Corollary 2.2.4, applied with P = π M ∗ S , Q = M , and R = M X .
## 3. Local minimality
After Proposition 2.1, all that is left to demonstrate Theorem 1.1 is to verify Gillam's criteria for
$$\text{Log} ( \text{Hom} _ { \text{LogSch} / S } ( M, M _ { X } ) ) = \text{Hom} _ { \text{Sch} / \text{Log} ( S ) } ( M, M _ { X } ).$$
As in the proof of Proposition 2.1 we separate this problem into local and global variants, the local version being the case S = X . We treat the local problem in this section and deduce the solution to the global problem in the next one.
Let X be a scheme equipped with three fine logarithmic structures, denoted π M ∗ S , M X , and M in order to emphasize the application in the next section, and morphisms of logarithmic structures,
$$\pi ^ { * } M _ { S } & \to M _ { X } \\ \pi ^ { * } M _ { S } & \to M.$$
Let GS loc ( X ) be the set of commutative diagrams
/d47
/d47
/d39
/d39
/d15
/d15
/d15
/d15
/d125
/d125
/d47
/d47
in which N is a quasi-logarithmic structure 5 (Definition 1.2) and the square on the left is cocartesian. These data are determined up to unique isomorphism by the quasi-logarithmic structure N , the morphism π M ∗ S → N , and the morphism ϕ . We will refer to an object of GS loc ( X ) with the pair ( N,ϕ ) with the morphism π M ∗ S → N specified tacitly. 6
Convention 3.1. As a matter of notation, whenever we have a morphism of monoids π M ∗ S → N (resp. π M ∗ S → N ), we write N X (resp. N X ) for the monoid obtained by pushout:
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
When N = N S above, we simply write N X rather than ( N S ) X .
The object of this section will be to prove the following two lemmas:
Lemma 3.2. For any X -scheme Y , any object of GS loc ( Y ) admits a morphism from a minimal object.
Lemma 3.3. The pullback of a minimal object of GS loc ( Y ) via any morphism Y ′ → Y is also minimal.
The construction of the minimal object appearing in Lemma 3.2 is done in Section 3.1, while the proof of its minimality appears in Section 3.2, along with the proof of Lemma 3.3.
5 The use of quasi-logarithmic structures here is entirely for convenience: it allows us to avoid repeated passage to associated logarithmic structures. The reader who would prefer not to worry about quasi-logarithmic structures should feel free to assume N is a logarithmic structure and worry instead about remembering to take associated logarithmic structures at the right moments.
6 Effectively, N is an object of the category of quasi-logarithmic structures equipped with a morphism from π M ∗ S .
3.1. Construction of minimal objects. Fixing ( N,ϕ ) ∈ GS loc ( X ), we construct an object ( R, ρ ) ∈ GS loc ( X ) and a morphism ( R, ρ ) → ( N,ϕ ). In Section 3.2 we verify that ( R, ρ ) is minimal and that its construction is stable under pullback.
We assemble R in steps: First we build the associated group of its characteristic monoid, then we identify its characteristic monoid within this group, and finally we build the quasi-logarithmic structure above the characteristic monoid.
Recall that the map ϕ : M → N X induces a map u : M → N /π N X ∗ S /similarequal M /π M X ∗ S known as the type of u . This generalizes [GS13, Definition 1.10]. For brevity, we write M X/S = M /π M X ∗ S = M /π M X ∗ S below. Note that u is equivariant with respect to the action of π M ∗ S on M and the (trivial) action of π M ∗ S on the relative characteristic monoid M X/S . Therefore u may equally well be considered a morphism M/π M ∗ S → M X/S .
Remark 3.1 . The following construction is technical, so the reader may find it helpful to keep in mind that it is really an elaboration of an exercise in homological algebra:
If 0 → A → B → C → 0 is an exact sequence of abelian groups, and u : M → C is a given homomorphism, there is a universal homomorphism A → A ′ such that u lifts to a homomorphism M → B ′ , where B ′ = A ′ /coproduct A B :
/d47
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d6
/d6
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
Moreover, A ′ may be taken to be M × C B .
The associated group of the characteristic monoid of R . We set R gp 0 = M gp × M gp X/S M gp X . This fits into a commutative diagram with exact rows:
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
Observe that R gp 0 comes with two maps π M ∗ gp S → R gp corresponding to the two maps
$$\pi ^ { * } \overline { M } _ { S } ^ { \text{gp} } & \rightarrow \overline { M } ^ { \text{gp} } \\ \pi ^ { * } \overline { M } _ { S } ^ { \text{gp} } & \rightarrow \overline { M } _ { X } ^ { \text{gp} }.$$
$$\nu _ { S } \, \rightarrow \, \nu _ { X } \,.$$
We take /epsilon1 : R gp 0 → R gp to be the quotient of R gp 0 by the diagonal copy of π M ∗ gp S . We may then define R gp X by pushout via π M ∗ gp S → M gp X (Convention 3.1).
The homomorphism ρ : M gp → R gp X . Let M + X be the pushout of M X by the homomorphism of monoids π M ∗ S → π M ∗ gp S . This is a submonoid of M gp X and fits into the exact sequence in the middle row of the diagram below. Let R + 0 be the pullback of M → M X/S to M + X (the upper right square of the diagram below). The diagram below is commutative except for the dashed arrows (which will be explained momentarily) and has exact rows:
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d4
/d4
/d4
/d4
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
Note that ( R gp ) X is the pushout of π M ∗ S → M X via π M ∗ S → R gp as a monoid . Equivalently, it is the pushout of π M ∗ gp S → M + X via π M ∗ gp S → R gp , again as a monoid. It is contained in but not necessarily equal to R gp X = ( R X ) gp .
The difference between the two compositions
$$\overline { R } _ { 0 } ^ { + } \stackrel { \beta } { \rightarrow } \overline { M } _ { X } ^ { + } \rightarrow ( \overline { R } ^ { \text{gp} } ) _ { X } \\ \overline { R } _ { 0 } ^ { + } \stackrel { \epsilon } { \rightarrow } \overline { R } ^ { \text{gp} } \stackrel { \alpha } { \rightarrow } ( \overline { R } ^ { \text{gp} } ) _ { X }$$
factors uniquely through a map M gp → ( R gp ) X ⊂ R gp X . We take this as the definition of ρ .
Remark 3.2 . Observe that when the maps π M ∗ gp S → R gp and π M ∗ gp S → M gp are the canonical ones, the diagram on the left commutes but the
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
diagram on the right does not:
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
This is the reason we introduced the quotient /epsilon1 earlier.
We view ( R gp , ρ ) as the initial object of GS loc ( X ) on the level of associated groups of characteristic monoids . Justification for this attitude will be given in Section 3.2 (see the proof of Lemma 3.4).
The characteristic monoid R . We identify the smallest sheaf of submonoids R ⊂ R gp that contains the image of π M ∗ S and whose pushout R X contains the image of ρ : M → R gp X . For each local section ξ of M we will identify a local section (or possibly a finite collection of local sections) of R gp for inclusion in R ; we will then take R to be the submonoid of R gp generated by these local sections. As M is assumed to be coherent, a finite number of these local sections suffice to generate R , which guarantees that R is coherent.
Suppose that ξ ∈ Γ( U, M ) is a section over some quasi-compact U that is ´ etale over X . Recall that ρ ξ ( ) lies in ( R gp ) X , which is the pushout of R gp via the integral homomorphism π M ∗ S → M X . At least after passage to a finer quasi-compact ´ etale cover, we can represent ρ ξ ( ) as a pair ( a, b ) where a ∈ R gp and b ∈ M X (cf. Appendix A).
Let B ⊂ Γ( U, M X ) be the collection of all b ∈ M X such that ρ ξ ( ) can be represented as ( a, b ) for some a ∈ Γ( U, R gp ). As R gp → R gp X is injective (it is integral), there is at most one a for any b ∈ Γ( U, M X ). Note that B carries an action of Γ( U, π ∗ M S ), for if ρ ξ ( ) is representable by ( a, b ) then it is also representable by ( a -c, b + ). c The action of the sharp monoid π M ∗ S gives B a partial order by setting b ≤ b + c for all c ∈ Γ( U, π ∗ M S ). We will show b has a least element with respect to this partial order.
Suppose b and b ′ are elements of B with ( a, b ) and ( a , b ′ ′ ) both representing ρ ξ ( ) ∈ Γ( U, R gp X ). As π M ∗ S → M X is integral, Lemma A.2 implies that there must be elements d ∈ M X and c, c ′ ∈ π M ∗ S with a + c = a ′ + c ′ and b = d + c and b ′ = d + c ′ . But then ρ ξ ( ) is also representable by ( a + c, d ) = ( a ′ + c , d ′ ). Therefore, for any pair b, b ′ ∈ B there is a d ∈ B with d ≤ b and d ≤ b ′ .
It will now follow that B has a least element if we can show that every infinite decreasing chain of elements of B stabilizes. But B is a subset of Γ( U, M X ), and, at least provided U has been chosen small
/d47
/d47
enough, this is a strict submonoid of a finitely generated abelian group. A strictly decreasing chain of elements must have strictly decreasing distance from the origin in Γ( U, M X ) ⊗ R , and there can be only a finite number of elements of B whose image in Γ( U, M X ) ⊗ R within a fixed distance of the origin. Therefore the chain must stabilize and B has a least element.
Writing b for the least element of B and a for the corresponding element of Γ( U, R gp ) such that ( a, b ) represents ρ ξ ( ), we include a as an element of R . As M is coherent, we can repeat this construction for each element in a finite collection of sections that generate M over U (provided that U has been chosen small enough).
By construction, R is locally of finite type and integral. Moreover, the following lemma says that ( R,ρ ) is the initial object of type u in GS loc ( X ) on the level of characteristic monoids . We defer its proof to Section 3.2 in order not to interrupt the construction of ( R, ρ ).
Lemma 3.4. For any ( N,ϕ ) ∈ GS loc ( X ) of type u there is a unique morphism ( R, ρ ) → ( N,ϕ ) .
The quasi-logarithmic structure R and the map ρ . This construction will require an object ( N,ϕ ) ∈ GS loc ( X ) and not just a type. Suppose ( N,ϕ ) has type u and ( R,ρ ) has been constructed as in the steps above. Then Lemma 3.4 implies that there is a canonical map R → N compatible with the tacit maps from π M ∗ S . By pulling back N from N , we obtain a quasi-logarithmic structure R with characteristic monoid R .
As we have a factorization (again by Lemma 3.4)
$$\overline { M } \stackrel { \overline { \rho } } { \rightarrow } \overline { R } _ { X } \rightarrow \overline { N } _ { X }$$
and R X is pulled back from N X over N X , the universal property of the fiber product yields an induced map ρ : M → R .
## 3.2. Verification of Gillam's criteria.
Proof of Lemma 3.4. To prove the lemma, we must show that there is a unique morphism µ : R → N such that the induced diagram below is commutative:
/d47
/d47
/d32
/d32
/d15
/d15
$$\overline { M } \xrightarrow { \bar { p } } \overline { R } _ { X } \\ \overbrace { \varphi } \searrow \coprod \overline { N } _ { X }$$
Given ( N,ϕ ), we have a diagram with exact rows that commutes except for some of the parts involving the dashed arrow:
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d5
/d5
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
The lower triangle involving ϕ commutes (because ( N,ϕ ) has type u ) but the upper one may not. The difference of the two compositions
$$\overline { R } _ { 0 } ^ { \text{gp} } & \rightarrow \overline { M } ^ { \text{gp} } \overset { \overline { \varphi } } { \rightarrow } \overline { N } _ { X } ^ { \text{gp} } \\ \overline { R } _ { 0 } ^ { \text{gp} } & \rightarrow \overline { M } _ { X } ^ { \text{gp} } \rightarrow \overline { N } _ { X } ^ { \text{gp} }$$
factors uniquely through a map µ : R gp 0 → N gp . Moreover, µ vanishes on the diagonal copy of π M ∗ gp S inside R gp 0 . This gives a factorization:
$$\pi ^ { * } \overline { M } _ { S } ^ { \text{gp} } \rightarrow \overline { R } ^ { \text{gp} } \stackrel { \overline { \mu } } { \rightarrow } \overline { N } ^ { \text{gp} }$$
Moreover, the construction of µ is easily reversed to give a bijective correspondence between maps µ : R gp → N gp compatible with the tacit maps from π M ∗ gp S and morphisms ϕ : M gp → N gp X compatible with the type (cf. Remark 3.1).
We must verify that the image of µ : R → N gp lies in N . By definition, N X ⊂ N gp X contains the image of ϕ : M → N gp X . Write R ′ ⊂ R gp for the pre-image of N via the map R gp → N gp ; thus R ′ → N is an exact morphism of monoids [Kat89a, Definition 4.6 (1)]. Then R ′ X → N X is also exact [ loc. cit. ], so R ′ X coincides with the pre-image of N X ⊂ N gp X . Furthermore, R ′ X contains the image of ρ : M → R gp X because N X contains the image of ϕ : M → N gp X . On the other hand, R was constructed as the smallest submonoid of R gp such that R X contains the image of ρ : M → R gp X . Therefore R ⊂ R ′ and the image of R → N X is contained in N .
Finally, to get the commutativity of (3.1), it is sufficient to work on the level of associated groups. Assemble the diagram below, which is
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
commutative except for some of the parts involving the dashed arrows:
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d124
/d124
/d15
/d15
/d124
/d124
/d15
/d15
/d5
/d5
/d5
/d5
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
We write d for any of the horizontal arrows. To show that ϕ = µ X ◦ ρ it is sufficient to show that ϕ ◦ d = µ X ◦ ρ ◦ d . Recall that ρ was constructed such that ρ ◦ d = β -d ◦ /epsilon1 and µ was constructed such that d ◦ µ ◦ /epsilon1 = µ X ◦ β -ϕ ◦ d . Therefore,
$$\overline { \mu } _ { X } \circ \overline { \rho } \circ d = \overline { \mu } _ { X } \circ \beta - \overline { \mu } _ { X } \circ d \circ \epsilon = \overline { \mu } _ { X } \circ \beta - d \circ \overline { \mu } \circ \epsilon = \overline { \varphi } \circ d \\ \text{as required.}$$
Proof of Lemma 3.2. To minimize excess notation, we assume (without loss of generality) that Y = X .
Consider a morphism ( N , ϕ ′ ′ ) → ( N,ϕ ) of GS loc ( X ). We verify that the map ( R, ρ ) → ( N,ϕ ) factors in a unique way through ( N , ϕ ′ ′ ). In Lemma 3.4, we have already seen that there is a unique map R → N ′ , compatible with the maps from π M ∗ S , and a unique factorization of ϕ : M → N ′ X through ρ : M → R X . In particular, the diagram below commutes:
/d47
/d47
/d31
/d31
/d15
/d15
Since N ′ is pulled back from N by the vertical arrow in the diagram above, this gives a uniquely determined arrow R → N ′ . Likewise, the diagrams of solid arrows below are commutative (the diagonal arrow on the left coming from Lemma 3.4):
/d47
/d47
/d47
/d47
/d15
/d15
/d125
/d125
/d15
/d15
/d15
/d15
/d125
/d125
/d47
/d47
/d15
/d15
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
As N ′ X is pulled back from N X via the map N ′ X → N X there is therefore a unique induced map R → N ′ X completing the diagram on the right. This proves the minimality of ( R, ρ ). /square
Proof of Lemma 3.3. We show that the tools used in the construction of R and ρ are all compatible with pullback of quasi-logarithmic structures. Pullback of quasi-logarithmic structures along a morphism g : Y ′ → Y involves two steps: pullback of ´tale sheaves along e g followed by pushout of extensions along g -1 O ∗ Y → O ∗ Y ′ . We verify that the construction of R and ρ commutes with these operations:
- (1) R gp was constructed as a quotient of a fiber product, and both fiber products and quotients are preserved by pullback of ´tale e sheaves;
- (2) ρ was induced by the universal property of M as a quotient, and quotients are preserved by pullback of ´tale sheaves; e
- (3) R was built as the sheaf of submonoids of R gp generated by a collection of local sections, and this construction is compatible with pullback of ´tale sheaves; e
- (4) R was constructed as a pullback of an extension by O ∗ Y , and such pullbacks are preserved by pullback of ´tale sheaves and e by pushout along g -1 O ∗ Y →O ∗ Y ′ ;
- (5) ρ was induced by the universal property of a base change of extensions, and, as remarked above, base change of extensions is preserved by pullback of ´tale sheaves and pushout along the e kernels.
/square
## 4. Global minimality
In this section, X = ( X,M X ) and S = ( S, M S ) will be fine logarithmic schemes. We assume that the projection π : X → S is proper and flat with reduced geometric fibers and that the morphism of logarithmic structures π M ∗ S → M X is integral. We also assume a second coherent logarithmic structure M on X has been specified, along with a morphism π M ∗ S → M . We will verify Gillam's minimality criterion (Proposition B.1) for the fibered category Hom LogSch /S ( M,M X ) over LogSch .
We continue to use Convention 3.1 to notate pushouts, as well as to work with quasi-logarithmic structures instead of logarithmic structures. Define GS( S ) to be the category of pairs ( N ,ϕ S ) where N S is a quasi-logarithmic structure on S equipped with a tacitly specified
morphism M S → N S and ϕ fits into a commutative diagram
/d47
/d47
/d40
/d40
/d15
/d15
/d15
/d15
/d124
/d124
/d47
/d47
whose square is cocartesian. By pullback of quasi-logarithmic structures, we may assemble this definition into a fibered category over LogSch /S . When T is strict over S , we write GS( T ) instead of GS( T ).
We may recognize Hom LogSch /S ( M,M X )( T ) 7 inside of GS( T ) as the opposite of the category of pairs ( N ,ϕ T ) where N T is a logarithmic structure, as opposed to merely quasi-logarithmic structure. We are free to work with GS( T ) in place of Hom LogSch /S ( M,M X )( T ) as minimal objects of the latter may be induced from minimal objects of the former by passage to the associated logarithmic structure.
Lemma 4.1. For any logarithmic scheme T over S , every object of GS( T ) admits a morphism from a minimal object.
Lemma 4.2. If f : T ′ → T is a morphism of logarithmic schemes over S and ( Q ,ψ T ) is minimal in GS( T ) then f ∗ ( Q ,ψ T ) is minimal in GS( T ′ ) .
Note that passage to the associated logarithmic structure commutes with pullback of pre-logarithmic structures [Kat89a, (1.4.2)], so Lemma 4.2 implies that minimal objects of Hom LogSch /S ( M,M X )( T ) pull back to minimal objects of Hom LogSch /S ( M,M X )( T ′ ).
The strategy of proof for Lemmas 4.1 and 4.2 will be to bootstrap from the minimal objects of GS loc ( X ) constructed in Section 3. The essential tool in this construction is a left adjoint to pullback for ´tale e sheaves, constructed in Section 4.1, for whose construction is the reason we must assume X has reduced geometric fibers over S . Having dispensed with generalities in Section 4.1, we take up the construction of minimal objects of GS( T ) in Section 4.2.
Zariski logarithmic structures. The following proposition will only be used in Appendix C. It shows that when M S and M are Zariski logarithmic structures, one can replace M X by its best approximation by a Zariski logarithmic structure for the purpose of constructing the category GS. At least in many situations, this means that one can work
7 The notation Hom LogSch /S ( M,M X ) refers to the fibered category over LogSch /S whose value on a logarithmic scheme T over S is the set of morphisms of logarithmic structures M ∣ ∣ T → M X T ∣ ∣ on X × S T , compatible with the tacit morphisms from π M ∗ T .
in the Zariski topology rather than the ´tale topology for the purpose e of constructing a minimal logarithmic structure. See Appendix C for more details.
Lemma 4.3. Let X be a scheme. Denote by τ : ´ et( X ) → zar( X ) the morphism of sites. Then Hom( τ ∗ F, τ ∗ G ) = Hom( F, G ) for any sheaves F and G on zar( X ) . In particular, τ τ ∗ ∗ /similarequal id .
Proof. By adjunction, we have Hom( τ ∗ F, τ ∗ G ) = Hom( F, τ ∗ τ ∗ G ). But we can calculate that τ τ ∗ ∗ G U ( ) = τ ∗ G U ( ) = G U ( ) for any open U ⊂ X . The first equality is the definition; the second equality holds because, for example, the espace ´tal´ of e e G (in the Zariski topology) is a scheme, hence satisfies ´tale descent. e /square
Proposition 4.4. Suppose that M and M S are Zariski logarithmic structures and that M gp S is torsion free. Let τ denote the canonical morphism from the ´ etale site to the Zariski site. Define GS ′ be the category obtained by imitating the definition of GS with M X replaced by τ ∗ τ M ∗ X . Then GS /similarequal GS ′ .
Proof. By assumption, we have M S = τ ∗ M ′ S and M = τ ∗ M ′ for some logarithmic strcuctures M ′ S on S and M ′ on zar( X ). Here τ ∗ denotes pullback of logarithmic structures.
We will begin by constructing a functor GS ′ → GS. Observe that an object of GS ′ is a commutative diagram, in which the square is cocartesian:
/d47
/d47
/d40
/d40
/d15
/d15
/d15
/d15
/d123
/d123
/d47
/d47
Then composition with τ ∗ τ M ∗ X → M X induces
/d47
/d47
/d41
/d41
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d125
/d125
/d47
/d47
/d47
/d47
and omitting τ ∗ τ M ∗ X and N ′ X yields an object of GS.
Now we construct the functor GS → GS . ′ Suppose that we have an object of GS:
/d47
/d47
/d41
/d41
/d15
/d15
/d15
/d15
/d123
/d123
/d47
/d47
Applying τ ∗ , this gives the following diagram:
/d47
/d47
/d40
/d40
/d15
/d15
/d15
/d15
/d124
/d124
/d47
/d47
Note that we have used τ π M ∗ ∗ S = τ τ ∗ ∗ π ∗ zar M ′ S = π ∗ zar M ′ S and τ M ∗ = τ τ ∗ ∗ M ′ = M ′ by Lemma 4.3. The square in the diagram above is cocartesian. Indeed, first construct an exact sequence:
$$0 \to \pi ^ { * } M _ { S } ^ { \text{gp} } \to ( \pi ^ { * } N _ { S } \times M _ { X } ) ^ { \sim } \to N _ { X } \to 0$$
where ( π N ∗ S × M S ) ∼ is the smallest submonoid of π N ∗ gp S × M gp X that contains π N ∗ S × M X and the image of π M ∗ gp S . Applying τ ∗ to this gives an exact sequence:
The notation in the middle term is unabiguous because
$$& \text{and execute.} \\ & ( 4. 2 ) \quad 0 \to \tau _ { * } \pi ^ { * } M _ { S } ^ { \text{p} } \to \tau _ { * } ( \pi ^ { * } N _ { S } \times M _ { X } ) ^ { \sim } ) \to \tau _ { * } N _ { X } \to R ^ { 1 } \tau _ { * } \pi ^ { * } M _ { X } ^ { \text{p} } \\ & \text{The notation in the middle term is ambiguous because}$$
$$\text{allow all the main values} & = \text{allowquoits} \, \text{$\text{$\text{$evaluation values}$} } \\ \left ( \tau _ { * } ( \pi ^ { * } N _ { S } \times M _ { X } ) \right ) ^ { \sim } & = \tau _ { * } \left ( ( \pi ^ { * } N _ { S } \times M _ { X } ) ^ { \sim } \right ) \\ \text{not not} \, \text{mod} \, \text{$\text{$Tot $\,$coo$ to $\,$fetch $not$ to $\,$fetch $it $is$ of $\alpha$} }$$
Now we show that R τ π M 1 ∗ ∗ gp S = 0. We can verify this by passing to stalks an assume that X is the spectrum of a field. Note that π M ∗ gp S is an extension of a torsion free abelian group by O ∗ X . We know that R τ 1 ∗ O ∗ X = 0 by Hilbert's Theorem 90, and R τ π M 1 ∗ ∗ gp S = 0 because we via the natural map. To see this, note first that it is sufficient to verify this at the level of characteristic monoids, since both sides are torsors under O ∗ X over their characteristic monoids (the pushforward of a O ∗ X -torsor being a O ∗ X -torsor by Hilbert's Theorem 90). It is also sufficient to check this on stalks, so we may assume that X is the spectrum of a field, and in particular that M ′ S is constant. An element of τ ∗ ( ( π N ∗ S × M X ) ∼ ) is then a section of π N ∗ gp S × M gp X that can be expressed as x -y for some x ∈ π N ∗ S × M X and y ∈ M S and is invariant under the action of the Galois group. An element of ( τ ∗ ( π N ∗ S × M X ) ) ∼ is of the form x -y where x is a Galois invariant section of π N ∗ S × M X and y is a section of M ′ S . But the Galois action on M S is trivial since M S = τ ∗ M ′ S , so x -y is Galois invariant if and only if x is.
can identify it with homomorphisms from the Galois group, which is profinite, into the discrete, torsion free abelian group M gp S .
Now the exact sequence (4.2) implies that the square in diagram (4.1) is cocartesian. Applying τ ∗ to diagram (4.1) we get an object of GS : ′
/d47
/d47
/d41
/d41
/d15
/d15
/d15
/d15
/d122
/d122
/d47
/d47
/d15
/d124
/d124
/d15
/d15
/d15
/d47
/d47
Here N ′ X is defined to make the bottom square cartesian. But pullback preserves cartesian diagrams, so both squares are cartesian and the outer part of the diagram is the desired object of GS . ′ We leave it to the reader to verify that these constructions are inverse to one another. /square
4.1. Left adjoint to pullback. In this section we prove that pullback for ´tale sheaves has a left adjoint under two natural hypotheses e (flatness and local finite presentation) and one apparently unnatural one (reduced geometric fibers). When f : X → S is ´tale, the left ade joint to pullback exists for obvious reasons and is well known: simply compose with the structure morphism of the espace ´tal´ with e e f . The construction in the present generality appears to be new.
Our construction is based on the following observation: If F is an ´ etale sheaf on X , write F ´ et for its espace ´tal´. e e When S is the spectrum of a separably closed field then f F ! has no choice but to be the set of connected components of F ´ et . In general, if the definition of f ! is to be compatible with base change in S , this forces f F ! to coincide with π 0 ( F ´ et /S ), as defined by Laumon and Moret-Bailly [LMB00, Section (6.8)] or Romagny [Rom11].
The results of [LMB00] and [Rom11] guarantee the existence of π 0 ( F ´ et /S ) as long as F ´ et is flat, of finite presentation, and possesses reduced geometric fibers over S . 8 This suffices to treat a large enough class of ´tale sheaves to generate all others under colimits when e X is merely locally of finite presentation over S . As f ! must respect colimits where defined, we can then extend the definition to any ´tale sheaf e F by applying f ! to a diagram of ´tale sheaves over e X with colimit F and then taking the colimit of the resulting sheaves over S .
8 In fact, [LMB00] assumes that X is smooth over S , but, as we will see below, only flatness is necessary in the construction.
Flatness and local finite presentation appear to be natural hypotheses for the existence of f ! in the sense that removing either leads immediately to counterexamples (the inclusion of a closed point or the spectrum of a local ring, respectively). It is less clear how essential it is to require reduced geometric fibers, as our construction makes use of that hypothesis only to ensure the existence of π 0 ( F ´ et /S ) as an ´tale e sheaf.
Gabber has argued [Gab14] that the natural condition on f under which f ∗ possesses a left adjoint is, in addition to suitable finiteness conditions, that the morphism ˜ X → ˜ S possess connected geometric fibers whenever ˜ X is the strict henselization of X at a geometric point x and ˜ S is the strict henselization of S at f ( x ).
Theorem 4.5. Suppose that f : X → S is a flat, local finite presentation morphism of algebraic spaces with reduced geometric fibers. Then the functor f ∗ : ´t( e S ) → ´ et( X ) on ´tale sheaves has a left adjoint, e f ! .
Proof. In this proof we will move freely between ´tale sheaves and their e espaces ´tal´s, which are algebraic spaces that are ´tale over the base. e e e The ´ etale site ´ et( -) will be taken to mean the category of all ´tale e algebraic spaces over the base, so that it coincides with the category of ´ etale sheaves.
For any U ∈ ´ et( X ), we may define a functor:
↦
$$F _ { U } \, \colon \acute { \mathrm e t } ( S ) \to \text{Sets} \, \colon V \mapsto \text{Hom} _ { S } ( U, V ) = \text{Hom} _ { X } ( U, f ^ { * } V )$$
Consider the collection C of all U ∈ ´ et( X ) for which F U is representable by an ´tale sheaf on e S . The existence of f ! is equivalent to the assertion that C = ´ et( X ).
Step 1. We observe first that C is closed under colimits: Suppose that U = lim - → U i and F U i is representable by f U ! i for all i . Then we may take f U ! = lim - → f U ! i :
$$\AA ^ { \prime } F _ { U } ( V ) & = \text{Hom} _ { \text{et} ( X ) } ( \underset { t } { \longrightarrow } U _ { i }, f ^ { * } V ) \\ & = \underset { \longleftarrow } { \longmapsto } \text{Hom} _ { \text{et} ( X ) } ( U _ { i }, f ^ { * } V ) \\ & = \underset { \longleftarrow } { \longmapsto } \text{Hom} _ { \text{et} ( S ) } ( \underset { t } { \longrightarrow } f _ {! } U _ { i }, V ) \\ \AA ^ { \dots } \underset { \dots } { \longrightarrow } \text{D} \, \dots \, \dots \, \dots \, \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \dots \, \AA ^ { \dots } \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dots \, \AA ^ { \dots } \, \dots \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dia \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dodelta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \ delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \Delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \ Delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \ddag \, \dots \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \dodag \, \dots \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \ delta \, \dodag \, \dots \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, delta \, \delta \, \delta. \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \} \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \cdag \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \delta \, \d$$
Every ´ etale algebraic space over X is a colimit of ´ etale algebraic spaces of finite presentation over S . For example, every ´tale algebraic e space over X is a colimit of ´tale algebraic spaces that are affine over e
affine open subsets of S . Therefore Step 1 implies that the construction of f F ! for arbitrary ´tale sheaves e F on X reduces to the construction for those representable by algebraic spaces of finite presentation over S .
Step 2. Following the construction of π 0 ( X/S ) from [LMB00, Section (6.8)], we argue next that C contains all ´tale e U over X that are of finite presentation over S . One could also use the construction of π 0 ( X/S ) from [Rom11, Th´ eor`me 2.5.2 (i)]. e
Suppose that U is flat, of finite presentation, and representable by schemes over S . By [Gro66, Corollaire (15.6.5)], there is an open subscheme W ⊂ U × S U such that, for each point x of U , the open set W ∩ { } × ( x U ) ⊂ U is the connected component of x in U . Thus a field-valued point of U × S U lies in W if and only if its two projections to U lie in the same connected component. Thus W ⊂ U × S U is a flat equivalence relation on U , hence has a quotient π 0 ( U/S ) = U/W that is an algebraic space over S .
We verify that U/W is ´ etale over S . It is certainly flat and locally of finite presentation since U is. It is therefore enough to verify it is formally unramified. This condition can be verified after base change to the geometric points of S . As the definition of W commutes with base change, so does the quotient U/W . We can therefore assume S is the spectrum of a separably closed field and then U/W = π 0 ( U/S ) = π 0 ( U ) is simply the set of connected components of U , which is certainly unramified over S .
Now we show that π 0 ( U/S ) represents F U . If g : U → V is a morphism from U to an ´tale e S -scheme V then the pre-images of points of V are open and closed in their fibers over S (since V has discrete fibers over S ). Therefore, U × V U contains W (viewing both as open subschemes of U × S U ), so f factors through U/W .
/square
Corollary 4.5.1. Let f : X → S be as in the statement of the theorem and let f ′ : X ′ → S ′ be deduced by base change via a morphism g : S ′ → S . Then the natural morphism f g ′ ! ∗ → g f ∗ ! is an isomorphism.
Proof. Since a morphism of ´tale sheaves is an isomorphism if and only e if it is an isomorphism on stalks, it is sufficient to verify the assertion upon base change to all geometric points of S ′ and therefore to assume that S ′ is itself a geometric point. Since every ´tale sheaf is a colimit e of representable ´tale sheaves that are of finite presentation over e S (as in the proof of Theorem 4.5), it is sufficient to show that
when F is representable by a scheme that is of finite presentation over S . In that case, f F ! = π 0 ( F ´ et /S ) and f g ′ ! ∗ F = π 0 ( F ´ et × S S /S ′ ′ ). But the fiber of π 0 ( F ´ et /S ) over S ′ is π 0 ( F ´ et × S S /S ′ ′ ) by definition! /square
The following proposition is well-known and included only for completeness.
↦
Proposition 4.6. Let X be a site. The inclusion of sheaves of abelian groups (resp. sheaves of commutative monoids) on X in sheaves of sets on X admits a left adjoint F → Z F (resp. F → N F ).
↦
Proof. The proofs for abelian groups and for commutative monoids are identical, so we only write the proof explicitly for abelian groups.
It is equivalent to demonstrate that, for any sheaf of sets F on X there is an initial pair ( G,ϕ ) where G is a sheaf of abelian groups and ϕ : F → G is a morphism of sheaves of sets. Denote the category of pairs ( G,ϕ ) by C . By the adjoint functor theorem, C has an initial object if it is closed under small limits and has an essentially small coinitial subcategory [ML98, Theorem X.2.1]. Closure under small limits is immediate.
For the essentially small coinitial subcategory, take the collection C 0 of all ( G,ϕ ) such that ϕ F ( ) generates G as a sheaf of abelian groups (i.e., the smallest subsheaf of abelian groups G ′ ⊂ G that contains ϕ F ( ) is G itself). The cardinalities of G U ′ ( ) for all U in a set of topological generators may be bounded in terms of the cardinalities of the F U ( ). It follows that C 0 is essentially small and by the adjoint functor theorem that the inclusion of sheaves of abelian groups in sheaves of sets has a left adjoint. /square
Proposition 4.7. Let f : X → S be flat and locally of finite presentation with reduced geometric fibers. The functor f ∗ on sheaves of abelian groups (resp. sheaves of commutative monoids) has a left adjoint, denoted f ! .
Proof. The proof is the same as the proof of the theorem above. We recognize that the class of sheaves of abelian groups (resp. sheaves of commutative monoids) F for which f F ! exists is closed under colimits. It contains Z U (resp. N U ) for all ´tale e U over X since we may take
$$f _ {! } ( \mathbf Z U ) = \mathbf Z f _ {! } ( U ) \quad ( \text{resp. } f _ {! } ( \mathbf N U ) = \mathbf N f _ {! } ( U ) ).$$
Finally, all sheaves of abelian groups are colimits of diagrams of Z U (resp. N U ) as above, so f ! is defined for all sheaves of abelian groups on X . /square
Zariski sheaves. We include a statement about the left adjoint to pullback on sheaves in the Zariski topology in a restricted situation when it agrees with the left adjoint on ´tale sheaves. e In practice, this can be used to compute the left adjoint on ´tale sheaves by working in the e Zariski topology, as in Appendix C.
Proposition 4.8. Let S be the spectrum of an algebraically closed field and let f : X → S be a reduced, finite type scheme over S . Then f ∗ : zar( S ) → zar( X ) has a left adjoint, given by f τ ! ∗ , where f ! denotes the left adjoint on ´tale sheaves. e
Proof. As in Lemma 4.3, we write τ for the morphism from the ´ etale site to the Zariski site. We have
Hom( f τ ! ∗ F, G ) = Hom( τ ∗ F, f ∗ ´ et G )
as required.
$$\Delta _ { \quad } \quad \dots \quad \Delta _ { \quad } = \text{Hom} ( \tau ^ { * } F, \tau ^ { * } f _ { z \text{ar} } ^ { * } G ) = \text{Hom} ( F, f _ { z \text{ar} } ^ { * } G ) \\ \Box$$
4.2. Reduction to the local problem. It is sufficient to construct minimal objects in GS( S ). When ( N ,ϕ S ) is an object of GS( S ), the pair ( π N , ϕ ∗ S ) is an object of GS loc ( X ). This determines a functor GS( S ) → GS loc ( X ), and when π : X → S is an isomorphism, this functor induces an equivalence between GS( S ) and GS loc ( X ).
Before giving the proof Lemma 4.1, we explain the construction. In order to minimize notation, we construct minimal objects of GS( S ); the same construction applies to GS( T ) for any S -scheme T after pulling back the relevant data.
We suppose that ( N ,ϕ S ) is an object of GS( S ) and we construct a pair ( Q , ψ S ) in GS( S ) and a morphism ( Q ,ψ S ) → ( N ,ϕ S ). Then we show ( Q ,ψ S ) is minimal in GS( S ) and that the construction of ( Q ,ψ S ) is stable under pullback.
Let ( R, ρ ) → ( π N , ϕ ∗ S ) be a morphism from a minimal object of GS loc ( X ), as guaranteed by Lemma 3.2.
Construction of Q S . Define Q S to be the pushout of the left half of the diagram of ´tale sheaves of monoids below: e
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d53
/d53
/d47
/d47
The commutativity of the diagram of solid lines and the universal property of pushout induce a morphism Q S → N S , as shown above. Pulling
back N S via this map gives a quasi-logarithmic structure Q S with characteristic monoid Q S .
Remark 4.1 . The construction of Q S can be simplified when π : X → S has connected fibers. Under that hypothesis, the counit π π M ! ∗ S → M S is an isomorphism and Q S = π R ! .
Construction of ψ . Pulling diagram (4.3) back to X we get a commutative diagram of ´ etale sheaves of monoids:
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d32
/d32
/d126
/d126
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
The vertical arrows on the left and right sides of the diagram compose to identities because π ! and π ∗ are adjoint functors. We isolate the commutative diagram
/d47
/d47
/d47
/d47
/d59
/d59
/d35
/d35
/d15
/d15
and push it out via π M ∗ S → M X to obtain the lower half of the diagram below:
/d15
/d15
/d33
/d33
/d47
/d47
/d47
/d47
/d61
/d61
/d33
/d33
/d15
/d15
The upper half of the diagram is provided by the morphism ( R, ρ ) → ( π N , ψ ∗ S ) of GS loc ( X ). By composing the vertical arrows in the center of the diagram, we obtain the definition of ψ :
$$\overline { \psi } \, \colon \, \overline { M } \, \stackrel { \overline { \rho } } { \rightarrow } \, \overline { R } _ { X } \rightarrow \overline { Q } _ { X }$$
/d47
/d47
/d47
/d47
Now observe that Q X is the pullback of N X via the map Q X → N X . The commutative triangle
/d15
/d15
/d33
/d33
/d47
/d47
yields a commutative triangle
✤
✤
/d15
/d15
/d34
/d34
✤
/d47
/d47
by the universal property of the fiber product.
Proof of Lemma 4.1. We check that the object ( Q , ψ S ) constructed above satisfies the universal property of a minimal object of GS( S ).
Consider a morphism ( N ,ϕ ′ S ′ ) → ( N ,ϕ S ) of GS( S ). We must show that there is a unique map ( Q ,ψ S ) → ( N ,ϕ ′ S ′ ) rendering the triangle below commutative:
/d47
/d47
/d37
$$\begin{matrix} \dots \dots \dots \dots \dots \dots \dots \\ & & ( Q _ { S }, \psi ) - \simeq ( N _ { S } ^ { \prime }, \varphi ^ { \prime } ) \\ & & \searrow \Big \downarrow \\ ( N _ { S }, \varphi ) \\ - & \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots
\end{matrix}$$
/d37
/d15
/d15
To specify the dashed arrow above we must give a factorization of Q S → N S through N ′ S and show the induced triangle
/d125

/d125
/d15
/d15
/d47
/d47
is commutative.
The dashed arrow in diagram (4.6) and the commutativity of diagram (4.7) are both determined at the level of characteristic monoids. That is, to give a factorization of Q S → N S through N ′ S is the same as to give a factorization of Q S → N S through N ′ S since the logarithmic structure N ′ S is pulled back from N S via N ′ S → N S . Similarly, to verify the commutativity of diagram (4.7) it is sufficient to show that the induced diagram of characteristic monoids commutes.
By the definition of Q S as a pushout in diagram (4.3), to give Q S → N ′ S compatible with the tacit maps from M S is the same as to give
π R ! → N ′ S compatible with the maps from π π M ! ∗ S . The latter is equivalent, by adjunction, to giving R → π N ∗ ′ S , compatible with the maps from π M ∗ S . But by the minimality of ( R, ρ ) in GS loc ( X ), there is a unique factorization of R → π N ∗ S through π N ∗ ′ S such that the induced triangle depicted in the upper half of the diagram below is commutative.
/d15
/d15
/d33
/d33
/d61
/d61
/d47
/d47
/d24
/d24
/d15
/d15
X
The lower triangle in the diagram is also commutative: As already noted, the map R → π N ∗ ′ S gives a factorization of π R ! → N ′ S through Q S , so by adjunction we get a factorization of R → π N ∗ ′ S through π Q ∗ S , and therefore a factorization R → π Q ∗ S → N ′ S . The lower triangle is the pushout of this sequence via R → R X . The outer triangle, which coincides with diagram (4.7), is therefore commutative, as desired. /square
Proof of Lemma 4.2. It is sufficient to treat the case where T = S . Suppose, then, that f : S ′ → S is a morphism of schemes and set X ′ = X × S S ′ . We show that ( f ∗ Q ,f ψ S ∗ ) is a minimal object of GS( S ′ ). We verify that all of the data that go into the construction of Q S are compatible with pullback:
- (1) the minimal object ( R, ρ ) of GS loc ( X ) pulls back to a minimal object of GS loc ( X ′ ) by Lemma 3.3;
- (2) the formation of π R ! is compatible with pullback by Corollary 4.5.1;
- (3) the pushout Q S is compatible with pullback by the preservation of colimits under pullback of sheaves;
- (4) the quasi-logarithmic structure Q S is formed as a fiber product of sheaves and these are preserved by pullback.
This shows that the construction of Q S is compatible with pullback. We make a similar verification for ψ :
- (5) The compatibility of π ! with f ∗ (Corollary 4.5.1) guarantees that diagram (4.4) pulls back to its analogue on X ′ ;
- (6) compatibility of pullback of sheaves with colimits guarantees the compatibility of the lower half of diagram (4.5) with pullback;
- (7) Lemma 3.3 and the assumption that ( R, ρ ) be minimal in GS loc ( X ) guarantee that the pullback of the upper half of diagram (4.5) coincides with its analogue constructed in GS loc ( X ′ ).
This shows that the construction of ψ is compatible with pullback and completes the proof. /square
## 5. Automorphisms of minimal logarithmic structures
Lemma 5.1. Suppose that ( R, ρ ) is a minimal object of GS loc ( X ) . Then the automorphism group of ( R, ρ ) is trivial.
Proof. It is equivalent to show that only the identity automorphism of R gp is compatible with both the inclusion of π M ∗ gp S and the map ρ : M gp → R gp X . Suppose that α is an automorphism of ( R, ρ ). Then the induced morphism α : R → R is the identity, by Lemma 3.4.
We use this to conclude that α = id. As α = id, the automorphism α is determined by a homomorphism λ : R gp →O ∗ X with
$$\alpha ( x ) = x + \log \lambda ( \overline { x } )$$
and x denoting the image of x under the projection R → R . By assumption, α restricts to the identity on π M ∗ gp S ⊂ R gp so λ restricts to the trivial homomorphism on π M ∗ gp S . Therefore, it must factor through the quotient M /π M gp ∗ gp S of R gp by π M ∗ gp S .
Let α X : R X → R X denote the automorphism induced by pushout of α . We investigate the condition that α X commute with ρ in terms of λ and show this implies λ = 1. Define λ X by the formula log λ X = α X -id and note that exp λ X : R gp X → O ∗ X is induced by pushout from the pair of morphisms λ : R gp → O ∗ X and 1 : M gp X → O ∗ X . This implies λ X ◦ q = 1 and λ X ◦ i = λ in the notation of the diagram below:
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d124
/d124
/d47
/d124
/d124
/d47
/d47
/d47
/d47
/d47
/d47
/d47
That λ X ◦ q = 1 follows from the fact that q factors through M gp X → R gp X . For any y ∈ R gp 0 , let r y ( ) be its image in M gp . Then we have
$$\cdots \cdots _ { J } \, \xi \, \cdots _ { U } \,, \, \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \, 0 \\ 0 = \alpha _ { X } ( \rho r ( y ) ) - \rho r ( y ) & = \log \lambda _ { X } \overline { \rho } r ( \overline { y } ) \\ & = \log \lambda _ { X } ( q ( \overline { y } ) - i \circ \epsilon ( \overline { y } ) ) \\ & = - \log \lambda _ { X } ( i \circ \epsilon ( \overline { y } ) ) \\ & = - \log \lambda ( \epsilon \overline { y } ).$$
## JONATHAN WISE
As /epsilon1 : R gp 0 → R gp is surjective, we conclude that α -id = log λ = 0 so α = id. /square
Corollary 5.1.1. The automorphism group of a minimal object of GS( S ) is trivial.
Proof. Suppose that α is an automorphism of a minimal object ( Q ,ψ S ). Then π α ∗ is an automorphism of the object ( π Q , ψ ∗ S ) ∈ GS loc ( X ). Choose a map ι : ( R, ρ ) → ( π Q , ψ ∗ S ) with ( R, ρ ) minimal. Then by the definition of minimality, there is a commutative diagram:
/d47
/d47
/d15
$$( R, \rho ) - \frac { 1 } { 2 } - \simeq ( R, \rho ) \\ \iota \Big \downarrow \Big \downarrow ^ { \iota } \\ ( \pi ^ { * } Q _ { S }, \psi ) \xrightarrow { \pi ^ { * } \alpha } ( \pi ^ { * } Q _ { S }, \psi ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
/d15
/d15
/d15
/d47
/d47
The dashed arrow is an automorphism of ( R, ρ ), hence must be the identity by the lemma. Therefore, by adjunction, the diagram below must commute:
/d124
/d34
/d34
/d124
/d47
/d47
But, by definition, Q gp S is generated by π R ! gp and M gp S (diagram (4.3) and the subsequent discussion). By assumption, α commutes with the map M gp S → Q gp S and we have just shown it commutes with the map π R ! gp . It follows that α is the identity map.
This implies that α must be induced from a map δ : Q gp S → O ∗ S , which we would like to show is trivial. This map is induced from a map Q gp S /M gp S → O ∗ S since δ is trivial on M gp S . Since π ! preserves colimits (it is a left adjoint) we use the pushout in the left half of diagram (4.3) to make identifications:
$$\overline { Q } _ { S } ^ { \text{gp} } / \overline { M } _ { S } ^ { \text{gp} } \simeq \pi _ {! } \overline { R } ^ { \text{gp} } / \pi _ {! } \pi ^ { * } \overline { M } _ { S } ^ { \text{gp} } \simeq \pi _ {! } ( \overline { R } ^ { \text{gp} } / \pi ^ { * } \overline { M } _ { S } ^ { \text{gp} } )$$
By adjunction, δ is therefore induced from a map
$$\tilde { \delta } \colon \overline { R } ^ { \text{gp} } / \pi ^ { * } \overline { M } _ { S } ^ { \text{gp} } \rightarrow \pi ^ { * } \mathcal { O } _ { S } ^ { * }.$$
But composing this with the map π ∗ O → O ∗ S ∗ X gives an automorphism of ( R, ρ ), which must be trivial, by the lemma. On the other hand, π ∗ O ∗ S injects into O X since X is flat over S , so the map ˜ -and by δ adjunction also δ -must be trivial. /square
Corollary 5.1.2. The functor Hom LogSch /S ( M,M X ) is representable by a logarithmic algebraic space.
Corollary 5.1.3. The morphism Hom LogSch /S ( X,Y ) → Hom LogSch /S ( X,Y ) is representable by logarithmic algebraic spaces.
## Appendix A. Integral morphisms of monoids
Recall that a morphism of monoids f : P → Q (written additively) is said to be integral if, for any a, a ′ ∈ P and b, b ′ ∈ Q such that
$$f ( a ) + b = f ( a ^ { \prime } ) + b ^ { \prime }$$
there are elements c, c ′ ∈ P and d ∈ Q such that a + c = a ′ + c ′ and b = d + f ( c ) and b ′ = d + f ( c ′ ).
Continue to assume that f : P → Q is integral and let P → P ′ be another morphism of monoids. Consider the collection of pairs ( a, b ) where a ∈ P ′ and b ∈ Q , modulo the relation ( a, b ) ∼ ( a , b ′ ′ ) if there are elements c, c ′ ∈ P and d ∈ Q such that a + c = a ′ + c ′ and b = d + f ( c ) and b ′ = d + f ( c ′ ).
The proofs of the following two lemmas are omitted as they are straightforward and likely well known.
Lemma A.1. If f : P → Q is integral then the relation defined above is an equivalence relation.
Lemma A.2. The monoid structure on P ′ × Q descends to the equivalence classes of the relation defined above and realizes the pushout of P → Q via P → P ′ .
## Appendix B. Minimality
B.1. Gillam's criteria. This section is included only for convenience. All of the results here may be found in greater detail in [Gil12]. Our Proposition B.1, below, is Descent Lemma 1.3 of op. cit.
Since our only application of this section is to the fibered category of logarithmic schemes, LogSch , over the category of schemes, Sch , we have not made any attempt to state the results below in their natural generality. The reader who is interested in that level of generality may easily verify that all of the arguments below are valid for an arbitrary fibered category.
Let Sch denote the category of schemes and let LogSch denote the category of logarithmic schemes. Note that LogSch is an ´ etale stack (not fibered in groupoids) over Sch . Recall that a logarithmic structure on a fibered category F over Sch is a cartesian section of LogSch over F .
Suppose that F is a fibered category over Sch with a logarithmic structure M : F → LogSch . There is an induced fibered category L ( F, M ) over LogSch : The objects of L ( F, M ) are pairs ( η, f ) where
η ∈ F and f : Y → M η ( ) is a morphism in LogSch such that Y = M η ( ) and f lies above the identity morphism.
When F is representable by a logarithmic scheme, this is the familiar construction that associates to F the functor it represents on logarithmic schemes.
We give a characterization of the fibered categories G on LogSch that are equivalent to L ( F, M ) for a fibered category F with logarithmic structure M .
An object ξ of G is called minimal if every diagram of solid lines in G ξ ( )
/d47
/d47
/d63
/d63
/d31
/d31
lying above id ξ admits a unique completion by a dashed arrow.
Proposition B.1. A fibered category G over LogSch is equivalent to L ( F, M ) if and only if the following two conditions hold:
- (1) for
- every η ∈ G there is a minimal object ξ ∈ G η ( ) and a morphism η → ξ lying above the identity of η , and
- (2) the pullback of a minimal object of G via a morphism of Sch is minimal.
Proof. Certainly L ( F, M ) has this property. The minimal object associated to ( α, f ) is ( α, id α ).
Conversely, let F be the full subcategory of minimal objects of G . By assumption, this is a fibered category over Sch with a map M : F → LogSch by composition of the inclusion F ⊂ G with the projection G → LogSch . This is cartesian over Sch because F cartesian in G over Sch and G → LogSch is cartesian over LogSch , hence over Sch .
We have a functor L ( F, M ) → G sending ( α, f ) to f ∗ α . We verify this is an equivalence. As this is a cartesian functor between fibered categories, the verification can be done fiberwise over Sch . That is, it is enough to show that the functors L ( F, M )( S ) → G S ( ) are equivalences for all schemes S .
But G S ( ) may be identified with
$$\coprod _ { \eta \in F ( S ) } ^ { \ell } G ( S ) / \eta \ \simeq \coprod _ { \eta \in F ( S ) } \, \text{LogSch} / M ( \eta ) \simeq \mathfrak { L } ( F, M ) ( S ).$$
/square
B.2. Openness of minimality. Unlike the previous section, this section is specific to logarithmic structures.
The proof of Proposition B.1 shows that G is L ( F, M ) where F ⊂ G is the open substack of minimal objects. The next proposition shows that when F and G are fibered over coherent logarithmic schemes (in other words, when minimal objects are coherent), F is an open substack of G .
For any ξ ∈ F , the image of ξ in LogSch is a logarithmic scheme S . We refer to the logarithmic structure on S also as the logarithmic structure on ξ .
Theorem B.2. Suppose that the logarithmic structure on each ξ ∈ F is coherent. Then F ⊂ Log ( G ) is open.
Proof. We must show that, for any η ∈ Log ( G ) lying above a scheme S , the locus in S where η is minimal is open in S . Let ξ be the minimal object admitting a morphism from η and let M η → M ξ be the associated morphism of logarithmic structures. The locus in S where η is minimal is the same as the locus where η → ξ restricts to an isomorphism. Since G is fibered in groupoids over LogSch , the map η → ξ restricts to an isomorphism if and only if M ξ → M η does. The following lemma therefore completes the proof. /square
Lemma B.3. Let α : M → M ′ be a morphism of coherent logarithmic structures on a scheme S . The locus in S where α is an isomorphism is an open subset of S .
Proof. It is sufficient to show that a morphism that is an isomorphism at a geometric point is an isomorphism in an ´tale neighborhood of e that point. Choose charts P → M and P ′ → M ′ near a geometric point ξ , 9 fitting into a commutative diagram:
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
As the monoids M ξ and M ′ ξ are of finite presentation (because they are finitely generated [RGS99, Theorem 5.12]), we can choose P and P ′ so that the maps P → M ξ and P ′ → M ′ ξ are isomorphisms, at least after shrinking the ´tale neighborhood of e ξ . But then P → P ′ is an
9 By a chart P → M we mean a homomorphism from a constant sheaf of monoids P to M such that if P is defined to be the extension of P by O ∗ S obtained by pulling back M → M , the associated logarithmic structure of P → M →O S is M .
isomorphism and M and M ′ are therefore the logarithmic structures associated to the same quasi-logarithmic structure. In particular, they are isomorphic. /square
## Appendix C. Explicit formulas: by Sam Molcho
The purpose of this appendix is to show that under certain reasonable simplifying assumptions, the minimal logarithmic structure constructed in the paper admits a rather concrete, simple description. Specifically, we will study minimal logarithmic structures in the case where we have a family of maps
/d47
/d47
/d15

/d15
/d126
/d126
over a geometric point S = Spec k , with π being flat and having reduced fibers, and where the logarithmic structure on V is a Zariski log structure. To our knowledge, these assumptions hold in all previous work where minimal logarithmic structures have been studied, e.g the papers, Gross-Siebert [GS13], Abramovich-Chen [AC11], Chen [Che10], Olsson [Ols08], and Ascher-Molcho [AM14]. In fact, in these papers the authors always begin with flat, proper families of schemes with reduced fibers, and construct a minimal logarithmic structure over each geometric point by writing down an explicit formula and then prove that a logarithmic structure is minimal over a general family if and only if it restricts to a minimal logarithmic structure over each point. In the cited papers, what are actually considered are 'absolute' families
/d47
/d47
/d15
/d15
We will show that in this absolute situation the notion of minimality defined in the present paper and the notion given in [GS13] (or, in fact, an evident extension of this notion) coincide. 10
- C.1. Structure of logarithmically smooth morphisms. Consider a logarithmically smooth morphism π : ( X,M X ) → ( S, M S ) which is flat, proper, and has reduced fibers, with S = Spec k a geometric point. The geometry of ( X,M X ) may be rather complicated; however, it is
10 The formula of [GS13] was only presented for families of nodal curves, but it works for more general X and the agreement we prove here holds in that generality.
simple to understand at the loci where the relative characteristic M X/S has rank 0 or 1. Specifically, we have
Theorem C.1. Suppose π : ( X,M X ) → ( S, M S ) is flat, proper, and has reduced fibers, and that S = Spec k is a geometric point. Then
- (1) Each irreducible component of X is smooth near its generic point η , and M X,η = M S .
- (2) Whenever two irreducible components intersect, they intersect in a divisor of each, which we will call a node. A node then generically is the intersection of precisely two irreducible components, and if q denotes the generic point of an irreducible component of the node, we have M X,q = M S ⊕ N N 2 , where N → N 2 is the diagonal map and ρ q : N → M S is some homomorphism determined by π .
- (3) There are certain divisors on the smooth locus of X so that at the generic point p of such a divisor, we have M X,p = M S ⊕ N .
The divisors in (3) are the higher dimensional analogue of marked points of logarithmic curves. In other words, the structure of a logarithmic morphism on the generic points of codimension 0 and 1 strata is precisely the same as the structure of a logarithmic curve, as discussed by F. Kato. To see why these claims are true, we apply the chart criterion for logarithmic smoothness [Kat89b], to obtain ´tale locally a e commutative diagram
/d47
/d47
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
where the square is cartesian and the morphism from ( X,M X ) to the fiber product with its induced logarithmic structure is smooth on the level of underlying schemes and strict. Since smooth morphisms preserve the information of how irreducible components intersect, the problem reduces to proving these claims for the fiber of a toric morphism of toric varieties X F,N ( ) → X κ,Q ( ) over the torus fixed point of X κ,Q ( ). Here we use the notation X F,N ( ) for the toric variety determined by a fan F in a lattice N , and similarily for X κ,Q ( ), where we may assume κ is a single cone. A generic component of the fiber over the fixed point of X κ ( ) then corresponds to a cone τ ∈ F such that τ maps isomorphically to κ , and a divisor in the fiber corresponds
to a cone σ that maps onto κ with relative dimension 1. Condition (1) then is equivalent to saying that τ ∩ N is isomorphic to κ ∩ Q , since the duals of these monoids are charts for the logarithmic structures M X,η and M S . Conditions (2) and (3) are equivalent to saying that every cone σ that maps onto κ with relative dimension 1 can have either one or two faces isomorphic to κ ; and, (2) if σ has two such faces, then that N ∩ σ ∼ = ( Q ∩ κ ) × N N 2 for some homomorphism e q : Q ∩ κ → N , while if (3) σ has precisely one such face, then σ ∩ N ∼ = ( Q ∩ κ ) × N . These statements, and the construction of the homomorphism e q are precisely the content of lemmas 3.11 and 3.12 of Ascher-Molcho [AM14], or equivalently lemmas 8 and 9 in Gillam-Molcho [GM13] from which lemmas 3.11 and 3.12 are derived.
The description given above holds ´tale locally on e X , for the ´tale e sheaf M X . In what follows, we also need to understand the induced Zariski sheaf τ M ∗ X on X , where τ denotes the morphism of sites ´ et( X ) → zar( X )-c.f. lemma 4.6 and proposition 4.7. We claim that the description of τ M ∗ X over the generic points η of irreducible components of X and over generic points q of irreducible components of nodes is only slightly more involved. Specifically, we have
Corollary C.1.1. The logarithmic structure τ M ∗ X satisfies τ M ∗ X,η = M S on the generic point of an irreducible component η . On the generic point of an irreducible component of a node, we have either
- (1) τ M ∗ X,q = M S ⊕ N N 2 , when the node is the intersection of two distinct irreducible components of X in the Zariski topology, or
- (2) τ M ∗ X,q = M S , when the node is the self-intersection of a single irreducible component.
Proof. We prove the statement about nodes first. The question is local on X , so we may assume for simplicity that X is the spectrum of O X,q According to theorem C.1 above, we can choose an ´tale cover e U of X , and a lift q ′ of q , with the property that M U,q ′ ∼ = M S ⊕ N N 2 ; here the two generators e , e 1 2 of N 2 correspond to the two branches of U around q ′ , and map to the two functions in O U,q which define these two branches. For every ´tale cover e V of U over X , and cover q ′′ of q ′ , we have M V,q ′′ ∼ = M S ⊕ N N 2 as well, as M U,q ′ and M V,q ′′ are both pulled back from M X,q . Thus, every ´ etale cover V of U over X induces an automorphism of M S ⊕ N N 2 . On the other hand, the sheaf τ M ∗ X is determined from M U by descent, hence τ M ∗ X,q is the submonoid of invariants of M S ⊕ N N 2 under all automorphisms of M S ⊕ N N 2 obtained by ´tale covers e V → U over X . Every such automorphism further lives over S , hence must fix
M S ; and since e 1 + e 2 ∈ N 2 is in M S , such an automorphism must fix e 1 + e 2 . We are thus looking at automorphisms of N 2 which fix (1 , 1), that is, matrices with coefficients in N , determinant 1, and that fix (1 , 1). The only two such matrices are the identity and the matrix e 1 → e , e 2 2 → e 1 . Thus, the invariants of M S ⊕ N N 2 are either all of M S ⊕ N N 2 or the diagonal M S ⊕ N N ( e 1 + e 2 ) ∼ = M S . To prove the corollary it remains to analyze when each case happens. Suppose first that q is the intersection of two distinct irreducible components of X . Since O X is determined from O U by descent as well, we see that the images of e , e 1 2 in U map to distinct functions in O X , which define q in each of the irreducible components. Thus, there can be no ´tale e cover V of U over X which interchanges e , e 1 2 in the automorphism M S ⊕ N N 2 , and we are in the situation where the invariants are all of M S ⊕ N N 2 . On the other hand, if q is the self intersection of a single component, the only linear combinations of e 1 and e 2 that descend are the ke 1 + ke 2 , which lie in M S .
To see the statement about the logarithmic structure over the generic points of irreducible components η , we simply observe that the invariants of M S over M S are always M S , hence τ M ∗ X,η = M S as well. /square
## C.2. The Minimal Log Structure Over a Geometric Point. We consider a family of logarithmic schemes
/d47
/d47
/d15

/d15
/d126
/d126
S
with S a geometric point, and π a logarithmic smooth morphism. The morphism f is not assumed to be a logarithmic morphism. We write M S for the logarithmic structure on S M , X for the logarithmic structure on X , and M V for the logarithmic structure on V . We further write M = f ∗ M V for the pullback of the logarithmic structure on V to X .
Out of X , we can create a category C . The objects of C are the generic points of the strata in the minimal stratification on which the relative characteristic M X is locally constant. Note that τ M ∗ X/S is constant on these strata. We have a morphism x → y in C whenever { x } ∈ { ¯ y } .
In the special case when X is a nodal curve, the category C is rather simple, with one object for each irreducible component η of X and an object for each node or marked point q , and a morphism q → η whenever q belongs to the component η . In fact, the same characterization holds for general X in depths 0 and 1: depth 0 objects correspond to
irreducible components of X , and depth 1 objects correspond to either marked divisors in X or nodes where irreducible components of X intersect, according to theorem C.1.
Lemma C.2. Let F be a sheaf in the ´tale topology on e X that is pulled back from a sheaf in the Zariski topology, which is constructible with respect to the category C . Then
$$\pi _ {! } ( F ) = \varinjlim _ { x \in \mathcal { C } } F _ { x }$$
Proof. By Proposition 4.8, π ! is the left adjoint to π ∗ zar the pullback functor on Zariski sheaves , so we only need to verify that for any sheaf G on S , Hom(lim - → x ∈C F , G x ) = Hom( F, π ∗ G ). A sheaf G on S is simply a monoid, so π G ∗ is the constant sheaf on X associated to G . Thus, to give a homomorphism F → π G ∗ is equivalent to giving homomorphims F x → G for each x ∈ C which are compatible with generization; but this is precisely the data of a homomorphism lim - → x ∈C F x → G . /square
Observe furthemore that the colimit over a finite indexing category only depends on the objects of depths 0 and 1, i.e in this case over the irreducible components η of X , the generic points q of the nodes of X , and the generic points of the marked divisors of X . Note that the marked divisors do not contribute to the colimit. The reason is that for each p ∈ C corresponding to a marked divisor, there is a unique morphism p → η , where η corresponds to the irreducible component containing the marked divisor. So the points corresponding to marked divisors can be ommited from the diagram without affecting the colimit. The same is true for nodes of X which are the self intersection of a single irreducible component.
From here on, η is always going to denote the generic point of an irreducible component of X , and q is always going to denote the generic point of an irreducible component of the intersection of two distinct irreducible components.
In what follows, we will replace M X with the sheaf τ ∗ τ M ∗ X . Note that while X equipped with τ ∗ τ M ∗ X is no longer log smooth over ( S, M S ), the minimal log structure obtained from τ ∗ τ M ∗ X and the minimal log structure obtained from M X coincide, according to 4.4. The reason we do this replacement is because this allows us to use C in the calculation of the minimal log structure, according to lemma C.2, rather than the far larger category of all ´tale specializations. e Furthermore, according to the preceeding remark, only irreducible components η and nodes q need to be included in the calculation and there we have
τ ∗ τ M ∗ X,η = M X,η , τ ∗ τ M ∗ X,q = M X,q according to corollary C.1.1. So this is in fact not a serious abuse of notation.
This allows us to work an explicit presentation for the minimal logarithmic structure. We first determine its associated group. Let us recall the notation. Diagram (C.1) gives us a diagram
u
/d119
/d119
/d111
/d111
/d111
/d111
/d79
/d79
/d59
/d59
S
where M = f ∗ M V and u is a given homomorphism which is fixed in advance, part of the discrete geometric data of the problem - the type of the morphism. The problem of finding a minimal logarithmic structure of the data is the same as finding a minimal object N S such that u factors through a homomorphism M gp → N gp S ⊕ π M ∗ gp S M gp X . To find the minimal logarithmic structure, we set
$$\overline { R } _ { 0 } ^ { \text{gp} } = \overline { M } _ { X } ^ { \text{gp} } \times _ { \overline { M } _ { X / S } ^ { \text{gp} } } \overline { M } ^ { \text{gp} }$$
and
$$\overline { R } ^ { \text{gp} } = \overline { R } ^ { \text{gp} } _ { 0 } / \Delta ( \pi ^ { * } \overline { M } ^ { \text{gp} } _ { S } )$$
where ∆ is the diagonal map π M ∗ gp S → M gp X × M gp X/S M gp .
Applying the lemma, we see that the associated group of the minimal logarithmic structure π R ! gp on S is given as the coequalizer
/d47
$$\varinjlim _ { x \in C } \overline { R } _ { x } ^ { \text{gp} } = \varinjlim _ { \text{$q$} } \left ( \, \bigoplus _ { q } \, \overline { R } _ { q } ^ { \text{gp} } \xrightarrow { \phi _ { 1 } } \bigoplus _ { \text{$q$} } \overline { R } _ { \text{$q$} } ^ { \text{gp} } \right )$$
/d47
/d47
/d47
where φ , φ 1 2 denote the two generization maps, induced by the generization morphisms M X,q → M X,η and M q → M η whenever q is contained in η . If we choose an ordering of the two components η , η 1 2 containing a node q , the coequalizer becomes the quotient
$$\bigoplus _ { q } \overline { R } _ { q } ^ { \text{gp} } \xrightarrow { \phi _ { 2 } - \phi _ { 1 } } \bigoplus _ { \eta } \overline { R } _ { \eta } ^ { \text{gp} }$$
On the other hand, even though R may be difficult to understand, its stalks at generic points and nodes are straightforward. We have
$$\overline { R } _ { 0, \eta } ^ { \text{gp} } = \overline { M } _ { X, \eta } ^ { \text{gp} } \times \overline { M } _ { \eta } ^ { \text{gp} } \cong \overline { M } _ { S } ^ { \text{gp} } \times \overline { M } _ { \eta } ^ { \text{gp} }$$
and so
$$\overline { R } _ { \eta } ^ { \text{gp} } = \overline { M } _ { \eta } ^ { \text{gp} }$$
Similarily, on a node q we have
$$\overline { R } _ { 0, q } ^ { \text{gp} } = \overline { M } _ { X, q } ^ { \text{gp} } \times \mathbf z \, \overline { M } _ { q } ^ { \text{gp} }$$
Now recall that M X,q = M S ⊕ N N 2 = { ( a, b ) : b -a = ρ d q } ⊂ M S × M S where ρ q : N → M S is a homomorphism determined by π , as discussed in section C.1. We abusively also write ρ q for the image ρ q (1) ∈ M S of ρ q . The morphism M gp X,q → Z is the canonical projection M gp X,q → M gp X/S , which, explicitly, is the homomorphism that sends a pair ( a, b ) such that b -a = ρ d q to d . Therefore,
$$\bar { R } _ { 0, q } ^ { \text{gp} } = \left \{ ( a, b, m ) \, \colon b - a = u _ { q } ( m ) \rho _ { q } \right \}$$
↦
The morphism π M ∗ gp S → R gp 0 ,q is the diagonal s → ( s, s, i ( s )), and hence the quotient
$$\overline { R } _ { q } ^ { \text{gp} } \cong \overline { M } _ { q } ^ { \text{gp} }$$
↦
the isomorphism sending [( a, b, m )] → m -i ( a ), with inverse m → [0 , u q ( m ρ , m ) q ]. The two generization morphisms R gp 0 ,q → R gp 0 ,η → R gp η are the two natural maps from M gp X,q × Z M gp q to M gp η , sending ( a, b, m ) to ( ( i a )+ φ 1 ( m )) or to ( ( i b )+ φ 2 ( m )) respectively, depending on whether η is the first or second irreducible component containing q , under our ordering. Thus, under the isomorphism above, the morphism R gp q → R gp η 1 × R gp η 2 becomes the map M gp q → M gp η 1 × M gp η 2 which sends m to ( -φ 1 ( m , φ ) 2 ( m ) + i ( u q ( m ρ ) q ) ) . The associated group of the minimal logarithmic structure thus has the very simple quotient presentation:
↦
$$\bigoplus _ { q } \overline { M } _ { q } ^ { \text{gp} } \xrightarrow [ ] { ( - \phi _ { 1 }, \phi _ { 2 }, i u _ { q } \rho _ { q } ) } \bigoplus _ { \eta } \overline { M } _ { \eta } ^ { \text{gp} }$$
The characteristic monoid of the actual logarithmic structure π R ! is then the image of ⊕ M η in π R ! gp .
C.3. Gross-Siebert Minimality. Wenow specialize to the case when the family of morphisms f : X → V is absolute, i.e of the form
/d47
/d47
/d15
$$\begin{matrix} \lambda & \cdot & \cdot & \cdot \\ & & X \xrightarrow { f } V \\ ( C. 3 ) & & \pi \Big | _ { S } \\ \end{matrix}$$
/d15
This point of view can be reconciled with that of the previous paragraph by simply redefining the logarithmic structure of V to be M ′ V = M V ⊕ π M ∗ S . At any rate, to avoid confusion and keep in line with existing literature, we will denote the sheaf of monoids f ∗ M V by P , and f ∗ M ′ V by M , as above. For a node q , specializing two irreducible components η , η 1 2 , let χ i : P q → P η i denote the two generization maps.
Definition C.3. Let S be a geometric point. A logarithmic structure N S on S is called a Gross-Siebert minimal logarithmic structure for f over M S if its characteristic monoid Q = N S has associated group isomorphic to the cokernel of
$$\begin{array} { c } \int \infty \infty \infty \\ \Phi \colon & \bigoplus _ { q } P _ { q } ^ { \text{gp} } \xrightarrow { ( - \chi _ { 1 }, \chi _ { 2 }, \rho _ { q } u _ { q } ) } & \overline { M } _ { S } ^ { \text{gp} } \oplus \bigoplus _ { \eta } P _ { \eta } ^ { \text{gp} } \end{array}$$
and Q is isomorphic to the image of M gp S ⊕ ⊕ η P gp η in the associated group.
Remark C.1 . In [GS13], the minimal logarithmic structure is in fact saturated by definition, i.e Q is the saturation of the monoid in the definition above. Since our results go through in case Q is merely integral, the definition is stated in this slightly more general form.
Remark C.2 . In [GS13], the object of study is stable logarithmic maps, in which case X → S is a logarithmic curve. In this case, there are canonical logarithmic structures on X and S which make X → S logarithmically smooth. Over a geometric point, the characteristic monoid of the canonical logarithmic structure on S is simply N m , where m is the number of nodes of X . The definition of minimality given in [GS13] has this canonical logarithmic structure as M S throughout. The definition presented here is the evident modification that allows the same flexibility as the present paper.
Theorem C.4. A Gross-Siebert minimal logarithmic structure is minimal.
Proof. Let ( X,N X ) → ( S, N S ) be any log morphism pulled back from ( X,M X ) → ( S, M S ) which admits a log morphism f to V , as in diagram (C.3). The morphism f induces morphisms P gp η → N gp X,η = N gp S
for each η . We thus have a unique extension to a summation morphism Σ : M gp S ⊕ ⊕ η P gp η → N gp S . On the other hand, for each node q , the diagram
/d47
/d47
/d62
/d62
/d61
/d61
/d32
/d32
/d47
/d47
must commute; thus the map Σ must descend uniquely to the (unsharpened) quotient of Φ. As N gp S is assumed torsion free, the morphism must descend to the sharpened quotient as well, i.e, the associated group of the minimal logarithmic structure, as desired. Since M S ⊕ ⊕ η P η → N gp S factors through N S , its image Q in Q gp maps to N S , as desired. /square
We are now ready for the comparison.
Theorem C.5. Suppose ( X,M X ) → ( S = Spec C , M S ) is a logarithmic smooth morphism which is flat and has reduced fibers, and f : X → ( V, M V ) is a morphism to a logarithmic scheme. The minimal logarithmic structure defined in the paper coincides with the GrossSiebert minimal logarithmic structure.
Proof. This is immediate as both logarithmic structures satisfy the same universal property. /square
It is actually rather interesting to give a direct proof of this fact, as the calculation is illuminating. We consider
/d47
/d47
/d15
/d15
S
/d47
/d47
/d15
/d15
/d126
/d126
and extend it to
/d47
/d47
/d32
/d32
↦
↦
as above by putting M ′ V = M V ⊕ π M ∗ S , M = f ∗ M ′ V . 11 Then, M q = P q ⊕ M S and M η = P η ⊕ M S . The morphism m → -( φ 1 ( m , φ ) 2 ( m ) + i ( u q ( m ρ ) q )) is identified with ( m,s ) → -( χ 1 ( m , ) -s, χ 2 ( m , u ) q ( m ρ ) q + s ). Therefore, by the results of section 1, we have that the associated group of the minimal logarithmic structure for the family is given as the quotient
/d47
$$\bigoplus _ { q } ( P _ { q } ^ { \text{gp} } \oplus M _ { S } ^ { \text{gp} } ) \xrightarrow { ( - \chi _ { 1 }, - i d, \chi _ { 2 }, i d + u _ { q } \rho _ { q } ) } \bigoplus _ { \eta } ( P _ { \eta } ^ { \text{gp} } \oplus M _ { S } ^ { \text{gp} } )$$
/d47
Then, if Σ denotes the summation map ⊕ M gp S → M gp S , we obtain a commutative diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
Thus, the morphism (Σ id) descends to a morphism of the quotients , π R ! gp → Q gp S , where Q is the characteristic monoid of the Gross-Siebert minimal logarithmic structure:
⊕
/d47
/d47
⊕(
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d15
/d15
/d47
/d47
/d47
Observe that the kernel of the map P gp q ⊕ M gp S → P gp q is simply M gp S . The kernel of the map on the right on the other hand is the kernel of the summation map ⊕ η M gp S → M gp S . The induced map of kernels then fits into the sequence
But this is precisely the part of the complex that computes the homology of the geometric realization B C of the category C with coefficients in the group M gp S , where the morphism on the right is the evaluation map. Since X is connected, so is C , and thus H B ,M 0 ( C gp S ) = M gp S , and thus ⊕ q M gp S surjects onto the kernel of the evaluation map Σ. Thus, the map π R ! gp → Q is injective. On the other hand, the morphism (Σ id) is certainly surjective, so , π R ! gp → Q gp is also surjective. We thus get the isomorphism on the level of associated groups.
To extend the isomorphism on the level of actual monoids, note that since the summation morphism is also surjective on the level of monoids, the image of ⊕ η ( M gp S ⊕ P η ) surjects onto the image of M S ⊕ ( ⊕ η P η ), and hence π R ! surjects onto Q . Since π R ! and Q are integral and the morphism of associated groups is injective, we obtain the desired isomorphism.
## References
[AC11] D. Abramovich and Q. Chen, Stable logarithmic maps to DeligneFaltings pairs II , February 2011, arXiv:1102.4531 .
[ACGM10] D. Abramovich, Q. Chen, W. D. Gillam, and S. Marcus, The Evaluation Space of Logarithmic Stable Maps , December 2010, arXiv:1012.5416 .
K. Ascher and S. Molcho, Logarithmic stable toric varieties and their moduli
[AM14] , ArXiv e-prints (2014).
[Che10]
Q. Chen, Stable logarithmic maps to Deligne-Faltings pairs I , August 2010, arXiv:1008.3090 .
[Gab14]
[Gil12]
[GM13]
O. Gabber, Personal communication, August 2014.
W. D. Gillam, Logarithmic stacks and minimality , International Journal of Mathematics 23 (2012), no. 07, 1250069.
W.D Gillam and S. Molcho, Stable Log Maps as Moduli of Flow Lines , http://www.math.brown.edu/ ~ smolcho/flows3.pdf , 2013.
[Gro66]
A. Grothendieck, ´ l´ments E e de g´om´ etrie e alg´brique. e IV. Etude locale ´ des sch´mas et des morphismes de sch´mas. III e e , Inst. Hautes Etudes ´ Sci. Publ. Math. (1966), no. 28, 255. MR MR0217086 (36 #178)
[GS13] Mark Gross and Bernd Siebert, Logarithmic Gromov-Witten invariants , J. Amer. Math. Soc. 26 (2013), no. 2, 451-510. MR 3011419
[HR14]
J. Hall and D. Rydh, Coherent Tannaka duality and algebraicity of Hom-stacks , ArXiv e-prints (2014).
[Kat89a]
[Kat89b]
Kazuya Kato, Logarithmic structures of Fontaine-Illusie , Algebraic analysis, geometry, and number theory (Baltimore, MD, 1988), Johns Hopkins Univ. Press, Baltimore, MD, 1989, pp. 191-224. MR 1463703 (99b:14020)
, Logarithmic structures of Fontaine-Illusie , Algebraic analysis, geometry, and number theory (Baltimore, MD, 1988), Johns Hopkins Univ. Press, Baltimore, MD, 1989, pp. 191-224. MR 1463703 (99b:14020)
[LMB00]
G´ erard Laumon and Laurent Moret-Bailly, Champs alg´ ebriques , Ergebnisse der Mathematik und ihrer Grenzgebiete. 3. Folge. A Series of Modern Surveys in Mathematics [Results in Mathematics and Related Areas. 3rd Series. A Series of Modern Surveys in Mathematics], vol. 39, Springer-Verlag, Berlin, 2000. MR 1771927 (2001f:14006)
[ML98]
Saunders Mac Lane, Categories for the working mathematician , second ed., Graduate Texts in Mathematics, vol. 5, Springer-Verlag, New York, 1998. MR 1712872 (2001j:18001)
Martin C. Olsson, Logarithmic geometry and algebraic stacks , Ann. Sci.
[Ols03] ´ cole Norm. Sup. (4) E 36 (2003), no. 5, 747-791.
[Ols08]
M.C. Olsson, Compactifying moduli spaces for abelian varieties , Compactifying Moduli Spaces for Abelian Varieties, Springer, 2008.
[RGS99]
J.C. Rosales and P.A. Garc´ ıa-S´nchez, a Finitely generated commutative monoids , Nova Science Publishers, 1999.
[Rom11]
Matthieu Romagny, Composantes connexes et irr´ductibles en familles e , Manuscripta Math. 136 (2011), no. 1-2, 1-32. MR 2820394 (2012g:14013)
University of Colorado, Boulder, Boulder, Colorado 80309-0395, USA | 10.2140/ant.2016.10.695 | [
"Jonathan Wise"
] | 2014-07-31T22:02:31+00:00 | 2015-11-06T18:39:10+00:00 | [
"math.AG"
] | Moduli of morphisms of logarithmic schemes | We show that there is a logarithmic algebraic space parameterizing
logarithmic morphisms between fixed logarithmic schemes when those logarithmic
schemes satisfy natural hypotheses. As a corollary, we obtain the algebraicity
of the stack of stable logarithmic maps without restriction on the logarithmic
structure of the target. |
1408.0038v2 | ## EQUIVALENCE OF MODELS FOR EQUIVARIANT ( ∞ , 1) -CATEGORIES
## JULIA E. BERGNER
Abstract. In this paper we show that the known models for ( ∞ , 1)-categories can all be extended to equivariant versions for any discrete group G . We show that in two of the models we can also consider actions of any simplicial group G .
## 1. Introduction
Two areas of much recent research in homotopy theory have been the development and application of homotopical categories, or ( ∞ , 1)-categories, and equivariant homotopy theory. In this paper, we seek to bring the two ideas together and investigate equivariant ( ∞ , 1)-categories.
There are many different models for ( ∞ , 1)-categories, all known to be equivalent in the sense that their respective model categories are all Quillen equivalent. Simplicial or topological categories are categories with a simplicial set or space of morphisms between any two objects. Segal categories and complete Segal spaces are bisimplicial sets having properties resembling the simplicial nerve of a simplicial category, but with a weaker form of composition. Quasi-categories encode the same information in a simplicial set. Each model for ( ∞ , 1)-categories can be thought of as living in its respective model category, in which a weak equivalence is defined by a homotopical version of equivalence of categories.
Given a group G , a G -equivariant ( ∞ , 1)-category should be one of the above structures equipped with an action of G . The morphisms in the category of such should respect the G -action, and a weak equivalence should be a map which induces weak equivalences on H -fixed point objects for all (closed) subgroups H of G .
To prove that each model for ( ∞ , 1)-categories has a good equivariant analogue, and that these models are in turn all equivalent to one another, we apply general tools of Stephan [19] and of Bohmann, Mazur, Osorno, Ozornova, Ponto, and Yarnall [4]. Their results give conditions under which a model category has a corresponding G -model category, and under which this process preserves Quillen equivalences. A related approach has also been described by Dotto and Moi [6].
For complete Segal spaces and quasi-categories, establishing that these conditions hold for an action by a discrete group G is immediate from Stephan's results. For simplicial categories and Segal categories, we give proofs here. These conditions
Date : October 7, 2014.
2010 Mathematics Subject Classification. 55U35, 55P91, 55U40, 18G55.
Key words and phrases. ( ∞ , 1)-categories, equivariant homotopy theory.
The author was partially supported by NSF grant DMS-1105766. This research was done while the author was in residence at MSRI during Spring 2014, supported by NSF grant 0932078 000.
also guarantee that we can carry over all the Quillen equivalences that we have non-equivariantly.
When G is a simplicial group, then we need the original model category to have the structure of a simplicial model category. This additional assumption holds for the complete Segal space and Segal category models, so we establish equivariant versions in these contexts.
It is perhaps more interesting to consider the case where G is a topological group, and in particular a compact Lie group. In this case, we need to begin with a topological (rather than simplicial) model category, so it is expected that the right models are complete Segal spaces and Segal categories taken in topological spaces rather than in simplicial sets. We pursue this perspective, as well as a more handson approach to the equivariant structures, in forthcoming work with Chadwick.
We expect that many examples of ( ∞ , 1)-categories have natural group actions that can be investigated from this perspective. For example, any monoidal ( ∞ , 1)category has an action of the automorphism group of a unit object.
The methods that we use in this paper can be extended to more general settings, such as equivariant ( ∞ , n )-categories and equivariant ( ∞ , 1)-operads. Again, for many of the known models we get equivariant versions immediately from Stephan's results; for the generalizations of simplicial categories (categories enriched in Θ n -spaces and simplicial operads, respectively), the proofs can be obtained by modifying the one given here appropriately. The framework of equivariant ( ∞ , n )-categories should give a context in which to understand equivariant (extended) topological field theories. A further extension is to the 2-Segal spaces of Dyckerhoff and Kapranov [8]; as these structures often arise from S · -constructions there are a number of examples to be investigated with group actions incorporated. We plan to look at such examples in future work.
We begin in Section 2 with a statement of the general theorems that we wish to use, in the case where G is a discrete group. In Section 3, we show that they can be applied immediately to the complete Segal space and quasi-category models. In Sections 4 and 5, we prove that they can be applied to the simplicial category and Segal category models. Lastly, in Section 6 we consider simplicial groups G and show that we get equivariant versions of the complete Segal space and Segal category models in this case.
Acknowledgments. The author would like to thank Anna Marie Bohmann, Ang´ elica Osorno, and Marc Stephan for several helpful conversations about this work.
## 2. Equivariant versions of model categories
In this section, we summarize results of Stephan, namely, sufficient conditions under which a G -equivariant version of a cofibrantly generated model category C exists [19]. To begin, we assume that G is discrete, and consider it as a category with a single object and morphisms given by the elements of G .
Definition 2.1. The category of G -objects in C , denoted by C G , is the category of functors G →C .
The key feature of a G -equivariant model structure, rather than just a model structure of objects equipped with a G -action, is that weak equivalences are defined using fixed point objects.
Definition 2.2. Given any subgroup H of G , define the H -fixed points functor , denoted by ( -) H , as the composite C G → C H → C where the first map is the restriction defined by the inclusion of H into G , and the second map is the limit functor.
Definition 2.3. Let G be a discrete group. The G -model structure on C G (if it exists) has weak equivalences the maps X → Y such that, for every subgroup H of G , the map X H → Y H is a weak equivalence in C , and likewise for the fibrations.
Remark 2.4. Stephan works in the following more general setting. Let F be a set of subgroups of G . The F -model structure on C is defined similarly to the G -model structure, but where H is taken to be an element of F . We are most interested in the G -model structure, but our results can be applied to the F -model structure as well.
Since C is a model category, and in particular is complete and cocomplete, we can think of it as being tensored and cotensored over the category of sets, as follows. Let A and B be objects of C and X a set. Then there is a tensor
$$\i u A & a \sec. \, \i m e n \, \i n \\ X & \otimes A = \coprod _ { X } A$$
and a cotensor
$$[ X, B ] = \prod _ { X } B$$
such that there are isomorphisms
Hom ( C X ⊗ A,B ) = Hom ∼ S ets ( X, Hom ( C A,B )) = Hom ( ∼ C A, X,B [ ]) .
Let A be an object of C and H a subgroup of G . Then we denote by G/H ⊗ A the object of C G given composing the map G →S ets given by sending G to G/H with the tensor map -⊗ A : S ets →C .
Lemma 2.5. [19] The functor G/H ⊗- C → C : G is left adjoint to the fixed point functor ( -) H .
We use the following criteria for determining the existence of the G -model structure on C G . Here, we use the formulation given by [4] which is slightly different from the original in [19].
Theorem 2.6. [19] , [4] Let G be a group, and let C be a cofibrantly generated model category. Suppose that, for each subgroup H of G , the fixed point functor ( -) H satisfies the following cellularity conditions:
- (1) the functor ( -) H preserves filtered colimits of diagrams in C G ,
- (2) the functor ( -) H preserves pushouts of diagrams where one arrow is of the form
$$G / K \otimes f \colon G / K \otimes A \rightarrow G / K \otimes B$$
- for some subgroup K of G and f a generating cofibration of C , and (3) for any subgroup K of G and object A of C , the induced map
$$( G / H ) ^ { K } \otimes A \rightarrow ( G / H \otimes A ) ^ { K }$$
is an isomorphism in C .
Then the category C G admits the G -model structure.
This result was further strengthened by Bohmann, Mazur, Osorno, Ozornova, Ponto, and Yarnall via the following result.
Theorem 2.7. [4] Suppose that F : M /arrowparrrightleft N : R be a Quillen equivalence between model categories satisfying the cellularity conditions of Theorem 2.6. Then there is an induced Quillen equivalence F G : M G /arrowparrrightleft N G : R G .
In fact, we have the stronger result that these model categories are actually Quillen equivalent to those described via orbit diagrams, generalizing a result of Elmendorf for topological spaces [9].
Definition 2.8. The orbit category of G is the full subcategory O G of the category of G -sets with objects the orbits G/H where H is a subgroup of G .
↦
Consider the category of functors O op G →C , equipped with the projective model structure, where weak equivalences and fibrations are defined levelwise. There is a functor i : G → O op G sending the single object of G to G/ e { } and a morphism g of G to the G -map G/ e { } → G/ e { } defined by h → hg . The induced map i ∗ : G O op G →C G has a left adjoint i ∗ given by left Kan extension.
Theorem 2.9. [19] Let G be a group, and let C be a cofibrantly generated model category. Suppose that, for each subgroup H of G , the fixed point functor ( -) H satisfies the cellularity conditions of Theorem 2.6. Then there is a Quillen equivalence i ∗ : C O op G /arrowparrrightleft C G : i ∗ .
Remark 2.10. If one instead uses the F -model structure, for a set F of subgroups of G , then it is necessary to assume that the trivial subgroup of G is included in F , so that the functor i is defined.
Combining this result with that of Theorem 2.7, we get a commutative square of Quillen equivalent model categories associated to a Quillen equivalence C /arrowparrrightleft D and a group G :
/d79
/d47
/d47
/d111
/d111
/d79
/d79
/d79
/d15
/d15
/d15
/d15
/d111
/d47
/d47
.
/d111
We conclude this section with two important families of examples.
Theorem 2.11. [19] Any category of functors D → S ets , equipped with a cofibrantly generated model structure in which the cofibrations are monomorphisms, admits the G -model structure.
Observe that we can apply the above theorem to any category of functors D → SS ets simply by viewing the objects instead as functors D× ∆ op →S ets .
Theorem 2.12. [19] Let C be a model category which satisfies the cellularity conditions of Theorem 2.6. Then any left Bousfield localization of C also satisfies the cellularity conditions, and hence admits the G -model structure.
## 3. Equivariant complete Segal spaces and quasi-categories
In this section, we consider the two models for ( ∞ , 1)-categories for which we get equivariant versions immediately from Stephan's results. Using Theorem 2.7, we can lift the Quillen equivalences between them to these equivariant versions.
We begin with the model of quasi-categories. Recall that, given any n ≥ 1 and 0 ≤ k ≤ n , the k th horn of the n -simplex ∆[ n ], denoted by V n, k [ ], is the boundary of ∆[ n ] with the k th face removed.
Definition 3.1. A quasi-category is a simplicial set K satisfying the inner horn filling conditions, i.e., that for any n ≥ 2 and 0 < k < n , in any diagram
/d47
/d47
/d60
/d60
/d15
/d15
the dotted arrow lift exists.
Recall the following result, proved using different methods by Joyal [12], Lurie [15], and Dugger and Spivak [7].
Theorem 3.2. There is a model structure QC at on the category of simplicial sets in which the cofibrations are the monomorphisms and the fibrant objects are the quasi-categories.
We can apply Theorem 2.11 and Theorem 2.9 to obtain the following result.
Theorem 3.3. The G -model structure for QC at exists, and there is a Quillen equivalence of model categories
$$i ^ { * } \colon \mathcal { Q } a t ^ { \mathcal { O } ^ { o p } _ { G } } \Rightarrow \mathcal { Q } \mathcal { C } a t ^ { G } \colon i _ { * }.$$
Now we turn to the complete Segal space model. The objects here are simplicial spaces, or functors ∆ op →SS ets . Recall that the category of simplicial spaces can be equipped with the Reedy model structure, in which the weak equivalences are given levelwise [17]. In this case, it is equivalent to the injective model structure, in which the cofibrations are also defined levelwise. Recall that the Reedy model structure is equipped with a compatible simplicial structure, so there is a mapping simplicial set Map( X,Y ) between any simplicial spaces X and Y .
Definition 3.4. A simplicial space W is a Segal space if it is Reedy fibrant and the Segal maps are weak equivalences.
$$W _ { k } \rightarrow \underbrace { W _ { 1 } \times _ { W _ { 0 } } \cdots \times _ { W _ { 0 } } W _ { 1 } } _ { k }$$
Let E denote the nerve of the groupoid with two objects and a single isomorphism between them. Denote by E t its corresponding discrete simplicial space (the 'transpose' of the constant simplicial space at E ).
Definition 3.5. A Segal space W is complete if the map W 0 → Map( E , W t ) is a weak equivalence of simplicial sets.
Theorem 3.6. [18, 7.2] There is a model structure CSS on the category of simplicial spaces, obtained as a left Bousfield localization of the Reedy model structure, which satisfies the following properties:
- (1) the cofibrations are the monomorphisms, and
- (2) the fibrant objects are the complete Segal spaces.
We obtain the following result by applying Theorems 2.11, 2.12, and 2.9.
Corollary 3.7. The model category CSS admits the G -model structure CSS G . There is a Quillen equivalences of model categories
$$i ^ { * } \colon \mathcal { C S S } ^ { \mathcal { O } ^ { o p } _ { G } } \Rightarrow \mathcal { C S S } ^ { G } \colon i _ { * }$$
We now turn to the comparison between the model structures QC at and CSS . There are two different Quillen equivalences, both due to Joyal and Tierney.
Theorem 3.8. [13, 4.11] The functor p ∗ : CSS → QC at , which associates to a complete Segal space W the simplicial set W ∗ , 0 , has a left adjoint p ! . This adjoint pair defines a Quillen equivalence
$$p ^ { * } \colon \mathcal { C S S } \Longrightarrow \mathcal { Q C } a t \colon p _ {! }.$$
The second Quillen equivalence between these two model categories is given by a total simplicial set functor t ! : CSS → QC at and its right adjoint t ! .
Theorem 3.9. [13, 4.12] The adjoint pair
$$t _ {! } \colon \mathcal { C S S } \Rightarrow \mathcal { Q C } a t \colon t ^ {! }$$
is a Quillen equivalence.
Corollary 3.10. There are two commuting squares of Quillen equivalences:
/d79
/d47
/d47
/d111
/d111
/d47
/d47
/d111
/d111
/d79
/d79
/d79
/d79
/d79
/d79
/d79
/d15
/d15
/d47
/d47
/d15
/d15
/d15
/d15
/d111
/d111
/d47
/d47
.
/d111
/d111
4. Equivariant simplicial categories
In this section we consider simplicial categories. Recall that a simplicial category is a category enriched in simplicial sets, so that between any two objects x and y , there is a simplicial set Map( x, y ), together with compatible composition. In this case, the G -equivariant model structure does not follow immediately from previous results.
We start by recalling some notation. Given any simplicial category C , there is an associated category of components π 0 C whose objects are the same as those of C and whose morphisms are the sets of components of the mapping spaces of C .
Define the functor U : SS ets → SC such that for any simplicial set K , the simplicial category UK has two objects, x and y , and only nonidentity morphisms the simplicial set K = Hom( x, y ).
Theorem 4.1. [2, 1.1] There is a cofibrantly generated model structure SC on the category of small simplicial categories with the following properties.
- (1) The weak equivalences are the simplicial functors f : C → D satisfying the following two conditions:
- · for any objects x and y in C , the map
$$M a p _ { \mathcal { C } } ( x, y ) \to M a p _ { \mathcal { D } } ( f x, f y )$$
is a weak equivalence of simplicial sets, and
- · the induced functor π f 0 : π 0 C → π 0 D on the categories of components is an equivalence of categories.
/d15
/d15
## (2) A set of generating cofibrations for SC contains the functors
- · U∂ ∆[ n ] → U ∆[ n ] for n ≥ 0 , and
- · ∅ →{ } x , where ∅ is the simplicial category with no objects and { x } denotes the simplicial category with one object x and no nonidentity morphisms.
To obtain a model structure for G -simplicial categories, we need to verify that the cellularity conditions hold.
Theorem 4.2. The model category SC satisfies the cellularity conditions of Theorem 2.6.
Proof. To establish condition (1), we modify the argument used for categories in [4]. Let I be a filtered category and F : I →SC G a functor. Consider the simplicial nerve functor N : SC → SS ets ∆ op . Thinking of a simplicial category as a special case of a simplicial object in C at , the simplicial nerve is given by levelwise nerve of categories. Therefore, the functor N commutes with filtered colimits [14]. Thus, we get an isomorphism
$$N \text{colim} _ { I } ( F ( i ) ^ { H } ) \cong \text{colim} _ { I } ( N ( F ( i ) ) ^ { H } ).$$
Since the fixed point functor ( -) H is defined as a limit and the simplicial nerve is a right adjoint functor, we get an isomorphism
$$N ( F ( i ) ^ { H } ) \cong ( N F ( i ) ) ^ { H }.$$
Since finite limits and filtered colimits commute in S ets and are computed levelwise in SS ets ∆ op , we obtain isomorphisms
$$\text{colim} _ { I } ( ( N F ( i ) ) ^ { H } ) \cong ( \text{colim} _ { I } N F ( I ) ) ^ { H } \cong ( N \text{colim} _ { I } F ( i ) ) ^ { H }$$
where the second isomorphism is a second application of commuting the filtered colimit with the nerve. We again use that N is a right adjoint, so that
$$( N \text{colim} _ { I } F ( i ) ) ^ { H } \cong N ( \text{colim} _ { I } F ( i ) ) ^ { H }.$$
Since the nerve functor is fully faithful, this isomorphism holds even before applying the nerve functor, which completes the proof of condition (1).
Next we consider condition (3). The tensor product is given by the disjoint union of categories, and we want to show that the map
$$\int \cos \max \min \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \, \Omega \
\coprod _ { ( G / K ) ^ { H } } A \to \left ( \coprod _ { G / K } A \right ) ^ { H }$$
is an isomorphism. The action of H on ∐ G/K A is given by permuting the copies of A , since each A itself has trivial G -action. Therefore, this action is determined precisely by the action of H on G/K . The desired isomorphism follows.
Finally, we establish condition (2). Given any pushout diagram of the form
∐
/d47
/d47
/d15
/d15
/d47
/d47
/d15
/d15
with A → B a generating cofibration in SC , we want to show, making use of condition (3), that the diagram
∐
/d47
/d47
∐
/d15
/d15
/d15
/d15
/d47
/d47
is again a pushout square.
We first consider the case where A is the initial simplicial category ∅ and B is a terminal simplicial category { x } . Then in the original pushout square, the simplicial category D is obtained from the simplicial category C simply by adjoining disjoint objects indexed by the cosets G/K . When we apply the fixed point functor ( -) H , we only adjoin those objects indexed by ( G/K ) H , which establishes the desired pushout.
It remains to consider the case where A → B is of the form U∂ ∆[ n ] → U ∆[ n ] for any n ≥ 0. In this case, D is obtained from C by attaching, for each coset G/K , an n -simplex of morphisms to the appropriate mapping space of C , then freely adjoining all necessary composites with other mapping spaces. Since this gluing is done in an equivariant manner, the adjoined simplices have H -action as specified by the H -action on ( G/K ) H . Since the composites are also included in a manner compatible with the G -action, again the only fixed points of D by the action of H can be those of C or those given by simplices indexed by ( G/K ) H , as desired. /square
Corollary 4.3. The model structure SC G exists and there is a Quillen equivalence
$$p ^ { * } \colon \mathcal { S C } ^ { \mathcal { O } ^ { o p } _ { G } } \Rightarrow \mathcal { S C } ^ { G } \colon i _ { * }.$$
We can now relate these model structures to the other models for equivariant ( ∞ , 1)-categories from the previous section. We use a direct Quillen equivalence between SC and QC at , defined using the coherent nerve functor ˜ N : SC → QC at , originally due to Cordier and Porter [5]. Given a simplicial category X and the simplicial resolution C ∗ [ n ] of the category [ n ] = (0 →··· → n ), the coherent nerve ˜ N X ( ) is defined by
This functor has a left adjoint J : QC at →SC .
$$\widetilde { N } ( X ) _ { n } = & \, \hom _ { \mathcal { S } C } ( C _ { * } [ n ], X ). \\ \text{t adjoint } J \colon & \, \mathcal { Q } \mathcal { A } t \rightarrow \mathcal { S } \mathcal { C }.$$
Theorem 4.4. [7] , [11] , [15] The adjoint pair
/d111
/d47
/d47
/d111
is a Quillen equivalence.
$$J \colon \mathcal { Q } a t \Longleftrightarrow \mathcal { S C } \colon \widetilde { N }$$
Corollary 4.5. There is a commuting square of Quillen equivalences
/d79
/d47
/d47
/d111
/d111
/d79
/d79
/d79
/d15
/d15
/d47
/d47
/d15
/d15
/d111
/d111
## 5. Equivariant Segal categories
Lastly, we turn to the model of Segal categories. In this case, we consider two different model structures with the same weak equivalences.
Definition 5.1. A simplicial space X is a Segal precategory if X 0 is a discrete simplicial set. It is a Segal category if additionally the Segal maps
$$X _ { k } & \rightarrow \underbrace { X _ { 1 } \times _ { X _ { 0 } } \cdots \times _ { X _ { 0 } } X _ { 1 } } _ { k } \\ \text{or all } k > 2.$$
are weak equivalences for all k ≥ 2.
For any Segal category X , we can take its objects to be the set X 0 . Its mapping spaces map X ( x, y ) are given by the fibers of the map ( d , d 1 0 ): X 1 → X 0 × X 0 over a given pair of objects ( x, y ). With notions of weak composition, one can define homotopy equivalences as in [18] and hence a homotopy category Ho( X ) associated to X .
Given a Segal precategory X , there is a functorial construction of a Segal category LX which is weakly equivalent to X in the Segal space model structure [3, § 5].
The inclusion functor from the category of Segal precategories into the category of simplicial spaces has a left adjoint which we denote by ( -) r . Recall that, for a simplicial set K we denote again by K the constant simplicial space, and by K t the discrete simplicial space defined by the set of n -simplices of K in degree n .
Theorem 5.2. [1, 3.2] , [3, 5.1, 5.13] , [16] There exists a cofibrantly generated model structure S C e at c on the category of Segal precategories satisfying the following conditions.
- · The weak equivalences are the Dwyer-Kan equivalences , or maps X → Y such that
- -for any objects x, y ∈ X 0 , map LX ( x, y ) → map LY ( fx, fy ) is a weak equivalence of simplicial sets, and
- -the induced functor Ho ( LX ) → Ho ( LY ) is an equivalence of categories.
- · The fibrant objects are the Reedy fibrant Segal categories.
- · Cofibrations are the monomorphisms.
- · A set of generating cofibrations for S C e at c is given by
$$I _ { c } = \{ ( \partial \Delta [ m ] \times \Delta [ n ] ^ { t } \cup \Delta [ m ] \times \partial \Delta [ n ] ^ { t } ) _ { r } \to ( \Delta [ m ] \times \Delta [ n ] ^ { t } ) _ { r } \}$$
for all m ≥ 0 when n ≥ 1 and for n = m = 0 .
Observe that this model structure actually satisfies the conditions of Theorem 2.11, since its objects are presheaves and the cofibrations are monomorphisms. However, since we have a restriction on those presheaves, namely that the degree zero space be discrete, some features of the model structure are less intuitive. Therefore, we include a complete proof.
Theorem 5.3. The model category S C e at c satisfies the cellularity conditions of Theorem 2.6.
Proof. To show that condition (1) is satisfied, we need only observe that finite limits and filtered colimits commute in the category of sets. Since limits are computed levelwise in the category of Segal precategories, and the fixed point functor ( -) H is defined as a finite limit, the desired condition holds.
Establishing condition (3) is similar to the case of simplicial categories.
It remains to show that condition (2) holds. Let A → B be a generating cofibration for the Reedy model structure on simplicial spaces, of the form
$$\partial \Delta [ m ] \times \Delta [ n ] ^ { t } \cup \Delta [ m ] \times \partial \Delta [ n ] ^ { t } \to \Delta [ m ] \times \Delta [ n ] ^ { t }$$
for some m,n ≥ 0. We know that the Reedy model structure satisfies the desired condition for these generating cofibrations, using Theorem 2.11.
Any generating cofibration of S C e at c is of the form A r → B r , where A → B is as above and ( -) r denotes the reduction functor. Suppose that we have a pushout diagram
∐
/d47
/d47
∐
/d15
/d15
/d15
/d15
/d47
/d47
∐
/d47
/d47
/d15
Consider also the pushout
/d15
/d15
/d15
/d47
/d47
taken in the category of simplicial spaces. If we assume that X is a Segal precategory, so that X = X r , then the fact that the reduction functor is a left adjoint implies that ( Y ′ ) r /similarequal Y . Therefore, in the diagram
∐
/d47
/d47
∐
/d47
/d47
∐
/d15
/d15
/d15
/d15
/d15
/d15
/d47
/d47
∐
/d47
/d47
the left square and the large rectangle are both pushouts; therefore, the right square is also a pushout. /square
Corollary 5.4. The model structure S C e at G c exists and there is a Quillen equiva- lence
$$i ^ { * } \colon \mathcal { S } e \mathcal { C } a t _ { c } ^ { \mathcal { O } _ { G } ^ { o p } } \Rightarrow \mathcal { S } e \mathcal { C } a t _ { c } ^ { G } \colon i _ { * }.$$
For the purposes of comparison with other models, we need another model structure with the same weak equivalences but different fibrations and cofibrations. To define a generating set of cofibrations, we require the following construction.
For m ≥ 1 and n ≥ 0, define P m,n to be the pushout of the diagram
/d47
/d47
/d15
/d15
/d47
/d47
/d15
/d15
If m = 0, then we define P m, 0 to be the empty simplicial space. For all m ≥ 0 and n ≥ 1, define Q m,n to be the pushout of the diagram
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
For each m and n , the map ∂ ∆[ m ] × ∆[ n ] t → ∆[ m ] × ∆[ n ] t induces a map i m,n : P m,n → Q m,n . Note that when m ≥ 2 this construction gives exactly the same objects as those given by reduction, namely that P m,n is precisely ( ∂ ∆[ m ] × ∆[ n ] t ) r and likewise Q m,n is precisely (∆[ m ] × ∆[ n ] t ) r .
Theorem 5.5. [3, 7.1] There is a model structure S C e at f on the category of Segal precategories with the following properties.
- · The weak equivalences are the Dwyer-Kan equivalences.
- · The cofibrations are the maps which can be formed by taking iterated pushouts along the maps of the set
$$I _ { f } = \{ i _ { m, n } \colon P _ { m, n } \to Q _ { m, n } \ | \ m, n \geq 0 \}.$$
- · The fibrant objects are the Segal categories which are fibrant in the projective model structure on simplicial spaces.
Theorem 5.6. The model category S C e at f satisfies the cellularity conditions of Theorem 2.6.
Proof. Since the objects and weak equivalences in S C e at c and S C e at f are the same, the cellularity conditions (1) and (3) continue to hold for S C e at f .
We need only prove that condition (2) holds. Consider a generating cofibration A → B for the projective model structure on simplicial spaces, which has the form
$$\partial \Delta [ m ] \times \Delta [ n ] ^ { t } \rightarrow \Delta [ m ] \times \Delta [ n ] ^ { t }$$
for some m,n ≥ 0. This model structure satisfies the cellularity conditions by Theorem 2.11.
For any m ≥ 2, the map P m,n → Q m,n coincides with A r → B r , so the argument given for S C e at c applies. When m = 0, the map is an isomorphism. Therefore, we need only consider the case when m = 1.
The pushout diagram defining P 1 ,n can be rewritten as
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
The top horizontal map is the inclusion, and the left horizontal map is the fold map, so it follows that P 1 ,m = ∆[ n ] t , which coincides with (∆[ n ] t ) r since ∆[ n ] t 0 is already discrete. Since Q 1 ,n = (∆[1] × ∆[ n ] t ) r , we simply need to consider the map (∆[ n ] t ) r → (∆[1] × ∆[ n ] t ) r . But this map is the reduction of a cofibration in the projective model structure, so we can apply the same argument as the one used for
S C e at c to the diagram
/d47
/d47
/d47
/d47
/d15
$$\begin{array} { c } \mathcal { S } \mathcal { C } a t _ { c } \text{ to the diagram} \\ \coprod _ { ( G / K ) ^ { H } } \Delta [ n ] ^ { t } \xrightarrow { \coprod _ { ( G / K ) ^ { H } } } \coprod _ { ( G / K ) ^ { H } } X ^ { H } \\ \downarrow \downarrow \downarrow \\ \coprod _ { ( G / K ) ^ { H } } \Delta [ 1 ] \times \Delta [ n ] ^ { t } \xrightarrow { \coprod _ { ( G / K ) ^ { H } } } ( \Delta [ 1 ] \times \Delta [ n ] ^ { t } ) _ { r } \xrightarrow { \coprod _ { ( G / K ) ^ { H } } } Y ^ { H }. \\ \text{It follows that the right-hand square is a subout, which is what we needed to} \end{array}$$
/d15
/d15
/d15
/d15
/d15
/d47
/d47
/d47
/d47
It follows that the right-hand square is a pushout, which is what we needed to prove. /square
Corollary 5.7. The model structure S C e at g f exists and there is a Quillen equiva- lence
$$i ^ { * } \colon \mathcal { S } e \mathcal { C } a t _ { f } ^ { \mathcal { O } _ { G } ^ { o p } } \Rightarrow \mathcal { S } e \mathcal { C } a t _ { f } ^ { G } \colon i _ { * }.$$
We now have a number of comparisons with other models, beginning with the one connecting S C e at c and S C e at f .
Proposition 5.8. [3, 7.5] The identity functor induces a Quillen equivalence
$$I \colon \mathcal { S } e \mathcal { C } a t _ { f } \Rightarrow \mathcal { S } e \mathcal { C } a t _ { c } \colon J.$$
Corollary 5.9. The identity functor induces a commutative square of Quillen equivalences
/d111
/d111
/d79
/d79
/d15
/d15
/d15
/d15
/d111
$$\begin{smallmatrix} \mathcal { S } e \mathcal { C } a t _ { f } ^ { G } \Longrightarrow \mathcal { S } e \mathcal { C } a t _ { c } ^ { G } \\ \downarrow \\ \mathcal { S } e \mathcal { C } a t _ { f } ^ { \mathcal { O } ^ { o p } _ { G } } \Longrightarrow \mathcal { S } e \mathcal { C } a t _ { c } ^ { \mathcal { O } ^ { o p } _ { G } }. \end{smallmatrix}$$
/d47
/d47
/d79
/d79
/d47
/d47
/d111
Next, we consider the comparison between simplicial categories and Segal categories. The functor N taking a simplicial category to its simplicial nerve, a Segal precategory (in fact, a Segal category) has a left adjoint which we denote by F .
Theorem 5.10. [3, 8.6] The Quillen pair
$$F \colon \mathcal { S } e \mathcal { C } a t _ { f } \Rightarrow \mathcal { S } \mathcal { C } \colon N$$
is a Quillen equivalence.
Corollary 5.11. There is a commutative square of Quillen equivalences
/d111
/d111
/d79
/d79
/d15
/d15
/d15
/d15
/d111
$$\begin{smallmatrix} & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \\ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &
& & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & && & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & - & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & } & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & 0 & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &. & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ; & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & + & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & _ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & \ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &, & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & = & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & b & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & ^ & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & | & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & & &$$
/d47
/d47
/d79
/d79
/d47
/d47
/d111
Next, we consider the inclusion functor I from the category of Segal precategories to the category of simplicial spaces, which has a right adjoint R .
Theorem 5.12. [3, 6.3] The adjoint pair
$$I \colon \mathcal { S } e \mathcal { C } a t _ { c } \Rightarrow \mathcal { C } \mathcal { S } \mathcal { S } \colon R$$
is a Quillen equivalence.
Corollary 5.13. There is a commutative square of Quillen equivalences
/d79
/d47
/d47
/d111
/d111
/d79
/d79
/d79
/d15
/d15
/d15
/d15
/d111
$$\begin{array} { c } \mathcal { S } e \mathcal { C } a t _ { c } ^ { G } \cong \mathcal { C } \mathcal { S } \mathcal { S } ^ { G } \\ \| \| _ { \mathcal { S } e \mathcal { C } a t _ { c } ^ { \mathcal { O } ^ { o p } _ { G } } \cong \mathcal { C } \mathcal { S } \mathcal { S } ^ { \mathcal { O } ^ { o p } _ { G } } }. \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{array}$$
/d47
/d47
/d111
Similarly to the comparison between complete Segal spaces and quasi-categories, Joyal and Tierney prove that there are also two different Quillen equivalences directly between QC at and S C e at c . The first of these functors is analogous to the pair given in Theorem 3.8; the functor j ∗ : S C e at c → QC at assigns to a Segal precategory X the simplicial set X ∗ 0 . Its left adjoint is denoted j ! .
Theorem 5.14. [13, 5.6] The adjoint pair
$$j _ {! } \colon \mathcal { Q } a t \Rightarrow \mathcal { S } e \mathcal { C } a t _ { c } \colon j ^ { * }$$
is a Quillen equivalence.
The second Quillen equivalence between these two model categories is given by the map d ∗ : S C e at c → QC at , which assigns to a Segal precategory its diagonal, and its right adjoint d ∗ .
Theorem 5.15. [13, 5.7] The adjoint pair
$$d ^ { * } \colon \mathcal { S } e \mathcal { C } a t _ { c } \Rightarrow \mathcal { Q } \mathcal { C } a t \colon d _ { * }$$
is a Quillen equivalence.
Corollary 5.16. There are two commutative squares of Quillen equivalences
/d79
/d47
/d47
/d111
/d111
/d47
/d47
/d111
/d111
/d79
/d79
/d79
/d79
/d79
/d79
/d79
/d15
/d15
/d47
/d47
/d111
/d111
/d15
/d15
/d15
/d15
/d47
/d47
.
/d111
/d111
6. Actions of simplicial groups
In this section, we consider the more general case of actions by any simplicial group G . Given a model category C , to make sense of the category C G , we need to require that C have the structure of a simplicial model category and consider simplicial functors G → C where G is regarded as a simplicial category with one object.
Stephan proves the following result for the topological case, but his proof holds in the simplicial case as well. He restricts to the case of compact Lie groups, partially because they are the case of most interest in equivariant homotopy theory, but also because they satisfy important cofibrancy conditions. In particular, if G is a compact Lie group, then the spaces G/H and ( G/H ) K are CW complexes for any closed subgroups H and K of G . In our case, the analogous statement is that the simplicial sets G/H and ( G/H ) K are cofibrant, which holds automatically since all simplicial sets are cofibrant.
Proposition 6.1. Suppose that G is a simplicial group and C is a cofibrantly generated simplicial model category. Then we have the following.
/d15
/d15
- (1) The category of G -objects in C admits the G -model structure if the conditions of Theorem 2.6 hold. In this case, C G is a simplicial model category.
- (3) There is a Quillen equivalence C O op G /arrowparrrightleft C G .
- (2) The orbit category model category C O op G exists and is a simplicial model category.
Since CSS is known to be a simplicial model category [18, 7.2], we have the following.
Corollary 6.2. The simplicial model categories CSS G and CSS O op G exist and there is a Quillen equivalence
$$i ^ { * } \colon \mathcal { C S S } ^ { \mathcal { O } ^ { o p } _ { G } } \Rightarrow \mathcal { C S S } ^ { G } \colon i _ { * }.$$
Proof. We have already proved that CSS satisfies the cellularity conditions. Therefore, the result follows immediately from Proposition 6.1. /square
However, we can also consider S C e at c ; we include here a proof that it is a simplicial model category.
Proposition 6.3. The model category S C e at c has the structure of a simplicial model category.
Proof. We need to show that the axioms (SM6) and (SM7) for a simplicial model category hold [10, 9.1.6]. We begin with (SM6). Suppose that X and Y are Segal precategories and K is a simplicial set. Recall that the left adjoint to the inclusion functor from Segal precategories to simplicial spaces is the reduction functor ( -) r . Define X ⊗ K = ( X × K ) r , where the product is taken in simplicial spaces. Then define Map( X,Y ) and Y K just as for simplicial spaces; for the latter, observe that if Y 0 is discrete, then so is ( Y K ) 0 = ( Y 0 ) K . Then one can verify the necessary isomorphisms to verify (SM6).
To check axiom (SM7), we need to show that if i : A → B is a cofibration and p : X → Y is a fibration in S C e at c , then the pullback-corner map
$$\text{Map} ( B, X ) \rightarrow \text{Map} ( A, X ) \times _ { \text{Map} ( A, Y ) } \text{Map} ( B, Y )$$
is a fibration of simplicial sets which is a weak equivalence if either i or p is. Since we have defined mapping spaces to be the same as in the category of simplicial spaces, we need only verify that a cofibration or fibration in S C e at c is still a cofibration or fibration, respectively, in the Reedy model structure on simplicial spaces. Since cofibrations are exactly the monomorphisms in both categories, the case of cofibrations is immediate.
Suppose, then, that p is a fibration in S C e at c , so that is has the right lifting property with respect to monomorphisms between Segal precategories which are also Dwyer-Kan equivalences. In particular, it has the right lifting property with respect to monomorphisms which are levelwise weak equivalences of simplicial sets. Suppose that A → B is an acyclic cofibration in the Reedy model structure. Then π 0 ( A 0 ) = ∼ π 0 ( B 0 ), so ( A r ) 0 ∼ = ( B r ) 0 . Therefore the map A r → B r is still a levelwise weak equivalence and monomorphism, and in particular a weak equivalence in S C e at c . Therefore we obtain a lifting
/d47
/d47
/d47
/d47
/d62
/d62
/d15
/d15
/d47
/d47
/d15
/d15
/d47
/d47
/d15
/d15
r
Therefore, p is also a fibration in the Reedy model structure on simplicial spaces. It follows that S C e at c satisfies axiom (SM7) and is a simplicial model category. /square
Since we have already verified that S C e at c satisfies the cellularity conditions, we have the following result.
Corollary 6.4. Let G be a simplicial group. The simplicial model categories S C e at G c and S C e at O op G c exist and there is a Quillen equivalence
$$i ^ { * } \colon \mathcal { S } e \mathcal { C } a t _ { c } ^ { \mathcal { O } _ { G } ^ { o p } } \Rightarrow \mathcal { S } e \mathcal { C } a t _ { c } ^ { G } \colon i _ { * }.$$
Using another application of Theorem 2.7, or rather, an analogue for simplicial model categories, we obtain the following.
Corollary 6.5. Let G be a simplicial group. Then there are Quillen equivalences of simplicial model categories
/d79
/d47
/d47
/d111
/d111
/d79
/d79
/d79
/d15
/d15
/d47
/d47
.
/d111
/d111
References
- [1] Julia E. Bergner, A characterization of fibrant Segal categories, Proc. Amer. Math. Soc. 135 (2007) 4031-4037.
- [2] Julia E. Bergner, A model category structure on the category of simplicial categories, Trans. Amer. Math. Soc. 359 (2007), 2043-2058.
- [3] Julia E. Bergner, Three models for the homotopy theory of homotopy theories, Topology 46 (2007), 397-436.
- [4] Anna Marie Bohmann, Kristen Mazur, Ang´ elica Osorno, Viktoriya Ozornova, Kate Ponto, and Carolyn Yarnall, A model structure on G at C , preprint available at math.AT/1311.4605.
- [5] J.M. Cordier and T. Porter, Vogt's theorem on categories of homotopy coherent diagrams, Math. Proc. Camb. Phil. Soc. (1986), 100, 65-90.
- [6] Emanuele Dotto and Kristian Moi, Homotopy theory of G -diagrams and equivariant excision, preprint available at math.AT/1403.6101.
- [7] Daniel Dugger and David I. Spivak, Rigidification of quasicategories, Algebr. Geom. Topol. 11 (2011) 225-261.
- [8] T. Dyckerhoff and M. Kapranov, Higher Segal spaces I, preprint available at math.AT/1212.3563.
- [9] A.D. Elmendorf, Systems of fixed point sets. Trans. Amer. Math. Soc. 277 (1983), no. 1, 275-284.
- [10] Philip S. Hirschhorn, Model Categories and Their Localizations, Mathematical Surveys and Monographs 99 , AMS, 2003.
- [11] A. Joyal, Simplicial categories vs quasi-categories, in preparation.
- [12] A. Joyal, The theory of quasi-categories I, in preparation.
- [13] Andr´ e Joyal and Myles Tierney, Quasi-categories vs Segal spaces, Contemp. Math. 431 (2007) 277-326.
- [14] Stephen Lack, Re: classifying functor and colimits, Category theory list, http://permalink.gmane.org/gmane.science.mathematic s.categories/3407.
- [15] Jacob Lurie, Higher topos theory. Annals of Mathematics Studies , 170. Princeton University Press, Princeton, NJ, 2009.
- [16] Regis Pelissier, Cat´gories enrichies faibles, preprint available at math.AT/0308246. e
- [17] C.L. Reedy, Homotopy theory of model categories, unpublished manuscript, available at http://www-math.mit.edu/ ∼ psh.
- [18] Charles Rezk, A model for the homotopy theory of homotopy theory, Trans. Amer. Math. Soc. , 353(3), 973-1007.
/d15
/d15
16
## J.E. BERGNER
- [19] Marc Stephan, On equivariant homotopy theory for model categories, preprint available at math.AT/1308.0856.
E-mail address : [email protected]
Department of Mathematics, University of California, Riverside, CA 92521 | null | [
"Julia E. Bergner"
] | 2014-07-31T22:03:28+00:00 | 2014-10-03T22:21:19+00:00 | [
"math.AT",
"math.CT",
"55U35, 55P91, 55U40, 18G55"
] | Equivalence of models for equivariant $(\infty, 1)$-categories | In this paper we show that the known models for $(\infty, 1)$-categories can
all be extended to equivariant versions for any discrete group $G$. We show
that in two of the models we can also consider actions of any simplicial group
$G$. |
1408.0039v2 | ## Strongly correlated growth of Rydberg aggregates in a vapor cell
A. Urvoy, 1, ∗ F. Ripka, 1 I. Lesanovsky, 2 D. Booth, 3 J.P. Shaffer, 3 T. Pfau, 1 and R. L¨ ow 1, † 1 5. Physikalisches Institut and Center for Integrated Quantum Science and Technology, Universit¨t a Stuttgart, Pfaffenwaldring 57, 70550 Stuttgart, Germany 2 School of Physics and Astronomy, University of Nottingham, Nottingham, NG7 2RD, UK 3 Homer L. Dodge Department of Physics and Astronomy, The University of Oklahoma, 440 West Brooks Street, Norman, Oklahoma 73019, USA
(Dated: March 10, 2015)
The observation of strongly interacting many-body phenomena in atomic gases typically requires ultracold samples. Here we show that the strong interaction potentials between Rydberg atoms enable the observation of many-body effects in an atomic vapor, even at room temperature. We excite Rydberg atoms in cesium vapor and observe in real-time an out-of-equilibrium excitation dynamics that is consistent with an aggregation mechanism. The experimental observations show qualitative and quantitative agreement with a microscopic theoretical model. Numerical simulations reveal that the strongly correlated growth of the emerging aggregates is reminiscent of soft-matter type systems.
PACS numbers: 32.80.Ee, 34.20.Cf, 03.65.Yz, 61.43.Hv
Due to their exaggerated properties, Rydberg atoms find applications in various research fields ranging from cavity QED [1], quantum information [2], quantum optics [3-7], microwave sensing [8] to molecular physics [9]. One particular area of research employs the strong interactions between Rydberg atoms to create strongly interacting many-body quantum systems for quantum simulation [10-12], quantum phase transitions [13] and the realization of correlated or spatially ordered states [1418]. In any system, gaseous, liquid, glass or solid, spatial correlations can only arise if interactions are present. In Rydberg gases these correlations have recently been revealed by the direct imaging of the resonant excitation blockade effect [17, 19]. In our experiment an initially nearly ideal gas of thermal atoms at room temperature is excited into a strongly interacting Rydberg state. The Rydberg excitations show correlated many-body dynamics that shares similarities with that of soft-matter systems.
We consider the situation of a dense atomic gas, where dense means that the mean inter-particle distance is smaller than the typical interaction distance. The interplay between these strong interactions and an offresonant excitation laser results in a non-equilibrium dynamics with pronounced spatial correlations (related is the antiblockade in ultracold atoms [20, 21]). At a certain distance r fac from a Rydberg atom the interaction shifts the Rydberg states in resonance with the detuned excitation light fields, as depicted in Fig. 1(a). The subsequent resonant excitations are restricted to specific distances and therefore result in the formation of so-called aggregates that feature non-trivial spatial correlations [22-25]. This so-called facilitated excitation occurs predominantly at the boundary of aggregates [see Fig. 1(b)], similarly to seeded nucleation. The number of Rydberg excitations grows increasingly faster as the size of the aggregates gets larger. After a certain time a (quasi) steady state is reached and the excitation saturates because the sample is maximally filled with Rydberg atoms. The spatial correlations expected for this steady state are depicted in Fig. 1(b). The density-density correlation function sketched here shows an enhanced probability for finding two atoms separated by the facilitation radius r fac . There is no apparent long-range order since the isotropic facilitation mechanism does not favor the creation of crystalline arrangements. The existence of such Rydberg aggregates has recently been observed in ultracold systems [24, 25]. In these studies the Rydberg number distributions were extracted and matched to the results of empirical rate equation models, proving the existence of small aggregates with up to 8 excitations.
In this Letter we investigate a complementary regime and study the dynamics of the aggregation process in an atomic vapor at room temperature. Central parameters such as the dephasing rate and the atomic density are up to 2 orders of magnitude larger than in previous work [24, 25]. To quantify the non-equilibrium dynamics we perform a systematic study of the characteristic time scale that underlies the aggregation process. We find that the functional dependence of this time scale on various system parameters can be approximated by power laws. The corresponding exponents agree well with those obtained from a theoretical aggregation model. Further evidence for the aggregation dynamics is found through a quantitative evaluation of the number of Rydberg excitations and the resulting mean inter-particle distance which is consistent with the existence of a facilitation radius.
We perform our experiments in a gas of cesium atoms at room temperature or above. The cesium atoms are confined in a 220 µ m thick glass cell [see Fig. 2(b)]. The atomic density N g ranges from 10 µ m -3 to 500 µ m -3 ,
FIG. 1. Principle of the aggregation. (a) Interaction induced level shift. An already excited Rydberg atom (red dot) at the origin produces an energy shift for the neighboring atoms. At the facilitation radius r fac , the atoms are exactly shifted in resonance with the excitation laser, red-detuned by ∆. The grey shaded area symbolizes the excitation bandwidth, a Gaussian whose width is given by the dephasing rate γ . (b) Left: Typical time evolution of the Rydberg population and of the transmission change of the exciting laser [experimental signal, which is proportional to the derivative of the Rydberg density, see text and Fig. 2 for details] during the aggregation process. Right: Snapshots of the aggregation at times A, B and C, illustrated for a frozen gas in 2D. Red dots correspond to Rydberg atoms. Blue dots correspond to resonant atoms. The dark grey line shows the 'resonant shell' in which the excitation of Rydberg atoms is facilitated. Inset: Sketch of the density-density correlation function expected for the steady state [corresponding to (C)].
which is large compared to previous experiments on interacting Rydberg atoms in thermal vapor [26-28] and nonBEC cold atomic gases [24, 25, 29] where N < g ∼ 10 µ m -3 . We excite cesium atoms from the ground state 6S 1 / 2 to a Rydberg state n S 1 / 2 off-resonantly via the intermediate state 7P 3 / 2 [see Fig. 2(a)]. The two-photon transition is red-detuned by ∆ with respect to the unperturbed Rydberg state. The lower transition is driven by a cw laser at 455 nm, which also serves as the probing field. For the upper transition a laser at ∼ 1070 nm is pulsed on the nanosecond scale using a fast Pockels cell. The effective Rabi frequency of the two-photon transition is then given by Ω = Ω 455 Ω 1070 / (2 δ 7P ), where Ω 455 and Ω 1070 are the respective single transition Rabi frequencies and δ 7P = 1 5 GHz is the detuning to the intermedi-. ate state [30]. We measure the transmission change of the lower 455 nm laser after suddenly switching on the upper
FIG. 2. (a) Schematic energy level diagram for the excitation to Rydberg states of cesium atoms. (b) Sketch of the experimental setup. (c) Transmission signals at different atom number densities for the 32S state. The two-photon detuning is ∆ ≈ 2 π × -2200 MHz. The two-photon Rabi frequency is Ω = 2 π × 100 MHz. The grey-shaded area in the background represents the temporal pulse shape of the infrared laser. The time delay t sat used for the quantitative analysis is also depicted. The black curve (upper panel) is the expected transmission signal (not to scale) for non-interacting atoms (following the approach from Ref. [31]).
1070 nm laser on. Note that this signal is directly proportional to the time derivative of the Rydberg population [30]. Typical transmission traces are shown in Fig. 2(c) for various atom number densities. Immediately after the 1070 nm laser is switched on (at t = 0) atoms are transferred to the Rydberg state, and for each excited Rydberg atom one photon is removed from the probe resulting in a decrease of the transmission. One striking feature is the large red detuning of up to 10 GHz at which these signals are observed, in contrast to previous work on coherent excitation in a more dilute gas [27, 31]. Line broadenings and shifts to the blue have been observed with S-states in cold atoms [24], and Rydberg aggregates have been observed only at blue detunings [24, 25], as expected from the repulsive Rydberg-Rydberg interaction potential for most Rydberg S-states [32]. However at large atomic densities, the mean inter-particle distance is so small that the perturbative character of the van-der-Waals potential is not valid anymore. Level crossings between
pair states now have to be considered. For Rydberg Sstates in cesium a strong resonant dipole-quadrupole interaction with neighboring pair-states occurs at 0 55 . µ m for n = 32 [30, 33]. Initially dipole-forbidden attractive pair states acquire some n Sn S admixture at short inter-atomic distances due to the dipole-quadrupole interaction. Therefore the Rydberg-Rydberg interaction for S-states in cesium also features an effective attractive component, allowing for us to observe an excitation signal at large red detunings.
A first indication for the collective nature of the excitation dynamics is provided by the data in Fig. 2. Here we consider the characteristic time scale of the excitation t sat , i.e. the time at which the transmission reaches its minimum [as shown in Fig. 2(c)]. In the non-interacting case this time scale is given by 1 / ∆ ∼ 0 1 ns (black line). . In the experiment however the excitation signal is slow ( t sat glyph[greatermuch] 1 / ∆) and density dependent, which is only possible if many-body effects are included. Pulse propagation effects can be excluded due to the small optical depth at the large detunings applied.
To analyze the dynamics, we systematically varied all accessible parameters independently: ∆, Ω, N g and n ∗ , where n ∗ = n -δ is the effective principal quantum number of the Rydberg state, δ being the quantum defect. Only the dephasing rate γ , determined by the Doppler shifts, the velocity of the atoms and the steep slope of the pair-state potentials, cannot easily be tuned over a significant range (for the derivation of the actual dephasing rate, see Supplemental Material [30]). The basic experimental settings are the following: ∆ ≈ 2 π ×-2200 MHz, Ω = 2 π × 100 MHz, N g = 36 µ m -3 and n ∗ = 27 95 . (32S state), and are all but one kept constant. First, by fitting the values of the time scale of the excitation t sat against ∆ we obtain a power law as t sat ∝ | ∆ | a with a = 1 99(14). . In the same way, we find that t sat ∝ Ω b with b = -2 10(5). . The power law for N g is t sat ∝ N c g with c = -1 09(6). . Finally we performed density scans at three different principal quantum numbers (32S, 34S and 36S states) and were able to extract a scaling behavior as N -1 g ( n ∗ ) d with d = -4 6(5). . These results are summarized in Table I.
By integrating the transmission signal over time we obtain an estimate of the actual number of Rydberg atoms present in the sample. At the time when the Rydberg excitation starts to saturate the Rydberg number in the excitation volume reaches approximately 50000 atoms. The corresponding mean inter-atomic distance is 〈 r 〉 = 0 65 . µ m, leading to approximative values for the effective van-der-Waals or dipole-dipole strength of interaction as C α = ∆ ×〈 〉 r α [22] with C 6 = 2 π ×-109 MHz · µ m and 6 C 3 = 2 π ×-405 MHz · µ m (at ∆ 3 ≈ 2 π ×-1500 MHz). We use these values as an input for simulations described in the following.
We compared these findings to the results of the Rydberg aggregation model adapted from Ref. [22]. This
| | ∆ a | Ω b | N g c | n ∗ d |
|-----|------------|-------------|-------------|-------------|
| Exp | 1 . 99(14) | - 2 . 10(5) | - 1 . 09(6) | - 4 . 6(5) |
| vdW | 2 . 15(1) | - 2 | - 0 . 86(1) | - 4 . 72(5) |
| dd | 2 . 38(0) | - 2 | - 0 . 74(1) | - 2 . 95(2) |
a Range: -4.5 . . . -1.3 GHz
b Range: 75 . . . 175 MHz
c Range: 28 . . . 101 µ m - 3
d Range: 32S - 34S - 36S
TABLE I. Power laws for the aggregation delay t sat . In the experiment ('Exp'), the parameters are ∆ ≈ 2 π ×-2200 MHz, Ω = 2 π × 100 MHz, N g = 36 µ m -3 and n = 32, or varied over the specified range. The power laws labeled as 'vdW' and 'dd' were extracted from simulations in an ensemble of randomly and uniformly distributed atoms with van-der-Waals (ensemble of 10 3 atoms) dipoledipole interaction (ensemble of 15 3 atoms) respectively, using the parameters from the experiment and the extracted interaction strengths (see text). The dephasing rate was also extracted from the experiment [30]. All uncertainties represent the confidence region of the fits. No uncertainty is given for the exponent of Ω in the theory, fixed at -2 as by the assumption of strong dephasing.
model describes the dynamics of Rydberg aggregation within a system of two-level atoms in the presence of strong dephasing. This central assumption of strong dephasing applies to the experimental situation discussed here since the motion-induced dephasing is larger than the Rabi frequency ( γ > ∼ 2 π × 0 5 GHz [30]). . The reduction to a two-level system is well justified in our case, although the commonly used adiabatic elimination of the intermediate state typically breaks down for quantitative considerations of the coherent evolution [27, 31]. Here however, because of the large dephasing rates due to the atomic motion we do not observe coherent evolution, and because of the large detunings we expect only less than 1 5% population of the intermediate state. . We performed simulations for an ensemble of randomly distributed atoms in 3D, assuming a pure van-der-Waals ( V vdW = C /r 6 6 ) or pure dipole-dipole ( V dd = C /r 3 3 ) attractive interaction potential. In fact the actual experimental potential curves have a more complex spatial dependence, due to strong state mixing [30]. The latter makes the actual microscopic description of the excitation dynamics rather intricate since a two-level description of an atom might not be sufficient for covering all possible pair excitation channels. Therefore the van-derWaals and dipole-dipole potential that are used in our two-level model should be regarded as the limiting approximations of the actual experimental situation. We evaluate the time scale of the excitation t sat defined by the transmission minimum, as in the experiment. All results are listed in Table I. We find an excellent agreement between the experimental and theoretical exponents. In particular the dependence of t sat on approximately Ω -2 indicates that a strong dephasing effect is present in our
FIG. 3. Density plots showing the transmission change as a function of time (vertical axis, from top to bottom) and detuning. The parameters are as in Table I. (a) Simulated data with pure van-der-Waals interaction. The Rabi frequency was rescaled with a factor 0 43. . (b) Simulated data with pure dipole-dipole interaction (for 15 3 atoms). The Rabi frequency was rescaled with a factor 0 26. . (c) Experimental data. The blue (resp. green) line shows the position of the absorption maximum t sat in the simulated data with van-der-Waals (resp. dipole-dipole) interaction.
system [22]. Moreover the power laws vary only slightly, independently of whether pure van-der-Waals or pure dipole-dipole interaction are used. Our experimental results are compatible with both potentials, suggesting a rather weak dependence on the actual shape of the potential and that the basic mechanism of aggregation only relies on the existence of a facilitation radius.
In Fig. 3(a) [resp. (b)] we show the transmission change extracted from the model with van-der-Waals [resp. dipole-dipole] interaction and in Fig. 3(c) from the experiment. The quantitative agreement for the time scale t sat between theory and experiment is excellent. Due to the complex pair state potentials and strong statemixing that are crucial here, an adaptation of the Rabi frequency has to be performed in order to use the twolevel model (i.e. a model with a single Rydberg state). In our simulations the Rabi frequency is reduced by a factor of 0.38 (for van-der-Waals interaction) and 0.23 (for dipole-dipole interaction) compared to the experiment. These factors are compatible with the n Sn S admixture that one can extract from the pair-state potentials [30]. Note that with dipole-dipole interaction there is a dependence on the system size due to the long-range character of the 1 /r 3 potential, hence the different rescaling factors applied in Fig. 3(a) and 3(b).
The comparison of the experimental results to those of the model show that facilitated excitation is occurring, which implies that an aggregation dynamics takes place. The frozen gas approximation which is used to model the aggregation in [22] holds strictly for time intervals of about 0.3 ns, the transit time of the atoms through the 'resonant shell' (see Figure 1). During this time aggregates consisting of up to 4 atoms are formed [30]. Their spatial correlations will then quickly decay to those of a non-interacting ideal gas. Note, however, that even after that time the aggregation of excitations continues at the boundary of the uncorrelated aggregates.
Despite this effect the agreement between the experimental values of t sat and those obtained from the simple theoretical model is in general good [see Fig. 3]. Yet the time evolution differs as the experimental signal appears much more narrow in time than in the simulations. We attribute this discrepancy to the inherent differences between the microscopics of the experimental system and the theoretical model (e.g. the complex potentials and the atomic motion). Interestingly, when considering the temporal width of the signal, the simulations with dipole-dipole interaction seem to agree best with the experiment, which is realistic considering that one component of the actual interaction potentials is of pure dipole-dipole nature. Moreover, the model does not account for the fact that the excitation of isolated, i.e. not facilitated, atoms is in fact coherent.
Another feature of the experimental data that is not reproduced by the theory is the small overshoot in transmission just before the system reaches the steady state [for instance at 20 ns for N g = 88 µ m -3 in Fig. 2(a)]. Remnants of coherent Rabi oscillations can be ruled out given the large dephasing rates and large detunings with respect to the single-atom resonance. Moreover the time scale of the overshoot, e.g. the time between the two maxima, does not show a specific dependency on the detuning, as is the case for Rabi flopping. Explaining this feature will require further study and a more sophisticated theory. Note that ion effects can be neglected. There are no ions in the sample prior to the excitation, otherwise they would act as aggregation seeds [35] at t = 0 and change the signal dramatically. Moreover plasma formation would occur only once Rydberg atoms have been excited [34] and therefore cannot explain our Rydberg excitation signal. In spite of the low collisional ionization rate ( ∼ 40 MHz [34]) it might happen that in the course of the experiment single ions are created. However single ions will not disturb the aggregation dynamics, because of the similarity between the ion-Rydberg and the Rydberg-Rydberg potentials [35].
In conclusion, we have shown a facilitated excitation process of Rydberg atoms in thermal vapor. We have characterized the dynamics by measuring power laws for all relevant experimental parameters. These power laws, as well as absolute numbers for the dynamics and Rydberg density are in excellent agreement with those from a model for Rydberg aggregation. These results were obtained in the framework of thermal vapors, but the general ideas also apply to experiments in ultracold atoms. In the ultracold regime it would be interesting to study how quantum effects influence the aggregation time scale when the strength of dephasing noise is systematically lowered.
The authors would like to thank D. Peter, S. Weber, S. Hofferberth and J.P. Garrahan for fruitful discussions,
as well as H. K¨bler for proof reading. u This project was supported by the Carl-Zeiss-Stiftung and the ERC under contract number 267100. I.L. acknowledges funding from the European Research Council under the European Union's Seventh Framework Programme (FP/20072013) / ERC Grant Agreement n. 335266 (ESCQUMA) and the EU-FET Grant No. 512862 (HAIRS). D.B. and J.P.S. acknowledge financial support from grants NSF(PHY-1205392) and DARPA(60181-PH-DRP) for this work.
- ∗ Electronic address: [email protected]
- † Electronic address: [email protected]
- [1] S. Haroche, Rev. Mod. Phys. 85 , 1083 (2013).
- [2] M. Saffman, T. G. Walker, and K. Mølmer, Rev. Mod. Phys. 82 , 2313 (2010).
- [3] Y. O. Dudin and A. Kuzmich, Science 336 , 887 (2012).
- [4] T. Peyronel, O. Firstenberg, Q.-Y. Liang, S. Hofferberth, A. V. Gorshkov, T. Pohl, M. D. Lukin, and V. Vuleti´, c Nature 488 , 57 (2012).
- [5] D. Maxwell, D.J. Szwer, D. Paredes-Barato, H. Busche, J.D. Pritchard, A. Gauguet, K.J. Weatherill, M.P.A. Jones, and C.S. Adams, Phys. Rev. Lett. 110 , 103001 (2013).
- [6] H. Gorniaczyk, C. Tresp, J. Schmidt, H. Fedder, and S. Hofferberth, Phys. Rev. Lett. 113 , 053601 (2014).
- [7] D. Tiarks, S. Baur, K. Schneider, S. D¨ urr, and G. Rempe, Phys. Rev. Lett. 113 , 053602 (2014).
- [8] J. A. Sedlacek, A. Schwettmann, H. K¨ ubler, R. L¨ ow, T. Pfau, and J. P. Shaffer, Nature Physics 8 , 819 (2012).
- [9] V. Bendkowsky, B. Butscher, J. Nipper, J. P. Shaffer, R. L¨w, o and T. Pfau, Nature 458 , 1005 (2009).
- [10] H. Weimer, M. M¨ller, I. Lesanovsky, P. Zoller, u and H. P. B¨ uchler, Nature Physics 6 , 382 (2010).
- [11] G. G¨ unter, H. Schempp, M. Robert-de Saint-Vincent, V. Gavryusev, S. Helmrich, C. S. Hofmann, S. Whitlock, and M. Weidem¨ uller, Science 342 , 954 (2013).
- [12] S. Ravets, H. Labuhn, D. Barredo, L. B´guin, T. Lahaye, e and A. Browaeys, Nature Physics 10 , 914 (2014).
- [13] R. L¨w, H. Weimer, U. Krohn, R. Heidemann, V. Bendo kowsky, B. Butscher, H.P. B¨chler, u and T. Pfau, Phys. Rev. A 80 , 033422 (2009).
- [14] T. Pohl, E. Demler, and M. D. Lukin, Phys. Rev. Lett. 104 , 043002 (2010).
- [15] F. Cinti, P. Jain, M. Boninsegni, A. Micheli, P. Zoller, and G. Pupillo, Phys. Rev. Lett. 105 , 135301 (2010).
- [16] R. M. W. van Bijnen, S. Smit, K. A. H. van Leeuwen, E. J. D. Vredenbregt, and S. J. J. M. F. Kokkelmans, J. Phys. B 44 , 184008 (2011).
- [17] P. Schauß, M. Cheneau, M. Endres, T. Fukuhara, S. Hild, A. Omran, T. Pohl, C. Gross, S. Kuhr, and I. Bloch, Nature 491 , 87 (2012).
- [18] P. Schauß, J. Zeiher, T. Fukuhara, S. Hild, M. Cheneau, T. Macr` ı, T. Pohl, I. Bloch, and C. Gross, arXiv:1404.0980.
- [19] A. Schwarzkopf, D. A. Anderson, N. Thaicharoen, and G. Raithel, Phys. Rev. A 88 , 061406 (2013).
- [20] C. Ates, T. Pohl, T. Pattard, and J.M. Rost, Phys. Rev. Lett. 98 , 023002 (2007).
- [21] T. Amthor, C. Giese, C. S. Hofmann, and M. Weidem¨ uller, Phys. Rev. Lett. 104 , 013001 (2010).
- [22] I. Lesanovsky and J. P. Garrahan, Phys. Rev. A 90 , 011603(R) (2014); M. Marcuzzi, J. Schick, B. Olmos, and I. Lesanovsky, J. Phys. A 47 , 482001 (2014).
- [23] M. G¨ arttner, K. P. Heeg, T. Gasenzer, and J. Evers, Phys. Rev. A 88 , 043410 (2013).
- [24] H. Schempp, G. G¨ unter, M. Robert-de-Saint-Vincent, C. S. Hofmann, D. Breyel, A. Komnik, D. W. Sch¨nleber, o M. G¨ arttner, J. Evers, S. Whitlock, and M. Weidem¨ller, u Phys. Rev. Lett. 112 , 013002 (2014).
- [25] N. Malossi, M.M. Valado, S. Scotto, P. Huillery, P. Pillet, D. Ciampini, E. Arimondo, and O. Morsch, Phys. Rev. Lett. 113 , 023006 (2014).
- [26] J. M. Raimond, G. Vitrant, and S. Haroche, J. Phys. B 14 , L655 (1981).
- [27] T. Baluktsian, B. Huber, R. L¨w, o and T. Pfau, Phys. Rev. Lett. 110 , 123001 (2013).
- [28] C. Carr, R. Ritter, C. G. Wade, C. S. Adams, and K. J. Weatherill, Phys. Rev. Lett. 111 , 113901 (2013).
- [29] R. Heidemann, U. Raitzsch, V. Bendkowsky, B. Butscher, R. L¨ ow, L. Santos, and T. Pfau, Phys. Rev. Lett. 99 , 163601 (2007).
- [30] See Supplemental Material at [URL] for details on the experimental procedure, the adiabatic elimination, the theoretical model, the pair-state potentials, the dephasing mechanism and the size of the aggregates..
- [31] B. Huber, T. Baluktsian, M. Schlagm¨ uller, A. K¨ olle, H. K¨ ubler, R. L¨w, o and T. Pfau, Phys. Rev. Lett. 107 , 243001 (2011).
- [32] K. Singer, J. Stanojevic, M. Weidem¨ller, u and R. Cˆ ot´, e J. Phys. B 38 , S295 (2005).
- [33] A. Schwettmann, J. Crawford, K.R. Overstreet, and J.P. Shaffer, Phys. Rev. A 74 , 020701 (2006).
- [34] G. Vitrant, J. M. Raimond, M. Gross, and S. Haroche, J. Phys. B 15 , L49 (1982).
- [35] The Stark-shift of an ion on the 32S state is C /r 4 4 with C 4 = 2 π ×-213 MHz · µ m , which is an attractive poten4 tial with comparable strength to the Rydberg-Rydberg potentials. Therefore facilitation would similarly occur around an ion, if created.
- [36] A. Urvoy, C. Carr, R. Ritter, C. S. Adams, K. J. Weatherill, and R. L¨w, J. Phys. B o 46 , 245001 (2013).
- [37] P. Siddons, C. S. Adams, C. Ge, and I. G. Hughes, J. Phys. B 41 , 155004 (2008).
## SUPPLEMENTAL MATERIAL
## Experimental details
The 455 nm laser is frequency-stabilized with a blue detuning of δ 7P = 1 5 . GHz to the 6S 1 / 2 , F = 4 → 7P 3 / 2 , F = 5 transition (see Fig. 2). The 1070 nm laser is ′ scanned over the two-photon resonance to the Rydberg state | n S 1 / 2 〉 . Both lasers have an estimated linewidth below 5 MHz. The frequency of the 1070 nm laser is calibrated for each measurement using a Fabry-P´rot ine terferometer and additionally by an EIT-signal [36] to fix the origin of the frequency axis. The 455 nm laser typically has a power of 3 mW. The 1070 nm laser has a power
of 15 W and passes through a Pockels cell, allowing to switch the power of this laser for the experiment as fast as 1 5 ns with a repetition rate of 10 kHz. . The two-photon Rabi frequency is Ω = 2 π × 0 05 . . . . 0 5 GHz, the detuning . to the Rydberg state is ∆ = 2 π ×-1 . . . -10 GHz.
The glass cell is home-made and consists of two 1 mmthick quartz optical flats of 5 × 5 cm 2 separated by a 220 µ m spacer and sealed at the edge. A glass tube was connected to the cell, filled with cesium under vacuum and sealed off. This glass tube serves as a reservoir. The temperature of the cell is kept constant at 200 ◦ C to prevent the metallic cesium from condensing, whereas the temperature of the reservoir is varied between 70 ◦ C and 150 C to tune the atom number density. ◦ The atom number density in the cell is determined for each measurement by performing absorption spectroscopy on the D2-line of cesium [37]. Both beams are linearly polarized, overlapped in a counter-propagating configuration and focused inside the cell to a beam waist of approx. 15 µ m. After passing through the cell the blue beam is focused on a pinhole in order to select the central part of radius 6.25 µ m inside the cell. We verified that the resulting imaged volume is indeed almost cylindrical inside the cell. The change in transmission is detected using a fast amplified silicon photodiode (Femto HSAX-S-1G4-Si). During the measurement, the transmission change of the 455 nm laser is monitored and averaged 300 times by a fast oscilloscope. We ensured that we operate in the linear response regime of the photodiode and measured the conversion efficiency of the detection to be approx. 850 V/W. This allows us to convert the transmission change into the real number of Rydberg atoms that are excited, assuming that no decays and losses of Rydberg atoms occur. This assumption is valid for short times as the time spent by an atom inside the excitation volume is on the order of 20 ns.
## Approximation to 2-level atoms
We reduce our 3-level system to a 2-level system by making use of the adiabatic elimination of the intermediate state. The basic principles of this approximation and the relevant parameters are shown in Fig. S1. The density matrix for the 3-level system is ρ = ( ρ ij ) i,j = g e r { , , } , and we define the density matrix for the effective 2-level system as ˆ = (ˆ ρ ρ ij ) i,j = g r { , } . The populations of states | g 〉 and | r 〉 coincide between both descriptions, i.e. ρ gg = ˆ ρ gg and ρ rr = ˆ ρ rr . The approximation relies on assuming that the intermediate state remains unpopulated ( ∂ ρ t ee = 0 and ρ ee | t =0 = 0). The resulting identity from the optical Bloch equations without decays is
$$0 = \Omega _ { g e } \, \text{Im} ( \rho _ { g e } ) - \Omega _ { e r } \, \text{Im} ( \rho _ { e r } ) \quad \text{(S1)} \quad \text{def}$$
FIG. S1. Left panel: 3-level ladder system with the useful definitions. The transition between the levels | i 〉 and | j 〉 is driven with the Rabi frequency Ω ij . The detuning to the intermediate state is δ . Right panel: Approximation to a 2-level system after adiabatic elimination of the intermediate state | e . 〉 The effective 2-level Rabi frequency is Ω eff = Ω ge Ω er / (2 | δ | ). For simplicity reasons the detuning to state | r 〉 and the arising light shifts are not shown.
Using ∂ ρ t rr = Ω er Im( ρ er ) one obtains
$$\text{Im} ( \rho _ { \text{ge} } ) = \frac { 1 } { \Omega _ { \text{ge} } } \partial _ { t } \rho _ { \text{rr} } \text{ \quad \ \ } ( S 2 )$$
which means that the absorption on the lower transition is proportional to the excitation rate to the Rydberg state | r . 〉 For the 2-level system we also obtain from the optical Bloch equations ∂ ρ t ˆ rr = Ω eff Im(ˆ ρ gr ) and therefore
$$\text{Im} ( \rho _ { \text{gc} } ) = \frac { \Omega _ { \text{eff} } } { \Omega _ { \text{gc} } } \text{Im} ( \hat { \rho } _ { \text{gr} } ) = \frac { \Omega _ { \text{err} } } { 2 | \delta | } \text{Im} ( \hat { \rho } _ { \text{gr} } ) \quad ( \text{S3} )$$
This last relation shows the link between the 2-level model and what is experimentally measured.
## S-state potentials in cesium
At short inter-atomic distances, i.e. below 1 µ m, the pair-state interaction potentials for Rydberg S-states become very complex, as shown in Fig. S2 for the 32S state. We will focus on this 32S state, but the situation is similar for other principal quantum numbers. Neighboring n ′ Pn ′′ D pair-states interact with the 32S-32S state with weak but resonant dipole-quadrupole interaction, leading to avoided crossings and state mixing. This means that the n ′ Pn ′′ D pair-states, which are dipoleforbidden for laser excitation from the 7P 3 / 2 state in the non-interacting case, carry some admixture ε 32S-32S of the 32S-32S state. Therefore it is possible to excite pair-states at negative detunings, where the detuning is defined with respect to the unperturbed 32S-32S state,
ε
FIG. S2. Top panel: Density plot of the 32S-32S admixture ε 32S-32S versus the inter-atomic distance. The molecular quantum number here is M = 0, and interactions up to the quadrupole-quadrupole order are included [33]. The green (resp. red) line depicts the extrapolated van-der-Waals (resp. dipole-dipole) pair-state potential. Bottom panel: 32S32S admixture ε 32S-32S versus the inter-atomic distance at a -2 GHz potential energy (depicted as the blue dash-dot line in the upper panel).

which would not be the case with purely repulsive vander-Waals interaction.
These pair state potentials are actually only valid for an excitation close to an atom in the 32S state. Once such a pair is created, it is mainly a n ′ Pn ′′ D pair, with an amplitude of 1 -ε 2 32S-32S > 0 99. . For any subsequent excitation around this pair, one therefore has to consider the pair-state interaction potentials for the 32Sn ′ P and 32Sn ′′ Dpair states. For an S-P pair state the interaction potential is purely of the form C /r 3 3 , since the dipoledipole interaction of an S-P pair with its permutation PS is resonant, and the symmetric (resp. antisymmetric) linear combination exhibits attractive (resp. repulsive) interaction. The corresponding interaction strength is C S-P 3 ≈ -290 MHz · µ m , which is in excellent agreement 3 with the value of C 3 = 2 π ×-258 MHz · µ m extracted 3 from the experimental results. For an S-D pair state the interaction is of van-der-Waals character and repulsive ( C S-D 6 ≈ 11 MHz · µ m ). 6 The n ′′ D component therefore plays no role in our case of aggregation with red detunings.
The admixture ε 32S-32S is the rescaling factor for the Rabi frequency when exciting a n ′ Pn ′′ D pair. Because of the nature of the aggregates, which enclose previously excited Rydberg atoms, at most every second Rydberg excitation is created via this process. The other exci- tations occur either as a direct off-resonant excitation from the ground state, or close to a n ′ Pn ′′ D pair. The Rabi frequency does not need rescaling in both cases. An estimate for the overall rescaling factor is therefore √ ε 32S-32S ∼ 0 3, which is close to the rescaling factors of . 0.38 (for van-der-Waals interaction) and 0.23 (for dipoledipole interaction) needed to match the experimental data to the results from the simulation.
In the whole treatment, we neglected the distance dependency of ε 32S-32S . In order to justify this approximation, let us consider just two pair states | 1 〉 and | 2 〉 with energies E 1 ( r ) = C /r 6 6 and E 2 ( r ) = E 0 -C /r 6 6 , and a small dipole quadrupole interaction W r ( ) = U/r 4 between the two pair states. The resulting admixture of pair state | 1 〉 at small r is ε 1 ≈ W r / E ( ) | 2 ( r ) -E 1 ( r ) | ∝ r 2 if we consider E 0 to be small, and the pair state energy is E ′ 1 ( r ) = ∆ ≈ -C /r 6 6 . Therefore ε 1 ∝ ∆ 1 / 3 under these rather crude approximations. Using the same argument as before we obtain Ω ∝ ∆ 1 / 6 which is a sufficiently weak dependence to be neglected.
## Dephasing rate
The first contribution to dephasing in the experiment is the Doppler effect, characterized by the two-photon Doppler width γ D = | k 455 -k 1070 | √ 8 ln 2 k B T m . Here m is the atomic mass of cesium, T is the temperature and k 455 and k 1070 the wavenumbers of the two lasers, from which we consider the difference because the lasers are counterpropagating. At 200 C we have ◦ γ D = 2 π × 512 MHz.
The other important source of dephasing arises from the short transit time during which the atoms are in the resonant shell (or facilitation region) of width ∆ . r In first approximation, only the velocity component perpendicular to the shell v ⊥ determines the transit time, as depicted in Fig.S3. Therefore we define this motional dephasing rate as
$$\gamma _ { m } = \frac { \langle \mathbf v _ { \perp } \rangle } { \Delta r }$$
where 〈 v ⊥ 〉 = 1 √ 3 √ 8 k B T πm is the one dimensional mean atomic velocity. For a temperature of 200 C, this 1D ◦ mean velocity is 〈 v ⊥ 〉 = 158 m s . -1 . Since both dephasing mechanisms are gaussian, the total dephasing rate is defined as γ = √ ( γ D ) 2 +( γ m 2 ) .
Moreover ∆ r is related to the total dephasing rate and on the interaction potential (see Fig.1). First assuming Rydberg interaction of the van-der-Waals (vdW) type, we rename the relevant quantities as ∆ r vdW , γ vdW m (motional dephasing rate) and γ vdW (total dephasing rate). The width of the resonant shell is also given by [22]
$$\Delta r ^ { \text{vdW} } \approx \frac { 1 } { 3 } \left ( \frac { C _ { 6 } } { \Delta } \right ) ^ { \frac { 1 } { 6 } } \left ( \frac { \gamma ^ { \text{vdW} } } { 2 | \Delta | } \right ) \quad \quad ( \text{S5} )$$
FIG. S3. Top: Sketched snapshots of the excitation process of a 3-atom aggregate. Red (resp. blue) dots represent Rydberg (resp. ground state) atoms. The grey lines show the resonant shell of width ∆ r for each atom, within which the excitation is facilitated. The velocity component v ⊥ perpendicular to the resonant shell is shown for an atom inside the shell. Bottom: Probabilities P n ( t f ) of creating an n -atom aggregate in an interval t f and typical number of n -atom aggregates η n for N fac = 5000 facilitating atoms, similarly to the experimental situation.
| n | 1 | 2 | 3 | 4 | 5 |
|-------------|---------|---------|---------|---------|---------|
| P n ( t f ) | 0.91 | 0.084 | 0.0061 | 0.00039 | 2.3e-05 |
| η n | 4740 | 436 | 32 | 2 | 0.12 |
By combining equations (S4) and (S5) we obtain the following self consistent equation for the motional dephasing rate γ vdW m :
$$\frac { \langle \nu _ { \perp } \rangle } { \gamma _ { m } ^ { \text{vdW} } } = \frac { 1 } { 3 } \left ( \frac { C _ { 6 } } { \Delta } \right ) ^ { \frac { 1 } { 6 } } \left ( \frac { \sqrt { \left ( \gamma _ { D } \right ) ^ { 2 } + \left ( \gamma _ { m } ^ { \text{vdW} } \right ) ^ { 2 } } } { 2 | \Delta | } \right ) \quad ( \text{S} ) \quad \text{ans} \ \frac { \text{and} \ c } { \text{prob} }$$
Solving equation (S6) yields γ vdW m = 2 π × 493 MHz, so that the total dephasing rate is γ vdW = 2 π × 711 MHz.
For the case of pure dipole-dipole (dd superscript) interaction, equation (S5) changes to
$$\Delta r ^ { \text{dd} } \approx \frac { 2 } { 3 } \left ( \frac { C _ { 3 } } { \Delta } \right ) ^ { \frac { 3 } { 3 } } \left ( \frac { \gamma ^ { \text{dd} } } { 2 | \Delta | } \right ) \quad \quad ( \text{S7} ) \quad \text{In 1}$$
and the dephasing rate can be estimated to γ dd = 2 π × 591 MHz with γ dd m = 2 π × 296 MHz. γ vdW and γ dd are the values that were used in the simulations.
## Aggregate size
Since we are not in the frozen gas regime, aggregates are only spatially correlated like the ones shown in the inset of Fig. 1(b) for a short period of time. At longer times the atomic motion will destroy the spatial correlations between the atoms. This will, however, have no impact on the fact that Rydberg excitations are facilitated by already existing one. In the following we will estimate the size of the 'frozen aggregates' [Fig. 1(b)]. The time scale over which the ensemble can be considered frozen is given the transit time of the atoms through the resonant shell of width ∆ r , given by t f = ( γ m ) -1 ≈ 0 32 ns. . During this time interval the ensemble can be considered as a frozen gas for our purposes. We estimate the size of the aggregates that can be formed during this time in a very simplified model. The parameters are the same as in Fig. 2(c) with the extracted values of γ and C 6 : ∆ ≈ 2 π × -2200 MHz, Ω = 2 π × 0 4 . × 100 MHz, N g = 88 µ m -3 , C 6 = 2 π × -109 MHz · µ m 6 and γ vdW = 2 π × 711 MHz. 0 4 . is the rescaling factor for Ω discussed in the main text.
Let us first consider one individual Rydberg atom which acts as the seed for an aggregate. In the resonant shell (sphere of radius r fac = 0 61 . µ m and width ∆ = 51 nm, see Eq. (S4)) around this first atom reside r ν res = N g × 4 πr 2 fac ∆ r = 20 7 atoms in average. . Moreover the size of the resonant shell grows with the number of Rydberg atoms. For this we approximate an n -atom aggregate to a sphere (whose volume is occupied by n Rydberg atoms separated by the facilitation radius). Then the entire resonant shell contains n 2 / 3 × ν res atoms. For each ground state atom in the shell, the time constant for the excitation is τ 0 = γ/ Ω 2 ≈ 71 ns, and therefore the excitation rate of the ( n +1)-th atom is Γ n +1 = n 2 / 3 × ν res /τ 0 . If we simplify the problem and consider that the atoms are excited sequentially, the probabilities P n ( ) that an aggregate formed by t n Rydberg atoms at the time t per pre-existing Rydberg atom obeys the following rate equation:
$$\partial _ { n } P _ { n } & = \Gamma _ { n - 1 } P _ { n - 1 } - \Gamma _ { n } P _ { n } \\ & = \frac { \nu _ { \text{res} } } { \tau _ { 0 } } \left ( ( n - 1 ) ^ { 2 / 3 } P _ { n - 1 } - n ^ { 2 / 3 } P _ { n } \right ) \quad \text{(S8)}$$
In the table in Figure S3 we show the solutions of these equations for aggregates consisting of up to 5 atoms at the time t f .
The number of n -atom aggregates that are excited in the whole excitation volume during t f is given by η n = N fac × P n ( t f ), where N fac is the number of Rydberg atoms which can act as a nucleation grains. As the excitation occur at the boundary of the already excited Rydberg ensemble N fac is only a fraction of the ∼ 50000 Rydberg atoms. The values of η n are shown in Figure S3, with N fac = 5000 (corresponding to the outer shell of a sphere with 50000 Rydberg atoms). For this Rydberg atom number the largest spatially correlated aggregates that we create in our experiment can thus be estimated to consist of approximately 4 atoms. | 10.1103/PhysRevLett.114.203002 | [
"A. Urvoy",
"F. Ripka",
"I. Lesanovsky",
"D. Booth",
"J. P. Shaffer",
"T. Pfau",
"R. Löw"
] | 2014-07-31T22:17:36+00:00 | 2015-03-09T15:22:59+00:00 | [
"physics.atom-ph",
"cond-mat.quant-gas",
"quant-ph"
] | Strongly correlated growth of Rydberg aggregates in a vapor cell | The observation of strongly interacting many-body phenomena in atomic gases
typically requires ultracold samples. Here we show that the strong interaction
potentials between Rydberg atoms enable the observation of many-body effects in
an atomic vapor, even at room temperature. We excite Rydberg atoms in cesium
vapor and observe in real-time an out-of-equilibrium excitation dynamics that
is consistent with an aggregation mechanism. The experimental observations show
qualitative and quantitative agreement with a microscopic theoretical model.
Numerical simulations reveal that the strongly correlated growth of the
emerging aggregates is reminiscent of soft-matter type systems. |
1408.0040v3 | ## WEAK SEQUENTIAL COMPLETENESS IN BANACH C K ( ) -MODULES OF FINITE MULTIPLICITY.
## ARKADY KITOVER AND MEHMET ORHON
Abstract. A well known result of Lozanovsky states that a Banach lattice is weakly sequentially complete if and only if it does not contain a copy of c 0 . In the current paper we extend this result to the class of Banach C K ( )-modules of finite multiplicity and, as a special case, to finitely generated Banach C K ( )-modules. Moreover, we prove that such a module is weakly sequentially complete if and only if each cyclic subspace of the module is weakly sequentially complete.
## 1. Introduction
It is well known that some important properties of Banach spaces (reflexivity, weak sequential completeness, et cetera) can be more readily studied if we restrict our attention to the class of Banach lattices. In particular, it was proved by Lozanovsky in [15] that a Banach lattice is reflexive if and only if it does not contain a subspace 1 isomorphic to either c 0 or l 1 , and that it is weakly sequentially complete if and only if it does not contain a subspace isomorphic to c 0 . The above results cannot be extended to the class of all Banach spaces: the famous James space [9] does not contain either l 1 or c 0 but is neither reflexive nor (see [14, page 34]) weakly sequentially complete.
Nevertheless, Lozanovsky's results remain true for arbitrary subspaces of Banach lattices with order continuous norm or complemented subspaces of arbitrary Banach lattices, see [24] and [14, Theorem 1.c.7, page 37]. We consider similar problems for two other subclasses of the class of Banach spaces, namely the class of finitely generated Banach C K ( )-modules (see Definition 2.3 below) and the class of Banach
Date : Tuesday 31 st March, 2015.
2010 Mathematics Subject Classification. Primary 46B20; Secondary 47B22, 46B42. Key words and phrases. Weak sequential completeness, Banach C K ( )-modules, Banach lattices.
1 By subspace we always mean closed subspace.
C K ( )-modules of finite multiplicity (Definition 3.7). 2 Because cyclic subspaces of Banach C K ( )-modules can be represented in a natural way as Banach lattices we have reason to believe that many 'nice' properties of Banach lattices would carry over to Banach C K ( )-modules of finite multiplicity. In particular, the authors proved in [12] that a Banach C K ( )-module of finite multiplicity is reflexive if and only if it does not contain a copy of either l 1 or c 0 . The goal of the current paper is to prove that Lozanovsky's characterization of weak sequential completeness of Banach lattices also remains true for such modules.
## 2. Preliminaries
All the linear spaces will be considered either over the field of real numbers R or the field of complex numbers C . If X is a Banach space we will denote its Banach dual by X /star .
Let us recall some definitions.
Definition 2.1. Let K be a compact Hausdorff space and X be a Banach space. We say that X is a Banach C K ( )-module if there is a continuous unital homomorphism m of C K ( ) into the algebra L X ( ) of all bounded linear operators on X .
Remark 2.2. Because ker m is a closed ideal in C K ( ) by considering, if needed, C K ( ˜ ) = C K / ( ) ker m we can and will assume without loss of generality that m is a contractive homomorphism (see [12]) and ker m = 0. Then (see [7, Lemma 2 (2)]) m is an isometry. Moreover, when it does not cause any ambiguity we will identify f ∈ C K ( ) and mf ∈ L X ( ).
Definition 2.3. Let X be a Banach C K ( )-module and x ∈ X . We introduce the cyclic subspace X x ( ) of X as X x ( ) = cl { fx : f ∈ C K ( ) } .
The following proposition was proved in [25] (see also [20]) in the case when the compact space K is extremally disconnected and announced for an arbitrary compact Hausdorff space K in [10]. It follows as a special case from [7, Lemma 2 (2)].
Proposition 2.4. Let X be a Banach C K ( ) -module, x ∈ X , and X x ( ) be the corresponding cyclic subspace. Then, endowed with the cone X x ( ) + = cl { fx : f ∈ C K ,f ( ) ≥ 0 } and the norm inherited from X , X x ( ) is a Banach lattice with positive quasi-interior point x .
2 It is worth emphasizing that under the condition that every cyclic subspace is a KB -space the former subclass is strictly smaller than the latter.
Our next proposition follows from Theorem 1 (3) in [17]
Proposition 2.5. The center Z X x ( ( )) of the Banach lattice X x ( ) is isometrically isomorphic to the weak operator closure of m C K ( ( )) in L X x ( ( )) .
Now we can introduce one of the two main objects of interest in the current paper.
Definition 2.6. Let X be a Banach C K ( )-module. We say that X is finitely generated if there are an n ∈ N and x , . . . , x 1 n ∈ X such that the set n ∑ i =1 X x ( i ) is dense in X .
Before we proceed with the statement and the proof of our main results (Theorem 3.1 and Theorem 3.8) we need to introduce a few more definitions and recall a couple of results.
Definition 2.7. Let X be a Banach space and B be a Boolean algebra of projections on X . The algebra B is called Bade complete (see [5, XVII.3.4, p.2197] and [22, V.3, p.315]) if
- (1) B is a complete Boolean algebra.
- (2) Let { χ γ } γ ∈ Γ be an increasing net in B , χ be the supremum of this net, and x ∈ X . Then the net { χ x γ } converges to χx in norm in X .
The following result was proved in [18, Theorem 3 and Remark 5].
Theorem 2.8. Let X be a Banach space, K be a compact Hausdorff space, and m be an isometric embedding of C K ( ) into L X ( ) . Assume that no cyclic subspace of X contains a copy of c 0 . Then
- (1) The closure of m C K ( ( )) in the weak operator topology is isometrically isomorphic to C Q ( ) where Q is a hyperstonian space.
- (2) The algebra of all idempotents in C Q ( ) is a Bade complete Boolean algebra of projections on X .
Remark 2.9. In virtue of Theorem 2.8 from now on, in this section, we will assume that the compact Hausdorff space K is hyperstonian and that B , the algebra of all idempotents in C K ( ), is a Bade complete Boolean algebra of projections on X .
Remark 2.10. Assume conditions of Remark 2.9. Because K is hyperstonian C K ( ) is a dual Banach space (see e.g. [22, Theorem 9.3, page 122]). Let us denote its predual by C K ( ) /star . Because C K ( ) /star is an AL -space it is isometrically isomorphic to a band in its second dual, i.e., to a band in C K ( ) /star (see [22, Page 92]).
Next notice (see [17]) that the center Z C K ( ( ) /star ) of C K ( ) /star is isometrically isomorphic to C K ( ) /star/star . We will denote by p the idempotent in C K ( ) /star/star corresponding to the band projection in C K ( ) /star onto the band C K ( ) /star .
Remark 2.11. Assume conditions of Remark 2.9 and assume also that X is cyclic. Then by [25] (see also [22, V.3]), X can be represented as a Banach lattice with order continuous norm and a positive quasi-interior point such that B coincides with the algebra of all band projections on X .
Remark 2.12. Consider X /star as a Banach C K ( )-module as follows. Let m /star : C K ( ) → L X ( /star ) be the isometric unital algebra and lattice homomorphism that describes this module structure. That is, for each a ∈ C K ( ), let m a /star ( ) be the Banach space adjoint of a acting as a bounded operator on X . Hence ax /star ( x ) = m a /star ( )( x /star )( x ) = x /star ( ax ) for all x ∈ X and x /star ∈ X /star .
Furthermore, by means of the Arens extension procedure [3], we will consider X /star/star as a Banach C K ( ) /star/star -module. Namely, for each x /star ∈ X /star , x /star/star ∈ X /star/star , a ∈ C K ( ), and a /star/star ∈ C K ( ) /star/star , we define µ x ,x /star /star/star ∈ C K ( ) /star and a /star/star · x /star/star ∈ X /star/star as follows
$$\mu _ { x ^ { * }, x ^ { * * } } ( a ) & = x ^ { * * } ( a x ^ { * } ), \\ a ^ { * * } \cdot x ^ { * * } ( x ^ { * } ) & = a ^ { * * } ( \mu _ { x ^ { * }, x ^ { * * } } ).$$
We will list the relevant easily checked properties of the above definitions in the following lemma.
Lemma 2.13. Let x /star ∈ X , x /star /star/star ∈ X /star/star , and a /star/star , b /star/star ∈ C K ( ) /star/star . Then
- (1) a /star/star µ x ,x /star /star/star = µ x ,a /star /star/star · x /star/star ;
- (2) ( a /star/star b /star/star ) · x /star/star = a /star/star · ( b /star/star · x /star/star ) ;
- (3) We have x /star/star ∈ p · X /star/star if and only if µ x ,x /star /star/star ∈ C K ( ) ∗ for all x /star .
Proof. (1) Given a /star/star in C K ( ) /star/star let { a α } be a net in C K ( ) that converges to a /star/star in the σ C K ( ( ) /star/star , C ( K ) /star )-topology. Then, for any a ∈ C K , ( ) we have
$$a ^ { * * } \mu _ { x ^ { * }, x ^ { * * } } ( a ) = & a ^ { * * } ( a \mu _ { x ^ { * }, x ^ { * * } } ) = \lim _ { \alpha } \mu _ { x ^ { * }, x ^ { * * } } ( a _ { \alpha } a ) = \lim _ { \alpha } x ^ { * * } ( a _ { \alpha } a x ^ { * } ) ; \\ \mu _ { x ^ { * }, a ^ { * * } \cdot x ^ { * * } } ( a ) = & a ^ { * * } \cdot x ^ { * * } ( a x ^ { * } ) = a ^ { * * } ( \mu _ { a x ^ { * }, x ^ { * * } } ) = \lim _ { \alpha } \mu _ { a x ^ { * }, x ^ { * * } } ( a _ { \alpha } ) = \lim _ { \alpha } x ^ { * * } ( a _ { \alpha } a x ^ { * } ).$$
$$\begin{smallmatrix} \dashrightarrow r \cdots r \cdots \cdots \\ \alpha \end{smallmatrix}, \cdots \cdots \cdots$$
- (2) Applying part (1) when necessary we have for any a ∈ C K ( ),
$$( a ^ { * * } b ^ { * * } ) \cdot x ^ { * * * } ( a x ^ { * } ) & = \mu _ { x ^ { * }, ( a ^ { * * } b ^ { * * } ) \cdot x ^ { * * * } } ( a ) = ( a ^ { * * } b ^ { * * } ) \mu _ { x ^ { * }, x ^ { * * * } } ( a ) = a ^ { * * } ( b ^ { * * } \mu _ { x ^ { * }, x ^ { * * * } } ) ( a ) \\ & = \mu _ { x ^ { * }, a ^ { * * } \cdot ( b ^ { * * } \cdot x ^ { * * * } ) } ( a ) = a ^ { * * } \cdot ( b ^ { * * } \cdot x ^ { * * } ) ( a x ^ { * } ).$$
- (3) Suppose x /star/star ∈ p · X /star/star . Then x /star/star = p · x /star/star . Hence, by part (1),
$$\mu _ { x ^ { * }, x ^ { * * } } = \mu _ { x ^ { * }, p \cdot x ^ { * * } } = p \mu _ { x ^ { * }, x ^ { * * } } \in C ( K ) _ { * }.$$
Conversely, suppose µ x ,x /star /star/star ∈ C K ( ) ∗ for all x /star ∈ X /star . Then µ x ,x /star /star/star = pµ x ,x /star /star/star = µ x ,p x /star · /star/star for all x /star ∈ X /star . It follows that x /star/star = p · x /star/star . /square
Lemma 2.14. Let X be a Banach lattice. Then p · X /star/star is equal to ( X /star ) /star n .
Proof. Let X be a Banach lattice. Then Z X ( /star ), the ideal center of X /star , is equal to C K ( ) where K is hyperstonian. Since X /star is Dedekind complete, Z X ( /star ) is topologically full in the sense of Wickstead [26]. That is for any x /star ∈ X /star + , one has that cl ( Z X ( /star ) x /star ) is the closed ideal generated by x /star . Then, by considering X /star as a C K ( )-module and applying the Arens extension process described above we obtain (see [17, Corollary 1]) that the ideal center Z X ( /star/star ) of X /star/star is equal to a band in C K ( ) /star/star . It is easy to see from Lemma 2.13 part (3) that in X /star/star , the set p · X /star/star is precisely the band of order continuous linear functionals on X /star . That is p · X /star/star = ( X /star ) /star n . /square
Remark 2.15. In the case of Riesz spaces, the statement of Lemma 2.14 remains true for the order bidual of the Riesz space. We refer the interested reader to Corollary 6 in [2].
Our next lemma shows that the property p X · /star/star = X is a three-space property.
Lemma 2.16. Suppose K is hyperstonian and X is a Banach C K ( ) -module such that B , the idempotents in C K ( ) , is a Bade complete Boolean algebra of projections on X .
- (1) Let Y be a closed submodule of X such that p · Y /star/star = Y and p · ( X/Y ) /star/star = X/Y . Then p · X /star/star = X .
- (2) Let p · X /star/star = X . Then for any closed submodule Y of X we have p · Y /star/star = Y and p · ( X/Y ) /star/star = X/Y .
Proof. (1) Let Y be a closed submodule of X . Then B is a Bade complete Boolean algebra of projections on both Y and X/Y (see [12, Lemma 1]). Hence it makes sense to consider the hypothesis in the statement of part (1) of the lemma and assume that it holds for these two spaces. It is familiar from standard duality that Y /star/star = Y oo ⊂ X /star/star and ( X/Y ) /star/star = X /star/star /Y oo where for a subspace Y ⊂ X , we let Y o denote the polar (or the annihilator) of Y in X /star and let Y oo denote the polar of Y o in X /star/star . Consider x /star/star ∈ X /star/star . Let [ x /star/star ] = x /star/star + Y oo ∈ X /star/star /Y oo . Then p · ( X/Y ) /star/star = X/Y means that, as a subset of X /star/star , p · [ x /star/star ] = [ p · x /star/star ] = p · x /star/star + Y oo has non-empty intersection with X . That is,
there is x ∈ X and y /star/star ∈ Y oo such that p · x /star/star + y /star/star = x (*). Now p · Y oo = Y means that p · y /star/star = y for some y ∈ Y and we also have that p · x = x trivially. Hence we apply p to both sides of the equality (*) to obtain p · x /star/star = x -y for some y ∈ Y and x ∈ X .
- (2) Assume p · X /star/star = X and Y is a closed submodule of X . It is familiar that Y = X ∩ Y oo by the bipolar theorem. Let y /star/star ∈ Y oo , then p · y /star/star ∈ X ∩ Y oo = Y . Hence p · Y /star/star = Y . Now take x /star/star ∈ X /star/star and consider [ x /star/star ] ∈ X /star/star /Y oo . Since p · x /star/star = x for some x ∈ X , we have p · [ x /star/star ] = [ p · x /star/star ] = [ x ]. Also, given ε > 0, there is y /star/star ∈ Y oo such that || p · x /star/star + y /star/star || < || p · [ x /star/star ] || (1 -ε ). Since p · y /star/star = y ∈ Y for some y ∈ Y , we have p · ( p · x /star/star + y /star/star ) = x + . Since y || p || = 1, we have, when p x · /star/star = x , || p · [ x /star/star ] || ( X/Y ) /star/star = || [ x ] || X/Y . Hence p · ( X/Y ) /star/star = X/Y . /square
The next lemma is a special case of Theorem 6 in [11, Page 297].
Lemma 2.17. Let X be a Banach lattice and let { x /star n } be a sequence of positive, increasing and norm bounded elements of X /star . Suppose M > 0 is the supremum of the norms of the functionals in the sequence. Then the sequence has a least upper bound x /star ∈ X /star + with norm equal M .
We will need the following complement to Lozanovsky's result that follows from Theorem 2.4.12 in [16].
Theorem 2.18. Let X be a Banach lattice. The following conditions are equivalent.
- (1) X is weakly sequentially complete.
- (2) X does not contain a sublattice that is lattice isomorphic to c 0 .
The following lemma will play a crucial role in the proof of Theorem 3.1.
Lemma 2.19. Suppose K is hyperstonian and X is a finitely generated Banach C K ( ) -module such that the algebra B of the idempotents in C K ( ) , is a Bade complete Boolean algebra of projections on X . If no cyclic subspace of X contains a copy of c , 0 then p · X /star/star = X.
Proof. We will prove the result by induction on the number of generators of X. Suppose X is cyclic. Then by Remark 2.11, X can be represented as a Banach lattice with order continuous norm such that B corresponds to the band projections on X. Since X is cyclic X does not contain a copy of c . 0 Then, by the well known result for Banach lattices (see e.g. [16, Theorem 2.4.12]), X is a KB-space and X = ( X /star ) /star n . But by Lemma 2.14 we have that p · X /star/star = ( X /star ) /star n for Banach lattices. Therefore p · X /star/star = X as required. Now suppose whenever X has r generators ( r ≥ 1 ) and no cyclic subspace of X contains a copy of c , 0
we have that p · X /star/star = X . Suppose that X has r +1 generators. Let { x , x 0 1 , · · · , x r } be a set of generators for X. Let Y = X x , x , ( 1 2 · · · , x r ) . Then, since no cyclic subspace of Y contains a copy of c 0 , we have that p · Y /star/star = Y or p · Y oo = Y since Y /star/star = Y oo ⊂ X /star/star . Now consider X/Y = X/Y ([ x 0 ]) . Since B is Bade complete on X , it is also Bade complete on X/Y ( [12, Lemma1]). Also since X/Y is cyclic it may be represented as a Banach lattice which, by means of the previous sentence, may be assumed to have an order continuous norm and such that B corresponds to the band projections of the Banach lattice. If X/Y contains no copy of c 0 , then, as in the case when X is cyclic, we may claim that p · ( X/Y ) /star/star = X/Y. So if this is not the case, X/Y must contain a copy of c . 0 In fact as remarked before since X/Y is a Banach lattice it must contain a copy of c 0 that is lattice isomorphic to a closed sublattice of X/Y. This is equivalent to the statement that there exists a sequence { u n } in X such that { [ u n ] } is a positive disjoint sequence in X/Y and there exists constants 0 < d < D with
$$d \leq | | [ u _ { n } ] | | \text{ and } | | [ u _ { 1 } ] + [ u _ { 2 } ] + \cdots + [ u _ { n } ] | | \leq D$$
for each n (see [16, Lemma 2.3.10]). Let { e n } be a sequence in B such that each e n is the band projection onto the band generated by [ u n ] in X/Y. Since the sequence { [ u n ] } is disjoint in the Banach lattice X/Y, the members of the sequence of band projections { e n } are also pairwise disjoint as idempotents in C K . ( ) Since e n [ u n ] = [ e n u n ] = [ u n ] for each n, we may assume without loss of generality that e n u n = u n . Let z n = u 1 + u 2 + · · · + u n ∈ X and χ n = e 1 + e 2 + · · · + e n ∈ B for each n. Then { [ z n ] } is a positive, increasing and norm bounded sequence in X/Y. By Lemma 2.17, there exists z ∈ X /star/star such that [ z ] = sup[ z n ].
Note that we consider X/Y ⊂ (( X/Y ) /star ) /star n . Since (( X/Y ) /star ) /star n is a band in ( X/Y ) /star/star , we have that [ z ] ∈ (( X/Y ) /star ) /star n . Then by Lemma 2.14, we have that p · [ z ] = [ ] z . Therefore without loss of generality we take p · z = z. The definition of { z n } implies that χ z n m = z n for all n ≤ m. Therefore χ n · [ z ] = [ z n ] for all n. This means that there exists y /star/star n ∈ Y oo such that χ n · z + y /star/star n = z n for each n. By induction hypothesis, we have p · y /star/star n = y n for some y n ∈ Y and since z n ∈ X, we have p · z n = z n for each n . Therefore if we apply the projection p to both sides of the above equality, we obtain χ n · z + y n = z n for each n. Now apply e n to the last equality to obtain
n
$$e _ { n } \cdot z = u _ { n } - e _ { n } y _ { n } \in X$$
for each n. Note that the sequence { e n · z } in X satisfies
$$\delta \leq | | [ u _ { n } ] | | \leq | | e _ { n } \cdot z | | \text{ and } | | e _ { 1 } \cdot z + e _ { 2 } \cdot z + \dots + e _ { n } \cdot z | | = | | \chi _ { n } \cdot z | | \leq | | z | |$$
for each n. Let w = ∑ 1 2 n e n · z in X and consider the cyclic subspace X w . ( ) Clearly we may represent X w ( ) as a Banach lattice with order continuous norm and positive quasi-interior point w . In virtue of Lemma 1 in [12] we may assume that B corresponds to the algebra of band projections on the Banach lattice X w ( ). Then e n w = 1 2 n e n · z for each n. Hence { e n · z } is a disjoint positive sequence in the Banach lattice X w . ( ) The displayed conditions above indicates that the sublattice generated by { e n · z } in X w ( ) is lattice isomorphic to c 0 [16, Lemma 2.3.10]. But this is a contradiction, because we assumed that no cyclic subspace of X contains a copy of c . 0 Thus we see that p · ( X/Y ) /star/star = X/Y as well as p · Y /star/star = Y. Finally Lemma 2.16 part (1) implies that p · X /star/star = X as required. /square
## 3. The main results.
## 3.1. Finitely generated C K ( ) -modules.
Theorem 3.1. Let X be a finitely generated Banach C K ( ) -module. Then the following conditions are equivalent.
- (1) X is weakly sequentially complete.
- (2) X does not contain a copy of c . 0
- (3) No cyclic subspace of X contains a copy of c . 0
- (4) Each cyclic subspace of X is weakly sequentially complete.
Proof. It is evident that we have (1) ⇒ (2) and (2) ⇒ (3). The equivalence (3) ⇔ (4) follows from Theorem 2.18 and Lozanovsky's result in [15]. Hence the proof will be completed if we show that (3) ⇒ (1) . Suppose no cyclic subspace of X contains a copy of c . 0 Then Theorem 2.8 guarantees that the weak operator closure of C K ( ) in L X ( ) is the norm closure of the linear span of a Bade complete Boolean algebra of projections on X. Since the closed submodules of X are the same with respect to either algebra of operators (i.e., either with respect to C K ( ) or with respect to its weak operator closure in L X ( ) ) we may assume that C K ( ) is weak operator closed in L X . ( ) Then (see Theorem 2.8) K is hyperstonian and B , the algebra of idempotents in C K , ( ) is the Bade complete Boolean algebra of projections that generate C K . ( ) Then (3) and Lemma 2.19 imply that p · X /star/star = X. To save space we will say that X satisfies ( /star ) if X is a C K ( )-module with hyperstonian K such that the idempotents in C K ( ) form a Bade complete Boolean algebra of projections on X and p X · /star/star = X . Hence (3) implies that X satisfies ( /star ). Once again we will use induction on the number of generators of X. If X is cyclic then it may be represented as a Banach lattice with order continuous norm such that the band projections correspond to B . By Lemma 2.14, we have p · X /star/star = ( X /star ) /star n . Therefore
p · X /star/star = X implies X = ( X /star ) /star n . Hence by Theorem 2.18, X is weakly sequentially complete (see also [11, Theorem 8, page 297]) . Now, as induction hypothesis, we suppose that whenever X is a C K ( )-module with at most r generators ( r ≥ 1 ) and X satisfies the condition ( /star ) then X is weakly sequentially complete. Suppose X has r +1 generators and satisfies ( /star ). Let { x , x 0 1 , · · · , x r } be a set of generators for X and let Y = X x , x , ( 1 2 · · · , x r ) . Then, by Lemma 2.16 part (2) , both Y and X/Y satisfy the condition ( /star ). Moreover Y has r generators and X/Y = X/Y ([ x 0 ]) is cyclic. Therefore by the induction hypothesis Y and X/Y are both weakly sequentially complete. Then the three-space property of weak sequential completeness (see [4, Theorem 4.7.a., page 122]) implies that X is weakly sequentially complete. /square
We conclude this section with two remarks.
Remark 3.2. The original example of Dieudonn´ [6] provides a Banach e C K ( )-module X with two generators such that every cyclic subspace is weakly sequentially complete but X cannot be represented as the sum of two cyclic subspaces.
Remark 3.3. The example of the Banach l ∞ -module l 1 ⊕ c 0 shows that in Theorem 3.1 we cannot substitute the condition that every cyclic subspace is weakly sequentially complete by a weaker condition that for some set of generators x , . . . , x 1 n of X , the cyclic subspaces X x ( i ) , i = 1 , . . . , n , are weakly sequentially complete.
## 3.2. Boolean algebras of projections of finite multiplicity.
Throughout this section we will assume that B is a Bade complete Boolean algebra of projections on the Banach space X. We let K denote the hyperstonian Stone representation space of B . As in section 2, we will assume that both X and X /star are modules over C K ( ) and that X /star/star is a module over C K ( ) /star/star .
Definition 3.4. Let B be a Bade complete Boolean algebra of projections on X . B is said to be of uniform multiplicity n, if there exist a set of nonzero pairwise disjoint idempotents { e α } in B with sup e α = 1 such that for any e α and for any e ∈ B , e ≤ e α the C K ( )-module eX has exactly n generators.
We will need the following result of Rall [21] (for a proof, see Lemma 2 in [19]).
Lemma 3.5. Let B be of uniform multiplicity one on X . Then X may be represented as a Banach lattice with order continuous norm such that B is the Boolean algebra of band projections on X .
Next, as in [12] we can state the following corollary of Theorem 3.1.
Corollary 3.6. Let X be a Banach space and let B be a Bade complete Boolean algebra of projections on X that is of uniform multiplicity n. Then conditions (1)-(4) of Theorem 3.1 and condition (5) p · X /star/star = X are equivalent.
/negationslash
Proof. We have that the implications (1) = ⇒ (2) = ⇒ (3) and (3) ⇐⇒ (4) hold as in the proof of Theorem 3.1. The proof would be complete if we show (3) = ⇒ (5) and (5) = ⇒ (1) . The proof of these implications follow exactly as in Lemma 2.19 for (3) = ⇒ (5) and as in Theorem 3.1 for (5) = ⇒ (1). Thus, provided that the case n = 1 is settled, we can finish the proof by induction. Therefore suppose B is of uniform multiplicity one on X. Then by Lemma 3.5, X may be represented as a Banach lattice with order continuous norm such that B corresponds to the band projections of the lattice. Assume that (3) holds and X is not a KB-space (i.e., p · X /star/star = ( X /star ) /star n = X ). Then by Theorem 2.18, X contains a sublattice isomorphic to c 0 . Suppose that { x n } is the disjoint sequence in this sublattice that corresponds to the standard basis of c 0 and let { e n } be the disjoint idempotents in B such that each e n is the band projection on the band generated by x n in X. Let u = ∑ 1 2 n x n in X . Consider the cyclic subspace (i.e. the band) X u ( ) of X . Since e n u = 1 2 n x n for each n , the sublattice generated by the positive disjoint sequence { x n } is in X u ( ) and this contradicts (3) . Therefore X is a KB-space, that is p · X /star/star = ( X /star ) /star n = X and X is weakly sequentially complete. Hence both (3) = ⇒ (5) and (5) = ⇒ (1) hold for n = 1 . /square
Definition 3.7. A Bade complete Boolean algebra of projections B on X is said to be of finite multiplicity on X if there exists a collection of disjoint idempotents { e α } in B such that, for each α, e α X is n α -generated and sup e α = 1 .
We note that the collection { n α } of positive integers need not be bounded. Then by a well known result of Bade [5, XVIII.3.8, p. 2267], there exists a sequence of disjoint idempotents { e n } in B such that, for each n, B is of uniform multiplicity n on e n X and sup e n = 1 . Also the norm closure of the sum of the sequence of the spaces { e n X } is equal to X. In our next result we will show that the conclusions of Corollary 3.6 extend to this case. In the proof of the theorem we will use a vector
version of a standard disjoint sequence method [13, Theorem 1.c.10, p. 23].
Theorem 3.8. Let X be a Banach space and let B be a Bade complete Boolean algebra of projections on X such that B is of finite multiplicity on X. Then conditions (1)-(4) of Theorem 3.1 and condition (5) p · X /star/star = X are equivalent.
Proof. It is clear that (1) = ⇒ (2) = ⇒ (3) ⇐⇒ (4) . Initially we will show (3) = ⇒ (1) . We will use the notation in the discussion before the statement. Since B is of finite multiplicity on X, by Corollary 3.6, for each n, e n X is weakly sequentially complete. Let χ n = e 1 + e 2 + . . . + e n for each n. Then χ X n is weakly sequentially complete for each n. Moreover χ n ↑ 1 in B implies that
$$( ^ { * } ) & & \lim _ { n \to \infty } \| ( 1 - \chi _ { n } ) \, x \| = 0$$
for any x ∈ X. Suppose { x i } is a weak Cauchy sequence in X such that
$$( ^ { * * } ) & & \lim _ { i \to \infty } f ( \chi _ { n } x _ { i } ) = 0$$
for each n and for all f ∈ X /star . Suppose, on the other hand, { x i } does not converge to 0 in the weak topology. Then, without loss of generality, we may suppose that for some real linear functional g on X with ‖ g ‖ = 1 and δ > 0 , we have that, for all i,
$$g ( x _ { i } ) \geq \delta \text{ and } \lim _ { i \to \infty } g ( x _ { i } ) \geq \delta > 0 \.$$
We define a sequence { Y i } ∞ i =0 of convex subsets of X by
$$Y _ { i } \coloneqq c o \{ x _ { k } \, \colon k = i + 1, i + 2, \dots \}.$$
Let ' cl ' denote norm closure of a set in X . Then ( ∗∗ ) and duality imply that
$$( \ast \ast ) \quad \quad 0 \in c l ( \chi _ { n } Y _ { i } ), \text{ for each } n \text{ and each } i.$$
(Note that y ∈ Y i may have several convex representations by elements of { x k : k = i + 1 , i + 2 , . . . } . If we pick some y ∈ Y , i it should be understood that at the same time we designate and fix some convex representation of y by elements of { x k : k = i + 1 , i + 2 , . . . } . From then onwards our references to the convex representation of y , will always be to the designated convex representation that we fixed. In particular, only finitely many elements of { x k : k = i + 1 , i + 2 , . . . } are involved in the convex representation. Namely the elements of { x k : k = i + 1 , i + 2 , . . . } that have a non-zero coefficient in the convex representation. One of the elements in this finite subset of
{ x k : k = i + 1 , i +2 , . . . } has the largest index. We will refer to this index as the largest index in the convex combination of y. )
We will choose a sequence { y n } ∞ n =1 that has the following properties:
- (1) y 1 ∈ co { x k : k = 1 2 , , . . . , p 1 - } ⊂ 1 Y 0 such that ‖ (1 -χ p 1 ) y 1 ‖ < δ 2 ;
∥ ∥ Note that when chosen as above, { p n } is a subsequence of { n } such that 1 < p 1 and p n -1 + 1 < p n ( n = 2 3 , , . . . ). Now to see that the sequence can be chosen as above, take y 1 ∈ Y 0 and take p 1 strictly greater than the largest index in the convex combination of y , 1 such that ‖ (1 -χ p 1 ) y 1 ‖ < δ 2 (use ( ∗ )). Then take y 2 ∈ Y p 1 such that ‖ χ p 1 y 2 ‖ < δ 2 4 (use ( ∗ ∗ ∗ )). Next take p 2 strictly greater than the largest index in the convex combination of y , 2 such that ‖ (1 -χ p 2 ) y 2 ‖ < δ 2 2 (use ( ∗ )). Suppose that we chose y , . . . , y 1 n ( n ≥ 2) and p 1 < .. . < p n as required. Then take y n +1 ∈ Y p n such that ‖ χ p n y n +1 ‖ < δ 2 2( n +1) (use ( ∗ ∗ ∗ )). Also take p n +1 strictly greater than the largest index in the convex combination of y n +1 such that ∥( ∥ 1 -χ p n +1 ) y n +1 ∥ ∥ < δ 2 n +1 (use ( ∗ )). This shows that we can choose inductively the sequence { y n } with the stated properties.
- (2) y n ∈ co { x k : k = p n -1 + 1 , . . . , p n -1 } ⊂ Y p n -1 such that ∥ χ p n -1 y n ∥ < δ 2 2 n and ‖ (1 -χ p n ) y n ‖ < δ 2 n for each n = 2 , . . . .
As chosen { y n } is a weak Cauchy sequence in X such that, for each f ∈ X , /star
$$\lim _ { n \to \infty } f ( y _ { n } ) = \lim _ { n \to \infty } f ( x _ { n } ).$$
This follows, since y n +1 ∈ co { x k : k = p n +1 , . . . p n +1 - } 1 and therefore all the indices in the convex combination of y n +1 are strictly greater than n. Also
$$\delta \leq g ( y _ { n } )$$
for all n = 1 2 , , . . . .
Now we define a new sequence { z n } such that
$$z _ { 1 } = \chi _ { p _ { 1 } } y _ { 1 } \text{ and } z _ { n } = ( \chi _ { p _ { n } } - \chi _ { p _ { n - 1 } } ) y _ { n }$$
for each n = 2 , . . . . Since
$$\| y _ { n } - z _ { n } \| = \left \| ( 1 - \chi _ { p _ { n } } ) y _ { n } + \chi _ { p _ { n - 1 } } y _ { n } \right \| < \frac { \delta } { 2 ^ { n } } ( 1 + \frac { 1 } { 2 ^ { n } } ) \\ \text{for each } n = 2 \dots \left \{ z _ { n } \right \} \text{ is also a weak Cauchy sequence such that}$$
for each n = 2 , . . . , { z n } is also a weak Cauchy sequence such that
$$( 4 ^ { * } ) \quad \lim _ { n \to \infty } f ( z _ { n } ) = \lim _ { n \to \infty } f ( y _ { n } ) = \lim _ { n \to \infty } f ( x _ { n } ).$$
Furthermore, we have from above
$$\frac { \delta } { 2 } \leq g ( z _ { n } )$$
/negationslash
$$\left \| \sum \xi _ { n } z _ { n } \right \| = \left \| \sum | \xi _ { n } | z _ { n } \right \|.$$
for each n = 1 2 , , . . . . Note that by definition the elements of the sequence { z n } are in the range of disjoint projections, that is if m = n then ( χ p m -χ p m -1 )( χ p n -χ p n -1 ) = 0 . This means that l ∞ may be considered as an isometric unital subalgebra of C K ( ) where the correspondence is given by ( α n ) ∈ l ∞ /squiggleleftright (∑ α n ( χ p n -χ p n -1 ) ) ∈ C K ( ) [12]. For any ( ξ n ) ∈ l 1 , there is ( α n ) ∈ l ∞ with | α n | = 1 for all n such that ( α ξ n n ) = ( | ξ n | ) and ( α n | ξ n | ) = ( ξ n ) . From this it follows that, when we consider ∑ ξ n z n ∈ X and use the embedding of l ∞ in C K , ( ) we have
Then, by (5*), we have
$$& \frac { \delta } { 2 } \left ( \sum | \xi _ { n } | \right ) \leq g \left ( \sum | \xi _ { n } | z _ { n } \right ) \leq \left \| \sum \xi _ { n } z _ { n } \right \| \leq \left ( \sup \left \| z _ { n } \right \| \right ) \left ( \sum | \xi _ { n } | \right ) \,. \\ & \text{That is $X$ has a subspace isomorphic to $l^{1}$ and $\{z_{n}\}$ corresponds to the}$$
That is X has a subspace isomorphic to l 1 and { z n } corresponds to the standard basis of l 1 in the subspace of X that is isomorphic to l 1 . But this means that there exists f ∈ X /star such that when restricted to { z n } we have
$$f ( z _ { n } ) = ( - 1 ) ^ { n }$$
for each n = 1 2 , , . . . . This contradicts the fact that { z n } is a weak Cauchy sequence and that lim n →∞ f ( z n ) exists. Therefore the real linear functional g with the stated properties on { x i } cannot exist. So if { x i } is a weak Cauchy sequence such that { χ x n i } converges weakly to 0 for each n , then { x i } also converges to 0 weakly in X.
Now suppose that { x n } is a weak Cauchy sequence in X such that { e x k n } converges weakly to u k ∈ e X k for each k . Since { x n } is bounded we have that the sequence { u k } is also bounded by the same constant. Consider the cyclic subspace X w ( ) of X that is generated by w = ∑ 1 2 k u . k By the hypothesis (3), X w ( ) does not contain any copy of c . 0 Therefore when represented as a Banach lattice with the positive quasi-interior point w, X w ( ) becomes a KB-space. Also e w k = 1 2 k u k for each k imply that { u k } is a positive disjoint sequence in X w . ( ) Let
$$v _ { k } = u _ { 1 } + u _ { 2 } + \dots + u _ { k }$$
for each k. Moreover { χ x k n } converges weakly to v k in χ X k for each k. It is clear that { v k } is a norm bounded sequence. (It has the same bound as { x n } . ) So { v k } is an increasing and bounded positive sequence in the KB-space X w . ( ) Whence there exists v = sup v k such that ‖ v -v k ‖ -→ 0 in X w . ( ) Therefore χ v k = v k for each k. That is { x n - } v is a weak Cauchy sequence such that { χ k ( x n -v ) } converges weakly to 0 for each k. Then by the first part of our proof { x n - } v also
converges weakly to 0 in X . This means that X is weakly sequentially complete. That is (3) = ⇒ (1) .
Now suppose (5) holds. By Lemma 2.16 part (2), we have that (5) holds on each closed submodule of X. In particular, we have that (5) holds for each cyclic subspace of X. That is p · X x ( ) /star/star = X x ( ) for each x ∈ X x . ( ) Since each cyclic subspace is represented as a Banach lattice, by Lemma 2.14, each cyclic subspace is a KB-space. This means that (5) = ⇒ (3) . Therefore (5) = ⇒ (1) .
Conversely, suppose (1) holds. In particular χ X n is weakly sequentially complete for each n. Then, by Corollary 3.6, each χ X n satisfies (5) . That is with ( χ X n ) /star/star = ( χ X n ) oo = χ n · X /star/star , we have p · ( χ n · X /star/star ) = χ X n for each n. Now suppose p · x /star/star = x /star/star for some x /star/star ∈ X /star/star . Then
$$( 6 ^ { * } ) \quad \ p \cdot ( \chi _ { n } \cdot x ^ { * * } ) = \chi _ { n } \cdot ( p \cdot x ^ { * * } ) = \chi _ { n } \cdot x ^ { * * } \in \chi _ { n } X \subset X$$
for each n. Furthermore, for each x /star ∈ X , p x /star · /star/star = x /star/star implies µ x ,x /star /star/star ∈ C K ( ) /star (Lemma 2.13(3)). Whence, since χ n ↑ 1 in C K , ( ) we have { χ n · x /star/star } converges to x /star/star in X /star/star in the weak*-topology. By (6*), this means that { χ n · x /star/star } is a weak Cauchy sequence in X. Therefore (1) implies that x /star/star ∈ X and the proof of (1) = ⇒ (5) is complete. /square
## 4. Examples.
We will end the paper by presenting some examples of Banach spaces X with a Bade complete Boolean algebra of projections B defined on X such that B is of finite multiplicity on X but X is not finitely generated. All the examples that we present are related to the example of Dieudonn´ e [6] mentioned in Remark 3.2. We need the following definition that was given by Tzafriri [23]. The definition is motivated by the Dieudonn´ e's example.
Definition 4.1. Let B be a Bade complete Boolean algebra of projections on a Banach space X. Suppose B is of uniform multiplicity n on X. Then B has property D on X if for any x i ∈ X i ( = 1 , . . . , n ), any e ∈ B \ { 0 } , and any p, 1 ≤ p < n , eX is not equal to the sum of eX x , . . . , x ( 1 p ) and eX x ( p +1 , . . . , x n ).
The example of Dieudonn´ e is a Banach L ∞ [0 , γ ]-module X with two generators and B [0 , γ ] is Bade complete on it . Here L ∞ [0 , γ ] is the algebra of equivalence classes of bounded Lebesgue measurable functions on the interval [0 , γ ] and B [0 , γ ] is the Boolean algebra of idempotents in L ∞ [0 , γ ] . The length of the interval, γ , is as computed by Dieudonn´. e Dieudonn´ e shows that B [0 , γ ] has property D on X for n = 2 Given any .
n ≥ 2 , it is clear that by following Dieudonn´'s procedure one may cone struct a Banach L ∞ [0 , γ ]-module X with n -generators such that B [0 , γ ] has property D on X for n . Also as mentioned in Remark 3.2 all these spaces are weakly sequentially complete since they are constructed as closed subspaces of KB -spaces.
Example 4.2. (1) Let X 2 denote the original space of Dieudonn´ in Ree mark 3.2. That is, it is a Banach L ∞ [0 , γ ]-module with two generators and B [0 , γ ] is Bade complete on X 2 with property D for n = 2. B [0 , γ ] is the Boolean algebra of the characteristic functions of the Lebesgue measurable sets with positive measure in [0 , γ ] . Similarly let X n denote the Banach L ∞ [0 , γ ]-module with n -generators such that B [0 , γ ] is Bade complete on X n with property D for n (constructed by following Dieudonn´ e's method as remarked above). Now consider l p ( { X n } ) as an l ∞ ( { L ∞ [0 , γ ] } )-module where 1 ≤ p < ∞ . It is to be understood that { x n } ∈ l p ( { X n } ) means x n ∈ X n for each n and {|| x n ||} ∈ l p . Similar understanding holds for the algebra l ∞ ( { L ∞ [0 , γ ] } ) . Let B be the Boolean algebra of the idempotents in l ∞ ( { L ∞ [0 , γ ] } ) . Then B is of finite multiplicity on l p ( { X n } ) . But l p ( { X n } ) is infinitely generated.
- (2) Let Γ be an uncountable set. Let { n α } α ∈ Γ be an unbounded subset of N . Now consider l p ( { X n α } ) as an l ∞ ( { L ∞ [0 , γ ] n α } )-module as in (1). Then once more B is of finite multiplicity on l p ( { X n α } ) . Moreover by Bade's theorem there exists a sequence { e n } in B such that B is of uniform multiplicity n on e n l p ( { X n α } ) and sup e n = 1. Since Γ is uncountable some of the e n l p ( { X n α } ) are necessarily infinitely generated.
- (3) Let Y 2 be the reflexive space in Example 3 of [12]. Since Y 2 is constructed by altering X 2 , one can construct similarly Y n from X n above with the same properties. However, in addition, Y n would be reflexive. So we can consider l p ( { Y n } ) and l p ( { Y n α } ) for 1 ≤ p < ∞ . These spaces will have the same multiplicity properties as their counterparts in (1) and (2).
Now all the spaces in (1), (2), (3) are weakly sequentially complete. But the ones in (3) are, in addition, reflexive for 1 < p < ∞ . To see this, initially consider an example as in (1). Take { x n } ∈ l p ( { X n } ) . Let X n ( x n ) be the cyclic subspace generated by x n in X n . The space X n is weakly sequentially complete and n -generated. Hence, by Theorem 3.1, as a Banach lattice, the cyclic subspace X n ( x n ) is a KB -space. Now the cyclic subspace generated by { x n } in l p ( { X n } ) is given by the Banach lattice l p ( { X n ( x n ) } ). It is immediate that l p ( { X n ( x n ) } ) is a KB -space and hence it is weakly sequentially complete. Then, by Theorem 3.8, l p ( { X n } ) is weakly sequentially complete. For examples in (2), suppose
/negationslash that { x n α } ∈ l p ( { X n α } ). Then x n α = 0 for at most countably many α ∈ Γ. Whence, the argument given for the examples in (1) shows that l p ( { X n α } ) is weakly sequentially complete. This also covers the weak sequential completeness for all the examples in (3). When 1 < p < ∞ , to see that the spaces in (3) are reflexive, it is sufficient to calculate the duals directly.
## References
- [1] Abramovich, Y.A., Arenson, E.L., Kitover, A.K.: Banach C K ( )-modules and operators preserving disjointness. Pitman Research Notes in Mathematics Series, vol. 277 , Longman, Scientific and Technical (1992)
- [2] Alpay, S., Orhon, M.: ¸ Characterization of Riesz spaces with topologically full center. arXiv:1406.6335 [math.FA] (2014)
- [3] Arens, R.: Operations induced in function classes. Monatsh. Math., 55 , 1-19 (1951)
- [4] Castillo, J.M.F., Gonzalez, M.: Three-space problems in Banach space theory. Lecture Notes in Mathematics, v. 1667 , Springer (1997)
- [5] Dunford, N., Schwartz, J.T.: Linear Operators, Part III: Spectral Operators. Wiley, New York (1971)
- [6] Dieudonn´ e, J.: Champs de vecteurs non localement trivaux. Archiv der Math. 7 , 610 (1956)
- [7] Hadwin, D., Orhon, M.: A noncommutative theory of Bade functionals. Glasgow Math. J., 33 , 73-81 (1991)
- [8] Hadwin, D., Orhon, M.: Reflexivity and approximate reflexivity for bounded Boolean algebras of projections. Journal of Functional Analysis, 87 , 348 - 358 (1989)
- [9] James, R.C.: Bases and reflexivity of Banach spaces. Annals of Mathematics, 52 (3), 518 - 527 (1950)
- [10] Kaijser, S.: Some representation theorems for Banach lattices. Ark. Mat. 16 , no. 2, 179 - 193 (1978)
- [11] Kantorovich, L.V., Akilov, G.P.: Functional Analysis. Pergamon Press (1982)
- [12] Kitover, A., Orhon, M.: Reflexivity of Banach C K ( )-modules via the reflexivity of Banach lattices. Positivity, 18 (3), 475 - 488 (2014)
- [13] Lindenstauss, J., Tzafriri, L.: Classical Banach Spaces I. Ergebnisse der Mathematik und ihre Grenzgebiete, vol. 92 (1977)
- [14] Lindenstauss, J., Tzafriri, L.: Classical Banach Spaces II. Ergebnisse der Mathematik und ihre Grenzgebiete, vol. 97 (1979)
- [15] Lozanovskii, G. Ja.: Banach structures and bases. Funct. Anal, and its Appl. 294 (1) (1967)
- [16] Meyer-Nieberg, P.: Banach Lattices. Springer (1991)
- [17] Orhon, M.: The ideal center of the dual of a Banach lattice. Positivity, 14 (4), 841 - 847 (2010)
- [18] Orhon, M.: Boolean Algebras of Commuting Projections. Math. Z. 183 , 531537 (1983)
- [19] Orhon, M.: Algebras of operators containing a Boolean algebra of projections of finite multiplicity. In: Operators in Indefinite Metric Spaces, Scattering
Theory And Other Topics (Bucharest, 1985). Oper. Theory: Adv. Appl., vol. 24 , 265-281. Birkh¨user, Basel (1987) a
- [20] Rall, C.: ¨ ber Boolesche Algebren von Projektionen. Math Z., U 153 , 199 - 217 (1977)
- [21] Rall, C.: Boolesche Algebren von Projectionen auf Banachr¨umen. PhD Thea sis, Universit¨t T¨bingen (1977) a u
- [22] Schaefer, H.H.: Banach lattices and positive operators. Springer, Berlin (1974)
- [23] Tzafriri, L.: On multiplicity theory for Boolean algebras of projections. Israel J. Math. 4 , 217-224 (1966)
- [24] Tzafriri, L.: Reflexivity in Banach lattices and their subspaces. J. Funct. Anal. 10 , 1-18 (1972)
- [25] Veksler, A.I.: Cyclic Banach spaces and Banach lattices. Soviet Math. Dokl. 14 , 1773-1779 (1973)
- [26] Wickstead, A. W.: Banach lattices with topologically full centre. Vladikavkaz Mat. Zh. 11 , 50-60, (2009)
Community College of Philadelphia, 1700 Spring Garden St., Philadelphia, PA 19154, USA
E-mail address : [email protected]
Department of Mathematics and Statistics, University of New Hampshire, Durham, NH 03824, USA E-mail address : [email protected] | null | [
"Arkady Kitover",
"Mehmet Orhon"
] | 2014-07-31T22:47:24+00:00 | 2015-03-27T23:33:29+00:00 | [
"math.FA",
"46B20"
] | Weak Sequential Completeness in Banach $C(K)$-modules of finite multiplicity | A well known result of Lozanovsky states that a Banach lattice is weakly
sequentially complete if and only if it does not contain a copy of $c_{0}$. In
the current paper we extend this result to the class of Banach $C(K)$ modules
of finite multiplicity and, as a special case, to finitely generated Banach
$C(K)$-modules. Moreover, we prove that such a module is weakly sequentially
complete if and only if each cyclic subspace of the module is weakly
sequentially complete. |
1408.0041v1 | ## Passive mode-locking under higher order effects
Theodoros P. Horikis 1 , ∗ and Mark J. Ablowitz 2
1 Department of Mathematics, University of Ioannina, Ioannina 45110, Greece
2 Department of Applied Mathematics, University of Colorado, 526 UCB, Boulder, CO 80309-0526, USA
compiled: August 4, 2014
The response of a passive mode-locking mechanism, where gain and spectral filtering are saturated with the energy and loss saturated with the power, is examined under the presence of higher order effects. These include third order dispersion, self-steepening and Raman gain. The locking mechanism is maintained even with these terms; mode-locking occurs for both the anomalous and normal regimes. In the anomalous regime, these perturbations are found to affect the speed but not the structure of the (locked) pulses. In fact, these pulses behave like solitons of a classical nonlinear Schr¨dinger equation and as such a soliton perturbation theory is o used to verify the numerical observations. In the normal regime, the effect of the perturbations is small, in line with recent experimental observations. The results in the normal regime are verified mathematically using a WKB type asymptotic theory. Finally, bi-solitons are found to behave as dark solitons on top of a stable background and are significantly affected by these perturbations.
OCIS codes: 140.4050 (Mode-locked lasers), 190.5530 (Pulse propagation and temporal solitons),
320.5540 (Pulse shaping)
http://dx.doi.org/10.1364/XX.99.099999
## 1. Introduction
Ultrashort pulses are used frequently in modern applications ranging from femtochemistry and medical imaging to micro-machining and optical communications. Consequently the study and modeling of such pulses is an important area of research. Kerr-lens mode locking (KLM) is a common technique used to generate these pulses. In fact, following the discovery of KLM mode-locked (ML) lasers have revolutionized the field of ultrafast science and their performance has led to their widespread use.
Mode-locked lasers operate under the requirement that sufficient amounts of gain and loss are present, otherwise, they are subject to radiation-mode instability. In addition, passive mode-locking generally utilizes fast saturable absorbers which are effectively simulated by KLM. Saturable absorbers are commonly modeled by a transfer function and as such loss is placed periodically during the evolution and not as part of a distributed model, i.e., an evolution equation. However, the qualitative features are the same in both cases [1] thus indicating that distributive models are very good descriptions of modes in mode-locked lasers.
Modeling these lasers must take into account their physical properties. For this, the distributive powerenergy saturation (PES) model was recently introduced [2]. This system is a variant of the well known nonlinear Schr¨dinger (NLS) equation with additional terms o to account for gain and spectral filtering, saturated with
∗ Corresponding author: [email protected]
energy, and loss, saturated with power. It is a generalization of the commonly used master-equation [3, 4] which is obtained as a limiting case. Mode-locking is much more robust in the PES model than in the masterequation. Indeed, while in the master-equation modelocking is achieved only for a narrow range of parameters [5, 6], the PES equation has only one key requirement for mode-locking: sufficient gain. Another important feature of the PES equation is that it leads to physically relevant results for both the anomalous and normal dispersive regimes.
Solitons in ML lasers are fundamentally different in the two dispersive regimes. Pulse formation, in the anomalous regime, is typically dominated by the interplay between dispersion and nonlinearity. Suitable gain media and an effective saturable absorber are required for initiation of pulsed operation. In contrast, pulses found in the normal regime are positively chirped throughout the cavity [7]. They are comprised of an approximately parabolic temporal amplitude profile near the peak of the pulse with a transition to steep decay [7]. Pulses in the normal regime have a much larger temporal width than those in the anomalous regime.
Here we study the response of a ML laser under higher order effects using the PES equation. These effects include third-order dispersion (TOD), self-steepening and Raman gain. Previous studies, in the anomalous dispersion regime, include variants of the master-equation [8, 9] and generalized Ginzburg-Landau type equations [10-12]. In the normal regime recent experiments [13] indicate that similariton (self-similar) evolution in these fiber lasers results in localized modes, i.e. solitons, which
are broad in the time domain; they are robust against perturbations. The effect of TOD on self-similar evolution and parabolic pulses was studied in Refs. [14-16].
Here we focus on the equation
$$i \frac { \partial u } { \partial z } + \frac { d _ { 0 } } { 2 } \frac { \partial ^ { 2 } u } { \partial t ^ { 2 } } + | u | ^ { 2 } u & = \frac { i g u } { 1 + \epsilon E } + \frac { i \tau } { 1 + \epsilon E } \frac { \partial ^ { 2 } u } { \partial t ^ { 2 } } - \frac { i l u } { 1 + \delta P } \\ & + i \beta \frac { \partial ^ { 3 } u } { \partial t ^ { 3 } } - i \gamma \frac { \partial ( | u | ^ { 2 } u ) } { \partial t } + R u \frac { \partial ( | u | ^ { 2 } ) } { \partial t }$$
where g represents gain saturated with the energy E = ∫ ∞ -∞ | u | 2 dt , τ is spectral filtering, l is the gain saturated with power P = | u | 2 , β represents TOD, γ selfsteepening and R the Raman gain. The parameters /epsilon1 > 0 and δ > 0 correspond to a measure of the saturation energy and power of the system, respectively. Unless otherwise stated all parameters, except d 0 , are positive. When β = γ = R = 0 this equation is the PES model. Finally, other linear and higher order nonlinear dissipative terms, such as terms proportional to iu and i u | | 2 u are included in Eq. (1) as limiting cases in the expansion for the saturable terms and will not be considered here.
## 2. The anomalous dispersion regime
Here we consider Eq. (1) with d 0 > 1 and we start our analysis by analyzing the effect of TOD. To do so, we fix the parameters such that τ = l = 0 1, . d 0 = /epsilon1 = δ = 1 and β = 0 01 while . γ = R = 0 and vary the gain parameter g . A unit gaussian is evolved under Eq. (1) with the resulting evolution shown in Fig. 1.
As seen here, the initial gaussian undergoes a locking procedure and subsequently locks to a pulse of constant height/shape. After that happens the effect of TOD shifts the soliton with constant velocity (seen as a straight line for the soliton center in the top of Fig. 1). Interestingly the resulting mode is a solution of the unperturbed NLS equation. Furthermore, when the gain is increased the angle of the displacement becomes more acute. This is reminiscent of the response of a single soliton of the classical NLS equation to TOD. Indeed, recall that under TOD the NLS soliton is slowed down and as a result the soliton peak is shifted by an amount that increases linearly with distance [17, 18].
Similarly, we repeat the analysis for β = R = 0 and γ = 0 01 so as to study the response to self-steepening. . The resulting evolution is depicted in Fig. 2.
The similarities between Figs. 1 and 2 are remarkable. Indeed, after mode-locking occurs the pulse is shifted linearly in a way that is similar to the way a classical NLS soliton propagates under this effect.
Finally, we repeat the analysis for β = γ = 0 and R = 0 01 so as to . study the response to the Raman gain. The resulting evolution is depicted in Fig. 3.
The phenomenon is repeated only now the displacement is sharper. Again, recall that Raman gain on solitons of the classical NLS equation gives rise to the so-
Fig. 1. (Color online) Mode-locking under TOD with (a) g = 0 2 and (b) . g = 0 3. . The bottom figures show the pulse at a distance z = 150 (a sufficient distance of propagation after mode-locking has occurred). The dashed lines correspond to the relative classical NLS solitons.
Fig. 2. (Color online) Mode-locking under self-steepening with (a) g = 0 2 and (b) . g = 0 3. . Profiles of mode-locked pulses resemble those of Fig. 1 (bottom).
called self-frequency shift [17, 18]. Note the size of the pulse amplitude is largely unaffected.
It is also important to stress that this locking behavior strongly depends on the saturation terms. If these terms/effects are absent more complicated dynamics can occur [12].
## 2.A. Perturbation theory
Now we shall explain the above features using soliton perturbation theory valid for small β , γ , R . This ap-
Fig. 3. (Color online) Mode-locking under Raman gain with (a) g = 0 2 and (b) . g = 0 3. . Profiles of mode-locked pulses resemble those of Fig. 1 (bottom).
proach leads to very good qualitative results since when β = γ = R = 0 general initial conditions, such as unit gaussians, will evolve to solitons of the unperturbed classical NLS equation [19]. To do this, we consider a solution ansatz for Eq. (1) of the form
$$u ( z, t ) = \eta ( z ) \text{sech} [ \eta ( z ) ( t - t _ { 0 } ( z ) ) ] e ^ { i \phi ( z ) - i \sigma ( z ) t }$$
Under the effect of the perturbed PES the soliton parameters evolve according to [17, 18, 20]
$$\frac { d \eta } { d z } & = \frac { 2 g \eta } { 1 + 2 \epsilon \eta } - \frac { 2 \tau ( \eta ^ { 2 } + 3 \sigma ^ { 2 } ) } { 3 ( 1 + 2 \epsilon \eta ) } \eta - \frac { 2 l \tanh ^ { - 1 } \left ( \frac { \sqrt { \delta } \eta } { \sqrt { 1 + \delta \eta ^ { 2 } } } \right ) } { \sqrt { \delta + \delta ^ { 2 } \eta ^ { 2 } } } \\ d \sigma \, & = \, 4 \tau \eta ^ { 2 } \sigma \, \quad \, 8 \, _ { \ D \dots } 4 \, \quad \, \text{fig. 4} }$$
$$\frac { d \sigma } { d z } = - \frac { 4 \tau \eta ^ { 2 } \sigma } { 3 ( 1 + 2 \epsilon \eta ) } - \frac { 8 } { 1 5 } R \eta ^ { 4 } & ( 2 b ) \quad \begin{array} { c } \text{Fig.} \\ \text{$value} \\ l = t \end{array}$$
$$\frac { d t _ { 0 } } { d z } = - \sigma + \beta ( \eta ^ { 2 } + 3 \sigma ^ { 2 } ) + \gamma \eta ^ { 2 } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 0 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdot \cdots } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \sum _ { \substack { 1 \\ 1 } } ^ { \cdot \cdots } \\ \end{pmatrix}$$
$$\stackrel { \ddots } { \frac { d \phi } { d z } } = \beta \sigma ( 3 \eta ^ { 2 } + \sigma ^ { 2 } ) + \gamma \eta ^ { 2 } + \frac { 1 } { 2 } ( \eta ^ { 2 } - \sigma ^ { 2 } ) + t _ { 0 } \frac { d \sigma } { d z } \ \ ( 2 d ) \quad \ \ \sigma \ a _ { \sigma \ a _ { \dots } }$$
When the pulse has mode-locked, the zeroes of the right hand side of Eq. (2a)-(2b) give the stationary solutions for η and σ . We denote the mode locked value of η and σ as η ML and σ ML , respectively. As such when the equilibrium has been reached
$$\sigma \equiv \sigma _ { M L } = - \frac { 2 R ( 1 + 2 \epsilon \eta ) \eta ^ { 2 } } { 5 \tau }$$
this results in the following equation for η
$$\max \text{rows in one moving equation } \eta \\ \frac { d \eta } { d z } = \frac { 2 g \eta } { 1 + 2 \epsilon \eta } - \frac { 2 \left [ 2 5 \tau ^ { 2 } \eta ^ { 2 } + 1 2 ( 2 \epsilon R \eta + R ) ^ { 2 } \eta ^ { 4 } \right ] } { 7 5 ( \tau + 2 \epsilon \tau \eta ) } \\ - \frac { 2 l \tanh ^ { - 1 } \left ( \frac { \sqrt { \delta } \eta } { \sqrt { 1 + \delta \eta ^ { 2 } } } \right ) } { \sqrt { \delta + \delta ^ { 2 } \eta ^ { 2 } } }$$
Clearly, η has at least one equilibrium at η = 0. To understand its stability consider the first derivative of η z with respect to η evaluated at η = 0,
$$\frac { d } { d \eta } \left ( \frac { d \eta } { d z } \right ) \Big | _ { \eta = 0 } = 2 ( g - l ) \\ \intertext { I, \eta = 0 \text{ is an unstable equilibrium} } \cdot \sum \dots \sum \dots$$
When g > l, η = 0 is an unstable equilibrium while for g < l, η = 0 is stable. The phase portrait for various values of g < l indicates that η z is a monotonic decreasing function in η and so η → 0 as z →∞ for any initial condition η > 0. Physically this corresponds to loss overtaking gain and the pulse decays. For g > l , η z is initially positive and as η increases the filtering term becomes dominant and η z takes on negative values. Thus, there must exist another equilibrium. Plotting the phase portrait for various values of g for g > l shows there is a single stable equilibrium for η > 0, as shown in Fig. 4.
η
Fig. 4. Phase portrait of the amplitude equation for several values of g illustrating the single stable equilibrium. Here l = 0 1. .
/negationslash
As η approaches its stable equilibrium, η ML = 0, and σ approaches its stable equilibrium, σ ML , the system of equations (2) tend to
$$\frac { d \eta } { d z } \Big | _ { \eta = \eta _ { M L } } = \frac { d \sigma } { d z } \Big | _ { \sigma = \sigma _ { M L } } = 0 \\ \text{ans the solution tends to a particular } \Big | _ { \quad }.$$
which means the solition tends to a particular NLS soliton of speed zero and height/width determined by η ML , thus suggesting the mode-locking capabilities of Eq. (1). In fact, η ML is an attractor that any arbitrary initial condition will eventually converge to, even when it is far way from its soliton solution [2, 19].
After η = η ML and mode-locking has been completed, we consider Eq. (2c)-(2d), which, interestingly, are independent of g, τ, l . This now explains the above dynamics. Indeed, when η = η ML (and the mode-locking mechanism has been completed) we get by direct integration
of Eq. (2c)
$$t _ { 0 } ( z ) & = t _ { 0 } ( 0 ) + \left \{ \left ( \beta + \gamma + \frac { 2 R } { 5 \tau } \right ) \eta _ { M L } ^ { 2 } \quad \begin{array} { c } \text{$\text{$\eta_{ML}$} \\ \text{$\text{has}$} \\ \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$
$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$ \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text`$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$ \text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\tt$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$\text$}\end{array} \right \}$$
The equations for the equilibria give now more insight as to the way each term affects the propagation. For instance, in the absence of spectral filtering there still exists a stable (nonzero) equilibrium for η but not for σ . While the amplitude is affected only in its magnitude the other quantities change in a more prominent way. Indeed, by direct integration of Eqs. (2b) and (2c) we obtain at η = η ML
$$\sigma ( z ) & = - \frac { 8 } { 1 5 } R \eta _ { M L } ^ { 4 } z + \sigma ( 0 ) \\ t _ { 0 } ( z ) & = \frac { 6 4 } { 2 2 5 } R ^ { 2 } \beta \eta _ { M L } ^ { 8 } z ^ { 3 } - \frac { 4 } { 1 5 } R \eta _ { M L } ^ { 4 } [ 6 \beta \sigma ( 0 ) - 1 ] z ^ { 2 } \\ & + [ ( \beta + \gamma ) \eta _ { M L } ^ { 2 } + 3 \beta \sigma ^ { 2 } ( 0 ) - 3 \sigma ( 0 ) ] z + t _ { 0 } ( 0 ) \\ \text{which suggests that the trajectory the soliton follows}$$
which suggests that the trajectory the soliton follows is no longer linear. Similarly when the Raman gain is not considered the only equilibrium is found for σ ≡ 0. Clearly when τ = R = 0 the soliton moves with constant velocity equal to ( β + γ η ) 2 ML ( σ ≡ 0). Also, note that as supported by the numerical computations the final amplitude of the pulse is not affected by the parameters β, γ .
The increase of η with g also explains the pronounced difference in the speed of the pulse when g is increased. In Fig. 5 we depict the dependance of the amplitude to the gain parameter, which attests to that. In fact, Eq.
η
Fig. 5. (Color online) The amplitude dependance on gain based on Eq. (2a).
(3) clearly suggests that the trajectories are highly dependent on powers of η ML . Hence, any increase on this amplitude is enhanced (when η ML > 1 or g > 0 22) mak-. ing the response to the perturbations more pronounced. This analysis also suggests that nonlinear phase shifts cannot compensate for TOD (or self-steepening) in this regime, unlike in the normal regime [21].
Thus, the mode-locking mechanism can now be summarized as follows: (i) solve Eqs. (2a)-(2b), to determine η ML and σ ML ; (ii) assume the mode-locking mechanism has been completed; (iii) treat the pulses as classical NLS solitons; and (iv) use Eq. (3) and (2d) to determine the adiabatic change of the rest of the soliton parameters.
## 3. The normal dispersion regime
We turn our attention to the normal regime ( d 0 = -1). The main difference these pulses exhibit from their anomalous regime counterparts is that they are highly chirped, very wide (almost parabolic) pulses in the time domain; the modes depend critically on the values of g, τ, l .
Recent experiments indicate that localized modessolitons in the normal regime are robust. They are not affected by perturbations [13] such as TOD and self steepening; this is also in agreement with the observation that nonlinear phase shifts (in terms of Raman gain here) can compensate for TOD or self-steepening [21]. To demonstrate this phenomena, we evolve a unit gaussian under Eq. (1), with all parameters as before ( τ = l = 0 1, . β = γ = R = 0 01) only now with . g = 1 5. . The reason for this increase in gain is the nature/size of these pulses (cf. Fig. 6). Since these pulses are much wider one expects that more energy (gain) is required for pulses to lock to noticeable amplitudes. Furthermore, in Fig. 6 (bottom) we depict the resulting pulse and its corresponding phase. The dashed line indicates the soliton of the unperturbed (i.e. β = γ = R = 0) PES equation. Indeed the experimental observations [7] on the shape and phase of the pulses are met. We also confirm subsequent observations that unlike the solitons of the anomalous regime these wide localized pulses are resistant to perturbations even when allowed to propagate for greater distances.
## 3.A. Asymptotic theory
Following the theory developed in Ref. [22] we write the solution of Eq. (1) in the form ψ z, t ( ) = A exp( iµz + iθ ), where A = A t ( ) and θ = θ t ( ) are the pulse amplitude and phase respectively. Since these pulses are slowly varying in t , with large phase, we can introduce a slow time scale in the equation and using perturbation theory, the soliton system can be reduced to simpler ordinary differential equations for the amplitude and the phase of the pulse. Substituting into the equation and equating
Fig. 6. (Color online) Mode-locking in the normal regime (a) under the unperturbed PES equation with β = γ = R = 0 and (b) under the PES with the higher order effects included. The bottom figure depicts the final pulse. The dashed line is the soliton of the unperturbed PES equation.
real and imaginary parts we get
$$& - \mu A - \frac { d _ { 0 } } { 2 } ( A _ { t t } - A \theta _ { t } ^ { 2 } ) + A ^ { 3 } = - \frac { \tau } { 1 + \epsilon E } ( 2 A _ { t } \theta _ { t } + A \theta _ { t t } ) \\ & + \beta ( A \theta _ { t t } - 3 A _ { t t } \theta _ { t } - 3 A _ { t } \theta _ { t t } - A \theta _ { t t t } ) + \gamma A ^ { 3 } \theta _ { t } + 2 R A ^ { 2 } A _ { t }$$
$$+ & \beta ( A \theta _ { t t } - 3 A _ { t t } \theta _ { t } - 3 A _ { t } \theta _ { t t t } ) + \gamma A ^ { 3 } \theta _ { t } + 2 R A ^ { 2 } A _ { t } \\ & - \frac { d _ { 0 } } { 2 } ( 2 A _ { t } \theta _ { t } + A \theta _ { t t } ) = \frac { g } { 1 + \epsilon E } A + \frac { \tau } { 1 + \epsilon E } ( A _ { t t } + A \theta _ { t } ^ { 2 } ) \\ & - \frac { l } { 1 + \delta A ^ { 2 } } A + \beta ( 3 A _ { t } \theta _ { t } ^ { 2 } - 3 A \theta _ { t } \theta _ { t t } + A _ { t t t } ) - 3 \gamma A ^ { 2 } A _ { t }$$
where we have replaced d 0 →-d 0 < 0 since we are in the normal dispersion regime. We then take the characteristic time length of the pulse to be such that we can define a scaling in the independent variable of the form ε = T/ε or T = εt so that R = R εt ( ), θ t = O (1) (i.e. θ is large) and θ tt = O ε ( ) where ε /lessmuch 1. Furthermore in the above simulations β , γ and R are all O ε ( ). Then Eq. (4a) becomes
$$- \mu A + \frac { d _ { 0 } } { 2 } A \theta _ { t } ^ { 2 } + A ^ { 3 } = \frac { d _ { 0 } } { 2 } \varepsilon ^ { 2 } A _ { T T } - \frac { \tau } { 1 + \epsilon E } ( 2 \varepsilon A _ { T } \theta _ { t } + A \theta _ { t t } ) \quad \text{lutio} \quad \text{--aged}$$
while the leading order equation is
$$\theta _ { t } ^ { 2 } = \frac { 2 } { d _ { 0 } } ( \mu - A ^ { 2 } )$$
Using the same argument and this newly derived Eq. (5) we then find that Eq. (4b) to leading order reads
$$A _ { t } & = - \text{sgn} ( t ) \frac { \sqrt { 2 ( \mu - A ^ { 2 } ) / d _ { 0 } } } { 3 A ^ { 2 } - 2 \mu } \\ & \quad \times \left ( \frac { g } { 1 + \epsilon E } - \frac { 4 \tau ( \mu - A ^ { 2 } ) / d _ { 0 } } { 1 + \epsilon E } - \frac { l } { 1 + \delta A ^ { 2 } } \right ) \quad ( 6 ) \\ \text{This is now a nonlocal first order differential equation}$$
This is now a nonlocal first order differential equation for A = A t ( ), since E = ∫ ∞ -∞ A 2 dt . We also note that imposing θ t ( t = 0) = 0 ⇒ µ ≈ A 2 (0).
To remove the nonlocality another condition is needed and it is based on the singular points of Eq. (6). Recall, A t ( ) is a decaying function in t ∈ [0 , + ∞ ) and µ ≈ A 2 (0) ≥ A t ( ) 2 . Thus there exists a point in t such that the denominator in the equation becomes zero. To remove the singularity we require that the numerator of the equation is also zero at the same point which leads to
$$1 + \epsilon E = \frac { 1 } { l } \left ( g - \frac { 2 \tau } { 3 d _ { 0 } } \mu \right ) \left ( 1 + \frac { 2 \delta } { 3 } \mu \right ) \\ \psi = \left ( \lambda \right ) \cdot \left ( \lambda \right ) \cdot \right ) \cdot \right ) \cdot \right )$$
Thus Eq. (6) is now a first order equation which can be solved by standard numerical methods and analyzed by phase plane methods. The resulting solutions from the PES equation and the reduced equations are compared in Fig. 7.
Fig. 7. (Color online) Solutions of the complete PES equation and the reduced system.
## 3.B. Higher order states
Remarkably, in the normal regime the PES also exhibits higher-order solutions in term of bi-solitons [23]. These are pairs of regular solitons whose peak amplitudes have a π difference in phase and an appropriate separation. They, also, differ significantly from the higher-order solutions of the classical NLS and the dispersion managed solitons since they do not exhibit any oscillatory
or breathing behavior as they propagate in the cavity. A typical such mode is given in Fig. 8. The dashed line corresponds to the relative 'ground state', i.e. the localized pulse of the unperturbed PES equation.
Fig. 8. (Color online) A typical bisoliton of the PES. Dashed lines correspond to the soliton and phase of the localized pulse of the unperturbed PES equation.
Higher order states and interaction of these structures have been discussed in Ref. [24]. It is, however, interesting to see their response to TOD and Raman gain. In order to generate these modes we use an antisymmetric initial condition such as u (0 , t ) = t exp( -t 2 ). The resulting evolution, under Eq. (1), is shown in Fig. 9.
Fig. 9. (Color online) Bisoliton evolution (a) under the PES equation; (b) under Eq. (1).
Under these higher order effects the dip characterizing the bi-soliton, which separates the two solitons, behaves as a dark soliton on a nearly constant background and starts moving until it disappears; see Fig. 9. This is reminiscent of the dark solitons generated in Bose-Einstein condensates [25]. We will further explore this elsewhere.
## 4. Conclusions
To conclude, we have studied the response of a PES model with additional higher order terms: third order dispersion, self-steepening and Raman gain. In the anomalous dispersion regime, it is found that the PES
equation provides the mode-locking mechanism and after that the resulting pulses propagate in a manner similar to solitons of a perturbed classical NLS equation. Perturbative soliton theory confirms numerical observations. On the other hand, in the normal dispersion regime, ground state pulses are more robust and are largely unaffected by these perturbing influences as also observed in experiments. However, this is not the case with higher order modes which are unstable when perturbed.
## Acknowledgments
This research was partially supported by the United States Air Force Office of Scientific Research (USAFOSR) under grant FA9550-12-1-0207.
## References
- [1] M. J. Ablowitz and T. P. Horikis, 'Solitons and spectral renormalization methods in nonlinear optics,' Eur. Phys. J. Special Topics 173 , 147-166 (2009).
- [2] M. J. Ablowitz, T. P. Horikis, and B. Ilan, 'Solitons in dispersion-managed mode-locked lasers,' Phys. Rev. A 77 , 033814 (2008).
- [3] H. A. Haus, 'Theory of mode locking with a fast saturable absorber,' J. Appl. Plys. 46 , 3049-3058 (1975).
- [4] H. A. Haus, J. G. Fujimoto, and E. P. Ippen, 'Analytic theory of additive pulse and kerr lens mode locking,' IEEE J. Quant. Elec. 28 , 2086-2096 (1992).
- [5] J. N. Kutz, 'Mode-locked soliton lasers,' SIAM Rev. 48 , 629-678 (2006).
- [6] T. Kapitula, J. N. Kutz, and B. Sandstede, 'Stability of pulses in the master mode-locking equation,' J. Opt. Soc. Am. B 19 , 740746 (2002).
- [7] F. O. Ilday, J. R. Buckley, W. G. Clark, and F. W. Wise, 'Self-similar evolution of parabolic pulses in a laser,' Phys. Rev. Lett. 92 , 213901 (2004).
- [8] H. A. Haus, J. D. Moores, and L. E. Nelson, 'Effect of third-order dispersion on passive mode locking,' Opt. Lett. 18 , 51-53 (1993).
- [9] Q. Lin and I. Sorokina, 'High-order dispersion effects in solitary mode-locked lasers: side-band generation,' Opt. Commun. 153 , 285-288 (1998).
- [10] V. L. Kalashnikov, A. Fern´ndez, a and A. Apolonski, 'High-order dispersion in chirped-pulse oscillators,' Opt. Express 16 , 4206-4216 (2008).
- [11] L. Song, L. Li, Z. Li, and G. Zhou, 'Effect of third-order dispersion on pulsating, erupting and creeping solitons,' Opt. Commun. 249 , 301-309 (2005).
- [12] E. Sorokin, N. Tolstik, V. L. Kalashnikov, and I. T. Sorokina, 'Chaotic chirped-pulse oscillators,' Opt. Express 21 , 29567-29577 (2013).
- [13] B. Oktem, C. ¨ lg¨d¨r, U u u and F. O. Ilday, 'Solitonsimilariton fibre laser,' Nature Photonics 4 , 307-311 (2010).
- [14] J. M. Dudley, C. Finot, D. J. Richardson, and G. Millot, 'Self-similarity in ultrafast nonlinear optics,' Nature Physics 3 , 597-603 (2007).
- [15] B. G. Bale and S. Boscolo, 'Impact of third-order fibre dispersion on the evolution of parabolic optical pulses,' J. Opt. 12 , 015202 (2010).
- [16] S. Zhang, G. Zhao, A. Luo, and Z. Zhang, 'Thirdorder dispersion role on parabolic pulse propagation in
- dispersion-decreasing fiber with normal group-velocity dispersion,' Appl. Phys. B 94 , 227-232 (2009).
- [17] A. Hasegawa and Y. Kodama, Solitons in Optical Communications (Claredo Press, 1995).
- [18] Y. S. Kivshar and G. P. Agrawal, Optical Solitons (Academic Press, 2003).
- [19] M. J. Ablowitz and T. P. Horikis, 'Pulse dynamics and solitons in mode-locked lasers,' Phys. Rev. A 78 , 011802(R) (2008).
- [20] M. J. Ablowitz, T. P. Horikis, S. D. Nixon, and Y. Zhu, 'Asymptotic analysis of pulse dynamics in mode-locked lasers,' Stud. Appl. Math 122 , 411-425 (2009).
- [21] S. Zhou, L. Kuznetsova, A. Chong, and F. W. Wise, 'Compensation of nonlinear phase shifts with third-
- order dispersion in short-pulse fiber amplifiers,' Opt. Express 13 , 4869-4877 (2005).
- [22] M. J. Ablowitz and T. P. Horikis, 'Solitons in normally dispersive mode-locked lasers,' Phys. Rev. A 79 , 063845 (2009).
- [23] A. Chong, W. H. Renninger, and F. W. Wise, 'Observation of antisymmetric dispersion-managed solitons in a mode-locked laser,' Opt. Lett. 33 , 1717-1719 (2008).
- [24] M. J. Ablowitz, T. P. Horikis, and S. D. Nixon, 'Soliton strings and interactions in mode-locked lasers,' Opt. Comm. 282 , 4127-4135 (2009).
- [25] D. J. Frantzeskakis, 'Dark solitons in atomic boseeinstein condensates: from theory to experiments,' J. Phys. A: Math. Theor. 43 , 213001 (2010). | 10.1364/JOSAB.31.002748 | [
"Theodoros P. Horikis",
"Mark J. Ablowitz"
] | 2014-07-31T23:14:33+00:00 | 2014-07-31T23:14:33+00:00 | [
"physics.optics",
"nlin.PS"
] | Passive mode-locking under higher order effects | The response of a passive mode-locking mechanism, where gain and spectral
filtering are saturated with the energy and loss saturated with the power, is
examined under the presence of higher order effects. These include third order
dispersion, self-steepening and Raman gain. The locking mechanism is maintained
even with these terms; mode-locking occurs for both the anomalous and normal
regimes. In the anomalous regime, these perturbations are found to affect the
speed but not the structure of the (locked) pulses. In fact, these pulses
behave like solitons of a classical nonlinear Schrodinger equation and as such
a soliton perturbation theory is used to verify the numerical observations. In
the normal regime, the effect of the perturbations is small, in line with
recent experimental observations. The results in the normal regime are verified
mathematically using a WKB type asymptotic theory. Finally, bi-solitons are
found to behave as dark solitons on top of a stable background and are
significantly affected by these perturbations. |
1408.0042v2 | ## PRECONDITIONED LOCALLY HARMONIC RESIDUAL METHOD FOR COMPUTING INTERIOR EIGENPAIRS OF CERTAIN CLASSES OF HERMITIAN MATRICES ∗
EUGENE VECHARYNSKI † AND ANDREW KNYAZEV ‡
Abstract. We propose a Preconditioned Locally Harmonic Residual (PLHR) method for computing several interior eigenpairs of a generalized Hermitian eigenvalue problem, without traditional spectral transformations, matrix factorizations, or inversions. PLHR is based on a short-term recurrence, easily extended to a block form, computing eigenpairs simultaneously. PLHR can take advantage of Hermitian positive definite preconditioning, e.g., based on an approximate inverse of an absolute value of a shifted matrix, introduced in [SISC, 35 (2013), pp. A696-A718]. Our numerical experiments demonstrate that PLHR is efficient and robust for certain classes of large-scale interior eigenvalue problems, involving Laplacian and Hamiltonian operators, especially if memory requirements are tight.
Key words. Eigenvalue, eigenvector, Hermitian, absolute value preconditioning, linear systems
- 1. Introduction. We are interested in computing a subset of eigenpairs of the generalized Hermitian eigenvalue problem
$$\underset { \longleftarrow } { \longleftarrow } \quad ( 1. 1 ) \quad \ A v = \lambda B v, \ A = A ^ { * } \in \mathbb { C } ^ { n \times n }, \ B = B ^ { * } > 0 \in \mathbb { C } ^ { n \times n },$$
that correspond to eigenvalues closest to a given shift σ , which is real and points to the eigenvalues in the interior of the spectrum. We refer to (1.1) as an interior eigenproblem, and call the targeted eigenpairs interior eigenpairs .
Interior eigenpairs are of fundamental interest in some physical models, e.g., for first-principles electronic structure analysis of materials using a semi-empirical potential or a charge patching method [37, 38, 39]. There, the requested eigenvalues correspond to energy levels around a material-dependent energy shift σ , and the eigenvectors represent the associated wave functions.
We assume that the size n of the matrices is so large that eigenvalue solvers based on explicit matrix transformations are impractical. Other conventional ways of solving the interior eigenvalue problems are based on spectral transformations that allow reducing the interior eigenproblem to an easier task of computing extreme (smallest or largest) eigenvalues of a transformed pencil. Such transformations include the socalled shift-and-invert (SI) and folded spectrum (FS) approaches; see, e.g., [2]. While both techniques are extensively used, they face serious issues as n increases.
In particular, SI relies on repeated solution of large shifted linear systems, which generally becomes extremely inefficient or infeasible for large n . Similar difficulties are experienced in methods relying on contour integration, e.g., [29].
glyph[negationslash]
The FS approach for standard , i.e., with identity B = I , eigenproblems is inversefree. However, in exact arithmetic, it is equivalent to solving an eigenproblem for the matrix ( A -σI ) 2 , which squares the condition number, resulting in severely tightened clustering of the targeted eigenvalues. For the generalized , i.e., with B = I , eigenproblems, FS requires inverting the matrix B , which can be problematic. Additionally,
∗ Preliminary version posted at http://arxiv.org/ . The results presented in this work are partially based on the PhD thesis of the first coauthor [34].
† Computational Research Division, Lawrence Berkeley National Laboratory, Berkeley, CA 94720 (eugene.vecharynski[at]gmail.com)
‡ Mitsubishi Electric Research Laboratories; 201 Broadway Cambridge, MA 02139 (knyazev[at]merl.com)
available preconditioning, normally based on approximating an inverse of A -σB , may not be applicable for FS, which should be preconditioned by an approximate inverse of the squared operator.
For certain classes of eigenproblems, multigrid (MG) algorithms have proved to be very efficient; see, e.g., [3, 10, 19, 20] and references therein. However, the applicability of such eigensolvers faces the same kind of limitations as exist for the MG linear solvers in that either geometric (grid) information must be available at solution time or the problem's structure should be appropriate for the algebraic MG approaches.
Another popular technique for interior eigenproblems is based on combining polynomial transformations, called filters , with the standard Lanczos method, as in filtered Lanczos procedure [6]. The approach cannot easily be extended to generalized eigenproblems and does not take advantage of preconditioners that may be available.
Residual minimization scheme, direct inversion in the iterative subspace (RMMDIIS), see [40], provides an alternative, but is known to be unreliable if the initial approximations are not close enough to the targeted eigenpairs. RMM-DIIS has to be preceded by, e.g., generalized Davidson [22] or Jacobi-Davidson [30] methods, such as, e.g., in Vienna ab initio simulations (VASP) package [18]. Combining harmonic Rayleigh-Ritz (RR) procedure [2] with the Davidson's family of methods has recently aimed at supplementing RMM-DIIS in VASP; see [12].
Success of the Davidson type methods is often determined by two interdependent algorithmic components: the maximum allowed size of the search subspace and the quality of the preconditioner, typically given as a form of an approximate solve of the system with a shifted matrix A -σB . The maximum size of the search subspace has to be increased if the preconditioner quality deteriorates. In practical computations, preconditioners that lack the desired quality are common, especially if the shift σ targets the eigenvalues that are deep in the interior of the spectrum.
We develop new preconditioned iterative schemes for interior eigenproblems that exhibit a lower sensitivity to the preconditioner quality and at the same time lead to fixed and relatively modest memory requirements. A connection between iterative methods for singular homogeneous Hermitian indefinite systems and eigenproblems in Section 2 motivates our development. Our base method, called Preconditioned Locally Harmonic Residual (PLHR) and presented in Section 3, computes a single eigenpair. In Section 4, we generalize PLHR to block iterations, where targeted eigenpairs, as determined by σ , are computed simultaneously, similar to LOBPCG [15].
PLHR requires that the preconditioner is Hermitian positive definite (HPD). In Section 5, we suggest that the preconditioner T should approximate the inverted matrix absolute value | A -σB | . Preconditioners of this kind, called the absolute value (AV) preconditioners, have been recently introduced in [35]. In particular, [35] describes an MG scheme for approximating the inverse of the AV of the shifted Laplacian. Thus, the approach can be directly applied as a PLHR preconditioner for computing interior eigenpairs of the Laplacian matrix, which is demonstrated in our numerical experiments in Section 6. Furthermore, the suitable HPD preconditioners are readily available in electronic structure calculations, where we combine PLHR with the existing state-of-the-art preconditioner [32], also in Section 6.
While, in this work, we focus only on several model problems with already available HPD preconditioners, the proposed PLHR approach can be applicable to broader classes of eigenproblems that admit appropriate HPD preconditioning. Investigation of such problems, as well as the development of the corresponding preconditioners, is a matter of future research, and is outside the scope of the current paper.
An important novelty of the proposed approach is a modification of the harmonic RR procedure, obtained by a proper utilization of the HPD preconditioner T in the Petrov-Galerkin condition for extracting the approximate eigenvectors, including its real arithmetic implementation. The new extraction technique, that we call the T -harmonic RR procedure in Section 3, is critical. Our tests demonstrate remarkable robustness if the T -harmonic procedure is used. The gains are especially evident if the preconditioner quality deteriorates, whereas the memory requirements remain fixed.
- 2. Preconditioned null space computations. We start with an easier problem of finding a null space component of a Hermitian matrix. Let λ q be a targeted eigenvalue of (1.1) closest to the shift σ . We assume that λ q is known. Then eigenproblem (1.1) turns into the singular homogeneous linear system
$$( 2. 1 ) & & ( A - \lambda _ { q } B ) v = 0.$$
It is clear that (2.1) has a non-trivial null space solution determining an eigenvector v q associated with λ q . Thus, in the idealized setting, where λ q is available, an eigensolver for (1.1) can be given by an appropriate solution scheme for linear system (2.1). In this sense, linear solvers for (2.1) can be viewed as prototypical, or idealized, methods for computing the eigenpair ( λ , v q q ).
The described connection between linear and eigenvalue solvers has been emphasized in literature; see, e.g., [13, 15]. For example, in [15], a special case is considered where λ q is the smallest eigenvalue of (1.1) and, hence, the system (2.1) is Hermitian positive semidefinite. A proper choice of the linear solver-a three-term recurrent form of the preconditioned conjugate gradient (PCG) method-has led to derivation of the popular LOBPCG algorithm for finding extreme eigenpairs; see [15, 16].
We follow a similar approach. Assuming that λ q is known, we select efficient preconditioned linear solvers capable of computing a non-trivial solution of (2.1). Viewing these linear solvers as idealized eigensolvers, we then extend them to the practical case where λ q is unknown.
Since the targeted eigenvalue λ q can be located anywhere in the interior of the spectrum of the pencil A -λB , the Hermitian coefficient matrix of system (2.1) is generally indefinite in contrast to [15], which makes PCG inapplicable. We look for suitable preconditioned short-term recurrent Krylov subspace type methods that can be applied to singular Hermitian indefinite systems of the form (2.1) and guarantee linear convergence.
An optimal technique in this class of methods is the preconditioned minimal residual (PMINRES) algorithm [25]. While most commonly applied to non-singular systems, the method is also guaranteed to work for a class of singular consistent Hermitian systems, such as (2.1). The preconditioner for PMINRES should normally be HPD, and the convergence of the method is governed by the spectrum distribution of the preconditioned matrix. However, the standard implementation of the algorithm is deeply rooted in the Lanczos procedure, where the availability of the matrix A -λ B q is crucial at every stage of the process. Since this assumption is not realistic in the context of eigenvalue computations, where only an approximation of λ q is at hand, PMINRES fails to provide a proper insight into the structure of local subspaces that determine a new approximate solution. Similar arguments apply to methods that are mathematically equivalent to PMINRES, such as, e.g., orthodir(3) [9, 27, 42].
Returning back for a moment to the special case where λ q is the smallest eigenvalue of (1.1), a preconditioned steepest descent (PSD) linear solver can be viewed
as a predecessor of the PCG linear solver, on the one hand, and as restarted preconditioned Lanczos linear solver, on the other hand. We use this viewpoint to describe an analog of a PSD-like linear solver for the indefinite case.
To that end, we restart PMINRES in such a way that linear convergence is preserved (possibly with a lower rate), whereas the number of steps between the restarts is kept to a minimum possible. It is shown in [34] that in order to maintain PMINRES convergence, the number of steps between the restarts should be no smaller than two. Thus, the simplest convergent residual minimizing iteration for (2.1) is
$$( 2. 2 ) \quad v ^ { ( i + 1 ) } = v ^ { ( i ) } + \alpha ^ { ( i ) } T r ^ { ( i ) } + \beta ^ { ( i ) } T \left ( A - \lambda _ { q } B \right ) T r ^ { ( i ) }, \ \ i = 0, 1, \dots ;$$
where r ( ) i = ( λ B q -A v ) ( ) i and the iteration parameters α ( ) i , β ( ) i are chosen to minimize the T -norm of the residual r ( +1) i , i.e., are such that
$$\| r ^ { ( i + 1 ) } \| _ { T } = \min _ { u \in \mathcal { K } ^ { ( i ) } } \| r ^ { ( i ) } - ( A - \lambda _ { q } B ) u \| _ { T },$$
where
$$\mathcal { K } ^ { ( i ) } = \text{span} \left \{ T r ^ { ( i ) }, T ( A - \lambda _ { q } B ) T r ^ { ( i ) } \right \}.$$
Here and throughout, for a given HPD matrix M , the corresponding vector M -norm is defined as ‖ · ‖ M = ( · , M · ) 1 / 2 .
Theorem 2.1 ( [34] ). Given an HPD preconditioner T , the iteration (2.2) -(2.4) converges to a nontrivial solution of (2.1), provided that the initial guess x (0) has a non-zero projection onto the null space of A -λ B q . Moreover, if λ q is a simple eigenvalue 1 of A -λB and µ 1 ≤ µ 2 ≤ . . . ≤ µ q -1 < µ q = 0 < µ q +1 < . . . µ n are the eigenvalues of the preconditioned matrix T A ( -λ B q ) , then the residual norm reduction is given by
$$\frac { \| r ^ { ( i + 1 ) } \| _ { T } } { \| r ^ { ( i ) } \| _ { T } } \leq \frac { \tilde { \kappa } - 1 } { \tilde { \kappa } + 1 } < 1,$$
where
$$\tilde { \kappa } = \begin{cases} \begin{array} { c } \left ( \frac { \mu _ { n } } { \mu _ { q + 1 } } \right ) \left ( 1 + \frac { \mu _ { n } - \mu _ { q + 1 } } { | \mu _ { q - 1 } | } \right ), & \text{if } | \mu _ { 1 } | - | \mu _ { q - 1 } | \leq \mu _ { n } - \mu _ { q + 1 } \\ \left ( \frac { \mu _ { 1 } } { \mu _ { q - 1 } } \right ) \left ( 1 + \frac { | \mu _ { 1 } | - | \mu _ { q - 1 } | } { \mu _ { q + 1 } } \right ), & \text{if } | \mu _ { 1 } | - | \mu _ { q - 1 } | > \mu _ { n } - \mu _ { q + 1 }. \end{array} \end{cases}$$
The proof of Theorem 2.1 relies on the analysis of iterations of the form (2.2), where the parameters α ( ) i and β ( ) i are fixed. In this case, (2.2) can be viewed as a stationary Richardson type scheme for a polynomially preconditioned system, and a standard convergence analysis (see, e.g., [1, Theorem 5.6]) applies to determine the values of the parameters that yield an optimal convergence, which is given by (2.5)(2.6). Since the convergence of the stationary iteration cannot be better then that of (2.2) with the residual minimizing parameters (2.3), bound (2.5)-(2.6) immediately applies to method (2.2)-(2.4). For more details, we refer the reader to [34].
1 This assumption is made only to simplify the statement of the theorem. The theorem can be similarly formulated for the case of multiple eigenvalue.
A natural way to enhance (2.2)-(2.4) is by introducing an additional term that holds information from the previous step. By analogy with a three-term recurrent form of PCG, consider the scheme
$$( 2. 7 ) \ v ^ { ( i + 1 ) } = v ^ { ( i ) } + \alpha ^ { ( i ) } T r ^ { ( i ) } + \beta ^ { ( i ) } T \left ( A - \lambda _ { q } B \right ) T r ^ { ( i ) } + \gamma ^ { ( i ) } ( v ^ { ( i ) } - v ^ { ( i - 1 ) } ), \ i = 0, 1, \dots,$$
where v ( -1) = 0. Here, the scalar parameters α ( ) i , β ( ) i , and γ ( ) i are chosen according to local minimality condition (2.3) with
$$\mathcal { K } ^ { ( i ) } = \text{span} \left \{ T r ^ { ( i ) }, T ( A - \lambda _ { q } B ) T r ^ { ( i ) }, v ^ { ( i ) } - v ^ { ( i - 1 ) } \right \}.$$
Since K ( ) i in (2.8) contains the subspace in (2.4), the employed minimality condition (2.3) implies that convergence of (2.7) is not worse than that of (2.2). Hence, the results of Theorem 2.1 also apply to (2.7) with (2.3) and (2.8). In this case, however, bound (2.5)-(2.6) is likely to be an overestimate, and in practice the presence of the additional vector in the recurrence leads to a faster convergence. In fact, the scheme (2.7) has been observed to exhibit behavior similar to PMINRES up to the occurrence of superlinear convergence [34], which is a consequence of the global optimality of the latter. Additionally, iteration (2.7) reveals the structure of local subspaces that are used to determine the improved approximate solution, which we exploit in the next section for constructing the trial subspaces in the context of the eigenvalue calculations.
For these reasons, we choose (2.7) with (2.3) and (2.8) to be a 'base' linear solver for the null space problem (2.1) and, in what follows, use it as a starting point for deriving preconditioned interior eigensolvers.
- 3. The Preconditioned Locally Harmonic Residual method. We now present an approach for computing an eigenpair ( λ , v q q ) of (1.1) that corresponds to the eigenvalue closest to a given shift σ . The method is motivated by the preconditioned null space finders discussed in the previous section. Our idea is to extend the 'base' linear solver (2.7) to the case of eigenvalue computations by introducing a series of approximations into recurrence (2.7) and optimality condition (2.3).
The null space finding scheme (2.7) suggests that, if λ q is known, the improved eigenvector approximation v ( +1) i belongs to the subspace
$$( 3. 1 ) \quad \text{span} \left \{ v ^ { ( i ) }, T ( A - \lambda _ { q } B ) v ^ { ( i ) }, T ( A - \lambda _ { q } B ) T ( A - \lambda _ { q } B ) v ^ { ( i ) }, v ^ { ( i - 1 ) } \right \}.$$
Clearly, in practice, the exact value of λ q is unavailable and, hence, the computation of (3.1) cannot be performed. In order to obtain a computable subspace in the context of eigenvalue problem (1.1), we approximate λ q by the Rayleigh Quotient (RQ)
$$\lambda ^ { ( i ) } \equiv \lambda ( v ^ { ( i ) } ) = ( v ^ { ( i ) }, A v ^ { ( i ) } ) / ( v ^ { ( i ) }, B v ^ { ( i ) } ).$$
As a result, at each iteration i , the following trial subspace is introduced:
$$\mathcal { Z } ^ { ( i ) } = \text{span} \left \{ v ^ { ( i ) }, w ^ { ( i ) }, s ^ { ( i ) }, v ^ { ( i - 1 ) } \right \},$$
where w ( ) i = T Av ( ( ) i -λ ( ) i v ( ) i ) is the preconditioned residual for problem (1.1), and s ( ) i = T Aw ( ( ) i -λ ( ) i w ( ) i ).
Next, we address the question of extracting an approximate eigenpair from the subspace Z ( ) i . Let us recall that minimality principle (2.3), utilized by the base null space finder, implies the orthogonality relation
$$r ^ { ( i + 1 ) } & \equiv ( A - \lambda _ { q } B ) v ^ { ( i + 1 ) } \perp _ { T } ( A - \lambda _ { q } B ) \mathcal { K } ^ { ( i ) },$$
where ' ⊥ T ' denotes the 'orthogonality in the T -based inner product' and K ( ) i is defined in (2.8). Following the analogy with the linear solver, in the context of the eigenvalue problem, we introduce a similar condition:
$$( 3. 4 ) \quad \ \ ( A - \theta B ) v ^ { ( i + 1 ) } \perp _ { T } ( A - \sigma B ) \mathcal { Z } ^ { ( i ) }, \ \| v ^ { ( i + 1 ) } \| _ { B } = 1.$$
Here, we find a B -unit vector v ( +1) i and a scalar θ ∈ C that ensure the orthogonality of the vector ( A -θB v ) ( +1) i to the subspace ( A -σB ) Z ( ) i .
Condition (3.4) has been obtained from (3.3) as a result of two modifications. First, the known eigenvalue λ q in the residual r ( +1) i of linear system (2.1) has been replaced by an unknown θ , giving rise to the residual like vector ( A -θB v ) ( +1) i for the eigenvalue problem. Note that this vector should be distinguished from the standard eigenresidual ( A -λ ( +1) i B v ) ( +1) i , where λ ( +1) i is the RQ. Since the orthogonality of ( A -θB v ) ( +1) i in (3.4) is invariant with respect to the norm of v ( +1) i , for definiteness, we request that the vector has a unit B -norm.
The second modification has been the replacement of the subspace ( A -λ B q ) K ( ) i in the right-hand side of (3.3) by ( A -σB ) Z ( ) i , where Z ( ) i is the trial subspace defined in (3.2). We expect that ( A -σB ) Z ( ) i captures well the ideal subspace ( A -λ B q ) K ( ) i . Note that in the case where λ q is known, K ( ) i ⊂ Z ( ) i . Hence, if σ is close to the targeted eigenvalue, both subspaces are close to each other.
We next discuss a procedure for computing the pair ( θ, v ( +1) i ) in (3.4).
- 3.1. The T -harmonic Rayleigh-Ritz procedure. Motivated by (3.4), let us consider a general problem, where we are interested in finding a number of pairs ( θ, v ) that approximate eigenpairs of (1.1) corresponding to the eigenvalues closest a given shift σ , such that each v belongs to a given m -dimensional subspace Z , and
$$( 3. 5 ) & & ( A - \theta B ) v \perp _ { T } ( A - \sigma B ) \mathcal { Z }, \ \| v \| _ { B } = 1.$$
One can immediately recognize that (3.5) represents the Petrov-Galerkin condition [2, 28] formulated with respect to the T -based inner product. In the standard case with T = I , this condition leads to the well known harmonic Rayleigh-Ritz (RR) procedure, where approximate eigenpairs are delivered by the harmonic Ritz pairs [22, 23, 24]. The corresponding vectors Av -θBv are sometimes called the harmonic residuals; see, e.g., [36].
Let a basis of Z be given by columns of an n -bym matrix Z , so that any element of the subspace can be expressed in the form v = Zy , where y is a vector of coefficients. Then the orthogonality constraint (3.5) translates into
$$Z ^ { * } ( A - \sigma B ) T ( A - \theta B ) Z y = \mathbf 0, \ \| Z y \| _ { B } = 1.$$
This is equivalent to the eigenvalue problem
$$( 3. 6 ) \quad Z ^ { * } ( A - \sigma B ) T ( A - \sigma B ) Z y = \xi Z ^ { * } ( A - \sigma B ) T B Z y, \ \| Z y \| _ { B } = 1,$$
where ξ ≡ θ -σ .
It is clear that the smallest in the absolute value eigenvalues ξ correspond to the values of θ closest to the shift σ . Thus, if ( ξ, y ) are the eigenpairs of (3.6) associated with the eigenvalues of the smallest absolute value, then the candidate approximations to the desired eigenpairs of the original problem (1.1) can be chosen as ( θ, Zy ).
Definition 3.1. Let ( ξ, y ) be an eigenpair of (3.6) . We call ( θ, Zy ) a T -harmonic Ritz pair , where θ = ξ + σ and v = Zy are a T -harmonic Ritz value and vector , respectively. The corresponding vector Av -θBv is then referred to as the T -harmonic residual with respect to the subspace Z (or, simply, the T -harmonic residual).
In order to see why T -harmonic Ritz pairs can be expected to deliver reasonable approximations to the interior eigenpairs, let us introduce the substitution Q = T 1 2 ( A -σB Z ) and rewrite (3.6) as
$$( 3. 7 ) \quad Q ^ { * } ( T ^ { \frac { 1 } { 2 } } B ) ( A - \sigma B ) ^ { - 1 } B ( T ^ { \frac { 1 } { 2 } } B ) ^ { - 1 } Q y = \tau Q ^ { * } Q y, \ \tau = \frac { 1 } { \xi } \equiv \frac { 1 } { \theta - \sigma }.$$
We note that (3.7) is the projected problem in the RR procedure for the matrix H = ( T 1 2 B )( A -σB ) -1 B T ( 1 2 B ) -1 with respect to the subspace spanned by the columns of Q . The solution of this problem yields the Ritz pairs ( τ, Qy ) that tend to approximate well the exterior eigenpairs of H ; see, e.g., [26, 28, 31].
Since the matrix H is similar through T 1 2 B to the 'shift-and-invert' operator ( A -σB ) -1 B , each of its eigenpairs is of the form (1 / λ ( -σ , T ) 1 2 Bv ), where ( λ, v ) is an eigenpair of (1.1). Thus, the desired interior eigenvalues of (1.1) near the target σ correspond to the exterior (largest in the absolute value) eigenvalues of H , which can be well approximated by the Ritz values of (3.7). The associated Ritz vectors Qy then represent approximations to the eigenvectors T 1 2 Bv of H , i.e., T 1 2 ( A -σB Zy ) ≡ Qy ≈ T 1 2 Bv . This implies that Zy ≈ αv for some scalar α .
3.2. The PLHR algorithm. We now summarize the developments of the preceding sections and introduce an iterative scheme that at each step constructs a lowdimensional trial subspace (3.2) and uses the T -harmonic RR procedure to extract an approximate eigenvector from this subspace. The extraction is based on solving a 4-by-4 (3-by-3, at the initial step) eigenvalue problem (3.6), which defines an appropriate T -harmonic Ritz pair. The T -harmonic Ritz vector is then used as a new eigenvector approximation. We call this scheme the Preconditioned Locally Harmonic Residual (PLHR) algorithm; see Algorithm 1 below.
The initial guess v (0) in Algorithm 1 can be chosen as a random vector. In practical applications, however, certain information about the solution is available, and v (0) can give a reasonable approximation to the eigenvector of interest. Utilizing such initial guesses typically leads to a substantial decrease in the iteration count and is therefore advisable.
Note that each PLHR iteration constructs a residual of the eigenvalue problem that can be used to determine the convergence in step 2 of Algorithm 1. In some applications, appropriate stopping criteria rely on tracking the difference between eigenvalue approximations, evaluated in step 8, at the subsequent iterations.
An important property of Algorithm 1 is that, in contrast to the original problem (1.1), the T -harmonic problem (3.6) is no longer Hermitian. As such, (3.6) can have complex eigenpairs, i.e., the iteration parameters y = ( α, β, γ, δ ) T can be complex. Thus, the PLHR algorithm should be implemented using complex arithmetic, even if A and B are real. This feature is undesirable, e.g., because of the need to
Algorithm 1: Preconditioned Locally Harmonic Residual (PLHR) algorithm
| Input : | Input : | The matrices A = A ∗ and B = B ∗ > 0, a preconditioner T = T ∗ > 0, the shift σ , and the initial guess v (0) for the eigenvector; |
|---------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Output : | Output : | An eigenvalue λ closest to σ and the associated eigenvector v , ‖ v ‖ B = 1; |
| 1: v ← v (0) ; v ← v/ ‖ v ‖ B ; λ ← ( v, Av ); p ← [ ]; | 1: v ← v (0) ; v ← v/ ‖ v ‖ B ; λ ← ( v, Av ); p ← [ ]; | 1: v ← v (0) ; v ← v/ ‖ v ‖ B ; λ ← ( v, Av ); p ← [ ]; |
| 2: | while convergence not reached do | while convergence not reached do |
| 3: | Compute the preconditioned residual w ← T ( Av - λBv ); | Compute the preconditioned residual w ← T ( Av - λBv ); |
| 4: | Compute s ← T ( Aw - λBw ); | Compute s ← T ( Aw - λBw ); |
| 5: | Find the eigenpair ( ξ, y ) of (3.6), where Z = [ v, w,s, p ], such that | ξ | is the smallest; y = ( α, β, γ, δ ) T (at the initial step, y = ( α, β, γ ) T and δ = 0); | Find the eigenpair ( ξ, y ) of (3.6), where Z = [ v, w,s, p ], such that | ξ | is the smallest; y = ( α, β, γ, δ ) T (at the initial step, y = ( α, β, γ ) T and δ = 0); |
| 6: | p ← βw + γs + δp ; | p ← βw + γs + δp ; |
| 7: | v ← αv + p ; | v ← αv + p ; |
| 8: | v ← v/ ‖ v ‖ B ; λ ← ( v, Av ); | v ← v/ ‖ v ‖ B ; λ ← ( v, Av ); |
| 9: | end while | end while |
| 10: | Return ( λ, v ). | Return ( λ, v ). |
double the required storage to accommodate complex numbers. A real arithmetic version of the method for the real case is presented in Section 4.1.
In Algorithm 1, we follow the common practice of discarding the harmonic Ritz values and replacing them with the RQs associated with the newly computed Ritz vectors; see, e.g., [22, 23] for the standard harmonic case. In particular, we skip the θ ( ≡ ξ + σ ) values (determined in step 5 of Algorithm 1) and replace them with λ v ( ) = ( v ∗ Av / v Bv ) ( ∗ ), where v = Zy is the T -harmonic Ritz vector.
Note that, at each iteration i , Algorithm 1 (step 6) constructs a conjugate direction that can be expressed, in the superscripted notation, as
$$p ^ { ( i + 1 ) } = v ^ { ( i + 1 ) } - \alpha ^ { ( i ) } v ^ { ( i ) } \equiv \beta ^ { ( i ) } w ^ { ( i ) } + \gamma ^ { ( i ) } s ^ { ( i ) } + \delta ^ { ( i ) } p ^ { ( i ) },$$
and the method extracts an approximate eigenvector from the subspace spanned by v ( ) i , w ( ) i , s ( ) i , and p ( ) i . In exact arithmetic, this subspace is the same as Z ( ) i defined in (3.2). The above formula is known to yield an improved numerical stability in calculating the trial subspaces in the LOBPCG algorithm [15]. We expect that a similar property will hold for PLHR, and therefore follow the same style for computing the conjugate directions in Algorithm 1.
If it is possible to store additional vectors that contain results of the matrix-vector multiplications with A B , , and T A ( -σB ), then Algorithm 1 can be implemented with two matrix-vector multiplications involving A and B , and four applications of the preconditioner T . Two of the preconditioning operations result from the construction of the trial subspace in steps 3 and 4, whereas the other two are the consequence of the T -harmonic extraction.
3.3. Possible variations. The choice of the trial subspaces and of the extraction procedure, motivated by the preconditioned null space finding framework in Section 2, is not unique. For example, one can define the 's-vector' as s ( ) i = T Aw ( ( ) i -θ ( ) i Bw ( ) i ), where instead of the RQ λ ( ) i the current T -harmonic value θ ( ) i is used. Alternatively, it is possible to set s ( ) i = T Aw ( ( ) i -σBw ( ) i ), i.e., use the fixed σ instead of λ ( ) i . However, our numerical experience suggests that these options do not lead to any better results compared to the original choice of s ( ) i in (3.2).
The minimal residual condition (2.3) can also motivate an extraction procedure that is different from the T -harmonic RR described in Section 3.1. In particular, let
us assume that ˜ λ ∈ R is some approximation to the targeted eigenvalue λ q and v ( ) i is the current approximate eigenvector. In this case, one can extend (2.3) to minimize the T -norm of the residual-like vector ˜ = r Av -˜ λBv , such that
$$v ^ { ( i + 1 ) } = \underset { v \in \mathcal { Z } ^ { ( i ) }, \| v \| _ { B } = 1 } { \arg \min } \| A v - \tilde { \lambda } B v \| _ { T }.$$
This minimization principle represents the refinement procedure [11], performed with respect to the T -norm.
Assuming that Z is a basis of the current trial subspace Z ( ) i , one can show that (3.8) yields the new approximate eigenvector v ( +1) i = Zy min , where y min minimizes the bilinear form
$$\theta ^ { 2 } ( y ) = \frac { ( y, Z ^ { * } ( A - \tilde { \lambda } B ) T ( A - \tilde { \lambda } B ) Z y ) } { ( y, Z ^ { * } B Z y ) }$$
over all vectors y of dimension 4. This is equivalent to solving the eigenvalue problem Z ∗ ( A -˜ λB T A ) ( -˜ λB Zy ) = θ 2 Z BZy, ∗ where the desired y min is the eigenvector associated with the smallest eigenvalue.
The described approach can be of interest, in particular, if v ( ) i is already reasonably close to the targeted eigenvector. In this case, ˜ in λ (3.8) can be set to the current RQ λ ( ) i . After the minimizer v ( +1) i is constructed and the corresponding RQ and the new trial subspace Z ( +1) i are computed, the procedure is repeated once again. Such an approach, called the Preconditioned Locally Minimal Residual (PLMR) method, which combines the trial subspaces (3.2) with the eigenvector extraction in (3.8), has been described in [34].
- 4. The block PLHR algorithm. In this Section, we extend PLHR to the block case, where several eigenpairs closest to σ are computed simultaneously.
We start by introducing the block notation. Let Λ = diag { λ , λ 1 2 , . . . , λ k } denote a k -byk diagonal matrix of the targeted eigenvalues, ordered according to their distances from the shift σ , so that | λ l -σ | ≤ | λ j -σ | for l < j , where j = 1 2 , , . . . , k . Let V be an n -byk matrix of the associated eigenvectors. We assume that
$$V ^ { ( i ) } = [ v _ { 1 } ^ { ( i ) }, v _ { 2 } ^ { ( i ) }, \, \dots, \, v _ { k } ^ { ( i ) } ], \ \Lambda ^ { ( i ) } = \text{diag} \{ \lambda _ { 1 } ^ { ( i ) }, \lambda _ { 2 } ^ { ( i ) }, \, \dots, \, \lambda _ { k } ^ { ( i ) } \}$$
are the matrices of the approximate eigenvectors and eigenvalues at iteration i , respectively. The diagonal entries of Λ ( ) i are the RQs
$$\lambda _ { j } ^ { ( i ) } \equiv \lambda ( v _ { j } ^ { ( i ) } ) = ( v _ { j } ^ { ( i ) }, A v _ { j } ^ { ( i ) } ) / ( v _ { j } ^ { ( i ) }, B v _ { j } ^ { ( i ) } ),$$
evaluated at the corresponding vectors v ( ) i j , such that | λ ( ) i l -σ | ≤ | λ ( ) i j -σ | for l < j . Given the approximate eigenpairs in V ( ) i and Λ ( ) i , let us define the block
$$W ^ { ( i ) } \equiv [ w _ { 1 } ^ { ( i ) }, w _ { 2 } ^ { ( i ) }, \, \dots, \, w _ { k } ^ { ( i ) } ] = T ( A V ^ { ( i ) } - B V ^ { ( i ) } \Lambda ^ { ( i ) } )$$
of the preconditioned residuals w ( ) i j = T Av ( ( ) i j -λ ( ) i j Bv ( ) i j ), and the block
$$S ^ { ( i ) } \equiv [ s _ { 1 } ^ { ( i ) }, s _ { 2 } ^ { ( i ) }, \, \dots, \, s _ { k } ^ { ( i ) } ] = T ( A W ^ { ( i ) } - B W ^ { ( i ) } \Lambda ^ { ( i ) } ),$$
of 's-vectors' s ( ) i j = T Aw ( ( ) i j -λ ( ) i j Bw ( ) i j ). We can then introduce a trial subspace Z ( ) i spanned by the columns of V ( ) i , W ( ) i , S ( ) i , and V ( i -1) ( V ( -1) = 0 ), i.e.,
$$( 4. 1 ) \quad \mathcal { Z } ^ { ( i ) } = \text{span} \left \{ v _ { 1 } ^ { ( i ) }, \dots, v _ { k } ^ { ( i ) }, w _ { 1 } ^ { ( i ) } \dots w _ { k } ^ { ( i ) }, s _ { 1 } ^ { ( i ) }, \dots, s _ { k } ^ { ( i ) }, v _ { 1 } ^ { ( i - 1 ) }, \dots v _ { k } ^ { ( i - 1 ) } \right \}.$$
Clearly, (4.1) is a block generalization of the trial subspace (3.2) constructed at each single-vector PLHR iteration.
Let Z be a matrix whose columns represent a basis of (4.1). Analogously to Algorithm 1, we require that new eigenvector approximations V ( +1) i are the T -harmonic Ritz vectors extracted from (4.1). Thus, the vectors V ( +1) i are defined by solving the 4 k -by-4 k (or, at the initial step, 3 k -by-3 k ) eigenvalue problem (3.6), and correspond to the k T -harmonic Ritz values that are closest to the shift σ . The entire approach, referred to as the block PLHR (BPLHR) , is summarized in Algorithm 2.
## Algorithm 2: The block PLHR (BPLHR) Algorithm
Input :
The matrices A and B , a preconditioner T = T ∗ > 0, the shift σ , and the initial guess V (0) for k eigenvectors;
Output :
Diagonal matrix Λ of eigenvalues closest to the target σ and the matrix V of the associated eigenvectors;
- 1: V ← V (0) ; P ← [ ];
- 2: Normalize columns of V to have a unit B -norm; Λ ← diag ( V ∗ AV );
- 3: while convergence not reached do
- 4: Compute the preconditioned residuals W ← T AV ( -BV Λ);
- 5: Compute S ← T AW ( -BW Λ);
- 6: Set Z ← [ V, W, S, P ]. B -orthonormalize the columns of Z . Let ˆ = [ ˆ Z V , ˆ W, S, P ˆ ˆ ] be the matrix of the resulting B -orthonormal columns.
- 7: Find eigenpairs of the projected problem (3.6) with Z ≡ ˆ . Z Define Y ≡ [ Y T V , Y T W , Y T S , Y T T P ] to be the matrix of k eigenvectors of (3.6) corresponding to the smallest in the absolute value eigenvalues.
- 8: Compute P ← ˆ WY W + ˆ SY S + ˆ PY P ;
- 9: Compute new approximate eigenvectors V ← ˆ V Y V + P ;
- 10: Normalize columns of V to have a unit B -norm; Λ ← diag ( V ∗ AV );
- 11: end while
- 12: Perform the standard RR procedure for (1.1) with respect to V . Update V to contain the Ritz vectors and Λ the corresponding Ritz values.
- 13: Return (Λ , V ).
Note that the set of approximate eigenvectors constructed by Algorithm 2 is generally not B -orthogonal. This is a consequence of the T -harmonic projection that is based on solving the non-Hermitian reduced problem (3.6). The eigenvectors Y of this problem are non-orthogonal. Therefore the corresponding T -harmonic Ritz vectors V = ZY are also non-orthogonal.
As iterations proceed and the approximate eigenpairs get closer to the solution, the (near) B -orthogonality of the columns of V starts to show up naturally, due to the intrinsic property of the symmetric eigenvalue problem. However, since in many applications the required accuracy of the solution may be low, in order to ensure that the returned eigenvector approximations are B -orthonormal, the algorithm performs the post-processing (step 12 of Algorithm 2), where the final block V is 'rotated' to the B -orthogonal set of the Ritz vectors.
For the purpose of numerical stability, at each iteration, Algorithm 2 B -orthogonalizes the set of vectors Z = [ V, W, S, P ] that span the trial subspace and performs the T -harmonic RR procedure with respect to the B -orthonormal basis ˆ Z = [ ˆ V , ˆ W, S, P ˆ ˆ ]. This is done by first B -orthonormalizing the columns of V , so that the column space of ˆ V and V is the same. Then the block W is B -orthogonalized against ˆ and the resulting set of vectors is V B -orthonormalized to obtain the block ˆ . W
The remaining blocks ˆ and S ˆ are obtained in the same manner, by orthogonalizing P against the currently available B -orthogonal blocks.
The BPLHR algorithm requires storage for 16 k vectors of Z , AZ , BZ , and T A ( -σB Z ) . If the storage is available, it can be implemented using 2 matrix-block multiplications involving A and B , and 4 applications of the preconditioner T to a block per iteration. Note that in the case of standard eigenvalue problem ( B = I ), the memory requirement reduces to storing 12 k vectors, and the two matrix-block multiplications with B are no longer needed. Additional cost reductions can result from locking the converged eigenpairs. In our BPLHR implementation, this is done by the standard soft locking procedure, similar to [16].
4.1. The BPLHR algorithm in real arithmetic. Each BPLHR iteration relies on the solution of the projected problem (3.6), which is generally non-Hermitian. As a consequence, (3.6) can have complex eigenpairs and, therefore, complex arithmetic should be assumed for Algorithm 2.
However, in the case where A and B are real symmetric, the use of the complex arithmetic is unnatural, since the solution of (1.1) is real. Moreover, the presence of complex-valued iterations translates into the undesirable requirement to double the memory allocation for each vector, or block of vectors, utilized in the computation. The goal of the present subsection is to discuss ways to overcome this issue and introduce a real arithmetic version of the BPLHR algorithm.
Let A and B be real, where A is symmetric and B symmetric positive definite (SPD). Let T be an SPD preconditioner, and assume that at the current iteration of Algorithm 2 the trial subspace is given by a real matrix Z . In this case the left- and right-hand side matrices in the T -harmonic problem (3.6) are real, implying that the eigenvalues ξ are either real or appear in the complex conjugate pairs. Specifically, if ( ξ, y ) is a complex eigenpair of (3.6) then ( ¯ ξ, y ¯) is also an eigenpair of (3.6).
Clearly, if y is a real eigenvector of (3.6) then the corresponding T -harmonic Ritz vector v = Zy is also real. If y is complex, then v = Zy is complex, and the conjugate eigenvector ¯ gives y ¯ = v Zy ¯, i.e., the presence of complex solutions in (3.6) yields complex conjugate T -harmonic Ritz vectors v and ¯. v
Complex solutions of (3.6) and, subsequently, the complex conjugate T -harmonic Ritz vectors, are not rare in practice. Their presence indicates that the extraction procedure is attempting to approximate eigenpairs associated with a (real) eigenvalue of multiplicity greater than one. In particular, if v = v R + iv I ∈ C n and ¯ = v v R -iv I ∈ C n is a pair of the complex conjugate T -harmonic Ritz vectors, where v R ∈ R n and v I ∈ R n are the real and imaginary parts of v , then the eigenvalue approximations given by the corresponding RQs coincide, i.e.,
$$\lambda ( v ) & = \lambda ( \bar { v } ) = \frac { v _ { \text{R} } ^ { * } A v _ { \text{R} } + v _ { \text{I} } ^ { * } A v _ { \text{I} } } { v _ { \text{R} } ^ { * } B v _ { \text{R} } + v _ { \text{I} } ^ { * } B v _ { \text{I} } }.$$
Thus, v and ¯ indeed approximate eigenvectors corresponding to the same eigenvalue. v Let Y denote the matrix of eigenvectors of (3.6) associated with k smallest magnitude eigenvalues. For simplicity, we assume that if y is a complex eigenvector in Y , then the eigenvector ¯ is y also included into Y , i.e., Y contains complex conjugate columns y and ¯ (the case where y Y contains only the column y will be discussed below). Then, for a given Y , let us define a real matrix Y ′ = [ Y 0 Y R Y I ], where the subblock Y 0 consists of the real columns of Y , whereas Y R and Y I contain the real and imaginary parts of the complex columns of Y . More precisely, corresponding to each complex conjugate pair of columns y = y R + iy I and ¯ = y y R -iy I in Y , we define two
real columns y R and y I , where the former is placed to Y R and the latter to Y I . It is assumed that all columns y R and y I appear in Y R and Y I in the same order. That is, if y R is the j th column in the subblock Y R , then y I is the j th column of Y I . Clearly, Y R and Y I contain the same number of columns, which is equal to the number of complex eigenvectors in Y divided by two. Thus, the sizes of Y and Y ′ are identical.
Let V = ZY be the block of approximate eigenvectors extracted by Algorithm 2 from the trial subspace defined by Z at the current BPLHR step, and let [ V, W, S, P ] be the basis of the trial subspace computed from V at the next iteration. It is clear that each block in this basis will have complex columns, provided that Y contains complex eigenvectors of (3.6). Additionally, according to the assumption on Y , for each complex column v of the block V , there exists a conjugate column ¯ in v V . Below we show that it is possible to replace [ V, W, S, P ] by a real basis [ V , ′ W , S , ′ ′ P ′ ] that spans exactly the same trial subspace. This idea will lead to a real arithmetic version of the BPLHR algorithm.
Our approach is based on the observation that span { v R , v I } = span { v, v ¯ } over the field of complex numbers. Therefore, if we define
$$V ^ { \prime } \equiv [ V _ { 0 } \ V _ { \text{R} } \ V _ { 1 } ] = [ Z Y _ { 0 } \ Z Y _ { \text{R} } \ Z Y _ { 1 } ],$$
then its column space will be exactly the same as that of V . Here the subblock V 0 of V ′ contains the real columns of the matrix V , whereas V R and V I correspond to the real and imaginary parts of V 's complex columns, respectively. Thus, one can replace the block V of T -harmonic Ritz vectors by the corresponding real-valued block V ′ without changing the column span.
Note that both V and V ′ have k columns. However, all columns of V ′ are real. Therefore, placing them into the new trial subspace does not lead to any increase in storage, in contrast to using V , whose complex columns would require extra memory.
Similarly, since the presence of the complex conjugate pair of columns v and ¯ in v V yields the conjugate columns w and ¯ in the block w W , the latter can be replaced by the real block
$$( 4. 4 ) \ W ^ { \prime } \equiv [ W _ { 0 } \ W _ { \mathrm R } \ W _ { 1 } ] = [ T ( A V _ { 0 } - B V _ { 0 } \Lambda _ { 0 } ) \ T ( A V _ { \mathrm R } - B V _ { \mathrm R } \Lambda _ { 1 } ) \ T ( A V _ { 1 } - B V _ { 1 } \Lambda _ { 1 } ) ],$$
where Λ 0 is the diagonal matrix of the RQs λ v ( ) = v ∗ Av/v Bv ∗ evaluated at the columns v of V 0 ; and Λ 1 is diagonal matrix that, for each column v R of V R and the corresponding v I of V I , contains the RQ defined in (4.2). Note that the matrix W ′ can be expressed as W ′ = T AV ( ′ -BV ′ Λ ), where Λ ′ ′ = diag(Λ 0 , Λ 1 , Λ ). 1
Finally, using the same argument, the block S constructed by Algorithm 2 can be replaced by the real block
$$( 4. 5 ) \ S ^ { \prime } \equiv [ S _ { 0 } \ S _ { R } \ S _ { 1 } ] = [ T ( A W _ { 0 } - B W _ { 0 } \Lambda _ { 0 } ) \ T ( A W _ { R } - B W _ { R } \Lambda _ { 1 } ) \ T ( A W _ { 1 } - B W _ { 1 } \Lambda _ { 1 } ) ],$$
i.e., S ′ = T AW ( ′ -BW ′ Λ ). ′ Thus, instead of using the possibly complex basis [ V, W, S, P ], constructed by Algorithm 2 for the next BPLHR iteration, one can set up the real basis [ V , ′ W , S , ′ ′ P ′ ] that defines the same trial subspace. The block P ′ is constructed exactly in the same way as P in Algorithm 2, with the difference that the coefficients given by Y are replaced by those in Y ′ . As a result, P ′ represents a combination of the new V ′ and of the subblock of Z that corresponds to the current eigenvector approximations. Clearly, this definition ensures that P ′ is real, and hence the same trial subspace is spanned by [ V, W, S, P ] and [ V , ′ W , S , ′ ′ P ′ ].
The above discussion is based on the assumptions that the matrix Y of eigenvectors of (3.6) contains the conjugate ¯ for y each complex column y . In practice,
however, this may not necessarily be the case. Since k is a fixed parameter, one can encounter the situation where all the complex columns y have the corresponding conjugate columns ¯ in y Y , but there exists a column ˜ = ˜ y y R + ˜ iy I whose conjugate is not among the k columns of Y . This happens if ˜ corresponds to the y k th eigenvalue of (3.6), whereas the conjugation of ˜ corresponds to the ( y k +1)st eigenvalue, where the eigenvalues are numbered in the ascending order of their magnitudes.
In this case, we ignore the imaginary part of ˜ and construct the matrix y Y ′ to be of the form Y ′ = [ Y 0 Y R ˜ y R Y I ], where Y R and Y I contain the real and imaginary parts of those vectors y that appear in Y in conjugate pairs. Given Y ′ , we proceed in the same fashion as has been described above. We introduce the block V ′ ≡ [ V 0 V R ˜ v R V I ] of approximate eigenvectors and the diagonal matrix Λ ′ = diag(Λ 0 , Λ 1 , λ, ˜ Λ ) of the 1 corresponding eigenvalue approximations, where ˜ v R = Zy ˜ R and ˜ is the RQ evaluated λ at ˜ v R , i.e., ˜ λ ≡ λ v (˜ R ) = (˜ v R , Av ˜ R ) / v (˜ R , Bv ˜ R ). The blocks W ′ and S ′ then take the form W ′ = T AV ( ′ -BV ′ Λ ) ′ = [ W W 0 R ˜ w R W I ] and S ′ = T AW ( ′ -BW ′ Λ ) ′ = [ S 0 S R ˜ s R S I ], where ˜ w R = Av ˜ R -˜ λBv R and ˜ s R = Aw ˜ R -˜ λBw ˜ R .
Clearly, if the imaginary part of ˜ is ignored, i.e., the vector ˜ y v I = Zy ˜ I is not in V ′ , then the columns of [ V , ′ W , S , ′ ′ P ′ ] span a slightly smaller subspace than those of [ V, W, S, P ] in Algorithm 2. This may lead to a slight convergence deterioration of the real arithmetic scheme compared to the original BPLHR version. Therefore, prior to the run, we suggest increasing the block size (at least) by 1 and running the algorithm for the extended block size. This removes the possible effects of 'cutting' in between the conjugate pair when eigenvectors of (3.6) are selected into Y .
The details of the real arithmetic version of BPLHR algorithm are summarized in Algorithm 3. Note that if at each step of the algorithm problem (3.6) gives only real eigenvectors Y , then Algorithm 3 becomes equivalent to the original version of BPLHR in Algorithm 2.
- 5. Preconditioning. In order to motivate preconditioning strategy, let us again consider the idealized trial subspaces (3.1). Assuming that the targeted eigenvalue λ q is known, we address the question of defining an optimal preconditioner T which ensures that the corresponding eigenvector v q is exactly in the trial subspace (3.1).
A possible choice of such a preconditioner is given by T = ( A -λ B q ) † [14]. In this case,
$$v _ { q } \equiv v ^ { ( i ) } - T ( A - \lambda _ { q } B ) v ^ { ( i ) } = ( I - K ) v ^ { ( i ) },$$
where K = ( A -λ B q ) † ( A -λ B q ). Clearly, v q is in (3.1). The fact that v q is an eigenvector follows from the observation that K is an orthogonal projector onto the range of A -λ B q . Hence, I -K projects v ( ) i onto the null space of A -λ B q , which gives the desired eigenvector. Note that v q is nonzero provided that v ( ) i has a nontrivial component in the direction of the targeted eigenvector.
In general, neither the idealized subspaces (3.1) nor the optimal preconditioner T = ( A -λ B q ) † are available at the PLHR iterations. However, the above analysis suggests that practical preconditioners can be defined as approximations of ( A -λ B q ) † . For example, one can aim at constructing T , such that T ≈ ( A -σB ) -1 . This gives rise to the inexact shift-and-invert type preconditioning, which represents a traditional approach for preconditioning eigenvalue problems; see, e.g., [8, 15].
Since preconditioners for PLHR should be HPD, the definition T ≈ ( A -σB ) -1 may not always be suitable. While one can expect to construct the HPD inexact shiftand-invert preconditioners for computing eigenpairs associated with the eigenvalues
## Algorithm 3: The real arithmetic version of the BPLHR algorithm
Input :
A symmetric matrix A , an SPD matrix B , an SPD preconditioner T , the shift σ , and the real initial guess V (0) for k eigenvectors;
:
Output
Diagonal matrix Λ of eigenvalues closest to the shift σ and the matrix V of the associated eigenvectors;
- 1: V ← V (0) ; P ← [ ];
- 2: Normalize columns of V to have a unit B -norm; Λ ← diag ( V ∗ AV );
- 3: while convergence not reached do
- 4: Compute the preconditioned residuals W ← T AV ( -BV Λ);
- 5: Compute S ← T AW ( -BW Λ);
- 6: Set Z ← [ V, W, S, P ]. B -orthonormalize the columns of Z . Let ˆ = [ ˆ Z V , ˆ W, S, P ˆ ˆ ] be the matrix of the resulting B -orthonormal columns.
- 7: Find eigenpairs of the projected problem (3.6) with Z ≡ ˆ . Z Sort the eigenvalues ξ in the ascending order of their absolute values, ensuring that in the sorted set every complex eigenvalue ξ is immediately followed by its conjugate ¯ . ξ
- 8: Select k eigenvectors of (3.6) associated with the smallest magnitude eigenvalues into the matrix Y .
- 9: Move real columns of Y into Y 0 . Define Y R and Y I to be the matrices containing the real and imaginary parts of the columns of Y that appear in complex pairs.
- 10: If Y contains a complex column ˜, such that the conjugate of ˜ is not in y y Y , then set ˜ y R to be the real part of ˜. y Otherwise, ˜ y R ← [ ]. Define Y ′ = [ Y 0 Y R ˜ y R Y I ] ≡ [ Y T V , Y T W , Y T S , Y T T P ] .
- 11: Compute P ← ˆ WY W + ˆ SY S + ˆ PY P ;
- 12: Compute new approximate eigenvectors V ← ˆ V Y V + P . Define the column partitioning V = [ V 0 V R ˜ v R V I ]( ≡ ˆ ZY ′ ) according to Y ′ (˜ v R ← [ ] if ˜ y R = [ ]).
- 13: For each column v of V 0 compute the RQ λ v ( ) ← v ∗ Av/v Bv ∗ and place it to the diagonal of Λ 0 . For each column v R of V R and the corresponding v I of V I , compute the diagonal entry of Λ 1 by (4.2). Set ˜ λ ← ˜ v ∗ R Av ˜ R /v ˜ ∗ R Bv ˜ R ( ˜ λ ← [ ] if ˜ v R = [ ]).
- 14: Normalize columns of V to have a unit B -norm; Λ ← diag(Λ 0 , Λ 1 , ˜ λ, Λ ). 1
## 15: end while
- 16: Perform the standard RR procedure for (1.1) with respect to V . Update V to contain the Ritz vectors and Λ the corresponding Ritz values.
- 17: Return (Λ , V ).
not far away from the ends of the spectrum, the approach will result in the indefinite preconditioning as the eigenvalues deeper in the interior of the spectrum are sought.
In order to define a preconditioner that is HPD and, at the same time, that preserves the desirable effects of 'shift-and-invert', let us consider the operator T = | A -λ B q | † , where | A -λ B q | is defined as a matrix function [7] of A -λ B q . Similar to T = ( A -λ B q ) † , this choice of preconditioner is also optimal with respect to the idealized trial subspaces (3.1). Indeed, if T = | A -λ B q | † , then
$$v _ { q } \equiv v ^ { ( i ) } - T ( A - \lambda _ { q } B ) T ( A - \lambda _ { q } B ) v ^ { ( i ) } = ( I - K ) v ^ { ( i ) },$$
where K = ( | A -λ B q | † ( A -λ B q ) ) 2 = ( ( A -λ B q ) † ( A -λ B q ) ) 2 = ( A -λ B q ) † ( A -λ B q ). Thus, v q belongs to (3.1) and represents the wanted eigenvector, since I -K projects v ( ) i onto the null space of A -λ B q .
As discussed above, the computation of idealized trial subspaces and an optimal preconditioner may be infeasible in practice. Instead, however, one can construct T that approximates the action of the (pseudo-) inverted absolute value operator. In particular, we can define T ≈ | A -σB | -1 . In the next section, we demonstrate that
such preconditioners exist for certain classes of problems and indeed lead to a rapid and robust convergence if used to construct the PLHR trial subspaces (3.2) (or (4.1), in the block case) and to perform the T -harmonic projection introduced in Section 3.1.
- 6. Numerical experiments. We organize our numerical experiments into three sets. The first set concerns a model generalized eigenvalue problem of a small size. This example is mainly of theoretical nature and is intended to demonstrate several features of the convergence behavior of the proposed method.
In the second test set, we consider a larger model problem, where a practical AV preconditioner is used. Specifically, we address a problem of computing a subset of interior eigenpairs of a discrete Laplacian. As an SPD preconditioner we use the multigrid (MG) scheme proposed in [35] in the context of solving symmetric indefinite Helmholtz type linear systems. We show that exactly the same AV preconditioner can be employed for the interior eigenvalue computations in the BPLHR algorithm.
The third series of experiments aims at a particular application. We consider several Hamiltonian matrices that arise in electronic structure calculations, and apply BPLHR to reveal eigenvectors (wave functions) that correspond to the eigenvalues (energy levels) around a given reference energy. The preconditioners available for this type of problems are diagonal and SPD [32].
In our experiments, we compare BPLHR with the a block version of the Generalized Davidson (BGD) method that is based on the harmonic projection [12, 22]. This choice has been motivated by several factors. First, we want to restrict our comparisons to the class of block methods which rely on the same type of computational kernels, such as multiplication of a block of vectors by a matrix or a preconditioner, dense matrix-matrix multiplication, etc. Secondly, the BGD algorithm represents a state-of-the-art approach for interior eigenvalue computations in a number of critical applications; see, e.g., [12]. In particular, we demonstrate that BPLHR can give a more robust solution option compared to BGD in cases where memory is limited and the available preconditioner is of a 'moderate' quality.
- 6.1. A small model problem: the finite element (FE) Laplacian. Let us consider the eigenvalue problem
$$( 6. 1 ) \quad \ \ - \Delta u ( x, y ) = \lambda u ( x, y ), \ ( x, y ) \in \Omega = ( 0, 1 ) \times ( 0, 1 ), \ u | _ { \Gamma } = 0,$$
where ∆ = ∂ /∂ 2 x 2 + ∂ /∂ 2 y 2 is the Laplace operator and Γ denotes the boundary of the unit square Ω. Assume that we are interested in approximating a number of eigenpairs ( λ, u (x y)) of (6.1) that are closest to a given shift , σ .
Discretizing (6.1) with standard bilinear finite elements results in the algebraic generalized eigenvalue problem Av = λBv , where A and B are the SPD stiffness and mass matrices, respectively. In this example, we assume a relatively small number of finite elements, 50 along each side of the unit square, which results in the total of 2 401 degrees of freedom, i.e., the size of the matrix problem is , n = 2 401. ,
Due to the small problem size, in this example, we can model high-quality AV preconditioners by perturbations of the operator | A -σB | -1 . In particular, we define T = | A -σB | -1 + E , where E is a random SPD matrix, such that ‖ E ‖ ≤ glyph[epsilon1] ‖ ( A -σB ) -1 ‖ and glyph[epsilon1] is a parameter that sets up the preconditioning quality; ‖·‖ denotes the spectral norm. As glyph[epsilon1] increases, so does the norm of the perturbation E , which means that T becomes more distant from | A -σB | -1 and hence the quality of the preconditioner deteriorates. The matrix E is fixed during the iterations, but is updated for every new run. We present typical results.
We first compare the convergence rate of PLHR to that of the 'base' preconditioned null space finder (2.7), with (2.3) and (2.8), applied to (2.1). As discussed in Section 2, this scheme, further referred to as BASE-NULL, represents an idealized interior eigenvalue solver with a proven convergence bound (2.5)-(2.6), and was used as a prototype of the PLHR algorithm. In particular, PLHR was derived in Section 3 by introducing a number of approximations into BASE-NULL. Therefore, it is of interest to see to what extent these approximations affect the behavior of the resulting eigenvalue algorithm if the understood BASE-NULL convergence is taken as a reference.
Fig. 6.1: A comparison of PLHR with preconditioned linear solvers for ( A -λ 31 B x ) = 0 (left) and ( A -λ 66 B x ) = 0 (right), where λ 31 ≈ 497 5521 and . λ 66 ≈ 979 7072. .
In Figure 6.1, we apply PLHR (Algorithm 1) and BASE-NULL to compute an eigenpair closest to the shift σ = 497 and σ = 980. These shift values target eigenpairs corresponding to the eigenvalues λ 31 ≈ 497 5521 and . λ 66 ≈ 979 7072, respectively. . Thus, BASE-NULL solves the homogeneous systems with matrices A -λ 31 B and A -λ 66 B . We also plot convergence curves that correspond to the runs of PMINRES (denoted PMINRES-NULL) applied to the same singular systems. This gives us an opportunity to compare the convergence of PLHR to that of an optimal Krylov subspace method used as an idealized eigenvalue solver; see the discussion in Section 2.
To assess the convergence, for all schemes in Figure 6.1, we measure the norms of the residuals ‖ Av ( ) i -λ ( ) i Bv ( ) i ‖ of the eigenvalue problem. In the definition of the random perturbation based preconditioner T , we set glyph[epsilon1] = 10 -5 .
Figure 6.1 shows that PLHR and BASE-NULL exhibit essentially the same convergence behavior. Additionally, at a number of initial steps, their convergence is similar to that of PMINRES-NULL. Thus, at least if the preconditioner is sufficiently strong, the approximations introduced into the idealized BASE-NULL to obtain PLHR do not significantly alter its convergence behavior. Moreover, the convergence is comparable to that of the optimal PMINRES-NULL.
Next, we would like demonstrate the effects of the vectors s ( ) i introduced into the PLHR trial subspaces (3.2). These subspaces can be viewed as the LOBPCGlike subspaces, spanned by v ( ) i , w ( ) i , and p ( ) i , extended by the additional vector. Therefore, a natural question is whether the occurrence of the new 's-vectors' has any impact on the convergence of the proposed scheme.
Figure 6.2 compares the PLHR iteration in Algorithm 1 to its variant where the
Fig. 6.2: The significance of 's-vectors' for the PLHR convergence. The PLHR algorithm with σ = 497 (left) and σ = 980 (right) is compared to its version without 's-vectors'. Each curve corresponds to a separate run with random initial guess and a preconditioner generated by a random SPD perturbation of | A -σB | -1 with glyph[epsilon1] = 10 -5 .
's-vectors' are not included into the trial subspaces, i.e., (3.2) are spanned only by v ( ) i , w ( ) i , and p ( ) i . We perform 10 runs of both versions of the algorithm, so that each curve in Figure 6.2 represents a separate execution with a random initial guess. As in the previous example, we consider shifts σ = 497 and σ = 980. For each run, the preconditioners are given by random SPD perturbations of | A -σB | -1 with glyph[epsilon1] = 10 -5 .
One can observe from Figure 6.2 that PLHR demonstrates a stable linear convergence at all runs regardless of the initial guess and a particular instance of the preconditioner. At the same time, despite the high preconditioning quality, the absence of 's-vectors' makes the method highly unstable, with a slower or stagnant convergence pattern. Therefore, the presence of s ( ) i in (3.2) is important. Such a behavior is consistent with the fact that linear solver (2.2) generally does not converge if s -vectors, defined as T ( A -λ B q ) Tr ( ) i , are removed from the iterative scheme.
Another new feature incorporated into PLHR is the T -harmonic RR procedure presented in Section 3.1. Similar to the above, we would like to address the question of whether any advantage is gained by the T -harmonic approach compared, e.g., to the standard harmonic RR [22]. To answer this question, let us compare the PLHR algorithm to its variant where the T -harmonic projection is replaced by the standard harmonic RR, whereas the same SPD (AV) preconditioner is used to generate the trial subspaces.
Since PLHR with a standard harmonic RR no longer requires the preconditioner to be SPD, we are also interested in the case where T is indefinite , i.e., the preconditioner is an approximation of the 'shift-and-invert' operator ( A -σB ) -1 . For this reason, let us consider a variant of PLHR with an indefinite T ≈ ( A -σB ) -1 , combined with the standard harmonic RR.
Figure 6.3 illustrates the collective impact of the T -harmonic RR and AV preconditioning on the convergence of the new eigensolver. Here, we set σ = 980 and apply all the three PLHR variants to compute the corresponding eigenpair.
In contrast to our previous tests, we now consider preconditioners of different quality. In particular, in Figure 6.3 (left) we set glyph[epsilon1] = 10 -4 , whereas in Figure 6.3 (right) we choose glyph[epsilon1] = 10 -3 , which gives weaker preconditioners. As previously, the AV
Number of iterations
Fig. 6.3: Effects of the SPD AV preconditioning and T -harmonic RR; σ = 980. Preconditioners generated by a random SPD perturbation of | A -σB | -1 (for the AV preconditioner) and of ( A -σB ) -1 (for the indefinite preconditioner) with glyph[epsilon1] = 10 -4 (left) and glyph[epsilon1] = 10 -3 (right).
preconditioning is obtained by perturbing | A -σB | -1 . The indefinite preconditioner is generated in a similar manner by a random perturbation E of ( A -σB ) -1 , i.e., T = ( A -σB ) -1 + E , where ‖ E ‖ ≤ glyph[epsilon1] ‖ ( A -σB ) -1 ‖ . In our tests, the same SPD perturbation E is used for both the AV and indefinite preconditioners to maintain a similar preconditioning quality.
Figure 6.3 (left) suggests that if a sufficiently strong preconditioner is at hand then neither the T -harmonic projection nor the SPD preconditioning lead to any significant improvement. In this case, the fastest convergence is attained by the version of PLHR with the standard harmonic RR and indefinite preconditioner. However, if preconditioning is not as strong, then the use of the SPD AV preconditioners along with the T -harmonic RR procedure becomes crucial. As can be seen in Figure 6.3 (right), the original PLHR version given by Algorithm 1 is the only scheme that is able to maintain convergence under the degraded preconditioning quality. Note that, in this example, the convergence of PLHR iterations could be preserved for values of glyph[epsilon1] up to 10 -2 . For glyph[epsilon1] = 10 -2 , the convergence behavior of all methods is similar to that in Figure 6.3 (right), though with an increased iteration count due to preconditioning deterioration.
The case where the preconditioner is only of a moderate quality is not uncommon in realistic applications, especially if the wanted eigenpairs are located deeper in the spectrum's interior. Thus, the decrease in the sensitivity to deterioration of the preconditioning quality, demonstrated by PLHR in Figure 6.3 (right), is of a practical interest. In the remaining experiments, we reaffirm this finding on the example of several model problems for which AV preconditioners can be constructed in practice.
- 6.2. A model problem: the finite-difference (FD) Laplacian. Let us consider the same continuous problem (6.1), but now apply a standard 5-point FD discretization with step h = 2 -7 . This gives an eigenvalue problem Lv = λv , where A ≡ L is a discrete Laplacian of size n = 16 129. ,
We are interested in computing a subset of eigenvalues closest to the shift σ using the block PLHR iteration. Since L is SPD, we employ the real arithmetic version of BPLHR in Algorithm 3. In contrast to the previous example, where an artificial
preconditioner has been constructed, we now utilize the practical SPD preconditioner T ≈ | L -σI | -1 introduced in [35]. For convenience, we state this preconditioning procedure in Algorithm 4 of Appendix A.
The objective of the current experiment is two-fold. On the one hand, we would like to compare BPLHR to a well-established solution scheme, such as the BGD method. On the other hand, similar to our previous test, we are interested in demonstrating effects of the T -harmonic extraction and AV preconditioning on the eigensolver convergence.
We consider two preconditioning options for the BGD algorithm. The first approach is exactly the same MG AV preconditioner [35] (Algorithm 4 of Appendix A) as the one used in the BPLHR algorithm, i.e., T ≈ | L -σI | -1 and it is SPD. The second preconditioner is given by a standard MG solve [4, 33] for the shifted matrix L -σI (see Algorithm 5 of Appendix A), which corresponds to an indefinite 'shift-and-invert' type preconditioner T ≈ ( L -σI ) -1 .
The preconditioners in Algorithms 4 and 5 are of the same nature. They represent a standard MG V-cycle, with the difference that the former is applied to solve the SPD system | L -σI w | = r [35], whereas the latter seeks to approximate the solution of the indefinite ( L -σI w ) = . Note that preconditioners stronger than Algorithm 5 r are available for the indefinite matrix L -σI , such as, e.g., in [21]. However, due to the algorithmic similarity to the employed MG AV preconditioner, for demonstration purposes, we use Algorithm 5 as a reference indefinite MG preconditioner.
In order to ensure a comparable (in terms of the approximate solves for the corresponding linear systems | L -σI w | = r and ( L -σI w ) = r ) preconditioning quality in the two variants of BGD, we require that the coarsest grid problems are of the same size (225 by 225) and that the same smoothing schemes (a single step of Richardson's iterations) are used on every level. Note that the computational costs of both preconditioners is essentially the same, with the AV preconditioner performing slightly more arithmetic operations because of the polynomial approximations of the absolute value operators on intermediate levels. However, these additional expenses are negligible relative to the overall preconditioning cost.
Recall that at every iteration the BGD algorithm expands the search subspace with a set of preconditioned residuals. Thus, an increased amount of memory is required by the method at every new step. This is in contrast to the BPLHR algorithm, where the requested storage size is fixed at every iteration. In particular, in our implementation, BPLHR has to store at most 12 k vectors corresponding to Z (= [ V ( ) i , W ( ) i , S ( ) i , P ( ) i ]), AZ , and T A ( -σB Z ) .
To maintain the same memory requirement in BGD, we restart the method once the size m of its search subspace becomes sufficiently large, reaching some prespecified m max . In this case, we collapse the search subspace, so that it only contains k available eigenvector approximations. Since in standard BGD implementations each iteration of the method stores the search subspace Z m together with the block AZ m (i.e., up to 2 m vectors total), we want 2 m not to exceed 12 k . Hence, to ensure the same memory requirement for BPLHR and BGD, we set m max = 6 . k This maximum size of the BGD subspace is somewhat larger than the size of the trial subspaces in BPLHR which is 4 k . Nevertheless, as we demonstrate below, BPLHR can be more robust, even though the extraction is performed with respect to the smaller subspaces.
While our main focus is on the comparison of the BPLHR and BGD methods, we are also interested in the question of how much the AV preconditioning affects the eigensolver's convergence and if any benefit is received from the T -harmonic RR.
Table 6.1: Iteration numbers required by different eigensolvers to converge to 10 eigenpairs of the 2D FD Laplacian closest to the shifts σ ; '-' corresponds to the cases where no convergence was reached within 1000 iteration; n = 16 129. , The AV and indefinite preconditioners are given by Algorithms 4 and 5, respectively.
| | | | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) |
|--------------|--------|----------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| Iter. scheme | Prec. | RR | 400 | 450 | 500 | 550 | 600 | 650 | 700 |
| BPLHR | AV | T -harm. | 57 | 81 | 68 | 133 | 117 | 190 | 278 |
| BPLHR | AV | harm. | 563 | - | 493 | 635 | - | - | - |
| BPLHR | Indef. | harm. | 30 | 40 | 45 | - | 59 | 338 | 424 |
| BGD | AV | harm. | 209 | - | 533 | - | 493 | - | - |
| BGD | Indef. | harm. | 36 | 46 | 57 | - | 376 | 763 | - |
For this reason, along with the original BPLHR version in Algorithm 3, we also consider its versions based on the standard harmonic RR with the AV and indefinite preconditioning options, similar to the previous section. Here, the AV and indefinite preconditioning strategies are based on the MG schemes in Algorithms 4 and 5, respectively.
In Table 6.1 we report the numbers of iterations required by different eigensolvers to converge to 10 eigenpairs closest to the given shift. The schemes were compared for a number of shifts in the range from 400 to 700. The convergence tolerance for the residual norms was set to 10 -6 and the same initial guess was used for each run corresponding to the same σ . Since the real arithmetic version of BPLHR is invoked, according to the discussion in Section 4.1, we increase the block size by one, i.e., apply Algorithm 3 with k = 11, but track the convergence only of the ten wanted eigenpairs. The maximum size m max of the BGD search subspace is 66.
Table 6.1 shows that the BPLHR algorithm (i.e., the original version with the AV preconditioner and T -harmonic RR) is robust with respect to the choice of the shift. It is the only method among the compared schemes that was able to converge all eigenpairs for each σ in the prescribed range. Note that the T -harmonic extraction is crucial-its replacement by the standard harmonic approach (while preserving the same AV preconditioner) resulted in a significant increase of the iteration count or a total loss of convergence. The demonstrated results also suggest that the standard harmonic extraction leads to more satisfactory results if an indefinite preconditioner is employed. However, this combination was still unable to maintain convergence for all shifts and required a noticeably larger amount of iterations for σ ≥ 650.
Regardless of the choice of the preconditioner, both BGD based schemes fail to converge for a number of shift values. Note that for smaller values of σ (400 to 500), BGD with the indefinite preconditioning gives the lowest number of iterations. However, as σ increases, either the iteration count grows dramatically or the convergence of the method is lost.
As has been discussed in Section 4, in the reported runs, the cost of each BPLHR iteration is dominated by 2 matrix-block multiplications and 4 block preconditioning operations. This is clearly more expensive than, e.g., in the BGD method, where only one of each is needed. However, as seen in Table 6.1, BGD fails to maintain convergence under the given memory constraint, whereas BPLHR succeeds, i.e., the increased iteration cost results in an improved robustness of the overall computation.
It is well known (e.g., [5, 35]) that the the increase of σ generally leads to the
| | | | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) | Shifts ( σ ) |
|--------------|--------|----------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| Iter. scheme | Prec. | RR | 800 | 900 | 1000 | 1100 | 1200 | 1300 | 1400 |
| BPLHR | AV | T -harm. | 270 | 168 | 177 | 344 | 365 | 363 | 192 |
| BPLHR | AV | harm. | 590 | 417 | 377 | 625 | 437 | 217 | 287 |
| BPLHR | Indef. | harm. | - | - | - | - | - | - | - |
| BGD | AV | harm. | 331 | 305 | 356 | 666 | 509 | 481 | 443 |
| BGD | Indef. | harm. | 230 | 818 | 837 | - | - | - | - |
Table 6.2: Iteration numbers required by different eigensolvers to converge to 20 eigenpairs of the 2D FD Laplacian closest to the shifts σ ; '-' corresponds to the cases where no convergence was reached within 1000 iteration; n = 16 129. , The AV and indefinite preconditioners are given by Algorithms 4 and 5, respectively.
Table 6.3: Mesh independence of the BPLHR algorithm with the MG AV preconditioner [35] for the 2D FD Laplacian. The mesh parameter is given by h = 1 (2 / ω +1). Four eigenpairs corresponding to the eigenvalues closest to σ = 400 are computed.
| ω | 6 | 7 | 8 | 9 |
|--------------|-----|-----|-----|-----|
| # iterations | 41 | 42 | 43 | 42 |
deterioration of the MG solves for | L -σI | and L -σI in Algorithms 4 and 5. Therefore, the observed shift robustness of BPLHR indicates that the method is more stable with respect to the loss of preconditioning quality compared to the other methods tested. Remarkably, as σ increases, the number of BPLHR iterations does not grow too fast.
In Table 6.2 we report a similar experiment, where the number k of targeted eigenpairs has been increased to 20; the maximum size of the BGD search subspace is set to 126. The range of shifts is between 800 and 1400. Again, we can see that BPLHR was able to converge for all values of σ and in most cases exhibited the lowest iteration count. The schemes based on BPLHR and BGD with the indefinite MG preconditioning failed to provide satisfactory convergence. We relate it to a deteriorated quality of the INV-MG preconditioner in Algorithm 5 for larger shift values. In particular, this shows that the AV preconditioning is more robust if the targeted eigenpairs are deeper in the spectrum's interior. Also, note that the increased block size, compared to the case in Table 6.1, allows PLHR to handle larger values of σ , due to the corresponding increase of the size of the trial subspaces.
It was demonstrated in [35] that, in the context of solving linear systems ( L -σI w ) = r , the MG AV preconditioner in Algorithm 4 leads to a mesh-independent convergence of an iterative solver. In Table 6.3, we show that this property also holds if the same AV preconditioning is combined with the BPLHR scheme for computing interior eigenpairs. In particular, we decrease the mesh size h = 1 (2 / ω +1) by varying the parameter ω between 6 and 9, and observe that the number of steps required to obtain the residual norm of 10 -4 is about the same for each run. Here, in order to mitigate the effects of deflation, we compute fewer ( k = 4) eigenpairs. The shift σ is set to 400.
6.3. Interior eigenpairs of the Kohn-Sham Hamiltonians. In this concluding set of experiments we apply BPLHR to several Hermitian matrices that arise
in the context of electronic structure calculations. These matrices correspond to plane wave discretizations of the Hamiltonian operators in the framework of the Kohn-Sham (KS) density functional theory [17]. All tests are performed within the KSSOLV package [41]-a matlab toolbox for solving the KS equations.
Fig. 6.4: Parts of spectra of the Hamiltonian matrices.
We consider three model systems of particles: the silane (SiH2) and planar singlet silysilylene (Si2H4) molecules, and a carbon nanotube (Ctube661). For each system, we set up the corresponding KS equations, which give a nonlinear eigenvalue problem. The problem is discretized and then solved using a self-consistent field iteration. As a result of this iteration, the nonlinear operator (Hamiltonian) of the discrete KS problem converges to a matrix which represents the Hamiltonian for the converged electron density. The spectrum of this converged Hamiltonian describes the electronic structure of the underlying system. Its eigenvalues represent different energy levels and the eigenvectors define the associated wavefunctions, or orbitals.
In our tests, we are interested in computing interior eigenpairs of the converged Hamiltonians corresponding to the three model systems. In particular, for each problem, we would like to compare the convergence of the BPLHR algorithm to that of BGD, where the schemes are applied to find k eigenpairs around a given shift σ . Throughout, we let k be equal to 10, i.e., ten eigenpairs closest to σ are sought in every test. Since the Hamiltonians are complex, all our computations are performed in the complex arithmetic, i.e., Algorithm 2 is employed.
We use the Teter-Payne-Allan preconditioner developed in [32]. This preconditioning approach is known to be effective for eigenvalue computations in the context of the plane wave electronic structure analysis, and is readily available in KSSOLV. Although the preconditioner is more commonly used for computing a number of lowest eigenpairs, it can also be applied to the interior eigenvalue computations provided that the targeted eigenvalues are not too deep inside the spectrum. For example, combining the preconditioning of [32] with a (block) Davidson algorithm based on the harmonic extraction was suggested for computing interior eigenpairs in [12]. The BGD scheme used in this section is similar to this approach.
The preconditioner in [32] represents a diagonal matrix with positive entries. Hence, the preconditioning is SPD and its application is extremely fast. This is especially beneficial for the BPLHR algorithm, where additional preconditioning operations are needed to accomplish the T -harmonic extraction. Since the cost of the diagonal preconditioning is negligible, the total cost of each BPLHR iteration is dominated by two matrix-block multiplications. The similar consideration applies to the
BGD algorithm, whose iteration cost is dominated by a single matrix-block product.
Following the discussion in the preceding subsection, we choose the restart parameter in BGD to be at least 6 k = 60. In this case BGD and BPLHR have the same memory requirement. In some of our tests, however, we will allow BGD to construct search subspaces that are larger than 60. For this reason, in order to distinguish between different subspace sizes, let us denote each BGD run by 'BGD( m max )', where m max specifies the corresponding restart parameter.
As previously, in order to address the effects of the T -harmonic extraction, we also consider the BPLHR variant with a standard harmonic RR procedure. It is combined with exactly the same SPD diagonal preconditioner [32] as the one used in BPLHR and BGD.
To discretize the three model Hamiltonians, we use the energy cut-off of 75 Ry for the SiH4 and Si2H4 systems, and 25 Ry for the carbon tube. This leads to the eigenvalue problems of size n = 11 019 (for SiH4 and Si2H4) and , n = 12 599 (for , Ctube661). The parts of spectrum that we are interested in for each of the three Hamiltonian matrices are plotted in Figure 6.4.
Iteration number, i
Fig. 6.5: Computing 10 eigenpairs closest to σ = 0 5 (left) and . σ = 0 8 (right) of the . converged Hamiltonian of the SiH4 system; n = 11 019. ,
Figure 6.5 shows the convergence of the three schemes for the SiH4 example. Here and below, we assess the convergence by monitoring the largest residual norm in the block. Note that in our experiments all the 10 targeted pairs converge essentially at the same rate. Therefore, tracking only the largest norm is indicative of the convergence behavior of each eigenpair in the block.
It can be seen from Figure 6.5 that for both shifts, σ = 0 5 (left) and . σ = 0 8 . (right), the BPLHR algorithm results in almost a three times reduction in the number of iterations compared to BGD. Even though each BPLHR iteration is (roughly) twice as expensive as the BGD step, the overall decrease of the computational work is evident. Additionally, note that the BGD run in Figure 6.5 (right) requires more memory than BPLHR, i.e., BPLHR gives a faster convergence while consuming less storage. Our experiments below will make this observation yet more pronounced.
We can see from Figure 6.5 (left) that the introduction of the T -harmonic projection results in a minor improvement of the convergence for σ = 0 5. . In this case, the number of BPLHR iterations is only slightly decreased compared to its version with the standard harmonic RR. However, for the larger shift ( σ = 0 8) in Figure 6.5 (right) .
the situation is substantially different. The T -harmonic projection in BPLHR allows reducing the iteration count by more than a factor of two. Thus, the T -harmonic RR procedure makes the scheme less sensitive to the choice of the shift and more stable with respect to deterioration of the preconditioning quality. Note that this is consistent with our observations in the previous subsections.
Iteration number, i
Fig. 6.6: Computing 10 eigenpairs closest to σ = 0 5 (left) and . σ = 0 7 (right) of the . converged Hamiltonian of the Si2H4 system; n = 11 019. ,
In Figure 6.6, we apply the eigensolvers to the Hamiltonian of the Si2H4 system. The targeted energy shifts are σ = 0 5 (left) and . σ = 0 7 (right). . In both cases, the BPLHR algorithm gives the smallest iteration count and a significant decrease of the overall computational work. For example, we can see around 4 time reduction in the number of iterations compared to BGD. The impact of the T -harmonic projection on the BPLHR convergence can be observed by comparing the method with its variant based on the standard harmonic RR. Similar to the previous test, note that BGD requires more memory than the BPLHR schemes.
Fig. 6.7: Commuting 10 eigenpairs closest to σ = -0 25 (left) and . σ = 0 (right) of the converged Hamiltonian of the carbon tube; n = 12 599. ,
Our last experiment for the carbon tube is presented in Figure 6.7. In this example, the BPLHR algorithm is the only scheme that is able to reach convergence
of the eigenpairs near the shift σ = -0 25 (left) and . σ = 0 (right). Remarkably, the BGD search subspaces are allowed to be 3 to 5 times larger than the BPLHR trial subspaces. Nevertheless, the increased memory consumption does not allow BGD to maintain the convergence, whereas the BPLHR algorithm computes the solution with a much tighter storage. The example also clearly demonstrates the importance of the T -harmonic RR. Substituting the procedure by the standard harmonic RR leads to the loss of convergence.
- 7. Conclusions. Wehave presented the Preconditioned Locally Harmonic Residual (PLHR) algorithm for computing interior eigenpairs closest to the shift σ . The method represents a preconditioned four-term recurrence and can be easily extended to the block case (BPLHR). It is equally applicable to the standard and generalized eigenvalue problems. The algorithm is based on the T -harmonic RR procedure, and does not require shift-and-invert or folded spectrum transformations.
The proposed approach has been tested for a number of model problems, including the Laplacian and Hamiltonian (arising from the density functional theory based electronic structure calculations) matrices. (B)PLHR has been shown to exhibit a lower sensitivity to the preconditioning quality and has been able to maintain convergence under stringent memory requirements.
A possible limitation of the method is given by the need to provide an HPD AV preconditioner. However, as demonstrated in the paper, such preconditioners are available for a number of important applications, such as the plane wave electronic structure calculations. In the case where an AV preconditioner is unavailable, one can use the algorithm version with the standard harmonic RR instead of the proposed T -harmonic scheme. However, we anticipate that the (B)PLHR approach would greatly benefit from further progress in developing efficient AV preconditioning techniques.
Appendix A. The AV-MG and INV-MG preconditioners. The idea behind the AV-MG preconditioner is to apply the formal MG V-cycle to the system | L -σI w | = r , where L is the Laplacian operator. A hierarchy of grids is introduced, and at each level l the corresponding absolute value operator | L l -σI l | is approximated by some B l . At finer grids, B l is chosen to be simply the Laplacian, i.e., B l = L l , whereas at coarser levels polynomial approximations are employed, so that B l = p m ( L l -σI l ), where m is a given degree of the polynomial. The (Richardson's) smoothing is performed with respect to B l . The restriction and prolongation are carried out in a standard way. The actual construction of | L -σI | appears only on the coarsest level, where the coarse grid solve is performed. The whole scheme is summarized in Algorithm 4. For more detail we refer the reader to [35].
The INV-MG preconditioner represents a standard V -cycle for system ( L -σI w ) = r and results in an indefinite preconditioner. The preconditioning scheme is stated in Algorithm 5. Note that, in this paper, the choice of the main MG components, such as smoothers, restriction and prolongation operators, for Algorithm 5 is identical to AV-MG in Algorithm 4.
## REFERENCES
- [1] O. Axelsson , Iterative solution methods , Cambridge University Press, New York, NY, 1994.
- [2] Z. Bai, J. Demmel, J. Dongarra, A. Ruhe, and H. van der Vorst , eds., Templates for the solution of algebraic eigenvalue problems , Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2000.
- [3] A. Borz` ı and G. Borz` ı , Algebraic multigrid methods for solving generalized eigenvalue problems , Int. J. Numer. Meth. Engng., 65 (2005), pp. 1186-1196.
## Algorithm 4: AV-MG( r l ): the MG AV preconditioner
Input :
The residual r l ; parameters δ , ν , and m
; - 1 ;
Output :
w l ≈ | L l - I l | r l
- 1: Set B l = L l if √ σh l < δ . Otherwise define B l as a polynomial approximation p m ( L l -σI l ) of | L l -σI l | , where m is the degree of the polynomial.
- 2: Presmoothing . Apply ν smoothing steps, ν ≥ 1:
$$w _ { l } ^ { ( i + 1 ) } = w _ { l } ^ { ( i ) } + M _ { l } ^ { - 1 } ( r _ { l } - B _ { l } w _ { l } ^ { ( i ) } ), \ i = 0, \dots, \nu - 1, \ w _ { l } ^ { ( 0 ) } = 0,$$
where M l defines a smoother on level l . Set w pre l = w ( ν ) l .
- 3: Coarse grid correction . Restrict ( R l -1 ) r l -B w l pre l to the grid l -1, recursively apply AV-MG, and prolongate ( P l ) back to the fine grid. This delivers the coarse grid correction added to w pre l :
$$w _ { l - 1 } = \begin{cases} \ | L _ { 0 } - \sigma I _ { 0 } | ^ { - 1 } \, R _ { 0 } \, ( r _ { 1 } - B _ { 1 } w _ { 1 } ^ { p r e } ) \,, & l = 1, \\ \text{AV-MG} \, ( R _ { l - 1 } \, ( r _ { l } - B _ { l } w _ { l } ^ { p r e } ) ) \,, & l > 1 ; \end{cases}$$
$$w _ { l } ^ { c g c } = w _ { l } ^ { p r e } + P _ { l } w _ { l - 1 }.$$
- 4: Postsmoothing . Apply ν smoothing steps:
$$( \text{A.1} ) \quad \ \ w _ { l } ^ { ( i + 1 ) } = w _ { l } ^ { ( i ) } + M _ { l } ^ { - * } ( r _ { l } - B _ { l } w _ { l } ^ { ( i ) } ), \ i = 0, \dots, \nu - 1, \ w _ { l } ^ { ( 0 ) } = w _ { l } ^ { c g c },$$
$$\text{ where } M _ { l } \text{ and } \nu _ { l } \text{ are the same as in step 2. Return } w _ { l } = w _ { l } ^ { p o s t } = w _ { l } ^ { ( \nu ) }.$$
## Algorithm 5: INV-MG( r l ): the MG preconditioner
Input :
The residual r l ; ν ;
Output :
w l ≈ ( L l - I l ) - 1 r l ;
- 1: Presmoothing . Apply ν smoothing steps, ν ≥ 1:
$$w _ { l } ^ { ( i + 1 ) } = w _ { l } ^ { ( i ) } + M _ { l } ^ { - 1 } ( r _ { l } - ( L _ { l } - \sigma I _ { l } ) w _ { l } ^ { ( i ) } ), \ i = 0, \dots, \nu - 1, \ w _ { l } ^ { ( 0 ) } = 0,$$
where M l defines a smoother on level l . Set w pre l = w ( ν ) l .
- 2: Coarse grid correction . Restrict ( R l -1 ) r l -( L l -σI l ) w pre l to the grid l -1, recursively apply INV-MG, and prolongate ( P l ) back to the fine grid. This delivers the coarse grid correction added to w pre l :
$$w _ { l - 1 } = \begin{cases} \ ( L _ { 0 } - \sigma I _ { 0 } ) ^ { - 1 } \, R _ { 0 } \, ( r _ { 1 } - B _ { 1 } w _ { 1 } ^ { p r e } ) \,, & l = 1, \\ \ A V { \text{-MG} } \, ( R _ { l - 1 } \, ( r _ { l } - ( L _ { l } - \sigma I _ { l } ) w _ { l } ^ { p r e } ) \, ) \,, & l > 1 ; \end{cases}$$
$$w _ { l } ^ { c g c } = w _ { l } ^ { p r e } + P _ { l } w _ { l - 1 }.$$
- 3: Postsmoothing . Apply ν smoothing steps:
$$w _ { l } ^ { ( i + 1 ) } = w _ { l } ^ { ( i ) } + M _ { l } ^ { - * } ( r _ { l } - ( L _ { l } - \sigma I _ { l } ) w _ { l } ^ { ( i ) } ), \ i = 0, \dots, \nu - 1, \ w _ { l } ^ { ( 0 ) } = w _ { l } ^ { e g c },$$
where M l and ν l are the same as in step 2. Return w l = w post l = w ( ν ) l .
- [4] W. L. Briggs, V. E. Henson, and S. F. McCormick , A Multigrid Tutorial , Society for Industrial and Applied Mathematics, 2nd ed., 2000.
- [5] H. C. Elman, O. G. Ernst, and D. O'Leary , A multigrid method enhanced by Krylov subspace iteration for discrete Helmholtz equations , SIAM J. Sci. Comput., 23 (2001), pp. 1291-1315.
- [6] H. Fang and Y. Saad , A filtered Lanczos procedure for extreme and interior eigenvalue problems , SIAM J. Sci. Comput., 34 (2012), pp. A2220-A2246.
- [7] G. H. Golub and C. F. V. Loan , Matrix Computations , The Johns Hopkins University Press, 3d ed., 1996.
- [8] G. H. Golub and Q. Ye , An inverse free preconditioned Krylov subspace method for symmetric generalized eigenvalue problems , SIAM J. Sci. Comput., 24 (2002), pp. 312-334.
- [9] A. Greenbaum , Iterative Methods for Solving Linear Systems , SIAM, 1997.
- [10] U. Hetmaniuk , A Rayleigh quotient minimization algorithm based on algebraic multigrid , Numer. Linear Algebra Appl., 14 (2007), pp. 563-580.
- [11] Z. Jia , Refined iterative algorithms based on Arnoldi's process for large unsymmetric eigenproblems , Linear Algebra and its Applications, 259 (1997), pp. 1-23.
- [12] G. Jordan, M. Marsman, Y.-S. Kim, and G. Kresse , Fast iterative interior eigensolver for millions of atoms , J. Comput. Phys., 231 (2012), pp. 4836-4847.
- [13] A. V. Knyazev , Computation of eigenvalues and eigenvectors for mesh problems: algorithms and error estimates , Dept. Numerical Math. USSR Academy of Sciences, Moscow, 1986. (In Russian).
- [14] A. V. Knyazev , Preconditioned eigensolvers - an oxymoron? , Electronic Transactions on Numerical Analysis, 7 (1998), pp. 104-123.
- [15] A. V. Knyazev , Toward the optimal preconditioned eigensolver: locally optimal block preconditioned conjugate gradient method , SIAM Journal on Scientific Computing, 23 (2001), pp. 517-541.
- [16] A. V. Knyazev, M. E. Argentati, I. Lashuk, and E. E. Ovtchinnikov , Block locally optimal preconditioned eigenvalue xolvers (BLOPEX) in hypre and PETSc , SIAM Journal on Scientific Computing, 25 (2007), pp. 2224-2239.
- [17] W. Kohn and L. Sham , Self-consistent equations including exchange and correlation effects , Phys. Rev., 140 (1965), pp. A1133-A1138.
- [18] G. Kresse and J. Furthm¨ller u , Efficiency of ab-initio total energy calculations for metals and semiconductors using a plane-wave basis set , Computational Materials Science, 6 (1996), pp. 15-50.
- [19] D. Kushnir, M. Galun, and A. Brandt , Efficient multilevel eigensolvers with applications to data analysis tasks , IEEE Trans. Pattern. Anal. Mach. Intell., 32 (2010), pp. 1377-1391.
- [20] I. Livshits , An algebraic multigrid wave-ray algorithm to solve eigenvalue problems for the Helmholtz operator , Numer. Linear Algebra Appl., 11 (2004), pp. 229-239.
- [21] I. Livshits and A. Brandt , Accuracy properties of the wave-ray multigrid algorithm for Helmholtz equations , SIAM J. on Sci. Comput., 28 (2006), pp. 1228-1251.
- [22] R. B. Morgan , Computing interior eigenvalues of large matrices , Linear Algebra Appl., 154156 (1991), pp. 289-309.
- [23] R. B. Morgan and M. Zeng , Harmonic projection methods for large non-symmetric eigenvalue problems , Numer. Linear Algebra Appl., 5 (1998), pp. 33-55.
- [24] C. C. Paige, B. N. Parlett, and H. A. van der Vorst , Approximate solutions and eigenvalue bounds from krylov subspaces , Numer. Linear Algebra Appl., 2 (1995), pp. 115-133.
- [25] C. C. Paige and M. A. Saunders , Solution of sparse indefinite systems of linear equations , SIAM Journal on Numerical Analysis, 12 (1975), pp. 617-629.
- [26] B. N. Parlett , The symmetric eigenvalue problem , vol. 20 of Classics in Applied Mathematics, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 1998. Corrected reprint of the 1980 original.
- [27] Y. Saad , Iterative Methods for Sparse Linear Systems , SIAM, Philadelpha, PA, 2003.
- [28] Y. Saad , Numerical Methods for Large Eigenvalue Problems- classics edition , SIAM, Philadelpha, PA, 2011.
- [29] T. SAKURAI and H. TADANO , Cirr: a rayleigh-ritz type method with contour integral for
- generalized eigenvalue problems , Hokkaido Mathematical Journal, 36 (2007), pp. 745-757. A Jacobi-Davidson Iteration Method for LinSIAM Journal on Matrix Analysis and Applications, 17 (1996),
- [30] G. L. G. Sleijpen and H. A. V. der Vorst , ear Eigenvalue Problems , pp. 401-425.
- [31] G. W. Stewart , Matrix algorithms. Vol. II , SIAM, Philadelpha, PA, 2001.
- [32] M. P. Teter, M. C. Payne, and D. C. Allan , Solution of Schr¨dinger's equation for large o systems , Physical Review B, 40 (1989), pp. 12255-12263.
- [33] U. Trottenberg, C. W. Oosterlee, and A. Sch¨ller u , Multigrid , Academic Press, 2001.
- [34] E. Vecharynski , Preconditioned Iterative Methods for Linear Systems, Eigenvalue and Singular Value Problems . PhD thesis, University of Colorado Denver, 2011.
- [35] E. Vecharynski and A. V. Knyazev , Absolute value preconditioning for symmetric indefinite linear systems , SIAM J. Sci. Comput., 35 (2013), pp. A696-A718.
- [36] C. V¨mel o , A note on harmonic Ritz values and their reciprocals , Numer. Linear Algebra Appl., 17 (2010), pp. 97-108.
- [37] L. W. Wang and J. Li , First-principles thousand-atom quantum dot calculations , Phys. Rev. B, 69 (2004), p. 153302.
- [38] L. W. Wang and A. Zunger , Local-density-derived semiempirical pseudopotentials , Phys. Rev. B, 51 (1995), pp. 17398-17416.
- [39] , Linear combination of bulk bands method for large-scale electronic structure calculations on strained nanostructures , Phys. Rev. B, 59 (1999), pp. 15806-15818.
- [40] D. Wood and A. Zunger , A new method for diagonalising large matrices , Journal of Physics A: Mathematical and General, 18 (1985), p. 1343.
- [41] C. Yang, J. Meza, B. Lee, and L.-W. Wang , KSSOLV-a MATLAB toolbox for solving the Kohn-Sham equations , ACM Trans. Math. Softw., 36 (2009), pp. 10:1-10:35.
- [42] D. M. Young and K. C. Jea , Generalized conjugate-gradient acceleration of nonsymmetrizable iterative methods , Linear Algebra and its Applications, 34 (1980), pp. 159-194. | 10.1137/14098048X | [
"Eugene Vecharynski",
"Andrew Knyazev"
] | 2014-07-31T23:27:09+00:00 | 2014-11-13T18:03:17+00:00 | [
"math.NA"
] | Preconditioned Locally Harmonic Residual Method for Computing Interior Eigenpairs of Certain Classes of Hermitian Matrices | We propose a Preconditioned Locally Harmonic Residual (PLHR) method for
computing several interior eigenpairs of a generalized Hermitian eigenvalue
problem, without traditional spectral transformations, matrix factorizations,
or inversions. PLHR is based on a short-term recurrence, easily extended to a
block form, computing eigenpairs simultaneously. PLHR can take advantage of
Hermitian positive definite preconditioning, e.g., based on an approximate
inverse of an absolute value of a shifted matrix, introduced in [SISC, 35
(2013), pp. A696-A718]. Our numerical experiments demonstrate that PLHR is
efficient and robust for certain classes of large-scale interior eigenvalue
problems, involving Laplacian and Hamiltonian operators, especially if memory
requirements are tight. |
1408.0043v1 | ## Learning From Ordered Sets and Applications in Collaborative Ranking
Truyen Tran †‡ , Dinh Phung , Svetha Venkatesh † † † Pattern Recognition and Data Analytics, Deakin University, Australia ‡ Department of Computing, Curtin University, Australia { truyen.tran,dinh.phung,svetha.venkatesh } @deakin.edu.au
## Abstract
Ranking over sets arise when users choose between groups of items. For example, a group may be of those movies deemed 5 stars to them, or a customized tour package. It turns out, to model this data type properly, we need to investigate the general combinatorics problem of partitioning a set and ordering the subsets. Here we construct a probabilistic log-linear model over a set of ordered subsets. Inference in this combinatorial space is highly challenging: The space size approaches ( N / ! 2)6 93145 . N +1 as N approaches infinity. We propose a split-and-merge Metropolis-Hastings procedure that can explore the statespace efficiently. For discovering hidden aspects in the data, we enrich the model with latent binary variables so that the posteriors can be efficiently evaluated. Finally, we evaluate the proposed model on large-scale collaborative filtering tasks and demonstrate that it is competitive against state-of-the-art methods.
## 1 Introduction
Rank data has recently generated a considerable interest within the machine learning community, as evidenced in ranking labels [7, 21] and ranking data instances [5, 23]. The problem is often cast as generating a list of objects (e.g., labels, documents) which are arranged in decreasing order of relevance with respect to some query (e.g., input features, keywords). The treatment effectively ignores the grouping property of compatible objects [22]. This phenomenon occurs when some objects are likely to be grouped with some others in certain ways. For example, a grocery basket is likely to contain a variety of goods which are complementary for household needs and at the same time, satisfy weekly budget constraints. Likewise, a set of movies are likely to given the same quality rating according to a particular user. In these situations, it is better to consider ranking groups instead of individual objects. It is beneficial not only when we need to recommend a subset (as in the case of grocery shopping), but also when we just want to produce a ranked list (as in the case of watching movies) because we would better exploit the compatibility among grouped items.
This poses a question of how to group individual objects into subsets given a list of all possible objects. Unlike the situation when the subsets are pre-defined and fixed (e.g., sport teams in a particular season), here we need to explore the space of set partitioning and ordering simultaneously. In the grocery example we need to partition the stocks in the store into baskets and then rank them with respect to their utilities; and in the movie rating example we group
movies in the same quality-package and then rank these groups according to their given ratings. The situation is somewhat related to multilabel learning, where our goal is to produce a subset of labels out of many for a given input, but it is inherently more complicated: not only we need to produce all subsets, but also to rank them.
This paper introduces a probabilistic model for this type of situations, i.e., we want to learn the statistical patterns from which a set of objects is partitioned and ordered, and to compute the probability of any scheme of partitioning and ordering. In particular, the model imposes a log-linear distribution over the joint events of partitioning and ordering. It turns out, however, that the state-space is prohibitively large: If the space of complete ranking has the complexity of N ! for N objects, then the space of partitioning a set and ordering approaches ( N / ! 2)6 93145 . N +1 in size as N approaches infinity [11, pp. 396-397]. Clearly, the latter grows much faster than the former by an exponential factor of 6 93145 . N +1 . To manage the exploration of this space, we design a split-and-merge Metropolis-Hastings procedure which iteratively visits all possible ways of partitioning and ordering. The procedure randomly alternates between the split move, where a subset is split into two consecutive parts, and the merge move, where two consecutive subsets are merged. The proposed model is termed Ordered Sets Model (OSM).
To discover hidden aspects in ordered sets (e.g., latent aspects that capture the taste of a user in his or her movie genre), we further introduce binary latent variables in a fashion similar to that of restricted Boltzmann machines (RBMs) [18]. The posteriors of hidden units given the visible rank data can be used as a vectorial representation of the data - this can be handy in tasks such as computing distance measures or visualisation. This results in a new model called Latent OSM.
Finally, we show how the proposed Latent OSM can be applied for collaborative filtering, e.g., when we need to take seen grouped item ratings as input and produce a ranked list of unseen item for each user. We then demonstrate and evaluate our model on large-scale public datasets. The experiments show that our approach is competitive against several state-of-the-art methods.
The rest of the paper is organised as follows. Section 2 presents the log-linear model over ordered sets (OSM) together with our main contribution - the split-and-merge procedure. Section 3 introduces Latent OSM, which extends the OSM to incorporate latent variables in the form of a set of binary factors. An application of the proposed Latent OSM for collaborative filtering is described in Section 4. Related work is reviewed in the next section, followed by the conclusions.
## 2 Ordered Set Log-linear Models
## 2.1 General Description
We first present an intuitive description of the problem and our solutions in modelling, learning and inference. Fig. 1(a) depicts the problem of grouping items into subsets (represented by a box of circles) and ordering these subsets (represented by arrows which indicate the ordering directions). This looks like a high-order Markov chain in a standard setting, and thus it is tempting to impose a chain-based distribution. However, the difficulty is that the partitioning of set into subsets is also random, and thus a simple treatment is not applicable. Recently, Truyen et al (2011) describe a model in this direction with a careful treatment of the partitioning effect. However, their model does not allow fast inference since we need to take care of the high-order properties.
Figure 1: (a) Ordered Set Model; (b) the split operator; and (c) the merge operator. The figure in (c) represents the result of a merge of the middle two subsets in (b). Conversely, the (b) figure can be considered as result of a splitting the middle subset of the (c) figure. Arrows represent the preference orders, not the causality or conditioning.
Our solution is as follows. To capture the grouping and relative ordering, we impose on each group a subset potential function capturing the relations among compatible elements, and on each pair of subsets a ordering potential function. The distribution over the space of grouping and ordering is defined using a log-linear model, where the product of all potentials accounts for the unnormalised probability. This log-linear parameterization allows flexible inference in the combinatorial space of all possible groupings and orderings.
In this paper inference is carried out in a MCMC manner. At each step, we randomly choose a split or a merge operator. The split operator takes a subset at random (e.g., Fig. 1(c)) and uniformly splits it into two smaller subsets. The order between these two smaller subset is also random, but their relative positions with respect to other subsets remain unchanged (e.g., Fig. 1(b)). The merge operator is the reverse (e.g., converting Fig. 1(b) into Fig. 1(c)). With an appropriate acceptance probability, this procedure is guaranteed to explore the entire combinatorial space.
Armed with this sampling procedure, learning can be carried out using stochastic gradient techniques [25].
## 2.2 Problem Description
Given two objects x i and x j , we use the notation x i glyph[follows] x j to denote the expression of x i is ranked higher than x j , and x i ∼ x j to denote the between the two belongs to the same group. Furthermore, we use the notation of X = { x , x 1 2 , . . . , x N } as a collection of N objects. Assume that X is partitioned into T subsets { X t } T t =1 . However, unlike usual notion of partitioning of a set, we further posit an order among these subsets in which members of each subset presumably share the same rank. Therefore, our partitioning process is order-sensitive instead of being exchangeable at the partition level. Specifically, we use the indices 1 2 , , ..., T to denote the decreasing order in the rank of subsets. These notations allow us to write the collection of objects X = { x , . . . , x 1 N } as a union of T ordered subsets: 1
$$X = \ X _ { 1 } \cup X _ { 2 } \dots \cup X _ { T }$$
glyph[negationslash]
where { X t } T t =1 are non-empty subsets of objects so that x i ∼ x , j ∀ x , x i j ∈ X i t = j, ∀ t .
1 Alternatively, we could have proceeded from the permutation perspective to indicate the ordering of the subsets, but we simplify the notation here for clarity.
As a special case when T = N , we obtain an exhaustive ordering among objects wherein each subset has exactly one element and there is no grouping among objects. This special case is equivalent with a complete ranking scenario. To illustrate the complexity of the problem, let us characterise the state-space, or more precisely, the number of all possible ways of partitioning and ordering governed by the above definition. Recall that there are s ( N,T ) ways to divide a set of N objects into T partitions, where s ( N,T ) denotes the Stirling numbers of second kind [20, p. 105]. Therefore, for each pair ( N,T ), there are s ( N,T ) T ! ways to perform the partitioning with ordering. Considering all the possible values of T give us the size of our model state-space:
$$\sum _ { T = 1 } ^ { N } s \left ( N, T \right ) T! \ = \ F u b { i } { \left ( N \right ) } = \sum _ { k = 1 } ^ { \infty } \frac { k ^ { N } } { 2 ^ { k + 1 } }$$
which is also known in combinatorics as the Fubini's number [11, pp. 396-397]. This number grows super-exponentially and it is known that it approaches N / ! (2 (log 2) N +1 ) as N →∞ [11, pp. 396-397]. Taking the logarithm, we get log N ! -( N +1)loglog 2 -log 2. As log log 2 < 0, this clearly grows faster than log N !, which is the log of the size of the standard complete permutations.
## 2.3 Model Specification
Denote by Φ( X t ) ∈ R + a positive potential function over a single subset 2 X t and by Ψ( X t glyph[follows] X t ′ ) ∈ R + a potential function over a ordered pair of subsets ( X , X t t ′ ) where t < t ′ . Our intention is to use Φ( X t ) to encode the compatibility among all member of X t , and Ψ( X t glyph[follows] X t ′ ) to encode the ordering properties between X t and X t ′ . We then impose a distribution over the collection of objects as:
$$P ( X ) \ = \ \frac { 1 } { Z } \Omega ( X ), \quad \text{ where } \Omega ( X ) = \prod _ { t } \Phi ( X _ { t } ) \prod _ { t ^ { \prime } > t } \Psi ( X _ { t } \succ X _ { t ^ { \prime } } ) \quad \quad ( 3 )$$
and Z = ∑ X Ω( X ) is the partition function. We further posit the following factorisation for the potential functions:
$$\Phi ( X _ { t } ) \ = \ \prod _ { i, j \in X _ { t } | j > i } \varphi ( x _ { i } \sim x _ { j } ) ; \quad \ \Psi ( X _ { t } \succ X _ { t ^ { \prime } } ) = \prod _ { i \in X _ { t } \ j \in X _ { t ^ { \prime } } } \psi ( x _ { i } \succ x _ { j } ) \quad ( 4 )$$
where ϕ x ( i ∼ x j ) ∈ R + captures the effect of grouping , and ψ x ( i glyph[follows] x j ) ∈ R + captures the relative ordering between objects x i and x j . Hereafter, we shall refer to this proposed model as the Ordered Set Model (OSM).
## 2.4 Split-and-Merge MCMC Inference
In order to evaluate P X ( ) we need to sum over all possible configurations of X which is in the complexity of the Fubini( N ) over the set of N objects (cf. Section 2.2, Eq. 2). We develop a Metropolis-Hastings (MH) procedure for sampling P X ( ). Recall that the MH sampling involves
2 In this paper, we do not consider the case of empty sets, but it can be assumed that φ ( ∅ ) = 1.
a proposal distribution Q that allows drawing a new sample X ′ from the current state X with probability Q X X ( ′ | ). The move is then accepted with probability
$$P _ { \text{accept} } = \min \left \{ 1, l \times p \right \}, \quad \text{ where } l = \frac { P ( X ^ { \prime } ) } { P ( X ) } = \frac { \Omega ( X ^ { \prime } ) } { \Omega ( X ) } \text{ and } p = \frac { Q ( X | X ^ { \prime } ) } { Q ( X ^ { \prime } | X ) } \text{ \quad \ } ( 5 )$$
To evaluate the likelihood ratio l we use the model specification defined in Eq (3). We then need to compute the proposal probability ratio p . The key intuition is to design a random local move from X to X ′ that makes a relatively small change to the current partitioning and ordering. If the change is large, then the rejection rate is high, thus leading to high cost (typically the computational cost increases with the step size of the local moves). On the other hand, if the change is small, then the random walks will explore the state-space too slowly.
We propose two operators to enable the proposal move: the split operator takes a nonsingleton subset X t and randomly splits it into two sub-subsets { X ,X 1 t 2 t } , where X 2 t is inserted right next to X 1 t ; and the merge operator takes two consecutive subsets { X , X t t +1 } and merges them. This dual procedure will guarantee exploration of all possible configurations of partitioning and ordering, given enough time (See Figure 1 for an illustration).
## 2.4.1 Split Operator
Assume that among the T subsets, there are T split non-singleton subsets from which we randomly select one subset to split, and let this be X t . Since we want the resulting sub-subsets to be non-empty, we first randomly draw two distinct objects from X t and place them into the two subsets. Then, for each remaining object, there is an equal chance going to either X 1 t or X 2 t . Let N t = | X t | , the probability of this drawing is ( N N t ( t -1)2 N t -2 ) -1 . Since the probability that these two sub-subsets will be merged back is T -1 , the proposal probability ratio p split can be computed as in Eq (6). Since our potential functions depend only on the relative orders between subsets and between objects in the same set, the likelihood ratio l split due to the split operator does not depend on other subsets, it can be given as in Eq (7). This is because the members of X 1 t are now ranked higher than those of X 2 t while they are of the same rank previously.
$$p _ { s p l i t } = \frac { T _ { s p l i t } N _ { t } ( N _ { t } - 1 ) 2 ^ { N _ { t } - 2 } } { T } \quad \ ( 6 ) \quad \ l _ { s p l i t } = \prod _ { x _ { i } \in X _ { i } ^ { 1 } } \prod _ { x _ { j } \in X _ { i } ^ { 2 } } \frac { \psi ( x _ { i } \succ x _ { j } ) } { \varphi ( x _ { i } \sim x _ { j } ) } \quad \ ( 7 )$$
## 2.4.2 Merge Operator
For T subsets, the probability of merging two consecutive ones will be ( T -1) -1 since there are T -1 pairs, and each pair can be merged in exactly one way. Let T merge be the number of non-singleton subsets after the merge, and let N t and N t +1 be the sizes of the two subsets X t and X t +1 , respectively. Let N ∗ t = N t + N t +1 , the probability of recovering the state before the merge (by applying the split operator) is ( T merge N ∗ t ( N ∗ t -1)2 N ∗ t -2 ) -1 . Consequently, the proposal probability ratio p merge can be given as in Eq (8), and the likelihood ratio l merge is clearly the inverse of the split case as shown in Eq (9).
$$p _ { \text{merge} } = \frac { T - 1 } { T _ { \text{merge} } N _ { t } ^ { * } ( N _ { t } ^ { * } - 1 ) 2 ^ { N _ { t } ^ { * } - 2 } } \quad ( 8 ) \quad l _ { \text{merge} } = \prod _ { x _ { i } \in X _ { t } } \prod _ { x _ { j } \in X _ { t + 1 } } \frac { \varphi ( x _ { i } \sim x _ { j } ) } { \psi ( x _ { i } \succ x _ { j } ) } \quad ( 9 )$$
Algorithm 1 Pseudo-code of the split-and-merge Metropolis-Hastings for OSM.
- 1. Given an initial state X .
- 2. Repeat until convergence
- 2a. Draw a random number η ∈ [0 , 1].
- 2b. If η < 0 5 . { Split }
- i. Randomly choose a non-singleton subset.
- ii. Split into two sub-subsets and insert one sub-subset right after the another.
- iii. Evaluate the acceptance probability P accept using Eqs.(6,7,5).
- iv. Accept the move with probability P accept .
## Else { Merge }
- i. Randomly choose two consecutive subsets.
- ii. Merge them in one, keeping the relative orders with other subsets unchanged.
- iii. Evaluate the acceptance probability P accept using Eqs.(8,9,5).
- iv. Accept the move with probability P accept .
## End
## End
Finally, the pseudo-code of the split-and-merge Metropolis-Hastings procedure for the OSM is presented in Algorithm 1.
## 2.5 Estimating Partition Function
To estimate the normalisation constant Z , we employ an efficient procedure called Annealed Importance Sampling (AIS) proposed recently [12]. More specifically, AIS introduces the notion of inverse-temperature τ into the model, that is P X τ ( | ) ∝ Ω( X ) τ .
Let { τ s } S s =0 be the (slowly) increasing sequence of temperature, where τ 0 = 0 and τ S = 1, that is τ 0 < τ ... < τ 1 S . At τ 0 = 0, we have a uniform distribution, and at τ S = 1, we obtain the desired distribution. At each step s , we draw a sample X s from the distribution P X τ ( | s -1 ) (e.g. using the split-and-merge procedure). Let P ∗ ( X τ | ) be the unnormalised distribution of P X τ ( | ), that is P X τ ( | ) = P ∗ ( X τ /Z τ | ) ( ). The final weight after the annealing process is computed as
$$w = \frac { P ^ { * } ( X ^ { 1 } | \tau _ { 1 } ) } { P ^ { * } ( X ^ { 1 } | \tau _ { 0 } ) } \frac { P ^ { * } ( X ^ { 2 } | \tau _ { 2 } ) } { P ^ { * } ( X ^ { 2 } | \tau _ { 1 } ) }.. \frac { P ^ { * } ( X ^ { S } | \tau _ { S } ) } { P ^ { * } ( X ^ { S } | \tau _ { S - 1 } ) }$$
The above procedure is repeated R times. Finally, the normalisation constant at τ = 1 is computed as Z (1) ≈ Z (0) ( ∑ R r =1 w ( r ) /R ) where Z (0) = Fubini( N ), which is the number of configurations of the model state variables X .
## 2.6 Log-linear Parameterisation and Learning
Here we assume that the model is in the log-linear form, that is ϕ x ( i ∼ x j ) = exp { ∑ a α f a a ( x , x i j ) } and ψ x ( i glyph[follows] x j ) = exp { ∑ b β g b b ( x , x i j ) } , where { f a ( ) · , g b ( ) · } are sufficient statistics (or feature functions) and { α , β a b } are free parameters.
Figure 2: (a) A Semi-Restricted Boltzmann Machine representation of vectorial data: each shaded node represents a visible variable and empty nodes the hidden units. (b) A Latent OSM for representing ordered sets: each box represents a subset of objects.
Learning by maximising (log-)likelihood in log-linear models with respect to free parameters often leads to computing the expectation of sufficient statistics. For example, 〈 f a ( x , x i j ) 〉 P x ( i ∼ x j ) is needed in the gradient of the log-likelihood with respect to α a , where P x ( i ∼ x j ) is the pairwise marginal. Unfortunately, computing P x ( i ∼ x j ) is inherently hard, and running a full MCMC chain to estimate it is too expensive for practical purposes. Here we follow the stochastic approximation proposed in [25], in that we iteratively update parameters after very short MCMC chains (e.g., using Algorithm 1).
## 3 Introducing Latent Variables to OSMs
In this section, we further extend the proposed OSM by introducing latent variables into the model. The latent variables serve multiple purposes. For example, in collaborative filtering, each person chooses only a small subset of objects, thus the specific choice of objects and the ranking reflects personal taste. This cannot be discovered by the standard OSM. Second, if we want to measure the distance or similarity between two ordered partitioned sets, e.g. for clustering or visualisation, it may be useful to first transform the data into some vectorial representation.
## 3.1 Model Specification
Denote by h = ( h , h 1 2 , ..., h K ) ∈ { 0 1 , } K the hidden units to be used in conjunction with the ordered sets. The idea is to estimate the posterior P h ( k = 1 | X ) - the probability that the k th hidden unit will be activated by the input X . Thus, the requirement is that the model should allow the evaluation of P h ( k = 1 | X ) efficiently. Borrowing from the Restricted Boltzmann Machine architecture [18, 24], we can extend the model potential function as follows:
$$\hat { \Omega } ( X, h ) = \Omega ( X ) \prod _ { k } \Omega _ { k } ( X ) ^ { h _ { k } }$$
where Ω ( k X ) admits the similar factorisation as Ω( X ), i.e. Ω ( k X ) = ∏ t Φ ( k X t ) ∏ t >t ′ Ψ ( k X t glyph[follows] X t ′ ), and
$$\Phi _ { k } ( X _ { t } ) \ = \ \prod _ { i, j \in X _ { t } | j > i } \varphi _ { k } ( x _ { i } \sim x _ { j } ) ; \quad \Psi _ { k } ( X _ { t } \succ X _ { t ^ { \prime } } ) = \prod _ { i \in X _ { t } } \prod _ { j \in X _ { t ^ { \prime } } } \psi _ { k } ( x _ { i } \succ x _ { j } ) \quad ( 1 2 )$$
where ϕ k ( x i ∼ x j ) and ψ k ( x i glyph[follows] x j ) capture the events of tie and relative ordering between objects x i and x j under the presence of the k th hidden unit , respectively.
We then define the model with hidden variables as P X, ( h ) = ˆ ( Ω X, h ) /Z , where Z = ∑ X, h ˆ ( Ω X, h ). A graphical representation is given in Figure 2b. Hereafter, we shall refer to this proposed model as the Latent OSM.
## 3.2 Inference
The posteriors are indeed efficient to evaluate:
$$P ( h \, | \, X ) \ = \ \prod _ { k } P ( h _ { k } \, | \, X ), \ \text{ where } P ( h _ { k } = 1 \, | \, X ) = \frac { 1 } { 1 + \Omega _ { k } ( X ) ^ { - 1 } } \quad \quad ( 1 3 )$$
Denote by h 1 k as the shorthand for h k = 1, the vector ( P h ( 1 1 | X ,P h ) ( 1 2 | X ,..., P ) ( h 1 K | X )) can then be used as a latent representation of the configuration X .
The generation of X given h is, however, much more involved as we need to explore the whole subset partitioning and ordering space:
$$P ( X \, | \, h ) = \frac { \hat { \Omega } ( X, h ) } { \sum _ { X } \hat { \Omega } ( X, h ) } = \frac { \Omega ( X ) \prod _ { k } \Omega _ { k } ( X ) ^ { h _ { k } } } { \sum _ { X } \Omega ( X ) \prod _ { k } \Omega _ { k } ( X ) ^ { h _ { k } } } \quad \ ( 1 4 )$$
For inference, since we have two layers X and h , we can alternate between them in a Gibbs sampling manner, that is, sampling X from P X ( | h ) and then h from P ( h | X ). Since sampling from P ( h | X ) is straightforward, it remains to sample from P X ( | h ) = ˆ ( Ω X, h ) / ∑ X ˆ ( Ω X, h ). Since ˆ ( Ω X, h ) has the same factorisation structure into a product of pairwise potentials as Ω( X ), we can employ the split-and-merge technique described in the previous section in a similar manner.
To see how, let ˆ( ϕ x i ∼ x , j h ) = ϕ x ( i ∼ x j ) ∏ k ϕ k ( x i ∼ x j ) h k and ˆ ( ψ x i glyph[follows] x , j h ) = ψ k ( x i glyph[follows] x j ) ∏ k ψ k ( x i glyph[follows] x j ) h k , then from Eqs.(4,11,12). We can see that Ω( ˆ X, h ) is now factorised into products of ˆ( ϕ x i ∼ x , j h ) and ˆ ( ψ x i glyph[follows] x , j h ) in the same way as Ω( X ) into products of ϕ x ( i ∼ x j ) and ψ x ( i glyph[follows] x j ):
$$\hat { \Omega } ( X, h ) \ = \ \Omega ( X ) \prod _ { k } \Omega _ { k } ( X ) ^ { h _ { k } } = \prod _ { t } \hat { \Phi } ( X _ { t }, h ) \prod _ { t ^ { \prime } > t } \hat { \Psi } ( X _ { t } \succ X _ { t ^ { \prime } }, h )$$
where
$$\hat { \Phi } ( X _ { t }, h ) \ = \ \prod _ { i, j \in X _ { t } | j > i } \hat { \varphi } ( x _ { i } \sim x _ { j }, h ) ; \quad \hat { \Psi } ( X _ { t } \succ X _ { t ^ { \prime } }, h ) = \prod _ { i \in X _ { t } } \prod _ { j \in X _ { t ^ { \prime } } } \hat { \psi } ( x _ { i } \succ x _ { j }, h )$$
Estimating the normalisation constant Z can be performed using the AIS procedure described earlier (cf. Section 2.5), except that the unnormalised distribution P ∗ ( X τ | ) is given as:
$$P ^ { * } ( X \, | \, \tau ) \ = \sum _ { h } \hat { \Omega } ( X, h ) ^ { \tau } = \ \Omega ( X ) ^ { \tau } \prod _ { k } ( 1 + \Omega _ { k } ( X ) ^ { \tau } )$$
Algorithm 2 Pseudo-code of the split-and-merge Gibbs/Metropolis-Hastings for Latent OSM.
- 1. Given an initial state X . 2. Repeat until convergence 2a. Sample h from P ( h | X ) using Eq.(13). 2b. Sample X from P X ( | h ) using Eq.(14) and Algorithm 1. End End
which can be computed efficiently for each X .
For sampling X s from P X ( | τ s -1 ), one way is to sample directly from the P X ( | τ s -1 ) in a Rao-Blackwellised fashion (e.g. by marginalising over h we obtain the unnormalised P ∗ ( X τ | )). A more straightforward way is alternating between X | h and h | X as usual. Although the former would give lower variance, we implement the latter for simplicity. The remaining is similar to the case without hidden variables, and we note that the base partition function Z (0) should be modified to Z (0) = Fubini( N )2 K , taking into account of K binary hidden variables. A pseudo-code for the split-and-merge algorithm for Latent OSM is given in Algorithm 8.
## 3.3 Parameter Specification and Learning
Like the OSM, we also assume log-linear parameterisation. In addition to those potentials shared with the OSM, here we specify hidden-specific potentials as follows: ϕ k ( x i ∼ x j ) h k = exp { ∑ a λ ak f a ( x , x i j ) h k } and ψ k ( x i glyph[follows] x j ) h k = exp { ∑ b µ bk g b ( x , x i j ) h k } . Now f a ( x , x i j ) h k and g b ( x , x i j ) h k are new sufficient statistics. As before, we need to estimate the expectation of sufficient statistics, e.g., 〈 f a ( x , x i j ) h k 〉 P x ,x ,h ( i j k ) . Equipped with Algorithm 8, the stochastic gradient trick as in Section 2.6 can then be used, that is, parameters are updated after very short chains (with respect to the model distribution P X, ( h )).
## 4 Application in Collaborative Filtering
In this section, we present one specific application of our Latent OSM in collaborative filtering. Recall that in this application, each user has usually expressed their preferences over a set of items by rating them (e.g., by assigning each item a small number of stars). Since it is cumbersome to rank all the items completely, the user often joins items into groups of similar ratings. As each user often rates only a handful of items out of thousands (or even millions), this creates a sparse ordering of subsets. Our goal is to first discover the latent taste factors for each user from their given ordered subsets, and then use these factors to recommend new items for each individual.
## 4.1 Rank Reconstruction and Completion
In this application, we are limited to producing a complete ranking over objects instead of subset partitioning and ordering. Here we consider two tasks: (i) rank completion where we want to rank unseen items given a partially ranked set 3 , and (ii) rank reconstruction 4 where we want to reconstruct the complete rank ˆ from the posterior vector ( X P h ( 1 1 | X ,P h ) ( 1 2 | X .., , P ) ( h 1 K | X )).
3 This is important in recommendation, as we shall see in the experiments.
4 This would be useful in data compression setting.
Rank completion. Assume that an unseen item x j might be ranked higher than any seen item { x i } N i =1 . Let us start from the mean-field approximation
$$P ( x _ { j } \, | \, X ) \ = \ \sum _ { h } P ( x _ { j }, h \, | \, X ) \approx Q _ { j } ( x _ { j } \, | \, X ) \prod _ { k } Q _ { k } ( h _ { k } \, | \, X )$$
From the mean-field theory, we arrive at Eq (15), which resembles the factorisation in (11).
$$Q _ { j } ( x _ { j } \, | \, X ) \ \in \ \Omega ( x _ { j }, X ) \prod _ { k } \Omega _ { k } ( x _ { j }, X ) ^ { Q _ { k } ( h _ { k } ^ { 1 } | X ) }$$
Now assume that X is sufficiently informative to estimate Q k ( h k | X ), we make further approximation Q k ( h 1 k | x ) ≈ P h ( 1 k | x ). Finally, due to the factorisation in (12), this reduces to
$$Q _ { j } ( x _ { j } \, | \, X ) \otimes \prod _ { i } \left [ \psi ( x _ { j } \succ x _ { i } ) \prod _ { k } \psi _ { k } ( x _ { j } \succ x _ { i } ) ^ { P _ { k } ( h _ { k } ^ { 1 } | X ) } \right ]$$
The RHS can be used for the purpose of ranking among new items { x j } .
Rank reconstruction. The rank reconstruction task can be thought as estimating ˆ X = arg max X ′ Q X X ( ′ | ) where Q X X ( ′ | ) = ∑ h P X ( ′ | h ) P ( h | X ). Since this maximisation is generally intractable, we may approximate it by treating X ′ as state variable of unseen items, and apply the mean-field technique as in the completion task.
## 4.2 Models Implementation
To enable fast recommendation, we use a rather simple scheme: Each item is assigned a worth φ x ( i ) ∈ R + which can be used for ranking purposes. Under the Latent OSM, the worth is also associated with a hidden unit, e.g. φ k ( x i ). Then the events of grouping and ordering can be simplified as
$$\varphi _ { k } ( x _ { i } \sim x _ { j } ) \ = \ \theta \sqrt { \phi _ { k } ( x _ { i } ) \phi _ { k } ( x _ { j } ) } ; \ \text{ and } \ \psi _ { k } ( x _ { i } \succ x _ { j } ) = \phi _ { k } ( x _ { i } )$$
where θ > 0 is a factor signifying the contribution of item compatibility to the model probability. Basically the first equation says that if the two items are compatible, their worth should be positively correlated. The second asserts that if there is an ordering, we should choose the better one. This reduces to the tie model of [6] when there are only two items.
For learning, we parameterise the models as follows
$$\theta = e ^ { \nu } ; \quad \phi ( x _ { i } ) \ = \ e ^ { u _ { i } } ; \quad \phi _ { k } ( x _ { i } ) = e ^ { W _ { i k } }$$
where ν , { u i } and { W ik } are free parameters. The Latent OSM is trained using stochastic gradient with a few samples per user to approximate the gradient (e.g., see Section 3.3). To speed up learning, parameters are updated after every block of 100 users. Figure 3(a) shows the learning progress with learning rate of 0 01 using parallel . persistent Markov chains, one chain per user [25]. The samples get closer to the observed data as the model is updated, while the acceptance rates of the split-and-merge decrease, possibly because the samplers are near the region of attraction. A notable effect is that the split-and-merge dual operators favour sets of small size due to the fact that there are far more many ways to split a big subset than to
Figure 3: Results with MovieLens data. (a) Learning progress with time: Dist(sample,observed) is the portion of pairwise orders being incorrectly sampled by the split-and-merge Markov chains ( N = 10, K = 20). (b) Rank completion, as measured in NDCG@T ( N = 20 , K = 50). (c) Rank reconstruction ( N = 10) - trained on 9 , 000 users and tested on 1 000 users. ,
merge them. For the AIS, we follow previous practice (e.g. see [16]), i.e. S = { 10 3 , 10 4 } and R = 10 100 . { , }
For comparison, we implemented existing methods including the Probabilistic Matrix Factorisation ( PMF ) [15] where the predicted rating is used as scoring function, the Probabilistic Latent Preference Analysis ( pLPA ) [10], the ListRank.MF [17] and the matrix-factored PlackettLuce model [19] ( Plackett-Luce.MF ). For the pLPA we did not use the MM algorithm but resorted to simple gradient ascent for the inner loop of the EM algorithm. We also ran the CoFi RANK variants [23] with code provided by the authors 5 . We found that the ListRank-MF and the Plackett-Luce.MF are very sensitive to initialisation, and good results can be obtained by randomly initialising the user-based parameter matrix with non-negative entries. To create a rank for Plackett-Luce.MF, we order the ratings according to quicksort .
The performance will be judged based on the correlation between the predicted rank and ground-truth ratings. Two performance metrics are reported: the Normalised Discounted Cumulative Gain at the truncated position T (NDCG@ T ) [9], and the Expected Reciprocal Rank (ERR) [4]:
$$\text{NDCG} \@@ T \ = \frac { 1 } { \kappa ( T ) } \sum _ { i = 1 } ^ { T } \frac { 2 ^ { r _ { i } } - 1 } { \log _ { 2 } ( 1 + i ) } ; \ \text{ERR} = \sum _ { i } \frac { 1 } { i } V ( r _ { i } ) \prod _ { j = 1 } ^ { i - 1 } ( 1 - V ( r _ { j } ) ) \ \text{ for } V ( r ) = \frac { 2 ^ { r - 1 } - 1 } { 1 6 }$$
where r i is the relevance judgment of the movie at position i , κ T ( ) is a normalisation constant to make sure that the gain is 1 if the rank is correct. Both the metrics put more emphasis on top ranked items.
Table 1: Average log-likelihood over 100 users of test data (Movie Lens 10M dataset), after training on the N = 10 movies per user ( K = 10). M is the number of test movies per user. The Plackett-Luce.MF and the Latent OSM are comparable because they are both probabilistic in ranks and can capture latent aspects of the data. The main difference is that the PlackettLuce.MF does not handle groupings or ties.
| | M = 10 | M = 20 | M = 30 |
|------------------|----------|----------|----------|
| Plackett-Luce.MF | -14.7 | -41.3 | -72.6 |
| Latent OSM | -9.8 | -37.9 | -73.4 |
## 4.3 Results
We evaluate our proposed model and inference on large-scale collaborative filtering datasets: the MovieLens 6 10M and the Netflix challenge 7 . The MovieLens dataset consists of slightly over 10 million half-integer ratings (from 0 to 5) applied to 10 681 movies by 71 567 users. , , The ratings are from 0 5 to 5 with 0 5 increments. . . We divide the rating range into 5 segments of equal length., and those ratings from the same segment will share the same rank. The Netflix dataset has slightly over 100 million ratings applied to 17 , 770 movies by 480 189 users, where , ratings are integers in a 5-star ordinal scale.
Data likelihood estimation . Table 1 shows the log-likelihood of test data averaged over 100 users with different numbers of movies per user. Results for the Latent OSM are estimated using the AIS procedure.
Rank reconstruction . Given the posterior vector, we ask whether we can reconstruct the original rank of movies for that data instance. For simplicity, we only wish to obtain a complete ranking, since it is very efficient (e.g. a typical cost would be N log N per user). Figure 3(c) indicates that high quality rank reconstruction (on both training and test data) is possible given enough hidden units. This suggests an interesting way to store and process rank data by using vectorial representation.
Rank completion . In collaborative filtering settings, we are interested in ranking unseen movies for a given user. To highlight the disparity between user tastes, we remove movies whose qualities are inherently good or bad, that is when there is a general agreement among users. More specifically, we compute the movie entropy as H i = -∑ 5 r =1 P i ( r ) log P i ( r ) where P i ( r ) is estimated as the proportion of users who rate the movie i by r points. We then remove half of the movies with lowest entropy. For each dataset, we split the data into a training set and a test set as follows. For each user, we randomly choose 10, 20 and 50 items for training, and the rest for testing. To ensure that each user has at least 10 test items, we keep only those users with no less than 20, 30 and 60 ratings, respectively.
Figs. 3(b), 4(a) and Table 2 report the results on the MovieLens 10M dataset; Figs. 4(b) and Table 3 show the results for the Netflix dataset. It can be seen that the Latent OSM performs better than rivals when N is moderate. For large N , the rating-based method (PMF) seems to work better, possibly because converting rating into ordering loses too much information in this case, and it is more difficult for the Latent OSM to explore the hyper-exponential state-space .
5 http://cofirank.org
6 http://www.grouplens.org/node/12
7 http://www.netflixprize.com
Figure 4: Rank completion quality vs. number of hidden units - note that since the PMF is not defined when hidden size is 0, we substitute using the result for hidden size 1.
Table 2: Model comparison on the MovieLens data for rank completion ( K = 50). N@ T is a shorthand for NDCG@ T .
| | N = 10 | N = 10 | N = 20 | N = 20 | N = 50 | N = 50 |
|--------------------|----------|----------|----------|----------|----------|----------|
| | ERR | N@5 | ERR | N@5 | ERR | N@5 |
| PMF | 0.673 | 0.603 | 0.687 | 0.612 | 0.717 | 0.638 |
| pLPA | 0.674 | 0.596 | 0.684 | 0.601 | 0.683 | 0.595 |
| ListRank.MF | 0.683 | 0.603 | 0.682 | 0.601 | 0.684 | 0.595 |
| Plackett-Luce.MF | 0.663 | 0.586 | 0.677 | 0.591 | 0.681 | 0.586 |
| CoFi RANK .Regress | 0.675 | 0.597 | 0.681 | 0.598 | 0.667 | 0.572 |
| CoFi RANK .Ordinal | 0.623 | 0.530 | 0.621 | 0.522 | 0.622 | 0.515 |
| CoFi RANK .N@10 | 0.615 | 0.522 | 0.623 | 0.517 | 0.602 | 0.491 |
| Latent OSM | 0.690 | 0.619 | 0.708 | 0.632 | 0.710 | 0.629 |
Table 3: Model comparison on the Netflix data for rank completion ( K = 50).
| | N = 10 | N = 10 | N = 10 | N = 10 | N = 20 | N = 20 | N = 20 | N = 20 |
|-------------|----------|----------|----------|----------|----------|----------|----------|----------|
| | ERR | N@1 | N@5 | N@10 | ERR | N@1 | N@5 | N@10 |
| PMF | 0.678 | 0.586 | 0.607 | 0.649 | 0.691 | 0.601 | 0.624 | 0.661 |
| ListRank.MF | 0.656 | 0.553 | 0.579 | 0.623 | 0.658 | 0.553 | 0.577 | 0.617 |
| Latent OSM | 0.694 | 0.611 | 0.628 | 0.666 | 0.714 | 0.638 | 0.648 | 0.680 |
## 5 Related Work
This work is closely related to the emerging concept of preferences over sets in AI [3, 22] and in social choice and utility theories [1]. However, most existing work has focused on representing preferences and computing the optimal set under preference constraints [2]. These differ from our goals to model a distribution over all possible set orderings and to learn from example orderings. Learning from expressed preferences has been studied intensively in AI and machine learning, but they are often limited to pairwise preferences or complete ordering [5, 23].
On the other hand, there has been very little work on learning from ordered sets [26, 22]. The most recent and closest to our is the PMOP which models ordered sets as a locally normalised high-order Markov chain [19]. This contrasts with our setting which involves a globally normalised log-linear solution. Note that since the high-order Markov chain involves all previously ranked subsets, while our OSM involves pairwise comparisons, the former is not a special case of ours. Our additional contribution is that we model the space of partitioning and ordering directly and offer sampling tools to explore the space. This ease of inference is not readily available for the PMOP. Finally, our solution easily leads to the introduction of latent variables, while their approach lacks that capacity.
Our split-and-merge sampling procedure bears some similarity to the one proposed in [8] for mixture assignment. The main difference is that we need to handle the extra orderings between partitions, while it is assumed to be exchangeable in [8]. This causes a subtle difference in generating proposal moves. Likewise, a similar method is employed in [14] for mapping a set of observations into a set of landmarks, but again, ranking is not considered.
With respect to collaborative ranking, there has been work focusing on producing a set of items instead of just ranking individual ones [13]. These can be considered as a special case of OSM where there are only two subsets (those selected and the rest).
## 6 Conclusion and Future Work
We have introduced a latent variable approach to modelling ranked groups. Our main contribution is an efficient split-and-merge MCMC inference procedure that can effectively explore the hyper-exponential state-space. We demonstrate how the proposed model can be useful in collaborative filtering. The empirical results suggest that proposed model is competitive against state-of-the-art rivals on a number of large-scale collaborative filtering datasets.
## References
- [1] S. Barber`, W. Bossert, and P.K. Pattanaik. a Ranking sets of objects. Handbook of Utility Theory: Extensions , 2:893, 2004.
- [2] M. Binshtok, R.I. Brafman, S.E. Shimony, A. Martin, and C. Boutilier. Computing optimal subsets. In Proceedings of the National Conference on Artificial Intelligence , volume 22, page 1231. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2007.
- [3] R.I. Brafman, C. Domshlak, S.E. Shimony, and Y. Silver. Preferences over sets. In Proceedings of the National Conference on Artificial Intelligence , volume 21, page 1101. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2006.
- [4] O. Chapelle, D. Metlzer, Y. Zhang, and P. Grinspan. Expected reciprocal rank for graded relevance. In CIKM , pages 621-630. ACM, 2009.
- [5] W.W. Cohen, R.E. Schapire, and Y. Singer. Learning to order things. J Artif Intell Res , 10:243-270, 1999.
- [6] R.R. Davidson. On extending the Bradley-Terry model to accommodate ties in paired comparison experiments. Journal of the American Statistical Association , 65(329):317-328, 1970.
- [7] O. Dekel, C. Manning, and Y. Singer. Log-linear models for label ranking. Advances in Neural Information Processing Systems , 16, 2003.
- [8] S. Jain and R.M. Neal. A split-merge Markov chain Monte Carlo procedure for the Dirichlet process mixture model. Journal of Computational and Graphical Statistics , 13(1):158-182, 2004.
- [9] K. J¨rvelin and J. Kek¨l¨inen. a a a Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems (TOIS) , 20(4):446, 2002.
- [10] N.N. Liu, M. Zhao, and Q. Yang. Probabilistic latent preference analysis for collaborative filtering. In CIKM , pages 759-766. ACM, 2009.
- [11] M. Mure¸ san. A concrete approach to classical analysis . Springer Verlag, 2008.
- [12] R.M. Neal. Annealed importance sampling. Statistics and Computing , 11(2):125-139, 2001.
- [13] R. Price and P.R. Messinger. Optimal recommendation sets: Covering uncertainty over user preferences. In Proceedings of the National Conference on Artificial Intelligence , volume 20, page 541. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2005.
- [14] A. Ranganathan, E. Menegatti, and F. Dellaert. Bayesian inference in the space of topological maps. Robotics, IEEE Transactions on , 22(1):92-107, 2006.
- [15] R. Salakhutdinov and A. Mnih. Probabilistic matrix factorization. Advances in neural information processing systems , 20:1257-1264, 2008.
- [16] R. Salakhutdinov and I. Murray. On the quantitative analysis of deep belief networks. In Proceedings of the 25th international conference on Machine learning , pages 872-879. ACM, 2008.
- [17] Y. Shi, M. Larson, and A. Hanjalic. List-wise learning to rank with matrix factorization for collaborative filtering. In ACM RecSys , pages 269-272. ACM, 2010.
- [18] P. Smolensky. Information processing in dynamical systems: Foundations of harmony theory. Parallel distributed processing: Explorations in the microstructure of cognition , 1:194-281, 1986.
- [19] T. Truyen, D.Q Phung, and S. Venkatesh. Probabilistic models over ordered partitions with applications in document ranking and collaborative filtering. In Proc. of SIAM Conference on Data Mining (SDM) , Mesa, Arizona, USA, 2011. SIAM.
- [20] J.H. van Lint and R.M. Wilson. A course in combinatorics . Cambridge Univ Pr, 1992.
- [21] S. Vembu and T. G¨ artner. Label ranking algorithms: A survey. Preference Learning , page 45, 2010.
- [22] K.L. Wagstaff, Marie desJardins, and E. Eaton. Modelling and learning user preferences over sets. Journal of Experimental & Theoretical Artificial Intelligence , 22(3):237-268, 2010.
- [23] M. Weimer, A. Karatzoglou, Q. Le, and A. Smola. CoFi RANK -maximum margin matrix factorization for collaborative ranking. Advances in neural information processing systems , 20:1593-1600, 2008.
- [24] M. Welling, M. Rosen-Zvi, and G. Hinton. Exponential family harmoniums with an application to information retrieval. In Advances in NIPS , volume 17, pages 1481-1488. 2005.
- [25] L. Younes. Parametric inference for imperfectly observed Gibbsian fields. Probability Theory and Related Fields , 82(4):625-645, 1989.
- [26] Y. Yue and T. Joachims. Predicting diverse subsets using structural SVMs. In Proceedings of the 25th international conference on Machine learning , pages 1224-1231. ACM, 2008. | null | [
"Truyen Tran",
"Dinh Phung",
"Svetha Venkatesh"
] | 2014-07-31T23:30:37+00:00 | 2014-07-31T23:30:37+00:00 | [
"cs.LG",
"cs.IR",
"stat.ML"
] | Learning From Ordered Sets and Applications in Collaborative Ranking | Ranking over sets arise when users choose between groups of items. For
example, a group may be of those movies deemed $5$ stars to them, or a
customized tour package. It turns out, to model this data type properly, we
need to investigate the general combinatorics problem of partitioning a set and
ordering the subsets. Here we construct a probabilistic log-linear model over a
set of ordered subsets. Inference in this combinatorial space is highly
challenging: The space size approaches $(N!/2)6.93145^{N+1}$ as $N$ approaches
infinity. We propose a \texttt{split-and-merge} Metropolis-Hastings procedure
that can explore the state-space efficiently. For discovering hidden aspects in
the data, we enrich the model with latent binary variables so that the
posteriors can be efficiently evaluated. Finally, we evaluate the proposed
model on large-scale collaborative filtering tasks and demonstrate that it is
competitive against state-of-the-art methods. |
1408.0044v1 | ## Particle and photon orbits in McVittie spacetimes
Brien C Nolan
School of Mathematical Sciences, Dublin City University, Glasnevin, Dublin 9, Ireland. (Dated: August 4, 2014)
McVittie spacetimes represent an embedding of the Schwarzschild field in isotropic cosmological backgrounds. Depending on the scale factor of the background, the resulting spacetime may contain black and white hole horizons, as well as other interesting boundary features. In order to further clarify the nature of these spacetimes, we address this question: do there exist bound particle and photon orbits in McVittie spacetimes? Considering first circular photon orbits, we obtain an explicit characterization of all McVittie spacetimes for which such orbits exist: there is a 2-parameter class of such spacetimes, and so the existence of a circular photon orbit is a highly specialised feature of a McVittie spacetime. However, we prove that in two large classes of McVittie spacetimes, there are bound particle and photon orbits: future-complete non-radial timelike and null geodesics along which the areal radius r has a finite upper bound. These geodesics are asymptotic at large times to circular orbits of a corresponding Schwarzschild or Schwarzschild-de Sitter spacetime. The existence of these geodesics lays the foundations for and shows the theoretical possibility of the formation of accretion disks in McVittie spacetimes. We also summarize and extend some previous results on the global structure of McVittie spacetimes. The results on bound orbits are established using centre manifold and other techniques from the theory of dynamical systems.
## I. INTRODUCTION AND SUMMARY.
Perhaps one of the most striking features of black holes is their ability to create circular photon orbits: by travelling to the vicinity of a Schwarzschild black hole and settling in an orbit at a radius r = 3 m , where m is the mass of the black hole, a physicist can exploit the existence of circular photon orbits at this radius to look at the back of their own head. If a Schwarzschild black hole is not available, a charged or rotating black hole can be used for the same purpose. See e.g. Sections 20, 40 and 61 of [1]. Indeed circular photon orbits exist in Kerr-Newman-(anti)de Sitter spacetime for all parameter values corresponding to black holes [2]. Thus it seems reasonable to say that the existence of circular photon orbits (CPOs) is a generic feature of black holes.
Similarly, in the case of massive particles, the existence of an innermost stable circular orbit (ISCO) is a feature of black holes that is not generally present in Newtonian gravity (but see [3]). The existence of the ISCO is central to the formation of thin accrection disks around the black hole which, in turn, encodes useful information about the black hole. See [4].
The question arises as to whether or not CPOs and ISCOs arise in black holes in more general, non-vacuum settings. A first step here is to consider how such black holes can be modelled, and this question has arisen in the broader discussion of how the background expansion of the universe affects local systems [5] and in the more wide-ranging study of inhomogeneous cosmological models (see e.g. [6]). An early contribution to this discussion was McVittie's discovery of an intriguing solution of Einstein's equations that the author himself referred to as a 'mass-particle in an expanding universe' [7]. McVittie's solution represents an embedding of the Schwarzschild field in an isotropic cosmological background. In the form presented in [7], three families of line element were given, corresponding to the curvature index k = 0 , ± 1 of the isotropic background. There appear to be clear reasons to dispute the interpretation that McVittie's solutions with k = ± 1 represent some form of isolated system in an isotropic background [8, 9], and so we will focus on the spatially flat case k = 0 [10]. In this case, the line element may be written in the form [11]
$$\begin{smallmatrix} \bullet & \text{look} \\ \text{black} \\ \kappa & \text{hole} \end{smallmatrix} \quad d s ^ { 2 } = - ( f - r ^ { 2 } H ^ { 2 } ) d t ^ { 2 } - 2 r H f ^ { - 1 / 2 } d t d r + f ^ { - 1 } d r ^ { 2 } + r ^ { 2 } d \Omega ^ { 2 }, \\ \kappa & \text{hole} \quad. \quad \kappa \quad \kappa \quad \kappa \quad \kappa \quad \kappa \,.$$
where m> 0 is a constant, f ( r ) = 1 -2 m/r > 0 (i.e. we restrict to r > 2 m ) and H = H t ( ) is the Hubble function of the isotropic background. That is,
$$H ( t ) = S ^ { \prime } ( t ) / S ( t ), \text{ \quad \ \ } ( 2 )$$
where S t ( ) is the scale factor S t ( ) of the spacetime obtained by setting m = 0 in (1):
$$\overset { \sim } { \text{n} } \quad d s ^ { 2 } = - ( 1 - r ^ { 2 } H ^ { 2 } ) d t ^ { 2 } - 2 r H d t d r + d r ^ { 2 } + r ^ { 2 } d \Omega ^ { 2 } \ ( 3 )$$
$$= - d t ^ { 2 } + S ^ { 2 } ( d x ^ { 2 } + x ^ { 2 } d \Omega ^ { 2 } ).$$
The spacetime with this line element will be referred to as the background , and we will use terms such as background metric in the obvious way. We note that t is a global time coordinate on the spacetime with line element (1): g ab t ,a t ,b = -f -1 < 0. We set the time orientation of the spacetime by taking t to increase into the future. In (4), x = rS -1 is the usual co-moving radial coordinate of the isotropic spacetime. (We note that in (2) and throughout the paper, a prime means derivative with respect to argument.)
The limit m = 0 of (1) is well-defined, as it corresponds to setting the Weyl tensor of the spacetime to zero. The invariantly defined Newman-Penrose Weyl scalar Ψ 2 of the spherically symmetric line element (1) is given by
$$\Psi _ { 2 } = - \frac { m } { r ^ { 3 } }.$$
With H = 0, (1) is the line element of the Schwarzschild exterior. With H = H 0 = constant, the line element is that of Schwarzschild-de Sitter spacetime with cosmological constant Λ = 3 H 2 0 . These limits are likewise well-defined, being respectively the vacuum and Einstein-space limits of (1). In the case H = H 0 , the coordinate transformation T = t + u r ( ) with u ′ ( r ) = H r/ 0 ( √ f ( f -r 2 H 2 0 )) yields the more familiar form
$$d s ^ { 2 } = - ( 1 - \frac { 2 m } { r } - \frac { \Lambda } { 3 } r ^ { 2 } ) d T ^ { 2 } - ( 1 - \frac { 2 m } { r } - \frac { \Lambda } { 3 } r ^ { 2 } ) ^ { - 1 } d r ^ { 2 } + r ^ { 2 } d \Omega ^ { 2 }. \quad & \text{from $t$} \\ \mathfrak { r } _ { \dots \dots \dots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots \vdots$$
Imposing the Einstein equations with a cosmological constant, and with a perfect fluid energy-momentum tensor, yields expressions for the density ρ and pressure p :
$$8 \pi \rho = 3 H ^ { 2 } - \Lambda, & & ( 7 ) & \quad \text{$\kappa$}$$
$$8 \pi p = - 2 H ^ { \prime } f ^ { - 1 / 2 } - 3 H ^ { 2 } + \Lambda. \quad \ \ ( 8 ) \quad \text{fect}$$
Setting m = 0 yields the background density and pressure:
$$8 \pi \rho _ { 0 } = 3 H ^ { 2 } - \Lambda, & & ( 9 ) & & \text{$\mathbb{Psa}$} \\ \text{clu}$$
$$8 \pi p _ { 0 } = - 2 H ^ { \prime } - 3 H ^ { 2 } + \Lambda. \quad \ \ ( 1 0 ) \quad \ \ ( \text{ra} )$$
glyph[negationslash]
Assuming that H t ′ ( ) = 0, we see that McVittie spacetimes always have a scalar curvature singularity at r = 2 m .
Comment 1 It should be noted that since ρ = ρ t ( ) and p = p t, r ( ), there is no equation of state of the form p = g ρ ( ) in the McVittie spacetime. Thus the term 'perfect fluid' is not fully appropriate: we use it in the not uncommon sense of a fluid with isotropic pressure - the radial and tangential pressures are equal. On the other hand, as the background m = 0 spacetime is homogeneous and isotropic, one can appeal to an equation of state to close the Einstein equations and so govern the evolution. This is the perspective that we take: the insertion of the mass parameter m is done post hoc , after the Hubble function has been determined. In theory, one could then consider back reaction effects, redoing CMB and other calculations to take account of the mass parameter m . As we will argue below, this mass parameter provides a model of a (highly) localized inhomogeneity in an otherwise isotropic universe (we use the qualification to reflect the fact that the energy density of the universe is unaffected by m ρ : = ρ t ( ) = ρ 0 ( ) - there is no 'addit tional' matter in the universe).
We note that the transformation ( t, r ) → ( T, x ) with T = t and
$$r ( T, x ) = u ( 1 + \frac { m } { 2 u } ) ^ { 2 }, \ \ u ( T, x ) = x a ( T ) \quad \ ( 1 1 ) \quad \ \text{Tr} \quad \text{th} \\ \text{have}$$
can be used to write the line element (1) in comoving coordinates, which is the form originally given by McVittie [7]. In these coordinates, the curvature singularity at r = 2 m arises at u = m/ 2. The coordinate transformation is a diffeomorphism only if we restrict u to either (0 , m/ 2) or ( m/ , 2 ∞ ). Either interval provides a full cover of r ∈ (2 m, ∞ ). Note also that at fixed T , lim x →∞ r T, x ( ) = ∞ .
With these properties, it is tempting to conclude that the line element (1) corresponds to a spacetime that contains a black hole embedded in an isotropic universe. However, this interpretation is too simplistic. A correct interpretation requires the thorough study of the global properties of the spacetime, based on an analysis of its geodesics. Perhaps the dominant theme that has emerged from the various studies along these lines is that different outcomes emerge depending on the background scale factor S t ( ) and corresponding Hubble function H t ( ).
As far as the author is aware, the first study of the global structure of McVittie spacetimes was undertaken by Sussman as part of a comprehensive study of the global properties of spherically symmetric, shear-free perfect fluid spacetimes [12]. In this work, a variety of possible global structures was identified. However, the interpretation of some of the results must be questioned as Sussman takes limits x → 0 and x →∞ within the same spacetimes. This does not seem possible without the inclusion of the singularity r = 2 m as part of the spacetime (rather than part of its boundary).
For expanding universe models with a big bang at a finite time in the past - that is, when the isotropic background (3) has these features - the singularity r = 2 m forms a past boundary of the spacetime. This was first pointed out in [11] for backgrounds satisfying a linear equation of state p 0 = κρ 0 and with Λ = 0, and the result was generalised in [13] and [14]. As we will see below, this feature of McVittie spacetimes is not universal, but does arise if the big bang condition lim t → 0 + S t ( ) = 0 holds. When Λ = 0, the singularity r = 2 m also arises as a future boundary of the spacetime: future-pointing ingoing radial null geodesics run into this singularity in finite affine parameter time. However, as pointed out in [13], when there is a positive cosmological constant (and when some other technical conditions on H t ( ) hold), ingoing radial null geodesics meet a horizon rather that this singularity. Subsequently, [14] showed how the spacetime can extend through the horizon to a Schwarzschild-de Sitter spacetime. Together, these points indicate that with a background Λ-CDM model with Λ > 0, McVittie spacetimes can indeed model black holes in expanding universes. In fact it was shown in [14] that the boundary includes a black hole horizon and a white hole horizon. However, when Λ = 0, it is very difficult to see how this interpretation can be given: all ingoing radial null geodesics either escape to infinity, or terminate at a scalar curvature singularity rather than reaching a horizon.
Thus, as emphasized in [15], McVittie spacetimes can have a variety of global structures depending on the scale factor of the background. In some cases, including the Λ-CDM model, black and white hole horizons arise. Returning to the question of how local systems are affected by cosmological expansion, it is clear that these McVittie spacetimes provide an interesting testing ground for such questions. On the other hand, studying e.g. the
existence of CPOs and ISCOs in McVittie spacetimes adds further to our understanding and correct interpretation of these spacetimes. So in this paper, we begin the study of particle and photon orbits in McVittie spacetimes by addressing these questions: do there exist CPOs in McVittie spacetimes? Do there exist bound particle and photon orbits in McVittie spacetimes? We obtain a complete answer to the first of these questions. That is, we explicitly determine all McVittie spacetimes that admit CPOs. Neither the Λ-CDM models of [13] and [14] nor the Λ = 0 models of [11] mentioned above are among these. Such McVittie spacetimes do not possess this characteristic feature of black hole spacetimes. However, both models do have the following feature: both admit bound particle and photon orbits. That is, there are futurecomplete, non-radial null and timelike geodesics γ in these spacetimes with the property that r | γ < + ∞ , and lim s →∞ r | γ = r c where s is an affine parameter (or proper time) along the geodesic. The constant r c corresponds to the radius of a circular orbit in either a Schwarzschild or Schwarzschild-de Sitter background. This result is established for two classes of McVittie spacetimes which we define below. These classes include, respectively, the spacetimes of [13] and [14] and those of [11]. Thus these two classes of McVittie spacetimes both have this characteristic black hole property: particles and photons can be confined to a spatially compact region of spacetime by means of the spacetime geometry.
Before proceeding, we give a brief but detailed summary of the results of this paper, and note their relation to previous work.
## A. Summary of Section II
In Section II, we write down the relevant geodesic equations and state relevant dynamical systems results. We point out useful bounds relating ˙ t and ˙ along individual r geodesics - see (20).
## B. Summary of Section III
In Section III, we derive and solve an equation that must hold for the Hubble function H t ( ) of a McVittie spacetime that admits a CPO. We briefly discuss global properties of the associated spacetime: a fuller discussion is given in Appendix A. As we see in (1), McVittie spacetimes are determined by a parameter m and a function H . We show in Section III that there is (only) a 2-parameter family of McVittie spacetimes that admit a CPO. Thus this is a 'no-go' result: CPOs are absent from nearly all McVittie spacetimes. We note that the same conclusion holds in relation to circular timelike orbits.
## C. Summary of Section IV
In Section IV we define a class of McVittie spacetimes that we will refer to as expanding McVittie spacetimes with a big bang background . These are the focus of the remainder of the paper: this class appears to us to be the class of McVittie spacetimes of most physical interest. See Definition 1. We prove that in this class, all causal geodesics (timelike and null, radial and non-radial) originate at the singular boundary r = 2 m at finite affine distance (proper time) in the past. This generalises previous results relating to radial null geodesics [11, 13, 14].
## D. Summary of Section V
Here, we deal with the future evolution of causal geodesics. We define two subclasses of expanding McVittie spacetimes with a big bang background that are distinguished by the (future) asymptotic value of the Hubble function H t ( ). For Class 1, H t ( ) → H > 0 0 as t → + ∞ and for Class 2, H t ( ) → 0. See Definitions 2 and 3. We derive rigorously and generalise results that have been presented previously either in a heuristic manner, or for special cases. In particular, we prove that the global structure (in the sense of a Penrose-Carter conformal diagram) obtained in [14] for a special case - i.e. H t ( ) specified -holds generally for Class 1 (we note that several of the results of [14] were proven in general). Included under this heading are existence proofs relating to important radial null geodesics that delineate the global structure (see Propositions 4 - 7). The crucial role of a non-zero value of H 0 was first identified in [13]: this has far-reaching consequences in that it changes radically the interpretation of the corresponding McVittie spacetime, as discussed above. In Section V, our intention, in part, is to put the physical insights of this paper on a sounder mathematical footing. We note also a generalisation and some corrections (Proposition 7 (b) - noted in [14]) to the results of [13]. For example, the linear equation of state used in Appendix A of that paper is not required. In addition, we generalise some previous results for the case H 0 = 0 [11].
## E. Summary of Section VI
The main results of the paper are given here. Using various techniques from dynamical systems, we prove the existence of bound photon and particle orbits in both Class 1 and Class 2 spacetimes. That is, we prove the existence of future-complete non-radial timelike and null geodesics γ with the property that r | γ is finite along the whole history of the geodesic. Taking s to be the parameter (affine parameter or proper time) along the geodesic, we show that lim s → ∞ + r s ( ) = r c , where r c is the radius of a circular orbit in the corresponding Schwarzschild-de Sitter (Class 1) or Schwarzschild (Class 2) spacetime. For
photon orbits, this forces r c = 3 m and for particle orbits, r c corresponds to a stable circular orbit. See Propositions 10 and 12-14.
We use units with G = c = 1, and we use a glyph[square] to indicate the end of a proof.
## II. GENERAL PROPERTIES OF CAUSAL GEODESICS
We begin with the line element (1) and define
$$\chi ( t, r ) = f - r ^ { 2 } H ^ { 2 }, \quad \alpha ( t, r ) = r f ^ { - 1 / 2 } H, \quad \lambda ( r ) = f ^ { - 1 }. \quad \text{ of } ( 1 7 \\ \psi \quad.. \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \ddots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
Recall that f ( r ) = 1 -2 m/r , and note that χλ + α 2 = 1. The geodesic equations of the spacetime may be written in the following form:
$$\ddot { r } = r f ^ { 1 / 2 } H ^ { \prime } \dot { t } ^ { 2 } + ( 1 - \frac { 3 m } { r } ) \frac { \ell ^ { 2 } } { r ^ { 3 } } + \epsilon ( \frac { m } { r ^ { 2 } } - r H ^ { 2 } ), \quad ( 1 3 ) \quad \text{so th} i$$
$$\ddot { t } = - ( 1 - \frac { 3 m } { r } ) f ^ { - 1 / 2 } H \dot { t } ^ { 2 } - \frac { 2 m } { r ^ { 2 } } f ^ { - 1 } \dot { t } \dot { r } - \epsilon f ^ { - 1 / 2 } H ( 1 4 )$$
where glyph[lscript] is the conserved angular momentum of the geodesic, glyph[epsilon1] = 0 for null geodesics and glyph[epsilon1] = -1 for timelike geodesics. The overdot represents the derivative with respect to the parameter along the geodesic: an affine parameter for null geodesics and proper time for timelike geodesics. Throughout the remainder of this paper, we use s to represent this parameter. We also have the first integral of (13)-(14):
$$- \, \chi \dot { t } ^ { 2 } - 2 \alpha \dot { t } \dot { r } + f ^ { - 1 } \dot { r } ^ { 2 } + \frac { \ell ^ { 2 } } { r ^ { 2 } } = \epsilon. \quad \ \ ( 1 5 )$$
glyph[negationslash]
It follows that ˙ t = 0 everywhere on a causal geodesic. Then by a choice of parameter orientation, we have ˙ t > 0 everywhere along all causal geodesics.
We consider the geodesic equations on the region Ω = { ( t, r ) : t > 0 , r > 2 m } . This region has boundaries ∂ Ω 0 = { (0 , r ) : r ≥ 2 m } and ∂ Ω 2 m = { ( t, 2 m ) : t > 0 } . It will be convenient to consider the geodesic equations as a first order dynamical system. To this end, we define glyph[vector] x = ( r, t, r, t ˙ ˙ ) and write the geodesic equations in the form
$$\frac { d \vec { x } } { d s } = \vec { F } ( \vec { x } ), \quad \quad ( 1 6 ) \quad w i$$
where F 1 ( glyph[vector] x ) = ˙ = r x 3 , F 2 ( glyph[vector] x ) = ˙ = t x 4 and F 3 ( glyph[vector] x , F ) 4 ( glyph[vector] x ) can be read-off the right hand sides of (13) and (14). We note that glyph[vector] F ∈ C 1 ( E ), where E = Ω × R 2 . In this context, (15) is a zero-order constraint that is propagated by the equations. That is, if (15) holds for glyph[vector] x = glyph[vector] x 0 , then this equation is valid everywhere along the solution glyph[vector] x of (16) with the initial condition glyph[vector] x (0) = glyph[vector] x 0 .
Local existence of C 1 solutions of (16) follows from standard results of dynamical systems (see e.g. [16]). For any glyph[vector] x 0 ∈ E , there is a maximal interval of existence ( s α , s ω ) = ( s α ( glyph[vector] x 0 ) , s ω ( glyph[vector] x 0 )) of the initial value problem
$$\frac { d \vec { x } } { d s } = \vec { F } ( \vec { x } ), \ \vec { x } ( 0 ) = \vec { x } _ { 0 }. \quad \quad ( 1 7 ) \quad \text{Th}$$
The intervals ( s α , 0] and [0 , s ω ) are respectively the leftmaximal and right-maximal intervals of existence. The following theorem plays an important role in the next section:
glyph[negationslash]
Theorem 1 (Perko,[16]) Let E be an open subset of R n containing glyph[vector] x 0 , let glyph[vector] F ∈ C 1 ( E ) and let ( s α , 0] be the leftmaximal interval of existence of the IVP (17). If s α > -∞ , then given any compact set K ⊂ E , there exists s ∈ ( s α , 0) such that glyph[vector] x s ( ) ∈ K .
Roughly speaking, this theorem tells us that solutions of (17) continue to exist while glyph[vector] x remains bounded. We will exploit this theorem to prove extension results for causal geodesics.
By completing a square, we can write (15) in the form
$$\dot { t } ^ { 2 } - ( \alpha \dot { t } - \lambda \dot { r } ) ^ { 2 } = \lambda ( \ell ^ { 2 } r ^ { - 2 } + | \epsilon | ), \quad \ \ ( 1 8 )$$
glyph[negationslash]
so that for non-radial geodesics ( glyph[lscript] = 0),
$$( ( 1 - \alpha ) \dot { t } + \lambda \dot { r } ) ( ( 1 + \alpha ) \dot { t } - \lambda \dot { r } ) > 0. \quad ( 1 9 )$$
Noting that λ and ˙ t are both positive, and that α > 0 in an expanding ( H > 0) McVittie spacetime, we obtain the following:
Lemma 1 At every point on a non-radial causal geodesic in an expanding McVittie spacetime,
$$( \alpha - 1 ) \dot { t } < \lambda \dot { r } < ( \alpha + 1 ) \dot { t }. \text{ \quad \ \ } ( 2 0 )$$
glyph[square]
## III. CIRCULAR PHOTON ORBITS
glyph[negationslash]
For circular photon orbits, we have r = a = constant along the null geodesic. We take a > 2 m . Imposing this condition in (13) and (15), eliminating glyph[lscript] and noting that ˙ t = 0, we obtain the following ODE:
$$H ^ { \prime } ( t ) = A ( H ^ { 2 } - H _ { 0 } ^ { 2 } ), \text{ \quad \ \ } ( 2 1 )$$
where
$$A = \frac { ( 1 - \frac { 3 m } { a } ) } { \sqrt { 1 - \frac { 2 m } { a } } }, \ \ H _ { 0 } = a ^ { - 1 } \sqrt { 1 - \frac { 2 m } { a } }. \quad ( 2 2 )$$
We note that if the circular photon orbit has radius a = 3 m , then A = 0 and we are in Schwarzschild-de Sitter spacetime. So for a non-trivial solution, we exclude a = 3 m . We note then that mH < 0 1 3 √ 3 (equality holds for a = 3 m ). The only remaining condition of (13)-(15) is
$$\chi ( t, a ) \dot { t } ^ { 2 } = \frac { \ell ^ { 2 } } { a ^ { 2 } }.$$
This yields the following result.
Proposition 1 The McVittie spacetime with line element (1) admits circular photon orbits if and only if the Hubble function H t ( ) satisfies (21), with the constants A,H 0 determined by the mass parameter m and the orbital radius a via (22), and χ t, a ( ) > 0 for all t along the orbit. glyph[square]
The function χ , which is invariantly defined by χ = g ab ∇ a r ∇ b r , plays an important role in spherical symmetry: this leads to an interesting corollary to Proposition 1. As is well known, χ is proportional to the product of the expansions of the ingoing and outgoing radial null geodesics of a spherically symmetric spacetime. Hence the surface (or surfaces) χ = 0 corresponds to a horizon, where (at least) one of the null expansions vanishes. The regular (or untrapped) region of the spacetime corresponds to χ > 0, where one null expansion is positive and one is negative, while χ < 0 corresponds to either a trapped region (two negative null expansions) or an antitrapped region (two positive null expansions). We immediately have the following, which is a particular case of a more general result:
Corollary 1 A circular photon orbit of a McVittie spacetime is confined to the regular region of the spacetime. glyph[square]
We can also see from (15) that any turning points (periapsis or apasis, whereat ˙ r = 0) of a photon orbit in a McVittie spacetime must lie in the regular region of the spacetime. The same conclusion holds for particle orbits (timelike geodesics), where (15) holds but with -1 on the right hand side. In fact it is readily seen that Corollary 1 holds much more generally in spherically symmetric spacetimes (this is the more general result referred to above). Using double null coordinates ( u, v ), both taken to increase into the future, the null expansion θ u along the future pointing null direction ∂ ∂u satisfies θ u = 1 κ 2 u ∂r ∂u for some positive function κ 2 u . A corresponding statement holds with u replaced by v . Then along any future pointing null geodesic,
$$\dot { r } = \kappa _ { u } ^ { 2 } \theta _ { u } \dot { u } + \kappa _ { v } ^ { 2 } \theta _ { v } \dot { v }.$$
With u, v increasing into the future, so that ˙ u > 0 and ˙ v > 0, we see that ˙ r can vanish only when either the null expansions θ u , θ v have opposite sign - that is, when the geodesic is in a regular region of the spacetime - or when both θ u and θ v vanish. This latter situation is non-generic: it occurs for example at the bifurcation 2sphere of the extended Schwarzschild (Kruskal-Szekeres) spacetime. The former conclusion should hold in general.
Corollary 1 is almost enough to rule out CPO's in any McVittie spacetime for which the isotropic background has a big bang - i.e. S t ( 0 ) = 0 at some time t 0 in the past. From (2), we see that H t ( ) will typically diverge as t → t + 0 . But then χ t, a ( ) = 1 -2 m a -a H 2 2 becomes negative at early times. It is very difficult to see how the CPOcan exit the trapped region, or terminate in the past at a finite positive value of t , without there being some
@ D
FIG. 1. The graph of (i) the Hubble function H t ( ) and (ii) the scale factor S t ( ) for the McVittie spacetime admitting a circular photon orbit at radius a < 3 m . Here m = 1 and a = 2 5, giving . A = -0 447214 . < 0 and H 0 = 0 178885. .
serious pathology of the spacetime. Thus the existence of a CPO is a very strong restriction on McVittie spacetimes with big bang backgrounds.
We turn now to determining which line elements of the form (1) are admitted by Proposition 1. This amounts to solving (21), and ensuring that the resulting χ t, a ( ) is positive. There is a unique non-trivial solution (where non-trivial means that H is not constant: recall that this corresponds to Schwarzschild-de Sitter spacetime):
$$H ( t ) = - H _ { 0 } \tanh ( A H _ { 0 } t ), \ \ t \in \mathbb { R }. \quad \ ( 2 5 )$$
We have used time translation freedom to set t = 0 at the zero of H . The corresponding scale factor is
$$S ( t ) = ( \cosh ( A H _ { 0 } t ) ) ^ { - 1 / A }, \text{ \quad \ \ } ( 2 6 )$$
and we find
$$\chi ( t, a ) = a ^ { 2 } H _ { 0 } ^ { 2 } / \cosh ^ { 2 } ( A H _ { 0 } t ). \quad \quad ( 2 7 )$$
There are two inequivalent spacetimes, depending on the sign of A . We see from (22) that A is positive (respectively negative) if the CPO radius a is greater than (respectively less than) 3 m . The expansion histories of the background universes corresponding to the two choices are shown in Figures 1 and 2, and their global structure is analysed in the Appendix A.
We find it curious that (21) has a solution which does satisfy the Λ-CDM conditions of [14] (see also Definition 1 below). This solution is H t ( ) = -H 0 coth( AH t 0 ). However this yields χ t, a ( ) = -a H / 2 2 0 sinh 2 ( AH t 0 ), and so the second condition (23) for a CPO is violated.
@ D
FIG. 2. The graph of (i) the Hubble function H t ( ) and (ii) the scale factor S t ( ) for the McVittie spacetime admitting a circular photon orbit at radius a > 3 m . Here m = 1 and a = 3 5,giving . A = 0 218218 . > 0 and H 0 = 0 187044. .
Wesummarise the main result of this section as follows.
Proposition 2 The McVittie spacetime with line element (1) admits a circular photon orbit if and only if the Hubble function is given by (25), with A,H 0 determined by the mass parameter m and photon orbital radius a as in (22). glyph[square]
Comment 2 It is straightforward to derive and solve the equation corresponding to (21) in the case of circular particle orbits. This yields a different McVittie spacetime to that of Proposition 2 - but again, only a 2-parameter family of spacetimes arises. We will not pursue this further: the main point is that circular orbits almost never exist in McVittie spacetimes.
## IV. PAST EVOLUTION
We begin the dicsussion by considering the past evolution of causal geodesics in the class of McVittie spacetimes of interest. These correspond to McVittie spacetimes for which the isotropic background is an expanding cosmological model - an expanding isotropic spacetime with a big bang at a finite time in the past.
Definition 1 The spacetime with line element (1) is said to be an expanding McVittie spacetime with a big bang background if the following conditions on the Hubble function hold:
$$( i ) \ H \in C ^ { 2 } ( ( 0, + \infty ), \mathbb { R } _ { + } ) ;$$
$$( i i ) \, \lim _ { t \rightarrow 0 ^ { + } } \int _ { t } ^ { t _ { 0 } } H ( u ) d u = + \infty \text{ for all } t _ { 0 } > 0 ;$$
$$( i i i ) \ H ^ { \prime } ( t ) < 0 \ f o r \ a l l \ t > 0.$$
The first condition here includes a technical differentiability condition and the condition for expansion: H t ( ) > 0 for all t > 0. The second incorporates the big bang condition. This is equivalent to the existence of some t 0 ∈ R -which we set to zero by a translation -for which the scale factor S satisfies S t ( 0 ) = 0. The third condition is equivalent to the weak energy condition ρ + p > 0 in both the background and the McVittie spacetime - see (7) and (8).
In this section, we establish the fact that ∂ Ω 2 m = { ( t, r ) : t > 0 , r = 2 m } -which, recall, is a curvature singularity - forms the past boundary of the spacetime. That is, all causal geodesics originate in the past at ∂ Ω 2 m at finite affine distance (null geodesics) or finite proper time (timelike geodesics). All such geodesics extend back to ∂ Ω 2 m at a positive value of t : the background big bang surface ∂ Ω 0 = { ( t, r ) : t = 0 , r ≥ 2 m } is cut off by ∂ Ω 2 m . These statements are non-trivial and so proofs are given below. We note that it is straightforward to see that r = 2 m forms a spacelike portion of the past boundary of the spacetime [13]: what is not obvious is that all causal geodesics originate here. This is stated formally as Proposition 3 below.
The radial null geodesics of (1) are of particular importance in determining the global structure of the spacetime. These are the geodesics satisfying (13)-(15) with glyph[lscript] = glyph[epsilon1] = 0. Noting that t is a global time coordinate of (1) that increases into the future by a choice made in Section I above, we have ˙ t > 0 everywhere along a causal geodesic, and so from (15) we can write down
$$\frac { d r } { d t } = H r ( 1 - \frac { 2 m } { r } ) ^ { 1 / 2 } \pm ( 1 - \frac { 2 m } { r } ) \quad \ ( 2 8 )$$
for radial null geodesics (RNG). There are two families: outgoing, corresponding to the upper sign, and ingoing, corresponding to the lower. We introduce the radial coordinate z as defined in [11]:
$$z = \sqrt { 1 - \frac { 2 m } { r } }. \quad \quad \quad ( 2 9 )$$
Notice then that z ∈ [0 , 1) with z = 0 ⇔ r = 2 m and z → 1 as r →∞ . In terms of z , Ω = { ( t, z ) : t ≥ 0 , z ∈ (0 1) , } and the RNGs satisfy
$$\frac { d z } { d t } = \frac { H } { 2 } ( 1 - z ^ { 2 } ) \pm \frac { z } { 4 m } ( 1 - z ^ { 2 } ) ^ { 2 }. \quad \ ( 3 0 )$$
Our first step is to establish the following: given any point P : ( t, z ) = ( t 1 , z 1 ) ∈ Ω (so that t 1 > 0 and z 1 ∈ (0 1)), , the ingoing and outgoing radial null geodesics (IRNGs and ORNGs) through P both originate on the surface ∂ Ω 2 m = { r = 2 m, 0 < t < ∞} =
{ z = 0 0 , < t < ∞} . We then show that the same holds for all causal geodesics passing through P , and thereby show that the set ∂ Ω 0 does not form part of the past boundary of the spacetime.
Lemma 2 In an expanding McVittie spacetime with a big bang background, all outgoing radial null geodesics of the spacetime originate at ∂ Ω 2 m at finite affine distance in the past. That is, for each ORNG γ , there exists s 0 > -∞ such that lim s → s + 0 ( ( t s , r ) ( s )) | γ = ( t 0 , 2 m ) for some t 0 > 0 .
Proof: Consider the ORNG through ( t, z ) = ( t 1 , z 1 ) with t 1 > 0 and z 1 ∈ (0 , 1). This satisfies
$$\frac { d z } { d t } = \frac { H } { 2 } ( 1 - z ^ { 2 } ) + \frac { z } { 4 m } ( 1 - z ^ { 2 } ) ^ { 2 } > 0 \quad ( 3 1 ) \quad \gamma ( 0 ) \quad \ s o i n$$
for t > 0 0 , ≤ z < 1. So for t < t 1 , we have z ≤ z 1 , and hence
$$\frac { d z } { d t } \geq \frac { H } { 2 } ( 1 - z _ { 1 } ^ { 2 } ) + \lambda _ { 1 } z, \quad \quad \ ( 3 2 ) \quad i s \ \tau \\ \ t h e$$
where λ 1 = (1 -z 2 1 ) 2 / 4 m > 0, and we recall from part (i) of Definition 1 that H > 0. Integrating this linear differential inequality from t to t 1 yields
$$z ( t ) & \leq z _ { 1 } e ^ { \lambda _ { 1 } ( t - t _ { 1 } ) } - \frac { ( 1 - z _ { 1 } ) ^ { 2 } } { 2 } \int _ { t } ^ { t _ { 1 } } H ( u ) e ^ { \lambda _ { 1 } ( t - u ) } d u \\ & \leq z _ { 1 } e ^ { \lambda _ { 1 } ( t - t _ { 1 } ) } - \frac { ( 1 - z _ { 1 } ) ^ { 2 } } { 2 } e ^ { - \lambda _ { 1 } t _ { 1 } } \int _ { t } ^ { t _ { 1 } } H ( u ) d u. \quad \ \text{T} \quad \mathfrak { d }$$
These inequalities hold for t < t 1 . From part (ii) of Definition 1, we see that z t ( ) must reach 0 (and so r reaches 2 m ) at some positive value t 0 of t . From (14) with glyph[lscript] = 0 and part (iii) of Definition 1, we see that ¨ r < 0 along the geodesic. This guarantees that r reaches 2 m at a finite value s 0 of the affine parameter s . glyph[square]
Lemma 3 In an expanding McVittie spacetime with a big bang background, all ingoing radial null geodesics of the spacetime originate at ∂ Ω 2 m at finite affine distance in the past. That is, for each IRNG γ , there exists s 0 > -∞ such that lim s → s + 0 ( ( t s , r ) ( s )) | γ = ( t 0 , 2 m ) for some t 0 > 0 .
Proof: For IRNGs, we have
$$\frac { d z } { d t } = \frac { H } { 2 } ( 1 - z ^ { 2 } ) - \frac { z } { 4 m } ( 1 - z ^ { 2 } ) ^ { 2 }. \quad \ \ ( 3 3 ) \quad \ \ g r o \iota ^ { \nu \ u } _ { \ } t h a t$$
We note that 0 ≤ z (1 -z 2 ) ≤ 2 / (3 √ 3) for all z ∈ [0 , 1). Then defining H c = 1 3 √ 3 m , we find
$$\frac { d z } { d t } \geq \frac { 1 } { 2 } ( H - H _ { c } ) ( 1 - z ^ { 2 } ), \quad t > 0, \ \ 0 \leq z < 1. \ ( 3 4 ) \quad \text{$groun$}$$
Integrating from ( t, z ) to ( t 1 , z 1 ) where t 1 > t eventually yields
$$z ( t ) \leq \frac { ( 1 + z _ { 1 } ) - ( 1 - z _ { 1 } ) e ^ { I ( t ) } } { ( 1 + z _ { 1 } ) + ( 1 - z _ { 1 } ) e ^ { I ( t ) } }, \quad t < t _ { 1 } \quad ( 3 5 )$$
where
$$I ( t ) = \int _ { t } ^ { t _ { 1 } } ( H ( u ) - H _ { c } ) d u.$$
Divergence of I in the limit t → 0 + (which comes from part (ii) of Definition 1) shows that z reaches 0 at a positive value of t . The proof that this occurs at a finite value of the affine parameter is identical to the corresponding proof in Lemma 2. glyph[square]
The following results establish that the results of these two lemmas apply to all causal geodesics. We first establish a somewhat obvious 'radial confinement' result.
Lemma 4 Let p ∈ Ω and let γ be a causal geodesic with γ (0) = p . Then the past branch of γ -that is, the set of points
$$\gamma ^ { - } = \{ \gamma ( s ) \, \colon s _ { \alpha } < s < 0 \} \, \text{ \quad \ \ } ( 3 7 )$$
is contained in the interior of the region of Ω bounded by the point p , by the paths of the past-directed radial null geodesics through p and by the boundary ∂ Ω 2 m .
Proof: Noting that ˙ t > 0 along γ , we find from (20) that
$$\lambda ^ { - 1 } ( \alpha - 1 ) < \frac { d r } { d t } < \lambda ^ { - 1 } ( \alpha + 1 ). \quad \ \ ( 3 8 )$$
The lower and upper bounds correspond to the uniquely defined value at each point of Ω of the slopes of the ingoing and outgoing radial null geodesics. Thus at any given point of Ω, the geodesic γ crosses the ingoing (respectively outgoing) radial null geodesic from below (respectively above). It follows that to the past of p (i.e. for s < 0), γ remains below (respectively above) the ingoing (respectively outgoing) radial null geodesic through p . The conclusion follows. glyph[square]
Comment 3 It is tempting to conclude on the basis of this lemma that any causal γ must extend back to r = 2 m . However it remains to prove that γ extends sufficiently far into the past in order that this happens. We now prove this extension result.
Proposition 3 Let γ be a future-pointing causal geodesic of an expanding McVittie spacetime with a big bang background. Then there exists t α > 0 and s α > -∞ such that lim s → s + α ( ( t s , r ) ( s )) | γ = ( t α , 2 m ) where s is an affine parameter (respectively proper time) along a null (respectively timelike) geodesic. That is, all causal geodesics of an expanding McVittie spacetime with a big bang background originate at ∂ Ω 2 m .
Proof: Let γ (0) = p ∈ Ω, and as before, let ( s α , 0] be the left maximal interval of existence for γ . Applying the radial confinement result of the previous lemma and recalling that ˙ t > 0 along γ , we have
$$t _ { i } ( p ) < t ( s ) < t ( 0 ), \ \ s \in ( s _ { \alpha }, 0 ), \quad \ \ ( 3 9 )$$
where t i ( p ) is the value of t at which the ingoing radial null geodesic through p meets ∂ Ω 2 m . Likewise,
$$r ( s ) < r _ { + } ( p ), \ \ s \in ( s _ { \alpha }, 0 ), \quad \ \ ( 4 0 ) \quad \ \stackrel { \ll } { F }$$
where r + ( p ) is the maximum of the value of r along the past branches of the radial null geodesics through p .
From Lemma 1, and recalling that λ = f -1 and that ˙ t > 0, we have
$$- \, \frac { 2 m } { r } f ^ { - 1 } \dot { t } \dot { r } > - \frac { 2 m } { r } ( \alpha + 1 ) \dot { t } ^ { 2 }. \quad \ \ ( 4 1 ) \quad I t \ f i$$
Then from (14), we can write
$$\ddot { t } > - \left ( ( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } H + \frac { 2 m } { r ^ { 2 } } \right ) \dot { t } ^ { 2 }, \quad ( 4 2 ) \quad \text{Usir}$$
where we note that the coefficient of ˙ t 2 on the right hand side is strictly negative on Ω.
For p ∈ Ω and glyph[epsilon1] > 0, define the compact sets
$$K _ { p, \epsilon } & = \{ ( t, r ) \, \colon t _ { i } ( p ) - \epsilon \leq t \leq t ( 0 ), 2 m + \epsilon \leq r \leq r _ { + } ( p ) \}. \quad \text{and } E \\ \underset { \longrightarrow } \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,. \,.$$
Then there exists a positive constant C p,glyph[epsilon1] such that
$$( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } H + \frac { 2 m } { r ^ { 2 } } \leq C _ { p, \epsilon }, \quad \text{for all $(t,r)\in K_{p,\epsilon}$}. \quad \text{may $\mathfrak{1}$} \\ \mathfrak { n } _ { \dots } \dots \dots \dots \lambda \dots \lambda \dots \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \lambda \dots \varphi$}$$
Now suppose that the past branch of γ is confined to K p,glyph[epsilon1] - that is, that ( ( t s , r ) ( s )) ∈ K p,glyph[epsilon1] for all s ∈ ( s α , 0). Then along γ ,
$$\ddot { t } \geq - C _ { p, \epsilon } \dot { t } ^ { 2 }, \ \ s \in ( s _ { \alpha }, 0 ). \quad \quad ( 4 5 )$$
Integrating yields
$$\dot { t } ( s ) < \dot { t } ( 0 ) \exp [ ( t ( 0 ) - t ( s ) ) C _ { p, \epsilon } ], \ \ s \in ( s _ { \alpha }, 0 ), \ \ ( 4 6 ) \quad \Box$$
and so
$$0 \leq \dot { t } ( s ) \leq \dot { t } ( 0 ) \exp [ t ( 0 ) C _ { p, \epsilon } ], \ \ s \in ( s _ { \alpha }, 0 ). \quad ( 4 7 )$$
Using (20), this yields finite upper and lower bounds for ˙: r
$$C _ { p, \epsilon } ^ { - } \leq \dot { r } ( s ) \leq C _ { p, \epsilon } ^ { + }, \ \ s \in ( s _ { \alpha }, 0 ), \quad \ ( 4 8 ) \quad \ r a d i$$
where the bounding constants C ± p,glyph[epsilon1] depend on the parameter glyph[epsilon1] , the initial point p and the initial value and derivative of t .
From (47) and (48), it follows that the corresponding solution glyph[vector] x s ( ) of the dynamical system (16) is confined to the compact subset K of E = Ω × R 2 , where
$$K = K _ { p, \epsilon } \times [ C _ { p, \epsilon } ^ { - }, C _ { p, \epsilon } ^ { + } ] \times [ 0, \dot { t } ( 0 ) \exp [ t ( 0 ) C _ { p, \epsilon } ]. \ \ ( 4 9 ) \quad \text{result}$$
This contradicts Theorem 1, and so γ must exit K p,glyph[epsilon1] . The radial confinement result indicates that γ must exit the set via the lower boundary r = 2 m + . That is, for glyph[epsilon1] every glyph[epsilon1] > 0, there exists s 0 ∈ ( s α , 0) so that r s ( 0 ) < 2 m + . It follows that there exists glyph[epsilon1] s 2 m ∈ -∞ [ , 0) such that lim s → s + 2 m r s ( ) = 2 m . We now show that s 2 m > -∞ , completing the proof. (Note that s 2 m = -∞ corresponds to s α = -∞ .)
Recall that f = 1 -2 m/r and that H t ( ) > 0 with H t ′ ( ) < 0. It follows that H t s ( ( )) ≤ H t ( i ( p )) for all s ∈ ( s α , 0). Recall that we may write (15) in the form
$$\dot { t } ^ { 2 } - ( \alpha \dot { t } - \lambda \dot { r } ) ^ { 2 } = f ^ { - 1 } ( | \epsilon | + \frac { \ell ^ { 2 } } { r ^ { 2 } } ). \quad \ \ ( 5 0 )$$
It follows that
$$\lim _ { s \to s _ { 2 m } ^ { + } } \dot { t } ( s ) = + \infty. \quad \quad \quad ( 5 1 )$$
Using the left-hand inequality of (20) in (14), we can write
$$\ddot { t } < - ( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } H \dot { t } ^ { 2 } + \frac { 2 m } { r ^ { 2 } } \dot { t } ^ { 2 } + f ^ { - 1 / 2 } H. \quad ( 5 2 )$$
On the right hand side, the terms (1 -m r ) f -1 / 2 H , 2 m r 2 and H all have finite positive limits as the geodesic approaches r = 2 m . As ˙ and t f -1 / 2 both diverge to + ∞ in the limit, it follows that the first term on the right hand side (rhs) of (52) dominates the other two, so that we may write
$$\stackrel { \mu } { ( 4 4 ) } _ { K _ { p, \epsilon } } \quad \stackrel { \dots } { t } < [ \text{rhs of } ( 5 2 ) ] \sim - ( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } \stackrel { \dots } { t } ^ { 2 }, \ \ s \to s _ { 2 m } ^ { + }. \ \ ( 5 3 )$$
Thus there exists s ∗ ∈ ( s 2 m , 0) such that
$$\ddot { t } ( s ) < 0, \ \ s < s _ { * }. \quad \quad \quad ( 5 4 )$$
It follows by integrating twice that s 2 m > -∞ : the geodesic reaches r = 2 m in finite affine (or proper) time. glyph[square]
## V. FUTURE EVOLUTION
The main aim of this section is to build a comprehensive picture of the future evolution of radial null geodesics in expanding McVittie spacetimes with a big bang. We will also, where possible, draw conclusions about nonradial geodesics. The results we obtain both generalise and (attempt to) clarify previous results. The intention is to clarify the connection between the different global structures derived in previous work and the features of the corresponding background spacetimes (as encoded in the Hubble function H ). The main results of the paper, which relate to bound photon and particle orbits, are presented in the following section and many of the results of this section are not required for those results. However this section is not wholly an aside: the reader interested in the results of Section VI should review Definitions 2 and 3, Lemmas 5 and 6 and the paragraphs between Propositions 4 and 5.
As is evident from the contrasting results of [11] and [13], the asymptotic value as t → + ∞ of the Hubble
function H t ( ) has a significant influence on the global structure of the spacetime. This is reflected in the results below, and to allow us to present those results in a clear manner, we define two subclasses of expanding McVittie spacetimes with a big bang.
The first class comprises McVittie spacetimes where the scale factor of the isotropic background is that of an expanding, k = 0, Λ-CDM isotropic universe. For the purposes of this paper, the defining properties are these:
Definition 2 The spacetime with line element (1) is a Class 1 McVittie spacetime if the Hubble function H satisfies (i)-(iii) of Definition 1, plus the following conditions:
$$( i v ) \lim _ { \substack { t \to \infty \\ H _ { 0 } > 0. } } ( H ( t ), H ^ { \prime } ( t ), H ^ { \prime \prime } ( t ) ) \ = \ ( H _ { 0 }, 0, 0 ) \ \text{where}$$
- (v) The background density and pressure satisfy (9) and (10) with Λ = 3 H 2 0 , and there is an equation of state p 0 = g ρ ( 0 ) satisfying g ∈ C 1 [0 , ∞ ) with the condition
$$\kappa \coloneqq \frac { 3 } { 2 } ( 1 + g ^ { \prime } ( 0 ) ) > 0 \quad \quad ( 5 5 ) \quad \text{ with } \quad \text{$w$} _ { \mathcal { L } \,. }$$
on the sound speed at zero density.
Comment 4 We note that the technical condition on the sound speed corresponds to the existence and positivity of the limit lim ρ 0 → 0 1 + p 0 ρ 0 and so expresses a physically motivated energy condition, as well as a differentiability condition on g .
The second class we consider corresponds to isotropic backgrounds that share features with spatially flat Robertson-Walker universes with equation of state p = constant × ρ and zero cosmological constant. The defining properties are these:
Definition 3 The spacetime with line element (1) is a Class 2 McVittie spacetime if the Hubble function H satisfies (i)-(iii) of Definition 1, plus the following conditions:
$$( i v ) \lim _ { t \rightarrow \infty } ( H ( t ), H ^ { \prime } ( t ), H ^ { \prime \prime } ( t ) ) = ( 0, 0, 0 ).$$
- (v) The background density and pressure satisfy (9) and (10) with Λ = 0 , and there is an equation of state p 0 = g ρ ( 0 ) satisfying g ∈ C 2 [0 , ∞ ) with the condition
$$\kappa \coloneqq \frac { 3 } { 2 } ( 1 + g ^ { \prime } ( 0 ) ) > 0 \quad \quad ( 5 6 ) \quad \text{$\text{Cl}$} \\ \Omega _ { R }$$
on the sound speed at zero density.
↦
Comment 5 The additional differentiability requirement on the equation of state function ρ 0 → g ρ ( 0 ) is a technical condition required for some of the proofs of Section VI below.
Our first result proves the existence of outgoing photon orbits that extend to infinity. This demonstrates the existence of an asymptotic region of every expanding McVittie spacetime with a big bang background where light rays extend to arbitrarily large radii.
Proposition 4 Let γ be an outgoing radial null geodesic of an expanding McVittie spacetime with a big bang background. Then γ is future complete, and lim s →∞ ( t, r ) | γ = (+ ∞ , + ∞ ) .
Proof: Along an outgoing radial null geodesic, we have
$$\frac { d z } { d t } = \frac { H } { 2 } ( 1 - z ^ { 2 } ) + \frac { z } { 4 m } ( 1 - z ^ { 2 } ) ^ { 2 }, \quad \ \ ( 5 7 )$$
which is positive so that z increases with t . Since H > 0 (part (i) of Definition 1), we see that
$$\Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \PhI _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ { 0 } \quad \Phi _ }$$
where z 0 = z t ( 0 ) and t 0 > 0 is arbitrary. Integrating shows that z → 1 (i.e. r → + ∞ ) as t → + ∞ . From (13) and part (iii) of Definition 1, we see that ¨ r < 0 along the geodesic, and so the affine parameter s must extend to + ∞ as t, r do. glyph[square]
Next, we show that in Class 2 McVittie spacetimes, all photon and particle orbits that originate outside a certain radius extend to infinity and are future complete. This and some subsequent proofs require some details of the horizon structure of McVittie spacetimes [11, 13, 14].
Recall that the horizon of the McVittie spacetime with line element (1) is the set of points with χ = g ab ∇ a r ∇ b r = 0, the regular region is the set of points with χ > 0 and the anti-trapped region is the set of points with χ < 0. It is straightforward to show that the expanding condition H > 0 leads to the region χ < 0 being anti-trapped rather than trapped. We will denote the regular region by Ω R , the anti-trapped region by Ω A and the horizon by H . We note that Ω is the disjoint union of Ω R , Ω A and H and that
$$\Omega _ { R } = \{ ( t, r ) \in \Omega \, \colon H ( t ) < \frac { 1 } { r } ( 1 - \frac { 2 m } { r } ) ^ { 1 / 2 } \}, \quad ( 5 9 )$$
$$\Omega _ { A } = \{ ( t, r ) \in \Omega \, \colon H ( t ) > \frac { \cdot } { r } ( 1 - \frac { \cdot } { r } ) ^ { 1 / 2 } \}, \quad ( 6 0 )$$
$$\mathcal { H } = \{ ( t, r ) \in \Omega \colon H ( t ) = \frac { \cdot } { r } ( 1 - \frac { \cdot } { r } ) ^ { 1 / 2 } \}. \quad ( 6 1 )$$
There are crucial differences between the horizons of Class 1 and Class 2 McVittie spacetimes. First, we note that in a Class 2 McVittie spacetime, all three sets Ω A , Ω R and H are non-empty. However, in Class 1, this is not necessarily the case. Noting that
$$H ( t ) > H _ { 0 } \text{ \ for all } \ t > 0 \text{ \quad \ \ } ( 6 2 )$$
and that
$$\frac { 1 } { r } ( 1 - \frac { 2 m } { r } ) ^ { 1 / 2 } \leq \frac { 1 } { 3 \sqrt { 3 } m },$$
$$( 6 3 )$$
we see that a necessary and sufficient condition for the existence of a horizon and a regular region in a Class 1 McVittie spacetime is that ([13, 14])
$$\ m H _ { 0 } < \frac { 1 } { 3 \sqrt { 3 } }. \quad \quad \quad ( 6 4 )$$
We note that this is identically the necessary and sufficient condition for the existence of horizons in the Schwarzschild-de Sitter spacetime with mass parameter m and cosmological constant Λ = 3 H 2 0 . For Class 1 McVittie spacetimes, we restrict our attention to those cases where a horizon exists:
## Definition 2 [continued]
(vi) The horizon existence condition (64) is satisfied.
↦
From (61) and monotonicity of t → H t ( ), we can describe the horizon by
$$t = t _ { h } ( r ) = H _ { \text{inv} } ( \frac { 1 } { r } \sqrt { 1 - \frac { 2 m } { r } } ), \quad \quad ( 6 5 )$$
↦
↦
where H inv is the inverse of the function t → H t ( ): H inv ( H t ( )) = t for all t > 0. The function r → t h ( r ) has a positive global minimum at r = 3 m , is decreasing on (2 m, 3 m ) and is increasing on (3 m, + ∞ ). We denote the global minimum by t h, 3 m . Then we may also describe the two branches of the horizon by functions
$$r _ { h } ^ { + } \colon [ t _ { h, 3 m }, + \infty ) \to [ 3 m, + \infty ) \quad \ \ ( 6 6 ) \quad \text{fig} \quad \text{ and}$$
and
$$r _ { h } ^ { - } \colon [ t _ { h, 3 m }, + \infty ) \to ( 2 m, 3 m ] \quad \ \ ( 6 7 ) \quad ^ { ( t, r } _ { \text{am} }$$
where by implicit differentiation we find
$$\frac { d r _ { h } ^ { \pm } } { d t } = - r ^ { 2 } ( 1 - \frac { 3 m } { r } ) ^ { - 1 } ( 1 - \frac { 2 m } { r } ) ^ { 1 / 2 } H ^ { \prime } ( t ) \Big | _ { r = r _ { h } ^ { \pm } }. \ \ ( 6 8 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
In a Class 1 McVittie spacetime, H t ( ) → H 0 > 0 as t →∞ . Then on the horizon, r is restricted to the interval ( r -, r + ) where r ± are the larger ( r + ) and the smaller ( r -) of the two positive roots of 1 -2 m r -r 2 H 2 0 = 0, and we have t → + ∞ as r → r ± along the horizon. It is straightforward to prove that
$$2 m < r _ { - } < 3 m < r _ { + }. \quad \quad ( 6 9 ) \quad \text{col} _ { h \infty }$$
From (68), we see that on the inner branch , r -h decreases with t from r = 3 m to r = r -, with lim t → ∞ + r -h = r -. On the outer branch , r + h increases with t from r = 3 m to r = r + , and lim t → ∞ + r + h = r + . Note in particular that χ t, r ( ) < 0 for all r > r + . See Figure 3.
FIG. 3. The horizon of (i) a Class 1 McVittie spacetime (top) and (ii) a Class 2 McVittie spacetime (bottom). In both cases, t and r are shown on the horizontal and vertical axes respectively, and m = 1. The point at which the horizon first forms, ( t, r ) = ( t h, 3 m , 3 m ), is also shown in both. For the Class 1 example, we have taken H 0 = 0 15 and . H t ( ) = H 0 coth(3 H t 0 ). This puts the asymptotes of the horizon at r = r -= 2 26 (in-. ner branch) and r = r + = 5 24 (outer branch). For the Class . 2 example, we have taken H t ( ) = 2 5 . t -1 . The asymptote of the inner branch of the horizon is r = 2 m , and r →∞ on the outer branch. In both cases, the regular region of spacetime ( χ t, r ( ) > 0) is the convex region bounded above and below by the horizon. The exterior of this region is the anti-trapped region ( χ t, r ( ) < 0).
In a Class 2 McVittie spacetime, we have H 0 = lim t →∞ H t ( ) = 0. There is no restriction of r - except of course that r > 2 m . From (68), we see that on the inner branch , r -h decreases with t from r = 3 m to r = 2 m , and lim t → ∞ + r -h = 2 m . On the outer branch , r -h increases with t from r = 3 m to r = + ∞ , and lim t → ∞ + r + h = + ∞ . See Figure 3.
The behaviour of ingoing radial null geodesics that are initially in the regular region of the spacetime is essen-
tially the same in Class 1 and Class 2 McVittie spacetimes, as the next result shows.
Proposition 5 Let γ be an IRNG of a Class 1 or a Class 2 McVittie spacetime with initial point γ (0) . If γ (0) ∈ Ω R ∪ H = { ( t, r ) ∈ Ω : χ t, r ( ) ≥ 0 } , then there exists s 0 ∈ (0 , ∞ ) such that lim s → s -0 ( ( t s , r ) ( s )) = (+ ∞ , r -) in Class 1, and lim s → s -0 ( ( t s , r ) ( s )) = (+ ∞ , 2 m ) in Class 2.
Proof: We use r in ( ) to denote the solution of the IRNG t equations considered as a curve in the t -r plane and we have
$$r ^ { \prime } _ { i n } ( t ) = r f ^ { 1 / 2 } H ( t ) - f. \text{ \quad \ \ } ( 7 0 ) \text{ \ \ } \text{ has}$$
Essentially by definition,
$$r _ { i n } ^ { \prime } ( t ) | _ { \mathcal { H } } = 0. \quad \quad \ \ ( 7 1 ) \quad \mathbf P _ { 1 }$$
It follows from the description given above that the horizon acts as a one-way membrane with respect to IRNGs, injecting the trajectories into the regular region. Thus an IRNG with initial point in Ω R remains in Ω R on the maximal interval of existence. Furthermore, it follows that the geodesic cannot meet H again at some finite value of t (this would violate uniqueness, as there is a unique IRNG at each point of the horizon which must enter rather than exit the regular region). It follows that r ′ in ( ) t < 0 on the maximal interval of existence and that r > r -along the geodesic. (We consider Class 1 explicitly. The proof is identical for Class 2, with r -replaced by 2 m .) Furthermore, equation (70) and the conditions on H t ( ) show that this slope is bounded below, and so global existence in t follows. By monotonicity, lim t →∞ r in ( ) t ≥ r -exists, and it is clear that the limit must in fact equal r -(any other limit would yield a contradiction when t → ∞ in (70)).
We prove that these geodesics have finite affine length to the future as follows. Using (14) with the null condition glyph[epsilon1] = 0 and the ingoing condition fr ˙ = ( rf -1 / 2 H -1) ˙ t we obtain
$$\ddot { t } = \left [ - ( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } H + \frac { 2 m } { r ^ { 2 } } \right ] \dot { t } ^ { 2 } \quad \ \ ( 7 2 ) \quad \ \ ( \text{th} { 8 } \\ \lim.$$
along IRNGs. Given that the geodesic is (eventually) confined to Ω R , we have χ > 0 or equivalently f -1 / 2 H > r -1 (see (59)). This yields
$$\ddot { t } > u ( r ) \dot { t } ^ { 2 }, \quad u ( r ) = \frac { 3 m } { r ^ { 2 } } - \frac { 1 } { r }. \quad \ \ ( 7 3 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
↦
It is straightforward to show that r → u r ( ) is a strictly decreasing function for 0 < r < 6 m : this condition holds along the geodesics in question for sufficiently late parameter times as r → r -< 3 m . Thus there exists s ∗ < s ω such that (recalling ˙ r < 0 along these geodesics)
$$u ( r ( s ) ) > u ( r ( s _ { * } ) ) > 0, \ \ s \in ( s _ { * }, s _ { \omega } ). \quad ( 7 4 ) \quad \text{RN} \quad.$$
Then
$$\ddot { t } > u ( r ( s _ { * } ) ) t ^ { 2 }, \ \ s \in ( s _ { * }, s _ { \omega } ). \quad \quad ( 7 5 )$$
Integrating twice shows that t → + ∞ in finite affine time - that is, s ω < + ∞ . glyph[square]
Comment 6 In [11], which dealt with a subset of Class 2 McVittie spacetimes, it was erroneously claimed that the IRNGs of the previous result have infinite affine length to the future. A heuristic argument was put forth in [13] correcting this claim, and generalising to Class 1 McVittie spacetimes. The result finite affine length to the future - was proven rigorously in Appendix A of [14], using the argument repeated above. We have included the proof of finite affine length for purposes of continuity and clarity.
In Class 1, we can identify the following universal behaviour for all causal geodesics that are initially at sufficiently large radius.
Proposition 6 Let γ be a causal geodesic of a Class 1 McVittie spacetime with initial point γ (0) . If r (0) = r | γ (0) > r + , then γ is future complete and r → ∞ as s →∞ .
Proof: We note first that χ t ( (0) , r (0)) < 0 where t (0) = t | γ (0) . From (15), we see that ˙(0) r > 0, and so the conditions r | γ s ( ) > r + and ˙( r s ) > 0 hold for s ∈ [0 , s ω ), the right-maximal interval of existence for the geodesic. Hence r s ( ) > r (0) > r + > 3 m for all s ∈ [0 , s ω ). It follows from (14) that
$$\ddot { t } < \left ( 1 - \frac { 2 m } { r ( 0 ) } \right ) ^ { - 1 / 2 } H ( t ( 0 ) ), \text{ \quad \ \ } ( 7 6 )$$
where we have used H t ′ ( ) < 0. Integrating shows that ˙ ( t s ) and t ( s ) are bounded on finite intervals. From (20) it follows that ˙( r s ) is bounded on finite intervals. Then a straightforward application of Theorem 1 (applied to the right-maximal rather than the left-maximal interval of existence) shows that s ω = + ∞ , i.e. the geodesic γ is future-complete. Since ˙( r s ) > 0 for all s ∈ [0 , ∞ ), the limit r ∞ = lim s →∞ r s ( ) ≤ + ∞ exists. If r ∞ < + ∞ (that is, if r has a finite limit along the geodesic), then lim s →∞ ˙ r = 0. From (20), we obtain
$$- \chi \dot { t } < ( \alpha + 1 ) \dot { r }.$$
Since r s ( ) > r (0) > r + , we know that χ is negative and bounded away from zero on the geodesic, and so ˙ r → 0 implies ˙ t → 0 as s → ∞ . But then taking the limit s →∞ in (15) yields glyph[lscript] 2 r 2 ∞ = . This yields a contradiction glyph[epsilon1] -and hence the conclusion that lim s →∞ r s ( ) = + ∞ -unless glyph[lscript] = glyph[epsilon1] = 0. So the theorem is proven except for the case of radial null geodesics. The case of outgoing RNGs is dealt with in Proposition 4. For ingoing RNGs satisfying the hypothesis of the theorem, we have the inequality
$$z ( s ) > z _ { + } = \sqrt { 1 - \frac { 2 m } { r _ { + } } }. \quad \quad \quad ( 7 8 )$$
Then
$$\frac { d z } { d t } & > \frac { ( 1 - z ^ { 2 } ) } { 2 } ( H - \frac { z } { 2 m } ( 1 - z _ { + } ^ { 2 } ) ) \\ & = \frac { ( 1 - z ^ { 2 } ) } { 2 } ( H - \frac { z } { z _ { + } } H _ { 0 } ) \\ & > \frac { H _ { 0 } } { 2 } ( 1 - z ^ { 2 } ) ( 1 - \frac { z } { z _ { + } } ), \\ \mathcal { U } ^ { \prime } / \omega \succ \partial _ { t \infty } + \mathfrak { h } \mathcal { H } / \omega \succ \mathcal { U } \mathcal { U } \mathcal { H } \mathcal { H } \mathcal { H } ^ { 2 }.$$
using H t ′ ( ) < 0 (so that H t ( ) > H 0 ) and H 0 = z + 2 m (1 -z 2 + ) which follows from the definition of r + . Integrating (and using the initial condition z t ( 0 ) > z + ) yields z → 1 (i.e. r → + ∞ ) as t →∞ . glyph[square]
We can identify two further special cases of IRNGs in Class 1 McVittie spacetimes.
## Proposition 7 In a Class 1 McVittie spacetime,
- (a) there exists a 1-parameter family of IRNGs with ( t, r ) → (+ ∞ , r -) and r t ( ) < r -for all t < + ∞ . These geodesics satisfy γ s ( ) ∈ Ω A throughout their interval of existence and have finite affine length.
- (b) There exists a unique IRNG with ( t, r ) → (+ ∞ , r + ) ; this geodesic is future-complete.
To prove these results, we use a dynamical systems approach. It is useful towards this end to consider as independent variables z t ( ) (i.e. the coordinate z considered as a function of t along the geodesic) and ξ = H t ( ). The evolution of z in terms of the state variables ( z, ξ ) is given by (30) (lower sign for IRNGs). The corresponding equation for the evolution of H is furnished by the following lemma. This lemma is central to the analysis of Section VI, and so results for both Classes 1 and 2 are given here.
Lemma 5 In any expanding McVittie spacetime with a big bang background, there exists a function w ∈ C 1 ([ H , 0 + ∞ ) , R -) such that
$$H ^ { \prime } ( t ) = w ( H ( t ) ). \text{ \quad \ \ } ( 7 9 )$$
In a Class 1 McVittie spacetime, this function satisfies
$$w ( H _ { 0 } ) = 0, \ \ w ^ { \prime } ( H _ { 0 } ) = - 2 H _ { 0 } \kappa, \quad \ ( 8 0 ) \quad \text{that} _ { - }$$
and in a Class 2 McVittie spacetime,
$$w ( 0 ) = w ^ { \prime } ( 0 ) = 0, \ \ w ^ { \prime \prime } ( 0 ) = - 2 \kappa, \quad \ ( 8 1 ) \quad \stackrel { \Theta \, \Theta _ { \Gamma } } { \text{rem} }$$
where κ is the constant defined in part (v) of Definition 2 and Definition 3. Furthermore, this function extends to a function w ∈ C 1 ( R R , ) .
↦
Proof: Since t → H t ( ) is monotone decreasing and C 1 , this function has a monotone C 1 inverse H inv . Thus we can write
$$\xi = H ( t ) \Leftrightarrow t = H _ { \text{inv} } ( \xi ), \text{ \quad \ \ } ( 8 2 ) \quad \text{def}$$
where H inv ∈ C 1 (( H , 0 + ∞ ) , R ) and satisfies lim ξ → H + 0 H inv ( ξ ) = + ∞ and lim ξ → ∞ + H inv ( ξ ) = 0. Then we can write
$$H ^ { \prime } ( t ) = w ( H ( t ) )$$
for the C 1 function w = H ′ ◦ H inv . This proves existence of the required function w and shows that w ∈ C 1 (( H , 0 + ∞ ) , R -), since we know by hypothesis that H t ′ ( ) < 0 for all t > 0. To prove the second part, we establish the equalities in limiting form (e.g. lim ξ → H + 0 w ξ ( ) = 0): this shows that w extends to a function with the required properties. For convenience, we use the same name w for this extension.
To derive the required limits, we take the derivative of the background field equations (9) and (10) with respect to t (with p 0 = g ρ ( 0 )) and eliminate
$$\rho _ { 0 } ^ { \prime } ( t ) = \frac { 3 } { 4 \pi } H ( t ) H ^ { \prime } ( t )$$
to obtain
$$\frac { H ^ { \prime \prime } ( t ) } { H ^ { \prime } ( t ) } = - 3 H ( t ) ( 1 + g ^ { \prime } ( \rho _ { 0 } ) ). \quad \quad ( 8 5 )$$
Taking the limit t →∞ and recalling that ρ 0 → 0 in this limit yields
$$\lim _ { t \to \infty } \frac { H ^ { \prime \prime } ( t ) } { H ^ { \prime } ( t ) } = - 2 H _ { 0 } \kappa,$$
using Definition 2(v). On the other hand, we note that
$$w ^ { \prime } ( \xi ) & = \frac { d } { d t } \left \{ H ^ { \prime } ( t ) \right \} \frac { d t } { d \xi } \\ & = H ^ { \prime \prime } ( t ) \frac { d t } { d H } = \frac { H ^ { \prime \prime } ( t ) } { H ^ { \prime } ( t ) }.$$
The result regarding the limit follows by noting that ξ → H + 0 ⇔ → t + ∞ . Using Definition 2(iv), we have
$$\lim _ { \xi \to H _ { 0 } ^ { + } } w ( \xi ) = \lim _ { t \to \infty } H ^ { \prime } ( t ) = 0. \quad \quad ( 8 8 )$$
Thus the domain of w may be extended to include H 0 , and the required one-sided derivative exists to guarantee that w ∈ C 1 ([ H , 0 ∞ )).
This completes the proof for Class 1 McVittie spacetimes. For Class 2, the results w (0) = w ′ (0) = 0 arise as a special case ( H 0 = 0) of the Class 1 results, so it only remains to show that w ′′ (0) = -2 κ . Combining the ξ derivative of (87) with the t derivative of (85) and using (84) yields
$$w ^ { \prime \prime } ( \xi ) = - 3 ( 1 + g ^ { \prime } ( \rho _ { 0 } ) ) - \frac { 9 H ^ { 2 } } { 4 \pi } g ^ { \prime \prime } ( \rho _ { 0 } ). \quad ( 8 9 )$$
Taking the limit ξ → 0 + yields the required result, recalling the definition of κ and that g ∈ C 2 [0 , + ∞ ).
To extend the domain of w to the whole real line, we define w H ( 0 -ξ ) = -w H ( 0 + ) for ξ ξ > 0. glyph[square]
Proof of Proposition 7 The equation governing IRNGs is (30) with the lower sign. Using Lemma 5 and taking ξ = H t ( ), we can write this as a 2-dimensional dynamical system:
$$\frac { d z } { \delta t } = \frac { \xi } { 2 } ( 1 - z ^ { 2 } ) - \frac { z } { 4 m } ( 1 - z ^ { 2 } ) ^ { 2 }, \quad \ \ ( 9 0 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\frac { d \xi } { d t } = w ( \xi ). \quad \begin{matrix} & \text{sum} \\ ( 9 1 ) & \text{can} \\ & \text{is tl} \end{matrix}$$
Then (90) and (91) define a C 1 dynamical system on R 2 . The points P 1 : ( z, ξ ) = ( z -, H 0 ) and P 2 : ( z, ξ ) = ( z + , H 0 ) are equilibrium points of this system, where z ± := z r ( ± ). Both are hyperbolic equilibrium points [16], with eigenvalues
$$\lambda _ { 1 } = - \frac { 1 } { 4 m } ( 1 - z _ { \pm } ^ { 2 } ) ( 1 - 3 z _ { \pm } ^ { 2 } ), \quad \lambda _ { 2 } = - 2 H _ { 0 } \kappa. \ ( 9 2 ) \quad \text{Class} \quad \text{correc} \quad \text{locio} \quad.$$
Thus λ 2 < 0 in both cases, but λ 1 < 0 for P 1 and λ 1 > 0 for P 2 . This follows from (69) and the definition (29) of z .
It follows that P 1 is an asymptotically stable equilibrium point: there exists a neighbourhood of P 1 in R 2 such that every solution of (90) and (91) with initial point in this neighbourhood satisfies lim t → ∞ + ( z t , ξ ( ) ( )) t = ( z -, H 0 ). Since the stable manifold is 2-dimensional, there are trajectories that approach the equilibrium point along every tangent at P 1 . The 1-parameter family of the statement of the theorem correspond to trajectories of the dynamical system that approach the equilibrium point along directions with z < z -. Thus these geodesics satisfy z < z -at late times, and so are confined to the anti-trapped region Ω A at late times ( z -< z for points in Ω R ∪ H ). But z ′ ( ) t > 0 for IRNGs in Ω A , so the geodesics are confined to Ω A for all times.
To complete the proof of part (a) of the proposition, it remains to prove that these geodesics have finite affine length. Proposition 3 establishes that the geodesics have finite affine length to the past. To show finite affine length to the future, we note that the coefficient of ˙ t 2 in the right hand side of (72) satsfies
$$\lim _ { s \to s _ { \omega } } - ( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } H + \frac { 2 m } { r ^ { 2 } } = u ( r _ { - } ), \quad ( 9 3 )$$
(see (73)) where ( s α , s ω ) is the maximal interval of existence of the geodesic. Since r -< 3 m , this coefficient is positive, and so there exists a positive constant k 2 and s ∗ < s ω such that
$$\ddot { t } > k ^ { 2 } \dot { t } ^ { 2 } \quad \text{for all } s \in ( s _ { * }, s _ { \omega } ). \quad \quad ( 9 4 ) \quad \Pr _ { \cdot \cdot \cdot }$$
Integrating twice shows that t diverges to + ∞ in finite s completing the proof of part (a).
For part (b), we note that P 2 is a saddle point of the dynamical system as λ 1 > 0 , λ 2 < 0. The stable manifold theorem tells us that the nonlinear system has a 1-dimensional stable manifold W s , tangent to the 1-dimensional stable space E s of the linearized system at P 2 . This stable manifold corresponds to a unique
IRNG satisfying lim t → ∞ + ( z, ξ ) = ( z + , H 0 ). Along this geodesic, we have
$$\lim _ { s \to s _ { \omega } } - ( 1 - \frac { m } { r } ) f ^ { - 1 / 2 } H + \frac { 2 m } { r ^ { 2 } } = u ( r _ { + } ) < 0, \quad ( 9 5 )$$
since r + > 3 m . Thus ¨ is eventually negative, t and so cannot diverge to + ∞ in finite affine time. This geodesic is therefore future-complete. glyph[square]
Comment 7 In [14], the Penrose-Carter diagram for the McVittie spacetime with H t ( ) = H 0 coth ( 3 H t 0 2 ) was constructed using a combination of analytical and numerical approaches. The results of Propositions 3-7 show that the resulting structure applies for all McVittie spacetimes of Class 1. This reinforces the results of [13], modulo the corrections of [14], e.g. the geodesic nature of the 'cosmological horizon' r = r + ( ) t in the language and notation of [13] (this is the geodesic η 1 of [14] and is the unique IRNG of Proposition 7(b) above) and the existence of the geodesics identified in Proposition 7(a) above (also identified numerically in [14]). We note also that the results establishing the affine lengths of the geodesics in Proposition 7 we first given in [14].
For Class 2 McVittie spacetimes, the asymptotic behaviour of ingoing radial null geodesics (IRNGs) is sensitive to the value of the constant κ introduced in Definition 3. Proposition 8 generalises results of [11]: the following lemma is required for its proof.
Lemma 6 In a Class 2 McVittie spacetime,
$$\lim _ { t \to \infty } - \frac { H ^ { \prime } ( t ) } { H ( t ) ^ { 2 } } = \kappa, \text{ \quad \quad } ( 9 6 )$$
where κ is the constant defined in part (v) of Definition 3.
Proof: From the Einstein equations (9), (10) and Definitions 1 and 3, we see that lim t →∞ ρ 0 = lim t →∞ p 0 = 0, and that
$$\frac { p _ { 0 } } { \rho _ { 0 } } = - \frac { 2 } { 3 } \frac { H ^ { \prime } } { H ^ { 2 } } - 1.$$
Appealing to part (v) of Definition 3 and taking the limit t →∞ yields the result. glyph[square]
Proposition 8 Let γ be an ingoing radial null geodesic of a Class 2 McVittie spacetime, and let κ be as defined in (56).
(a) If κ < 1 and γ (0) ∈ Ω A with r (0) = r | γ (0) sufficiently large, then γ remains in Ω A and is future complete with lim s →∞ ( ( t s , r ) ( s )) = (+ ∞ , + ∞ ) ;
(b) If κ > 1 and γ (0) ∈ Ω A , then γ enters Ω R and terminates at ∂ Ω 2 m in finite parameter time.
Proof of part (a): We prove this result by identifying a family of curves that extends to infinity, and then show that each IRNG satisfying the hypothesis of the proposition must remain above a member of this family.
We introduce a 1-parameter family { Σ ν : ν > 1 } of curves in Ω A = { ( t, r ) ∈ Ω : χ t, r ( ) < 0 } . These are defined to be the curves at each point of which the unique IRNG through that point has slope r ′ in ( ) = t ν -1. Then
$$\Sigma _ { \nu } = \{ ( t, r ) \in \Omega \colon H ( t ) = \frac { 1 } { r } ( \nu - \frac { 2 m } { r } ) ( 1 - \frac { 2 m } { r } ) ^ { - 1 / 2 } \}. \quad \begin{array} { c } \Box \\ \text{Proo} \\ \text{in the} \end{array}$$
↦
Notice that the horizon corresponds to Σ 1 . It is straightforward to show that { Σ ν : ν > 1 } provides a foliation of Ω , the anti-trapped region of the spacetime. A Since t → H t ( ) is monotone, we can invert (98) to obtain a 1-parameter family of functions t ν ∈ C 1 ((2 m, + ∞ ) , R + ) such that
$$( t, r ) \in \Sigma _ { \nu } \Leftrightarrow t = t _ { \nu } ( r ). \quad \quad ( 9 9 ) \quad \underset { \ m a } { \omega }$$
A straightforward calculation shows that t ′ ν ( r ) > 0 for all r > 3 m and all ν ≥ 1, and so there exists a 1-parameter family of functions r ν ∈ C 1 ( R + , (3 m, ∞ )) such that
$$( t, r ) \in \Sigma _ { \nu } \cap \{ ( t, r ) \in \Omega _ { A } \, \colon r > 3 m \} \Leftrightarrow r = r _ { \nu } ( t ). \ ( 1 0 0 ) \quad \text{Since}$$
This amounts to saying that the set { ( t, r ) ∈ Ω A : r > 3 m } may be foliation by C 1 curves in the t -r plane, indexed by ν > 1, each one of which has the property that the (different) IRNGs intersecting that curve all have slope r ′ in ( ) t = ν -1, and we note that r ν ( ) t → + ∞ as t → + ∞ (on account of H t ( ) → 0 in this limit).
We now show that r in ( ) t > r ν ( ) for all t t > t 0 and for an appropriate value of ν .
Implicit differentiation of the defining relation of Σ ν in (98) yields
$$\frac { d r _ { \nu } } { d t } = - \, \frac { H ^ { \prime } } { H ^ { 2 } } \left ( \nu - \frac { 2 m } { r } \right ) ^ { 2 } \left ( 1 - \frac { 2 m } { r } \right ) ^ { 1 / 2 } \left ( u _ { \nu } ( \frac { m } { r } ) \right ) ^ { - 1 } \Big | _ { r = r _ { \nu } ( t ) \ \kappa > 1, \, \text{where we} }, \, \\ \text{where } w h o r a \ w \ w \ - \, \nu \ - \, \nu \ \mp \ \Lambda \wr r \ \pm \, \kappa \wr ^ { 2 } \text{ and where two have} } \quad \ w \ h o r a \ h o r a$$
where u ν ( x ) = ν -( ν + 4) x + 6 x 2 and where we have repeatedly used (98) to make convenient substitutions. It follows from Lemma 6 that
$$\frac { d r _ { \nu } } { d t } = \kappa \left ( \nu + O ( \frac { m } { r _ { \nu } ( t ) } ) ^ { 2 } \right ), \ \ t \to \infty. \quad \ ( 1 0 2 ) \quad \text{This} _ { \iota \, - \iota \, - \iota \, - \iota }$$
Then we can calculate
$$& \frac { d } { d t } \left ( \frac { r _ { i n } } { r _ { \nu } } \right ) \Big | _ { r _ { i n } = r _ { \nu } } = \frac { 1 } { r _ { \nu } ( t ) } \left ( \nu - 1 - \kappa \nu + O ( \frac { m } { r _ { \nu } ( t ) } ) ^ { 2 } \right ), \quad t \to \frac { \nu _ { * } < \nu _ { \nu _ { \nu } } ^ { 2 } } { r _ { i n } ^ { \prime } = } \\ & \Lambda \sim \times 1 \quad \text{and} \, \text{and} \, \text{do} \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \infty \, \incolon$$
As κ < 1, we can choose ν > 1 such that ν -1 -κν > 0 (we require ν > 1 / (1 -κ )). From (103), we see that there exists r ∗ > m 3 such that
$$\frac { d } { d t } \left ( \frac { r _ { i n } } { r _ { \nu } } \right ) \Big | _ { r _ { i n } = r _ { \nu } } > 0 \text{ \ for all } r _ { \nu } ( t ) > r _ { * }. \text{ \ \ } ( 1 0 4 ) \text{ \ \ } \text{Since} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text
}$$
Now consider the IRNG that passes through the point ( t 0 , r 0 ) ∈ Σ ν with r 0 > r ∗ . According to (104), the geodesic crosses r = r ν ( ) from below, and cannot cross t this curve again for t > t 0 ( t → r ν ( ) t is increasing). Thus r in ( ) t > r ν ( ) t for all t > t 0 , and so r in ( ) t → + ∞ as t → ∞ along the geodesic. By uniqueness, the same conclusion holds for all IRNGs satisfying r | t 0 > r 0 . The usual convexity argument based on (13) indicates that these geodesics have infinite affine length to the future. glyph[square]
Proof of part (b): Again, let r in ( ) denote the IRNG t in the t -r plane, but with the additional condition that r in ( t 0 ) = r 0 where ( t 0 , r 0 ) = ( t, r ) | γ (0) ∈ Ω . A Then we initially have r ′ in ( ) t > 0. The IRNG thus either meets the horizon whereat r ′ in = 0 and then enters Ω R , or remains outside the horizon for all t > t 0 . OUr aim now is to rule out the latter case. In this latter case, there exists t 1 > t 0 such that lim t → t 1 r in ( ) = t ∞ (this follows from the fact that r → + ∞ on the relevant branch of the horizon). We may rule this out by the following convexity argument. First, we calculate that
$$\text{amer} \quad & r ^ { \prime \prime } _ { i n } ( t ) = r f ^ { 1 / 2 } H ^ { \prime } ( t ) + ( ( 1 - \frac { m } { r } ) H ( t ) - \frac { 2 m } { r ^ { 2 } } f ^ { 1 / 2 } ) ( r H ( t ) - f ^ { 1 / 2 } ). \\ ( 1 0 0 ) \quad & \circ \dots \dots \omega \dots \dots \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \dots \dots \omega \end{cases}$$
Since the geodesic remains in the anti-trapped region Ω A , we have H > r -1 f 1 / 2 . This allows us to identify the dominant terms in (105). If t 1 < + ∞ , we have
$$\frac { r _ { i n } ^ { \prime \prime } } { r _ { i n } } \sim H ^ { \prime } ( t _ { 1 } ) + H ( t _ { 1 } ) ^ { 2 }, \quad t \to t _ { 1 }. \quad ( 1 0 6 )$$
But this rules out r in →∞ in finite t . So we must have t 1 = + ∞ . In this case, we find
$$\frac { r _ { i n } ^ { \prime \prime } } { r _ { i n } } & \sim H ^ { \prime } ( t ) + H ( t ) ^ { 2 }, \quad t \to \infty \\ & \sim ( 1 - \kappa ) H ( t ) ^ { 2 }, \quad t \to \infty$$
, where we have used Lemma 6. So by the hypothesis that κ > 1, we see that r ′′ in ( ) t < 0 for sufficiently large t . Now choose t 2 > t 0 such that r ′′ in ( ) t < 0 for all t ≥ t 2 , and let ν 2 be the value of ν > 1 such that ( t 2 , r in ( t 2 )) ∈ Σ ν 2 . We consider the set
$$S = \{ \nu \geq 1 \, \colon r _ { i n } ( t ) > r _ { \nu } ( t ) \text{ for all } t \geq t _ { 2 } \}. \quad ( 1 0 7 )$$
→∞ . This set is non-empty (it contains ν = ν 2 ) and is bounded below by ν = 1, since Σ 1 is the horizon which r in does not cross. Hence S has a greatest lower bound ν ∗ with 1 ≤ ν ∗ < ν 2 . Then for any glyph[epsilon1] ∈ (0 , ν 2 -ν ∗ ), r in crosses Σ ν ∗ + glyph[epsilon1] from below at some time t glyph[epsilon1] . At the point of crossing, r ′ in = ν ∗ + , and by convexity, glyph[epsilon1] r ′ in ( ) t < ν ∗ + glyph[epsilon1] for all t > t glyph[epsilon1] . Now consider the surface Σ ν ∗ -δ (or r = r ν ∗ -δ ). From (102), r = r ν ∗ -δ ( ) has slope obeying t
$$r ^ { \prime } _ { \nu _ { * } - \delta } ( t ) \sim \kappa ( \nu _ { * } - \delta ), \ \ t \to + \infty. \quad ( 1 0 8 )$$
Since κ > 1, we can choose glyph[epsilon1] and δ so that κ ν ( ∗ -δ ) > ν ∗ + glyph[epsilon1] . This condition on the asymptotic slopes, along with
the convexity property r ′ in ( ) t < ν ∗ + glyph[epsilon1] for all t > t glyph[epsilon1] , tells us that r in crosses r ν ∗ -δ . This contradicts the infimum property of ν ∗ , and so we rule out the possibility that r in does not cross the horizon. The evolution of the geodesic is thus subject to Proposition 5. glyph[square]
Comment 8 It is evident from the previous proposition that there is no general result governing the future evolution of causal geodesics in a Class 2 McVittie spacetime as we have in Proposition 6 for Class 1. At the very least, this behaviour depends on the value of κ . However, we can conclude that if κ < 1, then a result corresponding to Proposition 6 applies. For κ ≥ 1, we have not been able to draw any general conclusions, and it may be the case that no causal geodesics escape to infinity, other than the outgoing radial null geodesics covered by Proposition 4.
Proposition 9 Let γ be a causal geodesic of a Class 2 McVittie spacetime with κ < 1 . If γ (0) ∈ Ω A and r (0) = r | γ (0) sufficiently large, then γ remains in Ω A and is future complete with lim s →∞ ( ( t s , r ) ( s )) = (+ ∞ , + ∞ ) .
Proof: This is a straightforward application of the 'radial confinement' result Lemma 4. As per Propositions 4 and 7, both the ingoing and outgoing radial null geodesics through γ (0) remain in Ω A , are future complete and extend to infinite values of both t and r . Thus χ is negative, and so by (15) ˙ r is positive, along the maximally extended geodesic. From (14), we then obtain
$$\ddot { t } \leq ( 1 - \frac { 2 m } { r ( 0 ) } ) ^ { - 1 / 2 } H ( t ( 0 ) ), \quad \ \ ( 1 0 9 )$$
where we have assumed (without loss of generality) that r (0) > 3 m , and we have used - ≤ glyph[epsilon1] 1. Integrating shows that ˙ t remains finite for finite parameter times s , and then Lemma 1 yields the same for ˙. Applying Theorem 1 r yields global existence for the geodesic, which, returning to the radial confinement result, completes the proof. glyph[square]
## VI. BOUND PARTICLE AND PHOTON ORBITS
We now come to our main results: we prove that in any Class 1 or Class 2 McVittie spacetime, there are bound photon and particle orbits. That is, there are futurecomplete causal geodesics satisfying r s ( ) < + ∞ for all s > 0. For photon orbits, we prove that these orbits approach r = 3 m as s →∞ . For particle orbits, we prove that the orbits are asymptotic to a radius corresponding to a stable circular orbit of the associated Scwarzschild(de Sitter) spacetime (Schwarzschild-de Sitter for Class 1, Schwarzschild for Class 2). To prove the relevant results, we use a dynamical systems approach. The proofs run along somewhat different lines for the two classes, and so we consider them separately. However, the initial steps are the same for both classes.
To begin, we write the geodesic equations as a dynamical system - that is, as a first order autonomous system of ODEs. We introduce the variables
$$x = ( x _ { 1 }, x _ { 2 }, x _ { 3 } ) = ( H, r, \dot { r } ), \ \ y = \dot { t }. \quad ( 1 1 0 )$$
Then using (13) and (14) we can write the geodesic equations as a 4-dimensional system
$$( \dot { x }, \dot { y } ) = G ( x, y ), \text{ \quad \ \ } ( 1 1 1 )$$
for some function G : R 4 → R 4 .
The condition (15) corresponds to a zero-order constraint:
$$( 1 5 ) \Leftrightarrow g ( x, y ) = 0, \text{ \quad \ \ } ( 1 1 2 )$$
where
$$g ( x, y ) \coloneqq - \chi y ^ { 2 } - 2 \alpha x _ { 3 } y + \lambda x _ { 3 } ^ { 2 } + \frac { \ell ^ { 2 } } { x _ { 2 } ^ { 2 } } + | \epsilon | \quad ( 1 1 3 )$$
and we note that making the appropriate substitutions we have
$$\chi = f - x _ { 1 } ^ { 2 } x _ { 2 } ^ { 2 }, \text{ \quad \quad } ( 1 1 4 )$$
$$\alpha = x _ { 1 } x _ { 2 } f ^ { - 1 / 2 }, \text{ \quad \ \ } ( 1 1 5 )$$
$$\lambda = f ^ { - 1 }, \quad \quad \quad ( 1 1 6 )$$
$$f = 1 - \frac { 2 m } { x _ { 2 } }. \quad \quad \quad ( 1 1 7 )$$
glyph[negationslash]
The implicit function theorem allows us to solve g x, y ( ) = 0 locally. Provided χy + αx 3 = 0 at some point P , there is a neighbourhood of P such that
$$g ( x, y ) = 0 \Leftrightarrow y = u ( x ) \text{ \quad \quad } ( 1 1 8 )$$
for some C 1 function u . We use this to reduce the dimension of the problem. That is, we eliminate y from G x, y ( ) and write the geodesic equations as
$$\dot { x } = F ( x ), \text{ \quad \ \ } ( 1 1 9 )$$
where F : R 3 → R 3 with components read off from (13) and (14), with the substitution ˙ t → y = u x ( ).
One other technical manoeuvre is required in this process. We note that Lemma 5 allows us to write H t ′ ( ) = w H t ( ( )) for the function w introduced in that lemma, and so
$$x _ { 1 } = \frac { d H } { d s } = w ( x _ { 1 } ) \dot { t }. \text{ \quad \ \ } ( 1 2 0 )$$
It is at this point that the methods of analysis diverge for the two classes. The difference arises due to the different structures of the function w in the two cases.
## A. Bound orbits in Class 1 McVittie spacetimes
Throughout this subsection, we assume that our metric is that of a Class 1 McVittie spacetime as defined by Definitions 1 and 2. To begin, we recap some relevant results (including Lemma 5) that allow us to write the geodesic equations in dynamical systems form.
Lemma 7 The geodesic equation for x 1 can be written as
$$\dot { x _ { 1 } } = w ( x _ { 1 } ) u ( x ), \text{ \quad \ \ } ( 1 2 1 ) \text{ \ \ } a l _ { \ell }$$
where w and u are as defined in (79), (113) and (118). The function w extends to a function w ∈ C 1 ( R R , ) satisfying
$$w ( H _ { 0 } ) = 0, \ \ w ^ { \prime } ( H _ { 0 } ) = - 2 H _ { 0 } \kappa, \quad \ ( 1 2 2 )$$
where κ is defined in part (v) of Definition 2, and we have
$$w ( x _ { 1 } ) < 0, \ \ \text{ for all } x _ { 1 } > H _ { 0 }, \quad \ \ ( 1 2 3 ) \quad \text{and}$$
$$w ( H _ { 0 } - \xi ) = - w ( H _ { 0 } + \xi ), \ \ \text{ for all } \xi > 0. \quad ( 1 2 4 ) \quad \ \ F$$
glyph[square]
By making the appropriate substitutions in (14), we can write down the other equations of the dynamical system:
$$\dot { x _ { 2 } } & = x _ { 3 }, & ( 1 2 5 ) & \overset { \ a o e s \, n } { \mathbb { R } } \, \text{ wit} \\ \dot { x _ { 3 } } & = x _ { 2 } f ^ { 1 / 2 } w ( x _ { 1 } ) u ( x ) ^ { 2 } + ( 1 - \frac { 3 m } { x _ { 2 } } ) \frac { \ell ^ { 2 } } { x _ { 2 } ^ { 3 } } + \epsilon ( \frac { m } { x _ { 2 } ^ { 2 } } - x _ { 1 } ^ { 2 } x _ { 2 } ). & \overset { \ a o e s \, n } { \mathbb { R } } \, \text{ with } \\ & \text{ then }$$
## 1. Photon orbits in Class 1
We focus on the point P : x = ( H , 0 3 m, 0). We find that
$$\chi ( P ) = \chi _ { | _ { r = 3 m, H = H _ { 0 } } } = \frac { 1 } { 3 } - 9 m ^ { 2 } H _ { 0 } ^ { 2 } > 0, \quad ( 1 2 7 )$$
and so χ is positive in a neighbourhood of P (note the application here of the horizon existence condition (64)). Recalling that ˙ t > 0 along all causal geodesics, we see that taking the appropriate solution of g x, y ( ) = 0 in (112) yields
$$u ( x ) = u _ { 1 } ( x ) \coloneqq - \frac { \alpha } { \chi } x _ { 3 } + \frac { 1 } { \chi } ( x _ { 3 } ^ { 2 } + \chi \frac { \ell ^ { 2 } } { x _ { 2 } ^ { 2 } } ) ^ { 1 / 2 }. \quad ( 1 2 8 ) \quad \text{by th} \\ \text{such}$$
This is a smooth function of x is a neighbourhood of P . For clarity, we collect some relevant results as follows.
Lemma 8 In a neighbourhood of P : x = ( H , 0 3 m, 0) , the equations governing null geodesics of a Class 1 McVittie spacetime may be written as (125), (126) with glyph[epsilon1] = 0 and (121) with u = u 1 and u 1 defined in (128). Furthermore, P is an equilibrium point of this system. | square
Our main result is obtained by a relatively straightforward application of standard results on dynamical systems.
Proposition 10 In a Class 1 McVittie spacetime, there exists a 3-parameter family of null geodesics that are future complete, with r → 3 m and t → + ∞ as s → ∞ along each member of the family. These geodesics correspond to bound photon orbits of the spacetime.
Proof: Our starting point is the dynamical system
$$\dot { x } = F ( x )$$
with
$$F _ { 1 } ( x ) = w ( x _ { 1 } ) u _ { 1 } ( x ), \quad F _ { 2 } ( x ) = x _ { 3 } \quad \ \ ( 1 3 0 )$$
and
$$& \downarrow ) \quad F _ { 3 } ( x ) = x _ { 2 } f ^ { 1 / 2 } w ( x _ { 1 } ) u _ { 1 } ( x ) ^ { 2 } + ( 1 - \frac { 3 m } { x _ { 2 } } ) \frac { \ell ^ { 2 } } { x _ { 2 } ^ { 3 } }. \quad ( 1 3 1 ) \\ & -$$
This is a C 1 dynamical system on a neighbourhood O P ⊆ R 3 of P . We note that the projection
$$\pi \colon \mathcal { O } _ { P } \to \mathbb { R } ^ { 2 } \colon x = ( x _ { 1 }, x _ { 2 }, x _ { 3 } ) \to ( x _ { 1 }, x _ { 2 } ) = ( H, r ) \\. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
does not project into Ω, as we must include values of H ∈ R with H < H 0 . Such points are not in the spacetime: the projection is into Ω if and only if x 1 = H > H 0 .
The Jacobian matrix at P is given by
$$J ( P ) = \left ( \begin{array} { c c c } a & 0 & 0 \\ 0 & 0 & 1 \\ b & c & 0 \end{array} \right ), \quad \quad \quad ( 1 3 3 )$$
where
$$a = - \kappa ^ { 2 } H _ { 0 } \frac { \ell } { m } ( \frac { 1 } { 3 } - 9 m ^ { 2 } H _ { 0 } ^ { 2 } ) ^ { - 1 / 2 }, \quad \ ( 1 3 4 )$$
$$b = - \underset { \lambda } { \sqrt { 3 } } \overset { \cdots } { H _ { 0 } } \frac { \check { \ell } ^ { 2 } } { m } ( \frac { 1 } { 3 } - 9 m ^ { 2 } H _ { 0 } ^ { 2 } ) ^ { - 1 }, \quad ( 1 3 5 )$$
$$c = \frac { \ell ^ { 2 } } { ( 3 m ) ^ { 4 } }. \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
c = \frac { \ell ^ { 2 } } { ( 3 m ) ^ { 4 } }.$$
This has eigenvalues σ = a, ± √ c , all of which are real, and so P is a hyperbolic equilibrium point of the system. Two of the eigenvalues ( a, - √ c ) are negative. Thus, by the Stable Manifold Theorem (see e.g.[16]), there exists a 2-dimensional differentiable manifold W s ⊆ O P such that any solution of (129) with x (0) ∈ W s satisfies lim s →∞ x s ( ) = P . This manifold is tangent to E s at P , where E s is the 2-dimensional stable space of the linearized system
$$\dot { \delta x } = J ( P ) \delta x. \text{ \quad \quad \ \ } ( 1 3 7 )$$
By calculating the relevant eigenvectors, we find that
$$E ^ { s } = \{ x ( P ) + \xi \vec { v } _ { 1 } + \eta \vec { v } _ { 2 } \colon \xi, \eta \in \mathbb { R } \}, \quad \ \ ( 1 3 8 )$$
where
$$\vec { v } _ { 1 } = ( ( c + a ^ { 2 } ) / b, 1, a ), \quad \vec { v } _ { 2 } = ( 0, 1, - \sqrt { c } ). \quad ( 1 3 9 )$$
So far, these results apply only to the 'unphysical' O P . To see the relevance to Ω, and hence complete the proof, we note that those trajectories of W s which have tangent at P corresponding to ξ < 0 in (138) satisfy x 1 ( s ) > H 0 for all sufficiently large s (note that b < 0). These trajectories, of which there is a 3-parameter family (two parameters coming from the dimension of W s and glyph[lscript] providing the third) correspond to null geodesics of the spacetime which are future complete and have the asymptotic behaviour given in the statement of the proposition. glyph[square]
Comment 9 We note that the orbits described in the previous result are asymptotic to the unique circular photon orbit r = 3 m of the Schwarzschild-de Sitter spacetime with positive cosmological constant Λ = 3 H 2 0 . They are essentially as unstable as this unstable orbit at r = 3 m . The photon orbits of Schwarzschild-de Sitter spacetime are governed by the equation
$$\ddot { r } = \left ( 1 - \frac { 3 m } { r } \right ) \frac { \ell ^ { 2 } } { r ^ { 3 } }, \text{ \quad \ \ } ( 1 4 0 )$$
which is (13) with the null condition glyph[epsilon1] = 0 and the Schwarzschild-de Sitter condition H t ′ ( ) ≡ 0. In terms of the dynamical system of Proposition 10, this equation corresponds to the invariant manifold { x : x 1 = H 0 } of the flow. Then the circular photon orbit corresponds to the stationary point ( x , x 2 3 ) = (3 m, 0). This is a saddle of the 2-dimensional flow: thus, as is well know, the circular photon orbit of Schwarzschild-de Sitter spacetime is unstable. In terms of initial data, for a given r (0) sufficiently close to 3 m , there are precisely (only) two values of ˙(0) for which the corresponding solution r of (140) lies on the stable manifold of the flow, giving lim s →∞ r s ( ) = 3 m . All other values of ˙(0) yield trajecr tories which do not approach r = 3 m . In the non-static setting - that is, in the Class 1 McVittie spacetime - the stable manifold has an additional dimension. This corresponds to the flow of H t ( ) to the asymptotic value H 0 . However infinite fine tuning of the initial data is still required to ensure that the trajectory approaches r = 3 m : the stable manifold has co-dimension 1.
## 2. Particle orbits in Class 1
For timelike geodesics, we find that there are bound orbits that are asymptotic to the stable circular particle orbits of the corresponding Schwarzschild-de Sitter spacetime. By 'corresponding', we mean that the mass parameter m and limiting Hubble value H 0 of the McVittie spacetime provide the mass parameter and positive cosmological constant Λ = 3 H 2 0 of the Schwarzschild-de Sitter spacetime. We recall that r s ( ) = r c is a circular orbit of Schwarschild-de Sitter spacetime if G r ( c ) = 0, where (see (13) with glyph[epsilon1] = -1 and H t ( ) ≡ H 0 )
$$G ( r ) = H _ { 0 } ^ { 2 } r - \frac { m } { r ^ { 2 } } + ( 1 - \frac { 3 m } { r } ) \frac { \ell ^ { 2 } } { r ^ { 3 } }, \quad ( 1 4 1 ) \quad \text{$C$}$$
and that this orbit is stable if in addition
$$G ^ { \prime } ( r _ { c } ) < 0. \text{ \quad \ \ } ( 1 4 2 )$$
Stable circular orbits (or indeed circular orbits of any stability type) do not exist in Schwarzschild-de Sitter spacetime for all ranges of the parameters m and H 0 . We have the following result, which is proven in Appendix B.
Proposition 11 The Schwarzschild-de Sitter spacetime with mass parameter m and positive cosmological constant Λ = 3 H 2 0 admits stable circular particle orbits if and only if mH 0 < 2 75 √ 3 . The radius of stable orbits satisfies r c ∈ (6 m,r + ) , where r + is the larger of the two positive roots of 1 -2 m/r -r 2 H 2 0 = 0 .
Comment 10 It is worth recalling what is meant by stability of these orbits. Let m H , 0 and glyph[lscript] be fixed. Write the timelike geodesic equations for Schwarzschild-de Sitter spacetime as the 2-dimensional dynamical system
$$\dot { r } = p, \quad \dot { p } = ( 1 - \frac { 3 m } { r } ) \frac { \ell ^ { 2 } } { r ^ { 3 } } - \frac { m } { r ^ { 2 } } + H _ { 0 } ^ { 2 } r. \quad ( 1 4 3 )$$
Let r c satisfy G r ( c ) = 0, so that ( r s , p ( ) ( s )) = ( r , c 0) is a circular orbit of the system. This orbit is said to be stable if for any glyph[epsilon1] > 0 there exists δ > 0 such that for all ( r , p 0 0 ) with | ( r , p 0 0 ) -( r , c 0) | < δ , the solution of (143) with ( r (0) , p (0)) = ( r , p 0 0 ) - that is, the unique geodesic through ( r , p 0 0 ) -satisfies | ( r s , p ( ) ( s )) -( r , c 0) | < glyph[epsilon1] for all s ≥ 0. By using a Lyapunov function argument, it is straightforward to see that the orbit is stable if G r ′ ( c ) < 0.
Corresponding to Lemma 8, we have this result:
Lemma 9 Let r c > 3 m satisfy G r ( c ) = 0 . In a neighbourhood of Q : x = ( H ,r , 0 c 0) , the equations governing timelike geodesics of a Class 1 McVittie spacetime may be written as (125), (126) with glyph[epsilon1] = -1 and (121) with
$$\cdot \quad u = u _ { 2 } \coloneqq - \frac { \alpha } { \chi } x _ { 3 } + \frac { 1 } { \chi } ( x _ { 3 } ^ { 2 } + \chi ( 1 + \frac { \ell ^ { 2 } } { x _ { 2 } ^ { 2 } } ) ) ^ { 1 / 2 }. \quad ( 1 4 4 )$$
Furthermore, Q is an equilibrium point and the hypersurface x 1 = H 0 is an invariant manifold of this system. The restriction of the dynamical system to x 1 = H 0 corresponds to the timelike geodesic equations of Schwarzschild-de Sitter spacetime.
Proof: Collecting relevant definitions establishes the first part of the proof. For the second, we use Lemma 5, and we note that a straightforward calculation yields
$$\dot { x _ { 3 } } | _ { Q } = G ( r _ { c } ). \text{ \quad \ \ } ( 1 4 5 )$$
We note also that
$$\stackrel { \text{w} } { \text{ar} } \\ 0, \quad \chi _ { Q } \coloneqq \chi | _ { r = r _ { c }, H = H _ { 0 } } = ( 1 - \frac { 3 m } { r _ { c } } ) ( 1 + \frac { \ell ^ { 2 } } { r _ { c } ^ { 2 } } ) > 0. \quad ( 1 4 6 )$$
glyph[square]
Corresponding to Proposition 10, we have this result which is established using centre manifold theory [17].
Proposition 12 In a Class 1 McVittie spacetime with line element (1), let r c satisfy G r ( c ) = 0 and G r ′ ( c ) < 0 where G is defined in (141). Then Q : x = ( H ,r , 0 c 0) is a stable equilibrium point of the timelike geodesic equations. Furthermore, there exists a neighbourhood N Q ⊆ R 3 of Q : x = ( H ,r , 0 c 0) such that for any x (0) ∈ N Q , there exists a positive constant γ and a stable solution ¯( x s ) = ( r s , p ( ) ( s )) of (143) such that where κ is defined in part (v) of Definition 3, and we have
$$w ( x _ { 1 } ) < 0, \ \ \ f o r \ a l l \ x _ { 1 } > 0, \ \ \ \ ( 1 5 0 )$$
$$w ( - \xi ) = - w ( \xi ), \quad \text{for all } \xi > 0. \quad \ ( 1 5 1 )$$
glyph[square]
$$x _ { 1 } ( s ) & = O ( e ^ { - \gamma s } ), \quad ( x _ { 2 } ( s ), x _ { 3 } ( s ) ) = \bar { x } ( s ) + O ( e ^ { - \gamma s } ), \quad s \to \infty \\. \quad \, \tau \, \quad \tau \, \quad \tau \, \quad \tau \, \cdots \quad \tau \, \cdots \quad \tau \, \cdots \quad \tau \, \cdots \quad \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text}$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text`$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text#$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text'$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text.$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text<$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\textf$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text51$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{#\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$$
where ( x 1 ( s , x ) 2 ( s , x ) 3 ( s )) = x s ( ) is the unique timelike geodesic with initial data x 0 .
Proof: A straightforward calculation of the Jacobian matrix corresponding to the equilibrium point Q shows that it has one negative and two purely imagininary eigenvalues. Thus the equilibrium point has a onedimensional stable manifold and a two-dimensional centre manifold. In fact the invariant manifold x 1 = H 0 is a centre manifold of the point [17]. As noted in Lemma 9, the flow on the centre manifold is equivalent to the geodesic flow on Schwarzschild-de Sitter spacetime. Thus the equilibrium point is a stable point of the centre manifold. It follows by Theorem 2 of [17] and by the comments above that the equilibrium point is a stable point of the full flow (i.e. not restricted to the centre manifold), and that the asymptotic behaviour of the flow is as described in the statement of the proposition.
Comment 11 The interpretation of Proposition 12 is as follows. The result tells us that for sufficiently late times ( H t ( ) close to H 0 ), timelike geodesics which are sufficiently close to r = r c with sufficiently small radial velocity ( ˙ close to 0), the orbit is equivalent to the correspondr ing orbit in Schwarzschild-de Sitter spacetime, modulo an exponentially decaying correction. These orbits are future complete, and correspond to bound particle orbits of the spacetime. Their past evolution is governed by Proposition 3. Note that to obtain geodesics of the spacetime, we must choose x (0) ∈ N Q with x 1 (0) > H 0 (i.e. H t ( (0)) > H 0 ).
## B. Bound orbits in Class 2 McVittie spacetimes
We now consider Class 2 McVittie spacetimes as defined by Definitions 1 and 3. Again, we begin by writing down the result that gives a key geodesic equation in dynamical systems form.
Lemma 10 The geodesic equation for x 1 can be written as
$$\dot { x _ { 1 } } = w ( x _ { 1 } ) u ( x ), \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where w and u are as defined in (79), (113) and (118). The function w extends to a function w ∈ C 2 ( R R , ) satisfying
$$( w ( 0 ), w ^ { \prime } ( 0 ), w ^ { \prime \prime } ( 0 ) ) = ( 0, 0, - 2 \kappa ), \quad ( 1 4 9 ) \quad \text{the} ^ { ^ { * } }$$
As in the Class 1 case, the other geodesic equations are given by (125) and (126).
## 1. Photon orbits in Class 2
The analysis above for photon orbits in Class 1 McVittie spacetimes follows through to the present case except in one important regard. The equilibrium point P is now given by x P ( ) = (0 3 , m, 0), and the Jacobian matrix at P is given by
$$J ( P ) = \left ( \begin{array} { c c c } 0 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & c & 0 \end{array} \right ), \quad c = \frac { \ell ^ { 2 } } { ( 3 m ) ^ { 4 } }. \quad \ ( 1 5 2 )$$
Thus the eigenvalues are 0 , ± √ c , and the equilibrium point in non-hyperbolic [16]. (This follows from the fact that w ′ (0) = 0, which is one of the features that distinguishes between Class 1 and Class 2.) Thus we must appeal to centre manifold theory [17]. For the linearized system at P , the centre space is given by E c = { x : x 2 = x 3 = 0 . } By Theorem 1 of [17], it follows that there is a local centre manifold W c of the nonlinear system which takes the form
$$\colon & \colon \text{$\alpha$} \\ \text{le or} \quad x _ { 2 } = h _ { 2 } ( x _ { 1 } ), \quad x _ { 3 } = h _ { 3 } ( x _ { 1 } ), \quad h _ { i } ( x _ { 1 } ) = O ( x _ { 1 } ^ { 2 } ), \quad x _ { 1 } \to 0, \\ \text{ermed} \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdots$$
where h i is C 2 in a neighbourhood of x 1 = 0. The dynamics on the local centre manifold are governed by
$$\dot { x _ { 1 } } = w ( x _ { 1 } ) u _ { 1 } ( x _ { 1 }, h _ { 2 } ( x _ { 1 } ), h _ { 3 } ( x _ { 1 } ) ). \quad ( 1 5 4 )$$
From Lemma 10 and (153), we see that this reads
$$\dot { x _ { 1 } } = - \kappa x _ { 1 } ^ { 2 } u _ { 1 } ( P ) + O ( x _ { 1 } ^ { 3 } ), \ \ x _ { 1 } \to 0. \quad \ ( 1 5 5 )$$
We note that (128) gives u 1 ( P ) = glyph[lscript] √ 3 m > 0. It follows that if x 1 (0) is sufficently small and positive, and if x (0) = ( x 1 (0) , h 2 ( x 1 (0)) , h 3 ( x 1 (0))) (that is, if the initial data for the geodesic correspond to a point of the centre manifold W c ), then x 1 ( s ) → 0 on the centre manifold as s →∞ .
In addition, there are local stable and unstable manifolds of the flow, W s and W u respectively. These are tangent at the equilibrium point to the stable and unstable spaces of the linearised system. The overall stability properties of the equilibrium point may be deduced from the topological equivalence of the nonlinear flow to the
flow described by the partitioned system obtained by restricting to the local centre, stable and unstable manifolds respectively (see e.g. Theorem 2.7.2 of [18]). Each of these is one dimensional, and given the description above of the stability properties of the flow on the local centre manifold, we conclude that we have the same result as applies in Class 1. Comment 8 following Proposition 10 also holds in the present case. We note that in the language of [19], there is a two-dimensional local centre-stable manifold of the flow. This plays essentially the same role as the 2-dimensional stable manifold of Proposition 10. We summarise as follows.
Proposition 13 In a Class 2 McVittie spacetime, there exists a 3-parameter family of null geodesics that are future complete, with r → 3 m and t → + ∞ as s → ∞ along each member of the family. These geodesics correspond to bound photon orbits of the spacetime. glyph[square]
## 2. Particle orbits in Class 2
Turning to the case of timelike geodesics in Class 2 McVittie spacetimes, we encounter a technical difficulty which is not resolved by general dynamical systems theory: all of the eigenvalues of the Jacobian matrix at the equilibrium point have zero real parts. However, a useful feature of the dynamical system allows us to circumvent this problem and show that the stability properties of timelike geodesics in Class 1, as described in Proposition 12, carry over to Class 2. This feature is that we can think of the dynamical system as being a perturbation of the system describing the timelike geodesics of Schwarzschild spacetime. This allows us to exploit the existence of a conserved energy in this latter system. This energy (or more accurately, the effective potential, which plays the role of a Lyapunov function) is of course no longer conserved in the non-static McVittie spacetime, but (i) it remains positive definite and (ii) its evolution can be controlled by a Gronwall type argument. These properties allow us to conclude that the equilibrium point x = (0 , r c , 0) is stable.
We begin by recalling the form of the relevant geodesic equations in a neighbourhood of x = (0 , r c , 0), where r c corresponds to a circular particle orbit of the Schwarzschild spacetime with mass parameter m .
## Lemma 11 Define
$$V ( r ) = - \frac { m } { r } + \frac { \ell ^ { 2 } } { 2 r ^ { 2 } } - \frac { m \ell ^ { 2 } } { r ^ { 3 } }, \quad \ \ ( 1 5 6 ) \quad \text{Ler} \\ \text{sol}$$
and let r c > 3 m satisfy V ′ ( r c ) = 0 . Then in a neighbourhood of Q : x = (0 , r c , 0) , the equations governing timelike geodesics of a Class 2 McVittie spacetime may be written as
$$x _ { 1 } & = w ( x _ { 1 } ) u _ { 2 } ( x ), & ( 1 5 7 )$$
$$\dot { x _ { 2 } } & = x _ { 3 }, & ( 1 5 8 )$$
$$\dot { x _ { 3 } } = - V ^ { \prime } ( x _ { 2 } ) + x _ { 2 } x _ { 1 } ^ { 2 } + x _ { 2 } f ^ { 1 / 2 } ( x _ { 2 } ) w ( x _ { 1 } ) u _ { 2 } ( x ) ^ { 2 } ( 1 5 9 )$$
where u 2 is defined in (144) and w satisfies the conditions of Lemma 10. Furthermore, Q is an equilibrium point and the hypersurface x 1 = 0 is an invariant manifold of this system. The restriction of the dynamical system to x 1 = 0 corresponds to the timelike geodesic equations of Schwarzschild spacetime. glyph[square]
Comment 12 With V ′ ( r c ) = 0, we see that r = r c corresponds to a circular orbit of the Schwarzschild spacetime obtained by setting H t ( ) ≡ 0 in (1). It is worth considering briefly how stability of such orbits may be deduced. We define the Lyapunov function
$$W ( x _ { 2 }, x _ { 3 } ) = \frac { 1 } { 2 } x _ { 3 } ^ { 2 } + V ( x _ { 2 } ) - V ( r _ { c } ). \quad ( 1 6 0 )$$
If x 2 = r c is a local minimum of V (which holds if V ′ ( r c ) = 0 , V ′′ ( r c ) > 0), then there exists glyph[epsilon1] > 0 such that
$$| ( x _ { 2 } - r _ { c }, x _ { 3 } ) | < \epsilon \Rightarrow \begin{cases} \begin{array} { c } W ( x _ { 2 }, x _ { 3 } ) \geq 0, \\ W ( x _ { 2 }, x _ { 3 } ) = 0 \Leftrightarrow ( x _ { 2 }, x _ { 3 } ) = ( r _ { c }, 0 ). \end{array} \\ \text{class 2} \quad \text{$\mathfrak{D.\sim\lim_{1}$ and\lim_{1}$} \end{cases}$$
By a simple calculation,
$$\dot { W } = 0, \quad \quad \quad ( 1 6 2 )$$
and so by Lyapunov's stability theorem (see e.g. [16], p. 130), ( x , x 2 3 ) = ( r , c 0) is a stable equilibrium point: given glyph[epsilon1] > 0 and sufficiently small, there exists δ > 0 such that initial data with
$$| ( x _ { 2 } ( 0 ), x _ { 3 } ( 0 ) ) - ( r _ { c }, 0 ) | < \delta \text{ \quad \ \ } ( 1 6 3 )$$
yield solutions with
$$\S _ { L } ^ { S } \quad | ( x _ { 2 } ( s ), x _ { 3 } ( s ) ) - ( r _ { c }, 0 ) | < \epsilon \quad \text{for all } s \geq 0. \quad ( 1 6 4 )$$
By (162), the flow is confined to the level set
$$W ( x _ { 2 }, x _ { 3 } ) = W ( x _ { 2 } ( 0 ), x _ { 3 } ( 0 ) ). \quad \ \ ( 1 6 5 )$$
We note that W is essentially (the square of) the conserved energy associated with the timelike Killing vector of the exterior Schwarzschild spacetime.
Moving away from the invariant manifold x 1 = 0, the flow no longer has a conserved energy. However, we can use the same function W to obtain useful control over the flow. The overall strategy is to introduce a mollified dynamical system that is equivalent to the system of Lemma 11 in a neighbourhood of Q . We use the properties of a mollified form of W to prove global existence of solutions and stability of Q in this system. Stability in the full system then follows as the systems coincide in a neighbourhood of Q .
We begin by noting that the geodesic equations of Lemma 11 may be written as
$$\dot { x _ { 1 } } = - k _ { 1 } x _ { 1 } ^ { 2 } A ( x ),$$
$$\dot { x _ { 2 } } & = x _ { 3 }, & ( 1 6 7 )$$
$$\dot { x _ { 3 } } = - V ^ { \prime } ( x _ { 2 } ) + k _ { 2 } x _ { 1 } ^ { 2 } B ( x ), \text{ \quad \ \ } ( 1 6 8 )$$
where k , k 1 2 are positive constants, A,B are C 2 in a neighbourhood of Q , and A Q ( ) = B Q ( ) = 1.
We introduce a mollifier ψ ∈ C ∞ 0 ( R 3 , R ) with the property that
$$\psi ( x ) = \begin{cases} \ 1 & \text{if} \quad | x - x ( Q ) | < 1, \\ 0 & \text{if} \quad | x - x ( Q ) | \geq 2, \end{cases} \quad ( 1 6 9 ) \quad \text{while}$$
and we introduce mollified versions of the coefficients of the dynamical system:
$$A _ { \epsilon } ( x ) = A ( x \psi ( \frac { x } { \epsilon } ) ), \ \ B _ { \epsilon } ( x ) = B ( x \psi ( \frac { x } { \epsilon } ) ). \quad ( 1 7 0 ) \quad \stackrel { W _ { \epsilon } ( s ) } { \text{for $A$} }$$
Then A glyph[epsilon1] and B glyph[epsilon1] coincide with A and B respectively for | x -x Q ( ) | < glyph[epsilon1] , and we have A glyph[epsilon1] ( x ) = B glyph[epsilon1] ( x ) = 1 for | x -x Q ( ) | > 2 . glyph[epsilon1] We also introduce a mollified form of the potential V . We introduce a smooth, bounded function V glyph[epsilon1] ∈ C ∞ 0 ( R R , ) with
$$V _ { \epsilon } ( x _ { 2 } ) = \begin{cases} \ V ( x _ { 2 } ), & | x _ { 2 } - r _ { c } | < \epsilon, \\ c, & | x _ { 2 } - r _ { c } | > 2 \epsilon, \end{cases} \quad ( 1 7 1 ) \quad.$$
with c > V ( r c ). It follows that V glyph[epsilon1] -V ( r c ) is smooth, bounded and nonnegative for all x 2 , coincides with V ( x 2 ) -V ( r c ) for | x 2 -r c | < glyph[epsilon1] and vanishes if and only if x 2 = r c . It follows that solutions of the system
$$\dot { x _ { 1 } } = - k _ { 1 } x _ { 1 } ^ { 2 } A _ { \epsilon } ( x ), \quad \quad ( 1 7 2 ) \quad \text{Int} \,,$$
$$\dot { x _ { 2 } } & = x _ { 3 }, & ( 1 7 3 )$$
$$\dot { x _ { 3 } } = - V _ { \epsilon } ^ { \prime } ( x _ { 2 } ) + k _ { 2 } x _ { 1 } ^ { 2 } B _ { \epsilon } ( x ) \text{ \quad \ \ } ( 1 7 4 )$$
coincide with solutions of the original system (166)-(168) when those solutions satisfy | x -x Q ( ) | < glyph[epsilon1] .
Lemma 12 Let x s ( ) be a solution of (172)-(174) with | x (0) -x Q ( ) | < glyph[epsilon1] and x 1 (0) > 0 . Then there exists δ ∈ (0 1) , such that
$$0 < x _ { 1 } ( s ) < \frac { x _ { 1 } ( 0 ) } { 1 + k _ { 1 } ( 1 - \delta ) x _ { 1 } ( 0 ) s } \ \text{ for all } s > 0. \ ( 1 7 5 ) \ \underset { \text{that } 1 } { \text{ since } 1 }$$
Proof: From the properties of A glyph[epsilon1] , we can choose glyph[epsilon1] > 0 so that there exists δ ∈ (0 1) such that ,
$$1 - \delta < A _ { \epsilon } ( x ) < 1 + \delta \quad \text{for all } x \in \mathbb { R } ^ { 3 }. \quad ( 1 7 6 ) \quad ^ { \iota \mu \nu \nu } _ { c o n s t }$$
Then (172) yields
$$\frac { d } { d s } \left ( \frac { 1 } { x _ { 1 } ( s ) } \right ) = k _ { 1 } A _ { \epsilon } ( x ( s ) ) > k _ { 1 } ( 1 - \delta ), \quad ( 1 7 7 )$$
and integrating yields the result.
glyph[square]
Corollary 2 Let x s ( ) be a solution of (172)-(174) with | x (0) -x Q ( ) | < glyph[epsilon1] and x 1 (0) > 0 . Then x 1 ( s ) < x 1 (0) and | sx 1 ( s ) | < k 1 (1 -δ ) for all s > 0 . | square
Now we define
$$W _ { \epsilon } ( x _ { 2 }, x _ { 3 } ) = \frac { 1 } { 2 } x _ { 3 } ^ { 2 } + V _ { \epsilon } ( x _ { 2 } ) - V ( r _ { c } ). \quad \ ( 1 7 8 ) \quad \ \ \ s m a l { \prod \nolimits }$$
Then using (173) and (174), we have
$$\frac { d W _ { \epsilon } } { d s } = k _ { 2 } B _ { \epsilon } ( x ) x _ { 1 } ^ { 2 } x _ { 3 }, \text{ \quad \ \ } ( 1 7 9 )$$
which has the formal solution
$$\underset { 3 \text{ of} } { W _ { \epsilon } ( s ) } = W _ { \epsilon } ( 0 ) + \int _ { 0 } ^ { s } k _ { 2 } B _ { \epsilon } ( x ( \sigma ) ) x _ { 1 } ^ { 2 } ( \sigma ) x _ { 3 } ( \sigma ) d \sigma, \ \ ( 1 8 0 )$$
where for convenience we write W x glyph[epsilon1] ( 2 ( s , x ) 3 ( s )) = W s glyph[epsilon1] ( ). Introducing the same bound for B glyph[epsilon1] as we did for A glyph[epsilon1] we can write
$$\inf _ { \substack { \epsilon \\ \epsilon \colon \_ \_ } } \left | W _ { \epsilon } ( s ) \right | \leq | W _ { \epsilon } ( 0 ) | + k _ { 2 } ( 1 + \delta ) \int _ { 0 } ^ { s } x _ { 1 } ^ { 2 } ( \sigma ) | x _ { 3 } ( \sigma ) | d \sigma. \ ( 1 8 1 )$$
Since V glyph[epsilon1] ( x 2 ) -V ( r c ) ≥ 0 for all x 2 ∈ R (see (171)), we have
$$\frac { 1 } { 2 } x _ { 3 } ^ { 2 } ( s ) \leq W _ { \epsilon } ( s ) \leq Z ( s ), \text{ \quad \ \ } ( 1 8 2 )$$
where Z s ( ) is the non-negative function on the right hand side of (181). Then
$$Z ^ { \prime } ( s ) & = k _ { 2 } ( 1 + \delta ) x _ { 1 } ^ { 2 } ( s ) | x _ { 3 } ( s ) | \\ & \leq \sqrt { 2 } k _ { 1 } ( 1 + \delta ) x _ { 1 } ^ { 2 } ( s ) ( Z ( s ) ) ^ { 1 / 2 }. \quad ( 1 8 3 )$$
Integrating and using Lemma 12 yields
$$( Z ( s ) ) ^ { 1 / 2 } & \leq | W _ { \epsilon } ( 0 ) | ^ { 1 / 2 } + \frac { 1 } { \sqrt { 2 } } \frac { k _ { 2 } ( 1 + \delta ) x _ { 1 } ^ { 2 } ( 0 ) s } { 1 + k _ { 1 } ( 1 - \delta ) x _ { 1 } ( 0 ) s } \\ & \leq | W _ { \epsilon } ( 0 ) | ^ { 1 / 2 } + c _ { 1 } x _ { 1 } ( 0 ).$$
where
$$c _ { 1 } = \frac { k _ { 1 } ( 1 + \delta ) } { \sqrt { 2 } k _ { 2 } ( 1 - \delta ) } > 0. \text{ \quad \ \ } ( 1 8 5 )$$
Since W s glyph[epsilon1] ( ) is positive semi-definite, and using the fact that r = r c is a local minimum of the potential, this yields the following a priori bounds:
Lemma 13 Let x s ( ) be a solution of (172)-(174) with | x (0) -x Q ( ) | < glyph[epsilon1] and x 1 (0) > 0 . Then there exist positive constants c 1 , c 2 and c 3 such that
$$| x _ { 2 } ( s ) | \leq c _ { 2 } ( | W _ { \epsilon } ( 0 ) | ^ { 1 / 2 } + c _ { 1 } x _ { 1 } ( 0 ) ), \quad s \geq 0, ( 1 8 6 )$$
$$| x _ { 3 } ( s ) | \leq c _ { 3 } ( | W _ { \epsilon } ( 0 ) | ^ { 1 / 2 } + c _ { 1 } x _ { 1 } ( 0 ) ), \quad s \geq 0. \ ( 1 8 7 )$$
glyph[square]
Thus we have shown that if we choose initial data with | x (0) -x Q ( ) | < glyph[epsilon1] , then Lemmas 12 and 13 show that solutions of the mollified system satisfy | x s ( ) -x Q ( ) | < O glyph[epsilon1] ( ) for all s > 0. In conjunction with Theorem 1 above, this is sufficient to prove global existence for solutions of the mollified system. Since solutions of the original system coincide with solutions of the mollified system for small | x -x Q ( ) , | this proves stability of the equilibrium point of the full system. We summarise as follows.
Proposition 14 In a Class 2 McVittie spacetime with line element (1), let r c satisfy V ′ ( r c ) = 0 and V ′′ ( r c ) > 0 where V is defined in (156). Let x Q ( ) = (0 , r c , 0) . There exists glyph[epsilon1] > 0 such that, if | x (0) -x Q ( ) | < glyph[epsilon1] , with x 1 (0) > 0 , then there exists a global, unique solution of the timelike geodesic equations (157)-(159) with initial data x (0) . | x s ( ) -x Q ( ) | < O glyph[epsilon1] ( ) for all s > 0 , and lim s → ∞ + x 1 ( s ) = 0 . glyph[square]
Comment 13 The geodesics described by this proposition are bound particle orbits of the Class 2 McVittie spacetime in question. The result shows that if a particle orbit, at sufficiently late times, is, at any instant, sufficiently close in ( r -˙) r phase space to a stable circular orbit of the corresponding Schwarzschild spacetime, then the orbit remains close for all future times.
## VII. CONCLUSIONS
McVittie spacetimes provide us with a conceptually very simple model of the gravitational field of a point mass embedded in an otherwise isotropic, spatially flat universe. By conceptual simplicity, we mean that we can write down simple conditions on a spacetime that lead uniquely to the McVittie metric (1). See for example [8] and [9]. The interpretation of the resulting spacetime is somewhat more complex. However, a clear picture has been established by this stage. In the case of an expanding spacetime, the hypersurface ∂ Ω 2 m = { ( t, r ) : t > 0 , r = 2 m } forms the past boundary of the spacetime: all causal geodesics originate at this singular surface at a finite time in the past. Outgoing rays (outgoing radial null geodesics) escape to infinity, and there are families of ingoing rays (ingoing radial null geodesics) that meet either a horizon (Class 1) or a singularity (Class 2) at a finite time in their future. In addition, we have shown that large, physically relevant classes of McVittie spacetimes can 'capture' both photons and massive particles, and keep them in orbit at finite radius for all time. This reinforces the interpretation of McVittie spacetimes as representing a central massive object in an otherwise isotropic universe. One can interpret all the results on test-particle (massive and massless) motion in McVittie spacetimes in terms of a balance between the attraction of the central mass and the expansion of the cosmological background. The results presented here show that there exists a region of the spacetime where the central mass always wins out, subject to initial conditions on the motion of the test particle - as in the vacuum black hole case (with or without a cosmological constant).
As noted, these results also lay the foundations for the study of accretion disks in McVittie spacetimes. We have essentially established the existence of ISCOs in these spacetimes, and our results also make it clear that significant gravitational lensing occurs. We speculate that this may provide a useful setting for the calculation of lensing effects by galactic clusters or other over-densities in the universe. Likewise, it is clear that the central mass of a McVittie metric significantly disturbs and traps a proportion of a cloud of photons that propagates through a region of spacetime sufficiently close to that central mass. It would be of interest to determine the effect of this central mass on CMB calculations, e.g. through the recalculation of distance relations [6]. We note in this context that while the McVittie spacetime in spatially homogenous in the sense that ρ = ρ t ( ), effects of inhomogeneity would be manifest in the angular diameter distance D A , which satisfies
$$\frac { d ^ { 2 } D _ { A } } { d s ^ { 2 } } = - ( | \sigma | ^ { 2 } + 4 \pi ( \rho + p ) ( u _ { a } k ^ { a } ) ^ { 2 } ) D _ { A }, \quad ( 1 8 8 )$$
where u a is the fluid 4-velocity, k a is tangent to a bundle of null geodesics (with shear σ ) emanating from the source and the deriative is along k a . In this and other ways, we believe that McVittie spacetimes could play an interesting role in inhomogeneous cosmological modelling, by providing a conceptually simple model of an overdensity in an otherwise spatially homogeneous universe.
## ACKNOWLEDGMENTS
I thank Kayll Lake for interesting discussions of McVittie spacetimes.
## Appendix A: Global structure of McVittie spacetimes admitting a circular photon orbit.
For convenience, we recall the following facts. A McVittie spacetime has line element
$$\begin{smallmatrix} ( \text{Class} & d s ^ { 2 } = - ( f - r ^ { 2 } H ^ { 2 } ) d t ^ { 2 } - 2 r H f ^ { - 1 / 2 } d t d r + f ^ { - 1 } d r ^ { 2 } + r ^ { 2 } d \Omega ^ { 2 }, \\ \text{have} & &. &. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &... &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. &.. \end{smallmatrix}$$
where H = H t ( ) is the Hubble function of the background and f = 1 -2 m/r . As proven in Section 3 above, the spacetime with this line element admits a circular photon orbit if and only if
$$H ( t ) = - H _ { 0 } \tanh ( A H _ { 0 } t ), \ \ t \in \mathbb { R }. \quad ( A 2 )$$
where
$$A = \frac { ( 1 - \frac { 3 m } { a } ) } { \sqrt { 1 - \frac { 2 m } { a } } }, \ \ H _ { 0 } = a ^ { - 1 } \sqrt { 1 - \frac { 2 m } { a } } \quad ( A 3 )$$
and the orbital radius is r = a > 2 m . The scale factor is given by
$$S ( t ) = ( \cosh ( A H _ { 0 } t ) ) ^ { - 1 / A }, \text{ \quad \ } ( A 4 )$$
which immediately shows that an important role is played by the sign of A . See Figures 1 and 2 in Section 3 above. We exclude the case a = 3 m (which corresponds to Schwarzschild-de Sitter spacetime) and note that A < 0 ⇔ a < 3 m .
Defining z = √ 1 -2 m/r (cf. (29)), the equations governing radial null geodesics are
$$\frac { d z } { d t } = \frac { H } { 2 } ( 1 - z ^ { 2 } ) \pm \frac { z } { 4 m } ( 1 - z ^ { 2 } ) ^ { 2 }. \quad \ ( A 5 )$$
Compactified representations of the outgoing (upper sign) and ingoing (lower sign) RNGs are shown in Figures 4 and 5. These diagrams also include the horizons of the spacetimes, given by
$$H ^ { 2 } ( t ) = \frac { z ^ { 2 } } { 4 m ^ { 2 } } ( 1 - z ^ { 2 } ) ^ { 2 }. \quad \quad ( \text{A6} ) \quad \text{Fig}$$
## 1. CPO at radius a < 3 m .
In Figure 4, we see that outgoing geodesics originate in the past at either (i) ( z, t ) = (0 , t 0 ) with t 0 > 0; (ii) ( z, t ) = ( z -, -∞ ); (iii) ( z, t ) = (+ ∞ -∞ , ) or (iv) ( z, t ) = ( z + , -∞ ). Note that z ± are the larger and smaller of the two roots in (0 , 1) of the asymptotic horizon equation
$$H _ { 0 } ^ { 2 } = \frac { z ^ { 2 } } { 4 m ^ { 2 } } ( 1 - z ^ { 2 } ) ^ { 2 }. \quad \quad ( \text{A7} ) \quad \begin{array} { c } \frac { \epsilon _ { 1 } } { ( \text{A} } \\ + \infty \end{array} }$$
There is a unique outgoing radial null geodesic (ORNG) in case (iv), which is a separatrix for cases (ii) and (iii). The existence of this geodesic may be established using dynamical systems, where ( z, t ) = ( z + , -∞ ) corresponds to a saddle. The ORNGs are either (v) future-complete, terminating at ( z, t ) = (+ ∞ , + ∞ ) or (vi) of finite affine length, terminate at a finite time ( t < 0) in the future at z = 0 ( r = 2 m ). The symmetry H ( -t ) = -H t ( ) and the form of the RNG equations (A5) shows that the ingoing RNGs are simply the time-reversed outoing RNGs (as is manifest in Figure 4). By appealing to the geodesic equation (see (13) with glyph[lscript] = glyph[epsilon1] = 0)
$$\ddot { r } = r f ^ { 1 / 2 } H ^ { \prime } ( t ) \dot { t } ^ { 2 }, \text{ \quad \ \ } ( A 8 ) \text{ \ \ IR }$$
it is readily established that the boundary r = 2 m is at finite affine distance in cases (i) and (v). Likewise, z = z -is at a finite affine distance to the past in case (ii), and geodesics extending to r = + ∞ (cases (iii) and (iv)) have infinite affine length in the relevant temporal direction.
It is straightforward to establish the following facts in relation to the corresponding background spacetime that is, the isotropic spacetime with line element (3) with H t ( ) given by (A2).
- · The comoving world-lines x = x 0 are complete timelike geodesics, and t is proper time along these geodesics. (Recall that x = rS -1 ( ) where t S is the scale factor.)
- · Outgoing RNGs are future complete and ingoing RNGs are past complete; r and | t | become infinite in the limit of infinite affine length.
- · Outgoing RNGs either meet the regular origin at finite affine time in the past, or are past complete.
- · Ingoing RNGs either meet the regulat origin at finite affine time in the future, or are future complete.
- · The comoving coordinate x has a finite limit as the affine parameter | s | →∞ along null geodesics.
These points give rise to the conformal diagrams of Figure 5 for the McVittie spacetime and its background.
## 2. CPO at radius a > 3 m .
As we see in Figure 6, all ORNGs originate at z = 0 ( r = 2 m ) at some time t < 0. There is a unique ORNG which terminates at ( z, t ) = ( z -, + ∞ ), and all others terminate at z = 0 , t > 0 or at ( z, t ) = ( z + , + ∞ ). The IRNGs are the time reversal of the ORNGs. Noting the exponential decay of S t ( ) as | t | → ∞ in this case (cf. (A4)), we find that the boundaries at r = 2 m and t = + ∞ are at finite affine distance.
The following properties hold in the background:
- · The comoving worldlines are complete timelike geodesics carrying proper time t , and r → 0 as t →±∞ along these geodesics.
- · Along RNGs, t becomes infinite in finite affine time, and r remains finite in this limit.
- · All ORNGs meet r = 0 at a finite t and at finite affine distance in the future; all IRNGs meet r = 0 in finite t and finite affine distance in the past.
The behaviour of the ORNGs as t → + ∞ and the IRNGs as t → -∞ suggests that the spacetime is extendible across these coordinate boundaries. We note that the scale factor is asymptotic to the scale factor of a de Sitter spacetime:
$$\text{and} \quad S ( t ) = ( \cosh ( A H _ { 0 } t ) ) ^ { - 1 / A } \sim 2 ^ { 1 / A } e ^ { - H _ { 0 } t }, \quad t \to + \infty, \\ \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
and so extending to de Sitter spacetime seems to be a natural possibility. We note that the time coordinate t here shares features of the time coordinate ˆ in t the representation
$$\L e ^ { \quad d s ^ { 2 } = - d \hat { t } ^ { 2 } + \exp ( 2 \alpha ^ { - 1 } \hat { t } ) ( d \hat { x } ^ { 2 } + d \hat { y } ^ { 2 } + d \hat { z } ^ { 2 } ) } \quad ( \mathbf A 1 0 )$$
of the de Sitter metric. These coordinates cover only half of the full de Sitter hyperboloid. See Section 5.2 of [20]. We conjecture that a similar extension to Schwarzschildde Sitter spacetime is possible in the McVittie case.
The conformal diagrams that ensue from these features are shown in Figure 7.
-
-
-
0.15
0.10
0.05
0.00
0.05
0.10
0.15
0.0
0.2
0.4
0.6
0.8
1.0
FIG. 4. Radial null geodesics and the horizon (red) of a McVittie spacetime admitting a circular photon orbit at radius a < 3 m . Here m = 1 and a = 2 5, . giving A = -0 447214 . < 0 and H 0 = 0 178885. . Outgoing geodesics are shown in the upper diagram, IRNGs in the lower. Due to time reversal properties of the spacetime, IRNGs are simply time reversed ORNGs: the corresponding diagram is obtained by inversion. In the diagram, the radial coordinate is z = √ 1 -2 m/r ∈ (0 1) and runs along the horizontal axis. , Thus r = 2 m at z = 0 and r →∞ at z = 1. The vertical axis corresponds to the value of H t ( ) along the geodesics.Referring to Figure 1, we note that t increases from bottom to top, giving the direction of flow along the geodesics. The critical geodesics ¯ γ O and ¯ γ I are shown in black: these are the unique ORNG/IRNG that originate/terminate at r = r + . The trapping properties of the different regions of the spacetime may be read from this diagram: for t < 0, there are trapped regions (both ORNGs and IRNGs move to the left - decreasing r - with increasing t ) and regular regions (ORNGs move right, IRNGs move left). For t > 0, there are anti-trapped regions (both families move right).
## Appendix B: Stable circular orbits in Schwarzschild-de Sitter spacetime.
The conditions for a stable circular (particle) orbit in the Schwarzschild-de Sitter spacetime with mass parameter m and cosmological constant Λ = 3 H 2 0 are G r ( c ) = 0 , G ′ ( r c ) < 0 where r c is the orbital radius and G is given in (141). We wish to answer two related questions: for what range of the parameters m,H 0
FIG. 5. Conformal diagrams for the McVittie spacetime (bottom) that admits a circular photon orbit at r = a < 3 m , and the corresponding isotropic background (top). In both cases, t increases in the vertical direction and J ± corresponds to r = + ∞ , t = ±∞ . The spacetime is collapsing ( H < 0) for t < 0 and expanding ( H > 0) for t > 0. In the McVittie case, we note the existence of ORNGs that (a) originate at r = r -and terminate at r = 2 m ; (b) originate at r = r -and extend to r = + ∞ ; (c) originate at r = + ∞ , t = -∞ and extend to r = + ∞ , t = + ∞ and (d) originate at r = 2 m and extend to r = + ∞ , t = + ∞ . Similar results hold for IRNGs.
do stable circular orbits exist? What is the radius of the innermost stable circular orbit (ISCO)? The algebra is simplified by introducing variables u > 2 , v > 0 and a parameter h 0 > 0 defined by r = mu,glyph[lscript] 2 = m v 2 and mH 0 = h 0 . Note that G r ( c ) = 0 , G ′ ( r c ) < 0 if and only if ¯ ( G r c ) = 0 , G ¯ ( ′ r c ) < 0 where ¯ ( G r ) = r 4 G r ( ) (recall that r > 2 m ). This allows us to deal with polynomial functions only. Then the condition for a circular orbit is
$$\alpha ( u, v ) \coloneqq h _ { 0 } ^ { 2 } u ^ { 5 } - u ^ { 2 } + ( u - 3 ) v = 0, \quad ( \mathbf B 1 )$$
and the condition for stability of this orbit is
$$\beta ( u, v ) \coloneqq 3 u ^ { 2 } - 4 u v + 1 5 v < 0. \quad \text{(B2)}$$
Note that we have used (B1) to eliminate the term in h 2 0 that naturally arises in β u, v ( ).
Considering β as a parametrised quadratic in u shows that we must have v > 45 4 and that (B2) holds if and only if
$$u _ { - } ( v ) < u < u _ { + } ( v ) \text{ \quad \quad } \text{(B3)}$$
FIG. 6. Radial null geodesics of a McVittie spacetime admitting a circular photon orbit at radius a > 3 m . Here m = 1 and a = 3 5,giving . A = 0 218218 . > 0 and H 0 = 0 187044. . Outgoing geodesics are shown in the top panel, and ingoing in the bottom. In the diagram, the radial coordinate is z = √ 1 -2 m/r ∈ (0 , 1) (see (29) below) and runs along the horizontal axis. Thus r = 2 m at z = 0 and r →∞ at z = 1. The vertical axis corresponds to the value of -H t ( ) along the geodesics. Referring to Figure 2, we note that t increases from bottom to top, giving the direction of flow along the geodesics. The expanding region of the spacetime ( t < 0) contains regular and anti-trapped regions, and the collapsing region ( t > 0) contains regular and trapped regions.
where
$$u _ { \pm } ( v ) = \frac { 2 v } { 3 } \left ( 1 \pm \sqrt { 1 - \frac { 4 5 } { 4 v } } \right ). \quad \quad ( B 4 )$$
We note that u ′ -( v ) < 0 for v > 45 4 and that lim v → ∞ + u -( v ) = 15 4 . This yields the (non-sharp) lower bound u > 15 4 for the radius of a stable circular orbit. We also have the upper bound u -( v ) ≤ u -( 45 4 ) = 15 2 .
Suppose that for a given value of h 0 , there exists a point ( u , v 1 1 ) such that α u , v ( 1 1 ) = 0 and β u , v ( 1 1 ) < 0 -that is, there is a stable circular orbit at u = u 1 with angular momentum parameter v 1 . Define
$$g ( u, v ) = \frac { u ^ { 2 } - ( u - 3 ) v } { u ^ { 5 } } \, \text{ \quad \ \ } \text{(B5)}$$
so that g u, v ( ) = h 2 0 if and only if α u, v ( ) = 0. Along the curve g u, v ( ) = h 2 0 we have have dv du > 0 for β u, v ( ) < 0. It follows that the minimum of u on g u, v ( ) = h 2 0 for which β < 0 occurs along u = u -( v ). Furthermore any value of h 0 for which there exists points ( u, v ) with g u, v ( ) = h 2 0 gives rise to a curve with this property.
Substituting then yields
$$h _ { 0 } ^ { 2 } = \frac { u _ { i s c o } - 6 } { u _ { i s c o } ^ { 3 } ( 4 u _ { i s c o } - 1 5 ) },$$
where u isco represents the ISCO radius for a given (scaled) Hubble parameter h 0 . We now have the improved lower bound u > 6. A straightforward calculation shows that h 0 and u isco increase together. If there exists stable circular orbits for a given value of h 0 , then there exists an ISCO for this value of h 0 . This yields the maximum value of h 2 0 for which a stable circular orbit exists: this corresponds to the (global) maximum ISCO value, which is the maximum of u on u -( v ), i.e. u = 15 2. / Hence
$$h _ { 0 } | _ { \max } = h _ { 0 } | _ { u _ { i s c o } = \frac { 1 5 } { 2 } } = \frac { 2 } { 7 5 \sqrt { 3 } }. \quad \quad ( B 7 )$$
- [1] S. Chandrasekhar. The mathematical theory of black holes . Oxford University Press, 1998.
- [2] Z. Stuchl´ ık and S. Hled´ ık. Equatorial photon motion in the Kerr-Newman spacetimes with a non-zero cosmological constant. Classical and Quantum Gravity , 17:4541, 2000.
- [3] P. Amsterdamski, T. Bulik, D. Gondek-Rosinska, and W. Kluzniak. Marginally stable orbits around Maclaurin spheroids and low-mass quark stars. Astronomy and Astrophysics , 381:L21-L24, 2002.
- [4] M.A. Abramowicz and C.P. Fragile. Foundations of Black Hole Accretion Disk Theory. Living Reviews in Relativity , 16(1), 2013.
- [5] V. Faraoni and A. Jacques. Cosmological expansion and local physics. Physical Review D , 76:063510, 2007.
- [6] K. Bolejko, M.-N. C´ el´rier, e and A. Krasi´ski. n Inhomogeneous cosmological models: exact solutions and their applications. Classical and Quantum Gravity , 28:164002, 2011.
- [7] G.C. McVittie. The mass-particle in an expanding universe. Monthly Notices of the Royal Astronomical Society , 93:325, 1933.
- [8] B.C. Nolan. A point mass in an isotropic universe: Existence, uniqueness, and basic properties. Physical Review D , 58:064006, 1998.
- [9] R. Nandra, A.N. Lasenby, and M.P. Hobson. The effect of a massive object on an expanding universe. Monthly Notices of the Royal Astronomical Society , 422:2931, 2012.
- [10] We note that both [8] and [9] identify solutions of the Einstein equations that do for the k = -1 isotropic spacetimes what the McVittie spacetime does for the k = 0 class. In comoving coordinates, these solutions are given in terms of elliptic integrals, and so are not readily amenable to the analytic studies that have been done in
- the k = 0 case. As far as the author is aware, the possibility that these solutions have an elementary form in area radial coordinates has not been investigated: this may make the solutions more tractable.
- [11] B.C. Nolan. A point mass in an isotropic universe: II. Global properties. Classical and Quantum Gravity , 16:1227, 1999.
- [12] R.A. Sussman. On spherically symmetric shear-free perfect fluid configurations (neutral and charged). III. Global view. Journal of Mathematical Physics , 29:1177, 1988.
- [13] N. Kaloper, M. Kleban, and D. Martin. McVittie's legacy: black holes in an expanding universe. Physical Review D , 81:104044, 2010.
- [14] K. Lake and M. Abdelqader. More on McVittie's legacy: A Schwarzschild-de Sitter black and white hole embedded in an asymptotically Λ CDM cosmology. Physical Review D , 84:044045, 2011.
- [15] A.M. da Silva, M. Fontanini, and D.C. Guariento. How the expansion of the universe determines the causal structure of McVittie spacetimes. Physical Review D , 87:064030, 2013.
- [16] L. Perko. Differential equations and dynamical systems . Springer-Verlag, New York, 1991.
- [17] J. Carr. Applications of centre manifold theory . SpringerVerlag New York, 1981.
- [18] D.K. Arrowsmith and C.M. Place. An introduction to dynamical systems . Cambridge University Press, 1990.
- [19] U. Kirchgraber and K.J. Palmer. Geometry in the neighborhood of invariant manifolds of maps and flows and linearization . Longman Scientific & Technical Harlow, 1990.
- [20] S.W. Hawking and G.F.R. Ellis. The large scale structure of space-time . Cambridge University Press, 1973.
-∞
FIG. 7. Conformal diagrams for the McVittie spacetime (bottom) that admits a circular photon orbit at r = a > 3 m , and the corresponding isotropic background (top). In both cases, t increases in the vertical direction and J ± corresponds to r = + ∞ , t = ±∞ . The spacetime is expanding ( H < 0) for t < 0 and collapsing ( H > 0) for t > 0. In the McVittie case, the past singular boundaries (serrated) are at r = 2 m,t < 0 and the future singular boundaries are at r = 2 m,t > 0. At A , ( t, r ) = (+ ∞ , r -and at B , ( t, r ) = ( -∞ , r -). We note the existence of (a) ORNGs that originate at r = 2 m and terminate at r = 2 m ; (b) a unique ORNG ¯ γ O that originates at r = 2 m and extends to r = r + with t → + ∞ and (c) ORNGs that originate at r = 2 m and extend to r = r + with t → + ∞ . Similar results hold for IRNGs: ¯ γ I is the unique IRNG that originates at r = r -. We speculate that the spacetime extends to a Schwarzschild-de Sitter spacetime across r = r + , t = ±∞ , but we have not addressed this in the paper.
 | 10.1088/0264-9381/31/23/235008 | [
"Brien C. Nolan"
] | 2014-07-31T23:33:28+00:00 | 2014-07-31T23:33:28+00:00 | [
"gr-qc",
"math-ph",
"math.MP"
] | Particle and photon orbits in McVittie spacetimes | McVittie spacetimes represent an embedding of the Schwarzschild field in
isotropic cosmological backgrounds. Depending on the scale factor of the
background, the resulting spacetime may contain black and white hole horizons,
as well as other interesting boundary features. In order to further clarify the
nature of these spacetimes, we address this question: do there exist bound
particle and photon orbits in McVittie spacetimes? Considering first circular
photon orbits, we obtain an explicit characterization of all McVittie
spacetimes for which such orbits exist: there is a 2-parameter class of such
spacetimes, and so the existence of a circular photon orbit is a highly
specialised feature of a McVittie spacetime. However, we prove that in two
large classes of McVittie spacetimes, there are bound particle and photon
orbits: future-complete non-radial timelike and null geodesics along which the
areal radius $r$ has a finite upper bound. These geodesics are asymptotic at
large times to circular orbits of a corresponding Schwarzschild or
Schwarzschild-de Sitter spacetime. The existence of these geodesics lays the
foundations for and shows the theoretical possibility of the formation of
accretion disks in McVittie spacetimes. We also summarize and extend some
previous results on the global structure of McVittie spacetimes. The results on
bound orbits are established using centre manifold and other techniques from
the theory of dynamical systems. |
1408.0045v1 | ## On-Line Monitoring for Temporal Logic Robustness
Adel Dokhanchi, Bardh Hoxha, and Georgios Fainekos
School of Computing, Informatics and Decision Systems Engineering Arizona State University f adokhanc,bhoxha,fainekos @asu.edu g
Abstract. In this paper, we provide a Dynamic Programming algorithm for online monitoring of the state robustness of Metric Temporal Logic specifications with past time operators. We compute the robustness of MTL with unbounded past and bounded future temporal operators (MTL < + 1 + pt ) over sampled traces of Cyber-Physical Systems. We implemented our tool in Matlab as a Simulink block that can be used in any Simulink model. We experimentally demonstrate that the overhead of the MTL < + 1 + pt robustness monitoring is acceptable for certain classes of practical specifications.
## 1 Introduction
Modern airplanes, automobiles and medical devices are prime examples of safety critical Cyber-Physical Systems (CPS). Nowadays, the majority of safety critical functions in such systems is controlled by embedded computers. Due to the critical nature of these components, it is of paramount importance to verify the functional correctness of the embedded software. However, as the number of computer controlled components increases so does the complexity of the verification of functional correctness. Moreover, the verification problem of most classes of CPS is even an undecidable problem [1].
As an alternative to verification and o GLYPH<11> -line testing, runtime monitoring has been proposed. The underlying idea is that given a set of formal requirements, these requirements are analyzed at runtime by an independent monitor and if a violation is detected, it is reported to a supervisor. The supervisor can then decide on remedial actions to fix the problem or reduce its impact to the system. The monitoring problem has been extensively studied [2-14] for the cases where the formal requirements are expressed in Linear Temporal Logic (LTL) [15] or in Metric Temporal Logic (MTL) [16].
In this paper, we revisit the MTL runtime monitoring problem when targeted to CPS. In particular, we claim that the classical Boolean semantics (or even three valued semantics) are not su GLYPH<14> ciently informative for CPS behaviors. For instance, consider the specification ' After a takeo GLYPH<11> command is received, then reach altitude of 600ft within 5 minutes ' for an autonomous Unmanned Aerial Vehicle (UAV) as introduced in [8]. Clearly, knowing that the specification failed or passed at runtime is important. However, more useful information from the perspective of the supervisor would be the knowledge of how far is the aircraft from satisfying the requirement. More specifically, -10ft from the requirement of 600ft at 1 min away from the 5 min threshold should potentially be less alarming than -100ft at exactly the same time. A supervisor that has a model of the dynamics of the aircraft can determine whether the UA V can climb 100ft
within 1 min or not. We remark that the determination of the climb rate can only occur at runtime since this depends on the atmospheric parameters, the payload of the UAV, etc. Hence, the climb rate cannot be a precomputed parameter unless it is very conservatively set.
Our goal is to construct MTL monitors for estimating the robustness of satisfaction [17-19]. Temporal logic robustness gives a quantitative interpretation of satisfaction of an MTL formula. In detail, if an MTL formula valuates to positive robustness " , then the specification is true and, moreover, the state sequences can tolerate perturbations up to " and still satisfy the specification. Similarly, if the robustness is negative, then the specification is false and, moreover, the state sequences under " perturbations still do not satisfy the specification. Thus, robust semantics can be used to give quantitative values to the satisfaction of MTL formulas when the target is CPS.
The challenge here is that automata based monitors [13, 14] cannot be synthesized for computing the robustness valuations. Therefore, formula rewriting methods [11] or dynamic programming [9] methods must be used. Here, we take the latter approach for combined unbounded past time and bounded future time MTL specifications. Since we are working with CPS, we assume that it is possible - if desired - to have a model predictive component in the system [20] which will provide a finite horizon prediction of the system behavior. That finite horizon prediction could be appended with the observed system behavior to provide a robustness estimate of a likely system behavior. Hence, it becomes possible to monitor specifications such as ' If at anytime in the past a takeo GLYPH<11> command is issued, then within 5 min the altitude of 600ft is reached '. Thus, such requirements can now be monitored using only the actual observed system behavior or the observed system behavior with the predicted system behavior.
Our contributions in this paper are as follows: We provide a dynamic programming algorithm for on-line monitoring of the robustness metric of MTL formulas with bounded future and unbounded past. In addition, we provide a Matlab Simulink tool-/ box that can be used in any Simulink model for runtime monitoring of MTL robustness. The memory usage of our method is bounded and its runtime overhead is negligible for practical applications. Additional benefits in utilizing an on-line monitor are that it can be used in temporal logic testing algorithms [21, 22], where it may be desirable that the simulation stops as soon as the property is violated, as well as in feedback control for MTL specifications. Although temporal logic robustness has been considered in previous works [17-19], the solutions were provided for o GLYPH<11> -line testing. To the best of our knowledge, this is the first attempt to solve the on-line MTL robustness monitoring problem e GLYPH<14> ciently.
## 2 Problem Formulation
In the following, we represent the set of natural numbers including zero by N and the finite interval of N up to m by N m = f 0 1 ; ; : : : ; m g . In this work, we consider monitoring of Cyber-Physical Systems (CPS). We assume that we have access to some discrete time execution or simulation traces of the CPS. We view (execution or simulation) traces as timed state sequences T = T T T 0 1 2 : : : T m = ( GLYPH<28> 0 ; s 0 ) ( GLYPH<28> 1 ; s 1 ) ( GLYPH<28> 2 ; s 2 ) : : : ( GLYPH<28> m ; sm ) where for each k 2 N m , GLYPH<28> k 2 R GLYPH<21> 0 is a time stamp and sk 2 S is a vector containing the
Fig. 1. Overview of the solution of the MTL < + 1 + pt on-line monitoring problem. The monitored robustness values could be used as feedback to the CPS or it could be plotted to be observed by a human supervisor if needed.
values of the state variables of the system at each sampling instance k . For example, for m = 2, the trace T = (0 ; (2 ; 0 34))(0 1 : : ; (3 ; 0 356))(0 2 : : ; (2 ; 0 36)) captures the finite : time execution of a CPS with two state variables in the vector sk : one ranging over the natural numbers N and the other over the reals R . That is, for k = 1, the state of the system at time GLYPH<28> 1 = 0 1 was : s 1 = (3 ; 0 356) : 2 N GLYPH<2> R . We further assume that S = ( S ; d ) is a generalized quasi-metric space [23]. The existence of metrics is necessary so that distances can be defined for quantitative valuations of the atomic propositions [18, 21].
Throughout the paper, the variable i , which ranges over N , is used to represent the current simulation step or the current index of the sampling process. We assume a fixed sampling period for the monitored system. Thus, there exists a fixed time period between consecutive time stamps. For the fixed time period GLYPH<1> t > 0, for all i GLYPH<21> 0, we have GLYPH<28> i + 1 GLYPH<0> GLYPH<28> i = GLYPH<1> t (or equivalently GLYPH<28> i = i GLYPH<1> t ). As a result, we can simply compute each time stamp GLYPH<28> i knowing the trace index (or simulation step) i by multiplication ( GLYPH<28> i = i GLYPH<1> t ). Therefore, we use the trace index (simulation step i ) as the reference of time.
The property of interest is stated in Metric Temporal Logic (MTL) with bounded future and unbounded past (MTL < + 1 + pt ) for timed state sequences [11]. More specifically, at each time i , we would like to monitor safety requirements represented as MTL < + 1 + pt formulas. These formulas capture safety properties of the system, such as bounded reactivity, which can be periodically analyzed for violation. In our formulation, we use the robust (quantitative) semantics [18] that quantify the distance between a given execution trace of a CPS and all the execution traces that violate the property. The robustness of a formula J ' K with respect to a trace T at time i is a value that measures how far is the trace from the satisfaction falsification. This measure is an extension of boolean val-/ ues representing satisfaction or falsification which is used in conventional monitoring. A positive robustness value means that the trace satisfies the property and a negative robustness means that the specification is not satisfied.
Our goal in this paper is to provide monitoring tools for temporal logic robustness. We assume that at each time i , the CPS outputs its current state si along with a finite prediction si + 1 , si + 2 , : : : , si + Hrz of horizon length Hrz 2 N (see Fig. 1). The horizon length Hrz will be formally defined in Sec. 4; however, informally, it is the required number of samples after time i so that any future requirements in the MTL specification GLYPH<30> are resolved, i.e., the horizon depends on the structure of the formula GLYPH<30> , Hrz = hrz ( GLYPH<30> ).
When dealing with CPS, there exist numerous methods by which such a prediction horizon (forecasting) can be computed [24-26].
Next, we formally define the main problem presented in this paper.
Problem 1 (MTL < + 1 + pt Robustness Monitoring) Given an MTL < + 1 + pt specification ' , a sampling instance i and an execution trace T = T T 0 1 : : : T m such that m = i + hrz ( ' ) , compute the current robustness estimate [ [ ' ] ]( T ; i ) at time GLYPH<28> i .
Intuitively, ' represents a system invariant that must hold at every point in the system execution. This can also be viewed as testing for the specification robustness [ [ GLYPH<3> ' ] ]( T ; 0), where GLYPH<3> is the operator for ' always in the future ' and ' is an arbitrary MTL < + 1 + pt specification. However, instead of caring about the satisfaction of the formula at the beginning of the time, we care about the potential of violating ' for which we design an on-line monitor.
Overview of solution and summary of contributions: We provide an on-line monitoring approach for computing the robustness of an MTL < + 1 + pt formula with respect to execution traces of a CPS. An overview of the solution for the MTL < + 1 + pt on-line monitoring problem appears in Fig. 1. Our method monitors the behavior of a CPS as it executes. Our toolbox is also useful for applications where Simulink models are actually used for process monitoring (and not simulation). In addition, it can also be used for code generation for general MTL < + 1 + pt monitors for deployment on actual systems. Our method computes the robustness of invariants [ [ ' ] ]( T ; i ) by storing previous specification robustness values - if needed - and by only utilizing a bounded number of pairs of the execution trace T Hst ; : : : ; T Hrz where Hst 2 N i and it will be formally defined in Sec. 4. Our monitor uses bounded memory and, in the worst case, it has quadratic time complexity that depends on the magnitude of Hrz GLYPH<0> Hst . In principle, our solution for robustness monitoring is inspired by the boolean temporal logic monitoring algorithm in [2].
## 3 Robustness of Metric Temporal Logic Specifications
In digital control and monitoring of CPS, it is inevitable that physical quantities are measured through a sampling process. As mentioned in the Problem Formulation section, when we mention time, we are actually referring to the corresponding sampling index i . With a slight abuse of notation and under the assumption of constant sampling rate, an execution trace T can also be represented by a function s : N i + Hrz ! S . The view of the sequence s 0 s 1 : : : si + Hrz as a function s simplifies the presentation of the robust semantics for MTL.
Using a metric d [23], we can define a distance function that captures how far away a point x 2 X is from a set S GLYPH<18> X . Intuitively, the distance function assigns positive values when x is in the set S and negative values when x is outside the set S . The metric d must be at least a generalized quasi-metric as described in [21] which also includes the case where d is a metric as it was introduced in [18].
Definition 1 (Signed Distance). Let x 2 X be a point, S GLYPH<18> X be a set and d be a metric. Then, we define the Signed Distance from x to S to be
$$\text{Dist} _ { d } ( x, S ) \coloneqq \begin{cases} - \inf \{ d ( x, y ) \, | \, y \in S \} & \text{if} \, x \notin S \\ \inf \{ d ( x, y ) \, | \, y \in X \bar { \ } S \} & \text{if} \, x \in S \end{cases}$$
where inf is the infimum.
Metric Temporal Logic (MTL) was introduced by Koymans [16] to reason about the quantitative timing properties of boolean signals. In this paper, we use the standard fragment of MTL with bounded future, but also we allow the use of past time operators.
Definition 2 (MTL < + 1 + pt Syntax). Let AP be the set of atomic propositions and I be any non-empty interval of N , and I be any non-empty interval of N [ f + 1g . The set MTL < + 1 + pt formulas is inductively defined as ' :: = > j p j : ' j \_ ' j UI ' j S I ' where p 2 AP and > stands for true .
Note that we use the number of samples to represent the time interval constraints of temporal operators. For example assume that GLYPH<1> t = 0 1, then the MTL formula : ^ [0 0 5] ; : a where the timing constraints are over time is instead represented by ^ [0 5] ; a in MTL < + 1 + pt .
The propositional operators conjunction ( ^ ) and implication ( ! ) are defined the usual way. All other bounded future temporal operators can be syntactically defined using Until ( UI ), where GLYPH<7> (Next), ^ (Eventually), and GLYPH<3> (Always) are defined as GLYPH<7> ' GLYPH<17> >U [1 1] ; ' , ^ I ' GLYPH<17> >UI ' , and GLYPH<3> I ' GLYPH<17> : ^ I: ' respectively. The intuitive meaning of the U [ a b ; ] ' operator at sampling time i is a follows: has to hold at least until ' becomes true within the time interval of [ i + a i ; + b ] in the future. Similarly, all other bounded unbounded past temporal operators can be defined using Since ( / S I ), where GLYPH<12> (Previous), GLYPH<144> (Eventually in the past), and GLYPH<26> (Always in the past) are defined as GLYPH<12> ' GLYPH<17> >S [1 1] ; ' , GLYPH<144> I ' GLYPH<17> >S I ' , and GLYPH<26> I ' GLYPH<17> : GLYPH<144> I : ' respectively. The intuitive meaning of the S [ a b ; ] ' operator at sampling time i is as follows: since ' becomes true within the interval [ i GLYPH<0> b i ; GLYPH<0> a ] in the past, must hold till now (current time i ).
MTL < + 1 + pt can state requirements over the observable trajectories of a CPS. In order to capture these requirements, each predicate p 2 AP is mapped to a subset of the metric space X . We use an observation map O to interpret each predicate p 2 AP . In other words, the observation map is defined as O : AP ! P X ( ) such that for each p 2 AP the corresponding set is O ( p ). Here, P S ( ) denotes the powerset of a set S . We define the robust valuation of an MTL < + 1 + pt formula ' over a trace s as follows [17].
Definition 3 (MTL < + 1 + pt Robustness Semantics). Let s be a trace s : N ! X, and O be an observation map O : AP ! P X , then the robust semantics of any formula ( ) ' 2
MTL < + 1 + pt with respect to s is recursively defined as:
$$\ n u \in \L _ { + p t } \ v u n \ r e s p e c t o v s i n c e v e y u e j n e u a u s. \\ [ [ T ] ] ( s, i ) \coloneqq + \infty \\ [ [ p ] ] ( s, i ) \coloneqq \text{Dist} _ { d } ( s ( i ), \mathcal { O } ( p ) ) \\ [ [ \neg \varphi ] ( s, i ) \coloneqq - [ \varphi ] ( s, i ) \\ [ \psi \vee \varphi ] ( s, i ) \coloneqq [ \psi ] ( s, i ) \sqcup [ \varphi ] ( s, i ) \\ [ [ \psi \mathcal { U } _ { [ l, u ] } \varphi ] ( s, i ) \coloneqq \bigsqcup _ { j = i + l } ^ { i + u } \left ( [ \varphi ] ( s, j ) \sqcap \prod _ { k = l } ^ { j - 1 } [ \psi ] ( s, k ) \right ) \\ [ \psi \mathcal { S } _ { [ l ^ { \prime }, u ^ { \prime } } \rangle \varphi ] ( s, i ) \coloneqq \bigsqcup _ { j = max \{ 0, i - u ^ { \prime } \} } ^ { i - l ^ { \prime } } \left ( [ \varphi ] ( s, j ) \sqcap \prod _ { k = j + 1 } ^ { i } [ \psi ] ( s, k ) \right ) \\ v h e r e \sqcup \text{ stands for max, } \sqcap \text{ stands for min, } p \in \text{ AP, } l, u, l ^ { \prime } \in \mathbb { N } \text{ and } u ^ { \prime } \in \mathbb { N } \cup \{ \infty \}$$
where t stands for max, u stands for min, p 2 AP, l u l ; ; 0 2 N and u 0 2 N [ f1g . Furthermore, the symbol i in S 0 [ l ; u 0 i will be ) when u 0 = + 1 and ] when u 0 , + 1 .
We should point out that we use the extended definition of maximum ( t ) and minimum ( u ), with slight abuse of notation, we let max( ; ) = GLYPH<0>1 and min( ; ) = + 1 . i.e., over empty sets we treat min and max as infimum and supremum, respectively. For exact definition of infimum and supremum see [27].
## 4 Robustness Monitoring of MTL < + 1 + pt
## 4.1 Finite horizon and history of MTL < + 1 + pt
For each MTL < + 1 + pt formula we define the finite horizon hrz ( ) as the number of samples we need to consider in the future. In MTL, the satisfaction of the formula depends on what will happen in the future. In bounded MTL, the finite horizon hrz ( ) is the number of steps (samples) which we need to consider in the future in order to evaluate the formula at the current time i . In other words, hrz ( ) is the number of steps into the future for which the truth value of the sub-formula depends on [2]. Similarly, we define the finite history hst ( ) of as the number of samples we need to look into the past. That is, the number of steps in the past for which the truth value of the sub-formula depends on. Intuitively, the hst ( ) is the size of the history we need to consider in order to keep track of what happened in the past to evaluate the formula at present time. The finite horizon and the history can be defined recursively. We define hrz ( ) (similar to h ( ) in [2]) and we add the recursive definition of hst ( ) in the following:
hrz p ( ) = 0 hst ( p ) = 0 hrz ( : ) = hrz ( ) hst ( : ) = hst ( ) hrz ( OP ' ) = max hrz f ( ; ) hrz ( ' ) g hst ( OP ' ) = max hst f ( ; ) hst ( ' ) g hrz ( U [ l u ; ] ' ) = max hrz f ( ) + u GLYPH<0> 1 ; hrz ( ' ) + u g hst ( U [ l u ; ] ' ) = max hst f ( ; ) hst ( ' ) g hrz ( S 0 [ l ; u 0 i ' ) = max hrz f ( ; ) hrz ( ' ) g hst ( S 0 [ l ; u 0 i ' ) = ( max hst f ( ) + u 0 GLYPH<0> 1 ; hst ( ' ) + u 0 g if u 0 , + 1 max hst f ( ) + l 0 GLYPH<0> 1 ; hst ( ' ) + l 0 g if u 0 = + 1
Table 1. Pre Vector and Robustness Table
| Pre[ k ] | T k ; j | column j ) | -2 | -1 | 0 | 1 | 2 |
|-----------------------|-----------|------------------------|---------------------------|---------------------------|-----------------|----------------------|--------------------|
| | row k + | Time( i ) | i GLYPH<0> 2 | i GLYPH<0> 1 | i | i + 1 | i + 2 |
| | 1 = ' | 2 ^ 3 | ' ( s ; i GLYPH<0> 2) | ' ( s ; i GLYPH<0> 1) | ' ( s ; i ) | ' ( s ; i + 1) | ' ( s ; i + 2) |
| | 2 | GLYPH<3> [1 ; 2] q | J K 2 ( s ; i GLYPH<0> 2) | J K 2 ( s ; i GLYPH<0> 1) | J K 2 ( s ; i ) | J K 2 ( s ; i + 1) | J K 2 ( s ; i + 2) |
| 3 ( s ; i GLYPH<0> 3) | 3 | GLYPH<26> [0 ; + 1 ) p | J K 3 ( s ; i GLYPH<0> 2) | J K 3 ( s ; i GLYPH<0> 1) | J K 3 ( s ; i ) | J K 3 ( s ; i + 1) | J K 3 ( s ; i + 2) |
| J K | 4 | p | J K 4 ( s ; i GLYPH<0> 2) | J K 4 ( s ; i GLYPH<0> 1) | J K 4 ( s ; i ) | J K 4 ( s ; i + 1) | J K 4 ( s ; i + 2) |
| | 5 | q | J K 5 ( s ; i GLYPH<0> 2) | J K 5 ( s ; i GLYPH<0> 1) | J K 5 ( s ; i ) | J K J 5 ( s ; i + 1) | K 5 ( s ; i + 2) |
J
K
J
K
J
K
J
K
J
K
where p 2 AP . Here, OP is any binary operator in propositional logic, and ; ' are MTL < + 1 + pt formulas. For the unbounded S [0 ; + 1 ) operator, the computation of finite history is more involved and needs more explanation. Namely, we need to restate the dynamic programming algorithm for monitoring a sub-formula S [0 ; + 1 ) ' based on the following works [9, 5]. According to the robustness semantics, the robustness of S [0 ; + 1 ) ' at time i is as follows:
$$[ \psi \mathcal { S } _ { [ 0, + \infty ) } \varphi ] ( s, i ) = \bigsqcup _ { j = 0 } ^ { i } \left ( [ \varphi ] ( s, j ) \cap \prod _ { k = j + 1 } ^ { i } [ \psi ] ( s, k ) \right ) \\. \quad \dots \, \dots$$
also robustness of S [0 ; + 1 ) ' at time i GLYPH<0> 1 is
$$\left [ \psi \mathcal { S } _ { [ 0, + \infty ) } \varphi \right ] ( s, i - 1 ) = \bigsqcup _ { j = 0 } ^ { i - 1 } \left ( \left [ \varphi \right ] ( s, j ) \cap \prod _ { k = j + 1 } ^ { i - 1 } \left [ \psi \right ] ( s, k ) \right )$$
Thus, we can rewrite J S [0 ; + 1 ) ' K ( s ; i ) as
$$[ \psi \mathcal { S } _ { ( 0, + \infty ) } \varphi ] ( s, i ) & = [ \varphi ] ( s, i ) \sqcup \left ( [ \psi ] ( s, i ) \sqcap \left ( \bigsqcup _ { j = 0 } ^ { i - 1 } \left ( [ \varphi ] ( s, j ) \sqcap \prod _ { k = j + 1 } ^ { i - 1 } [ \psi ] ( s, k ) \right ) \right ) \right ) \\ & = [ \varphi ] ( s, i ) \sqcup \left ( [ [ \psi ] ] ( s, i ) \sqcap \left ( [ [ \psi \mathcal { S } _ { ( 0, + \infty ) } \varphi ] ( s, i - 1 ) \right ) \right )$$
Therefore, similar to [5] we recursively update the robustness of S [0 ; + 1 ) ' at the current time i and save it in a variable called ' Pre ' to reuse it for the computation of the next time step (see [5] for more details). As a result, when we have an unbounded past time operator, we do not need the full history table. However, if the formula contains a nested future time operator, we need to extend the history to be long enough to contain the actual values. In other words, although for unbounded past time operators we do not need the whole history table, we should still extend the history to be able to store the actual simulation values (not the predicted values) in ' Pre '.
## 4.2 Robustness Computation Algorithm
For each MTL < + 1 + pt formula ' we construct a table called Robustness Table with width of Hst + 1 + Hrz , where Hrz = hrz ( ' ) is the finite horizon of the specification formula ' , and, Hst = Hrz + hst ( ' ), where hst ( ' ) is the finite history of the specification ' . Hst is extended conservatively due to the fact that ' Pre ' value can only store the robustness
## Algorithm 1 On-Line Monitor
Input : ' , s 0 i = si si + 1 : : : si + Hrz , d , O ; Global variables: T , Pre ; Output : T 1 0 ; ( robustness value ).
```
\text{Input: } \varphi, s _ { j } = s _ { i } s _ { i + 1 } \dots s _ { i + H r _ { 2 } }, d, O ; Global variables: T, \Pr e ; \text{Output: } T _ { 1, 0 } ( \text{robustness value} ). \\ \text{procedure Monitor} ( \varphi, s _ { j }, d, O ) & \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
1: \text{ for } k \leftarrow 1 \, \overline { \varphi } \, \text{ do } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
2: \text{ for } k \leftarrow 1 \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
3: \text{ end for } k \leftarrow 1 \, \overline { \varphi } \, \text{ do } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
4: \text{ for } j \leftarrow 1 - H s t \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
5: \text{ end for } k \leftarrow 1 \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
6: \text{ end for } k \leftarrow 1 - H s t \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
7: \text{ end for } k \leftarrow 1 - H s t \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
8: \text{ end if } k \leftarrow 1 - H s t \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
9: \text{ end for } k \leftarrow 1 - H s t \, \overline { \varphi } \rightarrow 0 \, \text{ then } \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
1: \text{ for } k \leftarrow \leftarrow \leftarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \leftarrow \rightarrow \rightarrow \leftarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow
\text{end for } k \leftarrow \leftarrow \leftarrow \leftarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow \rightarrow
\text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text$ \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \text` \end{array} }
```
values corresponding to the actual simulation. The height of the robustness table is the size of the formula ' ( j ' j ), where j ' j is the number of sub-formulas of ' including itself. For example, assume we have a formula ' = GLYPH<26> [0 ; + 1 ) p ^ GLYPH<3> [1 2] ; q and we intend to compute [ [ ' ] ]( T ; i ) at each time i . In formula ' , Hst = 2 and Hrz = 2. Since ' has unbounded past-time operators, it needs the Pre vector as well as the Robustness Table. The Pre vector appended to the Robustness Table is presented in Table 1. In particular, the Pre vector contains the value of past sub-formulas from the beginning of the time up to the current time.
In the following, we explain how the values of Table 2, the robustness table, are computed using Algorithms 1 and 2. In order to make our algorithms more readable, we used a vector to show the CPS output si , si + 1 , : : : , si + Hrz to the monitoring (see Fig. 1). We define a vector s 0 i = si si + 1 : : : si + Hrz which appends current state si with predictions si + 1 , si + 2 , : : : , si + Hrz . In Table 1, i is the current simulation step which corresponds to column 0. At each simulation step i , for each unbounded past time sub-formula GLYPH<30> , we first save the values of the column GLYPH<0> Hst + hst ( GLYPH<30> ) in the Pre vector (Algorithm 1 lines 1-3) since the column GLYPH<0> Hst + hst ( GLYPH<30> ) contains the robustness value of GLYPH<30> from the beginning of the simulation. We need the Pre vector to compute the robustness of GLYPH<30> at the next sampling time using the dynamic programming method. In the above example, for
Table 2. Robustness Computation of each table entries (Gray cells are unused)
| T k ; j | i GLYPH<0> 2 | i GLYPH<0> 1 | i | i + 1 | i + 2 |
|-----------|-------------------------------------|-------------------------------------|----------------------------|-----------------------------|-----------------------------|
| k + , j ) | j = GLYPH<0> 2 | j = GLYPH<0> 1 | j = 0 | j = 1 | j = 2 |
| Pre[1] | T 2 ; GLYPH<0> 2 u T 3 ; GLYPH<0> 2 | T 2 ; GLYPH<0> 1 u T 3 ; GLYPH<0> 1 | T 2 ; 0 u T 3 ; 0 | T 2 ; 1 u T 3 ; 1 | T 2 ; 2 u T 3 ; 2 |
| Pre[2] | T 5 ; GLYPH<0> 1 u T 5 ; 0 | T 5 ; 0 u T 5 ; 1 | T 5 ; 1 u T 5 ; 2 | T 5 ; 2 | + 1 |
| Pre[3] | Pre[3] u T 4 ; GLYPH<0> 2 | T 3 ; GLYPH<0> 2 u T 4 ; GLYPH<0> 1 | T 3 ; GLYPH<0> 1 u T 4 ; 0 | T 3 ; 0 u T 4 ; 1 | T 3 ; 1 u T 4 ; 2 |
| Pre[4] | Dist d ( s i GLYPH<0> 2 ; O ( p )) | Dist d ( s i GLYPH<0> 1 ; O ( p )) | Dist d ( s i ; O ( p )) | Dist d ( s i + 1 ; O ( p )) | Dist d ( s i + 2 ; O ( p )) |
| Pre[5] | Dist d ( s i GLYPH<0> 2 ; O ( q )) | Dist d ( s i GLYPH<0> 1 ; O ( q )) | Dist d ( s i ; O ( q )) | Dist d ( s i + 1 ; O ( q )) | Dist d ( s i + 2 ; O ( q )) |
Input : ' k , j , s 0 i = si si + 1 : : : si + Hrz , d , O ; Global variables: T , Pre ; Output : Tk j ; .
```
Algorithm 2 Robustness Computation (CR)
Input: \varphi _ { k }, j, s _ { j } = s _ { i } s _ { i + 1 } \dots s _ { i + H r _ { z } }, d, O ; Global variables: T, Pre ; Output: T _ { k, j }.
procedure CR(\varphi _ { k }, j, s _ { j }, d, O )
1: if \varphi _ { k } = T then T _ { k, j } \leftarrow + \infty 1: else if \varphi _ { m } S _ { j } ( r _ { v } ) \varphi _ { n } 2: 3: 3 0: 0 4: 4 6: 6 5: 5 7: 7 8: 8 9:
```
GLYPH<26> [0 ; + 1 ) p the value at column GLYPH<0> 2 is saved in Pre to be used during robustness computation. Then, we shift all the robustness table entries of the predicates by one position to the left (Algorithm 1, lines 4-10). Then the loop (Algorithm 1, lines 11-21) recursively calls Algorithm 2 to fill the robustness table for each sub-formula from bottom to top.
Each call of Algorithm 2 (CR) computes each table entry Tk j ; (see tables 1,2) where column j is the horizon history index and row / k is the sub-formula index. For past subformulas the table entries are computed from left to right (Algorithm 1, lines 13-15), and for future sub-formulas the table entries are computed from right to left (Algorithm 1, lines 17-19). New values for predicates (according to execution traces) will be placed in column 0 and the predicted values of the predicates will be saved in columns 1 to Hrz (Algorithm 2, lines 2-5). Table 2 shows the updates of predicate values in rows 4, and 5 which correspond to Algorithm 2, line 4.
In the following, we explain how the CR Algorithm 2 computes the MTL robustness values for three di GLYPH<11> erent cases of MTL:
Case 1 (Lines 10-20): The robustness of bounded future temporal sub-formulas with interval [ l ; u ] at each column j is computed given the values of its operands for columns j up-to min j f + u Hrz ; g (Line 14). For example, this case is used in Table 2 to compute the robustness of sub-formula 2 = GLYPH<3> [1 2] ; q from right to left. Case 1 in CR Algorithm is similar to the DP-TALIRO algorithm [28].
Case 2 (Lines 23-28): The robustness of bounded past temporal sub-formulas with interval [ l 0 ; u 0 ] at each column j is computed given the values of its operands for columns j down-to j GLYPH<0> u 0 (Line 25).
Case 3 (Lines 30-36): The robustness of unbounded past temporal sub-formulas with interval [ l 0 ; + 1 ) for column j is computed using the stored value in column j GLYPH<0> 1 in dynamic programming fashion (Line 33) and using the Pre vector (Line 31). For example, Case 3 is used to compute the robustness of 3 = GLYPH<26> [0 ; + 1 ] p using Pre [3] from left to right in Table 2.
Finally, we update table entries for the top row which corresponds to 1 = ' . Since its corresponding operator ^ is propositional (Algorithm 2 Lines 6-9), we can update its value from any direction. The high level explanation of Algorithm 1 is described as follows:
- 1. Store values of column GLYPH<0> Hst + hst ( GLYPH<30> k ) for each unbounded past sub-formula GLYPH<30> k in Pre k [ ] and shift the table entries of predicates one to the left (Lines 1-10).
- 2. For each row i from j ' j to 1 compute the robustness values according to:
- (a) If ' i is a future temporal operator, for each column j from Hrz down to GLYPH<0> Hst + hst ( ' i ), update table entry Ti j ; using Algorithm 2.
- (b) If ' i is a past temporal operator, for each column j from GLYPH<0> Hst + hst ( ' i ) up to Hrz update table entry Ti j ; using Algorithm 2.
- 3. Return the robustness ( T 1 0 ; ).
We provided the proof of this section in Appendix.
## 5 Experimental Analysis and Case Studies
## 5.1 Runtime Overhead
First, we measure the overhead of the proposed monitoring framework on a slightly modified version of the Automatic Transmission (AT) model provided by Mathworks as a Simulink demo 1 . The experiments were conducted on a Windows 7, Intel Core2 Quad (2.99 GHz) with 8 GB RAM.
The physical model of the AT system has two continuous (real-valued) state variables which are also its monitored outputs: the speed of the engine ! and the speed of the vehicle v . The model includes an automatic transmission controller that exhibits both continuous and discrete behavior. It is a typical CPS model and specifications over both boolean and continuous variables can be formalized. However, since the valuation of the robustness of predicates over continuous state variables is computationally more expensive than a boolean valuation, we consider only specifications over continuous state variables for the impact analysis.
We introduce our MTL < + 1 + pt monitoring block in the AT model and test the performance over a set of specifications. In order to test the runtime overhead of our work, we artificially generate 30 di GLYPH<11> erent MTL < + 1 + pt formulas based on typical critical safety formulas to show that the runtime overhead depends on both of the size of the formula and the horizon history. We test our method for 100 runs of monitoring algorithm for / each specification (formula), and for each run we use 100 simulation steps. Then, we compute the mean and variance of the overhead for each simulation step which is the
1 Available at: http://www.mathworks.com/help/simulink/examples/ modeling-an-automatic-transmission-controller.html
Table 3. The overhead on each simulation step on the Automatic Transmission model with specifications of increasing length. Table entries are in milliseconds.
| # | H = 1,000 | H = 1,000 | H = 1,000 | H = 1,000 | H = 2,000 | H = 2,000 | H = 2,000 | H = 2,000 | H = 10,000 | H = 10,000 | H = 10,000 |
|-------------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|-------------|--------------|--------------|--------------|
| | E | E | U | U | E | E | U | U | E | U | U |
| | Mean | Var. | Mean | Var. | Mean | Var. | Mean | Var. | Mean Var. | Mean Var. | |
| GLYPH<30> 1 ( H ) | 2.39 | 0.00 | 4.83 | 0.00 | 8.03 | 0.00 | 15.8 | 0.001 | 188.8 0.001 | 358.5 0.036 | |
| GLYPH<30> 3 ( H ) | 4.24 | 0.00 | 7.5 | 0.001 | 12.7 | 0.00 | 25.09 | 0.005 | 314.4 0.01 | 599 0.665 | |
| GLYPH<30> 5 ( H ) | 4.66 | 0.00 | 8.36 | 0.001 | 14.01 | 0.00 | 27.8 | 0.005 | 309.2 0.077 | 650 0.014 | |
| GLYPH<30> 7 ( H ) | 4.95 | 0.00 | 8.94 | 0.00 | 14.83 | 0.00 | 29.33 | 0.006 | 311 0.013 | 674.2 0.033 | |
| GLYPH<30> 9 ( H ) | 5.23 | 0.00 | 9.46 | 0.001 | 15.4 | 0.001 | 30.56 | 0.007 | 317.5 0.011 | 683.5 0.698 | |
execution time of Algorithm 1 in Table 3. In this table, the overhead is measured on specifications that contain either nested Until operators (U columns) or nested Eventually operators (E columns).
We generate 30 formulas according to the following templates:
- -E formulas: GLYPH<30> n ( H ) = pj GLYPH<0> ! n ( H n = )
where H 2 N is the finite horizon of the formula. In Table 3, we used 1,000, 2,000 and 10,000 for the size of the horizon. Here, pj is an arbitrary predicate and n ( H n = ) is defined recursively as follows:
where h = H n = , i.e., the finite horizon H divided by the number of nested subformulas n and ; are arbitrary predicates.
- 1 ( h ) = ^ [0 ; h ] pk and n ( h ) = ^ [0 ; h ] ( pl ^ n GLYPH<0> 1 ( h )), for 1 < n GLYPH<20> 9 pk pl
- -U formulas: GLYPH<30> n ( H ) = pj GLYPH<0> ! n ( H n = ) where H 2 N is the finite horizon of the formula. In Table 3, we used 1,000, 2,000 and 10,000 for the size of the horizon of H . Here, pj is an arbitrary predicate and n ( H n = ) is defined recursively as follows:
- 1 ( h ) = pk U [0 ; h ] pl and n ( h ) = pm U [0 ; h ] ( pn ^ n GLYPH<0> 1 ( Y )), for 1 < n GLYPH<20> 9 are arbitrary predicates.
where h = H n = and pk ; pl ; pm ; pm
As illustrated in Table 3, the computational complexity of the monitoring algorithm is closely related to the horizon and history size. Since the algorithm's complexity is of order O n ( 2 ) where n is the horizon history, the added overhead (in worst case execution) / is quadratic in terms of the size of the horizon for some formulas in Table 3 (like GLYPH<30> 1 ( H )). Moreover, in most cases, the impact of the number of nested temporal operators is not significant compared to the size of horizon history windows. From Table 3, we / notice that when the horizon and history size is less than 2,000, the overhead for each simulation step is negligible with our prototype implementation. Furthermore, for most practical reactivity requirements, it is quite unlikely that even a window size of 2,000 sampling points is necessary. Therefore, the method could be utilized in real world monitoring applications.
## 5.2 Case Study
In the following, we utilize the monitoring method on an industrial size high-fidelity engine model. The model is part of the SimuQuest Enginuity [29] Matlab Simulink tool /
package. The Enginuity tool package includes a library of modules for engine component blocks. It also includes pre-assembled models for standard engine configurations. In this work, we use the Port Fuel Injected (PFI) spark ignition, 4 cylinder inline engine configuration. It models the e GLYPH<11> ects of combustion from first physics principles on a cylinder-by-cylinder basis, while also including regression models for particularly complex physical phenomena. The model includes a tire-model, brake system model, and a drive train model (including final drive, torque converter and transmission). The input to the system is the throttle schedule. The output is the normalized air-to-fuel(A F) ra-/ tio. Simulink reports that this is a 56 state model. Note that this number represents only the visible states. It is possible that more states are present in the blackbox s-functions which are not accessible. This is a high dimensional non-linear system for which reachability analysis is very di GLYPH<14> cult. It also includes lookup tables, non-linear components, and inputs that a GLYPH<11> ect the switching guards.
## Enginuity High-Fidelity Engine Model with On-Line Monitoring
Fig. 2. SimuQuest [29] Enginuity Matlab Simulink engine model with the on-line monitoring block.
A specification of practical interest for an engine is the settling time for the A F / ratio, which is the quotient between the air mass and fuel mass flow. Ideally, the normalized A F ratio / GLYPH<21> should always be 1, indicating that the ratio of the air and fuel flow is the same as the stoichiometric ratio. Under engine operating conditions, this output fluctuates GLYPH<6> %10. We add the on-line monitoring block to the Simulink model as presented in Fig. 2.
Our goal is to monitor the engine while allowing temporary fluctuations to GLYPH<21> . We formally define the specification as follows:
GLYPH<30> pt = ( GLYPH<21> out of bounds) ! GLYPH<144> [0 1] ; [0 1] ; : ( GLYPH<21> out of bounds)
GLYPH<26> Here, the formal specification states that if the A F ratio exceeds the allowed bounds, / then the ratio should have been settled for at least one second within the last two seconds.
Notice that an alternative presentation of the formula would be to use the future eventually and always operators, i.e. the formula would be defined as follows:
Fig. 3. Runtime monitoring of specifications GLYPH<30> pt , GLYPH<30> f t and GLYPH<30> pt f t on the high-fidelity engine model. The figure presents a normalized stoichiometric ratio, and the corresponding robustness values for specifications GLYPH<30> pt , GLYPH<30> f t and GLYPH<30> pt f t . Note that no predictor is utilized when computing the robustness values.
## GLYPH<30> f t = ( GLYPH<21> out of bounds) ! ^ [0 1] ; GLYPH<3> [0 1] ; : ( GLYPH<21> out of bounds)
In this case, the specification states that always, if the A F ratio output exceeds the / allowed bounds, then within one second it should settle inside the bounds and stay there for a second.
Clearly, both GLYPH<30> pt and GLYPH<30> f t are equivalent in terms of the set of traces that satisfy falsify / each specification 2 . However, in real-time robustness monitoring, there is an important distinction between the two. When the specification requires future information, either a predictor is put in place or the semantics will handle only the current information. In this case, without a predictor, the future time formula reduces to the propositional formula GLYPH<30> f t = ( GLYPH<21> out of bounds) !: ( GLYPH<21> out of bounds) GLYPH<17> ( GLYPH<21> out of bounds). Therefore, past time operators should be used. Recall that when monitoring robustness, our goal is to provide early warning on when the specification may fail by approaching dangerously an undesired threshold. In other words, the past formula allows us to reason about the robustness of the actual system observations, while the future formula in collaboration with a forecast model would allow us to estimate the likely robustness. This is in contrast to many boolean monitoring algorithms which issue an ' undecided until further notice ' verdict that does not provide any actionable information.
A third alternative monitoring specification is the following formula:
2 Formally, this is the case if we ignore the first 2 seconds of the execution trace as well as the last 2 seconds - if the execution trace is finite.
GLYPH<30> pt f t = [0 2] ; (( GLYPH<21> out of bounds) ! ^ [0 1] ; GLYPH<3> [0 1] ; : ( GLYPH<21> out of bounds))
GLYPH<26> This specification states that at some point in the last two seconds, when GLYPH<21> is out of bounds then within the next second, GLYPH<21> will not be out of bounds and stay there for one second. This alternative seems to be the balance between the GLYPH<30> pt and GLYPH<30> f t formulas. Where GLYPH<30> pt purely relies on past information, and GLYPH<30> f t relies on information from a predictor, GLYPH<30> pt f t has the advantage that it utilizes both the information from the past but also it could include information from the predictor.
An example of real-time monitoring on the high-fidelity engine model is presented in Fig. 3. The figure illustrates the significance of using past time operators when defining specifications. Due to the lack of predictor information, the GLYPH<30> f t monitor falsely returns falsification at about 4 seconds whereas the GLYPH<30> pt monitor does not.
In the following, we analyze the overhead of the monitoring algorithm for this case study. Since the runtime is influenced by numerous sources of nondeterminism, we apply the central limit theorem to form confidence intervals for the mean simulation runtime when running the simulations with and without the monitor. To generate the results in Table 4, we collected 30 samples with 100 simulation runtimes in each sample. We note that the di GLYPH<11> erence between the estimated mean simulation runtime when adding the monitor is 0.97%. The experimental results were generated on an Intel Xeon X5647 (2.993GHz, 8 CPUs) machine with 12 GB RAM, Windows 7, and Matlab 2012a.
Table 4. Simulation runtime statistics for the high-fidelity engine model running for 35 seconds with simulation stepsize of 0.01s. The results include the confidence intervals for the mean simulation runtime.
| Simulation runtime(sec.) | Est. Mean | Est. Std. Dev | 95% | 95% | 99% | 99% |
|----------------------------|-------------|-----------------|--------|--------|--------|--------|
| | | | LB | UB | LB | UB |
| Without monitor | 10.811 | 0.090 | 10.778 | 10.844 | 10.766 | 10.857 |
| With monitor | 10.987 | 0.086 | 10.955 | 11.019 | 10.944 | 11.030 |
## 6 Conclusions and Future Work
We have presented an algorithm for monitoring the robustness of combined past and future MTL specifications. Our framework can incorporate predicted or estimated data as provided by a model predictive component. We have created a Simulink toolbox for MTL robustness monitoring which is distributed with the S-Taliro tools [30]. Our experiments indicate that the toolbox adds minimal overhead to the simulation time of Simulink models and it can be used for both runtime analysis of the models and for o GLYPH<11> -line testing. Our future work will concentrate on several aspects. First, the current version of the tool allows reasoning over timed state sequences generated under a constant sampling rate. We would like to relax this constraint so that we allow arbitrary sampling functions. Second, we would like to investigate the possibility of porting our monitor on FPGA platforms similar to [2, 8]. Finally, we envision that utilizing information about the system through the form of a model will permit us to move to an event based monitoring framework while still su GLYPH<14> ciently approximating the robustness estimate.
Acknowledgments This work was partially supported by NSF awards CNS 1116136 and CNS 1319560. The authors would also like to thank the anonymous reviewers for the very detailed comments.
## References
- 1. Alur, R., Courcoubetis, C., Halbwachs, N., Henzinger, T.A., Ho, P.H., Nicollin, X., Olivero, A., Sifakis, J., Yovine, S.: The algorithmic analysis of hybrid systems. Theoretical Computer Science 138 (1995) 3-34
- 2. Finkbeiner, B., Kuhtz, L.: Monitor circuits for ltl with bounded and unbounded future. In: Runtime Verification. Volume 5779 of LNCS., Springer (2009) 60-75
- 3. Havelund, K., Rosu, G.: Monitoring programs using rewriting. In: Proceedings of the 16th IEEE international conference on Automated software engineering. (2001)
- 4. Havelund, K., Rosu, G.: Synthesizing monitors for safety properties. In: Tools and Algorithms for the Construction and Analysis of Systems. Number 2280 in LNCS, Springer (2002) 342-356
- 5. Havelund, K., Rosu, G.: E GLYPH<14> cient monitoring of safety properties. STTT 6 (2004) 158-173
- 6. Kristo GLYPH<11> ersen, K.J., Pedersen, C., Andersen, H.R.: Runtime verification of timed LTL using disjunctive normalized equation systems. In: Proceedings of the 3rd Workshop on Run-time Verification. Volume 89 of ENTCS. (2003) 1-16
- 7. Maler, O., Nickovic, D.: Monitoring temporal properties of continuous signals. In: Proceedings of FORMATS-FTRTFT. Volume 3253 of LNCS. (2004) 152-166
- 8. Reinbacher, T., Rozier, K.Y., Schumann, J.: Temporal-logic based runtime observer pairs for system health management of real-time systems. In: Proceedings of the 20th International Conference on Tools and Algorithms for the Construction and Analysis of Systems. Volume 8413 of LNCS., Springer (2014) 357-372
- 9. Rosu, G., Havelund, K.: Synthesizing dynamic programming algorithms from linear temporal logic formulae. Technical report, Research Institute for Advanced Computer Science (RIACS) (2001)
- 10. Tan, L., Kim, J., Sokolsky, O., Lee, I.: Model-based testing and monitoring for hybrid embedded systems. In: Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration. (2004) 487-492
- 11. Thati, P., Rosu, G.: Monitoring algorithms for metric temporal logic specifications. In: Runtime Verification. Volume 113 of ENTCS., Elsevier (2005) 145-162
- 12. Basin, D.A., Klaedtke, F., Zalinescu, E.: Algorithms for monitoring real-time properties. In: Runtime Verification. Volume 7186 of LNCS., Springer (2011) 260-275
- 13. Geilen, M.: On the construction of monitors for temporal logic properties. In: Proceedings of the 1st Workshop on Runtime Verification. Volume 55 of ENTCS. (2001) 181-199
- 14. Maler, O., Nickovic, D., Pnueli, A.: From MITL to Timed Automata. In: Proceedings of FORMATS. Volume 4202 of LNCS., Springer (2006) 274-289
- 15. Pnueli, A.: The temporal logic of programs. In: Proceedings of the 18th IEEE Symposium Foundations of Computer Science. (1977) 46-57
- 16. Koymans, R.: Specifying real-time properties with metric temporal logic. Real-Time Systems 2 (1990) 255-299
- 17. Fainekos, G., Pappas, G.J.: Robustness of temporal logic specifications. In: Formal Approaches to Testing and Runtime Verification. Volume 4262 of LNCS., Springer (2006) 178192
- 18. Fainekos, G., Pappas, G.J.: Robustness of temporal logic specifications for continuous-time signals. Theor. Comput. Sci. 410 (2009) 4262-4291
- 19. Donze, A., Ferrre, T., Maler, O.: E GLYPH<14> cient robust monitoring for stl. In: Proceedings of the 25th International Conference on Computer Aided Verification. CAV, Berlin, Heidelberg, Springer-Verlag (2013) 264-279
- 20. Garcia, C.E., Prett, D.M., Morari, M.: Model predictive control: Theory and practice - a survey. Automatica 25 (1989) 335348
- 21. Abbas, H., Fainekos, G.E., Sankaranarayanan, S., Ivancic, F., Gupta, A.: Probabilistic temporal logic falsification of cyber-physical systems. ACM Trans. Embedded Comput. Syst. 12 (2013) 95
- 22. Jin, X., Donze, A., Deshmukh, J., Seshia, S.: Mining requirements from closed-loop control models. In: Hybrid Systems: Computation and Control, ACM Press (2013)
- 23. Seda, A.K., Hitzler, P.: Generalized distance functions in the theory of computation. The Computer Journal 53 (2008) bxm108443-464
- 24. Eklund, J.M., Sprinkle, J., Sastry, S.: Implementing and testing a nonlinear model predictive tracking controller for aerial pursuit evasion games on a fixed wing aircraft. / In: American Control Conference. (2005)
- 25. Bakirtzis, A., Petridis, V ., Kiartzis, S., Alexiadis, M., Maissis, A.: A neural network short term load forecasting model for the greek power system. IEEE Transactions on Power Systems 11 (1996) 858-863
- 26. Monteiro, C., Bessa, R., Miranda, V., Botterud, A., Wang, J., Conzelmann, G.: Wind power forecasting: State-of-the-art 2009. Technical Report ANL DIS-10-1, Argonne National Lab-/ oratory (2009)
- 27. Davey, B.A., Priestley, H.A.: Introduction to Lattices and Order (2. ed.). Cambridge University Press (2002)
- 28. Fainekos, G., Sankaranarayanan, S., Ueda, K., Yazarel, H.: Verification of automotive control applications using s-taliro. In: Proceedings of the American Control Conference. (2012)
- 29. Simuquest: Enginuity. http://www.simuquest.com/products/enginuity (2013) Accessed: 2013-10-14.
- 30. Annapureddy, Y.S.R., Liu, C., Fainekos, G.E., Sankaranarayanan, S.: S-taliro: A tool for temporal logic falsification for hybrid systems. In: Tools and algorithms for the construction and analysis of systems. Volume 6605 of LNCS., Springer (2011) 254-257
## Appendix: Proof of Section 4.2
We prove by induction the correctness of Algorithms 1 and 2. We need to prove that at each simulation step i , the returning value of the CR algorithm is the same as the robustness value. Without loss of generality, assume i GLYPH<21> Hst ; therefore, the values in the table columns GLYPH<0> Hst to 0 contain the robustness values based on the actual simulation. When i < Hst then the proof is immediate by the semantics of temporal logic. We must show that, for each sub-formula ' k the value stored in column j of robustness table Tk j ; should be correctly computed according to the semantics
$$\left [ \varphi _ { k } \right ] & ( s, i + j ) = T _ { k, j } = C R ( \varphi _ { k }, j, s _ { i } ^ { \prime }, \mathfrak { d }, \mathcal { O } ) \\ \dots \dots \dots \ n \dots$$
given matrix T and vector Pre
## Base case:
We will show that for each MTL < + 1 + pt sub-formula in the form of a predicate, the value which is returned by the CR algorithm (Algorithm 2) is equal to the semantics of the sub-formula. Assume the sub-formula is a predicate p = ' k , for each simulation time i + j , the corresponding robustness value is stored in the column j of robustness table as follows:
$$\forall j, - H s t \leq j \leq H r z, [ p ] ( s, i + j ) & = \text{Dist} _ { d } ( s ( i + j ), \mathcal { O } ( p ) ) = \text{Dist} _ { d } ( s _ { i + j }, \mathcal { O } ( p ) ) = \\ & \tau \quad \sim \infty \quad \cdot \, \varphi \ \lambda \ \wedge$$
$$T _ { k, j } = C R ( p, j, s _ { i } ^ { \prime }, \mathbf d, \mathcal { O } )$$
Therefore, for each predicate the algorithm 'CR' computes the correct robustness value.
## Induction Hypothesis:
For each temporal sub-formulas ' k , Hst GLYPH<0> hst ( ' k ) GLYPH<21> Hrz because of the fact that Hst = Hrz + hst ( ' ) GLYPH<21> Hrz + hst ( ' k ); therefore GLYPH<0> Hst + hst ( ' k ) GLYPH<20> GLYPH<0> Hrz .
As a result, the values at the columns from GLYPH<0> Hst up to GLYPH<0> Hst + hst ( ' k ) will only depend on the actual simulation values, i.e., the predicates from column GLYPH<0> Hst up to column 0 which will not change in next simulation steps. These values are shown in gray color cells of Table 5. As a result, all the table entries from GLYPH<0> Hst up to GLYPH<0> Hst + hst ( ' k ) will not change (in next run) and the re-computation is not needed. Therefore, we shift all the values of predicates one column to the left and we ignore columns GLYPH<0> Hst to GLYPH<0> Hst + hst ( ' k ) GLYPH<0> 1 in our current run of Algorithm1 (Lines 13 and 17). Therefore, it is not necessary to include the columns GLYPH<0> Hst to GLYPH<0> Hst + hst ( ' k ) GLYPH<0> 1 in proof and Induction Hypothesis.
For Induction Hypothesis, we assume that the value stored in the robustness table is the semantically correct robustness value for each sub-formula ' k :
$$\forall j, - H s t + h s t ( \varphi _ { k } ) \leq j \leq H r z, \left [ \varphi _ { k } \right ] ( s, i + j ) = T _ { k, j } = C R ( \varphi _ { k }, j, s _ { i } ^ { \prime }, \mathbf d, \mathcal { O } ) \\ \dots \colon c \colon \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots$$
And if there exists unbounded past operator sub-formula like ' k = S 0 [ l ; + 1 ) ' , we assume the Pre k ( ) = J S 0 [ l ; + 1 ) ' K ( s ; i GLYPH<0> 1 GLYPH<0> Hst + hst ( ' k ))) because it belongs to the previous run of i GLYPH<0> 1, i.e we store the value Tk ; ( GLYPH<0> Hst + hst ( ' k )) in Pre k ( ) before processing the current run ( ) (see Algorithm 1 line 2). i
## Induction Step:
## GLYPH<15> Negation:
8 j ; GLYPH<0> Hst + hst ( ' k ) GLYPH<20> j GLYPH<20> Hrz : J ' k K ( s ; i + j ) = J : ' m K ( s ; i + j ) = GLYPH<0> J ' m K ( s ; i + j ) = GLYPH<0> Tm j ; = CR ( : ' ; m j ; s 0 i ; d ; O )
## GLYPH<15>
- Disjunction:
8 j ; GLYPH<0> Hst + hst ( ' k ) GLYPH<20> j GLYPH<20> Hrz : J ' k K ( s ; i + j ) = J ' m \_ ' n K ( s ; i + j ) = J ' m K ( s ; i + j ) t J ' n K ( s ; i + j ) = Tm j ; t Tn j ; = CR ( ' m \_ ' ; n j ; s 0 i ; d ; O )
## GLYPH<15> Until:
For sub-formulas of the form ' k = ' m U [ l u ; ] ' n , either the corresponding robustness values are correctly saved in robustness matrix for ' ; ' m n or the semantics will satisfy the correctness if the corresponding values belong to columns beyond the Hrz :
$$\begin{array} { l } \ u r \leq. \\ \forall j, - H s t + h s t ( \varphi _ { k } ) \leq j \leq H r z \, \colon \, \left [ \varphi _ { k } \right ] = \left [ \varphi _ { m } \mathcal { U } _ { [ l, u ] } \varphi _ { n } \right ] ( s, i + j ) = \\ \bigsqcup _ { h = i + j + l } ^ { i + j + u } ( \left [ \varphi _ { n } \right ] ) ( s, h ) \, \sqcap \, \prod _ { r = i + j } ^ { h - 1 } \left [ \varphi _ { m } \right ] ( s, r ) ) = \\ \bigsqcup _ { h \in [ j + l, j + u ] \cap [ - H s t, H r z ] } ( T _ { n, h } \, \prod _ { r = j } ^ { h - 1 } T _ { m, r } ) = C R ( \varphi _ { m } \mathcal { U } _ { [ l, u ] } \varphi _ { n }, j, s ^ { \prime } _ { i }, \mathfrak { d }, \mathcal { O } ) \end{array}$$
$$\bigsqcup _ { h \in [ j + l, j + u ] \cap [ - H s t, H r z ] } ^ { \cdot } ( T _ { n, h } \sqcap \prod _ { r = j } ^ { \cdot } T _ { m, r } ) = C R ( \varphi _ { m } \mathcal { U } _ { [ l, u ] } \varphi _ { n }, j, s _ { i } ^ { \prime }, \mathfrak { d }, \mathcal { O } )$$
## GLYPH<15> Bounded Since:
For bounded sub-formula ' k = ' m S [ l u ; ] ' n , the robustness is defined as follows:
J ' k K ( s ; i + j ) = J ' m S [ l u ; ] ' n K ( s ; i + j ) = G i + j GLYPH<0> l h = + i j GLYPH<0> u ( J ' n K ( s ; h ) u l i + j r = + h 1 J ' m K ( s ; r )) Based on IH we know that j GLYPH<21> GLYPH<0> Hst + hst ( ' k ). We must show that the values of Tn p ; for j GLYPH<0> u GLYPH<20> p GLYPH<20> j GLYPH<0> l satisfy Tn p ; = J ' n K ( s ; i + p ) i.e. GLYPH<0> Hst + hst ( ' n ) GLYPH<20> j GLYPH<0> u and also we need to show that the values of Tmq ; for j GLYPH<0> u + 1 GLYPH<20> q GLYPH<20> j satisfy Tmq ; = J ' m K ( s ; i + q ) i.e. GLYPH<0> Hst + hst ( ' m ) GLYPH<20> j GLYPH<0> u + 1.
We have two cases for hst ( ' k ):
Case 1: hst ( ' k ) = hst ( ' n ) + u = max hst f ( ' n ) + u hst ; ( ' m ) + u GLYPH<0> 1 g According to IH, j GLYPH<21> GLYPH<0> Hst + hst ( ' k ), then j GLYPH<21> GLYPH<0> Hst + hst ( ' n ) + u . Thus j GLYPH<0> u GLYPH<21> GLYPH<0> Hst + hst ( ' n ) which satisfies the fact that Tn p ; = J ' n K ( s ; i + p ) for j GLYPH<0> u GLYPH<20> p GLYPH<20> j GLYPH<0> l . On the other hand, in this case: hst ( ' n ) + u GLYPH<21> hst ( ' m ) + u GLYPH<0> 1 1. )
According to IH, j + Hst GLYPH<21> hst ( ' k ) GLYPH<21> hst ( ' m ) + u GLYPH<0> 1, i.e., j + Hst GLYPH<21> hst ( ' m ) + u GLYPH<0> Thus j GLYPH<0> u + 1 GLYPH<21> GLYPH<0> Hst + hst ( ' m ), which satisfies the fact that Tmq ; = J ' m K ( s ; i + q for j GLYPH<0> u + 1 GLYPH<20> q GLYPH<20> j .
Table 5. Robustness Table (Unchangeable values in next runs are in gray color)
| column ( j ) ) | GLYPH<0> Hst | ... | GLYPH<0> Hst + hst ( ' k ) | ... | GLYPH<0> Hrz = GLYPH<0> Hst + hst ( ' ) ... | GLYPH<0> 1 | | 0 | 1 | ... | Hrz |
|-------------------------|----------------|-------|------------------------------|-------|-----------------------------------------------|--------------|------------|-----|-------|-------|---------|
| index ( time ) ) | i GLYPH<0> Hst | ... | i GLYPH<0> Hst + hst ( ' k ) | ... | i GLYPH<0> Hrz | ... i | GLYPH<0> 1 | i | i + 1 | ... | i + Hrz |
| Pre[1] | | | | | | | | | | | |
| Pre[...] | | | | | | | | | | | |
| Pre[k] | | | | | | | | | | | |
| Pre[...] | | | | | | | | | | | |
| Pre[ j ' j ](predicate) | | | | | | | | | | | |
Case 2: hst ( ' k ) = hst ( ' m ) + u GLYPH<0> 1 = max hst f ( ' n ) + u hst ; ( ' m ) + u GLYPH<0> 1 g According to IH, j GLYPH<21> GLYPH<0> Hst + hst ( ' k ) then j GLYPH<21> GLYPH<0> Hst + hst ( ' m ) + u GLYPH<0> 1. Thus j GLYPH<0> u + 1 GLYPH<21> GLYPH<0> Hst + hst ( ' m ) which satisfies the fact that Tmq ; = J ' m K ( s ; i + q ) for j GLYPH<0> u + 1 GLYPH<20> q GLYPH<20> j . On the other hand, in this case: hst ( ' m ) + u GLYPH<0> 1 GLYPH<21> hst ( ' n ) + u . According to IH, j + Hst GLYPH<21> hst ( ' k ) GLYPH<21> hst ( ' n ) + u i.e j + Hst GLYPH<21> hst ( ' n ) + u . Thus j GLYPH<0> u GLYPH<21> GLYPH<0> Hst + hst ( ' n ) which satisfies the fact that Tn p ; = J ' n K ( s ; i + p ) for j GLYPH<0> u GLYPH<20> p GLYPH<20> j GLYPH<0> l .
## As a result:
$$\begin{array} { l } \text{As a resu} \colon \\ \forall j, - H s t + h s t ( \varphi _ { k } ) \leq j \leq H r z \, \colon \, \left [ \varphi _ { k } \right ] \right ) ( s, i + j ) = \left [ \varphi _ { m } \mathcal { S } _ { [ l, u ] } \varphi _ { n } \right ] \left ( s, i + j \right ) = \\ \bigsqcup _ { h = i + j - u } ^ { i + j - l } ( \left [ \varphi _ { n } \right ] \right ] ( s, h ) \sqcap \prod _ { r = h + 1 } ^ { i + j } \left [ \varphi _ { m } \right ] \left ( s, r \right ) \right ) = \\ \bigsqcup _ { h = j - u } ^ { j - l } ( T _ { n, h } \sqcap \prod _ { r = h + 1 } ^ { j } T _ { m, r } ) = C R ( \varphi _ { m } \mathcal { S } _ { [ l, u ] } \varphi _ { n }, j, s _ { i } ^ { \prime }, \mathfrak { d }, \mathcal { O } ) \end{array}$$
## GLYPH<15> Unbounded Since:
For unbounded sub-formula ' k = ' m S [ l ; + 1 ) ' n , according to Induction Hypothesis:
$$P r e ( k ) = \left [ \varphi _ { m } \mathcal { S } _ { [ l, + \infty ) } \varphi _ { n } \right ] ( s, i - 1 - H s t + h s t ( \varphi _ { k } ) )$$
In dynamic programming we recursively update the value J ' m S [ l ; + 1 ) ' n K ( s ; i GLYPH<0> Hst + hst ( ' k ) + x ) given the previous robustness value in the table J ' m S [ l ; + 1 ) ' n K ( s ; i GLYPH<0> Hst + hst ( ' k ) + x GLYPH<0> 1)
(where x = 0 when we use the Pre k ( ))
According to Def. 3 the robustness semantics at time i + j :
$$\left [ \varphi _ { m } \mathcal { S } _ { [ l, + \infty ) } \varphi _ { n } \right ] ( s, i + j ) = \bigsqcup \int _ { h = 0 } ^ { i + j - l } \left ( \left [ \varphi _ { n } \right ] ( s, h ) \sqcap \prod \int _ { r = h + 1 } ^ { i + j } \left [ \varphi _ { m } \right ] ( s, r ) \right ) \\ \text{and robustness for previous time $i+i-1$} \colon$$
and robustness for previous time i + j GLYPH<0> 1:
$$& \left [ \varphi _ { m } \mathcal { S } _ { [ l, + \infty ) } \varphi _ { n } \right ] \left ( s, i + j - 1 \right ) = \bigsqcup _ { h = 0 } ^ { i + j - l ^ { - 1 } } \left ( \left [ \varphi _ { n } \right ] \right ] ( s, h ) \sqcap \prod _ { r = h + 1 } ^ { i + j - 1 } \left [ \varphi _ { m } \right ] \left ( s, r \right ) \right ) \\ & \text{We can define robustness value at time $i+j$ given the value at time $i+j-1$} \colon$$
We can define robustness value at time i + j given the value at time i + j GLYPH<0> 1:
$$& \text{We can define robustness value at time } i + j \, \text{given the value at time } i + j - 1 \colon \\ & \left [ \varphi _ { m } S _ { ( l, + \infty ) } \varphi _ { n } \right ] \right ] ( s, i + j ) = \bigsqcup _ { h = 0 } ^ { i + j - l } \left ( \left [ \varphi _ { n } \right ] ( s, h ) \, \Box \, \prod _ { r = h + 1 } ^ { i + j } \left [ \varphi _ { m } \right ] ( s, r ) \right ) = \\ & = \left ( \bigsqcup _ { l } ^ { i + j - l - 1 } \left ( \left [ \varphi _ { n } \right ] ( s, h ) \, \Box \, \prod _ { r = h + 1 } ^ { i + j - 1 } \left [ \varphi _ { m } \right ] ( s, r ) \right ) \, \Box \, \left [ \varphi _ { m } \right ] \right ] ( s, i + j ) \right ) \, \bigsqcup _ { l } \left [ \varphi _ { m } \right ] \right ] ( s, i + j ) \right ) \, \bigsqcup _ { l } \left ( \left [ \varphi _ { n } \right ] \right ] ( s, i + j - l ) \, \Box \, \prod _ { r = i + j - l + 1 } ^ { i + j } \left [ \varphi _ { m } \right ] ( s, r ) \right ) \\ & \text{Based on IH, we know that } j \, \geq \, - H s t + h s t ( \varphi _ { k } ). \, \text{We must show that } the \, \text{va} \, \\ & \sim \, \tau \, \tau \, \quad - \, \Pi _ { k } \, \cdots \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colots \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \text{$\alpha$} \, $\alpha$} \, $\alpha$} \, $ \alpha$}$$
Based on IH, we know that j GLYPH<21> GLYPH<0> Hst + hst ( ' k ). We must show that the value of Tn j ; GLYPH<0> l = J ' n K ( s ; i + j GLYPH<0> l ), i.e., GLYPH<0> Hst + hst ( ' n ) GLYPH<20> j GLYPH<0> l and also the values of Tmq ; for j GLYPH<0> l + 1 GLYPH<20> q GLYPH<20> j satisfy Tmq ; = J ' m K ( s ; i + q ), i.e., GLYPH<0> Hst + hst ( ' m ) GLYPH<20> j GLYPH<0> l + 1.
We have two cases for hst ( ' k ):
Case 1: hst ( ' k ) = hst ( ' n ) + l = max hst f ( ' n ) + l ; hst ( ' m ) + l GLYPH<0> 1 g According to IH, j GLYPH<21> GLYPH<0> Hst + hst ( ' k ); therefore, j GLYPH<21> GLYPH<0> Hst + hst ( ' n ) + l and j GLYPH<0> l GLYPH<21> GLYPH<0> Hst + hst ( ' n ) which satisfies Tn j ; GLYPH<0> l = J ' n K ( s ; i + j GLYPH<0> l ). On the other hand in this case: hst ( ' n ) + l GLYPH<21> hst ( ' m ) + l GLYPH<0> 1.
According to IH, j + Hst GLYPH<21> hst ( ' k ) GLYPH<21> hst ( ' m ) + l GLYPH<0> 1, i.e., j + Hst GLYPH<21> hst ( ' m ) + l GLYPH<0> 1. Thus j GLYPH<0> l + 1 GLYPH<21> GLYPH<0> Hst + hst ( ' m ) which satisfies the fact that Tmq ; = J ' m K ( s ; i + q ) for j GLYPH<0> l + 1 GLYPH<20> q GLYPH<20> j .
Case 2: hst ( ' k ) = hst ( ' m ) + l GLYPH<0> 1 = max hst f ( ' n ) + l ; hst ( ' m ) + l GLYPH<0> 1 g According to IH, j GLYPH<21> GLYPH<0> Hst + hst ( ' k ); therefore, j GLYPH<21> GLYPH<0> Hst + hst ( ' m ) + l GLYPH<0> 1 where j GLYPH<0> l + 1 GLYPH<21> GLYPH<0> Hst + hst ( ' m ) which satisfies the fact that Tmq ; = J ' m K ( s ; i + q ) for j GLYPH<0> l + 1 GLYPH<20> q GLYPH<20> j . On the other hand in this case: hst ( ' m ) + l GLYPH<0> 1 GLYPH<21> hst ( ' n ) + l . According to IH, j + Hst GLYPH<21> hst ( ' k ) GLYPH<21> hst ( ' n ) + l i.e. j + Hst GLYPH<21> hst ( ' n ) + l . thus j GLYPH<0> l GLYPH<21> GLYPH<0> Hst + hst ( ' n ) which satisfies Tn j ; GLYPH<0> l = J ' n K ( s ; i + j GLYPH<0> l )
## As a result:
8 j ; GLYPH<0> Hst + hst ( ' k ) GLYPH<20> j GLYPH<20> Hrz : J ' k K ( s ; i + j ) = J ' m S [ l ; + 1 ) ' n K ( s ; i + j ) = = GLYPH<18> J ' m S [ l ; + 1 ) ' n K ( s ; i + j GLYPH<0> 1) u J ' m K ( s ; i + j ) GLYPH<19> F
$$\begin{pmatrix} \nwarrow \\ \left ( \left [ \varphi _ { n } \right ] \right ) ( s, i + j - l ) \sqcap \prod _ { r = i + j - l + 1 } ^ { i + j } \left [ \varphi _ { m } \right ] ( s, r ) \right ) = \\ \cdot \, r \, \frac { r } { r } \, \frac { r } { r } \, \frac { r } { r } \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \end{pmatrix} ^ { \prime }$$
$$& = \left ( \begin{array} { c c } T _ { k, j - 1 } & \text{if $j>-Hs t+hst(\varphi_{k})$} \\ P r e [ k ] & \text{if $j=-Hs t+hst(\varphi_{k})$} \end{array} \right ) \sqcup \left ( T _ { m, j } \right ) \sqcup \left ( T _ { n, j - l } \sqcup \prod _ { r = j - l + 1 } ^ { j } T _ { m, r } \right ) =$$
GLYPH<16> tmp S GLYPH<17> F GLYPH<16> Tn j ; GLYPH<0> l u tmpmin GLYPH<17> = CR ( ' m S [ l ; + 1 ) ' ; n j ; s 0 i ; d ; O ). | null | [
"Adel Dokhanchi",
"Bardh Hoxha",
"Georgios Fainekos"
] | 2014-07-31T23:39:54+00:00 | 2014-07-31T23:39:54+00:00 | [
"cs.SY"
] | On-Line Monitoring for Temporal Logic Robustness | In this paper, we provide a Dynamic Programming algorithm for on-line
monitoring of the state robustness of Metric Temporal Logic specifications with
past time operators. We compute the robustness of MTL with unbounded past and
bounded future temporal operators MTL over sampled traces of Cyber-Physical
Systems. We implemented our tool in Matlab as a Simulink block that can be used
in any Simulink model. We experimentally demonstrate that the overhead of the
MTL robustness monitoring is acceptable for certain classes of practical
specifications. |
1408.0046v7 | 
## Hybrid Inflation with Planck Scale Fields
Michael Dine and Laurel Stephenson-Haskins
Santa Cruz Institute for Particle Physics and Department of Physics, Santa Cruz CA 95064
## Abstract
Observable B-mode polarization in the CMBR would point to a high scale of inflation and large field excursions during the inflationary era. Non-compact string moduli spaces are a suggestive setting for these phenomena. Although they are unlikely to be described by weak coupling models, effective field theories compatible with known features of cosmology do exist. These models can be viewed as generalizations to a large field regime of hybrid inflation. We note close parallels to small and large field axion models. This paper outlines the requirements for successful modular inflation, and gives examples of effective field theories which satisfy them. The required tunings are readily characterized. These models can also be thought of as models of chaotic inflation, in a way we describe. In the modular framework, one would expect that any would-be Peccei-Quinn symmetry would likely be badly broken during inflation, and the axion would have Hubble scale mass; in this situation, isocurvature fluctuations would be suppressed and the initial misalignment angle would be fixed, rather than being a random variable.
## 1 Small vs. Large Field Inflation
Models of slow roll inflation can be divided into two broad categories: small field and large field, where the small or large is relative to the Planck scale, M p (there are many good reviews; on this point, see, for example, [1]). These two classes of theories differ dramatically in whether or not they predict observable gravity waves. Each class of models poses theoretical challenges as well. In large field models, if φ is the inflaton, the field responsible for inflation, then one can't analyze an effective action for φ in powers of φ/M p . It is not, in fact, quite clear in what framework (outside of some larger theory of quantum gravity) one might understand such theories. As we will review, small field models also cannot be completely understood without a complete underlying theory of gravity. That said, the problem of inflation in these theories can be described by a small number of parameters.
The BICEP2 announcement of the possible observation of gravity waves in the CMB[2] brought the question of large vs small field inflation to the forefront. While there is no longer any claim to an observation[3], there are intense efforts to further constrain (or observe) B mode polarization in the CMBR. The BICEP2 result was suggestive of an energy sale of inflation would be about 2 × 10 16 GeV; Planck set limits of order 1/2 of this[4].
A great deal has been written on the subject of large field inflation, trying to accommodate the original BICEP2 claim, and suggesting, in any case, that such radiation should be observable. This work can again be divided into two broad categories (with some overlap): natural inflation[5] and chaotic inflation[6]. Natural inflation involves axion-like fields, with decay constants larger than M p . Because such decay constants seem hard to realize in string theory[7], much work has focussed on monodromy inflation and its variants (though see [8]), in which axions transit many times their nominal periods[9], or theories with multiple axions (or fields which can wander circuitously through field space)[10]. Chaotic inflation involves fields with monomial potentials with very small coefficients. As implemented in [9], monodromy inflation is actually a realization of chaotic inflation, with a monomial potential for the inflaton. It is argued that the features of the inflaton potential, in this case, can be understood within an ultraviolet complete theory,
string theory. Related ideas for achieving inflation have been considered in [11, 12, 13].
In this note, we examine a different arena for inflation: non-compact string moduli spaces. Classically, string compactifications with zero cosmological constant (c.c.) typically exhibit moduli of various sorts. Such light fields might exist quantum mechanically. One possible explanation for this is low energy supersymmetry, where the light non-compact moduli would be superpartners of axions. We will take this as our working model throughout this paper . 1 By low we mean that during inflation, the soft breaking terms, while possibly quite large compared to the scale at which supersymmetry is ultimately broken, are well below the energy scale of inflation. Supersymmetry breaking during inflation has been discussed in[15], where it is stressed that, for slowly varying fields, it is possible to use a supersymmetric effective action to describe the dynamics of the inflaton. This action can be organized in terms of a superpotential, Kahler potential, and higher derivative operators. The natural mass (curvature) scale for the moduli potential is of order H I , the Hubble constant during inflation. Given that slow-roll inflation requires an inflaton mass significantly less than H I , the models we consider, like essentially all models of inflation, will require some level of tuning of parameters. The inflaton may be part of a chiral multiplet responsible for supersymmetry breaking during inflation, i.e. its fermionic partner may be an approximate goldstino. This multiplet need not not necessarily contain the Goldstino (longitudinal component of the gravitino) responsible for supersymmetry breaking at lower scales (we will not make any particular assumption about the final scale of supersymmetry breaking, other than that it is low compared to the scale of inflation).
Ours is certainly not the first work to consider moduli as candidate inflatons. Some discussion occurs already in [16]. More recently, models relying on quite specific features of particular string models have been considered in some detail[17, 18]. Our goal here is to delineate some general issues. Some of the models have features which correspond to some of the general features discussed here, but we do not believe that all have been treated before.
We begin, in section 2 with a brief review of conventional small field inflation models,
1 An example of a landscape of non-supersymmetric vacua, in many cases with light moduli, appears in [14]; there are likely other non-supersymmetric possibilities, including simply anthropic selection.
and in particular of hybrid models. The essence of such models is that inflation occurs on a pseudomoduli space[19]. Standard analyses are restricted to small field inflation, and we ask what are the features intrinsic to such a regime. We also review the challenges of understanding the spectral index in these theories.
We then make a short excursion into axion physics in section 3. We note that there is a remarkably close parallel between large and small field inflation and large and small field solutions to the strong CP problem. The large and small fields we refer to here are precisely the non-compact (pseudo) moduli accompanying the axions (saxions), and large and small, again, means relative to the Planck scale. Indeed, existing small field solutions to the strong CP problem are quite complex and suffer from a lack of plausibility. Large field solutions (implemented in string theory) require far less theoretical gymnastics. They involve, however, regimes which are inherently inaccessible to weak coupling methods. Indeed, there is tension between the requirement of small exponentials (large values of non-compact moduli) and the absence of small parameters in the theory[20]. Within our present understanding, the large-field axion solution is at best a plausible hypothesis.
We argue that there are clear lessons from axion physics for inflation, and turn to modular inflation in section 4. We will assume some We begin by noting that the noncompact moduli of string theory models have properties that would seem well suited to inflation. We have in mind situations with at least some approximate supersymmetry, so that these moduli are accompanied by compact moduli (axions). Such moduli naturally have Planck scale variations. At the same time, for large values of the moduli, the energy scale is low compared to the Planck scale; in other words, the requirement of very small couplings is replaced by a condition on the moduli fields.We will argue that if inflation occurs in such a region of the (pseudo) moduli space, it can be described in the language of effective field theory, and one can formulate the required properties of that theory. We will describe simple model field theories which are consistent with the data on inflation. We stress, however, that these are only models. Extracting such a structure from an underlying theory is beyond present theoretical technology. The degree of (apparent) tuning in these models is readily characterized. We will see that, in such a framework, the lower the scale of inflation, the greater the degree of tuning.
Inflation on string moduli spaces provides a setting to address a much discussed issue: the seeming incompatability of large field inflation and the axion solution of the strong CP problem[21]. We recall that in such a framework, the Peccei-Quinn symmetry is necessarily an accident of the features of moduli fixing (and in particular the fixing of the saxion). These features need not hold during inflation, so the Peccei-Quinn symmetry may be badly broken during this period, and axion fluctuations suppressed[22]. We discuss some of the features required of the effective field theory to achieve this.
We do not, of course, have a detailed string construction which we can understand at the level required to test this picture. Instead, in the rest of this note, we describe the conditions on the field content and effective action of such theories required to obtain suitable inflation, consistent with current observations, including recent Planck and a possible observation of gravitational radiation. We will then include a requirement that the universe, in its present stage, include an axion, with suitable properties to solve the strong CP problem, and behavior in the early universe which suppresses would-be isocurvature fluctuations. Some aspects of inflation on non-compact moduli spaces have been considered in [18], though with a somewhat different focus.
## 2 Hybrid Inflation: Small Field and Large Field
Most models of large scale inflation are based either on polynomial potentials ('chaotic inflation') or axionic shift symmetries ('natural' inflation, and its variants including multi-axions and monodromy). (For a recent attempts to reconcile small field models with a large scale of inflation, see [23, 24]). But there is another possibility, raised by experience in supersymmetric field theories and string theory, involving non-compact moduli.
Indeed, one interesting class of inflationary models are so-called hybrid models[25, 26, 27, 28, 29]. These are often described in terms of fields and potentials with rather detailed, special features, but in [19, 30], hybrid inflation was characterized in a more conceptual way. Inflation is active all such models on a pseudomoduli space, in a region where superymmetry is badly broken (i.e. broken by a larger amount than in the present universe) and the potential is slowly varying; in fact, this is the defining feature of these
theories. For example, much has been made in these models of the role of a 'waterfall field', but in practice, inflation often ends well before reaching the regime where this field is active. All that is really required is that the fields settle into a region with much smaller cosmological constant after inflation ends.
Essentially all hybrid models in the literature are small field models; this allows quite explicit constructions using rules of conventional effective field theory, but it is not clear that small field inflation is selected by any deeper principle. The goal of this paper is to consider large field models. This is made all the more important given that the small field models would be ruled out by observation of B-mode polarization (many were already ruled out by the Planck measurement of the spectral index, n s [4], but for surviving alternatives, see, for example, [31, 32, 30]).
It is worth reviewing the simplest small-field hybrid model. Such a model is supersymmetric (this allows the natural appearance of a classical pseudomoduli space), with two fields, I (which will play the role of the inflaton) and φ (usually referred to as the 'waterfall field.' The superpotential is taken to be:
$$W = I ( \kappa \phi ^ { 2 } - \mu ^ { 2 } )$$
Classically, for large I , the potential is independent of I ; the quantum mechanical corrections control the potential. κ is constrained to be extremely small in order that the fluctuation spectrum be of the correct size; κ is proportional, in fact, to V I , the energy during inflation. The quantum corrections determine the slow roll parameters.
One expects corrections at least in powers of M p . If I /lessmuch M p , one can organize the effective field theory in powers of I . Particularly critical are higher powers of I in the K¨ ahler potential. The quartic term in K ,
$$K = \frac { \alpha } { M _ { p } ^ { 2 } } I ^ { \dagger } I I ^ { \dagger } I$$
gives too large an η , for example, unless α is suitably small[33, 19].
It is also necessary to suppress high powers of I in the superpotential. In general, terms of the form
$$\delta W = \frac { I ^ { n } } { M _ { p } ^ { n - 3 } }$$
will be allowed, and at least the low n terms must be suppressed. This might occur as a result of discrete symmetries. The leading power of I in the superpotential controls, for example, the scale of inflation. Higher powers allow larger scales; a scale of 10 15 requires n ≥ 11[19]. In [30], it was argued, based on a systematic study of the effective action, that obtaining n s < 1, consistent with Planck, required a balancing of K¨hler and a superpotential corrections.
In small field inflation models, it is still necessary to have control over Planck scale corrections, and tuning of parameters (at least at the part in 10 -2 level) seems required. One needs a large discrete symmetry to account for a low scale of inflation, and a very small dimensionless parameter, progressively smaller as the scale of inflation beomes smaller. So the theoretical arguments for small field over large field inflation are hardly so persuasive. Given both the theoretical situation and the ongoing searches for tensor modes, it is clearly interesting to explore the possibility of inflation on moduli spaces with Planck scale fields undergoing variations of order Planck scale or larger. Such moduli spaces are quite familiar from string theory. Though a reliable construction may be difficult, we can look to such theories for insights into how such a theory of inflation might look.
## 3 Small Field and Large Field Solutions to the Strong CP Problem
The situation in small vs large field inflation is reminiscent - and as we will see closely related to - that of the QCD axion. To solve the strong CP problem, it is not enough to postulate the existence of a light pseudoscalar; one must account for an accidental global symmetry which is of extremely high quality [34]. Here, too, there are small field and large field solutions. Most models designed to obtain a Peccei-Quinn symmetry are constructed with small axion decay constant, f a /lessmuch M p (analogous to the small value of I ). In such constructions, f a is related to the expectation value of some field, φ (possibly a fundamental scalar or a composite operator). In this case, near the scale f a one can write an effective field theory, organized in powers of φ/M p , where we have taken the relevant scale to be M p . If the scale is lower, the problem of obtaining a
suitable Peccei-Quinn symmetry, i.e. a solution of sufficient quality [34], is more daunting. It has long been appreciated that it is necessary to suppress many operators in order to have a sufficiently light axion to solve the strong CP problem. This can be achieved through discrete symmetries, but the symmetries must be quite intricate. For example, with a single Z N , with supersymmetry one needs minimally N = 11 or N = 12; without supersymmetry N must be somewhat larger[35, 36].
String theory has long suggested a different, large field, perspective on the axion problem[37]. This is particularly easy to describe in cases where there is some approximate supersymmetry (unbroken supersymmetry at scales at least somewhat below the string scale). In any theory with approximate supersymmetry, axions are accompanied by (non-compact) moduli. In string theory (with unbroken supersymmetry), there are frequently axions. These axions exhibit continuous shift symmetries in some approximation (e.g. perturbatively in the string coupling). These are non-perturbatively broken, but often there is a discrete shift symmetry which is exact. In other words, there is a dimensionless field, a , such that a → a + 2 π is an exact symmetry of the theory . 2 In this formulation, f a depends on the precise form of the axion kinetic term. The (noncompact) moduli which accompany these axions typically have Planck scale vev's (in a sense we will make precise in a moment). The size of terms in the effective action associated with these fields is controlled by the 2 π periodicity of the axions . If we denote the full chiral axion superfield by A = s + ia , this periodicity implies that, for large s , in the superpotential the axion appears as e - A n for integer n . In constructing models which include supersymmetry breaking, solving the strong CP problem requires suppressing only a small number of possible terms[38, 39].
Surveying known string compactifications, we might expect that there are several moduli which must be stabilized. This is generally not a weak coupling problem. In the framework of models with approximate supersymmetry (as above, this means supersymmetry broken at scales well below the string scale), the racetrack[40] idea and the KKLT model[41] are scenarios for obtaining moduli stabilization in systematic approximations in a small parameter. In both of these scenarios, the superpotential for the moduli plays an important role. Whether indeed there are systems which realize these ideas with
2 In models exhibiting monodromy, this shift typically must be accompanied by transformations of other fields under which the vacuum state is not invariant.
suitable parameters which can be taken arbitrarily small is unknown.
But, in any case, one might think the axion multiplet is special. If the superpotential plays a significant role in stabilization of the saxion , it is difficult to understand why the axion should be light. More plausibly, the saxion might be stabilized by features of the K¨ ahler potential (K¨ ahler stabilization), in such a way that the imaginary part is not affected. In perturbative string models, for example, the K¨ ahler potential is often a function of A + A † . There is no guarantee that would-be corrections to K which stabilize A do not violate this symmetry substantially, but this is a widely adopted hypothesis.
What would it mean to say that the dependence of the superpotential on s is suppressed? We might imagine that there is some other modulus, T = t + ib , appearing in the superpotential as e -T , where e -T might set the scale for supersymmetry breaking. We would also expect terms of order e - A n , e -A + T . One possibility to account for the lightness of the axion would be that s > t , say s = 2 . t Alternatively, S and T might be comparable, but n > 1. Then T might be stabilized approximately supersymmetrically in the manner discussed by KKLT:
$$W ( T ) = A e ^ { - T / b } + W _ { 0 }$$
with small W 0 , leading to
$$T & \approx b \log ( W _ { 0 } ).$$
The potential for s would arise from terms in the supergravity potential such as:
$$V _ { s } = e ^ { K } \left | \frac { \partial K } { \partial \mathcal { A } } W \right | ^ { 2 } g ^ { \mathcal { A } \ \mathcal { A } ^ { * } } + \dots \\ l, \mathcal { A } ^ { * } ), V \text{ might exhibit a minimum as a function of $s$}. \text{ if $s$ is, say, twice}$$
∣ ∣ For suitable K ( A A , ∗ ), V might exhibit a minimum as a function of s . If s is, say, twice t at the minimum, e -A is severely suppressed, as is the potential for the (QCD) axion, a . The fermionic component of A might be the goldstino (longitudinal component of the gravitino), but additional fields might well play a role. In such a picture, the gravitino mass would be of order e -t up to powers of t and s (and possibly other fields), with the axion potential exponentially suppressed relative to m 3 2 / .
Any such stabilization is inherently non-perturbative, and one might expect it to occur, generically, for small s . On the other hand, the fact that gauge couplings are
small in nature and the existence of hierarchies suggest that e -s is small (and similar factors for other moduli). In particular, we might hope that an effective lagrangian analysis would be valid, in a Wilsonian action with cutoff scale well below M p , and that we could organize the action in powers of e -S , e -T . 3 . For example, one might imagine that e -t accounts for the scale of supersymmetry breaking, while e -t accounts for the quality of the Peccei-Quinn symmetry. We will the existence of such small exponentials for granted, as is rather standard in discussions of string phenomenology and cosmology, in this section, and discuss the issue in more detail in section 5.
## 3.1 A Remark on Distances in the Modulus Geometry
Typical metrics for non-compact moduli fall off as powers of the field for large field. Defining s to be dimension one,
$$g _ { \mathcal { A }, \mathcal { A } ^ { * } } = C ^ { 2 } M _ { p } ^ { 2 } / s ^ { 2 }$$
for some constant, C . So large s is far away (a distance of order C M p log( s/M p ) away) in field space. If, for example, the smallness of e -( s + ia ) is to account for an axion mass small enough to solve the strong CP problem, we might require s ∼ 110 M p or larger, corresponding to a distance of order 8 M p from s = M p if C = √ 3.
## 4 Non-Compact Moduli as Inflatons
Wecan summarize the previous section by saying that, if string theory and its (pseudo)moduli spaces are relevant to nature, the strong CP problem points to Planck scale regions of field space as the arena for phenomenology. Given this, it is important to consider noncompact moduli spaces as the setting for inflation. As for the axion, we will assume some approximate supersymmetry. As in ordinary, supersymmetric hybrid inflation, supersymmetry breaking is described by the F component of the inflaton field (or a closely
3 It is quite possible - even likely - that there are situations where e -S is small in a region of the moduli space but the coefficients of e -nS are correspondingly large. This is known to occur in some string world sheet analyses involving non-trivial compactifications. This would invalidate the underlying assumptions here in cases where it occurred.
related field)[30]. One can write an effective field theory for the light fields (fields with masses of order H I or smaller) which is supersymmetric, with supersymmetry breaking described in terms of these supersymmetry breaking fields[15]. This structure, indeed, explains why the moduli masses are typically of order H I . As is typical of such theories, tuning is required to account for the small values of the slow roll parameters (essentially why the inflaton is significantly lighter than H I ). These issues will be discussed further in our subsequent discussion.
Our earlier discussion suggests some of the ingredients for such a structure:
- 1. In the present epoch, one or more moduli responsible for hierarchical supersymmetry breaking.
- 2. In the present epoch, a modulus whose superpotential is highly suppressed, whose compact component is the QCD axion. This is not necessary for inflation, but is the essence of a modular (large field) solution to the strong CP problem.
- 3. At an earlier epoch, a stationary point for some subset of fields in the effective action with higher scale supersymmetry breaking and a positive cosmological constant. The current limits on gravitational radiation imply a suppression by at least 10 8 relative to M 4 p . Setting this aside, we might contemplate significantly lower scales.
- 4. At an earlier epoch, a field with a particularly flat potential which is a candidate for slow roll.
Fields need not play the same role in the inflationary era that they do now. For example, the Peccei-Quinn symmetry might be badly broken during inflation. Then the axion will be heavy during this period and isocurvature fluctuations may not be an issue. In such a case the initial axion misalignment, θ 0 , would be fixed rather than being a random variable.
Any would-be energy density is still eight orders of magnitude below M 4 p . This suggests that moduli have large vev's, i.e. quantities like e -A , e -T we encountered before are quite small, though much larger than at present. We might, for example, have a pair of moduli, A , T responsible for supersymmetry breaking, and an additional field,
I , which will play the role of the inflaton. During inflation,
$$H _ { I } \sim W \sim e ^ { - t }$$
for example. For typical K¨hler potentials, the curvature of the a t and i potentials will be of order H I . We will exhibit a model with lower curvature below.
A successful model of this sort requires a complicated interplay between effects due to the K¨hler potential and superpotential. a Corresponding to the general requirements we listed above, we need, for this set of degrees of freedom:
- 1. The potential must possess at least two local, supersymmetry breaking minima in A and T , one of higher, one of lower, energy. The former is the setting for the inflationary phase; the latter for the current, nearly Minkowski, universe.
- 2. In the inflationary domain, the potential for I , on the other hand, must be comparatively flat over some range.
- 3. In the inflationary domain, the imaginary parts of A and T should be comparable in mass to H I (or slightly larger) , if the system is to avoid difficulties with isocurvature fluctuations. This would arise if e -s ≈ e -t .
- 4. In the present universe, the imaginary part of A should be quite light, along the lines described in the previous section. The imaginary part of I should be (as we will argue in more detail below) extremely light in the lower minimum.
- 5. There are additional constraints from the requirement that inflation ends. For some value of Re I , the inflationary minimum for T and A must be destabilized (presumably due to K¨hler potential couplings of a I to A and T ). At this point, the system must transit to another local minimum of the potential, with nearly vanishing cosmological constant.
- 6. The process of transiting from the inflationary region of the moduli space to the present day one is subject to serious constraints. Even assuming that there is a path from the inflationary regime to the present one, the system is subject to the well-known concerns about moduli in the early universe[42, 43]. If they are sufficiently massive (as might be expected given current constraints on supersymmetric
particles), they may reheat the universe to nucleosynthesis temperatures, avoiding the standard cosmological moduli problem. T and A are vulnerable to the moduli overshoot problem[43], for which various solutions have been proposed.
## 5 Effective Theories for Modular Inflation
In the previous section, we have listed some requirements for a successful theory of modular inflation. Needless to say, we don't know how to extract such a theory from string theory. In this section, we will content ourselves with writing down theories which satisfy (some of) the various requirements separately. We first discuss the question of the validity of effective field theory in the regimes of interest. Then we turn to features of the K¨hler potential and superpotential necessary to satisfy the requirements of modular a inflation.
## 5.1 The effective action on the moduli space
In any possible theory of quantum gravity, the effective action has, at best, limited applicability. Moduli stabilization as described above occurs, more or less by definition, in a region where standard perturbative methods are not valid[20]. In particular, in the large field regime in string theory, the metric for the moduli tends uniformly to zero and does not exhibit interesting structure. In cosmological situations, the motion on the moduli space exhibits singularities[44]. Finally, there are more general reasons of principle to question the use of effective field theory methods[45].
If moduli are stabilized in a region where weak coupling methods are not valid, in what sense might an effective action be useful or even meaningful? Without solving a (non-supersymmetric) string theory, this is a hard question to answer, but we can at least formulate a set of underlying - and widely held - assumptions which would provide a rationale for such a treatment. It is easiest to articulate the underlying assumptions - and some of their limitations - if we consider a moduli space which asymptotically is approximately supersymmetric.
The standard assumptions of string phenomenology are that moduli are stabilized in regions where the observed gauge couplings are weak; usually it is also assumed that there is an approximate supersymmetry with a hierarchy of scales. Suppose, first, that this occurs due purely to high energy effects, without, for example, the action of a strongly interacting gauge theory. Then the effective low energy theory might consist of moduli only (plus supergravity). Ignoring gravity at first, we can argue self consistently for the validity of a low energy effective theory, in much the way one argues for the non-linear pion lagrangian. In particular, we can study slowly varying classical field configurations. The existence of a light gravitino in regions of the field space implies that the effective lagrangian (in these regions) will be supersymmetric (with supersymmetry breaking described within the action itself). The fields can then be organized into chiral multiplets; the superpotential is constrained by the axion shift symmetries. This implies that for a range of fields, the superpotential is exponentially small . 4 It is difficult to make arguments about the K¨ ahler potential. Indeed, it has been argued[46] that large corrections to the K¨hler potential might be the source of moduli stabilization and we a have already invoked this possibility.
Now including gravity, the effective action has, at best, limited validity. For effective actions involving moduli and gravity, apart from stable AdS and Minkowski space, typical motions on the space will begin or end in singularities, where necessarily the effective field theory treatment breaks down[44]. The understanding/resolution of such singularities may require a framework such as eternal inflation or something yet unknown. In addition, the moduli space itself is expected to have singularities. For example, in a one complex dimensional space, with a constant superpotential, if the metric behaves asymptotically as 1 / S ( + S † ) 2 , there cannot be a stationary point unless the metric vanishes somewhere[46] . 5 One might expect these sorts of singularities even if there are multiple moduli, but they may be isolated, and there may be (and we will assume there are) cosmological histories which avoid them. They might be connected with the appearance of new massless states, or some strong coupling (or both).
So we content ourselves with the assumption that for the period of cosmic history of interest (inflation up to the present time) the motion of the system be through non-
4 Though it might be the sum of exponentially small terms with large coefficients
5 The issue of the vanishing metric was raised by Kaplunovsky in a private communication
singular regions of the space. We require our effective description only be valid during this period . 6
Such smooth behavior is indeed a requirement for inflation; if the metric on the space of fields becomes singular, fields become strongly coupled and it is hard to imagine that the slow roll conditions can be satisfied. It would seem to be a feature of the more recent history of the universe as well. For the discussion of inflation, it is necessary that there be trajectories which avoid the singular regions. To summarize, we assume that for the relevant period of cosmic history, motion on the pseudomoduli space can be described by a non-singular effective field theory. This does not mean that the moduli space is non-singular everywhere, nor that the full cosmic history is smooth (or that this history is everywhere describable through this effective theory).
## 5.2 Stabilizing Moduli in the Current Universe
We have already discussed stabilization of the moduli A and T within the context of large field solutions of the strong CP problem. We implemented stabilization of T in a manner similar to that of KKLT. We required that the terms in A in the superpotential be exponentially suppressed relative to e -T/b , so that s was stabilized by K¨hler potential a effects, while the leading contributions to the a potential arise from QCD. We require, for a successful inflationary model, that Re I also be fixed by K¨hler potential effects. a The goldstino is a linear combination of I and A . The imaginary part of I must be extremely light, so it does not constitute an appreciable part of the energy density today.
## 5.3 Stabilizing Moduli During Inflation
During inflation, we require e -T be small, but much larger than its value in the present universe. This might be achieved, in an approximately supersymmetric fashion, with a superpotential of the form:
$$W = \epsilon e ^ { - T } + e ^ { - 2 T } + e ^ { - ( T + \mathcal { A } ) } + e ^ { - \mathcal { A } } + W _ { 0 }.$$
6 An attempt to formulate a more global picture of cosmology in quantum gravity is the holographic cosmology of [47]
Here /epsilon1 ∼ 10 -2 , and W 0 is far smaller. Then there is a local minimum at e -T , e -A ∼ /epsilon1 . At this minimum, the masses of all of the components of T, A , and in particular, the axion, are comparable and can readily be somewhat large compared to the scale of inflation (by powers of T , s ).
I should not appear in the superpotential (or should be further suppressed). Sufficient flatness of the I potential to account for inflation places severe restrictions on the K¨ ahler potential. We will discuss models for the K¨hler potential and the inflaton a potential in the next section.
## 5.4 Requirements for the Transition Period
Couplings of the inflaton to the fields S and T must destabilize the inflationary minimum and end inflation. Given the restrictions we are imposing on the superpotential, this requires that couplings in the K¨hler potential, such as a
$$( I + I ^ { \dagger } ) ^ { 2 } ( ( S + S ^ { \dagger } ) ^ { 2 }, ( T + T ^ { \dagger } ) ^ { 2 } )$$
contribute negatively to the s and t masses at the later stages of inflation, in such a way that the system can transit smoothly from one state to the other. The details of the terms in the action which dominate during this period are likely to be rather involved, with mixings, for example, among the various fields during this phase. During the inflationary phase itself the requirement is that K is such that I is much lighter than the other fields (whose masses are of order H I , the Hubble scale during inflation, or larger). One can contemplate different possibles for the masses of these fields and their stabilization in the present universe. Given that, for this discussion, the Kahler potential is an arbitrary function of the fields, we do not see any difficulty in principle with satisfying these conditions. In the next section, we will be more explicit about possible behaviors of K and W during the inflationary era.
It should be stressed that the requirements for destabilization are, like those for stabilization, not consistent with a systematic expansion in 1 /s , 1 /t . In the region of large s, t , in particular, one would expect these fields to have masses parametrically large compared to m 3 2 / , and the K¨ ahler couplings could not destabilize this minimum.
We should stress again, as well, that typical Kahler potentials may lead to difficulties in settling into the correct, final vacuum[43]. The Kahler potential may have to be somewhat singular. This question will be explored elsewhere.
## 6 Inflationary Models: Large r
We consider, first, as a benchmark, the case where r is in the range of the reported BICEP2 result, corresponding to field excursions several times M p . In this regime, it is easy to construct models consistent with the data on r and n s as well as the fluctuation spectrum. As an example, we take the K¨hler potential for a I to be:
$$K = - \mathcal { N } ^ { 2 } \log ( I + I ^ { * } ).$$
Writing
$$I = e ^ { \phi / \mathcal { N } }$$
the kinetic term for φ is simply ( ∂φ ) 2 . N will serve as the small parameter accounting for slow roll. In the limit of very small N , the potential for φ becomes flat.
Indeed, the φ potential, with the assumption that all moduli besides I are fixed (and have masses greater than H ), and that I does not appear in the superpotential, with the Kahler potential above is
$$V ( \phi ) = e ^ { - \mathcal { N } \phi } V _ { 0 },$$
V 0 being the minimum of the S , T potential. So the slow roll parameters are:
$$\epsilon = \frac { 1 } { 2 } \mathcal { N } ^ { 2 } ; \eta = \mathcal { N } ^ { 2 } = 2 \epsilon.$$
Note
$$n - 1 = - 2 \epsilon.$$
If n s = 0 96, as measured by the Planck satellite[4], . /epsilon1 = -0 02, and . r = 16 /epsilon1 = 0 32. This . is well above the recent quoted limit on r from the joint BICEP2/Planck analysis[48]. In section 7, we will discuss modifications which, with tuning, permit smaller values
of r . From this viewpoint, one would expect r to be as large as permitted by present observations.
A model with features similar to that of this section (with cosh rather than exponential potential) has been discussed in [49]. Ref. [18] discusses a number of issues in large field inflation, and writes models with features similar to those of this section.
## 6.1 Connection to Chaotic Inflation
Chaotic inflation[6] has, for decades, provided a simple model for slow roll inflation, and its prediction of transplanckian field motion and observable gravitational radiation now may be validated. As we look at the moduli inflation model of the previous section (and more generally moduli models of large field inflation), we see, in fact, a realization of the ideas of chaotic inflation. Again, the potential behaves as
$$V \sim H _ { I } ^ { 2 } M _ { p } ^ { 2 } e ^ { - \mathcal { N } \phi }$$
We have seen that the exponent changes, during inflation, by a factor of about 3 / 2. So we can make a crude approximation, expanding the exponent and keeping only a few terms. If we focus on each monomial in the expansion, the coefficient of φ p , in Planck units, is:
$$\lambda ^ { p } = \frac { 1 0 ^ { - 8 } \mathcal { N } ^ { p } } { p! },$$
where N is the number of e -foldings. We can compare this with the required coefficients of chaotic inflation driven by a monomial potential, φ p . In this case,
$$\lambda _ { p } = \frac { 3 \times 1 0 ^ { - 7 } p ^ { 2 } } { ( 2 N p ) ^ { \frac { p } { 2 } + 1 } }$$
These coefficients are not so different. For example, for p = 1, the moduli coefficient is about 2 × 10 -9 , while for the chaotic case it is about four times smaller; the discrepancy is about a factor of two larger for p = 2. So we see that these numbers, which would one hardly expect to be identical, are in a similar ballpark.
So moduli inflation provides a rationale for the effective field theories of chaotic inflation. The typical potential is not a monomial, but one has motion on a non-compact
field space, over distances of several M p , with a scale, in Planck units, roughly that expected for chaotic inflation. The structure is enforced by supersymmetry and discrete shift symmetries.
## 7 Moduli Inflation: Small r
It is now clear that r < 0 1[48], and it is conceivable that it is significantly smaller. . Still, as we explain in this section, moduli inflation provides a setting, where fields would be of order M p , but their excursions would be small (as we will see, of order M p or less). An interesting question is whether these models are more or less tuned than models with a higher scale. We will argue, in fact, that the lower scale models are more highly tuned; this might be an argument in favor of high scale inflation.
In the large r model of the previous section, /epsilon1 and η were naturally comparable. In small r models, given our knowledge of n s , we have /epsilon1 /lessmuch η . We can be rather explicit if we assume that the superpotential (as in the previous models) is roughly constant during inflation ( W I ), and similarly that the order parameter for supersymmetry breaking, F Z , is roughly constant. Then
$$V = e ^ { K } \left [ \left | \frac { \partial K } { \partial I } W _ { I } \right | ^ { 2 } g ^ { I I ^ { * } } + V _ { 0 }. \right ]. \\ \ n b { \text{ination of the supersymmetry breaking terms and -3} | W _ { I } | ^ { 2 } }.$$
∣ ∣ Here V 0 is a combination of the supersymmetry breaking terms and - | 3 W I | 2 .
In the moduli cosmology framework, an inflationary model is characterized by a choice of K¨ ahler potential and superpotential. The requirements that V produce the desired values of /epsilon1 and η yield constraints on K . In general, smaller /epsilon1 implies greater tuning of the K¨hler potential. a The Planck results for n s , in addition, require that η be negative. To demonstrate that these requirements can be met, we study a class of K¨hler a potentials:
$$K ( I, I ^ { * } ) = - \mathcal { N } ^ { 2 } \log ( I + I ^ { * } ) + \frac { A } { I + I ^ { * } } + \frac { B } { ( I + I ^ { * } ) ^ { 2 } }.$$
We treat N as fixed, as well as I . We then take B = B A ( ) such that n s = 0 96, and vary . A . In order to achieve small /epsilon1 we demand that we sit near a point where V ′ ≡ ∂V/∂φ = 0.
At such a point, /epsilon1 = d/epsilon1 dA = 0 . So
$$\epsilon = \frac { 1 } { 2 } \frac { d ^ { 2 } \epsilon } { d A ^ { 2 } } \delta A ^ { 2 }.$$
We see, in this way, that studying just this subset of parameters, the tuning in A goes as √ /epsilon1 . Considering the full set of parameters, the tuning is arguably somewhat more severe.
We indeed find that for a range of parameters, one can have suitable n s with small /epsilon1 . As an example of a point with V ′ = 0,
$$\mathcal { N } =. 0 2 5 6 ; \ i = 7. 7 0 3 0 4 ; \ A =. 0 0 0 4 8 8 0 0 ; \ B = 0. 0 0 0 5 5 4.$$
So, for example, if V = (10 14 GeV) , then 4 A = 00048795, indicating the required degree . of tuning, about a part in 10 , as expected. 5
To summarize this section, small field inflation can be achieved within the moduli models. The fields should be thought of as Planck scale, but the excursions are Planck scale or less. These models are more tuned than the higher scale models, so this is an a priori argument in favor of higher scale inflation.
## 8 Conclusions
Explaining inflation from an underlying microscopic theory is an extremely challenging problem, quite possibly inaccessible to our current theoretical technologies. As we have reviewed, even in so-called small field inflation, it requires control over Planck scale phenomena. Within string theory, this requires understanding of supersymmetry breaking (whether large or small) and fixing of moduli in the present universe as well as at much earlier times. It requires an understanding of cosmological singularities, and almost certainly of something like a landscape.
That said, as we reviewed, the essence of hybrid inflation is motion on a (noncompact) pseudomoduli space. In string theory, at least at the classical level, such moduli spaces are ubiquitous, and the features of these moduli suggest a picture for inflation in which the (canonical) fields have Planck scale motions. We have stressed a
parallel between small/large field inflation and small/large field solutions to the strong CP problem. The existence of moduli in string models is strongly suggestive of the large field solutions to both problems. The proposal we have put forward here is similar to the large field solutions of the strong CP problem.
We have noted that in such a picture, several moduli likely play a role in inflation, achieving the needed degree of supersymmetry breaking and slow role. We have seen that small r is more tuned than large r , giving some weight to the former possibility. We have stressed the contrast with small field inflation, where extreme tuning to achieve low scale inflation is replaced by the requirement of an extremely small dimensionless coupling.
Returning to the strong CP problem, we have stressed that any would-be PecceiQuinn symmetry is an accident, and that the accident which holds in the current configuration of the universe need not hold during inflation; this would resolve the axion isocurvature problem.
We conclude by asking, in such a framework, what one means by a model and what might be tests or predictions of the framework. More precisely, the inflationary paradigm is highly successful; the question is whether we can provide some compelling microscopic framework and whether it is testable. As always in inflationary model building, this is a difficult question. First, one is typically introducing a great deal of structure with which to explain a small number of parameters. One has additional fields, which may, in the present universe, be quite heavy, and also may be weakly interacting with Standard Model particles. Moduli inflation suffers from the same issues. Indeed, our point of view has not been to obtain a particular, detailed model, but to ask what features might be generic in a plausible scenario for the implementation of inflation in the sorts of effective field theories which seem to emerge from string theory (or quantum theories of general relativity more generally). Two features which would seem generic would be:
- 1. Higher scales of inflation are preferred.
- 2. High scale axions (even an axiverse [50]).
In a more detailed picture, one might hope to connect some lower energy phenomenon,
such as supersymmetry breaking, with inflation. This would require significant more work to embed these models in theories with supersymmetry breaking, and to understand in more detail the end of inflation and the transition to a state more closely resembling our current universe.
Acknowledgements: This work was supported by the U.S. Department of Energy grant number DE-FG02-04ER41286. We thank Tom Banks and Patrick Draper for discussions.
## References
- [1] David H. Lyth. Particle physics models of inflation. Lect. Notes Phys. , 738:81-118, 2008.
- [2] P.A.R. Ade et al. Detection of B-Mode Polarization at Degree Angular Scales by BICEP2. Phys.Rev.Lett. , 112:241101, 2014.
- [3] P.A.R. Ade et al. Joint Analysis of BICEP2/Keck Array and Planck Data. Phys.Rev.Lett. , 114:101301, 2015.
- [4] P.A.R. Ade et al. Planck 2013 results. XXII. Constraints on inflation. 2013.
- [5] Katherine Freese, Joshua A. Frieman, and Angela V. Olinto. Natural inflation with pseudo - Nambu-Goldstone bosons. Phys.Rev.Lett. , 65:3233-3236, 1990.
- [6] Andrei D. Linde. Chaotic Inflation. Phys.Lett. , B129:177-181, 1983.
- [7] Tom Banks, Michael Dine, Patrick J. Fox, and Elie Gorbatov. On the possibility of large axion decay constants. JCAP , 0306:001, 2003.
- [8] Ki-Young Choi and Bumseok Kyae. Large tensor spectrum of BICEP2 in the natural SUSY hybrid model. Phys.Rev. , D90:023536, 2014.
- [9] Eva Silverstein and Alexander Westphal. Monodromy in the CMB: Gravity Waves and String Inflation. Phys.Rev. , D78:106003, 2008.
- [10] Jihn E. Kim, Hans Peter Nilles, and Marco Peloso. Completing natural inflation. JCAP , 0501:005, 2005.
- [11] A. Ashoorioon and M.M. Sheikh-Jabbari. Gauged M-flation After BICEP2. Phys.Lett. , B739:391-399, 2014.
- [12] Amjad Ashoorioon, Konstantinos Dimopoulos, M.M. Sheikh-Jabbari, and Gary Shiu. Reconciliation of High Energy Scale Models of Inflation with Planck. JCAP , 1402:025, 2014.
- [13] Sebastien Clesse and Jeremy Rekier. Updated Constraints on Large Field Hybrid Inflation. Phys.Rev. , D90(8):083527, 2014.
- [14] Alex Saltman and Eva Silverstein. A New handle on de Sitter compactifications. JHEP , 0601:139, 2006.
- [15] Michael Dine, Lisa Randall, and Scott D. Thomas. Supersymmetry breaking in the early universe. Phys.Rev.Lett. , 75:398-401, 1995.
- [16] Tom Banks. Remarks on M theoretic cosmology. 1999.
- [17] M. Cicoli and F. Quevedo. String moduli inflation: An overview. Class. Quant. Grav. , 28:204001, 2011.
- [18] C.P. Burgess, M. Cicoli, F. Quevedo, and M. Williams. Inflating with Large Effective Fields. 2014.
- [19] Michael Dine and Lawrence Pack. Studies in Small Field Inflation. JCAP , 1206:033, 2012.
- [20] Michael Dine and Nathan Seiberg. Is the Superstring Weakly Coupled? Phys.Lett. , B162:299, 1985.
- [21] Patrick Fox, Aaron Pierce, and Scott D. Thomas. Probing a QCD string axion with precision cosmological measurements. 2004.
- [22] Michael Dine and Alexey Anisimov. Is there a Peccei-Quinn phase transition? JCAP , 0507:009, 2005.
- [23] Linda M. Carpenter and Stuart Raby. Chaotic Hybrid Inflation with a Gauged B L. 2014.
- [24] Mark P. Hertzberg and Frank Wilczek. Inflation Driven by Unification Energy. 2014.
- [25] Andrei D. Linde. Hybrid inflation. Phys.Rev. , D49:748-754, 1994.
- [26] Edmund J. Copeland, Andrew R. Liddle, David H. Lyth, Ewan D. Stewart, and David Wands. False vacuum inflation with Einstein gravity. Phys.Rev. , D49:64106433, 1994.
- [27] G.R. Dvali, Q. Shafi, and Robert K. Schaefer. Large scale structure and supersymmetric inflation without fine tuning. Phys.Rev.Lett. , 73:1886-1889, 1994.
| [28] | David H. Lyth and Antonio Riotto. Particle physics models of inflation and the cosmological density perturbation. Phys.Rept. , 314:1-146, 1999. |
|--------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [29] | Kazuya Kumekawa, Takeo Moroi, and Tsutomu Yanagida. Flat potential for inflaton with a discrete R invariance in supergravity. Prog.Theor.Phys. , 92:437-448, 1994. |
| [30] | Milton Bose, Michael Dine, Angelo Monteux, and Laurel Stephenson Haskins. Small Field Inflation and the Spectral Index. JCAP , 1401:038, 2014. |
| [31] | Constantinos Pallis and Qaisar Shafi. Update on Minimal Supersymmetric Hybrid Inflation in Light of PLANCK. Phys.Lett. , B725:327-333, 2013. |
| [32] | Lotfi Boubekeur and David.H. Lyth. Hilltop inflation. JCAP , 0507:010, 2005. |
| [33] | Andrei D. Linde and Antonio Riotto. Hybrid inflation in supergravity. Phys.Rev. , D56:1841-1844, 1997. |
| [34] | Linda M. Carpenter, Michael Dine, Guido Festuccia, and Lorenzo Ubaldi. Axions in Gauge Mediation. Phys.Rev. , D80:125023, 2009. |
| [35] | George Lazarides, C. Panagiotakopoulos, and Q. Shafi. Phenomenology and Cos- mology With Superstrings. Phys.Rev.Lett. , 56:432, 1986. |
| [36] | Michael Dine. Problems of naturalness: Some lessons from string theory. 1992. |
| [37] | Edward Witten. Some Properties of O(32) Superstrings. Phys.Lett. , B149:351-356, 1984. |
| [38] | Konstantin Bobkov, Volker Braun, Piyush Kumar, and Stuart Raby. Stabilizing All Kahler Moduli in Type IIB Orientifolds. JHEP , 1012:056, 2010. |
| [39] | Michael Dine, Guido Festuccia, John Kehayias, and Weitao Wu. Axions in the Landscape and String Theory. JHEP , 1101:012, 2011. |
| [40] | N.V. Krasnikov. On Supersymmetry Breaking in Superstring Theories. Phys.Lett. , B193:37-40, 1987. |
| [41] | Shamit Kachru, Renata Kallosh, Andrei D. Linde, and Sandip P. Trivedi. De Sitter vacua in string theory. Phys.Rev. , D68:046005, 2003. |
- [42] Tom Banks, David B. Kaplan, and Ann E. Nelson. Cosmological implications of dynamical supersymmetry breaking. Phys.Rev. , D49:779-787, 1994.
- [43] Ram Brustein and Paul J. Steinhardt. Challenges for superstring cosmology. Phys.Lett. , B302:196-201, 1993.
- [44] Tom Banks and Michael Dine. Dark energy in perturbative string cosmology. JHEP , 0110:012, 2001.
- [45] T. Banks. Landskepticism or why effective potentials don't count string models. 2004.
- [46] Tom Banks and Michael Dine. Coping with strongly coupled string theory. Phys.Rev. , D50:7454-7466, 1994.
- [47] T. Banks and W. Fischler. The holographic approach to cosmology. 2004.
- [48] P.A.R. Ade et al. A Joint Analysis of BICEP2/Keck Array and Planck Data. Phys.Rev.Lett. , 2015.
- [49] Kazuharu Bamba, Shin'ichi Nojiri, and Sergei D. Odintsov. Reconstruction of scalar field theories realizing inflation consistent with the Planck and BICEP2 results. 2014.
- [50] Asimina Arvanitaki, Savas Dimopoulos, Sergei Dubovsky, Nemanja Kaloper, and John March-Russell. String Axiverse. Phys.Rev. , D81:123530, 2010. | null | [
"Michael Dine",
"Laurel Stephenson-Haskins"
] | 2014-07-31T23:42:40+00:00 | 2015-09-09T03:07:59+00:00 | [
"hep-ph",
"hep-th"
] | Hybrid Inflation with Planck Scale Fields | The BICEP2 observations, if confirmed, point to a high scale of inflation and
large field excursions during the inflationary era. Non-compact string moduli
spaces are a suggestive setting for these phenomena. While unlikely to be
described by weak coupling models, one can write down plausible effective field
theories compatible with known features of cosmology. These models can be
viewed as generalizations to a large field regime of hybrid inflation. We note
close parallels to small and large field axion models. This paper outlines the
requirements for successful modular inflation, and gives examples of effective
field theories which satisfy them. The required tunings are readily
characterized. These models can also be thought of as models of chaotic
inflation, in a way we describe. In the modular framework, one would expect
that any would-be Peccei-Quinn symmetry would likely be badly broken during
inflation, and the axion would have Hubble scale mass; in this situation,
isocurvature fluctuations would be suppressed and the initial misalignment
angle would be fixed, rather than being a random variable. |
1408.0047v1 | ## Cumulative Restricted Boltzmann Machines for Ordinal Matrix Data Analysis
Truyen Tran †‡ , Dinh Phung , Svetha Venkatesh † † † Pattern Recognition and Data Analytics, Deakin University, Australia ‡ Department of Computing, Curtin University, Australia { truyen.tran,dinh.phung,svetha.venkatesh } @deakin.edu.au
## Abstract
Ordinal data is omnipresent in almost all multiuser-generated feedback - questionnaires, preferences etc. This paper investigates modelling of ordinal data with Gaussian restricted Boltzmann machines (RBMs). In particular, we present the model architecture, learning and inference procedures for both vector-variate and matrix-variate ordinal data. We show that our model is able to capture latent opinion profile of citizens around the world, and is competitive against state-of-art collaborative filtering techniques on large-scale public datasets. The model thus has the potential to extend application of RBMs to diverse domains such as recommendation systems, product reviews and expert assessments.
## 1 Introduction
Restricted Boltzmann machines (RBMs) [36, 9, 20] have recently attracted significant interest due to their versatility in a variety of unsupervised and supervised learning tasks [35, 18, 25], and in building deep architectures [14, 31]. A RBM is a bipartite undirected model that captures the generative process in which a data vector is generated from a binary hidden vector. The bipartite architecture enables very fast data encoding and sampling-based inference; and together with recent advances in learning procedures, we can now process massive data with large models [13, 37, 2].
This paper presents our contributions in developing RBM specifications as well as learning and inference procedures for multivariate ordinal data. This extends and consolidates the reach of RBMs to a wide range of user-generated domains - social responses, recommender systems, product/paper reviews, and expert assessments of health and ecosystems indicators. Ordinal variables are qualitative in nature - the absolute numerical assignments are not important but the relative order is. This renders numerical transforms and real-valued treatments inadequate. Current RBM-based treatments, on the other hand, ignore the ordinal nature and treat data as unordered categories [35, 40]. While convenient, this has several drawbacks: First, order information is not utilised, leading to more parameters than necessary - each category needs parameters. Second, since categories are considered independently, it is less interpretable in terms of how ordinal levels are generated. Better modelling should account for the ordinal generation process.
Adapting the classic idea from [24], we assume that each ordinal variable is generated by an underlying latent utility, along with a threshold per ordinal level. As soon as the utility passes
the threshold, its corresponding level is selected. As a result, this process would implicitly encode the order. Our main contribution here is a novel RBM architecture that accounts for multivariate, ordinal data. More specifically, we further assume that the latent utilities are Gaussian variables connected to a set of binary hidden factors (i.e., together they form a Gaussian RBM [14]). This offers many advantages over the standard approach that imposes a fully connected Gaussian random field over utilities [17, 15]: First, utilities are seen as being generated from a set of binary factors, which in many cases represent the user's hidden profile. Second, utilities are decoupled given the hidden factors, making parallel sampling easier. And third, the posteriors of binary factors can be estimated from the ordinal observations, facilitating dimensionality reduction and visualisation. We term our model Cumulative RBM (CRBM) . 1
This new model behaves differently from standard Gaussian RBMs since utilities are never observed in full. Rather, when an ordinal level of an input variable is observed, it poses an interval constraint over the corresponding utility. The distribution over the utilities now becomes a truncated multivariate Gaussian. This also has another consequence during learning: While in standard RBMs we need to sample for the free-phase only (e.g., see [13]), now we also need to sample for the clamped-phase. As a result, we introduce a double persistent contrastive divergence (PCD) learning procedure, as opposed to the single PCD in [37].
The second contribution is in advancing these ordinal RBMs from modelling i.i.d. vectors to modelling matrices of correlated entries. These ordinal matrices are popular in multiusergenerated assessments: Each user would typically judge a number of items producing a userspecific data vector where intra-vector entries are inherently correlated. Since user's choices are influenced by their peers, these inter-vector entries are no longer independent. The idea is borrowed from a recent work in [40] which models both the user-specific and item-specific processes. More specifically, an ordinal entry is assumed to be jointly generated from user-specific latent factors and item-specific latent factors. This departs significantly from the standard RBM architecture: we no longer map from a visible vector to an hidden vector but rather map from a visible matrix to two hidden matrices.
In experiments, we demonstrate that our proposed CRBM is capable of capturing the latent profile of citizens around the world. Our model is also competitive against state-of-the-art collaborative filtering methods on large-scale public datasets.
We start with the RBM structure for ordinal vectors in Section 2, and end with the general structure for ordinal matrices in Section 3. Section 4 presents experiments validating our ordinal RBMsin modelling citizen's opinions worldwide and in collaborative filtering. Section 5 discusses related work, which is then followed by the conclusions.
## 2 Cumulative RBM for Vectorial Data
## 2.1 Model Definition
Denote by v = ( v , v 1 2 , ..., v N ) the set of ordinal observations. For ease of presentation we assume for the moment that observations are homogeneous, i.e., observations are drawn from the same discrete ordered category set S = { c 1 ≺ c 2 ≺ ..., ≺ c L } where ≺ denotes the order in some sense. We further assume that each ordinal v i is solely generated from an underlying latent
1 The term 'cumulative' is to be consistent with the statistical literature when referring to the ordinal treatment in [24].
Figure 1: Model architecture of the Cumulative Restricted Boltzmann Machine (CRBM). Filled nodes represent observed ordinal variables, shaded nodes are Gaussian utilities, and empty nodes represent binary hidden factors.
utility u i ∈ R as follows [24]
$$P ( v _ { i } = c _ { l } \, | \, u _ { i } ) = \begin{cases} \mathbb { I } \left [ - \infty < u _ { i } \leq \theta _ { i 1 } \right ] & l = 1 \\ \mathbb { I } \left [ \theta _ { i ( l - 1 ) } < u _ { i } \leq \theta _ { i l } \right ] & 1 < l \leq L - 1 \\ \mathbb { I } \left [ \theta _ { i ( L - 1 ) } < u _ { i } < \infty \right ] & l = L \end{cases}$$
where θ i 1 < θ i 2 < ... < θ i ( L -1) are threshold parameters. In words, we choose an ordered category on the basis of the interval to which the underlying utility belongs.
The utilities are connected with a set of hidden binary factors h = ( h , h 1 2 , ..., h K ) ∈ { 0 1 , } K so that the two layers of ( u h , ) form a undirectional bipartite graph of Restricted Boltzmann Machines (RBMs) [36, 9, 14]. Binary factors can be considered as the hidden features that govern the generation of the observed ordinal data. Thus the generative story is: we start from the binary factors to generate utilities, which, in turn, generate ordinal observations. See, for example, Fig. 1 for a graphical representation of the model.
Let Ψ( u h , ) ≥ 0 be the model potential function, which can be factorised as a result of the bipartite structure as follows
$$\Psi ( u, h ) = \left [ \prod _ { i } \phi _ { i } ( u _ { i } ) \right ] \left [ \prod _ { i, k } \psi _ { i k } ( u _ { i }, h _ { k } ) \right ] \left [ \prod _ { k } \phi _ { k } ( h _ { k } ) \right ]$$
where φ , ψ i ik and φ k are local potential functions. The model joint distribution is defined as
$$P ( v, u, h ) = \frac { 1 } { Z } \Psi ( u, h ) \prod _ { i } P ( v _ { i } \, | \, u _ { i } )$$
where Z = GLYPH<1> u ∑ h Ψ( u h , ) d u is the normalising constant.
We assume the utility layer and the binary factor layer form a Gaussian RBM 2 [14]. This translates into the local potential functions as follows
2 This is for convenience only. In fact, we can replace Gaussian by any continuous distribution in the exponential family.
$$\phi _ { i } ( u _ { i } ) = \exp \left \{ - \frac { u _ { i } ^ { 2 } } { 2 \sigma _ { i } ^ { 2 } } + \alpha _ { i } u _ { i } \right \} ; \quad \psi _ { i k } ( u _ { i }, h _ { k } ) = \exp \left \{ w _ { i k } u _ { i k } h _ { k } \right \} ; \quad \phi _ { k } ( h _ { k } ) = \exp \left \{ \gamma _ { k } h _ { k } \right \} \quad ( 3 )$$
where σ i is the standard deviation of the i -th utility, { α , γ i k , w ik } are free parameters for i = 1 2 , , .., N and k = 1 2 , , .., K .
The ordinal assumption in Eq. (1) introduces hard constraints that we do not see in standard Gaussian RBMs. Whenever an ordered category v i is observed, the corresponding utility is automatically truncated , i.e., u i ∈ Ω( v i ), where Ω( v i ) is the new domain of u i defined by v i as in Eq. (1). In particular, the utility is truncated from above if the ordinal level is the lowest, from below if the level is the largest, and from both sides otherwise. For example, the conditional distribution of the latent utility P u ( i | v , i h ) is a truncated Gaussian
$$P ( u _ { i } \ | \ v _ { i }, h ) \ \in \ \mathbb { I } \ [ u _ { i } \in \Omega ( v _ { i } ) ] \mathcal { N } \left ( u _ { i } ; \mu _ { i } ( h ), \sigma _ { i } \right )$$
where N ( u i ; µ i ( h ) , σ i ) is the normal density distribution of mean µ i ( h ) and standard deviation σ i . The mean µ i ( h ) is computed as
$$\mu _ { i } ( h ) = \sigma _ { i } ^ { 2 } \left ( \alpha _ { i } + \sum _ { k = 1 } ^ { K } w _ { i k } h _ { k } \right )$$
As a generative model, we can estimate the probability that an ordinal level is being generated from hidden factors h as follows
$$P ( v _ { i } = c _ { l } \, | \, h ) \ = \ \int _ { u _ { i } \in \Omega ( c _ { l } ) } P ( u _ { i } | h ) = \begin{cases} \Phi \left ( \theta _ { 1 } ^ { * } \right ) & l = 1 \\ \Phi \left ( \theta _ { l } ^ { * } \right ) - \Phi \left ( \theta _ { ( l - 1 ) } ^ { * } \right ) & 1 < l \leq L - 1 \\ 1 - \Phi \left ( \theta _ { L - 1 } ^ { * } \right ) & l = L \end{cases}$$
where θ ∗ l = θ l -µ i ( h ) σ i , and Φ( ) is the cumulative distribution function of the Gaussian. · Given this property, we term our model by Cumulative Restricted Boltzmann Machine (CRBM).
Finally, the thresholds are parameterised so that the lowest threshold is fixed to a constant θ i 1 = τ i 1 and the higher thresholds are spaced as θ il = θ i ( l -1) + e τ il with free parameter τ il for l = 2 3 , , .., L -1.
## 2.2 Factor Posteriors
Often we are interested in the posterior of factors { P h ( k | v ) } K k =1 as it can be considered as a summary of the data v . The nice thing is that it is now numerical and can be used for other tasks such as clustering, visualisation and prediction.
Like standard RBMs, the factor posteriors given the utilities are conditionally independent and assume the form of logistic units
$$P ( h _ { k } = 1 \ | \ u ) = \frac { 1 } { 1 + \exp \left ( - \gamma _ { k } - \sum _ { i } w _ { i k } u _ { i } \right ) } \quad \quad \quad \ \ \ ( 7 )$$
However, since the utilities are themselves hidden, the posteriors given only the ordinal observations are not independent:
$$P ( h _ { k } \, | \, v ) = \sum _ { h _ { \to k } } \int _ { u \in \Omega ( v ) } P ( h, u | v ) d u$$
where h ¬ k = h \ h k and Ω ( v ) = Ω( v 1 ) × Ω( v 2 ) × ... Ω( v N ) is the domain of the utility constrained by v (see Eq. (1)). Here we describe two approximation methods, namely Markov chain Monte Carlo (MCMC) and variational method (mean-field).
MCMC. We can exploit the bipartite structure of the RBM to run layer-wise Gibbs sampling: sample the truncated utilities in parallel using Eq. (4) and the binary factors using Eq. (7). Finally, the posteriors are estimated as P h ( k | v ) ≈ 1 n ∑ n s =1 h ( s ) k for n samples.
Variational method. We make the approximation
$$P ( h, u \, | \, v ) \approx \prod _ { k } Q _ { k } ( h _ { k } ) \prod _ { i } Q _ { i } ( u _ { i } )$$
Minimising the Kullback-Leibler divergence between P ( h u , | v ) and its approximation leads the following recursive update
$$Q _ { k } \left ( h _ { k } ^ { ( t + 1 ) } = 1 \right ) \leftarrow \frac { 1 } { \underset { \ell } { 1 + \exp \left ( - \gamma _ { k } - \sum _ { i } w _ { i k } \left \langle u _ { i } \right \rangle _ { Q _ { i } ^ { ( t ) } } \right ) } } \, _ { \ell } \,.$$
$$Q _ { i } \left ( u _ { i } ^ { ( t + 1 ) } \right ) \leftarrow \frac { 1 } { \kappa _ { i } ^ { ( t ) } } \mathbb { I } \left [ u _ { i } \right \rangle \in \Omega ( v _ { i } ) \right ] \mathcal { N } \left ( u _ { i } ; \hat { \mu } _ { i } ( h ^ { ( t ) } ), \sigma _ { i } \right )$$
where t is the update index of the recursion, 〈 u i 〉 Q ( t ) i is the mean of utility u i with respect to Q i ( u ( ) t i ) , κ ( ) t i = GLYPH<1> u i ∈ Ω( v i ) N ( u i ; µ i ( h ( ) t ) , σ i ) is the normalising constant, and ˆ ( µ i h ( ) t ) = σ 2 i ( α i + ∑ K k =1 w ik Q k ( h ( ) t k = 1 )) . Finally, we obtain P h ( k | v ) ≈ Q k ( h k = 1).
## 2.3 Prediction
An important task is prediction of the ordinal level of an unseen variable given the other seen variables, where we need to estimate the following predictive distribution
$$P ( v _ { j } \ | \ v ) = \sum _ { h } \int _ { u _ { j } \in \Omega ( v _ { j } ) } \int _ { u \in \Omega ( v ) } P ( h, u _ { j }, u \ | \ v ) d u d u _ { j }$$
Unfortunately, now ( h , h 1 2 , ..., h K ) are coupled due to the integration over { u , j u } making the evaluation intractable, and thus approximation is needed.
For simplicity, we assume that the seen data v is informative enough so that P ( h | v , j v ) ≈ P ( h v | ). Thus we can rewrite Eq. (11) as
$$P ( v _ { j } | v ) \approx \sum _ { h } P ( h | v ) P ( v _ { j } | h ) d u _ { j }$$
Now we make further approximations to deal with the exponential sum over h .
MCMC. Given the sampling from P ( h v | ) described in Section 2.2, we obtain
$$P ( v _ { j } | v ) \approx \frac { 1 } { n } \sum _ { s = 1 } ^ { n } P ( v _ { j } | h ^ { ( s ) } ) d u _ { j }$$
where n is the sample size, and P v ( j | h ( s ) ) is computed using Eq. (6).
Variational method. The idea is similar to mean-field described in Section 2.2. In particular, we estimate ˆ h k = P h ( k = 1 | v ) using either MCMC sampling or mean-field update. The predictive distribution is approximated as
$$P ( v _ { j } | v ) \approx \int _ { u _ { i } \in \Omega ( v _ { j } ) } P ( u _ { i } \, | \, \hat { h } _ { 1 }, \hat { h } _ { 2 }, \dots, \hat { h } _ { K } )$$
where P u ( i | ˆ h , h 1 ˆ 2 , ..., h ˆ K ) = N ( u i ; σ 2 i ( α i + ∑ K k =1 w ik ˆ h k ) , σ i ) . The computation is identical to that of Eq. (6) if we replace h k (binary) by ˆ h k (real-valued) .
## 2.4 Stochastic Gradient Learning with Persistent Markov Chains
Learning is based on maximising the data log-likelihood
$$\mathcal { L } \ & = \ \log P ( v ) = \log \sum _ { h } \int _ { u } P ( v, u, h ) d u \\ & = \ \log Z ( v ) - \log Z$$
where P ( v u h , , ) is defined in Eq. (2) and Z ( v ) = ∑ h GLYPH<1> u ∈ Ω ( v ) Ψ( u h , ) d u . Note that Z ( v ) includes Z as a special case when the domain Ω ( v ) is the whole real space R N .
Recall that the model belongs to the exponential family in that we can rewrite the potential function as
$$\Psi ( u, h ) = \exp \left \{ \sum _ { a } W _ { a } f _ { a } ( u, h ) \right \}$$
where f a ( u h , ) ∈ { u , u h i i k , h k } ( N,K ) ( i,k )=(1 1) , is a sufficient statistic, and W a ∈ { α , γ i k , w ik } ( N,K ) ( i,k )=(1 1) , is its associated parameter. Now the gradient of the log-likelihood has the standard form of difference of expected sufficient statistics (ESS)
$$\partial _ { W _ { a } } \mathcal { L } \ = \ \langle f _ { a } \rangle _ { P ( u, h | v ) } - \langle f _ { a } \rangle _ { P ( u, h ) }$$
where P ( u h , | v ) is a truncated Gaussian RBM and P ( u h , ) is the standard Gaussian RBM. Put in common RBM-terms, there are two learning phases: the clamped phase in which we estimate the ESS w.r.t. the empirical distribution P ( u h , | v ), and the free phase in which we compute the ESS w.r.t. model distribution P ( u h , ).
## 2.4.1 Persistent Markov Chains
The literature offers efficient stochastic gradient procedures to learn parameters, in which the method of [42] and its variants - the Contrastive Divergence of [13] and its persistent version of [37] - are highly effective in large-scale settings. The strategy is to update parameters after short Markov chains. Typically only the free phase requires the MCMC approximation. In our setting, on the other hand, both the clamped phase and the free phase require approximation.
Since it is possible to integrate over utilities when the binary factors are known, it is tempting so sample only the binary factors in the Rao-Blackwellisation fashion. However, here we take the advantage of the bipartite structure of the underlying RBM: the layer-wise sampling is efficient and much simpler. Once the hidden factor samples are obtained, we integrate over utilities for better numerical stability. The ESSes are the averaged over all factor samples.
For the clamped phase, we maintain one Markov chain per data instance. For memory efficiency, only the binary factor samples are stored between update steps. For the free phase, there are two strategies:
- · Contrastive chains : one short chain is needed per data instance, but initialised from the clamped chain. That is, we discard those chains after each update.
- · Persistent chains : free-phase chains are maintained during the course of learning, independent of the clamp-phase chains. If every data instance has the same dimensions (which they do not, in the case of missing data), we need to maintain a moderate number of chains (e.g., 20 -100). Otherwise, we need one chain per data instance.
At each step, we collect a small number of samples and estimate the approximate distributions ˜ ( P u h , | v ) and ˜ ( P u h , ). The parameters are updated according to the stochastic gradient ascent rule
$$W _ { s } \leftarrow W _ { s } + \nu \left ( \left \langle f _ { a } \right \rangle _ { \tilde { P } ( u, h | v ) } - \left \langle f _ { a } \right \rangle _ { \tilde { P } ( u, h ) } \right )$$
where ν ∈ (0 1) is the learning rate. ,
## 2.4.2 Learning Thresholds
Thresholds appear only in the computation of Z ( v ) as they define the utility domain Ω ( v ). Let ¯ ( Ω v ) + be the upper boundary of Ω ( v ), and ¯ ( Ω v ) -the lower boundary. The gradient of the log-likelihood w.r.t. boundaries reads
$$\partial _ { \tilde { \Omega } ( v ) ^ { + } } \mathcal { L } \ & = \ \frac { 1 } { Z ( v ) } \sum _ { h } \partial _ { \tilde { \Omega } ( v ) ^ { + } } \int _ { u \in \Omega ( v ) } \Psi ( h, u ) d u = \sum _ { h } P ( u = \bar { \Omega } ( v ) ^ { + }, h \ | \ v ) \\ \partial _ { \tilde { \Omega } ( v ) ^ { - } } \mathcal { L } \ & = \ \frac { - } { \sum _ { h } } P ( u = \bar { \Omega } ( v ) ^ { - }, h \ | \ v ) \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
Recall from Section 2.1 that the boundaries Ω( ¯ v i = ) l -and ¯ ( Ω v i = ) l + are the lower-threshold θ i ( l -1) and the upper-threshold θ il , respectively, where θ il = θ i ( l -1) + e τ il = τ i 1 + ∑ l m =2 e τ im . Using the chain rule, we would derive the derivatives w.r.t. to { τ im } L -1 m =2 .
## 2.5 Handling Heterogeneous Data
We now consider the case where ordinal variables do not share the same ordinal scales, that is, we have a separate ordered set S i = { c i 1 ≺ c i 2 ≺ ..., ≺ c iL i } for each variable i . This requires only slight change from the homogeneous case, e.g., by learning separate set of thresholds for each variable.
## 3 CRBM for Matrix Data
Often the data has the matrix form, i.e., a list of column vectors and we often assume columns as independent. However, this assumption is too strong in many applications. For example, in collaborative filtering where each user plays the role of a column, and each item the role of a row, a user's choice can be influenced by other users' choices (e.g., due to the popularity of a particular item), then columns are correlated. Second, it is also natural to switch the roles of the users and items and this clearly destroys the i.i.d assumption over the columns.
Thus, it is more precise to assume that an observation is jointly generated by both the rowwise and column-wise processes [40]. In particular, let d be the index of the data instance, each observation v di is generated from an utility u di . Each data instance (column) d is represented by a vector of binary hidden factors h d ∈ { 0 1 , } K and each item (row) i is represented by a vector of binary hidden factors g i ∈ { 0 1 , } S . Since our data matrix is usually incomplete, let us denote by W ∈ { 0 1 , } D N × the incidence matrix where W di = 1 if the cell ( d, i ) is observed, and W di = 0 otherwise. There is a single model for the whole incomplete data matrix. Every observed entry ( d, i ) is connected with two sets of hidden factors h d and g i . Consequently, there are DK + NS binary factor units in the entire model.
Let H = ( { u di } W di =1 , { h d } D d =1 , { g i } N i =1 ) denote all latent variables and V = { v di } W di =1 all visible ordinal variables. The matrix-variate model distribution has the usual form
$$P ( V, H ) = \frac { 1 } { Z ^ { * } } \Psi ^ { * } \left ( H \right ) \prod _ { d, i | W _ { d i } = 1 } P ( v _ { d i } \, | \, u _ { d i } )$$
where Z ∗ is the normalising constant and Ψ ∗ ( H ) is the product of all local potentials. More specifically,
$$\Psi ^ { * } \left ( H \right ) \ = \ \prod _ { d, i | W _ { d i } = 1 } \left ( \phi _ { d i } ( u _ { d i } ) \prod _ { k } \psi _ { i k } ( u _ { d i }, h _ { d k } ) \prod _ { s } \varphi _ { i s } ( u _ { d i }, g _ { i s } ) \right ) \left [ \prod _ { d, k } \phi _ { k } ( h _ { d k } ) \right ] \left [ \prod _ { i, s } \phi _ { s } ( g _ { i s } ) \right ]$$
where ψ ik ( u di , h k ) , φ k ( h dk ) are the same as those defined in Eq. (3), respectively, and
$$\phi _ { d i } ( u _ { d i } ) \ = \ \exp \left \{ - \frac { u _ { d i } ^ { 2 } } { 2 \sigma _ { d i } ^ { 2 } } + ( \alpha _ { i } + \beta _ { d } ) u _ { i } \right \} ; \ \ \varphi _ { d s } ( u _ { d i }, g _ { s } ) = \exp \left \{ \omega _ { d s } u _ { d i } g _ { s } \right \} ; \ \ \phi _ { s } ( g _ { i s } ) = \exp \left \{ \xi _ { s } g _ { i s } \right \}$$
The ordinal model P v ( di | u di ) is similar to that defined in Eq. (1) except for the thresholds, which are now functions of both the data instance and the item, that is θ di 1 = τ i 1 + κ d 1 and θ dil = θ di l ( -1) + e τ il + κ dl for l = 2 3 , , .., L -1.
## 3.1 Model Properties
It is easy to see that conditioned on the utilities, the posteriors of the binary factors are still factorisable. Likewise, given the factors, the utilities are univariate Gaussian
$$P ( u _ { d i } \, | \, h _ { d }, g _ { i } ) \ & = \ \mathcal { N } \left ( \mu _ { d i } ^ { * } ( h _ { d }, g _ { i } ), \sigma _ { d i } ^ { 2 } \right ) \\ P ( u _ { d i } \, | \, h _ { d }, g _ { i }, v _ { d i } ) \ & \in \ \mathbb { I } \left [ u _ { d i } \in \Omega ( v _ { d i } ) \right ] P ( u _ { d i } \, | \, h _ { d }, g _ { i } )$$
where Ω( v di ) is the domain defined by the thresholds at the level l = v di , and the mean structure is
$$\mu _ { d i } ^ { * } ( h _ { d }, g _ { i } ) = \sigma _ { d i } ^ { 2 } \left ( \alpha _ { i } + \beta _ { d } + \sum _ { k = 1 } ^ { K } w _ { i k } h _ { d k } + \sum _ { s = 1 } ^ { S } \omega _ { d s } g _ { i s } \right )$$
Previous inference tricks can be re-used by noting that for each column (i.e., data instance), we still enjoy the Gaussian RBM when conditioned on other columns . The same holds for rows (i.e., items) .
## 3.2 Stochastic Learning with Structured Mean-Fields
Although it is possible to explore the space of the whole model using Gibbs sampling and use the short MCMC chains as before, here we resort to structured mean-field methods to exploit the modularity in the model structure. The general idea is to alternate between the column-wise and the row-wise conditional processes:
- · In the column-wise process, we estimate item-specific factor posteriors { ˆ g i } N i =1 , where ˆ g is ← P ( g is = 1 | ( v di ) di W | id =1 ) and use them as if the item-specific factors ( g i ) N i =1 are given. For example, the mean structure in Eq. (12) now has the following form
$$\mu _ { d i } ^ { * } ( h _ { d }, \hat { g } _ { i } ) = \sigma _ { d i } ^ { 2 } \left ( \alpha _ { i } + \beta _ { d } + \sum _ { k = 1 } ^ { K } w _ { i k } h _ { d k } + \sum _ { s = 1 } ^ { S } \omega _ { d s } \hat { g } _ { i s } \right )$$
which is essentially the mean structure in Eq. (5) when β d + ∑ S s =1 ω ds ˆ g is is absorbed into α i . Conditioned on the estimated posteriors, the data likelihood is now factorisable ∏ d P ( v d · | { ˆ g i } N i =1 ) , where v d · denotes the observations of the d -th data instance.
- · Similarly, in the row-wise process we estimate data-specific posteriors { ˆ h d } D d =1 , where ˆ h dk = P ( h dk = 1 | ( v di ) W id =1 ) and use them as if the data-specific factors ( h d ) D d =1 are given. The data likelihood has the form ∏ i P ( v · i | { ˆ h d } D d =1 ) , where v · i denotes the observations of the i -th item.
At each step, we then improve the conditional data likelihood using the gradient technique described in Section 2.4, e.g., by running through the whole data once.
## 3.2.1 Online Estimation of Posteriors
The structured mean-fields technique requires the estimation of the factor posteriors. To reduce computation, we propose to treat the trajectory of the factor posteriors during learning as a stochastic process . This suggests a simple smoothing method, e.g., at step t :

Figure 2: Visualisation of world's opinions in 2008 by projecting latent posteriors ˆ h = ( P h ( 1 1 | v ) , P ( h 1 2 | v , ..., P ( h 1 K | v ) ) on 2D using t-SNE [41], where h 1 k is a shorthand for h k = 1. Best viewed in colours. .

$$\hat { h } _ { d } ^ { ( t ) } \leftarrow \eta \hat { h } _ { d } ^ { ( t - 1 ) } + ( 1 - \eta ) P \left ( h _ { d k } = 1 \, | \, u _ { d } ^ { ( t ) } \right )$$
where η ∈ (0 1) is the , smoothing factor, and u ( ) t d is a utility sample in the clamped phase . This effectively imposes an exponential decay to previous samples. The estimation of η would be of interest in its own right, but we would empirically set η ∈ (0 5 . , 0 9) and do not pursue the issue . further.
## 4 Experiments
In this section, we demonstrate how CRBM can be useful in real-world data analysis tasks. To monitor learning progress, we estimate the data pseudo-likelihood P v ( i | v ¬ i ). For simplicity, we treat v i as if it is not in v and replace v i by v . This enables us to use the same predictive methods in Section 2.3. See Fig. 3(a) for an example of the learning curves. To sample from the truncated Gaussian, we employ methods described in [30], which is more efficient than standard rejection sampling techniques. Mapping parameters { w ik } are initialised randomly, bias paramters are from zeros, and thresholds { θ il } are spaced evenly at the begining.
## 4.1 Global Attitude Analysis: Latent Profile Discovery
In this experiments we validate the capacity to discover meaningful latent profiles from people's opinions about their life and the social/political conditions in their country and around the world. We use the public world-wide survey by PewResearch Centre 3 in 2008 which interviewed 24 717 , people from 24 countries. After re-processing, we keep 165 ordinal responses per respondent.
3 http://pewresearch.org/
Example questions are: '(Q1) [..] how would you describe your day today-has it been a typical day, a particularly good day, or a particularly bad day?', '(Q5) [...] over the next 12 months do you expect the economic situation in our country to improve a lot, improve a little, remain the same, worsen a little or worsen a lot?'.
The data is heterogeneous since question types are different (see Section 2.5). For this we use a vector-based CRBM with K = 50 hidden units. After model fitting, we obtain a posterior vector ˆ h = ( P h ( 1 1 | v ) , P ( h 1 2 | v , ..., P ( h 1 K | v ) ) , which is then used as the representation of the respondent's latent profile. For visualisation, we project this vector onto the 2D plane using a locality-preserving dimensionality reduction method known as t-SNE 4 [41]. The opinions of citizens of 12 countries are depicted in Fig. 2. This clearly reveals how cultures (e.g., Islamic and Chinese) and nations (e.g., the US, China, Latin America) see the world.
## 4.2 Collaborative Filtering: Matrix Completion
We verify our models on three public rating datasets: MovieLens 5 - containing 1 million ratings by 6 thousand users on nearly 4 thousand movies; Dating 6 - consisting of 17 million ratings by 135 thousand users on nearly 169 thousand profiles; and Netflix 7 - 100 millions ratings by 480 thousand users on nearly 18 thousand movies. The Dating ratings are on the 10-point scale and the other two are on the 5-star scale. We then transform the Dating ratings to the 5-point scale for uniformity. For each data we remove those users with less than 30 ratings, 5 of which are used for tuning and stopping criterion, 10 for testing and the rest for training. For MovieLens and Netflix, we ensure that rating timestamps are ordered from training, to validation to testing. For the Dating dataset, the selection is at random.
For comparison, we implement state-of-the-art methods in the field, including: Matrix Factorisation (MF) with Gaussian assumption [34], MF with cumulative ordinal assumption [16] (without item-item neighbourhood), and RBM with multinomial assumption [35].For prediction in the CRBM, we employ the variational method (Section 11). The training and testing protocols are the same for all methods: Training stops where there is no improvement on the likelihood of the validation data. Two popular performance metrics are reported on the test data: the root-mean square error (RMSE), the mean absolute error (MAE). Prediction for ordinal MF and RBMs is a numerical mean in the case of RMSE: v RMSE j = ∑ L l =1 P v ( j = l | v ) , l and an MAP estimation in the case of MAE: v MAE j = arg max l P v ( j = l | v ).
Fig. 3(a) depicts the learning curve of the vector-based and matrix-based CRBMs, and Fig. 3(b) shows their predictive performance on test datasets. Clearly, the effect of matrix treatment is significant. Tables 1,2,3 report the performances of all methods on the three datasets. The (matrix) CRBM are often comparable with the best rivals on the RMSE scores and are competitive against all others on the MAE.
## 5 Related Work
This work partly belongs to the thread of research that extends RBMs for a variety of data types, including categories [35] , counts [10, 33, 32], bounded variables [19] and a mixture of these types
4 Note that the t-SNE does not do clustering, it tries only to map from the input to the 2D so that local properties of the data in preserved.
5 http://www.grouplens.org/node/12
6 http://www.occamslab.com/petricek/data/
7 http://netflixprize.com/
- (a) Monitoring pseudo-likelihood in training
Figure 3: Vector versus matrix CRBMs, where K = 50.
| | K = 50 | K = 50 | K = 100 | K = 100 | K = 200 | K = 200 |
|----------------------|----------|----------|-----------|-----------|-----------|-----------|
| | RMSE | MAE | RMSE | MAE | RMSE | MAE |
| Gaussian Matrix Fac. | 0.914 | 0.720 | 0.911 | 0.719 | 0.908 | 0.716 |
| Ordinal Matrix Fac. | 0.904 | 0.682 | 0.902 | 0.682 | 0.902 | 0.680 |
| Multinomial RBM | 0.928 | 0.711 | 0.926 | 0.707 | 0.928 | 0.708 |
| Matrix Cumul. RBM | 0.904 | 0.666 | 0.904 | 0.662 | 0.906 | 0.664 |
Table 1: Results on MovieLens (the smaller the better).
Table 2: Results on Dating (the smaller the better).
| | K = 50 | K = 50 | K = 100 | K = 100 | K = 200 | K = 200 |
|----------------------|----------|----------|-----------|-----------|-----------|-----------|
| | RMSE | MAE | RMSE | MAE | RMSE | MAE |
| Gaussian Matrix Fac. | 0.852 | 0.596 | 0.848 | 0.592 | 0.840 | 0.586 |
| Ordinal Matrix Fac. | 0.857 | 0.511 | 0.854 | 0.507 | 0.849 | 0.502 |
| Multinomial RBM | 0.815 | 0.483 | 0.794 | 0.470 | 0.787 | 0.463 |
| Matrix Cumul. RBM | 0.815 | 0.475 | 0.799 | 0.461 | 0.794 | 0.458 |
Table 3: Results on Netflix (the smaller the better).
| | K = 50 | K = 50 | K = 100 | K = 100 |
|----------------------|----------|----------|-----------|-----------|
| | RMSE | MAE | RMSE | MAE |
| Gaussian Matrix Fac. | 0.890 | 0.689 | 0.888 | 0.688 |
| Ordinal Matrix Fac. | 0.904 | 0.658 | 0.902 | 0.657 |
| Multinomial RBM | 0.894 | 0.659 | 0.887 | 0.650 |
| Matrix Cumul. RBM | 0.893 | 0.641 | 0.892 | 0.640 |
[38]. Gaussian RBMs have been only used for continuous variables [13, 25] - thus our use for ordinal variables is novel. There has also been recent work extending Gaussian RBMs to better model highly correlated input variables [28, 8]. For ordinal data, to the best of our knowledge, the first RBM-based work is [40], which also contains a treatment of matrix-wise data . However, their work indeed models multinomial data with knowledge of orders rather than modelling the ordinal nature directly. The result is that it is over-parameterised but less efficient and does not offer any underlying generative mechanism for ordinal data.
Ordinal data has been well investigated in statistical sciences, especially quantitative social studies, often under the name of ordinal regression , which refers to single ordinal output given a set of input covariates. The most popular method is by [24] which examines the level-wise cumulative distributions. Another well-known treatment is the sequential approach, also known as continuation ratio [23], in which the ordinal generation process is considered stepwise, starting from the lowest level until the best level is chosen. For reviews of recent development, we refer to [22]. In machine learning, this has attracted a moderate attention in the past decade [12, 6, 7, 3], adding machine learning flavours (e.g., large-margins) to existing statistical methods.
Multivariate ordinal variables have also been studied for several decades [1]. The most common theme is the assumption of the latent multivariate normal distribution that generates the ordinal observations, often referred to as multivariate probit models [5, 11, 17, 27, 15, 4]. The main problem with this setting is that it is only feasible for problems with small dimensions. Our treatment using RBMs offer a solution for large-scale settings by transferring the low-order interactions among the Gaussian variables onto higher-order interactions through the hidden binary layer. Not only this offers much faster inference, it also enables automatic discovery of latent aspects in the data.
For matrix data, the most well-known method is perhaps matrix factorisation [21, 29, 34]. However, this method assumes that the data is normally distributed, which does not meet the ordinal characteristics well. Recent research has attempted to address this issue [26, 16, 39]. In particular, [26, 16] adapt cumulative models of [24], and [39] tailors the sequential models of [23] for task.
## 6 Conclusion
We have presented CRBM, a novel probabilistic model to handle vector-variate and matrixvariate ordinal data. The model is based on Gaussian restricted Boltzmann machines and we present the model architecture, learning and inference procedures. We show that the model is useful in profiling opinions of people across cultures and nations. The model is also competitive against state-of-art methods in collaborative filtering using large-scale public datasets. Thus our work enriches the RBMs, and extends their use on multivariate ordinal data in diverse applications.
## References
- [1] J.A. Anderson and JD Pemberton. The grouped continuous model for multivariate ordered categorical variables and covariate adjustment. Biometrics , pages 875-885, 1985.
- [2] Bo Chen Benjamin Marlin, Kevin Swersky and Nando de Freitas. Inductive Principles for Restricted Boltzmann Machine Learning. In Proceedings of the 13rd International Con-
ference on Artificial Intelligence and Statistics , Chia Laguna Resort, Sardinia, Italy, May 2010.
- [3] J.S. Cardoso and J.F.P. da Costa. Learning to classify ordinal data: the data replication method. Journal of Machine Learning Research , 8(1393-1429):6, 2007.
- [4] P. Chagneau, F. Mortier, N. Picard, and J.N. Bacro. A hierarchical bayesian model for spatial prediction of multivariate non-gaussian random fields. Biometrics , 2010.
- [5] S. Chib and E. Greenberg. Analysis of multivariate probit models. Biometrika , 85(2):347361, 1998.
- [6] W. Chu and Z. Ghahramani. Gaussian processes for ordinal regression. Journal of Machine Learning Research , 6(1):1019, 2006.
- [7] W. Chu and S.S. Keerthi. Support vector ordinal regression. Neural computation , 19(3):792815, 2007.
- [8] A. Courville, J. Bergstra, and Y. Bengio. A spike and slab restricted Boltzmann machine. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS) , volume 15. Fort Lauderdale, USA, 2011.
- [9] Y. Freund and D. Haussler. Unsupervised learning of distributions on binary vectors using two layer networks. Advances in Neural Information Processing Systems , pages 912-919, 1993.
- [10] P.V. Gehler, A.D. Holub, and M. Welling. The rate adapting Poisson model for information retrieval and object recognition. In Proceedings of the 23rd international conference on Machine learning , pages 337-344. ACM New York, NY, USA, 2006.
- [11] Leonardo Grilli and Carla Rampichini. Alternative specifications of multivariate multilevel probit ordinal response models. Journal of Educational and Behavioral Statistics , 28(1):3144, 2003.
- [12] R. Herbrich, T. Graepel, and K. Obermayer. Large margin rank boundaries for ordinal regression. Advances in Neural Information Processing Systems , pages 115-132, 1999.
- [13] G.E. Hinton. Training products of experts by minimizing contrastive divergence. Neural Computation , 14:1771-1800, 2002.
- [14] G.E. Hinton and R.R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science , 313(5786):504-507, 2006.
- [15] I. Jeliazkov, J. Graves, and M. Kutzbach. Fitting and comparison of models for multivariate ordinal outcomes. Advances in Econometrics , 23:115-156, 2008.
- [16] Y. Koren and J. Sill. OrdRec: an ordinal model for predicting personalized item rating distributions. In Proceedings of the fifth ACM conference on Recommender systems , pages 117-124. ACM, 2011.
- [17] A. Kottas, P. M¨ller, and F. Quintana. Nonparametric Bayesian modeling for multivariate u ordinal data. Journal of Computational and Graphical Statistics , 14(3):610-625, 2005.
- [34] R. Salakhutdinov and A. Mnih. Probabilistic matrix factorization. Advances in neural information processing systems , 20:1257-1264, 2008.
- [35] R. Salakhutdinov, A. Mnih, and G. Hinton. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine Learning (ICML) , pages 791-798, 2007.
- [36] P. Smolensky. Information processing in dynamical systems: Foundations of harmony theory. Parallel distributed processing: Explorations in the microstructure of cognition , 1:194-281, 1986.
- [37] T. Tieleman. Training restricted Boltzmann machines using approximations to the likelihood gradient. In Proceedings of the 25th international conference on Machine learning , pages 1064-1071. ACM, 2008.
- [38] T. Tran, D.Q. Phung, and S. Venkatesh. Mixed-variate restricted Boltzmann machines. In Proc. of 3rd Asian Conference on Machine Learning (ACML) , Taoyuan, Taiwan, 2011.
- [39] T. Tran, D.Q. Phung, and S. Venkatesh. Sequential decision approach to ordinal preferences in recommender systems. In Proc. of the 26th AAAI Conference , Toronto, Ontario, Canada, 2012.
- [40] T.T. Truyen, D.Q. Phung, and S. Venkatesh. Ordinal Boltzmann machines for collaborative filtering. In Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI) , Montreal, Canada, June 2009.
- [41] L. van der Maaten and G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research , 9(2579-2605):85, 2008.
- [42] L. Younes. Parametric inference for imperfectly observed Gibbsian fields. Probability Theory and Related Fields , 82(4):625-645, 1989.
| [18] | H. Larochelle and Y. Bengio. Classification using discriminative restricted Boltzmann ma- chines. In Proceedings of the 25th international conference on Machine learning , pages 536-543. ACM, 2008. |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [19] | Q.V. Le, W.Y. Zou, S.Y. Yeung, and A.Y. Ng. Learning hierarchical invariant spatio- temporal features for action recognition with independent subspace analysis. CVPR , 2011. |
| [20] | N. Le Roux and Y. Bengio. Representational power of restricted Boltzmann machines and deep belief networks. Neural Computation , 20(6):1631-1649, 2008. |
| [21] | D.D. Lee and H.S. Seung. Learning the parts of objects by non-negative matrix factoriza- tion. Nature , 401(6755):788-791, 1999. |
| [22] | I. Liu and A. Agresti. The analysis of ordered categorical data: an overview and a survey of recent developments. TEST , 14(1):1-73, 2005. |
| [23] | R.D. Mare. Social background and school continuation decisions. Journal of the American Statistical Association , pages 295-305, 1980. |
| [24] | P. McCullagh. Regression models for ordinal data. Journal of the Royal Statistical Society. Series B (Methodological) , pages 109-142, 1980. |
| [25] | A.R. Mohamed and G. Hinton. Phone recognition using restricted Boltzmann machines. In Acoustics Speech and Signal Processing (ICASSP), 2010 IEEE International Conference on , pages 4354-4357. IEEE, 2010. |
| [26] | U. Paquet, B. Thomson, and O. Winther. A hierarchical model for ordinal matrix factor- ization. Statistics and Computing , pages 1-13, 2011. |
| [27] | J. Podani. Multivariate exploratory analysis of ordinal data in ecology: pitfalls, problems and solutions. Journal of Vegetation Science , 16(5):497-510, 2005. |
| [28] | M.A. Ranzato and G.E. Hinton. Modeling pixel means and covariances using factorized third-order Boltzmann machines. In CVPR , pages 2551-2558. IEEE, 2010. |
| [29] | J.D.M. Rennie and N. Srebro. Fast maximum margin matrix factorization for collabora- tive prediction. In Proceedings of the 22nd International Conference on Machine Learning (ICML) , pages 713-719, Bonn, Germany, 2005. |
| [30] | C.P. Robert. Simulation of truncated normal variables. Statistics and computing , 5(2):121- 125, 1995. |
| [31] | R. Salakhutdinov and G. Hinton. Deep Boltzmann Machines. In Proceedings of The Twelfth International Conference on Artificial Intelligence and Statistics (AISTATS'09 , volume 5, pages 448-455, 2009. |
| [32] | R. Salakhutdinov and G. Hinton. Replicated softmax: an undirected topic model. Advances in Neural Information Processing Systems , 22, 2009. |
| [33] | R. Salakhutdinov and G. Hinton. Semantic hashing. International Journal of Approximate Reasoning , 50(7):969-978, 2009. | | null | [
"Truyen Tran",
"Dinh Phung",
"Svetha Venkatesh"
] | 2014-07-31T23:54:16+00:00 | 2014-07-31T23:54:16+00:00 | [
"stat.ML",
"cs.IR",
"cs.LG",
"stat.AP",
"stat.ME"
] | Cumulative Restricted Boltzmann Machines for Ordinal Matrix Data Analysis | Ordinal data is omnipresent in almost all multiuser-generated feedback -
questionnaires, preferences etc. This paper investigates modelling of ordinal
data with Gaussian restricted Boltzmann machines (RBMs). In particular, we
present the model architecture, learning and inference procedures for both
vector-variate and matrix-variate ordinal data. We show that our model is able
to capture latent opinion profile of citizens around the world, and is
competitive against state-of-art collaborative filtering techniques on
large-scale public datasets. The model thus has the potential to extend
application of RBMs to diverse domains such as recommendation systems, product
reviews and expert assessments. |
1408.0049v1 | ## Categories of Quantum and Classical Channels
(extended abstract)
Bob Coecke ∗
Chris Heunen †
Aleks Kissinger ∗
University of Oxford, Department of Computer Science { coecke,heunen,alek @cs.ox.ac.uk }
We introduce the CP*-construction on a dagger compact closed category as a generalisation of Selinger's CPM-construction. While the latter takes a dagger compact closed category and forms its category of 'abstract matrix algebras' and completely positive maps, the CP*-construction forms its category of 'abstract C*-algebras' and completely positive maps. This analogy is justified by the case of finite-dimensional Hilbert spaces, where the CP*-construction yields the category of finite-dimensional C*-algebras and completely positive maps.
The CP*-construction fully embeds Selinger's CPM-construction in such a way that the objects in the image of the embedding can be thought of as 'purely quantum' state spaces. It also embeds the category of classical stochastic maps, whose image consists of 'purely classical' state spaces. By allowing classical and quantum data to coexist, this provides elegant abstract notions of preparation, measurement, and more general quantum channels.
## 1 Introduction
One of the motivations driving categorical treatments of quantum mechanics is to place classical and quantum systems on an equal footing in a single category, so that one can study their interactions. The main idea of categorical quantum mechanics [1] is to fix a category (usually dagger compact) whose objects are thought of as state spaces and whose morphisms are evolutions. There are two main variations.
- · 'Dirac style': Objects form pure state spaces, and isometric morphisms form pure state evolutions.
- · 'von Neumann style': Objects form spaces of mixed states, and morphisms form mixed quantum evolutions, also known as quantum channels .
The prototypical example of a 'Dirac style' category is FHilb , the category of finite-dimensional Hilbert spaces and linear maps. One can pass to a 'von Neumann style category' by considering the C*algebras of operators on these Hilbert spaces, with completely positive maps between them. Selinger's CPM-construction provides an abstract bridge from the former to the latter [18], turning morphisms in V into quantum channels in CPM [ V ] . However, this passage loses the connection between quantum and classical channels. For example, CPM [ FHilb ] only includes objects corresponding to the entire state space of some quantum system, whereas we would often like to focus in subspaces corresponding to particular classical contexts. There have been several proposals to remedy this situation, which typically involve augmenting CPM [ V ] with extra objects to carry this classical structure. Section 1.1 provides an overview.
This extended abstract 1 introduces a new solution to this problem, called the CP*-construction, which is closer in spirit to the study of quantum information using C*-algebras (see e.g. [15]). Rather than
∗ Supported by the John Templeton Foundation.
† Supported by EPSRC Fellowship EP/L002388/1.
1 A long version of this extended abstract is now available: [8].
freely augmenting a category of quantum data with classical objects, we define a new category whose objects are 'abstract C*-algebras', and whose morphisms are the analogue of completely positive maps. It is then possible to construct a full embedding of the category CPM [ V ] , whose image yields the purely quantum channels. Furthermore, there exists another full embedding of the category Stoch V [ ] of classical stochastic maps, whose image yields the purely classical channels. The remainder of the category CP ∗ [ V ] can be interpreted as mixed classical/quantum state spaces, which carry partially coherent quantum states, such as degenerate quantum measurement outcomes.
/
/
/
/
o
o
The paper is structured as follows. Section 2 introduces normalisable dagger Frobenius algebras. These form a crucial ingredient to the CP*-construction, which is defined in Section 3. Sections 4 and 5 then show that the CP*-construction simultaneously generalises Selinger's CPM-construction, consisting of 'quantum channels', and the Stoch -construction, consisting of 'classical channels'. We then consider two examples: Section 6 shows that CP ∗ [ FHilb ] is the category of finite- dimensional C*-algebras and completely positive maps, and Section 7 shows that CP ∗ [ Rel ] is the category of (small) groupoids and inverse-respecting relations. Section 8 compares CP ∗ [ V ] with Selinger's extension of the CPM-construction using split idempotents. Finally, Section 9 discusses the many possibilities this opens up.
## 1.1 Related Work
Selinger introduced two approaches to add classical data to CPM [ V ] by either freely adding biproducts to CPM [ V ] or freely splitting the †-idempotents of CPM [ V ] [19]. These new categories are referred to as CPM [ V ] ⊕ and Split † [ CPM [ V ]] , respectively.
glyph[negationslash]
When V = FHilb , both categories provide 'enough space' to reason about classical and quantum data, as any finite-dimensional C*-algebra can be defined as a sum of matrix algebras (as in CPM [ FHilb ] ⊕ ) or as a certain orthogonal subspace of a larger matrix algebra (as in Split † [ CPM [ FHilb ]] ). However, it is unclear whether the second construction captures too much: its may contain many more objects than simply mixtures of classical and quantum state spaces [19, Remark 4.9]. On the other hand, when V = FHilb , the category CPM [ FHilb ] ⊕ may be too small. That is, there may be interesting objects that are not just sums of quantum objects.
For this reason, it is interesting to study CP ∗ [ V ] , as it lies between these two constructions:
/
/
/
/
The first embedding is well-defined whenever V has biproducts, and the second when V satisfies a technical axiom about square roots (see Definition 8.2). In the former case, CP ∗ [ V ] inherits biproducts from V , so it is possible to lift the embedding of CPM [ V ] by the universal property of the free biproduct completion; this will be proved in detail in a subsequent paper. In the latter case, one can always construct the associated dagger-idempotent of an object in CP ∗ [ V ] , and (with the assumption from Definition 8.2), the notions of complete positivity in CP ∗ [ V ] and Split † [ CPM [ V ]] coincide. We provide the details of this construction in Section 8.
A third approach by Coecke, Paquette, and Pavlovic is similar to ours in that it makes use of commutative Frobenius algebras to represent classical data [9]. As in the previous two approaches, it takes CPM [ V ] and freely adds classical structure, this time by forming the comonad associated with a particular commutative Frobenius algebra and taking the Kleisli category. All such categories are then glued
together by Grothendieck construction. The CP*-construction was originally conceived as a way to simplify this approach and overcome is limitations.
## 2 Abstract C*-algebras
This section defines so-called normalisable dagger Frobenius algebras, which will play a central role in the CP*-construction of the next section. We start by recalling the notion of a Frobenius algebra. For an introduction to dagger (compact) categories and their graphical calculus, we refer to [1, 20].
Definition 2.1. A Frobenius algebra is an object A in a monoidal category together with morphisms depicted as , , and on it satisfying the following diagrammatic equations.
Any Frobenius algebra defines a cap and a cup that satisfy the snake equation.
:
=
:
=
=
=
Definition 2.2.
A Frobenius algebra is symmetric
when
=
and
=
.
In a dagger compact category V , a dagger Frobenius algebra is a Frobenius algebra that satisfies =( ) † and =( ) † . Their import for us starts with the following theorem.
Theorem 2.3 ([21]) . Given a dagger Frobenius algebra ( A , ) in FHilb , the following operation gives A the structure of a C*-algebra.
$$\left ( \boxed { \stackrel { \uparrow } { v } } \right ) ^ { * } \coloneqq \boxed { \stackrel { \uparrow } { \downarrow } } _ { \sigma }$$
Furthermore, all finite-dimensional C*-algebras arise this way.
In light of this theorem, one might be tempted to consider dagger Frobenius algebras to be the 'correct' way to define the abstract analogue of finite-dimensional C*-algebras. However, there is one more condition, called normalisability , that is satisfied by all dagger Frobenius algebras in FHilb , yet not by dagger Frobenius algebras in general. Before we come to that, we introduce the notion of a central map for a monoid.
Definition 2.4. A map z : A → A is central for a monoid when ◦ ( z ⊗ 1 A ) = z ◦ = ◦ ( 1 A ⊗ z ) .
We call such a map central, because it corresponds uniquely to a point pz : I → A in the centre of the monoid via left (or equivalently right) multiplication by pz .
Recall that a map g : A → A in a dagger category is positive when g = h † ◦ h for some map h . It is called positive definite when it is a positive isomorphism. Using these conditions, we give the definition of a normalisability as a well-behavedness property of the 'loop' map ◦ .
Definition 2.5. A dagger Frobenius algebra is normalisable when there is a central, positive-definite map z , called the normaliser and depicted as , satisfying the following diagrammatic equation.
Special dagger Frobenius algebras are normalisable dagger Frobenius algebra where z 2 = 1 . A Normalisable dagger Frobenius algebras are always symmetric.
Theorem 2.6. Normalisable dagger Frobenius algebras are symmetric.
Proof. The proof follows from expanding the counit and applying cyclicity of the trace ( ∗ ) .

Definition 2.7. An object X in a dagger compact category is positive-dimensional if there is a positive definite scalar z satisfying z z = X X X . A dagger compact closed category is called positive-dimensional if all its objects are.
Proposition 2.8. For a positive-dimensional dagger compact closed category V , every object of the form A ∗ ⊗ A carries a canonical normalisable dagger Frobenius algebra, given as follows.

Proof. The Frobenius axioms follow immediately from compact closure. By positive-dimensionality, there exists a positive-definite scalar z such that ( z 2 ◦ Tr A ( 1 A )) ⊗ 1 A = 1 . It is then possible to show that A 1 A ∗ ⊗ A ⊗ z is the normaliser.
From now on, we will always take V to be positive-dimensional.
## 3 The CP*-construction
↦
This section defines the CP*-construction. In fact, defining it is easy; most work goes into proving that it yields a dagger compact category. For the definition we need some (graphical) notation, generalising the left and right regular actions A → End A ( ) given by x → · -x ( ) and x → - · ( ) x for a finite-dimensional algebra A . More generally, for a monoid ( A , ) in a compact category, define its left and right action maps A → ∗ ⊗ A A as follows.
↦
↦

Similarly, we can define for any comonoid left and right coaction maps. By convention, we work primarily with right action and coaction maps, and express them more succinctly as follows.

Definition 3.1. Let V be a dagger compact category. Objects of CP ∗ [ V ] are normalizable dagger Frobenius algebras in V . Morphisms from ( A , ) to ( B , ) in CP ∗ [ V ] are morphisms f : A → B in V such that there exists an object X and g : A → X ⊗ B in V satisfying the following equation.

Composition and identities are inherited from V .
Equation (1) is called the CP*-condition . We first establish that CP ∗ [ V ] is a well-defined category.
$$\text{Lemma $3.2$. $Any symmetric Frobenius algebra satisfies $\mathbb{2}_{\mathbb{2}}$} = \mathbb{2} \mathbb{2} \mathbb{2}.$$
Proof. We can use symmetry to prove the result.

$$\text{Lemma} \, 3. 3. \ A n y \, n o r m a l i s a b l e \, d a g g e r \, F r o b e n i u s \, a l g e b r a \, s a t i s f i e s \, \stackrel { \mathfrak { L } } { \mathfrak { L } } \, \stackrel { \mathfrak { L } } { \mathfrak { L } } \, = \, \left |.$$
Proof. Follows from Frobenius equations and a trace identity ( ∗ ) for symmetric Frobenius algebras.

These lemmas can express the CP*-condition in the sometimes more convenient 'convolution form'. Proposition 3.4. Let V be a dagger compact category, ( A , ) and ( B , ) be normalisable dagger Frobenius algebras, and f : A → B a morphism.
Proof. For ( ⇒ ), apply ( ◦-◦ ) to both sides and use Lemma 3.3 and properties of normalisers. For ( ⇐ ), apply ( ◦-◦ ) to both sides and apply Lemma 3.2.
Theorem 3.5. If V is a dagger compact category V , so is CP ∗ [ V ] .
Proof. Identity maps 1 A : ( A , ) → ( A , ) satisfy the CP ∗ -condition: letting g = in (1) does the job by Lemma 3.2, whose left-hand side is ◦ 1 A ◦ .
Next, suppose f : ( A , ) → ( B , ) and g : ( B , ) → ( C , ) satisfy the CP*-condition. It then follows from Lemma 3.3 that their composition does, too.
For the monoidal structure, take ( A , ) ⊗ ( B , ) : = ( A ⊗ B , ) . For maps f : ( A , ) → ( C , ∗ ) and g : ( B , ) → ( D , ∗ ) satisfying (1), also f ⊗ g : ( A ⊗ B , ) → ( C ⊗ D , ∗ ∗ ) satisfies the CP*-condition. This can be seen by applying the coaction of and the action of ∗ ∗ , then decomposing f into h ∗ , h and g into i ∗ , i , as follows.
As for the tensor unit, note that I : =( I , r I ) is a normalisable dagger Frobenius algebra by monoidal coherence in V . Using this definition of ⊗ and I , the monoidal structure maps a , l , and r from V trivially satisfy the CP*-condition. Thus CP ∗ [ V ] is a monoidal category. CP ∗ [ V ] inherits the dagger from V . Symmetry and dual maps in V lift to the following morphisms in CP ∗ [ V ] .
$$\sigma _ { A, B } \colon ( A \otimes B, \hat { \bigtriangleup } _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \vare { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi | \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ \ | \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi | _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \ | \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \vare _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \chi _ { \bar { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare _ { \vare } } | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | w | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | t | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | v | s | \to I$$
The Frobenius identities and Lemma 3.2 establish the CP*-condition for these maps.
We refer to a morphism I → ( A , ) of CP ∗ [ V ] as a positive element of ( A , ) . Another way to express the CP*-condition for a V -morphism is to say that it preserves the property of being a positive element when applied to a some subsystem, as in the following theorem. This will be useful to connect to the traditional notion of complete positivity of linear maps between C*-algebras.
Theorem 3.6. Let ( A , ) and ( B , ) be normalisable dagger Frobenius algebras and f : A → B a morphism in a dagger compact category V . The following are equivalent:
- (a) f satisfies the CP*-condition;
(b) postcomposing with f ⊗ 1 C sends positive elements of ( A , ) ⊗ ( C , ) to positive elements of ( B , ) ⊗ ( C , ) for all dagger normalisable Frobenius algebras ( C , ) ;
(c) postcomposing with f ⊗ 1 X ∗ ⊗ X sends positive elements of ( A , ) ⊗ ( X ∗ ⊗ X , ) to positive elements of ( B , ) ⊗ ( X ∗ ⊗ X , ) for all objects X in V .
Proof. For (a) ⇒ (b): if r is a positive element of ( A , ) ⊗ ( C , ) and f satisfies the CP*-condition, then so does ( f ⊗ 1 C ) ◦ r , by Theorem 3.5. The implication (b) ⇒ (c) is trivial. Finally, for (c) ⇒ (a), take ( C , ) = ( A ∗ , ) . The action map : ( C , ) → ( C ∗ ⊗ C , ) is a morphism in CP ∗ [ V ] . As a consequence of this fact and Theorem 3.5, the following is a positive element of ( A , ) ⊗ ( X ∗ ⊗ X , ) .
$$\stackrel { \downarrow } { \rho } \rceil \, =$$
So, by assumption, ( f ⊗ 1 A ∗ ) ◦ r is also a positive element. Applying white caps to both sides finishes the proof.
See also [8, Proposition 3.4].
## 4 Embedding Selinger's CPM-construction
This section will concentrate on the 'purely quantum' objects in CP ∗ [ V ] , by proving that the latter embeds CPM [ V ] in a full, faithful, and strongly dagger symmetric monoidal way. First, we recall Selinger's CPM-construction [18].
Definition 4.1. For a dagger compact category V , form the dagger compact category CPM [ V ] as follows. Objects are the same as those in V , and morphisms f ∈ CPM [ V ]( A B , ) are V -morphisms f : A ∗ ⊗ A → B ∗ ⊗ B for which there is g : A → X ⊗ B satisfying the following condition.
Composition, identity maps, and ⊗ on objects are defined as in V . On morphisms, ⊗ is defined as:
A strongly dagger symmetric monoidal functor is a functor F along with a unitary natural isomorphism j A B , : F A ( ⊗ B ) → F A ( ) ⊗ F B ( ) satisfying several coherence properties that we have no space to go in to. Our next theorem shows that CPM [ V ] is equivalent to the full subcategory of CP ∗ [ V ] consisting of objects of the form ( A ∗ ⊗ A , ) . Its proof uses ∗ -homomorphisms, which we first define.
Definition 4.2. If ( A , ) and ( B , ) are normalisable dagger Frobenius algebras in a dagger compact category V , a morphism f : A → B is called a ∗ -homomorphism when it satisfies the following equations.
Lemma 4.3. Let ( A , ) and ( B , ) be normalisable dagger Frobenius algebras in a dagger compact category V . If f : A → B is a ∗ -homomorphism, then it is a well-defined morphism in CP ∗ [ V ] .
Proof. Using the definition: ◦ f ◦ =( ◦ ) ◦ ( f ∗ ⊗ f ) . Applying Lemma 3.2 completes the proof.
Theorem 4.4. Let V be a positive-dimensional dagger compact category. Define L : CPM [ V ] → CP ∗ [ V ] by setting L A ( ) : = ( A ∗ ⊗ A , ) on objects and L ( f ) = f on morphisms. Then L is a well-defined functor that is full, faithful, and strongly dagger symmetric monoidal.
Proof. For well-definedness, we show that a V -morphism f : A ∗ ⊗ A → ∗ ⊗ B B is a CPM [ V ] -morphism from A to B if and only if it is a CP ∗ [ V ] -morphism from ( A ∗ ⊗ A , ) to ( B ∗ ⊗ B , ) . First, assume f ∈ CPM [ V ] and compose with the action and coaction of the respective algebras to see that f satisfies the CP*-condition, as follows.
Conversely, if f is in CP ∗ [ V ] , then it is also in CPM [ V ] , as follows.
Composition is the same in CPM [ V ] and CP ∗ [ V ] , so L is a functor that is furthermore full and faithful. Similarly, daggers are the same in CPM [ V ] and CP ∗ [ V ] , so L trivially preserves daggers. It now suffices to show that L is strongly monoidal. Define the isomorphism j A B , : L A ( ⊗ B ) → L A ( ) ⊗ L B ( ) as the reshuffling map ( 321 )( 4 : ) B ∗ ⊗ A ∗ ⊗ A ⊗ B → ∗ ⊗ A A ⊗ B ∗ ⊗ B . One can verify that this map is a ∗ -homomorphism from L A ( ⊗ B ) to L A ( ) ⊗ L B ( ) , so it must satisfy the CP*-condition. This map is also unitary, and it is a routine calculation to show that it satisfies the coherence equations for a strong symmetric monoidal functor.
## 5 Generalised stochastic maps and measurement of quantum states
Whereas the previous section focused on 'purely quantum' objects in CP ∗ [ V ] , this section looks at the 'purely classical' ones. We will define a 'purely probabilistic' category Stoch V [ ] , that by construction embeds into CP ∗ [ V ] . Thus objects in CP ∗ [ V ] can be interpreted as being 'combined classical and quantum'. The category Stoch V [ ] was first considered in [9]. It was defined in a slightly different form there, but one can prove that this coincides with the following definition.
Definition 5.1. For a dagger compact category V , define Stoch V [ ] to be the full subcategory of CP ∗ [ V ] consisting of all commutative normalisable dagger Frobenius algebras.
The next proposition justifies why this category is that of 'classical channels'. We call a morphism f : ( A , ) → ( B , ) in CP ∗ [ V ] normalised if it preserves counits: ◦ f = . Because commutative finite-dimensional C*-algebras correspond to finite-dimensional Hilbert spaces with a choice of orthonormal basis, we can think of the latter as objects of Stoch FHilb [ ] [10, 2, 13]. Recall that a stochastic map between finite-dimensional Hilbert spaces is a matrix with positive real entries whose every column sums to one.
Proposition 5.2. Normalised morphisms in Stoch FHilb [ ] correspond to stochastic maps between finitedimensional Hilbert spaces.
Proof. See [15, 3.2.3 and 2.1.3].
For any Frobenius algebra ( A , ) we can consider its copyable points : the morphisms p : I → A that are 'copied' by the comultiplication, in the sense that ◦ p = p ⊗ p . This is especially interesting for commutative normalisable dagger Frobenius algebras, because in FHilb , copyable points form an orthonormal basis for A . Writing vectors in the basis of classical points, one can show that the normalised positive elements are precisely those vectors with positive coefficients that sum to 1. Thus, normalised positive elements of a commutative normalisable dagger Frobenius algebra can be regarded as probability distributions over its copyable points.
So far we have mostly looked at classical and quantum systems in isolation. But as they live together in a category CP ∗ [ V ] , we can also consider maps between them. Consider a normalised morphism P : L H ( ) → ( A , ) from a quantum to a classical system. Then P † ◦ xi is a positive element of for each copyable point xi . Furthermore, any commutative normalisable dagger Frobenius algebra in FHilb satisfies = GLYPH<229> i xi . Since P is normalised, GLYPH<229> P † ◦ xi = P † ◦ GLYPH<229> xi = P † ◦ = eH : I → H ∗ ⊗ H is the cup from the compact structure on H . Positive elements in H ∗ ⊗ H represent positive operators from H to itself, and eH represents the identity operator. Thus the set { P † ◦ xi } corresponds to a positive operator-valued measure (POVM). Furthermore, for any quantum state r (i.e. normalised positive element in L H ( ) ), it is straightforward to show that P ◦ r yields the probability distribution whose i th element is the probability of getting outcome xi , computed via the Born rule.
The dual notion of a morphism E : ( A , ) → L H ( ) from a classical system to a quantum system can be thought of as a preparation. Or, more precisely, as a map carrying a classical probability distribution over some fixed set of states to a single mixed state. Choosing a particular decomposition E ◦ r for a quantum state r gives us a way to represent quantum ensembles. See also [16, 3.2.4].
## 6 Hilbert spaces
It is high time we looked at some examples. This section proves that CP ∗ [ FHilb ] is the category of all finite-dimensional C*-algebras and completely positive maps. The proof also illuminates Theorem 4.4.
Namely, CPM [ FHilb ] has finite-dimensional C*factors for objects. Recall that a C*-algebra is a factor when its centre is 1-dimensional. Finite-dimensional C*-algebras in fact enjoy an easy structure theorem: they are finite direct sums of factors, and factors are precisely matrix algebras [12, Theorem III.1.1]. The following lemma recalls the structure of these factors, and the subsequent proposition determines the objects of CP ∗ [ FHilb ] .
Lemma 6.1. If H is an n-dimensional Hilbert space, then there is an isomorphism of algebras between L H ( ) and M C n ( ) . Therefore, H ∗ ⊗ H carries C*-algebra structure; the involution is as in Theorem 2.3.
Proof. First of all, M C n ( ) is a Hilbert space under the Hilbert-Schmidt inner product 〈 a b | 〉 = Tr ( a b † ) . It has a canonical orthonormal basis { ei j | i , j = 1 , . . . , n } , where ei j is the matrix all of whose entries are 0 except the ( i , j ) -entry, which is 1. Pick an orthonormal basis {| 1 〉 , . . . , | n 〉} for H , so that {〈 | ⊗ | i j 〉 | i , j = 1 , . . . , n } forms an orthonormal basis for H ∗ ⊗ H . Then the assignment 〈 | ⊗| i j 〉 ↦→ ei j implements a unitary isomorphism between H ∗ ⊗ H and M C n ( ) . Direct computation shows that matrix multiplication translates across this isomorphism to on H ∗ ⊗ H . Similarly, taking the conjugate transpose of a matrix corresponds to the involution on H ∗ ⊗ H given in Theorem 2.3.
Proposition 6.2. All dagger Frobenius algebras in FHilb are normalisable.
Proof. Let ( A , , ) be a dagger Frobenius algebra in FHilb . By Theorem 2.3, it must be isomorphic to a C*-algebra of the form ⊕ k M nk ( C ) , giving a unitary isomorphism of the associated dagger Frobenius algebras. Let { e ( k ) i j : 0 ≤ i , j < nk } form an orthonormal basis for A . We can define in terms of this basis as ( e ( k ) i j ⊗ e ( k ′ ) i ′ j ′ ) = d k ′ k d i ′ j e ( k ) i j ′ . From this, we can compute Tr A ( ) directly.
$$T r _ { A } ( \hat { \hat { \varphi } } _ { \lambda } ) ( e ^ { ( k ) } _ { i j } ) = \sum _ { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \that \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \t \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \t | \tilde { \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \ t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \t | \sum _ { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde } \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde $ \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde [ \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde | \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \t \t \t \t \t }
) .$$
↦
Note that ( e ( k ) i j ) = d j i . We can now define the normaliser as e ( k ) i j → √ 1 nk e ( k ) i j : this map is invertible, satisfies Tr A ( ) ◦ ( ) 2 = , and acts by a constant scalar on each summand of A and so is central.
Combining the previous proposition with Theorem 2.3, we see that the objects of CP ∗ [ FHilb ] are (in 1-to-1 correspondence with) finite-dimensional C*-algebras. We now turn to the morphisms of CP ∗ [ FHilb ] . First, let us review what (concrete) completely positive maps between C*-algebras are. Good references are [3, 17]. The main notion is that of a matrix algebra M n ( A ) over a C*-algebra A . Its elements are n -byn matrices with entries in A , given C*-structure by ( aij ) · ( bij ) = GLYPH<229> n k = 1 aik b k j , ( aij ) ∗ =( a ji ∗ ) , and ‖ ( aij ) ‖ = sup {‖ ( aij ) x ‖ | x ∈ A n , ‖ ‖ x = 1 , where } ‖ ( x 1 , . . . , xn ) ‖ 2 = GLYPH<229> n i = 1 ‖ x 1 ‖ 2 . The following well-known lemma then follows directly.
Lemma 6.3. If A is a finite-dimensional C*-algebra, then so is M n ( A . If ) f : A → B is a linear map, then so is the function M n ( f ) : M n ( A ) → M n ( B ) that sends ( aij ) to ( f ( aij )) . If f is a ∗ -homomorphism, then so is M n ( f ) .
Definition 6.4. Alinear map f : A → B between C*-algebras is positive when for every a ∈ A there exists b ∈ B satisfying f ( a a ∗ ) = b b ∗ . It is completely positive when M n ( f ) is positive for every n ∈ N .
For us it will be convenient to take another, well-known, viewpoint. If A and B are finite-dimensional C*-algebras, then so is the algebraic tensor product A ⊗ B .
Lemma 6.5. Any finite-dimensional C*-algebra A has a canonical ∗ -isomorphism M n ( A ) = ∼ A ⊗ M C n ( ) . Under this correspondence, a linear map f : A → B between C*-algebras is completely positive if and only if f ⊗ 1 M C n ( ) is positive for every n ∈ N .
↦
Proof. Borrowing notation from Lemma 6.1, the ∗ -isomorphism M n ( A ) → A ⊗ M C n ( ) is given by ( aij ) → GLYPH<229> n i , j = 1 aij ⊗ ei j . One easily verifies that this preserves the multiplication and involution. The second statement follows directly from Definition 6.4 by unfolding this isomorphism.
Now we have phrased the concrete notion of complete positivity in terms of tensor products with matrix algebras (cf. Theorem 3.6), and given that matrix algebras in FHilb are precisely the algebras of the form L H ( ) for some Hilbert space H , we can determine CP ∗ [ FHilb ] .
Theorem 6.6. CP ∗ [ FHilb ] is equivalent to the category of finite-dimensional C*-algebras and completely positive maps.
Proof. Define a functor E from CP ∗ [ FHilb ] to the category of finite-dimensional C*-algebras and completely positive maps, acting on objects as in Theorem 2.3 and as identity on morphisms.
Proposition 6.2 and Theorem 2.3 show that E is surjective on objects. Suppose f : ( A , ) → ( B , ) is a morphism in CP ∗ [ V ] . Then Theorem 3.6 shows that E ( f ) must be completely positive, as characterised by Lemma 6.5. Therefore E is well-defined. Conversely, any completely positive map g between C*-algebras satisfies the CP*-condition because of Lemma 6.5, so E is full and hence an equivalence of categories.
glyph[negationslash]
Remark 6.7. It follows from the previous theorem that the embedding L does not extend to an equivalence of categories because it is not essentially surjective. That is, there are finite-dimensional C*algebras, such as A = M C 1 ( ) ⊕ M C 2 ( ) , that are not isomorphic to a factor: dim ( A ) = 1 2 + 2 2 = 5 = n 2 = dim ( M C n ( )) .
## 7 Sets and relations
The previous section justified regarding normalisable dagger Frobenius algebras as generalised (finitedimensional) C*-algebras. This section considers CP ∗ [ V ] for V = Rel , the category of sets and relations. Starting with objects, we immediately see that these 'generalised C*-algebras' are quite different.
Proposition 7.1. All normalisable dagger Frobenius algebras in Rel are special. Therefore they are (in 1-to-1 correspondence with small) groupoids.
Proof. We have to prove that normalisability implies speciality in Rel ; for this it suffices to show that z 2 = 1. Now, the normaliser z is an isomorphism. In Rel , this means it is (the graph of) a bijection. But z is also positive, and hence self-adjoint. This means it is equal to its own inverse. Therefore z 2 = 1. The second statement now follows directly from [14, Theorem 7].
Next, we turn to determining the morphisms of CP ∗ [ Rel ] .
Definition 7.2. A relation R ⊆ Mor ( G ) × Mor ( H ) between groupoids G H , respects inverses when
$$\ g R h \Longleftrightarrow g ^ { - 1 } R h ^ { - 1 }, \quad \ g R h \Longrightarrow 1 _ { \text{dom} ( g ) } R 1 _ { \text{dom} ( h ) }.$$
Proposition 7.3. CP ∗ [ Rel ] is (isomorphic to) the category of groupoids and relations respecting inverses.
Proof. In general, a morphism R ⊆ ( X × X ) × ( Y × Y ) in Rel is completely positive if and only if
$$( x ^ { \prime }, x ) R ( y ^ { \prime }, y ) \Longleftrightarrow ( x, x ^ { \prime } ) R ( y, y ^ { \prime } ), \quad ( x ^ { \prime }, x ) R ( y ^ { \prime }, y ) \Longrightarrow ( x, x ) R ( y, y ).$$
If G and H are groupoids, corresponding to Frobenius algebras ( G , ) and ( H , ) , and R ⊆ G × H ,
$$\hat { \bigcirc } _ { \vdots } = \{ ( ( g, g ^ { \prime } ), g ^ { - 1 } \circ g ^ { \prime } ) \in G ^ { 3 } \, | \, \cot ( g ) = \cot ( g ^ { \prime } ) \},$$
$$\mathfrak { \varphi } ^ { \prime } \circ R \circ \mathring { \bigtriangleup } _ { \mathfrak { K } } = \{ ( ( g, g ^ { \prime } ), ( h, h ^ { \prime } ) ) \in G ^ { 2 } \times H ^ { 2 } \, | \, \cot ( g ) = \cot ( g ^ { \prime } ), \cot ( h ) = \cot ( h ^ { \prime } ), ( g ^ { - 1 } \circ g ^ { \prime } ) R ( h ^ { - 1 } \circ h ^ { \prime } ) \}.$$
$$& \colon \text{od} ( g ^ { \prime } ) \}, \\ & + = \text{cod} ( g ^ { \prime } ), \text{cod} ( h ) = \text{cod} ( h ^ { \prime } ), ( g ^ { - 1 } \circ g ^ { \prime } ) R ( h ^ { - 1 } \circ h ^ { \prime } ) \}.$$
Substituting this into (3) translates precisely into (2).
We close this section by investigating the embedding L : CPM [ Rel ] → CP ∗ [ Rel ] . Recall that a category is indiscrete when there is precisely one morphism between each two objects. Indiscrete categories are automatically groupoids.
Lemma 7.4. The essential image of the embedding L : CPM [ Rel ] → CP ∗ [ Rel ] is the full subcategory of CP ∗ [ Rel ] consisting of indiscrete (small) groupoids.
Proof. Let X be an object in CPM [ Rel ] , that is, a set. By definition, L X ( ) corresponds to a groupoid with set of morphisms X × X , and composition
$$( y _ { 1 }, y _ { 2 } ) \circ ( x _ { 1 }, x _ { 2 } ) = \begin{cases} \ ( y _ { 1 }, x _ { 2 } ) & \text{if $y_{2}=x1$}, \\ \text{undefined} & \text{otherwise}. \end{cases}$$
We deduce that the objects of L X ( ) correspond to identities, i.e. pairs ( x 1 , x 2 ) with x 1 = x 2. So objects of L X ( ) just correspond to elements of X . Similarly, we find that dom ( x 1 , x 2 ) = x 2 and cod ( x 1 , x 2 ) = x 1. Hence ( x 1 , x 2 ) is a morphism x 2 → x 1 in L X ( ) , and it is the unique such.
## 8 Splitting idempotents
This section compares the CP*-construction to Selinger's second solution to the problem of classical channels. First, recall this construction of splitting dagger idempotents [19].
Definition 8.1. Let V be a dagger category. The category Split † [ V ] has as objects ( A p , ) where p : A → A is a morphism in V satisfying p ◦ p = p = p † ; its morphisms ( A p , ) → ( B q , ) are morphisms f : A → B in V satisfying f = q ◦ f ◦ p .
If V is a dagger compact category, then so is Split † [ V ] (see [19, Proposition 3.16]). We will need the following assumption, that is satisfied in both Rel and FHilb .
Definition 8.2. A dagger compact category V is said to have algebraic square roots when, given any normalisable Frobenius algebra on A and any central positive definite morphism f : A → A , there exists a central morphism g : A → A such that f = g ◦ g .
We thank the anonymous referee for pointing us towards the following proposition.
Proposition 8.3. Let V be a dagger compact category that has algebraic square roots. There is a functor F : CP ∗ [ V ] → Split † [ CPM [ V ]] , acting as F ( A , , ) = ◦ ◦ ( ⊗ ) on objects, and as F ( f ) = ◦ ◦ f ◦ ◦ on morphisms. It is full, faithful, and strongly dagger symmetric monoidal.
Proof. First, notice that p = F A ( , , ) is indeed a well-defined object of Split † [ CPM [ V ]] : clearly p = ◦ ◦ ◦ = p † by centrality of the normaliser, p ◦ p = p follows from Lemma 3.3, and p is completely positive by Lemma 3.2. The assumption of algebraic square roots guarantees that F ( f ) is indeed a well-defined morphism in CPM [ V ] ; by Lemma 3.3, it is in fact a well-defined morphism in Split † [ CPM [ V ]] . Moreover, it is easy to see that an arbitrary V -morphism h : A ∗ ⊗ A → ∗ ⊗ B B is a well-defined morphism in CP ∗ [ V ] if and only if it is a well-defined morphism in Split † [ CPM [ V ]] .
Both CP ∗ [ V ] and Split † [ CPM [ V ]] inherit composition, identities, and daggers from V , so F is a full and faithful functor preserving daggers. The symmetric monoidal structure in both CP ∗ [ V ] and Split † [ CPM [ V ]] is similarly defined in terms of that of V , making F strongly symmetric monoidal.
Thus, when V has algebraic square roots, CP ∗ [ V ] is equivalent to a full subcategory of Split † [ CPM [ V ]] : the one obtained by splitting only the idempotents of the form F A ( , , ) . A variation of [19, Proposition 3.16] shows that splitting any family of dagger idempotents that is closed under tensor gives a dagger compact category, and Theorem 3.5 follows. The proof that we have written out does not need the assumption of algebraic square roots; moreover, it more explicitly exhibits the structure of CP ∗ [ V ] as a category of algebras.
In summary, in sufficiently nice cases, the CP*-construction fits between the CPM-construction and its idempotent splitting.
$$\text{CPM} [ \mathbf V ] \stackrel { L } { \longrightarrow } \text{CP} ^ { * } [ \mathbf V ] \stackrel { F } { \longrightarrow } \text{Split} ^ { \dagger } [ \text{CPM} [ \mathbf V ] ]$$
/
/
/
/
Both functors are strongly dagger symmetric monoidal, as well as full and faithful. Moreover, their composition is naturally isomorphic to the canonical inclusion CPM [ V ] → Split † [ CPM [ V ]] . However, the image of the left functor does not include classical channels. Similarly, a priori there is no reason why the right functor should be an equivalence. In particular, the middle category seems to capture the right amount of objects, and provides a constructive way to access them.
## 9 Future work
Having an abstract notion of C*-algebra, (and, by extension, an abstract categorical construction placing classical and quantum information on equal footing) opens up many avenues for exploration.
- · Quantum mechanics can be characterised in information-theoretic terms [4], but this argument is often criticised because it assumes a C*-algebraic framework from the start. The CP*-construction can investigate to what extent this criticism is valid and improve on those foundations.
- · We can now abstractly study all sorts of notions from the C*-algebraic formulation of quantum information theory [15, 16]. For example, notions of complementarity can be translated between abstract and concrete C*-algebras [6, 13].
- · The category Stab of stabiliser quantum mechanics embeds into CP ∗ [ Rel ] , opening the door to abstract considerations of classical simulable circuits.
- · It would be good to see whether algebraic square roots are necessary for Proposition 8.3. We also expect to find an example showing that F is not an equivalence.
- · One could characterise categories of the form CP ∗ [ V ] , perhaps using environments [5, 11, 7].
- · It is worth investigating to what extent our construction generalises to infinite dimension [2, 7].
- · On the theoretical side, the CP*-construction might be (lax) monadic.
- · Our construction seems related in spirit to [22]; it would be good to make connections precise.
## References
- [1] Samson Abramsky & Bob Coecke (2008): Categorical quantum mechanics . In: Handbook of quantum logic and quantum structures: quantum logic , Elsevier, pp. 261-324, doi:10.1016/B978-0-444-52869-8.50010-4.
- [2] Samson Abramsky & Chris Heunen (2012): H*-algebras and nonunital Frobenius algebras: first steps in infinite-dimensional categorical quantum mechanics . Clifford Lectures 71, pp. 1-24.
- [3] Rejandra Bhatia (2007): Positive definite matrices . Princeton University Press.
- [4] Rob Clifton, Jeffrey Bub & Hans Halvorson (2003): Characterizing quantum theory in terms of informationtheoretic constraints . Foundations of Physics 33(11), pp. 1561-1591, doi:10.1023/A:1026056716397.
- [5] Bob Coecke (2008): Axiomatic Description of Mixed States From Selinger's CPM-construction . Electronic Notes in Theoretical Computer Science 210, pp. 3-13, doi:10.1016/j.entcs.2008.04.014.
- [6] Bob Coecke & Ross Duncan (2011): Interacting Quantum Observables: Categorical Algebra and Diagrammatics . New Journal of Physics 13, p. 043016, doi:10.1088/1367-2630/13/4/043016.
- [7] Bob Coecke & Chris Heunen (2011): Pictures of complete positivity in arbitrary dimension . In: Proceedings of QPL , pp. 29-37, doi:10.4204/EPTCS.95.4.
- [8] Bob Coecke, Chris Heunen & Aleks Kissinger (2013): Categories of Classical and Quantum Channels . arXiv:1305.3821 .
- [9] Bob Coecke, ´ ric O. Paquette & Duˇ sko Pavlovi´ c (2010): E Classical and quantum structuralism . In S. Gay & I. Mackey, editors: Semantic Techniques in Quantum Computation , Cambridge University Press, pp. 29-69.
- [10] Bob Coecke, Duˇ sko Pavlovi´ c & Jamie Vicary (2012): A new description of orthogonal bases . Mathematical Structures in Computer Science 23(3), pp. 555-567, doi:10.1017/S0960129512000047.
- [11] Bob Coecke & Simon Perdrix (2010): Environment and classical channels in categorical quantum mechanics . In: CSL'10/EACSL'10 , Springer, pp. 230-244, doi:10.1007/978-3-642-15205-4 20.
- [12] Kenneth R. Davidson (1991): C*-algebras by example . American Mathematical Society.
- [13] Chris Heunen (2012): Complementarity in categorical quantum mechanics . Foundations of Physics 42(7), pp. 856-873, doi:10.1007/s10701-011-9585-9.
- [14] Chris Heunen, Ivan Contreras & Alberto S. Cattaneo (2012): Relative Frobenius algebras are groupoids . Journal of Pure and Applied Algebra 217, pp. 114-124, doi:10.1016/j.jpaa.2012.04.002.
- [15] Michael Keyl (2002): Fundamentals of quantum information theory . Physical Reports 369, pp. 431-548, doi:10.1016/S0370-1573(02)00266-1.
- [16] Michael Keyl & Reinhard F. Werner (2007): Channels and maps . In Dagmar Bruß & Gerd Leuchs, editors: Lectures on Quantum Information , Wiley-VCH, pp. 73-86, doi:10.1002/9783527618637.ch5.
- [17] Vern Paulsen (2002): Completely bounded maps and operators algebras . Cambridge University Press.
- [18] Peter Selinger (2007): Dagger compact closed categories and completely positive maps . In: QPL ENTCS , 170, Elsevier, pp. 139-163, doi:10.1016/j.entcs.2006.12.018.
- [19] Peter Selinger (2008): Idempotents in dagger categories . In: QPL ENTCS , 170, Elsevier, pp. 107-122, doi:10.1016/j.entcs.2008.04.021.
- [20] Peter Selinger (2010): A survey of graphical languages for monoidal categories . In: New Structures for Physics , Lecture Notes in Physics 813, Springer, pp. 289-355, doi:10.1007/978-3-642-12821-9 4.
- [21] Jamie Vicary (2011): Categorical formulation of finite-dimensional quantum algebras . Communications in Mathematical Physics 304(3), pp. 765-796, doi:10.1007/s00220-010-1138-0.
- [22] Jamie Vicary (2012): Higher quantum theory . Preprint, arXiv:1207.4563 . | 10.4204/EPTCS.158.1 | [
"Bob Coecke",
"Chris Heunen",
"Aleks Kissinger"
] | 2014-08-01T00:24:41+00:00 | 2014-08-01T00:24:41+00:00 | [
"cs.LO",
"math.CT"
] | Categories of Quantum and Classical Channels (extended abstract) | We introduce the CP*-construction on a dagger compact closed category as a
generalisation of Selinger's CPM-construction. While the latter takes a dagger
compact closed category and forms its category of "abstract matrix algebras"
and completely positive maps, the CP*-construction forms its category of
"abstract C*-algebras" and completely positive maps. This analogy is justified
by the case of finite-dimensional Hilbert spaces, where the CP*-construction
yields the category of finite-dimensional C*-algebras and completely positive
maps.
The CP*-construction fully embeds Selinger's CPM-construction in such a way
that the objects in the image of the embedding can be thought of as "purely
quantum" state spaces. It also embeds the category of classical stochastic
maps, whose image consists of "purely classical" state spaces. By allowing
classical and quantum data to coexist, this provides elegant abstract notions
of preparation, measurement, and more general quantum channels. |
1408.0050v1 | ## Coalgebraic Quantum Computation
## Frank Roumen
Institute for Mathematics, Astrophysics, and Particle Physics (IMAPP)
Radboud University Nijmegen
[email protected]
Coalgebras generalize various kinds of dynamical systems occuring in mathematics and computer science. Examples of systems that can be modeled as coalgebras include automata and Markov chains. We will present a coalgebraic representation of systems occuring in the field of quantum computation, using convex sets of density matrices as state spaces. This will allow us to derive a method to convert quantum mechanical systems into simpler probabilistic systems with the same probabilistic behaviour.
## 1 Introduction
For studying complex computational systems, it is often helpful to use an abstract description of the systems. This helps to focus on the most important parts of the system under consideration and see similarities and differences between distinct kinds of systems. The notion of a coalgebra, which originated in category theory, gives such an abstract view on dynamical systems. There is a large class of systems that can be described using coalgebras, including finite automata, Turing machines, Markov chains, and differential equations. Moreover one can reason about these system using a unified theory. An overview can be found in [15].
Our aim is to describe systems occuring in the field of quantum computation in the coalgebraic framework. This will facilitate comparison between quantum systems and, for example, deterministic and probabilistic systems. It will also enable us to apply facts from the general theory of coalgebras to quantum mechanical systems. In particular we will see what the minimization procedure from [3] amounts to for quantum coalgebras.
The use of categories in the foundations of quantum physics was initiated in [2], via tensor categories, and in [4], via topoi. Representation of quantum systems with coalgebras is also considered in [1]. However, there are several differences between [1] and our work. We focus on the dynamics of systems via unitary operators, whereas [1] models the dynamics of iterated measurements.
The outline of this paper is as follows. In Section 2 we discuss preliminaries on coalgebras. To illustrate the theory of coalgebras, Section 3 contains a coalgebraic description of probabilistic systems. Some of the constructions in that section are also necessary for understanding quantum systems coalgebraically. The main original contributions are in Sections 4 and 5. Section 4 shows how to represent quantum systems as coalgebras, and discusses the role of final coalgebras in this framework. Finally, in Section 5, the minimization procedure from Section 2 is applied to quantum coalgebras.
## 2 Coalgebras
In this section we will present some preliminary material on coalgebras, which are abstract generalizations of state-based systems. Let F be an endofunctor on a category C . An F-coalgebra consists of an
object X ∈ C and a morphism c : X → F X ( ) in C . The object X is called the state space of the coalgebra, and the morphism c is called the dynamics . The functor F in the definition is a parameter that determines the structure of the dynamics, and hence the kind of system. Coalgebras for a fixed endofunctor constitute a category, in which a morphism from c : X → F X ( ) to d : Y → F Y ( ) is a morphism f : X → Y in C making the following diagram commute.
/d47
/d47
/d15
/d15
/d15
/d15
/d47
/d47
The category of F -coalgebras and homomorphisms is denoted CoAlg ( F ) .
An F -coalgebra ω : Ω → F ( Ω ) is said to be final if it is a final object in the category CoAlg ( F ) , i.e. for every coalgebra c : X → F X ( ) there exists a unique coalgebra morphism from c to ω . This unique morphism is called the behaviour morphism of c and is denoted beh c : X → Ω .
Example 1. In theoretical computer science, finite automata provide a mechanical way to describe languages. An alphabet is a finite set, whose elements we call letters or symbols . The set of finite sequences, or words , with entries in an alphabet A is written as A ∗ . This set of words forms a monoid, where the monoid operation is concatenation and the empty word ε acts as an identity element. The monoid A ∗ is the free monoid over A . A language over A is a subset of A ∗ . A deterministic automaton over an alphabet A consists of a set X of states, a transition function δ : X × A → X , and a subset U ⊆ X of accepting states. The transition function δ : X × A → X can be extended to a function from X × A ∗ to X , also denoted δ , by defining δ ( x , ε ) = x and δ ( x au , ) = δ ( δ ( x a , ) , u ) .
Automata are often graphically represented by their state diagrams. In a state diagram, each state of the automaton is drawn as a circle. A transition δ ( x a , ) = y is indicated by an arrow, labeled with the letter a , from the circle x to the circle y . Accepting states are drawn as double circles. As an example, consider the automaton over A = { a b , } with the following diagram.
/d9
/d9
/d47
/d47
/d111
/d111
/d51
/d51
Here, the set of states is X = { x 0 , x 1 , x 2 , x 3 } , the transition function is completely determined by the arrows in the diagram, and the subset of accepting states is { x 0 , x 3 } .
The transition function and the subset of accepting states of an automaton can be merged into one function of type X → × 2 X A Thus deterministic automata are coalgebras for the endofunctor F X ( ) = 2 × X A on Sets . This functor F has a final coalgebra whose underlying state space is the set P ( A ∗ ) of all languages over A . To endow this set with an automaton structure, define the transition function by δ ( L a , ) = { u ∈ A ∗ | au ∈ L } , and let the subset of accepting states be { L ∈ P ( A ∗ ) | ε ∈ L } . Let c : X → × 2 X A be an arbitrary automaton, with transition function δ and accepting states U . Then the behaviour morphism beh c : X → P ( A ∗ ) assigns to a state x the language { u ∈ A ∗ | δ ( x u , ) ∈ U } . Thus the coalgebraic description gives a convenient way to characterize the language recognized by an automaton.
/d126
/d126
/d74
/d74
/d10
/d10
There are several other systems that can be modeled as coalgebras in such a way that the morphism into the final coalgebra corresponds to the observable behaviour of the system, see [15] for more examples.
Amorphism into the final coalgebra provides a method to obtain an external description of a system, given an internal description. We will now turn our attention to the reverse problem: if we know the behaviour of a system, how do we find a coalgebra having that behaviour? Of course, in practice there are many coalgebras with the same behaviour. We are often interested in the most efficient one, i.e. the coalgebra with the smallest state space among those with the same behaviour. Finding the coalgebra with a minimal state space is known as the problem of minimization. Here we will focus on the special case of minimizations of automata.
Minimal realizations of automata were first constructed in [12]. This was generalized to categorical settings in [6], see also [3, 14] for the coalgebraic version.
Definition 2. A subcoalgebra of a coalgebra c : X → F X ( ) in Sets is a coalgebra d : Y → F Y ( ) with Y ⊆ X for which the inclusion map Y ↪ → X is a coalgebra morphism.
Definition 3. Let c : X → F X ( ) be a coalgebra in Sets , and S ⊆ X . The subcoalgebra of c generated by S is the smallest subcoalgebra 〈 S 〉 of c whose state space includes S . If S is a singleton { } s , then we write 〈 S 〉 = 〈 〉 s .
Example 4. Consider an automaton c : X → × 2 X A , and denote its transition function by δ . For any subset S ⊆ X , the subcoalgebra 〈 S 〉 of c generated by S is obtained by closing S under the transitions of c . Thus the coalgebra 〈 S 〉 has state space
$$\left \{ \delta ( s ) ( u ) \ | \ s \in S, u$$
The observations and transitions are inherited from c .
The behaviour of an automaton together with an initial state is the language recognized by that state. Therefore the minimization problem amounts to the following question: given a language L , what is the minimal automaton recognizing L ?
Proposition 5. Let L be a language over A. The coalgebra with the least number of states recognizing L is the subcoalgebra 〈 L 〉 of the final coalgebra P ( A ∗ ) , with initial state L ∈〈 〉 L .
To generalize this to arbitrary coalgebras, one needs a factorization system on the underlying category. The abstract monos of the factorization system play the role of the subcoalgebras. This is worked out in [3, 13].
## 3 Probabilistic systems
Before representing quantum systems coalgebraically, it is useful to consider probabilistic systems first, because quantum mechanical behaviour is probabilistic.
Transitions to a probability distribution over successor states will be modeled using functors involving the so-called distribution monad . Define a functor D : Sets → Sets sending a set X to the set of finite convex combinations, or probability distributions, on X :
$$\mathcal { D } ( X ) = \{ \varphi \colon X \rightarrow$$
/negationslash
Here supp ( ϕ ) = { x ∈ X | ϕ ( x ) = 0 } is the support of ϕ . An element ϕ of D ( X ) can also be written as a formal sum r 1 x 1 + · · · + rnxn , where { x 1 , . . . , xn } = supp ( ϕ ) and ri = ϕ ( xi ) . On a morphism f : X → Y , the functor D is defined as
$$\mathcal { D } ( f ) ( r _ { 1 } x _ { 1 } + \$$
The functor D is a monad with unit and multiplication
$$\eta$$
↦
$$\begin{array} {$$
↦
We will show how the distribution monad is used in the representation of probabilistic systems by an example.
Example 6. Imagine a particle moving on the following graph.
Let X = { x 0 , x 1 , x 2 , x 3 } be the set of vertices. The particle starts at one of the vertices of the graph. In each time step, the particle can move to one of the two adjacent points. Each of these points is chosen with probability 1 2 . This system can be written as a coalgebra for the distribution monad:
↦
↦
$$\begin{matrix} c \colon X & \rightarrow & \mathcal { D } ( X ) \\ x _ { 0 } & \mapsto & \frac { 1 } { 2 } x _ { 1 } + \frac { 1 } { 2 } x _ { 2 } \\ x _ { 1 } & \mapsto & \frac { 1 } { 2 } x _ { 0 } + \frac { 1 } { 2 } x _ { 3 } \\ x _ { 2 } & \mapsto & \frac { 1 } { 2 } x _ { 0 } + \frac { 1 } { 2 } x _ { 3 } \\ x _ { 3 } & \mapsto & \frac { 1 } { 2 } x _ { 1 } + \frac { 1 } { 2 } x _ { 2 } \end{matrix} \\ \text{chain}.$$
↦
↦
A coalgebra for D is called a Markov chain .
We consider the trajectory of the particle when it starts in the vertex x 0. Let ϕ n ∈ D ( X ) denote the probability distribution over the vertices of the graph after n steps. Then the first few values of ϕ n are:
$$\begin{array} { l l l } \varphi _ { 0 } & = & x _ { 0 } \\ \varphi _ { 1 } & = & \frac { 1 } { 2 } x _ { 1 } + \frac { 1 } { 2 } x _ { 2 } \\ \varphi _ { 2 } & = & \frac { 1 } { 2 } x _ { 0 } + \frac { 1 } { 2 } x _ { 3 } \\ \varphi _ { 3 } & = & \frac { 1 } { 2 } x _ { 1 } + \frac { 1 } { 2 } x _ { 2 } \end{array}$$
We obtain a repetition after three steps, so ϕ 2 n = ϕ 2 for n > 0 and ϕ 2 n + 1 = ϕ 1 for all n ∈ N .
It is reasonable to view the sequence ( ϕ n ) n ∈ N as the behaviour of the Markov chain. However, if we model the system as a D -coalgebra, the morphism into the final coalgebra does not give the desired behaviour. This can be solved by replacing the underlying category Sets of the coalgebra by another category. There are at least two possible replacements known in the literature: [7] proposes to work in the Kleisli category of the monad D , and [16] proposes to work in the category of Eilenberg-Moore algebras for D . The solutions work for coalgebras for several monads, not only for the distribution monad. Both approaches are compared in [10]. Here we will briefly describe how to model probabilistic
systems in the category of Eilenberg-Moore algebras, since this approach will also be used for quantum systems.
↦
An Eilenberg-Moore algebra for the distribution monad is called a convex set. In a convex set X , we can assign to each convex combination ∑ n i = 1 ri = 1 a function X n → X denoted ( x 1 , . . . , xn ) → ∑ n i = 1 ri xi . Ahomomorphism of convex sets preserves all convex combinations and is called a convex or affine map. The category of convex sets and maps is written as Conv , and is also described in [8].
The next result ensures that several functors on the category Conv have a final coalgebra, which enables us to speak about the behaviour of probabilistic systems.
Lemma7. Let C be a category with all products. Fix an object B ∈ C and a set A. The functor F : C → C defined by F ( X ) = B × X A , where X A denotes a power, has a final coalgebra whose underlying state space is the power B A ∗ .
Proof. The projection B A ∗ → B onto the coordinate with index u ∈ A ∗ will be denoted π u . The dynamics is a map ω : B A ∗ → × B ( B A ∗ ) A , whose first component is πε and whose second component in the coordinates a ∈ A u , ∈ A ∗ is π au . We will now prove the finality of ω . Given a coalgebra c = 〈 f , 〈 ga 〉 a ∈ A 〉 : X → B × X A , define beh c : X → B A ∗ as follows: first extend the family of morphisms ( ga ) a ∈ A for a ∈ A to a family ( gu ) u ∈ A ∗ by defining inductively
$$g _ { \varepsilon } \ = \ \text{id}, \\ g _ { a u } \ = \ \ g _ { u } \circ g _ { a }. \\ \dots \dots \ e \dots \ \dots \ \dots \..$$
To show that beh c is the unique such coalgebra morphism, let ϕ : X → B A ∗ be any coalgebra morphism, and denote the component with coordinate u ∈ A ∗ by ϕ u . Induction on the word u ∈ A ∗ proves that ϕ u = f ◦ gu .
Then beh c = 〈 f ◦ gu 〉 u ∈ A ∗ is a coalgebra morphism from c to ω .
Example 8. The coalgebra from Example 6 can also be represented as a coalgebra in Conv , in such a way that the morphism into the final coalgebra yields the list of probability distributions associated to the Markov chain. Fix a set X and take the functor F Y ( ) = D ( X ) × Y on the category Conv , where X is the set of vertices of the graph. Represent the Markov chain as an F -coalgebra d with state space D ( X ) , i.e. a convex map D ( X ) → D ( X ) × D ( X ) . Since D ( X ) is the free convex set on X , it suffices to define d on the set X of generators. Let d x ( ) = ( 1 x c x , ( )) ∈ D ( X ) × D ( X ) . From Lemma 7 it follows that the final F -coalgebra exists and has state space D ( X ) N , so we obtain a map beh d : D ( X ) → D ( X ) N . This behaviour map sends the initial state x 0 ∈ D ( X ) to the list of probability distributions ( ϕ n ) n ∈ N obtained in Example 6.
## 4 Coalgebraic model of quantum computation
In this section we will show how to model discrete quantum systems as coalgebras. We will first introduce two running examples. The first example is the class of quantum automata. This quantum analogue of deterministic automata was defined in [11]. There are two differences between our definition and [11]: we generalize the output projections to effects on a Hilbert space, and we ignore initial states, which is often more convenient for coalgebras.
Definition 9. A quantum language over an alphabet A is a function A ∗ → [ 0 1 . , ] One can think of a quantum language as a fuzzy or probabilistic language. The function assigns to a word in A ∗ the probability that it is in the language.
A quantum automaton over an alphabet A consists of:
- · A complex Hilbert space H ;
- · An effect ε on H , i.e. a linear operator ε : H → H satisfying 0 ≤ ε ≤ id.
- · For each letter a ∈ A , a unitary operator δ a : H → H ;
Define, for each word u ∈ A ∗ , the extended transition operator δ u : H → H inductively by
$$\delta _ { \varepsilon } ( \psi ) = \psi, \\ \delta _ { a u } ( \psi ) = \delta _ { u } ( \delta _ { a } ( \psi ) ).$$
The probability that the word u is accepted by the automaton, starting from initial state ψ with norm 1, is
$$\begin{matrix} & \langle \delta _ { u } \psi | \varepsilon | \delta _ { u } \psi \rangle, \\ & \cdot & \cdot & \cdot & \cdot \end{matrix}$$
The quantum language recognized by a state ψ ∈ H is the function A ∗ → [ 0 1 , ] that sends a word u ∈ A ∗ to the probability that u is accepted by ψ .
that is, the probability that measurement of ε gives 'yes' in state δ ψ u .
The quantum walks form another class of examples of systems, discussed extensively in [17]. See also [9] for coalgebraic versions. We will take the example from the latter reference.
Example 10. Consider a particle walking on the line Z of integers. In addition to the position of the particle on Z , we take its spin into account. Then the Hilbert space modeling the composite system of the particle's spin and position is C 2 ⊗ /lscript 2 ( Z ) . Write the basis vectors in Dirac notation as |↑ k 〉 and |↓ k 〉 . We stipulate that the particle starts in state |↑ 0 . The dynamics of the walk is given by the unitary 〉 operator
↦
$$U \colon \ & | \uparrow k \rangle \quad \mapsto \quad \frac { 1 } { \sqrt { 2 } } | \uparrow k - 1 \rangle + \frac { 1 } { \sqrt { 2 } } | \downarrow k + 1 \rangle \\ & | \downarrow k \rangle \quad \mapsto \quad \frac { 1 } { \sqrt { 2 } } | \uparrow k - 1 \rangle - \frac { 1 } { \sqrt { 2 } } | \downarrow k + 1 \rangle \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{cases}$$
↦
Consider a situation in which it is possible to measure the position of the particle, but not the spin. Then the admissible observables are |↑ k 〉〈↑ k | + |↓ k 〉〈↓ k | for k ∈ Z .
If the particle walks during n time steps, then its position can be described using a probability distribution over Z . The probability that we encounter the particle on position k is
$$\langle U ^ { n } ( \uparrow 0 ) | \left ( | \uparrow k \rangle \langle \uparrow k | + | \downarrow k \rangle \langle \downarrow k | \right ) | U ^ { n } ( \uparrow 0 ) \rangle. \\ \text{distribution after $n$ steps by $\varphi_{n}\in\mathcal{D}(\mathbb{Z}$). The unit distrit}$$
Denote the probability distribution after n steps by ϕ n ∈ D ( Z ) . The unit distribution k is written using Dirac notation as | k 〉 . The first few probability distributions are:
$$\begin{array} { r c l c l } \cdot \cdot & & \cdot & \cdot \\ \varphi _ { 0 } & = & & | 0 \rangle \\ \varphi _ { 1 } & = & & \frac { 1 } { 2 } | - 1 \rangle & + & \frac { 1 } { 2 } | 1 \rangle \\ \varphi _ { 2 } & = & & \frac { 1 } { 4 } | - 2 \rangle & + & \frac { 1 } { 2 } | 0 \rangle & + & \frac { 1 } { 4 } | 2 \rangle \\ \varphi _ { 3 } & = & \frac { 1 } { 8 } | - 3 \rangle & + & \frac { 5 } { 8 } | - 1 \rangle & + & \frac { 1 } { 8 } | 1 \rangle & + & \frac { 1 } { 8 } | 3 \rangle \\ \end{array}$$
We would like to model quantum systems in such a way that the system is a coalgebra for a certain endofunctor, and the morphism into the final coalgebra gives the quantum language or probability distribution determined by the system. To achieve this, we will work with coalgebras in the category Conv of convex algebras. There are two reasons for this. Firstly, we can model computations for both systems in pure states and systems in mixed states. Secondly, the category Conv incorporates both quantum probability via density matrices and the classical probability that is needed for the output.
Let HilbIsomet be the category of Hilbert spaces with isometric embeddings as morphisms. Define a functor DM : HilbIsomet → Conv on objects by letting DM ( H ) be the set of density matrices on the Hilbert space H , and on morphisms by DM ( f : H → K )( ρ ) = f ρ f † .
Let H be a Hilbert space underlying a quantum system, and let S be a set of unitary operators that can be applied to the system. Represent the possible measurements on the system by a subset E of the set of effects E f ( H ) on H . We do not use the entire set E f ( H ) since usually not all effects are possible or interesting. It is often the case that the sum of the effects in E is id. In this case, the subset E is called a test , see [5] for more information. Consider the functor
$$F ( X ) = [ 0, 1 ] ^ { E } \times X ^ { S }$$
on the category Conv . Form the F -coalgebra
↦
The part tr ( ρε ) represents the observations on the coalgebra, since this is the probability that measurement of the effect ε succeeds when the system is in mixed state ρ . The part DM ( U )( ρ ) is the evolution of the system according to the density matrix formalism.
$$f \colon \mathcal { M } ( H ) \ \rightarrow \ \left [ 0, 1 \right ] ^ { E } \times \mathcal { M } ( H ) ^ { S } \\ \rho \ \mapsto \ \left ( \left ( \text{tr} ( \rho \varepsilon ) \right ) _ { \varepsilon \in E }, \left ( \mathcal { D } \mathcal { M } ( U ) ( \rho ) \right ) _ { U \in S } \right ). \\ \varepsilon \right ) \text{ represents the observations on the coalgebra, since this is the probability that measure} \\ \sim \ \right. \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot$$
Wewill now show that (2) has the desired behaviour. First we have to check that the behaviour exists, i.e. that F has a final coalgebra.
The category Conv inherits all products from Sets , so Lemma 7 applies to the functor defined in (1). The functor F has a final coalgebra with the convex set ([ 0 1 , ] E ) S ∗ as state space. The dynamics is a map ([ 0 1 , ] E ) S ∗ → [ 0 1 , ] E × (([ 0 1 , ] E ) S ∗ ) S . The first component of the dynamics is the projection onto the component with the empty word ε as index, and for the second component, the map with index a ∈ S and u ∈ S ∗ is the projection onto component au .
The coalgebra (2) gives a behaviour map beh f : DM ( H ) → ([ 0 1 , ] E ) S ∗ . This map can alternatively be seen as a indexed family of maps DM ( H ) → [ 0 1 , ] for each ε ∈ E and u ∈ S ∗ . The map with index ε and u = u 1 . . . un ∈ S ∗ sends the density matrix ρ to tr ( un . . . u 1 ρ u † 1 . . . u n † ε ) . Physically, if we view effects as yes-no questions about a system, this is the probability that measurement of the effect ε yields outcome 'yes', if the system starts in mixed state ρ and evolves according to the unitary operators u 1, . . . , un . Therefore the final coalgebra semantics corresponds exactly to the physical behaviour.
The construction of the coalgebra (2) involves three parameters: the underlying state space H , the set of unitary operators S , and the set of possible measurements E . By choosing these parameters appropriately we can fit the above examples in this framework.
Example 11. Let ( H , ( δ a ) a ∈ A , ε ) be a quantum automaton. The set of unitaries S is { δ a | a ∈ A } , and the set of possible measurements is the singleton set E = { ε } . The coalgebra (2) becomes
↦
If ψ ∈ H is a state, then the behaviour map DM ( H ) → [ 0 1 , ] A ∗ maps the associated density matrix | ψ 〉〈 ψ | to the quantum language recognized by ψ .
$$\begin{array} { c c c } \mathcal { D M } ( H ) & \rightarrow & [ 0, 1 ] \times \mathcal { D M } ( H ) ^ { A } \\ \rho & \mapsto & \left ( \text{tr} ( \rho \varepsilon ), \left ( \delta _ { a } \rho \delta _ { a } ^ { \dagger } \right ) _ { a \in A } \right ) \\ \text{behaviour map } \mathcal { D M } ( H ) \rightarrow [ 0, 1 ] ^ { A ^ { * } } \text{ maps the associ} \text{:} \end{array}$$
The quantum walk from Example 10 gives a coalgebra
↦
$$\begin{array} { c c c } \mathcal { D } \mathcal { M } ( \mathbb { C } ^ { 2 } \otimes \ell ^ { 2 } ( \mathbb { Z } ) ) & \to & [ 0, 1 ] ^ { \mathbb { Z } } \times \mathcal { D } \mathcal { M } ( \mathbb { C } ^ { 2 } \otimes \ell ^ { 2 } ( \mathbb { Z } ) ) \\ \rho & \mapsto & \left ( ( \mathbf r ( \rho | \uparrow k ) \langle \uparrow k | + \rho | \downarrow k \rangle \langle \downarrow k | ) \right ) _ { k \in \mathbb { Z } }, U \rho U ^ { \dagger } \right ). \end{array}$$
The codomain can be restricted to D ω ( Z ) × DM ( C 2 ⊗ /lscript 2 ( Z )) , because the effects in E sum to id. Here D ω is the infinite distribution monad, defined on objects by
$$\mathcal { D } _ { \omega } ( X ) & = \{ \varphi \colon X \to [ 0, 1 ] \ | \ \text{supp} ( \varphi ) \ \text{is at most countable and } \sum _ { x \in X } \varphi ( x ) = 1 \}. \\ \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot$$
On morphisms, D ω acts the same as the ordinary distribution monad D .
These examples show that the representation (2) captures many quantum systems in a uniform way.
## 5 Minimization
In Section 2 we presented a procedure to find minimal automata for classical languages. The same method can be used to find minimal realizations for quantum behaviour.
Consider coalgebras for the functor F X ( ) = [ 0 1 , ] E × X S , which was defined in (1). The final coalgebra for F has underlying state space ([ 0 1 , ] E ) S ∗ . Then the minimal realization of a behaviour L ∈ ([ 0 1 , ] E ) S ∗ is the smallest subcoalgebra of ([ 0 1 , ] E ) S ∗ containing L . An interesting feature of this approach is that the minimal coalgebra need not be a quantum coalgebra, even if the behaviour arises from a quantum mechanical system. Since the subcoalgebra of the final coalgebra lies in the category Conv , the minimal realization will certainly be a probabilistic system, but its state space is not necessarily of the form DM ( H ) . Thus minimization gives a procedure for turning quantum systems into simpler systems in Conv which nevertheless have the same behaviour.
Example 12. Weconsider a quantum version of Example 6. The square graph gives rise to the state space C 4 with basis | 0 , 〉 | 1 , 〉 | 2 , 〉 | 3 , and the walk of a quantum particle on the square graph is represented by 〉 the unitary matrix
$$U = \frac { 1 } { \sqrt { 2 } } \left ( \begin{array} { c c c c } 0 & 1 & 1 & 0 \\ 1 & 0 & 0 & 1 \\ 1 & 0 & 0 & - 1 \\ 0 & 1 & - 1 & 0 \end{array} \right ). \\ \text{sure the probability that the particle is in stat}$$
For each vertex k , we can measure the probability that the particle is in state k using the projection | k 〉〈 k | . This leads to the coalgebra
↦
Assume that | 0 〉〈 0 | ∈ DM ( C 4 ) is the initial state. The resulting output stream is
$$f \colon \mathcal { D M } ( \mathbb { C } ^ { 4 } ) \ \to \ \mathcal { D } ( 4 ) \times \mathcal { D M } ( \mathbb { C } ^ { 4 } ) \\ \rho \ \mapsto \ \left ( ( \text{tr} ( \rho | k \rangle \langle k | ) ) _ { k = 0, 1, 2, 3 }, U \rho U ^ { \dagger } \right ). \\ 0 | \in \mathcal { D M } ( \mathbb { C } ^ { 4 } ) \text{ is the initial state. The resulting output stream is}$$
$$\sigma = \left ( | 0 \rangle, \frac { 1 } { 2 } | 1 \rangle + \frac { 1 } { 2 } | 2 \rangle \right ) ^ { \omega }. \\ \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
The minimal coalgebra with this behaviour is the smallest subcoalgebra of D ( 4 ) N containing σ . We shall compute this subcoalgebra by determining the states of D ( 4 ) N that can be reached from σ with the transition structure, and then taking the convex set generated by the reachable states.
The transition structure of the final coalgebra is given by the function tail : D ( 4 ) N → D ( 4 ) N defined by tail ( x 0 , x 1 , x 2 , . . . ) = ( x 1 , x 2 , . . . ) . Applying the tail function repeatedly to σ gives the streams σ and σ ′ = ( 1 2 | 1 〉 + 1 2 | 2 〉 | , 0 〉 ) ω . The convex algebra generated by σ and σ ′ inside D ( 4 ) N is
$$\Psi _ { 1 } \, \partial _ { 2 } \, \Psi _ { 2 } \, \partial _ { 3 } \, \partial _ { 4 } \, \partial _ { 5 } \, \partial _ { 6 } \, \partial _ { 7 } \, \partial _ { 8 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 1 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 8 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 10 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 11 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 11 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 1 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 5 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 5 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 10 } \, \partial _ { 8 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 8 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 8 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 7 } \, \partial _ { 7 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 7 } \, \partial _ { 7 } \, \partial _ { 8 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \, \partial _ { 9 } \$$
This is the minimal coalgebra with behaviour σ and hence the minimization of f . The coalgebra structure is obtained as restriction of the final coalgebra D ( 4 ) N . By projecting onto the first coordinate twice we obtain an affine isomorphism between X and [ 0 1 . , ] Therefore a more elementary display of the minimization is
↦
$$\begin{array} { c c c } [ 0, 1 ] & \rightarrow & \mathcal { D } ( 4 ) \times [ 0, 1 ] \\ p & \mapsto & ( p | 0 \rangle + \frac { 1 } { 2 } ( 1 - p ) | 1 \rangle + \frac { 1 } { 2 } ( 1 - p ) | 2 \rangle, 1 - p ) \\ \L \text{ state space } [ 0, 1 ] \text{ of the minimization is more manageable than the or} \\ \text{minimization is not a quantum system anymore since } [ 0 \ 1 ] \text{ is not isome} \end{array}$$
) Observe that the state space [ 0 1 , ] of the minimization is more manageable than the original state space DM ( C 4 ) . The minimization is not a quantum system anymore, since [ 0 1 , ] is not isomorphic to a convex set of density matrices. It can be seen as a probabilistic system with two states, since [ 0 1 , ] ∼ = D ( 2 . ) Thus the behaviour of this quantum mechanical system can be reproduced with a simpler probabilistic system. Note that we only consider the classically observable probabilities as part of the behaviour, not the quantum mechanical amplitudes. Therefore the minimization only contains information about the classically probabilistic behaviour.
## 6 Conclusion
Quantum systems can be represented by using density matrices as states, with unitary operators acting on them as dynamics. We have exploited this fact to model quantum systems as coalgebras in the category Conv of convex sets, with a set of density matrices as state space. A consequence of this representation is that minimization of coalgebras gives a method to transform a quantum system into a probabilistic system that has the same probabilistic behaviour, but a simpler structure.
There are several possibilities for future research. We have only studied minimization of quantum systems empirically through examples. It would be nice to have more general results about the structure of minimal realizations. Moreover it is unclear if quantum systems can also be modeled in such a way that minimization gives a quantum coalgebra again.
Acknowledgements. This work is based on my master's thesis [13]. I would like to thank my thesis supervisor Bart Jacobs for many helpful discussions and comments.
## References
- [1] S. Abramsky (2010): Coalgebras, Chu spaces, and representations of physical systems . In: Proceedings of the 25th Annual IEEE Symposium on Logic in Computer Science, pp. 411-420, doi:10.1109/LICS.2010.35.
- [2] S. Abramsky & B. Coecke (2004): A categorical semantics of quantum protocols . In: Proceedings of the 19th Annual IEEE Symposium on Logic in Computer Science, pp. 415-425, doi:10.1109/LICS.2004.1319636.
- [3] J. Ad´ amek, F. Bonchi, M. H¨ ulsbusch, B. K¨ onig, S. Miliu s & A. Silva (2012): A coalgebraic perspective on minimization and determinization . In Lars Birkedal, editor: Foundations of Software Science and Computational Structures, Lecture Notes in Computer Science 7213, Springer Berlin Heidelberg, pp. 58-73, doi:10.1007/978-3-642-28729-9 4.
- [4] J. Butterfield & C. Isham (1998): A topos perspective on the Kochen-Specker theorem: I. Quantum states as generalized valuations . Int. Jour. Theor. Physics 37(11), pp. 2669-2733, doi:10.1023/A:1026680806775.
- [5] A. Dvureˇ censkij & S. Pulmannov´ a (2000): New Trends in Quantum Structures . Kluwer Academic Publishers, doi:10.1007/978-94-017-2422-7.
- [6] J. Goguen (1972): Minimal realizations of machines in closed categories . Bull. Amer. Math. Soc. 78(5), pp. 777-783, doi:10.1090/S0002-9904-1972-13032-5.
- [7] I. Hasuo, B. Jacobs & A. Sokolova (2007): Generic trace semantics via coinduction . Logical Methods in Computer Science 3(4:11), pp. 1-36.
- [8] B. Jacobs (2010): Convexity, duality and effects . In Cristian Calude & Vladimiro Sassone, editors: Theoretical Computer Science, IFIP Advances in Information and Communication Technology, Springer Boston, pp. 1-19, doi:10.1007/978-3-642-15240-5 1.
- [9] B. Jacobs (2011): Coalgebraic walks, in quantum and Turing computing . In: Lecture Notes in Computer Science, Foundations of Software Science and Computational Structures 6604, pp. 12-26, doi:10.1007/978-3-642-19805-2 2.
- [10] B. Jacobs, A. Silva & A. Sokolova (2012): Trace semantics via determinization . In: Lecture Notes in Computer Science, to appear, Proceedings of CMCS 2012, doi:10.1007/978-3-642-32784-1 7.
- [11] C. Moore & J. Crutchfield (2000): Quantum automata and quantum grammars . Theoretical Computer Science 237(1), pp. 275-306, doi:10.1016/S0304-3975(98)00191-1.
- [12] A. Nerode (1958): Linear automaton transformations . Proc. Amer. Math. Soc. 9(4), pp. 541-544, doi:10.1090/S0002-9939-1958-0135681-9.
- [13] F. Roumen (2012): Coalgebraic semantics for quantum computation . Master's thesis, Radboud University Nijmegen.
- [14] J. Rutten (1998): Automata and coinduction (an exercise in coalgebra) . In D. Sangiorigi & R. de Simone, editors: Proceedings of CONCUR '98, LNCS 1466, Springer, pp. 194-218, doi:10.1007/BFb0055624.
- [15] J. Rutten (2000): Universal coalgebra: a theory of systems . Theoretical Computer Science 249(1), pp. 3-80, doi:10.1016/S0304-3975(00)00056-6.
- [16] A. Silva, F. Bonchi, M. Bonsangue & J. Rutten (2010): Generalizing the powerset construction, coalgebraically . In: Proceedings of the IARCS Annual Conference on Foundations of Software Technology and Theoretical Computer Science, Leibniz International Proceedings in Informatics 8, pp. 272-283, doi:10.4230/LIPIcs.FSTTCS.2010.272.
- [17] S. El´ ıas Venegas-Andraca (2008): Quantum Walks for Computer Scientists . Morgan & Claypool. | 10.4204/EPTCS.158.3 | [
"Frank Roumen"
] | 2014-08-01T00:24:45+00:00 | 2014-08-01T00:24:45+00:00 | [
"cs.LO",
"math.CT"
] | Coalgebraic Quantum Computation | Coalgebras generalize various kinds of dynamical systems occuring in
mathematics and computer science. Examples of systems that can be modeled as
coalgebras include automata and Markov chains. We will present a coalgebraic
representation of systems occuring in the field of quantum computation, using
convex sets of density matrices as state spaces. This will allow us to derive a
method to convert quantum mechanical systems into simpler probabilistic systems
with the same probabilistic behaviour. |
1408.0051v1 | ## The expressive power of quantum walks in terms of language acceptance
Katie Barr
Viv Kendon
School of Physics and Astronomy, E. C. Stoner Building, University of Leeds, Leeds LS2 9 JT, UK
[email protected]
Discrete time quantum walks are known to be universal for quantum computation. This has been proven by showing that they can simulate a universal quantum gate set. In this paper, we examine computation by quantum walks in terms of language acceptance, and present two ways in which discrete time quantum walks can accept some languages with certainty. These walks can take quantum as well as classical inputs, and we show that when the input is quantum, the walks can also be interpreted as performing the task of quantum state discrimination.
## 1 Introduction
Quantum walks are the quantum generalisation of random walks on discrete structures [15, 1]. Both continuous and discrete time quantum walks are known to be Turing universal [12, 7, 8]. This has been proven by showing that in both cases an elementary universal gate set can be simulated by a quantum walk. This maps the quantum walk onto the quantum circuit model. Both types of walks propagate quantum amplitude deterministically along 'wires' punctuated by gates formed using an appropriate combination of graph structures. The discrete time walk additionally uses a set of coin operations designed to produce the required propagation. Despite much effort, quantum circuits have not yet been realised experimentally beyond a few qubits. The best quantum computation devices currently in existence are based on liquid state nuclear magnetic resonance (NMR) [14]. Other models of computation fit NMR devices better, in particular, the Latvian quantum finite automaton (LQFA) [3], which has been specially designed for that purpose. The computational capabilities of LQFAs are characterised in terms of language acceptance, prompting our investigation into language acceptance by other models of computation, specifically, discrete time quantum walks. Due to the construction in [12], we know that there must exist a mapping from a discrete time quantum walk onto any other Turing universal model of computation. Hence, non-universal tasks such as language acceptance must be possible, and the interest lies in the details of how a quantum walk can be configured to do it.
This work: we describe work in progress applying discrete time quantum walks to language acceptance. We show that there are multiple ways to do this, by exploring a range of small examples. We provide two simple constructions of graphs on which quantum walks can recognise the languages L eq and L ab . Furthermore, we show that exploiting explicitly quantum aspects of the walks allows for gains in efficiency. We introduce the concept of quantum inputs, and describe a preliminary investigation into the effect these have on word acceptance. Our work made use of numerical simulations; the technical details of how these were done have been published in [4].
The paper is arranged as follows: in section 2 we provide definitions covering the elements we use from formal languages and finite state automata; the Jaro distance; and discrete time quantum walks. In section 3, we give examples of languages which can be accepted by quantum walks using two different
graph formats and discuss their efficiency. In section 4, we note that the constructions permit quantum inputs, and briefly indicate how these might be used to apply the quantum walks to quantum state discrimination [6, 13]. We concludes with a summary and outline of future work in section 5.
## 2 Definitions and notation
Here we provide definitions used in the paper, thus setting up our notation.
## 2.1 Languages
We consider a binary alphabet S with two symbols { a b , } , from which words are formed as strings of symbols.
Definition 1. The language L ab is the set of words { ( ab ) n | n ∈ N } .
Remark. This is an example of a regular language. Each word in L ab is a different length.
Definition 2. The language L eq is the set of words { a m b m | m ∈ N } .
Remark. This is an example of a context-free language. Recognising this language requires a basic form of memory, to count how many times the first symbol occurs and check the second symbols then occurs the same number of times. However, like L ab , each word is a different length.
## 2.2 Jaro distance
The Jaro distance is a metric which indicates how similar two strings (words) are.
Definition 3. For strings w 1 and w 2, the match distance md is given by
$$m _ { d } = \left \lfloor \frac { \max ( | w _ { 1 } |, | w _ { 2 } | ) } { 2 } \right \rfloor - 1$$
Two charcters in strings w 1 and w 2 are said to match if (1) they are the same symbol and (2) if their positions within their respective strings lie within the match distance of each other. Let s denote the number of matching characters. Let w ′ 1 and w ′ 2 be the substrings derived from w 1 and w 2 respectively by erasing all the non-matching characters. Then t , the number of transpositions , is the number of positions at which w ′ 1 and w ′ 2 differ. Now we define the Jaro distance as follows.
Definition 4. For strings w 1 and w 2, the Jaro distance d j between w 1 and w 2 is given by
$$d _ { j } = \begin{cases} 0 & \text{ if } s = 0 \\ \frac { 1 } { 3 } ( \frac { s } { | w _ { 1 } | } + \frac { s } { | w _ { 2 } | } + \frac { s - t } { s } ) & \text{ otherwise} \end{cases}$$
where s is the number of matching characters, i.e., characters which occur in both strings, in the same order, within the match distance md . The value of t is obtained by dividing the number of matching characters which differ by sequence order by 2.
Remark. The three parts to the expression for the Jaro distance calculate the ratios of the number of matching characters to the lengths of w 1 and w 2 and then the fraction of non-transpositions among the matching characters. The Jaro distance was selected as it always has values between 0 and 1, with 1 indicating that two words are equal, hence it was easy to compare to the probability of acceptance. Other metrics with similar properties for comparing strings could have been used; the Jaro distance was available as a Python module, which made it a convenient choice for the numerical part of the work.
Figure 1: Two steps of a discrete time quantum walk on the line, starting at the origin, evolved with a Hadamard coin operator. The numbers in parentheses are the amplitudes for each basis state, one for each edge at each vertex.
## 2.3 Discrete time quantum walks
Definition 5. An undirected graph G = { E V , } consists of a set of vertices v ∈ V and edges e ∈ E joining pairs of vertices. The size of the graph N is the number of vertices N = | V | . The set of edges that meet at vertex v is denoted Ev . The degree dv of a vertex v is the number of edges meeting at that vertex, dv = | Ev | . The maximum degree d max is max v { dv | v ∈ V } . At each vertex v we label the edges from { 0 . . . dv - } 1 in an arbitrary but fixed order.
Remark. Each edge thus has two labels, one at each end, which will usually be different. This is not the only way to set up a discrete time quantum walk on an arbitrary graph, but it is the most convenient way for numerical calculations [10].
Definition 6. The Hilbert space of a discrete-time quantum walk on the graph G is H V × H d max , spanned by basis states | v c , 〉 , v ∈ V and c ∈ Ev . A state of the quantum walk is written as superposition of basis states, | y 〉 = GLYPH<229> v c , b v c , | v c , 〉 with amplitude b v c , ∈ C and with normalisation GLYPH<229> v c , | b v c , | 2 = 1.
Definition 7. A single-vertex coin operator Cv is a dv by dv unitary operator. A coin operator for the whole graph is the direct sum of single-vertex coin operators, C = GLYPH<229> v Cv .
Remark. The dimensions of this square matrix C are given by GLYPH<229> v dv .
Definition 8. The shift operator S is a unitary operator that translates the amplitude b v c , to the vertex v ′ that is connected to v by edge c , i.e., S v c | , 〉 = | v ′ , c ′ 〉 , where c ′ is the label of this edge at v ′ .
Definition 9. A discrete time quantum walk (DQW) on the graph G starting in initial state | y 0 〉 evolves according to a combined coin and shift unitary operator U = SC . The state | y ( T ) 〉 of the DQW after T steps is | y ( T ) 〉 = U T | y 0 〉 . The probability P v T ( , ) of finding the walker at a chosen vertex v at time T is
$$P ( v, T ) = \sum _ { c \in v } | \beta _ { c, v } ( T ) | ^ { 2 }$$
i.e., the sum of the square moduli of the amplitude for each edge at vertex v .
Remark. The discrete time quantum walk is the quantum analogue of the classical random walk, in the sense that if you measure the quantum walk after each step, the quantum behaviour is converted to a classical random walk. As an example, the quantum walk on the line is shown in figure 1. The vertices at the integer points on the line have degree two, so we use a coin operator given by the Hadamard operator (the only non-trivial type of degree two [2]),
$$H = \frac { 1 } { \sqrt { 2 } } \begin{pmatrix} 1 & 1 \\ 1 & - 1 \end{pmatrix}$$
## 3 Applying quantum walks to language recognition
To set up a discrete time quantum walk on a graph to differentiate between words, and hence determine whether they are in a given formal language, we need to specify suitable encodings of input and output that correspond with the graph structure and the quantum state of a quantum walk on that graph. The problem is thus under-specified: there are many possible graphs we could use and many ways to encode a sequence of symbols into a quantum state of a quantum walk on a graph. First of all, we will restrict ourselves to single quantum walkers. Although efficient universal quantum computation with quantum walks requires multiple walkers [8], our goal here is to find simple examples of non-universal computation, for which we can expect a single walker will be sufficient [12, 7], though not necessarily efficient.
We therefore first chose a simple encoding of a binary alphabet that will work for a single quantum walker. A dual rail encoding for the input word assigns each symbol to a pair of vertices. The initial state will have amplitude on the first vertex of the pair for the first symbol in the alphabet, and vice versa for the second symbol, see figure 2. A very similar dual rail encoding can instead assign each symbol to one of a pair of edges at a vertex, see section 3.2. Since quantum computations should start with an initial state that is easy to prepare, or else we could be hiding significant extra computation in the state preparation, we must check that such an input state is experimentally feasible. While it would require a multiport interferometer to split the quantum state over the different vertices, modulated to enable differentiation between a and b inputs, a dual rail encoding would be straightforward to configure for any given sequence of symbols.
Next, a graph structure and coin operations which transform the input into an appropriate output must be chosen. There are a variety of ways that this can be done. For example, if we use a single walker starting in a superposition that represents the input distributed along different vertices, the entire word can be operated on simultaneously. Alternatively, the superposition representing the input symbols can be fed into the graph structure one symbol after another. We will examine each of these in turn in the next two subsections.
The simplest way to deal with the output appears to be to designate an 'accepting vertex', which all accepting amplitude should be arrive at simultaneously. Measuring the position of the quantum walker after the appropriate number of time steps will then provide the output of the computation. If the position is found to be the accepting vertex, the quantum walk has accepted the input word. The outcome of a quantum measurement is in general not deterministic: we shall therefore use the following definition of acceptance for our quantum walk language recognition.
Definition 10. The language L recognised with cut-point l ∈ [ 0 1 , ) by a DQW is L = { w w | ∈ S ∗ P w ( ) > l } where P w ( ) is the probability measuring the DQW at the accepting node for input word w . The acceptance by a DQW of L is with bounded error if there is some e > 0 such that for all w ∈ L , the DQW accepts w with probability greater than l + e and any words w / ∈ L are accepted with probability less
Figure 2: Schema for the graph structure required by a quantum walk which accepts languages using a spatially distributed input. The initial state of the quantum walker is equally distributed over the vertices labeled a , with vertices labeled 0 being unoccupied. The corresponding symbols a and b are shown above the vertices, in this case the input is aa ... ab ... bb .
than l -e where e is the error margin. If there is no such e then the DQW accepts L with unbounded error .
Remark. This is based on the standard definition of acceptance for finite state automata and languages.
This can easily be generalised to a set of accepting vertices; finding the walker on any one of them indicating acceptance. The problem then is to find graph structures and sets of coin operations which transport a large proportion of the amplitude to the accepting vertex or vertices when the input is a word from the language the walk is designed to accept. If the remaining amplitude can be redirected to another vertex, the rejecting vertex, then the accepting and rejecting conditions can be inverted to allow the same walk to accept both the language and its complement - the set of words not in that language. By transferring the input superposition to an output vertex, the language acceptance problem can thus be seen as a variation of the the quantum state transfer problem, see, for example [11, 5, 9].
Some simple cases are immediately evident. The empty set and empty string are accepted trivially, as we can distinguish between no walk occurring and all amplitude being rejected. Singleton symbols can be accepted by paths of length three with the amplitude initially in the appropriate coin state of the central vertex and swap operators directing all the amplitude to one end vertex or the other, depending on which of the two singleton symbols is encoded. These are too trivial to make use of any quantum properties of the quantum walk, we simply note them for completeness.
## 3.1 Spatially distributed input
We will first consider the case where the input is prepared in a dual rail encoding across a row of vertices of the graph structure, the general form of which is shown schematically in figure 2. There are two vertices for each input symbol with alternate vertices representing a or b . The length n of the input must be known. For each input symbol s j , 0 < j ≤ n , the vertex 2 j -1 is populated with amplitude 1 / √ n if s j = a else 2 j contains amplitude if s j = b . The structure of the graph and coin for a walk testing whether a word is in a given language depends on n . The walk is then run for a predetermined number of steps. When the initial state encodes a word in the language accepted by the walk, the amplitude should be directed to the designated accepting vertex. If a word not in the language accepted is encoded in the
Figure 3: Graphs on which quantum walks accept a) L eq and b) L ab with each input symbol being operated on simultaneously. Edges join only at vertices indicated by black circles. Grover coins of the appropriate dimensions are used at each vertex, and only two of the G 4 vertices are shown - there are m in total for words of length 2 m , with the j th G 4 connected to the inputs representing the j th a and j th b . These graphs are used in the proof of Proposition 1 and Corollary 1.
initial state then less of the amplitude should be directed towards the accepting vertex, so the acceptance will be with bounded error (Definition 10). The modulus squared of the final amplitude at the accepting vertex, equation (3) yields the probability of acceptance.
This design is most easily used to swiftly accept languages which contain at most one word of each length, so the quantum walk graph structure tests for that specific word. We use the examples L eq = { a m b m | m ∈ N } and L ab = ( { ab ) m m | ∈ N } and the graphs accepting them can be seen in figure 3. The constructions are based on a d dimensional Grover operator:
$$G _ { d } = \begin{pmatrix} \frac { 2 - d } { d } & \frac { 2 } { d } & \cdots & \frac { 2 } { d } \\ \frac { 2 } { d } & \frac { 2 - d } { d } & \cdots & \frac { 2 } { d } \\ \vdots & \vdots & \ddots & \vdots \\ \frac { 2 } { d } & \frac { 2 } { d } & \cdots & \frac { 2 - d } { d } \end{pmatrix} \\ \text{the vertex. With $d$ even. if $d/2$ of the edges contain amnlitude equally distributed}$$
where d is the degree of the vertex. With d even, if d / 2 of the edges contain amplitude equally distributed between them, this coin operator transfers all the amplitude to the other d / 2 edges. The shift operator then moves the amplitude to the connected vertices. The deterministic evolution that the Grover operator can produce was used to design the 'wires' which transmitted the amplitude between gates in [12].
Proposition 1. The language L eq is accepted with certainty by the graph and choice of operators shown in figure 3 (a). Words not in the language are accepted with bounded error.
Proof. Words in L eq: The result follows by induction on m . For the base step, simple calculation and equation 5 shows that ab will be accepted with certainty. For the induction step, suppose that a word a m b m is accepted with certainty, and consider the word a m + 1 b m + 1 . Due to the construction of the graph, every pair aibi + m where i ≤ m is treated independently, so by the induction hypothesis all amplitude from the first m a 's and b 's is transmitted to the accepting vertex. The calculation to show that all amplitude
from the subsequent pair of a 's and b 's is identical to the base step.
Words not in L eq: As there is no path between the input vertices representing symbols which do not occur in words from L eq , their amplitudes cannot contribute to the accepting probability. To prove the acceptance is with bounded error, consider a word which differs from a word in L eq by one symbol, for example a m b m -1 a . This will be accepted with the maximum possible probability for a word not in L eq . The amplitude from the final a cannot be transmitted to the accepting vertex, so the word cannot be accepted with probability > 1 -1 2 m . Additionally, after step one of the walk the m 'th a goes to the Grover operator, and now some of this amplitude will be transmitted back to the input vertex:
$$G _ { 4 } \left ( \begin{smallmatrix} \frac { 1 } { \sqrt { 2 m } } \\ 0 \\ 0 \\ 0 \end{smallmatrix} \right ) = \left ( \begin{smallmatrix} - \frac { 1 } { 2 } & \frac { 1 } { 2 } & \frac { 1 } { 2 } & \frac { 1 } { 2 } \\ \frac { 1 } { 2 } & - \frac { 1 } { 2 } & \frac { 1 } { 2 } & \frac { 1 } { 2 } \\ \frac { 1 } { 2 } & \frac { 1 } { 2 } & - \frac { 1 } { 2 } & \frac { 1 } { 2 } \\ \frac { 1 } { 2 } & \frac { 1 } { 2 } & - \frac { 1 } { 2 } \end{smallmatrix} \right ) \left ( \begin{smallmatrix} \frac { 1 } { \sqrt { 2 m } } \\ 0 \\ 0 \\ 0 \end{smallmatrix} \right ) = \left ( \begin{smallmatrix} - \frac { 1 } { 2 \sqrt { 2 m } } \\ \frac { 1 } { 2 \sqrt { 2 m } } \\ \frac { 1 } { 2 \sqrt { 2 m } } \\ \frac { 1 } { 2 \sqrt { 2 m } } \end{smallmatrix} \right ) \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \quad m \colon m - 1 & \cdots \cdots & 1 & 1 & 1 & \quad & \quad \end{smallmatrix} \quad & \quad \ \rightarrow$$
Hence the total probability of accepting a m b m -1 a is 1 -1 -1 .
8 m 4 m
Corollary 1. The language L ab is accepted with certainty by the graph and choice of operators shown in figure 4 (b).
In both of these walks, the input is processed in three full steps of the walk, regardless of the length of the input word. However the O ( 1 ) time complexity is at the expense of O n ( ) spatial complexity. For inputs of length n , the walks accepting L eq and L ab require 4 n + 3 and 4 n + 1 vertices respectively. The Grover operator can also be exploited to generate quantum walks accepting with certainty other languages such as L twin = { ww w | ∈{ a b , } ∗ } and L rev = { ww r | w ∈{ a b , } ∗ } where w r denotes the symbols of w in reverse order. The graph from figure 3 a) can be extended to accept the archetypal contextsensitive language L = { a m b m c m | m ∈ N } and b) to accept L = ( { abc ) m m | ∈ N } = { abc } ∗ . In this case we must extend the model to deal with more than two input symbols which will involve a corresponding increase in the number of vertices required.
Numerical study: the properties of the walks over the graphs depicted in figure 3 were investigated by simulating them using the Python programming language for all possible inputs of a given length, up to n = 16. As well as the acceptance probability, the Jaro distance between the input and the closest word to a word in the language under consideration for that length was also calculated. In the case of even length inputs, the comparison is made with the word from the language of that length, for odd inputs with length n the word was compared to the word in the language of length n -1. For both languages the results were very similar so we limit the discussion to L eq here. The results for the first 200 words are illustrated in figure 4. The points at which both curves peak at the value one are at the position of the words ab , aabb , and aaabbb .
By numerically comparing the probability of accepting an arbitrary word to a measure of how similar that word is to one of the required form, the algorithm's correctness is shown, and more detail concerning the behaviour of the walk on words not in the language can be ascertained. The disparity between the Jaro distance and the probability of acceptance for words not in L eq illustrates how effective the quantum walk algorithm is. A low probability of acceptance for any word not in the language, regardless of how close that word is to a word in L eq indicates the language acceptance is robust. Hence this probability cannot be used as a good measure of how close the input word is to one in that language in cases where it is not equal to one.
Using a spatially distributed input allows for long words to be accepted with the same number of operations as short words. However, the number of vertices required in the graph structure grows, albeit
Figure 4: The probability of acceptance for the walk detecting words from L eq for the first 200 words (black). The Jaro distance between the input word and an appropriately sized word from L eq is indicated in red. Both curves go to unity at the positions representing the words ab aabb , and aaabbb .
linearly, with the length of the word. The number of vertices required to accept a given language can be held constant regardless of input length if each input symbol is fed into the structure in turn, so we now turn to this case.
## 3.2 Sequentially distributed input
We can make use of the 'wires' from [12] with a slightly different encoding to design a sequential input. An input of length n can be treated sequentially if we start with it distributed along a chain of length n with two links between each vertex, as shown in the leftmost portions of the graphs in figure 5. The two symbols are represented thus:
$$\ n u s \colon \quad & a \Rightarrow \begin{pmatrix} \alpha \\ 0 \\ 0 \\ 0 \end{pmatrix} \quad & b \Rightarrow \begin{pmatrix} 0 \\ \alpha \\ 0 \\ 0 \end{pmatrix} \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \ & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad &\quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad & \quad$$
where the entries in the vector contain the amplitude for each of the four edges at the vertex, before the coin operator is applied. The coin on this part of the graph is s x ⊗ I 2, where s x is the Pauli-X operator,
$$\sigma _ { x } = \begin{pmatrix} 0 & 1 \\ 1 & 0 \end{pmatrix}.$$
This four-dimensional operator s x ⊗ I 2 simply swaps amplitude to the 'leaving' edges of the current vertices, the lower pair of entries. The swap operator then transfers all the amplitude to the 'arriving' edges of the next vertex. This choice of coin operator feeds the input amplitude into a graph which has either 'accepting paths' and 'rejecting paths', or 'accepting vertices' and 'rejecting vertices'. The sum of the square moduli of the amplitudes on the accepting vertex/path after a number of steps determined by n gives the probability of accepting the input word. The shape of the graph and the coins at each vertex determine which words will be accepted.
Results: in some cases, such as walks accepting specific words of known length, the only coins required are trivial swap operators. More complex languages require less trivial coin operators, such as in figure 5 (a), the graph accepting the language L ab . This graph uses the Hadamard operator, defined in equation (4), to determine whether each pair of symbols is of the form ab or not. The swap operator then moves the amplitude from both symbols into the accepting path if they are of that form. Words in the language are accepted with certainty and those not in the language are accepted with probability 1 / 2. Figure 5 illustrates two different graphs which both accept the same specific word. Either a specific graph
Figure 5: a) Graph structure and coins accepting language L ab b) Graph specifically accepting the word of length 4 from that language
or the graph accepting L ab can be used to accept abab , as shown in figure 5 (b) and (a) respectively. We tested numerically whether these different graphs accepting the same word give rise to different probability distributions. In this case, the probability of acceptance of words not equal to abab did not depend on the graph, however, this property is not generally expected to hold. We can also see that exploiting quantum properties, using the Hadamard operator as in figure 5 (a) to control interference between different parts of the amplitude, rather than permuting amplitude so that it all arrives at the right place eventually as in figure 5 (b), gains us efficiency. The simple swapping version of the graph accepting abab has 8 vertices (discounting the input vertices) and takes 6 steps to accept the word. The more general graph not only accepts more words, but accepts abab in 5 steps. To accept longer words from L ab using a permutation scheme rather than the graph using the Hadamard operator, more steps are required and the size of the graph increases accordingly. The correctness of these quantum walk algorithms can be proven easily by induction on m , where m is the number of times the string ab is repeated.
This scheme can be modified to accept L eq . This is because in the quantum walk shown in figure 5 a), if a pair ab was contained in the input, the amplitude from the a and b symbols arrives at the vertex where the s x ⊗ H at the same time, and interference can then occur. If the amplitude from the a symbol
Figure 6: Probability of acceptance using the graph from figure 5 (a) accepting L ab for the first 200 words (black). The Jaro distance between the input word and an appropriately sized word from the language is indicated in red.
is instead directed to a path of m vertices prior to the vertex where s x ⊗ H is applied, then interference cannot occur until m steps of the walk have taken place. If the m + 1'th symbol of the input is then a b , then constructive interference will occur. Therefore if there are m a 's followed by m b 's in the input, it will be accepted with certainty by the modified graph. The graph now requires O n ( ) vertices besides the input vertices, reflecting the need for a simple memory to recognise a context free language.
Numerical study: as for the spatially distributed input case, the probability of accepting each word was calculated for all possible inputs up to length 16. This was plotted alongside the Jaro distance from the input word to a word of an appropriate length in the language as shown in figure 6. As in figure 4, points at which both values go to unity indicate the positions of the word ab , abab , ababab . Although acceptance is still with bounded error, comparing with figure 4 we see that the rejection of words not in the language is not so robust, all words are accepted with probability at least a half.
A simple way of finding a graph which accepts the string abb concatenated onto a single symbol given either aabb or babb is to add further self loops (with a coin state for each end) to the accepting node. A b symbol requires two self loops for each portion of the existing amplitude to go around, and an a symbol requires one self loop for each portion of the existing amplitude to go around. The rejecting paths leaving the accepting node will have to be increased accordingly. Whilst this will accept the new word with probability 1, if the process is repeated it will increase the probability of accepting other strings dramatically, though it will never be equal to unity.
## 4 Quantum Inputs
The inputs used so far have all been classical, represented by a quantum superposition state. However, the way these walks have been set up allows us to do more than this. Each symbol in the input word can be in a superposition of a or b , for example, x a | 〉 + y b | 〉 such that | x | 2 + | y | 2 = a 2 . Recall that a = 1 / √ n and n is the length of the input. Superpositions of words, such as abab and bbbb can then be created by using the appropriate superposition for each symbol in the word. Where symbols match, the amplitude is allocated to that symbol as for the classical encoding. Where symbols do not match, the amplitude is
Figure 7: Fidelity of final state to accepting state for quantum inputs in a superposition of aabb and: the string with no matching characters, bbaa (blue); the strings with one matching character, abaa , baaa , bbab and bbba (green); the strings with two matching characters aaaa abab abba baab baba , , , , and bbbb (black); the strings with three matching characters aaab , aaba abbb , and babb (red)
distributed between the a and b states accordingly.
Definition 11. A h -quantum input | s 1 2 , 〉 is a superposition of the symbols in words w 1 and w 2 with amplitude ratios h and √ 1 -| h | 2 . Where symbols of w 1 and w 2 match, so wi 1 = wi 2 , | s 1 2 , i 〉 = | wi 1 〉 . Where symbols differ | s 1 2 , i 〉 = a h ( | wi 1 〉 + √ 1 -| h | 2 | wi 2 〉 ).
Remark. This is not the same as a superposition of the whole words, for example, with h = 1 / √ 2, glyph[negationslash]
$$( | a b a \rangle + | b b b \rangle ) / \sqrt { 2 } \neq ( | a \rangle + | b \rangle ) | b \rangle ( | a \rangle + | b \rangle ) / 2 = ( | a b a \rangle + | a b b \rangle + | b b a \rangle + | b b b \rangle ) / 2.$$
We chose to begin with symbol-by-symbol superpositions because they are simple to prepare. Preparing superpositions of whole words would require more resources, so while they are undoubtedly also interesting, the preparation resources would need to be accounted for in the overall assessment of the algorithm.
Numerical study: as a preliminary investigation into using quantum inputs, we numerically tested the effects of using a quantum input consisting of a word accepted by the quantum walk superposed with a word not accepted. We used the walks accepting Leq and tested the spatially distributed input as given in figure 3 (a). We used the fidelity between the state obtained and the accepting state to make our comparison. The fidelity between states | y 〉 and | f 〉 is defined as:
$$F = | \langle \phi | \psi \rangle | ^ { 2 }$$
We tested a range of superpositions from the word being entirely aabb to the word being entirely another word, for every word of length four. The effect of the quantum input on the fidelity fell into four distinct cases, as shown in figure 7. These cases correspond to the number of characters a word of length four can differ by, with the probability of being able to accurately determine which input was used diminishing as the number of symbols which match exactly between the two strings increases, as would be expected.
Using a quantum input frames the question of language acceptance in terms of quantum state discrimination. If we know we have been given one of two states | y 〉 and | f 〉 , one of which encodes a word
in the language accepted by the walk while the other does not, then we can gain information about which state we are likely to have been given by whether or not it is accepted by the walk. Another approach to using discrete time quantum walks to perform quantum state discrimination, by measuring at specific positions, is presented in [13].
## 5 Summary
We have presented a preliminary investigation into using discrete time quantum walks to recognise formal languages. We developed two different types of graph structures, one using spatially distributed input, the other using sequential input. We observed the expected trade off between space and time resources. Spatially distributed input requires O n ( ) vertices, but can recognise regular and context free languages in O ( 1 ) steps of the quantum walk. Sequential input requires only O ( 1 ) vertices (besides those encoding the input) but uses O n ( ) steps to recognise regular languages. However, to recognise context free languages with sequential input requires O n ( ) vertices, the extra vertices providing the necessary memory functionality.
To gain insight into the behaviour of the quantum walks for input words not in the language, numerical testing was done for all possible inputs up to length 16. The probability of acceptance was calculated and found to take a few specific values between 0 and 1, rather than varying over the entire range. It would thus be interesting to classify which types of strings give rise to which values for the probability of acceptance. This could aid the process of finding walks that accept further languages.
It would be interesting to extend the work to find general ways of specifying graphs accepting arbitrary regular expressions, or even arbitrary formal languages. Or one could restrict attention to specific, appropriately defined subclasses of regular expressions to relate the work to other aspects of logic. In order to compare the walks with other standard models of computation in terms of language acceptance, relations between the efficiency measures used here and other standard efficiency measures such as the minimal number of computational states, or tape squares traversed, must be found.
The two approaches discussed in this paper are unlikely to be the only ways to specify quantum walks such that they can be interpreted as accepting formal languages. It is not yet clear what the most fruitful approach will be. A better understanding of the relative merits of using spatially versus sequentially distributed inputs will be informative, and gaining insights into their limitations may suggest further ways of specifying walks to recognise languages.
Wehave briefly described how the constructions presented here allow quantum inputs. This new form of input opens many further avenues for investigation. As well as finding out more about the quantum state discrimination performed by the walks presented here, it would be interesting to generalise the inputs themselves to superpositions of whole words rather than single symbols, and consider how they might be developed to form quantum languages.
## References
- [1] Dorit Aharonov, Andris Ambainis, Julia Kempe & Umesh Vazirani (2001): Quantum walks on graphs . In: Proceedings of the thirty-third annual ACM symposium on Theory of computing , ACM, pp. 50-59. doi:10.1145/380752.380758
- [2] Andris Ambainis, Eric Bach, Ashwin Nayak, Ashvin Vishwanath & John Watrous (2001): One-dimensional quantum walks . In: Proceedings of the thirty-third annual ACM symposium on Theory of computing , ACM, pp. 37-49. doi:10.1145/380752.380757
- [3] Andris Ambainis, Martin Beaudry, Marats Golovkins, Arnolds Kikusts, Mark Mercer & Denis Therien (2006): Algebraic Results on Quantum Automata . Theory of Computing Systems 39(1), pp. 165-188, doi:10.1007/s00224-005-1263-x.
- [4] K. Barr, T. Fleming & V. Kendon (2013): Simulation methods for quantum walks on graphs applied to perfect state transfer and formal language recognition . In Susan Stepney & Paul S. Andrews, editors: CoSMoS 2013. Proceedings of the 2013 Workshop on Complex Systems Modelling and Simulation , Luniver Press, pp. 1-19. Available at http://www.cs.york.ac.uk/nature/cosmos/docs/cosmos2013-proceedings. pdf . Presented at the CoSMoS Workshop of UCNC 2013 in Milan, July 2013; post-proceedings journal version forthcoming.
- [5] Sougato Bose (2003): Quantum Communication through an Unmodulated Spin Chain . Phys. Rev. Lett. 91, p. 207901, doi:10.1103/PhysRevLett.91.207901. Available at http://link.aps.org/doi/10.1103/ PhysRevLett.91.207901 .
- [6] Anthony Chefles (2000): Quantum state discrimination . Contemporary Physics 41(6), pp. 401-424, doi:10.1080/00107510010002599. Available at http://www.tandfonline.com/doi/abs/10.1080/ 00107510010002599 .
- [7] Andrew M. Childs (2009): Universal Computation by Quantum Walk . Phys. Rev. Lett. 102, p. 180501, doi:10.1103/PhysRevLett.102.180501. Available at http://link.aps.org/doi/10.1103/ PhysRevLett.102.180501 .
- [8] Andrew M. Childs, David Gosset & Zak Webb (2013): Universal Computation by Multiparticle Quantum Walk . Science 339(6121), pp. 791-794, doi:10.1126/science.1229957. Available at http://www. sciencemag.org/content/339/6121/791.abstract .
- [9] Matthias Christandl, Nilanjana Datta, Tony C. Dorlas, Artur Ekert, Alastair Kay & Andrew J. Landahl (2005): Perfect transfer of arbitrary states in quantum spin networks . Phys. Rev. A 71, p. 032312, doi:10.1103/PhysRevA.71.032312. Available at http://link.aps.org/doi/10.1103/PhysRevA.71. 032312 .
- [10] Viv Kendon (2006): Quantum walks on general graphs . International Journal of Quantum Information 04(05), pp. 791-805, doi:10.1142/S0219749906002195. Available at http://www.worldscientific. com/doi/abs/10.1142/S0219749906002195 .
- [11] Vivien M. Kendon & Christino Tamon (2011): Perfect State Transfer in Quantum Walks on Graphs . Journal of Computational and Theoretical Nanoscience 8(3), pp. 422-433. Available at http://www.ingentaconnect.com/content/asp/jctn/2011/00000008/00000003/art00015 . doi:10.1166/jctn.2011.1706
- [12] Neil B. Lovett, Sally Cooper, Matthew Everitt, Matthew Trevers & Viv Kendon (2010): Universal quantum computation using the discrete-time quantum walk . Phys. Rev. A 81, p. 042330, doi:10.1103/PhysRevA.81.042330. Available at http://link.aps.org/doi/10.1103/PhysRevA.81. 042330 .
- [13] Paweł Kurzy´ nski & Antoni W´ ojcik (2013): Quantum Walk as a Generalized Measuring Device . Phys. Rev. Lett. 110, p. 200404, doi:10.1103/PhysRevLett.110.200404. Available at http://link.aps.org/doi/10. 1103/PhysRevLett.110.200404 .
- [14] LMK Vandersypen, M Steffen, G Breyta, CS Yannoni, MH Sher wood & IL Chuang (2001): Experimental realization of Shor's quantum factoring algorithm using nu clear magnetic resonance . Nature 414(6866), pp. 883-887, doi:10.1038/414883a.
- [15] Y. Aharonov, L. Davidovich & N. Zagury (1993): Quantum random walks . Physical Review A 48(2), pp. 1687-1690. doi:10.1103/PhysRevA.48.1687 | 10.4204/EPTCS.158.4 | [
"Katie Barr",
"Viv Kendon"
] | 2014-08-01T00:24:58+00:00 | 2014-08-01T00:24:58+00:00 | [
"cs.FL",
"cs.ET",
"quant-ph"
] | The expressive power of quantum walks in terms of language acceptance | Discrete time quantum walks are known to be universal for quantum
computation. This has been proven by showing that they can simulate a universal
quantum gate set. In this paper, we examine computation by quantum walks in
terms of language acceptance, and present two ways in which discrete time
quantum walks can accept some languages with certainty. These walks can take
quantum as well as classical inputs, and we show that when the input is
quantum, the walks can also be interpreted as performing the task of quantum
state discrimination. |
1408.0052v1 | ## Speakable in quantum mechanics: babbling on
## Ronnie Hermens
Department of Theoretical Philosophy University of Groningen [email protected]
This paper summarizes and elaborates on some of the results in [14]. The summary consists of a short version of the derivation of the intuitionistic quantum logic LQM (which was originally introduced in [6]). The elaboration consists of extending this logic to a classical logic CLQM . Some first steps are then taken towards setting up a probabilistic framework based on CLQM in terms of R´ enyi's conditional probability spaces. Comparisons are then made with the traditional framework for quantum probabilities.
## 1 Introduction
In the Hilbert space formalism of quantum mechanics (QM), a quantum probability function is a function P from the lattice L ( H ) of projection operators acting on the Hilbert space H , to the unit interval [ 0 1 , , ] which satisfies the rules
- · P ( 1 ) = 1,
/negationslash
- · P ( P 1 ∨ P 2 ∨ . . . ) = P ( P 1 ) + P ( P 2 ) + . . . whenever PiPj = 0 for all i = j .
This characterization of quantum probabilities is reminiscent (at least in form) of the classical structure, where a probability function is specified by a pair ( F , P ) where F denotes a σ -algebra of subsets of some space Ω and P : F → [ 0 1 , ] is a function which satisfies
- · P ( Ω ) = 1,
/negationslash
- · P ( ∆ 1 ∪ ∆ 2 ∪ . . . ) = P ( ∆ 1 ) + P ( ∆ 2 ) + . . . whenever ∆ i ∩ ∆ j = ∅ for all i = j .
Because of the resemblance in structure between the two definitions, it is tempting to think that one must be able to find resemblances between admissible interpretations of the probabilities. However, as indicated in [27], such a program has to face the problem of explaining the non-Boolean nature of L ( H ) . This issue may best be understood by contrasting the quantum structure with the classical structure of σ -algebras. By far the majority of philosophical approaches to classical probability agree on one thing. Namely, that the probability P ( ∆ ) can be understood as the probability that some proposition S ∆ codified by ∆ is true. For example, if Ω is understood as the set of all possible worlds, then ∆ corresponds to the subset of all possible worlds in which S ∆ is true. The question for the quantum case is now straightforward: if the elements of L ( H ) correspond to propositions, what do these propositions express?
The most prominent early contribution to this question is undoubtedly the work of Birkhoff and von Neumann [3]. The backbone of this paper already appeared in [18] where the idea of taking projections as propositions was introduced. It is roughly motivated as follows. If A is an observable, and ∆ a (measurable) subset of the reals, then the proposition A ∈ ∆ is taken to be true if and only if the probability that a measurement of A reveals some value in ∆ equals one. This is then the case if and only if the state
of the system lies in P A ∆ H , with H the Hilbert space describing the system, and PA the projection valued measure generated by A . Or, in terms of density operators, if and only if Tr ( ρ P A ∆ ) = 1.
Of course this raises the question of what is meant by 'a measurement of A reveals some value in ∆ '. The most tempting answer is the one suggested by the notation A ∈ ∆ , i.e., that a measurement of A reveals some value in ∆ if and only if the observable A has some value in ∆ , independent of the measurement. A straightforward adoption of this realist reading is bound to run into difficulties posed by results such as the Kochen-Specker theorem [16] or the Bell inequalities [2, 7]. A possible escape is to deny that A ∈ ∆ expresses a proposition (or has a truth value) for every pair ( A , ∆ ) at every instant. This can be done by, for example, adopting the strong property postulate ( A has a value if and only if the system is in an eigen state of A ). Another possibility is to deny the bijection between observables and self-adjoint operators such as in Bohmian mechanics, where position observables play a privileged role. 1 Or one may suggest that these propositions do not obey the laws of classical logic. This last option was the one suggested by Putnam in [21]. He argued that, apart from coinciding with a set of propositions about values possessed by observables, the lattice L ( H ) also describes the correct logic for these propositions. However, this realist interpretation of the quantum logic L ( H ) is known to lead to problems [10, 26] and the consensus seems to be that there is no hope for this direction [17].
In contrast to these difficulties encountered in realist approaches to understanding L ( H ) , it is often thought that an operationalist interpretation is unproblematic, and perhaps even straightforward:
If we put aside scruples about 'measurement' as a primitive term in physical theory, and accept a principled distinction between 'testable' and non-testable properties, then the fact that L ( H ) is not Boolean is unremarkable, and carries no implication about logic per se. Quantum mechanics is, on this view, a theory about the possible statistical distributions of outcomes of certain measurements, and its non-classical 'logic' simply reflects the fact that not all observable phenomena can be observed simultaneously. - Wilce [27, § 2]
The idea is that the task of interpreting the structure of L ( H ) is tied up with explicating the notion of measurement. Then, since the operationalist takes the notion of measurement as primitive, the structure of L ( H ) may also be taken as primitive. This line of reasoning seems unsatisfactory to me and I think that the questions of what the propositions in L ( H ) express, and what the logic is that governs them, are also meaningful and require study from an operationalist point of view. And as a guide to such a logic one may take into account Bohr's demand that all well-defined experimental evidence, even if it cannot be analyzed in terms of classical physics, must be expressed in ordinary language making use of common logic. - Bohr [4]
In this paper I continue the work done in [14] to meet this demand. Specifically, in section 2 I first introduce a lattice of experimental propositions SQM which is then extended to an intuitionistic logic LQM in section 3. These results comprise a summary of some of the results in [14]. Then, also in section 3, this logic is extended to a classical logic CLQM for experimental propositions. In section 4 R´ enyi's theory of conditional probability spaces [23] is applied to CLQM and it is shown that the quantum probabilities as given by the Born rule can be reproduced. This is followed by a short discussion on the issue that non-quantum probabilities are also allowed in this framework. Finally, in section 5, the results of this paper are evaluated and some ideas on what further role they may play in foundational debates are given.
1 In this approach, observables are associated with functions on the configuration space of particle positions. Every proposition A ∈ ∆ then reduces to a proposition on particle positions. This reduction is contextual in a sense; the function associated with A is not the same for every experimental setup used to measure A .
## 2 The lattice of experimental propositions
The idea to focus on the experimental side of QM is reminiscent of the approach of Birkhoff and von Neumann in [3]. They start by introducing 'experimental propositions' which are identified with subsets of 'observation spaces'. An observation space is the Cartesian product of the spectra of a set of pairwise commuting observables. However, once such a subset is associated with a projection operator in the familiar way, the experimental context (i.e., the set of pairwise commuting observables) is no longer being considered. For example, one may have that P A ∆ 1 1 = P A ∆ 2 2 even though A 1 and A 2 may be incompatible. This indicates that whatever is encoded by propositions in L ( H ) , they do not refer to actual experiments.
To avoid a cumbersome direct discussion of L ( H ) , it is then appropriate to instead develop a logic of propositions that do encode these experimental contexts. As an elementary example of what Bohr may have had in mind when speaking of 'well-defined experimental evidence' I take propositions of the form
$$M _ { A } ( \Delta ) = \text{``A is measured and the result lies in } \Delta. \text{``}$$
Of course, no logical structure can be derived for these propositions without some structural assumptions. I will adopt the following two assumptions which I believe to be quite innocent 2 :
LMR (Law-Measurement Relation) If A 1 and A 2 are two observables that can be measured together, and if f is a function such that whenever A 1 and A 2 are measured together the outcomes a 1 and a 2 satisfy a 1 = f ( a 2 ) (i.e., f represents a law), then a measurement of A 2 alone also counts as a measurement of A 1 with outcome f ( a 2 ) . 3
- IEA (Idealized Experimenter Assumption) Every experiment has an outcome, i.e., for every observable A MA ( ∅ ) is understood as a contradiction.
The following lemma describes the structure arising from these assumptions for QM. A more elaborate exposition may be found in [14].
Lemma 2.1. Under the assumptions LMR and IEA the set of (equivalence classes of) experimental propositions for quantum mechanics lead to the lattice
$$S _ { Q M } \, \coloneqq \, \{ ( \mathcal { A }, P ) \, ; \, \mathcal { A } \in \mathfrak { A }, P \in L ( \mathcal { A } ) \, \langle \{ 0 \} \} \cup \{ \perp \},$$
where A denotes the set of all Abelian operator algebras on H and L ( A ) the Boolean lattice A ∩ L ( H ) . The partial order is given by
$$( \mathcal { A } _ { 1 }, P _ { 1 } ) \leq ( \mathcal { A } _ { 2 }, P _ { 2 } ) \text{ iff } P _ { 1 } = 0 \text{ or } \mathcal { A } _ { 1 } \supset \mathcal { A } _ { 2 }, P _ { 1 } \leq P _ { 2 }.$$
Proof. A proposition MA 1 ( ∆ 1 ) implies MA 2 ( ∆ 2 ) if and only if a measurement of A 1 implies a measurement of A 2 and every outcome in ∆ 1 implies an outcome in ∆ 2 for the measurement of A 2 (or if MA 1 ∆ 1 expresses a contradiction). By LMR, this is the case if and only if the Abelian algebra A 2 generated by A 2 is a subalgebra of the Abelian algebra A 1 generated by A 1 and P A ∆ 1 1 ≤ P A ∆ 2 2 (or P A ∆ 1 1 = 0). This also establishes that MA 1 ( ∆ 1 ) and MA 2 ( ∆ 2 ) are equivalent if and only if ( A 1 , P A ∆ 1 1 ) = ( A 2 , P A ∆ 2 2 ) (or both express a contradiction).
2 These assumptions are the ones also adopted in [14] although there the second was implicit and the first was formulated to also apply to other theories.
3 This assumption is reminiscent of the FUNC rule adopted in the Kochen-Specker theorem (c.f. [22, p.121]). However, FUNCis a much stronger assumption stating that whenever measurement outcomes for a pair of observables satisfy a functional relation, the values possessed by these observables must satisfy the same relationship. That is, FUNC is the conjunction of LMR together with the idea that measurements reveal pre-existing values.
The meet on SQM is given by
/negationslash
$$( \mathcal { A } _ { 1 }, P _ { 1 } ) \wedge ( \mathcal { A } _ { 2 }, P _ { 2 } ) = \begin{cases} ( \mathcal { A } _ { 1 } ( \mathcal { A } _ { 1 }, \mathcal { A } _ { 2 } ), P _ { 1 } \wedge P _ { 2 } ), & \text{if } [ \mathcal { A } _ { 1 }, \mathcal { A } _ { 2 } ] = 0, P _ { 1 } \wedge P _ { 2 } \neq 0, \\ \perp, & \text{otherwise}, \end{cases}$$
where P 1 ∧ P 2 is the meet on L ( H ) . It is consistent with the interpretation given to MA ( ∆ ) in the sense that this meet 'distributes' over the 'and' in ' A is measured and the result lies in ∆ '. In particular, it assigns a contradiction to a simultaneous measurement of two observables whenever their corresponding operators do not commute.
It is harder to interpret the join on this lattice as a disjunction. When restricting to joins of two elements of SQM with the same algebra, the results seem intuitively correct. In this case one has
$$( \mathcal { A }, P _ { 1 } ) \vee ( \mathcal { A }, P _ { 2 } ) = ( \mathcal { A }, P _ { 1 } \vee P _ { 2 } ).$$
And indeed, ' A is measured and the measurement reveals some value in ∆ 1 ∪ ∆ 2' sounds like a good paraphrase of ' A is measured and the measurement reveals some value in ∆ 1 or A is measured and the measurement reveals some value in ∆ 2'. But in more general cases problems arise. For example, one has ( A 1 , 1 ) ∨ ( A 2 , 1 ) = ( A 1 ∩ A 2 , 1 . ) Then, if the two algebras are completely incompatible (i.e. A 1 ∩ A 2 = C 1), this equation states that ' A 1 is measured or A 2 is measured' is a tautology even though one can consider situations in which neither is measured.
The example can further be used to show that SQM is not distributive. Let A 3 be a third observable that is totally incompatible with both A 1 and A 2. One then has
/negationslash
$$( \mathcal { A } _ { 3 }, 1 ) \wedge ( ( \mathcal { A } _ { 1 }, 1 ) \vee ( \mathcal { A } _ { 2 }, 1 ) ) = ( \mathcal { A } _ { 3 }, 1 ) \neq \perp = ( ( \mathcal { A } _ { 3 }, 1 ) \wedge ( \mathcal { A } _ { 1 }, 1 ) ) \vee ( ( \mathcal { A } _ { 3 }, 1 ) \wedge ( \mathcal { A } _ { 2 }, 1 ) ). \quad \text{(6)}$$
Hence, when it comes to providing a logic that fares well with natural language, SQM doesn't perform much better than the original L ( H ) .
## 3 Deriving the logics LQM and CLQM
To solve the problem of non-distributivity of SQM the lattice has to be extended by formally introducing disjunctions which in general are stronger than the join on SQM . The outcome of this process is described by the following theorem. 4
Theorem 3.1. Formally introducing disjunctions to SQM while respecting (5) results in the complete distributive lattice with partial order on LQM defined by
$$? \tan c e \\ L _ { Q M } & = \left \{ S \colon \mathfrak { A } \to L ( \mathcal { H } ) \, ; \, \underset { S ( \mathcal { A } _ { 1 } ) \leq S ( \mathcal { A } _ { 2 } ) } { S ( \mathcal { A } _ { 2 } ) \text{ whenever } \mathcal { A } _ { 1 } \subset \mathcal { A } _ { 2 } } \right \} \\ \omega \, \text{order on } L _ { Q M } \, \text{defined by}$$
$$S _ { 1 } \leq S _ { 2 } \text{ iff } S _ { 1 } ( \mathcal { A } ) \leq S _ { 2 } ( \mathcal { A } ) \forall \mathcal { A } \in \mathfrak { A }$$
giving the meet and join
$$( S _ { 1 } \vee S _ { 2 } ) ( \mathcal { A } ) & = S _ { 1 } ( \mathcal { A } ) \vee S _ { 2 } ( \mathcal { A } ), \\ ( S _ { 1 } \wedge S _ { 2 } ) ( \mathcal { A } ) & = S _ { 1 } ( \mathcal { A } ) \wedge S _ { 2 } ( \mathcal { A } ).$$
4 Again, more details may be found in [14].
The embedding of SQM into LQM is given by 5
↦
$$i \colon ( \mathcal { A }, P ) \mapsto S _ { ( \mathcal { A }, P ) }, \, S _ { ( \mathcal { A }, P ) } ( \mathcal { A } ^ { \prime } ) \coloneqq \begin{cases} P, & \mathcal { A } \subset \mathcal { A } ^ { \prime }, \\ 0, & \text{otherwise}. \end{cases}$$
Proof. The key to the extension of SQM to LQM lies in noting that the embedding (10) satisfies the relation
$$S = \bigvee _ { \mathcal { A } \in \mathfrak { A } } i ( \mathcal { A }, S ( \mathcal { A } ) ). \quad \quad \quad$$
This gives the intended reading of elements of LQM , namely, as a disjunction of experimental propositions. By LMR it follows that i preserves the interpretation of elements of SQM . The conjunctions on LQM further agree with those on SQM :
$$S _ { ( \mathcal { A } _ { 1 }, P _ { 1 } ) } \wedge S _ { ( \mathcal { A } _ { 2 }, P _ { 2 } ) } = S _ { ($$
Further, LQM respects (5) while introducing 'new' elements for other disjunctions, i.e.,
$$S _ { ( \mathcal { A } ^ { \prime } _ { 1 }, P _ { 1 } ) } \vee S _ { ( \mathcal { A } ^ { \prime } _ { 2 }, P _$$
with equality if and only if either P 1 or P 2 equals 0, or A 1 = A 2. Finally, that LQM is a complete distributive lattice follows from (9) and observing that L ( A ) is a complete distributive lattice for every A ∈ A .
The lattice LQM is turned into a Heyting algebra by obtaining the relative pseudo-complement in the usual way:
$$S _ { 1 } \to S _ { 2 } & = \bigvee \{ S \in L _ { Q M } \, ; \, S \wedge S _ { 1 } \leq S _ { 2 } \$$
And negation is introduced by ¬ S : = S →⊥ thus obtaining an intuitionistic logic for reasoning with experimental propositions. The logic LQM is also a proper Heyting algebra and, in fact, is radically nonclassical. That is, the law of excluded middle only holds for the top and bottom element. This is easily checked by observing that S ( C 1 ) = 1 if and only if S = /latticetop . It then follows that S ∨¬ S = /latticetop if and only if S = /latticetop or ¬ S = /latticetop .
The strong non-classical behavior can be understood by noting that the logic is entirely built up from propositions about performed measurements. The negation of MA ( ∆ ) is identified with other propositions about measurements that exclude the possibility of MA ( ∆ ) but leave open the option of no experiment having been performed:
/negationslash
An unexcluded middle thus presents itself as the proposition ¬ MA =' A is not measured'. It was suggested in [14, § 2] that incorporating such propositions could lead to a classical logic. I will now show that this is indeed the case.
$$\neg S _ { ( \mathcal { A } ^ { \prime }, P ) } = \bigvee \left \{ S _ { ( \mathcal { A } ^ { \prime }, P ^ { \prime }$$
It is tempting to start the program for a classical logic for experimental propositions by formally adding the suggested propositions ¬ MA and building on from there. However, it turns out that it is much more convenient to introduce new elementary experimental propositions, namely
MA ! ( ∆ ) = ' A is measured with result in ∆ , and no finer grained measurement has been performed' .
(16)
5 For notational convenience ( A , 0 ) is identified with ⊥∈ SQM .
The notion of fine graining here relies on LMR. Another way of expressing the conjunct added is to state that 'only A and all the observables implied to be measured by the measurement of A have been measured'. With this concept the following can now be shown. 6
Theorem 3.2. The classical logic for experimental propositions is given by 7
$$C L _ { Q M } = \mathcal { P } ( S ^ {! } _ { Q M } ), \, S ^ {! } _ { Q M } \, \coloneqq \left \{ ( \mathcal { A } ^ {! }, P ) \, ; \, \mathcal { A } \in \mathfrak { A }, P \in L _ { 0 } ( \mathcal { A } ) \right \}, \\ L _ { 0 } ( \mathcal { A } ) \, \text{ denotes the set of atoms of the lattice } L ( \mathcal { A } ).$$
where L 0 ( A ) denotes the set of atoms of the lattice L ( A ) .
Proof. Being defined as a power set, it is clear that CLQM is a classical propositional lattice. So it only has to be shown that every element signifies an experimental proposition, and that it is rich enough to incorporate the propositions already introduced by LQM . The first issue is readily established by the identification
↦
$$M _ { A } ^ {! } ( \Delta ) \mapsto \{ ( \mathcal { A } ^ {! }, P ) \in S _ { Q M } ^ {! } \, ; \, P \leq \mu _ { A } ( \Delta ) \},$$
with A the algebra generated by A . Identifying A with A is again justified by LMR, and IEA is incorporated by the fact that, whenever ∆ contains no elements in the spectrum of A M A , ! ( ∆ ) is identified with the empty set. Thus (18) ensures that every element of CLQM is understood as a disjunction of experimental propositions, i.e., every singleton set in CLQM encodes a proposition of the form MA ! ( { } a ) .
That CLQM is indeed rich enough follows by observing that the map
↦
$$c \colon L _ { Q M } \to C L _ { Q M }, \, S \mapsto \bigcup _ { \mathcal { A } \in \mathfrak { A } } \left \{ ( \mathcal { A } ^ {! }, P ) \in S _ { Q M } ^ {! } ; \, P \leq S ( \mathcal { A } ) \right \} & & ( 1 9 ) \\. \dots \dots \dots \dots \dots \dots \dots \dots & & \exists$$
is an injective complete homomorphism.
Some additional reflections are helpful to get a grip on CLQM . First one may note that the map ( c ◦ i ) : SQM → CLQM , encoding propositions of the form MA ( ∆ ) , acts as
↦
$$c \circ i \colon ( \mathcal { A }, P ) \mapsto \left \{ ( \mathcal { A } ^ { \prime \prime }, P ^ { \prime } ) \in S _ { Q M } ^ {! } \, ; \, ( \mathcal { A } ^ { \prime }, P ^ { \prime } ) \leq ( \mathcal { A }, P ) \right \}. & & ( 2 0 ) \\ \text{provision ``and no finer grained measurement has been performed`` that distinguishes M _ { A } ^ {! } ( \Delta )$$
/negationslash
Thus the provision 'and no finer grained measurement has been performed' that distinguishes MA ! ( ∆ ) from MA ( ∆ ) precisely excludes all the ( A ′ ! , P ′ ) ∈ ( c ◦ i )( A , P ) with A ′ = A , i.e., the finer grained measurements (c.f. (18) and (20)).
The non-classicality of LQM is also explicated by CLQM . For any ( A , P ) ∈ SQM , the complement of
$$c ( S _ { ( \mathcal { A }, P ) } \vee \neg S _ { ( \mathcal { A }, P ) } )$$
consists of all the ( A ′ ! , P ′ ) ∈ S QM ! with A ′ /subsetnoteql A and P ′ ≤ P . This is because only the added provision in (16) makes ( A ′ ! , P ′ ) exclude the measurement of A , while within LQM there is nothing to denote a possible incompatibility for A and A ′ . A proposition in CLQM of special interest in this context is the singleton { ( C 1 1 , ) } which expresses that only the trivial measurement is performed. In light of IEA this is just the same as saying that no measurement is performed; the most typical proposition in CLQM not present in LQM .
6 In the remainder of this paper it is tacitly assumed that H is finite-dimensional.
7 The exclamation mark is merely a notational artifact introduced to discern the elements of S QM ! from those of SQM . That is, without the exclamation mark, S QM ! would be a subset of SQM .
To conclude this section I compare the constructions of LQM and CLQM to another way of extending SQM to a distributive lattice, namely, by using the Bruns-Lakser theory of distributive hulls [5] as advocated in [8]. In this approach SQM is embedded into the lattice of its distributive ideals 8 DI ( SQM ) by taking each element to its downward set, i.e.,
↦
$$( \mathcal { A }, P ) \mapsto \downarrow ( \mathcal { A }, P ) \coloneqq \{ ( \mathcal { A } ^ { \prime }, P ^ { \prime } ) \in S _ { Q M } \, ; \, ( \mathcal { A } ^ { \prime }, P ^ { \prime } ) \leq ( \mathcal { A }, P ) \}.$$
Generally, the abstract nature of the extension DI ( L ) for some non-distributive lattice L prevents a straightforward identification of distributive ideals with propositions. In the present situation, for example, it is not immediately clear whether the resulting lattice operations behave consistently with respect to the intended reading of the elements ↓ ( A , P ) given by (1). Fortunately, this issue can be resolved for SQM by noting that the resulting lattice of its distributive ideals is isomorphic to the power set of the atoms in SQM :
$$\mathcal { D I } ( S _ { Q M } ) \simeq \mathcal { P } ( S _ { Q M } ^ { * } ), \, S _ { Q M } ^ { * } \colon = \{ ( \mathcal { A }, P ) \in S _ { Q M } \, ; \, \mathcal { A } \in \mathfrak { A } _ { \max }, P \in L _ { 0 } ( \mathcal { A } ) \},$$
where A max is the set of maximal Abelian algebras. Here then one sees that the proposition identified with ( A , P ) ∈ SQM is understood in P ( S QM ∗ ) as a disjunction over all possible complete measurements compatible with a measurement of A . That is, MA ( ∆ ) in this setting may be rephrased as 'some complete measurement A ′ has been performed with outcome a ′ which implies MA ( ∆ ) '. Although this provides a consistent reading, the underlying presupposition that every measurement in fact constitutes a complete measurement seems somewhat reckless.
## 4 Quantum logic and probability
If the logic CLQM is to play any significant role in quantum mechanics, it has to be connected with quantum probability theory. That is, one has to know how the Born rule can be expressed using the language of CLQM . Ideally this consists of two parts. First, to show that probability functions on CLQM can be introduced that are in accordance with the Born rule. And secondly, to show that the Born rule comes out as a necessary consequence holding for all probability functions on CLQM (i.e., a result similar to Gleason's theorem for L ( H ) ([12])). In this section some first investigations in this direction are made.
The first approach for probabilities on CLQM undoubtedly is to note that ( S QM ! , CLQM ) is a measure space. Hence, it is tempting to state that all probability functions are simply all probability measures on this space. However, this does not do justice to the quantum formalism. For example, one possible probability measure is the Dirac measure peaked at { ( C 1 1 , ) } expressing certainty that no measurement will be performed. This is likely to be too minimalistic even for the hardened instrumentalist. That is, although one may adhere to the idea that 'unperformed experiments have no results' [19], a central idea in QM is that possible outcomes for measurements do have probabilities irrespective of whether the measurements are performed. Indeed, it is a trait of QM that certain conditional probabilities have definite values even if the propositions on which one conditions have prior probability zero. The Dirac measure does not provide these conditional probabilities.
8 A distributive ideal is a subset I ⊂ SQM that is downward closed and further contains the join ∨ { ( A , P ) ∈ J } for every subset J ⊂ I that satisfies (∨ ( A , P ) ∈ J ( A , P ) ) ∧ ( A ′ , P ′ ) = ∨ ( A , P ) ∈ J ( ( A , P ) ∧ ( A ′ , P ′ ) ) for all ( A ′ , P ′ ) ∈ SQM .
To get around this it is natural to take conditional probabilities as primitive in the quantum case. 9 For this approach the axiomatic scheme of R´ enyi is an appropriate choice. 10
Definition 4.1. Let ( Ω , F ) be a measurable space and C ⊂ F \{ ∅ } be a non-empty set, then ( Ω , F C , , P ) is called a conditional probability space (CPS) if P : F × C → [ 0 1 , ] satisfies
↦
- 1. for every C ∈ C the function A → P ( A C | ) is a probability measure on ( Ω , F ) ,
- 2. for all A B C , , ∈ F with C B , ∩ C ∈ C one has
$$\mathbb { P } ( A \cap B | C ) = \mathbb { P } ( A | B \cap C ) \, \mathbb { P } ( B | C ).$$
If in addition to these criteria C is closed under finite unions, the space is called an additive CPS , and if C = F \{ ∅ } it is called a full CPS .
In the present situation it is straightforward to take ( S QM ! , CLQM ) as the measure space. For the set of conditions a modest choice is to take the set of propositions expressing the performance of a measurement:
$$\mathcal { C } _ { Q M } \coloneqq \{ F _ { \mathcal { A } } \, ; \, \mathcal { A } \in \mathfrak { A } \} \,, \, F _ { \mathcal { A } } \coloneqq ( c \circ i ) ( \mathcal { A }, 1 ).$$
For this set of conditions the Born rule can easily be captured with the CPS ( S QM ! , CLQM , C QM , P ρ ) with the probability function given by
$$\psi _ { 0 } \quad \Phi _ { \rho } ( F | F _ { \mathcal { A } } ) \coloneqq \sum _ { \begin{subarray} { c } \left \{ P \in L ( \mathcal { H } ) ; \\ ( \mathcal { A } ^ { \prime }, P ) \in F \end{subarray} \right \} } \text{Tr} ( \rho P ), & & ( 2 6 )$$
for F ∈ CLQM and with ρ a density operator on H . 11
It would however be more interesting to take C = CLQM \{ ∅ } for the set of conditions. At the present it is not clear to me if this is possible, as extending the set of conditions seems a non-trivial matter. There is a positive result on this matter however, namely, the CPS ( S QM ! , CLQM , C QM , P ρ ) can be extended to an additive CPS. The proof for this claim relies on the following definition and theorem.
Definition 4.2. A family of measures ( µ i ) i ∈ I on ( Ω , F ) is called a generating family of measures for the CPS ( Ω , F C , , P ) if and only if for all C ∈ C there exists i ∈ I such that 0 < µ i ( C ) < ∞ and for all F ∈ F , for all C ∈ C and for all i ∈ I with 0 < µ i ( C ) < ∞
$$\mathbb { P } ( F | C ) = \frac { \mu _ { i } ( F \cap C ) } { \mu _ { i } ( C ) }.$$
9 Quantum mechanics has even been used as an example to advocate that conditional probability should be considered more fundamental than unconditional probability, c.f. [13].
10 C.f., [23]. A similar axiomatic approach was developed independently by Popper [20, A *ii-*v]. The present presentation is taken from [25].
11 Another possibility is to take for the conditions the set of propositions expressing the performance of a measurement excluding the possibility of a finer grained measurement:
$$\mathcal { C } _ { Q M } ^ {! } \colon = \left \{ F _ { \mathcal { A } } ^ {! } ; \, \mathcal { A } \in \mathfrak { A } \right \}, \, F _ { \mathcal { A } } ^ {! } \colon = \{ ( \mathcal { A } ^ {! }, P ) \in S _ { Q M } ^ {! } ; \, P \in L ( \mathcal { A } ) \}. \\ \text{the Born rule can be recovered by taking the CPS ( S ^ {! } \dots C L o m. \mathcal { C } ^ {! } \dots \mathbb { P } ^ {! } ) \text{ with the}$$
$$\mathbb { P } _ { \rho } ^ {! } ( F | F _ { \mathcal { A } } ^ {! } ) \coloneqq \sum _ { \left \{ P \in L ( \mathcal { H } ) ; \right \} } \text{Tr} ( \rho P ) = \mathbb { P } _ { \rho } ( F | F _ { \mathcal { A } } ). \\ \text{section can also be nhrased in terms of this CPS. I will however}$$
Also in this setting the Born rule can be recovered by taking the CPS ( S QM ! , CLQM , C ! QM , P ! ρ ) with the probability function given by
Much of the remainder of this section can also be phrased in terms of this CPS. I will however restrict myself to (26) for the sake of clarity.
The family is called dimensionally ordered if and only if there is a total order < on I such that for all F ∈ F and i , j ∈ I : i < j µ j ( F ) = 0 whenever µ i ( F ) < ∞ .
Theorem 4.1 (Cs´ asz´r 1955 [9]) a . ACPS ( Ω , F C , , P ) can be extended to an additive CPS ( Ω , F C , ′ , P ′ ) (i.e., C ⊂ C ′ , and P ′ acts as P when restricted to F × C ) if and only if it is generated by a dimensionally ordered family of measures on ( Ω , F ) .
Thus to show that the CPS given by P ρ in (26) can be extended to an additive CPS it suffices to give a dimensionally ordered family of measures that generates it. The construction of this family relies on the following dimensionality function
$$d \colon \mathfrak { A } & \to \mathbb { N }, d ( \mathcal { A } ) \colon = \# L _ { 0 } ( \mathcal { A } ), \\ d \colon C L _ { Q M } & \to \mathbb { N }, d ( F ) \colon = \min \{ d ( \mathcal { A } ) \, ; \, ( \mathcal { A } ^ {! }, P ) \in F \}.$$
That is, d picks out the coarsest measurements in F . In particular, d F ( A ) = d ( A ) . The family of measures ( µ ρ i ) i ∈ N is now defined as
$$\mu _ { i } ^ { \rho } ( F ) \coloneqq \delta _ { i d ( F ) } \sum _ { \substack { \left \{ P \in L ( \mathcal { H } ) ; \, \exists \, \mathcal { A } \in \mathfrak { A } s. t. \right \} \\ ( \mathcal { A } ^ { \prime }, P ) \in F, d ( \mathcal { A } ) = i } } \text{Tr} ( \rho P ),$$
where δ id ( F ) denotes the Kronecker delta. This Kronecker delta warrants that the family is indeed dimensionally ordered where the order is the usual one on N . Using that
$$\mu _ { i } ^ { \rho } ( F _ { \mathcal { A } } ) = \delta _ { i d ( \mathcal { A } ) }$$
one may easily check that this is indeed a generating family for the CPS ( S QM ! , CLQM , C QM , P ρ ) .
Another open issue with the CPS approach to quantum probabilities is that of deriving the Born rule, i.e., to derive the conditions under which P is of the form P ρ . Aparticular difficulty here is that quantum probabilities are non-contextual, a property that is not expected to hold in general for an admissible probability function on ( S QM ! , CLQM ) . That is, one may have that for A 1 , A 2 ⊃ A the equality
$$\mathbb { P } \left ( \left \{ ( \mathcal { A } ^ {! }, P ) \right \} | F _ { \mathcal { A } _ { 1 } } \right ) & = \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ {! }, P ) \right \} | F _ { \mathcal { A } _ { 2 } } \right ), & & ( 3 1 ) \\ \text{hough it is satisfied for the Born rule (26).} \\ \text{$\text{in addition to $/31\theta$ the amount} }$$
∣ does not hold, although it is satisfied for the Born rule (26).
Conversely, if in addition to (31) the equality
$$\mathbb { P } \left ( \left \{ ( \mathcal { A } _ { 1 } ^ {! }, P ) \right \} \Big | F _ { \mathcal { A } } \right ) & = \mathbb { P } \left ( \left \{ ( \mathcal { A } _ { 2 } ^ {! }, P ) \right \} \Big | F _ { \mathcal { A } } \right ) \\ \text{whenever} \, \mathcal { A } _ { 1 }, \mathcal { A } _ { 2 } \subset \mathcal { A }, \text{the Born rule would follow}. ^ { 1 2 } \text{ This is because then the function}$$
∣ ∣ were also to hold whenever A 1 , A 2 ⊂ A , the Born rule would follow. 12 This is because then the function
$$\mathbb { P } _ { Q M } \colon L ( \mathcal { H } ) \to [ 0, 1 ], \ \mathbb { P } _ { Q M } ( P ) \coloneqq \mathbb { P } \left \{ \left ( \mathcal { A } ^ { \prime }, P \right ) \right \} | F _ { \mathcal { A } ^ { \prime } } \right ) \\ \mathcal { A } \text{ is well defined (i.e., independent of the choice of $\mathcal{A}$ and $\mathcal{A}^{\prime}$) and satisfies}$$
∣ with A ′ ⊃ A is well defined (i.e., independent of the choice of A and A ′ ) and satisfies
- · P QM ( 1 ) = 1,
/negationslash
- · P QM ( P 1 ∨ P 2 ∨ . . . ) = P ( P 1 ) + P ( P 2 ) + . . . whenever PiPj = 0 for all i = j .
12 Provided that the dimension of H is greater than 2.
Hence, Gleason's theorem applies.
Now, before coming to an end it is interesting to take a quick look at the connection between possible extensions of the CPSs and Bell inequalities. Consider the standard EPR-Bohm situation where Alice can choose between two possible measurements A A 1 and A A 2 , whilst Bob can choose between two possible measurements A B 1 and A B 2 . Let A i j denote the algebra generated by A A i and A B j . It is further presupposed that each measurement has two possible outcomes associated with the projections P X i 0 and P X i 1 in A X i .
The CPSs given by (26) aren't rich enough to evaluate possible derivations for a Bell inequality. For that, the set of conditions has to be extended to
$$\mathcal { C } _ { Q M } ^ { \prime } \coloneqq \left \{ F _ { ( \mathcal { A } ^ { \prime }, P ) } \, ; \, ( \mathcal { A }, P ) \in S _ { Q M } \right \}, \, F _ { ( \mathcal { A } ^ { \prime }, P ) } \coloneqq ( c \circ i ) ( \mathcal { A }, P ). \\ \text{se conditions the requirements of outcome independence (OI) and parameter independence (PI) } \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
With these conditions the requirements of outcome independence (OI) and parameter independence (PI) from which the Bell inequality can be derived [15, 24] can be stated:
$$\begin{array} { l l } \overset {. } { \mathbb { P } } \left ( \{ ( \mathcal { A } _ { i } ^ { A! }, P _ { i 0 } ^ { A } ) \} | F _ { ( \mathcal { A } _ { i 1 }, 1 ) } \right ) = \mathbb { P } \left ( \{ ( \mathcal { A } _ { i } ^ { A! }, P _ { i 0 } ^ { A } ) \} | F _ { ( \mathcal { A } _ { i 2 }, 1 ) } \right ) \\ \mathbb { P } \left ( \{ ( \mathcal { A } _ { i } ^ { B! }, P _ { i 0 } ^ { B } ) \} | F _ { ( \mathcal { A } _ { 1 i }, 1 ) } \right ) = \mathbb { P } \left ( \{ ( \mathcal { A } _ { i } ^ { B! }, P _ { i 0 } ^ { B } ) \} | F _ { ( \mathcal { A } _ { 2 i }, 1 ) } \right ) \\ \mathbb { P } \left ( \{ ( \mathcal { A } _ { i } ^ { A! }, P _ { i 0 } ^ { A } ) \} \Big | F _ { ( \mathcal { A } _ { i j }, 1 ) } \right ) = \mathbb { P } \left ( \{ ( \mathcal { A } _ { i } ^ { A! }, P _ { i 0 } ^ { A } ) \} \Big | F _ { ( \mathcal { A } _ { i j }, P _ { i k } ^ { B } ) } \right ) \\ \end{array}$$
∣ ∣ The violation of Bell inequalities in QM shows that OI must fail for any extension of P ρ to C ′ QM . This may be indicative of the idea that the development of any full CPS ( S QM ! , CLQM CLQM , \{ ∅ } , P ) is a non-trivial matter. 13
$$\begin{array} { c } \ll \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ { B } _ { i }, P ^ { B } _ { 0 } ) \right \} \Big | F _ { ( \mathcal { A } ^ { 1, 1 } ), 1 } \right ) = \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ { B } _ { i }, P ^ { B } _ { 0 } ) \right \} \Big | F _ { ( \mathcal { A } ^ { 2, 1 } ), 1 } \right ) \\ \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ { B } _ { i }, P ^ { A } _ { 0 } ) \right \} \Big | F _ { ( \mathcal { A } ^ { 1, 1 } ), 1 } \right ) = \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ { B } _ { i }, P ^ { B } _ { 0 } ) \right \} \Big | F _ { ( \mathcal { A } ^ { 1, 1 } ), P ^ { B } _ { k } ) \right ) \\ \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ { B } _ { i }, P ^ { B } _ { 0 } ) \right \} \Big | F _ { ( \mathcal { A } ^ { 1, 1 } ), 1 } \right ) = \mathbb { P } \left ( \left \{ ( \mathcal { A } ^ { B } _ { i }, P ^ { B } _ { 0 } ) \right \} \Big | F _ { ( \mathcal { A } ^ { 1, 1 } ), P ^ { A } _ { k } ) \right ) \\ \intertext {tion of Bell inequalities in QM shows that OI must fail for any extension of $\mathbb{ }P_{\rho}$ to $\mathbb{ }G_{QM}$}. \text{ This} \\ \text{ndicative of the idea that the development of any full CPS $(QM$}, C L _ { Q M }, C L _ { Q M } \langle \mathfrak { O } \}, \mathbb { P } ) \text{ is a} \end{array}$$
## 5 Conclusion and outlook
With the construction of CLQM a concrete formalism is provided that adheres to the Bohrian view that also for quantum mechanics experimental reports must be communicable in unambiguous common language. However, the association with the Copenhagen doctrine ends there. Although the notion of measurement is taken as primitive here, no demand is made for the necessity of this. That is, the current program should not be seen as a method to dismiss the measurement problem, but merely as a way of making sense of the formalism without endorsing a particular solution to the problem. In this paper one obstacle in such investigations has been overcome, namely, the non-distributivity of quantum logic. In return a less abstract obstacle has emerged, namely, the justification of the Born rule in quantum mechanics. To get a further grip on this issue it may be fruitful future work to seek connections with other programs in quantum foundations such as generalized probability theory [1] or the Bayesian approach to quantum probabilities [11].
## Acknowledgments
I would like to thank the people at the QPL 2012 conference in Brussels and at the first Quantum Toposophy workshop in Nijmegen for useful questions and discussions. And further J. W. Romeijn for insisting
13 Note that I'm thinking here of interesting cases. A trivial CPS is easily constructed. Just fix one ( A ! , P ) ∈ S QM ! and take P ( F C | ) = { 1 ( A ! , P ) ∈ F , 0 otherwise , for all C ∈ CLQM \{ ∅ } .
on the use of classical logic. This work was supported by the NWO (Vidi project nr. 016.114.354).
## References
- [1] J. Barrett (2007): Information processing in generalized probabilistic theories . Physical Review A 75, p. 032304, doi:10.1103/PhysRevA.75.032304.
- [2] J. S. Bell (1964): On the Einstein Podolsky Rosen paradox . Physics 1(3), pp. 195-200.
- [3] G. Birkhoff & J. von Neumann (1936): The logic of quantum mechanics . Annals of Mathematics 37(4), pp. 823-843, doi:10.2307/1968621.
- [4] N. Bohr (1948): On the notions of causality and complementarity . Dialectica 2(3-4), pp. 312-319, doi:10.1111/j.1746-8361.1948.tb00703.x.
- [5] G. Bruns & H. Lakser (1970): Injective hulls of semilattices . Canadian Mathematical Bulletin 13, pp. 115118, doi:10.4153/CMB-1970-023-6.
- [6] M. Caspers, C. Heunen, N. P. Landsman & B. Spitters (2009): Intuitionistic quantum logic of an n-level system . Foundations of Physics 39, pp. 731-759, doi:10.1007/s10701-009-9308-7.
- [7] J. F. Clauser, M. A. Horne, A. Shimony & R. A. Holt (1969): Proposed experiment to test local hiddenvariable theories . Physical Review Letters 23(15), pp. 880-884, doi:10.1103/PhysRevLett.23.880.
- [8] B. Coecke (2002): Quantum logic in intuitionistic perspective . Studia Logica 70(3), pp. 411-440, doi:10.1023/A:1015106515413.
- [9] ´ A. Cs´ asz´r (1955): a Sur la structure des escapes de probabilit´ e conditionnelle . Acta Mathematica Academiae Scientiarum Hungarica 6(3-4), pp. 337-360, doi:10.1007/BF02024394.
- [10] M. Dummett (1976): Is logic empirical? In H. D. Lewis, editor: Contemporary British Philosophy Volume IV, George Allen and Unwin, pp. 45-68.
- [11] C. A. Fuchs (2010): QBism, the perimeter of Quantum Bayesianism . Available at http://arxiv.org/abs/1003.5209 .
- [12] A. Gleason (1957): Measures on the closed subspaces of a Hilbert space . Indiana University Mathematics Journal 6, pp. 885-893, doi:10.1512/iumj.1957.6.56050.
- [13] A. H´ ajek (2003): What conditional probability could not be . Synthese 137(3), pp. 273-323, doi:10.1023/B:SYNT.0000004904.91112.16.
- [14] R. Hermens (2012): Speakable in quantum mechanics . Synthese, doi:10.1007/s11229-012-0158-z.
- [15] J. P. Jarrett (1984): On the physical significance of the locality conditions in the Bell arguments . Noˆ us 18(4), pp. 569-589, doi:10.2307/2214878.
- [16] S. Kochen & E. P. Specker (1967): The problem of hidden variables in quantum mechanics . Journal of Mathematics and Mechanics 17, pp. 59-67.
- [17] T. Maudlin (2005): The tale of quantum logic . In Y. Ben-Menahem, editor: Hilary Putnam (Contemporary Philosophy in Focus), Cambridge University Press, pp. 156-187, doi:10.1017/CBO9780511614187.006.
- [18] J. von Neumann (1955): Mathematical Foundations of Quantum Mechanics . Princeton University Press. Translated from the German by R. T. Beyer. Original title: Mathematische Grundlagen der Quantenmechanik, Berlin 1932.
- [19] A. Peres (1978): Unperformed experiments have no results . American Journal of Physics 46(7), pp. 745-747, doi:10.1119/1.11393.
- [20] K. Popper (1959): The Logic of Scientific Discovery . Hutchinson, London.
- [21] H. Putnam (1969): Is logic empirical? Boston Studies in the Philosophy of Science V, doi:10.1007/978-94-010-3381-7 5.
- [22] M. Redhead (1987): Incompleteness, Nonlocality, and Realism . Clarendon Press, Oxford.
- [23] A. R´ enyi (1955): On a new axiomatic theory of probability . Acta Mathematica Academiae Scientiarum Hungarica 6(3-4), pp. 285-335, doi:10.1007/BF02024393.
- [24] A. Shimony (1984): Controllable and uncontrollable non-locality . In S. Kamafuchi et. al., editor: Foundations of Quantum Mechanics in the Light of New Technology, Physical Society of Japan, Tokyo, pp. 225-230, doi:10.1017/CBO9781139172196.010.
- [25] W. Spohn (1986): The representation of Popper measures . Topoi 5, pp. 69-74, doi:10.1007/BF00137831.
- [26] A. Stairs (1983): Quantum logic, realism, and value definiteness . Philosophy of Science 50, pp. 578-602, doi:10.1086/289140.
- [27] A. Wilce (2012): Quantum logic and probability theory . In E. N. Zalta, editor: The Stanford Encyclopedia of Philosophy, fall 2012 edition. | 10.4204/EPTCS.158.5 | [
"Ronnie Hermens"
] | 2014-08-01T00:25:06+00:00 | 2014-08-01T00:25:06+00:00 | [
"cs.LO",
"quant-ph"
] | Speakable in quantum mechanics: babbling on | This paper consists of a short version of the derivation of the
intuitionistic quantum logic L_QM (which was originally introduced by Caspers,
Heunen, Landsman and Spitters). The elaboration consists of extending this
logic to a classical logic CL_QM. Some first steps are then taken towards
setting up a probabilistic framework based on CL_QM in terms of R\'enyi's
conditional probability spaces. Comparisons are then made with the traditional
framework for quantum probabilities. |
1408.0053v1 | ## Between quantum logic and concurrency
## Luca Bernardinello
Carlo Ferigato
DISCo, Universit` a degli studi di Milano-Bicocca viale Sarca 336 U14, Milano, Italia
JRC, Joint Research Centre of the European Commission via E. Fermi, 1 21027 Ispra, Italia
## Lucia Pomello
DISCo, Universit` a degli studi di Milano-Bicocca viale Sarca 336 U14, Milano, Italia
We start from two closure operators defined on the elements of a special kind of partially ordered sets, called causal nets. Causal nets are used to model histories of concurrent processes, recording occurrences of local states and of events. If every maximal chain (line) of such a partially ordered set meets every maximal antichain (cut), then the two closure operators coincide, and generate a complete orthomodular lattice. In this paper we recall that, for any closed set in this lattice, every line meets either it or its orthocomplement in the lattice, and show that to any line, a two-valued state on the lattice can be associated. Starting from this result, we delineate a logical language whose formulas are interpreted over closed sets of a causal net, where every line induces an assignment of truth values to formulas. The resulting logic is non-classical; we show that maximal antichains in a causal net are associated to Boolean (hence 'classical') substructures of the overall quantum logic.
## 1 Introduction
Partially ordered sets are a natural framework to model concurrent processes, namely processes where several components evolve in parallel, possibly interacting with each other. In Petri net theory (see, for example, [8], [3]) the behaviour of concurrent systems is modelled by causal nets, a class of Petri nets which records a partial order between occurrences of local states and events.
The partial order reflects relations of causal dependence, while concurrency (or independence) is given by lack of mutual order. Petri axiomatized such partial orders, with the aim of describing the flow of information in non-sequential processes, by drawing from the laws of physics, and especially from the theory of relativity ([9]). Among other properties, Petri introduced K-density , which requires that any maximal antichain (or cut ) in the partial order and any maximal chain (or line ) have a non-empty intersection. A line can be interpreted as the history of a sequential subprocess (a particle, a signal), while cuts correspond to time instants, where time is to be intended in a way analogous to the time coordinate in relativistic spacetime. K-density then requires that, at any instant, any sequential subprocess must be in a definite local state or involved in a change of state, modelled by an event (see [3]).
Two binary relations, corresponding to causal dependence and to concurrency, can be defined on the elements of an occurrence net. This suggests an analogy with relativistic spacetime, and in particular with Minkowski spacetime. Several authors have studied algebraic structures derived from Minkowski spacetime (in particular, see [5, 6]). The main result related to our work consists in defining a lattice whose elements are special sets of points in Minkowski, or even in more general, spacetimes, and in showing that such a lattice is complete and orthomodular.
Following similar ideas, but working on discrete partial orders, in [2] a closure operator is defined, whose closed sets are subsets of points of the partial order. It is furthermore shown that under a weak form of K-density, which holds for Petri causal nets, the closed sets form a complete orthomodular lattice.
In the same work it is shown that, in a discrete and locally finite framework, K-dense posets are exactly those in which, chosen an arbitrary closed set, any line intersects either it or its orthocomplement.
In this paper, we strengthen this last result by showing that each line identifies a two-valued state, in the sense of quantum logic. This suggests to look at the closed sets as propositions in a logical language (see Section 3.1), where orthocomplementation corresponds to negation, so that any line induces an interpretation. The resulting logical framework is obviously non-classical.
While lines (or maximal chains) correspond, in this sense, to two-valued states in a quantum logic, cuts (or maximal antichains) correspond to Boolean substructures of the logic, as stated in Section 3.
In the next section, we recall definitions and properties to be used later, related to quantum logics, closure operators, and Petri nets. Section 3 collects our main results.
## 2 Preliminaries
In this section, we recall some basic definitions and results, which will be used in the rest of the paper, related to quantum logics, Petri nets, and closure operators.
## 2.1 Quantum logic
The main reference for this section is [10]. A useful treatment of quantum logic, also in relation to an alternative formulation based on partial Boolean algebras, can be found in [7].
Definition 1 [10] A quantum logic ( P , ≤ , 0 1 , , ( ) ) . ′ is a partially ordered set ( P , ≤ ) , equipped with a minimum element, denoted by 0, and a maximum element, denoted by 1, and with a map ( ) . ′ : P → P called orthocomplementation -such that the following conditions are satisfied (where ∨ and ∧ denote, respectively, the least upper bound and the greatest lower bound with respect to ≤ , when they exist): ∀ x y , ∈ P
- 1. ( x ′ ) ′ = x
- 2. x ≤ y ⇒ ′ ≤ y x ′
- 3. x ∧ x ′ = 0 and x ∨ x ′ = 1
Two elements x y , ∈ P are orthogonal , denoted x ⊥ y, if x ≤ ′ y . P is orthocomplete when every countable subset of pairwise orthogonal elements of P has a least upper bound. Moreover, P is orthomodular when the following condition, called orthomodular law ,
$$x \leq y \ \Rightarrow \ y = x \vee ( y \wedge x ^ { \prime } )$$
is satisfied.
Figure 1 shows one finite and one infinite quantum logic. In a quantum logic, ⊥ is a symmetric relation and the De Morgan laws hold: ( x ∨ y ) ′ = x ′ ∧ y ′ , ( x ∧ y ) ′ = x ′ ∨ y ′ whenever one of the members of the equation exists. We will sometimes use meet and join to denote, respectively, ∧ and ∨ with the obvious extension to families of elements, denoted by ∧ and ∨ . In the following we will sometimes use logic as a shorthand for quantum logic .
Definition 2 Two elements x y of a logic P are said to be , compatible - denoted by x ↔ y - if there exist in P three mutually orthogonal elements x 1 , z and y 1 such that x = x 1 ∨ z and y = y 1 ∨ z.
Definition 3 A logic P is called regular if for any set { x y z , , } of pairwise compatible elements in P, it holds that x ↔ ( y ∨ z . )
Figure 1: Examples of orthomodular quantum logics.
Every logic whose supporting poset is a lattice is regular ([10], proposition 1.3.27).
Aregular quantum logic admits an alternative characterization, as a partial Boolean algebra (see [7]). We will not give the formal definitions related to this view, but only recall it informally. A partial Boolean algebra is a family of partially overlapping Boolean algebras, which share the minimum and the maximum element, and satisfy a set of axioms on the shared elements.
Definition 4 [10] A two-valued state on a logic P is a map s : P →{ 0 1 , } such that, for any sequence ( ai ) i ∈ I of mutually orthogonal elements in P:
- 1. s ( 1 ) = 1
- 2. s (∨ i ∈ I ai ) = S i ∈ I s ai ( )
The set of two-valued states on a logic P will be called S 2 ( P ) . If the elements of a quantum logic are interpreted as propositions of a logical language, two-valued states can be considered as consistent assignments of truth values to those propositions.
## 2.2 Petri nets and causal nets
A Petri net is a discrete model of a concurrent system, based on the notions of local state (or condition) and of local change of state (or event). Formally, they are bipartite graphs, where the arcs encode immediate causal relations.
Here, we will focus on a special case of Petri nets, where the underlying graph induces a partial order on the set of local states and events.
Definition 5 A net is a triple N =( B E F , where B and E are countable sets, F , , ) ⊆ ( B × E ) ∪ ( E × B , ) and
- 1. B ∩ E = / 0 ;
- 2. dom ( F ) ∪ ran ( F ) = B ∪ E.
The elements of B are called conditions , the elements of E are called events and F is called flow relation .
The standard graphical notation for nets represents conditions as circles, events as squares and the flow relation as directed arcs.
The intuitive meaning associated to conditions and events is that conditions represent local states of a system while events represent local changes of state .
For each x ∈ B ∪ E , define · x = { y ∈ B ∪ E | ( y x , ) ∈ F } , x · = { y ∈ B ∪ E | ( x y , ) ∈ F } . For e ∈ E , an element b ∈ B is a precondition of e if b ∈ · e ; it is a postcondition of e if b ∈ e · . In the basic model of Petri nets, which we refer to in this paper, a condition is either true or false ; an event can fire (happen) if its preconditions are all true and its postconditions are false; the effect of an event firing consists in making its preconditions false and its postconditions true.
A net N =( B E F , , ) is simple if for each x y , ∈ B ∪ E : ( · x = · y and x · = y · ) ⇒ x = y .
By F + we denote the irreflexive, transitive closure of F , by F ∗ we denote F + ∪ id X .
Definition 6 A causal net is a net in which the following conditions hold:
$$I. \ \forall b \in B \colon | \{ e \in E \ | \ ( e, b ) \in F \} | \leq 1 \ \wedge \ | \{ e \in E \ | \ ( b, e ) \in F \} | \leq 1 ;$$
glyph[negationslash]
- 2. ∀ x y , ∈ B ∪ E : ( x y , ) ∈ F + ⇒ ( y x , ) = F + .
A causal net is a net without cycles, and such that branches can occur only at events. In the standard terminology, no choices are allowed.
The structure ( X , glyph[subsetsqequal] ) derived from a causal net N by putting X = B ∪ E and glyph[subsetsqequal] = F ∗ is a partially ordered set (shortly a poset ). A subset S ⊆ X is said to be convex if, for each pair of its elements, S contains the interval between them: ∀ x y , ∈ S : [ x y , ] ⊆ S where [ x y , ] = { z ∈ X | x glyph[subsetsqequal] z glyph[subsetsqequal] y } .
Definition 7 ( X , glyph[subsetsqequal] ) is interval-finite ⇔∀ x y , ∈ X : | [ x y , ] | < ¥ . ( X , glyph[subsetsqequal] ) is degree-finite ⇔∀ ∈ x X : | · x | < ¥ and | x · | < ¥ . When ( X , glyph[subsetsqequal] ) is both interval and degree-finite, we will say that it is locally finite . We will apply these terms also to the causal net from which ( X , glyph[subsetsqequal] ) is obtained.
When using discrete partial orders to model processes of real systems, local finiteness is a natural assumption since synchronization of infinite events or causal dependence at infinite distance between the events cannot be realized.
On the poset ( X , glyph[subsetsqequal] ) , the relations li = glyph[subsetsqequal] ∪ glyph[subsetsqequal] -1 , and co =( X × X ) \ li can be defined. Intuitively, x li y means that x and y are connected by a causal relation while x co y means that x and y are causally independent. The relations li and co are symmetric and not transitive. Moreover, li is a reflexive relation, while co is irreflexive.
Given an element x ∈ X and a set S ⊆ X , we write x co S if ∀ y ∈ S : x co y . Given two sets S 1 ⊆ X and S 2 ⊆ X , we write S 1 co S 2 if ∀ x ∈ S 1 , ∀ y ∈ S 2 : x co y .
A clique of a binary relation is a set of pairwise related elements; a clique of co ∪ id X will be also called a coset ; a coset made of conditions only will be called a B-coset . Maximal cliques of co ∪ id X and li are called, respectively, cuts and lines . Given a poset ( X , glyph[subsetsqequal] ) , its cuts and lines will be denoted, respectively, as:
$$\mathcal { C } ( X ) = \{ c \subseteq X \ | \ c \text{ is a maximal clique of $\,cosh_{X}$} \}$$
and
$$\mathcal { L } ( X ) = \{ \, l \subseteq X \ | \ l \text{ is a maximal clique of } \mathbf l \}.$$
We assume the axiom of choice, so any clique of co ∪ id X and of li can be extended to a maximal clique. This will be used in particular in the proof of Theorem 2 below.
In the following, ( X , glyph[subsetsqequal] ) will always be the poset obtained from a causal net N , we will indicate the cuts and lines in X as well as C ( N ) and L ( N ) . When a cut is composed exclusively of conditions, it will be referred to as a B-cut . If A ⊆ X , the definition is restricted naturally to the maximal cliques in A with the notation C ( A ) and L ( A ) .
glyph[negationslash]
Definition 8 ( X , glyph[subsetsqequal] ) is K-dense ⇔∀ ∈ c C ( N ) , ∀ ∈ l L ( N ) : c ∩ l = / 0 .
From their definition, it follows immediately that, if a line and a cut have a non-empty intersection, then the intersection will consist in exactly one point. When this is the case, we will say that the line and the cut meet at a point, or that the line crosses the cut, or viceversa.
## 2.3 Closure operators on causal nets
In this section, we recall the definition and some basic properties of two closure operators on the set of elements of a partially ordered set and, more specifically, on the set of elements of a causal net.
In general, by closure operator on a set Z , we mean a map g : P ( Z ) → P ( Z ) (where P ( Z ) denotes the powerset of Z ), satisfying the following, for all A B , ⊆ Z :
- 1. A ⊆ g ( A ) (increasing)
- 2. if A ⊆ B , then g ( A ) ⊆ g ( B ) (monotone)
- 3. g ( g ( A )) = g ( A ) (idempotent)
A subset A of Z is called closed with respect to g if A = ( ) g A .
The first operator with which we will deal here is defined indirectly, starting from the definition of causally closed sets . These form a family of sets closed by intersection, and with a maximum, with respect to set inclusion. As usual, the closure of an arbitrary set A ⊆ B ∪ E is by definition the intersection of all the causally closed sets that contain A .
Let N =( B E F , , ) be a locally-finite causal net, and X = B ∪ E . A subset of X is causally closed if it is convex with respect to the partial order induced by N , and if it is closed with respect to local causes (preconditions) and local effects (postconditions).
Definition 9 A set C ⊆ X = B ∪ E is a causally closed set if
- (i) ∀ e ∈ E, · e ⊆ C ⇒ ∈ e C,
- (ii) ∀ e ∈ E, e · ⊆ C ⇒ ∈ e C,
- (iii) ∀ e ∈ E, e ∈ C ⇒ · e ∪ e · ⊆ C,
- (iv) ∀ x y , ∈ C, x li y ⇒ [ x y , ] ⊆ C.
The family of causally closed sets of N will be called G ( N . )
Define the border of a subset A ⊆ X as those elements of A which are directly linked, by F-arcs, to elements outside of A : b ( A ) = { x ∈ A | ∃ y ∈ X \ A : ( x y , ) ∈ F ∪ F -1 } . As shown in [2], the border of a causally closed set is made of local states only:
$$\forall A \in \Gamma ( N ) \ \beta ( A ) \subseteq B$$
Moreover, G ( N ) is closed by intersection and 0 / ∈ G ( N ) and B ∪ E ∈ G ( N ) . Hence, the family G ( N ) forms a complete lattice - non orthocomplemented in the general case - where meet is given by set intersection and join is given by the causal closure of the set union of the operands. The associated closure operator, here denoted by f , can now be defined as usual. Let X = B ∪ E .
Definition 10 Define f : P ( X ) → P ( X ) as follows: ∀ A ⊆ X, f ( A ) = ⋂ { Ci | Ci ∈ G ( N ) and A ⊆ Ci } .
Figure 2: Iterative closure of a B-coset.
So, given two elements A and B in G ( N ) , A ∨ B is defined to be f ( A ∪ B ) . As shown in [2], the causal closure of a B-coset can be defined by means of an iterative procedure, which adds new elements according to the axioms in Definition 9. An example is shown in Figure 2. The picture on the left shows a B-coset; the middle picture shows an intermediate step in the procedure, while the picture on the right shows the final step (other intermediate steps are omitted).
The second closure operator is defined following a well-known construction, to be found in [4], and recalled below.
Given a set Z , a symmetric relation a ⊆ Z × Z and a subset A of Z , define
$$A ^ { \prime } = \{ x \in Z \ | \ \forall y \in A \, \colon ( x, y ) \in \alpha \}.$$
By applying twice this operator, we get a new operator ( ) . ′′ , which can be shown to be a closure operator. A subset A of Z is closed if A = A ′′ . The family L Z ( ) of all closed sets of Z , ordered by set inclusion, is then a complete lattice. When a is also irreflexive, the operator ( ) . ′ , applied to elements of L Z ( ) , is an orthocomplementation; the structure L =( ( L Z ) , ⊆ , / 0 , Z , ( ) ) . ′ then forms an orthocomplemented complete lattice [4]. Let us now consider the poset ( X , glyph[subsetsqequal] ) derived from a causal net N together with the irreflexive relation co as in Section 2.2. By applying the construction above, with co as irreflexive and symmetric relation, to the subsets of X , we obtain the orthocomplemented complete lattice ( L N ( ) , ⊆ , / 0 , X , ( ) ) . ′ , where L N ( ) denotes the family of closed subsets of X .
Figure 3 shows a set A of elements of a causal net, together with its orthocomplement, A ′ , and its closure, A ′′ .
In [2] it is shown that this lattice is orthomodular if the construction above is applied to a locally finite poset satisfying a weak form of K-density, called N-density. All causal nets are N-dense ([3]), hence the lattice of closed sets derived from the concurrency relation in a locally finite causal net is complete orthomodular.
As already noted, in general, the lattice of causally closed sets of a locally finite causal net is not even orthocomplemented; however, if the causal net is K-dense, then the two closure operators coincide, and the lattice of causally closed sets is complete orthomodular.
Theorem 1 [2] Let N = ( B E F , , ) be a locally finite, K-dense causal net. Let A ⊆ B ∪ E. Then A ∈ G ( N ) ⇐⇒ A ∈ L N . ( )
Figure 3: A set A , its orthocomplement A ′ , and its closure A ′′ .
## 3 Towards a logical view of closed sets
In this section, we collect the main results of our contribution. The first states that every line in a Kdense causal net N identifies a two-valued state in the lattice (or quantum logic) of closed sets, L N ( ) . This suggests to look at the closed sets as propositions in a logical language (see Section 3.1). The second result concerns the relation between B-cuts and Boolean subalgebras of a quantum logic.
Throughout this section, N =( B E F , , ) will denote an arbitrary locally finite, K-dense causal net. The following lemma states that any closed set can be obtained as the closure of any of its local B-cuts.
## Lemma 1 Let A ∈ L N , and ( ) t a B-cut of A. Then A = t ′′ .
glyph[negationslash]
glyph[negationslash]
Proof. The closure operator is idempotent and monotone; hence, from t ⊆ A , we get t ′′ ⊆ A ′′ = A . To show the inclusion in the other direction, take x ∈ A . If x ∈ t , then x ∈ t ′′ . Suppose x ∈ t . Since t is a B-cut, x li z for some z ∈ t . By way of contradiction, suppose x ∈ t ′′ ; then, there must be w ∈ t ′ , with x li w .
Put x < z (the symmetric case is treated analogously); then x < w , because z co w . Choose a path from x to w ; this path must cross the border of A at an F -arc from a condition b to an event e . Then b must be concurrent to all the elements of t , because A is convex, but this contradicts the hypothesis that t is a cut (maximal antichain) of A .
The previous lemma implies that, for each x ∈ B ∪ E , if x co t , then x co A . This will be used in later proofs.
Now we can prove a crucial relation between lines and closed sets. This is actually a corollary of Theorem 3.2 in [2], but we think that a direct proof could be useful. It says that, given a closed set A , a line crosses either A or A ′ (but not both). The statement is illustrated in Figure 4, where a line is shown with a thicker stroke.
Proposition 1 Let A ∈ L N , and ( ) l ∈ L ( N . Then )
glyph[negationslash]
$$\lambda \cap A \neq \emptyset \Leftrightarrow \lambda \cap A ^ { \prime } = \emptyset$$
Figure 4: A line crosses either a closed set or its orthocomplement.
glyph[negationslash]
Proof. Suppose l ∩ A = / . 0 Any element in A ′ is concurrent with any element in A . Since l is a clique of the li relation, no element in l can be in A ′ .
Suppose now that l ∩ A = / . 0 Take a B-cut of A , say t 1. This is a B-coset of N , and can be extended to a B-cut of N , say t . Since N is K-dense, t crosses l at a point b ∈ B . Then b co t 1, and, by Lemma 1, b co A , which means b ∈ A ′ .
Building on the previous proposition, we now define a map associated to a line in N . The map can be seen as the characteristic map of the family of closed sets that cross the given line.
glyph[negationslash]
Definition 11 Let l be a line of N. Define D ( l ) = { A ∈ L N ( ) | A ∩ l = / 0 } , and dl : L N ( ) →{ 0 1 , } in this way: for each A ∈ L N , ( ) dl ( A ) = 1 if A ∈ D ( l ) , 0 otherwise.
Theorem 2 The map dl is a two-valued state of L ( N . )
glyph[negationslash]
glyph[negationslash]
Proof. Let ( Ai ) i ∈ I be a family of pairwise orthogonal closed sets. Then, for each i , j , i = j , Ai ⊆ A j ′ . Hence, if l crosses one of the Ai s, it cannot cross any of the others because of Proposition 1. From this, it follows that, if dl ( Ai ) = 1, then dl ( Aj ) = 0 for any j = i , and dl ( ∨ Ai ) = 1.
Suppose now that dl ( Ai ) = 0 for each i ∈ I . We will show that l does not cross ∨ Ai . For each i ∈ I , take a B-cut of Ai . The elements of all the B-cuts of the Ai 's are pairwise concurrent; hence their union is a B-coset, and can be extended to a B-cut of N . Since N is K-dense, this cut crosses l at a point, say s , and s is concurrent with all the Ai s. By way of contradiction, suppose now that ∨ Ai crosses l at a point b . Since this point is in the closure of ⋃ Ai , it must satisfy b co ( ∨ Ai ) ′ . But this implies b co s , contradicting the hypothesis that b and s are on the same line.
The previous results relate lines and two-valued states in quantum logics. We now briefly point out a dual relation between cuts in a causal net and Boolean subalgebras in the lattice of closed sets.
We have already noted that a regular quantum logic can be seen as a family of partially overlapping Boolean algebras. In our context, these component Boolean algebras are atomic.
Consider a B-cut of N , say t = { b 1 , . . . , bi , . . . } . For each bi in t , compute { bi } ′′ = b i . The closed sets obtained in this way are pairwise orthogonal in the lattice of closed sets, which means that they are pairwise concurrent in N . Their join gives B ∪ E .
Then, the set { b 1 , . . . , b i , . . . } is the set of atoms of a (maximal) Boolean subalgebra of L N ( ) . More generally, given a family ( Ai ) i ∈ I of pairwise orthogonal (concurrent) closed sets, such that ∨ i ∈ I Ai = B ∪ E , there is a Boolean subalgebra of L N ( ) such that the Ai s are its atoms.
## 3.1 Logic
The statement of Theorem 2 suggests to look at the closed sets in L N ( ) as propositions of a logical language, which admits a different interpretation for each line in N .
In fact, each line selects exactly one closed set for each pair ( A A , ′ ) , and this selection is consistent with the structure of the lattice of closed sets: let us say that the proposition associated to A is true, with respect to a line l , if l crosses A , and false otherwise. Then, we can take ( ) . ′ as a negation, while the lattice operations correspond to the logical connectives, disjunction (join), and conjunction (meet). Theorem 2 guarantees that, under this interpretation, if two propositions are true, then also their conjunction is true, while the conjunction of two 'compatible' propositions is true only if at least one of them is true, where two propositions are compatible if their corresponding closed sets are compatible in the quantum logic L N ( ) (or, equivalently, if there is a Boolean subalgebra of L N ( ) which contains both).
The resulting logic is obviously non-classical, since the lattice of closed sets is not, in general, distributive. It is, so to speak, locally classical, in the sense that the set of closed sets associated to true propositions, projected on a Boolean subalgebra of L N ( ) gives an ultrafilter.
Formally, we define the propositional language F P and its interpretation over the orthomodular lattice L N ( ) . Let P =( p i ) i ∈ I be a set of propositions . Define the set F P of formulas over P , inductively, as follows:
- (i) every p i is a formula;
- (ii) if f 1 , f 2 are formulas, then f 1 ∨ f 2, f 1 ∧ f 2, ¬ f 1, f 1 → f 2 are formulas;
- (iii) nothing else is a formula.
An interpretation of the language of formulas F P is a pair J = 〈 h : P → L N ( ) , l ∈ L ( N ) 〉 .
To each formula f , we can associate an element of L N ( ) , by defining a map i : F P → L N ( ) , as follows. If f = p i , then i ( f ) = h ( p i ) ; if f = ¬ ( f 1 ) , then i ( f ) = ( ( i f 1 )) ′ ; if f = f 1 ∨ f 2, then i ( f ) = i ( f 1 ) ∨ i ( f 2 ) , where ∨ is the join operation in the lattice L N ( ) ; if f = f 1 ∧ f 2, then i ( f ) = i ( f 1 ) ∧ i ( f 2 ) , where ∧ is the meet operation in the lattice L N ( ) ; if f = f 1 → f 2, then i ( f ) = ( ( i f 1 )) ′ ∨ i ( f 2 ) .
With this definition, the implication connective and the partial order on L N ( ) are related by the following statement: if i ( f 1 ) ⊆ i ( f 2 ) , then i ( f 1 → f 2 ) = B ∪ E .
The choice of the line l in an interpretation determines the assignment of truth values to formulas: a formula is true if l crosses the closed set associated to the formula by the map i . Formally, we define a satisfiability relation between interpretations and formulas:
glyph[negationslash]
$$J \models f \ \Leftrightarrow \ i ( f ) \cap \lambda \neq \emptyset.$$
This definition is consistent, in the sense that, by direct verification, one can prove the following:
- 1. J | = f ∧ g if, and only if, J | = f and J | = g
glyph[negationslash]
- 2. J | = ¬ f if, and only if, J | = f
- 3. J | = f ∨ g if, and only if, i ( f ) ↔ i ( g ) , and either J | = f or J | = g ;
- 4. J | = f → g if, and only if, i ( f ) ⊆ i ( g ) .
The case of disjunctive formulas can be illustrated by means of a simple example. Consider the net below (which might be a fragment of a larger net).
Let f and g be two propositions interpreted, respectively, over { p } and { } r , which are closed sets. Then i ( f ∨ g ) = { p q e r s , , , , } . With respect to a line l containing { q e s , , } , the formula f ∨ g is true, while f and g are false. In this case i ( f ) and i ( g ) are not compatible in L N ( ) .
Suppose now to interpret f and g over { p } and { } q , which are compatible in L N ( ) . The interpretation of f ∨ g is the same as before, namely { p q e r s , , , , } , but any line crossing this closed set is bound to cross either { p } or { } q , so that either f or g is true.
## 4 Conclusion and prospects
A first connection between orthomodular structures and concurrency theory emerged by studying an abstract notion of local state in automata and in Petri nets (see [1]).
Later, a different connection was found, which bears a more direct relation with special relativity theory. Several authors had previously shown that a closure operator, and a corresponding orthomodular lattice, can be derived from the 'spacelike' relation between points in Minkowski spacetime ([5, 6]).
A similar construction was then applied to discrete partially ordered sets modelling the history of concurrent, or distributed, system. In the discrete case, the orthomodularity of the resulting lattice of closed sets depends on a feature of the partially ordered set which was called N-density by C.A. Petri ([2]).
In this context, the specific character of the causal nets introduced by Petri is the distinction between synchronization events and local properties changed by the occurrence of the events. With this distinction, lines can be interpreted as signals whose status is changed by the interaction event with other signals and preserving their local status until another interaction occurs. This in analogy with flows of particles in space whose mutual interactions are collisions .
For causal nets and in partial orders derived from causal nets, density properties were studied mainly with the aim of providing a sound set of axioms for the definition of the causal structures representing concurrent processes of systems. In this respect, [3] gives a comprehensive survey of the properties of partially ordered sets related to causal nets. In particular, the relations between N-density and K-density are presented in the specific context of models of concurrent systems.
Starting from what we have presented here, we will undertake several further steps: characterize those orthomodular lattices that can be obtained as lattices of closed sets induced by concurrency; building a causal net whose lattice of closed sets is isomorphic to a given lattice; study lattices of closed sets induced by concurrency in other classes of Petri nets; give a meaning to the logical language here defined.
## Acknowledgments
This work was partially supported by MIUR and by MIUR-PRIN 2010/2011 grant 'Automi e Linguaggi Formali: Aspetti Matematici e Applicativi', code H41J12000190001.
## References
- [1] Luca Bernardinello, Carlo Ferigato & Lucia Pomello (2003): An algebraic model of observable properties in distributed systems . Theor. Comput. Sci. 290(1), pp. 637-668, doi:10.1016/S0304-3975(02)00046-4.
- [2] Luca Bernardinello, Lucia Pomello & Stefania Rombol` a (2010): Closure Operators and Lattices Derived from Concurrency in Posets and Occurrence Nets . Fundamenta Informaticae 105(3), pp. 211-235. Available at http://dx.doi.org/10.3233/FI-2010-365 .
- [3] E. Best & C. Fernandez (1988): Nonsequential Processes-A Petri Net View . EATCS Monographs on Theoretical Computer Science 13, Springer-Verlag, doi:10.1007/978-3-642-73483-0.
- [4] G. Birkhoff (1979): Lattice Theory . American Mathematical Society; 3rd Ed.
- [5] H. Casini (2002): The logic of causally closed spacetime subsets . Class. Quantum Grav. 19, pp. 6389-6404, doi:10.1088/0264-9381/19/24/308.
- [6] Z. Cegła, W. Jadczyk (1977): Causal logic of Minkowski space . Commun. Math. Phys. 57, pp. 213-217, doi:10.1007/bf01614163.
- [7] R.I.G. Hughes (1989): The Structure and Interpretation of Quantum Mechanics . Harvard University Press.
- [8] C. A. Petri (1977): Non-Sequential Processes . Technical Report ISF-77-5, GMD Bonn. Translation of a lecture given at the IMMD Jubilee Colloquium on 'Parallelism in Computer Science', Universit¨ at ErlangenN¨ urnberg. June 1976.
- [9] C.A. Petri (1982): State-transition structures in physics and in computation . International Journal of Theoretical Physics 21(12), pp. 979-992, doi:10.1007/BF02084163.
- [10] P. Pt´k, P. Pulmannov´ a (1991): a Orthomodular Structures as Quantum Logics . Kluwer Academic Publishers. | 10.4204/EPTCS.158.6 | [
"Luca Bernardinello",
"Carlo Ferigato",
"Lucia Pomello"
] | 2014-08-01T00:25:18+00:00 | 2014-08-01T00:25:18+00:00 | [
"cs.LO",
"cs.DM"
] | Between quantum logic and concurrency | We start from two closure operators defined on the elements of a special kind
of partially ordered sets, called causal nets. Causal nets are used to model
histories of concurrent processes, recording occurrences of local states and of
events. If every maximal chain (line) of such a partially ordered set meets
every maximal antichain (cut), then the two closure operators coincide, and
generate a complete orthomodular lattice. In this paper we recall that, for any
closed set in this lattice, every line meets either it or its orthocomplement
in the lattice, and show that to any line, a two-valued state on the lattice
can be associated. Starting from this result, we delineate a logical language
whose formulas are interpreted over closed sets of a causal net, where every
line induces an assignment of truth values to formulas. The resulting logic is
non-classical; we show that maximal antichains in a causal net are associated
to Boolean (hence "classical") substructures of the overall quantum logic. |
1408.0054v1 | ## Quantum Gauge Field Theory
## in
## Cohesive Homotopy Type Theory
Urs Schreiber
University Nijmegen The Netherlands
[email protected]
Michael Shulman
University of San Diego San Diego, CA, USA
[email protected]
We implement in the formal language of homotopy type theory a new set of axioms called cohesion . Then we indicate how the resulting cohesive homotopy type theory naturally serves as a formal foundation for central concepts in quantum gauge field theory. This is a brief survey of work by the authors developed in detail elsewhere [47, 44].
## 1 Introduction
The observable world of physical phenomena is fundamentally governed by quantum gauge field theory (QFT) [16], as was recently once more confirmed by the detection [13] of the Higgs boson [8]. On the other hand, the world of mathematical concepts is fundamentally governed by formal logic , as elaborated in a foundational system such as axiomatic set theory or type theory.
Quantum gauge field theory is traditionally valued for the elegance and beauty of its mathematical description (as far as this has been understood). Formal logic is likewise valued for elegance and simplicity; aspects which have become especially important recently because they enable formalized mathematics to be verified by computers. This is generally most convenient using type-theoretic foundations [33]; see e.g. [15].
However, the mathematical machinery of quantum gauge field theory - such as differential geometry (for the description of spacetime [34]), differential cohomology (for the description of gauge force fields [24, 21]) and symplectic geometry (for the description of geometric quantization [10]) - has always seemed to be many levels of complexity above the mathematical foundations. Thus, while automated proof-checkers can deal with fields like linear algebra [15], even formalizing a basic differentialgeometric definition (such as a principal connection on a smooth manifold) seems intractable, not to speak of proving its basic properties.
We claim that this situation improves drastically by combining two insights from type theory. The first is that type theory can be interpreted 'internally' in locally Cartesian closed categories (see e.g. [14]), including categories of smooth spaces (which contain the classical category of smooth manifolds). In this way, type-theoretic arguments which appear to speak about discrete sets may be interpreted to speak about smooth spaces, with the smooth structure automatically 'carried along for the ride'. Thus, differential notions can be developed in a simple and elegant axiomatic framework - avoiding the complexity of the classical definitions by working in a formal system whose basic objects are already 'smooth'. This is known as synthetic differential geometry (SDG) [27, 28, 36]. In this paper, we will axiomatize it in a way which does not require that our basic objects are 'smooth', only that they are 'cohesive' as in [29]. This includes topological objects as well as smooth ones, and also variants of differential geometry such
c © U. Schreiber & M. Shulman
as supergeometry , which is necessary for a full treatment of quantum field theory (for the description of fermions).
The second insight is that types in intensional type theory can also behave like homotopy types , a.k.a. ¥ -groupoids , which are not just sets of points but contain higher homotopy information. Just as SDG imports differential geometry directly into type theory, this one imports homotopy theory , and as such is called homotopy type theory [56, 1, 51, 40].
Combining these insights, we obtain cohesive homotopy type theory [47, 44]. Its basic objects (the 'types') have both cohesive structure and higher homotopy structure . These two kinds of structure are independent, in contrast to how classical algebraic topology identifies homotopy types with the topological spaces that present them. For instance, the geometric circle S 1 is categorically 0-truncated (it has a mere set of points with no isotropy), but carries an interesting topological or smooth structure - whereas the homotopy type it presents, denoted P ( S 1 ) or B Z (see below), has (up to equivalence) only one point (with trivial topology), but that point has a countably infinite isotropy group. More general cohesive homotopy types can be nontrivial in both ways, such as orbifolds [35, 30] and moduli stacks [57]. In particular the standard model of SDG known as the Cahiers topos lifts to a model of cohesive homotopy type theory that contains orbifolds and generally moduli stacks equipped with synthetic differential structure (section 4.5 of [44]).
Today it is clear that homotopy theory is at the heart of quantum field theory. One way to define an n -dimensional QFT is as a rule that assigns to each closed ( n -1 -dimensional manifold, a vector space ) -its space of quantum states -and to each n -dimensional cobordism , a linear map between the corresponding vector spaces - a correlator -in a way which respects gluing of cobordisms. An extended or local QFT also assigns data to all ( 0 ≤ k ≤ n ) -dimensional manifolds, such that the data assigned to any manifold can be reconstructed by gluing along lower dimensional boundaries. By [3, 32], the case of extended topological QFT (where the manifolds are equipped only with smooth structure) is entirely defined and classified by a universal construction in directed homotopy theory , i.e. ( ¥ , n ) -category theory [7, 50]. For non-topological QFTs, where the cobordisms have conformal or metric structure, the situation is more complicated, but directed homtopy type theory still governs the construction; see [42] for recent developments. We will see in section 3.3 how in cohesive homotopy type theory one naturally obtains such higher spaces of (pre-)quantum states assigned to manifolds of higher codimension.
Notice, as discussed in the introduction of [42], that many of the developments that led to these insights about the role of homotopy theory in quantum field theory originate in string theory , but they are now statements in pure QFT. String theory is the investigation of the second quantization of 1dimensional quanta ('strings') instead of 0-dimensional quanta ('particles') and this increase in geometric dimension induces a corresponding increase of homotopical dimension of many aspects. At least some of these are also usefully captured by cohesive homotopy type theory [45]. But while the phenomenological relevance of string theory for fundamental physics remains speculative, its proposal alone led to further investigation into the nature of pure quantum field theories which showed how this alone already involves homotopy theory, as used here.
The value of cohesive homotopy theory for physics lies in the observation that the QFTs observed to govern our world at the fundamental level - namely, Yang-Mills theory (for electromagnetism and the weak and strong nuclear forces) and Einstein general relativity (for gravity) - are not random instances of such QFTs. Instead (1) their construction follows a geometric principle, traditionally called the gauge symmetry principle [39], and (2) they are obtained by quantization from ('classical') data that lives in differential cohomology . Both of these aspects are actually native to cohesive homotopy type theory, as follows:
- 1. The very concept of a collection of quantum field configurations with gauge transformations between them is really that of a configuration groupoid , hence of a homotopy 1-type. More generally, in higher gauge theories such as those that appear in string theory, the higher gauge symmetries make the configurations form higher groupoids, hence general homotopy types. Furthermore, these configuration groupoids of gauge fields have smooth structure : they are smooth homotopy types .
To physicists, these smooth configuration groupoids are most familiar in their infinitesimal Lietheoretic approximation: the (higher) Lie algebroids whose function algebras constitute the BRST complex , in terms of which modern quantum gauge theory is formulated [22]. The degreen BRST cohomology of these complexes corresponds to the n th homotopy group of the cohesive homotopy types.
- 2. Gauge fields are cocycles in a cohomology theory (sheaf hyper-cohomology), and the gauge transformations between them are its coboundaries. A classical result [9] says, in modern language, that all such cohomology theories are realized in some interpretation of homotopy type theory (in some ( ¥ , 1 -category of ) ( ¥ , 1 -sheaves): the cocycles on ) X with coefficients in A are just functions X → A . Moreover, if A is the coefficients of some differential cohomology theory, then the type of all such functions is exactly the configuration gauge groupoid of quantum fields on A from above. This cannot be expressed in plain homotopy theory, but it can be in cohesive homotopy theory.
Finally, differential cohomology is also the natural context for geometric quantization , so that central aspects of this process can also be formalized in cohesive homotopy type theory.
In § 2, we briefly review homotopy type theory and then describe the axiomatic formulation of cohesion. The axiomatization is chosen so that if we do build things from the ground up out of sets, then we can construct categories (technically, ( ¥ , 1 -categories of ) ( ¥ , 1 -sheaves) in which cohesive homotopy ) type theory is valid internally. This shows that the results we obtain can always be referred back to a classical context. However, we emphasize that the axiomatization stands on its own as a formal system.
Then in § 3, we show how cohesive homotopy type theory directly expresses fundamental concepts in differential geometry, such as differential forms, Maurer-Cartan forms, and connections on principal bundles. Moreover, by the homotopy-theoretic ambient logic, these concepts are thereby automatically generalized to higher differential geometry [37]. In particular, we show how to naturally formulate higher moduli stacks for cocycles in differential cohomology . Their 0-truncation shadow has been known to formalize gauge fields and higher gauge fields [21]. We observe that their full homotopy formalization yields a refinement of the Chern-Weil homomorphism from secondary characteristic classes to cocycles, and also the action functional of generalized Chern-Simons-type gauge theories with an extended geometric prequantization. At present, however, completing the process of quantization requires special properties of the usual models; work is in progress isolating exactly how much quantization can be done formally in cohesive homotopy type theory.
The constructions of § 2 have been fully implemented in Coq 1 [55]; the source code can be found at [49]. With this as foundation, the implementation of much of § 3 is straightforward.
1 Currently, this requires a patch to Coq that collapses universe levels (making it technically inconsistent). However, true 'universe polymorphism' is slated for future inclusion in Coq, which should should make this no longer necessary.
## 2 Cohesive homotopy type theory
## 2.1 Categorical type theory
Atype theory is a formal system whose basic objects are types and terms , and whose basic assertions are that a term a belongs to a type A , written ' a : A '. More generally, ( x : A ) , ( y : B ) glyph[turnstileleft] ( c : C ) means that given variables x and y of types A and B , the term c has type C . For us, types themselves are terms of type Type . (One avoids paradoxes arising from Type : Type with a hierarchy of universes.) Types involving variables are called dependent types .
Operations on types include cartesian product A × B , disjoint union A + B , and function space A → B , each with corresponding rules for terms. Thus A × B contains pairs ( a b , ) with a : A and b : B , while A → B contains functions l x A . b where b : B may involve the variable x : A , i.e. ( x : A ) glyph[turnstileleft] ( b : B ) . Similarly, if ( x : A ) glyph[turnstileleft] ( B x ( ) : Type ) is a dependent type, its dependent sum GLYPH<229> x A : B x ( ) contains pairs ( a b , ) with a : A and b : B a ( ) , while its dependent product GLYPH<213> x A : B x ( ) contains functions l x A . b where ( x : A ) glyph[turnstileleft] ( b : B x ( )) .
In many ways, types and terms behave like sets and elements as a foundation for mathematics. One fundamental difference is that in type theory, rather than proving theorems about types and terms, one identifies 'propositions' with types containing at most one term (also called 'mere propositions', for emphasis), and 'proofs' with terms belonging to such types. Constructions such as × → , , GLYPH<213> restrict to logical operations such as ∧ ⇒ ∀ , , , embedding logic into type theory. By default, this logic is constructive , but one can force it to be classical.
Type theory also admits categorical models , where types are interpreted by objects of a category H , while a term ( x : A ) , ( y : B ) glyph[turnstileleft] ( c : C ) is interpreted by a morphism A × B → C . A dependent type ( x : A ) glyph[turnstileleft] ( B x ( ) : Type ) is interpreted by B ∈ H / A , while ( x : A ) glyph[turnstileleft] ( b : B x ( )) is interpreted by a section of B , and substitution of a term for x in B x ( ) is interpreted by pullback. Thus, we can 'do mathematics' internal to H , with any additional structure on its objects carried along automatically. In this case, the logic is usually unavoidably constructive.
In the context of quantum physics, such 'internalization' has been used in the 'Bohrification' program [23] to make noncommutative von Neumann algebras into internal commutative ones. There are also 'linear' type theories which describe mathematics internal to monoidal categories (such as Hilbert spaces); see [5].
## 2.2 Homotopy type theory
Since propositions are types, we expect equality types
$$( x \colon A ) \,, \, ( y \colon A ) \, \vdash \, \left ( ( x = y ) \colon \text{Type} \right ).$$
But surprisingly, ( x = ) y is naturally not a mere proposition. We can add axioms forcing it to be so, but if we don't, we obtain homotopy type theory [40], where types behave less like sets and more like homotopy types or ¥ -groupoids . 2 Space does not permit an introduction to homotopy theory and higher category theory here; see e.g. [31, § 1.1]. We re-emphasize that in cohesive homotopy type theory, simplicial or algebraic models for homotopy types are usually less confusing than topological ones.
Homotopy type theory admits models in ( ¥ , 1 ) -categories , where the equality type of A indicates its diagonal A → × A A . Voevodsky's univalence axiom [26] implies that the type Type is an object classifier : there is a morphism p : Type · → Type such that pullback of p induces an equivalence of ¥ -groupoids
$$\mathbf H ( A, \text{Type} ) \simeq \text{Core} _ { \kappa } ( \mathbf H / A ).$$
$$\kappa$$
2 The associativity of terminology 'homotopy (type theory) = (homotopy type) theory' is coincidental, though fortunate!
(The core of an ( ¥ , 1 -category contains all objects, the morphisms that are equivalences, and all higher ) cells; Core k denotes the small full subcategory of ' k -small' objects.) A well-behaved ( ¥ , 1 -category ) with object classifiers is called an ( ¥ , 1 ) -topos ; these are the natural places to internalize homotopy type theory. 3
An object X ∈ H is n-truncated if it has no homotopy above level n . The 0-truncated objects are like sets, with no higher homotopy, while the ( -1 -truncated objects are the propositions. ) The n -truncated objects in an ( ¥ , 1 -topos are reflective, with reflector ) p n ; in type theory, this is an example of a higher inductive type [54, 40],which is the homotopy-theoretic refinement of a type defined by induction, such as the natural numbers. The ( -1 -truncation of a morphism ) X → Y , regarded as an object of H / Y , is its image factorization .
## 2.3 Cohesive ( ¥ , 1 ) -toposes
A cohesive ( ¥ , 1 ) -topos is an ( ¥ , 1 -category whose objects can be thought of as ) ¥ -groupoids endowed with 'cohesive structure', such as a topology or a smooth structure. As observed in [29] for 1-categories, this gives rise to a string of adjoint functors relating H to ¥ -Gpd (which replaces Set in [29]). First, the underlying functor G : H → ¥ -Gpd forgets the cohesion. This can be identified with the hom-functor H ( ∗ -, ) , where the terminal object ∗ is a single point with its trivial cohesion.
Secondly, any ¥ -groupoid admits both a discrete cohesion, where no distinct points 'cohere' nontrivially, and a codiscrete cohesion, where all points 'cohere' in every possible way. This gives two fully faithful functors D : ¥ -Gpd → H and GLYPH<209> : ¥ -Gpd → H , left and right adjoint to G respectively.
Finally, D also has a left adjoint P , which preserves finite products. In [29], P computes sets of connected components , but for ( ¥ , 1 -categories, ) P computes entire fundamental ¥ -groupoids . There are two origins of higher morphisms in P ( X ) : the higher morphisms of X , and the cohesion of X . If X = D Y is an ordinary ¥ -groupoid with discrete cohesion, then P ( X ) glyph[similarequal] Y . But if X is a plain set with some cohesion (such as an ordinary smooth manifold), then P ( X ) is its ordinary fundamental ¥ -groupoid, whose higher cells are paths and homotopies in X . If X has both higher morphisms and cohesion, then P ( X ) automatically combines these two sorts of higher morphisms sensibly, like the Borel construction of an orbifold.
Thus, we define an ( ¥ , 1 -topos ) H to be cohesive if it has an adjoint string
O
O
O
O
GLYPH<15>

GLYPH<15>
GLYPH<15>
GLYPH<15>
where D and GLYPH<209> are fully faithful and P preserves finite products. Using ¥ -sheaves on sites [46], we can obtain such H 's which contain smooth manifolds as a full subcategory; we call these smooth models .
Now we plan to work in the internal type theory of such an H , so we must reformulate cohesiveness internally to H . But since D and GLYPH<209> are fully faithful, from inside H we see two subcategories, of which the codiscrete objects are reflective, and the discrete objects are both reflective (with reflector preserving finite products) and coreflective. We write glyph[sharp] : = GLYPH<209>G for the codiscrete reflector, glyph[flat] : = DG for the discrete coreflector, and P : = DP for the discrete reflector. Assuming only this, if A is discrete and B is codiscrete, we have
$$\mathbf H ( \ddagger A, B ) \simeq \mathbf H ( A, B ) \simeq \mathbf H ( A, \flat B )$$
3 There are, however, coherence issues in making this precise, which are a subject of current research; see e.g. [52, 53].
so that glyph[sharp] glyph[turnstileright] glyph[flat] is an adjunction between the discrete and codiscrete objects. If we assume that for any A ∈ H , the maps glyph[flat] A → glyph[flat]glyph[sharp] A and glyph[sharp]glyph[flat] A → glyph[sharp] A induced by glyph[flat] A → A → glyph[sharp] A are equivalences, this adjunction becomes an equivalence, modulo which glyph[flat] is identified with glyph[sharp] (i.e. G ). From this we can reconstruct (2), except that the lower ( ¥ , 1 -topos need not be ) ¥ -Gpd . This is expected: just as homotopy type theory admits models in all ( ¥ , 1 -toposes, cohesive homotopy type theory admits models that are 'cohesive over any ) base'.
We think of glyph[sharp] , glyph[flat] , and P as modalities , like those of [2], but which apply to all types, not just propositions. Note also that as functors H → H , we have P glyph[turnstileright] glyph[flat] , since for any A and B
$$\mathbf H ( \Pi A, B ) \simeq \mathbf H ( \Pi A, \flat B ) \simeq \mathbf H ( A, \flat B )$$
as both P A and glyph[flat] B are discrete.
## 2.4 Axiomatic cohesion I: Reflective subfibrations
We begin our internal axiomatization with the reflective subcategory of codiscrete objects. An obvious way to describe a reflective subcategory in type theory is to use Type . (This idea is also somewhat na¨ ıve; in a moment we will discuss an important subtlety.) First we need, for any type A , a proposition expressing the assertion ' A is codiscrete'. Since propositions are particular types, this can simply be a function term
$$\text{isCodisc} \, \colon \text{Type} \rightarrow \text{Type}$$
together with an axiom asserting that for any type A , the type isCodisc ( A ) is a proposition:
$$( A \colon \text{Type} ) \vdash ( \text{isCodiscIsProp} _ { A } \colon \text{isProp} ( \text{isCodisc} ( A ) ) )$$
Next we need the reflector glyph[sharp] and its unit:
$$\mathfrak { k } \colon \text{Type} \to \text{Type}.$$
$$( A \colon \text{Type} ) \vdash ( \text{sharpIsCodisc} _ { A } \colon \text{isCodisc} ( \i A ) )$$
$$( A \colon \text{Type} ) \, \vdash \, ( \eta _ { A } \, \colon A \to \ddot { \pi } A ) \,.$$
Finally, we assert the universal property of the reflection: if B is codiscrete, then the space of morphisms glyph[sharp] A → B is equivalent, by precomposition with h A , to the space of morphisms A → B .
$$( A \colon \text{Type} ), ( B \colon \text{Type} ), ( \text{bc} \colon \text{isCodisc} ( B ) ) \vdash \left ( t s r \colon \text{isEquiv} ( \lambda f ^ { \tilde { A } \to B }. f \circ \eta _ { A } ) \right )$$
This looks like a complete axiomatization of a reflective subcategory, but in fact it describes more data than we want, because Type is an object classifer for all slice categories. If H satisfies these axioms, then each H / X is equipped with a reflective subcategory, and moreover these subcategories and their reflectors are stable under pullback. For instance, if A ∈ H / X is represented by ( x : X ) glyph[turnstileleft] ( A x ( ) : Type ) , then the dependent type ( x : X ) glyph[turnstileleft] ( ( glyph[sharp] A x ( )) : Type ) represents a 'fiberwise reflection' glyph[sharp] X ( A ) ∈ H / X .
We call such data a reflective subfibration [11]. If a reflective subcategory underlies some reflective subfibration, then its reflector preserves finite products, and the converse holds in good situations [48]. If the reflector even preserves all finite limits , as glyph[sharp] does, then there is a canonical extension to a reflective subfibration. Namely, we define A ∈ H / X to be relatively codiscrete if the naturality square for h :
/
/
GLYPH<15>
GLYPH<15>
/
/
GLYPH<15>
GLYPH<15>
is a pullback. (This says that A has the 'initial cohesive structure' induced from X : elements of A cohere in precisely the ways that their images in X cohere.) For general A ∈ H / X , we define glyph[sharp] X A to be the pullback of glyph[sharp] A → glyph[sharp] X along X → glyph[sharp] X . When glyph[sharp] preserves finite limits, this defines a reflective subfibration.
Reflective subfibrations constructed in this way are characterized by two special properties. The first is that the relatively codiscrete morphisms are closed under composition. A reflective subfibration with this property is equivalent to a stable factorization system : a pair of classes of morphisms ( E , M ) such that every morphism factors essentially uniquely as an E -morphism followed by an M -morphism, stably under pullback. (The corresponding reflective subcategory of H / X is the category of M -morphisms into X .) If a reflective subcategory underlies a stable factorization system, its reflector preserve all pullbacks over objects in the subcategory - and again, the converse holds in good situations [48]; such a reflector has stable units [12].
We can axiomatize this property as follows. Axiom (8) implies, in particular, a factorization operation:
$$( \text{bc} \, \colon \text{isCodisc} ( B ) ) \,, ( f \, \colon \text{$A\to B$} ) \, \vdash \, ( \text{fact} _ { \natural } ( f ) \, \colon \natural A \to B )$$
$$\left ( \text{bc} \, \colon \text{isCodisc} ( B ) \right ), \left ( f \, \colon A \rightarrow B \right ) \, \vdash \, \left ( \text{ff} _ { f } \, \colon \left ( \text{fact} _ { \natural } ( f ) \circ \eta _ { A } = f ) \right )$$
It turns out that relatively codiscrete morphisms are closed under composition if and only if we have a more general factorization operation, where B may depend on glyph[sharp] A :
$$\left ( \text{bc} \colon \Pi _ { x \tilde { \epsilon } A } \text{ isCodisc} ( B ( x ) ) \right ), \left ( f \colon \Pi _ { x A } B ( \eta _ { A } ( x ) ) \right ) \vdash \left ( \text{fact} _ { \tilde { \epsilon } } ( f ) \colon \Pi _ { x \tilde { \epsilon } A } B ( x ) \right ) \quad \text{(11)}$$
$$\left ( \mathrm b c \colon \Pi _ { x ; \mathring { A } } \, \text{isCodisc} ( B ( x ) ) \right ), \left ( f \colon \Pi _ { \mathring { c } A } \, B ( \eta _ { A } ( x ) ) \right ) \vdash \, \left ( \mathbf f _ { f } \colon \left ( \mathrm a f _ { \mathring { d } } ( f ) \circ \eta _ { A } = f ) \right ) \, \quad \, ( 1 2 )$$
This sort of 'dependent factorization' is familiar in type theory; it is related to (9)-(10) in the same way that proof by induction is related to definition by recursion.
The second property is that if g ∈ E and gf ∈ E , then f ∈ E . If a stable factorization system has this property, then it is determined by its underlying reflective subcategory, whose reflector must preserve finite limits. ( E is the class of morphisms inverted by the reflector, and M is defined by pullback as above.) We can state this in type theory as the preservation of glyph[sharp] -contractibility by homotopy fibers:
$$( \text{acs} \, \colon \, \text{isContr} ( \mathfrak { f } A ) ) \,, \, ( \text{bcs} \, \colon \, \text{isContr} ( \mathfrak { f } B ) ) \,, \, ( f \, \colon A \rightarrow B ) \,, \, ( b \, \colon B ) \ \vdash \ \, ( \text{fcs} \, \colon \, \text{isContr} ( \mathfrak { f } \sum _ { \mathfrak { r } A } ( f ( x ) = b ) ) )$$
This completes our axiomatization of the reflective subcategory of codiscrete objects. We can apply the same reasoning to the reflective subcategory of discrete objects. Now P does not preserve all finite limits, only finite products, so we cannot push the characterization all the way as we did for glyph[sharp] . But because the target of P is ¥ -Gpd , it automatically has stable units; thus the discrete objects underlie some stable factorization system ( E , M ) , which can be axiomatized as above with (13) omitted. (For cohesion over a general base, we ought to demand stable units explicitly.) We do not know whether there is a particular choice of such an ( E , M ) to be preferred. In § 2.5, we will mention a different way to axiomatize P which is less convenient, but does not require choosing ( E , M ) .
## 2.5 Axiomatic cohesion II: glyph[sharp] Type
We consider now an axiomatization of the external hom H ( A B , ) in addition to the internal hom A → B . The latter we will equivalently write also as [ A B , ] , which better matches the convention in algebraic topology and in geometry. More precisely, we consider the external ¥ -groupoid H ( A B , ) , re-internalized
as a codiscrete object. (Since glyph[sharp] preserves more limits than P , the codiscrete objects are a better choice for this sort of thing.)
To construct such an external function-type, consider glyph[sharp] Type . This is a codiscrete object, which as an ¥ -groupoid is interpreted by the core of (some small full subcategory of) H . Any type A : Type has an 'externalized' version h Type ( A ) : glyph[sharp] Type , which we denote J A K . And since glyph[sharp] preserves products, the operation
$$[ -, - ] & \colon \text{Type} \times \text{Type} \to \text{Type} \quad \text{induces an operation} \\ [ -, - ] & \colon \text{Type} \times \text{Type} \to \text{Type}$$
which is interpreted by the internal-hom [ - -, ] as an operation Core ( H ) × Core ( H ) → Core ( H ) . We now define the escaping morphism ↑ : glyph[sharp] Type → Type as follows. 4
$$\uparrow A \coloneqq \sum _ { B \colon \natural \sum _ { X \colon T y p e } X } ( \natural ( \mathbf p r _ { 1 } ) ( B ) = A )$$
Here GLYPH<229> X : Type X is the type-theoretic version of the domain Type · of the morphism p : Type · → Type from § 2.2, with p being the first projection pr 1 : GLYPH<229> X : Type X → Type . Thus functoriality of glyph[sharp] gives glyph[sharp] ( pr 1 ) : glyph[sharp] GLYPH<229> X : Type X → glyph[sharp] Type , and so glyph[sharp] ( pr 1 )( B ) : glyph[sharp] Type can be compared with A . Now it turns out that ↑ A is codiscrete (i.e. isCodisc ( ↑ A ) is inhabited), and the composite
$$T y p e \xrightarrow { \eta _ { T y p e } } \ddot { \AA } T y p e \xrightarrow { \uparrow } T y p e$$
is equivalent to glyph[sharp] . Thus, since in the intended categorical semantics H ( A B , ) = G [ A B , ] , we can define the external function-type as
$$\mathbf H ( A, B ) \coloneqq \uparrow \left ( [ A, B ] ^ { \ddagger } \right )$$
Note that this makes sense for any A B , : glyph[sharp] Type . If instead A B , : Type , then H ( J A K J , B K ) glyph[similarequal] glyph[sharp] [ A B , ] . Thus, if f : [ A B , ] , then applying this equivalence to h [ A B , ] ( f ) : glyph[sharp] [ A B , ] , we obtain an 'externalized' version of f , which we denote J f K : J A K → J B K . Now using dependent factorization for the modality glyph[sharp] , we can define all sorts of categorical operations externally. We have composition:
$$( A, B, C \colon \mathfrak { f } \text{Type} ) \,, ( f \colon \mathbf H ( A, B ) ) \,, ( g \colon \mathbf H ( B, C ) ) \, \vdash \, ( g \circ f \colon \mathbf H ( A, C ) )$$
and the property of being an equivalence:
$$( A, B \colon \mathfrak { f } \text{Type} ) \,, ( f \colon \mathbf H ( A, B ) ) \, \vdash \, ( \text{elseEquiv} ( f ) \colon \text{Type} ) \,.$$
Using these external tools, we can now complete our internal axiomatization of cohesion. One may be tempted to define the coreflection glyph[flat] as we did the reflections glyph[sharp] and P , but this would amount to asking for a pullback-stable system of coreflective subcategories of each H / X , and at present we do not know any way to obtain this in models. Instead, we work externally:
$$\ e i s D i s c \colon [ \mathfrak { f } T y p e, T y p e ]$$
$$( A \colon \vec { \text{Type} } ) \vdash ( \text{eisDiscsProp} _ { A } \colon \text{isProp} ( \text{eisDisc} ( A ) ) )$$
glyph[flat]
:
[
glyph[sharp]
Type
, glyph[sharp]
Type
]
(16)
$$( A \colon \# \text{Type} ) \vdash ( \text{flatIsDisc} _ { A } \colon \text{isDisc} ( \theta A ) )$$
$$( A \colon \mathfrak { f } T y p e ) \vdash ( \varepsilon _ { A } \colon \mathbf H ( \mathfrak { b } A, A ) )$$
$$( A, B \colon \mathfrak { f } { \text{Type} } ), ( \text{ad} \, \colon \text{eisDisc} ( A ) ) \, \vdash \, \left ( \text{fir} \, \colon \text{isEquiv} ( \lambda f ^ { \mathfrak { H } ( A, \mathfrak { b } ) }. \, \epsilon _ { B } \circ f ) \right ).$$
4 Technically, ↑ A lives in a higher universe than A , but we ignore this as it causes no problems.
If we axiomatize discrete objects as in § 2.4, we can define eisDisc ( A ) : = ( ( ↑ glyph[sharp] isDisc )( A )) . But we can also treat discrete objects externally only, with eisDisc axiomatic and P defined analogously to glyph[flat] . This would allow us to avoid choosing an ( E , M ) for the categorical interpretation. In any case, (19) implies factorizations:
$$( \text{ad} \, \colon \text{eisDisc} ( A ) ) \,, ( f \colon \text{H} ( A, B ) ) \, \vdash \, ( \text{fact} _ { \flat } ( f ) \, \colon \text{H} ( A, \flat B ) ) \\ ( \text{ad} \, \colon \text{eisDisc} ( A ) ) \,, ( f \, \colon \text{H} ( A, B ) ) \, \vdash \, ( \text{ff} _ { f } \, \colon \left ( \varepsilon _ { B } \circ \text{fact} _ { \flat } ( f ) = f \right ) ) \,.$$
Thus, we can state the final axioms internally as
$$( A \colon \natural \text{Type} ) \vdash ( s f e \colon e i s E q u i v ( f a c t _ { \natural } ( \left [ \eta _ { A } \right ] \circ \varepsilon _ { A } ) ) )$$
$$( A \colon \natural \, \mathfrak { f } \, \text{Type} ) \, \vdash \, ( \text{ste} \, \colon \text{isEquiv} ( \text{fact} _ { \mathfrak { a } } ( \left [ \eta _ { A } \right ] \circ \epsilon _ { A } ) ) ) & & ( 2 0 ) \\ ( A \colon \natural \, \mathfrak { f } \, \text{Type} ) \, \vdash \, ( \text{fse} \, \colon \text{isEquiv} ( \text{fact} _ { \mathfrak { a } } ( \left [ \eta _ { A } \right ] \circ \epsilon _ { A } ) ) ) & & ( 2 1 ) \\ \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \col: \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \col. \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colots \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \color \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \col.: \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \col:( \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \, \text{f-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{\text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon \text{-} \colon$$
This completes the axiomatization of the internal homotopy type theory of a cohesive ( ¥ , 1 -topos, yield-) ing the formal system that we call cohesive homotopy type theory .
## 3 Quantum gauge field theory
We now give a list of constructions in this axiomatics whose interpretation in cohesive ( ¥ , 1 -toposes ) H reproduces various notions in differential geometry, differential cohomology, geometric quantization and quantum gauge field theory. Because of the homotopy theory built into the type theory, this also automatically generalizes all these notions to homotopy theory. For instance, a gauge group in the following may be interpreted as an ordinary gauge group such as the Spin-group, but may also be interpreted as a higher gauge group, such as the String-2-group or the Fivebrane-6-group [43]. Similarly, all fiber products are automatically homotopy fiber products, and so on. (The fiber product of f : [ A C , ] and g : [ B C , ] is A × C B : = GLYPH<229> x A : GLYPH<229> y B : ( f ( x ) = g y ( )) , and this can be externalized easily.)
In this section we will mostly speak 'externally' about a cohesive ( ¥ , 1 -topos ) H . This can all be expressed in type theory using the technology of § 2.5, but due to space constraints we will not do so.
## 3.1 Gauge fields
The concept of a gauge field is usefully decomposed into two stages, the kinematical aspect and the dynamical aspect bulding on that:
| gauge field: | kinematics | dynamics |
|------------------|----------------------------------|----------------------------------------------|
| physics term: | instanton sector / charge sector | gauge potential |
| formalized as: | cocycle in (twisted) cohomology | cocycle in (twisted) differential cohomology |
| diff. geo. term: | fiber bundle | connection |
| ambient logic: | homotopy type theory | cohesive homotopy type theory |
## 3.1.1 Kinematics
↦
Suppose A is a pointed connected type, i.e. we have a 0 : A and p 0 ( A ) is contractible. Then its loop type W A : = ∗× ∗ glyph[similarequal] A ( a 0 = a 0 ) is a group. This establishes an equivalence between pointed connected homotopy types and group homotopy types; its inverse is called delooping and denoted G → B G . 5 For
5 Currently, we cannot fully formalize completely general ¥ -groups and their deloopings, because they involve infinitely many higher homotopies. This is a mere technical obstruction that will hopefully soon be overcome. It is not really a problem for us, since we generally care more about deloopings than groups themselves, and pointed connected types are easy to formalize.
instance, the automorphism group Aut ( V ) of a homotopy type V is the looping of the image factorization
/
/
/
/
GLYPH<127>
4
4
GLYPH<31>
/
/
It can also be defined as the space of self-equivalences, Aut ( V ) = GLYPH<229> f : [ V V , ] isEquiv ( f ) ; this is roughly the content of the univalence axiom.
Given a group G and a homotopy type X , we write H 1 ( X G , ) : = p 0 H ( X , B G ) for the degree-1 cohomology of X with coefficients in G . If G has higher deloopings B n G , we write H n ( X G , ) : = p 0 H ( X , B n G ) and speak of the degree-n cohomology of X with coefficients in G . The interpretation of this simple definition in homotopy type theory is very general, and (if we allow disconnected choices of deloopings) much more general than what is traditionally called generalized cohomology : in traditional terms, it would be called non-abelian equivariant twisted sheaf hyper-cohomology .
A G-principal bundle over X is a function p : P → X where P is equipped with a G -action over X and such that p is the quotient P → P GLYPH<12> G (as always, this is a homotopy quotient , constructible as a higher inductive type [54, 40],, see above. One finds that the delooping B G is the moduli stack of G -principal bundles: for any g : X → B G , its (homotopy) fiber is canonically a G -principal bundle over X , and this establishes an equivalence G Bund ( X ) glyph[similarequal] H ( X , B G ) between G -principal bundles and cocycles in G-cohomology . In particular, equivalence classes of G -principal bundles on X are classified by H 1 ( X G , ) .
/
Conversely, any G -action r : G × V → V is equivalently encoded in a fiber sequence V V GLYPH<12> G ¯ r B G , hence in a V -fiber bundle V GLYPH<12> G over B G . This is the universal r -associated V -fiber bundle in that, for g and P as above, the V -bundle E : = P × GV → X is equivalent to the pullback g ∗ ¯ . r
/
/
/
Syntactically, this means that homotopy type theory in the context of a pointed connected type B G is the representation theory of G : the fiber sequence above is the interpretation of a dependent type ( x : B G ) glyph[turnstileleft] ( V : Type ) which hence encodes a G -¥ -representation on a type V . One finds that the dependent product glyph[turnstileleft] ( GLYPH<213> x : B G V : Type ) is the type of invariants of the G -action, while the dependent sum glyph[turnstileleft] ( GLYPH<229> x : B G V : Type ) is the syntax for the quotient V GLYPH<12> G mentioned above. Moreover, for V 1 , V 2 two such G -representations, the dependent product of their function type glyph[turnstileleft] ( GLYPH<213> x : B G V [ 1 , V 2 ] : Type ) is interpreted as the type of G -action homomorphisms, while the dependent sum glyph[turnstileleft] ( GLYPH<229> x : B G V [ 1 , V 2 ] : Type ) is interpreted as the quotient [ V 1 , V 2 ] GLYPH<12> G of the space of all morphisms modulo the conjugation action by G . It follows that the homotopy type of sections G X ( E ) above is the interpretation of the syntax glyph[turnstileleft] ( GLYPH<213> x : B G P V [ , ] : Type ) . Notice that this expression reproduces almost verbatim the traditional statement that a section of a r -associated V -bundle is a G -equivariant map from the total space P to V , only that the interpretation of this statement in homotopy type theory here generalizes it to higher bundles.
In particular, the homotopy type of sections G X ( E ) of the associated bundle E above is equivalent to the dependent product of the mapping space [ g , ¯ r ] formed in the slice, the homotopy type theory syntax for it being glyph[turnstileleft] ( GLYPH<213> x : B G P V [ , ] : Type ) .
Since all the bundles involved are locally trivial with respect to the intrinsic notion of covers (epimorphic maps) it follows that elements of G X ( E ) are locally maps to V . If V here is pointed connected, and hence V glyph[similarequal] B H , then E is called an H-gerbe over X . In this case a section of E → X is therefore locally a cocycle in H -cohomology, and hence globally a cocycle in g-twisted H-cohomology with respect to the local coefficient bundle E → X . Hence twisted cohomology in H is ordinary cohomology in a slice H B / G . All this is discussed in detail in [37].
In gauge field theory a group H as above serves as the gauge group and then an H -principal bundle on X is the charge/kinematic part of an H-gauge field on X . (In the special case that H is a discrete homotopy type, this is already the full gauge field, as in this case the dynamical part is trivial). The mapping type
[ X , B H ] interprets as the moduli stack of kinematic H -gauge fields on X , and a term of identity type l : ( f 1 = f 2 ) is a gauge transformation between two gauge field configurations f 1 , f 2 : [ X , B H ] .
It frequently happens that the charge of one G -gauge field F shifts another H -gauge field f , in generalization of the way that magnetic charge shifts the electromagnetic field. Such shifts are controlled by an action r of G on B H and in this case F is a cocycle in G -cohomology and f is a cocycle in F -twisted H -cohomology with respect to the local coefficient bundle ¯ . r
An example of this phenomenon is given by the field configurations in Einstein-gravity (general relativity). For this we assume that the general linear group GL ( n ) in dimension n exists as a group type, which is the case in the standard models for smooth cohesion. Notably if we pass to a context of synthetic differential cohesion then the first order infintesimal neighbourhood of the origin of R n exists as a type D n and we have GL ( n ) = Aut ( D n ) . By the above, for an n -dimensional smooth manifold S (to be thought of as spacetime ) the frame bundle T S → S is characterized as the type sitting in a fiber sequence
/
/
GLYPH<15>
GLYPH<15>
which syntactically is therefore the dependent type ( x : B GL n ( )) glyph[turnstileleft] ( T S : Type ) . Let then B O n ( ) → B GL ( n ) be the delooping of the inclusion of the maximal compact subgroup 6 , the orthogonal group, into the general linear group. This sits in a homotopy fiber sequence
/
/
GLYPH<15>
$$\text{GL} ( n ) / O ( n ) \xrightarrow { \mathbf B O } & \mathbf ( n ) \\ & \downarrow \\ & \mathbf B G L ( n )$$
GLYPH<15>
with the smooth coset space, exhibiting the canonical GL ( n ) -action on that space. Syntactically this is therefore the dependent type ( x : B GL ( n )) glyph[turnstileleft] ( GL ( n ) / O n ( ) : Type ) . With the above one finds then that the homotopy type theory syntax
$$\vdash \left ( \prod _ { x \colon \text{BGL} ( n ) } [ T \Sigma, \text{GL} ( n ) / O ( n ) ] \colon \text{Type} \right )$$
is interpreted as the space of diagrams
/
/
s
{
"
"
y
y
Here T S × GL ( n ) GL ( n ) / O n ( ) denotes the ( GL ( n ) / O n ( )) -bundle associated to the frame bundle (so × GL ( n ) denotes not a pullback but a tensor product over GL ( n ) -actions). The homotopy type theory syntax here is manifestly the expression for GL ( n ) -equivariant maps from the frame bundle to the coset, while the
6 Assuming that we can talk about general colimits, which is work in progress in fully formal HoTT, then geometric compactness can be axiomatized as smallness with respect to filtered colimits whose structure maps are monomorphisms.
diagram manifestly expresses a reduction of the structure group of the frame bundle to an O n ( ) -bundle. Both of these equivalent constructions encode a choice of vielbein , hence of a Riemannian metric on S , hence of a field of gravity. (We could just as well discuss genuine pseudo-Riemannian metrics.) Moreover, by the homotopy-theoretic construction this space of fields automatically contains the O n ( ) -gauge transformations on the vielbein fields corresponding to choices of reference frames . But since gravity is a generally covariant field theory, the correct configuration space of gravity is furthermore the quotient of this space of vielbein fields by the diffeomorphism action on T S . One finds from the above that in homotopy type theory syntax this is simply expressed by interpreting the space of fields in the context of the delooped automorphism group of S and then forming the dependent sum: the interpretation of
$$\vdash \left ( \prod _ { x \colon B G L ( n ) } \sum _ { y \colon B A u t ( T \Sigma ) } [ T \Sigma, G L ( n ) / O ( n ) ] \colon \text{Type} \right )$$
is the moduli stack of the generally covariant field of gravity. In the smooth context it is the Lie integration of the gravitational (off-shell) BRST complex with diffeomorphism ghosts in degree 1.
Further discussion of examples and further pointers are in [45, 17].
## 3.1.2 Dynamics
Given a G -principal bundle in the presence of cohesion, we may ask if its cocycle g : X → B G lifts through the counit e B G : glyph[flat] B G → B G from (18) to a cocycle GLYPH<209> : X → glyph[flat] B G . By the ( P glyph[turnstileright] glyph[flat] ) -adjunction this is equivalently a map P ( X ) → B G . Since P ( X ) is interpreted as the path ¥ -groupoid of X , such a GLYPH<209> is a flat parallel transport on X with values in G , equivalently a flat G-principal connection on X .
Consider then the homotopy fiber glyph[flat] dR B G : = glyph[flat] B G × B G ∗ . By definition, a map w : X → glyph[flat] dR B G is a flat G -connection on X together with a trivialization of the underlying G -principal bundle. This is interpreted as a flat g -valued differential form , where g is the Lie algebra of G . By using this definition in the statement of the above classification of G -principal bundles, one finds that every flat connection GLYPH<209> : X → glyph[flat] B G is locally given by a flat g -valued form: GLYPH<209> is equivalently a form A : P → glyph[flat] dR B G on the total space of the underlying G -principal bundle, such that this is G -equivariant in a natural sense. Such an A is interpreted as the incarnation of the connection GLYPH<209> in the form of an Ehresmann connection on P → X .
Moreover, the coefficient glyph[flat] dR B G sits in a long fiber sequence of the form
/
$$G \xrightarrow { \theta _ { G } } \beta _ { d R } \mathbf B G \xrightarrow { \beta _ { B G } } \beta G \.$$
/
/
/
/
/
with the further homotopy fiber q G giving a canonical flat g -valued differential form on G . This is the Maurer-Cartan form of G , in that when interpreted in smooth homotopy types and for G an ordinary Lie group, it is canonically identified with the classical differential-geometric object of this name. Here in cohesive homotopy type theory it exists in much greater generality.
/
/
/
/
Specifically, assume that G itself is once more deloopable, hence assume that B 2 G exists. Then the above long fiber sequence extends further to the right as glyph[flat] B G e B G B G q B G glyph[flat] dR B 2 G , since glyph[flat] is right adjoint. This means, by the universal property of homotopy fibers, that if g : X → B G is the cocycle for a G -principal bundle on X , then the class of the differential form q B G ( g ) is the obstruction to the existence of a flat connection GLYPH<209> on this bundle. Hence this class is interpreted as the curvature of the bundle, and we interpret the Maurer-Cartan form q B G of the delooped group B G as the universal curvature characteristic for G -principal bundles.
This universal curvature characteristic is the key to the notion of non-flat connections, for it allows us to define these in the sense of twisted cohomology as curvature-twisted flat cohomology . There is, however, a choice involved in defining the universal curvature-twist, which depends on the intended application. But in standard interpretations there is a collection of types singled out, called the manifolds , and the standard universal curvature twist can then be characterized as a map i : W 2 cl ( -, g ) → glyph[flat] dR B 2 G out of a 0-truncated homotopy type such that for all manifolds S its image under [ S , -] is epi, meaning that W 2 cl ( S , g ) → [ S , glyph[flat] dR B 2 G ] is an atlas in the sense of geometric stack theory.
Assuming such a choice of universal curvature twists has been made, we may then define the moduli of general (non-flat) G -principal connections to be the homotopy fiber product
$$\mathbb { B } G _ { \text{conn} } \coloneqq i ^ { * } \theta _ { \mathbb { B } G } = \mathbb { B } G \times _ { \mathbb { B } _ { d R } \mathbb { B } ^ { 2 } G } \Omega ^ { 2 } ( -, \mathfrak { g } ) \,.$$
In practice one is usually interested in a canonical abelian (meaning arbitrarily deloopable, i.e. E ¥ ) group A and the tower of delooping groups B n A that it induces. In this case we write B n A conn : = B n A × glyph[flat] dR B n + 1 A W n + 1 ( -, A ) . When interpreted in smooth homotopy types and choosing the Lie group A = C × or = U ( 1 ) one finds that B n A conn is the coefficient for ordinary differential cohomology , specifically that it is presented by the ¥ -stack given by the Deligne complex .
Notice that the pasting law for homotopy pullbacks implies generally that the restriction of B G conn to vanishing curvature indeed coincides with the universal flat coefficients: glyph[flat] B G glyph[similarequal] B G conn × W 2 ( -, g ) {∗} . This means that we obtain a factorization of e B G as glyph[flat] B G → B G conn → B G .
Let then G be a group which is not twice deloopable, hence to which the above universal definition of B G conn does not apply. If we have in addition a map c : B G → B n A given (representing a universal characteristic class in H n ( B G A , ) ), then we may still ask for some homotopy type B G conn that supports a differential refinement c conn : B G conn → B n A conn of c in that it lifts the factorization of e B n A by B n A conn. Such a c conn interprets, down on cohomology, as a secondary universal characteristic class in the sense of refined Chern-Weil theory. Details on all this are in [20, 44].
With these choices and for G regarded as a gauge group, a genuine G-gauge field on S is a map f : S → B G conn. For G twice deloopable, the field strength of f is the composite F f : S → B G conn F ( -) - - → W 2 cl ( -, g ) .
Moreover, the choice of c conn specifies an exended action functional on the moduli type [ S , B G conn ] of G -gauge field configurations, and hence specifies an actual quantum gauge field theory. This we turn to now.
## 3.2 s -Model QFTs
An n -dimensional ('nonlinear') s -model quantum field theory describes the dynamics of an ( n -1 -) dimensional quantum 'particle' (for instance an electron for n = 1, a string for n = 2, and generally an ' ( n -1 -brane') that propagates in a ) target space X (for instance our spacetime) while acted on by forces (for instance the Lorentz force ) exerted by a fixed background A -gauge field on X (for instance the electromagnetic field for n = 1 or the Kalb-Ramond B-field for n = 2 or the supergravity C-field for n = 3). By the above, this background gauge field is the interpretation of a map c conn : X → B n A conn.
Let then S be a cohesive homotopy type of cohomological dimension n , to be thought of as the abstract worldvolume of the ( n -1 -brane. ) The homotopy type [ S , X ] of cohesive maps from S to X is interpreted as the moduli space of field configurations of the s -model for this choice of shape of worldvolume. The (gauge-coupling part of) the action functional of the s -model is then to be the nvolume holonomy of the background gauge field over a given field configuration S → X .
To formalize this, we need the notion of concreteness . If X is a cohesive homotopy type, its concretization is the image factorization X glyph[dblarrowheadright] conc X ↪ → glyph[sharp] X of h X : X → glyph[sharp] X (7). We call X concrete if X → conc X is an equivalence. In the standard smooth model, the 0-truncated concrete cohesive homotopy types are precisely the diffeological spaces (see [6]). Generally, for models over concrete sites , they are the concrete sheaves .
Now we can define the action functional of the s -model associated to the background gauge field c conn to be the composite
/
$$\exp ( i S ( - ) ) \, \colon \, [ \Sigma, X ] \xrightarrow { [ \Sigma, \mathfrak { c } _ { \text{conn} } ] } \, [ \Sigma, B ^ { n } A _ { \text{conn} } ] \, \longrightarrow \, \text{conc} \, \pi _ { 0 } [ \Sigma, B ^ { n } A _ { \text{conn} } ] \.$$
/
/
/
In the standard smooth model, with A = C × or U ( 1 , the second morphism is ) fiber integration in differential cohomology exp 2 ( p i ∫ S ( -)) . For n = 1 this computes the line holonomy of a circle bundle with connection, hence the correct gauge coupling action functional of the 1-dimensional s -model; for n = 2 it computes the surface holonomy of a circle 2-bundle, hence the correct 'WZW-term' of the string; and so on.
Traditionally, s -models are thought of as having as target space X a manifold or at most an orbifold. However, since these are smooth homotopy n -types for n ≤ 1, it is natural to allow X to be a general cohesive homotopy type. If we do so, then a variety of quantum field theories that are not traditionally considered as s -models become special cases of the above general setup. Notably, if X = B G conn is the moduli for G -principal connections, then a s -model with target space X is a G -gauge theory on S . Moreover, as we have seen above, in this case the background gauge field is a secondary universal characteristic invariant. One finds that the corresponding action functional exp 2 ( p i ∫ S [ S , c conn ]) : [ S , B G conn ] → A is that of Chern-Simons -type gauge field theories [18, 19], including the standard 3-dimensional Chern-Simons theories as well a various higher generalizations.
More generally, at least in the smooth model, there is a transgression map for differential cocycles: for S d a manifold of dimension d there is a canonical map
/
$$\exp ( 2 \pi i \int _ { \Sigma } [ \Sigma, \mathfrak { c } _ { \text{conn} } ] ) \, \colon \, [ \Sigma _ { d }, X ] \xrightarrow { [ \Sigma _ { d }, \mathfrak { c } _ { \text{conn} } ] } \, [ \Sigma _ { d }, \mathbf B ^ { n } A _ { \text{conn} } ] \xrightarrow { \exp ( 2 \pi i \int _ { \Sigma } ) } \, \mathbf B ^ { n - d } A _ { \text{conn} }$$
/
/
/
modulating an n -bundle on the S d -mapping space. For d = n -1 and quadratic Chern-Simons-type theories this turns out to be the (off-shell) prequantum bundle of the QFT. See [18] for details on these matters. Thus the differential characteristic cocycle c conn should itself be regarded as a higher prequantum bundle , in the sense we now discuss.
## 3.3 Geometric quantization
Action functionals as above are supposed to induce n -dimensional quantum field theories by a process called quantization . One formalization of what this means is geometric quantization , which is wellsuited to formalization in cohesive homotopy type theory. We indicate here how to formalize the spaces of higher (pre)quatum states that an extended QFT assigns in codimension n .
The critical locus of a local action functional - its phase space or Euler-Lagrange solution space -carries a canonical closed 2-form w , and standard geometric quantization gives a method for constructing the space of quantum states assigned by the QFT in dimension n -1 as a space of certain sections of a prequantum bundle whose curvature is w . This works well for non-extended topological quantum field theories and generally for n = 1 (quantum mechanics). The generalization to n ≥ 2 is called multisymplectic or higher symplectic geometry [41], for here w is promoted to an ( n + ) 1 -form which reproduces
the former 2-form upon transgression to a mapping space. Exposition of the string s -model ( n = 2) in the context of higher symplectic geometry is in [4], and discussion of quantum Yang-Mills theory ( n = 4) and further pointers are in [25]. A homotopy-theoretic formulation is given in [17]: here the prequantum bundle is promoted to a prequantum n -bundle, a ( B n -1 A ) -principal connection as formalized above.
Based on this we can give a formalization of central ingredients of geometric quantization in cohesive homotopy type theory. When interpreted in the standard smooth model with A = C × or = U ( 1 ) the following reproduces the traditional notions for n = 1, and for n ≥ 2 consistently generalizes them to higher geometric quantization.
Let X be any cohesive homotopy type. A closed ( n + ) 1 -form on X is a map w : X → W n + 1 cl ( -, A ) , as discussed in section 3.1.2. We may call the pair ( X , w ) a pre-n-plectic cohesive homotopy type. The group of symplectomorphisms or canonical transformations of ( X , w ) is the automorphism group of w :
/
/
$
$
z
z
regarded as an object in the slice H / W n + 1 cl ( -, A ) . A prequantization of ( X , w ) is a lift
:
:
/
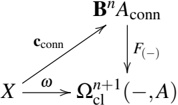
GLYPH<15>
GLYPH<15>
/
through the defining projection from the moduli of ( B n -1 A ) -principal connections. This c conn modulates the prequantum n-bundle . Since A is assumed abelian, there is abelian group structure on p 0 ( X → B n A conn ) and hence we may rescale c conn by a natural number k . This corresponds to rescaling Planck's constant h ¯ by 1 / k . The limit k → ¥ in which ¯ h → 0 is the classical limit .
The automorphism group of the prequantum bundle
/
/
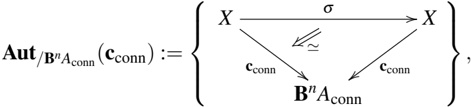
t
|
#
#
{
{
in the slice H B / n A conn , is the quantomorphism group of the system. Syntactically this is
$$\vdash \left ( \prod _ { \nabla \colon B ^ { \prime } A _ { \text{conn} } } \text{at} ( X ( \nabla ) ) \colon \text{Type} \right ).$$
See [17] for more on this.
There is an evident projection from the quantomorphism group to the symplectomorphism group, and its image is the group of Hamiltonian symplectomorphisms . The Lie algebra of the quantomorphism group is that of Hamiltonian observables equipped with the Poisson bracket . If X itself has abelian group structure, then the subgroup of the quantomorphism group covering the action on X on itself is the Heisenberg group of the system. An action of any group G on X by quantomorphisms, i.e. a
map m : B G → BAut B / n A conn ( c conn ) , is a Hamiltonian G-action on ( X , w ) . The (homotopy) quotient c conn G : X G → B n A conn is the corresponding gauge reduction of the system.
GLYPH<12> GLYPH<12> After a choice of representation r of B n -1 A on some V , the space of prequantum states is
/
/
s
{
y
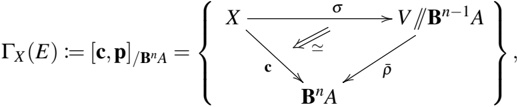
y
the space of c -twisted cocycles with respect to the local coefficient bundle ¯ . r There is an evident action of the quantomorphism group on G X ( E ) and this is the action of prequantum operators on the space of states.
It remains to formalize in cohesive homotopy type theory the quantization step from this pre quantum data to actual quantized field theory. This is discussed, in terms of standard homotopy theory and ¥ -topos theory, in [38], to which we refer the reader for further details. This quantization step involves, naturally, linear algebra, which internal to homotopy theory is stable homotopy theory , the theory of spectra and ring spectra. This has not been fully formalized in homotopy type theory at the moment, but it seems clear that this can be done. In any case, a discussion of the quantization step in the language of homotopy type theory is possible, but beyond the scope of this article.
In conclusion then, the amount of gauge QFT notions naturally formalized here in cohesive homotopy type theory seems to be remarkable, emphasizing the value of a formal, logical, approach to concepts like smoothness and cohomology.
## References
- [1] S. Awodey (2010): Type theory and homotopy . arXiv:1010.1810.
- [2] S. Awodey & L. Birkedal (2003): Elementary axioms for local maps of toposes . Journal of Pure and Applied Algebra 177(3), pp. 215-230, doi:10.1016/S0022-4049(02)00283-9.
- [3] J. Baez & J. Dolan (1995): Higher-Dimensional Algebra and Topological Quantum Field Theory . J. Math. Phys. 36(11), p. 60736105, doi:10.1063/1.531236. arXiv:q-alg/9503002.
- [4] J. Baez, E. Hoffnung & L. Rogers (2010): Categorified Symplectic Geometry and the Classical String . Commun. Math. Phys. 293(3), pp. 701-725, doi:10.1007/s00220-009-0951-9. arXiv:0808.0246.
- [5] J. Baez & M. Stay (2011): Physics, Topology, Logic and Computation: A Rosetta Stone . In Bob Coecke, editor: New Structures for Physics , Lecture Notes in Physics 813, Springer, pp. 95-174, doi:10.1007/978-3642-12821-9 2. arXiv:0903.0340.
- [6] J. C. Baez & A. E. Hoffnung (2011): Convenient categories of smooth spaces . Trans. Amer. Math. Soc. 363(11), pp. 5789-5825, doi:10.1090/S0002-9947-2011-05107-X. arXiv:0807.1704.
- [7] C. Barwick & C. Schommer-Pries: On the Unicity of the Homotopy Theory of Higher Categories . arXiv:1112.0040.
- [8] J. Bernstein (1974): Spontaneous symmetry breaking, gauge theories, the Higgs mechanism and all that . Rev. Mod. Phys. 46, pp. 7-48, doi:10.1103/RevModPhys.46.7.
- [9] K. Brown (1973): Abstract homotopy theory and generalized sheaf cohomology . Transactions of the American Mathematical Society 186, pp. 419-458, doi:10.1090/S0002-9947-1973-0341469-9.
- [10] J.-L. Brylinski (1993): Loop Spaces, Characteristic Classes, and Geometric Quantization . Birkh¨ auser, doi:10.1007/978-0-8176-4731-5.
- [11] A. Carboni, G. Janelidze, G. M. Kelly & R. Par´ e (1997): On localization and stabilization for factorization systems . Appl. Categ. Structures 5(1), pp. 1-58, doi:10.1023/A:1008620404444.
- [12] C. Cassidy, M. H´ ebert & G. M. Kelly (1985): Reflective subcategories, localizations and factorization systems . J. Austral. Math. Soc. Ser. A 38(3), pp. 287-329, doi:10.1017/S1446788700023624.
- [13] CERN (2012): CERN experiments observe particle consistent with long-sought Higgs boson . press-archived.web.cern.ch/press-archived/PressReleases/Releases2012/PR17.12E.html.
- [14] P. Clairambault & P. Dybjer (2011): The biequivalence of locally cartesian closed categories and Martin-L¨f o type theories . In: Proceedings of the 10th international conference on Typed lambda calculi and applications , TLCA'11, Springer-Verlag, Berlin, Heidelberg, pp. 91-106, doi:10.1007/978-3-642-21691-6 10. Available at http://dl.acm.org/citation.cfm?id=2021953.2021965 .
- [15] T. Coquand: ForMath: Formalisation of Mathematics research project . wiki.portal.chalmers.se/cse/pmwiki.php/ForMath/ForMath.
- [16] P. Deligne, P. Etingof, D. Freed, L. Jeffrey, D. Kazhdan, J. Morgan, D.R. Morrison & E. Witten (1999): Quantum Fields and Strings, A course for mathematicians . Amer. Math. Soc.
- [17] D. Fiorenza, C. L. Rogers & U. Schreiber (2013): Higher geometric prequantum theory . arXiv:1304.0236.
- [18] D. Fiorenza, H. Sati & U. Schreiber (2013): Extended higher cup-product Chern-Simons theories . Journal of Geometry and Physics 74, pp. 130-163, doi:10.1016/j.geomphys.2013.07.011. arXiv:1207.5449.
- [19] D. Fiorenza & U. Schreiber: ¥ -Chern-Simons theory . ncatlab.org/schreiber/show/infinity-Chern-Simons+theory.
- [20] D. Fiorenza, U. Schreiber & J. Stasheff (2012): ˇ ech cocycles for differential characteristic classes C . Advances in Theoretical and Mathematical Phyiscs 16(1), pp. 149-250, doi:10.4310/ATMP.2012.v16.n1.a5. arXiv:1011.4735.
- [21] D. Freed (2002): Dirac charge quantization and generalized differential cohomology . In: Surveys in Differential Geometry , 7, Int. Press, pp. 129-194, doi:10.4310/SDG.2002.v7.n1.a6. arXiv:hep-th/0011220.
- [22] M. Henneaux & C. Teitelboim (1992): Quantization of gauge systems . Princeton University Press.
- [23] C. Heunen, N. P. Landsman & B. Spitters (2011): Bohrification . In H. Halvorson, editor: Deep Beauty , Cambridge University Press, pp. 271-313, doi:10.1017/CBO9780511976971.008. arXiv:0909.3468.
- [24] M. Hopkins & I. Singer (2005): Quadratic Functions in Geometry, Topology, and M-Theory . J. Differential Geom. 70(3), pp. 329-452. arXiv:math/0211216.
- [25] I.V. Kanatchikov (2004): Precanonical quantization of Yang-Mills fields and the functional Schroedinger representation . Rept. Math. Phys. 53, pp. 181-193, doi:10.1016/S0034-4877(04)90011-0. arXiv:hepth/0301001.
- [26] C. Kapulkin, P. L. Lumsdaine & V. Voevodsky (2012): Univalence in simplicial sets . arXiv:1203.2553.
- [27] A. Kock (1981): Synthetic differential geometry . London Mathematical Society Lecture Note Series 51, Cambridge University Press, Cambridge, doi:10.1017/CBO9780511550812
- [28] R. Lavendhomme (1996): Basic concepts of synthetic differential geometry . Kluwer Texts in the Mathematical Sciences 13, Kluwer Academic Publishers Group, Dordrecht, doi:10.1007/978-1-4757-4588-7 8. Translated from the 1987 French original, Revised by the author.
- [29] W. Lawvere (2007): Axiomatic cohesion . Theory and Applications of Categories 19(3), pp. 41-49. www.tac.mta.ca/tac/volumes/19/3/19-03abs.html.
- [30] E. Lerman (2010): Orbifolds as stacks? L'Enseign. Math. 56(3-4), pp. 315-363, doi:10.4171/LEM/56-3-4. arXiv:0806.4160.
- [31] J. Lurie (2009): Higher topos theory . Annals of Mathematics Studies 170, Princeton University Press. arXiv:math.CT/0608040.
- [32] J. Lurie (2009): On the Classification of Topological Field Theories . Current Developments in Mathematics 2008, pp. 129-280, doi:10.4310/CDM.2008.v2008.n1.a3. arXiv:0905.0465.
- [33] P. Martin-L¨ of (1984): Intuitionistic type theory . Studies in Proof Theory 1, Bibliopolis, Naples.
- [34] M.G¨ ockeler & T. Sch¨ ucker (1987): Differential geometry, gauge theories, and gravity . Cambridge monographs on Mathematical Physics, Cambridge University Press, doi:10.1017/CBO9780511628818.
- [35] I. Moerdijk & D. Pronk (1997): Orbifolds, sheaves and groupoids . K-theory 12, pp. 3-21, doi:10.1023/A:1007767628271.
- [36] I. Moerdijk & G. E. Reyes (1991): Models for smooth infinitesimal analysis . Springer-Verlag, New York, doi:10.1007/978-1-4757-4143-8.
- [37] T. Nikolaus, U. Schreiber & D. Stevenson (2014): Principal ¥ -bundles - General theory . Journal of Homotopy and Related Structures . arXiv:1207.0248.
- [38] J. Nuiten (2013): Cohomological quantization of local boundary prequantum field theory . Master's thesis, University Utrecht, the Netherlands. dspace.library.uu.nl/handle/1874/282756.
- [39] L. ORaifeartaigh & N. Straumann (2000): Gauge Theory: Historical Origins and Some Modern Developments . Rev. Mod. Phys. 72, pp. 1-23, doi:10.1103/RevModPhys.72.1.
- [40] The Univalent Foundations Program (2013): Homotopy Type Theory: Univalent Foundations of Mathematics . homotopytypetheory.org/book/.
- [41] C. Rogers (2011): Higher Symplectic Geometry . Ph.D. thesis, UC Riverside. arXiv:1106.4068.
- [42] H. Sati & U. Schreiber (2011): Mathematical Foundations of Quantum Field and Perturbative String Theory . Proceedings of symposia in pure mathematics 83, American Mathematical Society, doi:10.1090/pspum/083. arXiv:1109.0955.
- [43] H. Sati, U. Schreiber & J. Stacheff (2012): Twisted differential String- and Fivebrane-structures . Communications in Mathematical Physics 315(1), pp. 169-213, doi:10.1007/s00220-012-1510-3. arXiv:0910.4001.
- [44] U. Schreiber (2012): Differential cohomology in a cohesive ¥ -topos . arXiv:1310.7930.
- [45] U. Schreiber (2012): Twisted smooth cohomology in string theory . ESI Lecture series. ncatlab.org/nlab/show/twisted+smooth+cohomology+in+string+theory.
- [46] U. Schreiber et al.: ¥ -cohesive site . ncatlab.org/nlab/show/infinity-cohesive+site.
- [47] M. Shulman: Internalizing the External, or The Joys of Codiscreteness . golem.ph.utexas.edu/category/2011/11/internalizing the external or.html.
- [48] M. Shulman: Reflective Subfibrations, Factorization Systems, and Stable Units . golem.ph.utexas.edu/category/2011/12/reflective subfibrations facto.html.
- [49] M. Shulman (2011): Coq code for cohesive homotopy type theory . github.com/mikeshulman/HoTT/tree/modalities/Coq/Subcategories.
- [50] M. Shulman (2012): Directed homotopy type theory .
golem.ph.utexas.edu/category/2012/06/directed homotopy type theory.html.
- [51] M. Shulman (2012): Minicourse on homotopy type theory . www.math.ucsd.edu/ mshulman/hottminicourse2012/.
- [52] M. Shulman (2012): Univalence for inverse diagrams and homotopy canonicity . arXiv:1203.3253.
- [53] M. Shulman (2013): The univalence axiom for elegant Reedy presheaves . arXiv:1307.6248.
- [54] M. Shulman & P. L. Lumsdaine: Higher inductive types . In preparation.
- [55] Coq development team: The Coq proof assistant . coq.inria.fr/.
- [56] V. Voevodsky (2011): Univalent foundations of mathematics . Logic, Language, Information and Computation , doi:10.1007/978-3-642-20920-8 4. www.math.ias.edu/˜vladimir/Site3/Univalent Foundations.html.
- [57] J. Wang (2011): The moduli stack of G-bundles . arXiv:1104.4828. | 10.4204/EPTCS.158.8 | [
"Urs Schreiber",
"Michael Shulman"
] | 2014-08-01T00:25:33+00:00 | 2014-08-01T00:25:33+00:00 | [
"math-ph",
"cs.LO",
"math.CT",
"math.MP"
] | Quantum Gauge Field Theory in Cohesive Homotopy Type Theory | We implement in the formal language of homotopy type theory a new set of
axioms called cohesion. Then we indicate how the resulting cohesive homotopy
type theory naturally serves as a formal foundation for central concepts in
quantum gauge field theory. This is a brief survey of work by the authors
developed in detail elsewhere. |
1408.0055v1 | ## Thurstonian Boltzmann Machines: Learning from Multiple Inequalities
Truyen Tran †‡ , Dinh Phung , Svetha Venkatesh † † † Pattern Recognition and Data Analytics, Deakin University, Australia ‡ Department of Computing, Curtin University, Australia { truyen.tran,dinh.phung,svetha.venkatesh } @deakin.edu.au
## Abstract
We introduce Thurstonian Boltzmann Machines (TBM), a unified architecture that can naturally incorporate a wide range of data inputs at the same time. Our motivation rests in the Thurstonian view that many discrete data types can be considered as being generated from a subset of underlying latent continuous variables, and in the observation that each realisation of a discrete type imposes certain inequalities on those variables. Thus learning and inference in TBM reduce to making sense of a set of inequalities. Our proposed TBM naturally supports the following types: Gaussian, intervals, censored, binary, categorical, muticategorical, ordinal, (in)-complete rank with and without ties. We demonstrate the versatility and capacity of the proposed model on three applications of very different natures; namely handwritten digit recognition, collaborative filtering and complex social survey analysis.
## 1 Introduction
Restricted Boltzmann machines (RBMs) have proved to be a versatile tool for a wide variety of machine learning tasks and as a building block for deep architectures [12, 24, 28]. The original proposals mainly handle binary visible and hidden units. Whilst binary hidden units are broadly applicable as feature detectors, non-binary visible data requires different designs. Recent extensions to other data types result in type-dependent models: the Gaussian for continuous inputs [12], Beta for bounded continuous inputs [16], Poisson for count data [9], multinomial for unordered categories [25], and ordinal models for ordered categories [37, 35].
The Boltzmann distribution permits several types to be jointly modelled, thus making the RBM a good tool for multimodal and complex social survey analysis. The work of [20, 29, 40] combines continuous (e.g., visual and audio) and discrete modalities (e.g., words). The work of [34] extends the idea further to incorporate ordinal and rank data. However, there are conceptual drawbacks: First, conditioned on the hidden layer, they are still separate type-specific models; second, handling ordered categories and ranks is not natural; and third, specifying direct correlation between these types remains difficult.
The main thesis of this paper is that many data types can be captured in one unified model. The key observations are that (i) type-specific properties can be modelled using
one or several underlying continuous variables , in the spirit of Thurstonian models 1 [31], and (ii) evidences be expressed in the form of one or several inequalities of these underlying variables. For example, a binary visible unit is turned on if the underlying variable is beyond a threshold; and a category is chosen if its utility is the largest among all those of competing categories. The use of underlying variables is desirable when we want to explicitly model the generative mechanism of the data. In psychology and economics, for example, it gives much better interpretation on why a particular choice is made given the perceived utilities [2]. Further, it is natural to model the correlation among type-specific inputs using a covariance structure on the underlying variables.
The inequality observation is interesting in its own right: Instead of learning from assigned values, we learn from the inequality expression of evidences , which can be much more relaxed than the value assignments. This class of evidences indeed covers a wide range of practical situations, many of which have not been studied in the context of Boltzmann machines, as we shall see throughout the paper.
To this end, we propose a novel class of models called Thurstonian Boltzmann Machine (TBM). The TBM utilises the Gaussian restricted Boltzmann machine (GRBM): The top layer consists of binary hidden units as in standard RBMs; the bottom layer contains a collection of Gaussian variable groups, one per input type. The main difference is that TBM does not require valued assignments for the bottom layer but a set of inequalities expressing the constraints imposed by the evidences . Except for a limiting case of point assignments where the inequalities are strictly equalities, the Gaussian layer is never fully observed. The TBM supports more data types in a unified manner than ever before: For any combination of the point assignments, intervals, censored values, binary, unordered categories, multi-categories, ordered categories, (in)-complete ranks with and without ties, all we need to do is to supply relevant subset of inequalities.
We evaluate the proposed model on three applications of very different natures: handwritten digit recognitions, collaborative filtering and complex survey analysis. For the first two applications, the performance is competitive against methods designed for those data types. On the last application, we believe we are among the first to propose a scalable and generic machinery for handle those complex data types.
## 2 Gaussian RBM
Let x = ( x , x 1 2 , ..., x N ) glyph[latticetop] ∈ R N be a vector of input variables. Let h = ( h , h 1 2 , ..., h K ) glyph[latticetop] ∈ { 0 1 , } K be a set of hidden factors which are designed to capture the variations in the observations. The input layer and the hidden layer form an undirected bipartite graph, i.e., only cross-layer connections are allowed. The model admits the Boltzmann distribution
$$P ( x, h ) = \frac { 1 } { Z } \exp \left \{ - E ( x, h ) \right \}$$
where Z = ∑ h GLYPH<1> exp {-E ( x h , ) } d x is the normalising constant and E ( x h , ) is the state energy. The energy is decomposed as
$$E ( x, h ) = \sum _ { i } \left ( \frac { x _ { i } ^ { 2 } } { 2 } - ( \alpha _ { i } + W _ { i } \bullet h ) \, x _ { i } \right ) - \gamma ^ { \top } h$$
1 Whilst Thurstonian models often refer to human's judgment of discrete choices, we use the term 'Thurstonian' more freely without the notion of human's decision.
where { α i } N i =1 , W = { W ik } , γ = { γ k } are free parameters and W i · denotes the i -th row. Given the input x , the posterior has a simple form
$$P ( h \, | \, x ) \ & = \ \prod _ { k } P ( h _ { k } \, | \, x ) \\ P ( h _ { k } = 1 \, | \, x ) \ & = \ \frac { 1 } { 1 + e ^ { - \gamma _ { k } - W ^ { \prime } _ { \bullet k } x } }$$
where W · k denotes the k -th column. Similarly, the generative process given the binary factor h is also factorisable
$$P ( x \, | \, h ) \ & = \ \prod _ { i } P ( x _ { i } \, | \, h ) \\ P ( x _ { i } \, | \, h ) \ & = \ \mathcal { N } ( \alpha _ { i } + W _ { i }, h, 1 )$$
where N ( µ, 1) is the normal distribution of mean µ and unit deviation.
## 3 Thurstonian Boltzmann Machines
We now generalise the Gaussian RBM into the Thurstonian Boltzmann Machine (TBM). Denote by e an observed evidence of x . Standard evidences are the point assignment of x to some specific real-valued vector, i.e., x = e . Generalised evidences can be expressed using inequality constraints
$$b \leq _ { \odot } A x \leq _ { \odot } c$$
for some transform matrix A ∈ R M N × and vectors b c , ∈ R M , where ≤ glyph[circledot] denotes elementwise inequalities. Thus an evidence can be completely realised by specifying the triple 〈 A, b c , 〉 . For example, for the point assignment, 〈 A = I , b = e c , = e 〉 , where I is the identity matrix. In what follows, we will detail other useful popular realisations of these quantities.
## 3.1 Boxed Constraints
This refers to the case where input variables are independently constrained, i.e., A = I , and thus we need only to specify the pair 〈 b c , 〉 .
Censored observations. This refers to situation where we only know the continuous observation beyond a certain point, i.e., b = e and c = + ∞ . For example, in survival analysis, the life expectancy of a person might be observed up to a certain age, and we have no further information afterward.
Interval observations . When the measurements are imprecise, it may be better to specify the range of possible observations with greater confidence rather than a singe point, i.e., b = e -δ and c = e + δ for some pair ( e δ , ). For instance, missile tracking may estimate the position of the target with certain precision.
Binary observations . A binary observation e i can be thought as a result of clipping x i by a threshold θ i , that is e i = 1 if x i ≥ θ i and e i = 0 otherwise. The boundaries in Eq. (3.2) become:
$$\langle b _ { i }, c _ { i } \rangle = \begin{cases} \langle - \infty, \theta _ { i } \rangle & \ e _ { i } = 0 \\ \langle \theta _ { i }, + \infty \rangle & \ e _ { i } = 1 \end{cases}$$
Thus, this model offers an alternative 2 to standard binary RBMs of [28, 8].
Ordinal observations. Denote by e = ( e , e 1 2 , ..., e N ) the set of ordinal observations, where each e i is drawn from an ordered set { 1 2 , , .., L } . The common assumption is that the ordinal level e i = l is observed given x i ∈ [ θ l -1 , θ l ] for some thresholds θ 1 ≤ θ 2 ≤ ...θ L -1 . The boundaries thus read
$$\langle b _ { i }, c _ { i } \rangle = \begin{cases} \langle - \infty, \theta _ { 1 } \rangle & l = 1 \\ \langle \theta _ { l - 1 }, \theta _ { l } \rangle & l = 2, 3,.. L - 1 \\ \langle \theta _ { L - 1 }, + \infty \rangle & \text{otherwise} \end{cases}$$
This offers an alternative 3 to the ordinal RBMs of [37].
## 3.2 Inequality Constraints
glyph[negationslash]
Categorical observations . This refers to the situation where out of an unordered set of categories, we observe only one category at a time. This can be formulated as follows. Each category is associated with a 'utility' variable. The category l is observed (i.e., e i = m ) if it has the largest utility, that is x il ≥ max m l = x im . Thus, x il is the upperthreshold for all other utilities. On the other hand, max m l = x im is the lower-threshold for x il . This suggests an EM-style procedure: ( ) fix i x il (or treat it as a threshold) and learn the model under the intervals x im ≤ x il for all m = , and ( l ii ) fix all categories other than l , learn the model under the interval x il ≥ max m l = x im . This offers an alternative 4 to the multinomial logit treatment in [26].
glyph[negationslash]
glyph[negationslash]
To illustrate the point, suppose there are only four variables z , z 1 2 , z 3 , z 4 , and z 1 is observed, then we have z 1 ≥ max { z , z 2 3 , z 4 } . This can be expressed as z 1 -z 2 ≥ 0; z 1 -z 3 ≥ 0 and z 1 -z 4 ≥ 0. These are equivalent to
$$\left \langle A = \left [ \begin{array} { c c c } 1 & - 1 & 0 & 0 \\ 1 & 0 & - 1 & 0 \\ 1 & 0 & 0 & - 1 \end{array} \right ] ; \ \ b = 0 ; \ \ c = + \infty \right \rangle$$
Imprecise categorical observations . This generalises the categorical case : The observation is a subset of a set, where any member of the subset can be a possible observation . 5 For example, when asked to choose the best sport team of interest, a person
2 To be consistent with the statistical literature, we can call it the probit RBM , which we will study in Section 6.1.
3 This can be called ordered probit RBM .
4 We can call this model multinomial probit RBM.
5 This is different from saying that all the members of the subset must be observed.
glyph[negationslash]
may pick two teams without saying which is the best. For instance, suppose the subset is { z , z 1 2 } , then min { z , z 1 2 } ≥ max { z , z 3 4 } , which can be expressed as z 1 -z 3 ≥ 0; z 2 -z 3 ≥ 0, z 1 -z 4 ≥ 0 and z 2 -z 4 ≥ 0. This translates to the following triple
$$\left \langle A = \left [ \begin{array} { c c c c } 1 & 0 & - 1 & 0 \\ 1 & 0 & 0 & - 1 \\ 0 & 1 & - 1 & 0 \\ 0 & 1 & 0 & - 1 \end{array} \right ] ; \ \ b = 0 ; \ \ c = + \infty \right \rangle$$
Rank (with Ties) observations . This generalises the imprecise categorical cases : Here we have a (partially) ranked set of categories. Assume that the rank is produced in a stagewise manner as follows: The best category subset is selected out of all categories, the second best is selected out of all categories except for the best one, and so on. Thus, at each stage we have an imprecise categorical setting, but now the utilities of middle categories are constrained from both sides - the previous utilities as the upper-bound, and the next utilities as the lower-bound.
As an illustration, suppose there are four variables z , z 1 2 , z 3 , z 4 and a particular rank (with ties) imposes that min { z , z 1 2 } ≥ z 3 ≥ z 4 . This be rewritten as z 1 ≥ z 3 ; z 2 ≥ z 3 ; z 3 ≥ z 4 , which is equivalent to
$$\left \langle A = \left [ \begin{array} { c c c } 1 & 0 & - 1 & 0 \\ 0 & 1 & - 1 & 0 \\ 0 & 0 & 1 & - 1 \end{array} \right ] ; \ \ b = 0 ; \ \ c = + \infty \right \rangle$$
## 4 Inference Under Linear Constraints
Under the TBM, MCMC-based inference without evidences is simple: we alternate between P ( h | x ) and P ( x | h ). This is efficient because of the factorisations in Eqs. (3,4). Inference with inequality-based evidence e is, however, much more involved except for the limiting case of point assignments.
Denote by Ω ( e ) = { x | b ≤ glyph[circledot] A x ≤ glyph[circledot] c } the constrained domain of x defined by the evidence e . Now we need to specify and sample from the constrained distribution P ( x h , | e ) defined on Ω ( e ). Sampling P ( h | x ) remains unchanged, and in what follows we focus on sampling from P ( x | h e , ).
## 4.1 Inference under Boxed Constraints
For boxed constraints (Section 3.1), due to the conditional independence, we still enjoy the factorisation P ( x | h e , ) = ∏ i P x ( i | h e , ). We further have
$$P ( x _ { i } \, | \, h, e ) \ = \ \frac { P ( x _ { i } \, | \, h ) } { \Phi ( c _ { i } \, | \, h ) - \Phi ( b _ { i } \, | \, h ) }$$
where Φ( · | h ) is the normal cumulative distribution function of P x ( i | h ). Now P x ( i | h e , ) is a truncated normal distribution, from which we can sample using the simple rejection method, or more advanced methods such as those in [23].
## 4.2 Inference under Inequality Constraints
For general inequality constraints (Section 3.2), the input variables are interdependent due to the linear transform A . However, we can specify the conditional distribution P x ( i | x ¬ i , h e , ) (here x ¬ i = x \ x i ) by realising that glyph[negationslash]
$$b _ { m } - \sum _ { j \neq i } A _ { m j } x _ { j } \leq A _ { m i } x _ { i } \leq c _ { m } - \sum _ { j \neq i } A _ { m j } x _ { j }$$
glyph[negationslash]
glyph[negationslash]
where A mi = 0 for m = 1 2 , , ..., M . In other words, x i is conditionally box-constrained given other variables.
glyph[negationslash]
This suggests a Gibbs procedure by looping through x , x 1 2 , ..., x N . With some abuse of notation, let ˜ b mi = ( b m -∑ j = i A mj x j ) /A mi and ˜ c mi = ( c m -∑ j = i A mj x j ) /A mi . The constraints can be summarised as glyph[negationslash]
$$x _ { i } \ & \in \ \cap _ { m = 1 } ^ { M } \left [ \min \left \{ \tilde { b } _ { m i }, \tilde { c } _ { m i } \right \}, \max \left \{ \tilde { b } _ { m i }, \tilde { c } _ { m i } \right \} \right ] \\ & = \ \left [ \max _ { m } \min \left \{ \tilde { b } _ { m i }, \tilde { c } _ { m i } \right \}, \min _ { m } \max \left \{ \tilde { b } _ { m i }, \tilde { c } _ { m i } \right \} \right ]$$
The min and max operators are needed to handle change in inequality direction with the sign of A mi , and the join operator is due to multiple constraints.
For more sophisticated Gibbs procedures, we refer to the work in [10].
## 4.3 Estimating the Binary Posteriors
We are often interested in the posteriors P ( h | e ), e.g., for further processing. Unlike the standard RBMs, the binary latent variables here are coupled through the unknown Gaussians and thus there are no exact solutions unless the evidences are all point assignments. The MCMC-based techniques described above offer an approximate estimation by averaging the samples { h ( s ) } S s =1 . For the case of boxed constraints, mean-field offers an alternative approach which may be numerically faster. In particular, the mean-field updates are recursive:
$$Q _ { i }$$
$$\begin{matrix} \\ \end{matrix}$$
$$Q _ { k } \quad & \leftarrow \quad \frac { 1 } { 1 + \exp \left \{ - \gamma _ { k } - \sum _ { i } W _ { i k } \hat { \mu } _ { i } \right \} } \\ \mu _ { i } \quad & \leftarrow \quad \alpha _ { i } + \sum _ { k } W _ { i k } Q _ { k } \\ \hat { \mu } _ { i } \quad & = \quad \mu _ { i } + \frac { \phi ( b _ { i } - \mu _ { i } ) - \phi ( c _ { i } - \mu _ { i } ) } { \Phi ( c _ { i } - \mu _ { i } ) - \Phi ( b _ { i } - \mu _ { i } ) } \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \end{array}$$
where Q k is the probability of the unit k being activated, ˆ µ i is the mean of the normal distribution truncated in the interval [ b , c i i ], φ z ( ) is the probability density function, and Φ( ) is normal cumulative distribution function. z Interested readers are referred to the Supplement 6 for more details.
6 Supplement material will be available at: http://truyen.vietlabs.com
## 4.4 Estimating Probability of Evidence Generation
Given the hidden states h we want to estimate the probability that hidden states generate a particular evidence e
$$P ( e \, | \, h ) = \int _ { \Omega ( e ) } P ( x \, | \, h ) d x$$
For boxed constraints, analytic solution is available since the Gaussian variables are decoupled, i.e., P e ( i | h ) = Φ( c i -µ i ) -Φ( b i -µ i ), where µ i = α i + ∑ k W h ik k . For general inequality constraints, however, these variables are coupled by the inequalities. The general strategy is to sample from P ( x | h ) and compute the portion of samples falling into the constrained domain Ω ( e ). For certain classes of inequalities we can approximate the Gaussian by appropriate distributions from which the integration has the closed form. In particular, those inequalities imposed by the categorical and rank evidences can be dealt with by using the extreme value distributions . The integration will give the logit form on distribution of categories and Plackett-Luce distribution of ranks. For details, we refer to the Supplement.
## 5 Stochastic Gradient Learning with Persistent Markov Chains
Learning is based on maximising the evidence likelihood
$$\mathcal { L } \ = \ \log P ( e ) = \log \sum _ { h } \int _ { \Omega ( e ) } P ( h, x ) d x$$
where P ( h x , ) is defined in Eq. (1). Let Z ( e ) = ∑ h GLYPH<1> Ω ( e ) exp {-E ( x h , ) } d x , then L = log Z ( e ) -log Z . The gradient w.r.t. the mapping parameter reads
$$\partial _ { W _ { i k } } \mathcal { L } \ = \ \mathbb { E } _ { P ( x _ { i }, h _ { k } | e ) } \left [ x _ { i } h _ { k } \right ] - \mathbb { E } _ { P ( x _ { i }, h _ { k } ) } \left [ x _ { i } h _ { k } \right ]$$
The derivation is left to the Supplement.
## 5.1 Estimating Data Statistics
The data-dependent statistics E P x ,h ( i k | e ) [ x h i k ] and the data-independent statistics E P x ,h ( i k ) [ x h i k ] are not tractable to compute in general, and thus approximations are needed.
Data-dependent statistics. Under the box constraints, the mean-field technique (Section 4.3) can be employed as follows
$$\mathbb { E } _ { P ( x _ { i }, h _ { k } | e ) } \left [ x _ { i } h _ { k } \right ] \approx \hat { \mu } _ { i } Q _ { k }$$
For general cases, sampling methods are applicable. In particular, we maintain one persistent Markov chain [42, 32] per data instance and estimate the statistics after a very short run. This would explore the space of the data-dependent distribution P ( x h , | e ) by alternating between P ( h | x ) and P ( x | h e , ) using techniques described in Section 4.
Data-independent statistics. Mean-field distributions are not appropriate for exploring the entire state space because they tend to fit into one mode. One practical solution is based on the idea of Hinton's Contrastive Divergence (CD), where we create another Markov chain on-the-fly starting from the latest state of the clamped chain. This chain will be discarded after each parameter update. This is particular useful when the models are instance-specific, e.g., in collaborative filtering, it is much cheaper to build one model per user, all share the same parameters. If it is not the case, then we can maintain a moderate set of parallel chains and collect the samples after a short run at every updating step [42, 32].
## 5.2 Learning the Box Boundaries
In the case of boxed constraints, sometimes it is helpful to learn the boundaries 〈 b , c i i 〉 themselves. The gradient of the log-likelihood w.r.t. the lower boundaries reads
$$\text{s. The gradient of the log-likelihood w.r.t. the lower boundaries read} \\ \partial _ { b _ { i } } \mathcal { L } \ & = \ \frac { 1 } { Z ( e ) } \sum _ { h } \partial _ { b _ { i } } \int _ { \Omega ( e ) } \exp \left \{ - E ( x, h ) \right \} d x \\ & = \ \sum _ { h } \partial _ { b _ { i } } \int _ { \Omega ( e ) } P \left ( x, h \, | \, e \right ) d x \\ & \approx \ \frac { 1 } { S } \partial _ { b _ { i } } \int _ { b _ { i } } ^ { c _ { i } } \int _ { \Omega ( e ) \left \lfloor b _ { i }, c _ { i } \right \rfloor } P \left ( x \, | \, h ^ { ( s ) }, e \right ) d x _ { - i } d x _ { i } \\ & = \ \frac { 1 } { S } \sum _ { h } P \left ( x _ { i } = b _ { i } \, | \, h ^ { ( s ) }, e \right ) \\ ( s ) \right \} S \ &, \quad \,, \quad \,, \quad \,, \quad \,, \quad \,, \quad \,.$$
where { h ( s ) } S s =1 are samples collected during the MCMC procedure running on the datadependent distribution P ( x h , | e ). Similarly we would have the gradient w.r.t. the upper boundaries:
$$\partial _ { c _ { i } } \mathcal { L } = \frac { 1 } { S } \sum _ { h } P \left ( x = c _ { i } \, | \, h ^ { ( s ) }, e \right ).$$
## 6 Applications
In this section, we describe applications of the TBM for three realistic domains, namely handwritten digit recognition, collaborative filtering and worldwide survey analysis. Before going to the details, let us first address key implementation issues (see Supplement for more details).
One observed difficulty in training the TBM is that the hidden samples can get stuck in one of the two ends and thus learning cannot progress. The reasons might be the large mapping parameters or the unbounded nature of the underlying Gaussian variables, which can saturate the hidden units. We can control the norm of the mapping parameters, either by using the standard glyph[lscript] 2 -norm regularisation, or by rescaling the norm of the parameter vector for each hidden unit. To deal with the non-boundedness of the Gaussian variables, then we can restrict their range, making the model bounded.
Another effective solution is to impose a constraint on the posteriors by adding the
regularising term to the log-likelihood, e.g.,
$$\lambda \left \{ \sum _ { k } \left [ \rho \log P ( h _ { k } ^ { 1 } \, | \, e ) + ( 1 - \rho ) \log \left ( 1 - P ( h _ { k } ^ { 1 } \, | \, e ) \right ) \right ] \right \}$$
where ρ ∈ (0 1) is , the expected probability that a hidden unit will turn on given the evidence and λ > 0 is the regularisation weight. Maximising this quantity is essentially minimising the Kullback-Leibler divergence between the expected posteriors and the true posteriors. In our experiments, we found ρ ∈ (0 1 . , 0 3) and . λ ∈ (0 1 . , 1) gave satisfying results.
The main technical issue is that P h ( 1 k | e ) does not have a simple form due to the integration over all the constrained Gaussian variables. Approximation is thus needed. The use of mean-field methods will lead to the simple sigmoid form, but it is only applicable for boxed constraints since it breaks down deterministic constraints among variables (Section 4.3). However, we can estimate the 'mean' truncated Gaussian ˆ µ i by averaging the recent samples of the Gaussian variables in the data-dependent phase.
Once these safeguards are in place, learning can greatly benefit from quite large learning rate and small batches as it appears to quickly get the samples out off the local energy traps by significantly distorting the energy landscape. Depending on the problem sizes, we vary the batch sizes in the range [100 , 1000].
## 6.1 Probit RBM for Handwritten Digits
We use the name Probit RBM to denote the special case of TBM where the observations are binary (i.e., boxed constraints, see Section 3.1). The threshold θ i for each visible unit i is chosen so that under the zero mean, the probability of generating a binary evidence equals the empirical probability, i.e., 1 -Φ( θ i ) = ¯ , and thus e i θ i = Φ -1 (1 -¯ ). e i Since any mismatch in thresholds can be corrected by shifting the corresponding biases, we do not need to update the thresholds further.
We report here the result of the mean-field method for computing data-dependent statistics, which are averaged over a random batch of 500 images. For the data-independent statistics, 500 persistent chains are run in parallel with samples collected after every 5 Gibbs steps. The sparsity level ρ is set to 0 3 and the sparseness weight . λ is set to 0 5. . Once the model has been learned, mean-field is used to estimate the hidden posteriors. Typically this mean-field is quite fast as it converges in a few steps.
We take the data from MNIST and binarize the images using a mid-intensity threshold. The learned representation is shown in Figure 2. Most digits are well separated in 2D except for digits 4 and 9. The learned representation can be used for classifications, e.g., by feeding to the multiclass logistic classifier. For 500 hidden units, the Probit RBM achieves the error rate of 3 28%, comparable with those obtained by the RBM trained . with CD-1 (3 02%), and much better than the raw pixels (8 46%). The features discovered . . by the Probit RBM and RBM with CD-1 are very different (Figure 1), and this is expected because they operate on different input representations. The energy surface learned by the Probit RBM is smooth enough to allow efficient exploration of modes, as shown in Figure 3.
Figure 1: 100 MNIST feature weights (one image per hidden unit) learned by Probit RBM (left) and RBM with CD-1 (right).


Figure 2: t-SNE visualisation of the learned representations on MNIST (left) and random samples of two confused digits (4,9) (right). Best viewed in colours.


Figure 3: Samples generated from the Probit RBM (left) and RBM with CD-1 (right) by mode seeking procedures (see Supplement).

## 6.2 Rank Evidences for Collaborative Filtering
In collaborative filtering, one of the main goals is to produce a personalized ranked list of items. Until very recently, the majority in the area, on the other hand, focused on predicting the ratings, which are then used for ranking items. It can be arguably more efficient to learn a rank model directly instead of going through the intermediate steps.
We build one TBM for ranking with ties (i.e., inequality constraints, see Section 3.2) per user due to the variation in item choices but all the TBMs share the same parameter set. The handling of ties is necessary because during training, many items share the same rating. Unseen items are simply not accounted for in each model: We only need to compare the utilities between the items seen by each person. The result is that the models are very sparse and fast to run. For the data-dependent statistics, we maintain one Markov chain per user. Since there is no single model for all data instances, the dataindependent statistics cannot be estimated from a small set of Markov chains. Rather we also maintain a data-independent chain per data instance, which can be persistent on their own, or restarted from the data-dependent chains after every parameter updating step. The latter case, which is reported here, is in the spirit of the Hinton's Contrastive Divergence, where the data-independent chain is just a few steps away from the datadependent chain.
Once the model has been trained, the hidden posterior vector ˆ h = ( ˆ h , h 1 ˆ 2 , ..., h ˆ K ) , where ˆ h k = P h ( k = 1 | e u ), is used as the new representation of the tastes of user u . The rank of unseen movies is the mode of the distribution P ( e ∗ | ˆ ), h where e ∗ are the rankbased evidences (see Section 4.4). For fast computation of P ( e ∗ | ˆ ), we approximate the h Gaussian by a Gumbel distribution, which leads to a simple way of ranking movies using the mean 'utility' µ ui = α i + W i · ˆ h u for user u (see the Supplement for more details).
The data used in this experiment is the MovieLens, which contains 1M ratings by approximately 6K users on 4K movies. To encourage diversity in the rank lists, we remove the top 10% most popular movies. We then remove users with less than 30 ratings on the
Table 1: Item ranking results on MovieLens - the higher the better ( K = 50). Here N@T is a shorthand for NDCG@T .
| | ERR | N@1 | N@5 | N@10 |
|-----------------|-------|-------|-------|--------|
| Item popularity | 0.587 | 0.56 | 0.68 | 0.835 |
| ListRank.MF | 0.653 | 0.673 | 0.751 | 0.873 |
| PMOP | 0.648 | 0.664 | 0.747 | 0.871 |
| TBM | 0.678 | 0.722 | 0.792 | 0.893 |
remaining movies. The most recently rated 10 movies per user are held out for testing, the next most recent 5 movies are used for tuning hyper-parameters, and the rest for training.
For comparison, we implement a simple baseline using item popularity for ranking, and thus offering a naive non-personalized solution. For personalized alternatives, we implement two recent rank-based matrix factorisation methods, namely ListRank.MF [27] and PMOP [36]. Two ranking metrics from the information retrieval literature are used: the ERR [3] and the NDCG@T [13]. These metrics place more emphasis on the top-ranked items. Table 1 reports the movie ranking results on test subset (each user is presented with a ranked list of unseen movies), demonstrating that the TBM is a clear winner in all metrics.
## 6.3 Mixed Evidences for World Attitude Analysis
Finally, we demonstrate the TBM on mixed evidences. The data is from the survey analysis domain, which mostly consists of multiple questions of different natures such as basic facts (e.g., ages and genders) and opinions (e.g., binary choices, single choices, multiple choices, ordinal judgments, preferences and ranks). The standard approach to deal with such heterogeneity is to perform the so-called 'coding', which converts types into some numerical representations (e.g., ordinal scales into stars, ranks into multiple pairwise comparisons) so that standard processing tools can handle. However, this coding process breaks the structure in the data and thus significant information will be lost. Thus our TBM offers a scalable and generic machinery to process the data in its native format and then convert the mixed types into a more homogeneous posterior vector.
We use the global attitude survey dataset collected by the PewResearch Centre 7 . The survey was conducted on 24 717 people from 24 countries during the period of March 17 , - April 21, 2008 on a variety of topics concerning people's life, opinions on issues in their countries and around the world as well as future expectations. There are 52 binary, 124 categorical (of variable category sizes), 3 continuous, 165 ordinal (of variable level sizes) question types.
Like the case of collaborative filtering, we build one TBM per respondent due to the variation in questions and answers but all the TBMs share the same parameter set. Unanswered/inappropriate questions are ignored. For each respondent, we maintain 2 persistent and non-interacting Markov chains for the data-dependent statistics and the data-independent statistics, respectively.
Figure 4 shows the 2D distribution of respondents from 24 countries obtained by feeding the posteriors to the t-SNE [38] (here no explicit information of countries is used).
7 The datasets are publicly available from http://pewresearch.org/
Figure 4: Distribution of global attitudes obtained by projecting the hidden posteriors (100 hidden units) on 2D using t-SNE. A dot represents one respondent. Best viewed in colours.
It is interesting to see the cultural/social clustering and gaps between countries as opposed to the geographical distribution (e.g., between Indonesia and Egypt, Australia and UK and the relative separation of the China, Pakistan, Turkey and the US from the rest). To predict the 24 countries, we feed the posteriors into the standard multiclass logistic regression and achieve an error rate of 0 49%, suggesting that the TBM has captured the . intrastate regularities and separated the interstate variations well.
## 7 Related Work
Latent multivariate Gaussian variables have been widely studied in statistical analysis, initially to model correlated binary data 8 [1, 4] then now used for a variety of data types such as ordered categories [15], unordered categories [43], and the mixture of types [6] . Learning with the underlying Gaussian model is notoriously difficult for large-scale setting: independent sampling costs cubic time due to the need of inverting the covariance matrix, while MCMC techniques such as Gibbs sampling can be very slow if the graph is dense and the interactions between variables are strong. This can be partly overcome by adding one more layer of latent variables as in factor analysis [39, 14] and probabilistic principle component analysis [33]. The main difference from our TBM is that those models are directed with continuous factors while ours is undirected with binary factors.
Gaussian RBMs have been used for modelling continuous data such as visual features [12], where the evidences are the value assignments, and thus a limiting case of our evidence system. Some restrictions to the continuous Boltzmann machines have been studied: In [5], Gaussian variables are assumed to be non-negative, and in [41], continuous variables are bounded. However, we do not make these restrictions on the model but rather placing restrictions during the training phase only. GRBMs that handle ordinal evidences have been studied in [35], which is an instance of the boxed-constraints in our TBM.
## 8 Discussion and Conclusion
Since the underlying variables of the TBM are Gaussian, various extensions can be made without much difficulty. For example, direct correlations among variables, regardless of their types , can be readily modelled by introducing the non-identity covariance matrix [22]. This is clearly a good choice for image modelling since nearby pixels are strongly correlated. Another situation is when the input units are associated with their own attributes. Each unit can be extended naturally by adding a linear combination of attributes to the mean structure of the Gaussian.
The additive nature of the mean-structure allows the natural extension to matrix modelling (e.g., see [37, 35]). That is, we do not distinguish the role of rows and columns, and thus each row and column can be modelled using their own hidden units (the row parameters and columns parameters are different). Conditioned on the row-based hidden units, we return to the standard TBM for column vectors. Inversely, conditioned on the column-based hidden units, we have the TBM for row vectors.
To sum up, we have proposed a generic class of models called Thurstonian Boltzmann machine (TBM) to unify many type-specific modelling problems and generalise them
8 This is often known as multivariate probit models .
to the general problem of learning from multiple groups of inequalities. Our framework utilises the Gaussian restricted Boltzmann machines, but the Gaussian variables are never observed except for one limiting case. Rather, those variables are subject to inequality constraints whenever an evidence is observed. Under this representation, the TBM supports a very wide range of evidences, many of which were not possible before in the Boltzmann machine literature, without the need to specify type-specific models. In particular, the TBM supports any combination of the point assignments, intervals, censored values, binary, unordered categories, multi-categories, ordered categories, (in)-complete ranks with and without ties.
We demonstrated the TBM on three applications of very different natures, namely handwritten digit recognition, collaborative filtering and complex survey analysis. The results are satisfying and the performance is competitive with those obtained by typespecific models.
## A Supplementary Material
## A.1 Inference
## A.1.1 Estimating the Partition Function
For convenience, let us re-parameterise the distribution as follows
$$\phi _ { i } ( x _ { i } ) \ & = \ \exp \left \{ - \frac { x _ { i } ^ { 2 } } { 2 } + \alpha _ { i } x _ { i } \right \} & & ( 9 ) \\ \psi _ { i k } ( x _ { i }, h _ { k } ) \ & = \ \exp \left \{ W _ { i k } x _ { i } h _ { k } \right \} & & \\ \phi _ { k } ( h _ { k } ) \ & = \ \exp \left \{ \gamma _ { k } h _ { k } \right \}$$
The model potential is then the product of all local potentials
$$\Psi ( x, h ) = \left [ \prod _ { i } \phi _ { i } ( x _ { i } ) \right ] \left [ \prod _ { i k } \psi _ { i k } ( x _ { i }, h _ { k } ) \right ] \left [ \prod _ { k } \phi _ { k } ( h _ { k } ) \right ]$$
The partition function can be rewritten as
$$Z \ & = \ \sum _ { h } \int _ { x } \Psi ( x, h ) d x \\ & = \ \sum _ { h } \Omega ( h )$$
where Ω( h ) = GLYPH<1> x Ψ( x h , ) d x . We now proceed to compute Ω( h ):
$$\text{where} \, \Omega ( h ) = \int _ { x } & \Psi ( x, h ) d x. \, \text{We now proceed to compute } \Omega ( h ) \colon \\ \Omega ( h ) & \ = \ \left [ \prod _ { k } \phi _ { k } ( h _ { k } ) \right ] \int _ { x } \left [ \prod _ { i } \phi _ { i } ( x _ { i } ) \right ] \left [ \prod _ { i k } \psi _ { i k } ( x _ { i }, h _ { k } ) \right ] d x \\ & \ = \ \left [ \prod _ { k } \phi _ { k } ( h _ { k } ) \right ] \prod _ { i } \int _ { x _ { i } } \exp \left \{ - \frac { x _ { i } ^ { 2 } } { 2 } + ( \alpha _ { i } + \sum _ { k } W _ { i k } h _ { k } ) x _ { i } \right \} d x _ { i } \\ & \ = \ \left [ \prod _ { k } \phi _ { k } ( h _ { k } ) \right ] \prod _ { i } C _ { i } \int _ { x _ { i } } \exp \left \{ - \frac { ( x _ { i } - \mu _ { i } ( h ) ) ^ { 2 } } { 2 } \right \} d x _ { i } \\ & \ = \ \left [ \prod _ { k } \phi _ { k } ( h _ { k } ) \right ] \prod _ { i } C _ { i } \sqrt { 2 \pi \sigma _ { i } ^ { 2 } } \\ \text{where}$$
where
$$\mu _ { i } ( h ) \ & = \ \alpha _ { i d } + \sum _ { k = 1 } ^ { K } W _ { i k } h _ { k } \\ C _ { i } \ & = \ \exp \left \{ \frac { 1 } { 2 } \left ( \frac { \mu _ { i } ( h ) } { \sigma _ { i } } \right ) ^ { 2 } \right \}$$
Now we can define the distribution over the hidden layer as follows
$$P ( h ) = \frac { 1 } { Z } \Omega ( h )$$
Now we apply the Annealed Importance Sampling (AIS) [19]. The idea is to introduces the notion of inverse-temperature τ into the model, i.e., P ( h | τ ) ∝ Ω( h ) τ .
Let { τ s } S s =0 be the (slowly) increasing sequence of temperature, where τ 0 = 0 and τ S = 1, that is τ 0 < τ ... 1 < τ S . At τ 0 = 0, we have a uniform distribution, and at τ S = 1, we obtain the desired distribution. At each step s , we draw a sample h s from the distribution P ( h | τ s -1 ) (e.g. using some Metropolis-Hastings procedure). Let P ∗ ( h | τ ) be the unnormalised distribution of P ( h | τ ), that is P ( h | τ ) = P ∗ ( h | τ ) /Z τ ( ). The final weight after the annealing process is computed as
$$\omega = \frac { P ^ { * } ( h ^ { 1 } | \tau _ { 1 } ) } { P ^ { * } ( h ^ { 1 } | \tau _ { 0 } ) } \frac { P ^ { * } ( h ^ { 2 } | \tau _ { 2 } ) } { P ^ { * } ( h ^ { 2 } | \tau _ { 1 } ) } \dots \frac { P ^ { * } ( h ^ { S } | \tau _ { S } ) } { P ^ { * } ( h ^ { S } | \tau _ { S - 1 } ) }$$
The above procedure is repeated T times. Finally, the normalisation constant at τ = 1 is computed as Z (1) ≈ Z (0) ( ∑ T t =1 ω ( ) t /T ) where Z (0) = 2 K , which is the number of configurations of the hidden variables h .
## A.1.2 Estimating Posteriors using Mean-field
Recall that for evidence e we want to estimate posteriors P ( h | e ) = ∑ x ∈ Ω( ) e P Ω( ) e ( h x , | e ). Assume that the evidences can be expressed in term of boxed constraints, which lead
to the following factorisation
$$P ( x \, | \, e, h ) = \prod _ { i } P ( x _ { i } \, | \, e, h )$$
This factorisation is critical because it ensures that there are no deterministic constraints among { x i } n i =1 , which are the conditions that variational methods such as mean-fields would work well. This is because mean-field solution will generally not satisfy deterministic constraints, and thus may assign non-zeros probability to improbably areas.
To be more concrete, the mean-field approximation would be Q ( h x , ) ≈ P ( h x , | e )
$$Q ( h, x ) \ & = \ \prod _ { k } Q _ { k } ( h _ { k } ) \prod _ { i } Q _ { i } ( x _ { i } ) \\ \text{s.t.} \ \ x \ \in \ \Omega ( e )$$
The best mean-field approximation will be the minimiser of the Kullback-Leibler divergence
$$\mathcal { D } \left ( Q \| P \right ) \ & = \ \sum _ { h } \sum _ { x \in \Omega \left ( e \right ) } Q \left ( h, x \right ) \log \frac { Q \left ( h, x \right ) } { P \left ( h, x \, | \, e \right ) } \\ & = \ - H \left [ Q \left ( h, x \right ) \right ] - \sum _ { h } \sum _ { x \in \Omega \left ( e \right ) } Q \left ( h, x \right ) \log P \left ( h, x \, | \, e \right ) \quad \ \ ( 1 1 )$$
where H Q [ ( h x , )] is the entropy function. Now first, exploit the fact that Q is factorisable, and thus its entropy is decomposable, i.e.,
$$H \left [ Q ( h, x ) \right ] = \sum _ { k } H \left [ Q _ { k } ( h _ { k } ) \right ] + \sum _ { i } H \left [ Q _ { i } ( x _ { i } ) \right ]$$
Second recall from Eq. (17) that
$$P ( h, x \, | \, e ) = \frac { 1 } { Z ( e ) } \exp \left \{ - E ( x, h ) \right \}$$
and thus
$$\sum _ { h } \sum _ { x \in \Omega ( e ) } Q ($$
Since log Z ( e ) is a constraint w.r.t. Q ( h x , ), we can safely ignore it here.
Now since E ( x h , ) is decomposable (see Eq. (2)), we have
$$\begin{array} {$$
where
$$E _ { i } ( x _ { i } ) \ & = \ \frac { x _ {$$
Combining this decomposition and Eq. (12), we have completely decomposed the Kullback-Leibler divergence in Eq. (11) into local terms:
$$\mathcal { D } ( Q | | P ) \ = \ & \sum _ { i }$$
Now we wish to minimise the divergence with respect to the local distributions { Q x i ( i ) , Q k ( h k ) } for i = 1 2 , , ..., N and k = 1 2 , , ..., K knowing the proper distribution constraints
$$\int _ { x _ { i } \in \Omega ( e _ { i } ) }$$
By the method of Lagrangian multiplier, we have
$$L ( \lambda ) = \mathcal { D } \left ( Q | | P \right ) + \sum _ { i } \lambda _ { i } \left ( \int _ { x _ { i } \in \Omega ( e _ { i } ) } Q _ { i } ( x _ { i } ) - 1 \right ) + \sum _ { k } \kappa _ { k } \left ( \sum _ { h _ { k } } Q _ { k } ( h _ { k } ) - 1 \right )$$
- · Let us compute the partial derivative w.r.t. Q x i ( i ):
$$\partial _ { Q _ { i } ( x _ { i } ) } L ( \lambda ) \ = \ \log Q _ { i } ( x _ { i } ) + 1 + E _ { i } ( x _ { i } ) + \sum _ { k } Q _ { k } ( h _ { k } ^ { 1 } ) E _ { i k } ( x _ { i }, h _ { k } ^ { 1 } ) + \lambda _ { i }$$
where h 1 k is a short hand for h k = 1 and we have made use of the fact that E ik ( x , h i k = 0) = 0. Setting this gradient to zero yields
$$\begin{array} { r c l } \cdot \cdot \cdot & \cdot & \cdot & \cdot \\ Q _ { i } ( x _ { i } ) & = & \exp \left \{ - \left ( E _ { i } ( x _ { i } ) + \sum _ { k } Q _ { k } ( h _ { k } ^ { 1 } ) E _ { i k } ( x _ { i }, h _ { k } ^ { 1 } ) \right ) - 1 - \lambda _ { i } \right \} \\ & = & \exp \left \{ - \frac { 1 } { 2 } \left ( x _ { i } - \left ( \alpha _ { i } + \sum _ { k } Q _ { k } ( h _ { k } ^ { 1 } ) W _ { i k } \right ) \right ) ^ { 2 } - 1 - \lambda _ { i } \right \} \end{array}$$
for x i ∈ Ω( e i ). Normalising this distribution would lead to the truncated form of the normal distribution those the mean is
$$\mu _ { i } = \alpha _ { i } + \sum _ { k } Q _ { k } ( h _ { k } ^ { 1 } ) W _ { i k } h _ { k }$$
- · In a similar way, the partial derivative w.r.t. Q k ( h k ) would be
$$\partial _ { Q _ { k } ( h _ { k } ) } L ( \lambda ) = \log Q _ { k } ( h _ { k } ) - h _ { k } \left ( \gamma _ { k } + \sum _ { i } W _ { i k } \sum _ { x _ { i } \in \Omega ( e _ { i } ) } Q _ { i } ( x _ { i } ) x _ { i } \right ) + 1 + \kappa _ { k }$$
Equating the gradient to zero, we have
$$Q _ { k } ( h _ { k } ) \infty \exp \left \{ h _ { k } \left ( \gamma _ { k } + \sum _ { i } W _ { i k } \hat { \mu } _ { i } \right ) \right \}$$
where ˆ µ i is the mean of the truncated normal distribution
$$\hat { \mu } _ { i } = \sum _ { x _ { i } \in \Omega ( e _ { i } ) } Q _ { i } ( x _ { i } ) x _ { i }$$
Normalising Q k ( h k ) would lead to
$$Q _ { k } ( h _ { k } ^ { 1 } ) = \left [ 1 + \exp \left \{ - \gamma _ { k } - \sum _ { i } W _ { i k } \hat { \mu } _ { i } \right \} \right ] ^ { - 1 }$$
- · Finally, combining these findings in Eqs. (13,14,15), and letting Ω( e i ) = [ b , c i i ] be the boxed constraint, and using the fact that the mean of the truncated distribution is
$$\hat { \mu } _ { i } = \mu _ { i } + \frac { \phi ( b _ { i } - \mu _ { i } ) - \phi ( c _ { i } - \mu _ { i } ) } { \Phi ( c _ { i } - \mu _ { i } ) - \Phi ( b _ { i } - \mu _ { i } ) }$$
we would arrive at the three recursive equations
$$\begin{matrix} \\ \end{matrix}$$
$$\omega \, \max \, \max \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col: \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col.: \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colot \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colots \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col on \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colons \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colON \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \color \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colOn \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colun \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col>. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col.. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \col { \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \. \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \text{ } \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \
\colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \colon \, \$$
where q k is a short hand for Q k ( h 1 k ) and φ z ( ) is the normal probability density function, and Φ( z ) is the cumulative distribution function ♣
## A.1.3 Seeking Modes and Generating Representative Samples
Once the model has been learned, samples can be generated straightforwardly by first sampling the underlying Gaussian RBM and then collect the true samples that satisfy the inequalities of interest. For example, for binary samples, if the generated Gaussian value for a visible unit is larger than the threshold, then we have an active sample. Likewise, rank samples, we only need to rank the sampled Gaussian values.
However, this may suffer from the poor mixing if we use standard Gibbs sampling, that is the Markov chain may get stuck in some energy traps. To jump out of the trap
we propose to periodically raise the temperature to a certain level (e.g., 10) and then slowly cool down to the original temperature (which is 1). In our experiment, the cooling is scheduled as follows
$$T \leftarrow \eta T$$
where η ∈ (0 1) is estimated so that for , n steps, the temperature will drop from T max to T min . That is, T min = η n T max , leading to η = ( T min /T max ) 1 /n .
To locate a basis of attraction, we can lower the temperature further (e.g., to 0 1) to . trap the particles there. Then we collect k successive samples and take the average to be the representative sample. In our experiments, k = 50.
## A.2 Learning
## A.2.1 Gradient of the Likelihood
The log-likelihood of an evidence is
$$\mathcal { L } \ & = \ \log P ( e ) = \log \sum _ { h } \int _ { \Omega ( e ) } P ( h, x ) d x \\ & = \ \log \sum _ { h } \int _ { \Omega ( e ) } \exp \left \{ - E ( x, h ) \right \} d x - \log Z \\ & = \ \log Z ( e ) - \log Z \\ \mathcal { \Phi } \quad \ \. \quad \. \quad \. \quad \.$$
where Z ( e ) = ∑ h GLYPH<1> Ω ( e ) exp {-E ( x h , ) } d x . The gradient of log Z ( e ) w.r.t. the mapping parameter W ik reads
$$\partial _ { W _ { i k } } \log Z ( e ) \ & = \ \frac { - 1 } { Z ( e ) } \sum _ { h } \int _ { \Omega ( e ) } \exp \left \{ - E ( x, h ) \right \} \partial _ { W _ { i k } } E ( x, h ) d x \\ & = \ - \sum _ { h } \int _ { \Omega ( e ) } P ( x, h \, | \, e ) \partial _ { W _ { i k } } E ( x, h ) d x$$
where we have moved the constant Z -1 ( e ) into the sum and integration and make use of the fact that
$$P ( x, h \, | \, e ) = \frac { P ( x, h ) } { P ( e ) } = \frac { 1 } { Z ( e ) } \exp \left \{ - E ( x, h ) \right \}$$
where the domain of the Gaussian is constrained to x ∈ Ω ( e ).
From the definition of the energy function in Eq. (2), we know that the energy is decomposable, and thus the gradient w.r.t. W ik only involves the pair ( x , h i k ). In particular
$$\partial _ { W _ { i k } } E ( x, h ) = - x _ { i } h _ { k }$$
This simplifies Eq. (16)
$$\partial _ { W _ { i k } } \log Z ( e ) \ & = \ - \sum _ { h _ { i } } \int _ { \Omega ( e _ { i } ) } P ( x _ { i }, h _ { k } \ | \ e ) \partial _ { W _ { i k } } E ( x, h ) d x _ { i } \\ & = \ \mathbb { E } _ { P ( x, h | e ) } \left [ x _ { i } h _ { k } \right ]$$
A similar process would lead to
$$\partial _ { W _ { i k } } \log Z = \mathbb { E } _ { P ( x _ { i }, h _ { k } ) } \left [ x _ { i } h _ { k } \right ]$$
and finally:
$$\partial _ { W _ { i k } } \mathcal { L } \ = \ \mathbb { E } _ { P ( x _ { i }, h _ { k } | e ) } \left [ x _ { i } h _ { k } \right ] - \mathbb { E } _ { P ( x _ { i }, h _ { k } ) } \left [ x _ { i } h _ { k } \right ] \bullet$$
## A.2.2 Regularising the Markov Chains
One undesirable feature of the MCMC chains used in learning we have experiences so far is the tendency for the binary hidden states to get stuck, i.e., after some point they do not flip their assignments as learning progresses. We conjecture that this phenomenon may be due to the saturation effect inherent in the factor posterior:
$$P ( h _ { k } = 1 \ | \ x ) = \frac { 1 } { 1 + \exp \left ( - \gamma _ { k } - \sum _ { i } W _ { i k } x _ { i } \right ) }$$
i.e., once the collected value to a node ( γ k + ∑ i W x ik i ) is too high or too low, it is very hard to over turn.
Fortunately, there is a known technique to regularise the chain: we enforce that at a time, there should be only a fraction ρ of nodes which are active, where ρ ∈ (0 1). , One way is to maximise the following objective function
$$\mathcal { L } _ { 2 } \ = \ \mathcal { L } + \lambda \int \left [ \sum _ { k } \sum _ { h _ { k } } \rho ( h _ { k } ) \log P ( h _ { k } \, | \, x ) \right ] P ( x \, | \, e ) d x$$
where λ > 0 is the weighting factor, ρ h ( k ) = ρ if h k = 1 and ρ h ( k ) = 1 -ρ otherwise. The gradient with respect to g k = ( γ k + ∑ i W x ik i ) is then
$$\partial _ { g _ { k } } \mathcal { L } _ { 2 } \ & = \ \partial _ { g _ { k } } \mathcal { L } + \lambda \int \left [ \partial _ { g _ { k } } \sum _ { h _ { k } } \rho ( h _ { k } ) \log P ( h _ { k } \, | \, x ) \right ] P ( x | e ) d x \\ & = \ \partial _ { g _ { k } } \mathcal { L } + \lambda \int \left [ \rho - P ( h _ { k } ^ { 1 } \, | \, x ) \right ] P ( x | e ) d x \\ & \approx \ \partial _ { g _ { k } } \mathcal { L } + \frac { 1 } { S } \lambda \sum _ { s } \left [ \rho - P ( h _ { k } ^ { 1 } \, | \, x ^ { ( s ) } ) \right ] \\ \intertext { h o w o d o n d o n d } \, \mathcal { G } \, \intertext { h o w o d o n d o n d } \, \mathcal { D } ( h ^ { 1 } + \mathcal { G } ) \, \intertext { h o w o d o n d o n d o n d } \, \mathcal { D } ( h ^ { 1 } + \mathcal { G } ) \, \intertext { H o w o d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d o n d }$$
where S is the number of samples and P h ( 1 k | x ) is a shorthand for P h ( k = 1 | x ). Using the chain rule, we have:
$$\partial _ { \gamma _ { k } } \mathcal { L } _ { 2 } \ \ & \approx \ \partial _ { \gamma _ { k } } \mathcal { L } + \frac { 1 } { S } \lambda \sum _ { s } \left [ \rho - P ( h _ { k } ^ { 1 } \, | \, x ^ { ( s ) } ) \right ] \\ \partial _ { W _ { i k } } \mathcal { L } _ { 2 } \ \ & \approx \ \partial _ { w _ { i k d } } \mathcal { L } + \frac { 1 } { S } \lambda \sum _ { s } x _ { i } \left [ \rho - P ( h _ { k } ^ { 1 } \, | \, x ^ { ( s ) } ) \right ]$$
## A.2.3 Online Estimation of Posteriors
For tasks such as data completion (e.g., collaborative filtering) we need the posteriors P ( h | e ) for the prediction phase. One way is to run the Markov chain or doing meanfield from scratch. Here we suggest a simple way to obtain an approximation directly from the training phase without any further cost. The idea is to update the estimated posterior ˆ at each learning step h t in an exponential smoothing fashion:
$$\hat { h } ^ { ( t ) } \leftarrow \eta \hat { h } ^ { ( t - 1 ) } + ( 1 - \eta ) \hat { h } ^ { ( t ) }$$
for some smoothing factor η ∈ (0 1) and initial , ˆ h (0) , where ¯ h ( ) t k = P h ( 1 k | x ( ) t , e ) and x ( ) t is the sampled Gaussian at time t .
As learning progresses, early samples, which are from incorrect models, will be exponentially weighted down. Typically we choose η close to 1, e.g., η = 0 9. .
## A.2.4 Monitoring the Learning Progress
It is often of practical importance to track the learning progress, either by the reconstruction errors or by the data likelihood. The data likelihood can be estimated as
$$P ( e ) \approx \frac { 1 } { S } \sum _ { s = 1 } ^ { S } \int _ { \Omega ( e ) } P ( x \, | \, h ^ { ( s ) } ) d x$$
where h ( s ) are those samples collected as learning progressed in the data-independent phase, and the integration can be carried out using the technique described in the main text.
## A.3 Extreme Value Distributions
Extreme value distributions are a class of distributions of extremal measurements [11]. Here we are concerned about the popular Gumbel's distribution.
## A.3.1 Gumbel Distribution for Categorical Choices
Let us start from the Gumbel density function
$$P ( x ) = \frac { 1 } { \sigma } \exp \left \{ - \left ( \frac { x - \mu } { \sigma } + e ^ { - \frac { x - \mu } { \sigma } } \right ) \right \}$$
where µ is the mode (location) and σ is the scale parameter.
Using Laplace's approximation (e.g., via Taylor's expansion of ( x -µ σ + e -x -µ σ ) using the second-order polynomial around µ ), we have
$$P ( x ) \in \frac { 1 } { e \sigma } \exp \left \{ - \frac { ( x - \mu ) ^ { 2 } } { 2 \sigma ^ { 2 } } \right \}$$
Renormalising this distribution, e.g., by replacing e ≈ 2 7183 by . √ 2 π ≈ 2 5066 we obtain . the standard Gaussian distribution. Thus, we can use the Gumbel as an approximation to the Gaussian distribution .
Now we turn to the categorical model using Gumbel variables. We maintain one variable per category, which plays the role of the utility for the category. Assume that all utilities share the same scale parameter σ . The existing literature [18] asserts that the probability of choosing the m -th category is
$$P ( e = c _ { m } ) = \frac { e ^ { \mu _ { m } / \sigma } } { \sum _ { l } e ^ { \mu _ { l } / \sigma } }$$
where µ l is the location of the l -th utility.
glyph[negationslash]
When we choose a the m -th category we must ensure that x m > max l = m x l . Let y l = exp ( -x l -µ l σ ) or equivalently x l = µ l -σ log y l . Thus x l < x m means µ l -σ log y l < µ m -σ log y m , or y l > y m exp ( µ l -µ m σ ) .
The CDF of the l -th Gumbel distribution is
$$\iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iia \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \julia \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota\iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \jul \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ jul \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota\ iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \ioda \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \iota \sigma \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \sigma \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi$$
Thus choosing category c m would mean glyph[negationslash]
glyph[negationslash]
$$P ( e = c _ { m } ) \ = \ \int P ( x _ { m } ) \left ( \prod _ { l \neq m } \int ^ { x m } P ( x _ { l } ) d x _ { l } \right ) d x _ { m } \\ = \ \int P ( x _ { m } ) \prod _ { l \neq m } F _ { l } ( x _ { m } ) d x _ { m } \\ \dots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \colon \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdot \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdclots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \cdots \, \end{array}$$
We rewrite the Gumbel density function by changing variable from x m to y m :
$$P ( y _ { m } ) = \frac { 1 } { \sigma } y _ { m } \exp \left \{ - y _ { m } \right \}$$
for y m ≥ 0. Thus glyph[negationslash]
$$P ( x _ { m } ) \prod _ { l \neq m } F _ { l } ( x _ { m } ) = \frac { 1 } { \sigma } y _ { m } \exp \left ( - y _ { m } \left \{ 1 + \sum _ { l \neq m } e ^ { \frac { \mu _ { l } - \mu _ { m } } { \sigma } } \right \} \right )$$
glyph[negationslash]
Now, by changing variable under the integration from x m to y m , we have glyph[negationslash]
glyph[negationslash]
$$\text{by changing variable under the integration from $x_{m}$ to $y_{m}$, we have} \\ P ( e = c _ { m } ) & \ = \ \sigma \int _ { 0 } ^ { \infty } P ( y _ { m } ) \prod _ { l \neq m } F _ { l } ( y _ { m } ) ^ { \frac { 1 } { y _ { l } } } d y _ { m } \\ & = \ \int _ { 0 } ^ { \infty } \exp \left ( - y _ { m } \left \{ 1 + \sum _ { l \neq m } e ^ { \frac { \mu _ { l } - \mu _ { m } } { \sigma } } \right \} \right ) d y _ { m } \\ & = \ \frac { 1 } { 1 + \sum _ { l \neq m } e ^ { \frac { \mu _ { l } - \mu _ { m } } { \sigma } } } \\ & = \ \frac { e ^ { \mu _ { m } / \sigma } } { \sum _ { l } e ^ { \mu _ { l } / \sigma } } \\ & \quad \text{$\in$}$$
glyph[negationslash]
## A.3.2 Gumbel Distribution for Rank
We now extend the case of categorical evidences rank evidences. Again we maintain one Gaussian variable per category. Without loss of generality, for a particular rank π we assume that we must ensure that x 1 > x 2 > ... > x D . This is equivalent to
$$\left [ x _ { 1 } > \max _ { l > 1 } x _ { l } \right ] \cap \left [ x _ { 2 } > \max _ { l > 2 } x _ { l } \right ] \cap \dots \cap [ x _ { D = 1 } > x _ { D } ]$$
The probability of this is essentially
$$P \left ( \{ e _ { m } = m \} _ { m = 1 } ^ { D } \right ) = P ( e _ { 1 } = 1 ) \prod _ { m > 2 } P \left ( e _ { l } = m \ | \ \{ e _ { d } = l \} _ { l = 1 } ^ { m - 1 } \right )$$
In words, this offers a stagewise process to rank categories: first we pick the best category, the pick the second best from the remaining categories and so on (see also [7]). The probability of picking the best category out of a subset is already given in Appendix A.3.1:
$$P ( e _ { 1 } = 1 ) \ & = \ \frac { e ^ { \mu _ { 1 } / \sigma } } { \sum _ { l \geq 1 } e ^ { \mu _ { l } / \sigma } } \\ P \left ( e _ { l } = m \ | \ \{ e _ { d } = l \} _ { l = 1 } ^ { m - 1 } \right ) \ & = \ \frac { e ^ { \mu _ { m } / \sigma } } { \sum _ { l \geq m } e ^ { \mu _ { l } / \sigma } } \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
This gives us the Plackett-Luce model [17, 21] as mentioned in [30].
## A.4 Global Attitude: Sample Questions
- · Q4 ( Ordinal ): [...] how would you describe the current economic situation in (survey country) -{ very good, somewhat good, somewhat bad, or very bad } ?
- · Q11a ( Binary ): How do you think people in other countries of the world feel about China? -{ like, disliked } ?
- · Q35,35a ( Category-ranking ): Which one of the following, if any, is hurting the world's environment the most/second-most { India, Germany, China, Brazil, Japan, United States, Russia, Other } ?
- · Q76 ( Continuous ): How old were you at your last birthday?
- · Q85 ( Categorical ): What is your current employment situation { A list of employment categories } ?
## A.5 Other Supporting Materials
## A.5.1 Laplace Approximation
Laplace approximation is the technique using a Gaussian distribution to approximate another distribution. For the univariate case, assume that the original density distribution has the form
$$P ( x ) \in \exp \left \{ - f ( x ) \right \}$$
First we find the mode µ of P x ( ) or equivalently the minimiser of f ( x ) given it exists. Then we apply Taylor's expansion
$$f ( x ) \approx f ( \mu ) + f ^ { \prime \prime } ( \mu ) \frac { \left ( x - \mu \right ) ^ { 2 } } { 2 }$$
The Gaussian approximation has the form
$$P ^ { * } ( x ) \in \exp \left \{ - f ^ { \prime \prime } ( \mu ) \frac { \left ( x - \mu \right ) ^ { 2 } } { 2 } \right \}$$
where 1 /f ′′ ( µ ) is the new variance.
## A.5.2 Some Properties of the Truncated Normal Distribution
For a normal distribution P x µ, σ ( | ) of mean µ and standard deviation σ truncated from both sides, i.e., α < x < β , the new density reads
$$\bar { P } _ { [ \alpha, \beta ] } ( x \, |, \mu, \sigma ) = \frac { Q ( x ^ { * } ) } { \sigma \left [ \Phi ( \beta ^ { * } ) - \Phi ( \alpha ^ { * } ) \right ] }$$
where
$$x ^ { * } \ = \ \frac { x - \mu } { \sigma } ; \ \alpha ^ { * } = \frac { \alpha - \mu } { \sigma } ; \ \beta ^ { * } = \frac { \beta - \mu } { \sigma }$$
and Q ( ) · and Φ( ) are the probability density function and the cumulative distribution · of the standard normal distribution, respectively. In particular, we are interested in the mean of the distribution ¯ P [ α,β ] :
$$\bar { \mu } = \mu _ { i } + \sigma \frac { Q ( \alpha ^ { * } ) - Q ( \beta ^ { * } ) } { \Phi ( \beta ^ { * } ) - \Phi ( \alpha ^ { * } ) }$$
Some special cases:
- · When α = β , this distribution reduces to the Dirac's delta.
- · When α = -∞ , we have a one-sided truncation from above since Φ( α ∗ ) = 0.
- · When β = + ∞ , we obtain a one-sided truncation form below since Φ( β ∗ ) = 0.
## References
- [1] JR Ashford and RR Sowden. Multi-variate probit analysis. Biometrics , pages 535546, 1970. 7
- [2] U. B¨ ockenholt. Thurstonian-based analyses: past, present, and future utilities. Psychometrika , 71(4):615-629, 2006. 1
- [3] O. Chapelle, D. Metlzer, Y. Zhang, and P. Grinspan. Expected reciprocal rank for graded relevance. In CIKM , pages 621-630. ACM, 2009. 6.2
- [4] S. Chib and E. Greenberg. Analysis of multivariate probit models. Biometrika , 85(2):347-361, 1998. 7
- [5] O.B. Downs, D.J.C. MacKay, and D.D. Lee. The nonnegative Boltzmann machine. Advances in Neural Information Processing Systems , 12:428-434, 2000. 7
- [6] D.B. Dunson and A.H. Herring. Bayesian latent variable models for mixed discrete outcomes. Biostatistics , 6(1):11, 2005. 7
- [7] M.A. Fligner and J.S. Verducci. Multistage ranking models. Journal of the American Statistical Association , 83(403):892-901, 1988. A.3.2
- [8] Y. Freund and D. Haussler. Unsupervised learning of distributions on binary vectors using two layer networks. Advances in Neural Information Processing Systems , pages 912-919, 1993. 3.1
- [9] P.V. Gehler, A.D. Holub, and M. Welling. The rate adapting Poisson model for information retrieval and object recognition. In Proceedings of the ICML , pages 337-344, 2006. 1
- [10] J. Geweke. Efficient simulation from the multivariate normal and student-t distributions subject to linear constraints and the evaluation of constraint probabilities. In Computing science and statistics: Proceedings of the 23rd symposium on the interface , pages 571-578, 1991. 4.2
- [11] EJ Gumbel. Statistical of extremes . Columbia University Press, New York, 1958. A.3
- [12] G.E. Hinton and R.R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science , 313(5786):504-507, 2006. 1, 7
- [13] K. J¨rvelin and J. Kek¨l¨inen. a a a Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems (TOIS) , 20(4):446, 2002. 6.2
- [14] E. Khan, B. Marlin, and K. Murphy. Variational bounds for mixed-data factor analysis. In Proc. of Neural Information Processing Systems , 2010. 7
- [15] A. Kottas, P. M¨ller, and F. Quintana. Nonparametric Bayesian modeling for multiu variate ordinal data. Journal of Computational and Graphical Statistics , 14(3):610625, 2005. 7
- [16] N. Le Roux, N. Heess, J. Shotton, and J. Winn. Learning a generative model of images by factoring appearance and shape. Neural Computation , 23(3):593-650, 2011. 1
- [17] R.D. Luce. Individual choice behavior . Wiley New York, 1959. A.3.2
- [18] D. McFadden. Conditional logit analysis of qualitative choice behavior. Frontiers in Econometrics , pages 105-142, 1973. A.3.1
- [19] R.M. Neal. Annealed importance sampling. Statistics and Computing , 11(2):125-139, 2001. A.1.1
| [20] | J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A.Y. Ng. Multimodal deep learning. In ICML , 2011. 1 |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [21] | R.L. Plackett. The analysis of permutations. Applied Statistics , pages 193-202, 1975. A.3.2 |
| [22] | M.A. Ranzato and G.E. Hinton. Modeling pixel means and covariances using fac- torized third-order Boltzmann machines. In CVPR , pages 2551-2558. IEEE, 2010. 8 |
| [23] | C.P. Robert. Simulation of truncated normal variables. Statistics and computing , 5(2):121-125, 1995. 4.1 |
| [24] | R. Salakhutdinov and G. Hinton. Deep Boltzmann Machines. In Proceedings of 20th AISTATS , volume 5, pages 448-455, 2009. 1 |
| [25] | R. Salakhutdinov and G. Hinton. Replicated softmax: an undirected topic model. Advances in Neural Information Processing Systems , 22, 2009. 1 |
| [26] | R. Salakhutdinov, A. Mnih, and G. Hinton. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th ICML , pages 791-798, 2007. 3.2 |
| [27] | Y. Shi, M. Larson, and A. Hanjalic. List-wise learning to rank with matrix fac- torization for collaborative filtering. In ACM RecSys , pages 269-272. ACM, 2010. 6.2 |
| [28] | P. Smolensky. Information processing in dynamical systems: Foundations of har- mony theory. Parallel distributed processing: Explorations in the microstructure of cognition , 1:194-281, 1986. 1, 3.1 |
| [29] | N. Srivastava and R. Salakhutdinov. Multimodal learning with deep Boltzmann machines. In NIPS , pages 2231-2239, 2012. 1 |
| [30] | H. Stern. Models for distributions on permutations. Journal of the American Sta- tistical Association , 85(410):558-564, 1990. A.3.2 |
| [31] | L.L. Thurstone. A law of comparative judgment. Psychological review , 34(4):273, 1927. 1 |
| [32] | T. Tieleman. Training restricted Boltzmann machines using approximations to the likelihood gradient. In Proceedings of the 25th ICML , pages 1064-1071, 2008. 5.1, 5.1 |
| [33] | M.E. Tipping and C.M. Bishop. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B , 61(3):611-622, 1999. 7 |
| [34] | T. Tran, D.Q. Phung, and S. Venkatesh. Mixed-variate restricted Boltzmann ma- chines. In Proc. of 3rd Asian Conference on Machine Learning (ACML) , Taoyuan, Taiwan, 2011. 1 |
| [35] | T. Tran, D.Q. Phung, and S. Venkatesh. Cumulative restricted Boltzmann machines for ordinal matrix data analysis. In Proc. of 4th Asian Conference on Machine Learning (ACML) , Singapore, 2012. 1, 7, 8 |
| [36] | T. Truyen, D.Q Phung, and S. Venkatesh. Probabilistic models over ordered parti- tions with applications in document ranking and collaborative filtering. In Proc. of SIAM Conference on Data Mining (SDM) , Mesa, Arizona, USA, 2011. SIAM. 6.2 |
|--------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [37] | T.T. Truyen, D.Q. Phung, and S. Venkatesh. Ordinal Boltzmann machines for collab- orative filtering. In Twenty-Fifth Conference on Uncertainty in Artificial Intelligence (UAI) , Montreal, Canada, June 2009. 1, 3.1, 8 |
| [38] | L. van der Maaten and G. Hinton. Visualizing data using t-SNE. Journal of Machine Learning Research , 9(2579-2605):85, 2008. 6.3 |
| [39] | M. Wedel and W.A. Kamakura. Factor analysis with (mixed) observed and latent variables in the exponential family. Psychometrika , 66(4):515-530, 2001. 7 |
| [40] | E. Xing, R. Yan, and A.G. Hauptmann. Mining associated text and images with dual-wing harmoniums. In Proceedings of the 21st UAI , 2005. 1 |
| [41] | M. Yasuda and K. Tanaka. Boltzmann machines with bounded continuous random variables. Interdisciplinary Information Sciences , 13(1):25-31, 2007. 7 |
| [42] | L. Younes. Parametric inference for imperfectly observed Gibbsian fields. Probability Theory and Related Fields , 82(4):625-645, 1989. 5.1, 5.1 |
| [43] | X. Zhang, W.J. Boscardin, and T.R. Belin. Bayesian analysis of multivariate nominal measures using multivariate multinomial probit models. Computational statistics & data analysis , 52(7):3697-3708, 2008. 7 | | null | [
"Truyen Tran",
"Dinh Phung",
"Svetha Venkatesh"
] | 2014-08-01T00:32:32+00:00 | 2014-08-01T00:32:32+00:00 | [
"stat.ML",
"cs.LG",
"stat.ME"
] | Thurstonian Boltzmann Machines: Learning from Multiple Inequalities | We introduce Thurstonian Boltzmann Machines (TBM), a unified architecture
that can naturally incorporate a wide range of data inputs at the same time.
Our motivation rests in the Thurstonian view that many discrete data types can
be considered as being generated from a subset of underlying latent continuous
variables, and in the observation that each realisation of a discrete type
imposes certain inequalities on those variables. Thus learning and inference in
TBM reduce to making sense of a set of inequalities. Our proposed TBM naturally
supports the following types: Gaussian, intervals, censored, binary,
categorical, muticategorical, ordinal, (in)-complete rank with and without
ties. We demonstrate the versatility and capacity of the proposed model on
three applications of very different natures; namely handwritten digit
recognition, collaborative filtering and complex social survey analysis. |
1408.0056v1 | ## Indecomposable Decomposition and Couniserial Dimension
## A. Ghorbani a , S. K. Jain b c , ∗ and Z. Nazemian a †
- a Department of Mathematical Sciences, Isfahan University of Technology P.O.Box: 84156-83111, Isfahan, Iran
b Department of Mathematics, Ohio University, Athens, OH 45701, USA
- c King Abdulaziz University, Jeddah, SA
- a [email protected]
- [email protected]
[email protected]
## Abstract
Dimensions like Gelfand, Krull, Goldie have an intrinsic role in the study of theory of rings and modules. They provide useful technical tools for studying their structure. In this paper we define one of the dimensions called couniserial dimension that measures how close a ring or module is to being uniform. Despite their different objectives, it turns out that there are certain common properties between the couniserial dimension and Krull dimension like each module having such a dimension contains a uniform submodule and has finite uniform dimension, among others. Like all dimensions, this is an ordinal valued invariant. Every module of finite length has couniserial dimension and its value lies between the uniform dimension and the length of the module. Modules with countable couniserial dimension are shown to possess indecomposable
Key Words : Uniform module; Maximal right quotient ring; Indecomposable decomposition; Uniserial dimension; Couniserial dimension; Von Neumann regular ring; Semisimple module.
2010 Mathematics Subject Classification . Primary 16D70, 16D90, 16P70, Secondary 03E10, 13E10.
∗ Corresponding author;
† This paper was presented at the OSU-Denison conference, May 10, 2014 and at the University of California, San Diego, June 21, 2014.
decomposition. In particular, von Neumann regular ring with countable couniserial dimension is semisimple artinian. If the maximal right quotient ring of a non-singular ring R has a couniserial dimension as an R -module, then R is a semiprime right Goldie ring. As one of the applications, it follows that all right R -modules have couniserial dimension if and only if R is a semisimple artinian ring.
0. Introduction In this article we introduce a notion of dimension of a module, to be called couniserial dimension. It is an ordinal valued invariant that is in some sense a measure of how far a module is from being uniform. In order to define couniserial dimension for modules over a ring R , we first define, by transfinite induction, classes ζ α of R -modules for all ordinals α ≥ 1. First we remark that if a module M is isomorphic to all its non-zero submodules, then M must be uniform. To start with, let ζ 1 be the class of all uniform modules. Next, consider an ordinal α > 1; if ζ β has been defined for all ordinals β < α , let ζ α be the class of those R -modules M such that for every non-zero submodule N of M , where N /notapproxequal M , we have N ∈ ⋃ β<α ζ β . If an R -module M belongs to some ζ α , then the least such α is called the couniserial dimension of M , denoted by c.u.dim( M ). For M = 0, we define c.u.dim( M ) = 0. If a non-zero module M does not belong to any ζ α , then we say that c.u.dim( M ) is not defined, or that M has no couniserial dimension. Equivalently, Proposition 2.3 shows that an R -module M has couniserial dimension if and only if for each descending chain of submodules of M M , 1 ≥ M 2 ≥ ... , there exists n ≥ 1, either M n is uniform or M n ∼ = M k for all k ≥ n . It is clear by the definition that every submodule and so every summand of a module with couniserial dimension has couniserial dimension. Also note that, for the integer number n , couniserial dimension of Z n is n . An example is given to show that the direct sum of two modules each with couniserial dimension (even copies of a module) need not have couniserial dimension. In Section 2, we prove some basic properties of the couniserial dimension. In Section 3, we prove our main results. It is shown in Theorem 3.3 that a module of countable (finite or infinite) couniserial dimension can be decomposed in to indecomposable modules. Theorem 3.5 shows that a Dedekind finite module with couniserial dimension is a finite direct sum of indecomposable modules. Theorem 3.10 in Section 3 shows that for a right non-singuar ring R with maximal right quotient ring Q , if Q R has couniserial dimension, then R is a semiprime right Goldie ring which is a finite product of piecewise domains. The reader may compare this with the wellknown result that a prime ring with Krull dimension is a right Goldie ring but need not be a piecewise domain. Furthermore, a prime right Goldie ring need not have couniserial dimension as is also the case for Krull dimension.
In Section 4, we give some applications of couniserial dimension. It is shown in Proposition 4.2 that a module M with finite length is semisimple if and only if for every submodule N of M the right R -module ⊕ ∞ i =1 M/N has couniserial dimension. As a consequence a commutative noetherian ring R is semisimple if and only if for every finite length module M the module ⊕ ∞ i =1 M has couniserial dimension. It is shown in Proposition 4.4 that if P is an anticoHopfian projective right R -module and ⊕ ∞ i =1 E P ( ) has couniserial dimension, then P is injective. As another application we show that all right (left) R -module have couniserial dimension if and only if R is semisimple artinian (see Theorem 4.8). Several examples are included in the paper that demonstrates as to why the conditions imposed are necessary and what, if any, there is any relation with the corresponding result in the literature.
## 1. Definitions and Notation.
Recall that a semisimple module M is said to be homogeneous if M is a direct sum of pairwise isomorphic simple submodules. A module M has finite uniform dimension (or finite Goldie rank ) if M contains no infinite direct sum of non-zero submodules, or equivalently, there exist independent uniform submodules U , ..., U 1 n in M such that ⊕ n i =1 U i is an essential submodule of M . Note that n is uniquely determined by M . In this case, it is written u.dim( M ) = n .
For any module M , we define Z( M ) = { x ∈ M : r.ann( x ) is an essential right ideal of R } . It can be easily checked that Z( M ) is a submodule of M . If Z( M ) = 0, then M is called a non-singular module. In particular, if we take M = R R , then R is called right non-singular if Z( R R ) = 0.
A ring R is a called right Goldie ring if it satisfies the following two conditions: (i) R has ascending chain condition on right annihilator ideals and, (ii) u.dim( R R ) is finite.
Recall that a ring R is right V-ring if all right simple R -modules are injective. A ring R is called fully right idempotent if I = I 2 , for every right ideal I . We recall that a right V-ring is fully right idempotent (see [19, Corollary 2.2]) and a prime fully right idempotent ring is right non-singular (see [2, Lemma 4.3]). So a prime right V-ring is right non-singular. Recall that a module M is called Σ -injective if every direct sum of copies of M is injective. A ring R is called right Σ -V-ring if each simple right module is Σ-injective.
In this paper, for a ring R Q , = Q max ( R ) stands maximal right quotient ring R . It is well known that if R is a right non-singular, then the injective hull of R R , E R ( R ), is a ring and is equal to the maximal right quotient ring of
## R , [9, Corollary 2.31].
A module M is called Hopfian if M is not isomorphic to any of its proper factor modules (equivalently, every onto endomorphism of M is 1-1). AntiHopfian modules are introduced by Hirano and Mogami [13]. Such modules are isomorphic to all its non-zero factor modules. A module M is called uniserial if the lattice of submodules are linearly ordered. Anti-Hopfian modules are uniserial artinian.
Recall that a module M is called coHopfian if it is not isomorphic to a proper submodule (equivalently, every 1-1 endomorphism of M is onto). Varadarjan [22] dualized the concept of anti-Hopfian module and called it anti-coHopfian module. With slight modification we will call a non-zero module to be anti-coHopfian if is isomorphic to all its non-zero submodules. A non-zero module M is called uniform if the intersection of any two non-zero submodules is non-zero. We see an anti-coHopfian module is noetherian and uniform.
An R -module M has cancellation property if for every R -modules N and T , M ⊕ N ∼ = M ⊕ T implies N ∼ = T . Every module with semilocal endomorphism ring has cancellation property [16]. Since endomorphism ring of a simple module is a division ring, it has cancellation property.
Throughout this paper, let R denote an arbitrary ring with identity and all modules are assumed to be unitary and right modules, unless other words stated. If N is a submodule (resp. proper submodule) of M we write N ≤ M (resp. N < M ). Also, for a module M , ⊕ ∞ i =1 M stands for countably infinite direct sum of copies of M . If N is a submodule of M and k > 1, ⊕ ∞ i = k N = ⊕ ∞ i =1 N i is a submodule of ⊕ ∞ i =1 M with N 1 = N 2 = ... = N k -1 = 0 and for i ≥ k N i = N .
## 2. Basic and Preliminary Results.
As defined in the introduction, couniserial dimension is an ordinal valued number. The reader may refer to [21] regarding ordinal numbers. We begin this section with a lemma and a remark on the definition of couniserial dimension.
Lemma 2.1 An anti-coHopfian module is uniform noetherian.
Proof. Since M is isomorphic to each cyclic submodules, M is cyclic and every submodule of M is cyclic and so M is noetherian. Thus M has a uniform submodule, say U . Since U ∼ = M M , is uniform. /square
Remark 2.2 We make the convention that a statement 'c.u.dim( M ) = α ' will mean that the couniserial dimension of M exists and equals α . By the definition of couniserial dimension, if M has couniserial dimension and N is a submodule of M , then N has couniserial dimension and c.u.dim( N ) ≤ c.u.dim( M ). Moreover, if M is not uniform and c.u.dim( M ) = c.u.dim( N ), where N is a submodule of M , then M ∼ = N . On the other hand, since every set of ordinal numbers has supremum, it follows immediately from the definition that M has couniserial dimension if and only if for all submodules N of M with N /notapproxequal M , c.u.dim( N ) is defined. In the latter case, if α = sup { c.u.dim( N ) | N ≤ M,N /notapproxequal M } , then c.u.dim( M ) ≤ α +1.
The next proposition provides a working definition for a module M that has couniserial dimension.
Proposition 2.3 An R -module M has couniserial dimension if and only if for every descending chain of submodules M 1 ≥ M 2 ≥ ... , there exists n ≥ 1 such that M n is uniform or M n ∼ = M k for all k ≥ n .
Proof. ( ⇒ ) Let M 1 ≥ M 2 ≥ ... be a descending chain of submodules of M . Put γ = inf { c.u.dim( M n ) | n ≥ 1 } . So γ = c.u.dim ( M n ) for some n ≥ 1. If M n is not uniform, then M n ∼ = M k for all k ≥ n , because γ is infimum. ( ⇐ ) If M does not have couniserial dimension, then M is not uniform and so there exists a submodule M 1 of M such that M 1 /notapproxequal M and M 1 does not have couniserial dimension, by the above remark. So there exists a submodule M 2 of M 1 such that M 2 /notapproxequal M 1 and M 2 does not have couniserial dimension. Continuing in this manner, we obtain a descending chain of submodules M 1 ≥ M 2 ≥ ... , such that for every i ≥ 1, M i does not have couniserial dimension and M i /notapproxequal M i +1 , a contradiction. This completes the proof. /square
As a consequence, we have the following corollary.
Corollary 2.4 Every artinian module has couniserial dimension.
Lemma 2.5 If M is an R -module and c.u.dim( M ) = α , then for any 0 ≤ β ≤ α , there exists a submodule N of M such that c.u.dim( N ) = β .
Proof. The proof is by transfinite induction on c.u.dim( M ) = α . The case α = 1 is clear. Let α > 1 and 0 ≤ β < α , then, using Remark 2.2, there exists a submodule K of M such that K /notapproxequal M and β ≤ c.u.dim( K ). Now since β ≤
c.u.dim( K ) < α , by induction hypothesis, there exists a submodule N of K such that c.u.dim( N ) = β . /square
As a consequence we have the following.
Lemma 2.6 Every module with couniserial dimension has a uniform submodule.
In the next proposition we observe that every module of finite couniserial dimension has finite uniform dimension.
Lemma 2.7 Let M be an R -module of finite couniserial dimension. Then M has finite uniform dimension and u.dim( M ) ≤ c.u.dim( M ) .
Proof. The proof is by induction on c.u.dim( M ) = n . The case n = 1 is clear. Let n > 1 and N be a submodule of M such that c.u.dim( N ) = n -1. Thus by the inductive hypothesis, N has finite uniform dimension. Put m = u.dim( N ). If N is not essential in M , then there exists a uniform submodule U of M such that N ∩ U = 0. Thus N ⊕ U is a submodule of M of uniform dimension m +1. Then ( N ⊕ U ) /notapproxequal N and so n -1 < c.u.dim( N ⊕ U ) ≤ n . Thus ( N ⊕ U ) = ∼ M , by Remark 2.2. This proves the lemma. /square
Example 2.8 There exist modules of infinite couniserial dimension but of finite uniform dimension. Take M = Z p ∞ ⊕ Z p ∞ . Then M is artinian Z -module of infinite couniserial dimension but of finite uniform dimension 2.
In the following we consider equality in the above lemma in a special case.
Lemma 2.9 Let M be an injective non-uniform R -module of finite couniserial dimension. Then c.u.dim( M ) = u.dim( M ) if and only if M is finitely generated semisimple module.
## Proof. ( ⇐ ) is clear.
( ⇒ ). Let c.u.dim( M ) = u.dim( M ) = m > 1. Then M = E 1 ⊕ ... ⊕ E m , where E i are uniform injective modules. If E 1 is not simple then there exists a non-injective submodule K of E 1 . Thus K ⊕ E 2 ⊕ ... ⊕ E m is not isomorphic to M . But clearly c.u.dim( K ⊕ E 2 ⊕ ... ⊕ E m ) ≥ m , a contradiction. This completes the proof. /square
Note that the condition being injective is necessary in the above proposition.
Example 2.10 Wecan see easily that for M = Z ⊕ Z , c.u.dim( M ) = u.dim( M ) = 2 but M is not semisimple. Also, the next lemma shows that there exists a module of finite uniform dimension without couniserial dimension.
The following lemma shows that direct sum of two uniform modules may not have couniserial dimension.
Lemma 2.11 Let D be a domain and S be a simple D -module. If S ⊕ D as D -module has couniserial dimension, then D is principal right ideal domain.
Proof. Let I be a non-cyclic right ideal of D . Choose a non-zero element x ∈ I . Set J 1 = xR which is isomorphic to D . Thus there exists a right ideal J 2 of D such that J 2 ∼ = I and J 2 ≤ J 1 . Now let J 3 be a cyclic right ideal contained in J 2 and by continuing this manner we have a descending chain J 1 ≥ J 2 ≥ ... of right ideals of D where for each odd integer i , J i is cyclic and for each even integer i , J i is not cyclic. Now consider the descending chain S ⊕ J 1 ≥ S ⊕ J 2 ≥ ... of submodules of S ⊕ D . Since S has cancellation property and for each i , S ⊕ J i is not uniform, by using Proposition 2.3, we see that, for some n , J n ∼ = J n +1 , a contradiction. Thus D is a principal right ideal domain.
Remark 2.12 (1) The simple module S in the statement of the Lemma 2.11 can be replaced by any cancellable module. Indeed it follows from the Theorem 3.10, proved latter if the maximal right quotient ring Q of a domain D as D -module has couniserial dimension, then Q D has cancellation property and so if Q ⊕ D as D -module has couniserial dimension, D must be right principal ideal domain.
(2) Also, since a Dedekind domain has cancellation property, similar proof shows that if D is a Dedekind domain which is not right principal ideal domain, then D ⊕ D does not have couniserial dimension. This example shows that even direct sum of a uniform module with itself may not have couniserial dimension.
The definition of addition two ordinal numbers can be given inductively. If α and β are two ordinal numbers then α +0 = α , α +( β +1) = ( α + β ) + 1 and if γ is a limit ordinal then α + γ is the limit of α + β for all β < γ (See [21]).
Lemma 2.13 (See [21, Theorem 7.10]). For ordinal numbers α β , and γ , we have the following:
- (1) If α < β , then γ + α < γ + β .
- (2) If α < β , then α + γ ≤ β + γ .
We call an R -module M fully coHopfian if every submodule of M is coHopfian. Note that artinian modules are fully coHopfian. If I is the set of prime numbers, then ⊕ p ∈ I Z p is an example of fully coHopfian Z -module that it is not artinian.
Proposition 2.14 Let M = M 1 ⊕ M 2 be a fully coHopfian R -module with couniserial dimension. Then c.u.dim ( M ) ≥ c.u.dim ( M 1 )+ c.u.dim ( M 2 ) .
/negationslash
Proof. We may assume M ,M 1 2 = 0. We use transfinite induction on c.u.dim( M 2 ) = α . Since M 1 /notapproxequal M , c.u.dim( M ) ≥ c.u.dim( M 1 ) +1. So the case α = 1 is clear. Thus, suppose α > 1 and for every right R -module L of couniserial dimension less than α , c.u.dim( M 1 ⊕ L ) ≥ c.u.dim( M 1 )+ c.u.dim( L ). If α is a successor ordinal, then there exists an ordinal number γ such that c.u.dim( M 2 ) = γ +1. Using Lemma 2.5, there exists a non-zero submodule K of M 2 such that c.u.dim( K ) = γ < α . So by induction hypothesis c u dim( . . M 1 ) + γ = c u dim( . . M 1 ) + c u dim( . . K ) ≤ c u dim( . . M 1 ⊕ K . )
Using our assumption and Remark 2.2, we have c.u.dim( M 1 ⊕ K < ) c.u.dim( M ) and hence c.u.dim( M 1 )+ c.u.dim( M 2 ) ≤ c.u.dim( M ).
If α is a limit ordinal and 1 ≤ β < α , then by Remark 2.2, there exists a non-zero submodule K of M 2 such that β ≤ c.u.dim( K ). Then by induction hypothesis c u dim( . . M 1 )+ β ≤ c u dim( . . M 1 )+c u dim( . . K ) ≤ c u dim( . . M 1 ⊕ K < ) c u dim( . . M . ) Therefore c.u.dim( M 1 ) + α = sup { c.u.dim( M 1 ) + β | β < α } ≤ c.u.dim( M ). /square
The condition fully coHopfian of Proposition 2.14 is necessary.
Example 2.15 For the Z -modules M = ⊕ ∞ i =1 Z p , and L = Z p , we have M ∼ = M ⊕ L . One can see c.u.dim( M ) = ω and so c.u.dim( M ) /notgreaterequal c.u.dim( M )+ c.u.dim( L ). Also, in general, we don't have the equality in Proposition 2.14. Consider the Z -module M = Z 2 ⊕ Z 4 . Then, M is fully coHopfian and 3 = c.u.dim( M > ) c.u.dim( Z 2 )+ c.u.dim( Z 4 ).
Here we prove another result on fully coHopfian module:
Proposition 2.16 Let M be an R -module and N be a cancellable module (for example a simple module) such that N ⊕ M has couniserial dimension. If M is fully coHopfian, then M is artinian.
Proof. Let M be fully coHopfian and let M 1 ≥ M 2 ≥ ... be a descending chain of submodules of M . Then N ⊕ M 1 ≥ N ⊕ M 2 ≥ ... is a descending chain of submodules of N ⊕ M and so for some n , M i ∼ = M n for each i ≥ n . Now since M is fully coHopfian, we have M i = M n for each i ≥ n . /square
Let us recall the definition of uniserial dimension [20].
Definition 2.17 In order to define uniserial dimension for modules over a ring R , we first define, by transfinite induction, classes ζ α of R -modules for all ordinals α ≥ 1. To start with, let ζ 1 be the class of non-zero uniserial modules. Next, consider an ordinal α > 1; if ζ β has been defined for all ordinals β < α , let ζ α be the class of those R -modules M such that, for every submodule N < M , where M/N /notapproxequal M , we have M/N ∈ ⋃ β<α ζ β . If an R -module M belongs to some ζ α , then the least such α is the uniserial dimension of M , denoted u.s.dim( M ). For M = 0, we define u.s.dim( M ) = 0. If M is nonzero and M does not belong to any ζ α , then we say that 'u.s.dim( M ) is not defined,' or that ' M has no uniserial dimension.'
Remark 2.18 Note that, in general, there is no relation between the existence of the uniserial dimension and the existence of the couniserial dimension of a module. For example, the polynomial ring in infinite number of commutative indeterminates over a field k , R = k x , x , ... [ 1 2 ] has this property that c.u.dim( R R ) = 1 but R R does not have uniserial dimension (see [6, Remark 2.3]). It follows by the definition that a semisimple module M has uniserial dimension if and only if M has couniserial dimension, in which case u.s.dim( M ) = α if and only if c.u.dim( M ) = α . Furthermore a semisimple module M has couniserial dimension if and only if M is a finite direct sum of homogeneous semisimple modules ( see [20, Proposition 1.18]).
Using the above remark we have the following interesting results.
Corollary 2.19 All right semisimple modules over a ring R have couniserial dimension if and only if there exist only finitely many non-isomorphic simple right R -modules.
Lemma 2.20 Suppose that M is simple. Then ⊕ ∞ i =1 E M ( ) has couniserial dimension if and only if M is injective.
Proof.
( ⇒
( ⇐ ) It is clear by the statement in Remark 2.18. ) Consider the descending chain
$$M \oplus \left ( \oplus _ { i = 2 } ^ { \infty } E ( M ) \right ) \geq M ^ { ( 2 ) } \oplus \left ( \oplus _ { i = 3 } ^ { \infty } E ( M ) \right ) \geq \dots$$
of submodules of ⊕ ∞ i =1 E M ( ) where M ( n ) = ⊕ ∞ i =1 M i with M 1 = ... = M n = M and for each i > n , M i = 0. Then, by Proposition 2.3, there exists n ≥ 1 such that
$$M ^ { ( n ) } \oplus ( \oplus _ { i = n + 1 } ^ { \infty } E ( M ) ) \cong M ^ { ( n + 1 ) } \oplus ( \oplus _ { i = n + 2 } ^ { \infty } E ( M ) )$$
and so ⊕ ∞ i = +1 n E M ( ) = ∼ M ⊕ ⊕ ( ∞ i = +2 n E M ( )), because M is cancelable . Since M is cyclic, there exists a right module L such that for some k , E M ( ) k ∼ = M ⊕ L . This shows M is injective. /square
## 3. Main Results.
In this section we use our basic results to prove the main results.
Proposition 3.1 Let M R be an injective module and N R be a cancellable module over a commmutative ring R (for example a simple module) such that N ⊕ M has couniserial dimension. Then M is Σ -injective.
Proof. According to [15, Theorem 6.17], it is enough to show that R satisfies the ascending chain condition on ideals of R that are annihilators of subsets of M . Let I 1 ≤ I 2 ≤ ... be a chain of such annihilator ideals. Then for each i , M i = ann M ( I i ) is a submodule of M and so we have descending chain N ⊕ M 1 ≥ N ⊕ M 2 ≥ ... of submodules of N ⊕ M . Then there exists a positive integer n such that M n ∼ = M i for all i ≥ n . Thus ann( M i ) = ann( M n ). Therefore for each i ≥ n , I i = I n . /square
Remark 3.2 One can see that the above result provides another proof for the fact that commutative V-rings (i.e, von Neumann regular rings ) are Σ-V-ring. For an example of right V-rings that is not Σ-V-ring, the reader may refer to [15, Example, page 60].
The next result shows that if a module has countable couniserial dimension then it can be decomposed into indecomposable modules.
Theorem 3.3 For an R -module M , if c.u.dim( M ) ≤ ω , then M has indecomposable decomposition.
Proof. The proof is by induction on c.u.dim( M ) = α . The case α = 1 is clear. If α > 1 and M is not indecomposable, then M = N 1 ⊕ N 2 , where N 1
and N 2 are non-zero submodules of M . If c.u.dim( N i ) < c.u.dim( M ), i = 1 2, , then by induction hypothesis M has indecomposable decomposition. If not, for definiteness let c.u.dim( N 1 ) = c.u.dim( M ). Then M ∼ = N 1 , by Remark 2.2. Thus it contains an infinite direct sum of uniform modules, say ⊕ ∞ i =1 K i . Clearly, c.u.dim( ⊕ ∞ i =1 K i ) ≥ ω . Thus we have M ∼ ⊕ = ∞ i =1 K i . /square
Remark 3.4 We do not know whether the above proposition holds for a module of arbitrary couniserial dimension. For infinite countable couniserial dimension one can show under some condition that the module can be represented as a direct sum of uniform modules.
Recall that a module M is called Dedekind finite if M is not isomorphic to any proper direct summand of itself. Clearly, every direct summand of a Dedekind finite module is a Dedekind finite module. Obviously, a Hopfian module is Dedekind finite. Since all finitely generated modules over a commutative ring are Hopfian (see [10]), they provide examples of Dedekind finite modules.
Theorem 3.5 If M is a Dedekind finite module with couniserial dimension, then M has finite indecomposable decomposition.
Proof. The proof is by induction on c.u.dim( M ) = α . The case α = 1 is clear. Let α > 1 and every Dedekind finite module with c.u.dim less than α be decomposed to finitely many indecomposable modules. If M is not indecomposable, then M = M 1 ⊕ M 2 . Since M i /notapproxequal M , using Remark 2.2, c.u.dim( M i ) < c.u.dim( M ) and so, by induction hypothesis, M i have finite indecomposable decomposition. This completes the proof. /square
A ring R is called a von Neumann regular ring if for each x ∈ R , there exists y ∈ R such that xyx = x , equivalently, every principal right ideal is a direct summand. R is unit regular ring if for each x ∈ R, there exists a unit element u ∈ R such that x = xux. As a consequence of the above theorem we have the following corollary.
Corollary 3.6 Every Dedekind finite von Neumann regular ring (in particular, unit regular rings ) with couniserial dimension is semisimple artinian.
A ring R is called a PWD (piecewise domain) if it possesses a complete set { e i | 0 ≤ i ≤ n } of orthogonal idempotents such that xy = 0 implies x = 0 or y = 0 whenever x ∈ e Re i k and y ∈ e Re k j . Note that the definition is left-right symmetric and all e Re i i are domain, see [12].
An element x of R is called regular if its right and left annihilators are zero.
Proposition 3.7 Let R be a semiprime right Goldie ring with couniserial dimension. If u.dim ( R R ) = n , then R has a decomposition into n uniform modules. In particular, it is a piecewise domain.
Proof. We can assume that n > 1. Let I 1 = U 1 ⊕ ... ⊕ U n be an essential right ideal of R . Then, by [8, Proposition 6.13], I 1 contains a regular element x and thus J 1 = xR is a right ideal of R which is R -isomorphic to R . So u.dim( J 1 ) = n and it contains an essential right ideal I 2 of R such that it is a direct sum of n uniform right ideals. By continuing in this manner we obtain a descending chain I 1 ≥ J 1 ≥ I 2 ≥ ... of right ideals of R such that I i are direct sum of n uniform and J i are isomorphic to R . Since R has couniserial dimension, for some n , I n ∼ = R . The last statement follows from [12, Pages 2-3]. This completes the proof. /square
Remark 3.8 There exists an example of simple noetherian ring of uniform dimension 2 which has no non-trivial idempotents (c.f. [18, Example 7.16, page 441 ]). So by the above proposition this provides an example of prime right Goldie ring without couniserial dimension.
Lemma 3.9 Let R be a right non-singular ring with maximal right quotient ring Q . Let M be a Q -module. If M is non-singular R -module, such that M R has couniserial dimension, then M Q has couniserial dimension.
Proof. Let M ≥ M 1 ≥ M 2 ≥ ... be a descending chain of Q -submodules of M . So it is a descending chain of R -submodules of M and thus, for some n , M n is uniform R -module or M n ∼ = M i as R -modules for all i ≥ n . If M n is uniform R -module, then it is also uniform Q -module. So let M n ∼ = M i as R -modules and let ϕ i be this isomorphism. If q ∈ Q and t ∈ M n there exists an essential right ideal E of R such that qE ≤ R . So ϕ i ( tqE ) = ϕ i ( tq ) E and also ϕ i ( tqE ) = ϕ i ( ) t qE . Then ϕ i ( tq ) E = ϕ i ( ) t qE . Since Q is right non-singular, ϕ i ( tq ) = ϕ i ( ) t q . Thus ϕ i is a Q -isomorphism. This completes the proof. /square
A ring R is semiprime (prime) right Goldie ring if and only if its maximal right quotient ring is semisimple (simple) artinian ring, [9, Theorems 3.35 and 3.36]. Semiprime right Goldie rings are non-singular. A right non-singular ring R is semiprime right Goldie ring if and only if u.dim( R R ) is finite, [9, Theorem 3.17]. Recall that a right full linear ring is the ring of all linear transformations (written on the left) of a right vector space over a division ring. If the dimension of the vector space is finite, a right full linear ring is exactly a simple artinian ring.
Theorem 3.10 Let R be a right non-singular ring with maximal right quotient ring, Q . If Q as an R -module has couniserial dimension, then R is a semiprime right Goldie ring which is a finite product of prime Goldie rings, each of which is a piecewise domain.
Proof. It is enough to show that R has finite uniform dimension. Since Q R has couniserial dimension, R R has couniserial dimension and so every right ideal of R has couniserial dimension. Thus Lemma 2.6 implies that every right ideal contains a uniform submodule. Now by [8, Theorem 3.29] the maximal right quotient ring of R is a product of right full linear rings, say Q = ∏ i ∈ I Q i , where Q i are right full linear rings. Note that since R R is right non-singular, Q R is also non-singular and so, using Lemma 3.9, Q Q has couniserial dimension. At first we claim each Q i is endomorphism ring of a finite dimensional vector space. Assume the contrary. Then Q j is the endomorphism ring of an infinite dimensional vector space, for some j . Thus Q j ∼ = Q j × Q j and so if ι : Q j -→ Q be the canonical embedding, then ι ( Q j ) is a right ideal of Q and there exists a Q -isomorphism Q ∼ = ι ( Q j ) × Q . Then there exist right ideals T 1 and T of Q such that Q = T 1 ⊕ T , T 1 and Q are isomorphic as Q -modules and T ∼ = ( ι Q j ) as Q -module. Because Q j is the endomorphism ring of an infinite dimensional vector space, it has a right ideal which is not principal, for example its socle. So ι ( Q j ) and thus T contains a non-cyclic right ideal of Q and thus since T ∼ = Q/T 1 , there exists a non-cyclic right ideal of Q , say K 1 such that Q ≥ K 1 ≥ T 1 . Now T 1 is isomorphic to Q . So we can have a descending chain Q > K 1 > T 1 > K 2 > T 2 > ... of right ideals of Q such that T i are cyclic but K i are not cyclic. This is a contradiction. So all Q i are endomorphism ring of finite dimensional vector spaces. Now to show R is semiprime right Goldie ring it is enough to show that the index set I is finite. If I is infinite, there exist infinite subsets I 1 and I 2 of I such that I = I 1 ∪ I 2 . and I 1 ∩ I 2 is empty. Let T 1 = ∏ i ∈ I N i such that N i = Q i for all i ∈ I 1 and N i = 0 for all i ∈ I 2 . Similarly let T = ∏ i ∈ I M i such that M i = Q i for all i ∈ I 2 and M i = 0 for all i ∈ I 1 . Then T 1 and T are right ideals of Q and Q = T 1 ⊕ T . T contains a right ideal of Q which is not cyclic, for example ⊕ i ∈ I M i . Since T ∼ = Q/T 1 , there exists a non-cyclic right ideal K 1 of Q such that Q ≥ K 1 ≥ T 1 . Note that T 1 is a cyclic Q -module and because I 1 is infinite, the structure of T 1 is similar to that of Q . We can continue in this manner and find a descending chain of right ideals of Q such that K i are non cyclic Q -modules and T i are cyclic Q modules, which is a contradiction. Therefore I is finite and R must have finite uniform dimension. This shows R is semiprime right Goldie ring and so Proposition 3.7 and [12, Corollary 3] imply that it is a direct sum of prime right Goldie rings. /square
The reader may ask what if R R has couniserial dimension instead of Q R . Indeed we may point out that unlike a semiprime ring with right Krull dimension, a semiprime ring with couniserial dimension need not be a right Goldie ring. See Dubrovin [5] that contains an example of a primitive uniserial ring with non-zero nilpotent elements.
Next we show that the converse of the above theorem is not true, in general. In fact we show that there exists a prime right Goldie ring R such that c.u.dim( R R ) = 2 and Q R does not have couniserial dimension. We need the following lemma to give the example.
Lemma 3.11 For an ordinal number α , being of couniserial dimension α is a Morita invariant property for modules.
Proof. This is clear by the definition of couniserial dimension and [1, Proposition 21.7 ]. /square
Example 3.12 Here we give an example of a prime right Goldie ring R with maximal right quotient ring Q such that Q R does not have couniserial dimension. Take R = M 2 ( Z ), the 2 × 2 matrix ring over Z . Then R is a prime right Goldie ring with maximal right quotient ring Q = M 2 ( Q ). Note that under the standard Morita equivalent between the ring Z and R = M 2 ( Z ), see [17, Theorem 17.20 ], R corresponds to Z ⊕ Z and so using the above lemma R has couniserial dimension 2. If { p i | i ≥ 1 } is the set of all prime numbers, then Q Z / = ∑ ∞ i =1 K / i Z , where K i = { m/p n i | n ≥ 0 and m ∈ Z } . Then take Q n = ∑ ∞ i = n K i . Then M Q 2 ( 1 ) ≥ M Q 2 ( 2 ) ≥ ... is a descending chain of R -submodules of Q which are not uniform R -modules. Assume that for some n , M Q 2 ( n ) ∼ = M Q 2 ( n +1 ) with an R -isomorphism φ . Let φ ( ( 1 0 0 1 ) ) = ( m /t 1 1 m /t 2 2 m /t 3 3 m /t 4 4 ) , where m/t i i ∈ Q n +1 . Suppose that j ≥ 1 and φ ( ( 1 /p j n 0 0 1 /p j n ) ) = ( m 1 ,j /t 1 ,j m 2 ,j /t 2 ,j m 3 ,j /t 3 ,j m 4 ,j /t 4 ,j ) , where p n does not odd non of t i,j for all 1 ≤ i ≤ 4. Then since φ is additive, we can easily see that ( m 1 ,j p /t j n 1 ,j m 2 ,j p /t j n 2 ,j m 3 ,j p /t j n 3 ,j m 4 ,j p /t j n 4 ,j ) = ( m /t 1 1 m /t 2 2 m /t 3 3 m /t 4 4 ) and this implies that p j n | m i for all j ≥ 1 and 0 ≤ i ≤ 4 and so m i = 0, a contradiction. So Q R does not have couniserial dimension.
## 4. Some Applications.
A right R -module M which has a composition series is called a module of finite length. A right R -module M is of finite length if and only if M is both artinian and noetherian. The length of a composition series of M R is said to be the length of M R and is denoted by length( M ). Clearly, by Corollary 2.4, a module of finite length has couniserial dimension. The next result shows a relation between couniserial dimension of a finite length module M and length( M ).
Proposition 4.1 Let M be a right R -module of finite length. Then the following statements hold:
- (1) If N is a submodule of M , then c.u.dim( M/N ) ≤ c.u.dim( M ) .
- (2) c.u.dim( M ) ≤ length( M ) .
Proof. (1) The proof is by induction on n , where length( M ) = n . The case n = 1 is clear. Now, let n > 1 and assume that the assertion is true for all modules with length less than n . If N is a non-zero submodule of M , then the length( M/N ) < n . Thus for every proper submodule K/N of M/N , by induction, c.u.dim( K/N ) ≤ c.u.dim( K < ) c.u.dim( M ). Now, Remark 2.2 implies that c.u.dim( M/N ) ≤ c.u.dim( M ).
(2) The proof is by induction on length( M ) = n . The case n = 1 is clear. Now if n > 1 and K is a proper submodule of M , then, by assumption, c.u.dim( K ) ≤ length( K < ) length( M ). Thus by Remark 2.2, c.u.dim( M ) ≤ length( M ). /square
Recall that an R -module M is called co-semisimple if every simple R -module is M -injective, or equivalently, Rad( M/N ) = 0 for every submodule N ≤ M (See [23, Theorem 23.1]). The next proposition gives a condition as to when a module of finite length is semisimple. It may be of interest to state that for the finite length Z -module Z 4 , ⊕ ∞ i =1 Z 4 does not possess couniserial dimension.
Proposition 4.2 Let M be a non-zero right R -module of finite length. Then M is a semisimple R -module if and only if for every submodule N of M the right R -module ⊕ ∞ i =1 M/N has couniserial dimension.
## Proof. ( ⇒ ) c.f. Remark 2.18.
/negationslash
( ⇐ ) For every submodule N of M the right R -module ⊕ ∞ i =1 M/N has couniserial dimension. Clearly, this also holds for any factor module of M . We will proof the result by induction on the length( M ) = n . The case n = 1 is clear. Now assume that n > 1 and the result is true for all modules of length less that n . Let K be a non-zero submodule of M . Since length( M/K ) < n , by the inductive hypothesis, M/K is semisimple. Therefore, for every nonzero submodule K of M , Rad( M/K ) = 0. If Rad( M ) = 0, then M is cosemisimple. Let S be a simple submodule of M . Consider the exact sequence 0 -→ S -→ M -→ M/S -→ 0 which splits, because M is co-semisimple. Therefore, M is semisimple. Next suppose that Rad( M ) = 0. Let S be a simple submodule of M . Because by the above Rad( M/S ) = 0, we obtain Rad( M ) ≤ S . This implies Rad( M ) = S and so M has only one simple submodule. Thus Rad( M ) = soc( M ) = S is a simple module. Suppose that M is not semisimple. Let N be a maximal submodule of M . Then for every submodule K ≤ N < M , ⊕ ∞ i =1 N/K is a submodule of ⊕ ∞ i =1 M/K and thus ⊕ ∞ i =1 N/K has couniserial dimension. Since length( N ) < n , we conclude that N is semisimple. Thus N = soc( M ) = Rad( M ) is a simple module and so M is of length 2.
Now consider the descending chain
$$N \oplus ( \oplus _ { i = 2 } ^ { \infty } M ) > N ^ { ( 2 ) } \oplus ( \oplus _ { i = 3 } ^ { \infty } M ) > \dots$$
of submodules of ⊕ ∞ i =1 M . Using Proposition 2.3, there exists k ≥ 1 such that N ( k ) ⊕ ⊕ ( ∞ i = +1 k M ) = ∼ N ( k +1) ⊕ ⊕ ( ∞ i = +2 k M ). Since N ( k +1) is finitely generated, there exists m ≥ 0 and an R -module T , such that N ( k ) ⊕ M m ∼ = N ( k +1) ⊕ T . N is simple and so it has cancellation property and thus M m ∼ = N ⊕ T . This implies Rad( T ) is semisimple of length m and length(soc( T )) = m -1, a contradiction. /square
Recall that a ring R is called right bounded if every essential right ideal contains a two-sided ideal which is essential as a right ideal. A ring R is called right fully bunded if every prime factor ring is right bounded. A right noetherian right fully bounded ring is commonly abbreviated as a right FBN ring. Clearly all commutative noetherian rings are example of right FBN rings. Finite matrix rings over commutative noetherian rings are a large class of right FBN rings which are not commutative. In [14, Theorem 2.11], Hirano and et.al.
showed that a right FBN ring R is semisimple if and only if every right module of finite length is semisimple. As a consequence of the above proposition we have:
Corollary 4.3 A right FBN ring R is semisimple if and only if for every finite length module M , the module ⊕ ∞ i =1 M has couniserial dimension.
Proposition 4.4 Let P be an anti-coHopfian projective right R -module. If ⊕ ∞ i =1 E P ( ) has couniserial dimension, then P is injective.
Proof. We first show that P has cancellation property. Let M = P ⊕ B ∼ = P ⊕ B ′ . So there exist submodules P ′ and C of M such that M = P ⊕ B = P ′ ⊕ C and P ′ ∼ = P and C ∼ = B ′ . If p 1 is a projection map from M = P ⊕ B on to P . Then with restriction of p 1 to C we have an exact sequence 0 -→ C ∩ B -→ C -→ I -→ 0, such that I is a submodule of P . Note that every submodule of P is projective, because it is anti-coHopfian. So I is projective and thus C ∼ = C ∩ B ⊕ I . Similarly by considering map p 2 from M = P ′ ⊕ C to P ′ we have B ∼ = C ∩ B ⊕ J for some submodule J of P ′ . Since J ∼ = I ∼ = P , we have B ∼ = C and so B ∼ = B ′ . Then P has cancellation property. Now consider the descending chain
$$P \oplus \left ( \oplus _ { i = 2 } ^ { \infty } E ( P ) \right ) \geq P ^ { ( 2 ) } \oplus \left ( \oplus _ { i = 3 } ^ { \infty } E ( P ) \right ) \geq \dots$$
of submodules of ⊕ ∞ i =1 E P ( ). Then, by Proposition 2.3, there exists n ≥ 1 such that
$$P ^ { ( n ) } \oplus \left ( \oplus _ { i = n + 1 } ^ { \infty } E ( P ) \right ) \cong P ^ { ( n + 1 ) } \oplus \left ( \oplus _ { i = n + 2 } ^ { \infty } E ( P ) \right )$$
and so ⊕ ∞ i = +1 n E P ( ) ∼ = P ⊕ ⊕ ( ∞ i = +2 n E P ( )) , because P is cancelable . Since P is finitely generated, there exists a right module L such that for some k , E P ( ) k ∼ = P ⊕ L . This shows P is injective. /square
As a consequence of the above proposition we have the following corollary:
Corollary 4.5 Let R be a principal right ideal domain with maximal right quotient ring Q ( which is a division ring). If the right R -module ⊕ ∞ i =1 Q has couniserial dimension, then R = Q .
We need the following lemmas to prove the next theorem. Using Proposition 2.3 we can see that:
Lemma 4.6 Let I be a two sided ideal of R and M be an R/I -module. If M as R -module has couniserial dimension, then M as R/I -module has couniserial dimension.
Lemma 4.7 If all finitely generated right modules have couniserial dimension, then every right module contains a noetherian uniform module.
Proof. By Lemma 2.1 it is enough to show that every cyclic module contains an anti-coHopfian module. Let M be a non-zero cyclic right module which does not contain anti-coHopfian module and let S be a simple module. M is not anti-coHopfian, then M has a non-zero submodule M 1 /notapproxequal M and M 1 has a non-zero submodule M 2 such that M 2 /notapproxequal M 1 . By continuing in this manner we have a descending chain S ⊕ M ≥ S ⊕ M 1 ≥ S ⊕ M 2 ≥ ... of submodules of S ⊕ M . Since S ⊕ M is finitely generated, by Proposition 2.3, S ⊕ M n ∼ = S ⊕ M n +1 for some n . This implies that M n ∼ = M n +1 for some n , because S is cancellable and this is a contradiction. /square
Theorem 4.8 For a ring R the following are equivalent.
- (1) R is a semisimple artinian ring.
- (2) All right R -modules have couniserial dimension.
- (3) All left R -modules have couniserial dimension.
- (4) All right R -modules have uniserial dimension.
- (5) All left R -modules have uniserial dimension.
Proof. For equivalence of (1), (4) and (5) refer [20, Theorem 2.6].
- (1) ⇒ (2). This is clear by Corollary 2.19.
(2) ⇒ (1). At first we show R satisfies ascending chain condition on two sided deals. Let I 1 ≤ I 2 ≤ ... be a chain of ideals of R . Since the right module ⊕ ∞ i =1 R/I i has couniserial dimension, there exists n such that, for each j ≥ n , ⊕ ∞ i = n R/I i ∼ ⊕ = ∞ i = j R/I i . Thus they have the same annihilators and so for each j ≥ n , I n = I j . Suppose R is a non-semisimple ring. By Lemma 4.6 every module over a factor ring of R also has couniserial dimension. Thus by invoking the ascending chain condition on two sided ideals we may assume R is not semisimple artinian but every factor ring of R is semisimple artinian. Using Lemma 2.20, R is a right V-ring. First let us assume that R is primitive. So, by Theorem 3.10, R is a prime right Goldie ring. By [4, Theorem 5.16], a prime right V-ring right Goldie is simple. By Lemma 4.7, R has a right noetheian uniform submodule and so using [8, Corollary 7.25], R is right noetherian. Now we show that R is Morita equivalent to a domain. By [7, lemma 5.12], the endomorphism ring of every uniform right ideal of a prime right Goldie ring is a right ore domain. So by [11, Theorem 1.2], it is enough to show that R has a uniform projective generator U . Let us assume that R is not uniform and u.dim( R ) = n and let U be a uniform right ideal of R . By [8, Corollary 7.25], U n can be embedded in R and also R can be embedded in U n . Then c.u.dim( R ) = c.u.dim( U n ) and hence R ∼ = U n , because R is not uniform. Thus U is a projective generator uniform right ideal of R . So R is Morita equivalent to a domain. Now Lemma 3.11 and Lemma 2.11 and Corollary 4.5 show that R is simple artinian, a contradiction. So R is not primitive, but every primitive factor ring is artinian (indeed all proper factor rings are artinian). Then since R is a right V-ring, by [3], R is regular and Σ-V-ring. Also every right ideal contains a non-zero uniform right ideal, hence minimal. So R has non-zero essential soc( R ). But R is Σ-V-ring and by Corollary 2.19 , we have only finitely many non-isomorphic simple modules. Thus soc( R ) is injective. This implies R is semisimple, a contradiction. This completes the proof. /square
## Summary
This paper defines couniserial dimension of a module that measures how far a module is from being uniform. The results proved in the paper demonstrate its importance for studding the structure of modules and rings and is a beginning of a larger project to study its impact. We close with some open questions:
- 1) Does a module with arbitrary couniserial dimension possesses indecomposable dimension?
- 2) Is there a theory for modules with both finite uniserial and couniserial dimensions that parallels to Krull-Schmidt-Remak-Azumaya theorem?
## Acknowledgments
This paper was written when the third author was visiting Ohio University, United States during May-August 2014. She wishes to express her deepest gratitude to Professor S. K. Jain for his kind guidance in her research project and Mrs. Parvesh Jain for the warm hospitality extended to her during her stay. She would also like to express her thanks to Professor E. Zelmanov for his kind invitation to visit the of University of Californian at San Diego and to give a talk.
## References
- [1] F. W. Anderson and, K. R. Fuller, Rings and Categories of Modules, second ed., Grad. Texts in Math., Vol. 13, Springer, Berlin, (1992).
- [2] G. Baccella, On flat factor rings and fully right idempotent rings, Ann. Univ. Ferrara Sez. 26 (1980), 125-141
- [3] G. Baccella, Von Neumann regularity of V-rings with artinian primitive factor rings, Proc. Amer. Math. Soc., 103, 3 (1988), 747-749.
- [4] J. Cozzens and C. Faith, Simple noetherian rings, Cambridge Univ. Press, Cambridge, (1975).
- [5] N. I. Dubrovin, An example of a chain primitive ring with nilpotent elements, Mat. Sb. (N.S.) 120(162) (1983), no. 3, 441-447 (Russian). MR 691988 (84f:16012)
- [6] A. Ghorbani, Z. Nazemian, On commutative rings with uniserial dimension, Journal of Algebra and Its Applications, 14 (1) (2015), 1550008. (Available on line).
- [7] A. W. Goldie, Rings with maximum condition, Lecture Notes, Yale University, New Haven, Conn., (1961).
- [8] K. R. Goodearl, An Introduction to Non commutative noetherian Rings, London Math. Soc. 61, Cambridge University Press, Cambridge, (2004).
- [9] K. R. Goodearl, Ring Theory: Nonsingular Rings and Modules, Dekker, New York (1976).
- [10] K. R. Goodearl, Surjective endomorphisms of finitely generated modules, Comm. Algebra. 15 (1987), 589-609.
- [11] R. Hart, J. C. Robson, Simple rings and rings Morita equivalent to ore domains. Proc. London Math. Soc. 21 (3) (1970), 232-242.
- [12] R. Gordon and L. W. Small, Piecewise domains, J. Algebra 23 (1972), 553-564.
- [13] Y. Hirano and I. Mogami, Modules whose proper submodules are non-hopf kernels, Comm. Algebra. 15 (8) (1987), 1549-1567.
- [14] Y. Hirano , E. Poon and H. Tsutsui, A Generalization of Complete Reducibility, Comm. Algebra. 40 (6) (2012), 1901-1910.
- [15] S. K. Jain, Ashish K. Srivastava and Askar A. Tuganbaev, Cyclic modules and the structure of rings, Oxford Mathematical Monographs, Oxford University Press, (2012).
- [16] T. Y. Lam, A crash course on stable range, cancellation, substitution, and exchange. J. Algebra Appl. 3 (2004), 301-343.
- [17] T. Y. Lam, Lectures on Modules and Rings, Grad. Texts in Math., Vol. 189, Springer, New York, (1999).
- [18] J.C. McConnell, J.C. Robson, Noncommutative noetherian Rings, Wiley, New York (1987)
- [19] G. O. Michler and O. E. Villamayor, On rings whose simple modules are injective, J. Algebra 25 (1973), 185-201.
- [20] Z. Nazemian, A. Ghorbani, M. Behboodi, Uniserial dimension of modules, J. Algebra, 399 (2014), 894-903.
- [21] R. R. Stoll, Set Theory and Logic. Dover Publication Inc, New York, (1961).
- [22] K.Varadarajan, Anti hopfian and anti coHopfian modules, AMS Contemporary Math Series 456, (2008), 205-218.
- [23] R. Wisbauer, Foundations of Module and Ring Theory, Gordon and Breach, Reading, (1991). | null | [
"A. Ghorbani",
"S. K. Jain",
"Z. Nazemian"
] | 2014-08-01T00:59:50+00:00 | 2014-08-01T00:59:50+00:00 | [
"math.RA"
] | Indecomposable Decomposition and couniserial dimension | Dimensions like Gelfand, Krull, Goldie have an intrinsic role in the study of
theory of rings and modules. They provide useful technical tools for studying
their structure. In this paper we define one of the dimensions called
couniserial dimension that measures how close a ring or module is to being
uniform. Despite their different objectives, it turns out that there are
certain common properties between the couniserial dimension and Krull dimension
like each module having such a dimension contains a uniform submodule and has
finite uniform dimension, among others. Like all dimensions, this is an ordinal
valued invariant. Every module of finite length has couniserial dimension and
its value lies between the uniform dimension and the length of the module.
Modules with countable couniserial dimension are shown to possess
indecomposable decomposition. In particular, von Neumann regular ring with
countable couniserial dimension is semisimple artinian. If the maximal right
quotient ring of a non-singular ring R has a couniserial dimension as an
R-module, then R is a semiprime right Goldie ring. As one of the applications,
it follows that all right R-modules have couniserial dimension if and only if R
is a semisimple artinian ring. |
1408.0057v1 | ∗
## Charge-Stripe Order in a Parent Compound of Iron-based Superconductors
Wei Li, 1 2 , Wei-Guo Yin, 3 ∗ Lili Wang, 1 2 , Ke He, 1 2 , Xucun Ma, 1 2 , Qi-Kun Xue, 1 2 , ∗ Xi Chen 1 2 , ∗
1
State Key Laboratory of Low-Dimensional Quantum Physics,
Department of Physics, Tsinghua University, Beijing 100084, China 2 Collaborative Innovation Center of Quantum Matter, Beijing 100084, China 3 Condensed Matter Physics and Materials Science Department, Brookhaven National Laboratory, Upton, New York 11973, USA To whom correspondence should be addressed. E-mail: [email protected] (W. G. Y); [email protected] (Q. K. X.); [email protected] (X. C.).
## Abstract
Charge ordering is one of the most intriguing and extensively studied phenomena in correlated electronic materials because of its strong impact on electron transport properties including superconductivity. Despite its ubiquitousness in correlated systems, the occurrence of charge ordering in iron-based superconductors is still unresolved. Here we use scanning tunneling microscopy to reveal a long-range charge-stripe order and a highly anisotropic dispersion of electronic states in the ground state of stoichiometric FeTe, the parent compound of the Fe(Te, Se, S) superconductor family. The formation of charge order in a strongly correlated electron system with integer nominal valence (here Fe 2+ ) is unexpected and suggests that the iron-based superconductors may exhibit more complex charge dynamics than originally expected. We show that the present observations can be attributed to the surpassing of the role of local Coulomb interaction by the poorly screened longer-range Coulomb interactions, facilitated by large Hund's rule coupling.
Charge order (CO) has been observed in a wide range of strongly correlated electron systems (SCESs), such as manganites [1, 2], magnetite [3], cobaltates [4], nickelates [5], and cuprates [6-9]. Such ubiquity comes unexpected since the two generic leading energy scales in electron systems-the kinetic energy and local Coulomb interaction U -generally favor uniform charge distribution instead. However, it has been shown that CO may result from a compromised interplay of charge with the spin [10] and/or orbital [11, 12] degrees of freedom. Moreover, the bad-metal behavior of SCESs [13, 14] implies that CO can also be driven by the poorly screened longer-range Coulomb interactions. Usually, the SCESs that exhibit CO have fractional nominal valence due to charge doping or mixed valence in nature [15], which allows charge fluctuation free of the energy penalty from U . An exception comes when U is surpassed by Hund's rule coupling [16]. The ubiquity of CO is thus a manifestation of electronic correlation effects [1]. Experimentally, CO is readily characterized by diffraction, x-ray scattering, and scanning tunneling microscopy (STM) techniques [6-9]. These features of CO have made its study an effective route to understanding SCESs in general and helping resolve some current grand problems in condensed matter physics, such as high-temperature superconductivity in cuprates and colossal magnetoresistance in manganites in particular.
Naturally, it is desirable to know how CO emerges in iron-based superconductors (FeSCs) [17], which appear to have all the aforementioned ingredients for CO: they contain the charge, spin, orbital degrees of freedom [18] and show bad-metal behavior [19]. Oddly enough, to date, convincing evidence of CO in FeSCs is still lacking. Compared with the other SCESs, FeSCs are indeed somehow different. For example, the origin of strong electron correlation in FeSCs is attributed to the Hund's rule coupling instead of U [20-23] likely due to the suppression of U via strongly coupled charge multipole polarizations of Fe and anion [24]. This peculiar charge dynamics could mediate electron pairing for superconductivity [25]. On the other hand, the suppression of U also favor the formation of CO. Hence, finding CO in FeSCs has become an important step to our understanding of FeSCs and CO mechanisms in SCESs.
Here we report the direct observation of long-range static charge order in FeSCs with systematic STM measurement on FeTe, the parent compound of the Fe(Te,Se,S) family of FeSCs [26-30]. FeTe was chosen because of its simple structure (Fig. 1A) and arguably strongest electronic correlation in the FeSC system [21]. The ground state of bulk FeTe is known to possess the metallic bicollinear antiferromagnetic (AFM) spin order [28-30], named
after the pattern of alternating two columns of Fe sites with spin-up and two columns of Fe sites with spin-down (see Fig. 1B). Alternatively, the two columns of Fe sites of the same spin can be viewed as a zigzag chain formed by the nearest Fe-Fe bonds; this AFM order is called E -type in the context of manganites [22]. The latter viewpoint bridges these two important classes of SCESs: FeSCs and manganites. In fact, it has been shown that various material-dependent magnetic orders in FeSCs [22, 23] and manganites [31] are unified in a spin-fermion model. In this work, we find that CO in FeTe peculiarly follows the same bicollinear E -type order, a pattern that has not been observed or predicted before in the charge channel. Even more strikingly, this CO is realized in a SCES with integer nominal valence. We suggest that the E -type CO can be well accounted for by including long-range Coulomb interaction in the spin-fermion model.
The experiments were carried out in a Unisoku UHV 3 He STM system equipped with a molecular beam epitaxy (MBE) chamber for in situ film growth. Single crystal Fe 1+ x Te samples usually contain a sizeable amount of excessive Fe atoms, which are known to bring substantial extrinsic effects such as transforming the metallic FeTe to a semiconductor [28, 32]. To avoid these extrinsic effects, we grew stoichiometric FeTe single-crystalline films with MBE in ultra-high vacuum (UHV) and performed the STM experiment in the same UHV system [33]. Topography of the Te-terminated FeTe film (Fig. 1C) shows the atomically flat surface with broad terraces. The step height is 0.63 nm. The image with atomic resolution (Fig. 1C, inset) exhibits a quasi-square lattice of Te atoms with lattice constant of ∼ 3.8 ˚. Previous studies [28, 29] on bulk FeTe show a tetragonal to monoclinic structural phase A transition at T s ∼ 65 K with a simultaneous development of the E -type AFM order (i.e., T N = T s ).
The STM images at different temperatures (Fig. 2, A to D) shows that the structural transition is correlated with the appearance of a striped pattern. The pattern is barely visible at 63 K and completely disappears at T N ∼ 65 K. The stripes are formed by the Te atoms and only visible at very low bias voltage, which rules out the possibility of surface reconstruction. Measurement of lattice constants by STM identifies the stripe orientation as the FM direction (b-axis) [33].
The energy dependence of the stripes is presented in Fig. 2, E to H, with the STM images of the same location under different bias voltages. The pattern is only visible at low energy within ± 30 meV of the Fermi level. Inside this energy window, the stripes are static and
FIG. 1: Structure and MBE film of FeTe. (A) Crystal structure of FeTe. (B) Bicollinear spin structure of FeTe. The arrows indicate the spin orientations of iron atoms. The smaller balls indicate the second-layer Te atoms. (C) Topography of stoichiometric (no excess Fe) FeTe(001) film (3.3 V, 0.03 nA, 200 nm × 200 nm). The inset shows the square lattice (-2.6 mV, 0.05 nA, 9 nm × 9 nm).
remain unchanged with different bias voltage. As clearly demonstrated in the figures, the bright stripes of Te atoms in the topmost layer alternate with the dark ones in the AFM direction. Therefore the periodicity is 2 a Te , the same as that of the E -type spin order. To gain more insight into the origin of the stripes, we mark two adjacent Te atoms in Fig. 1B as 'A' and 'B'. If A is bright, then B must be dark. Here the key point is that these two sites A and B differ in the configuration of their neighboring Fe spins: A is adjacent to one up and three down spins on Fe, while B to one down and three up spins. Since the charge fluctuations on Fe cations and Te anions are strongly coupled [24], the contrast displayed by the Te atoms actually reflects the existence of a charge-stripe order in the Fe plane. In addition, the concurrence of stripe and AFM order at the structural transition indicates that the charge-stripe order is tied to the long-range E -type AFM order.
We note that previous neutron scattering studies [34] revealed the existence of strong spin fluctuations in the FeTe system. It is shown that the long-range E -type AFM order only makes a small and very low-energy contribution to the entire spin dynamics, while the higher energy part is governed by other competing orders such as the 2 × 2 plaquette spin order [23, 34]. Thus, the correlation between CO and AFM helps explain the appearance of stripes at low energy.
Another relevant finding is that the electrons are much more itinerant in the FM direction than in the AFM direction. An anisotropic dispersion is revealed by scanning tunneling
FIG. 2: STM characterization of the charge-stripe order in FeTe. (A-D) Temperature-dependence of the surface electronic structure (-5 mV, 0.02 nA, 10 nm × 10 nm). Above 65 K, the stripe-like anisotropy completely disappears. (E-H) Energy-dependence of the charge order (0.02 nA, 8 nm × 8 nm). The period is 2 a Te along the AFM direction. The temperature is 4.2 K.

spectroscopy (STS) measurement. The STS detects the differential tunneling conductance dI/dV , which gives a measure of the local density of states (LDOS) of electrons at energy eV . The dI/dV mapping was performed on the surface of FeTe. At each data point, the feedback was turned off and the bias modulation was turned on to record dI/dV . This procedure resulted in a series of spatial mapping of LDOS at various bias voltages. A typical dI/dV mapping at 60 mV is shown in Fig. 3A. The autocorrelation analysis (inset of Fig. 3A) reveals a wave vector exclusively along the b-axis. A parabolic dispersion (Fig. 3B) is obtained by plotting the wave vector versus energy. The dispersion is highly anisotropic and only observed in the FM direction. The parent compound of iron-pnictide superconductor Ca(Fe 1 -x Co ) As x 2 2 also exhibits similar property [35]. However, the present results for FeTe are nontrivial because of the different electron transport behavior in FeTe from that in the iron pnictides. In FeTe, the electric conductivity in the FM direction is larger than that in the AFM direction [36], while the opposite is observed for iron pnictides [36, 37]. The consistency between the anisotropy in band dispersion and electric conductivity in FeTe unambiguously indicates that the itinerant electrons hop much more easily along the FM direction.

FIG. 3: Dispersive electronic states along the FM direction. (A) dI/dV mapping at 60 mV (0.1 nA, 80 nm × 80 nm). The scattering wave vector is determined by the auto-correlation analysis (see the inset). (B) Dispersion of the itinerant electrons.
The highly anisotropic itinerancy is a reminiscence of the electron behavior in the manganites [31] and suggests that the itinerant electrons in FeTe move in a localized spin background and are favorably described by the double-exchange mechanism in the spin-fermion model [22]. In this model, the itinerant electrons and the localized spins S are coupled by the strong on-site Hund's rule coupling K , which is a FM exchange interaction. Therefore, an itinerant electron hopping between two sites with the same (opposite) localized spins will experience zero ( KS ) energy barrier, leading to dispersive (nondispersive) electronic states along the FM (AFM) directions and the so-called double-exchange ferromagnetism [38]. The metallic E -type AFM spin order in FeTe itself results from a compromised interplay between the double-exchange ferromagnetism and the antiferromagnetism that originates from the superexchange between the localized spins [22].
The observed charge-stripe order in FeTe can be readily reproduced by inclusion of longrange intersite Coulomb interactions V ij (thanks to the poor screening in FeTe) into a model H V =0 that can account for the metallic E -type AFM spin order with highly anisotropic dispersion. The Hamiltonian reads H = H V =0 + H V , where
$$H _ { V } = \sum _ { i j } V _ { i j } n _ { i } n _ { j }.$$
Here n i is the electron number operator on the i th Fe site. If m refers to the m th-neighbor,
one may use V m = 1 //epsilon1r m to approximate the screened Coulomb potential, where /epsilon1 is the dielectric constant of the material and r m the m th-neighbor Fe-Fe bond length. Then the Fe square sublattice leads to V 1 : V 2 : V 3 = 2 : √ 2 : 1.
We first analyze the effect of H V alone without considering the kinetic energy. Let ˜ S z i = n i -〈 n i 〉 , where 〈 n i 〉 is the averaged filling of the itinerant electrons per Fe site. Then, the problem can be mapped to a classical spin model H V ≡ ∑ ij V ij ˜ S S z i ˜ z j plus a constant. Substituting V m by J m , we arrive at the J 1 -J 2 -J 3 spin model, which is known to yield the E -type AFM 'spin' order when J 2 > J / 1 2 and J 3 > J / 2 2 [30]. This numerical condition is satisfied by V 1 : V 2 : V 3 = 2 : √ 2 : 1. Hence, the V 1 -V 2 -V 3 model alone is ready to yield the observed E -type charge order with n i = 2 〈 n i 〉 on the 'spin'-up sites and n i = 0 on the 'spin'-down sites.
The above charge-stripe order is expected to be weakened by the kinetic energy contributed from H V =0 . However, the negligible kinetic energy along the AFM direction compared with that along the FM direction warrants the Stoner-type instability of 'spin' polarization, namely the charge difference ∆ n between the spin-up Fe site and the spin-down Fe site. Therefore, the charge-stripe order still survives even for small V ij . The situation is explicitly shown in fig. S2, where ∆ n is calculated using the aforementioned spin-fermion model for H V =0 . In the supplemental material [33], we also demonstrate how the effect of local Coulomb interactions is suppressed by the double-exchange mechanism, which is necessary for V ij to be effective in driving the CO instability.
Finally, the stripe structure of FeTe indicates two types of domain boundaries: orthorhombic twin boundary and anti-phase boundary. Both of them have been observed and are shown in Fig. 4. The continuity of the charge stripes ends at the domain boundaries (marked by the dash lines). The stripes either rotate by 90 ◦ (Fig. 4A) or shift by a Te (Fig. 4B) upon crossing the boundary while the (1 × 1)-Te lattice in the topmost layer remains uninterrupted. This rules out the effects of possible defects (for example, excessive Fe atoms) as the cause of the observed electronic nematicity.
The E -type charge-stripe order revealed in stoichiometric FeTe with integer nominal valence affirms the ubiquity of the phenomenology of CO in SCESs, and suggests a more complex charge dynamics and pairing mechanism than originally expected. It implies that the effect of local Coulomb interaction can be surpassed by the poorly screened longer-range Coulomb interactions in FeSCs, and that bad metallicity, strong correlation from Hund's

B
FIG. 4: Stripes across the domain boundaries. (A) Twin boundary. The direction of stripes rotate by 90 . ◦ (B) Anti-phase boundary. Half period is shifted (indicated by the arrows) across the boundary. The dash lines in both images highlight the boundaries. The bias voltages for the two images are 0.2 mV and -5 mV, respectively. For both images, the scanning size is 15 nm × 15 nm, and tunneling current is 0.03 nA.

rule coupling, and strongly coupled charge multipole polarizations of Fe and anion are key to understanding FeSCs.
- [1] E. Dagotto, Science 309 , 257 (2005).
- [2] M. Coey, Nature 430 , 155 (2004).
- [3] M. S. Senn, J. P. Wright, J. P. Attfield, Nature 481 , 173 (2012).
- [4] M. Cwik et al. , Phys. Rev. Lett. 102 , 057201 (2009).
- [5] A. M. M. Abeykoon, E. S. Boˇ zin, W.-G. Yin, G. Gu, J. P. Hill, J. M. Tranquada, S. J. L. Billinge, Phys. Rev. Lett. 111 , 096404 (2013).
- [6] J. M. Tranquada, B. J. Sternlieb, J. D. Axe, Y. Nakamura, S. Uchida, Nature 375 , 561 (1995).
- [7] M. J. Lawler et al. , Nature 466 , 347 (2010).
- [8] R. Comin et al. , Science 343 , 390 (2014);
- [9] E. H. da Silva Neto et al. , Science 343 , 393 (2014).
- [10] J. Zaanen, O. Gunnarsson, Phys. Rev. B 40 , 7391 (1989).
- [11] D. Volja, W.-G. Yin, W. Ku, Europhys. Lett. 89 , 27008 (2010).
- [12] J. van den Brink et al. , Phys. Rev. Lett. 83 , 5118 (1999).
- [13] V. J. Emery, S. A. Kivelson, Physica C 263 , 44 (1996).
- [14] Bad metals are referred to materials whose electric resistivity shows metallic-like temperature dependence but large (usually of the order of mΩ cm) absolute value and whose optical Drude weight is finite but small.
- [15] For example, Mn 3 5+ . (Mn 3+ /Mn 4+ ) in La 0 5 . Ca 0 5 . MnO , Fe 3 2+ /Fe 3+ in Fe 3 O , Cu 4 2+ /Cu 3+ in La 1 875 . Ba 0 125 . CuO . 4
- [16] I. I. Mazin et al. , Phys. Rev. Lett. 98 , 176406 (2007).
- [17] Y. Kamihara, T. Watanabe, M. Hirano, H. Hosono, J. Am. Chem. Soc. 130 , 3296 (2008).
- [18] C.-C. Lee, W.-G. Yin, W. Ku, Phys. Rev. Lett. 103 , 267001 (2009).
- [19] Q. Si, E. Abrahams, Phys. Rev. Lett. 101 , 076401 (2008).
- [20] L. de' Medici, G. Giovannetti, M. Capone, Phys. Rev. Lett. 112 , 177001 (2014).
- [21] Z. P. Yin, K. Haule, G. Kotliar, Nature Materials 10 , 932 (2011).
- [22] W.-G. Yin, C.-C. Lee, W. Ku, Phys. Rev. Lett 105 , 107004 (2010).
- [23] W.-G. Yin, C.-H. Lin, W. Ku, Phys. Rev. B 86 081106 (2012).
- [24] C. Ma, L. Wu, W.-G. Yin, H. Yang, H. Shi, Z. Wang, J. Li, C. C. Homes, Y. Zhu, Phys. Rev. Lett. 112 , 077001 (2014).
- [25] G. A. Sawatzky, I. S. Elfimov, J. van den Brink, J. Zaanen, Europhys. Lett. 86 , 17006 (2009).
- [26] F.-C. Hsu et al. , Proc. Nat. Acad. Sci. 105 , 14262 (2008).
- [27] N. Karayama et al. , J. Phys. Soc. Jpn. 79 , 113702 (2010).
- [28] W. Bao et al. , Phys. Rev. Lett. 102 , 247001 (2009).
- [29] S. L. Li et al. , Phys. Rev. B 79 , 054503 (2009).
- [30] F. J. Ma, W. Ji, J. P. Hu, Z.-Y. Lu, T. Xiang, Phys. Rev. Lett. 102 , 177003 (2009).
- [31] T. Hotta, M. Moraghebi, A. Feiguin, A. Moreo, S. Yunoki, E. Dagotto, Phys. Rev. Lett. 90 , 247203 (2003).
- [32] A previous STM study [Y. Kawashima et al. , Physica B 407 , 1796 (2012)] of a semiconducting Fe 1+ x Te film reported the G -type CO, where charge alternates among nearest neighboring Fe sites. The semiconducting nature of that film implies that the CO is likely caused by extrinsic effects.
- [33] Materials and methods are available as online supporting material.
- [34] I. A. Zaliznyak et al. , Phys. Rev. Lett 107 , 216403 (2011).
- [35] T.-M. Chuang, M. P. Allan, J. H. Lee, Y. Xie, N. Ni, S. L. Bud'ko, G. S. Boebinger, P. C. Canfield, J. C. Davis, Science 327 , 181 (2010).
- [36] J. Jiang et al. , Phys. Rev. B 88 , 115130 (2013).
- [37] J.-H. Chu, J. G. Analytis, K. De Greve, P. L. McMahon, Z. Islam, Y. Yamamoto, I. R. Fisher, Science 329 , 824 (2010).
- [38] P.W. Anderson, Phys. Rev. 100 , 675 (1955).
- [ Acknowledgments ] This work was supported by National Natural Science Foundation and Ministry of Science and Technology of China and by the U.S. Department of Energy (DOE), Office
of Basic Energy Science, under Contract No. DE-AC02-98CH10886.
## Supporting Materials for
## Observation of Long-Range Charge Order in Stoichiometric FeTe Films
by W. Li, W.-G. Yin, L. L. Wang, K. He, X. C. Ma, Q.-K. Xue, and X. Chen
## MATERIALS AND METHODS
The FeTe (001) film was prepared on the graphitized 6H-SiC (0001) substrate. Highpurity Fe (99.995%) and Te (99.9999%) were evaporated from two standard Knudsen cells. The growth was performed in the Te-rich conditions with a nominal Te/Fe flux ratio of ∼ 15 to avoid excess Fe in the film, while the substrate temperature was held at 310 C. The growth ◦ follows the typical layer-by-layer mode. The as-grown films were directly transferred to STM. A polycrystalline PtIr STM tip was used in the experiments. The STM topographic images were processed using WSxM (www.nanotec.es). We studied the samples with the thickness of 15, 20, and 30 unit cells and found similar results. We present here the measurements on the 30-unit-cell sample.
## SUPPORTING ONLINE TEXT AND FIGURES
## Identification of the FM and AFM directions from topographic images
The image with atomic resolution in Fig. S1 exhibits a quasi-square lattice of Te atoms with lattice constant of a Te /similarequal 3.8 ˚ . Previous studies [1, 2] on bulk FeTe show a tetragonal A to monoclinic (approximately orthorhombic) structural phase transition at T s ∼ 65 K with a simultaneous development of the E -type antiferromagnetic (AFM) order (i.e., T N = T s ); the long axis of the Te lattice is along the AFM direction (the a-axis in Fig. 1B). To determine the lattice orientation of the film, we performed the Fourier transform of Fig. S1 (see the inset of Fig. S1). The lattice constant along the a-axis is 2% larger than that along the baxis. We therefore identify the a-axis as the AFM direction and b-axis as the ferromagnetic
(FM) direction in the film.
FIG. S1: Atomic resolution STM topography of FeTe film (1.5 mV, 0.08 nA, 15 nm × 15 nm). Inset is the Fourier transformation, from which the FM and AFM directions are identified.

## Calculation of charge order in the spin-fermion model
The effective Hamiltonian becomes H = H S -F + H V . The spin-fermion model H S -F , where the Fe d xz and d yz orbitals were treated to host itinerant electrons and the rest Fe 3 d orbitals were treated as an effective localized spin, was proposed as a minimal model to unify the various magnetic orders observed in FeSCs, such as metallic E -type in FeTe, metallic C -type in LaOFeAs and BaFe As 2 2 [3, 4] and insulating 2 × 2 block-type in K Fe Se 2 4 5 and BaFe Se 2 3 [5], A -type in TaFeTe 3 [6, 7], and FM in CuFeSb [8], etc. It reads [3, 4, 9-12]
$$H _ { S - F } = \, & - \, \sum _ { i j \gamma \gamma ^ { \prime } \mu } ( t _ { i j } ^ { \gamma \gamma ^ { \prime } } C _ { i \gamma \mu } ^ { \dagger } C _ { j \gamma ^ { \prime } \mu } + h. c. ) - \frac { K } { 2 } \sum _ { i \gamma \mu ^ { \prime } } C _ { i \gamma \mu } ^ { \dagger } \vec { \sigma } _ { \mu \mu ^ { \prime } } C _ { i \gamma \mu ^ { \prime } } \cdot \vec { S } _ { i } + \sum _ { i j } J _ { i j } \vec { S } _ { i } \cdot \vec { S } _ { j } \\ & + \, U \sum _ { i \mu } n _ { i \gamma \uparrow } n _ { i \gamma \downarrow } + U ^ { \prime } \sum _ { i \mu \mu ^ { \prime } } n _ { i, x z, \mu } n _ { i, y z, \mu ^ { \prime } } - J _ { H } \sum _ { i \mu } n _ { i, x z, \mu } n _ { i, y z, \mu },$$
where C iγµ denotes the annihilation operator of an itinerant electron with spin µ = ↑ or ↓ in the γ = d xz or d yz orbital on site i . t γγ ′ ij 's are the electron hopping parameters. /vector σ µµ ′ is the Pauli matrix and /vector S i is the localized spin whose magnitude is S . K is the effective Hund's rule coupling between the itinerant electrons and the localized spins. J ij is the AF
## W. Li et al.
superexchange couplings between the localized spins; in particular, J and J ′ are respectively the nearest-neighbor (NN) and next-nearest-neighbor (NNN) ones. The U , U ′ , and J H terms on the second line of Eq. S1 describes the on-site intraorbital Columbic, interorbital orbital Columbic, and Hund's rule interactions between the itinerant electrons, respectively. The filling of the itinerant electrons is three per Fe site, corresponding to the high-spin configuration of Fe 3 d 6 [13].
To minimize the number of free parameters, we take U and V 3 as free parameters, set V 1 : V 2 : V 3 = 2 : √ 2 : 1 and U ′ = U -2 J H , and keep the other parameters the same as previously used for FeTe [3], notably KS = J H = 0 8 eV. We also keep the same treatment . of the localized spins as Ising spins, which has been shown to suffice for the problem of interest.
In Fig. S2, we present the calculated ∆ n as a function of V 3 for three typical cases: (i) U = U ′ = J H = 0 (black solid line), (ii) U = 2 4 eV, . U ′ = 0 8 eV, and . J H = 0 8 eV (red . dotted line), and (iii) U = 4 eV, U ′ = 2 4 eV, and . J H = 0 8 eV (blue dashed line). . It shows that as V 3 increases, the E -type CO saturates to ∆ n = 2 〈 n i 〉 as discussed in the main text. As U increases, the CO is suppressed considerably as expected. The results for the first two cases are comparable to each other. This is understandable as the double-exchange effect: The strong KS term tends to align the spins of the itinerant electrons with the localized spins, thus suppressing the effect of U and the effective interaction between the itinerant electrons becomes U ′ -J H , which is zero in case (ii). This justifies the use of the noninteracting case (i) to approximate the interacting case (ii) [3-5]. We show that the CO starts to appear at small V 3 /similarequal 0 1 eV. .
- [1] W. Bao et al. , Phys. Rev. Lett. 102 , 247001 (2009).
- [2] S. L. Li et al. , Phys. Rev. B 79 , 054503 (2009).
- [3] W.-G. Yin, C.-C. Lee, and W. Ku, Phys. Rev. Lett 105 , 107004 (2010).
- [4] W.-G. Yin, C.-C. Lee, and W. Ku, Superconductor Science & Technology 25 , 084007 (2012).
- [5] W.-G. Yin, C.-H. Lin, and W. Ku, Phys. Rev. B 86 081106(R) (2012).
- [6] X. Ke et al. , Phys. Rev. B 85 , 214404 (2012).
- [7] M. Xu et al. , arXiv:1310.7348 (2014).
## W. Li et al.
FIG. S2: The charge difference ∆ n between the spin-up Fe site and the spin-down Fe site as a function of V 3 calculated from using the spin-fermion model [3, 5] with an addition of V 1 : V 2 : V 3 = 2 : √ 2 : 1 for three typical cases.
- [8] B. Qian et al. , Phys. Rev. B 85 , 144427 (2012).
- [9] W. Lv, F. Kr¨ger, and P. Phillips, u Phys. Rev. B 82 , 045125 (2010).
- [10] S. P. Kou, T. Li, and Z. Y. Weng, Europhys. Lett. 88 , 17010 (2009).
- [11] A. M. Turner, F. Wang, and A. Vishwanath, Phys. Rev. B 80 , 224504 (2009).
- [12] S. Liang, G. Alvarez, C. Sen, A. Moreo, and E. Dagotto, ¸ Phys. Rev. Lett 109 , 047001 (2012).
- [13] C.-C. Lee, W.-G. Yin, W. Ku, Phys. Rev. Lett. 103 , 267001 (2009). | 10.1103/PhysRevB.93.041101 | [
"Wei Li",
"Wei-Guo Yin",
"Lili Wang",
"Ke He",
"Xucun Ma",
"Qi-Kun Xue",
"Xi Chen"
] | 2014-08-01T01:16:24+00:00 | 2014-08-01T01:16:24+00:00 | [
"cond-mat.str-el",
"cond-mat.supr-con"
] | Charge-Stripe Order in a Parent Compound of Iron-based Superconductors | Charge ordering is one of the most intriguing and extensively studied
phenomena in correlated electronic materials because of its strong impact on
electron transport properties including superconductivity. Despite its
ubiquitousness in correlated systems, the occurrence of charge ordering in
iron-based superconductors is still unresolved. Here we use scanning tunneling
microscopy to reveal a long-range charge-stripe order and a highly anisotropic
dispersion of electronic states in the ground state of stoichiometric FeTe, the
parent compound of the Fe(Te, Se, S) superconductor family. The formation of
charge order in a strongly correlated electron system with integer nominal
valence (here Fe$^{2+}$) is unexpected and suggests that the iron-based
superconductors may exhibit more complex charge dynamics than originally
expected. We show that the present observations can be attributed to the
surpassing of the role of local Coulomb interaction by the poorly screened
longer-range Coulomb interactions, facilitated by large Hund's rule coupling. |
1408.0058v1 | ## A Framework for learning multi-agent dynamic formation strategy in real-time applications
Mehrab Norouzitallab , Valiallah Monajjemi , Saeed Shiry Ghidary , Mohammad Bagher a b c Menhaj d
a [email protected] [email protected] [email protected] b c d [email protected]
a, c Department of Computer Engineering and Information Technology,
Amirkabir University of Technology, Tehran, Iran
b, d Department of Electrical Engineering,
Amirkabir University of Technology, Tehran, Iran
Abstract. Formation strategy is one of the most important parts of many multi-agent systems with many applications in real world problems. In this paper, a framework for learning this task in a limited domain (restricted environment) is proposed. In this framework, agents learn either directly by observing an expert's behavior or indirectly by observing other agents' or objects' behavior. First, a group of algorithms for learning formation strategy based on limited features will be presented. Due to distributed and complex nature of many multi-agent systems, it is impossible to include all features directly in the learning process; thus, a modular scheme is proposed in order to reduce the number of features. In this method, some important features have indirect influence in learning instead of directly involving them as input features. This framework has the ability to dynamically assign a group of positions to a group of agents to improve system's performance. In addition, it can change the formation strategy when the context changes. Finally, this framework is able to automatically produce many complex and flexible formation strategy algorithms without directly involving an expert to present and implement such complex algorithms.
Keywords: multi-agent systems, formation strategy, machine learning, framework, modular scheme, context based reasoning, dynamic position assignment
## 1. Introduction
Formation Strategy is one of the state of the art research topics in multi-agent systems attracted many attentions [1-8]. In formation strategy, an agent tries to find a proper position for itself based on the environment's state in order to increase its performance. Concerning a set of features that defines the environment's state, an agent tries to decrease the error between its current and the desired position to increase its cooperation with other agents. In other words, formation strategy for each agent can be viewed as a function whose inputs are
some features elicited from the environment and its output is a target position for the agent. During execution time, agents try to get close to their target positions.
Formation Strategy is used in many applications, such as behavior analysis of fishes [9] and birds [10] and capturing/enclosing an invader [15]. It is also being used in many systems such as autonomous highway systems [8] satellites and spacecraft [11-13], UAV and AUV [14].
Depending on the problem, different models for Formation Strategy have been developed. Some of the most famous models are 'Leader Follower' [3, 7, and 16], 'Behavior Based Model' [17, 18], 'Virtual Structure' [19] and 'Model Based Formation Strategy' [20].
In the leader follower model, a leader is being followed by a group of agents. The main problem of this approach occurs when the leader suffers from a fault, thus generating inappropriate and weak features. Neglecting this drawback, this approach is widely used because of its simple and extensible nature.
In the behavior based model, a set of default behaviors are defined for each agent. The agent assigns some degree of importance to each behavior during execution, and then selects an action consistent with the most important behavior. Analytical formulation and theoretical analysis for this approach is difficult, so convergence to optimal configuration is not guaranteed.
In model based formation strategy, there are well-defined analytical models for the agent, tasks and the environment. In addition to time and effort needed to generate these models, the performance of the model is limited to known environments. In comparison to behavior based model, in this method there is no need to extract a model during execution. Furthermore, a goal is defined for each behavior and the entire task can be covered by the all behaviors.
Formation strategy based on virtual structure uses a fixed model. In this method, tasks are not individually assigned to agents; instead the whole formation strategy is presented to the all agents. Using this approach, the agent's behavior is predictable; as a result, agent's formation will be appropriate. One of the disadvantages of this method is the high bandwidth required for communication among agents.
In multi-agent systems, formation strategy function should possess some qualities such as smoothness of a sequence of target positions in a period of execution time. Moreover, being robust to the errors in input features is vitally important. Perception noise and partial observability of the environment are two prevalent causes of the errors. Furthermore, the most important quality of a formation strategy in a multi-agent is its responsibility of organizing agents in the environment in such a way that their consistency and coalition become guaranteed. Beside, this organization should prime a basis for agents in order to improve their behaviors' performance.
In this paper a framework is proposed to address diverse variety aspects of generating an appropriate formation strategy using supervised learning algorithms in many multi-agent systems with restricted environments . The main parts of this
framework are Context Based Reasoning, Modular Scheme, Formation Strategy Function and Dynamic Position Assignment. Each part is responsible for solving a distinct problem concerned in a proper formation strategy.
Context based reasoning [21] allows agents adapt their formation strategy to the variations in environment's contexts, like humans who can make decisions based on a limited amount of data in different situations.
Formation strategy is an operation which the agents must be organized to perform their task. Indeed, there is a well-defined goal which is broken down into simpler sub-goals for different contexts. A hierarchical structure is proposed to reach these sub-goals. This structure is a powerful tool which eases the process of dividing a complex task into manageable sub tasks. First, the environmental status determines the context of the environment in each moment of the agents' execution time. For each context, an organization is conducted for agents by modular scheme. For example, agents with similar duties are grouped together. Agents in each group can learn their formation strategy based on local features of the environment and their leaders' position. By organizing the leaders based on global features of the environment, the coordination can be improved. In this way, the local features of the environment are directly presented to the formation strategy function of each agent and the global features are propagated through leaders' positions. It is clear that a high consistency among agents as a whole is feasible in this framework.
The framework emphasizes the application of machine learning to produce a complex formation strategy functions with ease. To this end, there are many difficulties concerned in using machine learning algorithms. The high coalition among agents causes the machine learning approaches to confront difficulties. Therefore, modular scheme is proposed to overcome such problems beside its application to agents' organization.
Considering the characteristics of the formation strategy problem, developing a general approach which could be used in different environments is of great interest. Machine learning is one of the methods that can be used to overcome this problem. Using machine learning, an agent is able to learn formation strategy, without the need for using any particular algorithms to reflect different requisites of each environment separately. This can be conducted either by using data generated by an expert, or data that is obtained by the agent itself via interaction with the environment. In fact, using machine learning methods, the expert can teach the agent complex and efficient behaviors via demonstration, rather than using complex algorithms.
In machine learning, patterns and features are extracted from experimental data. Learning from observation [22] is one of the methods to supply required data needed in machine learning problems. In this method, data are gathered by observing an expert's actions; next a learning algorithm is applied to extract expert's behaviors from the data. The learning phase is conducted according to other parts of the framework and especially modular scheme. Moreover, some regulations are proposed in order to specify the form that the data must be gathered and presented to the learning algorithm. These regulations influence the result formation strategy.
Many multi-agent systems in real world problems are complex and under burden of many details. Considering all their features or even effective ones (which are usually many) is impossible in practice. First, large amount of data are needed for learning which consequently increases the learning time. Second, problems like agents' position instability, features' redundancy, poor coordination, perception noise, and lack of enough information about a large amount of features will occur due to partial observabilty.
The modular scheme is crucially important in the framework, because it is responsible for organizing agents as well as eliminating problems concerned in the learning process. By using the modular scheme, the most important features of the environment are considered either directly or indirectly in formation strategy. The modular scheme is itself a hierarchy. Each group of agents is broken down into smaller groups and a leader (or some local features) is selected for each group. While other agents try to learn to follow their group's leader, leaders themselves are coordinated by following a common leader or other global features of the environment. The modular scheme is efficiently flexible as agents can adapt their formation strategy according to both a leader and a set of environmental features simultaneously. These features are considered in group levels. This structure increases both the intra-group and inter-group coordination as well as the learning accuracy.
In order to use the framework, each agent must first find its relevant section of the hierarchical structure. By using the local or global features of that section, it should then find its goal position. Finding the relevant section of the hierarchy, which is usually the role of the agent, can be done either statically or by dynamic position assignment method. In the latter case, a group of agents can choose their target positions from a group of proper positions in a way that brings maximum profit for the whole system.
In sum, the formation strategy framework has different parts with different duties. First, the formation strategy task is divided into some context. In each context, modular scheme organizes agents and prime a structure for learning the formation strategy function in each context. Each agent learns its formation strategy based on experimental data which is input-output features specified by the modular scheme. During execution time, agents determine the context of the environment and its related modular scheme. Then, agents present the value of features specified by the modular scheme to their learned formation strategy function as inputs to obtain their target positions. If dynamic position assignment method is active, agents can estimate the target positions of some other agents (if the other agents have the same ability) and choose their proper target positions to increase the system's performance. Dynamic position assignment method has some characteristics to avoid conflicts among agents even in a partial observable environment.
The remainder of this paper is organized as follows. Section two describes main parts of the framework. In section three, Context Based Reasoning is reviewed while section four is devoted to modular scheme's explanations. In Section five,
Dynamic Position Assignment method is proposed. Experiments are presented in Section six and finally section seven concludes the paper.
## 2. A framework for leaning formation strategy
Methods like formation strategy function, modular scheme, context based reasoning, and dynamic position assignment, each represents a distinct set of features for the problem of formation strategy. Integrating all these features in a framework in order to be used in multi agent systems in restricted environment can be significantly considerable. This integration is obtained in the framework by a hierarchical structure.
Figure 1. Hierarchical Structure
In figure 1, a diagram of the hierarchical scheme for the formation strategy task is depicted. In this method, formation strategy task is divided into some contexts; each of them contains a hierarchical set related to its modular scheme. In modular scheme's hierarchical structure, each leaf represents an agent, which follows a leader or a set of features (if exists). With the help of its formation strategy function for specific context and based on a set of features, each agent finds its target position. In case that some agents know the other's proper positions or they want to choose their positions from a group of candidate positions, while avoiding interference and increasing system performance, the dynamic position assignment method is used. The dynamic position assignment method substitutes optimally the roles of agents according to their target positions during the execution time.
Figure 2. The framework's block diagram for formation strategy
Figure 2 shows the framework for learning formation strategy. According to this diagram, the expert first defines some contexts as well as transitions between them. Then he defines a hierarchical structure for each context by modular scheme. Generating a formation strategy algorithm according to this structure needs data gathering as well as specifying dependency graph which is a representation of modular scheme. In the next step, the formation strategy function for each context is approximated using a supervised learning method like neural networks. This approximation is based on gathered data and the dependency graph. In order to use the dynamic position assignment method, weighting each agent-location pair to specify the assignment performance is vital.
It is apparent that the expert does not need to implement the formation strategy directly. This framework is general enough to be used in many multi-agent systems in restricted environments, therefore by developing a graphical user interface or a toolbox; experts without explicit knowledge about implementation methods can apply this approach.
## 3. Context Based Reasoning
Context based reasoning allows the agents to exhibit high level behaviors. This reasoning is based on the idea [38] that:
- 1. Context is a set of actions and procedures that properly addresses the current environment's conditions.
- 2. As a task evolves, a transition to another set of actions and procedures is required to address a new context.
- 3. Everything happens in a contexts is influenced by and limited to the same context.
Agents can perform predefined tasks using context based reasoning. For each task, some goals are defined for each agent. There are limitations to reach each goal [38]. Each context represents a state, based on environment's status and agent's motives. This state causes a specific behavior for each agent in that context [38].
The main three concepts of context based reasoning are task, context and transaction function.
A task is an abstraction defined inside a model which is set for an agent prior to runtime. A task consists of a target, a set of constrains and a context that dictates high level behaviors to the agent. The target defines the conditions in which the task terminates. The target can be well defined by environment's (physical or environmental) conditions. Limitations are physical, logical and environmental.
In [38], physical and environmental conditions that represent a specific behavior are considered to comprise a context. Context based reasoning's model requires that agents to be active during each time-step. A context in the model is said to be active when the condition implying its validity is satisfied and the agent uses its own knowledge to make decisions for its task.
The task describes an agent's high level behavior by defining groups of contextcontext transitions pairs. Context transition denotes specific changes between contexts during the task's execution.
A set of contexts n 1 2 C={c ,c ,...,c } are considered for a task. The role of an expert is to design a model by defining contexts, consistent with his intuition about the task. Each context needs to be paired with a behavior in order to perform a task. This technique is more appropriate for tasks that agent's behaviors and activities are well defined. In addition, this technique is useful when each task execution is dependent on a series of sub-tasks.
## 4. Learning Formation Strategy Using the Proposed Modular Scheme
## 4.1 Definition of Learning Formation Strategy
Assume that n 1 2 A={a ,a ,...,a } is a set of attributes of the environment. t t t t n 1 2 V ={v , v , …, v } is a set consisting of the values that represent the degree of similarity of the environment at time t to set A . If the environment is partially observable at t , some of V values are not measurable and thus are considered t unknown.
A history of measured values of attributes for k time-steps is defined as 1 2 , , , , v t k t k t k t hist V V V V . number of features that have influence on m formation strategy are extracted using function : v hist P in form of set 1 2 3 { , , , , }. Formation strategy for an agent is defined as function m P p p p p : P T where T is agents' target positions in their formation strategy.
In learning formation strategy, the function is approximated using data gathered by an expert. In this paper, supervised learning methods are used for function approximation. According to the definition, the output of the function ( T ) is the target position for the agent. It is assumed that there exists a motion planning method to reach the target position. The motion planning can also be learned using other methods which are not covered in this paper.
## 4.2. Modular Scheme
One of the important issues in learning the formation strategy in multi agent environments is the features and their relations to each other. The changes made by each agent in the environment when executing its formation strategy, have direct influence on features spotted by other agents. Therefore, the agent's formation strategy has to be defined in a way that can maintain the system's coordination. There are several concerns about learning an effective formation strategy.
- · Coordination reduction among agents: If in learning formation strategy, there were no features defined to increase agents' coordination, each agent would use environment's local and global features, without considering the performance of other cooperating agents, in order to improve the performance of its own formation strategy. This solo improvement may cause a dramatic drop in performance of cooperative agents, thus the whole system. Considering the coordination in formation strategy, will cause the agents to support each other when executing tasks.
- · Instability: Consider two agents, agent 1 and 2. If agent 1 observes the position of agent 2 and agent 2 observes the position of agent 1, either directly or indirectly, with every move of agent 1, there will be a change in target position of agent 2 and vice versa. The dependency between two agents will cause instability in agents' positions until one agent stops moving.
·
- Lack of proper information about features during run-time: Observation in many multi agent systems are partial, in addition, communication between agents are costly. As a result, when the number of features which have direct influence on formation strategy increases, some of those features may not be available or with much error during run-time.
Feature redundancy: If a set of features can be extracted from another set, considering both in a single set directly in learning will cause extra overhead during run-time. In addition, if an agent receives each similar set with different delay from different source, an additional noise is not
avoidable. For example, in a partially observable environment, this extra overhead will force the agent to extract information from both sets, nevertheless only one feature set is adequate. Considering three agents, agent 1, 2 and 3, If agent 2 follows agent 1 and agent 3 wants to consider the features used by agent 1 and 2, the position of agent 2 will provide enough information about those features because the feature set used by agent 1 will be propagated to agent 3 through agent 2 Taking into account the positions of both agent 1 and 2 or the other features will cause feature redundancy.
A modular scheme is proposed which can suitably overcome the mentioned issues. This modular scheme will be effective and useful in many multi agent systems. In this scheme, agents are grouped together based on some similarity factors. A leader is determined for each group, which other group members will follow its position. The leader will learn its formation strategy based on local and global features. Each agent will find its proper position based on its leader position. Considering common global features in learning formation strategy for leaders, increases the coordination between groups. In addition, it is possible to use a leader who only uses system's global features in order to coordinate the whole system. This modular scheme causes the transfer of prominent features from leaders to their follower agents. Furthermore, each group's agents are coordinated by following their common leader, which consequently increases the cooperation among them. The presence of a leader, gives agents the ability to consider the leader's position as a local feature in their formation strategy to increase their coordination with other agents. Agents are not restricted to follow just a leader. Instead, agents of a group can consider a set of global features alongside a set of local features or even status of more than one agent in their formation strategy. Furthermore, the modular scheme is flexible enough to cover many models for formation strategy as well as leader-follower.
Figure 3. An overview of modular scheme alongside with the leader follower model
Figure 3 demonstrates the modular scheme's organization alongside with the leader-follower model. This combination transfers the attributes sensed by the leader to the agent with some delay proportional to the importance of the feature. During this transfer, other delays relevant to the perception process of the leader, like partial observation delay and the delay of communication between agents have less effect. In other words, if a global feature is passed through different leaders before it reaches an agent, it will cause more delay comparing to the features transferred from the main leader of an agent. Furthermore, when the number of leaders in the hierarchy increases or the error appears in a leader position - when it tries to reach its proper position - the transferred features to the agent will contain more errors.
Using machine learning methods with modular scheme based on a training dataset will help the agents in a group follow a leader using different methods when necessary.
In order to learn formation strategy with the help of modular scheme, it is needed that an expert gathers a training set. Then, this training set can be used to train a machine learning method like neural networks or support vector machines. In practice, this process can be time consuming in complex systems; therefore a systematic approach is proposed. In this approach, an expert gathers snapshots of the system, either manually or automatically. Each snapshot includes an instant
set of features elicited from an environment status. Furthermore, the expert can manually determine the appropriate target position of each agent reflecting the environment status. When the goal is simulating or extracting an algorithm used by other agents or even creatures in real-world, the expert can be neglected in this process and the positions of the other agents (creatures) mirrors the target positions of the agents. The snapshots form a training set in a matrix form.Each row of the matrices represents a data related to a feature or a coordination of an agent's position. Each column is related to a snapshot. The expert must define the modular scheme as an acyclic directed graph, called the 'dependency graph'. Each node of this graph, stores the number of a specific row in the data matrix. Directed edges traveling outside of a node, the end node specifies the sources (features or other agents), from which the agent learns its formation strategy function. Thus, for each node representing an agent, a function approximation algorithm is used to learn the formation strategy function based on the knowledge represented by its dependencies and the training set.
The error of the estimator causes an extra error in formation strategy function learned by the agents following a leader. Assume that, each snapshot contains information about a group of features, the proper position of the leader and the proper position of a follower. In addition, the dependency graph contains a relation between the leader and the features as well as a relation between a follower and the leader. In order to reduce this extra error, it is better for the agent to use the estimated position of the leader - which contains the learning errorinstead of leader's proper position existed in the data-set. The leader's proper position in the data-set is replaced by its estimated position during execution time. In order to solve this problem, first the dependency graph is topologically sorted [36] in reverse order (from features to agents). The agent's positions in the data matrices are then replaced by the outputs of the estimated formation strategy function, based on the input data, recursively.
## 4.3. Formation Strategy Function Approximation
To learn the formation strategy function, the expert must consider a set of features. Then, based on the selected features, he/she must gather data-set D containing ( , ) pairs. In this pair, p t p is the feature vector of a specific state and t represents the proper position of the agents for that state. The data could also be gathered via observing other agents or objects.
Different methods can be employed to approximate a given function based on the date set D . None of these methods are error free. We can define the approximation error of the formation strategy function as follows:
$$E = \frac { 1 } { N } \sum _ { i = 1 } ^ { N } d i s t ( t _ { i }, \delta ( p _ { i } ) )$$
In this equation, N is the number of samples, t is the i i th coordination of t and dist is a function to measure distance between two points. i p is a set of features and is the approximated formation strategy function. If the points are defined in Euclidean space, the equation can be defined as follows
$$E = \frac { 1 } { N } \sum _ { i = 1 } ^ { N } \sqrt { \sum _ { j = 1 } ^ { d } \left ( t _ { i j } - \delta _ { j } \left ( p _ { i } \right ) \right ) ^ { 2 } }$$
In this equation, d is the dimension of the environment, t ij is the j th coordination of the target position in i th datum sample and j is the j th estimated coordination of the target position regarding i p .
We can also define the 'Sum Square Error' in this domain as follows:
$$S S E = \sum _ { i = 1 } ^ { N } \sum _ { j = 1 } ^ { d } ( t _ { i j } - \delta _ { j } \left ( p _ { i } \right ) ) ^ { 2 }$$
It is easily apparent that equation (eq.1) is always lesser or equal than equation (eq.2).
As a result, the reduction in SSE will reduce the approximation error which appears in formation strategy function. A wide variety of learning methods can be used to reduce SSE.
## 5. Dynamic Position Assignment
In dynamic position assignment method, it is assumed that a set of agents 1 2 n Agents {Agent , Agent , , Agent }exists and each agent wants to choose a target position from the set P 1 2 k { p , p , , p } where k n . In this method, the function : , weight i j R R is defined to specify the appropriateness of assigning the position p j to Agent i .This weight function is used by agent i Agent for position selection. Then for each agent a distinct point will be assigned in a way that sum of weights for agent-position pairs become maximized.
Figure 4. Dynamic Position Assignment's graph
According to figure 4, the problem can be modeled as a complete weighted biparted graph. The graph consists of two sets of independent nodes. ,1 i Node in the first set represents Agents while ,2 i Node in the second set represents i p . The weight of each edge , ,1 ,2 { , }is determined by weight function. i j i i Edge Node Node The weight function is defined in an application dependent manner, for example in a multi robot system, the weight of each agent-position pair, can be determined based on some factors such as the distance between the agent and the position, agents' current battery (energy) status, agents' priority, agents' physical abilities, etc. These factors can be combined using arbitrary functions. Moreover, the weight function can be determined using machine learning or optimization techniques which are not covered in this paper.
In the next step, Hangarian algorithm [39] is used to match agent-positions in the graph in an optimized way. Matching in this problem means selecting a set of edges, each of them connects an agent to a unique position. Optimized matching (Maximum weighted matching) means selecting the set that maximizes the sum of assigned edges' weights. In other words, agent-position pairs are selected in a way that the system's performance becomes optimized based on weight function.
Dynamic position assignment is applicable in problems where agents of a group have some sort of approximation of other agents' formation positions in the group. Formation position of other agents can be estimated in various ways such as communication or using stored function approximation method of other agents. It is obvious that mentioned methods will cause some overloads and errors.
Using dynamic position assignment approach has significant improvements both on system's performance and agents' cooperation. Using this approach, if any agent's movement is changed toward a behavior other than formation strategy, its role in formation strategy can be changed dynamically with another agent in order to avoid inference between agents' tasks. In addition when an important agent such as a leader in leader-follower model, faces fault in a situation, its role can be substituted with another agent using dynamic position assignment approach. Moreover, this approach can reduce energy consumption in systems where agents have limited energy resources.
## 6. Experiments
In order to examine the proposed framework, we have used RoboCup soccer 2D simulation environment [24]. RoboCup soccer simulator 2D is a tool for research and education about multi-agent systems and artificial intelligence. This tool lets two teams of autonomous simulated agents to play soccer against each other and can be used to examine and compare different machine learning approaches in a complex multi-agent system.
The aim of a team in this simulated environment is to score more goals and receive fewer goals during a match. The formation strategy is one of the most important behaviors of each team's agents. Each agent must find its target position in a way that both its personal activities and its cooperation with other teammates improve.
The soccer simulator is a complex multi-agent system with many effective features. Objects in this environment are represented in two-dimensional Euclidean space. The field size is 105 x 68 meters.
The contexts in soccer simulation environment has been defined as 'Attack', 'Defense', 'Mark', 'Run Away' and 'Dead Balls' (Throw-in, Corner Kick and Free Kick). Contexts' transitions are based on current game state and the active context. Then some data are generated for each context using a graphical tool by the expert. The formation strategy function for each context is approximated based on those data and a dependency graph.
Two separate data-sets have been generated by two different people with different field knowledge, one who was experienced expert in soccer simulation and one who was just familiar with that. Each set consists of some snapshots. Each snapshot contains the position of the ball and the proper position for eleven agents. These data has been generated using a graphical tool. The first set contains 955 snapshots and the second one contains 1000 snapshots.
In this paper, neural networks with Levenberg-Marquatre [31] back-prorogation algorithm is employed among applicable methods used to approximate the
formation strategy function which reduces SSE function mentioned in section 4.3. In theory, a three layered neural network with sigmoid units in hidden layer and linear units in output layer is able to approximate every arbitrary function with reasonable error [30]. A neural network can extract expert knowledge from data to build a model with high generalization ability.
One of the main drawbacks of using a neural network is the risk of over-fitting on training set. In order to overcome this problem, we use early stopping method [40] in which, the training process will be stopped when the error is increasing on an independent validation data-set.
For training, data-set is divided into three sets, training, validation and test. Training set is used to train the neural network, Validation set is used for early stopping method and Test set is used to measure the generalize ability of the trained neural network. To this end, 70% of the data has been used for learning, 20% for testing and 10% for validation. The testing part of the each data-set was constant during and is used as an identical scale for error measurement in different experiments. A feed-forward neural network has been used to learn each mapping. The main focus was on the first data-set, the one which was generated by the expert.
Figure 5. Positions of ball for training and test set
Figure 5 depicts the ball position in training (right) and test (left) portions of the expert's data-set.
(a)
Figure 6. A view of modular scheme in a team of agents in Soccer Simulation environment in normal context (a) and attack context (b)
Figure 6 shows two different modular schemes in Normal and Attack contexts. This figure also shows the agents' groups and their dependency graph. It is possible to use more complex modular schemes in the simulation's environment based on local and global features in order to improve the system's performance. However, simpler schemes are used to better demonstrate the proposed approach's capabilities. Similar schemes have been generated for different context. In this section all experiments has been done using the Normal context. The experiments for other contexts shed similar results.
In the Normal context, agents have been divided into four groups: Goalie, Defenders, Midfielders and Attackers. Each group has a leader for coordination of agents. Leaders are coordinated based on the ball's position which is a global feature and also provides useful information about a game.
After creating the dependency graphs (Figure 6), agents' learning priorities is calculated using topological sorting. In this order (1-4-5-3-2-7-6-8-10-9-11), first agent number 1 learns its formation strategy based on ball's position from training data and then it updates training data. Next, agent number 4 as the defenders' leader learns its formation strategy in the same way. Then, agent number 3 learns
its formation strategy function using the updated data-set (which includes its leader updated positions). This is done in order until the end of learning phase.
After the learning phase, the approach's accuracy has been tested using test portion of the data-set. For examining the test error, it is assumed that agents will reach their target position without considering transition delay and environmental features' value changes meanwhile the transition. First, the leaders find their proper position using the test data and topological order of the dependency graph based on the ball position and their approximated formation strategy function. Then, follower agents find their proper position based on their leader's position. The approximation error is then calculated based on the difference between the agents' position with their positions in test data. Using the expert's data-set, the formation strategy function based on modular scheme has been approximated with the error of 0.89 meters and standard deviation of 0.81 meters. The error has been increased by 5% when the data-set update after each learning step was omitted.
In order to examine the effect of using modular scheme and its stability, a scenario has been simulated. In this scenario, first a force is applied to a stationary ball, and then agents determine their formation strategy while the ball is moving. In each time step, each agent moves toward the proper position calculated using the formation strategy function with maximum speed of 0.5 meters /cycle (If the difference between its current position and the desired position is greater than 0.5 meters). The closest agent to the ball tries to approach the ball with maximum speed of 0.5 meters/cycle in each time step. This task added to the scenario to examine the coordination level of the framework when an agent executes a task independent to formation strategy.
(b)
(c)
Figure 7. The output of learned formation strategy function for all agents according to
Only ball position (b) Ball position and teammates' positions
(c) Modular Scheme
(d) Presenting all the direct and indirect effective features of modular scheme directly
Figure 7 shows the trace of agents' and ball' position during the experiment. In (a) agents only used current ball position in learning their formation strategy. As it is
shown in this figure, when each agent moves toward the ball, some vacant places created in different parts of the field, especially in defense, which adversely affects the team's overall aim of not receiving a goal. In (b) each agent uses a strategy function based on current position of the ball and all of other agents. This led to instability. (c) Shows the team's performance using modular scheme. As it is shown, the team's behavior is well coordinated via having some information about a leader's position(considering observation and communication delay will lead to a negligible more error). In (d) each agent uses a formation strategy function which involves all the features considered in modular scheme (even indirectly via a leader's) directly. As it is clear, agents' coordination and the quality of formation strategy under this strategy is lower comparing to the (c). For example, the bad performance of the left defender might be because of the absence of any relation between features (the ball and the other two defenders) as well as inadequate training data.
In fact, it can be concluded that, the modular scheme is helpful for learning formation strategy in soccer simulation environment. The resulting formation strategy is stable, coordinated and with good performance.
The dynamic position assignment has been used for the 'Mark' context. Similar to [26] the learned formation strategy function for each player only determines positions where the opponent's movements can be under control. Other teammates mark other opponents using similar function. The resulting marking positions form the set needed in dynamic position assignment method. Some extra information like position of teammates (with some error) is also available to this method. A linear function as the method's weight function has been defined for each specific position (usually an opponent) using the value of features like the distance between the team's agents to the opponent position, distance between that specific position to the goal, distance between the position to the ball and the priority of the position (how much the position is dangerous). The weight of each factor in the aforementioned function is calculated using PSO optimization method in automated scenarios. This method resulted in a proper marking in which each agent marked an opponent without any inference with other agents. The most dangerous opponent was also marked in minimum time. All this performance has been obtained under the presence of noise in the environment, error in approximations and partial observation. Agents also were not being able to communicate with each other to share any information. Consequently, using dynamic position assignment in other contexts will cause the agents to swap their positions intelligently while doing tasks not defined in formation strategy, like intercepting a moving ball.
As a conclusion, using the proposed framework for the task of formation strategy in a team of agents in the soccer simulation environment resulted in a proper formation strategy and increased coordination among agents.
## 6.1 Approximating Formation Strategy Function using Neural Networks
In order to approximate the formation strategy functions with neural networks based on the features which are directly involving, the position of the ball which is represented by a couple ( , ) is used as input feature set. The position of B B X Y the ball carries lots of information about the game state. Learning formation strategy function as a mapping from the position of the ball to target position for an agent can increase the coordination among agents, because the ball's position is a prominent global feature. Neglecting the fact that ball position is not a sufficient input feature for learning formation strategy as mentioned before, the analysis of the formation strategy function approximated by neural networks and a simple feature set like ball position sheds some interesting results. An approximation for formation strategy function according to another set of input features has similar results.
A separate neural network has been used for each agent to map the position of the ball to its target position using training data. In order to evaluate the approximation error, the approximation error of the formation strategy function defined in section 5 has been used. In addition the maximum error has been defined as the average maximum approximation error of all agents over the test data. For finding the proper neural network's structure, parameters and the size of data-set to train a neural network, some experiments are conducted considering special cases such as using early-stopping algorithm to avoid over-fitting. Therefore, the effect of increasing the number of neurons in the hidden layer and increasing the number of data on the average error and the maximum error are examined. In order to increase reliability, the results have been averaged over several experiments. The neural network structure and parameters have been kept constants for different agents to make this approach applicable to large environments with many agents.
(b)
Figure 8. The effect of increasing the number of hidden layer's units on
Average error (b) Maximum error
In figure 8, the effect of increasing number of neurons in hidden layer on average and the maximum error on data-set 1 (provided by an experienced expert) is depicted. With the increase of number of neurons in hidden layer, the error first decreases, then remains steady after a certain point because of using earlystopping algorithm to avoid over-fitting. According to this figure, the proper number of neurons for the hidden layer is 36. When the data-set 2 used for learning the formation strategy function, the average and maximum error has been 300% and 670% more than the data-set 1 respectively. This shows the amount of error exists in this data-set which is not provided by an expert. data-set 2 has not been used in the following experiments.
Figure 9. The effect of increasing the number of samples
Figure 9 shows the effect of increasing the number of samples in training data-set on learning formation strategy function. As it is depicted, the average error has been decreased with the increase in the number of samples. The slope of this decrease is low after a certain point. The maximum error follows a similar trend. According to figure 9, 764 samples of the training data are sufficient for approximating the formation strategy function. The average and maximum error using calculated optimized parameters has been 0.72 and 0.64 meters respectively.
In addition to error over test data, two other factors are important in approximating formation strategy function. The 'smoothness' which increases while number of direction changes in each agent's movement's decreases and the robustness to noise which is the consequence of observation error in a nondeterministic environment.
Figure 10. Examination of formation strategy's smoothness
Figure 10 shows the smoothness of the learned formation strategy function. In this experiment, the ball has been placed on a random initial position and started moving with a random velocity vector. While the ball was moving, agents followed their formation strategy function. In this experiment, a noise with variance of 0.15 meters has been added to the position of the ball in each cycle. To achieve better results, the experiments have been repeated for 100 times. The average change in agents' angle of movement during the experiment has been 12.62 degree with the standard deviation of 25.37 without adding noise to the ball's position. These values have been increased to 19.9 and 30.0 respectively after noise added to the ball's position. The average total distance that all agents moved in each cycle has been 0.64 meters with standard deviation of 0.53 meters without noise and 0.63 meters with standard deviation of 0.51 meters with noise. This shows the low effect of noise on the total distance. This experiment shows that the noise in position of the ball affects the angle of movement. It can be also stated that the high changes in angle of movement happened when the small distances has been traveled. According to these results, it can be seen that the resulting formation strategy function has a good smoothness in the soccer simulation environment. This is because of good training data, as well as continuity in the approximated formation strategy function.
Table 1. The effect of noise on average error and errors' variance
| Noise Variance | Average Error | Errors' Variance |
|------------------|-----------------|--------------------|
| 0 | 0.72 | 0.64 |
| 0.15 | 0.73 | 0.642 |
| 0.3 | 0.76 | 0.652 |
| 0.45 | 0.78 | 0.662 |
| 0.6 | 0.82 | 0.665 |
In order to analyze the robustness, a Gaussian noise with different variances has been added to position of the ball. Then the error of the resulting agents' positions has been compared to the target positions in the test data. This experiment can show the effect of noise on the output of the formation strategy function. Table 1 shows that the noise has a low effect on average error and the standard deviation. The experiments show that the resulting formation strategy is both smooth and robust to noise.
Using clustering with feed-forward neural networks for each cluster resulted in a performance similar to the networks without clustering. This method not only did not increase network's accuracy but also decreased the smoothness of the
formation strategy function in boundaries. In addition, this method has more learning parameters which leads to slower learning speed, higher execution time and higher memory consumption.
In order to demonstrate another capability of the proposed method for formation strategy, learning has been done based on observing another set of agents. To achieve this, a set of training data has been prepared by observing the behavior of agents who followed SBSP algorithm [35] as their formation strategy. Their formation strategy function has been approximated with the error of 0.031 and standard deviation of 0.032 in a noise-free environment. It can be claimed that, the proposed method is able to learn different formation strategy methods.
## 7. Conclusion
In this paper, a framework for learning formation strategy was proposed. The framework possesses a diverse variety of features to address different issues associated in formation strategy behavior of agents in many multi-agent systems with restricted environment.
The four main parts of the framework are context based reasoning, modular scheme, dynamic position assignment method, and formation strategy function approximation. The integration of these parts conveniently generates a complex formation strategy algorithm for a multi-agent system.
Context based reasoning reflects the variations of environment status by changing its active context. Modular scheme provides an exhaustive organization of agents and primes the basis for learning formation strategy function. Formation strategy function approximation estimates the formation strategy function of agents according to a data-set and the modular scheme specifications. Dynamic position assignment method is able to dynamically specify the role of each agent during execution time to increase the performance of a system.
Finally, the framework was completely examined in a complex multi-agent system to demonstrate its capabilities. The results are very promising.
## 8. Acknowledgments
The authors thank Mohammad Mehdi Korjani for his valuable comments and sharing his knowledge.
## 9. References
[1] S. Liu, D. Sun, Ch. Zhu, W. Shang, A dynamic priority strategy in decentralized motion planning for formation forming of multiple mobile robots, in: IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 2009, pp. 3774-3779.
- [2] Ch. Xiang, A.G. Aghdam, A Two-Stage Formation Flying Strategy to Reduce the Mission Time, in: IEEE International Conference on System of Systems Engineering, San Antonio, TX, 2007, pp. 1-4.
- [3] Y. Wang, W. Yan, W. Yan, A leader-follower formation control strategy for AUVs based on line-of-sight guidance, in: International Conference on Mechatronics and Automation, Changchun, 2009, pp. 4863-4867.
- [4] W. Ren, Consensus based formation control strategies for multi-vehicle systems, in: American Control Conference, USA, 2006, pp. 14-16.
- [5] L. Sabattini, C. Secchi, C. Fantuzzi, Potential based control strategy for arbitrary shape formations of mobile robots, in: in: IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 2009, pp. 3762-3767.
- [6] W. Ren, Consensus strategies for cooperative control of vehicle formations, Control Theory & Applications, Volume 1 (2) (2007) 505-512.
- [7] W. Ding, G. Yan, Z. Lin, Y. Lan, Leader-following formation control based on pursuit strategies, in: IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 2009, pp. 4825-4830.
- [8] A. Gil-Pinto, P. Fraisse, R. Zapata, Decentralized strategy for car-like robot formations, IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 2007, pp. 4176-4181.
- [9] Y. Yang; Y. Tian, Swarm robots aggregation formation control inspired by fish school, International Conference on Robotics and Biomimetics, Sanya, 2007, pp. 805-809.
- [10] F. Cattivelli, A.H. Sayed, Self-organization in bird flight formations using diffusion adaptation, IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing, Aruba, Dutch Antilles, 2009, pp. 49-52.
- [11] B. Wu, E.K. Poh, D. Wang, G. Xu, Satellite formation keeping via real-time optimal control and iterative learning control, IEEE Aerospace Conference, 2009, Big Sky, MT, pp. 1-8.
- [12] F. Wang, A. Nabil, A. Tsourdos, Centralized/decentralized control for spacecraft formation flying near Sun-Earth L2 point, IEEE Conference on Industrial Electronics and Applications, Xi'an, 2009 pp. 1159-1166.
- [13] D.P. Scharf, F.Y. Hadaegh, S.R. Ploen, A survey of spacecraft formation flying guidance and control. Part II: control, American Control Conference, Boston, MA, USA , 2004, pp. 2976- 2985.
- [14] Z. Wang, Y. He, J. Han, Multi-Unmanned Helicopter formation control on relative dynamics, International Conference on Mechatronics and Automation, Changchun, China, 2009, pp. 43814386.
- [15] H. Yamaguchi, A cooperative hunting behavior by mobile robot troops, IEEE International Conference on Robotics and Automation, Leuven , Belgium, 1998, pp. 3204-3209.
- [16] A.S Brandao, M. Sarcinelli-Filho, R. Carelli, T.F Bastos-Filho, Decentralized control of leader-follower formations of mobile robots with obstacle avoidance, IEEE International Conference on Mechatronics, Malaga, 2009, pp. 1-6.
- [17] T. Balch, M. Hybinette, Behavior-based coordination of large-scale robot formations, International Conference on MultiAgent Systems, Boston, MA , USA, 2000, pp. 363364.
- [18] R.C. Arkin, Behavior-Based Robotics, MIT Press, Cambridge, 1998.
- [19] J. Ghommem, F. Mnif, G. Poisson, N. Derbel, Nonlinear Formation Control of a Group of Underactuated Ships, OCEANS-Europe, Aberdeen, 2007, pp.1-8.
- [20] M. Uchiyama, P. Dauchez, A symmetric hybrid position/force control scheme for the coordination of two robots, IEEE International Conference on Robotics and Automation, Philadelphia, PA , USA, 1988, pp. 350-356.
- [21] A.J. Gonzalez, J. Nguyen, S. Tsuruta, Y. Sakurai, K. Takada, K. Uchida, Using contexts to supervise a collaborative process, Systems, Man and Cybernetics, Philadelphia, PA, USA, 2008, pp. 2706-2711.
- [22] J. Carbonell, R. Michalski, T. Mitchell, Machine Learning: An Artificial Intelligence Approach, Morgan Kaufmann Publishers, Los Altos, 1986, CA, Vol. 2, pp.167-192.
- [23] H. Fernlund, A.J. Gonzalez, M. Georgiopoulos, R.F. DeMara, Learning tactical human behavior through observation of human performance, Systems, Man, and Cybernetics, Part B: Cybernetics, Volume 36 (1) (2006) 128-140.
- [24] The RoboCup Soccer Simulator, http://sserver.sourceforge.net/
- [25] J. Gmytrasiewicz, P. Doshi, A Framework for Sequential Planning in Multi-Agent Settings, Journal of Artificial Intelligence Research, Volume 24 (1) (2005) 49-75.
- [26] M. Norouzitallab, A. Javari, A. Norouzi, S.M.A Sallehizadeh, Nemesis Team Description 2010, In Proceeding of Robocup, Singapore, 2010.
- [27] S. Kalyanakrishnan, P. Stone, Learning Complementary Multiagent Behaviors: A Case Study, Lecture Notes in Computer Science, Volume 5949 (1) 2010 153-165.
- [28] Y. Duan, B. Xia Cui, X H. Xu, A Multi-Agent Reinforcement Learning Approach to Robot Soccer, Artificial Intelligence Review, Volume 38 (1) (2012) 193-211.
- [29] M. Riedmiller, T. Gabel, J. Knabe, H. Strasdat, Brainstormers Team Description 2005, In Proceeding of Robocup, Osaka, Japan, 2005.
- [30] G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals, and Systems, Volume 2 (5) (1989) 303-314.
- [31] M.T. Hagan, M.B. Menhaj, Training feedforward networks with the Marquardt algorithm, IEEE Transactions on Neural Networks, Volume 5 (6) (1994) 989-993.
- [32] R. Hecht-Nielsen, Theory of the backpropagation neural network, Neural Networks for Perception: Computation, Learning, Architectures, Volume 2 (1) (1992) 65-93.
- [33] I. Erev, A E. Roth, Multi-agent learning and the descriptive value of simple models, Artificial Intelligence, Volume 171 (7) (2007) 423-428.
- [34] G. Weiss, Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence, The MIT Press, 2000.
- [35] L.P Reis, N. Lau, E. Oliveira, Situation based strategic positioning for coordinating a team of homogeneous agents, Lecture Notes In Computer Science, Volume 2103 (1) (2001) 175197.
- [36] J. Siek, L.Q. Lee, A. Lumsdaine, The Boost Graph Library User Guide and Reference Manual, Addison-Wesley Professional, 2001.
- [37] H.K. Fernlund, A.J. Gonzalez, An approach towards building human behavior models automatically by observation, Technical Report, Intelligent Systems Laboratory, Orlando, FL, 2001.
- [38] B.S. Stensrud, A.J. Gonzalez, Context-Based Reasoning: A Revised Specification, Florida Artificial Intelligence Research Society Conference, AAAI Press, 2004.
- [39] H.W. Kuhn, The Hungarian method for the assignment problem, Naval Research Logistics Quarterly, Volume 2 (1-2) (1955) 83-97.
- [40] J. Sjoberg, L. Ljung, Overtraining, Regularization, and Searching for Minimum in Neural Networks, Technical Report, Department of Electrical Engineering, Linkpoing University, 1992.
- [41] S. Nadarajah, K. Sundaraj, A Survey on team Strategies in Robot Soccer: Team Strategies and Role Description, Artificial Intelligence Review, (DOI: 10.1007/s10462-011-9284-0) 2011.
- [42] L. Michael, Learning from Partial Observations, International joint conference on Artificial intelligence, San Francisco, CA, USA, 2007, pp. 968-974.
- [43] Y. Shoham, R. Powers, T. Grenager, If multi-agent learning is the answer, what is the question?, Artificial Intelligence, Volume 171 (7) (2007) 365-377.
- [44] Y.D. Hauwere, P. Vrancx, A. Nowe, Learning Multi-agent State Space Representation, Proceeding of the 9th International Conference on Autonomous Agents and Multiagent Systems, Toronto, Canada, 2010, pp. 715-722.
- [45] R. Asadi, N. Mustapha, N. Sulaiman, A Framework for Intelligent Multi-Agent System Based Neural Network Classification Model, International Journal of Computer Science and Information Security, Volume 5 (1) (2009), 168-174.
- [46] Y. Lasheng, J. Zhongbin, L. Kang, Research on Task Decomposition and State Abstraction in Reinforcement Learning, Artificial Intelligence Review, Volume 38 (1) (2012) 199-127. | null | [
"Mehrab Norouzitallab",
"Valiallah Monajjemi",
"Saeed Shiry Ghidary",
"Mohammad Bagher Menhaj"
] | 2014-08-01T01:29:08+00:00 | 2014-08-01T01:29:08+00:00 | [
"cs.RO",
"cs.LG",
"cs.MA"
] | A Framework for learning multi-agent dynamic formation strategy in real-time applications | Formation strategy is one of the most important parts of many multi-agent
systems with many applications in real world problems. In this paper, a
framework for learning this task in a limited domain (restricted environment)
is proposed. In this framework, agents learn either directly by observing an
expert behavior or indirectly by observing other agents or objects behavior.
First, a group of algorithms for learning formation strategy based on limited
features will be presented. Due to distributed and complex nature of many
multi-agent systems, it is impossible to include all features directly in the
learning process; thus, a modular scheme is proposed in order to reduce the
number of features. In this method, some important features have indirect
influence in learning instead of directly involving them as input features.
This framework has the ability to dynamically assign a group of positions to a
group of agents to improve system performance. In addition, it can change the
formation strategy when the context changes. Finally, this framework is able to
automatically produce many complex and flexible formation strategy algorithms
without directly involving an expert to present and implement such complex
algorithms. |
1408.0059v1 | ## Measurement of photon correlations with multipixel photon counters
## Dmitry Kalashnikov, and Leonid Krivitsky*
Data Storage Institute, Agency for Science Technology and Research (A-STAR), 5 Engineering Drive I, 117608 Singapore *Corresponding author: Leonid\[email protected]
Development of reliable photon number resolving detectors (PNRD), devices which are capable to distinguish 1,2,3.. photons, is of a great importance for quantum optics and its applications. A new class of affordable PNRD is based on multipixel photon counters (MPPC). Here we review results of experiments on using MPPCs for direct characterization of squeezed vacuum (SV) states, generated via parametric downconversion (PDC). We use MPPCs to measure the second order normalized intensity correlation function ( ) and directly detect the two-mode squeezing of SV states. We also present a method of calibration of crosstalk probability in MPPCs based on measurements of coherent states.
## 1. Introduction
Multiphoton entangled states hold the promise to advance both practical and fundamental aspects of future quantum technologies. They play an important role in linear optical quantum computation [1-3], quantum metrology [4], imaging [5, 6], and tests of fundamentals of quantum mechanics [7]. Accurate measurement of such states is also of crucial importance for security analysis in quantum cryptography [8], and in implementation of quantum teleportation [9] and entanglement swapping [10] protocols.
Two major challenges in experimental studies of multiphoton entangled states are their generation and measurement. The first challenge can be addressed, for example, by using pulsed laser with high-peak power values in various nonlinear optical processes, possibly enhanced by using cavities and/or nonlinear waveguides. The detailed analysis of the generation problem is outside the scope of this paper, and we direct readers to detailed reviews on this subject [11, 12]. The measurement problem will be addressed here in greater details. We consider direct detection of multiphoton states by using specialized photon number resolving detectors (PNRD) -devices where the produced outcome corresponds to the number of photons in an optical pulse.
Conventional single photon detectors, such as avalanche photodiode (APD) and photomultiplier tubes (PMT), discriminate only between 'zero photons' and 'one photon or more' because of the 'dead time' effect [13]. The straightforward way to overcome this limitation relies upon splitting the incoming optical pulse into different spatial (or temporal) modes, and detection of single photons in each mode by independent APDs [14-16]. The photon number distribution is then derived from the joint statistics of APD responses. Although a remarkable resolution of up to 9 photons was demonstrated with temporal multiplexing, future expansion of such schemes is limited by the necessity to use more beamsplitters and photodetectors, which makes such schemes bulky and challenging to operate. Moreover, since the detection of multiphoton events requires simultaneous firing of several detectors, their non-unity quantum efficiency leads to the loss of a large fraction of multiphoton events.
The next approach is based on using cryogenic detectors, such as visible-light photon counters (VLPC) and transition edge sensors (TES) [17-22]. These devices have moderate photon number resolution (up to 7-9 photons), low noise (<1 c/s), and high quantum efficiency (~80%). One of the approaches relies upon integration of several niobium nitride superconducting nanowire single photon detectors into a waveguide, which results in low jitter and fast recovery time [23]. However, the main limitation of the mentioned above technologies is the requirement of cryogenic cooling (down to 0.1K for TES, 6K for VLPC, and below 10K for superconducting nanowire), which is expensive and demands highly skilled operation.
Another class of devices can be used as PNRD without the necessity of cryogenic cooling. Here we mention a hybrid photomultiplier tube, which demonstrates discrimination of up to 3 photons [24]. A resolution of up to 5 photons was demonstrated with a single InGAs detector by careful characterization of the early stage of the avalanche [25]. Another approach is based on SiAPD with a strongly modulated lateral electric field profile realized by modulated doping profile of p-n junctions [26]. The high speed and discrimination of up to 4 photons has been demonstrated, but the realized device has comparatively low quantum efficiency (~8 %) and exhibits the space-charge effect, which prevents resolution of higher number of photons.
Recently a new approach for realization of the PNRD was suggested based on silicon multipixel photon counters (MPPCs) [27]. In MPPC several hundred silicon APDs, referred to as pixels, are integrated into a single chip of several millimeter size, see Fig.1a,b. Each pixel outputs a pulse signal when it detects a photon. Signals from all the fired pixels are summed at the output of the MPPC. The chip of the MPPC is illuminated by a diffused light in order to minimize the probability of a single pixel to be hit by several photons. Thus the amplitude of the MPPC output is, in an ideal case, equivalent to the number of detected incident photons, see Fig.1c. The concept of MPPC is in some sense similar to the traditional approach of separating an incoming pulse into multiple spatial modes and detection by independent APDs, which is similar to the concept of single photon CCD cameras (EMCCD, ICCD). However, it provides striking advantages in compactness, ease-of-use, photon-number resolution, and cost. Currently, MPPCs find their applications in quantum optics experiments [28-33], as well as in highenergy physics experiments as photosensors for scintillate detectors [34].
Fig.1 (a) Principle of MPPC operation. A diffused light is impinging on the MPPC matrix, consisting of few hundreds of APD pixels. Signals from all the pixels are summarized at the output. (b) Photo of the MPPC chip with 400 pixels. The scale bar corresponds to 1.5 mm. (c) Example of a histogram of the MPPC output for coherent state. Different peaks correspond to the resolution of photon numbers.
The major drawbacks of MPPC are relatively high dark counts, and the optical crosstalk among pixels. The high dark count rate is due to a large number of individual APDs in the MPPC matrix, with each of the APD gives its contribution to the dark noise, contributing a bit to the dark noise. The dark noise can be significantly reduced by cooling MPPC and providing time gating to the signal. In contrast, the crosstalk requires more elaborated attention. The crosstalk occurs because secondary photons, which are re-emitted during the avalanche in the pixel, may trigger simultaneous additional photon counts in neighboring pixels [35, 36]. Since the crosstalk happens almost simultaneously with the detection event, it is undistinguishable from the actual counts, and thus its impact requires accurate theoretical modelling and characterization.
In this paper we review experiments on using MPPCs for characterization of various entangled multiphoton states. Primary objects of our studies are squeezed vacuum (SV) states, generated via parametric downconversion (PDC), which is the nonlinear process producing pairs of strongly correlated photons. We explore different regimes of PDC and measure the normalized second-order intensity correlation function of SV states, and also directly detect the two-mode squeezing. We also present a novel method of calibration of MPPC crosstalk probability based on the measurement of the correlation function of coherent light.
The paper is organized as follows. In Section 2 we derive the algorithm of obtaining the normalized second-order correlation function ( ) from the MPPC data, introduce a model of the MPPC crosstalk, and model the MPPC saturation. In Section 3 we describe an experiment, where we use the MPPC to measure of SV states with much less than one photon per pulse. In Section 4 we present a method of calibration of the crosstalk probability of MPPCs based on measurements of coherent states, and test it with several commercially available devices. In Section 5 we describe an experiment, where MPPCs are used for direct observation of the two-mode squeezing of relatively bright SV states with up to 10 photons per pulse. The results are summarized in the Conclusions section.
## 2. Theoretical modelling of the MPPC
## 2.1 Measurement of correlation functions
Characterization of various states of light in quantum optics is conveniently performed in terms of normalized Glauber's correlation functions (CFs) [37]. The th order CF at zero time delay is defined as
$$g ^ { ( l ) } = \langle a ^ { + l } a ^ { l } \rangle / \langle a ^ { + } a \rangle ^ { l } \text{ \quad \ \ } ( 1 )$$
Where are photon creation and annihilation operators, respectively. The remarkable feature of normalized CFs is that they are insensitive to optical losses and finite efficiencies of the detectors, which may be not always precisely known in experiments [38]. Here we focus on the analysis of the second-order CF, .
Conventionally is measured in a Hanbury-Brown and Twiss (HBT) setup consisting of two single photon detectors with their outputs addressed to a coincidence circuit. Let be the measured number of coincidences of photocounts of two detectors, and is the measured number of photocounts of individual photodetectors, then is given by:
$$( 2 )$$
Let us now consider measurement of using the MPPC. We can treat each pair of pixels in the MPPC matrix as a single HBT setup. The number of such HBT setups is equal to the number of -combination of : , where is the total number of pixels in the matrix (typically ). Let be the number of detected photon events ( ). The total number of pairwise coincidences is given by ∑ , where is the number of 2-combinations in , which describes the contribution of a detected photon event into twofold coincidences. The total amount of photocounts is given by ∑ . In analogy with Eq.(2), is calculated as a ratio of the number of pairwise coincidences per one HBT setup to the squared total number of detected photons per one detector (pixel):
$$g ^ { ( 2 ) } = \left ( \frac { N _ { C o i n c / ( m ^ { 2 } / _ { 2 } ) } } { N _ { \tau \sim \tau \sim 1 } / m ^ { 2 } } \right ) = 2 \sum _ { k = 2 } ^ { \infty } C _ { 2 } ^ { k } \, N _ { k } / ( \Sigma _ { k = 1 } ^ { \infty } k N _ { k } ) ^ { 2 } \quad ( 3 )$$
Thus, once the histogram of detected -photon events is obtained in the experiment, see Fig. 1c, can be directly calculated from Eq.(3). Moreover, any spatially resolving single-photon detector can be used for these measurements, such as, for instance, single-photon sensitive charge coupling devices (EMCCD, ICCD) [39, 40].
## 2.2 Modelling the crosstalk in MPPC
Let us now take into account the MPPC crosstalk, which is introduced through the crosstalk probability for one pixel The model under consideration is restricted to the second order crosstalk under the assumption of low mean photon number of the detected light, and the following condition for the crosstalk probability has to be fulfilled . One can express the number of -photon events with crosstalk probability through the corresponding number of events in the absence of crosstalk as follows:
$$\varepsilon ^ { 2 } N _ { 1 }, \quad \quad \ \ ( 4 a )$$
Where the second term on the right corresponds to the number of single photon events converted to two-photon events, and the third term is the number of single photon events converted to 3photon events.
$$N _ { 2 } \,, \quad ( 4 b )$$
Where the second term on the right corresponds to the number of two-photon events converted into three-photon events, the third term arises due to the impact from one-photon events, and the fourth term describes two-photon events influenced by the double crosstalk. Finally,
$$( 4 c )$$
In Eq.(4c) the second term on the right is the number of photon events being converted by crosstalk into photon events, and the third term is the number of photon events that gained an extra photon due to crosstalk to become photon events; the fourth term represents the number of photon events converted into -photon events due to double crosstalk, and the fifth term is the number of photon events which contributed to photon events, also due to double crosstalk.
Assuming the crosstalk model mentioned above, the numerator and the denominator of Eq.3 in the presence of the crosstalk take the form:
$$\underset { \colon o i n c, C T } { \colon } & = ( 1 + 2 p + 4 p ^ { 2 } ) \sum \nolimits _ { k = 2 } ^ { \infty } C _ { 2 } ^ { k } \, N _ { k } + \\ & \quad p ( 1 + 3 p ) \sum \nolimits _ { k = 1 } ^ { \infty } k \, N _ { k }, \quad ( 5 a )$$
$$\dot { \ } o t a l, C T = ( 1 + p + 2 p ^ { 2 } ) \sum _ { k = 1 } ^ { \infty } k \, N _ { k }. \quad ( 5 b )$$
From Eqs.(3, 5a, 5b) takes the following form:
$$g ^ { ( 2 ) } \left ( N _ { T o t a l, C T } \right ) = A g _ { 0 } ^ { ( 2 ) } + B \frac { 1 } { N _ { T o t a l, C T } }, \quad ( 6 )$$
where ∑ ∑ is the initial second order correlation of light, and
$$\frac { r ^ { 4 p ^ { - } } } { \psi ^ { 2 \vee 2 } }, \quad \ \ B \equiv \frac { r ^ { p ( 1 + 3 p ) } } { 1 + \psi + 2 \psi ^ { 2 } }.$$
There are two main conclusions followed from Eq.(6). First, the measured by the MPPC, is different from the of the incident light by a normalization coefficient and an additive term scaling as . Second, the crosstalk probability can be easily measured using some light source with known , for instance coherent light with =1. Both of these aspects will be addressed experimentally in Sections 3 and 4.
## 2.3 Modelling saturation in MPPC
In case when beams of relatively high intensities are considered, saturation of the MPPCs has to be taken into account by assuming that each MPPC can only resolve up to photocounts, given by the number of illuminated pixels. When more than photons incident on the detector, not more than photocounts will be produced. For modeling of a realistic MPPC, we follow [28, 30], where the loss and crosstalk are considered as Bayesian processes. Let us denote 〈 ̂〉 as the mean number of photons impinging on the detector, as a crosstalk probability , and as a quantum efficiency of each MPPC pixel, which also accounts for losses in an optical system. The positiveoperator valued measure (POVM) effecting the measurement of photons with crosstalk with one MPPC, for is:
$$\tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde \tilde { \tilde \tilde { \tilde { \tilde { \tilde { \tilde \tilde \tilde { \tilde { \tilde { \tilde { \tilde \tilde \tilde \tilde \tilde \tilde \tilde { \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \ tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde \tilde
} .$$
where is the number of -combinations of . The finite quantum efficiency of detection of incident photons is described by the following POVM:
where is the number of -combinations of . By combining the two, a set of POVMs that would predict the outcome of the MPPC with loss, saturation and crosstalk is obtained:
$$\Pi _ { N } = \begin{cases} \sum _ { n = [ N / 2 ] } ^ { N } \sum _ { k = n } ^ { \infty } B _ { n, k, N } | k \rangle \langle k |, \ N < N _ { m a x } \\ I - \sum _ { k = 0 } ^ { N _ { m a x } } \Pi _ { k } \end{cases}, \ N = N _ { m a x }$$
where
$$\begin{smallmatrix} 0 \\ 0 \\ 0 \end{smallmatrix}$$
The -moment operator of the photocount is given by
$$\widehat { N } ^ { m } = \Sigma _ { N = 0 } ^ { N _ { m a x } } N ^ { m } \Pi _ { N }. \text{ \quad \ \ } \text{(8)}$$
Eq.(8) allows calculation of a mean and a variance of photocounts, which will be used in Section 5 to reveal suppression of intensity fluctuations of two-mode squeezed vacuum states.
## 3. Assessing photon bunching with MPPC
In this section we describe an experiment, where we use the MPPC for measurements of the second order correlation function (CF) of coherent and squeezed vacuum (SV) states. Let us consider the PDC in frequency degenerate collinear regime. In this case the signal and idler photons are indistinguishable, and the state produced is a single-mode squeezed vacuum, with the state vector given by a superposition of evennumber Fock states [41]:
$$| \psi \rangle = \Sigma _ { n = 0 } ^ { \infty } C _ { 2 n } | 2 n \rangle$$
The index is related to the ensembles of modes, accessed via multimode detection [41]. The state vector of a coherent state is
$$| \psi _ { c o h } \rangle = \Sigma _ { n = 0 } ^ { \infty } C _ { n } | n \rangle \text{ \quad \ \ } ( 1 0 )$$
The probability amplitudes in Eq.(9, 10) obey the Poissonian distribution, with | | √ 〈 〉 〈 〉 and | | √ 〈 〉 〈 〉 where 〈 〉 〈 〉 , are the mean photon numbers, respectively. From Eqs.(1, 9, 10), one can show that for the case of multimode detection, the measured 〈 〉 for the SV state, where is the inverse number of detected frequency and spatial modes, while for the coherent state. However, as one can see from Eq.(6), the crosstalk modifies the initial second-order correlation function.
The detailed description of the experimental setup is presented elsewhere [31]. In brief, a ns-pulsed Nd:YAG laser at 266 nm is used to pump a BBO crystal, where PDC occurs, see Fig.2. Collinear PDC photons at 532 nm are directed to a MPPC module (Hamamatsu C10751-02, 400 pixels). The MPPC is sealed into a custom-made housing with a coated optical window and is thermoelectrically cooled down to -4.5ºC to reduce the dark noise. A digital oscilloscope is used to capture the analogue output from the MPPC and plot the histogram of its amplitude. The results of the measurements on the coherent state are obtained with a pulsed laser at 532 nm. The MPPC dark noise and ambient luminescence of the setup are measured by extinguishing PDC by tilting the polarization of the pump at 90 degrees by a HWP. The noise is estimated to be 0.001 photon/pulse, and it is subtracted from the PDC signal. The measurement time is increased for the values of photocounts in the range of less than 0.01 photon/pulse in order to mitigate the statistical impact of the noise.
The results of the MPPC measurements are compared with the ones obtained by a traditional HBT experiment, by using a 50/50 beam splitter and two APDs, whose outputs are addressed to a coincidence circuit.
Fig.2 Schematic of the experimental setup for measurement of photon bunching. PDC in collinear regime is generated in a BBO crystal, which is pumped by a pulsed UV-laser (pump). PDC photons (signal and idler) with the same wavelengths impinge onto the MPPC. is inferred from the MPPC response histogram using Eq.(3).
First, measurements are carried out with the MPPC by measuring coherent states produced by the laser. The dependence of on the mean number of photocounts, calculated using Eq.(3), is shown in Fig.3a (black dashed trace, squares). We consider the Poissonian statistics of photocounts. The standard deviation of each photon-number component is calculated as the square root of the total number of counts. The standard deviations values are propagated according to Eqs.(3, 6) for calculation of corresponding error bars for the crosstalk probability and . The curve is fitted by Eq.(6) with being the only fitting parameter (here we consider only linear terms in ). The value of the crosstalk probability is found to be . As shown in Fig.3a, although excess two-photon correlations are not expected for the coherent state ( ), the dependence of CF obtained by the MPPC exhibits strong photon bunching due to the crosstalk.
Fig.3 (a) Dependence of on the mean number of photocounts per pulse, obtained via MPPC for the coherent state (black dashed trace, squares) and for the single-mode SV state (red solid trace, circles). The curves are experimental fits. (b) Comparison of the dependence of the inferred on the mean number of photocounts per pulse for singlemode squeezed vacuum, measured by the MPPC (red solid trace), with the one obtained with a traditional HBT setup (black dashed trace, squares).
Next, measurements of the single-mode SV state are made. Analogous to the previous case, the dependence of is calculated from the MPPC amplitude histograms according to Eq.(3). The result is shown in Fig.3a (red solid trace, circles) and fitted by Eq.(6). From the obtained results it is clearly seen that on top of the crosstalk reveals additional two-photon correlations, which are attributed to the two-photon nature of the SV.
In order to infer the actual of the SV state from the MPPC measurements, Eq.(6) is used with the value of obtained from the earlier measurements of the coherent state. The resulting curve is shown in Fig.3b (red solid trace). The results are compared with the ones obtained in the HBT experiment, which are also shown in Fig.3b (black dashed trace, squares). The results of the measurements with MPPC and HBT setup show reasonable agreement. Slight deviation is most likely caused by inaccuracies in adjustment of relative quantum efficiencies of MPPC and APDs.
The obtained results demonstrate that with a proper account for the crosstalk, MPPC detectors can be used for measurements of the second-order correlation function. It is worth mentioning that a similar algorithm can be used for the measurement of higherorder correlation functions by using just a single MPPC [31].
## 4. Calibration of MPPC crosstalk using coherent states
As it was demonstrated in the previous section, the crosstalk modifies the initial statistics of photons, and that is why its accurate calibration is needed. A widely implemented approach is based on the measurement of the photocount distribution of dark noise [34, 42]. Assuming that dark counts obey a Poisson distribution, one can calculate the expected mean number of dark counts 〈 〉 . The probability of the crosstalk is calculated as the difference between the number of single photon events expected from the Poisson distribution with the mean 〈 〉 and the actual number of single photon events observed for the dark noise. This approach allows calibration of the crosstalk without much effort. However, the method is highly sensitive to statistical errors for the case of low-noise detectors, which are of most practical interest.
Other methods rely on statistical modeling of the measured photon statistics of well characterized light sources and solving an inverse problem. However, in the analysis either the probability of crosstalk has been analyzed as one of several fitting parameters [30] or the assumption has been made that for a given pixel only one crosstalk event could occur, which may not always be the case [28, 31, 43].
Here we develop an alternative approach which is based on the measurements of the second order correlation function. From Eq.(6) it follows that the crosstalk probability can be found from measurements of the correlation function for some source with known statistics, such as, a coherent source with . Remarkably, since is insensitive to optical losses, the method does not require a-priori knowledge of the quantum efficiency of the detector under test. Here we experimentally test the approach with several commercially available MPPCs.
We use a ns-pulsed Nd:YAG laser at 532 nm which provides a good quality coherent state ( ). The laser beam is attenuated by a variable filter and then impinges onto the MPPC, see Fig.4. Three different MPPC's (Hamamatsu, C10507-11-XXXU series) with 100, 400, 1600 pixels per chip with the corresponding pixel sizes of 100x100 μm 2 , 50x50 μm 2 , and 25x25 μm 2 are studied. The temperature of MPPC can be varied thermoelectrically from the room temperature down to -8ºC. The dark noise is measured by blocking the laser beam and then subtracted from the signal. The signals from MPPCs are digitized and used for evaluation of . The experimental dependence of is fitted with Eq.(6) with being a single fitting parameter.
Fig.4 Schematic of the experimental setup for calibration of the MPPC crosstalk probability. A pulsed laser at 532 nm is used as a source of coherent states. Attenuator allows controlling the average number of photons impinging onto MPPC. Three different MPPCs have been tested at different temperatures. Crosstalk probability is calculated from the measured using Eq.(6).
The resulting dependencies of for three different detectors at -4.5ºC are shown in Fig.5. The crosstalk probabilities , are obtained from fits of the experimental data which yield typical values of coefficient of determination (COD) 0.983-0.99. For the sake of future comparison with the conventional method of crosstalk calibration using dark noise [34, 42], we calculate the expression +2 , which is shown in Table 1.
Table 1. Experimental results of crosstalk calibration
| Pixel size, μm 2 | Dark counts/pulse | p+2p 2 | p DC |
|--------------------|---------------------|------------|-------------|
| 100x100 | 0.021 | 0.87±0.01 | 0.610±0.015 |
| 50x50 | 0.008 | 0.21±0.005 | 0.23±0.03 |
| 25x25 | 0.002 | 0.07±0.002 | 0.10±0.11 |
Fig.5 Dependencies of on the mean number of photocounts per pulse measured by the MPPC at -4.5ºC with 25x25 μm 2 (black squares, dashed line), 50x50 μm 2 (red circles, dotted line), and 100x100 μm 2 pixel size (blue triangles, solid line). Lines are fits to experimental data.
From the presented results it follows, that those detectors with larger pixel size have larger crosstalk. This result is qualitatively confirmed by other groups using alternative calibration techniques, and explained by the quadratic dependence of the crosstalk probability on the gain of the detector [44, 45]. The gain of each pixel is given by , where is the capacitance of the pixel and , where is the breakdown voltage and is the operational voltage [44]. Detectors with larger size of the pixels have larger capacitance, and consequently exhibit larger probability of crosstalk.
Additionally, the crosstalk is measured at four different temperatures of 25ºC, 12.5ºC, 5ºC, - 4.5ºC for the MPPC with 50x50 μm 2 pixel size. The estimated crosstalk probabilities are obtained similar to the above and shown in Fig.6 (red squares). The dependence of the crosstalk probability on the temperature is again attributed to the corresponding change of the gain [34]. The results are compared with those obtained by the method based on the measurement of dark counts. For each detector under test, the number of dark counts measurements is intentionally chosen to be ~40 % larger than the number of measurements of . Even in this case, the method based on the measurement of gives the crosstalk probability with significantly smaller experimental uncertainty, see Fig.6. Thus the method represents considerable practical interest for characterization of low-noise MPPCs.
Fig.6 Dependence of crosstalk probability found from measurements (red squares), and measured from the dark noise (black circles) on temperature for the MPPC with 50x50 μm 2 pixel size. Solid line is a fit with a quadratic function.
## 5. Measurement of two-mode squeezing with MPPC
So far we considered the use of MPPC in the measurements of squeezed vacuum (SV) states, in the regime of less than one photon per pulse. In this section we describe the application of the MPPC to the study of relatively bright SV states.
Let us consider PDC in frequency non-degenerate regime. The state vector, of the SV state, can be written in the Fock-state basis as follows [46]:
$$| \psi \rangle = \sum _ { n = 0 } ^ { \infty } C _ { n } \, | n \rangle _ { s } | n \rangle _ { i }, \text{ \quad \ \ } ( 1 1 )$$
where | ⟩ denotes the Fock-state of n photons in the th mode, where denote signal and idler modes respectively, and | | is the probability amplitude. Strong correlation between the photon numbers in the signal and idler modes results in the suppression of the variance of their difference below the classical limit [47, 48]. This effect, referred to as a two-mode squeezing, can be quantified by the noise reduction factor ( ), given by
$$\ell = \frac { V a r ( \widehat { N } _ { s } - \widehat { N } _ { l } ) } { \langle \widehat { N } _ { s } + \widehat { N } _ { l } \rangle }, \text{ \quad \ \ } \text{ (1 2)}$$
where ̂ and ̂ are the photocounts of the detectors in the signal and idler modes respectively, and 〈 ̂ 〉 stands for the mean value of an observable ̂ for a given quantum state. For the coherent light photon numbers in two modes are statistically independent and thus NRF is equal to unity. In the PDC process the number of photons in conjugated modes are strongly correlated and NRF is less than unity. Thus NRF measurements allow convenient characterization of multiphoton entangled states.
The two-mode squeezing can be studied with various types of photodetectors, depending on the photon fluxes of the PDC. At a moderate gain, when the SV state contains several photons per pulse, it is essential that the detector is able to resolve several simultaneously impinging photons. Here we use the MPPC to directly observe the two-mode squeezing of relatively bright SV state of up to almost 10 photons per pulse.
The variance of the difference of photocount numbers in signal and idler modes is given by
$$\begin{array} { c } \text{Var} \, \langle \widehat { N _ { s } } - \widehat { N _ { t } } \rangle = \langle \widehat { N _ { s } } ^ { 2 } \rangle - \langle \widehat { N _ { s } } \rangle ^ { 2 } + \langle \widehat { N _ { t } } ^ { 2 } \rangle - \langle \widehat { N _ { t } } \rangle ^ { 2 } - \\ 2 \langle \widehat { N _ { s } } \widehat { N _ { t } } \rangle + 2 \langle N _ { s } \rangle \langle N _ { i } \rangle \end{array}$$
From Eqs.(7, 8, 12, 13) the NRF can be calculated for any given two-mode state. Further we assume that two MPPCs, used in joint detection, have the same values of , , and . When 〈 ̂〉 the model yields for the coherent state which is greater than unity-the value expected for a lossy PNRD without the crosstalk. Thus, the effect of the crosstalk for small photon numbers results in the increase of the . Also, as 〈 ̂〉 for the SV state the model yields . Thus the difference in values for the coherent and SV states is equal to the quantum efficiency of the detectors differing from the absolute q.e. due to the presence of crosstalk [32, 49]. Numerical calculations show that the effect of saturation decreases the with increasing 〈 ̂〉 (see Fig.8a).
The experimental setup is shown in Fig.7. The 4th harmonic of Nd:YAG pulsed laser at 266 nm (repetition rate 20kHz, 30 nsec pulse width) is used as a pump two 5 mm length BBO crystals where PDC occurs. Each crystal is cut for collinear frequency non-degenerate type I PDC with signal and idler modes at nm and nm, respectively. The half-wave plate and polarization beamsplitter (PBS) (not shown) are used to change the pump power. After passing through the BBOs the pump beam is rejected by a UV-mirror while
PDC radiation passed through it. The signal and idler beams are split by a dichroic mirror (DM): the former is transmitted and the latter is reflected. At each arm there are lenses (f=500 mm) with their front focuses at the BBOs. Two iris apertures are set according to after the lenses, selecting the conjugated spatial modes [48]. The irises are set to 10 mm and 11.36 mm in the arms with 500 nm and 568 nm, respectively. The spatially selected spectral bandwidth of PDC is calculated to be 3 nm. The PDC is then collected by lenses (f=200 mm) and formed a beam spot of 1.2 mm at the MPPC chip. The ambient light is suppressed by means of interference filters centered at 500 and 568 nm, respectively, both being 15 nm FWHM and a peak transmission of 95%. Two identical MPPCs, model Hamamatsu 10751-02, are used. The saturation behavior is checked by measuring the dependence of photocounts versus the number of incident photons (see inset in Fig.8a), and it is found to be identical for both MPPCs. The crosstalk values are checked by the method described in Section 4, and the values are found to be identical. A 0.1dB neutral density filter is introduced in one of the arms to equilibrate the quantum efficiencies of MPPCs at different wavelengths. Both MPPCs are cooled to reduce the dark noise, see Section 3. The signals from the MPPCs are digitized by an AD card (NI PCI-5154) and discriminated according to their amplitudes. The AD card is synchronized with a pump laser and detection window was set to 70 ns. For each power level 10 6 triggers are collected. The data analysis is done using LabView and Mathlab software. The MPPC dark noise and ambient luminescence of the setup are measured similarly to the procedure described in Section 3. The measurements performed at different pump powers provide the dependence of NRF and on the number of photocounts per pulse.
Similar measurements are performed for the coherent light emitted from an attenuated cw Nd:YAG laser ( at 532 nm) which is chopped by an acoustic optical modulator (AOM) at the frequency of 20 kHz with the pulse duration of 30 ns. Then it is fed into a single mode fiber and collimated by a lens (f=6,24 mm) at the MPPCs. Interference filters centered at 532 nm with 1.5 nm FWHM are used to filter out an ambient light.
Fig.7 Schematic of the experimental setup for measurement of the twomode squeezing. PDC in collinear regime is generated in a BBO crystal, which is pumped by a pulsed UV-laser (pump). PDC photons (signal and idler) have different wavelengths. They are split by a dichroic mirror (DM) and addressed to two MPPCs. NRF and are calculated from joint statistics of photocounts.
Fig.8a shows the experimental data and theoretical fits of versus 〈 〉 ̂ for the coherent and SV states. From the difference of the measured for the two states close to 〈 ̂〉 , one finds the experimental value of the effective quantum efficiency for the SV state at 568 nm. The value yields , and it isfurther used for the conversion of photocounts to photon numbers. Effective quantum efficiency for the coherent state at 532 nm is found from assuming the dependence of quantum efficiency on the wavelength, provided by the manufacturer, and yielding . The theoretical fits of the data to the model yield , and for the coherent state, and and for the SV state. These parameters yield for the coherent state, and , which are in good agreement with the experimental values of used for the calculation of photon numbers.
The results clearly demonstrate that gradually decreases with the increasing 〈 〉 ̂ for both studied states, which is caused by the saturation of the MPPC. At the same time, the for the SV state lies below the one for the coherent state-a signature of squeezing. The crosstalk elevates the at low 〈 〉 ̂ to values above unity, as predicted by the theory. Surprisingly, the obtained value of appears to be much smaller than the one expected from the MPPC with 400 pixels. We have found that the MPPC modules do not allow reliable discrimination of photon numbers beyond 〈 〉 ̂ due to the limitations of the built-in electronic circuitry, which is inaccessible for adjustment. This might also be the cause of the deviation of the measured from the theoretical prediction for 〈 〉 ̂ . Note that reliable photon number resolution up to 20 photons was demonstrated with similar detectors using customized electronics [50]. Also, the obtained value of is higher than an earlier result, obtained for the same detector, see Section 4, [32] which can be due to the presence of higher-order crosstalk events which are not considered in the present model.
Fig.8 (a) Dependence of the NRF on the mean number of photons measured for the coherent state (black squares) and the SV state (red circles). The theoretical fits for the NRF are performed in the range of up to 6 photons (vertical dashed line), which marks the range of reliable photon number resolution. The inset shows the mean number of photocounts versus the mean number of incident photons in one of the MPPCs for the coherent state. (b) Dependence of on the mean number of photons measured for coherent light (black squares) and squeezed vacuum (red circles).
It is also of interest to analyze the dependence of the second order intensity correlation function, defined here as [37]. For PDC it is shown in Fig.8b (red circules), and demonstrates the rise with the decreasing of the number of photons per pulse, according to 〈 〉 , where is an inverse number of detected modes. At the same time, for coherent states was almost constant, yielding , despite of the cross-talk and the dark noise which still presents in both MPPCs (black squares). It is explained by the fact that the crosstalk and dark counts in two MPPCs are uncorrelated and do not contribute to . It is worth to compare this result with the one obtained in [31, 32], where only a single MPPC was used for the measurements of . In that case the crosstalk has added considerable 'false' correlations, mimicking in this way the true photon bunching.
## Conclusions
In conclusion, we experimentally studied detection of various non-classical states of light with photon number resolving MPPCs. Based on the developed algorithm of obtaining the second order correlation function and the nonlinear crosstalk model, we measured for coherent and squeezed vacuum states. It was demonstrated that the crosstalk leads to additional terms in the correlation function for both of the studied states. The presented analysis can be directly applied to other types of spatially resolving detectors such as, single photon resolving ICCD and EMCCD, as well as for measurements of higher order correlation functions.
We also presented a new accessible method for calibration of the MPPC crosstalk probability. The method relies on the fundamental properties of coherent states, and the generalized crosstalk model. It was tested for three commercial MPPCs with different pixel sizes and at different temperatures. The new method exhibited much less uncertainty in determination of the crosstalk probability compared to conventional method based on measurements of dark noise. The method may represent practical interest for applications, and future development of optimized low noise MPPCs.
Finally, we used MPPCs to reveal the two-mode squeezing of relatively bright SV states. We developed a theoretical POVM model, which accounts for MPPC saturation and finite quantum efficiency. We analyzed fluctuations of the difference of the intensities in two modes by measuring for coherent and SV states.
We demonstrated that the crosstalk in the MPPC leads to an increase of the for both coherent and SV states. Moreover we analyzed the effect of the MPPC saturation, which leads to the decrease of with increasing photon numbers. We also showed that, in contrast to the measurements by a single MPPC, was not affected by the crosstalk. The experimental data agrees with the trend of the presented theoretical model which takes into account the saturation and the crosstalk. Our results extended the use of MPPCs for the characterization of quantum light in a significantly broader dynamic range than that of conventional SPADs, thus allowing access to affordable detectors with photon number resolution.
Currently, implementation of the MPPC technology is restricted by several technical issues, where the problem of the crosstalk is the major one. Development of advanced techniques of chip fabrication and better optical isolation of pixels, will allow to mitigate the problem of crosstalk, and open the way towards implementation of the MPPC technology in the broad range of applications ranging from the studies of atomic-photon interfaces to astronomy applications.
## Acknowledgements
We would like to thank Maria V. Chekhova, Timur Sh. Iskhakov and Si Hui Tan for their contributions at various stages of this project. We acknowledge financial support by A-STAR Investigatorship grant.
## References and links
- 1. E. Knill, R. Laflamme, G.J. Milburn, 'A scheme for efficient quantum computation with linear optics,' Nature 409, 46-52 (2001).
- 2. P. Kok, W.J. Munro, K. Nemoto, T.C. Ralph, J.P. Dowling, G.J. Milburn, 'Linear optical quantum computing with photonic qubits,' Rev. Mod. Phys. 79, 135-175 (2007).
- 3. J.L. O'Brien, 'Optical quantum computing,' Science 318, 1567-1570 (2007).
- 4. M.W. Mitchell, J.S. Lundeen, A.M. Steinberg, 'Super-resolving phase measurements with a multiphoton entangled state,' Nature, 429, 161-164 (2004).
- 5. P. Walther, J.-W. Pan, M. Aspelmeyer, R Ursin, S. Gasparoni, A. Zeilinger, 'De Broglie wavelength of a non-local four-photon state,' Nature, 429, 158-161 (2004).
- 6. I.B. Bobrov. D.A. Kalashnikov, and L.A. Krivitsky, 'Imaging of spatial correlations of two-photon states', Phys. Rev. A 89, 043814 (2014).
- 7. L. Pezzé and A. Smerzi, 'Mach-Zehnder interferometry at the Heisenberg limit with coherent and squeezed vacuum light,' Phys. Rev. Lett. 100(7), 073601 (2008).
- 8. G. Brassard, N. Lütkenhaus, T. Mor, and B.C. Sanders 'Limitations on practical quantum cryptography,' Phys. Rev. Lett. 85, 1330-1333 (2000).
- 9. D. Bouwmeester, J.-W. Pan, K. Mattle, M. Eibl, H. Weinfurter, and A. Zeilinger 'Experimental quantum teleportation,' Nature 390, 575-579 (1997).
- 10. M. Żukowski, A. Zeilinger, M.A. Horne, and M.A. Ekert, 'Event-ready-detectors' Bell experiment via entanglement swapping,' Phys. Rev. Lett. 71, 4287-4290 (1993).
- 11. F. Dell'Anno, S. De Siena, F. Illuminati, 'Multiphoton quantum optics and quantum state engineering,' Physics Reports 428, 53-168 (2006).
- 12. J.-W. Pan, Z.-B. Chen, C.-Y. Lu, H. Weinfurter, A. Zeilinger, and M. Zukowski, 'Multiphoton entanglement and interferometry,' Rev. Mod. Phys. 84, 777-838 (2012).
- 13. R. H. Hadfield, 'Single-photon detectors for optical quantum information applications' Nature Photonics, 3, 696-705, (2009).
- 14. D. Achilles, C. Silberhorn, C. Sliwa, K. Banaszek, and I.A. Walmsley, "Fiber assisted detection with photon-number resolution," Opt. Lett. 28, 2387-2389 (2003).
- 15. M. J. Fitch, B. C. Jacobs, T. B. Pittman, J. D. Franson, "Photon-number resolution using timemultiplexed single-photon detectors," Phys. Rev. A 68, 043814 (2003).
- 16. M. Mičuda, O. Haderka, M. Ježek, "High-efficiency photon-number-resolving multichannel detector," Phys Rev A 78, 025804 (2008).
- 17. S. Takeuchi, J. Kim, Y. Yamamoto, H.H. Hogue, 'Development of a high quantum-efficiency singlephoton counting system,' Appl. Phys. Lett. 74, 1063-1065 (1999).
- 18. J. Kim, S. Takeuchi, Y. Yamamoto, H.H. Hogue, 'Multiphoton detection using visible light photon counter,' Appl. Phys. Lett. 74, 902-904 (1999).
- 19. E. Waks, K. Inoue, E. Diamanti, Y. Yamamoto, 'High-efficiency photon-number detection for quantum information processing,' IEEE J. Sel. Top. Quant. 9, 1502-1511 (2003).
- 20. B. Cabrera, R. M. Clarke, P. Colling, A. J. Miller, S. Nam, R. W. Romani, 'Detection of single infrared, optical, and ultraviolet photons using superconducting transition edge sensors,' Appl. Phys. Lett. 73, 735 (1998).
- 21. D. Rosemberg, A.E. Lita, A.J. Miller, S.W. Nam, 'Noise-free high-efficiency photon-number-resolving detectors,' Phys Rev A, 71, 061803R (2005).
- A.E. Lita, A.J. Miller, S.W. Nam, "Counting near-infrared single- photons with 95% efficiency," Opt.
- 22. Express 16, 3032-3040 (2008).
- 23. D. Sahin, and et al. 'Waveguide photon-number-resolving detectors for quantum photonic integrated circuits,' Appl. Phys. Lett, 103, 111116 (2013).
- 24. M. Bondani, A. Allevi, A. Agliati, A. Andreoni, "Self-consistent characterization of light statistics," J. Mod. Opt 56, 226 - 231, (2009).
- 25. B. E. Kardynal, Z. L. Yuan A. J. Shields, "An avalanche-photodiode-based photon-number-resolving detector," Nature Photonics 2, 425-428 (2008).
- 26. O. Thomas, Z.L. Yuan and A.J. Shields 'Practical photon number detection with electric fieldmodulated silicon avalanche photodiodes,' Nature Communication 3, 644 (2012).
- 27. Hamamatsu web-page http://jp.hamamatsu.com/
- 28. I. Afek, A. Natan, O. Ambar, Y. Silberberg, 'Quantum state measurements using multipixel photon detectors,' Phys. Rev. A 79, 043830 (2009).
- 29. S.-H. Tan, L. A. Krivitsky, B. -G. Englert 'Measuring Quantum Correlations using Lossy PhotonNumber-Resolving Detectors with Saturation' Pre-print: arXiv:1210.8022.
- 30. M. Ramilli, A. Allevi, V. Chmill, M. Bondani, M. Caccia, A. Andreoni, 'Photon-number statistics with silicon photomultipliers,' J. Opt. Soc. Am. B 27, 852-862 (2010).
- 31. D.A. Kalashnikov, S.-H. Tan, M.V. Chekhova, L.A. Krivitsky, 'Accessing photon bunching with photon number resolving multi-pixel detector,' Opt. Express 19, 9352-9363 (2011).
- 32. D.A. Kalashnikov, S.-H. Tan, L.A. Krivitsky, 'Crosstalk calibration of multi-pixel photon counters using coherent states', Opt. Express 20, 5044-5051 (2012).
- 33. D. A. Kalashnikov, S.-H. Tan, T. Sh. Iskhakov, M. V. Chekhova, and L. A. Krivitsky 'Measurement of two-mode squeezing with photon number resolving multipixel detectors', Opt. Lett. 37, 2829-2831 (2012).
- 34. A. Vacheret and et al. 'Characterization and Simulation of the Response of Multi Pixel Photon Counters to Low Light Levels,' Nuclear Instruments and Methods in Physics Research A 656, 69-83 (2011).
- 35. A. Spinelli and A. L. Lacaita, 'Physics and numerical simulation of single photon avalanche diodes,' IEEE Trans. Electron. Dev. 44(11), 1931-1943 (1997) .
- 36. I. Rech, A. Ingargiola, R. Spinelli, I. Labanca, S. Marangoni, M. Ghioni, and S. Cova, 'Optical crosstalk in single photon avalanche diode arrays: a new complete model,' Opt. Express 16, 83818394 (2008).
- 37. R.J. Glauber, Quantum Optics and Electronics (Gordon and Breach, New York, 1965).
- 38. M. Avenhaus, K. Laiho, M. V. Chekhova, and C. Silberhorn, 'Accessing higher order correlations in quantum optical states by time multiplexing,' Phys. Rev. Lett. 104, 063602 (2010).
- 39. O. Haderka, J. Perina, Jr., M. Hamar, and J. Perina, 'Direct measurement and reconstruction of nonclassical features of twin beams generated in spontaneous parametric down-conversion,' Phys. Rev. A 71(3), 033815 (2005).
- 40. J.-L. Blanchet, F. Devaux, L. Furfaro, and E. Lantz, 'Measurement of sub-shot-noise correlations of spatial fluctuations in the photon-counting regime,' Phys. Rev. Lett. 101, 233604 (2008).
- 41. D. N. Klyshko, Photons and Nonlinear Optics (Gordon and Breach, New York, 1988).
- 42. M. Yokoyama, A. Minamino, S. Gomi, K. Ieki, N. Nagai, T. Nakaya, K. Nitta, D. Orme, M. Otani, T. Murakami, T. Nakadaira, and M. Tanaka, 'Performance of multi-pixel photon counters for the T2K near detectors,' Nuclear Instruments and Methods in Physics Research A 622, 567-573 (2010).
- 43. P. Eraerds, M. Legré, A. Rochas, H. Zbinden, and N. Gisin, 'SiPM for fast photon-counting and multiphoton detection,' Opt. Express 15, 14539-14549 (2007).
- 44. Hamamatsu web-page http://jp.hamamatsu.com/products/sensor-ssd/4010/index\_en.html
- 45. A. L. Lacaita, F. Zappa, S. Bigliardi, and M. Manfredi, 'On the bremsstrahlung origin of hot-carrierinduced photons in silicon devices,' IEEE Trans. Electron. Dev. 40(3), 577-582 (1993).
- 46. D.N. Klyshko, 'The nonclassical light', Phys. Usp. 39, 573-596 (1996).
- 47. A. Heidmann, R.J. Horowicz, S. Reynaud, E. Giacobino, C. Fabre and G. Camy, 'Observation of quantum noise reduction on twin laser beams', Phys. Rev. Lett. 59, 2555-2557 (1987).
- 48. I.N. Agafonov, M.V. Chekhova, and G. Leuchs, 'Two-color bright squeezed vacuum', Phys. Rev. A 82, 011801 (2010).
- 49. I. N. Agafonov, M.V. Chekhova, T. S. Iskhakov, A. N. Penin, G. O. Rytikov, O. A. Shcherbina, 'Absolute calibration of photodetectors: photocurrent multiplication versus photocurrent subtraction' Opt. Lett. 36, 1329 (2011).
- 50. L. Dovrat, M. Bakstein, D. Istrati, A. Shaham, H. S. Eisenberg, 'Measurements of the dependence of the photon-number distribution on the number of modes in parametric down-conversion', Opt. Express 20, 2266-2276 (2012). | 10.1364/JOSAB.31.000B25 | [
"Dmitry Kalashnikov",
"Leonid A. Krivitsky"
] | 2014-08-01T01:50:59+00:00 | 2014-08-01T01:50:59+00:00 | [
"quant-ph",
"physics.optics"
] | Measurement of photon correlations with multipixel photon counters | Development of reliable photon number resolving detectors (PNRD), devices
which are capable to distinguish 1,2,3.. photons, is of a great importance for
quantum optics and its applications. A new class of affordable PNRD is based on
multipixel photon counters (MPPC). Here we review results of experiments on
using MPPCs for direct characterization of squeezed vacuum (SV) states,
generated via parametric downconversion (PDC). We use MPPCs to measure the
second order normalized intensity correlation function (g^(2)) and directly
detect the two-mode squeezing of SV states. We also present a method of
calibration of crosstalk probability in MPPCs based on g^(2) measurements of
coherent states. |
1408.0060v3 | ## The dual foliation of some singular Riemannian foliations
## Yi Shi
School of Mathematical Sciences, Shanxi University, Taiyuan 030006, China, e-mail: [email protected]
Abstract: In this paper, we use the methods of subriemannian geometry to study the dual foliation of the singular Riemannian foliation induced by isometric Lie group actions on a complete Riemannian manifold M . We show that under some conditions, the dual foliation has only one leaf.
Key Words: dual foliation, torus actions, subriemannian geometry
MSC(2010) Subject Classification: 53C12, 53C17.
## 1 Introduction
We recall some basic notions about singular Riemannian foliations, for further details we refer the readers to [1, 8, 13, 16]. A singular Riemannian foliation F on a Riemannian manifold M is a decomposition of M into smooth injectively immersed submanifolds L p ( ), called leaves, such that it is a singular foliation and any geodesic starting orthogonally to a leaf remains orthogonal to all leaves it intersects. Such a geodesic is called a horizontal geodesic . For all p ∈ M , we denote by H p the orthogonal complement to the tangent space T p ( L p ( )), and call it the horizontal space at p . If all the leaves have the same dimension, then F is called a regular Riemannian foliation .
A curve is called horizontal if it meets the leaves of F perpendicularly. In [16], Wilking associates to a given singular Riemannian foliation F the so-called dual foliation F # . The dual leaf through a point p ∈ M is defined as all points q ∈ M such that there is a piecewise smooth, horizontal curve from p to q . We denote by L # p the dual leaf through p . Wilking proved that when M has positive curvature, the horizontal connectivity holds on M , i.e. the dual foliation has only one leaf. Wilking also used the theory of dual foliations to show that the Sharafutdinov projection is smooth. For more applications of dual foliations, the reader is referred to [7, 9, 10, 11, 12, 16].
Let ( M, F ) be a singular Riemannian foliation F on Riemannian manifold M . Applying Wilking's theorem, we can get the horizontal connectivity by assuming that M has positive curvature. However, in this paper we are interested in getting the horizontal connectivity by applying the methods of subriemannian geometry. For a more extensive exposition of subriemannian geometry, we refer the readers to [4, 5, 14].
Recall that a subriemannian geometry on a manifold M consists of a distribution, which is to say a vector subbundle H ⊂ TM of the tangent bundle of M , together with
a fiber inner-product on H . We call H the horizontal distribution. A curve on M is called horizontal if it is tangent to H .
Let H be the horizontal distribution on M , the Lie brackets of vector fields in H generate the flag
$$H = H ^ { 1 } \subset H ^ { 2 } \subset \dots \subset H ^ { r } \subset \dots \subset T M$$
with where
$$[ H, H ^ { r } ] = s p a n \{ [ X, Y ] \, \colon X \in H, Y \in H ^ { r } \}$$
At a point p ∈ M , this flag gives a flag of subspaces of T M p :
$$H _ { p } = H _ { p } ^ { 1 } \subset H _ { p } ^ { 2 } \subset \dots \subset H _ { p } ^ { r } \subset \dots \subset T _ { p } M$$
We say that H is bracket generating at p if there is an r ∈ Z + such that H r p = T M p , and H is bracket generating if for all x ∈ M there is an r x ( ) ∈ Z + such that H r x ( ) x = T M x . The smallest integer r such that H r p = T M p is called the step of the distribution at p .
Chow s ′ Theorem ([6]). Let M be a connected manifold and H ∈ TM be a bracket generating distribution, then the set of points that can be connected to p ∈ M by a horizontal path coincides with M .
When Chow's condition fails on some subset of M , sometimes the horizontal connectivity also fails ([5], P. 82).
Suppose a compact connected Lie group G acts isometrically on manifold M . Throughout the paper, every action will be assumed to be effective . It is well known that the action of G induces a singular Riemannian foliation ( M, F ) on M . Let M ′ denote the union of all principal orbits in M . An basic fact is that the restricted foliation ( M , ′ F| M ′ ) is a regular Riemannian foliation on M ′ . Denote by H ′ the collection of horizontal spaces H x with x ∈ M ′ , then H ′ is the horizontal distribution of F| M ′ on M ′ . Contrast to Chow's Theorem, to connect any two points on M by a horizontal curve, we only need to assume that H ′ is bracket-generating at one point:
Lemma 1.1. Let G be a compact connected Lie group, acting isometrically on a complete Riemannian manifold M . If H ′ is bracket-generating at some point p ∈ M ′ , then the dual foliation has only one leaf. If M is compact, then there exists a constant C = C M,G ( ) such that any two points of M can be connected by a horizontal curve of length ≤ C .
Let G × M → M denote an isometric action by principal orbits of a compact Lie group G on a complete Riemannian manifold M . The orbit space B := M/G is also a manifold, and inherits a quotient metric from M for which π : M → B becomes a Riemannian submersion. π is then said to be a homogeneous submersion or fibration .
The following corollary of Lemma 1.2 gives a generalization of Theorem 3.1 in [10].
Corollary 1.2. Let π : M → B = M/G be a homogeneous G -fibration with compact connected Lie group G . If the horizontal distribution H is bracket-generating at some point p ∈ M , then π : M → B is a principal G -bundle.
$$H ^ { r + 1 } = H ^ { r } + [ H, H ^ { r } ] \ f o r \ r \geq 1$$
Using Lemma 1.2 we can also get the following:
Theorem 1.3. Suppose circle T 1 acts isometrically on a complete manifold M . If M is simply connected, then the dual foliation has only one leaf. If M is compact, then there exists a constant C = C M,T ( 1 ) such that any two points of M can be connected by a horizontal curve of length ≤ C .
Notice that Wilking's horizontal connectivity theorem doesn't hold for nonnegatively curved manifolds in general, but as showed in [3], the horizontal connectivity phenomenon often occurs for nonnegatively curved spaces. The main result of this paper continues this investigation:
Theorem 1.4. Suppose torus T k acts isometrically on a complete nonnegatively curved Riemannian manifold M . Then either the dual foliation has only one leaf, or else M locally splits.
As an application of Theorem 1.3 and Theorem 1.4, the following theorem gives a generalization of Theorem 4 in [3].
Theorem 1.5. Suppose torus T k acts isometrically on a complete, simply connected Riemannian manifold M . Then the dual foliation has only one leaf if one of the following holds:
- (a) the action of T k is free.
- (b) M has nonnegative curvature.
## 2 Bracket-generating at one point
In this section, we use the methods of subriemannian geometry to give a proof of Lemma 1.1. The proof of Corollary 1.2 follows as an application of Lemma 1.1.
Proof of Lemma 1.1 Suppose that H ′ is bracket-generating at some point p ∈ M ′ . Since M ′ is open and dense in M , by the continuity of Lie brackets, H ′ is also bracketgenerating in a neighbourhood U p ⊂ M ′ of p . By the Ball-box theorem ([14], P. 29) we know that there is a positive constant /epsilon1 0 and a box neighborhood Box( /epsilon1 0 , p ) ⊂ U p of p , such that any point in Box( /epsilon1 0 , p ) can be connected to p by a horizontal curve of length ≤ /epsilon1 0 .
We claim that G p ( ) ⊂ L # p , where G p ( ) is the orbit of p . For any q ∈ G p ( ), assume q = gp for some g ∈ G . Denote the differential of g by g ∗ , for any two vector fields X Y , ∈ H ′ , we have g ∗ [ X,Y ] = [ g X, g Y ∗ ∗ ]. Assume that H ′ is bracket-generating at p ∈ M ′ with step r , i.e., ( H ′ ) r p = T M p . Then by ( H ′ ) r q = g ∗ (( H ′ ) r p ) = g ∗ ( T M p ) = T M q , H ′ is also bracket-generating at q with step r . Since g ∗ is a isometric map, there is a same size box neighborhood Box( /epsilon1 0 , q ) of q , as that of p , such that any point in Box( /epsilon1 0 , q ) can be connected to q by a horizontal curve of length ≤ /epsilon1 0 . Since G p ( ) is compact connected, we can cover G p ( ) by finitely many successive box neighborhoods. Denote the number of these covering boxes by N 0 . Then any two points x, y ∈ G p ( ) can be connected by a horizontal curve with length ≤ 2 N /epsilon1 0 0 . This proves that G p ( ) ⊂ L # p .
For any x / G p ∈ ( ), since G p ( ) is compact, there is a minimal geodesic γ : [0 , 1] → M from x to G p ( ). Thus γ must be a horizontal geodesic. By γ (1) ∈ G p ( ) ⊂ L # p , we get x ∈ L # p . This proves that L # p = M , i.e., the dual foliation has only one leaf.
If M is compact, then for any x , x 1 2 ∈ M , we have two minimal geodesics γ i : [0 , 1] → M from γ i (0) = x i to G p ( ) for i = 1 2. , Thus both γ 1 and γ 2 are horizontal geodesics. We have proved that γ 1 (1) and γ 2 (1) can be connected by a horizontal curve of length ≤ 2 N /epsilon1 0 0 . Denote by diam M ( ) the diameter of M , since length( γ i ) ≤ diam M ( ) for i = 1 2, , x 1 and x 2 can be connected by a horizontal curve of length ≤ C M,G ( ) := 2 diam M ( ) + 2 N /epsilon1 0 0 . /square
Proof of Corollary 1.2 For p ∈ M , let G p be the isotropy group of the action of G at p . By Lemma 1.1 we know that L # p = M , then by [16] one can connect any two points of M by a piecewise horizontal geodesic. In [10] it was shown that, if γ is a horizontal geodesic with respect to a homogeneous fibration of a manifold M , then the isotropy groups of the action coincide for every point of γ . Hence, we get that the isotropy group of any point must coincide with G p . Since the action of G is effective, we have that G p is the identity, so the action of G is free, and π : M → B is a principal G -bundle. /square
## 3 Torus action and horizontal connectivity
In this section, we study the dual foliation of the singular Riemannian foliation induced by isometric torus actions and prove Theorem 1.3, Theorem 1.4 and Theorem 1.5.
Proof of Theorem 1.3 If there is a singular orbit x = T 1 ( x ) on M , then the horizontal space at x is H x = T M x . Since the exponential map exp x : H x → M is onto, we get that L # x = M . Thus we can assume all the orbits are regular, and we get a codimension one globally horizontal distribution H on M . If H is not integrable at some point p ∈ M , then H is bracket-generating at p . By Lemma 1.1 we get that L # p = M . So it is enough to show that there is no globally integrable horizontal distribution H on M .
If H is integrable on M , since M is simply connected, by Theorem 1.5 in [2] there are no exceptional orbits on M , so T 1 acts freely on M , it follows that the orbit space B := M/T 1 is also a manifold, and inherits the quotient metric from M for which π : M → B becomes a Riemannian submersion with fiber F = T 1 . By the long exact homotopy sequence of the fibration π , B is simply connected since M is. We claim that M is homeomorphic to B × T 1 .
Since H is integrable, by the Frobenius theorem, for any p ∈ M L , # p is the integral leaf of H that contains p . Since π is a locally trivial bundle, π | L # p : L # p → B is a covering map and therefore a diffeomorphsm, B being simply connected. Hence L # p is a section of π : M → B . Since it was proved already that π : M → B is a principal bundle, the existence of a global section implies immediately that M is homeomorphic to B × T 1 . However, this is a contradiction since M is simply connected.
We have proved the horizontal connectivity on M , assume now that M is compact, denote by diam M ( ) the original diameter of M , by diam H ( M ) the horizontal diameter of M defined by horizontal metric. If there is a singular orbit x = T 1 ( x ) on M ,
then L # x = M , thus diam H ( M ) ≤ 2 diam M ( ). If all the orbits are regular, then we get a codimension one globally horizontal distribution H on M . Since H is bracketgenerating at some point p ∈ M , by Lemma 1.1, we get that diam H ( M ) ≤ C = C M,T ( 1 ). /square
The following lemma will be used in the proof of Theorem 1.4:
Lemma 3.1. Let G be a compact connected Lie group, acting isometrically on a complete Riemannian manifold M . For any p ∈ M , define the subset S ⊂ G via S := { g ∈ G | gp ∈ L # p ∩ G p ( ) } . Then S is a subgroup of G and the action of S on M preserves L # p .
Proof. To show that S is a subgroup of G , we need to prove that g -1 1 g 2 ∈ S for any g , g 1 2 ∈ S . It is enough to show that g -1 1 g 2 ( p ) ∈ L # p . By [16] one can connect p and g i ( p ) by a piecewise horizontal geodesic γ i , i = 1 2. , It follows that one can connect g -1 1 p and p = g -1 1 ( g p 1 ) by the piecewise horizontal geodesic g -1 1 ◦ γ 1 , thus g -1 1 p ∈ L # p . Also, one can connect g -1 1 p and g -1 1 ( g p 2 ) by the piecewise horizontal geodesic g -1 1 ◦ γ 2 . Since g -1 1 p ∈ L # p , g -1 1 g 2 ( p ) ∈ L # p as desired.
We claim that the action of S on M preserves L # p . For any g ∈ S and q ∈ L # p , we need to show that gq ∈ L # p . Since one can connect p and q by a piecewise horizontal geodesic γ , one can connect gp and gq by the piecewise horizontal geodesic g ◦ γ . Since g ∈ S , by definition gp ∈ L # p . Thus gq ∈ L # p as claimed.
Proof of Theorem 1.4 Suppose the dual foliation has more than one leaf. Since T k acts transitively on the space of dual leaves, all dual leaves have the same dimension. Then by theorem 2 and 3 in [16] these dual leaves form a regular Riemannian foliations F # . Let M ′ denote the union of all principal orbits in M , and let p ∈ M ′ . Since the torus is an abelian group, the isometric action of T k induces k commuting Killing fields on M . Consider a Killing field X which is perpendicular to L # p at p , we will prove that X is perpendicular to L # p for all x ∈ L # p . To prove this we may assume that x ∈ L # p ∩ M ′ since M ′ is open and dense in M . Denote the normal space of L # p at x by N x ( L # p ). We first plan to show that X q ( ) ∈ N L q ( # p ) for all q ∈ L # p ∩ T k ( p ).
Denote the one-parameter subgroup of T k corresponding to X by φ s , s ( ) ∈ R . Define the subset S ⊂ T k via S := { g ∈ T k | gp ∈ L # p ∩ T k ( p ) } , by Lemma 3.1 the action of S on M preserves L # p . Let q ∈ L # p ∩ T k ( p ), by definition q = gp for some g ∈ S . Since T k is abelian, g ◦ φ s ( )( p ) = φ s ( )( q ). Denote the differential of g by g ∗ , then g ∗ ( X p ( )) = X q ( ). Since X p ( ) ∈ N L p ( # p ) and the action of S preserves L # p , we get that X q ( ) = g ∗ ( X p ( )) ∈ N L q ( # p ).
Denote the codimension of L # p by n , then n ≤ k . We can choose n Killing fields X , 1 · · · , X n such that { X p , 1 ( ) · · · , X n ( p ) } is an orthonormal basis of N L p ( # p ). We claim that the normal bundle of L # p is spanned by { X , 1 · · · , X n } .
For any x ∈ L # p ∩ M ′ , we can find some q ∈ L # p ∩ T k ( p ) and a piecewise horizontal geodesic γ in M ′ connect x and q . Since X q ( ) ∈ N L q ( # p ), by the proof of Corollary 8 in [16] X is perpendicular to L # p along γ . Thus X is perpendicular to L # p for all x ∈ L # p ∩ M ′ , which in turn shows X is perpendicular to L # p .
For any x ∈ L # p , we can find some q ∈ L # p ∩ T k ( p ) and an horizontal geodesic c from q = (0) to c x = (1). It is clear that c { X q , 1 ( ) · · · , X n ( q ) } is an orthonormal basis
/negationslash of N L q ( # p ). Set W = span R { X , . . . , X 1 n } and X t ( ) = X c t ( ( )) for X ∈ W t , ∈ [0 , 1], let W t ( ) = { X t ( ) | X ∈ W } . We will show that X t ( ) = 0 for any non-zero X ∈ W and t ∈ [0 , 1], thus dim( W t ( )) ≡ n . Indeed, if X t ( 0 ) = 0 for some X := ∑ i ≤ n a X i i ∈ W and t 0 ∈ [0 , 1], then X can be written also as a variation of c by horizontal geodesics with a fixed value c t ( 0 ) at time t 0 . Therefore X is everywhere tangential to L # p , so X (0) = ∑ i ≤ n a X i i ( q ) ⊥ N L q ( # p ). But then X (0) = 0 and a i = 0 for every i ≤ n , hence X = 0.
Since we have proved that any X ∈ W is perpendicular to L # p , now by dim( W t ( )) ≡ n , we get that the normal bundle of L # p is spanned by n linearly independent commuting Killing fields X , 1 · · · , X n . Thus the horizontal distribution with respect to F # is integrable, then by Theorem 1.3 in [15] M locally splits. /square
Proof of Theorem 1.5 (a) We first consider the case that the action of T k is free. We get a sequence of principal T 1 -bundles
$$M = M _ { 0 } \xrightarrow { \pi _ { 1 } } M _ { 1 } \xrightarrow { \pi _ { 2 } } \cdots M _ { k - 1 } \xrightarrow { \pi _ { k } } M _ { k } = M / T ^ { k },$$
so M i is simply connected for any 0 ≤ i ≤ k . Notice that for any 0 ≤ i ≤ k -1, there is a subgroup T k -i of T k acts freely on M i , so this action induces a Riemannian foliation F i on M i . For any p i ∈ M i , denote by L # p i the dual leaf of F i that through p i . We claim that if L # p i = M i for some p i ∈ M i and 1 ≤ i ≤ k -1, then L # p i -1 = M i -1 for any p i -1 ∈ π -1 i ( p i ). This in fact shows L # p = M for any p ∈ M .
/negationslash
By Theorem 1.3 we get L # p k -1 = M k -1 for any p k -1 ∈ M k -1 . Now suppose L # p i = M i for some p i ∈ M i and 1 ≤ i ≤ k -1. Assume to the contrary that L # p i -1 = M i -1 for some p i -1 ∈ π -1 i ( p i ). By [16] L # p i -1 is a complete smooth immersed submanifold of M i -1 of dimension dim( L # p i -1 ) ≤ dim( M i ), it is easy to see that π i | L # p i -1 : L # p i -1 → L # p i = M i is a smooth surjective map, thus dim( L # p i -1 ) = dim( M i ). Thus by the implicit function theorem π i | L # p i -1 : L # p i -1 → L # p i = M i is a locally diffeomorphsm, and therefore a diffeomorphsm, M i being simply connected. Now using the same method as that of Theorem 1.3, we get that M i -1 is homeomorphic to M i × T 1 , which is a contradiction since M i -1 is simply connected.
(b) We next consider the case that M has nonnegative curvature. Suppose the dual foliation has more than one leaf, then these dual leaves form a regular Riemannian foliations F # . Denote by H # the horizontal distribution with respect to F # . Then by Theorem 1.4 M locally splits. Since M is simply connected, M globally splits. Then M is isometric to the Riemannian product L # p × A , where L # p is a dual leaf and A is an integral manifold of H # . Therefore L # p is not dence. By Proposition 9.1 in [16] there is a closed subgroup T n /subsetnoteql T k and a Riemannian submersion σ : M → T k -n = T /T k n , where the fibers of σ are closures of leaves of F # . By the long exact homotopy sequence of σ , T k -n is simply connected since M is. This is a contradiction since T k -n is not simply connected. /square
Acknowledgement . The author thanks Martin Kerin for helpful comments on a previous version of this paper.
## References
- [1] Alexandrino,M., Briquet, R. and T¨ben, D.: o Progress in the theory of singular Riemannian foliations, Diff. Geom. Appl., 31 (2), 248-267 (2013)
- [2] Alexandrino, M. and T¨ben, D.: o Singular Riemannian foliations on simply connected spaces, Diff. Geom. Appl., 24 (4), 383-397 (2006)
- [3] Angulo-Ardoy, P., Guijarro, L. and Walschap, G.,: Twisted submersions in nonnegative sectional curvature, Arch. Math. (Basel), 101 (2), 171-180 (2013)
- [4] Bellaiche, A. and Risler, J. J., (eds): Sub-Riemannian Geometry, Birkh¨user, a Basel, 1996
- [5] Calin, O. and Chang, D. C.: Sub-Riemannian Geometry: General Theory and Examples, Encyclopedia of Mathematics and Its Applications, vol. 126 . Cambridge University Press, Cambridge, 2009
- [6] Chow, W. L.: Uber Systeme von linearen partiellen Differentialgleichungen erster Ordnung, Math. Ann, 117 , 98-105 (1939)
- [7] Fang, F., Grove, K. and Thorbergsson, G.: Tits geometry and positive curvature, to appear in Acta Math., arXiv:1205.6222 [math.DG].
- [8] Gromoll, D. and Walschap, G.: Metric Foliations and Curvature, Progress in Mathematics 268 , Birkh¨user Verlag, Basel, 2009. a
- [9] Grove, K. and Ziller, W.: Polar manifolds and actions, J. Fixed Point Theory Appl., 11 (2), 279-313 (2012)
- [10] Guijarro, L. and Walschap, G.: When is a Riemannian submersion homogeneous?, Geom. Dedicata, 125 , 47-52 (2007)
- [11] Guijarro, L. and Walschap, G.: The dual foliation in open manifolds with nonnegative sectional curvature, Proc. Amer. Math. Soc., 136 (4), 1419-1425 (2008)
- [12] Lytchak, A.: Polar foliations on symmetric spaces, Geom. Funct. Anal, 24 (4), 1298-1315 (2014)
- [13] Molino, P.: Riemannian Foliations, Birkh¨user Boston, Inc., Boston, MA, 1988 a
- [14] Montgomery, R.: A tour of subriemannian geometries, their geodesics and applications. Mathematical Surveys and Monographs, 91 . American Mathematical Society, Providence, RI, 2002
- [15] Walschap, G.: Metric foliations and curvature, J. Geom. Anal, 2 , 373-381 (1992)
- [16] Wilking, B.: A duality theorem for Riemannian foliations in nonnegative sectional curvature, Geom. Funct. Anal, 17 , 1297-1320 (2007) | null | [
"Yi Shi"
] | 2014-08-01T02:13:17+00:00 | 2017-01-05T09:16:34+00:00 | [
"math.DG",
"53C12, 53C17"
] | The dual foliation of some singular Riemannian foliations | In this paper, we use the methods of subriemannian geometry to study the dual
foliation of the singular Riemannian foliation induced by isometric Lie group
actions on a complete Riemannian manifold M. We show that under some
conditions, the dual foliation has only one leaf. |
1408.0061v1 | ## VLA and GBT Observations of Orion B (NGC 2024, W12) : Photo-dissociation Region Properties and Magnetic field
## D. Anish Roshi
National Radio Astronomy Observatory , Charlottesville & Green Bank, 520 Edgemont 1 Road, Charlottesville, VA 22903, USA; [email protected]
W. M. Goss
National Radio Astronomy Observatory, P.O. Box O, Socorro, NM 87801, USA; [email protected]
S. Jeyakumar
Departamento de Astronom´ ıa, Universidad de Guanajuato, AP 144, Guanajuato CP 36000, Mexico; [email protected]
## ABSTRACT
We present images of C110 α and H110 α radio recombination line (RRL) emission at 4.8 GHz and images of H166 α , C166 α and X166 α RRL emission at 1.4 GHz, observed toward the starforming region NGC 2024. The 1.4 GHz image with angular resolution ∼ 70 ′′ is obtained using VLA data. The 4.8 GHz image with angular resolution ∼ 17 ′′ is obtained by combining VLA and GBT data in order to add the short and zero spacing data in the uv plane. These images reveal that the spatial distributions of C110 α line emission is confined to the southern rim of the H ii region close to the ionization front whereas the C166 α line emission is extended in the north-south direction across the H ii region. The LSR velocity of the C110 α line is 10.3 km s -1 similar to that of lines observed from molecular material located at the far side of the H ii region. This similarity suggests that the photo dissociation region (PDR) responsible for C110 α line emission is at the far side of the H ii region. The LSR velocity of C166 α is 8.8 km s -1 . This
1 The National Radio Astronomy Observatory is a facility of the National Science Foundation operated under a cooperative agreement by Associated Universities, Inc.
velocity is comparable with the velocity of molecular absorption lines observed from the foreground gas, suggesting that the PDR is at the near side of the H ii region. Non-LTE models for carbon line forming regions are presented. Typical properties of the foreground PDR are T PDR ∼ 100 K, n PDR e ∼ 5 cm -3 , n H ∼ 1 7 . × 10 4 cm -3 , path length l ∼ 0 06 pc and those of the far side . PDR are T PDR ∼ 200 K, n PDR e ∼ 50 cm -3 , n H ∼ 1 7 . × 10 5 cm -3 , l ∼ 0.03 pc. Our modeling indicates that the far side PDR is located within the H ii region. We estimate magnetic field strength in the foreground PDR to be 60 µ G and that in the far side PDR to be 220 µ G. Our field estimates compare well with the values obtained from OH Zeeman observations toward NGC 2024. The H166 α spectrum shows narrow (1.7 km s -1 ) and broad (33 km s -1 ) line features. The narrow line has spatial distribution and central velocity ( ∼ 9 km s -1 ) similar to that of the foreground carbon line emission, suggesting that they are associated. Modeling the narrow H166 α emission provides physical properties T PDR ∼ 50 K, n PDR e ∼ 4 cm -3 and l ∼ 0 01 pc and implies an ionization fraction of . ∼ 10 -4 . The broad H166 α line originates from the H ii region. The X166 α line has a different spatial distribution compared to other RRLs observed toward NGC 2024 and is probably associated with cold dust clouds. Based on the expected low depletion of sulphur in such clouds and the -8.1 km s -1 velocity separation between X166 α and C166 α lines, we interpret that the X166 α transition arises from sulphur.
Subject headings: ISM: general - ISM: H ii regions - ISM: individual objects (NGC 2024) - ISM: magnetic field - radio lines: ISM - photon-dominated region (PDR)
## 1. Introduction
NGC 2024 (Orion B, W12, Flame Nebula) is a well studied starforming region located at a distance of 415 pc (Anthony-Twarog 1982) in an extended ( ∼ 1 .5 o × 4 ) molecular cloud o complex of mass ∼ 10 5 M /circledot (Tucker et al. 1973). It is located about 4 o north of the Great Orion Nebula (Orion A). The optical emission from the nebula is obscured by a dark dusty structure in the molecular material. The main ionizing star is IRS2b, a star in the spectral range O8 V - B2 V (Bik et al. 2003).
At radio wavelengths, NGC 2024 is a source of abundant molecular and recombination line emission (see for example, Buckle et al. 2010, Anantharamaiah et al. 1990). Radio recombination line (RRL) emission from NGC 2024 is particularly striking as spectral transitions of hydrogen, carbon and a heavy element are observed. The richness of RRL emission
toward NGC 2024 has led to several single dish recombination line observations (Palmer et al. 1967, Gordon 1969, Chaisson 1973, MacLeod et al. 1975, Rickard et al. 1977, Wilson & Thomasson 1975, Pankonin et al. 1977, Kr¨gel et al. 1982). u
The hydrogen radio recombination lines (HRRLs) observed at frequencies < ∼ 2 GHz show broad ( ∼ 30 km s -1 ) and narrow ( < ∼ 4 km s -1 ) components. The broad HRRL arises from the H ii region and is also observed at frequencies > 2 GHz (Kr¨gel et al. 1982). The central u velocity and turbulent width features of broad HRRL as well as the radio continuum emission suggest that the H ii region is ionization bounded to the S (Kr¨gel et al. 1982). u The narrow hydrogen line, referred to as H RRL, has an LSR velocity 0 ∼ 9 km s -1 (Ball et al. 1970).
The carbon radio recombination line (CRRL) observed toward NGC 2024 at low frequencies ( < ∼ 2 GHz) has an LSR velocity of ∼ 9 km s -1 . At these frequencies, the CRRL emission is dominated by stimulated emission, suggesting that the carbon line originates from partially ionized gas in front of the H ii region (Dupree 1974, Hoang-Binh & Walmsley 1974, Wilson & Thomasson 1975, Pankonin et al. 1977, Kr¨gel et al. 1982). This partially ionized u gas, located at the interface between the H ii region and molecular material, is referred to as photo-dissociation region (PDR). The high resolution (45 ) interferometric observation of ′′ RRLs toward NGC 2024 at 1.4 GHz shows velocity and spatial coincidence of CRRL and H RRL emission, suggesting that the two line forming regions coexist (Anantharamaiah et 0 al. 1990).
The CRRLs observed at high frequencies ( > ∼ 5 GHz) have LSR velocity ∼ 10 km s -1 (Pankonin et al. 1977) similar to that of line emission from dense molecular material at the far side of the H ii region. This similarity suggests that the high frequency carbon lines originate from PDR located at the far side (Pankonin et al. 1977, Kr¨gel et al. 1982). u
The spectrum at frequencies < ∼ 2 GHz also shows a line component with LSR velocity ∼ 0 km s -1 with respect to carbon line. This line is attributed to emission from a heavy element and is referred to as Xn α , where n is the principal quantum number.
In addition to RRL detections, there are numerous observations of molecular lines (CS, HCN, OH, H CO, CO; Buckle et al. 2010, Graf et al. 1993 and reference therein), IR fine 2 structure lines (CI, CII; eg. Graf et al. 2012 and reference therein), H i 21cm line (van der Werf et al. 1993 and reference therein) and IR continuum (Mezger et al. 1992 and reference therein) toward NGC 2024. High angular resolution ( ∼ 13 ) H CO observations ′′ 2 at 6 cm have shown absorption lines against the H ii region with a velocity of ∼ 9 km s -1 (Crutcher et al. 1986). This gas, located in front of the H ii region, has a density, n H ∼ 8 × 10 4 cm -3 (Henkel et al. 1980). Millimeter wave emission lines of H CO, on the other 2 hand, are observed at a velocity ∼ 10.5 km s -1 with a derived gas density, n H ∼ 3.6 × 10 5
cm -3 (Mangnum & Wootten 1993). The study of CS line emission at 10.5 km s -1 has shown that the core of the molecular cloud may have density ∼ 2 × 10 6 cm -3 (Snell et al. 1984). The presence of a two component gas structure is also evident from other molecular line (eg. CO) observations (eg. Graf et al. 1993), as well as H i absorption line data (van der Werf et al. 1993).
The picture of the NGC 2024 gas distribution that emerges from previous studies is the following : the low density ( ∼ 10 5 cm -3 ) component, part of which is located in front of the H ii region, has a total mass ∼ 300 M /circledot and the dense ( ∼ 10 6 cm -3 ) gas, located at the far side and S of the H ii region, has size 0.04 × 0.3 pc extending along a N-S direction with mass ∼ 140 M /circledot (Barnes et al. 1989, Mezger et al. 1992). In this picture, the PDR responsible for the low frequency CRRL and H RRL emissions is co-located with the foreground low 0 density gas while the high frequency CRRLs originate from the PDR associated with the denser material at the far side of the H ii region (eg. Wilson & Thomasson 1975, Pankonin et al. 1977, Kr¨gel et al. 1982). u
Almost all previous studies of RRL emission toward NGC 2024 were single dish observations. At frequencies < ∼ 15 GHz, the angular resolutions of these observations are several arcminutes. The angular resolution of the single dish observations are, however, inadequate for modeling CRRL and H RRL emission as the beam dilution factor is unknown. 0 High angular resolution images at frequencies < ∼ 15 GHz with full spatial information are needed to better estimate the physical properties of the PDR. In this paper, we present new high sensitive, high angular resolution RRL observations toward NGC 2024 at 1.4 GHz (angular resolution ∼ 70 ) and 4.8 GHz (angular resolution ′′ ∼ 17 ) with the VLA (Very Large ′′ Array). To obtain the complete spatial information at 4.8 GHz, we combined RRL observations made with the GBT (Green Bank Telescope) to VLA data. The observations and data analysis methods are described in Section 2. The observed features of the continuum and RRL emission are discussed in Section 3 and 4, respectively. The data set is used to model the physical properties of the region responsible for CRRL and H RRL emission, which is 0 discussed in Section 5. In Section 6, the physical properties are used to derive the magnetic field in the CRRL emitting region using method proposed by Roshi (2007). Discussion and summary of the results are given in Section 7.
## 2. Observation and data reduction
We observed recombination lines toward NGC 2024 using the D-configuration of the VLA near 1.4 and 4.8 GHz in dual polarization mode. The RRLs observed are the 166 α transition of carbon (1425.444 MHz) and hydrogen (1424.734 MHz) near 1.4 GHz and the
110 α transition of carbon (4876.589 MHz) and hydrogen (4874.157 MHz) near 4.8 GHz. The uv sampling of VLA at the shortest spacing is not adequate to image the full angular extent of NGC 2024 at 4.8 GHz. Therefore we observed the source in 'On-the-fly' mapping mode with the Green Bank Telescope (GBT) at 4.8 GHz and combined this data with that obtained with the VLA at the same frequency. Both VLA and GBT observations were done during test times. A summary of the observation log is given in Table 1.
The interferometric data was analyzed using Astronomical Image Processing Software (AIPS). After editing and calibration of the default continuum data provided by the VLA (channel 0 data), the flag and calibration tables were transferred to the spectral line data set. The system band-shapes were obtained with the AIPS task BPASS. 3C48 was observed at both frequencies for bandpass and flux density calibration. For continuum subtraction the task UVLSF was used, which also provided the continuum data. The spectral cubes and continuum images were obtained with the AIPS task IMAGR. The final images were corrected for primary beam gain variation using the task PBCOR.
An 'On-the-fly' map of size about 0 .5 o × 0 .5 o centered at RA(2000) 05 41 h m 43 s . 1, DEC(2000) -01 54 00 o ′ ′′ was made with the GBT. The telescope was scanned along RA and at the end of every 6 th RA scan a reference position (RA(2000) 05 35 h m 04 s . 2, DEC(2000) -01 54 38 o ′ ′′ ) was observed. The FWHM beam width of the GBT at the observing freq of 4.9 GHz is 2 .5. ′ The RA scan rate and integration time were chosen to provide about 4 samples within the 2 .5 beam. Along the declination direction, the telescope was scanned at ′ an interval of 0 .5. ′ The GBT data were analyzed using GBTIDL. A modified version of task 'getrefscan' was used to obtain the spectra in units of antenna temperature and re-sampled to the spectral resolution corresponding to the VLA data. A telescope gain of 2 K/Jy was used to convert the spectra in units of Jy per beam. The telescope gain was also measured by observing the calibrator source 3C123. A 3 rd order polynomial baseline was removed from each of the calibrated spectrum. The zeroth order coefficient of the polynomial baseline was used to obtain the continuum data set. The calibrated data were converted to a UVFITS file using the program SDFITS2UV, developed by Glenn Langston. The UVFITS file was transferred to AIPS and the image was made using the SDGRID task. The VLA and GBT data were combined using the CASA function Feather.
## 3. Continuum Emission
The continuum images of NGC 2024 at 1.4 GHz and 4.8 GHz are shown in Fig. 1. The angular resolution of the 1.4 GHz image obtained from VLA data is 75 ′′ × 67 ′′ and the total flux density is 61.0 ± 1.2 Jy. The image at 4.8 GHz, obtained from the combined
GBT and VLA data, has an angular resolution of 22 ′′ × 20 . ′′ The total flux density in this image is 52.5 ± 0.2 Jy. This value is less than the flux-density (57 ± 3 Jy) in the low resolution (152 ′′ × 152 ) GBT image. ′′ The half power beamwidth of the VLA antenna at 4.8 GHz is ∼ 10 ′ and, for our observations, centered at RA(2000) 05 h 41 m 44 5 , DEC(2000) . s -01 54 39 o ′ ′′ . As seen in Fig. 1, the continuum emission in the GBT image and the 1.4 GHz VLA image extends beyond the 10 ′ beamwidth of the VLA antennas at 4.8 GHz. We therefore attribute the difference in flux density in the 4.8 GHz GBT image and the 4.8 GHz combined data image to emission extending beyond the half power beam width of the VLA antenna. The flux density obtained for NGC 2024 at the two frequencies are consistent with earlier observations (eg. Barnes et al. 1989).
Our continuum images are consistent with higher resolution (4 .9 ′′ × 3 .8) ′′ images of Barnes et al. (1989) as well as those presented by Anantharamaiah et al. (1990). A radio plume extending roughly 5 ′ northwards from the main nebula emission is detected in both the 1.4 GHz VLA image and 4.8 GHz GBT image (see Fig. 1). The radio plume was detected and imaged earlier at other frequencies as well (see, for example, Subrahmanyan et al. 1997 at 327 MHz).
## 4. Recombination Line Emission towards NGC 2024
We have detected broad (∆ V ∼ 25 km s -1 ) H166 α and H110 α lines at the two observed frequencies (1.4 and 4.8 GHz). The C166 α and C110 α transitions are also detected. In addition, the H 166 0 α and X166 α lines are detected at 1.4 GHz observations. In this Section, we present images of the line emission and their observed characteristics.
## 4.1. H and H 0 Recombination Lines
Representative profiles of H110 α and H166 α line emission are shown in Fig. 2. The line parameters are summarized in Table 2. The regions over which the data is averaged to obtain the profiles are also included in Table 2. The H166 α line emission shows a narrow component (∆ V ∼ 1.7 km s -1 ) in addition to a broad feature (∆ V ∼ 33 km s -1 ). At 4.8 GHz only the broad component is detected, with a line width ∼ 23 km s -1 . The spatial distributions of the broad HRRL at the two observed frequencies are shown in Fig. 3.
The line-to-continuum ratio of the broad H110 α provides an electron temperature of 7200 K (assuming LTE). This value is consistent with the electron temperature obtained by Kr¨ ugel et al. (1982) from H76 α observations. As mentioned above, the observed H166 α line
width is 1.5 times higher than the width of H110 α line. We suggest that the increase in line width is due to pressure broadening. The inferred local electron density is ∼ 1400 cm -3 . The transverse size of the H ii region is ∼ 0.3 pc. If we assume that the extent of the H ii region along the line-of-sight is also ∼ 0.3 pc, then the derived electron density indicates an emission measure of 6 × 10 5 cm -6 pc. This value is comparable to the emission measure derived from other observations (eg. Subrahmanyan et al. 1997 at 327 MHz).
The H 166 0 α line is detected over a ∼ 2 ′ × 4 ′ region and is centered near the continuum peak (see Fig. 3). The spatial distribution of line emission obtained from our data is similar to that observed earlier by Anantharamaiah et al. (1990). The LSR velocity ( ∼ 9 km s -1 ) of this feature is about 5 km s -1 higher than that of the broad H166 α line and is closer to the central velocity of the C166 α line emission (see below). The spatial distributions of both H 166 0 α and C166 α lines are also in good agreement.
## 4.2. Carbon Recombination Lines
Representative profiles and images of carbon line emission are shown in Fig. 2 and Fig. 3, respectively. The C110 α line emission is detected over a region ∼ 0 .5 ′ × 2 .5, ′ confined to the southern ridge along the H ii region - molecular cloud interface. The integrated line flux density of C110 α transition is ∼ 425 mJy. The central velocity of the C110 α line ranges between 10.0 and 10.5 km s -1 , with an average 10.25 km s -1 .
The angular size of C166 α line emission is ∼ 2.5 ′ × 5 , ′ larger than the angular size of C110 α line emission. The distinct feature of C166 α emission is that the LSR velocity ranges from 8.7 km s -1 to 10.5 km s -1 . The C166 α line emission to the N has velocity ∼ 8.8 km s -1 while the emission to the SE, nearer the ionization front, has a velocity ∼ 10.0 km s -1 . The similar central velocity of the southern C166 α emission and C110 α line emission suggests that the two line forming regions are associated.
The spatial distributions of the H 166 0 α and C166 α line emissions in the VLA images are similar (see Fig. 3). Further, the central velocity of H 166 0 α line ( ∼ 9 km s -1 ) is comparable to the northern C166 α line emission. The line widths of the two lines are also comparable. These similarities suggest that the two line forming regions are spatially co-located (see also Anantharamaiah et al. 1990).
Molecular line observations over a wide range of frequencies (1.6 GHz to 100 GHz) have shown that the H ii region is partially enclosed by the parent molecular cloud (Barnes et al. 1989; see also Fig. 5 and Section 7). The LSR velocity of the gas in front of the H ii region is ∼ 9 km s -1 , similar to the central velocity of the northern C166 α line emission. This
similarity in LSR velocity suggests that the low frequency ( < 2 GHz) carbon line forming region is associated with molecular gas in front of the H ii region. The dense gas located on the far side has an LSR velocity 10.5 km s -1 (see for example Mangnum & Wootten 1993). This LSR velocity compares well with that of the C110 α line, suggesting that the line emission is associated with the dense gas located on the far side of the H ii region. (see also Section 7 and Fig. 5).
## 4.3. X Recombination Lines
The velocity of X166 α is -8.1 km s -1 relative to the C166 α line, which implies a transition from a heavy element such as S, Mg, Si or Fe. The spatial distribution of X166 α emission is shown in Fig. 3 and representative line profiles are shown in Fig 2. The spatial distribution and line width of X166 α are different from those of C166 α and H 166 0 α . We conclude that the X166 α line emission is not associated with the carbon and H 0 line forming regions. Anantharamaiah et al. (1990) came to a similar conclusion based on their 1.4 GHz observations. The X166 α line width is about 0.8 km s -1 , which is about one third that of the carbon line. This smaller width may suggest that the X166 α line is associated with colder ( < 100 K) dust clouds. In such clouds sulphur is less depleted relative to other heaver elements such as Mg, Si and Fe (Pankonin et al. 1977). Based on the expected low depletion of sulphur and velocity separation, we suggest that the X166 α line emission arises from sulphur.
## 5. Models for Carbon and H 166 0 α Line emission
We consider a simplified model consisting of homogeneous 'slabs' of PDR, co-located with the molecular gas. The recombination line flux density from the PDRs is obtained by solving the radiative transfer equation for non-LTE cases. A program to compute the non-LTE departure coefficients b n and β n was developed. This program uses new numerical techniques to solve for the departure coefficients based on the formulism developed by Brocklehurst & Salem (1977) and Walmsley & Watson (1982). For a given gas temperature ( T PDR ) and electron density ( n PDR e ), we solve separately for the departure co-efficients of hydrogenic and carbon cases. The atomic level population is altered by stimulated emission, which is due to background radiation field. Therefore, a background thermal radiation field from the H ii region (see below) is included when solving for the departure co-efficients. The depletion of carbon in PDR is inferred to be small ( ∼ 25 % Natta et al. 1994). Therefore in our computation the abundance of carbon is taken to be 0.75 of the cosmic value 3.98 × 10 -4 (Morton 1974). The dielectronic like recombination process that modifies the level
population of the carbon atom (Walmsley & Watson 1982) is also included in the calculation. The coefficients are computed by considering a 10000 level atom with the boundary condition b n → 1 at higher quantum states.
The line brightness temperature, T LB , due to the slab is given by (Shaver 1975)
$$T _ { L B } = T _ { b g, \nu } + T _ { i n, \nu }$$
where
$$T _ { b g, \nu } \ & = \ T _ { 0 b g, \nu } e ^ { - \tau _ { C \nu } } ( e ^ { - \tau _ { L \nu } } - 1 ) \, \\ T _ { i n, \nu } \ & = \ T _ { P D R } \left ( \frac { b _ { m } \tau _ { L \nu } ^ { * } + \tau _ { C \nu } } { \tau _ { L \nu } + \tau _ { C \nu } } ( 1 - e ^ { - ( \tau _ { L \nu } + \tau _ { C \nu } ) } ) - ( 1 - e ^ { - \tau _ { C \nu } } ) \right ).$$
T bg,ν is the contribution to the line temperature due to the background radiation field and T in,ν is the intrinsic line emission from the slab. In Eq. 2, T 0 bg,ν is the background radiation temperature due to the H ii region; τ Cν is the continuum optical depth of the PDR. The nonLTE line optical depth of the spectral transition from energy state m to n , τ Lν , is defined as τ Lν = b n β τ n ∗ Lν where τ ∗ Lν is the LTE line optical depth, b n and β n are the departure coefficients of energy state n . τ ∗ Lν ∝ n PDR e n l i , where n i is the ion density and l is the line-of-sight path length of the PDR; n i is equal to n C + for the carbon line computation, while n i is equal to n H + for the hydrogen line computation. For the carbon line computation we assume that n PDR e = n C + = n e ; thus τ ∗ Lν ∝ n l 2 e . The neutral density, n H , in the PDR is obtained as n H = n PDR e / (0 75 . × 3 98 . × 10 -4 ). The line brightness temperature is finally converted to flux density using the observed angular sizes of the line emission, tabulated in Table 2.
## 5.1. Foreground Carbon line emission
The observed parameters of the line emission from the foreground PDR is obtained by averaging the spectra over region A shown in Fig. 2. The region is selected such that it is northward of the C110 α line emission, thus avoiding contribution from the PDR emission from the far side of the H ii region. The line and continuum parameters are given in Table 2. The images at the two observed frequencies are convolved to the same angular resolution (73 ′′ × 69 ) before obtaining these parameters. ′′ The continuum flux density at 1.4 and 4.8 GHz toward region A is consistent with emission from an H ii region with parameters Te ∼ 7000 K and EM ∼ 3.5 × 10 5 pc cm -6 .
The foreground PDR is approximated with a slab of partially ionized gas with background radio continuum emission due to H ii region with the above mentioned properties.
Departure coefficients are obtained for a set of T PDR between 100 and 200 K and n PDR e between 1 and 10 cm -3 . The model flux density for these gas properties are required to be consistent with the observed values. This requirement is realized by varying l . A range of models are found to be consistent with the observed RRL data. Model flux density vs frequency for three gas properties are shown in Fig. 4. Modeling shows that the upper limit on n PDR e is ∼ 5 cm -3 , corresponding to a neutral density of 1.7 × 10 4 cm -3 . For this density, the thickness of the PDR would be 0.06 pc, if the gas temperature is 100 K. To further constrain the PDR properties, we compare the neutral density with values obtained for the foreground gas from molecular line observations. The density obtained from H CO 2 absorption studies is ∼ 4 × 10 4 cm -3 . This density is in rough agreement with the neutral density for the n PDR e ∼ 5 cm -3 model. Based on this agreement, we conclude that the physical properties of the foreground PDR is T PDR ∼ 100 K, n PDR e ∼ 5 cm -3 , n H ∼ 1 7 . × 10 4 cm -3 and l ∼ 0 06 pc. .
The H ii region in NGC 2024 is partially enclosed in the parent molecular cloud (see Fig. 5). In this geometry, a PDR with similar physical properties as that of the foreground PDR should exist on the far side of the H ii region. This PDR is referred to as 'far side low-density PDR' in Fig. 5. We investigate whether such a PDR would produce observable RRLs. For this investigation, the line flux density is calculated by setting the background continuum emission to zero (ie T 0 bg = 0 in Eq. 2). The computed line flux density is < ∼ 10 mJy at all the observed frequencies and therefore we conclude that RRLs from such a PDR would not be detectable. This lower flux density is due to lack of stimulated emission in the absence of background continuum emission.
## 5.2. Carbon line emission from the far side of the H ii region
The observed parameters of the carbon line from the far side of the H ii region are obtained by averaging the data over region B shown in Fig 2. Region B is chosen so as to minimize contamination from the foreground PDR at 1.4 GHz. The images at the two observed frequencies are convolved to the same angular resolution (73 ′′ × 69 ) ′′ to obtain these parameters. The line and continuum parameters are listed in Table 2. The continuum emission within region B is consistent with emission from ionized gas of Te ∼ 7000 K, EM ∼ 5 × 10 5 pc cm -6 .
The LSR velocity of carbon line (10.3 km s -1 ), is similar to the velocity of dense molecular tracers observed from the far side of the H ii region. H i , OH and H CO lines show 2 absorption features near 10 km s -1 as well as a component near 9 km s -1 . The component near 9 km s -1 is due to foreground gas. The absorption line near 10 km s -1 indicates that
a part of the continuum emission is located behind the gas responsible for this line component (see also Crutcher et al. 1999). As mentioned earlier, the PDR responsible for the 10 km s -1 carbon line emission is co-located with this gas. Thus the PDR responsible for the 10 km s -1 line component must be located within the H ii region (see Fig. 5 and Section 7). As discussed below such a geometry is required to explain the CRRL emission from this PDR.
To model carbon line emission, we approximate the far side PDR to be a single slab of partially ionized gas. OH observation shows that a small part of the radio continuum is located behind this PDR (Crutcher et al. 1999). For modeling, we assume that ∼ 10 % of the observed radio continuum emission is located behind the PDR. The line flux densities used to constrain the model are those of C166 α , C110 α (see Table 2) and C76 α emission. The line flux density of C76 α averaged over region B is estimated to be 255 ± 26 mJy from the Kr¨gel u et al. (1982) observations. The foreground PDR contributes to the C166 α emission, thus this line flux density defines an upper limit to the emission from the far side PDR at 1.4 GHz. The departure coefficients for T PDR between 100 and 500 K are computed with a thermal radiation field from ionized gas of Te ∼ 7000 K, EM ∼ 5 × 10 5 pc cm -6 . Results from three representative models are shown in Fig. 4. We found that for gas temperature between 100 and 500 K, models with n PDR e in the range 25 to 300 cm -3 are consistent with the carbon line observations. The temperature of the PDR cannot be constrained. Representative physical properties for the far side PDR are T PDR ∼ 200 K, n PDR e ∼ 50 cm -3 , l ∼ 0 03 pc. . The C166 α flux density predicted by the model is about half the observed value. Since the electron density is an order of magnitude larger than that of the foreground PDR, we refer to this interface region as the 'far side dense PDR' (see Fig. 5). The neutral density in the PDR is 1.7 × 10 5 cm -3 , comparable to the density derived from H CO emission line (LSR 2 velocity 10.5 km s -1 ) observations (3.6 × 10 5 cm -3 ; Mangnum & Wootten 1993).
## 5.3. H line forming region 0
For modeling H 0 line emission, the line parameters are obtained by averaging the spectra over region B shown in Fig. 2. The line and continuum parameters are given in Table 2. The observed continuum emission from this region is consistent with emission from ionized gas with T e ∼ 7000 K and EM ∼ 5 × 10 5 pc cm -6 . The upper limit on the temperature of the PDR obtained from the width of H 166 0 α line is ∼ 70 K. Therefore, for modeling H 0 line emission, we considered T PDR in the range 20 to 70 K. The departure coefficients for these models were obtained for the hydrogenic case. Model flux density vs frequency is shown for three models in Fig. 4. Our data provide an upper limit for n PDR e of ∼ 4 cm -3 for the H 0 region; for higher density the model line flux density exceeds the observed upper limit at 4.8
GHz. No additional constraints on the PDR properties can be obtained from the existing data set. Representative PDR properties are : T PDR ∼ 50 K, n e ∼ 4 cm -3 and l ∼ 0 01 . pc. As suggested in Section 4.2, the H 0 region is co-located with the foreground carbon line forming region. If we assume that the neutral density of the H 0 line forming region is similar to that of the foreground PDR, the ionization fraction is ∼ 10 -4 .
## 6. Magnetic field in the PDR
Alf´en waves in the PDR are strongly coupled to ions, affecting the non-thermal width v of the spectral lines. Roshi (2007) used this effect to derive magnetic fields from the observed widths of carbon recombination lines. The thermal contribution to the line width is removed using the values for T PDR to obtain the non-thermal width V nth . The magnetic field is then obtained as:
where V nth is in cm sec -1 , ρ is the mass density in grams and B is in Gauss. The density, ρ , is obtained from the neutral density in the PDR by considering the effective mass of the gas as 1.4. The derived magnetic field for the foreground PDR is 60 µ G and that for the far side dense PDR is 220 µ G. The error in the estimated field strength is due to error in the observed line width and PDR modeling limitations. We estimate the error in the derived field strength to be about 60 %.
$$B = \frac { \sqrt { 3 } } { 2 } \times \frac { V _ { n t h } } { \sqrt { 8 l n ( 2 ) } } \sqrt { 4 \pi \rho }, \\ \text{ec} ^ { - 1 }, \, \rho \text{ is the mass density in grams and } B \text{ is in Gauss. The density},$$
Crutcher et al. (1999) used OH Zeeman observations to determine the distribution of magnetic field across NGC 2024. The angular resolution of their observation is ∼ 1 , ′ comparable to our observations. The OH line component used to derive the magnetic field has LSR velocity 10.2 km s -1 , similar to the carbon line emission from the far side PDR. A peak field strength of 87 ± 5.5 µ G is obtained toward RA(2000): 05 41 h m 41 5 , DEC(2000): . s -01 55 04 o ′ ′′ . Zeeman observations measure the line-of-sight component of the magnetic field; the measured field strengths are scaled by a factor of 2 to obtain the total magnetic field strength (Crutcher 1999). Our analysis provides the total magnetic field (see Roshi 2007) and the field strength obtained toward RA(2000): 05 41 h m 41 s . 6, DEC(2000): -01 55 03 o ′ ′′ is 220 µ G, which compares well with the total field strength (ie 87 × 2 = 174 µ G) obtained from OH Zeeman measurements. To our knowledge no Zeeman measurements of the magnetic field strength of the foreground gas exists.
## 7. Discussion and Summary
Radio Recombination line transitions H166 α , C166 α , X166 α , H110 α and C110 α were imaged towards the starforming region NGC 2024. We deduced the spatial location and extent of line emitting regions from the images and the LSR velocity structure. Further, we constructed non-LTE models for RRL emission to obtain the physical properties of the line forming regions.
A schematic of NGC 2024 is shown in Fig. 5. This schematic is based on the structure of NGC 2024 proposed by Barnes et al. (1989) and Kr¨gel et al. u (1982). As illustrated, the starforming region comprises of H ii region partially enclosed by the parent molecular cloud with mean density ∼ 10 5 cm -3 . A dense molecular clump, with core density larger than ∼ 10 6 cm -3 , is located at the far side of the H ii region. Photo dissociation regions exist at the H ii -molecular gas interface. We refer to the interface between the parent molecular cloud and H ii region at the near side as the 'foreground PDR' and that at the far side as the 'far side low-density PDR'. The interface between the dense clump and H ii region is referred to as the 'far side dense PDR'.
The C166 α line image reveals that the emission extends in the N-S direction. The LSR velocity of the line ranges from ∼ 8 km s -1 in the N to ∼ 10 km s -1 in the SE, with a mean velocity of 9 km s -1 . The mean velocity is similar to that of molecular lines observed from the near side of the H ii region. Thus we conclude that the C166 α emission originates in the foreground PDR. Non-LTE modeling of CRRL emission shows that this PDR has properties T PDR ∼ 100 K, n e ∼ 5 cm -3 , n H ∼ 1 7 . × 10 4 cm -3 and l ∼ 0 06 pc. . The model also shows that in the absence of stimulated emission, CRRL emission from the far side low-density PDR is not detectable. The estimated magnetic field in the PDR is ∼ 60 µ G.
The image of C110 α line shows that the emission is confined close to the southern boundary of the H ii region with an LSR velocity of 10.3 km s -1 . This LSR velocity is similar to that of molecular lines observed from the dense clump at the far side. We conclude that the C110 α originates from the far side dense PDR. From CRRL modeling we obtain properties for this PDR i.e T PDR ∼ 200 K, n e ∼ 50 cm -3 , n H ∼ 1 7 . × 10 5 cm -3 and l ∼ 0.03 pc. To explain the observed CRRL emission we postulate that the far side dense PDR protrudes into the H ii region (see Fig. 5). We suggest that this protrusion is due to Lyman continuum photons eroding the low density molecular material on either side of the dense clump. This geometry is consistent with the detection of OH absorption line at 10 km s -1 , since part of the radio continuum originates from behind the far side dense PDR (Crutcher et al. 1999). The estimated magnetic field in this PDR is ∼ 220 µ G, comparable with field strength obtained from OH Zeeman observations (Crutcher et al. 1999).
The H166 α line exhibits narrow and broad components. The LSR velocity of narrow hydrogen is ∼ 9 km s -1 , similar to that of molecular lines in the foreground gas and C166 α . Images of H 166 0 α shows that the emission extends in the N-S direction and is similar to C166 α emission. We conclude that the H 166 0 α line emission is co-located with the foreground PDR. The gas properties deduced from modeling H 166 0 α line emission are T PDR ∼ 50 K, n e ∼ 4 cm -3 and l ∼ 0 01 pc. . The ionization fraction in the H 0 line forming region is ∼ 10 -4 . The broad H166 α line originates from the H ii region.
A recombination line from a heaver element has been observed at 1.4 GHz. The spatial distribution of the X166 α is different from that of H 166 0 α and C166 α line emission. The smaller line width of X166 α compared to C166 α line may indicate that the line emission is associated with colder dust clouds. Based on the expected low depletion of sulphur in such clouds and the -8.1 km s -1 velocity offset relative to C166 α , we conclude that the X166 α line emission arises from sulphur.
Observations presented in this paper are the first high-angular resolution RRL observations with full spatial information at 4.8 GHz. The 1.4 GHz observations complement earlier interferometric observations presented by Anantharamaiah et al. (1990). Our data set was used to constrain non-LTE models of CRRL and H RRL line emission. 0 The high angular resolution of the observations allowed us to measure the angular size and construct models for the line forming region. Based on this modeling we have presented a new geometry for the H ii /molecular cloud toward NGC 2024 (see Fig 5). We have also used the data set to demonstrate for the first time that the magnetic field obtained using CRRLs is comparable with values obtained from Zeeman observations.
We are grateful to the anonymous referee for the critical comments and suggestions which have helped in refining the interpretation of our observations and also significantly improved the paper. We thank F.J. Lockman for his help and advice during data reduction, Glen Langston for sharing his computer code to convert GBT data format to UVFITS fits and Dana Balser for his useful comments on the manuscript.
Table 1. Observing log
| Parameters | Values | Values |
|----------------------------------------------|--------------------|--------------------|
| | 166 α | 110 α |
| VLA observations | VLA observations | VLA observations |
| Date of observations | 08-SEP-2000 | 01-AUG-2000 |
| Field center RA (J2000) | 05 h 41 m 44 . 5 s | 05 h 41 m 44 . 5 s |
| Field center DEC (J2000) | - 01 o 54 ′ 39 ′′ | - 01 o 54 ′ 39 ′′ |
| RRLs observed | C166 α | C110 α |
| | H166 α | H110 α |
| Velocity range (km s - 1 ) - CRRL | 40 | 47 |
| - HRRL | 162 | 95 |
| Velocity resolution (km s - 1 )- CRRL | 1.3 | 1.5 |
| - HRRL | 3.1 | 1.8 |
| Phase calibrator | J0521+166 | J0530+135 |
| On-source observing time (hrs) | 2.9 | 2.6 |
| Synthesized beam (arcsec) | 75 × 67 | 18 × 15 |
| Position angle of the synthesized beam (deg) | - 81 o | - 41 o |
| Largest angular size (arcmin) | 20 | 6.5 |
| RMS noise in the spectral cube (mJy/beam) | 8 | 15 |
| RMS noise in the continuum images (mJy/beam) | 4 | 22 |
| GBT observations | GBT observations |
|---------------------------------|--------------------|
| Date of observations | 12-AUG-2002 |
| Field center RA (J2000) | 05 h 39 m 13 s .0 |
| Field center DEC (J2000) | - 01 o 56 ′ 04 ′′ |
| RRLs observed | C110 α , H110 α |
| Velocity range (km s - 1 ) | 308 |
| Velocity resolution (km s - 1 ) | 0.3 |
| On-source observing time (hrs) | 1.0 |
· · ·
Table 1-Continued
| Parameters | Values | Values | Values | |
|----------------------------------------------|-------------|----------|----------|----|
| | 166 α | 110 α | 110 α | |
| Beam (arcmin) | · · · | 2.7 | × 2.7 | |
| RMS noise in the spectral cube (mJy/beam) | · · · · · · | | 34 | |
| RMS noise in the continuum images (mJy/beam) | · · · · · · | | 12 | |
Table 2. Observed parameters
| Line | Flux density | Flux density | V LSR | ∆ V a | Size | b | Comment |
|---------------------------------|---------------------------------|---------------------------------|---------------------------------|---------------------------------|---------------------------------|---------------------------------|---------------------------------|
| | cont (Jy) | line (Jy) | (km s - 1 ) | (km s - 1 ) | ( ′′ × | ′′ ) | |
| HII region | HII region | HII region | HII region | HII region | HII region | HII region | HII region |
| H166 α | 7.1 | 0.044(0.004) | 3.3(1.2) | 33.4(2.8) | 76 | × 76 | Note c |
| H110 α | 6.9 | 0.444(0.006) | 5.7(0.1) | 22.6(0.3) | 76 | × 76 | Note c |
| H 0 line | H 0 line | H 0 line | H 0 line | H 0 line | H 0 line | H 0 line | H 0 line |
| H 0 166 α | 7.1 | 0.09(0.01 g ) | 9.0 | 1.7(1.5) | 76 | × 76 | Note c |
| H 0 110 α | 6.9 | (0.02) | · · · | · · · | 76 | × 76 | Note c |
| Far side carbon line emission | Far side carbon line emission | Far side carbon line emission | Far side carbon line emission | Far side carbon line emission | Far side carbon line emission | Far side carbon line emission | Far side carbon line emission |
| C166 α | 7.1 | 0.08(0.01) f | 8.8(0.1) | 2.4(0.2) | 76 | × 76 | Note c |
| C110 α | 6.9 | 0.10(0.01) | 10.3(0.2) | 2.8(0.4) | 76 | × 76 | Note c |
| Foreground carbon line emission | Foreground carbon line emission | Foreground carbon line emission | Foreground carbon line emission | Foreground carbon line emission | Foreground carbon line emission | Foreground carbon line emission | Foreground carbon line emission |
| C166 α | 22.3 | 0.18(0.02) | 8.8(0.2) | 2.5(0.3) | 236 | × 108 | Note d |
| C110 α | 20.1 | (0.06) | · · · | · · · | 236 | × 108 | Note d |
| X region | X region | X region | X region | X region | X region | X region | X region |
| X166 α | 22.3 | 0.10(0.03) | 0.7 e (0.2) | 0.8(0.4) | 236 | × 108 | Note d |
| X110 α | 20.1 | (0.06) | · · · | · · · | 236 | × 108 | Note d |
a ine widths are corrected for the broadening due to finite spectral resolution.
b Size of the region over which the data are averaged to obtain the spectra.
c Spectra averaged over Region B shown in Fig. 2. The region is centered at
RA(2000): 05 h 41 m 41 s . 6, DEC(2000): -01 55 03 o ′ ′′ .
d Spectra averaged over Region A in Fig. 2, The region is centered at RA(2000): 05 h 41 m 42 s . 7, DEC(2000): -01 53 55 o ′ ′′ .
e SR velocity with respect to carbon.
f The C166 α line flux density can have a contribution from foreground PDR and therefore the listed flux density should be considered as an upper limit to the emission from the far side PDR.
g The error in amplitude is estimated from the residual spectrum obtained after subtracting the Gaussian components
## REFERENCES
Anantharamaiah, K. R., Goss, W. M. & Dewdney, P. E. 1990, in Proceedings of IAU Colloq. 125, Radio Recombination Lines: 25 Years of Investigation, ed. M. A. Gordon & R. L. Sorochenko ( Puschino, USSR: Dordrecht:Kluwer), 123
Anthony-Twarog, B. J. 1982, AJ, 87, 1213
Ball, J. A., Cesarsky, D., Dupree, A. K., Goldberg, L., & Lilley, A. E. 1970, ApJ, 162L, 25
Barnes, P. J., Crutcher, R. M., Bieging, J. H., Storey, J. W. V., & Willner, S. P. 1989, ApJ, 342, 883
Bik, A., Lenorzer, A., Kaper, L., et al. 2003, A&A, 404, 249
Brocklehurst, M. & Salem, M. 1977, Computer Phys. Commun., 13, 39
Buckle, J. V., Curtis, E. I., Roberts, J. F., et al. 2010, MNRAS, 401, 204
Chaisson, E. J. 1973, ApJ, 182, 767
Crutcher, R. M., Roberts, D. A., Troland, T. H., & Goss, W. M. 1999, ApJ, 515, 275
Crutcher, R. M. 1999, ApJ, 520, 706
Crutcher, R. M., Henkel, C., Wilson, T. L., Johnston, K. J., & Bieging, J. H. 1986, ApJ, 307, 302
Dupree, A. K. 1974, ApJ, 187, 25
Gordon, M. A. 1969, ApJ, 158, 479
Graf, U. U., Eckart, A., Genzel, R., et al. 1993, ApJ, 405, 249
Graf, U. U., Simon, R., Stutzki, J., et al. 2012, A&A, 542L, 16
Henkel, C., Walmsley, C. M., & Wilson, T. L. 1980, A&A, 82, 41
Hoang-Binh, D., & Walmsley, C. M. 1974, A&A, 35, 49
Kr¨ ugel, E., Thum, C., Pankonin, V., & Martin-Pintado, J. 1982, A&AS, 48, 345
MacLeod, J. M., Doherty, L. H., & Higgs, L. A. 1975, A&A, 42, 195
Mangnum, G. J., & Wootten, A. 1993, ApJS, 89, 123
Mezger, P. G., Sievers, A. W., Haslam, C. G. T., et al. 1992, A&A, 256, 631
Morton, D. C, 1974, ApJL 193, L35
Natta, A., Walmsley, C. M., & Tielens, A. G. G. M. 1994, ApJ, 428, 209
Palmer, P., Zuckerman, B., Penfield, H., Lilley, A. F., & Mezger, P. G. 1967, AJ, 72, 821
Pankonin, V., Walmsley, C. M., Wilson, T. L., & Thomasson, P. 1977, A&A, 57, 341
Roshi, D. A. 2007, ApJ, 658L, 41
Shaver, P. A. 1975, Parmana, 5, 1
Snell, R. L, Mundy, L. G., Goldsmith, P. F., Evans II, N. J., & Erickson, N. R. 1984, ApJ, 276, 625
Subrahmanyan, R., Goss, W. M., Megeath, S. T., & Barnes, P. J. 1997, MNRAS, 290, 431
Tucker, K. D., Kutner, M. L., & Thaddeus, P. 1973, ApJ, 186L, 13
Rickard, L. J, Zuckerman, B., Palmer, P., & Turner, B. E. 1977, ApJ, 218, 659
van der Werf, P. P., Goss. W. M., Heiles, C., Crutcher, R. M., & Troland, T. H. 1993, ApJ, 411, 247
Walmsley C. M., & Watson W. D. 1982, ApJ, 260, 317
Wilson, T. L., & Thomasson, P. 1975, A&A, 43, 167
This preprint was prepared with the AAS LT E X macros v5.2. A
Fig. 1.The continuum images of NGC 2024. (a) The image made with the GBT at 4.8 GHz. The angular resolution of the image is 152 . ′′ The contour levels are ( -3,3,5,10,20,30,40,50,100,150,200,250,300,350,400) × 50 mJy/beam. (b) The image made from the combined GBT and VLA data at 4.8 GHz with an angular resolution of 22 ′′ × 20 ( ′′ -71 ). o The contour levels are ( -1,1,2,3,5,10,20,30,40,50,100,150,200) × 50 mJy/beam. (c) VLA image of NGC 2024 at 1.4 GHz. The angular resolution of the image is 75 ′′ × 67 ( ′′ -81 ). o The contour levels are ( -1,1,2,4,10,20,40,60,80,100,200,400,500) × 20 mJy/beam.
0.2
1.5
Fig. 2.Representative spectra of the observed lines toward NGC 2024. The spectra are obtained by averaging the data over the region A (top) and B (bottom). The observed transitions are marked on the plot. The observed spectrum is shown by dashed line, Gaussian component model for the line emission is shown by the solid line and the residual obtained after subtracting the model from the observed spectrum is shown by the dotted line.
RIGHT ASCENSION (J2000) Fig. 3.Contours of different spectral line emission observed toward NGC 2024. (a) Contours of the peak line amplitude of the H110 α emission. The contour levels are (1 to 25) × 5.2 mJy/beam. The angular resolution of the line image is 22 ′′ × 20 ( ′′ -71 ). o (b) Contours of the peak line amplitude of the C110 α emission. The contour levels are (1 to 20) × 5.1 mJy/beam. The angular resolution of the image is 22 ′′ × 20 ( ′′ -70 ). (c) Contours of the peak o line amplitude of the H166 α emission. The contour levels are (5 to 25) × 3.2 mJy/beam. The angular resolution of the image is 75 ′′ × 67 ( ′′ -82 ). o (d) Contours of the peak line amplitude of the C166 α emission. The contour levels are (1 to 20) × 13.2 mJy/beam. The angular resolution of the image is 73 ′′ × 69 ( ′′ -89 ). o (e) Contours of the peak line amplitude of the H 166 0 α emission. The contour levels are (1 to 20 ) × 5.3 mJy/beam. The angular resolution of the image is 75 ′′ × 67 ( ′′ -82 ). o (f) Contours of the peak line amplitude of the X166 α emission. The contour levels are (1 to 20) × 5.3 mJy/beam. The angular resolution of the line image is 73 ′′ 69 ( ′′ 89 ) o
Fig. 4.- Line flux density as a function of frequency for a subset of models consistent with RRL observations. Results of modeling for the foreground PDR, far side PDR and H 0 region are shown respectively on the top, middle and bottom panels. The flux density of the detected lines along with ± 1 σ error bars are shown in the top and middle panel; the error bar is ± 3 σ in the bottom panel. The upper limit for line flux density at 4.8 GHz are shown by triangles in the top and bottom panels. The flux density of the C166 α line is shown as an upper limit in the middle panel, since this line could have a contribution from the foreground PDR. The line flux density of C76 α transition (near 15 GHz) shown in the middle panel is estimated from Kr¨gel et al. (1982) data. u The model parameters corresponding to the different curves are shown on each plot.
Fig. 5.- Schematic of the H ii /molecular cloud toward NGC 2024. This schematic is based on the structure of NGC 2024 proposed by Barnes et al. (1989) and Kr¨gel et al. u (1982). The starforming region comprises of H ii region partially enclosed by the parent molecular cloud with mean density ∼ 10 5 cm -3 . A dense molecular clump is located at the far side of the H ii region. Photo dissociation regions exist at the H ii -molecular gas interface. To explain the observed CRRL emission and OH absorption feature at 10 km s -1 (Crutcher et al. 1999), we suggest that the far side dense PDR protrudes into the H ii region.
 | 10.1088/0004-637X/793/2/83 | [
"D. Anish Roshi",
"W. M. Goss",
"S. Jeyakumar"
] | 2014-08-01T02:17:16+00:00 | 2014-08-01T02:17:16+00:00 | [
"astro-ph.GA"
] | VLA and GBT Observations of Orion B (NGC 2024, W12) : Photo-dissociation Region Properties and Magnetic field | We present images of C110$\alpha$ and H110$\alpha$ radio recombination line
(RRL) emission at 4.8 GHz and images of H166$\alpha$, C166$\alpha$ and
X166$\alpha$ RRL emission at 1.4 GHz, observed toward the starforming region
NGC 2024. The 1.4 GHz image with angular resolution $\sim$ 70\arcsec\ is
obtained using VLA data. The 4.8 GHz image with angular resolution $\sim$
17\arcsec\ is obtained by combining VLA and GBT data. The similarity of the LSR
velocity (10.3 \kms\) of the C110$\alpha$ line to that of lines observed from
molecular material located at the far side of the \HII\ region suggests that
the photo dissociation region (PDR) responsible for C110$\alpha$ line emission
is at the far side. The LSR velocity of C166$\alpha$ is 8.8 \kms. This velocity
is comparable with the velocity of molecular absorption lines observed from the
foreground gas, suggesting that the PDR is at the near side of the \HII\
region. Non-LTE models for carbon line forming regions are presented. Typical
properties of the foreground PDR are $T_{PDR} \sim 100$ K, $n_e^{PDR} \sim 5$
\cmthree, $n_H \sim 1.7 \times 10^4$ \cmthree, path length $l \sim 0.06$ pc and
those of the far side PDR are $T_{PDR} \sim$ 200 K, $n_e^{PDR} \sim$ 50
\cmthree, $n_H \sim 1.7 \times 10^5$ \cmthree, $l \sim$ 0.03 pc. Our modeling
indicates that the far side PDR is located within the \HII\ region. We estimate
magnetic field strength in the foreground PDR to be 60 $\mu$G and that in the
far side PDR to be 220 $\mu$G. Our field estimates compare well with the values
obtained from OH Zeeman observations toward NGC 2024. |
1408.0062v1 | ## Energy Efficiency Scheme with Cellular Partition Zooming for Massive MIMO Systems
Di Zhang , Zhenyu Zhou , Keping Yu ∗ † ∗ and Takuro Sato ∗ ∗ Globle Information and Telecommunication Studies, Waseda University, Tokyo, Japan, 169-8050 Email: di [email protected] † State Key Laboratory of Alternate Electrical Power System with Renewable Energy Sources, School of Electrical and Electronic Engineering, North China Electric Power University, Beijing, China, 102206 Email: zhenyu [email protected]
Abstract -Massive multiple-input multiple-output (Massive MIMO) has been realized as a promising technology for next generation wireless mobile communications, in which Spectral efficiency (SE) and energy efficiency (EE) are two critical issues. Prior estimates have indicated that 57% energy of the cellular system need to be supplied by the operator, especially to feed the base station (BS). While varies scheduling studies concerned on the user equipment (UE) to reduce the total energy consumption instead of BS. Fewer literatures address EE issues from a BS perspective. In this paper, an EE scheme is proposed by reducing the energy consumption of BS. The transmission model and parameters related to EE is formulated first. Afterwards, an cellular partition zooming (CPZ) scheme is proposed where the BS can zoom in to maintain the coverage area. Specifically, if no user exists in the rare area of the coverage, BS will zoom out to sleep mode to save energy. Comprehensive simulation results demonstrate that CPZ has better EE performance with negligible impact on transmission rate.
## I. INTRODUCTION
GREEN technology attacked plentiful attention worldwide because the global political agenda it is. And according to International Telecommunications Union (ITU), information communication industry (ICT) consuming 10% energy worldwide [1]. In wireless mobile communications, it is estimated that nearly 80% energy consumption comes from the operator while 57% consist of cellular BS energy consumption is used to feed the BS for its coverage, QoS of the UE transmission, etc. [2] [3]. Hence, while talking about reducing energy consumption and enhance EE feature of cellular network, more attention should be paid to BS terminal. But unfortunately, previously, most of the studies focus on UE terminal, to reduce the energy consumption or to enhance the EE feature of the whole system by scheduling mechanisms at UE terminal or by better network deployments. Fewer attentions are paid on BS. Another, as the studies, traffic load of wireless mobile networks varies by spatial and time [4] [5]. It is demonstrated that traffic peak epoch appears frequently in urban downtown comparing with rural village [4]. For time distribution, 10:00 12:00 together with 20:00 23:00 are traffic peak time comparing with other periods [4] [5]. That will be realistic for energy saving while concentrating on the power allocation for various requirements and conditions.
and network architecture optimization [6], by improving the EE feature of individual BS area [7] and by energy scheduling schemes that keep the system adaptive to variational network loads [4] [8]. These three categories base on different perspectives, namely network designing, BS optimization, and scheduling mechanism [1]. In [4], a dynamic turn off scheme is proposed for energy saving. In [9], the turn off scheme is adopted with two cellular cooperative systems. But these works only focus on traditional cellular networks conditions. In [10], the zooming scheme is proposed towards EE of cellular networks with CoMP strategy. Where the cellular BS can zoom in to cover more area and zoom out with sleeping mode to save energy. However, the author only draws a framework without further discussion. Those days, more scholars concentrate on the BS optimization that a great deal of algorithms are proposed towards EE with BS, such as [11] [12]. But previously seldom attention is paid to the condition in massive MIMO, which is a potential technology towards 5G [13]. Yet in massive MIMO system, huge number of antennas are deployed. While communicating, one or more antennas that can provide better transmission quality (QoT) will be selected to serve a signal UE. Which is different from previous conditions that one antenna or 4-8 antennas working together (traditional MIMO) to serve all of the UEs. The previous zooming mechanism will not be so good while adopted in massive MIMO because the antennas with no corresponding UEs will be still working. In our previous studies [14] [15], some power allocation mechanisms are proposed towards massive MIMO, but antenna selection is focused in those paper. The individual BS coverage area is neglected.
As the prior studies, EE schemes of cellular network are mainly divided into three categories, by network deployment
Based on all of those, in this paper, to further optimize the EE feature, proposed CPZ scheme divides the coverage area of massive MIMO cellular into partition areas by radius angle and distance. That is,the coverage area is divided not only according to the distance from BS to UEs, but also the angle of coverage circumference. Then we allocate power to the fan section if there are active UEs, otherwise, turn the fan section related antennas to sleep mode. For intra-cell interference between UEs, zero forcing beamforming (ZFBF) [13] technology is adopted. Comparing with dirty paper coding (DPC) [13], ZFBF can approach the fairly large fraction of
DPC capacity. Note that in this paper, we focus on the zooming mechanism of massive MIMO cellular system to save more energy while satisfying the quality of service (QoS). Detail discussion of antenna selection scheme [14] [15] is left for further study. Here we assume that the selected antennas is optimal for transmission of active UEs. The zooming scheme is compared with previous scheme in [10], results demonstrate that it possesses better EE feature with respect to the quality of service (QoS).
Remaining parts of this paper are structured as follows. Section II introduces the detail system model, max transmission rate with signal to interference plus noise ratio (SINR) and radiated power, the wireless propagation model of BS and its coverage area. In Section III, the CPZ scheme is described. Section IV is the simulation results part. Detail comparison is drawn in this section. In Section V, we conclude this paper.
## II. ANALYSIS OF SYSTEM MODEL
## A. Analysis of Channle Model
Massive MIMO has been approved as one feasible technology for 5G cellular network. In massive MIMO systems, a great deal of antenna dispositions was proposed, for instance, linear, rectangular, cylinder, etc.. Here we consider the cylinder disposition conditions for outdoor environment. In cylinder disposition, typically, there is one massive MIMO BS with hundreds of antennas (here the number denotes as N) and K UEs where K << N (typically, for a massive MIMO system, there are 100 ∼ 200 antennas distributed by cylinder shape that serves 42 UEs.). For simplicity, we assume that the ergodic capacity can be formulated by perfect channel state information (CSI) through pilot of the transmitter. Furthermore, in this paper, only the downlink transmission is considered. The uplink transmission is left for further study.
ZF-BF is used for interference eliminating where the ZFBF matrix is W = [ w , w , ..., w 1 2 k ] . And it is proved to be asymptotically optimal for sum rate sense with respect to huge number of antennas. W is utilized as the beamformer for the N × K channels with w k , a N × 1 vector. Here h k , channel from BS to UE is 1 × N complex-Gaussian entries vector with zero mean and unit variance. Then the total channel matrix, a K × N complex matrix can be defined as H = [ h T 1 , h T 2 , ..., h T k ] . Then following the definition in [12], the ZF-BF matrix can be expressed as:
$$W = H ^ { T } ( H H ^ { T } ) ^ { - 1 } \quad \quad ( 1 ) \quad _ { \cdot } \text{ A}$$
where ( ) . H and ( ) . -1 stand for the conjugate and inverse transpose of a matrix. While adoping ZFBF technology in massive MIMO, received signal of the k th user can be expressed as:
$$y = h _ { k } \frac { w _ { k } } { \sqrt { \gamma } } x _ { k } + h _ { k } \sum _ { i = 1, i \neq k } ^ { K } \frac { w _ { k } } { \sqrt { \gamma } } x _ { k } + n _ { k } \quad \ \ ( 2 ) \quad \ \ t r$$
/negationslash where x k denotes the transmitted signal at the BS terminal of the k th user, that can be expressed as x k = √ P s k k with P k , transmission power of UE k of each UE. Detail relationships of total received power and BS transmission power can be
formulated by wireless propagation model, which is shown in the following discussion in part B. And s k is the transmission signal at the BS terminal of k th user that obeys independent Gaussian distribution that obeys complex Gaussian distribution with zero mean and uniform variance, n k noise signal with zero mean and N 0 variance, γ the normalization factor of signal of the k th user with expression γ = ‖ W ‖ 2 F /K . And ‖ ‖ . 2 F denotes for the matrix Frobenius norm.
Suppose the downlink channels are constituted by components carriers (CCs) where the CCs are sufficient for the usage of kth users, and the maximum bandwidth each CC can carry is B CCs . If SINR k is taken as the signal to interference plus noise ratio of the k th user. Received bit rate of k th UE can be expressed as:
$$R _ { k } = B _ { C C s } \log _ { 2 } ( 1 + S I N R _ { k } ) \text{ \quad \ \ } ( 3 )$$
As the assumption in this paper, B CCS is known with constant value, SINR k should be focused for further study. For simplicity, we assume that the BS power is allocated equally to K UEs. That is, for k th UE, the power is allocated by β = P BS /K . Taking ρ = β/N 0 as the signal to noise (SNR), Thus, the SINR of UE k can be formulated as:
/negationslash
$$S I N R _ { k } = \frac { \rho | h _ { k } w _ { k } | ^ { 2 } } { \rho \sum _ { j = 1, j \neq k } ^ { j = K } | h _ { k } w _ { j } | ^ { 2 } + 1 } \quad ( 4 ) \\ \text{coordine to an 1} \text{ } \text{the bottom or minus vector can be defined}$$
According to equ.1, the beamforming vector can be deduced as:
$$w _ { k } = \frac { h _ { k } ^ { H } } { \| h _ { k } \| }, \ k = 1, \dots, K \quad \text{(5)} \\ \text{hed aforementioned the $7FRF$ can eliminate the}$$
As described aforementioned, the ZFBF can eliminate the intra-interference. While subsituing equ. 5 into equ. 4, the SINR k will be:
$$S I N R _ { k } = \frac { \rho } { ( H H ^ { H } ) ^ { - 1 } / K } \, \text{ \quad \ } \text{(6)}$$
Then substituting equ.6 into equ.3, with arbitrary user selection mechanism and total power constraint to P BS , the achievable ergodic rate of k th UE can be described as:
$$R _ { k } ^ { \prime } & = E \{ B _ { C C s } \log _ { 2 } ( 1 + \frac { \rho K } { t r \{ ( H H ^ { H } ) ^ { - 1 } \} } ) \} \\ & \approx B _ { C C s } \log _ { 2 } ( 1 + \frac { \rho K } { E \{ t r \{ ( H H ^ { H } ) ^ { - 1 } \} \} } ) \\ \text{According to the random matrix theory, the matrix H} ^ { H }$$
According to the random matrix theory, the matrix HH H is a central Wishart matrix. suppose the number of antenna is larger than UE, then the matrix would be a K × K central Wishart matrix with N degrees of freedom, with covariance matrix I , a unitary matrix. Then tr { ( HH H ) -1 } can be deduced as:
$$( 2 ) \quad & \text{coco as}. \\ & \ t r \{ ( H H ^ { H } ) ^ { - 1 } \} = t r \{ ( H H ^ { H } ) ^ { - 1 } H H ^ { H } ( H H ^ { H } ) ^ { - 1 } \} \\ & = t r \{ W ^ { H } W \} \quad & ( 8 ) \\ P _ { k }, \quad & = \| W \| _ { F } ^ { 2 } \\ \text{ips} \quad & \text{According to random matrix theory, as } K, M \text{ growing with a}$$
According to random matrix theory, as K, M growing with a constant ratio α = M/K , it converges to a fixed deterministic value:
Then the max-sum ergodic of per cell can be formulated as:
$$E \{ \| W \| _ { F } ^ { 2 } \} = \frac { K } { M - K } & \quad ( 9 ) \\ \text{ax-sum erocotic of ner cell can be formulated as} \,.$$
$$R _ { s u m } = K B _ { C C s } \log _ { 2 } ( 1 + \frac { \rho K } { E \{ \| W \| _ { F } ^ { 2 } \} } ) \quad ( 1 0 ) \\ \intertext { a m b i n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e n d e s t }$$
## B. Analysis of Propagation Model
While considering about SINR , in the discussion above, like most of the previous studies, the propagation attenuation of power allocation is neglected [4] [6] [13] to keep things simple or focuse on other factors. Yet attenuation do happen during propagation in wireless environment. Here in the following step, we will take attenuation during propagation into consideration while analysing SINR to keep it closer to reality. According to wireless propagation model, after counting on the path loss, shadowing and multi path effect, received power can be formulated as:
$$P _ { k } = \frac { G ( \frac { r } { r _ { 0 } } ) ^ { - \alpha } \Psi P _ { B S } } { K } \quad \quad \ \ ( 1 1 ) \quad \text{acco} \\ \text{alloc}$$
where G denotes for path gain at free space, r propagation distance, r 0 omnidirectional antennas ( value of 1 ∼ 10m for indoor and 10 ∼ 100m for outdoor environment). α path loss exponent, Ψ random variable for slow fading effects, P BS radius power at BS terminal.
While comparing the β in section A and P k here, we can amend the β and ρ as:
$$\beta = \frac { G ( \frac { r } { r _ { 0 } } ) ^ { - \alpha } \Psi P _ { B S } } { K } \quad \quad \ \ ( 1 2 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\rho = \frac { G ( \frac { r } { r _ { 0 } } ) ^ { - \alpha } \Psi P _ { B S } } { K N _ { 0 } } \quad \quad \ \ ( 1 3 ) \quad \text{Site}$$
Take equ.13 into equ.10, the max-sum ergodic bit rate can be expressed as:
$$\text{presseu as}. \\ R _ { s u m } & = K B _ { C C s } \log _ { 2 } ( 1 + \frac { \rho K } { E \{ \| W \| _ { F } ^ { 2 } \} } ) \quad \text{--} \\ & \approx K B _ { C C s } \log _ { 2 } ( 1 + \frac { \rho K } { M - K } ) \quad \text{--} ( 1 4 ) \quad \text{--} N o v \\ & = K B _ { C C s } \log _ { 2 } ( 1 + \rho ( M - K ) ) \quad \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{-- } \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--}; \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--}" \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--}\text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--} \text{--}
\text{III.} &. \text{CPZ SCHEME FOR EE FEATURE} & \text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{---\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{-\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text----\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text---\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\text{--\-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-]+}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}+}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}--}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}}-}-}}-}-}}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-]-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-;-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-)-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}-}$$
## III. CPZ SCHEME FOR EE FEATURE
Assume that the active power of BS for UEs cell search is puny, and further, here we only concern about the traffic request of internet service, for the voice request, it is assumed to be accomplished by other techniques, remote access unites (RAUs), CoMP, etc. In this paper, power consumption is the power for transmission together with the power attenuation during wireless propagation model, other power (e.g., circuit power, etc.) is not taken into account for intractability problem it is. Now the EE formula with bit/joule can be formulated as:
$$\eta = R _ { s u m } / P _ { B S } \text{ \quad \ \ } ( 1 5 ) \text{ \ user }$$
Then the objective of EE optimization can be shown as:
$$\begin{array} { l l } \in \text{$the$ objective of $EE$ optimization can be shown as} \\ & \max \sum _ { i = 0 } ^ { K } B _ { C C s } \log _ { 2 } ( 1 + \rho ( M - K ) ) \\ & \min \sum _ { i = 0 } ^ { K } P _ { i } & & ( 1 6 ) \\ & s. t. & \sum _ { i = 0 } ^ { K } P _ { i } \leq P _ { B S }, & P _ { i } \in [ 0, P _ { B S } ] \\ \end{array}$$
where P i is separately to each UE at the transmission terminal by BS. Now lets take a further look at equ. 16, for the first two function, they are increasing function of variable P i . That is hard to fulfill them at the same time. But take the equ. 12, 13 into account, that will be possible to divide the coverage area into separate parts to decrease the power consumption while assuming the max bit rate of UEs. And as the discussion in section I, the circumference coverage of BS is not always fulfilled by UEs. If the angle of the distribution is taken into account, the power consumption can be further decreased by allocating power for transmission to the destination area but other areas.
TABLE I THE PARTITION ZOOMING ALGORITHM FOR EE IN CELLULAR NETWORKS
| Algorithm 1: the CPZ algorithm | Algorithm 1: the CPZ algorithm |
|----------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|
| Step 1: | Initialization: divide the coverage area into several pieces by the distance and angle |
| Step 2: | When UE joins, execute the cell search and initialization, report the location of UE |
| Step 3: | Calculate the annular coverage, if A UE new ⊆ { A UE exist } , A = A UE new , else A = A UE new , update { A UE exist } with new element A UE new |
| Step 4: | Compare the distance, if d UE new ≤ max d UE exist , d = max d UE exist , else d = d UE new |
| Step 5: | Allocate the BS power by equ. 17 with new A and d . For the other areas without active UEs, BS goes to sleep mode. |
Now we will give the EE scheme based on this conception. As shown in Fig. 1, the cylindrical square above the BS station stands for the massive MIMO antenna arrays. BS can zoom in to cover the UEs or out for energy saving. Firstly, we divided the coverage area into several parts by angle and distance that from UE to BS. While communicating, UE report its location information to BS firstly, then BS calculates the information with angle and distance, and compares it with information of exist UEs. Afterwards, allocate power for transmission. For instance, as shown in Fig. 1, the coverage area is divided into 3 × 18 parts by 3 annulus and 18 equal parts of circumference. For the two UEs right, the minimum annual will be the second annual area counting from the outermost, and here the θ stands for the angle of the separation. Afterwards, the BS allocates the requisite power to satisfy the QoS of transmission of the users, which is decided by the minimum power needed of the
Fig. 1. System model with different annular region.
UEs in each region. It is known that the angle of a circle is 2 π , then we can get the power allocation with function as:
$$P _ { i } = \frac { \rho \theta } { 2 \pi } & & ( 1 7 ) & \text{ eac} \\ & & \text{con}$$
This scheme can be accomplished by the LTE protocols and signaling with UEs information such as location, maximum transmission rate, etc. If we take A stands for the angle that BS needed to cover the UE, d distance of UEs from BS, d UE new distance of new UE from BS, d UE exist distance of existed UEs from BS, A UE new required angle of BS to cover the new UE, A UE exist needed angle of BS to cover the existed UEs, Detail processing process can be shown as in algorithm 1.
## IV. SIMULATION RESULTS
In this section, the proposed scheme for EE of massive MIMO system if described while comparing with traditional coverage scheme of BS and zooming scheme of BS. As for our simulation, we consider the outdoor environment, where take the value of 100 for simulation. And for the distribution of UEs in the coverage area, we assume that the max bit rates are of same value but the location for simulation. All of the values can be found in table 1.
TABLE II SIMULATIONPARAMETERS
| Parameters | Value |
|----------------------------|---------|
| Cell radius R | 1000m |
| Path loss exponent α | 3.7 |
| Shadow fading Ψ | 8db |
| Omnidirectional antennas r | 100m |
| Path gain G | 1 |
| Peak bit rate | 20Mb/s |
| Number of antemmas M | 200 |
| Bandwidth B CCs | 5MHz |
As we can see, as the bit rate has positive correlation relationship with BS power and negative correlation relationship with zoom radius, if the edge transmission is guaranteed, all of the other UEs transmission should be guaranteed. That is because max rate transmission bit rate of UEs is set to
Fig. 2. Power allocation of cellular system with zooming scheme.
be 20Mb/s here. And because of the distances to BS of each UE are randomly distributed, it will be meaningless for comparison with some constant number of UEs. But we can get qualitative simulation results by angle and distances of the UEs comparing with traditional BS coverage scheme.
As shown in Fig.2, we compared the traditional power allocation scheme for cellular coverage with the traditional zooming scheme. In the case that without zooming, the power allocation will be always be maximum as shown by the top line in Fig. 2 for the coverage of cellular system no matter active UEs exist or not. It is clearly that the zooming scheme can reduce the power consumption as described in [10]. That is BS can zoom out to sleep mode for energy saving while no active UEs at the remote area.
Fig.3 compares the proposed CPZ scheme for EE of cellular system with traditional zooming scheme. With top curve denotes for the traditional zooming scheme and other remaining curves, the proposed CPZ scheme, it is clearly that proposed CPZ scheme can further reduce the energy consumption with annular partition methods. But note that the circumference divided by different factors here means that the distribution of UEs is located in the arc segment of coverage in cellular system. If other active UEs appear besides the segment coverage, the CPZ scheme should zoom in for the transmission. On condition that huge numbers of random UEs jointed randomly, the proposed CPZ scheme would approach to traditional zooming scheme.
Fig.4 manifests the energy efficiency of the proposed CPZ scheme and traditional zooming scheme. As described by the curves, the proposed CPZ scheme possess better EE character comparing with the traditional zooming scheme with further divided fan coverage area. The value of EE feature decreases with distance increasing and increases with pies that the circum is divided. It is clearly that the proposed CPZ scheme can enhance the EE feature of massive MIMO system by dividing the coverage area into separate parts with angel and distance. And as described, EE feature possesses positive correction feature with the number of segments of partition
Fig. 3. Power allocation of cellular system with zooming scheme.
Fig. 4. Energy efficiency of CPZ scheme with different distances and angle.
that divided.
## V. CONCLUSION
In this paper, an energy efficiency scheme for massive MIMO system has been proposed. For the coverage areas that with UEs located, BS power is allocated for transmission, in other areas, the BS goes to sleep mode for energy saving. The proposed CPZ scheme in massive MIMO cellular system can save more energy and possess better EE feature comparing with previous methods as discussed above. And it is obviously that when the number and location distribution of UEs are given, the more segments of the annular, the more energy will be saved. The proposed CPZ scheme can be effectively applied to the cellular network for energy saving with respect to EE feature. For the huge number of UEs with random distribution, we should notice with more UEs located outside the edge area of the partition arc areas that divided, more segments should be allocated to cover the new UEs. In this case, it will approach to zooming scheme proposed previously with annular division. And if more UEs located at the remote annular coverage area, the segment division of angle would become the main factor for energy saving. Antenna selection method will be combined next step of this study.
## ACKNOWLEDGEMENT
The author would like to thank Chinese Scholarship Council (CSC) for its financial support of this study, Yu-yang Wang, Southeast University, China, for the valuable discussion.
## REFERENCES
- [1] H.-X. Chen, Y. Jiang, J. Xu, and H. Hu, 'Energy-efficient coordinated scheduling mechanism for cellular communication systems with multiple component carriers,' IEEE J. Sel. Areas Commun. , vol. 31, no. 5, pp. 959-968, May. 2013.
- [2] K. Abdallah, I. Cerutti, and P. Castoldi, 'Energy-efficient coordinated sleep of lte cells,' in IEEE ICC , Jun. 2012, pp. 5238-5242.
- [3] C. Han, S. A. T. Harrold, I. Krikidis, S. Videv, P. Grant, H. Haas, J. S. Thompson, I. Ku, C. Wang, T. Anhle, M. Nakhai, J. Zhang, and L. Hanzo, 'Green radio: radio techniques to enable energy-efficient wireless networks,' IEEE Comm. Mag. , vol. 49, no. 8, pp. 46-54, Jun. 2011.
- [4] S. Zhou, J. Gong, Z. Yang, Z. Niu, and P. Yang, 'Green mobile access network with dynamic base station energy saving,' in ACM MobiCom. , Sep. 2009, pp. 10-12.
- [5] M. Marsan, L. Chiaraviglio, D. Ciullo, and M. Meo, 'Optimal energy savings in cellular access networks,' in IEEE ICC , Jun. 2009, pp. 1-5.
- [6] X. Cheng, C. Wang, H. Wang, X. Gao, X. You, D. Yung, B. Ai, Q. Huo, L. Song, and B. Jiao, 'Cooperative mimo channel modeling and multilink spatial coorelation properties,' IEEE J. Sel. Areas Commun. , vol. 30, no. 2, pp. 388-396, Feb. 2012.
- [7] L. Correia, D. Zeller, O. Blume, D. Ferling, Y . Jading, I. Godor, G. Auer, and L. Vanderperre, 'Challenges and enabling technologies for energy aware mobile radio networks,' IEEE Commun. Mag. , vol. 48, no. 6, pp. 66-72, Nov. 2012.
- [8] S. Kyuho, K. Hongseok, and Y. Y. B. Krishnamachari, 'Base station operation and user association mechanisms for energy delay tradeoffs in green cellular networks,' IEEE J. Sel. Areas Commun. , vol. 29, no. 8, pp. 1525-1536, Sep. 2011.
- [9] M. Marsan and M. Meo, 'Energy efficient management of two cellular access networks,' in ACM SIGMETRICS workshop , Jun. 2009, pp. 1-5.
- [10] Z. Niu, Y. Wu, J. Gong, and Z. Yang, 'Cell zooming for cost efficient green cellular networks,' IEEE Commun. Mag. , vol. 48, no. 11, pp. 74-79, Nov. 2010.
- [11] R. Li, Z. Zhao, X. Chen, J. Palicot, and H. Zhang, 'Tact: A transfer actor-critic learning framework for energy saving in cellular radio access networks,' IEEE Trans. Wireless Commun. , vol. 13, no. 4, pp. 20002011, Apr. 2014.
- [12] M. Hossain, K. Munasinghe, and A. Jamalipour, 'Distributed inter-bs cooperation aided energy efficient load balancing for cellular networks,' IEEE Trans. Wireless Commun. , vol. 12, no. 11, pp. 5929-5939, Nov. 2013.
- [13] M. Jung, T. Kim, K. Min, Y. Kim, J. Lee, and S. Choi, 'Asymptotic distribution of system capacity in multiuser mimo systems with large number of antennas,' in IEEE VTC , Jun. 2013, pp. 1-5.
- [14] Z. Zhou, S. Zhou, J. Gong, and Z. Niu, 'Energy-efficient antenna selection and power allocation for large-scale multiple antenna systems with hybrid energy supply,' in IEEE Globecom Accepted , Austin, TX, USA, Dec. 2014.
- [15] H. Li, L. Song, and M. Debbah, 'Energy efficiency of large-scale multiple antenna systems with transmit antenna selection,' IEEE Trans. Commun. , vol. 62, no. 2, pp. 638-647, Feb. 2014. | null | [
"Di Zhang",
"Zhenyu Zhou",
"Keping Yu",
"Takuro Sato"
] | 2014-08-01T02:32:05+00:00 | 2014-08-01T02:32:05+00:00 | [
"cs.IT",
"math.IT"
] | Energy Efficiency Scheme with Cellular Partition Zooming for Massive MIMO Systems | Massive multiple-input multiple-output (Massive MIMO) has been realized as a
promising technology for next generation wireless mobile communications, in
which Spectral efficiency (SE) and energy efficiency (EE) are two critical
issues. Prior estimates have indicated that 57% energy of the cellular system
need to be supplied by the operator, especially to feed the base station (BS).
While varies scheduling studies concerned on the user equipment (UE) to reduce
the total energy consumption instead of BS. Fewer literatures address EE issues
from a BS perspective. In this paper, an EE scheme is proposed by reducing the
energy consumption of BS. The transmission model and parameters related to EE
is formulated first. Afterwards, an cellular partition zooming (CPZ) scheme is
proposed where the BS can zoom in to maintain the coverage area. Specifically,
if no user exists in the rare area of the coverage, BS will zoom out to sleep
mode to save energy. Comprehensive simulation results demonstrate that CPZ has
better EE performance with negligible impact on transmission rate. |
1408.0063v1 | ## Epidemic spreading driven by biased random walks
Cunlai Pu, Siyuan Li, Jian Yang
Nanjing University of Science and Technology, Nanjing 210094, China
## Abstract
Random walk is one of the basic mechanisms found in many network applications. We study the epidemic spreading dynamics driven by biased random walks on complex networks. In our epidemic model, each time infected nodes constantly spread some infected packets by biased random walks to their neighbor nodes causing the infection of the susceptible nodes that receive the packets. An infected node get recovered from infection with a fixed probability. Simulation and analytical results on model and real-world networks show that the epidemic spreading becomes intense and wide with the increase of delivery capacity of infected nodes, average node degree, homogeneity of node degree distribution. Furthermore, there are corresponding optimal parameters such that the infected nodes have instantaneously the largest population, and the epidemic spreading process covers the largest part of a network.
Keywords: epidemic spreading, biased random walks, complex networks
## 1. Introduction
Unexpected outbreak of many epidemics in biological systems[1, 2] and the spread of viruses in technology systems[3, 4, 5] result in a lot of death or great damage in related systems. The study of epidemiological models has a long history, especially in the field of social science[6, 7]. The SIR (susceptible-infected-removed) model and the SIS (susceptible-infectedsusceptible) model are two representative models which capture the basic properties of epidemic spreading through the transition among several disease states[8, 9]. In SIR model, a susceptible individual will become infected with certain rate when it has contact with infected individuals. An infected individual will get immunity to the disease or die at some constant rate,
and becomes a removed node which means it can not get infected again. Therefore, the spread of disease will terminate when all the infected individuals are removed from the disease. Differently in SIS model, there are just two states, susceptible and infected. A recovered individual can get infected again. If the fraction of infected individuals is large enough the disease will spread indefinitely, otherwise it will die out after sometime. Initially, the epidemic models are considered under the homogeneous mixing hypothesis[10], in which it assumes that each time an arbitrary individual has an equal opportunity to contact with everyone else in the population. Later, results from network science community demonstrate that most real-world networked systems have heterogeneous topological structures[11, 12, 13], and this greatly promote many mathematicians and physicists to explore epidemic models on heterogeneous random networks[14, 15, 16, 17] by means of mean-field approximation[18, 19, 20], generating functions formalism[21] and percolation theory[22]. It was found that for random networks with strongly heterogeneous degree distribution, like many real-world networks, the epidemic threshold is absent, which means epidemics always have a finite probability to survive indefinitely[11, 18].
Besides of topological properities, traffics in networks also have great impacts on the epidemic spreading. For instance, in the Internet computer viruses transmit from a node to another one with data packets. Without transmission of packets, viruses can not spread even if the two nodes are physically connected. Another example is the air traffics speed the spread of disease among different spatial areas. The combination between epidemic spread and traffic dynamics were first considered in the metapopulation model[23] which characterizes the dynamics of systems composed of subpopulations. Then, Meloni et al[24] studied the impact of traffic dynamics on the spread of virus in the Internet, in which the information packets are transmitted with the shortest path protocol. Later, many mechanisms were proposed to suppress the traffic-driven epidemic spreading, for instance controlling the traffic flow[25], the routing strategy[26, 27], or the heterogeneous curing rate[28], deleting some particular edges[29], etc.
Random walk is one of the basic mechanisms related to spreading processes[30, 31, 32]. For example, a mobile phone virus may randomly dial some phone numbers from the directory. Some computer viruses propagate randomly by email or other online communication tools. Therefore, the role of random walks in the epidemic spreading should be explored. We propose an epidemic model driven by biased random walks. In our model, an infected node sends
infected packets at a constant rate to its neighbor nodes through biased random walks. A susceptible node gets infected after receive the infected packets, and will be removed from the set of infected nodes with a constant rate. We inverstigate the spreading dynamics, the optimal control parameter of our model and the influence of network topologies on our model.
## 2. SIR model
We improve the traditional SIR model by incorporating the traffic dynamics driven by random walks. The SIR model is one of the traditional epidemic spread models in literature. In the SIR model, there are three types of nodes including susceptible nodes, infected nodes and removed nodes. A susceptible node is susceptible to epidemics. An infected node is already infected by the epidemic. A recovered node is the one that is removed from the set of infected nodes. Assume the numbers of susceptible, infected and removed nodes at time t are denoted as S t ( ), I ( ) t and R t ( ) respectively. There are three basic elements in the SIR model as follows[8]:
- (1) Assume the number of nodes in the network is fixed to N . Then N = S t ( ) + I ( ) + t R t ( ) for all t .
- (2) At time t , an arbitrary infected node infects the susceptible nodes by a ratio β . Then the increased number of infected nodes at t is β ∗ s t ( ) ∗ I ( ). t
- (3) At time t, the number of infected nodes removed is proportional to the total number of infected nodes I ( ), which is t λ ∗ I ( ). t
According to the three elements, the dynamics of the SIR model can be expressed as follows[8]:
$$\begin{cases} \begin{array} { c } \frac { d I } { d t } & = \beta S I - \lambda I, \\ \frac { d S } { d t } & = - \beta S I, \\ \frac { d R } { d t } & = \lambda I. \end{array} \end{cases} ( 1 ) \\ \sigma \text{ enough all the infected nodes will eventually becomes}$$
When time t is large enough, all the infected nodes will eventually becomes removed nodes, and the epidemic spreading stops.
The SIR model is based on the assumption that a node has equal probability to contact with every other node in a network. However, in real situations, individuals often have heterogeneous numbers of contacts[11]. A few individuals have large number of contacts which will get more contacts according to the rich-get-richer mechanism, while most of the individuals
Figure 1: Illustration of the transitions among the susceptible, infected and removed nodes in our model.

have a few contacts. Especially in the Internet, the epidemic can not spread from a node to another node unless there is transport of infected packets between the two nodes. Additionally, in city networks even the cities are physically well connected, an epidemic can not spread among cities unless individuals who get infected by the disease move among the cities. Therefore, epidemics are often correlated with traffics for their spreading.
## 3. Epidemic model driven by biased random walks
We consider the traffic dynamics driven by biased random walks in the epidemic spreading process. In our model, each time an infected nodes will delivery constantly C infected packets to its neighbor nodes through biased random walks. If an infected or removed node receives the packets, it will drop the packets. If a susceptible node receives the packet, it becomes an infected node and starts delivering infected packets from next time step. An infected node has the probability λ to become a removed node. The transitions among susceptible, infected and removed nodes are shown in Fig. 1.
## 3.1. Dynamics of our model
Assume an arbitrary infected node a which has 〈 K 〉 neighbor nodes. 〈 K 〉 is the average node degree of the network. The degrees of a 's neighbor nodes are k , k 1 2 , · · · , k 〈 K 〉 respectively. According to the biased random walk mechanism, for a neighbor node i the probability that node a sends an infected packet to node i is as follows:
$$P _ { a i } = \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } }.$$
Where α is the control parameter of the biased random walk. When α = 0, all the neighbor nodes have equal opportunity to receive an infected packet delivered from node a which means they have equal probability to get infected. When α > 0, nodes of larger degree have larger probability to receive the packet. When α < 0, nodes of smaller degree have larger probability to receive the packet. Since a send C infected packets each time, the probability that node i will not receive any packets from node a is:
$$\bar { P } _ { a i } & = ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { C }. \\, & \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
Assume X i is an random variable that represents the event that node i is infected. Then X i = 0 means node i hasn't get any infected packet from node a , and node i is not infected. X i = 1 means node i has received at least one of the infected packets from node a , and node i is infected. Then we have:
Then the expected value of X i is:
$$\begin{cases} \ P ( X _ { i } = 0 ) = ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { ( K ) } k _ { j } ^ { \alpha } } ) ^ { C }, \\ \ P ( X _ { i } = 1 ) = 1 - ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { ( K ) } k _ { j } ^ { \alpha } } ) ^ { C }. \end{cases} \\ \text{expected value of $X_{i}$ is: }$$
$$E ( X _ { i } ) = 1 - ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { C }. \quad \quad \quad ( 5 ) \\. \quad \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
Assume a random variable Y that represents the number of neighbor nodes infected by node a . Then the average value of Y is:
$$\Lambda \quad & \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{E} ( Y ) \ & = \ & \sum _ { i = 1 } ^ { \langle K \rangle } E ( X _ { i } ) \\ & = \ & \langle K \rangle - \sum _ { i = 1 } ^ { \langle K \rangle } ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { C }. \\ \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\end{cases} \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \text{e sum is over all the $\langle K \rangle$ neighbor nodes of node $a$. However, in the}$$
Where the sum is over all the 〈 K 〉 neighbor nodes of node a . However, in the epidemic spreading process the neighbor nodes of node a may not be only susceptible nodes. To effevtively estimate the number of neighbor nodes that node a infects, we need to know the number of susceptible nodes among all the neighbor nodes of node a . To estimate the total number of new infected
nodes at time t , we count the ratio µ of susceptible nodes among neighbor nodes of infected nodes in the network, which is as follows:
$$\mu \ & = \ \frac { \sum _ { j = 1 } ^ { I ( t ) } n _ { j } } { \sum _ { j = 1 } ^ { I ( t ) } k _ { j } } \\ & \approx \ \frac { \langle n \rangle } { \langle K \rangle }.$$
Where n j is the number of susceptible nodes among the neighbor nodes of an infected node j . 〈 n 〉 represents the average number of susceptible nodes among all the neighbors of infected nodes at time t . According to Eq. 6 and Eq. 7, the total new infected nodes at time t is:
$$I _ { n e w } ( t ) \ & \approx \ \mathbb { E } ( Y ) * \mu * I ( t ) \\ & \approx \ ( \langle K \rangle - \sum _ { i = 1 } ^ { \langle K \rangle } ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { C } ) * \frac { \langle n \rangle } { \langle K \rangle } * I ( t ). \\ \text{Combinine $Eq $1$ with $Eq $8$ we set the dynamic amounts of our modal}$$
Combining Eq. 1 with Eq. 8, we get the dynamics equations of our model as follows:
$$\begin{cases} \begin{array} { c c } \frac { d I } { d t } & = ( \langle K \rangle - \sum _ { i = 1 } ^ { ( K ) } ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { ( K ) } k _ { j } ^ { \alpha } } ) ^ { C } ) * \frac { ( n ) } { ( K ) } * I ( t ) - \lambda I, \\ \frac { d S } { d t } & = - ( \langle K \rangle - \sum _ { i = 1 } ^ { ( K ) } ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { ( K ) } k _ { j } ^ { \alpha } } ) ^ { C } ) * \frac { ( n ) } { ( K ) } * I ( t ), \\ \frac { d R } { d t } & = \lambda I. \end{array} \end{cases} \\ \text{We study the behaviours of $S(t). $I(t)$ and $R(t)$ with increase of time $t$ on a}$$
We study the behaviours of S t ( ), I ( ) and R(t) with increase of time t t on a large-scale scale-free network. In Fig. 2, S t ( ) decreases abruptly, and then saturates with t . I ( ) t increases with t , then decreases with t , and finally saturates. There is a peak of I ( ) t that corresponds to the instantaneous maximum population of infected nodes. R t ( ) increases abruptly, and then saturates with t , which is opposite to S t ( ). When t is large enough, the epidemic spreading process stops, and R t ( ) is number of all the nodes that have ever been infected and removed finally from the disease. The trends of the curves for biased random walks of α = -1 are similar with that of simple random walks of α = 0. Also, the simulation results and the analytical results obtained from Eq. 9 are consistent, as shown in Fig. 2.
/s32
/s32
/s32
/s32
/s32
Figure 2: S t ( ), I ( ), t and R t ( ) vs. t for α = 0 and α = -1. A randomly selected node is set to be infected initially. Delivery capacity of infected nodes is C = 5. λ = 0 1. . The network is generated by the static model[33]. The parameters are N = 10000, 〈 k 〉 = 5, and γ = 2 5. .
/s32
/s32
/s32
/s32
Figure 3: S t ( ), I ( ), and t R t ( ) vs. t for various delivery capacities C. A randomly selected node is set to be infected initially. α = 0. λ = 0 1. The network is generated by the static . model. The parameters of the network are N = 10000, 〈 k 〉 = 5, and γ = 2 5. .
/s32
/s32
/s32
/s32
Figure 4: S t ( ), I ( ), t and R t ( ) vs. t for various α . A randomly selected node is set to be infected initially. C = 5. λ = 0 1. . The network for (a), (b) and (c) is generated by the static model. The parameters of the network are N = 10000, 〈 k 〉 = 5, and γ = 2 5. . The Epinions network for (d), (e) and (f) has 75, 879 nodes and 508, 960 edges.
## 3.2. Factors of our model
Delivery capacity C of infected nodes is a critical factor in our epidemic spreading model. The larger the delivery capacity of an infected node, the more susceptible neighbor nodes an infected node will likely infects each time. When C →∞ , I new ( ) t →〈 〉 ∗ n I ( ). t Then Eq. 9 is reduced as follows:
$$\begin{cases} \quad \frac { d I } { d t } & = \langle n \rangle * I ( t ) - \lambda I, \\ \quad \frac { d S } { d t } & = - \langle n \rangle * I ( t ), \\ \quad \frac { d R } { d t } & = \lambda I. \end{cases} \\ \intertext { \text{tion results of $S(t)\ I(t)\ and $R(t)\ for different value of $C$ in} }$$
We show simulation results of S t ( ), I ( ) and t R t ( ) for different value of C in Fig.3. Clearly, the larger C , the faster S t ( ), I ( ) and t R t ( ) convergence, and the epidemic spreads. The larger C , the larger population of nodes that has ever been infected which is inferred from S(t) and R(t) when t is large enough. The larger C , the larger instantaneous population of infected nodes which is indicated from the peak of I ( ). t The parameter α is another key factor in our epidemic model which determines the probability that the neighbors of an infected node get infected when C is a limited constant. In Fig. 4, we
/s32
see that α is correlated with the instantaneous maximum number of infected nodes I peak , and the range of the spread that is reflected by the ultimate number of removed nodes R end . α = -1 corresponds to a larger I peak and a larger R end than α = 0 and α = 1. This indicates that random walks biased on small-degree nodes favors the epidemic spreading which is hold for the model network and the Epinions network, as shown in Fig.4. Then we investigate the optimal parameters α opt that lead to the maximum I peak and the maximum R end on the model network and the Epinions network. In Fig.5, we see I peak and R end as a function of α . Clearly, I peak and R end increase with α first, then decrease with α respectively. There are α opt that correspond to maximum I peak and maximum R end respectively. We present the results of maximum I peak , maximum R end , and the corresponding α opt for some real-world networks, as shown in Table 1.
Table 1: maximum I peak and maximum R end with corresponding optimal parameters α for real-world networks. C = 5. λ = 0 1. .
| NAME | NODES | EDGES | I peak | α opt | R end | α opt |
|-----------------|---------|---------|----------|---------|----------|---------|
| Oregon-1 | 10790 | 22469 | 2903.33 | -0.4 | 6010.37 | -0.8 |
| Gnutella | 62586 | 147892 | 37833.4 | -0.8 | 58155.7 | -1.4 |
| Epinions | 75879 | 508837 | 35274.1 | -0.8 | 61560.2 | -1.2 |
| Wiki-Vote | 7115 | 103689 | 4294.22 | -1 | 6623.23 | -1.4 |
| Yeast | 2361 | 7182 | 1314.21 | -0.8 | 2214.63 | -1.2 |
| email-Enron | 36692 | 183831 | 12789.5 | -0.8 | 24254.2 | -1.4 |
| Facebook | 4039 | 88234 | 2105.11 | -0.8 | 3920.21 | -0.4 |
| Geom | 7343 | 11898 | 1778.5 | -0.4 | 3202.5 | -1 |
| Political blogs | 1222 | 19021 | 813.26 | -1.2 | 1192.14 | -2.2 |
| Power grid | 4941 | 6594 | 1278.36 | 0.4 | 4304.27 | -0.2 |
## 4. Impacts of networks structures on our model
We investigate the influence of topological properties of complex networks including average node degree and degree distribution, on the behaviors of our epidemic spreading model. We focus on the spontaneous number of infected nodes I peak and the final population of nodes that have ever been infected R end , as well as the related optimal parameters α opt . According Eq.
/s32
/s32
/s32
Figure 5: I peak and R end vs. α . A randomly selected node is set to be infected initially. C = 5. λ = 0 1. . The networks are the same as in Fig. 4. The results are the average of 100 independent runs.
## 6, we have:
$$6, \, \text{we have} \colon \\ E ( Y ) \ & = \ \langle K \rangle - \sum _ { i = 1 } ^ { \langle K \rangle } ( 1 - \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { C } \\ & = \ \langle K \rangle - \sum _ { i = 1 } ^ { \langle K \rangle } ( 1 - C \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } + \frac { C ( C - 1 ) } { 2 } ( \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { 2 } - \cdots ) \\ & = \ \sum _ { i = 1 } ^ { \langle K \rangle } ( C \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } - \frac { C ( C - 1 ) } { 2 } ( \frac { k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } ) ^ { 2 } + \cdots ). \\ \text{When} \, \langle K \rangle & \to \infty, \, \text{we get} \colon$$
When 〈 K 〉 → ∞ , we get:
$$E ( Y ) \ & \approx \ \sum _ { \begin{subarray} { c } i = 1 \end{subarray} } ^ { \langle K \rangle } \frac { C k _ { i } ^ { \alpha } } { \sum _ { j = 1 } ^ { \langle K \rangle } k _ { j } ^ { \alpha } } \\ \approx \ C$$
Eq. 12 means that generally the number of nodes that an infected nodes infects in one time step increases with average degree 〈 K 〉 , and tends to C , which is further confirmed in Fig. 6. Also, for the whole epidemic spreading process, the maximum I peak and the maximum R end increase substantially, then saturate with 〈 K 〉 respectively, as shown in Fig. 7 and 8. Their corresponding optimal parameters α opt are generally negative and decrease with
/s32
/s32
Figure 6: E( Y ) vs. 〈 K 〉 obtained from Eq. 6.
〈 K 〉 . This indicates that when the networks become dense, random walks should be more biased on small-degree nodes to make the epidemic spreading more intense and wide. These results are consistent both for random networks (Fig. 7) and scale-free networks (Fig. 8). We also investigate the impact of degree distribution on the epidemic spreading dynamics. In Fig. 9, the maximum I peak and the maximum R end increase abruptly, then saturate with γ respectively, and this means when the degree distribution becomes homogeneous, the spread of the epidemic becomes more fierce and wide in the network. The optimal parameters for I peak and R end increase with γ . This indicates when the network becomes homogeneous, the extent that random walks are biased on small-degree nodes to get a wide and fierce epidemic spreading decreases. need less However, the fluctuations in the curves are clear.
## 5. Conclusions and discussions
In summary, we investigate the epidemic spreading on complex networks including model networks and real-world networks. In our model, the epidemic spreading goes with packets transmission driven by biased random walks. Analytical and simulation results demonstrate that Epidemic spreading becomes fierce and wide with increase of delivery capacity of infected nodes, average node degree, and the homogeneity of the network. The optimal parameters of the biased random walks in epidemic spreading are generally negative values. This means the random walks are biased on small-degree nodes to make an intense and wide spread of the epidemic. However, the bi-
/s32
/s32
/s32
/s32
Figure 7: α opt and the corresponding I peak and R end vs. 〈 K 〉 for random networks. The networks are generated by the ER (Erd¨s-R´ enyi) model[34], and the network size is o N = 5000. A randomly selected node is set to be infected initially. C = 5. λ = 0 1. . The results are the average of 10 4 independent runs.
/s32
/s32
/s32
/s32
Figure 8: α opt and the corresponding I peak and R end vs. 〈 K 〉 for scale-free networks. The networks are generated by the static model, the network size is N = 5000, and the power-law parameter is γ = 2 5. . A randomly selected node is set to be infected initially. C = 5. λ = 0 1. The results are the average of 10 . 4 independent runs.
/s32
/s32
/s32
/s32
Figure 9: α opt and the corresponding I peak and R end vs. power-law parameter γ . The networks are generated by the static model, the network size is N = 5000, and the average node degree is 〈 K 〉 = 5. A randomly selected node is set to be infected initially. C = 10. λ = 0 1. The results are the average of 10 . 4 independent runs.
ased random walks are based on only degrees of the nearest neighbor nodes in our model. The effects of biased random walks with more topological information on the epidemic spreading still need to be explored.
## Acknowledgments
This work was supported by the Natural Science Foundation of China (Grant No. 61304154), the Specialized Research Fund for the Doctoral Program of Higher Education of China (Grant No. 20133219120032), and the Postdoctoral Science Foundation of China (Grant No. 2013M541673).
## References
- [1] D. G. Green, T. Bossomaier, eds, Complex systems: from biology to computation, IOS press, 1993.
- [2] H. W. Hethcote, SIAM Rev. 42 (2000) 599.
- [3] J. Balthrop, S. Forrest, M. E. J. Newman, et al, arXiv preprint cs/0407048, 2004.
- [4] P. Wang, M. C. Gonz´lez, C. A. Hidalgo, et al, a Science 324 (2009) 1071.
- [5] A. Vespignani, Nature Physics 8 (2012) 32.
- [6] F. Brauer, C. Castillo-Chavez, Mathematical models in population biology and epidemiology, Springer, 2011.
- [7] L. F. Berkman, I. Kawachi, eds, Social epidemiology, Oxford University Press, 2000.
- [8] N. T. J. Bailey, The Mathematical Theory of Infectious Diseases and its Applications, Griffin, London, 1975.
- [9] R. M. May, Infectious diseases of humans: dynamics and control, Oxford University Press, 1995.
- [10] R. M. Anderson, R. M. May, Infectious diseases of humans, Oxford: Oxford university press, 1991.
- [11] M. Newman, Networks: an introduction, Oxford University Press, 2010.
- [12] S. N. Dorogovtsev, A. V. Goltsev, J. F. F. Mendes, Rev. Mod. Phys. 80 (2008) 1275.
- [13] A. Barrat, M. Barthelemy, A. Vespignani, Dynamical processes on complex networks, Cambridge University Press, Cambridge, 2008.
- [14] T. Zhou, Z. Q. Fu, B. H. Wang, Progress in Natural Science 16 (2006) 452.
- [15] R. Yang, B. H. Wang, J. Ren, et al, Phys. Lett. A 364 (2007) 189.
- [16] G. Yan, Z. Q. Fu, J. Ren, W. X. Wang, Phys. Rev. E 75 (2007) 016108.
- [17] S. W. Chou, K. Wang, Q. Liu, et al, Acta Phys. Sin 61 (2012) 150201.
- [18] R. Pastor-Satorras, A. Vespignani, Phys. Rev. Lett. 86 (2001) 3200.
- [19] Z. Yang, T. Zhou, Phys. Rev. E 85 (2012) 056106.
- [20] F. D. Sahneh, C. Scoglio, P. Van Mieghem, IEEE/ACM Transactions on Networking (TON) 21 (2013) 1609.
- [21] M. E. J. Newman, Phys. Rev. E 66 (2002) 016128.
- [22] R. Cohen, K. Erez, D. ben Avraham, et al, Phys. Rev. Lett. 85 (2000) 4626.
- [23] V. Colizza, A. Vespignani, Journal of Theoretical Biology 251 (2008) 450.
- [24] S. Meloni, A. Arenas, Y. Moreno, PNAS 106 (2009) 16897.
- [25] P. Bajardi, C. Poletto, J. J. Ramasco, et al, PLoS ONE 6 (2011) e16591.
- [26] H. X. Yang, W. X. Wang, Y. C. Lai, et al, Phys. Rev. E 84 (2011) 045101(R).
- [27] H. X. Yang, Z. X. Wu, J. Stat. Mech. 3 (2014) P03018.
- [28] C. Shen, H. Chen, Z. Hou, Phys. Rev. E 86 (2012) 036114.
- [29] H. X. Yang, Z. X. Wu, B. H. Wang, Phys. Rev. E 87 (2013) 064801.
- [30] L. Lov´sz, a Combinatorics: Paul Erd¨s is eighty o 2 (1993) 1.
- [31] J. D. Noh, H. Rieger, Phys. Rev. Lett. 92 (2004) 118701.
- [32] M. Bonaventura, V. Nicosia, V. Latora, Phys. Rev. E 89 (2014) 012803.
- [33] K.-I. Goh, B. Kahng, D. Kim, Phys. Rev. Lett. 87 (2001) 278701.
- [34] P. Erd¨s, A. R´nyi, o e Publ. Math. Inst. Hung. Acad. Sci. 5 (1960) 17. | 10.1016/j.physa.2015.03.035 | [
"Cunlai Pu",
"Siyuan Li",
"Jian Yang"
] | 2014-08-01T02:38:38+00:00 | 2014-08-01T02:38:38+00:00 | [
"physics.soc-ph",
"cs.SI",
"physics.data-an"
] | Epidemic spreading driven by biased random walks | Random walk is one of the basic mechanisms found in many network
applications. We study the epidemic spreading dynamics driven by biased random
walks on complex networks. In our epidemic model, each time infected nodes
constantly spread some infected packets by biased random walks to their
neighbor nodes causing the infection of the susceptible nodes that receive the
packets. An infected node get recovered from infection with a fixed
probability. Simulation and analytical results on model and real-world networks
show that the epidemic spreading becomes intense and wide with the increase of
delivery capacity of infected nodes, average node degree, homogeneity of node
degree distribution. Furthermore, there are corresponding optimal parameters
such that the infected nodes have instantaneously the largest population, and
the epidemic spreading process covers the largest part of a network. |
1408.0065v1 | ## Gas-liquid coexistence for the bosons square-well fluid and the 4 He binodal anomaly
Riccardo Fantoni 1, ∗
1 Dipartimento di Scienze Molecolari e Nanosistemi, Universit` a Ca' Foscari Venezia, Calle Larga S. Marta DD2137, I-30123 Venezia, Italy
(Dated: August 4, 2014)
The binodal of a boson square-well fluid is determined as a function of the particle mass through the newly devised quantum Gibbs ensemble Monte Carlo algorithm [R. Fantoni and S. Moroni, to be published ]. In the infinite mass limit we recover the classical result. As the particle mass decreases the gas-liquid critical point moves at lower temperatures. We explicitely study the case of a quantum delocalization de Boer parameter close to the one of 4 He. For comparison we also determine the gas-liquid coexistence curve of 4 He for which we are able to observe the binodal anomaly below the λ -transition temperature.
PACS numbers: 05.30.Rt,64.60.-i,64.70.F-,67.10.Fj
Keywords: Quantum statistical physics, path integral Monte Carlo, Quantum Gibbs ensemble Monte Carlo, vapor-liquid phase transition, square well bosons, Helium-4, quantum fluids
Soon after Feynman rewriting of quantum mechanics and quantum statistical physics in terms of the path integral [1, 2] it was realized that the new mathematical object could be used as a powerful numerical instrument.
The statistical physics community soon realized that a path integral could be calculated using the Monte Carlo method [3].
Consider a fluid of N bosons at a given absolute temperature T = 1 /k B β with k B Boltzmann constant. Let the system of particles have a Hamiltonian ˆ H = -λ ∑ N i =1 ∇ 2 i + ∑ i<j φ ( | r i -r j | ) symmetric under particle exchange, with λ = /planckover2pi1 2 / 2 m m , the mass of the particles, and φ ( | r i -r j | ) the pair-potential of interaction between particle i at r i and particle j at r j . The many-particles system will have spatial configurations { R } , with R ≡ ( r 1 , . . . , r N ) the coordinates of the N particles. The partition function of the fluid can be calculated [3] as a sum over the N ! possible particles permutations, P , of a path integral over closed many-particles paths X ≡ ( R , . . . , R 0 P ) in the imaginary time interval τ ∈ [0 , β = P/epsilon1 ], discretized into P intervals of equal length /epsilon1 , the time-step, with R P = P R 0 the β -periodic boundary condition.
extensions of Gibbs ensemble Monte Carlo to include quantum effects (some [8] only consider fluids with internal quantum states; others [9] successfully exploit the path integral Monte Carlo isomorphism between quantum particles and classical ring polymers, but lack the structure of particle exchanges which underlies Bose or Fermi statistics), the QGEMC scheme is viable even for systems with strong quantum delocalization in the degenerate regime of temperature. Details of the QGEMC algorithm will be presented elsewhere [5].
More recently a grand canonical ensemble algorithm has been devised by Massimo Boninsegni et al. [4] for the path integral Monte Carlo method. This paved the way to the development of a quantum Gibbs ensemble Monte Carlo algorithm (QGEMC) to study the gas-liquid coexistence of a generic boson fluid [5]. This algorithm is the quantum analogue of Athanassios Panagiotopoulos [6] method which has now been successfully used for several decades to study first order phase transitions in classical fluids [7]. However, like simulations in the grandcanonical ensemble, the method does rely on a reasonable number of successful particle insertions to achieve compositional equilibrium. As a consequence, the Gibbs ensemble Monte Carlo method cannot be used to study equilibria involving very dense phases. Unlike previous
In this communication we will apply the QGEMC method to the fluid of square well bosons in three spatial dimensions as an extension of the work of Vega et al. [10] on the classical fluid. The de Boer quantum delocalization parameter Λ = /planckover2pi1 /σ m ( E ) 1 / 2 , with E and σ measures of the energy and length scale of the potential energy, can be used to estimate the quantum mechanical effects on the thermodynamic properties of nearly classical liquids [11]. We will consider square well fluids with two values of the particle mass m : Λ = 1 / √ 50, close but different from zero, and Λ = 1 / √ 5. In the first case we compare our result with the one of Vega and in the second case with the one of 4 He which we consider in our second application. When studying the binodal of 4 He in three spatial dimensions we are able to reproduce the binodal anomaly appearing below the λ -point where the liquid branch of the coexistence curve shows a re-entrant behavior.
In our implementation of the QGEMC [5] algorithm we choose the primitive approximation to the path integral action discussed in Ref. [3]. The simulation is performed in two boxes (representing the two coexisting phases) of varying volumes V 1 and V 2 = V -V 1 and numbers of particles N 1 = V ρ 1 1 and N 2 = V ρ 2 2 = N -N 1 with V and N = V ρ constants. The Gibbs equilibrium conditions of pressures and chemical potentials equality between the two boxes is enforced by allowing changes in the volumes of the two boxes (the volume move , q = 5)
and by allowing exchanges of particles between the two boxes (the open-insert move , q = 1, plus the complementary close-remove move , q = 2, plus the advance-recede move , q = 3) while at the same time sampling the closed paths configuration space (the swap move , q = 4, plus the displace move , q = 6, plus the wiggle move , q = 7). We thus have a menu of seven, q = 1 2 , , . . . , 7, different Monte Carlo moves where a single random attempt of any one of them with probability G q = g / q ∑ 7 q =1 g q constitutes a Monte Carlo step.
/negationslash
Letting the system evolve at a given absolute temperature T from a given initial state (for example we shall take ρ 1 = ρ 2 = ρ ) we measure the densities of the two coexisting phases, ρ 1 < ρ and ρ 2 > ρ , which soon approach the coexistence equilibrium values.
We denote with V the maximum displacement of ln( V /V 1 2 ) in the volume move, with L ( p ) the maximum particle displacement in box p = 1 2 in the displacement , move, and with M q < P the maximum number of time slices involved in the q = 5 6 move. , In order to fulfill detailed balance we must choose M 1 = M 2 .
First we study a system of bosons in three dimensions interacting with a square well pair-potential
$$\lambda \quad \phi ( r ) = \begin{cases} + \infty \ r < \sigma & \text{$\alpha$} \\ - \mathcal { A } \ \sigma \leq r < \sigma ( 1 + \Delta ) \quad & ( 1 ) \quad & \text{extr} \\ 0 \quad \sigma ( 1 + \Delta ) \leq r \quad & \text{in $F$} \\ \text{ich, for example, can be used as an effective poten-} \quad \text{me} \\ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \\ \end{cases}$$
which, for example, can be used as an effective potential for cold atoms [12] with a scattering length a = σ (1 + ∆)[1 -tan( σ ∆ √ A / 2 λ /σ ) (1 + ∆) √ A / 2 λ ]. We choose A > 0 as the unit of energies and σ as the unit of lengths. We then introduce a reduced temperature T ∗ = k B T/ A and a reduced density ρ ∗ = ρσ 3 . When the mass of the boson is very big, i.e. λ ∗ = λ/ ( A σ 2 ) /lessmuch 1 we are in the classical limit. The classical fluid has been studied originally by Vega et al. [10] who found that the critical point of the gas-liquid coexistence moves at lower temperatures and higher densities as ∆ gets smaller. The quantum mechanical effects on the thermodynamic properties of nearly classical liquids can be estimated by the de Boer quantum delocalization parameter Λ = √ 2 λ ∗ .
During the subcritical temperature runs we register the densities of the gas, ρ g , and of the liquid, ρ l ( > ρ g ), phase (box). When the densities of the two boxes are too close one another we may observe curves crossing which implies that the two boxes exchange identity. It is then necessary the computation of a density probability distribution function, created using the densities of both boxes. When we are at temperatures sufficiently below the critical point, this distribution appears to be bimodal, i.e. it has two peaks approximated by Gaussians. In some representative cases we checked that the peaks of the bimodal so calculated occur at the same densities as the peaks of the bimodal obtained from the single density distribution of the worm algorithm after a careful tuning of the chemical potential [13].
We study the model with ∆ = 0 5 near their classical . limit λ ∗ = 1 100 (Λ / ≈ 0 14 . , a ∗ = a/σ ≈ 1 44) and at an . intermediate case λ ∗ = 1 10 (Λ / ≈ 0 45 . , a ∗ ≈ 0 58). . We choose N = 50, ρ ∗ = 0 3, . L ( p ) = V 1 / 3 p / 10, V = 1 10, we / take all M q equal, adjusted so as to have the acceptance ratios of the wiggle move close to 50%, g 1 = g 2 = g 3 = g 4 = g 7 = 1, g 5 = 0 0001, and . g 6 = 0 1. . Moreover we choose the relative weight of the Z and G sectors of our extended worm algorithm, C [4], so as to have the Zsector acceptance ratios close to 50%. We started from an initial configuration where we have an equal number of particles in boxes of equal volumes at a total density ρ ∗ = 0 3. .
All our runs were made of 10 5 blocks of 10 5 MC steps with properties measurements every 10 2 steps [14]. The time needed to reach the equilibrium coexistence increases with P and in general with a lowering of the temperature.
If we choose λ ∗ = 1 100 and / P = 2, M q = 1 (in this case the advance-recede move cannot occur) we find that our algorithm gives results close to the ones of Vega [10] obtained with the classical statistical mechanics ( λ ∗ = 0) algorithm of Panagiotopoulos [6] [15]. As we diminish the time-step /epsilon1 ∗ = 1 /PT ∗ at a given temperature we can extrapolate to the zero time-step limit P →∞ as shown in Fig. 2. We thus obtain the fully quantum statistical mechanics result for the binodal shown in Fig. 1 which turns out to exist for T ∗ /lessorsimilar 1. This shows that the critical point due to the effect of the quantum statistics moves at lower temperatures. For the studied temperatures the superfluid fraction [16] of the system was always negligible as in the systems studied in Ref. [9] like Neon (Λ ≈ 0 095) and molecular Hydrogen (Λ . ≈ 0 276). .
/negationslash
/negationslash
In order to extrapolate the binodal to the critical point we used the law of 'rectilinear diameters', ρ l + ρ g = 2 ρ c + a T | -T c | , and the Fisher expansion [17], ρ l -ρ g = b T | -T c | β 1 ( | T -T c | + ) c β 0 -β 1 , with β 1 = 1 2 and / β 0 = 0 3265, and . a, b, c fitting parameters with c = 0 for λ = 0 and c = 0 for λ = 0.
Upon increasing λ ∗ to 1 / 10 the binodal now appears at T ∗ /lessorsimilar 0 008 where we had a non negligible superfluid . fraction [16] ( ρ /ρ s ≈ 0 32(2) at . T ∗ = 0 006 on the liq-. uid branch). As a consequence it proves necessary to use bigger P in the extrapolation to the zero time-step limit. Notice also that at lower temperature it is necessary to run longer simulations due to the longer paths and equilibration times. We generally expect that increasing λ ∗ the gas-liquid critical temperature decreases and the normalsuper fluid critical temperature increases. So the window of temperature for the normal liquid tends to close.
Our second study is on 4 He, for which λ ∗ = 6 0596. . We now take 1 ˚ as unit of lengths and A k B K as unit of energies. In this case σ ≈ 2 5 ˚ , . A E ≈ 10 9K, and Λ . ≈ 0 42. . A situation comparable to the square well case with λ ∗ = 1 10. We use / N = 128 and the Aziz HFDHE2
FIG. 1. (color online) Binodal for the square well fluid in three dimensions. Shown are the classical results of Vega et al. [10] at λ ∗ = 0 and our results in the P → ∞ limit for λ ∗ = 1 100 1 10. In the simulations we used / , / N = 50 and for the extrapolation to the zero time-step limit up to P = 20 for λ ∗ = 1 100 and / P = 500 for λ ∗ = 1 10. / The curves extrapolating to the critical point are obtained as described in the text. The filled triangles are the expected critical points.
FIG. 2. (color online) Linear fit to the zero time-step limit P →∞ for T ∗ = 1 and λ ∗ = 1 100. /
pair-potential [18]
$$\phi ( r ) = \begin{cases} \, \epsilon \phi ^ { * } ( x ) \ r < r _ { \text{cut} } \\ 0 \, & r \geq r _ { \text{cut} } \\ & / C _ { \epsilon } \, & C _ { \epsilon } \, \cdot \, & C _ { \epsilon } \, \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \cdot \, & \dots \end{cases}$$
$$\phi ^ { * } ( x ) = A \exp ( - \alpha x ) - \left ( \frac { C _ { 6 } } { x ^ { 6 } } + \frac { C _ { 8 } } { x ^ { 8 } } + \frac { C _ { 1 0 } } { x ^ { 1 0 } } \right ) F ( x ), \, ( 3 ) \quad \text{a squ} \\ \quad \text{cle m}$$
$$F ( x ) = \begin{cases} \exp [ - ( D / x - 1 ) ^ { 2 } ] & x < D \\ 1 & x \geq D \end{cases}, \quad \begin{pmatrix} \Gamma & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phphi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \PhPh & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Php & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phph & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phip & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Ph i & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phigma & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phia & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Ph & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phis & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phish & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phih & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phrib & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phig & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phj & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phie & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phsi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phs & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi & \Phi &$$
where x = r/r m , r m = 2 9673, . /epsilon1/k B = 10 8, . A = 0 5448504, . α = 13 353384, . C 6 = 1 3732412, . C 8 = 0 4253785, . C 10 = 0 178100, . D = 1 241314, and . r cut = 6 ˚ A (here we explicitly checked that during the simulation the conditions V 1 / 3 p > 2 r cut for p = 1 2 are always satisfied). ,
In this case it proves convenient to choose ρ ∗ = 0 01, . L ( p ) = V 1 / 3 p / 10, V = 1 10, / g 1 = g 2 = g 3 = g 4 = g 7 = 1, g 5 = 0 0001, and . g 6 = 0 1. As for the SW case we observe . a decrease of the width of the coexistence curve ρ l -ρ g as the number of time slices increases. We thus work at a small (fixed) time-step /epsilon1 ∗ = 0 002 about 1 . / 1000 of the superfluid transition temperature as advised in Ref. [3] to be necessary when studying Helium with the primitive approximation for the action.
The results for the binodal are shown in Fig. 3. The experimental critical point is at T c = 5 25K and . ρ c = 17 3mol/l [19]. . Factors explaining the discrepancy with experiment could be the size error or the choice of the pair-potential. Choosing bigger sizes N it is possible to increase r cut and this shifts the simulated critical temperature to higher values. For the three dimensional 4 He we expect to have the superfluid below a λ -temperature T ∗ λ = 2 193(6) [4], . so our results again show that our method works well even in the presence of a non negligible superfluid fraction. Moreover as shown by the points at the two lowest temperatures we are observing the expected [20] binodal anomaly below the λ -point.
FIG. 3. (color online) Binodal for the 4 He of Aziz [18] in three dimensions. In our simulations we used N = 128, r ∗ cut = 6, and a time-step /epsilon1 ∗ = 0 002. . The continuous (red) curve extrapolating to the critical point are obtained as described in the text. The filled triangle is the estimated critical point. The experimental results from Ref. [19] are also shown as a dashed curve.
In conclusion we determined the gas-liquid binodal of a square well fluid of bosons as a function of the particle mass and of 4 He, in three spatial dimensions, from first principles. The critical point of the square well fluid moves to lower temperatures as the mass of the particles decreases, or as the de Boer parameter increases, while the critical density stays approximately constant.
Our results for 4 He compare well with the experimental critical density even if a lower critical temperature is observed in the simulation. We expect this to be due mainly to a finite size effect unavoidable in the simula-
tion. Nonetheless we are able to determine the binodal anomaly [20] occurring below the λ -transition temperature. The anomaly that we observe in the simulation appears to be more accentuated than in the experiment and the liquid branch of the binodal falls at slightly lower densities.
Even if our QGEMC method is more efficient at high temperatures it is able to detect the liquid phase at low temperatures even below the superfluid transition temperature. The new numerical method is extremely simple to use and unlike current methods does not need the matching of free energies calculated separately for each phase or the simulation of large systems containing both phases and their interface.
R.F. would like to acknowledge the use of the PLX computational facility of CINECA through the ISCRA grant. We are grateful to Michael Ellis Fisher for correspondence and helpful comments.
- ∗ [email protected]
- [1] R. P. Feynman, Rev. Mod. Phys. 20 , 367 (1948).
- [2] R. P. Feynman, Statistical Mechanics: A Set of Lectures , Frontiers in Physics, Vol. 36 (W. A. Benjamin, Inc., 1972) notes taken by R. Kikuchi and H. A. Feiveson, edited by Jacob Shaham.
- [3] D. M. Ceperley, Rev. Mod. Phys. 67 , 279 (1995).
- [4] M. Boninsegni, N. Prokof'ev, and B. Svistunov, Phys. Rev. Lett. 96 , 070601 (2006); M. Boninsegni, N. V. Prokof'ev, and B. V. Svistunov, Phys. Rev. E 74 , 036701 (2006).
- [5] R. Fantoni and S. Moroni, (2014), to be published.
- [6] A. Z. Panagiotopoulos, Mol. Phys. 61 , 813 (1987); A. Z. Panagiotopoulos, N. Quirke, M. Stapleton, and D. J. Tildesley, ibid . 63 , 527 (1988); B. Smit, Ph. De Smedt, and D. Frenkel, ibid . 68 , 931 (1989); B. Smit and D.
- Frenkel, ibid . 68 , 951 (1989); D. Frenkel and B. Smit, Understanding Molecular Simulation (Academic Press, San Diego, 1996).
- [7] A. Z. Panagiotopoulos, Mol. Sim. 9 , 1 (1992); F. Sciortino, A. Giacometti, and G. Pastore, Phys. Rev. Lett. 103 , 237801 (2009); R. Fantoni and G. Pastore, Phys. Rev. E 87 , 052303 (2013).
- [8] F. Schneider, D. Marx, and P. Nielaba, Phys. Rev. E 51 , 5162 (1995); P. Nielaba, Int. J. of Thermophys. 17 , 157 (1996).
- [9] Q. Wang and J. K. Johnson, Fluid Phase Equilibria 132 , 93 (1997); I. Georgescu, S. E. Brown, and V. A. Mandelshtam, J. Chem. Phys. 138 , 134502 (2013); P. Kowalczyk, P. A. Gauden, A. P. Terzyk, E. Pantatosaki, and G. K. Papadopoulos, J. Chem. Theory Comput. 9 , 2922 (2013).
- [10] L. Vega, E. de Miguel, L. F. Rull, G. Jackson, and I. A. McLure, J. Chem. Phys. 96 , 2296 (1992); H. Liu, S. Garde, and S. Kumar, ibid . 123 , 174505 (2005).
- [11] R. A. Young, Phys. Rev. Lett. 45 , 638 (1980).
- [12] C. J. Pethik and H. Smith, Bose-Einstein condensation in dilute gases (Cambridge University Press, Cambridge, 2002) chapter 5.
- [13] N. B. Wilding, Phys. Rev. E 52 , 602 (1995).
- [14] Our QGEMC code took ≈ 90 seconds of CPU time for one million steps of a system of size N = 50 , P = 10 , M q = 5 calculating properties every 100 steps, on an IBM iDataPlex DX360M3 Cluster (2.40GHz). The algorithm scales as N 2 , due to the potential energy calculation, and as P , due to the volume move.
- [15] Note that there is no difference between our algorithm in the limit P = 2 , M q = 1, and λ ∗ → 0 and the one of Panagiotopoulos [6].
- [16] E. L. Pollock and D. M. Ceperley, Phys. Rev. B 36 , 8343 (1987).
- [17] M. E. Fisher, Phys. Rev. Lett. 16 , 11 (1966).
- [18] R. A. Aziz, V. P. S. Nain, J. S. Carley, W. L. Taylor, and G. T. McConville, J. Chem. Phys. 70 , 4330 (1979).
- [19] R. D. McCarty, J. Phys. Chem. Ref. Data 2 (1973); NBS TN , 1024 (1980).
- [20] H. Stein, C. Porthun, and G. R¨pke, Eur. Phys. J. B o 2 , 393 (1998). | 10.1103/PhysRevE.90.020102 | [
"Riccardo Fantoni"
] | 2014-08-01T02:45:34+00:00 | 2014-08-01T02:45:34+00:00 | [
"cond-mat.stat-mech",
"cond-mat.mtrl-sci",
"quant-ph"
] | Gas-liquid coexistence for the bosons square-well fluid and the $\mbox{}^4$He binodal anomaly | The binodal of a boson square-well fluid is determined as a function of the
particle mass through the newly devised quantum Gibbs ensemble Monte Carlo
algorithm [R. Fantoni and S. Moroni, {\sl to be published}]. In the infinite
mass limit we recover the classical result. As the particle mass decreases the
gas-liquid critical point moves at lower temperatures. We explicitely study the
case of a quantum delocalization de Boer parameter close to the one of
$\mbox{}^4$He. For comparison we also determine the gas-liquid coexistence
curve of $\mbox{}^4$He for which we are able to observe the binodal anomaly
below the $\lambda$-transition temperature. |
1408.0066v1 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-8
## Collective phenomena in high-energy nuclear collisions
## Jiangyong Jia
Department of Chemistry, Stony Brook University, Stony Brook, NY 11794, USA,
Physics Department, Brookhaven National Laboratory, Upton, NY 11796, USA
## Abstract
I review experimental studies of collective phenomena in p + Aand A + Acollisions presented in the Quark Matter 2014 conference.
Keywords: Heavy-ion collisions, Fluctuations, Correlations, Collective flow, Ridge
## 1. Introduction
The goal of high-energy nuclear experiments is to understand the properties of the QCD matter created in the heavy-ion collisions. Most progress to this end has been obtained from study of collective flow phenomena, which are sensitive to the dynamics of the system at various stages of the space-time evolution. Extensive measurements of various flow observables in A + A collisions at RHIC and the LHC, in combination with successful modeling by relativistic viscous hydrodynamics, have placed important constraints the transport properties and initial conditions of the produced matter [1, 2].
Recently, qualitatively similar collective behaviour has also been observed in high-multiplicity p + Acollisions [3]. Current debate is focused on the e GLYPH<11> ective mechanism behind the apparent collectivity in these small systems: Is it initial state e GLYPH<11> ect, final state e GLYPH<11> ect or both?
This proceedings reviews the new results from p + A and A + A collisions from RHIC and the LHC, obtained with various flow observables. I first summarize experimental progresses in studying the collectivity in small collision systems. I then make a few remarks on flow results in A + A collisions that I personally found interesting. This is followed by a focused discussion of the event-by-event (EbyE) flow fluctuations measurements in A + A collisions. Finally I discuss open issues and future physics opportunities.
## 2. Collectivity in small system
The observation of collective behaviour in high-multiplicity p + A collisions [3] came as a surprise, since the transverse size of the produced system was thought to be too small for the hydrodynamic description to work. Experimentalists attempt to elucidate this puzzle by mapping out the detailed properties of the azimuthal harmonics in p + A collisions and comparing with those in peripheral A + A collisions.
Figure 1 (a) shows the first five azimuthal harmonics v 1 to v 5 as a function of p T in high-multiplicity p + Pb collisions, obtained from a two-particle correlation (2PC) method [4]. The away-side and near-side short-range correlations have been estimated from events with low multiplicity and subtracted. The vn magnitude is largest for n = 2, and decreases with increasing n . All vn increase with p T up to 3-5 GeV and then decrease, but remain positive at higher p T. It is interesting that the v 2 and v 3 values are sizable at p T > 8 GeV (3-5%), reflecting a significant near-side
Figure 1. The vn ( p T) with n = 2 to 5 for pairs with j GLYPH<1> GLYPH<17> j > 2 [4]. An overlay sketch of rapidity-even v 1 data is also shown. Results are compared to the CMS data with comparable multiplicity.
ridge regardless of the recoil subtraction procedure as shown in the right panels of Figure 1. This maybe the first indication of a small azimuthal anisotropy of jet yield in high-multiplicity p + Pb collisions.
Figure 1 also shows an overlay sketch of the preliminary rapidity-even v 1 [4]. The values of v 1 are comparable to v 3 at p T GLYPH<24> 4 GeV, albeit with larger uncertainties since they are directly sensitive to the recoil subtraction.
Figure 2. The v 2 results obtained from two, four, six, eight-particle cumulants, as well as Lee-Yang Zero (LYZ) method, averaged over the p T range of 0.3-3.0 GeV, as a function of number of charged particles in Pb + Pb (left panel) and p + Pb (right panel) collisions [5].
Multi-particle cumulants beyond 2PC have been argued to be able to distinguish the correlation arising from collective dynamics from those arise from sources involving a few particles. CMS presents a detailed measurement of multi-particle cumulants v 2 f 4 , g v 2 f 6 g and v 2 f 8 , as well as Lee-Yang Zero (LYZ) method g v 2 f LYZ [5]. They agree g within GLYPH<6> 10% over a broad multiplicity range in p + Pb or Pb + Pb collisions (Figure 2), confirming the collective nature of the observed correlations in both systems. The apparent di GLYPH<11> erence from v 2 f 2 g reflects the fluctuations either present in the initial geometry or generated in the collective expansion.
Hydrodynamic is the commonly accepted description for vn in central and mid-central A + A collisions. However, as the system size decreases, this description is expected to break down at some point. Comparison of vn between p + Pb and Pb + Pb at similar multiplicity can help us to understand where and how the break down takes place. Figure 3 compares the multiplicity dependence of the integral v 3 (left panel) and the p T dependence of v 3 (right panel) [6] between the two collision systems. Very similar multiplicity and p T dependence are observed between the two systems, suggesting that the collectivity is controlled by total multiplicity, as expected from a argument based on conformal hydrodynamic [7]. This conformal scaling argument also qualitatively explains the similarity of the multiplicity dependence of the HBT radii in p + p , p + Pb and Pb + Pb collisions [8]. CMS also presents a precision measurement of v 2
and v 3 for Ks 0 and GLYPH<3> in p + Pb collisions [9], a clear particle-mass dependence is seen that is persist to at least 5 GeV in p T with a magnitude similar to values in Pb + Pb collisions at comparable multiplicity.
Figure 3. The v 3 data compared between p + Pb and Pb + Pb collisions as a function of charged particle multiplicity in j GLYPH<17> j < 1 [6] (left panel) and as a function of p T [4] at approximately the same multiplicity (right panel) in the two systems. In the right panel, the Pb + Pb data are rescaled horizontally by a constant factor of 1.25 to match the h p T i in p + Pb collisions.
Here I would like to caution people about one technical aspect of those 2PC analyses that rely on the ZYAM (zero-yield at minimum) procedure. In this procedure, the near-side excess associated with the long-range ridge is obtained by subtracting a constant pedestal that is matched to the minimum of the correlation function. Due to the large and broad away-side jet peak (especially at low p T), the tail of the away-side peak tends to feed into the near-side region and create a minimum at GLYPH<1> GLYPH<30> ZYAM = 0. As long as the ridge yield is not enough to fill the near-side jet valley, one always finds zero ridge yield despite the apparent change in the near-side shape of the correlation function (see Figure 4(a) from [10]). Consequently, the multiplicity dependence of the extracted near-side per-trigger yield exhibits a step-like structure at small N ch [3] (Figure 4(b)). This step could be misinterpreted as the onset of ridge or saturation physics.
Figure 4. (a) Azimuthal correlations between mid-rapidity hadrons and forward E T in the d-going direction in p s NN = 200 GeV d + Au collisions [10]. (b) The per-trigger yield for particle pairs selected in 1 < p T < 2 GeV as a function of charged particle multiplicity in p s NN = 2 76 : TeV p + Pb collisions [3].
## 3. Comments on selected flow results in A + A collisions
Several new flow results are worthy of mentioning. ALICE publishes a detailed measurement of v 2 for many identified particles [11]. Comparing to the RHIC results, ALICE results imply stronger radial flow and hadronic rescattering e GLYPH<11> ects. The latter is responsible for a poor number-of-constituent-quark (NCQ) scaling for di GLYPH<11> erent particle species. In particular, the NCQ-scaling of GLYPH<30> -meson v 2 suggests that it flows like a baryon in central collisions and
like a meson in mid-central collisions. This could happen if GLYPH<30> meson undergoes significant hadronic re-scattering in central collision where the radial flow is the largest, despite its small hadronic cross-section.
New flow results in Cu + Au and U + U collisions are reported by PHENIX and STAR [12]. Significant v 1 is measured in Cu + Au collisions with respect to the spectators, reflecting the average dipolar geometry in these collisions. The dependence of the multiplicity dependence of v 2 in ultra-central U + U collisions is found to di GLYPH<11> er from that in the Au + Au collisions, reflecting the influence of the deformed geometry in U + U collisions. However, each collision system introduces its own uncertain in collision geometry, which need to be understood in order to make good use of these new results.
Due to event-by-event fluctuations, it was predicted that the event-plane angle GLYPH<8> n fluctuates in p T, leading to a breakdown of the factorization in extracting the vn from azimuthal harmonics Vn GLYPH<1> in two-particle correlations [13]. This breakdown can be quantified by the rn factor:
$$r _ { n } = \frac { V _ { n \Delta } ( p _ { T } ^ { a }, p _ { T } ^ { b } ) } { \sqrt { V _ { n \Delta } ( p _ { T } ^ { a }, p _ { T } ^ { a } ) V _ { n \Delta } ( p _ { T } ^ { b }, p _ { T } ^ { b } ) } } \approx \frac { \left \langle v _ { n } ( p _ { T } ^ { a } ) v _ { n } ( p _ { T } ^ { b } ) \cos n ( \Phi _ { n } ( p _ { T } ^ { a } ) - \Phi ( p _ { T } ^ { b } ) ) \right \rangle } { \sqrt { \left \langle v _ { n } ^ { 2 } ( p _ { T } ^ { a } ) \right \rangle \left \langle v _ { n } ^ { 2 } ( p _ { T } ^ { b } ) \right \rangle } }$$
rn is expected to be less than one if GLYPH<8> n depends on p T. Experimental data show significant factorization breaking for v 2 in ultra-central Pb + Pb collisions on the order of up to 20% ( r 2 reaches 0.8), consistent with viscous hydrodynamic model predictions [14]. However, the breaking is much smaller for v 2 in other centrality ranges and for other harmonics in the full centrality range [14, 15]. New data in p + Pb collisions from CMS and ALICE suggest the level of breaking is at most a few percents in low p T region [16]. But even some of these deviations could be due to nonflow e GLYPH<11> ects from jets, hence the use of recoil subtraction procedure [4] could be important.
The vn spectrum in ultra-central A + A collisions post a challenge for theory. The original motivation is that the initial conditions in these collisions are predominantly generated by fluctuations such that the magnitudes of first several " n are comparable, and that the hydrodynamic response is expected to be linear vn / " n for all harmonics. Hence these collisions are expected to provide better constraints on the mechanism of the density fluctuations. The precision data from ATLAS [15] and CMS [14] show several features that are not described by models: 1) v 3 is comparable or larger than v 2 , which is challenging since naively one expect " 3 GLYPH<25> " 2 , but the v 3 should su GLYPH<11> er larger viscous correction. 2) The v 2 ( p T) has very di GLYPH<11> erent shape comparing to other harmonics; It peaks at much lower p T, around 1.5 GeV compare to 3-4 GeV for other harmonics. Calculation in Ref. [17] shows that the nucleon-nucleon correlation and e GLYPH<11> ects of bulk viscosity can reduce the v 2 values relative to v 3 .
## 4. Event-by-event flow fluctuations in A + A collisions
In heavy-ion collisions, the number of participating nucleons N part is finite and their positions fluctuate randomly in the transverse plane, leading to strong EbyE fluctuations of " n and participant plane angle GLYPH<8> GLYPH<3> n . Consequently, the matter created in each collision has it own set of flow harmonics, described by a joint probability distribution (pdf):
$$p ( v _ { n }, v _ { m }, \dots, \Phi _ { n }, \Phi _ { m }, \dots ) = \frac { 1 } { N _ { e v t s } } \, \frac { d N _ { e v t s } } { d v _ { n } d v _ { m } \dots d \Phi _ { n } d \Phi _ { m } \dots }.$$
Some projections of this pdf, such as p vn ( ), can be measured directly via unfolding method [18]. But they are more generally studied via m -particle correlations of the following form [19]:
$$\langle \cos ( n _ { 1 } \phi _ { 1 } + n _ { 2 } \phi _ { 2 } \dots + n _ { m } \phi _ { m } ) \rangle = \langle v _ { n _ { 1 } } v _ { n _ { 2 } } \dots v _ { n _ { m } } \cos ( n _ { 1 } \Phi _ { n _ { 1 } } + n _ { 2 } \Phi _ { n _ { 2 } } \dots + n _ { m } \Phi _ { n _ { m } } ) \rangle \,, \Sigma n _ { i } = 0.$$
For example (more can be found in Ref. [21]), the two-particle cumulant of p vn ( ) is obtained as h cos( n GLYPH<30> 1 GLYPH<0> n GLYPH<30> 2 ) i = D v 2 n cos( n GLYPH<8> n GLYPH<0> n GLYPH<8> n ) E = D v 2 n E ; the lowest-order cumulant for p vn ( ; vm ) requires a four-particle correlation of the form [20]:
$$\langle \cos ( n \phi _ { 1 } - n \phi _ { 2 } + m \phi _ { 3 } - m \phi _ { 4 } ) \rangle _ { c } = \langle \cos ( n \phi _ { 1 } - n \phi _ { 2 } + m \phi _ { 3 } - m \phi _ { 4 } ) \rangle - \langle \cos ( n \phi _ { 1 } - n \phi _ { 2 } ) \rangle \langle \cos ( m \phi _ { 3 } - m \phi _ { 4 } ) \rangle = \langle \varkappa _ { n } ^ { 2 } v _ { m } ^ { 2 } \rangle - \langle v _ { n } ^ { 2 } \rangle \langle v _ { m } ^ { 2 } \rangle \ ; \ \ ( 4 )$$
the event-plane correlations p ( GLYPH<8> n ; GLYPH<8> m ; ::: ) can be accessed via a GLYPH<6> ci -particle correlation of the form:
$$\langle \cos ( \Sigma _ { i _ { 1 } = 1 } ^ { c _ { 1 } } \phi _ { i _ { 1 } } + \Sigma _ { i _ { 2 } = 1 } ^ { c _ { 2 } } 2 \phi _ { i _ { 2 } } + \dots + \Sigma _ { i _ { 1 } = 1 } ^ { c _ { 1 } } l \phi _ { i _ { 1 } } \rangle ) = \left \langle v _ { 1 } ^ { c _ { 1 } } v _ { 2 } ^ { c _ { 2 } } \dots v _ { i } ^ { c _ { 1 } } \cos ( c _ { 1 } \Phi _ { 1 } + 2 c _ { 2 } \Phi _ { 2 } \dots + l c _ { 1 } \Phi _ { 1 } ) \right \rangle, \ \ \Sigma i c _ { i } = 0.$$
In the last few years, impressive progresses have been made in studying these flow observables [21]. We now understand that v 2 and v 3 are the dominant harmonics, driven mainly by the linear response to the ellipticity and triangularity of the initially produced fireball [22]: v e i 2 2 GLYPH<8> 2 / " 2 e i 2 GLYPH<8> GLYPH<3> 2 ; v e i 3 3 GLYPH<8> 3 / " 3 e i 3 GLYPH<8> GLYPH<3> 3 . In contrast, the higher-order harmonics v 4 ; v 5 and v 6 arise from both the initial geometry and non-linear mixing of lower-order harmonics [23, 24]:
$$v _ { 4 } e ^ { i 4 \phi _ { 4 } } & = a _ { 0 } \, \varepsilon _ { 4 } e ^ { i 4 \phi _ { 4 } ^ { \prime } } + a _ { 1 } \, \left ( \varepsilon _ { 2 } e ^ { j 2 \phi _ { 1 } ^ { \prime } } \right ) ^ { 2 } + \dots = c _ { 0 } \, e ^ { i 4 \phi _ { 1 } ^ { \prime } } + c _ { 1 } v _ { 2 } ^ { 2 } e ^ { j 4 \phi _ { 2 } } + \dots \,, \\ v _ { 5 } e ^ { i 5 \phi _ { 9 } } & = a _ { 0 } \varepsilon _ { 5 } e ^ { i 5 \phi _ { 9 } ^ { \prime } } + a _ { 1 } \varepsilon _ { 2 } e ^ { j 2 \phi _ { 2 } ^ { \prime } } \varepsilon _ { 3 } e ^ { j 3 \phi _ { 9 } ^ { \prime } } + \dots = c _ { 0 } e ^ { j 5 \phi _ { 9 } ^ { \prime } } + c _ { 1 } v _ { 2 } v _ { 3 } e ^ { j ( 2 0 \varepsilon _ { 2 } + 3 0 _ { 3 } ) } + \dots \,, \\ v _ { 6 } e ^ { i 6 \phi _ { 6 } } & = a _ { 0 } \varepsilon _ { 6 } e ^ { i 6 \phi _ { 6 } ^ { \prime } } + a _ { 1 } \left ( \varepsilon _ { 2 } e ^ { j 2 \phi _ { 2 } ^ { \prime } } \right ) ^ { 3 } + a _ { 2 } \left ( \varepsilon _ { 3 } e ^ { j 3 \phi _ { 9 } ^ { \prime } } \right ) ^ { 2 } + a _ { 3 } \varepsilon _ { 2 } e ^ { j 2 \phi _ { 2 } ^ { \prime } } \varepsilon _ { 4 } e _ { 4 } e ^ { j 4 \phi _ { 4 } ^ { \prime } } + \dots = c _ { 0 } e ^ { j 6 \phi _ { 6 } ^ { \prime } } + c _ { 1 } v _ { 2 } ^ { 3 } e ^ { j ( 6 0 _ { 2 } } + c _ { 2 } v _ { 3 } ^ { 2 } e ^ { j 6 \phi _ { 3 } } + \dots \, ( 6 )$$
Furthermore, the measured p v ( 2 ) distributions show significant deviation in the tail from Bessel-Gaussian function[18], suggesting either the p ( " 2 ) is non-Gaussian [25] or the response of v 2 to " 2 is not strictly linear [26]. New ATLAS results show that the non-Gaussian behavior is captured by < 1 GLYPH<0> 2% di GLYPH<11> erence between v 2 f 4 g and v 2 f 6 , suggesting g that vn f 2 k g for k > 1 are not very sensitive to flow fluctuations given their current systematic uncertainties [27, 21].
The EbyE flow fluctuations can also be studied using various event-shape selection methods [28, 29]. The performances of these methods have been validated in a AMPT model framework [29, 30] and applied in the ATLAS data analysis [31]. In this analysis, the azimuthal angle distribution of the transverse energy E T in the forward calorimeter over 3 3 : < GLYPH<17> j j < 4 9 is expanded into a Fourier series for each event: :
$$2 \pi \frac { d E _ { T } } { d \phi } = \Sigma E _ { T } \left ( 1 + 2 \Sigma _ { n = 1 } ^ { \infty } q _ { n } \cos n ( \phi - \Psi _ { n } ) \right )$$
where the reduced flow vector qn represents the E T-weighted raw flow coe GLYPH<14> cients v obs n , qn = GLYPH<6> GLYPH<16> E v n T obs GLYPH<17> = GLYPH<6> E T. Events are first divided according to GLYPH<6> E T into centrality classes, events in each class are further divided according to the q 2 . This classification separates events with similar multiplicity but with very di GLYPH<11> erent ellipticity. The values of vn are then calculated at mid-rapidity ( j GLYPH<17> j < 2 5) using a 2PC method. :
The correlation of v 2 between two di GLYPH<11> erent p T ranges from ATLAS, presented in Figure 5(a), shows a boomeranglike centrality dependence due to a stronger viscous correction for v 2 at higher p T. In contrast, the correlation within a narrow centrality interval is found to be always linear, suggesting that viscous e GLYPH<11> ects are controlled by the system size not its overall shape. The v 3 -v 2 correlations, shown in Figure 5(b), reveal an anti-correlation that is similar in magnitude to the correlation between " 3 and " 2 (see Figure 6(a)), implying that this correlation reflects mostly initial geometry e GLYPH<11> ects. ATLAS also studied v 4 -v 2 (Figure 5(c)) and v 5 -v 2 correlations. The patterns in these correlations are found to be well described by two-parameter fits of the following form, motivated by interplay between the linear
Figure 5. The correlation of (panel a) v 2 in two di GLYPH<11> erent p T ranges, (panel b) v 3 and v 2 in the same p T range and (panel c) v 4 and v 2 in the same p T range. The data points in each centrality interval correspond to 14 di GLYPH<11> erent ellipticity classes selected via an event-shape engineering technique. These data are overlaid with the centrality dependence without event-shape selection (think grey lines). The thin solid straight lines in the left panel represent a linear fit of the data in each centrality. Results taken from Ref. [31].
Figure 6. The v 3v 2 (left), v 4v 2 (middle) and v 5v 2 (right) correlations measured in 0 5 : < p T < 2 GeV 10-15% centrality interval. The correlation data are fit to functions that include both linear and non-linear contributions. The correlation data are also compared with re-scaled " n -" 2 correlation from the MC Glauber and MC-KLN models. Results taken from Ref. [31].
Figure 7. The centrality dependence of the v 4 (left) and v 5 (right) in 0.5-2 GeV and the associated linear and non-linear components extracted from the fit in Figure 6. They are compared with the linear and non-linear components estimated from the previous published event-plane correlations [24]. Results taken from Ref. [31].
and non-linear collective dynamics given by Eq. 6:
$$v _ { 4 } = \sqrt { c _ { 0 } ^ { 2 } + ( c _ { 1 } v _ { 2 } ^ { 2 } ) ^ { 2 } } \, v _ { 5 } = \sqrt { c _ { 0 } ^ { 2 } + ( c _ { 1 } v _ { 2 } v _ { 3 } ) ^ { 2 } }$$
These fits allow ATLAS to decompose the v 4 and v 5 , centrality by centrality, into linear and non-linear terms as v L n = c 0 and v NL n = q v 2 n GLYPH<0> c 2 0 , respectively, as shown in Figure 7. The linear term associated with " n depends only weakly on centrality, and dominates the vn signal in central collisions. The excellent agreement with a similar decomposition based on the measured EP correlations [24] implies that the correlations between flow magnitudes arise mostly from the correlations between the flow angles.
## 5. Future prospects
The application of event-shape selection techinique is not only limited to flow observables. It should be straightforward to apply this technique to other observables, such as HBT correlation, R AA, dihadron correlation, chiral magnetic e GLYPH<11> ects and more. A study by PHENIX [32] shows that the measured 2 nd -order freezeout eccentricity " f 2 is strongly correlated with selection on the ellipticity. This is qualitatively expected, as events with large v 2 should on average have large " 2 , and hence they may have larger " f 2 .
One open issue is the response or back-reaction of the medium to the energy deposited by jets. CMS results suggest that the lost energy of very high p T jets are transported to very large angle and to low p T particles [33], but not much is know about the back-reaction of the mini-jets that have the energy of a few GeV to few ten's of GeV. These mini-jets are abundantly produced and dominate particle spectrum at intermediate p T. The back-reaction of mini-jets
was historically studied using 2PC analysis aided by flow background subtraction, which su GLYPH<11> ers large systematics due to dominance of collective flow in the correlation structure. We can improve the situation by performing the analysis in events selected to have small vn . But ultimately, 2PC method may not be the best approach to investigate the jetmedium interactions. Instead, we need methods that looks directly the localized GLYPH<17> GLYPH<2> GLYPH<30> structures in the EbyE particle multiplicity or E T distributions. To motivate this idea, Figure 8 shows the EbyE GLYPH<17> GLYPH<2> GLYPH<30> distribution of particle density from a 3 + 1D hydrodynamic calculation based on the AMPT initial condition [34]. The localized peaks and valleys in these events could be remnant of the mini-jets in the initial state. These localized structures, or 'hydro-jets', are much broader than typical highp T jets. They can be found, possibly as fake-jets, by running standard jet reconstruction algorithm. Obviously, the jet finding algorithm may need to be modified in order to maximize the finding e GLYPH<14> ciency and better adapt to the shape of these objects. One can then perform a detailed study of the spectrum and substructure of these hydro-jets.
Figure 8. The distributions of the particles in GLYPH<17> GLYPH<2> GLYPH<30> space for three typical Au + Au collisions at p s NN = 200 GeV in 0-10% centrality interval, obtained from 3 + 1D calculation based on ideal hydrodynamics [34].
Most studies in A + Acollisions consider only fluctuations in the transverse plane, and dynamics in the longitudinal direction are often assumed to be boost invariant. However, a Glauber model calculation [30] shows that the number of participating nucleons and eccentricity vectors ~ " n GLYPH<17> ( " ; n GLYPH<8> n GLYPH<3> ), defined separately for the two colliding nuclei, can di GLYPH<11> er strongly on EbyE basis due to fluctuations: N F part , N B part and ~ " F n , ~ " B . n Furthermore, the energy deposition for each participating nucleon is not symmetric: Particles in the forward (backward) rapidity are preferably produced by the participants in the forward-going (backward-going) nucleus [35]. Due to these two e GLYPH<11> ects, the eccentricity vector and the flow vector ~ vn GLYPH<17> ( vn ; GLYPH<8> n ) of the initially produced fireball should depend on GLYPH<17> (see Figure 9) [30]:
$$\vec { v } _ { n } ( \eta ) \in \vec { \varepsilon } _ { n } ^ { \text{ot} } ( \eta ) \approx \alpha ( \eta ) \vec { \varepsilon } _ { n } ^ { F } + ( 1 - \alpha ( \eta ) ) \vec { \varepsilon } _ { n } ^ { B } \equiv \varepsilon _ { n } ^ { \text{ot} } ( \eta ) e ^ { i n \Phi _ { n } ^ { \text{ot} } ( \eta ) }, \alpha ( \eta ) \approx \frac { f ( \eta ) } { f ( \eta ) + f ( - \eta ) } \, n = 2 \text{ or } 3$$
where GLYPH<11> ( GLYPH<17> ) is a GLYPH<17> -dependent weight factor for the forward-going participating nucleons, and f ( GLYPH<17> ) is the average emission profile per-nucleon [35]. This relation has been verified using the Glauber model and AMPT model. The asymmetry between ~ " F n and ~ " B n are very large and they are shown to be converted into similar asymmetry of ~ vn between forward and backward GLYPH<17> . This F B asymmetry is expected to be particularly large for / p + Pb collisions, and initial indication of such F B asymmetry has indeed been observed in / p + Pb collisions [37].
## 6. Summary
The Quark Matter 2014 conference has seen impressive progresses in the study of collective behavior in high energy nuclear collisions. Significant azimuthal harmonics have been measured for v 1 to v 5 in p + A collisions over broad range of p T and event multiplicity. The v 2 signal from multi-particle correlations are large, suggesting that the ridge in p + A collisions reflects the genuine collectivity of the produced medium. Remarkable agreement of the vn ( p T ; N ch ) between p + A and A + A collisions suggests that the observed collectivity is driven by similar dynamics in the two systems. Several new flow results in A + A collisions, such as vn for di GLYPH<11> erent particle species and collision systems and vn in ultra-central collisions, serve to refine the hydrodynamic models. Important progresses have also been made in measuring a large class of event-by-event flow observables, in particular a brand-new detailed study of the v 2 -v 2 and vn -v 2 correlations using the event-shape selection technique. A coherent picture of initial condition and
Figure 9. Schematic illustration of the forward-backward fluctuation of second-order eccentricity and participant plane in A + A collisions. The dashed-lines indicate the particle production profiles for forward-going and backward-going participants, respectively [30, 36].
collective flow based on linear and non-linear hydrodynamic responses is derived, which qualitatively describe most results on these observables. Several new types of fluctuation measurements should be pursued, which can further our understanding of the event-shape fluctuations and collective expansion dynamics.
This research is supported by NSF under grant number PHY-1305037 and by DOE through BNL under grant number DE-AC02-98CH10886.
## References
- [1] U. Heinz and R. Snellings, Ann. Rev. Nucl. Part. Sci. 63 , 123 (2013).
- [2] M. Luzum and H. Petersen, J. Phys. G 41 , 063102 (2014).
- [3] CMS Collaboration, Phys. Lett. B 718 , 795 (2013), Phys. Lett. B 724 , 213 (2013); ALICE Collaboration, Phys. Lett. B 719 , 29 (2013),Phys. Lett. B 726 , 164 (2013); ATLAS Collaboration, Phys. Rev. Lett. 110 , 182302 (2013), Phys. Lett. B 725 , 60 (2013); PHENIX Collaboration, Phys. Rev. Lett. 111 , 212301 (2013).
- [4] S. Krishnnan, this proceedings.
- [5] Q. Wang, this proceedings.
- [6] A. Timmons, this proceedings.
- [7] G. Basar and D. Teaney, arXiv:1312.6770 [nucl-th].
- [8] D. Gangadharan, this proceedings; Dogra, this proceedings.
- [9] M. Sharma, this proceedings.
- [10] S. Huang, this proceedings.
- [11] ALICE Collaboration, arXiv:1405.4632 [nucl-ex].
- [12] H. Nakagomi, this proceedings; H. Wang, this proceedings.
- [13] F. G. Gardim, F. Grassi, M. Luzum and J. -Y. Ollitrault, Phys. Rev. C 87 , no. 3, 031901 (2013)
- [14] CMS Collaboration, JHEP 1402 , 088 (2014).
- [15] ATLAS Collaboration, Phys. Rev. C 86 , 014907 (2012).
- [16] Devetak, this proceedings; Y. Zhou, this proceedings.
- [17] G. Denicol, this proceedings.
- [18] ATLAS Collaboration, JHEP 1311 , 183 (2013); J. Jia and S. Mohapatra, Phys. Rev. C 88 , 014907 (2013).
- [19] R. S. Bhalerao, M. Luzum and J. -Y. Ollitrault, Phys. Rev. C 84 , 034910 (2011)
- [20] A. Bilandzic, C. H. Christensen, K. Gulbrandsen, A. Hansen and Y. Zhou, Phys. Rev. C 89 , 064904 (2014)
- [21] J. Jia, arXiv:1407.6057 [nucl-ex].
- [22] Z. Qiu and U. W. Heinz, Phys. Rev. C 84 , 024911 (2011);
- [23] F. G. Gardim, et al. , Phys. Rev. C 85 , 024908 (2012);D. Teaney and L. Yan, Phys. Rev. C 86 , 044908 (2012).
- [24] ATLAS Collaboration, arXiv:1403.0489 [hep-ex].
- [25] L. Yan, this proceedings.
- [26] H. Niemi, this proceedings.
- [27] D. Derendarz, this proceedings.
- [28] J. Schukraft, A. Timmins and S. A. Voloshin, Phys. Lett. B 719 , 394 (2013).
- [29] P. Huo, J. Jia and S. Mohapatra, arXiv:1311.7091 [nucl-ex].
- [30] J. Jia and P. Huo, arXiv:1402.6680 [nucl-th], arXiv:1403.6077 [nucl-th].
- [31] S. Mohapatra, this proceedings, ATLAS-CONF-2014-022, http: // cdsweb.cern.ch record 1702980 / /
- [32] S. Esumi, this proceedings.
- [33] CMS Collaboration, Phys. Rev. C 84 , 024906 (2011)
- [34] X.N. Wang and L. Pang, poster and privite communications.
- [35] A. Bialas and K. Zalewski, Phys. Rev. C 82 , 034911 (2010) [Erratum-ibid. C 85 , 029903 (2012)] [arXiv:1008.4690 [hep-ph]].
- [36] P. Bozek, W. Broniowski and J. Moreira, Phys. Rev. C 83 , 034911 (2011).
- [37] L. Xu, this proceedings. | 10.1016/j.nuclphysa.2014.08.045 | [
"Jiangyong Jia"
] | 2014-08-01T02:49:05+00:00 | 2014-08-01T02:49:05+00:00 | [
"nucl-ex",
"nucl-th"
] | Collective phenomena in high-energy nuclear collisions | I review experimental studies of collective phenomena in $\pA$ and A+A
collisions presented in the Quark Matter 2014 conference. |
1408.0067v3 | ## Squeezed-light-enhanced atom interferometry below the standard quantum limit
Stuart S. Szigeti 1 2 , , ∗ , Behnam Tonekaboni , Wing Yung S. Lau , Samantha N. Hood , and Simon A. Haine 1 1 1 1
1 School of Mathematics and Physics, University of Queensland, Brisbane, QLD, 4072, Australia and
2 ARC Centre for Engineered Quantum Systems, The University of Queensland, Brisbane, QLD 4072, Australia ∗
Weinvestigate the prospect of enhancing the phase sensitivity of atom interferometers in the MachZehnder configuration with squeezed light. Ultimately, this enhancement is achieved by transferring the quantum state of squeezed light to one or more of the atomic input beams, thereby allowing operation below the standard quantum limit. We analyze in detail three specific schemes that utilize (1) single-mode squeezed optical vacuum (i.e. low frequency squeezing), (2) two-mode squeezed optical vacuum (i.e. high frequency squeezing) transferred to both atomic inputs, and (3) two-mode squeezed optical vacuum transferred to a single atomic input. Crucially, our analysis considers incomplete quantum state transfer (QST) between the optical and atomic modes, and the effects of depleting the initially-prepared atomic source. Unsurprisingly, incomplete QST degrades the sensitivity in all three schemes. We show that by measuring the transmitted photons and using information recycling [Phys. Rev. Lett. 110 , 053002 (2013)], the degrading effects of incomplete QST on the sensitivity can be substantially reduced. In particular, information recycling allows scheme (2) to operate at the Heisenberg limit irrespective of the QST efficiency, even when depletion is significant. Although we concentrate on Bose-condensed atomic systems, our scheme is equally applicable to ultracold thermal vapors.
PACS numbers: 03.75.Dg, 42.50.Gy, 42.50.Dv, 03.75.Be, 42.50.-p
## I. INTRODUCTION
Atom interferometry is a leading precision measurement technology, having demonstrated state-of-the-art measurements of accelerations and rotations [1-6], gravity gradients [7, 8], magnetic fields [9], the fine structure constant ( α ) [10, 11], and Newton's gravitational constant ( G ) [12-15]. Further increases to the sensitivity of atom interferometers would allow for some exciting science, such as improved tests of the weak equivalence principle [16-18], searches for quantum gravitational effects [19], and the measurement of gravitational waves [20, 21]. Current state-of-the-art atom interferometers utilize uncorrelated sources, which can operate no better than the standard quantum limit (SQL) - i.e. the sensitivity scales as 1 / √ N where N is the number of detected atoms. Unfortunately, current atomic sources have low fluxes (in comparison with photon sources), and there exist considerable technical barriers to increasing this flux [22]. Hence, developing atom interferometers that operate below the SQL, which have a better 'per atom sensitivity' than current devices, is of great interest.
schemes require large inter-atomic interactions, small atom number, and give little control over the motional atomic state. These are the opposite conditions required for precision atom interferometry. Alternatively, squeezed atomic states can be generated by mapping the quantum state of squeezed light to an atomic field [3843]. Given that squeezed light is known to give sub-SQL sensitivities in optical interferometers [44], transferring the entanglement to atomic degrees of freedom should similarly allow sub-SQL atom interferometry. Importantly, since the squeezing is generated independently of the atomic source, in principle this technique gives high flux (relative to state-of-the-art atomic sources), weaklyinteracting squeezed atomic states in targeted motional states - ideal for atom interferometry.
Sub-SQL atom interferometers necessarily exploit entanglement, and a number of proposals exist for generating the required entanglement between the atomic degrees of freedom. These are based on phenomena as diverse as molecular dissociation [23], spin-exchange collisions [24-26], atomic four-wave mixing [27-30], and atomic Kerr squeezing [31-37]. However, all these
∗ [email protected]
In this paper, we present three squeezed-lightenhanced atom interferometry schemes, and show that these are all capable of sub-SQL phase sensitivities. We explicitly consider Bose-condensed atomic sources, as the narrow velocity distribution and large coherence length of a Bose-Einstein condensate (BEC) offers considerable advantages over thermal sources, including more precise manipulation of the motional state, increased visibility, and the prospect of feedback-stabilization under high flux outcoupling [45-51]. However, many of the results in this paper are equally applicable to ultracold thermal sources. Our analysis considers the effects of incomplete quantum state transfer (QST) between the optical and atomic modes, and the effect of depleting the initial condensate mode. We also incorporate the technique of information recycling [52] into our schemes, and demonstrate that this can be used to combat the negative effects of incomplete QST. Given the maturity of squeezed light generation
technology, and the high efficiency of photon detection, it would be relatively straightforward to incorporate our schemes into existing state-of-the-art atom interferometers. Consequently, squeezed-light enhancement and information recycling offer a promising path to improved sensitivity in atom-interferometer-based technologies.
The structure of our paper is as follows. In Sec. II we derive a simplified quantum model of atom-light coupling, based on two-photon Raman transitions, and show how this atom-light coupling can be used to achieve QST between the optical and atomic modes (Sec. II A), and coherent atomic beamsplitting (Sec. II B). Sec. III briefly reviews atom interferometry in the Mach-Zehnder configuration. Our first interferometry scheme, where enhancement is achieved with a single-mode squeezed optical vacuum (i.e. low frequency squeezing), is presented in Sec. IV. The sensitivity of this scheme is derived for complete QST and an undepleted initial atomic source (Sec. IVA), and compared to truncated Wigner simulations that include depletion. The effects of incomplete QST on this scheme, and how such effects can be reduced with information recycling, are considered in Sec. IV B. The effects of losses are briefly explored in Sec. IVC. In Sec. V, we present our second scheme, which utilizes a two-mode squeezed optical vacuum (i.e. high frequency squeezing) transferred to both atomic inputs. Once again, we quantitatively examine the phase sensitivity when QST is both complete (Sec. V A) and incomplete (Sec. V B), and numerically consider the effects of depletion (Sec. VC). Section VI presents and analyses our final atom interferometry scheme, where only a single atomic input is enhanced with a two-mode squeezed optical vacuum. These three schemes are then compared and summarized in Sec. VII.
## II. THEORETICAL MODEL FOR ATOM-LIGHT COUPLING
Our system has been previously described in [40-42]. We begin with a BEC consisting of atoms with two hyperfine states | 1 〉 and | 2 , 〉 separated in energy by an amount glyph[planckover2pi1] ω 2 . These two levels are coupled with a Raman transition via two optical fields, ˆ E 1 (probe beam, wavevector k 1 ) and ˆ E 2 (control beam, wavevector k 2 ), which are both detuned from an excited state | 3 〉 (see Fig. 1). We assume that the control field ˆ E 2 is much more intense than the probe field ˆ E 1 , allowing us to ignore depletion and quantum fluctuations and approximate the control field as a classical plane wave i.e. ˆ E 2 ( r , t ) ≈ E 2 exp[ ( i k 2 · r -ω t c )]. Furthermore, by design ∆ p ≡ ω 3 -ω p and ∆ c ≡ ω 3 -ω 2 -ω c are large compared with the Rabi frequencies of the | 1 〉 → | 〉 3 and | 2 〉 → | 〉 3 transitions. Therefore, the excited state can be adiabatically eliminated [53-55], giving an effective coupling between atomic states | 1 〉 and | 2 . 〉 Finally, we assume a dilute atomic sample, since it is generally optimal for atom interferometry to operate in a regime
FIG. 1. Energy level scheme for a three-level Raman transition comprising two non-degenerate hyperfine ground states, | 1 〉 and | 2 . 〉 The BEC is initially formed in the state | 1 , and 〉 population is transferred to | 2 〉 via the absorption of a photon from E 1 (the probe beam) and the emission of a photon into E 2 (the control beam). The probe and control beams are detuned from the excited state | 3 〉 by an amount ∆ p = ω 3 -ω p and ∆ c = ω 3 -ω 2 -ω c , respectively.
where the inter-atomic interactions are negligible [45, 5658]. Under these approximations and the rotating-wave approximation [59], the Hamiltonian for the system becomes
$$\text{igh} \quad & \text{comes} \\ \text{is} \text{-} \\ \text{m-} \\ \text{of} \quad & \text{$\hat{\Psi}_{1}(\mathbf r)$} \hat{\Psi}_{2}(\mathbf r)$} \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{2}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{2}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbb { \Phi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{2}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbb { \Phi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r)\hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psis}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}\mathbf r \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Phi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_\text{$\hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Phis}_\text{$\hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathsf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \text{$\hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r) \hat{\Psi}_{1}(\mathbf r)$$
where ˆ H light is the Hamiltonian for the free photon field. Here, H 1 ( r ) = H ( r ) and H 2 ( r ) = H ( r ) + glyph[planckover2pi1] ω 2 , where H ( r ) is the single-atom Hamiltonian common to both hyperfine states. ˆ ( ψ 1 r ) and ˆ ( ψ 2 r ) are the usual bosonic field operators for atoms in hyperfine states | 1 〉 and | 2 , 〉 respectively, satisfying the commutation relation [ ˆ ( ψ i r ) , ψ ˆ ( † j r ′ )] = δ ij δ ( r -r ′ ). Similarly, ˆ E 1 ( r ) is the annihilation operator for the probe field satisfying [ ˆ E 1 ( r ) , E ˆ † 1 ( r ′ )] = δ ( r -r ′ ). We assume that the probe field ˆ E 1 ( r ) has a small spread of frequencies around ω p = c | k 1 | , in which case the effective coupling strength is given by
$$g = d _ { 1 2 } \sqrt { \frac { \omega _ { p } } { 2 \hbar { \epsilon } _ { 0 } } } \frac { \Omega } { \Delta _ { p } },$$
where d 12 is the dipole moment of the | 1 〉 → | 3 〉 transition, Ω is the Rabi frequency for the | 2 〉 → | 3 〉 transition, effected by the classical control field, and glyph[epsilon1] 0 is the permittivity of free space.
As is typical in atom interferometry, we assume that all atoms are initially in a single motional mode u 0 ( r ) of state | 1 . 〉 Furthermore, we will assume that our probe field is vacuum, except for occupation in a pulse characterized by a wave packet propagating in the z -direction:
$$\Gamma _ { 0 } ^ { \prime } \quad u _ { p } ( { \mathbf r }, t ) e ^ { i { \mathbf k } _ { 1 } \cdot { \mathbf r } } = u _ { \mathrm t r a n s } ( x, y ) u _ { \mathrm p r o p } ( z - c t ) e ^ { i { \mathbf k } _ { 1 } \cdot { \mathbf r } }, \quad ( 3 )$$
satisfying L | k 1 | glyph[greatermuch] 1, where L is the characteristic length scale of u prop ( z ). Provided the timescale for population transfer is fast compared with the timescale for atomic motion, the Hamiltonian (1) can be simplified considerably by expanding the field operators in the appropriate mode basis, and keeping only those modes that are highly occupied. Explicitly, we approximate
$$\hat { \psi } _ { 1 } ( { \mathbf r } ) \approx u _ { 0 } ( { \mathbf r } ) \hat { a } _ { 1 }, \quad \ \ \ ( 4 \mathbf a ) \quad \ \ \ n m r$$
$$\hat { \psi } _ { 2 } ( { \mathbf r } ) \approx u _ { 0 } ( { \mathbf r } ) e ^ { i ( { \mathbf k } _ { 1 } - { \mathbf k } _ { 2 } ) \cdot { \mathbf r } } \hat { a } _ { 2 }, \quad \quad ( 4 b ) \quad \text{ now}$$
$$\hat { E } _ { 1 } ( { \mathbf r } ) \approx u _ { p } ( { \mathbf r }, t ) e ^ { i { \mathbf k } _ { 1 } \cdot { \mathbf r } } \hat { b }. \quad \quad ( 4 c ) \quad \text{whi}$$
The simplified Hamiltonian is therefore ˆ H ≈ H ˆ 0 + ˆ H ′ int , where
$$\hat { \mathcal { H } } _ { 0 } = \left ( \hbar { \omega } _ { 2 } + \frac { \hbar { ^ { 2 } } } { 2 m } | { \mathbf k } _ { 1 } - { \mathbf k } _ { 2 } | ^ { 2 } \right ) \hat { a } _ { 2 } ^ { \dagger } \hat { a } _ { 2 } + \hbar { \omega } _ { p } \hat { b } ^ { \dagger } \hat { b } \quad ( 5 \mathbf a ) \quad \text{the d} \quad$$
$$\hat { \mathcal { H } } ^ { \prime } _ { \text{int} } = \hbar { g } f ( t ) \left ( \hat { a } _ { 1 } \hat { a } _ { 2 } ^ { \dagger } \hat { b } \, e ^ { i \omega _ { c } t } + h. c. \right ), \quad \quad ( 5 b ) \quad \hat { a } _ { 2 } ($$
and
$$f ( t ) = \int d { \mathbf r } \, | u _ { 0 } ( { \mathbf r } ) | ^ { 2 } u _ { p } ( { \mathbf r }, t ). \quad \quad ( 6 ) \quad \text{when}$$
Note that we have neglected the single-atom energy contribution due to H j ( r ), which is approximately a constant energy offset on the timescale of the population transfer. The time dependence in ˆ is due to the propH agation of the probe wave packet u p ( r , t ). Interestingly, an identical Hamiltonian is obtained if the probe beam is continuous-wave and the classical control field is shaped by the temporal function f ( ). t This would couple the mode of the probe field defined by the mode function u p ( r , t ) to the condensate.
Finally, after moving to the interaction picture ˆ H → ˆ H int = ˆ U † ˆ H ′ int ˆ U with ˆ U = exp( i ˆ H 0 t/ glyph[planckover2pi1] ), we obtain the following Heisenberg equations of motion:
$$i \dot { \hat { a } } _ { 1 } = g f ( t ) \hat { a } _ { 2 } \hat { b } ^ { \dagger } e ^ { i \delta t } \, \quad \, \quad \, ( 7 \tt a ) \quad \, \ s c r$$
$$i \dot { \hat { a } } _ { 2 } = g f ( t ) \hat { a } _ { 1 } \hat { b } e ^ { - i \delta t } \, \quad \ \ ( 7 b ) \quad \text{th}$$
$$i \dot { \hat { b } } = g f ( t ) \hat { a } _ { 2 } \hat { a } _ { 1 } ^ { \dagger } e ^ { i \delta t } \,, \quad \quad \quad ( 7 c )$$
where δ = ω p -ω c -ω 2 -glyph[planckover2pi1] | k 1 -k 2 | 2 / (2 m ) is the two-photon detuning, which is an experimental parameter freely adjustable by tuning the frequency offset between E 1 and E 2 . We only consider the optimal case δ = 0, when the system is on-resonance such that the energy transferred by the two-photon transition perfectly matches the change in electronic and kinetic energies of the atom. Equations (7) form the basis for the rest of this paper, as they allow us to describe the process of QST (of the light state to the atomic state) and our conventional coherent atomic beamsplitters. Each of these processes is discussed in more detail below.
## A. Quantum state transfer (QST)
The goal of this process is to take a pulse of light, described by annihilation operator ˆ , b and coherently map its quantum state onto the atomic mode ˆ . a 2 Thus, if ˆ b was initially in some interesting quantum state, such as a squeezed state, or was entangled with another mode, after QST ˆ a 2 will also be in this state and/or be entangled with this other mode. To achieve perfect QST, the number of photons in mode ˆ must be much less than the b initial number of condensate atoms in mode ˆ . a 1 Then, for a sufficiently short atom-light coupling time, a small number of atoms can be transferred to mode ˆ , which a 2 now have the initial quantum state of the light in mode ˆ , b while leaving the number of atoms in mode ˆ a 1 essentially unchanged. We can therefore make the undepleted reservoir approximation ˆ a 1 → √ N a 1 , where N a 1 is the mean number of atoms in mode ˆ . Under this approximation, a 1 the dynamics of QST are described wholly by Eqs (7b) and (7c), which can be solved exactly:
$$\hat { a } _ { 2 } ( t ) = \hat { a } _ { 2 } ( t _ { 0 } ) \cos ( \theta _ { Q S T } / 2 ) - i \hat { b } ( t _ { 0 } ) \sin ( \theta _ { Q S T } / 2 ), \ \ ( 8 a )$$
$$\hat { b } ( t ) = \hat { b } ( t _ { 0 } ) \cos ( \theta _ { Q S T } / 2 ) - i \hat { a } _ { 2 } ( t _ { 0 } ) \sin ( \theta _ { Q S T } / 2 ) \,, \ \ ( 8 b )$$
where θ QST ( ) t ≡ 2 g √ N a 1 ∫ t 0 dt ′ f ( t ′ ). As was shown in Jing et al. [38], when θ QST = π we have complete QST , such that the quantum state of ˆ ( b t 0 ) is perfectly mapped to the quantum state of ˆ a 2 ( t 1 ), up to a phase factor. However, achieving the required coupling strength for complete QST is likely to be challenging in practice. Thus incomplete QST , with 0 < θ QST < π , is the likely experimental regime, and consequently is considered in detail throughout this paper. Of course, incomplete QST also occurs when the undepleted reservoir approximation breaks down, which occurs when the initial number of photons in ˆ becomes comparable to the number of atoms b in ˆ a 1 . In this regime the solution (8) is invalid, and we require a numeric solution to Eqs (7). Moreover, as θ QST is no longer well-defined, the QST process must be described by an alternative metric. The natural choice is the QST efficiency :
$$\mathcal { Q } ( t ) \equiv \frac { \langle \hat { a } _ { 2 } ^ { \dagger } ( t ) \hat { a } _ { 2 } ( t ) \rangle } { \langle \hat { b } ^ { \dagger } ( t _ { 0 } ) \hat { b } ( t _ { 0 } ) \rangle },$$
which is a measure of the percentage of atoms outcoupled compared with the total number of input photons. Although this is a somewhat cruder metric than the fidelity, it is operationally more convenient, and certainly more than adequate for our purposes. When ˆ a 1 is treated as an undepleted reservoir, and Eqs (8) apply, then Q = sin ( 2 θ QST / 2).
It is instructive to conceptualize the process of QST as an atom-light beamsplitter . That is, a type of beamsplitter that distributes an initial quantum state of light ˆ ( b t 0 ) amongst an atomic mode ˆ ( a 2 t 1 ) and an outgoing mode of light ˆ ( b t 1 ), in much the same way as a conventional beamsplitter distributes a quantum state of light amongst two outgoing modes of light. This helpful analogy is illustrated diagrammatically in Fig. 2. As a concrete example, note that when θ QST = π/ 2, we have a
FIG. 2. Analogy between atom-light QST process, and a beamsplitter. A photon from mode ˆ can either implement b a Raman transition, resulting in an atom being outcoupled into mode ˆ , or the photon can be transmitted, remaining in a 2 mode ˆ . b In the regime where the number of photons in mode ˆ is b much less than the number of atoms in the condensate ˆ , we can treat ˆ a 1 a 1 as an undepletable reservoir.
50 50 atom-light beamsplitter, corresponding to a QST / efficiency of 50%. We invoke the atom-light beamsplitter analogy throughout this paper, as it allows quite complicated atom-interferometric schemes to be conceptualized as simple linear-optical setups.
## B. Coherent atomic beamsplitters
The coherent beamsplitting and reflection of two atomic modes via two-photon Raman transitions is a mature experimental technique that has been used with much success in atom interferometry [60]. In these experiments, both light pulses have a mean photon number much larger than the number of atoms in modes ˆ a 1 and ˆ , and are therefore well-approximated as undepletable a 2 coherent states. In this regime, the atom-light coupling is a conventional Raman transition, in the sense that the coupling coherently transfers population between the two atomic modes without significantly affecting the state of the optical modes. This can be explicitly seen by making the replacement ˆ b → √ N b , for mean photon number N b , and subsequently solving Eqs (7a) and (7b), yielding
$$\hat { a } _ { 1 } ( t ) = \hat { a } _ { 1 } ( t _ { 0 } ) \cos ( \theta _ { \text{BS} } / 2 ) - i \hat { a } _ { 2 } ( t _ { 0 } ) \sin ( \theta _ { \text{BS} } / 2 ), \ \ ( 1 0 \text{a} )$$
$$\hat { a } _ { 2 } ( t ) = \hat { a } _ { 2 } ( t _ { 0 } ) \cos ( \theta _ { \text{BS} } / 2 ) - i \hat { a } _ { 1 } ( t _ { 0 } ) \sin ( \theta _ { \text{BS} } / 2 ), \ \ ( 1 0 \text{b} )$$
with θ BS ( ) t ≡ 2 g √ N b ∫ t 0 dt ′ f ( t ′ ). When θ BS = π/ 2 and θ BS = π , we have a 50 / 50 atomic beamsplitter and mirror, respectively.
It is worth noting that Eqs (10) apply to other coherent beamsplitting techniques, such as Bragg pulses [61, 62] and Bloch oscillations [63]. Indeed, given that inertial sensors based on Bose-condensed sources and large momentum transfer beamsplitters offer a promising alternative route to improved sensitivity [46, 64, 65], incorporating such interferometers within the squeezed-light enhanced schemes outlined below is a most attractive prospect.
FIG. 3. Analogy between a conventional two-photon Raman transition and a beamsplitter. An atom in mode ˆ a 1 can absorb a photon from mode ˆ , and emit it into b E 2 via stimulated emission, producing one atom in mode ˆ a 2 . An atom can be transferred from ˆ a 2 to ˆ a 1 via the reverse process. In the regime where the number of photons in both ˆ and b E 2 is much greater than the number of photons in mode ˆ a 1 , we can treat the optical modes as undepletable reservoirs, and the process behaves as an atomic beamsplitter.
## III. REVIEW: THE MACH-ZEHNDER ATOM INTERFEROMETER
A standard atom interferometer in the Mach-Zehnder (MZ) configuration operates by first splitting a singlemode population of atoms (in mode ˆ a 1 , say) with a 50 / 50 beamsplitter, and then letting a phase difference between the two modes accumulate due to the physical process of interest (e.g. linear acceleration). The two modes are redirected together via an atomic mirror, and subsequently mixed with a second 50 / 50 beamsplitter. This converts the phase shift φ into a population difference between the two modes, ˆ N a 1 -ˆ N a 2 , where ˆ N a i = ˆ ˆ . a a † i i The population difference at the output can be measured, allowing for an accurate estimate of the phase shift and hence the relevant physical quantity of interest. This output signal can be expressed in terms of the two input modes (i.e. the atomic modes prior to the first beamsplitter) by repeated application of Eqs (10):
$$\hat { S } _ { a } & = \hat { N } _ { a _ { 1 } } ( t _ { f } ) - \hat { N } _ { a _ { 2 } } ( t _ { f } ) \\ & = \cos \phi \left ( \hat { N } _ { a _ { 2 } } ( t _ { 1 } ) - \hat { N } _ { a _ { 1 } } ( t _ { 1 } ) \right ) \\ & + \sin \phi \left ( \hat { a } _ { 1 } ^ { \dagger } ( t _ { 1 } ) \hat { a } _ { 2 } ( t _ { 1 } ) + \hat { a } _ { 2 } ^ { \dagger } ( t _ { 1 } ) \hat { a } _ { 1 } ( t _ { 1 } ) \right ) \,, \quad ( 1 1 )$$
where t 1 and t f are the times immediately before the first beamsplitter and immediately after the second beamsplitter, respectively. The phase sensitivity of the interferometer can be determined from this output signal via the expression [66]
$$\Delta \phi = \sqrt { \frac { V ( S _ { a } ) } { ( d \langle \hat { S } _ { a } \rangle / d \phi ) ^ { 2 } } } \,, \quad \quad ( 1 2 )$$
where V ( Q ) ≡ 〈 ˆ Q 2 〉 - 〈 ˆ Q 〉 2 is the variance. If one input is either a traditionally prepared Bose-condensed source
(modelled as a coherent state or Fock state) or a lasercooled thermal source, and the other input is vacuum, then the standard MZ interferometer can achieve a sensitivity no better than the SQL ∆ φ = 1 / √ N t , where N t is the total number of atoms measured at the output. SubSQL sensitivities require a more exotic initial state [67]. As shown below, QST is a neat and practical method of generating just such a state.
## IV. ENHANCED ATOM INTERFEROMETRY WITH SINGLE-MODE SQUEEZED LIGHT
We first consider using a single-mode squeezed optical vacuum to enhance the sensitivity of atom interferometry. Although generating the single-mode squeezed vacuum state considered here is feasible, it is likely to be a technically challenging procedure. Ultimately, the difficulty stems from the frequencies of the light field where squeezing can be observed. Conceptually, it is impossible to squeeze only a single frequency of light; naturally squeezing occurs across a range of frequencies. More precisely, an optically squeezed state has quantum correlations between sidebands symmetrically distributed around a central carrier frequency, ω p = c | k 2 | [see Fig. 11(a)]. Below some critical frequency ω crit , technical considerations usually ensure that these correlations are masked by uncorrelated classical noise [the red frequencies in Fig. 11(a)]. Hence, in order for the optical mode taking part in the QST process to display quantum correlations, we require ∆ ω glyph[greatermuch] 2 ω crit , where ∆ ω is the characteristic width of F ω ( ), the Fourier transform of f ( ). t Although this is technically challenging, there has recently been demonstrations of significant squeezing at frequencies below 100 Hz [68]. We consider the application of higher-frequency squeezed light sources, which are easier to generate, in later sections of this paper.
To begin, suppose that the squeezed light is generated via an optical parametric oscillator (OPO) [69]. Without loss of generality, we assume that k 1 points in the z -direction, i.e. ˆ ( E r , t ) ≈ u trans ( x, y ) ˆ ( E z, t ). Then, in the momentum basis, the photon fields that form the inputs and outputs of the OPO, at times t i and t 0 respectively, are related by:
$$\hat { \phi } ( q, t _ { 0 } ) = \hat { \phi } ( q, t _ { i } ) \cosh r - i e ^ { i \theta _ { s q } } \hat { \phi } ^ { \dagger } ( - q, t _ { i } ) \sinh r \,, \ \ ( 1 3 ) \quad \text{the} \, 1$$
where q = k -k 1 , and r and θ sq are the squeezing parameter and angle, respectively. Strictly, ˆ ( φ q, t ) and ˆ ( φ † q, t ) are defined in terms of the position-space photon field ˆ ( E z, t ):
$$\hat { \phi } ( q, t ) = \frac { 1 } { \frac { } { \sqrt { 2 \pi } } } \int _ { \substack { d z \, e ^ { - i ( q + k _ { 1 } ) z } \hat { E } ( z, t ) \quad ( 1 4 \text{a} ) } }$$
$$\hat { \phi } ^ { \dagger } ( q, t ) = \frac { \cdot } { \sqrt { 2 \pi } } \int d z \, e ^ { i ( q + k _ { 1 } ) z } \hat { E } ^ { \dagger } ( z, t ). \quad ( 1 4 b ) \quad \text{when}$$
Only the portion of the photon field under the pulse envelope u p ( r , t ) interacts with the atoms at a given time t . Furthermore, the physics of the atom-light interaction is determined by the temporal area of the probe pulse. Consequently, the relevant mode of the photon field is
$$\dashrightarrow \lambda \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \dashrightarrow \lambda \\ \hat { b } ( t ) & \equiv \int \, d { \mathbf r } \, u _ { p } ^ { * } ( { \mathbf r }, t ) e ^ { - i { \mathbf k } _ { 1 } \cdot { \mathbf r } } \hat { E } ( { \mathbf r }, t ) \\ & = \int d q \, e ^ { i q c t } U _ { \text{prop} } ^ { * } ( q ) \hat { \phi } ( q, t ) \\ & \approx \int d q \, U _ { \text{prop} } ^ { * } ( q ) \hat { \phi } ( q, t ), & ( 1 5 )$$
where
$$U _ { \text{prop} } ( q ) = \frac { 1 } { \sqrt { 2 \pi } } \int d z \, e ^ { - i q z } u _ { \text{prop} } ( z ). \quad ( 1 6 )$$
The second line of Eq. (15) follows from Eq. (14a) and ∫ dxdy u | trans ( x, y ) | 2 = 1, and the dominant contribution to the integral occurs close to the carrier frequency k 1 (i.e. q = 0), thereby justifying the approximate expression in the third line [70]. It then follows from Eq. (13) that
$$\hat { b } ( t _ { 0 } ) & = \left [ \int d q \, U _ { \text{prop} } ^ { * } ( q ) \hat { \phi } ( q, t _ { i } ) \right ] \cosh r \\ & \quad - i e ^ { i \theta _ { \text{sq} } } \left [ \int d q \, U _ { \text{prop} } ^ { * } ( q ) \hat { \phi } ^ { \dagger } ( - q, t _ { i } ) \right ] \sinh r. \quad ( 1 7 )$$
The first term in square brackets is clearly ˆ ( b t i ). The second term in square brackets equals [ ˆ ( b t i )] † = ˆ ( b † t i ) provided U prop ( k ) is real and symmetric, which in practice is easy to satisfy. Consequently, the photon mode output from the OPO is simply
$$\hat { b } ( t _ { 0 } ) = \hat { b } ( t _ { i } ) \cosh r - i e ^ { i \theta _ { s q } } \hat { b } ^ { \dagger } ( t _ { i } ) \sinh r, \quad ( 1 8 )$$
which for initial vacuum input is a single-mode squeezed state. Eq. (17) and Eq. (18) illustrate the relationship between the squeezing spectra, which is typically measured in optical squeezing experiments, and the temporal modes relevant for quantum state transfer.
Our scheme is summarized in Fig. 4. An initial squeezed vacuum state ˆ ( b t 0 ) is used to transfer a small number of atoms from mode ˆ a 1 to ˆ a 2 via the QST process (8), thereby transferring some or all of the quantum state from ˆ ( b t 0 ) to ˆ a 2 ( t 1 ). The modes ˆ ( a 1 t 1 ) and ˆ ( a 2 t 1 ) then form the two input modes for a MZ atom interferometer (i.e. are coherently split, reflected and recombined), yielding the two outputs ˆ a 1 ( t f ) and ˆ a 2 ( t f ), used to construct the difference signal ˆ S a [see Eq. (11)]. Expectations are calculated with respect to the initial state | Ψ(0) , defined such that 〉
$$\hat { \phi } ( q, t _ { i } ) | \Psi ( 0 ) \rangle = \hat { a } _ { 2 } ( t _ { 0 } ) | \Psi ( 0 ) \rangle = 0 \quad \ ( 1 9 \text{a} )$$
$$\hat { a } _ { 1 } ( t _ { 1 } ) | \Psi ( 0 ) \rangle = \sqrt { N _ { a _ { 1 } } ( t _ { 1 } ) } | \Psi ( 0 ) \rangle \,, \quad ( 1 9 b )$$
where conservation of total atom number N t implies that N a 1 ( t 1 ) = N t -〈 ˆ N a 2 ( t 1 ) 〉 . Of course, in writing Eq. (19b) we have assumed that the condensate is initially in a
FIG. 4. A scheme for enhancing an atom interferometer with a single-mode squeezed optical vacuum. The squeezed light is used to outcouple a small number of atoms from a BEC. These outcoupled atoms and the remaining condensate atoms form the two inputs to a MZ atom interferometer.
coherent state, and remains in a coherent state during the QST process. As shown below, this assumption is only valid when the number of outcoupled atoms 〈 ˆ N a 2 ( t 1 ) 〉 is much less than N t .
## A. Complete quantum state transfer
We first consider the optimal regime of complete QST θ QST = π (i.e. Q = 1). In this case Eq. (8a) implies that ˆ a 2 ( t 1 ) = -ib ˆ ( t 0 ). The expectation of the difference signal (11) simplifies to
$$\langle \hat { S } _ { a } \rangle = \left ( N _ { t } - 2 \sinh ^ { 2 } r \right ) \cos \phi \,. \quad \ \ ( 2 0 ) \quad \hat { \mathfrak { n r } }$$
In order to achieve minimum phase sensitivity, the variance in the signal must attain a minimum when the slope of the output signal is a maximum [see Eq. (12)]. This occurs at phase φ = π/ 2 and squeezing angle θ sq = π/ 2. Figure 5 shows the signal and phase sensitivity as a function of φ for θ sq = π/ 2. For r = 3 8, we achieve an en-. hancement in sensitivity of approximately 30 times better than the SQL. For comparison, we have shown the case where the two inputs to the MZ interferometer are a coherent state and a vacuum state, respectively.
For these optimal values, the variance is simply
$$V ( S _ { a } ) = N _ { t } e ^ { - 2 r } + 2 e ^ { - r } \sinh ^ { 3 } r. \quad \ \ ( 2 1 ) \quad \text{ one}$$
The minimum phase sensitivity, as a function of r and
FIG. 5. (Top). The expectation value (black, solid line) and quantum uncertainty (light blue, shading) for the signal ˆ normalized by total number of atoms ( S N t = 10 ) for 6 θ sq = π/ 2, and r = r opt ≈ 3 8. . The inset shows that the variance is less than the SQL near φ = π/ 2. (Bottom) The phase sensitivity for complete QST (blue, solid line), compared to the SQL.
## N t , is therefore
$$\Delta \phi _ { \min } & = \frac { \sqrt { N _ { t } e ^ { - 2 r } + 2 e ^ { - r } \sinh ^ { 3 } r } } { N _ { t } - 2 \sinh ^ { 2 } r } \quad \ ( 2 2 ) \\ & \approx \frac { e ^ { - r } } { \sqrt { N _ { t } } },$$
where the approximate expression in the second line is only true in the limit 〈 ˆ ( N t b 0 ) 〉 = sinh 2 r glyph[lessmuch] N t , where ˆ N b = ˆ ˆ . b b †
Figure 6 shows the minimum interferometer sensitivity [Eq. (22)] as a function of the squeezing parameter r , which determines the average number of input photons via 〈 ˆ ( N t b 0 ) 〉 = sinh 2 r , for a range of initial BEC atom numbers. When N t glyph[greatermuch] 1, our analytic model predicts that an optimal squeezing parameter of r opt ≈ ln(4 N / t ) 4 yields a minimum sensitivity of ∆ φ min ≈ 1 /N 3 / 4 t . This is significantly less than the SQL, and furthermore is the best sensitivity possible in this undepleted regime provided sinh 2 r glyph[lessmuch] N t [71, 72]. For N t = 10 , this gives 6 an enhancement in sensitivity of approximately 32 compared with the SQL, which is equivalent to increasing the total number of atoms by a factor of 10 3 at the SQL. For this value of N t , the number of atoms outcoupled at r = r opt is sinh 2 r opt ≈ 500, suggesting that the undepleted reservoir model is still reasonably valid in this
FIG. 6. (Top) Minimum phase sensitivity (i.e. at φ = θ sq = π/ 2) as a function of squeezing parameter r for initial atom numbers N t = 10 4 (blue, top), N t = 10 5 (green, middle) and N t = 10 6 (magenta, bottom). The solid curves are the analytic solution [Eq. (22)], while the points correspond to a TW numerical solution. The standard error in the TW solutions is no larger than the point width. There is good agreement between the analytics and numerics when 〈 ˆ ( N t b 0 ) 〉 glyph[lessmuch] N t , where the initial condensate is not significantly depleted. (Bottom) The maximum QST efficiency Q max = max t Q ( ) t as a function of r . Theoretically, complete QST ( Q = 1) is achievable provided less than ∼ 10% of the total condensate number is outcoupled. The analytics predict Q = 1 always, so any deviation from this is due to depletion from the condensate mode ˆ . Note, however, that there exist regimes where a 1 mode ˆ a 1 must be treated quantum mechanically even though Q max = 1.
regime.
To include the effects of depletion from the condensate, we need to treat mode ˆ a 1 quantum mechanically, and simulate the full quantum dynamics of the QST process, which are governed by Eqs (7). This can be done via the truncated Wigner (TW) phase space method [7376]. Following standard methods [69, 77], the Heisenberg equations of motion are converted into a partial differential equation (PDE) for the Wigner quasi-probability distribution. Once third and higher-order derivatives are truncated (an uncontrolled approximation, but one that is typically valid provided the occupation per mode is not too small for appreciable time periods [78, 79]), this PDE takes the form of a Fokker-Planck equation, which can be efficiently simulated by a set of stochastic differential equations (SDEs) for complex numbers α j ( ). t In our case, the set of SDEs corresponding to Eqs (7) (with
δ = 0) is
$$i \dot { \alpha _ { 1 } } = g f ( t ) \alpha _ { 2 } \beta ^ { * }, \text{ \quad \ \ } ( 2 3 \text{a} )$$
$$i \dot { \alpha _ { 2 } } = g f ( t ) \alpha _ { 1 } \beta, \text{ \quad \ \ } ( 2 3 b )$$
$$i \dot { \beta } = g f ( t ) \alpha _ { 2 } \alpha _ { 1 } ^ { * }, \text{ \quad \ \ } ( 2 3 c )$$
where we have made the correspondences ˆ ( ) a i t → α i ( ) t and ˆ ( ) b t → β t ( ). The initial conditions for these SDEs are randomly sampled from the Wigner distribution corresponding to the initial quantum state [80]. Specifically, just before the QST process, ˆ a 1 is in a coherent state of mean number N t , ˆ a 2 is in a vacuum state, and ˆ is in b a single-mode squeezed vacuum state. The initial conditions corresponding to these initial states are
$$\alpha _ { 1 } ( t _ { 0 } ) = \sqrt { N _ { t } } + \eta _ { \alpha _ { 1 } },$$
$$\alpha _ { 2 } ( t _ { 0 } ) = \eta _ { \alpha _ { 2 } },$$
$$\beta ( t _ { 0 } ) = \eta _ { \beta } \cosh r - i e ^ { i \theta _ { s q } } \eta _ { \beta } ^ { * } \sinh r. \quad ( 2 4 c )$$
The η i are complex, independent Gaussian noises satisfying η i = 0 and η η ∗ i j = δ ij . The expectation value of some arbitrary operator function h is then computed by averaging over solutions to Eqs (23) with initial conditions (24):
$$\ a n a ^ { \dots \dots } _ { \text{TW} } \quad & \langle \{ h ( \hat { a } _ { 1 } ^ { \dagger }, \hat { a } _ { 2 } ^ { \dagger }, \hat { b } ^ { \dagger }, \hat { a } _ { 1 }, \hat { a } _ { 2 }, \hat { b } ) \} _ { s y m } \rangle = \overline { h \left ( \alpha _ { 1 } ^ { * }, \alpha _ { 2 } ^ { * }, \beta ^ { * }, \alpha _ { 1 }, \alpha _ { 2 }, \beta \right ) } \,, \\ \text{ms is } \quad & \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \.$$
where 'sym' denotes symmetric ordering [69], and the overline denotes the average of simulated trajectories.
Since beamsplitting and mirror operations are implemented by strong coherent optical fields, we can approximate them as linear, and the complex amplitudes α 1 ( t f ) and α 2 ( t f ) can be directly evolved from α 1 ( t 1 ) and α 2 ( t 1 ) by repeated application of Eqs (10). The mean 〈 ˆ S a 〉 and variance V ( S a ) can then be computed using the relations
$$\langle \hat { N } _ { i } \rangle = \overline { | \alpha _ { i } | ^ { 2 } } - 1 / 2,$$
$$\langle \hat { N } _ { i } ^ { 2 } \rangle = \overline { | \alpha _ { i } | ^ { 4 } } - \overline { | \alpha _ { i } | ^ { 2 } },$$
$$\langle \hat { N } _ { 1 } \hat { N } _ { 2 } \rangle = \overline { \left ( | \alpha _ { 1 } | ^ { 2 } - 1 / 2 \right ) \left ( | \alpha _ { 2 } | ^ { 2 } - 1 / 2 \right ) }. \quad \ \ ( 2 6 c )$$
The effects of depletion on the minimum interferometer sensitivity, as numerically modelled by TW simulations, is shown in Fig. 6. Since the efficiency of the QST process does not uniquely depend upon the dynamics of the QST process (i.e. Q is not uniquely defined by the choice of f ( )), for simplicity simulations were performed t with a uniform f ( ). t For small r we find good agreement between the undepleted reservoir approximation and the full quantum dynamics. However, as r increases, the full quantum simulations actually predict a better sensitivity than the undepleted reservoir model, reaching a minimum at an r = r TW > r opt . We can understand this feature by looking at the quadratures of the modes, for example ˆ X θ a 1 = exp( iθ )ˆ a 1 + exp( -iθ )ˆ a † 1 . As shown in Fig. 7, the discrepancy is due to changes in ˆ a 1 under
FIG. 7. (Top) TW simulations for the variance of atomic quadratures ˆ X θ c = exp( iθ )ˆ + exp( c -iθ )ˆ , c † where ˆ is an arc bitrary mode, for an initial condensate number of N t = 10 . 6 The quadratures for the initial squeezed optical input ˆ b 0 are analytic, and can easily be computed from Eq. (18). According to the undepleted reservoir analytics, which assumes ˆ a 1 is always coherent, the variance of any quadrature ˆ X θ a 1 ( t 1 ) is unity, and ˆ X 0 a 2 ( t 1 ) = ˆ X π/ 2 b t ( 0 ) and ˆ X π/ 2 a 2 ( t 1 ) = ˆ X 0 b t ( 0 ) when QST is complete. However, even though Q = 1 for all values of r shown here, TW simulations show that ˆ X 0 a 1 ( t 1 ) and ˆ X 0 a 2 ( t 1 ) diverge from the undepleted reservoir solution once r glyph[greaterorsimilar] 3 11. . (Bottom) Plot showing that the quantum noise (i.e. variance) on the signal ˆ S a also diverges from the undepleted reservoir model for r glyph[greaterorsimilar] 3 11. .
depletion, evidenced by V ( ˆ X 0 a 1 ( t 1 ) ) and V ( ˆ X 0 a 2 ( t 1 ) ) deviating from the analytic solution. Although the state of ˆ a 1 is coherent under the undepleted reservoir approximation, quantum depletion creates a state with decreased variance in ˆ J x = [ˆ ( a 1 t 1 )ˆ a † 2 ( t 1 ) + ˆ a 2 ( t 1 )ˆ a † 1 ( t 1 )] / 2 (and increased variance in ˆ X 0 a 1 ( t 1 ) and ˆ X 0 a 2 ( t 1 ) ). This gives a reduction in the sensitivity at φ = π/ 2, since the noise in the signal is directly proportional to ˆ J x by virtue of Eq. (11).
For further increases in r , the effects of depletion become significant, and complete QST (i.e. Q = 1) is no longer possible. The maximum possible QST efficiency, as a function of r , is shown in Fig. 6. Unsurprisingly, this is contrary to the undepleted reservoir model, where Q = 1 always for θ QST = π .
## B. Incomplete quantum state transfer and information recycling
In practice, it may be difficult to achieve the required coupling strength g for complete QST. When θ QST < π , and optimal values φ = π/ 2 and θ sq = π/ 2 are chosen, the undepleted reservoir model predicts a signal slope and variance of
$$\frac { d \langle \hat { S } _ { a } \rangle } { d \phi } = - \left ( N _ { t } - 2 \sin ^ { 2 } \left ( \theta _ { Q S T } / 2 \right ) \sinh ^ { 2 } r \right ), \quad ( 2 7 \mathbf a )$$
and
$$V ( S _ { a } ) & = N _ { t } e ^ { - r } \left ( \cosh r + \cos \theta _ { Q S T } \sinh r \right ) \\ & + 2 e ^ { - r } \sin ^ { 4 } \left ( \theta _ { Q S T } / 2 \right ) \sinh ^ { 3 } r, \text{ \quad \ \ } \text{(27b)}$$
respectively. This gives a minimum phase sensitivity of
$$\overset {. } {. } \underset { 6 } { \Delta } \phi _ { \min } = \frac { \sqrt { N _ { t } \left ( 1 - 2 Q e ^ { - r } \sinh r \right ) + 2 \mathcal { Q } ^ { 2 } e ^ { - r } \sinh ^ { 3 } r } } { N _ { t } - 2 \mathcal { Q } \sinh ^ { 2 } r }.$$
(28)
The blue curve in Fig. 8 shows ∆ φ min vs. Q at optimum squeezing parameter ( r = r opt when the undepleted reservoir approximation holds) for an initial condensate of N = 10 6 atoms. Although sub-SQL sensitivities are still possible for incomplete QST, the enhancement sharply reduces from the optimal 1 /N 3 / 4 t scaling as Q decreases from unity. For instance, at Q = 0 5, correspond-. ing to θ QST = π/ 2 in the undepleted reservoir regime, the enhancement to the sensitivity beyond the SQL has dropped by a factor of 20 to ∼ √ 2. The blue curve in Fig. 8 shows ∆ φ min vs. Q at optimum squeezing parameter ( r = r opt when the undepleted reservoir approximation holds) for an initial condensate of N = 10 6 atoms. Although sub-SQL sensitivities are still possible for incomplete QST, the enhancement sharply reduces from the optimal 1 /N 3 / 4 t scaling as Q decreases from unity. For instance, at Q = 0 5, corresponding to . θ QST = π/ 2 in the undepleted reservoir regime, the enhancement to the sensitivity beyond the SQL has dropped by a factor of 20 to ∼ √ 2.
Fortunately, this degradation to the sensitivity due to incomplete QST can be ameliorated with the technique of information recycling [52]. Specifically, after the atomlight beamsplitter, a quadrature of the transmitted field ˆ ( b t 1 ) can be measured via homodyne detection by mixing the field ˆ ( b t 1 ) with a bright local oscillator ˆ b LO ( t 1 ), which is assumed to be a large amplitude coherent state (see Fig. 9). In order to pick out the mode corresponding to ˆ , b the local oscillator would need to be temporally shaped such that it is mode-matched to u p ( r , t ). The noise on this homodyne signal is correlated with the noise on the atomic signal ˆ , S a and hence can be combined with the atomic signal to reduce the overall noise of the phase measurement. That is, from the apparatus depicted in Fig. 9 we construct the signal
$$\hat { S } = \hat { S } _ { a } - \mathcal { G } \hat { S } _ { b }, \text{ \quad \ \ } \text{(2)}$$
FIG. 8. Plots showing the QST efficiency dependence of the minimum phase sensitivity ∆ φ min for an atom interferometer enhanced by single-mode squeezing, and initial atom number N t = 10 . 6 For r = r opt ≈ 3 8, . the sensitivity of the purely atomic signal ˆ S a sharply degrades with decreasing Q , and the TW simulations (blue diamonds) agree with the analytic undepleted reservoir prediction (solid blue line) except near Q = 1. In contrast, the information-recycled signal ˆ = ˆ S S a -G ˆ S b displays considerably better sensitivities and a slower degradation as Q decreases. For r = r opt , the TW simulations (red circles) predict a slightly better sensitivity for Q glyph[greaterorsimilar] 0 4 than . the analytic undepleted reservoir prediction (red dashed line). For comparison, the upper and lower horizontal black dotted lines show the SQL and the theoretical limit reached by perfect QST (i.e. ∆ φ = 1 /N 3 / 4 t ), respectively. Interestingly, the TW simulations (red crosses) demonstrate that better sensitivities can be achieved for r = r TW ≈ 4 8 . > r opt ; for ˆ S a this is only true near Q = 1 (blue squares).
where
$$\hat { S } _ { b } = \hat { N } _ { b _ { L O } } ( t _ { f } ) - \hat { N } _ { b } ( t _ { f } ), \text{ \quad \ \ } ( 3 0 \text{a} )$$
$$\hat { b } ( t _ { f } ) = \frac { 1 } { \sqrt { 2 } } \left ( \hat { b } ( t _ { 1 } ) - i \hat { b } _ { \text{LO} } ( t _ { 1 } ) \right ), \quad \ \ ( 3 0 b ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\hat { b } _ { \text{LO} } ( t _ { f } ) = \frac { \cdot } { \sqrt { 2 } } \left ( \hat { b } _ { \text{LO} } ( t _ { 1 } ) - i \hat { b } ( t _ { 1 } ) \right ), \quad ( 3 0 c ) \quad \text{$\substack{\partial \mu$\mu$}$}$$
and G is an adjustable gain parameter .
In order to see more clearly how information recycling improves the phase sensitivity, it is instructive to first consider the optical analogy of the incomplete QST process - a beamsplitter. We know from the quantum optics literature that a single-mode squeezed state ˆ b sq incident on a 50 / 50 beamsplitter leads to entanglement between the two output fields. Specifically, the two beamsplitter outputs are ˆ = ( ˆ a ϑ -ib ˆ sq ) / √ 2 and ˆ = ( ˆ b b sq -iϑ / ˆ ) √ 2, where ˆ is ϑ a vacuum input. The entanglement leads to a variance V ( ( ˆ X 0 a -ˆ X π/ 2 b ) / √ 2 ) = exp( -2 ), r which is less than for two uncorrelated coherent inputs, where we have defined the generalized quadrature of each output as ˆ X θ a b ( ) = ˆ( ˆ ) exp( a b iθ ) + ˆ ( ˆ a † b † ) exp( -iθ ). More generally,
FIG. 9. An atom interferometer enhanced by both singlemode squeezed light and information recycling. The transmitted component of ˆ ( b t 1 ) is interfered with a bright local oscillator, thereby allowing a homodyne measurement. The information from this measurement is then combined with the atomic signal. Information recycling gives an improvement to the sensitivity when the QST efficiency Q is less than unity.
for an asymmetric beamsplitter with beamsplitting ratio (i.e. reflection coefficient ) sin 2 ( θ QST / 2), the quantity
$$\underset { \text{er-} } { \text{ted} } \quad V \left ( \sin ( \theta _ { Q \text{ST} } / 2 ) \hat { X } _ { a } ^ { 0 } - \cos ( \theta _ { Q \text{ST} } / 2 ) \hat { X } _ { b } ^ { \pi / 2 } \right ) = e ^ { - 2 r } \ \ ( 3 1 )$$
is less than for two uncorrelated states. Essentially the same argument can be used to show that the informationrecycled signal (29) has a smaller variance, and therefore gives a smaller phase sensitivity, than the signal ˆ . Since S a ˆ b LO ( t 1 ) is a bright coherent state of complex amplitude √ N LO exp( iθ LO ), N LO glyph[greatermuch] 〈 ˆ ( N t b 1 ) 〉 and therefore
$$\hat { S } _ { b } \approx \sqrt { N _ { \text{LO} } } \hat { X } _ { b ( t _ { 1 } ) } ^ { \theta _ { \text{LO} } } \,. \quad \quad ( 3 2 )$$
Similarly, N a 1 ( t 1 ) glyph[greatermuch] 〈 ˆ N a 2 ( t 1 ) 〉 , and so at the most sensitive point of the atom interferometer, φ = π/ 2,
$$\hat { S } _ { a } \approx \sqrt { N _ { a _ { 1 } } ( t _ { 1 } ) } \hat { X } _ { a _ { 2 } ( t _ { 1 } ) } ^ { 0 } \,. \quad \quad ( 3 3 )$$
Thus, choosing θ LO = π/ 2 (i.e. we measure the phase quadrature of the transmitted photons), and
$$\det _ { \ v e e n } \quad \mathcal { G } = \sqrt { \frac { N _ { a _ { 1 } } ( t _ { 1 } ) } { N _ { \text{LO} } } \left ( \frac { 1 - \mathcal { Q } } { \mathcal { Q } } \right ) } = \sqrt { \frac { N _ { a _ { 1 } } ( t _ { 1 } ) } { N _ { \text{LO} } } } \cot ( \frac { \theta _ { \text{QST} } } { 2 } ), \ ( 3 4 )$$
yields the combined (information-recycled) signal
$$\underset { \substack { \i d s \ t o \\ \text{the is} \\ \text{re we} \\ \text{out as} \\ \text{and}... } } \quad \hat { S } \approx \frac { \sqrt { N _ { a _ { 1 } } ( t _ { 1 } ) } } { \sin ( \frac { \theta _ { Q S T } } { 2 } ) } \left ( \sin ( \frac { \theta _ { Q S T } } { 2 } ) \hat { X } _ { a _ { 2 } ( t _ { 1 } ) } ^ { 0 } - \cos ( \frac { \theta _ { Q S T } } { 2 } ) \hat { X } _ { b ( t _ { 1 } ) } ^ { \pi / 2 } \right ),$$
which can have smaller variance than ˆ . S a
Figure 8 plots the minimum phase sensitivity ∆ φ min as a function of QST efficiency Q corresponding to both the purely atomic signal ˆ S a (solid, blue curve) and the information-recycled signal ˆ = S ˆ S a - G ˆ S b (dashed, red curve). Although both instances suffer a degradation of sensitivity with poorer QST, this degradation is significantly arrested for the information-recycled signal. As a specific comparison, when Q = 0 5, . the analytic model predicts that information recycling gives ∆ φ min ≈ 0 035 . / √ N t , compared with ∆ φ min ≈ 0 71 . / √ N t in the absence of information recycling. Even at 10% QST efficiency, information recycling gives a sensitivity more than a factor of ten better than the SQL, whereas there is a negligible enhancement in the absence of information recycling. For very low levels of QST ( < 0 05% for . r = r opt ), the information recycling scheme gives sensitivities above the SQL. This is because V ( S ) is very sensitive to slight imperfections in the estimates of the quadratures when QST is very low. Such imperfections arise due to the finite size of the condensate initially populating mode ˆ . For although the approximation (33) is a 1 exact in the limit of an infinitely large condensate, we are typically only working with 10 4 -10 6 atoms. Hence the deviation of ˆ S a from a perfect quadrature measurement is considerable, which is the cause of the discrepancy at low values of Q .
Figure 8 also compares the sensitivities predicted by the analytic undepleted reservoir solutions to TW simulations [see Eqs (23)]. Without information recycling, the agreement is excellent except near Q = 1. In contrast, TW simulations predict better sensitivities from the information-recycled signal ˆ S (by a factor between four and five), occurring at a squeezing parameter r TW larger than the analytic optimum r opt . As discussed in Sec. IV A, this improvement is due to ˆ a 1 deviating from a coherent state, leading to a reduced variance in ˆ J x at the output.
## C. Effect of losses on phase sensitivity
Quantifying the effects of losses on the sensitivity is an important experimental consideration. The simplest method of accounting for losses is by introducing virtual beamsplitters with a transmission coefficient of η that input vacuum noise ˆ at various points within the interϑ ferometry scheme. Specifically, this maps some mode ˆ c to √ ηc ˆ+ √ 1 -ηϑ ˆ .
Using this approach, we considered four types of losses:
- 1. Losses in the generation and transmission of the squeezed optical state before the QST process - i.e. ˆ = ˆ ( c b t 0 ).
- 2. Losses in the mode ˆ a 2 after the QST process, due to imperfections in the QST process such as spontaneous emission - i.e. ˆ = ˆ c a 2 ( t 1 ).
- 3. Losses in the transmitted optical state, including detection inefficiency - i.e. ˆ = ˆ ( c b t 1 ).
- 4. Symmetric losses within the atom interferometer, which also accounts for inefficient atom detection -i.e. ˆ = [ˆ c a 1 ( t 1 ) -ia ˆ ( 2 t 1 )] / √ 2 and ˆ = [ˆ ( c a 2 t 1 ) -ia ˆ ( 1 t 1 )] / √ 2.
FIG. 10. An illustration of the effects of losses ( η = 0 95) on . the phase sensitivity within the undepleted reservoir model for N t = 10 6 and r = 3. Although losses clearly degrade the sensitivity, in most cases information recycling ameliorates this degradation.
Figure 10 illustrates the various effects of these losses on the sensitivity for an inefficiency of η = 0 95. . Unsurprisingly, losses degrade the phase sensitivity, both with and without the inclusion of information recycling. Nevertheless, it is interesting that any type of loss is never worse than losses affecting the initial squeezed optical state. Furthermore, information recycling still delivers sensitivities below the SQL, and for values of Q > 5 -10% these are much better than what is possible without information recycling.
Since losses affect other squeezed-light enhanced atom interferometry schemes in a qualitatively similar fashion, we will not discuss losses further. We simply note that losses degrade the effects of squeezing, as they do in any optical squeezing experiment, and that if losses are not too great then information recycling can somewhat ameliorate the effects of this degradation.
## V. ENHANCED ATOM INTERFEROMETRY WITH TWO-MODE SQUEEZED LIGHT
We now consider the case of high frequency squeezed light, which is experimentally less challenging to generate than low frequency squeezed light. We model this as a state of light that is dominated by uncorrelated classical noise at sideband frequencies below some frequency
ω crit , while containing quantum correlations above this frequency. Specifically, the mode with frequency ω p + ω is correlated with the mode with frequency ω p -ω only when ω > ω crit . Implementing the scheme from Sec. IV would result in atoms being outcoupled without quantum correlations [see Fig. 11(a)]. We can, however, exploit this source of high-frequency squeezing in order to generate an atomic state that displays two-mode squeezing. By adjusting the frequency of the classical control field from ω c to ω c + ω s , where ω s > ω crit , the mode that is on two-photon resonance δ = 0 becomes far from the probe carrier frequency ω p , and outside the noisy low frequency region. Consequently, QST occurs within a spectral region of width ∆ ω centered around ω p + ω s . However, this does not yield an enhancement to the sensitivity of our atom interferometer, as a mode in this region displays no special quantum correlations in isolation; it only displays squeezing when considered in conjunction with the modes centered around ω p -ω s . We therefore include a second classical control beam of frequency ω c -ω s , which is on two-photon resonance and thereby causes QST at those frequencies between ω p -( ω s -∆ ω/ 2) and ω p -( ω s + ∆ ω/ 2) [see Fig. 11(b)]. By making these two control fields counter-propagating (i.e. wavevectors k 2 and -k 2 ), the atom-light interaction results in two correlated modes of outcoupled atoms with different momenta, which can be easily distinguished.
More precisely, modifying Hamiltonian (1) such that there are two counter-propagating classical control fields at frequencies ω c ± ω s and wavevectors ± k 2 , respectively, both shaped by the pulse envelope u c ( r , t ) = u trans ( x, y ) u prop ( z -ct ), gives
$$\hat { \mathcal { H } } = \sum _ { j = 1, 2 } \int d { \mathbf r } \, \hat { \psi } _ { j } ^ { \dagger } ( { \mathbf r } ) H _ { j } ( { \mathbf r } ) \hat { \psi } _ { j } ( { \mathbf r } ) + \hat { \mathcal { H } } _ { \text{light} }$$
$$& + \hbar { g } \overset { \prime - \cdot, \cdot } { \int d \mathbf r } \left [ \hat { \psi } _ { 1 } ( \mathbf r ) \hat { \psi } _ { 2 } ^ { \dagger } ( \mathbf r ) \hat { E } _ { 1 } ( \mathbf r ) u _ { c } ^ { * } ( \mathbf r, t ) \left ( e ^ { - i [ \mathbf k _ { 2 } \cdot \mathbf r - ( \omega _ { c } + \omega _ { s } ) t ] } \\ & + \ e ^ { - i [ - \mathbf k _ { 2 } \cdot \mathbf r - ( \omega _ { c } - \omega _ { s } ) t ] } \right ) + h. c. \right ]. \quad & ( 3 6 ) \quad \text{$\theta_{\theta}$} \\ & \quad. / N _ { \cdot }.$$
As in Sec. II, we assume that the entire atomic population is initially in hyperfine state | 1 〉 and in spatial mode u 0 ( r ). Conservation of energy and momentum implies that the modes resonant with the atom-light coupling are:
$$\hat { a } _ { 1 } = \int d { \mathbf r } \, u _ { 0 } ^ { * } ( { \mathbf r } ) \hat { \psi } _ { 1 } ( { \mathbf r } ), \quad \quad ( 3 7 \mathbf a ) \quad \text{$Not$} _ { \mathbf Q S }.$$
$$\hat { a } _ { \pm } = \int d { \mathbf r } \, u _ { 0 } ^ { * } ( { \mathbf r } ) e ^ { i ( { \mathbf k } _ { \pm } \mp { \mathbf k } _ { 2 } ) \cdot { \mathbf r } } \hat { \psi } _ { 2 } ( { \mathbf r } ), \quad ( 3 7 b ) \quad \overset { \text{two} } { \text{ref} } \quad \Phi$$
$$\hat { b } _ { \pm } ( t ) = \, \int \, d { \mathbf r } \, u _ { c } ^ { * } ( { \mathbf r }, t ) e ^ { - i { \mathbf k } _ { \pm } \cdot { \mathbf r } } \hat { E } _ { 1 } ( { \mathbf r } ), \quad ( 3 7 c ) \quad \text{corr}$$
where k ± = ( ω p ± ω s )ˆ z /c . Note that the mode expansion in Eq. (37b) is approximate, and only valid in the regime where the two mode functions u 0 ( r ) exp[ ( i k ± ∓ k 2 ) · r ] are approximately orthonormal. This is true provided the wavelength of the control fields is much smaller than the spatial extent of the condensate, or equivalently that the momentum kick imparted to the atoms is larger than the momentum width of the atomic cloud. Such a condition is easily satisfied in typical atom interferometers with Bose-condensed sources. Substituting Eqs (37) into Eq. (36) gives ˆ H ≈ H ˆ 0 + ˆ H ′ int , where
$$\text{ploit} \begin{array} { c } \kappa \cdots \ni \cdots & \cdots & \cdots \ni \cdots \\ \text{m} \end{array} \quad \text{.} \\ \text{gen-} \\ \text{zing.} \quad \hat { \mathcal { H } } _ { 0 } & = \left ( \hbar { \omega } _ { 2 } + \frac { \hbar { 2 } ^ { 2 } } { 2 m } | \mathbf k _ { 1 } - \mathbf k _ { 2 } | ^ { 2 } \right ) \left ( \hat { a } _ { + } ^ { \dagger } \hat { a } _ { + } + \hat { a } _ { - } ^ { \dagger } \hat { a } _ { - } \right ) \\ \text{field} \quad & + \hbar { ( \omega } _ { p } + \omega _ { s } ) \hat { b } _ { + } ^ { \dagger } \hat { b } _ { + } + \hbar { ( \omega } _ { p } - \omega _ { s } ) \hat { b } _ { - } ^ { \dagger } \hat { b } _ { - }, & ( 3 8 ) \\ \text{is on} \\ \text{robe} & \hat { \mathcal { H } } _ { \text{int} } ^ { \prime } & = \hbar { g } f ( t ) \hat { a } _ { 1 } ( \hat { a } _ { + } ^ { \dagger } e ^ { i ( \omega _ { c } + \omega _ { s } ) t } + \hat { a } _ { - } ^ { \dagger } e ^ { i ( \omega _ { c } - \omega _ { s } ) t } ) ( \hat { b } _ { + } + \hat { b } _ { - } ) \\ \text{ency} & + \hbar {. } c. \,, & ( 3 9 ) \\ \text{al re} \quad &. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
where we have chosen the orientation of our control and probe fields such that | k + -k 2 | 2 = | k -+ k 2 | 2 ≡ | k 1 + k 2 | 2 , where k 1 = ( ω /c p ) ˆ z . Making the transformation ˆ H → ˆ H int = ˆ U † ˆ H ′ ˆ U with ˆ = exp( U - H i ˆ 0 t/ glyph[planckover2pi1] ) yields
$$\hat { \mathcal { H } } _ { \text{int} } & = \hbar { g } f ( t ) \left [ \hat { a } _ { + } ^ { \dagger } \hat { a } _ { 1 } \left ( \hat { b } _ { + } e ^ { - i \delta t } + \hat { b } _ { - } e ^ { i ( 2 \omega _ { s } - \delta ) t } \right ) \\ & + \hat { a } _ { - } ^ { \dagger } \hat { a } _ { 1 } \left ( \hat { b } _ { + } e ^ { - i ( 2 \omega _ { s } + \delta ) t } + \hat { b } _ { - } e ^ { - i \delta t } \right ) + h. c. \right ], ( 4 0 )$$
where δ = ω p -ω c -ω 2 - | glyph[planckover2pi1] k 1 -k 2 | 2 / (2 m ). If we assume ω s glyph[greatermuch] ∆ , and adjust ω ω c such that δ = 0, the contribution from the fast rotating terms can be neglected, and we obtain
$$\hat { \mathcal { H } } _ { \text{int} } \approx \hbar { g } f ( t ) \left [ \hat { a } _ { 1 } \left ( \hat { a } _ { + } ^ { \dagger } \hat { b } _ { + } + \hat { a } _ { - } ^ { \dagger } \hat { b } _ { - } \right ) + h. c. \right ]. \quad ( 4 1 )$$
The Heisenberg equations of motion for this Hamiltonian are [ c.f. Eqs (7)]:
$$i \dot { \hat { a } } _ { 1 } = g f ( t ) \left ( \hat { a } _ { + } \hat { b } _ { + } ^ { \dagger } + \hat { a } _ { - } \hat { b } _ { - } ^ { \dagger } \right ), \quad \ \ ( 4 2 \mathbf a )$$
$$i \dot { \hat { a } } _ { \pm } = g f ( t ) \hat { a } _ { 1 } \hat { b } _ { \pm }, & & ( 4 2 b )$$
$$i \dot { \hat { b } } _ { \pm } = g f ( t ) \hat { a } _ { 1 } ^ { \dagger } \hat { a } _ { \pm }.$$
In the regime of low depletion from the condensate, we make the undepleted reservoir approximation ˆ a 1 → √ N a 1 as in Sec. II A, and obtain
$$\hat { a } _ { \pm } ( t _ { 1 } ) = \hat { a } _ { \pm } ( t _ { 0 } ) \cos ( \frac { \theta _ { Q S T } } { 2 } ) - i \hat { b } _ { \pm } ( t _ { 0 } ) \sin ( \frac { \theta _ { Q S T } } { 2 } ) ( 4 3 \mathbf a )$$
$$\hat { b } _ { \pm } ( t _ { 1 } ) = \hat { b } _ { \pm } ( t _ { 0 } ) \cos ( \frac { \theta _ { Q S T } } { 2 } ) - i \hat { a } _ { \pm } ( t _ { 0 } ) \sin ( \frac { \theta _ { Q S T } } { 2 } ) ( 4 3 b )$$
$$\colon & \cos ( \frac { \theta _ { Q S T } } { 2 } ) - i \hat { b } _ { \pm } ( t _ { 0 } ) \sin ( \frac { \theta _ { Q S T } } { 2 } ) ( 4 3 \tt a ) \\ & \cos ( \frac { \theta _ { Q S T } } { 2 } ) - i \hat { a } _ { \pm } ( t _ { 0 } ) \sin ( \frac { \theta _ { Q S T } } { 2 } ) ( 4 3 b )$$
Note that the '+' and '-' modes decouple, and so the QST process depicted in Fig. 12 can be conceptualized as two independent atom-light beamsplitters with the same 'reflectivity'.
It is not difficult to define input states ˆ b ± ( t 0 ) that are correlated, and more specifically correspond to a twomode squeezed vacuum state. The argument follows that laid out in Sec. IV. First, we assume ˆ E 1 ( r , t ) ≈ u trans ( x, y ) ˆ E 1 ( z, t ), and rewrite Eq. (37c) in terms of the momentum modes of ˆ E 1 ( z, t ) [ c.f. Eq. (15)]:
$$\hat { b } _ { \pm } ( t ) = \int d q \, U _ { \text{prop} } ^ { * } ( q \mp q _ { s } ) \hat { \phi } ( q, t ), \quad \ ( 4 4 )$$
FIG. 11. (a): Single-mode outcoupling scheme. If 2 ω crit > ∆ , then only the uncorrelated part of the spectrum of ω ˆ E 1 takes part in the outcoupling process. No enhancement to the sensitivity is possible in this case. (b): An outcoupling method for utilizing high frequency squeezing. Two control beams (frequencies ω c -ω s and ω c + ω s ) are used to outcouple from the region of the spectrum of ˆ E 1 centered around ω p -ω s and ω p + ω s , respectively. Since ∆ p glyph[greatermuch] ω s , the coupling strengths of the two control beams are nearly identical. Here δ 0 = ω p -ω c -ω 2 , which equals the change in the atomic kinetic energy glyph[planckover2pi1] | k 1 -k 2 | 2 / (2 m ) on two-photon resonance.
where q s = | k ± -k 1 | = ω /c s . Therefore, since Eq. (13) is the optical state output from the OPO:
the modes ˆ b ± ( t 0 ) comprise a two-mode squeezed vacuum state.
$$\hat { b } _ { \pm } ( t _ { 0 } ) = \left [ \int d q \, U _ { \text{prop} } ^ { * } ( q \mp q _ { s } ) \hat { \phi } ( q, t _ { i } ) \right ] \cosh r & & \text{Ou} \\ - \, i e ^ { i \theta _ { \text{sq} } } \left [ \int d q \, U _ { \text{prop} } ^ { * } ( q \mp q _ { s } ) \hat { \phi } ^ { \dagger } ( - q, t _ { i } ) \right ] \sinh r. \ \ ( 4 5 ) & & \text{all or} \\ & \text{and } \hat { a }$$
The term in the first set of square brackets is ˆ b ± ( t i ). Since U prop ( q ) is assumed real and symmetric,
$$\int d q \, U _ { \text{prop} } ^ { * } ( q \mp q _ { s } ) \hat { \phi } ^ { \dagger } ( - q, t _ { i } ) & = \int d q \, U _ { \text{prop} } ( q \pm q _ { s } ) \hat { \phi } ^ { \dagger } ( q, t ) \\ & = \hat { b } _ { \mp } ^ { \dagger } ( t _ { i } ).$$
Hence, we arrive at
$$\hat { b } _ { \pm } ( t _ { 0 } ) = \hat { b } _ { \pm } ( t _ { i } ) \cosh r - i e ^ { i \theta _ { s q } } \hat { b } _ { \mp } ^ { \dagger } ( t _ { i } ) \sinh r. \quad ( 4 7 ) \quad \frac { 1 } { 2 } \mathfrak { a } ^ { \dagger } _ { \neq \infty }$$
Since the initial quantum state is chosen such that
$$\hat { \phi } ( q, t _ { i } ) | \Psi ( 0 ) \rangle = \hat { a } _ { \pm } ( t _ { 0 } ) | \Psi ( 0 ) \rangle = 0, \quad ( 4 8 \tt a ) \quad \text{cho}$$
$$\hat { a } _ { 1 } ( t _ { 0 } ) | \Psi ( 0 ) \rangle = \sqrt { N _ { a _ { 1 } } ( t _ { 0 } ) } | \Psi ( 0 ) \rangle, \quad ( 4 8 b ) \quad \overset { \text{on a} } { \langle \Delta ^ { l } }$$
Our scheme that utilizes this two-mode squeezed optical vacuum is shown in Fig. 13. The modes ˆ b + ( t 0 ) and ˆ b -( t 0 ) form the inputs for the QST process, transferring all or part of their quantum state to the modes ˆ a + ( t 1 ) and ˆ a -( t 1 ) respectively [see Eqs (43)]. These two atomic modes form the input for the atom interferometer, where after the usual Mach-Zehnder interferometry sequence (beam split, reflect, beam split), the atom number difference at the outputs is measured:
$$\Delta \hat { N } _ { a } ( t _ { f } ) & \equiv \hat { N } _ { a _ { + } } ( t _ { f } ) - \hat { N } _ { a _ { - } } ( t _ { f } ) \\ & = 2 \hat { J } _ { z } \cos \phi + 2 \hat { J } _ { x } \sin \phi. \quad \quad ( 4 9 )$$
Here we have used the pseudo-spin operators ˆ J k ≡ 1 2 a † σ k a , where a = (ˆ a + ( t 1 ) , a ˆ -( t 1 )) T and σ k are the set of Pauli spin matrices; this notation is convenient for some of the expressions below. However, ∆ ˆ N a is a poor choice for our signal, since the average number difference of a two-mode squeezed vacuum state is zero, and hence 〈 ∆ ˆ N a 〉 = 0 even for the case of incomplete QST. Conse-
FIG. 12. QST scheme for a two-mode squeezed optical input. Two counter-propagating classical control beams E + (frequency ω c + ω s ) and E -(frequency ω c -ω s ) are used to implement a Raman transition with ˆ E 1 . Due to energymomentum resonance, E ± is resonant with the region of ˆ E 1 centered at frequency ω p ± ω s . This outcouples atoms from mode ˆ , and results in QST between the optical modes ˆ a 1 b ± and atomic modes ˆ a ± . Note that ˆ a ± recoils with momentum glyph[planckover2pi1] k 1 ± glyph[planckover2pi1] k 2 , where ± k 2 is the wavevector of E ± .
quently, we choose a signal based on the fluctuations of the output number difference:
$$\hat { S } _ { a } = \left ( \hat { N } _ { a _ { + } } ( t _ { f } ) - \hat { N } _ { a _ { - } } ( t _ { f } ) \right ) ^ { 2 }. \quad \ \ ( 5 0 ) \quad \ \text{is c}$$
## A. Complete quantum state transfer
When QST is perfect (i.e. θ QST = π ) and ˆ a ± ( t 1 ) = -ib ˆ ± ( t 0 ), the average and variance of the signal (50) are
$$\langle \hat { S } _ { a } \rangle & = \sinh ^ { 2 } ( 2 r ) \sin ^ { 2 } \phi, \quad & ( 5 1 a ) \quad \text{than} \quad \text{order} \\ V ( \hat { S } _ { a } ) & = \frac { 1 } { 2 } \sinh ^ { 2 } ( 2 r ) \left [ 1 + \cosh ( 4 r ) \left ( 3 - 4 \cos ( 2 \phi ) \right ) \right ] \quad \text{the s} \quad \text{of } \, 1 0 \\ & + \sinh ^ { 4 } ( 2 r ) \cos ( 4 \phi ), \quad & ( 5 1 b ) \quad \text{with} \quad \text{with} \quad \text{$N_{t} \sim$}$$
respectively. Note that these expressions are independent of the squeezing angle θ sq . Equations (51) yield a phase sensitivity of
$$\Delta \phi = \frac { \sqrt { 1 + \cosh ( 4 r ) \tan ^ { 2 } \phi } } { \sinh ( 2 r ) }. \quad \quad ( 5 2 )$$
A minimum sensitivity of ∆ φ min = 1 / sinh(2 r ) occurs at φ = π . However, since the total number of atoms detected at the interferometer output is N t = 〈 ˆ N a + ( t f )+ ˆ N a -( t f ) 〉 = 2sinh 2 r , we can rewrite
$$\Delta \phi _ { \min } = \frac { 1 } { \sqrt { N _ { t } ( N _ { t } + 2 ) } }, \quad \ \ ( 5 3 ) \quad ( \text{wl}$$
FIG. 13. Analogous optical circuit for an atom interferometer enhanced with two-mode squeezed light. The atom-light coupling (partially) maps the quantum state of the optical modes ˆ b + ( t 0 ) and ˆ b -( t 0 ) onto the atomic modes ˆ a + ( t 1 ) and ˆ a -( t 1 ), respectively. These two atomic modes form the inputs to a Mach-Zehnder atom interferometer. The modes ˆ b + and ˆ b -are co-propagating, but shown here to be spatially separated for the purposes of visual clarity. Likewise, the blue atomlight beamsplitter represents the condensate mode ˆ a 1 , which is common to both QST processes (see Fig. 12).
which is approximately the Heisenberg limit 1 /N t in the limit of large N t .
Na¨ ıvely, this interferometer scheme compares favourably to the single-mode squeezed-light enhanced scheme considered in Sec. IV. For instance, in order to achieve a sensitivity of ∆ φ ∼ 10 -5 , which is the sensitivity obtained by an ideal atom interferometer of 10 6 atoms enhanced by single-mode squeezed light with r = r TW ≈ 4 8 (see Fig. 6), we need to outcouple . N t ∼ 10 5 atoms, which requires a squeezing parameter of r ∼ 6 1. . However, the story is not quite as simple once the effects of incomplete QST and depletion are considered.
## B. Incomplete quantum state transfer and information recycling
For incomplete QST, the minimum phase sensitivity (which occurs at φ = tan -1 [( V ( ˆ J 2 z ) /V ( ˆ J 2 x )) 1 / 4 ]) is [81]
$$( \Delta _ { \ell } )$$
$$( \Delta \phi _ { \min } ) ^ { 2 } & = \frac { 2 \sqrt { V ( \tilde { J } _ { z } ^ { 2 } ) V ( \tilde { J } _ { z } ^ { 2 } ) } + C ( \tilde { J } _ { z } ^ { 2 }, \tilde { J } _ { z } ^ { 2 } ) + \langle ( \tilde { J } _ { x } \tilde { J } _ { z } + \tilde { J } _ { x } \tilde { J } _ { x } ) ^ { 2 } \rangle } { 4 ( \langle \tilde { J } _ { z } ^ { 2 } ) - ( \tilde { J } _ { z } ^ { 2 } ) ) ^ { 2 } }, \\ & = \frac { \sqrt { ( 1 - \Omega ) ( 1 + 5 ( 1 - \Omega ) N _ { t } ) \left ( 4 + 2 ( N _ { t } - 2 \Omega ) + \frac { N _ { t } ( 9 - \Omega ( 4 2 - 3 7 \Omega ) ) - 6 4 \Omega ^ { 2 } ( 1 - \Omega ) + 7 \Omega + 1 } { 4 ( N _ { t } + 2 \Omega ) ^ { 2 } } \right ) } { N _ { t } ( N _ { t } + 2 \Omega ) } \\ & + \frac { \left ( 1 + \frac { 1 - \Omega } { 2 ( N _ { t } + 2 \Omega ) } \right ) + N _ { t } ( 1 - \Omega ) \left ( 3 + \frac { 2 N _ { t } + 5 - \Omega } { 2 ( N _ { t } + 2 \Omega ) } \right ) } { N _ { t } ( N _ { t } + 2 \Omega ) },$$
where V ( ˆ ) X = 〈 ˆ X 2 〉 - 〈 ˆ X 〉 2 is the variance of ˆ , X C X,Y ( ˆ ˆ ) = 〈 ˆ ˆ XY + ˆ ˆ Y X 〉 -2 〈 ˆ X 〉〈 ˆ Y 〉 is the symmetrized covariance of ˆ X and ˆ , Y Q = sin ( 2 θ QST / 2) and N t = 2 Q sinh 2 r . As shown in Fig. 14, even small decreases from complete QST result in a rapid degradation of sensitivity. Indeed, provided N t glyph[greatermuch] 1 and (1 -Q glyph[greatermuch] ) 1 /N t , both of which are easily satisfied in practice, then
$$\Delta \phi _ { \min } \approx \sqrt { \frac { ( 1 -$$
Although sensitivities below the SQL are obtainable for Q > (2 + √ 10) / 6 ≈ 0 86, . Heisenberg scaling is lost for extremely small perturbations from complete QST.
As for the interferometer enhanced by single-mode squeezed light, we can arrest the loss of sensitivity at incomplete QST via information recycling. Specifically, we directly measure the number of photons output after the QST process [i.e. ˆ N b ± = ˆ b † ± ( t 1 ) ˆ b ± ( t 1 )] via photodetection, and subtract these counts from the number of atoms outcoupled during the QST process (i.e. ˆ N a ± ). Explicitly, we construct the signal
$$\hat { S } = \left ( \Delta \hat { N } _ { a } ( t$$
where ∆ ˆ N b ≡ ˆ N b + -ˆ N b -Thus, at the optimum phase φ = π , the minimum sensitivity with information recycling takes the remarkably simple form:
$$\begin{array} {$$
which for large N t is approximately the Heisenberg limit, but most importantly is almost independent of Q and approximately equal to the sensitivity when Q = 1 [see Eq. (53)].
Unlike the atom interferometry scheme enhanced with single-mode squeezed light, information recycling almost completely removes any degradation due to incomplete QST. However, this does not imply that the QST efficiency does not matter, since N t ∝ Q . Nevertheless,
Q
FIG. 14. Plots demonstrating the QST efficiency dependence of the minimum phase sensitivity ∆ φ min for an atom interferometer enhanced by two-mode optical squeezing [Eq. (55)]. The horizontal dashed lines that intercept each curve at Q = (2 + √ 10) / 6 indicate the SQL for N t = 10 6 (black, top), 10 5 (red, middle) and 10 4 (blue, bottom). The Heisenberg scaling is quickly lost for small perturbations of Q from unity. In contract, when information recycling is applied ∆ φ min remains at the Heisenberg limit for all Q [see Eq. (58)].
Eq. (58) represents the minimum sensitivity attainable for a fixed N t , and certainly gives better sensitivities than for the purely atomic signal ˆ . Perhaps surprisingly, this S a remains true even under the effects of depletion, as shown in the next subsection.
## C. Effects of depletion
The analytics presented in this section thus far have assumed the undepleted reservoir approximation ˆ a 1 → √ N a 1 . However, this approximation breaks down for even moderate values of r . Thus, following Sec. IV we treated mode ˆ a 1 as a quantum dynamical degree of freedom by performing numerical TW simulations of the QST process. Under TW, the operators are mapped to
complex stochastic amplitudes via the correspondences ˆ a i → α i and ˆ b i → β i . These stochastic variables evolve according to the SDEs [ c.f. Eqs (42)]:
$$i \dot { \alpha } _ { 1 } = g f ( t ) \left ( \alpha$$
$$i \dot { \alpha } _ { \pm } = g f ( t ) \alpha _ {$$
$$i \dot { \beta } _ { \pm } = g f ( t ) \alpha _ { 1 } ^ { * } \alpha _ { \pm }, \quad \quad \quad ( 5 9 c ) \quad \Big | \check { \gtrsim } ^ { \cdot }$$
with initial conditions
$$\alpha _ { 1 } ( 0 ) & = \sqrt { N _ { a _ { 1 } } ( t _ { 0 } ) } + \eta _ { \alpha _ { 1 } }, & ( 6 0 \text{a} ) \quad \stackrel { \Xi } { \Xi }$$
$$\alpha _ { \pm } ( 0 ) & = \eta _ { \alpha _ { \pm } }, & ( 6 0 b ) & \quad \check { \triangleleft 1 }$$
$$\beta _ { \pm } ( 0 ) = \eta _ { \beta _ { \pm } } \cosh r - i e ^ { i \theta _ { s q } } \eta _ { \beta _ { \mp } } ^ { * } \sinh r. \quad ( 6 0 c )$$
The η i are complex, independent Gaussian noises with zero mean and variance 1 / 2. Without loss of generality, we assumed a uniform f ( ) t for the TW simulations presented below.
The phase sensitivity without information recycling was calculated using Eq. (54) and the following expressions:
$$\langle \hat { J } _ { x } ^ { 2 } \rangle = \overline { \mathcal { J } _ { x } ^ { 2 } } - \frac { 1 } { 8 },$$
$$\langle \hat { J } _ { z } ^ { 2 } \rangle = \overline { \mathcal { J } _ { z } ^ { 2 } } - \frac { \vec { 1 } } { \vec { 8 } }, \quad \quad \quad ( 6 1 b )$$
$$\langle \hat { J } _ { x } ^ { 4 } \rangle = \overline { \mathcal { J } _ { x } ^ { 4 } } - \frac { \bar { 5 } } { 4 } \overline { \mathcal { J } _ { x } ^ { 2 } } + \frac { 1 } { 1 6 }, \quad \quad \quad ( 6 1 c ) \quad \text{fig} \quad \text{fig}$$
$$\langle \hat { J } _ { z } ^ { 4 } \rangle = \overline { \mathcal { J } _ { z } ^ { 4 } } - \frac { \bar { 5 } } { 4 } \overline { \mathcal { J } _ { z } ^ { 2 } } + \frac { \bar { 1 } } { 1 6 }, \quad \quad ( 6 1 d ) \quad \begin{array} { c } \text{$\text{$visit$} \\ \text{Eq.} \end{array}$$
$$\langle \hat { J } _ { x } ^ { 2 } \hat { J } _ { z } ^ { 2 } + \hat { J } _ { z } ^ { 2 } \hat { J } _ { x } ^ { 2 } \rangle = 2 \overline { \mathcal { J } _ { x } ^ { 2 } \mathcal { J } _ { z } ^ { 2 } } + \frac { 5 } { 4 } \overline { \mathcal { J } _ { x } ^ { 2 } } + \frac { 1 } { 4 } \overline { \mathcal { J } _ { z } ^ { 2 } } - \overline { | \alpha _ { + } | ^ { 2 } | \alpha _ { - } | ^ { 2 } }, \quad \text{$\emph{atoms} l$} \\ ( 6 1 e ) \quad \text{error} \ \cdot \quad \text{$\vdots$} \ \end{matrix}$$
$$\langle ( \hat { J } _ { x } \hat { J } _ { z } + \hat { J } _ { z } \hat { J } _ { x } ) ^ { 2 } \rangle = 4 \overline { \mathcal { J } _ { x } ^ { 2 } \mathcal { J } _ { z } ^ { 2 } } - \frac { 5 } { 2 } \overline { \mathcal { J } _ { x } ^ { 2 } } - \frac { 3 } { 2 } \overline { \mathcal { J } _ { z } ^ { 2 } } + \overline { | \alpha _ { + } | ^ { 2 } | \alpha _ { - } | ^ { 2 } }, \quad \text{$the$so$} \\ ( 6 1 f ) \quad \text{$eval tl$} \\ \text{$hold $fc$}$$
where J z = | α + ( t 1 ) | 2 - | α -( t 1 ) | 2 and J x = α + ( t 1 ) α ∗ -( t 1 ) + α ∗ + ( t 1 ) α -( t 1 ). The phase sensitivity with information recycling was computed using ∆ φ min = 1 / √ 4 〈 ˆ J 2 x 〉 [81].
Figure 15 shows that the effects of depletion cause a serious degradation to the sensitivity, even when QST is complete. The cause of this degradation is shown in the bottom panel of Fig. 15, which plots the variance in ˆ J z (which is proportional to the number difference of the two input ports of the atom interferometer). A large, nonzero variance implies that there exist low (but not negligible) probability trajectories where the quantum state of a photon in ˆ b + is successfully mapped to an atom in mode ˆ a + , but ˆ b -is not mapped to ˆ a -(and similarly for an exchange of '+' and '-'). The inclusion of unequal atom numbers in the two paths of the atom interferometer inevitably degrades the phase sensitivity. Fortunately, the effect is entirely reversed with information recycling, as measurement of the transmitted photons provides information about the full quantum correlations within the system.
FIG. 15. (Top) TW calculations of the minimum phase sensitivity, normalized to the sensitivity for complete QST [see Eq. (53)], with (red asterisks) and without (blue circles) information recycling, assuming an initial BEC of N a 1 ( t 0 ) = 10 6 atoms. N t was varied by adjusting the number of input photons N t b ( 0 ) = 2sinh 2 r from zero to ∼ 10 . 8 The standard error of each point is on the order of the point width, and the solid red line is the analytic solution (53), which is approximately the Heisenberg limit. The TW simulations reveal that the undepleted reservoir approximation ceases to hold for relatively small values of N t ; however, the negative effect of depletion is (almost) completely removed when information recycling is used. (Bottom) TW calculations of the variance in ˆ J z and the maximum possible QST efficiency, Q max = max t Q ( ), t as a function of the total number of atoms detected at the outputs. V ( J z ) has been normalized to N / t 4, which is the variance in ˆ J z for two uncorrelated coherent states each with a mean number of N / t 2. In the undepleted reservoir approximation, the analytic solution predicts V ( J z ) = 0 always. However, as N t increases beyond ∼ 10 , a full quantum treatment of mode ˆ 5 a 1 shows that there are increasingly large fluctuations in the number difference of the two MZ input ports, which suppress correlations between ˆ a + ( t 1 ) and ˆ a -( t 1 ).
The bottom panel of Fig. 15 shows that the maximum possible QST efficiency rapidly drops below 100% once N t is glyph[greaterorsimilar] 10% of the initial number of atoms populating mode ˆ . a 1 This is what we intuitively expect; it is impossible to outcouple more than N t = N a 1 ( t 0 ) atoms from the condensate, and so increasing r only results in a lower Q . Furthermore, in this regime depletion causes
a slight increase to the minimum phase sensitivity of the information-recycled signal. Here, the finite size of the BEC necessarily truncates the atom number probability distribution for the MZ input state at N = N a 1 ( t 0 ). Consequently, at best the input atomic state will have an atom number probability distribution corresponding to a two-mode squeezed optical state with a truncated 'tail'. When N t ≈ N a 1 ( t 0 ), this distribution will be somewhere between a twin-Fock state and a two-mode squeezed vacuum state, and as discussed in [81] this yields a minimum phase sensitivity of ∆ φ glyph[lessorsimilar] √ 2 /N t . This is consistent with the TW simulations shown in the top panel of Fig. 15.
## VI. A SINGLE INPUT ENHANCEMENT WITH TWO-MODE SQUEEZED-LIGHT AND INFORMATION RECYCLING
Although the previously presented two-mode squeezed light enhanced atom interferometry scheme has many advantages (e.g. it utilizes high frequency squeezing and can attain Heisenberg scaling), one disadvantage is that the number of atoms detected at the output is proportional to the number of atoms outcoupled during the QST process. Consequently, a high atom number interferometer requires both a large squeezing parameter and good QST efficiency. In contrast, the number of detected atoms in the scheme enhanced by single-mode squeezed light is independent of r and Q ; it only depends on the atom number of the initial condensate.
In this section we present an alternative scheme based on high frequency squeezing [i.e. a two-mode squeezed state; see Eq. (47)] that also utilizes all the atoms in the condensate, independent of the squeezing parameter and QST efficiency. This scheme is summarized in Fig. 16. Instead of using two control beams, this scheme uses just one, detuned from two-photon resonance by an amount ω s > ω crit . This ensures that the QST process only occurs for a region of probe frequencies centered about ω p + ω s . This corresponds to the optical mode ˆ b + ( t 0 ) interacting with the initial condensate mode ˆ a 1 , leading to outcoupled atoms in mode ˆ . Since there is only one a 2 control beam, the portion of the spectrum correlated with this region (i.e. the region centered around ω p -ω s ) does not couple to the atoms, and is therefore transmitted. This transmitted light is described by the mode ˆ b -. By monitoring this transmitted light with homodyne detection, the quantum correlations of the two-mode squeezed state can still be used to enhance the sensitivity via information recycling. Furthermore, any incomplete QST can similarly be ameliorated by monitoring any transmitted light in the region centered around ω p + ω s . The outcoupled atomic mode and the remaining condensate are then used as the two inputs to an atom interferometer. The relevant (information-recycled) signal is then a linear combination of the atomic number difference at the output of the atom interferometer and the photon number differences of the transmitted light centered around
FIG. 16. Analgous optical circuit for modified atom interferometry utilizing two-mode optical squeezing. Only one of the modes (which corresponds to photons in a particular frequency band) is coupled to the atoms, while the other mode is measured directly. ˆ b + and ˆ b -are co-propagaiting, but shown here to be spatially separated to highlight their distiniguishability.
ω p + ω s and ω p -ω s . We call this scheme a single input enhancement with two-mode squeezed light, since only one mode of the two-mode squeezed optical vacuum directly interacts with the atoms. This is in contrast to the scheme considered in Sec. V, which we could describe as a double input enhancement with two-mode squeezed light, since both modes of the two-mode squeezed optical vacuum couple to the BEC.
We compute the phase sensitivity of this interferometry scheme from the information-recycled signal
$$\hat { S } = \sqrt { \mathcal { Q } } \hat { S } _ { a } - \mathcal { G } _ { + } \sqrt { 1 - \mathcal { Q } } \hat { S } _ { b _ { + } } + \mathcal { G } _ { - } \hat { S } _ { b _ { - } } \,, \quad ( 6 2 )$$
where ˆ S a is given by Eq. (11),
$$\hat { S } _ { b _ { \pm } } = \hat { b } ^ { \dagger } _ { \text{LO} _ { \pm } } ( t _ { f } ) \hat { b } _ { \text{LO} _ { \pm } } ( t _ { f } ) - \hat { b } ^ { \dagger } _ { \pm } ( t _ { f } ) \hat { b } _ { \pm } ( t _ { f } ), \quad ( 6 3 )$$
and
$$\mathcal { G } _ { \pm } = \sqrt { \frac { \langle \hat { a } _ { 1 } ^ { \dagger } ( t _ { 1 } ) \hat { a } _ { 1 } ( t _ { 1 } ) \rangle } { \langle \hat { b } _ { \text{LO} _ { \pm } } ^ { \dagger } ( t _ { 1 } ) \rangle } } \,. \quad \quad ( 6 4 )$$
Note that the photon modes at time t f are related to those at t 1 by the simple beamsplitting relations:
$$\hat { b } _ { \pm } ( t _ { f } ) = \frac { 1 } { \sqrt { 2 } } \left ( \hat { b } _ { \pm } ( t _ { 1 } ) - i \hat { b } _ { \text{LO} _ { \pm } } ( t _ { 1 } ) \right ) \quad \ \ ( 6 5 \text{a} )$$
$$\hat { b } _ { \text{LO} _ { \pm } } ( t _ { f } ) = \frac { \cdot } { \sqrt { 2 } } \left ( \hat { b } _ { \text{LO} _ { \pm } } ( t _ { 1 } ) - i \hat { b } _ { \pm } ( t _ { 1 } ) \right ), \quad ( 6 5 b )$$
and of course the trivial relation ˆ b -( t 1 ) = ˆ b -( t 0 ) holds. Our justification for this choice of signal follows an argument similar to that used to justify the choice of ˆ in S Sec. IV B. In brief, in the regime where depletion from
FIG. 17. The minimum phase sensitivity ∆ φ min (i.e. for φ = θ sq = π/ 2) for a single input two-mode optical squeezed vacuum enhanced atom interferometer, corresponding to a purely atomic signal ˆ S a (undepleted reservoir approximation: solid blue curve; TW: blue squares), partial information-recycled signal ˆ S a -G -ˆ S b -(undepleted reservoir approximation: green dashed curve; TW: green circles), and complete informationrecycled signal ˆ = S √ Q ˆ S a -G + √ 1 -Q ˆ S b + + G -ˆ S b -(undepleted reservoir approximation: red dot-dashed curve; TW: red crosses). All these plots assumed N t = 10 6 and r = r opt ≈ 3 8. . For convenience, these curves have been normalized relative to the SQL 1 / √ N t . The upper and lower horizontal dotted lines show the SQL, and the theoretical limit reached by a single-mode squeezed optical vacuum enhancement with perfect QST (i.e. 1 /N 3 / 4 t ), respectively.
the condensate is minimal during the QST process, the undepleted reservoir approximation ˆ a 1 → √ N a 1 gives the familiar atom-light beamsplitter relations:
$$\hat { a } _ { 2 } ( t _ { 1 } ) & = \hat { a } _ { 2 } ( t _ { 0 } ) \cos ( \frac { \theta _ { Q S T } } { 2 } ) - i \hat { b } _ { + } ( t _ { 0 } ) \sin ( \frac { \theta _ { Q S T } } { 2 } ), ( 6 6 a ) \quad \text{choic} \\ \hat { b } _ { + } ( t _ { 1 } ) & = \hat { b } _ { + } ( t _ { 0 } ) \cos ( \frac { \theta _ { Q S T } } { 2 } ) - i \hat { a } _ { 2 } ( t _ { 0 } ) \sin ( \frac { \theta _ { Q S T } } { 2 } ), ( 6 6 b ) \quad \text{be a} \\ \quad \text{detur}$$
$$\nu _ { 2 } ^ { 2 } \nu _ { 2 } ^ { 2 } \nu _ { 0 / 2 } \nu _ { 0 / 2 } \nu _ { 0 / 2 } ^ { 2 } \nu _ { 0 / 2 } ^ { 2 }$$
and Q = sin ( 2 θ QST / 2). Since ˆ S a ≈ √ N a 1 ( t 1 ) ˆ X 0 a 2 ( t 1 ) and ˆ S b ± ≈ √ N LO ± ˆ X θ LO ± b ± ( t 1 ) , then for θ LO ± = π/ 2:
$$\hat { S } \approx \sqrt { N _ { a _ { 1 } } ( t _ { 1 } ) } \left ( \hat { X } _ { b _ { - } ( t _ { 0 } ) } ^ { \pi / 2 } - \hat { X } _ { b _ { + } ( t _ { 0 } ) } ^ { \pi / 2 } \right ), \quad ( 6 7 ) \quad \text{furl}$$
which for optimal squeezing angle θ sq = π/ 2 has a variance V ( S ) = 2 √ N a 1 ( t 1 ) exp( -2 ), which can be smaller r than V ( S a ).
The dependence of the minimum sensitivity on the QST efficiency is shown in Fig. 17. There are clear similarities to the plots shown in Fig. 8 corresponding to the scheme enhanced by single-mode squeezed optical vacuum. Nevertheless, we highlight some important differences. Firstly, the pure atomic signal ˆ S a always gives a sensitivity worse than the SQL. Secondly, when the QST efficiency is close to 100%, it is sufficient to use a partial information-recycled signal ˆ S a -G -ˆ S b -. Thirdly, even for the signal ˆ the sensitivity remains above the S analytic limit ∆ φ = 1 /N 3 / 4 t derived for the single-mode squeezed optical vacuum enhanced atom interferometer, since for finite levels of squeezing measurements of ˆ S b -are not perfectly correlated with √ Q ˆ S a -G + √ 1 -Q ˆ S b + . Finally, the TW simulations predict that the effects of depletion lead to a poorer sensitivity than that given by the analytic sensitivity for the information-recycled signal ˆ . S
## VII. SUMMARY AND DISCUSSION.
In this paper we have shown how squeezed light can be used to enhance the sensitivity of atom interferometers. We have specifically considered three schemes: (Sec. IV) enhancement with a single-mode squeezed optical vacuum (i.e. low frequency squeezing), (Sec. V) double input enhancement with two-mode squeezed optical vacuum (i.e. high frequency squeezing), and (Sec. VI) single input enhancement with two-mode squeezed optical vacuum. We have shown that all three schemes give sensitivities below the SQL - even when the effects of depletion from the initial condensate and incomplete QST are included. Furthermore, we have demonstrated that information recycling provides a further enhancement to the sensitivity when QST between the atoms and light is incomplete.
Table I provides a quantitative comparison of the sensitivities for the three schemes for complete QST, and for incomplete QST ( Q = 0 2) with and without information . recycling. This is a concise demonstration of the different sensitivities obtainable (including the effects of depletion), the degrading effects of incomplete QST, and how information recycling ameliorates this degradation. The choice of Q = 0 2 is not unrealistic given current technol-. ogy. For example, the 780 nm D2 transition of 87 Rb can be addressed with a Rabi frequency of Ω ∼ 20 MHz and detunings ∆ p ≈ ∆ c ∼ 70 GHz. Since the electric dipole moment of this transition is d 12 ∼ 2 × 10 -29 C/m, Eq. (2) implies that an effective coupling of g ∼ 65 × 10 -3 m 3 / 2 /s is obtainable. If we assume a condensate of Gaussian spatial profile u 0 ( r ), with transverse width R ⊥ ∼ 15 µ m, and further assume the pulse envelope u p (r , t ) is also Gaussian with the same transverse width R ⊥ and pulse duration T ∼ 1 ms, then
$$\theta _ { \text{QST} } = \frac { 4 } { 3 } ( 2 \pi ) ^ { 1 / 4 } g \sqrt { \frac { N T } { c A _ { \perp } } } \sim \frac { 3 \pi } { 1 0 }, \quad \quad ( 6 8 )$$
where A ⊥ = πR 2 ⊥ and we have used N = 10 . This gives 6 a QST efficiency of Q ∼ 20%.
Furthermore, losses due to spontaneous emission during the QST process are small in this regime. An estimate for the (time-dependent) rate at which atoms in
| | ∆ φ min | ∆ φ min | ∆ φ min |
|-------------------------------------------------------------------------------------------------------------------------|--------------------|-------------------|-----------------|
| Interferometer scheme | ˆ S a and Q = 100% | ˆ S a and Q = 20% | ˆ S and Q = 20% |
| Enhancement with single-mode squeezed state, r = 4 . 8, and N t = 10 6 (Sec. IV) | 1 × 10 - 5 | 9 × 10 - 4 | 1 . 9 × 10 - 5 |
| Double input enhancement with two-mode squeezed state and | 1 . 6 × 10 - 6 | 2 . 1 × 10 - 3 | 2 × 10 - 6 |
| N t = 6 . 2 × 10 5 (Sec. V) Single input enhancement with two-mode squeezed state, r = 3 . 8 and N t = 10 6 (Sec. VI) a | 3 . 2 × 10 - 2 | 1 . 4 × 10 - 2 | 1 . 6 × 10 - 4 |
a Note that ˆ gives ∆ S φ = 3 8 . × 10 -5 for Q = 100%.
TABLE I. Numerical values of the minimum phase sensitivities for the three different squeezed-light enhanced atom interferometry schemes, in three distinct scenarios. These values were obtained via TW simulations. All three schemes assumed an initial condensate of N a 1 ( t 0 ) = 10 6 atoms; a large but achievable [82] number of atoms. All these atoms can be detected at the outputs for the two schemes utilizing a single port enhancement (i.e. the first and third rows of the table). In contrast, N t depends on the value of r for the double input enhancement (i.e. the middle row of the table); the choice N t ∼ 6 2 . × 10 5 corresponds to Q ≈ 0 2 and . r ≈ 7 8. . For comparison, an atom interferometer operating at the SQL with N a 1 ( t 0 ) = 10 6 atoms has a sensitivity of ∆ φ = 10 -3 .
the excited state | 3 〉 are lost due to spontaneous emission is Γ( ) t = Ω eff ( ) t γ/ ∆ , where p γ = 2 π × 6 07 MHz . is the natural linewidth for 87 Rb and Ω eff is the effective Rabi frequency between modes ˆ a 1 and ˆ a 2 during the QST process. Assuming a beamsplitter-like coupling [such as described by Eqs (10)], then N a 1 ( t 1 ) = N t cos 2 ( ∫ dt ′ Ω eff ( t ′ ) / 2) = N t - 〈 ˆ ( N t b 0 ) 〉 sin 2 ( θ QST / 2), where the final equality follows from conservation of atom number. Therefore, the total loss is
$$l = \int d t ^ { \prime } \, \Gamma ( t ^ { \prime } ) = \frac { \gamma } { \Delta _ { p } } \cos ^ { - 1 } \sqrt { 1 - \frac { \langle \hat { N } _ { b } ( t _ { 0 } ) \rangle } { N _ { t } } \sin ^ { 2 } ( \frac { \theta _ { Q S T } } { 2 } ) }. \quad \stackrel { \text{comp} } { \text{Morti} } \\ \pi _ { \dots } \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \, - \tau } \, \lambda \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nu \, \nolimits }$$
For a squeezing parameter of r = 3 5 (i.e. . ˆ ( N t b 0 ) ∼ 270) and the parameters specified above, l ∼ 6 5 . × 10 -7 .
[1] A. Peters, K. Y. Chung, and S. Chu, Nature 400 , 849 (1999).
[2] H. M¨ uller, S.-w. Chiow, S. Herrmann, S. Chu, and K.-Y. Chung, Phys. Rev. Lett. 100 , 031101 (2008).
However, l is an estimate of the fraction of the total atoms lost; what is more important is the number of atoms lost compared to the total number of atoms in ˆ , which is a 2 lN /N t a 2 ∼ 1%.
As mentioned throughout the paper, there are some important differences between the three schemes. The single-mode squeezed optical vacuum enhancement has the advantages of conceptual simplicity and full utilization of all the atoms in the condensate. However, the generation of a single-mode squeezed optical vacuum occurs at low frequencies which, while possible, is technically challenging. The double input enhancement with two-mode squeezed optical vacuum uses technically less challenging high-frequency squeezing, and its approximate Heisenberg scaling independent of the QST efficiency with information recycling - is clearly the best of the three schemes. However, achieving a large N t , and therefore a small absolute sensitivity, requires a relatively large squeezing parameter r and good QST efficiency Q . The single input enhancement with two-mode squeezed optical vacuum can be thought of as a compromise between the former two schemes. Although it attains a minimum sensitivity similar in magnitude to the singlemode squeezed optical vacuum enhancement, it utilizes both high-frequency squeezing and all the atoms in the initially prepared condensate.
Ultimately, however, all three schemes attain sensitivities that are substantially below the SQL, that are robust to imperfect QST once information recycling is incorporated, and are strongly compatible with the practical requirements of current state-of-the-art atom interferometry. This provides a compelling case for the further development of atom interferometers that are enhanced by squeezed optical states and/or information recycling.
## ACKNOWLEDGEMENTS
We would like to acknowledge useful discussions with Warwick Bowen, John Close, Joel Corney, Saleh RahimiKeshari and Nicholas Robins. Numerical simulations were performed using XMDS2 [83] on the University of Queensland (UQ) School of Mathematics and Physics computer 'Obelix', with thanks to Elliott Hilaire and Ian Mortimer for computing support. SSS acknowledges the support of Ian P. McCulloch and the Australian Research Council (ARC) Centre of Excellence for Engineered Quantum Systems (project no. CE110001013). SAH acknowledges the support of ARC Project DE130100575.
[3] P. A. Altin, M. T. Johnsson, V. Negnevitsky, G. R. Dennis, R. P. Anderson, J. E. Debs, S. S. Szigeti, K. S. Hardman, S. Bennetts, G. D. McDonald, L. D. Turner, J. D. Close, and N. P. Robins, New J. Phys. 15 , 023009 (2013).
- [4] B. Canuel, F. Leduc, D. Holleville, A. Gauguet, J. Fils, A. Virdis, A. Clairon, N. Dimarcq, C. J. Bord´, A. Lane dragin, and P. Bouyer, Phys. Rev. Lett. 97 , 010402 (2006).
- [5] A. Lenef, T. D. Hammond, E. T. Smith, M. S. Chapman, R. A. Rubenstein, and D. E. Pritchard, Phys. Rev. Lett. 78 , 760 (1997).
- [6] T. L. Gustavson, P. Bouyer, and M. A. Kasevich, Phys. Rev. Lett. 78 , 2046 (1997).
- [7] M. J. Snadden, J. M. McGuirk, P. Bouyer, K. G. Haritos, and M. A. Kasevich, Phys. Rev. Lett. 81 , 971 (1998).
- [8] J. M. McGuirk, G. T. Foster, J. B. Fixler, M. J. Snadden, and M. A. Kasevich, Phys. Rev. A 65 , 033608 (2002).
- [9] M. Vengalattore, J. M. Higbie, S. R. Leslie, J. Guzman, L. E. Sadler, and D. M. Stamper-Kurn, Phys. Rev. Lett. 98 , 200801 (2007).
- [10] S. Gupta, K. Dieckmann, Z. Hadzibabic, and D. E. Pritchard, Phys. Rev. Lett. 89 , 140401 (2002).
- [11] R. Bouchendira, P. Clad´ e, S. Guellati-Kh´lifa, e F. Nez, and F. Biraben, Phys. Rev. Lett. 106 , 080801 (2011).
- [12] J. B. Fixler, G. T. Foster, J. M. McGuirk, and M. A. Kasevich, Science 315 , 74 (2007).
- [13] G. Lamporesi, A. Bertoldi, L. Cacciapuoti, M. Prevedelli, and G. M. Tino, Phys. Rev. Lett. 100 , 050801 (2008).
- [14] M. Andia, R. Jannin, F. Nez, F. Biraben, S. GuellatiKh´ elifa, and P. Clad´ e, Phys. Rev. A 88 , 031605 (2013).
- [15] G. Rosi, F. Sorrentino, L. Cacciapuoti, M. Prevedelli, and G. M. Tino, Nature 510 , 518 (2014).
- [16] S. Fray, C. A. Diez, T. W. H¨nsch, a and M. Weitz, Phys. Rev. Lett. 93 , 240404 (2004).
- [17] S. Dimopoulos, P. W. Graham, J. M. Hogan, and M. A. Kasevich, Phys. Rev. Lett. 98 , 111102 (2007).
- [18] D. Schlippert, J. Hartwig, H. Albers, L. L. Richardson, C. Schubert, A. Roura, W. P. Schleich, W. Ertmer, and E. M. Rasel, Phys. Rev. Lett. 112 , 203002 (2014).
- [19] G. Amelino-Camelia, C. L¨mmerzahl, F. Mercati, a and G. M. Tino, Phys. Rev. Lett. 103 , 171302 (2009).
- [20] G. M. Tino and F. Vetrano, Class. Quantum Grav. 24 , 2167 (2007).
- [21] S. Dimopoulos, P. W. Graham, J. M. Hogan, M. A. Kasevich, and S. Rajendran, Phys. Rev. D 78 , 122002 (2008).
- [22] N. P. Robins, P. A. Altin, J. E. Debs, and J. D. Close, Physics Reports 529 , 265 (2013).
- [23] K. V. Kheruntsyan, M. K. Olsen, and P. D. Drummond, Phys. Rev. Lett. 95 , 150405 (2005).
- [24] H. Pu and P. Meystre, Phys. Rev. Lett. 85 , 3987 (2000).
- [25] B. L¨ ucke, M. Scherer, J. Kruse, L. Pezz´ e, F. Deuretzbacher, P. Hyllus, O. Topic, J. Peise, W. Ertmer, J. Arlt, L. Santos, A. Smerzi, and C. Klempt, Science 334 , 773 (2011).
- [26] C. Gross, H. Strobel, E. Nicklas, T. Zibold, N. Bar-Gill, G. Kurizki, and M. K. Oberthaler, Nature 480 , 219 (2011).
- [27] J.-C. Jaskula, M. Bonneau, G. B. Partridge, V. Krachmalnicoff, P. Deuar, K. V. Kheruntsyan, A. Aspect, D. Boiron, and C. I. Westbrook, Phys. Rev. Lett. 105 , 190402 (2010).
- [28] R. Bucker, J. Grond, S. Manz, T. Berrada, T. Betz, C. Koller, U. Hohenester, T. Schumm, A. Perrin, and J. Schmiedmayer, Nat Phys 7 , 608 (2011).
- [29] S. A. Haine and A. J. Ferris, Phys. Rev. A 84 , 043624 (2011).
- [30] R. J. Lewis-Swan and K. V. Kheruntsyan, Nat Commun 5 (2014).
- [31] M. Kitagawa and M. Ueda, Phys. Rev. A 47 , 5138 (1993).
- [32] A. Søndberg Sørensen, Phys. Rev. A 65 , 043610 (2002).
- [33] C. Gross, T. Zibold, E. Nicklas, J. Est`ve, e and M. K. Oberthaler, Nature 464 , 1165 (2010).
- [34] M. F. Riedel, P. B¨hi, Y. Li, T. W. H¨nsch, A. Sinatra, o a and P. Treutlein, Nature 464 , 1170 (2010).
- [35] M. T. Johnsson and S. A. Haine, Phys. Rev. Lett. 99 , 010401 (2007).
- [36] S. A. Haine and M. T. Johnsson, Phys. Rev. A 80 , 023611 (2009).
- [37] S. A. Haine, J. Lau, R. P. Anderson, and M. T. Johnsson, Phys. Rev. A 90 , 023613 (2014).
- [38] H. Jing, J.-L. Chen, and M.-L. Ge, Phys. Rev. A 63 , 015601 (2000).
- [39] M. Fleischhauer and S. Gong, Phys. Rev. Lett. 88 , 070404 (2002).
- [40] S. A. Haine and J. J. Hope, Phys. Rev. A 72 , 033601 (2005).
- [41] S. A. Haine and J. J. Hope, Laser Phys. Lett. 2 , 597 (2005).
- [42] S. A. Haine, M. K. Olsen, and J. J. Hope, Phys. Rev. Lett. 96 , 133601 (2006).
- [43] K. Hammerer, A. S. Sørensen, and E. S. Polzik, Rev. Mod. Phys. 82 , 1041 (2010).
- [44] C. M. Caves, Phys. Rev. D 23 , 1693 (1981).
- [45] J. E. Debs, P. A. Altin, T. H. Barter, D. D¨ring, G. R. o Dennis, G. McDonald, R. P. Anderson, J. D. Close, and N. P. Robins, Phys. Rev. A 84 , 033610 (2011).
- [46] S. S. Szigeti, J. E. Debs, J. J. Hope, N. P. Robins, and J. D. Close, New J. Phys. 14 , 023009 (2012).
- [47] S. A. Haine, A. J. Ferris, J. D. Close, and J. J. Hope, Phys. Rev. A 69 , 013605 (2004).
- [48] S. S. Szigeti, M. R. Hush, A. R. R. Carvalho, and J. J. Hope, Phys. Rev. A 80 , 013614 (2009).
- [49] S. S. Szigeti, M. R. Hush, A. R. R. Carvalho, and J. J. Hope, Phys. Rev. A 82 , 043632 (2010).
- [50] S. S. Szigeti, S. J. Adlong, M. R. Hush, A. R. R. Carvalho, and J. J. Hope, Phys. Rev. A 87 , 013626 (2013).
- [51] M. R. Hush, S. S. Szigeti, A. R. R. Carvalho, and J. J. Hope, New J. Phys. 15 , 113060 (2013).
- [52] S. A. Haine, Phys. Rev. Lett. 110 , 053002 (2013).
- [53] A. Sinatra, F. Castelli, L. A. Lugiato, P. Grangier, and J. P. Poizat, Quantum Semiclass. Opt. 7 , 405 (1995).
- [54] E. Brion, L. H. Pedersen, and K. Mølmer, J. Phys. A: Math. Theor. 40 , 1033 (2007).
- [55] V. Paulisch, H. Rui, H. Ng, and B.-G. Englert, Eur. Phys. J. Plus 129 , 12 (2014), 10.1140/epjp/i2014-140128.
- [56] A. O. Jamison, J. N. Kutz, and S. Gupta, Phys. Rev. A 84 , 043643 (2011).
- [57] P. A. Altin, G. McDonald, D. D¨ring, J. E. Debs, T. H. o Barter, J. D. Close, N. P. Robins, S. A. Haine, T. M. Hanna, and R. P. Anderson, New J. Phys. 13 , 065020 (2011).
- [58] P. A. Altin, G. McDonald, D. D¨ring, J. E. Debs, T. H. o Barter, J. D. Close, N. P. Robins, S. A. Haine, T. M. Hanna, and R. P. Anderson, New J. Phys. 13 , 119401 (2011).
- [59] M. P. Fewell, Opt. Commun. 253 , 125 (2005).
- [60] M. Kasevich and S. Chu, Appl. Phys. B 54 , 321 (1992), 10.1007/BF00325375.
- [61] D. M. Giltner, R. W. McGowan, and S. A. Lee, Phys. Rev. A 52 , 3966 (1995).
- [62] H. M¨ uller, S.-w. Chiow, and S. Chu, Phys. Rev. A 77 , 023609 (2008).
- [63] P. Clad´ e, T. Plisson, S. Guellati-Kh´lifa, e F. Nez, and F. Biraben, Eur. Phys. J. D 59 , 349 (2010-09-01).
- [64] S.-w. Chiow, T. Kovachy, H.-C. Chien, and M. A. Kasevich, Phys. Rev. Lett. 107 , 130403 (2011).
- [65] K. S. Hardman, C. C. N. Kuhn, G. D. McDonald, J. E. Debs, S. Bennetts, J. D. Close, and N. P. Robins, Phys. Rev. A 89 , 023626 (2014).
- [66] M. O. Scully and M. S. Zubairy, Quantum Optics , 1st ed. (Cambridge University Press, 1997).
- [67] L. Pezz´ e and A. Smerzi, Phys. Rev. Lett. 102 , 100401 (2009).
- [68] M. S. Stefszky, C. M. Mow-Lowry, S. S. Y. Chua, D. A. Shaddock, B. C. Buchler, H. Vahlbruch, A. Khalaidovski, R. Schnabel, P. K. Lam, and D. E. McClelland, Class. Quantum Grav. 29 , 145015 (2012).
- [69] D. F. Walls and G. J. Milburn, Quantum Optics , 2nd ed. (Springer-Verlag, Berlin and Heidelberg, 2008).
- [70] Actually, this phase factor exp( iqct ) is an artefact of writing the pulse shape u p ( r , t ) exp( i k 1 · r ) as a single frequency pulse with a slowly-varying envelope. Strictly, this pulse contains a range of frequencies about k 1 which exactly cancel exp( iqct ) in the above integral.
- [71] L. Pezz´ e and A. Smerzi, Phys. Rev. Lett. 100 , 073601 (2008).
- [72] M. D. Lang and C. M. Caves, Phys. Rev. Lett. 111 , 173601 (2013).
- [73] M. J. Steel, M. K. Olsen, L. I. Plimak, P. D. Drummond, S. M. Tan, M. J. Collett, D. F. Walls, and R. Graham, Phys. Rev. A 58 , 4824 (1998).
- [74] P. B. Blakie, A. S. Bradley, M. J. Davis, R. J. Ballagh, and C. W. Gardiner, Advances in Physics 57 , 363 (2008).
- [75] A. Polkovnikov, Ann. Phys. (N.Y.) 325 , 1790 (2010).
- [76] B. Opanchuk and P. D. Drummond, J. Math. Phys. 54 , 042107 (2013).
- [77] C. W. Gardiner and P. Zoller, Quantum Noise: A Handbook of Markovian and Non-Markovian Quantum Stochastic Methods with Applications to Quantum Optics , 3rd ed. (Springer, Berlin and Heidelberg, 2004).
- [78] A. Sinatra, C. Lobo, and Y. Castin, J. Phys. B: At. Mol. Opt. Phys. 35 , 3599 (2002).
- [79] M. T. Johnsson, G. R. Dennis, and J. J. Hope, New J. Phys. 15 , 123024 (2013).
- [80] M. Olsen and A. Bradley, Opt. Commun. 282 , 3924 (2009).
- [81] S. A. Haine, S. S. Szigeti, M. D. Lang, and C. M. Caves, arXiv:1411.5111 (2014).
- [82] K. M. R. van der Stam, E. D. van Ooijen, R. Meppelink, J. M. Vogels, and P. van der Straten, Rev. Sci. Instrum. 78 , 013102 (2007).
- [83] G. R. Dennis, J. J. Hope, and M. T. Johnsson, Comput. Phys. Commun. 184 , 201 (2013). | 10.1103/PhysRevA.90.063630 | [
"Stuart S. Szigeti",
"Behnam Tonekaboni",
"Wing Yung S. Lau",
"Samantha N. Hood",
"Simon A. Haine"
] | 2014-08-01T03:03:08+00:00 | 2014-12-22T22:29:16+00:00 | [
"quant-ph",
"cond-mat.quant-gas",
"physics.atom-ph",
"physics.optics"
] | Squeezed-light-enhanced atom interferometry below the standard quantum limit | We investigate the prospect of enhancing the phase sensitivity of atom
interferometers in the Mach-Zehnder configuration with squeezed light.
Ultimately, this enhancement is achieved by transferring the quantum state of
squeezed light to one or more of the atomic input beams, thereby allowing
operation below the standard quantum limit. We analyze in detail three specific
schemes that utilize (1) single-mode squeezed optical vacuum (i.e. low
frequency squeezing), (2) two-mode squeezed optical vacuum (i.e. high frequency
squeezing) transferred to both atomic inputs, and (3) two-mode squeezed optical
vacuum transferred to a single atomic input. Crucially, our analysis considers
incomplete quantum state transfer (QST) between the optical and atomic modes,
and the effects of depleting the initially-prepared atomic source.
Unsurprisingly, incomplete QST degrades the sensitivity in all three schemes.
We show that by measuring the transmitted photons and using information
recycling [Phys. Rev. Lett. 110, 053002 (2013)], the degrading effects of
incomplete QST on the sensitivity can be substantially reduced. In particular,
information recycling allows scheme (2) to operate at the Heisenberg limit
irrespective of the QST efficiency, even when depletion is significant.
Although we concentrate on Bose-condensed atomic systems, our scheme is equally
applicable to ultracold thermal vapors. |
1408.0068v1 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-4
## Azimuthally differential pion femtoscopy in Pb-Pb collisions at 2.76 TeV with ALICE at the LHC
Vera Loggins (for the ALICE Collaboration) 1
Wayne State University, 42 W. Warren Ave, Detroit, MI 48202
## Abstract
Femtoscopy of non-central heavy ion collisions provides access to information on the geometry of the effective pionemitting source. In particular, the source shape can be studied by measuring femtoscopic radii as a function of the pion emission angle relative to the collision symmetry planes. We present the results of azimuthally differential femtoscopy of Pb-Pb collisions at √ s NN = 2 76 TeV at the LHC relative to the second harmonic event plane. We observe a clear . oscillation of the extracted radii as a function of the emission angle. We find that R side and R out oscillate out of phase for all centralities and pion transverse momenta. The relative amplitude of R side oscillation decreases in more central collisions, but remains positive, which indicates that the source remains out-of-plane extended qualitatively similar to what was observed at RHIC energies. We compare our results to existing hydrodynamical and transport model calculations.
Keywords: LHC, ALICE, femtoscopy, radii oscillation, final eccentricity, freeze-out
## 1. Introduction
Two particle correlations at small relative momenta (commonly known as femtoscopy ) is an effective tool to probe the space and time characteristics of the particle emitting source in relativistic heavy ion collisions [1, 2]. The results presented here are obtained in the so-called Longitudinal CoMoving System (LCMS) in which the total pair momentum along the z direction is zero, ( p 1 ,z = -p 2 ,z ). In this system, the extracted freeze-out radii provide information on the system evolution in the following manner: R side is mostly determined by the system geometrical size, R out is mostly determined by the system geometrical size and the emission duration, and R long is mostly determined by the total emission time. Dependence of the radii on the transverse momentum provides information on the system's collective radial expansion (flow) [3]. Flow is due to pressure gradients which are higher in the plane of reaction (in-plane) than perpendicular to it (out-of-plane). Due to flow, the freeze-out source shape may be less out-of-plane extended, and more in-plane extended [3]. In this analysis, we focus on the azimuthal dependence of the radii with respect to the reaction plane to get information on the shape of the source at freeze-out.
## 2. Data Analysis
The data sample used for this analysis is recorded by ALICE during the 2011 heavy-ion run, Pb-Pb collisions at √ s NN = 2 76 TeV. There are roughly 30 million min-bias and triggered (central and semi-.
1 A list of members of the ALICE Collaboration and acknowledgements can be found at the end of this issue.
central) events used in this analysis. The tracks are reconstructed using the Time Projection Chamber (TPC) [4]. Both the TPC and the Time of Flight (TOF) [4] were used for pion identification in the pseudorapidity range | η | < 0 8. . The correlation function is defined as the ratio of signal and background relative momentum distribution of two identical pions. The signal distribution was formed using particles from the same event, whereas the background distribution was formed using particles from different events. The pair cuts have been applied to reduce 'track splitting' (false pairs created at low relative momentum) and 'track merging' (when two tracks are reconstructed as one).
## 3. Azimuthally Differential Pion Femtoscopy Results
Azimuthally differential femtoscopic analysis of pion production relative to the second harmonic event plane has been performed for Pb-Pb collisions at √ s NN = 2 76 TeV. Femtoscopic radii have been extracted . from the fit to the correlation function using Bowler-Sinyukov fitting procedure [5]:
$$C ( \vec { q }, \Delta \phi ) = N [ ( 1 - \lambda ) + \lambda K ( \vec { q } ) ( 1 + G ( \vec { q }, \Delta \phi ) ], & & ( 1 )$$
where G glyph[vector], ( q ∆ ) = φ e -q 2 out R 2 out (∆ ) φ -q 2 side R 2 side (∆ ) φ -q 2 long R 2 long (∆ ) φ -q out q side R 2 os (∆ ) φ , N is the normalization parameter, K glyph[vector] ( q ) is the Coulomb component, λ is the fraction of pairs participating in the Bose-Einstein correlation, and ∆ φ = ϕ pair -Ψ EP, 2 is the relative pair angle with respect to the second harmonic event plane defined by the TPC tracks. The extracted radii as a function of ∆ φ are fitted by the following Fourier expansion:
$$R _ { \mu } ^ { 2 } = R _ { \mu, 0 } ^ { 2 } + 2 R _ { \mu, 2 } ^ { 2 } \cos [ 2 ( \Delta \phi ) ] \ ( \mu = o u t, s i d e, l o n g ), \\ R _ { \mu } ^ { 2 } = 2 R _ { \mu, 2 } ^ { 2 } \sin [ 2 ( \Delta \phi ) ] \ ( \mu = o u t \text{-} s i d e ).$$
Figure 1: R 2 out , R 2 side , R 2 long , and λ (left) and R 2 os , R 2 sl , and R 2 ol (right) at 20-30% centrality as a function of emission angle ∆ φ for different k T intervals: 0.2-0.3, 0.3-0.4, 0.4-0.5, and 0.5-0.7 GeV/ c . Lines represent the fits to the radii using Eq. 2. The statistical errors are shown by the error bars and systematic errors are indicated by shaded regions.
Figure 1 (left) presents the R 2 out , R 2 side , R 2 long radii and λ dependence on transverse momentum k T , ( k T = p 1 + p / 2 2) at 20-30% centrality. Figure 1 (right) shows similar dependence of out-side , R os , side-long , R sl , and out-long , R ol , the cross-radii. The values of the radii R 2 out , R 2 side , and R 2 long at 0 2 . < k T < . 0 3 GeV/ c are higher than the values of the radii obtained at a high k T , 0 5 . < k T < 0 7 GeV/ , as expected due to . c radial flow. The oscillations for R 2 out and R 2 side are out-of-phase at all measured k T ranges. We compare results obtained at √ s NN = 2 76 TeV in Pb-Pb collisions to results obtained at RHIC [6] in Au-Au collisions . at √ s NN = 200 GeV in Figure 2. The radii oscillations are similar between RHIC and LHC. The results
## V. Loggins / Nuclear Physics A 00 (2014) 1-4
Figure 2: Centrality comparison of radii vs. pair emission angle at ALICE k T of 0.2-0.3 GeV/ , 0.4-0.5 c GeV/ , and STAR c k T ranges 0.15-0.25 GeV/ , and 0.35-0.45 GeV/ c c [6] for 20-30% centrality. The statistical errors are shown by the error bars and the systematic errors are indicated by shaded regions.
contradict to AZHYDRO calculations [7] that predicted a sign inversion in the oscillation amplitude for R side at low k T .
Figure 3 shows comparisons of R 2 side, 0 , (left), and R 2 side, 2 / R 2 side, 0 , (right), with the most recent (3+1D) hydrodynamical calculations [8]. As was shown in [3], 2 R 2 side, 2 / R 2 side, 0 at small k T can be used as an estimate for the final freeze-out eccentricity. We compare the final source eccentricity with experiments at lower energies in Figure 4. Final source eccentricity is lower at higher energies as expected due to longer evolution time [9]. HYDRO calculations [10] predict much stronger energy dependence than observed experimentally. UrQMD model [11] describes the energy dependence of the final source eccentricity rather well, but it fails to describe R side, 0 and R side, 2 separately (not shown).
Figure 3: (3+1D) HYDRO model by P. Bozek [8] compared to R 2 side, 0 (fm ) (left) and 2 R 2 side, 2 / R 2 side, 0 (right). The statistical errors are shown by the error bars and the systematics are indicated by boxes.
Figure 4: √ s NN dependence of the final spatial eccentricity. The statistical (systematic) errors are shown by the error bars (boxes).
## 4. Summary
We have performed an analysis of azimuthally differential pion femtoscopy relative to the second-order event plane for Pb-Pb collisions at √ s NN =2.76 TeV. The radii oscillations as a function of two particle emission angle relative to the second order harmonic plane are found very similar at LHC to those at RHIC. The relative amplitude of oscillation, R 2 side, 2 /R 2 side, 0 is found to decrease with collision energy reflecting lower source eccentricity in the freeze-out stage. We obtain a positive value for glyph[epsilon1] f indicating no change in the source geometry at freeze-out. In the future, these observations will be studied further with additional measurements at higher energies.
## References
- [1] G. I. Kopylov, M. I. Podgoretsky, Sov. J. Nucl. Phys. 15, 219-223 (1972).
- [2] G. I. Kopylov, V. L. Lyuboshits, M. I. Podgoretsky, JINR-P2-8069.
- [3] M. A. Lisa, S. Pratt, R. Soltz and U. Wiedemann, Ann. Rev. Nucl. Part. Sci. 55, 357 (2005).
- [4] K. Aamodt et al., JINST 3 (2008) S08002.
- [5] K. Aamodt et al. (ALICE Collaboration), Phys.Rev. D84 (2011) 112004, arXiv:1101.3665 [hep-ex].
- [6] J. Adams et al. [STAR Collaboration], Phys. Rev. Lett. 93, 012301 (2004), arXiv:nucl-ex/0312009].
- [7] E. Frodermann, Rupa Chatterjee, and Ulrich Heinz, J. Phys. G: Nucl Part. Phys. 34 (2007) 2249-2254.
- [8] P. Bozek, Phys. Rev. C 89, 044904 (2014), arXiv:1401.4894 [nucl-th].
- [9] Adam Kisiel et al., Phys. Rev. C 79, 014902 (2009).
- [10] C. Shen and U. Heinz, Nucl. Phys. 2 A904-905 2013, 361c (2013), arXiv:1210.2074 [nucl-th].
- [11] M. A. Lisa, E. Frodermann, G. Graef, M. Mitrovski, E. Mount, H. Petersen and M. Bleicher, New J. Phys. 13, 065006 (2011) 12, arXiv:1104.5267 [nucl-th]. | 10.1016/j.nuclphysa.2014.08.061 | [
"Vera Loggins"
] | 2014-08-01T03:04:51+00:00 | 2014-08-01T03:04:51+00:00 | [
"nucl-ex",
"hep-ex"
] | Azimuthally differential pion femtoscopy in Pb-Pb collisions at 2.76 TeV with ALICE at the LHC | Femtoscopy of non-central heavy ion collisions provides access to information
on the geometry of the effective pion-emitting source. In particular, the
source shape can be studied by measuring femtoscopic radii as a function of the
pion emission angle relative to the collision symmetry planes. We present the
results of azimuthally differential femtoscopy of Pb-Pb collisions at
$\sqrt{s_{NN}}=2.76$ TeV at the LHC relative to the second harmonic event
plane. We observe a clear oscillation of the extracted radii as a function of
the emission angle. We find that $R_{side}$ and $R_{out}$ oscillate out of
phase for all centralities and pion transverse momenta. The relative amplitude
of $R_{side}$ oscillation decreases in more central collisions, but remains
positive, which indicates that the source remains out-of-plane extended
qualitatively similar to what was observed at RHIC energies. We compare our
results to existing hydrodynamical and transport model calculations. |
1408.0069v2 | ## The effect of premature wall yield on creep testing of stronglyflocculated suspensions
Anthony D Stickland *,1 , Ashish Kumar , Tiara E Kusuma , Peter J Scales , Amy Tindley , 1 1 1 2 Simon Biggs and Richard Buscall 2 1,2,3
1 Particulate Fluids Processing Centre, Department of Chemical and Biomolecular Engineering, The University of
Melbourne, Victoria 3010, Australia
2 Institute of Particle Science and Engineering, School of Process, Environmental and Materials Engineering, The University of Leeds, Leeds LS2 9JT, United Kingdom
3 MSACT Research and Consulting, 34, Maritime Court, Haven Road, Exeter, EX2 8GP, United Kingdom
## Abstract
Measuring yielding in cohesive suspensions is often hampered by slip at measurement surfaces. This paper presents creep data for strongly-flocculated suspensions obtained using vane-in-cup tools with differing cup-to-vane diameter ratios. The three suspensions were titania and alumina aggregated at their isoelectric points and polymer-flocculated alumina.
The aim was to find the diameter ratio where slip or premature yielding at the cup wall had no effect on the transient behaviour. The large diameter ratio results showed readily understandable material behaviour comprising linear viscoelasticity at low stresses, strainsoftening close to yielding, time-dependent yield across a range of stresses and then viscous flow. Tests in small ratio geometries however showed more complex responses. Effects attributed to the cup wall included delayed softening, slip, multiple yielding and stick-slip events, and unsteady flow. The conclusion was that cups have to be relatively large to eliminate wall artefacts. A diameter ratio of three was sufficient in practice, although the minimum ratio must be material dependent.
## Keywords
Suspension rheology, creep, vane-in-cup, wall slip, strongly-flocculated suspension
* Tel.: +61 3 8344 3430; Fax: +61 3 8344 4153 Email address : [email protected].
## 1 Introduction
The rheological properties of industrial suspensions such as mineral tailings, biosludges, pigments and ceramics, and household products including cosmetics, paints and foods, are often the major factor determining their use and applicability. In the industrial setting, a thorough understanding of suspension rheology allows for better prediction and optimisation of transport and handling processes, such as pipelining, mixing, solid-liquid separation and pumping. At some point, the suspension rheology limits the maximum particulate concentration that can be processed. In other cases, the flow properties of suspensions are formulated to produce a particular flow response such as when a toothpaste tube is squeezed Ð toothpaste yields and flows onto the toothbrush but stops flowing on cessation of the applied stress.
Flocculated suspensions, where the particles are attracted to each other, develop a networked structure capable of withstanding an applied load at solids concentrations above the gel point φ g (Michaels and Bolger 1962; Rehbinder 1954). At sufficiently small loads or deformations, such suspensions behave as viscoelastic solids. If a shear load is large enough, the suspensions yield and flow viscously. φ g can be much lower than random close packing Ð as low as 1 volume percent for biosludges (Stickland et al. 2008), for example Ð such that the yielding behaviour of strongly flocculated suspensions is important over a wide range of concentrations.
In shear, it is common to extract parameters from the flow curves for strongly-flocculated suspensions by fitting them to viscoplastic models such as Bingham (Bingham 1916) or Herschel-Bulkley (Herschel and Bulkley 1926), where the strength of the network is represented by the shear yield stress τ y , which is a function of the density and distribution of bonds in the system. The assumption embodied in these simple models and in yield stress as an operational parameter is that, at some critical stress, the material converts instantaneously from a perfectly rigid solid to a viscous liquid (Bird et al. 1982; Hartnett and Hu 1989; Liddell and Boger 1995). This is unlikely to be true in reality, even if it suffices to model many flow curves approximately. Hence, it comes as no surprise that experiments that probe yielding itself show the transition to be more progressive and to have an intrinsic timedependence. For example, creep testing reveals viscoelasticity at stresses below yielding followed by time-dependent yield over a range of stresses rather than at a single stress (Barrie et al. 2004; Gibaud et al. 2010; Le Grand and Petekidis 2008; Uhlherr et al. 2005). Other descriptions of yield such as critical strain energy Wy or yield strain γ y may be more
appropriate for suspension behaviour (ten Brinke et al. 2008) compared to yield stress. For example, yield may be described by sharp (but not instantaneous) strain thinning or strain softening (Klein et al. 2007; Kobelev and Schweizer 2005; Kumar et al. 2012). In fact, as demonstrated here, an elastic body can yield without any need for an explicit yield criterion if the strain-softening of the modulus is strong enough.
The study of suspension viscoelastic and yielding properties and consequently the development of strongly-flocculated suspension constitutive descriptions cannot proceed without accurate measurement. Unfortunately, the accurate measurement of suspension properties is inherently difficult due to complex inter-particle and hydrodynamic interactions. The results from conventional rotational geometries such as cone-and-plate or cup-and-bob (Couette) are influenced by wall effects. Adhesive yielding allows depletion and slip (Buscall et al. 2009; Buscall et al. 1993). In addition, narrow gaps such as cone-and-plate are not suitable due to particle bridging (Boger 1999).
Since the 1980Õs, various authors (Barnes and Carnali 1990; Keentok et al. 1985; Nguyen and Boger 1985a) have substituted the concentric cylinder system of a Couette geometry with the vane-in-cup geometry (see in Figure 1) to alleviate the problem of slip at the surface of the inner cylinder surface in suspension rheology (Barnes 1995; Nguyen and Boger 1983). The vane also has the advantage of minimal structural disruption during testing (Barnes 1995; Barnes and Carnali 1990). The flow start up at controlled shear-rate vane technique (Nguyen and Boger 1983; 1985a) has been used in characterising a wide array of concentrated networked suspensions, including for example titania (Uhlherr et al. 2005; Zhou et al. 2001), alumina (Fisher et al. 2007; Johnson et al. 2000; Zhou et al. 2001; Zhou et al. 1999), brown coal (Leong et al. 1995) and wastewater sludges (Baudez et al. 2011).
Figure 1: (a) Side and (b) Top views of the four-bladed vane-in-cup geometry with a wide gap. and
## are the height and diameter of the vane while hc and dc
hv dv are the height and diameter of the cup
The vane replaces the inner cylinder in a concentric cylinder arrangement and thus alleviates slip at the inner surface. In a radial geometry, the stress and deformation decay with radial position in the gap relative to the vane diameter. In most cases, vanes are used in cup-to-vane diameter ratios of approximately 1.1 so that the deformation is approximately linear and the transformation of angle to strain is straightforward. However, since the wall yield stress of a suspension is typically less than the bulk yield stress (Buscall et al. 1993; Grenard et al. 2014; Saak et al. 2001; Walls et al. 2003), small diameter ratios are subject to slip at the cup wall. Whilst roughened surfaces have been employed with mixed success, the vane-in-infinite-cup geometry alleviates all wall effects and has been shown (Fisher et al. 2007) to be a suitable method for determining the yield stress and steady-state flow behaviour of strongly-flocculated particulate suspensions. However, the geometry has had limited use studying the transient elastic deformation of suspensions prior to yielding or the time dependencies of yielding and it is unclear what constitutes an infinite gap. Coussot and coworkers (Coussot et al. 2006) used a 25 mm diameter six-bladed vane in a 36 mm cup ( dc / dv = 1.44) to study the creep behaviour of a networked bentonite suspension (along with Maille mustard and Vivelle Dop hair gel as examples of a particulate suspension in an oil-in-water emulsion and a Carbopol gel respectively). They too justified using a larger than normal diameter ratio in order to minimise wall and edge effects; however, they did not vary the gap to show if indeed this had been achieved.
The work in this paper compared the creep behaviour of strongly-flocculated alumina and zirconia systems as functions of cup-to-vane diameter ratio, dc/dv . The expectation was that there would be a critical dc/dv value above which the results would show no wall effects. A constitutive description when there is first wall yield and then true yield is complicated. The behaviours at the wall and in the bulk are both highly non-linear and hence it is difficult to posit a constitutive equation in advance, except in very general terms. We have used a power-law dependent model for the elastic modulus here, but in general, there is limited discussion of a constitutive description for suspensions. Whilst this is vitally important and the subject of current research (Buscall et al. 2014a; Buscall et al. 2014b; Lester et al. 2014), the aim of this work was to qualitatively compare the measured data to show when there was no influence of the cup wall. Development cannot proceed without data that is clear of wall artefacts, otherwise material behaviour is attributed that is in fact due to the measurement.
Two types of strongly-flocculated particulate mineral oxide suspensions were tested in this work. The term strongly-flocculated reflects that the strength of the inter-particle bonds was greater than about 20 kT such that the suspensions were not influenced by Brownian motion, compared to weakly-flocculated suspensions that show long-term fluctuations and creep. The first type of suspension was either zirconia or alumina coagulated by van der Waals forces at their respective iso-electric points (IEPs). The second type was alumina flocculated with a high molecular weight polymer flocculant. The creep results from these suspensions were compared to highlight the susceptibility of different systems to apparent wall effects. In particular, the stresses where wall slip was observed in small diameter ratios were used to determine the ratio of bulk to wall yield stresses. In addition, the elastic deformation was analysed using an appropriate non-linear to show wall effects on suspension strain softening.
## 2 Theory
Most rheometer geometries use a relatively small gap so that the shear stress τ is approximately uniform and the shear strain γ is easy to calculate (Barnes et al. 1989). Using the vane-in-infinite-cup geometry presents the problem of extracting stress-strain information from the test results. The vane-in-infinite-cup is the vane analogy of the wide-gap concentric cylinder geometry (Krieger and Maron 1952; 1954). The shear stress distribution as a function of radial position r for concentric cylinders is given by setting the inertial and viscous terms of the momentum balance to zero:
$$\frac { \partial \tau } { \partial r } + \frac { 2 \tau } { r } = 0$$
Integrating and evaluating the shear stress at the vane, τ v = τ ( rv ), gives:
$$\tau ( r, t ) = \tau _ { v } \left ( \frac { r _ { v } } { r } \right ) ^ { 2 }$$
Thus the shear stress diminishes with the radial position squared. The stress propagates to the walls of the container and the cup-to-vane diameter ratio determines the magnitude of the stress at the cup wall. If yielding at the wall is characterised by a critical wall yield stress τ y,wall and yielding in the bulk by τ y,bulk , the critical diameter ratio at which premature yielding will be observed is given by the square-root of the ratio of the bulk and wall yield stresses (Buscall et al. 1993; Grenard et al. 2014; Saak et al. 2001; Walls et al. 2003):
$$\left ( \frac { d _ { c } } { d _ { v } } \right ) _ { \min } = \sqrt { \frac { \tau _ { y, b u l k } } { \tau _ { y, w d l } } }$$
Thus, measurements in a relatively large gap to determine the bulk yield stress and in a relatively small gap to determine the wall yield stress would give an estimate of the minimum critical diameter ratio.
In the cylindrical geometry, the strain γ at position r and time is defined as t
$$\gamma = - r \frac { \partial \theta } { \partial r }$$
where θ ( r t , ) is the angular displacement. Since the stress varies as a function of radial position in the wide gap, a constitutive relationship is required to combine equations 2 and 4 in order to convert displacement (or rotational rate) into strain (or strain-rate).
If the stress and stress-rate are linear functions with respect to strain and strain-rate then the material is linear viscoelastic and the solution is relatively straight-forward. By way of example of the expected variation with gap width for a linear material, the Standard Linear Solid (Voigt form) (SLS) is solved under constant stress creep conditions. The SLS, also known as the Zener model, is a Hookean spring with instantaneous elasticity Gi in series with a Kelvin-Voigt element with a retarded elasticity Gr and retardation time, t r . The constitutive equation for this arrangement is (Roylance 2001):
$$\frac { t _ { r } } { G _ { i } } \dot { \tau } + \left ( \frac { 1 } { G _ { r } } + \frac { 1 } { G _ { i } } \right ) \tilde { \tau } = t _ { r } \dot { \gamma } + \gamma$$
Under constant stress conditions ( τ ! = 0, τ = τ 0 ) in Cartesian coordinates, the solution to Eq. 5 is:
$$\gamma ( t ) = \tau _ { _ { 0 } } \left [ \frac { 1 } { G _ { i } } + \frac { 1 } { G _ { r } } \left [ 1 - \exp \left ( - \frac { t } { t _ { r } } \right ) \right ] \right ] \, & \dots ( 6 )$$
In radial coordinates with the vane rotating ( τ ( rv , t ) = τ v , θ ( rv , t ) = θ v ) and the cup static ( θ ( rc , t ) = 0), the solution for θ v ( ) using Eqs 2, 4 and 5 is: t
$$\theta _ { v } ( t ) = \frac { \tau _ { v } } { 2 } \left [ 1 - \left ( \frac { r _ { v } } { r _ { c } } \right ) ^ { 2 } \right ] \right ] \left [ \frac { 1 } { G _ { i } } + \frac { 1 } { G _ { r } } \left [ 1 - \exp \left ( - \frac { t } { t _ { r } } \right ) \right ] \right ] \right ] \quad \dots ( 7 )$$
The relationship between the rotation of the vane in a finite medium and in an infinite medium θ v, ∞ is given by:
Figure 2: Variation of creep angle with time for various cup-to-vane diameter ratios for a Standard Linear Solid ( Gi = 1000 Pa, Gr = 100 Pa, t r = 10 s, τ = 100 Pa)
Thus, for a linear material, diameter ratio does not affect the time dependency of the creep angle, just the magnitude. The creep angle θ v ( ) is plotted in Figure 2 using the cup-tot vane diameter ratios used in the alumina experiments for arbitrary material properties. The results show instantaneous compliance (1/ Gi ) followed by retarded compliance (1/ Gr ). For the smallest gap the creep angle is only 8% of the value for the infinite gap. As the gap
increases, the creep angle asymptotes towards the infinite solution. The 4.2 cup-to-vane diameter ratio gives a creep angle of 94% of the infinite solution.
Comparing Eqs. (5) and (6) leads to the commonly used linear relationship between strain and angle of rotation at the vane (Krieger and Maron 1954):
$$\gamma _ { v } = 2 \theta _ { v } \left [ 1 - \left ( \frac { r _ { v } } { r _ { c } } \right ) ^ { 2 } \right ] ^ { - 1 }$$
This relationship holds for all linear materials and in the small gap limit (when all materials are approximately linear). To complicate matters, suspensions are non-linear, such that the conversion between angle and strain is not straightforward. The steady-state angular displacement or rotational rate can be converted to steady-state strain and strain-rate respectively (Krieger and Maron 1952), but it is not possible to use the same method to convert time-dependent data for non-linear materials since their deformation history is stress and time dependent. For suspensions that yield, for example, it would be necessary to know the radial position within the gap at which the suspension is yielding in order to define the strain.
For creep data prior to yielding that is not time-dependent such as the initial or steadystate elastic deformation (that is, either none or all of the stresses have relaxed), it is possible to use a power-law approximation akin to Krieger and Maron to extract the non-linear strain and strain modulus. For a power-law dependent modulus G ( γ ) = A γ n (where τ = G ( γ γ ) ), the conversion from angle to strain is given by:
$$\gamma _ { _ { v } } = & \frac { 2 } { ( 1 + n ) } \theta _ { _ { v } } \left [ 1 - \left ( \frac { r _ { _ { v } } } { r _ { _ { c } } } \right ) ^ { \frac { 2 } { 1 + n } } \right ] ^ { - 1 } \\ - - \. \. \. \. \. \. \. \ - - \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \. \........................................................................................................................................................................................................ \..................................................................................................................................................................................................... \. \...................................................................................................................................................................................................$$
The linear approximation (Eq. 9) can therefore be used to determine the local slope of the power-law (calculated over 3 or 5 points, for example), which can then be used to calculate the real strain and modulus.
The results herein generally showed a low shear modulus G0 followed by strain-softening that asymptoted to a constant power-law index. This motivated using a modified Cross equation (with modulus and strain instead of viscosity and strain-rate) to fit G ( γ ):
$$G ( \gamma ) & = \frac { G _ { 0 } } { 1 + \left ( \frac { \gamma } { \gamma _ { y } } \right ) ^ { - n } } \quad & \dots ( 1 1 )$$
where γ y is the Ôyield strainÕ when the modulus is ½ G0 . This equation gives a linear material with modulus G0 for γ << γ y and strain-softening varying with γ n for γ >> γ y . Note that at large strains and if n ≤ -1 then the material softens as fast or faster than it can strain (the stress τ = G ( γ γ ) shows a maximum). If n < -1, the stress is non-monotonic with strain.
There is no explicit solution for stress as a function of strain based on Eq. 11 such that it is not possible to pose a direct analytical conversion from angle to strain. However, there is an explicit solution in the special case where n = -1. In this case, the modulus can be written as a function of stress:
$$G ( \tau ) = \frac { \tau } { \gamma } = G _ { _ { 0 } } \left ( 1 - \frac { \tau } { \tau _ { _ { y } } } \right ) & & \dots ( 1 2 )$$
G ( τ ) asymptotes to a Ôyield stressÕ τ y where τ y = G0 y γ . Integrating the combination of G ( τ ), the stress as a function of radius (Eq. 2) and the definition of strain (Eq. 4) from θ ( rv ) = θ v ( τ v ) to θ ( rc ) = 0 gives:
$$\theta _ { v } ( \tau _ { v } ) = \frac { \tau _ { y } } { 2 G _ { 0 } } \left [ \ln \left ( 1 - \frac { \tau _ { v } } { \tau _ { y } } \frac { r _ { v } ^ { 2 } } { r _ { c } ^ { 2 } } \right ) - \ln \left ( 1 - \frac { \tau _ { v } } { \tau _ { y } } \right ) \right ]$$
Thus, for materials that have a zero strain modulus G0 and strain-soften with a slope of n = -1, Eq. 13 provides an analytical equation that can be fitted directly to experimental data to extract G0 and τ y .
In order to get the conversion factor between γ and θ for n = -1, simply substitute τ v ( γ v ) = G ( γ v ) γ v and rearrange in terms of γ v ( θ v ):
$$\gamma _ { v } = \frac { \tau _ { y } } { G _ { 0 } } \left [ \exp \left ( \frac { 2 G _ { 0 } \theta _ { v } } { \tau _ { y } } \right ) - 1 \right ] \left ( 1 - \frac { r _ { v } ^ { 2 } } { r _ { c } ^ { 2 } } \right ) ^ { - 1 }$$
## 3 Materials and Methods
All reagents used were analytical grade and used without further purification. All reagents were prepared using Milli-Q water (Milliporeª Synergy¨, 0.22 ∝ m filter).
## 3.1 Coagulated Titania Suspensions
Rheological tests were performed using high purity anatase titania (ANX type-N, Degussa) in the laboratory at Leeds University. The purity and lack of surface contamination was verified using ion chromatography analysis (Thermo Dionex). The mean diameter D [4,3]
estimated from low angle laser light scattering data (Malvern Mastersizer 2000) was 1.96 ∝ m. The density was 3.78 g/cm . The IEP was measured (Colloidal Dynamics Zeta probe, 3 Colloidal Dynamics Pty Ltd, Australia) as pH 6.5 (Biggs and Tindley 2007). The titania was prepared at a volume fraction of 0.153 by dispersion into 0.01 M KNO3 at pH 3 using vigorous agitation by hand for 5 mins. The samples were pH adjusted and allowed to age for between 18 and 24 h to ensure chemical equilibrium. The pH was adjusted to the IEP and allowed to equilibrate prior to measurement.
## 3.2 Coagulated Alumina Suspensions
Rheological tests were performed using alumina (AKP-30, Sumitomo Chemicals Pty. Ltd, Japan) at The University of Melbourne. This system has been characterised in detail by Zhou et al (Zhou et al. 2001; Zhou et al. 1999). The alumina was nearly spherical with a density of 4.0 g/cm and a mean diameter of 360 nm (Malvern Mastersizer 2000). 3
Coagulated alumina suspensions were prepared at a solids volume fraction of 0.20 in a 0.01 M KNO3 background electrolyte solution. The mixture was acidified using 1 M HNO3 to pH 5 (EZDO PL-600 pH meter with Sensorex Combination pH electrode, Denver Instrument Company), at which the suspension was fully dispersed. The mixture was then sonicated with a high intensity sonic probe (Misonixª S4000 Sonicator, 12.5 mm horn, 20 kHz, 800 W) to ensure complete dispersion and then left to rest for 24 to 48 hours to establish physical and chemical equilibrium. Before measurements, the pH was adjusted using 1 M KOH to the isoelectric point (IEP) of approximately pH 9.2 (Foong 2008; Zhou 2000) and allowed to rest for a minimum of 2 hours. The sample had a nominal yield stress of 85 Pa, as measured using the Nguyen and Boger (Nguyen and Boger 1983; 1985a) vane technique.
## 3.3 Flocculated Alumina Suspensions
Polymer-flocculated systems are known to be irreversibly shear-history dependent. Therefore, an experimental protocol was implemented here that minimised shear degradation. Dispersed alumina suspensions were prepared at a volume fraction of 0.03 at pH 5 by dispersing the alumina powder in Milli-Q water and then sonicating, as above. Suspensions were then transferred to specially designed cylinders (see Figure 3) for flocculation.
The flocculant was an anionic, high MW polyacrylate / polyacrylamide copolymer flocculant (AN934SH, SNF Australia, 30% anionic). Stock polymer solutions were prepared at 2 g/L and agitated overnight on a rotary shaker. Stock bottles were covered with aluminium foil and kept refrigerated to minimise polymer degradation; unused stock was
discarded after a week. An hour prior to use, the flocculant stock was diluted to 0.1 g/L and homogenised using a magnetic stirrer (Gladman et al. 2005).
Figure 3: (a) Perspex cylinder with detachable top segment. The detachment point is indicated by the black marks on the cylinder. (b and c) Upon flocculation and settling, the top segment was removed allowing subsequent rheological testing

The polymer dose was 40 gram per tonne of suspended solids, which was chosen from preliminary flocculation tests. Higher dosages showed little or no improvement in turbidity or settling rate, indicating the dose of 40 g/t was an optimum dosage under the flocculation conditions. Polymer solutions were added directly to suspensions in the settling cylinders using the ÔplungerÕ method. This was a simple, low-cost method of achieving consistent mixing and flocculation conditions (Gladman et al. 2005; Usher 2002). Upon addition of flocculant, a perforated disk attached to a long rod (the plunger) was manually moved up and down the cylinder at a constant rate (3 s per stroke) a fixed number of times (4 strokes).
The flocculated suspensions were allowed to settle for a minimum of 24 hours, or until no discernable change in sediment bed height was detectable. The cylinders had detachable top segments (see Figure 3(a)) such that, upon flocculation and settling, the supernatant could be removed with a syringe, the top segment removed and the remaining cup with sediment used in rheological testing (Jeldres et al. 2014). The average solids volume fraction of the settled sediment was determined by weight loss on drying to be 0.122 ± 0.010. This design limited exposure to shear. The only shear that the flocculated material would have experienced would have been during floc formation, during settling (van Deventer et al.
2011) and during insertion of the vane (although the vane does minimise sample disturbance compared to other rheometer geometries (Nguyen and Boger 1985b)). This experimental protocol was Ôsingle-useÕ based on the premise that the flocculated samples were irreversibly changed by the rheological test.
## 3.4 Rheology
Constant stress creep experiments were performed using stress-controlled rheometers at Leeds University (C-VOR, Bohlin) and at The University of Melbourne (AR-G2, TA Instruments). The vane-in-cup geometry was used with a combination of vanes and cups to provide the range of dc/dv ratios shown in Table 1. The tests on coagulated titania used two cup sizes with the same vane (combinations A and B), leading to cup-to-vane diameter ratios of 1.1 and 2.0 respectively. The creep tests were performed over a range of stresses for 50 s. The tests on coagulated alumina involved four different cup sizes with the same vane, leading to the ratios of 1.1, 2.1, 3.0 and 4.2 (combinations C to F). The polymer-flocculated tests involved the same cup (see Figure 3) with progressively smaller vanes (combinations G, H and I). The 10 mm vane was the smallest available, so a larger cup was used to give the ratio of 4.2 (combination J). The vanes were inserted into the middle of the sample with the same distance from the vane to the top of the sample and from the vane to the bottom of the cup.
During the creep test, a constant torque T was applied and the creep angle, θ , measured as a function of time. The torque was converted to shear stress using the relationship (Nguyen and Boger 1983):
$$T = \frac { \pi d _ { v } ^ { 3 } } { 2 } \left ( \frac { h _ { v } } { d _ { v } } + \frac { 1 } { 3 } \right ) \tilde { \gamma }$$
Table 1. Vane-and-cup combinations with associated gap widths and cup-to-vane diameter ratios, dc/dv .
| Combination | Vane dimensions | Vane dimensions | Cup dimensions | Cup dimensions | Gap width | d c /d v |
|---------------|-------------------|-------------------|------------------|------------------|-------------|------------|
| Combination | h v (mm) | d v (mm) | h v (mm) | d v (mm) | (mm) | |
| A | 30 | 14 | 47 | 15 | 1 | 1.1 |
| B | 30 | 14 | 60 | 28 | 7 | 2.0 |
| C | 42 | 28 | 80 | 30 | 1 | 1.1 |
| D | 42 | 28 | 105 | 60 | 16 | 2.1 |
| E | 42 | 28 | 95 | 85 | 28.5 | 3.0 |
| F | 42 | 28 | 200 | 118 | 45 | 4.2 |
| G | 42 | 28 | 78 | 32 | 2 | 1.1 |
| H | 50 | 15 | 78 | 32 | 8.5 | 2.1 |
| I | 40 | 10 | 78 | 32 | 11 | 3.2 |
| J | 40 | 10 | 80 | 41.5 | 15.8 | 4.2 |
In the case of coagulated titania, the samples were pre-sheared for 60 s at 100 s -1 followed by a 300 s rest period. Between successive applied stresses, the coagulated alumina samples were sheared vigorously by hand with a spatula and then tapped on the bench to remove air bubbles before inserting the vane and waiting 20 minutes to reach thermal equilibration. Flocculated suspensions were replaced with new samples between each applied stress.
## 4 Results and Discussion
The creep results for the coagulated titania with two diameter ratios are presented first, followed by the results for coagulated and flocculated alumina in four different diameter ratios.
## 4.1 Coagulated Titania
Large Diameter Ratio ( dc / dv = 2.0)
The raw data of creep angle as a function of time for applied stresses between 30 and 80 Pa for the coagulated titania sample is presented in Figure 4(a), with the corresponding plot of rotational rate versus time shown in Figure 4(b) (the rotational rate was calculated from a 3-point running average over the angular displacement data). The coagulated titania in the 2.0 diameter ratio showed instantaneous elasticity convoluted with inertia (as signified by θ ∝ t 2 ) up to about 0.2 s, followed by retarded elastic deformation. The retarded elasticity became less pronounced at stresses closer to yielding (for example the 50 and 55 Pa angles
only increased by 30% beyond 0.3 s compared with 160% at 30 Pa). At stresses less than 55 Pa, the samples did not yield within the experimental timeframe of 50 s, although there was some creeping flow at the higher two stresses (50 and 55 Pa) Ð this could have been wall slip perhaps, albeit much diminished in effect because of the wide gap. Above 60 Pa, the material showed instantaneous viscous flow. In the narrow stress range between 56 and 60 Pa, the material exhibited time-dependent yielding, with a maximum measured yield time of about 20 s at 56 Pa.
## Small Diameter Ratio ( dc / dv = 1.1)
The coagulated titania was also tested using a small diameter ratio geometry as recommended by rheometer manufacturers. The vane diameter was the same as above ( dv = 14 mm) but the cup was smaller ( dc = 15.4 mm), leading to a cup-to-vane diameter ratio of 1.1. The creep angle and rotational rate results for the coagulated titania in the narrow gap are shown in Figure 5. A linear plot of angle is shown in Figure 6 for an alternative perspective.
Since the cup was not roughened, it was expected to see evidence of slip at the cup wall and it was immediately apparent that the small diameter ratio results were more complicated than the large ratio results.
- -The initial inertia and instantaneous deformation were much reduced.
- -At the lowest stress (30 Pa), the titania had solid-like retarded viscoelasticity, similar to the Standard Linear Solid behaviour in Figure 2.
- -Next, at 40 to 46 Pa, the samples flowed at very slow rates, which was likely due to wall slip.
Figure 4: (a) Angular displacement and (b) Rotational rate as functions of time for creep testing of coagulated titania in a cup-to-vane diameter ratio of 2.0
Figure 5: (a) Angular displacement and (b) Rotational rate as functions of time for creep testing of coagulated titania in a cup-to-vane diameter ratio of 1.1
- -Above that (47 to 52 Pa), there were various stick-slip events combined with viscoelasticity. The slope at longer times was less than 1 on a logarithmic plot, indicating that steady-state viscous flow was not achieved.
- -For stresses between 53 and 60 Pa, the coagulated titania initially showed retarded viscoelasticity before a sudden increase in displacement from about 0.08 rad to 0.5 rad at some time between 1 and 10 s. However, the material did not continue to flow, instead returning to retarded viscoelastic behaviour. The tests then showed subsequent yielding and stick-slip events. Presumably the suspension was yielding at the wall rather than in the bulk.
- -For stresses 65 Pa and above, the suspension yielding almost instantaneously, although the rotational rate was not steady.
Figure 6: Linear plot of angular displacement as a function of time for creep testing of coagulated titania in a cup-to-vane diameter ratio of 1.1
## Comparison between cup-to-vane diameter ratios
In order to account for the different geometries, the linear approximation given by Eq. 9 was used to calculate the apparent strain, which was divided by the stress to give the apparent compliance. A selection of results between 40 and 60 Pa are shown in Figure 7. There was stress dependence to the compliance such that the suspension rheology was non-linear at
these stresses. Whilst this contradicted the use of the linear approximation, the linear conversion at least gave a first-order comparison of the narrow and wide gaps.
Figure 7: Apparent compliance for a selection of creep stresses for coagulated titania in both small and large diameter ratios
The large diameter ratio creep behaviour was relatively straightforward for this sample, with instantaneous deformation followed by retarded elasticity at low stresses (40, 50 and 55 Pa) and instantaneous and retarded elasticity followed by time dependent yield over a narrow stress range (56 to 60 Pa). The small diameter ratio creep behaviour was much more complicated with limited instantaneous elasticity, extended retarded viscoelasticity and longterm flow at low stresses (40 Pa). Stresses 47 Pa and above showed multiple yielding events followed by retarded deformation.
56 Pa was the lowest stress that showed yielding in the large cup, whereas the behaviour was consistent with yielding or slipping at the cup wall at 47 Pa vane stress for the small diameter ratio. Based on the 1/ r 2 dependency for stress, the wall stress in the narrow gap was 41 Pa for a vane stress of 47 Pa. Thus, the apparent adhesive to cohesive yield stress ratio was 0.73, which was consistent with the notion of wall yielding or adhesive failure occurring at significantly lower stresses than within the bulk (or cohesive failure) (Buscall et al. 1993; Grenard et al. 2014; Saak et al. 2001; Walls et al. 2003). Applying Eq. 3 gave a critical cupto-vane diameter ratio of 1.17.
## 4.2 Coagulated Alumina
Creep testing of the coagulated alumina was performed using four different cup sizes over stresses ranging from 1 to 150 Pa. The tests at 1 Pa were at the limit of sensitivity and were removed from the graphs here for the sake of clarity. The apparent compliance was calculated from J t ( ) = γ ( )/ t τ , where the apparent linear strain was given by Eq. 10. Due to a higher data collection rate compared to the previous coagulated titania results, the rotational rate was calculated using a running average over 11 points. Rotational data for early time creep ringing at low stresses have been removed.
## dc / dv = 4.2
The apparent compliance and rotational rate results for coagulated alumina in the largest diameter ratio are presented in Figure 8(a) and (b) respectively.
- -At the lower stresses from 5 to 70 Pa, the results initially showed creep ringing (up to about 3 s for). The ringing was followed by retarded viscoelastic behaviour. The results at 5, 10 and 25 Pa were very similar, suggesting linear behaviour (that is, no stress dependence of the compliance). Non-linearity, through softening of the retarded elasticity, began to appear at 40 Pa.
- -At higher stresses but still below yielding (85 to 113 Pa), the samples showed greater instantaneous deformation followed by gradual retarded deformation, with the creep angle roughly doubling compared to orders of ten times bigger at lower stresses. The instantaneous deformation was convoluted with inertia, as signified by J ∝ t 2 and ω ∝ t , which extended to about 0.05 s. Interestingly, the 110 and 113 Pa tests looked like they were about to yield between 100 to 200 s, showing an increase in rate, but they did not yield and continued to show solid-like creep. This may have been due to ratedependent hardening of the suspension at decreasing strain-rates (Buscall et al. 2014a).
- -At 115 Pa and greater, the results showed instantaneous deformation, some retarded deformation and then time-dependent yield to steady-state flow. By 150 Pa, the yield was essentially instantaneous. The rotational rate showed a gradual increase over the experimental timeframe and did not reach steady-state within 1000 s.
Figure 8: (a) Apparent compliance and (b) Rotational rate as functions of time for creep testing of coagulated alumina in a wide gap ( dc / dv = 4.2)
## dc / dv = 3.0
The creep behaviour in the 3.0x diameter ratio was very similar to the 4.2x ratio and is therefore not presented for brevity. The same non-linear softening began to appear at 40 Pa. Time-dependent yield was observed at 113 Pa compared with 115 Pa in 4.2x ratio. There was no evidence of slip.
## dc / dv = 2.1
The results for coagulated alumina in a cup-to-vane diameter ratio of 2.1 began to show notable differences compared to the 3.0x and 4.2x ratios (see Figure 9).
- -The low stress results from 5 to 85 Pa showed the same creep ringing and retarded viscoelasticity as the wider gaps. However, the 2.1x ratio results were linear to higher stresses (up to 55 Pa).
- -The 85 and 100 Pa results for the 2.1x ratio did not show the same increased instantaneous deformation and softening of the retardation as observed in the larger diameter ratios.
- -At 115, 120 and 130 Pa, the suspension continued to show significant retarded deformation prior to time-dependent yielding. The retarded deformation was similar to inertia with J ∝ t 2 , but only after an initial delay.
## dc / dv = 1.1
The apparent compliance and rotational rate results for the coagulated alumina in the smallest cup-to-vane diameter ratio are shown in Figure 10(a) and (b) respectively. The tests included two repeat measurements at 110 and 100 Pa.
- -The low stresses (5 to 85 Pa) showed creep ringing (up to 3 s for 5 Pa) followed by retarded viscoelasticity. The results started to become non-linear at 40 Pa.
- -The tests at 95 Pa, 97 Pa and 100 Pa (2) exhibited similar behaviour to 100 Pa for the 2.1x ratio with reduced instantaneous deformation compared to the wider gaps.
Figure 9: (a) Apparent compliance and (b) Rotational rate as functions of time for creep testing of coagulated alumina in a wide gap ( dc / dv = 2.1)
Figure 10: Apparent compliance as a function of time for creep testing of coagulated alumina in a narrow gap ( dc / dv = 1.1). (1) and (2) refer to repeats at the same stress
- -The material yielded at 100 Pa and above. This was significantly lower than the 113 Ð 115 Pa measured in the larger diameter ratios and consistent with slip at the cup wall. The transient behaviour was also phenomenologically different to the wider gaps. There were no clear yielding events, rather reduced instantaneous deformation followed by un-steady flow. The delayed deformation suggested that slip had to occur at the cup wall before the suspension could flow. The rate for 105 Pa appeared to jam briefly at around 20 s, which could have been a wall artefact. Only the 120 Pa and 150 Pa tests reached steady-state.
It was difficult to get reproducible measurements in the small diameter ratio geometry, as evidenced by the repeated experiments at 100 and 110 Pa. The sample yielded for one test at 100 Pa (1) but not for the other (2). Likewise, the two tests at 110 Pa showed variable behaviour. This is in contrast to the larger ratio results that showed excellent progression through the stresses. All possible precautions were made to minimise experimental variability including concentration changes due to evaporation.
The coagulated alumina in the smaller two diameter ratios showed the same delayed deformation seen in the narrow gap results for the coagulated titania, although there was not the same dramatic oscillation in the rotational rate upon slipping. There were only small indications of the stick-slip behaviour in the alumina data that were so pronounced in the titania results. Likewise the low stress results did not show long term creep, although this may have been the short time scale of the titania experiments. In both cases, the cup wall was clearly influencing the suspension behaviour before and upon yielding.
## Analysis of Coagulated Alumina Data
Given a wall yield stress of 100 x (14/15) = 87 Pa and a bulk yield stress of 115 Pa, the 2 ratio of the adhesive to cohesive yield stresses was 0.76 for the coagulated alumina. The critical cup-to-vane diameter ratio given by Eq. 3 was 1.15. This was similar to the 1.17 for the coagulated titania. However, one of the trends identified in the coagulated alumina data was that the 2.1x ratio had significantly reduced instantaneous deformation at stresses closer to yielding, suggesting the cup wall was not only affecting the yielding behaviour, but also the viscoelastic behaviour prior to yielding.
To illustrate, the creep angles at the start and finish of the experiments were extracted from the results. The early time, chosen to represent the instantaneous deformation θ i , was selected as 0.1 s, a time where the quadratic dependency due to inertia was diminished. The
angle at 1000 s was assumed to be the steady-state creep angle θ ∞ . The time-dependency of the creep tests was characterised by a retardation time, t r , which was determined empirically from the Ôhalf-lifeÕ t ½ taken to reach half the deformation between the instantaneous and steady-state deformations, i.e. t r = t ½ /ln(2), where θ ( t ½ ) = ½ ( θ i + θ ∞ ).
The apparent linear strain and moduli were calculated using the linear approximation (Eq. 9). A running 3 point average power-law index was then calculated, allowing the real strain and moduli to be calculated using Eq. 10. This was then fitted using the modified Cross model (Eq. 11), giving G0 , γ y (or τ y ) and n . In order to then demonstrate the accuracy of the extracted parameters, the model was used in a finite difference numerical scheme to repredict the creep angle.
For the smaller two diameter ratios, the analysis gave a modulus with an asymptotic index of close to -1 ( ± 0.05). In these cases, it was much simpler to fit the exact solution for creep angle as a function of stress for n = -1 (see Eq. 13) and directly extract G0 and γ y (or τ y ).
The results for the instantaneous deformation are shown in Figure 11 with the modified Cross model parameters given in Table 2. The creep angle data was initially linear with stress, as illustrated by the dotted lines. The fitted zero strain moduli G0,i varied from 90 to 270 kPa, although the low strain data were somewhat suspect due to experimental sensitivity and creep ringing. Gi was not expected to increase with strain for the 2.1x ratio, for example.
Instantaneous Strain,
γ
i
(-)
Figure 11: (a) Instantaneous creep angle θ i = θ (0.1 s) as a function of stress and (b) instantaneous modulus as a function of instantaneous strain for coagulated alumina in various cup-to-vane diameter ratios. The modified Cross model had either variable n or fixed n = -1.
Table 2: Modified Cross model fit parameters (see Eq. 11) for instantaneous modulus as a function of
instantaneous strain for coagulated alumina in various cup-to-vane diameter ratios
| d c / d v | G 0,i (Pa) | γ y,i | τ y,i (Pa) | n i |
|-------------|--------------|--------------|--------------|--------|
| 1.1 | 92224 | 1.05 x 10 -3 | 97.1 | -1 |
| 2.1 | 271648 | 4.05 x 10 -4 | 110 | -1 |
| 3 | 172774 | 2.69 x 10 -4 | 46.5 | -0.887 |
| 4.2 | 267516 | 1.42 x 10 -4 | 38.1 | -0.896 |
As the strain increased, inter-particle bonds started being broken rather than just stretched or compressed and the modulus began to decrease. The onset of strain softening differed for the 4.2x and 3.0x diameter ratios compared to the 2.1x and 1.1x ratios. The 4.2x and 3.0x ratios showed critical strains about 0.0002 (corresponding to stresses about 40 Pa) followed by asymptotic power-law behaviour with an index of -0.9, whereas the 1.1x and 2.1x data began softening at higher stresses and strains with a strain softening slope of -1. In the softening region, the smaller two diameter ratios appeared stiffer with a higher modulus than the larger ratios up until a strain of 1.
This material yielded at strains of order 1, indicating Ôcage meltingÕ or steric hindrance as the yielding mechanism (Koumakis and Petekidis 2011; Pham et al. 2008) compared with bond breaking, which would lead to yielding at much lower strains. Strains greater than 1 were typical for the highest stresses that had presumably yielded instantaneously (< 0.1 s) and the deformation was no longer governed by just the material elasticity; the data in these cases were not included in the model fitting.
The suspensions deformed viscoelastically with time. The steady-state deformation results taken at 1000 s are shown in Figure 12 with the model parameters given in Table 3. The steady-state modulus showed similar trends to the instantaneous modulus, with the smaller diameter ratios having a higher modulus than the larger ratios up until strains of about
- 1. The strain softening indices for the larger diameter ratios were -0.83 and -0.9 whereas the smaller ratios were still at -1.
Steady-State Strain, γ ∞ (-)
Figure 12: (a) Steady-state creep angle θ θ (1000 s) as a function of stress and (b) steady-state modulus
∞ = as a function of steady-state strain for coagulated alumina in various cup-to-vane diameter ratios. The modified Cross model had either variable n or fixed n = -1
Table 3: Modified Cross model fit parameters (see Eq. 11) for steady-state modulus as a function of steady-state strain for coagulated alumina in various cup-to-vane diameter ratios
| d c / d v | G 0, ∞ (Pa) | γ y, ∞ | τ y, ∞ (Pa) | n ∞ |
|-------------|---------------|--------------|---------------|--------|
| 1.1 | 5199 | 1.83 x 10 -2 | 95.3 | -1 |
| 2.1 | 4928 | 2.23 x 10 -2 | 110 | -1 |
| 3 | 3902 | 1.37 x 10 -2 | 53.6 | -0.829 |
| 4.2 | 5091 | 1.20 x 10 -2 | 60.9 | -0.9 |
Given that the moduli were non-linear, the retardation time was also expected to vary with stress. The retardation times (see Figure 13) decreased from as much as 450 s at low stresses (although some of the very low stresses did not reach steady-state and the calculated retardation time was a lower estimate) to as little as 35 s at stresses close to yielding. The smaller (1.1x and 2.1x) and larger (3.0x and 4.2x) diameter ratios began to diverge at 55 Pa, which coincided with the point when the larger diameter ratios showed the onset of softening in the modulus results. Calculating the true retardation time would require a historydependent constitutive model Ð the data here suggested a decaying power-law or exponential may be appropriate.
The onset of softening and the value of the softening index are important for understanding how suspensions yield. Using the data for the small diameter ratios of 1.1x and 2.1x at stresses close to yielding to give constitutive parameters would get the wrong material properties and the wrong interpretation of behaviour. Whilst the softening exponents were within the range observed for suspensions (which can vary from -0.7 (Pham et al. 2008) to -1.4 (Yin and Solomon 2008), for example), the outcome that the softening behaviour differed with diameter ratio confirmed that the phenomenological observation of different creep behaviours was not just due to non-linear affects but that the wall was preventing the deformation of the suspension. In other words, the suspension needed to soften at the wall in the small diameter ratios.
Figure 13: Retardation times for coagulated alumina in various cup-to-vane diameter ratios (calculated from the half-life of the decay from 0.1 s to 1000 s)
## 4.3 Polymer-Flocculated Alumina
Creep tests were performed on polymer-flocculated alumina in order to investigate if a different category of strongly-flocculated suspension behaved in a similar manner as the ÔpHÕ coagulated systems. A separate settling experiment was performed to prepare the sample in each case to minimise shear degradation. The tests were performed at four different cup-tovane diameter ratios at stresses of 10, 50 and 80 Pa, with each test requiring a separate batch settling experiment due to the shear-sensitive network.
The angular displacement results are shown in Figure 14. Although the 80 Pa tests did pass relatively large angles, which suggested they were close to yielding, the stresses were all below yielding. The tests showed inertia and creep ringing in some cases, then retarded viscoelastic behaviour. A difference between the cup-to-vane diameter ratios emerged at 80 Pa. The two larger diameter ratios showed significant instantaneous deformation followed by long-term creep, whereas the 1.1x and 2.1x diameter ratios did not show the same increase in instantaneous deformation. The ratios of the creep angles at 1000 s and 0.1 s are shown in Figure 15, along with the retardation time as calculated from the half-life. The larger diameter ratios had smaller relative retardation. For example, the angle ratio at 80 Pain the 4.2x case was 9.97 whereas it was 105 in the 2.1x test, more than an order of magnitude
different. The retardation time generally decreased with increasing stress, with shorter times for the larger diameter ratios at 80 Pa. There was an anomalous result that the 3.0x angular displacement was greater than for the 4.2x, which may be a reflection of the difficulty of preparing polymers solutions at the same state of ageing.
With only three values for each diameter ratio, analysis using the modified Cross model was difficult and very subjective. Therefore, the analysis was limited to the simpler linear approximation. The apparent linear moduli were calculated as a function of strain from the angles at 0.1 s and 1000 s (see Figure 16). The results for all the diameter ratios except 1.1x were in good agreement, except Gi at 80 Pa for 2.1x. The 1.1x diameter ratio had higher instantaneous moduli, suggesting that it was stiffer than it should have been. The slopes at larger strains were Gi ∝ γ -0.877 and G ∞ ∝ γ -0.806 , although there was not enough data to conclude whether these values were asymptotic or whether there was a difference between the diameter ratios. The steady-state strains at 80 Pa approached order 1, which suggested polymer-flocculated systems also had Ôcage-meltingÕ yielding.
Thus, the limited data for the polymer-flocculated alumina showed some of the same trends as the coagulated alumina sample at stresses below yielding, with increased instantaneous deformation followed by faster and relatively smaller retarded deformation for the larger diameter ratios. This indicates that wall effects on pre-yield viscoelasticity may manifest for all strongly-flocculated suspensions.
It was noted that each creep test on the flocculated alumina settled slightly by the end of the test (< 1 mm). Since the suspension had already settled to equilibrium, the additional settling after the application of shear stress indicated synaereses of the flocculated network, similar to the shear-densification seen in flocs at concentrations below the gel point (van Deventer et al. 2011). The shear stress was insufficient to yield the suspension in shear but large enough to locally densify the network.
Figure 14: Angular displacement as a function of time for creep testing of polymer flocculated
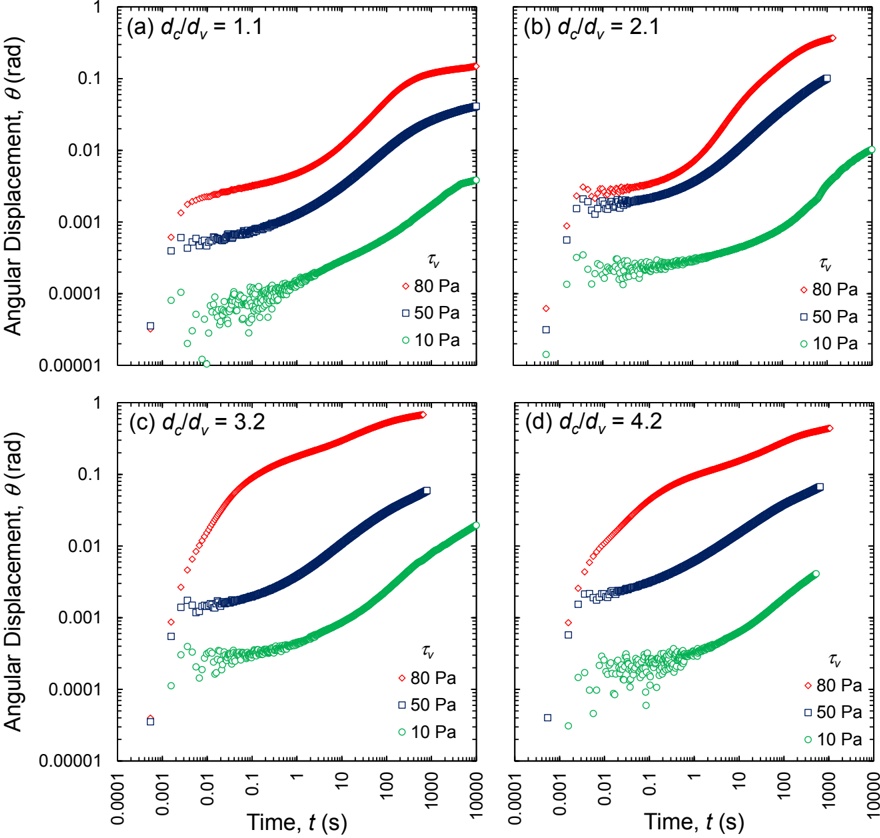
alumina in four cup-to-vane diameter ratios
Figure 15: Retardation times and ratios of infinite to instantaneous creep angles for polymer-flocculated
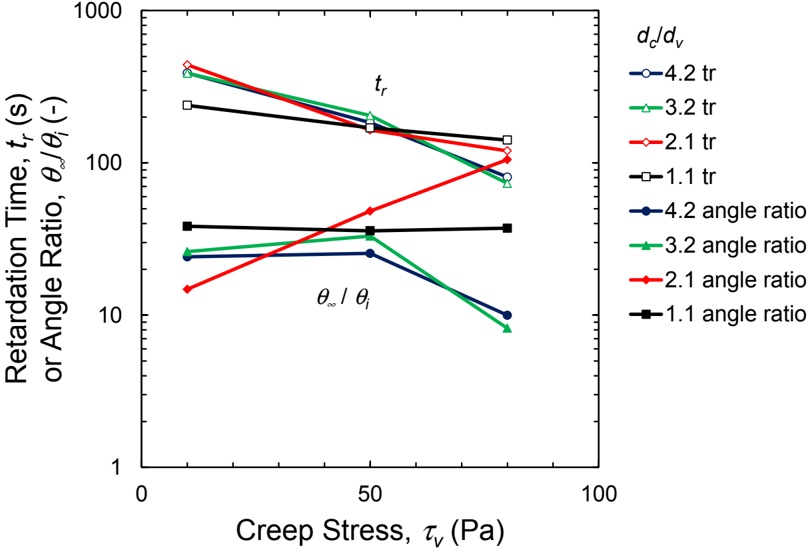
alumina in various cup-to-vane diameter ratios. θ i = θ (0.1 s), θ ∞ = θ (1000 s), θ ( t ½ ) = ½ ( θ i + θ ∞ )
Figure 16: Instantaneous and infinite moduli and strain for polymer-flocculated alumina in various
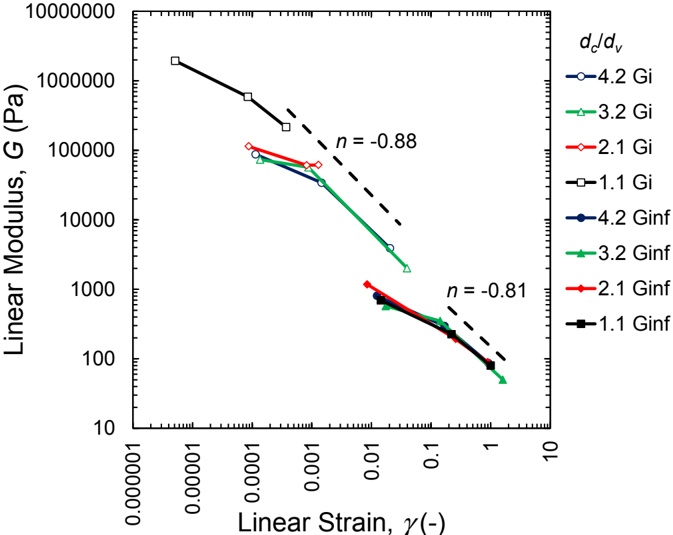
cup-to-vane diameter ratios. Gi and γ i were calculated from θ (0.1 s) while G ∞ and γ ∞ were calculated from θ (1000 s), both using a linear approximation
## 5 Conclusions
Understanding the shear rheology of strongly-flocculated suspensions and improving current viscoplastic constitutive descriptions are important steps for improved prediction of suspension processing. In order to provide an enriched constitutive description, it is vital to have experimental data that are free from artefacts caused by the measurement geometry. The vane-in-infinite-cup geometry minimises wall effects by design. The aim of this work was to investigate the ratio of cup to vane diameter at which wall effects were minimised.
The results in this exploratory work showed consistent behaviour in larger diameter ratios across all three model systems, with linear viscoelasticity at low stresses, increased instantaneous compliance or non-linear strain softening at stresses closer to yielding, timedependent yield over a range of stresses and finally instantaneous flow.
In contrast to the large diameter ratio results, the small diameter ratios showed a range of behaviours attributed to anomalous suspension behaviour at or near the cup wall. The coagulated titania and alumina at a diameter ratio of 1.1x showed yielding and subsequent slip at the wall, which indicated that the adhesive or wall yield stress was less than the cohesive or bulk yield stress. The apparent adhesive to cohesive yield stress ratios of 0.73 and 0.76 for the two coagulated suspensions here were used to estimate critical cup-to-vane diameter ratios of 1.17 and 1.15 to avoid wall slip. It is very important to realise though that the adhesive to cohesive yield stress ratio is likely to vary from one suspension to another and to depend upon the nature of the wall. For example, plastic walls might give lower adhesive to cohesive yield stress ratios and higher critical diameter ratios for aqueous mineral systems compared to metal walls, perhaps.
In addition to slip, the cup wall was observed to affect the pre-yield viscoelastic behaviour at cup-to-vane diameter ratios of 2.0x and 2.1x for the coagulated and polymerflocculated alumina. In general, the suspensions appeared stiffer at stresses closer to yielding in the smaller diameter ratios. Analysis of the instantaneous and steady-state moduli for the coagulated alumina system using a modified Cross equation showed that the softening exponents decreased whereas the ratio of creep angles increased. Use of the small diameter ratio results to extract viscoelastic parameters ( Gi , Gr and t r from the SLS model as a minimum) would be incorrect by over an order of magnitude and mislead efforts to understand suspension rheology.
The strain softening behaviour of suspensions would not be expected to show constant softening index behaviour across all strains due to complex interactions at multiple length
scales. For example, non-linear stretching and compression of inter-particle bonds could lead to strain hardening between the linear and softening regions. At higher deformations, ratedependent viscous forces must also come into play. However, for a simple model with only three parameters, the modified Cross equation (especially the exact solution for n = -1) provided a good method of analysing the non-linear behaviour of the instantaneous and steady-state data.
The conclusion from this work was that artefact-free experimental results for studying the yielding behaviour of strongly flocculated suspensions required a vane-in-cup geometry with a minimum cup-to-vane diameter ratio of 3, although this value is conservative and must be dependent on the material. Based on this, existing creep results in the literature using a range of configurations with smaller diameter ratios and smooth tools may require reinterpretation.
Although premature or adhesive wall yielding and slip can be eliminated by means of wide gaps, their use is far from ideal in other regards as data analysis or inversion is then problematic, given non-linear viscoelasticity. It would be preferable arguably to use roughened cylinders and narrow gaps, although the problem then is to determine how rough the outer surface needs be to in order to cope with any material of interest. There is a need for more systematic work clearly, which could for example involve the use of splined outer cylinders in combination with a range of inner geometries, including a splined cylinder, a vane and a series of smooth cylinders of differing materials of construction. From data obtained using such it should then be possible to reconstruct what would be expected with a vane in wide and narrow smooth cylinders. More generally, the aim would be to determine the adhesive to cohesive yield stress ratio for a range of suspensions and materials in order to see how much it varies typically.
## Notation
## Latin alphabet
| d | Diameter, m |
|----------------|--------------------|
| h | Height, m |
| G | Modulus, Pa |
| r | Radial position, m |
| t | Time, s |
| Greek alphabet | Greek alphabet |
| γ | Strain, - |
|------------|---------------------------|
| θ | Angular displacement, rad |
| τ | Shear stress, Pa |
| ω | Rotational rate, rad/s |
| Subscripts | Subscripts |
| c | Cup |
| i | Instantaneous |
| r | Retarded |
| v | Vane |
| ∞ | Infinity |
## Acknowledgements
The authors thank Daniel Lester for insightful discussions. Ashish Kumar was supported in this work by an Australian Postgraduate Award through the Australian Research Council. Tiara Kusuma was funded by a Melbourne International Research Scholarship through The University of Melbourne. Infrastructure support at Melbourne was provided by the Particulate Fluids Processing Centre, a Special Research Centre of the Australian Research Council. Simon Biggs acknowledges the support of the Nexia Solutions University Research Alliance for Particle Science and Technology and the University of Leeds. Simon Biggs and Amy Tindley were supported in this work as part of the TSEC programme KNOO and are grateful to the EPSRC for funding under grant EP/C549465/1.
## References
Barnes HA (1995) A review of the slip (wall depletion) of polymer-solutions, emulsions and particle suspensions in viscometers - its cause, character, and cure. J Non-Newtonian Fluid Mech 56: 221-251.
Barnes HA, Carnali JO (1990) The vane-in-cup as a novel rheometer geometry for shear thinning and thixotropic materials. J Rheology 34: 841-866.
Barnes HA, Hutton JF, Walters K (1989) An Introduction to Rheology. Elsevier, Amsterdam Barrie CL, Griffiths PC, Abbott RJ, Grillo I, Kudryashov E, Smyth C (2004) Rheology of aqueous carbon black dispersions. J Colloid Interface Sci 272: 210-217.
Baudez JC, Markis F, Eshtiaghi N, Slatter PT (2011) The rheological behaviour of digested sludge. Water Res 45: 5675-5680.
Biggs S, Tindley A (2007) The rheology of oxide dispersions and the role of concentrated electrolyte solutions. ICEM2007: Proceedings of the 11th International Conference on Environmental Remediation and Radioactive Waste Management. Bruges, Belgium, 2-6 Sept 2007. 249-254
Bingham EC (1916) An investigation of the laws of plastic flow. US Bureau of Standards Bulletin 13: 309-353.
Bird RB, Dai G, Yarusso BJ (1982) The rheology and flow of viscoplastic materials. Rev Chem Eng 1: 1-70.
Boger DV (1999) Rheology and the minerals industry. Miner Process Extract Metall Rev 20: 1-25.
Buscall R, Choudhury TH, Faers MA, Goodwin JW, Luckham PA, Partridge SJ (2009) Towards rationalising collapse times for the delayed sedimentation of weaklyaggregated colloidal gels. Soft Matter 5: 1345-1349.
Buscall R, Kusuma TE, Stickland AD, Rubasingha S, Scales PJ, Teo HE, Worrall GL (2014a) The non-monotonic shear-thinning flow of two strongly cohesive concentrated suspensions. J Non-Newtonian Fluid Mech (in press, available online 28 Sept).
Buscall R, McGowan JI, Morton-Jones AJ (1993) The rheology of concentrated dispersions of weakly attracting colloidal particles with and without wall slip. J Rheology 37: 621-641.
Buscall R, Scales PJ, Stickland AD, Teo HE, Lester DR (2014b) Dynamic and ratedependent yielding in model cohesive suspensions. J Non-Newtonian Fluid Mech (submitted Sept 2014) arxiv.org/abs/1410.0179.
Coussot P, Tabuteau H, Chateau X, Tocquer L, Ovarlez G (2006) Aging and solid or liquid behavior in pastes. J Rheology 50: 975-994.
Fisher DT, Clayton SA, Boger DV, Scales PJ (2007) The bucket rheometer for shear stressshear rate measurement of industrial suspensions. J Rheology 51: 821-831.
Foong J (2008) PhD Thesis: Yielding, linear and non-linear viscoelastic behaviour of concentrated coagulated suspensions. The University of Melbourne, Melbourne, pp 385
Gibaud T, Frelat D, Manneville S (2010) Heterogeneous yielding dynamics in a colloidal gel. Soft Matter 6: 3482-3488.
Gladman B, de Kretser RG, Rudman M, Scales PJ (2005) Effect of shear on particulate suspension dewatering. Chem Eng Res Des 83: 933-936.
Grenard V, Divoux T, Taberlet N, Manneville S (2014) Timescales in creep and yielding of attractive gels. Soft Matter 10: 1555-1571.
Hartnett JP, Hu RYZ (1989) Technical note: The yield stress - an engineering reality. J Rheology 33: 671-679.
Herschel W, Bulkley R (1926) Konsistenzmessungen von Gummi-Benzollšsungen. Colloid Polymer Sci 39: 291-300.
Jeldres RI, Toledo PG, Concha F, Stickland AD, Usher SP, Scales PJ (2014) Impact of seawater salts on the viscoelastic behavior of flocculated mineral suspensions. Colloids Surf, A 461: 295-302.
Johnson SB, Franks GV, Scales PJ, Boger DV, Healy TW (2000) Surface chemistry-rheology relationships in concentrated mineral suspensions. Int J Miner Proc 58: 267-304.
Keentok M, Milthorpe JF, Odonovan E (1985) On the shearing zone around rotating vanes in plastic liquids - theory and experiment. J Non-Newtonian Fluid Mech 17: 23-35.
Klein CO, Spiess HW, Calin A, Balan C, Wilhelm M (2007) Separation of the nonlinear oscillatory response into a superposition of linear, strain hardening, strain softening, and wall slip response. Macromolecules 40: 4250-4259.
Kobelev V, Schweizer KS (2005) Strain softening, yielding, and shear thinning in glassy colloidal suspensions. Phys Rev E 71.
Koumakis N, Petekidis G (2011) Two step yielding in attractive colloids: transition from gels to attractive glasses. Soft Matter 7: 2456-2470.
Krieger IM, Maron SH (1952) Direct determination of the flow curves of non-Newtonian fluids. J Appl Phys 23: 147-149.
Krieger IM, Maron SH (1954) Direct determination of the flow curves of non-newtonian fluids. III. Standardized treatment of viscometric data. J Appl Phys 25: 72-75.
Kumar A, Stickland AD, Scales PJ (2012) Viscoelasticity of coagulated alumina suspensions.
Korea-Australia Rheology J 24: 105-111.
Le Grand A, Petekidis G (2008) Effects of particle softness on the rheology and yielding of colloidal glasses. Rheol Acta 47: 579-590.
Leong YK, Scales PJ, Healy TW, Boger DV (1995) Effect of particle-size on colloidal zirconia rheology at the isoelectric point. J Am Ceram Soc 78: 2209-2213.
Lester DR, Buscall R, Stickland AD, Scales PJ (2014) Wall adhesion and constitutive modeling of strong colloidal gels. J Rheology 58: 1247-1276.
Liddell PV, Boger DV (1995) Yield stress measurement with the vane. J Non-Newtonian Fluid Mech 63: 235-261.
Michaels AS, Bolger JC (1962) Plastic flow behavior of flocculated kaolin suspensions. Ind Eng Chem Fundamen 1: 153-162.
Nguyen QD, Boger DV (1983) Yield stress measurement for concentrated suspensions. J Rheology 27: 321-349.
Nguyen QD, Boger DV (1985a) Direct yield stress measurement with the vane method. J Rheology 29: 335-347.
Nguyen QD, Boger DV (1985b) Thixotropic behavior of concentrated bauxite residue suspensions. Rheol Acta 24: 427-437.
Pham K, Petekidis G, Vlassopoulos D, Egelhaaf S, Poon W, Pusey P (2008) Yielding behavior of repulsion-and attraction-dominated colloidal glasses. Journal of Rheology (1978-present) 52: 649-676.
Rehbinder P (1954) Coagulation and thixotropic structures. Discuss Faraday Soc 18: 151160.
Roylance D (2001) Engineering viscoelasticity. MIT Press, Cambridge, MA
Saak AW, Jennings HM, Shah SP (2001) The influence of wall slip on yield stress and viscoelastic measurements of cement paste. Cement Concrete Res 31: 205-212.
Stickland AD, Burgess C, Dixon DR, Harbour PJ, Scales PJ, Studer LJ, Usher SP (2008) Fundamental dewatering properties of wastewater treatment sludges from filtration and sedimentation testing. Chem Eng Sci 63: 5283-5290.
ten Brinke AJW, Bailey L, Lekkerkerker HNW, Maitland GC (2008) Rheology modification in mixed shape colloidal dispersions. Part II: mixtures. Soft Matter 4: 337-348.
Uhlherr PHT, Guo J, Tiu C, Zhang XM, Zhou JZQ, Fang TN (2005) The shear-induced solidliquid transition in yield stress materials with chemically different structures. J NonNewtonian Fluid Mech 125: 101-119. Usher SP (2002) PhD Thesis: Suspension Dewatering: Characterisation and Optimisation. Department of Chemical Engineering. The University of Melbourne, Melbourne van Deventer BBG, Usher SP, Kumar A, Rudman M, Scales PJ (2011) Aggregate densification and batch settling. Chem Eng J 171: 141-151. Walls HJ, Caines SB, Sanchez AM, Khan SA (2003) Yield stress and wall slip phenomena in colloidal silica gels. J Rheology 47: 847-868. Yin G, Solomon MJ (2008) Soft glassy rheology model applied to stress relaxation of a thermoreversible colloidal gel. J Rheology 52: 785-800. Zhou ZW (2000) PhD Thesis: Rheology of metal oxide suspensions. Department of Chemcial Engineering. The University of Melbourne, Melbourne Zhou ZW, Scales PJ, Boger DV (2001) Chemical and physical control of the rheology of concentrated metal oxide suspensions. Chem Eng Sci 56: 2901-2920. Zhou ZW, Solomon MJ, Scales PJ, Boger DV (1999) The yield stress of concentrated flocculated suspensions of size distributed particles. J Rheology 43: 651-671. | null | [
"Anthony D. Stickland",
"Ashish Kumar",
"Tiara E. Kusuma",
"Peter J. Scales",
"Amy Tindley",
"Simon Biggs",
"Richard Buscall"
] | 2014-08-01T03:08:38+00:00 | 2015-01-23T17:25:50+00:00 | [
"cond-mat.soft"
] | The effect of premature wall yield on creep testing of strongly-flocculated suspensions | Measuring yielding in cohesive suspensions is often hampered by slip at
measurement surfaces. This paper presents creep data for strongly-flocculated
suspensions obtained using vane-in-cup tools with differing cup-to-vane
diameter ratios. The three suspensions were titania and alumina aggregated at
their isoelectric points and polymer-flocculated alumina. The aim was to find
the diameter ratio where slip or premature yielding at the cup wall had no
effect on the transient behaviour. The large diameter ratio results showed
readily understandable material behaviour comprising linear viscoelasticity at
low stresses, strain-softening close to yielding, time-dependent yield across a
range of stresses and then viscous flow. Tests in small ratio geometries
however showed more complex responses. Effects attributed to the cup wall
included delayed softening, slip, multiple yielding and stick-slip events, and
unsteady flow. The conclusion was that cups have to be relatively large to
eliminate wall artefacts. A diameter ratio of three was sufficient in practice,
although the minimum ratio must be material dependent. |
1408.0070v1 | ## Galaxies with Supermassive Binary Black Holes: (II) A Model with Cuspy Galactic Density Profiles
Ing-Guey Jiang 1 and Li-Chin Yeh 2
- 1
Department of Physics and Institute of Astronomy, National Tsing-Hua University, Hsin-Chu, Taiwan 2 Department of Applied Mathematics, National Hsinchu University of Education, Hsin-Chu, Taiwan
[email protected]
## ABSTRACT
The existence and uniqueness of equilibrium points, including Lagrange Points and Jiang-Yeh Points, of a galactic system with supermassive binary black holes embedded in a centrally cuspy galactic halo are investigated herein. Differing from the previous results of non-cuspy galactic profiles that Jiang-Yeh Points only exist under a particular condition, it is found here that the Lagrange Points, L2, L3, L4 and L5, Jiang-Yeh Points, JY1 and JY2, exist under general conditions. The stability analysis shows that L2, L3, JY1 and JY2 are unstable. However, L4 and L5 are only unstable when the galactic total mass is smaller than a critical mass; otherwise they become neutrally stable centers. These results will be important for further studies on the cores of early-type galaxies.
## 1. Introduction
The general structure of galaxies has been one of the most interesting astronomical subjects due to the beauty and diversity of their morphological shapes. It is also an important research field in that galaxies are building blocks of the universe; so the formation and evolution of galactic structures, which are imprints left by the interactions of galaxies, can trace the history of the universe.
Through astronomical observations, the interaction between galaxies is confirmed to be taking place frequently, for example, the mergers of mice galaxies (NGC 4674 A&B), NGC 2207/IC 2163 and NGC 2623. These results have triggered many further investigations related to mergers. For example, Wu & Jiang (2009) showed that the inter-galactic population
could be ejected from galaxies during merging events. Furthermore, the ring galaxies are likely to be the outcome of major mergers, as shown in Wu & Jiang (2012).
On the other hand, it is generally believed that there is a supermassive black hole at the center of galaxies. A merger of two galaxies with supermassive black holes is likely to form a supermassive binary black hole (SBBH) near the center of the newly formed galactic merging system. In fact, the major mergers of two disk galaxies are believed to be the main mechanism forming elliptical galaxies. This is partially due to the fact that elliptical galaxies are generally massive and gas-poor, and major mergers can produce a larger galactic system and reduce the gaseous component by rapid star formation or gas diffusion during merging processes. Thus, the investigations on the dynamics of elliptical galaxies are usually based on the gas-poor assumption.
In order to study the dynamic evolution of SBBH, Quinlan (1996) carried out numerical experiments on the scattering processes for the restricted three-body problem. The main issue addressed in that work was the SBBH hardening. In fact, modifications of the restricted three body problem were employed to model various problems related to planetary systems (Chermnykh 1987; Papadakis 2004, 2005a, 2005b, Jiang & Yeh 2006; Yeh & Jiang 2006; Kushvah 2008a, 2008b, 2009, 2011a, 2011b, 2012). In addition, the discoveries of extra-solar planets have triggered many investigations in the field of planetary systems (see Jiang & Ip 2001; Ji et al. 2002; Jiang & Yeh 2003, 2004a, 2004b, 2004c, 2007, 2009, 2011; Jiang et al. 2003, 2006, 2007, 2009, 2010, 2013; Chatterjee et al. 2008).
Milosavljevic and Merritt (2001) used N-body simulations to investigate the orbital decay of black holes and the formation of SBBHs during galactic mergers. They found that it only takes about a million years for black holes to sink to the center and become a hard binary. However, they claimed that black holes stall at separations of sub-parsec scales. Then, Yu (2002) semi-analytically estimated the possible time-scales to form SBBHs and found that the time-scale of dynamical friction is too long for small black holes to sink into the center, so it is difficult to form SBBHs with very small mass ratio. Thus, the SBBHs with moderate mass ratios are most likely to form and survive with semi-major axes around 10 -3 to 10 pc in spherical or nearly spherical galaxies.
Moreover, in order to explain the surface brightness of NGC 3706, Kandrup et al. (2003) considered the stellar dynamics under the gravitational fields of SBBH and a fixed galactic potential. They found that the transition between the inner and outer power-law profiles predicted by a Dehnen potential is too gradual to represent real galaxies, so the Nuker law was used in their model.
Motivated by the above work, as in Kandrup et al. (2003), a model of modified restricted
three body problems was used in Jiang & Yeh (2014) to study a galactic system with SBBH. Both Kandrup et al. (2003) and Jiang & Yeh (2014) employed the Nuker law as their three dimensional spherical galactic density profiles because the Nuker law is a simple and neat way to present a smooth broken power-law with two power-indexes, and the transition is located at a well defined radius, i.e. the break radius. Note that the Nuker law was originally introduced in Lauer et al. (1992) to fit the two dimensional surface brightness of M32, and later for other galaxies in Lauer et al. (1995). In order to make it clear, we will use the term spherical Nuker law to name the galactic density profiles in this paper.
Jiang & Yeh (2014) discovered that when the galactic density profile is a spherical Nuker law with γ = 0 (i.e. no cusp), α = 2, β = 4, the usual five Lagrange Points always exist, and the new equilibrium points, i.e. Jiang-Yeh Points, exist if and only if the total galactic mass is larger than the critical mass. The analytic expression of this critical mass was provided and the stability analysis was performed. These results give important implications for the orbital evolution near the centers of galaxies with SBBH, and lead to a possible mechanism to form the cores of early-type galaxies through the existence of unstable Jiang-Yeh Points near supermassive black holes.
However, because the cuspy density profile is expected for the dark matter halo through cosmological simulations, it will be interesting to investigate the existence of Jiang-Yeh Points in a system with SBBH and a central cusp. For spherical Nuker law, i.e. Eq.(6) of Jiang & Yeh (2014), the density profile has a cuspy center when γ ≥ 1. We find that when α = 2, β = 5, γ = 1, the corresponding gravitational potential of the density profile has an analytic form. Therefore, in this paper, we study the dynamics of a system wherein a test particle moves under the influence of SBBH and a galactic potential, which is dominated by a cuspy dark matter halo following a spherical Nuker law with α = 2, β = 5, γ = 1. We will investigate the existence of equilibrium points and also perform the stability analysis of these points.
We present our model in Section 2, and the analytical results for the existence of equilibrium points are in Section 3. The bifurcation diagrams, locations of equilibrium points and zero-velocity curves are shown in Section 4. The stability analysis is presented in Section 5, and the concluding remarks are offered in Section 6.
## 2. The Model
We consider the motion of test particles influenced by the gravitational force from the central binary black holes and the galaxy. The test particles are considered to move on the
same plane of the orbital plane of binary black holes.
For the description below, those parts which are exactly the same as the equations in Jiang & Yeh (2014) will be skipped (refer to Jiang & Yeh 2014). After the procedure of non-dimensionalization as done in Yeh et al. (2012) and Jiang & Yeh (2014), in which the scale length is set to be the break radius, i.e. L 0 = r b , the density profile of the galaxy is expressed as:
where ρ c is a constant; r is the distance (in the unit of break radius r b ) from the origin in this spherical distribution. This profile gives an NFW central cusp (Navarro, Frenk, White 1995) and also a realistic sharper outer edge, i.e. when r → 0, the density ρ ∝ r -1 is the cusp in NFW profile; when r >> 1, the density decays as ρ ∝ r -5 which is sharper than the NFW's profile ( ρ ∝ r -3 for r >> 1). Because NFW profile is not for an equilibrium galaxy (Binney & Trmaine 2008), our profile is a more realistic model for the system considered here. Note that all variables, functions and parameters, such as mass, potential, radius, normalization constants etc., are all written as dimensionless quantities in this paper.
$$\rho = \rho _ { c } r ^ { - 1 } \left \{ 1 + r ^ { 2 } \right \} ^ { - 2 } \,. & & ( 1 ) \\ \text{is the distance} \left ( \text{in the unit of break radius } r _ { b } \right ) from the origin in this$$
The mass of the galaxy up to r is thus:
$$M ( r ) = 2 \pi \rho _ { c } \left \{ 1 - \frac { 1 } { 1 + r ^ { 2 } } \right \}.$$
If the total galactic mass is M g , we have ρ c = M g 2 π . The corresponding potential is:
$$V ( r ) = - 4 \pi \left [ \frac { 1 } { r } \int _ { 0 } ^ { r } \rho ( r ^ { \prime } ) r ^ { \prime 2 } d r ^ { \prime } + \int _ { r } ^ { \infty } \rho ( r ^ { \prime } ) r ^ { \prime } d r ^ { \prime } \right ] = - M _ { g } \left \{ \frac { \pi } { 2 } - \tan ^ { - 1 } r \right \},$$
Moreover, from the potential, we can obtain the gravitational force as:
$$f _ { g } ( r ) \equiv - \frac { \partial V } { \partial r } = - M _ { g } \left ( \frac { 1 } { 1 + r ^ { 2 } } \right ).$$
Considering the motion on the x -y plane of the rotating frame, binary black holes, each with mass m at ( R, 0), ( -R, 0), and a test particle located on x, y with velocity u , v , the equations of motion would be as follows:
$$\cdot \\ \begin{cases} & \frac { d x } { d t } = u \\ & \frac { d y } { d t } = v \\ & \frac { d u } { d t } = 2 n v + n ^ { 2 } x - \frac { m ( x + R ) } { r _ { 1 } ^ { 3 } } - \frac { m ( x - R ) } { r _ { 2 } ^ { 3 } } - \frac { M _ { g } x } { r } \left ( \frac { 1 } { 1 + r ^ { 2 } } \right ), \\ & \frac { d v } { d t } = - 2 n u + n ^ { 2 } y - \frac { m y } { r _ { 1 } ^ { 3 } } - \frac { m y } { r _ { 2 } ^ { 3 } } - \frac { M _ { g } y } { r } \left ( \frac { 1 } { 1 + r ^ { 2 } } \right ), \end{cases}$$
where r 1 = √ ( x + R ) 2 + y 2 , r 2 = √ ( x -R ) 2 + y 2 , r = √ x 2 + y 2 and n is the angular velocity of black holes. That is, in the inertial frame, each black hole moves along the circular orbit at r = R with an angular velocity, i.e. mean motion:
$$n = \left \{ \frac { m } { 4 R ^ { 3 } } + \frac { 1 } { R } | f _ { g } ( R ) | \right \} ^ { 1 / 2 } = \left \{ \frac { m } { 4 R ^ { 3 } } + \frac { M _ { g } } { R ( 1 + R ^ { 2 } ) } \right \} ^ { 1 / 2 }$$
The corresponding Jacobi integral of this system is similar as the one in Jiang & Yeh (2006, 2014):
$$C _ { J } = - u ^ { 2 } - v ^ { 2 } + n ^ { 2 } ( x ^ { 2 } + y ^ { 2 } ) + \frac { 2 m } { r _ { 1 } } + \frac { 2 m } { r _ { 2 } } + 2 M _ { g } \left \{ \frac { \pi } { 2 } - \tan ^ { - 1 } ( \sqrt { x ^ { 2 } + y ^ { 2 } } ) \right \}.$$
## 3. The Equilibrium Points
The existence and uniqueness of equilibrium points are investigated in this section. We follow the convention introduced in Jiang & Yeh (2014) in naming the equilibrium points except that due to the singular property of the central point of the system, the origin will be named as the singular point . Because the singular point is not considered as an equilibrium point in our system, there will be no stability analysis of this point. The existence and uniqueness of Lagrange Points L4 and L5 will be presented in Theorem 1. The existence and uniqueness of Lagrange Points L2 and L3, and the singularity of the origin of the system will be presented in Theorem 2. The existence and uniqueness of Jiang-Yeh Points JY1 and JY2, will be presented in Theorem 3.
In general, for System (5), equilibrium points ( x , y e e ) satisfy A x , y ( e e ) = 0 and B x , y ( e e ) = 0, where:
$$A ( x, y ) = n ^ { 2 } x - \frac { m ( x + R ) } { r _ { 1 } ^ { 3 } } - \frac { m ( x - R ) } { r _ { 2 } ^ { 3 } } - \frac { M _ { g } x } { r } \frac { 1 } { ( 1 + r ^ { 2 } ) },$$
$$B ( x, y ) = n ^ { 2 } y - \frac { m y } { r _ { 1 } ^ { 3 } } - \frac { m y } { r _ { 2 } ^ { 3 } } - \frac { M _ { g } y } { r } \frac { \ell } { ( 1 + r ^ { 2 } ) }.$$
For convenience, for y = 0, we define:
/negationslash
$$h ( y ) \equiv \frac { B ( 0, y ) } { y } = n ^ { 2 } - \frac { 2 m } { [ R ^ { 2 } + y ^ { 2 } ] ^ { 3 / 2 } } - \frac { M _ { g } } { | y | } \frac { 1 } { ( 1 + y ^ { 2 } ) }$$
and
$$k ( x ) \equiv A ( x, 0 ) = n ^ { 2 } x - \frac { m ( x + R ) } { | x + R | ^ { 3 } } - \frac { m ( x - R ) } { | x - R | ^ { 3 } } - \frac { M _ { g } x } { | x | } \frac { 1 } { ( 1 + x ^ { 2 } ) } \quad \ ( 1 1 )$$
From the results in Jiang & Yeh (2006), we have the following remarks:
## Remark A:
/negationslash
For y e = 0, y e satisfies h y ( ) = 0, if and only if (0 , y e Remark B:
) is the equilibrium point of System (5).
x e satisfies k x ( ) = 0, if and only if ( x , e 0) is the equilibrium point of System (5). Then, Remark (A) will be used to study the equilibrium points L4 and L5 in Theorem 1. Remark (B) will be used for all other points in Theorem 2 and 3.
Theorem 1: The Existence and Uniqueness of Lagrange Points L4 and L5 There is one and only one ¯ y 1 > 0 such that h y ( ¯ ) 1 = 0 , and only one ¯ y 2 < 0 such that h y ( ¯ ) = 0 2 . That is, excluding the origin (0,0) of x -y plane, there are two equilibrium points on the y -axis, i.e. L4 and L5, for System (5).
Proof:
We define
$$P ( y ) \equiv \frac { 2 m } { [ R ^ { 2 } + y ^ { 2 } ] ^ { 3 / 2 } } - n ^ { 2 }$$
$$& \text{and} \quad Q ( y ) \equiv \frac { - M _ { g } } { | y | ( 1 + y ^ { 2 } ) } \\ \text{ave } h ( u ) = - P ( u ) + O ( u )$$
so from Eq.(10), we have h y ( ) = -P y ( ) + Q y ( ).
At first, we consider the case when y > 0. Because lim y → 0 Q y ( ) = -∞ , we have:
$$\lim _ { y \to 0 } h ( y ) = \lim _ { y \to 0 } - P ( y ) + Q ( y ) = - \infty ;$$
and since lim y →∞ P y ( ) = -n 2 , lim y →∞ Q y ( ) = 0, we have lim y →∞ h y ( ) = n 2 > 0. Moreover, from Eqs.(12)-(13), we have:
$$P ^ { \prime } ( y ) = - 6 m y \left [ R ^ { 2 } + y ^ { 2 } \right ] ^ { - 5 / 2 },$$
and
$$Q ^ { \prime } ( y ) = M _ { g } \frac { 1 + 3 y ^ { 2 } } { y ^ { 2 } ( 1 + y ^ { 2 } ) ^ { 2 } }.$$
Since P ′ ( y ) < 0 and Q y ′ ( ) > 0, h ′ ( y ) = -P ′ ( y ) + Q y ′ ( ) > 0 for any y > 0. Thus, h y ( ) is a monotonically increasing function for any y ∈ (0 , ∞ ). With lim y → 0 h y ( ) = -∞ and lim y →∞ h y ( ) > 0, we conclude there is a unique point ¯ y 1 > 0 such that h y ( ¯ ) = 0. 1
For the case when y < 0, from Eqs.(15)-(16), we have P ′ ( y ) > 0, Q y ′ ( ) < 0, so h y ( ) is a monotonically decreasing function. We also have lim y →∞ h y ( ) = n 2 > 0 and lim y → 0 h y ( ) = -∞ . Thus, we find that there is a unique point ¯ y 2 < 0 such that h y ( ¯ ) = 0. 2 ✷
Now we investigate the existence of equilibrium points on the x -axis. For convenience, we define and therefore,
$$S ( x ) \equiv \frac { m ( x + R ) } { | x + R | ^ { 3 } } + \frac { m ( x - R ) } { | x - R | ^ { 3 } } - n ^ { 2 } x,$$
We also define:
$$S ( x ) = \begin{cases} & \frac { m } { ( x + R ) ^ { 2 } } + \frac { m } { ( x - R ) ^ { 2 } } - n ^ { 2 } x, \quad & \text{for $x>R$,} \\ & \frac { m } { ( x + R ) ^ { 2 } } - \frac { m } { ( x - R ) ^ { 2 } } - n ^ { 2 } x, \quad & \text{for $-R<x<R$,} \\ & - \frac { m } { ( x + R ) ^ { 2 } } - \frac { m } { ( x - R ) ^ { 2 } } - n ^ { 2 } x, \quad & \text{for $x<-R$.} \end{cases} \\ \text{te also define:} & M _ { \kappa }$$
$$T ( x ) \equiv - \frac { M _ { g } x } { | x | ( 1 + x ^ { 2 } ) }. \\ ( 1 9 ) \text{, we have} \colon$$
From Eqs.(11), (17) and (19), we have:
$$k ( x ) = - S ( x ) + T ( x ).$$
In the following Theorem 2, the results show that Lagrange Points L2 and L3 exist. However, due to the singular property, the origin (0,0) is a singular point, though the net force shall be physically balanced there. In Theorem 3, it is shown that another two equilibrium points, JY1 and JY2, exist. JY1 is in the region ( -R, 0) and JY2 is in the region (0 , R ) of x-axis.
## Theorem 2: The Existence and Uniqueness of Lagrange Points L2 and L3 and the Singularity of the Origin Point (0,0)
- (i) There is an unique x 1 > R such that k x ( 1 ) = 0 and an unique x 2 < -R such that k x ( 2 ) = 0. That is, on the x -axis, there is one and only one equilibrium point in the region ( R, ∞ ), i.e. L2, and there is one and only one equilibrium point in the region ( -∞ -, R ), i.e. L3.
/negationslash
- (ii) Due to the singularity at x = 0, the origin is not an equilibrium point (i.e. k (0) = 0), but is a singular point.
## Proof of (i):
When x > R , from Eqs. (18)-(20),
$$k ( x ) = - S ( x ) + T ( x ) = - \frac { m } { ( x + R ) ^ { 2 } } - \frac { m } { ( x - R ) ^ { 2 } } + n ^ { 2 } x - \frac { M _ { g } } { 1 + x ^ { 2 } } \\ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \colon$$
$$\text{and} \ \ k ^ { \prime } ( x ) = - S ^ { \prime } ( x ) + T ^ { \prime } ( x ) = \frac { 2 m } { ( x + R ) ^ { 3 } } + \frac { 2 m } { ( x - R ) ^ { 3 } } + n ^ { 2 } + \frac { 2 x M _ { g } } { ( 1 + x ^ { 2 } ) ^ { 2 } } > 0.$$
Thus, we have lim x → R + k x ( ) = -∞ , lim x →∞ k x ( ) = ∞ . Moreover, from k ′ ( x ) > 0, we know that k x ( ) is a monotonic function. Therefore, there is a unique x 1 > R , such that k x ( 1 ) = 0.
When x < -R , similarly, since k ′ ( x ) > 0, lim x →-R -k x ( ) = ∞ , and lim x →-∞ k x ( ) = -∞ , there is a unique x 2 < -R such that k x ( 2 ) = 0. ✷
## Proof of (ii):
When -R < x < R , from Eq. (18), we have:
$$S ( x ) & = \frac { m } { ( x + R ) ^ { 2 } } - \frac { m } { ( x - R ) ^ { 2 } } - n ^ { 2 } x, \\ \intertext { n \dots \dots \dots } \, \stackrel { n \dots } { n \dots } \, \sum \nolimits \, \dots \, \dots.$$
Thus, S (0) = 0. Moreover, from Eq.(19), we have :
$$\lim _ { x \to 0 ^ { + } } T ( x ) = \lim _ { x \to 0 ^ { + } } - \frac { M _ { g } } { ( 1 + x ^ { 2 } ) } = - M _ { g }$$
and so lim x → 0 T x ( ) does not exist. Therefore, k x ( ) is not a continuous function at x = 0, and so the origin (0,0) is a singular point. ✷
$$\lim _ { x \to 0 ^ { - } } T ( x ) = \lim _ { x \to 0 ^ { - } } - & \frac { M _ { g } x } { ( - x ) ( 1 + x ^ { 2 } ) } = M _ { g }, \\ \text{s not exist.} \text{ Therefore, $k(x)$ is not a continuous function}$$
## Theorem 3: The Existence and Uniqueness of Jiang-Yeh Points JY1 and JY2
There is a unique x 3 ∈ (0 , R ) such that k x ( 3 ) = 0 and a unique x 4 ∈ ( -R, 0) such that k x ( 4 ) = 0. That is, on the x -axis, there is one and only one equilibrium point in the region (0 , R ), i.e. JY1, and there is one and only one equilibrium point in the region ( -R, 0), i.e. JY2.
## Proof:
When -R < x < R , from Eq.(21), we have:
$$S ^ { \prime } ( x ) = - \frac { 2 m } { ( x + R ) ^ { 3 } } + \frac { 2 m } { ( x - R ) ^ { 3 } } - n ^ { 2 } < 0.$$
We first consider the region with 0 < x < R . From Eq.(19):
$$T ^ { \prime } ( x ) = - \frac { - 2 x M _ { g } } { ( 1 + x ^ { 2 } ) ^ { 2 } } = \frac { 2 x M _ { g } } { ( 1 + x ^ { 2 } ) ^ { 2 } } > 0,$$
we have k ′ ( x ) = -S ′ ( x ) + T ′ ( x ) > 0, and thus k x ( ) is a monotonic function in this region. Due to the singularity at 0 for T x ( ) and at R for S(x), we consider the limits and find
lim x → 0 + k x ( ) = -S (0)+lim x → 0 + T x ( ) = -M g and lim x → R -k x ( ) = -lim x → R -S x ( )+ T R ( ) = ∞ . Thus, there is a unique x 3 ∈ (0 , R ) such that k x ( 3 ) = 0.
Similarly, for the region with -R < x < 0, from Eq.(19):
$$T ^ { \prime } ( x ) = \frac { - 2 x M _ { g } } { ( 1 + x ^ { 2 } ) ^ { 2 } } > 0,$$
so we have k ′ ( x ) = -S ′ ( x ) + T ′ ( x ) > 0 and k x ( ) is a monotonic function in this region. Because lim x →-R + k x ( ) = -∞ and lim x → 0 -k x ( ) = M > g 0, there is a unique x 4 ∈ ( -R, 0) such that k x ( 4 ) = 0. ✷
## 4. The Bifurcations and Zero-Velocity Curves
In order to demonstrate the analytic results proved above, we numerically determine the locations of equilibrium points by solving k x ( ) = 0. The locations of the equilibrium points on the x-axis with m = 1 as a function of M g are shown in Figs.1-2. Fig. 1(a) is for R = 0 25, Fig. . 1(b) is for R = 0 5, Fig. . 2(a) is for R = 1 and Fig. 2(b) is for R = 2.
It is clear that when M g = 0, there are three equilibrium points, L1, L2 and L3 on x -axis; when M > g 0, there are four equilibrium points, L2, L3, JY1 and JY2 on x -axis. The separations between these equilibrium points are larger for larger R . Moreover, it is interesting that when M g increases from 0 to 20, the separation between L2 and L3 decreases, but the separation between JY1 and JY2 increases.
In Fig. 3, the zero-velocity curves, which are obtained through Eq.(7), of the case with m = 1 and R = 1 are presented. Fig. 3(a) is for M g = 1, Fig. 3(b) is for M g = 10, Fig. 3(c) is for M g = 30 and Fig. 3(d) is for M g = 100. The + signs are the locations for Lagrange Points, and the squares indicate the Jiang-Yeh Points. These points are numerically determined by solving k x ( ) = 0 and h y ( ) = 0. It is shown that they are completely consistent with the locations of equilibrium points implied by zero-velocity curves. The locations and the values of Jacobi integral C J of all equilibrium points shown in Fig. 3 are summarized in Table 1.
Table 1. The Locations and C J of Equilibrium Points
| | | L2 | L3 | L4 | L5 | JY1 | JY2 |
|-----------|---------------|----------|-----------|----------|-----------|----------|-----------|
| | ( x e , y e ) | (1.94,0) | (-1.94,0) | (0,1.29) | (0,-1.29) | (0.19,0) | (-0.19,0) |
| | C J | 6.58 | 6.58 | 5.02 | 5.02 | 6.94 | 6.94 |
| | | L2 | L3 | L4 | L5 | JY1 | JY2 |
| | ( x e , y e ) | (1.47,0) | (-1.47,0) | (0,1.04) | (0,-1.04) | (0.56,0) | (-0.56,0) |
| | C J | 28.36 | 28.36 | 23.77 | 23.77 | 28.67 | 28.67 |
| | | L2 | L3 | L4 | L5 | JY1 | JY2 |
| | ( x e , y e ) | (1.33,0) | (-1.33,0) | (0,1.01) | (0,-1.01) | (0.69,0) | (-0.69,0) |
| | C J | 72.58 | 72.58 | 65.20 | 65.20 | 72.90 | 72.90 |
| M g = 100 | | L2 | L3 | L4 | L5 | JY1 | JY2 |
| M g = 100 | ( x e , y e ) | (1.22,0) | (-1.22,0) | (0,1.0) | (0,-1.0) | (0.79,0) | (-0.79,0) |
| M g = 100 | C J | 222.11 | 222.11 | 210.16 | 210.16 | 222.43 | 222.43 |
## 5. The Stability of Equilibrium Points
After the existence of equilibrium points is confirmed, and the locations of equilibrium points are determined, it would be interesting to understand the stability around these points. We now consider the following system:
$$\begin{cases} \quad \frac { d x } { d t } = u, \\ \quad \frac { d y } { d t } = v, \\ \quad \frac { d u } { d t } = 2 n v + A ( x, y ), \\ \quad \frac { d v } { d t } = - 2 n u + B ( x, y ), \end{cases} \\ ) \, \text{are defined in Eqs.} ( 8 ) - ( 9 ).$$
where A x, y ( ), B x, y ( ) are defined in Eqs.(8)-(9).
To study the stability of equilibrium points, we need to know the properties of the eigenvalues of equilibrium points. The characteristic equation of the eigenvalue λ is
$$\lambda ^ { 4 } + ( 4 n ^ { 2 } - A _ { x } - B _ { y } ) \lambda ^ { 2 } + 2 n ( A _ { y } - B _ { x } ) \lambda + A _ { x } B _ { y } - B _ { x } A _ { y } = 0,$$
where A x ≡ ∂A x, y /∂x ( ) , A y ≡ ∂A x, y /∂y ( ) , B x ≡ ∂B x, y /∂x ( ) , and B y ≡ ∂B x, y /∂y ( ) . Thus,
$$A _ { x } = \sum _ { \infty } ^ { 2 } - \frac { m } { r _ { 1 } ^ { 3 } } - \frac { m } { r _ { 2 } ^ { 3 } } + \frac { 3 m ( x + R ) ^ { 2 } } { r _ { 1 } ^ { 5 } } + \frac { 3 m ( x - R ) ^ { 2 } } { r _ { 2 } ^ { 5 } } - \frac { M _ { g } } { r ( 1 + r ^ { 2 } ) } + \frac { M _ { g } x ^ { 2 } ( 1 + 3 r ^ { 2 } ) } { r ( r + r ^ { 3 } ) ^ { 2 } }, ( 2 7 )$$
$$A _ { y } = \frac { 3 m ( x + R ) y ^ { 2 } } { r _ { 1 } ^ { 5 } } + \frac { 3 m ( x - R ) y } { r _ { 2 } ^ { 5 } } + \frac { M _ { g } x y ( 1 + 3 r ^ { 2 } ) } { r ( r + r ^ { 3 } ) ^ { 2 } }, \quad \cdots \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \occ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \circ \OC },$$
$$B _ { x } = \frac { 3 m y ( \stackrel { \ell } { x } + R ) } { r _ { 1 } ^ { 5 } } + \frac { 3 m y ( \stackrel { \ell } { x } - R ) } { r _ { 2 } ^ { 5 } } + \frac { \stackrel { \ell } { M _ { g } x y ( 1 + 3 r ^ { 2 } ) } } { r ( r + r ^ { 3 } ) ^ { 2 } },$$
$$B _ { y } = n ^ { 2 } - \frac { m } { r _ { 1 } ^ { 3 } } - \frac { m } { r _ { 2 } ^ { 3 } } + \frac { 3 m y ^ { 2 } } { r _ { 1 } ^ { 5 } } + \frac { 3 m y ^ { 2 } } { r _ { 2 } ^ { 5 } } - \frac { M _ { g } } { r ( 1 + r ^ { 2 } ) } + \frac { M _ { g } y ^ { 2 } ( 1 + 3 r ^ { 2 } ) } { r ( r + r ^ { 3 } ) ^ { 2 } }.$$
From Eqs.(28) and (29), for any x e we have A y ( x , e 0) = B x ( x , e 0) = 0, and for any y e we have A y (0 , y e ) = B x (0 , y e ) = 0. In order to do further investigation, some parameters need to be specified: we set m = 1 and R = 1 for all the results in this section. Thus, from Eq.(6) we have:
$$n ^ { 2 } = \frac { 1 } { 4 } + \frac { M _ { g } } { 2 }.$$
At first, we consider the equilibrium point L2 and JY1, ( x , y e e ), which satisfies k x ( e ) = 0 with x e > 0 and y e = 0. Due to A y ( x , e 0) = 0 and B x ( x , e 0) = 0, Eq.(26) becomes:
$$\lambda ^ { 4 } + ( 4 n ^ { 2 } - A _ { x } - B _ { y } ) \lambda ^ { 2 } + A _ { x } B _ { y } = 0.$$
For convenience, we define Ω = A B x y and Π ≡ A x + B y -4 n 2 . Therefore, we have roots :
$$\max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \max \\ \lambda _ { + } ^ { 2 } = \frac { \Pi - \sqrt { \Pi ^ { 2 } - 4 \Omega } } } { 2 }.$$
Moreover, A x ( x , e 0) and B y ( x , e 0) can be expressed as:
$$& A _ { x } ( x _ { e }, 0 ) = n ^ { 2 } + \frac { 2 } { | x _ { e } + 1 | ^ { 3 } } + \frac { 2 } { | x _ { e } - 1 | ^ { 3 } } + \frac { 2 x _ { e } M _ { g } } { ( 1 + x _ { e } ^ { 2 } ) ^ { 2 } } > 0, \\ & \sim \varphi \quad \sim \quad 1 \, / \quad 1 \, 1 \, \bigwedge \quad \sim \quad \varphi \, \quad \, \varphi \, \quad \, \lambda \, \lambda$$
$$B _ { y } ( x _ { e }, 0 ) & = \frac { 1 } { x _ { e } } \left ( \frac { \lambda \lambda _ { 1 } ^ { 2 } } { | x _ { e } + 1 | ^ { 3 } } - \frac { \lambda \lambda _ { 1 } ^ { 2 } } { | x _ { e } - 1 | ^ { 3 } } \right ) < 0 \\ \intertext { m a l i w e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e d e }$$
(see Appendix A for details).
For L2, x e > R = 1, from Eqs. (33)-(34), since A x ( x , e 0) > 0 and B y ( x , e 0) < 0, we have Ω = A x ( x , e 0) B y ( x , e 0) < 0. Thus, Π 2 -4Ω > 0, and we have λ 2 + > 0 and λ 2 -< 0. As in Szebehely (1967); this indicates that it is an unstable equilibrium point.
For JY1, it has 0 < x e < 1 and y e = 0. From Eqs. (33)-(34), A x ( x , e 0) > 0 and B y ( x , e 0) < 0, so Ω = A B x y < 0. Thus, Π 2 -4Ω > 0, we have λ 2 + > 0 and λ 2 -< 0. Therefore, JY1 is also an unstable equilibrium point.
Because our system is symmetric with respect to the y -axis, the above results are also valid for L3 and JY2. Thus, the equilibrium points L3 and JY2 are unstable.
Secondly, we study the equilibrium point L4, which can be written as (0 , y e ) with y e > 0. As mentioned previously, we have A y (0 , y e ) = B x (0 , y e ) = 0. Thus, Eqs.(31) and (32) are also valid here. We find that:
$$A _ { x } ( 0, y _ { e } ) = \frac { 6 } { ( 1 + y _ { e } ^ { 2 } ) ^ { 5 / 2 } } > 0,$$
but cannot determine the sign of B y (0 , y e ) analytically here. Thus, for each given M g , the location of L4, (0 , y e ), and then the corresponding value of B y (0 , y e ), Π 2 -4Ω, and Π are determined numerically, as shown in Fig. 4(a)-(c). From Fig. 4(a), we know B y (0 , y e ) > 0 and so Ω = A B x y > 0. Fig. 4(b) shows the value of Π 2 -4Ω as a function of M g . It is clear that Π 2 -4Ω is not a monotonic function of M g . There is a critical value M cr ∼ 4 213, such . that when 0 < M g < M cr , we have Π 2 -4Ω < 0; when M g ≥ M cr , we have Π 2 -4Ω ≥ 0. For the case when Π 2 -4Ω < 0, both λ 2 + and λ 2 -are complex numbers. This leads to both λ + and λ -having a root which contains a positive real part, so that L4 is unstable. For the case when Π 2 -4Ω ≥ 0, we need to know the value of Π. As shown in Fig. 4(c), we find that Π < 0 for the considered value of M g . We thus have λ 2 + < 0 and λ 2 -< 0. This leads to both λ + and λ -being pure imaginary numbers, so that L4 is a center.
Because our system is symmetric with respect to the x -axis, the above results are also valid for L5. Thus, the equilibrium point L5 is either an unstable point or a center.
## 6. Concluding Remarks
We have studied the existence and uniqueness of equilibrium points, including Lagrange Points and Jiang-Yeh Points, of a galactic system with supermassive binary black holes embedded in a central cuspy galactic halo. Due to the cuspy density profile and focusing on the case with an equal mass binary black hole, we found that the central origin is a singular point. We also found that the Lagrange Points, L2, L3, L4 and L5, and Jiang-Yeh Points, JY1 and JY2, always exist, i.e. there are six equilibrium points in the considered system. This differs from the previous results of non-cuspy galactic profiles that Jiang-Yeh Points only exist under a particular condition (Jiang & Yeh 2014).
The stability analysis was performed for these equilibrium points. It is found that the equilibrium points L2, L3, JY1 and JY2 are unstable. The equilibrium point L4 (L5) is unstable when the galactic total mass M < M g cr , and is a neutrally stable center when M g ≥ M cr . This critical mass M cr , which is about 4.213, is therefore an important condition for the stability of L4 and L5. These new results will be employed to investigate the cores of early-type galaxies in the near future.
## Acknowledgment
We thank the referee for very helpful suggestions. We are grateful to the National Center for High-performance Computing for computer time and facilities. This work is
supported in part by the National Science Council, Taiwan, under Ing-Guey Jiang's Grants NSC 100-2112-M-007-003-MY3 and Li-Chin Yeh's Grants NSC 100-2115-M-134-004.
## REFERENCES
Binney J., Tremaine S., 2008, Galactic Dynamics, Second Edition (Princeton University Press)
Chatterjee, S., Ford, E. B., Matsumura, S., Rasio, F. A., 2008, ApJ, 686, 580
Chermnykh, S. V., 1987, Vest. Leningrad Univ. 2, 10
- Ji, J., Li, G., Liu, L., 2002, ApJ, 572, 1041
- Jiang, I.-G., Ip, W.-H., 2001, A&A, 367, 943
- Jiang, I.-G., Ip, W.-H., Yeh, L.-C., 2003, ApJ, 582, 449
- Jiang, I.-G., Yeh, L.-C., 2003, Int. J. Bifurcation and Chaos, 13, 617
- Jiang, I.-G., Yeh, L.-C., 2004a, AJ, 128, 923
- Jiang, I.-G., Yeh, L.-C., 2004b, Int. J. Bifurcation and Chaos, 14, 3153
- Jiang, I.-G., Yeh, L.-C., 2004c, MNRAS, 355, L29
- Jiang, I.-G., Yeh, L.-C., 2006, Astrophysics and Space Science, 305, 341
- Jiang, I.-G., Yeh, L.-C., 2007, ApJ, 656, 534
- Jiang, I.-G., Yeh, L.-C., 2009, AJ, 137, 4169
- Jiang, I.-G., Yeh, L.-C., 2011, MNRAS, 415, 2859
- Jiang, I.-G., Yeh, L.-C., Hung, W.-L., Yang, M.-S., 2006, MNRAS, 370, 1379
- Jiang, I.-G., Yeh, L.-C., Chang, Y.-C., Hung, W.-L., 2007, AJ, 134, 2061
- Jiang, I.-G., Yeh, L.-C., Chang, Y.-C., Hung, W.-L., 2009, AJ, 137, 329
- Jiang, I.-G., Yeh, L.-C., Chang, Y.-C., Hung, W.-L., 2010, ApJS, 186, 48
- Jiang, I.-G. et al., 2013, AJ, 145, 68
- Jiang, I.-G., Yeh, L.-C., 2014, Astrophysics and Space Science, 349, 881
- Kandrup, H. E., Sideris, I. V., Terzic, B. Bohn, C. L., 2003, ApJ, 597, 111
Kushvah, B. S., 2008a, Astrophysics and Space Science, 315, 231
Kushvah, B. S., 2008b, Astrophysics and Space Science, 318, 41 Kushvah, B. S., 2009, Astrophysics and Space Science, 323, 57 Kushvah, B. S., 2011a, Astrophysics and Space Science, 332, 99 Kushvah, B. S., 2011b, Astrophysics and Space Science, 333, 49 Kushvah, B. S., Kishor, R., Dolas, U., 2012, Astrophysics and Space Science, 337, 115 Lauer, T. R. et al., 1992, AJ, 104, 552 Lauer, T. R. et al., 1995, AJ, 110, 2622 Milosavljevic, M., Merritt, D., 2001, ApJ, 563, 34 Navarro, J. F., Frenk, C. S., White, S. D. M., 1995, MNRAS, 275, 720 Papadakis, K. E., 2004, A&A, 425, 1133 Papadakis, K. E., 2005a, Astrophysics and Space Science, 299, 67 Papadakis, K. E., 2005b, Astrophysics and Space Science, 299, 129 Quinlan, G. D., 1996, New Astronomy, 1, 35 Szebehely, V., 1967, Theory of Orbits: The Restricted Problem of Three Bodies (London: Academic Press, Inc.) Wu, Y.-T., Jiang, I.-G., 2009, MNRAS, 399, 628 Wu, Y.-T., Jiang, I.-G., 2012, ApJ, 745, 105 Yeh, L.-C., Chen, Y.-C., Jiang, I.-G., 2012, Int. J. Bifurcation and Chaos, 22, 1230040 Yeh, L.-C., Jiang, I.-G., 2006, Astrophysics and Space Science, 306, 189
Yu, Q., 2002, MNRAS, 331, 935
This preprint was prepared with the AAS LT E X macros v5.0. A
## Appendix A
The details of the calculations of A x ( x , e 0) and B y ( x , e 0) in Section 5 are presented here. If m = R = 1, then r 2 1 = ( x +1) + 2 y 2 and r 2 2 = ( x -1) 2 + y 2 . From Eq. (27),
$$& \, = R = 1, \text{ then } r _ { 1 } ^ { 2 } = ( x + 1 ) ^ { 2 } + y ^ { 2 } \text{ and } r _ { 2 } ^ { 2 } = ( x - 1 ) ^ { 2 } + y ^ { 2 }. \text{ From Eq. (27),} \\ & \, A _ { x } ( x _ { e }, 0 ) = n ^ { 2 } - \frac { 1 } { | x _ { e } + 1 | ^ { 3 } } - \frac { 1 } { | x _ { e } - 1 | ^ { 3 } } + \frac { 3 ( x _ { e } + 1 ) ^ { 2 } } { | x _ { e } + 1 | ^ { 5 } } - \frac { 3 ( x _ { e } - 1 ) ^ { 2 } } { | x _ { e } - 1 | ^ { 5 } } \\ & \quad \, \quad - \frac { M _ { g } } { | x _ { e } | ( 1 + x _ { e } ^ { 2 } ) } + \frac { M _ { g } x _ { e } ^ { 2 } ( 1 + 3 x _ { e } ^ { 2 } ) } { | x _ { e } | ^ { 3 } ( 1 + x _ { e } ^ { 2 } ) ^ { 2 } } \\ & \, = n ^ { 2 } + \frac { 2 } { | x _ { e } + 1 | ^ { 3 } } + \frac { 2 } { | x _ { e } - 1 | ^ { 3 } } - \frac { M _ { g } ( 1 + x _ { e } ^ { 2 } ) } { | x _ { e } | ( 1 + x _ { e } ^ { 2 } ) ^ { 2 } } + \frac { M _ { g } ( 1 + 3 x _ { e } ^ { 2 } ) } { | x _ { e } | ( 1 + x _ { e } ^ { 2 } ) ^ { 2 } } \\ & \, = n ^ { 2 } + \frac { 2 } { | x _ { e } + 1 | ^ { 3 } } + \frac { 2 } { | x _ { e } - 1 | ^ { 3 } } + \frac { 2 | x _ { e } | M _ { g } } { ( 1 + x _ { e } ^ { 2 } ) ^ { 2 } } > 0. \\ \\ & \text{ On the other hand, from Remark } B, \text{ since } ( x _ { e }, 0 ) \text{ is an equilibrium point, } k ( x _ { e } ) = 0$$
On the other hand, from Remark B , since ( x , e 0) is an equilibrium point, k x ( e ) = 0. By Eq.(11) and m = R = 1, we have
$$- \frac { M _ { g } } { | x _ { e } | ( 1 + x _ { e } ^ { 2 } ) } & = \frac { ( x _ { e } + 1 ) } { x _ { e } | x _ { e } + 1 | ^ { 3 } } + \frac { ( x _ { e } - 1 ) } { x _ { e } | x _ { e } - 1 | ^ { 3 } } - n ^ { 2 }. \\ \tilde { \wedge \wedge } \quad \cdot = \tilde { \wedge \wedge } \quad \cdot$$
From Eq. (30) and Eq. (36), we have:
$$\Pi \, \mathcal { L } _ { \ell } \, \langle \mathfrak { O } _ { \ell } \, \text{and} \, \mathfrak { L } _ { \ell } \, \langle \mathfrak { O } _ { \ell } \, \text{,} \, \text{we move.} \\ & B _ { y } ( x _ { e }, 0 ) = n ^ { 2 } - \frac { 1 } { | x _ { e } + 1 | ^ { 3 } } - \frac { 1 } { | x _ { e } - 1 | ^ { 3 } } - \frac { M _ { g } } { | x _ { e } | ( 1 + x _ { e } ^ { 2 } ) } \\ & = n ^ { 2 } - \frac { x _ { e } } { x _ { e } | x _ { e } + 1 | ^ { 3 } } - \frac { x _ { e } } { x _ { e } | x _ { e } - 1 | ^ { 3 } } + \frac { ( x _ { e } + 1 ) } { x _ { e } | x _ { e } + 1 | ^ { 3 } } + \frac { ( x _ { e } - 1 ) } { x _ { e } | x _ { e } - 1 | ^ { 3 } } - n ^ { 2 } \\ & = \frac { 1 } { x _ { e } } \left ( \frac { 1 } { | x _ { e } + 1 | ^ { 3 } } - \frac { 1 } { | x _ { e } - 1 | ^ { 3 } } \right ) < 0.$$
Fig. 1.- The locations of the equilibrium points on the x -axis with m = 1 as a function of M g . (a) is for R = 0 25 and (b) is for . R = 0 5. .
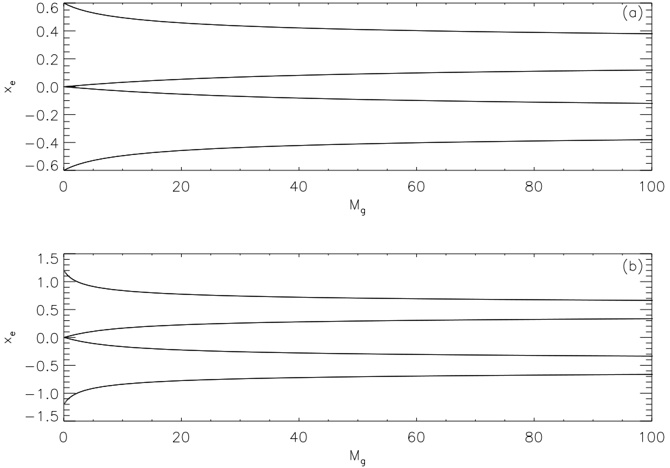
Fig. 2.- The locations of the equilibrium points on the x -axis with m = 1 as a function of M g . (a) is for R = 1 and (b) is for R = 2.
Fig. 3.- The zero-velocity curves of the system when R = 1 and m = 1, on which the corresponding values of the Jacobi integral C J are labeled. (a) is for M g = 1, (b) is for M g = 10, (c) is for M g = 30, (d) is for M g = 100. The + signs indicate the locations of Lagrange Points and the squares indicate the locations of Jiang-Yeh Points.
Fig. 4.(a) The value of B y (0 , y e ) as a function of M g for L4. (b) Π 2 -4Ω as a function of M g for L4. (c) Π as a function of M g for L4.
 | 10.1007/s10509-014-2114-5 | [
"Ing-Guey Jiang",
"Li-Chin Yeh"
] | 2014-08-01T03:28:29+00:00 | 2014-08-01T03:28:29+00:00 | [
"astro-ph.GA",
"math-ph",
"math.MP",
"nlin.CD"
] | Galaxies with Supermassive Binary Black Holes: (II) A Model with Cuspy Galactic Density Profiles | The existence and uniqueness of equilibrium points, including Lagrange Points
and Jiang-Yeh Points, of a galactic system with supermassive binary black holes
embedded in a centrally cuspy galactic halo are investigated herein. Differing
from the previous results of non-cuspy galactic profiles that Jiang-Yeh Points
only exist under a particular condition, it is found here that the Lagrange
Points, L2, L3, L4 and L5, Jiang-Yeh Points, JY1 and JY2, exist under general
conditions. The stability analysis shows that L2, L3, JY1 and JY2 are unstable.
However, L4 and L5 are only unstable when the galactic total mass is smaller
than a critical mass; otherwise they become neutrally stable centers. These
results will be important for further studies on the cores of early-type
galaxies. |
1408.0071v2 | ## WILLMORE SUBMANIFOLDS IN THE UNIT SPHERE VIA ISOPARAMETRIC FUNCTIONS
YUQUAN XIE
Abstract. This paper is a continuation of [TY12] and [QTY13]. We show that both focal submanifolds of each isoparametric hypersurface in the sphere with six distinct principal curvatures are Willmore.
## 1. Introduction
Let x : N n → S n + p be an immersion from an n -dimensional compact submanifold to an ( n + )-dimensional unit sphere. p Then N is called a Willmore submanifold in S n + p if it is an extremal submanifold of the Willmore functional ( cf. [Wan98])
$$W ( x ) = \int _ { N } ( S - n | H | ^ { 2 } ) ^ { \frac { n } { 2 } } d v.$$
Here S is the square norm of the second fundamental form of x , and H is the mean curvature vector field. In [GLW01] and [PW88], the authors gave an equivalent condition for N n to be Willmore. In particular, if N is minimal with constant S , the criterion for Willmore reduces to a simple equation (see (5) in section 2).
It follows immediately from the criterion (5) that all the Einstein manifolds minimally immersed in the unit sphere are Willmore submanifolds. However, there exist examples of minimal Willmore submanifolds which are not Einstein, for example, Cartan's minimal isoparametric hypersurfaces. In addition, [Li01] characterized all the isoparametric Willmore hypersurfaces in the unite sphere. In 2012, Tang and Yan [TY12] proved that one of the focal submanifolds of OT-FKM type is Willmore. Qian, Tang and Yan [QTY13] extended this result, they showed that
Theorem 1.1 ([QTY13]) . Both the focal submanifolds of every isoparametric hypersurface in S n +1 with four distinct principal curvatures are Willmore.
Furthermore, they completely determine the focal submanifolds which are Einstein except for one case (for details, see [QTY13]). Recently, Tang and Yan [TY13b] showed that the focal submanifolds with g = 4 are all Amanifolds but rarely Ricci parallel, except possibly for the only unclassified case. For the case g = 6, Li and Yan [LY14] proved that none of them are Ricci parallel.
2000 Mathematics Subject Classification. 53A30, 53C42.
Key words and phrases. Willmore submanifold, isoparametric hypersurface, focal submanifold.
The project is supported by the NSFC ( No.11326071 ).
In this paper, we will give a new proof of theorem 1.1. Moreover, we establish our result as follows
Theorem 1.2. Both the focal submanifolds of each isoparametric hypersurface in the unit sphere with six distinct principal curvatures are Willmore.
Recall that an isoparametric hypersurface M in the sphere is one whose principal curvatures and their multiplicities are fixed constants. In virtue of M¨ unzner's work [M¨ un80] [M¨ un81], the number g of distinct principal curvatures must be 1 2 3 4 or , , , 6, and there are at most two multiplicities { m ,m 1 2 } of principal curvatures ( m 1 = m 2 , if g is odd). The classification problem has been completed except for one case (see [Tho00] and [Cec08] for excellent surveys and [CCJ07], [Imm08], [Chi13],[Miy13], [TY13a], [TXY14] for recent progresses).
The isoparametric hypersurfaces with g = 1 2 3 were classified by Cartan to be , , homogeneous [Car39a] [Car39b]. Clearly, in these cases, the focal submanifolds are Willmore. For g = 6, Abresch [Abr83] proved that m 1 = m 2 = 1 or 2. Dorfmeister and Neher [DN85] showed that the isoparametric hypersurface is homogeneous in the first case and Miyaoka [Miy13] showed the same result in the second case.
Based on all the results mentioned above, we obtain the following
Theorem 1.3. All the focal submanifolds of the isoparametric hypersurfaces in the unit sphere are Willmore submanifolds.
## 2. Notation and preliminary results
Let N n be a minimal submanifold in the unit sphere S n + p with constant square norm S of the second fundamental form. We choose a local field of orthonormal frames e , 1 · · · , e n + p in S n + p such that, restricted to N , the vectors e , 1 · · · , e n are tangent to N and, consequently, the remaining vectors e n +1 , · · · , e n + p are normal to N . Throughout this paper we will adopt the following ranges of indices:
$$1 \leq i, j, \cdots \leq n, \quad n + 1 \leq \alpha, \beta, \gamma \cdots \leq n + p, \quad 1 \leq A, B, C, \cdots \leq n + p,$$
and we shall agree that repeated indices are summed over the respected ranges. With respect to the frame field in S n + p chosen above, let θ , 1 · · · , θ n + p be the field of dual frames. Then the structure equations of S n + p are given by
$$& d \theta _ { A } = \sum \omega _ { A B } \wedge \theta _ { B }, \quad \omega _ { A B } = - \omega _ { B A }, \\ & d \omega _ { A B } = \sum \omega _ { A C } \wedge \omega _ { C B } - \theta _ { A } \wedge \theta _ { B }. \\ \ni \text{form to } N, \text{ then }$$
We restrict these form to N , then
$$\theta _ { \alpha } = 0.$$
Since 0 = dθ α = -∑ ω iα ∧ θ i , by Cartan's lemma we may write
$$\omega _ { i \alpha } = \sum h _ { i j } ^ { \alpha } \theta _ { j }, \quad h _ { i j } ^ { \alpha } = h _ { j i } ^ { \alpha }.$$
From these formulas, we obtain
$$d \theta _ { i } = & \sum \omega _ { i j } \wedge \theta _ { j }, \quad \omega _ { i j } = - \omega _ { j i }, \\ \omega _ { i } \quad, \quad \varsigma \quad. \quad \varsigma \quad \varsigma \quad 1 \, \varsigma$$
$$& ( 3 ) R _ { i j k l } = \delta _ { i k } \delta _ { j l } - \delta _ { i l } \delta _ { j k } + \sum \left ( h ^ { \alpha } _ { i k } h ^ { \alpha } _ { j l } - h ^ { \alpha } _ { i l } h ^ { \alpha } _ { j k } \right ). \\ & \text{Hero, we... o... are the connection form and structure form of $N$ reconnect}$$
$$& d \omega _ { i j } = \sqrt { \sum } \omega _ { i k } \wedge \omega _ { k j } - \Omega _ { i j }, \quad \Omega _ { i j } = \frac { 1 } { 2 } \sum R _ { k l i j } \theta _ { k } \wedge \theta _ { l }, \\ & R _ { \dots } - \delta _ { \dots } \delta _ { \dots } - \delta _ { \dots } \delta _ { \dots } \perp \sum ( h ^ { \alpha } h ^ { \alpha } _ { \dots } - h ^ { \alpha } _ { \dots } h ^ { \alpha } _ { \dots } )$$
Here ω ij , Ω ij are the connection form and curvature form of N , respectively. The Ricci curvature of N is then given by
$$( 4 )$$
$$R _ { i j } & = \sum _ { k } R _ { i k j k } = ( n - 1 ) \delta _ { i j } + \sum _ { k, \alpha } \left ( h ^ { \alpha } _ { i j } h ^ { \alpha } _ { k k } - h ^ { \alpha } _ { i k } h ^ { \alpha } _ { k j } \right ) \\ & = ( n - 1 ) \delta _ { i j } - \sum _ { k, \alpha } h ^ { \alpha } _ { i k } h ^ { \alpha } _ { k j }.$$
The last equation successes, since N is minimal.
Recall that if N is minimal with constant S , the equivalent condition for N to be Willmore is given by ( cf. [GLW01],[TY12])
$$\sum _ { i, j } R _ { i j } h _ { i j } ^ { \alpha } = 0, \quad \text{ for any } \alpha = n + 1, \cdots, n + p.$$
Combining with (4), we conclude that N is a Willmore submanifold, if it satisfies
$$\sum _ { i, j, k, \beta } h _ { i k } ^ { \beta } h _ { k j } ^ { \beta } h _ { i j } ^ { \alpha } = 0, \quad \text{ for any } \alpha = n + 1, \cdots, n + p.$$
Let A α be the shape operator along the unit normal vector e α , that is, 〈 A α ( e i ) , e j 〉 = h α ij . We also denote by A α the corresponding matrix with respect to the orthonormal basis e , 1 · · · , e n . Since N is minimal, the trace of the shape operator is
$$\text{Tr} \, A _ { \alpha } = 0 \quad \text{ for any } \alpha = n + 1, \cdots, n + p.$$
Using the fact
Tr
A A
2
β
α
=
h
β
ik
h
β
kj
h
ij
,
β
{
∑
}
∑
i,j,k,β
we see that N is a Willmore submanifold in S n + p , if it satisfies
$$\text{Tr} \{ \sum _ { \beta } A _ { \beta } ^ { 2 } A _ { \alpha } \} = 0, \quad \text{ for any } \alpha = n + 1, \cdots, n + p.$$
## 3. Proof of the Theorem
Let N n be a focal submanifold of the isoparametric hypersurface in the sphere S n + p . It is well known that N is a minimal submanifold in S n + p with constant square norm S .
α
3.1. Case g = 4 . In this subsection, we shall give a new proof of Theorem 1.1.
In this case, as we know, the principal curvatures of N with respect to any unit normal vector are 1 0 , , -1. Therefore, if ξ = ∑ t α e α is any unit normal vector, and its shape operator is denoted by A , then A 3 = A .
By a further discussion (for details, one can find it in the previous version (arXiv0402272v1, Page 19) of [CCJ07]), we have
$$A _ { \alpha } = A _ { \alpha } ^ { 3 }, \quad \text{for all } \alpha,$$
$$A _ { \alpha } = A _ { \beta } ^ { 2 } A _ { \alpha } + A _ { \beta } A _ { \alpha } A _ { \beta } + A _ { \alpha } A _ { \beta } ^ { 2 }, \quad \text{for all } \alpha \neq \beta.$$
/negationslash
Hence for any α , Tr A α = Tr A 3 α , and for any α = β
/negationslash
$$\int _ { \substack { \int _ { \substack { \int _ { \substack { \int _ { \substack { \int _ { \beta } } } } } } } } } \tilde { \Gamma } \, A _ { \alpha } = \tilde { \Gamma } \{ A _ { \beta } ^ { 2 } A _ { \alpha } + A _ { \beta } A _ { \alpha } A _ { \beta } + A _ { \alpha } A _ { \beta } ^ { 2 } \} } = 3 \, \tilde { \Gamma } \, \{ A _ { \beta } ^ { 2 } A _ { \alpha } \}.$$
Combining with (7), we have for any α ,
/negationslash
$$+ ( 7 ), \, \text{we have for any } \alpha, \\ \text{Tr} \{ \sum _ { \beta } A _ { \beta } ^ { 2 } A _ { \alpha } \} & = \text{Tr} \{ A _ { \alpha } ^ { 3 } + \sum _ { \beta \neq \alpha } A _ { \beta } ^ { 2 } A _ { \alpha } \} \\ & = \text{Tr} \, A _ { \alpha } + \sum _ { \beta \neq \alpha } \text{Tr} \{ A _ { \beta } ^ { 2 } A _ { \alpha } \} \\ & = \text{Tr} \, A _ { \alpha } + \sum _ { \beta \neq \alpha } \frac { 1 } { 3 } \, \text{Tr} \, A _ { \alpha } \\ & = 0, \\ \text{t} \, N \, \text{is Willmore.\ } \text{This completes the proof of theorem}$$
/negationslash
/negationslash which yields that N is Willmore. This completes the proof of theorem 1.1.
3.2. Case g = 6 . As mentioned before, m 1 = m 2 = 1 or 2 and the isoparametric hypersurfaces in these two cases are homogeneous. Denote by M ,M 1 2 the corresponding focal submanifolds.
For m 1 = m 2 = 1, given p ∈ M 5 1 ⊂ S 7 , with respect to a suitable tangent orthonormal basis e , 1 · · · , e 5 of T M p 1 , Miyaoka [Miy93] showed that the shape operators of M 1 are given by
$$A _ { 6 } = \begin{pmatrix} \psi _ { 1 } & \psi _ { 2 } & \psi _ { 3 } & \psi _ { 4 } & \psi _ { 5 } & \psi _ { 6 } & \psi _ { 7 } \\ 0 & \frac { 1 } { \sqrt { 3 } } & 0 & 0 & 0 \\ 0 & \frac { 1 } { \sqrt { 3 } } & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & - \frac { 1 } { \sqrt { 3 } } & 0 \\ 0 & 0 & 0 & 0 & - \sqrt { 3 } \end{pmatrix}, \quad \begin{pmatrix} 0 & 0 & 0 & 0 & \sqrt { 3 } \\ 0 & 0 & 0 & \frac { 1 } { \sqrt { 3 } } & 0 \\ 0 & 0 & 0 & 0 \\ 0 & \frac { 1 } { \sqrt { 3 } } & 0 & 0 & 0 \\ \sqrt { 3 } & 0 & 0 & 0 & 0 \end{pmatrix}. \\ A \text{ direct computation leads to}$$
A direct computation leads to
$$A _ { 6 } ^ { 2 } + A _ { 7 } ^ { 2 } = \begin{pmatrix} 6 & 0 & 0 & 0 & 0 \\ 0 & \frac { 2 } { 3 } & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & \frac { 2 } { 3 } & 0 \\ 0 & 0 & 0 & 0 & 6 \end{pmatrix}.$$
It is not difficult to check that
$$\text{Tr} \{ ( A _ { 6 } ^ { 2 } + A _ { 7 } ^ { 2 } ) A _ { \alpha } \} = 0, \quad \alpha = 6 \text{ or } 7.$$
Hence M 1 is a Willmore submanifold in S 7 .
Similarly, for the focal submanifold M 5 2 , the shape operators are given by ( c.f. [Miy93] )
$$\psi$$
$$A _ { 6 } = \begin{pmatrix} \sqrt { 3 } & 0 & 0 & 0 & 0 \\ 0 & \frac { 1 } { \sqrt { 3 } } & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & - \frac { 1 } { \sqrt { 3 } } & 0 \\ 0 & 0 & 0 & 0 & - \sqrt { 3 } \end{pmatrix}, \quad \ \ A _ { 7 } = \begin{pmatrix} 0 & 1 & 0 & 0 & 0 \\ 1 & 0 & 0 & - \frac { 2 } { \sqrt { 3 } } & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & - \frac { 2 } { \sqrt { 3 } } & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 & 0 \end{pmatrix}.$$
Consequently,
$$A _ { 6 } ^ { 2 } + A _ { 7 } ^ { 2 } = \begin{pmatrix} 4 & 0 & 0 & - \frac { 2 } { \sqrt { 3 } } & 0 \\ 0 & \frac { 8 } { 3 } & 0 & 0 & - \frac { 2 } { \sqrt { 3 } } \\ 0 & 0 & 0 & 0 & 0 \\ - \frac { 2 } { \sqrt { 3 } } & 0 & 0 & \frac { 8 } { 3 } & 0 \\ 0 & - \frac { 2 } { \sqrt { 3 } } & 0 & 0 & 4 \end{pmatrix} \,, \quad \text{$r\{(A _ { 6 } ^ { 2 } + A _ { 7 } ^ { 2 } ) A_{\alpha}\} =0$,} \quad \alpha = 6 \text{ or } 7, \\ \text{which implies that $M$ is Willmore in $\mathbb{S}^{7}$}$$
which implies that M 2 is Willmore in S 7 .
For the case m 1 = m 2 = 2, the focal submanifolds M ,M 10 1 10 2 are also homogeneous in S 13 . As asserted by Miyaoka [Miy13], the shape operators A 11 , A 12 , A 13 of M 1 are expressed respectively by diagonal matrix
$$\text{ly by diagonal matrix} \\ \begin{pmatrix} \sqrt { 3 } I & 0 & 0 & 0 & 0 \\ 0 & \frac { 1 } { \sqrt { 3 } } I & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & - \frac { 1 } { \sqrt { 3 } } I & 0 \\ 0 & 0 & 0 & 0 & - \sqrt { 3 } I \end{pmatrix},$$
and
$$\text{and} \\ \text{and} \\ \text{$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\ \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $ \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\ \text{and} \\ \text{$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $
\text{$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\ \text{$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $
\text{$\quad $\quad \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\ $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $
\text{$.} \\ \text{$\quad \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\ \text{$\quad \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\ \text{$\quad $$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $$\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $
\text$\quad \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\ $\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$
\text$\quad \quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad $\quad$\quad$\quad $\quad$\quad $\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\ \quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\ \quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\quad$\ \quad$\ \quad$\ \quad$\ \quad$\quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \quad$\ \$$
$$\text{where $I=\binom{1}{0}$}, J = \binom { 0 } { 1 }.$$
Hence
{ }
$$\text{e} \\ A _ { 1 1 } ^ { 2 } + A _ { 1 2 } ^ { 2 } + A _ { 1 3 } ^ { 2 } = \begin{pmatrix} 9 I & 0 & 0 & 0 & 0 \\ 0 & I & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & I & 0 \\ 0 & 0 & 0 & 0 & 9 I \end{pmatrix}, \\ \text{Ids } M _ { 1 } \text{ is Willmore in } S ^ { 1 3 }.$$
which yields M 1 is Willmore in S 13 .
For M 2 , the shaper operator A 11 is the same as in M 1 , and A 12 , A 13 are given respectively by,
$$\text{specuevely } \, \mathfrak { y }, \\ \text{hus}, \\ \text{s. } \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \end{cases}.$$
Thus,
$$A _ { 1 1 } ^ { 2 } + A _ { 1 2 } ^ { 2 } + A _ { 1 3 } ^ { 2 } = \begin{pmatrix} 5 I & 0 & 0 & 0 & 0 \\ 0 & 5 I & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 5 I & 0 \\ 0 & 0 & 0 & 0 & 5 I \end{pmatrix}, \\ \text{Tr} \{ ( A _ { 1 1 } ^ { 2 } + A _ { 1 2 } ^ { 2 } + A _ { 1 3 } ^ { 2 } ) A _ { \alpha } \} = 0, \quad \alpha = 1 1, 1 2 \text{ or } 1 3.$$
This implies that M 2 is Willmore in S 13 .
Tr ( { A 2 11 + A 2 12 + A 2 13 ) A α } = 0 , α = 11 12 or 13 , .
In summery, we conclude the theorem 1.2.
Acknowledgements . The author would like to express his hearty thanks to Professor Zizhou Tang for valuable discussions and constant encouragement, and Dr. Wenjiao Yan and Chao Qian for their useful suggestions during the preparation of this paper.
## References
[Abr83] U. Abresch, Isoparametric hypersurfaces with four or six distinct principal curvatures , Math. Ann. 264 (1983), 283-302.
[Car39a] E. Cartan, Sur des familles remarquables d'hypersurfaces isoparam´triques dans les espaces e sph´riques e , Math. Z. 45 (1939), 335-367.
[Car39b] , Sur quelque familles remarquables d'hypersurfaces , C. R. Congr`s Math. Li`ge (1939), e e 30-41.
[CCJ07] T. E. Cecil, Q. S. Chi, and G. R. Jensen, Isoparametric hypersurfaces with four principal curvatures , Ann. Math. 166 (2007), 1-76.
[Cec08] T. E. Cecil, Isoparametric and Dupin hypersurfaces , SIGMA 4 (2008), Paper 062, 28 pages. [Chi13] Q. S. Chi, , J. Differential Geom.
Isoparametric hypersurfaces with four principal curvatures 94 (2013), 469-504.
[DN85] J. Dorfmeister and E. Neher, Isoparametric hypersurfaces, case g = 6 , m = 1, Comm. in Algebra 13 (1985), 2299-2368.
| [GLW01] | Zhen Guo, Haizhong Li, and Changping Wang, The second variational formaula for Willmore submanifolds in S n , Results in Math. 40 (2001), 205-225. |
|---------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Imm08] | S. Immervoll, On the classification of isoparametric hypersurfaces with four distinct principal curvatures in spheres , Ann. Math. 168 (2008), 1011-1024. |
| [Li01] | Haizhong Li, Willmore hypersurfaces in a sphere , Asian J. Math. 5 (2001), 365-377. |
| [LY14] | Qichao Li and Wenjiao Yan, On Ricci tensor of focal submanifolds of isoparametric hyper- surfaces , preprint, 2014. |
| [Miy93] | R. Miyaoka, The linear isotropy group of G 2 /SO (4) , the Hopf fibering and isoparametric hypersurfaces , Osaka J. Math 30 (1993), 179-202. |
| [Miy13] | , Isoparametric hypersurfaces with ( g, m ) = (6 , 2), Ann. Math. 177 (2013), 53-110. |
| [M¨n80] u [M¨n81] u | H. F. M¨nzer, u Isoparametrische hyperfl¨chen a in sph¨ren, a I , Math. Ann. 251 (1980), 57-71. , Isoparametrische hyperfl¨chen a in sph¨ren, a II , Math. Ann. 256 (1981), 215-232. |
| [PW88] | F. J. Pedit and T. J. Willmore, Comformal geometry , Atti Sem. Mat. Fis. Univ. Modena 36 (1988), 237-245. |
| [QTY13] | Chao Qian, Zizhou Tang, and Wenjiao Yan, New examples of Willmore submanifolds in the unit sphere via isoparametric functions, II , Ann. Glob. Anal. Geom. 43 (2013), 47-62. |
| [Tho00] | G. Thorbergsson, A survey on isoparametric hypersurfaces and their generalizations , Hand- book of differential geometry, vol. 1, pp. 963-995, North-Holland, Amsterdam, 2000. |
| [TXY14] | Zizhou Tang, Yuquan Xie, and Wenjiao Yan, Isoparametric foliation and Yau conjecture on the first eigenvalue, II , J. Funct. Anal. 266 (2014), 6174-6199. |
| [TY12] | Zizhou Tang and Wenjiao Yan, New examples of Willmore submanifolds in the unit sphere via isoparametric functions , Ann. Glob. Anal. Geom. 42 (2012), 403-410. |
| [TY13a] | , Isoparametric foliation and Yau conjecture on the first eigenvalue , J. Differential Geom. 94 (2013), 521-540. |
| [TY13b] | , Isoparametric foliation and a problem of Besse on generalizations of Einstein condi- tion , arXiv:1307.3807v2, 2013. |
| [Wan98] | Changping Wang, Moebius geometry of submanifolds in S n , Manu. Math. 96 (1998), 517-534. |
Department of Mathematics, Hangzhou Normal University, Zhejiang 310036, China E-mail address : [email protected] | null | [
"Yuquan Xie"
] | 2014-08-01T03:37:09+00:00 | 2014-08-05T13:23:15+00:00 | [
"math.DG"
] | Willmore submanifolds in the unit sphere via isoparametric functions | This paper is a continuation of [TY12] and [QTY13]. We show that both focal
submanifolds of each isoparametric hypersurface in the sphere with six distinct
principal curvatures are Willmore. |
1408.0072v1 | ## A Correspondence between Phenomenological and IBM -1 Models of Even Isotopes of Y b
Abdurahim Okhunov 1 4 , , Fadhil I. Sharrad , and Anwer A. Al-Sammarea 2 3 5 ,
- 1 Department of Science in Engineering, Faculty of Engineering
International Islamic University Malaysia
P.O. Box 10, 50728 Kuala Lumpur, Selangor, Malaysia [email protected]
- 2 Department of Physics, College of Science University of Kerbala, Karbala, Iraq
- 3 Department of Chemistry, College of Education, Faculty of Science
University of Samara, Selah, Iraq
- 4 Institute of Nuclear Physics, Academy of Science Republic of Uzbekistan
100214 Ulugbek, Tashkent, Uzbekistan
- 5 Quantum Science Centre, Department of Physics, Faculty of Science University of Malaya, 50603 Kuala Lumpur, Malaysia
Abstract. This paper studies the nonterminal complexity of weakly conditional grammars, and it proves that every recursively enumerable language can be generated by a weak conditional grammar with no more than seven nonterminals. Moreover, it is shown that the number of nonterminals in weakly conditional grammars without erasing rules leads to an infinite hierarchy of families of languages generated by weakly conditional grammars.
Energy levels and the reduced probability of E 2- transitions for Ytterbium isotopes with proton number Z = 70 and neutron numbers between 100 and 106 have been calculated through phenomenological ( PhM ) and interacting boson ( IBM -1) models. The predicted low-lying levels (energies, spins and parities) and the reduced probability for E 2- transitions results are reasonably consistent with the available experimental data. The predicted low-lying levels ( gr -, β 1 - and γ 1 - band) by produced in the PhM are in good agreement with the experimental data comparison with those by IBM -1 for all nuclei of interest. In addition, the phenomenological model was successful in predicted the β 2 -, β 3 -, β 4 -, γ 2 - and 1 + - band while it was a failure with IBM -1. Also, the 3 + -band is predicted by the IBM -1 model for 172 Y b and 174 Y b nuclei. All calculations are compared with the available experimental data.
Keywords : Ytterbium ( Y b ); Energy levels; model; even-even; isotopes; nuclei
PACS No. : 21.10.-k, 21.10.Ky, 21.10.Hw
## 1 Introduction
The medium-to heavy-mass Ytterbium ( Y b ) isotopes located in the rare-earth mass region are well-deformed nuclei that can be populated to very high spin. Much experimental information on even-odd-mass of Y b isotopes has become more abundant [1]-[6]. For the heavier A = 174 to 178 nuclei [7], previous work using deep inelastic reactions and Gammasphere have begun to reveal much information about the high-spin behavior of these neutron-rich Y b isotopes. The yrast states in the well deformed rare-earth region have been described by using the projected shell model [8]-[14].
Prior to the present work the level structure of ground band state and lowlying excited states of even-even nuclei has been studied both theoretically and experimentally [15], including the decay, Coulomb excitation and various transfer reactions.
In this study, two calculations for energy levels of 170 172 174 176 , , , Y b isotopes have been done by using two different models phenomenological model ( PhM ), and interacting boson model ( IBM -1). Positive parity state energies and the reduced probability of E2 transitions are calculated and compared with the available experimental data. The structure of excited levels is discussed.
## 2 Theoretical models
The calculations have been performed by using the phenomenological and interacting boson models. In the next subsection, we will explain these models.
## 2.1 Phenomenological model ( PhM )
To analyze the properties of low-lying positive parity states in Y b isotopes, the PhM of [16,17] is used. This model takes into account the mixing of states of the gr -, β -, γ - and K π = 1 + - band. The model Hamiltonian is chosen in the following form
$$H = H _ { r o t } ( I ^ { 2 } ) + H _ { K, K ^ { \prime } } ^ { \sigma } & & ( 1 )$$
here H rot ( I 2 - is rotational part of Hamiltonian,
$$H ^ { \sigma } _ { K ^ { \prime } K } ( I ) = \omega _ { _ { K } } \delta _ { _ { K, K ^ { \prime } } } - \omega _ { r o t } ( I ) ( j _ { x } ) _ { _ { K, K ^ { \prime } } } \xi ( I, K ) \delta _ { _ { K, K ^ { \prime } \pm 1 } } \quad \ ( 2 )$$
where ω K - bandhead energy of rotational band, ω rot ( I )- is the rotational frequency of core, ( j x ) K,K ′ - is the matrix elements which describe Coriolis mixture between rotational bands:
$$\left ( j _ { x } \right ) _ { g r, 1 } = - \sqrt { 3 } \cdot \tau _ { 0 }, ( j _ { x } ) _ { \beta, 1 } = - \sqrt { 3 } \cdot \tau _ { 1 }, ( j _ { x } ) _ { \gamma, 1 } = - 1 \cdot \tau _ { 2 }$$
and
$$\xi ( I, 0 ) = 1 \quad \xi ( I, 2 ) = \sqrt { 1 - \frac { 2 } { I ( I + 1 ) } }$$
The eigenfunction of Hamiltonian model (1) has the form
$$| I M K > & = \left [ \frac { 2 I + 1 } { 1 6 \pi ^ { 2 } } \right ] ^ { \frac { 1 } { 2 } } \left \{ \sqrt { 2 } \Psi _ { g r, K } ^ { I } D _ { M K } ^ { I } ( \theta ) \\ & + \sum _ { K ^ { \prime } } \frac { \Psi _ { K ^ { \prime }, K } ^ { I } } { \sqrt { 1 + \delta _ { K ^ { \prime }, 0 } } } \left [ D _ { M, K ^ { \prime } } ^ { I } ( \theta ) b _ { K ^ { \prime } } ^ { + } + ( - 1 ) ^ { I + K ^ { \prime } } D _ { M, - K ^ { \prime } } ^ { I } ( \theta ) b _ { - K ^ { \prime } } ^ { + } _ { K ^ { \prime } } \right ] \right \} | 0 > \\ \text{ here } \Psi _ { K ^ { \prime }, K } ^ { I } \text{ is the amplitude of mixture of basis states.}$$
here Ψ I K ,K ′ is the amplitude of mixture of basis states.
Solving the Schr¨dinger equation one can determine the eigenfunctions and o eigenenergies of the positive parity states.
$$\left ( H _ { K, \nu } ^ { I } - \varepsilon _ { \nu } ^ { I } \right ) \Psi _ { K, \nu } ^ { I } = 0$$
we can determined the eigenfunctions and eigenenergies of the positive-parity states.
The complete energy of a state is given by
$$E _ { \nu } ^ { I } ( I ) = E _ { r o t } ( I ) + \varepsilon _ { \nu } ^ { I } ( I )$$
The rotating-core energy E rot ( I ) is calculated by using the Harris parameterizations [18] of the energy and the angular momentum, that is
$$E _ { r o t } ( I ) = \frac { 1 } { 2 } \jmath _ { 0 } \omega _ { r o t } ^ { 2 } ( I ) + \frac { 3 } { 4 } \jmath _ { 1 } \omega _ { r o t } ^ { 4 } ( I )$$
$$\sqrt { I ( I + 1 ) } = \eta _ { 0 } \omega _ { r o t } ( I ) + \eta _ { 1 } \omega _ { r o t } ^ { 3 } ( I )$$
where 0 and 1 are the inertial parameters of the rotational core.
The rotational frequency of the core ω rot ( I ) is found by solving the cubic equation (7). This equation has two imaginary roots and one real root. The real root is
$$\omega _ { r o t } ( I ) & = \left \{ \frac { \widetilde { I } } { 2 \eta _ { 1 } } + \left [ \left ( \frac { \eta _ { 0 } } { 3 \eta _ { 1 } } \right ) ^ { 3 } + \left ( \frac { \widetilde { I } } { 2 \eta _ { 1 } } \right ) ^ { 2 } \right ] ^ { \frac { 1 } { 2 } } \right \} ^ { \frac { 1 } { 3 } } \\ & \quad + \left \{ \frac { \widetilde { I } } { 2 \eta _ { 1 } } - \left [ \left ( \frac { \eta _ { 0 } } { 3 \eta _ { 1 } } \right ) ^ { 3 } + \left ( \frac { \widetilde { I } } { 2 \eta _ { 1 } } \right ) ^ { 2 } \right ] ^ { \frac { 1 } { 2 } } \right \} ^ { \frac { 1 } { 3 } } \\ \\ \widetilde { I } =. \sqrt { I ( I + 1 ) } \text{ Fation} \, ( 8 \rangle \text{ views } \partial \dots ( I ) \, at the \, \text{ given} \, \sin I \, of the core}$$
where ˜ I = √ I ( I +1). Equation (8) gives ω rot ( I ) at the given spin I of the core.
## 2.2 Interacting boson model ( IBM -1)
The IBM has become one of the most intensively used nuclear models, due to its ability to describe the low-lying collective properties of nuclei across an entire major shell with a Hamiltonian. In the IBM -1 the spectroscopies of lowlying collective properties of even-even nuclei are described in terms of a system of interacting s bosons ( L = 0) and d bosons ( L = 2). Furthermore, the model assumes that the structure of low-lying levels is dominated by excitations among the valence partials outside major closed shells. In the particle space the number of proton bosons N π and neutron bosons N ϑ is counted from the nearest closed shell, and the resulting total boson number is a strictly conserved quantity. The underlying structure of the six-dimensional unitary group SU (6) of the model leads to a Hamiltonian, capable of describing the three specific types of collective structures with classical geometrical analogues (vibrational [19], rotational [20], and γ - unstable [21]) and also the transitional nuclei [22] whose structures are intermediate. The IBM -1 Hamiltonian can be expressed as [21]
$$H & = \varepsilon _ { s } ( s ^ { + } \widetilde { s } ) + \varepsilon _ { d } \left ( d ^ { + } \vec { d } \right ) \\ & + \sum _ { L = 0, 2, 4 } \frac { 1 } { 2 } ( 2 L + 1 ) ^ { \frac { 1 } { 2 } } C _ { L } \left [ \left ( d ^ { + } \times d ^ { + } \right ) ^ { ( L ) } \left ( \vec { d } \times \vec { d } \right ) ^ { ( L ) } \right ] ^ { ( 0 ) } \\ & + \frac { 1 } { 2 } \widetilde { \vartheta } _ { 0 } \left [ \left ( d ^ { + } \times d ^ { + } \right ) ^ { ( 0 ) } \left ( \widetilde { s } \times \widetilde { s } \right ) ^ { ( 0 ) } + \left ( s ^ { + } \times s ^ { + } \right ) ^ { ( 0 ) } \left ( \widetilde { d } \times \vec { d } \right ) ^ { ( 0 ) } \right ] ^ { ( 0 ) } \\ & + \frac { 1 } { \sqrt { 2 } } \widetilde { \vartheta } _ { 2 } \left [ \left ( d ^ { + } \times d ^ { + } \right ) ^ { ( 2 ) } \left ( \widetilde { d } \times \widetilde { s } \right ) ^ { ( 2 ) } + \left ( d ^ { + } \times s ^ { + } \right ) ^ { ( 2 ) } \left ( \widetilde { d } \times \vec { d } \right ) ^ { ( 2 ) } \right ] ^ { ( 0 ) } \\ & + u _ { 2 } \left [ \left ( d ^ { + } \times s ^ { + } \right ) ^ { ( 2 ) } \left ( \widetilde { d } \times \widetilde { s } \right ) ^ { ( 2 ) } \right ] ^ { ( 0 ) } + \frac { 1 } { 2 } u _ { 0 } \left [ \left ( s ^ { + } \times s ^ { + } \right ) ^ { ( 0 ) } \left ( \widetilde { s } \times \widetilde { s } \right ) ^ { ( 0 ) } \right ] ^ { ( 0 ) } \\ \text{where $(^{ \dagger}, d^{ \dagger} )$ and $(s,d)$ are creation and annihilation operators for $s$ and $d$} \\ \text{bosons, respectively.}$$
where ( s , d † † ) and ( s, d ) are creation and annihilation operators for s and d bosons, respectively.
The IBM -1 Hamiltonian equation (9) can be written in general form as [23]
$$H = \varepsilon n _ { d } + a _ { 0 } P ^ { \dagger } P + a _ { 1 } L L + a _ { 2 } Q Q + a _ { 3 } T 3 T 3 + a _ { 4 } T 4 T 4 \quad \quad ( 1 0 )$$
The full Hamiltonian H contains six adjustable parameters, where ε = ε d -ε S is the boson energy and Q = ( d + × ˜ s + s + × ˜ d ) 2 + X d ( + × ˜ d ) 2 here X = CHI . The parameters a 0 , a 1 , a 2 , a 3 and a 4 designate the strength of the pairing, angular momentum, quadrupole, octupole and hexadecapole interaction between the bosons.
## 3 Result and Discussion
In this section, the calculated results can be discussed separately for low -lying states of even-even isotopes of Y b , with neutron number from 100 to 106. Our results include energy levels and the reduced probability of E 2- transitions.
## 3.1 Energy levels
To describe the positive parity states in PhM , we determine the model parameters via the following procedure. In accordance with [24], we suppose that, at low spins, the rotational core energy is the same as the energies of the ground band states.
## Description of the parameters:
- - the inertial parameters 0 and 1 of rotational core determined by (6), using the experimental energy of ground band states up to spin I ≤ 10 /planckover2pi1 ;
- - headband energy of ground ( gr )-, β 1 - and β 2 - band states taken from experimental data, because they are not perturbed by the Coriolis forces at I = 0;
- - headband energy of γ -, K π = 1 + bands ( ω γ and ω 1 + ) and also matrix elements 〈 K j | x | K ′ ± 〉 1 are free parameters of the model. They have been fitted by the least squares method requiring the best agreement between the theoretical energies and experimental data. The fitting parameters of model are given in Table 1.
Also, in the present work the rotational limit of the IBM -1 has been applied to 170 -176 Y b , from the ratio ( E (4 + ) /E (2 + )) it has been found that the 170 -176 Y b isotopes are rotational (deformed nuclei) and these nuclei have been successfully treated as axhibiting the SU (3) symmetry of IBM -1. The calculations have been performed with the code IBM -1 .for and hence, no distinction is made between neutron and proton bosons. For the analysis of excitation energies in Y b isotopes it we tried to keep to the minimum the number of free parameters in Hamiltonian. The explicit expression of Hamiltonian adopted in calculations is [23].
$$H = a _ { 1 } L \cdot L + a _ { 2 } Q \cdot Q$$
In framework of the IBM -1, the isotopic chains of Y b with Z = 70 nuclei, having a number of proton bosons holes 6, a number of neutron bosons particles varies from 9 to 11 for 170 -174 Y b , and number of neutron boson hole for 176 Y b is 10. In Table 2 shown the coefficient values which we are using in IBM -1 .for . The comparison of calculated energy levels and experimental data of low-lying states of 170 Y b , 172 Y b , 174 Y b and 176 Y b isotopes are presented in the Fig. 1-4, respectively. The PhM calculations are plotted on the left of the experimental data and IBM -1 calculations on the right of it for gr -, β 1 - and γ 1 - band. The experimental data are taken from [25] for all isotopes of Y b and also from [26][29] for 170 -174 Y b and 176 Y b , respectively. From these figures, we can see that our calculated results (energies, spin and parity) in both models are reasonably consistent with experimental data, except γ 1 - band energies in IBM -1 calculations for 172 Y b and 174 Y b nuclei disagree with the experimental data. Also the phenomenological calculations are in good agreement with the experimental data than from those of IBM -1. In the high spin these figures show that the difference between our calculation and the experimental data. Furthermore the phenomenological model predicts the energies, spin and parity of β 2 -, β 3 -, β 4 -, γ 2 - and 1 + band and as it shown in the Tables 3-7, respectively. Finally, we believe that the failure to use pairing parameter was the cause of the disagreement between the IBM -1 calculations and experimental data that will be discussed in future studies.
## 3.2 The Reduced probability of B E ( 2)- transitions
In the PhM , with the wave functions calculated by solving the Shr¨dinger eq. o (4), the reduced probabilities of E 2- transitions between states I K i i and states
I f K f are calculated [16,17] as:
$$I _ { f } K _ { f } & \text{ are calculated } [ 1 6, 1 7 ] \text{ as} \colon \\ B ( E 2 ; I _ { i } K _ { i } & \rightarrow I _ { f } K _ { f } ) & = \left \{ \sqrt { \frac { 5 } { 1 6 \pi } } e Q _ { 0 } \left [ \Psi _ { g ^ { \prime }, g ^ { \prime } } ^ { I _ { f } } \Psi _ { g ^ { \prime }, K _ { i } } ^ { I _ { i } } C ^ { I _ { f } ^ { 0 } } _ { I _ { i } 0 ; 2 0 } \\ & + \sum _ { n } \Psi ^ { I _ { f } } _ { K _ { n }, g ^ { \prime } } \Psi ^ { I _ { i } } _ { K _ { n }, K _ { i } } C ^ { I _ { f } K _ { n } } _ { I _ { i } K _ { n } ; 2 0 } \right ] \\ & + \sqrt { 2 } \left [ \Psi _ { g ^ { \prime }, g ^ { \prime } } ^ { I _ { f } } \sum _ { n } \frac { ( - 1 ) ^ { K _ { n } } m _ { K _ { n } } \Psi ^ { K _ { n } } _ { K _ { n } }, K _ { i } } { \sqrt { 1 + \delta _ { K _ { n }, 0 } } } C ^ { I _ { f } } _ { I _ { i } K _ { n } ; 2 - K _ { n } } \\ & + \Psi ^ { I _ { i } } _ { g ^ { \prime }, K _ { i } } \sum _ { n } \frac { m _ { K _ { n } } \Psi ^ { I _ { f } } _ { K _ { n }, g ^ { \prime } } } { \sqrt { 1 + \delta _ { K _ { n }, 0 } } } C ^ { I _ { f } K _ { n } } _ { I _ { i } K _ { n } ; 2 K _ { n } } \right ] \right \} ^ { 2 } \\ \\ & \text{where } m _ { K _ { n } } = < \text{ g/i\hat{n} } ( E 2 ) | K ^ { \pi } > ( K ^ { \pi } = 0 ^ { + }, 2 ^ { + } \text{ and } 1 ^ { + } ) \text{ are constants to be} \\ & \text{determined from the environmental data } \varphi \text{ is the internal quadruneolue moment}$$
where m Kn = < gr m E | ˆ ( 2) | K π > ( K π = 0 + , 2 + and 1 + ) are constants to be determined from the experimental data, Q 0 is the internal quadrupole moment of the nucleus, and C I f K f I K i i ;2( K i + K f ) and are the Clebsch-Gordon coefficients.
Another advantage of the interacting d -boson model is that the matrix elements of the electric quadrupole operator. The reduced matrix elements of the E 2 operator ̂ T E ( 2) has the form [19]-[21]
$$\widehat { T } ( E 2 ) & = \alpha 2 \left [ d ^ { \dagger } \widetilde { s } + s ^ { \dagger } \widetilde { d } \right ] ^ { 2 } + \beta 2 \left [ d ^ { \dagger } \widetilde { d } \right ] ^ { 2 } & ( 1 3 ) \\ & = \alpha 2 \left \{ \left [ d ^ { \dagger } \widetilde { s } + s ^ { \dagger } \widetilde { d } \right ] ^ { 2 } + \chi \left [ d ^ { \dagger } \widetilde { d } \right ] ^ { 2 } \right \} = e _ { B } Q \\ \\ \alpha 2 \text{ and } \beta 2 \text{ are two parameters and } \beta 2 = \chi \alpha 2, \alpha 2 = e _ { B } \ ( e f f e c t i v e c h a r g e ).$$
here α 2 and β 2 are two parameters and β 2 = χα ,α 2 2 = e B ( effectivecharge ). The values of these parameters are presented in Table 3. Then the B E ( 2) values are given by
$$B \left ( E 2 ; J _ { i } \rightarrow J _ { f } \right ) = \frac { 1 } { 2 J _ { i } + 1 } | \langle J _ { f } \| \widehat { T } ( E 2 ) \| J _ { i } \rangle | ^ { 2 } \quad \quad ( 1 4 ) \\ \intertext { a l l i n d } \Phi \left ( \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Phi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi \right ) \Psi 0 \right )$$
For the calculations of the absolute B E ( 2) values two parameters α 2 and β 2 of equation (13) are adjusted according to the experimental B E ( 2; 2 + gr → 0 + gr ).
Table 8 shows the values of the parameters α 2 and β 2, obtained in the present calculations. We present our calculated results of the reduced probability of E 2transitions of both models, and the comparison of calculated values of B E ( 2) transitions with experimental data [30] are given in Table 9 for all nuclei of interest. In general, most of the calculated results in both models are reasonably consistent with the available experimental data, except for few cases that deviate from the experimental data. As mentioned in Table 9 PhM calculations are better than those of IBM -1 when compare with the experimental data, except B E ( 2; 2 + gr → 0 + gr ) for 170 Y b , 174 Y b and 176 Y b , B E ( 2; 6 + gr → 4 + gr ) for 172 Y b , B E ( 2; 4 + gr → 2 + gr ) and B E ( 2; 14 + gr → 12 + gr ) for 174Yb and also B E ( 2; 12 + gr → 10 + gr ) B(E2; ) for 170 Y b .
## 4 Summary
In this paper, energy levels and the reduced probability of E 2transitions positive parity for 170 -176 Y b isotopes with neutron numbers between 100 and 106 have been calculated through PhM and IBM -1 calculations using the IBM.for and IBMT.for programs. The predicted low-lying levels ( gr -, β 1 -and γ 1 -band) by PhM are in good agreement with the experimental data as compared with those by IBM -1 for all nuclei of interest. In addition, the PhM is successful in predicting the β 2 -, β 3 -, β 4 -, γ 2 -and 1 + - band while IBM -1 fails. Also, the 3 + - band is predicted by IBM -1 for 172 Y b and 174 Y b nuclei. All calculations are compared with the available experimental data. Also, the reduced probability of E 2- transitions of PhM calculations are better than those of IBM -1 when compare with the experimental data, except B E ( 2; 2 + gr → 0 + gr ) for 170 Y b , 174 Y b and 176 Y b , B E ( 2; 6 + gr → 4 + gr ) for 172 Y b , B E ( 2; 4 + gr → 2 + gr ) and B E ( 2; 14 + gr → 12 + gr ) for 174Yb and also B E ( 2; 12 + gr → 10 + gr ) B(E2; ) for 170 Y b .
## Acknowledgements
This work has been financial supported by IIUM University Research Grant (Type B) EDW B13-034-0919 and MOHE Fundamental Research Grant Scheme FRGS13-077-0315. We thank the Islamic Development Bank (IDB) for supporting this work under scholarships Nos. 36/11201905/35/IRQ/D31and 37/IRQ/P30. The author A. A. Okhunov is grateful to Prof. Ph.N. Usmanov for useful discussion and exchange ideas.
## References
- 1. J N Mo et al. Nucl. Phys. A 472 295 (1987)
- 2. S Jonsson, N Roy, H Ryde, W Walus et al. Nucl. Phys. A 449 537 (1986)
- 3. E M Beck, J C.Bcelar, M A Deleplanque, R M Diamond et al. Nucl. Phys. A 464 472 (1987)
- 4. T Byrski et al. Nucl. Phys. A 474 193 (1987)
- 5. M P Fewell et al. Phys. Rev. C 37 101 (1988)
- 6. C Granja, S Pos´ ıˇil, s R E Chrien and S.A.Telezhnikovc Nucl. Phys. A 757 287 (2005)
- 7. I Y Lee et al. Phys. Rev. C 56 753 (1997)
- 8. K Hara and S Iwasaki Nucl. Phys. A 348 200 (1980)
- 9. K Hara and S Iwasaki Nucl. Phys. A 430 175 (1984)
- 10. K Hara and Y Sun Nucl. Phys. A 529 445 (1991)
- 11. K Hara and Y Sun Nucl. Phys. A 531 221 (1991)
- 12. K Hara and Y Sun Nucl. Phys. A 537 77 (1992)
- 13. Y Sun and J L Egido Nucl. Phys. A 580 1 (1994)
- 14. D E Archer et al. Phys. Rev. C 57 2924 (1998)
- 15. WGelletly et al. J. Phys. G: Nucle. Phys. 13 , 69 (1987)
- 16. Ph N Usmanov and I N Mikhailov Phys. Part. Nucl. Lett. 28 , 348 (1997) [ Fiz.Elem.Chastits At. Yadra 28 , 887 (1997)]
- 17. Ph N Usmanov, A A Okhunov, U S Salikhbaev and A Vdovin Phys. Part. Nucl. Lett. 7 , 185 (2010) [ Fiz.Elem.Chastits At. Yadra 159 , 306 (2010)]
- 18. S M Harris Phys. Rev. B 138 509, (1965)
- 19. A Arima and F Iachello Ann. Phys. NY 99 253 (1976)
- 20. A Arima and F Iachello Ann. Phys. NY 111 201 (1978)
- 21. A Arima and F Iachello Ann. Phys. NY 123 468 (1979)
- 22. O Scholten, F Iachello, and A Arima Ann. Phys. NY 115 325 (1978)
- 23. R F Casten and D D Warner Rev. Mod. Phys. 60 389 (1988)
- 24. R Bengtsson and S Fraundorf Nucl.Phys. A 327 139 (1979)
- 25. R B Begzhanov et al. Handbook on Nuclear Physics Vol 1.2 (Tashkent: FAN) (1989)
- 26. C M Baglin Nucl. Data. Sheets 96 611 (2002)
- 27. B Singh Nucl. Data. Sheets 75 199 (1995)
- 28. E Browne and H Junde Nucl. Data. Sheets 87 15 (1999)
- 29. M S Basunia Nucl. Data. Sheets 107 791 (2006)
- 30. http://www.nndc.bnl.gov/chart/getENSDFDatasets.jsp
List of Table captions
Table 1 The used parameters of PhM to calculate energy of low excited states in Y b isotopes.
Table 2 The used parameters of IBM -1 to calculate energy of excited states in Y b isotopes.
Table 3 The value of parameters obtained from ̂ T E ( 2) operator in program IBMT.for for calculate the absolute values of B E ( 2) in (in eb ).
Table 4 The energy levels of β 2 - band of Y b isotopes (in MeV ).
- Table 5 The energy levels of β 3 - band of Y b isotopes (in MeV ).
- Table 6 The energy levels of β 4 - band of Y b isotopes (in MeV ).
- Table 7 The energy levels of γ 2 - band of Y b isotopes (in MeV ).
- Table 8 The energy levels of 1 + - band of Y b isotopes (in MeV ).
Table 9 The values of B E ( 2)- transitions isotopes of Y b (in W.u. ).
Table 1.
| A | ( j x ) gr, 1 | ( j x ) β 1 , 1 | ( j x ) β 2 , 1 | ( j x ) β 3 , 1 | ( j x ) β 4 , 1 | ( j x ) γ 1 , 1 | ( j x ) γ 2 , 1 | Q 0 |
|-----|-----------------|-------------------|-------------------|-------------------|-------------------|-------------------|-------------------|----------|
| 170 | 0.186 | 0.394 | 0.659 | 0.908 | - | 0.728 | - | 780 (30) |
| 172 | 0.275 | 0.978 | 0.718 | 0.11 | 0.300 | 0.325 | 0.210 | 791 (18) |
| 174 | 0.185 | 0.4 | 0.25 | 0.15 | 0.200 | 0.085 | 0.100 | 782 (24) |
| 176 | 0.2 | 0.54 | 0.4 | 0.1 | - | 0.09 | - | 759 (3) |
Note: ( j x ) K ,K ′ - are matrix elements of the Coriolis interactions and Q 0 - is intrinsic quadrupole moment of the nucleus (in fm 2 units) taken from [25].
Table 2.
| A | a 1 | a 2 | CHI |
|-----|--------|---------|-------|
| 170 | 0.0094 | -0.012 | -1.3 |
| 172 | 0.0091 | -0.0112 | -1.2 |
| 174 | 0.0084 | -0.015 | -1.24 |
| 176 | 0.0089 | -0.0126 | -1.3 |
Table 3.
| A | α 2 | β 2 |
|-----|--------|--------|
| 170 | 0.106 | -0.14 |
| 172 | 0.1037 | -0.137 |
| 174 | 0.096 | -0.126 |
| 176 | 0.098 | -0.129 |
Table 4.
| | 170 Y b | 170 Y b | 172 Y b | 172 Y b | 174 Y b | 174 Y b | 176 Y b | 176 Y b |
|------|-------------|-----------|-------------|-----------|-------------|-----------|-------------|-----------|
| I | Exp.[25,26] | PhM | Exp.[25,27] | PhM | Exp.[25,28] | PhM | Exp.[25,29] | PhM |
| 0 + | 1.228 | 1.228 | 1.404 | 1.404 | 1.885 | 1.885 | 1.518 | 1.518 |
| 2 + | 1.306 | 1.313 | 1.476 | 1.483 | 1.958 | 1.962 | 1.610 | 1.601 |
| 4 + | - | 1.507 | 1.632 | 1.666 | 2.123 | 2.140 | - | 1.792 |
| 6 + | - | 1.804 | - | 1.947 | - | 2.414 | - | 2.086 |
| 8 + | - | 2.195 | - | 2.317 | - | 2.770 | - | 2.476 |
| 10 + | - | 2.669 | - | 2.769 | - | 3.221 | - | 2.954 |
| 12 + | - | 3.220 | - | 3.295 | - | 3.740 | - | 3.512 |
Table 5.
| | 170 Y b | 170 Y b | 172 Y b | 172 Y b | 174 Y b | 174 Y b | 176 Y b | 176 Y b |
|------|-------------|-----------|-------------|-----------|-------------|-----------|-------------|-----------|
| I | Exp.[25,26] | PhM | Exp.[25,27] | PhM | Exp.[25,28] | PhM | Exp.[25,29] | PhM |
| 0 + | 1.479 | 1.479 | 1.794 | 1.794 | 2.113 | 2.110 | 1.779 | 1.779 |
| 2 + | 1.534 | 1.564 | 1.849 | 1.873 | 2.172 | 2.178 | - | 1.862 |
| 4 + | 1.667 | 1.758 | 1.975 | 2.056 | 2.336 | 2.356 | - | 2.053 |
| 6 + | - | 2.055 | 2.156 | 2.156 | - | 2.630 | - | 2.347 |
| 8 + | - | 2.446 | - | 2.707 | - | 2.993 | - | 2.737 |
| 10 + | - | 2.920 | - | 3.159 | - | 3.437 | - | 3.215 |
| 12 + | - | 3.471 | - | 3.685 | - | 3.956 | - | 3.773 |
Table 6.
| | 172 Y b | 172 Y b | 174 Y b | 174 Y b |
|------|-------------|-----------|-------------|-----------|
| I | Exp.[25,27] | PhM | Exp.[25,28] | PhM |
| 0 + | 1.894 | 1.894 | 2.821 | 2.821 |
| 2 + | 1.956 | 1.973 | - | 2.898 |
| 4 + | 2.100 | 2.156 | - | 3.076 |
| 6 + | - | 2.437 | - | 3.350 |
| 8 + | - | 2.807 | - | 3.713 |
| 10 + | - | 3.259 | - | 4.157 |
| 12 + | - | 3.785 | - | 4.676 |
Table 7.
| | 172 Y b | 172 Y b | 174 Y b | 174 Y b |
|------|-------------|-----------|-------------|-----------|
| I | Exp.[25,27] | PhM | Exp.[25,28] | PhM |
| 2 + | 1.608 | 1.619 | 2.728 | 2.727 |
| 3 + | 1.700 | 1.698 | 2.793 | 2.804 |
| 4 + | 1.803 | 1.802 | 2.882 | 2.905 |
| 5 + | 1.926 | 1.931 | - | 3.031 |
| 6 + | 2.075 | 2.083 | - | 3.179 |
| 7 + | - | 2.257 | - | 3.350 |
| 8 + | - | 2.453 | - | 3.542 |
| 9 + | - | 2.669 | - | 3.754 |
| 10 + | - | 2.905 | - | 3.986 |
| 11 + | - | 3.159 | - | 4.236 |
| 12 + | - | 3.431 | - | 4.505 |
| 13 + | - | 3.720 | - | 4.791 |
| 14 + | - | 4.026 | - | 5.093 |
Table 8.
| | 170 Y b | 170 Y b | 172 Y b | 172 Y b | 174 Y b | 174 Y b | 176 Y b | 176 Y b |
|------|-------------|-----------|-------------|-----------|-------------|-----------|-------------|-----------|
| I | Exp.[25,26] | PhM | Exp.[25,27] | PhM | Exp.[25,28] | PhM | Exp.[25,29] | PhM |
| 1 + | 1.606 | 1.605 | 2.009 | 2.006 | 1.624 | 1.605 | 1.819 | 1.818 |
| 2 + | 1.832 | 1.662 | 2.047 | 2.059 | 1.674 | 1.657 | 1.867 | 1.874 |
| 3 + | - | 1.746 | 2.109 | 2.138 | 1.733 | 1.734 | - | 1.956 |
| 4 + | - | 1.856 | 2.193 | 2.242 | 1.859 | 1.835 | - | 2.065 |
| 5 + | - | 1.993 | - | 2.371 | - | 1.961 | - | 2.200 |
| 6 + | - | 2.153 | - | 2.523 | - | 2.109 | - | 2.359 |
| 7 + | - | 2.337 | - | 2.697 | - | 2.280 | - | 2.542 |
| 8 + | - | 2.544 | - | 2.893 | - | 2.472 | - | 2.749 |
| 9 + | - | 2.771 | - | 3.109 | - | 2.684 | - | 2.977 |
| 10 + | - | 3.018 | - | 3.345 | - | 2.916 | - | 3.227 |
| 11 + | - | 3.285 | - | 3.599 | - | 3.166 | - | 3.496 |
| 12 + | - | 3.569 | - | 3.871 | - | 3.435 | - | 3.785 |
| 13 + | - | 3.871 | - | 4.160 | - | 3.721 | - | 4.093 |
| 14 + | - | 4.190 | - | 4.466 | - | 4.023 | - | 4.419 |
List of figure captions
Figure 1 The comparison of calculation energy values by PhM and IBM -1 with experimental data for 170 Y b .
Figure 2 The comparison of calculation energy values by PhM and IBM -1 with experimental data for 172 Y b .
Figure 3 The comparison of calculation energy values by PhM and IBM -1 with experimental data for 174 Y b .
Figure 4 The comparison of calculation energy values by PhM and IBM -1 with experimental data for 176 Y b .
Table 9.
| | 170 Y b | 170 Y b | 170 Y b | 172 Y b | 172 Y b | 172 Y b |
|-------------------|-----------|-----------|-----------|--------------|-----------|-----------|
| I i K i → I f K f | Exp.[30] | PhM | IBM - 1 | Exp.[30] | PhM | IBM - 1 |
| 2 + gr → 0 + gr | 201(6) | 216 | 198.543 | 212(2) | 212 | 211.689 |
| 4 + gr → 2 + gr | - | 309 | 280.768 | 301(20) | 303 | 299.697 |
| 6 + gr → 4 + gr | - | 340 | 303.549 | 320(30) | 334 | 324.746 |
| 8 + gr → 6 + gr | 360(30) | 356 | 309.178 | 400(40) | 350 | 331.835 |
| 10 + gr → 8 + gr | 356(25) | 366 | 306.15 | 375(23) | 359 | 329.971 |
| 12 + gr → 10 + gr | 268(21) | 372 | 296.956 | 430(60) | 366 | 322.160 |
| 14 + gr → 12 + gr | - | 377 | 283.181 | 394 +60 - 45 | 370 | 309.724 |
| 16 + gr → 14 + gr | - | 381 | 265.349 | - | 374 | 293.311 |
| 18 + gr → 16 + gr | - | 383 | 243.819 | - | 376 | 273.310 |
| 20 + gr 18 + gr | - | 386 | 218.751 | - | 379 | 249.967 |
Y b
→
174
176
| I i K i → I f K f | Exp.[30] | PhM | IBM - 1 | Exp.[30] | PhM | IBM - 1 |
|---------------------|------------|-------|-----------|------------|-------|-----------|
| 2 + gr → 0 + gr | 201(7) | 205 | 199.908 | 183(7) | 184 | 182.916 |
| 4 + gr → 2 + gr | 280(9) | 294 | 283.321 | 270(25) | 263 | 258.969 |
| 6 + gr → 4 + gr | 370(50) | 324 | 307.532 | 298(22) | 290 | 280.618 |
| 8 + gr → 6 + gr | 388(21) | 339 | 315.122 | 300(5) | 303 | 286.743 |
| 10 + gr → 8 + gr | 335(22) | 348 | 314.533 | - | 312 | 285.139 |
| 12 + gr → 10 + gr | 369(23) | 354 | 308.624 | - | 317 | 278.384 |
| 14 + gr → 12 + gr | 320(8) | 359 | 298.941 | - | 321 | 267.636 |
| 16 + gr → 14 + gr | - | 362 | 285.192 | - | 324 | 253.459 |
| 18 + gr → 16 + gr | - | 365 | 268.659 | - | 327 | 236.177 |
| 20 + gr 18 + gr | - | 367 | 249.249 | - | 328 | 215.995 |
Y b
→
/s32
/s32
/s32
Fig. 1.
/s32
/s32
/s32
/s32
/s52
/s32
Fig. 2.
/s32
/s54
/s32
Fig. 3.
/s32
/s32
/s32
/s32
/s54
/s32
Fig. 4.
/s32 | null | [
"Abdurahim Okhunov",
"Fadhil I. Sharrad",
"Anwer A. Al-Sammarea"
] | 2014-08-01T04:00:19+00:00 | 2014-08-01T04:00:19+00:00 | [
"nucl-th"
] | A Correspondence between Phenomenological and IBM-1 Models of Even Isotopes of Yb | This paper studies the nonterminal complexity of weakly conditional grammars,
and it proves that every recursively enumerable language can be generated by a
weak conditional grammar with no more than \textit{seven} nonterminals.
Moreover, it is shown that the number of nonterminals in weakly conditional
grammars without erasing rules leads to an infinite hierarchy of families of
languages generated by weakly conditional grammars.
Energy levels and the reduced probability of $E2$-- transitions for Ytterbium
isotopes with proton number $Z=70$ and neutron numbers between 100 and 106 have
been calculated through phenomenological ($PhM$) and interacting boson
($IBM-1$) models. The predicted low-lying levels (energies, spins and parities)
and the reduced probability for $E2$-- transitions results are reasonably
consistent with the available experimental data. The predicted low-lying levels
($gr$--, $\beta_1$-- and $\gamma_1$-- band) by produced in the $PhM$ are in
good agreement with the experimental data comparison with those by $IBM-1$ for
all nuclei of interest. In addition, the phenomenological model was successful
in predicted the $\beta_2$--, $\beta_3$--, $\beta_4$--, $\gamma_2$-- and
$1^+$-- band while it was a failure with $IBM-1$. Also, the $3^+$-- band is
predicted by the $IBM-1$ model for $^{172}Yb$ and $^{174}Yb$ nuclei. All
calculations are compared with the available experimental data. |
1408.0073v1 | ## First Lunar Occultation Results from the 2.4 m Thai National Telescope equipped with ULTRASPEC
A. Richichi , P. Irawati , B. Soonthornthum , V.S. Dhillon , T.R. Marsh 1 1 1 2 3 [email protected]
## ABSTRACT
The recently inaugurated 2.4 m Thai National Telescope (TNT) is equipped, among other instruments, with the ULTRASPEC low-noise, frame-transfer EMCCD camera. At the end of its first official observing season, we report on the use of this facility to record high time resolution imaging using small detector subarrays with sampling as fast as several 10 2 Hz. In particular, we have recorded lunar occultations of several stars which represent the first contribution to this area of research made from South-East Asia with a telescope of this class. Among the results, we discuss an accurate measurement of α Cnc, which has been reported previously as a suspected close binary. Attempts to resolve this star by several authors have so far met with a lack of unambiguous confirmation. With our observation we are able to place stringent limits on the projected angular separation ( < . 0 ′′ 003) and brightness ( ∆ m > 5) of a putative companion. We also present a measurement of the binary HR 7072, which extends considerably the time coverage available for its yet undetermined orbit. We discuss our precise determination of the flux ratio and projected separation in the context of other available data. We conclude by providing an estimate of the performance of ULTRASPEC at TNT for lunar occultation work. This facility can help to extend the lunar occultation technique in a geographical area where no comparable resources were available until now.
Subject headings: techniques: high angular resolution - occultations - binaries: general - stars: individual: α Cnc stars: individual: HR 7072
## 1. Introduction
Lunar occultations (LO) are a method to obtain high angular resolution by means of the analysis of the diffraction pattern generated when a background source is occulted by the lunar limb. One major advantage of LO is the fact that the angular resolution achieved is mainly dependent on relations between the wavelength and the distance to the Moon, rather than the aperture of the telescope as in standard imaging. Thus, the measurement of angular sizes well beyond the diffraction limit of even the largest telescopes on the ground or in space becomes possible. Significant limitations of the method are that the sources cannot be chosen at will, that the events are time-critical, and that opportunities to repeat the observations are rare. In order to detect and measure the diffraction fringes, it is necessary to sample the light curves with time resolutions of order 1 ms.
1 National Astronomical Research Institute of Thailand, 191 Siriphanich Bldg., Huay Kaew Rd., Suthep, Muang, Chiang Mai 50200, Thailand
2 Department of Physics and Astronomy, University of Sheffield, Sheffield S3 7RH, UK
3 Department of Physics, University of Warwick, Gibbet Hill Road, Coventry CV4 7AL, UK
At least three major goals can be achieved by LO: the measurement of stellar angular diameters, the detection and characterization of circumstellar envelopes and extended emissions, and finally the study of smallseparation binary stars. For decades, LO have made contributions in the first two areas above, but currently long-baseline interferometry, more time consuming but more complete in its results, is often used (see CHARM2 catalog, Richichi et al. 2005). Concerning binary stars, however, LO maintain an edge in that they are quick to observe, easy to analyze, and offer a combination of sensitivity and dynamic range which remains unsurpassed. In the course of a
long program of occultations with the ISAAC instrument at the ESO VLT, Richichi et al. (2014, and references therein) have recorded over a thousand occultation events with an ≈ 8% detection rate of mostly new binary or multiple systems, the majority of which are out of reach of other techniques. The ISAAC instrument has now been decommissioned, and only few observatories around the world remain suitably equipped to observe LO.
In this paper we first introduce the Thai National Telescope (TNT), in conjunction with the ULTRASPEC fast camera, as a new facility capable of recording high quality LO light curves in a geographical area where this technique was so far precluded. We then present the first LO results obtained at the TNT, and discuss in detail two of them: α Cnc, a claimed binary star for which we can put stringent upper limits on the separation and flux of the putative companion; and HR 7072, a known binary star for which the numerous measurements available until now seem to be not always in agreement and for which we provide a new accurate flux and separation determination.
## 2. A New Facility for High-Time Resolution Astronomy
The Thai National Observatory, which includes also the flagship 2.4 m Thai National Telescope (TNT), is located on one of the highest ridges of Doi Inthanon, the tallest peak in Thailand. At 2457m elevation, the site has observing conditions which compare favorably with those of most other locations in the region in terms of seeing and photometric conditions. It has a dry season which runs approximately from November to April, while the rest of the year is largely lost to observations due to high humidity and rainy conditions. The TNT was erected in 2012 and inaugurated in January 2013. It is a Ritchey-Chrètien with two Nasmyth foci, one of them being equipped with a multiinstrument port which mounts permanently also the ULTRASPECinstrument. Although a similarly named instrument based on the same detector has been used before, e.g. at the ESO New Technology Telescope in Chile (Dhillon et al. 2008; Ives et al. 2008), the one described here is novel in several aspects: in particular the optics have been specifically developed for TNT, and specific data acquisition modes have been developed. ULTRASPEC at the TNT had its first light in November 2013 and is described in detail elsewhere (Dhillon et al. 2014). Here, we summarize only its
## capabilities for LO work.
In order to increase the time sampling, ULTRASPEC offers the possibility to read out only parts of the detector. One of its features is the 2k × 1k EMCCD chip, half of which is used for imaging and half for fast frame transfer. One or several subarray windows can be defined and read out simultaneously, and this is optimal to reach rates up to about 10 Hz. For LO measurements, however, faster rates are needed. For this, the so-called drift-mode of the related instrument ULTRACAM Dhillon et al. (2007) has been specifically adapted. In summary, two small windows can be selected along the same detector rows. Although their position is freely selectable, the most efficient configuration is to place them close to the lower edge of the detector. A mask is then remotely positioned to cover the rest of the detector area. As the selected windows are pushed to the frame transfer area, the rows immediately above are shifted down and are ready for the next integration. Other features that we do not describe in detail here are the possibility of on-chip rebinning and three levels of detector read-out speed. We have successfully tested the drift mode up to rates of 450 Hz. Thanks to a large memory and to fast fiber links between the instrument electronics, the control computer and the data reduction machine, it is possible to obtain uninterrupted data sequences of any desired duration and to examine the data almost in real time. Finally, we mention that a dedicated GPS is used to stamp each frame with its mid-exposure time.
## 3. Observations and Data Analysis
The first LO observations recorded from TNT with ULTRASPEC are listed in Table 1, in chronological order. D and R refer to disappearances and reappearances, respectively. The magnitudes and spectra are quoted from Simbad. Concerning the filters, we adopted mainly narrow-band ones in the attempt to reduce the lunar background. The latter is strongly wavelength dependent, and also diffraction is inherently chromatic. Thus, the red part of the spectrum is usually better suited for LO observations. In the table, H α N and H α B differ slightly in central wavelength (6564 and 6554 Å, respectively), and in FWHM (54 and 94 Å, respectively). We also employed a standard SDSS z ′ filter. The columns Sub and Bin list, respectively, the size of the detector subarray adopted in the drift-mode and the on-chip rebinning - so that Sub 32x32 and Bin 2x2 would effectively result in a 16x16
TABLE 1 SUMMARY OF OBSERVED EVENTS
| Date | Time | Type | Source | V | Sp | Filter | Sub | Bin | τ ∆ T | τ ∆ T | S/N | Notes |
|-----------|--------|--------|-----------|-------|-----------|----------|----------|----------|---------|---------|-------|------------|
| (UT) | | | | (mag) | | | (pixels) | (pixels) | (ms) | (ms) | | |
| 11-Jan-14 | 17:12 | D | SAO 93721 | 5.9 | F4V | z ′ | 16x16 | 2x2 | 6.6 | 6.8 | 34 | Unresolved |
| 11-Feb-14 | 16:10 | D | SAO 96543 | 7.5 | F5V | H α B | 16x16 | no | 11.8 | 12.1 | 10 | Unresolved |
| 12-Mar-14 | 18:26 | D | SAO 97913 | 6.3 | K0III | H α B | 16x16 | 2x2 | 6.6 | 6.8 | 45 | Unresolved |
| 09-Apr-14 | 13:20 | D | α Cnc | 4.3 | A5m | H α N | 16x16 | 2x2 | 6.6 | 6.8 | 104 | Not Binary |
| 20-Apr-14 | 21:44 | R | HR 7072 | 6.5 | A1V+K1III | H α B | 32x32 | 2x2 | 12.3 | 12.8 | 18 | Binary |
output. The frame integration time and the sampling time between frames are denoted by τ and ∆ T in the table. This latter is the average value across all frames. In reality, there are small variations (always < 1%) in the time differences between subsequent frames. In our data analysis, the actual individual time stamps are used. S/N is the signal-to-noise ratio, measured as the unocculted stellar signal divided by the rms of the fit residuals.
The raw binary output from ULTRASPEC is then converted to FITS cubes, with the first two dimensions set by the combination of Sub and Bin, and thousands of frames long. From this point, our data analysis procedure follows closely the methods already described in our previous papers, see e.g. Richichi et al. (2014) and references therein. In summary, we adopt a mask extraction that allows us to reject unnecessary signal (and related noise) from the background, and end up with fast photometry sequences which are further restricted to very few seconds around the events.
and 1.5 mas for SAO 93721 and SAO 97913, respectively. These are consistent with the values expected from their spectral types and distances. The S/N of the SAO 96543 light curve was insufficient for an upper limit determination. There were no previous literature reports on possible binarity for two of these sources, while SAO 93721 is listed in the Washington Double Star Catalog. It has a faint, distant companion at about 170 ′′ which is not included in our observation, and is also listed as a spectroscopic binary which we could not resolve. In the following, we concentrate on the remaining two stars in our list.
We use a model-independent maximum-likelihood (CAL, Richichi 1989) method to estimate the brightness profile of the source, for example to detect possible multiple components in the light curve. A modeldependent least-squares method, whose convergence in χ 2 is driven by noise components derived from the unocculted and totally occulted portions of the light curve, is used to derive precise values and errors of parameters such as intensities and separation in a binary model (Richichi et al. 1996). This reference also describes additional features used in our fits such as the modelling of low-frequency scintillation.
## 4. Results
The first three sources in Table 1 were found to be point-like, with upper limits on the angular size of 2.4
Although these first measurements are few, Table 1 can be used for some initial estimate of the performance of LO with ULTRASPEC at the TNT. Using S/N=1 as a detection limit, the sensitivity achieved in the 5 light curves ranged from 9.3 to 10.4 mag, with a dynamic range that in the best case was 5 mag. The ability to resolve close companions was tested by means of simulations on the data of SAO 93721 and α Cnc. We conclude that hypothetical companions with 1:1 flux ratio could have been detected as close as 2 mas.
## 4.1. Alpha Cancri
We obtained a good quality (S/N=104) light curve of the bright star α Cnc (HR 3572, Acubens), shown in Fig. 1, along the position angle (PA) 77 ◦ . The diffraction fringe pattern is well resolved thanks to the use of a narrow band filter and also to a contact angle of 40 ◦ that contributed to slow down the apparent fringe motion. We could thus accurately measure the local limb slope, found to be close to 0 ◦ , obtaining in turn a reliable conversion from time to angular scale. The star is known to have a companion forming the ADS 7115 pair; this is however about 10 ′′ away and several magnitudes fainter, and we do not concern ourselves with
it here.
More interestingly, α Cnc has been claimed as a close double, mainly from previous LO observations but also from the analysis of Hipparcos data. These are listed in the Fourth Catalog of Interferometric Measurements of Binary Stars (by Hartkopf, Mason and Wycoff, available online ; INT4 hereafter). 1 The two claims from previous occultations come from observations by amateur astronomers with small telescopes, and are not well documented. They claim a binary with equal components separated by 50 mas in one case (with no PA listed), or 4.2 mas along PA=113 ◦ in the other. We note that the ability to measure such a small separation by LO usually demands a rigorous treatment of high quality data. The Bright Star Catalogue mentions in a note that α Cnc is a LO binary with 0 . ′′ 1 separation, but without a reference. Several speckle measurements with the SOAR 4.1 m telescope (Tokovinin et al. 2010; Hartkopf et al. 2012) have not detected the companion, with upper limits ≤ 0 . ′′ 15 on the angular separation and 4 to 6 mag on the flux difference. In fact, for ∆ m ≤ 1mag the separation limit is 25mas (Tokovinin, priv. comm.).
Our data appear to be the first LO light curve recorded of this bright star with professional equipment at a medium-sized telescope. We can reliably exclude two components of similar brightness, to projected separations as small as 3 mas (see Fig. 1). In fact, an analysis by a method developed for unresolved sources (see Richichi et al. 1996, 2012) results in a limit of 1.35 mas on the angular size of the star. This is consistent with a stellar dimension roughly comparable to solar and a distance of 53 pc as derived by Hipparcos. For a simple comparison, we assume that the 50 mas binary separation previously claimed was at a random position angle, and we consider an average projection factor 2 /π . The resulting estimated 79 mas true separation, against our upper limit of 3 mas, would indicate a likelihood of 1 -(acos(3 / 79) / 90 ) ◦ ≈ 2%that our lack of detection was due to projection effects. We note that the previously claimed binary separation would imply a period of very few years, and therefore any link between the geometry during our measurement in 2014 and the previous ones (as much as 30 years earlier) would not be preserved. The S/N of our light curve can also be used to assess an upper limit in flux on the presence of a companion with a more
1 http://www.usno.navy.mil/USNO/astrometry/optical-IRprod/wds/int4
significant separation, of about 5 mag in the red part of the spectrum. We mention also two light curves α Cnc, the disappearance and reappearance of the same event, observed with a 30-inch telescope in a 5214 Å interference filter by Africano et al. (1978). The authors also found no evidence of binarity, but given the small telescope size scintillation was significant and the constraint on a putative companion was weaker than that from our data.
The other indication of binarity in α Cnc comes from Hipparcos, which detected an acceleration in the proper motion, interpreted as due to a companion. However no orbital solution could be derived and the nature of the companion (separation and mass, hence brightness) remains undetermined, and likely unrelated to the putative companion claimed by previous LO reports. Frankowski et al. (2007), after examining several radial velocities catalogs, found no evidence of α Cnc being a spectroscopic binary.
## 4.2. HR7072
Our reappearance light curve of HR 7072 (Kui 88AB, HIP 92301) is shown in Fig. 2 and it clearly reveals a companion. We find a flux ratio of 3.38 ± 0.01, and a projected separation of 90.7 ± 0.2mas along PA=238 . ◦ In order to successfully record the reappearance event, we opted for a larger subarray which resulted in a relatively slow sampling. Thus, we are not able to determine independently the speed of the fringe pattern, and in turn we have an uncertainty on the the local limb slope and correspondingly on the PA and projected separation. However, an analysis of the lunar limb at the given point of contact and libration angles was made using the altimetry data from the Kaguya probe (Herald, priv. comm.), and no significant local limb slope was found.
HR 7072 is a known sub-arcsecond binary, with over 30 previous astrometric and LO determinations, starting from the initial discovery by Wilson (1950) and extending over 54 years. A list can be found in INT4, and additionally we mention Muller (1958). Our result extends the time coverage to almost 65 years. An orbital solution has not yet been established, and in fact the interpretation of the available data is not straightforward.
The left panel of Fig. 3 shows the RA, Dec position of the companion. For the LO results, which only provide a projected separation, we have plotted the lines that represent the loci of equivalent position. At a
Fig. 3.Left: astrometric (circles) and LO (lines) determinations of the position of the companion of HR 7072 with respect to the primary (cross). The LO are a) Africano et al. (1978), b) Edwards et al. (1980), c) our measurement. Right: the same data, converted to PA (top) and separation (bottom) and plotted as a function of time. In this plot, the crossed symbols represent estimated LO positions, extrapolated from the lines in the left panel. The open symbols in both plots are discussed in the text. Errors are mostly not available. A color version of this figure is available online.
Fig. 1.- Top panel: occultation data (dots) for α Cnc, and best fit by a point-like source (solid line). The fit residuals are shown in the lower panel, enlarged for clarity. The curves labelled a) and b) are models for a binary star with equal components and projected separations of 3 and 10 mas, respectively. They are shown, shifted by arbitrary vertical offsets for clarity, to prove the inconsistency of the data with such scenarios. A color version of this figure is available online.
Fig. 2.- The light curve data for HR 7072 (dots) and the best fit by a binary star model (solid line). The fit residuals are shown in the lower panel.
first glance, it can be noticed that the positions tend to cluster around the [+150, -400]mas region, with the notable exception of the points on the negative RA half-plane which are all prior to 1960. These were visual determinations, while later measurements were obtained by speckle interferometry, The right panel of Fig. 3 puts the measurements, expressed now as PA and separation, along a time sequence. It can be seen that both quantities follow an almost linear evolution with time, however with the noticeable exception of two points. These are marked as outlined, rather than solid, symbols, on both panels of Fig. 3. The first one is the discovery measurement by Wilson (1950), the second one is the latest measurement, prior to ours, obtained by Mason et al. (2004). The former was obtained by visual interferometry, the latter by speckle, but both at relatively smaller telescopes than the majority of the other determinations. We remark that most of the literature values do not have an associated error, so that it is difficult to verify quantitatively possible discrepancies.
In the right panel of Fig. 3 we have made an attempt to estimate PA and separation for the two previous LO measurements and our own, based also on a visual fit to the rest of the points in the left panel. It can be seen that in this view the apparent discrepancy of the Wilson (1950) measurement could in fact be reconciled given a reasonable error, as expected from the method. The Mason et al. (2004) measurement is critical, in that taken at face value it points to a significant turn in the orbit. Accordingly, we provide two PA-sep equivalents for our LO result: one fits a linear trend in time of PA and separation, consistent with a very long orbital period. The other follows the indication of the Mason et al. (2004) measurement, and reinforces the view of a closed orbit which would then seem to have a period of few 10 2 y.
Concerning the flux ratio, the available data span the range from 400 to 800 nm, and are quite consistent in their trend indicating that significant variability of either component can probably be excluded, see Fig. 4. Our own determination is in close agreement with this trend. The conclusion is that one of the two stars is significantly bluer than the other. Andersen et al. (1985) measured the radial velocity of this system on two dates only, separated by just one year. They did not detect any variations. They quote the spectrum as composed of A1 and K0. Houk & Smith-Moore (1988) reported A1V and K1III. This, together with the integrated color of V -K = 2 8 mag, points to the fact .
that the two stars have similar brightness in the blue, but that at longer wavelengths the K0 component is the primary. This is consistent with Jaschek et al. (1991), who found a 12 µ m excess for this star and mentioned binarity as a possible explanation.
## 5. Conclusions
We reported the first LO observations from the Thai National Telescope equipped with the ULTRASPEC instrument. Using the specifically developed drift-mode, time sampling of few milliseconds can be achieved. In the first observing season of this new facility, we have recorded 5 LO light curves and we have discussed in detail two of them.
In the case of α Cnc a duplicity has been previously claimed, although not convincingly demonstrated. We do not detect the companion, with an upper limit of 3mas in projected separation and 5 mag in flux ratio. In the case of HR 7072, our measurement goes to complement a set of over 30 previous determinations, extending the time coverage from 54 to 65 years. We show that the data are still ambiguous, pointing to the detection of an orbital arch and a few 10 2 y period, or alternatively to a much wider and longer orbit. Observations by adaptive optics would quickly confirm one of the two scenarios. The flux ratios are consistent with an early A and an early K spectral types, with similar brightness in the blue but with the K type component dominating at longer wavelengths.
The TNT with ULTRASPEC in drift mode has successfully demonstrated high performance LO results, with a sensitivity estimated at I ≈ 10mag at S/N=1, an angular resolution close to 1 mas, and a dynamic range of at least 5 mag. This facility is especially attractive in consideration of the fact the LO events are observable only along restricted ground tracks, and that no comparable capabilities existed until now in South-East Asia.
VSD and TRM acknowledge the support of the Royal Society and the Leverhulme Trust for the operation of ULTRASPEC at the TNT. We are grateful to Dr. A. Tokovinin for useful discussions. The estimation of the lunar limb slope for the occultation of HR 7072 was provided by Dr. D. Herald. This research made use of the Simbad database, operated at the CDS, Strasbourg, France.
## REFERENCES
| Africano, J. L., Evans, D. S., Fekel, F. C., Smith, B. W., Morgan, C. A. 1978, AJ, 83, 1100 |
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Andersen, J., Nordstrom, B., Ardeberg, A., et al. 1985, A&ASS, 59, 15 |
| Dhillon, V. S., Marsh, T. R., Stevenson, M. J., et al. 2007, MNRAS, 378, 825 |
| Dhillon, V. S., Marsh, T. R., Copperwheat, C., et al. 2008, High Time Resolution Astrophysics: The Universe at Sub-Second Timescales, 984, 132 |
| Dhillon et al, 2014, About to be submitted, more de- tails before proofs. |
| Edwards, D. A., Evans, D. S., Fekel, F. C., Smith, B. W. 1980, AJ, 85, 478 |
| Frankowski, A., Jancart, S., Jorissen, A. 2007, A&A, 464, 377 |
| Hartkopf, W. I., Tokovinin, A., Mason, B. D. 2012, AJ, 143, 42 |
| Houk, N., & Smith-Moore, M. 1988, Michigan Cat- alogue of Two-dimensional Spectral Types for the HD Stars. Volume 4, Declinations -26 ◦ .0 to -12 ◦ .0, University of Michigan, Ann Arbor, MI 48109- 1090, USA |
| Ives, D., Bezawada, N., Dhillon, V., Marsh, T. 2008, SPIE Conference Series, 7021, 10 |
| Jaschek, C., Jaschek, M., Egret, D., Andrillat, Y. 1991, A&A, 252, 229 |
| Mason, B. D., Hartkopf, W. I., Wycoff, G. L., et al. 2004, AJ, 128, 3012 |
| Muller, P. 1958, Journal des Observateurs, 41, 109 |
| Richichi, A., Baffa, C., Calamai, G., Lisi, F. 1996, |
| AJ, 112, 2786 |
| Richichi, A., Percheron, I., &Khristoforova, M. 2005, A&A, 431, 773 |
| Richichi, A., Cusano, F., Fors, O., Moerchen, M. 2012, ApJSS, 203, 33 |
| Richichi, A., Fors, O., Cusano, F., Ivanov, V. D. 2014, AJ, 147, 57 |
Tokovinin, A., Mason, B. D., Hartkopf, W. I. 2010, AJ, 139, 743
Wilson, R. H., Jr. 1950, AJ 55, 153
This 2-column preprint was prepared with the AAS L A T E X macros v5.2.
Fig. 4.- The flux ratio of the two components of HR 7072, as a function of wavelength. Solid dots are previous results, the outlined circle is our measurement. Some errorbars are too small to be seen clearly on this scale.
 | 10.1088/0004-6256/148/5/100 | [
"A. Richichi",
"P. Irawati",
"B. Soonthornthum",
"V. S. Dhillon",
"T. R. Marsh"
] | 2014-08-01T04:01:08+00:00 | 2014-08-01T04:01:08+00:00 | [
"astro-ph.SR"
] | First Lunar Occultation Results from the 2.4 m Thai National Telescope equipped with ULTRASPEC | The recently inaugurated 2.4\,m Thai National Telescope (TNT) is equipped,
among other instruments, with the ULTRASPEC low-noise, frame-transfer EMCCD
camera. At the end of its first official observing season, we report on the use
of this facility to record high time resolution imaging using small detector
subarrays with sampling as fast as several $10^2$\,Hz. In particular, we have
recorded lunar occultations of several stars which represent the first
contribution to this area of research made from South-East Asia with a
telescope of this class. Among the results, we discuss an accurate measurement
of $\alpha $~Cnc, which has been reported previously as a suspected close
binary. Attempts to resolve this star by several authors have so far met with a
lack of unambiguous confirmation. With our observation we are able to place
stringent limits on the projected angular separation ($<0\farcs003$) and
brightness ($\Delta{\rm m} > 5$) of a putative companion. We also present a
measurement of the binary {HR~7072}, which extends considerably the time
coverage available for its yet undetermined orbit. We discuss our precise
determination of the flux ratio and projected separation in the context of
other available data. We conclude by providing an estimate of the performance
of ULTRASPEC at TNT for lunar occultation work. This facility can help to
extend the lunar occultation technique in a geographical area where no
comparable resources were available until now. |
1408.0074v1 | ## Software for Computing the Spheroidal Wave Functions Using Arbitrary Precision Arithmetic
Ross Adelman, Nail A. Gumerov, and Ramani Duraiswami
## Abstract
The spheroidal wave functions, which are the solutions to the Helmholtz equation in spheroidal coordinates, are notoriously difficult to compute. Because of this, practically no programming language comes equipped with the means to compute them. This makes problems that require their use hard to tackle. We have developed computational software for calculating these special functions. Our software is called spheroidal and includes several novel features, such as: using arbitrary precision arithmetic; adaptively choosing the number of expansion coefficients to compute and use; and using the Wronskian to choose from several different methods for computing the spheroidal radial functions to improve their accuracy. There are two types of spheroidal wave functions: the prolate kind when prolate spheroidal coordinates are used; and the oblate kind when oblate spheroidal coordinate are used. In this paper, we describe both, methods for computing them, and our software. We have made our software freely available on our webpage.
## 1 Introduction
Elementary functions, such as powers, sines, and exponentials, are solutions to differential equations arising in various math, science, and engineering problems. Other elementary functions, such as roots, arcsines, and logarithms, are inverses of these. They are called elementary because the differential equations from which they are derived are usually linear, homogenous, and have constant coefficients. This makes them easy to solve and the expressions for their solutions easy to compute. In many problems, however, the differential equations encountered are not so easy to solve, and their solutions can be extremely complicated. The functions arising from these are called special functions. Examples of such functions are the associated Legendre polynomials and the spherical Bessel functions.
In this paper, we explore the spheroidal wave functions. These special functions are the solutions to the differential equations obtained by applying the method of separation of variables to the Helmholtz equation in spheroidal coordinates. There are two cases: the prolate spheroidal wave functions when prolate spheroidal coordinates are used; and the oblate spheroidal wave functions when oblate spheroidal coordinates are used. Unfortunately, there are no simple expressions for computing them. Instead, they must be written as infinite series expansions in terms of various other special functions. For example, the spheroidal
angle functions can be written in terms of the associated Legendre polynomials, and the spheroidal radial functions can be written in terms of the spherical Bessel and Neumann functions. Depending on the method used, there are three or four different sets of expansion coefficients that need to be computed.
The spheroidal wave functions have applications in many disciplines. Our primary motivation for studying them was for computing the solutions to acoustic scattering problems involving prolate spheroids, oblate spheroids, and disks [1]. However, they are also encountered in signal processing [2].
We have developed computational software for calculating the spheroidal wave functions using C++ and MATLAB. Our software is called spheroidal and includes the following features. First, the software uses GNU MPFR, a library for performing arbitrary precision arithmetic [3]. Using arbitrary precision arithmetic provides greater accuracy in many of the computations, especially for higher wavenumbers and modes. Second, the software allows the user to specify the level of precision to use at every computational step. For example, different levels of precision can be used for computing the different sets of expansion coefficients that need to be computed. Third, the software allows the user to specify in two different ways how many expansion coefficients to compute and use. In the first way, the user specifies the number of expansion coefficients exactly (e.g., compute 200 of this type and 300 of that type). In the second way, the user allows the software to choose the number of expansion coefficients adaptively. All of the expansion coefficients decay exponentially in the long run, so in this method, the user specifies the minimum magnitude that the expansion coefficients should reach (e.g., keep computing expansion coefficients until the next one drops below 10 -200 ). Fourth, the expansion coefficients, as well as other special values, are saved to disk. This way, they can be reused later on without having to recompute them from scratch. Fifth, there are several methods for computing the spheroidal radial functions. The actual value of the Wronskian of these functions is easy to compute, so the combination of methods for computing the spheroidal radial functions is chosen so that the computed Wronskian has the smallest error. We have made our software freely available for download on our webpage.
The spheroidal wave functions have been studied for over six decades. Perhaps the most complete description of the spheroidal wave functions is given by Flammer [4]. As pointed out by [5], some of the expressions in [4] are incorrect. Nevertheless, Flammer's book is an invaluable resource. Actually implementing the spheroidal wave functions in code is very involved. In [6], they were implemented in Fortran, and in [7, 8], they were implemented in C. These implementations used double precision. Due to round-off errors, double precision can lead to large errors, especially for higher frequencies and modes. In [9, 10], they were implemented in Fortran using quad precision and expressions that converge faster and more accurately in some cases to obtain better accuracy over a wide range of frequencies, modes, and argument values. These implementations, as well as our own, are only for real frequnecies and integer modes. Other authors have investigated complex frequnecies and non-integer modes [11, 12], and in these particular references, the respective authors used Mathematica, which can work in arbitrary precision. Some have also looked at numerical techniques, such as finite difference approximations and relaxation methods [13, 14]. Many of these authors have released their code free to use.
Figure 1. The prolate (left) and oblate (right) spheroidal coordinate systems. The three colored surfaces are isosurfaces for η = ± 1 / 2 (red), ξ = 3 2 for the prolate case and / ξ = 1 2 / for the oblate case (green), and φ = 0 (blue).
## 2 Spheroidal Coordinates
The prolate spheroidal coordinate system, shown in Figure 1, is related to the Cartesian coordinate system by [4]
$$x = a \left ( 1 - \eta ^ { 2 } \right ) ^ { 1 / 2 } \left ( \xi ^ { 2 } - 1 \right ) ^ { 1 / 2 } \cos \left ( \phi \right ), \quad y = a \left ( 1 - \eta ^ { 2 } \right ) ^ { 1 / 2 } \left ( \xi ^ { 2 } - 1 \right ) ^ { 1 / 2 } \sin \left ( \phi \right ), \quad z = a \eta \xi, \ \ ( 1 )$$
where 2 a is the interfocal distance. The Helmholtz equation, ∇ 2 V + k V 2 = 0, where k is the wavenumber, can be written in prolate spheroidal coordinates as
$$\left ( \frac { \partial } { \partial \eta } \left ( 1 - \eta ^ { 2 } \right ) \frac { \partial } { \partial \eta } + \frac { \partial } { \partial \xi } \left ( \xi ^ { 2 } - 1 \right ) \frac { \partial } { \partial \xi } + \frac { \xi ^ { 2 } - \eta ^ { 2 } } { \left ( 1 - \eta ^ { 2 } \right ) \left ( \xi ^ { 2 } - 1 \right ) } \frac { \partial ^ { 2 } } { \partial \phi ^ { 2 } } + c ^ { 2 } \left ( \xi ^ { 2 } - \eta ^ { 2 } \right ) \right ) V = 0, \quad ( 2 )$$
where c = ka . Applying the method of separation of variables yields three uncoupled ordinary differential equations, one for each coordinate:
$$\frac { \partial } { \partial \eta } \left ( \left ( 1 - \eta ^ { 2 } \right ) \frac { \partial } { \partial \eta } S _ { m n } \left ( c, \eta \right ) \right ) + \left ( \lambda _ { m n } - c ^ { 2 } \eta ^ { 2 } - \frac { m ^ { 2 } } { 1 - \eta ^ { 2 } } \right ) S _ { m n } \left ( c, \eta \right ) = 0,$$
$$\frac { \partial } { \partial \xi } \left ( \left ( \xi ^ { 2 } - 1 \right ) \frac { \partial } { \partial \xi } R _ { m n } \left ( c, \xi \right ) \right ) - \left ( \lambda _ { m n } - c ^ { 2 } \xi ^ { 2 } + \frac { m ^ { 2 } } { \xi ^ { 2 } - 1 } \right ) R _ { m n } \left ( c, \xi \right ) = 0,$$
$$\frac { \partial ^ { 2 } } { \partial \phi ^ { 2 } } \Phi _ { m } \left ( \phi \right ) + m ^ { 2 } \Phi _ { m } \left ( \phi \right ) = 0,$$
where m = 0 1 , , . . . and n = m,m +1 , . . . . While Eq. (5) is easily solved, Eqs. (3) and (4) are much more complicated. The solutions to Eq. (3) are called the prolate spheroidal angle functions, and the solutions to Eq. (4) are called the prolate spheroidal radial functions. Collectively, they are called the prolate spheroidal wave functions. Any solution to Eq. (2) can be written as
$$V = \sum _ { m = 0 } ^ { \infty } \sum _ { n = m } ^ { \infty } S _ { m n } \left ( c, \eta \right ) \left ( A _ { m n } R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) + B _ { m n } R _ { m n } ^ { \left ( 3 \right ) } \left ( c, \xi \right ) \right ) \cos \left ( m \phi \right ),$$
Figure 2. Characteristic and other special values for the prolate spheroidal wave functions for c = 10, m = 0 1 , , . . . , 29, and n = m,m +1 , . . . , m +29.
where the expansion coefficients, A mn and B mn , depend on the problem being solved.
The expressions arising in the oblate case are very similar to (and sometimes exactly the same as) those arising in the prolate case. In many cases, simply letting c, ξ →-ic, iξ provides a transformation from the prolate case to the oblate case [4]. Indeed, the preceeding paragraphs and equations for the prolate case can be transformed into those for the oblate case by using this transformation. The oblate spheroidal coordinate system is shown in Figure 1.
Figure 3. The prolate spheroidal wave functions and their derivatives for c = 10, m = 10, and n = 10 11 , , . . . , 39.
## 3 Spheroidal Wave Functions
## 3.1 Prolate Spheroidal Wave Functions
## 3.1.1 Angle Functions
The prolate spheroidal angle functions of the first and second kinds can be written in terms of the associated Legendre polynomials of the first and second kinds, respectively:
$$S _ { m n } ^ { \left ( 1 \right ) } \left ( c, \eta \right ) = \sum _ { r = 0, 1 } ^ { \infty } d _ { r } ^ { m n } \left ( c \right ) P _ { m + r } ^ { m } \left ( \eta \right ),$$
$$S _ { m n } ^ { \left ( 2 \right ) } \left ( c, \eta \right ) = \sum _ { r = - \infty } ^ { \infty } d _ { r } ^ { m n } \left ( c \right ) Q _ { m + r } ^ { m } \left ( \eta \right ),$$
where the prime over the sum means that only the even terms are included when n -m = even and only the odd terms are included when n -m = odd. The angle functions of the first kind are orthogonal over [ -1 1]: ,
$$\int _ { - 1 } ^ { 1 } S _ { m n } ^ { \left ( 1 \right ) } \left ( c, \eta \right ) S _ { m n ^ { \prime } } ^ { \left ( 1 \right ) } \left ( c, \eta \right ) d \eta = \delta _ { n n ^ { \prime } } N _ { m n } \left ( c \right ),$$
where glyph[negationslash]
$$\text{where} \quad \delta _ { n n ^ { \prime } } = \begin{cases} \ 1, & n = n ^ { \prime } \\ 0, & n \neq n ^ { \prime } \end{cases} \, \quad N _ { m n } \left ( c \right ) = 2 \sum _ { r = 0, 1 } ^ { \infty } d _ { r } ^ { m n } \left ( c \right ) ^ { 2 } \frac { ( 2 m + r )! } { ( 2 m + 2 r + 1 ) \, r! }. \quad \ \ ( 1 0 )$$
The angle functions of the first kind can also be written as a power series. This can be done with the help of the hypergeometric function. When n -m = even,
$$S _ { m n } ^ { \left ( 1 \right ) } \left ( c, \eta \right ) = \sum _ { r = 0 } ^ { \infty } d _ { 2 r } ^ { m n } \left ( c \right ) P _ { m + 2 r } ^ { m } \left ( \eta \right ).$$
The associated Legendre polynomials of the first kind can be written as
$$P _ { n } ^ { m } \left ( x \right ) = \frac { \left ( - 1 \right ) ^ { m } \left ( n + m \right )! } { 2 ^ { m } m! \left ( n - m \right )! } \left ( 1 - x ^ { 2 } \right ) ^ { m / 2 } F \left ( m - n, n + m + 1 ; m + 1 ; \frac { 1 - x } { 2 } \right ),$$
where
$$F \left ( \alpha, \beta ; \gamma ; x \right ) = \sum _ { k = 0 } ^ { \infty } \frac { \left ( \alpha \right ) _ { k } \left ( \beta \right ) _ { k } } { k! \left ( \gamma \right ) _ { k } } x ^ { k }$$
is the hypergeometric function and
$$( a ) _ { 0 } = 1, \quad ( a ) _ { k } = a \, ( a + 1 ) \dots ( a + k - 1 )$$
is the rising Pochhammer symbol. Using this, the associated Legendre polynomials of the first kind in Eq. (11) can be written as
$$P _ { m + 2 r } ^ { m } \left ( x \right ) = \frac { \left ( - 1 \right ) ^ { m } \left ( 2 m + 2 r \right )! } { 2 ^ { m } m! \left ( 2 r \right )! } \left ( 1 - x ^ { 2 } \right ) ^ { m / 2 } F \left ( - 2 r, 2 m + 2 r + 1 ; m + 1 ; \frac { 1 - x } { 2 } \right ).$$
Using the following identity for the hypergeometric function, we can rearrange the previous expression slightly:
$$F \left ( \alpha, \beta ; \frac { \alpha + \beta + 1 } { 2 } ; x \right ) = F \left ( \frac { \alpha } { 2 }, \frac { \beta } { 2 } ; \frac { \alpha + \beta + 1 } { 2 } ; 4 x \left ( 1 - x \right ) \right ),$$
$$P _ { m + 2 r } ^ { m } \left ( x \right ) = \frac { \left ( - 1 \right ) ^ { m } \left ( 2 m + 2 r \right )! } { 2 ^ { m } m! \left ( 2 r \right )! } \left ( 1 - x ^ { 2 } \right ) ^ { m / 2 } F \left ( - r, m + r + \frac { 1 } { 2 } ; m + 1 ; 1 - x ^ { 2 } \right ), \quad \left ( 1 7 \right )$$
$$P _ { m + 2 r } ^ { m } \left ( x \right ) = \frac { \left ( - 1 \right ) ^ { m } \left ( 2 m + 2 r \right )! } { 2 ^ { m } m! \left ( 2 r \right )! } \left ( 1 - x ^ { 2 } \right ) ^ { m / 2 } \sum _ { k = 0 } ^ { \infty } \frac { \left ( - r \right ) _ { k } \left ( m + r + \frac { 1 } { 2 } \right ) _ { k } } { k! \left ( m + 1 \right ) _ { k } } \left ( 1 - x ^ { 2 } \right ) ^ { k }.$$
Plugging this into Eq. (11), we have
$$S _ { m n } ^ { ( 1 ) } \left ( c, \eta \right ) & = \sum _ { r = 0 } ^ { \infty } d _ { 2 r } ^ { m n } \left ( c \right ) \frac { \left ( - 1 \right ) ^ { m } \left ( 2 m + 2 r \right )! } { 2 ^ { m } m! \left ( 2 r \right )! } \left ( 1 - \eta ^ { 2 } \right ) ^ { m / 2 } \sum _ { k = 0 } ^ { \infty } \frac { \left ( - r \right ) _ { k } \left ( m + r + \frac { 1 } { 2 } \right ) _ { k } } { k! \left ( m + 1 \right ) _ { k } } \left ( 1 - \eta ^ { 2 } \right ) ^ { k }.$$
Rearranging,
$$\text{gmg}, & S _ { m n } ^ { ( 1 ) } \left ( c, \eta \right ) = \left ( - 1 \right ) ^ { m } \left ( 1 - \eta ^ { 2 } \right ) ^ { m / 2 } \sum _ { k = 0 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( c \right ) \left ( 1 - \eta ^ { 2 } \right ) ^ { k }, & ( 2 0 )$$
where
$$\text{where} \\ c _ { 2 k } ^ { m n } \left ( c \right ) = \frac { 1 } { 2 ^ { m } \left ( m + k \right )! k! } \sum _ { r = 2 k } ^ { \infty } d _ { r } ^ { m n } \left ( c \right ) \frac { ( 2 m +$$
When n -m = odd,
$$S _ { m n } ^ { ( 1 ) } \left ( c, \eta \right ) = \sum _ { r = 0 } ^ { \infty } d _ { 2 r + 1 } ^ { m n } \left ( c \right ) P _ { m + 2 r + 1 } ^ { m } \left ( \eta \right ). \quad \quad \quad$$
Recall the following identity for the associated Legendre polynomials of the first kind:
$$\left ( n - m + 1 \right ) P _ { n + 1 } ^ { m } \left ( x \right ) = \left ( n + 1 \right ) x P _ { n } ^ { m } \left ( x \right ) - \left ( 1 - x ^ { 2 } \right ) P _ { n } ^ { m \prime } \left ( x \right )$$
Setting n = m +2 , plugging in Eq. (18), and rearranging, r
$$P _ { m + 2 r + 1 } ^ { m } \left ( x \right ) = \frac { \left ( - 1 \right ) ^ { m } \left ( 2 m + 2 r + 1 \right )! } { 2 ^ { m } m! \left ( 2 r + 1 \right )! } x \left ( 1 - x ^ { 2 } \right ) ^ {$$
Finally, plugging this into Eq. (22),
$$\dots \dots _ { J }, r \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \dots \circ \$$
Rearranging,
$$\text{augg}, & S _ { m n } ^ { ( 1 ) } \left ( c, \eta \right ) = \left ( - 1 \right ) ^ { m } \eta \left ( 1 - \eta ^ { 2 } \right ) ^ { m / 2 } \sum _ { k = 0 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( c \right ) \left ( 1 - \eta ^ { 2 } \right ) ^ { k },$$
where
$$c _ { 2 k } ^ { m n } \left ( c \right ) = \frac { 1 } { 2 ^ { m } \left ( m + k \right )! k! } \sum _ { r = 2 k + 1 } ^ { \infty } { ^ { \prime } } d _ { r } ^ { m n } \left ( c \right ) \frac { ( 2 m + r )! } { r! } \left ( - \frac { r - 1 } { 2 } \right ) _ { k } \left ( m + \frac { r } { 2 } + 1 \right ) _ { k }.$$
## 3.1.2 Radial Functions
The prolate spheroidal radial functions of the first and second kinds can be written in terms of the spherical Bessel and Neumann functions, respectively:
$$R _ { m n } ^ { ( 1 ) } \left ( c, \xi \right ) = F _ { m n } \left ( c \right ) ^ { - 1 } \left ( 1 - \frac { 1 } { \xi ^ { 2 } } \right ) ^ { m / 2 } \sum _ { r = 0, 1 } ^ { \infty } \, ^ { \prime } \, ( - 1 ) ^ { ( r - ( n - m ) ) / 2 } \, d _ { r } ^ { m n } \left ( c \right ) \frac { ( 2 m + r )! } { r! } j _ { m + r } \left ( c \xi \right ), \ \ ( 2 8 )$$
$$R _ { m n } ^ { ( 2 ) } \left ( c, \xi \right ) = F _ { m n } \left ( c \right ) ^ { - 1 } \left ( 1 - \frac { 1 } { \xi ^ { 2 } } \right ) ^ { m / 2 } \sum _ { r = 0, 1 } ^ { \infty } \, ^ { \prime } \, ( - 1 ) ^ { ( r - ( n - m ) ) / 2 } \, d _ { r } ^ { m n } \left ( c \right ) \frac { ( 2 m + r )! } { r! } y _ { m + r } \left ( c \xi \right ), \ \ ( 2 9 )$$
where
$$F _ { m n } \left ( c \right ) = \sum _ { r = 0, 1 } ^ { \infty } { ^ { \prime } } d _ { r } ^ { m n } \left ( c \right ) \frac { ( 2 m + r )! } { r! }.$$
The radial functions of the third and fourth kinds are linear combinations of those of the first and second kinds:
$$R _ { m n } ^ { \left ( 3 \right ) } \left ( c, \xi \right ) = R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) + i R _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ),$$
$$R _ { m n } ^ { \left ( 4 \right ) } \left ( c, \xi \right ) = R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) - i R _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ).$$
The Wronskian of the radial functions of the first and second kinds is given by
$$W _ { m n } \left ( c, \xi \right ) = R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) \frac { \partial } { \partial \xi } R _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ) - \frac { \partial } { \partial \xi } R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) R _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ) = \frac { 1 } { c \left ( \xi ^ { 2 } - 1 \right ) } \quad \left ( 3 3 \right )$$
and is useful for validating computed values of these functions.
The radial functions are related to the angle functions by
$$S _ { m n } ^ { \left ( 1 \right ) } \left ( c, z \right ) = k _ { m n } ^ { \left ( 1 \right ) } \left ( c \right ) R _ { m n } ^ { \left ( 1 \right ) } \left ( c, z \right ),$$
$$S _ { m n } ^ { \left ( 2 \right ) } \left ( c, z \right ) = k _ { m n } ^ { \left ( 2 \right ) } \left ( c \right ) R _ { m n } ^ { \left ( 2 \right ) } \left ( c, z \right ),$$
where k (1) mn ( c ) is given by
$$k _ { m n } ^ { \left ( 1 \right ) } \left ( c \right ) = \frac { \left ( 2 m + 1 \right ) \left ( m + n \right )! F _ { m n } \left ( c \right ) } { 2 ^ { m + n } d _ { 0 } ^ { m n } \left ( c \right ) c ^ { m } m! \left ( \frac { n - m } { 2 } \right )! \left ( \frac { m + n } { 2 } \right )! }, \quad n - m = \text{even},$$
$$k _ { m n } ^ { ( 1 ) } \left ( c \right ) = \frac { \left ( 2 m + 3 \right ) \left ( m + n + 1 \right )! F _ { m n } \left ( c \right ) } { 2 ^ { m + n } d _ { 1 } ^ { m n } \left ( c \right ) c ^ { m + 1 } m! } \left ( \frac { n - m - 1 } { 2 } \right )! \left ( \frac { m + n + 1 } { 2 } \right )! }, \quad n - m = \text{odd}, \quad \left ( 3 7 \right )$$
and k (2) mn ( c ) is given by
$$k _ { m n } ^ { ( 2 ) } \left ( c \right ) = \frac { 2 ^ { n - m } \left ( 2 m \right )! \left ( \frac { n - m } { 2 } \right )! \left ( \frac { m + n } { 2 } \right )! d _ { - 2 m } ^ { m n } \left ( c \right ) F _ { m n } \left ( c \right ) } { \left ( 2 m - 1 \right ) m! \left ( m + n \right )! c ^ { m - 1 } }, \quad n - m = \text{even},$$
$$k _ { m n } ^ { ( 2 ) } \left ( c \right ) = - \frac { 2 ^ { n - m } \left ( 2 m \right )! \left ( \frac { n - m - 1 } { 2 } \right )! \left ( \frac { m + n + 1 } { 2 } \right )! d _ { - 2 m + 1 } ^ { m n } \left ( c \right ) F _ { m n } \left ( c \right ) } { \left ( 2 m - 3 \right ) \left ( 2 m - 1 \right ) m! \left ( m + n + 1 \right )! c ^ { m - 2 } }, \quad n - m = \text{odd}. \\ \text{The envsision for the radial functions of the second kind using} \text{ the spherical Neumann}$$
The expression for the radial functions of the second kind using the spherical Neumann functions converges very slowly for values of ξ near 1 and is, therefore, inaccurate in these cases. While the expression for the radial functions of the first kind is accurate for all values of ξ , having a second method can be used as a check on the first method. Thus, these relationships can be used to construct secondary methods for computing these functions. For the radial functions of the first kind,
$$R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) = k _ { m n } ^ { \left ( 1 \right ) } \left ( c \right ) ^ { - 1 } S _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ),$$
$$R _ { m n } ^ { \left ( 1 \right ) } \left ( c, \xi \right ) = k _ { m n } ^ { \left ( 1 \right ) } \left ( c \right ) ^ { - 1 } \sum _ { r = 0, 1 } ^ { \infty } \| ^ { \prime } d _ { r } ^ { m n } \left ( c \right ) P _ { m + r } ^ { m } \left ( \xi \right ).$$
Similar to the angle functions of the first kind, this expression can be written as a power series with the help of the hypergeometric function. Because the argument is ξ ≥ 1 as opposed to | η | ≤ 1, the relationship between the associated Legendre polynomials of the first kind and the hypergeometric function is slightly different. In particular, there is no factor of ( -1) m :
$$P _ { n } ^ { m } \left ( x \right ) = \frac { \left ( n + m \right )! } { 2 ^ { m } m! \left ( n - m \right )! } \left ( x ^ { 2 } - 1 \right ) ^ { m / 2 } F \left ( m - n, n + m + 1 ; m + 1 ; \frac { 1 - x } { 2 } \right ).$$
Following a procedure similar to the one followed for the angle functions of the first kind, we have
$$R _ { m n } ^ { ( 1 ) } \left ( c, \xi \right ) = k _ { m n } ^ { ( 1 ) } \left ( c \right ) ^ { - 1 } \left ( \xi ^ { 2 } - 1 \right ) ^ { m / 2 } \sum _ { k = 0 } ^ { \infty } \left ( - 1 \right ) ^ { k } c _ { 2 k } ^ { m n } \left ( c \right ) \left ( \xi ^ { 2 } - 1 \right ) ^ { k }, \quad n - m = \text{even}, \quad \text{(43)}$$
$$R _ { m n } ^ { ( 1 ) } \left ( c, \xi \right ) = k _ { m n } ^ { ( 1 ) } \left ( c \right ) ^ { - 1 } \xi \left ( \xi ^ { 2 } - 1 \right ) ^ { m / 2 } \sum _ { k = 0 } ^ { \infty } \left ( - 1 \right ) ^ { k } c _ { 2 k } ^ { m n } \left ( c \right ) \left ( \xi ^ { 2 } - 1 \right ) ^ { k }, \quad n - m = \text{odd}, \quad \text{(44)}$$
where c mn 2 k ( c ) is the same as before. For the radial functions of the second kind,
$$R _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ) = k _ { m n } ^ { \left ( 2 \right ) } \left ( c \right ) ^ { - 1 } S _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ),$$
$$R _ { m n } ^ { \left ( 2 \right ) } \left ( c, \xi \right ) = k _ { m n } ^ { \left ( 2 \right ) } \left ( c \right ) ^ { - 1 } \sum _ { r = - \infty } ^ { \infty } d _ { r } ^ { m n } \left ( c \right ) Q _ { m + r } ^ { m } \left ( \xi \right ).$$
## 3.1.3 Calculating the Characteristic Value and Expansion Coefficients
All of the expressions introduced in the previous sections require, either directly or indirectly, the characteristic value, λ mn ( c ), and expansion coefficients, d mn r ( c ). Below, we derive expressions for computing them.
There are several methods for computing the characterstic value, but here, we use a combination of two: method (1) involves solving for the eigenvalues of a tridiagonal matrix [15]; and method (2) involves solving for the roots of a transcendental equation [4]. To begin, method (1) is used to compute an approximate value for the characteristic value. Then, method (2) is used to compute a more accurate value for the characteristic value using the approximate value computed by method (1) as a starting point. This procedure is similar to the one used in [12]. In our software, we use double precision for method (1) and arbitrary precision for method (2).
Both methods rely on the following recurrence relation, which can be obtained by plugging Eq. (7) into Eq. (3):
$$\alpha _ { r } d _ { r + 2 } ^ { m n } \left ( c \right ) + \left ( \beta _ { r } - \lambda _ { m n } \left ( c \right ) \right ) d _ { r } ^ { m n } \left ( c \right ) + \gamma _ { r } d _ { r - 2 } ^ { m n } \left ( c \right ) = 0,$$
where
$$\alpha _ { r } = \frac { \left ( 2 m + r + 2 \right ) \left ( 2 m + r + 1 \right ) } { \left ( 2 m + 2 r + 5 \right ) \left ( 2 m + 2 r + 3 \right ) } c ^ { 2 },$$
$$\beta _ { r } = \left ( m + r \right ) \left ( m + r + 1 \right ) + \frac { 2 \left ( m + r \right ) \left ( m + r + 1 \right ) - 2 m ^ { 2 } - 1 } { \left ( 2 m + 2 r - 1 \right ) \left ( 2 m + 2 r + 3 \right ) } c ^ { 2 },$$
$$\gamma _ { r } = \frac { r \left ( r - 1 \right ) } { \left ( 2 m + 2 r - 3 \right ) \left ( 2 m + 2 r - 1 \right ) } c ^ { 2 }.$$
For method (1), this recurrence relation is rearranged slightly:
$$\alpha _ { r } d _ { r + 2 } ^ { m n } \left ( c \right ) + \beta _ { r } d _ { r } ^ { m n } \left ( c \right ) + \gamma _ { r } d _ { r - 2 } ^ { m n } \left ( c \right ) = \lambda _ { m n } \left ( c \right ) d _ { r } ^ { m n } \left ( c \right ).$$
In matrix form,
$$\left [ \begin{array} { c c c } \beta _ { 0 } & \alpha _ { 0 } \\ \gamma _ { 2 } & \beta _ { 2 } & \alpha _ { 2 } \\ & \gamma _ { 4 } & \beta _ { 4 } & \alpha _ { 4 } \\ & & \ddots \end{array} \right ] \left [ \begin{array} { c } d _ { 0 } ^ { m n } \left ( c \right ) \\ d _ { 2 } ^ { m n } \left ( c \right ) \\ d _ { 4 } ^ { m n } \left ( c \right ) \\ \vdots \end{array} \right ] = \lambda _ { m n } \left ( c \right ) \left [ \begin{array} { c } d _ { 0 } ^ { m n } \left ( c \right ) \\ d _ { 2 } ^ { m n } \left ( c \right ) \\ d _ { 4 } ^ { m n } \left ( c \right ) \\ \vdots \end{array} \right ], \quad n - m = \text{even,}$$
$$\left [ \begin{array} { c c c } \beta _ { 1 } & \alpha _ { 1 } & & \\ \gamma _ { 3 } & \beta _ { 3 } & \alpha _ { 3 } & \\ & \gamma _ { 5 } & \beta _ { 5 } & \alpha _ { 5 } \\ & & & \ddots \end{array} \right ] \left [ \begin{array} { c } d _ { 1 } ^ { m n } \left ( c \right ) \\ d _ { 3 } ^ { m n } \left ( c \right ) \\ d _ { 5 } ^ { m n } \left ( c \right ) \\ \vdots \end{array} \right ] = \lambda _ { m n } \left ( c \right ) \left [ \begin{array} { c } d _ { 1 } ^ { m n } \left ( c \right ) \\ d _ { 3 } ^ { m n } \left ( c \right ) \\ d _ { 5 } ^ { m n } \left ( c \right ) \\ \vdots \end{array} \right ], \quad n - m = \text{odd.} \quad \quad \quad$$
When n -m = even, the eigenvalues are λ mn ( c ) for n = m,m + 2 , m + 4 , . . . , and when n -m = odd, the eigenvalues are λ mn ( c ) for n = m +1 , m +3 , m +5 , . . . . Thus, we can compute λ mn ( c ) by plugging these tridiagonal matrices into an eigenvalue solver. In our software, we use the eig function in MATLAB.
In method (2), the recurrence relation in Eq. (47) is divided through by d mn r ( c ), which yields
$$\alpha _ { r } \frac { d _ { r + 2 } ^ { m n } \left ( c \right ) } { d _ { r } ^ { m n } \left ( c \right ) } + \beta _ { r } - \lambda _ { m n } \left ( c \right ) + \gamma _ { r } \frac { d _ { r - 2 } ^ { m n } \left ( c \right ) } { d _ { r } ^ { m n } \left ( c \right ) } = 0.$$
Setting
$$N _ { r } ^ { m } = - \alpha _ { r - 2 } \frac { d _ { r } ^ { m n } \left ( c \right ) } { d _ { r - 2 } ^ { m n } \left ( c \right ) }, \quad \gamma _ { r } ^ { m } = \beta _ { r }, \quad \beta _ { r } ^ { m } = \gamma _ { r } \alpha _ { r - 2 }$$
allows us to write Eq. (54) as
$$- \, N _ { r + 2 } ^ { m } + \gamma _ { r } ^ { m } - \lambda _ { m n } \left ( c \right ) - \frac { \beta _ { r } ^ { m } } { N _ { r } ^ { m } } = 0.$$
Rearranging one way leads to a continued fraction in decreasing r :
$$N _ { r } ^ { m } = \gamma _ { r - 2 } ^ { m } - \lambda _ { m n } \left ( c \right ) - \frac { \beta _ { r - 2 } ^ { m } } { \gamma _ { r - 4 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \frac { \beta _ { r - 4 } ^ { m } } { \gamma _ { r - 6 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \cdots.$$
Rearranging the other way leads to a continued fraction in increasing r :
$$N _ { r } ^ { m } = \frac { \beta _ { r } ^ { m } } { \gamma _ { r } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \frac { \beta _ { r + 2 } ^ { m } } { \gamma _ { r + 2 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \cdots.$$
The two expression for N m r should be equal to each other. Setting r = n -m +2 in Eqs. (57) and (58),
$$U _ { 1 } \left ( \lambda _ { m n } \left ( c \right ) \right ) = \gamma _ { n - m } ^ { m } - \lambda _ { m n } \left ( c \right ) - \frac { \beta _ { n - m } ^ { m } } { \gamma _ { n - m - 2 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \frac { \beta _ { n - m - 2 } ^ { m } } { \gamma _ { n - m - 4 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \cdots, \quad \text{(59)}$$
$$U _ { 2 } \left ( \lambda _ { m n } \left ( c \right ) \right ) = - \frac { \beta _ { n - m + 2 } ^ { m } } { \gamma _ { n - m + 2 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \frac { \beta _ { n - m + 4 } ^ { m } } { \gamma _ { n - m + 4 } ^ { m } - \lambda _ { m n } \left ( c \right ) - } \cdots.$$
Adding these together yields a transcendental equation in λ mn ( c ):
$$U \left ( \lambda _ { m n } \left ( c \right ) \right ) = U _ { 1 } \left ( \lambda _ { m n } \left ( c \right ) \right ) + U _ { 2 } \left ( \lambda _ { m n } \left ( c \right ) \right ) = 0.$$
We can compute λ mn ( c ) by solving this transcendental equation. In our software, we use the secant method.
Once λ mn ( c ) is known, Eqs. (55) and (58) can be used to compute d mn r ( c ). The expansion coefficients are unique up to a constant factor, though, so the following normalization scheme is used. When n -m = even,
$$S _ { m n } ^ { \left ( 1 \right ) } \left ( c, 0 \right ) = P _ { n } ^ { m } \left ( 0 \right ),$$
$$\sum _ { r = 0 } ^ { \infty } ^ { \prime } d _ { r } ^ { m n } \left ( c \right ) \frac { \left ( - 1 \right ) ^ { r / 2 } \left ( 2 m + r \right )! } { 2 ^ { r } \left ( \frac { 2 m + r } { 2 } \right )! \left ( \frac { r } { 2 } \right )! } = \frac { \left ( - 1 \right ) ^ { ( n - m ) / 2 } \left ( n + m \right )! } { 2 ^ { n - m } \left ( \frac { n + m } { 2 } \right )! \left ( \frac { n - m } { 2 } \right )! }.$$
When n -m = odd,
$$S _ { m n } ^ { \left ( 1 \right ) \prime } \left ( c, 0 \right ) = P _ { n } ^ { m \prime } \left ( 0 \right ),$$
$$\sum _ { r = 1 } ^ { \infty } ^ { \prime } d _ { r } ^ { m n } \left ( c \right ) \frac { ( - 1 ) ^ { ( r - 1 ) / 2 } \left ( 2 m + r + 1 \right )! } { 2 ^ { r } \left ( \frac { 2 m + r + 1 } { 2 } \right )! \left ( \frac { r - 1 } { 2 } \right )! } = \frac { n \cdots \, \nu \, \nu \, \nu } { ( - 1 ) ^ { ( n - m - 1 ) / 2 } \left ( n + m + 1 \right )! } \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots } { 2 ^ { n - m } \left ( \frac { n + m + 1 } { 2 } \right )! \left ( \frac { n - m - 1 } { 2 } \right )! }.$$
To use Eq. (46), d mn r ( c ) must be computed for negative r as well. To begin, Eq. (47) is rewritten as
$$A _ { r + 2 } ^ { m } d _ { r + 2 } ^ { m n } \left ( c \right ) + B _ { r } ^ { m } d _ { r } ^ { m n } \left ( c \right ) + C _ { r - 2 } ^ { m } d _ { r - 2 } ^ { m n } \left ( c \right ) = 0,$$
where
Rearranging,
$$\frac { d _ { r } ^ { m n } \left ( c \right ) } { d _ { r + 2 } ^ { m n } \left ( c \right ) } & = - \frac { A _ { r + 2 } ^ { m } } { B _ { r } ^ { m } + C _ { r - 2 } ^ { m } \frac { d _ { r - 2 } ^ { m n } \left ( c \right ) } { d _ { r } ^ { m n } \left ( c \right ) } }, \\, \,, \quad. \quad, \,, \, e \quad. \quad, \quad.$$
which can be expanded as a continued fraction in decreasing r :
$$\frac { d _ { r } ^ { m n } \left ( c \right ) } { d _ { r + 2 } ^ { m n } \left ( c \right ) } = - \frac { A _ { r + 2 } ^ { m } } { B _ { r } ^ { m } - } \frac { C _ { r - 2 } ^ { m } A _ { r } ^ { m } } { B _ { r - 2 } ^ { m } - } \frac { C _ { r - 4 } ^ { m } A _ { r - 2 } ^ { m } } { B _ { r - 4 } ^ { m } - } \cdots.$$
$$A _ { r } ^ { m } = \alpha _ { r - 2 }, \ \ B _ { r } ^ { m } = \beta _ { r } - \lambda _ { m n } \left ( c \right ), \ \ C _ { r } ^ { m } = \gamma _ { r + 2 }.$$
Because A m r = 0 when r = -2 m or r = -2 m +1, this continued fraction ends:
$$\frac { d _ { r } ^ { m n } \left ( c \right ) } { d _ { r + 2 } ^ { m n } \left ( c \right ) } = - \frac { A _ { r + 2 } ^ { m } } { B _ { r } ^ { m } - } \frac { C _ { r - 2 } ^ { m } A _ { r } ^ { m } } { B _ { r - 2 } ^ { m } - } \frac { C _ { r - 4 } ^ { m } A _ { r - 2 } ^ { m } } { B _ { r - 4 } ^ { m } - } \cdots \frac { A _ { - 2 m + 2 } ^ { m } } { B _ { - 2 m } ^ { m } + C _ { - 2 m - 2 } ^ { m } }$$
when n -m = even, and
$$\frac { d _ { r } ^ { m n } \left ( c \right ) } { d _ { r + 2 } ^ { m n } \left ( c \right ) } = - \frac { A _ { r + 2 } ^ { m } } { B _ { r } ^ { m } - } \frac { C _ { r - 2 } ^ { m } A _ { r } ^ { m } } { B _ { r - 2 } ^ { m } - } \frac { C _ { r - 4 } ^ { m } A _ { r - 2 } ^ { m } } { B _ { r - 4 } ^ { m } - } \cdots \frac { A _ { - 2 m + 3 } ^ { m } } { B _ { - 2 m + 1 } ^ { m } + C _ { - 2 m - 1 } ^ { m } }$$
when n -m = odd. This also means that d mn r ( c ) → 0 when r ≤ -2 m -2 for n -m = even and r ≤ -2 m -1 for n -m = odd. However, Q m m r + ( ξ ) → ∞ in these cases, and d mn r ( c ) Q m m r + ( ξ ) < ∞ :
$$d _ { r } ^ { m n } \left ( c \right ) Q _ { m + r } ^ { m } \left ( \xi \right ) = d _ { r | \epsilon } ^ { m n } \left ( c \right ) P _ { - r - m - 1 } ^ { m } \left ( \xi \right ).$$
The sum in Eq. (46) is, therefore, separated into two pieces:
$$R _ { m n } ^ { ( 2 ) } \left ( c, \xi \right ) & = I _ { m n } ^ { ( 2 ) } \left ( \sum _ { r = - \infty } ^ { - 2 m - 2, - 2 m - 1 } ^ { \prime } d _ { r | c } ^ { m n } \left ( c \right ) P _ { - r - m - 1 } ^ { m } \left ( \xi \right ) + \sum _ { r = - 2 m, - 2 m + 1 } ^ { \infty } d _ { r } ^ { m n } \left ( c \right ) Q _ { m + r } ^ { m } \left ( \xi \right ) \right ), \\ \text{where} \, d ^ { m n } \quad \left ( \vec { \wedge } \, \text{and} \, d ^ { m n } \quad \left ( \vec { \wedge } \, \text{ are committed using} \,.$$
where d mn -2 m - | 2 glyph[epsilon1] ( c ) and d mn -2 m - | 1 glyph[epsilon1] ( c ) are computed using
$$\frac { d _ { - 2 m - 2 | \epsilon } ^ { m n } \left ( c \right ) } { d _ { - 2 m } ^ { m n } \left ( c \right ) } = \frac { c ^ { 2 } } { \left ( 2 m - 1 \right ) \left ( 2 m + 1 \right ) } \frac { 1 } { B _ { - 2 m - 2 } ^ { m } - ^ { - } } \frac { C _ { - 2 m - 4 } ^ { m } A _ { - 2 m - 2 } ^ { m } } { B _ { - 2 m - 4 } ^ { m } - ^ { - } } \frac { C _ { - 2 m - 6 } ^ { m } A _ { - 2 m - 4 } ^ { m } } { B _ { - 2 m - 6 } ^ { m } - ^ { - } } \cdots, \quad \text{(74)}$$
$$\frac { d _ { - 2 m - 1 | \epsilon } ^ { m n } ( c ) } { d _ { - 2 m + 1 } ^ { m n } ( c ) } = - \frac { c ^ { 2 } } { ( 2 m - 1 ) \, ( 2 m - 3 ) } \frac { 1 } { B _ { - 2 m - 1 } ^ { m } - } \frac { C _ { - 2 m - 3 } ^ { m } A _ { - 2 m - 1 } ^ { m } } { B _ { - 2 m - 3 } ^ { m } - } \frac { C _ { - 2 m - 5 } ^ { m } A _ { - 2 m - 3 } ^ { m } } { B _ { - 2 m - 5 } ^ { m } - } \cdots. \quad ( 7 5 )$$
For r < -2 m -2 when n -m = even and r < -2 m -1 when n -m = odd, the remaining expansion coefficients can be computed using
$$\frac { d _ { r | \epsilon } ^ { m n } \left ( c \right ) } { d _ { r + 2 | \epsilon } ^ { m n } \left ( c \right ) } = - \frac { A _ { r + 2 } ^ { m } } { B _ { r } ^ { m } - } \frac { C _ { r - 2 } ^ { m } A _ { r } ^ { m } } { B _ { r - 2 } ^ { m } - } \frac { C _ { r - 4 } ^ { m } A _ { r - 2 } ^ { m } } { B _ { r - 4 } ^ { m } - } \cdots.$$
## 3.2 Oblate Spheroidal Wave Functions
## 3.2.1 Angle Functions
The expressions for the prolate spheroidal angle functions, including the ones written in terms of the associated Legendre polynomials as well as the ones expanded as power series, can be transformed into those for the oblate spheroidal angle functions by letting c →-ic .
Figure 4. Characteristic and other special values for the oblate spheroidal wave functions for c = 10, m = 0 1 , , . . . , 29, and n = m,m +1 , . . . , m +29.
## 3.2.2 Radial Functions
The oblate spheroidal radial functions of the first and second kinds can be written in terms of the spherical Bessel and Neumann functions, respectively:
$$m / 2$$
$$I _ { m n } ^ { \sim } \left ( - i c, i \xi \right ) & = r _ { m n } \left ( - i c \right ) \quad \left \{ 1 + \frac { 1 } { \xi ^ { 2 } } \right \} \quad \times \\ \sum _ { r = 0, 1 } ^ { \infty } \left ( - 1 \right ) ^ { ( r - ( n - m ) ) / 2 } d _ { r } ^ { m n } \left ( - i c \right ) \frac { ( 2 m + r )! } { r! } j _ { m + r } \left ( c \xi \right ), \\ \\ R _ { m n } ^ { ( 2 ) } \left ( - i c, i \xi \right ) & = F _ { m n } \left ( - i c \right ) ^ { - 1 } \left ( 1 + \frac { 1 } { \xi ^ { 2 } } \right ) ^ { m / 2 } \times \\ \sum _ { r = 0, 1 } ^ { \infty } \left ( - 1 \right ) ^ { ( r - ( n - m ) ) / 2 } d _ { r } ^ { m n } \left ( - i c \right ) \frac { ( 2 m + r )! } {. } y _ { m + r } \left ( c \xi \right ),$$
$$R _ { m n } ^ { ( 1 ) } \left ( - i c, i \xi \right ) = F _ { m n } \left ( - i c \right ) ^ { - 1 } \left ( 1 + \frac { 1 } { \xi ^ { 2 } } \right ) ^ { m / 2 } \times \\ \sum _ { r = 0, 1 } ^ { \infty } ^ { \prime } \left ( - 1 \right ) ^ { \left ( r - \left ( n - m \right ) \right ) / 2 } d _ { r } ^ { m n } \left ( - i c \right ) \frac { \left ( 2 m + r \right )! } { r! } j _ { m + r } \left ( c \xi \right ),$$
$$R _ { m n } ^ { ( 2 ) } \left ( - i c, i \xi \right ) = F _ { m n } \left ( - i c \right ) ^ { - 1 } \left ( 1 + \frac { 1 } { \xi ^ { 2 } } \right ) ^ { m / 2 } \times \\ \sum _ { r = 0, 1 } ^ { \infty } ^ { \prime } \left ( - 1 \right ) ^ { \left ( r - \left ( n - m \right ) \right ) / 2 } d _ { r } ^ { m n } \left ( - i c \right ) \frac { \left ( 2 m + r \right )! } { r! } y _ { m + r } \left ( c \xi \right ),$$
Figure 5. The oblate spheroidal wave functions and their derivatives for c = 10, m = 10, and n = 10 11 , , . . . , 39.
where
$$F _ { m n } \left ( - i c \right ) = \sum _ { r = 0, 1 } ^ { \infty } ^ { \prime } d _ { r } ^ { m n } \left ( - i c \right ) \frac { ( 2 m + r )! } { r! }.$$
The radial functions of the third and fourth kinds are linear combinations of those of the first and second kinds:
$$R _ { m n } ^ { ( 3 ) } \left ( - i c, i \xi \right ) = R _ { m n } ^ { ( 1 ) } \left ( - i c, i \xi \right ) + i R _ { m n } ^ { ( 2 ) } \left ( - i c, i \xi \right ),$$
$$R _ { m n } ^ { ( 4 ) } \left ( - i c, i \xi \right ) = R _ { m n } ^ { ( 1 ) } \left ( - i c, i \xi \right ) - i R _ { m n } ^ { ( 2 ) } \left ( - i c, i \xi \right ).$$
The Wronskian of the radial functions of the first and second kinds is given by
$$W _ { m n } \left ( - i c, i \xi \right ) & = R _ { m n } ^ { \left ( 1 \right ) } \left ( - i c, i \xi \right ) \frac { \partial } { \partial \xi } R _ { m n } ^ { \left ( 2 \right ) } \left ( - i c, i \xi \right ) - \frac { \partial } { \partial \xi } R _ { m n } ^ { \left ( 1 \right ) } \left ( - i c, i \xi \right ) R _ { m n } ^ { \left ( 2 \right ) } \left ( - i c, i \xi \right ) = \frac { 1 } { c \left ( \xi ^ { 2 } + 1 \right ) } \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{$$
and is useful for validating computed values of these functions.
The radial functions are related to the angle functions by
$$S _ { m n } ^ { \left ( 1 \right ) } \left ( - i c, i z \right ) = k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) R _ { m n } ^ { \left ( 1 \right ) } \left ( - i c, i z \right ),$$
$$S _ { m n } ^ { \left ( 2 \right ) } \left ( - i c, i z \right ) = k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) R _ { m n } ^ { \left ( 2 \right ) } \left ( - i c, i z \right ),$$
where k (1) mn ( -ic ) and k (2) mn ( -ic ) are given by the same expressions as in the prolate case, provided that c →-ic . The expression for the radial functions of the first kind using the
spherical Bessel functions converges and is accurate for all values of ξ , except for ξ = 0, where the expression is undefined due to a divide by zero. The expression for the radial functions of the second kind using the spherical Neumann functions converges very slowly for values of ξ near 0 and is, therefore, inaccurate in these cases. Thus, these relationships can be used to construct secondary methods for computing these functions. The same procedures used in the prolate case for doing so can also be used here, provided that c, ξ → -ic, iξ where necessary.
A tertiary method for computing the radial functions of the second kind can also be constructed using a power series:
$$R _ { m n } ^ { \left ( 2 \right ) } \left ( - i c, i \xi \right ) = Q _ { m n } ^ { * } \left ( - i c \right ) R _ { m n } ^ { \left ( 1 \right ) } \left ( - i c, i \xi \right ) \left ( \arctan \left ( \xi \right ) - \frac { \pi } { 2 } \right ) + g _ { m n } \left ( - i c, i \xi \right ),$$
where
$$Q _ { m n } ^ { * } \left ( - i c \right ) = \frac { \left ( i ^ { - m } k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) \right ) ^ { 2 } } { c } \sum _ { r = 0 } ^ { m } \alpha _ { r } ^ { m n } \left ( - i c \right ) \frac { \left ( 2 m - 2 r \right )! } { r! \left ( 2 ^ { m - r } \left ( m - r \right )! \right ) ^ { 2 } }, \quad n - m = \text{even}, \quad ( 8 6 )$$
$$Q _ { m n } ^ { * } \left ( - i c \right ) = - \frac { \left ( i ^ { - \left ( m + 1 \right ) } k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) \right ) ^ { 2 } } { c } \sum _ { r = 0 } ^ { m } \alpha _ { r } ^ { m n } \left ( - i c \right ) \frac { \left ( 2 m - 2 r + 1 \right )! } { r! \left ( 2 ^ { m - r } \left ( m - r \right )! \right ) ^ { 2 } }, \quad n - m = \text{odd, } ( 8 7 )$$
$$\alpha _ { r } ^ { m n } \left ( - i c \right ) = \left [ \frac { d ^ { r } } { d x ^ { r } } \frac { 1 } { \left ( \sum _ { k = 0 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) x ^ { k } \right ) ^ { 2 } } \right ] _ { x = 0 },$$
$$g _ { m n } \left ( - i c, i \xi \right ) = \xi \left ( \xi ^ { 2 } + 1 \right ) ^ { - m / 2 } \sum _ { r = 0 } ^ { \infty } B _ { 2 r } ^ { m n } \left ( - i c \right ) \xi ^ { 2 r }, \quad n - m = \text{even},$$
$$g _ { m n } \left ( - i c, i \xi \right ) = \left ( \xi ^ { 2 } + 1 \right ) ^ { - m / 2 } \sum _ { r = 0 } ^ { \infty } B _ { 2 r } ^ { m n } \left ( - i c \right ) \xi ^ { 2 r }, \quad n - m = \text{odd}.$$
To compute α mn r ( -ic ), we use the following procedure, which was described in [6] and uses some properties of Cauchy products. Let C k = c mn 2 k ( -ic ), and expand the denominator in Eq. (88) as
$$\left ( \sum _ { k = 0 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) x ^ { k } \right ) ^ { 2 } = \sum _ { n = 0 } ^ { \infty } \sum _ { k = 0 } ^ { n } C _ { k } x ^ { k } C _ { n - k } x ^ { n - k } = \sum _ { n = 0 } ^ { \infty } B _ { n } x ^ { n },$$
$$B _ { n } = \sum _ { k = 0 } ^ { n } C _ { k } C _ { n - k },$$
$$\frac { 1 } { \left ( \sum _ { k = 0 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) x ^ { k } \right ) ^ { 2 } } & = \frac { 1 } { \infty } = \sum _ { n = 0 } ^ { \infty } A _ { n } x ^ { n },$$
$$\sum _ { n = 0 } ^ { \infty } A _ { n } x ^ { n } \sum _ { n = 0 } ^ { \infty } B _ { n } x ^ { n } = 1,$$
$$\sum _ { n = 0 } ^ { \infty } \left ( \sum _ { k = 0 } ^ { n } A _ { k } B _ { n - k } \right ) x ^ { n } = 1.$$
In order for this equality to hold,
$$A _ { 0 } B _ { 0 } = 1, \quad \sum _ { k = 0 } ^ { n } A _ { k } B _ { n - k } = 0, \quad n > 0.$$
Rearranging,
$$A _ { 0 } = \frac { 1 } { B _ { 0 } }, \quad A _ { n } = - \frac { 1 } { B _ { 0 } } \sum _ { k = 0 } ^ { n - 1 } A _ { k } B _ { n - k }, \quad n > 0.$$
We can now compute α mn r ( -ic ):
$$\alpha _ { r } ^ { m n } \left ( - i c \right ) = \left [ \frac { d ^ { r } } { d x ^ { r } } \sum _ { n = 0 } ^ { \infty } A _ { n } x ^ { n } \right ] _ { x = 0 } = A _ { r } r!.$$
Plugging Eq. (85) into the oblate version of Eq. (4) yields the following recurrence relation in B mn 2 r ( -ic ):
$$\alpha _ { 2 r } B _ { 2 r + 2 } ^ { m n } \left ( - i c \right ) + \beta _ { 2 r } B _ { 2 r } ^ { m n } \left ( - i c \right ) + \gamma _ { 2 r } B _ { 2 r - 2 } ^ { m n } \left ( - i c \right ) = h _ { 2 r },$$
where
$$\alpha _ { 2 r } & = \left ( 2 r + 2 \right ) \left ( 2 r + 3 \right ), & ( 1 0 0 )$$
$$\beta _ { 2 r } = \left ( 2 r + 1 \right ) \left ( 2 r - 2 m + 2 \right ) + m \left ( m - 1 \right ) - \lambda _ { m n } \left ( - i c \right ), \quad \ \ ( 1 0 1 )$$
$$\gamma _ { 2 r } = c ^ { 2 },$$
$$h _ { 2 r } = - 2 Q _ { m n } ^ { * } \left ( - i c \right ) \left ( i ^ { - m } k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) \right ) ^ { - 1 } \sum _ { k = r - m + 1 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) \left ( m + 2 k \right ) \frac { \left ( m + k - 1 \right )! } { \left ( m + k - 1 - r \right )! r! } \ \left ( 1 0 3 \right )$$
when n -m = even, and
$$\alpha _ { 2 r } = \left ( 2 r + 1 \right ) \left ( 2 r + 2 \right ),$$
$$\beta _ { 2 r } & = 2 r \left ( 2 r - 2 m + 1 \right ) + m \left ( m - 1 \right ) - \lambda _ { m n } \left ( - i c \right ), & ( 1 0 5 )$$
$$\gamma _ { 2 r } = c ^ { 2 },$$
$$h _ { 2 r } = - 2 Q _ { m n } ^ { * } \left ( - i c \right ) \left ( i ^ { - \left ( m + 1 \right ) } k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) \right ) ^ { - 1 } \left ( \sum _ { k = r - m } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) \left ( m + 2 k + 1 \right ) \frac { \left ( m + k \right )! } { \left ( m + k - r \right )! r! }$$
$$- \sum _ { k = r - m + 1 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) ( m + 2 k ) \, \frac { ( m + k - 1 )! } { ( m + k - 1 - r )! r! } \right ) \\ m = \cap \partial \Delta \, & \, C \sin \, \cos \, \detect \, \max \, \Delta \, & \, \underline { R } ^ { m n } \left ( \Delta \, \partial \, \cap \, \cos \, \cos \, \det \, \max \, \Delta \, \det \, \cos \, \min \, \det \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \sin \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \tan \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \ sin \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \ cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \cos \, \colon$$
when n -m = odd. Given a starting value, B mn 0 ( -ic ), Eq. (99) can be used to compute B mn 2 r ( -ic ). The starting values are
$$B _ { 0 } ^ { m n } \left ( - i c \right ) = \left ( c R _ { m n } ^ { ( 1 ) } \left ( - i c, i 0 \right ) \right ) ^ { - 1 } - Q _ { m n } ^ { * } \left ( - i c \right ) R _ { m n } ^ { ( 1 ) } \left ( - i c, i 0 \right ), \quad n - m = \text{even}, \quad \text{(108)}$$
$$B _ { 0 } ^ { m n } \left ( - i c \right ) = - \left ( c R _ { m n } ^ { \left ( 1 \right ) \prime } \left ( - i c, i 0 \right ) \right ) ^ { - 1 }, \quad n - m = \text{odd}.$$
## 3.2.3 Calculating the Characteristic Value and Expansion Coefficients
The procedures for computing the characteristic value and expansion coefficients for the oblate case are exactly the same as those for the prolate case, provided that c →-ic .
## 4 Software
We implemented our software in C++ and MATLAB. Our code is called spheroidal and is primarily called via the command line. Many programming languages have interfaces to the command line (e.g., the system function in MATLAB), so they can access our code in this way. There are two programs: pro\_sphwv computes the prolate spheroidal wave functions; and obl\_sphwv computes the oblate spheroidal wave functions. Like any piece of software, our code contains many subtleties and nuances. We have commented and documented our code to explain all of these. Below, we describe some of the more important ones.
## 4.1 Using the MPFR Library
Except in a few places, our code uses the GNU MPFR library, which provides interfaces and routines for performing arbitrary precision arithmetic [3]. We created a C++ class, real , which encapsulates many of the features provided by GNU MPFR. These features include: basic arithmetic by overloading the + , -, * , and / operators; comparisons by overloading the > , >= , < , <= , == , and != operators; and some elementary functions, including abs , atan , cos , log , pow , and sin . GNU MPFR allows the programmer to specify the precision to use for these operations by setting the number of bits of precision. As a reference, single and double precision arithmetic found in most programming languages have 24 and 53 bits of precision, respectively. We experimented with several different levels of precision (as low as 24 and as high as 5000 bits of precision). In general, as we increased the precision, the accuracy of the computations increased as well. For lower c , m , and n , single and double precision were good enough. However, for higher values, using such low precision yielded very large errors, and only by increasing the precision were these errors reduced.
## 4.2 Prolate Spheroidal Wave Functions
The code for computing the prolate spheroidal wave functions, as well as the characteristic and other special values and expansion coefficients required for computing them, is called via the command line. Every command uses the same general structure. The program is called pro\_sphwv . Seven arguments are required:
- 1. -max\_memory is the maximum amount of memory, in MB, the program can use before automatically terminating;
- 2. -prec is the number of bits of precision to use;
- 3. -verbose is whether the program should output diagnostic and other information about the computations (accepted values are 'y' and 'n');
- 4. -c is equal to ka , where k is the wavenumber and 2 a is the interfocal distance;
- 5. -m is one modal value;
- 6. -n is the other modal value and is equal to m,m +1 , . . . ; and
- 7. -w is what the program should do.
Following the -w argument are zero or more arguments, the number and type of which depend on the value given for the -w argument. The following sequence of commands computes the characteristic and other special values and expansion coefficients required for computing the prolate spheroidal wave functions:
```
<_C_>
```
- \
The command, ./pro\_sphwv ... -w lambda , uses method (2) from Section 3.1.3 to compute the characteristic value. Method (2) requires an approximate value for the characteristic value, which can be computed by using method (1). We wrote a small MATLAB program for doing so. Once this program has run, the preceeding sequence of commands can be called using one command:
```
./pro_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 \
-w everything -n_dr 10 -dr_min 1.0e-200 -n_dr_neg 10 \
-dr_neg_min 1.0e-200 -n_c2k 10 -c2k_min 1.0e-200
```
The computed values are stored as ASCII in .txt files in the data directory. This way, they can be reused later on without having to recompute them from scratch. The following two commands compute the prolate spheroidal wave functions over a range of values:
```
./pro_sphwv -max_memory 2000 -prec 100 -verbose n -c 10.0 -m 0 -n 0 -w S1 \
-a -1.0 -b 1.0 -d 0.125 -arg_type eta \
-p 20 > data/pro_00010000_000_000_S1.txt
./pro_sphwv -max_memory 2000 -prec 100 -verbose n -c 10.0 -m 0 -n 0 -w R \
-a 1.0 -b 9.0 -d 0.125 -arg_type xi -which R1_1,R1_2,R2_1,R2_2 \
-p 20 > data/pro_00010000_000_000_R.txt
```
- \
where the range is determined by the values passed in for -a (the starting point), -b (the ending point), and -d (the spacing between the points). Normally, the angle functions take η as their argument, and the radial functions take ξ as their argument. The argument, -arg\_type , allows one to use η = cos ( xπ ) for the angle functions, where the range is over x , not η . In this case, -arg\_type should be set to theta/pi . Likewise, for the radial functions, one can use ξ = ( x 2 +1) 1 2 / , where the range is over x , not ξ . In this case, -arg\_type should be set to x . The argument, -which , tells the program which of the different methods for computing the radial functions should be used. The argument, -p , is how many digits of precision to output. There is no guarantee that all of these digits will be accurate. How many digits are actually accurate depends on the level of precision and how many expansion coefficients are computed and used.
## 4.3 Oblate Spheroidal Wave Functions
The calling convention for obl\_sphwv is the same as pro\_sphwv . There are some differences since a couple extra sets of expansion coefficients are computed. The following sequence of commands computes the characteristic and other special values and expansion coefficients required for computing the oblate spheroidal wave functions:
```
commands computes the characteristic and other special values and expansion coefficients
required for computing the oblate spheroidal wave functions:
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 \
-w lambda
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 -w dr \
-n_dr 10 -dr_min 1.0e-200
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 \
-w dr_neg -n_dr_neg 10 -dr_neg_min 1.0e-200
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -w N
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -w F
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -w k1
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -w k2
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 \
-w c2k -n_c2k 10 -c2k_min 1.0e-200
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -w Q
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 \
-w B2r -n_B2r 10 -B2r_min 1.0e-200
Like in the prolate case, the command,./pro_sphwv ... -w lambda, must be preceeded by
running a small MATLAB program to compute an approximate value for the characteristic
```
- \
Like in the prolate case, the command, ./pro\_sphwv ... -w lambda , must be preceeded by running a small MATLAB program to compute an approximate value for the characteristic value. The preceeding sequence of commands can be called using one command:
```
./obl_sphwv -max_memory 2000 -prec 100 -verbose y -c 10.0 -m 0 -n 0 \
-w everything -n_dr 10 -dr_min 1.0e-200 -n_dr_neg 10 \
-dr_neg_min 1.0e-200 -n_c2k 10 -c2k_min 1.0e-200 -n_B2r 10 \
-B2r_min 1.0e-200
```
The computed values are stored as ASCII in .txt files in the data directory. This way, they can be reused later on without having to recompute them from scratch. The following two commands compute the oblate spheroidal wave functions over a range of values:
Figure 6. The relative error of the computed Wronskian when using different combinations of the methods for computing the prolate spheroidal radial functions for c = 10, m = 10, and n = 39.
```
./obl_sphw -max_memory 2000 -prec 100 -verbose n -c 10.0 -m 0 -n 0 -w S1 \
-a -1.0 -b 1.0 -d 0.125 -arg_type eta \
-p 20 > data/obl_00010000_000_000_000_S1.txt
./obl_sphw -max_memory 2000 -prec 100 -verbose n -c 10.0 -m 0 -n 0 -w R \
-a 0.0 -b 8.0 -d 0.125 -arg_type xi \
-which R1_1,R1_2,R2_1,R2_2,R2_31,R2_32 \
-p 20 > data/obl_00010000_000_000_000_R.txt
```
where the arguments are the same as in the prolate case. The only difference is that, for the radial functions, there is only one valid value for -arg\_type , which is xi .
## 4.4 Using the Wronskian
Two methods were given for computing the prolate spheroidal radial functions of the first kind. One method uses the spherical Bessel functions, and the other method uses a power series. Call these methods R1\_1 and R1\_2 , respectively. Likewise, two methods were given for computing the prolate spheroidal radial functions of the second kind. One method uses the spherical Neumann functions, and the other method uses the associated Legendre polynomials of the second kind. Call these methods R2\_1 and R2\_2 , respectively. In each of these pairs of methods, one is better for certain values of ξ than the other, and vice versa. In particular, R1\_1 is better for larger ξ and R1\_2 is better for smaller ξ . Similarly, R2\_1 is better for larger ξ and R2\_2 is better for smaller ξ . However, when to use which method is not always clear: the exact value of ξ below which one is better and above which the other is better is different for different values of c , m , and n . We solved this dilemma in the following manner. For a given ξ , all four methods are used to compute their respective functions, and the combination that yields the smallest error in the computed Wronskian is used. An example of this can be seen in Figure 6. As expected, the combination, R1\_2, R2\_2 , was superior for smaller ξ and the combination, R1\_1, R2\_1 , was superior for larger ξ .
Figure 7. The relative error of the computed Wronskian when using different combinations of the methods for computing the oblate spheroidal radial functions for c = 10, m = 10, and n = 39.
This procedure is also used for the oblate spheroidal radial functions. There are two methods for computing the oblate spheroidal radial functions of the first kind, one that uses the spherical Bessel functions and one that uses a power series. Call these methods R1\_1 and R1\_2 , respectively. There are three methods for computing the oblate spheroidal radial functions of the second kind, one that uses the spherical Neumann functions, one that uses the associated Legendre polynomials of the second kind, and one that uses a power series. Call these methods R2\_1 , R2\_2 , and R2\_3 , respectively. Internally, R2\_3 uses the oblate spheroidal radial functions of the first kind, so when R1\_1 is used, call this method R2\_31 , and when R1\_2 is used, call this method R2\_32 . Thus, there are eight possible combinations, but only six are considered: R1\_1 and R2\_1 ; R1\_1 and R2\_2 ; R1\_1 and R2\_31 ; R1\_2 and R2\_1 ; R1\_2 and R2\_2 ; and R1\_2 and R2\_32 . For a given ξ , of these six, the one that yields the smallest error in the computed Wronskian is used. An example of this can be seen in Figure 7. As expected, the combination, R1\_1, R2\_2 , was superior for smaller ξ and the combination, R1\_1, R2\_1 , was superior for larger ξ .
## 4.5 Solving Forward and Backward Recurrences
Several recurrence relations need to be solved in order to compute the characterstic and other special values, expansion coefficients, and special functions required by many of the expressions for the spheroidal wave functions. These recurrence relations can either have a starting value (e.g., for B mn 2 r ( -ic )) or some kind of normalization scheme (e.g., for d mn r ( ic )). Except for one case, all of the recurrence relations encountered in the previous sections were homogeneous. Depending on whether the solution to a particular recurrence relation grows or decays, the method of solution is different. For solutions that grow (e.g., the spherical Neumann functions), the forward recurrence approach is used (i.e., the recurrence relation is used directly to compute succeeding values). For solutions that decay (e.g., d mn r ( ic )), the forward recurrence approach is numerically unstable. Instead, the continued fraction approach, which is described in [4], is used.
or,
n - m
Figure 8. The order of magnitude of the expansion coefficients, B mn 2 r ( -ic ), for c = 25, m = 49, and n = 49 50 , , . . . , 98.
Nonhomogeneous recurrence relations are more complicated. For solutions that grow, the foward recurrence approach can still be used. However, for solutions that decay, the continued fraction approach no longer works. Instead, we use the tridiagonal matrix method described in [16, 17]: the recurrence relation is written for each index, these are combined into a tridiagonal system of equations, and this system is inverted. The case of computing the expansion coefficients, B mn 2 r ( -ic ), is further complicated by the fact that, for many values of c , m , and n , B mn 2 r ( -ic ) grows for lower r , but decays for higher r . See, for example, Figure 8. Thus, the forward recurrence approach is used when B mn 2 r ( -ic ) is growing, and the tridiagonal matrix method is used when B mn 2 r ( -ic ) is decaying.
## 4.6 Optimizing Factorials and Rising Pochhammer Symbols
Many of the expressions for the characteristic and other special values, expansion coefficients, and spheroidal wave functions involve infinite series expansions. The terms in these series often include factorials and rising Pochhammer symbols. Computing these can be rather expensive: for example, computing a ! and ( a ) k require a -1 and k -1 multiplies, respectively. Because a and k are usually functions of the term number, as the number of terms computed in these series increases, the number of multiplies required increases quadratically. This can be very slow. However, this problem can be solved in the following manner: the products arising from these factorials and rising Pochhammer symbols can be factored across terms, so that only a constant number of multiplies are required for each term.
For example, consider here, again, Eq. (103):
$$h _ { 2 r } = - 2 Q _ { m n } ^ { * } \left ( - i c \right ) \left ( i ^ { - m } k _ { m n } ^ { ( 1 ) } \left ( - i c \right ) \right ) ^ { - 1 } \sum _ { k = r - m + 1 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) \left ( m + 2 k \right ) \frac { ( m + k - 1 )! } { ( m + k - 1 - r )! r! }, \\ \sim$$
$$\alpha, \\ h _ { 2 r } = - 2 Q _ { m n } ^ { * } \left ( - i c \right ) \left ( i ^ { - m } k _ { m n } ^ { \left ( 1 \right ) } \left ( - i c \right ) \right ) ^ { - 1 } \sum _ { k = r - m + 1 } ^ { \infty } c _ { 2 k } ^ { m n } \left ( - i c \right ) \left ( m + 2 k \right ) a _ { k }, \quad \left ( 1 1 1 \right )$$
where
$$a _ { k } & = \frac { ( m + k - 1 )! } { ( m + k - 1 - r )! r! }.$$
Computing a k requires O m ( + k + ) multiplies. For large r m r , , and k , carrying out these operations for every a k would be time consuming. Fortunately, a k is related to a k -1 by a constant number of operations. Starting with a r -m +1 , every a k can be computed recursively and plugged into Eq. (111). To begin,
$$a _ { r - m + 1 } = 1.$$
For increasing k ,
$$a _ { k } = a _ { k - 1 } \frac { ( m + k - 1 ) } { ( m + k - r - 1 ) }.$$
## 5 Conclusion
The spheroidal wave functions are among the most complicated special functions. There are no simple ways to compute them. However, because the solutions to so many interesting problems require them, software for computing them accurately is needed. We have developed computational software for doing so using C++, MATLAB, and GNU MPFR, a library for performing arbitrary precision arithmetic. In this paper, we have described the prolate and oblate spheroidal coordinate systems and wave functions, methods for deriving analytical expressions for computing them, and our software that implements these expressions. Our software includes many novel features. Some of these features include: using arbitrary precision arithmetic; adaptively choosing the number of expansion coefficients to compute and use; and using the Wronskian to choose from several different methods for computing the spheroidal radial functions to improve their accuracy. We have made our software freely available on our webpage.
## References
- [1] J. J. Bowman, T. B. A. Senior, and P. L. E. Uslenghi, Electromagnetic and acoustic scattering by simple shapes (Hemisphere Publishing Corporation, New York) (1987).
- [2] D. Slepian, 'Some comments on Fourier analysis, uncertainty and modeling', SIAM Review 25(3) (1983).
- [3] L. Fousse, G. Hanrot, V. Lefevre, P. Pelissier, and P. Zimmermann, 'MPFR: A multipleprecision binary floating-point library with correct rounding', ACM Trans. Math. Softw. 33(2) (2007).
- [4] C. Flammer, Spheroidal wave functions (Dover Publications, Mineola) (2005).
- [5] T. Do-Nhat and R. H. MacPhie, 'Accurate values of prolate spheroidal radial functions of the second kind', Can. J. Phys. 75 (1997).
- [6] S. Zhang and J. Jin, Computation of special functions (Wiley-Interscience) (1996).
- [7] W. J. Thompson, Atlas for computing mathematical functions (John Wiley and Sons) (1997).
- [8] W. J. Thompson, 'Spheroidal wave functions', Computing in Science and Engineering 1(3) (1999).
- [9] A. L. V. Buren and J. E. Boisvert, 'Accurate calculation of prolate spheroidal radial functions of the first kind and their first derivatives', Quart. Appl. Math. 60 (2002).
- [10] A. L. V. Buren and J. E. Boisvert, 'Improved calculation of prolate spheroidal radial functions of the second kind and their first derivatives', Quart. Appl. Math. 62 (2004).
- [11] L. Li, M. Leong, T. Yeo, P. Kooi, , and K. Tan, 'Computations of spheroidal harmonics with complex arguments: a review with an algorithm', Phys. Rev. 58 (1998).
- [12] P. E. Falloon, P. C. Abbott, and J. B. Wang, 'Theory and computation of the spheroidal wave functions', J. Physics A 36 (2003).
- [13] J. Caldwell, 'Computation of eigenvalues of spheroidal harmonics using relaxation', J. Phys. A 21 (1988).
- [14] D. X. Ogburn, C. L. Waters, M. D. Sciffer, J. A. Hogan, and P. C. Abbott, 'A finite difference construction of the spheroidal wave functions', Computer Physics Communications 185 (2014).
- [15] D. B. Hodge, 'Eigenvalues and eigenfunctions of the spheroidal wave equation', J. Math. Phys. 11 (1970).
- [16] F. W. J. Olver, 'Numerical solution of second-order linear difference equations', Journal of Research of the National Bureau of Standards 71B (1967).
- [17] F. W. J. Olver and D. J. Sookne, 'Note on backward recurrence algorithms', Mathematics of Computation 26(120) (1972). | null | [
"Ross Adelman",
"Nail A. Gumerov",
"Ramani Duraiswami"
] | 2014-08-01T04:29:30+00:00 | 2014-08-01T04:29:30+00:00 | [
"cs.MS",
"cs.NA"
] | Software for Computing the Spheroidal Wave Functions Using Arbitrary Precision Arithmetic | The spheroidal wave functions, which are the solutions to the Helmholtz
equation in spheroidal coordinates, are notoriously difficult to compute.
Because of this, practically no programming language comes equipped with the
means to compute them. This makes problems that require their use hard to
tackle. We have developed computational software for calculating these special
functions. Our software is called spheroidal and includes several novel
features, such as: using arbitrary precision arithmetic; adaptively choosing
the number of expansion coefficients to compute and use; and using the
Wronskian to choose from several different methods for computing the spheroidal
radial functions to improve their accuracy. There are two types of spheroidal
wave functions: the prolate kind when prolate spheroidal coordinates are used;
and the oblate kind when oblate spheroidal coordinate are used. In this paper,
we describe both, methods for computing them, and our software. We have made
our software freely available on our webpage. |
1408.0075v1 | ## Study of the characteristics of GEM detectors for the future FAIR experiment CBM
S. Biswas a, ∗ , A. Abuhoza a,b , U. Frankenfeld , J. Hehner , C. J. Schmidt , H.R. Schmidt , M. Tr¨ ager , S. Colafranceschi , a a a c a d A. Marinov d , A. Sharma d
a
GSI Helmholtzzentrum f¨ ur Schwerionenforschung GmbH, Dar mstadt, Germany-64291 b King Abdulaziz City for Science and Technology (KACST),Riyadh, Saudi Arabia c Eberhard-Karls-Universit¨ at, T¨bingen, Germany u d Physics Department, CERN - Geneva, Switzerland
## Abstract
Characteristics of triple GEM detector has been studied systematically. The variation of the e ff ective gain and energy resolution of GEM with variation of the applied voltage has been measured with Fe 55 X-ray source for di ff erent gas mixtures and with di ff erent gas flow rates. Long-term test of the GEM has also been performed.
Keywords: FAIR, CBM, Gas Electron Multiplier, Gas gain, Resolution PACS: 29.40.Cs
## 1. Introduction
## 2. Detector descriptions and tests
The Compressed Baryonic Matter (CBM) experiment at the future Facility for Antiproton and Ion Research (FAIR) in Darmstadt, Germany will use proton and heavy ion beams to study matter at extreme conditions [1, 2]. The CBM experiment at FAIR is designed to explore the QCD phase diagram in the region of high baryon densities [3]. This will only be possible with the application of advanced instrumentation, including highly segmented and fast gaseous detectors.
Gas Electron multipliers (GEM) will be used in CBM Muon Chamber (MUCH) located downstream of the Silicon Tracking System (STS) of the CBM experiment along with other sophisticated detectors [4]. The main goal of MUCH is to detect the dimuon signals arising from the decay of the low mass vector mesons and those from the decay of charmonia produced in the heavy ion collisions at FAIR.
In GSI detector laboratory an R&D e ff ort is launched to study the characteristics of GEM detectors for the CBM experiment. The primary goals of this R&D program are: (a) to verify the stability and integrity of the GEM detectors over a period of time, during which a charge density of the order of several Coulomb cm 2 / is accumulated in the detector; (b) to establish the functioning of triple GEM as a precise tracking detector under the extreme condition of the CBM experiment; (c) to study usual parameters e.g., e ffi ciency, rate capability, long term stability, spark probability by varying conditions like temperature, gas composition or radiation dose.
In this article, we would like to present the initial results of characterisation of triple GEM detectors for CBM.
∗
Corresponding author
Email address: [email protected] (S. Biswas)
A triple GEM detector, consisting of double mask foils, obtained from CERN has been studied systematically. The drift, transfer and induction gaps of the detector are 3 mm, 2 mm and 2 mm respectively. The voltage to the drift plane and individual GEM plates has been applied through a voltage divider chain. Although there is a segmented readout pad the signal in this study was obtained from all the pads summed by a add up board and a single input is fed to a charge sensitive preamplifier. After that a PXI LabVIEW based data acquisition system is used. The gain of the detector has been measured by obtaining the mean position of 5.9 keV peak of Fe 55 X-ray spectrum with Gaussian fitting. A typical spectrum recorded with a Fe 55 source is shown in Fig. 1. The variation of the gain and energy resolution of this detector with that of the applied voltage has been measured for di ff erent gas mixtures and with di ff erent gas flow rates.
Figure 1: Fe 55 X-ray spectrum obtained with triple GEM detector.
## 3. Results
The detector has been operated with Argon and CO2 in 60 40, 70 30, 80 20 mixing ratios with di / / / ff erent flow rates e.g. 50 ml min, 100 ml min and 200 ml min. / / / The variation of effective gain and energy resolution with that of global voltage ( ∆ V1 +∆ V2 +∆ V3) are shown in Fig. 2 and Fig. 3 respectively for the gas mixture Ar CO2 / in 70 30 with di / ff erent flow rates. It is clear that the gain increases exponentially and the energy resolution improves with the increase of voltage. The gain is relatively higher with the higher gas flow rate. This is due to the less oxygen contents (shown in Fig. 2) during higher flow rate. Same behavior is also observed for the other two gas mixtures.
The detector is operated continuously for five days with Ar CO2 / in 70 30 ratio with 100 ml min flow rate at a global / / voltage 1176 V. The gain and resolution as function of time are shown in Fig. 4 and Fig. 5 respectively.
Figure 2: Gain vs. global voltage.
Figure 3: Resolution vs. global voltage.
## 4. Conclusions and outlook
Variation of gain and resolution with voltage for di ff erent gas mixtures and with di ff erent gas flow rates has been measured in GEM detectors. It is clear that oxygen content in the gas has a very important role in GEM performance even in a few ppm level.
In an initial continuous operation of five days the gain fluctuates with time, and resolution varies about 4%. Further investigation is necessary to correlate this variation with other ambient parameters.
Figure 4: Gain as a funcion of period of operation.
Figure 5: Resolution as a funcion of period of operation.
Figure 6: New GEM box designed at GSI.

Fabrication of new 10 cm × 10 cm GEM detector with newly designed box (shown in Fig. 6) and their characterisation is also carried out. Further studies are still in progress and will be communicated at a later stage.
## 5. Acknowledgement
We are thankful to Dr. Ingo Fr¨hlich of University of Franko furt, Prof. Dr. Peter Fischer of Institut f¨r Technische In foru matik der Universit¨ at Heidelberg, Prof. Dr. Peter Senger,CBM Spokeperson and Dr. Subhasis Chattopadhyay of VECC, India for their support in course of this work.
## References
- [1] http: // www.gsi.de forschung fair / / experiments CBM / /
- [2] http: // www.fair-center.org /
- [3] CBM Progress report 2008.
- [4] F. Sauli, Nucl. Instr. and Meth. A 386 (1997) 531. | 10.1016/j.nima.2012.08.044 | [
"S. Biswas",
"A. Abuhoza",
"U. Frankenfeld",
"J. Hehner",
"C. J. Schmidt",
"H. R. Schmidt",
"M. Traeger",
"S. Colafranceschi",
"A. Marinov",
"A. Sharma"
] | 2014-08-01T04:33:38+00:00 | 2014-08-01T04:33:38+00:00 | [
"physics.ins-det",
"nucl-ex"
] | Study of the characteristics of GEM detectors for the future FAIR experiment CBM | Characteristics of triple GEM detector have been studied systematically. The
variation of the effective gain and energy resolution of GEM with variation of
the applied voltage has been measured with Fe55 X-ray source for different gas
mixtures and with different gas flow rates. Long-term test of the GEM has also
been performed. |
1408.0076v2 | ## Embedding Properties in Central Products
## Dandrielle Lewis, Ayah Almousa, and Eric Elert
December 16, 2014
## Abstract
In this article, we study group theoretical embedding properties of subgroups in central products of finite groups. Specifically, we give characterizations of normal, subnormal, and abnormal subgroups of a central product of two groups, prove these characterizations, and provide examples.
## 1 Introduction
In group theory, studying subgroups of groups is important, but it is not easy to answer the question 'What can we say about the subgroups?' for products of groups. Hence, investigating subgroups that satisfy specific properties, known as characterizations, in products of groups is of particular interest. Edouard Goursat first determined how to identify and describe a subgroup of a direct product of two groups in [7], and his result has been refined as can be seen in [4]. Goursat's work provides the backbone necessary to understand subgroups of a direct product, and many mathematicians have since made significant contributions to this area.This article presents characterizations of subgroups in a central product of two groups, where a central product is a direct product with an amalgamated center.
Recently, more work has been done on subgroups of a direct product of two groups. For example, in [3], [4],[1], and [2], necessary and sufficient conditions have been provided to characterize subgroups of a direct product including normal and subnormal subgroups. However, very little work has been done to characterize these subgroups for a central product of two groups. In this article, we begin to characterize subgroups of central products, focusing on normal, subnormal, and abnormal subgroups. We provide equivalent conditions for normality, subnormality, and abnormality, and give applications of our results.
In Section 2, we define and review basic group theory terms and discuss direct products by introducing notation necessary to understand propositions presented from other work on direct products. In Section 3, central products are defined internally and externally, and a concrete example of a central product is provided. In Section 4, we characterize normal subgroups by examining the commutator of subgroups of a central product; we prove this result and provide an application using the example introduced in Section 3. In Section 5, subnormal subgroups are defined, and a characterization of subnormal subgroups of a central product and an example are provided. In Section 6, we define abnormal subgroups, determine and prove lemmas concerning abnormal subgroups, and present a characterization of abnormal subgroups in a central product. Finally, in Section 7, a summary of our results and future work on characterizations of pronormal subgroups of central products are given.
## 2 Preliminaries
In this article, we consider only finite groups. Our notation and terminology are standard, but we define terms and state lemmas that are necessary to understand later information.
Let G be a group. We say G is simple if it has no normal subgroups other than itself and the trivial subgroup. For elements a, b ∈ G , we write a b = b -1 ab , and if A is a nonempty subset of G ,
$$A ^ { G } = \{ A ^ { g } | \ g \in G \}.$$
The commutator of a and b , [ a, b ], is given by a -1 a b . For A,B ≤ G , [ A,B ] will denote the subgroup generated by all the commutators [ a, b ] where a ∈ A and b ∈ B . We define [ a , a 1 2 , a 3 ] = [[ a , a 1 2 ] , a 3 ] and define commutators of n elements recursively where [ a , a 1 2 , . . . , a n ] = [[ a , a 1 2 , ...a n -1 ] , a n ] for a i in
a group G , for all i ∈ N , i ≤ n . The center of a group G is Z G ( ) = { g ∈ G gx | = xg , ∀ x ∈ G } . The derived series of a group G is the series
$$G = G ^ { ( 0 ) } \geq G ^ { ( 1 ) } \geq \cdots$$
where G ( ) i = [ G ( i -1) , G ( i -1) ]. A group G is solvable if G ( ) i = 1 for some i ≥ 1.
The following lemma contains classical results about the commutator subgroup [ A,B ]. This lemma is presented here because it is useful in later proofs.
Lemma 2.1. Let A,B,C be subgroups of a group G .
- (i) [ A,B ] = [ B,A ] ✂ 〈 A,B 〉 .
- (ii) [ A,B ] ≤ A if and only if B ≤ N G ( A ) , where N G ( A ) is the normalizer of A in G .
- (iii) If α : G → α G ( ) is a group homomorphism, then α ([ A,B ]) = [ α A , α B ( ) ( )] .
- (iv) If A and B are normal subgroups of G , then [ A,B ] is a normal subgroup of G .
- (v) 〈 A B 〉 = A A,B [ ] .
Proof. See [5].
Whenever we discuss direct products, they will be viewed externally unless otherwise stated. Let U 1 and U 2 be groups and consider the direct product U 1 × U 2 . The maps π i : U 1 × U 2 → U i given by π i (( u , u 1 2 )) = u i for i = 1 2 are standard projections. , U 1 = { ( u , 1 1) | u 1 ∈ U 1 } and U 2 = { (1 , u 2 ) | u 2 ∈ U 2 } , where U i is a subgroup of U 1 × U 2 for i = 1 2. ,
The following lemma is utilized throughout this article, and it provides us with a one-to-one correspondence between normal subgroups. This result can be found in abstract algebra textbooks such as [6] and [9] and follows from the classical Lattice Isomorphism Theorem.
↦
Lemma 2.2. If ϕ : G → H is an epimorphism of groups and S ϕ ( G ) = { K ≤ G | ker ϕ ⊆ K } and S H ( ) is the set of all subgroups of H , then the assignment K → ϕ K ( ) is a one-to-one correspondence between S ϕ ( G ) and S H ( ) . Under this correspondence, normal subgroups correspond to normal subgroups.
Proof.
$$\text{See } [ 9 ].$$
Remark 2.3 . Let φ : G → H be a group epimorphism, and let W ≤ H . For the remainder of this article, under such an epimorphism φ , we will assume that ker φ ≤ φ -1 ( W ), where φ -1 ( W ) is the preimage of W .
## 3 Central Products
/negationslash
Central products have historically been useful for the characterization of extraspecial groups. Let p be a prime. Extraspecial groups are p -groups where the center, commutator subgroup, and the intersection of all the maximal subgroups have order p . All extraspecial groups of order p 2 n +1 for some n > 0 and p = 2 or p = 2 can always be written as a central product of extraspecial groups of order p 3 [10]. When discussing central products, we will adopt the definition and notation presented in [5]:
Definition 3.1. Let U , U 1 2 ≤ G . Then G is an internal central product of U 1 and U 2 if
- (i) G = U U 1 2 , and
- (ii) [ U , U 1 2 ] = 1 .
This definition is standard as can be seen in [10], and observe that it implies that U i ✂ G for i = 1 2 , and U 1 ∩ U 2 ≤ Z U ( 1 ) ∩ Z U ( 2 ). The following lemma establishes the relationship between central products and direct products and serves as a powerful tool for proving results.
Lemma 3.2. [5] Let G be a group such that U , U 1 2 ≤ G D , = U 1 × U 2 is the external direct product, U 1 = { ( u , 1 1) | u 1 ∈ U 1 } and U 2 = { (1 , u 2 ) | u 2 ∈ U 2 } . Then the following are equivalent:
- (i) G is an internal central product of U 1 and U 2 .
- (ii) There exists an epimorphism ε : D → G such that ε U ( 1 ) = U 1 and ε U ( 2 ) = U 2 .
Remark 3.3 . Throughout this article we will view central products internally wherever it is sensible. When central products are discussed externally, we will do so as is described in the following construction:
Theorem 3.4. [5] Let V , V 1 2 be finite groups, and assume that A is an abelian group for which there exists monomorphisms µ i : A → Z V ( i ) for i = 1 2 , . Let D denote the external direct product V 1 × V 2 , let V 1 = { ( v , 1 1) | v 1 ∈ V 1 } , and V 2 = { (1 , v 2 ) | v 2 ∈ V 2 } . Then V i ∼ = V i . Set
$$N = \{ ( \mu _ { 1 } ( a ), \mu _ { 2 } ( a ^ { - 1 } ) ) | \, a \in A \}$$
Then N ✂ D V , i ∩ N = 1 , and with U i = V N/N i , the quotient group G = D/N has the following properties:
- (i) G is a central product of the subgroups U 1 and U 2 , and U i ∼ = V i for i = 1 2 , .
- (ii) U 1 ∩ U 2 = A N/N i ∼ = A , where
$$A _ { 1 } & = \{ ( \mu _ { 1 } ( a ), 1 ) | \, a \in A \} \\ A _ { 2 } & = \{ ( 1, \mu _ { 2 } ( a ) ) | \, a \in A \}$$
The external central product D/N as constructed above is isomorphic to the internal central product G = U U 1 2 where U i ∼ = V i for i = 1 2. We now show that , φ : D/N → G given by φ (( a, b ) N ) = ab is well defined but leave it to the reader to prove φ an isomorphism.
Well defined: Let ( u , u 1 2 ) N = ( v , v 1 2 ) N. We wish to show that φ (( u , u 1 2 ) N ) = φ (( v , v 1 2 ) N . ) By assumption, ( v , v 1 2 ) -1 ( u , u 1 2 ) N = N . Hence, ( v , v 1 2 ) -1 ( u , u 1 2 ) = ( v -1 1 u , v 1 -1 2 u 2 ) ∈ N . Because the identity maps to the identity,
$$\phi ( ( v _ { 1 } ^ { - 1 } u _ { 1 }, v _ { 2 } ^ { - 1 } u _ { 2 } ) N ) = v _ { 1 } ^ { - 1 } u _ { 1 } v _ { 2 } ^ { - 1 } u _ { 2 } = 1$$
Now,
$$\phi ( ( u _ { 1 }, u _ { 2 } ) N ) = u _ { 1 } u _ { 2 } = ( v _ { 1 } v _ { 1 } ^ { - 1 } ) u _ { 1 } ( v _ { 2 } v _ { 2 } ^ { - 1 } ) u _ { 2 }$$
However, elements of U 2 commute with elements of U 1 , which yields
$$v _ { 1 } v _ { 2 } ( v _ { 1 } ^ { - 1 } u _ { 1 } v _ { 2 } ^ { - 1 } u _ { 2 } ) = v _ { 1 } v _ { 2 } = \phi ( ( v _ { 1 }, v _ { 2 } ) N ).$$
Therefore, φ is well defined.
Internal central products are unique because G = U U 1 2 is determined by the choice of subgroups U 1 and U 2 of G . However, external central products are not unique because the construction depends on the choice of monomorphisms µ 1 and µ 2 .
Let us develop an intuition for the construction of an external central product via an example that we will return to in later sections.
Example 3.5. Consider the dihedral group of order eight, D 8 , and the cyclic group of order four, C 4 , with the following respective group presentations:
$$D _ { 8 } & = \langle r, s | \, r ^ { 4 } = s ^ { 2 } = 1, r s r = s \rangle \\ C _ { 4 } & = \langle y | \, y ^ { 4 } = 1 \rangle$$
We use 3.4 to construct D 8 ◦ C 4 , a central product of D 8 and C 4 , which is a group of order 16. Let U 1 = D ,U 8 2 = C 4 . Fix A = Z D ( 8 ) = ∼ C 2 . Then we define the monomorphisms
$$\mu _ { 1 } & \colon Z ( D _ { 8 } ) \to Z ( D _ { 8 } ) \\ \mu _ { 2 } & \colon Z ( D _ { 8 } ) \to Z ( C _ { 4 } )$$
by µ 1 as the identity map and µ 2 ( r 2 ) = y 2 . Then N = { ( µ 1 ( a , µ ) 2 ( a -1 )) | a ∈ A } = { (1 , 1) ( , r 2 , y 2 ) } , and
$$D _ { 8 } \circ C _ { 4 } = \frac { D _ { 8 } \times C _ { 4 } } { N }.$$
Without loss of generality, suppose r = ( r, 1) N s , = ( s, 1) N , and y = (1 , y ) N . Then
$$D _ { 8 } \circ C _ { 4 } = \langle \overline { r }, \overline { s }, \overline { y } | \, \overline { r } ^ { 4 } = \overline { s } ^ { 2 } = N, \, \overline { r s r } = \overline { s }, \, \overline { r } ^ { 2 } = \overline { y } ^ { 2 }, \, \overline { r y } = \overline { y r }, \, \overline { s y } = \overline { y s } \rangle.$$
Note that because of the isomorphism between the internal and external presentation of a central product, we know that we may also write this group as
$$D _ { 8 } C _ { 4 } = \langle r, s, y, | \ r ^ { 4 } = s ^ { 2 } = 1, \ r s r = s, \ r ^ { 2 } = y ^ { 2 }, \ r y = y r, \ s y = y s \rangle.$$
Remark 3.6 . All results characterizing subgroups of central products in the remaining sections will be stated for internal central products. It is important to note that all results will apply to external central products due to the isomorphism between internal and external central products.
## 4 Normal Subgroups of Central Products
The goal of this section is to characterize normal subgroups of a central product of two groups. 3.2 allows us to define the central products of groups U 1 and U 2 by an epimorphism from D = U 1 × U 2 onto G = U U 1 2 with ε U ( i ) = U i for i = 1 2. We begin with a lemma from [1] that characterizes normal , subgroups of a direct product and serves as the inspiration for our characterization.
$$\text{Lemma $4.1$. $Let $U_{1}$, $U_{2}$ be groups. $Then $N\leq U_{1} \times U_{2}$ if and only if $[N,\overline{U}_{i}] \leq N\cap \overline{U}_{i}$ where $i = 1,2$.}$$
In 3.2, an epimorphism between direct products and central products was established to give an alternate and more useful way of viewing central products. Given an epimorphism, we know by 2.2 that there is a one-to-one correspondence between normal subgroups of a domain which contain the kernel and normal subgroups of the codomain. This serves as a motivation for the following result.
Proposition 4.2. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G , where D = U 1 × U 2 . Let H ≤ G . Then H ✂ G if and only if ε -1 ( H ) ✂ D .
Proof. By 3.2, an epimorphism ε : D → G exists. Since there is a one-to-one correspondence between the set S ε ( D ) = { K ≤ D | ker ε ≤ K } and S G ( ), the set of all subgroups of G , we know for any normal subgroup of D containing ker ε , its image is a normal subgroup of G . That is,
$$H \unlhd G \iff \ker \varepsilon \leq \varepsilon ^ { - 1 } ( H ) \unlhd D$$
as desired.
The following diagram demonstrates the relationship established in 4.2 between normal subgroups of U U 1 2 and the normal subgroups of U 1 × U 2 containing the ker ε :
ε
/d47
/d47
Figure 1: Diagram for 4.2
To further characterize normal subgroups of the central product U U 1 2 , we generalize 4.1. This generalization provides an efficient way to find normal subgroups of U U 1 2 and can be easily implemented in computer algebra systems such as GAP or Sage.
Proposition 4.3. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 . Then H ✂ G if and only if [ U , H i ] ≤ U i ∩ H where i = 1 2 , .
Proof. If H ✂ G , then N G ( H ) = G and U i ≤ N G ( H ). So [ U , H i ] ≤ H by 2.1. Similarly, because U i ✂ G , we know [ U , H i ] ≤ U i . Therefore, [ U , H i ] ≤ U i ∩ H for i = 1 2 as desired. ,
Assume that [ U , H i ] ≤ U i ∩ H for i = 1 2. Let , h ∈ H and g ∈ G , and consider h g . Because G is an internal central product, we can write g = u u 1 2 for some u 1 ∈ U 1 and u 2 ∈ U 2 . Therefore,
$$h ^ { g } = h ^ { u _ { 1 } u _ { 2 } } = ( u _ { 1 } u _ { 2 } ) ^ { - 1 } h ( u _ { 1 } u _ { 2 } ) = u _ { 2 } ^ { - 1 } u _ { 1 } ^ { - 1 } h u _ { 1 } u _ { 2 } = u _ { 2 } ^ { - 1 } ( h h ^ { - 1 } ) u _ { 1 } ^ { - 1 } h u _ { 1 } u _ { 2 }.$$
Note that h -1 u -1 1 hu 1 ∈ H ∩ U 1 by assumption. Let h 1 = h -1 h u 1 and h 2 = hh 1 . Then
$$h ^ { g } = h _ { 2 } ^ { u _ { 2 } } = h _ { 2 } h _ { 2 } ^ { - 1 } h _ { 2 } ^ { u _ { 2 } }.$$
Since h -1 2 h u 2 2 ∈ U 2 ∩ H , it follows that h g ∈ H and H ✂ G .
In the following diagram we give a visual representation of 4.3.
Figure 2: Diagram for 4.3. Observe that we must have H ✁ U U 1 2 for accuracy; otherwise, the commutator subgroup [ U , H i ] would not be a subgroup of U i ∩ H for i = 1 2. , Lines without arrowheads indicate subgroup containment with smaller groups below the groups in which they are contained.
The following theorem provides a summary of our results shown in this section.
Theorem 4.4. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G where D = U 1 × U 2 . Let H ≤ G . Then the following are equivalent:
- (i) H ✂ G .
- (ii) ε -1 ( H ) ✂ D .
- (iii) [ U , ε i -1 ( H )] ≤ U i ∩ ε -1 ( H ) for i = 1 2 , .
- (iv) [ U , H i ] ≤ H ∩ U i for i = 1 2 , .
Note that ( ii ) ⇐⇒ ( iii ) is a direct application of 4.1.
Example 4.5. To illustrate the usefulness of 4.4, consider D C 8 4 from 3.5. In this example, we determined its subgroups, their respective orders, their isomorphism types, and the normal subgroups using our results. This information is provided in the table below.
| Isomorphism Type | # | Subgroups | # Normal | Normal Subgroups |
|--------------------|-----|-------------------------------------------------------------------------------------|------------|--------------------|
| Trivial group | 1 | { 1 } | 1 | All |
| C 2 | 7 | 〈 r 2 〉 , 〈 s 〉 , 〈 rs 〉 , 〈 r 2 s 〉 , 〈 r 3 s 〉 , 〈 ry 〉 , 〈 r 3 y 〉 | 1 | 〈 r 2 〉 |
| C 4 | 4 | 〈 y 〉 , 〈 r 〉 , 〈 sy 〉 , 〈 rsy 〉 | 4 | All |
| V 4 | 4 | 〈 r 2 , s 〉 , 〈 r 2 , rs 〉 , 〈 r 2 , sy 〉 | 4 | All |
| Q 8 | 1 | 〈 r, sy 〉 | 1 | All |
| C 4 × C 2 | 3 | 〈 r, y 〉 , 〈 s, y 〉 , 〈 rs, y 〉 | 3 | All |
| D 8 | 3 | 〈 r, s 〉 , 〈 ry, sy 〉 , 〈 rsy, ry 〉 | 3 | All |
| D 8 C 4 | 1 | D 8 C 4 | 1 | All |
| Total | 23 | | 17 | |
We provide a sample calculation using 4.4. Consider the subgroup 〈 rsy 〉 ≤ D C 8 4 . To show this subgroup is normal, it suffices to verify that [ 〈 rsy , D 〉 8 ] ≤ 〈 rsy 〉 ∩ D 8 and [ 〈 rsy , C 〉 4 ] ≤ 〈 rsy 〉 ∩ C 4 . It is sufficient to check this using the generators of each group:
$$& [ r s y, y ] = 1 \leq \langle r s y \rangle \cap C _ { 4 } \\ & [ r s y, s ] = r ^ { 3 } s y s r s y s = y ^ { 2 } = r ^ { 2 } \\ & [ r s y, r ] = r ^ { 3 } s y r ^ { 3 } r s y r = r ^ { 2 } \\ & [ \langle r s y \rangle, D _ { 8 } ] = \langle r ^ { 2 } \rangle \leq \langle r s y \rangle \cap D _ { 8 }$$
$$\ 8$$
Hence, 〈 rsy 〉 ✂ D C 8 4 . Our result is also helpful to identify subgroups that are not normal. For example, to see the subgroup 〈 s 〉 ≤ D C 8 4 is not normal, we verify that [ 〈 s , D 〉 8 ] /notlessequal 〈 s 〉 ∩ D 8 .
$$[ s, r ] = s r ^ { 3 } s r = r ^ { 2 } \notin \langle s \rangle.$$
So, 〈 s 〉 is not a normal subgroup of D C 8 4 .
## 5 Subnormal Subgroups of Central Products
Our next goal is to characterize subnormal subgroups of central products. We use the following definition of subnormal from [5] with adjusted notation.
Definition 5.1. Let H ≤ G . We call H subnormal in G , written H sn G , if there exists a chain of subgroups H ,H ,..., H 0 1 r such that
$$H = H _ { 0 } \unlhd H _ { 1 } \unlhd \dots \unlhd H _ { r - 1 } \unlhd H _ { r } = G$$
This is called a subnormal chain from H to G . If such a chain is the minimal possible chain from H to G , we say that the subnormal subgroup is of defect r .
Subnormal subgroups were completely characterized in direct products by Hauck in [8]. In the following theorems, we adopt, with some modifications, the notation for this classification as it is presented in [1].
Lemma 5.2. A subgroup K of U 1 × U 2 is subnormal in U 1 × U 2 (of defect r ) if and only if
$$[ U _ { i }, \pi _ { i } ( K ),.. ^ { r }., \pi _ { i } ( K ) ] \leq K \cap U _ { i }$$
for i = 1 2 , .
In order to classify subnormal subgroups of central products, we seek a correspondence theorem similar to 2.2 in order to establish a relationship between subnormal subgroups of the direct product of two groups and subnormal subgroups of a central product of two groups. We do so using the following proposition.
↦
Proposition 5.3. Let f : G → H be an epimorphism. Let S f ( G ) = { K ≤ G | ker f ≤ K } , and let S H ( ) be the set of all subgroups of H . Then there is a one-to-one correspondence K → f ( K ) between S f ( G ) and S H ( ) , where subnormal subgroups correspond to subnormal subgroups.
Proof. To show that subnormal subgroups correspond to subnormal subgroups under the bijection between S f ( G ) and S H ( ), it suffices to show that for U, V ∈ S f ( G ), V ✂ U if and only if f ( V ) ✂ f ( U ). To prove this, we construct an epimorphism φ : U → f ( U ) given by φ u ( ) = f ( u ) for all u ∈ U .
- φ is a homomorphism: For any u, v ∈ U , φ uv ( ) = f ( uv ) = f ( u f ) ( v ) = φ u φ v ( ) ( ) because f is a homomorphism.
φ is surjective: Let x ∈ f ( U ). Then x = f ( u ) for some u ∈ U , but φ u ( ) = f ( u ) = x . So φ is onto and is therefore an epimorphism.
Now it suffices to show that ker φ = ker f . Let a ∈ ker φ . Then φ a ( ) = f ( a ) = 1, and ker φ ⊆ ker f . Similarly, because ker f ≤ U , we have that if b ∈ ker f , then f ( b ) = φ b ( ) = 1. Hence, ker f ⊆ ker φ and we have equality, as desired.
By 2.2, we know that there exists a one-to-one correspondence between subgroups of U containing ker φ = ker f and subgroups f ( U ) such that normal subgroups correspond to normal subgroups. Then ker f ≤ V ✂ U ≤ G if and only if f ( V ) ✂ f ( U ).
Applying this result to a chain of normal subgroups will prove the desired theorem. Specifically, for ker f ≤ A , we get A = A 0 ✂ A 1 ✂ . . . ✂ A r = G if and only if f ( A 0 ) ✂ f ( A 1 ) ✂ . . . ✂ f ( A r ) = f ( G ) = H . Therefore, f ( A ) sn H .
Utilizing 5.3 and 3.2, we obtain the following characterization of subnormal subgroups.
Proposition 5.4. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G where D = U 1 × U 2 . Then H sn G if and only if ε -1 ( H ) sn D .
Proof. By 3.2, we know that for any central product G there exists an epimorphism ε : D → G such that ε U ( i ) = U i . By 5.3, we know that ε gives rise to a one-to-one correspondence between the set of subnormal subgroups of D which contain ker ε and the set of subnormal subgroups of G . Therefore, H sn G if and only ε -1 ( H ) sn D as desired.
Naturally, our next goal was to answer the question: 'Could we further characterize subnormal subgroups in a way that would be useful for computations?' In the following result, we provide a characterization of subnormal subgroups for central products which could be implemented in GAP or Sage.
Proposition 5.5. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 . Then H sn G of defect r if and only if [ U , H, . . ., H i r ] ≤ U i ∩ H.
Figure 3: Observe that we must have H sn U U 1 2 for accuracy; otherwise, the commutator subgroup [ U , H, . . ., H i r ] would not be a subgroup of U i ∩ H for i = 1 2. , Lines without arrowheads indicate subgroup containment with smaller groups below the groups in which they are contained.
The following theorem provides a summary of our results shown in this section.
Theorem 5.6. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G where D = U 1 × U 2 . Let H ≤ G . Then the following are equivalent:
- (i) H sn G of defect less than or equal to r .
- (ii) ε -1 ( H ) sn D of defect less than or equal to r .
- (iii) [ U , ε i -1 ( H ,. . ., ε ) r -1 ( H )] ≤ U i ∩ ε -1 ( H ) .
- (iv) [ U , H, . . ., H i r ] ≤ U i ∩ H .
Proof. For ease of notation set K = ε -1 ( H
For ( ) i ⇐⇒ ( ii ) and ( ii ) ⇐⇒ ( iii
). ) see 5.4 and 5.2 respectively.
( iii ) ⇒ ( iv ): Suppose [ U , K, . . ., K i r ] ≤ U i ∩ K . Because ε is a homomorphism, we know that
$$\left ( \overline { U } _ { i }, K,. ^ { r }., K \right ] \leq \overline { U } _ { i } \cap K \ \text{ implies } \ \varepsilon ( \left ( \overline { U } _ { i }, K,. ^ { r }., K \right ) ) \leq \varepsilon ( \overline { U } _ { i } \cap K ).$$
Additionally, since ε is onto, ε U ( i ∩ K ) ≤ ε U ( i ) ∩ ε K ( ). Therefore,
$$[ U _ { i }, H,. ^ { r }.., H ] = [ \varepsilon ( \overline { U } _ { i } ), \varepsilon ( K ),. ^ { r }.., \varepsilon ( K ) ] = \varepsilon [ \overline { U } _ { i }, K,. ^ { r }.., K ] \leq \varepsilon ( \overline { U } _ { i } \cap K ) \leq \varepsilon ( \overline { U } _ { i } ) \cap \varepsilon ( K ) = U _ { i } \cap H$$
as desired.
( iv ) ⇒ ( iii ): Suppose [ U , H, . . ., H i r ] ≤ U ∩ H . Now ε -1 ([ U , H, . . ., H i r ]) ≤ ε -1 ( U i ∩ H ). Since U i ≤ ε -1 ( U i ), we know [ U , ε i -1 ( H ,. . . , ε ) -1 ( H )] ≤ [ ε -1 ( U i ) , ε -1 ( H ,. . . , ε ) -1 ( H )] and U i ∩ ε -1 ( H ) ≤ ε -1 ( U i ) ∩ ε -1 ( H ).
Without loss of generality, consider U 1 . Let [( u, 1) ( , h , h 1 2 )] be an arbitrary element of [ U , ε 1 -1 ( H )]. Then [( u, 1) ( , h , h 1 2 )] = ( u, 1) -1 ( h , h 1 2 ) -1 ( u, 1)( h , h 1 2 ) = ( u -1 h -1 1 uh , h 1 -1 2 h 2 ) = ( u -1 h -1 1 uh , 1 1) ≤ U 1 . Now if ( d , d 1 2 ) ∈ D and ( u, 1) ∈ U 1 , then [( u, 1) ( , d , d 1 2 )] = ( u -1 h -1 1 uh , 1 1) ≤ U 1 .
By induction, [ U , ε i -1 ( H ,. . . , ε ) -1 ( H )] ≤ U i . Since [ U , ε i -1 ( H ,. . . , ε ) -1 ( H )] ≤ ε -1 ( U i ) ∩ ε -1 ( H ), we have
$$[ \overline { U } _ { i }, \varepsilon ^ { - 1 } ( H ), \dots, \varepsilon ^ { - 1 } ( H ) ] \leq \overline { U } _ { i } \cap \varepsilon ^ { - 1 } ( U _ { i } )$$
Remark 5.7 . If we defined multi-fold commutators as [ a , a 1 2 , . . . , a n ] = [ a , 1 [ a , ..., a 2 n ]] for a i in a group G instead of [[ a , a 1 2 , ..., a n -1 ] , a n ], our result in 5.5 would change to H ≤ G is subnormal in G of defect r if and only if [ H,.. ., H, U r i ] ≤ U i ∩ H . Similar for 5.6.
Example 5.8. To illustrate 5.6, consider D C 8 4 from 3.5. Using this example, we found that every subgroup of D C 8 4 is subnormal.
Consider the subgroup 〈 s 〉 ≤ D C 8 4 . It will be shown that 〈 s 〉 sn D C 8 4 with defect 2. Applying 5.6, we verify that [ D , 8 〈 s , 〉 〈 s 〉 ] ≤ D 8 ∩〈 〉 s and [ C , 4 〈 s , 〉 〈 s 〉 ] ≤ C 4 ∩〈 〉 s . It is sufficient to check this using the generators of each group:
$$[ r, s, s ] & = [ [ r, s ], s ] = [ r ^ { - 1 } s ^ { - 1 } r s, s ] = [ r ^ { 3 } s r s, s ] = [ r ^ { 2 }, s ] = r ^ { 2 } s r ^ { 2 } s = 1 \leq D _ { 8 } \cap \langle s \rangle \\ [ s, s, s ] & = [ [ s, s ], s ] = [ 1, s ] = 1 \leq D _ { 8 } \cap \langle s \rangle \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon$$
$$[ y, s, s ] = [ [ y, s ], s ] = [ y ^ { - 1 } s ^ { - 1 } y s, s ] = [ y ^ { 3 } s y s, s ] = [ y ^ { 4 } s ^ { 2 }, s ] = [ 1, s ] = 1 \leq C _ { 4 } \cap \langle s \rangle$$
Hence, [ D , 8 〈 s , 〉 〈 s 〉 ] ≤ D 8 ∩ 〈 s 〉 and [ C , 4 〈 s , 〉 〈 s 〉 ] ≤ C 4 ∩ 〈 s 〉 implies 〈 s 〉 sn D C 8 4 of defect 2.
## 6 Abnormal Subgroups of Central Products
Our final goal is to characterize abnormal subgroups of central products of two groups. Abnormal subgroups were originally studied due to their connection to the classification of finite groups because the normalizer of any Sylow subgroup of a group is always abnormal. There are many properties known about abnormal subgroups in finite solvable groups. Abnormal subgroups and normal subgroups are opposites. Moreover, a maximal subgroup is abnormal if and only if it is not normal.
To establish properties of abnormal subgroups and how they are viewed in central products, we begin this section by presenting technical lemmas.
Lemma 6.1. Let ε : D → G be an epimorphism. Let g = ( ) ε d and W ≤ G. Then ε -1 ( W g ) = ( ε -1 ( W )) d .
Proof. Let x ∈ ε -1 ( W ) d . Then x = y d for some y ∈ ε -1 ( W ). So, ε y ( ) ∈ W and as a consequence ( ε y ( )) g ∈ W g . Also, ( ε y ( )) g = ( ε y d ) = ε x ( ) which implies that ε x ( ) ∈ W g . Therefore, x ∈ ε -1 ( W g ).
Suppose x ∈ ε -1 ( W g ). Then for some h ∈ W ε x , ( ) = h g = h ε d ( ) = ( ( ε a )) ε d ( ) = ε a ( d ) for some a ∈ D . Therefore, x -1 a d = z , where z ∈ ker ε . That is, x = a z d -1 ∈ ( ε -1 ( W )) d . Therefore, ε -1 ( W g ) = ( ε -1 ( W )) d .
Lemma 6.2. Let ε : D → G be an epimorphism, g = ε d ( ) , and H ≤ G. Then 〈 ε -1 ( H , ) ( ε -1 ( H )) d 〉 = ε -1 〈 H,H g 〉 .
Proof. Let x ∈ 〈 H,H 〉 . Then x = a b a b 1 2 2 2 · · · a n n b where a i ∈ H,b i ∈ H . Since ε is an epimorphism, there exists a y ∈ D such that ε y ( ) = x . Furthermore, for a , b i i ∈ G , there exists c , d i i ∈ D respectively such that ε c ( i ) = a i and ε d ( i ) = b i . Then ε y ( ) = x ∈ 〈 H,H g 〉 implies y ∈ ε -1 〈 H,H g 〉 = 〈 ε -1 ( H ,ε ) -1 ( H g ) 〉 = 〈 ε -1 ( H ,ε ) -1 ( H ) d 〉 by 6.1.
Let x ∈ 〈 ε -1 ( H , ) ( ε -1 ( H )) d 〉 . Then x = k /lscript 1 1 · · · k m m /lscript , where k i ∈ ε -1 ( H ,/lscript ) i ∈ ( ε -1 ( H )) d = ε -1 ( H g ), and ε x ( ) = ε k ( ) ε /lscript ( ) · · · ε k ( ) ε /lscript ( ). Therefore, ε x ( ) ∈ 〈 H,H g 〉 , and x ∈ ε -1 〈 H,H g 〉 .
g g 1 1 m m
We present the formal definition of abnormal subgroups from [5].
Definition 6.3. Consider H ≤ G . H is abnormal in G , written H abn G , if g ∈ 〈 H,H g 〉 , for all g ∈ G .
Note if H abn G and G and G ′ are groups, then the following properties are satisfied.[5]
- (i) If H ≤ L ≤ G , then H abn L and L abn G .
- (ii) N G ( H ) = H .
- (iii) If φ : G → G ′ is a homomorphism, then φ H ( ) abn φ G ( ).
Example 6.4. Let G be a group. The diagonal subgroup of G × G is defined as ∆ = { ( g, g ) | g ∈ G } . Observe that ∆ = ∼ G .
Consider G = A 5 , the alternating group of degree of five, which is a classic example of a simple, nonsolvable group. By [11], we know G is simple if and only if ∆ is maximal in G × G . Therefore, ∆ is maximal in A 5 × A 5 . Because ∆ is maximal and not normal in A 5 × A 5 , ∆abn A 5 × A 5 .
In [2], abnormal subgroups were characterized for direct products of two groups, where one of the direct factors is solvable. This result is presented in the following lemma.
Lemma 6.5. Let D = U 1 × U 2 , where either U 1 or U 2 is solvable. Let K ≤ D . Then K abn D if and only if π i ( K ) abn U i and K = π 1 ( K ) × π 2 ( K ) .
Observe that the above lemma applies when either U 1 or U 2 is solvable. If U 1 or U 2 is not solvable, the result will not work. For example, in A 5 × A 5 , ∆ = A 5 cannot be written as a product of two subgroups. Therefore, one can see that 6.5 does not apply.
To characterize abnormal subgroups of central products, a correspondence theorem similar to 2.2 and 5.3 was needed to establish a relationship between abnormal subgroups of a direct product of two groups and abnormal subgroups of a central product of two groups. The following lemma provides the necessary correspondence.
Lemma 6.6. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G , where D = U 1 × U 2 . Let H ≤ G . Then H abn G if and only if ε -1 ( H ) abn D .
Proof. For ease of notation, define K = ε -1 ( H ).
- If K abn D , then x ∈ 〈 K,K x 〉 , ∀ x ∈ D . This implies ε x ( ) ∈ 〈 ε K , ε K ( ) ( ) ε x ( ) 〉 . Because ε is an epimorphism, ε D ( ) = G , and without loss of generality, ε x ( ) corresponds to an arbitrary element y of G . Therefore, y ∈ 〈 H,H y 〉 , ∀ y ∈ G and H abn G .
Suppose H abn G . By definition g ∈ 〈 H,H g 〉 , ∀ g ∈ G . Because ε is surjective, we know there exists some d ∈ D such that ε d ( ) = g . Therefore, d ∈ ε -1 〈 H,H g 〉 . By 6.2 ε -1 〈 H,H g 〉 = 〈 K,K d 〉 , where ε d ( ) = g . Since ε is an epimorphism, d ∈ 〈 K,K d 〉 , ∀ d ∈ D . Hence K abn D .
To further characterize abnormal subgroups of the central product U U 1 2 , we generalized 6.5. This generalization provides an efficient way to find abnormal subgroups of U U 1 2 and can be easily implemented in computer algebra systems such as GAP or Sage.
The following result provides a summary of the lemmas above.
Theorem 6.7. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G where D = U 1 × U 2 . Let H ≤ G . Suppose U 1 or U 2 is solvable. Then the following are equivalent:
- (i) H abn G .
- (ii) ε -1 ( H ) abn D .
(iii) π i ( K ) abn U i and K = π 1 ( K ) × π 2 ( K ) , where K = ε -1 ( H ) .
Theorem 6.8. Let G = U U 1 2 be the central product of subgroups U 1 and U 2 defined by the epimorphism ε : D → G , where D = U 1 × U 2 and either U 1 or U 2 is solvable. If H = V V 1 2 is a subgroup of G such that V i ≤ U i and ε -1 ( H ) = V 1 × V 2 contains ker ε , then H abn G if and only if V i abn U i , for i = 1 2 , .
Proof. ' ⇒ ': From 6.6 we know H abn G if and only if ker ε ≤ ε -1 ( H ) abn D . By 6.5, ε -1 ( H ) abn D if and only if π i ( ε -1 ( H )) abn U i and ε -1 ( H ) = π 1 ( ε -1 ( H )) × π 2 ( ε -1 ( H )).
Let V i = π i ( ε -1 ( H )). Consider the restriction of ε to ε -1 ( H ) given by:
$$\varepsilon \, \colon V _ { 1 } \times V _ { 2 } \rightarrow \varepsilon ( V _ { 1 } \times V _ { 2 } )$$
It is left to the reader to verify that ε V ( i ) = V i . Hence, by 3.2 so ε V ( 1 × V 2 ) is an internal central product of V 1 and V 2 and ε V ( 1 × V 2 ) = V V 1 2 .
But note that V 1 × V 2 = ε -1 ( H ) and ε ε ( -1 ( H )) = H . Therefore, H = V V 1 2 where V i abn U i , for i = 1 2. ,
' ⇐ ': Suppose H = V V 1 2 where V i ≤ U i , for i = 1 2. , By assumption, ε -1 ( H ) = V 1 × V 2 and V i abn U i , for i = 1 2. , By 6.5, we know V 1 × V 2 abn U 1 × U 2 if and only if V i abn U i . Finally, since H abn G if and only if ε -1 ( H ) abn D by 6.6, H abn G , as desired.
Figure 4: Note H = V V 1 2 must be abnormal in G for accuracy. As shown, H must be able to be written as a central product of V 1 and V 2 where V i is an abnormal subgroup U i for i = 1 2. , Lines without arrowheads indicate subgroup containment with smaller groups below the groups in which they are contained.
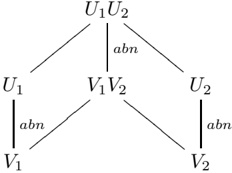
Note for this result about abnormal subgroups of central products of two groups, solvability of one of the central factors is still required.
## 7 Future Work
While characterizing normal, subnormal, and abnormal subgroups in a central product of groups, many other open questions did arise. One open question is to characterize pronormal subgroups of central products. Results on pronormal subgroups of direct products, as in [2], may be especially useful and inspirational for this direction of work.
Additionally, we would like to explore the characterization of abnormal subgroups of direct products and central products of two non-solvable groups.
## 8 Acknowledgments
We would like to thank the University of Wisconsin-Stout REU for providing us with the opportunity to pursue this project, and the NSF for funding this project via NSF Grant DMS-1062403.
## References
- [1] Brewster, B. and Mart´ ınez-Pastor, A. and P´rez-Ramos, M. D., e Embedding properties in direct products, London Math. Soc. Lecture Note Ser. , 339:246-255, 2007.
- [2] Brewster, B. and Mart´ ınez-Pastor, A. and P´rez-Ramos, M. D., Pronormal subgroups of a direct e product of groups, Journal of Algebra , 321(6):1734-1745, 2009.
- [3] Brewster, B. and Evan, J. and Hauck, P. and Reifferscheid, S., Subgroups of a direct product of groups that satisfy the strong Frattini argument, Comm. Algebra , 38(11):3993-4004, 2010.
- [4] Brewster, B. and Lewis, D., A characterization of subgroup containment in direct products, Ricerche di Matematica , 61(2):347-354, 2012.
- [5] Doerk, K. and Hawkes, T.O., Finite Soluble Groups , De Gruyter expositions in mathematics. W. de Gruyter, 1992.
- [6] Dummit, D.S. and Foote, R.M., Abstract Algebra , John Wiley & Sons Canada, Limited, 2004.
- [7] Goursat, E., Sur les substitutions orthogonales et les divisions r´guli`res de l'espace, e e Annales scientifiques de l' ´ cole E Normale Sup´ erieure , 6:9-102, 1889.
- [8] Hauck,P., Subnormal subgroups in direct products of groups, Journal of the Australian Mathematical Society (Series A) , 42:147-172, 4 1987.
- [9] Hungerford, T.W., Algebra , Graduate Texts in Mathematics. Holt, Rinehart and Winston, 1974.
- [10] Leedham-Green, C.R, and McKay, S., The Structure of Groups of Prime Power Order . Oxford University Press, 2002.
- [11] Jacques Th´ evenaz, Maximal Subgroups of Direct Products, Journal of Algebra , 198(2):352-361, 1997. | null | [
"Dandrielle Lewis",
"Ayah Almousa",
"Eric Elert"
] | 2014-08-01T04:36:27+00:00 | 2014-12-13T02:06:44+00:00 | [
"math.GR",
"20D40 (Primary), 20.25, 20D25, 20E07, 20D35 (Secondary)"
] | Embedding Properties in Central Products | In this article, we study group theoretical embedding properties of subgroups
in central products of finite groups. Specifically, we give characterizations
of normal, subnormal, and abnormal subgroups of a central product of two
groups. |
1408.0078v2 | ## NMR investigation of atomic and electronic structures of half-Heusler topologically nontrivial semimetals
Chenglong Shi , Xuekui Xi 1 *,1 , Zhipeng Hou 1,2 , Xiaoming Zhang , Guizhou Xu , 1 1 Enke Liu , Wenquan Wang , Wenhong Wang , Jinglan Chen ,and Guangheng Wu 1 2 1 1 1
1 State Key Laboratory for Magnetism, Beijing National Laboratory for Condensed Matter Physics,
- Institute of Physics, Chinese Academy of Sciences, Beijing 100190, People's Republic of China
2 College of Physics, Jilin University, Changchun 130023, People's Republic of China
## ABSTRACT
Recent band structure calculations predict that YPdBi is topologically trivial while its isostructural analogue YPtBi is topologically nontrivial. 209 Bi nuclear magnetic resonance (NMR) spectroscopy is employed to investigate the atomic and electronic structures of both compounds and test this theoretical hypothesis. The observed sign and magnitude of 209 Bi isotropic shifts of YPtBi at various temperatures are systematically distinct from YPdBi. Combined with Hall effect measurements, these results support the band inversion model.
Keywords topological insulators; NMR; half-Heusler alloy; spintronics
- * Author to whom the correspondence should be addressed: e-mail: [email protected]
## 1. Introduction
There has been a resurgence of interest in the family of RTX (R = rare earth elements including Sc,Y and Lanthanide elements, T=Ni,Pd,Pt, and X=Sb, Bi) half-Heusler alloys, not only for the fundamental importance but also for their potential applications as spintronic or thermoelectric materials [1-3]. Electronic band structure computations have discovered a topologically nontrivial characteristic in terms of a substantial band inversion in some half-Heusler compounds [2-7]. The computed band inversion strength (BIS, defined as energy difference between two bands, ∆ = E Γ 6 - E Γ 8 ) has been suggested as a measure of spin-orbit coupling (SOC) [4,5]. In particular, first principle computations with appropriate functionals indicate that YPdBi is a topologically trivial narrow band semiconductor/semimetal ( ∆ >0) while YPtBi is a potential topologically nontrivial semimetal ( ∆ <0) [4,5,7]. Experimental evidence for such bulk band structural characteristics, however, has rarely been reported [1]. This information should be observable by local susceptibility sensitive methods, such as solid state nuclear magnetic resonance (NMR).
Recently, cubic Yb(Sc,Y)-Pd(Pt)-Sb(Bi) and hexagonal Ce-Pd(Pt)-Sb half-Heusler compounds have been successfully characterized by solid state NMR [8-12]. However, the intrinsic magnetic response of band structural characteristics was frequently masked by localized magnetism from R 3+ ions. In this work, non 4 f electron/hole containing YPdBi and YPtBi half-Heusler compounds are investigated to probe atomic and electronic structures by 209 Bi NMR spectroscopy. This choice makes experimental comparison of intrinsic magnetic response of their band structures quite possible since 209 Bi NMR isotropic shift is sensitive to local electronic properties. At room temperature, the measured 209 Bi isotropic shift for YPdBi is (1200±10) ppm while it is (-1748±10) ppm for YPtBi, This large difference is correlated with the theoretically predicted Bi Γ 6 band inversion and its vicinity to the Fermi energy. Beyond the measurement at room temperature, we've further discovered that 209 Bi NMR shifts are sensitive to temperature in both compounds. In
combination with Hall effect measurements and first principle calculations, 209 Bi NMR isotropic shifts at various temperatures are found to reveal more detailed information about their characteristic band structures. This investigation indicates that 209 Bi NMR can be considered as an alternate powerful method to characterize the band structural features that are relevant for understanding their band topology in the family of Bi containing half-Heusler alloys.
## 2. Experimental procedures
Single crystals of YPdBi and YPtBi were grown out of Bi flux and characterized by X-ray diffraction (XRD) with Cu K radiation. More details on fabrication α procedures can be found elsewhere [13]. 209 Bi NMR spectra of powdered single crystals were obtained by integrating the spin-echo intensity with a Bruker Avance III 400 HD spectrometer in a magnetic field of ~9.39 Tesla. Hahn echo pulse sequence was used for recording echo intensity. The first pulse length (~5 μ s) is close to the 90 degree time ( t π /2 ) of the samples as determined by nutation. A typical pulse delay for the crystals is about 0.3 seconds according to their very short spin-lattice relaxation time (~60 ms). 209 Bi chemical shifts were referenced to 1M Bi(NO3)2 aqueous nitrate solution (Bi(NO3) ·5H2O in nitrate solution at 298 K). The Hall effects were 3 performed by rotating the crystals by 180º in a magnetic field of 5 Tesla using a commercial Physical Properties Measurement System from Quantum Design between 2 and 300 K. Hall coefficients were calculated from the slope of the measured Hall effect curves.
## 3. Results and discussion
Figure 1 presents static 209 Bi (spin = 9/2) NMR spectra of powdered YPdBi and I YPtBi crystals at room temperature. Only central lines can be observed. The central line width defined as full linewidth at half magnitude for YPdBi is ~32 kHz, much larger than that estimated for dipolar broadening (~ 1 kHz), indicating the existence of other contributions such as second order quadrupolar broadening, chemical shift anisotropy or site distributions. The inset in this figure illustrates that this compound
crystallizes in a cubic AgAsMg structure with space group number 216 ( m F 3 4 ). Y, Bi and Pd atoms occupy the positions 4 a (0, 0, 0), 4 b (1/2, 1/2, 1/2), and 4 c (1/4, 1/4, 1/4), respectively. By the way, the site occupancy in ref [13] is incorrect. The electric field gradients (EFGs) at the Bi sites is equal to zero based on crystallographic analysis of point symmetry and first principle calculations. No quadrupole interactions could be expected for ideal stoichiometric phase. Quadrupole interactions show up in the nutation measurements but the magnitudes turn out to be small [14,15], suggesting the existence of some EFGs produced by structural defects and 209 Bi central line broadening from second order quadrupole interactions be small [16]. Different types of atomic disorder are possible including antisite defects in samples. Disorders will cause some EFGs and site distributions. The central line broadening is probably from site distributions. The central line width of YPtBi sample is only ~20 kHz, indicating the site occupancy of Bi atoms in YPtBi are more ordering than YPdBi. In addition, the central lines for both samples are nearly symmetric. This means the anisotropic shifts can be considered to be zero. 209 Bi isotropic shift is then determined by the peak position. This choice can be justified by variable magnetic field dependence of peak position. At room temperature, the measured 209 Bi isotropic shift is about (1200±10) ppm for YPdBi while it is (-1748±10) ppm for its isostructural analogue YPtBi. Similar observation of this large difference in 209 Bi isotropic shifts between the two compounds was also noted in ref [12]. The measured shifts and quadrupole parameters including NMR data for YPdSb and YPtSb from literatures [11] are listed in Table 1 for comparison.
209 Bi NMR isotropic shifts ( 209 K iso ) and spin-lattice relaxation behaviors of YPdBi and YPtBi were further examined at variable temperatures. In wide band gap semiconducting materials, diamagnetic susceptibility and NMR isotropic shift are usually temperature independent while it is not the case in band gapless semiconductors or semimetals. As shown in Fig. 2a, 209 Bi shifts of YPd(Pt)Bi display temperature dependency. The temperature dependence of 209 Bi NMR shifts for both compounds follows a power law relationship within the same temperature range
investigated. After closer examination, the shifts for YPdBi drop from 1325 ppm to 1170 ppm from 455 to 220 K. For YPtBi, 209 Bi shifts decreases from -1538 to -1777 ppm from 455 to 220 K. Clearly, 209 Bi shifts for YPdBi are systematically distinct from YPtBi, pointing to their distinct electronic structures. The distinct electronic structures between YPdBi and YPtBi can be supported by the temperature dependence of charge carrier concentration ( n ) of YPdBi [13] and YPtBi [17], as determined from the Hall coefficients. Fig.2b shows that n for both compounds follows a power law relationship with temperature: T n , where α is a material constant. The fittings yield α = 1.9 for YPtBi and α = 4.0 for YPdBi. This result distinguishes YPtBi from YPdBi and supports the theoretical predication that YPtBi is a topologically nontrivial semimetal since the intrinsic charge carrier concentration of a topologically nontrivial semimetal changes with temperature following the power law, n T 3/2 [18].
Bulk band structures have been calculated with the Tran-Blaha modified Becke-Johnson density functional [19] implemented in WIEN 2k code [20]. The spin-orbit interactions are respected in the calculations. The radii of muffin-tin (RMT) are set to be 2.5 a.u. for all atoms. The calculated band structures for YPdBi and YPtBi are consistent with previous calculations [4,5]. YPdBi is shown to be trivial while YPtBi is topologically nontrivial, as shown in Fig. 3. The nontrivial topology of the electronic band structure is characterized by the inversion of 6 band at the point. The s -like band 6 in the valence band is situated below p -like 8 and the latter is close to the Fermi level. The band inversion strength ∆ (=E Γ 6 - E Γ 8 ) of YPdBi is 0.29 eV, which is, in magnitude, less than that (-0.87 eV) of YPtBi [4,5]. As shown in Fig. 2a, the observed 209 Bi isotropic shifts of YPtBi at various temperatures are distinct from YPdBi in both sign and magnitude and correlated with the band inversion. This correlation can be simply understood that NMR isotropic shifts of semiconductor or semimetals in a magnetic field are very sensitive to the symmetry of the conduction bands. In YPdBi, the conduction bands have s -symmetry while in YPtBi, conduction bands have p or d -symmetry from transition metals and at the same time Bi Γ 6 band is inverted to the valence band due to SOC [2,3]. The s character conduction electrons
contribute shifts via a Fermi contact mechanism which is positive. The p or d character electrons in the conduction band contribute to 209 Bi NMR shifts through negative core polarization mechanism in the materials studied. Again, 209 Bi NMR shifts and spin dynamics in this type of materials are related to the topology of the bulk band structures.
## 4. Conclusions
The atomic and electronic structures of YPdBi and YPtBi have been systematically examined by 209 Bi NMR spectroscopy at various temperatures. The observed 209 Bi NMR shifts and their temperature dependence reveal the distinct nature of band structures between YPdBi and YPtBi. 209 Bi NMR shifts are found to be correlated with the band inversion strength. In combination with Hall effect measurements, our result indicates that 209 Bi NMR isotropic shifts are very sensitive to different chemical environments, which is useful in search of interesting topological nontrivial phases among the family of Bi-containing half-Heusler alloys in the future.
Acknowledgements This work was supported by the 973 program (2011CB012800), the NSFC (Nrs. 51371190 and 51171207), and the 100 Talents Program of the Chinese Academy of Sciences.
## Figure Captions
FIG. 1 Static 209 Bi NMR spectra of powdered crystals of YPdBi and YPtBi, taken at 298 K.
FIG. 2 Temperature dependence of 209 Bi NMR isotropic shifts (a) and charge carrier concentration (b) for YPdBi and YPtBi crystals. The lines in (b) are fit with a power law: AT n . The fitting parameter are α =1.9 for YPtBi; α = 4.0 for YPdBi. The dashed lines in (a) are guide for eyes.
FIG. 3 Calculated bulk band structure of YPdBi (a) and YPtBi (b) compounds with spin-orbit interactions. The nontrivial topology of the electronic band structures for YPtBi is characterized by the band inversion of 6 (red) and 8 (blue) at the point. The band 6 symmetry is situated below 8 which is located at the Fermi level. From orbital symmetries, 6 is s -like band, 8 is pd hybrid bands.
Table 1 209 Bi anisotropic shift, isotropic shift and quadrupole coupling constant, CQ (= e qQ/h 2 ) parameters for two half-Heusler compounds measured at 298 K.
| Alloys | Anisotropic shift (ppm) | Isotropic shift (ppm) | e 2 qQ/h (MHz) | Ref |
|----------|---------------------------|-------------------------|------------------|-----------|
| YPdBi | 0 | 1200±10 | 0.86 | This work |
| YPtBi | 0 | -1748±10 | ~0 | This work |
| YPdSb | 0 | 924 | ~0 | [11] |
| YPtSb | 0 | 885 | ~0 | [11] |
Intensity (a.u.)
Fig. 1
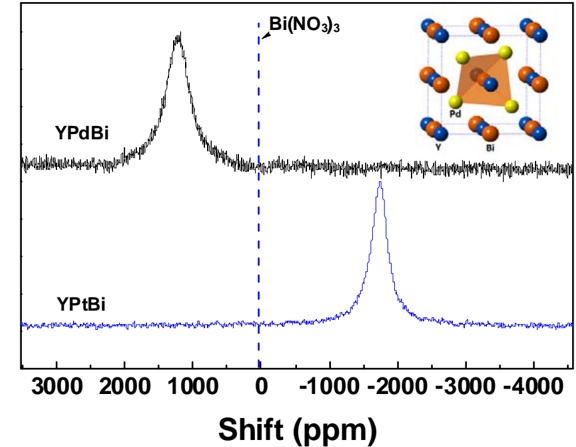
Fig. 2
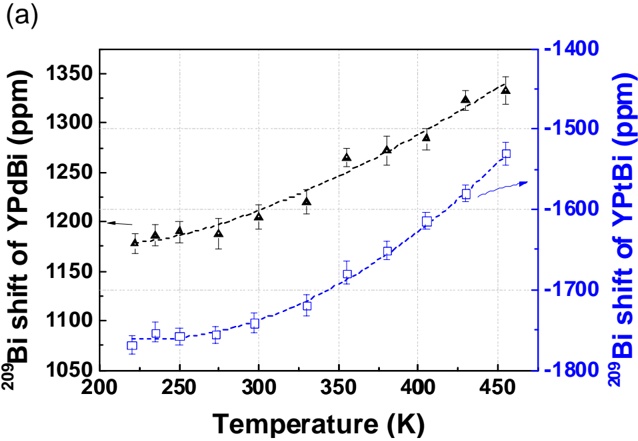
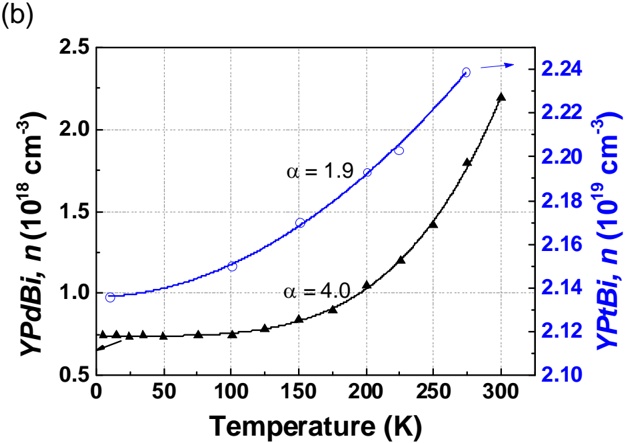
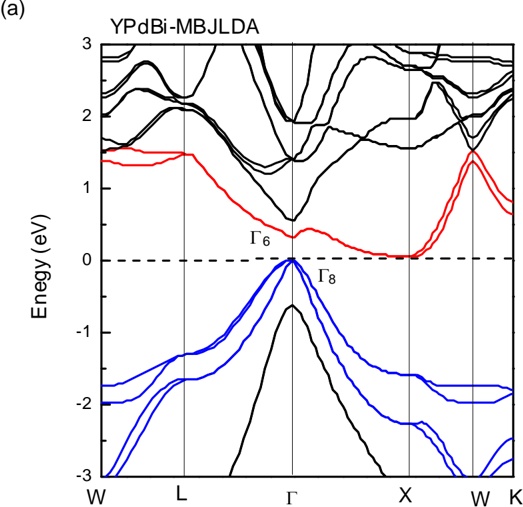
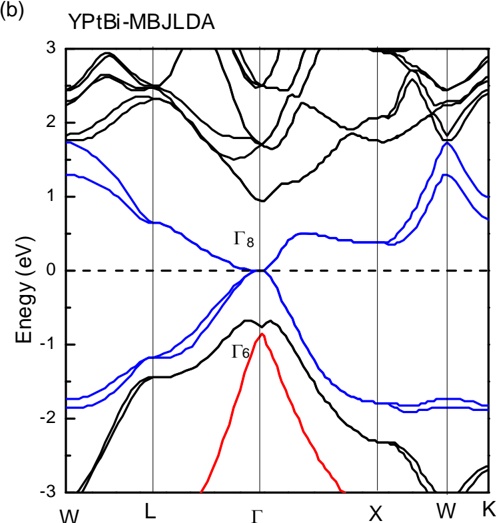
W
Fig. 3
## REFERENCES
- [1] T. Graf, C. Felser, and S. S. P. Parkin, Prog. Solid State Chem. 39 , 1 (2011).
- [2] S. Chadov, X. Qi, J. Kübler, G. H. Fecher, C. Felser, and S. C. Zhang, Nat. Mater. 9 , 541 (2010).
- [3] H. Lin, L. A. Wray, Y. Xia, S. Xu, S. Jia, R. J. Cava, A. Bansil, and M. Z. Hasan, Nat. Mater. 9 , 546 (2010).
- [4] W. Al-Sawai, H. Lin, R. S. Markiewicz, L. A. Wray, Y. Xia, S. Y. Xu, M. Z.
- Hasan, and A. Bansil, Phys. Rev. B 82 , 125208 (2010).
- [5] W. X. Feng, D. Xiao, Y. Zhang, and Y. G. Yao, Phys. Rev. B 82 , 235121 (2010).
- [6] C. Liu, Y. Lee, T. Kondo, E. D. Mun, M. Caudle, B. N. Harmon, S. L. Bud'ko, P.
- C. Canfield, and A. Kaminski, Phys. Rev. B 83, 205133 (2011).
- [7] J. Vidal, X. Zhang, L. Yu, J. W. Luo, and A. Zunger, Phys. Rev. B 84, 041109 (2011).
- [8] D. T. Adroja, J. G. M. Armitage, P. C. Riedi, M. R. Lees, and O. A. Petrenko, Phys. Rev. B 61 , 1232 (2000).
- [9] T. Harmening, H. Eckert, and R. Pöttgen, Solid State Sci. 11, 900 (2009).
- [10] T. Koyama, M. Abe, T. Mito, K.-i. Ueda, T. Kohara, and H. S. Suzuki, J. Phys. Soc. Jpn. 80 , SA097 (2011).
- [11] B. Nowak and D. Kaczorowski, Intermetallics 40 , 28 (2013).
- [12] B. Nowak and D. Kaczorowski, J. Phys. Chem. C 118 , 18021 (2014).
- [13] W. H. Wang, Y. Du, G. Z. Xu, X. M. Zhang, E. K. Liu, Z. Y. Liu, Y. G. Shi, J. L. Chen, G. H. Wu, and X.-X. Zhang, Sci. Reports 3 , 2181 (2013).
- [14] The measured quadrupole coupling constant by nutation is 0.86 MHz.
- [15] F. Haarmann, in Encyclopedia of Magnetic Resonance (John Wiley & Sons, Ltd, 2007).
- [16] T. J. Bastow and H. J. Whitfield, Solid State Commun. 18 , 955 (1976).
- [17] T. V. Bay, T. Naka, Y. K. Huang, and A. de Visser, Phys. Rev. B 86 , 064515 (2012).
- [18] I. M. Tsidilkovski, Electron Spectrum of Gapless Semiconductors , Vol. 116 (Springer, New York, 1996).
- [19] F. Tran and P. Blaha, Phys. Rev. Lett. 102 , 226401 (2009).
- [20] P. Blaha, K. Schwarz, G. Madsen, D. Kvasnicka, and J. Luitz, WIEN 2k, Augmented Plane Wave Local Orbitals Program for Calculating Crystals Properties, Katheinz Schwarz, Techn. Universitat Wien, Austria, 2001. | 10.1002/pssb.201451436 | [
"Chenglong Shi",
"Xuekui Xi",
"Zhipeng Hou",
"Xiaoming Zhang",
"Guizhou Xu",
"Enke Liu",
"Wenquan Wang",
"Wenhong Wang",
"Guangheng Wu"
] | 2014-08-01T04:52:07+00:00 | 2014-11-28T07:25:47+00:00 | [
"cond-mat.str-el",
"cond-mat.mtrl-sci"
] | NMR evidence for enhanced orbital diamagnetism in topologically nontrivial half-Heusler semimetals | 209Bi nuclear magnetic resonance (NMR) spectroscopy was employed to probe
potential spin-orbit effects on orbital diamagnetism in YPtBi and YPdBi
crystals. The observed opposite sign and temperature dependent magnitude of
209Bi NMR shifts of both crystals reveal experimental signatures of enhanced
orbital diamagnetism induced by spin-orbit interactions. This investigation
indicates that NMR isotropic shifts might be beneficial in search of
interesting spin-electronic phases among a vast number of topological
nontrivial half-Heusler semimetals. |
1408.0079v1 | ## PROPERTIES OF HIGH-DENSITY MATTER IN NEUTRON STARS
## Fridolin Weber ∗
Department of Physics, San Diego State University, 5500 Campanile Drive, San Diego, California 92182, USA and Center for Astrophysics and Space Sciences, University of California, San Diego, La Jolla, California 92093, USA.
## Gustavo A. Contrera †
Department of Physics, San Diego State University, 5500 Campanile Drive, San Diego, California 92182, USA, CONICET, Rivadavia 1917, 1033 Buenos Aires, Argentina, IFLP, CONICET - Dpto. de F´ ısica, UNLP, La Plata, Argentina and Gravitation, Astrophysics and Cosmology Group, Facultad de Ciencias Astron´micas o y Geof´ ısicas, UNLP, Paseo del Bosque S/N (1900), La Plata, Argentina.
## Milva G. Orsaria ‡
Department of Physics, San Diego State University, 5500 Campanile Drive, San Diego, California 92182, USA, CONICET, Rivadavia 1917, 1033 Buenos Aires, Argentina and Gravitation, Astrophysics and Cosmology Group, Facultad de Ciencias Astron´micas o y Geof´ ısicas, UNLP, Paseo del Bosque S/N (1900), La Plata, Argentina.
## William Spinella § and Omair Zubairi ¶
Department of Physics & Computational Science Researech Center, San Diego State University, 5500 Campanile Drive, San Diego, California 92182, USA. (Dated: August 4, 2014)
This short review aims at giving a brief overview of the various states of matter that have been suggested to exist in the ultra-dense centers of neutron stars. Particular emphasis is put on the role of quark deconfinement in neutron stars and on the possible existence of compact stars made of absolutely stable strange quark matter (strange stars). Astrophysical phenomena, which distinguish neutron stars from quark stars, are discussed and the question of whether or not quark deconfinement may occur in neutron stars is investigated. Combined with observed astrophysical data, such studies are invaluable to delineate the complex structure of compressed baryonic matter and to put firm constraints on the largely unknown equation of state of such matter.
## I. INTRODUCTION
Exploring the properties of compressed baryonic matter, or, more generally, strongly interacting matter at high densities and/or temperatures, has become a forefront area of modern physics. Experimentally, the properties of such matter are being probed with the Relativistic Heavy Ion Collider RHIC at Brookhaven and the Large Hadron Collider (LHC at CERN). Great advances in our understanding of such matter are expected from the next generation of heavyion collision experiments at FAIR (Facility for Antiproton and Ion Research at GSI) and NICA (Nuclotron-bases Ion Collider fAcility at JINR) [1-3].
Neutron stars contain compressed baryonic matter permanently in their centers. Such stars are remnants of massive stars that blew apart in core-collapse supernova explosions. They are typically about 20 kilometers across and spin rapidly, often making many hundred rotations per second. Many neutron stars form radio pulsars, emitting radio
∗ Electronic address: [email protected]
† Electronic address: [email protected]
‡ Electronic address: [email protected]
§ Electronic address: [email protected]
¶ Electronic address: [email protected]
waves that appear from the Earth to pulse on and off like a lighthouse beacon as the star rotates at very high
Figure 1: (Color online) Schematic structures of quark stars (left) and neutron stars (right). If the strange quark matter hypothesis should be correct, most, if not all, neutron stars should in fact be strange quark stars.
speeds. Neutron stars in X-ray binaries accrete material from a companion star and flare to life with tremendous bursts of X-rays. Depending on mass and rotational frequency, gravity compresses the matter in the cores of neutron stars to densities that are several times higher than the density of ordinary atomic nuclei. At such huge densities atoms themselves collapse, and atomic nuclei are squeezed so tightly together that new fundamental particles may be produced and novel states of matter be created. The most spectacular phenomena stretch from the generation of hyperons and delta particles, to the formation of meson condensates, to the formation of a plasma of deconfined quarks (see Fig. 1). The interest in the role of quark deconfinement for astrophysics has received renewed interest by the discovery that quark matter at low temperatures ought to be a color superconductor (see Ref. [4] and references therein).
All these features make neutron stars superb astrophysical laboratories for a wide range of physical studies [5-12]. And with observational data accumulating rapidly from both orbiting and ground based observatories spanning the spectrum from X-rays to radio wavelengths, there has never been a more exiting time than today to study neutron stars and associated catastrophic astrophysical events. The Hubble Space Telescope and X-ray satellites such as Chandra and XMM-Newton in particular have proven especially valuable. New astrophysical instruments such as the Five hundred meter Aperture Spherical Telescope (FAST), the square kilometer Array (skA), Fermi Gamma-ray Space Telescope (formerly GLAST), Astrosat, ATHENA (Advanced Telescope for High ENergy Astrophysics), and the Neutron Star Interior Composition Explorer (NICER) promise the discovery of tens of thousands of new neutron stars. Of particular interest will be the proposed NICER mission (scheduled to launch in 2016), which is dedicated to the study of extraordinary gravitational, electromagnetic, and nuclear-physics environments embodied by neutron stars. NICER will explore the exotic states of matter in the core regions of neutron stars, where, as mentioned just above, density and pressure are considerably higher than in atomic nuclei, confronting nuclear theory with unique observational constraints.
There is also the theoretical possibility that quark matter made of up, down and strange quarks (so-called strange quark matter [13]) may be more stable than ordinary nuclear matter [14]. This so-called strange matter hypothesis constitutes one of the most startling possibilities regarding the behavior of superdense matter, which, if true, would have implications of fundamental importance for cosmology, the early universe, its evolution to the present day, and astrophysical compact objects such as neutron stars and white dwarfs (see Ref. [15] and references therein). The properties of compact stars made of strange quark matter, referred to as strange (quark) stars, are compared with those of neutron stars in Table I and Fig. 1. Even after three decades of research, there is no sound scientific basis on
Table I: Theoretical properties of strange quark stars and neutron stars compared.
| Strange Quark Stars | Neutron Stars |
|--------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------|
| Made entirely of deconfined up, down, strange quarks, and electrons | Nucleons, hyperons, boson condensates, deconfined quarks, electrons, and muons |
| Absent | Superfluid neutrons |
| Absent | Superconducting protons |
| Color superconducting quarks | Color superconducting quarks |
| Energy per baryon < ∼ 930 MeV | Energy per baryon > 930 MeV |
| Self-bound ( M ∝ R 3 ) | Bound by gravity |
| Maximum mass ∼ 2 M /circledot | Same |
| No minimum mass if bare | Minimum mass ∼ 0 . 1 M /circledot |
| Radii R < ∼ 10 - 12 km | Radii R > ∼ 10 - 12 km |
| Baryon numbers B < ∼ 10 57 | Baryon numbers 10 56 < ∼ B < ∼ 10 57 |
| Electric surface fields ∼ 10 18 to ∼ 10 19 V/cm | Absent |
| Can either be bare or enveloped in thin nuclear crusts (masses < ∼ 10 - 5 M /circledot ) | Always have nuclear crusts |
| Maximum density of crust set by neutron drip, i.e., strange stars posses only outer crusts | Does not apply, i.e., neutron stars posses inner and outer crusts |
| Form two-parameter stellar sequences | Form one-parameter stellar sequences |
which one can either confirm or reject the strange quark matter hypothesis so that it remains a serious possibility of fundamental significance for various astrophysical phenomena, as discussed in the next section [16].
## II. PROPERTIES OF STRANGE QUARK STARS
A bare quark star differs qualitatively from a neutron star which has a density at the surface of about 0.1 to 1 g / cm . The thickness of the quark surface is just 3 ∼ 1 fm, the length scale of the strong interaction. The electrons at the surface of a quark star are held to quark matter electrostatically, and the thickness of the electron surface is several hundred fermis. Since neither component, electrons and quark matter, is held in place gravitationally, the Eddington limit to the luminosity that a static surface may emit does not apply, so that bare quark stars may have photon luminosities much greater than 10 38 erg / s. It has been shown in Ref. [17] that this value may be exceeded by many orders of magnitude by the luminosity of e + e -pairs produced by the Coulomb barrier at the surface of a hot strange star. For a surface temperature of ∼ 10 11 K, the luminosity in the outflowing pair plasma was calculated to be as high as ∼ 3 × 10 51 erg / s. Such an effect may be a good observational signature of bare strange stars [17-20]. If the strange star is dressed, that is, enveloped in a nuclear crust, however, the surface made of ordinary atomic matter would be subject to the Eddington limit. Hence the photon emissivity of a dressed quark star would be the same as for an ordinary neutron star. If quark matter at the stellar surface is in the CFL (Color-Flavor Locked) phase the process of e + e -pair creation at the stellar quark matter surface may be turned off. This may be different for the early stages of a very hot CFL quark star [21].
In contrast to neutron stars, the radii of self-bound quark stars decrease the lighter the stars, according to M ∝ R 3 . The existence of nuclear crusts on quark stars changes the situation drastically [15, 22]. Since the crust is bound gravitationally, the mass-radius relationship of quark stars with crusts can be qualitatively similar to mass-radius relationships of neutron stars and white dwarfs [22]. In general, quark stars with or without nuclear crusts possess smaller radii than neutron stars. This implies that quark stars have smaller mass shedding (break-up) periods than neutron stars. Moreover, due to the smaller radii of quarks stars, the complete sequence of quark stars-and not just those close to the mass peak, as it is the case for neutron stars-can sustain extremely rapid rotation [15, 22]. In particular, a strange star with a typical pulsar mass of around 1 45 . M /circledot has a Kepler period in the approximate range of 0 55 . < P ∼ K / msec < ∼ 0 8 [22, 23]. . This is to be compared with P K ∼ 1 msec for neutron stars of the same mass.
One of the most amazing features of strange quark stars concerns the existence of ultra-high electric fields on their surfaces, which, for ordinary (i.e., non-superconducting) quark matter, is around 10 18 V/cm. If strange matter forms a color superconductor, as expected for such matter, the strength of the electric field may increase to values that exceed 10 19 V/cm. The energy density associated with such huge electric fields is on the same order of magnitude as the energy density of strange matter itself, which may alter the masses and radii of strange quark stars at the 15%
and 5% level, respectively [24].
The electrons at the surface of a quark star are not necessarily in a fixed position but may rotate with respect to the quark matter star [25]. In this event magnetic fields can be generated which, for moderate effective rotational frequencies between the electron layer and the stellar body, agree with the magnetic fields inferred for several Central Compact Objects (CCOs). These objects could thus be interpreted as quark stars whose electron atmospheres rotate at frequencies that are moderately different ( ∼ 10 Hz) from the rotational frequency of the quark star itself.
Last but not least, we mention that the electron surface layer may be strongly affected by the magnetic field of a quark star in such a way that the electron layer performs vortex hydrodynamical oscillations [26]. The frequency spectrum of these oscillations has been derived in analytic form in Ref. [26]. If the thermal X-ray spectra of quark stars are modulated by vortex hydrodynamical oscillations, the thermal spectra of compact stars, foremost central compact objects (CCOs) and X-ray dim isolated neutron stars (XDINSs), could be used to verify the existence of these vibrational modes observationally. The central compact object 1E 1207.4-5209 appears particularly interesting in this context, since its absorption features at 0.7 keV and 1.4 keV can be comfortably explained in the framework of the hydro-cyclotron oscillation model [26].
Rotating superconducting quark stars ought to be threaded with rotational vortex lines, within which the star's interior magnetic field is at least partially confined. The vortices (and thus magnetic flux) would be expelled from the star during stellar spin-down, leading to magnetic re-connection at the surface of the star and the prolific production of thermal energy. It has been shown in Ref. [27] that this energy release can re-heat quark stars to exceptionally high temperatures, such as observed for Soft Gamma Repeaters (SGRs), Anomalous X-Ray pulsars (AXPs), and X-ray dim isolated neutron stars (XDINs), and that SGRs, AXPs, and XDINs may be linked ancestrally [27].
The conversion of a neutron star to a hypothetical quark star could lead to quark novae. Such events could explain gamma ray bursts [28], the production of heavy elements such as platinum through r-process nucleosynthesis [29], and double-humped super-luminous supernovae [30].
## III. NEUTRON STARS
## A. Non-spherical neutron stars
Usually, the structure of neutron stars is modeled with the assumption that they are perfect spheres. However, due to to very high magnetic fields, certain classes of neutron stars, such as magnetars and neutron stars containing cores of color superconducting quark matter [31], may be deformed. The stellar structure equation of such stars is given by [32]
$$\frac { d P } { d r } = - ( \epsilon + P ) \left ( \frac { 1 } { 2 } r + 4 \pi r ^ { 3 } P - \frac { 1 } { 2 } r \left ( 1 - \frac { 2 m } { r } \right ) ^ { \gamma } \right ) \left ( r ^ { 2 } \left ( 1 - \frac { 2 m } { r } \right ) ^ { \gamma } \right ) ^ { - 1 } \,.$$
Figure 2: Oblate spheroid ( γ = 0 70) .
Figure 3: Prolate spheroid ( γ = 1 30) .
Figure 4: (Color online) Mass-radius relationships of sequences of oblate strange quark stars. The mass is increasing with increasing oblateness (decreasing values of γ ). The range of observed neutron star masses is indicated.
Here, /epsilon1 is the energy-density, P is the pressure, m is the gravitational mass, and γ is a deformation constant. The star's total mass is given by M = γm . Oblate (prolate) neutron stars are obtained for γ < 1 ( γ > 1), as shown in Figs. 2 and 3, respectively. For γ = 1, equation (1) reduces to the well known Tolman-Oppenheimer-Volkoff equation, which describes the properties of spherically symmetric neutron (compact) stars [5, 6, 15].
The mass-radius relationship of oblate compact stars, computed from Eq. (1) for different γ values, are shown in Fig. 4.
For simplicity, the equation of state of a relativistic gas of deconfined quarks described by the MIT bag model, P = ( /epsilon1 -4 B / ) 3, has been used here [32]. The value of the bag constant is B = 57 MeV fm / 3 ( B 1 / 4 = 145 MeV), which makes the quark gas absolutely stable with respect to nuclear matter. The results shown in Figs. 2 to 4 therefore are for strange quark stars. One sees that already relatively small deviations from spherical symmetry increase the masses of strange stars substantially.
## B. Rotation-driven compositional changes
The change in central density of a neutron star whose frequency varies from zero to the mass shedding (Kepler) frequency can be as large as 50 to 60% [15]. This suggests that changes in the rotation rate of a neutron star may drive phase transitions and/or lead to significant compositional changes in the star's core [15, 33, 34]. As a case in point, for some rotating neutron stars the mass and initial rotational frequency may be just such that the central density rises from below to above the critical density for dissolution of baryons into their quark constituents. This may be accompanied by a sudden shrinkage of the neutron star, effecting the star's moment of inertia and, thus, its spin-down behavior. As shown in Ref. [35], the spin-down of such a neutron star may be stopped or even reversed for tens of thousands to hundreds of thousands of years [15, 35]. The observation of an isolated neutron star which is spinning-up, rather than down, could thus hint at the existence of quark matter in its core.
## C. Quark deconfinement in high-mass neutron stars
Quark deconfinement in high-mass neutron stars has very recently been studied using extensions of the local and non-local 3-flavor Nambu-Jona Lasinio (NJL) model supplemented with repulsive vector interactions among the quarks (see Refs. [36, 37] and references therein). The phase transition from confined hadronic matter to deconfined quark matter has been constructed via the Gibbs condition, which imposes global rather than local electric charge neutrality and baryon number conservation. Depending on the strength of the quark vector repulsion, it was found that an extended mixed phase of confined hadronic matter and deconfined quarks can exist in neutron stars as massive as 2 1 to 2 4 . . M /circledot . A phase of pure quark matter inside such high-mass neutron stars, while not excluded, is only obtained for certain parametrizations of the underlying lagrangians. The radii of all these stars are between 12 and 13 km, as expected for neutron stars of that mass [38-40].
/s49
/s32
/s32
/s32
Figure 5: (Color online) Particle population of neutron star matter computed for the non-local SU(3) NJL model. The yellow areas highlight the mixed phase. The solid vertical lines indicate the central densities of the associated maximum-mass NSs. The hadronic model parametrization is NL3 and the vector repulsions are (a) G /G V S = 0 and (b) G /G V S = 0 09. .
In Fig. 5 we show the relative particle fractions Y i ( ≡ ρ /ρ i ) of neutron star matter as a function of baryon number density for the non-local NJL model and using NL3 parametrization of Ref. [41] for the hadronic model. It can be seen that by increasing the strength of the vector interaction, negatively charged particles like µ -'s and ∆ -'s take on the role of electrons, whose primary duty is to make the stellar matter electrically neutral. Because of the early onset of the ∆ population in this model, there is less need for electrons so that their number density in the mixed phase is
/s32
/s32
Figure 6: (Color online) Pressure P (solid lines), baryon chemical potential µ B = µ / n 3 (dashed lines), and electron chemical potential µ e (dotted lines) as a function of baryon number density (in units of ρ 0 = 0 16 fm . -3 ). In all the cases a non local SU(3) NJL and non linear Walecka (with parametrization NL3) models are considered for quark matter and hadronic phases, respectively. The hatched areas denote the mixed phase regions where confined hadronic matter and deconfined quark matter coexist. Panel (a) is computed for zero vector repulsion. The impact of finite values of the vector repulsion ( G V = 0 09 . G S ) on the data is shown in panel (b).
reduced compared to the outcome of standard mean-field/bag model calculations. The corresponding deleptonization densities, i.e. the densities beyond which leptons are no longer present in quark-hybrid matter, depend on the ratio G /G V S ( ρ G V =0 = 4 55 . ρ 0 and ρ G V =0 09 . G S = 5 33 . ρ 0 ) [37].
Since we model the quark-hadron phase transition in three-space, accounting for the fact that the electric and baryonic charge are conserved for neutron star matter, the pressure varies monotonically with the proportion of the phases in equilibrium, as shown in Fig. 6. The hatched areas shown in this figure denote the mixed phase regions where confined hadronic matter and deconfined quark matter coexist. The quark matter contents of the maximummass neutron stars computed for these equations of state are also indicated ( χ values). Pure quark matter would exist for χ = 1. Our calculations show that, in the non-local case, the inclusion of the quark vector coupling contribution shifts the onset of the phase transition to higher densities and narrows the width of the mixed quark-hadron phase, when compared to the case G V = 0. To the contrary, when the quark matter phase is represented by the local NJL model, the width of the mixed phase tends to be broader for finite G /G V S values [37].
To account for the uncertainty in the theoretical predictions of the ratio G /G V S , we treat the vector coupling constant as a free parameter. We observed that the non local NJL model is more sensitive to the increase of G /G V S than the local model. For G /G V S > 0 09 we have a shift of the onset of the quark-hadron phase transition to higher . and higher densities, preventing quark deconfinement in the cores of neutron stars. However, we can reach values of G /G V S up to 0 3 for the local NJL case. .
## D. 'Backbending'-a possible signal of quark deconfinement
Whether or not quark deconfinement exists in static (non-rotating) neutron stars makes only very little difference to their properties, such as the range of possible masses and radii, which renders the detection of quark matter in such objects extremely complicated. This may be strikingly different for rotating neutron stars which develop quark matter cores in the course of spin-down. The reason being that such stars become more and more compressed as they spin down from high to low frequencies. For some rotating neutron stars the mass and initial rotational frequency may be just such that the central density rises from below to above the critical density for the dissolution of baryons into their quark constituents. This could affect the star's moment of inertia dramatically [15, 35]. Depending on the rate at which quark matter is produced, the moment of inertia can decrease very anomalously, and could even introduce an era of stellar spin-up (so-called 'backbending') lasting for ∼ 10 8 years [35]. Since the dipole age of millisecond pulsars is about 10 9 years, one may estimate that roughly about 10% of the solitary millisecond pulsars presently known could be in the quark transition epoch and thus could be signaling the ongoing process of quark deconfinement. Changes in the moment of inertia reflect themselves in the braking index, n , of a rotating neutron star, as can be seen from [15, 35, 42]
$$n ( \Omega ) \equiv \frac { \Omega \ddot { \Omega } } { \dot { \Omega } ^ { 2 } } = 3 - \frac { I + 3 \, I ^ { \prime } \, \Omega + I ^ { \prime \prime } \, \Omega ^ { 2 } } { I + I ^ { \prime } \, \Omega } \rightarrow 3 - \frac { 3 \, I ^ { \prime } \, \Omega + I ^ { \prime \prime } \, \Omega ^ { 2 } } { 2 \, I + I ^ { \prime } \, \Omega }$$
where dots and primes denote derivatives with respect to time and Ω, respectively. The last relation in Eq. (2) constitutes the non-relativistic limit of the braking index. It is obvious that these expressions reduce to the canonical limit, n = 3, if the moment of inertia is completely independent of frequency. Evidently, this is not the case for rapidly rotating neutron stars, and it fails for stars that experience pronounced internal changes (as possibly driven by phase transitions) which alter the moment of inertia significantly. In Ref. [43] it was shown that the changes in the moment of inertia caused by the gradual transformation of hadronic matter into quark matter may lead to n (Ω) → ±∞ at the transition frequency where pure quark matter is produced. Such dramatic anomalies in n (Ω) are not known for conventional neutron stars (see, however, Ref. [44]), because their moments of inertia appear to vary smoothly with Ω [6]. The future astrophysical observation of a strong anomaly in the braking behavior of a pulsar may thus indicate that quark deconfinement is occurring at the pulsar's center.
## E. Quark-hadron Coulomb lattices in the cores of neutron stars
Because of the competition between the Coulomb and the surface energies associated with the positively charged regions of nuclear matter and negatively charged regions of quark matter, the mixed phase may develop geometrical structures (e.g., blobs, rods, slabs, as schematically illustrated in Fig. 7 [45]), similarly to what is expected of the subnuclear liquid-gas phase transition [46-49]. The consequences of such a Coulomb lattice for the thermal and transport properties of neutron stars have been studied in Ref. [45]. It was found that at low temperatures of T < ∼ 10 8 K the neutrino emissivity from electron-blob Bremsstrahlung scattering is at least as important as the total contribution from all other Bremsstrahlung processes (such as nucleon-nucleon and quark-quark Bremsstrahlung) and modified nucleon and quark Urca processes. It is also worth noting that the scattering of degenerate electrons off rare phase
## Density
Figure 7: Schematic illustration of possible geometrical structures in the quark-hadron mixed phase of neutron stars. The structures may form because of the competition between the Coulomb and the surface energies associated with the positively charged regions of nuclear matter and negatively charged regions of quark matter.
blobs in the mixed phase region lowers the thermal conductivity by several orders of magnitude compared to a quarkhadron phase without geometric patterns. This may lead to significant changes in the thermal evolution of the neutron stars containing solid quark-hadron cores, which has not yet been studied.
## F. Pycnonuclear reaction rates
The presence of strange quark nuggets in the crustal matter of neutron stars could be a consequence of Witten's strange quark matter hypothesis [14]. The impact of such nuggets on the pycnonuclear reaction rates among heavy atomic nuclei has been studied in Ref. [50]. Particular emphasis was put on the consequences of color superconductivity on the reaction rates. Depending on whether or not quark nuggets are in a color superconducting state, their electric charge distributions differ drastically, which was found to have dramatic consequences for the pycnonuclear reaction rates in the crusts of neutron stars. Future nuclear fusion network calculations may thus have the potential to shed light on the existence of strange quark matter nuggets and on whether they are in a color superconducting state, as suggested by QCD.
## G. Rotational instabilities
The r-mode instability of a rotating neutron star dissipates the star's rotational energy by coupling the angular momentum of the star to gravitational waves [51-53]. This instability can be active in a newly formed isolated neutron star as well as in old neutron stars being spun up by accretion of matter from binary stars. If the interior contains quark matter, the r-mode instability and the gravitational wave signal may carry information about quark matter [54-58].
## Acknowledgments
F. W. is supported by the National Science Foundation (USA) under Grants PHY-0854699 and PHY-1411708. M. O. and G. C. acknowledge CONICET and SeCyT-UNLP (Argentina) for financial support. M. O. and G. C. are thankful for hospitality extended to them during their visits at the SDSU, supported by a NSF-CONICET International Cooperation Project.
[1] The CBM Physics Book, B. Friman, C. H¨hne, J. Knoll, S. Leupold, J. Randrup, R. Rapp, and P. Senger (Eds.), o Lecture Notes in Physics 814 (Springer, 2011).
[2] NICA White Paper, http://nica.jinr.ru/files/WhitePaper.pdf .
[3] T. Kl¨hn, D. Blaschke, and F. Weber, a Phys. Part. Nucl. Lett. 9 , 484 (2012).
- [4] M. G. Alford, A. Schmitt, K. Rajagopal, & T. Sch¨fer, a Rev. Mod. Phys. 13 , 1455 (2008).
- [5] N. K. Glendenning, Compact Stars, Nuclear Physics, Particle Physics, and General Relativity , 2nd ed. (Springer-Verlag, New York, 2000).
- [6] F. Weber, Pulsars as Astrophysical Laboratories for Nuclear and Particle Physics , High Energy Physics, Cosmology and Gravitation Series (IOP Publishing, Bristol, Great Britain, 1999).
- [7] F. Weber, Prog. Part. Nucl. Phys. 54 , 193 (2005).
- [8] J. M. Lattimer and M. Prakash, ApJ 550 , 426 (2001).
- [9] Physics of Neutron Star Interiors, D. Blaschke, N. K. Glendenning, and A. Sedrakian (Eds.), Lecture Notes in Physics 578 (Springer, 2001).
- [10] A. Sedrakian, Prog. Part. Nucl. Phys. 58 , 168 (2007).
- [11] D. Page and S. Reddy, Ann. Rev. Nucl. Part. Sci. 56 , 327 (2006).
- [12] T. Hell and W. Weise, arXiv:1402.4098 [nucl-th] .
- [13] E. Farhi and R. L. Jaffe Phys. Rev. D 30 , 2379 (1984).
- [14] E. Witten, Phys. Rev. D 30 , 272 (1984).
- [15] F. Weber, Prog. Part. Nucl. Phys. , 54 , 193 (2005).
- [16] M. Buballa et al. , EMMI Rapid Reaction Task Force Meeting on 'Quark Matter in Compact Star', arXiv:1402.6911 [astro-ph.HE] .
- [17] V. V. Usov, Phys. Rev. Lett. 80 , 230 (1998).
- [18] V. V. Usov, ApJ 550 , L179 (2001).
- [19] V. V. Usov, ApJ 559 , L137 (2001).
- [20] K. S. Cheng and T. Harko, ApJ 596 , 451 (2003).
- [21] C. Vogt, R. Rapp and R. Ouyed, Nucl. Phys. A 735 , 543 (2004).
- [22] N. K. Glendenning, Ch. Kettner, and F. Weber, ApJ 450 , 253 (1995).
- [23] N. K. Glendenning and F. Weber, ApJ 400 , 647 (1992).
- [24] R. Negreiros, F. Weber, M. Malheiro, and V. Usov, Phys. Rev. D 80 , 083006 (2009).
- [25] R. Negreiros, I. N. Mishustin, S. Schramm, and F. Weber, Phys. Rev. D 82 , 103010 (2010).
- [26] R. X. Xu, S. I. Bastrukov, F. Weber, J. W. Yu, and I. V. Molodtsova, Phys. Rev. D 85 , 023008 (2012).
- [27] B. Niebergal, R. Ouyed, R. Negreiros, and F. Weber, Phys. Rev. D 81 , 043005 (2010).
- [28] J. Staff, B. Niebergal, and R. Ouyed, MNRAS 391 , 178 (2008).
- [29] P. Jaikumar, B. S. Meyer, K. Otsuki and R. Ouyed, A&A 471 , 227 (2007).
- [30] R. Ouyed and D. Leahy, A&A 13 , 1202 (2013).
- [31] E. J. Ferrer et al. , Phys. Rev. C 82 , 065802 (2010).
- [32] O. Zubairi Non-spherical Models of Neutron Stars , thesis proposal, San Diego State University, 2014.
- [33] F. Weber, R. Negreiros, P. Rosenfield, and M. Stejner, Prog. Part. Nucl. Phys. 59 , 94 (2007).
- [34] R. Negreiros, S. Schramm, and F. Weber, Phys. Lett. B 718 , 1176 (2013).
- [35] N. K. Glendenning, S. Pei, and F. Weber, Phys. Rev. Lett. 79 , 1603 (1997).
- [36] M. Orsaria, H. Rodrigues, F. Weber and G. A. Contrera, Phys. Rev. D 87 , 023001 (2013).
- [37] M. Orsaria, H. Rodrigues, F. Weber and G. A. Contrera, Phys. Rev. C 89 , 015806 (2014).
- [38] A. W. Steiner, J. M. Lattimer and E. F. Brown, ApJ 722 , 33 (2010).
- [39] A. W. Steiner, J. M. Lattimer and E. F. Brown, ApJ 765 , L5 (2013).
- [40] J. M. Lattimer and A. W. Steiner, ApJ 784 , 123 (2014).
- [41] G. A. Lalazissis, J. Konig, and P. Ring, Phys. Rev. C 55 , 540 (1997).
- [42] N. K. Spyrou and N. Stergioulas, A&A 395 , 151 (2002).
- [43] N. K. Glendenning and S. Pei, Phys. Rev. C 52 , 2250 (1995).
- [44] J. L. Zdunik, P. Haensel and M. Bejger, A&A 441 , 207 (2005).
- [45]
- X. Na, R. Xu, F. Weber, and R. Negreiros, Phys. Rev. D 86 , 123016 (2012).
- [46] D. G. Ravenhall, C. J. Pethick, and J. R. Wilson, Phys. Rev. Lett. 50 , 2066 (1983).
- [47] D. G. Ravenhall, C. J. Pethick, and J. M. Lattimer, Nucl. Phys. A 407 , 571 (1983).
- [48] R. D. Williams and S. E. Koonin, Nucl. Phys. A 435 , 844 (1985).
- [49] N. K. Glendenning, Phys. Rev. D 46 , 1274 (1992).
- [50] B. Golf, J. Hellmers, and F. Weber, Phys. Rev. C 80 , 015804 (2009).
- [51] N. Andersson, ApJ 502 , 708 (1998).
- [52] L. Lindblom, B. J. Owen and S. M. Morsink, Phys. Rev. Lett. 80 , 4843 (1998).
- [53] J. L. Friedman and S. M. Morsink, ApJ 502 , 714 (1998).
- [54] P. Jaikumar, G. Rupak and A. W. Steiner, Phys. Rev. D 78 , 123007 (2008).
- [55] G. Rupak and P. Jaikumar, Phys. Rev. C 82 055806 (2010).
- [56] G. Rupak and P. Jaikumar, Phys. Rev. C 88 , 065801 (2013).
- [57] B. A. Sa'd, arXiv:0806.3359 [astro-ph] .
- [58] M. Mannarelli, C. Manuel and B. A. Sa'd, Phys. Rev. Lett. 101 , 241101 (2008). | 10.1142/S0217732314300225 | [
"Fridolin Weber",
"Gustavo A. Contrera",
"Milva G. Orsaria",
"William Spinella",
"Omair Zubairi"
] | 2014-08-01T05:01:20+00:00 | 2014-08-01T05:01:20+00:00 | [
"astro-ph.SR",
"hep-ph",
"nucl-th"
] | Properties of High-Density Matter in Neutron Stars | This short review aims at giving a brief overview of the various states of
matter that have been suggested to exist in the ultra-dense centers of neutron
stars. Particular emphasis is put on the role of quark deconfinement in neutron
stars and on the possible existence of compact stars made of absolutely stable
strange quark matter (strange stars). Astrophysical phenomena, which
distinguish neutron stars from quark stars, are discussed and the question of
whether or not quark deconfinement may occur in neutron stars is investigated.
Combined with observed astrophysical data, such studies are invaluable to
delineate the complex structure of compressed baryonic matter and to put firm
constraints on the largely unknown equation of state of such matter. |
1408.0080v1 | ## Quantum discord and measurement-induced disturbance in the background of dilaton black holes
Jieci Wang 1 2 , ∗ , Jiliang Jing 1 and Heng Fan 2 † 1 Department of Physics and Key Laboratory of Low Dimensional Quantum Structures and Quantum Control of Ministry of Education, Hunan Normal University, Changsha, Hunan 410081, People's Republic of China 2 Beijing National Laboratory for Condensed Matter Physics, Institute of Physics, Chinese Academy of Sciences, Beijing 100190, People's Republic of China
We study the dynamics of classical correlation, quantum discord and measurement-induced disturbance of Dirac fields in the background of a dilaton black hole. We present an alternative physical interpretation of single mode approximation for Dirac fields in black hole spacetimes. We show that the classical and quantum correlations are degraded as the increase of black hole's dilaton. We find that, comparing to the inertial systems, the quantum correlation measured by the one-side measuring discord is always not symmetric with respect to the measured subsystems, while the measurementinduced disturbance is symmetric. The symmetry of classical correlation and quantum discord is influenced by gravitation produced by the dilaton of the black hole.
PACS numbers: 03.67.-a,03.67.Mn, 04.70.Dy
## I. INTRODUCTION
Relativistic quantum information [1], which is the combination of general relativity, quantum field theory and quantum information, has been a focus of research for both conceptual and experimental reasons. Understanding quantum effects in a relativistic framework is ultimately necessary because the world is essentially noninertial. Also, quantum correlation plays a prominent role in the study of the thermodynamics and information loss problem [2, 3] of black holes. It is of a great interest to study how the relativistic effects influence the properties of entanglement, classical correlation, quantum discord, quantum nonlocality, as well as Fisher information [414] in the last few years. Recently, exotic classes of black holes derived from the string theory, i.e., the dilaton black holes [15-17] formed by gravitational systems coupled to Maxwell and dilaton fields, have attracted much attention. It is widely believed that the study of dilaton black holes may lead to a deeper understanding of quantum gravity because it emerges from several fundamental theories, such as string theory, black hole physics, and loop quantum gravity.
On the other hand, quantum correlation measured by discord [18-21] is regarded as a valuable resource for quantum computation and communication in some sit-
∗ [email protected]
† [email protected]
uations. To calculate the discord of a bipartite state, one makes a one-side measurement on a subsystem A of ρ AB by a complete set of projectors { Π A j } which yields ρ B j | = Tr A (Π A j ρ AB Π ) A j /p j with p j = Tr AB (Π A j ρ AB Π ). A j The mutual information [22] of ρ AB can alternatively be defined by J { Π A j } ( A : B ) = S ρ ( B ) -S { Π A j } ( B A , | ) where S { Π A j } ( B A | ) = ∑ j p S ρ j ( B j | ) is conditional entropy [23] of the state. This quantity strongly depends on the choice of the measurements { Π A j } . One should minimize the conditional entropy over all possible measurements on A which corresponds to finding the measurement that disturbs least the overall quantum state [18]. The quantum discord between parts A and B has the form D ( A : B ) = I ( A : B ) -C ( A : B ), where C ( A : B ) is the classical correlation C ( A : B ) = max { Π A j } J { Π A j } ( A : B ) and I ( A : B ) is the quantum mutual information quantifying the total correlation. So quantum discord describes the discrepancy between total correlation and classical correlation, and it thus provides a measure of quantumness of correlations. In most situations of inertial systems, the quantum discord is symmetric with respect to the subsystem to be measured [18, 19, 24]. However, is the symmetry still tenable in the noninertial systems, especially in the curved spacetimes? Besides, does the spacetime background also affects the quantum correlations by some other measures such as the measurementinduced disturbance (MID)?
In this paper we discuss the properties of classical correlation, quantum discord and MID [25] for free modes in the background of a dilaton black hole [15]. The study
of relativistic quantum information on accelerated free modes has its own advantages other than that of local modes [13, 14] in the understanding of quantum effects in curved spacetimes in the sense that there are no proved feasible localized detector models inside the event horizon of a black hole. We assume that two observers, Alice and Bob, measure their local state respectively. After sharing an entangled initial state, Alice stays stationary at an asymptotically flat region, while Bob moves with uniform acceleration and hovers near the event horizon of the dilaton black hole. We calculate the classical correlation and quantum discord by making one-side measurements on a subsystem of the bipartite system, and then get the MID measurement correlations by measuring both of the two subsystems. We are interested in how the dilaton charge will influence the classical correlation, quantum discord, and MID, as well as if these correlations are symmetric under the effect of gravitation produced by the dilaton of the black hole.
The paper is organized as follows. In the next section we discuss the quantization of Dirac fields in the background of the dilaton black hole beyond single mode approximation [26, 27]. In Sec. III we study the properties of classical correlation, quantum discord, and MID for Dirac fields in the dilaton spacetime. We will summarize and discuss our conclusions in the last section.
## II. QUANTIZATION OF DIRAC FIELDS IN DILATON BLACK HOLE SPACETIMES
The massless Dirac equation in a general background spacetime can be written as [28]
$$[ \gamma ^ { a } e _ { a } ^ { \mu } ( \partial _ { \mu } + \Gamma _ { \mu } ) ] \Psi = 0, \text{ \quad \ \ } ( 1 ) \text{ \ \ } \text{int},$$
where γ a are the Dirac matrices, the four-vectors e a µ represent the inverse of the tetrad e a µ defined by g µν = η ab e a µ e b ν with η ab = diag( -1 1 1 1), , , , Γ µ = 1 8 [ γ a , γ b ] e a ν e bν µ ; are the spin connection coefficients.
The metric for a Garfinkle-Horowitz-Strominger dilaton black hole spacetime can be expressed as [15]
$$d s ^ { 2 } & = \, - \, \left ( \frac { r - 2 M } { r - 2 \alpha } \right ) d t ^ { 2 } + \left ( \frac { r - 2 M } { r - 2 \alpha } \right ) ^ { - 1 } d r ^ { 2 } \\ & \quad + \, r ( r - 2 \alpha ) d \Omega ^ { 2 }, \quad ( 2 ) \quad \text{where} \quad \text{$space$} \\ \text{where $M$ and $\neg$ are the mese of the black hole and $two$} \quad [ 3 2 ] \, r$$
where M and α are the mass of the black hole and the dilaton. Throughout this paper we set G = c = /planckover2pi1 = κ B = 1. This black hole has two singular points at r = 2 M and r = 2 α . Besides, the dilaton α and the mass M of the black hole should satisfy α < M . In order to separate the Dirac equation, we adopt a tetrad as
$$e ^ { a } _ { \mu } = d i a g \left ( \sqrt { f }, \frac { 1 } { \sqrt { f } }, \sqrt { r \tilde { r } }, \sqrt { r \tilde { r } } \sin \theta \right ), \quad \ \ ( 3 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where f = ( r -2 M /r ) ˜ and ˜ = r r -2 α . Then Eq. (1) in the Garfinkle-Horowitz-Strominger dilaton black-hole spacetime becomes
$$\text{space} \, \text{seconds} \\ & - \, \frac { \gamma _ { 0 } } { \sqrt { f } } \frac { \partial \Psi } { \partial t } + \sqrt { f } \gamma _ { 1 } \left [ \frac { \partial } { \partial r } + \frac { r - \alpha } { r \tilde { r } } + \frac { 1 } { 4 f } \frac { d f } { d r } \right ] \Psi \quad ( 4 ) \\ & + \, \frac { \gamma _ { 2 } } { \sqrt { r \tilde { r } } } ( \frac { \partial } { \partial \theta } + \frac { 1 } { 2 } \cot \theta ) \Psi \\ & + \, \frac { \gamma _ { 3 } } { \sqrt { r \tilde { r } } \sin \theta } \frac { \partial \Psi } { \partial \varphi } = 0.$$
$$+ \ \overline { \sqrt { r \tilde { r } } \sin \theta } \, \overline { \partial \varphi } = 0.$$
If we rescale Ψ as Ψ = f -1 4 Φ and use an ansatz for the Dirac spinor similar to Ref. [29], we can solving the Dirac equation near the event horizon. For the outside and inside region of the event horizon, we obtain the positive frequency outgoing solutions [30, 31]
$$\Psi _ { o u t, { \mathbf k } } ^ { + } = \mathcal { G } e ^ { - i \omega \mathcal { U } },$$
$$\Psi _ { i n, \mathbf k } ^ { + } & = \mathcal { G } e ^ { i \omega \mathcal { U } }, \quad \quad \quad ( 7 ) \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon$$
where U = t -r ∗ and G is a four-component Dirac spinor, k is the wavevector we used to label the modes hereafter and for massless Dirac field ω = | k | . In terms of these basis the Dirac field Ψ can be expanded as
$$\Psi & \ = \ \int d { \mathbf k } [ \hat { a } _ { \mathbf k } ^ { o u t } \Psi _ { o u t, \mathbf k } ^ { + } + \hat { b } _ { - \mathbf k } ^ { o u t \dagger } \Psi _ { o u t, \mathbf k } ^ { - } \\ & + \ \hat { a } _ { \mathbf k } ^ { i n } \Psi _ { i n, \mathbf k } ^ { + } + \hat { b } _ { - \mathbf k } ^ { i n \dagger } \Psi _ { i n, \mathbf k } ^ { - } ],$$
where ˆ a out k and ˆ b out † k are the fermion annihilation and antifermion creation operators acting on the state of the exterior region, and ˆ a in k and ˆ b in † k are the fermion annihilation and antifermion creation operators acting on the interior vacuum of the black hole respectively. The annihilation operator ˆ a out k and creation operator ˆ a out k satisfy the canonical anticommutation { ˆ a out k , a ˆ out k ′ } = δ kk ′ and { ˆ a out k , a ˆ out † k ′ } = { ˆ a out † k , a ˆ out † k ′ } = 0, where { ., . } denotes the anticommutator. Clearly, two fermionic Fock are antisymmetric with respect to the exchange of the mode labels k and k ′ due to the anticommutation relations. We therefore define
$$| | 1 _ { k } 1 _ { k ^ { \prime } } \rangle \rangle = \hat { a } _ { k } ^ { \dagger }, \hat { b } _ { k ^ { \prime } } ^ { \dagger } | | 0 \rangle \rangle = - \hat { b } _ { k ^ { \prime } } ^ { \dagger }, \hat { a } _ { k } ^ { \dagger } | | 0 \rangle \rangle, \quad \ \ ( 9 )$$
where the states in the antisymmetric fermionic Fock space are denoted by double-lined Dirac notation || . 〉〉 [32] rather than the single-lined notations.
Making analytic continuation for Eqs. (6) and (7), we find a complete basis for positive energy modes, i.e., the Kruskal modes, according to the suggestion of Domour-Ruffini [30]. Then we can quantize the massless Dirac field in black hole and Kruskal modes respectively [29, 31], from which we can easily get the Bogoliubov transformations [33] between the creation and annihilation operators in different coordinates [29]. Considering that it is more interesting to quantize the Dirac field beyond the single mode approximation [26, 27]. We construct a different set of creation operators that are linear
combinations of creation operators in the inside and outside regions [26, 27]
$$\mu _ { \circ \dots } ^ { \dots - 1 } \iota _ { \circ }, - \iota _ { 1 } & \dots \dots \dots \\ \tilde { c } _ { \mathbf k, R } \ = \ \cos r \hat { a } _ { \mathbf k } ^ { o u t } - \sin r \hat { b } _ { - \mathbf k } ^ { i n \dagger }, & \text{ atio} \\ \tilde { c } _ { \mathbf k, L } \ = \ \cos r \hat { a } _ { \mathbf k } ^ { i n } - \sin r \hat { b } _ { - \mathbf k } ^ { o u t \dagger }, & \text{flux} \\ \tilde { c } _ { \mathbf k, L } ^ { \dagger } \ = \ \cos r \hat { a } _ { \mathbf k } ^ { o u t \dagger } - \sin r \hat { b } _ { - \mathbf k } ^ { i n }, & \text{ regi} \\ \tilde { c } _ { \mathbf k, L } ^ { \dagger } \ = \ \cos r \hat { a } _ { \mathbf k } ^ { i n \dagger } - \sin r \hat { b } _ { - \mathbf k } ^ { o u t }, & \text{ (10)} \\ \, \cos r \ = \ [ \varrho ^ { - 8 \pi \omega ( M - \alpha ) } \ + \ 1 ] ^ { - \frac { 1 } { 2 } } \ \text{ and } \ \sin r \ = \ \.$$
where cos r = [ e -8 πω M ( -α ) + 1] -1 2 and sin r = [ e 8 πω M ( -α ) + 1] -1 2 . We name the modes (or operators) with subscripts L and R by 'left' and 'right' modes (or operators), respectively. After properly normalizing the state vector, the Kruskal vacuum is found to be || 0 〉〉 K = ⊗ k || 0 k 〉〉 K = ⊗ k || 0 k 〉〉 R ⊗ || 0 k 〉〉 L , where ||| 0 k 〉〉 R and ||| 0 k 〉〉 L are annihilated by the annihilation operators ˜ c k ,R and ˜ c k ,L . The vacuum state || 0 k 〉〉 K for mode k is given by
$$| | 0 _ { \mathbf k } \rangle \rangle _ { K } \ & = \ \cos ^ { 2 } r | | 0 0 0 0 \rangle \rangle - \sin r | | 0 0 1 1 \rangle \rangle \\ & \quad + \ \sin r \cos r | | 1 1 0 0 \rangle \rangle - \sin ^ { 2 } r | | 1 1 1 1 \rangle \rangle, \ ( 1 1 ) \\. \quad \ \nu \quad \nu \quad \nu \quad \nu + \nu \quad \nu - \nu \quad \nu - \nu \quad \nu \quad + \quad \nu.$$
where || mnm n ′ ′ 〉〉 = || m k 〉〉 + out || n -k 〉〉 -in || m ′ -k 〉〉 -out || n ′ k 〉〉 + in , {|| n -k 〉〉 -in } and {|| n k 〉〉 + out } are the orthonormal bases for the inside and outside region of the dilaton black hole respectively, and the { + , -} superscript on the kets is used to indicate the fermion and antifermion vacua. For the observer Bob who travels outside the event horizon, the Hawking radiation spectrum from the view of his detector can be obtained by
$$N _ { \omega } ^ { 2 } = _ { K } \langle 0 | \hat { a } _ { \mathbf k } ^ { o u t \dagger } \hat { a } _ { \mathbf k } ^ { o u t } | 0 \rangle _ { K } = \frac { 1 } { e ^ { \omega / T } + 1 },$$
where T = 1 8 π M ( -α ) is Hawking temperature [34] of the black hole. This equation shows that the observer in the exterior of the Garfinkle-Horowitz-Strominger dilaton black hole detects a thermal Fermi-Dirac distribution of particles. Because of the Pauli exclusion principle, only the first excited state for each fermion mode || 1 k 〉〉 + K is allowed, and similarly for antifermions. The first excited state for the fermion mode is given by
$$| | 1 _ { \mathbf k } \rangle \rangle _ { K } ^ { + } \ = & \left [ q _ { R } ( \tilde { c } _ { \mathbf k, R } ^ { \dagger } \otimes I _ { L } ) + q _ { L } ( I _ { R } \otimes \tilde { c } _ { \mathbf k, L } ^ { \dagger } ) \right ] | | 0 _ { \mathbf k } \rangle \rangle _ { K } \\ & = q _ { R } [ \cos r | | 1 0 0 0 \rangle \rangle - \sin r | | 1 0 1 1 \rangle \rangle ] \\ & + q _ { L } [ \sin r | | 1 1 0 0 \rangle \rangle + \cos r | | 0 0 0 1 \rangle \rangle ], \quad \quad ( 1 2 ) \\ \text{with } | \alpha _ { n } | ^ { 2 } + | \alpha _ { n } | ^ { 2 } \ = \ 1 \quad \text{The student} \quad \text{for} \text{ inonic an}.$$
with | q R | 2 + | q L | 2 = 1. The study of fermionic quantum information beyond the single mode approximation, which was proposed in [26] and widely adopted recently, has a lack of physical interpretation so far. Here we present an alternative physical interpretation on the operators and states that obtained beyond such an approximation in black hole spacetimes. The operator ˜ c † k ,R in Eq.(10) indicates the creation of two particles, i.e., a fermion in the exterior vacuum and an antifermion in the interior vacuum of the black hole. Similarly, the create operator ˜ c † k ,L means that an antifermion and an fermion are created outside and inside the event horizon, respectively. Hawking radiation comes from spontaneous creation of paired particles and antiparticles by quantum fluctuations near the event horizon. The particles and antiparticles can radiate toward the inside and outside regions randomly from the event horizon with the total probability | q R | 2 + | q L | 2 = 1. Thus, | q R | = 1 means that all the particles move toward the black hole exteriors while all the antiparticles move to the inside region, i.e., only particles can be detected as Hawking radiation. Similarly, | q L | = 1 indicates that only antiparticles escapes from the event horizon. Therefore, the single mode approximation (either | q R | = 1 or | q L | = 1) is a special case when either only particles or only antiparticles are detected.
## III. QUANTUM DISCORD AND MID IN DILATON BLACK HOLE SPACETIMES
We assume that Alice and Bob share a maximally entangled state
$$| | \Phi \rangle \rangle _ { A B } = \frac { 1 } { \sqrt { 2 } } ( | | 0 \rangle \rangle _ { A } | | 0 \rangle \rangle _ { B } + | | 1 \rangle \rangle _ { A } ^ { + } | | 1 \rangle \rangle _ { B } ^ { + } ), \quad ( 1 3 )$$
at the same point in the asymptotically flat region of the dilaton black hole. Then Alice stays stationary at the asymptotically flat region, while Bob moves with uniform acceleration and hovers near the event horizon of the dilaton black hole. Bob will detects a thermal FermiDirac distribution of particles and his detector is found to be excited. Using Eqs. (11) and (12), we can rewrite Eq. (13). Since Bob is causally disconnected from the region inside the event horizon we should trace over the state of the inside region and obtain
$$\text{ only } \text{ state of the inside region and obtain } \\ \gamma _ { K } ^ { + } \text{ is } \\ \text{cited } \quad \varrho ^ { A B _ { o u t } } \, = \, \frac { 1 } { 2 } \left [ C ^ { 4 } \, | | 0 0 0 \right ) \, \langle \left ( 0 0 0 | \, | + S ^ { 2 } C ^ { 2 } ( | | 0 0 1 \right ) \, \rangle \, \left ( 0 1 0 | \, | \\ \quad \, + \, | | 0 0 1 \right ) \, \rangle \, \left ( \left ( 0 0 1 | \, | + S ^ { 2 } \, | | 1 1 1 \right ) \, \rangle \, \left ( \left ( 1 1 1 | \, | \\ \right ) _ { K } \, \left ( 1 2 \right ) _ { L } | ^ { 2 } ( C ^ { 2 } \, | | 1 1 0 \right ) \, \rangle \, \left ( \left ( 1 1 0 | \, | + S ^ { 2 } \, | | 1 1 1 \right ) \, \rangle \, \left ( \left ( 1 1 1 | \, | \right ) \\ \left ( 1 2 \right ) _ { L } | ^ { 2 } ( S ^ { 2 } | | 1 1 0 \right ) \, \rangle \, \left ( \left ( 1 1 0 | \, | + C ^ { 2 } | | 1 0 0 \right ) \, \rangle \, \left ( \left ( 1 0 0 | \, | \right ) \\ \left | \text{uan-} } \quad \, + \, q _ { R } ^ { * } ( C ^ { 3 } | | 0 0 0 \right ) \, \rangle \, \left ( \left ( 1 1 0 | \, | + S ^ { 2 } C \, | | 0 0 1 \right ) \, \rangle \, \left ( \left ( 1 1 1 | \, | \right ) \\ \text{tion,} } \quad \, - \, q _ { L } ^ { * } ( C ^ { 2 } S | | 0 0 1 \right ) \, \rangle \, \left ( \left ( 1 0 0 | \, | + S ^ { 3 } | | 0 1 1 \right ) \, \rangle \, \left ( \left ( 1 1 0 | \, | \right ) \\ \text{ntly} } \quad \, - q _ { R } q _ { L } ^ { * } S C | | 1 1 1 \right ) \, \rangle \, \left ( \left ( 1 0 0 | \, | \right ] + ( H. c. ) _ { n o n - d i a g. } \left ( 1 4 \right ) \\ \right ) _ { o p } \, \text{rox} \quad \, \text{ where } | | l m n \right ) \rangle \, = \, | | \rangle \right ) _ { A } | | m _ { K } \rangle \rangle _ { o u t } ^ { + } | | n _ { - K } \rangle \rangle _ { o u t } ^ { - }, \, S = \sin r \, \text{ and}$$
where || lmn 〉〉 = || l 〉〉 A || m k 〉〉 + out || n -k 〉〉 -out , S = sin r and C = cos r . We assume that Bob has a detector sensitive only to the particle modes, which means that an antifermion cannot be excited in a single detector when a fermion was detected. Thus, we should also trace out the
antifermion mode || n -k 〉〉 -out in the outside region [27]
$$\varrho ^ { A \bar { B } } & \ = \ \frac { 1 } { 2 } \left [ C ^ { 2 } | | 0 0 \rangle \rangle \langle \langle 0 0 | + q _ { R } ^ { * } C | | 0 0 \rangle \rangle \langle \langle 1 1 | | & & \mathcal { D } \\ & + \ q _ { R } C | | 1 1 \rangle \rangle \langle \langle 0 0 | | ) + q _ { L } C ^ { 2 } | | 1 0 \rangle \rangle \langle \langle 1 0 | | & & \ N c \\ & + \ S ^ { 2 } | | 0 1 \rangle \rangle \langle \langle 0 1 | | + \chi _ { 0 } | | 1 1 \rangle \rangle \langle \langle 1 1 | | \right ], & & \text{(15)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(15)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(14)} \quad \text{(14)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13)} \quad \text{(13$$
where || lm 〉〉 = || l 〉〉 A || m k 〉〉 + out and χ 0 = | q R | 2 + | q L | 2 S 2 . Hereafter we call the mode ‖| m k 〉〉 + out as ˜ . B Now our system has two subsystems, i.e., the inertial subsystem A and accelerated subsystem ˜ . B We can easily obtain the von Neumann entropy S ρ ( A,B ˜ ) of this state, S ρ ( A ) for the reduced density matrix of the mode A and S ρ ( ˜ B ) for the mode ˜ , B respectively.
## A. Measurements on subsystem A
Now let us first make measurements on the subsystem A , the projectors are defined as [7, 18, 20]
$$\Pi _ { + } ^ { A } = \frac { I _ { 2 } + \mathbf n \cdot \sigma } { 2 } \otimes I _ { 2 }, \quad \Pi _ { - } ^ { A } = \frac { I _ { 2 } - \mathbf n \cdot \sigma } { 2 } \otimes I _ { 2 }, \ ( 1 6 )$$
where n 1 = sin θ cos ϕ, n 2 = sin θ sin ϕ, n 3 = cos θ and σ i are Pauli matrices. The measurement operators in Eq. (16) include a two-outcome projective measurement operator I 2 ± · n σ 2 on subsystem A and an identity operator on subsystem B . These operators are orthogonal projectors spanning the qubit Hilbert space and can therefore be parameterized by the unit vector n = ( n , n 1 2 , n 3 ). For simplicity, here we can take the measurements on the particle-number degree of freedom, i.e., to measure whether or not a fermion with wave vector k is excited in the particle detector. After the measurement of Π A + , the quantum state ρ A,B ˜ changes to
$$\rho _ { + } ^ { M A } \ & = \ T r _ { A } ( \Pi _ { + } ^ { A } \rho _ { A, \tilde { B } } \Pi _ { + } ^ { A } ) / p _ { + } ^ { A } \\ & = \ \frac { 1 } { 2 } \left [ \begin{array} { c } \varsigma _ { 1 } \\ e ^ { - i \varphi } q _ { R } C \sin \theta \end{array} e ^ { i \varphi } q _ { R } ^ { * } C \sin \theta \right ], \ \ ( 1 7 )$$
where p A + = Tr (Π A + ρ A,B ˜ Π ) = 1 2, A + / ς 1 = C 2 [1 + cos θ + q L (1 -cos θ )] and χ 1 = χ 0 (1 -cos θ ) + (1 + cos θ S ) 2 . The same method is used to compute the state after measurement Π A -, then we have
$$\rho _ { - } ^ { M A } = \frac { 1 } { 4 p _ { - } ^ { A } } \left [ \begin{array} { c } \varsigma _ { 2 } & - e ^ { i \varphi } q _ { R } ^ { * } C \sin \theta \\ - e ^ { - i \varphi } q _ { R } C \sin \theta \end{array} \right ], \ \ ( 1 8 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where p A -= Tr (Π A -ρ A,B ˜ Π ) = 1 2, A -/ ς 2 = C 2 [1 -cos θ + q L (1+cos θ )] and χ 2 = χ 0 (1+cos θ )+(1 -cos θ S ) 2 . Now we can obtain the conditional entropy S { Π A j } ( ˜ B A | ) ≡ ∑ j p S B j j ( ˜ | ). The classical correlation in this case is
$$\mathcal { C } ( \tilde { B } | A ) = S ( \rho _ { \tilde { B } } ) - \min _ { \Pi _ { j } ^ { A } } S _ { \{ \Pi _ { j } ^ { A } \} } ( \tilde { B } | A ),$$
and the quantum discord is
$$\mathcal { D } ( \tilde { B } | A ) = S ( \rho _ { \tilde { A } } ) - S ( \rho _ { A, \tilde { B } } ) + \min _ { \Pi _ { j } ^ { A } } S _ { \{ \Pi _ { j } ^ { A } \} } ( \tilde { B } | A ).$$
Note that the conditional entropy has to be numerically evaluated by optimizing over the angles θ and φ . Thus we should minimize it over all possible measurements on A [18]. We find that the condition entropy is independent of ϕ and its minimum can be obtained when θ = π/ 2.
## B. Measurements on subsystem ˜ B
Then let us make our measurements on the subsystem ˜ ; B the projectors are defined as
$$\Pi _ { + } ^ { \tilde { B } } = I _ { 2 } \otimes \frac { I _ { 2 } + \mathbf n \cdot \sigma } { 2 }, \quad \Pi _ { - } ^ { \tilde { B } } = I _ { 2 } \otimes \frac { I _ { 2 } - \mathbf n \cdot \sigma } { 2 }. \ ( 1 9 )$$
After the measurement of Π ˜ B + , the state ρ A,B ˜ changes to
$$( 1 6 ) \quad \rho _ { + } ^ { M \tilde { B } } = \frac { 1 } { 4 p _ { + } ^ { \tilde { B } } } \left [ \begin{array} { c } \varsigma _ { 3 } & e ^ { i \varphi } q _ { R } ^ { * } \sin r \sin \theta \\ e ^ { - i \varphi } q _ { R } \sin r \sin \theta \end{array} \right ],$$
where p ˜ B + = (1 -cos 2 r cos θ )(1 + q 2 L ) + q 2 R (1 + cos θ ), ς 3 = (1 + cos θ C ) 2 + (1 -cos θ S ) 2 and χ 3 = q 2 L C 2 (1 -cos θ )+ χ 0 (1+cos θ ). Similarly, we can calculate the state after Π ˜ B -and get the classical correlation C ( A B | ˜ ) and the quantum discord D ( A B | ˜ ) respectively.
Α
FIG. 1: (Color online) The classical correlation C ( ˜ B A | ) obtained by measuring the subsystem A and the classical correlation C ( A B | ˜ ) (dashed line) as a function of the dilaton α . We set M = ω = 1 and q R = 1.
Figure 1 shows how the dilaton α of the black hole influences the classical correlations of the system when we obtain them by measuring the subsystem A and ˜ , B respectively. From which we can see that for all the two cases the classical correlations decrease with increasing dilaton α . The classical correlation C ( ˜ B A | ) obtained by the one-side measurements on subsystem A , is always not equal to C ( A B | ˜ ) for any dilaton value. In contrast, the classical correlations satisfy C ( B A | ) = C ( A B | ) = 1
for the initial state, Eq.(13), in the asymptotically flat region. Comparing to the flat spacetime, the classical correlation (of course the related quantum correlation) is not symmetrical in the dilaton black hole spacetime. This asymmetry is due to the effect of gravitation produced by the black hole. We also note that C ( ˜ B A | ) is larger than C ( A B | ˜ ) when the dilaton is smaller than a fixed value ( α /similarequal 0 9451), while it is smaller than . C ( A B | ˜ ) when the dilaton is larger than this value.
## C. Symmetric measurement of the correlations
From the foregoing discussion, we see that the classical and quantum correlations in the curved spacetime depend on the measurement process. At the same time, a symmetric measurement of the quantum correlation was proposed recently. The MID measurement [25], which is obtained by a complete set of projective measurements over both partitions of a bipartite state, is given by [25]
$$\mathcal { D } ( M I D ) = \mathcal { I } ( \rho _ { A, \tilde { B } } ) - \mathcal { I } ( \eta _ { A, \tilde { B } } ) \quad \quad ( 2 0 )$$
with
$$\eta _ { A, \tilde { B } } = \sum _ { i = 1 } ^ { m } \sum _ { j = 1 } ^ { n } \pi _ { i } ^ { A } \otimes \pi _ { j } ^ { \tilde { B } } \rho _ { A, \tilde { B } } \pi _ { i } ^ { A } \otimes \pi _ { j } ^ { \tilde { B } }. \quad ( 2 1 ) \quad \text{$\text{$tatic$} \\ \text{space$} \\ \text{when}.$$
where π A i = || i 〉〉〈〈 || i and π ˜ B j = || j 〉〉〈〈 j || are onedimensional orthogonal projections for parties A and ˜ , B respectively. Such a symmetrized version of the quantum correlation was recently discussed theoretically [25] and experimentally measured by anuclear magnetic resonance setup at room temperature [35]. Besides, MID requires only the local measurement strategy rather than the cumbersome optimization required by the derivation of discord [36]. Here we can easily obtain η A,B ˜ and find the MID measure of classical correlation C ( MID ) and quantum correlation D ( MID ).
FIG. 2: (Color online) The quantum discord D ( ˜ B A | )(solid line), D ( A B | ˜ ) (dashed line), and D ( MID ) (dotted line) of ρ A,B ˜ as a function of the dilaton α . We set M = ω = 1 and q R = 1.
Figure 2 shows how the dilaton of the black hole affects the quantum correlations (discord and MID) that obtained by different measuring methods. Both the quantum discord and the MID decrease as the increasing of α , which means the quantum correlations degraded as the increase of dilaton α . It is shown that the discord D ( A B | ˜ ) is not equal to D ( ˜ B A | ) for any α , which is extremely different from D ( B A | ) = D ( A B | ) = 1 in the initial state Eq. (13). Comparing to the flat spacetime, the quantum discord is not symmetric for any α in the dilaton black hole spacetime. The symmetry of quantum discord is truly influenced by the dilaton of the black hole. It is also noted that the quantum correlation obtained via the MID measurement is always larger than that obtained by the one-side measurement.
## IV. SUMMARY
The effect of black hole's dilaton on the symmetry of classical correlation, quantum discord, and MID for the Dirac fields is investigated. We give a physical interpretation of the single mode approximation in the curved spacetime, i.e., such an approximation is a special case when either only particles or only antiparticles are detected. It is shown that the classical and quantum correlations decrease monotonously as increasing dilaton, which means all type of correlations are degraded due to the effect of gravitation generated by the dilaton of the black hole. We find that both the one-side measured classical and quantum correlations are not symmetric with respect to the subsystem being measured. So both the quantification and the symmetry of classical correlation and quantum discord are influenced by the gravitation when taking the one-side measurement. This is a sharp comparison between the inertial systems and the system in the curved spacetime. The results obtained here are not only helpful to understanding the symmetric properties of classical and quantum correlations in the presence of strong gravitation but also give a better insight into quantum properties of dilaton black holes.
## Acknowledgments
This work is supported by the 973 program through 2010CB922904, the National Natural Science Foundation of China under Grant No. 11305058, No.11175248, No.11175065, the Doctoral Scientific Fund Project of the Ministry of Education of China under Grant No. 20134306120003, and CAS.
- [1] A. Peres and D. R. Terno, Rev. Mod. Phys. 76 , 93 (2004).
- [2] L. Bombelli, R. K. Koul, J. Lee, and R. D. Sorkin, Phys. Rev. D 34 , 373 (1986).
- [3] S. W. Hawking, Commun. Math. Phys. 43 , 199 (1975); Phys. Rev. D 14 , 2460 (1976); H. Terashima, Phys. Rev. D 61 , 104016 (2000).
- [4] P. M. Alsing and G. J. Milburn, Phys. Rev. Lett. 91 , 180404 (2003).
- [5] I. Fuentes-Schuller and R. B. Mann, Phys. Rev. Lett. 95 , 120404 (2005).
- [6] T. C. Ralph, G. J. Milburn, and T. Downes, Phys. Rev. A 79 , 022121 (2009); J. Doukas and L. C.L. Hollenberg, Phys. Rev. A 79 , 052109 (2009); S. Moradi, Phys. Rev. A 79 , 064301 (2009).
- [7] A. Datta, Phys. Rev. A 80 , 052304 (2009); J. Wang, J. Deng, and J. Jing, Phys. Rev. A 81 , 052120 (2010); E. G. Brown, K. Cormier, E. Mart´ ın-Mart´ ınez, and R. B. Mann, Phys. Rev. A 86 , 032108 (2012).
- [8] J. Wang and J. Jing, Phys. Rev. A 82 , 032324 (2010); 83 , 022314 (2011).
- [9] M. Aspachs, G. Adesso, and I. Fuentes, Phys. Rev. Lett 105 , 151301 (2010).
- [10] S. Khan and M. K. Khan, J. Phys. A 44 , 045305, (2011); X. Xiao and M. Fang, J. Phys. A 44 , 145306 (2011); M. Z. Piao and X. Ji, J. Mod. Opt., 59 , 21 (2012); M. Ramzan, Eur.Phys. J. D 67 , 170 (2013).
- [11] J. Feng, Y.-Z. Zhang, M. D. Gould, and H. Fan, Phys. Lett. B 726 , 527(2013); D. J. Hosler and P. Kok, Phys. Rev. A 88 , 052112. (2013).
- [12] S. Xu, X.-K. Song, J.-D. Shi, and L. Ye, Phys. Rev. D 89 ,065022 (2014); Y. Yao, X. Xiao, L. Ge, X. G. Wang, and C. P. Sun, Phys. Rev. A 89 , 042336 (2014).
- [13] N. Friis, A. R. Lee, D. E. Bruschi, and J. Louko, Phys. Rev. D 85 , 025012 (2012); D. E. Bruschi, I. Fuentes, and J. Louko, Phys. Rev. D 85 , 061701(R)(2012).
- [14] N. Friis, A. R. Lee, K. Truong, C. Sab´ ın, E. Solano, G. Johansson, and I. Fuentes, Phys. Rev. Lett. 110 , 113602 (2013); E. Mart´ ın-Mart´ ınez, D. Aasen, and A. Kempf, Phys. Rev. Lett. 110 , 160501 (2013).
- [15] D. Garfinkle, G. T. Horowitz, and A. Strominger, Phys. Rev. D 43 , 3140 (1991); A. Garcia, D. Galtsov and O. Kechkin, Phys. Rev. Lett. 74 1276, (1995); J. Wang, Q. Pan, S. Chen, and J. Jing, Phys. Lett. B 677 , 186 (2009).
- [16] L. Nakonieczny and M. Rogatko, Phys. Rev. D 84 , 044029 (2011); A. Anabalon, D. Astefanesei, R. Mann, J. High Energy Phys. 10 , (2013)184.
- [17] L. Amarilla and E. F. Eiroa, Phys. Rev. D 87 , 044057
(2013).
- [18] H. Ollivier and W. H. Zurek, Phys. Rev. Lett. 88 , 017901 (2001).
- [19] J. Maziero et al. , Phys. Rev. A 81 , 022116 (2010).
- [20] A. Datta, A. Shaji, and C. M. Caves, Phys. Rev. Lett. 100 , 050502 (2008).
- [21] B. P. Lanyon, M. Barbieri, M. P. Almeida, and A. G. White, Phys. Rev. Lett. 101 , 200501 (2008).
- [22] R. S. Ingarden, A. Kossakowski, and M. Ohya, Information Dynamics and Open Systems - Classical and Quantum Approach (Kluwer Academic Publishers, Dordrecht, 1997).
- [23] N. J. Cerf and C. Adami, Phys. Rev. Lett. 79 , 5194 (1997).
- [24] M. Horodecki et al. , Phys. Rev. A 71 , 062307 (2005).
- [25] D. P. DiVincenzo et al. , Phys. Rev. Lett. 92 , 067902 (2004); S. Luo, Phys. Rev. A 77 , 022301 (2008); K. Modi et al. , Phys. Rev. Lett. 104 , 080501 (2010); K. Modi, A. Brodutch, H. Cable, T. Paterek, and V. Vedral Rev.Mod. Phys. 84 , 1655 (2012).
- [26] D. E. Bruschi, J. Louko, E. Mart´ ın-Mart´ ınez, A. Dragan, and I. Fuentes, Phys. Rev. A 82 , 042332 (2010).
- [27] N. Friis et al. , Phys. Rev. A 84 , 062111 (2011); M. Montero, J. Leon, and E. Mart´ ın-Mart´ ınez, Phys. Rev. A 84 , 042320 (2011); J. Chang and Y. Kwon, Phys. Rev. A 85 , 032302 (2012).
- [28] D. R. Brill and J. A. Wheeler, Rev. Mod. Phys. 29 , 465 (1957); Phys. Rev. D 45 , 3888(E) (1992).
- [29] J. Wang, Q. Pan, S. Chen, and J. Jing, Quantum Inf. Comput. 10 , 0947 (2010).
- [30] T. Damoar and R. Ruffini, Phys. Rev. D 14 , 332 (1976).
- [31] J. Wang, Q. Pan, and J. Jing, Ann. Phys. (New York) 325 , 1190 (2010); Phys. Lett. B 602 , 202 (2010).
- [32] N. Friis, A. R. Lee, and D. E. Bruschi, Phys. Rev. A 87 , 022338 (2013).
- [33] S. M. Barnett and P. M. Radmore, Methods in Theoretical Quantum Optics (Oxford University Press, New York, 1997), pp. 67-80.
- [34] S. W. Hawking, Nature(London) 248 , 30 (1974); S. A. Haywarda, R. Di Criscienzob, M. Nadalinic, L. Vanzoc, and S. Zerbini, Classcal Quantum Gravity 26 , 062001 (2009).
- [35] D. O. Soares-Pinto et al. , Phys. Rev. A 81 , 062118 (2010).
- [36] B. R. Rao, R. Srikanth, C. M. Chandrashekar, and S. Banerjee Phys. Rev. A 83 , 064302(2011). | 10.1103/PhysRevD.90.025032 | [
"Jieci Wang",
"Jiliang Jing",
"Heng Fan"
] | 2014-08-01T05:07:27+00:00 | 2014-08-01T05:07:27+00:00 | [
"quant-ph"
] | Quantum discord and measurement-induced disturbance in the background of dilaton black holes | We study the dynamics of classical correlation, quantum discord and
measurement-induced disturbance of Dirac fields in the background of a dilaton
black hole. We present an alternative physical interpretation of single mode
approximation for Dirac fields in black hole spacetimes. We show that the
classical and quantum correlations are degraded as the increase of black hole's
dilaton. We find that, comparing to the inertial systems, the quantum
correlation measured by the one-side measuring discord is always not symmetric
with respect to the measured subsystems, while the measurement-induced
disturbance is symmetric. The symmetry of classical correlation and quantum
discord is influenced by gravitation produced by the dilaton of the black hole. |
1408.0081v1 | ## Nuclear deformation at finite temperature
Y. Alhassid, 1 C.N. Gilbreth, 1 and G.F. Bertsch 2 1 Center for Theoretical Physics, Sloane Physics Laboratory, Yale University, New Haven, CT 06520 2 Department of Physics and Institute of Nuclear Theory, Box 351560 University of Washington, Seattle, WA 98915
(Dated: August 4, 2014)
Deformation, a key concept in our understanding of heavy nuclei, is based on a mean-field description that breaks the rotational invariance of the nuclear many-body Hamiltonian. We present a method to analyze nuclear deformations at finite temperature in a framework that preserves rotational invariance. The auxiliary-field Monte-Carlo method is used to generate the statistical ensemble and calculate the probability distribution associated with the quadrupole operator. Applying the technique to nuclei in the rare-earth region, we identify model-independent signatures of deformation and find that deformation effects persist to higher temperatures than the spherical-todeformed shape phase-transition temperature of mean-field theory.
PACS numbers: 21.60.Cs, 21.60.Ka, 21.10.Ma, 02.70.Ss
Motivation .- Mean-field theory is a useful method for studying correlated many-body systems. However, it often breaks symmetries, making it difficult to compare its results with physical spectra that preserve these symmetries. In addition, although mean-field theory often predicts sharp phase transitions at finite temperature, they are washed out in finite-size systems. The challenge is to find tools to study the properties of finite-size systems within a framework that preserves the underlying symmetries while also allowing calculation of the quantities that describe symmetry breaking in mean-field theory.
In nuclear physics, this issue is especially important in the understanding of heavy deformed nuclei, which are of wide experimental and theoretical interest. The current theory of these nuclei is based on self-consistent mean-field (SCMF) theory, which predicts both spherical and deformed ground states [1] depending on the nucleus. SCMF is a convenient tool to study their intrinsic structure but it breaks rotational invariance, a prominent symmetry in nuclear spectroscopy. The occurrence of large deformations in the ground state and at low excitations gives rise to rotational bands and large electric quadrupole transition intensities between states within the bands. At higher excitations, much less is known experimentally. Characterization of this part of the spectrum is needed for accurate calculation of the nuclear level density, which is very sensitive to deformation and other structure effects; observed level densities in rare-earth nuclei at the neutron evaporation threshold vary by more than an order of magnitude [3]. In addition, nuclear fission is a phenomenon of shape dynamics, and calculation of fission rates for excited nuclei requires their level densities as a function of deformation [4].
Here we investigate nuclear deformation at finite temperature using the auxilliary-field Monte Carlo (AFMC) method, which is well suited to the study of the evolution of nuclear properties with excitation energy while preserving rotational invariance. In particular, we cal- culate the distribution of the quadrupole operator in the lab frame and demonstrate that it exhibits modelindependent signatures of deformation. We use moments of this distribution to calculate rotationally invariant observables, which allow us to extract effective values of the intrinsic deformation and its fluctuations. Deformations have been studied previously by the AFMC method, but with an ad hoc prescription to extract the intrinsic-frame properties [5]. The methods presented here should be applicable to other finite-size systems in which correlations beyond the mean field are important.
Methodology .- Formally, we can examine the statistical characteristics of nuclei at finite excitations by calculating the thermal expectation values of observables ˆ O associated with the property of interest, 〈 ˆ O 〉 = Tr( ˆ Oe -βH ˆ ) / Tr e -βH ˆ . Here β -1 is the temperature and ˆ H is the Hamiltonian, which we assume to be rotationally invariant. We denote operators in the many-particle space with a circumflex, to be distinguished from operators in the single-particle space, which are ordinary matrices, denoted by bold-face symbols. Also, we denote the trace over the full many-particle Fock space as Tr and the trace of matrices in the single-particle space by tr. The probability distribution of an operator ˆ , O P β ( o ) = Tr( δ O [ ˆ -o e ) -βH ˆ ] / Tr e -βH ˆ can be calculated using the Fourier representation of the δ function:
$$\underset { \text{old} } { \text{is} } \quad P _ { \beta } ( o ) = \frac { 1 } { \text{Tr} \, e ^ { - \beta \hat { H } } } \int _ { - \infty } ^ { \infty } \frac { d \varphi } { 2 \pi } e ^ { - i \varphi o } \, \text{Tr} \, \left ( e ^ { i \varphi \hat { O } } e ^ { - \beta \hat { H } } \right ). \quad ( 1 ) \\ \cdot \quad \quad - \quad \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \,.$$
Eq. (1) is well-known for one-body observables ˆ O that commute with the Hamiltonian, e.g., the number operator and the z -component of the angular momentum [6].
Nuclear shape is different in that the relevant operators, e.g., the quadrupole operators, do not commute with the Hamiltonian. Nevertheless, it is possible with Eq. (1) to define the distribution of quantum-mechanical observables that carry information about deformation as
well as energy. The distribution (1) can be expressed in terms of the many-particle eigenstates of ˆ and O ˆ H as
$$P _ { \beta } ( o ) = \sum _ { n } \delta ( o - o _ { n } ) \sum _ { m } \langle o, n | e, m \rangle ^ { 2 } e ^ { - \beta e _ { m } }. \quad ( 2 ) \quad \ e ^ { - \beta \tilde { h } } \\ \quad \text{$\text{$\text{$\text{$\text{$nron}$} } }. \quad. \quad \text{$\text{$\text{$\text{$nron}$} } }.$$
Here | o, n 〉 are eigenstates of ˆ O satisfying ˆ O o, n | 〉 = o n | o, n 〉 and similarly for | e, m 〉 . Eq. (2) is valid whether or not the operators ˆ and O ˆ H commute. When they do commute, they share a common basis of eigenstates such that 〈 o, n e, m | 〉 = δ m,n and the distribution (2) reduces to its more familiar form P β ( o ) = ∑ n δ o ( -o n ) e -βe n . Note that in a finite model space the eigenvalues o n form a discrete set and P β ( o ) is a finite sum of δ functions.
In this work we consider the observable ˆ O to be the spectroscopic mass quadrupole operator ˆ Q 20 = ∑ ( i 2 z 2 i -x 2 i -y 2 i ) where the sum is taken over all nucleons. The probability distribution P β ( q ) of ˆ Q 20 is defined as in Eq. (1) with ˆ = O ˆ Q 20 and o = . q
As we will show, this distribution can be accurately computed by the AFMC method. However, the intrinsicframe properties are not directly accessed by the operator ˆ Q 20 , which is a laboratory-frame observable. We shall demonstrate in this work that nevertheless the distribution P β ( q ) is sensitive to deformation effects and that the main properties of the deformation in the intrinsic frame can be recovered from moments of this distribution.
Intrinsic frame quantities may be defined in terms of the expectation values of rotationally invariant combinations of the quadrupole tensor operator ˆ Q 2 µ ( µ = -2 , . . . , 2) [7, 8]. The lowest-order invariant is quadratic, ˆ Q · ˆ Q = ∑ µ ( -) µ ˆ Q 2 µ ˆ Q 2 -µ . There is one third-order invariant defined by coupling three quadrupole operators to angular momentum zero, ( ˆ Q × ˆ ) Q · ˆ Q = √ 5 ∑ µ ,µ ,µ 1 2 3 ( 2 2 2 µ 1 µ 2 µ 3 ) ˆ Q 2 µ 1 ˆ Q 2 µ 2 ˆ Q 2 µ 3 . The fourthand fifth-order invariants are also unique [9] and we define them as ( ˆ Q Q · ˆ ) 2 and ( ˆ Q Q · ˆ )(( ˆ Q × ˆ ) Q Q · ˆ ), respectively. When the invariant is unique at a given order, its expectation value can be computed directly from the lab-frame moments of ˆ Q 20 , defined by 〈 ˆ Q n 20 〉 β = ∫ q n P β ( q dq ) . The conversion factors are given in Table I.
TABLE I: First line: the ratio of the expectation value of the invariant of order n (see text) to the n -th moment of ˆ Q 20 . Second line: the n -th moment of ˆ Q 20 for the rigid rotor in units of q n 0 ( q 0 is the rotor's intrinsic quadrupole moment).
| n | 2 | 3 | 4 | 5 |
|-----------|-----|------------------|------|-------------------------|
| invariant | 5 | - 5(7 / 2) 1 / 2 | 35/3 | - (11 / 2)(7 / 2) 1 / 2 |
| rotor | 1/5 | 2/35 | 3/35 | 4/77 |
AFMC .- We shall use the AFMC to evaluate the distribution in Eq. (1) for ˆ = O ˆ Q 20 . AFMC is arguably the most powerful computational tool for finding the ground states and thermal properties in large-dimension manyparticle spaces. It is based on the Hubbard-Stratonovich representation [10] of the imaginary-time propagator, e -βH ˆ = ∫ D σ G U [ ] σ ˆ σ , where D σ [ ] is the integration measure, G σ ( ) is a Gaussian weight, and ˆ U σ is a one-body propagator of non-interacting nucleons moving in auxiliary fields σ . Practical implementations require that the Hamiltonian be restricted to oneand two-body terms, and that the two-body terms have the so-called good sign [11]. The method has been applied to nuclei in the framework of the configuration-interaction shell model [12-14], where it is called the shell-model Monte Carlo (SMMC). It has been particularly successful in calculating statistical properties of nuclei such as level densities [15]. The distribution of ˆ Q 20 is obtained from the Monte Carlo sampling of fields σ as a ratio of averages
$$\overset { \nearrow } { 1 } \\ y$$
Here 〈 X 〉 W = ∫ D σ W X / [ ] σ σ ∫ D σ W [ ] σ , where W σ = G σ | Tr ˆ U σ | is used for the Monte Carlo sampling and Φ σ = Tr ˆ U / σ | Tr ˆ U σ | is the Monte Carlo sign function.
For a given ˆ U σ , we carry out the ˆ Q 20 projection using a discretized version of the Fourier decomposition in Eq. (1). We take an interval [ -q max , q max ] and divide it into 2 M +1 equal intervals of length ∆ q = 2 q max / (2 M + 1). We define q m = m q ∆ , where m = -M,...,M , and approximate the quadrupole-projected trace in (3) by
$$\overset { \mathbf V ^ { \mu } } { \text{lract} }, & \overset { \mathbf V } { \text{lract} }, \\ \overset { \mathbf V } { \text{order} } & \overset { \mathbf V } { \text{Tr} } \left ( \delta ( \hat { Q } _ { 2 0 } - q _ { m } ) U _ { \sigma } \right ) \approx \frac { 1 } { 2 q _ { \max } } \sum _ { k = - M } ^ { M } e ^ { - i \varphi _ { k } q _ { m } } \text{Tr} ( e ^ { i \varphi _ { k } \hat { Q } _ { 2 0 } } \hat { U } _ { \sigma } ) \, \\ \overset { \mathbf V } { \text{oper} } & \overset { \mathbf V } { \text{where} } \ \overset { \mathbf V } { \text{$\mathbf V} }, \ - \ \pi k \cdot / \alpha \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
We found the thermalization of ˆ Q n 20 to be slow with the pure Metropolis sampling. This can be overcome by augmenting the Metropolis-generated configurations by rotating them through a properly chosen set of N Ω rotation angles Ω. In practice, it is easier to rotate the observables, i.e., we replace 〈 e iϕQ ˆ 20 〉 σ by 1 N Ω ∑ j 〈 e iϕQ ˆ 20 (Ω ) j 〉 σ . ˆ ˆ ˆ ˆ 1 ˆ being the rotation op- where ϕ k = πk/q max ( k = -M,...,M ). Since ˆ Q 20 is a one-body operator and ˆ U σ is a one-body propagator, the Fock space many-particle traces on the r.h.s. of Eq. (4) reduce to determinants in the single-particle space Tr ( e iϕ k ˆ Q 20 ˆ U σ ) = det ( 1 + e iϕ k Q 20 U σ ) . Here Q 20 and U σ are the matrices representing, respectively, ˆ Q 20 and ˆ U σ , in the single-particle space. In practice, projections are carried on the neutron and proton number operators as well to fix the Z and N of the ensemble [14].
Here Q 20 (Ω) = RQ 20 R -with R erator for angle Ω. Details will be given elsewhere.
We next discuss a few simple examples that can be treated analytically or nearly so.
Rigid rotor .- As a first simple example, we consider an axially symmetric rigid rotor with an intrinsic quadrupole
FIG. 1: The ground-state distribution P g s . . ( q ) vs q/q 0 for a prolate rotor with intrinsic quadrupole moment q 0 .
moment q 0 in its ground state. The distribution of its spectroscopic quadrupole operator in the laboratory frame Q 20 = q 0 (3 cos 2 θ -1) / 2 can be calculated in closed form. For a prolate rotor ( q 0 > 0)
$$P _ { g. s. } ( q ) = \begin{cases} \begin{array} { c c } \left ( \sqrt { 3 } q _ { 0 } \sqrt { 1 + 2 \frac { q } { q _ { 0 } } } \right ) & \text{for } - \frac { q _ { 0 } } { 2 } \leq q \leq q _ { 0 } \\ 0 & \text{otherwise } \end{array} \cdot ( 5 ) & \text{groun } \\ \text{for } \mu \\ \text{and} \end{cases}$$
This distribution is shown in Fig. 1. The oblate rotor ( q 0 < 0) distribution is obtained from (5) by replacing q with -q and q 0 with | q 0 | . The moments of the distribution (5) can be calculated from a simple recursion relation; their values for 2 ≤ n ≤ 5 are given in Table I.
20 Ne .-As a simple illustration in nuclear spectroscopy, we consider the light deformed nucleus 20 Ne. The orbital part of the single-particle wave functions are taken to be the states of the N = 2 harmonic oscillator shell, i.e., the sd -shell. The single-particle eigenvalues of Q 20 are -2, 1, and 4 (in units of b 2 [16]) with degeneracies of 6, 4 and 2, respectively. The many-particle eigenvalues of ˆ Q 20 for 20 Ne in the valence sd -shell thus range from -8 to 16 with a uniform spacing of 3. The distribution P β ( q ) at β = 0 is just the distribution of these eigenvalues.
We have used this nucleus as a simple test of the AFMC. Here we take the single-particle energies according to the USD interaction [17] and consider an attractive quadrupole-quadrupole interaction -χQ ˜ · ˜ , Q with ˜ Q 2 µ = ∑ i r 2 i Y 2 µ (ˆ ) r i and χ = 8 π 5 38 5 . A 5 / 3 MeV /b 4 [18]. In Fig. 2 we show the quadrupole distribution of the 20 Ne ground state. The discrete nature of the many-particle eigenvalues of ˆ Q 20 is evident; the distribution is a set δ functions at integers -8 , -5 , . . . , 13 16. The envelope of , the strengths has the skewed shape that looks qualitatively similar to the prolate rigid-rotor distribution.
SCMF .- It is instructive to compare our results with those of the thermal SCMF, e.g., the finite-temperature Hartree-Fock-Bogoliubov (HFB) approximation. The HFB solution is characterized by temperature-dependent one-body density matrix ρ β and pairing tensor κ β . In general, two types of phase transitions can occur vs
FIG. 2: The AFMC ground-state quadrupole distribution P g s . . ( q ) for 20 Ne. The sharp δ -like peaks demonstrate the discrete nature of the spectrum of ˆ Q 20 and their envelope resembles the prolate rigid-rotor distribution in Fig. 1.
/negationslash temperature, a pairing transition and a deformed-tospherical shape transition [19-21]. A shape phase transition is also the generic result of a Landau theory in which the order parameter is the quadrupole deformation tensor [22]. The vast majority of deformed HFB ground states are axially symmetric [23], i.e., 〈 ˆ Q 2 µ 〉 = 0 for µ = 0. The second-order invariant 〈 ˆ Q · ˆ Q 〉 may be calculated in HFB by using Wick's theorem
$$\intertext { t o r } \underset { \mu } { \mathrm i n g } \quad \langle \hat { Q } \cdot \hat { Q } \rangle = Q _ { 0 } ^ { 2 } + \sum _ { \mu } ^ { \kappa } ( - ) ^ { \mu } \text{tr} \left [ Q _ { 2 \mu } \left ( 1 - \rho _ { \beta } \right ) \mathbf Q _ { 2 - \mu } \rho _ { \beta } \right ] \\ \intertext { s i o n } \mathrm i. \quad \ \ \ \ + \sum _ { \mu } ( - ) ^ { \mu } \text{tr} \left [ Q _ { 2 \mu } \kappa _ { \beta } \, \mathbf Q _ { 2 - \mu } ^ { T } \kappa _ { \beta } ^ { * } \right ] \, \ \ ( 6 ) \\ \intertext { e c - } \mathrm i \text{Ne. } \quad \text{ where } Q _ { 0 } \equiv \text{tr} ( Q _ { 2 0 } \rho _ { \beta } ) \text{ is the intrinsic axial quadrupole}$$
where Q 0 ≡ tr( Q 20 ρ β ) is the intrinsic axial quadrupole moment. The remaining terms on the r.h.s. of (6) represent the contributions due to quantal and thermal fluctuations. We shall compare our AFMC results for rareearth nuclei with the HFB theory in the next section.
Rare-earth nuclei .- Here we present results for rareearth nuclei. The single-particle orbitals are taken from a Woods-Saxon potential plus spin-orbit interaction; they span the 50 -82 shell plus 1 f 7 / 2 orbital for protons and the 82 -126 shell plus 0 h 11 / 2 , 1 g 9 / 2 orbitals for neutrons. We use the same interaction as in Refs. [24, 25]. The quadrupole moments are scaled by a factor of 2 to account for the model space truncation.
We first examine 154 Sm, a strongly deformed nucleus with an intrinsic quadrupole moment of Q 0 ∼ 1600 fm , as determined experimentally from in-band electric 2 quadrupole transitions [26]. AFMC P β ( q ) distributions are shown in Fig. 3 at three temperatures. The distributions appear continuous because the many-particle eigenvalues of ˆ Q 20 are closely spaced. At the lowest temperature of T = 0 1 MeV (bottom panel), . e -βH ˆ effectively projects out the ground-state band. We observe the characteristic skewed distribution of the prolate rotor. The dashed line is the rotor distribution (5) with q 0 taken at the HFB value of Q 0 . The middle panel is the distribution at the HFB shape transition temperature, T = 1 14 .
FIG. 3: Probability distributions P β ( q ) for 154 Sm at T = 0 1 MeV, . T = 1 14 MeV (shape transition temperature) and . T = 4 MeV. The low-temperature distribution is compared with the rigid-rotor distribution (dashed line) and reflects the strongly deformed character of this nucleus.
MeV. The distribution is less skewed, but nevertheless it retains some trace of a prolate character. The HFB excitation energy at this temperature is about 25 MeV, much higher than energies of interest for spectroscopy and for the neutron-capture reaction. The top panel shows the distribution at T = 4 MeV. At this high excitation the distribution is featureless and close to a Gaussian.
We have also calculated P β ( q ) for 148 Sm, which is spherical in its HFB ground state. They are more symmetric and change less with temperature, consistent with the absence of a coherent quadrupole moment.
Invariants .- Fig. 4 shows the second-order invariant 〈 ˆ Q · ˆ Q 〉 vs temperature T for 148 Sm and 154 Sm. The AFMC results (circles) are compared with the HFB results (dashed lines) of Eq. (6). In HFB, 〈 ˆ Q Q · ˆ 〉 for 148 Sm can be entirely attributed to the fluctuation terms in (6). There is a small kink at T = 0 4 MeV associated with . the pairing transition, but by and large the curve is flat. The same is true of the AFMC curve. In contrast, 〈 ˆ Q Q · ˆ 〉 in 154 Sm is very different at low temperatures. In HFB, the intrinsic quadrupole moment Q 0 is large, and it persists up to a temperature of the order of 1 MeV, close to the spherical-to-deformed phase-transition temperature. The AFMC results are in semiquantitative agreement at the lowest temperatures showing that the coherent intrinsic quadrupole moment is not an artifact of the HFB. The sharp kink characterizing the HFB shape transition [19, 20] is washed out, as is expected in a finite-size system. Nevertheless a signature of this phase transition remains in the rapid decrease of 〈 Q · Q 〉 with temperature. In AFMC deformation effects survive well above
FIG. 4: 〈 Q Q · 〉 vs temperature T for the spherical 148 Sm (left) and the deformed 154 Sm (right). The AFMC results (solid circles) are compared with the HFB results (dashed lines).
the transition temperature, in that 〈 Q Q · 〉 continues to be enhanced beyond its uncorrelated mean-field value.
The secondand third-order invariants can be used to define effective values of the intrinsic shape parameters β, γ [27] of the collective Bohr model [28, Sec. 6B-1a]. The model assumes an intrinsic frame in which the quadrupole deformation parameters α 2 µ = √ 5 π Q 〈 ˆ 2 µ 〉 / 3 r 2 0 A 5 / 3 are expressed as α 20 = β cos γ , α 22 = α 2 -2 = 1 √ 2 β sin γ , and α 2 ± 1 = 0. Effective β and γ can then be determined from the corresponding invariants
$$\text{-} \text{$\text{ can use common from corresponding invations}$} \\ \text{much} \\ \text{id for} \quad \beta = \frac { \sqrt { 5 \pi } } { 3 r _ { 0 } ^ { 2 } A ^ { 5 / 3 } } \langle \hat { Q } \cdot \hat { Q } \rangle ^ { 1 / 2 } \, ; \, \cos 3 \gamma = - \sqrt { \frac { 7 } { 2 } } \frac { \langle ( \hat { Q } \times \hat { Q } ) \cdot \hat { Q } \rangle } { \langle \hat { Q } \cdot \hat { Q } \rangle ^ { 3 / 2 } } \,. \\ \text{in the} \quad \text{$\text{ in addition we can extract a measure } \Lambda \, \hat { Q } \, of the flatten}.$$
In addition, we can extract a measure ∆ β of the fluctuations in β using the second- and fourth-order invariants
$$\mathbf n _ { \mathbf t } \quad & ( \Delta \beta / \beta ) ^ { 2 } = \left [ \langle ( \hat { Q } \cdot \hat { Q } ) ^ { 2 } \rangle - \langle \hat { Q } \cdot \hat { Q } \rangle ^ { 2 } \right ] ^ { 1 / 2 } / \langle \hat { Q } \cdot \hat { Q } \rangle \,. \quad ( 8 ) \\ \mathbf n t \quad & \text{The invariants themselves are calculated from the $\mathbf moc$}$$
The invariants themselves are calculated from the moments of P β ( q ) using the relations in Table I. As expected, the deformed 154 Sm has a larger deformation β than 148 Sm (0 232 vs 0 137), but a smaller deforma-. . tion angle γ (13 4 . ◦ vs 21 6 ) that is . ◦ closer to an axial shape. The deformed nucleus is more rigid in that it has a smaller ∆ β/β , 0 51 for . 154 Sm vs 0 72 for . 148 Sm.
Summary .- We have demonstrated that the distribution of the axial quadrupole operator can be computed in the AFMC method, and that it conveys important information about deformation and the intrinsic shapes of nuclei at finite temperature. In particular, the expectation values of β 2 , β 3 cos 3 γ and the fluctuation in β 2 can be extracted as a function of temperature. With these moments, it should be possible to construct models of the joint level density distribution ρ β, E ( x ) = ρ E ( x ) P E x ( β ), where ρ E ( x ) is the total level density and P E x ( β ) is the intrinsic shape distribution at excitation energy E x . This joint distribution is an important component in the theory of fission and will be discussed in a future publication.
Acknowledgments .-Y. Alhassid acknowledges the hospitality of the Institute of Nuclear Theory in Seattle, where part of this work was completed. We thank H. Nakada for the HFB code. This work was supported in part by the U.S. DOE grant Nos. DE-FG02-91ER40608 and DE-FG02-00ER411132. Computational cycles were provided by the NERSC high performance computing facility and by the facilities of the Yale University Faculty of Arts and Sciences High Performance Computing Center.
- [1] The SU (3) representation provides an alternate way to study deformation effects [2], but it has not been widely applied to heavy nuclei.
- [2] C.E. Vargas, J.G. Hirsch, and J.P. Draayer, Nucl. Phys. A 697 , 655 (2002).
- [3] The RIPL3 database containing tables of experimental level densities can be accessed at https://www-nds.iaea.org/RIPL-3/resonances/ .
- [4] J.C. Pei, W. Nazarewicz, J.A. Sheikh, and A.K. Kerman, Phys. Rev. Lett. 102 , 192501 (2009).
- [5] Y. Alhassid, G.F. Bertsch, D.J. Dean, and S.E. Koonin, Phys. Rev. Lett. 77 , 1444 (1996).
- [6] Y. Alhassid, S. Liu, and H. Nakada, Phys. Rev. Lett. 99 , 162504 (2007).
- [7] K. Kumar, Phys. Rev. Lett. 28 , 249 (1972).
- [8] D. Cline, Ann. Rev. Nucl. Part. Sci. 36 , 683 (1986).
- [9] Strictly speaking the uniqueness of the fourth- and fifthorder invariants holds when the operators ˆ Q 2 µ commute among themselves. The quadrupole operators commute in coordinate space but generally not in a truncated shell model space. However, the effects due to their noncommutation is small.
- [10] J. Hubbard, Phys. Rev. Lett. 3 , 77 (1959); R. L. Stratonovich, Dokl. Akad. Nauk SSSR [Sov. Phys. -
- Dokl.] 115 , 1097 (1957).
- [11] Small bad-sign interaction terms can be treated using the extrapolation method of Ref. [12].
- [12] Y. Alhassid, D.J. Dean, S.E. Koonin, G. Lang, and W.E. Ormand, Phys. Rev. Lett. 72 , 613 (1994).
- [13] G.H. Lang, C.W. Johnson, S.E. Koonin, and W.E. Ormand, Phys. Rev. C 48 , 1518 (1993).
- [14] S.E. Koonin, D.J. Dean, and K. Langanke, Phys. Rep. 278 , 2 (1997); Y. Alhassid, Int. J. Mod. Phys. B 15 , 1447 (2001).
- [15] H. Nakada and Y. Alhassid, Phys. Rev. Lett. 79 , 2939 (1997); Y. Alhassid, S. Liu, and H. Nakada, Phys. Rev. Lett. 83 , 4265 (1999).
- [16] The oscillator length parameter b is defined to give a ground-state wave function of the form ∼ exp( -r 2 / b 2 2 ).
- [17] B.A. Brown and W.A. Richter, Phys. Rev. C 74 , 034315 (2006).
- [18] B. Lauritzen and G.F. Bertsch, Phys. Rev. C 39 , 2412 (1989).
- [19] A.L. Goodman, Phys. Rev. C 33 , 2212 (1986).
- [20] V. Martin, J. L. Egido and L. M. Robledo, Phys. Rev. C 68 , 034327 (2003).
- [21] B. K. Agrawal, T. Sil, J. N. De, and S. K. Samaddar, Phys. Rev. C 62 , 044307 (2000).
- [22] Y. Alhassid, S. Levit, and J. Zingman, Phys. Rev. Lett. 57 , 539 (1986).
- [23] J.-P. Delaroche, et al., Phys. Rev. C 81 , 014303 (2010).
- [24] Y. Alhassid, L. Fang and H. Nakada, Phys. Rev. Lett. 101 , 082501 (2008).
- [25] C. Ozen, Y. Alhassid, and H. Nakada, Phys. Rev. Lett. ¨ 110 , 042502 (2013).
- [26] S. Raman, C.W. Nestor, and P. Tikkanen, At. Data Nucl. Data Tables 78 , 1 (2001).
- [27] We use the symbol β for both the inverse temperature and the dimensionless deformation parameter; the meaning should be clear from the context.
- [28] A. Bohr and B. Mottelson, Nuclear Structure , Vol. II (Benjamin, 1975). | 10.1103/PhysRevLett.113.262503 | [
"Y. Alhassid",
"C. N. Gilbreth",
"G. F. Bertsch"
] | 2014-08-01T05:11:17+00:00 | 2014-08-01T05:11:17+00:00 | [
"nucl-th",
"cond-mat.mes-hall"
] | Nuclear deformation at finite temperature | Deformation, a key concept in our understanding of heavy nuclei, is based on
a mean-field description that breaks the rotational invariance of the nuclear
many-body Hamiltonian. We present a method to analyze nuclear deformations at
finite temperature in a framework that preserves rotational invariance. The
auxiliary-field Monte-Carlo method is used to generate the statistical ensemble
and calculate the probability distribution associated with the quadrupole
operator. Applying the technique to nuclei in the rare-earth region, we
identify model-independent signatures of deformation and find that deformation
effects persist to higher temperatures than the spherical-to-deformed shape
phase-transition temperature of mean-field theory. |
1408.0083v1 | The Annals of Applied Statistics 2014, Vol. 8, No. 2, 1232-1255 DOI: 10.1214/14-AOAS735 c © Institute of Mathematical Statistics, 2014
## GENE-LEVEL PHARMACOGENETIC ANALYSIS ON SURVIVAL OUTCOMES USING GENE-TRAIT SIMILARITY REGRESSION
By Jung-Ying Tzeng ∗ ‡ , , 1 2 , , Wenbin Lu ∗ , 1 3 , and Fang-Chi Hsu † , 4
North Carolina State University , Wake Forest University ∗ † and National Cheng-Kung University ‡
Gene/pathway-based methods are drawing significant attention due to their usefulness in detecting rare and common variants that affect disease susceptibility. The biological mechanism of drug responses indicates that a gene-based analysis has even greater potential in pharmacogenetics. Motivated by a study from the Vitamin Intervention for Stroke Prevention (VISP) trial, we develop a genetrait similarity regression for survival analysis to assess the effect of a gene or pathway on time-to-event outcomes. The similarity regression has a general framework that covers a range of survival models, such as the proportional hazards model and the proportional odds model. The inference procedure developed under the proportional hazards model is robust against model misspecification. We derive the equivalence between the similarity survival regression and a random effects model, which further unifies the current variance component-based methods. We demonstrate the effectiveness of the proposed method through simulation studies. In addition, we apply the method to the VISP trial data to identify the genes that exhibit an association with the risk of a recurrent stroke. The TCN2 gene was found to be associated with the recurrent stroke risk in the low-dose arm. This gene may impact recurrent stroke risk in response to cofactor therapy.
1. Introduction. Genetic variations play a significant role in drug responses. A gene that participates in a particular physiological mechanism might influence the response to a specific therapeutic agent that targets the mechanism. Identifying these influential genes may help to clarify if an
Received March 2012; revised January 2014.
1 Equal contribution.
2 Supported by National Institutes of Health Grants R01 MH084022 and P01 CA142538.
3 Supported by National Institutes of Health Grants R01 CA140632 and P01 CA142538.
4
Supported by National Institutes of Health Grant U01 HG005160.
Key words and phrases. Association study, gene/pathway, pharmacogenetics, similarity regression, survival data, proportional odds model, proportional hazards model.
This is an electronic reprint of the original article published by the
Institute of Mathematical Statistics in The Annals of Applied Statistics ,
2014, Vol. 8, No. 2, 1232-1255. This reprint differs from the original in pagination and typographic detail.
individual might benefit from or be harmed by the therapy. Understanding the genetic diversity of drug responses can help to identify medications that maximize treatment effectiveness and minimize the risk of adverse effects for individuals. Such an understanding will also lead to improved risk stratification, prevention and treatment strategies for human diseases. Pharmacogenetics studies show how an adverse reaction or positive response to pharmaceutical treatment is affected by an individual's genetic makeup and has the potential to deliver both public health and economic benefits rapidly. With the recent advancements in high-throughput technologies, it is becoming common for pharmacogenetic researches to systematically investigate genetic markers across the genome. Nevertheless, appropriate and efficient analysis of the data remains a challenge.
Gene- or pathway-based analyses can assess pharmacogenetic effects more effectively than single-marker based analyses [Goldstein, Tate and Sisodiya (2003); Goldstein (2005)]. First, there often exist obvious candidate genes and pathways that metabolize the drug and carry variants that are relevant to the drug responses. Responses to therapies usually involve complex relationships between gene variants within the same molecular pathway or functional gene set. When applied to pharmacogenetic studies, geneor pathway-based methods might identify multiple variants of subtle effects that are missed by single marker-based methods. Second, pharmacogenetic studies typically enroll only a moderate number of patients, which limits the power of the association detection. Gene-based analyses have been shown to yield higher power than standard single marker and haplotype analyses. This type of analysis can particularly facilitate studies on rare-event drug responses, such as adverse reactions, where it could take many years to collect a sufficient number of samples to obtain adequate power for standard analyses. In gene-based analyses, the association signals are aggregated across variants, and the total number of tests is reduced; the amplification of the association signals and the alleviation of the multiple testing burdens result in improved power.
Our study was motivated by the need for a gene-based analysis of the timeto-event data of the Vitamin Intervention for Stroke Prevention (VISP) trial [Toole, Malinow and Chambless (2004); Hsu, Sides and Mychalecky (2011)]. Our goal is to assess the association between the recurrent stroke risk and the 9 candidate genes involved in the homocystein (Hcy) metabolic pathway (see Data section for more details). In our preliminary analysis, we used the Cox proportional hazards (PH) model [Cox (1972)] to perform single-SNP screening on 69 SNPs across 9 genes from 969 individuals. There were no SNPs past the significance threshold after accounting for multiple testing. However, the top 6 hits, thresholding at unadjusted p -values < 0.05, were concentrated in two genes. Specifically, 4 SNPs are from TCN2 (i.e., rs1544468, rs731991, rs2301955 and rs2301957 have Wald's test p -values of 0.0065, 0.0072, 0.0346
Fig. 1. The Kaplan-Meier survival curves for the top 6 SNPs identified from the single SNP association analysis with risk of recurrent stroke.
and 0.0346, resp.) and 2 SNPs are from CTH (i.e., rs648743 and rs663465 each have a Wald's test p -value of 0.0115). The Kaplan-Meier curves of these 6 SNPs are shown in Figure 1 and indicate the potential for different risk patterns among different variants at these loci. The clustering within the two genes suggests that it would be more efficient to combine the individual signal strengths and model the joint effect of multiple loci in a gene.
We perform the gene-based analysis using a gene-trait similarity regression inspired by Haseman-Elston regression from linkage analysis [Elston et al. (2000); Haseman and Elston (1972)] and haplotype similarity tests for regional association [Beckmann et al. (2005); Qian and Thomas (2001); Tzeng et al. (2003)]. First, we quantify the genetic and trait similarities for
each pair of individuals. The genetic similarity is determined using identity by state (IBS) methods. The trait similarity is obtained from the covariance of the transformed survival time conditional on the covariates. We then regress the trait similarity on the genetic similarity and test the regression coefficient to detect the genetic association. There are several gene-based approaches for censored time-to-event phenotypes in the literature, including Goeman et al. (2005) and Lin and colleagues [Cai, Tonini and Lin (2011); Lin et al. (2011)]. In these approaches, the multimarker effects were modeled under the Cox PH model using linear random effects [Goeman et al. (2005)] or a nonparametric function induced by a kernel machine [Cai, Tonini and Lin (2011); Lin et al. (2011)]. The global effect of a gene was detected by testing for the corresponding genetic variance component. These approaches were found to be superior in identifying pathways or genes that are associated with survival.
For many years, similarity-based methods have been successfully used to evaluate gene-based associations in quantitative and binary traits [Beckmann et al. (2005); Lin and Schaid (2009); Qian and Thomas (2001); Tzeng et al. (2003); Wessel and Schork (2006)]. Our work makes such approaches available for survival phenotypes. In addition, our similarity regression covers a variety of risk models, including the commonly used PH model and the proportional odds (PO) model. Furthermore, we show that the coefficient of the similarity regression obtained for survival phenotypes can be reexpressed as a variance component of a certain working random effects model. Such results facilitate the derivation of the test statistic and unify the similarity model and previous variance component methods [Goeman et al. (2005); Cai, Tonini and Lin (2011); Lin et al. (2011)]. Specifically, under the Cox PH model, our test statistic is equivalent to the test statistic defined by a kernel machine approach [Lin et al. (2011)]. We also show that the test statistic can be robust to model misspecification. Specifically, the proposed test gives the correct type I error even if the true risk model is misspecified. However, the correct specification of the true risk model generally leads to a test with better power. Finally, we demonstrate the utility of the similarity regression by identifying the important TCN2 gene in the VISP study. The significance of TCN2 to stroke risk has been reported by other association studies [Giusti et al. (2010); Low et al. (2011)] and has been supported by molecular biology evidence [Afman et al. (2003); von Castel-Dunwoody et al. (2005)]. Our findings further suggest potential interactions between TCN2 and B12 supplementation. This new information furthers the possibility that TCN2 could be utilized to predict recurrent strokes, identify at-risk individuals and identify therapeutic targets for ischemic stroke.
- 2. Data. The VISP study was a prospective, double-blind, randomized clinical trial [Toole, Malinow and Chambless (2004)]. The trial was designed to study if high doses of folic acid, vitamin B6 and vitamin B12 reduce the
risk of a recurrent stroke as compared to low doses of these vitamins. The trial enrolled patients who were 35 or older, had a nondisabling cerebral infarction within 120 days of randomization, and had Hcy levels in the top quartile of the U.S. population. Subjects were randomly assigned to receive daily doses of either a high-dose formulation (containing 25 mg vitamin B6, 0.4 mg vitamin B12 and 2.5 mg folic acid) or a low-dose formulation (containing 200 µ g vitamin B6, 6 µ g vitamin B12 and 20 µ g folic acid). Patient recruitment began in August 1997 and was completed in December 2001. A total of 3680 participants were enrolled at 56 clinical sites across the United States, Canada and Scotland. The patients were followed for a maximum of two years, and the average follow-up duration was 1.7 years. In the VISP genetic study, 2206 participants provided informed consent and blood samples. The SNP genotypes of 9 genes related to the enzymes and cofactors in the Hcy metabolic pathway were collected: BHMT1, BHMT2, CBS, CTH, MTHFR, MTR, MTRR, TCN1 and TCN2 [Hsu, Sides and Mychalecky (2011)]. In a previous study, Hsu, Sides and Mychalecky (2011) conducted single-SNP analyses on targeted loci (e.g., Hcy-associated variants) to examine the genetic association with the recurrent stroke risk. In the low-dose arm, the authors found that TCN2 SNP rs731991 under a recessive mode was associated with the risk of a recurrent stroke with an unadjusted logrank test p -value of 0.009. The associations for the remaining SNPs within the 9 genes in the low-dose arm were not studied. We extend this previous analysis to all 9 genes using a gene-based approach. After quality control screening of the data (e.g., removing loci with > 99% missing proportion or Hardy-Weinberg disequilibrium under additive mode and removing individuals with missing genotypes), the analysis included 969 individuals in the low-dose arm with 69 recessively coded SNPs.
## 3. Gene-trait similarity regression for survival traits.
3.1. The model. For individual i ( i =1 2 , , . . . , n ), let T i denote the survival time of interest and C i denote the censoring time. We observe ˜ T i = min( T , C i i ) and the censoring indicator δ i = ( I T i ≤ C i ). In addition, let X i denote the K × 1 vector of covariates and g mi denote the allele count vector of marker m for person i , where the length of g mi , /lscript m is the number of distinct alleles at marker m m , =1 2 , , . . . , M . For example, for a tri-allelic locus m , g mi =(1 0 1) , , T if person i has genotype ' A A 1 3 ' and (0 2 0) , , T if person i has genotype ' A A 2 2 .'
For each pair of individuals i and j , we measure the genetic similarity, S ij , of the targeted gene and the trait similarity, Z ij . The genetic similarity is quantified using the weighted IBS sum across the M markers in the gene, that is, S ij = ∑ M m =1 w m ij S m , where S m ij = 2 if | g m,i -g m,j | is a zero vector, S m ij =1 if | g m,i -g m,j | contains exactly two 1's (and if /lscript m > 2,
the remaining entries are 0), and S m ij =0 otherwise. The weights, w m , are specified to up-weight or down-weight a variant based on certain features. Examples include weights that are based on allele frequencies, the degree of evolutionary conservation or the functionality of the variations [Wessel and Schork (2006); Schaid (2010a, 2010b); Price et al. (2010)]. We can use the minor allele frequency of marker m , denoted as q m , to up-weight similarities that are contributed by rare variants. Specifically, one can set a moderate weight, such as w m = q -3 4 / m [Pongpanich, Neely and Tzeng (2012)] or w m = q -1 m [Tzeng et al. (2011)], to promote similarity attributed by rare alleles, or use a more extreme weight, such as w m =(1 -q m ) 24 [Wu et al. (2011)], to target rare variants only.
The trait similarity, Z ij , is quantified as follows. First, we define Y i = H T ( i ), where H ( ) · is an (unspecified) monotonic increasing transformation function, such as the logarithm transformation Y i = log( T i ). Assume that the conditional mean of Y i given the covariates and genes is E Y ( i | X ,g i i ) = θ + X γ T i + g i , where θ is the intercept, g i is the multi-locus genetic effect of person i , and γ is the K -dimensional covariate effect. Further, define µ 0 i = θ + X γ T i . The trait similarity is defined as the product of the paired residuals adjusting for the covariate effects, that is, Z ij =( Y i -µ 0 i )( Y j -µ 0 j ). The expected value of the trait similarity is the covariance between the transformed survival times of subjects i and j .
The gene-trait similarity regression has the form
$$& ( 3. 1 ) & & E ( Z _ { i j } \, | \, X _ { i }, X _ { j } ) = b \times S _ { i j }, \quad i \neq j. \\ &. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
/negationslash
Just as in Tzeng et al. (2009, 2011), the regression has a zero intercept and does not have the covariate term X X i j because the baseline and covariate effects have been adjusted when defining Z ij . This argument will become more obvious from the viewpoint of variance components in the following subsection. Under model (3.1), the overall association of a gene can be evaluated by testing the null hypothesis: b =0.
- 3.2. Score test for the gene-level effect. We derive the score test statistic based on the equivalence between the similarity regression and a mixed model. This equivalence is demonstrated as follows. Consider a working mixed model for the transformed survival time:
$$Y _ { i } = H ( T _ { i } ) = X _ { i } ^ { T } \gamma + g _ { i } + \theta + \varepsilon _ { i },$$
where ( g , . . . , g 1 n ) T ∼ N (0 , τ S ) with S = { S ij } n i,j =1 , that is, the covariance between g i and g j depends on the genetic similarity between subjects i and j , and ε ∗ i ≡ θ + ε i , i =1 , . . . , n are independently and identically distributed with a known distribution that is independent of X i and g i . Given X i and g i , model (3.2) specifies a general class of linear transformation models [Cheng,
Wei and Ying (1995)], which contains many popular survival models as special cases. For example, when ε ∗ i follows the standard extreme value distribution, the linear transformation model becomes the PH model [Cox (1972)]. When ε ∗ i follows the standard logistic distribution, the linear transformation model becomes the PO model [Bennett (1983)].
Under (3.2), the conditional expectation of the trait similarity between individuals i and j ( i = ) is j
$$\dots \dots \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \\ E ( Z _ { i j } \, | \, X _ { i }, X _ { j } ) & = \text{cov} ( Y _ { i }, Y _ { j } \, | \, X _ { i }, X _ { j } ) = \text{cov} ( g _ { i } + \varepsilon _ { i } ^ { * }, g _ { j } + \varepsilon _ { i } ^ { * } ) \\ & = \text{cov} ( g _ { i }, g _ { j } ) \\ & = \tau \times S _ { i j }. \\ \text{Therefore, we have } b = \tau, \text{ that is, the regression coefficient in the similarity}$$
/negationslash
Therefore, we have b = , that is, the regression coefficient in the similarity τ regression (3.1) is the genetic variance component in the mixed model (3.2). This motivates us to develop a score test for the variance component in the working model. As shown in the Appendix, the score test statistics for τ =0 can be written as
$$Q _ { n } = \frac { 1 } { n } ( \hat { r } _ { 1 }, \dots, \hat { r } _ { n } ) S ( \hat { r } _ { 1 }, \dots, \hat { r } _ { n } ) ^ { T },$$
where
$$\i = \partial _ { i } \frac { \lambda } { \lambda \{ \hat { H } ( \tilde { T } _ { i } ) - \hat { \gamma } ^ { T } X _ { i } \} } - \xi.$$
$$\hat { r } _ { i } & = \int _ { 0 } ^ { \infty } \hat { \omega } _ { i } ( t ) \, d M _ { i } ( t ; \hat { \gamma }, \hat { H } ) \\ & = \delta _ { i } \frac { \dot { \lambda } \{ \hat { H } ( \tilde { T } _ { i } ) - \hat { \gamma } ^ { T } X _ { i } \} } { \lambda \{ \hat { H } ( \tilde { T } _ { i } ) - \hat { \gamma } ^ { T } X _ { i } \} } - \lambda \{ \hat { H } ( \tilde { T } _ { i } ) - \hat { \gamma } ^ { T } X _ { i } \}, \\ & \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \ \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \,$$
$$M _ { i } ( t ; \gamma, H ) = \delta _ { i } I ( \tilde { T } _ { i } \leq t ) - \int _ { 0 } ^ { t } I ( \tilde { T } _ { i } \geq s ) \, d \Lambda \{ H ( s ) - \gamma ^ { T } X _ { i } \},$$
ˆ ( ) = ω i t ˙ λ H t { ˆ ( ) -ˆ γ T X /λ H t i } { ˆ ( ) -ˆ γ T X i } , and S is as defined after equation (3.2). Here, λ ( ) · and Λ( ) are the hazard and cumulative hazard func-· tions of ε ∗ i , respectively, ˙ λ ( ) · is the first derivative of λ ( ), · and ˆ and γ ˆ ( ) H · are the estimates of γ and H ( ), · respectively, in model (3.2) under the null hypothesis: τ =0. For example, if the PH model is imposed, that is, λ u ( ) = ˙ λ u ( ) = e u , the estimators ˆ and Γ( ) γ ˆ · ≡ e ˆ ( ) H · can be taken as the maximum partial likelihood estimator and Breslow's estimator, respectively. Under this case, ˆ ( ) ω i t ≡ 1 and ˆ = r i δ i -ˆ ( ˜ ) exp( Γ T i -ˆ γ T X i ), that is, the martingale residual for the null model. If the PO model is used, that is, λ u ( ) = e u / (1+ e u ) and ˙ λ u ( ) = e u / (1 + e u ) 2 , we have ˆ ( ) = 1 ω i t / [1 + exp { ˆ ( H t ) -ˆ γ T X i } ]. In general, γ and H ( ) · can be estimated using the martingale-based estimating equations [Chen, Jing and Ying (2002)] or the nonparametric maximum likelihood estimation method [Zeng and Lin (2006)] for the semiparametric linear
transformation model. In the Appendix, we show that under the null hypothesis the test statistic, Q n , asymptotically follows a weighted χ 2 distribution where the weights can be estimated consistently. The p -values can then be calculated numerically using a resampling method or moment-matching approximations [Pearson (1959); Duchesne and Lafaye De Micheaux (2010)].
We note that the proposed score test can be robust to the misspecification of the true survival model. As an illustration, consider the test derived under the PH model. Based on the results for the robust inference of the PH model [Lin and Wei (1989)], when the PH model is misspecified, the maximum partial likelihood estimator, ˆ, and Breslow's estimator, Γ( ), do γ ˆ · not converge to the true parameters but converge to some deterministic values γ ∗ and Γ ( ) under certain regularity conditions. The corresponding ∗ · r ∗ i = δ i -Γ ( ˜ ) exp( ∗ T i -X γ T i ∗ ) is not a martingale residual but has a mean of 0 under the null hypothesis. Therefore, it can be shown that Q n converges in distribution to a weighted χ 2 distribution under the null hypothesis even with model misspecification. As shown in our simulation studies, the proposed score test derived under the PH model still gives correct type-I error when the true model is the PO model. However, the power of the test depends on the assumed working model. In general, the test derived under the true risk model may have better power.
4. Results of the analysis of the VISP trial data. We now return to the VISP trial to evaluate the association between the recurrent stroke risk and the 9 candidate genes studied in Hsu, Sides and Mychalecky (2011). In our analysis, we conducted a gene-based screening on the 9 genes using the low-dose samples. After removing loci with > 1% of missingness and subjects with missing genotypes, there were 969 individuals with 69 polymorphic SNPs under recessive coding. Of the 969 individuals, 86 experienced a recurrent stroke (i.e., 91.1% censoring). We used the proposed similarity regression (referred to as SimReg) with inverse allele frequency weights w m = q -3 4 / m , that is, the weight recommended in Pongpanich, Neely and Tzeng (2012) when analyzing a mixture of common and rare variants. We calculated the p -values of the SimReg statistics using the resampling method. Specifically, we computed the nonzero eigenvalues, ˆ ξ 1 , . . . , ξ ˆ , of Σ d ˆ as defined in the Appendix. We generated 10 4 sets of ( χ 2 1 1 , , . . . , χ 2 1 ,d ). Each set consisted of d independently and identically distributed χ 2 1 random variables. For each set, we calculated the value ∑ d k =1 ˆ ξ k χ 2 1 ,k , and the 10 4 values formed an empirical null distribution of the SimReg statistics. The SimReg p -value was the proportion of the generated null statistics that were greater than the observed statistic. We performed SimReg analyses under the PH model (referred to as SimReg-PH) and the PO model (referred to as SimReg-PO). The performances of the SimReg methods were benchmarked
Table 1 Results of the VISP genetic study
| | BHMT1 BHMT2 | BHMT1 BHMT2 | CBS | CTH | MTHFR | MTR | MTRR | TCN1 | TCN2 |
|-----------------|---------------|---------------|--------|--------|---------|---------|--------|--------|---------|
| Numbers of SNPs | 5 | 3 | 6 | 10 | 7 | 20 | 5 | 3 | 15 |
| minP | 0.3399 | 0.5968 | 0.3354 | 0.0918 | 0.9105 | 0.8933 | 0.6183 | 0.9764 | 0.0704 |
| ( K eff ) | (3.99) | (2.83) | (4.41) | (8.35) | (4.64) | (10.64) | (4.78) | (2.77) | (11.28) |
| Global | 0.6457 | 0.7391 | 0.2669 | 0.0518 | 0.7819 | 0.9154 | 0.7363 | 0.9689 | 0.0457 |
| KM | 0.4863 | 0.6142 | 0.2386 | 0.0078 | 0.7094 | 0.8289 | 0.7289 | 1.0000 | 0.0075 |
| SimReg-PH | 0.5794 | 0.6402 | 0.1889 | 0.0073 | 0.6833 | 0.8835 | 0.5988 | 0.9845 | 0.0040 |
| SimReg-PO | 0.6136 | 0.6942 | 0.2877 | 0.0075 | 0.7807 | 0.9011 | 0.6422 | 0.9922 | 0.0052 |
The adjusted p -values for the gene were obtained using 1 -(1 -minimum raw p -value) K eff . Significance is concluded by comparing the p -values with the Bonferroni threshold 0 05 . / 9 = 0 0056, which accounts for the 9 gene analysis. .
against three approaches: (a) the single SNP minimum p -value method using the Cox PH model (referred to as minP), (b) the multi-SNP method using the global test for survival under the PH model [Goeman et al. (2005)] as implemented in the R-package globaltest (referred to as Global), and (c) the multi-SNP method using the kernel machine [Lin et al. (2011)] as implemented in the R-package KMTest.surv (referred to as KM) with 10 4 resamplings. Although the SimReg-PH test statistic is identical to the KM test statistic, the results may be slightly different due to the different resampling methods adopted to obtain the p -values. Specifically, in the KM method, the score statistic was perturbed by multiplying i.i.d. normal random variables to achieve the same limiting distribution of the test statistic. In SimReg-PH, the weights in the limiting weighted χ 2 distribution, that is, ξ , . . . , ξ 1 d , were consistently estimated and then the samples were directly generated from the estimated weighted χ 2 distribution based on a large number of i.i.d. χ 2 1 random variables. The different resampling approaches also lead to different computational burden. For example, using a 3.6 GHz Xeon Processor with 60 GB RAM with 10 4 resamplings, the system run-time of SimReg-PH was < / 1 6 of KM in the VISP analysis, and the time difference became greater with a larger number of resamplings. For the minP method, we fitted the standard PH model to each SNP in a gene, took the smallest p -value and calculated the adjusted p -value of a gene to correct for the multiple SNPs using 1 -(1 -minimum raw p -value) K eff . The effective number of independent tests, K eff , was estimated using the method of Moskvina and Schmidt (2008) and accounts for the correlations in recessive coding of loci. As studied by Hsu, Sides and Mychalecky (2011), all analyses were considered under the recessive mode and were adjusted for age, sex and race.
The p -values for each of the methods are shown in Table 1, and the p -values are compared with the Bonferroni threshold adjusted for the 9 gene
analyses, that is, 0 05 . / 9 = 0 0056. SimReg-PH detected a significant associ-. ation between the recurrent stroke risk and TCN2 (i.e., p -value = 0 0040), . which strengthens the observation of differential survival between different variants from the single SNP analysis. Gene CTH had the second smallest p -value (0.0073), which did not pass the Bonferroni threshold but was near the cutoff. These results also agree with the findings in the single SNP analysis. The results of SimReg-PO are similar to those of SimReg-PH except that the p -values are slightly larger, that is, p -value = 0 0052 for . TCN2 and 0.0075 for CTH . On the other hand, the KM, Global and minP methods did not yield any significant findings. However, the smallest p -values of the 9 genes were obtained for TCN2 (i.e., p -values of TCN2 are 0.0075 for KM, 0.0457 for Global and 0.0704 for minP). As expected, the results of KM were very similar to those of SimReg-PH, except that the p -value of TCN2 was slightly above the 0.0056 threshold. The smallest p -values for the minP method were from the TCN2 SNP rs731991 with a raw Wald's test p -value of 0.0065. However, neither the raw minimum p -value (0.0065) nor the adjusted p -value (0.0704) survived the significance threshold corrected for multiple testing (0.0056). All methods also had CTH as the gene with the second smallest p -value (i.e., p -values 0.0078 for KM, 0.0518 for Global, and 0.00918 for minP).
Next, we assessed the prediction performance of Cox PH models built with and without TCN2 using the procedure described in Li and Luan (2005). Specifically, we randomly divided the samples into a training set ( n =646) and a testing set ( n =323). Based on the training set, we fitted the Cox PH regression with two models: Model 1 included only the baseline covariates (age, sex and race), that is, no genetic information, and model 2 included the baseline covariates plus the top 7 principal components (PCs) of TCN2 SNPs that explained 95% of the variations. The PCs were used instead of the 15 original genotypes because of the high linkage disequilibrium among them. Based on the fits of the PH model from the training set, we obtained the risk scores of every subject under each model and computed the medians of the risk scores. We also computed the risk scores for the testing set using the estimated coefficients from the training set. Next, we divided the subjects into 2 risk groups: high-risk and low-risk. Individuals with a risk score higher/lower than the median risk scores obtained from the training data comprised the high-risk/low-risk group. Finally, we plotted the Kaplan-Meier curves for the 2 risk groups in the training data and the two risk groups in the testing data separately and obtained the p -values of the corresponding log-rank tests. The results are given in Figure 2. As expected, the p -values for both models under the training set were very significant. However, only model 2 is significant ( p -value is 0.048) under the testing set. This result implies that TCN2 gives a more accurate prediction of the risk for recurrent stroke.
Fig. 2. The Kaplan-Meier survival curves for the two risk groups of patients.
Vitamin supplements have been identified as a potential treatment for vascular diseases. The beneficial effects of vitamin supplements on stroke recurrence are not yet fully understood. In VISP, vitamin supplements did not show an effect on the recurrent stroke risk during the 2 years of followup. However, we found that genetic variants, such as SNPs in TCN2 , were associated with the recurrent stroke risk in the low-dose arm. This finding is consistent with the literature. TCN2 was previously found to be associated with ischemic stroke risk [Low et al. (2011); Giusti et al. (2010)] and premature ischemic stroke risk [Giusti et al. (2010)]. It has been reported that TCN2 interferes with the intracellular availability of vitamin B12 [von Castel-Dunwoody et al. (2005)]. The gene is associated with plasma homocysteine levels and affects the proportion of vitamin B12 bound to transcobalamin [Afman et al. (2003)]. It is suspected that SNPs on the genes coding for enzymes involved in the methionine metabolism have been suspected to be associated with hyperhomocysteinaemia, which can result in occurrence of stroke [Giusti et al. (2010)]. Our significant findings in the low-dose arm suggest that there may be an interaction between TCN2 and
B12 supplementation, a finding that warrants further studies. The findings lead to a hypothesis that there may be one specific combination of genotypes of TCN2 that is more efficient at transporting B12 and thus impacts the effectiveness of cofactor therapy on recurrent stroke risk. A functional study is being planned to localize possibly independent regions of association and determine their function.
Besides TCN2 CTH , is marginally associated with recurrent stroke risk in the low-dose arm. It encodes cystathionine gamma-lyase, which is an enzyme that converts cystathionine to cysteine in the trans-sulfuration pathway [Wang et al. (2004)]. It may be a determinant of plasma Hcy concentrations, which may increase the risk of recurrent stroke because of arterial disease. It is worth further study as well.
5. Simulation studies. We performed simulations to assess the validity and effectiveness of the proposed SimReg methods based on the 15 SNPs in TCN2 of the 969 VISP low-arm samples. The rarest minor allele frequency (MAF) is approximately 3%. We generated genotypes of n individuals by randomly sampling with replacement from the 15-SNP genotypes of the 969 samples. For individual i , we generated the covariate, X i , from N (0 1). , We generated the survival time, T i , based on the genetic and covariate information under two models: the PH model and the PO model. Specifically, for the PH model, log( T i ) = -( X i + ∑ /lscript γ /lscript G /lscripti ) + ε ∗ i , where ε ∗ i follows the standard extreme value distribution; for the PO model, log { exp( T i ) - } 1 = -( X i + ∑ /lscript γ /lscript G /lscripti ) + ε ∗ i , where ε ∗ i follows the standard logistic distribution. The value of G /lscripti is determined by the genotypes at the causal locus /lscript and the mode of inheritance. For example, if A is the causal allele at locus /lscript , then G /lscripti =2 1 and 0 for genotypes , AA, Aa and aa , respectively, under an additive mode. Under a dominant mode, G · i =1 1 and 0, , respectively. Under a recessive mode, G · i =1 0 and 0, respectively. For type , I error analysis, no SNPs were set to be causal, that is, γ /lscript was set to be 0 for all /lscript . For power analysis, we selected 3 SNPs with different MAFs and LD patterns as causal loci from the 15 SNPs in TCN2 and referred to them as SNP R, SNP U and SNP C. The MAFs are 0.036 (rare) for SNP R, 0.132 (uncommon) for SNP U and 0.419 (common) for SNP C. The average R 2 's between a causal locus and the remaining loci are 0.002 (low) for SNP R, 0.003 (low) for SNP U and 0.216 (high) for SNP C. The specific values of γ /lscript 's are given in Table 2 for each scenario under different inheritance modes and censoring rates. The values were set to consider 1, 2 and 3 causal loci in the gene and to consider causal loci that have either the same or different effect sizes (e.g., rarer variants with larger effect sizes). All of the power scenarios assumed linear additive effects of the causal loci, which favors the linear random effects model (e.g., Global) and can be used to examine the utility of using the nonlinear IBS function to capture the multi-marker effects.
Table 2 Effect sizes for power analyses
| | | Additive and dominant | Recessive |
|---------------------------|---------------------------|-----------------------------------------------------------------------|-------------------------------------------------------------------|
| ScenarioCausal SNPs (MAF) | ScenarioCausal SNPs (MAF) | 15% ∗ 40% 90% n =500 n =500 n =1000 n Effect size ( γ R , γ U , γ C ) | 15% 40% 90% =1000 n =1000 n =1000 Effect size ( γ R , γ U , γ C ) |
| 1 | R (0.036) | (1.5, 0.0, 0.0) | (4.0, 0.0, 0.0) |
| 2 | U (0.132) | (0.0, 1.0, 0.0) | (0.0, 3.0, 0.0) |
| 3 | C (0.419) | (0.0, 0.0, 0.3) | (0.0, 0.0, 0.3) |
| 4 | R, U | (0.6, 0.6, 0.0) | (4.0, 4.0, 0.0) |
| 5 | R, U | (0.6, 0.4, 0.0) | (2.5, 2.0, 0.0) |
| 6 | R, C | (0.3, 0.0, 0.3) | (0.3, 0.0, 0.3) |
| 7 | R, C | (0.6, 0.0, 0.2) | (2.5, 0.0, 0.2) |
| 8 | U, C | (0.0, 0.3, 0.3) | (0.0, 0.3, 0.3) |
| 9 | U, C | (0.0, 0.4, 0.2) | (0.0, 2.0, 0.2) |
| 10 | R, U, C | (0.3, 0.3, 0.3) | (0.3, 0.3, 0.3) |
| 11 | R, U, C | (0.6, 0.4, 0.2) | (2.5, 2.0, 0.2) |
∗ censoring proportion.
We generated the censoring time, C i , from Unif(0 , c ), where c is uniquely chosen for each of 3 censoring rates: 15%, 40% and 90%. Specifically, we set c =6 7, 2.0 and 0.2 for censoring rates of 15%, 40% and 90%, respectively. . The sample sizes, n , were 500 for the 15% and 40% censoring rates under the additive and dominant modes. For the 90% censoring rate under the additive and dominant modes and all censoring rates under the recessive mode, n = 1000. Each scenario was analyzed using SimReg (PH and/or PO), minP, Global and KM. SimReg-PH and KM have identical test statistics but used different resampling approaches to obtain p -values. Because both resampling approaches are asymptotically equivalent, we expect minor differences in finite sample performance between SimReg-PH and KM. In all analyses, the causal loci were excluded.
5.1. Results of type I error analyses. We first examined the performance of the proposed SimReg-PH model. Table 3 displays the type I error rates of different methods when the survival times were generated from the PH model. The results were based on 10 5 replications except that KM was based on 5 × 10 4 replications due to computational cost. In each replication, the p -values of SimReg-PH were obtained from 5 × 10 5 resamplings. We report the type I error rates evaluated at the nominal levels of 5 × 10 -2 , 5 × 10 -3 and 5 × 10 -4 . The type I error rates obtained by SimReg-PH remained around the nominal levels. However, the deviations were larger for α =5 × 10 -4 , mainly due to fewer resampled statistics observed on the extreme tail. In particular, for the low censoring proportion (i.e., 15%), the type I
Table 3 Type I error rates for survival time generated from the PH model
| Analyzed under | Additive | Additive | Additive | Dominant | Dominant | Dominant | Recessive | Recessive | Recessive | |
|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|
| Analyzed under | 15% n =500) | 40% ( n =500) | 90% ( n =1000) | 15% ( n =500) | 40% ( n =500) | 90% ( n =1000) | 15% ( n =1000) | 40% ( n =1000) | 90% ( n =1000) | J.-Y. |
| α =5 × 10 (Rates shown on the scale of 10 ) | - 2 - 2 | - 2 - 2 | - 2 - 2 | - 2 - 2 | - 2 - 2 | - 2 - 2 | - 2 - 2 | - 2 - 2 | - 2 - 2 | |
| minP | 4 . 89 | 4 . 85 | 4 . 44 | 4 . 92 | 4 . 84 | 4 . 16 | 7 . 63 | 7 . 46 | 7 . 25 | |
| Global | 2 . 73 | 2 . 71 | 2 . 72 | 3 . 01 | 2 . 99 | 2 . 96 | 2 . 75 | 2 . 74 | 2 . 73 | |
| KM | 5 . 07 | 5 . 11 | 4 . 73 | 5 . 10 | 5 . 17 | 4 . 81 | 5 . 12 | 4 . 97 | 4 . 78 | TZENG, |
| SimReg-PH | 5 . 11 | 5 . 10 | 4 . 79 | 5 . 15 | 5 . 11 | 4 . 83 | 5 . 21 | 5 . 04 | 5 . 01 | |
| α =5 × 10 (Rates shown on the scale of 10 ) | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 | W. - 3 - 3 |
| minP | 6 . 52 | 6 . 22 | 5 . 50 | 6 . 13 | 5 . 44 | 4 . 39 | 17 . 09 | 17 . 62 | 19 . 21 | LU |
| Global | 2 . 82 | 2 . 65 | 2 . 67 | 2 . 98 | 2 . 74 | 2 . 86 | 2 . 61 | 2 . 50 | 2 . 59 | |
| KM | 5 . 18 | 4 . 86 | 4 . 02 | 5 . 26 | 4 . 86 | 4 . 28 | 5 . 40 | 5 . 54 | 4 . 96 | AND |
| SimReg-PH | 5 . 18 | 4 . 91 | 4 . 15 | 5 . 22 | 5 . 03 | 4 . 38 | 5 . 84 | 5 . 20 | 5 . 96 | |
| F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) | F.-C. α =5 × 10 - 4 (Rates shown on the scale of 10 - 4 ) |
| minP | 8 . 6 | 8 . 1 | 6 . 8 | 8 . 0 | 7 . 0 | 6 . 2 | 48 . 4 | 47 . 9 | 60 . 3 | |
| Global | 2 . 9 | 3 . 9 | 2 . 7 | 4 . 0 | 3 . 2 | 2 . 4 | 3 . 1 | 2 . 9 | 2 . 8 | HSU |
| KM | 5 . 8 | 5 . 2 | 2 . 8 | 6 . 8 | 5 . 8 | 4 . 4 | 8 . 4 | 4 . 4 | 6 . 6 | |
| SimReg-PH | 7 . 1 | 5 . 7 | 2 . 7 | 6 . 9 | 5 . 4 | 3 . 2 | 8 . 0 | 4 . 6 | 8 . 1 | |
The type I error rates are shown on the scale of 10 2 , 10 , and 10 3 4 for nominal level at 0.05, 0.005, and 0.0005, respectively. The survival times were generated from the PH model and were analyzed using different approaches under the PH model. The results were based on 10 5 replications except that the results for KM were based on 5 × 10 4 replications.
error rates were slightly inflated, while for the high censoring proportion (i.e., 90%), the type I error rates became a little conservative when α = 5 × 10 -4 . Nevertheless, the overall results suggest that the SimReg-PH test maintained an appropriate size, which confirms the validity of the derived null distribution of the test statistic, Q n . As expected, the type I error rates obtained by KM were very similar to SimReg-PH. The type I error rates obtained by the Global test are overly conservative; similar behavior has been reported in the literature [Zhong and Chen (2011)]. The minP method had correct type I error rates under additive and dominant modes. However, the method had inflated type I error rates under the recessive mode, and the inflation was more severe with smaller α . Under the recessive mode, the Bonferroni corrected p -values obtained by replacing K eff with the total number of SNPs also yielded inflated type I error rates. Specifically, the empirical type I error rates for 15%, 40% and 90% censoring are (0.0627, 0.0687, 0.0608) for α =5 × 10 -2 , (0.0145, 0.0152, 0.0163) for α =5 × 10 -3 and (0.0042, 0.0041, 0.0053) for α =5 × 10 -4 , respectively. The anti-conservation appears to be somewhat related to the rare recessive loci; when the rare loci are excluded from the analysis, the empirical type I error rate became closer to the nominal level (data not shown). However, such an exclusion strategy might give uninformative results because the relevant signals were excluded from the analysis.
Table 4 displays the type I error rates when the survival times were generated from the PO model. Both SimReg-PH and SimReg-PO were implemented. The results were based on 5000 replications, and the type I error rates were calculated at the nominal level of 0.05. The type I error rates for both SimReg-PO and SimReg-PH were close to 0.05 independent of the inheritance mode and the censoring proportions. These results show the validity of the SimReg-PO tests and the robustness of the SimReg-PH tests. Though not performed, KM is expected to have the same robustness as SimReg-PH. As seen previously, the Global test had conservative type I error rates, but the magnitude of conservation is less than that seen in Table 3. The minP method yielded slightly inflated type I error rates for the additive and dominant modes with low censoring proportion (i.e., 15%). As before, it yielded inflated type I error rates for the recessive mode.
5.2. Results of power analyses. The power analyses were performed using the settings specified in Table 2. The results were based on 100 replications under each scenario. Figure 3 shows the power when the survival times were generated from the PH model. We first consider the additive mode. When one large-effect causal locus has low MAF and low LD with the other markers (e.g., Scenarios 1, 5 and 11), minP tends to have the highest power independent of the censoring proportion. The good performance of minP is not unexpected in these scenarios because the overall association of the
Table 4 Type I error rates for survival time generated from the PO model
| | Additive | Additive | Additive | Dominant | Dominant | Dominant | Recessive | Recessive | Recessive |
|-----------|---------------|---------------|----------------|---------------|---------------|----------------|----------------|----------------|----------------|
| | 15% ( n =500) | 40% ( n =500) | 90% ( n =1000) | 15% ( n =500) | 40% ( n =500) | 90% ( n =1000) | 15% ( n =1000) | 40% ( n =1000) | 90% ( n =1000) |
| minP | 0.0584 | 0.0548 | 0.0444 | 0.0560 | 0.0492 | 0.0410 | 0.0798 | 0.0774 | 0.0740 |
| Global | 0.0358 | 0.0320 | 0.0256 | 0.0352 | 0.0332 | 0.0266 | 0.0342 | 0.0312 | 0.0250 |
| SimReg-PH | 0.0488 | 0.0496 | 0.0464 | 0.0492 | 0.0504 | 0.0478 | 0.0526 | 0.0518 | 0.0480 |
| SimReg-PO | 0.0446 | 0.0486 | 0.0468 | 0.0452 | 0.0496 | 0.0508 | 0.0544 | 0.0492 | 0.0490 |
The survival times were generated from the PO model and were analyzed using different approaches under the PO model or the PH model (to examine the impact of model misspecification). The results were based on 5000 replications.
Fig. 3. Power when the survival times are generated from the PH model.
gene was driven by a single large-effect locus, for which the majority of the other SNPs did not carry much information. As a result, there is no power gain when borrowing information from other SNPs, which is what SimRegPH does. However, the power gain of minP over other methods generally diminishes as the number of causal loci increases (e.g., Scenarios 5 to 10). In scenarios where the marker set is not dominated by a single causal locus of low MAF and low LD, SimReg-PH showed comparable or higher power. As expected, KM had near identical power as SimReg-PH in all scenarios. In most scenarios, the Global test produces the least amount of power largely
Fig. 4. Power when the survival times are generated from the PO model.
due to the over-conservative test size. The overall performance under the dominant mode has a similar trend to that of the additive mode. However, the power of SimReg-PH is comparable to or better power than the power of minP in more cases under the dominant mode than under the additive mode. For the recessive mode, SimReg-PH appears to have better power than the Global test. We did not perform a power analysis for minP because the type I error rates were inflated.
Figure 4 shows the power performance when the survival times were generated from the PO model. The power obtained using SimReg-PO is similar
to or better than the power obtained using SimReg-PH, indicating that efficiency is gained when the correct model is used. The power gain of SimRegPO is more substantial when the censoring proportion is low to medium, and the power is comparable to or better power than the minP power in some of those difficult cases, such as Scenario 1.
6. Discussion. In this work we extended the similarity regression (SimReg) approaches, which have shown effectiveness in modeling marker-set effects on binary and continuous outcomes, to survival models to facilitate the assessment of gene or pathway effects on drug responses. The genetic effect is evaluated by assessing the association between the IBS status of a pair of individuals and the covariance of their survival times. We derived the equivalence between the similarity survival regression and a random effects model. The equivalence facilitates the derivation of the score test statistics and unifies the current variance component-based methods. Specifically, the KM approach [Lin et al. (2011)] is equivalent to SimReg-PH when the same kernel function is used to quantify the genetic similarity, S ij . The Global test [Goeman et al. (2005)] can be viewed as a special case of SimRegPH with S ij = ∑ m g T m,i g m,j (i.e., the linear kernel). However, the results of Global and SimReg-PH with linear kernels may be different because different approaches were used to derive the asymptotic distributions of the test statistics. Compared to these existing gene-based approaches, our proposed method has the generality to incorporate a variety of risk models in the class of linear transformation models, and we explicitly constructed the SimReg tests under the PH model and the PO model in this work. We also proposed a resampling approach to obtain the p -values that improves the computational efficiency. Finally, we showed that the derived inference procedure is robust against the misspecification of the risk model, which is an attractive feature because the underlying risk model is often unknown. Through simulations, we showed that the power of the SimReg method is comparable to or higher than the power of the minP and Global methods across various scenarios. We also verified that the SimReg-PH test statistics remain valid even if the risk model is misspecified.
In the data application on the VISP study, we illustrated how SimReg can be used to search for genes or pathways that are associated with a timeto-event outcome and confirmed previous findings using this gene-based approach with statistical significance. Although we focused our method development and demonstrated its utility based on pharmacogenetics studies, the proposed method is applicable to other genetic clinical researches or observational studies with time-to-event outcomes. For a pharmacogenetic study with sample sizes 1000, such as the VISP trial, 1000 runs of the SimReg analyses took ≤ 1 hour to complete on an Intel Xeon 3.33 GHz machine with 12 Gb RAM using one processing core. We expect a gene-based whole genome
analysis on ∼ 20K genes should be completed in a day using a comparable computing facility. We implemented the proposed methods in R and made it available at the authors' websites. We are incorporating the software into the SimReg R package.
Motivated by the data application where the risk variant acted recessively, we further investigated the behavior of the gene-based approaches under different modes of inheritance. We found that all of the studied genebased methods performed appropriately under the additive and dominant modes. However, caution should be used when performing the minimal p -value approaches under the recessive mode; the minimal p -value approaches had severely inflated type I error rates. The inflation might be related to the extremely rare recessive loci. However, excluding those rare recessive loci is suboptimal because the important signals can be artificially removed and lead to power loss. In contrast, the global test and the similarity regression are not vulnerable to such a situation and appear to be more suitable options given their reasonable performance under the recessive mode.
This work focused on assessing the genetic main effect on drug response in an effort to understand how individual variation affects drug efficacy and toxicity. In pharmacogenetics and personalized medicine, one major topic is to study if the genetic effects are modified by treatments and how the effects differ across treatment options. As observed in the VISP genetic studies, the effect of TCN2 on recurrent stroke risk is restricted to the low-dose treatment. An analysis stratified by treatments allows for the evaluation of such heterogeneous effects between different treatment groups, but its efficiency can be further improved by incorporating the gene-treatment interaction in the regression model. Such an extension is not straightforward because the calculation of the score test requires the variance component estimates for the genetic main effect under a mixed-effects survival model. We are developing further extensions of SimReg to incorporate interaction effects.
## APPENDIX
Derivation of the score statistic Q n : Given the working mixed model H T ( i ) = γ T X i + g i + ε ∗ i , the log-likelihood function of the observed data can be written as
$$l _ { n } ( \gamma, H, \tau )$$
$$\Phi _ { 0 } = \log \int \cdots \int \prod _ { i = 1 } ^ { n } [ \lambda \{ H ( \tilde { T } _ { i } ) - \gamma ^ { T } X _ { i } - g _ { i } \} ] ^ { \delta _ { i } }$$
$$\times e ^ { - \Lambda \{ H ( \tilde { T } _ { i } ) - \gamma ^ { T } X _ { i } - g _ { i } \} } f _ { G } ( g _ { 1 }, \dots, g _ { n } ) \, d g _ { 1 } \cdots d g _ { n }, \\ \intertext { two the anciiad backward and commelli t i n o b o r d \ f i n t o m e }$$
where λ and Λ are the specified hazard and cumulative hazard functions of ε ∗ i , and f G ( g , . . . , g 1 n ) is the joint density of g , . . . , g 1 n , that is, a multivariate normal density with mean 0 and variance-covariance matrix τS .
Consider the variable transformation ( g ∗ 1 , . . . , g ∗ n ) ′ = τ -1 2 / S -1 2 / ( g , . . . , g 1 n ) , ′ where S = S 1 2 / S 1 2 / . Then ( g , . . . , g ∗ 1 ∗ n ) ′ follows a standard multivariate normal distribution. The result leads to
$$\text{al distribution. } I \text{the result leads to} \\ l _ { n } ( \gamma, H, \tau ) \\ = \log \int \dots \int \prod _ { i = 1 } ^ { n } [ \lambda \{ H ( \tilde { T } _ { i } ) - \gamma ^ { T } X _ { i } - \tau ^ { 1 / 2 } S ^ { 1 / 2 } g _ { i } ^ { * } \} ] ^ { \delta _ { i } } \\ \times e ^ { - \Lambda \{ H ( \tilde { T } _ { i } ) - \gamma ^ { T } X _ { i } - \tau ^ { 1 / 2 } S ^ { 1 / 2 } g _ { i } ^ { * } \} } \\ \times f _ { G } ^ { * } ( g _ { 1 } ^ { * }, \dots, g _ { n } ^ { * } ) \, d g _ { 1 } ^ { * } \cdots d g _ { n } ^ { * }, \\ \text{here } f _ { G } ^ { * } \text{ is the density for the standard multivariate normal distribution.} \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots \, \dots$$
where f ∗ G is the density for the standard multivariate normal distribution. After some algebra, we have
$$\text{er some algebra, we have} \\ \frac { 1 } { n } \frac { \partial l _ { n } ( \gamma, H, \tau ) } { \partial \tau } \Big | _ { \tau = 0 } \\ = \frac { 1 } { 2 n } ( r _ { 1 }, \dots, r _ { n } ) S ( r _ { 1 }, \dots, r _ { n } ) ^ { T } \\ & + \frac { 1 } { 2 n } \sum _ { i = 1 } ^ { n } \left [ \frac { \ddot { \lambda } ( e _ { i } ) \lambda ( e _ { i } ) - \{ \dot { \lambda } ( e _ { i } ) \} ^ { 2 } } { \lambda ^ { 2 } ( e _ { i } ) } - \dot { \lambda } ( e _ { i } ) \right ] s _ { i } ^ { T } s _ { i }, \\ \text{ere } e _ { i } = H ( \tilde { T } _ { i } ) - \gamma ^ { T } X _ { i }, \ddot { \lambda } ( \cdot ) \text{ is the second derivative of } \lambda ( \cdot ), \, s _ { i } \text{ is the it}$$
where e i = H T ( ˜ ) i -γ T X i , ¨ ( ) λ · is the second derivative of λ ( ), · s i is the i th row of the matrix S 1 2 / and r i = ∫ ∞ 0 ˙ λ H t { ( ) -γ T X /λ H t i } { ( ) -γ T X i } dM t i ( ; γ, H ). The equality in the above equation is obtained by first taking the derivative of l n ( γ, H, τ ) with respect to τ and then deriving its limit as τ → 0 using L'Hˆpital's o rule. Note that the first term on the right-hand side of the above equation is nonnegative, and the second term converges in probability to a constant as n goes to infinity. In addition, under the null hypothesis, r i 's have expectation of 0 at the true values of γ and H because they are martingale integrations. Therefore, if the null hypothesis is correct, the first term in the summation should be close to 0. This result motivates us to consider a score test and reject the null hypothesis when the score (1 /n ∂l ) n (ˆ γ, H,τ ˆ ) /∂τ | τ =0 is bigger than some value, where ˆ and γ ˆ H are the estimates of γ and H , respectively, under the null model. It is asymptotically equivalent to consider the test statistic Q n = n -1 (ˆ r , . . . , r 1 ˆ ) n S r ,...,r (ˆ 1 ˆ ) n T and reject the null hypothesis when Q >c n α , where c α is the critical value for a levelα test.
Null distribution of the score statistic Q n : Here, we consider the estimators ˆ and γ ˆ ( ) H · obtained via the martingale-based estimating equations for the standard linear transformation model [Chen, Jin and Ying (2002)] under the null hypothesis. Note that Q n =( n -1 2 / ∑ n i =1 ˆ r s i i ) T ( n -1 2 / ∑ n i =1 ˆ r s i i ). Let γ 0 and H 0 denote the true values of γ and H , respectively, in the null model.
Based on the derivations given in Chen, Jin and Ying (2002), we have the following asymptotic representations:
$$\stackrel { \mu } { \sqrt { n } } ( \hat { \gamma } - \gamma _ { 0 } ) = - A ^ { - 1 } \frac { 1 } { \sqrt { n } } \sum _ { i = 1 } ^ { n } \int _ { 0 } ^ { \infty } \{ X _ { i } - \mu _ { X } ( t ) \} \, d M _ { i } ( t ; \gamma _ { 0 }, H _ { 0 } ) + o _ { p } ( 1 ),$$
$$\sqrt { n } \{ \hat { H } ( t ) - H _ { 0 } ( t ) \} = - b _ { 1 } ( t ) ^ { T } A ^ { - 1 } \frac { 1 } { \sqrt { n } } \sum _ { i = 1 } ^ { n } \int _ { 0 } ^ { \infty } \{ X _ { i } - \mu _ { X } ( t ) \} \, d M _ { i } ( t ; \gamma _ { 0 }, H _ { 0 } )$$
$$+ \frac { 1 } { \sqrt { n } } \sum _ { i = 1 } ^ { n } \int _ { 0 } ^ { t } \phi ( t, s ) \, d M _ { i } ( s ; \gamma _ { 0 }, H _ { 0 } ) + o _ { p } ( 1 ).$$
The definitions of A µ , X ( ), · b 1 ( ) · and φ ( · , · ) can be found in Chen, Jin and Ying (2002). By the Taylor expansion, we can show that
$$\frac { 1 } { \sqrt { n } } \sum _ { i = 1 } ^ { n } \hat { r } _ { i } s _ { i } \rightarrow _ { d } N ( 0, \Sigma ),$$
as n →∞ , where Σ = E ψ ψ ( i T i ) and
$$\mathfrak { s n } \to \infty, \, \text{where } \Sigma = E ( \psi _ { i } \psi _ { i } ^ { t } ) \text{ and } \\ \psi _ { i } = & \left [ \delta _ { i } \frac { \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} } { \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} } - \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \right ] s _ { i } \\ & - ( B _ { 1 } - B _ { 2 } ) A ^ { - 1 } \int _ { 0 } ^ { \infty } \{ X _ { i } - \mu _ { X } ( t ) \} \, d M _ { i } ( t ; \gamma _ { 0 }, H _ { 0 } ) \\ & - \int _ { 0 } ^ { \infty } b _ { 2 } ( t ) \, d M _ { i } ( t ; \gamma _ { 0 }, H _ { 0 } ). \\ \text{lere}$$
Here
$$B _ { 1 } = \lim _ { n \to \infty } \frac { 1 } { n } \sum _ { i = 1 } ^ { n } s _ { i } X _ { i } ^ { T } [ \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \}$$
$$B _ { 2 } = \lim _ { n \to \infty } \frac { 1 } { n } \sum _ { i = 1 } ^ { n } s _ { i } b _ { 1 } ( \tilde { T } _ { i } ) ^ { T } [ \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} _ { - } \\.$$
$$& = \lim _ { n \to \infty } \frac { 1 } { n } \sum _ { i = 1 } ^ { n } s _ { i } X _ { i } ^ { T } [ \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \\ & \quad - \delta _ { i } ( \ddot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \\ & \quad - ( \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} ) ^ { 2 } ) \\ & \quad / ( \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} ) ^ { 2 } ], \\ & = \lim \, \frac { 1 } { } \sum _ { i } ^ { n } s _ { i } b _ { 1 } ( \tilde { T } _ { i } ) ^ { T } [ \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \}$$
$$- \, \delta _ { i } ( \ddot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \\ - \, & ( \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} ) ^ { 2 } ) \\ & / ( \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} ) ^ { 2 } ],$$
$$b _ { 2 } ( t ) = \lim _ { n \to \infty } \frac { 1 } { n } \sum _ { i = 1 } ^ { n } s _ { i } I ( \tilde { T } _ { i } \geq t )$$
Therefore, Q n converges in distribution to a weighted χ 2 distribution: ∑ d k =1 ξ k χ 2 1 ,k , where χ 2 1 1 , , . . . , χ 2 1 ,d are d independently and identically distributed χ 2 random variables with degree freedom of 1, and ξ , . . . , ξ 1 d are the d nonzero eigenvalues of the matrix Σ. To obtain the critical value, c α , of the limiting weighted χ 2 distribution, we use a numerical method. Specifically, we first obtain a consistent estimator, Σ, of Σ using the usual plug-in ˆ method and compute the nonzero eigenvalues ˆ ξ , . . . , ξ 1 ˆ d of the matrix Σ. ˆ Next we generate a large set (e.g., 10,000 sets) of independent and identically distributed random variables χ 2 1 1 , , . . . , χ 2 1 ,d . For each set of χ 2 random variables, we compute ∑ d k =1 ˆ ξ k χ 2 1 ,k . We can then estimate c α by the upper α -quantile of ∑ d k =1 ˆ ξ k χ 2 1 ,k 's and the associated p -value of the score test can be computed accordingly.
$$= \lim _ { n \to \infty } \frac { 1 } { n } \sum _ { i = 1 } ^ { n } s _ { i } I ( \tilde { T } _ { i } \geq t ) \\ \times \phi ( \tilde { T } _ { i }, t ) [ \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \\ - \, \delta _ { i } ( \ddot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} } \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} \\ - \, ( \dot { \lambda } \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} ) ^ { 2 } ) \\ / ( \lambda \{ H _ { 0 } ( \tilde { T } _ { i } ) - \gamma _ { 0 } ^ { T } X _ { i } \} ) ^ { 2 } ]. \\ \text{refore, } Q _ { n } \text{ converges in distribution to a weighted } \chi ^ { 2 } \text{ distribution:} \\ \varepsilon _ { i } \nu ^ { 2 } \dots \text{ where } \nu ^ { 2 } \dots \nu ^ { 2 } \text{. are } d \text{ independently and identically } d i s \text{-}$$
Acknowledgments. The authors thank Dr. Mich`le M. Sale and Dr. Brade ford B. Worrall for providing the data. They thank Dr. Chen-Hsin Chen for his insightful discussion and helpful suggestions to improve the work. They also thank Dr. Shannon Holloway for her constructive input and proofreading to improve the manuscript and assistance in creating the software package.
## REFERENCES
Afman, L. A. , Lievers, K. J. A. , Kluijtmans, L. A. J. , Trijbels, F. J. M. and Blom, H. J. (2003). Gene-gene interaction between the cystathionine beta-synthase 31 base pair variable number of tandem repeats and the methylenetetrahydrofolate reductase 677C > T polymorphism on homocysteine levels and risk for neural tube defects. Mol. Genet. Metab. 78 211-215.
Beckmann, L. , Thomas, D. C. , Fischer, C. and Chang-Claude, J. (2005). Haplotype sharing analysis using mantel statistics. Hum. Hered. 59 67-78.
Bennett, S. (1983). Analysis of survival data by the proportional odds model. Stat. Med. 2 273-277.
- Cai, T. , Tonini, G. and Lin, X. (2011). Kernel machine approach to testing the significance of multiple genetic markers for risk prediction. Biometrics 67 975-986. MR2829272
Chen, K. , Jin, Z. and Ying, Z. (2002). Semiparametric analysis of transformation models with censored data. Biometrika 89 659-668. MR1929170
- Cheng, S. C. , Wei, L. J. and Ying, Z. (1995). Analysis of transformation models with censored data. Biometrika 82 835-845. MR1380818
- Cox, D. R. (1972). Regression models and life-tables. J. R. Stat. Soc. Ser. B Stat. Methodol. 34 187-220. MR0341758
- Duchesne, P. and Lafaye De Micheaux, P. (2010). Computing the distribution of quadratic forms: Further comparisons between the Liu-Tang-Zhang approximation and exact methods. Comput. Statist. Data Anal. 54 858-862. MR2580921
Elston, R. C. , Buxbaum, S. , Jacobs, K. B. and Olson, J. M. (2000). Haseman and Elston revisited. Genet. Epidemiol. 19 1-17.
- Giusti, B. , Saracinim, C. , Bolli, P. , Magi, A. , Martinelli, I. , Peyvandi, F. , Rasura, M. , Volpe, M. Lotta, L. A. , , Rubattu, S. Mannucci, P. M. , and Abbate, R. (2010). Early-onset ischaemic stroke: Analysis of 58 polymorphisms in 17 genes involved in methionine metabolism. Thrombosis and Haemostasis 104 231-242.
- Goeman, J. J. , Oosting, J. , Cleton-Jansen, A.-M. , Anninga, J. K. and van Houwelingen, H. C. (2005). Testing association of a pathway with survival using gene expression data. Bioinformatics 21 1950-1957.
- Goldstein, D. B. (2005). The genetics of human drug response. Philosophical Transactions of the Royal Society B: Biological Sciences 360 1571-1572.
- Goldstein, D. B. , Tate, S. K. and Sisodiya, S. M. (2003). Pharmacogenetics goes genomic. Nat. Rev. Genet. 4 937-947.
- Haseman, J. K. and Elston, R. C. (1972). The investigation of linkage between a quantitative trait and a marker locus. Behav. Genet. 2 3-19.
- Hsu, F. C. , Sides, E. G. and Mychaleckyj, J. C.et al. (2011). A Transcobalamin 2 gene variant associated with post-stroke homocysteine modifies recurrent stroke risk. Neurology 77 1543-1550.
- Li, H. and Luan, Y. (2005). Boosting proportional hazards models using smoothing spline, with application to high-dimensional microarray data. Biostatistics 21 2403-2409.
- Lin, D. Y. and Wei, L. J. (1989). The robust inference for the Cox proportional hazards model. J. Amer. Statist. Assoc. 84 1074-1078. MR1134495
Lin, W.-Y. and Schaid, D. J. (2009). Power comparisons between similarity-based multilocus association methods, logistic regression, and score tests for haplotypes. Genet. Epidemiol. 33 183-197.
Lin, X. , Cai, T. , Wu, M. C. , Zhou, Q. , Liu, G. , Christiani, D. C. and Lin, X. (2011). Kernel machine SNP-set analysis for censored survival outcomes in genomewide association studies. Genet. Epidemiol. 35 620-631.
Low, H.-Q. , Chen, C. P. L. H. , Kasiman, K. , Thalamuthu, A. , Ng, S.-S. , Foo, J.N. , Chang, H.-M. , Wong, M.-C. , Tai, E.-S. and Liu, J. (2011). A comprehensive association analysis of homocysteine metabolic pathway genes in Singaporean Chinese with ischemic stroke. PLoS ONE 6 e24757.
Moskvina, V. and Schmidt, K. M. (2008). On multiple-testing correction in genomewide association studies. Genet. Epidemiol. 32 567-573.
- Pearson, E. S. (1959). Note on an approximation to the distribution of non-central χ 2 . Biometrika 46 364. MR0109380
Pongpanich, M. , Neely, M. and Tzeng, J. Y. (2012). On the aggregation of multimarker information for marker-set and sequencing data analysis: Genotype collapsing vs. similarity collapsing. Frontiers in Statistical Genetics and Methodology 2 110.
Price, A. L. , Kryukov, G. V. , de Bakker, P. I. W. , Purcell, S. M. , Staples, J. , Wei, L.-J. and Sunyaev, S. R. (2010). Pooled association tests for rare variants in exon-resequencing studies. Am. J. Hum. Genet. 86 832-838.
Qian, D. and Thomas, D. (2001). Genome scan of complex traits by haplotype sharing correlation. Genetic Epidemiology 21 S582-S587.
- Schaid, D. J. (2010a). Genomic similarity and kernel methods I: Advancements by building on mathematical and statistical foundations. Human Heredity 70 109-131.
- Schaid, D. J. (2010b). Genomic similarity and kernel methods II: Methods for genomic information. Human Heredity 70 132-140.
- Toole, J. F. , Malinow, M. R. Chambless, L. E. et al. , (2004). Lowering homocysteine in patients with ischemic stroke to prevent recurrent stroke, myocardial infarction, and death: The Vitamin Intervention for Stroke Prevention (VISP) randomized controlled trial. Journal of American Medical Association 291 565-575.
Tzeng, J. Y. , Devlin, D. , Wasserman, L. and Roeder, K. (2003). On the identification of disease mutations by the analysis of haplotype similarity and goodness of fit. The American Journal of Human Genetics 72 891-902.
- Tzeng, J.-Y. , Zhang, D. , Chang, S.-M. , Thomas, D. C. and Davidian, M. (2009). Gene-trait similarity regression for multimarker-based association analysis. Biometrics 65 822-832. MR2649855
Tzeng, J.-Y. , Zhang, D. , Pongpanich, M. , Smith, C. , McCarthy, M. I. , Sale, M. M. , Worrall, B. B. , Hsu, F.-C. , Thomas, D. C. and Sullivan, P. F. (2011). Studying gene and gene-environment effects of uncommon and common variants on continuous traits: A marker-set approach using gene-trait similarity regression. Am. J. Hum. Genet. 89 277-288.
von Castel-Dunwoody, K. M. Kauwell, G. P. A. Shelnutt, K. P. Vaughn, J. D. , , , , Griffin, E. R. , Maneval, D. R. , Theriaque, D. W. and Bailey, L. B. (2005). Transcobalamin 776C → G polymorphism negatively affects vitamin B-12 metabolism. Am. J. Clin. Nutr. 81 1436-1441.
Wang, J. , Huff, A. M. , Spence, J. D. and Hegele, R. A. (2004). Single nucleotide polymorphism in CTH associated with variation in plasma homocysteine concentration. Clin. Genet. 65 483-486.
Wessel, J. and Schork, N. J. (2006). Generalized genomic distance-based regression methodology for multilocus association analysis. Am. J. Hum. Genet. 79 792-806.
- Wu, M. C. , Lee, S. , Cai, T. , Li, Y. , Boehnke, M. and Lin, X. (2011). Rare-variant association testing for sequencing data with the sequence kernel association test. Am. J. Hum. Genet. 89 82-93.
Zeng, D. and Lin, D. Y. (2006). Efficient estimation of semiparametric transformation models for counting processes. Biometrika 93 627-640. MR2261447
Zhong, P.-S. and Chen, S. X. (2011). Tests for high-dimensional regression coefficients with factorial designs. J. Amer. Statist. Assoc. 106 260-274. MR2816719
J.-Y. Tzeng Department of Statistics North Carolina State University Raleigh, North Carolina 27695-8203 USA and Department of Statistics National Cheng Kung University Tainan City Taiwan (R.O.C.) E-mail: [email protected]
W. Lu Department of Statistics North Carolina State University Raleigh, North Carolina 27695-8203 USA E-mail: [email protected]
## F.-C. Hsu
Department of Biostatistical Sciences Wake Forest School of Medicine Winston-Salem, North Carolina 27157 USA
E-mail:
[email protected] | 10.1214/14-AOAS735 | [
"Jung-Ying Tzeng",
"Wenbin Lu",
"Fang-Chi Hsu"
] | 2014-08-01T05:36:59+00:00 | 2014-08-01T05:36:59+00:00 | [
"stat.AP"
] | Gene-level pharmacogenetic analysis on survival outcomes using gene-trait similarity regression | Gene/pathway-based methods are drawing significant attention due to their
usefulness in detecting rare and common variants that affect disease
susceptibility. The biological mechanism of drug responses indicates that a
gene-based analysis has even greater potential in pharmacogenetics. Motivated
by a study from the Vitamin Intervention for Stroke Prevention (VISP) trial, we
develop a gene-trait similarity regression for survival analysis to assess the
effect of a gene or pathway on time-to-event outcomes. The similarity
regression has a general framework that covers a range of survival models, such
as the proportional hazards model and the proportional odds model. The
inference procedure developed under the proportional hazards model is robust
against model misspecification. We derive the equivalence between the
similarity survival regression and a random effects model, which further
unifies the current variance component-based methods. We demonstrate the
effectiveness of the proposed method through simulation studies. In addition,
we apply the method to the VISP trial data to identify the genes that exhibit
an association with the risk of a recurrent stroke. The TCN2 gene was found to
be associated with the recurrent stroke risk in the low-dose arm. This gene may
impact recurrent stroke risk in response to cofactor therapy. |
1408.0084v2 | ## BILLEY-POSTNIKOV DECOMPOSITIONS AND THE FIBRE BUNDLE STRUCTURE OF SCHUBERT VARIETIES
## EDWARD RICHMOND AND WILLIAM SLOFSTRA
Abstract. A theorem of Ryan and Wolper states that a type A Schubert variety is smooth if and only if it is an iterated fibre bundle of Grassmannians. We extend this theorem to arbitrary finite type, showing that a Schubert variety in a generalized flag variety is rationally smooth if and only if it is an iterated fibre bundle of rationally smooth Grassmannian Schubert varieties. The proof depends on deep combinatorial results of Billey-Postnikov on Weyl groups. We determine all smooth and rationally smooth Grassmannian Schubert varieties, and give a new proof of Peterson's theorem that all simply-laced rationally smooth Schubert varieties are smooth. Taken together, our results give a fairly complete geometric description of smooth and rationally smooth Schubert varieties using primarily combinatorial methods.
## 1. Introduction
Let G be a connected semisimple algebraic group over an algebraically closed field k , and let X be a partial flag variety of type G . The variety X is stratified by Schubert varieties X w ( ), which are indexed by minimal length coset representatives w in the Weyl group W of G . When k = C and G = SL ( n C ) is the semisimple group of type A n -1 , the partial flag varieties parametrize flags of subspaces in C n . When X is the complete flag variety in type A , Ryan proved that smooth Schubert varieties are iterated fibre bundles of Grassmannians [Rya87]. This result was extended to the partial flag varieties of type A over any algebraically closed field k of characteristic zero by Wolper [Wol89]. The main result of this paper is an extension of Ryan and Wolper's theorems to flag varieties of all finite types. We consider both the class of smooth Schubert varieties, and the larger class of rationally smooth Schubert varieties, proving the following result: a finite type Schubert variety is (rationally) smooth if and only if it is an iterated fibre bundle of (rationally) smooth Grassmannian Schubert varieties.
In type A , every smooth Grassmannian Schubert variety is a sub-Grassmannian [BL00, Theorem 9.3.1], and thus we recover Ryan and Wolper's theorem from our results. However, in other types there are (rationally) smooth Grassmannian Schubert varieties which are not sub-Grassmannians. Fortunately, the singular locus of these Schubert varieties has been extensively studied [LW90] [BP99]; a summary can be found in [BL00]. More recently, smooth Grassmannian Schubert varieties have been studied in the context of homological rigidity [Rob14] [HM13]. From this work, the list of smooth Schubert varieties is known for many generalized Grassmannians. As part of our results, we finish this line of inquiry by giving a complete list of both smooth and rationally smooth Grassmannian Schubert varieties in all finite types. When combined with our extension of Ryan and Wolper's theorem, this gives a fairly complete geometric description of (rationally) smooth Schubert varieties in any finite type.
There are several well known characterizations of (rationally) smooth Schubert varieties. If P w ( ) is the Poincar´ polynomial of t e X w ( ), then a theorem of Carrell-Peterson states that
X w ( ) is rationally smooth if and only if P w ( ) is a palindromic polynomial [Car94]. Another t characterization says that X w ( ) is rationally smooth if and only if the Weyl group element w has trivial Kazhdan-Lusztig polynomials. For type A Schubert varieties, the LakshmibaiSandya theorem [LS90] states that a Schubert variety X w ( ) is smooth if and only if w , as a permutation, avoids 3412 and 4231. This pattern-avoidance criterion has been extended to classical types by Billey [Bil98] and to all finite types using root-system pattern avoidance by Billey-Postnikov [BP05]. These pattern avoidance criteria provide an efficient way to test if a given Schubert variety X w ( ) is smooth or rationally smooth. In contrast, our results provide information about the geometric structure of (rationally) smooth Schubert varieties. For instance, Peterson's theorem, proved in full generality by Carrell-Kuttler, states that if G is simply-laced then X w ( ) is rationally smooth if and only if it is smooth [CK03]. Other proofs of Peterson's theorem have been given in [Dye] and [JW14]. Using our results, we give a new proof of Peterson's theorem; compared to the proofs listed above, our proof is more combinatorial. Using the list of (rationally) smooth Grassmannian Schubert varieties, we can also efficiently generate the list of (rationally) smooth Schubert varieties in any partial flag variety. This method can be extended to enumerate (rationally) smooth Schubert varieties in complete flag varieties; since this requires a new combinatorial data structure, we leave this to another paper.
The central idea behind our results is the notion of a Billey-Postnikov decomposition. To explain this, let X J denote the partial flag variety associated to a subset J of the simple generators S of W . If J ⊆ K ⊆ S , then there is a natural projection π : X J → X K . If X J ( w ) is a Schubert variety of X J and w = vu is the parabolic decomposition of w with respect to K , then the restriction of π to X J ( w ) gives a projection
$$\pi \colon X ^ { J } ( w ) \to X ^ { K } ( v )$$
with generic fibre X J ( u ). While π : X J → X K is a fibre bundle, the restriction in equation (1) is not a fibre bundle in general (see, for instance, example 3.4). If this projection is a fibre bundle, then the Leray-Hirsch theorem states that the singular cohomology ring H ∗ ( X J ( w )) is a free H ∗ ( X K ( v ))-module over H ∗ ( X J ( u )). As a consequence, if P J w ( ) t denotes the Poincar´ polynomial of e X J ( w ), then
$$P _ { w } ^ { J } ( t ) = P _ { v } ^ { K } ( t ) \cdot P _ { u } ^ { J } ( t ).$$
We prove that equation (2) is also a sufficient condition for the projection in equation (1) to be a fibre bundle. This result is stated in Theorem 3.3, and holds for Schubert varieties of any Kac-Moody group.
Factorizations of P J w ( ) t have been studied by a number of authors, most notably by Gasharov [Gas98], Billey [Bil98], and Billey-Postnikov [BP05]. Billey and Postnikov show that if X ∅ ( w ) is a rationally smooth Schubert variety of finite type, then there exists a subset K of simple generators for which either w or w -1 has a parabolic decomposition vu with respect to K such that the Poincar´ polynomial factors as e P ∅ w ( ) = t P K v ( ) t · P ∅ u ( ) t [BP05]. Moreover, K can be choosen such that S \ K = { } s for some leaf s of the Dynkin diagram of G . In [OY10], Oh and Yoo call such a parabolic decomposition a Billey-Postnikov decomposition. In this paper, we say that a parabolic decomposition w = vu with respect to K is Billey-Postnikov (BP) if the polynomial P J w ( ) factors as in t equation (2) (dropping the condition that S \ K = { } s for some leaf s ). When J = , this ∅ agrees with the definition used by the authors in [RS14]. We then prove that if X J ( w ) is rationally smooth and of finite type, then there exists a nontrivial K containing J for which w has a BP decomposition. This result is stated in Theorem 3.6. The proof uses
the existence theorem in [BP05] combined with an inductive argument. Note that we cannot apply the existence theorem for BP decompositions stated in [BP05] to construct fibre bundle structures on Schubert varieties directly. While the Bruhat intervals [ e, w ] and [ e, w -1 ] are order isomorphic, the Schubert varieties X ∅ ( w ) and X ∅ ( w -1 ) are not necessarily isomorphic. Hence a fibre bundle structure on X ∅ ( w -1 ) may not yield a fibre bundle structure on X ∅ ( w ).
1.1. Acknowledgements. We would like to thank Dave Anderson, Sara Billey, Jim Carrell, and Alex Woo for helpful discussions. We thank the anonymous referee for useful suggestions on the manuscript. The first author was partially supported by the Natural Sciences and Engineering Research Council of Canada.
## 2. Background and terminology
We use the notation from the introduction throughout the paper. In particular, we work over a fixed algebraically closed field k of arbitrary characteristic. Let G denote a semisimple algebraic group over k or, as long as k = C , a Kac-Moody group. When working with Kac-Moody groups, we take G to be the minimum Kac-Moody group G min as defined in [Kum02]. Fix a choice of maximal torus and Borel T ⊂ B ⊂ G . Let W = N T /T ( ) denote the Weyl group of G and fix a simple generating set S for W . We choose a representative in the normalizer N T ( ) of T for each element w ∈ W . If S = { s , s 1 2 , . . . , s n } is the generating set of a specific Weyl group of finite type, we use the Bourbaki labeling of Dynkin diagrams in [Bou68] to describe the Coxeter relations.
For basic facts about Schubert varieties, we refer again to [Kum02], and in particular to the facts about Tits systems in [Kum02, section 5.1]. As in loc. cit., a (standard) parabolic subgroup of W is a subgroup W J generated by a subset J ⊂ S . If J ⊆ S , we let P J := BW B J be the parabolic subgroup of G corresponding to J . The partial flag variety associated to J is then X J := G/P J . Let W J /similarequal W/W J denote the set of minimal length coset representatives. If w ∈ W J , then the Schubert variety associated to w is the closure X J ( w ) := BwP /P J J . The dimension of X J ( w ) is /lscript ( w ), the Coxeter length of w with respect to S . Note that for Kac-Moody groups G , the flag variety X J can be an infinitedimensional ind-variety, but the Schubert varieties X J ( w ) are always finite-dimensional.
If J ⊆ K ⊆ S , then every element w ∈ W J can be written uniquely as w = vu , where v ∈ W K and u ∈ W K ∩ W J . This is called the (right) parabolic decomposition of w with respect to K . We say w = w 1 · · · w k is a reduced decomposition if /lscript ( w ) = ∑ i /lscript ( w i ). Note that all parabolic decompositions are reduced.
If ≤ denotes Bruhat order on W , then
$$\Phi _ { \quad X ^ { J } ( w ) } = \coprod _ { x \in [ e, w ] \cap W ^ { J } } B x P _ { J } / P _ { J } \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \ dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
where [ e, w ] denotes the interval in Bruhat order between e and w . If W J is finite and w ∈ W J , then the preimage of X J ( w ) in G/B is X ∅ ( w ′ ), where w ′ is the maximal length representative of the coset wW J . Alternatively, w ′ = wu 0 , where u 0 is the longest element of W J . If w 1 and w 2 are in W J , then w 1 ≤ w 2 if and only if w ′ 1 ≤ w ′ 2 , where w ′ i is the longest element in the coset w W i J . Geometrically, w 1 ≤ w 2 if and only if X J ( w 1 ) ⊆ X J ( w 2 ).
The Poincar´ e polynomial P J w ( ) of an element t w ∈ W J is defined as
$$\Psi _ { w } ^ { J } ( t ) \coloneqq \sum _ { x \in [ e, w ] \cap W ^ { J } } t ^ { \ell ( x ) }.$$
It is well-known that P J w ( t 2 ) = ∑ dim H X i ( J ( w )) t i , the Poincar´ polynomial for the coe homology of X J ( w ). The Poincar´ e polynomial is palindromic if P J w ( ) = t t /lscript ( w ) P J w ( t -1 ), or in other words if the coefficients form a palindrome when ordered by degree.
The support of an element w ∈ W is defined as
$$S ( w ) \coloneqq \{ s \in S \ | \ s \leq w \}.$$
Equivalently, S w ( ) is the set of simple reflections appearing in any reduced decomposition of w . The left and right descents set of w are
$$D _ { L } ( w ) & \coloneqq \{ s \in S \ | \ \ell ( s w ) \leq \ell ( w ) \} \\ D _ { R } ( w ) & \coloneqq \{ s \in S \ | \ \ell ( w s ) \leq \ell ( w ) \}.$$
A generalized Grassmannian is a flag variety X J where | S \ J | = 1. In other words, P J is a maximal parabolic subgroup of G where X J = G/P J . A Schubert variety X J ( w ) of a generalized Grassmannian is called a Grassmannian Schubert variety . An element w ∈ W is called a Grassmannian element if w ∈ W J for some generalized Grassmannian X J . Equivalently, w ∈ W is Grassmannian if and only if w has a unique right descent. By a Grassmannian parabolic decomposition , we mean a parabolic decomposition w = vu with respect to a set K such that | K ∩ S w ( ) | = | S w ( ) | -1.
For more information about Schubert varieties over an arbitrary field, we point to [Bor91] and [BK04].
## 3. Main results
As stated in the introduction, we define Billey-Postnikov decompositions as follows:
Definition 3.1. Let w ∈ W J , and let w = vu be a parabolic decomposition with respect to K , where J ⊆ K ⊆ S . We say that w = vu is a Billey-Postnikov (BP) decomposition with respect to ( J, K ) if
$$P _ { w } ^ { J } ( t ) = P _ { v } ^ { K } ( t ) \cdot P _ { u } ^ { J } ( t ).$$
When J = ∅ , we simply say that w = vu is a BP decomposition with respect to K .
Some elementary equivalent definitions of BP decompositions are given in Proposition 4.2. In particular, checking whether or not a given parabolic decomposition is a BP decomposition is computationally easy, and does not require working with Bruhat order.
Example 3.2. Let G = SL ( 4 k ) , with Weyl group W generated by S = { s , s 1 2 , s 3 } . If J = { s , s 1 3 } , then the parabolic decomposition w = vu = ( s s s 1 3 2 )( s s 3 1 ) is a BP decomposition with respect to J since
$$P _ { w } ^ { \emptyset } ( t ) = P _ { v } ^ { J } ( t ) \cdot P _ { u } ^ { \emptyset } ( t ) & = ( t ^ { 3 } + 2 t ^ { 2 } + t + 1 ) ( t ^ { 2 } + 2 t + 1 ) \\ & = t ^ { 5 } + 4 t ^ { 4 } + 6 t ^ { 3 } + 5 t ^ { 2 } + 3 t + 1.$$
$$= t ^ { 5 } + 4 t ^ { 4 } + 6 t ^ { 3 } + 5 t ^ { 2 } + 3 t + 1.$$
The parabolic decomposition w = vu = ( s s s 1 3 2 )( s 1 ) is not a BP decomposition with respect to J since
$$P _ { w } ^ { \emptyset } ( t ) = t ^ { 4 } + 3 t ^ { 3 } + 4 t ^ { 2 } + 3 t + 1$$
and
$$P _ { v } ^ { J } ( t ) \cdot P _ { u } ^ { \emptyset } ( t ) = ( t ^ { 3 } + 2 t ^ { 2 } + t + 1 ) ( t + 1 ) = t ^ { 4 } + 3 t ^ { 3 } + 5 t ^ { 2 } + 2 t + 1.$$
Our first main theorem is a geometric characterization of BP decompositions. Note that this theorem holds when G is a general Kac-Moody group.
Theorem 3.3. Let w ∈ W J and w = vu be a parabolic decomposition with respect to K . Then the following are equivalent:
- (a) The decomposition w = vu is a BP decomposition with respect to ( J, K ) .
- (b) The projection π : X J ( w ) → X K ( v ) is Zariski-locally trivial with fibre X J ( u ) .
Consequently, if w = vu is a BP decomposition then:
- (1) X J ( w ) is (rationally) smooth if and only if X J ( u ) and X K ( v ) are (rationally) smooth.
- (2) The projection π : X J ( w ) → X K ( v ) is smooth if and only if X J ( u ) is smooth.
Example 3.4. Let G = SL ( 4 k ) . Geometrically, we have
$$G / B = \{ V _ { \bullet } = ( V _ { 1 } \subset V _ { 2 } \subset V _ { 3 } \subset k ^ { 4 } ) \ | \ \dim V _ { i } = i \}.$$
Let E · denote the flag corresponding to eB . If w = s s s s s 1 2 3 2 1 , then
$$X ^ { \emptyset } ( w ) = \{ V _ { \bullet } \ | \ \dim ( V _ { 2 } \cap E _ { 2 } ) \geq 1 \}.$$
If J = { s , s 1 3 } , then π V ( · ) = V 2 . From Example 3.2, w = vu = ( s s s 1 3 2 )( s s 3 1 ) is a BP decomposition with respect to J . In particular, the Schubert variety
$$X ^ { J } ( v ) = \{ V _ { 2 } \ | \ \dim ( V _ { 2 } \cap E _ { 2 } ) \geq 1 \}$$
and the fibre over V 2 in the projection π : X ∅ ( w ) → X J ( v ) is
$$\pi ^ { - 1 } ( V _ { 2 } ) = \{ ( V _ { 1 }, V _ { 3 } ) \ | \ V _ { 1 } \subset V _ { 2 } \subset V _ { 3 } \} \cong X ^ { \emptyset } ( u ) \cong \mathbb { P } ^ { 1 } \times \mathbb { P } ^ { 1 }.$$
In this case, the uniform fibre X ∅ ( u ) is smooth. However since X J ( v ) is singular, we have that X ∅ ( w ) is singular. If J = { s , s 1 2 } , then π V ( · ) = V 3 and w = vu = ( s s s 1 2 3 )( s s 2 1 ) is not a BP decomposition. The fiber over V 3 is given by
$$\nu _ { 1 } \quad \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \ sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \osigma \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \ sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \ sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \ sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \sin \cos \cos \cos \cos \sin \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \osigma \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \cos \\ \nu _ { 1 } } \quad \ \nu _ { 2 } } \quad \ \nu _ { 3 } \quad \ \nu _ { 4 } \quad \ \nu _ { 5 } \quad \ \nu _ { 6 } \quad \ \nu _ { 7 } \quad \ \nu _ { 8 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \ \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu _ { 9 } \\ \quad \nu _ { 9 } \quad \nu _ { 9 } \quad \nu$$
Note that the fibres are not equidimensional.
If Y is a variety over k , let H ∗ ( Y ) denote either etale cohomology, or, when k = C , singular cohomology. For etale cohomology, we take coefficients in Q l , where l is a prime not equal to the characteristic of k , while for singular cohomology we take coefficients in C .
Corollary 3.5. Let w = vu be a parabolic decomposition with respect to K . Then the following are equivalent:
- (a) The decomposition w = vu is a BP decomposition with respect to ( J, K ) .
- (b) There is an isomorphism
$$H ^ { * } ( X ^ { J } ( w ) ) \cong H ^ { * } ( X ^ { K } ( v ) ) \otimes H ^ { * } ( X ^ { J } ( u ) )$$
$$a s \, H ^ { * } ( X ^ { K } ( v ) ) \text{-} m o d u l e s.$$
It is well known that the Poincar´ polynomial e P w ( t 2 ) = ∑ H X i ( J ( w )) t i , so the ( b ) ⇒ ( a ) direction of Corollary 3.5 follows immediately from the definition. The ( a ) ⇒ ( b ) direction of Corollary 3.5 and Theorem 3.3 will be proved in Section 4.2.
Our second main theorem concerns the existence of BP decompositions when G is semisimple, or equivalently when W is finite.
Theorem 3.6. Let w ∈ W J , where W is finite, and suppose | S w ( ) \ J | ≥ 2 . If X J ( w ) is rationally smooth, then w has a Grassmannian BP decomposition with respect to ( J, K ) for some maximal proper K containing J.
As an application of our main theorems, we get the following extension of the RyanWolper theorem to arbitrary finite type.
Corollary 3.7. Let w ∈ W J , where W is finite, and set m = | S v ( ) \ J | . Then X J ( w ) is rationally smooth if and only if there is a sequence
- (3) X J ( w ) = X 0 → X 1 →··· → X m -1 → X m = Spec k,
where each morphism is a Zariski locally-trivial fibre bundle, and the fibres are rationally smooth Grassmannian Schubert varieties.
Similarly, X J ( w ) is smooth if and only if there is a sequence as in (3) where all the fibres, or equivalently, all the morphisms, are smooth.
Each projection X i → X i +1 in Corollary 3.7 corresponds to a BP decomposition. However, these BP decompositions are not usually Grassmannian, since the fibre of the projection is Grassmannian rather than the base. To deduce Corollary 3.7 from Theorem 3.6, we start with the morphisms X i → X m -1 (which do correspond to Grassmannian BP decompositions), and then apply a certain associativity property (stated in Lemma 4.3) for BP decompositions. Theorem 3.6 and Corollary 3.7 are proved in Section 6.
To complete the description of rationally smooth Schubert varieties, we list all rationally smooth Grassmannian Schubert varieties of finite type.
Theorem 3.8. Let W be a finite Weyl group. Suppose w ∈ W J for some J = S \ { s } , and that S w ( ) = S . Then X J ( w ) is rationally smooth if and only if either
- (1) w is the maximal element of W J , in which case X J ( w ) is smooth.
- (2) w is one of the following elements:
| W | s | w | index set | X J ( w ) smooth? |
|-----|-----|-----------------------------------------|-------------|---------------------|
| B n | s 1 | s k s k +1 · · · s n s n - 1 · · · s 1 | 1 < k ≤ n | no |
| B n | s k | u n,k +1 s 1 · · · s k | 1 < k < n | no |
| B n | s n | s 1 . . . s n | n ≥ 2 | yes |
| C n | s 1 | s k s k +1 · · · s n s n - 1 · · · s 1 | 1 < k ≤ n | yes |
| C n | s k | u n,k +1 s 1 · · · s k | 1 < k < n | yes |
| C n | s n | s 1 . . . s n | n ≥ 2 | no |
| F 4 | s 1 | s 4 s 3 s 2 s 1 | n/a | no |
| F 4 | s 2 | s 3 s 2 s 4 s 3 s 4 s 2 s 3 s 1 s 2 | n/a | no |
| F 4 | s 3 | s 2 s 3 s 1 s 2 s 1 s 3 s 2 s 4 s 3 | n/a | yes |
| F 4 | s 4 | s 1 s 2 s 3 s 4 | n/a | yes |
| G 2 | s 1 | s 2 s 1 , s 1 s 2 s 1 , s 2 s 1 s 2 s 1 | n/a | no |
| G 2 | s 2 | s 1 s 2 | n/a | yes |
| G 2 | s 2 | s 2 s 1 s 2 , s 1 s 2 s 1 s 2 | n/a | no |
The simple generators { s i } are the simple reflections corresponding to the labelled Dynkin diagrams in [Bou68] . When W has type B n or C n , we let u n,k be the maximal element in W S \{ s 1 ,s k } ∩ W S \{ s 1 } . In each case, the set J = S \ { s } , where s is listed in the table.
Remark 3.9. All the elements listed in part (2) of Theorem 3.8 satisfy a Coxeter-theoretic property which we term almost maximality . This property is defined in Definition 5.2, and plays an important role in the proof of Theorem 3.6.
Remark 3.10. The assumption in Theorem 3.8 that S w ( ) = S does not weaken the characterization. If S w ( ) is a strict subset of S , then X J ( w ) is isomorphic to the Schubert variety indexed by w in the smaller flag variety G S w ( ) /P S w ( ) ∩ J corresponding to the algebraic subgroup G S w ( ) ⊂ G with Weyl group W S w ( ) . For a precise statement, see Lemma 4.8.
As mentioned in the introduction, the list of smooth Schubert varieties in a generalized Grassmannian is known in many cases [LW90] [BP99] [BL00] [Rob14] [HM13]. In particular, Hong and Mok show that if X J ( w ) is a smooth Schubert variety in a generalized Grassmannian corresponding to a long root, then w must be the maximal element of W J S w ( ) (in the cominuscule case this also follows from the earlier work of Brion-Polo). The smooth Schubert varieties in C n with s = s k with 1 < k < n arise as 'odd symplectic manifolds', and have been studied by Mihai [Mih07]. To the best of the authors' knowledge, the cases F 4 , s = s 3 and s = s 4 are not covered by previous work, and the completeness of the above list has not been addressed outside of the cases mentioned above.
It is well known that a Schubert variety X J ( w ) is rationally smooth if and only if the corresponding Kazhdan-Lusztig polynomials are trivial. While there are a number of explicit formulas for Kazhdan-Lusztig polynomials of the Schubert varieties of minuscule and cominuscule generalized Grassmannians (see sections 9.1 and 9.2 of [BL00] for a summary), the authors' are not aware of any complete list of rationally smooth Grassmannian Schubert varieties of finite type in previous work.
Combining Theorem 3.8 with our main results, we get a new proof of Peterson's theorem:
Corollary 3.11. Suppose W is simply-laced. Then X J ( w ) is rationally smooth if and only if it is smooth.
Proof. If W is simply-laced, then all rationally smooth Grassmannian Schubert varieties are smooth by Theorem 3.8, part (1). So if X J ( w ) is rationally smooth, then it is smooth by Corollary 3.7. /square
Corollary 3.11 is a consequence of a more general theorem proved by Peterson, which states that if W is simply-laced then the rationally smooth and smooth locus of any Schubert variety coincide [CK03]. Peterson's proof is more algebro-geometric, while our proof is more combinatorial. Unfortunately our methods do not seem to apply to Peterson's more general theorem.
## 4. Characterization of Billey-Postnikov decompositions
The goal of this section is to prove Theorem 3.3 and Corollary 3.5. We first give several equivalent combinatorial characterizations of BP decompositions, and then apply these characterizations to the geometry of Schubert varieties.
- 4.1. Combinatorial characterizations. In this section, we can assume W is an arbitrary Coxeter group with simple generating set S . Note that Definition 3.1 still makes sense for arbitrary Coxeter groups. We restrict to the finite or crystallographic case only when necessary. We start by proving some important facts about BP decompositions based on known facts from the case J = . For notational simplicity, define ∅
$$W _ { K } ^ { J } \coloneqq W ^ { J } \cap W _ { K }$$
for any J ⊆ K ⊆ S .
Lemma 4.1. For every element w ∈ W J and subset K ⊆ S containing J , there is a unique maximal element ¯ u in [ e, w ] ∩ W J K with respect to Bruhat order. If w = vu is the parabolic decomposition of w with respect to K , then ¯ u has a reduced decomposition ¯ = ¯ u vu , where ¯ v ∈ [ e, v ] ∩ W K .
/negationslash
Proof. When J = ∅ , the existence of ¯ is proved in [vdH74, Lemma 7]. u Let u ′ denote the maximal element of [ e, w ] ∩ W K and let u ′ = ¯ uu ′′ be the parabolic decomposition of u ′ with respect to J , so ¯ u ∈ W J K and u ′′ ∈ W J . If u 0 ∈ [ e, w ] ∩ W J K , then u 0 ≤ u and hence u 0 ≤ ¯. u For the second part of the lemma, if we take J = ∅ then it is easy to prove by induction on /lscript ( u ) that u ′ above has a reduced decomposition u ′ = v u ′ , where v ′ ∈ [ e, v ] ∩ W K . For arbitrary J , observe that if u ∈ W J K and s ∈ K such that /lscript ( su ) = /lscript ( u ) + 1, then either su ∈ W J K , or su = ut for some t ∈ J . Indeed, su = u t 1 where u 1 ∈ W J and t ∈ W J . Since u ≤ su , we get that u ≤ u 1 , and if t = e then we must have u 1 = u and /lscript ( ) = 1. t Taking a reduced decomposition s 1 · · · s k for v ′ and considering the products s u k , s k -1 s u k , . . . , we eventually conclude that ¯ has reduced decomposition u s i 1 · · · s i m u , where 1 ≤ i 1 < . . . < i m ≤ k . /square
Recall that Bruhat order on W J induces a relative Bruhat order ≤ J on the coset space W/W J . By definition,
$$w _ { 1 } W _ { J } \leq _ { J } w _ { 2 } W _ { J }$$
/negationslash if and only if ¯ w 1 ≤ ¯ w 2 in the usual Bruhat order, where ¯ w i is the minimal length coset representative of w W i J . Note that if w 1 ≤ w 2 in Bruhat order, then w W 1 J ≤ w W 2 J even if w , w 1 2 ∈ W J . Define the descent set relative to J to be
$$D _ { L } ^ { J } ( w ) \coloneqq \{ s \in S \ | \ s w W _ { J } \leq _ { J } w W _ { J } \}$$
Proposition 4.2. Let w = vu ∈ W J be a parabolic decomposition with respect to K , so v ∈ W K , u ∈ W J K . The following are equivalent:
- (a) w = vu is a BP decomposition with respect to ( J, K ) .
- (b) The multiplication map
is surjective.
- (c) The element u is the maximal element of [ e, w ] ∩ W J K .
$$\begin{array} { c } \, ^ { * } & \, ^ { * } \\ & \left ( [ e, v ] \cap W ^ { K } \right ) \times \left ( [ e, u ] \cap W ^ { J } _ { K } \right ) \to [ e, w ] \cap W ^ { J } \\ \text{ctive.} \\ & \text{ment} \, u \, \text{is the maximal elements of} \, [ e \, u ] \cap W ^ { J } \end{array}$$
- (d) S v ( ) ∩ K ⊆ D J L ( u ) .
Furthermore, if W J is a finite Coxeter group and u ′ the maximal element of coset uW J , then the following are equivalent to parts (a)-(d).
- (e) S v ( ) ∩ K ⊆ D L ( u ′ ) .
- (g) w = vu ′ is a BP decomposition with respect to K .
- (f) The element u ′ has reduced decomposition u u 0 1 , where u 0 is the maximal element of W S v ( ) ∩ K .
Since the descent and support sets can be calculated efficiently, part (d) gives a practical criterion for checking whether a parabolic decomposition is a BP decomposition.
Proof. Note that the multiplication map in part (b) is always injective. Hence part (b) is equivalent to part (c). The multiplication map is also length preserving, so part (b) is equivalent to part (a).
To show that parts (c) and (d) are equivalent, suppose u is the maximal element of [ e, w ] ∩ W J K . If s ∈ S v ( ) ∩ K then su ∈ W K and hence suW J ≤ J uW J . For the converse, suppose ¯ is the maximal element of [ u e, w ] ∩ W J K , so u ≤ ¯ u ≤ w . By Lemma 4.1, if u < u ¯ then there is a simple reflection s ∈ S v ( ) ∩ K such that u < su ≤ ¯ and u su ∈ W J . Hence S v ( ) ∩ K is not a subset of D J L ( u ).
The equivalence of parts (e) and (f) is immediate. Let w ′ be the maximal element in the coset wW J . Then u is maximal in [ e, w ] ∩ W J K if and only if u ′ is maximal in [ e, w ′ ] ∩ W K . This implies part (f) is equivalent to part (c).
Finally, u ′ is the maximal element of [ e, w ′ ] ∩ W K if and only if su ′ ≤ u ′ for all s ∈ S v ( ) ∩ K . Hence part (g) is equivalent to part (e). This completes the proof. /square
In the case when J = ∅ , the equivalence of Proposition 4.2 parts (a)-(c) is proved in [BP05, Theorem 6.4], (a) ⇒ (d) in [OY10, Lemma 10], and (a) ⇐ (d) in [RS14, Lemma 2.2]. Using Proposition 4.2, it is easy to show that BP decompositions are associative, in the same way that parabolic decompositions are associative:
Lemma 4.3. Let I ⊆ J ⊆ K ⊆ S and w ∈ W I . Write w = xyz where x ∈ W K , y ∈ W J K , and z ∈ W I J . Then the following are equivalent:
- (a) x yz ( ) is a BP decomposition with respect to ( I, K ) and yz is a BP decomposition with respect to ( I, J ) .
- (b) ( xy z ) is a BP decomposition with respect to ( I, J ) and xy is a BP decomposition with respect to ( J, K ) .
The last combinatorial property concerns Poincar´ polynomials. e
Lemma 4.4. Let W be a crystallographic Coxeter group and w ∈ W. Let w = vu ∈ W J be a parabolic decomposition with respect to K . If w = vu is a BP decomposition with respect to ( J, K ) , then P J w ( ) t is palindromic if and only if P K v ( ) t and P J u ( ) t are palindromic.
Proof. Let P 1 ( ) t and P 2 ( ) t be polynomials of degree d 1 and d 2 respectively. Suppose P j ( ) = t ∑ i c t j i i has the property that c j i ≤ c j d j -i for all i ≤ /floorleft d / j 2 /floorright and j = 1 2. , Then it is easy to check that P 1 · P 2 is palindromic if and only if P 1 and P 2 are palindromic. By [BE09, Theorem A], the relative Poincar´ polynomials e P J w of elements in crystallographic Coxeter groups have this property. /square
Remark 4.5. For arbitrary Coxeter groups, Lemma 4.4 holds in the case that J = ∅ . Indeed, it suffices to prove that if P J w ( ) t is palindromic, then P J u ( ) t is palindromic. This follows from [BP05, Lemma 6.6] and [Car94, Theorem B] along with the recent result in [EW14] that the Kazhdan-Lusztig polynomials of arbitrary Coxeter groups have nonnegative coefficients.
- 4.2. Geometric characterizations. In this section we give some geometric properties of BP decompositions, finishing with the proof of Theorem 3.3. We return to the assumption that W is the Weyl group of some Kac-Moody group G , and hence is crystallographic.
For the remainder of the section, we fix J ⊆ K ⊆ S and the corresponding parabolic subgroups P J ⊆ P K ⊆ G . For any g ∈ G , let [ g ] ∈ G/P K denote the image of g under the projection G → G/P K .
Lemma 4.6. Let w = vu ∈ W J be a parabolic decomposition with respect to K and recall the projection π : X J ( w ) → X K ( v ) . Let [ b 0 v 0 ] be a point of X K ( v ) , where b 0 ∈ B and v 0 ∈ [ e, v ] ∩ W K . Then
$$\pi ^ { - 1 } ( [ b _ { 0 } v _ { 0 } ] ) = b _ { 0 } v _ { 0 } \bigcup B u ^ { \prime } P _ { J } / P _ { J }$$
where the union is over u ′ ∈ W J K such that v u 0 ′ ≤ w .
Proof. Using the parabolic decomposition of W K , we get that
$$\mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \colon } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } \times \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\Dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \text{$\dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathcc { \dots} = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } \\ \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } {\vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } \ = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m }{ \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots}} = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots } } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m {\vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots} } = \mathbb { m } { \vec { \dots } }$$
So the fibre of G → G/P K over [ b v 0 0 ] is
$$\dots \dots \dots \dots \dots \dots \\ b _ { 0 } v _ { 0 } P _ { K } = \bigcup _ { u ^ { \prime } \in W _ { K } ^ { J } } b _ { 0 } v _ { 0 } B u ^ { \prime } P _ { J }, \\ \cdot \dots \dots \dots \dots \dots \dots \dots \dots$$
Since /lscript ( v u 0 ′ ) = /lscript ( v 0 ) + /lscript ( u ′ ), we have that b 0 v Bu P 0 ′ J is a subset of Bv u P 0 ′ J . The image of the set Bv u P 0 ′ J under the projection G → G/P J lies outside of X J ( w ) unless v u 0 ′ ≤ w , in which case the image is contained in X J ( w ). /square
Lemma 4.6 yields the following intermediate criterion for BP decompositions.
Proposition 4.7. Let w = vu ∈ W J be a parabolic decomposition with respect to K . Then w = vu is a BP decomposition with respect to ( J, K ) if and only if the fibres of the projection π : X J ( w ) → X K ( v ) are equidimensional.
Proof. Suppose w = vu is a BP decomposition and take b 0 ∈ B v , 0 ∈ [ e, v ] ∩ W K . Then the fibre π -1 ([ b 0 v 0 ]) = b 0 v X 0 J ( u ), since if u ′ ∈ [ e, w ] ∩ W J K then u ′ ≤ u by Proposition 4.2 part (c).
Conversely, the fibre π -1 ([ e ]) = X J (¯), where ¯ is the maximal element of [ u u e, w ] ∩ W J K , while the fibre π -1 ([ v ]) = vX J ( u ). Hence if π : X J ( w ) → X K ( v ) is equidimensional, then we must have /lscript ( u ) = /lscript (¯). u But u ≤ ¯, so this implies u u = ¯. u /square
To finish the proof of Theorem 3.3, we need two standard lemmas.
Lemma 4.8. Let v ∈ W K and I = S v ( ) . Let G I be the reductive subgroup of P I , and let P I,I ∩ K := G I ∩ P K be the parabolic subgroup of G I generated by I ∩ K . Finally, let X I ∩ K I ( v ) ⊆ G /P I I,I ∩ K be the Schubert variety indexed by v ∈ W K I . Then the map G /P I I,I ∩ K ↪ → G/P K induces an isomorphism X I ∩ K I ( v ) → X K ( v ) .
Proof. It suffices to show that the induced map X I ∩ K I ( v ) ↪ → X K ( v ) is surjective. Write P I = G N I I where N I is the unipotent subgroup of P I and let B I = G I ∩ B denote the Borel of G . I If v ′ ∈ W I , then N I is stable under conjugation by v ′-1 . Write B = B N I I . Then for any v ′ ∈ W I , the Schubert cell
Bv P ′ K /P K = B N v P I I ′ K /P K = B I ( v v ′ ′-1 ) N v P I ′ K /P K = B v P I ′ K /P K .
Since v ∈ W K I ⊆ W I , we have that X I ∩ K I ( v ) ↪ → X K ( v
) is surjective. /square
Lemma 4.9. If u ∈ W J , then X J ( u ) is closed under the action of P D J L ( u ) , the parabolic subgroup generated by the left descent set D J L ( u ) of u relative to J .
Proof. Let Z be the inverse image of X J ( u ) under the projection G → G/P J . Then
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdot \\ Z = \bigcup _ { u ^ { \prime } \leq u } B u ^ { \prime } B W _ { J } B = \bigcup _ { u ^ { \prime } \leq u } B u ^ { \prime } W _ { J } B. \\ [ W _ { \epsilon } < \epsilon _ { u } W _ { \epsilon } \ t h o n \ e o u ^ { \prime } W _ { \epsilon } < \epsilon _ { u } W _ { \epsilon } \ t h o n.$$
If s ∈ D J L ( u ) and u W ′ J ≤ J uW J , then su W ′ J ≤ J uW J . Thus sBu W B ′ J ⊆ Bsu W B ′ J ∪ Bu W B ′ J ⊆ Z.
So Z is closed under D J L ( u ), and therefore X J ( u ) is closed under P D J L ( u )
. /square
Proof of Theorem 3.3. If π : X J ( w ) → X K ( v ) is locally-trivial then the fibres of π are equidimensional. Thus w = vu is a BP decomposition with respect to ( J, K ) by Proposition 4.7.
Conversely, suppose that w = vu is a BP decomposition with respect to ( J, K ), and let I = S v ( ) as in Lemma 4.8. Recall from the proof of Proposition 4.7 that if b 0 ∈ B , v 0 ∈ [ e, v ] ∩ W K , then the fibre π -1 ([ b 0 v 0 ]) = b 0 v X 0 J ( u ). Suppose g ∈ G I maps to [ b 0 v 0 ] in G/P K . Then we can write g = b 1 v p 0 , where b 1 ∈ B I and p ∈ P I,I ∩ K . By Proposition 4.2 part (d), I ∩ K ⊆ D J L ( u ). Hence by Lemma 4.9, pX J ( u ) = X J ( u ), and we conclude that gX J ( u ) = b 1 v X 0 J ( u ) is the fibre of π over [ g ] = [ b 1 v 0 ].
↦
By [Kum02, Corollary 7.4.15 and Exercise 7.4.5] the projection G I → G /P I I,I ∩ K is locally trivial, and thus has local sections. Given x ∈ X K ( v ), there is a Zariski open neighbourhood U x ⊆ X K ( v ) of x with a local section s : U x → G I ⊆ G of the projection G → G/P K . Let m U : x × X J ( u ) → G/P J denote the multiplication map ( u, y ) → s u ( ) · y . The image of m is contained in X J ( w ), and thus we get a commuting square
/d47
/d47
/d15
/d15
/d15
/d15
/d31
$$\begin{array} { c } \theta ^ { \prime } & \lambda \\ U _ { x } \times X ^ { J } ( u ) \xrightarrow { m } X ^ { J } ( w ) \\ \downarrow & \downarrow & \downarrow ^ { \pi } \\ U _ { x } \xrightarrow { K } X ^ { K } ( v ) \\ \downarrow & \end{array}$$
/d127
/d47
/d47
↦
in which the fibres of projection U x × X J ( u ) → U x are mapped bijectively onto the fibres of π . If z ∈ π -1 ( U x ) and g = ( ( )), then s π z z ∈ gX J ( u ). So m maps bijectively onto π -1 ( U x ), and we can define an inverse π -1 ( U x ) → U x × X J ( u ) by z → ( π z , g ( ) -1 z ) where g = ( ( )). s π z We conclude that m is an isomorphism, and ultimately that π : X J ( w ) → X K ( v ) is locally trivial.
Now the projection U x × X J ( u ) → U x is smooth if and only if X J ( u ) is smooth, and thus the projection π : X J ( w ) → X K ( v ) is smooth if and only if X J ( u ) is smooth. In particular, if X J ( u ) and X K ( v ) are both smooth, then X J ( w ) is smooth. Conversely, if X J ( w ) is smooth then the product U x × X J ( u ) must be smooth whenever the projection G I → X K ( v ) has a local section over U . Looking at Zariski tangent spaces, we conclude that dim T X x K ( v ) + dim T X y J ( u ) ≤ /lscript ( w ) for all x ∈ X K ( v ), y ∈ X J ( u ). Since /lscript ( w ) = /lscript ( u ) + /lscript ( v ), both X K ( v ) and X J ( u ) must be smooth.
The Schubert variety X J ( w ) is rationally smooth if and only if X J ( u ) and X K ( v ) are rationally smooth by Lemma 4.4. /square
We finish the section by proving Corollary 3.5.
Proof of Corollary 3.5. For singular cohomology, the proof follows easily from the LerayHirsch theorem. For etale cohomology, we use the Leray-Serre spectral sequence
E ∗ ∗ , 2 = H r et ( X K ( v , R ) s π ∗ Q l ) = ⇒ H r + s et ( X J ( w , ) Q l ) for the projection π : X J ( w ) → X K ( v ) (see, e.g. [Tam94]). Since π is locally trivial, the sheaf R π ∗ ∗ Q l is locally constant, and by the proper base change theorem we see that it is in fact isomorphic to H ∗ et ( X J ( u , ) Q l ). Since H ∗ et ( X K ( v , ) Q l ) and H ∗ et ( X J ( u , ) Q l ) are concentrated in even dimensions, the Leray-Serre spectral sequence collapses at the E 2 -term, and the spectral sequence converges to H ∗ et ( X K ( v )) ⊗ H ∗ et ( X J ( u )) as an algebra. Using the action of H ∗ et ( X K ( v )) on H ∗ et ( X J ( w )), we can solve the lifting problem to get an isomorphism
$$\ n s m { H _ { e t } ^ { * } \left ( X ^ { K } ( v ), \mathbb { Q } _ { l } \right ) \otimes H _ { e t } ^ { * } \left ( X ^ { J } ( u ), \mathbb { Q } _ { l } \right ) } \rightarrow H _ { e t } ^ { * } \left ( X ^ { J } ( w ), \mathbb { Q } _ { l } \right )$$
of H ∗ et ( X K ( v ))-modules.
/square
## 5. Rationally smooth Grassmannian Schubert varieties
In this section we define almost maximal elements of a Weyl group and prove Theorem 3.8. We take G to a be simple Lie group of finite type, and hence the Weyl group W is a finite Coxeter group. It is well known that simple Lie groups are classified into four classical families A ,B ,C ,D n n n n and exceptional types E , E , E , F 6 7 8 4 and G 2 . We begin with the following theorem.
Theorem 5.1 ([Bil98], [Gas98], [Las98], [BP05], [OY10]) . Let X ∅ ( w ) be rationally smooth Schubert variety with | S w ( ) | ≥ 2 . Then there is a leaf s ∈ S w ( ) of the Dynkin diagram of W S w ( ) such that either w or w -1 has a BP decomposition vu with respect to J = S \ { s } .
Furthermore, s can be chosen so that v is either the maximal length element in W J , or one of the following holds:
- (a) W S v is of type B n or C n , with either
- J = S \ { s } , and v = s s · · · s s · · · s , for some 1 < k ≤ n .
- ( ) (1) 1 k k +2 n n -1 1 (2) J = S \ { s n } with n ≥ 2 , and v = s 1 · · · s n .
- (b) W S v ( ) is of type F 4 , with either
- (1) J = S \ { s 1 } and v = s s s s 4 3 2 1 .
- (2) J = S \ { s 4 } and v = s s s s 1 2 3 4 .
- (c) W S v ( ) is of type G 2 , and v is one of the elements
s s , 2 1 s s s , 1 2 1 s s s s , 2 1 2 1 s s , 1 2 s s s , 2 1 2 s s s s . 1 2 1 2
Note that the elements listed in parts (a)-(c) of Theorem 5.1 correspond to the elements listed in part (2) of Theorem 3.8 for which s is a leaf of the Dynkin diagram. The result that w or w -1 has a BP decomposition with respect to a leaf is due to Billey [Bil98, Theorem 3.3 and Proposition 6.3] in the classical types and Billey-Postnikov [BP05] in the exceptional types. The type A case was also proved by Gasharov [Gas98] and Lascoux [Las98]. For the second part of Theorem 5.1 on the presentation of v , the proof for the classical types is again due to Billey [Bil98]. The type E case is due to Oh-Yoo in [OY10] 1 and types F 4 and G 2 can be easily verified by computer using Kumar's criteria for rational smoothness [Kum96]. We remark that computer calculation plays an important role in the proof of Theorem 5.1. In particular, the results of [BP05] and [OY10] on the exceptional types both require exhaustive computer verification.
Note that the condition that either w or w -1 has a BP decomposition in Theorem 5.1 can be rephrased as w having 'left' or 'right' sided BP decompositions. For any J ⊆ S, let J W /similarequal W J \ W denote the set of minimal length left sided coset representatives. Any w ∈ W has unique left sided parabolic decomposition w = uv with respect to J where u ∈ W J and v ∈ J W. We say a left sided parabolic decomposition w = uv is a left sided BP decomposition with respect to J if
$$P _ { w } ( t ) = P _ { u } ( t ) \cdot ^ { J } P _ { v } ( t )$$
where
$$^ { J } P _ { v } ( t ) \coloneqq \sum _ { x \in [ e, v ] \cap ^ { J } W } t ^ { \ell ( x ) }.$$
1 This also follows from the geometric results of [HM13] together with Peterson's theorem that all rationally smooth elements in type E are smooth.
By a right sided parabolic or BP decomposition w = vu with respect to J, we simply mean a usual parabolic or BP decomposition where v ∈ W J and u ∈ W J . With this terminology, w = vu is a right sided BP decomposition if and only if w -1 = u -1 v -1 is a left sided BP decomposition. The combinatorial characterizations given in Proposition 4.2 have left sided BP decomposition analogues. In particular, for Proposition 4.2, part (e) we let u ′ be the maximal element of the coset ( W u J ) and replace the left descents D L ( u ′ ) with right descents D R ( u ′ ).
The elements listed in Theorem 5.1 parts (a)-(c) share an important property we term 'almost maximality'. Recall that an element w ∈ W is the maximal element in W S w ( ) if and only if D L ( w ) = S w ( ), or equivalently if D R ( w ) = S w ( ). An element w ∈ W J is the maximal element in W S w ( ) ∩ J S w ( ) if and only if the longest element of wW S w ( ) ∩ J is in fact the longest element of W S w ( ) . Based on these properties of maximal elements, we make the following definition.
Definition 5.2. Given w ∈ W J , let w ′ be the longest element in wW S w ( ) ∩ J . We say that w is almost-maximal in W S w ( ) ∩ J S w ( ) if all of the following are true.
- (a) There are elements s, t ∈ S w ( ) (not necessarily distinct) such that
$$D _ { R } ( w ^ { \prime } ) = S ( w ^ { \prime } ) \, \wedge \, \{ s \} \ \ a n d \ \ D _ { L } ( w ^ { \prime } ) = S ( w ^ { \prime } ) \, \wedge \, \{ t \}.$$
- (b) If w ′ = vu is the right sided parabolic decomposition with respect to D R ( w ′ ) , then S v ( ) = S w ( ′ ) .
- (c) If w ′ = uv is the left sided parabolic decomposition with respect to D L ( w ′ ) , then S v ( ) = S w ( ′ ) .
Similarly, if w ∈ J W , we say w is almost-maximal in S w ( ) ∩ J W S w ( ) if parts (a)-(c) are true with w ′ the longest element in the coset ( W S w ( ) ∩ J ) w .
Note that an almost-maximal element is not maximal in W S w ( ) ∩ J S w ( ) by definition. If W S w ( ) ∩ J S w ( ) is clear from context, we will omit it. By the following lemma, the most interesting case is when J = S \ { s } for some s ∈ S .
Lemma 5.3. Let w ∈ W J and assume J ⊆ S = S w ( ) . If w is almost maximal, then there exists s / J ∈ and parabolic decomposition w = vu with respect to K = S \ { s } such that v is an almost-maximal element of W K and u is the maximal element of W J K .
Proof. Assume that w ∈ W J is almost-maximal. Let w ′ be the longest element of wW J . Let s be the unique element of S \ D R ( w ′ ) and consider the parabolic decomposition w ′ = vu ′ with respect to K = S \ { s } = D R ( w ′ ). Note that S v ( ) = S w ( ′ ) = S and u ′ is maximal in W K since J ⊆ K . Write u ′ = uu 0 where u and u 0 are maximal in W J K and W J respectively. Then
︸ ︷︷ ︸ which implies that w = vu . Since w is almost-maximal and w ′ is the maximal element of vW K , we have that v is almost maximal. /square
$$w ^ { \prime } = w u _ { 0 } = v \underbrace { ( u u _ { 0 } ) } _ { u ^ { \prime } }.$$
- 5.1. Proof of Theorem 3.8. We begin with the following proposition.
Proposition 5.4. Let J = S \ { s } for some s and suppose v ∈ W J such that S v ( ) = S and X J ( v ) is rationally smooth. Then the following are equivalent.
- (i) v is not maximal in W J
- (ii) v is almost-maximal in W J
- (iii) v appears on the list in Theorem 3.8 part (2).
Remark 5.5. If v ∈ W J is almost maximal, then X J ( v ) is not necessarily rationally smooth. For example, let W be of type D 4 with J = S \ { s 4 } . Then v = s s s s 1 3 2 4 ∈ W J is almost maximal but X J ( v ) is not rationally smooth.
Most of Theorem 3.8 follows from Proposition 5.4, leaving only the determination of which Schubert varieties listed in Theorem 3.8 part (2) are smooth. Before we prove Proposition 5.4, we first analyze the elements arising in parts (a) and (b) of Theorem 5.1.
Lemma 5.6. Let W = B n or C n and J = { s , . . . , s 2 n } . Let v = s k · · · s n -1 s n s n -1 · · · s 1 where 1 < k ≤ n and w ′ be the longest element of vW J . Then the following are true:
- (1) D L ( w ′ ) = S \ { s k -1 } .
- (2) The minimal length representative of W D L ( w ′ ) w ′ is s k -1 · · · s u 1 -1 n,k , where u n,k is the maximal length element of W J \{ s k } J .
Proof. Partition S into S 1 = { s , . . . , s 1 k -1 } and S 2 = { s k , . . . , s n } . If w 0 denotes the maximal element of W J then w ′ = vw 0 . Since the elements of W S 1 and W S 2 \{ s k } commute, we can write
$$w _ { 0 } = u _ { 0 } u _ { 1 } u _ { n, k } ^ { - 1 },$$
where u 0 is maximal in W S 1 ∩ J and u 1 is maximal in W S 2 \{ s k } . Then
$$u ^ { \prime } = ( s _ { 1 } \cdots s _ { 2 } \cdots s _ { 3 } ) ( u _ { 0 } u _ { 1 } u ^ { - 1 } )$$
$$w ^ { \prime } & = ( s _ { k } \cdots s _ { n } \cdots s _ { 1 } ) ( u _ { 0 } u _ { 1 } u _ { n, k } ^ { - 1 } ) \\ & = ( s _ { k } \cdots s _ { n } \cdots s _ { k } u _ { 1 } ) ( s _ { k - 1 } \cdots s _ { 1 } u _ { 0 } ) u _ { n, k } ^ { - 1 }.$$
Since ( s k · · · s n · · · s k ) is maximal in W S 2 \{ s k } S 2 , we have that ( s k · · · s n · · · s u k 1 ) is a maximal element in W S 2 . In particular, S 2 ⊆ D L ( w . ′ ) Similarly ( s k -1 · · · s 1 ) is maximal in W S 1 \{ s 1 } S 1 , and hence ( s k -1 · · · s u 1 0 ) is maximal in W S 1 . Consequently
$$s _ { k - 1 } \cdots s _ { 1 } u _ { 0 } = u _ { 2 } s _ { k - 1 } \cdots s _ { 1 },$$
where u 2 is the maximal element in W S 1 \{ s k -1 } . Now we have
$$w ^ { \prime } & = ( s _ { k } \cdots s _ { n } \cdots s _ { k } u _ { 1 } ) \cdot ( u _ { 2 } s _ { k - 1 } \cdots s _ { 1 } u _ { n, k } ^ { - 1 } ) \\ & = ( u _ { 2 } s _ { k } \cdots s _ { n } \cdots s _ { k } u _ { 1 } ) \cdot ( s _ { k - 1 } \cdots s _ { 1 } u _ { n, k } ^ { - 1 } ).$$
$$\iota _ { n, k } ^ { - 1 } ).$$
Thus S 1 \ { s k -1 } ⊆ D L ( w ′ ) and hence S \ { s k -1 } ⊆ D L ( w ′ ). Since w ′ is not maximal in W , the element s k -1 / D ∈ L ( w . ′ ) This proves part (1), and part (2) follows from the fact that ( u s 2 k · · · s n · · · s u k 1 ) is maximal in W D L ( w ′ ) . /square
Note that if k = 2 in Lemma 5.6, then D L ( w ′ ) = J , and the minimal length representative of W w J ′ is s u 1 -1 n,k = w -1 .
Lemma 5.7. Let W = B n or C n and J = { s , . . . , s 1 n -1 } where n ≥ 2 . Let v = s 1 · · · s n and w ′ be the longest element of vW J . Then the following are true:
- (1) D L ( w ′ ) = J
- (2) The minimal length representative of W D L ( w ′ ) w ′ is s n · · · s 1 .
Proof. If w 0 denotes the longest element of W J , then w ′ = vw 0 , and we can write
$$w _ { 0 } = u _ { 0 } s _ { n - 1 } \cdots s _ { 1 },$$
where u 0 is the longest element of W J \{ s n -1 } . Hence
$$w ^ { \prime } = ( s _ { 1 } \cdots s _ { n - 1 } s _ { n } ) ( u _ { 0 } s _ { n - 1 } \cdots s _ { 1 } ) = ( s _ { 1 } \cdots s _ { n - 1 } u _ { 0 } ) ( s _ { n } s _ { n - 1 } \cdots s _ { 1 } ).$$
The lemma now follows from the fact that s 1 · · · s n -1 u 0 = w 0
. /square
Lemma 5.8. Let W = F 4 and J = { s , s 2 3 , s 4 } . Let v = s s s s 4 3 2 1 and w ′ be the longest element of wW J . Then the following are true:
- (1) D L ( w ′ ) = { s , s 1 3 , s 4 }
- (2) The minimal length representative of W D L ( w ′ ) w ′ is s s s s s s s s s 2 1 3 2 4 3 4 2 3 .
Proof. Computation in F 4 shows that
$$w ^ { \prime } = ( s _ { 4 } s _ { 3 } s _ { 2 } s _ { 1 } ) ( s _ { 4 } s _ { 3 } s _ { 2 } s _ { 3 } s _ { 4 } s _ { 3 } s _ { 2 } s _ { 3 } s _ { 2 } )$$
$$= ( s _ { 1 } s _ { 3 } s _ { 4 } s _ { 3 } ) ( s _ { 2 } s _ { 1 } s _ { 3 } s _ { 2 } s _ { 4 } s _ { 3 } s _ { 4 } s _ { 2 } s _ { 3 } ). \tag* { \square }$$
↦
Note that Lemma 5.8 also applies to v = s s s s 1 3 2 4 in F 4 , since F 4 has an automorphism sending the simple generator s k → s 5 -k for k ≤ 4. (This automorphism is not a diagram automorphism, and hence is not defined on the root system, but it is defined for the Coxeter group).
Lemma 5.9. Let v be almost-maximal in W S v ( ) ∩ J S v ( ) and let w ′ be the longest element in vW S v ( ) ∩ J . Let w ′ = u v 1 1 be the left sided parabolic decomposition of w ′ with respect to J ′ := D L ( w ′ ) . Then the following are true:
- (1) v -1 1 is almost-maximal in W J ′ S v ( 1 )
- (2) X J ( v ) is rationally smooth if and only X J ′ ( v -1 1 ) is rationally smooth.
Proof. Part (1) of the lemma is immediate from Definition 5.2 of almost-maximal. For the second part, let u 0 be the maximal element of W S v ( ) ∩ J , so w ′ = vu 0 . By Proposition 4.2, w ′ = vu 0 is a BP decomposition and hence by Lemma 4.4, we have X J ( v ) is rationally smooth if and only if X ∅ ( w ′ ) is rationally smooth. But
$$P _ { w ^ { \prime } } ( t ) = P _ { ( w ^ { \prime } ) ^ { - 1 } } ( t ),$$
and so X ∅ ( w ′ ) is rationally smooth if and only if X ∅ (( w ′ ) -1 ) is rationally smooth. Finally, since u 1 is the maximal element of W J ′ , we have w ′ = u v 1 1 is a left sided BP decomposition. Thus X ∅ (( w ′ ) -1 ) is rationally smooth if and only if X J ′ ( v -1 1 ) is rationally smooth. /square
Proof of Proposition 5.4. Clearly (ii) ⇒ (i) in the proposition. We will show (iii) ⇒ (ii) and (i) ⇒ (iii). We start with the proof of (iii) ⇒ (ii). Suppose v ∈ W J is an element listed in parts (a)-(c) of Theorem 5.1. If v is of type G 2 , then it is easy to see that v is almostmaximal. For types B,C and F , it follows from Lemmas 5.6, 5.7, and 5.8 that all elements listed in parts (a)-(c) are almost-maximal. As mentioned previously, the elements listed in parts (a)-(c) of Theorem 5.1 are precisely the elements listed in the table of Theorem 3.8 for which s is a leaf of the Dynkin diagram. By the second parts of Lemmas 5.6, 5.7, and 5.8, if v ′ is any another element listed in Theorem 3.8, then there is a leaf s of the Dynkin diagram, and a rationally smooth element v ∈ W S \{ } s listed in Theorem 5.1, such that the longest element w ′ in vW S v ( ) ∩ J has left-sided parabolic decomposition w ′ = u v 1 1 , where
v ′ = v -1 1 . Lemma 5.9 now implies that all the elements listed in Theorem 3.8 are almostmaximal and the corresponding Schubert varieties are rationally smooth. This proves (iii) ⇒ (ii) of the proposition.
Now we prove (i) ⇒ (iii). Suppose v ∈ W J is not maximal and let w ′ be the longest element of vW J . Theorem 5.1 implies there exists a leaf s ′ ∈ S such that either w ′ or ( w ′ ) -1 has a BP decomposition v u ′ ′ where v ′ appears on the list given in parts (a)-(c) of Theorem 5.1. If w ′ = v u ′ ′ , then the fact that D R ( w ′ ) = J and w ′ is not maximal implies that s ′ = s and hence, u ′ = u and v ′ = v . Now suppose that ( w ′ ) -1 = v u ′ ′ and let J ′ = S \ { s ′ } . By Proposition 4.2, part (e) we have S v ( ′ ) ∩ J ′ = J ′ ⊆ D L ( u ′ ) . Since w ′ is not maximal, we must have J ′ = D L ( u ′ ) and that u ′ is the longest element of W ′ J . Thus w ′ is almost-maximal. Lemma 5.9 together with Lemmas 5.6, 5.7, and 5.8 imply that v is an element listed in Theorem 3.8. /square
The equivalence of Proposition 5.4 parts (ii) and (iii) gives the following rephrasing Theorem 5.1.
Corollary 5.10. Let X ∅ ( w ) be rationally smooth, where | S w ( ) | ≥ 2 . Then there is a leaf s ∈ S w ( ) of the Dynkin diagram of W S w ( ) such that either w or w -1 has a BP decomposition vu with respect to J = S \ { s } . Furthermore, s can be chosen so that v is either maximal or almost-maximal in W S v ( ) ∩ J S v ( ) .
Corollary 5.10 plays an important role in the proof of Theorem 3.6 in the next section. We finish the proof of Theorem 3.8 by determining which Schubert varieties listed in Theorem 3.8, part (2) are smooth.
Lemma 5.11. Let v ∈ W S v ( ) ∩ J S v ( ) and let w ′ be the longest element in vW S v ( ) ∩ J . Let w ′ = u v 1 1 be the left sided parabolic decomposition of w ′ with respect to J ′ := D L ( w ′ ) . Then X J ( v ) is smooth if and only if X J ′ ( v -1 1 ) is smooth.
Proof. Let u 0 be maximal in W S ( v ) ∩ J , so that w ′ = vu 0 , and let
$$Z = \bigcup _ { x \leq w ^ { \prime } } B x B \\ \cdots \quad \cdots \quad \cdots.$$
be the inverse image of X J ( v ) in G . Then Z is a principal P J -bundle over X J ( w ), so Z is smooth if and only if X J ( w ) is smooth. But Z is isomorphic to the inverse image
$$\bigcup _ { x \leq ( w ^ { \prime } ) ^ { - 1 } } B x B$$
of X J ′ ( v -1 1 ) in G , so the lemma follows.
/square
By Lemma 5.11 and Lemmas 5.6, 5.7, and 5.8, it suffices to determine when X J ( w ) is smooth for J = S \ { s } , s a leaf. Note that Kumar has given a general criterion for smoothness of Schubert varieties, and by this criterion the smoothness of Schubert varieties is independent of characteristic [Kum96].
If W is of type B n or C n , then the singular locus of X J ( w ) when J = S \{ } s , s a leaf, is well-known (see pages 138-142 of [BL00]). In type G 2 , the smooth Schubert varieties are also well-known (see the exercise on page 464 of [Kum02]). Finally, for type F 4 we use a computer program to apply Kumar's criterion to the Schubert varieties in question.
Remark 5.12. Note that we only use prior results on smoothness for the rationally smooth almost-maximal elements, which do not occur in the simply-laced case. Hence the proof of Peterson's theorem (Corollary 3.11) depends only on Theorem 5.1.
## 6. Existence of Billey-Postnikov decompositions
In this section, we prove Theorem 3.6 and Corollary 3.7. The main theorem, stated below, is an extension of Theorem 5.1, wherein we show that if X ∅ ( w ) is rationally smooth then w has a right-sided Grassmannian BP decomposition.
Theorem 6.1. Let W be a finite Weyl group. Suppose X ∅ ( w ) is rationally smooth for some w ∈ W . Then one of the following is true:
- (a) The element w is the maximal element of W S w ( ) .
- (b) There exists s ∈ S w ( ) \ D R ( w ) such that w has a right sided BP decomposition w = vu with respect to J = S \ { s } , where v is either the maximal or an almostmaximal element of W S v ( ) ∩ J S v ( ) .
Note that if w is almost-maximal (relative to J = ) then ∅ w satisfies part (b) of Theorem 6.1 by definition. The requirement that s not belong to D R ( w ) in part (2) of the theorem is critical both for the inductive proof of the theorem, and for showing that BP decompositions exist in the relative case.
We introduce some terminology for subsets of the generating set S .
Definition 6.2. A subset T ⊆ S is connected if the Dynkin diagram of W T is connected. The connected components of a subset T ⊆ S are the maximal connected subsets of T .
Definition 6.3. We say that s and t in S are adjacent if s and t are adjacent in the Dynkin diagram. We also say that s is adjacent to a subset T if s is adjacent to some t ∈ T , and that two subsets T , T 1 2 are adjacent if there is some element of T 1 adjacent to T 2 .
We use this terminology for the following lemma:
Lemma 6.4. Let w = vu be a right sided parabolic decomposition with respect to some J ⊆ S . If s ∈ S \ S v ( ) is adjacent to S v ( ) , then s / D ∈ L ( w ) .
Similarly, let w = uv be a left sided parabolic decomposition with respect to some J ⊆ S . If s ∈ S \ S v ( ) is adjacent to S v ( ) , then s / D ∈ R ( w ) .
Proof. Clearly the second statement of the lemma follows from the first by considering w -1 . We proceed by induction on the length of v . If /lscript ( v ) = 1 then the proof is obvious. Otherwise take a reduced decomposition v = v tv 1 0 , where s is adjacent to t , but not adjacent to S v ( 0 ). (Note that v 0 could be equal to the identity.) Then tv 0 ∈ W J and since s / S v ∈ ( ), we have s ∈ D L ( w ) only if s ∈ D L ( u ). Assume that s ∈ D L ( u ) and write
$$w = ( v _ { 1 } t v _ { 0 } ) ( u ) = ( v _ { 1 } t s v _ { 0 } ) ( s u ).$$
Once again, we have s ∈ D L ( w ) only if s ∈ D L ( tsv 0 ( su )). But since t and s are adjacent, we have s ∈ D L ( tsv 0 ( su )) only if t ∈ D L ( v 0 ( su )). If t / J ∈ , then t / S v ∈ ( 0 ( su )), and we are done. Otherwise, if t ∈ J , then t must be adjacent to S v ( 0 ) since tv 0 ∈ W J . But v 0 ∈ W J , so by induction, we get t / D ∈ L ( v 0 ( su )). /square
We now proceed to the proof of Theorem 6.1. The proof uses multiple reduced decompositions for the same element, so we have included certain schematic diagrams to aid the reader in keeping track of the reduced decompositions under consideration. For example,
if w = w w w 1 2 3 is a reduced decomposition with v = w w 1 2 and u = w w 2 3 , then we diagram this relation by
Proof of Theorem 6.1. We proceed by induction on | S w ( ) . | It is easy to see that the theorem is true if | S w ( ) | = 1 2. , Hence we can assume that | S w ( ) | > 2. We can also assume without loss of generality that the Dynkin diagram of W S w ( ) is connected. Since w is rationally smooth, we can apply Corollary 5.10 to get that w has either a right sided BP decomposition w = vu , or a left sided BP decomposition w = uv , with respect to J = S \ { s } where s ∈ S is a leaf of the Dynkin diagram of W S w ( ) . Note that in both cases, X ∅ ( u ) is rationally smooth by Lemma 4.4. We now consider four cases, depending on whether we get a right or left BP decomposition from Corollary 5.10, and depending on whether or not u is maximal in W S u ( ) .
Case 1 : w has a right sided BP decomposition w = vu as in Corollary 5.10, where u is maximal in W S u ( ) . If s ∈ D R ( w , ) then w is the maximal element of W . Otherwise, if s / D ∈ R ( w , ) then the decomposition w = vu satisfies condition (b) in Theorem 6.1, since v is maximal or almost-maximal in W S v ( ) ∩ J S v ( ) by Corollary 5.10.
Case 2 : w has a left sided BP decomposition w = uv as in Corollary 5.10, where u is maximal in W S u ( ) , and v is either maximal or almost-maximal in S v ( ) ∩ J W S v ( ) . If S u ( ) = S v ( ) ∩ J , then w is either maximal or almost-maximal respectively, in which case we are done.
Since S w ( ) is connected, if S v ( ) ∩ J /subsetnoteql S u ( ) then we can choose s ′ ∈ S u ( ) \ S v ( ) adjacent to S v ( ). Since u is maximal in W S u ( ) , the parabolic decomposition u = v u ′ ′ with respect to J ′ := S u ( ) \{ s ′ } is a BP decomposition with v ′ is maximal in W J ′ S u ( ) . Moreover, s ′ / D ∈ R ( w ) by Lemma 6.4. Hence the decomposition w = v ′ ( u v ′ ) satisfies condition (b) in Theorem 6.1.
/negationslash
Case 3 : w has a left sided BP decomposition w = uv as in Corollary 5.10, where u is not maximal in W S u ( ) . Then by induction, we have a right BP decomposition u = v u ′ ′ with respect to J ′ := S u ( ) \ { s ′ } for some s ′ ∈ S u ( ), satisfying the conditions of Theorem 6.1. Since s ′ / D ∈ R ( u ), we must have s ′ / S v ∈ ( ) \{ } ⊆ s D R ( u ), so w = v ′ ( u v ′ ) is a parabolic decomposition, and s ′ ∈ D R ( w ). But
$$S ( v ^ { \prime } ) \cap J ^ { \prime } \subseteq D _ { L } ( u ^ { \prime } ) \subseteq D _ { L } ( u ^ { \prime } v ),$$
and thus w = v ′ ( u v ′ ) is a BP decomposition with respect to S w ( ) \ { s ′ } , by Proposition 4.2 (d). Since v ′ is either maximal or almost-maximal by the inductive hypothesis, the decomposition w = v ′ ( u v ′ ) satisfies condition (b) of Theorem 6.1.
Figure 1: w = uv in Cases 2 and 3.
Case 4 : w has a right BP decomposition w = vu as in Corollary 5.10, where u is not maximal in W S u ( ) . Note that if s / D ∈ R ( w ) then condition (b) of Theorem 6.1 is satisfied immediately, and we would be done. We consider several subcases where we either prove s / D ∈ R ( w ) or we find s ′ / D ∈ R ( w ) that satisfies condition (b) of Theorem 6.1.
First, suppose that v is almost maximal in W S v ( ) ∩ J S v ( ) . Take a reduced decomposition u = u u 0 1 , where u 0 is the maximal element in W S v ( ) ∩ J . Then
S v ( ) ∩ J ⊆ D R ( vu 0 ) /subsetnoteql S v , ( )
/negationslash implying that s / D ∈ R ( vu 0 ). It follows that s ∈ D R ( w ).
Figure 2: w = vu with u not maximal and v almost maximal.
| w | w | w |
|-----|-----|-----|
| v | | u |
| v | u 0 | u 1 |
Now assume v is maximal in W S v ( ) ∩ J S v ( ) , and apply induction to get a BP decomposition u = v u ′ ′ with respect to S u ( ) \{ s ′ } , satisfying condition (b) of Theorem 6.1. By Proposition 4.2, S v ( ) \ { s } ⊆ D L ( u ), and hence if t ∈ S v ( ) \ { s } is adjacent to S v ( ′ ), then t ∈ S v ( ′ ) by Lemma 6.4. Now since v is Grassmannian, the set S v ( ) is connected, and since s is a leaf, the set S v ( ) \ { s } is also connected. We conclude that if S v ( ) \ { s } is adjacent to S v ( ′ ), then S v ( ) \ { s } ⊆ S v ( ′ ). Furthermore s is adjacent to S v ( ) \ { s } , and hence s is adjacent to S v ( ′ ). Conversely, if S v ( ) \{ } s is non-empty and s is adjacent to some element of S v ( ′ ), then this element must be contained in S v ( ) \ { s } , since S v ( ) is connected and s is adjacent to a unique element of S w ( ). We conclude that either S v ( ) is not adjacent to S v ( ′ ), or S v ( ) \ { s } ⊆ S v ( ′ ) with s adjacent to S v ( ′ ).
In the former case, when S v ( ) is not adjacent to S v ( ′ ), the elements of S v ( ) pairwise commute with the elements of S v ( ′ ). Hence the decomposition w = v ′ ( vu ′ ) is a BP decomposition with respect to S w ( ) \ { s ′ } . The element v ′ is either maximal or almost-maximal in W S v ( ′ ) \{ s ′ } S v ( ′ ) by induction. Since s ′ / D ∈ R ( u ) and s ′ ∈ J , we conclude that s ′ / D ∈ R ( w ).
Figure 3: w = vu with u not maximal, v maximal, and S v , S ( ) ( v ′ ) not adjacent.
This leaves the case that s is adjacent to S v ( ′ ) and S v ( ) \ { s } ⊆ S v ( ′ ). Take a reduced decomposition u ′ = u u ′ 0 ′ 1 , where u ′ 0 is maximal in W S v ( ′ ) \{ s ′ } . Suppose first that v ′ is maximal, so that v u ′ ′ 0 is maximal W S v ( ′ ) . If S v ( ) \ { s } = S v ( ′ ), then vv u ′ ′ 0 is the maximal element of W S v ( ) , and hence there is a BP decomposition vv u ′ ′ 0 = x x 1 0 , where x 1 is the maximal element of W S v ( ) \{ s ′ } S v ( ) and x 0 is the maximal element of W S v ( ) \{ s ′ } . Since s ′ / D ∈ R ( u ) and s ′ ∈ J , we have s ′ / D ∈ R ( w ), and thus w = x 1 ( x u 0 ′ 1 ) is a BP decomposition with respect to S w ( ) \ { s ′ } satisfying the condition of Theorem 6.1. If S v ( ) \ { s } is a strict subset of S v ( ′ ), then find t ∈ S v ( ′ ) such that t / S v ∈ ( ) \ { s } . Consider the parabolic
decomposition v u ′ 0 = y y 0 1 , where y 0 ∈ W S v ( ′ ) \{ } t and y 1 ∈ S v ( ′ ) \{ } t W S v ( ′ ) . Since t / S v ∈ ( ) and s is adjacent to S v ( ′ ) = S y ( 1 ), we conclude from Lemma 6.4 that s / D ∈ R ( vv u ′ ′ 0 ). Since s / S u ∈ ( ′ 1 ), we get that s / D ∈ R ( w ).
Figure 4: w = vu with u not maximal, v maximal, and S v , S ( ) ( v ′ ) adjacent.
| w | w | w | w |
|---------|---------|---------|-------|
| v | u | u | u |
| v | v ′ | u ′ | u ′ |
| v | v ′ | u ′ 0 | u ′ 1 |
| v | y 0 | y 1 | u ′ 1 |
| x 1 x 0 | x 1 x 0 | x 1 x 0 | u ′ 1 |
We use a similar argument for the case that v ′ is almost-maximal in W S v ( ′ ) \{ } s S v ( ′ ) . By definition v u ′ ′ 0 is almost maximal in W S v ( ′ ) , meaning that D L ( v u ′ ′ 0 ) = S v ( ′ ) \ { } t for some t ∈ S v ( ′ ). Since s ′ / ∈ S u ( 1 ) and u ′ 0 is maximal in W S v ( ′ ) \{ s ′ } , the element u ′ 1 belongs to S v ( ′ ) W S u ( ) . Thus t does not belong to D L ( u ), since otherwise t ∈ D L ( v u ′ ′ 0 ), and we conclude that t / S v ∈ ( ). Take the unique left sided BP decomposition v u ′ ′ 0 = y y 0 1 , where y 0 is the maximal element in W D L ( v ′ ) , and y 1 ∈ S v ( ′ ) \{ } t W S v ( ′ ) . Then S y ( 1 ) = S v ( ′ ) by the definition of almost-maximal, and since s is adjacent to S y ( 1 ), we conclude from Lemma 6.4 that s / D ∈ R ( vv u ′ ′ 0 ). Consequently s / D ∈ R ( w ). /square
Using Theorem 6.1, we can prove Theorem 3.6 for relative Schubert varieties.
Proof of Theorem 3.6. Suppose X J ( w ) is rationally smooth and that | S w ( ) \ J | ≥ 2. Let w 0 be maximal in W J , so w ′ = ww 0 is the longest element of wW J . Then w ′ is rationally smooth by Lemma 4.4, so we can apply Theorem 6.1. If w ′ is maximal, then w is the maximal element in W J ∩ S w ( ) S w ( ) , and hence by choosing any s ∈ S w ( ) \ J we get a Grassmannian BP decomposition of w with respect to K = S \ { s } as required.
If w ′ is not maximal, then there exists s ∈ S w ( ) \ D R ( w ) such that w ′ has a BP decomposition w ′ = vu with respect to K = S \ { s } . Since s / ∈ D R ( w ), s must not be in J , so u has parabolic decomposition u = u w 1 0 with respect to W J , and w has parabolic decomposition w = vu 1 with respect to K . This latter decomposition is a BP decomposition by Proposition 4.2. /square
6.1. The Ryan-Wolper theorem. In this section we use our results to prove Corollary 3.7 on iterated fibre bundle structures of smooth and rationally smooth Schubert varieties. We assume that X J ( w ) is a rationally smooth Schubert variety of finite type.
Proof of Corollary 3.7. Suppose that W is a finite Weyl group, and that X J ( w ) is rationally smooth. By repeatedly applying Theorems 3.3 and 3.6, we can write
$$w = v _ { m } \cdots v _ { 1 },$$
where v i ∈ W J i -1 J i for J i := J ∪ ⋃ j ≤ i S v ( j ), and v i ( v i -1 · · · v 1 ) is a Grassmannian BP decomposition. Let w i := v m · · · v i +1 ∈ W J i , so w 0 = w and w m is the identity . By Lemma 4.3, w i = w i +1 v i +1 is a BP decomposition with respect to ( J , J i i +1 ), so the morphism
$$X ^ { J _ { i } } ( w _ { i } ) \to X ^ { J _ { i + 1 } } ( w _ { i + 1 } )$$
is a locally-trivial fibre bundle with fibre X J i ( v i +1 ). Hence the sequence
$$X ^ { J } ( w ) = X ^ { J _ { 0 } } ( w _ { 0 } ) \to X ^ { J _ { 1 } } ( w _ { 1 } ) \to \dots \to X ^ { J _ { m - 1 } } ( w _ { m - 1 } ) = X ^ { J _ { m - 1 } } ( v _ { m } ) \to \text{Spec} \, k$$
meets the required conditions in Corollary 3.7. If X J ( w ) is smooth, then by Theorem 3.3 all the fibres X J i ( v i ) are smooth, and hence so are the morphisms.
Conversely, given a locally-trivial morphism X → Y with fibre F such that the cohomology H ∗ ( Y ) of the base and the cohomology H ∗ ( F ) of the fibre are concentrated in even degrees, we can argue as in the proof of Corollary 3.5 that H ∗ ( X ) is isomorphic to H ∗ ( Y ) ⊗ H ∗ ( F ). Thus H ∗ ( X ) will be concentrated in even degrees, and if H ∗ ( Y ) and H ∗ ( F ) satisfy Poincar´ duality, then so does e H ∗ ( X ). If there is a sequence
$$X ^ { J } ( w ) = X _ { 0 } \rightarrow X _ { 1 } \rightarrow \dots \rightarrow X _ { m } = \text{Spec} \, k$$
in which all the morphisms are locally trivial, and all the fibres are rationally smooth Schubert varieties, then H ∗ ( X i ) satisfies Poincar´ duality for all e i = 0 , . . . , m . In particular, X J ( w ) will be rationally smooth by the Carrell-Peterson theorem [Car94]. /square
Only limited results are known about BP decompositions outside of finite type. Billey and Crites have shown that if X w ( ) is a rationally smooth Schubert variety of affine type ˜ , A then (a la Theorem 5.1) either w or w -1 has a BP decomposition [BC12]. Using this result, the proof of Theorem 6.1 extends to the affine setting with minor modifications, and thus the Ryan-Wolper theorem also holds in affine type ˜ . A The framework of BP decompositions also allows us to prove [BC12, Conjecture 1], that X w ( ) is smooth in affine type ˜ if and only if A w avoids (as an affine permutation) 3412 and 4231.
In [RS14], the authors show that right-sided BP decompositions exist for rationally smooth Schubert varieties in the full flag varieties of a large class of non-finite Weyl groups. Hence the Ryan-Wolper theorem also holds for Schubert varieties X ∅ ( w ) in this class via the application of Theorem 3.3. However, with the exception of ˜ , A 3 all of the Coxeter groups in this class are of indefinite type. It is an open problem to prove the existence of BP decompositions for this class when J is non-empty.
Based on this evidence, the following conjecture seems plausible:
Conjecture 6.5. If W is any Coxeter group, and w belongs to W J with P J w ( ) t palindromic, then w has a Grassmannian BP decomposition. As a result, the Ryan-Wolper theorem holds in any Kac-Moody flag variety.
## References
[BC12] Sara Billey and Andrew Crites, Pattern characterization of rationally smooth affine Schubert varieties of type A , J. Algebra 361 (2012), 107-133.
[BE09] Anders Bj¨rner and Torsten Ekedahl, o On the shape of Bruhat intervals , Ann. of Math. (2) 170 (2009), no. 2, 799-817.
[Bil98] Sara C. Billey, Pattern avoidance and rational smoothness of Schubert varieties , Adv. Math. 139 (1998), no. 1, 141-156.
[BK04] M. Brion and S. Kumar, Frobenius splitting methods in geometry and representation theory , Progress in Mathematics, Birkh¨user Boston, 2004. a
[BL00] Sara Billey and V. Lakshmibai, Singular loci of Schubert varieties , Progress in Mathematics, vol. 182, Birkh¨user Boston, Inc., Boston, MA, 2000. a
[Bor91] A. Borel, Linear algebraic groups , Graduate Texts in Mathematics, vol. 126, Springer-Verlag, 1991.
[Bou68] N. Bourbaki, ´ l´ments E e de math´ ematique. Fasc. XXXIV. Groupes et alg` ebres de Lie. Chapitre IV: Groupes de Coxeter et syst`mes de Tits. Chapitre V: Groupes engendr´s par des r´flexions. e e e Chapitre VI: syst`mes de racines e , Actualit´s Scientifiques et Industrielles, e No. 1337, Hermann, Paris, 1968.
| [BP99] | Michel Brion and Patrick Polo, Generic singularities of certain Schubert varieties , Math. Z. 231 (1999), no. 2, 301-324. |
|----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [BP05] | Sara Billey and Alexander Postnikov, Smoothness of Schubert varieties via patterns in root sub- systems , Adv. in Appl. Math. 34 (2005), no. 3, 447-466. |
| [Car94] | James B. Carrell, The Bruhat graph of a Coxeter group, a conjecture of Deodhar, and rational smoothness of Schubert varieties , Algebraic groups and their generalizations: classical methods (University Park, PA, 1991), Proc. Sympos. Pure Math., vol. 56, Amer. Math. Soc., Providence, RI, 1994, pp. 53-61. |
| [CK03] | James B. Carrell and Jochen Kuttler, Smooth points of T -stable varieties in G/B and the Peterson map , Invent. Math. 151 (2003), no. 2, 353-379. |
| [Dye] | Matt Dyer, Rank two detection of singularities of Schubert varieties , preprint. |
| [EW14] | Ben Elias and Goerdie Williamson, The Hodge theory of Soergel bimodules , Annals of Mathematics 180 (2014), no. 3, 1089-1136. |
| [Gas98] | Vesselin Gasharov, Factoring the Poincar´ e polynomials for the Bruhat order on S n , J. Combin. Theory Ser. A 83 (1998), no. 1, 159-164. |
| [HM13] | Jaehyun Hong and Ngaiming Mok, Characterization of smooth Schubert varieties in rational ho- mogeneous manifolds of Picard number 1 , Journal of Algebraic Geometry 22 (2013), 333-362. |
| [JW14] | Daniel Juteau and Geordie Williamson, Kumar's criterion modulo p , Duke Math. J. 163 (2014), no. 14, 2617-2638. |
| [Kum96] | Shrawan Kumar, The nil Hecke ring and singularity of Schubert varieties , Invent. Math. 123 (1996), no. 3, 471-506. |
| [Kum02] | , Kac-Moody groups, their flag varieties and representation theory , Progress in Mathemat- ics, vol. 204, Birkh¨user a Boston Inc., Boston, MA, 2002. |
| [Las98] | Alain Lascoux, Ordonner le groupe sym´trique: e pourquoi utiliser l'alg`bre e de Iwahori-Hecke? , Documenta Mathematica Extra Volume ICM III (1998), 355-364. |
| [LS90] | V. Lakshmibai and B. Sandhya, Criterion for smoothness of Schubert varieties in Sl( n ) /B , Proc. Indian Acad. Sci. Math. Sci. 100 (1990), no. 1, 45-52. |
| [LW90] | V. Lakshmibai and J. Weyman, Multiplicities of points on a Schubert variety in a minuscule G/P , Adv. Math. 84 (1990), no. 2, 179-208. |
| [Mih07] | Ion Alexandru Mihai, Odd symplectic flag manifolds , Transformation Groups 12 (2007), no. 3, 573-599. |
| [OY10] | Suho Oh and Hwanchul Yoo, Bruhat order, rationally smooth Schubert varieties, and hyperplane arrangements , DMTCS Proceedings FPSAC (2010). |
| [Rob14] | C. Robles, Singular loci of cominuscule Schubert varieties , Journal of Pure and Applied Algebra 218 (2014), no. 4, 745-759. |
| [RS14] | Edward Richmond and William Slofstra, Rationally smooth elements of Coxeter groups and tri- angle group avoidance , J. Algebraic Combin. 39 (2014), no. 3, 659-681. |
| [Rya87] | Kevin M. Ryan, On Schubert varieties in the flag manifold of Sl( n, C ), Mathematische Annalen 276 (1987), no. 2, 205-224. |
| [Tam94] | G¨nter u Tamme, Introduction to ´tale e cohomology , Universitext, Springer-Verlag, Berlin, 1994, Translated from the German by Manfred Kolster. |
| [vdH74] | A van den Hombergh, About the automorphisms of the bruhat-ordering in a coxeter group , Inda- gationes Mathematicae (Proceedings) 77 (1974), no. 2, 125-131. |
| [Wol89] | James S Wolper, A combinatorial approach to the singularities of Schubert varieties , Advances in Mathematics 76 (1989), no. 2, 184-193. |
E-mail address : [email protected]
E-mail address : [email protected] | 10.1007/s00208-015-1299-4 | [
"Edward Richmond",
"William Slofstra"
] | 2014-08-01T05:57:38+00:00 | 2017-02-09T17:27:43+00:00 | [
"math.AG",
"math.CO"
] | Billey-Postnikov decompositions and the fibre bundle structure of Schubert varieties | A theorem of Ryan and Wolper states that a type A Schubert variety is smooth
if and only if it is an iterated fibre bundle of Grassmannians. We extend this
theorem to arbitrary finite type, showing that a Schubert variety in a
generalized flag variety is rationally smooth if and only if it is an iterated
fibre bundle of rationally smooth Grassmannian Schubert varieties. The proof
depends on deep combinatorial results of Billey-Postnikov on Weyl groups. We
determine all smooth and rationally smooth Grassmannian Schubert varieties, and
give a new proof of Peterson's theorem that all simply-laced rationally smooth
Schubert varieties are smooth. Taken together, our results give a fairly
complete geometric description of smooth and rationally smooth Schubert
varieties using primarily combinatorial methods. |
1408.0086v1 | ## Direct CP violation in τ ± → K ρ ± 0 ( ω ν ) τ → K π π ν ± + -τ
Chao Wang 1 ∗ , Xin-Heng Guo 1 † , Ying Liu 1 ‡ , Rui-Cheng Li 1 §
1 College of Nuclear Science and Technology, Beijing Normal University, Beijing 100875, China
We study the direct CP violation in the τ ± → K ρ ± 0 ( ω ν ) τ → K π π ± + -ν τ decay process in the Standard Model. An interesting mechanism involving the charge symmetry violating mixing between ρ 0 and ω is applied to enlarge the CP asymmetry. With this mechanism, the maximum differential and localized integrated CP asymmetries can reach -(5 6 . +2 9 . -1 7 . ) × 10 -12 and 6 3 . +2 4 . -3 3 . × 10 -11 , respectively, which still leave plenty room for CP-violating New Physics to be discovered through this process.
PACS numbers: 11.30.Er, 13.30.Eg, 13.35.-r, 12.39.-x
## I. INTRODUCTION
CP violation was first observed in the neutral kaon system fifty years ago [1]. The asymmetry of CP in the K meson system can be explained by a weak complex phase in the Cabibbo-Kobayashi-Maskawa (CKM) matrix in the Standard Model (SM) [2, 3]. However, the fundamental origin of CP violation is still an open problem and it is not clear if the CKM mechanism is the only source for CP violation. New Physics (NP) may exist [4-6] and cause CP violation. To verify the origin of CP violation and look for NP, one needs to collect more information about CP violation in as many processes as possible. One such possible process is the τ decay. τ is the only lepton which is heavy enough to decay into hadrons and the pure leptonic and semileptonic character of τ decays provides a clean laboratory to test the structure of the weak currents and the universality of their couplings to the gauge bosons [5]. More importantly, with the establishment of the high-luminosity Super τ -Charm factories, more τ leptons will be produced and its properties will be measured to a very high precision [4]. After the CLEO-c experiment ceased data collection in March 2008, the BESIII experiment began to collect data, and the luminosity reached 10 32 cm -2 s -1 in 2013 [7]. Future high luminosity Super τ -Charm factories are also being considered in Russia and Italy and may reach the luminosity of 10 35 cm -2 s -1 [8-11]. Moreover, Super B -Factories (with the luminosity of 10 36 cm -2 s -1 ) will produce about 10 10 τ pairs per year at the Υ(4S) peak [12, 13]. The large statistics collected have considerably improved the statistical accuracy of the τ measurements and brought a new level of systematic understanding, allowing us to make sensible tests of the τ properties, provide more information about CP asymmetries in τ decay processes and seek for the fundamental origin of CP violation.
Experimental searches for CP violating asymmetries in τ lepton semileptonic decays have been carried out. The
∗ Email: [email protected]
† Corresponding author, Email: [email protected]
‡ Email: [email protected]
§ Email: [email protected]
missing evidence for a nonzero CP asymmetry was interpreted in terms of a coupling Λ in the decay τ ± → π ± π ν 0 τ [14]. Recently, the τ ± → K π S ± ν τ rate asymmetry was measured to be of order O (10 -3 ) by Belle [15] and BaBar [16]. In order to improve our understanding of CP violation in τ decays, more efforts should be put on the theoretical side and it is important to study the possibility of finding CP signals in τ decays. In the framework of the SM, the direct CP asymmetries come about due to a relative weak (CP-odd) and a relative strong (CP-even) phase. This mechanism is forbidden in τ decays in the leading order of the Fermi coupling constant G F [17]. Explicit studies of the decay modes τ ± → K π π ± + -ν τ [18, 19], τ ± → π ± K K ν + -τ [18], τ ± → (3 π ) ± ν τ [20, 21] and τ ± → (4 π ) ± ν τ [20] show that sizeable CP-violating effects could be generated in some models of CP violation involving several Higgs doublets or left-right symmetry. In order to be sure that any eventual observation of CP violation in τ decays has its origin beyond the SM, it is essential to study the magnitude of CP violation within the SM.
Usually, vanishingly small CP violation in τ decays is predicted in the SM. For example, the CP violation in the τ ± → K π ν ± 0 τ mode is estimated to be of order O (10 -12 ) when one takes higher order electroweak corrections into account [22]. Note that for the decay τ ± → K π S ± ν τ , the SM predicts a CP violating asymmetry of 3 3 . × 10 -3 due to the K 0 -¯ K 0 mixing amplitude [23]. In order to obtain a larger CP asymmetry in the SM, one needs to appeal to some phenomenological mechanisms. The charge symmetry violating mixing between ρ 0 and ω ( ρ ω -mixing) has been applied in hadron decays for this purpose in the past few years. ρ ω -mixing has the dual advantages that the strong phase difference is large and well known [24, 25]. From a series of studies on CP violation, it has already been found that this mechanism can provide a very large strong phase difference (usually 90 degrees) when the mass of the decay product of ρ 0 ( ω ) , π + π -, is in the vicinity of the ω resonance in some decay channels of heavy hadrons including B , Λ , and b D [24-28]. We will apply this mechanism to the τ lepton decay in the present paper.
We will consider the decay process τ ± → K π π ± + -ν τ . The CP violation of this process was analyzed theoretically with NP effects in the past [18, 19]. Now, we investigate the CP violation in this decay mode in the framework of the SM. The interference between the leading order diagram in G F [Fig. 1(a)] and the second order weak diagrams [Fig. 1(b) and (c)] generates a small CP violation phase [22]. ρ ω -mixing has been applied for getting a large strong phase when the invariant mass of the π + π -pair is near the ω resonance. Hence one can expect that there could be a bigger CP violating asymmetry in the τ ± → K ρ ± 0 ( ω ν ) τ → K π π ± + -ν τ process. Actually, it will be shown from our explicit calculations that ρ ω -mixing does enlarge the differential CP violating asymmetry by a maximum of four orders of magnitude and the localized integrated CP asymmetry by a maximum of three orders of magnitude. Even though, there is still a large window for studying effects of nonstandard sources of CP violation in experiments.
The remainder of this paper is organized as follows. In Sec. II, we first present the formalism for the CP asymmetry in τ ± → K ρ ± 0 ( ω ν ) τ → K π π ± + -ν τ via ρ ω -mixing. Then we give the derivation details of the leading order and the second order weak process matrix elements and apply ρ ω -mixing to generate a large CP asymmetry. In Sec. III, with the expression of meson wave functions and form factors and several parameters we calculate numerical results of the differential and localized integrated CP asymmetries. Our conclusion is included in Sec. IV.
## II. CP VIOLATION IN τ ± → K ρ ± 0 ( ω ν ) τ → K π π ± + -ν τ
A decay process described by some amplitudes may have CP-even and -odd relative phases. Within the SM, the CP-odd relative phase is always a weak phase difference which is directly determined by the CKM matrix. On the
FIG. 1. The leading order [(a)] and higher order diagrams [(b) and (c)] in G F contributing to the decay τ -→ K ρ ν -0 τ → K π π -+ -ν τ . Gluons in (a) are soft ones representing nonperturbative QCD interaction. u i = u, c, t in (b) and d i = d, s, b in (c).
contrary, the CP-even relative phase is usually a strong phase difference due to some complicated phenomenological mechanism. Letting M and ¯ M be the amplitudes for τ -→ K ρ -0 ( ω ν ) τ → K π π -+ -ν τ and its CP conjugate one, respectively, we define the two amplitudes as follows:
$$M \ = \ g _ { 1 } r _ { 1 } e ^ { i \phi _ { 1 } } + g _ { 2 } r _ { 2 } e ^ { i \phi _ { 2 } },$$
$$\bar { M } \, = \, g _ { 1 } ^ { * } r _ { 1 } e ^ { i \phi _ { 1 } } + g _ { 2 } ^ { * } r _ { 2 } e ^ { i \phi _ { 2 } },$$
where g 1 and g 2 represent CP-odd complex terms which involve coupling constants and CKM matrix elements, r 1 e i φ 1 and r 2 e i φ 2 terms are even under the CP transformation. Then, one has
$$| M | ^ { 2 } - | \bar { M } | ^ { 2 } & \ = \ 4 r _ { 1 } r _ { 2 } \Im ( g _ { 1 } ^ { * } g _ { 2 } ) \sin ( \phi _ { 1 } - \phi _ { 2 } ) \\ & \ = \ 4 r _ { 1 } r _ { 2 } | g _ { 1 } | | g _ { 2 } | \sin [ \Larg ( g _ { 2 } / g _ { 1 } ) ] \sin ( \phi _ { 1 } - \phi _ { 2 } ),$$
from which, we can see explicitly that both the CP-odd phase difference Arg( g /g 2 1 ) and the CP-even phase difference φ 1 -φ 2 are needed to produce CP violation. It will be shown below that the CP-odd phase difference arises from the second order weak processes and the CP-even phase difference is determined by the decay widths of intermediate resonances and ρ ω -mixing in the τ -→ K ρ ± 0 ( ω ν ) τ → K π π ± + -ν τ decay mode.
## A. General formalism for CP asymmetry
The hadronic τ decay amplitude can be factorized into a purely leptonic part including τ lepton and neutrino and a hadronic part, where the hadronic system is created from the vacuum via the charged weak current. Thus, the amplitude of τ -decaying into the K π π -+ -ν τ final state through K ρ ν -0 τ with the invariant mass of the π + π -pair near the ρ 0 resonance can be written in the following general form:
$$M ^ { \rho } \, = \, \frac { G _ { F } } { \sqrt { 2 } } g _ { \rho \pi \pi } s _ { \rho } L ^ { \mu } H ^ { \rho } _ { \mu },$$
where g ρππ is the effective coupling for ρ → ππ , H ρ µ is the hadronic matrix element creating ρ K 0 -, L µ is the lepton transition matrix element which can be written as ¯ u ν τ γ µ (1 -γ 5 ) u τ with u ν τ and u τ being the Dirac spinors of ν τ and τ , respectively, and s ρ is the propagator of the ρ 0 meson,
$$s _ { \rho } = \frac { 1 } { s - m _ { \rho } ^ { 2 } + \i m _ { \rho } \Gamma _ { \rho } },$$
where √ s is the invariant mass of the π + π -pair, and m ρ and Γ ρ are the mass and width of the ρ 0 meson, respectively. It should be noted that we assume that the ρ 0 meson is on-shell since the invariant mass of the π + π -pair is near the mass of the ρ 0 meson.
Because of the absence of the CP-odd phase, the CP asymmetry is zero in the leading order in G F in the SM in the τ decay. In order to have a nonzero CP violating asymmetry, the second order weak terms corresponding to Fig. 1(b) and (c) (with u i = u, c, t and d i = d, s, b ), which provide a CP-odd phase difference, should be taken into account [22]. The leading order amplitude is denoted by M ρ 0 corresponding to Fig. 1(a) and the second order weak terms are denoted by M ρ 1 and M ρ 2 corresponding to Fig. 1(b) and (c), respectively.
As mentioned before, in order to obtain a large CP violation, we intend to apply the ρ ω -mixing mechanism, which leads to large strong phase differences in heavy hadron decays. In this scenario, to the first order of isospin violation, we have the following total amplitude when the invariant mass of the π + π -pair is near the ω resonance mass:
$$M = M ^ { \rho } + M ^ { \rho - \omega },$$
with
$$M ^ { \rho - \omega } = \frac { G _ { F } } { \sqrt { 2 } } g _ { \rho \pi \pi } s _ { \rho } L ^ { \mu } H ^ { \omega } _ { \mu } s _ { \omega } \tilde { \Pi } _ { \rho \omega },$$
where Π ˜ ρω is the effective ρ ω -mixing amplitude, s ω is the propagator of the ω meson, and H ω µ includes three ωK annihilation terms H 0 ω µ , H 1 ω µ and H 2 ω µ corresponding to Fig. 1(a), (b) and (c), but through the ω intermediate resonance, respectively. We also assume that the ω meson is on-shell. It should be noted that the ρ → ω → π + π -process has been neglected since it is of the second order of isospin violation. The direct coupling ω → π + π -has been effectively absorbed into Π ˜ ρω [29]. This leads to the explicit s dependence of Π ˜ ρω . Making the expansion ˜ Π ρω ( s ) = ˜ Π ρω ( m 2 ω ) + ( s -m ω ) ˜ Π ′ ρω ( m 2 ω ), the ρ ω -mixing parameters were fitted by Gardner and O'Connell [30]:
$$\Re \tilde { \Pi } _ { \rho \omega } ( m _ { \omega } ^ { 2 } ) \ & = \ - 3 5 0 0 \pm 3 0 0 \ M e V ^ { 2 }, \\ \Im \tilde { \Pi } _ { \rho \omega } ( m _ { \omega } ^ { 2 } ) \ & = \ - 3 0 0 \pm 3 0 0 \ M e V ^ { 2 }, \\ \tilde { \Pi } ^ { \prime } _ { \rho \omega } ( m _ { \omega } ^ { 2 } ) \ & = \ 0. 0 3 \pm \ 0. 0 4.$$
We define M 0 = M ρ 0 + M ρ -ω 0 , M 1 = M ρ 1 + M ρ -ω 1 and M 2 = M ρ 2 + M ρ -ω 2 , where M ρ -ω 0 , M ρ -ω 1 and M ρ -ω 2 correspond to H 0 ω µ , H 1 ω µ and H 2 ω µ , respectively. The CP violation can arise from the interference between M 0 and M 1 , M 2 . It should be noted that M 1 and M 2 are the second order in G F . Therefore, to the G 3 F order, the square of the total
FIG. 2. The Feynman diagrams with the intermediate virtual mesons that connect the weak current and the strong vertex in the decay τ -→ V K -ν τ [ V is ρ 0 (or ω )]. (a) represents the total effective strong vertex; (b), (c) and (d) correspond to the V i (vector), A i (axial-vector) and P i (pseudoscalar) intermediate meson processes, respectively.
amplitude M = M 0 + M 1 + M 2 can be written as
$$| M | ^ { 2 } = ( M _ { 0 } + M _ { 1 } + M _ { 2 } ) ^ { \dagger } ( M _ { 0 } + M _ { 1 } + M _ { 2 } ) = M _ { 0 } ^ { \dagger } M _ { 0 } + ( M _ { 0 } ^ { \dagger } M _ { 1 } + M _ { 0 } M _ { 1 } ^ { \dagger } ) + ( M _ { 0 } ^ { \dagger } M _ { 2 } + M _ { 0 } M _ { 2 } ^ { \dagger } ).$$
Then, the differential CP asymmetry which is defined as
$$A _ { C P } = \frac { \left | M \right | ^ { 2 } - \left | \bar { M } \right | ^ { 2 } } { \left | M \right | ^ { 2 } + \left | \bar { M } \right | ^ { 2 } },$$
can be written as the following to the order G F :
$$A _ { C P } & = \frac { | M | ^ { 2 } - | \bar { M } | ^ { 2 } } { | M _ { 0 } | ^ { 2 } + | \bar { M } _ { 0 } | ^ { 2 } },$$
where the M M † 0 1 + M M 0 † 1 and M M † 0 2 + M M 0 † 2 terms are negligible in the denominator since they do not contribute to the second order in G F . When we take ρ ω -mixing into account, the three terms in Eq. (9) can be rewritten in the following forms:
$$M _ { 0 } M _ { 0 } ^ { \dagger } \, & = \, ( G _ { F } / \sqrt { 2 } ) ^ { 2 } g _ { \rho \pi n } ^ { 2 } s _ { \rho } ^ { 2 } L ^ { \mu \nu } ( H _ { \mu \nu } ^ { 0 \rho _ { \rho } } + H _ { \mu \nu } ^ { 0 \rho _ { \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } ^ { * } + H _ { \mu \nu } ^ { 0 \omega _ { \rho } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } + H _ { \mu \nu } ^ { 0 \omega _ { \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } ^ { 2 } s _ { \omega } ^ { 2 } ), \\ M _ { 0 } M _ { 1 } ^ { \dagger } \, & = \, ( G _ { F } / \sqrt { 2 } ) ^ { 2 } g _ { \rho \pi n } ^ { 2 } s _ { \rho } ^ { 2 } L ^ { \mu \nu } ( H _ { \mu \nu } ^ { 0 \rho _ { \mu \nu } } + H _ { \mu \nu } ^ { 0 \rho _ { \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } ^ { * } + H _ { \mu \nu } ^ { 0 \omega _ { 1 \nu } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } + H _ { \mu \nu } ^ { 0 \omega _ { 1 \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } ^ { 2 } ), \\ M _ { 0 } M _ { 2 } ^ { \dagger } \, & = \, ( G _ { F } / \sqrt { 2 } ) ^ { 2 } g _ { \rho \pi n } ^ { 2 } s _ { \rho } ^ { 2 } L ^ { \mu \nu } ( H _ { \mu \nu } ^ { 0 \rho _ { 2 \rho } } + H _ { \mu \nu } ^ { 0 \rho _ { 2 \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } ^ { * } + H _ { \mu \nu } ^ { 0 \omega _ { 2 \rho } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } + H _ { \mu \nu } ^ { 0 \omega _ { 2 \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } + H _ { \mu \nu } ^ { 0 \omega _ { 2 \omega } } \tilde { \Pi } _ { \rho \omega } s _ { \omega } ^ { 2 } ),$$
where L µν = L µ ( L ν ) † and for example, H 0 ρ ρ 0 µν = H 0 ρ µ ( H 0 ρ ν ) † .
## B. Derivation details of matrix elements
The transition from the vacuum to the pseudoscalar meson K -and the vector one ρ 0 ( ω ) occurs via weak vector and axial-vector current. Based on Lorentz invariance and parity and time-reversal invariance, one can decompose
the hadronic matrix element in terms of four form factors in the leading order in G F [31]:
$$H _ { \mu } ^ { 0 \rho ( \omega ) } \, & = \, - i V _ { u s } ^ { * } < \rho ^ { 0 } ( \omega ) K ^ { - } | \overline { s } \gamma _ { \mu } ( 1 - \gamma _ { 5 } ) u | 0 > \\ & = \, V _ { u s } ^ { * } \left [ - \, g \varepsilon _ { \mu \nu \alpha \beta } \epsilon ^ { * \nu } p _ { 1 } ^ { \alpha } p _ { 2 } ^ { \beta } - i f \epsilon _ { \mu } ^ { * } - i ( a _ { 1 } p _ { 1 \mu } + a _ { 2 } p _ { 2 \mu } ) ( \epsilon ^ { * } \cdot Q ) \right ],$$
where V us is the CKM matrix element, ¯ and s u are quark field operators, p 1 and p 2 are momenta of ρ 0 (or ω ) and K -, respectively, Q = p 1 + p 2 is the momentum transfer to the hadronic system, g is the vector current form factor, f , a 1 and a 2 are axial-vector current form factors, and /epsilon1 µ denotes the polarization vector of ρ 0 (or ω ) which satisfies p 1 · /epsilon1 = 0 and ∑ λ =0 , ± /epsilon1 ∗ µ ( q, λ ) /epsilon1 ν ( q, λ ) = -g µν + q µ q ν /m V , where λ = ± , 0 represent the traverse and longitudinal polarizations, respectively, and m V is the mass of the vector meson V ( V = ρ 0 or ω ). The form factors are functions of Q 2 only. They are difficult to be related directly to experimental measurements but can be dealt with in phenomenological models. We will calculate the form factors with the meson dominance model [31]. The pseudoscalar and vector meson annihilation process in the leading order in G F is generated by the strong interaction. In the meson dominance model it is assumed that intermediate mesons connect the weak current and the strong vertex shown in the Feynman diagrams in Fig. 2. Using the Feynman rules for these diagrams, the following expressions for the form factors are obtained [31]:
$$f \ & = \ - \frac { 1 } { 2 } ( Q ^ { 2 } + m _ { V } ^ { 2 } - m _ { K } ^ { 2 } ) \sum _ { i } \frac { h _ { A _ { i } } t _ { A _ { V K } } } { D _ { A _ { i } } ( Q ^ { 2 } ) }, \quad g = \frac { 1 } { 2 } \sum _ { i } \frac { h _ { V _ { i } } t _ { V _ { V K } } } { D _ { V _ { i } } ( Q ^ { 2 } ) }, \\ a _ { 1 } \ & = \ \frac { 5 } { 2 } \sum _ { i } \frac { h _ { P _ { i } } t _ { P _ { i } V K } } { D _ { P _ { i } } ( Q ^ { 2 } ) } + \frac { 1 } { 2 } \sum _ { i } \frac { h _ { A _ { i } } t _ { A _ { i } V K } } { D _ { A _ { i } } ( Q ^ { 2 } ) }, \quad a _ { 2 } = \frac { 3 } { 2 } \sum _ { i } \frac { h _ { P _ { i } } t _ { P _ { i } V K } } { D _ { P _ { i } } ( Q ^ { 2 } ) } + \frac { 1 } { 2 } \sum _ { i } \frac { h _ { A _ { i } } t _ { A _ { i } V K } } { D _ { A _ { i } } ( Q ^ { 2 } ) },$$
where V i , A i and P i denote vector, axial-vector and pseudoscalar intermediate meson resonances, respectively, h M i ( M i = A i , V i or P i ) denotes the weak coupling of the M i intermediate meson, t M VK i is its strong coupling to the V K final state, m K is the mass of the K meson, and D M i ≡ Q 2 -m 2 M i + im M i Γ M i where m M i (Γ M i ) is the mass (width) of the corresponding intermediate meson. The details about the intermediate mesons and their weak couplings and strong vertex coupling constants will be given in Section III. From Eqs. (12) and (13) it can be found that in the leading order in G F the CP-odd phase is absent, and the CP-even phase is determined by the decay widths of intermediate resonances when ρ ω -mixing is not considered.
Next, we proceed to evaluate M 1 and M 2 based on the perturbation method. Note that M M 0 † 2 + M M † 0 2 in Eq. (9) is proportional to | V ud i | 2 | V us | 2 and will not contribute to CP violation. Hence we only have to consider M 1 . In the framework of perturbation method, it can be evaluated in a similar way to B decays [32]. Since the τ mass is much smaller than the W -boson mass M W , the momenta of all the particles involved in the τ decay are much smaller than M W . As a result, we can approximate the denominator of the W -boson propagator ( p 1 + p 2 ) 2 -M 2 W by -M 2 W in the numerator of the W -boson propagator. The wave functions including spin factors of pseudoscalar and vector mesons are taken as [33]
$$\Psi _ { V } ( x, p ) \ = \ - \frac { I } { 2 \sqrt { 2 } \sqrt { 3 } m _ { V } } \phi _ { V } ( x ) ( m _ { V } + p ) \acute { f },$$
$$\Psi _ { P } ( x, p ) \ = \ - \frac { \cdot \cdot \cdot \cdot } { 2 \sqrt { 2 } \sqrt { 3 } m _ { P } } \phi _ { P } ( x ) ( m _ { P } + p ) \gamma _ { 5 },$$
where I = 3 is an identity in color space, m P and m V are the masses of the pseudoscalar and vector mesons, respectively, p represents the momentum of the meson P or V , x is the longitudinal momentum fraction of the constituent quark, and the non-perturbution effects are included in the distribution amplitudes φ V ( x ) and φ P ( x ), which satisfy ∫ 1 0 φ V ( P ) ( x )d x = f V ( P ) / (2 √ 6), where f V ( P ) is the decay constant of V ( P ). According to the Feynman diagram (b) in Fig. 1, the hadronic matrix elements H 1 ρ (or H 1 ω ) can be expressed as
$$H ^ { 1 \rho ( \omega ) } _ { \mu } \, = \, + ( - ) \frac { G _ { F } } { \sqrt { 2 } } ( 2 \pi ) ^ { 3 } I \sum _ { i } V ^ { * } _ { u _ { i } } V _ { u _ { i } } d V ^ { * } _ { u d } \sqrt { m _ { u } m _ { d } ^ { 2 } m _ { s } } \int _ { 0 } ^ { 1 } \, d x d y \phi ^ { * } _ { \rho ( \omega ) } ( x ) \phi ^ { * } _ { K } ( y ) \\ - \frac { 1 } { 2 \sqrt { 2 } m _ { \rho ( \omega ) } } ( m _ { \rho ( \omega ) } - p _ { 2 } ) \ell ^ { * } \gamma _ { \alpha } ( 1 - \gamma _ { 5 } ) \frac { 1 } { 2 \sqrt { 2 } m _ { K } } ( m _ { K } - p _ { 1 } ) \gamma _ { 5 } \gamma _ { \mu } ( 1 - \gamma _ { 5 } ) I _ { u _ { i } } \gamma ^ { \alpha } ( 1 - \gamma _ { 5 } ),$$
where V u s i and V u d i are the CKM matrix elements, +( -) corresponds to ρ ω ( ) and we define I u i = i( p / u i + m u i ) / p ( 2 u i -m 2 u i ) with m u i and p u i being the current quark mass and the momentum of the intermediate quark u i , respectively. We will neglect the difference between the masses of ρ 0 and ω mesons in the following, i.e., we take m ρ = m ω .
Using the unitarity of the CKM matrix, we have
$$\sum _ { i } V _ { u _ { i } s } ^ { * } V _ { u _ { i } d } I _ { u _ { i } } \ & = \ V _ { u d } ^ { * } V _ { u s } ( I _ { u } - I _ { c } ) + V _ { t d } ^ { * } V _ { t s } ( I _ { t } - I _ { c } ) \\ & \approx \ V _ { u d } ^ { * } V _ { u s } ( I _ { u } - I _ { c } ) - V _ { t d } ^ { * } V _ { t s } I _ { c }$$
where the last line is obtained using the fact that m t is much larger than masses of other quarks involved in this process. We note that only V ∗ td V ts provides a weak CP-violation phase, so it is unnecessary to consider the contribution of the first term. As a consequence, the CP asymmetry only depends on V ∗ td V ts I c . We define
$$\text{nrst term. As a consequence, tne \, \mathcal { r } \, \text{ asymmetry only eepenas on } v _ { t d } v _ { t s } v _ { t s } \cdot \, \text{ we geeme} \\ A _ { 1 } \, & \, \equiv \, \int _ { 0 } ^ { 1 } d x d y \phi _ { \rho ( \omega ) } ^ { * } ( y ) \phi _ { K } ^ { * } ( x ) \frac { 1 } { x Q ^ { 2 } + ( 1 - x ) m _ { \rho } ^ { 2 } + ( x ^ { 2 } - x ) m _ { K } ^ { 2 } - m _ { c } ^ { 2 } }, \\ & = \, \int _ { 0 } ^ { 1 } d x \phi _ { K } ^ { * } ( x ) \frac { f _ { \rho } } { 2 \sqrt { 6 } [ x Q ^ { 2 } + ( 1 - x ) m _ { \rho } ^ { 2 } + ( x ^ { 2 } - x ) m _ { K } ^ { 2 } - m _ { c } ^ { 2 } ] }, \\ B _ { 1 } \, & \, \equiv \, \int _ { 0 } ^ { 1 } d x d y \phi _ { \rho ( \omega ) } ^ { * } ( y ) \phi _ { K } ^ { * } ( x ) \frac { x } { x Q ^ { 2 } + ( 1 - x ) m _ { \rho } ^ { 2 } + ( x ^ { 2 } - x ) m _ { K } ^ { 2 } - m _ { c } ^ { 2 } } \\ & = \, \int _ { 0 } ^ { 1 } d x \phi _ { K } ^ { * } ( x ) \frac { x f _ { \rho } } { 2 \sqrt { 6 } [ x Q ^ { 2 } + ( 1 - x ) m _ { \rho } ^ { 2 } + ( x ^ { 2 } - x ) m _ { K } ^ { 2 } - m _ { c } ^ { 2 } ] }. \\ \tag Eqs. ( 18 ), ( 19 ) \, \text{and} \, ( 2 0 ) \, \text{into} \, Eq. \, ( 1 7 ) \, \text{and only considering the CP asymmetry term, } H _ { \mu } ^ { 1 \rho ( \omega ) } \, \text{ can be simplified}$$
Inserting Eqs. (18), (19) and (20) into Eq. (17) and only considering the CP asymmetry term, H 1 ρ ω ( ) µ can be simplified as
$$H _ { \mu } ^ { 1 \rho ( \omega ) } \ = \ \frac { 6 \sqrt { 2 } ( 2 \pi ) ^ { 3 } \sqrt { m _ { u } m _ { i } ^ { 2 } m _ { s } } G _ { F } V _ { t s } ^ { * } V _ { t d } V _ { u d } ^ { * } } { m _ { k } } \\ & \quad \cdot \left \{ - A _ { 1 } \varepsilon _ { \mu \nu \alpha \beta } \epsilon ^ { * \nu } p _ { 1 } ^ { \alpha } p _ { 2 } ^ { \beta } - i \epsilon ^ { * \mu } \left [ \frac { 1 } { 2 } A _ { 1 } ( Q ^ { 2 } - m _ { \rho } ^ { 2 } - m _ { K } ^ { 2 } ) + B _ { 1 } m _ { K } ^ { 2 } \right ] \\ & \quad + i A _ { 1 } p _ { 1 } ^ { \mu } ( Q \cdot \epsilon ^ { * } ) + i 2 B _ { 1 } p _ { 2 } ^ { \mu } ( Q \cdot \epsilon ^ { * } ) \right \}. \\. \. \. \. \ \cdot \. \ \cdot \. \ \cdot \. \ \cdot \. \ \cdot \. \. \. \.. \.. \.. \.. \........................................................................................................................................................................................................$$
We can see that the weak phase appears but the strong phase is absent in this amplitude if ρ ω -mixing is not included.
Now we take ρ ω -mixing into account and show how ρ ω -mixing enlarges the CP violation. In the meson dominance
model, the form factors of the annihilation process are dominated by strong interaction. So, we adopt the same form factors in the Kρ and Kω annihilation processes. According to Eq. (13), we have H 0 ρ µ = H 0 ω µ . H 1 ρ ω ( ) µ is dependent on the hadronic wave functions. Since the wave functions of mesons are determined by strong interaction, which preserves isospin, we assume that the ρ 0 and ω mesons have the same hadronic wave functions. Therefore, from Eq. (17), we have H 1 ρ µ = -H 1 ω µ . Then, the first two equations of Eq. (12) can be written as
$$M _ { 0 } M _ { 0 } ^ { \dagger } \ = \ ( G _ { F } / \sqrt { 2 } ) ^ { 2 } g _ { \rho \pi \pi } ^ { 2 } s _ { \rho } ^ { 2 } L ^ { \mu \nu } H _ { \mu \nu } ^ { 0 \rho 0 \rho } ( 1 + \tilde { \Pi } _ { \rho \omega } ^ { * } s _ { \omega } ^ { * } + \tilde { \Pi } _ { \rho \omega } s _ { \omega } + \tilde { \Pi } _ { \rho \omega } ^ { 2 } s _ { \omega } ^ { 2 } ) \\ M _ { 0 } M _ { 1 } ^ { \dagger } \ = \ ( G _ { F } / \sqrt { 2 } ) ^ { 2 } g _ { \rho \pi \pi } ^ { 2 } s _ { \rho } ^ { 2 } L ^ { \mu \nu } H _ { \mu \nu } ^ { 0 \rho 1 \rho } ( 1 - \tilde { \Pi } _ { \rho \omega } ^ { * } s _ { \omega } ^ { * } + \tilde { \Pi } _ { \rho \omega } s _ { \omega } - \tilde { \Pi } _ { \rho \omega } ^ { 2 } s _ { \omega } ^ { 2 } ).$$
We can see explicitly that ρ ω -mixing provides additional complex terms to A CP . As will be shown later, these complex terms enlarge the CP-even phase, which leads to a bigger CP asymmetry.
Finally, we will calculate L µν H 0 ρ ρ 0 µν and L µν H 0 ρ ρ 1 µν . For simplicity, we will consider the unpolarized τ decay process. The unpolarized leptonic scattering tensor is
$$L ^ { \mu \nu } & \ = \ \frac { 1 } { 2 } \sum _ { \lambda _ { 3 }, \lambda _ { 4 } } \ t r [ \bar { u } _ { \nu _ { \tau } } ( p _ { 3 }, \lambda _ { 3 } ) \gamma ^ { \mu } ( 1 - \gamma _ { 5 } ) u _ { \tau } ( p _ { 4 }, \lambda _ { 4 } ) \bar { u } _ { \tau } \gamma ^ { \nu } ( p _ { 4 }, \lambda _ { 4 } ) ( 1 - \gamma _ { 5 } ) u _ { \nu _ { \tau } } ( p _ { 3 }, \lambda _ { 3 } ) ] \\ & \ = \ 4 [ - \ g ^ { \mu \nu } ( p _ { 3 } \cdot p _ { 4 } ) + p _ { 3 } ^ { \mu } \cdot p _ { 4 } ^ { \nu } + p _ { 3 } ^ { \nu } \cdot p _ { 4 } ^ { \mu } + i \epsilon ^ { \mu \nu \alpha \beta } p _ { 3 \alpha } p _ { 4 \beta } ],$$
where p 3 and p 4 represent the momenta of ν τ and τ , respectively, and λ 3 and λ 4 represent the helicities of ν τ and τ , respectively. We also sum over the spins of hadrons. Then, from Eqs. (13) and (23), one has
$$L ^ { \mu \nu } H _ { \mu \nu } ^ { 0 p 0 p _ { \rho } } & = \ 4 | V _ { u s } | ^ { 2 } & [ ( - 2 x _ { 0 } - m _ { \rho } ^ { 2 } x _ { 1 } - m _ { K } ^ { 2 } x _ { 2 } ) ( p _ { 3 } \cdot p _ { 4 } ) + 2 x _ { 1 } ( p _ { 1 } \cdot p _ { 3 } ) ( p _ { 1 } \cdot p _ { 4 } ) + 2 x _ { 2 } ( p _ { 2 } \cdot p _ { 3 } ) ( p _ { 2 } \cdot p _ { 4 } ) \\ & \quad - ( x _ { + } + x _ { - } ) ( p _ { 1 } \cdot p _ { 2 } ) ( p _ { 3 } \cdot p _ { 4 } ) + ( x _ { + } + x _ { - } + 2 g f ^ { * } + 2 g ^ { * } f ) ( p _ { 1 } \cdot p _ { 3 } ) ( p _ { 2 } \cdot p _ { 4 } ) \\ & \quad + ( x _ { + } + x _ { - } - 2 g f ^ { * } - 2 g ^ { * } f ) ( p _ { 1 } \cdot p _ { 4 } ) ( p _ { 2 } \cdot p _ { 3 } ) ], & ( 2 4 ) \\.$$
where
$$x _ { 0 } \ & = \ - \frac { 1 } { 4 } g ^ { 2 } ( Q ^ { 4 } + m _ { \rho } ^ { 4 } + m _ { K } ^ { 4 } - 2 m _ { \rho } ^ { 2 } Q ^ { 2 } - 2 m _ { K } ^ { 2 } Q ^ { 2 } - 2 m _ { K } ^ { 2 } ) - f ^ { 2 }, \\ x _ { 1 } \ & = \ g ^ { 2 } m _ { K } ^ { 2 } + a _ { 1 } ^ { 2 } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ) ^ { 2 } } { m _ { \rho } ^ { 2 } } \right ] + \frac { f ^ { 2 } } { m _ { \rho } ^ { 2 } } + \frac { p _ { 1 } \cdot p _ { 2 } } { m _ { \rho } ^ { 2 } } f ^ { * } a _ { 1 }, \\ x _ { 2 } \ & = \ g ^ { 2 } m _ { \rho } ^ { 2 } + a _ { 2 } ^ { 2 } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ) ^ { 2 } } { m _ { \rho } ^ { 2 } } \right ] - ( a _ { 2 } f ^ { * } + a _ { 2 } ^ { 2 } f ), \\ x _ { + } \ & = \ - \frac { 1 } { 2 } g ^ { 2 } ( Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } ) + a _ { 1 } a _ { 2 } ^ { * } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ) ^ { 2 } } { m _ { \rho } ^ { 2 } } \right ] - a _ { 1 } f ^ { * } + \frac { p _ { 1 } \cdot p _ { 2 } } { m _ { \rho } ^ { 2 } } f a _ { 2 } ^ { * }, \\ x _ { - } \ & = \ - \frac { 1 } { 2 } g ^ { 2 } ( Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } ) + a _ { 1 } ^ { * } a _ { 2 } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ) ^ { 2 } } { m _ { \rho } ^ { 2 } } \right ] - a _ { 1 } ^ { * } f + \frac { p _ { 1 } \cdot p _ { 2 } } { m _ { \rho } ^ { 2 } } f ^ { * } a _ { 2 }.$$
From Eqs. (21) and (23), one has
$$& \text{from $Eqs. (21)$ and (23), one has} \\ & L ^ { \mu \nu } H ^ { 0 p 1 \rho } _ { \mu \nu } = \, & \frac { 6 \sqrt { 2 } ( 2 \pi ) ^ { 3 } \sqrt { m _ { u } } ^ { 2 } _ { d } m _ { s } G _ { F } V _ { t s } V _ { t d } V _ { u d } V _ { u s } ^ { * } } { m _ { K } } \\ & \quad \cdot [ ( - 2 x _ { 0 } ^ { \prime } - x _ { 1 } ^ { \prime } m _ { \rho } ^ { 2 } - x _ { 2 } ^ { \prime } m _ { K } ^ { 2 } ) ( p _ { 3 } \cdot p _ { 4 } ) + 2 x _ { 1 } ^ { \prime } ( p _ { 1 } \cdot p _ { 3 } ) ( p _ { 1 } \cdot p _ { 4 } ) + 2 x _ { 2 } ^ { \prime } ( p _ { 2 } \cdot p _ { 3 } ) ( p _ { 2 } \cdot p _ { 4 } ) \\ & \quad + ( x _ { + } ^ { \prime } + x _ { - } ^ { \prime } + 2 f B _ { 1 } + 2 g \lambda ) ( p _ { 1 } \cdot p _ { 3 } ) ( p _ { 2 } \cdot p _ { 4 } ) + ( x _ { + } ^ { \prime } + x _ { - } ^ { \prime } - 2 f ^ { * } B _ { 1 } - 2 g ^ { * } \lambda ) ( p _ { 1 } \cdot p _ { 4 } ) ( p _ { 2 } \cdot p _ { 3 } ) \\ & \quad - ( x _ { + } ^ { \prime } + x _ { - } ^ { \prime } ) ( p _ { 1 } \cdot p _ { 2 } ) ( p _ { 3 } \cdot p _ { 4 } ) ], \\ & \quad \text{where}$$
where
$$x _ { 0 } ^ { \prime } \ = \ - \frac { 1 } { 4 } g A _ { 1 } ( Q ^ { 4 } + m _ { \rho } ^ { 4 } + m _ { K } ^ { 4 } - 2 m _ { \rho } ^ { 2 } Q ^ { 2 } - 2 m _ { K } ^ { 2 } Q ^ { 2 } - 2 m _ { \rho } ^ { 2 } m _ { K } ^ { 2 } ) - f \lambda, \\ x _ { 1 } ^ { \prime } \ = \ - g A _ { 1 } m _ { K } ^ { 2 } + \frac { 1 } { 2 } g B _ { 1 } ( Q ^ { 2 } - m _ { \rho } ^ { 2 } - m _ { K } ^ { 2 } ) - a _ { 1 } A _ { 1 } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ^ { 2 } ) } { m _ { \rho } ^ { \prime } } \right ] - A _ { 1 } f \frac { p _ { 1 } \cdot p _ { 2 } } { m _ { \rho } ^ { \prime } } + a _ { 1 } \lambda \frac { p _ { 1 } \cdot p _ { 2 } } { m _ { \rho } ^ { \prime } }, \\ x _ { 2 } ^ { \prime } \ = \ - g A _ { 1 } m _ { \rho } ^ { 2 } - 2 a _ { 2 } B _ { 1 } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ^ { 2 } ) } { m _ { \rho } ^ { \prime } } \right ] + 2 B _ { 1 } f + a _ { 2 } \lambda, \\ x _ { + } ^ { \prime } \ = \ \frac { 1 } { 2 } g A _ { 1 } ( Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } ) - g A _ { 1 } m _ { K } ^ { 2 } - 2 B _ { 1 } f \frac { m _ { \rho } ^ { 2 } } { m _ { \rho } ^ { \prime } } - a _ { 1 } \lambda, \\ x _ { - } ^ { \prime } \ = \ \frac { 1 } { 2 } g A _ { 1 } ( Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } ) - a _ { 2 } A _ { 1 } \left [ - Q ^ { 2 } + \frac { ( p _ { 1 } \cdot Q ^ { 2 } ) } { m _ { \rho } ^ { \prime } } \right ] - A _ { 1 } f + a _ { 2 } \lambda \frac { p _ { 1 } \cdot p _ { 2 } } { m _ { \rho } ^ { \prime } }, \\ \lambda \ = \ \frac { 1 } { 2 } A _ { 1 } ( Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } ) + B _ { 1 } m _ { K } ^ { 2 }.$$
$$\mathbf \langle \ = \ \frac { 1 } { 2 } A _ { 1 } ( Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } ) + B _ { 1 } m _ { K } ^ { 2 }.$$
## C. Hadronic rest-frame
In the previous subsections, we have given the the general expression of CP asymmetry and derivations of matrix elements. For simplicity, we choose to work in a special reference frame and express the products among vectors p 1 , p 2 , p 3 , p 4 , Q and /epsilon1 in terms of the square of momentum transfer Q 2 , the invariant mass of the π + π -pair √ s , and a distribution angle θ in this subsection. We note that it is convenient to express the momenta of hadrons and leptons and calculate various components of the matrix elements in the hadronic rest-frame [34]. This frame is defined in Fig. 3. The z axis is chosen to be in the direction of motion of the ρ 0 (or ω ) meson. The three-momentum of K is chosen to be p 2 = -p 1 . The ( x, z ) plane is aligned with the ρ 0 and ν τ movement plane, with n ⊥ =( p 1 × p 3 ) / p | 1 × p 3 | (the normal to the ρ 0 and ν τ movement plane) pointing along the y axis. The distribution angle θ is the one between the motion direction of ρ 0 (or ω ) and the neutrino. Then, the momenta of hadrons and leptons in this hadronic rest frame are given as follows:
$$p _ { 1 } ^ { \mu } \, = \, ( E _ { 1 }, \, 0, \, 0, \, P ), \\ p _ { 2 } ^ { \mu } \, = \, ( E _ { 2 }, \, 0, \, 0, \, - P ), \\ p _ { 3 } ^ { \mu } \, = \, ( K, \, K \sin \theta, \, 0, \, K \cos \theta ), \\ p _ { 4 } ^ { \mu } \, = \, ( E _ { 4 }, \, K \sin \theta, \, 0, \, K \cos \theta ), \\ Q ^ { \mu } \, = \, ( E _ { 1 } + E _ { 2 }, \, 0, \, 0, \, 0 ) \\ \quad = \, ( E _ { 4 } - K, \, 0, \, 0, \, 0 ),$$
z
FIG. 3. The hadronic rest-frame. The z axis is chosen to be in the direction of the motion of the ρ 0 (or ω ) meson. The three-momentum of K is chosen to be p 2 = -p 1 . The ( x, z ) plane is aligned with the ρ 0 and ν τ movement plane, with n ⊥ =( p 1 × p 3 ) / p | 1 × p 3 | (the normal to the ρ 0 and ν τ movement plane) pointing along the y axis. The distribution angle θ is the one between the motion direction of ρ 0 (or ω ) and the neutrino.
and the polarization vectors of ρ 0 (or ω ) in this hadronic rest frame are
$$\epsilon ^ { \lambda = \pm 1 } & \ = \ ( 0, \, 1, \, \pm i \,, 0 ), \\ \epsilon ^ { \lambda = 0 } & \ = \ \frac { 1 } { \sqrt { m _ { \rho } } } ( P, \, 0, \, 0, \, E _ { 1 } ),$$
with
$$E _ { 1 } \ = \ \frac { Q ^ { 2 } + m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } } { 2 \sqrt { Q ^ { 2 } } }, \quad E _ { 2 } = \frac { Q ^ { 2 } - m _ { K } ^ { 2 } - m _ { \rho } ^ { 2 } } { 2 \sqrt { Q ^ { 2 } } }, \\ P \ = \ \frac { \sqrt { m _ { K } ^ { 4 } + m _ { \rho } ^ { 4 } - 2 m _ { K } ^ { 2 } Q ^ { 2 } - 2 m _ { K } ^ { 2 } m _ { \rho } ^ { 2 } - 2 Q ^ { 2 } m _ { \rho } ^ { 2 } } } { 2 \sqrt { Q ^ { 2 } } }, \\ K \ = \ \frac { m _ { \tau } ^ { 2 } - Q ^ { 2 } } { 2 \sqrt { Q ^ { 2 } } }, \quad E _ { 4 } = \frac { m _ { \tau } ^ { 2 } + Q ^ { 2 } } { 2 \sqrt { Q ^ { 2 } } }. \\ \ \\ \text{resions for various hadron and lepton momentum vectors allow us to determine simple expressions}$$
The above expressions for various hadron and lepton momentum vectors allow us to determine simple expressions for matrix elements which involve products including p 1 · p 2 , p 1 · p 3 , p 1 · p 4 , p 2 · p 3 , p 2 · p 4 , p 3 · p 4 , p 1 · Q p , 2 · Q p , 3 · Q , p 4 · Q , and Q /epsilon1 · in the term of Q 2 , √ s and θ . We will integrate over the angle θ since we will not consider the angle distribution. Furthermore, by integrating A CP in the region Ω in which Q 2 and s vary in some areas, we obtain the
localized integrated CP asymmetry which takes the following form:
$$A _ { C P } ^ { \Omega } = \frac { \int _ { \Omega } \mathrm d Q ^ { 2 } \mathrm d s ( | M | ^ { 2 } - | \bar { M } | ^ { 2 } ) } { \int _ { \Omega } \mathrm d Q ^ { 2 } \mathrm d s ( | M _ { 0 } | ^ { 2 } + | \bar { M } _ { 0 } | ^ { 2 } ) }.$$
## III. NUMERICAL RESULTS
From the above discussions, the CP violating asymmetries depend on the values of Q 2 and s . In this section we give the explicit expressions of meson wave functions and form factors, and values of several parameters in order to calculate the CP violating asymmetries. We find that significant cancellation occurs as one performs the integration over Q 2 . To show more details about this cancellation, we calculate both the differential and the integrated CP asymmetries. We also compare CP asymmetries with and without ρ ω -mixing.
## A. Models for form factors and meson wave functions
The hadronic τ decay is dominated by the meson annihilation diagram, Fig. 1(a). As mentioned before, the vector and pseudoscalar meson annihilation form factors in this decay mode are difficult to be related directly to experimental measurements. One therefore needs to adopt phenomenological models. Following Ref. [31] we use the meson dominance model in our calculation. In this model it is assumed that the vector form factor g is dominated by the K ∗ (892) and K ∗ (1410) vector mesons and f and a ± are dominated by the exchange of the K -pseudoscalar meson and the K 1 (1270) and K 1 (1400) axial-vector mesons [31]. The expressions for the form factors are given in Eq. (14). In Ref. [31], the values of weak couplings and strong vertex couplings were extracted from experiments and fixed by the SU(3) flavor symmetry. We display these values in Table I.
TABLE I. The values of h M i , t M V K i , m M i and Γ M i in the numerical calculations.
| | Pseudoscalar | Axial Vector | Axial Vector | Vector | Vector |
|-----------------------------|-----------------------|-----------------|----------------|-------------|-----------------|
| Intermediate mesons | K - | K 1 (1270) | K 1 (1400) | K ∗ (892) | K ∗ (1680) |
| h M i (10 3 MeV 2 ) | 0.159 ± 0.0015MeV - 1 | 215 ± 25 | 170 ± 130 | 188 ± 4 | 242 ± 25 |
| t M i V K (10 - 3 MeV - 1 ) | - 3170 ± 30MeV | - 1 . 94 ± 0.10 | 0.48 ± 0.24 | 8.71 ± 0.95 | - 3 . 71 ± 2.60 |
| m M i (MeV) | 494 ± 0.016 | 1272 ± 7 | 1403 ± 7 | 892 ± 0.26 | 1717 ± 27 |
| Γ M i (MeV) | 0 | 90 ± 20 | 174 ± 13 | 50.8 ± 0.9 | 322 ± 110 |
We use the K meson wave function of the Brodsky-Huang-Lepage prescription which have the following form [35]:
$$\Phi _ { K } ( x, \, k _ { \perp } ) \, = \, A _ { K } ( 1 - 2 x ) ^ { 2 } \exp \left [ - \, b _ { K } ^ { 2 } \left ( \frac { k _ { \perp } ^ { 2 } + m _ { s } ^ { \prime 2 } } { x } + \frac { k _ { \perp } ^ { 2 } + m _ { u } ^ { \prime 2 } } { 1 - x } \right ) \right ],$$
where k ⊥ is the transverse momentum of the constituents of K m , ′ u and m ′ s are the constituent quark masses of u and s , respectively. Integrating Φ K ( x, k ⊥ ) over k ⊥ one has the following distribution amplitude:
$$\phi _ { K } ( x ) \ = \ \frac { A _ { K } } { 1 6 \pi ^ { 2 } b _ { K } ^ { 2 } } x ( 1 - x ) ( 1 - 2 x ) ^ { 2 } \exp \left [ - b _ { K } ^ { 2 } \left ( \frac { m _ { s } ^ { \prime 2 } } { x } + \frac { m _ { u } ^ { \prime 2 } } { 1 - x } \right ) \right ].$$
In the following numerical calculations we use the parameters A K = 232GeV -1 , b 2 K = 0 61 GeV . -2 , m ′ u = 350MeV, m ′ s = 550MeV and f ρ = 221MeV [35].
## B. Numerical results for the CP asymmetries
We are now ready to evaluate numerical results of CP asymmetries. We take the meson masses m ρ = 770MeV and m K = 493MeV, the lepton mass m τ = 1776MeV, the current quark masses m u = 2 3MeV, . m d = 4 8MeV, . m s = 95MeV and m c = 1275MeV [36]. The CKM matrix, which elements are determined from experiments, can be expressed in terms of the Wolfenstein parameters A ρ λ , , and η [36]:
$$\begin{pmatrix} 1 - \frac { 1 } { 2 } \lambda ^ { 2 } & \lambda & A \lambda ^ { 3 } ( \rho - i \eta ) \\ - \lambda & 1 - \frac { 1 } { 2 } \lambda ^ { 2 } & A \lambda ^ { 2 } \\ A \lambda ^ { 3 } ( 1 - \rho - i \eta ) & - A \lambda ^ { 2 } & 1 \end{pmatrix},$$
where O ( λ 4 ) corrections are neglected. The latest values for the parameters in the CKM matrix are [36]:
$$\lambda \ & = \ 0. 2 2 5 3 5 \pm 0. 0 0 0 6 5, \quad & A = 0. 8 1 1 ^ { + 0. 0 2 2 } _ { - 0. 0 1 2 }, \\ \bar { \rho } \ & = \ 0. 1 3 1 ^ { + 0. 0 0 2 6 } _ { - 0. 0 1 3 }, \quad & \bar { \eta } = 0. 3 4 5 ^ { + 0. 0 1 3 } _ { - 0. 0 1 4 },$$
with
$$\bar { \rho } = \rho ( 1 - \frac { \lambda ^ { 2 } } { 2 } ), \quad \bar { \eta } = \eta ( 1 - \frac { \eta ^ { 2 } } { 2 } ).$$
FIG. 4. The differential CP asymmetry as a function of √ s and √ Q 2 . The numerical results correspond to central values of the parameters involved in the calculation.
In our numerical calculations, the most uncertain factors come from the CKM matrix elements and the form factors in the leading order in G F . In fact, the uncertainties due to the CKM matrix elements are mostly from η since λ is
s
FIG. 5. The localized integrated CP asymmetry A s CP as a function of √ s . (a) For integrating over Q 2 in √ Q 2 =(1.30 GeV, 1.35 GeV): the dash-dotted line corresponds to the CP asymmetry including ρ ω -mixing and the solid line corresponds to the CP asymmetry without ρ ω -mixing; (b), (c), (d), (e), (f), (g) and (h) correspond to the integration intervals (1.35 GeV, 1.40 GeV), (1.40 GeV, 1.45 GeV), (1.45 GeV, 1.50 GeV), (1.50 GeV, 1.55 GeV), (1.55 GeV, 1.60 GeV), (1.60 GeV, 1.65 GeV) and (1.65 GeV, 1.70 GeV), respectively. We take central values of the parameters involved in the calculation.
well determined and the CP violating asymmetries are independent of ρ . Hence in the following we take the central value of λ , 0.225. In the meson dominance model, the uncertainties arising from form factors are dominated by those of the strong and weak coupling constants of the K 1 (1400) meson due to the poor quality of measurements. The values of ρ ω -mixing paraments also bring some uncertainties.
In order to find the details about the dependence of the CP violating asymmetries on Q 2 and s , we study the differential CP asymmetries. Since CP asymmetries are calculated around the ω (782) resonance region, we take the range of √ s as 760 MeV ≤ √ s ≤ 800MeV. From Eqs. (27) and (29), we obtain ( m ρ + m K ) 2 < Q 2 < m 2 τ . Hence we take the range of √ Q 2 from ( m ρ + m K ) = 1270MeV to m τ =1770MeV. The differential CP asymmetry A CP depending on Q 2 and s is displayed in Fig. 4, where we take central values of the parameters involved in the calculation. We can see that A CP varies from around 10 -12 to around 10 -14 . The maximum differential CP violating asymmetry can reach -(5 6 . +2 9 . -1 7 . ) × 10 -12 , where the errors come from the uncertainties of the CKM matrix elements, the ρ ω -mixing parameters and the form factors in the leading order in G F . As we expect, there is a peak for the CP violating
parameter A CP when the invariant mass of the π + π -pair is in the vicinity of the ω resonance for a certain √ Q 2 . ρ ω -mixing enlarges A CP by four orders of magnitude in some regions. Furthermore, we also find that the sign of A CP changes frequently in some regions of Q 2 . This behaviour can be easily understood if one notes that the denominator of A 1 (and B 1 ), which is defined in Eq. (19) [and (20)], changes its sign when √ Q 2 crosses the pole. This will lead to cancellations when one performs the integration over Q 2 in some regions. These cancellations are found be be quite obvious around the peak when √ s = 784 MeV. In the experimental study of three-body decays of the B meson, one divides the Dalitz plot of candidates into bins with equal population using an adaptive binning algorithm and the CP violating parameter is calculated from the number of B event candidates in each bin [37]. In the following, we will calculate the localized integrated CP violating parameter in the τ lepton decay, which may be measured in the future experiments. We will also compare CP asymmetries with and without ρ ω -mixing in the following.
Firstly, we preform the integration over √ Q 2 while keeping √ s fixed. We divide the integration region into eight equal intervals: (1.30 GeV, 1.35 GeV), (1.35 GeV, 1.40 GeV), (1.40 GeV, 1.45 GeV), (1.45 GeV, 1.50 GeV), (1.50 GeV, 1.55 GeV), (1.55 GeV, 1.60 GeV), (1.60 GeV, 1.65 GeV) and (1.65 GeV, 1.70 GeV). In each interval, we integrate over √ Q 2 and calculate the CP asymmetries with and without ρ ω -mixing. The results are denoted by A s CP and shown in Fig. 5. Our numerical results show that the ρ ω -mixing mechanism enlarges the A s CP by about 1-2 order when √ s is around 0 784 MeV. All the three NP models in Ref. [19] predict that the . s -depending differential CP asymmetries are to be order of O (10 -3 ) when √ s varies in the region (0.760 MeV, 0.800 MeV). It can be seen from Fig. 5 that the maximum values of our results including ρ ω -mixing are about nine orders smaller than these predictions. Since the ρ ω -mixing mechanism provides an extra strong phase which enlarges the CP asymmetry, we suggest to measure the localized CP asymmetry in the region where the invariant mass of the π + π -pair is around 780 MeV in this decay process.
TABLE II. The localized integrated asymmetries (in units of 10 -12 ) with (without) ρ ω -mixing. The central values of the numerical results correspond to central values of the parameters involved in the calculation and the errors are from the uncertainties of the CKM matrix elements, the ρ ω -mixing parameters, and the form factors in the leading order in G F .
| √ Q 2 (GeV) | A Ω CP | √ Q 2 (GeV) | A Ω CP |
|---------------|----------------------------------------------------|---------------|----------------------------------------------------|
| (1.30, 1.35) | 3 . 4 +1 . 3 - 2 . 6 ( - 0 . 30 +0 . 07 - 0 . 19 ) | (1.50, 1.55) | - 6 . 6 +3 . 5 - 4 . 1 (0 . 43 +0 . 27 - 0 . 30 ) |
| (1.35, 1.40) | 9 . 6 +3 . 3 - 4 . 9 (0 . 093 +0 . 053 - 0 . 041 ) | (1.55, 1.60) | - 2 . 2 +1 . 8 - 0 . 9 (0 . 12 +0 . 05 - 0 . 06 ) |
| (1.40, 1.45) | 63 +24 - 33 (0 . 013 +0 . 008 - 0 . 004 ) | (1.60, 1.65) | - 3 . 8 +1 . 8 - 2 . 2 ( - 82 +47 - 60 ) |
| (1.45, 1.50) | 51 +42 - 16 ( - 0 . 20 +0 . 03 - 0 . 09 ) | (1.65, 1.70) | - 3 . 4 +2 . 2 - 1 . 5 ( - 0 . 14 +0 . 05 - 0 . 01 |
Finally, we integrate A CP over both √ Q 2 and √ s and obtain the localized integrated asymmetries A Ω CP . Considering the significant region of ρ ω -mixing shown in Fig. 5, we choose the integration interval of √ s to be from 0.775MeV to 0.795 MeV. The numerical results of the localized integrated asymmetries with (without) ρ ω -mixing are shown in Table. ?? , where the central values of the numerical results correspond to central values of the parameters involved in the calculation and the errors are again from the uncertainties of the CKM matrix elements, the ρ ω -mixing parameters, and the form factors in the leading order in G F . We can see in most of the intervals ρ ω -mixing enlarges the localized integrated asymmetries. The maximum increase is three orders of magnitude. These predictions lead to
a new upper limit of the CP asymmetries based on the SM in this decay channel.
We have calculated the differential and integrated CP asymmetries within the SM in the τ ± → K π π ± + -ν τ decay taking ρ ω -mixing into account. It is worth noting that even the maximum localized integrated CP asymmetry, 6 3 . +2 4 . -3 3 . × 10 -11 , is at least six orders smaller than that predicted based on NP in Ref. [19]. If any CP violation bigger than our predicted values is observed in experiments, one may consider the possibility of NP.
## IV. CONCLUSION
In the framework of the SM, CP violation in the τ lepton decay process arises from a nontrivial phase in the CKM matrix and is predicted to be zero in the leading order in G F . However, Delepine pointed out that the CP-odd phase can arise from the second order weak process in the τ ± → K π ν ± 0 τ decay mode [22]. Since ρ ω -mixing can provide very large CP asymmetries in some decay channels of heavy hadrons, we have tried to enlarge the CP asymmetry in the τ -→ K ρ -0 ( ω ν ) τ → K π π -+ -ν τ decay via this mechanism.
After integrating over √ Q 2 in serval intervals, we have shown that the ρ ω -mixing mechanism enlarges the √ s dependent CP asymmetry by about 1-2 order when √ s is around 0 784 MeV. . The maximum value of these results including ρ ω -mixing is about nine orders smaller than that predicted by NP model [19]. Since the ρ ω -mixing mechanism provides an extra strong phase which enlarges the CP asymmetry, we suggest to measure the localized CP asymmetry in the region where the invariant mass of the π + π -pair is around 780 MeV in this decay process. Furthermore, the mechanism in present paper can also be considered in the (3 π ) ± ν τ and (4 π ) ± ν τ final states in the τ lepton decay.
We have first studied the differential CP asymmetry depending on √ Q 2 and √ s . The numerical results show that it varies from around 10 -12 to around 10 -14 and the maximum CP violating asymmetry can reach -(5 6 . +2 9 . -1 7 . ) × 10 -12 . We have found that there is a peak for the CP violating parameter A CP when the invariant mass of the π + π -pair is in the vicinity of the ω resonance. The advantage of ρ ω -mixing is that it makes the strong phase difference between the hadronic matrix elements of the leading order and the second order in G F larger at the ω resonance. Consequently, the CP violating asymmetry reaches the maximum value when the invariant mass of the π + π -pair in the decay product is in the vicinity of the ω resonance. We have also found that A CP changes its sign when √ Q 2 varies. Then, we have calculated the localized integrated CP violating parameter in the τ lepton decay, which may be measured in the future experiments.
At last, we also have preformed integration over both √ Q 2 and √ s to obtain A Ω CP . The maximum value of A Ω CP turns out to be 6 3 . +2 4 . -3 3 . × 10 -11 . This value is the largest CP asymmetry in this decay channel within the SM predicted at present, which is still at least six orders smaller than that predicted based on NP in Ref. [19], leaving plenty room for CP-violating NP to be discovered in the τ decay. If any differential CP asymmetry bigger than 10 -12 or localized integrated CP violation bigger than 10 -11 is observed in the future, it may be the signal of NP.
[1] J. Christenson et al., Phys. Rev. Lett. 13 , 138 (1964).
- [2] N. Cabibbo, Phys. Rev. Lett. 10 , 531 (1963).
- [3] M. Kobayashi and T. Maskawa, Prog. Theor. Phys. 49 , 652 (1973).
- [4] Tao Huang, Wei Lu, and Zhijian Tao, Phys. Rev. D 55 , 1643 (1997)
- [5] Antonio Pich, Prog. Part. Nucl. Phys. 75 , 41-85 (2014). arXiv:1310.7922 [hep-ph].
- [6] Daiji Kimura et al., arXiv:0905.1802 [hep-ph].
- [7] Qing Qin, Workshop on Tau Charm at High Luminosity, Elba (Italy), May 2013.
- [8] Peter Zweber et al. (BESIII Collaboration), AIP Conf. Proc. 1182 , 406 (2009).
- [9] E. Levichev, Workshop on Tau Charm at High Luminosity, Elba (Italy), May 2013.
- [10] A. E. Bondar, Phys. Atom. Nucl. 76 , 1072-1085 (2013).
- [11] Mikhail Zobov (INFN LNF), arXiv:1106.5329.
- [12] HaiBo Li, Workshop for Super Tau-Charm Factory in Hefei, Hefei (China), June 2013.
- [13] M. Baszczyk et al. (SuperB Collaboration), arXiv:1306.5655 [physics.ins-det].
- [14] P. Avery et al. (CLEO Collaboration), Phys. Rev. D 64 , 092005 (2001).
- [15] M. Bischofberger et al. (Belle Collaboration), Phys. Rev. Lett. 107 , 131801 (2011).
- [16] J. P. Lees et al. (BABAR Collaboration), Phys. Rev. D 85 , 031102 (2012).
- [17] Alakabha Datta et al., Phys. Rev. D 75 , 074007 (2007).
- [18] U. Kilian, J. G. Korner, K. Schilcher and Y. L. Wu, Z. Phys. C 62 , 413 (1994)
- [19] Ken Kiers et al., Phys. Rev. D 78 , 113008 (2008).
- [20] A. Datta et al., Phys. Rev. D 76 , 079902 (2007).
- [21] S. Y. Choi, K. Hagiwara, and M. Tanabashi, Phys. Rev. D 52 , 1614 (1995).
- [22] D. Delepine, G. L´pez Castro, and L.-T. L´pez Lozano, Phys. Rev. D o o 72 , 033009 (2005).
- [23] I. I. Bigi and A. I. Sanda, Phys. Lett. B 625 , 47 (2005).
- [24] R. Enomoto and M. Tanabashi, Phys. Lett. B 386 , 413 (1996).
- [25] S. Gardner, H. B. OConnell and A. W. Thomas, Phys. Rev. Lett. 80 , 1834 (1998).
- [26] X.-H. Guo and A. W. Thomas, Phys. Rev. D 63 , 096013 (1998); 61 , 116009 (2000).
- [27] X.-H. Guo, O. Leitner, and A. W. Thomas, Phys. Rev. D 63 , 056012 (2001).
- [28] O. Leitner, X.-H. Guo, and A. W. Thomas, Eur. Phys. J. C 32 , 215 (2003).
- [29] H. B. O'Connell, A. W. Thomas, and A. G. Williams, Nucl. Phys. A 623 , 559 (1997); K. Maltman, H. B. O'Connell, and A. G. Williams Phys. Lett. B 376 , 19 (1996).
- [30] S. Gardner and H. B. O'Connell, Phys. Rev. D 57 , 2716 (1998).
- [31] A. Flores-Tlalpa and G. L´pez Castro, Phys. Rev. D o 77 , 113011 (2008).
- [32] Dongsheng Du, Deshan Yang, and Guohuai Zhu, Phys. Rev. D 60 , 054015 (1999).
- [33] Adam F. Falk, Nucl. Phys. B 378 , 79-94 (1992).
- [34] Adam J. H. K¨hn and E. Mirkes, Z. Phys. C u 56 , 661-671 (1992).
- [35] X.-H. Guo and T. Huang, Phys. Rev. D 43 , 2931 (1991).
- [36] J. Beringer et al. (Particle Data Group), Phys. Rev. D 86 , 010001 (2012).
- [37] R. Aaij et al. (LHCb Collaboration), Phys. Rev. Lett. 112 , 011801 (2014).
 | 10.1140/epjc/s10052-014-3140-8 | [
"Chao Wang",
"Xin-Heng Guo",
"Ying Liu",
"Rui-Cheng Li"
] | 2014-08-01T06:14:40+00:00 | 2014-08-01T06:14:40+00:00 | [
"hep-ph"
] | Direct CP violation in $τ^\pm\rightarrow K^\pm ρ^0 (ω)ν_τ\rightarrow K^\pm π^+π^-ν_τ$ | We study the direct CP violation in the $\tau^\pm\rightarrow K^\pm \rho^0
(\omega)\nu_\tau \rightarrow K^\pm \pi^+\pi^-\nu_\tau$ decay process in the
Standard Model. An interesting mechanism involving the charge symmetry
violating mixing between $\rho^0$ and $\omega$ is applied to enlarge the CP
asymmetry. With this mechanism, the maximum differential and localized
integrated CP asymmetries can reach $-(5.6^{+2.9}_{-1.7})\times10^{-12}$ and
$6.3^{+2.4}_{-3.3}\times 10^{-11}$, respectively, which still leave plenty room
for CP-violating New Physics to be discovered through this process. |
1408.0087v1 | The Annals of Applied Statistics 2014, Vol. 8, No. 2, 1256-1280 DOI: 10.1214/14-AOAS739 c © Institute of Mathematical Statistics, 2014
## PROBABILITY AGGREGATION IN TIME-SERIES: DYNAMIC HIERARCHICAL MODELING OF SPARSE EXPERT BELIEFS 1
By Ville A. Satop¨¨, Shane T. Jensen, Barbara A. Mellers, aa Philip E. Tetlock and Lyle H. Ungar
University of Pennsylvania
Most subjective probability aggregation procedures use a single probability judgment from each expert, even though it is common for experts studying real problems to update their probability estimates over time. This paper advances into unexplored areas of probability aggregation by considering a dynamic context in which experts can update their beliefs at random intervals. The updates occur very infrequently, resulting in a sparse data set that cannot be modeled by standard time-series procedures. In response to the lack of appropriate methodology, this paper presents a hierarchical model that takes into account the expert's level of self-reported expertise and produces aggregate probabilities that are sharp and well calibrated both inand out-of-sample. The model is demonstrated on a real-world data set that includes over 2300 experts making multiple probability forecasts over two years on different subsets of 166 international political events.
1. Introduction. Experts' probability assessments are often evaluated on calibration , which measures how closely the frequency of event occurrence agrees with the assigned probabilities. For instance, consider all events that an expert believes to occur with a 60% probability. If the expert is well calibrated, 60% of these events will actually end up occurring. Even though several experiments have shown that experts are often poorly calibrated [see, e.g., Cooke (1991), Shlyakhter et al. (1994)], these are noteworthy exceptions. In particular, Wright et al. (1994) argue that higher self-reported expertise can be associated with better calibration.
Received September 2013; revised March 2014.
1 Supported by a research contract to the University of Pennsylvania and the University of California from the Intelligence Advanced Research Projects Activity (IARPA) via the Department of Interior National Business Center contract number D11PC20061.
Key words and phrases. Probability aggregation, dynamic linear model, hierarchical modeling, expert forecast, subjective probability, bias estimation, calibration, time series.
This is an electronic reprint of the original article published by the
Institute of Mathematical Statistics in The Annals of Applied Statistics ,
2014, Vol. 8, No. 2, 1256-1280. This reprint differs from the original in pagination and typographic detail.
Calibration by itself, however, is not sufficient for useful probability estimation. Consider a relatively stationary process, such as rain on different days in a given geographic region, where the observed frequency of occurrence in the last 10 years is 45%. In this setting an expert could always assign a constant probability of 0.45 and be well-calibrated. This assessment, however, can be made without any subject-matter expertise. For this reason the long-term frequency is often considered the baseline probability-a naive assessment that provides the decision-maker very little extra information. Experts should make probability assessments that are as far from the baseline as possible. The extent to which their probabilities differ from the baseline is measured by sharpness [Gneiting et al. (2008), Winkler and Jose (2008)]. If the experts are both sharp and well calibrated, they can forecast the behavior of the process with high certainty and accuracy. Therefore, useful probability estimation should maximize sharpness subject to calibration [see, e.g., Raftery et al. (2005), Murphy and Winkler (1987)].
There is strong empirical evidence that bringing together the strengths of different experts by combining their probability forecasts into a single consensus, known as the crowd belief , improves predictive performance. Prompted by the many applications of probability forecasts, including medical diagnosis [Wilson et al. (1998), Pepe (2003)], political and socio-economic foresight [Tetlock (2005)], and meteorology [Sanders (1963), Vislocky and Fritsch (1995), Baars and Mass (2005)], researchers have proposed many approaches to combining probability forecasts [see, e.g., Ranjan and Gneiting (2010), Satop¨¨ et al. (2014a), Batchelder, Strashny and Romney (2010) aa for some recent studies, and Genest and Zidek (1986), Wallsten, Budescu and Erev (1997), Clemen and Winkler (2007), Primo et al. (2009) for a comprehensive overview]. The general focus, however, has been on developing one-time aggregation procedures that consult the experts' advice only once before the event resolves.
Consequently, many areas of probability aggregation still remain rather unexplored. For instance, consider investors aiming to assess whether a stock index will finish trading above a threshold on a given date. To maximize their overall predictive accuracy, they may consult a group of experts repeatedly over a period of time and adjust their estimate of the aggregate probability accordingly. Given that the experts are allowed to update their probability assessments, the aggregation should be performed by taking into account the temporal correlation in their advice.
This paper adds another layer of complexity by assuming a heterogeneous set of experts, most of whom only make one or two probability assessments over the hundred or so days before the event resolves. This means that the decision-maker faces a different group of experts every day, with only a few experts returning later on for a second round of advice. The problem at hand is therefore strikingly different from many time-series estimation
problems, where one has an observation at every time point-or almost every time point. As a result, standard time-series procedures like ARIMA [see, e.g., Mills (1991)] are not directly applicable. This paper introduces a time-series model that incorporates self-reported expertise and captures a sharp and well-calibrated estimate of the crowd belief. The model is highly interpretable and can be used for the following:
- · analyzing under and overconfidence in different groups of experts,
- · gaining question-specific quantities with easy interpretations, such as expert disagreement and problem difficulty.
- · obtaining accurate probability forecasts, and
This paper begins by describing our geopolitical database. It then introduces a dynamic hierarchical model for capturing the crowd belief. The model is estimated in a two-step procedure: first, a sampling step produces constrained parameter estimates via Gibbs sampling [see, e.g., Geman and Geman (1984)]; second, a calibration step transforms these estimates to their unconstrained equivalents via a one-dimensional optimization procedure. The model introduction is followed by the first evaluation section that uses synthetic data to study how accurately the two-step procedure can estimate the crowd belief. The second evaluation section applies the model to our real-world geopolitical forecasting database. The paper concludes with a discussion of future research directions and model limitations.
2. Geopolitical forecasting data. Forecasters were recruited from professional societies, research centers, alumni associations, science bloggers and word of mouth ( n =2365). Requirements included at least a Bachelor's degree and completion of psychological and political tests that took roughly two hours. These measures assessed cognitive styles, cognitive abilities, personality traits, political attitudes and real-world knowledge. The experts were asked to give probability forecasts (to the second decimal point) and to self-assess their level of expertise (on a 1-to-5 scale with 1 = Not At All Expert and 5 = Extremely Expert) on a number of 166 geopolitical binary events taking place between September 29, 2011 and May 8, 2013. Each question was active for a period during which the participating experts could update their forecasts as frequently as they liked without penalty. The experts knew that their probability estimates would be assessed for accuracy using Brier scores. 2 This incentivized them to report their true beliefs instead of attempting to game the system [Winkler and Murphy (1968)]. In addition to receiving $150 for meeting minimum participation requirements that did
2 The Brier score is the squared distance between the probability forecast and the event indicator that equals 1.0 or 0.0 depending on whether the event happened or not, respectively. See Brier (1950) for the original introduction.
Table 1 Five-number summaries of our real-world data
| Statistic | Min. | Q 1 | Median | Mean | Q 3 | Max. |
|------------------------------------------------|--------|---------|----------|---------|----------|--------|
| # of days a question is active | 4 | 35 . 6 | 72 . 0 | 106 . 3 | 145 . 20 | 418 |
| # of experts per question | 212 | 543 . 2 | 693 . 5 | 783 . 7 | 983 . 2 | 1690 |
| # forecasts given by each expert on a question | 1 | 1 . 0 | 1 . 0 | 1 . 8 | 2 . 0 | 131 |
| # questions participated by an expert | 1 | 14 . 0 | 36 . 0 | 55 . 0 | 90 . 0 | 166 |
not depend on prediction accuracy, the experts received status rewards for their performance via leader-boards displaying Brier scores for the top 20 experts. Given that a typical expert participated only in a small subset of the 166 questions, the experts are considered indistinguishable conditional on the level of self-reported expertise.
The average number of forecasts made by a single expert in one day was around 0.017, and the average group-level response rate was around 13.5 forecasts per day. Given that the group of experts is large and diverse, the resulting data set is very sparse. Tables 1 and 2 provide relevant summary statistics on the data. Notice that the distribution of the self-reported expertise is skewed to the right and that some questions remained active longer than others. For more details on the data set and its collection see Ungar et al. (2012).
To illustrate the data with some concrete examples, Figure 1(a) and 1(b) show scatterplots of the probability forecasts given for (a) Will the expansion of the European bailout fund be ratified by all 17 Eurozone nations before 1 November 2011? and (b) Will the Nikkei 225 index finish trading at or above 9500 on 30 September 2011? The points have been shaded according to the level of self-reported expertise and jittered slightly to make overlaps visible. The solid line gives the posterior mean of the calibrated crowd belief as estimated by our model. The surrounding dashed lines connect the point-wise 95% posterior intervals. Given that the European bailout fund was ratified before November 1, 2011 and that the Nikkei 225 index finished trading at around 8700 on September 30, 2011, the general trend of the probability forecasts tends to converge toward the correct answers. The individual experts, however, sometimes disagree strongly, with the disagreement persisting even near the closing dates of the questions.
Table 2 Frequencies of the self-reported expertise (1 = Not At All Expert and 5 = Extremely Expert) levels across all the 166 questions in our real-world data
| Expertise level | 1 | 2 | 3 | 4 | 5 |
|-------------------|--------|--------|--------|-------|-------|
| Frequency (%) | 25 . 3 | 30 . 7 | 33 . 6 | 8 . 2 | 2 . 1 |
## Self-Reported Expertise
## 2 3 0 5
(a) Will the expansion of the European bailout fund be ratified by 17 Eurozone nations before 1 November 2011? all
(b) Will the Nikkei 225 index finish trading at or above 9,500 on 30 September 2011?
Fig. 1. Scatterplots of the probability forecasts given for two questions in our data set. The solid line gives the posterior mean of the calibrated crowd belief as estimated by our model. The surrounding dashed lines connect the point-wise 95% posterior intervals.
3. Model. Let p i,t,k ∈ (0 1) be the probability forecast given by the , i th expert at time t for the k th question, where i =1 , . . . , I k , t =1 , . . . , T k , and k =1 , . . . , K . Denote the logit probabilities with
$$Y _ { i, t, k } = \log i t ( p _ { i, t, k } ) = \log \left ( \frac { p _ { i, t, k } } { 1 - p _ { i, t, k } } \right ) \in \mathbb { R } \\ \intertext { + h o n t + n o b i l i t i o n } \, \text{ for completion } \, k \text{ at } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{\ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text$$
and collect the logit probabilities for question k at time t into a vector Y t,k =[ Y 1 ,t,k Y 2 ,t,k · · · Y I k ,t,k ] T . Partition the experts into J groups based on some individual feature, such as self-reported expertise, with each group sharing a common multiplicative bias term b j ∈ R for j =1 , . . . , J . Collect these bias terms into a bias vector b =[ b 1 b 2 · · · b J ] T . Let M k be a I k × J matrix denoting the group memberships of the experts in question k ; that is, if the i th expert participating in the k th question belongs to the j th group, then the i th row of M k is the j th standard basis vector e j . The bias vector b is assumed to be identical across all K questions. Under this notation, the model for the k th question can be expressed as
$$\mathbf Y _ { t, k } = M _ { k } \mathbf b X _ { t, k } + \mathbf v _ { t, k },$$
$$& 6 & V. \ A. \ \text{SATOP} \ddot { \Lambda } \text{ET} \text{AL}. \\ & ( 3. 2 ) & X _ { t, k } = \gamma _ { k } X _ { t - 1, k } + w _ { t, k }, \\ & & X _ { 0, k } \sim \mathcal { N } ( \mu _ { 0 }, \sigma _ { 0 } ^ { 2 } ), \\ & \text{where} \, ( 3. 1 ) \ \text{ denotes the observed process, (3. 2 ) shows the h}.$$
where (3.1) denotes the observed process, (3.2) shows the hidden process that is driven by the constant γ k ∈ R , and ( µ ,σ 0 2 0 ) ∈ ( R R , + ) are hyperparameters fixed a priori to 0 and 1, respectively. The error terms follow:
$$& \mathbf v _ { t, k } | \sigma _ { k } ^ { 2 } \stackrel { \text{i.i.d.} } { \sim } \mathcal { N } _ { I _ { k } } ( 0, \sigma _ { k } ^ { 2 } \mathbf I _ { I _ { k } } ), \\ & w _ { t, k } | \tau _ { k } ^ { 2 } \stackrel { \text{i.i.d.} } { \sim } \mathcal { N } ( 0, \tau _ { k } ^ { 2 } ).$$
$$w _ { t, k } | \tau _ { k } ^ { 2 } \stackrel { i. i. d. } { \sim } \mathcal { N } ( 0, \tau _ { k } ^ { 2 } ). \\ \dots \dots \dots$$
Therefore, the parameters of the model are b , σ 2 k , γ k and τ 2 k for k =1 , . . . , K . Their prior distributions are chosen to be noninformative, p ( b , σ 2 k | X k ) ∝ σ 2 k and p γ ( k , τ 2 k | X k ) ∝ τ 2 k .
Given that the experts may believe in false information, hide their true beliefs or be biased for many other reasons, their probability assessments should be aggregated via a model that can detect potential bias, separate signal from noise and use the collective opinion to estimate X t,k . In our model the experts are assumed to be, on average, a multiplicative constant b away from X t,k . Therefore, an individual element of b can be interpreted as a group-specific systematic bias that labels the group either as overconfident [ b j ∈ (1 , ∞ )] or as underconfident [ b j ∈ (0 1)]. , See Section 3 for a brief discussion on different bias structures. Any other deviation from X t,k is considered random noise . This noise is measured in terms of σ 2 k and can be assumed to be caused by momentary over-optimism (or pessimism), false beliefs or other misconceptions.
The hidden state X t,k represents the aggregate logit probability for the k th event given all the information available up to and including time t . To make this more specific, let Z k ∈ { 0 1 , } indicate whether the event associated with the k th question happened ( Z k =1) or did not happen ( Z k =0). If {F t,k } T k t =1 is a filtration representing the information available up to and including a given time point, then according to our model E [ Z k |F t,k ] = P ( Z k = 1 |F t,k ) = logit -1 ( X t,k ). Ideally this probability maximizes sharpness subject to calibration [for technical definitions of calibration and sharpness see Ranjan and Gneiting (2010), Gneiting and Ranjan (2013)]. Even though a single expert is unlikely to have access to all the available information, a large and diverse group of experts may share a considerable portion of the available information. The collective wisdom of the group therefore provides an attractive proxy for F t,k .
The random fluctuations in the hidden process are measured by τ 2 k and are assumed to represent changes or shocks to the underlying circumstances that ultimately decide the outcome of the event. The systematic component γ k allows the model to incorporate a constant signal stream that drifts the
hidden process. If the uncertainty in the question diminishes [ γ k ∈ (1 , ∞ )], the hidden process drifts to positive or negative infinity. Alternatively, the hidden process can drift to zero, in which case any available information does not improve predictive accuracy [ γ k ∈ (0 1)]. , Given that all the questions in our data set were resolved within a prespecified timeframe, we expect γ k ∈ (1 , ∞ ) for all k =1 , . . . , K .
As for any future time T ∗ ≥ t ,
$$X _ { T ^ { * }, k } = \gamma _ { k } ^ { T ^ { * } - t } X _ { t } + \sum _ { i = k + k } ^ { T ^ { * } } \gamma _ { k } ^ { T ^ { * } - i } w _ { i }$$
$$\sim \mathcal { N } & \left ( \gamma _ { k } ^ { T ^ { * } - t } X _ { t, k }, \tau _ { k } ^ { 2 } \sum _ { i = t + 1 } ^ { T ^ { * } } \gamma _ { k } ^ { T ^ { * } - i } \right ), \\ \text{mod for time forward prediction as well } T h$$
$$+ \sum _ { i = t + 1 } ^ { T ^ { * } } \gamma _ { k } ^ { T ^ { * } - i } w _ { i } \\. \quad \sim \stackrel { T ^ { * } } { \sim } \quad \sigma _ { * }$$
the model can be used for time-forward prediction as well. The prediction for the aggregate logit probability at time T ∗ is given by an estimate of γ T ∗ -t X t,k . Naturally the uncertainty in this prediction grows in T . To make such time-forward predictions, it is necessary to assume that the past population of experts is representative of the future population. This is a reasonable assumption because even though the future population may consist of entirely different individuals, on average the population is likely to look very similar to the past population. In practice, however, social scientists are generally more interested in an estimate of the current probability than the probability under unknown conditions in the future. For this reason, our analysis focuses on probability aggregation only up to the current time t .
For the sake of model identifiability, it is sufficient to share only one of the elements of b among the K questions. In this paper, however, all the elements of b are assumed to be identical across the questions because some of the questions in our real-world data set involve very few experts with the highest level of self-reported expertise. The model can be extended rather easily to estimate bias at a more general level. For instance, by assuming a hierarchical structure b ik ∼N ( b j ( i,k ) , σ 2 j ( i,k ) ), where j ( i, k ) denotes the selfreported expertise of the i th expert in question k , the bias can be estimated at an individual-level. These estimates can then be compared across questions. Individual-level analysis was not performed in our analysis for two reasons. First, most experts gave only a single prediction per problem, which makes accurate bias estimation at the individual-level very difficult. Second, it is unclear how the individually estimated bias terms can be validated.
If the future event can take upon M > 2 possible outcomes, the hidden state X t,k is extended to a vector of size M -1 and one of the outcomes, for example, the M th one, is chosen as the base case to ensure that the probabilities will sum to one at any given time point. Each of the remaining
- M -1 possible outcomes is represented by an observed process similar to (3.1). Given that this multinomial extension is equivalent to having M -1 independent binary-outcome models, the estimation and properties of the model are easily extended to the multi-outcome case. This paper focuses on binary outcomes because it is the most commonly encountered setting in practice.
- 4. Model estimation. This section introduces a two-step procedure, called Sample-And-Calibrate (SAC), that captures a well-calibrated estimate of the hidden process without sacrificing the interpretability of our model.
/negationslash
- 4.1. Sampling step. Given that ( a b , X t,k /a,a τ 2 2 k ) = ( b , X t,k , τ 2 k ) for any a > 0 yield the same likelihood for Y t,k , the model as described by (3.1) and (3.2) is not identifiable. A well-known solution is to choose one of the elements of b , say, b 3 , as the reference point and fix b 3 =1. In Section 5 we provide a guideline for choosing the reference point. Denote the constrained version of the model by
$$\begin{array} { c c c } \text{move } \upsilon _ { y } \\ \text{Y} _ { t, k } & = & M _ { k } b ( 1 ) X _ { t, k } ( 1 ) + \text{v} _ { t, k }, \\ X _ { t, k } ( 1 ) & = & \gamma _ { k } ( 1 ) X _ { t - 1, k } ( 1 ) + w _ { t, k }, \\ \text{v} _ { t, k } | \sigma _ { k } ^ { 2 } ( 1 ) & \stackrel { i. i. d. } { \sim } \mathcal { N } _ { I _ { k } } ( 0, \sigma _ { k } ^ { 2 } ( 1 ) \text{I} _ { I _ { k } } ), \\ w _ { t, k } | \tau _ { k } ^ { 2 } ( 1 ) & \stackrel { i. i. d. } { \sim } \mathcal { N } ( 0, \tau _ { k } ^ { 2 } ( 1 ) ), \\ \text{ailing input notation, } ( a ), \text{ signifies the value } u \end{array}$$
where the trailing input notation, (a), signifies the value under the constraint b 3 = . Given that this version is identifiable, estimates of the model a parameters can be obtained. Denote the estimates by placing a hat on the parameter symbol. For instance, ˆ (1) and b ˆ X t,k (1) represent the estimates of b (1) and X t,k (1), respectively.
These estimates are obtained by first computing a posterior sample via Gibbs sampling and then taking the average of the posterior sample. The first step of our Gibbs sampler is to sample the hidden states via the ForwardFiltering-Backward-Sampling (FFBS) algorithm. FFBS first predicts the hidden states using a Kalman filter and then performs a backward sampling procedure that treats these predicted states as additional observations [see, e.g., Carter and Kohn (1994), Migon et al. (2005) for details on FFBS]. Given that the Kalman filter can handle varying numbers or even no forecasts at different time points, it plays a very crucial role in our probability aggregation under sparse data.
Our implementation of the sampling step is written in C++ and runs quite quickly. To obtain 1000 posterior samples for 50 questions each with 100 time points and 50 experts takes about 215 seconds on a 1.7 GHz Intel
Core i5 computer. See the supplemental article for the technical details of the sampling steps [Satop¨¨ et al. (2014b)] and, for example, Gelman et al. aa (2003) for a discussion on the general principles of Gibbs sampling.
4.2. Calibration step. Given that the model parameters can be estimated by fixing b 3 to any constant, the next step is to search for the constant that gives an optimally sharp and calibrated estimate of the hidden process. This section introduces an efficient procedure that finds the optimal constant without requiring any additional runs of the sampling step. First, assume that parameter estimates ˆ (1) and b ˆ X t,k (1) have already been obtained via the sampling step described in Section 4.1. Given that for any β ∈ R / { } 0 ,
$$Y _ { 1 }$$
$$\mu _ { r } \stackrel { \dots } { \dots } \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \mathbf Y _ { t, k } & = \mathbf M _ { k } b ( 1 ) X _ { t, k } ( 1 ) + \mathbf v _ { t, k } \\ & = \mathbf M _ { k } ( b ( 1 ) \beta ) ( X _ { t, k } ( 1 ) / \beta ) + \mathbf v _ { t, k } \\ & = \mathbf M _ { k } b ( \beta ) X _ { t, k } ( \beta ) + \mathbf v _ { t, k }, \\ \partial \quad \mathbf v _ { 1 } \vee \partial \, \dots \cdots \cdots \mathbf v _ { 2 } \, \mathbf v _ { 3 } \, \partial \, \mathbf v _ { 4 } \, \partial \, \mathbf v _ { 5 } \, \Delta \, \dots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
we have that b ( β ) = b (1) β and X t,k ( β ) = X t,k (1) /β . Recall that the hidden process X t,k is assumed to be sharp and well calibrated. Therefore, b 3 can be estimated with the value of β that simultaneously maximizes the sharpness and calibration of ˆ X t,k (1) /β . A natural criterion for this maximization is given by the class of proper scoring rules that combine sharpness and calibration [Gneiting et al. (2008), Buja, Stuetzle and Shen (2005)]. Due to the possibility of complete separation in any one question [see, e.g., Gelman et al. (2008)], the maximization must be performed over multiple questions. Therefore,
$$& ( 4. 1 ) & & \hat { \beta } = \arg \max _ { \beta \in \mathbb { R } / \{ 0 \} } \sum _ { k = 1 } ^ { K } \sum _ { t = 1 } ^ { T _ { k } } S ( Z _ { k }, \hat { X } _ { k, t } ( 1 ) / \beta ), \\ & \text{where } Z _ { k } \in \{ 0, 1 \} \text{ is the event indicator for question $k$. The funct}.$$
where Z k ∈{ 0 1 , } is the event indicator for question k . The function S is a strictly proper scoring rule such as the negative Brier score [Brier (1950)]
$$S _ { \text{BRI} } ( Z, X ) = - ( Z - \text{logit} ^ { - 1 } ( X ) ) ^ { 2 } \\ \text{nio core } [ \text{Coord } ( 1 0 5 ) ]$$
or the logarithmic score [Good (1952)]
$$S _ { \text{LOG} } ( Z, X ) = Z \log ( \text{git} ^ { - 1 } ( X ) ) + ( 1 - Z ) \log ( 1 - \text{git} ^ { - 1 } ( X ) ). \\ \text{The attempt of the uncomtant modal random rate are than vision}$$
The estimates of the unconstrained model parameters are then given by
$$\ n s t r a i n e d \ \text{model param} \\ \hat { X } _ { t, k } & = \hat { X } _ { k, t } ( 1 ) / \hat { \beta }, \\ \hat { b } & = \hat { b } ( 1 ) \hat { \beta }, \\ \hat { \tau } _ { k } ^ { 2 } & = \hat { \tau } _ { k } ^ { 2 } ( 1 ) / \hat { \beta } ^ { 2 }, \\ \hat { \sigma } _ { k } ^ { 2 } & = \hat { \sigma } _ { k } ^ { 2 } ( 1 ), \\ \hat { \gamma } _ { k } & = \hat { \gamma } _ { k } ( 1 ). \\ \hat { \tau } _ { k } ^ { 2 } \ \text{and} \ \gamma _ { k } \ \text{are not affect}$$
Notice that estimates of σ 2 k and γ k are not affected by the constraint.
5. Synthetic data results. This section uses synthetic data to evaluate how accurately the SAC-procedure captures the hidden states and bias vector. The hidden process is generated from standard Brownian motion. More specifically, if Z t,k denotes the value of a path at time t , then
$$Z _ { k } & = \mathbb { 1 } ( Z _ { T _ { k }, k } > 0 ), \\ X _ { t, k } & = \log \text{t} \left [ \Phi \left ( \frac { Z _ { t, k } } { \sqrt { T _ { k } - t } } \right ) \right ] \\ \colon T _ { k } & \text{calibrated } \log \text{pit probabilities for}$$
gives a sequence of T k calibrated logit probabilities for the event Z k = 1. A hidden process is generated for K questions with a time horizon of T k = 101. The questions involve 50 experts allocated evenly among five expertise groups. Each expert gives one probability forecast per day with the exception of time t = 101 when the event resolves. The forecasts are generated by applying bias and noise to the hidden process as described by (3.1). Our simulation study considers a three-dimensional grid of parameter values:
$$\succeq \begin{matrix} \succeq \\ \sigma ^ { 2 } \in \{ 1 / 2, 1, 3 / 2, 2, 5 / 2 \}, \\ \beta \in \{ 1 / 2, 3 / 4, 1, 4 / 3, 2 / 1 \}, \\ K \in \{ 2 0, 4 0, 6 0, 8 0, 1 0 0 \}, \\ \end{matrix}$$
where β varies the bias vector by b = [1 / , 2 3 / , 4 1 4 , / , 3 2 / 1] T β . Forty synthetic data sets are generated for each combination of σ 2 , β and K values. The SAC-procedure runs for 200 iterations of which the first 100 are used for burn-in.
$$K \in \{ 2 0, 4 0, 6 0, 8 0, 1 0 0 \}, \\. \quad. \quad. \quad. \quad. \quad. \quad..$$
SAC under the Brier (SAC BRI ) and logarithm score (SAC LOG ) are compared with the Exponentially Weighted Moving Average (EWMA). EWMA, which serves as a baseline, can be understood by first denoting the (expertiseweighted) average forecast at time t for the k th question with
$$\bar { p } _ { t, k } & = \sum _ { j = 1 } ^ { J } \omega _ { j } \left ( \frac { 1 } { | E _ { j } | } \sum _ { i \in E _ { j } } p _ { i, t, k } \right ), \\ \text{who is to one to all overwrite in the $i$} \text{sorted}$$
where E j refers to an index set of all experts in the j th expertise group and ω j denotes the weight associated with the j th expertise group. The EWMA forecasts for the k th problem are then constructed recursively from
$$\hat { p } _ { t, k } ( \alpha ) = \begin{cases} \bar { p } _ { 1, k }, & \text{for $t=1$}, \\ \alpha \bar { p } _ { t, k } + ( 1 - \alpha ) \hat { p } _ { t - 1, k } ( \alpha ), & \text{for $t>1$}, \end{cases} \\ \text{ro $\alpha$ and $\bullet$ or found from $two$ to $minimum cost $b$},$$
where α and ω are learned from the training set by
$$( \hat { \alpha }, \hat { \omega } ) = \arg \min _ { \alpha, \omega _ { j } \in [ 0, 1 ] } \sum _ { k = 1 } ^ { K } \sum _ { t = 1 } ^ { T _ { k } } ( Z _ { k } - \hat { p } _ { t, k } ( \alpha, \omega ) ) ^ { 2 } \quad \text{s.t.} \ \sum _ { j = 1 } ^ { J } \omega _ { j } = 1.$$
Table 3 Summary measures of the estimation accuracy under synthetic data. As EWMA does not produce an estimate of the bias vector, its accuracy on the bias term cannot be reported
| Model | Quadratic loss | Absolute loss |
|---------|------------------------|-----------------|
| SAC BRI | Hidden process 0.00226 | 0.0334 |
| SAC LOG | 0.00200 | 0.0313 |
| EWMA | 0.00225 | 0.0339 |
| SAC BRI | Bias vector 0.147 | 0.217 |
| SAC LOG | 0.077 | 0.171 |
If p t,k =logit -1 ( X t,k ) and ˆ p t,k is the corresponding probability estimated by the model, the model's accuracy to estimate the hidden process is measured with the quadratic loss, ( p t,k -ˆ p t,k ) 2 , and the absolute loss, | p t,k -ˆ p t,k | . Table 3 reports these losses averaged over all conditions, simulations and time points. The three competing methods, SAC BRI , SAC LOG and EWMA, estimate the hidden process with great accuracy. Based on other performance measures that are not shown for the sake of brevity, all three methods suffer from an increasing level of noise in the expert logit probabilities but can make efficient use of extra data.
Some interesting differences emerge from Figure 2 which shows the marginal effect of β on the average quadratic loss. As can be expected, EWMA per-
Fig. 2. The marginal effect of β on the average quadratic loss.
forms well when the experts are, on average, close to unbiased. Interestingly, SAC estimates the hidden process more accurately when the experts are overconfident (large β ) compared to underconfident (small β ). To understand this result, assume that the experts in the third group are highly underconfident. Their logit probabilities are then expected to be closer to zero than the corresponding hidden states. After adding white noise to these expected logit probabilities, they are likely to cross to the other side of zero. If the sampling step fixes b 3 =1, as it does in our case, the third group is treated as unbiased and some of the constrained estimates of the hidden states are likely to be on the other side of zero as well. Unfortunately, this discrepancy cannot be corrected by the calibration step that is restricted to shifting the constrained estimates either closer or further away from zero but not across it. To maximize the likelihood of having all the constrained estimates on the right side of zero and hence avoiding the discrepancy, the reference point in the sampling step should be chosen with care. A helpful guideline is to fix the element of b that is a priori believed to be the largest.
The accuracy of the estimated bias vector is measured with the quadratic loss, ( b j -ˆ ) b j 2 , and the absolute loss, | b j -ˆ b j | . Table 3 reports these losses averaged over all conditions, simulations and elements of the bias vector. Unfortunately, EWMA does not produce an estimate of the bias vector. Therefore, it cannot be used as a baseline for the estimation accuracy in this case. Given that the losses for SAC BRI and SAC LOG are quite small, they estimate the bias vector accurately.
- 6. Geopolitical data results. This section presents results for the realworld data described in Section 2. The goal is to provide application specific insight by discussing the specific research objectives itemized in Section 1. First, however, we discuss two practical matters that must be taken into account when aggregating real-world probability forecasts.
- 6.1. Incoherent and imbalanced data. The first matter regards human experts making probability forecasts of 0.0 or 1.0 even if they are not completely sure of the outcome of the event. For instance, all 166 questions in our data set contain both a zero and a one. Transforming such forecasts into the logit space yields infinities that can cause problems in model estimation. To avoid this, Ariely et al. (2000) suggest changing p = 0 00 . and 1 00 to . p =0 02 and 0 98, respectively. This is similar to . . winsorising that sets the extreme probabilities to a specified percentile of the data [see, e.g., Hastings et al. (1947) for more details on winsorising]. Allard, Comunian and Renard (2012), on the other hand, consider only probabilities that fall within a constrained interval, say, [0 001 0 999], . , . and discard the rest. Given that this implies ignoring a portion of the data, we adopt a censoring approach similar to Ariely et al. (2000) by changing p = 0 00 . and 1 00 to . p = 0 01 . and 0 99, respectively. Our results remain insensitive to the exact choice of .
censoring as long as this is done in a reasonable manner to keep the extreme probabilities from becoming highly influential in the logit space.
The second matter is related to the distribution of the class labels in the data. If the set of occurrences is much larger than the set of nonoccurrences (or vice versa), the data set is called imbalanced . On such data the modeling procedure can end up over-focusing on the larger class and, as a result, give very accurate forecast performance over the larger class at the cost of performing poorly over the smaller class [see, e.g., Chen (2008), Wallace and Dahabreh (2012)]. Fortunately, it is often possible to use a well-balanced version of the data. The first step is to find a partition S 0 and S 1 of the question indices { 1 2 , , . . . , K } such that the equality ∑ k ∈ S 0 T k = ∑ k ∈ S 1 T k is as closely approximated as possible. This is equivalent to an NP-hard problem known in computer science as the Partition Problem : determine whether a given set of positive integers can be partitioned into two sets such that the sums of the two sets are equal to each other [see, e.g., Karmarkar and Karp (1982), Hayes (2002)]. A simple solution is to use a greedy algorithm that iterates through the values of T k in descending order, assigning each T k to the subset that currently has the smaller sum [see, e.g., Kellerer, Pferschy and Pisinger (2004), Gent and Walsh (1996) for more details on the Partition Problem ]. After finding a well-balanced partition, the next step is to assign the class labels such that the labels for the questions in S x are equal to x for x =0 or 1. Recall from Section 4.2 that Z k represents the event indicator for the k th question. To define a balanced set of indicators ˜ Z k for all k ∈ S x , let
$$\tilde { Z } _ { k } & = x, \\ \tilde { p } _ { i, t, k } & = \begin{cases} 1 - p _ { i, t, k }, & \text{ if } Z _ { k } = 1 - x, \\ p _ { i, t, k }, & \text{ if } Z _ { k } = x, \end{cases} \\.., I _ { k }, \text{ and } t = 1, \dots, T _ { k }. \text{ The resulting set}$$
where i =1 , . . . , I k , and t =1 , . . . , T k . The resulting set
$$\{ ( \tilde { Z } _ { k }, \{ \tilde { p } _ { i, t, k } | i = 1, \dots, I _ { k }, t = 1, \dots, T _ { k } \} ) \} _ { k = 1 } ^ { K } \\ \dots \lambda \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{cases}$$
is a balanced version of the data. This procedure was used to balance our real-world data set both in terms of events and time points. The final output splits the events exactly in half ( | S 0 | = | S 1 | =83) such that the number of time points in the first and second halves are 8737 and 8738, respectively.
6.2. Out-of-sample aggregation. The goal of this section is to evaluate the accuracy of the aggregate probabilities made by SAC and several other procedures. The models are allowed to utilize a training set before making aggregations on an independent testing set. To clarify some of the upcoming notation, let S train and S test be index sets that partition the data into training and testing sets of sizes | S train | = N train and | S test | =166 -N train , respectively. This means that the k th question is in the training set if and
only if k ∈ S train . Before introducing the competing models, note that all choices of thinning and burn-in made in this section are conservative and have been made based on pilot runs of the models. This was done to ensure a posterior sample that has low autocorrelation and arises from a converged chain. The competing models are as follows:
- 1. Simple Dynamic Linear Model (SDLM). This is equivalent to the dynamic model from Section 3 but with b = 1 and β =1. Thus,
$$\mathbf Y _ { t, k } & = X _ { t, k } + \mathbf v _ { t, k }, \\ X _ { t, k } & = \gamma _ { k } X _ { t - 1, k } + w _ { t, k },$$
where X t,k is the aggregate logit probability. Given that this model does not share any parameters across questions, estimates of the hidden process can be obtained directly for the questions in the testing set without fitting the model first on the training set. The Gibbs sampler is run for 500 iterations of which the first 200 are used for burn-in. The remaining 300 iterations are thinned by discarding every other observation, leaving a final posterior sample of 150 observations. The average of this sample gives the final estimates.
- 2. The Sample-And-Calibrate procedure both under the Brier (SAC BRI ) and the Logarithmic score (SAC LOG ). The model is first fit on the training set by running the sampling step for 3000 iterations of which the first 500 iterations are used for burn-in. The remaining 2500 observations are thinned by keeping every fifth observation. The calibration step is performed for the final 500 observations. The out-of-sample aggregation is done by running the sampling step for 500 iterations with each consecutive iteration reading in and conditioning on the next value of β and b found during the training period. The first 200 iterations are used for burn-in. The remaining 300 iterations are thinned by discarding every other observation, leaving a final posterior sample of 150 observations. The average of this sample gives the final estimates.
- 3. A fully Bayesian version of SAC LOG (BSAC LOG ). Denote the calibrated logit probabilities and event indicators across all K questions with X (1) and Z , respectively. The posterior distribution of β conditional on X (1) is given by p β ( | X (1) , Z ) ∝ p ( Z | β, X (1)) p β ( | X (1)). The likelihood is
$$. 1 ) & \quad \in \prod _ { k = 1 } ^ { K } \prod _ { t = 1 } ^ { T _ { k } } \log i t ^ { - 1 } ( X _ { t, k } ( 1 ) / \beta ) ^ { Z _ { k } } ( 1 - \log i t ^ { - 1 } ( X _ { t, k } ( 1 ) / \beta ) ) ^ { 1 - Z _ { k } }. \\ \text{As in Gelman et al. (2003). the prior for $\beta$ is chosen to be locally uniform.}$$
$$( 6. 1 ) \, \begin{matrix} p ( \mathbf Z | \beta, \mathbf X ( 1 ) ) \\ \kappa _ { \ } r. \end{matrix}$$
As in Gelman et al. (2003), the prior for β is chosen to be locally uniform, p (1 /β ) ∝ 1. Given that this model estimates X t,k (1) and β simultaneously, it is a little more flexible than SAC. Posterior estimates of β can be sam-
pled from (6.1) using generic sampling algorithms such as the Metropolis algorithm [Metropolis et al. (1953)] or slice sampling [Neal (2003)]. Given that the sampling procedure conditions on the event indicators, the full conditional distribution of the hidden states is not in a standard form. Therefore, the Metropolis algorithm is also used for sampling the hidden states. Estimation is made with the same choices of thinning and burn-in as described under Sample-And-Calibrate .
- 4. Due to the lack of previous literature on dynamic aggregation of expert probability forecasts, the main competitors are exponentially weighted versions of procedures that have been proposed for static probability aggregation:
- (a) Exponentially Weighted Moving Average (EWMA) as described in Section 5.
- (b) Exponentially Weighted Moving Logit Aggregator (EWMLA). This is a moving version of the aggregator ˆ p G ( b ) that was introduced in Satop¨¨ et al. (2014a). The EWMLA aggregate probabilities are aa found recursively from
$$\hat { p } _ { t, k } ( \alpha, \mathbf b ) & = \begin{cases} G _ { 1, k } ( \mathbf b ), & \text{for $t=1$}, \\ \alpha G _ { t, k } ( \mathbf b ) + ( 1 - \alpha ) \hat { p } _ { t - 1, k } ( \alpha, \mathbf b ), & \text{for $t>1$}, \end{cases} \\ \text{where to two vector $ \mathbf b \equiv \mathbb { R } ^ { J } $ collection of those these terms of the entire}.$$
where the vector b ∈ R J collects the bias terms of the expertise groups, and
$$& G _ { t, k } ( \nu ) = \left ( \prod _ { i = 1 } ^ { N _ { t, k } } \left ( \frac { p _ { i, t, k } } { 1 - p _ { i, t, k } } \right ) ^ { b _ { j ( i, k ) } / N _ { t, k } } \right ) \Big / \left ( 1 + \prod _ { i = 1 } ^ { N _ { t, k } } \left ( \frac { p _ { i, t, k } } { 1 - p _ { i, t, k } } \right ) ^ { b _ { j ( i, k ) } / N _ { t, k } } \right ). \\ & \text{The parameters $\alpha$ and $b$ are learned from the training set by}$$
The parameters α and b are learned from the training set by
$$( \hat { \alpha }, \hat { \mathbf b } ) & = \underset { \mathbf b \in \mathbb { R } ^ { 5 }, \alpha \in [ 0, 1 ] } { \arg \min } \sum _ { k \in S _ { \text{train} } } \sum _ { t = 1 } ^ { T _ { k } } ( Z _ { k } - \hat { p } _ { t, k } ( \alpha, \mathbf b ) ) ^ { 2 }. \\ \underset { \mathbf r o n e n t i a l l u } { \text{wield} } \quad W e i a h t e d \quad M o v i n a \quad B e t a { - t r a n s f o r m e d } \quad A a a r e a t$$
- (c) Exponentially Weighted Moving Beta-transformed Aggregator (EWMBA) . The static version of the Beta-transformed aggregator was introduced in Ranjan and Gneiting (2010). A dynamic version can be obtained by replacing G t,k ( ν ) in the EWMLA description with H ν,τ (¯ p t,k ), where H ν,τ is the cumulative distribution function of the Beta distribution and ¯ p t,k is given by (5.1). The parameters α,ν,τ and ω are learned from the training set by
$$( \hat { \alpha }, \hat { \nu }, \hat { \tau }, \hat { \omega } ) = \underset { \nu, \tau > 0 } { \arg \min } \underset { k \in S _ { \text{train} } } { \sum } \underset { t = 1 } { \sum } \underset { k \in S _ { \text{train} } } { \sum } ( Z _ { k } - \hat { p } _ { t, k } ( \alpha, \nu, \tau, \omega ) ) ^ { 2 }$$
$$s. t. \, \sum _ { j = 1 } ^ { J } \omega _ { j } = 1.$$
## Table 4
Brier scores based on 10-fold cross-validation. Scores by Day weighs a question by the number of days the question remained open. Scores by Problem gives each question an equal weight regardless of how long the question remained open. The bolded values indicate the best scores in each column. The values in the parenthesis represent standard errors in the scores
| Model | All | Short | Medium Long |
|----------|-----------------------------|-----------------------------|---------------|
| | Scores by day | | |
| SDLM | 0.100 (0.156) | 0.066 (0.116) 0.098 (0.154) | 0.102 (0.157) |
| BSAC LOG | 0.097 (0.213) 0.053 (0.147) | 0.100 (0.215) | 0.098 (0.215) |
| SAC BRI | 0.096 (0.190) 0.056 (0.134) | 0.097 (0.190) | 0.098 (0.192) |
| SAC LOG | 0.096 (0.191) 0.056 (0.134) | 0.096 (0.189) | 0.098 (0.193) |
| EWMBA | 0.104 (0.204) 0.057 (0.120) | 0.113 (0.205) | 0.105 (0.206) |
| EWMLA | 0.102 (0.199) 0.061 | (0.130) 0.111 (0.214) | 0.103 (0.200) |
| EWMA | 0.111 (0.146) 0.080 | (0.101) 0.116 (0.152) | 0.112 (0.146) |
| | Scores | problem | |
| SDLM | 0.089 (0.116) 0.064 (0.085) | 0.106 (0.141) | 0.092 (0.117) |
| BSAC LOG | 0.083 (0.160) 0.052 (0.103) | 0.110 (0.198) | 0.085 (0.162) |
| SAC BRI | 0.083 (0.142) 0.055 (0.096) | 0.106 (0.174) | 0.085 (0.144) |
| SAC LOG | 0.082 (0.142) 0.055 | (0.096) 0.105 (0.174) | 0.085 (0.144) |
| EWMBA | 0.091 (0.157) 0.057 (0.095) | 0.121 (0.187) | 0.093 (0.164) |
| EWMLA | 0.090 (0.159) 0.064 | (0.109) 0.120 (0.200) | 0.090 (0.159) |
| EWMA | 0.102 (0.108) 0.080 (0.075) | 0.123 (0.130) | 0.103 (0.110) |
The competing models are evaluated via a 10-fold cross-validation 3 that first partitions the 166 questions into 10 sets such that each set has approximately the same number of questions (16 or 17 questions in our case) and the same number of time points (between 1760 and 1764 time points in our case). The evaluation then iterates 10 times, each time using one of the 10 sets as the testing set and the remaining 9 sets as the training set. Therefore, each question is used nine times for training and exactly once for testing. The testing proceeds sequentially one testing question at a time as follows: First, for a question with a time horizon of T k , give an aggregate probability at time t =2 based on the first two days. Compute the Brier score for this probability. Next give an aggregate probability at time t =3 based on the first three days and compute the Brier score for this probability. Repeat this process for all of the T k -1 days. This leads to T k -1 Brier scores per testing question and a total of 17,475 Brier scores across the entire data set.
Table 4 summarizes these scores in different ways. The first option, denoted by Scores by Day , weighs each question by the number of days the question remained open. This is performed by computing the average of the
3 A 5-fold cross-validation was also performed. The results were, however, very similar to the 10-fold cross-validation and hence not presented in the paper.
17,475 scores. The second option, denoted by Scores by Problem , gives each question an equal weight regardless of how long the question remained open. This is done by first averaging the scores within a question and then averaging the average scores across all the questions. Both scores can be further broken down into subcategories by considering the length of the questions. The final three columns of Table 4 divide the questions into Short questions (30 days or fewer), Medium questions (between 31 and 59 days) and Long Problems (60 days or more). The number of questions in these subcategories were 36, 32 and 98, respectively. The bolded scores indicate the best score in each column. The values in the parenthesis quantify the variability in the scores: Under Scores by Day the values give the standard errors of all the scores. Under Scores by Problem , on the other hand, the values represent the standard errors of the average scores of the different questions.
As can be seen in Table 4, SAC LOG achieves the lowest score across all columns except Short where it is outperformed by BSAC LOG . It turns out that BSAC LOG is overconfident (see Section 6.3). This means that BSAC LOG underestimates the uncertainty in the events and outputs aggregate probabilities that are typically too near 0.0 or 1.0. This results into highly variable performance. The short questions generally involved very little uncertainty. On such easy questions, overconfidence can pay off frequently enough to compensate for a few large losses arising from the overconfident and drastically incorrect forecasts.
SDLM, on the other hand, lacks sharpness and is highly underconfident (see Section 6.3). This behavior is expected, as the experts are underconfident at the group level (see Section 6.4) and SDLM does not use the training set to explicitly calibrate its aggregate probabilities. Instead, it merely smooths the forecasts given by the experts. The resulting aggregate probabilities are therefore necessarily conservative, resulting into high average scores with low variability.
Similar behavior is exhibited by EWMA that performs the worst of all the competing models. The other two exponentially weighted aggregators, EWMLA and EWMBA, make efficient use of the training set and present moderate forecasting performance in most columns of Table 4. Neither approach, however, appears to dominate the other. The high variability and average of their performance scores indicate that their performance suffers from overconfidence.
6.3. In- and out-of-sample sharpness and calibration. A calibration plot is a simple tool for visually assessing the sharpness and calibration of a model. The idea is to plot the aggregate probabilities against the observed empirical frequencies. Therefore, any deviation from the diagonal line suggests poor calibration. A model is considered underconfident (or overconfident) if the points follow an S-shaped (or S -shaped) trend. To assess sharpness of the model, it is common practice to place a histogram of the given
Fig. 3. The top and bottom rows show in- and out-of-sample calibration and sharpness, respectively.
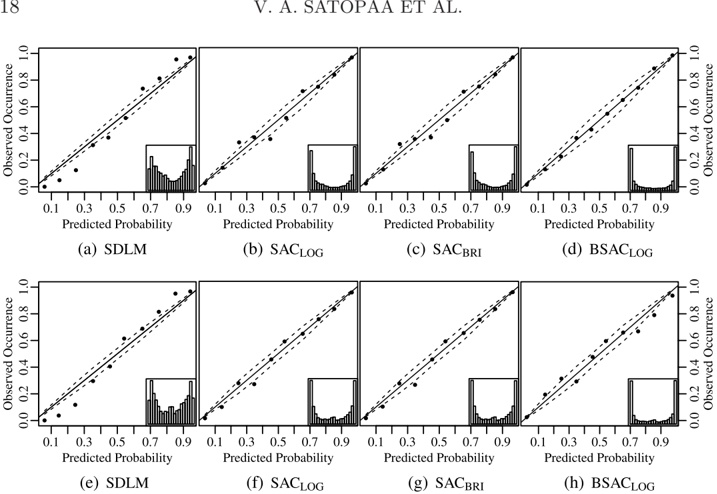
forecasts in the corner of the plot. Given that the data were balanced, any deviation from the the baseline probability of 0.5 suggests improved sharpness.
The top and bottom rows of Figure 3 present calibration plots for SDLM, SAC LOG , SAC BRI and BSAC LOG under in- and out-of-sample probability aggregation, respectively. Each setting is of interest in its own right: Good in-sample calibration is crucial for model interpretability. In particular, if the estimated crowd belief is well calibrated, then the elements of the bias vector b can be used to study the amount of under or overconfidence in the different expertise groups. Good out-of-sample calibration and sharpness, on the other hand, are necessary properties in decision making. To guide our assessment, the dashed bands around the diagonal connect the point-wise, Bonferronicorrected [Bonferroni (1936)] 95% lower and upper critical values under the null hypothesis of calibration. These have been computed by running the bootstrap technique described in Br¨cker and Smith (2007) for 10,000 o iterations. The in-sample predictions were obtained by running the models for 10,200 iterations, leading to a final posterior sample of 1000 observations after thinning and using the first 200 iterations for burn-in. The out-ofsample predictions were given by the 10-fold cross-validation discussed in Section 6.2.
Fig. 4. Posterior distributions of b j for j =1 , . . . , 5 .
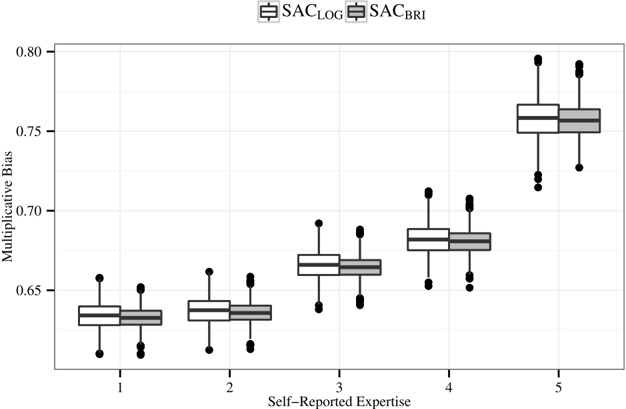
Overall, SAC is sharp and well calibrated both in- and out-of-sample with only a few points barely falling outside the point-wise critical values. Given that the calibration does not change drastically from the top to the bottom row, SAC can be considered robust against overfitting. This, however, is not the case with BSAC LOG that is well calibrated in-sample but presents overconfidence out-of-sample. Figure 3(a) and (e) serve as baselines by showing the calibration plots for SDLM. Given that this model does not perform any explicit calibration, it is not surprising to see most points outside the critical values. The pattern in the deviations suggests strong underconfidence. Furthermore, the inset histogram reveals drastic lack of sharpness. Therefore, SAC can be viewed as a well-performing compromise between SDLM and BSAC LOG that avoids overconfidence without being too conservative.
6.4. Group-level expertise bias. This section explores the bias among the five expertise groups in our data set. Figure 4 compares the posterior distributions of the individual elements of b with side-by-side boxplots. Given that the distributions fall completely below the no-bias reference line at 1.0, all the expertise groups are deemed underconfident. Even though the exact level of underconfidence is affected slightly by the extent to which the extreme probabilities are censored (see Section 6.1), the qualitative results in this section remain insensitive to different levels of censoring.
Figure 4 shows that underconfidence decreases as expertise increases. The posterior probability that the most expert group is the least underconfident
is approximately equal to 1 0, . and the posterior probability of a strictly decreasing level of underconfidence is approximately 0.87. The latter probability is driven down by the inseparability of the two groups with the lowest levels of self-reported expertise. This inseparability suggests that the experts are poor at assessing how little they know about a topic that is strange to them. If these groups are combined into a single group, the posterior probability of a strictly decreasing level of underconfidence is approximately 1.0.
The decreasing trend in underconfidence can be viewed as a process of Bayesian updating. A completely ignorant expert aiming to minimize a reasonable loss function, such as the Brier score, has no reason to give anything but 0.5 as his probability forecast. However, as soon as the expert gains some knowledge about the event, he produces an updated forecast that is a compromise between his initial forecast and the new information acquired. The updated forecast is therefore conservative and too close to 0.5 as long as the expert remains only partially informed about the event. If most experts fall somewhere on this spectrum between ignorance and full information, their average forecast tends to fall strictly between 0.5 and the most informed probability forecast [see Baron et al. (2014) for more details]. Given that expertise is to a large extent determined by subject matter knowledge, the level of underconfidence can be expected to decrease as a function of the group's level of self-reported expertise.
Finding underconfidence in all the groups may seem like a surprising result given that many previous studies have shown that experts are often overconfident [see, e.g., Lichtenstein, Fischhoff and Phillips (1977), Morgan (1992), Bier (2004) for a summary of numerous calibration studies]. It is, however, worth emphasizing three points: First, our result is a statement about groups of experts and hence does not invalidate the possibility of the individual experts being overconfident. To make conclusions at the individual level based on the group level bias terms would be considered an ecological inference fallacy [see, e.g., Lubinski and Humphreys (1996)]. Second, the experts involved in our data set are overall very well calibrated [Mellers et al. (2014)]. A group of well-calibrated experts, however, can produce an aggregate forecast that is underconfident. In fact, if the aggregate is linear, the group is necessarily underconfident [see Theorem 1 of Ranjan and Gneiting (2010)]. Third, according to Erev, Wallsten and Budescu (1994), the level of confidence depends on the way the data were analyzed. They explain that experts' probability forecasts suggest underconfidence when the forecasts are averaged or presented as a function of independently defined objective probabilities, that is, the probabilities given by logit -1 ( X t,k ) in our case. This is similar to our context and opposite to many empirical studies on confidence calibration.
6.5. Question difficulty and other measures. One advantage of our model arises from its ability to produce estimates of interpretable question-specific parameters γ k , σ 2 k and τ 2 k . These quantities can be combined in many interesting ways to answer questions about different groups of experts or the questions themselves. For instance, being able to assess the difficulty of a question could lead to more principled ways of aggregating performance measures across questions or to novel insight on the kinds of questions that are found difficult by experts [see, e.g., a discussion on the Hard-Easy Effect in Wilson (1994)]. To illustrate, recall that higher values of σ 2 k suggest greater disagreement among the participating experts. Given that experts are more likely to disagree over a difficult question than an easy one, it is reasonable to assume that σ 2 k has a positive relationship with question difficulty. An alternative measure is given by τ 2 k that quantifies the volatility of the underlying circumstances that ultimately decide the outcome of the event. Therefore, a high value of τ 2 k can cause the outcome of the event to appear unstable and difficult to predict.
As a final illustration of our model, we return to the two example questions introduced in Figure 1. Given that ˆ σ 2 k =2 43 and ˆ . σ 2 k =1 77 for the questions . depicted in Figure 1(a) and 1(b), respectively, the first question provokes more disagreement among the experts than the second one. Intuitively this makes sense because the target event in Figure 1(a) is determined by several conditions that may change radically from one day to the next while the target event in Figure 1(b) is determined by a relatively steady stock market index. Therefore, it is not surprising to find that in Figure 1(a) ˆ τ 2 k =0 269, . which is much higher than ˆ τ 2 k =0 039 in Figure 1(b). We may conclude that . the first question is inherently more difficult than the second one.
7. Discussion. This paper began by introducing a rather unorthodox but nonetheless realistic time-series setting where probability forecasts are made very infrequently by a heterogeneous group of experts. The resulting data is too sparse to be modeled well with standard time-series methods. In response to this lack of appropriate modeling procedures, we propose an interpretable time-series model that incorporates self-reported expertise to capture a sharp and well-calibrated estimate of the crowd belief. This procedure extends the forecasting literature into an under-explored area of probability aggregation.
Our model preserves parsimony while addressing the main challenges in modeling sparse probability forecasting data. Therefore, it can be viewed as a basis for many future extensions. To give some ideas, recall that most of the model parameters were assumed constant over time. It is intuitively reasonable, however, that these parameters behave differently during different time intervals of the question. For instance, the level of disagreement (represented by σ 2 k in our model) among the experts can be expected to
decrease toward the final time point when the question resolves. This hypothesis could be explored by letting σ 2 t,k evolve dynamically as a function of the previous term σ 2 t -1 ,k and random noise.
This paper modeled the bias separately within each expertise group. This is by no means restricted to the study of bias or its relation to self-reported expertise. Different parameter dependencies could be constructed based on many other expert characteristics, such as gender, education or specialty, to produce a range of novel insights on the forecasting behavior of experts. It would also be useful to know how expert characteristics interact with question types, such as economic, domestic or international. The results would be of interest to the decision-maker who could use the information as a basis for hiring only a high-performing subset of the available experts.
Other future directions could remove some of the obvious limitations of our model. For instance, recall that the random components are assumed to follow a normal distribution. This is a strong assumption that may not always be justified. Logit probabilities, however, have been modeled with the normal distribution before [see, e.g., Erev, Wallsten and Budescu (1994)]. Furthermore, the normal distribution is a rather standard assumption in psychological models [see, e.g., signal-detection theory in Tanner, Wilson and Swets (1954)].
A second limitation resides in the assumption that both the observed and hidden processes are expected to grow linearly. This assumption could be relaxed, for instance, by adding higher order terms to the model. A more complex model, however, is likely to sacrifice interpretability. Given that our model can detect very intricate patterns in the crowd belief (see Figure 1), compromising interpretability for the sake of facilitating nonlinear growth is hardly necessary.
A third limitation appears in an online setting where new forecasts are received at a fast rate. Given that our model is fit in a retrospective fashion, it is necessary to refit the model every time a new forecast becomes available. Therefore, our model can be applied only to offline aggregation and online problems that tolerate some delay. A more scalable and efficient alternative would be to develop an aggregator that operates recursively on streams of forecasts. Such a filtering perspective would offer an aggregator that estimates the current crowd belief accurately without having to refit the entire model each time a new forecast arrives. Unfortunately, this typically implies being less accurate in estimating the model parameters such as the bias term. However, as estimation of the model parameters was addressed in this paper, designing a filter for probability forecasts seems like the next natural development in time-series probability aggregation.
Acknowledgments. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright
annotation thereon. Disclaimer: The views and conclusions expressed herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DoI/NBC or the U.S. Government.
We deeply appreciate the project management skills and work of Terry Murray and David Wayrynen, which went far beyond the call of duty on this project.
## SUPPLEMENTARY MATERIAL
Sampling step (DOI: 10.1214/14-AOAS739SUPP; .pdf). This supplementary material provides a technical description of the sampling step of the SAC-algorithm.
## REFERENCES
Allard, D. , Comunian, A. and Renard, P. (2012). Probability aggregation methods in geoscience. Math. Geosci. 44 545-581. MR2947804
Ariely, D. , Au, W. T. , Bender, R. H. , Budescu, D. V. , Dietz, C. B. , Gu, H. , Wallsten, T. S. and Zauberman, G. (2000). The effects of averaging subjective probability estimates between and within judges. Journal of Experimental Psychology: Applied 6 130-147.
Baars, J. A. and Mass, C. F. (2005). Performance of national weather service forecasts compared to operational, consensus, and weighted model output statistics. Weather and Forecasting 20 1034-1047.
Baron, J. , Mellers, B. A. , Tetlock, P. E. , Stone, E. and Ungar, L. H. (2014). Two reasons to make aggregated probability forecasts more extreme. Decis. Anal. 11 . DOI:10.1287/deca.2014.0293.
Batchelder, W. H. , Strashny, A. and Romney, A. K. (2010). Cultural consensus theory: Aggregating continuous responses in a finite interval. In Advances in Social Computing ( S.-K. Chaim , J. J. Salerno and P. L. Mabry , eds.) 98-107. Springer, Berlin.
Bier, V. (2004). Implications of the research on expert overconfidence and dependence. Reliability Engineering & System Safety 85 321-329.
Bonferroni, C. E. (1936). Teoria Statistica Delle Classi e Calcolo Delle Probabilit´. a Pubblicazioni del R Istituto Superiore di Scienze Economiche e Commerciali di Firenze 8 3-62.
- Brier, G. W. (1950). Verification of forecasts expressed in terms of probability. Monthly Weather Review 78 1-3.
Br¨ ocker, J. and Smith, L. A. (2007). Increasing the reliability of reliability diagrams. Weather and Forecasting 22 651-661.
Buja, A. , Stuetzle, W. and Shen, Y. (2005). Loss functions for binary class probability estimation and classification: Structure and applications. Statistics Department, Univ. Pennsylvania, Philadelphia, PA. Available at http://stat.wharton.upenn.edu/ ~ buja/PAPERS/paper-proper-scoring.pdf .
Carter, C. K. and Kohn, R. (1994). On Gibbs sampling for state space models. Biometrika 81 541-553. MR1311096
- Chen, Y. (2008). Learning classifiers from imbalanced, only positive and unlabeled data sets. Project Report for UC San Diego Data Mining Contest. Dept. Computer Science,
Iowa State Univ., Ames, IA. Available at https://www.cs.iastate.edu/ ~ yetianc/ cs573/files/CS573\_ProjectReport\_YetianChen.pdf .
- Clemen, R. T. and Winkler, R. L. (2007). Aggregating probability distributions. In Advances in Decision Analysis: From Foundations to Applications ( W. Edwards , R. F. Miles and D. von Winterfeldt , eds.) 154-176. Cambridge Univ. Press, Cambridge.
- Cooke, R. M. (1991). Experts in Uncertainty: Opinion and Subjective Probability in Science . Clarendon Press, New York. MR1136548
- Erev, I. , Wallsten, T. S. and Budescu, D. V. (1994). Simultaneous over- and underconfidence: The role of error in judgment processes. Psychological Review 66 519-527.
- Gelman, A. , Carlin, J. B. , Stern, H. S. and Rubin, D. B. (2003). Bayesian data analysis . CRC press, Boca Raton.
- Gelman, A. , Jakulin, A. , Pittau, M. G. and Su, Y.-S. (2008). A weakly informative default prior distribution for logistic and other regression models. Ann. Appl. Stat. 2 1360-1383. MR2655663
- Geman, S. and Geman, D. (1984). Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. Institute of Electrical and Electronics Engineer (IEEE) Transactions on Pattern Analysis and Machine Intelligence 6 721-741.
- Genest, C. and Zidek, J. V. (1986). Combining probability distributions: A critique and an annotated bibliography. Statist. Sci. 1 114-148. MR0833278
- Gent, I. P. and Walsh, T. (1996). Phase transitions and annealed theories: Number partitioning as a case study. In Proceedings of European Conference on Artificial Intelligence (ECAI 1996) 170-174. Wiley, New York.
- Gneiting, T. and Ranjan, R. (2013). Combining predictive distributions. Electron. J. Stat. 7 1747-1782. MR3080409
- Gneiting, T. , Stanberry, L. I. , Grimit, E. P. , Held, L. and Johnson, N. A. (2008). Rejoinder on: Assessing probabilistic forecasts of multivariate quantities, with an application to ensemble predictions of surface winds [MR2434318]. TEST 17 256-264. MR2434326
- Good, I. J. (1952). Rational decisions. J. R. Stat. Soc. Ser. B Stat. Methodol. 14 107-114. MR0077033
- Hastings, C. Jr. , Mosteller, F. , Tukey, J. W. and Winsor, C. P. (1947). Low moments for small samples: A comparative study of order statistics. Ann. Math. Statistics 18 413-426. MR0022335
Hayes, B. (2002). The easiest hard problem. American Scientist 90 113-117.
- Karmarkar, N. and Karp, R. M. (1982). The differencing method of set partitioning. Technical Report UCB/CSD 82/113, Computer Science Division, Univ. California, Berkeley, CA.
Kellerer, H. , Pferschy, U. and Pisinger, D. (2004). Knapsack Problems . Springer, Dordrecht. MR2161720
- Lichtenstein, S. , Fischhoff, B. and Phillips, L. D. (1977). Calibration of Probabilities: The State of the Art. In Decision Making and Change in Human Affairs ( H. Jungermann and G. De Zeeuw , eds.) 275-324. Springer, Berlin.
- Lubinski, D. and Humphreys, L. G. (1996). Seeing the forest from the trees: When predicting the behavior or status of groups, correlate means. Psychology, Public Policy, and Law 2 363.
Mellers, B. , Ungar, L. , Baron, J. , Ramos, J. , Gurcay, B. , Fincher, K. , Scott, S. E. , Moore, D. , Atanasov, P. and Swift, S. A. et al. (2014). Psychological strategies for winning a geopolitical forecasting tournament. Psychological Science 25 . DOI:10.1177/0956797614524255.
Metropolis, N. , Rosenbluth, A. W. , Rosenbluth, M. N. , Teller, A. H. and Teller, E. (1953). Equation of state calculations by fast computing machines. The Journal of Chemical Physics 21 1087-1092.
- Migon, H. S. , Gamerman, D. Lopes, H. F. , and Ferreira, M. A. R. (2005). Dynamic models. In Bayesian Thinking: Modeling and Computation . Handbook of Statist. 25 553-588. Elsevier/North-Holland, Amsterdam. MR2490539
Mills, T. C. (1991). Time series techniques for economists . Cambridge Univ. Press, Cambridge.
Morgan, M. G. (1992). Uncertainty: A Guide to Dealing with Uncertainty in Quantitative Risk and Policy Analysis . Cambridge Univ. Press, Cambridge.
- Murphy, A. H. and Winkler, R. L. (1987). A general framework for forecast verification. Monthly Weather Review 115 1330-1338.
Neal, R. M. (2003). Slice sampling. Ann. Statist. 31 705-767. MR1994729
Pepe, M. S. (2003). The Statistical Evaluation of Medical Tests for Classification and Prediction . Oxford Statistical Science Series 28 . Oxford Univ. Press, Oxford. MR2260483
Primo, C. , Ferro, C. A. , Jolliffe, I. T. and Stephenson, D. B. (2009). Calibration of probabilistic forecasts of binary events. Monthly Weather Review 137 1142-1149.
Raftery, A. E. , Gneiting, T. , Balabdaoui, F. and Polakowski, M. (2005). Using Bayesian model averaging to calibrate forecast ensembles. Monthly Weather Review 133 1155-1174.
Ranjan, R. and Gneiting, T. (2010). Combining probability forecasts. J. R. Stat. Soc. Ser. B Stat. Methodol. 72 71-91. MR2751244
- Sanders, F. (1963). On subjective probability forecasting. Journal of Applied Meteorology 2 191-201.
- Satop¨ a¨, a V. A. , Baron, J. , Foster, D. P. , Mellers, B. A. , Tetlock, P. E. and Ungar, L. H. (2014a). Combining multiple probability predictions using a simple logit model. International Journal of Forecasting 30 344-356.
Satop¨ a¨, V. A. a , Jensen, S. T. , Mellers, B. A. , Tetlock, P. E. and Ungar, L. H. (2014b). Supplement to 'Probability aggregation in time-series: Dynamic hierarchical modeling of sparse expert beliefs.' DOI:10.1214/14-AOAS739SUPP.
Shlyakhter, A. I. , Kammen, D. M. Broido, C. L. , and Wilson, R. (1994). Quantifying the credibility of energy projections from trends in past data: The US energy sector. Energy Policy 22 119-130.
Tanner, J. , Wilson, P. and Swets, J. A. (1954). A decision-making theory of visual detection. Psychological Review 61 401-409.
Tetlock, P. E. (2005). Expert Political Judgment: How Good Is It? How Can We Know? Princeton Univ. Press, Princeton, NJ.
Ungar, L. , Mellers, B. , Satop¨ a¨, V. a , Tetlock, P. and Baron, J. (2012). The good judgment project: A large scale test of different methods of combining expert predictions. In The Association for the Advancement of Artificial Intelligence 2012 Fall Symposium Series , Univ. Pennsylvania, Philadelphia, PA.
Vislocky, R. L. and Fritsch, J. M. (1995). Improved model output statistics forecasts through model consensus. Bulletin of the American Meteorological Society 76 11571164.
Wallace, B. C. and Dahabreh, I. J. (2012). Class probability estimates are unreliable for imbalanced data (and how to fix them). In Institute of Electrical and Electronics Engineers (IEEE) 12th International Conference on Data Mining (International Conference on Data Mining) 695-704. IEEE Computer Society, Washington, DC.
Wallsten, T. S. , Budescu, D. V. and Erev, I. (1997). Evaluating and combining subjective probability estimates. Journal of Behavioral Decision Making 10 243-268.
## V. A. SATOP ¨ ¨ ET AL. AA
Wilson, A. G. (1994). Cognitive factors affecting subjective probability assessment. Discussion Paper 94-02, Institute of Statistics and Decision Sciences, Duke Univ., Chapel Hill, NC.
- Wilson, P. W. , D'Agostino, R. B. , Levy, D. , Belanger, A. M. , Silbershatz, H. and Kannel, W. B. (1998). Prediction of coronary heart disease using risk factor categories. Circulation 97 1837-1847.
- Winkler, R. L. and Jose, V. R. R. (2008). Comments on: Assessing probabilistic forecasts of multivariate quantities, with an application to ensemble predictions of surface winds [MR2434318]. TEST 17 251-255. MR2434325
Winkler, R. L. and Murphy, A. H. (1968). 'Good' probability assessors. Journal of Applied Meteorology 7 751-758.
Wright, G. , Rowe, G. , Bolger, F. and Gammack, J. (1994). Coherence, calibration, and expertise in judgmental probability forecasting. Organizational Behavior and Human Decision Processes 57 1-25.
V. A. Satop¨¨ aa
S. T. Jensen
Department of Statistics
The Wharton School
University of Pennsylvania
Philadelphia, Pennsylvania 19104-6340
USA
E-mail:
[email protected]
B. A. Mellers
P. E. Tetlock
Department of Psychology
University of Pennsylvania
Philadelphia, Pennsylvania 19104-6340
USA
E-mail:
[email protected]
[email protected]
[email protected]
L. H. Ungar Department of Computer and Information Science University of Pennsylvania Philadelphia, Pennsylvania 19104-6309 USA E-mail: [email protected] | 10.1214/14-AOAS739 | [
"Ville A. Satopää",
"Shane T. Jensen",
"Barbara A. Mellers",
"Philip E. Tetlock",
"Lyle H. Ungar"
] | 2014-08-01T06:22:11+00:00 | 2014-08-01T06:22:11+00:00 | [
"stat.AP"
] | Probability aggregation in time-series: Dynamic hierarchical modeling of sparse expert beliefs | Most subjective probability aggregation procedures use a single probability
judgment from each expert, even though it is common for experts studying real
problems to update their probability estimates over time. This paper advances
into unexplored areas of probability aggregation by considering a dynamic
context in which experts can update their beliefs at random intervals. The
updates occur very infrequently, resulting in a sparse data set that cannot be
modeled by standard time-series procedures. In response to the lack of
appropriate methodology, this paper presents a hierarchical model that takes
into account the expert's level of self-reported expertise and produces
aggregate probabilities that are sharp and well calibrated both in- and
out-of-sample. The model is demonstrated on a real-world data set that includes
over 2300 experts making multiple probability forecasts over two years on
different subsets of 166 international political events. |
1408.0088v2 | ## Probabilistic model of N correlated binary random variables and non-extensive statistical mechanics
Julius Ruseckas ∗
Institute of Theoretical Physics and Astronomy, Vilnius University, A. Goˇtauto 12, LT-01108 Vilnius, Lithuania s
The framework of non-extensive statistical mechanics, proposed by Tsallis, has been used to describe a variety of systems. The non-extensive statistical mechanics is usually introduced in a formal way, thus simple models exhibiting some important properties described by the non-extensive statistical mechanics are useful to provide deeper physical insights. In this article we present a simple model, consisting of a one-dimensional chain of particles characterized by binary random variables, that exhibits both the extensivity of the generalized entropy with q < 1 and a q -Gaussian distribution in the limit of the large number of particles.
## I. INTRODUCTION
There exist a number of systems featuring long-range interactions, long-range memory, and anomalous diffusion, that possess anomalous properties in view of traditional Boltzmann-Gibbs statistical mechanics. Non-extensive statistical mechanics is intended to describe such systems by generalizing the Boltzmann-Gibbs statistics [1-3]. In general, the non-extensive statistical mechanics can be applied to describe the systems that, depending on the initial conditions, are not ergodic in the entire phase space and may prefer a particular subspace which has a scale invariant geometry, a hierarchical or multifractal structure. Concepts related to the non-extensive statistical mechanics have found applications in a variety of disciplines: physics, chemistry, biology, mathematics, economics, and informatics [4-6].
The non-extensive statistical mechanics is based on a generalized entropy [1]
$$S _ { q } = \frac { 1 - \int [ p ( x ) ] ^ { q } d x } { q - 1 } \,,$$
where p x ( ) is a probability density function of finding the system in the state characterized by the parameter x , while q is a parameter describing the non-extensiveness of the system. Entropy (1) is an extension of the Boltzmann-Gibbs entropy
$$S _ { \text{BG} } = - \int p ( x ) \ln p ( x ) d x$$
which is recovered from Eq. (1) in the limit q → 1 [1, 2]. More generalized entropies and distribution functions are introduced in Refs. [7, 8]. Statistics associated to Eq. (1) has been successfully applied to phenomena with the scale-invariant geometry, like in low-dimensional dissipative and conservative maps in the dynamical systems [9-11], anomalous diffusion [12, 13], turbulent flows [14], Langevin dynamics with fluctuating temperature [15, 16], spin-glasses [17], plasma [18] and to the financial systems [19-21].
By maximizing the entropy (1) with the constraints ∫ + ∞ -∞ p x dx ( ) = 1 and
$$\frac { \int _ { - \infty } ^ { + \infty } x ^ { 2 } [ p ( x ) ] ^ { q } d x } { \int _ { - \infty } ^ { + \infty } [ p ( x ) ] ^ { q } d x } = \sigma _ { q } ^ { 2 } \,,$$
where σ 2 q is the generalized second-order moment [22-24], one obtains the q -Gaussian distribution density
$$p _ { q } ( x ) = C \exp _ { q } ( - A _ { q } x ^ { 2 } ) \,.$$
Here exp ( ) is the q · q -exponential function, defined as
$$\exp _ { q } ( x ) \equiv [ 1 + ( 1 - q ) x ] _ { + } ^ { \frac { 1 } { 1 - q } } \,,$$
∗ [email protected]; http://www.itpa.lt/˜ruseckas
glyph[negationslash]
with [ x ] + = x if x > 0, and [ x ] + = 0 otherwise. The q -Gaussian distribution (or distribution very close to it) appears in many physical systems, such as cold atoms in dissipative optical lattices [25], dusty plasma [18], motion of hydra cells [26], and defect turbulence [27]. The q -Gaussian distribution is one of the most important distributions in the nonextensive statistical mechanics. It's importance stems from the generalized central limit theorems [28-30]. According to q -generalized central limit theorem, q -Gaussian can result from a sum of N q -independent random variables. The q -independence is defined in [28] through the q -product [31, 32], and the q -generalized Fourier transform [28]. When q = 1, q -independence corresponds to a global correlation of the N random variables. However, the rigorous definition of q -independence is not transparent enough in physical terms.
glyph[negationslash]
The non-extensive statistical mechanics is introduced in a formal way, starting from the maximization of the generalized entropy [1]. Therefore, simple models providing some degree of intuition about non-extensive statistical mechanics can be useful for understanding it. There has been some effort to create such simple models. In Ref. [33] a system composed of N distinguishable particles, each particle characterized by a binary random variable, has been constructed so that the number of states with non-zero probability grows with the number of particles N not exponentially, but as a power law. For such a system in the limit N → ∞ the ratio S q ( N /N ) is finite not for the Boltzmann-Gibbs entropy but for the generalized entropy with some specific value of q . The starting point in the construction is the Leibnitz triangle, then initial probabilities are redistributed into a small number of all the other possible states, in such a way that the norm is preserved. For example, in the restricted uniform model [33] for a fixed value of N all nonvanishing probabilities are equal. In the proposed models that yield q = 1 there are d +1 no-zero probabilities and the value of q is given by q = 1 -1 /d .
In Refs. [34, 35], the goal has been to construct simple models providing q -Gaussian distributions. As in [33], the models considered in [34] consist of N independent and distinguishable binary variables, each of them having two equally probable states. The models presented in [34] are strictly scale-invariant, however, they do not approach a q -Gaussian form when the number of particles N in the model increases [36]. The situation is different with the models presented in [35]: the two proposed models do approach a q -Gaussian form, the second of them does so by construction. All models in [34, 35], except the last model of [35] are for q ≤ 1. The drawback of the models from Ref. [35] is that the standard Boltzmann-Gibbs entropy remains extensive. In addition, the models are constructed artificially and it is hard to see how they can be related to real physical systems.
glyph[negationslash]
The goal of this paper is to provide a simple model that achieves both the extensivity of the generalized entropy with q = 1 and q -Gaussian distribution in the limit of the large number of particles. In addition, we want to construct a model that is closer to situations in physical systems. We expect that such a model can provide deeper insights into non-extensive statistical mechanics than the previously constructed simple models.
glyph[negationslash]
The paper is organized as follows: To highlight differences from our proposed model, a simple model consisting of uncorrelated binary random variables and leading to extensive Boltzmann-Gibbs entropy and a Gaussian distribution is presented in Section II. In Section III we construct a simple model exhibiting the extensivity of the generalized entropy with q = 1 and q -Gaussian distribution in the limit of the large number of particles. Section IV summarizes our findings.
## II. MODEL OF UNCORRELATED BINARY RANDOM VARIABLES
At first let us consider a model consisting from N uncorrelated binary random variables. Physical implementation of such a model could be N particles of spin 1 2 , the projection of each spin to the z axis can acquire the values ± 1 2 . The microscopic configuration of the system can be described by a sequence of spin projections s s 1 2 . . . s N , where each s i = ± 1 2 . There are W = 2 N different microscopic configurations. As is usual in statistical mechanics for the description of a microcanonical ensemble, we assign to each microscopic configuration the same probability. Thus the probability of each microscopic configuration is
$$P = \frac { 1 } { W } = \frac { 1 } { 2 ^ { N } } \,.$$
Note, that this system has a property of composability: if we have two spin chains with W 1 and W 2 microscopic configurations, then we can join them to form a larger system. The description of a larger system is just concatenation of the descriptions of each subsystems and the number of microscopic configurations of the whole system is W = W W 1 2 . The standard Boltzmann-Gibbs entropy S BG = k B ln W is extensive for this system: S BG = Nk B ln 2 grows linearly with N .
Let us consider a macroscopic quantity, the total spin of the system
$$M = \sum _ { i = 1 } ^ { N } s _ { i } \,.$$
FIG. 1. One-dimensional spin chain having N spins. There are d spin flips, so that the spin chain consists of d +1 domains of spins pointing to the same direction. The lengths of the domains are n , n 1 2 , . . . , n d +1 .
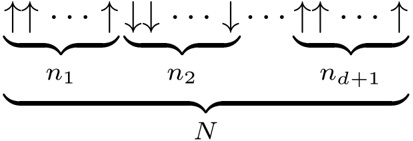
The total spin can take values M = -N 2 , -N 2 + 1 , . . . , N 2 -1 , N 2 . The value of M can be obtained when there are n = M + N 2 spins with the projection + 1 2 , the remaining spins have projection -1 2 . The macroscopic configuration corresponding to the given value of M can be realized by N ! n !( N -n )! microscopic configurations, thus using Eq. (6) the probability of each macroscopic configuration is
$$P _ { M } = \frac { 1 } { 2 ^ { N } } \frac { N! } { n! ( N - n )! } \,.$$
Note, that the probabilities of macroscopic configurations are normalized:
$$\sum _ { M = - N } ^ { N } P _ { M } = 1 \,.$$
Using Eq. (8) we can calculate the average spin of the system 〈 M 〉 = 0 and the standard deviation
$$\mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ {\ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \\ \sqrt { \langle M ^ { 2 } \rangle } - \langle M ^ { 2 } \rangle \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \mu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ { \ } \nu _ }$$
From Eq. (10) it follows that the relative width of the distribution of the total spin M decreases with number of spins N as 1 √ N . When N is large then we can approximate the factorials using Stirling formula
$$n! & \approx \sqrt { 2 \pi n } n ^ { n } e ^ { - n }$$
and obtain a Gaussian distribution
$$P _ { M } & \approx \frac { 1 } { \sqrt { \pi \frac { N } { 2 } } } e ^ { - \frac { 2 M ^ { 2 } } { N } }$$
The Gaussian distribution can be obtained by maximizing the Boltzmann-Gibbs entropy (2) with appropriate constraints.
## III. MODEL OF CORRELATED SPINS
In this Section we investigate a system consisting from N correlated binary random variables. Similarly as in the previous Section, we can think about a one-dimensional spin chain consisting from N spins. However, the spins are correlated: spins next to each other have almost always the same direction, except there are d cases when the next spin has an opposite direction, as is shown in Fig. 1. Thus the spin chain consists from d + 1 domains with spins pointing in the same direction and has d boundaries between domains. This model is inspired by a connection between non-extensive statistics and critical phenomena [37-39]. As it has been shown in Refs. [37-39], the properties of a single large cluster of the order parameter at a critical point in thermal systems can be described by non-extensive statistics. The restriction of the number of allowed states in our model is very similar to the models presented in [33].
Let us calculate the number of allowed microscopic configurations of the spin chain. If the length of i -th domain is n i then we need to calculate the number of possible partitions such that
$$\sum _ { i = 1 } ^ { d + 1 } n _ { i } & = N \,.$$
FIG. 2. Dependence of the generalized entropy S q on the number of particles N in the spin chain for various values of q . The number of domain walls d = 4. Only for q = q stat = 1 -1 /d = 0 75 the limit lim . N →∞ S q ( N /N ) has a finite value; the limit vanishes (diverges) for q > 0 75 ( . q < 0 75). .
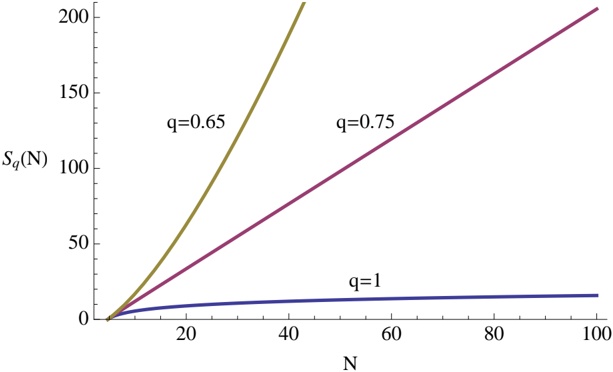
This number is equivalent to the number of ways one can place d domain boundaries into N -1 possible positions. Since the spins in the first domain can be up or down, the number of microscopic configurations is twice as large. Thus the number of allowed microscopic configurations of the spin chain is
$$W = \frac { 2 ( N - 1 )! } { d! ( N - d - 1 )! } = \frac { 2 } { d! } ( N - 1 ) \cdots ( N - d ) \,.$$
For large N glyph[greatermuch] d we have that the number of microscopic configurations grows as a power-law of the number of spins, not exponentially:
$$W & \sim \frac { 2 } { d! } N ^ { d } \,.$$
Assigning to each allowed microscopic configuration the same probability P = 1 /W we get that in this situation the traditional Boltzmann-Gibbs entropy is not linearly proportional to N and thus is not extensive. The generalized entropy Eq. (1) for equal probabilities 1 /W takes the form
$$S _ { q } = k _ { B } \frac { 1 - W ^ { 1 - q } } { q - 1 } \,.$$
Using Eqs. (15) and (16) on gets that the generalized entropy is extensive (proportional to N ) only when q is
$$q _ { \text{stat} } & = 1 - \frac { 1 } { d } \,.$$
This is the same dependency of q on d as in [33].
In Fig. 2 the dependence of the generalized entropy (16) on the size N of the spin chain for various values of q is shown. As one can see, only for q = q stat the limit lim N →∞ S /N q is finite, this limit vanishes or diverges for all other values of q . Thus our simple model can be characterized by the generalized entropy with q < 1.
Now let us consider the macroscopic variable, the total spin M . If there are d +1 domains and the total spin is M then we have the equality
$$s _ { 1 } \sum _ { i = 1 } ^ { d + 1 } ( - 1 ) ^ { i - 1 } n _ { i } = M \,.$$
Eq. (18) can be written as
$$N _ { \text{odd} } - N _ { \text{even} } = \frac { M } { s _ { 1 } } \,,$$
where is the total length of odd-numbered domains,
$$N _ { \text{even} } = \sum _ { k = 1 } ^ { \lfloor \frac { d + 1 } { 2 } \rfloor } n _ { 2 k }$$
is the total length of even-numbered domains. Here glyph[floorleft]·glyph[floorright] denotes an integer part of a number. In addition, the total lengths of odd- and even-numbered domains should obey the equation
$$N _ { \text{odd} } + N _ { \text{even} } = N \,.$$
Eqs. (19) and (22) have only one solution
$$N _ { \text{odd} } = \frac { 1 } { 2 } \left ( N + \frac { M } { s _ { 1 } } \right ) \,, \quad N _ { \text{even} } = \frac { 1 } { 2 } \left ( N - \frac { M } { s _ { 1 } } \right ) \,.$$
The total length of odd-numbered domains N odd is a sum of ⌊ d 2 ⌋ +1 terms, the total length of even-numbered domains N even is a sum of ⌊ d +1 2 ⌋ terms. Similarly as in Eq. (14), the number of ways to choose n , n 1 2 , . . . , n d +1 is equal to the number of ways to place ⌊ d 2 ⌋ domain boundaries into N odd -1 positions multiplied by the number of ways to place ⌊ d +1 2 ⌋ -1 domain boundaries into N even -1 positions. Thus the number of ways to choose the domain lengths when M N , and s 1 are given is
$$W ( N, M, s _ { 1 } ) = \frac { 1 } { ( [ \frac { d } { 2 } ] )! } \left ( N _ { \text{odd} } - 1 \right ) \cdots \left ( N _ { \text{odd} } - \left \lfloor \frac { d } { 2 } \right \rfloor \right ) \frac { 1 } { ( [ \frac { d - 1 } { 2 } ] )! } \left ( N _ { \text{even} } - 1 \right ) \cdots \left ( N _ { \text{even} } - \left \lfloor \frac { d - 1 } { 2 } \right \rfloor \right ).$$
The number of microscopic configurations corresponding to a given value of M is
$$W ( N, M ) = \sum _ { s _ { 1 } = \pm 1 / 2 } W ( N, M, s _ { 1 } ) \,.$$
Using Eqs. (23)-(25) we obtain that the number of microscopic configurations corresponding to a given value of M is
$$W ( N, M ) = \frac { 1 } { 2 ^ { d - 2 } \left [ \left ( \frac { d - 1 } { 2 } \right )! \right ] ^ { 2 } } \left ( ( N - 2 ) ^ { 2 } - 4 M ^ { 2 } \right ) \cdots \left ( ( N - ( d - 1 ) ) ^ { 2 } - 4 M ^ { 2 } \right )$$
when d is odd and
$$W ( N, M ) = \frac { ( N - d ) } { 2 ^ { d - 2 } \frac { d } { 2 } \left [ \left ( \frac { d } { 2 } - 1 \right )! \right ] ^ { 2 } } \left ( ( N - 2 ) ^ { 2 } - 4 M ^ { 2 } \right ) \cdots \left ( ( N - ( d - 2 ) ) ^ { 2 } - 4 M ^ { 2 } \right )$$
when d is even. When N glyph[greatermuch] d then Eqs. (26) and (27) can be approximated as
$$W ( N, M ) \approx \frac { N ^ { d - 1 } } { 2 ^ { d - 2 } \left ( \lfloor \frac { d } { 2 } \rfloor \right )! \left ( \lfloor \frac { d - 1 } { 2 } \rfloor \right )! } \left ( 1 - \frac { 4 M ^ { 2 } } { N ^ { 2 } } \right ) ^ { \lfloor \frac { d - 1 } { 2 } \rfloor } \,.$$
Instead of the total spin M it is convenient to consider a scaled variable
$$x = \frac { 2 M } { N } \,.$$
From Eq. (28) we get that the distribution P x ( x ) of the variable x for large N is proportional to
$$P _ { x } ( x ) \in ( 1 - x ^ { 2 } ) ^ { \left \lfloor \frac { d - 1 } { 2 } \right \rfloor } \,.$$
$$N _ { \text{odd} } & = \sum _ { k = 0 } ^ { \lfloor \frac { d } { 2 } \rfloor } n _ { 1 + 2 k }$$
FIG. 3. Comparison of numerically obtained histogram of total spin M (gray area) with q -Gaussian distribution (solid red line). The histogram is calculated using an ensemble of randomly generated spin chains that have the length N = 1000 spins and d = 5 spin flips. The q -Gaussian distribution is given by Eq. (32) with x q = N/ 2.
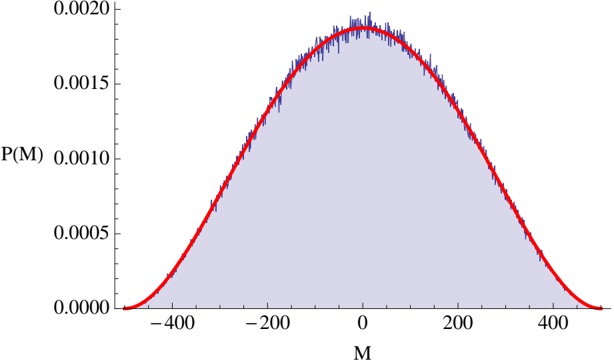
When q < 1 then the q -Gaussian distribution (4) has compact support, the range of possible values of x is limited by the condition | x | glyph[lessorequalslant] x q , where
$$x _ { q } = \frac { 1 } { \sqrt { ( 1 - q ) A _ { q } } } \,.$$
Using the limiting value x q the expression (4) for the q -Gaussian distribution takes the form
$$p _ { q } ( x ) = \frac { \Gamma \left ( \frac { 5 - 3 q } { 2 ( 1 - q ) } \right ) } { \sqrt { \pi } x _ { q } \Gamma \left ( \frac { 2 - q } { 1 - q } \right ) } \left [ 1 - \frac { x ^ { 2 } } { x _ { q } ^ { 2 } } \right ] _ { + } ^ { \frac { 1 } { 1 - q } }.$$
By rescaling the variable x the expression (32) for q -Gaussian distribution in the case of q < 1 can be written as
$$p _ { q } ( x ) \in ( 1 - x ^ { 2 } ) ^ { \frac { 1 } { 1 - q } } \,.$$
Comparing Eq. (30) with Eq. (33) we see that the distribution of the total spin M in our model in the limit of large number of spins N is a q -Gaussian with
$$q _ { \text{dist} } & = 1 - \frac { 1 } { \left [ \frac { d - 1 } { 2 } \right ] } \,.$$
Comparison of the histogram of the total spin M , calculated using an ans amble of randomly generated spin chains, with a q -Gaussian distribution (32) is shown in Fig. 3. We see that the q -Gaussian describes the distribution of the total spin very well. By increasing the number of spin flips d , both q stat and q dist approaches the value of 1, as follows from Eqs. (17) and (34). In the limit of d →∞ the distribution of total spin becomes Gaussian.
From Eqs. (17) and (34) follows the relationship between the two q values:
$$\frac { 1 } { 1 - q _ { \text{dist} } } = \left \lfloor \frac { 1 } { 2 } \left ( \frac { 1 } { 1 - q _ { \text{stat} } } - 1 \right ) \right \rfloor \,.$$
This equation is similar to relations presented in Eq. (18) of Ref. [40], in the footnote in page 15378 of Ref. [33], and Eq. (5) in Ref. [41].
## IV. DISCUSSION
Our simple model of a spin chain exhibits both non-extensive behavior of Boltzmann-Gibbs entropy and q -Gaussian distribution of the total spin. This is in contrast to the other models involving N binary random variables: the
glyph[negationslash]
models presented in [33] demonstrate that the generalized entropy with q = 1 can be extensive, but they do not provide q -Gaussian distribution, whereas the models from Ref. [35] yield q -Gaussians but for them the BoltzmannGibbs entropy is extensive. Thus the model, presented in this paper, is an improvement over earlier models and may provide deeper insights into non-extensive statistical mechanics.
By comparing the model with the chain of uncorrelated spins, presented in Section II, we see that the reason for the non-extensivity of Boltzmann-Gibbs entropy and the extensivity of the generalized entropy is the reduction of the number of allowed microscopic configurations, resulting from the restriction of the number of allowed spin flips. Similar reason is behind the differences in the distribution of the total spin M : the number of possible configurations having N odd spins pointing in one direction and N even spins in the opposite direction in the chain of uncorrelated spins is the exponential function of N odd N even , resulting in the Gaussian function of M . When the number of spin flips is restricted, the number of configurations is a power-law function of N odd N even , resulting in the q -Gaussian.
The model can be slightly modified by requiring that the number of spin flips is not constant, but can be a random number not larger than d . Since the number of microscopic configurations having d spin flips grows as N d , the contribution of configurations with smaller number of spin flips becomes negligible in the limit of large N . Thus the conclusions of Section III remain valid also for this modified model.
Note, that the values of q obtained from the entropy (17) and from the distribution (34) are different. This difference is not surprising and is similar to the q -triplet in the non-extensive statistical mechanics. Usually the systems described by the non-extensive statistical mechanics have three different values of q , the q -triplet [1]. This triplet consist from the values of q , ( q sen , q rel , q stat ) obtained from the sensitivity to the initial conditions, the relaxation in phase-space, and the distribution of energies at a stationary state [1]. Since our model does not involve the energy and there is no evolution in time, we have obtained only two values q . It would be interesting task for the future to extend the model and get the full q -triplet.
The model presented here provides q -Gaussian distribution with q < 1. Thus another open question is whether it is possible to modify the model to obtain q -Gaussian distribution with q > 1.
- [1] C. Tsallis, Introduction to Nonextensive Statistical Mechanics - Approaching a Complex World (Springer, New York, 2009).
- [2] C. Tsallis, Braz. J. Phys. 39 , 337 (2009).
- [3] L. Telesca, Tectonophysics 494 , 155 (2010).
- [4] C. M. Gell-Mann and C. Tsallis, Nonextensive Entropy-Interdisciplinary Applications (Oxford University Press, NY, 2004).
- [5] S. Abe, Astrophys. Space Sci. 305 , 241 (2006).
- [6] S. Picoli, R. S. Mendes, L. C. Malacarne, and R. P. B. Santos, Braz. J. Phys. 39 , 468 (2009).
- [7] R. Hanel and S. Thurner, EPL 93 , 20006 (2011).
- [8] R. Hanel, S. Thurner, and M. Gell-Mann, PNAS 108 , 6390 (2011).
- [9] O. Afsar and U. Tirnakli, EPL 101 , 20003 (2013).
- [10] U. Tirnakli, C. Tsallis, and C. Beck, Phys. Rev. E 79 , 056209 (2009).
- [11] G. Ruiz, T. Bountis, and C. Tsallis, Int. J. Bifurcation Chaos 22 , 1250208 (2012).
- [12] Z. Huang, G. Su, A. El Kaabouchi, Q. A. Wang, and J. Chen, J. Stat. Mech. 2010 , L05001 (2010).
- [13] J. Prehl, C. Essex, and K. H. Hoffman, Entropy 14 , 701 (2012).
- [14] C. Beck and S. Miah, Phys. Rev. E 87 , 031002 (2013).
- [15] A. A. Budini, Phys. Rev. E 86 , 011109 (2012).
- [16] J.-L. Du, J. Stat. Mech. 2012 , P02006 (2012).
- [17] R. M. Pickup, R. Cywinski, C. Pappas, B. Farago, and P. Fouquet, Phys. Rev. Lett. 102 , 097202 (2009).
- [18] B. Liu and J. Goree, Phys. Rev. Lett. 100 , 055003 (2008).
- [19] L. Borland, Quantit. Finance 12 , 1367 (2012).
- [20] S. Drozdz, J. Kwapien, P. Oswiecimka, and R. Rak, New J. Phys. 12 , 105003 (2010).
- [21] V. Gontis, J. Ruseckas, and A. Kononovicius, Physica A 389 , 100 (2010).
- [22] C. Tsallis, A. R. Plastino, and R. S. Mendes, Physica A 261 , 534 (1998).
- [23] D. Prato and C. Tsallis, Phys. Rev. E 60 , 2398 (1999).
- [24] C. Tsallis, Braz. J. Phys 29 , 1 (1999).
- [25] P. Douglas, S. Bergamini, and F. Renzoni, Phys. Rev. Lett. 96 , 110601 (2006).
- [26] A. Upaddhyaya, J. P. Rieu, J. A. Glazier, and Y. Sawada, Physica A 293 , 459 (2001).
- [27] K. E. Daniels, C. Beck, and E. Bodenschatz, Physica D 193 , 208 (2004).
- [28] S. Umarov, C. Tsallis, and S. Steinberg, Milan J. Math. 76 , 307 (2008).
- [29] S. Umarov, C. Tsallis, M. Gell-Mann, and S. Steinberg, J. Math. Phys. 51 , 033502 (2010).
- [30] S. Umarov and C. Tsallis, in Complexity, Metastability and Nonextensivity , American Institute of Physics Conference Proceedings, Vol. 965, edited by S. Abe, H. Herrmann, P. Quarati, A. Rapisarda, and C. Tsallis (New York, 2007) pp. 34-42.
- [31] L. Nivanen, A. Le Mehaute, and Q. A. Wang, Rep. Math. Phys. 52 , 437 (2003).
- [32] E. P. Borges, Physica A 340 , 95 (2004).
- [33] C. Tsallis, M. Gell-Mann, and Y. Sato, Proc. Natl. Acad. Sc. USA 102 , 15377 (2005).
- [34] L. G. Moyano, C. Tsallis, and M. Gell-Mann, Europhys. Lett. 73 , 813 (2006).
- [35] A. Rodriguez, V. Schwammle, and C. Tsallis, J. Stat. Mech. 2008 , P09006 (2008).
- [36] H. J. Hilhorst and G. Schehr, J. Stat. Mech. 2007 , P06003 (2007).
- [37] A. Robledo, Phys. Rev. Lett. 83 , 2289 (1999).
- [38] A. Robledo, Mol. Phys. 103 , 3025 (2005).
- [39] A. Robledo, Int. J. Mod. Phys. B 21 , 3947 (2007).
- [40] G. Ruiz and C. Tsallis, Phys. Lett. A 376 , 2451 (2012).
- [41] A. Celikoglu, U. Tirnakli, and S. Queir´s, Phys. Rev. E o 82 , 021124 (2010). | null | [
"Julius Ruseckas"
] | 2014-08-01T06:23:30+00:00 | 2014-08-05T12:32:03+00:00 | [
"cond-mat.stat-mech"
] | Probabilistic model of N correlated binary random variables and non-extensive statistical mechanics | The framework of non-extensive statistical mechanics, proposed by Tsallis,
has been used to describe a variety of systems. The non-extensive statistical
mechanics is usually introduced in a formal way, thus simple models exhibiting
some important properties described by the non-extensive statistical mechanics
are useful to provide deeper physical insights. In this article we present a
simple model, consisting of a one-dimensional chain of particles characterized
by binary random variables, that exhibits both the extensivity of the
generalized entropy with q<1 and a q-Gaussian distribution in the limit of the
large number of particles. |
1408.0089v2 | Modern Physics Letters B c
- © World Scientific Publishing Company
## LATTICE GAUGE THEORY FOR CONDENSED MATTER PHYSICS: FERROMAGNETIC SUPERCONDUCTIVITY AS ITS EXAMPLE
## IKUO ICHINOSE
Department of Applied Physics, Nagoya Institute of Technology, Nagoya, 466-8555, Japan
## TETSUO MATSUI
Department of Physics, Kinki University, Higashi-Osaka, 577-8502, Japan
Received (Day Month Year) Revised (Day Month Year)
Recent theoretical studies of various strongly-correlated systems in condensed matter physics reveal that the lattice gauge theory(LGT) developed in high-energy physics is quite a useful tool to understand physics of these systems. Knowledges of LGT are to become a necessary item even for condensed matter physicists. In the first part of this paper, we present a concise review of LGT for the reader who wants to understand its basics for the first time. For illustration, we choose the abelian Higgs model, a typical and quite useful LGT, which is the lattice verison of the Ginzburg-Landau model interacting with a U(1) gauge field (vector potential). In the second part, we present an account of the recent progress in the study of ferromagnetic superconductivity (SC) as an example of application of LGT to topics in condensed matter physics, . As the ferromagnetism (FM) and SC are competing orders with each other, large fluctuations are expected to take place and therefore nonperturbative methods are required for theoretical investigation. After we introduce a LGT describing the FMSC, we study its phase diagram and topological excitations (vortices of Cooper pairs) by Monte-Carlo simulations.
Keywords : Lattice gauge theory; Strongly-correlated systems; Ginzburg-Landau theory; Ferromagnetic superconductivity; Monte-Carlo simulation; Path-integral
## 1. Introduction
A strongly-correlated system is a set of either fermions or bosons which interact strongly each other. Such a system may exhibit collective behaviors that cannot be expected from the behaviors of each single particle, and has been the subject of great interest in various fields of condensed matter physics. For example, the t -J model, which is a typical model of electrons interacting via strong Coulomb repulsion, is taken as a standard model of high-temperature superconductors 1 . Another example is the Bose Hubbard model 3 and the related bosonic t -J model 4 , which are to be used to study cold bosonic atoms put on an optical lattice 5 and tuned to have
2
large interaction parameters. In the last two decades, theoretical approach using gauge theory and the associated concepts has proved itself a convincing way to understand essentials of their physics 6 7 . ,
The gauge theory put on a spatial lattice (and even on the imaginary discrete time in the path-integral formalism) is known as lattice gauge theory (LGT), which is introduced by Wilson in 1974 as a model of quark confinement 8 . Since then, it has contributed to increase our knowledges not only of quantum chromodynamics (QCD) itself, but also of nonperturbative aspects of general quantum field theory 9 . The reason to consider a lattice instead of the usual continuum space is to reduce the degrees of freedom from uncountable infinity to countable infinity, which allows us a concrete definition of the field theory in the nonperturbative region and also ways to examine it such as the strong-coupling (high-temperature) expansion. Concerning to the global phase structure, LGT shows, in addition to the ordinary Coulomb phase and Higgs phase of gauge dynamics (they are sometimes called deconfinement phases), the existence of so called confinement phase. This phase was crucial to explain confinement of quarks 8 , one of the longstanding problem in high-energy physics, because, in the confinement phase, the potential energy V ( r ) between a pair of static quark and anti-quark separated by the distance r increases linearly in r and costs infinite energy to separate them ( r →∞ ). These three phases are classified by the magnitude of fluctuations of gauge field (See Table I below). The gauge field put on the lattice can be treated as periodic variables (one calls this case a compact gauge field; see Sect.2.1), and the gauge-field configurations reflecting this periodicity may involve large spatial variations beyond the conventional perturbative ones. Monopoles are a typical and important example of such configurations (monopoles in the continuum gauge theory cost infinite energy and so not possible). In the confinement phase, such monopoles condense 10 , and the resulting strong fluctuations of gauge field are argued to generate squeezed one-dimensional line of electric flux (variables conjugate the the gauge field itself). Then, in the confinement phase, such an electric flux gives rise to the linearly-rising confining potential. This phenomenon of formation of electric fluxes is sometimes called the 'dual' Meissner effect in contrast to the Meissner effect in ordinary superconductors where magnetic field is squeezed into magnetic fluxes due to Cooper-pair condensation. One way to recognize the relevance of monopoles among other possible (topological) excitations is to perform the duality transformation 11 , which rewrites the system as an ensemble of monopoles or monopole loops.
Table 1. Three phases of gauge dynamics: V ( r ) is the potential energy stored between a pair of point charges with the opposite signs and separated by the distance r .
| hase | fluctuation of gauge field | potential energy V ( r ) |
|-------------|------------------------------|----------------------------|
| Higgs | small | ∝ exp( - mr ) r |
| Coulomb | medium | ∝ 1 r |
| Confinement | large | ∝ r |
Also, in some restricted fields of condensed matter physics, LGT has been applied successfully. One example is the t -J model of high-T c superconductivity (SC) 6 . Here the strong correlations are implemented by excluding the double occupancy state of electrons, the state of two electrons with the opposite spin directions occupying the same site, from the physical states. This may be achieved by viewing an electron as a composite of fictitious particles, a so-called holon carrying the charge degree of freedom of the electron and a spinon carrying the spin degree of freedom 12 . By the method of auxiliary field in path-integral, one may introduce U(1) gauge field which binds holon and spinon. Then the possible phases may be classified according to the dynamics of this U(1) gauge field. In the confinement phase, the relevant quasiparticles are the original electrons in which holons and spinons are confined. This corresponds to the state at the overdoped high temperature region. In the deconfinement Coulomb phase, quasiparticles are holons and spinons in which charge and spin degrees of freedom behave independently. This phenomenon is called the charge-spin separation 13 and are to describe the anomalous behavior of the normal state such as the liner-T resistivity. Further correspondence between the gauge dynamics and the observed phases are also satisfactory as discussed in Refs. 1 6 13 . In particular, possibility of experimental observation of , , spinons is discussed in Ref. 2 .
Another application of LGT to relate the dynamics of auxiliary gauge field and the observed phases is the (fractional) Hall effect 14 . Among a couple of parallel formulations 15 , one may view an electron as a composite of a so called bosonic fluxon carrying fictitious (Chern-Simons) gauge flux and a so called fermionic chargon carrying the electric charge 7 . In the deconfinement phase, these fluxons and chargons are separated, i.e., particle-flux separation takes place. If fluxons Bose condense at sufficiently low temperatures, the resulting system is fermionic chargons in a reduced uniform magnetic field. These chargons are nothing but the Jain's composite fermions, and the integer Hall effect of them explain the fractional Hall effect of the original electron system.
In this paper, we shall see yet another example of LGT approach to condensed matter physics. Namely, we consider a lattice model of ferromagnetic SC, which exhibits the ferromagnetism (FM) and/or SC, two typical and important phenomena in condensed matter physics. We note here that the introduction of a spatial lattice in the original LGT in high-energy theory is traced back, as mentioned, to the necessity to define a nonperturbative field theory. The lattice spacing there should be taken as a running cutoff(scale) parameter in the renormalization-group theory 18 and the continuum limit should be taken carefully. However, in condensed matter physics, introduction of a lattice has often a practical support independent of the above meaning, i.e., the system itself has a lattice structure. One may naturally regard the lattice of the model as the real lattice of material in question. In this paper, we shall not touch the continuum limit in the sense of renormalization group.
The layout of the paper is as follows: In Sect. 2, we review LGT. The reader who is not familiar with this subject may acquire necessary knowledge to understand
## 4 I.Ichinose and T.Matsui
Fig. 1. i -j plane of the 3d lattice and ˆ φ r defined on the site r and ˆ θ ri and ˆ E ri defined on the link ( ri ) = ( r, r + ). i
the successive sections. In Sect. 3, we explain the lattice model of ferromagnetic superconductivity (FMSC). It is based on the known Ginzburg-Landau theory defined in the continuum space. In Sect. 4, we present numerical results of Monte Carlo simulations for the lattice model in Sect. 3. In Sect. 5, we give conclusion.
## 2. Introduction to lattice gauge thoery
Formulating field-theoretical models by using space(-time) lattice is quite useful for studying their properties nonperturbatively. In particular, because of the lattice formulation itself, the high-temperature expansion (strong-coupling expansion) can be performed analytically even for the case in which fluctuations of the fields are very strong. Furthermore, numerical studies like the Monte-Carlo simulation can be applicable for wide range of the lattice field theories. In this section, we review LGT consisting of a U(1) gauge field and a charged bosonic matter field.
## 2.1. Lattice gauge theory in Hamiltonian formalism
In this subsection, we explain the Hamiltonian formalism of LGT 16 . The reasons are two fold: (i) it gives rise to an intuitive picture of the relevant states in terms of electric field and magnetic field, and (ii) it plays an important role in recent development in quantum simulations of the dynamical gauge field by using ultracold atomic systems put on an optical lattice.
Let us start with an example of Hamiltonian system defined on a threedimensional ( d = 3) spatial cubic lattice with lattice spacing a . Its sites are labeled by r , and its links (bonds) are labeled as ( r, i ) where i is the direction index i = 1 2 3. We sometimes use , , i also for the unit vector in the i th-direction, such as ( r, i ) = ( r, r + ) (See Fig.1). i
One may put matter fields on each site r , which may be bosons/fermions composing materials in question, e.g., electrons, atoms in an optical lattice, Coope-pair field of SC, spins, or even more complicated ones. For definiteness, we put below a one-component canonical nonrelativistic boson field 17 , whose annihilation and
creation operators ˆ φ , φ r ˆ † r satisfy
$$[ \hat { \phi } _ { r }, \hat { \phi } _ { r ^ { \prime } } ^ { \dagger } ] = \delta _ { r r ^ { \prime } }.$$
Gauge fields are put on each link ( r, i ) in LGT (See Fig.1). They may be associated with the gauge group U(1), SU(N), etc, and meditate interactions between matters. They are viewed as connections in differential geometry that relate two local frames of the internal space of matter field at neighboring lattice sites r and r + . i For definiteness, we consider below a U(1) gauge field operator ˆ θ ri (= ˆ θ † ri ). This is viewed as the lattice version of well-known vector potential field ˆ ( A r i ) (we use the same letter r for the coordinate of the continuum space) describing the electromagnetic(EM) interaction, but may have different origins, e.g., mediating interactions between holons and spinons, as explained in Section 1. The momentum operator ˆ E ri conjugate to ˆ θ ri describes the electric field and satisfy
$$[ \hat { \theta } _ { r i }, \hat { E } _ { r ^ { \prime } j } ] = i \delta _ { r r ^ { \prime } } \delta _ { i j }, \ [ \hat { \theta } _ { r i }, \hat { \theta } _ { r ^ { \prime } j } ] = [ \hat { E } _ { r i }, \hat { E } _ { r ^ { \prime } j } ] = 0.$$
To understand the LGT Hamiltonian, it is helpful to start with a model Hamiltonian ˆ H c defined in the continuum space. Let us consider the following GinzburgLandau(GL)-type model:
$$H _ { \text{c} } & = \int \stackrel { \ell } { d ^ { 3 } r } \Big [ \sum _ { i } | D _ { i } \hat { \phi } ( r ) | ^ { 2 } + m ^ { 2 } \hat { \rho } ( r ) + \lambda \hat { \rho } ( r ) ^ { 2 } + \frac { 1 } { 2 } \sum _ { i } \hat { E } _ { i } ( r ) ^ { 2 } + \frac { 1 } { 4 } \sum _ { i, j } \hat { F } _ { i j } ( r ) ^ { 2 } \Big ], \\ D _ { i } & = \partial _ { i } + i g \hat { A } _ { i } ( r ), \ \hat { \rho } ( r ) = \hat { \phi } ^ { \dagger } ( r ) \hat { \phi } ( r ), \ \hat { F } _ { i j } ( r ) = \partial _ { i } \hat { A } _ { j } ( r ) - \partial _ { j } \hat { A } _ { i } ( r ),$$
where D i is the covariant derivative expressing the minimal coupling of φ -particle with the EM field, g is the coupling constant (charge of φ -particle 20 ), m, λ are GL parameters whose meaning is explained later, and ˆ F ij ( r ) is the magnetic field B r i ( ) = /epsilon1 ijk F jk ( r ). One may check that the each term of H c is invariant under the local gauge transformation,
$$\hat { \phi } ( r ) \to e ^ { i \Lambda ( r ) } \hat { \phi } ( r ), \ \hat { A } _ { i } ( r ) \to \hat { A } _ { i } ( r ) - \frac { 1 } { g } \partial _ { i } \Lambda ( r ), \ \hat { E } _ { i } ( r ) \to \hat { E } _ { i } ( r ), \quad ( 2. 4 )$$
for an arbitrary function Λ( ). r By using the canonical commutation relations [ ˆ ( φ r , φ ) ˆ ( † r ′ )] = δ (3) ( r -r ′ ) and [ ˆ ( A r ,E i ) ˆ ( j r ′ )] = iδ ij δ (3) ( r -r ′ ) , one may check that its generator ˆ ( Q r ) is given by
$$\hat { Q } ( r ) = \sum _ { i } \partial _ { i } \hat { E } _ { i } ( r ) - g \hat { \rho } ( r ),$$
and ˆ ( Q r ) commutes with ˆ H c , [ ˆ ( Q r , H ) ˆ c ] = 0. So one may define the physical states | phys 〉 so that they are eigenstates of ˆ ( Q r ) (superselection rule). In the usual case, i.e., when there are no external electric field, one imposes the local constraint,
$$\hat { Q } ( r ) | \text{phys} \rangle = 0,$$
which leads to the lattice version of the Gauss' law ˆ Q r = 0 [See Eq.(2.17].
Now we consider the Hamiltonian on the cubic lattice. In LGT, the operator ˆ θ ri defined on link ( r, i ) is assumed to approach as ˆ θ ri → agA ˆ ( i r ) as the lattice
## 6 I.Ichinose and T.Matsui
spacing a becomes small. Furthermore, as we shall see, the natural U(1) gauge field operator in LGT is not ˆ θ ri but its exponential,
$$\hat { U } _ { r i } \equiv \exp ( i \hat { \theta } _ { r i } ), \, \hat { U } _ { r i } ^ { \dagger } \hat { U } _ { r i } = \hat { 1 },$$
and so ˆ θ ri is viewed as an angle operator (we discuss this point in detail later). Then, by using Eq.(2.2) we have ˆ E ri → a E 2 i ( r ) as a → 0 (note ˆ E ri is dimensionless and δ (3) ( r ) /similarequal δ r 0 a -3 ) and
$$[ \hat { E } _ { r i }, \hat { U } _ { r ^ { \prime } j } ] = \delta _ { i j } \delta _ { r r ^ { \prime } } \hat { U } _ { r i }.$$
(Note that Eq.(2.2) implies the replacement ˆ E ri → -i∂/∂θ ri .) To construct a set of eigenstates satisfying the completeness conditions, let us start with a pair of operators ˆ U and ˆ sitting on certain link (we suppress their link index). Then we E have
$$\overset { \sim } { \hat { U } } | \theta \rangle = e ^ { i \theta } | \theta \rangle, \ \theta \in [ 0, 2 \pi \}, \ \hat { E } | n \rangle = n | n \rangle, \ n \in \mathbf Z, \\ \langle \theta | n \rangle = \frac { e ^ { i n \theta } } { \sqrt { 2 \pi } }, \ \hat { 1 } _ { U } = \int _ { 0 } ^ { 2 \pi } d \theta | \theta \rangle \langle \theta |, \ \hat { 1 } _ { E } = \sum _ { n = - \infty } ^ { \infty } | n \rangle \langle n |. \quad \ ( 2. 9 ) \\ \hat { \theta } \text{ and } \hat { E } \text{ correspond to the position and momentum operators in the ordinary}$$
So ˆ and θ ˆ E correspond to the position and momentum operators in the ordinary quantum mechanics respectively, but the significant difference is that the theory is taken to be compact , i.e., the physical state | phys 〉 is imposed to be periodic in θ ,
$$\langle \theta | \text{phys} \rangle = \langle \theta + 2 \pi | \text{phys} \rangle,$$
which implies that the eigenvalues are an angle θ ∈ [0 , 2 π ) defined by mod 2 π , and integers n , instead of two real numbers. Because one may write
$$& | n \rangle = \hat { 1 } _ { U } | n \rangle = \int \frac { d \theta } { \sqrt { 2 \pi } } e ^ { i n \theta } | \theta \rangle = e ^ { i n \hat { \theta } } \cdot \int \frac { d \theta } { \sqrt { 2 \pi } } | \theta \rangle = e ^ { i n \hat { \theta } } | n = 0 \rangle = \hat { U } ^ { n } | n = 0 \rangle, ( 2. 1 1 ) \\ & \hat { U } ^ { ( \dagger ) } \text{ is just the creation (annihilation)} \text{ operator of the electric field of unit electric}$$
ˆ U ( † ) is just the creation (annihilation) operator of the electric field of unit electric flux (the signature of n distinguishes the direction of the flux), which is called a 'string bit'. These relations remind us the analogy with the angular momentum operators /vector L as ˆ E ↔ ˆ L z ( n ↔ L / z /planckover2pi1 ) , U ˆ ↔ ˆ L x + iL , θ ˆ y ↔ ϕ (azimuthal angle) with the limit of large angular momentum /lscript → ∞ . We note that there holds the uncertainty principle,
$$\Delta \theta \cdot \Delta n \geq \frac { 1 } { 2 }.$$
The Hamiltonian ˆ H of LGT should (i) reduce to ˆ H c of Eq.(2.3) in the naive continuum limit a → 0, and (ii) respect the U(1) local gauge symmetry as in the continuum. A simple example of ˆ H satisfying these two conditions is given by
$$\text{continuation}. A \, \text{on} p r e \, \text{campaign} \, \text{or} \, \text{in} \, \text{saving} \, \text{use} \, \text{when} \, \text{in} \, \text{given} \, \text{by} \\ \hat { H } & = t \sum _ { r, i } ( \hat { \phi } _ { r + i } ^ { \dagger } - \hat { U } _ { r i } \hat { \phi } _ { r } ^ { \dagger } ) ( \hat { \phi } _ { r + i } - \hat { U } _ { r i } ^ { \dagger } \hat { \phi } _ { r } ) + \sum _ { r } V ( \hat { \phi } _ { r } ) + \hat { H } _ { g }, \\ \hat { H } _ { g } & = \frac { g ^ { 2 } } { 2 a } \sum _ { r, i } ( \hat { E } _ { r i } ) ^ { 2 } + \frac { 1 } { 2 g ^ { 2 } a } \sum _ { r } \sum _ { i < j } \left ( \hat { U } _ { r j } \hat { U } _ { r + j, i } \hat { U } _ { r + i, j } ^ { \dagger } \hat { U } _ { r i } ^ { \dagger } + \text{H.c.} - 2 \right ).$$
Here V ( ˆ φ r ) represents the self-interaction of ˆ . The naive continuum limit of φ r ˆ H is checked as ˆ H → ˆ H c + O a ( 2 ) with a suitable choice of V ( ˆ φ r ) by using the following relations as a → 0:
$$\iota \iota \iota \iota \iota \sigma \, \alpha \to \, \iota. \quad & \hat { \phi } _ { r } \to a ^ { \frac { 3 } { 2 } } \hat { \phi } ( r ), \ \hat { U } _ { r i } \to e ^ { i g a \hat { A } _ { i } ( r ) } \simeq 1 + i g a \hat { A } _ { i } ( r ) - \frac { a ^ { 2 } g ^ { 2 } } { 2 } ( \hat { A } _ { i } ( r ) ) ^ { 2 }, \\ \hat { E } _ { r i } \to \frac { a ^ { 2 } } { g } \hat { E } _ { i } ( r ), \ \sum _ { r } \to \frac { 1 } { a ^ { 3 } } \int d ^ { 3 } r. \\ \iota \iota \iota \iota \iota \iota \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \, \alpha \to \}$$
In particular, the last UUUU -term reduces to the magnetic term FF as
$$& \ U U U + c. c. \to \exp [ i g a ( A + A - A - A ) ] + c. c. \\ & = \exp [ i g a ^ { 2 } ( \partial _ { i } A _ { j } ( r ) - \partial _ { j } A _ { i } ( r ) ) ] + c. c. \to 2 \cos ( g a ^ { 2 } F _ { i j } ( r ) ) \to 2 - g ^ { 2 } a ^ { 4 } F _ { i j } ^ { 2 } ( r ). \ ( 2. 1 5 )$$
For gauge invariance, one may define the gauge transformation on the lattice as
$$\hat { U } _ { r i } \rightarrow V _ { r + i } ^ { * } \hat { U } _ { r i } V _ { r }, \ V _ { r } = e ^ { i \Lambda _ { r } } \in \mathbf U ( 1 ), \ \hat { \phi } _ { r } \rightarrow V _ { r } \hat { \phi } _ { r },$$
which reduces to Eq.(2.4) by scaling Λ r → Λ( ) as r a → 0, and check that each term of ˆ H is invariant under Eq.(2.16). We define the physical states in the same manner as in the continuum case,
$$Q _ { r } \equiv \sum _ { i } \nabla _ { i } \hat { E } _ { r i } - \hat { \phi } _ { r } ^ { \dagger } \hat { \phi } _ { r }, \ [ \hat { H }, \hat { Q } _ { r } ] = 0, \ \hat { Q } _ { r } | \text{phys} \rangle = 0,$$
where the forward difference operator ∇ i is defined as ∇ i f r ≡ f r + i -f r . Both ∇ i ˆ E ri and ˆ φ φ † r ˆ r have integer eigenvalues. We note that ˆ H of Eq.(2.13) has the periodicity ˆ θ ri → ˆ θ ri +2 , which may be regarded as a gauge symmetry under a special gauge π transformation Λ r = 2 πr i .
## 2.2. Physical properties of LGT
Let us discuss the expected properties of the model (2.13). First, we focus on the case of pure gauge theory ˆ H g without matter field. In te continuum theory, the corresponding system,
$$\hat { H } _ { g } \rightarrow \frac { 1 } { 2 } \int d ^ { 3 } r \sum _ { i } \left ( \hat { E } _ { i } ( r ) \hat { E } _ { i } ( r ) + \hat { B } _ { i } ( r ) \hat { B } _ { i } ( r ) \right ),$$
is well known to describe the ensemble of free photons. In contrast, ˆ H g on the lattice is an interacting theory. One can confirm it from cos( ga F 2 ij ( r )) in Eq.(2.15). It contains, in addition to the leading F ij ( r ) 2 term, F ij ( r ) 4 and higher interaction terms describing scattering of gauge bosons. These terms are traced back to the compactness of the model (the periodicity (2.10)).
For large g /greatermuch 1, which is called the strong coupling region, one may take the electric term as the unperturbed Hamiltonian and the magnetic term as a perturbation. By recalling Eq.(2.17), the unperturbed eigenstate | eigen 〉 is the eigenstate of ˆ E ri with their eigenvalues satisfying the divergenceless condition. A simple example
## 8 I.Ichinose and T.Matsui
is an electric flux of strength n along a closed loop C on the 3D lattice. The general eigenstate may be composed of such loops. So one may write
$$| \text{eigen} \rangle = \prod _ { k } \prod _ { \ell _ { k } \in C _ { k } } ( \hat { U } _ { \ell _ { k } } ) ^ { n _ { k } } | 0 \rangle,$$
where C k denotes the k -th flux loop, /lscript k denotes links composing C k , and n k is the strength of the k -th flux. If there are two external sources of charge g at r 1 and -g at r 2 , the lowest-energy state is an electrix flux state forming a straight line ˜ C 12 (on the lattice) connecting these two charges and written as
$$\prod _ { \ell \in \tilde { C } _ { 1 2 } } \hat { U } _ { \ell } | 0 \rangle,$$
(See Fig.2a). This state has an energy g 2 / (2 a ) × number of links in C 12 , thus proportional to the distance r . If these two charges are quark and antiquark, isolation of each quark from the other implies r → ∞ and costs infinite amount of energy, being impossible to be realized. This is Wilson's explanation of quark confinement 8 .
On the other hand, for the weak-coupling region, g /lessmuch 1, the magnetic term is leading. Up to the gauge transformation, the energy eigenstates in the limit g → 0 should be the eigenstate of ˆ θ ri in contrast to the strong-coupling limit. By the uncertainty principle (2.12), the eigenstate there should be a superposition of electric fluxes of various strength and locations as in the ordinary classical Coulombic electromagnetism shown in Table.1. So the physical state corresponding to the state considered in Eq.(2.20) is replaced by
$$\sum _ { C _ { 1 2 } } \Gamma ( C _ { 1 2 } ) \prod _ { \ell \in C _ { 1 2 } } \hat { U } _ { \ell } | 0 \rangle,$$
where the coefficient Γ( C 12 ) is the weight for the path C 12 connecting the sites 1 and 2. For the lowest-energy state, Γ( C 12 ) is to be determined by the minimum-energy condition, and the energy stored in the two charges here should be proportional to 1 /r as in the Coulomb potential energy (See Fig.2b).
The above qualitative consideration may indicate that there exists a phase boundary separating the strong and weak-coupling regions. Dynamics of the pure
a
b
c
/negationslash
Fig. 2. Illustration of electric flux lines between two oppositely charged particles in the three phases. (a) confinement phase; (b) Coulomb phase; (c) Higgs phase. Dashed lines in (c) imply that the strength of fluxes are not conserved as Eq.(2.17) with 〈 ˆ φ φ † r ˆ r 〉 = const = 0 shows.
gauge system H g in (2.13) is quite nontrivial and careful investigation such as numerical study is required to obtain the phase diagram. At present, it is known that the 3D pure U(1) gauge system H g has two phases; The phase at strong coupling region is called the confinement phase, and the phase at weak coupling region is called Coulomb phase. The phase transition is said to be weak first order 26 . These two phases are characterized by the behavior of the potential energy V ( r ) for a pair of static charges of opposite signs and separated by a distance r ; ∝ r or ∝ 1 /r . Also they are distinguished by the fluctuation of gauge field ˆ θ ri , ∆ , as ∆ θ θ /greatermuch 1 in the confinement phase and ∆ θ /lessmuch 1 in Coulomb phase. We note that, for the 2D spatial lattice in contrast, there are no phase transitions, and only the confinement phase exists 21 .
Now let us include the matter part and consider the full Hamiltonian ˆ H of Eq.(2.13). By referring to Eq.(2.3), one may write V ( ˆ φ r ) as
$$V ( \hat { \phi } _ { r } ) = \lambda ( \hat { \phi } _ { r } ^ { \dagger } \hat { \phi } _ { r } - v ) ^ { 2 }.$$
/negationslash
Let us recall that the GL theory with the gauge interaction being turned off by setting g = 0 and for sufficiently large and positive λ , the system exhibits a secondorder phase transition by varying v . It is signaled by the order parameter φ = 〈 ˆ φ r 〉 , (or more strictly defined as | φ | 2 ≡ lim | r -r ′ |→∞ 〈 ˆ φ φ † r ˆ r ′ 〉 ), and separates the ordered (condensed) phase 〈 φ 〉 = 0 and the disordered phase 〈 φ 〉 = 0. In the mean-field theory, the transition temperature T c is determined as the vanishing point of v as v ∝ ( T c -T ). However, the fluctuations of the phase degree of freedom ϕ r of ˆ φ r = | ˆ φ r | exp( iϕ r ), which are controlled by the hopping t -term of Eq.(2.13), play an essentially important role for realization of a condensation. In fact, these two phases may be characterized by the magnitude of fluctuation ∆ ϕ of ϕ r as ∆ ϕ /lessmuch 1 (ordered phase) and ∆ ϕ /greatermuch 1(disordered phase). To obtain the correct transition temperature T c , more detailed study such as MC simulation is required as we discuss later.
For the full fledged gauge-matter system ˆ H of Eq.(2.13), one may naively consider four combinations such as (∆ θ /lessmuch 1 or /greatermuch 1) and (∆ ϕ /lessmuch 1 or /greatermuch 1) for a possible phase. However, one may easily recognize that the combination ∆ ϕ /lessmuch 1 and ∆ θ /greatermuch 1 is impossible. This is because ˆ ϕ r appears in the hopping term with the combination ∇ i ˆ ϕ r -ˆ θ ri and the condition ∆ θ /greatermuch 1 destroys the phase coherence ∇ i ˆ ϕ r /similarequal 0. In fact, the numerical study and the mean field theory predict the three phases listed in Table 1; (1) confinement phase ∆ θ /greatermuch 1 ∆ , ϕ /greatermuch 1, (2) Coulomb phase ∆ θ /lessmuch 1 ∆ , ϕ /greatermuch 1, (3) Higgs phase ∆ θ /lessmuch 1 ∆ , ϕ /lessmuch 1.
Let us see this point in some details because it helps us to understand the property of each phase appeared in an effective LGT of various condensed-matter systems.
- (1) The confinement phase appears for the parameter region of small t [ t is the hopping amplitude in Eq.(2.13)] and large g regardless of the values of λ and v . In a sense, this phase corresponds to the high-temperature ( T ) region and
## 10 I.Ichinose and T.Matsui
there exist no long-range orders. The parameter region of the confinement phase is enlarged by decreasing a value of v . For pure U(1) gauge theory without matter field ˆ , a potential φ r V ( r ) for a pair of oppositely charged static sources separated with distance r behaves as V ( r ) ∝ r as explained.
- (2) The Coulomb phase appears for small g and small t . Fluctuations of the gauge field is suppressed by the plaquette terms in Eq.(2.13) and the compactness of ˆ θ ri plays no role. The potential of a pair of two static charges is given by the Coulomb law, which is V ( r ) ∝ 1 /r for 3D space.
- (3) In the Higgs phase, a coherent condensation of the boson field ˆ φ r takes place. Then the hopping term in Eq.(2.13) gives the following term of U xµ ,
$$t \hat { \phi } _ { r + i } ^ { \dagger } \hat { U } _ { r i } ^ { \dagger } \hat { \phi } _ { r } + \text{H.c.} \to t v \ ( \hat { U } _ { r i } ^ { \dagger } + U _ { r i } ) + \dots \simeq - t v a ^ { 2 } g ^ { 2 } \hat { \theta } _ { r i } ^ { 2 } + \dots \,. \quad ( 2. 2 3 )$$
As a result, the gauge field acquires a mass m θ = √ 2 tv and a force mediated by the gauge field ˆ θ ri becomes short range like 〈 ˆ θ r + Ri,j ˆ θ tj 〉 = e -m R θ (See Fig.2c). The Higgs phase is realized for large value of t and a finite v (in addition to small g ). Superconducting (SC) phase is a kind of the Higgs phase in which the boson field ˆ φ r describes Cooper pairs, and the gauge field becomes short-ranged by the Meissner effect.
So far, we studied the compact LGT. In some literatures, so called noncompact LGT is considered 22 . The noncompact U(1) LGT is given by the following Hamiltonian for the gauge part,
$$\hat { H } _ { g } ^ { \prime } = \frac { g ^ { 2 } } { 2 a } \sum _ { r, i } ( \hat { E } _ { r i } ) ^ { 2 } + \frac { 1 } { 2 g ^ { 2 } a } \sum _ { r } \sum _ { i < j } ( \nabla _ { i } \hat { \theta } _ { r j } - \nabla _ { j } \hat { \theta } _ { r i } ) ^ { 2 }.$$
The eigenvalue of ˆ θ ri now runs in ( -∞ ∞ , ) and ˆ H ′ g loses the periodicity and describes a set of free photons. For small fluctuations ∆ θ /lessmuch 1, the compact pure gauge theory (2.13) reduces to above ˆ H ′ g . However, for large fluctuations, these two models behave quite differently and they generally have different phase diagrams. In the noncompact gauge theories with the gauge part (2.24), the Coulomb and Higgs phases are realized but the confinement phase is impossible because of the suppression of large fluctuations. In other words, the large fluctuations of ˆ θ ri in the confinement phase are achieved by large-field configurations called topological excitations, the typical examples of which are instantons and monopoles. They are allowed only for a system with periodicity such as compact LGT. To describe a SC phase transition with the ordinary EM interactions, one should use the noncompact U(1) gauge theory. The gauge field ˆ θ ri there is nothing but the vector potential for the electro-magnetism, and the single-component boson field ˆ φ r corresponds to the s -wave Cooper-pair field as mentioned. Therefore, as we have explained above, the Higgs phase is nothing but the SC phase. In order to describe a multi-component SC state such as the p -wave SC, introduction of a multi-component boson field is necessary. This system will be discussed rather in detail in the subsequent sections.
## 2.3. Partition function in the path-integral representation on the Euclidean lattice
Let us consider the partition function Z for ˆ H of Eq.(2.13) at the temperature T ,
$$Z = \text{Tr} \hat { P } \exp ( - \beta \hat { H } ), \ \beta \equiv \frac { 1 } { k _ { B } T }, \ \hat { P } \equiv \prod _ { r } \delta _ { \hat { Q } _ { r }, 0 },$$
where Tr is over the space of all the values of ˆ Q r , and ˆ is the projection operator P to the physical states. As usual, we start by factorizing the Boltzmann factor into N factors but with care of ˆ as P
$$\hat { P } \exp ( - \beta \hat { H } ) = [ \hat { P } \exp ( - \Delta \beta \hat { H } ) ] ^ { N }, \ \Delta \beta \equiv \frac { \beta } { N },$$
where we used ˆ P 2 = ˆ [ ˆ P, P,H ˆ ] = 0, and then insert the complete set between every successive factors.
For ˆ , we use the following coherent states φ r | φ 〉 :
$$\hat { \phi } | \phi \rangle = \phi | \phi \rangle, | \phi \rangle = \exp ( - \bar { \phi } \hat { \phi } + \hat { \phi } ^ { \dagger } \phi ) | 0 \rangle, \ \hat { \phi } | 0 \rangle = 0, \ \langle \phi ^ { \prime } | \phi \rangle = \exp ( - \frac { \bar { \phi } ^ { \prime } \phi ^ { \prime } } { 2 } - \frac { \bar { \phi } \phi } { 2 } + \bar { \phi } ^ { \prime } \phi ^ { \prime } ), \\ | \{ \phi \} \rangle = \prod _ { r } | \phi _ { r } \rangle, \ \int d ^ { 2 } \phi = \prod _ { r } \int \frac { d ^ { 2 } \phi _ { r } } { \pi }, \ \hat { 1 } _ { \phi } = \int d ^ { 2 } \phi | \{ \phi \} \rangle \langle \{ \phi \} |,$$
where φ is a complex number and ¯ is its complex conjugate (The bar denotes the φ complex-conjugate quantity).
The eigenstates and the completeness of gauge field for the entire lattice are written by using Eqs.(2.9) as
$$\hat { 1 } _ { \theta } = \int d \theta | \{ \theta \} \rangle \langle \{ \theta \} |, \ \hat { 1 } _ { n } = \sum _ { n } | \{ n \} \rangle \langle \{ n \} |, \ | \{ \theta \} \rangle = \prod _ { r, i } | \theta _ { r i } \rangle, \ | \{ n \} \rangle = \prod _ { r, i } | n _ { r i } \rangle, \\ \int d \theta = \prod _ { r, i } \int d \theta _ { r i }, \ \sum _ { n } = \prod _ { r, i } \sum _ { n _ { r i } \in \mathbf z }.$$
(We abbreviate the symbol ⊗ of tensor product in |{ θ }〉 and |{ n }〉 .) For example, the matrix element of ˆ is calculated as P
$$& \delta _ { \hat { Q } _ { r }, 0 } = \int _ { 0 } ^ { 2 \pi } \frac { d \theta _ { r 0 } } { 2 \pi } \exp ( i \theta _ { r 0 } \hat { Q } _ { r } ), \ \langle \{ \phi ^ { \prime }, n ^ { \prime } \} | \hat { P } | \{ \phi, n \} \rangle = \prod _ { r } \int \frac { d \theta _ { r 0 } } { 2 \pi } \prod _ { i } \delta _ { n _ { r i } ^ { \prime } n _ { r i } } \,. \\ & \prod _ { r } \exp ( - \frac { 1 } { 2 } \bar { \phi } _ { r } ^ { \prime } \phi _ { r } ^ { \prime } - \frac { 1 } { 2 } \bar { \phi } _ { r } \phi _ { r } + \bar { \phi } _ { r } ^ { \prime } e ^ { - i \theta _ { r 0 } } \phi _ { r } ) \exp ( i \theta _ { r 0 } \sum _ { i } \nabla _ { i } E _ { r i } ).$$
The Lagrange multiplier θ r 0 will be interpreted as the imaginary-time component of gauge field. Then we obtain the following expression of Z for sufficiently large
N :
$$& N \colon \\ & Z = \int [ d U ] \int [ d \phi ] \sum _ { \{ n \} } \exp ( A _ { H } ), \ [ d U ] = \prod _ { x, \mu } d U _ { x \mu }, \ [ d \phi ] = \prod _ { x } d \phi _ { x }, \sum _ { \{ n \} } = \prod _ { x, i } \sum _ { n _ { x i } }, \\ & A _ { H } = \Delta \beta \sum _ { x } \left [ \frac { i } { \Delta \beta } \sum _ { i } ( E _ { x i } \nabla _ { 0 } \theta _ { x i } + \theta _ { x 0 } \nabla _ { i } E _ { x i } ) - \frac { 1 } { \Delta \beta } \bar { \phi } _ { x + 0 } ( \phi _ { x + 0 } - e ^ { - i \theta _ { x 0 } } \phi _ { x } ) - V ( \phi _ { x } ) \\ & - t \sum _ { i } | \phi _ { x + i } - \bar { U } _ { x i } \phi _ { x } | ^ { 2 } - \frac { g ^ { 2 } } { 2 a } \sum _ { i } E _ { x i } ^ { 2 } + \frac { 1 } { 2 g ^ { 2 } a } \sum _ { i < j } ( U _ { x j } U _ { x + j, i } \bar { U } _ { x + i, j } \bar { U } _ { x i } + \text{c.c.} ) \right ].$$
$$- t \sum _ { i } | \phi _ { x + i } - \bar { U } _ { x i } \phi _ { x } | ^ { 2 } - \frac { g ^ { 2 } } { 2 a } \sum _ { i } E _ { x i } ^ { 2 } + \frac { 1 } { 2 g ^ { 2 } a } \sum _ { i < j } ( U _ { x j } U _ { x + j, i } \bar { U } _ { x + i, j } \bar { U } _ { x i } + c. c. ) \Big ].$$
where we assume that V ( ˆ φ x ) is normal ordered. In Eq.(2.30) we introduced the imaginary-time coordinate x 0 (= 0 , · · · , N -1), the site index of 4D Euclidean lattice x ≡ ( x , r 0 ) with r = ( x , x 1 2 , x 3 ), and its direction index/unit vector µ = 0 1 2 3. , , , In path integral, every field φ , θ x xµ , n xi is defined on each time slice x 0 together with the spatial site r . We note that φ , θ x xµ are periodic under x 0 → x 0 + N . The 4-component U(1) gauge field U xµ = exp( iθ xµ ) and its complex conjugate ¯ U xµ are sitting on the link ( x, x + µ ).
Next, we carry out the summation over n xi to obtain 23
$$c$$
$$\text{Next, we carry out the summation over $n_{xi}$ to obtain $\vdots$} \\ Z & = \int [ d U ] [ d \phi ] \ \exp ( A ), \ A = \sum _ { x } \left [ - \bar { \phi } _ { x + 0 } ( \phi _ { x + 0 } - \bar { U } _ { x 0 } \phi _ { x } ) - \Delta \beta V ( \phi _ { x } ) \\ & \quad - t \Delta \beta \sum _ { i } | \phi _ { x + i } - \bar { U } _ { x i } \phi _ { x } | ^ { 2 } + \frac { 1 } { 2 } \sum _ { \mu < \nu } c _ { 2 \mu \nu } ( U _ { x \nu } U _ { x + \nu, \mu } \bar { U } _ { x + \mu, \nu } \bar { U } _ { x \mu } + c. c. ) \right ], \\ c _ { 2 i j } & = \frac { \Delta \beta } { g ^ { 2 } a }, \ c _ { 2 0 i } = \frac { a } { g ^ { 2 } \Delta \beta }, \ U _ { x 0 } \equiv \exp ( i \theta _ { x 0 } ). \\ \pi \dots \dots \dots \lambda _ { x } - e. \pi \dots \dots \dots \dots \lambda _ { x } - \dots \dots \dots \dots \lambda _ { x } - \dots \dots \dots \dots \lambda _ { x }.$$
$$- \, \overline { g ^ { 2 } a }, \, \lambda _ { 2 0 n } - \overline { g ^ { 2 } \Delta \beta }, \, \mathfrak { c }$$
Here we made the following replacement in ∑ n xi respecting the periodicity in θ :
$$\sum _ { n } e ^ { - a n ^ { 2 } + i n \theta } \simeq \int _ { - \infty } ^ { \infty } d n \ e ^ { - a n ^ { 2 } + i n \theta } = C \exp ( - \frac { \theta ^ { 2 } } { 4 a } ) \to C ^ { \prime } \exp ( \frac { 1 } { 2 a } \cos \theta ).$$
The action A and the measure [ dU ][ dφ ] in Eq.(2.31 are invaraiant under the U(1) gauge transformation rotating the local internal coordinate of complex field at each site x on the 4-dimensional lattice,
$$U _ { x \mu } \to \bar { V } _ { x + \mu } U _ { x \mu } V _ { x }, \ V _ { x } = e ^ { i \Lambda _ { x } } \in \mathbf U ( 1 ), \ \phi _ { x } \to V _ { x } \phi _ { x },.$$
## 2.4. Phase structure and Correlation functions
Phase structure of various gauge-field models has been investigated by both analytic and numerical methods. In particular, for the gauge-Higgs model, which describes the SC phase transitions, interesting phase diagrams have been obtained. To this end, the numerical study by the Monte-Carlo (MC) simulations plays a very important role as they provide us reliable results including all nonperturbative effects. Here we present some known schematic phase diagrams restricting the system to the relativistic Higgs coupling and the frozen radial degrees of freedom of φ x field,
$$c _ { 1 } ( \underset { x } { \overset { \phi } { x } } \bar { \underline { U } } _ { x \mu } \bar { \phi } _ { x + \mu } + \underset { x + \mu } { \overset { x + \nu } { x + \mu } } ) + c _ { 2 } \left ( \underset { x } { \overset { x + \nu } { \underline { U } } _ { x \mu } } + \underset { x } { \overset { x + \nu } { \underline { U } } } \right ) \\ \text{ illustration of the action A of the compact LGT (2.34). Open (filled) circle denot}$$
Fig. 3. Illustration of the action A of the compact LGT (2.34). Open (filled) circle denotes φ x = exp( iϕ x )( ¯ φ x ) and straight line with an arrow in the negative (positive) µ -direction denotes U xµ = exp( iθ xµ )( ¯ U xµ )
i.e., φ x = exp( iϕ x ), but with spatial dimensions d = 2 and 3 (dimension of the corresponding Euclidean lattice D = d +1 is 3 and 4). Explicitly, we consider the following partition function;
$$& \text{sources} \text{,} \\ & Z = \int [ d \varphi ] [ d \theta ] _ { G } \exp ( A ), \ A = c _ { 1 } \sum _ { x, \mu } \cos ( \varphi _ { x + \mu } + \theta _ { x \mu } - \varphi _ { x } ) + A _ { g } ^ { ( ^ { \prime } ) }, \\ & A _ { g } = c _ { 2 } \sum _ { x, \mu < \nu } \cos \theta _ { x \mu \nu }, \ A _ { g } ^ { \prime } = - \frac { c _ { 2 } } { 2 } \sum _ { x, \mu < \nu } \theta _ { x \mu \nu } ^ { 2 }, \ \theta _ { x \mu \nu } \equiv \theta _ { x \nu } + \theta _ { x + \nu, \mu } - \theta _ { x + \mu, \nu } - \theta _ { x \mu }, ( 2. 3 4 ) \\ & \text{s.s.s. \dots - \infty } \quad \ A \ \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. \dots - \infty } \quad \text{s.s.s. C }$$
where µ = 0 , · · · , d, and c 1 and c 2 are the parameters. A g is for the compact LGT and A ′ g is for the noncompact LGT. Each term of the action A is depicted in Fig.3. This model is sometimes called the Abelian Higgs model 11 . Note that the Higgs coupling (the c 1 term) along the imaginary time µ = 0 direction has the same form as the spatial directions, i.e., every direction has couplings both in the positive and negative directions. This is in contrast to the nonrelativistic model (2.31) in which the coupling for µ = 0 is only in the positive direction. In short, the coupling in the negative µ = 0 direction describes the existence of antiparticles which are allowed in the relativistic theory but not in nonrelativistic theory 27 .
Here we comment on the integration measure [ dθ ] G and gauge fixing. The path integral (2.34) involves the same contributions from a set of configurations of { ϕ, θ } (so called gauge copies) that are connected with each other by gauge transformations. So one may reduce this redundancy by choosing only one representative from each set of gauge copies without changing physical contents. This procedure is called gauge fixing and achieved by inserting the gauge fixing function G ( { ϕ, θ } ), which is not gauge invariant under Eq.(2.33), to the measure, [ dϕ dθ ][ ] → [ dϕ dθ ][ ] G ≡ G ( { ϕ, θ } )[ dϕ dθ ][ ]. The difference between the gauge fixed case [ dθ ] G and the nonfixed case [ dθ ] appears as a multiplicative factor in Z ,
$$Z _ { \text{nonfixed} } = C _ { \text{gv} } Z _ { \text{fixed} }, \ C _ { \text{gv} } = \prod _ { x, \mu } \int d \Lambda _ { x \mu },$$
where the constant C gv is called gauge volume. In the compact case, the region of θ xµ and Λ xµ are both compact [0 2 , π ). Therefore C gv is finite and the gauge fixing is irrelevant (either choice of fixing gauge or not will do). In the noncompact case, the region of θ xµ and Λ xµ is ( -∞ ∞ , ), so C gv diverges. Thus, one must fix the
gauge in formal argument in the noncompact case, [ dϕ dθ ][ ] G . We said 'in formal argument' here because the choice G ( { ϕ, θ } ) = 1 works even in the noncompact case as long as one calculate the average of gauge-invariant quantities, e.g., in the MC simulations. This is because the average does not suffer from the overall factor in Z . We shall present in Sect.4.1. another reason supporting this point, which is special in MC simulations.
Fig. 4. Schematic phase diagrams in the c 2 -c 1 plane of the 3D and 4D LGT with compact and noncompact action. All the Higgs-Coulomb transitions are of second order. The Higgs-confinement one in (d) is first order and the confinemnet-Coulomb one in (d) is weak first order. The partition function along the line c 2 = 0 is evaluated exactly by single link integral. It is an analytic function of c 1 and so no transitions exist along this line.
In Fig.4 we present the schematic phase diagrams in the c 2 -c 1 plane. The noncompact 3D and 4D models have the Coulomb phase and the Higgs phase. The compact 3D model has only the confinement phase. The compact 4D model has all the three phases. These points are understood as follows; (i) the Higgs phase may exist at large c 1 above the Coulomb phase in 3D and 4D, and above the confinement phase in 4D, (ii) the Coulomb phase may exist at sufficiently large c 2 in 4D case, (iii) the confinement phase exists in the compact case, but not in the noncompact phase.
We note that, as c 2 decreases, all the existing confinement-Higgs transition curves terminate at points with c 2 > 0. This can be understood by calculating Z for c 2 = 0 exactly. Because the integration over θ xµ there is factorized as
$$Z ( c _ { 1 }, c _ { 2 } = 0 ) = \prod _ { x, \mu } \int d \theta _ { x \mu } ^ { \prime } \ e ^ { c _ { 1 } \cos \theta _ { x \mu } ^ { \prime } } = I _ { 0 } ( c _ { 1 } ) ^ { N _ { \ell } }, \ \theta _ { x \mu } ^ { \prime } \equiv \varphi _ { x + \mu } + \theta _ { x \mu } - \varphi _ { x }, \ ( 2. 3 6 )$$
where I 0 ( c 1 ) is the modified Bessel function and N /lscript ( ≡ ∑ x,µ 1) is the total number of links. Z c , c ( 1 2 = 0) is then an analytic function of c 1 and no phase transition can exists along the c 1 axis. This fact is known as complementarity and implies that the confinement phase and the Higgs phase are connected with each other without crossing a phase boundary.
Another limiting case c 2 → ∞ may imply ∆ θ → 0. Therefore the resulting system becomes
$$Z ( c _ { 1 }, c _ { 2 } \rightarrow \infty ) = \prod _ { x, \mu } \int d \varphi _ { x } ^ { \prime } \exp [ c _ { 1 } \sum _ { x, \mu } \cos ( \varphi _ { x + \mu } ^ { \prime } - \varphi _ { x } ^ { \prime } ) ],$$
by setting as θ xµ = ∇ µ Λ x (pure gauge configuration) with ϕ ′ x ≡ ϕ x + Λ . This x system is just the 3D and 4D XY spin models with the XY spin (cos ϕ , x sin ϕ x ), which are known to exhibit a second-order transition. This corresponds to the Higgs-Coulomb transition in Fig.4.
Let us discuss a general correlation function 〈 O ( { } { θ , ϕ } 〉 ) (the expectation value of the function O ( { } { θ , ϕ } )) of the model (2.34) defined as
$$\langle O ( \{ \theta \}, \{ \varphi \} ) \rangle = \frac { 1 } { Z } \int [ d \varphi ] [ d \theta ] O ( \{ \theta \}, \{ \varphi \} ) \exp ( A ).$$
First, 〈 O ( { } { θ , ϕ } 〉 ) is known to satisfy the Elitzur theorem 24 , which says
$$\langle O ( \{ \theta \}, \{ \varphi \} ) \rangle = 0 \text{ if } O ( \{ \theta \}, \{ \varphi \} ) \text{ is not gauge invariant.}$$
Its proof is rather simple and given by making a change of variables in a form of gauge transformation and noting the measure [ dθ ][ dϕ ] is invariant under it. A famous example of gauge-invariant correlation function is the Wilson loop defined on a closed loop C along successive links as
$$W ( C ) = \langle \prod _ { \ell \in C } U _ { \ell } \rangle.$$
It is used by Wilson as a nonlocal 'order parameter' to distinguish a confinement phase and a deconfinement phase for pure gauge system (i.e., involving no dynamical charged particles). If W C ( ) satisfies the 'area law' as C becomes large, W C ( ) ∼ exp( -aS C ( )) where a > 0 and S C ( ) is the minimum area bound by C , the system is in the confinement phase. On the other hand, if it satisfies the perimeter law, W C ( ) ∼ exp( -a L C ′ ( )) where L C ( ) is the length of C , it is in the deconfinement phase. This interpretation comes from the fact that for the rectangular C of the horizontal size R and the vertical size T [The coordinate ( x , x 0 1 ) of four corners in the 0-1 plane, e.g., are (0,0), (0,R), (T,0), (T,R)], V ( R ) defined through W C ( ) ∼ exp( -V ( R T ) ) at sufficiently large T expresses the lowest potential energy stored by a pair of external charges separated by the distance R . The area law implies the confining potential V ( R ) = aR .
Second, one may estimate Z and the correlation functions of gauge-invariant objects by fixing the gauge because they are gauge invariant. Fixing implies to fix one degree of freedom per site x corresponding to Λ x whatever one wants.
For example, the choice ϕ x = 0 is called the unitary gauge, and another choice θ x 0 = 0 is called the temporal gauge. In the mean field theory for the compact LGT, one choose gauge variant quantities 〈 exp( iθ xµ ) 〉 and 〈 exp( iϕ x ) 〉 as a set of order parameters and predicts the phase structure involving the above mentioned three phases. They should be considered as a result after gauge fixing. If one wants to make it compatible with the Elitzur theorem, one simply need to superpose over the gauge copies of these order parameters as Drouffe suggested 25 . For 〈 exp( iθ xµ ) , 〉 it implies
$$\prod _ { x } \int _ { 0 } ^ { 2 \pi } \frac { d \Lambda _ { x } } { 2 \pi } \cdot \langle \exp ( i \theta _ { x \mu } ^ { \prime } ) \rangle = 0, \ \theta _ { x \mu } ^ { \prime } = \theta _ { x \mu } - \nabla _ { \mu } \Lambda _ { x }, \quad \quad ( 2. 4 1 )$$
without changing the gauge-invariant results such as phase diagram, etc..
## 3. Ferromagnetic Superconductivity and its Lattice Gauge Model
In this section and Sect.4, we shall consider a theoretical model for the FMSC, which can be regarded as a kind of LGT. In some materials such as UGe , it has 2 been observed that SC can coexist with a FM long-range order 29 . In UGe 2 and URhGe, a SC appears only within the FM state in the pressure-temperature ( P T -) phase diagram, whereas, in UCoGe, the SC exists both in the FM and paramagnetic states. Soon after their discovery, phenomenological models of FMSC materials were proposed 30 . In those studies, the FMSC state is characterized as a spin-triplet p -wave state of electron pairs as suggested experimentally 31 . In this section, we introduce the GL theory of FMSC materials defined on the 3d spatial lattice (4D Euclidean lattice). As we see, the FM order naturally induces nontrivial vector potential (gauge field) and it competes with another order, the SC order, therefore a nonperturbative study is required in order to clarify the phase diagram etc.
## 3.1. Ginzburg Landau theory of FMSC in the continuum space
Before considering a lattice model of FMSC itself, let us start with the GL theory of FMSC in the 3d continuum space 30 . It was introduced phenomenologically for the case with strong spin-orbit coupling, although the origin of SC, etc. had not been clarified. Its free energy density f GL contains a pair of basic 3d-vector fields, /vector ψ r ( ) and /vector m r ( ), which are to be regarded as c-numbers appearing in the pathintegral expression for the partition function of the underlying quantum theory as in Eq.(2.31) [We discuss the partition function in detail later; see Eq.(3.16)].
The three-component complex field /vector ψ = ( ψ , ψ 1 2 , ψ 3 ) t is the SC order parameter, describing the degrees of freedom of electrons participating in SC. More explicitly, /vector ψ r ( ) describes Cooper-pairs of electrons with total spin s = 1 (triplet) and the relative angular momentum /lscript = 1 ( p -wave) (Note that only odd /lscript 's are allowe for s = 1 by Pauli principle). The complex Cooper-pair field Φ ( q r ) for a s = 1 and /lscript = 1 state generally has 3 × 3 = 9 components ( q = 1 , · · · , 9). The strong spinorbit coupling forces the spin /vector S r ( ) and the angular momentum /vector L r ( ) made of Φ ( q r )
parallel each other, and reduces their degrees of freedom down to 3. Such a Cooper pair is directly expressed in terms of the amplitudes defined as
$$\Delta _ { \sigma \sigma ^ { \prime } } ( r ) \equiv \int d r _ { 0 } \Gamma ( r _ { 0 } ) \langle \hat { C } _ { \sigma } ( r + \frac { r _ { 0 } } { 2 } ) \hat { C } _ { \sigma ^ { \prime } } ( r - \frac { r _ { 0 } } { 2 } ) \rangle.$$
ˆ C σ ( r ) is the annihilation operator of electron at r and spin σ = ↑ ↓ , . Γ( r 0 ) with r 0 being the relative coordinate of electrons is the weight reflecting the attractive interaction and the p -wave nature. Because we assign /vector ψ r ( ) as a 3d vector, it is convenient to use the so called /vector d -vector, which transforms also as a vector in the 3d space;
$$\cdot \quad \vec { \psi } ( r ) \in \vec { d } ( r ) = \begin{pmatrix} d _ { x } ( r ) \\ d _ { y } ( r ) \\ d _ { z } ( r ) \end{pmatrix} \equiv \begin{pmatrix} - \frac { 1 } { 2 } ( \Delta _ { \uparrow \uparrow } ( r ) - \Delta _ { \downarrow \downarrow } ( r ) ) \\ - \frac { 1 } { 2 } ( \Delta _ { \uparrow \uparrow } ( r ) + \Delta _ { \downarrow \downarrow } ( r ) ) \\ \Delta _ { \uparrow \downarrow } ( r ) ( = \Delta _ { \downarrow \uparrow } ( r ) ) \end{pmatrix}. \quad \quad \ ( 3. 2 ) \\ \text{The road vector field $\vec{m}/r\}$ is the FM order parameter, discovery of}$$
The real vector field /vector m r ( ) is the FM order parameter, describing the degrees of freedom of electrons participating in the normal state. More explicitly, it describes their magnetization,
$$\vec { m } ( r ) = \langle \hat { C } ^ { \prime } _ { \sigma } ( r ) \Big ( - \, i \delta _ { \sigma \sigma ^ { \prime } } \vec { r } \times \vec { \nabla } + \frac { 1 } { 2 } \vec { \sigma } _ { \sigma \sigma ^ { \prime } } \Big ) \hat { C } ^ { \prime } _ { \sigma ^ { \prime } } ( r ) \rangle, \quad \quad ( 3. 3 ) \\ \hat { \sim } \, \omega \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots$$
where ˆ C ′ σ ( r ) denotes the annihilation operator of electrons not participating in the SC state. Because there holds div /vector m r ( ) = 0 as in the usual magnetic field, /vector m r ( ) is expressed by using the vector potential /vector A r ( ) (gauge field) as
$$\vec { m } ( r ) = \text{rot} \vec { A } ( r ).$$
Therefore, the fundamental fields may be /vector ψ r ( ) and /vector A r ( ), The GL free energy density f GL is then given by ?
$$\text{$i$ me $ or $i$ree energy energy $JGL$ is $i$} \text{$given $y$} \\ f _ { \text{GL} } & = f _ { \psi } + f _ { m } + f _ { \text{Z} }, \\ f _ { \psi } & = K \sum _ { i } ( D _ { i } \vec { \psi } ) ^ { * } \cdot ( D _ { i } \vec { \psi } ) + \alpha ( T - T _ { \text{SC} } ^ { 0 } ) \vec { \psi } ^ { * } \cdot \vec { \psi } + \lambda ( \vec { \psi } ^ { * } \cdot \vec { \psi } ) ^ { 2 }, \\ f _ { m } & = K ^ { \prime } \sum _ { i } ( \partial _ { i } \vec { m } ) ^ { 2 } + \alpha ^ { \prime } ( T - T _ { \text{FM} } ^ { 0 } ) \vec { m } ^ { 2 } + \lambda ^ { \prime } ( \vec { m } ^ { 2 } ) ^ { 2 }, \\ f _ { \text{Z} } & = - J \vec { m } \cdot \vec { S }, \ D _ { i } = \partial _ { i } - 2 i e A _ { i }, \ \vec { S } = - i \vec { \psi } ^ { * } \times \vec { \psi }. \\ K ^ { ( \prime ) } \cdot \alpha ^ { ( \prime ) } \cdot \lambda ^ { ( \prime ) } \text{ are $GL$ numerates: real positive numerates characterizing each $ma$}.$$
K ( ) ′ , α ( ) ′ , λ ( ) ′ are GL parameters; real positive parameters characterizing each material. /vector S r ( ) is a real vector field describing the spin of Cooper pairs. For example, S 3 = 1 2 ( ∆ | ↑↑ | 2 -| ∆ ↓↓ | 2 ). f Z with J > 0 is nothing but the Zeeman coupling of /vector S and /vector m , which enhances the coexistence of the FM and SC orders as one easily expects. Although the existence of f Z term is supported phenomenologically, its microscopic origin should be clarified by detailed study of the interactions of electrons (and nuclei) in each material.
f GL is gauge invariant under the following U(1) gauge transformation,
$$\vec { \psi } ( r ) \rightarrow \vec { \psi } ^ { \prime } ( r ) = e ^ { i \lambda ( r ) } \vec { \psi } ( r ), \ \vec { A } ( r ) \rightarrow \vec { A } ^ { \prime } ( r ) = \vec { A } ( r ) + \frac { 1 } { 2 e } \vec { \nabla } \lambda ( r ). \quad ( 3. 6 )$$
So /vector m r ( ) and /vector S r ( ) are gauge invariant. This gauge invariance reflects the original U(1) gauge invariance of the EM interaction of electrons. For example, the K term with the covariant derivative D i describes the interaction of SC Cooper pairs of charge -2 e with the vector potential /vector A made of the normal electrons. Its microscopic origin should be traced back to the repulsive Coulombic interactions between electrons.
Before introducing the lattice GL theory, let us list up some main characteristics suggested by the continuum GL theory (3.5).
- · In the mean-field approximation with ignoring the Zeeman coupling f Z , T 0 FM and T 0 SC are critical temperatures of the FM and SC phase transitions, respectively.
- · Existence of a finite magnetization, 〈 /vector m 〉 /negationslash = 0, means a nontrivial configuration of A r i ( ). This induces nontrivial spatial dependence of the Cooper pair /vector ψ through the kinetic term K D /vector ( i ψ ) ∗ · ( D /vector i ψ ) in f GL , because this term favors D /vector i ψ /similarequal 0. A typical example of such configurations is a vortex configuration characterized by a nonvanishing vorticity /vector v r ( ) of /vector ψ . The 3d vector /vector v r ( ) of a complex field φ r ( ) = | φ r ( ) | exp( iϕ r ( )) is defined generally as the winding number of its phase ϕ r ( ). Explicitly, the component of /vector v r ( ) along the direction of a normal vector /vector n is defined by the circle integral over ϕ r ( ),
$$\vec { n } \cdot \vec { v } ( r ^ { \prime } ) = \frac { 1 } { 2 \pi } \oint _ { C _ { \vec { n } } ( r ^ { \prime } ) } d \varphi ( r ) \ ( \in \mathbf Z ),$$
where C /vector n ( r ′ ) is a circle lying in the plane parpendicular to /vector n with its center at r ′ . /vector n · /vector v r ( ) takes integers due to the single-valuedness of φ r ( ). In the later sections, we shall consider two vorticities /vector v ± ( r ) corresponding to ψ 1 ( r ) ± iψ 2 ( r ) respectively. Then the simple mean-field like estimation of the SC critical temperature has to be reexamined by more reliable analysis.
- · The Zeeman coupling f Z obviously enhances the coexisting phase of the FM and SC orders, since it favors a set of antiparallel /vector S and /vector m with large | /vector ψ | and | /vector m | .
/negationslash
- · In the FM phase, /vector A produces a nonvanishing magnetic field /vector m r ( ) inside the materials. Because the K term in f ψ of Eq.(3.5) disfavors the coherent (spatially uniform) condensation of /vector ψ ∂ /vector ( i ψ = 0), due to rot A = 0 (favoring nontrivial ones such as vortices as explained above), the SC in a magnetic field is disfavored. In this sense, the system (3.5) is a kind of a frustrated system (the K term disfavors coexistence although the Zeeman term does).
Then a detailed study by using numerical methods is needed to obtain the correct phase diagram. To this end, we shall introduce a lattice version of the GL theory (3.5) that is suitable for the investigation by using MC simulations.
## 3.2. GL theory on the lattice
In this subsection we explain the lattice GL theory introduced in Ref. 32 . In constructing the theory, we start with the following two simplifications:
- (1) We consider the 'London' limit of the SC, i.e., we assume /vector ψ ∗ ( r ) · /vector ψ r ( ) = const . ignoring the fluctuations of the radial degrees of freedom | /vector ψ r ( ) . | This assumption is legitimate as the phase degrees of freedom /vector ψ r ( ) themselves play an essentially important role in the SC transition (Recall the account of phase coherence for a Bose-Einstein condensate) 28 .
- (2) We assume that the third component ψ 3 ( r ) ∝ ∆ ↑↓ ( r ) is negligibly small compared to the remaining ones ψ 1 2 , ( r ),
$$\psi _ { \pm } \equiv \frac { 1 } { \sqrt { 2 } } ( \psi _ { 1 } \pm i \psi _ { 2 } ), \, \psi _ { \uparrow \uparrow } \equiv \psi _ { - } \, \infty \, \Delta _ { \uparrow \uparrow }, \, \psi _ { \downarrow \downarrow } \equiv - \psi _ { + } \, \infty \, \Delta _ { \downarrow \downarrow }. \quad \ \ ( 3. 8 ) \\ \text{This simplification is consistent with the fact that the real materials exhibit}$$
This simplification is consistent with the fact that the real materials exhibit FM orders of Ising-type with the i = 3-direction as the easy axis. In fact, /vector S = -i /vector ψ ∗ × /vector ψ is calculated with ψ ↑↓ ≡ ψ 3 as
$$\vec { S } = ( - \sqrt { 2 } \, \text{Re} ( \psi _ { \uparrow \uparrow } + \psi _ { \downarrow } ) \psi _ { \uparrow \downarrow } ^ { * }, \sqrt { 2 } \, \text{Im} ( \psi _ { \uparrow \uparrow } - \psi _ { \downarrow } ) \psi _ { \uparrow \downarrow } ^ { * }, | \psi _ { \uparrow \uparrow } | ^ { 2 } - | \psi _ { \downarrow \downarrow } | ^ { 2 } ) ^ { t }. \quad ( 3. 9 ) \\ \intertext { \Sigma \, \text{the 7\,\text{common column $f$} \, \text{for\,\text{our\,as} \,\text{more\,as} } \, \text{more\,and} \, \text{to\,as} \, \text{for\,\text{our} } \, \vec { m } \, \sim }$$
So the Zeeman coupling f Z requires large ψ 1 2 , compared to ψ 3 to favor /vector m ∝ (0 , 0 , m ).
In summary, we parametrize the Cooper-pair field in the London limit, | ψ r ( ) | 2 = [ α/ (2 λ )]( T 0 SC -T ), at low T < T ( 0 SC ) with the third easy axis as
$$\binom { \psi _ { 1 } ( r ) } { \psi _ { 2 } ( r ) } = \sqrt { \frac { \alpha } { 2 \lambda } ( T _ { \text{SC} } ^ { 0 } - T ) } \times \binom { z _ { 1 } ( r ) } { z _ { 2 } ( r ) } \,, \ | z _ { 1 } ( r ) | ^ { 2 } + | z _ { 2 } ( r ) | ^ { 2 } = 1. \quad ( 3. 1 0 ) \\ \tau _ { 1 } \, - \, \alpha _ { 1 } \, \dots \, \tau _ { 2 } \, - \, \dots \, \tau _ { 3 } \, - \, \tau _ { 4 } \, - \, \tau _ { 5 } \, - \, \tau _ { 6 } \, - \, \tau _ { 7 } \, - \, \tau _ { 8 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \tau _ { 9 } \, - \, \ t }$$
The 'normalized' two-component complex field z a ( r ) ( a = 1 2) satisfying the con-, straint (3.10) is called CP 1 variable (CP stands for complex projective group). In terms of the SC order-parameter field z a ( r ), the first K term of (3.5) is rewritten as Kα (2 λ ) -1 ( T 0 SC -T ) i a D z i a · D z i a .
∑ ∑ Now let us introduce the lattice GL theory of FMSC defined on the 3d cubic lattice. Its free energy density per site f r is given by 32
$$\text{www.w3.org/wiki/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/h3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3//w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w1/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/g3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3\w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w4/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/W3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3/w3:/
f_r = - \frac { c _ { 1 } } { 2 } \sum _ { i = 1 } ^ { 3 } \sum _ { a = 1 } ^ { 2 } \frac { c _ { 3 } } { c _ { 4 } } \sum _ { r = 1 } ^ { 2 } \frac { c _ { 5 } } { c _ { 6 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 7 } } { c _ { 8 } } \sum _ { a = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac < c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { [ } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _{ i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 ] } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _{{ i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1. } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 3 } \frac { c _ { 9 } } { c _ { 9 } } \sum _ { i = 1 } ^ { 2 } \frac { c _ { 9$$
The five coefficients c i ( i = 1 ∼ 5) in (3.11) are real nonnegative parameters that are to distinguish various materials in various environments. z ra is the CP 1 variable put on the site r and plays the role of SC order-parameter field. U ri is the exponentiated
vector potential, θ ri , put on the link ( r, r + ). i /vector m r = ( m ,m r 1 r 2 , m r 3 ) t is the magnetic field made out of θ ri as
$$m _ { r i } \equiv \sum _ { j, k = 1 } ^ { 3 } \epsilon _ { i j k } \nabla _ { j } \theta _ { r k }, \ \nabla _ { j } \theta _ { r k } \equiv \theta _ { r + j, k } - \theta _ { r k }.$$
/vector m r serves as the FM order-parameter field. Following Eq.(3.5), the spin /vector S r of the Cooper pair is defined as
$$\vec { S } _ { r } = ( 0, 0, S _ { r 3 } ), \ S _ { r 3 } \equiv - i ( \bar { z } _ { r 1 } z _ { r 2 } - \bar { z } _ { r 2 } z _ { r 1 } ) \ ( \in | \psi _ { \uparrow \uparrow } | ^ { 2 } - | \psi _ { \downarrow \downarrow } | ^ { 2 } ), \quad ( 3. 1 3 )$$
where we absorbed the normalization of /vector S r ( ) into the coefficient c 3 . /vector m r , /vector S r and f r are invariant under the following gauge transformation,
$$z _ { r a } \to z _ { r a } ^ { \prime } = e ^ { i \lambda _ { r } } z _ { r a }, \ U _ { r i } \to U _ { r i } ^ { \prime } = e ^ { - i \lambda _ { r + i } } \ U _ { r i } \ e ^ { i \lambda _ { r } }. \quad \quad ( 3. 1 4 )$$
Here we comment on the way of putting a 3d continuum vector field on the 3d lattice. It sounds natural that a vector field /vector B r ( ) should be put on the link ( r, r + ) as i B ri . However, it is too naive. In fact, the gauge field /vector A r ( ) has the nature of connection as explained and the connection between two points separated by finite distance such as nearest-neighbor pair of sites cannot be implemented by θ ri itself but by its exponentiated form such as U ri . This is the reason why one has ¯ z r + i,a ¯ U ri z ra term in Eq.(3.11). On the other hands, concerning to the SC order field /vector ψ r ( ), its suitable lattice version depends on the coherence length ξ . If ξ is of the same order of lattice spacing a , its vector nature should be respected and the link field ψ ri is adequate. If ξ /greatermuch a , the detailed lattice structure is irrelevant and a simpler version ψ ra ( a = 1 2 3) on the site (or its Ising counterpart , , z ra ( a = 1 2)) , will do. Eq.(3.11) corresponds to the latter case ξ /greatermuch a as some materials show.
Let us see the meaning of each term in f r . The c 1 -term describes a hopping of Cooper pairs from site r to r + i (and from r + i to r ). As the Cooper pair has the electric charge -2 , it minimally couples with the vector potential e θ ri via U ri as explained above. It is important to observe the relation between the hopping parameter c 1 and T . From the expression given in the paragraph below Eq. (3.5), we have
$$c _ { 1 } \sim K \alpha \lambda ^ { - 1 } ( T _ { S C } ^ { 0 } - T ) a.$$
At sufficiently large βc 1 = c 1 /T (we set k B = 1) that corresponds to low T 's, the c 1 -term stabilizes the combination of phases of ¯ z r + i,a ¯ U ri z ra , and then, if U ri is stabilized already by other mechanism, a coherent condensation of the phase degrees of freedom of z r is realized inducing the superconductivity . The c 2 and c 4 -terms are the quartic GL potential of /vector m r , favoring a finite amount of local magnetization 〈 /vector m r 〉 /negationslash = 0 (note that we take c 2 > 0). We should remark that these terms controls intrinsic magnetization, which is different from the fluctuating but external magnetic field. The c 5 -term represents the NN coupling of the magnetization and corresponds to the K ′ term of Eq.(3.5). It enhances uniform configurations of /vector m r , i.e., a FM longrange order signaled by a finite magnetization m m , 2 ≡ lim | r -r ′ |→∞ 〈 /vector m r · /vector m r ′ 〉 /negationslash = 0.
The c 3 -term is the Zeeman coupling, which favors collinear configurations of /vector m r and /vector S r , i.e., enhances the coexistence of FM and SC orders.
The partition function Z at T for the energy density f r of Eq.(3.11) is given by the integral over a set of two fundamental fields z ra and θ ri as
$$\text{integral over a set or two runamental neas } z _ { r a } \text{ and } \nu _ { r i } \text{ as} \\ Z & = \int [ d z ] [ d \theta ] \exp ( - \beta F ), \ \beta = T ^ { - 1 }, \ F = \sum _ { r } f _ { r }, \\ [ d z ] & = \prod _ { r } d ^ { 2 } z _ { r 1 } d ^ { 2 } z _ { r 2 } \ \delta ( | z _ { r 1 } | ^ { 2 } + | z _ { r 2 } | ^ { 2 } - 1 ), \\ [ d \theta ] & = G ( \{ \theta \} ) \prod _ { r, i } d \theta _ { r i }, \ \theta _ { r i } \in ( - \infty, \infty ). \\ \text{re} C ( I \theta ) \, \text{ is a square fusion function} [ \succeq the naraarh contain} \, F ( 9 3 ) ]$$
where G ( { } θ ) is a gauge fixing function[see the paragraph containing Eq.(2.35)].
We stress here that the free energy F and the integration variables in Eq.(3.16) have no dependence on the imaginary time x 0 in contrast with the expression (2.34). The ordinary GL theory explained in the literature also shares this properties. This implies that we ignore the x 0 -dependent modes of would-be ϕ x and θ xµ as A ( { ϕ x } { , θ xµ } ) → βF ( { ϕ r } { , θ ri } ). This is an approximation applicable for small β 's, i.e., for high T 's. This procedure allows us to make use of MC method that is based on the probabilistic process. In fact, the form (3.16) has a real function F and the Boltzmann factor exp( -βF /Z ) is able to be interpreted as a probability. This is in contrast with the original action A corresponding to F ; A is certainly a complex function as Eq.(2.34) giving rise to a complex probability. We come back to this point later.
The coefficients c i ( i = 1 , · · · , 5) in f r may have nontrivial T -dependence as Eqs.(3.5) and (3.15) suggest. However, in the present study we consider the response of the system by varying the 'temperature' T ≡ 1 /β defined by β , an overall prefactor in Eq.(3.16), while keeping c i fixed. This method corresponds to well-known studies such as the FM transition by means of the O (3) nonlinearσ model 33 and the lattice gauge-Higgs models discussed in Sec.2.1, and is sufficient to determine the critical temperature [See, e.g., Eq.(4.7)].
In the following section, we shall show the results obtained by MC numerical evaluation of Eq.(3.16). Physical quantities O ( z, θ ) like the internal energy, specific heat, correlation functions, etc. are also calculated by the MC simulations as
$$\langle \mathcal { O } ( z, \theta ) \rangle = \frac { 1 } { Z } \int [ d z ] [ d \theta ] \mathcal { O } ( z, \theta ) \exp ( - \beta F ).$$
From the obtained results, we shall clarify the phase diagram of the system and physical properties of each phase.
## 4. Results of Monte Carlo simulation
In the present section, we introduce and discuss the results of numerical calculations 32 34 , for the lattice GL model (3.11), which include the phase diagram
and Meissner effect in the SC phase. Figs.5 ∼ 9 presented below are from Ref. 32 and Fig.10 ∼ 13 are from Ref. 34 .
## 4.1. Phase diagram and Meissner effect
We first seek for a suitable boundary condition (BC) of θ ri as the magnetization is expressed by θ ri as Eq.(3.12). A familiar condition is the periodic boundary condition such as θ r + Li,j = θ rj for the linear system size L . However, this condition necessarily gives rise to a vanishing net mean magnetization due to the lattice Storkes theorem. So we consider the 3d lattice of the size (2 + L +2) 2 × L and take a 'free BC' on z r in the i = 1 2 directions defined by ,
$$z _ { r + i, a } - \bar { U } _ { r i } z _ { r a } = 0 \text{ for } r = \begin{cases} ( 0, r _ { 2 }, r _ { 3 } ), & i = 1, \\ ( L + 2, r _ { 2 }, r _ { 3 } ), i = 1, \\ ( r _ { 1 }, 0, r _ { 3 } ), & i = 2, \\ ( r _ { 1 }, L + 2, r _ { 3 } ), i = 2, \end{cases} & ( 4. 1 ) \\ \text{hereas we impose the free boundary condition on } \theta _ { r i }. \text{ It is easily shown that the amount } i \text{$\mathbb{C}$}$$
whereas we impose the free boundary condition on θ ri . It is easily shown that the BC (4.1) implies that the suppercurrent j SC ri ,
$$j _ { r i } ^ { \text{SC} } \in \text{Im} \ ( \sum _ { a } \bar { z } _ { r + i, a } \bar { U } _ { r i } z _ { r a } ),$$
satisfies j SC r 1(2) = 0 on the boundary surfaces in the 2(1) -3 planes. That is, the supercurrent does not leak out of the SC material. Another possible BC is the one that imposes vanishing Cooper-pair amplitude z ra , but we expect, as usual, that the qualitative bulk properties of the results are not affected by the BC seriously. [The above BC (4.1) means that the magnetization is just like the Ising type and 〈 /vector m x 〉 = (0 0 , , m 3 ), which describes the real materials properly.]
In the simulation made in Refs. 32 34 , we use the standard Metropolis algorithm 35 for the lattice size up to L = 30. The typical number of sweeps for a measurement is (30000 ∼ 50000) × 10 and the acceptance ratio is 40% ∼ 50%. The error is calculated as the standard deviation of 10 samples obtained by dividing one measurement run into 10 pieces. Concerning to the gauge-fixing term of Eq.(2.35), even for a noncompact gauge theory such as the present one, gauge fixing is not necessary in practical MC simulations. This is because, in addition to the reasons given at the end of paragraph of Eq.(2.35), the MC updates using random numbers almost never generate exactly gauge-equivalent configurations.
We calculate the internal energy U , the specific heat C of the central region R of the size L 3 , the magnetization m i , which are defined as follows,
$$U = \frac { 1 } { L ^ { 3 } } \langle F _ { L } \rangle, \ C = \frac { 1 } { L ^ { 3 } } \langle ( F _ { L } - \langle F _ { L } \rangle ) ^ { 2 } \rangle, \ F _ { L } \equiv \sum _ { r \in R } f _ { r }, \ m _ { i } \equiv \frac { 1 } { L ^ { 3 } } \langle | \sum _ { r \in R } m _ { r i } | \rangle, \ \ ( 4. 3 )$$
and the normalized correlation functions,
$$G _ { m } ( r - r _ { 0 } ) = \frac { \langle \vec { m } _ { r } \cdot \vec { m } _ { r _ { 0 } } \rangle } { \langle \vec { m } _ { r _ { 0 } } \cdot \vec { m } _ { r _ { 0 } } \rangle }, \, G _ { S } ( r - r _ { 0 } ) = \frac { \langle S _ { r 3 } S _ { r _ { 0 }, 3 } \rangle } { \langle S _ { r _ { 0 }, 3 } S _ { r _ { 0 }, 3 } \rangle }, \quad \quad ( 4. 4 )$$
where r 0 is chosen on the boundary of R such as (3 , 2+ L/ , z 2 ). Singular behaviors of U and/or C indicate the existence of phase transitions, and the magnetization m i and the correlation functions in Eqs.(4.4) clarify the physical meaning of the observed phase transitions. As the present system is a frustrated system as we explained above, G m and G S may exhibit some peculiar behavior in the FMSC state (the state in which FM and SC orders coexist).
To verify that the model (3.16) actually exhibits a FM phase transition as T is lowered, we put c 1 = c 3 = 0 and ( c 2 , c 4 , c 5 ) = (0 5 4 0 1 0), . , . , . and measured C increasing β in the Boltzmann factor of Eq.(3.16). In Fig.5 we show C and m i , which obviously indicate that a second-order phase transition to the FM state takes place at β FM = 1 /T FM /similarequal 2 0. We observed that other cases with various values of . c 2 4 5 , , exhibit similar FM phase transitions.
Let us see the SC phase transition and how it coexists with the FM. We recall that the case of all c i = 0 except for c 1 was studied in the previous paper Ref. 19 . There it was found that the phase transition from the confinement phase to the Higgs phase takes place at c 1 /similarequal 2 85. This result suggests that the SC state exists . at sufficiently large c 1 also in the present system with c i (=1) = 0.
/negationslash
/negationslash
To study this possibility, we use ( c 2 , c 4 , c 5 ) = (0 5 . , 4 0 . , 1 0) as in the FM sector . above and ( c 1 , c 3 ) = (0 2 . , 0 2). In Fig.6a, we show . C vs β , which exhibits a large and sharp peak at β /similarequal 2 1 and a small and broad one at . β /similarequal 4 5. To understand the . physical meaning of the second broad peak, it is useful to measure 'partial specific heat' C i for each term F i in the free energy (3.11) defined by
$$C _ { i } = \frac { 1 } { L ^ { 3 } } \langle ( F _ { i } - \langle F _ { i } \rangle ) ^ { 2 } \rangle, \ F _ { i } = \sum _ { r \in R } f _ { i r },$$
where f ir is the c i -term in f r of Eq.(3.11).
Figs.6b,c show that the partial specific heat C 2 4 5 , , have a sharp peak at β /similarequal 2 1. . Thus the peak of total C there should indicate the FM phase transition. The analysis of Meissner effect (see the discussion below using Fig.8) supports this point. On the other hand, C 1 of the c 1 -term has a relatively large and broad peak at β /similarequal 4 5. . C 3 also shows a broader peak there. Then we judge that the SC phase transition
Fig. 5. (a) Specific heat for ( c 2 , c 4 , c 5 ) = (0 5 . , 4 0 . , 1 0) and . c 1 = c 3 = 0. At β /similarequal 2 0, . C exhibits a sharp peak indicating a second-order FM phase transition. (b) Each component of magnetization m µ vs β . For T < T FM , m 3 develops, whereas m 1 and m 2 are zero within the errors as expected.
## 24 I.Ichinose and T.Matsui
Fig. 6. (a) Specific heat vs β for ( c 1 , c 3 ) = (0 2 0 2) and ( . , . c 2 , c 4 , c 5 ) = (0 5 4 0 1 0) ( . , . , . L = 20). There are a large peak at β /similarequal 2 1 and a small one at . β /similarequal 4 5. . (b,c) Partial specific heat C i of Eq.(4.5) vs β . The small and broad peak at β /similarequal 4 5 in . C is related to fluctuations of c 1 -term.
/negationslash takes place at β SC /similarequal 4 5. To support these conclusions, we show . G m ( r ) and G S ( r ) in Fig.7. At β = 2 5, . G m ( r ) exhibits a finite amount of the FM order, whereas G S ( r ) decreases very rapidly to vanish. This means that, as T is decreased, the FM transition takes place first and then the SC transition does. Therefore, for β ≥ β SC /similarequal 4 5, the FM and SC orders coexist. In this way, the partial specific heat . may be used to judge the nature of each transition found by the peak of full specific heat C (We note C = i C i in general due to interference).
∑ As we explained in the previous section, the bare transition temperature T 0 SC in Eq.(3.5) and the genuine transition temperature T SC are different. Then it is interesting to clarify the relation between them. From Eq.(3.16), any physical quantity is a function of βc i . In the numerical simulations, we fix the values of c i and vary β as explained. Then the result β SC /similarequal 4 5 means .
Fig. 7. Correlation functions G m ( r ) and G S ( r ) at various T 's for L = 20. c i 's are the same as in Fig.6.
Fig. 8. Gauge-boson mass M G of the external magnetic field propagating in x y -plane vs β for the same c i as in Fig.6 and c 2 ′ = 3 0 ( . L = 16). At the SC phase transition point β SC /similarequal 4 5 (indicated . by an arrow) determined by the peak of C M , G starts to increase from small values.
By using Eq.(3.15), this gives the following relation;
$$\frac { 1 } { T _ { \text{SC} } } \frac { K \alpha ( T _ { \text{SC} } ^ { 0 } - T _ { \text{SC} } ) a } { \lambda } = 0. 9 0 \ \to T _ { \text{SC} } = \left ( 1 + \frac { 0. 9 0 \ \lambda } { K \alpha \ a } \right ) ^ { - 1 } T _ { \text{SC} } ^ { 0 }. \quad ( 4. 7 ) \\ \quad \ \times \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \dots \ \delta \ \ \end{array}$$
Eq.(4.7) shows that the transition temperature is lowered by the fluctuations of the phase degrees of freedom of Cooper pairs. We expect that a relevant contribution to lowering the SC transition temperature comes from vortices that are generated spontaneously in the FMSC as we shall show in Sec.4.2.
After having confirmed that the genuine critical temperature can be calculated by the critical value of β with fixed c i , we use the word temperature in the rest of the paper just as the one defined by T ≡ 1 /β while c i are T -independent parameters.
One of the most important phenomena of the SC is the appearance of a finite mass of the electromagnetic field, i.e., the Meissner effect. In theoretical study of the SC that includes the effect of fluctuations of the Cooper-pair wave function as in the present one, a finite mass of the photon is the genuine order parameter of the SC. To study it, we follow the following steps 19 ; (i) introduce a vector potential θ ex ri for an external magnetic field, (ii) couple it to Cooper pairs by replacing U ri → U ri exp( iθ ex ri ) in the c 1 term of f x and add its magnetic term f ex r = + c 2 ′ ( /vector m ex r ) 2 ( c ′ 2 > 0) to f r with /vector m ex r defined in the same way as (3.12) by using θ ex ri , (iii) let θ ex ri fluctuate together with z xa and θ ri and measure an effective mass M G of θ ex ri via the decay of correlation functions of /vector m ex r . The result of /vector m ex r propagating in the 1-2 plane is shown in Fig.8. It is obvious that the mass M G starts to develop at the SC phase transition point, and we conclude that Meissner effect takes place in the SC state.
## 4.2. Vortices in FMSC state
In this section, we study the FMSC state observed in the previous section in detail. In particular, we are interested in whether there exist vortices and their density if any. There are two kinds of vortices as the present SC state contains two gaps described by ψ + r ∝ z + r and ψ -r ∝ z -r , where z ± r are defined as
$$\cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad\cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \ \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd. \quad \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cd. \quad \quad \quad$$
Corresponding to the above Cooper pair fields, one may define the following two kinds of gauge-invariant vortex densities V + r and V -r in the 1-2 plane;
$$& \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \alpha \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \lambda \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xi \xright ], \quad ( 4. 9 ) \\ & \quad - \mod \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad \, \quad$$
where mod( x ) ≡ mod( x, 2 π ). In short, V ± r describes vortices of electron pairs with the amplitude z ± r .
To study the behaviors of vortices step by step, we first consider the case of constant magnetization (magnetic field), i.e., we set θ ri by hand so that
$$m _ { r 1 } = m _ { r 2 } = 0, \ m _ { r 3 } = f = \text{constant},$$
freezing their fluctuations. As the above numerical studies show that a typical magnitude of the magnetization 〈 m r 3 〉 = 0 8 . · · · , we put f = π 4 . In this case, the SC phase transition takes place at β = 4 8. Snapshots of vortices are shown in Fig.9. . It is obvious that at lowerT , i.e., β = 7 0, densities of vortices are low compared to . the higherT ( β = 3 0) case but they are still nonvanishing. This result obviously . comes from the existence of the finite magnetization, i.e., the internal magnetic field.
Fig. 9. Snapshots of vortex densities V ± r at ( c 1 , c 2 , c 3 , c 4 , c 5 ) = (0 2 0 5 0 2 . , . , . , 4 0 . , 1 0) for a . fixed magnetization /vector m r = (0 0 , , π/ 4) ( L = 16) from Ref. 32 . Black dots; V ± r = 0.875, Dark gray dots; -1.125, Light gray dots; -0.125. (A) V + r at β = 3 0, (B) . V -r at β = 3 0, (C) . V + r at β = 7 0, (D) . V -r at β = 7 0. The average magnitude . 〈| V r ± |〉 is (A) 0.387, (B) 0.380, (C) 0.331 and (D) 0.335. The points V ± r = -0 125 = . -m / 3 (2 π ) reflect /vector m itself, and corresponds to the state without genuine vortices.

Fig. 10. Snapshot at β = 2 0 . with dynamically fluctuating /vector m r . The values of c i are ( c 1 , c 2 , c 3 , c 4 , c 5 ) = (0 2 . , 0 5 . , 0 2 . , 4 0 . , 1 0). .
It is interesting to study behavior of vortices and the magnetization in the FMSC state rather in detail. We now allow for fluctuations of θ ri . In this state, the magnetization m r 3 fluctuates around its mean value. As we showed in the previous section, the FM and SC phase transitions take place at β FM /similarequal 2 1 and . β SC /similarequal 4 5, . respectively. We are interested in the β -dependence of various quantities such as the magnetic field 〈 m r 3 〉 , the vortex densities V ± r , and the Cooper-pair densities 〈 ρ ± r 〉 .
In Figs. 10 ∼ 13 we show these quantities as snapshots at β = 2 0 3 0 4 0 . , . , . , 5 2 for . the set of parameters ( c 1 , c 2 , c 3 , c 4 , c 5 ) = (0 2 . , 0 5 . , 0 2 . , 4 0 . , 1 0). At . β = 2 0 (Fig.10), . the local magnetization m r 3 fluctuates rather strongly, and also the density of Cooper pairs ρ + r and ρ -r are almost equal. Densities of vortices V ± r are also fairly large. At β = 3 0(Fig.11), . m r 3 tends to have a positive value. This corresponds to the fact that the system has the FM long-range order. At β = 4 0(Fig.12), . ρ + r
Fig. 11. Snapshot at β = 3 0 with . dynamically fluctuating /vector m r . The values of c i are the same as in Fig.10.
## 28 I.Ichinose and T.Matsui
- density
Fig. 12. Snapshot at β = 4 0 with . dynamically fluctuating /vector m r . The values of c i are the same as in Fig.10.
is getting larger compared to ρ -r . Similarly, V -r is sightly larger than V + r . These results reflect the Zeeman coupling. At β = 5 2(Fig.13), vortex-antivortex pairs are . formed, and V -r is larger than V + . As in the case of the constant magnetic field, r the densities of vortices are nonvanishing even in the SC phase.
## 5. Conclusion
In this paper, we present a brief review of LGT with Higgs matter field, and then apply it to the GL lattice model of FMSC. The detailed MC simulations of the model reveal the global structure such as the phase diagram and the physical characteristics of each phase in an explicit manner. The concepts and knowledges of LGT considerably help us to build an appropriate lattice model as well as to interpret the results of MC simulations. We want to add this example to the rather
Fig. 13. Snapshot at β = 5 2 with . dynamically fluctuating /vector m r . The values of c i are the same as in Fig.10.
long list of studies that have utilized the following common three-step method: (i) Establishing a lattice gauge model of the phenomenon of one's interest, (ii) Performing MC simulations of the model, (iii) Intepreting the MC results according to LGT. Here we list up a couple of tips to remove obstacles in carrying out this program.
- · MC simulations become more effective with less variables. To avoid unnecessary inflation of degrees of freedom, one should identify what are the relevant variables. Neglecting the radial degrees of freedom of the Higgs field φ r is an example 28 .
- · MC simulations require positive measure to make use of a probabilistic (Markoff) process. Fermionic systems in their original forms suffer from the well known negative-sign problem, which generates negative probabilities. By restricting the region of parameters of the model, it could be possible to avoid this problem. For example, the critical region around a continuous phase transition, the order-parameters are small and the GL expansion may assure us a positive provability 6 .
- · Another example to avoid nonpositive provability is the case of bosonic system at finite temperatures. The path integral of bosonic variables usually contain the imaginary kinetic term like i ∫ dτφ dφ/dτ ¯ ( ) in the action, where τ ∈ (0 , β = 1 / k ( B T )) is the imaginary time. By focusing in the high-temperature region, the τ -dependent modes of φ τ ( ) may be ignored and so is this kinetic term. This is the case of FMSC studied in Sect. 3 and 4, and some of the cases studied in Ref. 6 7 . , This procedure has an extra merit that the dimension of the effective lattice system is reduce to d -dimensions instead of D = d +1 dimensions due to the absence of the x 0 -direction.
Nowadays, it is well known that a quite wide variety of systems of cold atoms put on an optical lattice may serve as a quantum simulator of certain definite quantum model with almost arbitrary values of interaction parameters. Such a simulator is to clarify the dynamical (time-dependent) properties of the quantum model. Therefore, the importance of theoretical analysis of such models become increased as a guide for experiments. For example, information on the global phase structure of a quantum model is quite useful to perform experiments in an effective manner, although the former is confined to the static (time-independent) properties in thermal equilibrium. We expect that the above path (i-iii) with the successive tips may be useful for this purpose, in particular to simulate the model including compact or noncompact gauge fields. We hope as many readers as possible make use of this practical but powerful tool to strengthen and expand their researches.
## Acknowledgments
We thank Mr. T. Noguchi, our coauthor of Ref. 34 , for his help and discussions. We also thank Dr. K. Kasamatsu for reading the manuscript and presenting comments and suggestions. This work was supported by JSPS KAKENHI Grantnumbers 23540301, 26400246, 26400412.
## References
- 1. See, e.g. a review; P. A. Lee, N. Nagaosa, and X-G Wen, Rev. Mod. Phys. 78 , 17 (2006).
- 2. P. A. Lee, Science 321, 1306 (2008).
- 3. M. P. A. Fisher, P. B. Weichman, G. Grinstein, and D. S. Fisher, Phys. Rev. B 40 , 546 (1989); D. Jaksch, C. Bruder, J. I. Cirac, C. W. Cardiner, and P. Zoller, Phys. Rev. Lett. 81 , 3108 (1998).
- 4. M. W. Long and X. Zotos, Phys. Rev. B 45 , 9932 (1992); M. Boninsegni, Phys. Rev. Lett. 87 , 087201 (2001); Phys. Rev. B 65 , 134403 (2002); L.-M. Duan, E. Demler, and M. D. Lukin, Phys. Rev. Lett. 91 , 090402 (2003); E. Altman,W. Hofstetter, E. Demler, andM. D. Lukin, New J. Phys. 5 , 113 (2003). For the relation between the Bose Hubbard model and the bosonic t -J model, see Appendix A of the last reference of Ref. 7 .
- 5. See, e.g., M. Lewenstein, A. Sanpera, and V. Ahufinger, ' Ultracold Atoms in Optical Lattices: Simulating Quantum Many-body Systems ', (Oxford University Press, 2012).
- 6. For the t -J model of electrons, see G. Baskaran and P. W. Anderson, Phys. Rev. B 37 , 580 (1988); A. Nakamura and T. Matsui, Phys. Rev. B 37 , 7940 (1988); I. Ichinose and T. Matsui, Phys. Rev. B 45 , 9776 (1992); Nucl. Phys. B 394 , 281 (1993); Phys. Rev. B 51 , 11860 (1995); P. A. Lee and N. Nagaosa, Phys. Rev. B 46 , 5621 (1992); N. Nagaosa and P. A. Lee, Phys. Rev. Lett. 64 , 2450 (1990); Phys. Rev. B 43 , 1233 (1991). I. Ichinose, T. Matsui and M. Onoda, Phys. Rev. B 64 , 104516 (2001).
- 7. K. Aoki, K. Sakakibara, I. Ichinose, and T. Matsui, Phys. Rev. B 80 , 144510 (2009). Y. Nakano, T. Ishima, N. Kobayashi, K. Sakakibara, I. Ichinose, and T. Matsui, Phys. Rev. B 83 , 235116 (2011).
- 8. K. G. Wilson, Phys. Rev. D 10 , 2445 (1974).
- 9. For earlier reviews and books of LGT, see, e.g., J. B. Kogut, Rev. Mod. Phys. 51 , 659 (1979); M. Creutz, ' Quarks, gluons and lattices ', (Cambridge University Press 1985); I. Montvay and G. M¨nster, ' u Quantum Fields on a Lattice ', (Cambridge University Press 1997).
- 10. G. 't Hooft, Nucl. Phys. B 138 ,1 (1978); M. E. Peskin, Ann. Phys. 113 , 122 (1978).
- 11. M. B. Einhorn and R. Savit, Phys. Rev. D 17 , 2583 (1978).
- 12. G. Kotliar and A . Ruckenstein, Phys. Rev. Lett. 57 , 2790 (1987); Z. Zou and P. W. Anderson, Phys. Rev. B 37 , 627 (1988).
- 13. P. W. Anderson, Phys. Rev. Lett. 64 , 1839 (1990).
- 14. See, e.g., J. K. Jain, ' Composite fermions ', (Cambridge University Press, 2007) and references cited therein.
- 15. For composite boson formalism, see M. P. A. Fisher and D. H. Lee, Phys. Rev. B 39 , 2756 (1989); S. C. Zhang, Int. J. Mod. Phys. B 6 , 25 (1992). For composite fermion, formalism, see J. Jain, Phys. Rev. Lett. 63 , 199 (1989), Phys. Rev. B 40 , 8079 (1989); 41 , 7653 (1990).
- 16. J. Kogut and L. Susskind, Phys. Rev. D 11 , 3376 (1974).
- 17. For inclusion of relativistic fermions, see Refs. 8 9 16 , , For relativistic bosons, see Sect.2.4 and Ref. 11 . For nonrelativistic fermions, see I. Ichinose and T. Matsui, Phys.
## Rev. B 45 , 9776 (1992).
- 18. K. G. Wilson and J. Kogut, Phys. Rep. 12 , 75 (1974).
- 19. S. Takashima, I. Ichinose and T. Matsui, Phys. Rev. B 72 , 075112 (2005).
- 20. In the relativistic theory, the charge-conjugate pair of φ -particle (antiparticle) having the charge -g should appear on an equal footing.
- 21. A. M. Polyakov, Phys. Lett. B 59 , 82 (1975).
- 22. Sometimes the noncompact model is studied just for the purpose of comparison with the compact model. In general, one must ask for every system and situation under consideration which model (compact vs. noncompact) is more suitable.
- 23. In some literatures, the term | φ x + µ -U xµ φ x | 2 appears instead of | φ x + µ -¯ U xµ φ x | 2 . They are related by φ x ↔ ¯ φ x or U xµ ↔ ¯ U xµ and equivalent each other.
- 24. S. Elitzur, Phys. Rev. D 12 , 3978 (1975).
- 25. J. M. Drouffe, Nucl. Phys. B 170 , 211 (1980).
- 26. See, e.g., E. Sa'nchez-Velasco, Phys. Rev. E 54 , 5819 (1996), and references cited therein.
- 27. In the relativistic theory, Eq.(2.34) is obtained by starting with a set of annihilation operator, ˆ a r of particle and ˆ b r of antiparticle. Then, the charge operator is written as q a (ˆ † r ˆ a r -ˆ ˆ b † r b r ). One writes the path-integral expression of Z by using the canonical pair ( ˆ φ ± r , π ˆ ± r ) with ˆ a r = ˆ φ + r + ˆ iπ + r , ˆ b r = ˆ φ -r + ˆ iπ -r . Then by integrating over π ± r ∈ C one arrives at Eq.(2.34) with φ r = φ + r + iφ -r ∈ C . This φ r is a canonical field in contrast with the coherent-state field φ r in Eq.(2.31) although the same symbol φ r is used.
- 28. Of course, the fluctuations of radial component | φ x | may give rise to certain effects. For example, in the abelian Higgs model, fluctuations of | φ x | may change the secondorder SC transition to a first-order one if the coefficient λ of the | φ x | 4 coupling [See Eq.(2.22)] becomes sufficiently small. See, e.g., K. Jansen, J. Jers´k, C. B. Lang, T. a Neuhaus, G. Vones, Nucl. Phys. B 265 , 129 (1986).
- 29. For UGe , see S. S. Saxena 2 et al. , Nature (London) 406 , 587 (2000); A. Huxley et al. , Phys. Rev. B 63 , 144519 (2001); N. Tateiwa et al. , J. Phys. Condens. Matter 13 , L17 (2001). For URhGe, see D. Aoki et al. , Nature (London) 413 , 613 (2001). For UCoGe, see N. T. Huy et al. , Phys. Rev. Lett. 99 , 067006 (2007); E. Slooten et al. Phys. Rev. Lett. 103 , 097003 (2009).
- 30. K. Machida and T. Ohmi, Phys. Rev. Lett. 86 , 850 (2001); M. B. Walker and K. V. Samokhin, Phys. Rev. Lett. 88 , 207001 (2002).
- 31. F. Hardy and A. D. Huxley, Phys. Rev. Lett. 94 , 247006 (2005); Harada et al. , Phys. Rev. B 75 , 140502 (2007).
- 32. A. Shimizu, H. Ozawa, I. Ichinose, and T. Matsui, Phys. Rev. B 85 , 144524 (2012). Here, we adopted the alternative notation explained in Ref. 23 .
- 33. See, e.g., J. Cardy, ' Scaling and Renormalization in Statistical Physics ', (Cambridge University Press, 1996).
- 34. T. Noguchi, I. Ichinose and T. Matsui in preparation.
- 35. N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. M. Teller, and E. Teller, J. Chem. Phys. 21 , 1087 (1953); J. M. Thijssen, ' Computational Physics ', (Cambridge University Press, 1999). | 10.1142/S0217984914300129 | [
"Ikuo Ichinose",
"Tetsuo Matsui"
] | 2014-08-01T06:29:17+00:00 | 2014-09-07T07:39:45+00:00 | [
"cond-mat.str-el",
"hep-lat"
] | Lattice Gauge Theory for Condensed Matter Physics: Ferromagnetic Superconductivity as its Example | Recent theoretical studies of various strongly-correlated systems in
condensed matter physics reveal that the lattice gauge theory(LGT) developed in
high-energy physics is quite a useful tool to understand physics of these
systems. Knowledges of LGT are to become a necessary item even for condensed
matter physicists. In the first part of this paper, we present a concise review
of LGT for the reader who wants to understand its basics for the first time.
For illustration, we choose the abelian Higgs model, a typical and quite useful
LGT, which is the lattice verison of the Ginzburg-Landau model interacting with
a U(1) gauge field (vector potential). In the second part, we present an
account of the recent progress in the study of ferromagnetic superconductivity
(SC) as an example of application of LGT to topics in condensed matter physics,
. As the ferromagnetism (FM) and SC are competing orders with each other, large
fluctuations are expected to take place and therefore nonperturbative methods
are required for theoretical investigation. After we introduce a LGT describing
the FMSC, we study its phase diagram and topological excitations (vortices of
Cooper pairs) by Monte-Carlo simulations. |
1408.0090v2 | ## Genesis of altmetrics or article-level metrics for measuring efficacy of scholarly communications: Current perspectives
Anup Kumar Das*, Sanjaya Mishra 1
Centre for Studies in Science Policy, School of Social Sciences, Jawaharlal Nehru University, 1 Commonwealth Educational Media Centre for Asia, New Delhi, India
## ABSTRACT
The article-level metrics (ALMs) or altmetrics becomes a new trendsetter in recent times for measuring the impact of scientific publications and their social outreach to intended audiences. The popular social networks such as Facebook, Twitter, and Linkedin and social bookmarks such as Mendeley and CiteULike are nowadays widely used for communicating research to larger transnational audiences. In 2012, the San Francisco Declaration on Research Assessment got signed by the scientific and researchers communities across the world. This declaration has given preference to the ALM or altmetrics over traditional but faulty journal impact factor (JIF)-based assessment of career scientists. JIF does not consider impact or influence beyond citations count as this count reflected only through Thomson Reuters' Web of Science ® database. Furthermore, JIF provides indicator related to the journal, but not related to a published paper. Thus, altmetrics now becomes an alternative metrics for performance assessment of individual scientists and their contributed scholarly publications. This paper provides a glimpse of genesis of altmetrics in measuring efficacy of scholarly communications and highlights available altmetric tools and social platforms linking altmetric tools, which are widely used in deriving altmetric scores of scholarly publications. The paper thus argues for institutions and policy makers to pay more attention to altmetrics based indicators for evaluation purpose but cautions that proper safeguards and validations are needed before their adoption.
Keywords: Altmetrics, article-level metrics, citation database, research assessment, research communication, science communication
## INTRODUCTION
In 2014, the Science Citation Index (SCI) - a pioneering product of erstwhile Institute of Scientific Information - completed a journey of 50 years. SCI is considered as a key enabler in making of topical areas of bibliometrics and scientometric. While SCI is completing its 50 th anniversary, another related area - altmetrics or article-level metrics (ALMs)
*Address for correspondence:
E-mail: [email protected]
## Access this article online
Quick Response Code:

Website: www.jscires.org
DOI:
10.4103/2320-0057.145622
is gaining substantial popularity amongst scientific communities, research communicators and research funders. Open access (OA) movement at the beginning of the 21 st century has strengthened online availability of scholarly publications across the world. The researchers and research communicators attribute the BBB OA declarations as game changers and greater enablers for promotion of scholarly research to larger communities beyond the researchers' fraternities, but also to common citizens and taxpayers. BBB declarations are a group of OA-related declarations namely Budapest declaration in 2002, Berlin declaration in 2003 and Bethesda declaration in 2003 prompting public funded research to be made available and accessible in the public domain. These declarations ensured majority of research publications will be distributed or disseminated through OA channels such as OA knowledge repositories (i.e., green OA channel) and OA journals (i.e., gold OA channel). In this process, a silent transformation also takes place. There is a
shift in measuring author's productivity from journal-level indicators to ALM. The citation metrics using journal impact factor (JIF) and Journal immediacy index - both are associated with erstwhile SCI and now Web of Science ® and Journal Citation Reports ® of Thomson Reuter are felt inadequate in present circumstances while there is increased availability of scholarly publications in online public domain. ALM not only counts citations an individual research papers obtained, but also other influences such as number of downloads, social media share, coverage in news media, etc. The performance measurement for assessing research productivity of individual scientists, as obtained solely from counting number of citations or aggregate/average values of JIF, is no longer valued by funding agencies in developed countries. Rather they started impact evaluation of research publications or funded research projects very differently. Thus, altmetrics of a published paper is measured multi-dimensionally integrating its usage (downloads, views), peer-review (expert opinion), citations, and online interactions (storage, links, bookmarks, conversations).
The San Francisco Declaration on Research Assessment (DORA), singed in 2012 by the scientific and researchers communities across the world, has given preference to the ALM or altmetrics over traditional but faulty JIF-based assessment of career scientists DORA, 2012. [1] The concept of altmetrics explores the potentialities of social media and academic social networks, which helps in increasing global visibility, accessibility and readability of publications shared by the contributing authors Liu, et al ., 2014. [2] The researchers in the twenty-first century are very keen to maintain online researchers' profiles in academic social networking websites. They are also interested in transnational networking through online discussion forums and peer-to-peer collaborative platforms. While a plenty of general purpose social networking sites are globally available, some online social networks are meant for academics and researchers. Academic social networking websites facilitate creation of online groups for discussions based on particular research interests. Table 1 in the later part of this paper provides an indicative list of social networking websites that facilitate networking of academics and researchers. All these social networking websites facilitate researchers in building their public profiles - listing their research publications, research projects, research positions or training. While ResearchGate.net, Academia.edu, Linkedin. com, and few others facilitate user-to-user interactions and e-collaborations through e-groups; getCITED.org, SSRN. com and few others do not have such web 2.0 features. Further details of some of these academic social networks are available in the following sub-sections.
## GENESIS AND INSTITUTIONAL FRAMEWORKS
The altmetrics manifesto was published in 2010 by a group of enthusiasts and subsequently it becomes a baseline for a burgeoning altmetrics movement that achieves a global appreciation (Altmetrics.org/manifesto/). In 2011, a dynamic organization was born to technologically support multi-dimensional measurements of published works, beyond citation counts. The name of this start-up company is altmetric LLP, a new avatar in providing online services for generating ALM as a new performance indicator. Simultaneously, the concept of altmetrics is increasingly getting popular since the San Francisco DORA was made public in 2012. Altmetric. com narrates its genesis, as describe below:
'Altmetric LLP was founded by Euan Adie in 2011 and grew out of the burgeoning altmetrics movement.
Table 1: Major academic social networks
| | ResearchGate.net | Academia.edu | getCITED.org | SSRN.com |
|-------------------------------|-----------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------|------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------|
| Target group | Researchers | Academics: Researchers, students | Researchers | Researchers, authors |
| Founded in | 2008 | 2008 | 2004 | 1994 |
| Subject coverage | All | All | All | Social sciences, humanities and law |
| Mission | To give science back to the people who make it happen and to help researchers build reputation and accelerate scientific progress | To accelerate the world's research; to make science faster and more open | To make records of scholarly work publicly available | To provide rapid worldwide distribution of research to authors and their readers and to facilitate communication among them at the lowest possible cost |
| Account creation | Free | Free | Free | Free |
| Public profile of researchers | Yes | Yes | Yes | Yes |
| Web 2.0 interactivity | Yes | Yes | No | No |
SSRN = Social Science Research Network; getCITED.org = same as getcited.org
D
a
Euan had previously worked on Postgenomic.com, an open source scientific blog aggregator founded in 2006. Interested in taking the ideas from postgenomic forward, we entered an altmetrics app into Elsevier's Apps for Science competition and ended up winning. The prize money helped us to grow from an evenings and weekends project into a full-fledged product: The first standalone version of the Altmetric Explorer was released in February 2012. In July 2012, we took on additional investment from Digital Science. Our users now include some of the world's leading journals, funders and institutions. We remain a relatively small company and take pride in our strong focus on engineering and domain knowledge (Source: www. altmetric.com/about.php).'
Since 2013, several scholarly journals and newsletters published special issues on altmetrics. In 2013 the Bulletin of the Association for Information Science and Technology (Bulletin of the ASISandT) published a special issue 'altmetrics: What, Why and Where?' with eight articles detailing altmetrics frameworks and possibilities Piwowar, 2013. [3] In the same year, Information Standards Quarterly (ISQ) published a special issue on altmetrics with five articles and an editorial. In June 2014, Research Trends published a special issue 'alternative metrics' with nine articles and an editorial (www.researchtrends.com/ issue-37-june-2014/) Taylor, et al ., 2014. [4] Recently National Information Standards Organization (NISO) of the United States has initiated publishing a whitepaper as an outcome of its ongoing project NISO altmetrics standards project. A draft version of NISO altmetrics Standards Project White Paper got published in May 2014 (See www.niso.org/ topics/tl/altmetrics\_initiative/). In the same year, Leiden University of the Netherlands publishes a working paper titled Do 'altmetrics' Correlate with Citations? Extensive Comparison of altmetric Indicators with Citations from a Multidisciplinary Perspective Fenner, 2013 [5] (http://arxiv. org/abs/1401.4321) Costas, et al ., 2014. [6]
The CWTS (Center for Science and Technology Studies) of Leiden University has already initiated a research line in altmetrics (www.cwts.nl/Altmetrics), where altmetrics is studied under the umbrella of 'Societal Impact of Research'. Similarly, LSE (London School of Economics and Political Science, United Kingdom) initiated the LSE Impact of Social Sciences blog in 2011, where different dimensions of ALM are greatly discussed on regular basis (see http://blogs.lse.ac.uk/impactofsocialsciences/ tag/altmetrics/). The number of institutions engaged in altmetrics research is growing in western countries.
However, in the global south still there is no formal scholarly research project or research group engaged in-depth studies in this nascent area.
The scholarly publishers, particularly OA publishers, have ridden over altmetrics movement to reach a new height. The Public Library of Science (PLOS) is the most pioneer and early implementer of altmetrics in their OA journals. Every article published in PLOS journals gives instant access to ALM derived from their own algorithms and chosen data sources.
## GROWTH OF LITERATURE ON ALTMETRICS AND ARTICLE-LEVEL METRICS
For the purpose of this paper, the authors have performed an online search in Scopus database using search terms TITLE-ABS-KEY (altmetric*) OR TITLE-ABS-KEY (ALM*), searchable in the title, abstract and keyword fields. The search query retrieved 70 documents as available within Scopus database on July 22, 2014. Retrieved documents were further analyzed to derive year-wise and country-wise distribution of published papers, top contributing authors, and top contributing institutions.
Figure 1 shows the year-wise distribution of papers since the origination or conceptualization of term ALM in 2009. Year 2013 has been most productive in terms of producing literature on altmetrics. Till July 2014, only 14 documents published within year 2014 added to Scopus database. It is expected that more documents will be added for remaining part of year 2014 and will outnumber year 2013.
Figure 2 shows country-wise distribution of papers on the topic of altmetrics. The United States of America stands highest producing 21 papers, United Kingdom stands second with 17 papers and Canada stands third with
Figure 1: Year-wise distribution of Altmetrics Papers (as in Scopus till July 22, 2014)
6 papers. Other contributing countries include Germany, Netherlands, China, Israel, Spain, and Sweden. Countries have one paper each are namely Australia, Austria, Belgium, Brazil, Croatia, Hong Kong, India, Japan, Malaysia, Russian Federation and Switzerland.
Table 2 shows top cited papers on the topic of altmetrics. This table also gives comparative scores of each paper's citations (cited by) statistics as recorded in both in Scopus database as well as Google Scholar (GS) search engine. Paper titled 'can tweets predict citations? Metrics of social impact based on Twitter and correlation with traditional metrics of scientific impact', published in 2011, attracted highest number of citations, that is, cited by 59 papers. This paper also attracted 152 citations as recorded in GS
Figure 2: Country-wise distribution of Altmetrics Papers (as in Scopus till July 22, 2014)
database. Paper titled 'ALM and the evolution of scientific impact', published in 2009 in PLOS Biology, received the second highest number of citations, that is, cited by 34 papers as in Scopus and 82 papers as in GS.
Table 3 records the top cited papers as retrieved with GS search engine. Publication titled altmetrics: A Manifesto gets the maximum number of citations followed by some papers not covered in Scopus database Priem, et al ., 2010. [7] Papers appeared in altmetrics special issues of the Bulletin of the American Society for Information Science and Technology (2013) and ISQ (2013), respectively, started receiving a good number of citations. Interestingly, many of the papers appeared in Tables 2 and 3 are OA contents or freely available online, as indicated in these two tables.
Table 4 shows top contributing authors and their respective affiliation and country. M. Thelwall of United Kingdom contributed the highest number of papers with six contributions on altmetrics topic as recorded in Scopus database, followed by J. Priem of the United States with five contributions. Other authors contributed three papers each. Interestingly, many of them associated with global altmetrics movement and projects related to altmetrics. Table 5 shows top contributing institutions in altmetrics area. The Statistical Cybermetrics Research Group of the University of Wolverhampton, UK is top contributing institution and followed by the School of Information and
Table 2: Top 10 highly cited papers (as in Scopus till 22 nd July 2014)
| Paper details | Cited by | Google scholar citations | Open access article |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------|----------------------------|-----------------------|
| Eysenbach G. (2011). Can Tweets Predict Citations? Metrics of Social Impact Based on Twitter and Correlation with Traditional Metrics of Scientific Impact. Journal of Medical Internet Research, 13(4) | 59 | 152 | Yes |
| Neylon C. and Wu S. (2009). Article-Level Metrics and the Evolution of Scientific Impact. PLOS Biology, 7(11), e1000242 | 34 | 82 | Yes |
| Piwowar H. (2013). Altmetrics: Value All Research Products. Nature, 493(7431), 159-159 | 16 | 58 | No |
| Thelwall M., Haustein S., Larivière V. and Sugimoto C. R. (2013). Do Altmetrics Work? Twitter and Ten Other Social Web Services. PLOS One, 8(5), e64841 | 14 | 47 | Yes |
| Ware M. (2011). Peer Review: Recent Experience and Future Directions. New Review of Information Networking, 16(1), 23-53 | 14 | 19 | No |
| Priem J., Groth P. and Taraborelli D (2012). The Altmetrics Collection. PLOS One, 7(11), e48753 | 13 | 28 | Yes |
| Yan K. K. and Gerstein M. (2011). The Spread of Scientific Information: Insights from the Web Usage Statistics in PLOS Article-Level Metrics. PLOS One, 6(5), e19917 | 10 | 23 | Yes |
| Schloegl C. and Gorraiz J. (2011). Global usage versus global citation metrics: The case of pharmacology journals. Journal of the American Society for Information Science and Technology, 62(1), 161-170 | 10 | 16 | No |
| Galligan F. and Dyas-Correia S. (2013). Altmetrics: Rethinking the Way We Measure. Serials Review, 39(1), 56-61 | 6 | 18 | No |
| Jacsó P. (2010). Eigenfactor and Article Influence Scores in the Journal Citation Reports. Online Information Review, 34(2), 339-348 | 6 | 12 | No |
PLOS=Public library of science
D
a
Table 3: Other important publications on altmetrics covered in GS search engine
| Paper details | Google scholar citations | Open access article |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------|-----------------------|
| Priem J., Taraborelli D., Groth P. and Neylon, C. (2010). Altmetrics: A Manifesto | 114 | Yes |
| Priem J., Piwowar H. A. and Hemminger B. M. (2012). Altmetrics in the Wild: Using Social Media to Explore Scholarly Impact. arXiv preprint arXiv: 1203.4745 | 67 | Yes |
| Roemer R. C. and Borchardt R. (2012). From Bibliometrics to Altmetrics A Changing Scholarly Landscape. College and Research Libraries News, 73(10), 596-600 | 21 | Yes |
| Adie E. Roe W. (2013). Altmetric: Enriching Scholarly Content with Article-Level Discussion and Metrics. Learned Publishing, 26(1), 11-17 | 18 | Yes |
| Konkiel S. and Scherer D. (2013). New Opportunities for Repositories in the Age of Altmetrics. Bulletin of the ASISandT, 39(4), 22-26 | 15 | Yes |
| Piwowar H. and Priem J. (2013). The Power of Altmetrics on a CV. Bulletin of the ASISandT, 39(4), 10-13 | 15 | Yes |
| Buschman M. and Michalek A. (2013). Are Alternative Metrics Still Alternative?. Bulletin of the ASISandT, 39(4), 35-39 | 13 | Yes |
| Mohammadi E. and Thelwall M. (2014). Mendeley Readership Altmetrics for the Social Sciences and Humanities: Research Evaluation and Knowledge Flows. Journal of the ASISandT, 65(8), 1627-1638 | 13 | No |
| Binfield P. (2009). PLOS One: Background, Future Development, and Article-Level Metrics. Rethinking Electronic Publishing, ELPUB, 69-86 | 12 | Yes |
| Mounce R. (2013). Open Access and Altmetrics: Distinct but Complementary. Bulletin of the ASISandT, 39(4), 14-17 | 11 | Yes |
| Tananbaum G. (2013). Article-Level Metrics: A SPARC Primer. Available from: http://www.sparc.arl.org/sites/default/files/sparc-alm-primer.pdf | 7 | Yes |
GS=Google scholar, PLOS=Public library of science
Table 4: Top authors in altmetrics (as in Scopus till 22 nd July 2014)
| Name of author | Affiliation | Country | Number of papers |
|------------------|----------------------------------------------------------------------------------------------------------------------------------|-------------|--------------------|
| M. Thelwall | Statistical Cybermetrics Research Group, Faculty of Science and Engineering, University of Wolverhampton, Wolverhampton | U.K. | 6 |
| J. Priem | School of Information and Library Science, University of North Carolina at Chapel Hill | USA | 5 |
| P. Groth | Department of Computer Science and The Network Institute, VU University Amsterdam | Netherlands | 3 |
| J. Bar-Ilan | Department of Information Science, Bar-Ilan University, Ramat Gan | Israel | 3 |
| S. Haustein | École de bibliothéconomie et des sciences de l'information, Université de Montréal, Montréal, Canada; b Science-Metrix, Montréal | Canada | 3 |
| I. Peters | Department of Information Science, Heinrich-Heine-University, Düsseldorf | Germany | 3 |
| H. Piwowar | Department of Biology, Duke University | USA | 3 |
| J. Terliesner | Department of Information Science, Heinrich Heine University, Duesseldorf | Germany | 3 |
Library Science of University of North Carolina at Chapel Hill, USA. These institutions are also associated with global altmetrics movement and projects related to altmetrics.
## ALTMETRICS TOOLS
The altmetric LLP remains a pioneer in providing altmetric-related solutions to specifically academic publishers, who would embed altmetric score in each scholarly article they publish in their e-journal gateways. Thus, altmetric score of an online scholarly article is instantly known to visitors of that particular e-journal. In some cases, readers even have convenient options to share bibliographic details of 'liked' papers through their social media account. Here, users can instantly share any of these papers through Facebook, Twitter, Google+, Linkedin, Mendeley, CiteULike, or similar interactive social networks.
Figure 3 shows an indicative list of altmetrics tools available to the publishers, funders and researchers. In this figure, symbol '#' denotes that these web services are not comprehensive ones, only provide some aspects of altmetrics. Some web services which have discontinued their experimental beta version of potential altmetric application (but referred in other publications) are not included in this figure, namely ReaderMeter. org, CrowdoMeter.org and ScienceCard.org. Presently, serious contenders of altmetric tools which have much comprehensive approaches are namely Altmetric.com, ImpactStory.org, PlumAnalytics.com and PLOS ALMs. Whereas providers such as PeerEvaluation.org yet to generate a critical mass to be considered as serious contenders of altmetric tools. Some of these tools are also mentioned in the Altmetrics.org/tools/website. Table 6 provides a comparative analysis of major altmetrics
Table 5: Top institutions in altmetrics (as in Scopus till 22nd July 2014)
| Name of institution and country | Number of papers |
|------------------------------------------------------------------------------------------------------|--------------------|
| Statistical Cybermetrics Research Group, University of Wolverhampton, Wolverhampton, UK | 6 |
| School of Information and Library Science, University of North Carolina at Chapel Hill, USA | 6 |
| Department of Information Science, Bar-Ilan University, Ramat Gan, Israel | 3 |
| VU University, Amsterdam, Netherlands | 3 |
| École de bibliothéconomie et des sciences de l'information, Université de Montréal, Montréal, Canada | 3 |
| Department of Information Science, Heinrich- Heine-University, Düsseldorf, Germany | 3 |
| School of Information and Library Science, Indiana University, USA | 3 |
Figure 3: Altmetrics tools available to the publishers, funders, and researchers
providers, namely, Altmetric.com, ImpactStory.org, and PlumAnalytics.com. As indicated in this table, some of the functionalities are common in every platform. These websites provides application programming interface (API) and bookmarklet to publishers and users to fetch altmetric data from different sources. For example, altmetric API of Altmetric.com is an API that enables the publisher to enrich their article pages with ALM data. It helps system to system interaction and obtaining ALM data from different data sources as indicated later. Similarly, altmetric bookmarklet of Altmetric.com is a simple browser tool that lets a researcher instantly gets ALM data for any recent paper. It is a kind of browser plugin that can be integrated into researcher's web browser Chrome, Firefox or Safari.
## DERIVING ALTMETRIC SCORES
## Using Altmetric.com
As indicated in Figure 4, Altmetric Explorer of the Altmetric.com derives altmetric scores from a weighted algorithm covering article-level statistics of viewed, downloaded, cited, saved and discussed. A scholarly article's popularity, usage, acceptance and availability are reflected in an altmetric score. Only articles with digital object identifier (DOI) are considered in arriving at a conclusive altmetric score. Thus, the primary requirement for having an altmetric score is to establish DOI of every published article in electronic journals. Altmetric.com covers about 900+ news sources across the world. Most of them belong to developed or western countries. Few of them belong to developing countries. About 20 news sources are covered from India, namely. The Hindu, Hindustan Times, Times of India, Deccan Herald, Indian Express, the Telegraph, DNA, Asian Age, Business Standard, Dainik Jagran, Dainik Bhaskar, etc., Hence, if a scholarly article is mentioned in any of the news item in 900 + news sources, an artmetric score gets a higher value.
## Altmetric badge
Altmetric.com provides a ready-to-use embeddable badge to journal publishers. This badge is embeddable in an article page to help the publishers showcasing impact in a beautiful way. This tool generates small donut shaped multicolor, multilayer visualizations to quickly convey information about each article, with a summary of the score from different data sources. Figure 5 shows an altmetric badge depicting how an article is being outreached and appraised
D
a
## Table 6: Major altmetrics providers
Figure 4: Deriving an altmetric score
| | Altmetric.com | Impactstory.org | Plumanalytics.com |
|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------|
| Target group | Researchers, publishers, librarians, editors, funders | Researchers, publishers, funders | Researchers, publishers, funders |
| Founded in | 2011 | 2012 | 2011 |
| Mission | To track and analyze the online activity around scholarly literature | Discover the full impact of your research | To figure out more accurate ways of assessing research by analyzing the five categories of metrics Usage Captures Mentions Social media |
| Functionalities | Authors should be able to see the attention that their articles are receiving in real-time Publishers, librarians and repository managers should be able to show authors and readers the conversations surrounding their content | Researchers who want to know how many times their work has been downloaded, bookmarked, and blogged Research groups who want to look at the broad impact of their work and see what has demonstrated interest Funders who want to see what sort of impact they may be missing when only considering citations to papers Repositories who want to report on how their research products are being discussed of us who believe that people should be rewarded | Assess your impact Track immediate impact Gain an advantage Measure all of your output Group metrics Answer important questions |
| Functionalities | Editors should be able to quickly identify commentary where a response is required | All when their work (no matter what the format) makes a positive impact (no matter what the venue) | |
| Functionalities | Researchers should be able to see which recent papers their peers think are interesting | Aggregating evidence of impact will facilitate appropriate rewards, thereby encouraging additional openness of useful forms of research output | |
through social media. However, this altmetric score does not include download statistics of the said article.
## Using Public Library of Science Article-level Metric
The PLOS is one of the pioneering publisher that introduced ALM for its OA journals much earlier than many other e-journal gateways. PLOS ALM derived from different data sources as indicated in Figure 6. It includes counts with respect to usage, views, downloads, citations, social bookmarking, blogs, media coverage, and comments. Figure also indicates that PLOS ALM gets view or download statistics not only from PLOS journals but also from the PubMed Central database. Text Box 1 indicates purposes, usages and target users of PLOS ALM. It also helps you understand how PLOS ALM functions. PLOS metrics can be customized to address the needs of researchers, publishers, institutional decision makers, and funders.
## Using ImpactStory.org
The ImpactStory.org is another leading provider of ALM data. This website offers registered users creating their impact profile on the web, revealing diverse impacts of their articles, datasets, software, and more. This
is a collaborative not-for-profit open source project supported by the US National Science Foundation, Alfred P. Sloan Foundation and Open Society Foundation. ImpactStory.org helps in creating author's profile and adding publication list through importing bibliographic records from different sources such as Scopus database, ORCID.org, GS citations, SlideShare.net and many others.
A researcher can create a profile for free in this website to know how many times his/her work has been downloaded, bookmarked, and blogged. A researcher can also generate code to embed ImpactStory profile into his institutional CV and the research blog. The homepage of ImpactStory profile of the registered researcher shows
Figure 5: An altmetric badge
## Text Box 1: Understanding PLOS ALMs
## PLOS ALMs
Purpose: ALMs provide a suite of established metrics that measure the overall performance and reach of published research articles
For whom
Researchers: Maximize the impact of your research
Publishers: Enhance publication value through real-time views of reach and influence
Institutions: Capture researcher impact for hiring, tenure, and promotion decisions
Funders: Track the performance and impact of research funding
ALMs measure the dissemination and reach of published research articles. Traditionally, the impact of research articles has been measured by the publication journal. But a more informative view is one that examines the overall performance and reach of the articles themselves. ALM are a comprehensive set of impact indicators that enable numerous ways to assess and navigate research most relevant to the field itself, including
Usage
Citations
Social bookmarking and dissemination activity
Media and blog coverage
Discussion activity and ratings
ALMs are available, upon publication, for every article published by PLOS. Researchers can stay up-to-date with their published work and share information about the impact of their publications with collaborators, funders, institutions, and the research community at large. These metrics are also a powerful way to navigate and discover others' work. Metrics can be customized to address the needs of researchers, publishers, institutional decision-makers, or funders
Source: http://article-level-metrics.plos.org/alm-info/
ALMs=Article-level metrics, PLOS=Public library of science a list of contributed papers or presentations. These are categorized as < highly saved>, <highly discussed>, <highly cited>, <saved>, <discussed>, <cited>, and < viewed>. When you click on the title of the paper, you will get a detail ALM score indicating counts from different data sources.
Figure 6: Data sources for public library of science article-level metrics

D
a
## Using PlumAnalytics.com
The fourth major altmetric provider is the PlumAnalytics. com. It categorizes metrics into five separate types: Usage, captures, mentions, social media, and citations. PlumAnalytics tracks more than 20 different types of artifacts, including journal articles, books, videos, presentations, conference proceedings, datasets, source code, cases, and more. Figure 7 indicates different data sources used in PlumAnalytics for deriving altmetrics of scholarly publications. As indicated here, PlumAnalytics also includes citation statistics from global patent databases. This is very unique, as compared to other three altmetrics providers. In January 2014, EBSCO has acquired this start-up company Enis, 2014. [8]
## SOCIAL NETWORKS HELPING IMPROVEMENT OF RESEARCHERS' ALTMETRIC SCORES
As we saw in the earlier sections, altmetrics data are derived from various social media and social bookmarking platforms. Researchers of the 21 st century need to collaborate with transnational researchers for a successful academic career. They have increased their visibility and participation at the global level through maintaining online profiles, both in general and academic social networking
Figure 7: Data sources for PlumAnalytics.com article-level metrics

platforms. Their participation in transnational e-groups in online forums, including E-mail-based forums, increased possibilities of peer-to-peer collaborations. While a plenty of general purpose social networking sites are globally available, some online social networks are meant for academics and researchers. Academic social networks facilitate creation of online groups for discussion based on particular research interests. Table 7 provides an indicative list of general purpose social networking websites that also facilitate networking of academics and researchers, besides other citizens. Table 1 provides an indicative list of special purpose websites that mainly facilitate social networking of academics and researchers. While ResearchGate and Academia.edu facilitate user-to-user interactions through e-groups, getCITED.org, and SSRN.com do not have such web 2.0 feature. These academic research networks also ensure peer-to-peer communications through special interest e-groups, where sometimes membership is offered based on prior publications or prior contributions in the research fields
## USING ONLINE SOCIAL BOOKMARKS AND REFERENCE MANAGERS FOR IMPROVING ALTMETRIC SCORES
As we saw in the earlier sections, altmetrics data are also derived from online social bookmarks, and citation or reference managers. Some of the online reference managers also act as PDF organizers, and let others know which papers you read, reviewed or referred to your colleagues. Some of these citation managers also help you to produce subject bibliographies, based on recommended reading lists of your colleagues and e-group members. Thus, online reference managers and social bookmarks play important roles in deciding popularity metrics of research publications accessible online. Individual scholars also get tremendous encouragement when they see their publications are stored, reviewed, recommended and shared by e-groups. There also researchers can create online public profile for highlighting their research publications and reading lists. Table 8 briefly describes major online reference managers and social bookmarks, namely, CiteULike.org, Mendeley. com, Delicious.com and Zotero.org. Zotero is not presently linked to Altmetric.com. Similar few more online reference managers exist, but these are not linked to any altmetric tool used for deriving altmetric score. Some online reference managers, not mentioned in Table 8 although exist, are namely Flow (Flow .proquest.com), EndNote Basic (Endnote. com/basic/), and GS library (Scholar.google.com). Here also users can create an online account for storing references and
Table 7: Important general purpose social networks useful for authors and researchers
| | Facebook | Twitter | Google+ | LinkedIn | Slideshare | Figshare |
|-------------------------------|------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------|------------------------------------------------------------------------|---------------------------------------|
| Target group | Any citizen | Any citizen | Any citizen | Professionals | Researchers; professionals | Researchers |
| Founded | 2004 | 2006 | 2011 | 2003 | 2006 | 2011 |
| Mission | To give people the power to share and make the world more open and connected | To give everyone the power to create and share ideas and information instantly, without barriers | To bring the nuance and richness of real-life sharing to the web, and making all of Google better by including people, their relationships and their interests | Connect the world's professionals to make them more productive and successful | The world's largest community to share and upload presentations online | Publish all of your research outputs! |
| Public profile of individuals | Yes | Yes | Yes | Yes | Yes | Yes |
| Type of social media | General purpose | General purpose | General purpose | Professional | Format specific | Format specific |
| Acceptable formats | - | - | - | - | Presentations | Datasets, figures and tables |
Table 8: Major online reference managers and social bookmarks
| | CiteULike | Mendeley | Delicious | Zotero |
|------------------|-----------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
| Target group | Researchers | Academics: Researchers, students | Researchers, professionals | Researchers |
| Founded in | 2004 | 2008 | 2003 | 2006 |
| About | Afree service for managing and discovering scholarly references | Afree reference manager and academic social network that can help you organize your research, collaborate with others online, and discover the latest research | Never lose a link again: Delicious is a free and easy tool to save, organize and discover interesting links on the web | Afree, easy-to-use tool to help you collect, organize, cite, and share your research sources |
| Ownership | | Elsevier B.V. | Science Inc. | Center for History and New Media at George Mason University, USA |
| Account creation | Free | Free | Free | Free |
preparing bibliographies. These are also extensively used by researchers across disciplines. Some reference managers have desktop versions, which are freely downloadable and can be integrated with online accounts. Examples of desktop versions of reference managers are Mendeley and Zotero. EndNote also has a desktop version of the reference manager, although that is not freely available. ProQuest's RefWorks is a reference manager having both online and desktop version. RefWorks' simplified and free version is named Flow, which was launched in 2013 by ProQuest Inc. to be an earnest competitor of the Mendeley, EndNote Basic and Zotero. They will compete each other to increase their market share in the growing segment of online reference managers. Some of them will also be measured for deriving altmetric score of stored or shared research publications.
are still naïve in handling highly-interactive academic communication channels available to them with web 2.0 readiness. They need to have the necessary information and digital literacy competencies to be conversant with born-digital documents and sharing them with academic social networking platforms. The new-age researchers need to understand and grasp changing landscape of research communications, particularly which are helping global visibility of research communications. To become a successful researcher, one should first become a successful research communicator. One's altmetric score will be increased significantly if he/she manages to reach out to researchers in his/her core and peripheral subject areas using a wide array of social networking platforms available to them. Thus, the nuance of research communication is commensurate with knowledge diffusion to the society.
## CONCLUSION
Nowadays the researchers' communities along with research funding agencies are giving much importance to altmetrics, due to better reflection of social impact and outreach of scientific publications using altmetric tools. However, scientific communities in the developing countries
On the other hand, while discussing efficacy of altmetric indicators and altmetric tools in online discussion groups such as the SIGMETRICS (ASIS and T Special Interest Group on Metrics, [email protected]) and the GOAL (Global OA List, [email protected]) during year 2013 to 14, several discussants have pointed out certain
D
a
limitations or pitfalls of altmetrics. Their concerns are likely: Motivated downloading, automated downloading by special apps or robots, and publisher's inflated downloading data in addition to misuse of traditional citation-based indicators, viz., authors' and journals' self-citation. As social media shares and likes are counted in altmetric scores, researchers and publishers may also push social media shares through undeclared paid advertisements. Although, some discussants do not mind sharing tables of contents in online mailing lists, social media groups, blogs and microblogs, as they considered this as part of research communications strategies adopted by many institutions, individuals, publishers and funders.
Researchers and authors may liberally and ethically use social media tools to boost availability and accessibility of their published works. While other researchers and popular science writers would find the primary research works worthwhile or pioneering, these get mentioned in media articles, science blogs and micro blogs in addition to social bookmarking sites and online reference managers.
Another concern is raised about acquisitions of start-up altmetric providing companies by large corporations. For example, PlumAnalytics.com was acquired by EBSCO LLC in January 2014. This will lead to further commercialization of altmetric business while nonprofit and developing countries' publishers will be marginalized as they have less affordability of portraying altmetric data for every paper they publish. Till today, big publishers and publishers from developed countries are only portraying altmetric data on their respective article page. We need to re-look at these issues before advocating widespread use of altmetric indicators for research assessment.
## ACKNOWLEDGMENTS
This paper is an outcome of a study carried out under the auspices of UNESCO-CEMCA Project titled 'Development of curricula and self-directed learning Tools on Open Access.' The authors greatly acknowledge supports and professional inputs received from the UNESCO and CEMCA. The authors are also thankful to Dr. Bidyarthi Dutta of DLIS, Vidyasagar University, West Bengal, India for his valuable feedbacks while preparation of this paper.
## REFERENCES
- 1. DORA. The San Francisco Declaration on Research Assessment (DORA). USA: American Society for Cell Biology (ASCB); 2012. Available from: http://www.ascb.org/dora/ files/SFDeclarationFINAL.pdf [Last accessed on 2014 Aug 1].
- 2. Liu J, Adie E. Realising the Potential of Altmetrics with in Institutions. Ariadne, Issue 72; 2014. Available from: http://www. ariadne.ac.uk/issue72/liu-adie [Last accessed on 2014 Aug 1].
- 3. Piwowar H. Introduction - Altmetrics: What, Why and Where? Bull Assoc Inf Sci Technol 2013;39:8-9.
- 4. Taylor M, Halevi G, Moed HF. Special Issue on Alternative Metrics. Research Trends, 37, 01; 2014. Available from: http://www. researchtrends.com/category/issue-37-june-2014/ [Last accessed on 2014 Aug 1].
- 5. Fenner M. Letter from the guest content editor: Altmetrics have come of age. Inf Stand Q 2013;25:3.
- 6. Costas R, Zahedi Z, Wouters P. Do altmetrics correlate with citations? Extensive comparison of altmetric indicators with citations from a multidisciplinary perspective. Available from: http:// arxiv.org/abs/1401.4321 [Last accessed on 2014 Aug 1].
- 7. Priem J, Taraborelli D, Groth P, Neylon C. Altmetrics: A Manifesto; 2010. Available from: http://www.altmetrics.org/manifesto/ [Last accessed on 2014 Aug 1].
- 8. Enis M. Altmetrics: EBSCO Acquires Plum Analytics; 2014. Available from: http://www.thedigitalshift.com/2014/01/publishing/ ebsco-acquires-altmetrics-provider-plum-analytics/ [Last accessed on 2014 Aug 1].
How to cite this article: Das AK, Mishra S. Genesis of altmetrics or article-level metrics for measuring efficacy of scholarly communications: Current perspectives. J Sci Res 2014;3:82-92.
Source of Support: Nil, Conflict of Interest: None declared
Announcement
## iPhone App

A free application to browse and search the journal's content is now available for iPhone/iPad. The application provides 'Table of Contents' of the latest issues, which are stored on the device for future offline browsing. Internet connection is required to access the back issues and search facility. The application is Compatible with iPhone, iPod touch, and iPad and Requires iOS 3.1 or later. The application can be downloaded from http://itunes.apple.com/us/app/medknow-journals/ id458064375?ls=1&mt=8. For suggestions and comments do write back to us. | null | [
"Anup Kumar Das",
"Sanjaya Mishra"
] | 2014-08-01T06:36:40+00:00 | 2014-12-10T12:07:12+00:00 | [
"cs.DL",
"cs.IR"
] | Genesis of Altmetrics or Article-level Metrics for Measuring Efficacy of Scholarly Communications: Current Perspectives | The article-level metrics (ALMs) or altmetrics becomes a new trendsetter in
recent times for measuring the impact of scientific publications and their
social outreach to intended audiences. The popular social networks such as
Facebook, Twitter, and Linkedin and social bookmarks such as Mendeley and
CiteULike are nowadays widely used for communicating research to larger
transnational audiences. In 2012, the San Francisco Declaration on Research
Assessment got signed by the scientific and researchers communities across the
world. This declaration has given preference to the ALM or altmetrics over
traditional but faulty journal impact factor (JIF)-based assessment of career
scientists. JIF does not consider impact or influence beyond citations count as
this count reflected only through Thomson Reuters' Web of Science database.
Furthermore, JIF provides indicator related to the journal, but not related to
a published paper. Thus, altmetrics now becomes an alternative metrics for
performance assessment of individual scientists and their contributed scholarly
publications. This paper provides a glimpse of genesis of altmetrics in
measuring efficacy of scholarly communications and highlights available
altmetric tools and social platforms linking altmetric tools, which are widely
used in deriving altmetric scores of scholarly publications. The paper thus
argues for institutions and policy makers to pay more attention to altmetrics
based indicators for evaluation purpose but cautions that proper safeguards and
validations are needed before their adoption. |
1408.0091v1 | ## On the density limit in the helicon plasma sources
Igor A. Kotelnikov ∗ Budker Institute of Nuclear Physics, Novosibirsk, Russia and Novosibirsk State University, Novosibirsk, Russia
Existence of the density limit in the helicon plasma sources is critically revisited. The lowand high-frequency regimes of a helicon plasma source operation are distinguished. In the lowfrequency regime with ω < √ ω ci ω ce the density limit is deduced from the Golant-Stix criterion of the accessibility of the lower hybrid resonance. In the high-frequency case, ω > √ ω ci ω ce , an appropriate limit is given by the Shamrai-Taranov criterion. Both these criteria are closely related to the phenomenon of the coalescence of the helicon wave with the Trivelpiece-Gould mode. We argue that theoretical density limits are not achieved in existing devices but might be met in the future with the increase of applied rf power.
PACS numbers: 52.35.Hr; 52.50.Qt; 52.50.Sw;
## I. INTRODUCTION
One of the most challenging problems in the theory of helicon plasma sources is a supposed existence of the plasma density limit [1-5]. For the helicon plasma sources, it is conventional to consider the density of the order of 10 12 cm -3 as very high, but preproduction of plasma for fusion devices needs the density of the order of 10 14 cm -3 , at least. For this reason, in this paper we critically revisit the foundations of the theory of helicon heating, assuming that rf power is sufficiently large for a plasma source to operate in the so called W-mode (helicon-Wave mode) as explained in Refs. [6, 7].
We distinguish a low-frequency and a high-frequency regimes of operation of a helicon source where the frequency ω is respectively smaller and larger than the hybrid cyclotron frequency √ ω ce ω ci .
In the high-frequency regime ( √ ω ce ω ci < ω < ω ce ), hybrid resonances are not available, and the density limit occurs because of the coalescence of the helicon and Trivelpiece-Gould (TG) waves. Corresponding density
The low-frequency regime ( ω ci < ω < √ ω ce ω ci ) is characterized by existence of the lower hybrid resonance. We reexamine the accessibility condition of the resonance in a radially inhomogeneous cylindrical plasma column, which is uniform along its axis. This condition is known as the Golant-Stix criterion [8-10]. We provide a new derivation of this criterion, which reveals its connection to the effect of the wave coalescence. We find that a density limit indeed exist in this regime. However it has not a feature of a threshold since the limiting density depends on the value of the longitudinal refractive index N ‖ = k c/ω ‖ (the larger N ‖ , the larger the limit), whereas the spectrum of the plasma oscillations excited by an antenna is usually quite wide. Therefore, speaking about a limiting density, we imply a value of N ‖ , which corresponds approximately to the maximum in the absorption spectrum of the antenna.
∗ [email protected]
limit is given by the Shamrai-Taranov criterion [3].
The paper is organized as follows. The main equations are reviewed in Secs. II and III. The Golant-Stix criterion is discussed in Sec. IV. A limiting plasma density in the low-frequency mode of operation of the helicon source is found in Sec. V. An optimal magnetic field is evaluated in Sec. VI. The high-frequency mode of the helicon source is considered in Sec. VII, where a new simple derivation of the Shamrai-Taranov criterion is given. Finally, in Sec. VIII we discuss how the low-frequency regime matches the high-frequency regime of operation.
## II. DISPERSION EQUATION
We consider a simple plasma consisting of the electrons and a single kind of ions. In the approximation of cold collisionless plasma, both plasma species are characterized by the two quantities each, the Langmuir frequency ω ps = √ 4 πe n /m 2 s s s and the Larmor frequency Ω s = e B/m c s s with the subscript s = e standing for the electrons and s = i for the ions. Assuming that the magnetic field B is directed along the axis z of the axial symmetry of the plasma column, the permittivity tensor reads
$$\leftrightarrow \begin{pmatrix} \varepsilon & i g & 0 \\ - i g & \varepsilon & 0 \\ 0 & 0 & \eta \end{pmatrix},$$
where
$$\varepsilon = \frac { \varepsilon _ { + } + \varepsilon _ { - } } { 2 } = 1 - \frac { \omega _ { p } ^ { 2 } \left ( \omega ^ { 2 } + \Omega _ { e } \Omega _ { i } \right ) } { \left ( \omega ^ { 2 } - \Omega _ { e } ^ { 2 } \right ) \left ( \omega ^ { 2 } - \Omega _ { i } ^ { 2 } \right ) }, \quad \left ( 2 a \right ) \\ \varepsilon _ { \perp } - \varepsilon _ { - } \quad \omega _ { n } ^ { 2 } \omega \left ( \Omega _ { e } + \Omega _ { i } \right ) \quad \,.$$
$$\eta = 1 - \frac { \theta _ { p } ^ { 2 } } { \omega ^ { 2 } }, \quad \ \ \ \ \ \ ( 2 c )$$
$$g = \frac { \varepsilon _ { + } - \varepsilon _ { - } } { 2 } = - \frac { \mu ^ { \mu } } { \omega _ { p } ^ { 2 } \omega ^ { \mu } ( \Omega _ { e } + \Omega _ { i } ) } ^ { e ^ { \prime } \, \cdots ^ { \mu } } { \omega _ { e } ^ { 2 } ) \, ( \omega ^ { 2 } - \Omega _ { i } ^ { 2 } ) }, \quad ( 2 b )$$
$$\varepsilon _ { \pm } = 1 - \frac { \stackrel { \omega } { \omega _ { p } ^ { 2 } } } { \left ( \omega \mp \Omega _ { e } \right ) \left ( \omega \mp \Omega _ { i } \right ) }, \quad \quad \left ( 2 d \right ) \\ \omega _ { - } ^ { 2 } \equiv \omega _ { - - } ^ { 2 } + \omega _ { - i } ^ { 2 }. \quad \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
$$\omega _ { p } ^ { 2 } \equiv \omega _ { p e } ^ { 2 } + \omega _ { p i } ^ { 2 }. \text{ \quad \quad \ \ } ( 2 e )$$
These expressions are derived from the well-known formulas
$$\varepsilon = 1 - \sum _ { s } \frac { \omega _ { p s } ^ { 2 } } { \omega ^ { 2 } - \Omega _ { s } ^ { 2 } }, \\ g = \sum _ { s } \frac { \Omega _ { s } } { \omega } \frac { \omega _ { p s } ^ { 2 } } { \omega ^ { 2 } - \Omega _ { s } ^ { 2 } }, \\ \varepsilon _ { \pm } = \varepsilon \mp g, \\ \text{si-neutrality condition}$$
using the quasi-neutrality condition
$$\omega _ { p e } ^ { 2 } \Omega _ { i } + \omega _ { p i } ^ { 2 } \Omega _ { e } = 0. \text{ \quad \ \ } ( 3 )$$
Since Ω e < 0 , below we also use alternative notations
$$\omega _ { c e } = - \Omega _ { e } = \frac { | e | B } { m _ { e } c }, \quad \omega _ { c i } = \Omega _ { i } = \frac { e _ { i } B } { m _ { i } c }$$
for the cyclotron frequencies when it is more convenient to operate with designedly positive frequencies.
A dispersion equation is obtained from the wave equation
$$\overleftarrow { \epsilon } \cdot { \mathbf E } + { \mathbf N } \left ( { \mathbf N } \cdot { \mathbf E } \right ) - { \mathbf N } ^ { 2 } { \mathbf E } = 0,$$
written in the Fourier domain with N = c k /ω denoting the vector of the refractive index. The same equation in the matrix form reads
$$\begin{pmatrix} \varepsilon - N _ { \| } ^ { 2 } & - i g & N _ { \perp } N _ { \| } \\ i g & \varepsilon - N ^ { 2 } & 0 \\ N _ { \| } N _ { \perp } & 0 & \eta - N _ { \perp } ^ { 2 } \end{pmatrix} \begin{pmatrix} E _ { x } \\ E _ { y } \\ E _ { z } \end{pmatrix} = 0, \\ \vdots & \tau & \tau & \tau & \tau & \tau & \tau & \tau \end{pmatrix}$$
where N ⊥ = N x = N sin θ , N ‖ = N z = N cos θ , and N y is assumed to be zero. Equating the determinant of this equation to zero yields the dispersion equation
$$\mathbb { A } N _ { \perp } ^ { 4 } - \mathbb { B } N _ { \perp } ^ { 2 } + \mathbb { C } = 0, \text{ \quad \ \ } ( 4 ) \text{ \ \ } \text{fix} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{} \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text$$
where
$$\mathbb { A } = \varepsilon, \\ \mathbb { B } = \varepsilon _ { + } \varepsilon _ { - } + \eta \varepsilon - \varepsilon N _ { \| } ^ { 2 } - \eta N _ { \| } ^ { 2 }, \\ \mathbb { C } = \eta \left ( N _ { \| } ^ { 2 } - \varepsilon _ { + } \right ) \left ( N _ { \| } ^ { 2 } - \varepsilon _ { - } \right ). \\ \mathbb { A } \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \cdots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots.$$
It is quadratic regarding N 2 ⊥ and consequently has two solutions
$$N _ { \perp \pm } ^ { 2 } = ( \mathbb { B } \pm \sqrt { \mathbb { B } ^ { 2 } - 4 \mathbb { A C } } ) / 2 \mathbb { A }. \quad \quad ( 5 ) \\ \dots \quad \dots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \cdots \quad \end{array}$$
However at a given k and θ the same dispersion equation yields 5 eigenfrequencies ω ( j ) as shown in Fig. 1. The two solutions (5) mean that only 2 eigenmodes at most can simultaneously propagate at a given frequency ω . They differ by the magnitude of k and their polarizations. We will focus on the eigenfrequency ω (2) which is the second by the magnitude of ω ; it is shown in purple color in Fig. 1.
glyph<c=4,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>
glyph<c=4,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>
glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=3,font=/QGQWRV+ArialMT>glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=3,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=3,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=3,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=3,font=/QGQWRV+ArialMT>glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=4,font=/QGQWRV+ArialMT>
glyph<c=3,font=/BHKCMA+Arial-ItalicMT>
glyph<c=20,font=/FFMRHV+ArialMT>glyph<c=6,font=/FFMRHV+ArialMT>glyph<c=11,font=/FFMRHV+ArialMT>glyph<c=12,font=/FFMRHV+ArialMT>glyph<c=13,font=/FFMRHV+ArialMT>glyph<c=19,font=/FFMRHV+ArialMT>
glyph<c=2,font=/NJOZWO+MicrosoftYaHei>
glyph<c=16,font=/FFMRHV+ArialMT>glyph<c=11,font=/FFMRHV+ArialMT>glyph<c=17,font=/FFMRHV+ArialMT>glyph<c=9,font=/FFMRHV+ArialMT>glyph<c=8,font=/FFMRHV+ArialMT>glyph<c=13,font=/FFMRHV+ArialMT>glyph<c=6,font=/FFMRHV+ArialMT>glyph<c=8,font=/FFMRHV+ArialMT>glyph<c=12,font=/FFMRHV+ArialMT>glyph<c=6,font=/FFMRHV+ArialMT>glyph<c=8,font=/FFMRHV+ArialMT>glyph<c=5,font=/FFMRHV+ArialMT>glyph<c=18,font=/FFMRHV+ArialMT>glyph<c=11,font=/FFMRHV+ArialMT>glyph<c=10,font=/FFMRHV+ArialMT>glyph<c=12,font=/FFMRHV+ArialMT>glyph<c=19,font=/FFMRHV+ArialMT>
glyph<c=5,font=/FFMRHV+ArialMT>glyph<c=7,font=/FFMRHV+ArialMT>glyph<c=8,font=/FFMRHV+ArialMT>glyph<c=9,font=/FFMRHV+ArialMT>glyph<c=10,font=/FFMRHV+ArialMT>glyph<c=6,font=/FFMRHV+ArialMT>glyph<c=11,font=/FFMRHV+ArialMT>glyph<c=12,font=/FFMRHV+ArialMT>glyph<c=13,font=/FFMRHV+ArialMT>
glyph<c=14,font=/FFMRHV+ArialMT>glyph<c=15,font=/FFMRHV+ArialMT>
glyph<c=21,font=/FFMRHV+ArialMT>glyph<c=7,font=/FFMRHV+ArialMT>glyph<c=22,font=/FFMRHV+ArialMT>
glyph<c=4,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>
glyph<c=4,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>glyph<c=2,font=/QGQWRV+ArialMT>
glyph<c=3,font=/FOSTFL+Arial-ItalicMT>
glyph<c=2,font=/WFZZVN+Mathematica3>
glyph<c=2,font=/BHKCMA+Arial-ItalicMT>
glyph<c=4,font=/FOSTFL+Arial-ItalicMT>
glyph<c=6,font=/QGQWRV+ArialMT>
glyph<c=2,font=/EDKLWF+ArialMT>
glyph<c=5,font=/FFMRHV+ArialMT>glyph<c=5,font=/FFMRHV+ArialMT>
glyph<c=7,font=/QGQWRV+ArialMT>glyph<c=5,font=/QGQWRV+ArialMT>
Figure 1. (Color online) Dispersion of the cold plasma waves at fixed angle of propagation: θ = π/ 6 , ω /ω 2 p 2 ce = 3 . The terms helicons (whistlers), TrivelpieceGould (TG) and low hybrid resonance (LHR) designate different parts of the same branch ω (2) of the dispersion relation (purple curve).
Figure 2. (Color online) Dispersion of the cold plasma waves at fixed k ‖ = ω ce /c , ω /ω 2 p 2 ce = 10 . The helicons and TG modes are separated by a coalescence point. Other branches: Alfven wave (blue lower curve); slow extraordinary, upper hybrid wave (yellow); ordinary wave (green); fast extraordinary wave (upper blue).
In the region of interest ω ∼ √ ω ce ω ci near the lower hybrid frequency ω LH (see below) the larger root N ⊥ + corresponds to a lower hybrid wave, which in last years is also called the Trivelpiece-Gould (TG) wave [11]. The smaller root N ⊥-corresponds to the helicons which were called whistlers in the past. However, all these waves lie on the same curve on the graph of the frequency ω (2) ( k, θ ) versus the wave number k if a value of the angle θ between the direction of the wave vector k and magnetic field B is fixed as shown in Fig. 1. The lowest frequency portion of the purple curve, where ω (2) ∝ k , corresponds to the fast magnetosonic wave. When ω (2) > ω ci , it transforms into the helicons with the dispersion ω (2) ∝ k 2 cos θ . Finally, as we approach the lower hybrid frequency ω LH , which in a dense plasma is approximately equal to ω LH ≈ √ ω ce ω ci the helicons are transformed into the Trivelpiece-Gould waves; in this region ω ≈ ω LH and the frequency is almost independent of k .
## III. SINGULAR POINTS
Standard approach to the study of wave propagation in a cold magnetized plasma includes a search of singular points. Most textbooks distinguish two kinds of such points, namely the plasma (hybrid) resonances, where N → ∞ , and the cutoffs, where N → 0 ; see e.g. [10, 12, 13]. This exhausts the list of singular points in a cold plasma at a fixed angle θ between the wave vector k and the magnetic field B . When considering the propaga- glyph<c=5,font=/QGQWRV+ArialMT>
glyph<c=2,font=/EDKLWF+ArialMT>
glyph<c=5,font=/FFMRHV+ArialMT>glyph<c=6,font=/FFMRHV+ArialMT>
glyph<c=4,font=/FFMRHV+ArialMT>
glyph<c=3,font=/FFMRHV+ArialMT>
glyph<c=2,font=/FOSTFL+Arial-ItalicMT>
glyph<c=2,font=/FFMRHV+ArialMT>
glyph<c=2,font=/EDKLWF+ArialMT>
tion of waves in a cylinder with a radially inhomogeneous profile of the plasma density, we should rather assume that a fixed quantity is the longitudinal component of the wave vector k ‖ = k cos θ , or, equivalently, the longitudinal component of the refractive index N ‖ = k c/ω ‖ . For a fixed N ‖ , one more type of the singular points appears, namely the point of coalescence, where the two roots (5) of the dispersion equation merge. The coalescence point of the helicon and TG waves is readily seen in Fig. 2. In contrast to Fig. 1, the curve ω (2) ( k , k ‖ ⊥ ) is not a monotonically rising function of k ⊥ , and, at a fixed plasma density, it assumes a maximal value at the coalescence point rather than at the lower hybrid resonance as in Fig. 1.
Below we briefly review all three types of the singular points in a simple plasma in order to introduce notations required for further treatment.
## A. Hybrid resonances
For a fixed N ‖ , the resonant points are determined by the condition
$$\mathbb { A } = 0.$$
When it is satisfied, the larger of the two solutions (5) of the dispersion equation (4) tends to infinity, N 2 ⊥ + →∞ .
Equation (6) determines the so-called plasma or hybrid resonances . Since it is linear with respect to the square of the total plasma frequency ω 2 p = ω 2 pe + ω 2 pi , it has a unique solution
$$\omega _ { p, \text{res} } ^ { 2 } & = \frac { \left ( \omega _ { c e } ^ { 2 } - \omega ^ { 2 } \right ) \left ( \omega ^ { 2 } - \omega _ { c i } ^ { 2 } \right ) } { \omega _ { c e } \omega _ { c i } - \omega ^ { 2 } }. \quad \quad ( 7 ) \\ \text{modify the main } \alpha, 2 \, \text{has no mon-line } \text{$two$ but $the$} \text{$head}.$$
As a negative value of ω 2 p has no meaning, the right-handside of Eq. (7) must be positive. It occurs in the range of frequencies
$$\omega _ { c i } < \omega < \sqrt { \omega _ { c e } \omega _ { c i } }, \quad \ \ ( 8 )$$
which corresponds to the lower hybrid resonance (LHR). Another range of frequencies
$$\omega > \omega _ { c e } \quad \quad \ \ ( 9 ) \quad \ \ \ f _ { a }$$
corresponds to the upper hybrid resonance . There are no plasma resonances if ω < ω ci or
$$\sqrt { \omega _ { c e } \omega _ { c i } } < \omega < \omega _ { c e }. \quad \quad \quad ( 1 0 )$$
Below we will say that Eq. (7) determines the resonant electron density n res , which can be expressed from Eq. (7) using the definition of ω 2 p . Note also that so far all the formulas were exact and, in particular, we have not neglected the small ratio m /m e i . However in the range of frequencies ω ∼ √ ω ce ω ci Eq. (7) can be simplified to the following expression
$$\omega _ { p e, r e s } ^ { 2 } \approx \frac { \omega _ { c e } ^ { 2 } \omega ^ { 2 } } { \omega _ { c e } \omega _ { c i } - \omega ^ { 2 } }. \quad \quad ( 1 1 ) \quad \text{cas}$$
Taking into account the quasi-neutrality condition (3), it can be easily reduced to the form
$$\frac { 1 } { \omega _ { \text{LH} } ^ { 2 } } \approx \frac { 1 } { \omega _ { p i } ^ { 2 } } + \frac { 1 } { \omega _ { c e } \omega _ { c i } }, \quad \quad \quad ( 1 2 )$$
known in the literature. It approximately determines the frequency of the lower hybrid resonance and can be found in many textbooks while an exact expression for ω LH can be readily derived from Eq. (7).
## B. Cutoffs
The cutoff points N 2 ⊥ = 0 are found from the equation
$$\mathbb { C } = 0. \text{ \quad \ \ } ( 1 3 )$$
Since
$$\mathbb { C } = \eta \left ( N _ { \| } ^ { 2 } - \varepsilon _ { + } \right ) \left ( N _ { \| } ^ { 2 } - \varepsilon _ { - } \right ),$$
the first of the cutoffs is found from the equation η = 0 . It occurs at the density such that
$$\omega _ { p } ^ { 2 } = \omega ^ { 2 } = \omega _ { p, \text{cut} 1 } ^ { 2 }. \text{ \quad \ \ } ( 1 4 )$$
This density is usually very low. For example, for the frequency ω/ π 2 = 13 56 . MHz, which is often used in the helicon plasma sources, it is as low as n e = 2 28 . × 10 6 cm -3 .
Two more cutoffs are found by equating N 2 ‖ to ε ± , which yields
$$\omega _ { p } ^ { 2 } = \left ( 1 - N _ { | | } ^ { 2 } \right ) \left ( \omega \pm \omega _ { c e } \right ) \left ( \omega \mp \omega _ { c i } \right ).$$
For any sign of the factor (1 -N 2 ‖ ) only one of them hits the interval ω ci < ω < √ ω ce ω ci . In case of slow wave with N 2 ‖ > 1 and ω ci < ω < ω ce ,
$$\Lambda. \quad \omega _ { p } ^ { 2 } = \left ( N _ { \| } ^ { 2 } - 1 \right ) \left ( \omega _ { c e } - \omega \right ) \left ( \omega + \omega _ { c i } \right ) = \omega _ { p, \text{cut} 2 } ^ { 2 }. \quad \left ( 1 5 \right )$$
In a typical helicon plasma source, the first cutoff (14) falls on the periphery of a plasma column, where the density is low, while the second cutoff (15) is located in a more dense plasma core.
## C. Coalescence points
The monographs on plasma physics usually describe the wave dispersion in a cold magnetized plasma at a fixed angle of propagation θ = arccos( N /N ‖ ) . In this case, as seen in Fig. 1, the dispersion curves are monotonically rising functions of the wavenumber k , they do not intersect and do not touch each other (except for the case θ = 0 ). However, at a fixed value of N ‖ , there appear the points of coalescence, where the roots of Eq. (4)
Figure 3. (Color online) To the derivation of the Golant-Stix criterion. The solid line shows N 2 ⊥ for a propagating solution N 2 ⊥ > 0 of the dispersion equation (4), and the dashed line shows -N 2 ⊥ for an evanescent solution N 2 ⊥ < 0 ; ω/ √ ω ci ω ce = 0 8 . , ω ce /ω ci = 1836 15 . , (a) N ‖ = 0 9 . , (b) N ‖ = 1 2 . , (c) N ‖ = 5 3 / , (d) N ‖ = 2 9 . . The vertical dashed line indicates the position of the lower hybrid resonance.
merge as shown in Fig. 2. The coalescence points are found from the equation
$$\mathbb { B } ^ { 2 } - 4 \mathbb { A } \mathbb { C } = 0, \quad \ \ ( 1 6 ) \quad \ \ w _ { 1 }$$
which means that N 2 ⊥ + = N 2 ⊥-. Equation (16) is quadratic with respect to ω 2 p and, therefore, has two solutions, which we denote as ω 2 p, coal 1 and ω 2 p, coal 2 ; we do not give here explicit expressions for these quantities because they are too complex.
A solution of the dispersion equation (4) for several values of the refractive index N ‖ and a fixed frequency ω is shown in Fig. 3 depending on the dimensionless parameter ω /ω 2 p 2 ce . Figures 3,a and 3,b show that at a relatively low value of N ‖ a zone of opacity, where N 2 ⊥ is negative or complex for both branches (5), is located between the two zones of transparency, where N 2 ⊥ > 0 for at least one of the two branches. The lower hybrid resonance is located in the upper density zone of transparency. The opaque zone makes it inaccessible for a wave propagating inward radially from outside of the plasma column. A low density zone of transparency matches a vacuum region (where ω /ω 2 p 2 ce = 0 ) if N 2 ‖ < 1 (Fig. 3,a). However, the vacuum region becomes opaque if N 2 ‖ > 1 (Fig. 3,b); in this case, the low density zone of transparency begins from the first cutoff (14). As N ‖ increases, the opaque zone, located between the low density and the high density zones of transparency, gradually shrinks. Its boundaries are the points of coalescence, where ω 2 p is either equal to ω 2 p, coal 1 or ω 2 p, coal 2 .
## IV. THE GOLANT-STIX CRITERION
The opaque zone, described in Sec. III C, disappears when
$$\omega _ { p, \text{coal} 1 } ^ { 2 } = \omega _ { p, \text{coal} 2 } ^ { 2 } \text{ \quad \quad } ( 1 7 )$$
and the two coalescence points merge as shown in Fig. 3,c. Equation (17) has a unique solution with respect to N 2 ‖ and determines a critical value
$$N _ { \|, \text{crit} } ^ { 2 } = \frac { \omega _ { c e } \omega _ { c i } } { \omega _ { c e } \omega _ { c i } - \omega ^ { 2 } } \quad \quad ( 1 8 ) \\ \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \dots \end{cases}$$
of the longitudinal refractive index. The opaque zone is absent and, hence, the lower hybrid resonance is accessible, if
$$N _ { \| } ^ { 2 } \geqslant N _ { \|, \text{crit} } ^ { 2 }. \text{ \quad \ \ } ( 1 9 )$$
Note that the expression (18) is exact and obtained without any simplifying assumption. Although it is rather simple, its derivation is somewhat cumbersome and was performed using the Wolfram Mathematica [14].
The condition (19) is equivalent to the Golant-Stix criterion, which specifies the conditions of the penetration into the plasma of an electromagnetic wave with a frequency of the order of the lower hybrid resonance frequency. The criterion was previously derived by V.E. Golant in Ref. [8]. He discarded some small terms and wrote his criterion in the form
$$N _ { \| } ^ { 2 } \geqslant 1 + \frac { \omega _ { p e, r e s } ^ { 2 } } { \omega _ { c e } ^ { 2 } } \quad \quad ( 2 0 )$$
(see Eq. (12) in [8]), where the resonant value of the electron plasma frequency ω 2 pe, res was determined from the approximate equation
$$1 - \frac { \omega _ { p e } ^ { 2 } } { \omega _ { c e } ^ { 2 } } + \frac { \omega _ { p i } ^ { 2 } } { \omega ^ { 2 } } = 1 + \frac { \omega _ { p e } ^ { 2 } } { \omega _ { p e, r e s } ^ { 2 } }.$$
Its solution coincides with approximate Eq. (11). Surprisingly, but the substitution of the approximate expression (11) to approximate inequality (20) recovers the exact criterion (18).
A subtle derivation of a criterion similar to (20) can be found in the textbook [10] (see §4-12 and Eq. (103) there). For this reason, the authorship of the criterion (20) is also attributed to R.H. Stix.
Before concluding this section, it should be emphasized that the Golant-Stix criterion refers to the case when ω < √ ω ce ω ci , so that a lower hybrid resonance can exist in the plasma column. As is clear from Eq. (18), the critical value N 2 ‖ , crit of the square of the refractive index formally becomes negative if ω > √ ω ce ω ci . It means that the opaque zone cannot shrink to zero and, hence, the high density transparent zone is inaccessible in if ω > √ ω ce ω ci . The high-frequency regime of the helicon plasma sources operation is considered in Sec. VII.
## V. LIMITING DENSITY
Equation (18) determines a critical value of the longitudinal wave number k ‖ , crit = ( ω/c ) N ‖ , crit . Since N ‖ , crit > 1 , an antenna must launch a slowed wave. The slower the wave, the higher the density of the plasma that can be heated. Indeed,
$$\omega _ { p, \text{res} } ^ { 2 } = \frac { \left ( \omega _ { c e } ^ { 2 } - \omega ^ { 2 } \right ) \left ( \omega ^ { 2 } - \omega _ { c i } ^ { 2 } \right ) } { \omega _ { c e } \omega _ { c i } - \omega ^ { 2 } } \approx \frac { \omega _ { c e } } { \omega _ { c i } } k _ { \|, \text{crit} } ^ { 2 } c ^ { 2 }. \quad ( 2 1 ) \quad B _ { * } = \\ \intertext { t, \text{ and to 1, m i t } \, \text{the most random, at least } \, \text{is} \quad } B _ { * }, t l$$
In practical units, the resonant electron density is
$$n _ { e, \text{res} } \left [ \text{cm} ^ { - 3 } \right ] = 2 \times 1 0 ^ { 1 6 } A Z ^ { - 1 } ( \lambda _ { \| } \left [ \text{cm} \right ] ) ^ { - 2 }, \quad ( 2 2 ) \quad \omega _ { p, \text{co} } ^ { 2 } \\ \text{wave}$$
where A it the atomic weight of the plasma ions, Z is their charge state, n e is expressed in cm -3 , and the wave length λ ‖ = 2 π/k ‖ in cm.
In the vacuum region the wave is evanescent since
$$N _ { \perp, \text{vac} } ^ { 2 } = 1 - N _ { \|, \text{crit} } ^ { 2 } = \frac { - \omega ^ { 2 } } { \omega _ { c e } \omega _ { c i } - \omega ^ { 2 } } \approx - \frac { \omega _ { p, \text{res} } ^ { 2 } } { \omega _ { c e } ^ { 2 } } < 0. \quad \ \text{or} \\ \tau \pi \quad e \quad e \quad \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \ddots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots$$
Therefore, for achieving a higher density an antenna must be placed as closer to the plasma as possible in order to reduce the wave attenuation in the opaque area at the plasma periphery; this might be a difficult technical problem.
Rarefied periphery of the plasma is also opaque to the wave up to the first cutoff, i.e. at
$$\omega _ { p } ^ { 2 } < \omega ^ { 2 }.$$
The cutoff density is substantially smaller than the resonant one since
$$\frac { \omega ^ { 2 } } { \omega _ { p, \text{res} } ^ { 2 } } \approx \frac { \omega _ { c i } } { \omega _ { c e } } \, N _ { \|, \text{crit} } ^ { - 2 } < \frac { Z m _ { e } } { m _ { i } }.$$
Therefore one can hope that external rf field can tunnel through the peripheral opaque zone to the plasma core.
Equations (18) and (21) in principle solve the problem of optimization of a helicon plasma source at a given frequency of the RF field and a given magnetic field. Equation (18) yields the required wavelength, and Eq. (21) gives the maximal density of the plasma, which can be heated at such parameters.
## VI. OPTIMAL MAGNETIC FIELD
We can change a statement of the problem to begin with, so to speak, the antenna. Suppose that the frequency and wavelength are fixed by the antenna system design; it means that N ‖ = k c/ω ‖ is a given parameter. Rewriting Eq. (18) in the form
$$\omega _ { c i } \omega _ { c e } = \omega ^ { 2 } \frac { N _ { \| } ^ { 2 } } { N _ { \| } ^ { 2 } - 1 } \quad \quad ( 2 3 ) \quad \text{wa} \\ \text{pai}$$
then determines the magnitude of the magnetic field. In practical units,
$$B _ { * } \left [ k G \right ] = 1 5. 3 \, \sqrt { \frac { A } { Z } } \frac { N _ { \| } } { \sqrt { N _ { \| } ^ { 2 } - 1 } } f \left [ G H z \right ], \quad ( 2 4 ) \\ \intertext { h o w n e r $ e $ - $ d / o _ { m } $ e $ $ h o w n e r $ e $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m ow n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r$ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o s $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o w n e r $ m o }$$
where f = ω/ π 2 is the linear frequency, expressed in gigahertz. For f = 13 56 . MHz and N 2 ‖ /greatermuch 1 it yields B ∗ = 208 G.
Meaning of B ∗ can be understood as follows. If B < B ∗ , the lower hybrid resonance is separated from the low density zone of transparency by the opaque zone where ω 2 p, coal 1 < ω 2 p < ω 2 p, coal 2 . In this case, the helicon and TG waves merge at ω 2 p = ω 2 p, coal 1 . Conversely, when B > B ∗ TG branch propagates till the lower hybrid resonance at ω 2 p = ω 2 p, res , and the helicon branch can penetrate into even more dense plasma where it can deposit energy due to particle collisions.
Thus, B ∗ is a minimal magnetic field required to switch on the mechanism of plasma heating due to lower hybrid resonance. Some experiments (see in particular [15-17]) demonstrate that helicon discharge is most easily fired when B ∼ B ∗ in that sense that required rf power supply is minimal. However, the helicon plasma sources are known to effectively operate even at smaller magnetic field. In other words, a frequency in the range (10) can also be effectively used in such sources. We proceed to the analysis of this range in the next Section.
## VII. HIGH-FREQUENCY HELICON SOURCES
Figure 4. (Color online) To the derivation of the Shamrai-Taranov criterion. Solid line shows an exact solution of Eq.(4), and dashed line is approximate solution (28). Accuracy of the approximation improves as N 2 ‖ grows; ω/ √ ω ci ω ce = 4 : (a) N ‖ = 2 , (b) N ‖ = 4 , (c) N ‖ = 8 , (d) N ‖ = 16 . Blue and purple curves are respectively the helicon and TG waves.
For a frequency in the range (10), the helicon and TG waves can propagate in the low density zone of transparency as shown in Fig. 4. In this case, the maximal
plasma density, that can be heated by these waves at given ω and k ‖ , is defined by
$$\omega ^ { 2 } = \omega _ { p, \text{coal} 1 } ^ { 2 }. \text{ \quad \ \ } ( 2 5 )$$
It is limited by the coalescence of the helicon and TG waves. The effect of coalescence can be understood using the Appleton-Hartree-Booker simplified dispersion relation of the helicon waves (see eg. [13, 18])
$$\omega = \frac { \omega _ { c e } k k _ { \| } c ^ { 2 } } { \omega _ { p e } ^ { 2 } + k ^ { 2 } c ^ { 2 } }, \quad \quad ( 2 6 ) \quad \quad \quad$$
where k = √ k 2 ⊥ + k 2 ‖ . In the limit k ⊥ → ∞ it also describes TG waves.
Figure 5. (Color online) Eigenfrequency of the helicon and TG waves vs. k ⊥ for different values of the plasma density and a fixed k ‖ .
The eigenfrequencies (26) are drawn in Fig. 5 for various values of ω pe at a fixed value of k ‖ . The upper curves correspond to the periphery of the plasma column where ω 2 pe is small whereas the bottom curves represent the column core where ω 2 pe is larger. A horizontal line represents frequency ω of the antenna so that propagating waves correspond to the intersection point of the solid curves with this line. The horizontal line crosses the upper curves only once (eg., blue upper curve in the figure), which means that only one branch of the waves can propagate at the plasma periphery, namely the TG wave. A second intersection point with smaller k ⊥ , which corresponds to the helicon wave, appears closer to the center plasma (dark-yellow curve). Even closer to the plasma column core, the dispersion curves pass below the horizontal line, which means that a sufficiently dense plasma is not transparent to the waves with given ω and k ‖ . This conclusion is qualitatively confirmed by Fig. 4 which draws both exact and approximate solutions of the dispersion equation.
Equation (26), rewritten in the form
$$k ^ { 2 } c ^ { 2 } - \omega _ { c e } N _ { \| } k c + \omega _ { p e } ^ { 2 } = 0, \quad \quad ( 2 7 ) \quad \text{In } \mathbb { m }$$
has a solution
$$k _ { \pm } c = \frac { 1 } { 2 } \omega _ { c e } N _ { \| } \pm \sqrt { \frac { 1 } { 4 } \omega _ { c e } ^ { 2 } N _ { \| } ^ { 2 } - \omega$$
It is real, and therefore describes two propagating waves, when
$$\omega _ { p e } ^ { 2 } < \frac { 1 } { 4 } \omega _ { c e } ^ { 2 } N _ { \| } ^ { 2 } = \omega _ { p e, \max } ^ { 2 }. \quad \quad ( 2 9 )$$
The condition (29) poses the density limit in the highfrequency regime of operation of a helicon plasma source. In practical units
$$n _ { e, \max } \left [ \text{cm} ^ { - 3 } \right ] = 0. 5 \times 1 0 ^ { 1 6 } A Z ^ { - 1 } ( \omega _ { c i } \omega _ { c e } / \omega ^ { 2 } )$$
The condition (29) was first obtained by K. P. Shamrai and V. B. Taranov in Ref. [3]. In comparison with the accurate criterion
$$\omega _ { p } ^ { 2 } < \omega _ { p, \text{coal} 1 } ^ { 2 }, \text{ \quad \ \ } ( 3 1 )$$
it provides a reasonable accuracy only if N 2 ‖ /greatermuch 1 . Indeed, as seen from Fig. 4, Eq. (28) becomes accurate at sufficiently large N ‖ .
A dense plasma, ω 2 pe > ω 2 pe, max , is opaque for both branches of the waves (the helicons and TG modes) since k 2 ⊥± are complex there. In a non-uniform plasma, merging (degeneration) of the two different wave branches is expected to be followed by the mutual linear conversion of these waves (see e.g. [10]). Thus, a helicon wave converts into a TG wave near the surface ω pe = ω max and vice versa. Note that the smaller of the two wave branches (28), which corresponds to the minus sign, is the helicon wave; the second, signed by + , is the TG wave. The helicons also have a lower limit on the density defined by k ⊥ = 0 , ie, k = k ‖ so the rarefied plasmas are opaque for helicons as seen in Fig. 4. Substituting k = k ‖ in (27) yields the cutoff plasma frequency
$$\omega _ { p e, \min } ^ { 2 } = \omega \left ( \omega _ { c e } - \omega \right ) N _ { \| } ^ { 2 }. \quad \quad ( 3 2 )$$
Thus, the helicon wave can propagate in the finite density range
$$\omega _ { p e, \min } ^ { 2 } < \omega _ { p e } ^ { 2 } < \omega _ { p e, \max } ^ { 2 }. \quad \quad ( 3 3 )$$
It shrinks to zero width at ω = 1 2 ω ce .
## VIII. DISCUSSION
We have derived two expressions for the limiting plasma density in a helicon plasma source. According to Eq. (21), obtained for the case ω < √ ω ce ω ci , at a given k ‖ maximal density is defined by the relation
$$\omega _ { p e, \max } ^ { 2 } \approx \frac { \omega _ { c e } } { \omega _ { c i } } k _ { \| } ^ { 2 } c ^ { 2 }. \quad \quad \quad ( 3 4 )$$
In case ω > √ ω ce ω ci , according to Eq. (29)
$$\omega _ { p e, \max } ^ { 2 } \approx \frac { \omega _ { c e } ^ { 2 } } { 4 \omega ^ { 2 } } k _ { \| } ^ { 2 } c ^ { 2 }.$$
The expressions (34) and (35) match each other at ω = 1 2 √ ω ce ω ci and, thus, provide a smooth objective function for choosing optimal parameters of a helicon plasma source. If we assume that ω and k ‖ are fixed by rf system design, the only remaining parameter will be the magnetic field B . Starting an optimization procedure from a low magnetic field, we see that, according to Eq. (35), increasing B would increase allowed plasma density. However, increasing B above the limit ω = √ ω ce ω ci reverts the density scaling from Eq. (35) to Eq. (34). Then, the limiting density becomes insensitive to B . From this rea-
- [1] F. F. Chen, 'Helicon plasma sources,' in High Density Plasma Sources , edited by O. A. Popov (Noyes Publications, Park Ridge, NJ, 1995) Chap. 1, pp. 1-75.
- [2] A. R. Ellingboe and R. W. Boswell, Physics of Plasmas 3 , 2797 (1996).
- [3] K. P. Shamrai and V. B. Taranov, Plasma Sources Science and Technology 5 , 474-491 (1996).
- [4] T. Lafleur, C. Charles, and R. W. Boswell, Journal of Physics D: Applied Physics 44 , 055202 (2011).
- [5] S. Shinohara, T. Tanikawa, T. Hada, I. Funaki, H. Nishida, T. Matsuoka, F. Otsuka, K. Shamrai, T. Rudenko, T. Nakamura, et al. , Fusion Science and Technology 63 , 164 (2013).
- [6] A. R. Ellingboe and R. W. Boswell, Physics of Plasmas 3 (1996).
- [7] P. Chabert, N. Braithwaite, and N. S. J. Braithwaite, Physics of Radio-Frequency Plasmas (Cambridge University Press, 2011).
- [8] V. Golant, Sov. Phys.-Tech. Phys. 16 , 1980 (1972).
- [9] T. H. Stix, The Theory of Plasma Waves (McGraw-Hill, New York, 1962).
- [10] T. H. Stix, Waves in Plasmas (AIP, New York, 1992).
- [11] A. W. Trivelpiece and R. W. Gould, Journal of Applied
soning, we see that the condition ω ≈ √ ω ce ω ci might be optimal for the operation of a helicon source as we suggested in Sec. VII. Some experiments [15-17] indicate that a helicon discharge is fired at a minimal rf power provided that magnetic field is within some range around the value given by Eq. (24) although the range of allowed magnetic fields widens as rf power increases.
To the best of our knowledge, the density limits given by Eqs. (34) and (35) are not achieved in existing helicon plasma sources. However the results instantly grow with the increase of applied rf power so one may suppose that these limits might be met in the future.
Physics 30 , 1784 (1959).
- [12] V. D. Shafranov, 'Electromagnetic waves in a plasma,' in Reviews of plasma physics , Vol. 3, edited by M. A. Leontovich (Consultants Bureau, New York, 1967).
- [13] A. I. Akhiezer, I. A. Akhiezer, R. V. Polovin, A. G. Sitenko, and K. N. Stepanov, Plasma electrodynamics , Vol. 1 (Pergamon Press Oxford, 1975).
- [14] 'Wolfram mathematica,' (2014).
- [15] Y. Mori, H. Nakashima, F. W. Baity, R. H. Goulding, M. D. Carter, and D. O. Sparks, Plasma Sources Science and Technology 13 , 424 (2004).
- [16] V. Dudnikov, R. P. Johnson, S. Murray, T. Pennisi, C. Piller, M. Santana, M. Stockli, and R. Welton, in Proceedings of IPAC2012, New Orleans, Louisiana, USA , MOPPD047 (New Orleans, Louisiana, USA, 20-25 May, 2012, 2012) pp. 469-471.
- [17] V. Dudnikov, R. P. Johnson, S. Murray, T. Pennisi, C. Piller, M. Santana, M. Stockli, and R. Welton, in XXIII Russian Particle Accelerator Conference RuPAC'2012 (Saint-Petersburg, Russia, September, 24 -28, 2012, 2012) pp. 439-441.
- [18] R. W. Boswell and F. F. Chen, IEEE Transactions On Plasma Science 25 , 1229 (1997). | 10.1063/1.4903329 | [
"Igor A. Kotelnikov"
] | 2014-08-01T06:42:51+00:00 | 2014-08-01T06:42:51+00:00 | [
"physics.plasm-ph"
] | On the density limit in the helicon plasma sources | Existence of the density limit in the helicon plasma sources is critically
revisited. The low- and high-frequency regimes of a helicon plasma source
operation are distinguished. In the low-frequency regime with $\omega <
\sqrt{\omega_{ci}\omega_{ce}}$ the density limit is deduced from the
Golant-Stix criterion of the accessibility of the lower hybrid resonance. In
the high-frequency case, $\omega > \sqrt{\omega_{ci}\omega_{ce}}$, an
appropriate limit is given by the Shamrai-Taranov criterion. Both these
criteria are closely related to the phenomenon of the coalescence of the
helicon wave with the Trivelpiece-Gould mode. We argue that theoretical density
limits are not achieved in existing devices but might be met in the future with
the increase of applied rf power. |
1408.0092v1 | ## ANNULUS TWIST AND DIFFEOMORPHIC 4-MANIFOLDS II
## TETSUYA ABE AND IN DAE JONG
Abstract. We solve a strong version of Problem 3.6 (D) in Kirby's list, that is, we show that for any integer n , there exist infinitely many mutually distinct knots such that 2-handle additions along them with framing n yield the same 4-manifold.
## 1. Introduction
For a knot K in the 3-sphere S 3 = ∂B 4 , we denote by M K ( n ) the 3-manifold obtained from S 3 by n -surgery on K , and by X K ( n ) the smooth 4-manifold obtained from B 4 by attaching a 2-handle along K with framing n . The symbol ≈ stands for a diffeomorphism. In [1], the authors, Omae, and Takeuchi asked the following problem, a strong version of Problem 3.6 (D) in Kirby's list [9] (see also Problem 2 in [10]).
Problem 1.1. Let γ be an integer. Find infinitely many mutually distinct knots K , K , . . . 1 2 such that X K i ( γ ) ≈ X K j ( γ ) for each i, j ∈ N .
In [3, 4], Akbulut gave a partial answer to Problem 1.1 by finding a pair of distinct knots K and K ′ such that X K ( γ ) ≈ X K ′ ( γ ) for each γ ∈ Z . Using an annulus twist introduced by Osoinach [12], Problem 1.1 was solved affirmatively for γ = 0 , ± 4 in [1].
In this paper, we generalize an annulus twist in a somewhat unexpected way, and solve Problem 1.1 affirmatively by using the new operation.
Theorem 1.2. For every n ∈ Z , there exist distinct knots J , J 0 1 , J 2 , . . . such that
$$X _ { J _ { 0 } } ( n ) \approx X _ { J _ { 1 } } ( n ) \approx X _ { J _ { 2 } } ( n ) \approx \cdots.$$
The knots J 0 and J 1 in Theorem 1.2 (for n > 0) are depicted in Figure 1. In the figure, the rectangle labelled n stands for n times right-handed full twists. Note that J 0 is the knot 8 20 in Rolfsen's table [14].
This paper is organized as follows: In Section 2, we recall the definition of an annulus presentation of a knot and introduce the notion of a 'simple' annulus presentation. We define a new operation ( ∗ n ) on an annulus presentation, which is a generalization of an annulus twist. For a knot K with an annulus presentation and an integer n , we construct a knot K ′ (with an annulus presentation) such that M K ( n ) ≈ M K ′ ( n ) by using the operation ( ∗ n ) (Theorem 2.7). In Section 3, for a knot K with a simple annulus presentation and any integer n , we construct a knot K ′ (with a simple annulus presentation) such that X K ( n ) ≈ X K ′ ( n ) by using the operation ( ∗ n ) (Theorem 3.2). Note that the two knots K and K ′ are possibly
2010 Mathematics Subject Classification. 57M25, 57R65.
Key words and phrases. Kirby calculus; Annulus twist; Dehn surgery; 2-handle addition.
Figure 1. The knots J 0 and J 1 such that X J 0 ( n ) ≈ X J 1 ( n ).
/negationslash the same. In Section 4, we introduce the notion of a 'good' annulus presentation, and show that, for a given knot with a good annulus presentation, the infinitely many knots constructed by using the operation ( ∗ n ) have mutually distinct Alexander polynomials when n = 0 (Theorem 4.2). This yields Theorem 1.2 as an immediate corollary. In Appendix A, we give a potential application of Theorem 2.7 to the cabling conjecture.
Acknowledgments. The authors would like to express their gratitude to Yuichi Yamada and other participants of handle seminar organized by Motoo Tange. This paper would not be produced without Yamada's interest to annulus twists. The first author was supported by JSPS KAKENHI Grant Number 25005998.
## 2. Construction of knots
2.1. Annulus presentation. We recall the definition of an annulus presentation 1 of a knot. Let A ⊂ R 2 ∪{∞} ⊂ S 3 be a trivially embedded annulus with an ε -framed unknot c in S 3 as shown in the left side of Figure 2, where ε = ± 1. Take an embedding of a band b : I × I → S 3 such that
- · b I ( × I ) ∩ ∂A = ( b ∂I × I ),
- · b I ( × I ) ∩ int A consists of ribbon singularities, and
- · b I ( × I ) ∩ c = ∅ ,
where I = [0 1]. , Throughout this paper, we assume that A ∪ b I ( × I ) is orientable. This assumption implies that the induced framing is zero (see [1]). Unless otherwise stated, we also assume for simplicity that ε = -1. If a knot K in S 3 is isotopic to the knot ( ∂A \ b ∂I ( × I )) ∪ b I ( × ∂I ) in M c ( -1) ≈ S 3 , then we say that K admits an annulus presentation ( A, b, c ). It is easy to see that a knot admitting an annulus presentation is obtained from the Hopf link by a single band surgery (see [1]). A typical example of a knot admitting an annulus presentation is given in Figure 2.
For an annulus presentation ( A, b, c ), ( R 2 ∪ {∞} ) \ int A consists of two disks D and D ′ , see Figure 3. Assume that ∞∈ D ′ .
Definition 2.1. An annulus presentation ( A, b, c ) is called simple if b I ( × I ) ∩ int D = ∅ .
1 In [1], it was called a band presentation .
Figure 2. The knot depicted in the center admits an annulus presentation as in the right side.
For example, in Figure 3, the annulus presentation depicted in the center is simple, and the right one is not.
Figure 3. The position of D , a simple annulus presentation and a non-simple annulus presentation.
Let ( A, b, c ) be an annulus presentation of a knot. In a situation where it is inessential how the band b I ( × I ) is embedded, we often indicate ( A, b, c ) in an abbreviated form as in Figure 4.
Figure 4. Thick arcs stand for b ∂I ( × I ).
2.2. Operations. To construct knots yielding the same 4-manifold by a 2-handle attaching, we define operations on an annulus presentation.
Definition 2.2. Let ( A, b, c ) be an annulus presentation, and n an integer.
- · The operation ( A ) is to apply an annulus twist 2 along the annulus A .
- · The operation ( T n ) is defined as follows:
- (1) Adding the ( -1 /n )-framed unknot as in Figure 5, and
- (2) (after isotopy) blowing down along the ( -1 /n )-framed unknot.
- · The operation ( ∗ n ) is the composition of ( A ) and ( T n ).
In the operation ( T n ), the added ( -1 /n )-framed unknot is lying on the neighborhood of c and ∂A , and does not intersect b I ( × I ). The intersection of A and the added unknot is just one point.
The operation ( ∗ n ) is a generalization of an annulus twist, in particular, ( ∗ 0) = ( A ).
Figure 5. Add the ( -1 /n )-framed unknot in the operation ( T n ).
2.3. Construction. For a given knot K with an annulus presentation, we can obtain a new knot K ′ with a new annulus presentation by applying the operation ( ∗ n ). By abuse of notation, we call K ′ the knot obtained from K by the operation ( ∗ n ). Here we give examples.
Example 2.3. Let J 0 be the knot with the simple annulus presentation as in Figure 6. Let J 1 be the knot obtained from J 0 by the operation ( ∗ n ). Then J 1 is as in Figure 6.
Remark 2.4 . Let K be a knot with an annulus presentation ( A, b, c ), and K ′ the knot obtained from K by ( ∗ n ). If ( A, b, c ) is simple, then the resulting annulus presentation of K ′ is also simple.
Example 2.5. For the knot J 1 in Example 2.3 with n = 1, let J 2 be the knot obtained from J 1 by applying the operation ( ∗ 1). Then J 2 is as in Figure 7.
The following lemma is obvious, however, important in our argument.
2 For the definition of an annulus twist, see [2, Section 2].
1
Figure 6. By the operation ( ∗ n ), the knot J 0 with the annulus presentation is deformed into the knot J 1 with the annulus presentation.
Lemma 2.6. Let L be a 2 -component framed link which consists of L 1 with framing ( -1 /n ) and L 2 with framing 0 as in the left side of Figure 8. Suppose that the linking number of L 1 and L 2 is ± 1 (with some orientation). Then two Kirby diagrams in Figure 8 represent the same 3 -manifold.
Theorem 2.7. Let K be a knot with an annulus presentation and K ′ be the knot obtain from K by the operation ( ∗ n ) . Then
$$M _ { K } ( n ) \approx M _ { K ^ { \prime } } ( n ) \,.$$
Proof. First, we consider the case where K = J 0 = 8 20 with the usual annulus presentation as in Figure 6. Figure 9 shows that M K ( n ) is represented by the last diagram in Figure 9, and this is diffeomorphic to M K ′ ( n ) by Figure 10. The moves in Figure 10 correspond to the operation ( ∗ n ).
Next we consider a general case. Let ( A, b, c ) be an annulus presentation of K . As seen in Figure 11, M K ( n ) is represented by the last diagram in Figure 11. Now it is not difficult to see that this is diffeomorphic to M K ′ ( n ). /square
Remark 2.8 . Let K be a knot with an annulus presentation ( A, b, c ) and K ′ be the knot obtain from K by the operation ( ∗ n ). In general, K ′ is much complicated than K . If the annulus presentation ( A, b, c ) is simple, then K ′ is not too complicated. Indeed, let ( A, b A , c ) be the annulus presentation obtained from ( A, b, c ) by applying the operation ( A ) as in the left side of Figure 12. Then the knot K ′ is indicated as in the right side of Figure 12.
Figure 7. An annulus presentation of the knot J 2 (lower half) obtained from J 0 by applying ( ∗ 1) two times.
Figure 8. Two Kirby diagrams represent the same 3-manifold.
## 3. Extension of a diffeomorphism between 3-manifolds
In his seminal work, Cerf [7] proved that Γ 4 = 0, that is, any orientation preserving self diffeomorphism of S 3 extends to a self diffeomorphism of B 4 . As an application of Γ 4 = 0, Akbulut obtained the following lemma.
Lemma 3.1 ([4]) . Let K and K ′ be knots in S 3 = ∂D 4 with a diffeomorphism g : ∂X K ( n ) → ∂X K ′ ( n ) , and let µ be a meridian of K . Suppose that
- (1) if µ is 0 -framed, then g µ ( ) is the 0 -framed unknot in the Kirby diagram representing X K ′ ( n ) , and
7
Figure 10. Moves which correspond to the operation ( ∗ n ).
- (2) the Kirby diagram X K ′ ( n ) ∪ h 1 represents D 4 , where h 1 is the 1 -handle represented by (dotted) g µ ( ) .
Then g extends to a diffeomorphism ˜ g : X K ( n ) → X K ′ ( n ) such that ˜ g | ∂X K ( n ) = g . This technique is called 'carving' in [5]. For a proof, we refer the reader to [1, Lemma 2.9]. Applying Lemma 3.1, we show the following.
Theorem 3.2. Let K be a knot with a simple annulus presentation and K ′ be the knot obtain from K by the operation ( ∗ n ) . Then X K ( n ) ≈ X K ′ ( n ) .
Proof. First, we consider the case where K = 8 20 with the usual simple annulus presentation. Let f : ∂X K ( n ) → ∂X K ′ ( n ) be the diffeomorphism given in Figures 9 and 10. Let µ be the meridian of K . If we suppose that µ is 0-framed, then we can check that f ( µ ) is the 0-framed unknot in the Kirby diagram of X K ′ (0) as in Figure 13. Let W be the 4-manifold D 4 ∪ h 1 ∪ h 2 , where h 1 is the dotted 1-handle represented by f ( µ ) and h 2 is the 2-handle represented by K ′ with framing n . Sliding h 2 over h 1 , we obtain a canceling pair (see Figure 14), implying that W ≈ B 4 . By Lemma 3.1, we have ˜ : f X K (0) ≈ X K ′ (0).
Next, We consider a general case. Let g : ∂X K ( n ) → ∂X K ′ ( n ) be the diffeomorphism given in the proof of Theorem 2.7 in a general case (see Figure 15), and µ the meridian of
Figure 12. The annulus presentation ( A, b A , c ) and the knot K ′ .
∂X K ( n ). In Figure 15, the annulus presentation in the right hand side represents K ′ , see Remark 2.8. If we suppose that µ is 0-framed, then we can check that g µ ( ) is the 0-framed unknot in the Kirby diagram of X K ′ (0) as in Figure 15. Let W be the 4-manifold D 4 ∪ h 1 ∪ h 2 , where h 1 is the dotted 1-handle represented by g µ ( ) and h 2 is the 2-handle represented by K ′ with framing n . Sliding h 2 over h 1 , we obtain a canceling pair (see Figure 16), implying that W ≈ B 4 . By Lemma 3.1 again, we have ˜ : g X K (0) ≈ X K ′ (0). /square
Remark 3.3 . It is important which knot admits a simple annulus presentation. An answer is a knot with unknotting number one (see [1, Lemma 2.2]).
Figure 14. The 4-manifold W is diffeomorphic to B 4 .
Figure 15. The image of µ under g .
## 4. Proof of Theorem 1.2
For a knot K , we denote by ∆ K ( ) the Alexander polynomial of t K . We assume that ∆ K ( ) t is of the symmetric form
$$\Delta _ { K } ( t ) = a _ { 0 } + \sum _ { i = 1 } ^ { d } a _ { i } ( t ^ { i } + t ^ { - i } ) \,. \\ \intertext { a \dots \dots a \wedge \, \overbrace { \wedge } \, \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots a \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots b \dots c }$$
We call the integer d the degree of ∆ K ( ), and denote it by deg ∆ t K ( ). t
In this section, we define a 'good' annulus presentation. Theorem 1.2 will be shown as a typical case of the argument in this section. The following technical lemma plays an important role.
## TETSUYA ABE AND IN DAE JONG
Figure 16. The 4-manifold W is diffeomorphic to B 4 .
Lemma 4.1. Let n be a positive integer. Let K be a knot with a good annulus presentation, and K ′ be the knot obtained from K by applying the operation ( ∗ n ) . Then
- (i) K ′ also admits a good annulus presentation, and
- (ii) deg ∆ K ( ) t < deg ∆ K ′ ( ) t .
We will prove Lemma 4.1 later. Using Lemma 4.1, we show the following which yields Theorem 1.2 as an immediate corollary.
Theorem 4.2. Let n be a positive integer. Let K 0 be a knot with a good annulus presentation and K i ( i ≥ 1) the knot obtained from K i -1 by applying the operation ( ∗ n ) . Then
- (1) X K 0 ( n ) ≈ X K 1 ( n ) ≈ X K 2 ( n ) ≈ · · · , and
- (2) the knots K , K , K , 0 1 2 · · · are mutually distinct.
Let K i be the mirror image of K i . Then
- (3) X K 0 ( -n ) ≈ X K 1 ( -n ) ≈ X K 2 ( -n ) ≈ · · · , and
- (4) the knots K ,K ,K , 0 1 2 · · · are mutually distinct.
Proof. By the definition (Definition 4.3), any good annulus presentation is simple. Thus, by Theorem 3.2, we have
$$X _ { K _ { 0 } } ( n ) \approx X _ { K _ { 1 } } ( n ) \approx X _ { K _ { 2 } } ( n ) \approx \cdots.$$
By Lemma 4.1 (i), each K i ( i ≥ 1) also admits a good annulus presentation. Thus, by Lemma 4.1 (ii), we have
$$\deg \Delta _ { K _ { 0 } } ( t ) < \deg \Delta _ { K _ { 1 } } ( t ) < \deg \Delta _ { K _ { 2 } } ( t ) < \cdots.$$
This implies that the knots K , K , K , 0 1 2 · · · are mutually distinct.
$$\text{Since } X _ { K _ { i } } ( n ) \approx X _ { \overline { K _ { i } } } ( - n ) \text{ and } \deg \Delta _ { K _ { i } } ( t ) = \deg \Delta _ { \overline { K _ { i } } } ( t ), \text{ we have}$$
$$X _ { \overline { K } _ { 0 } } ( - n ) \approx X _ { \overline { K } _ { 1 } } ( - n ) \approx X _ { \overline { K } _ { 2 } } ( - n ) \approx \cdots, \text{ and}$$
$$\deg \Delta _ { \overline { K } _ { 0 } } ( t ) < \deg \Delta _ { \overline { K } _ { 1 } } ( t ) < \deg \Delta _ { \overline { K } _ { 2 } } ( t ) < \cdots.$$
This completes the proof of Theorem 4.2.

4.1. Good annulus presentation and the Alexander polynomial. Let K be a knot with a simple annulus presentation ( A, b, c ). Note that the knot ( ∂A \ b ∂I ( × I )) ∪ b I ( × ∂I ) is trivial 3 in S 3 if we ignore the ( -1)-framed loop c . We denote by U this trivial knot. Since ( A, b, c ) is simple, U ∪ c can be isotoped so that U bounds a 'flat' disk D (contained in R 2 ∪ {∞} ). This isotopy, denote by ϕ b , is realized by shrinking the band b I ( × I ). For example, see Figure 17. In the abbreviated form, ϕ b is represented as in Figure 18. Here we note that the linking number of U and c is zero since we assumed that A ∪ b I ( × I ) is orientable (see subsection 2.1). Let Σ be the disk bounded by c as in Figure 18. We assume that Σ stays during the isotopy ϕ b .
Figure 17. By the isotopy ϕ b (shrinking the band b I ( × I )), U ∪ c (the left side) is changed to the right side.
Figure 18. The isotopy ϕ b in the abbreviated form of ( A, b, c ). Assume that Σ stays during the isotopy.
After the isotopy ϕ b , cutting along the disk D , the loop c is separated into arcs whose endpoints are in D . Furthermore, choosing orientations on c and U , these arcs are oriented. Unless otherwise noted, we choose the orientations of c and U as in Figure 18. These oriented arcs are classified into four types as follows: For p ∈ c ∩ D , let sign( p ) = ± according to the sign of the intersection between D and c at p . For an oriented arc α , let p s (resp. p t ) be the starting point (resp. terminal point) of α . Then we say that α is of type (sign( p s ) sign( p t )). That is, the oriented arc α is of type (++), ( --), (+ -), or ( -+). For example, see Figure 19.
3 K is the knot ( ∂A \ b ∂ ( × I )) ∪ b I ( × ∂I ) in M c ( -1).
Figure 19. The four types of arcs.
Here we consider the infinite cyclic covering ˜ ( E U ) of E U ( ). Notice that ˜ ( E U ) consists of infinitely many copies of a cylinder obtained from E U ( ) by cutting along D . Thus ˜ ( E U ) is diffeomorphic to D × R ≈ ∪ i ∈ Z ( D × [ i, i +1]). Each oriented arc is lifted in ˜ ( E U ) as shown in Figure 20. Hereafter, for simplicity, we say an arc instead of an oriented arc.
Figure 20. Lifts of oriented arcs of type (++) , ( --) , (+ -), and ( -+) respectively.
Figure 21. Lifts of the arcs of type (+ -) and ( -+) from a good annulus presentation.
Definition 4.3. We say that a simple annulus presentation ( A, b, c ) is good if the set of arcs A obtained as above satisfies the following up to isotopy.
- (1) A contains just one (+ -) arc and one ( -+) arc, and they are lifted as in Figure 21.
/negationslash
- (2) For α ∈ A , if Σ ∩ α = ∅ , then α is of type (++) (resp. ( --) arc) and the sign of each intersection point in Σ ∩ α is + (resp. -).
/negationslash
- (3) b I ( × ∂I ) ∩ int A = ∅ .
Remark 4.4 . For a simple annulus presentation ( A, b, c ), after the isotopy ϕ b , the intersection c ∩ D corresponds to the intersection b I ( × ∂I ) ∩ int A and further two points p ∗ and p ′ ∗ depicted in Figure 18. Notice that
$$b ( I \times \partial I ) \cap \text{int} A = \sqcup _ { i } b ( \{ t _ { i } \} \times \partial I )$$
for some 0 < t 1 < · · · < t r < 1. For each i , b ( { t i } × ∂I ) consists of two points whose signs are differ. Furthermore, with the orientation as in Figure 18, we have
$$\text{sign} ( p _ { * } ) = - \text{ \ and \ } \text{sign} ( p _ { * } ^ { \prime } ) = +.$$
Example 4.5. The annulus presentation obtained by applying ϕ b on Figure 19 is not good since the condition (2) does not hold. In such a case, changing the position of an intersection as in Figure 22 by an isotopy, we can obtain a good annulus presentation. We often apply such an argument in the proof of Lemma 4.1.
Figure 22. By an isotopy, we move the intersection point of c ∩ D .
Considering a surgery description of the infinite cyclic covering of the exterior of K , we can easily show the following.
Lemma 4.6. If a knot K admits a good annulus presentation, then
$$\deg \Delta _ { K } ( t ) & = \# \{ a r c s \ o f \ t y p e \ ( + + ) \} + 1 \,.$$
For the details of a surgery description of ˜ ( E K ) and the Alexander polynomial, we refer the reader to Rolfsen's book [14, Chapter 7].
Remark 4.7 . To show Lemma 4.6, we do not need the conditions (2) and (3) in Defitnition 4.3. These conditions are used to prove Lemma 4.1.
Remark 4.8 . If a knot K admits a good annulus presentation, then we can see that ∆ K ( ) t is monic.
Now we are ready to prove the main result in this paper.
/negationslash
Proof of Theorem 1.2. The case where n = 0 was proved in [1]. We can check that the simple annulus presentation of the knot 8 20 in Figure 2 is good. Thus the proof for the case where n = 0 is obtained by Theorem 4.2 immediately. /square
4.2. Proof of Lemma 4.1. We start the proof of Lemma 4.1. Let ( A, b, c ) be a good annulus presentation of a knot K . Recall that the operation ( ∗ n ) is a composition of the two operations ( A ) and ( T n ) for an annulus presentation. Let ( A, b A , c ) be the annulus presentation obtained from ( A, b, c ) by applying the operation ( A ), and ( A, b , c ′ ) the annulus presentation obtained from ( A, b A , c ) by applying the operation ( T n ). That is,
$$( A, b, c ) \stackrel { ( A ) } { \longrightarrow } ( A, b _ { A }, c ) \stackrel { ( T _ { n } ) } { \longrightarrow } ( A, b ^ { \prime }, c ).$$
Note that K ′ admits the annulus presentation ( A, b , c ′ ).
First we show that ( A, b A , c ) is good. The operation ( A ) preserves the number of arcs and type of each arc. Furthermore we can suppose that the (+ -) arc and ( -+) arc are fixed by the operation ( A ) up to isotopy. Therefore ( A, b A , c ) satisfies the condition (1) of Definition 4.3. We can also check that ( A, b A , c ) satisfies the conditions (2) and (3) of Definition 4.3. Therefore ( A, b A , c ) is good.
Next we show that ( A, b , c ′ ) is good. The operation ( T n ) may increase the number of arcs. Indeed a (++) (resp. ( --)) arc through Σ is changed to n + 1 (++) (resp. ( --)) arcs since ( A, b A , c ) is good, in particular, a (++) arc (resp. ( --) arc) intersects Σ positively (resp. negatively). Note that the (+ -) arc and the ( -+) arc are fixed by the operation ( T n ). Hence (+ -) arcs and ( -+) arcs do not produced by the operation ( T n ). Therefore ( A, b , c ′ ) satisfies the condition (1). We can also check that ( A, b , c ′ ) satisfies the conditions (2) and (3). Therefore ( A, b , c ′ ) (of K ′ ) is good. This completes the proof of the claim (i) of Lemma 4.1.
Let δ = #( A ∩ b I ( × ∂I )) / 2 and σ = #(Σ ∩ b I ( × ∂I )) / 2. Then we see that
$$\# ( A \cap b _ { A } ( I \times \partial I ) ) / 2 = \delta \,, \quad \# ( \Sigma \cap b _ { A } ( I \times \partial I ) ) / 2 = \sigma + \delta \,.$$
Then we have
$$\# ( A \cap b ^ { \prime } ( I \times \partial I ) ) / 2 & = \# ( A \cap b _ { A } ( I \times \partial I ) ) / 2 + n \cdot \# ( \Sigma \cap b _ { A } ( I \times \partial I ) ) / 2 \\ & = ( n + 1 ) \delta + n \sigma \,,$$
and
$$\# ( \Sigma \cap b ^ { \prime } ( I \times \partial I ) ) = \# ( \Sigma \cap b _ { A } ( I \times \partial I ) ) \,.$$
These are equivalent to
$$\binom { \delta ^ { \prime } } { \sigma ^ { \prime } } = \binom { n + 1 } { 1 } \binom { \delta } { \sigma }.$$
Since n ≥ 1 and δ ≥ 1, we have
$$\delta & < \delta ^ { \prime } \,.$$
By the condition that ( A, b, c ) and ( A, b , c ′ ) is good, and by Remark 4.4, we see that
$$\delta = \# \left \{ \left ( + + \right ) \arcsin \, \text{$(A,b,c)\}$} \,, \quad \delta ^ { \prime } = \# \left \{ \left ( + + \right ) \arcsin \, \text{$(A,b^{\prime},c)\}$} \,.$$
.
Therefore, by Lemma 4.6, we have
$$\deg \Delta _ { K } = \delta + 1 \,, \quad \deg \Delta _ { K ^ { \prime } } = \delta ^ { \prime } + 1 \,.$$
By (4.2) and (4.3), we have deg ∆ K ( ) t < deg ∆ K ′ ( ). t This completes the proof of the claim (ii) of Lemma 4.1, and thus, the proof of Lemma 4.1.
## Appendix A. Potential application
We introduce a potential application of our technique to the cabling conjecture.
Conjecture A.1 (cabling conjecture, [8]) . Let K be a knot in S 3 . If M K ( γ ) is a reducible manifold for some integer γ , then K is a ( p, q ) -cable of a knot and γ = pq .
It is known that this conjecture is true for many knots, in particular, torus knots and satellite knots. Therefore if any hyperbolic knot admits no reducible surgery, then Conjecture A.1 is true. For details, we refer the reader to [11], [6]. Here we explain a potential application of Theorem 2.7 to Conjecture A.1. Suppose that K is a ( p, q )-cable of a knot admitting an annulus presentation, and K ′ the knot obtain from K by the operation ( ∗ pq ). Then M K ′ ( pq ) is a reducible manifold since M K ( pq ) is reducible and M K ( pq ) ≈ M K ′ ( pq ) by Theorem 2.7. If K ′ is a hyperbolic knot, then it is a counterexample to the cabling conjecture. Therefore it is interesting to determine whether a ( p, q )-cable of a knot admits an annulus presentation or not.
Recall that a ( p, q )-torus knot is a ( p, q )-cable of the trivial knot.
Lemma A.2. A torus knot admits an annulus presentation with ε = -1 (resp. ε = 1 ) if and only if it is the unknot or the negative (reps. positive) trefoil knot .
Proof. We only show the case where ε = -1 since the proof for the case where ε = 1 is achieved in a similar way. Let T be a torus knot which admits an annulus presentation and H the negative Hopf link. Then T and H are related by a single band surgery. Therefore
$$| \sigma ( T ) - \sigma ( H ) | \leq 1.$$
That is,
$$0 \leq \sigma ( T ) \leq 2.$$
This implies that T is the unknot or the negative trefoil knot. On the other hand, the unknot and the negative trefoil knot have annulus presentations, see Figure 23. /square
Figure 23. Annulus presentations of the unknot and the negative trefoil knot.
Let K be the unknot (resp. the negative trefoil knot). If M K ( γ ) ≈ M K ′ ( γ ) for some knot K ′ and an integer γ , then K ′ is the unknot (resp. the trefoil knot), see [13]. Therefore, by
using an annulus presentation of the trivial knot, we can not obtain a counterexample of the cabling conjecture by using Theorem 2.7 unfortunately. Then we propose the following question.
Question A.3. Let K be a ( p, q ) -cable knot of a non-trivial knot. Then does K admit any annulus presentation?
Remark A.4 . If the 4-ball genus of a knot K is greater than one, then K does not admit any annulus presentations. Therefore, for example, the (2,1)-cable of the trefoil knot does not admit any annulus presentations. On the other hand, it is not known whether the (2 , 1)-cable of the figure-eight admits an annulus presentation or not.
## References
- [1] T. Abe, I. D. Jong, Y. Omae, and M. Takeuchi, Annulus twist and diffeomorphic 4-manifolds , Math. Proc. Cambridge Philos. Soc. 155 (2013), 219-235.
- T. Abe and M. Tange, A construction of slice knots via annulus twists ,
- [2] arXiv:1305.7492v2 [math.GT], preprint.
- [3] S. Akbulut, Knots and exotic smooth structures on 4 -manifolds , J. Knot Theory Ramifications 2 (1993), no. 1, 1-10.
- [4] S. Akbulut, On 2 -dimensional homology classes of 4 -manifolds , Math. Proc. Cambridge Philos. Soc. 82 (1977), no. 1, 99-106.
- [5] S. Akbulut, 4 -manifolds , draft of a book (2012), available at http://www.math.msu.edu/~akbulut/papers/akbulut.lec.pdf
- [6] S. Boyer, Dehn surgery on knots , Chapter 4 of the Handbook of Geometric Topology, R.J. Daverman, R.B. Sher, ed., Amsterd am, Elsevier, 2002.
- [7] J. Cerf, Sur les diffeomorphismes de la sphere de dimension trois (Γ 4 = 0), Lecture Notes in Mathematics, No. 53, Springer-Verlag, Berlin-New York (1968) xii+133 pp.
- [8] F. Gonz´ alez-Acu˜a and H. Short, n Knot surgery and primeness , Math. Proc. Cambridge Philos. Soc. 99 (1986), no. 1, 89-102.
- [9] R. Kirby, Problems in Low-Dimensional Topology , AMS/IP Stud. Adv. Math., 2 (2), Geometric topology (Athens, GA, 1993), 35-473, Amer. Math. Soc., Providence, RI, 1997.
- [10] J. Luecke and J. Osoinach, Infinitely many knots admitting the same integer surgery , arXiv:1407.1529.
- [11] T. Mrowka and P. Ozsvath, Low Dimensional Topology .
- [12] J. Osoinach Manifolds obtained by surgery on an infinite number of knots in S 3 , Topology 45 (2006), 725-733.
- [13] P. Ozsvath and Z. Szabo, The Dehn surgery characterization of the trefoil and the figure eight knot , math.GT/0604079.
- [14] D. Rolfsen, Knots and Links , Mathematics Lecture Series, No. 7. Publish or Perish, Inc., Berkeley, Calif., 1976.
Department of Mathematics, Tokyo Institute of Technology, 2-12-1 Ookayama, Meguroku, Tokyo 152-8551, Japan
E-mail address : [email protected]
Department of Mathematics, Kinki University, 3-4-1 Kowakae, Higashiosaka City, Osaka 577-0818, Japan
E-mail address : [email protected] | null | [
"Tetsuya Abe",
"In Dae Jong"
] | 2014-08-01T07:03:07+00:00 | 2014-08-01T07:03:07+00:00 | [
"math.GT",
"57M25, 57R65"
] | Annulus twist and diffeomorphic 4-manifolds II | We solve a strong version of Problem 3.6 (D) in Kirby's list, that is, we
show that for any integer $n$, there exist infinitely many mutually distinct
knots such that $2$-handle additions along them with framing $n$ yield the same
$4$-manifold. |
1408.0093v1 | 
Nuclear Physics A

Nuclear Physics A 00 (2014) 1-4
## Light flavor hadron spectra at low p T and search for collective phenomena in high multiplicity pp, p-Pb and Pb-Pb collisions measured with the ALICE experiment
C. Andrei (for the ALICE Collaboration)
National Institute for Physics and Nuclear Engineering, Bucharest, Romania
## Abstract
Comprehensive results on transverse momentum distributions and their ratios for identified light flavor hadrons ( GLYPH<25> , K, p) at low pT and mid-rapidity as a function of charged particle multiplicity are reported for pp collisions at 7 TeV. Particle mass dependent hardening of the spectral shapes in Pb-Pb collisions at 2.76 TeV were attributed to hydrodynamical flow and quantitatively parameterized with Boltzmann-Gibbs Blast Wave fits. In this contribution, we investigate the existence of collective phenomena in small systems: pp, p-Pb and peripheral Pb-Pb where similar patterns are observed in multiplicity dependent studies.
Keywords: LHC, ALICE, light-flavor hadrons, multiplicity, transverse momentum spectra, collective phenomena
Identified charged particle transverse momentum spectra in p-pbar collisions were extensively studied as a function of incident energy below 900 GeV at CERN SppS [1] and up to 1800 GeV at Fermilab Tevatron [2]. Starting from 200 GeV, a deviation of the h pT i of kaons as a function of p s relative to the expectations based on the extrapolation of ISR data was reported by the UA5 Collaboration [3]. The E735 Collaboration saw evidence for a mass dependence of the h pT i as a function of c.m. energy from 300 to 1800 GeV and of the h pT i as a function of d Nch = d GLYPH<17> at 1800 GeV [2]. The origin of these experimental observations is still under debate. QCD inspired models like PYTHIA [4] and EPOS [5] reproduce the experimental trends observed at Tevatron considering multiple partonic interactions and rescattering or a hydrodynamic type evolution with flux tube initial conditions, respectively. At about four times larger incident energies, the case of the present study, such processes become more important and contribute to a large energy transfer, well beyond the deconfinement energy density. Therefore, it is quite probable that at such energies a piece of matter of proton size explodes hydrodynamically once the energy transfer becomes significantly large [6].
Transverse momentum distributions and their relative ratios for identified positive charged hadrons GLYPH<25> + , K , p at + mid-rapidity in pp collisions at p s = 7 TeV, measured by the ALICE experiment [7] at the LHC, as a function of charged particle multiplicity are obtained. The p T range goes from 0.2 GeV / c , 0.3 GeV / c and 0.5 GeV / c to 2.6 GeV / c , 1.4 GeV / c and 2.6 GeV / c for GLYPH<25> + , K + and p respectively, significantly larger than previously reported results [8]. 60 million inelastic pp collisions collected by the ALICE experiment during the 2010 run at LHC, using minimum bias (MB) and high multiplicity (HM) triggers [9], at p s = 7 TeV, were analyzed. Events corresponding to the measured charged particle multiplicity within the pseudorapidity range j GLYPH<17> j < 0.8 were selected. The multiplicity was estimated summing the global tracks and complementary Inner Tracking System (ITS) standalone tracks and Silicon Pixel Detector (SPD) tracklets. Events were required to have a primary vertex within GLYPH<6> 10 cm from the center of the Time Projection Chamber (TPC) and the Time-Of-Flight array (TOF) subdetectors. A p T dependent Distance of Closest
Figure 1: a) Upper row - charged particle multiplicity dependence of the transverse momentum distributions for GLYPH<25> + , K + and p in pp collisions at 7 TeV; z raw = D N raw ch E mult bin = D N raw ch E mult > 0 . Bottom row - ratio of transverse momentum distributions in a given multiplicity bin (z) relative to mult > 0; b) Upper row p T dependence of the particle ratios K + / p, p / GLYPH<25> + and p K / + in pp collisions at 7 TeV for two multiplicity bins. Bottom row - the ratio of the upper distributions relative to the one for mult > 0.
Approach (DCA) cut of (0.018 + 0.035 p GLYPH<0> 1 01 : T ) cm in the transverse plane and 2 cm in the longitudinal direction were used in order to reduce the contamination from weak decays of strange particles, conversion or secondary hadronic interactions in the detector material. The present analysis has been done in j y j < 0.5. The particle identification was based on a Bayesian approach using the information from ITS, TPC and TOF. The detector response functions and the a priori probabilities were obtained from the experimental data. The contaminations from weak decays products and from particles produced by the interactions with the detector material were estimated based on a data driven method. All the correction factors were estimated using simulations based on the PYTHIA event generator [10] (tune Perugia0 [11]) and the GEANT3 [12] transport code. The corrections determined for the MB case were applied for all the multiplicity bins and their variations as a function of multiplicity, proved to be very small, were included in the systematic errors.
The fully corrected p T spectra for GLYPH<25> + , K + and p were obtained by selecting events in eight multiplicity bins in the raw charged particle multiplicity distribution, 7-12, 13-19, 20-28, 29-39, 40-49, 50-59, 60-71 and 72-82 or, using the scaled multiplicity z raw = D N raw ch E mult bin = D N raw ch E mult > 0 , [0.7-1.4), [1.4-2.1), [2.1-3.0), [3.0-4.2), [4.2-5.2), [5.2-6.3), [6.3-7.5) and [7.5-8.6]. The results are presented in Fig. 1a - upper row. In the bottom row of Fig. 1a the ratios of p T distributions at di GLYPH<11> erent multiplicities relative to the mult > 0 case are represented. One could observe a systematic change in the shape of the ratios, i.e. a depletion in the low p T region which shows a tendency to level o GLYPH<11> at larger p T values. The amount of depletion clearly depends on the mass of the species and on the multiplicity, i.e. it is enhanced going from pions to protons and with increasing multiplicity for a given mass. The K + / GLYPH<25> + , p / GLYPH<25> + and p K / + ratios as a function of p T are plotted in Fig. 1b - upper row for the second and the sixth multiplicity bins. The general trends observed in Fig. 1a can be seen in a more quantitative way in these representations, especially in the bottom row of Fig. 1b, where the ratios of relative yields for the two multiplicities to the ones corresponding to N raw ch > 0 are represented. The observed depletion of p / GLYPH<25> + and p K / + at low p T, increasing with the multiplicity and decreasing towards 1.4-2.0 GeV / c looks similar with the trends observed in A-A collisions, the heavier particles being pushed towards larger transverse momenta. Such behavior, observed in Pb-Pb collisions at 2.76 TeV [13], was attributed to
Figure 2: a) p T dependence of p / GLYPH<25> + ratio for the second and highest multiplicity bins in pp collisions; b) p T dependence of (p + p) ( / GLYPH<25> + + GLYPH<25> GLYPH<0> ) ratio in p-Pb for 60-80% and 0-5% multiplicity classes and Pb-Pb for 80-90% and 0-5% centrality [14]; c) The ratios of the ratios presented in a) and b).
the existence of collective transverse flow. The evolution of the p T spectra shape with charged particle multiplicity in pp collisions at 7 TeV and p-Pb at 5.02 TeV [14] and with centrality in Pb-Pb at 2.76 TeV [13] is rather similar.
The p T dependence of p / GLYPH<25> + for the second and highest multiplicity bins and of (p + p) ( / GLYPH<25> + + GLYPH<25> GLYPH<0> ) ratio for p-Pb in 60-80% and 0-5% multiplicity classes and for Pb-Pb at 80-90% and 0-5% centrality [14] are presented in Fig. 2a and Fig. 2b, respectively. The push of protons towards larger p T values relative to pions with increasing centrality or multiplicity is present for all three systems. Quantitatively, this can be followed in Fig. 2c where the ratios of the ratios shown in Fig. 2a and Fig. 2b are presented. The ratio for pp follows closely the p-Pb trend as a function of p T.
Based on these similarities one could investigate to what extent the quality and parameters of simultaneous fits of transverse momentum distributions for di GLYPH<11> erent multiplicities or centralities using expressions inspired by hydrodynamic models are also similar. The quality of fits for GLYPH<25> + , K + and p, based on the Boltzman-Gibbs Blast Wave (BGBW) expression [15]:
$$\ddot { \mu } \cdot \cdot \cdot \cdot \cdot \cdot \\ E \frac { d ^ { 3 } N } { d p ^ { 3 } } \sim f ( p _ { T } ) = \int _ { 0 } ^ { R } m _ { T } K _ { 1 } ( m _ { T } c o s h \rho / T _ { k i n } ) I _ { 0 } ( p _ { T } s i n h \rho / T _ { k i n } ) r d r$$
where mT = q m 2 + p 2 T ; GLYPH<12> r ( r ) = GLYPH<12> s ( r R ) n ; GLYPH<26> = tanh GLYPH<0> 1 GLYPH<12> r , is similar within the error bars for all three systems. The p T range on which the p T spectra follows the hydro shape increases going towards higher multiplicity in pp and p-Pb or higher centrality in Pb-Pb.
In Fig. 3a the results of the fits for pp collisions at 7 TeV in terms of kinetic freeze-out temperature ( Tkin ) versus transverse expansion velocity ( h GLYPH<12> T i ) are presented for di GLYPH<11> erent multiplicity bins and compared with the results obtained for p-Pb and Pb-Pb as a function of multiplicity classes and centrality, respectively [14]. While the Tkin -h GLYPH<12> T i correlation as a function of multiplicity in pp overlaps with the one corresponding to p-Pb as a function of multiplicity classes, for Pb-Pb the decrease of Tkin and increase of h GLYPH<12> T i with centrality is more enhanced. The observed trends are not reproduced by PYTHIA in absolute values although a somewhat similar trend seems to be present if Color Reconnection is included.
Further information accessed from these fits is the expansion profile, given by the parameter n. The nh GLYPH<12> T i correlation as a function of multiplicity or centrality for the three systems is presented in Fig. 3b. Towards high charged particle multiplicity, the transverse expansion velocity approaches a linear dependence as a function of position in the fireball for pp, the trend overlapping with the one corresponding to p-Pb and Pb-Pb.
In conclusion, transverse momentum spectra of positive identified charged hadrons as a function of charged particle multiplicity in pp collisions at p s = 7 TeV, up to multiplicity values never measured before, are reported. A clear depletion of p / GLYPH<25> + and p K / + at low p T , increasing with the multiplicity and decreasing towards larger p T, similar with the trends observed in p-Pb and Pb-Pb collisions, is seen. The kinetic freeze-out temperature ( Tkin ), expansion
Figure 3: a) Freeze-out Tkin versus transverse expansion velocity h GLYPH<12> T i for di GLYPH<11> erent multiplicity bins for pp collisions at 7 TeV (black triangles) comparison with the results obtained for p-Pb (dark blue dots) for di GLYPH<11> erent multiplicity classes and Pb-Pb (red circles) as a function of centrality [14]; b) Expansion profile n versus transverse expansion velocity h GLYPH<12> T i for di GLYPH<11> erent multiplicity bins for pp collisions at 7 TeV (green dots) compared with the results obtained for p-Pb (dark blue triangles) dots for di GLYPH<11> erent multiplicity classes and Pb-Pb (red squares) as a function of centrality [14]. The h GLYPH<12> T i values increase with multiplicity (pp and p-Pb) or centrality (Pb-Pb).
velocity ( h GLYPH<12> T i ) and its profile extracted from the simultaneous fits of the GLYPH<25> + , K + and p spectra with BGBW, show a multiplicity dependence trend similar with the ones obtained for p-Pb and Pb-Pb collisions as a function of multiplicity classes or centrality, respectively. However, a conclusion about similar mechanisms for the three systems has to be taken with caution. Detailed investigations based on theoretical approaches such as hydrodynamic models, parton based Gribov-Regge theory, Color Glass Condensate, Color Reconnection, will give insight to the underlying physics of this similar behavior observed at LHC energies.
## References
- [1] R.E.Ansorge et al., Phys.Lett.B, 167, (1986), p. 476.
- [2] T.Alexopoulos et al., Phys.Rev.D, 48, (1993), p. 984.
- [3] G.J.Alner et al., Nucl.Phys.B, 258, (1985), p. 505.
- [4] T.Sj¨strand and P.Z.Skands, arXiv:hep-ph 0402078; R.Corke, arXiv:hep-ph o901.2852. o / /
- [5] K.Werner et al., Phys.Rev.C, 74, (2006), p. 044902.
- [6] S.Z.Belenkji, L.D. Landau, Del Nuov.Cim., Suppl. Vol.III, Serie X, (1956), p. 15; G.A.Malekhin, Zh.Eksp.Teor.Fiz., 35, (1958), p. 1185; L.Van Hove, Phys.Lett.B, 118, (1982), p. 138; B.Andersson et al., Physica Scripta, 20, (1979), p. 10.
- [7] K.Aamodt et al., Eur. Phys. J. C, 68, (2010), p. 345.
- [8] CMS Collaboration, Eur. Phys. J. C, 72, (2012), p. 2164.
- [9] ALICE Collaboration, arXiv:nucl-ex 1402.4476. /
- [10] T. Sj¨strand, S.Mrenna, P.Z.Skands, arXiv:hep-ph 0603175. o /
- [11] M.G.Albrow et al., arXiv:hep-ph 0610012. /
- [12] R.Brun, F.Carminati, S.Giani, CERN-W5013.
- [13] B. Abelev et al., Phys.Rev.C, 88, (2013), p. 044910.
- [14] B. Abelev et al., Phys.Lett.B, 728, (2014), p. 25.
- [15] E.Schnedermann et al., Phys.Rev.C, 48, (1993), p. 2462. | 10.1016/j.nuclphysa.2014.08.002 | [
"C. Andrei"
] | 2014-08-01T07:31:30+00:00 | 2014-08-01T07:31:30+00:00 | [
"hep-ex",
"nucl-ex"
] | Light flavor hadron spectra at low $p_{T}$ and search for collective phenomena in high multiplicity pp, p-Pb and Pb-Pb collisions measured with the ALICE experiment | Comprehensive results on transverse momentum distributions and their ratios
for identified light flavor hadrons ($\pi$, K, p) at low $p_{T}$ and
mid-rapidity as a function of charged particle multiplicity are reported for pp
collisions at 7 TeV. Particle mass dependent hardening of the spectral shapes
in Pb-Pb collisions at 2.76 TeV were attributed to hydrodynamical flow and
quantitatively parameterized with Boltzmann-Gibbs Blast Wave fits. In this
contribution, we investigate the existence of collective phenomena in small
systems: pp, p-Pb and peripheral Pb-Pb where similar patterns are observed in
multiplicity dependent studies. |
1408.0095v1 | The Annals of Applied Statistics
2014, Vol. 8, No. 2, 1209-1231
DOI: 10.1214/14-AOAS731
c
©
Institute of Mathematical Statistics, 2014
## A NEW METHOD OF PEAK DETECTION FOR ANALYSIS OF COMPREHENSIVE TWO-DIMENSIONAL GAS CHROMATOGRAPHY MASS SPECTROMETRY DATA 1
By Seongho Kim , Ming Ouyang , Jaesik Jeong , ∗ † ‡ Changyu Shen § and Xiang Zhang ¶
Wayne State University , University of Massachusetts Boston , Chonnam ∗ † National University , Indiana University ‡ § and University of Louisville ¶
We develop a novel peak detection algorithm for the analysis of comprehensive two-dimensional gas chromatography time-of-flight mass spectrometry (GC × GC-TOF MS) data using normal-exponentialBernoulli (NEB) and mixture probability models. The algorithm first performs baseline correction and denoising simultaneously using the NEB model, which also defines peak regions. Peaks are then picked using a mixture of probability distribution to deal with the co-eluting peaks. Peak merging is further carried out based on the mass spectral similarities among the peaks within the same peak group. The algorithm is evaluated using experimental data to study the effect of different cutoffs of the conditional Bayes factors and the effect of different mixture models including Poisson, truncated Gaussian, Gaussian, Gamma and exponentially modified Gaussian (EMG) distributions, and the optimal version is introduced using a trial-and-error approach. We then compare the new algorithm with two existing algorithms in terms of compound identification. Data analysis shows that the developed algorithm can detect the peaks with lower false discovery rates than the existing algorithms, and a less complicated peak picking model is a promising alternative to the more complicated and widely used EMG mixture models.
1. Introduction. Multiple analytical approaches such as liquid chromatography mass spectrometry (LC-MS), gas chromatography mass spectrometry (GC-MS) and nuclear magnetic resonance spectroscopy (NMR) have been employed for the comprehensive characterization of metabolites in biological
Received December 2013; revised February 2014.
1 Supported in part by NSF Grant DMS-13-12603, NIH Grants 1RO1GM087735, R21ES021311 and P30 CA022453.
Key words and phrases. Bayes factor, GC × GC-TOF MS, metabolomics, mixture model, normal-exponential-Bernoulli (NEB) model, peak detection.
This is an electronic reprint of the original article published by the
Institute of Mathematical Statistics in The Annals of Applied Statistics ,
2014, Vol. 8, No. 2, 1209-1231. This reprint differs from the original in pagination and typographic detail.
systems. One such powerful approach is comprehensive two-dimensional gas chromatography time-of-flight mass spectrometry (GC × GC-TOF MS). Unlike other existing analytical platforms, GC × GC-TOF MS provides much increased separation capacity, chemical selectivity and sensitivity for the analysis of metabolites present in complex samples. The information-rich output content of GC × GC-TOF MS data has huge potential in metabolite profiling, identification, quantification and metabolic network analysis [Castillo et al. (2011); Jeong et al. (2011); Kim et al. (2011); Pierce et al. (2005); Sinha et al. (2004)].
Metabolites analyzed on a GC × GC-TOF MS system are first separated on two-dimensional GC columns and then subjected to a mass spectrometer, which is usually equipped with an electron ionization (EI) ion source. The EI process fragments the metabolite's molecular ions and results in a fragment ion mass spectrum. For metabolite identification and quantification using the EI mass spectra, the first step is to reduce the instrument data, that is, a collection of EI mass spectra, to chromatographic peaks. To help readers understand the GC × GC-TOF MS data, a brief introduction is given in the Supplementary Information [Kim et al. (2014)].
Although numerous algorithms have been developed for peak detection in one-dimensional GC-MS data [Dixon et al. (2006); Nicol` et al. (2012); e O'Callaghan et al. (2012); Yang, He and Yu (2009)], there are only four algorithms available for the two-dimensional GC-MS [Peters et al. (2007); Reichenbach et al. (2005); Viv´-Truyols (2012)], including commercial softo ware ChromaTOF from LECO company. However, none of these software packages is publicly available yet, except ChromaTOF that is commercially embedded in the GC × GC-TOF MS instrument. It is therefore highly desirable to develop publicly available peak detection methods for the analysis of GC × GC-TOF MS data. On the other hand, the existing peak detection algorithms for the analysis of GC × GC-TOF MS data perform baseline correction and denoising separately, which may greatly increase the risk of introducing errors from each independent stage. In fact, Wang et al. (2008) introduced a reversible jump Markov chain Monte Carlo (RJ-MCMC)-based peak detection algorithm to perform simultaneous baseline, denoising and peak identification for analysis of one-dimensional surface enhanced laser desorption/ionization (SELDI) MS data and demonstrated that the simultaneous process reduces false discovery rate. However, in practice, the use of applications of RJ-MCMC is limited due to that prior distributions should be appropriately assigned in order to design an effective RJ-MCMC algorithm and make posterior distributions of parameters computationally tractable and that constructing an MCMC chain is in general computationally extensive. Yang, He and Yu (2009) compared the performance of peak detection among several peak detection algorithms for one-dimensional matrixassisted laser desorption/ionization (MALDI) MS data and showed that the
continuous wavelet-based (CWT) algorithm, which has simultaneous baseline and denoising, provides the best performance, but it is still a major challenge to compute accurate peak abundance (area), which is very important in compound quantification, due to its model-free approach. Furthermore, the existing algorithms require a manually assigned signal-to-noise ratio (SNR) threshold and/or denoising parameters that are usually not optimized in the existing peak detection algorithms, resulting in a high rate of false-positive and/or false-negative peaks.
To avoid the aforementioned difficulties in analysis of GC × GC-TOF MS data, we propose a novel peak detection algorithm using a normal-exponential-Bernoulli (NEB) model and mixture probability models, and the developed R package msPeak is publicly-available at http://mrr.sourceforge. net . The developed algorithm is composed of the following components: (i) the proposed NEB model performs simultaneous baseline correction and denoising, followed by finding the potential peak regions using a conditional Bayes factor-based statistical test, (ii) the peak picking and area calculations are carried out by fitting experimental data with a mixture of probability model, and (iii) the detected peaks originating from the same compound are further merged based on mass spectral similarity. The advantages of the proposed method are that the proposed NEB-based preprocessing requires no manually assigned SNR threshold and denoising parameters from users, which makes it easy to use; and, instead of searching for the potential peaks using the entire data, the proposed algorithm reduces the entire data to peak regions using a conditional Bayes factor of the test, eliminating the possible computational burden as well as improving the quality of peak abundance (area). The developed algorithm is further compared with two existing algorithms in terms of compound identification.
Besides, we investigated the performance of several probability mixture models for peak picking based on peak regions identified by the NEB model. It has been known that the model-based approach measures more accurately peak abundance (area) and the exponentially modified Gaussian (EMG) probability model performs well for fitting asymmetric chromatographic peaks and the detection of peak position [Di Marco and Bombi (2001); Viv´ o-Truyols (2012); Wei et al. (2012)]. However, to our knowledge, there is no study to evaluate the EMG model by comparing with other possible probability models in analysis of GC × GC-TOF MS data. To address this, we employed five probability mixture models: Poisson mixture models (PMM), truncated Gaussian mixture models (tGMM), Gaussian mixture models (GMM), Gamma mixture models (GaMM) and exponentially modified Gaussian mixture models (EGMM). Here PMM, GMM and EGMM were chosen based on Di Marco and Bombi's (2001) work, and we proposed two new models, tGMM and GaMM, as alternatives to GMM and EGMM, respectively.
We hope our research can provide some insight on the following computational/statistical challenges of the current peak detection approaches: (i) baseline correction and denoising are performed separately so that there is no way to communicate the information with each step, (ii) user-defined input values are needed, (iii) entire data are used for peak detection (compared to our proposed approach that finds peak regions first and then detect peaks), and (iv) there is no comparison analysis for the performance of different chromatographic peak models.
The rest of the paper is organized as follows. Section 2 presents the proposed peak detection algorithm and introduces a trial-and-error optimization of the developed algorithm. The real GC × GC-TOF MS data is described in Section 3. In Section 4 we apply the developed algorithm to real experimental GC × GC-TOF MS data, followed by the comparison with two existing algorithms in Section 5. In Section 6 we discuss the results and then conclude our work in Section 7.
2. Algorithms. The proposed peak detection algorithm consists of three components with the following four steps: finding potential peak regions, simultaneous denoising and baseline correction, peak picking and area calculation, and peak merging (Supplementary Information Figure S1). The first two steps are performed by hierarchical statistical models at a time, while the peak picking and area calculation are carried out by model-based approaches in conjunction with the first derivative test. The peak merging then uses mass spectral similarities to recognize peaks originated from the same metabolite. The selection of the cutoff value of the conditional Bayes factor and the probability model is further optimized by a trial-and-error optimization. On the other hand, when multiple samples are analyzed, each sample will generate a peak list after peak detection. A cross sample peak list alignment is needed to recognize chromatographic peaks generated by the same compound in different samples. Current existing peak-based methods generally perform peak alignment using the mass spectral similarity and peak position (location) distance [e.g., Kim et al. (2011)]. This peak alignment process will generate a matched peak table for downstream data analysis, such as quantification and network analysis. In this regard, the peak detection process plays an important role in generating the peak list. It should be noted that, due to either systematic (technical) or biological variations, some peaks (molecules) may not be detected in all samples, resulting in an incomplete peak table. There are several remedies to deal with the issue, such as ignoring missing data, filling in zero or imputing/estimating missing data [e.g., Hrydziuszko and Viant (2012); Liew, Law and Yan (2011)].
2.1. Finding peak regions. Newton et al. (2001) proposed a hierarchical approach to the microarray data analysis using the gamma-gammaBernoulli model. Their purpose was to detect the genes that are differen-
tially expressed. In this study, we adopted their idea to simultaneously perform baseline correction and denoising, by replacing the gamma-gammaBernoulli model with the normal-exponential-Bernoulli (NEB) model. The proposed hierarchical NEB model has three layers. In the first layer, the observed data, X i , are modeled through the normal distribution with mean Θ + i µ and variance σ 2 for each i th total ion chromatogram (TIC), where i = 1 , . . . , N and N is the number of TICs. Note that a TIC is a chromatogram created by summing up intensities of all mass spectral peaks collected during a given scan (or a given instrumental time). In other words, we assume that the noise follows the normal distribution with mean zero and variance σ 2 . For simplicity, the homogeneous variance is assumed in this model. Here Θ i is the true signal of the observed signal X i and µ is either a baseline or a background. The true signal, Θ , is further modeled by the i exponential distribution with mean φ in the second layer. In the case that there is only noise, meaning that no signal is present, the observed signal, X i , is modeled only with the background and noise signal. Consequently, X i follows the normal distribution with mean µ and variance σ 2 .
/negationslash
In this approach, we pay attention to whether the observed TIC at a given position is significantly different from the background signal. To do this, one more layer is introduced in the model using a Bernoulli distribution, resulting in the NEB model. The true TICs of some proportion r are present (i.e., Θ =0), while others remain at zero (Θ i i =0). For positions where the true TIC is present, we use the following model:
$$X _ { i } \sim N D ( \Theta _ { i } + \mu, \$$
where ND stands for a normal distribution, X i is an observed TIC at the i th position, Θ i is the true TIC of X i of the exponential distribution with φ , and µ is the mean background or baseline with variance σ 2 . In the case that no TIC is present, the background signal follows:
$$X _ { i } \sim \text{ND} ( \mu, \sigma ^ { 2$$
/negationslash
Therefore, the marginal density of X i when Θ = 0 is driven by i
$$& ( 2. 3 ) \quad \ p _ { 1 } ( x _ { i } ) =$$
where Φ( ) is the cumulative distribution function (c.d.f.) of the standard · normal distribution. When Θ i =0, the marginal density of x i becomes the probability density function (p.d.f.) of a normal distribution with mean µ and variance σ 2 . The detail derivation of equation (2.3) can be found in the Supplementary Information. The loglikelihood l ( µ,σ ,φ,r 2 ) is
$$\dots$$
$$\begin{array} {$$
Fig. 1. The graphical representation of a normal-exponential-Bernoulli (NEB) model.
where y i is the value of the binary indicator variable, Y i , at the i th TIC with 0 unless there is a true significant signal and r is the proportion of the true TICs. As a result, there are four parameters ( µ,σ ,φ,r 2 ) along with the indicator variable Y i ( i =1 , . . . , N ) to estimate. The graphical representation of the proposed NEB model is depicted in Figure 1.
Parameter estimation : The EM algorithm [Dempster, Laird and Rubin (1977)] is employed to estimate the parameters of equation (2.4) by considering the indicator variable Y i ( i = 1 , . . . , N ) as the latent (or missing) variable. In the E-step, the latent variable Y i ( i = 1 , . . . , N ) is estimated, after fixing the parameters ( µ,σ ,φ,r 2 ) at the current estimates, by
$$\hat { y } _ { i } = P ( y _ { i } = 1 | x _ { i }, \hat { \mu }, \hat { \sigma } ^ { 2 }, \hat { \phi }, \hat { r } ) = \frac { \hat { r } p _ { 1 } ( x _ { i } ) } { \hat { r } p _ { 1 } ( x _ { i } ) + ( 1 - \hat { r } ) p _ { 0 } ( x _ { i } ) }.$$
To simplify the M-step, the mixture structure has been separated so that the update estimate of r is the arithmetic mean of ˆ 's y i and the remaining parameters ( µ,σ ,φ 2 ) are optimized by a numerical approach such as the R package nlminb . It should be noted that our optimization does not guarantee a global optimum since the R package nlminb used is a local optimization. In particular, a Beta(2 2) is placed as a prior over , r to stabilize the computation as well as to enable a nice interpretation of the output, according to Newton et al. (2001), resulting in the following ˆ: r
$$& ( 2. 6 ) & & \hat { r } = \frac { 2 + \sum _ { i } \hat { y } _ { i } } { 2 \cdot 2 + N }, \\ & \text{where $N$ is the total number of TIC} \ A f t e r \, \text{fixing} \, \hat { r } \, \text{th}$$
where N is the total number of TIC. After fixing ˆ, the remaining parameters r are estimated by maximizing the loglikelihood as follows:
$$( 2. 7 ) & & ( \hat { \mu }, \hat { \sigma } ^ { 2 }, \hat { \phi } ) = \arg \max _ { \mu, \sigma ^ { 2 }, \phi } l ( \mu, \sigma ^ { 2 }, \phi, \hat { r } ).$$
Finding true signals : The true signals are found by performing the significant test based on the posterior odds. The posterior odds of signal at the i th TIC are expressed by
$$\frac { P ( y _ { i } = 1 | x _ { 1 }, \dots, x _ { N } ) } { P ( y _ { i } = 0 | x _ { 1 }, \dots, x _ { N } ) }.$$
The posterior probability of y i given the entire TIC is
$$& \text{The posterior probability of $y_{i}$ given the entire TIC is} \\ & P ( y _ { i } | x _ { 1 }, \dots, x _ { N } ) = \int _ { 0 } ^ { 1 } p ( y _ { i }, r | x _ { 1 }, \dots, x _ { N } ) \, d r \\ & = \int _ { 0 } ^ { 1 } P ( y _ { i } | r, x _ { 1 }, \dots, x _ { N } ) p ( r | x _ { 1 }, \dots, x _ { N } ) \, d r \\ & = \int _ { 0 } ^ { 1 } P ( y _ { i } | r, x _ { i } ) p ( r | x _ { 1 }, \dots, x _ { N } ) \, d r \\ & \text{by conditional independence of the data at different TICs given the param-} \\ & \text{et $r$ is in the annroach in Newton et al. (2001)$ theosterior odds can}$$
by conditional independence of the data at different TICs given the parameter r . Using the approach in Newton et al. (2001), the posterior odds can be approximated by
$$\frac { p _ { 1 } ( x _ { i } ) } { p _ { 0 } ( x _ { i } ) } \frac { \hat { r } } { 1 - \hat { r } },$$
/negationslash where w can be called conditional Bayes factors since the prior odds equal unity, P y ( i =1 | x ,. . . , x 1 N ) ≈ p 1 ( x i )ˆ and r P y ( i =0 | x ,. . . , x 1 N ) ≈ p 0 ( x i )(1 -ˆ), r by approximating equation (2.9) at the model r = ˆ. According to Jefr freys' (1961) scales, the three values of 1, 10 and 100 are used to interpret the posterior odds, meaning that the TICs are selected using three cutoff values. That is, if the posterior odds of a TIC are less than a selected cutoff value, then this TIC is considered as a noise by fixing it at zero (i.e., Θ i =0). Otherwise, the TIC will be preserved for future analysis (i.e., Θ i =0).
/negationslash
2.2. Denoising and baseline correction. Once the significant TICs (true signals) are detected by the posterior odds, the baseline correction and denoising are performed simultaneously based on the estimated parameters. That is, under the assumption that the TIC is the true signal (Θ i =0), the convoluted TIC, ˆ , x i is predicted by the expected true TIC (signal) given an observed TIC, that is, E (Θ i | x i ). By doing the calculation described in the Supplementary Information, we can obtain the convoluted TIC, ˆ , as x i follows:
$$\begin{array} { c } \text{follows} \colon & & \\ & \hat { x } _ { i } = x _ { i } - \left ( \hat { \mu } + \frac { \hat { \sigma } ^ { 2 } } { \hat { \phi } } \right ) \\ & & + \hat { \sigma } \varphi \left ( \frac { x _ { i } - ( \hat { \mu } + \hat { \sigma } ^ { 2 } / \hat { \phi } ) } { \hat { \sigma } } \right ) / \Phi \left ( \frac { x _ { i } - ( \hat { \mu } + \hat { \sigma } ^ { 2 } / \hat { \phi } ) } { \hat { \sigma } } \right ), \end{array}$$
$$\begin{matrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ \end{matrix}$$
where ϕ and Φ are the probability density and cumulative distribution functions of the standard normal distribution ND(0 1), respectively. ,
2.3. Peak detection and area calculation. After denoising and baseline correction, the vector of predicted TICs, { ˆ x i } i =1 ,...,N , is converted into the N 1 by N 2 matrix D (= [ d kl k ] =1 ,...,N 1 ; l =1 ,...,N 2 ), where N = N 1 · N 2 . Here the sizes of the rows and columns of the matrix D are the same as the intervals of the first and the second dimension retention times, respectively. In order to detect peaks for each significant peak region, we employ five different model-based approaches along with the first derivative test (FDT): Poisson mixture models (PMM), truncated Gaussian mixture models (tGMM), Gaussian mixture models (GMM), Gamma mixture models (GaMM) and exponentially modified Gaussian mixture models (EGMM).
The peak area is calculated based on the highest probability density (HPD) regions of 95% for model-based approaches. We assume that D k is the k th row vector of the matrix D , where the size of D k is N 2 and 1 ≤ k ≤ N 1 , and D k = { d kl } l =1 ,...,N 2 . In other words, D k is a vector of intensities at each second dimension retention time given the k th first dimension retention time. Then D k is partitioned into several nonzero peak regions, that is, D k := Z k = { Z ,Z ,...,Z 1 k 2 k M k k } , where 1 ≤ k ≤ N 1 ; Z m k = { z kl } l =1 ,...,N m,k 2 ; 1 ≤ m ≤ M N k ; 2 ≥ ∑ M k m =1 N m,k 2 . It is noteworthy that Z m k is a nonzero peak region and its intensities z kl 's are always nonzero.
First derivative test (FDT) : FDT is used to infer the maximum number of components (peaks) of the mixture probability models. The first derivative is calculated over the converted nonzero vector Z m k with respect to the second dimension retention times to find a peak, for the given k th first dimension retention time and the m th nonzero peak region where 1 ≤ k ≤ N 1 and 1 ≤ m ≤ M k . By doing so, the local maxima are found with respect to the second dimension retention time. That is, for each converted vector Z m k , we examine z kl whether it is a local maximum with respect to the second dimension retention time as follows:
$$& ( 2. 1 2 ) \quad I _ { k l } = \begin{cases} 1 & \text{if $z_{k(l-1)} - z_{kl} < 0$ and $z_{kl} - z_{k(l+1)} > 0$,} \\ 0 & \text{otherwise,} \end{cases} \\ & \text{where $I$... is the indicator variable for make dotoctod union the second $di$}$$
where I kl is the indicator variable for peaks detected using the second dimension retention time; 1 indicates a local maximum. In fact, we observed that the first derivative test with respect to the first dimension retention time has little information in most cases, due to the relatively large value of the modulation period compared to the chromatographic peak width in the first dimension GC. For this reason, we used only the second dimension retention time for peak picking. It is noteworthy to mention again that we use the FDT only for guessing the maximum number of the possible peaks and for an initial value of the optimization of the model-based approach.
Model-based approach : The five different probability models including Poisson, truncated Gaussian, Gaussian, Gamma and exponentially modified Gaussian distributions are employed along with mixture models. For each converted nonzero vector Z m k = { z kl } l =1 ,...,N m,k 2 , a mixture of the selected probability models are fitted to the observed, convoluted intensities. Suppose f s ( ·| ξ s ) is a p.d.f. with a parameter of ξ s of the s th component, where 1 ≤ s ≤ S,ξ s is a scalar or a vector, and S is the number of mixture components. Then the converted nonzero intensity z kl at the k th first dimension retention time is modeled as follows:
$$& \text{2.13} ) & \text{$z_{k} \sim ND\left\{sum_{s=1}^{S} w_{s} \cdot f_{s}(t_{l}|\xi_{s}),\tau^{2}\right\}$}, \\ & \text{where $t_{l}$ is the second dimension retention time at the $l$th pc}$$
where t l is the second dimension retention time at the l th position, w s is the non-negative weight factor of the s th component, ∑ S s =1 w s =1, and ND stands for a normal distribution with variance τ 2 . The parameters ( ζ, S ) are estimated by minimizing -2 times loglikelihood function:
$$\Big [ \begin{matrix} \\ \end{matrix}$$
$$\begin{matrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ \end{matrix}$$
where ˆ = ( ˆ ζ w ,ξ s ˆ ) s ˆ S s =1 , and ˆ w s and ˆ ξ s are the estimated parameters of the s th component. The p.d.f. and its parameters for Poisson, truncated Gaussian, Gaussian, Gamma and exponentially modified Gaussian can be found in the Supplementary Information.
$$( \hat { \zeta }, \hat { S }, \hat { \tau } ^ { 2 } ) = & \underset { \zeta, S, \tau ^ { 2 } } { \overset { \cdot } { \sim } } \min _ { \zeta, S, \tau ^ { 2 } } \left [ N _ { 2 } ^ { m, k } \log ( 2 \pi \tau ^ { 2 } ) \\ & + \frac { 1 } { \tau ^ { 2 } } \sum _ { l = 1 } ^ { N _ { 2 } ^ { m, k } } \left \{ z _ { k l } - \sum _ { s = 1 } ^ { S } w _ { s } \cdot f _ { s } ( t _ { l } | \xi _ { s } ) \right \} ^ { 2 } \right ], \\ \text{where } \hat { \zeta } = ( \hat { w } _ { s }, \hat { \xi } _ { s } ) ^ { \hat { S } } _ { s = 1 }, \text{ and } \hat { w } _ { s } \text{ and } \hat { \xi } _ { s } \text{ are the estimated parameters of the sth}$$
Then 95% highest probability density (HPD) intervals are calculated with the estimated ˆ w s and ˆ ξ s for each k th peak, 1 ≤ s ≤ ˆ , S and the length of its 95% HPD interval is assigned as the peak area. As mentioned before, we consider the number of peaks detected by FDT as the maximum number of peaks that can be detected. Therefore, the number of mixture components estimated by each model-based approach ( ˆ ) always becomes less than or S equal to the number of peaks detected by FDT. Furthermore, the intensities are divided by the total sum of nonzero intensities in a given peak region for the purpose of normalization since each model is a probability distribution.
2.4. Peak grouping and merging. It is likely that multiple peaks detected can be from the same compound due to systemic variations. To correct these multiple peaks, we use the mass spectrum (MS) information by calculating the MS similarity among the peaks. Since it might be computationally expensive if all the pairwise MS similarities are calculated, we first group the peaks according to their nonzero peak regions and then merge the peaks hav-
ing the higher MS similarity using a user-defined cutoff value, only if these peaks are present in the adjacent nonzero peak region(s). For instance, assuming that two peaks z kl and z mn belong to the nonzero peak regions Z i k and Z j m , respectively, z kl and z mn are considered as members of the same group if these two peak regions are adjacent to each other. Otherwise, they are assigned to different groups. The MS similarities among all peaks within the same group are calculated, and the peak with the highest TIC is selected as the representative peak in the case that multiple peaks have the MS similarities greater than the user defined cutoff value (e.g., 0.95) by replacing the peak area with the sum of peak areas of all merged peaks.
2.5. Optimal selection of the cutoff value and the probability model. As can be observed in Section 3, the optimal probability mixture model can be different according to the detected peak regions, and so can the cutoff value of the conditional Bayes factor. For this reason, we further consider a trial-and-error optimization of the developed algorithm in order to select the optimal cutoff value of the conditional Bayes factor and the optimal probability mixture model. To do this, three objective functions are considered, which are mean squared error (MSE), Akaike information criterion (AIC) and Bayesian information criterion (BIC) that were used in Section 3. That is, given a selected objective function, we first look for the optimal probability mixture model for each detected peak region and then find the optimal cutoff value of the conditional Bayes factor by the minimum of the sums of all the objective functions for each cutoff value. In detail, the optimal cutoff value ˜ is selected by the following trial-and-error optimization: ν
$$\tilde { \nu } = \arg \min _ { \nu } & \left \{ \sum _ { k = 1 } ^ { N _ { 1 } } \sum _ { m = 1 } ^ { M _ { k } } \tilde { J } ( Z _ { k } ^ { m }, \tilde { \beta } _ { m } | \nu ) \right \} \\ & \quad \text{with } \tilde { I } ( Z _ { \cdot } ^ { m } \hat { \mathcal { A } } _ { \cdot } \dots | \nu ) = \min I ($$
with ˜ ( J Z m k ˆ β m | ν ) = min β m J Z ( m k | β m , ν ) , where ν ∈{ 1 10 100 , , } is a cutoff value, β m ∈ { PMM, tGMM, GMM, GaMM, EGMM } is a probability model, and ˜ β m =argmin β m J Z ( m k | β m , ν ). In particular, the function J Z ( m k | β m , ν ) is varied with respect to the choice of the objective function:
$$( 2. 1 6 ) \ J ( Z _ { k } ^ { m } | \beta _ { m }, \nu ) = \begin{cases} \frac { 1 } { N _ { 2 } ^ { m, k } } \cdot S S & \text{for MSE} ; \\ N _ { 2 } ^ { m, k } \log ( 2 \pi \hat { \tau } _ { \beta _ { m } } ^ { 2 } ) + \frac { 1 } { \hat { \tau } _ { \beta _ { m } } ^ { 2 } } \cdot S S + 2 \cdot | \hat { \zeta } ^ { \beta _ { m } } | \\ \text{for AIC} ; \\ N _ { 2 } ^ { m, k } \log ( 2 \pi \hat { \tau } _ { \beta _ { m } } ^ { 2 } ) + \frac { 1 } { \hat { \tau } _ { \beta _ { m } } ^ { 2 } } \cdot S S + N _ { 2 } ^ { m, k } \cdot | \hat { \zeta } ^ { \beta _ { m } } | \\ \text{for BIC}, \end{cases}$$
where SS = ∑ N m,k 2 l =1 { z kl -∑ S s =1 w s · f β m s ( t l | ˆ ξ β m s ) } 2 ; (ˆ τ 2 β m , ˆ ζ β m ) are the parameter estimates of a given probability model f β m s , and | ˆ ζ β m | is the number of the parameters of a given probability model. For the case that a certain probability model is preferred, we can just optimize the cutoff value of the conditional Bayes factor by fixing ˆ β m at a user-defined model. In addition, we can also just optimize the probability model by fixing ˜ at a certain cutoff ν value. Note that the last two approaches are computationally less expensive.
- 3. GC × GC-MS data and software. To evaluate the performance of the developed peak finding algorithm, an experimental data set generated from a comprehensive two-dimensional gas chromatography time-of-flight mass spectrometry (GC × GC-TOF MS) was used. The sample analyzed on GC × GC-TOF MS is a mixture of 76 compound standards (8270 MegaMix, Restek Corp., Bellefonte, PA) and C 7 -C 40 n -alkanes (Sigma-Aldrich Corp., St. Louis, MO). The concentration of each compound in the mixture is 2.5 µ g/mL. The mixture was analyzed on a LECO Pegasus 4D GC × GC-TOF MS instrument (LECO Corporation, St. Joseph, MI, USA) equipped with a cryogenic modulator. All the statistical analyses were performed using statistical software R 2.13.1, and the developed R package msPeak is available at http://mrr. sourceforge.net .
- 4. Applications. We applied the developed algorithm to the two sets of the experimental GC × GC-TOF MS data described in the previous section. The first data set is a small region selected from the experimental data, while the second data set is the entire experimental data. The developed algorithm was further compared with the two existing algorithms, the continuous wavelet-based (CWT) algorithm and ChromaTOF, in terms of compound identification in Section 5.
- 4.1. Analysis of selected data. For illustration purpose, we selected a small region from the entire experimental data as shown in Supplementary Information Figure S2(b). Upon this selected data, we performed the process of peak finding according to the algorithm described in Section 2.
Figure S2(c) displays the results of the NEB model-based significant test as well as denoising and baseline correction for the selected data. As described in Section 2, the significant test is rendered by a conditional Bayes factor of the test in equation (2.10) with the three different odds (cutoff) values such as 1, 10 and 100. Of these, the largest cutoff value is the strictest condition in that there are fewer significant TICs. In other words, there are more TICs of zero in the case of the odds of 100. In this figure, the black open circles represent the original TIC, and the red cross ' × ,' green plus '+' and blue open circles indicate the convoluted TICs of the odds of 1, 10
and 100, respectively. Figure S2(d) is the magnified plot of the green box in Figure S2(c). Clearly, we can see that the odds of 1 (red cross ' × ') have the most nonzero convoluted TICs as depicted in Figure S2(d). The detected peak regions are plotted in Figure S3 of the Supplementary Information. In Figure S3, the total number of nonzero peak regions detected is 36, 28 and 27 when the cutoff value of odds is 1, 10 and 100, respectively. As expected, the odds of 1 have the most nonzero peak regions.
Once the nonzero peak regions were detected, we searched for the significant peaks at each nonzero peak region using five probability mixture models, PMM, tGMM, GMM, GaMM and EGMM. As mentioned before, the number of peaks detected by FDT is considered as the maximum number of peaks to be fitted by each of five probability mixture models. Each of PMM, tGMM, GMM, GaMM and EGMM has ( S · 1 + 1), ( S · 2 + 1), ( S · 2 + 1), ( S · 2 + 1) and ( S · 3 + 1) parameters to estimate, where S is the number of mixture components. Note that the truncated Gaussian distribution has four parameters including the lower and the upper bounds, but, in this study, these bounds are fixed with the starting and ending indices of a given nonzero peak region. Only when the number of data points for a given nonzero peak region is more than or equal to the required number of parameters for a selected probability model, then the normalized intensities are fitted using the probability model.
To evaluate the performance of each probability model for fitting the normalized intensities, we consider four measures: mean squared error (MSE), -2 times loglikelihood (LL), Akaike information criterion (AIC) and Bayesian information criterion (BIC). A probability model is considered as performing better if its MSE, LL, AIC or BIC is lower. It is noteworthy that LL is given only as a reference and will not be directly used for comparison since each model is not nested. The results of fitting the normalized intensities using the proposed five probability mixture models are reported in Table 1.
In the case of odds of 1, the MSE, LL and AIC of EGMM are the lowest and these of PMM are the largest. However, the lowest BIC happens with PMM that has the smallest number of parameters to estimate. On the other hand, when the cutoff value of odds is 10, the MSEs are dramatically reduced up to five times lower than those of odds 1. In this case, tGMM has the lowest MSE, and the largest MSE still occurs when PMM is employed. However, EGMM has the lowest LL, AIC and BIC. Interestingly, the overall MSE becomes worse than that of odds 1, when the cutoff value increases to 100. Nevertheless, its trend is similar to that of odds 10. Overall, in terms of MSE, a better fitting is achieved when 10 is considered as the cutoff value of odds and when the truncated Gaussian mixture model is used.
Figure 2 shows the cases when each probability model performs best among other mixture models in terms of MSE, when the cutoff value is 10. That is, Figures 2(a)-2(e) display the fitted curves when PMM, tGMM,
Table 1 Results of fitting the normalized intensities using five probability models
| Odds | Measure | PMM | tGMM | GMM | GaMM | EGMM |
|--------|-----------|----------|----------|----------|----------|----------|
| 1 | MSE 1 | 41.34 | 30.35 | 28.29 | 33.85 | 15.63 |
| | | (15.03) | (19.65) | (15.21) | (15.92) | (9.64) |
| | LL | - 285.42 | - 324.10 | - 322.91 | - 320.51 | - 371.78 |
| | | (41.38) | (41.27) | (41.66) | (41.24) | (46.43) |
| | AIC | - 277.42 | - 313.76 | - 312.57 | - 308.51 | - 358.92 |
| | | (40.89) | (40.81) | (41.21) | (40.43) | (46.01) |
| | BIC | - 116.04 | - 112.24 | - 111.05 | - 61.99 | - 110.92 |
| | | (18.08) | (17.01) | (17.42) | (18.07) | (20.20) |
| 10 | MSE | 38.34 | 2.72 | 6.41 | 7.39 | 5.54 |
| | | (10.52) | (0.64) | (1.95) | (2.52) | (2.00) |
| | LL | - 255.80 | - 310.07 | - 305.90 | - 301.83 | - 336.24 |
| | | (39.72) | (39.88) | (40.63) | (39.57) | (44.09) |
| | AIC | - 248.98 | - 300.51 | - 296.34 | - 292.05 | - 324.98 |
| | | (39.28) | (39.36) | (40.11) | (38.91) | (43.67) |
| | BIC | - 119.43 | - 119.40 | - 115.23 | - 101.50 | - 121.72 |
| | | (18.77) | (15.84) | (16.56) | (17.26) | (17.19) |
| 100 | MSE | 53.75 | 11.94 | 19.25 | 21.05 | 18.03 |
| | | (13.52) | (7.73) | (9.70) | (10.54) | (9.77) |
| | LL | - 223.97 | - 279.79 | - 277.68 | - 272.47 | - 313.56 |
| | | (36.80) | (39.20) | (39.85) | (37.51) | (44.15) |
| | AIC | - 218.05 | - 271.12 | - 269.01 | - 263.58 | - 302.60 |
| | | (36.46) | (38.63) | (39.30) | (36.92) | (43.48) |
| | BIC | - 113.46 | - 113.01 | - 112.45 | - 101.47 | - 107.04 |
| | | (18.06) | (16.28) | (15.65) | (14.15) | (15.20) |
1 The values in parentheses are empirical standard errors.
GMM, GaMM and EGMM fit the normalized intensities with the lowest MSE, respectively. In Figure 2(a), PMM has the largest number of peaks detected, which is four as FDT does, while PMM has the lowest MSE [MSE ( × 10 ) 5 = 0.06 (PMM), 0.09 (tGMM), 0.10 (GMM), 1.19 (GaMM), 0.21 (EGMM)]. Although there is only one peak in this figure, only EGMM detected one peak. tGMM and GMM have the peaks in a very similar position, as expected. GaMM has two peaks detected, with one peak positioned at the upper bound of the second dimension retention time. This peak region corresponds to the peak region (a) in Figure 2(f). tGMM has the lowest MSE in Figure 2(b) [MSE ( × 10 ) = 83.01 (PMM), 3.20 (tGMM), 6.08 (GMM), 5 7.40 (GaMM), 5.56 (EGMM)]. In this case, all the detected peaks are located at the same position except for GaMM, which is shifted to the left. PMM has much larger MSE, indicating the worst fitted curve to the data points. Figure 2(c) has a similar peak shape to that of Figure 2(a), while GMM is the best fitted model and is marginally better than tGMM at the third decimal point in this case [MSE ( × 10 ) = 0.88 (PMM), 0.36 (tGMM), 5
Fig. 2. The fitted peak regions and the detected peaks when the cutoff value of odds is 10. The detected peak positions are indicated by a black circle (FDT), red triangle (PMM), green ' + ' (tGMM), blue ' × ' (GMM), sky-blue rhombus (GaMM) and purple inverted-triangle (EGMM). 'Obs' means the observed intensities. The detected nonzero peak regions and peaks before peak merging are in (f) . The indices (a)-(e) in (f) indicate the peak region corresponding to each of the fitted plots (a)-(e) .
0.36 (GMM), 0.69 (GaMM), 0.54 (EGMM)]. Likewise, all the probability models detected two or more peaks except for EGMM, even though there is only one chromatographic peak. Its index of peak region is (c) as shown in Figure 2(f). Three chromatographic peaks are observed in Figure 2(d). PMM and EGMM detect no peak in the beginning of the curve, while the other models correctly detect this peak. GaMM has the lowest MSE [MSE ( × 10 ) 5 = 1.90 (PMM), 0.75 (tGMM), 0.76 (GMM), 0.46 (GaMM), 0.62 (EGMM)]. The case that EGMM has the lowest MSE is depicted in Figure 2(e) [MSE ( × 10 ) 5 = 0.49 (PMM), 0.36 (tGMM), 0.35 (GMM), 0.24 (GaMM), 0.15 (EGMM)]. Only tGMM and GMM resolve the peak in the middle of the curve, although their peak positions are shifted to the left. Overall, EGMM fits the normalized intensities well with the smaller MSE, but tGMM and GMM have a better capability of detecting the peaks that have a relatively smaller peak height.
The detected peaks are indicated in the selected GC × GC-TOF MS data as shown in Supplementary Information Figure S4. In this figure, the dotted red box represents the nonzero peak region detected from the proposed NEB model, and the grey contour is plotted based on the original TIC. When the cutoff value of odds is 1, the total number of peaks detected by PMM, tGMM, GMM, GaMM and EGMM is 61, 53, 53, 60 and 47, respectively, as shown in Figure S4(a). Of these probability models, PMM has the largest number of detected peaks and EGMM has the smallest number of peaks detected. In the case of odds 10 and 100, PMM and GaMM have the largest numbers of peaks detected out of five probability mixture models, which are 43 and 40 for odds of 10 and 100, respectively. EGMM still has the smallest number of detected peaks of 37, as can be seen in Figures S4(c) and S4(e). For illustration purposes, the detected peaks when the cutoff is 10 are depicted in Figure 2(f). Comparing Figure S4(a) with Figures S4(c) and S4(e), it can be seen that the peak regions of small sizes have vanished in Figures S4(c) and S4(e) when the odds increase. The detected peaks after peak merging are shown in Figures S4(b), S4(d) and S4(f). The peak merging dramatically reduced the number of detected peaks up to one-third of the number of peaks before peak merging.
Furthermore, three interesting points can be observed. One is that the cutoff value has little effect on the overall performance of peak detection, although the odds of 10 give us the best average performance. The second is that the peaks detected by each probability model become similar to each other after peak merging. The last is that the detected peaks by EGMM are very similar to those by PMM, after peak merging, although PMM has the worst MSE, as can be seen in Table 1. That is, the peak merging makes all probability models comparable to each other in terms of the position of peaks detected.
4.2. Analysis of entire data. We here applied the proposed peak detection algorithm to the entire data. Before using the entire data, we removed the uninteresting areas that were produced due to experimental noise. This can be seen in Supplementary Information Figures S5(a) and S5(b). Then, we found the nonzero TICs by the proposed NEB model as depicted in Supplementary Information Figure S5(c). Similarly to the selected data in the previous section, we selected the nonzero peak regions and then detected the peaks using the proposed methods with the three cutoff values, 1, 10 and 100, of odds. In the case of the cutoff value of odds 10 (1 and 100, resp.), the numbers of detected peaks are 230 (263 and 215), 223 (249 and 211), 225 (254 and 211), 229 (265 and 213) and 215 (230 and 201), for PMM, tGMM, GMM, GaMM and EGMM, respectively, before peak merging, while the numbers of detected peaks after peak merging are 97 (104 and 96), 99 (107 and 97), 99 (105 and 96), 99 (106 and 96) and 96 (103 and 92), respectively. As before, the peak merging reduces the variation in the number of detected peaks among different methods.
We further evaluated the performance of peak finding by compound identification using Person's correlation. To standardize the comparison, we focused on the identification of the 76 compound standards from the peak list generated by each method. Since we knew that 76 compound standards should be present in the sample, we examined the quality of detected peaks by each mixture model through counting the number of 76 compound standards that were identified out of the detected peaks. Table 2 shows the results of the comparison.
As expected, the odds of one have the most peaks detected for every model. After peak merging, the total number of detected peaks decreased up to more than 50%, while the number of unique compounds identified and the number of 76 compound standards identified have little variation. Interestingly, the difference among models disappears when we consider the total number of 76 compound standards identified, which ranges from 30 to 32 across all the models.
The trial-and-error optimization was also applied to the entire data using equation (2.15). The last three rows of Table 2 show the results of the optimization with the three different objective functions, MSE, AIC and BIC. The optimal cutoff values of odds with MSE, AIC and BIC are 10, 1 and 1, respectively, which is consistent with the results of the selected data (Table 1). Since the optimization with either AIC or BIC selects the cutoff value of one, it detects more peaks than that with MSE. The results are shown in Figure 3 when the objective function is MSE. Overall, the optimization with MSE performs best in the sense that it finds the smallest number of peaks but the same number of 76 compound standards. The peak detection results of the trial-and-error optimization using another replicated data set can be found in Supplementary Information Figures S7 and S8.
Table 2
Results of compound identification of peaks detected before/after peak merging
| | | Before peak merging | Before peak merging | Before peak merging | After peak merging | After peak merging | After peak merging |
|------|-----------|-----------------------|-----------------------|-----------------------|----------------------|----------------------|----------------------|
| Odds | Model | Standard 1 | Unique 2 | Peak 3 | Standard | Unique | Peak |
| 1 | PMM | 32 | 72 | 263 | 32 | 64 | 104 |
| | tGMM | 32 | 72 | 249 | 32 | 64 | 107 |
| | GMM | 32 | 72 | 254 | 31 | 63 | 105 |
| | GaMM | 32 | 73 | 265 | 31 | 64 | 106 |
| | EGMM | 32 | 69 | 230 | 32 | 63 | 103 |
| 10 | PMM | 32 | 68 | 230 | 31 | 61 | 97 |
| | tGMM | 32 | 70 | 223 | 31 | 62 | 99 |
| | GMM | 32 | 70 | 225 | 31 | 61 | 99 |
| | GaMM | 32 | 71 | 229 | 31 | 63 | 99 |
| | EGMM | 32 | 67 | 215 | 32 | 61 | 96 |
| 100 | PMM | 31 | 66 | 215 | 30 | 60 | 96 |
| | tGMM | 31 | 67 | 211 | 31 | 60 | 97 |
| | GMM | 31 | 65 | 211 | 30 | 58 | 96 |
| | GaMM | 31 | 68 | 213 | 30 | 60 | 96 |
| | EGMM | 31 | 64 | 201 | 30 | 58 | 92 |
| 10 | OPT-MSE 4 | 32 | 69 | 230 | 31 | 61 | 97 |
| 1 | OPT-AIC | 32 | 71 | 255 | 32 | 64 | 104 |
| 1 | OPT-BIC | 32 | 70 | 240 | 32 | 64 | 104 |
- 1 The number of 76 compound standards present in the list of 'Unique' peaks;
- 2 the number of unique compound names in the list of peaks detected by each method;
3 the number of peaks detected by each method;
4 the trial-and-error optimization.
5. Comparison with existing algorithms. We further evaluated the developed algorithm by comparing with existing algorithms in terms of compound identification. To do this, we employed the two algorithms, the continuous wavelet-based (CWT) algorithm and ChromaTOF. As mentioned earlier, there is no publicly available software for GC × GC-TOF MS data and most existing algorithms used the one-dimensional approach for denoising and baseline correction, so we employed CWT, which was the best-performing method based on Yang, He and Yu's (2009) work. Note that ChromaTOF is the only commercial software embedded in the GC × GC-TOF MS instrument. To avoid bias in peak merging, we used the peak list generated by each method before peak merging. We examined the performance of CWT with the three different signal-to-noise (SNR) ratios, 1, 2 and 3, using the R/Bioconductor package MassSpecWavelet . As for ChromaTOF, we used the SNR threshold of 100. It should be noted that the unit of the SNR threshold of ChromaTOF is different from that of CWT, so the SNR thresh-
## S. KIM ET AL.
Fig. 3. The detected nonzero peak regions and peaks by the trial-and-error optimization with MSE before (a) /after (b) peak merging.
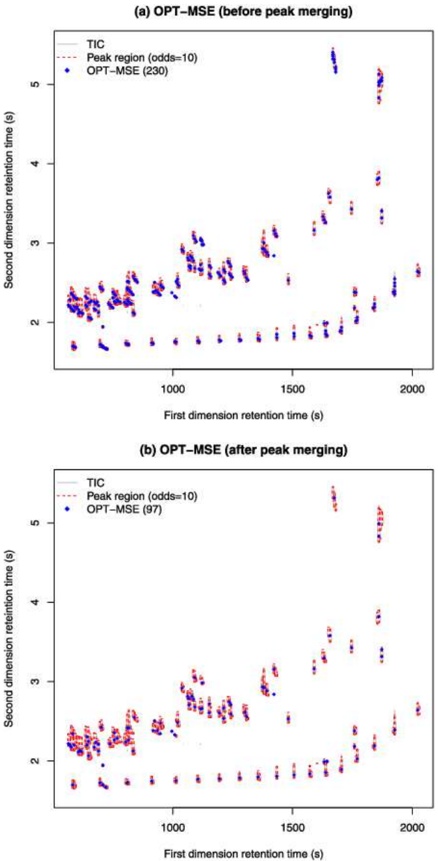
olds cannot be compared directly with each other. For example, the CWT detected no peak with SNR of 100.
Table 3 shows the results of compound identification of the entire data using CWT and ChromaTOF before peak merging. For ease of comparison, we added the results for the MSE-based trial-and-error optimization of Table 2, which performs best in Section 4.2, into the table and measured the
Results of compound identification of peaks detected by the developed algorithm, CWT,
Table 3 and ChromaTOF before peak merging
| | Before peak merging | Before peak merging | Before peak merging | Before peak merging | Before peak merging | Before peak merging |
|-----------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|-----------------------|
| Method (Cutoff) | Standard | Unique | Peak | SUR 1 ( % | SPR 2 ( % ) | UPR 3 ( % ) |
| OPT-MSE (10) | 32 | 69 | 230 | 46 . 38 | 13 . 91 | 30 . 00 |
| CWT (1) | 25 | 61 | 1242 | 40 . 98 | 2 . 01 | 4 . 91 |
| CWT (2) | 22 | 50 | 880 | 44 . 00 | 2 . 50 | 5 . 68 |
| CWT (3) | 26 | 43 | 618 | 37 . 21 | 2 . 59 | 6 . 96 |
| ChromaTOF (100) | 34 | 178 | 391 | 19 . 1 | 8 . 7 | 45 . 52 |
1 Standard/Unique;
2 Standard/Peak;
3 Unique/Peak.
ratios (%) of the number of Standard compounds to the number of Unique compounds (SUR), the number of Standard compounds to the number of detected peaks (SPR), and the number of Unique compounds to the number of detected peaks (UPR).
CWTdetects the largest number of peaks before compound identification, but it detects the smallest number of unique compounds as well as the smallest number of the 76 compound standards (the true positive compounds) identified by compound identification, resulting in the highest false discovery rate. The commercial software ChromaTOF detects the largest number of unique compounds and the largest number of 76 compound standards. On the other hand, although the developed algorithm finds the smallest number of peaks, the identified number of 76 compound standards is comparable to that of ChromaTOF. Furthermore, the highest SUR and the highest SPR are achieved by the developed algorithm, while the highest UPR is carried out by ChromaTOF. It suggests that the developed algorithm greatly reduces the false discovery rate in terms of SPR. In addition, the number of detected peaks of CWT is very sensitive to the choice of SNR threshold, while the developed algorithm has little effect of the cutoff value of odds on peak detection as can be seen in Table 2. Overall, the comparison analysis shows that ChromaTOF has much worse specificity than our algorithm although it has better sensitivity. Moreover, CWT has similar specificity to the developed algorithm, but the developed algorithm has better sensitivity,
6. Discussion. To analyze GC × GC-TOF MS data, we developed a new peak detection algorithm. Unlike the existing peak detection algorithms, the proposed algorithm performs baseline correction and denoising simultaneously using the NEB model without any input, such as manually assigned SNR threshold and denoising parameters, from users. In particular, the pro-
posed NEB model has the ability to remove the background noise (the series of black dots in the middle of the plot) from the raw signal as shown in Supplementary Information Figure S5(d). Another advantage is that it can reduce the entire data into a set of peak regions using a statistical test of conditional Bayes factors. This is an important aspect on peak detection because the information-rich output of MS data is usually enormous and so the processing time is one of key bottlenecks in data analysis.
In this work, we marginalized the MS information and then detected the peaks using the marginalized chromatogram data (i.e., TIC). In our proposed peak detection, the marginalization of the MS data is used only for the peak detection. As for the metabolite identification, we used the nonmarginalized mass spectrum for each metabolite. In the ideal case, each peak of chromatogram (marginalized MS data, i.e., TIC) should represent a unique metabolite (compound or peak) in GC × GC-TOF MS data. However, there are still co-eluting metabolites from GC × GC-TOF MS due to limited separation power. For this reason, to resolve the co-eluting metabolites, ChromaTOF uses the nonmarginalized MS data (i.e., Single Ion Chromatogram: XIC). A key objective of using XICs of ChromaTOF is to resolve the co-eluting metabolites, so, if there is no co-eluting peak, we think TIC should be sufficient to detect the peaks. Furthermore, there is a much lesser amount of metabolites co-eluting from GC × GC than GC does, owing to the increased separation power. For these reasons, we tried to resolve the co-eluting metabolites based on TIC along with a mixture model in the proposed approach. By doing so, although there is a certain degree of information loss due to marginalization, we could also see several benefits from this marginalization: (i) it reduced the size of data, (ii) consequently, it spent less computational expense, and (iii) it made the data much smoother [Morris et al. (2005)]. Furthermore, in comparison analysis, our approach is comparable with ChromaTOF, which uses no marginalization of the MS data. It should be noted that neither the commercial software ChromaTOF nor our developed method completely detected all of the known compounds. There could be many reasons for this, including low concentration, low ionization frequency, inaccuracy of the peak detection algorithms, etc.
It is a challenge to estimate the unknown number of components for a mixture model, especially under the presence of many local optima. To circumvent this potential issue, the developed algorithm uses the number of peaks detected by FDT as the upper bound of the number of components. Although this saves the computation time as well as removes the potential difficulty, it can be a potential drawback of the proposed algorithm when the true number of components is larger than the number of peaks detected by FDT. However, since the FDT used in this study was very sensitive to noise, we observed, with limited testing data, that FDT overestimates the number of peaks in most cases (e.g., Figure 2).
The most dominated parametric model to describe the shape of chromatographic peaks in GC-MS and LC-MS data is an exponentially modified Gaussian (EMG) function [Di Marco and Bombi (2001)]. In this work, four mixture models were compared with the EMG model as can be seen in Tables 1 and 2. The EMG model shows the least MSE and the least number of detected peaks. However, there is no performance difference between the mixture models in terms of metabolite identification and detected peaks, implying that the less complicated model has an advantage on the computation.
/negationslash
As mentioned, Table 2 shows no preference among different mixture models on compound identification, although there is a clear difference in fitting the intensities (Table 1). For this reason, we analyzed the MS similarity within a peak region displayed in Figure 2(e). The results of MS similarity analysis are depicted in Supplementary Information Figure S6. In this analysis, we calculated the pairwise MS similarities among the data points, and then displayed the pairwise MS similarities for each data point in Figure S6(a). For example, a dotted line represents the MS similarities between the i th point and all other j th points, j = , given the i i th data point. Therefore, the i th data point must have the MS similarity of one at the i th point in the plot since it is the MS self-similarity. In this figure, we can cluster the MS similarity lines into three groups which are the same as the number of apparent local maxima. Furthermore, although a data point is located far from its local maximum, its MS similarity is more than 0.8, demonstrating that the peak region plays a more important role in compound identification than the peak position. A similar trend can be seen in the heatmap depicted in Figure S6(b). This can not only explain why we observe no difference among the different models in compound identification, but also give an insight that MS similarity-based peak detection is a promising approach.
Since the proposed model-based algorithms require a fitting of the peak shape, the peak finding procedure would run a long time. To evaluate the running time, we compared the computation time between CWT with the cutoff of 1 and the proposed algorithm with/without optimization with odds of 10, on a desktop with Intel Core 2 Duo CPU 3.00 GHz. The running time of CWT was 0.24 minutes, while the proposed algorithms with PMM and optimization took 6.86 minutes and 14.10 minutes, respectively. The full optimization version of the proposed algorithm further took 33.37 minutes. Although the proposed algorithms relatively take more running time than CWT, it still finds peaks in a reasonable time frame. The running time of the full optimization approach may be a bottleneck compared to CWT, however. One solution to speed up the computation time is to rely on parallel computation. In general, the parallel computation is more efficient when a lot of independent calculations are required, and the peak shape fitting of the proposed method can be performed independently using parallel computation for each of the peak regions.
Even though there is not much of a difference between the developed algorithm and the only commercial software available for GC × GC-TOF MS in terms of the number of 76 compound standards identified, the total number of peaks detected by the proposed algorithm is about 100 peaks less than that of ChromaTOF (e.g., 230 vs. 391 in Table 3). This is because ChromaTOF uses XIC, while the developed algorithm uses total ion chromatogram (TIC). The XIC-based approach requires more computation since it independently deals with each XIC of m/z values, while the TIC-based approach needs a one-time computation. The use of XIC on the developed algorithm is left as future work.
7. Conclusions. We developed a novel, publicly-available algorithm to identify chromatogram peaks using GC × GC-TOF MS data, which includes three components: simultaneous baseline correction and denoising by the NEB model, peak picking with various choices of mixture models, and peak merging. The proposed algorithm requires no SNR threshold and denoising parameters from users to perform baseline correction and denoising. The data analysis demonstrated that the NEB model-based method can detect the peak regions in the two-dimensional chromatogram that have chromatographic peaks, with a simultaneous baseline removal and denoising process. Furthermore, the comparison analysis with limited data shows that the developed algorithm can greatly reduce false discovery rate in terms of compound identification. Among the model-based approaches for peak picking, PMM and GMM detect more peaks, while tGMM and EGMM have smaller MSE. However, there is no apparent preference among the five model-based approaches in terms of compound identification, and the peak shape is data-dependent. For this reason, we further introduced a trial-anderror optimization into the proposed algorithm to select a proper peak shape model according to a different peak region. Among the four measures (MSE, LL, AIC and BIC), MSE will be considered to find an optimal peak shape model in terms of the compound identification.
## SUPPLEMENTARY MATERIAL
Supplementary Information (DOI: 10.1214/14-AOAS731SUPP; .pdf). A brief introduction to GC × GC-TOF MS data, derivations of Equations (2.3) and (2.11), the p.d.f.s of five probability models and Figures S1-S8 are in this Supplementary Information.
## REFERENCES
Castillo, S. , Mattila, I. , Miettinen, J. , Oreˇ siˇ, M. c and Hy¨ otyl¨inen, T. a (2011). Data analysis tool for comprehensive two-dimensional gas chromatography/time-offlight mass spectrometry. Anal. Chem. 83 3058-3067.
Dempster, A. P. , Laird, N. M. and Rubin, D. B. (1977). Maximum likelihood from incomplete data via the EM algorithm. J. Roy. Statist. Soc. Ser. B 39 1-38. MR0501537 Dixon, S. J. , Brereton, R. G. , Soini, H. A. , Novotny, M. V. and Penn, D. J. (2006). An automated method for peak detection and matching in large gas chromatographymass spectrometry data sets. Journal of Chemometrics 20 325-340.
Di Marco, V. B. and Bombi, G. G. (2001). Mathematical functions for the representation of chromatographic peaks. J. Chromatogr. A 931 1-30.
Hrydziuszko, O. and Viant, M. R. (2012). Missing values in mass spectrometry based metabolomics: An undervalued step in data processing pipeline. Metabolomics 8 S161S174.
Jeffreys, H. (1961). Theory of Probability , 3rd ed. Clarendon Press, Oxford. MR0187257 Jeong, J. , Shi, X. , Zhang, X. , Kim, S. and Shen, C. (2011). An empirical Bayes model using a competition score for metabolite identification in gas chromatography mass spectrometry. BMC Bioinformatics 12 392.
- Kim, S. , Fang, A. , Wang, B. , Jeong, J. and Zhang, X. (2011). An optimal peak alignment for comprehensive two-dimensional gas chromatography mass spectrometry using mixture similarity measure. Bioinformatics 27 1660-1666.
Kim, S. , Ouyang, M. , Jeong, J. , Shen, C. and Zhang, X. (2014). Supplement to 'A new method of peak detection for analysis of comprehensive two-dimensional gas chromatography mass spectrometry data.' DOI:10.1214/14-AOAS731SUPP.
- Liew, A. W.-C. , Law, N.-F. and Yan, H. (2011). Missing value imputation for gene expression data: Computational techniques to recover missing data from available information. Brief. Bioinformatics 12 498-513.
Morris, J. S. , Coombes, K. R. , Koomen, J. , Baggerly, K. A. and Kobayashi, R. (2005). Feature extraction and quantification for mass spectrometry in biomedical applications using the mean spectrum. Bioinformatics 21 1764-1775.
Newton, M. A. , Kendziorski, C. M. , Richmond, C. S. , Blattner, E. R. and Tsui, K. W. (2001). On differential variability of expression ratios: Improving statistical inference about gene expression changes from microarray data. J. Comput. Biol. 8 37-52.
Nicol` e, F. , Guitton, Y. , Courtois, E. A. , Moja, S. , Legendre, L. and HossaertMckey, M. (2012). MSeasy: Unsupervised and untargeted GC-MS data processing. Bioinformatics 28 2278-2280.
O'Callaghan, S. , De Souza, D. P. , Isaac, A. , Wang, Q. , Hodkinson, L. , Olshansky, M. , Erwin, T. , Appelbe, B. , Tull, D. L. , Roessner, U. , Bacic, A. , McConville, M. J. and Liki´, V. A. c (2012). PyMS: A Python toolkit for processing of gas chromatography-mass spectrometry (GC-MS) data. Application and comparative study of selected tools. BMC Bioinformatics 30 115.
Peters, S. , Viv´-Truyols, G. o , Marriott, P. J. and Schoenmakers, P. J. (2007). Development of an algorithm for peak detection in comprehensive two-dimensional chromatography. J. Chromatogr. A 1156 14-24.
Pierce, K. M. , Wood, L. F. , Wright, B. W. and Synovec, R. E. (2005). A comprehensive two-dimensional retention time alignment algorithm to enhance chemometric analysis of comprehensive two-dimensional separation data. Anal. Chem. 77 7735-7743. Reichenbach, S. E. , Kottapalli, V. , Ni, M. T. and Visvanathan, A. (2005). Computer language for identifying chemicals with comprehensive two-dimensional gas chromatography and mass spectrometry. J. Chromatogr. A 1071 263-269.
Sinha, A. , Fraga, G. , Prazen, B. and Synovec, R. (2004). Trilinear chemometric analysis of two-dimensional comprehensive gas chromatography-time-of-flight mass spectrometry data. J. Chromatogr. A 1027 269-277.
- Viv´-Truyols, G. o (2012). Bayesian approach for peak detection in two-dimensional chromatography. Anal. Chem. 84 2622-2630.
- Wang, Y. , Zhou, X. O. , Wang, H. H. , Li, K. , Yao, L. X. and Wong, S. T. C. (2008). Reversible jump MCMC approach for peak identification for stroke SELDI mass spectrometry using mixture model. Bioinformatics 24 1407-1413.
- Wei, X. , Xue, S. , Kim, S. , Zhang, L. , Patrick, J. , Binkley, J. , McClain, C. and Zhang, X. (2012). Data preprocessing method for liquid chromatography-mass spectrometry based metabolomics. Anal. Chem. 84 7963-7971.
- Yang, C. , He, Z. and Yu, W. (2009). Comparison of public peak detection algorithms for MALDI mass spectrometry data analysis. BMC Bioinformatics 10 4.
## S. Kim
Biostatistics Core
Karmanos Cancer Insitute
Wayne State University
Detroit, Michigan 48201
USA
E-mail:
[email protected]
M. Ouyang Department of Computer Science University of Massachusetts Boston Boston, Massachusetts 02125
USA
## J. Jeong
Department of Statistics
Chonnam National University Gwangju 500757
Korea
C. Shen
Department of Biostatistics Indiana University Indianapolis, Indiana 46202 USA
X. Zhang Department of Chemistry University of Louisville Louisville, Kentucky 40292 USA E-mail:
[email protected] | 10.1214/14-AOAS731 | [
"Seongho Kim",
"Ming Ouyang",
"Jaesik Jeong",
"Changyu Shen",
"Xiang Zhang"
] | 2014-08-01T07:49:21+00:00 | 2014-08-01T07:49:21+00:00 | [
"stat.AP"
] | A new method of peak detection for analysis of comprehensive two-dimensional gas chromatography mass spectrometry data | We develop a novel peak detection algorithm for the analysis of comprehensive
two-dimensional gas chromatography time-of-flight mass spectrometry
(GC$\times$GC-TOF MS) data using normal-exponential-Bernoulli (NEB) and mixture
probability models. The algorithm first performs baseline correction and
denoising simultaneously using the NEB model, which also defines peak regions.
Peaks are then picked using a mixture of probability distribution to deal with
the co-eluting peaks. Peak merging is further carried out based on the mass
spectral similarities among the peaks within the same peak group. The algorithm
is evaluated using experimental data to study the effect of different cutoffs
of the conditional Bayes factors and the effect of different mixture models
including Poisson, truncated Gaussian, Gaussian, Gamma and exponentially
modified Gaussian (EMG) distributions, and the optimal version is introduced
using a trial-and-error approach. We then compare the new algorithm with two
existing algorithms in terms of compound identification. Data analysis shows
that the developed algorithm can detect the peaks with lower false discovery
rates than the existing algorithms, and a less complicated peak picking model
is a promising alternative to the more complicated and widely used EMG mixture
models. |
1408.0096v1 | ## Conditional Restricted Boltzmann Machines for Cold Start Recommendations
Jiankou Li 1 2 , and Wei Zhang 1 2 ,
- 1
State Key Laboratory of Computer Science, Institute of Software, Chinese Academy of Sciences, P.O. Box 8718, Beijing, 100190, P.R.China 2 School of Information Science and Engineering, University of Chinese Academy of Sciences, P.R.China
Abstract. Restricted Boltzman Machines (RBMs) have been successfully used in recommender systems. However, as with most of other collaborative filtering techniques, it cannot solve cold start problems for there is no rating for a new item. In this paper, we first apply conditional RBM (CRBM) which could take extra information into account and show that CRBM could solve cold start problem very well, especially for rating prediction task. CRBM naturally combine the content and collaborative data under a single framework which could be fitted effectively. Experiments show that CRBM can be compared favourably with matrix factorization models, while hidden features learned from the former models are more easy to be interpreted.
Keywords: cold start, conditional RBM, rating prediction
## 1 Introduction
The cold start problem generally means making recommendations for new items or new users. It has attracted attentions of many researchers for its importance. Collaborative filtering(CF) techniques make prediction of unknown preference by known preferences of a group of users [22]. Preferences here maybe explicit movie rating or implicit item buying in the online services. Though CF technique has been successfully used in recommender system, when there is no rating for new items or new users such methods become invalid. So pure CF could not solve cold start problems.
Different from CF, content-based techniques do not suffer from the cold start problem, as they make recommendations based on content of items, e.g. actors, genres of a movie is usually used. However, a pure content-based techniques only recommends items that are similar to users' previously consumed items and so its result lack diversity [16].
A key step for solving the cold start problem is how to combine the collaborative information and content information. Hybrid techniques retain the advantages of CF as well as not suffer from the cold start problem [1], [4], [6], [14], [19]. In the paper, we firstly use condition restricted Boltzmann machines that could combine the collaborative information and content information naturally to solve cold start problem.
RBMs are powerful undirected graphical models for rating prediction [18]. Different from directed graphical models [1], [4], [6], [14], [19], whose exact inference is usually hard, inferring latent feature of RBMs is exact and efficient. An important feature of undirected graphical model is that they do not suffer the 'explaining-away' problem of directed graphical models [21]. What's more important is that RBMs could be efficiently trained using Contrastive Divergence [7], [8]. Based on RBM, CRBM takes the extra information into account [24], [25]. The items content feature like actors, genres etc could be added into CRBM naturally, with little more extra fitting procedure.
The remainder of this paper is organized as follows. Section 2 is devoted to related work. Section 3 introduces the models we used including RBM and CRBM. In section 4 we show the results of our experiments. Finally we conclude the paper with a summary and discuss the work in the future in section 5.
## 2 Related Work
Cold start problems have attracted lots of researchers. The key step for solving cold start problem is combining content feature with collaborative filtering techniques. On one hand, topic models could model content information well. On the other hand, matrix factorization is one of the most successful techniques for collaborative. So most previous works for solving cold start problem are based on these two techniques.
Previous work [19] uses a probabilistic topic model to solve the cold start problem in three step. Firstly, they map users into a latent space by features of their related items. Every user could be represented by some topics of features. Then a 'folding-in' algorithm is used to fold new items into a user-feature aspect model. Finally, the probability of a user given a new movie (could be seen as some similarity measure) was calculated in order to make recommendation.
Gantner et all propose a high-level framework for solving cold start problem. They train a factorization model to learn the latent factors and then learn the mapping function from features of entities to their latent features [4]. This kind of model use the content feature while retain the advantages of matrix factorization [12], [15], [17] and could generalize well to other latent factor models and mapping functions.
Another matrix factorization based model is the regression-based latent factor model (RLFM). RLFM simultaneously incorporate user features, item features, into a single modeling framework. Different from [4], where the latent factors' learning phase and mapping phase are separated, a Gaussian prior with a feature-base regression was added to the latent factors for regularization. RLFM provided a modeling framework through hierarchical models which add more flexibility to the factorization methods.
In [26], the collaborative filtering and probabilistic topic modeling were combined through latent factors. Making recommendations is a process of balancing the influence of the content of articles and the libraries of the other users. Techniques used for solving cold start problem falling into the directed graphical models include latent Dirichlet allocation [2], [14], probabilistic latent semantic indexing [10] etc. Other technique for solving cold start problem include semisupervised [28], decision trees [23] etc.
Besides directed graphical models, undirected graphical models also found application in recommender systems. A tied Boltzmann machine in [6] captures the pairwise interactions between items by features of items. Then a probability of new items could be given to users in order to be ranked. A more powerful model of undirected graphical model is Restricted Boltzmann Machines which has found wide application. RBM was first introduced in [20] named as harmonium. In [13], the Discriminative RBM was successfully used for character recognition and text classification. The most important success of RBMs are as initial training phase for deep neural networks [9] and as feature extractors for text and image [5]. [18] firstly introduce the RBM for collaborative filtering. In this paper we will show its good performance for solving cold start problem.
## 3 The Models
## 3.1 Restricted Boltzmann Machines
Fig. 1. Illustration of a restricted Boltzmann machine with binary hidden units and binary visual units. In this paper, each RBM represents an movie, each visual unit represents a user that has rated the item and each hidden unit represents a feature of movies.
RBM is a two-layer undirected graphical model, see figure 1. It defines a joint distribution over visible variables v and a hidden variable h . In the cold start situation, we consider the case where both v and h are binary vectors.
RBM is an energy-based model, whose energy function is given by
$$E ( v, h ) = - \sum _ { m = 1 } ^ { M } a _ { m } v _ { m } - \sum _ { n = 1 } ^ { N } b _ { n } h _ { n } - \sum _ { m = 1 } ^ { M } \sum _ { n = 1 } ^ { N } v _ { m } h _ { n } W _ { m n } \quad \quad ( 1 )$$
where M is the number of visual units, N is the number of hidden units, v m , h n are the binary states of visible unit m and hidden unit n, a m , b n are their biases and W mn is the weight between v and h . Every joint configuration ( v, h ) has probability of the form:
$$p ( v, h ) = \frac { 1 } { Z } e ^ { - E ( v, h ) } _ { \cdot \cdot \cdot \cdot } \quad \quad \quad \ \ ( 2 )$$
where Z is the partition function given by summing over all possible configuration of ( v, h ):
$$Z = \sum _ { v, h } e ^ { - E ( v, h ) }$$
For a given visible vector v , the marginal probability of p v ( ) is given by
$$p ( v ) = \frac { 1 } { Z } \sum _ { h } e ^ { - E ( v, h ) }$$
The condition distribution of a visible unit given all the hidden units and the condition distribution of a hidden unit given all the visible units are as follows:
$$p ( v _ { m } | h ) = \sigma ( a _ { m } + \sum _ { n = 1 } ^ { M } h _ { n } W _ { m n } )$$
$$p ( h _ { n } | v ) = \sigma ( b _ { n } + \sum _ { m = 1 } ^ { N } v _ { m } W _ { m n } )$$
where σ x ( ) = 1 / (1 + e -x ) is the logistic function.
In this paper, each RBM represents a movie, each visual unit represents a user that has rated the movie. This differs from [18] where each RBM represents a user and each visual unit represents a movie. All RBMs have the same number of hidden units and different number of visible units because different movies are rated by different users. The corresponding weights and biases are tied together in all RBMS. So if two movies are rated by the same people, then these two RBM have the same weights and biases. In other words, we could say all movies use the same RBM while the missing value of users that do not rating a specific movie are ignored. This idea is similar to the matrix factorization based technique [11], [15] that only model the observing ratings and ignore the missing values.
## 3.2 Learning RBM
We need learn the model by adjusting the weights and biases to lower the energy of the item while in the same time arise the energy of other configuration. This could be done by performing the gradient ascent in the log-likelihood of eq. 4,
$$\sum _ { t = 1 } ^ { T } \ln p ( v ^ { t } | \theta )$$
where T is the number of movies, θ = { w, a, b } is the parameter of RBM. The gradient is as follows,
$$\frac { \partial \log p ( v ) } { \partial a _ { m } } = \langle v _ { m } \rangle _ { d a t a } - \langle v _ { m } \rangle _ { m o d e l }$$
$$\frac { \partial \log p ( v ) } { \partial b _ { n } } = \langle h _ { n } \rangle _ { d a t a } - \langle h _ { n } \rangle _ { m o d e l }$$
$$\frac { \partial \log p ( v ) } { \partial W _ { m n } } = \langle v _ { m } h _ { n } \rangle _ { d a t a } - \langle v _ { m } h _ { n } \rangle _ { m o d e l } \quad \quad ( 1 0 )$$
where 〈〉 represents the expectations under the distribution of data and model respectively. 〈〉 data is generally easy to get, while 〈〉 model cannot be computed in less than exponential time. So we use the Contrastive Divergence (CD) algorithm which is much faster [8]. Instead of 〈〉 model , the CD algorithm use 〈〉 recon , the 'reconstruction' produced by setting each v m to 1 with probability in equation 5.
Indeed, maximizing the log likelihood of the data is equivalent to minimizing the Kullback-Liebler divergence between the data distribution and the model distribution. CD only minimizing the data distribution and the reconstruction distribution, and usually the one step reconstruction works well [18]. The update rule is as follows.
$$a _ { m } ^ { \tau + 1 } = a _ { m } ^ { \tau } + \epsilon ( \langle v _ { m } \rangle _ { d a t a } - \langle v _ { m } \rangle _ { T _ { 1 } } ) & & ( 1 1 )$$
$$b _ { n } ^ { \tau + 1 } = a _ { m } ^ { \tau } + \epsilon ( \langle h _ { n } \rangle _ { d a t a } - \langle h _ { n } \rangle _ { T _ { 1 } } )$$
$$W _ { m n } ^ { \tau + 1 } = W _ { m n } ^ { \tau } + \epsilon ( \langle v _ { m } h _ { n } \rangle _ { d a t a } - \langle v _ { m } h _ { n } \rangle _ { T _ { 1 } } )$$
where T 1 represent the one step reconstruction, /epsilon1 is the learning rate.
## 3.3 Conditional Restricted Boltzmann Machines (CRBMs)
The above model could be used in collaborative filtering as in [18]. But it becomes invalid for new items as there are no rating and the correspond hidden units could not be activated. We must add extra information to this model for solving cold start problem. Conditional RBM (CRBM) could easily take these extra information into account [24], [25].
For each movie we use a binary vector f to denote its feature and then add directed connection from f to its hidden factors h . So the joint distribution over ( v, h ) conditional on f is defined, see figure 2. The energy function becomes the following form.
$$E ( v, h, f ) = - \sum _ { m = 1 } ^ { M } a _ { m } v _ { m } - \sum _ { n = 1 } ^ { N } b _ { n } h _ { n } - \sum _ { m = 1 } ^ { M } \sum _ { n = 1 } ^ { N } v _ { m } h _ { n } W _ { m n } - \sum _ { k = 1 } ^ { K } \sum _ { n = 1 } ^ { N } f _ { k } h _ { n } U _ { k n }$$
Fig. 2. Illustration of a conditional restricted Boltzmann machine with binary hidden units and binary visual units
The conditional distinction of v m given hidden units is just the same as eq.5. The conditional distribution of h n becomes the following form.
$$E ( h _ { n } | f, v ) = \sigma ( b _ { n } + \sum _ { \substack { m = 1 \\ \sim } } ^ { M } v _ { m } w _ { m n } + \sum _ { k = 1 } ^ { K } f _ { k } U _ { k n } ) \quad \quad ( 1 5 )$$
In CRBM, the hidden states are affected by the feature vector f . When we have new items, there are no rating by users, but the hidden state could still be activated by f , then the visible unit could be reconstructed as the usual RBM. What's more, this does not add much extra computation.
Learning the weight matrix U is just like learning the bias of hidden unit. In our experiments, we add an regularization term to the normal gradient known as weight-decay [7]. We used the ' L 2 ' penalty function to avoid large weights. The update rule becomes follows.
$$U _ { k n } ^ { \tau + 1 } = U _ { k n } ^ { \tau } + \epsilon ( ( \langle h _ { n } \rangle _ { d a t a } - \langle h _ { n } \rangle _ { T _ { 1 } } ) f _ { k } + \lambda U _ { k n } ) \quad \quad ( 1 6 )$$
Weight-decay for U brings some advantages. On one hand, it improves the performance of CRBM by avoid overfitting in the train process. On the other hand, small weight can be more interpretable than very large values which will be shown in section 4. More reasons for weight-decay could be found in [7].
## 4 Experiment
## 4.1 DataSet
We illustrate the results on benchmark datasets (MovieLens-100K). In this dataset, there are 100K ratings between 943 users and 1,682 movies. As we mainly focus on the new item cold start problem, we use the items features only (actors and genres). We randomly split the items into two sets. In the test set there are 333 movies which do not appear in the train set to used for cold start. The dataset set comes from the GroupLens project and the items' feature are downloaded from the Internet Movie Database (http://www.imdb.com).
## 4.2 Recommendation Task
In this section, we make a distinguish among different recommendation task in real world applications. There are mainly three recommendation tasks depending on the data we have. They are one-class explicit prediction, one-class implicit prediction, and rating prediction.
## 1. One-class explicit prediction
This task is usually arised where we have data that only contains explict possitive feedback. Our goal is to predict whether a user likes an item or not. In this paper, we convert the original integer rating values from 1 to 5 into binary state 0 and 1. Concretely, if a rating is bigger than 3, we take it as 1, otherwise we take it as 0. As a result, all the rating not bigger than 3 or missing rating are taken to be 0.
## 2. One-class implicit prediction
Implicit rating means some feedback of a user which does not give explicit preference, e.g. the purchase history, watching habits and browsing activity etc. In this task we would predict probability that a user will rate a given movie. In this paper, all the observed ratings are taken to be 1 and all the missing rating are taken to be 0.
## 3. Rating prediction
Rating imputation is to predict whether a user will like an item or not condition on his implicit rating. Usually this could be used to evaluate an algorithm's performance by holding out some rating from training data and then predicting their ratings. In the train phase, all missing value are ignored and only the observed value are used. In the test phase, only the observed value in the test set are evaluated. This is very different from the former two taskes where all missing value are taken to be 0.
In the first two recommendation taskes all the missing values are taken to be zeros. As a result, the rating matrix becomes dense. While in the rating prediction task, rating matrix could remain sparse. [19] also give three recommendation task which are similar to ours. It's important to make such a distinction as models can give notable different performance in difference task. In this paper we compare algorithms on these tasks and analysis their performance.
## 4.3 Evaluation Metrics
Precision-recall curve and root mean square error (RMSE) are two popular evaluation metrics. But both of them may be pitfall when the data class has skew distribution. As we know, the rating data is usually sparse and each user only rates a very small fraction of all the items. A trivial idea is that we take all the pair as 0, then we will get a not very bad result according RMSE or precisionrecall curve. Besides they also suffer from the problem of zero rating's uncertain. Zero rating's uncertain here means that a missing rating may either indicate the user does not like the item or that the user does not know the item at all.
In this paper, we use receiver operating characteristics (ROC) graph to evaluate the performance of different models. ROC graphs have long been used for organizing classifiers and visualizing their performance. One attractive property of ROC curve is that they are insensitive to changes in class distribution. We could also reduce ROC performance to a single scalar value to compare classifiers, that is the area under the ROC curve (AUC) [3].
## 4.4 Baselines
In this paper, we mainly focus on the cold start problem. As there are so many techniques for recommender systems, we select three typical models as our baselines. They are aspect model (AS)[19], tied Boltzmann machine (TBM)[6] and regression-based latent factor model (RLFM) [1]. We select these three models because they belong to discrete latent factor model, continuous latent factor model and undirected graphical models respectively. They represent three directions for sovling cold start problems.
The former two models both of which are latent factor models belong to the directed graphical models. Their difference mainly lie in the type of latent factors. In the aspect model, the latent factor is discrete, so aspect model is a mixture model indeed. RLFM is strongly correlated with SVD style matrix factorization methods where the latent factors are continuous. TBM is another type of model belonging to the undirected graphical model which directly models the relationship between items.
## 4.5 Result
(a) implicit rating prediction
(b) rating prediction
- (c) rating imputation
Fig. 3. Performance of different algorithm in three recommendation tasks
We compare the performance of these four algorithms, including TBM, AS, RLFM and CRBM, in three recommendation tasks, see figure 3. As the one-class implicit prediction and one-class explicit prediction give very similar results, we will use one-class prediction for brief. According to figure 3(a) and figure 3(b), we could sort these models by their performance in descending order and get the result (TBM, RLFM, AS, CRBM). However, we get almost an opposite result when considering figure 3(c). In the following, we discuss how the difference arise. A key difference between one-class prediction and rating prediction is how to deal with the missing value.
On one hand, all user-item pairs have a certain value in the one-class prediction task. All missing value between users and items take value 0 when we train models, see section 4.2. When predicting for cold start items, all user will be considered. The ROC curve is plotted using all pairs between users and new items. On the other hand, we remain the missing state of the corresponding user-item pair. When predicting for new items we only test users that have rated them. The ROC curve is plotted only using user-item pairs in the test set. Concretely, in one-class prediction there are two states for each user-item pair 0 and 1, the rating matrix is a dense. While in rating prediction, the rating matrix is sparse. This difference is of significance and play an important role for evaluate the performance of models. In the former case we need to predict ratings between all user-item pairs. Problems arise when we fill 0 value to the missing pairs which will be illustrated by the following example.
Suppose there are 1000 users and 1000 movies in our data set. Without loss of generality, suppose a user in the test set likes 20 movies. Now we need evaluate an algorithm using this data set. In the one-class prediction task a perfect model should put these 20 movies on the top of the prediction rank list, which means we assume this user like these 20 movies better than other movies. This assumption does not seem rational. It's very likely that the user likes the other movie better than these 20 ones. Putting these 20 ones in the top rank list is not what we really want to do. We want to know the correct rank of all 1000 movies, but this is impossible generally as the other 900 movies rating are missing. So the problem of rating prediction we caused by its filling missing value.
When comes to the rating prediction, the situation is difference. We only need predict whether a user will like or not for each of the test movie which are all given in the test set. In other words, we just to give a rank list of the test set but not the whole movie set. When we do not know the correct the answer, it's better to ignore them than to take them as 0. In the above, we analysis the main problem of rating prediction. We must realize that we could not ignore the missing in one-class prediction task just as in rating prediction. Rating prediction could not replace one-class prediction completely because the later is suitable when there are only posititve feedback and no negative feedback. Collaborative filtering techniques, such as use-based CF, item-based CF or matrix factorization, become invalid in such situation. These techniques always give some trivial result, all user liking all items.
It's easy for us to understand the performance of these four models as we know about the difference and characteristic about the recommendation task. Our data set contains both possitive feedback and negative feedback. So we should use the rating prediction task to evaluate the performance. Though AS model and TBM gives perfect resutls in one-class prediction, they predict ratings in the dense way. They use missing values which includes uncertainty. RFLM and
CRBM could deal with the origin sparse raing matrix. If we also sample some negative feedback from the missing pair, they could give good performance in the one-class prediction. In our experiment we sample the negative feedback about 10 times the possitive sapmle.
In the one-class prediction, we ignore the negative feedback and use fewer information both in train and test phase. RFLM and CRBM could deal with this situation. But in the opposite, AS and TBM could only deal with one-class problem, when we ignore the negative feedback in the train phase and predict more informative result, they become invalid, just as the performance of AS and TBM in rating prediction.
## 4.6 Interpretation
In this section, we will show the matrix U we have learned indeed make sense. The matrix U gives us more intuition. Every row of U could be seen as a feature of movies. A movie has a feature if the feature's corresponding state is active. Every column could be seen as the correspondence value of actor or genre. So every movie has a representation by actors. If two actors are similar (similar means user has similar rating for movies of these actors), then the value of the distance of correspond column should be small. So we could cluster the actors by U. In this paper we use the k-mean algorithm to cluster the actors. Table 1 illustrates 8 clusters from our experiment. In each cluster, we show 4 actors or genres. we could see who and who are more similary with each other and in which type of movie one actor is usually appear. For example, we see Brad Pitt and Kevin Bacon are more likely appear in the same type movie. Also, the main movie types comedy, crime, war etc. are partitioned into different clusters.
Table 1. Cluster actors and genres based on U
| Topic Number | Actors and Genres |
|----------------|---------------------------------------------------------|
| 1 | Rance Howard,Parker Posey,James Earl Jones,John Cusack |
| 2 | Children's, Brad Pitt, Kevin Bacon, Western |
| 3 | Comedy, Paul Herman, Michael Rapaport, John Diehl |
| 4 | R. Lee Ermey, Tim Roth, Dermot Mulroney, War |
| 5 | Wallace Shawn, James Gandolfini, Crime, Sci-Fi |
| 6 | Action, Bruce Willis, Sigourney Weaver, Xander Berkeley |
| 7 | Adventure, Drama, John Travolta, David Paymer |
| 8 | Thriller, Paul Calderon, Gene Hackman, Steve Buscemi |
## 5 Conclusion and Future work
In this paper, we apply CRBM to solve the new items cold-start problem. In fact, it could be easily extended for new user situation. We compare CRBM with other three typical techniques and show that in the implicit rating prediction and rating prediction task, CRBM gives comparable performance, while in the rating imputation task CRBM gives the best result. According our analysis, the rating imputation task is more coincidence with the real situation. So CRBM shows its superiority to other models. Such results give us more indication for future researches. Firstly, RBM-based models are good at extract features, so we could give more easy explainable result. Secondly, this kinds of model are easily to be applied for online application. When there are new items, we just need update the parameters by the reconstruction. Thirdly, RBM-based model could be easily combined with deep models to extract more feature for recommendation [21].
Just as [27], we do not want to show CRBM models are more superior than the directed graphical models. But the energy-based model give us some more information in different application. In the future we will use deep models to solve the cold start problem.
## References
- 1. Deepak Agarwal and Bee-Chung Chen. Regression-based latent factor models. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 19-28. ACM, 2009.
- 2. David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation. the Journal of Machine Learning Research , 3:993-1022, 2003.
- 3. Tom Fawcett. An introduction to roc analysis. Pattern recognition letters , 27(8):861-874, 2006.
- 4. Zeno Gantner, Lucas Drumond, Christoph Freudenthaler, Steffen Rendle, and Lars Schmidt-Thieme. Learning attribute-to-feature mappings for cold-start recommendations. In International Conference on Data Mining , pages 176-185. IEEE, 2010.
- 5. Peter V Gehler, Alex D Holub, and Max Welling. The rate adapting poisson model for information retrieval and object recognition. In Proceedings of the 23rd International Conference on Machine learning , pages 337-344. ACM, 2006.
- 6. Asela Gunawardana and Christopher Meek. Tied boltzmann machines for cold start recommendations. In Proceedings of the 2008 ACM conference on Recommender Systems , pages 19-26. ACM, 2008.
- 7. Geoffrey Hinton. A practical guide to training restricted boltzmann machines. Momentum , 9(1):926, 2010.
- 8. Geoffrey E Hinton. Training products of experts by minimizing contrastive divergence. Neural Computation , 14(8):1771-1800, 2002.
- 9. Geoffrey E Hinton. To recognize shapes, first learn to generate images. Progress in brain research , 165:535-547, 2007.
- 10. Thomas Hofmann. Probabilistic latent semantic indexing. In Proceedings of the 22nd annual International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 50-57. ACM, 1999.
- 11. Yehuda Koren. Factorization meets the neighborhood: a multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining , pages 426-434. ACM, 2008.
- 12. Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. Computer , 42(8):30-37, 2009.
- 13. Hugo Larochelle and Yoshua Bengio. Classification using discriminative restricted boltzmann machines. In Proceedings of the 25th International Conference on Machine learning , pages 536-543. ACM, 2008.
- 14. Jovian Lin, Kazunari Sugiyama, Min-Yen Kan, and Tat-Seng Chua. Addressing cold-start in app recommendation: latent user models constructed from twitter followers. In Proceedings of the 36th international ACM SIGIR Conference on Research and Development in Information Retrieval , pages 283-292. ACM, 2013.
- 15. Andriy Mnih and Ruslan Salakhutdinov. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems , pages 1257-1264, 2007.
- 16. Seung-Taek Park and Wei Chu. Pairwise preference regression for cold-start recommendation. In Proceedings of the third ACM Conference on Recommender Systems , pages 21-28. ACM, 2009.
- 17. Ruslan Salakhutdinov and Andriy Mnih. Bayesian probabilistic matrix factorization using markov chain monte carlo. In Proceedings of the 25th International Conference on Machine learning , pages 880-887. ACM, 2008.
- 18. Ruslan Salakhutdinov, Andriy Mnih, and Geoffrey Hinton. Restricted boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine learning , pages 791-798. ACM, 2007.
- 19. Andrew I Schein, Alexandrin Popescul, Lyle H Ungar, and David M Pennock. Methods and metrics for cold-start recommendations. In Proceedings of the 25th annual International ACM SIGIR Conference on Research and Development in Information Retrieval , pages 253-260. ACM, 2002.
- 20. Paul Smolensky. Information processing in dynamical systems: Foundations of harmony theory. 1986.
- 21. Nitish Srivastava, Ruslan R Salakhutdinov, and Geoffrey E Hinton. Modeling documents with deep boltzmann machines. arXiv preprint arXiv:1309.6865 , 2013.
- 22. Xiaoyuan Su and Taghi M Khoshgoftaar. A survey of collaborative filtering techniques. Advances in Artificial Intelligence , page 4, 2009.
- 23. Mingxuan Sun, Fuxin Li, Joonseok Lee, Ke Zhou, Guy Lebanon, and Hongyuan Zha. Learning multiple-question decision trees for cold-start recommendation. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining , WSDM '13, pages 445-454, New York, NY, USA, 2013. ACM.
- 24. Ilya Sutskever and Geoffrey E Hinton. Learning multilevel distributed representations for high-dimensional sequences. In International Conference on Artificial Intelligence and Statistics , pages 548-555, 2007.
- 25. Graham W Taylor, Geoffrey E Hinton, and Sam T Roweis. Modeling human motion using binary latent variables. Advances in Neural Information Processing Systems , 19:1345, 2007.
- 26. Chong Wang and David M Blei. Collaborative topic modeling for recommending scientific articles. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 448-456. ACM, 2011.
- 27. Max Welling, Michal Rosen-Zvi, and Geoffrey E Hinton. Exponential family harmoniums with an application to information retrieval. In Advances in Neural Information Processing Systems , volume 17, pages 1481-1488, 2004.
- 28. Mi Zhang, Jie Tang, Xuchen Zhang, and Xiangyang Xue. Addressing cold start in recommender systems: A semi-supervised co-training algorithm. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval , 2014. | null | [
"Jiankou Li",
"Wei Zhang"
] | 2014-08-01T07:51:37+00:00 | 2014-08-01T07:51:37+00:00 | [
"cs.IR",
"cs.LG",
"stat.ML"
] | Conditional Restricted Boltzmann Machines for Cold Start Recommendations | Restricted Boltzman Machines (RBMs) have been successfully used in
recommender systems. However, as with most of other collaborative filtering
techniques, it cannot solve cold start problems for there is no rating for a
new item. In this paper, we first apply conditional RBM (CRBM) which could take
extra information into account and show that CRBM could solve cold start
problem very well, especially for rating prediction task. CRBM naturally
combine the content and collaborative data under a single framework which could
be fitted effectively. Experiments show that CRBM can be compared favourably
with matrix factorization models, while hidden features learned from the former
models are more easy to be interpreted. |
1408.0097v2 | ## Re-entrant spin-flop transition in nanomagnets
Mattia Crescioli, 1, 2 Paolo Politi, 2, 3, ∗ and Ruggero Vaia 2, 3 1 Dipartimento di Fisica e Astronomia, Universit` a di Firenze, via G. Sansone 1, I-50019 Sesto Fiorentino, Italy 2 Istituto dei Sistemi Complessi, Consiglio Nazionale delle Ricerche, via Madonna del Piano 10, I-50019 Sesto Fiorentino, Italy 3 Istituto Nazionale di Fisica Nucleare, Sezione di Firenze, via G. Sansone 1, I-50019 Sesto Fiorentino, Italy
(Dated: August 28, 2014)
Antiferromagnetic chains with an odd number of spins are known to undergo a transition from an antiparallel to a spin-flop configuration when subjected to an increasing magnetic field. We show that in the presence of an anisotropy favoring alignment perpendicular to the field, the spin-flop state appears for both weak and strong field, the antiparallel state appearing for intermediate fields. Both transitions are second order, the configuration varying continuously with the field intensity. Such re-entrant transition is robust with respect to quantum fluctuations and it might be observed in different types of nanomagnets.
PACS numbers: 75.10.Pq,75.10.Hk,75.10.Jm
Introduction The ability to manipulate atoms adsorbed on a substrate, 1-3 the possibility to choose a suitable combination of substrate and adatoms, and the recent capacity to tailor microscopic interactions 4,5 permit to obtain nanosystems with specific magnetic properties. Adatoms may interact either ferromagnetically or antiferromagnetically; the coupling with a ferromagnetic substrate may mimic an external field and it also induces spin anisotropies via spin-orbit interaction. These couplings are the building blocks of a variety of magnetic configurations, so it is not surprising that in atomic chains one can recognize phenomena and transitions originally discovered in bulk samples, then also studied in stratified systems.
The spin-flop transition is a well suited and important example of magnetic phenomenon whose study has accompanied the race to miniaturization. This transition is due to the competition between antiferromagnetic coupling and magnetic field, and it connects an antiferromagnetic configuration with spins aligned along the field to a configuration where they are almost perpendicular to the field, with a small tilting angle ε producing a nonvanishing magnetization. In the simplest case, an isotropic infinite system, the critical field for such transition is zero, because the Zeeman energy gain ( -Hε ) in tilting the angle dominates upon the exchange energy loss ( Jε 2 ) due to spin misalignment. On the other hand, in the presence of a small easy-axis anisotropy κ < 0, a field applied along such axis must overcome a finite critical threshold H c ≈ J √ | κ | in order to produce the spin-flop reorientation. This transition is first order, the system passing with discontinuity from the antiparallel (AP) to the spin-flop (SF) phase. The metastability region has size δH , with δH/H c ≈ | κ | .
When interfaces or finiteness are introduced, the magnetic phase diagram becomes richer and new effects arise. An especially relevant example is the parity effect 3,6-8 : systems of different parity have different behaviors be- cause an antiferromagnetic (AFM) chain of N spins has (odd N ) or has not (even N ) a finite magnetization which couples to the external field. In particular, for odd N such residual magnetization may stabilize the AP configuration with respect to the SF phase for fields which can be much larger than H c 8-12 . Here we show that the presence of an anisotropy favoring alignment perpendicular to the field alters the above scenario, determining two critical fields H ± ( N ), with the AP phase appearing for H -( N ) < H < H + ( N ) and the SF phase outside such interval. For N = N ∗ , H -( N ∗ ) = H + ( N ∗ ) so that only the SF phase appears for N > N ∗ . Furthermore, both transitions at H ± ( N ) are continuous.
Models and main results We consider a chain with an odd number N ≡ 2 M +1 of spins, described by the Heisenberg Hamiltonian
$$\stackrel { \cdot } { \text{ic} } \\ \circ _ { \text{ld} } \quad \hat { \mathcal { H } } = J \sum _ { i = 1 } ^ { N - 1 } \hat { \mathbf S } _ { i } \cdot \hat { \mathbf S } _ { i + 1 } - H \sum _ { i = 1 } ^ { N } \hat { S } _ { i } ^ { z } + J \kappa \sum _ { i = 1 } ^ { N } ( \hat { S } _ { i } ^ { z } ) ^ { 2 } \. \quad ( 1 ) \\ \intertext { o } \quad \circ _ { \dots \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \dots \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdots \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \dots \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \. \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cd. \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \cdot \, \delta \, \, \,$$
Special attention will be given to the easy-plane case ( κ > 0), but we will also refer to κ ≤ 0. Its classical counterpart (in units of JS 2 ) is given by
$$\begin{smallmatrix} \text{lting} \\ J \varepsilon ^ { 2 } ) \\ \text{the} \\ \text{field} \\ \text{itical} \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad, \quad \end{smallmatrix}$$
where the azimuthal angles ϕ i have been taken equal, our purpose being that of characterizing the minimum-energy state (ground state); note that the physically relevant values of the anisotropy are small, | κ | /lessmuch 1.
It is possible to qualitatively illustrate in simple terms the main results that are more rigorously studied in the following Sections. Assuming the SF configuration to be uniform, as in the infinite system, θ i = ( -1) i θ , from (2) its classical energy per site is about e SF ( θ ) /similarequal cos 2 θ -h cos θ + κ cos 2 θ , which is minimal for 2 cos θ = h/ (2+ κ ),
giving e SF /similarequal - -1 h / 2 8. As for the AP configuration, θ i = iπ , one easily finds e AP = -1+ κ -h/N , the last term being due to the balance between M +1 up and M down spins, respectively. The condition e AP < e SF reads
$$\frac { h ^ { 2 } } { 8 } \, - \frac { h } { N } + \kappa < 0 \, \quad \ \ \ ( 3 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
implying that the AP phase is energetically favored for
$$N < N _ { c } ( h, \kappa ) = \frac { h } { \kappa + h ^ { 2 } / 8 } \, \quad \ \ ( 4 ) \quad \lesssim \sin \text{di}$$
i.e., for h between two 'critical' field values
$$h \in [ h _ { - }, h _ { + } ] \,, \ \ h _ { \pm } ( N, \kappa ) = \frac { 4 } { N } \left ( 1 \pm \sqrt { 1 - \frac { \kappa \, N ^ { 2 } } { 2 } } \, \right ) \,. \ ( 5 ) \quad \text{$Cla$} \quad \text{tion in} \\ \text{$sough} \quad \text{$i\in\sigma$ to}$$
Hence, when rising the field from zero: first, the system enters in the SF phase; at h -such phase is left and the AP one shows up; finally, beyond h + the system re-enters the SF phase. Evidently, this happens for small enough N /lessorsimilar √ 2 /κ , a value beyond which the intermediate AP configuration disappears. It is worth stressing that for a vanishing or easy-axis anisotropy ( κ ≤ 0), the lower 'critical' field h -≤ 0, meaning that at small field the system is in the AP state for any N , and the only transition at h + is left.
The above SF-AP-SF re-entrant transition should be accessible to experiment (see the final Discussion). However, as real systems at a few Kelvin are quantum mechanical, one has to account for the effect of quantum fluctuations (QFs). Any classically ordered state, such as the AP one, is usually weakened by QFs. For instance, the quantum threeand two-dimensional isotropic antiferromagnets are subject to spin reduction 13 , namely, QFs make the ground-state sublattice magnetization smaller than S , while in the one-dimensional case the ground state does not even show order, the N´ eel AFM state being unstable under soft spin-wave excitations. Therefore, it makes sense to ask whether QFs destroy the re-entrant transition in the finite chain or not, a question that can be answered by studying the stability of the AP state under QFs. A na¨ ıve approach is to apply the renormalization scheme 14 known as self-consistent harmonic approximation (SCHA) as done in Refs. 15-18 for a translation invariant two-dimensional AFM. In this approach, zeroT QFs can be substantially accounted for by the classical system, but taking spins reduced by a factor α S ( ) = 1 -D (i.e., each quantum spin ˆ S i has a classical counterpart α S i ). In the one-dimensional case
$$D = \frac { 1 } { ( 2 S + 1 ) N } \sum _ { k } \sqrt { 1 - \cos ^ { 2 } k } = \frac { 2 } { \pi ( 2 S + 1 ) } \. \quad ( 6 ) \quad \text{$\quadquam{sum}_{inclu}$}$$
It is then straightforward to see from Eq. (1) that J gains a factor α 2 , and H a plain factor α , so h is replaced by h/α in Eqs. (2) and (3), and eventually the quantum transition fields are expected at h (q) ± = αh ± ( N,κ ). According to this argument the AP region should be maintained, but with smaller critical fields, h (q) ± < h ± . However, as we will see in more detail later on, this argument fails because it assumes homogeneous QFs. Instead, the breaking of translation symmetry causes, in the vicinity of the chain ends, smaller fluctuations of the odd spins (parallel to the field) and larger ones for the even ones (antiparallel to the field). The picture of 'equal spin reduction' breaks down and the boundary spins, which are less affected by QFs, remain more 'resistant' towards the incipient SF configuration. As a consequence, the stability of the AP state is unexpectedly reinforced, and h (q) + becomes even larger than h + ( N,κ ).
Classical model -Because of the broken translation invariance, minimum energy configurations must be sought in the N -dimensional space θ , . . . , θ 1 N , minimizing the energy (2). Defining s i = sin( θ i -θ i -1 ), the equations ∂E/∂θ i = 0 can be cast in the form of a twodimensional mapping, 7
$$\begin{cases} s _ { i + 1 } = s _ { i } - h \, \sin \theta _ { i } + \kappa \, \sin 2 \theta _ { i } \\ \theta _ { i + 1 } = \theta _ { i } + \sin ^ { - 1 } s _ { i + 1 }. \end{cases}$$
The function sin -1 in (7) has two solutions; since the AFM exchange coupling is strong, we must choose the solution such that ( θ i +1 -θ i ) ∈ [ π 2 , 3 π 2 ]. The absence of spins at i = 0 and i = N +1 can be accounted by the boundary conditions s 1 = s N +1 = 0. The angle θ 1 is determined imposing that after N iterations we can satisfy the condition s N +1 = 0. It is worth remarking that the AP configuration θ i = iπ is always a solution of Eqs. (7). Its energy must be compared with possible nonuniform solutions (SF) in order to identify the ground state.
In Fig. 1 we plot the angle between the first (or last) spin and the field for N < N ∗ , so that two transitions are crossed when increasing h . The continuous character of both transitions will be discussed in the final Section. Generally speaking, it is possible to numerically determine the phase diagram in the ( h, N ) plane for different values of κ using the map method, but this would be very lengthy. In Ref. 9 the limit of the AP phase has been determined analytically when κ = 0, the transition corresponding to the vanishing of s ′ N +1 ( θ 1 ) in θ 1 = 0. In fact, it is possible to extend the same procedure 19 to the anisotropic case, obtaining the curves shown in Fig. 2. We have also derived the analytical phase boundaries by studying the stability of the AP phase, which is also needed for the quantum treatment explained below. In the classical limit this approach yields the very same results obtained by the map analysis 9,19 . In view of the quantum treatment it is useful to extend the model to include an exchange anisotropy, described by adding to Eq. (1) the term
$$- J \lambda \sum _ { i = 1 } ^ { N - 1 } \hat { S } _ { i } ^ { z } \hat { S } _ { i + 1 } ^ { z } \,.$$
FIG. 1. The angle θ 1 corresponding to the classical groundstate configuration as a function of h , for N = 15 and κ = 0 001. . It varies with continuity in the whole range of h . For large h (not shown) θ 1 attains a maximum, then it decreases because the SF phase gets ferromagnetic for h /similarequal 2(2 + κ ).
Such a different anisotropy makes our results more general and allows us to show that they do not depend on the details of the anisotropy, but only on its sign. The exact result for the phase-boundary is
$$N _ { c } ( h, \kappa, \lambda ) = \frac { \tan ^ { - 1 } \left [ \frac { 1 } { 2 } \, \frac { h + 2 \lambda \mu } { \kappa + \lambda \mu } \, a ( h, \kappa + \lambda ) \right ] } { \tan ^ { - 1 } \, a ( h, \kappa + \lambda ) } \, \quad ( 9 )$$
where tan -1 is defined with the codomain [0 , π ], µ = (1 -λ/ 2)(1 - - -κ λ h/ 2), and
$$a ( h, x ) = \sqrt { \left [ ( 1 - x ) ^ { 2 } - h ^ { 2 } / 4 \right ] ^ { - 1 } - 1 } \. \quad ( 1 0 ) \quad N \ ( \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lambda _ { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \Lamb { \L | \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \d | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L } \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \ delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L. \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L! \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \Ld } \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \d } } \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L } \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L } \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L } \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \delta _ { \L | \delta _ { \L | \delta _ { \L | \delta _ { \L | \d } } \delta } \delta } \delta } \.$$
When κ and λ are small, µ /similarequal 1, so that N c only depends on the sum κ + , i.e., λ exchange- and single-site anisotropies are almost equivalent in the classical system.
In Fig. 2 we report the results of the above analysis for three cases: easy-axis anisotropy ( κ < 0), no anisotropy ( κ = 0), and easy-plane anisotropy ( κ > 0). All the curves are qualitatively reproduced by Eq. (5): for κ > 0 the AP state exists for h -< h < h + up to a value N ∗ of the chain length; for κ ≤ 0 such state exists for 0 < h < h + , with h + ( N ) vanishing at large N for κ = 0 and going to the limit h + ( ∞ ≈ ) √ | κ | for κ < 0.
Quantum model In order to estimate the effects on the finite quantum chain one has to account for the lack of translation symmetry and for the different behavior of the two sublattices by means of a more accurate quantum SCHA. The strategy is to study the linear excitations in the AP ordered phase, which is assumed to be stable if the corresponding frequencies are positive: at the
FIG. 2. Phase diagram for a classical spin chain of length N (odd), for easy-plane, easy-axis, and no anisotropy.
FIG. 3. Phase diagram for a quantum spin chain of length N (odd), for easy-plane exchange anisotropy λ = 0 001 and . no anisotropy ( λ = 0) and for selected spin values.
phase boundary at least one frequency vanishes, so that calculating the quantum-renormalized mode frequencies allows us to draw conclusions for the quantum phase diagram.
We restrict the quantum approach to the case of exchange anisotropy, which can be treated unambiguously with respect to single-site anisotropy: for instance, the latter is completely ineffective for S = 1 2, / as ( ˆ S z ) 2 = 1 4. Therefore, we consider the Hamiltonian (1) / with κ = 0 and with the additional term (8). Performing the canonical transformation ( ˆ S , S x ˆ y , S ˆ z ) -→ ( -ˆ S , S x ˆ y , -ˆ S z ) on the even indexed sites we get the following Hamiltonian
$$\begin{smallmatrix} \text{ations} \\ \text{e sta-} \\ \text{at the} \end{smallmatrix} \quad \hat { \mathcal { H } } = - J \sum _ { i = 1 } ^ { N - 1 } \left ( \hat { S } _ { i } ^ { x } \hat { S } _ { i + 1 } ^ { x } - \hat { S } _ { i } ^ { y } \hat { S } _ { i + 1 } ^ { y } + \lambda \hat { S } _ { i } ^ { z } \hat { S } _ { i + 1 } ^ { z } \right ) + H \sum _ { i = 1 } ^ { N } ( - ) ^ { i } \hat { S } _ { i } ^ { z }.$$
The AP state corresponds to the fully aligned (N´ eel) state: evidently, it is not an eigenstate of ˆ . H However, the exact ground state is expected to be 'close' to it, as it happens with the ground state of bulk antiferromagnets; in the latter case, the ground state and its linear excitations are found by means of a Bogoliubov transformation for the Fourier-transformed operators. But in our problem there is no translation symmetry, so the procedure is necessarily more involute.
To proceed, we use the magnon creation and annihilation operators defined by the Holstein-Primakoff 20 transformation: ˆ S x + ˆ iS y = √ 2 S -ˆ ˆ ˆ, a a a † ˆ S z = S -ˆ ˆ. a a † Then, we introduce coordinates and momenta defined by ˆ = (ˆ +ˆ ) q i a † i a i / √ 2 S +1 and ˆ p i = (ˆ i a † i -ˆ ) a i / √ 2 S +1, in such a way that [ˆ q , p i ˆ ] = j iδ ij ( S + ) 1 2 -1 (the classical limit occurring for S →∞ ). It is easier to work with their Weyl symbols 21 q i and p i , so complex quantities do not appear, and expanding up to quartic terms 18 one is left with a quadratic Hamiltonian and a quartic interaction,
$$\text{quadratic Hamiltonian and a quartic interaction}, \quad \text{ for } h \\ \mathcal { H } _ { 2 } = \sum _ { i = 1 } ^ { N - 1 } \left [ p _ { i } p _ { i + 1 } - q _ { i } q _ { i + 1 } + \lambda ( z _ { i } + z _ { i + 1 } ) \right ] - h \sum _ { i = 1 } ^ { N } ( - ) ^ { i } z _ { i } \, \quad \text{ not } s \\ \mathcal { H } _ { 4 } = \sum _ { i = 1 } ^ { N - 1 } \left [ \frac { 1 } { 4 } ( z _ { i } + z _ { i + 1 } ) ( q _ { i } q _ { i + 1 } - p _ { i } p _ { i + 1 } ) - \lambda z _ { i } z _ { i + 1 } \right ] \, \quad \text{ verif} \\ \text{where } z _ { i } \ \infty \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cdot \ \cd.$$
/negationslash where z i ≡ ( p 2 i + q 2 i ) / 2. Note that H 2 = 1 2 ( p A p t 2 + q B q t 2 ) is a quadratic form with [ A 2 , B 2 ] = 0, so its reduction to independent normal modes 22-24 is nontrivial. First, one has to assume the N × N matrices A 2 and B 2 to be positive definite: thanks to their structure, this can be assessed analytically, and gives the classical AP phase boundary mentioned above. Then, one performs the canonical transformation ( q p , ) -→ ( Aq A , -1 p ), so that H 2 -→ 1 2 ( p p t + q AB Aq t 2 ) and eventually the eigenfrequencies ω 2 k arise as eigenvalues of AB A 2 , while the decoupled modes have the ground-state QFs 〈 p 2 k 〉 = ω / k (2 S +1) and 〈 q 2 k 〉 = 1 [ / ω k (2 S +1)]. Renormalizations come into play through H 4 , which is treated within the SCHA 14 , yielding for A 2 and B 2 corrections which self-consistently depend on the correlators generated by H 2 . Such a perturbative approximation is the more reliable the smaller the corrections it gives. For systems in three and two dimensions the high coordination degree yields small fluctuations, which only slightly modify the ground state and the low temperature phase, while in the present quasi-one-dimensional system the matrix elements of A 2 and B 2 are corrected by terms of order 1 /S which become rapidly large when considering small spin values; however, if one 'switches on quanticity' starting from large spin values, the trend towards an extension of the AP region is evident. The above procedure can be easily implemented numerically and the final quantum results are reported in Fig. 3, which confirms the overall classical scenario of Fig. 2.
Discussion -We have proven that an AFM chain composed by an odd number of spins undergoes an unusual re-entrant spin-flop transition, if the magnetic field is applied along a hard axis. This result appears to be rather robust: the details of the anisotropy and the classical or quantum character of the model are irrelevant. In fact, the qualitative explanation of the double transition we have given in Eqs. (3)-(5) is fairly simple and the subsequent Sections confirm such a result. It is worth stressing that, at least classically, the ground state of the chain in the presence of an easy-plane anisotropy favoring the ˆ xy plane ( κ > 0) does not change if the anisotropy is easy-axis and favors any direction in such plane. 25
Figure 1 shows that θ 1 varies with continuity with h , making second order the SF-AP (at h = h -) and the AP-SF (at h = h + ) transitions. Such character is in contrast with the standard spin-flop transition appearing when the field is applied along an easy axis ( κ < 0). In this case, the infinite system undergoes a first order transition at h c = 2 √ | κ | (2 -| | κ ), with a metastability region of size δh ≈ | κ | 3 / 2 . This behavior is maintained for finite systems if (odd) N is large enough. When κ = 0, h c = 0 and the transition gets continuous, which is not surprising, since the metastability region is negligibly small with respect to h c , when κ → 0 -. The continuous character at κ = 0 is preserved when κ > 0, as we have verified for N = 15 (Fig. 1) and for large N (not shown).
Our models, either classical, Eq. (2), or quantum, Eq. (1), have several possible experimental counterparts. We cite here the most relevant two, namely layered systems and chains of magnetic adatoms on a magnetic substrate. A superlattice A/B, if one of the two materials (A) is ferromagnetic and the indirect coupling between A layers, mediated by the spacer B is antiferromagnetic, can be studied by our model Eq. (2), where each spin represents the effective magnetization of a single A layer (quantum effects are therefore negligible, since S is macroscopic and the temperature is high). In fact, Fe/Cr(211) superlattices have been used 6 to study surface effects on the spin-flop transition, but the field was applied in an easy direction ( κ < 0). So, parity effects were visible, but the distinctive spin-flop transitions appearing for odd N when the field is along an hard axis were overlooked.
In the last few years, much experimental effort has been devoted to completely different magnetic systems undergoing a spin-flop transition: magnetic atoms deposited on a substrate and forming a linear chain. An existing experimental set-up which is appropriate for our study is a recent one 3 , where Mn adatoms were deposited and manipulated on top of a Ni(110) surface. In that paper authors compare successfully experiment and theory for the ground states of a dimer ( N = 2) and a trimer ( N = 3). For N = 3 they actually find an AP state, which is in agreement with our phase diagram if we use their experimental values h /similarequal 0 5 and . κ ≈ 0 001. . The limit of using adatom chains for studying SF transitions is that the field is fixed, because it is not a true magnetic, external field. On the contrary, changing N is much easier than for layered systems. However, recent experimental results suggest that tuning the parameters
of Eqs. (1)-(2) is indeed possible 4,5 .
Our results might also be relevant for a third class of nanosystems, namely molecular nanomagnets 26-28 . In this case, the coupling between spins is weaker and an external magnetic field can be applied to tune the configuration. In conclusion, the SF-AP-SF re-entrant tran-
- ∗ [email protected]
- 1 C. F. Hirjibehedin, C. P. Lutz, and A. J. Heinrich, Science 312 , 1021 (2006).
- 2 S. Loth, S. Baumann, C. P. Lutz, D. M. Eigler, and A. J. Heinrich, Science 335 , 196 (2012).
- 3 S. Holzberger, T. Schuh, S. Bl¨gel, u S. Lounis, and W. Wulfhekel, Phys. Rev. Lett. 110 , 157206 (2013).
- 4 M. M. Bezerra-Neto, M. S. Ribeiro, B. Sanyal, A. Bergman, R. B. Muniz, O. Eriksson, and A. B. Klautau, Scientific reports 3 (2013).
- 5 O. O. Brovko, P. Ruiz-Daz, T. R. Dasa, and V. S. Stepanyuk, Journal of Physics: Condensed Matter 26 , 093001 (2014).
- 6 R. W. Wang, D. L. Mills, E. E. Fullerton, J. E. Mattson, and S. D. Bader, Phys. Rev. Lett. 72 , 920 (1994).
- 7 L. Trallori, M. Gloria Pini, A. Rettori, M. Macci`, o and P. Politi, International Journal of Modern Physics B 10 , 1935 (1996).
- 8 S. Lounis, P. H. Dederichs, and S. Bl¨gel, u Phys. Rev. Lett. 101 , 107204 (2008).
- 9 P. Politi and M. G. Pini, Phys. Rev. B 79 , 012405 (2009).
- 10 A. Berzin, A. Morosov, and A. Sigov, Physics of the Solid State 52 , 117 (2010).
- 11 A. I. Morosov and A. S. Sigov, Physics-Uspekhi 53 , 677 (2010).
- 12 M. Crescioli, Frustrazione e parit` in cateme di spin clasa siche , Master's thesis, Universit` a degli Studi di Firenze, unpublished (2013).
- 13 R. Kubo, Phys. Rev. 87 , 568 (1952).
sition we have discussed in this paper might be really accessible to experiments.
We thank Gloria Pini for useful discussions and Wulf Wulfhekel for pointing out some relevant references.
- 14 T. R. Koehler, Phys. Rev. Lett. 17 , 89 (1966).
- 15 A. Cuccoli, V. Tognetti, P. Verrucchi, and R. Vaia, Phys. Rev. A 45 , 8418 (1992).
- 16 A. Cuccoli, R. Giachetti, V. Tognetti, R. Vaia, and P. Verrucchi, J. Phys.: Condens. Matter 7 , 7891 (1995).
- 17 A. Cuccoli, V. Tognetti, P. Verrucchi, and R. Vaia, Phys. Rev. Lett. 77 , 3439 (1996).
- 18 A. Cuccoli, V. Tognetti, P. Verrucchi, and R. Vaia, Phys. Rev. B 56 , 14456 (1997).
- 19 M. Crescioli, Unpublished.
- 20 F. Holstein and H. Primakoff, Phys. Rev. 58 , 1048 (1940).
- 21 F. A. Berezin, Usp. Fiz. Nauk. 132 , 497 (1980).
- 22 J. H. P. Colpa, Physica 93A , 327 (1978).
- 23 C. Tsallis, J. Math. Phys. 19 , 277 (1978).
- 24 V. I. Arnold, Mathematical Methods of Classical Mechanics (Springer Verlag, Berlin, 1978).
- 25 Spin-wave excitations and zero-point fluctuations make the two models different, because their symmetry properties are different, but their classical ground states are the same.
- 26 D. Gatteschi, R. Sessoli, and J. Villain, Molecular nanomagnets (Oxford University Press, 2006).
- 27 E. Micotti, Y. Furukawa, K. Kumagai, S. Carretta, A. Lascialfari, F. Borsa, G. A. Timco, and R. E. P. Winpenny, Phys. Rev. Lett. 97 , 267204 (2006).
- 28 S. Ochsenbein, F. Tuna, M. Rancan, R. Davies, C. Muryn, O. Waldmann, R. Bircher, A. Sieber, G. Carver, H. Mutka, F. Fernandez-Alonso, A. Podlesnyak, L. Engelhardt, G. Timco, H. Gdel, and R. Winpenny, Chemistry A European Journal 14 , 5144 (2008). | 10.1103/PhysRevB.90.100401 | [
"Mattia Crescioli",
"Paolo Politi",
"Ruggero Vaia"
] | 2014-08-01T07:59:16+00:00 | 2014-08-27T14:03:41+00:00 | [
"cond-mat.mes-hall",
"cond-mat.mtrl-sci"
] | Re-entrant spin-flop transition in nanomagnets | Antiferromagnetic chains with an odd number of spins are known to undergo a
transition from an antiparallel to a spin-flop configuration when subjected to
an increasing magnetic field. We show that in the presence of an anisotropy
favoring alignment perpendicular to the field, the spin-flop state appears for
both weak and strong field, the antiparallel state appearing for intermediate
fields. Both transitions are second order, the configuration varying
continuously with the field intensity. Such re-entrant transition is robust
with respect to quantum fluctuations and it might be observed in different
types of nanomagnets. |
1408.0098v1 | ## What the collective flow excitation function can tell about the quark-gluon plasma
Jussi Auvinen ∗
Frankfurt Institute for Advanced Studies (FIAS), Ruth-Moufang-Strasse 1, D-60438 Frankfurt am Main, Germany
Jan Steinheimer † and Hannah Petersen ‡
Frankfurt Institute for Advanced Studies (FIAS), Ruth-Moufang-Strasse 1, D-60438 Frankfurt am Main, Germany and Institut f¨r u Theoretische Physik, Goethe Universit¨t, a Max-von-Laue-Strasse 1, D-60438 Frankfurt am Main, Germany
## Abstract
Recent STAR data from the RHIC beam energy scan (BES) show that the midrapidity slope dv /dy 1 of the directed flow v 1 of net-protons changes sign twice within the collision energy range 7.7 - 39 GeV. To investigate this phenomenon, we study the collision energy dependence of v 1 utilizing a Boltzmann + hydrodynamics hybrid model. Calculations with dynamically evolved initial and final state show no qualitative difference between an equation of state with a cross-over and one with a first-order phase transition, in contrast to earlier pure fluid predictions. Furthermore, our analysis of the elliptic flow v 2 shows that pre-equilibrium transport dynamics are partially compensating for the diminished elliptic flow production in the hydrodynamical phase at lower energies, which leads to a qualitative agreement with STAR BES results in midcentral collisions. No compensation from transport is found in our model for integrated v 3 , which decreases from ≈ 0 02 at . √ s NN = 27 GeV to ≈ 0 005 at . √ s NN = 7 7 GeV in midcentral collisions. .
PACS numbers: 24.10.Lx,24.10.Nz,25.75.Ld
∗ Electronic address: [email protected]
† Electronic address: [email protected]
‡ Electronic address: [email protected]
## I. INTRODUCTION
In 2010, a beam energy scan program was launched at the Relativistic Heavy Ion Collider (RHIC) to study the features of the QCD phase diagram, in particular the location and the order of the phase transition between the hadronic and QCD matter in the plane of baryochemical potential µ B and temperature T . The main observables are the coefficients v n of the Fourier expansion of the azimuthal angle distribution of final-state particle momenta, which are typically associated with collective flow.
Fluid dynamical calculations have predicted that the slope of the directed flow v 1 of baryons will turn negative and then positive again as a function of energy if there is a first order phase transition between hadronic and QCD matter [1-4]. Qualitatively similar behavior of the midrapidity slope of the net-proton directed flow, dv /dy 1 , has been found by STAR experiment in the RHIC beam energy scan, with a minimum in the energy interval √ s NN = 11 5 . -19 6 GeV [5]. . The elliptic flow v 2 is one of the key observables supporting the formation of a strongly coupled quark-gluon plasma (QGP) at the highest energies of RHIC and the Large Hadron Collider (LHC). However, the measured differential elliptic flow v 2 ( p T ) for charged hadrons remains nearly unchanged from the collision energy range √ s NN = 39 GeV down to 7.7 GeV [6], where the formation of hydrodynamically evolving QCD matter is expected to be considerably diminished compared to top RHIC energies. In addition, the preliminary STAR data suggests that the magnitude of the triangular flow v 3 remains constant at lower collision energies [7].
We study the collision energy dependence of the collective flow in the RHIC BES range with a hybrid approach, where the non-equilibrium phases at the beginning and in the end of a heavy-ion collision event are described by a transport model, while a hydrodynamic description is used for the intermediate hot and dense stage and the phase transition between the QGP and hadronic matter. This provides a consistent framework for investigating both high-energy heavy ion collisions with negligible net-baryon density and notable quark-gluon plasma phase, and the collisions at smaller energies with finite net-baryon density, where less QGP is expected to form. This approach should thus be ideal for beam energy scan studies.
## II. HYBRID MODEL
In this study, the transport + hydrodynamics hybrid model by Petersen et al. [8] is utilized. The transport model describing the initial and final state is the Ultrarelativistic Quantum Molecular Dynamics (UrQMD) string / hadron cascade [9, 10]. The transition time to hydrodynamics is defined as the moment when the two colliding nuclei have passed through each other: t start = 2 R/ √ γ 2 CM -1, where R represents the nuclear radius and γ CM = 1 / √ 1 -v 2 CM is the Lorentz factor.
The (3+1)-D ideal hydrodynamics evolution equations are solved with the SHASTA algorithm [11, 12]. The equation of state (EoS) which is utilized most of this study is from Steinheimer et al. [13]. It is a combination of a chiral hadronic and a constituent quark model and has the important feature of being applicable also at finite net-baryon densities found at lower collision energies.
The transition from hydro to transport (aka 'particlization'), is done when the energy density glyph[epsilon1] reaches the critical value glyph[epsilon1] C = nglyph[epsilon1] 0 , where glyph[epsilon1] 0 = 146 MeV/fm 3 is the nuclear ground state energy density. In this study, the values n = 2 and n = 4 are used. The particle distributions are generated according to the Cooper-Frye formula from the iso-energy density hypersurface, which is constructed using the Cornelius hypersurface finder [14]. The final rescatterings and decays of these particles are then computed in the UrQMD.
## III. RESULTS
To investigate the sensitivity of the directed flow v 1 ( y ) = 〈 p x p T 〉 y i = y on the order of the phase transition, we run the simulations with a first-order phase transition 'Bag model' EoS as an alternative to the above described chiral model EoS which has a cross-over phase transition. The transition from fluid dynamics back to transport happens on an iso-energy density glyph[epsilon1] C = 4 glyph[epsilon1] 0 ≈ 0 6 GeV . / fm 3 hypersurface.
To emulate the earlier fluid calculations, we first utilize a cold nuclear matter initialization, where the colliding nuclei are represented by two distributions of energy and baryon density, which respect boosted Woods-Saxon profiles with a central density of saturated nuclear matter ρ 0 ≈ 0 16 fm . -3 . The starting point of the simulation is just before the two nuclei first make contact; in the early stage of the collision the kinetic energy of the nuclei is
then transformed into large local densities. Figures 1a and 1b show the difference in dv /dy 1 between the two equations of state with a cold nuclear matter initialization and the UrQMD afterburner for Au+Au collisions at impact parameter b = 8 fm. The predicted minimum in dv /dy 1 as a function of √ s NN with a first-order phase transition is clearly observed when using isochronous particlization condition; however, the difference between the two equations of state diminishes greatly when using iso-energy density fluid-to-particles switching condition instead.
Figure 1c shows the result of the full hybrid simulation with the initial non-equilibrium transport phase for the energy dependence of midrapidity slopes of proton and antiproton v 1 . The directed flow was calculated using events with impact parameter b = 4 6 . -9 4 . fm, to approximate the (10 -40)% centrality range of the STAR data. The hybrid model overestimates the experimental data and also the pure UrQMD transport result in the whole examined collision energy range. The two EoS are completely indistinguishable in the hybrid simulations, questioning the validity of v 1 as a signal of the first-order phase transition. Some possible sources for the difference between the model and the experimental data are the momentum transfer between the spectator particles and the fireball, which is not accounted for in this study, and the method used to determine the event plane, as here v 1 was calculated with respect to the reaction plane of the simulation. These uncertainties need further investigation before drawing definite conclusions.
Utilizing the hybrid model with the crossover EoS, the flow coefficients v 2 and v 3 are calculated from the particle momentum distributions using the event plane method [18, 19]. Figure 2a shows the elliptic flow v 2 produced in Au+Au -collisions, integrated over the p T range 0.2 - 2 GeV, compared with the STAR data for the (0-5)%, (20-30)% and (30-40)% centrality classes. In the model these are respectively represented by the impact parameter intervals b = 0 -3 4 fm, . b = 6 7 . -8 2 fm and . b = 8 2 . -9 4 fm. . Critical energy density glyph[epsilon1] C = 2 glyph[epsilon1] 0 is used here, as this value has been found to give a reasonable agreement with the experimental data for particle m T spectra at midrapidity | y | < 0 5 for energies ranging . from E lab = 40 AGeV to √ s NN = 200 GeV [21, 22]. Figure 2b demonstrates the magnitude of v 2 at three different times: just before the hydrodynamical evolution, right after the particlization, and the final result after the hadronic rescatterings have been performed in the UrQMD model.
In the impact parameter range b = 8 2 . -9 4 . fm the rescatterings contribute roughly
FIG. 1: a) and b) Slope of v 1 of protons around midrapidity | y | < . 0 5 with an equation of state with first-order phase transition (black) and cross-over phase transition (red) for isochronous fluid-toparticles transition hypersurface (a) and iso-energy density transition hypersurface (b) for Au+Au collisions at impact parameter b = 8 fm. c) Midrapidity slope dv /dy 1 of protons (solid symbols) and anti-protons (open symbols) for impact parameter range b = 4 6 . -9 4 . fm, extracted from the hybrid model calculations with a bag model (black) and crossover EoS (red). Compared with standard UrQMD (grey) and experimental data [5, 15, 16] (green). Plots from [17].
10% on the final result. The hydrodynamics produce very little elliptic flow at √ s NN ≤ 7 7 GeV; . v 2 below √ s NN = 10 GeV is in practice completely produced by the transport dynamics (resonance formations and decays, string excitations and fragmentation). This initial transport gains importance at lower energies due to the prolonged pre-equilibrium phase. On the other hand, above √ s NN = 19 6 GeV the hydrodynamics are clearly the . dominant source of v 2 .
The simulation results overshoot the experimental data for all collision energies. This suggests that the viscous corrections should be included - indeed, good results have already been achieved using similar hybrid approach with viscous hydro [23]. In the most central collisions below √ s NN = 11 5 GeV, the model deviates from the observed energy dependence; . it is likely that the abrupt change from the pre-equilibrium phase to hydro is not a valid assumption in this regime and a more dynamic procedure should be implemented. For the purposes of this study, however, the most important feature is the good qualitative agreement in the midcentral collisions, as here the flow effects are at their largest.
Based on the above results, it appears that the decrease in the hydrodynamically produced elliptic flow is partially compensated by the increased flow production in the transport phase, and so the observed v 2 has weaker collision energy dependence than one would have naively
FIG. 2: a) Integrated v 2 at midrapidity | η | < 1 0 from hybrid model (circles) in collision energy . range √ s NN = 7 7 . -200 GeV at three impact parameter ranges, compared to the STAR data [6, 20] (stars). b) Integrated v 2 for impact parameter range b = 8 2 . -9 4 at . √ s NN = 5 -200 GeV, at the beginning of hydrodynamical evolution (diamonds), immediately after particlization (squares) and after the full simulation (circles). c) Integrated v 3 at midrapidity | η | < 1 0 for . b = 0 -3 4 fm . and b = 6 7 . -8 2 fm at . √ s NN = 5 -200 GeV. Plots from [21].
expected. To study this phenomenon further, we do the same analysis for the triangular flow v 3 , which originates purely from the event-by-event variations in the initial spatial configuration of the colliding nucleons.
As illustrated by Figure 2c, the p T -integrated v 3 increases from ≈ 0 01 to above 0.015 . with increasing collision energy in the most central collisions. However, in midcentrality b = 6 7 . -8 2 fm there is a rapid rise from . ≈ 0 at √ s NN = 5 GeV to the value of ≈ 0 02 . for √ s NN = 27 GeV, after which the magnitude remains constant. The energy dependence of v 3 in midcentral collisions qualitatively resembles the hydrodynamically produced v 2 in Figure 2b; the viscous medium described by transport smears the anisotropies in the initial energy density profile instead of converting them into momentum anisotropy, and is thus unable to compensate for the lack of ideal fluid described by hydrodynamics. This makes v 3 the clearer signal of the presence of low-viscous medium.
## IV. CONCLUSIONS
Contrary to the earlier fluid calculations, we have found no difference between an equation of state with a first order phase transition and one with a cross-over phase transition for the midrapidity slope of the directed flow v 1 , when utilizing the full hybrid model with an iso-energy density switching criterion between hydrodynamics and final transport. Thus
dv /dy 1 cannot currently be considered as a good signal for the existence of a first-order phase transition. However, there is currently a notable discrepancy between the model results and the experimental data which necessitates further investigation.
We have demonstrated that a hybrid transport + hydrodynamics approach can qualitatively reproduce the experimentally observed behavior of v 2 as a function of collision energy √ s NN . While the v 2 production by hydrodynamics is diminished at lower collision energies, this is partially compensated by the pre-equilibrium transport dynamics. Same does not apply to triangular flow v 3 , which decreases considerably faster, reaching zero in midcentral collisions at √ s NN = 5 GeV. Thus v 3 is the better signal for the formation of quark-gluon plasma in heavy ion collisions.
## V. ACKNOWLEDGEMENTS
This work was supported by GSI and the Hessian initiative for excellence (LOEWE) through the Helmholtz International Center for FAIR (HIC for FAIR). H.P. and J.A. acknowledge funding by the Helmholtz Association and GSI through the Helmholtz Young Investigator Grant No. VH-NG-822. The computational resources were provided by the LOEWE Frankfurt Center for Scientific Computing (LOEWE-CSC).
- [1] D. H. Rischke, Y. P¨ urs¨n, u J. A. Maruhn, H. St¨ ocker and W. Greiner, Heavy Ion Phys. 1 (1995) 309.
- [2] L. P. Csernai and D. R¨hrich, Phys. Lett. B 458 (1999) 454. o
- [3] J. Brachmann et al. , Phys. Rev. C 61 (2000) 024909.
- [4] H. St¨cker, Nucl. Phys. A 750 (2005) 121. o
- [5] L. Adamczyk et al. [STAR Collaboration], arXiv:1401.3043 [nucl-ex].
- [6] L. Adamczyk et al. [STAR Collaboration], Phys. Rev. C 86 (2012) 054908.
- [7] Y. Pandit [STAR Collaboration] Talk at Quark Matter 2012.
- [8] H. Petersen, J. Steinheimer, G. Burau, M. Bleicher and H. St¨cker, Phys. Rev. C 78 (2008) o 044901.
- [9] S. A. Bass, M. Belkacem, M. Bleicher, M. Brandstetter, L. Bravina, C. Ernst, L. Gerland and
- M. Hofmann et al. , Prog. Part. Nucl. Phys. 41 (1998) 255.
- [10] M. Bleicher, E. Zabrodin, C. Spieles, S. A. Bass, C. Ernst, S. Soff, L. Bravina and M. Belkacem et al. , J. Phys. G 25 (1999) 1859.
- [11] D. H. Rischke, S. Bernard and J. A. Maruhn, Nucl. Phys. A 595 (1995) 346.
- [12] D. H. Rischke, Y. Pursun and J. A. Maruhn, Nucl. Phys. A 595 (1995) 383 [Erratum Nucl. Phys. A 596 (1996) 717].
- [13] J. Steinheimer, S. Schramm and H. St¨cker, Phys. Rev. C 84 (2011) 045208. o
- [14] P. Huovinen and H. Petersen, Eur. Phys. J. A 48 (2012) 171.
- [15] C. Alt et al. [NA49 Collaboration], Phys. Rev. C 68 (2003) 034903.
- [16] H. Liu et al. [E895 Collaboration], Phys. Rev. Lett. 84 (2000) 5488.
- [17] J. Steinheimer, J. Auvinen, H. Petersen, M. Bleicher and H. St¨cker, Phys. Rev. C 89 (2014) o 054913.
- [18] A. M. Poskanzer and S. A. Voloshin, Phys. Rev. C 58 (1998) 1671.
- [19] J. Y. Ollitrault, Preprint nucl-ex/9711003 (1997).
- [20] J. Adams et al. [STAR Collaboration], Phys. Rev. C 72 (2005) 014904.
- [21] J. Auvinen and H. Petersen, Phys. Rev. C 88 (2013) 064908.
- [22] J. Auvinen and H. Petersen, PoS CPOD 2013 (2013) 034.
- [23] I. .A. Karpenko, M. Bleicher, P. Huovinen and H. Petersen, J. Phys. Conf. Ser. 503 (2014) 012040. | 10.1016/j.nuclphysa.2014.09.056 | [
"Jussi Auvinen",
"Jan Steinheimer",
"Hannah Petersen"
] | 2014-08-01T08:01:34+00:00 | 2014-08-01T08:01:34+00:00 | [
"nucl-th",
"nucl-ex"
] | What the collective flow excitation function can tell about the quark-gluon plasma | Recent STAR data from the RHIC beam energy scan (BES) show that the
midrapidity slope dv1/dy of the directed flow v1 of net-protons changes sign
twice within the collision energy range 7.7 - 39 GeV. To investigate this
phenomenon, we study the collision energy dependence of v1 utilizing a
Boltzmann + hydrodynamics hybrid model. Calculations with dynamically evolved
initial and final state show no qualitative difference between an equation of
state with a cross-over and one with a first-order phase transition, in
contrast to earlier pure fluid predictions. Furthermore, our analysis of the
elliptic flow v2 shows that pre-equilibrium transport dynamics are partially
compensating for the diminished elliptic flow production in the hydrodynamical
phase at lower energies, which leads to a qualitative agreement with STAR BES
results in midcentral collisions. No compensation from transport is found in
our model for integrated v3, which decreases from approx 0.02 at sqrt(sNN) = 27
GeV to approx 0.005 at sqrt(sNN) = 7.7 GeV in midcentral collisions. |
1408.0099v1 | ## Chemical bond and entanglement of electrons in the hydrogen molecule
Nikos Iliopoulos 1 and Andreas F. Terzis 1, ∗
1 Department of Physics, School of Natural Sciences, University of Patras, Patras 265 04, Greece (Dated: August 4, 2014)
We theoretically investigate the quantum correlations (in terms of concurrence of indistinguishable electrons) in a prototype molecular system (hydrogen molecule). With the assistance of the standard approximations of the linear combination of atomic orbitals and the configuration interaction methods we describe the electronic wavefunction of the ground state of the H 2 molecule. Moreover, we managed to find a rather simple analytic expression for the concurrence (the most used measure of quantum entanglement) of the two electrons when the molecule is in its lowest energy. We have found that concurrence does not really show any relation to the construction of the chemical bond.
PACS numbers: 03.67.-a,05.30.-d,75.10.Pq
## I. INTRODUCTION
During the last two decades a lot of work has been done in the relatively new scientific field of quantum information and quantum computation [1]. In this new field of physics it became soon apparent that one of the most, if not the most, important physical quantity -a measure of quantum correlationsis the quantum entanglement [1, 2]. Historically, entanglement is the first type among quantum correlations which studied intensively demonstrating the difference between classical and quantum mechanics. Dated back to the Schr¨dinger era, o introduced by him to describe the correlations between two particles that interact and then separate, as in the EPR expertiment. Actually, nowadays exist many measures of quantum entanglement. Entanglement of formation (EoF) or its computationally equivalent, concurrence (Con), is the most widespread among them [3]. It is widely accepted that EoF is a very reasonable and decent measure of quantum entanglement having the advantage that, in most cases, it can be computed easily. However, it became soon apparent that there are other quantum correlations which cannot be included in entanglement. Quantum discord [4, 5] is the most well-studied measure for the total quantum correlations. Quantum discord takes into account all possible sources of quantum correlations but its computation, requiring optimaztion procedures, is much more complicated and time consuming compared to the corresponding computation of the Con.
All previously mentioned measures are well-studied for distinguishable particles. However, they are not so widely used in indistinguishable particles. Especially for fermions (indistinguishable particles, having half-integer spin) obeying the Pauli exclusion principle, there are many difficulties in order to implement the measures used for distinguishable particles. Schliemann et al. [6, 7] have, recently, presented a corresponding measure of Con of fermionin pure states, taking into account the con-
∗ [email protected]
straints due to the Pauli exclusion principle.
In the present study we investigate the simplest (prototype) realistic two- electrons molecular system, the hydrogen molecule which has been extensively studied [8] for almost a century. Due to the well known principle of minimum energy the chemical bond is traditionally described and specified in energy terms. Hence, we concentrate in the study of the ground state of the molecular system which is the most stable state, especially in the low temperature case where the thermal energy is not enough to excite the molecule. More specifically, in the present article, we investigate the possibility of any relationship between quantum correlations and the chemical bond.
This paper is organized as follows: In section II we present the basic theory of indistinguishable particles and we highlight the differences between indistinguishable and distinguishable ones. In the same section, we find an analytical expression for the Con of any two electrons being in a pure quantum state. In section III we apply this formula to the hydrogen molecule being in its ground state. Also, we apply the configuration interaction (CI) method in order to properly describe the ground state of the hydrogen molecule. In the same section we present and analyze our results. Finally, we summarize and conclude in section IV.
## II. THEORY
To begin with, we report some basic properties of indinguishable particles, which are necessary in order to develop the quantum correlation identifiers. A general pure state of two fermions is given by the equation [6, 7]
$$| w \rangle = \sum _ { i, j = 1 } ^ { n } w _ { i j } f _ { i } ^ { \dagger } f _ { j } ^ { \dagger } | 0 \rangle, \text{ \quad \ \ } ( 1 )$$
f † i , f † j are the single particle creation operators for two corresponding subsystems acting on the vacuum state and n is the dimensionality of the single-particle (oneelectron) Hilbert space. Also, w is an antisymmetric coefficient complex square matrix ( n × n ), with w ij = -w ji .
The antisymmetric matrix fullfils the normalization condition
$$T r ( w ^ { * } w ) = - 1 / 2 \quad \quad ( 2 ) \quad \stackrel { \overline { k = } } { \text{given} }$$
According to Ref. [6] an equivalent to Schmidt decomposition [2] can be constructed in the case of fermions. Under a unitary transformation of f i = ∑ j U ij f ′ j , we take new fermionic operators as well as new coefficient matrix w ′ . So, the pure fermionic state of Eq. (1) takes the form
$$| w \rangle = \sum _ { i, j = 1 } ^ { n } w _ { i j } ^ { \prime } f _ { i } ^ { \prime \dagger } f _ { j } ^ { \prime \dagger } | 0 \rangle \quad \quad ( 3 ) \quad \ m e _ { \ z e r \choose \dots }$$
where w ′ ij = ( U wU † ∗ ) ij . This new matrix have a block diagonal form [9], containing 2 × 2 blocks of the type
$$\begin{matrix} \left [ \begin{array} { c c c c c } 0 & z _ { k } \\ - z _ { k } & 0 \end{array} \right ] & \quad & \quad ( 4 ) & \quad \text{th} \\. &. &. &. &. &. &. & B \end{matrix}$$
Each block has eigevalue z k . As a result the state of Eq. (1) takes the diagonal form
$$| w \rangle = 2 \sum _ { k = 1 } ^ { \leq \frac { n } { 2 } } z _ { k } f ^ { \prime \dagger } _ { \ 2 k - 1 } f ^ { \prime \dagger } _ { \ 2 k } | 0 \rangle & & ( 5 ) \quad \text{ is } \text{$i$} \\ & \text{bec} \\ & \text{me} ;$$
This is the equivallent of Schmidt decomposition in indistinguishable particles [2]. Instead, now we have a sum of 2 × 2 blocks (Slater determinants) instead of sum of product states. We know in the case of distinguishable particles that if the Schmidt number is one then our state is a product state. Respectively, in order to have pure state in indistinguishable particles the Slater number, the equivalent of Schmidt number in this case, should be one too, i.e. our state of eq. (5) must contain only one Slater determinant. Otherwise it is an entangled state.
Next, we give the definition of the entropy and the Con for the case of indistinguishable particles.
According to Schliemann et al. [9], Con( C ) for such a pure state of eq. (1) with n = 4 is given by the equation
$$C ( | w \rangle ) = 8 | w _ { 1 2 } w _ { 3 4 } + w _ { 1 3 } w _ { 4 2 } + w _ { 1 4 } w _ { 2 3 } |, \quad ( 6 ) \quad \underset { \quad \dim } { \text{$\quad \colon$} }$$
w ij are elements of the antisymmetric matrix w . As in the case of distinguishable particles, Con takes values from zero to one. If Con is zero then the fermionic state has no entanglement and it has fermionic slater rank one and could be represented by only one Slater determinant.
Now, in order to find an equation for the entropy of each subsystem we have to trace out the other. Due to the fact that fermions are indistinguishable particles the two parties have the same entropy. Also, the two fermion density matrix is given by ρ F = | w 〉〈 w | . According to R. Paskauskas and L. You [10] the single particle density matrix is
$$\rho _ { \nu \mu } ^ { f } = \frac { T r ( \rho _ { F } f _ { \mu } ^ { \dagger } f _ { \nu } ) } { T r ( \rho _ { F } \sum _ { \mu } f _ { \mu } ^ { \dagger } f _ { \mu } ) } = 2 ( \omega ^ { \dagger } \omega ) _ { \mu \nu } \quad \ \ ( 7 ) \quad \ \ r e p c \\ | B \rangle |$$
Now, the normalization condition takes the form ≤ n ∑ k =1 | z k | 2 = 1 4. / Finally, the von Neumann entropy is given by the equation
$$\underset { \text{we} \\ \text{ent} }$$
This single particle entropy ranges from unit to log( n E ) and n E is the largest even number not larger than n.
Both Con and entropy are measures of the entanglement of our system. However, concurrence ranges from zero to unit, as in the case of separable particles, but entropy takes values 1 ≤ S f ≤ 2 in contrast to the case of indistinguishable particles which ranges from zero to unity. This may have a simple interpetation. First of all, the von Neumann entropy is the measure of uncertainty that we have before performing a measurement. For example, if we have two separable particles which are in a Bell state, e.g. 1 √ 2 ( 0 | 〉 A ⊗ | 0 〉 B + 1 | 〉 A ⊗ | 1 〉 B ), and we want to find the state of particle A then the von Neumann entropy is unit as the uncertainty about its state is maximum. In the case of indistinguishable particles, we cannot separate them, thus there is extra uncertainty because we do not know to which particle we perform the measurement. Nevertheless, this uncertainty does not affect the range of concurrence.
From another point of view, the entanglement in the case of sepable particles is due to spatial coordinates or spin. For instance, the states | 0 〉 and | 1 〉 above could represent the possible states of spin (e.g. | 0 〉 = | ↓〉 and | 1 〉 = | ↑〉 ) or any other spatial separation. However, in order to have Con or entropy different than zero and one respectively, in the case of indistinguishable particles, the two particles should be entangled for spin and spatial coordinates. A fine example is given by Eckert et al. [7].
In the hydrogen molecule there are two nuclei (protons) as well as two electrons occupying the region outside the protons. As a result each electron could be in nucleus A or B and has spin | ↑〉 or | ↓〉 . Consequently, in our case the single-particle (one- electron) Hilbert space is fourdimensional and this resulting in a six-dimensional twoparticle (two- electrons) Hilbert space. For this reason, from now on, we will deal with the pure state of eq. (1) for n = 4.
## III. ENTANGLEMENT IN HYDROGEN MOLECULE
Now, we turn our attention to the hydrogen molecule. As we said above, we have two electrons which wander around the two nucleus, A and B. Each electron could have spin +1/2 ( | ↑〉 ) or -1/2 ( | ↓〉 ). As a result the single-particle Hilbert space is four dimensional as it was reported above ( | A 〉| ↑〉 = 1 , | 〉 | A 〉| ↓〉 = 2 , | 〉 | B 〉| ↑〉 = 3 , | 〉 | B 〉| ↓〉 = 4 ). | 〉
The Hamiltonian of our system is given by the equation (see for example, the classic book by P. Atkins and R. Friedman [8])
$$H = H _ { 1 } + H _ { 2 } + \frac { e ^ { 2 } } { 4 \pi \epsilon _ { 0 } R } + \frac { e ^ { 2 } } { 4 \pi \epsilon _ { 0 } r _ { 1 2 } } \quad \ \ ( 9 ) \quad \stackrel { \text{aver} } { \text{the} } ^ { ( 1 0 t ) }$$
and H i = -/planckover2pi1 2 2 m e ∇ -i e 2 4 π/epsilon1 0 r iA -e 2 4 π/epsilon1 0 r iB , with i = 1 2. ,
Here, R is the distance between the nuclei and r 12 the distance between the electrons. In addition, the two final terms represent the repulsive interaction between the nuclei and electrons respectively.
As electrons are fermions, their wavefunction must be antisymmetric in order to obey in the Pauli exclusion principle. With the assistance of the linear combination of atomic orbitals (LCAO) method [8] we conclude that the only possible wavefunctions of electrons are
$$\Psi _ { 1 } & = \psi _ { + } \psi _ { + } \sigma _ { - } ( 1, 2 ) \\ \tilde { \pi } \quad - \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \, \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \dots$$
$$\Psi _ { 2 } = \psi _ { - } \psi _ { - } \sigma _ { - } ( 1, 2 ) \quad \quad ( 1 0 b ) \quad \text{with}$$
ψ + = c + ( φ A + φ B ), ψ -= c -( φ A -φ B ) and σ (1 2) , = 1 √ 2 ( | ↑〉 1 | ↓〉 -| ↓〉 | ↑〉 2 1 2 ). Here, φ A and φ B are the atomic orbitals of the hydrogen atom on ground state and c ± are normaliztion factors which are c ± = 1 √ 2(1 ± S ) , where S is the overlap integral (see the appendix).
FIG. 1. Plots of the average energy of the H 2 molecule (actually the energy difference of the H molecule minus the energy of two separated H atom) in Hartree units (i.e. devided by the constant hcR H ) as a function of the internuclear distance ( s = R/α 0 , where α 0 is the Bohr radius). The solid curve corresponds to the energy (eq.(11)) of the molecule which is computed for a pure state described by eq.(10a). The dasheddotted curve is the energy estimated for pure state described by the linear combination (CI method) of eq.(12)
Using the wavefunction, Ψ , of equation (10a) the hy1 drogen molecule has an average energy given by the expression
$$E _ { 1 } = 2 E _ { 1 s } + \frac { j _ { 0 } } { R } - \frac { 2 j ^ { \prime } + 2 k ^ { \prime } } { 1 + S } + \frac { j + 2 k + m + 4 l } { 2 ( 1 + S ) ^ { 2 } } \quad ( 1 1 )$$
where E 1 s is the energy of the H atom in the ground state Its plot as a function of the distance between the two nucleus is shows in Fig.(1) (solid curve). Then, if we find the average energy of the wavefunction given by the equation (10b), we find that these is not an absolute minimum, and the energy is a decreasing function of the distance between the two protons and finally taking a plateau value equal to the plateau value of the energy of wavefunction of equation (10a). For all distances the average energy of the Ψ 2 state is larger than the energy of the wavefunction of equation (10a). However, we can achieve a lower average energy for the hydrogen molecule by describing the molecule by a wavefunction which is a linear combination of the two previously mentioned wavefunctions. This is the well known configuration interaction (CI) method [8]. Hence, in the CI method the wavefunctions is described by the following expression
$$\Psi = c _ { 1 } \Psi _ { 1 } + c _ { 2 } \Psi _ { 2 } \text{ \quad \quad } ( 1 2 )$$
with | c 1 | 2 + | c 2 | 2 = 1.
At this paragraph we show how in the context of the linear combination state (CI method) we estimate the coefficients c 1 and c 2 in order to achieve the lowest energy for any given internuclear distance R . The expectation value of energy is given by E = | c 1 | 2 H 11 + c 1 c ∗ 2 H 12 + c ∗ 1 c 2 H 21 + | c 2 | 2 H 22 , where H 11 (= E 1 ) is the energy given by eq.(11) and
Using the wavefunction given by equation (12) we can find lower values for the energy of the ground state of the hydrogen molecule. The energy of the H 2 molecule is for all distances lower than the energy of the wavefunction Ψ as it is indicated in Fig. 1 1 (compare the dashed-dotted to the solid curve). Its minimum is at approximately -0 237 Hartree ( . ≈ -6 457 eV) for . R ≈ 1 67 . α 0 .
$$\frac { 1 } { 2 } \quad & H _ { 1 2 } = \frac { m - j } { 2 ( 1 - S ^ { 2 } ) }, \quad & ( 1 3 a ) \\ \frac { \ r r } { m - j } \quad & \rho \circ \, \cdot$$
$$\stackrel { \rightharpoonup } { - 5 } \quad & \stackrel { \theta } { H _ { 2 2 } } = 2 E _ { 1 s } + \frac { j _ { 0 } ^ { ^ { \prime } } } { R } - \frac { 2 j ^ { \prime } - 2 k ^ { \prime } } { 1 + S } + \frac { j + 2 k + m - 4 l } { 2 ( 1 + S ) ^ { 2 } } \ ( 1 3 c )$$
$$\frac { 1 } { 2 \pi } \sum _ { \varepsilon } ^ { i } \sum _ { \varepsilon } ^ { \mu \nu } \sum _ { \varepsilon } ^ { \mu \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \sum _ { \varepsilon } ^ { \nu } \dots$$
where we point out that the H ij are functions of the distance s . Now as | c 1 | 2 + | c 2 | 2 = 1, we can set c 1 = cos ω and c 2 = sin ω , assuming only real coefficients. The minimization procedure is taken by the vanishing of the derivative ∂E/∂ω = 0. Consequently, we take the values of c 1 and c 2 for which the energy is least in every given distance R . More specifically, the coefficients c 1 and c 2 are given by the following equations
$$c _ { 1 } & = \frac { 1 } { 2 } + \frac { 1 } { 2 \sqrt { 1 + ( \frac { 2 H _ { 1 2 } } { H _ { 1 1 } - H _ { 2 2 } } ) ^ { 2 } } } \quad \quad ( 1 4 \mathbf a ) \\ & \quad 1 \quad \ \ \ \ \ \ \$$
$$c _ { 2 } = \frac { 1 } { 2 } - \frac { \mathfrak { v } \quad \cdots \quad \cdots \quad } { 1 } } { 2 \sqrt { 1 + ( \frac { 2 H _ { 1 2 } } { H _ { 1 1 } - H _ { 2 2 } } ) ^ { 2 } } } \quad \quad ( 1 4 b )$$
Figure 2 shows the dependence of the values of the squares of the c i 's as a function of the internuclear distance. Note that the minimization predict negative values for the c 2 .
s
FIG. 2. Plots of the squares of the coefficients c i ( c 2 i ) for i = 1 2 , for which a minimum average energy is achieved as a function of distance s = R/α 0 between the two protons in the H 2 molecule. The upper (lower) curve describes the c 1 ( c 2 ) coefficient.
Now, we turn our attention to the quantum entanglement that the two electrons may have in the ground state. As it was mentioned above, the wavefunction of two fermions is given by the eq. (1). Also the singleparticle space is four-dimensional and more specifically {| 1 〉 , | 2 〉 , | 3 〉 , | 4 〉} . However, in our case we have to set the elements w 13 and w 24 of antisymmetric matrix equal to zero because in the ground state the total spin of electrons must be zero. As a result the antisymmetric coefficient matrix w has the form
$$\begin{bmatrix} 0 & w _ { 1 2 } & 0 & w _ { 1 4 } \\ - w _ { 1 2 } & 0 & w _ { 2 3 } & 0 \\ 0 & - w _ { 2 3 } & 0 & w _ { 3 4 } \\ - w _ { 1 4 } & 0 & - w _ { 3 4 } & 0 \end{bmatrix} \quad ( 1 5 ) \quad \begin{matrix} 0 \\ 0 \\ 0 \end{matrix} \\ \text{all\,\,concurrency} \, \text{on\,on\,on\,from\,\infty} \, \text{for\,the\,the\,for\,from\,} \quad \begin{matrix} 0 \\ 0 \end{matrix}$$
Additionally, concurrence from eq. (6) has the form
$$C ( | w \rangle ) = 8 | w _ { 1 2 } w _ { 3 4 } + w _ { 1 4 } w _ { 2 3 } | \quad \ \ ( 1 6 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
By writing again the wavefunction for the ground state of the hydrogen molecule from eq. (12) we assign the coeffients of each state with the corresponding ones from matrix of eq. (15) and we find that
$$w _ { 1 2 } = w _ { 3 4 } = \frac { c _ { 1 } c _ { + } ^ { 2 } + c _ { 2 } c _ { - } ^ { 2 } } { 2 }, \quad \quad ( 1 7 \mathbf a )$$
$$w _ { 1 4 } = - w _ { 2 3 } = \frac { c _ { 1 } c _ { + } ^ { 2 } + c _ { 2 } c _ { - } ^ { 2 } } { 2 } \quad \quad ( 1 7 b ) \quad \text{(sol)} \quad \text{(sel)}$$
Substituting these values in eq. (16) we take
$$C ( | w \rangle ) = 2 | c _ { 1 } c _ { 2 } | \text{ \quad \ \ } ( 1 8 ) \text{ \quad g l \epsilon }$$
FIG. 3. Concurrence as a function of the coefficient c 1 for the ground state of the hydrogen molecule in the CI method.
Figure 3 shows how Con varies for different values of c 1 . It is obvious that Con takes its maximum value for c 1 = 1 √ 2 . However, from Figs. 1 and 2 we see that energy takes its minimum value for a different value of c 1 . The c 1 = 1 √ 2 corresponds to internuclear distances R > larger than 8 α 0 (i.e rather large distances). This fact is, also, amply demonstrated in Figure 4 as we can see how the energy and Con vary as a function of the internuclear distance. It is evident that Con takes small values for small internuclear distances and becomes bigger as the distance R is rising. Finally, it becomes essentially unit for R > 8 α 0 .The internuclear distance for which the molecule has its minimum energy, i.e. has its most stable form, is R ≈ 1 67 . α 0 . For this distance Con takes the value 0.2378.
s
FIG. 4. This figure shows Con (dashed curve) and energy (solid curve) as a function of the internuclear distance. The energy have been calculated by CI method.
As a result, one may conclude that quantum entanglement is uncorrelated concerning the construction of a
chemical bond.
Furthermore, we know from [9] that the product of elements w 12 w 34 represent the entanglement which arises due to the orbital degrees of freedom and the product w 14 w 23 the corresponding entanglement due to the spin degrees of freedom. It is easily seemed that in our case both kinds of entanglement contribute to concurrence.
To be more specific the fact the Con does not take its maximum value at the most stable state of the hydrogen molecule, most probably means that it is not the proper measure of the quantum correlations. Actually, this is what is now believed by the scientific community. Quantum discord provides all the quantum correlations and not simply the Con [11, 12]. This could be one of the future plans, as for the moment these is no straightforward definition for the quantum discord for indistinguishable particles. Another future project, could be to study the case of finite temperature, where not only the ground state is occupied. In this case we believe a more obvious measure of the quantum correlations will be the entropy (see section II), as we now have a statistical mixtures. Hence, the chemical bond will correspond to maximization of a physical quantity that depend on both the energy and the entropy (i.e. the free energy of the system).
## IV. CONCLUSIONS
In conclusion, we have presented a review of the theory for indistinguishable particles and we have reported two measures of quantum correlations, the concurrence and the von Neumann entropy. Next, taking advantage of this theoretical knowledge we implemented it in the prototype two- electrons hydrogen molecule. With the assistance of two well known approximations in molcecular physics (LCAO and CI methods) we systematically investigated the ground state of the H 2 molecule. As a result, we managed to find a closed form expression which estimates a typical measure of quantum entanglement (concurrence) for the two electrons when the molecule has its lowest energy.
Finally, we expect (mainly by physical intuition) that the ground state of the molecule should be an entangled one. However, we have shown that the concurrence (an extensively used measure of quantum entanglement), is unrelated to the construction of the chemical bond. In this paper we computed the entanglement of the electrons which are in the hydrogen molecule as this is the simplest two- electrons system in the universe and the most well studied as well as we need the minimum number approximations in order to find its ground state wavefunctions. In addition, we believe that the present methodology and systematic theoretical research can be also applied to other much more complicated molecular systems.
[1] M.A. Nielsen and I.L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press,
## APPENDIX
Here we give some extra information concerning the integrals which we used in our computations. Again, we have in all of the following equations that j 0 = e 2 4 π/epsilon1 0 as well as s = R/α 0 , with α 0 the Bohr radius. Additionally, φ α and φ β are the atomic orbitals of each hydrogen atom in the ground state. The required integrals for all computations are:
$$\frac { j ^ { \prime } } { j _ { 0 } } = \int \frac { \phi _ { \alpha } ^ { 2 } ( 1 ) } { r _ { 1 b } } d \tau _ { 1 } = \frac { 1 } { R } [ 1 - ( 1 + s ) e ^ { - 2 s } ] \quad ( 1 9 )$$
$$\frac { k ^ { \prime } } { j _ { 0 } } = \int \frac { \phi _ { \alpha } ( 1 ) \phi _ { \beta } ( 1 ) } { r _ { 1 b } } d \tau _ { 1 } = \frac { 1 } { \alpha _ { 0 } } ( 1 + s ) e ^ { - s } \quad ( 2 0 )$$
$$\underset { \text{tripsize} } { \text{twous} } \underset { \text{ntropy} } { \text{ntropy} } \underset { \text{tures} } { \text{intra-} } \frac { j } { j _ { 0 } } = \int \frac { \phi _ { \alpha } ^ { 2 } ( 1 ) \phi _ { \beta } ^ { 2 } ( 2 ) } { r _ { 1 2 } } d \tau _ { 1 } d \tau _ { 2 } = \frac { 1 } { R } - \frac { 1 } { 2 \alpha _ { 0 } } ( \frac { 2 } { s } + \frac { 1 1 } { 4 } + \frac { 3 } { 2 } s + \frac { 1 } { 3 } s ^ { 2 } ) e ^ { - 2 s } \\ \underset { \text{intra-} } { \text{intra-} }$$
$$\stackrel { \dots } { \text{en} } _ { \text{m} } \quad \frac { k } { j _ { 0 } } = \int \frac { \phi _ { \alpha } ( 1 ) \phi _ { \beta } ( 1 ) \phi _ { \alpha } ( 2 ) \phi _ { \beta } ( 2 ) } { r _ { 1 2 } } d \tau _ { 1 } d \tau _ { 2 } = \frac { A ( s ) - B ( s ) } { 5 \alpha _ { 0 } } \quad \text{(2)}$$
$$\text{the the-} \text{-} \text{or to} \, \quad \frac { l } { j _ { 0 } } = \int \frac { \phi _ { \alpha } ^ { 2 } ( 1 ) \phi _ { \alpha } ( 2 ) \phi _ { \beta } ( 2 ) } { r _ { 1 2 } } d \tau _ { 1 } d \tau _ { 2 } = \frac { 1 } { 2 \alpha _ { 0 } } [ ( 2 s + \frac { 1 } { 4 } + \frac { 5 } { 8 s } ) e ^ { - s } - ( \frac { 1 } { 4 } + \frac { 5 } { 8 s } ) e ^ { - i }$$
$$\frac { m } { j _ { 0 } } = \int \frac { \phi _ { \alpha } ^ { 2 } ( 1 ) \phi _ { \alpha } ^ { 2 } ( 2 ) } { r _ { 1 2 } } d \tau _ { 1 } d \tau _ { 2 } = \frac { 5 } { 8 \alpha _ { 0 } } \quad \ ( 2 4 )$$
with
$$\text{leec} ^ { - } \\ \text{ally} \quad A ( s ) = \frac { 6 } { s } [ ( \gamma + \ln s ) S ^ { 2 } - E _ { 1 } ( 4 s ) S ^ { \prime 2 } + 2 E _ { 1 } ( 2 s ) S S ^ { \prime } ] \ ( 2 5 )$$
$$B ( s ) = [ - \frac { 2 5 } { 8 } + \frac { 2 3 } { 4 } s + 3 s ^ { 2 } + \frac { 1 } { 3 } s ^ { 3 } ] e ^ { - 2 s } \quad ( 2 6 )$$
$$S ( s ) = ( 1 + s + \frac { 1 } { 3 } s ^ { 2 } ) e ^ { - s } \text{ \quad \ \ } ( 2 7 )$$
$$S ^ { \prime } ( s ) = S ( - s ) = ( 1 - s + \frac { 1 } { 3 } s ^ { 2 } ) e ^ { s } \quad \ \ ( 2 8 )$$
Finally γ is Euler's constant and E 1 ( x ) is the well-known exponential integral which is given by the equation
$$E _ { 1 } ( x ) = \int _ { x } ^ { \infty } \frac { e ^ { - z } } { z } d z$$
- [2] J. Audretsch, Entangled Systems: New Directions in Quantum Physics (Wiley-VCH, Weinheim, 2007).
- [3] W.K. Wootters, Phys. Rev. Lett. 80 2245 (1998).
- [4] H. Ollivier and W. H. Zurek, Phys. Rev. Lett. 88 017901 (2001).
- [5] L. Henderson and V. Vedral, J. Phys. A 34 6899 (2001).
- [6] J. Schliemann, J. Ignacio Cirac, M. Kus, M. Lewenstein and D. Loss, Phys. Rev. A 64 022303 (2001).
- [7] K. Eckert, J. Schliemann, D. Bruss and M. Lewenstein, Annals of Physics 299 88-127 (2002).
- [8] Peter Atkins and Ronald Friedman, Molecular Quantum Mechanics (Oxford University Press,Oxford, 2005).
- [9] J. Schliemann, D. Loss and A.H. MacDonald, Phys. Rev. B 63 085311 (2011).
- [10] R. Paskauskas and L. You, Phys. Rev. A 64 042310 (2001).
- [11] C.E. Susa, J.H. Reina and L.L. Sanchez-Soto, J. Phys. B: At. Mol. Opt. Phys. 46, 224022 (2013).
- [12] J. Jurkowski, International Journal of Quantum Information. 11, 1350013 (2013). | null | [
"Nikos Iliopoulos",
"Andreas F. Terzis"
] | 2014-08-01T08:06:39+00:00 | 2014-08-01T08:06:39+00:00 | [
"quant-ph"
] | Chemical bond and entanglement of electrons in the hydrogen molecule | We theoretically investigate the quantum correlations (in terms of
concurrence of indistinguishable electrons) in a prototype molecular system
(hydrogen molecule). With the assistance of the standard approximations of the
linear combination of atomic orbitals and the configuration interaction methods
we describe the electronic wavefunction of the ground state of the H2 molecule.
Moreover, we managed to find a rather simple analytic expression for the
concurrence (the most used measure of quantum entanglement) of the two
electrons when the molecule is in its lowest energy. We have found that
concurrence does not really show any relation to the construction of the
chemical bond. |
1408.0100v3 | ## Hexagonal High-Entropy Alloys
Michael
Feuerbacher * ,
Markus
Heidelmann
and
Carsten
Thomas Peter
Grünberg
Institut
PGI--5,
Forschungszentrum
Jülich
GmbH,
D--52425
Jülich,
Germany
Accepted
for
publication
in
Materials
Research
Letters
1.
August
2014 Submission
Date:
6.
May
2014 DOI:10.1080/21663831.2014.95149
We
report
on
the
discovery
of
a
high--entropy
alloy
with
a
hexagonal
crystal
structure. Equiatomic
samples
in the alloy system
Ho--Dy--Y--Gd--Tb were found to solidify as homogeneous
single--phase
high--entropy
alloys.
The
results
of
our
electron
diffraction investigations and high--resolution scanning transmission electron microscopy are consistent
with a Mg--type hexagonal
structure.
The possibility of hexagonal
high-entropy
alloys
in
other
alloy
systems
is
discussed.
## Keywords: High--Entropy
Alloy,
Structure,
Transmission
Electron
Microscopy
High--entropy
alloys
(HEAs)
constitute
a
novel
field
in
materials
science,
currently attracting
increasing
research
interest.
The
basic
idea,
pioneered
by
Yeh
in
2004,
[1]
is to study
alloys
composed
of
multiple
principal
elements
solidifying
as
metallic
solid solutions
on
a
simple
crystal
lattice.
Usually,
alloys
with
4
to
9,
occasionally
up
to
20 components
[2]
are
considered.
In
a
multicomponent
alloy,
the
total
free
energy
is
largely
determined
by
the
free energy
of
mixing, ∆ 𝐺 !"# = ∆ 𝐻 !"# -𝑇 ∆ 𝑆 !"# , where Δ Hmix is the mixing
enthalpy
and Δ Smix the mixing
entropy.
In
equimolar
or
near
equimolar
compositions,
the
mixing entropy
can
become
dominant,
stabilizing
a
random
solid
solution,
if
the
elements
are chosen such that the mixing enthalpy is neither too high positive (leading to segregation)
nor
too
high
negative
(leading
to
the
formation
of
ordered
structures).
In the
ideal
case
the
resulting
material
is
a
perfectly
disordered
solid
solution
with
a
simple average
crystal
structure.
HEAs
are
thus
related
to
metallic
glasses,
but
in
contrast
to
the latter,
they
are
thermodynamically
stable,
in
particular
at
high
temperatures.
Up
to
now
numerous
alloy
systems
have
been
reported
in
which
HEAs
exist. Without
exception
only
HEAs
with
body--centered
or
face
centered
cubic
structures
have been
found.
In
this
paper,
we
report
on
the
observation
of
a
HEA
with
a
hexagonal crystal
structure.
We
have
prepared
samples
of
equiatomic
composition
in
the
rare earth
(RE)
system
Ho--Dy--Y--Gd--Tb
and
characterized
them
by
means
of
transmission electron
microscopy
(TEM),
scanning
electron
microscopy
(SEM),
energy
dispersive
x-ray
diffraction
(EDX),
and
scanning
transmission
electron
microscopy
(STEM).
* Corresponding
author.
Email:
m.feuerbacher@fz--juelich.de
Figure 1. (a) SEM micrograph
using a backscattered--electron detector and (b) HAADF--STEM
overview
of
a
FIB
sample
of
equiatomic
Ho--Dy--Y--Gd--Tb.
The
material
is perfectly homogeneous;
no features due to composition variation, precipation, dendrite
formation
etc.
can
be
seen.
In
both
micrographs
sample
edges
(dark)
are visible.

We have prepared
ingots
of equiatomic
Ho--Dy--Y--Gd--Tb in a high--frequency levitation
furnace
under
1
bar
Ar
atmosphere
using
3N
high--purity
elements.
Each
ingot was
remelted
four
times
to
ensure
to
achieve
proper
homogenization
of
the
sample. Specimens
for
microstructural
characterization
were
prepared
by
means
of
a
dual--beam FEI
Helios
Nanolab
400S
focused
ion--beam
(FIB)
from
the
centres
of
the
ingots.
TEM was
carried
out
using
a
Philips
CM20
transmission
electron
microscope
operated
at
200 kV,
SEM
work
using
a
JEOL
840
equipped
with
an
EDAX
energy
dispersive
analytical system,
and
STEM
work
using
a
probe
corrected
FEI
Titan
80
-
300
operated
at
300
kV and
equipped
with
a
high--angle
annular
dark--field
(HAADF)
detector.
Fig. 1 (a) displays a scanning
electron micrograph
of the material using a composition--sensitive backscattered--electron detector. Fig. 1(b) displays a STEM micrograph
of
the
thin
part
of
a
typical
FIB
sample
taken
using
a
Z--contrast
sensitive HAADF
detector.
Both
images
demonstrate
that
the
sample
is
perfectly
homogeneous,
in particular
there
are
no
composition
variations,
no
precipitates
or
secondary
phases
and no
dendrites.
We
obtain
these
results
consistently
with
FIB
samples
taken
from
various positions in the ingots. Note also that the cooling rate after levitation melting is sufficiently
slow
to
allow
for
the
formation
of
a
homogeneous
single
phase.
The
average composition
measured
by
EDX
at
eight
different
specimen
positions
is
Ho
19.8
at.%,
Dy 20.0
at.%,
Y
20.4
at.%,
Gd
20.1
at.%,
Tb19.7
at.%.
Within
the
experimental
uncertainty this
corresponds
to
the
nominal
equiatomic
sample
composition,
and
hence
we
conclude that
the
material
solidifies
congruently.
Fig.
2(a)
is
an
electron
diffraction
pattern
taken
at
the
[0
0
0
1]
zone
axis.
The pattern
displays
perfect
hexagonal
symmetry,
a
number
of
reflections
are
indexed.
Figure
2.
Electron
diffraction
patterns
along
different
zone
axes
of
the
hexagonal structure:
(a)
[0
0
0
1]
zone
axis.
(b)
[1
1 2 ! 1] zone
axis:
overlay
of
a
short--time-exposure
displaying zero--order Laue zone reflections and a long--time--exposure (inverted
to
enhance
the
weak
spots)
including
first--order
Laue
zone
reflections.
(c) [1
1 2 ! 0]
zone
axis.
(d)
[4
1 5 ! 0]
zone
axis.
(e)
[1
0 1 ! 0]
zone
axis.
In
order
to
determine
the
space
group
we
follow
a
procedure
described
in
[3]. Fig.
2
(b)
is
an
overlay
of
two
electron
diffraction
patterns
at
the
[1
1 2 1]
zone
axis,
a short--time--exposure to display zero--order Laue zone reflections and a long--time-exposure (inverted to enhance the weak spots) including first--order Laue zone reflections.
The
whole
pattern
has
an m symmetry,
which
corresponds
to
the
point group
6/ mmm in
a
hexagonal
system.
Figs.
2
(c)
to
(e)
show
diffraction
patterns
at
the
[1 1 2 0],
[4
1 5 0],
and
[1
0 1 0]
zone
axes,
respectively,
which
are
all
perpendicular
to
[0
0 0
1].
Figure
3.
Arrangement
of
zone
axes
and
corresponding
electron
diffraction
patterns, indexed
according
to
a
hexagonal
Mg--type
structure.
The
lines
correspond
to
Kikuchi lines
as
seen
in
the
TEM.
Only
half
of
the
patterns
surrounding
[0
0
0
1]
are
shown.
The indicated
angle
between
[ 1 2 1 3 ]
and
[ 1 2 1 6 ]
is
not
to
scale
as
indicated
by
the
broken lines.
The
(0
0
0
1)
reflection
is
visible
at
the
[1
1 2 0]
zone
axis
but
diminishes
when
tilting
to [4
1 5 0] and
essentially
vanishes
when
tilting
further
to
[1
0 1 0]. This
indicates
the presence
of
a
6 3 screw
axis
parallel
to
[0
0
0
1].
In
the
[1
1 2 0]
pattern
the
(1 1 0 1) reflections
are
present,
which
rules
out
the
P6 3/ mcm case
[4].
Consequently
the
space group
must
be
P63/ mmc .
Under
stern
scrutiny,
an
extremely
weak
residual
intensity
of
| Zone | Angle
to
[0
0
0
1]
exp./deg | Angle
to
[0
0
0
1]
calc./deg | R hkil
ratio
exp. | Inverse
d hkil ratio
calc. |
|-------------|-------|-------|---------|-------|
| 1 !
1
0
4 | 15.24 | 15.36 | 1.192 a | 1.198 |
| 1 !
2
1 !
6 | 16.90 | 17.60 | 1.853 b | 1.817 |
| 1 ! 2 1 ! 3 | 32.00 | 32.39 | 1.151 c | 1.141 |
| 1 ! 2 1 ! 3 | ' | ' | 1.000 d | 1 |
Table 1: Comparison between experiment and calculations on the basis of a hexagonal
Mg--type
structure
with
lattice
parameters
a
=
361
pm
and
c
=
569
pm. First
and
second
row:
tilting
angle
of
zone
with
respect
to
[0
0
0
1].
Third
row:
ratio of R hkil values of reflections spanning the diffraction patterns. Fourth row: corresponding
inverse d hkil ratios. a
2 2 ! 0
1
and
1
1 2 ! 0 reflections; b 1 ! 2 1 ! 1 ! and
1
0 1 ! 0 reflections; c 0
1 1 ! 1 ! and
1
0 1 ! 0
reflections; d
0
1 1 ! 1 ! and
1 1 ! 0
1
reflections.
the
(0
0
0
1)
reflection
in
the
[1
0 1 0]
zone
can
be
seen.
This
may
be
due
to
a
minor deviation
from
perfect
disorder
and
is
neglected
in
our
analysis.
We
have
carried
out
tilting
diffraction
experiments
on
a
single
grain
to
determine the
symmetry
and
angular
distance
of
zone
axes
around
[0
0
0
1].
The
results
are summarized
in Fig. 3, which displays the zone axes relevant for structure type determination
within
reach
of
the
double--tilt
goniometer
stage.
The
[0
0
0
1]
zone
is surrounded
by
six
< 1 1
0
4>
and
six
< 1 2 1 6>
zone
axes
(only
half
of
which
are
shown).
The
[ 1 1 0 4] zone
is
tilted
by
15.24°
with
respect
to
[0
0
0
1]
and
shows
a rectangular
pattern
that
is
repeated
by
five
further
zone
axes
rotated
by
60°
around
[0
0 0
1].
The
[ 1 2 1 6]
zone
is
tilted
by
17.60°
with
respect
to
[0
0
0
1]
and
shows
a
pattern with
a
different
aspect
ratio
of
the
two
reflections
spanning
the
rectangular
pattern.
Five further
equivalent
zone
axes
are
arranged
around
[0
0
0
1]
rotated
by
angles
of
60°.
The dark
lines
represent
the
Kikuchi
lines
as
seen
in
the
TEM.
The
arrangement
of
the
zone axes
as
well
as
the
Kikuchi
lines
perfectly
reproduces
the
hexagonal
structure.
A
further zone
axis
displaying
an
almost
hexagonal
pattern,
[ 1 2 1 3 ],
which
is
tilted
by
32°
with respect
to
[0
0
0
1]
was
recorded.
Note
that
some
of
the
diffraction
patterns
contain
very weak
additional
reflections,
the
origin
of
which
is
not
clear.
They
may
be
due
to
double diffraction,
minor
deviations
from
perfect
disorder,
or
electron
diffraction
taking
place in
neighboured
grains.
These
reflections
were
not
taken
into
account
in
our
analyses.
All
zone
axes,
Kikuchi
lines
and
reflections
can
consistently
be
indexed
on
the basis
of
a
hexagonal
structure.
We
compared
calculated
and
experimental
tilting
angles of
different
zone
axes
as
well
as
distances
of
reflections
from
the
direct
beam R hkil . For the
latter,
we
compared
the
ratio
of R hkil values
of
reflections
spanning
a
diffraction pattern
to
the
corresponding
calculated d hkil ratio.
Due
to
the
relationship R hkil d hkil = const,
where
the
imprecisely
known
constant
is
given
by
the
electron
wavelength
and the
camera
length
of
the
microscope,
these
ratios
should
inversely
correspond.
Good agreement
could
be
achieved
using
the
lattice
parameters
a
=
361
pm
and
c
=
569
pm. These
lattice
parameters
correspond
to
the
weighted
average
of
the
parameters
of
the
Figure 4. HAADF--STEM micrographs of equiatomic Ho--Dy--Y--Gd--Tb with insets displaying
the
corresponding
FFTs.
(a)
along
the
[0
0
0
1]
direction.
(b)
along
the
[1
1 2 ! 0]
direction.

constituting
elements.
A
comparison
of
the
experimental
and
calculated
quantities
using these
parameters
is
presented
in
Table
1.
Fig. 4 shows
STEM
micrographs,
which
were
slightly FFT--filtered for high-frequency
noise
reduction.
Fig
4(a)
was
taken
along
the
[0
0
0
1]
direction
and
in consistency
with a Mg--type structure displays a pattern of interconnected
hollow hexagons.
The
inset
is
a
FFT
of
the
image
also
reflecting
the
hexagonal
structure.
Fig. 4(b)
was
taken
along
[1
1 2 0]
and
the
FFT
in
the
inset
corresponds
to
the
diffraction pattern
in Fig. 2(c). The image
is also in consistency
with
a
Mg--type
structure.
In particular,
the atomic
arrangement
along
this
direction
excludes
a
P63/ mcm space group,
which
would
lead
to
a
pattern
of
paired
atomic
rows
parallel
to
the
[0
0
0
1] direction.
This
significantly
differs
from
the
almost
hexagonal
pattern
expected
for
the P63/ mmc space group, which
directly corresponds
to
the experimentally
observed HAADF--STEM
image.
This
observation
is
consistent
with
our
electron
diffraction
results. Both
images,
which
were
taken
with
a
Z--contrast
sensitive
HAADF
detector,
show
that also
on
this
small
scale
the
material
is
perfectly
homogeneous.
There
is
no
indication
of precipitation
or
ordering.
The
lattice
parameters
directly
measured
from
the
image
amount
to
a
=
(363
± 30)
pm
and
c
=
(566
±
20)
pm,
which
is
in
agreement
with
the
weighted
average
of
the parameters
of
the constituting
elements.
It
was
observed
earlier
that the a--lattice constant
in
cubic
HEAs
follows
a
rule
of
mixtures.[5]
Our
results
indicate
that
a
rule
of mixtures
also
applies
to
the
c--lattice
parameter
and
the
c/a
ratio.
Our electron diffraction and STEM results are consistent with a Mg--type hexagonal
structure.
That
is,
the
unit
cell
has
space
group
P63/mmc
(No.
194)
and
two
atoms
per
unit
cell,
on
the
(1/3,
2/3,
1/4)
position
and
its
symmetric
equivalent.
The structure
of
the
HEA
is
identical
to
the
structures
of
the
constituting
elements,
which
are also
of
Mg--type.
Criteria
for
the
formation
of
HEAs
are
commonly
discussed
in
terms
of
radius differences
and
a
parameter Ω referring
to
the
thermodynamic
properties
of
the
alloy [6].
The
radius
difference 𝛿𝑟 = 𝑐 ! ( 1 -𝑟 ! 𝑟 ) ! ! , where r i are
the
element
radii, c i the mole
percentages,
and 𝑟 is
the
weighted
average
radius,
should
be
as
small
as
possible.
A value
below
about
6.5
%
for
HEAs
in
general
and
below
3.8
%
for
single--phase
HEAs
[7] is required. In our case δ r = 0.77 %. The thermodynamic parameter Ω = 𝑇 ! Δ 𝑆 !"# Δ 𝐻 !"# , where Tm is the weighted average melting temperature, Δ 𝑆 !"# the mixing
entropy,
and Δ 𝐻 !"# = 𝑐 ! 𝑐 ! 𝐻 !" ! , ! , ! ! ! ,[6] should
exceed
1.1 (which means
that
the
entropy
contribution
to
the
free
energy
should
dominate
the
enthalpy).
Since
the
alloy
investigated
is
equiatomic, Δ 𝑆 !"# reaches
the
maximum
value
1.61 R,[1]
where
R=
8.314
J
K -1
mol -1
is
the
gas
constant. Δ 𝐻 !"# calculated
using
values
from the
tables
provided
by
Takeuchi
and
Inoue
[8]
amounts
to
0
kJ
mol -1 .
For
Ho--Dy--Y--Gd-Tb not only the sum of the mutual
mixing
enthalpies
is
zero but each individual component Hij = 0 kJ mol -1 for all i and j . The
alloy
thus
fulfills
an even
stronger formation
criterion.
Formally,
taking
the
calculated
values
for Δ 𝐻 !"# [8] into
account, the
parameter Ω in
our
case
diverges.
Further
criteria
supporting
HEA
formation
are
equal
crystal
structures,
a
high mutual
solubility
in
the
binary
phase
diagrams
of
all
constituting
elements,
and,
from
a practical
point
of
view,
close
melting
points.
All
formation
criteria
are
ideally
fulfilled
for the
system
investigated.
Note
that
the
same
is
true
for
numerous
further
RE
elements.
Similarly
positive conditions
are
present
for
La,
Er,
Tm,
Lu,
Pr,
Pm
and
Nd.
If
we
exclude
Pm
due
to
its radioactivity,
in
total
we
are
left
with
11
practically
useable
elements
for
which
we expect the formation of hexagonal HEAs. Hence HEAs with higher numbers of components
up
to
11
and
numerous
combinations
should
be
possible.
The
number
of possible
equiatomic
five--element
HEAs
is
462,
and
altogether
1486
different
HEAs
with five
to
11
different
elements
can
be
combined.
The
elements
Ho,
Dy,
Y,
Gd,
and
Tb
used for
the
alloy
investigated
in
this
work,
which
can
be
considered
a
feasibility
study,
were chosen
more
or
less
arbitrarily
from
the
potential
candidates
due
to
their
immediate availability
in
our
stock.
We
should
point
out
that
some
of
the
elements
used
undergo
a high--temperature
transition
from
hexagonal
to
cubic
structure
at
95
%
(Gd
and
Tb)
and 98
%
(Dy
and
Y)
of
their
melting
point.
The
exclusive
use
of
elements
that
have
a hexagonal
structure
up
to
their
melting
point
may
lead
to
a
larger
grained
structure. This
however
would
limit
the
system
to
the
four
elements
Er--Tm--Lu--Ho.
The
list
can
probably
be
further
extended
by
taking
into
account
elements
that have
a
different
crystal
structure
but
also
similar
radii
and
low
mixing
enthalpies
with the elements
mentioned
above.
Ce,
for
example,
shows
high
solubility
with
all
RE elements
(with
the presence
of a miscibility
gap, however)
and
mixing
enthalpies
between
0
and
1
kJ/mol.
The
same
seems
to
hold
for
Sm,
as
far
as
phase
diagrams
are available.
We
have
chosen
an
equiatomic
alloy
composition
for
the
present
work
but
we expect
that due to the similarity
of the constituting
elements
and
hence
generous compliance
of
the
formation
criteria,
the
existence
ranges
of
the
HEAs
are
very
wide. The
production
of
single--phase
ingots
with
different
compositions
should
therefore
also be possible. This expected tolerance to composition variation may open up the possibility
to form single--phase
HEAs
using Mischmetall,
which
is a more
or less undefined alloy of RE elements in various naturally occurring proportions. Since Mischmetall
is
considerably
cheaper
than
high--purity
single
RE
elements,
this
would eliminate
the
economical
disadvantage
of
the
RE--systems
under
consideration.
The hexagonal HEAs presented may offer a unique chance to study the magnetism
of RE--systems. Mainly related to their 4f electron configurations, RE-elements possess highly complex magnetic behavior displaying a wide variety of properties
[9].
The
systems
presented
are
unique
in
the
sense
that
they
are
topologically ordered
but
possess
random
bonds.
In
the
present
HEA
systems
the
included
elements and
the
composition
can
most
freely
be
varied
at
constant
structure,
which
may
allow for
insightful
comparative
measurements.
Furthermore,
hexagonal
HEAs
including
Tm, Yb,
and
Ce
may
provide
a
way
to
study
heavy--fermion
behavior
in
a
disordered
system.
The
hexagonal
high--entropy
systems
also
include
the
possibility
to
incorporate intentional second phases, i.e. for the increase of strength, high--temperature applicability,
etc.
Potential
candidates
are
Yb,
Eu,
Zr,
and
Hf,
which
have
a
high
melting temperature
and
a
high
positive
mixing
enthalpy
with
the
RE
elements
considered.
The mixing
enthalpies
with
these
elements
are
between
6
and
18
kJ
mol --1 ,
which
will
lead
to segregation.
We should also point out that recently Gao and Alman
[10] predicted
the existence
of
a
hexagonal
HEA
in
the
system
Co--Os--Re--Ru.
In
this
system
the
formation criteria
are
indeed
well
fulfilled
and
all
constituting
elements
are
mutually
soluble.
The drawback
of
this
system
is
that
Os
reacts
with
oxygen
at
room
temperature
forming
the highly
toxic
osmium
tetroxide.
Furthermore
for
the
elements
proposed,
the
melting points are strongly different (1768 K (Co) vs. 3459 K (Re)) making the growth procedure
practically
difficult.
Further
candidates
along
these
lines
are
Co--Re--Ru--Tc
or the
five--element
system
Co--Re--Ru--Tc--Os,
both
of
which
involve
the
radioactive
element Tc.
In conclusion,
in this paper
we report
on the observation
of
a HEA
in the HoDyYGdTb
alloy
system.
Our
samples
are
homogeneous
and
single
phased,
and
of hexagonal
Mg--type
structure.
Acknowledgments The authors thank Ms D. Meertens for focused ion--beam preparation
of
the
TEM
samples,
and
W.
Steurer,
J.
Dolinsek,
and
M.
Heggen
for
inspiring discussions.
## References
- [1] Yeh JW, Chen SK, Lin SJ, Gan JY, Chin TS, Shun TT, Tsau CH, Chang SY. Nanostructured
high--entropy
alloys
with
multiple
principal
elements:
novel
alloy
design concepts
and
outcomes.
Adv.
Eng.
Mater.
2004;6:299
-
303.
- [2] Cantor B, Chang ITH, Knight P, Vincent AJB. Microstructural development
in equiatomic
multicomponent
alloys.
Mat.
Sci.
Engng
A
2004;375--377:213
--
218.
- [3] Wei
Q, Wanderka,
N,
Schubert--Bischoff
P,
Macht
MP,
Friedrich
S.
Crystallization phases
of
the
Zr41Ti14Cu12.5Ni10Be22.5
alloy
after
slow
solidification.
J.
Mater.
Res. 2000;15:1729--1734.
- [4]
Morniroli
JP,
Steeds
JW.
Microdiffraction
as
a
tool
for
crystal
structure
identification and
determination.
Ultramic.
1992;45:219--239.
- [5] Senkov
ON,
Scott
JM, Senkova
SV,
Miracle
DB,
Woodward
CF.
Refractory
high-entropy
alloys.
Intermetallics
2010;18:1758--1765.
- [6]
Yang
X,
Zhang
Y.
Prediction
of
high--entropy
stabilized
solid--solution
multicomponent alloys.
Mat.
Chem.
Phys.
2012;
132:
233
-
238.
- [7]
Miracle
DB,
Miller
JD,
Senkov
ON,
Woodward
C,
Uchic
MD,
Tiley
J.
Exploration
and development
of
high
entropy
alloys
for
structural
applications.
Entropy
2014;16:494-525.
- [8]
Takeuchi
A,
Inoue
A.
Classification
of
bulk
metallic
glasses
by
atomic
size
difference, heat
of
mixing
and
period
of
constituent
elements
and
its
application
to
characterization of
the
main
alloying
element.
Mat.
Trans.
2005;46:
2817
-
2829.
- [9]
Jensen
J,
Mackintosh
AR.
Rare
earth
magnetism:
Structures
and
excitations.
Oxford: Clarendon
press;
1991.
- [10] Gao MC, Alman DE. Searching for next single--phase high--entropy alloy compositions.
Entropy
2013;
15:
4504
-
4519. | 10.1080/21663831.2014.951493 | [
"Michael Feuerbacher",
"Markus Heidelmann",
"Carsten Thomas"
] | 2014-08-01T08:17:54+00:00 | 2014-08-14T08:07:34+00:00 | [
"cond-mat.mtrl-sci"
] | Hexagonal High-Entropy Alloys | We report on the discovery of a high-entropy alloy with a hexagonal crystal
structure. Equiatomic samples in the alloy system Ho-Dy-Y-Gd-Tb were found to
solidify as homogeneous single-phase high-entropy alloys. The results of our
electron diffraction investigations and high-resolution scanning transmission
electron microscopy are consistent with a Mg-type hexagonal structure. The
possibility of hexagonal high-entropy alloys in other alloy systems is
discussed. |
1408.0101v1 | Volume 90 - No 6, March 2014
## Memetic Search in Differential Evolution Algorithm
Sandeep Kumar Jagannath University Chaksu, Jaipur, Rajasthan, India - 303901
Vivek Kumar Sharma, Ph.D Jagannath University Chaksu, Jaipur, Rajasthan, India - 303901
Rajani Kumari Jagannath University Chaksu, Jaipur, Rajasthan, India - 303901
## ABSTRACT
Differential Evolution (DE) is a renowned optimization stratagem that can easily solve nonlinear and comprehensive problems. DE is a well known and uncomplicated population based probabilistic approach for comprehensive optimization. It has apparently outperformed a number of Evolutionary Algorithms and further search heuristics in the vein of Particle Swarm Optimization at what time of testing over both yardstick and actual world problems. Nevertheless, DE, like other probabilistic optimization algorithms, from time to time exhibits precipitate convergence and stagnates at suboptimal position. In order to stay away from stagnation behavior while maintaining an excellent convergence speed, an innovative search strategy is introduced, named memetic search in DE. In the planned strategy, positions update equation customized as per a memetic search stratagem. In this strategy a better solution participates more times in the position modernize procedure. The position update equation is inspired from the memetic search in artificial bee colony algorithm. The proposed strategy is named as Memetic Search in Differential Evolution (MSDE). To prove efficiency and efficacy of MSDE, it is tested over 8 benchmark optimization problems and three real world optimization problems. A comparative analysis has also been carried out among proposed MSDE and original DE. Results show that the anticipated algorithm go one better than the basic DE and its recent deviations in a good number of the experiments.
## General Terms
Computer Science, Nature Inspired Algorithms, Metaheuristics promise in many numerical benchmark problems as well as real-world optimization problems. Differential evolution (DE) is a stochastic, population-based search strategy anticipated by Storn and Price [9] in 1995. While DE shares similarities with other evolutionary algorithms (EA), it differs considerably in the sense that distance and direction information from the current population is used to steer the search progression. In DE algorithm, all solutions have an equal opportunity of being preferred as parents, i.e. selection does not depend on their fitness values. In DE, each new solution fashioned competes with its parent and the superior one wins the contest. DE intensification and diversification capabilities depend on the two processes, that is to say mutation process and crossover process. In these two processes, intensification and diversification are evenhanded using the fine tuning of two parameters that is to say scale factor 'F' and crossover probability 'CR'. In DE the child vector is generated by applying the mutation and crossover operation. In mutation operation, a trial vector is generated with the help of the objective vector and two erratically preferred individuals. The perturbation in objective vector depends on F and the difference between the randomly selected individuals. Further, a crossover operation is applied between the objective vector and parent vector for generating the child vector using crossover probability (CR). So, it is clear that the discrepancy in the child vector from the parent vector depends on the values of F and CR. This discrepancy is measured as a step size for the candidate solution/parent vector. Large step size may results in skipping of actual solutions that is due to large value of CR and F while if these values are low then the step size will be small and performance degrades.
## Keywords
Differential Evolution, Swarm intelligence, Evolutionary computation, Memetic algorithm
## 1. INTRODUCTION
Population-based optimization algorithms find near-optimal solutions to the easier said than done optimization problems by inspiration from nature or natural entities. A widespread characteristic of each and every one population-based algorithm is that the population consisting of potential solutions to the problem is tailored by applying some operators on the solutions depending on the information of their fitness. Hence, the population is moved towards better solution areas of the search space. Two essential classes of population-based optimization algorithms are evolutionary algorithms [1] and swarm intelligence-based algorithms [2]. Although Genetic Algorithm (GA) [3], Genetic Programming (GP) [4], Evolution Strategy (ES) [5] and Evolutionary Programming (EP) [6] are popular evolutionary algorithms, DE comes underneath the class of Evolutionary algorithms. Among an assortment of EAs, differential evolution (DE), which characterized by the diverse mutation operator and antagonism strategy from the other EAs, has shown immense
The hybridization of some local search techniques in DE may diminish the possibility of skipping factual solution. In hybridized search algorithms, the global search capability of the main algorithm explore the search space, trying to identify the most promising search space regions while the local search part scrutinizes the surroundings of some initial solution, exploiting it in this way. Therefore, steps sizes play an important role in exploiting the identified region and these step sizes can be controlled by incorporating a local search algorithm with the global search algorithm.
Differential evolution (DE) has come into sight as one of the high-speed, robust, and well-organized global search heuristics of in progress significance. Over and over again real world provides some very complex optimization problems that cannot be easily dealt with existing classical mathematical optimization methods. If the user is not very susceptible about the exact solution of the problem in hand then nature-inspired algorithms may be used to solve these kinds of problems. It is shown in this paper that the natureinspired algorithms have been gaining to a great extent of recognition now a day due to the fact that numerous realworld optimization problems have turn out to be progressively more large, multifarious and self-motivated. The size and
complication of the problems at the present time necessitate the development of methods and solutions whose efficiency is considered by their ability to find up to standard results within a levelheaded amount of time, rather than an aptitude to guarantee the optimal solution. The paper also includes a concise appraisal of well-organized and newly developed nature-inspired algorithm, that is to say Differential Evolution. In addition, to get better effectiveness, correctness and trustworthiness, the considered algorithm is analyzed, research gaps are identified. DE has apparently outperformed a number of Evolutionary Algorithms (EAs) and other search heuristics in the vein of the Particle Swarm Optimization (PSO) at what time tested over together benchmark and real world problems. The scale factor (F) and crossover probability (CR) are the two major parameters which controls the performance of DE in its mutation and crossover processes by maintain the balance between intensification and diversification in search space. Literature suggests that due to large step sizes, DE is somewhat less capable of exploiting the on hand solutions than the exploration of search space. Therefore unlike the deterministic methods, DE has intrinsic negative aspect of skipping the accurate optima. This paper incorporates the memetic search strategy inspired by golden section search [42] which exploits the best solution after each and every iteration in order to generate its neighborhood solutions. To validate the proposed MSDE's performance, experiments are carried out on 11 benchmark as well as real life problems of different complexities and results reflect the superiority of the proposed strategy than the basic DE.
Rest of the paper is systematized as follows: Sect. 2 describes brief overview of the basic DE. Memetic algorithms explained in Sect. 3. Memetic search in DE (MSDE) is proposed and tested in Sect. 4. In Sect. 5, a comprehensive set of experimental results are provided. Finally, in Sect. 6, paper is concluded.
## 2. DIFFERENTIAL EVOLUTION ALGORITHM
Differential evolution is a strategy that optimizes a dilemma by iteratively trying to enhance an individual solution with regard to a specified gauge of excellence. DE algorithm is used for multidimensional real-valued functions but it does not put together the ascent of the problem being optimized, which means DE does not have need of that the optimization problem to be differentiable as is mandatory for traditional optimization methods such as gradient descent and quasiNewton techniques. DE algorithm optimizes a problem by considering a population of candidate solutions and generating new contestant solutions by combining existing ones according to its straightforward formulae, and then memorizing whichever candidate solution has the superlative score or fitness on the optimization problem at hand. Thus in this manner the optimization problem is treated as a black box that simply makes available a gauge of quality specified a candidate solution and the gradient is for that reason not considered necessary. DE has a number of strategies based on method of selecting the objective vector, number of difference vectors used and the crossover type [8]. Here in this paper DE/rand/1/bin scheme is used where DE stands for differential evolution, 'rand' indicates that the target vector is preferred haphazardly, '1' is for number of differential vectors and 'bin' notation is for binomial crossover. The popularity of Differential Evolution is due to its applicability to a wider class of problems and ease of implementation. Differential Evolution has properties of evolutionary algorithms as well as swarm intelligence. The detailed description of DE is as follows:
In the vein of other population based search algorithms, in DE a population of probable solutions (individuals) searches the solution. In a D-dimensional search space, an individual is represented by a D-dimensional vector (xi1 , xi2, . . ., xiD ), i = 1, 2, . . ., NP where NP is the population size (number of individuals). In DE, there are three operators: mutation, crossover and selection. Initially, a population is generated randomly with uniform distribution then the mutation, crossover and selection operators are applied to generate a new population. Trial vector generation is a critical step in DE progression. The two operators, mutation and crossover are used to engender the tryout vectors. The selection operator is used to decide on the best tryout vector for the subsequently age bracket. DE operators are explained for a split second in following subsections.
## 2.1 Mutation
A tryout vector is generated by the DE mutation operator for each individual of the in progress population. For generating the tryout vector, an objective vector is mutated with a biased differential. A progeny is fashioned in the crossover operation using the recently generated tryout vector. If G is the index for generation counter, the mutation operator for generating a trial vector v i (G) from the parent vector xi (G) is defined as follows:
- Choose a objective vector xi 1 (G) from the population such that and i i 1 are poles apart.
- All over again, haphazardly pick two individuals, xi 2 and xi 3 , from the population such that i, i 1 , i 2 and i 3 all are distinct to each other.
- After that the objective vector is mutated for calculating the tryout vector in the following manner:
$$( 1 )$$
Here F ∈ [0 , 1] is the mutation scale factor which is used in controlling the strengthening of the differential variation [7].
## 2.2 Crossover
Offspring x ' i (G) is generated using the crossover of parent vector xi (G) and the tryout vector ui (G) as follows:
$$\lambda _ { l } \cup \nolimits \, \text{and} \, \text{any you even} \, \iota _ { l } \cup \nolimits \, \text{as inrows}. \\ \text{) = \begin{cases} \ v _ { i j ( G ), \ i f \, j \in J } & \\ x _ { i i } ( G ). \ o t h e r w i s e & \end{cases} \quad ( 2 )$$
Here J is the set of cross over points or the points that will go under perturbation, xij (G) is the j th element of the vector xi (G) . Diverse methods possibly will be used to settle on the set J in which binomial crossover and exponential crossover are the most commonly used [7]. Here this paper used the binomial crossover. In this crossover, the crossover points are arbitrarily preferred from the set of potential crossover points, {1 , 2 , . . ., D }, where D is the dimension of problem.
## 2.3 Selection
There are a couple of functions for the selection operator: First it selects the individual for the mutation operation to generate the trial vector and second, it selects the most excellent, between the parent and the offspring based on their fitness value for the next generation. If fitness of parent is superior than the offspring then parent is selected otherwise offspring is selected:
$$\begin{smallmatrix} \prime \prime \\ \dots \end{smallmatrix} \quad ( 3 )$$
The above equation makes sure that the population's average fitness does not get worse. The Pseudo-code for Differential Evolutionary strategy is described in Algorithm 1 [7].
## Algorithm 1 Differential Evolution Algorithm
Initialize the control parameters, F and CR F ( (scale factor) and CR (crossover probability)).
Generate and initialize the population, P(0) , of NP individuals ( P is the population vector) while stopping criteria not meet do for each individual, xi (G) ∈ P(G) do
Estimate the fitness, f(x (G)) i ;
Generate the trial vector, v i (G) by using the mutation operator;
Generate an offspring, x′ (G), by using the crossover i operator;
if f(x′ (G) i is better than f(x (G)) i then
Add x′ (G) i to P(G + 1) ;
else
Add xi (G) to P(G + 1) ;
end if end for
end while
Memorize the individual with the best fitness as the solution
## 3. MEMETIC ALGORITHMS
Memetic algorithms (MA) characterize one of the most up to date mounting fields to do research in evolutionary computation. The name MA is now a day commonly used as coactions of evolutionary or several population-based algorithms with separate individual learning or local development events for problem search. Sometimes MA is moreover specified in the text as Baldwinian evolutionary algorithms (EA), Lamarckian EAs, genetic local search strategy or cultural algorithms. The theory of 'Universal Darwinism' was given by Richard Dawkins in 1983[12] to make available a amalgamate structure governing the evolution of any intricate system. In particular, 'Universal Darwinism' put forward that development is not restricted to biological systems; i.e., it is not limited to the tapered circumstance of the genes, but it is applicable to almost all multifarious system that show evidence of the principles of inheritance, disparity and assortment, thus satisfying the individuality of an evolving system. For instance, the new science of memetics symbolizes the mind-universe corresponds to genetics in way of life progression that stretches transversely the fields of biology, psychology and cognition, which has fascinated significant concentration in the last two decades. The term 'meme' was also introduced and defined by Dawkins in 1976[13] as 'the basic unit of cultural transmission, or imitation', and in the English Dictionary of Oxford as 'an element of culture that may be considered to be passed on by non-genetic means'.
Inspired by both Darwinian philosophy of ordinary evolution and Dawkins' conception of a meme, the term 'Memetic Algorithm' (MA) was first given by Moscato in his technical report [14] in 1989 where he observed MA as being very analogous to a outward appearance of population-based hybrid genetic algorithm (GA) together with an individual learning modus operandi talented to perform local refinements. The allegorical analogous, one side occupied by Darwinian evolution and, other side, between memes and domain specific (local search) heuristics are incarcerate within memetic algorithms as a consequence rendering a methodology that balances well between generality and problem specificity. In a more assorted context, memetic algorithms are now used under a variety of names together with Baldwinian Evolutionary Algorithms, Cultural Algorithms, Genetic Local Search, Hybrid Evolutionary Algorithms and Lamarckian Evolutionary Algorithms. In the circumstance of intricate optimization, many different instantiations of memetic algorithms have been reported athwart an extensive range of application domains, in general, converging to premium solutions more efficiently than their unadventurous evolutionary matching part. In broadspectrum, using the thoughts of memetics surrounded by a computational structure is called "Memetic Computing or Memetic Computation" (MC) [15]16] With MC, the individuality of Universal Darwinism are more appropriately captured. In all viewpoints, MA is a more constrained impression of MC. Exclusively; MA covers vicinity of MC, in meticulous dealing with areas of evolutionary algorithms that get hitched other deterministic enhancement techniques for solving optimization problems. MC lengthens the impression of memes to cover up conceptual entities of knowledgeenhanced measures or representations.
Memetic algorithms are the area under discussion of intense scientific research and have been fruitfully applied to a massive amount of real-world problems. Even though many people make use of techniques intimately associated to memetic algorithms, unconventional names such as hybrid genetic algorithms are also in employment. Moreover, many people name their memetic techniques as genetic algorithms. The prevalent use of this misnomer hampers the measurement of the total amount of applications. MAs are a course group of stochastic global search heuristics in which Evolutionary Algorithms-based approaches are pooled with problemspecific solvers. After that might be implemented as local search heuristics techniques, approximation algorithms or, sometimes, even precise methods. The hybridization is preordained to either speed up the discovery of good solutions, for which evolution alone would take too long to discover, or to attain solutions that would otherwise be out-ofthe-way by evolution or a local method alone. As the great preponderance of Memetic Algorithms use heuristic local searches rather than precise methods. It is tacit that the evolutionary search provides for an extensive exploration of the search space while the local search by some means zoomin on the sink of magnetism of talented solutions Researchers have used memetic algorithms to embark upon many conventional NP problems. To mention some of them: bin packing problem, generalized assignment problem, graph partitioning, max independent set problem, minimal graph coloring, multidimensional knapsack, quadratic assignment problem, set cover problem and travelling salesman problem.
MAs have been demonstrated very triumphant transversely an extensive range of problem domains. More topical applications take account of (but are not limited to) artificial neural network training,[17] pattern recognition,[18] motion planning in robotic,[19] beam orientation,[20] circuit design,[21] electric service restoration,[22] expert systems for medical field,[23] scheduling on single machine,[24] automatic timetabling,[25] manpower scheduling,[26] nurse rostering and function optimization [27] allocation of processor,[28] maintenance scheduling (for instance, of an electric distribution network),[29] multidimensional knapsack problem by E ozcan et al.[30] VLSI design,[31] clustering of gene expression profiles,[32] feature/gene selection or
extraction,[33][34] and multi-class, multi-objective feature selection.[35][36]. M Marinaki et al. [37] proposed an island memetic differential evolution algorithm, for solving the feature subset selection problem while the nearest neighbor categorization method is used for the classification task. CG Uzcátegui et al. [38] developed a memetic differential evolution algorithm to solve the inverse kinematics problem of robot manipulators. S Goudos [39] designed a memetic differential evolution algorithm to design multi-objective approach to sub arrayed linear antenna arrays. Memetic algorithm also hybridized with artificial bee colony algorithm like JC Bansal et al. [40] anticipated a memetic search in artificial bee colony algorithm. S Kumar et al. [41] developed a randomized memetic artificial bee colony algorithm and applied those algorithms to solve various problems.
## 4. MEMETIC SEARCH IN DIFFERENTIAL EVOLUTION (MSDE) ALGORITHM
Exploration of the entire search space and exploitation of the most favorable solution region in close proximity may be unprejudiced by maintaining the diversity in the early hours and later on iterations of any random number based search algorithm. It is unambiguous from the Eqs. (1) and (2) that exploration of the search space in DE algorithm controlled by two parameters ( CR and F ). In case of DE algorithm, exploration and exploitation of the search space depend on the value of CR and F that is to say if value of CR and F are high then exploration will be high and exploitation will be high if value of CR and F are low. This paper introduced a new search strategy in order to balance the process of exploration and exploitation of the search space. The new search strategy is inspired from the memetic search in Artificial Bee Colony (MeABC) algorithm [40]. The MeABC algorithm developed by J. C. Bansal et al [40] aggravated by Golden Section Search (GSS) [42]. In MeABC only the best individual of the in progress population updates themselves in its concurrence. GSS processes the interval [a = -1.2, b = 1.2] and initiates two intermediate points ( f 1 , f 2 ) with help of golden ratio (Ѱ = 0.618). The GSS process summarized in algorithm 2 as follow:
## Algorithm 2: Golden Section Search
Repeat while termination criteria meet
Compute 1 ( ) , and f b b a 2 ( ) , f a b a
Calculate
1
f
f
and
2
f
f
$$\text{If } f ( f _ { 1 } ) < f ( f _ { 2 } ) \text{ then }$$
b = f 2 and the solution lies in the range [a, b]
else a =
f
1
and the solution lies in the range [a, b]
End of if
End of while
The proposed memetic search strategy modifies the mutation operator of DE algorithm and modifies the Eqs. (1) as follow:
Here f
$$\text{Iere} f _ { j } \text{ is decided by algorithm 2}.$$
The proposed changes in original DE algorithm control the search process adaptively and provide more chances to explore the large search space and exploit the better solution in more efficient way. This change in DE tries to balance intensification and diversification of search space. The detailed Memetic search in DE (MSDE) outlined in algorithm 3 as follow:
## Algorithm 3 Memetic Search in Differential Evolution (MSDE) Algorithm
Initialize the control parameters, F and CR F ( (scale factor) and CR (crossover probability)).
Generate and initialize the population, P(0) , of NP individuals ( P is the population vector) while stopping criteria not meet do for each individual, (G) ∈ P(G)
Estimate the fitness, f(x (G))
xi do i ;
Generate the trial vector, v i (G) by using the mutation operator and incorporate algorithm 2 as per the following equation;
Generate an offspring, x′ (G), i by using the crossover operator;
if f(x′ (G) i is better than f(x (G)) i then
Add x′ (G) i to P(G + 1) ;
else
Add xi (G) to P(G + 1) ;
end if end for
end while
Memorize the individual with the best fitness as the solution
## 5. EXPERIMENTAL RESULTS
## 5.1 Test problems under consideration
Differential Evolution algorithm with improvement in search phase applied to the eight benchmark functions for whether it gives better result or not at different probability and also applied for three real world problems. Benchmark functions taken in this paper are of different characteristics like unimodel or multi-model and separable or non-separable and of different dimensions. In order to analyze the performance of MSDE, it is applied to global optimization problems ( f 1 to f 8 ) listed in Table I. Test problems f 1 -f 8 are taken from [8],[44]. Three real world problems (Pressure Vessel Design, Lennard Jones and Parameter estimation for frequency modulated sound wave) are described as follow:
Pressure Vessel Design (f9): The problem of minimizing total cost of the material, forming and welding of a cylindrical vessel [43]. In case of pressure vessel design generally four design variables are considered: shell thickness (x ), spherical 1 head thickness (x2), radius of cylindrical shell (x ) and shell 3 length (x4 ). Simple mathematical representation of this problem is as follow:
Subject to
The search boundaries for the variables are
$$^ { s } \leq x _ { 3 } \leq 2 4 0 \text{ and } 1. 0 ^ { * } 1 0 ^ { * } \leq x _ { 4 } \leq 2 4 0.$$
$$1. 1 2 5 \leq x _ { 1 } \leq & 1 2. 5, \, 0. 6 2 5 \leq x _ { 2 } \leq 1 2. 5, \\ 1. 0 ^ { * } 1 0 ^ { - 8 } \leq x _ { 3 } \leq 2 4 0 \text{ and } 1. 0 ^ { * } 1 0 ^ { - 8 } \leq x _ { 4 } \leq 2 4 0$$
The best ever identified global optimum solution is f (1.125, 0.625, 55.8592, 57.7315) = 7197.729 [43]. The tolerable error for considered problem is 1.0 E -05.
Table 1. Test Problems
| Test Problem | Objective Function | Search Range | Optimum Value | D | Acceptable Error |
|------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------|-------------------------------------------------|-----|--------------------|
| Step Function | 2 1 1 ( ) ( 0.5 ) D i i f x x | [-100, 100] | f(-0.5≤x≤0.5)=0 | 30 | 1.0E-05 |
| Colville function | 2 2 2 2 2 2 2 2 1 1 4 3 3 2 2 2 4 2 4 ( ) 100( ) (1 ) 90( ) (1 ) 10.1 [( 1) ( 1) ] 19.8( 1)( 1) f x x x x x x x x x x x | [-10, 10] | f (1) = 0 | 4 | 1.0 E -05 |
| Kowalik function | 2 11 2 1 2 3 2 1 3 4 ( ) ( ) ( ) i i i i i i x b b x f x a b b x x | [-5, 5] | f (0.1928, 0.1908, 0.1231, 0.1357) = 3.07 E -04 | 4 | 1.0 E -05 |
| Shifted Rosenbrock | 1 2 2 2 4 1 1 1, 2 1 2 ( ) (100( ) ( 1) , 1, [ ,... ], [ , ,....... ] D i i i bias i D D f x z z z f z x o x x x x o o o o | [-100, 100] | f(o)=f bias =390 | 10 | 1.0 E -01 |
| Six-hump camel back | 2 4 2 2 2 5 1 1 1 1 2 2 2 1 ( ) (4 2.1 ) ( 4 4 ) 3 f x x x x x x x x | [-5, 5] | f(-0.0898, 0.7126) = - 1.0316 | 2 | 1.0E-05 |
| Hosaki Problem | 2 3 4 2 6 1 1 1 1 2 2 7 1 ( ) (1 8 7 ) exp( ) 3 4 f x x x x x x x | 1 2 [0,5], [0,6] x x | -2.3458 | 2 | 1.0 E -06 |
| Meyer and Roth Problem | 5 2 1 3 7 1 1 2 ( ) ( ) 1 i i i i i x x t f x y x t x v | [-10, 10] | f(3.13, 15.16,0.78) = 0.4E -04 | 3 | 1.0 E -03 |
| Shubert | 5 5 8 1 2 1 1 ( ) cos(( 1) 1) cos(( 1) 1) t i f x i i x i i x | [-10, 10] | f(7.0835, 4.8580)= - 186.7309 | 2 | 1.0 E -05 |
Parameter Estimation for Frequency-Modulated (FM) sound wave (f11): Frequency-Modulated (FM) sound wave amalgamation has a significant role in several modern music systems. The parameter optimization of an FM synthesizer is an optimization problem with six dimension where the vector to be optimized is X = {a , w , a , w , a , w } of the sound 1 1 2 2 3 3 wave given in equation (4). The problem is to generate a sound (1) similar to target (2). This problem is a highly complex multimodal one having strong epistasis, with minimum value f(X) = 0. This problem has been tackled using Artificial bee colony algorithms (ABC) in [43].The expressions for the estimated sound and the target sound waves are given as:
$$( 4 )$$
$$\mathfrak { ) } t \theta \mathfrak { ) } \mathfrak { \mathfrak { \Phi } }$$
Respectively where θ = 2π/100 and the parameters are defined in the range [-6.4, 6.35]. The fitness function is the summation of square errors between the estimated wave (1) and the target wave (2) as follows:
$$\dots \cdots - \cdots \cdots \\ f _ { 1 1 } ( x ) = \sum _ { i = 0 } ^ { 1 0 0 } \left ( y ( t ) - y _ { 0 } ( t ) \right ) ^ { 2 }$$
Acceptable error for this problem is 1.0E-05, i.e. an algorithm is considered successful if it finds the error less than acceptable error in a given number of generations.
Fig 1: Effect of CR on AFE
## 5.2 Experimental Setup
To prove the efficiency of MSDE, it is compared with original DE algorithm over well thought-out seventeen problems, following experimental setting is adopted:
- Population Size NP = 50
- The Scale factor F= 0.5
- Limit = D*NP/2.
- Number of Run =100
- Sopping criteria is either reached the corresponding acceptable error or maximum function evaluation (which is set as 200000).
- Crossover probability CR = 0.9, in order to identify the effect of the parameter CR on the performance
of MSDE, its effect at different CR in range [0.1, 1] is experimented as shown in figure 1. It can be easily observed from the graph that best value of CR is 0.9 for considered as problems.
- The mean function values (MFV), standard deviation (SD), mean error (ME), average function evaluation (AFE) and success rate (SR) of considered problem have been recorded.
- Experimental setting for DE is same as MSDE.
## 5.3 Result Comparison
Mathematical results of MSDE with experimental setting as per section 5.2 are discussed in Table 2. Table 2 show the relationship of results based on mean function value (MFV), standard deviation (SD), mean error (ME), average function evaluations (AFE) and success rate (SR). Table 2 shows that a good number of the times MSDE outperforms in terms of efficiency (with less number of function evaluations) and reliability as compare to other considered algorithms. The proposed algorithm all the time improves AFE. It is due to balancing between exploration and exploitation of search space. Table 3 contains summary of table 2 outcomes. In Table 3, '+' indicates that the MSDE is better than the well thought-out algorithms and '-' indicates that the algorithm is not better or the divergence is very small. The last row of Table 3, establishes the superiority of MSDE over DE.
Table 2. Comparison of the results of test problems
| Test Problem | Algorithm\Measure | MFV | SD | ME | AFE | SR |
|----------------|---------------------|-------------|----------|----------|----------|------|
| f 1 | DE | 0.12 | 0.475 | 0.12 | 31942.5 | 91 |
| f 1 | MSDE | 0.01 | 0.0995 | 0.02 | 21319 | 99 |
| f 2 | DE | 0.147 | 0.646 | 0.147 | 26918 | 89 |
| f 2 | MSDE | 0.000457 | 0.000512 | 0.00075 | 31196 | 95 |
| f 3 | DE | 0.000572 | 0.000329 | 0.000265 | 61900 | 71 |
| f 3 | MSDE | 0.000553 | 0.000355 | 0.000251 | 74294 | 82 |
| f 4 | DE | 392 | 2.09 | 2.13 | 194914 | 3 |
| f 4 | MSDE | 391 | 2.49 | 0.865 | 197758 | 7 |
| f 5 | DE | -1.03 | 1.42e-05 | 1.79e-05 | 112618 | 44 |
| f 5 | MSDE | -1.03 | 4.58e-06 | 1.12e-05 | 57491.5 | 72 |
| f 6 | DE | -2.35 | 5.96e-06 | 5.26e-06 | 10858 | 95 |
| f 6 | MSDE | -2.35 | 2.53e-06 | 5.19e-06 | 1261 | 100 |
| f 7 | DE | 0.00191 | 1.64e-05 | 0.00195 | 3744 | 99 |
| f 7 | MSDE | 0.0019 | 2.33e-06 | 0.00195 | 4621 | 99 |
| f 8 | DE | -187 | 5.37e-06 | 4.59e-06 | 8122 | 100 |
| f 8 | MSDE | -187 | 2.53e-06 | 4.66e-06 | 7375.5 | 100 |
| f 9 | DE | 7200 | 3.38e-05 | 2.43e-05 | 65912.5 | 71 |
| f 9 | MSDE | 7200 | 1.51e-05 | 7.88e-06 | 19772 | 96 |
| f 10 | DE | -9.1 | 1.45e-05 | 8.13e-05 | 72866 | 100 |
| f 10 | MSDE | -9.1 | 1.65e-05 | 7.71e-05 | 69196.5 | 100 |
| f 11 | DE | 5.83 | 6.33 | 5.83 | 113179 | 48 |
| f 11 | MSDE | 4.83 | 6.49 | 4.84 | 83060 | 63 |
## 6. CONCLUSION
This paper, modify the search process in original DE by introducing customized Golden Section Search process. Newly introduced line of attack added in mutation process. Proposed algorithm modifies step size with the help of GSS process and update target vector. Further, the modified strategy is applied to solve 8 well-known standard benchmark functions and three real world problems. With the help of experiments over test problems and real world problems, it is shown that the insertion of the proposed strategy in the original DE algorithm improves the steadfastness, efficiency and accuracy as compare to its original version. Table 2 and 3 shows that the proposed MSDE is able to solve almost all the considered problems with fewer efforts. Numerical results show that the improved algorithm is superior to original DE algorithm. Proposed algorithm has the ability to get out of a local minimum and has higher rate of convergence. It can be resourcefully applied for separable, multivariable, multimodal function optimization. The proposed strategy also improves results for three real world problems: Pressure Vessel Design, Lennard Jones and Parameter estimation for frequency modulated sound wave.
Table 3. Summary of table II outcome
| Test Problem | MSDEvs. DE |
|------------------------|--------------|
| f 1 | + |
| f 2 | + |
| f 3 | + |
| f 4 | + |
| f 5 | + |
| f 6 | + |
| f 7 | - |
| f 8 | + |
| f 9 | + |
| f 10 | + |
| f 11 | + |
| Total Number of + sign | 10 |
## 7. REFERENCES
- [1] D Fogel, 'Introduction to evolutionary computation,' Evolutionary Computation: Basic algorithms and operators, vol. 1, p. 1, 2000.
- [2] JF Kennedy, J Kennedy, and RC Eberhart, Swarm intelligence. Morgan Kaufmann Pub, 2001.
- [3] J Holland, Adaptation in natural and artificial systems. The University of Michigan Press, Ann Arbor, 1975.
- [4] JR Koza, Genetic programming: A paradigm for genetically breeding populations of computer programs to solve problems. Stanford University, Department of Computer Science, 1990.
- [5] I Rechenberg, 'Cybernetic solution path of an experimental problem. royal aircraft establishment, library translation 1122, 1965. reprinted in evolutionary computation the fossil record, db fogel, ed.' Chap. 8, pp. 297-309, 1998.
- [6] D Fogel and Z Michalewicz, Handbook of evolutionary computation. Taylor & Francis, 1997.
- [7] A Engelbrecht, Computational intelligence: an introduction. Wiley, 2007.
- [8] MM Ali, C Khompatraporn, and Z Zabinsky, 'A numerical evaluation of several stochastic algorithms on selected continuous global optimization test problems,' Journal of Global Optimization, vol. 31, no. 4, pp. 635672, 2005.
- [9] KV Price, RM Storn, JA Lampinen (2005) Differential evolution: a practical approach to global optimization. Springer, Berlin
- [10] F Kang, J Li, Z Ma, H Li (2011) Artificial bee colony algorithm with local search for numerical optimization. J Softw 6(3):490-497
- [11] R Hooke, TA Jeeves (1961) 'Direct search' solution of numerical and statistical problems. J ACM (JACM) 8(2):212-229
- [12] R Dawkins (1983). "Universal Darwinism". In Bendall, DS Evolution from molecules to man . Cambridge University Press.
- [13] R Dawkins (1976). The Selfish Gene . Oxford University Press. ISBN 0-19-929115-2.
- [14] P Moscato, (1989). "On Evolution, Search, Optimization, Genetic Algorithms and Martial Arts: Towards Memetic Algorithms". Caltech Concurrent Computation Program (report 826).
- [15] XS Chen, YS Ong, MH Lim, KC Tan, (2011). "A MultiFacet Survey on Memetic Computation". IEEE Transactions on Evolutionary Computation 15 (5): 591607.
- [16] XS Chen, YS Ong, MH Lim, (2010). "Research Frontier: Memetic Computation - Past, Present & Future". IEEE Computational Intelligence Magazine 5 (2): 24-36.
- [17] T Ichimura, Y Kuriyama, (1998). "Learning of neural networks with parallel hybrid GA using a royal road function". IEEE International Joint Conference on Neural Networks 2. New York, NY. pp. 1131-1136.
- [18] J Aguilar, A Colmenares, (1998). "Resolution of pattern recognition problems using a hybrid genetic/random neural network learning algorithm". Pattern Analysis and Applications 1 (1): 52-61. doi:10.1007/BF01238026.
- [19] M Ridao, J Riquelme, E Camacho, M Toro, (1998). "An evolutionary and local search algorithm for planning two manipulators motion". Lecture Notes in Computer Science . Lecture Notes in Computer Science (SpringerVerlag) 1416: 105-114. doi:10.1007/3-540-64574-8\_396. ISBN 3-540-64574-8.
- [20] O Haas, K Burnham, J Mills, (1998). "Optimization of beam orientation in radiotherapy using planar geometry". Physics in Medicine and Biology 43 (8): 2179-2193. doi:10.1088/0031-9155/43/8/013. PMID 9725597.
- [21] S Harris, E Ifeachor, (1998). "Automatic design of frequency sampling filters by hybrid genetic algorithm techniques". IEEE Transactions on Signal Processing 46 (12): 3304-3314. doi:10.1109/78.735305.
- [22] A Augugliaro, L Dusonchet, E Riva-Sanseverino, (1998). "Service restoration in compensated distribution networks using a hybrid genetic algorithm". Electric Power Systems Research 46 (1): 59-66. doi:10.1016/S0378-7796(98)00025-X.
- [23] R Wehrens, C Lucasius, L Buydens, G Kateman, (1993). "HIPS, A hybrid self-adapting expert system for nuclear magnetic resonance spectrum interpretation using genetic algorithms". Analytica Chimica ACTA 277 (2): 313-324. doi:10.1016/0003-2670(93)80444-P.
- [24] P França, A Mendes, P Moscato, (1999). "Memetic algorithms to minimize tardiness on a single machine with sequence-dependent setup times". Proceedings of the 5th International Conference of the Decision Sciences Institute. Athens, Greece. pp. 1708-1710.
- [25] D Costa, (1995). "An evolutionary tabu search algorithm and the NHL scheduling problem". Infor 33 : 161-178.
- [26] U Aickelin, (1998). "Nurse rostering with genetic algorithms". Proceedings of young operational research conference 1998. Guildford, UK.
- [27] E Ozcan, (2007). "Memes, Self-generation and Nurse Rostering". Lecture Notes in Computer Science . Lecture Notes in Computer Science (Springer-Verlag) 3867: 85104. doi:10.1007/978-3-540-77345-0\_6. ISBN 978-3540-77344-3.
- [28] E Ozcan, E Onbasioglu, (2006). "Memetic Algorithms for Parallel Code Optimization". International Journal of Parallel Programming 35 (1): 33-61. doi:10.1007/s10766-006-0026-x.
- [29] E Burke, A Smith, (1999). "A memetic algorithm to schedule planned maintenance for the national grid". Journal of Experimental Algorithmics 4 (4): 1-13. doi:10.1145/347792.347801.
- [30] E Ozcan, C Basaran, (2009). "A Case Study of Memetic Algorithms for Constraint Optimization". Soft Computing: A Fusion of Foundations, Methodologies and Applications 13 (8-9): 871-882. doi:10.1007/s00500-008-0354-4.
- [31] S Areibi, Z Yang, (2004). "Effective memetic algorithms for VLSI design automation = genetic algorithms + local search + multi-level clustering". Evolutionary Computation (MIT Press) 12 (3): 327353.doi:10.1162/1063656041774947. PMID 15355604.
- [32] P Merz, A Zell, (2002). "Clustering Gene Expression Profiles with Memetic Algorithms". Parallel Problem Solving from Nature - PPSN VII . Springer. pp. 811820. doi:10.1007/3-540-45712-7\_78.
- [33] Z Zexuan, YS Ong and M Dash (2007). "Markov Blanket-Embedded Genetic Algorithm for Gene Selection". Pattern Recognition 49 (11): 3236-3248.
- [34] Z Zexuan, YS Ong and M Dash (2007). "Wrapper-Filter Feature Selection Algorithm Using A Memetic Framework". IEEE Transactions on Systems, Man and Cybernetics -Part B 37 (1): 70-76. doi:10.1109/TSMCB.2006.883267.
- [35] Z Zexuan, YS Ong and M. Zurada (2008). "Simultaneous Identification of Full Class Relevant and Partial Class Relevant Genes". IEEE/ACM Transactions on Computational Biology and Bioinformatics .
- [36] G Karkavitsas and G Tsihrintzis (2011). "Automatic Music Genre Classification Using Hybrid Genetic Algorithms". Intelligent Interactive Multimedia Systems and Services (Springer) 11: 323-335. doi:10.1007/978-3642-22158-3\_32.
- [37] M Marinaki, and Y Marinakis. "An Island Memetic Differential Evolution Algorithm for the Feature Selection Problem." Nature Inspired Cooperative Strategies for Optimization (NICSO 2013). Springer International Publishing, 2014. 29-42.
- [38] CG Uzcátegui, and DB Rojas. "A memetic differential evolution algorithm for the inverse kinematics problem of robot manipulators." International Journal of Mechatronics and Automation 3.2 (2013): 118-131.
- [39] S Goudos, K Gotsis, K Siakavara, E Vafiadis, and J Sahalos. "A Multi-Objective Approach to Subarrayed Linear Antenna Arrays Design Based on Memetic Differential Evolution." Antennas and Propagation, IEEE Transactions on (Volume: 61 , Issue: 6 ) (2013): 30423052.
- [40] JC Bansal, H Sharma, KV Arya and A Nagar, 'Memetic search in artificial bee colony algorithm.' Soft Computing (2013): 1-18.
- [41] S Kumar, VK Sharma and R Kumari (2014) Randomized Memetic Artificial Bee Colony Algorithm. International Journal of Emerging Trends & Technology in Computer Science (IJETTCS).In Print.
- [42] J Kiefer, 'Sequential minimax search for a maximum.' In Proc. Amer. Math. Soc, volume 4, pages 502-506, 1953.
- [43] H Sharma, JC Bansal, and KV Arya. "Opposition based lévy flight artificial bee colony." Memetic Computing (2012): 1-15.
- [44] PN Suganthan, N Hansen, JJ Liang, K Deb, YP Chen, A Auger, and S Tiwari. 'Problem definitions and evaluation criteria for the CEC 2005 special session on real-parameter optimization.' In CEC 2005, 2005. | 10.5120/15582-4406 | [
"Sandeep Kumar",
"Vivek Kumar Sharma",
"Rajani Kumari"
] | 2014-08-01T08:45:14+00:00 | 2014-08-01T08:45:14+00:00 | [
"cs.NE"
] | Memetic Search in Differential Evolution Algorithm | Differential Evolution (DE) is a renowned optimization stratagem that can
easily solve nonlinear and comprehensive problems. DE is a well known and
uncomplicated population based probabilistic approach for comprehensive
optimization. It has apparently outperformed a number of Evolutionary
Algorithms and further search heuristics in the vein of Particle Swarm
Optimization at what time of testing over both yardstick and actual world
problems. Nevertheless, DE, like other probabilistic optimization algorithms,
from time to time exhibits precipitate convergence and stagnates at suboptimal
position. In order to stay away from stagnation behavior while maintaining an
excellent convergence speed, an innovative search strategy is introduced, named
memetic search in DE. In the planned strategy, positions update equation
customized as per a memetic search stratagem. In this strategy a better
solution participates more times in the position modernize procedure. The
position update equation is inspired from the memetic search in artificial bee
colony algorithm. The proposed strategy is named as Memetic Search in
Differential Evolution (MSDE). To prove efficiency and efficacy of MSDE, it is
tested over 8 benchmark optimization problems and three real world optimization
problems. A comparative analysis has also been carried out among proposed MSDE
and original DE. Results show that the anticipated algorithm go one better than
the basic DE and its recent deviations in a good number of the experiments. |
1408.0102v1 | ## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
## Randomized Memetic Artificial Bee Colony Algorithm
Sandeep Kumar 1 , Dr. Vivek Kumar Sharma and Rajani Kumari 2 3
1,2 & 3 Faculty of Engineering and Technology, Jagannath University, Chaksu, Jaipur, Rajasthan 303901, India
Abstract: Artificial Bee Colony (ABC) optimization algorithm is one of the recent population based probabilistic approach developed for global optimization. ABC is simple and has been showed significant improvement over other Nature Inspired Algorithms (NIAs) when tested over some standard benchmark functions and for some complex real world optimization problems. Memetic Algorithms also become one of the key methodologies to solve the very large and complex real-world optimization problems. The solution search equation of Memetic ABC is based on Golden Section Search and an arbitrary value which tries to balance exploration and exploitation of search space. But still there are some chances to skip the exact solution due to its step size. In order to balance between diversification and intensification capability of the Memetic ABC, it is randomized the step size in Memetic ABC. The proposed algorithm is named as Randomized Memetic ABC (RMABC). In RMABC, new solutions are generated nearby the best so far solution and it helps to increase the exploitation capability of Memetic ABC. The experiments on some test problems of different complexities and one well known engineering optimization application show that the proposed algorithm outperforms over Memetic ABC (MeABC) and some other variant of ABC algorithm(like Gbest guided ABC (GABC),Hooke Jeeves ABC (HJABC), Best-So-Far ABC (BSFABC) and Modified ABC (MABC) in case of almost all the problems.
collective intelligent behavior of social insects [3]. These strategies are meta-heuristic and swarm-based, still they share some common characteristics with genetic algorithms [2], [4], [5], but these methods are much simpler as they do not use mutation or crossover operators. Genetic algorithms are population-based, biology inspired algorithm, which was based on the evolution theory and survival of the fittest [6]. Similarly, PSO is also population-based, but it was inspired by the intelligent behavior of swarm like fish and birds, and therefore falls into the different class from genetic algorithms. Swarm-based or population-based algorithms fall in category of nature-inspired meta-heuristic algorithms [7]-[11] with a great range of applications areas [12]-[17]. Since the inception of swarm intelligence strategies such as PSO in the early 1990s, more than a dozen of new meta-heuristic algorithms have been developed [18]-[29], and these algorithms have been applied to almost every field of optimization, engineering, design, image, scheduling, data mining, machine intelligence etc.
Keywords: Artificial Bee Colony Algorithm, Memetic Computing, Swarm Intelligence, Nature Inspired Computing.
## 1. INTRODUCTION
Optimization is a field of research with large number of applications in almost each and every area of science, management and engineering, where mathematical modeling is used. Global optimization is a very challenging task due to diversity of objective functions and complex real world optimization problems as they may vary unimodel to multimodal, linear to highly nonlinear and irregularities [1].
The growing trend of apprehensive informatics is to use swarm intelligence to search solutions to challenging optimization problems and real-world applications. A classical example is the evolution of particle swarm optimization (PSO) that may be recognized as a representative milestone in using swarm intelligence or collective intelligence [2]. One more, good example is the ant colony optimization algorithm which shows the
The intelligent foraging behavior, learning capability, memorizing power and information sharing properties of honey bees have recently been one of the most interesting research areas in swarm intelligence. Research and studies on honey bees are setting a new trend in the literature during the last decade [30]. Artificial bee colony (ABC) algorithm was proposed by D. Karaboga in 2005 [31]. It is an optimization algorithm based on particular intelligent behavior of honey bee swarms. Since its inception it has been modified and compared with other meta-heuristics like genetic algorithm, particle swarm optimization (PSO), differential evolution (DE), and evolutionary algorithms[32], [33] on standard benchmark functions. It also has been used for designing of digital IIR filters [34], for training of feed forward neural network [35], to solve the leaf-constrained minimum spanning tree problem [36], for optimization of distribution network configuration[37], For optimization of truss structure [38] and for inverse analysis of structural parameter [39].
The rest of the paper is organized as follow: section 2 discuss original ABC algorithm in detail. Next section contains introduction to Memetic algorithms. Section 4 outlines proposed algorithm followed by experimental setup, results and discussion. Section 6 contains conclusions followed by references.
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
## 2. ARTIFICIAL BEE COLONY ALGORITHM
Artificial Bee Colony (ABC) Algorithm is inspired by the intuitive food foraging behavior of honey bee insects. Honey bee swarm is one of the most insightful insect exists in nature; it shows collective intelligent behavior while searching the food. The honey bee swarm has a number of good features like bees can interchange the information, can remember the environmental conditions, can store and share the information and take decisions based these observations. According to changes in the environment, the honey bee swarm updates itself, allocate the tasks actively and proceed further by social learning and teaching. This intelligent behavior of honey bees inspires researchers and scientists to simulate the intelligent food foraging behavior of the honey bee swarm.
## 2.1 Analogy of Artificial Bee Colony Algorithm with Bee
The algorithm suggested by D. Karaboga [31] is collection of three major elements: employed bees, unemployed bees and food sources. The employed bees are associated with a good quality food source. Employed bees have good knowledge about existing food source. Exploitation of food sources completed by employed bees. When a food source rejected employed bee turn to be as unemployed. The idle foragers are bees acquiring no information about food sources and searching for a new food source to accomplish it. Unemployed bees can be classified in two categories: scout bees and onlooker bees. Scout bees randomly search for new food sources neighboring the hive. Onlooker bees monitor the waggle dance in hive, in order to select a food source for the purpose of exploitation. The third element is the good food sources nearby the beehive.
nectar information of the sources with the onlooker bees waiting at the dance area within the hive. After exchanging this information, each employed bee returns to the food source checked during the previous cycle, as the position of the food source had been recalled and then selects new food source using its perceived information in the neighborhood of the present food source. In the last phase, an onlooker bee uses the information retrieved from the employed bees at the dance area to select a good food source. The chances for the food sources to be elected boosts with boost in its quality of nectar. Hence , the employed bee with information of a food source with the highest quality of nectar employs the onlookers to that food source. It eventually chooses another food source close by the one presently in her memory depending on perceived information. A new food source is arbitrarily generated by a scout bee to replace the one abandoned by the onlooker bees. This complete search process of ABC algorithm could be outlined in Fig. 1 as follows [31]:
Comparatively in the optimization context, the number of food sources (that is the employed or onlooker bees) in ABC algorithm, is commensurate to the number of solutions in the population. Moreover, the location of a food source indicates the position of an encouraging solution to the optimization problem, after all the virtue of nectar of a food source represents the fitness cost (quality) of the correlated solution.
## 2.2 Phases of Artificial Bee Colony Algorithm
The search process of ABC has three major steps [31]:
- Send the employed bees to a food source and estimate their nectar quality;
- Onlooker bees select the food sources based on information collected from employed bees and estimate their nectar quality;
- Determine the scout bees and employ them on possible food sources for exploitation.
The position of the food sources are arbitrarily selected by the bees at the initial stage and their nectar qualities are measured. The employed bees then communicate the
Figure 1: Phases of Artificial Bee Colony Algorithm
## 2.2.1 Initialization of Swarm
The ABC algorithm has three main parameters: the number of food sources (population), the number of attempt after which a food source is treated to be jilted (limit) and the criteria for termination (maximum number of cycle). In the initial ABC proposed by D. Karaboga [31], initial population (SN) divided in two equal parts (employed bees (SN/2) or onlooker bees (SN/2)); the number of food sources was equal to the employed bees (SN/2). Initially it consider an evenly dealt swarm of food sources (SN), where each food source xi (i = 1, 2 ...SN) is a vector of D-dimension. Each food source is evaluated using following method [40]:
$$x _ { i j } = x \min j + r a n d [ 0, 1 ] ( x _ { \max j } - x \min j ) \quad ( 1 )$$
Where
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
- rand[0,1] is a function that arbitrarily generates an evenly distributed random number in range [0,1].
## 2.2.2 Employed Bee
Employed bees phase modify the existing solution according to information of individual experiences and the fitness value of the newly raised solution. New food source with higher fitness value take over the existing one. The position of i th candidate in j th dimension updated during this phase as shown below [40]:
$$v _ { i j } = x _ { i j } + \phi ( x _ { i j } - x _ { k j } )$$
)
(2)
Where
- ( ) is known as step size, k ij kj x x ∈ {1, 2, ..., SN}, j ∈ {1, 2, ...,D} are two randomly chosen indices. k ≠i ensure that step size has some indicative improvement.
## 2.2.3 Onlooker Bee
The number of food sources for onlooker bee is same as the employed. All along this phase all employed bee exchange fitness information about new food sources with onlooker bees. Onlooker bees estimate the probability of selection for each food source generated by the employed bee. The onlooker bee select best fittest food source. There may be some other methods for calculation of probability, but it is required to include fitness. In this paper probability of each food source is decided using its fitness as follow [40]:
$$P _ { i j } & = \frac { \dot { \vec { f i t } } } { \sum _ { i = 1 } ^ { \mathbf i t i } } & ( 3 ) & \text{New} \quad \\ \cdots & \cdots \quad \frac { \cdots } { \cdots } \quad \frac { \cdots } { \cdots }$$
## 2.2.4 Scout Bee Phase
If the location of a food source is not modified for a predefined number of evaluations, then the food source is assumed to be neglected and scout bees phase is initialized. All along this phase the bee associated with the neglected food source converted into scout bee and the food source is replaced by the arbitrarily chosen food source inside the search space. In ABC, the pretended number of cycles plays an important role in form of control parameter which is called limit for rejection of food sources. Now the scout bees replace the abandoned food source with new one using following equation [40].
$$x _ { i j } = x _ { \min \, j } + r a n d [ 0, 1 ] ( x _ { \max \, j } - x _ { \min \, j } )$$
(4)
Based on the above description, it is clear that in ABC search process there are three main control parameters: the number of food sources SN, the limit and the maximum number of cycles. The steps of ABC algorithm are outlined as follow [40]:
Algorithm 1: Artificial Bee Colony Algorithm Initialize all parameters;
Repeat while Termination criteria is not fulfilled
Step 1: Employed bee phase for calculating new food sources.
Step 2: Onlooker bees phase for updating location the food sources based on their amount of nectar.
Step 3: Scout bee phase in order to search new food sources in place of rejected food sources.
Step 4: Remember the best food source identified so far. End of while
Output the best solution found so far.
## 3. MEMETIC ALGORITHMS
Memetic Algorithms (MAs) was the name introduced by P.A. Moscato [41] to a class of stochastic global search techniques that, commonly speaking, combine within the framework of Evolutionary Algorithms (EAs) the benefits of problem-specific local search heuristics and multiagent systems. In ethnic advancement processes, information is processed and magnified by the communicating parts, it is not only transmitted unaltered between entities. This enhancement is realized in MAs by assimilating heuristics, approximation algorithms, metaheuristics, local search techniques, particular recombination operators, truncated exact search methods, etc. In aspect, almost all MAs can be illustrate as a search technique in which a population of optimizing operator co-operate and contest. MAs have been successfully enforced to a wide range of domains that envelop problems in combinatorial optimization, like E. Burke, J. Newall, R. Weare [42] applied memetic algorithm for university exam timetabling. R. Carr, W. Hart, N. Krasnogor, E. Burke, J. Hirst, J. Smith [43] used a memetic evolutionary algorithm for alignment of protein structures. R. Cheng, M. Gen [44] scheduled parallel machine using memetic algorithms. C. Fleurent, J. Ferland [45] developed a graph coloring algorithm with hybridization of Genetic algorithm. It is also applied for travelling salesman problem [46], back routing in telecommunication [47], bin packing [48], VLSI floor planning [49] continuous optimization [50],[51], dynamic optimization [52], multi-objective optimization [53].
Memetic Algorithm play an important role in evolutionary computing as it provide better exploitation capability of search space in local search. Application area of memetic algorithms continuously expending after its inception. Y. Wang et al [54] developed a memetic algorithm for the maximum diversity problem based on tabu search. X. Xue et al [55] Optimize ontology alignment with help of Memetic Algorithm based on partial reference alignment. O. Chertov and Dan Tavrov [56] proposed a memetic algorithm for solution of the
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
## Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
task of providing group anonymity. J. C. Bansal et al [57] incorporated Memetic search in artificial bee colony algorithm. F. Kang et al [58] developed a new memetic algorithm HJABC. I. Fister et al [59] proposed a memetic artificial bee colony algorithm for large-scale global optimization.
Memetic algorithm proposed by Kang et al. [58] incorporates Hooke Jeeves [60] local search method in Artificial Bee Colony algorithm. HJABC is an algorithm with intensification search based on the Hooke Jeeves pattern search and the ABC. In the HJABC, two modification are proposed, one is the fitness ( Fiti ) calculation function of basic ABC is changed and calculated by equation (5) and another is that a HookeJeeves local search is incorporated with the basic ABC.
$$\beta t _ { i } & = 2 - S P + \frac { 2 ( S P - 1 ) ( p _ { i } - 1 ) } { ( N P - 1 ) } & ( 5 ) & \quad \text{First } 1$$
Here pi is the position of the solution in the whole population after ranking, SP glyph<c=0,font=/FNTSBS+TimesNewRomanPSMT> [1.0, 2.0] is the selection pressure. A medium value of SP = 1.5 can be a good choice and NP is the number of solutions.
HJABC contains iterations of exploratory move and pattern move to search optimum result of problem. Exploratory move consider one variable at a time in order to decide appropriate direction of search. The next step is pattern search to speed up search in decided direction by exploratory move. These two steps repeated until the termination criteria meet. The Hooke-Jeeves pattern move is a contentious attempt of the algorithms for the exploitation of promising search directions as it collect information from previous successful search iteration. Algorithm 2 outlines major steps of HJABC [58].

The MeABC algorithm proposed by J. C. Bansal et al [57] inspired by Golden Section Search (GSS) [61]. In MeABC only the best particle of the current swarm updates itself in its proximity. Original GSS method does not use any gradient information of the function to finds the optima of a uni-modal continuous function. GSS processes the interval [a = -1.2, b = 1.2] and initiates two intermediate points:
$$\text{rithm} \quad F _ { 1 } = b - ( b - a ) \times \psi,$$
$$J \text{eves} \quad F _ { 2 } = a + ( b - a ) \times \psi,$$
Here ψ = 0.618 is the golden ratio.
The MeABC contains four steps:
- employed bee phase,
- onlooker bee phase,
- scout bee phase and
- memetic search phase
First three steps are similar to the original ABC [31] except updating of position of an individual. It updates position as per the following equation.
$$\begin{matrix} \cdot & \cdot & \cdot \\ & x ^ { \cdot } _ { i j } = x _ { i j } + \phi _ { i j } ( x _ { i j } - x _ { k j } ) + \psi _ { i j } ( x b e s t j - x _ { i j } ) \\ & & ( 8 ) \\ & \quad \dots & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdots & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \, \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot & \cdot \\ \end{matrix}$$
Where Ѱ ij is a random number in interval [0, C], here C is a positive constant. The detailed working of the MeABC [57] explained in Algorithm 3.
Algorithm 3: MeABC Algorithm
Initialize the parameters.
Repeat while termination criteria meet
Step I: Produce new solutions for the employed bees Step II: Produce the new solutions for the onlookers from the solutions selected depending on pi and evaluate them.
Step III: Determine the abandoned solution for the scout, if exists, and replace it with a new randomly produced solution.
Step IV: Memorize the best solution achieved so far. Phase V: Apply Memetic search as given by [57]
## 4. RANDOMIZED MEMETIC ARTIFICIAL BEE COLONY ALGORITHM
- J. C. Bansal, H. Sharma and S. S. Jadon [17] indicate some drawbacks of population based stochastic algorithms. It is observed that the early convergence or stagnation occurs in ABC. The position update in ABC takes place with help of equation
$$v _ { i j } = x _ { i j } + \phi ( x _ { i j } - x _ { k j } )$$
After a certain number of iterations, normally all probable solutions work within a very small neighborhood. In this case the variation xij -x kj becomes very small and so the enhancement in the position becomes inconsequential. This event is known as the stagnation or premature convergence if the global optimal solution is not present
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
in this small neighborhood. Any population based algorithm is observed as an adequate algorithm if it is swift in convergence and able to explore the large area of the search space. Especially, if a population based stochastic algorithm is able to balance between exploration and exploitation of the search space, then the algorithm is regarded an adequate algorithm. From this point of view, original ABC is not an efficient algorithm [40].
D. Karaboga and B. Akay [40] analyzed the distinct variants of ABC for global optimization and conclude that ABC shows a poor performance and remains incompetent in exploring the search space. The problem of early convergence and stagnation is a matter of severe consideration for evolution a relatively more efficient ABC algorithm. The proposed randomized memetic ABC introduce two new control parameters in memetic search phase.
The proposed RMABC contains four phases. First three phases: employed bee phase, onlooker bee phase and scout bee phase are similar to original MeABC [57]. During fourth phase (memetic search phase), it introduce two new parameters in order to strengthen local search process. Golden section search [61] process controls the step size during updating of best individual in current swarm. In RMABC the GSS processes the interval [a = 1.2, b = 1.2] and generate two intermediate points:
$$f _ { 1 } = \phi _ { 1 } * ( b - ( b - a ) \, * \, \Psi )$$
$$f _ { 2 } = \phi _ { 2 } * ( a + ( b - a ) * \Psi )$$
$$\begin{smallmatrix} ( 1 0 ) \\ ( 1 1 ) \end{smallmatrix}$$
Where
- ɸ 1 is a positive constant in interval [0, 1],
- ɸ 2 is a Negative constant in interval [-1, 0] and
- ψ = 0.618 is the golden ratio.
Opposite sign of ɸ 1 and ɸ 2 make it convenient to explore local search space. Randomly generated value of ɸ 1 and ɸ 2 in specified range avoid stagnation and premature convergence. The proposed population based stochastic algorithm tries to balance between intensification and diversification of the large search space. It arbitrarily navigates almost complete search space during local search phase and inching ahead towards global optimum. In RMABC only the best solution of the current population modify itself in its proximity. Here position update process also modified as shown in equation (8). This modified memetic search phase applied after scout bee phase of original ABC not during local search phase. Algorithm 4 outlines RMABC in detail with description of each step. The symbol and parameters all are taken as it was in original memetic artificial bee colony algorithm [57].
Algorithmn 4: Randomized Memetic ABC Algorithm Initialize the =1, 2, , NS and Evaluate population using populati the
Repeat while termination criteria meet
Generate and evaluate new solutions vj (
$$x _ { j } + \phi ( x _ { j } - x _ { j } )$$
Apply the greedy selection approach for employed bees. the
Grade the population and quantify the fitness by if (fun\_val >= 0)
$$\_ _ { \nu a l + 1 }$$
else
$$\hat { \ f i t } = ( 1 + \ f a b s { ( \frac { 1 } { \gamma _ { i o n } } ) }$$
Quantify the probability P for the solutions x with fitness fît; by
$$P _ { \psi } \cdot \frac { \hat { \ f u t } } { \succeq \succeq }$$
Generate the new solutions X for the onlooker bees from the solutions selected based on P. and assess them using
Determine the discarded solution for the scout, if new randomly produced and
Retain the best solution Xbest attained so far . Memetic search phase
Initialize a= -1.2 and b = 1.2
Repeat while (la-bk<e)
Generate two new solutions Xnew! and Xnw2 using fp and f, respectively according to MeABC
Calculate f(Xnewl) and f(Xnew2) for objective function if (f(Xnewi) < f(Xnew2)) then b = fz
$$\text{ then } X _ { \text{best} } < X _ { \text{new} }$$
else
$$\text{then} \, X _ { \text{best} } < X _ { \text{new} }$$
Table 1 : Test Problems
| | | FITOI |
|--------|------|---------|
| Shuted | 100] | |
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
## 5. Experimental results and discussion
## 5.1 Test problems under consideration
In order to analyze the performance of RMABC, 9 different global optimization problems (f1 to f ) 9 are selected (listed in Table 1). These are continuous optimization problems and have different degrees of complexity and multimodality. Test problems f1 -f8 are taken from [62] and test problems f is taken from [63] 9 with the associated offset values.
## 5.2 Experimental setting
To prove the efficiency of RMABC, it is compared with ABC and recent variants of ABC named MeABC [57], Gbestguided ABC (GABC) [64], Best-So-Far ABC (BSFABC) [65], HJABC [58] and Modified ABC (MABC) [66]. To test Randomized memetic ABC (RMABC) over considered problems, following experimental setting is adopted:
- Colony size NP = 50 [57],
- ɸ ij = rand[ -1, 1],
- Number of food sources SN = NP/2,
- The stopping touchstone is either maximum number of function evaluations (which is set to be 200000) is reached or the acceptable error (outlined in Table 1) has been achieved,
- The number of simulations/run =100,
- Value of termination criteria in memetic search phase is set to be ǫ = 0.01.
Parameter settings for the algorithms ABC, MeABC, GABC, BSFABC, HJABC and MABC are similar to their original research papers.
## 5.3 Results Comparison
Numerical results of RMABC with experimental setting as per subsection 5.2 are outlined in Table 2. Table 2 show the comparison of results based on standard deviation (SD), mean error (ME), average function evaluations (AFE) and success rate (SR) are reported. Table 2 shows that most of the time RMABC outperforms in terms of efficiency (with less number of function evaluations) and accuracy as compare to other considered algorithms.
- limit = 1500 [57],
Table 2: Comparison of the results of test problems
| Function | | | MeABC | ABC | | | BSFABC | |
|------------|-----|----------|-----------|-----------|-----------|-----------|-----------|-----------|
| | SD | 3 SSE-04 | | | | | | |
| | ME | | | | | | | |
| | | | | | | | | 1 99E-06 |
| | | | 5.24E-06 | | | | | |
| | AFE | | | 15619.5 | | | 14278 | |
| | | | | | | 100 | | |
| | SD | | | | | | | |
| | | | 9.16E-06 | | | | | |
| | | | | 2 13E-06 | | | 241E-06 | 8 14E-07 |
| | ME | 9.06E-06 | 9.1OE-06 | 7.35E-06 | 9 18E-06 | 8 1OE-06 | 7 13E-06 | |
| | AFE | 11261.3 | 13031.58 | 22016 | 17368 82 | 14283 | 28573 5 | 20985.5 |
| | SR | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| f6 | SD | 3 [OE-06 | 2 9OE-06 | 1 73E-06 | 2 99E-06 | 292 E-06 | 6 O7E-05 | 3 06E-06 |
| f6 | ME | 4 94E-06 | 5.14E-06 | 8 58E-06 | 4 76E-06 | 5 14E-06 | 2 19E-05 | 5.24E-06 |
| f6 | AFE | 1594.35 | 2688 15 | 15768 28 | 4839 56 | 9344 1 | 50222 41 | 10082 84 |
| f6 | SR | 100 | 100 | 100 | 100 | 100 | 92 | 100 |
| | SD | 2 62E-03 | 2 42E-03 | 1 O7E-01 | 252E-03 | 1 24E-02 | 299E-02 | |
| | ME | 6 99E-03 | | | 7 14E-03 | 1 58E-02 | | 1 26E-02 |
| | AFE | 29441.96 | 30813 41 | 198058 11 | 43566 59 | 154523 83 | 155548 21 | 144033 7 |
| | SR | 100 | 100 | | 100 | 42 | 47 | 54 |
| fs | SD | 1 98E-05 | 2 O3E-05 | 132E-05 | | 3 S7E-05 | 8 16E-05 | 6 84E-05 |
| fs | ME | 8 3OE-05 | 8 17E-05 | 1.69E-04 | 1 18E-04 | 9 27E-05 | 1 45E-04 | 1 9OE-04 |
| fs | AFE | 43472.89 | 47100 43 | 17835583 | 127096 42 | 98389 57 | 140918 92 | 191449 61 |
| fs | SR | 100 | 100 | 23 | 58 | 90 | 51 | 10 |
| | SD | 3 86E-02 | | 9 44E-01 | 7 24E-01 | 7 56E-02 | 563+00 | 9 67E-01 |
| | ME | 9 82E-02 | | 6 79E-01 | 5 79E-01 | 9 3OE-02 | 2 96E+00 | 6 8OE-01 |
| | AFE | 98163.41 | 103949.03 | 175270.8 | 151927.05 | 100594,41 | 185221.92 | 163969.65 |
| | SR | 91 | 97 | 24 | 46 | 93 | 13 | 39 |
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
Some more intensive analyses based on performance indices have been carried out for results of ABC and its variants in figure 2 to 8. Table 4 proves that the proposed method is superior to others considered algorithms. The proposed RMABC algorithm drastically reduces number of function evaluation for al problems. Entries shown in bold font in table 2 represents improved solutions. The proposed algorithm sometimes reduces number of AFE upto 40%. Here except function f2, each time it improves in terms of AFE.
## 6. Applications of RMABC to Engineering Optimization Problem
To see the robustness of the proposed strategy, a well known engineering optimization problems, namely, Compression Spring [67] [68] is solved. The considered engineering optimization problem is described as follows:
## 6.1 Compression Spring
The considered engineering optimization application is compression spring problem [48], [56]. This problem minimizes the weight of a compression spring, subject to constraints of minimum bending, prune stress, deluge frequency, and limits on outside diameter and on design variables. There are three important design variables: the diameter of wire x1, the diameter of the mean coil x2, and the count of active coils x3. Here it is presented in simplified manner. The mathematical formulation of this problem is outlined below:
$$x _ { 1 } \in \{ 1, 2, 3, \quad \ \., 7 0 \} g r a n u l a r i t y _ { 1 }$$
$$A _ { 1 } \subseteq \{ 1, 4, \mathcal { J }, \dots \dots \dots, \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \cdots \dots \dots, \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J} \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \matrix \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \kappa \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \mathcal { J } \text{ }$$
$$x _ { 2 } \in [ 0. 6 ; 3 ], x _ { 3 } \in [ 0. 2 0 7 ; 0. 5 ] g r a n u l a r i t y _ { 0. 0 0 1 }$$
And four constraints
$$g _ { 1 } \coloneqq \frac { 8 c _ { f } F _ { \max } x _ { 2 } } { \pi x _ { 3 } ^ { 3 } } - S \leq 0, g _ { 2 } \coloneqq l _ { f } - l _ { \max } \leq 0 \\ - \quad - \quad -$$
$$g _ { 3 } \coloneqq \sigma _ { p } - \sigma _ { p m } \leq 0, g _ { 4 } \coloneqq \sigma _ { _ { w } } - \frac { F _ { m } a x - F _ { p } } { K } \leq 0$$
Where:
$$& \text{where} \colon \\ & c _ { f } = 1 + 0. 7 5 \frac { x _ { 3 } } { x _ { 2 } - x _ { 3 } } + 0. 6 1 5 \frac { x _ { 3 } } { x _ { 2 } } \\ & F _ { \max } = 1 0 0 0, S = 1 8 9 0 0 0, l _ { f } = \frac { F _ { \max } } { K } + 1. 0 5 ( x _ { 1 } + 2 ) x _ { 3 }$$
$$l _ { \max } = 1 4, \sigma _ { _ { p } } = \frac { F _ { _ { p } } } { K }, \sigma _ { _ { p m } } = 6, F _ { _ { p } } = 3 0 0$$
$$K = 1 1. 5 \times 1 0 ^ { 6 } \frac { x _ { 3 } ^ { 4 } } { 8 x _ { 1 } x _ { 2 } ^ { 3 } }, \sigma _ { w } = 1. 2 5 \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot$$
And the function to be minimized is
$$\frac { f _ { 1 0 } ( X ) = \pi ^ { 2 } \frac { x _ { 2 } x _ { 3 } ^ { 2 } ( x _ { 1 } + 2 ) } { 4 } } { }$$
The best known solution is (7, 1.386599591, 0.292), which gives the fitness value f = 2.6254. Acceptable error for compression spring problem is 1.0 E -04.
Table 3: Comparison of the results of Compression spring problem (f10)
| Algorithm | SD | ME | AFE | SR |
|-------------|----------|----------|----------|------|
| RMABC | 0.000421 | 0.000488 | 38052.3 | 99 |
| MeABC | 0.00237 | 0.00171 | 123440 | 62 |
| ABC | 0.0117 | 0.0136 | 187602 | 10 |
| HJABC | 0.00153 | 0.00117 | 109737 | 70 |
| GABC | 0.0095 | 0.00864 | 189544 | 11 |
| BSFABC | 0.00308 | 0.0302 | 200031 | 0 |
| MABC | 0.00659 | 0.00528 | 181705 | 15 |
Average Function Evaluation
Figure 2: Comparison of AFE for function f1
Figure 3: Comparison of AFE for function f3
Figure 4: Comparison of AFE for function f4

## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
Figure 5: Comparison of AFE for function f5
Figure 6: Comparison of AFE for function f6
Figure 8: Comparison of AFE for function f10
## 7. CONCLUSION
Here in this paper, two new parameters, ɸ 1 and ɸ 2 are introduced in memetic search phase of MeABC. Value of these parameters is arbitrarily chosen every time so obtained modified MeABC is named as Randomized Memetic ABC (RMABC). During its memetic search phase, Golden Section Search method is used for generating the new solutions nearby the best solution. Due to newly introduced parameter ( ɸ 1 and ɸ 2 ) new solutions are evolved in the proximity the best solution. Further, the modified strategy is also applied to the recent variants of ABC, namely, GABC, HJABC, BSFABC and MABC. With the help of experiments over test problems and a well known engineering optimization application, it is shown that the inclusion of the proposed strategy in the memetic ABC improves the reliability, efficiency and accuracy as compare to their original version. Table 4 show that the proposed RMABC is able solves almost all the considered problems.
Figure 7: Comparison of AFE for function f9
Table 4: Summary of table 2 and 3 outcome
| Function | RMABC Vs MeABC | RMABCVs ABC | RMABC HJABC | Vs | RMABC GABC | Vs | RMABC BSFABC | Vs | RMABC MABC |
|------------------------|------------------|---------------|---------------|------|--------------|------|----------------|------|--------------|
| f 1 | + | + | + | | + | | + | | + |
| f 2 | + | + | + | | + | | + | | + |
| f 3 | + | + | + | | + | | + | | + |
| f 4 | + | + | + | | + | | + | | + |
| f 5 | + | + | + | | + | | + | | + |
| f 6 | + | + | + | | + | | + | | + |
| f 7 | + | + | + | | + | | + | | + |
| f 8 | + | + | + | | + | | + | | + |
| f 9 | - | + | + | | + | | + | | + |
| f 10 | + | + | + | | + | | + | | + |
| Total number of + sign | 9 | 10 | 10 | | 10 | | 10 | | 10 |
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
## References
- [1] Georgieva and I. Jordanov, 'Global optimization based on novel heuristics, low-discrepancy sequences and genetic algorithms,' Eur. J. Oper. Res., vol. 196, pp. 413-422, 2009.
- [18] S. Das, A. Abraham, U.K. Chakraborty, and A. Konar, 'Differential evolution using a neighborhoodbased mutation operator.' Evolutionary Computation, IEEE Transactions on, 13(3):526-553, 2009.
- [2] J. Kennedy and R.C. Eberhart, 'Particle swarm optimization,' in: Proc. of IEEE International Conference on Neural Networks, Piscataway, NJ. pp. 1942-1948, 1995.
- [3] M. Dorigo, 'Optimization, Learning and Natural Algorithms,' PhD thesis, Politecnico di Milano, Italy, 1992.
- [4] W.J. Bell, 'Searching Behaviour: The Behavioural Ecology of Finding Resources,' Chapman & Hall, London, 1991.
- [5] A.P. Engelbrecht, 'Fundamentals of Computational Swarm Intelligence,' Wiley, 2005.
- [6] J. Holland, 'Adaptation in Natural and Artificial systems,' University of Michigan Press, Ann Anbor, 1975.
- [7] C. Blum and A. Roli, 'Metaheuristics in combinatorial optimization: Overview and conceptural comparison,' ACM Comput. Surv., 35, 268-308, 2003.
- [8] E.G. Talbi, Metaheuristics: From Design to Implementation, Wiley, 2009.
- [9] X.S. Yang, Nature-Inspired Metaheuristic Algorithms, Luniver Press, 2008.
- [10] X.S. Yang and S.Deb, 'Engineering optimization by cuckoo search,' Int. J. Math. Modelling & Num. Optimization, 1, 330-343, 2010.
- [11] X.S. Yang, 'A new metaheuristic bat-inspired algorithm,' in: Nature Inspired Cooperative Strategies for Optimization. (Eds. J. R. Gonzalez et al.), Springer, SCI 284, 65-74 (2010b).
- [12] A. Ayesh, 'Swarm-based emotion modelling,' Int. J. Bio-Inspired Computation, 118-124, 2009.
- [13] R. Gross and M. Dorigo, 'Towards group transport by swarms of robots,' Int. J. Bio-Inspired Computation, 1, 1-13, 2009.
- [14] J. Kennedy, R.C. Eberhart, Swarm intelligence, Academic Press, 2001.
- [15] S. Kumar, V.K. Sharma, and R. Kumari. "A Novel Hybrid Crossover based Artificial Bee Colony Algorithm for Optimization Problem." International Journal of Computer Applications 82, 2013.
- [16] S. Pandey and S. Kumar "Enhanced Artificial Bee Colony Algorithm and It's Application to Travelling Salesman Problem." HCTL Open International Journal of Technology Innovations and Research, Volume 2, 2013:137-146.
- [17] J.C. Bansal, H. Sharma and S.S. Jadon "Artificial bee colony algorithm: a survey." International Journal of Advanced Intelligence Paradigms 5.1 (2013): 123159.
- [19] R.C. Eberhart, Y. Shi, and J. Kennedy. Swarm intelligence. Elsevier, 2001.
- [20] D.B. Fogel. 'Introduction to evolutionary computation,' Evolutionary Computation: Basic algorithms and operators, 1:1, 2000.
- [21] L.J. Fogel, A.J. Owens, and M.J. Walsh. Artificial intelligence through simulated evolution. 1966.
- [22] J.R. Koza. Genetic programming: A paradigm for genetically breeding populations of computer programs to solve problems. Citeseer, 1990.
- [23] M.G.H. Omran, A.P. Engelbrecht, and A. Salman. 'Differential evolution methods for unsupervised image classification.' In Evolutionary Computation, 2005. The 2005 IEEE Congress on, volume 2, pages 966-973. IEEE, 2005.
- [24] A. Ozturk, S. Cobanli, P. Erdogmus, and S. Tosun. 'Reactive power optimization with artificial bee colony algorithm.' Scientific Research and Essays, 5(19):2848-2857, 2010.
- [25] K.V. Price, R.M. Storn, and J.A. Lampinen. 'Differential evolution: a practical approach to global optimization,' Springer Verlag, 2005.
- [26] AK Qin, VL Huang, and PN Suganthan. Differential evolution algorithm with strategy adaptation for global numerical optimization. Evolutionary Computation, IEEE Transactions on, 13(2):398-417, 2009.
- [27] I. Rechenberg. Cybernetic solution path of an experimental problem. Royal aircraft establishment, library translation 1122, 1965. reprinted in evolutionary computationthe fossil record, db fogel, ed., chap. 8, pp297-309, 1998.
- [28] T. Rogalsky, S. Kocabiyik, and RW Derksen. Differential evolution in aerodynamic optimization. Canadian Aeronautics and Space Journal, 46(4):183190, 2000.
- [29] R. Storn and K. Price. Differential evolution-a simple and efficient adaptive scheme for global optimization over continuous spaces. International computer science institute - publications - TR, 1995.
- [30] A. Baykasoglu, L. Ozbakir, and P. Tapkan, 'Artificial bee colony algorithm and its application to generalized assignment problem,' In Swarm Intelligence, Focus on Ant and Particle Swarm Optimization, ITech Education and Publishing, Vienna, Austria, pp. 113-144, 2007.
[31] D.Karaboga, 'An idea based on bee swarm for numerical optimization,' Tech. Rep. TR-06, Erciyes University , Engineering Faculty , Computer Engineering Department, 2005.
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
[32] D. Karaboga and B. Basturk. 'A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm,' J. Global Optim., vol. 39, pp. 459-471, 2007.
[45] C. Fleurent, J. Ferland, 'Genetic and hybrid algorithms for graph coloring.' Annals of Operations Research 63, 437-461 (1997).
[33] D. Karaboga and B. Basturk. 'On the performance of artificial bee colony (ABC) algorithm,' Appl. Soft Comput., vol. 8, pp. 687-697, 2008.
[34] N. Karaboga, 'A new design method based on artificial bee colony algorithm for digital IIR filters,' J. Franklin I., vol. 346, pp. 328-348, May 2009.
[35] D. Karaboga, B. Akay, and C. Ozturk. "Artificial bee colony (ABC) optimization algorithm for training feed-forward neural networks." Modeling decisions for artificial intelligence. Springer Berlin Heidelberg, 2007. 318-329.
[36] A. Singh, 'An artificial bee colony algorithm for the leafconstrained minimum spanning tree problem,' Appl. Soft Comput., vol. 9, pp. 625-631, March 2009.
[37] R. S. Rao, S. V. L. Narasimham, and M. Ramalingaraju. "Optimization of distribution network configuration for loss reduction using artificial bee colony algorithm." International Journal of Electrical Power and Energy Systems Engineering 1.2 (2008): 116-122.
- [38] M. Sonmez, "Artificial bee colony algorithm for optimization of truss structures." Applied Soft Computing 11.2 (2011): 2406-2418.
[39] F. Kang, J. Li, and Q. Xu, 'Structural inverse analysis by hybrid simplex artificial bee colony algorithms,' Comput. Struct., vol. 87, pp. 861-870, July 2009.
[40] D. Karaboga and B. Akay, 'A comparative study of artificial bee colony algorithm'. Applied Mathematics and Computation, 214(1):108-132, 2009.
[41] P. Moscato, 'On evolution, search, optimization, genetic algorithms and martial arts: Towards memetic algorithms.' Tech. Rep. Caltech Concurrent Computation Program, Report. 826, California Inst. of Tech., Pasadena, California, USA (1989).
[42] E. Burke, J. Newall, R. Weare.: A memetic algorithm for university exam timetabling. In: E. Burke, P. Ross (eds.) The Practice and Theory of Automated Timetabling, Lecture Notes in Computer Science, vol. 1153, pp. 241-250. Springer Verlag (1996).
[43] R. Carr, W. Hart, N. Krasnogor, E. Burke, J. Hirst, J. Smith, 'Alignment of protein structures with a memetic evolutionary algorithm,' In: Proceedings of the Genetic and Evolutionary Computation Conference. Morgan Kaufman (2002).
[44] R. Cheng, M. Gen, 'Parallel machine scheduling problems using memetic algorithms.' Computers & Industrial Engineering 33(3-4), 761-764 (1997).
[46] G. Gutin, D. Karapetyan, N. Krasnogor, 'Memetic algorithm for the generalized asymmetric traveling salesman problem.' In: M. Pavone, G. Nicosia, D. Pelta, N. Krasnogor (eds.) Proceedings of the 2007Workshop On Nature Inspired Cooperative Strategies for Optimisation. Lecture Notes in Computer Science (LNCS), vol. to appear. Springer (2007)
[47] L. He, N. Mort, 'Hybrid genetic algorithms for telecomunications network back-up routeing.' BT Technology Journal 18(4) (2000)
[48] C. Reeves, 'Hybrid genetic algorithms for binpacking and related problems.' Annals of Operations Research 63, 371-396 (1996)
[49] M. Tang, X. Yao, 'A memetic algorithm for VLSI floorplanning.' Systems, Man, and Cybernetics, Part B, IEEE Transactions on 37(1), 62-69 (2007). DOI 10.1109/TSMCB.2006.883268.
[50] W. E. Hart, 'Adaptive Global Optimization with Local Search.' Ph.D. Thesis, University of California, San Diego (1994)
[51] G. M. Morris,D. S. Goodsell,R. S. Halliday, R. Huey, W. E. Hart, R. K. Belew, A. J. Olson,: 'Automated docking using a lamarkian genetic algorithm and an empirical binding free energy function.' J Comp Chem 14, 1639-1662 (1998)
[52] H. Wang, D. Wang, and S. Yang. "A memetic algorithm with adaptive hill climbing strategy for dynamic optimization problems." Soft Computing 13.8-9 (2009): 763-780.
[53] D. Liu, K. C. Tan, C. K. Goh, W. K. Ho, 'A multiobjective memetic algorithm based on particle swarm optimization.' Systems, Man, and Cybernetics, Part B, IEEE Transactions on 37(1), 42-50 (2007).
[54] Y Wang, JK Hao, F Glover, Z Lü, 'A tabu search based memetic algorithm for the maximum diversity problem.' Engineering Applications of Artificial Intelligence 27 (2014): 103-114.
[55] X. Xue, Y. Wang, and A. Ren. 'Optimizing ontology alignment through Memetic Algorithm based on Partial Reference Alignment.' Expert Systems with Applications 41.7 (2014): 3213-3222.
[56] O. Chertov and Dan Tavrov. "Memetic Algorithm for Solving the Task of Providing Group Anonymity." Advance Trends in Soft Computing. Springer International Publishing, 2014. 281-292.
[57] J.C. Bansal, H. Sharma, K.V. Arya and A. Nagar, 'Memetic search in artificial bee colony algorithm.' Soft Computing (2013): 1-18.
[58] F Kang, J Li, Z Ma, H Li , 'Artificial bee colony algorithm with local search for numerical optimization.' Journal of Software 6.3 (2011): 490497.
## International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)
Web Site: www.ijettcs.org Email: [email protected], [email protected] Volume 3, Issue 1, January - February 2014 ISSN 2278-6856
- [59] I. Fister, I. Fister Jr, J. Bres, V. Zumer. "Memetic artificial bee colony algorithm for large-scale global optimization." Evolutionary Computation (CEC), 2012 IEEE Congress on. IEEE, 2012.
- [60] R. Hooke and T.A. Jeeves. 'Direct search solution of numerical and statistical problems.' Journal of the ACM, 8(2):212-229, 1961.
- [61] J. Kiefer, 'Sequential minimax search for a maximum.' In Proc. Amer. Math. Soc, volume 4, pages 502-506, 1953.
- [62] M.M. Ali, C. Khompatraporn, and Z.B. Zabinsky. 'A numerical evaluation of several stochastic algorithms on selected continuous global optimization test problems.' Journal of Global Optimization, 31(4):635-672, 2005.
- [63] P.N. Suganthan, N. Hansen, J.J. Liang, K. Deb, YP Chen, A. Auger, and S. Tiwari. 'Problem definitions and evaluation criteria for the CEC 2005 special session on real-parameter optimization.' In CEC 2005, 2005.
- [64] G. Zhu and S. Kwong, 'Gbest-guided artificial bee colony algorithm for numerical function optimization.' Applied Mathematics and Computation, 217(7):3166-3173, 2010.
- [65] A. Banharnsakun, T. Achalakul, and B. Sirinaovakul, 'The best-so-far selection in artificial bee colony algorithm.' Applied Soft Computing, 11(2):2888-2901, 2011.
- [66] B. Akay and D. Karaboga. 'A modified artificial bee colony algorithm for real-parameter optimization.' Information Sciences, doi:10.1016/j.ins.2010.07.015, 2010.
- [67] G.C. Onwubolu and B.V. Babu. 'New optimization techniques in engineering.' Springer Verlag, 2004.
- [68] E. Sandgren, 'Nonlinear integer and discrete programming in mechanical design optimization.' Journal of Mechanical Design, 112:223, 1990. | null | [
"Sandeep Kumar",
"Vivek Kumar Sharma",
"Rajani Kumari"
] | 2014-08-01T08:49:25+00:00 | 2014-08-01T08:49:25+00:00 | [
"cs.NE"
] | Randomized Memetic Artificial Bee Colony Algorithm | Artificial Bee Colony (ABC) optimization algorithm is one of the recent
population based probabilistic approach developed for global optimization. ABC
is simple and has been showed significant improvement over other Nature
Inspired Algorithms (NIAs) when tested over some standard benchmark functions
and for some complex real world optimization problems. Memetic Algorithms also
become one of the key methodologies to solve the very large and complex
real-world optimization problems. The solution search equation of Memetic ABC
is based on Golden Section Search and an arbitrary value which tries to balance
exploration and exploitation of search space. But still there are some chances
to skip the exact solution due to its step size. In order to balance between
diversification and intensification capability of the Memetic ABC, it is
randomized the step size in Memetic ABC. The proposed algorithm is named as
Randomized Memetic ABC (RMABC). In RMABC, new solutions are generated nearby
the best so far solution and it helps to increase the exploitation capability
of Memetic ABC. The experiments on some test problems of different complexities
and one well known engineering optimization application show that the proposed
algorithm outperforms over Memetic ABC (MeABC) and some other variant of ABC
algorithm(like Gbest guided ABC (GABC),Hooke Jeeves ABC (HJABC), Best-So-Far
ABC (BSFABC) and Modified ABC (MABC) in case of almost all the problems. |
1408.0103v1 | ## Resistive switching in ultra-thin La0.7Sr0.3MnO3 / SrRuO3 superlattices
- S. Narayana Jammalamadaka 1,2 , Johan Vanacken and V. V. Moshchalkov 1 1
- 1 INPAC - Institute for Nanoscale Physics and Chemistry, K.U. Leuven, Celestijnenlaan 200D, B-3001 Leuven, Belgium
- 2 Magnetic Materials and Device Physics Laboratory, Department of Physics, Indian Institute of Technology Hyderabad, Hyderabad, Andhra Pradesh, PIN - 502 205, India.
Corresponding author: [email protected]
Superlattices may play an important role in next generation electronic and spintronic devices if the key-challenge of the reading and writing data can be solved. This challenge emerges from the coupling of low dimensional individual layers with macroscopic world. Here we report the study of the resistive switching characteristics of a of hybrid structure made out of a superlattice with ultrathin layers of two ferromagnetic metallic oxides, La0.7Sr0.3MnO3 (LSMO) and SrRuO3 (SRO). Bipolar resistive switching memory effects are measured on these LSMO/SRO superlattices, and the observed switching is explainable by ohmic and space charge-limited conduction laws. It is evident from the endurance characteristics that the on/off memory window of the cell is greater than 14, which indicates that this cell can reliably distinguish the stored information between high and low resistance states. The findings may pave a way to the construction of devices based on nonvolatile resistive memory effects.
Keywords: Superlattice, resistive switching, random access memory, memory effects, ultra-thin films
Reaching closely to the limitations of Silicon-based technologies, research is driven by the quest of developing smaller, faster, cheaper and more capable electronic devices . In this quest, devices 1 which reproducibly switch their resistance state between a high resistance state and a low resistance state with respect to the voltage sweep (Resistive Random Access Memory devices, RRAM) have generated tremendous interest due to their low power consumption, high write/read speed, simple structure and high scalability characteristics 2-4 . The resistance switching can occur in different manners, i.e. a switching is called unipolar if the switching process does not depend on the polarity of voltage and current signal . In contrast, if the switching depends on the polarity 2 it is called bipolar resistive switching . Several reports have shown such resistive switching 2 characteristics on metal oxide films 5-8 , organic films and thin film based heterostructures 9 10 . It is however expectable that superlattice structures with few unit cells thick layers of metal oxides merge the low dimensionality (~10 -9 m) of the individual layer thicknesses with the utility of large - scale films that can be handily linked to the real world 11 . Hence, one can establish a unique and potentially important stable resistance switching throughout transport measurement in a metal oxide superlattice structure.
Motivated by the above, here La0.7Sr0.3MnO3 (LSMO) / SrRuO3 (SRO) superlattices grown on SrTiO3(100) single crystals are studied for resistive switching and endurance characteristics. La0.7Sr0.3MnO3 (LSMO) 12 and SrRuO3 (SRO) 13 exhibit ferromagnetic order below their bulk Curie temperatures of 370 and 160 K, respectively. In these superlattices, the magnetically soft LSMO layers, are antiferromagnetically coupled with the magnetically hard SRO layers below 150 K, when all layers order ferromagnetically. In these superlattices by changing the magnetization state with a suitably applied magnetic field, exchange bias effects have been observed 14 - 16 . Having superlattice structure with 30 layers of LSMO and SRO allowed us to have more magnetic signal and hence significant exchange bias field, this may indeed allow us to control resistive switching behavior, which is of our future goal.
Keeping the above goal in mind, in this manuscript, we would like to demonstrate the resistive switching characteristics of LSMO/SRO superlattices which have not been studied until now. Precisely, in the present work we demonstrate: (a) resistive switching characteristics in a LSMO/SRO superlattice, with a validation of these results presenting various models; (b) endurance characteristics of the superlattice by changing the resistance state between on-state and off-state. Salient features of the present work are that a stable resistive switching is observed while sweeping the voltage and the current-voltage characteristics are well explained by space charge limited conduction (SCLC) model. Apart from that we also present results revealing a low-voltage (0.5 - 0.7 V) switching mechanism. Pertinent to the endurance characteristics, the on/off memory window of the cell is about 14, which indicates that this cell can be used to store information in the high- and low-resistance state.
Pulsed laser deposition technique, employing a KrF excimer laser, was used to fabricate a superlattice of La0.7Sr0.3MnO3/SrRuO3. Oxygen partial pressure and substrate temperature were 0.14 mbar and 650°C, respectively. In total 30 layers of La0.7Sr0.3MnO3 and SrRuO3 with thicknesses of 2.3 nm and 3.3 nm, respectively, were grown on SrTiO3 (001) substrate. Details about the fabrication and the properties of such superlattices can be found in Ref. 17, 18. X-ray diffraction, atomic force microscopy, high resolution transmission electron microscope and high angle annular dark field scanning transmission electron microscopy (HAADF-STEM) were used to investigate the microstructure of the superlattice 17, 18 . HAADF-STEM micrograph of the La0.7Sr0.3MnO3 / SrRuO3 superlattice is shown in Figure 1. Misfit dislocations were found at the interfaces between the La0.7Sr0.3MnO3 and SrRuO3 layers. However, the interfacial atomic layers were affected by intermixing; both A-site (La/Sr) and B-site (Mn/Ru) cations intermix in 1-2 unit cells across the interface, as marked by the rectangles in Fig 1(b). The contacts (Fig. 1(a)) to the top layer were made by the wire bonder, the distance between two planar electrodes is 1 mm. Using Keithley 2400, two probe method was employed in order to measure I - V characteristics.
All the measurements were carried out at room temperature. Top SRO layer showed the resistance ~ K Ω . At this point it is worth quoting about the nature of SRO layer with different superlattice structures where essentially SRO layer behaved vividly in its bulk and ultra-thinfilm form. On top of that in general an important issue on using ultrathin films of metal oxides is the significant enhancement in the resistivity, which has been clearly manifested in SRO thin films 1922 .
Before the forming process, resistive switching at low voltages is not consistently observed in LSMO/SRO superlattice, between -1 V and +1 V. In order to make filaments between the electrodes, I - V characteristics were measured by sweeping voltage from 0 to 20 V with a current compliance of 10 mA. Essentially, the electro-forming process is necessary to get a stable and reproducible resistive switching behavior in the resistive switching devices. Compliance current of 10 mA is used to avoid the dielectric break down of the device during the forming process due to leakage current which may arise by the application of very high voltages. Essentially, during this process, current -limited electric breakdown is induced in the superlattice and subsequently, conductive ON state and a less conductive OFF states are streamlined. Immediately after the forming process, keeping the current compliance of 10 mA, the voltage was varied in the range of -1 and 1 V. Basically, stable switching of the voltages is observed in the low voltage limit. Starting with negative field sweep, initially the device is at low resistance state (LRS). During the voltage sweep rate, the device continued to be in the LRS up to - 0.5 V. At - 0.5 V, a sudden drop in the leakage current is evident as a consequence of the high resistance state (HRS). This process is called as RESET switching. Further increase in the voltage causes the device to stay at the same HRS up to - 1 V. While in the reverse run, the device stayed at HRS up to the positive 0.7 V and above which there is a sudden increase in the leakage current as a result of change in the resistance state to LRS. This process is called as SET process. Above 0.7 V, the leakage current is constant as a result of compliance limit. From positive 1 V, the device stayed in low resistance state up to 0 V. This kind of change in resistance state from LRS - HRS - LRS is a signature of bi - polar resistive switching 23-25 . This indeed means that in order to change the resistance state, voltage polarity needs to be changed. It is evident from the Fig. 2(a) that the resistive switching behavior is quite stable. Above procedure was repeated for 20 times to observe the stable RS. The arrows on the figure show the sequence of the applied voltage. Fig. 2(b) shows the same graph in logarithmic plot. As soon as we increased the compliance limit until 100 mA, we could see dielectric breakdown in the device. Hence, we fixed the compliance limit to 10 mA for all the devices.
To probe the current conduction mechanism of LSMO/SRO superlattices, I - V characteristics are analyzed with respect to space charge limited conduction (SCLC) mechanism 26, 27 . Logarithmic I - V plots for both the positive and negative regions are depicted in Fig. (3a, 3b).
Fig. 3(a) shows the log - log plot of such device. During the positive voltage sweeping, as we mentioned, the device is at high resistance state and changed its memory state to LRS. The initial region of the log - log plot is followed the linear ohmic behavior. In contrast, the fitting results of HRS are more complicated and exhibit different switching mechanism. Essentially, the charge transfer mechanism comprises of three parts, namely, ohmic region ( I V ∝ ), the Child's law region ( 2 I V ∝ ), and the steep current increase region, which is in accordance with the classical space charge limited conduction (SCLC) 26, 27 . Fig. 3(b) shows the log - log plot pertinent to the negative voltage sweep region. In the negative voltage sweeping region, the behavior in LRS is similar to the positive voltage sweep region, however, the variation in the HRS is different. Such behavior in HRS region can be explained by a model called weak filamentary conduction channels 28 . According to this model, charge transport consists of two parts: weak filamentary channels current (If) and the current in bulk (Ii). In this model, when the temperature is below 250 K, If dominates in HRS 28 , however, in the present case, since the measurements were conducted at room temperature, current in HRS goes with the SCLC principle. Ultimately, the conduction behaviors in both the LRS and HRS also suggest that the high conductivity in on-state device should be a confined, filamentary effect rather than a homogenously distributed one, hinting that the active region where the actual phenomena happens is much smaller than the device size.
Endurance characteristics of LSMO/SRO superlattice memory cell are shown in fig. 3(c). Memory window of the cell is found using the formula (ROFF-RON)/RON ≈ ROFF/RON, is nearly 14, such a huge memory margin essentially makes the device circuit capable to distinguish between the storage information 1 and 0. During the cycling there exist scattering of the resistance in
HRS, however, due to high R OFF/ R ON ratio of the present device, this kind of scattering may be admitted. It can be seen that the memory margin keeps beyond 14 times during cycling, and the cell shows little degradation even after repeated sweep cycles. Hence, the endurance measurements essentially ensure the switching between on and off states is highly controllable, reversible and reproducible. We could switch the device for about 30 - 40 times. No electrical power is required to maintain the resistance state within the given state after the device switched on or off.
Fig. 3(d) shows the threshold voltage of SET and RESET process when the device is repeatedly switched between high resistance and low resistance states. From our observation, it is evident that the VSET varies from 0.5 to 1 V whereas VRESET varies between -0.5 to -0.6 V, which indicates more variation for VSET probably due to the filamentary switching. Zeng Wang et. al, 29 reported that competition between different filaments paths can decide the formation of key conducting filaments in SET process. So it is more random than break of filaments in the reset process resulting in different variation between VRESET and VSET.
Conceivable mechanisms for the resistive switching behaviors discussed until now in LSMO/SRO superlattices can be interpreted by the conducting filament model 30, 31 . We believe that the actual phenomenon happens in the top layer of the superlattice. The possible mechanism could be that under a high electrical field, oxygen ions in the top layer of the superlattice (SRO) might have migrated from the lattice positions, as a result of thermal effects and such oxygen vacancies can be seen in the form of defects. This would eventually results change in the stoichiometry and enhancement in the electronic conductivity of the superlattice. Aforementioned vacancies form local paths/filaments which might eventually switch the device to low resistance state. The change of the device from low resistance state to high resistive state is possible by rupture of filament, which essentially lead the switching of a device from a LRS to a high resistive state (HRS, or 'OFF state') is labeled as RESET process. We believe that filaments in the present superlattice might have formed in the top layer as this device consists of planar structure. Finally, superlattice structure with LSMO/SRO allowed us to get stable switching. Schematic of such phenomenon is shown in Fig. 4. Moreover, as the superlattice structure merges the low dimensionality of the individual layer thicknesses with the utility of large - scale films, we could achieve unique and potentially important stable resistance switching throughout transport measurement.
In conclusion, a stable bipolar resistive switching characteristic prevails in LSMO/SRO superlattice. Merging of a superlattice structure with the low dimensionality of individual layer allowed us to attain very stable and reproducible bipolar resistive switching characteristics. We also ascertain that the memory window that is observed between ON and OFF state would indeed allow one to distinguish the information, which is a potential characteristic of present superlattice device for future data storage applications.
## Acknowledgements
SNJ would like to thank IIT Hyderabad and K.U. Leuven Excellence financing (INPAC), the Flemish Methusalem financing and the IAP network of the Belgian Government. SNJ would also like to thank Dr. Ionela Vrejoiu for providing the superlattice sample and Dr. Eckhard Pippel and Dr. Miryam Arrdondo from Max-Planck-Institut für Mikrostrukturphysik (MPI) - Halle for the
STEM investigation of the sample.
## References:-
- 1. James D. Meindl, Q. Chen, and J. A. Davis, Science 293 , 2044 (2001).
- 2. Rainer Waser and Masakazu Aono, Nature Materials 6 , 833 (2007).
- 3. G. I. Meijer, Science 319 , 1625 (2008).
- 4. M. J. Lee, Y. Park, D. S. Suh, E. H. Lee, S. Seo, D. C. Kim, R. Jung, B. S. Kang, S. E. Ahn, C. B. Lee, D. H. Seo, Y. K. Cha, I. K. Yoo, J. S. Kim and B. H. Park, Adv. Mater. 19 , 3919 (2007).
- 5. J. C. Bruyere and B. K. Chakraverty, Appl. Phys. Lett. 16 , 40 (1970).
- 6. K. L. Chopra, J. Appl. Phys. 36 , 184 (1965).
- 7. A. Beck, J. G. Bednorz, Ch. Gerber, C. Rossel, and D. Widmer, Appl. Phys. Lett. 77 , 139 (2000).
- 8. Alan Kalitsov, Ajeesh M. Sahadevan, S. Narayana Jammalamadaka, Gopinadhan Kalon, Charanjit S. Bhatia, Guangcheng Xiong and Hyunsoo Yang, AIP Advances 1 , 042158 (2011).
- 9. Byungjin Cho, Sunghun Song, Yongsung Ji, Tae-Wook Ki, and Takhee Lee, Adv. Funct. Mater , 21 , 2806 (2011)
- 10. Y. C. Bae, Ah Rahm Lee, Ja Bin Lee, Ja Hyun Koo, Kyung Cheol Kwon, Jea Gun Park, Hyun Sik Im, and Jin Pyo Hong, Adv. Funct. Mater, 22 , 709 (2012)
- 11. Jay A. Switzer, Rakesh V. Gudavarthy, Elizabeth A. Kulp, Guojun Mu, Zhen He, and Andrew J. Wessel, J. Am. Chem. Soc. 132 , 1258 (2010)
- 12. Michael C. Martin, G. Shirane, Y. Endoh and K. Hirota, Y. Moritomo and Y. Yokura Phys. Rev. B. 53 14285 (1996).
- 13. J. J. Hamlin, S. Deemyad, J. S. Schilling, M. K. Jacobsen, R. S. Kumar, and A. L. Cornelius, G. Cao and J. J. Neumeier Phys. Rev. B. 76 , 014432 (2007).
- 14. 14. S. Narayana Jammalamadaka, J. Vanacken and V. V. Moshchalkov Euro.Phys. Lett., 98 (2012) 17002
- 15. M. Ziese , I. Vrejoiu and D. Hesse Appl. Phys. Lett. 97 052504 (2010)
- 16. M. Ziese, I. Vrejoiu, E. Pippel, P. Esquinazi, D. Hesse, E. Etz, J. Henk, A. Ernst, I. V. Maznichenko, W. Hergert and I. Merting Phys. Rev. Lett. 104 167203(2010)
- 17. Hillebrand R., Pippel E. and Hesse D., Phys. Status Solidi (a), 208 2144 (2011)
- 18. M. Ziese and I. Vrejoiu, Phys. Status Solidi RRL 7 , No. 4, 243-257 (2013)
- 19. Z. Q. Liu, Y. Ming, W. M. Lü, Z. Huang, X. Wang, B. M. Zhang, C. J. Li, K. Gopinadhan, S.
- W. Zeng, A. Annadi, Y. P. Feng, T. Venkatesan, and Ariando, Appl. Phys. Lett. 101, 223105 (2012).
- 20. C.H. Ahn, R.H. Hammond, T.H. Geballe, M.R. Beasley, J.-M. Triscone, M. Decroux,
- Ø. Fischer, L. Antognazza, and K. Char, Appl. Phys. Lett. 70 , 206 (1997).
- 21. D. Toyota, I. Ohkubo, H. Kumigashira, M. Oshima, T. Ohnishi, M. Lippmaa, M. Takizawa, A. Fujimori, K. Ono, M. Kawasaki, and H. Koinuma, Appl. Phys. Lett. 87 , 162508 (2005).
- 22. Priya Mahadevan, F. Aryasetiawan, A. Janotti, and T. Sasaki, Phys. Rev. B 80, 035106 (2009).
- 23. Hu Young Jeong, Jeong Yong Lee, Sung-Yool Choi and Jeong Won Kim Appl. Phys. Lett. 95 , 162108 (2009)
- 24. R. Müller, J. Genoe and P. Heremans Appl. Phys. Lett. 95 , 133509 (2009)
- 25. Bharti Singh, B. R. Mehta, Deepak Varandani, Govind, A. Narita, X. Feng and K. Müllen J. Appl. Phys. 113 , 203706 (2013).
- 26. A. Lampert and P. Mark, Current Injection in Solids (Academic, New York, 1970).
- 27. Q. Liu, W. H. Guan, S. B. Long, R. Jia, M. Liu, and J. N. Chen, Appl. Phys. Lett. 92 , 012117 (2008)
- 28. K. Jung, H. Seo, Y. Kim, H. Im, J. Hong, J. W. Park, and J. K. Lee, Appl. Phys. Lett. 90 , 052104 (2007).
- 29. Z. Wang, P. Giffin, J. McVittie, S. Wong, P. McIntyre, and Y. Nishi, IEEE Electron Device Lett. 28 , 14 (2007)
- 30. Jui-Yuan Chen, Chun-Wei Huang, Chung-Hua Chiu, Yu-Ting Huang, Su-Jien Lin, Wen-Wei Wu, and Lih-Juann Chen, Nano Lett. , 13 (8), 3671 (2013)
- 31. Seul Ji Song, Jun Yeong Seok, Jung Ho Yoon, Kyung Min Kim, Gun Hwan Kim, Min Hwan Lee & Cheol Seong Hwang Scientific Reports 3 , Article number: 3443 (2013)
## Figure captions:
Fig. 1: (a) Schematic of device that was made using La0.7Sr0.3MnO3 (LSMO)/ SrRuO3 (SRO) superlattice. The superlattice consist of 30 layers of LSMO (2.3 nm) and SRO (3.3 nm) deposited on SrTiO3 (001), as shown in the schematic. (b) HAADF-STEM micrograph of the La0.7Sr0.3MnO3 / SrRuO3 superlattices: the brown rectangles indicate the interfacial regions that are affected by intermixing.
Fig. 2: Bipolar resistive switching characteristics of LSMO/SRO superlattice at room temperature (300 K) . (a) I - V characteristics indicates that the current switching behavior is quite stable. (b) Shows the same graph in logarithmic plot
Fig. 3: (a) Current vs voltage plot in logarithmic scales of LSMO/SRO superlattice during positive voltage sweep (b) Current vs voltage plot in logarithmic scales of LSMO/SRO superlattice device during negative voltage sweep (c) Endurance characteristics of LSMO/SRO superlattice memory cell. Memory window of the cell is found using the formula (ROFFRON)/RON ≈ ROFF/RON, is nearly 14, such a huge memory margin essentially make the device circuit to distinguish the storage information between 1 and 0 (d) Threshold voltage of SET and RESET process with respect to the cycle number when the device is repeatedly switched between high resistance and low resistance states
Fig. 4: Schematic to explain the possible mechanism for the resistive switching in LSMO/SRO superlattices. Essentially, the filaments in the present superlattice might have formed along the surface as this device consists of planar structure.
Fig. 1: (a) Schematic of device that was made using La0.7Sr0.3MnO3 (LSMO)/ SrRuO3 (SRO) superlattice. The superlattice consist of 30 layers of LSMO (2.3 nm) and SRO (3.3 nm) deposited on SrTiO3 (001), as shown in the schematic. (b) HAADF-STEM micrograph of the La0.7Sr0.3MnO3 / SrRuO3 superlattices: the brown rectangles indicate the interfacial regions that are affected by intermixing.
Fig. 2: Bipolar resistive switching characteristics of LSMO/SRO superlattice at room temperature (300 K) . (a) I - V characteristics indicates that the current switching behavior is quite stable. (b) Shows the same graph in logarithmic plot
Fig. 3: (a) Current vs voltage plot in logarithmic scales of LSMO/SRO superlattice during positive voltage sweep (b) Current vs voltage plot in logarithmic scales of LSMO/SRO superlattice device during negative voltage sweep (c) Endurance characteristics of LSMO/SRO superlattice memory cell. Memory window of the cell is found using the formula (ROFFRON)/RON ≈ ROFF/RON, is nearly 14, such a huge memory margin essentially make the device circuit to distinguish the storage information between 1 and 0 (d) Threshold voltage of SET and RESET process with respect to the cycle number when the device is repeatedly switched between high resistance and low resistance states
Fig. 4: Schematic to explain the possible mechanism for the resistive switching in LSMO/SRO superlattices. Essentially, the filaments in the present superlattice might have formed along the surface as this device consists of planar structure.
 | null | [
"S. Narayana Jammalamadaka",
"Johan Vanacken",
"V. V. Moshchalkov"
] | 2014-08-01T08:56:02+00:00 | 2014-08-01T08:56:02+00:00 | [
"cond-mat.mes-hall",
"cond-mat.mtrl-sci"
] | Resistive switching in ultra-thin La0.7Sr0.3MnO3 / SrRuO3 superlattices | Superlattices may play an important role in next generation electronic and
spintronic devices if the key-challenge of the reading and writing data can be
solved. This challenge emerges from the coupling of low dimensional individual
layers with macroscopic world. Here we report the study of the resistive
switching characteristics of a of hybrid structure made out of a superlattice
with ultrathin layers of two ferromagnetic metallic oxides, La0.7Sr0.3MnO3
(LSMO) and SrRuO3 (SRO). Bipolar resistive switching memory effects are
measured on these LSMO/SRO superlattices, and the observed switching is
explainable by ohmic and space charge-limited conduction laws. It is evident
from the endurance characteristics that the on/off memory window of the cell is
greater than 14, which indicates that this cell can reliably distinguish the
stored information between high and low resistance states. The findings may
pave a way to the construction of devices based on nonvolatile resistive memory
effects. |
1408.0104v1 | ## Impact of Human Behavior on Social Opportunistic Forwarding
Waldir Moreira a, ∗ , Paulo Mendes a a COPELABS, University Lusofona, Lisbon, Portugal
## Abstract
The current Internet design is not capable to support communications in environments characterized by very long delays and frequent network partitions. To allow devices to communicate in such environments, delay-tolerant networking solutions have been proposed by exploiting opportunistic message forwarding, with limited expectations of end-to-end connectivity and node resources. Such solutions envision non-traditional communication scenarios, such as disaster areas and development regions. Several forwarding algorithms have been investigated, aiming to offer the best trade-off between cost (number of message replicas) and rate of successful message delivery. Among such proposals, there has been an effort to employ social similarity inferred from user mobility patterns in opportunistic routing solutions to improve forwarding. However, these research effort presents two major limitations: first, it is focused on distribution of the intercontact time over the complete network structure, ignoring the impact that human behavior has on the dynamics of the network; and second, most of the proposed solutions look at challenging networking environments where networks have low density, ignoring the potential use of delay-tolerant networking to support low cost communications in networks with higher density, such as urban scenarios. This paper presents a study of the impact that human behavior has
∗ This is the author's pre-print version. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotion or for creating new collective works for resale or for redistribution to thirds must be obtained from the copyright owner. The camera-ready version of this work is being published at Elsevier Ad Hoc Networks, 2014 and is property of Elsevier B.V.
Email address: [email protected] (Waldir Moreira)
on opportunistic forwarding. Our goal is twofold: i) to show that performance in low and high density networks can be improved by taking the dynamics of the network into account; and ii) to show that the delay-tolerant networking can be used to reduce communication costs in networks with higher density by taking the behavior of the user into account.
Keywords: opportunistic networks, delay/disruption-tolerant networks, social-networking communications, human dynamics, application awareness, challenging environments
2000 MSC: [2010] 00-01, 99-00
## 1. Introduction
Wireless devices have become more portable and with increased capabilities (e.g., processing, storage), which is creating the foundations for the deployment of pervasive wireless networks, encompassing personal devices (e.g. smartphones and tablets). Additionally, wireless technology has been extended to allow direct communication: vehicle-to-vehicle for safety information exchange; device-to-device - aiming at 3G offloading; Wi-Fi direct - overcome the need for infrastructure entities (i.e., access points).
The combination of pervasive wireless devices and direct wireless communication solutions can be used to support the deployment of two major type of applications: end-to-end communication in development regions, since today's Internet routing protocols may operate poorly in such environments, characterized by very long delay paths and frequent network partitions; and low cost communication, namely data sharing, in urban scenarios, to bypass expensive data mobile communications and the unreliable presence of open Wi-Fi access points.
These networking scenarios (from development regional to large urban scenarios) are characterized by network graphs with different densities, which pose different challenges in terms of data forwarding. The challenge that we aim to tackle in this paper is to investigate the impact of human behavior on oppor-
tunistic forwarding, namely the awareness about users' social and data similarities.
Most of the prior art has been studying data transfer opportunities between wireless devices carried by humans, by looking at the distribution of the intercontact time, which is the time gap separating two contacts between the same pair of devices [1]. In challenging networking environments, opportunistic contacts among mobile devices may improve communications among peers as well as content dissemination, mitigating the effects of network disruption. This gave rise to the investigation of opportunistic networks, of which DelayTolerant Networks (DTN) are an example, encompassing different forwarding proposals to quickly send data from one point to another even in the absence of an end-to-end path between them. Such proposals range from flooding content [2] in the network up to solutions that take into account the social interactions among users [3, 4, 5, 6, 7, 8]. In the latter case, wireless contacts are aggregated into a social graph, and a variety of metrics (e.g., centrality and similarity) or algorithms (e.g., community detection) have been proposed to assess the utility of a node to deliver a content or bring it closer to the destination. Nevertheless, the structure of such graphs is rather dynamic, since users' social behavior and interactions vary throughout their daily routines. This brings us to our first assumption: forwarding algorithms should be able to exploit social graphs that reflect people's dynamic behavior. Prior art have studied forwarding algorithms that consider only the global network structure, without taking people's behavior into account [9]. In this paper, we show that forwarding algorithms that exploit social graphs reflecting the variations in people's daily routines are able to improve the performance of social-aware opportunistic networking.
Our second challenge was to analyze how to expand the deployment of DTN technology, which is normally seen only as useful to allow communications in challenging environments, such as development regions. For this study, we focus on data sharing since this should be the most interesting application to take advantage of low cost communication in dense networks, such as in an urban scenario. In this case, we studied two hypothesis to ensure good performance
when the density of the network increases: i) forwarding based on social graphs, where aggregation is based only on social similarities; and ii) forwarding based on behavior graphs, where aggregation is done by combining different aspects of human behavior, such as social similarities and data similarities (derived from the interests that users demonstrate in specific type of data).
Hence, in this paper we aim to investigate the possibility of developing an opportunistic forwarding system able to support low-cost services in dense networking scenarios as well as basic services in extreme networking conditions, by exploiting social as well as data similarities among users. Our work shows which type of opportunistic forwarding scheme is more suitable for delay-tolerant applications, based on the density of the network in scenarios spanning from developing regions to urban environments. Our findings lead to a new research challenge aiming to expand the impact of DTNs: the investigation of self-awareness mechanisms able to adapt their forwarding schemes based on the context of the user, namely the density of the network where he/she is currently.
The remainder of the paper is structured as follows. Section 2 aims to motivate our work, namely in what concerns the goal to study methods to expand the deployment of DTNs, and the impact that a better understanding of human behavior can have in the development of efficient forwarding solutions. In Section 3 we present our definition of network density based on the deployment scenarios that we look at to pursuit our study and experiments. Section 4 presents a set of forwarding algorithms that are considered in our study, including our proposals. In Section 5, we show the performance results of opportunistic forwarding over different network densities. Section 6 concludes our work, and identifies future research challenges to expand the impact of DTNs.
## 2. Motivation
The growing number of mobile devices equipped with a wireless interface and the end-user trend to shift toward wireless technology are opening new possibilities for networking. In particular, opportunistic communication embodies
a feasible solution for environments with scarce or costly infrastructure-based connectivity. A lot of attention has been given to the development of opportunistic forwarding solutions for networks with scarce connectivity, which are considered a natural fit for DTN technology. However, it is our belief that opportunistic forwarding can also be applied to more dense networks, were Internet communications are expensive, or applications aim to take advantage of direct communications among people.
In what concerns challenging networks, the most common approach has been to make use of social similarities to improve performance over the overall network. In this case, our work is motivated by the fact that such approaches ignore the behavior patterns that people present in their daily routines [10], which may lead to further performance improvements.
In what concerns the application of DTN and opportunistic forwarding to dense networks, most of the prior art aims to implement a store-carry-andforward communication model that exploits specific devices found in urban scenarios, such as buses [11] and cars [12]. It is our understanding that the development of opportunistic forwarding solutions should not depend upon specific equipments only found is some scenarios, since this mitigates the deployment expansion of such proposals. It is our belief that the success of the DTN technology depends on its deployment range, which can only be ensured if such technology is based on pervasive wireless devices, such as smartphones: these devices are present in development regions as well as urban scenarios. In the latter case, communications between smartphones can also exploit mobility patterns of different vehicles ridden by people.
In order to design useful applications, it is vital to have a good understanding of the target environment and its users. Different types of user behavior may result in different network conditions and shall have a huge impact on whether or not a particular application is of interest to the user. A fair amount of work has been done on studying human mobility traces in order to gain understanding of real life mobility patterns and how those affect the properties of the opportunistic networks that are possible in that environment [13, 1, 14].
Although mobility patterns are important properties of the network, it is also important to understand the impact the human behavior, such as data interests, have on these networks. Hence, our work aims to tackle this new research trend, expanding social awareness to human behavior awareness. Among the different human behavior metrics that can be considered, we focus our attention on data similarities since data sharing is the most common application in the Internet. The study of data similarities depends on which applications are in place in the network and how the users use them. Usage patterns also depend on the users' context, so the same data patterns do not apply to all users. Approximations of some use cases might be possible to derive from the way cellular networks are used, but that will most likely not be applicable to all types of applications.
Looking at data similarities may improve the performance of opportunistic forwarding [3, 4]. However it is not clear if the improvement is higher than exploiting social interactions and structure (i.e., communities [5], as well as levels of social interaction [6, 7]). Thus, combining social and data similarities shall bring benefits (i.e., faster, better content reachability) to opportunistic forwarding. Hence, in this work we aim to show when the exploitation of social similarities results in a good performance, and when such performance can be augmented by combining them with data similarity metrics.
## 3. Network Scenario Characterization
One can observe that a networking scenario may vary according to its density. Sparse scenarios are characterized by very long delays (e.g., space communications [15]) and communication suffers with frequent disruption mostly due to the lack of infrastructure and geographic location (e.g., rural areas [16], riverside communities [17, 18]). It is common to see solutions relying on message ferries [19] or data mules [20] as to overcome the missing infrastructure. This is a classic scenario whose challenges are more related to transport protocols (i.e., dealing with extremely high delays) than routing itself.
Table 1: Network densities of the considered scenarios
| Scenario | Cambridge | MIT | Synthetic |
|--------------------|-------------|-------|-------------|
| Identified density | 26.83 | 47.01 | 148.8 |
In what concerns dense scenarios, communication can take place through both infrastructured (e.g., access points, cell towers) and infrastructureless (e.g., WiFi direct, bluetooth) means. Still, disruption remains a problem, but now seen from a different perspective: the dynamic bebavior of users (e.g., high mobility), different sources of interference (e.g., overlapping spectrum), poor coverage (e.g., areas full of closed access points) are factors that may contribute to link intermittency, despite all the available surrounding infrastructure. With the advances in the industry for portable devices and wireless technologies, this type of scenario is easily observed nowadays in urban settings.
In this work, we see dense (urban) scenarios as imposing new research challenges for opportunistic networks given the aforementioned characteristics. Due to the popularity and capabilities of mobile devices, users want to be able to sent and retrieve data anytime and anywhere. In other words, a free Internet scenario with low cost denominator networking imposed to users is a reality.
With this in mind, we define the density of the network according to the surroundings of the users and independently of the existence of infrastructure: what matters is i) that nodes can communicate directly; and ii) that the average node degree reflects the number of contact opportunities a node may have in such specific scenarios. We studied the characteristics of the three scenarios which are considered in the experiments in Sec. 5: the CRAWDAD traces of Cambridge [21] that corresponds to contacts of 36 students during their daily activities, the MIT [22] traces comprising 97 Nokia 6600 smart phones distributed among the students and staff of this institution, and the synthetic mobility scenario that encompasses 150 walking people, following the Shortest Path Map Based Movement model (i.e., nodes randomly choose destinations and use the shortest path to reach them). With the Gephi v0.8.2 [23] analysis tool, we accounted for the network densities of these scenarios summarized in Table 1.
Table 1 displays the scenarios in increasing order of density. Thus, it is expected that the routing solutions have an increasing performance behavior as network density increases. This is due to the different contact opportunities that a node may have, which increase (and therefore can be beneficial) for routing purposes.
## 4. Opportunistic Forwarding in Wireless Networks
This section presents the most relevant and latest opportunistic forwarding proposals, considering whether they make use of social and/or data similarity metrics. Similarity metrics are used to build graphs over which such forwarding proposals operate [24]. That is, instead of considering the number and frequency of contacts due to the mobility of hosts, such approaches take into account more stable social (e.g., common social groups and communities, node popularity, levels of centrality, social relationships and interactions, user profiles) and/or data (e.g., shared interests, interest of users in the content traversing network, content availability, type of content) aspects, aiming to reduce the cost of opportunistic forwarding. Moreover, opportunistic forwarding proposals may take into account the dynamics of user behavior, i.e., the resulting social graphs may consider what happens in terms of social interactions throughout the daily routine of the users.
Table 2 summarizes the type of similarity (i.e., social and/or data) considered by the opportunistic forwarding proposals and whether (or not) they consider the observed user behavior to build dynamic social graphs.
Bubble Rap [5], CiPRO [7], SocialCast [3], and ContentPlace [4] belong to the category that considers social similarity and/or data similarity metrics, but does not suitably reflect the dynamism of user behavior in the underlying social graph.
Bubble Rap combines node centrality with the notion of community to make forwarding decisions. The centrality metric identifies hub nodes inside (i.e., local) or outside (i.e., global) communities. Messages are replicated based on
Table 2: Opportunistic Forwarding Proposals
| Proposals | Social similarity metrics | Data similarity metrics | Dynamic graphs |
|--------------|-------------------------------------|------------------------------------------|------------------|
| Bubble Rap | Communities and centrality | | |
| CiPRO | User profile | | |
| SocialCast | | Shared interests | |
| ContentPlace | Social relationship and communities | Interest on the content | |
| dLife | Social weight and node importance | | /check |
| SCORP | Social weight | Content type and interest on the content | /check |
global centrality until they reach the community of the destination host (i.e., a node belonging to the same community). Then, it uses the local centrality to reach the destination inside the community.
CiPRO considers the time and place nodes meet throughout their routines. CiPRO holds knowledge of nodes (e.g., carrier's name, address, nationality, ...) expressed by means of profiles that are used to compute the encounter probability among nodes in specific time periods. Nodes that meet occasionally get a copy of the message only if they have higher encounter probability towards its destination. If nodes meet frequently, history of encounters is used to predict encounter probabilities for efficient broadcasting of control packets and messages.
SocialCast considers the interest shared among nodes. It devises a utility function that captures the future co-location of the node (with others sharing the same interest) and the change in its connectivity degree. Thus, the utility function measures how good message carrier a node can be regarding a given interest. SocialCast functions are based on the publish-subscribe paradigm, where users broadcast their interests, and content is disseminated to interested parties and/or to new carriers with high utility.
ContentPlace considers information about the users' social relationships to improve content availability. It computes a utility function for each data object
considering: i) the access probability to each object and the involved cost in accessing it; ii) the social strength of the user towards the different communities which he/she belongs to and/or has interacted with. The idea is having the users to fetch data objects that maximize the utility function with respect to local cache limitations, and choosing those objects that are of interest to users and can be further disseminated in the communities they have strong social ties.
The next category considers solely social similarity metrics and take into account the dynamism of user behavior while building the underlying social graph. dLife [6] is in this category and it takes into account the dynamism of users' behavior found in their daily life routines to aid forwarding. The goal is to keep track of the different levels of social interactions (in terms of contact duration) nodes have throughout their daily activities in order to infer how well socially connected they are in different periods of the day. Forwarding takes place by considering either the social strength (i.e., weight) among users or their importance in specific time periods.
Finally, the last category comprises both social and data similarity metrics and the dynamism observed in the behavior of users. SCORP [8] belongs to this category. It considers the type of content and the social relationship between the parties interested in such content type. SCORP nodes are expected to receive and store messages considering their own interests as well as interests of other nodes with whom they have interacted before. Data forwarding takes place by considering the social weight of the encountered node towards nodes interested in the message that is about to be replicated.
For the remainder of this paper, we consider one representative from each of the described categories: Bubble Rap , for being solely based on social similarity metrics; dLife and SCORP , for considering social and data similarity metrics and for being the proposals which satisfactory capture the dynamic user behavior in the resulting social graphs. These proposals are enough to help us illustrate how the performance of opportunistic routing proposals in networks with different densities can be further improved by considering the user dynamic behavior.
## 5. Evaluation of Opportunistic Forwarding over Different Network Density Scenarios
In this section, we analyze the performance behavior of Bubble Rap , dLife, and SCORP over different network density scenarios. With the experiments in this section, we want i) to show that performance in low (Sec. 5.2) and high (Sec. 5.3) density networks can be improved by taking the dynamics of the network into account; and ii) to show that the delay-tolerant networking can be used to reduce communication costs in networks with higher density by taking the behavior of the user into account (Sec. 5.4).
## 5.1. Methodology and Simulation Settings
Simulations are carried out in the Opportunistic Network Environment (ONE) simulator [25]. Results are presented with a 95% confidence interval and in terms of averaged delivery probability (i.e., ratio between the number of delivered messages and the number of messages that should have been delivered), cost (i.e., number of replicas per delivered message), and latency (i.e., time elapsed between message creation and delivery).
The trace scenarios comprise 36 (Cambridge) and 97 (MIT) nodes carrying devices during their daily activities. The synthetic mobility scenario simulates 3 groups ( A M , , and B ) of 50 people each, who carry nodes equipped with 250Kbps Bluetooth interfaces, and moving with speed up to 1.4 m/s. The reason for considering traces and synthetic mobility scenario relates to the fact that: i) with the former, we have a representation of real user behavior; and ii) with the latter, we are able to have a network density much higher from the perspective of the user, as defined in Sec. 3. Most analysis have been based on datasets with low density, collected in a constrained setting, which is not representative for realistic use cases of the networks being studied. If one is interested in the properties of a large scale urban environment, it is probably not meaningful to study traces collected from 36 or 97 user at a conference or university campus.
Across all experiments, proposals experience the same load and number of messages that must reach the destinations. In the Cambridge trace (cf. Sec.
5.2), the Bubble Rap / dLife source sends 1, 5, 10, 20 and 35 different messages to each of the 35 destinations, while the SCORP source creates 35 messages with unique content types, and the receivers are configured with 1, 5, 10, 20, and 35 randomly assigned interests. Thus, we have a total of 35, 175, 350, 700, and 1225 generated messages. The msg/int notation represents the number of messages sent by Bubble Rap and dLife sources, or the number of interests of each of the SCORP receivers. Since Bubble Rap / dLife sources generate more messages, in this scenario node 0 (the source) has no buffer restriction and message generation varies with the load: 35 messages/day rate (load of 1, 5, and 10 messages), and 70 and 140 messages/day rates (load of 20 and 35 messages, respectively).
As for the synthetic mobility scenario (cf. Sec. 5.3), 200 messages are generated. With Bubble Rap and dLife , node 0 (group A ) generates 100 messages to nodes in groups B and M , and node 100 (group B ) generates 100 messages to nodes in groups A and M . For SCORP , each group has different interests: group A ( reading ), group B ( games ), and group M ( reading and games ). The source nodes, 0 and 100, generate only one message for each content type, game and reading . This guarantees the same number of messages expected to be received, i.e., 200. Also, by varying the node pause times between 100 and 100000 seconds, we have different levels of mobility (varying from 3456 to 3.4 movements in the simulation). In this scenario, all source nodes have restricted buffer, but rate is of 25 messages every 12 hours. This is done so that Bubble Rap dLife / do not discard messages prior to even trying exchange/deliver them given the buffer constraint.
Finally, in Sec. 5.4, the load generated is equivalent to 6000, 78000, and 200 messages to be delivered across all experiments for Cambridge, MIT, and synthetic mobility scenarios, respectively.
Regarding message TTL, we set it to be unlimited in order to observe the performance behavior (i.e., buffer consumption, number of replicas) of the forwarding proposals in networks with high traffic load. Message size ranges from 1 to 100 kB. Despite nodes may have plenty of storage, we consider nodes having different capabilities (i.e., smartphones). Thus, nodes have buffers limited
to 2 MB as we consider that nodes may not be willing to share all their storage space. The performance evaluation follows the guidelines of a Universal Evaluation Framework (UEF) [26 ? ] to guarantee fairness in the assessment.
As for proposals, Bubble Rap uses the K-Clique and cumulative window algorithms for community formation and centrality computation as in [5]. As for dLife and SCORP , both consider 24 daily samples (i.e., each of one hour) as mentioned in [8].
## 5.2. Performance over Low Density Network
This section presents the performance of opportunistic forwarding proposals over a low density network scenario. Fig. 1 presents the average delivery probability with different messages and interests being generated.
Figure 1: Delivery under different network loads
In the 1 msg/int configuration, formed communities comprise almost all nodes. This means that each node has high probability to meet any other node, which is advantageous for Bubble Rap since most of its deliveries happen to nodes sharing communities. Due to the dense properties of the network, dLife and SCORP take advantage of direct delivery: 57% and 51% of messages, respectively, are delivered directly to destinations.
As load increases, Bubble Rap has an 50% decrease in delivery performance. This occurs since it relies on communities to perform forwardings, and conse-
quently buffer space becomes an issue. To support this claim, we estimate buffer usage for the 5 msg/int configuration: there is an average of 80340.7 forwardings, and if this number is divided by the number of days (12 ) and by the number 1 of nodes (35, source not included), we get an average of 191.28 replications per node. Multiplied by the average message size (52kB), the buffer occupancy is roughly 9.94 MB in each node, which exceeds the 2MB allowed (cf. Sec. 4.1).
This estimation is for a worst case scenario, where Bubble Rap spreads copies to every encountered node. Since this cannot happen, as Bubble Rap also relies on local centrality to reduce replication, buffer exhaustion is really an issue given that messages are replicated to fewer nodes and not to all as in our estimation. As more messages are generated, replication increases: this causes the spread of messages that potentially take over forwarding opportunities from other messages, reducing Bubble Rap 's delivery capability.
dLife has a 43% performance decrease when network load increases, as it takes time to have an accurate view of the social weights. This leads to forwardings that never reach destinations given the contact sporadicity. For the 10 msg/int configuration, dLife also experiences buffer exhaustion: estimated consumption is 2.17 MB per node. Still, by considering social weights or node importance allows dLife a more stable behavior than Bubble Rap .
Since content is only replicated to nodes that are interested in it, or have a strong social interaction with other nodes interested in such content, the delivery capability of SCORP raises as the ability of nodes to become a good carrier increases (i.e., the more interests a node has, the better it is to deliver content to others, since they potentially share interests). The maximum estimated buffer consumption of SCORP is of 0.16 MB (35 msg/int).
Fig. 2 presents the average cost behavior. In the 1 msg/int configuration, all proposals create very few replicas to perform a successful delivery, 7.95 ( Bubble Rap ), 14.32 ( dLife ), and 23.46 ( SCORP ), as they rely mostly on shared communities and/or direct deliveries. We also observe that SCORP produces more
1 In simulation it is worth ˜12 days of communications.
replicas than dLife due to a particularity in its implementation: SCORP nodes with interest in a specific content of a message not only process it, but also replicate it to other interested nodes, thus creating extra replicas.
For the 5, 10, 20 and 35 msg/int configurations, replication is directly proportional to the load. Thus, cost is expected to increase as load increases, as seen with dLife . The same performance behavior was expected for Bubble Rap . However, the observed cost peaks relate to the message creation time and contact sporadicity: when a message is created in a period of high number of contacts, which results in much more replications. This is more evident with Bubble Rap at the 5 msg/int configuration as it relies on shared communities to forward: as mentioned earlier, most of the communities comprise almost all nodes, which increases its replication rate.
Despite their efforts, these replications do not improve their delivery probabilities, contributing only to the associated cost for performing successful deliveries.
Figure 2: Cost under different network loads
With more interests, a SCORP node can serve as a carrier for a larger number of nodes. Consequently, the observed extra replicas make the proposal rather efficient: SCORP creates an average of 6.39 replicas across all msg/int
configurations, while Bubble Rap and dLife produce an average 452.41 and 96 replicas, respectively.
Fig. 3 shows the average latency that messages experience. The latency peak in the 1 msg/int configuration refers to the message generation time: some messages are created during periods where very few contacts (and sometimes none) take place followed by long periods (12 to 23 hours) with almost no contact. Consequently, messages are stored longer, contributing to the increase of the overall latency. This effect is mitigated as the load increases with messages being created almost immediately before a high number of contacts take place.
Figure 3: Latency under different network loads
Since latency is in function of the delivered messages, the decrease and variable behavior of Bubble Rap and dLife is due to their delivery rates decrease and increase, and also to their choices of next forwarders that may take longer to deliver content to destinations. SCORP experiences latencies up to approx. 90.2% and 92.2% less than Bubble Rap and dLife , respectively. The ability of a node to deliver content increases with the number of its interests. Thus, a node can receive more messages when it is interested in their contents, and consequently becomes a better forwarder since the probability of coming into contact with other nodes sharing similar interests is very high, thus reducing latency.
## 5.3. Performance over High Density Network
This section presents the performance of opportunistic forwarding proposals over a high density network scenario.
Fig. 4 presents the average delivery probability. Given the community formation characteristic of this scenario, Bubble Rap relies mostly on the global centrality to deliver content. By looking at centrality [5], we observe very few nodes (out of the 150) with global centrality that can actually aid in forwarding, i.e., 19.33% (29 nodes), 10.67% (16 nodes), 21.33% (32 nodes), and 2% (3 nodes) for 100, 1000, 10000, and 100000 pause time configurations, respectively. So, these nodes become hubs and given buffer constraint and infinite TTL (i.e., messages created earlier take the opportunity of newly created ones), message drop is certain, directly impacting Bubble Rap .
Figure 4: Delivery under varied mobility rates
Given the high number of contacts, the computation of social weight and node importance done by dLife takes longer to reflect reality: thus dLife replicates more and experiences buffer exhaustion. Indeed, social awareness is advantageous, but still not enough to reach optimal delivery rate in such conditions.
Independent of the number of contacts among nodes, SCORP can still identify nodes that are better related to others sharing similar interests, reaching optimal delivery rate for 100, 1000, and 10000 pause time configurations. By
considering nodes' interest in content and their social weights, SCORP does not suffer as much with node mobility as dLife and Bubble Rap .
With 100000 seconds of pause time, the little interaction happening in a sporadic manner (with intervals between 20 and 26 hours) affects Bubble Rap , dLife and SCORP as they depend on such interactions to compute centrality, node importance, and social weights, as well as to exchange/deliver content.
Fig. 5 presents the average cost behavior. As pause time increases, the number of contacts among nodes decreases, providing all solutions with the opportunity to have a stable view of the network in terms of their social metrics with 100, 1000, and 10000 seconds of pause time. This explains the cost reduction experienced by Bubble Rap and dLife : both are able to identify the best next forwarders, which results in the creation of less replicas to perform a successful delivery.
Figure 5: Cost under varied mobility rates
SCORP has a very low replication rate (average of 0.5 replicas) given its choice to replicate based on the interest that nodes have on content and on their social weight towards other nodes interested in such content. When the intermediate node has an increased number of interests (i.e., by having different interests, the node can potentially deliver more content) as observed in Sec. 5.2, replication costs are even lower. Furthermore, SCORP suitably uses buffer space with an estimated average occupancy of 0.03 MB per node per day.
With 100000 seconds of pause time, as cost is in function of delivered messages (and deliveries are very low, due to contact sporadicity), proposals have a low cost.
Figure 6: Latency under varied mobility rates
As expected (cf. Fig. 6), latency increases as node mobility decreases: encounters are less frequent, and so content must be stored for longer times. Also, the time that the social metrics take to converge (i.e., a more stable view of the network in terms of centrality, social weight, and node importance) contributes for the increase in the experienced latency. The highest increase in latency with 100000 seconds of pause time is due to contacts happening in a sporadic fashion with intervals between them of up to 26 hours, thus proposals take much longer to perform a delivery.
## 5.4. Performance over Different Network Densities
This section shows how network density impacts on the performance of opportunistic forwarding proposals. As mentioned before, we want to bring attention to dense scenarios found in urban settings: a panoply of heterogenous devices that could overcome disruption by interacting directly with one another to improve the networking experience of users. Fig. 7 presents the average delivery probability with different network densities.
## Average Delivery Probability
Figure 7: Delivery under different network densities
As mentioned in Sec. 3, it was expected that the performance of social-aware opportunistic routing improve with the increase of network density. However, we can observe that content-oblivious Bubble Rap and dLife experience a decrease in performance in the MIT scenario despite of its identified density (47.01) being almost almost twice as the one identified in Cambridge (26.83). The reason for such behavior lies on the characteristics of each scenario, with MIT nodes covering a much bigger area. Despite of having a higher number of contacts between nodes, the MIT scenario may lead to messages reaching nodes that are not the best forwarders, and these messages, given the unlimited TTL, may end up taking the delivery opportunity of newly created messages. This directly affects the performance of both Bubble Rap and dLife.
Yet the content-oriented SCORP overcomes such features of the MIT scenario since it also considers those nodes that are interested in the content being replicated or that are strongly related to interested parties. Unlike the contentoblivious solutions, SCORP has a 6.14% improvement despite the challenging scenario.
Performance behavior for all proposal indeed improve with higher network density (148.8, Synthetic scenario). The reason is tied to the fact that a higher density indicates more contact opportunities for the exchange of messages.
Fig. 8 presents the average cost which is expected to increase with network density. This is because the more contact opportunities the scenario has, the more replicas are created by proposals. This can be easily seen with Bubble Rap , which creates an average of more than 5000 replicas to perform a successful delivery.
## Average Cost
Figure 8: Cost under different network densities
The same cost increasing trend is observed with dLife , but in different orders and especially for the synthetic scenario. We believe that the much higher number of copies (up to 98% when compared to other scenarios) is related to the mobility rate. In the Synthetic experiment nodes move a lot, which results in a high number of contacts with many nodes. Consequently, dLife takes longer to have a stable view of the network in terms of its social weights and node importances, which leads to the creation of unwanted replicas. SCORP has the best cost performance (up to 0.5 replicas to perform a successful delivery), since the more interests a node has, the better forwarder it is. The M group (cf. Sec. 5.1) accounts for 50% of the interests existing in the network, which makes it a greater carrier for messages.
Fig. 9 shows the average latency experienced by messages since their creation up to their reception at destination. In the traces experiments, all proposals keep the same trend: average latency increases. This is due to the fact that
nodes in these experiments span different areas and the encounter frequency happens at different rates. This can result in messages being forwarded to nodes who may reach a given destination, but delivery time increases with the area and duration of experiments. SCORP presents a much higher increase in the MIT experiment, as it takes its time to suitably choose the next forwarders (based on their interest on the message's content or social relationship to other interested parties). This added to fact that interactions among nodes happen according to area they move jointly contribute to such latency peak.
## Average Latency
Figure 9: Latency under different network densities
As for the Synthetic mobility experiment, not only the proposals have many different contact opportunities, but also nodes encounter more frequently. This consequently has a positive impact for Bubble Rap , dLife , and SCORP that are able to deliver content in less time (12486s, 11710s , and 6864s, respectively).
## 6. Conclusions
Opportunistic forwarding can aid communication in two major application scenarios: end-to-end communication in development regions and low cost communication in urban scenarios. Such scenarios do have different network densities which adds more challenges to opportunistic forwarding. The underlying graphs, over which these opportunistic forwarding proposals operate, comprise
(e.g., common social groups and communities, node popularity, levels of centrality, social relationships and interactions, user profiles) and/or data (e.g., shared interests, interest of users in the content traversing network, content availability, type of content) aspects. Additionally, such graphs may (or not) take into account the dynamics of user behavior.
Thus, in this paper, we exploit the possibility of having an opportunistic forwarding system that can provide support to i) low-cost services in dense networking scenarios; and ii) basic services in extreme networking conditions (e.g., communications in development regions), considering social and data similarities among users as well as the dynamic behavior found in the users' daily routines.
Our results show that opportunistic forwarding, based on social and data similarity metrics and considering the dynamism observed in the users behavior, does answer the communication needs of users in both dense (i.e., urban) and challenged (i.e., development region) scenarios. Performance improvements go up to 54% regarding delivery capability while latency and cost can be reduced by 45% and 99% respectively, when compared to forwarding solely based on data similarity and completely agnostic to user behavior.
These findings point to a new research challenge regarding the impact of DTN application: the investigation of self-awareness mechanisms able to adapt their forwarding schemes based on the context of the user, namely the density of the network where he/she is currently.
## References
- [1] A. Chaintreau, P. Hui, J. Crowcroft, C. Diot, R. Gass, J. Scott, Impact of human mobility on opportunistic forwarding algorithms, IEEE Trans. Mobile Comput. 6 (6) (2007) 606-620.
- [2] A. Vahdat, D. Becker, Epidemic routing for partially connected ad hoc networks, Tech. Rep. CS-200006, Duke University (2000).
- [3] P. Costa, C. Mascolo, M. Musolesi, G. P. Picco, Socially-aware routing for publish-subscribe in delay-tolerant mobile ad hoc networks, IEEE J.Sel. A. Commun. 26 (5) (2008) 748-760.
- [4] C. Boldrini, M. Conti, A. Passarella, Design and performance evaluation of contentplace, a social-aware data dissemination system for opportunistic networks, Comput. Netw. 54 (4) (2010) 589-604.
- [5] P. Hui, J. Crowcroft, E. Yoneki, Bubble rap: Social-based forwarding in delay-tolerant networks, IEEE Trans. Mobile Comput. 10 (11) (2011) 15761589.
- [6] W. Moreira, P. Mendes, S. Sargento, Opportunistic routing based on daily routines, in: Proceedings of IEEE WoWMoM, San Francisco, USA, 2012.
- [7] H. A. Nguyen, S. Giordano, Context information prediction for social-based routing in opportunistic networks, Ad Hoc Netw. 10 (8) (2012) 1557-1569.
- [8] W. Moreira, P. Mendes, S. Sargento, Social-aware opportunistic routing protocol based on user's interactions and interests, in: M. H. Sherif, A. Mellouk, J. Li, P. Bellavista (Eds.), Ad Hoc Networks, Springer International Publishing, 2014, pp. 100-115.
- [9] T. Hossmann, T. Spyropoulos, F. Legendre, Know thy neighbor: towards optimal mapping of contacts to social graphs for dtn routing, in: Proceedings of INFOCOM, San Diego, USA, 2010, pp. 866-874.
- [10] N. Eagle, A. Pentland, Eigenbehaviors: identifying structure in routine, Behavioral Ecology and Sociobiology 63 (7) (2009) 1057-1066.
- [11] I. Komnios, V. Tsaoussidis, Carpool: Extending free internet access over dtn in urban environment, in: Proceedings of ACM MobiCom LCDNet, Miami, USA, 2013.
- [12] P.-C. Cheng, K. Lee, M. Gerla, J. Harri, Geodtn+nav: Geographic dtn routing with navigator prediction for urban vehicular environments, Mobile Networks and Applications 15 (1) (2010) 61-82.
- [13] P. Hui, A. Chaintreau, J. Scott, R. Gass, J. Crowcroft, C. Diot, Pocket switched networks and human mobility in conference environments, in: Proceedings of ACM SIGCOMM WDTN, Philadelphia, USA, 2005.
- [14] T. Hossmann, T. Spyropoulos, F. Legendre, A complex network analysis of human mobility, in: Proceedings of INFOCOM, Shanghai, China, 2011.
- [15] S. Farrell, V. Cahill, Delay- and disruption-tolerant networking, Artech House telecommunications library, Artech House, 2006.
- [16] S. Jain, K. Fall, R. Patra, Routing in a delay tolerant network, in: Proceedings of SIGCOMM, Portland, USA, 2004.
- [17] W. Moreira, R. Ferreira, D. Cirqueira, P. Mendes, E. Cerqueira, Socialdtn: A dtn implementation for digital and social inclusion, in: Proceedings of ACM MobiCom LCDNet, Miami, USA, 2013.
- [18] R. Ferreira, W. Moreira, P. Mendes, M. Gerla, E. Cerqueira, Improving the delivery rate of digital inclusion applications for amazon riverside communities by using an integrated bluetooth dtn architecture, International Journal of Computer Science and Network Security 14 (1) (2014) 17-24.
- [19] W. Zhao, M. Ammar, E. Zegura, A message ferrying approach for data delivery in sparse mobile ad hoc networks, in: Proceedings of ACM MobiHoc, Roppongi Hills, Japan, 2004.
- [20] R. Shah, S. Roy, S. Jain, W. Brunette, Data mules: modeling a three-tier architecture for sparse sensor networks, in: Proceedings of IEEE Workshop SNPA, Anchorage, USA, 2003.
- [21] J. Scott, R. Gass, J. Crowcroft, P. Hui, C. Diot, A. Chaintreau, CRAWDAD trace cambridge/haggle/imote/content (v. 2006-09-15), http://crawdad.cs.dartmouth.edu/cambridge/haggle/ imote/content (Sep. 2006).
- [22] N. Eagle, A. Pentland, CRAWDAD data set mit/reality (v. 2005-07-01), http://crawdad.cs.dartmouth.edu/mit/reality (Jul. 2005).
- [23] M. Bastian, S. Heymann, M. Jacomy, Gephi: An open source software for exploring and manipulating networks, in: Proceedings of AAAI Conference on Weblogs and Social Media, San Jose, California, 2009.
- [24] W. Moreira, P. Mendes, Social-aware opportunistic routing: The new trend, in: I. Woungang, S. K. Dhurandher, A. Anpalagan, A. V. Vasilakos (Eds.), Routing in Opportunistic Networks, Springer New York, 2013, pp. 27-68.
- [25] A. Ker¨ anen, J. Ott, T. K¨ arkk¨inen, a The one simulator for dtn protocol evaluation, in: Proceedings of Simutools, Rome, Italy, 2009.
- [26] W. Moreira, P. Mendes, S. Sargento, Assessment model for opportunistic routing, in: Proceedings of LATINCOM, Belem, Brazil, 2011. | 10.1016/j.adhoc.2014.07.001 | [
"Waldir Moreira",
"Paulo Mendes"
] | 2014-08-01T09:04:36+00:00 | 2014-08-01T09:04:36+00:00 | [
"cs.NI"
] | Impact of Human Behavior on Social Opportunistic Forwarding | The current Internet design is not capable to support communications in
environments characterized by very long delays and frequent network partitions.
To allow devices to communicate in such environments, delay-tolerant networking
solutions have been proposed by exploiting opportunistic message forwarding,
with limited expectations of end-to-end connectivity and node resources. Such
solutions envision non-traditional communication scenarios, such as disaster
areas and development regions. Several forwarding algorithms have been
investigated, aiming to offer the best trade-off between cost (number of
message replicas) and rate of successful message delivery. Among such
proposals, there has been an effort to employ social similarity inferred from
user mobility patterns in opportunistic routing solutions to improve
forwarding. However, these research effort presents two major limitations:
first, it is focused on distribution of the intercontact time over the complete
network structure, ignoring the impact that human behavior has on the dynamics
of the network; and second, most of the proposed solutions look at challenging
networking environments where networks have low density, ignoring the potential
use of delay-tolerant networking to support low cost communications in networks
with higher density, such as urban scenarios. This paper presents a study of
the impact that human behavior has on opportunistic forwarding. Our goal is
twofold: i) to show that performance in low and high density networks can be
improved by taking the dynamics of the network into account; and ii) to show
that the delay-tolerant networking can be used to reduce communication costs in
networks with higher density by taking the behavior of the user into account. |
1408.0105v2 | ## Floquet control of quantum dissipation in spin chains
Chong Chen, 1 Jun-Hong An, 1, 2, 3, ∗ Hong-Gang Luo, 1, 2 C. P. Sun, 2 and C. H. Oh 3
1 Center for Interdisciplinary Studies & Key Laboratory for Magnetism and
Magnetic Materials of the MoE, Lanzhou University, Lanzhou 730000, China
2 Beijing Computational Science Research Center, Beijing 100084, China
3 Centre for Quantum Technologies, National University of Singapore, 3 Science Drive 2, Singapore 117543, Singapore
Controlling the decoherence induced by the interaction of quantum system with its environment is a fundamental challenge in quantum technology. Utilizing Floquet theory, we explore the constructive role of temporal periodic driving in suppressing decoherence of a spin-1/2 particle coupled to a spin bath. It is revealed that, accompanying the formation of a Floquet bound state in the quasienergy spectrum of the whole system including the system and its environment, the dissipation of the spin system can be inhibited and the system tends to coherently synchronize with the driving. It can be seen as an analog to the decoherence suppression induced by the structured environment in spatially periodic photonic crystal setting. Comparing with other decoherence control schemes, our protocol is robust against the fluctuation of control parameters and easy to realize in practice. It suggests a promising perspective of periodic driving in decoherence control.
PACS numbers: 03.65.Yz, 03.67.Pp, 75.10.Jm
## I. INTRODUCTION
As a ubiquitous phenomenon in microscopic world, decoherence is a main obstacle to the realization of any applications of quantum coherence, e.g., quantum information processing [1], quantum metrology [2], and quantum simulation [3]. Many methods, such as feedback control [4, 5], decoherence-free subspace encoding [6, 7], and dynamical decoupling [8-11], have been proposed to beat this unwanted effect. The dynamical decoupling scheme can be generally described by the so-called spectral filtering theory in the first-order Magnus expansion [12-16], which is valid when the control pulses are sufficiently rapid. Based on the spin echo technique, this scheme is widely exploited to suppress dephasing [8, 10, 11, 13], where the system has no energy exchange with the environment, and classical noises [14-16]. It requires a high controllability to the system due to its sensitivity to the time instants at which the inverse pulses are applied [17]. Furthermore, when dissipation and quantum noises are involved, it generally cannot perform well. Although the dissipation control was partially touched in the original form of the spectral filtering theory [12], whether the first-Markovian approximation used there can capture well the physics for such time-dependent systems is still an open question. This is because that new time scales would be introduced to the systems by the timedependent control field, which might invalidate the application of the Markovian approximation.
As a main inspiration, we notice that the decoherence of dissipative systems connects tightly with the energyspectrum characters of the total system consisting of the system and its environment [18-20]. If a bound state residing in the energy bandgap of the whole system is
∗ [email protected]
formed by changing the environmental spectral density, the decoherence of the system can be suppressed. Thus one can artificially engineer the bound state to suppress decoherence of quantum emitters by introducing spatial periodic confinement in a photonic crystal setting [2124]. Here the spatial periodic confinement dramatically alters the dispersion relation of the radiation field of the quantum emitter such that a certain bandgap structure is present in the spectral density. If the frequency of the quantum emitter resides in the bandgap region, then a bound state is formed and thus the decoherence of the emitter can be suppressed. However, in practical solidstate systems, one generally faces that it is hard to manipulate the spectral density via changing the spatial confinement once the material of system is fabricated. Thus a more efficient way in engineering the bound state than changing the spectral density is desired.
Recently, temporal periodic driving has become a highly controllable and versatile tool in quantum control. Many efforts have been devoted to explore non-trivial effects induced by periodic driving on physical systems. It has been proven to play profound role not only in controlling single-quantum-state of microscopic systems [2532] and implementing geometric phase gates in quantum computation [33, 34], but also in generating novel states of matter absent in the original static system [35-42]. Different from static systems, periodically driven systems have no stationary states because the energy is not conserved. Due to Floquet theory, they have well-defined quasi-stationary-state properties described by the Floquet eigen-values, which are called quasienergies. The distinguished role of periodic driving in these diverse systems is that the versatility of driving schemes can induce more colorful quasi-stationary-state behaviors than the static case by controlling the quasi-energy spectrum.
In this paper, we explore the possibility of periodic driving on engineering the bound state of a spin-1/2 system interacting with a XX-type coupled spin bath.
Via manipulating the quasi-energy spectrum by periodic driving, we find that a Floquet eigenstate with discrete quasienergy, which we name a Floquet bound state (FBS), can be formed within the bandgap of the quasienergy spectrum. We further reveal that the presence of the FBS would dynamically cause the dissipation of the system spin inhibited. The result suggests that we can manipulate the periodicity in a temporal domain instead of the one in a spatial domain to suppress decoherence, which relaxes greatly the experimental difficulty in fabricating periodic confinement in a photonic crystal.
Our paper is organized as follows. In Sec. II, we present our model of a periodically driven spin-1 / 2 particle coupled to a spin chain bath and its exact decoherence dynamics. In Sec. III, the Floquet theory is used to obtain the quasi-energy spectrum of the whole system. In Sec. IV, the mechanism of decoherence inhabitation induced by the periodic driving is revealed. The comparisons of this mechanism with the previous methods are also shown in this section. Finally, a summary is given in Sec. V.
## II. MODEL AND DYNAMICS
We consider a periodically driven spin-1 / 2 particle interacting with a one-dimensional spin chain, which is composed of L spin-1 / 2 particles coupled via XX-type interactions. The Hamiltonian of the total system is ˆ ( H t ) = ˆ H S ( ) + t ˆ H I + ˆ H E with
$$\hat { H } _ { \text{S} } ( t ) = \frac { 1 } { 2 } [ \lambda + A ( t ) ] \hat { \sigma } _ { 0 } ^ { z }, \ \hat { H } _ { 1 } = \frac { g } { 2 } ( \hat { \sigma } _ { 0 } ^ { x } \hat { \sigma } _ { 1 } ^ { x } + \hat { \sigma } _ { 0 } ^ { y } \hat { \sigma } _ { 1 } ^ { y } ), \ ( 1 ) \quad \text{$\hat{H} | \varphi_{n}$} \\ \text{array $s$} \quad \text{$\Delta$} \ t$$
$$\hat { H } _ { \text{E} } = \frac { \mu } { 2 } \sum _ { j = 1 } ^ { L } \hat { \sigma } _ { j } ^ { z } + \frac { J } { 2 } \sum _ { j = 1 } ^ { L - 1 } ( \hat { \sigma } _ { j } ^ { x } \hat { \sigma } _ { j + 1 } ^ { x } + \hat { \sigma } _ { j } ^ { y } \hat { \sigma } _ { j + 1 } ^ { y } ), \quad ( 2 ) \quad T ) \ c ; \quad \text{powc} _ { \text{der} \, d }$$
where ˆ σ α j ( α = x, y, z ) are the Pauli matrices with j = 0 and 1 , · · · , L , respectively, labeling the system spin and the spins in the chain; λ denotes the longitudinal magnetic field exerted homogeneously on all the spins; A t ( ) is the always-on periodic driving [43, 44] only on the system; J and g are, respectively, the coupling strengths between the nearest-neighbour spins of the chain and between the system and the first-site spin of the chain. ˆ H E yields a phase transition at the critical point | λ | = 2 J [45]. This type of system has been widely used to realize quantum state transfer, where the XX-coupling chain is used as a bridge [46, 47], and to analyze decoherence caused by a spin bath [48]. Diagonalizing ˆ H E in the single-excitation subspace, we can obtain its eigenstate | ϕ k 〉 = ∑ L j =1 e ikjx 0 √ L ˆ σ + j |{↓ }〉 j , which is a spin wave with wave vector k , and the eigenenergy E k = λ +2 J cos kx 0 with x 0 being the spatial separation of the two neighbor sites. Here |{↓ }〉 j is the ferromagnetic state of the chain with all its spins pointing to the -ˆ e z direction and ˆ σ + j = (ˆ σ x j + ˆ ) 2. Obviously, the spin chain defines an iσ y j / environment with finite bandwidth 4 J .
We are interested in how the spin chain results in decoherence to the system spin and how it can be suppressed by periodic driving. Since the excitation number ˆ N ≡ ∑ L j =0 ˆ σ + j ˆ σ -j is conserved, the Hilbert space is divided into independent subspaces with definite N . Consider that the spin chain is initially polarized in a ferromagnetic state and the system is in an up state | Ψ(0) 〉 = | φ 〉 ⊗ |{↓ }〉 j with | φ 〉 = | ↑ 〉 0 , and its evolution can be expanded as | Ψ( ) t 〉 = e i Lλt 2 ∑ L j =0 c j ( )ˆ t σ + j |{↓ }〉 j , where c 0 ( ) satisfies t
$$\overset { \dots } { \ v e } _ { r - } \quad & \dot { c } _ { 0 } ^ { \prime } ( t ) + i [ \lambda + A ( t ) ] c _ { 0 } ^ { \prime } ( t ) + \int _ { 0 } ^ { t } f ( t - \tau ) c _ { 0 } ^ { \prime } ( \tau ) d \tau = 0, ( 3 )$$
with c ′ 0 ( ) t = c 0 ( ) t e -i 2 ∫ t 0 [ λ + ( )] A τ dτ and f ( x ) ≡ ( g 2 /L ) ∑ k e -iE k x and c 0 (0) = 1. Denoting the excitedstate probability of the system, | c 0 ( ) t | 2 characterizes the environmental decoherence effect on the system. Equation (3) provides us with the exact description to the decoherence of the system.
## III. FLOQUET QUASI-ENERGY SPECTRUM
For a static system governed by ˆ , H any time-evolved state can be expanded as
$$| \Psi ( t ) \rangle = \sum _ { n } C _ { n } e ^ { i E _ { n } t } | \varphi _ { n } \rangle \, \text{ \quad \ \ } \text{ (4)}$$
where C n = 〈 ϕ n | Ψ(0) , 〉 E n and | ϕ n 〉 determined by ˆ H ϕ | n 〉 = E n | ϕ n 〉 are called as eigenenergies and stationary states, respectively.
A temporal periodic system governed by ˆ ( H t ) = ˆ ( H t + T ) can be treated by Floquet theory [49], which, as a powerful approach to map a non-equilibrium system under driving to a static one, can be seen as the application of Bloch theorem in the time domain. According to this theory, the periodic system has a complete set of basis | u α ( ) t 〉 determined by
$$[ \hat { H } ( t ) - i \partial _ { t } ] | u _ { \alpha } ( t ) \rangle = \epsilon _ { \alpha } | u _ { \alpha } ( t ) \rangle \text{ \quad \ \ } ( 5 )$$
such that any state can be expanded as
$$| \Psi ( t ) \rangle = \sum _ { \alpha } C _ { \alpha } e ^ { - i \epsilon _ { \alpha } t } | u _ { \alpha } ( t ) \rangle \quad \quad ( 6 )$$
with C α = 〈 u α (0) Ψ(0) . | 〉 The similar time-independence of C α as C n in Eq. (4) implies that /epsilon1 α and | u α ( ) t 〉 play the same roles in a periodic system as eigenenergies and stationary states do in static system. Such similarity leads us to call them quasienergies and quasi-stationary states, respectively. Carrying all the quasi-stationarystate characters, the quasienergy spectrum formed by all /epsilon1 α is a key to study periodic system. Note that /epsilon1 α is periodic with period 2 π/T because e ilωt | u α ( ) t 〉 with ω = 2 π/T is also the eigenstate of Eq. (5) with eigenvalue /epsilon1 α + lω .
The Floquet operator acts on an extended Hilbert space named Sambe space, which is made up of the usual Hilbert space and an extra temporal space [50, 51]. To calculate the quasienergies, one first expands | u α ( ) t 〉 in a complete set of basis of the temporal space, which is generally chosen as { e ikωt | k ∈ Z } . We have | u α ( ) t 〉 = ∑ k | ˜ u α ( k ) 〉 e ikωt , with which Eq. (5) is recast into
$$\sum _ { k \in Z } [ \hat { \tilde { H } } _ { l - k } + k \omega \delta _ { l, k } ] | \tilde { u } _ { \alpha } ( k ) \rangle = \epsilon _ { \alpha } | \tilde { u } _ { \alpha } ( l ) \rangle, \quad ( 7 ) \quad \text{ }$$
with ˆ ˜ H l -k ≡ ∫ T 0 ˆ ( H t ) e -i l ( -k ωt ) T dt . Then expanding each ˆ ˜ H l in the complete basis of Hilbert subspace with N = 1, we get an infinite matrix equation. The quasienergies are obtained by truncating the basis of the temporal space to the rank such that the obtained magnitudes converge.
## IV. DECOHERENCE INHIBITION BY PERIODIC DRIVING
## A. The mechanism of the decoherence inhibition
To reveal the mechanism of decoherence inhibition by the periodic driving, we consider explicitly that the energy splitting of the system is modulated as [48]
$$A ( t ) = \begin{cases} \ a _ { 1 }, & \ n T < t \leq n T + \tau \\ \ a _ { 2 }, & \ n T + \tau < t \leq ( n + 1 ) T \end{cases} \. \quad ( 8 ) \quad \ \forall$$
It is realizable by adding a time-dependent longitudinal magnetic field. Note that although only the driving periodic in this step function is considered, the mechanism revealed in the following is also applicable to other forms. To Eq. (8), we have
$$\hat { \tilde { H } }$$
$$\hat { \tilde { H } } _ { l } & = ( \hat { H } _ { \text{E} } + \hat { H } _ { 1 } ) \delta _ { l, 0 } + ( \omega _ { l } / 2 ) \hat { \sigma } _ { 0 } ^ { z }, \quad ( 9 ) \quad \text{fig.\ } \text{and} \,. \\ \omega _ { l } & = \frac { a _ { 1 } ( 1 - e ^ { - i l \omega \tau } ) - a _ { 2 } ( e ^ { - i 2 \pi l } - e ^ { - i l \omega \tau } ) } { 2 i \pi l }. \quad ( 1 0 ) \quad \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{fig.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ } \text{text.\ }$$
We first study the asymmetric driving situation by choosing a 1 = 0. Figure 1(a) shows the time evolution of the excited-state probability P t = | c 0 ( ) t | 2 with the change of the driving amplitude a 2 via numerically solving Eq. (3). When the driving is switched off, i.e., a 2 = 0, P t decays monotonically to zero, which means a complete decoherence exerted by the spin chain to the system spin. When the driving is switched on, it is interesting to see that, dramatically different from the switch-off case, P t is stabilized repeatedly with the increase of a 2 . To explain this, we plot in Fig. 1(b) the quasienergy spectrum obtained by solving Eq. (7). We can find that an FBS is possible to be formed within the bandgap with the increase of a 2 . It is remarkable to see that the regimes where the decoherence is inhibited match well with the ones where the FBS is present. To understand the decoherence inhibition induced by the FBS, we, according to
FIG. 1. (Color online) (a) Evolution of the excited-state probability P t of the system spin in different driving amplitude a 2 . (b) Floquet quasienergy spectrum of the whole system with the change of the driving amplitude a 2 in step δa 2 = 0 5 . J . The parameters T = 0 25 . πJ -1 , a 1 = 0, τ = 0 1 . πJ -1 , g = 1 0 . J , λ = 20 0 . J , and L = 800 are used.
FIG. 2. (Color online) Evolution of P t for | φ 〉 = | ↑ 〉 0 in (a) and F t for | φ 〉 = ( | ↑ 〉 0 + | ↓ 〉 0 ) / √ 2 in (b) when a 2 = 36 0 . J with the FBS (cyan solid line) and a 2 = 1 5 . J without the FBS (red dashed line) via numerically solving Eq. (3). The blue dotdashed lines show the results obtained via analytically evaluating the contribution of the FBS to the asymptotic state, which match with the numerical ones. The parameters are the same as Fig. 1 except for T = 0 05 . πJ -1 and τ = 0 02 . πJ -1 .
Eq. (6), rewrite
$$| \Psi ( t ) \rangle & = e ^ { i \frac { L \lambda t } { 2 } } [ x e ^ { - i \epsilon _ { F B S } t } | u _ { F B S } ( t ) \rangle \\ & \quad + \sum _ { \alpha \in \text{Band} } y _ { \alpha } e ^ { - i \epsilon _ { \alpha } t } | u _ { \alpha } ( t ) \rangle ], \quad \ ( 1 1 ) \\ \intertext { w o s } = / \lambda _ { \beta } - / \lambda _ { \beta } - / \partial \nabla | \Psi / \partial \nabla | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial | \partial |$$
where x = 〈 u FBS (0) Ψ(0) | 〉 and y α = 〈 u α (0) Ψ(0) . | 〉 Then one can get that P t evolves asymptotically to P ∞ ≡ x 2 |〈 Ψ(0) | u FBS ( ) t 〉| 2 with all the components in the quasienergy band vanishing due to the out-of-phase interference contributed by the continuous phases (see Appendix A), as confirmed in Fig. 2(a). In the absence of the FBS,
FIG. 3. (Color online) Floquet quasienergy spectrum of the whole system in (a) and evolution of P t in (b) with the change of τ when T = 0 25 . πJ -1 . The increase step δτ = 0 03 . J -1 is used in (a). Floquet quasienergy spectrum in (c) and time evolution of P t in (d) with the change of of T when τ = 0 1 . πJ -1 . The increase step δT = 0 09 . J -1 is used in (c). Other parameters are the same as Fig. 1.
although it is dramatically interrupted by the driving, P t decays to zero finally. Whenever the FBS is formed, P t would be stabilized to P ∞ , which is periodic with period T [see the inset of Fig. 2(a)]. It means that the presence of the FBS would cause P t to survive in the only component of the FBS and thus synchronize with the driving field [52]. Figure 2(b) plots the performance of the formed FBS in an arbitrary initial state | φ 〉 = ( | ↑ 〉 0 + | ↓ 〉 0 ) / √ 2. We can see that the decay of the initial-state-fidelity F t ≡ 〈 φ | Tr E [ | Ψ( ) t 〉〈 Ψ( ) ] t | | φ 〉 , to 50% can be stabilized even as high as the ideal lossless case (i.e., between 0 and 1) with the formation of the FBS. Characterizing the quantum coherence between the two spin states, such stabilized oscillation means that the quantum coherence is preserved. We can check that F t tends to F ∞ = 〈 φ ρ φ | | 〉 , where
$$\rho & = ( 1 - \frac { | x | ^ { 2 } } { 2 } ) | \downarrow _ { 0 } \rangle \langle \downarrow _ { 0 } | + \frac { | x | ^ { 2 } } { 2 } \rho _ { \text{FBS} } ( t ) & \quad \text{state} \\ & \quad + \{ \frac { x ^ { * } } { 2 } \mu ( t ) \text{Tr} _ { \text{E} } [ | \{ \downarrow _ { j } \} \rangle \langle u _ { \text{FBS} } ( t ) | ] + \text{h.c.} \} \quad ( 1 2 ) & \text{icity} \\ \dots & \quad \text{$\dots$} \quad \text{$\nu$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$ } \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \ \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \text{$\dots$} \quad \end{$$
with ρ FBS ( ) t = Tr E [ | u FBS ( ) t 〉〈 u FBS ( ) ] t | and µ t ( ) = e i ∫ t 0 λ + A t ( ′ )+2 FBS /epsilon1 2 dt ′ (see Appendix B). We plot this F ∞ with the blue dotdashed line in Fig. 2(b), which matches with the asymptotical result from numerically solving Eq. (3).
The result reveals that we can manipulate the quasienergy spectrum forming the FBS to suppress decoherence. A prerequisite for forming the FBS is the existence of finite quasienergy gap in the spectrum. We plot in Fig. 3 the Floquet quasienergy spectrum and P t with the change of τ as well as T . We can see that, irrespective of which driving parameter is changed, the firm correspondence between the formation of the FBS and the decoherence inhibition can be established. The common character between Fig. 1(b) and Fig. 3(a) is that the width of the formed bandgap is kept constant during the change of driving parameters, which is not true for Fig. 3(c). This can be understood in the following way. Periodic in 2 π/T , the quasienergy has a full width 2 π/T . The energy band of the whole system is 4 J . Therefore, a bandgap with finite width 2 π/T -4 J can be present in the quasienergy spectrum only in the high-frequency (i.e. 2 π/T > 4 J ) driving case. This can be tested by Fig. 3(c) where the bandgap vanishes whenever 2 π/T < 4 J . It leads to the continuous energy band of the environment filling up the Floquet spectrum. Thus there is no room for forming the FBS here. Reflecting on P t in Fig. 3(d), although it is greatly slowed, P t approaches zero eventually. Therefore, we conclude that the FBS can be present only in the high frequency driving case 2 π/T > 4 J , which supplies a necessary condition to stabilize decoherence. It is a very useful criterion on designing a driving scheme for decoherence control.
Our finding in the periodically driven system is an analog to the bound-state-induced decoherence suppression revealed in a static system [18-20]. For a static two-level system [19, 20] or a harmonic oscillator [53] interacting with an environment, depending on the parameters in the spectral density, the total system may possess a stationary state named a bound state [19] localized out of the continuous energy band of the environment. As a stationary state, the bound state contained as one superposition component in the initial state does not lose its quantum coherence during time evolution. Thus the system evolves exclusively to the time-invariant component of the bound state with other components in the continuous band vanishing due to their out-of-phase interference. This idea was used previously to suppress spontaneous emission of quantum emitters via introducing spatial periodic confinement to the radiation field in a photonic crystal setting [21-24]. The spatial periodicity introduces a bandgap structure to the environmental energy spectrum such that an emitter-environment bound state is formed when the frequency of the emitter falls in the bandgap. Here we demonstrate that the parallel picture can be set up by introducing temporal periodicity to the system. The benefit of using the temporal periodic driving instead of the spatial periodic confinement is that its high controllability greatly relaxes the experimental difficulty in fabricating the spatial periodic confinement. Thus it is easier to realize in practice.
## B. Comparisons with the previous methods
There are several methods in the literature to explore the effects of periodic driving on quantum systems. For example, via neglecting the coupling between different temporal subspaces of the Floquet eigenequation (7) in the high-frequency driving condition, it was shown that
FIG. 4. (Color online) The renomalization factor | F 0 | 2 in (a) and the evolution of P t in (b) with the change of a 2 in the symmetric driving case (i.e. a 1 = -a 2 ). The inset of (a) shows the Floquet quasienergy spectrum revealing the absence of the FBS. The parameters are T = 0 4 . πJ -1 and τ = 0 2 . πJ -1 and the others are the same as Fig. 1.
the periodic driving can induce the suppressed tunneling of a quantum particle, a phenomenon called coherent destruction of tunneling [25-27], and the decoupling between open system and its environment [30, 31]. It was also revealed that, via introducing the first-Markovian approximation to Eq. (3), the dynamics of the open system under periodic control can be characterized by an overlap integration of the noise spectrum and the spectrum of the control and thus one can craft the filtertransfer function of the control field to suppress decoherence [12]. It is called spectral filtering theory and has been generalized to give a unified description to a dynamical decoupling method [12-16]. In the following we compare our exact treatment with the above approximate methods.
First, our decoherence inhibition mechanism is more robust to the imperfect fluctuation of the driving parameters than the decoupling mechanism revealed in Ref. [30, 31], where the decoupling is achieved only in certain single values of the driving parameters. To see this, we resort to the same approximate method as in Refs. [27, 30, 31]. Expanding | u α ( ) t 〉 in a new set of basis of the temporal space as | u α ( ) t 〉 = ∑ k ˆ U e t ikωt | ˜ u α ( k ) 〉〉 , where ˆ U t = exp[ -( i/ 2) ∫ t 0 ( A t ( ′ ) -¯ )ˆ A σ dt z ′ ] with ¯ A = (1 /T ) ∫ T 0 A t dt ( ) subtracted to guarantee the periodicity of | u α ( ) t 〉 , we can obtain a similar form as Eq. (7) but
$$\underline { + \bar { A } } ;$$
$$\hat { \tilde { H } } _ { l - k } & = [ \frac { \lambda + \tilde { A } } { 2 } \hat { \sigma } _ { 0 } ^ { z } + \hat { H } _ { E } ] \delta _ { l, k } + g ( F _ { l - k } \hat { \sigma } _ { 1 } ^ { + } \hat { \sigma } _ { 0 } ^ { - } + \text{h.c.} ), ( 1 3 ) \quad \text{the d} \\ F _ { l - k } & = \int _ { 0 } ^ { T } \frac { \exp \{ - i \int _ { 0 } ^ { t } [ A ( t ^ { \prime } ) - \tilde { A } ] d t ^ { \prime } \} e ^ { - i ( l - k ) \omega t } } { T } d t. \ ( 1 4 ) \quad \text{the fo} \\ \dashrightarrow \cdot \quad. \quad. \quad. \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightore \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightory \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightarrow \ \dashrightropodatrix \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
/negationslash
Using the approximation in Refs. [30, 31], we neglect the terms F l -k with l = k and keep only F 0 . It reduces to a spin system coupled to an environment with the coupling strength renormalized by a factor F 0 . In Fig. 4, we plot
| F 0 | 2 and P t with the change of a 2 in the symmetric driving situation, i.e. a 1 = -a 2 . It shows that although no FBS is formed, F 0 = 0 is achievable in certain values of driving parameters. As expected, it induces the decoherence inhibited [see Fig. 4(b)]. However, the decoupling is sensitive to the driving parameters and any small deviation to the decoupling driving values would cause the asymptotic vanishing of P t . Different from this, it is a wide parameter regime in our mechanism which makes decoherence inhibited (see Figs. 1 and 3), which is more stable to the parameter fluctuation in the practical experiments than the decoupling one.
Second, we emphasize that, our mechanism is substantially different from the spectral filtering theory [12-16]. That theory works only in the first-Markovian approximation, with which the convolution in the exact evolution equation (3) can be removed [12], i.e.,
$$\dot { \alpha } ( t ) \approx - \alpha ( t ) \int _ { 0 } ^ { t } d \tau \varepsilon ^ { * } ( t ) \varepsilon ( \tau ) f ( t - \tau ) e ^ { i \omega _ { a } ( t - \tau ) }, \ ( 1 5 )$$
with α t ( ) = c ′ 0 ( ) t e i ∫ t 0 [ λ + ( )] A τ dτ , ε t ( ) = e i ∫ t 0 [ A τ ( ) -¯ ] A dτ , and ω a = λ + ¯ . A Its solution can be obtained readily as
$$| \alpha ( t ) | = | c _ { 0 } ( t ) | = \exp [ - R ( t ) Q ( t ) / 2 ], \quad ( 1 6 )$$
where
$$R ( t ) \equiv 2 \pi \int _ { - \infty } ^ { + \infty } G ( \omega + \omega _ { a } ) \frac { | \varepsilon _ { t } ( \omega ) | ^ { 2 } } { Q ( t ) } d \omega, \quad ( 1 7 )$$
$$Q ( t ) = \int _ { 0 } ^ { t } d \tau | \varepsilon ( \tau ) | ^ { 2 }$$
with the environmental spectral density G ω ( ) relating to its correlation function f ( t -τ ) as f ( t -τ ) = ∫ G ω e ( ) -iω t ( -τ ) dω and ε t ( ω ) = 1 √ 2 π ∫ t 0 ε τ ( ) e iωτ dτ . Thus it is only under the first Markovian approximation that | c 0 ( ) t | can be denoted by such filtered spectrum form. To check the physics missed by this approximation, we plot in Fig. 5 the comparison of our exact result with the one obtained firmly from the spectral filtering theory. We can see from Fig. 5(a) that the spectral filtering theory shows a complete decoherence to zero because of a dramatic overlap between the environmental spectrum and the control spectrum [see Fig. 5(b)]. However, our exact result in Fig. 5(c) shows a stabilization on decoherence due to the existence of the FBS in the quasi-energy spectrum [see Fig. 5(d)]. It means that the spectral filtering theory totally breaks down in describing the long-time steady state behavior here. To give more evidence on the dominate role of the formed FBS in the steady-state behavior, we plot in Fig. 5(c) the fidelity of the FBS in the time-evolved state, which matches well with P t in the long-time limit. Therefore, it confirms again that the formed FBS is the physical reason for decoherence inhibition in long-time limit of our model. Thus the decoherence cannot be simply described as an overlap between the noise spectrum and the control field here and the spectral filtering theory is inapplicable to explain our result.
FIG. 5. (Color online) The comparison of P t calculated by the spectral filtering method in (a) and our exact method in (c). (b): The noise spectrum G ω ( + ω 0 ) and the spectrum of the control F t ( ω ) ≡ | ε t ( ω ) | 2 /Q t ( ) used in the spectral filtering method to determine P t . The contribution of the formed FBS to P t is also plotted in (c). The Floquet quasi-energy spectrum in (d) shows the existence of the FBS. a 2 = 3 2 . J is further used in (a-c) and other parameters are same as Fig. 1.
As a final remark, the mechanism revealed in our spin-bath model can also be readily extended to other excitation-number-conserving models, e.g. a two-level system in a coupled cavity array [30, 31] and a harmonic oscillator in a bosonic bath model [53].
## V. CONCLUSIONS
We have studied the decoherence dynamics of a periodically driven spin-1/2 particle interacting with an XX coupled spin chain. It is found that the decoherence of the system can be inhibited by the periodic driving. We have revealed that the mechanism of such decoherence inhibition induced by the periodic driving is the formation of a FBS in the quasienergy spectrum. This can be seen as a close analog of the bound-state induced decoherence suppression in a photonic crystal system, but it relaxes greatly the experimental difficulties of a photonic crystal system in fabricating specific spatial periodicity to engineer a bound state. It opens a door to beat decoherence by tailoring temporal periodicity. Compared with the conventional schemes of decoherence control using periodic driving or pulses, our scheme is robust to the practical driving parameter fluctuation. Given the fact that periodic driving offers a high controllability to quantum system, our decoherence inhibition mechanism provides us with a promising and realistic way to practical decoherence control.
## ACKNOWLEDGMENTS
This work is supported by the Fundamental Research Funds for the Central Universities, by the Specialized Research Fund for the Doctoral Program of Higher Education, by the Program for NCET, the National 973-program (Grant No. 2012CB922104 and No. 2014CB921403), by the NSF of China (Grants No. 11175072, No. 11174115, No. 11121403, No. 11325417, and No. 11474139), and by the National Research Foundation and Ministry of Education, Singapore (Grant No. WBS: R-710-000-008-271).
## Appendix A: The contribution of the formed FBS to the long-time steady state
For the initial state | Ψ(0) 〉 = | ↑〉⊗|{↓ 1 · · · ↓ L }〉 , | Ψ( ) t 〉 can also be expanded in the Floquet basis as
$$| \Psi ( t ) \rangle & = e ^ { i \frac { L \lambda t } { 2 } } [ x e ^ { - i \epsilon _ { F B S } t } | u _ { F B S } ( t ) \rangle \\ & \quad + \sum _ { \alpha \in B } y _ { \alpha } e ^ { - i \epsilon _ { \alpha } t } | u _ { \alpha } ( t ) \rangle ], \quad \text{ (A1)} \\ \text{...} \, | | \, | |, \quad | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
\| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | \| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |. \, | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
\| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |. \, | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |........................................................................................................................................................................................................ .......................................................................................................................................................................................................$$
where | u FBS ( ) t 〉 is the formed FBS with quasienergy /epsilon1 FBS , | u α ( ) t 〉 are the Floquet eigenstates in the continuous band with quasienergies /epsilon1 α , x = 〈 u FBS (0) Ψ(0) , and | 〉 y α = 〈 u α (0) Ψ(0) . | 〉 Then we can calculate the probability of the system spin keeping in up state as
$$\text{other} \\ - \text{level} \\ \text{nonic} \\ + \sum _ { \alpha, \beta \in B } y _ { \alpha } ^ { * } y _ { \beta } e ^ { - i ( \epsilon _ { \beta } - \epsilon _ { \alpha } ) t } \langle \Psi ( 0 ) | u _ { F B S } ( t ) \rangle | ^ { 2 } \\ + \sum _ { \alpha \in B } y _ { \alpha } ^ { * } e ^ { - i ( \epsilon _ { F B S } - \epsilon _ { \alpha } ) t } \langle \Psi ( 0 ) | u _ { F B S } ( t ) \rangle \langle u _ { \alpha } ( t ) | \Psi ( 0 ) \rangle \\ + \sum _ { \alpha \in B } [ x y _ { \alpha } ^ { * } e ^ { - i ( \epsilon _ { F B S } - \epsilon _ { \alpha } ) t } \langle \Psi ( 0 ) | u _ { F B S } ( t ) \rangle \langle u _ { \alpha } ( t ) | \Psi ( 0 ) \rangle \\ + c. c. ] \quad & ( A 2 ) \\ \text{$\mathfrak{mu}$ to the out of $theo$ into for non-out build from}$$
Due to the out-of-phase interference contributed from e -i ( /epsilon1 β -/epsilon1 α ) t with α = β and e -i ( /epsilon1 FBS -/epsilon1 α ) t , P t tends to
/negationslash
$$\intertext { n e o f } _ { \substack { P _ { \infty } \\ g. \, \text{We} \\ \text{rence} } } \quad P _ { \infty } & = | x | ^ { 2 } | \langle \Psi ( 0 ) | u _ { F B S } ( \infty ) \rangle | ^ { 2 } + \sum _ { \alpha \in B } | y _ { \alpha } | ^ { 2 } | \langle \Psi ( 0 ) | u _ { \alpha } ( \infty ) \rangle | ^ { 2 } \\ & = | \lambda | ^ { 2 } | / \mathfrak { W } / \infty | u _ { \alpha \in B } / \infty \| \lambda | ^ { 2 }$$
$$\stackrel { \sim } { e } & = | x | ^ { 2 } | \langle \Psi ( 0 ) | u _ { F B S } ( \infty ) \rangle | ^ { 2 } \\ e & \quad + \sum _ { \alpha \in B } | y _ { \alpha } | ^ { 4 } | \langle u _ { \alpha } ( 0 ) | u _ { \alpha } ( \infty ) \rangle | ^ { 2 } & ( A 3 ) \\ \vdots & \quad \text{$\theta$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$ } \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \quad \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \text{$two$} \, \colon$$
where the orthogonality of Floquet eigenstates has been used. Noticing the fact that ∑ α ∈ B | y α | 2 = ∑ L α =1 | y α | 2 ∼ 1 (because we have L Floquet eigenstates forming the continuous quasienergy band), we can estimate that | y α | 2 ∼ 1 /L . In the thermodynamics limit L ⇒ ∞ , the last term tends to zero. Thus we have
$$P _ { \infty } = | x | ^ { 2 } | \langle \Psi ( 0 ) | u _ { \text{FBS} } ( \infty ) \rangle | ^ { 2 }. \quad \ \ ( A 4 ) \\. \. \. \. \. \. \. \. \.$$
From the above analysis, we can see that the preserved excited-state probability is determined by the weight of | u FBS (0) 〉 in the initial state | Ψ(0) 〉 and the excited-state
FIG. 6. (Color online) The distribution of excited-state population of the formed Floquet bound state at time t = T/ 4 over the spin sites. The parameters used are T = 0 25 . πJ -1 , τ = 0 1 . πJ -1 , a 2 = 3 2 . J , and a 1 = 0.
probability of the system spin in | u FBS ( ∞ 〉 ) itself. In Fig. 6, we plot the distribution of excited-state population of the formed FBS at time t = T/ 4 over the spin sites. We can see that its excited-state population is mainly confined in the site of the system spin, which acts as an impurity in the whole system.
## Appendix B: The effect of periodic driving on the initial superposition state
/negationslash
For the general initial state | Ψ(0) 〉 = | φ 〉 ⊗ |{↓ j =0 }〉 with | φ 〉 = α | ↑ 〉 0 + β | ↓ 〉 0 under | α | 2 + | β | 2 = 1, its evolved state | Ψ( ) t 〉 can be expanded as
$$\cdot \cdot \cdot \cdot \cdot \cdot \\ | \Psi ( t ) \rangle & = e ^ { i \frac { L \lambda t } { 2 } } \left ( \alpha \sum _ { j = 0 } ^ { L } c _ { j } ( t ) \hat { \sigma } _ { j } ^ { + } | \{ \downarrow _ { j } \} \rangle \\ & \quad + \beta e ^ { i \int _ { 0 } ^ { t } \frac { \lambda + A ( t ^ { \prime } ) } { 2 } d t ^ { \prime } } | \{ \downarrow _ { j } \} \rangle \right ), \quad ( B 1 ) \quad \mu ( t ) \quad \text{(} ) \quad \text{(} \quad \text{(} ) \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \tau } \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \vec { \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \text{(} \quad \vec { \vec { \text{(} \quad \vec { \text{(} \quad \vec { \vec { \text{(} \quad \vec { \vec { \text{(} \quad \vec { \vec { \text{(} \quad \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \bar { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { \vec { } \vec { \vec { \vec { \vec { \bar { \vec { \bar { \bar { \bar { \bar { \vec { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { | \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \hat { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { - \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ } { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { } { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar } { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \ | { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar {'\bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar { \bar {$$
where c 0 ( ) satisfies Eq. t (3) in the main text. The fidelity of the system in its initial state | φ 〉 can be calculated as
$$\begin{array} { c c c c } \cdot & \cdots & \text{This} \\ \mathcal { F } _ { t } = \langle \phi | \text{Tr} _ { E } [ | \Psi ( t ) \rangle \langle \Psi ( t ) | ] | \phi \rangle \\ = & \left | | \alpha | ^ { 2 } c _ { 0 } ( t ) e ^ { - i \int _ { 0 } ^ { t } \frac { \lambda + A ( t ^ { \prime } ) } { 2 } d t ^ { \prime } } + | \beta | ^ { 2 } \right | ^ { 2 } \\ & + | \alpha \beta | ^ { 2 } | [ 1 - | c _ { 0 } ( t ) | ^ { 2 } ], & ( B 2 ) \\ \text{ince} | \phi \rangle \text{ is not an eigenstate of the svstem even in the ab} \text{-} \quad \text{limit} \end{array}$$
Since | φ 〉 is not an eigenstate of the system even in the absence of the environmental influence, F t is a temporally oscillating function even in the long time limit. To qualitatively reflect the performance of the periodic driving
[1] M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press, 2010).
on suppressing decoherence, we use the maximal value F t to characterize it. This happens at a set of times τ n such that c 0 ( τ n ) e -i ∫ τn λ 0 + A t ( ′ ) 2 dt ′ = | c 0 ( τ n ) . | Under this condition, Eq. (B2) has the form
$$\mathcal { F } _ { \tau _ { n } } & = 1 - | \alpha | ^ { 4 } [ 1 - | c _ { 0 } ( \tau _ { n } ) | ^ { 2 } ] - | \alpha \beta | ^ { 2 } [ 1 - | c _ { 0 } ( \tau _ { n } ) | ] ^ { 2 } \\ & \geq | \beta | ^ { 2 } + | \alpha | ^ { 2 } | c _ { 0 } ( \tau _ { n } ) | ^ { 2 }. \quad \text{(B3)} \\ \text{When the FBS is absent, } | c _ { 0 } ( \infty ) | \, = \, 0 \text{ and thus } \mathcal { F } _ { \tau _ { n } } \, =$$
When the FBS is absent, | c 0 ( ∞ | ) = 0 and thus F τ n = | β | 2 . This corresponds to the complete decoherence (i.e, the system spin decays totally to its low-energy spin down state). Whenever the FBS is formed, a non-zero | c 0 ( ∞ | ) would be achieved. Then we could have F τ n > β | | 2 in the steady state. From this analysis, we can see that the preserved probability for arbitrary initial state is determined by the same long-time behavior of | c 0 ( ∞ | ) as the one for the spin up initial state. This proves well that our mechanism of dissipation suppression can also be applied to the initial superposition state.
More precisely, we can evaluate the contribution of the formed FBS to the steady state. | Ψ( ) t 〉 can also be expanded in the Floquet basis as
$$\text{S.} \\ \text{ly} \\ \text{an} & \quad | \Psi ( t ) \rangle = e ^ { i \frac { L \lambda t } { 2 } } \left [ \beta e ^ { i \int _ { 0 } ^ { t } \frac { \lambda + A ( t ^ { \prime } ) } { 2 } d t ^ { \prime } } | \{ \downarrow _ { j } \} \rangle + \alpha ( x e ^ { - i \epsilon _ { F B S } t } \\ & \quad \times | u _ { F B S } ( t ) \rangle + \sum _ { \gamma \in B } y _ { \gamma } e ^ { - i \epsilon _ { \gamma } t } | u _ { \gamma } ( t ) \rangle ) \right ] \quad ( B 4 ) \\ & \quad \text{$\mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad \mathbb{ }R$} \quad.$$
Due to the out-of-phase interference, the reduced density matrix tends to
$$\lfloor _ { j \neq 0 } \rangle \quad \rho ( \infty ) & = \text{Tr} _ { E } [ | \Psi ( \infty ) \rangle \langle \Psi ( \infty ) | ] = | \beta | ^ { 2 } | \downarrow _ { 0 } \rangle \langle \downarrow _ { 0 } | \\ 1, \text{ its } & \quad + | \alpha | ^ { 2 } \{ | x | ^ { 2 } \rho _ { \text{FBS} } ( t ) + \sum _ { \gamma } | y _ { \gamma } | ^ { 2 } \text{Tr} _ { E } [ | u _ { \gamma } ( t ) \rangle \langle u _ { \gamma } ( t ) | ] \} \\ & \quad + \{ \beta \alpha ^ { * } x ^ { * } \mu ( t ) \text{Tr} _ { E } [ | \{ \downarrow _ { j } \} \rangle \langle u _ { \text{FBS} } ( t ) | ] + \text{h.c.} \}, \quad ( B 5 ) \\ & \text{where } \quad a _ { \text{VDO} } ( t ) \quad = \quad \text{Tr} _ { E } [ | u _ { \text{VDO} } ( t ) \rangle \langle u _ { \text{VDO} } ( t ) | ] \quad \text{and}$$
where ρ FBS ( ) t = Tr E [ | u FBS ( ) t 〉〈 u FBS ( ) ] t | and µ t ( ) = e i ∫ t 0 λ + A t ( ′ )+2 FBS /epsilon1 2 dt ′ . Noticing the fact that Tr E [ | u γ ( ) t 〉〈 u γ ( ) ] t | is dominated by | ↓ 〉〈↓ 0 0 | and ∑ γ | y γ | 2 + | x | 2 = 1, we have ∑ γ | y γ | 2 Tr E [ | u γ ( ) t 〉〈 u γ ( ) ] t | ≈ (1 - | x | 2 ) | ↓ 〉〈↓ 0 0 | . Thus the asymptotic state of the system spin is
$$& \rho ( \infty ) = ( 1 - | \alpha | ^ { 2 } | x | ^ { 2 } ) | \downarrow _ { 0 } \rangle \langle \downarrow _ { 0 } | + | \alpha | ^ { 2 } | x | ^ { 2 } \rho _ { \text{FBS} } ( t ) \\ & + \{ \beta \alpha ^ { * } x ^ { * } \mu ( t ) \text{Tr} _ { \text{E} } [ | \{ \downarrow _ { j } \} \rangle \langle u _ { \text{FBS} } ( t ) | ] + \text{h.c.} \}. \quad ( B 6 ) \\ ) \quad \dots \quad. \quad. \cdots \cdots \cdots \cdots \cdots \cdots \cdots.$$
Then the analytical form of the fidelity in the long-time limit can be calculated by F ∞ = 〈 φ ρ | ( ∞ | ) φ 〉 . It gives the contribution of the formed FBS to the asymptotical state and can be used to check the validity of our FBS theory in explaining the dynamics of the system spin.
[2] A. W. Chin, S. F. Huelga, and M. B. Plenio, Phys. Rev. Lett. 109 , 233601 (2012).
[3] J. W. Britton, B. C. Sawyer, A. C. Keith, C.-C. Joseph
- Wang, J. K. Freericks, H. Uys, M. J. Biercuk, and J. J. Bollinger, Nature 484 , 489 (2012).
- [4] H. M. Wiseman and G. J. Milburn, Phys. Rev. Lett. 70 , 548 (1993).
- [5] M. P. A. Branderhorst, P. Londero, P. Wasylczyk, C. Brif, R. L. Kosut, H. Rabitz, and I. A. Walmsley, Science 320 , 638 (2008).
- [6] D. A. Lidar, I. L. Chuang, and K. B. Whaley, Phys. Rev. Lett. 81 , 2594 (1998).
- [7] L. Viola, E. M. Fortunato, M. A. Pravia, E. Knill, R. Laflamme, and D. G. Cory, Science 293 , 2059 (2001).
- [8] L. Viola and S. Lloyd, Phys. Rev. A 58 , 2733 (1998).
- [9] L. Viola, E. Knill, and S. Lloyd, Phys. Rev. Lett. 82 , 2417 (1999).
- [10] J. Du, X. Rong, N. Zhao, Y. Wang, J. Yang, and R. B. Liu, Nature 461 , 1265 (2009); Y. Wang, X. Rong, P. Feng, W. Xu, B. Chong, J.-H. Su, J. Gong, and J. Du, Phys. Rev. Lett. 106 , 040501 (2011).
- [11] G. de Lange, Z. H. Wang, D. Rist` e, V. V. Dobrovitski, and R. Hanson, Science 330 , 60 (2010).
- [12] A. G. Kofman and G. Kurizki, Phys. Rev. Lett. 87 , 270405 (2001).
- [13] G. S. Uhrig, Phys. Rev. Lett. 98 , 100504 (2007).
- [14] L. Cywi´ nski, R. M. Lutchyn, C. P. Nave, and S. Das Sarma, Phys. Rev. B 77 , 174509 (2008).
- [15] M. J. Biercuk, A. C. Doherty, and H. Uys, J. Phys. B: At. Mol. Opt. Phys. 44 , 154002 (2011).
- [16] T. J. Green, J. Sastrawan, H. Uys, and M. J. Biercuk, New J. Phys. 15 , 095004 (2013).
- [17] A. M. Souza, G. A. Alvarez, and D. Sutter, Phil. Trans. ´ R. Soc. A 370 , 4748 (2012).
- [18] M. Miyamoto, Phys. Rev. A 72 , 063405 (2005).
- [19] Q.-J. Tong, J.-H. An, H.-G. Luo, and C. H. Oh, Phys. Rev. A 81 , 052330 (2010).
- [20] P. Zhang, B. You, and L.-X. Cen, Opt. Lett. 38 , 3650 (2013).
- [21] M. R. Jorgensen, J. W. Galusha, and M. H. Bartl, Phys. Rev. Lett. 107 , 143902 (2011).
- [22] M. Fujita, S. Takahashi, Y. Tanaka, T. Asano, and S. Noda, Science 308 , 1296 (2005).
- [23] D. Englund, D. Fattal, E. Waks, G. Solomon, B. Zhang, T. Nakaoka, Y. Arakawa, Y. Yamamoto, and J. Vuˇkovi`, c c Phys. Rev. Lett. 95 , 013904 (2005).
- [24] M. D. Leistikow, A. P. Mosk, E. Yeganegi, S. R. Huisman, A. Lagendijk, and W. L. Vos, Phys. Rev. Lett. 107 , 193903 (2011).
- [25] F. Grossmann, T. Dittrich, P. Jung, and P. H¨nggi, Phys. a Rev. Lett. 67 , 516 (1991).
- [26] M. Grifoni and P. H¨nggi, Phys. Rep. a 304 , 229 (1998).
- [27] X. Luo, L. Li, L. You, and B. Wu, New J. Phys. 16 , 013007 (2014).
- [28] H. Lignier, C. Sias, D. Ciampini, Y. Singh, A. Zenesini, O. Morsch, and E. Arimondo, Phys. Rev. Lett. 99 , 220403 (2007);
- A. Eckardt, M. Holthaus, H. Lignier, A. Zenesini, D.
- Ciampini, O. Morsch, and E. Arimondo, Phys. Rev. A 79 , 013611 (2009).
- [29] Q.-J. Tong, J.-H. An, L. C. Kwek, H.-G. Luo, and C. H. Oh, Phys. Rev. A 89 , 060101(R) (2014).
- [30] L. Zhou, S. Yang, Y.-x. Liu, C. P. Sun, and F. Nori, Phys. Rev. A 80 , 062109 (2009).
- [31] L. Zhou and L.-M. Kuang, Phys. Rev. A 82 , 042113 (2010).
- [32] A. Das, Phys. Rev. B 82 , 172402 (2010).
- [33] A. Bermudez, P. O. Schmidt, M. B. Plenio, and A. Retzker, Phys. Rev. A 85 , 040302(R) (2012).
- [34] A. Lemmer, A. Bermudez, and M. B. Plenio, New J. Phys. 15 , 083001 (2013).
- [35] D. Vorberg, W. Wustmann, R. Ketzmerick, and A. Eckardt, Phys. Rev. Lett. 111 , 240405 (2013).
- [36] P. Hauke, O. Tieleman, A. Celi, C. Olschl¨ger, ¨ a J. Simonet, J. Struck, M. Weinberg, P. Windpassinger, K. Sengstock, M. Lewenstein, and A. Eckardt, Phys. Rev. Lett. 109 , 145301 (2012).
- [37] N. H. Lindner, G. Refael, and V. Galitski, Nature Physics 7, 490 (2011).
- [38] M. C. Rechtsman, J. M. Zeuner, Y. Plotnik, Y. Lumer, S. Nolte, M. Segev, and A. Szameit, Nature 496, 196 (2013).
- [39] J. Cayssol, B. D´ra, F. Simon, and R. Moessner, Phys. o Status Solidi RRL 7 , 101 (2013).
- [40] M. Nakagawa and N. Kawakami, Phys. Rev. A 89 , 013627 (2014).
- [41] Q.-J. Tong, J.-H. An, J. Gong, H.-G. Luo, and C. H. Oh, Phys. Rev. B 87 , 201109(R) (2013).
- [42] L. Guo, M. Marthaler, and G. Sch¨n , Phys. Rev. Lett. o 111 , 205303 (2013).
- [43] J.-M. Cai, B. Naydenov, R. Pfeiffer, L. P. McGuinness, L. D. Jahnke, F. Jelezko, M. B. Plenio, and A. Retzker, New J. Phys. 14 , 113023 (2012).
- [44] N. C. Jones, T. D. Ladd, and B. H. Fong, New J. Phys. 14 , 093045 (2012).
- [45] S. Katsura, Phys. Rev. 127 , 1508 (1962).
- [46] M. Christandl, N. Datta, A. Ekert, and A. J. Landahl, Phys. Rev. Lett. 92, 187902(2004).
- [47] D. Zueco, F. Galve, S. Kohler, and P. Hanggi, Phys. Rev. A 80, 042303(2009).
- [48] Z.-M. Wang, L.-A. Wu, J. Jing, B. Shao, and T. Yu, Phys. Rev. A 86 , 032303 (2012).
- [49] A. Verdeny, A. Mielke, and F. Mintert, Phys. Rev. Lett. 111 , 175301 (2013).
- [50] J. H. Shirley, Phys. Rev. 138 , B979 (1965).
- [51] H. Sambe, Phys. Rev. A 7 , 2203 (1973).
- [52] A. Russomanno, A. Silva, and G. E. Santoro, Phys. Rev. Lett. 109 , 257201 (2012).
- [53] Y.-Q. L¨, J.-H. An, X.-M. Chen, H.-G. Luo, and C. H. u Oh, Phys. Rev. A 88 , 012129 (2013). | 10.1103/PhysRevA.91.052122 | [
"Chong Chen",
"Jun-Hong An",
"Hong-Gang Luo",
"C. P. Sun",
"C. H. Oh"
] | 2014-08-01T09:09:34+00:00 | 2015-05-27T14:58:37+00:00 | [
"quant-ph"
] | Floquet control of quantum dissipation in spin chains | Controlling the decoherence induced by the interaction of quantum system with
its environment is a fundamental challenge in quantum technology. Utilizing
Floquet theory, we explore the constructive role of temporal periodic driving
in suppressing decoherence of a spin-1/2 particle coupled to a spin bath. It is
revealed that, accompanying the formation of a Floquet bound state in the
quasienergy spectrum of the whole system including the system and its
environment, the dissipation of the spin system can be inhibited and the system
tends to coherently synchronize with the driving. It can be seen as an analog
to the decoherence suppression induced by the structured environment in
spatially periodic photonic crystal setting. Comparing with other decoherence
control schemes, our protocol is robust against the fluctuation of control
parameters and easy to realize in practice. It suggests a promising perspective
of periodic driving in decoherence control. |
1408.0106v1 | ## Ab initio study of InxGa 1 -xN -performance of the alchemical mixing approximation.
P. Scharoch , M.J. Winiarski a b , M.P. Polak a
- a Institute of Physics, Wroc law University of Technology, Wybrzeze Wyspianskiego 27, 50-370 Wroc/suppress law, Poland
b Institute of Low Temperature and Structure Research, Polish Academy of Sciences,
- Ok´ olna 2, 50-422 Wroc/suppress law, Poland
## Abstract
The alchemical mixing approximation which is the ab initio pseudopotential specific implementation of the virtual crystal approximation (VCA), offered in the ABINIT package, has been employed to study the wurtzite (WZ) and zinc blende (ZB) In Ga x 1 -x N alloy from first principles. The investigations were focused on structural properties (the equilibrium geometries), elastic properties (elastic constants and their pressure derivatives), and on the band-gap. Owing to the ABINIT functionality of calculating the HellmannFeynmann stresses, the elastic constants have been evaluated directly from the strain-stress relation. Values of all the quantities calculated for parent InN and GaN have been compared with the literature data and then evaluated as functions of composition x on a dense, 0 05 step, . grid. Some results have been obtained which, to authors' knowledge, have not yet been reported in the literature, like composition dependent elastic constants in ZB structures or composition dependent pressure derivatives of elastic constants. The band-gap has been calculated within the MBJLDA approximation. Additionally, the band-gaps for pure InN and GaN have been calculated with
the Wien2k code, for comparison purposes. The evaluated quantities have been compared with the available literature reporting supercell-based ab initio calculations and on that basis conclusions concerning the performance of the alchemical mixing approach have been drawn. An overall agreement of the results with the literature data is satisfactory. A small deviation from linearity of the lattice parameters and some elastic constants has been found to be due to the lack of the local relaxation of the structure in the VCA. The big bowing of the band-gap, characteristic of the clustered structure, is also mainly due to the lack of the local relaxation in the VCA. The method, when applied with caution, may serve as supplementary tool to other approaches in ab initio studies of alloy systems.
Keywords: semiconductor alloys, ab initio, virtual crystal approximation, elastic constants, band-gap bowing
## 1. Introduction
Semiconducting group III metal nitrides have been drawing an interest over the last decades because of their potential applications in optoelectronics. The direct band gaps starting from 0.65-0.69eV [1, 2, 3] for InN , through 3.50-3.51eV [4, 5] for GaN , up to 6.1eV for AlN [5], together with their ability to form ternary and quaternary alloys, open an interesting perspective for tuning the band gap which is of crucial importance for optoelectronic applications. The structural and electronic properties of nitride alloys have already been intensively studied, both experimentally and theoretically. The idea of tuning the band-gap, although simple in principle, is connected with a variety of practical problems like lattice constants mismatch of parent
compounds, thermodynamically determined phase segregation, the effect of band-gab bowing, the efficiency of radiative transitions etc. The ab initio investigations are of particular importance in the field owing to their predictive power. They provide a hint in which direction, technologically and experimentally, to proceed. A lot of ab initio works have already been reported, dealing with the structural, elastic, thermodynamical and electronic properties, including bulk systems, thin layers, and interfaces. A popular, supercell (SC) approach in which an alloy is modeled by periodically repeated large cell containing a few primitive cells offers an opportunity to vary compositions and ionic configurations. For example in wurtzite (WZ) structure a 32-atoms cell (8 primitive cells) contains 16 nitrogen and 16 group III metal atoms which for ternary alloy gives 16 possible compositions and a number of configurations at each [6]. In ZB structure and 8 primitive cells in a supercell this number is respectively reduced. A great advantage of the supercell approach is the possibility to study the effect of various atomic configurations on physical properties, in particular the extreme cases of the clustered and the uniform one. However, the configurational space is still significantly limited by the supercell size which, if too big, leads to unrealistic computation time. For this reason for example, studying the alloy thermodynamics from first principles becomes a challenging task requiring various approximations [7, 8, 9]. Moreover, a simulated alloy is never a random alloy, i.e. the microscopic configuration of atoms in a supercell is periodically repeated which has an effect on the electronic structure [10, 11].
In this paper we employ an approach which is called the alchemical mixing approximation, following the nomenclature introduced by the authors of
the ABINIT package [12, 13]. This is the modern, ab initio pseudopotential based, implementation of the old idea of the virtual crystal approximation (VCA) whose main advantage is that the alloy can be studied within a primitive cell, which significantly reduces the computational costs. In the cell, at a metal site, the norm-conserving pseudopotential which is constructed of two pseudopotentials and which represents the scattering properties of two metal atoms entering the alloy is placed, at a given proportion. Thus, the composition becomes a continuous (not a discrete, like in supercells) parameter. One of important shortcomings of the approximation is that the 'alchemical' atom is always on the ideal position, which means that the lattice distortion caused by different sizes of atoms, very characteristic of alloy systems, is not represented here, and which is (as we discuss later) the main reason of the deviation of the results from those obtained within the SC approach. Also, studying the thermodynamics is not possible within the approximation since the lattice dynamics would be very poorly represented (the 'alchemical' atom would have to have an unphysical intermediate mass). The aim of this work was to study the performance of the approximation in various applications, to find its strong or weak points and possible reasons of deficiencies, believing that when applied with caution can provide a useful reference for experiment and for the other ab initio studies. We have concentrated on the structural, elastic and electronic properties. The ground state calculations gave us the opportunity to evaluate the LDA band-gap within the MBJLDA approximation [14]. An overall agreement of the results with the literature data has appeared very satisfactory. A small deviation from linearity of the lattice parameters and some elastic constants, showing an intermediate be-
havior between the clustered and the uniform structure of the alloy, has been found to be due to the lack of the local relaxation of the structure in the VCA. The apparent big bowing of the band-gap, characteristic of the clustered structure, points at certain inconsistency in the behavior of the VCA, which is supposed to simulate rather a perfectly uniform medium. An argumentation is given according to which this effect is also mainly due to the lack of the local relaxation in the VCA.
## 2. Computational methods
The alchemical mixing of pseudopotentials implemented in the ABINIT package has been employed to emulate the In Ga x 1 -x N alloy. The prototype of the idea is the virtual-crystal approximation (VCA), used to describe mixed crystals within empirical potential approach. In the approximation the main idea is to introduce an object (an ion, scattering center) whose properties would reflect the properties of two atoms simultaneously, at a given proportion. The VCA is simply a linear combination of two one-electron potentials describing pure crystals. The alchemical mixing of pseudopotentials implemented in the ABINIT package uses the following construction [15]: the local potentials are mixed in the proportion given by mixing coefficients, the form factors of the non-local projectors are all preserved, and all considered to generate the alchemical potential, the scalar coefficients of the non-local projectors are multiplied by the proportion of the corresponding type of atom, the characteristic radius of the core charge is a linear combination of the characteristic radii of the core charges, the core charge function f ( r/rc ) is a linear combination of the core charge functions. In all the lin-
ear combinations the mixing coefficients reflecting the proportion at which particular atoms enter the alloy are used. Norm conserving pseudopotentials with the same valence electronic configuration must be used, like e.g. In and Ga. It would be impossible then to emulate e.g. the In Al x 1 -x N with In d -electrons included.
The norm conserving pseudopotentials have been generated with the OPIUM package [16]. The Perdew-Zunger form [17] of the local density approximation (LDA) for the exchange-correlation functional was employed in the scalar relativistic mode. The cut-off radii: 2 0, 1 8, and 1 4 . . . Bohr were selected respectively for In (4 d : 5 s : 5 p ), Ga (3 d : 4 s : 4 p ), and N (2 s : 2 p ) pseudo-orbitals. The non-linear core-valence correction (NLCV) radii [18] were: 1 0, 0 8 and 0 5 . . . Bohr , for In, Ga, and N, respectively. Psedopotentials were optimized with the Rappe-Rabe-Kaxiras-Joannopoulos method [19].
All the calculations have been performed with the ABINIT package [12, 13]. The total energy values were converged with the accuracy ≈ 1 meV on the 8 × 8 × 8 Monkhorst-Pack grid [20] with standard shifts for ZB and WZ structures [15]. Since the pseudpotentials used were rather hard, the 90Ha energy cut-off for the plane-wave basis set was used. The full geometry optimization, i.e. the cell and the ionic positions, has been performed with standard convergence criteria for forces and stresses [15].
The elastic constants have been evaluated from the stress-strain relation (the direct method). For ZB structure two strains have been applied: a tensile strain ( /epsilon1, 0 0 0 0 0) and a shear strain (0 , , , , , 0 0 , , /epsilon1, 0 0) (in the Voight, , vector notation). For WZ structure one more tensile strain (0 0 , , /epsilon1, 0 0 0) , , was needed. In each case the calculations were performed for a few values
of /epsilon1 , in the range ( ± 0 05 . , ± 0 2). . At every value of /epsilon1 the ions have been relaxed to their equilibrium positions. The values of the stress tensor from the ground state calculations (Hellmann-Feynman stresses) were used to calculate the C ′ ij ( /epsilon1 ) constants from the stress-strain relation. Obtained in that way /epsilon1 dependent C ′ ij values have been extrapolated to /epsilon1 = 0 giving the elastic constants at equilibrium state C ij , corresponding to infinitesimal strains. The pressure derivatives of elastic constants have been calculated as directional coefficients of straight lines fitted to 3-points. The values of elastic constants, necessary for that purpose, have been evaluated at 3 hydrostatic pressures (not exceeding 5 GPa) in the same way as described above, except the preliminary ground state calculations were performed to find the reference states of a crystal at given pressure targets.
The related quantities, like the bulk modulus and Poisson's ratio have been calculated within the Voight-Reus-Hill approximation [21] (according to [22]). First, the Reuss (lower) [23] and Voight (upper) [24] bounds, for the bulk ( B ) and for the shear ( G ) modulus have been evaluated, corresponding to policrystalline values at uniform stress and uniform strain respectively. Thus, for the cubic phase we have:
$$B _ { V } & = B _ { R } = ( C _ { 1 1 } + 2 C _ { 1 2 } ) / 3 \\ G _ { V } & = ( C _ { 1 1 } - C _ { 1 2 } + 3 C _ { 4 4 } ) / 5 \\ G _ { R } & = 5 ( C _ { 1 1 } - C _ { 1 2 } ) C _ { 4 4 } / [ 4 C _ { 4 4 } + 3 ( C _ { 1 1 } - C _ { 1 2 } ) ]$$
and for the hexagonal phase:
$$B _ { V } & = ( 1 / 9 ) [ 2 ( C _ { 1 1 } + C _ { 1 2 } ) + 4 C _ { 1 3 } + C _ { 3 3 } ] \\ G _ { V } & = ( 1 / 3 0 ) ( M + 1 2 C _ { 4 4 } + 1 2 C _ { 6 6 } ) \\ B _ { R } & = C ^ { 2 } / M \\ G _ { R } & = ( 5 / 2 ) [ C ^ { 2 } C _ { 4 4 } C _ { 6 6 } ] / [ 3 B _ { V } C _ { 4 4 } C _ { 6 6 } + C ^ { 2 } ( C _ { 4 4 } + C _ { 6 6 } ) ] \\ M & = C _ { 1 1 } + C _ { 1 2 } + 2 C _ { 3 3 } - 4 C _ { 1 3 } \\ C ^ { 2 } & = ( C _ { 1 1 } + C _ { 1 2 } ) C _ { 3 3 } - 2 C _ { 1 3 } ^ { 2 } \\ \text{Then the Young modulus} ( E ) \text{ and the Poisson's ratio} ( \nu ) \text{ have been calcu-}$$
Then the Young modulus ( E ) and the Poisson's ratio ( ν ) have been calculated from the average values of B and G, M H = (1 / 2)( M R + M V ) , M = B,G (Voight-Reus-Hill approximation):
$$E = 9 B G / ( 3 B + G ), \nu = ( 1 / 2 ) ( 3 B - 2 G ) / ( 3 B + G )$$
Additionally, the ratio of shear modulus to bulk modulus B/G has been calculated to estimate the brittle or ductile behavior of the material. A high B/G ratio is associated with ductility, whereas a low value corresponds to the brittle nature. The critical value which separates ductile and brittle material is 1 75. . If B/G > 1 75, the material tends to be ductile, otherwise, it behaves . in a brittle manner [25].
The biaxial relaxation coefficients have been calculated from the formulae: R WZ c = 2 C 13 /C 33 for WZ and R ZB c = 2 C 12 /C 11 for ZB structure.
The LDA band-gap as a function of composition has been calculated within the MBJLDA approximation [14]. The C m parameter for the parent compounds has been fitted so that the values of band-gap it produced matched the experimental ones from []. It was then interpolated linearly to become a function of composition x .
## 3. Results and discussion
The ab inito values of equilibrium lattice parameters a and c/a ratio and internal parameter u for parent GaN and InN compounds are presented in Tab.1. The quality of used pseudopotentials is confirmed by a good agreement with former results both experimental and theoretical. Fig.1 shows the composition dependence of the lattice constants of WZ and ZB structures which agree very well with independent supercell-based ab initio calculations [6]. In Fig.1 it can be seen that the alloy lattice parameters for ZB and WZ structures change nearly linearly with the indium content x , although a small deviation from linearity can be observed, especially for the c parameter. The results reported in [6] show that the linear composition dependence of the lattice constants (obeying Vegard's law) is characteristic of the uniform configuration of indium whereas a small deviation from linearity of c parameter appears in clustered configuration (Fig.1 in [6]). The effect can be explained by the fact that when InN component is gathered in clusters then it tends to keep its original lattice constant which is higher than that of GaN . Similarly, in the alchemical mixing approximation the atoms stay at their ideal lattice positions (do not relax), and the 'rigid' contribution of indium pseudopotential results in the bowing characteristic of the clustered case. Similar effect has been observed in AlN 1 -x P x [26] and BN 1 -x P x alloys [27]. According to our experience the effect of bowing in the VCA can be artificially suppressed by setting small orbital (hard) but big NLCC (soft) cut-off radii in the construction of pseudopotentials.
In Tab.2 the values of elastic constants calculated in this work for parent GaN and InN are compared with the literature data, both theoretical and
experimental. One can see that the present results fit well into the ranges of values reported earlier. One exception are the ZB C 44 constants whose values (210 GPa for GaN and 141 GPa for InN ) are significantly larger than other reported values (by more than 30%). The problem has already appeared and has been discussed in the literature, namely, similar large values (respectively 206 and 177 GPa ) have been reported in [28] and then corrected in [29] to 142 and 79 GPa . According to discussion in [29] the discrepancy is due to simultaneous effect of semicore Ga 3d and In 4d states and high-lying conduction-band like Ga 4d and In 5d states on the valence band, which when poorly represented lead to high values of ZB C 44 constants. In the pseudopotential approximation used in this work, although the semicore Ga 3d and In 4d states are included, the high-lying conduction-band states are not represented sufficiently well. In Figs.2 and 3 the composition dependent elastic constants, bulk modulus, shear modulus and Young modulus are presented for ZB and WZ structures respectively. The results for WZ structure can be directly compared with the supercell based calculations reported in [30] and an excellent agreement can be observed. In the work [30] a distinction has been made between the case of the uniform and the clustered configuration of In in In Ga x 1 -x N . The particular elastic constants show either linear (Vegard's law) or sublinear behavior with composition depending on the indium configuration. We find our results to correspond neither to clustered nor to uniform case, although they are close to both, i.e. they represent an intermediate (or mixed) state. To authors knowledge, there are no data for the composition dependent elastic constants in ZB structure (Fig.2) reported in the literature. In that case a small bowing (deviation
from Vegard's law) is characteristic of all the dependencies.
There are rather few works reporting pressure derivatives of elastic constants. Some reference data for parent GaN and InN are gathered in Tab.3, to compare them with the results of this work. The agreement of most of present results with the literature data is satisfactory, although some values ( dC 12 /dP , dC 13 /dP ) are higher (by 10 -30%). A big difference can be seen in the case of dC 44 /dP which might be due to the reasons discussed in the previous paragraph. The original result of this work seem to be the composition dependent pressure derivatives of elastic constants, bulk modulus, Young modulus and shear modulus for ZB and WZ structures which are shown in Figs.4 and 5. In Fig.4 points represent the ab initio data, whereas in Fig.5, to make the graph clearer, the second order polynomials have been fitted to ab initio results with the standard deviation not exceeding 0 3. The . bowing (deviations from Vegard's) of majority of the quantities is rather small, except for dC 33 /dP in WZ structure exhibiting an anomalously large bowing (a maximum of the pressure derivatives appears at x = 3 5). . In this work no second order term in the pressure dependence of elastic constants has been evaluated. However, it is easy to estimate the expected corrections to the pressure derivatives which are due to the second order term using data reported in [31, 32]. In most cases the correction is negative and small. For testing values of pressure applied in this work (up to 5 GPa ) its value is between 0 1 and 5 percent. .
In Fig.6 the composition dependent biaxial relaxation coefficient R c and Poisson's ratio ν are presented for ZB and WZ structures. The results can be compared with those reported in [33], where the parameters have been
calculated for WZ structure ab initio within the supercell approach and the effect of In distribution investigated. An excellent agreement of our results with those corresponding to the uniform distribution of In, for both parameters can be seen. Some reference values for parent GaN and InN in WZ structure can be found in [34] and [35] where the reported (calculated) values of the R c are respectively for GaN: 0 510 . , 0 509 and for InN: 0 940 . . , 0 821, and . are in a good agreement with present results.
In Fig.7 the B/G ratio is shown. Except for small range of x ∈ (0 0 . , 0 2) in . ZB structure the material shows ductile character, according to the criterium presented in the previous chapter.
Finally, in Tab.4 data for the band-gaps of parent GaN and InN obtained in this work and reported in the literature are collected. The values in this work has been obtained within MBJLDA approximation [14], with the use of ABINIT and Wien2k codes. The values obtained with ABINIT coincide with experimental ones owing to appropriate fitting of the C m parameter mentioned earlier. Its values are: InN (ZB) 1 505 ( . Eg = 0 78 . eV ), InN (WZ) 1 36 ( . Eg = 0 69 . eV ), GaN (ZB) 1 67 ( . Eg = 3 30 . eV ), GaN (WZ) 1 63 ( . Eg = 3 50 . eV ). For the alloy, its values are obtained form the linear interpolation. In Fig.8 the In Ga x 1 -x N band-gap vs. composition is plotted, calculated within VCA. For comparison, the values of Eg from SC calculations, for x = 0 25 and . x = 0 75 and two In configurations (clustered and . uniform), are given. The SC values of the band-gaps are in good agreement with the values obtained in [6] and with experiment. However, the band-gap bowing obtained within VCA is bigger than even that in the SC clustered configuration, which somehow disagrees with expectation that the
VCA should rather simulate a perfectly uniform alloy. For comparison, the calculations reported in [36], based on LMTO-CPA-MBJ for WZ In Ga x 1 -x N show smaller bowing of the band-gap (corresponding rather to the uniform configuration of In [6]) than in the present work. Bellow, an argumentation according to which the anomalous bowing in VCA can be attributed to the fact that the 'alchemical' atoms are always in ideal (unrelaxed) positions and thus the distance between metal and nitrogen atoms is averaged, is given.
## 4. An anomalous In Ga x 1 -x N band-gap bowing in alchemical mixing approximation
The admixture of InN in GaN leads to a lowering of the band gap for two reasons: first, InN has in nature much lower band-gap than GaN , and second, the involved expansion of the lattice constants leads to a lowering of the band gap in GaN . The latter effect appears also in InN and is responsible for the difference in the band-gap between the uniform and the clustered configuration of In [6], i.e. the bigger bowing for the clustered case is due to the locally expanded bonds between In and N atoms in the InN cluster region. Thus, the band-gap appears to be very sensitive to bond lengths. As mentioned above, in the VCA the bond lengths between the metal and the nitrogen atom are averaged, i.e. they are the same for partially contributing In and Ga. For example, at x = 0 25, in SC uniform . case the distances are: Ga N -1 94 ˚ , . A In N -2 12 ˚ , whereas in VCA, metal-. A N 2 01. . The differences do not exceed 5% but as will be shown below they are crucial for the band-gap behavior.
In Fig.9 the effect of In doping in GaN is presented in terms of the total
density of states. The large CB negative offset (the electron trapping case) appears to be the same in the VCA and the SC approaches, however, the VB offsets are very different. Thus, the direct reason for the large band-gap bowing in VCA is the wrong behavior of the VB with doping and can be understood by analyzing the DOSes projected on the angular momentum eigenstates of chosen atoms (partial DOSes). From Fig.10, which shows a near the band-gap fragment of the projected DOS for GaN , it is clear that the main contribution to the bottom of CB comes from the metal s -state and the N s -state, whereas the top of the VB is formed mainly by the N p -states and the metal p d , -states. The situation is the same in alloy simulated either within the VCA or SC. Since the reason for the deep bowing in VCA is the VB behavior we will concentrate on that region now. In Fig.11 the projected DOSes are plotted in the region of the VB for three cases: 1. VCA, relaxed lattice, 2. VCA, lattice compressed by 5%, 3. SC, with the uniform In distribution. A large shift of the VB towards the correct SC position can be seen for the compressed VCA lattice, which confirms the fact of high sensitivity of the bond lengths on the band-gap and the presented above hypothesis of the bond length effect on the VCA band-gap.
It should be mentioned that the VCA band-gap behavior in alloy systems can be different in different systems. For example, in AlN P x 1 -x the tendency is opposite, i.e. the VCA shows smaller bowing than in SC based calculations [26]. An analysis similar to that presented in this work should be done to explain this fact. It's worth to add that some purely technical procedure, based on averaging over the transition energies near the transition point, can be applied within VCA approach to obtain the correct composition dependent
band-gap of InGaN alloy, as we have shown in [37]. Thus, in spite of the discussed difficulties, the alchemical pseudopotential method can be used for band-gap calculations.
## 5. Conclusions
The main objective of this work was to test the performance of the alchemical mixing of pseudopotentials approximation in theoretical ab initio studies of structural, elastic and electronic properties of semiconductor alloys, on the example of In Ga x 1 -x N . We find the results for various calculated parameters to be in an overall good or very good agreement with other ab initio calculations, performed within the supercell approach, and with the experimental values. The behavior of the lattice parameters and the elastic constants together with the related quantities as a function of composition appears to be intermediate between the uniform and clustered structure of the alloy, whereas the band-gap would rather behave like the alloy with clustered structure, which is, as discussed above, an artefact connected mainly with the VCA inherent feature of the lack of the local relaxation of atomic positions. This seems to be also the main reason for the discrepancy (although rather small) between other VCA and SC results. As an additional result of this work, some composition dependent quantities, such as composition dependent elastic constants and related quantities in ZB structures, or composition dependent pressure derivatives of elastic constants, have been calculated. Their values, to authors' knowledge, have not been reported previously. The obtained results lead to a conclusion that the ab initio alchemical mixing approximation, if used with caution, can serve as a supplementary
Figure 1: Equilibrium lattice constants for In Ga x 1 -x N alloy; calculated values are marked with points
tool for semiconductor alloy studies.
## 6. Acknowledgments
Calculations have been carried out in Wroclaw Centre for Networking and Supercomputing.
## References
## References
- [1] V. Y.Davydov, Phys. Stat. Sol. B 229 , R1 (2002).
Table 1: Lattice parameters of GaN and InN; a in WZ and ZB structures; the c/a ratio and internal parameter u in WZ structure.
| | | a (A) ˚ | c/a | u |
|--------|-------------|-------------------------|-------------------------|-------------------|
| GaN-wz | this work | 3.17 | 1.632 | 0.375 |
| GaN-wz | other calc. | 3.16 d ,3.17 c | 1.626 d ,1.628 c | 0.377 cd |
| GaN-wz | exp. | 3.19 a | 1.627 a | 0.377 a |
| InN-wz | this work | 3.53 | 1.615 | 0.377 |
| InN-wz | other calc. | 3.50 d ,3.52 gc | 1.612 c ,1.614 g ,1.619 | 0.378 d ,0.380 gc |
| InN-wz | exp. | 3.53 f | 1.613 f | - |
| GaN-zb | this work | 4.49 | - | - |
| GaN-zb | other calc. | 4.461 j ,4.46 k ,4.46 m | - | - |
| GaN-zb | exp. | 4.5 l | - | - |
| InN-zb | this work | 4.97 | - | |
| InN-zb | other calc. | 4.932 d ,4.95 m | - | - |
| InN-zb | exp. | 4.98 l | - | - |
a Ref. [38].
b Ref. [39].
c Ref. [40].
d Ref. [41].
e Ref. [42].
f Ref. [43].
g Ref. [44].
h Ref. [45].
i Ref. [46].
j Ref. [47].
k Ref. [34].
l Ref. [48].
m Ref. [49].
Table 2: Elastic constants and bulk modulus of GaN and InN in WZ and ZB structures (in GPa).
| System | Data from | C 11 | C 12 | C 13 | C 33 | C 44 | C 66 | B |
|----------|-------------|---------------|---------------|--------------|----------------|---------------|--------|---------------------|
| | this work | 290 | 169 | - | - | 210 | - | 209 |
| | other calc. | 293 a , 282 b | 159 a , 159 b | - | - | 155 a , 142 b | - | 184 n ,197.88 o |
| GaN-zb | | 305 f ,264 g | 128 f ,153 g | - | - | 147 f ,68 g | - | |
| | exp. | - | - | - | - | - | - | 237 n ,245 n ,195 n |
| | this work | 188 | 134 | - | - | 141 | - | 152 |
| | other calc. | 187 a , 182 b | 125 a , 125 b | - | - | 86 a , 79 b | - | 137 n |
| InN-zb | | 217 f ,172 g | 101 f ,119 g | - | - | 104 f ,37 g | - | |
| | exp. | - | - | - | - | - | - | 125.5 n |
| | this work | 364 | 150 | 111 | 412 | 90 | 107 | 210 |
| | other calc. | 367 a ,346 b | 135 a ,148 b | 103 a ,105 b | 405 a ,389 b | 95 a ,76 b | 121 f | 202 a ,210 m |
| GaN-wz | | 357 f ,337 h | 116 f ,113 h | 89 f ,97 h | 383 f ,353 h | 102 f ,95 h | | |
| | exp. | 390 c ,374 d | 145 c ,106 d | 106 c ,70 d | 398 c ,379 d | 105 c ,101 d | | 210 c ,180 d |
| | | 377 i ,390 j | 160 i ,145 j | 114 i ,106 j | 209 i ,398 j , | 81 i ,105 j | | |
| | this work | 231 | 124 | 106 | 242 | 46 | 54 | 154 |
| | other calc. | 223 a ,220 b | 115 a ,120 b | 92 a ,91 b | 224 a ,249 b | 48 a ,36 b | 82 f | 141 a ,152 l |
| InN-wz | | 257 f ,211 h | 92 f ,95 h | 70 f ,86 h | 278 f ,220 h | 68 f ,48 h | | |
| | exp. | 190 e ,223 j | 104 e ,115 j | 121 e ,92 j | 182 e ,224 j | 10 e ,48 j | | 139 e ,126 k |
a Ref. [35].
- b Ref. [29].
- c Ref. [50].
- d Ref. [51].
- e Ref. [52].
- f Ref. [53].
- g Ref. [54].
- h Ref. [55].
i Ref. [56].
- j recommended values Ref. [57].
k Ref. [44].
l Ref. [40].
m Ref. [42].
n according to Ref. [49].
o Ref. [58].
Table 3: Pressure derivatives of elastic constants and bulk moduli of GaN and InN in WZ and ZB structures.
| System | Data from | dC 11 /dP | dC 12 /dP | dC 13 /dP | dC 33 /dP | dC 44 /dP | dC 66 /dP | dB/dP |
|----------|-------------|----------------|----------------|-------------|----------------|-----------------|-------------|----------------|
| GaN-zb | this work | 4.3 | 4.8 | 0 | 0 | 3.4 | 0 | 4.6 |
| | other calc. | 3.88 c ,3.64 d | 3.33 c ,4.87 d | 0 | 0 | 1.02 c ,-0.55 d | 0 | 3.51 c ,4.32 d |
| InN-zb | this work | 4.2 | 5.2 | 0 | 0 | 3.4 | 0 | 4.9 |
| | other calc. | 3.81 c | 4.01 c | 0 | 0 | 0.05 c | 0 | 3.94 c |
| GaN-wz | this work | 4.5 | 4.4 | 4.4 | 5.4 | 0.024 | 0.22 | 4.5 |
| | other calc. | 3.74 a ,4.54 b | 3.67 b | 3.19 b | 4.54 a ,5.4 b | 0.58 a ,0.49 b | 0.48 a | 4.3 c |
| | | 4.88 c | 3.69 c | 3.75 c | 6.54 c | 0.49 c | | |
| InN-wz | this work | 3.6 | 5.2 | 5.2 | 3.9 | 0.36 | 0.72 | 4.7 |
| | other calc. | 3.86 a ,3.88 b | 4.04 b | 3.88 b | 4.72 a ,3.69 b | 0.24 a ,0.1 b | -0.08 a | 3.92 c |
| | | 3.66 c | 3.51 c | 4.11 c | 4.26 c | 0.15 c | | |
a Ref. [31].
b Ref. [32].
c Ref. [59].
d Ref. [47].
Table 4: The calculated band gaps in comparison with experimental values and other theoretical results for GaN and InN in WZ and ZB structures (all values in eV). In this work the calculations have been done within MBJLDA [14], with the use of Abinit and Wien2k codes. In Abinit the C M parameter has been fitted to give experimental values.
| System | Exp. | Abinit | Wien2k | other calc. |
|----------|-----------------------|----------|----------|-------------------------------------------------------|
| GaN-zb | 3.30 j | 3.3 | 3.03 | 3.05 l , 3.06 l 2.81 m ,3.03 n |
| InN-zb | 0.78 j | 0.78 | 0.64 | 0.55 l , 0.63 l |
| GaN-wz | 3.50 f ,3.51 j | 3.5 | 3.3 | 3.56 a ,3.47 h ,3.50 i 3.23 k ,3.26 l 3.27 l , 3.21 n |
| InN-wz | 0.65 c ,0.63 d 0.69 e | 0.65 | 0.86 | 0.60 b ,0.69 a ,0.65 g 0.66 k ,0.74 l 0.63 l , 0.71 n |
a Reference [6]
b Reference [44]
c Reference [1]
d Reference [2]
e Reference [3]
f Reference [4]
g Reference [60]
h Reference [61]
i Reference [62]
j Reference [5]
k Reference [63]
l Reference [36]
m Reference [14]
Figure 2: Ab initio elastic constants ( C ij ), bulk modulus ( B ), shear modulus ( G ) and Young modulus ( E ) of In Ga x 1 -x N alloy (ZB structure)
Figure 3: Elastic constants ( C ij ), bulk modulus ( B ), shear modulus ( G ) and Young modulus ( E ) of In Ga x 1 -x N alloy (WZ structure)
Figure 4: Pressure derivatives of elastic constants ( C ij ), bulk modulus ( B ), shear modulus ( G ) and Young modulus ( E ) of In Ga x 1 -x N alloy (ZB structure)
Figure 5: Pressure derivatives of elastic constants ( C ij ), bulk modulus ( B ), shear modulus ( G ) and Young modulus ( E ) of In Ga x 1 -x N alloy (WZ structure); curves fitted to ab initio data with standard deviation not exceeding 0.3.
Figure 6: Poisson's ratio and biaxial relaxation coefficient of In Ga x 1 -x N alloy (ZB and WZ structures)
Figure 7: The B/G of In Ga x 1 -x N alloy (ZB and WZ structures).
Figure 8: The band gap of In Ga x 1 -x N alloy (ZB and WZ structures) calculated with ABINIT (MBJLDA); the results of supercell calculations (WZ) are shown for comparison.
Figure 9: The effect of In doping ( x = 0 25) in . GaN on the total DOS (the 32-atoms supercell DOS has been normalized to an elementary cell).
Figure 10: Near the band-gap fragment of the partial DOSes for GaN .
- [2] S. X. Li, J. Wu, E. E. Haller, W. Walukiewicz, W. Shan, H. Lu, and W. J. Schaff, Appl. Phys. Lett. 83 , 4963 (2003).
- [3] J. Wu, W. Walukiewicz, W. Shan, K. M. Yu, J. W. Ager, S. X. Li, E. E. Haller, H. Lu, and W. J. Schaff, J. Appl. Phys. 94 , 4457 (2003).
- [4] Y. C. Yeo, T. C. Chong, and M. F. Li, J. Appl. Phys. 83 , 1429 (1998).
- [5] I. Vurgaftman and J. R. Meyer, J. Appl. Phys. 94 , 3675 (2003).
- [6] I. Gorczyca, S. P. Lepkowski, T. Suski, N. E. Christensen, and A. Svane, Phys. Rev. B 80 , 075202 (2009).
- [7] J. Z. Liu and A. Zunger, Phys. Rev. B 77 , 205201 (2008).
Figure 11: Partial DOSes near the VB for In Ga x 1 -x N at x = 0 25, three cases: 1. . VCA, relaxed lattice, 2. VCA, lattice compressed by 5%, 3. SC, a uniform In distribution (the bottom of the CB has been taken as the reference point).
- [8] L. K. Teles, L. M. R. Scolfaro, J. R. Leite, J. Furthmller, and F. Bechstedt, J. Appl. Phys. 92 , 7109 (2002).
- [9] F. Grosse and J. Neugebauer, Phys. Rev. B 63 , 085207 (2001).
- [10] A. Zunger, S. H. Wei, L. G. Ferreira, and J. E. Bernard, Phys. Rev. Lett. 65 , 354 (1990).
- [11] S. H. Wei, L. G. Ferreira, J. E. Bernard, and A. Zunger, Phys. Rev. B 42 , 9622 (1990).
- [12] X. Gonze, J.-M. Beuken, R. Caracas, F. Detraux, M. Fuchs, G.-M. Rignanese, L. Sindic, M. Verstraete, G. Zerah, F. Jollet, et al., Comput. Mater. Sci. 25 , 478 (2002).
- [13] X. Gonze, G.-M. Rignanese, M. Verstraete, J.-M. Beuken, Y. Pouillon, R. Caracas, F. Jollet, M. Torrent, G. Zerah, M. Mikami, et al., Zeit. Kristallogr. 220 , 558 (2005).
- [14] F. Tran and P. Blaha, Phys. Rev. Lett. 102 , 226401 (2009).
- [15] http://www.abinit.org/ .
- [16] I. Grinberg, N. J. Ramer, and A. M. Rappe, Phys. Rev. B 62 , 2311 (2000).
- [17] J. P. Perdew and A. Zunger, Phys. Rev. B 23 , 5048 (1981).
- [18] M. Fuchs and M. Scheffler, Comput. Phys. Commum. 119 , 67 (1999).
- [19] A. M. Rappe, K. M. Rabe, E. Kaxiras, and J. D. Joannopoulos, Phys. Rev. B 41 , 1227 (1990).
- [20] H. J. Monkhorst and J. D. Pack, Phys. Rev. B 13 , 5188 (1976).
- [21] R. Hill, Proc. Phys. Soc. 65 , 350 (1952).
- [22] Z. jian Wu, E. jun Zhao, H. ping Xiang, X. feng Hao, X. juan Liu, and J. Meng, Phys. Rev. B 76 , 054115 (2007).
- [23] A. Reuss, Z. Angew. Math. Mech. 9 , 49 (1929).
- [24] W. Voight, Lehrburch der Kristallphysic Tebner, Leipzig (1928).
- [25] S. F. Pugh, Philos. Mag 45 , 823 (1954).
- [26] M. Winiarski, M. Polak, and P. Scharoch, J. Alloys Compd 575 , 158 (2013).
- [27] M. Benkraouda and N. Amrane, J. Alloy. Compd. 546 , 151 (2013).
- [28] K. Kim, R. L. Lambrecht, and B. Segall, Phys. Rev. B 53 , 16310 (1996).
- [29] K. Kim, R. L. Lambrecht, and B. Segall, Phys. Rev. B - ERRATA 56 , 7018 (1997).
- [30] S. P. Lepkowski and I. Gorczyca, Phys. Rev. B 83 , 203201 (2011).
- [31] K. Sarasamak, S. Limpijumnong, and W. R. L. Lambrecht, Phys. Rev. B 82 , 035201 (2010).
- [32] S. P. Lepkowski, Phys. Rev. B 75 , 1953035 (2007).
- [33] S. P. Lepkowski and I. Gorczyca, Acta Physica Polonica 120 , 902 (2011).
- [34] K. Kim, R. L. Lambrecht, and B. Segall, Phys. Rev. B 50 , 1502 (1994).
- [35] A. F. Wright, J. Appl. Phys. 82 , 2833 (1997).
- [36] M. Cesar, Y. Ke, W. Ji, and H. G. adn Z. Mi, App. Phys. Lett. 98 , 202107 (2011).
- [37] P. Scharoch and M. Winiarski, Comp. Phys. Comm. (2013), doi: 10.1016/j.cpc.2013.07.008.
- [38] H. Schulz and K. H. Thiemann, Solid State Commun. 23 , 815 (1977).
- [39] M. Ueno, M. Yoshida, A. Onodera, O. Shimomura, and K. Takemura, Phys. Rev. B 49 , 14 (1994).
- [40] Z. Dridi, B. Bouhafs, and P. Ruterana, Semicond. Sci. Technol. 18 , 850 (2003).
- [41] A. F. Wright and J. S. Nelson, Phys. Rev. B 51 , 7866 (1995).
- [42] I. Gorczyca, A. Kamiska, G. Staszczak, R. Czernecki, S. P. Lepkowski, T. Suski, H. P. D. Schenk, M. Glauser, R. Butt, J.-F. Carlin, et al., Phys. Rev. B 81 , 235206 (2010).
- [43] K. Osamura, S. Naka, and Y. Murakami, J. Appl. Phys. 46 , 3432 (1975).
- [44] I. Gorczyca, J. Plesiewicz, L. Dmowski, T. Suski, N. E. Christensen, A. Svane, C. S. Gallinat, G. Koblmueller, and J. S. Speck, J. Appl. Phys. 104 , 013704 (2008).
- [45] P. Perlin, C. Jauberthie-Carillon, J. P. Itie, A. S. Miguel, I. Grzegory, and A. Polian, Phys. Rev. B 45 , 83 (1992).
- [46] A. U. Sheleg and V. A. Savastenko, Inorg. Mater. 15 , 1257 (1979).
- [47] M. B. Kanoun, S. Goumri-Said, A. E. Merad, G. Merad, J. Cibert, and H. Aourag, Semicond. Sci. Technol. 19 , 1220 (2004).
- [48] P. Rinke, M. Scheffler, A. Qteish, M. Winkelnkemper, D. Bimberg, and J. Neugebauer, App. Phys. Lett. 89 , 161919 (2006).
- [49] E. Christensen and I. Gorczyca, Phys. Rev. B 50 , 4397 (1994).
- [50] A. Polian, M. Grimsditch, and I. Grzegory, J. Appl. Phys. 79 , 3343 (1996).
- [51] Y. Takagi, M. Ahart, T. Azuhata, T. Sota, K. Suzuki, , and S. Nakamura, Physica B 219&220 , 547 (1996).
- [52] A. U. Sheleg and V. A. Savastenko, Izv. Akad. Nauk SSSR, Neorg. Mater. 15 , 1598 (1979).
- [53] A. A. Marmalyuk, R. K. Akchurin, and V. A. Gorbylev, Inorganic Materials 34 , 691 (1998).
- [54] M. E. Sherwin and T. J. Drummond, J. Appl. Phys. 69 , 8423 (1991).
- [55] M. Lopuszynski and J. A. Majewski, J. Appl. Phys. 111 , 033502 (2012).
- [56] Madelung, Semiconductors: Data Handbook, 3rd ed. (Springer, 2004).
- [57] I. Vurgaftman and J. R. Meyer, J. Appl. Phys. 94 , 3675 (2003).
- [58] Y. Al-Douri, J. Appl. Phys. 93 , 9730 (2003).
- [59] S. P. Lepkowski, J. A. Majewski, and G. Jurczak, Phys. Rev. B 72 72 , 245201 (2005).
- [60] H. Jin, G. L. Zhao, and D. Bagayoko, J. Appl. Phys. 101 , 033123 (2007).
- [61] D. Fritsch, H. Schmidt, and M. Grundmann, Phys. Rev. B 67 , 235205 (2003).
- [62] A. Rubio, J. L. Corkill, M. L. Cohen, E. L. Shirley, and S. G. Louie, Phys. Rev. B 48 , 11810 (1993).
- [63] P. G. Moses and C. G. V. de Walle, App. Phys. Lett. 96 , 021908 (2010). | 10.1016/j.commatsci.2013.08.047 | [
"P. Scharoch",
"M. J. Winiarski",
"M. P. Polak"
] | 2014-08-01T09:12:06+00:00 | 2014-08-01T09:12:06+00:00 | [
"cond-mat.mtrl-sci"
] | Ab initio study of InxGa(1-x)N - performance of the alchemical mixing approximation | The alchemical mixing approximation which is the ab initio pseudopotential
specific implementation of the virtual crystal approximation (VCA), offered in
the ABINIT package, has been employed to study the wurtzite (WZ) and zinc
blende (ZB) InxGa(1-x)N alloy from first principles. The investigations were
focused on structural properties (the equilibrium geometries), elastic
properties (elastic constants and their pressure derivatives), and on the
band-gap. Owing to the ABINIT functionality of calculating the
Hellmann-Feynmann stresses, the elastic constants have been evaluated directly
from the strain-stress relation. Values of all the quantities calculated for
parent InN and GaN have been compared with the literature data and then
evaluated as functions of composition x on a dense, 0.05 step, grid. Some
results have been obtained which, to authors' knowledge, have not yet been
reported in the literature, like composition dependent elastic constants in ZB
structures or composition dependent pressure derivatives of elastic constants.
The band-gap has been calculated within the MBJLDA approximation. Additionally,
the band-gaps for pure $InN$ and GaN have been calculated with the Wien2k code,
for comparison purposes. The evaluated quantities have been compared with the
available literature reporting supercell-based ab initio calculations and on
that basis conclusions concerning the performance of the alchemical mixing
approach have been drawn. ... |
1408.0107v2 | ## Cosmological applications of F T,T ( G ) gravity
Georgios Kofinas 1, ∗ and Emmanuel N. Saridakis 2, 3, †
1 Research Group of Geometry, Dynamical Systems and Cosmology,
Department of Information and Communication Systems Engineering University of the Aegean, Karlovassi 83200, Samos, Greece 2
- Physics Division, National Technical University of Athens, 15780 Zografou Campus, Athens, Greece
3 Instituto de F´ ısica, Pontificia Universidad de Cat´lica de Valpara´ ıso, Casilla 4950, Valpara´ ıso, o Chile
We investigate the cosmological applications of F T,T ( G ) gravity, which is a novel modified gravitational theory based on the torsion invariant T and the teleparallel equivalent of the Gauss-Bonnet term T G . F T,T ( G ) gravity differs from both F T ( ) theories as well as from F R,G ( ) class of curvature modified gravity, and thus its corresponding cosmology proves to be very interesting. In particular, it provides a unified description of the cosmological history from early-times inflation to late-times self-acceleration, without the inclusion of a cosmological constant. Moreover, the dark energy equation-of-state parameter can be quintessence or phantom-like, or experience the phantom-divide crossing, depending on the parameters of the model.
PACS numbers: 04.50.Kd, 98.80.-k, 95.36.+x
## I. INTRODUCTION
Since theoretical arguments and observational data suggest that the universe passed through an early-times inflationary stage and resulted in a late-times accelerated phase, a large amount of research was devoted to explain this behavior. In general, one can follow two ways to achieve it. The first direction is to alter the universe content by introducing additional fields, canonical scalar, phantom scalar, both scalars, vector fields etc, that is introducing the concepts of the inflaton and/or the dark energy, which can be extended in a huge class of models (see [1-3] and references therein). The second way is to modify the gravitational sector instead (see [4] and references therein). Note however that one can in principle transform from one approach to the other, since the important point is the number of degrees of freedom beyond standard model particles and General Relativity (GR) [5].
In modified gravitational theories one usually extends the curvature-based Einstein-Hilbert action. However, a different and interesting class of gravitational modification arises when one extends the action of the equivalent torsional formulation of General Relativity. In particular, since Einstein's years it was known that one can construct the so-called 'Teleparallel Equivalent of General Relativity' (TEGR) [6-10], that is attributing gravity to torsion instead of curvature, by using instead of the torsion-less Levi-Civita connection the curvature-less Weitzenb¨ ock one. In such a formulation the gravitational Lagrangian results from contractions of the torsion tensor and is called the 'torsion scalar' T , similarly to the General Relativity Lagrangian, i.e. the 'curvature scalar' R , which is constructed by contractions of the curvature ten-
∗ Electronic address: [email protected]
† Electronic address: Emmanuel˙[email protected]
sor. Hence, similarly to the f ( R ) extensions of General Relativity [11, 12], one can construct f ( T ) extensions of TEGR [13, 14]. The interesting feature in this extension is that f ( T ) does not coincide with f ( R ) gravity, despite the fact that TEGR coincides with General Relativity. Since it is a new gravitational modification class, its corresponding cosmological behavior and black hole solutions have been studied in detail [13-19].
However, apart from the simple modifications of curvature gravity, one can construct more complicated actions introducing higher-curvature corrections such as the Gauss-Bonnet combination G [20, 21] or arbitrary functions f ( G ) [22-24], Weyl combinations [25], Lovelock combinations [26, 27] etc. Hence, one can follow the same direction starting from the teleparallel formulation of gravity, and construct actions involving higher-torsion corrections. Indeed, in our recent work [28] we first constructed the teleparallel equivalent of the Gauss-Bonnet term T G (which is a new quartic torsional scalar which reduces to a topological invariant in four dimensions), and then, using also the torsion scalar T , we constructed F T,T ( G ) gravity (see [29-31] for different constructions of torsional actions). This is a new class of gravitational modification, since it is different from both f ( T ) gravity as well as from f ( R,G ) gravity.
Since F T,T ( G ) gravity is a novel modified gravity theory, in the present work we are interested in investigating its cosmological applications. In particular, after extracting the Friedmann equations, we define the effective dark energy sector and the various observables such as the density parameters and the dark energy equationof-state parameter. Then, considering specific F T,T ( G ) ansatzes we investigate the inflation realization and the late-times acceleration. The plan of the work is as follows: In section II we review F T,T ( G ) gravity. In section III we apply it in a cosmological framework, extracting the corresponding equations and defining the various observables, while in section IV we analyze some specific cases. Finally, section V is devoted to the conclusions.
## II. F T,T ( G ) GRAVITY
Let us give a brief review of F T,T ( G ) gravity [28]. Although in this manuscript we are interested in its cosmological application, we will present the formulation in D -dimensions where it is non-trivial, and then discuss F T,T ( G ) gravity in D = 4. In the teleparallel formulation of gravity theories, the dynamical variables are the vielbein field e a ( x µ ) and the connection 1-forms ω a b ( x µ ) which defines the parallel transportation . 1 We can express them in components in terms of coordinates as e a = e µ a ∂ µ and ω a b = ω a bµ dx µ = ω a bc e c , while we define the dual vielbein as e a = e a µ dx µ . The vielbein commutation relations read
$$[ e _ { a }, e _ { b } ] = C _ { \ a b } ^ { c } e _ { c } \,,$$
where the structure coefficients functions C c ab are written as
$$C ^ { c } _ { \ a b } = e _ { a } ^ { \ \mu } e _ { b } ^ { \ \nu } ( e _ { \ \mu, \nu } ^ { c } - e _ { \ \nu, \mu } ^ { c } ) \,, \quad \quad ( 2 ) \quad \text{ric}$$
with a comma denoting differentiation. Thus, we can define the torsion tensor, expressed in tangent components as
$$T ^ { a } _ { \ b c } = \omega ^ { a } _ { \ c b } - \omega ^ { a } _ { \ b c } - C ^ { a } _ { \ b c } \,, \quad \quad \ \ ( 3 ) \quad \text{of} \,,$$
while the curvature tensor is
$$R ^ { a } _ { \ b c d } = \omega ^ { a } _ { \ b d, c } - \omega ^ { a } _ { \ b c, d } + \omega ^ { e } _ { \ b d } \omega ^ { a } _ { \ e c } - \omega ^ { e } _ { \ b c } \omega ^ { a } _ { \ e d } - C ^ { e } _ { \ c d } \omega ^ { a } _ { \ b e }. \quad \text{Civita} \\ \vdots \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad. \quad.$$
Furthermore, we use the metric tensor g to make the vielbein orthonormal g e ( a , e b ) = η ab , where η ab = diag( -1 1 , , ... 1), and thus we obtain the useful relation
$$g _ { \mu \nu } = \eta _ { a b } \, e ^ { a } _ { \ \mu } \, e ^ { b } _ { \ \nu }, \quad \ \ ( 5 ) \quad \ \ s c a$$
and indices a, b, ... are raised/lowered with the Minkowski metric η ab . Finally, it proves convenient to define the contorsion tensor as
$$\mathcal { K } _ { a b c } = \frac { 1 } { 2 } ( T _ { c a b } - T _ { b c a } - T _ { a b c } ) = - \mathcal { K$$
We now impose the condition of teleparallelism, namely R a bcd = 0, which holds in all frames. One way to realize this condition is by assuming the Weitzenb¨ck o connection ˜ ω λ µν defined in terms of the vielbein in all coordinate frames as ˜ ω λ µν = e λ a e a µ,ν , or expressed in the preferred tangent-space components as ˜ ω a bc = 0. The Ricci scalar ¯ R corresponding to the usual Levi-Civita connection can be expressed as [8, 9]
$$e \bar { R } = - e T + 2 ( e T _ { \nu } ^ { \ \nu \mu } ) _ {, \mu } \,, \quad \quad ( 7 ) \quad \quad \quad$$
1 In this manuscript the notation is as follows: Greek indices µ, ν, ... run over all space-time coordinates, while Latin indices a, b, ... run over the tangent space.
where we have defined the 'torsion scalar' T as
$$T \ = \ \frac { 1 } { 4 } T ^ { \mu \nu \lambda } T _ { \mu \nu \lambda } + \frac { 1 } { 2 } T ^ { \mu \nu \lambda } T _$$
and e = det ( e a µ ) = √ | g | . One can now clearly see that the Lagrangian density eR ¯ of General Relativity, that is the one calculated with the Levi-Civita connection, and the torsional density -eT differ only by a total derivative. Hence, the Einstein-Hilbert action
$$S _ { E H } = \frac { 1 } { 2 \kappa _ { D } ^ { 2 } } \int _ { M } d ^ { D } x \, e \, \bar { R }, \quad$$
up to boundary terms is equivalent to the action
$$S _ { t e l } ^ { ( 1 ) } & = - \frac { 1 } { 2 \kappa _ { D } ^ { 2 } } \int _ { M } d ^ { D } x \, e \, T$$
in the sense that varying (9) with respect to the metric and varying (10) with respect to the vielbein gives rise to the same equations of motion ( κ 2 D is the D -dimensional gravitational constant) [10]. That is why the above theory, where one uses torsion to describe the gravitational field and imposes the teleparallelism condition, was dubbed by Einstein as Teleparallel Equivalent of General Relativity (TEGR).
The recipe of the construction of TEGR was to express the Ricci scalar R corresponding to a general connection as the Ricci scalar ¯ R calculated with the LeviCivita connection, plus terms arising from the torsion tensor. Then, by imposing the teleparallelism condition R a bcd = 0, we obtained that ¯ R is equal to a torsion scalar plus a total derivative. Hence, we can follow the same steps, but using the Gauss-Bonnet combination G = R 2 -4 R µν R µν + R µνκλ R µνκλ instead of the Ricci scalar. In [28] we have derived the teleparallel equivalent of Gauss-Bonnet gravity characterized by the new torsion scalar T G , as well as the equations of motion of the modified gravity defined by the function F T,T ( G ). In the following, we give the corresponding expressions when restricted to the Weitzenb¨ck connection o ω a bc = 0 (the tildes are withdrawn for notational simplicity). It is
$$e \bar { G } = e T _ { G } + \text{total diverg}., \quad \quad ( 1 1 )$$
where ¯ G is the Gauss-Bonnet term calculated by the Levi-Civita connection, and
$$\text{the} \quad & T _ { G } = ( \mathcal { K } _ { \ e a } ^ { a _ { 1 } } \mathcal { K } _ { \ b } ^ { e a _ { 2 } } \mathcal { K } _ { \ f c } ^ { a _ { 3 } } \mathcal { K } _ { \ d } ^ { f a _ { 4 } } - 2 \mathcal { K } _ { \ a } ^ { a _ { 1 } a _ { 2 } } \mathcal { K } _ { \ e b } ^ { a _ { 3 } } \mathcal { K } _ { \ f c } ^ { e } \mathcal { K } _ { \ d } ^ { f a _ { 4 } } \\ & \quad + 2 \mathcal { K } _ { \ a } ^ { a _ { 1 } a _ { 2 } } \mathcal { K } _ { \ e b } ^ { a _ { 3 } } \mathcal { K } _ { \ f } ^ { e a _ { 4 } } \mathcal { K } _ { \ c d } ^ { f } \\ & \quad + 2 \mathcal { K } _ { \ a } ^ { a _ { 1 } a _ { 2 } } \mathcal { K } _ { \ e b } ^ { a _ { 3 } } \mathcal { K } _ { \ c, d } ^ { e a _ { 4 } } ) \delta _ { a _ { 1 } a _ { 2 } a _ { 3 } a _ { 4 } } ^ { a b c d }, \quad & ( 1 2 )$$
with the generalized δ being the determinant of the Kronecker deltas. Thus, T G is the teleparallel equivalent of ¯ , G in the sense that the action
$$S _ { t e l } ^ { ( 2 ) } = \frac { 1 } { 2 \kappa _ { D } ^ { 2 } } \int _ { M } d ^ { D } x \, e \, T _ { G } \,, \quad \quad ( 1 3 )$$
varied in terms of the vielbein gives exactly the same equations with the action
$$S _ { G B } = \frac { 1 } { 2 \kappa _ { D } ^ { 2 } } \int _ { M } d ^ { D } x \, e \, \bar { G } \,, \quad \quad ( 1 4 ) \quad \text{ eve} \\ \cdot \cdot \cdot \cdot$$
varied in terms of the metric.
Having constructed the teleparallel equivalent of curvature invariants, one can be based on them in order to build modified gravitational theories. Thus, one can start from an action where T is generalized to F T ( ), resulting to the so-called F T ( ) gravity [13-19]. Similarly, one can extend T G to F T ( G ) in the action, and since T G is quartic in torsion then F T ( G ) cannot arise from any F T ( ). Hence, in [28] we combined both possible extensions and we constructed the F T,T ( G ) modified gravity
$$S = \frac { 1 } { 2 \kappa _ { D } ^ { 2 } } \int d ^ { D } x \, e \, F ( T, T _ { G } ) \,, \quad \quad ( 1 5 ) \quad \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{ } \text{$$
which is clearly different from both F T ( ) theory as well as from F R,G ( ) gravity [22-24], and therefore it is novel gravitational modification. We mention that TEGR (and therefore GR) is obtained for F T,T ( G ) = -T , while the usual Einstein-Gauss-Bonnet theory arises for F T,T ( G ) = -T + αT G , with α the Gauss-Bonnet coupling.
Let us now give the equations of motion in D = 4 which is our main interest in the present paper. Varying the action (15) in terms of the vierbein, after various steps, we finally obtain [28]
$$& 2 ( H ^ { [ a c ] b } + H ^ { [ b a ] c } - H ^ { [ c b ] a } ) _ {, c } + 2 ( H ^ { [ a c ] b } + H ^ { [ b a ] c } - H ^ { [ c b ] a } ) C _ { \ d c } ^ { d } \quad \text{gravity} \quad \text{$\kappa$} } \\ + & ( 2 H ^ { [ a c ] d } + H ^ { d c a } ) C _ { \ c d } ^ { b } + 4 H ^ { [ d b ] c } C _ { ( d c ) } ^ { a } + T _ { \ c d } ^ { a } H ^ { c d b } - h ^ { a b } \quad \text{of freed} \quad \\ & \quad + ( F - T F _ { T } F _ { T } - T _ { G } F _ { T _ { G } } ) \eta ^ { a b } = 0 \,, \quad ( 1 6 ) \quad \text{(alterna} \quad \\ & \quad \text{range} \quad.$$
where
$$\text{where} \\ H ^ { a b c } = F _ { T } ( \eta ^ { a c } \mathcal { K } ^ { b d } _ { \, d } - \mathcal { K } ^ { b c a } ) + F _ { T _ { G } } \left [ \begin{array} { c } \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text }
$ # \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ $\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\test
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{ \text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{
$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\text{$\$$$
and
$$h ^ { a b } = F _ { T } \epsilon ^ { a } _ { \ k c d } \epsilon ^ { b p q d } \mathcal { K } ^ { k } _ { \ f p } \mathcal { K } ^ { f c } _ { \ q } \,. \quad \ \ ( 1 8 ) \quad \text{in}$$
We have used the notation F T = ∂F/∂T , F T G = ∂F/∂T G , the (anti)symmetrization symbol contains the factor 1 / 2, while the antisymmetric symbol /epsilon1 abcd has /epsilon1 1234 = 1, /epsilon1 1234 = -1.
We close this section by making some comments on F T,T ( G ) modified gravity itself, before proceeding to its cosmological investigation. The first has to do with the
Lorentz violation. In particular, as we discussed also in [28], under the use of the Weitzenb¨ ock connection the torsion scalar T remains diffeomorphism invariant, however the Lorentz invariance has been lost since we have chosen a specific class of frames, namely the autoparallel orthonormal frames. Nevertheless, the equations of motion of the Lagrangian eT , being the Einstein equations, are still Lorentz covariant. On the contrary, when we replace T by a general function f ( T ) in the action, the new equations of motion will not be covariant under Lorentz rotations of the vielbein, although they will indeed be form-invariant, and the same features appear in the F T,T ( G ) extension. However, this is not a deficit (it is a sort of analogue of gauge fixing in gauge theories), and the theory, although not Lorentz covariant, is meaningful. Definitely, not all vielbeins will be solutions of the equations of motion, but those which solve the equations will determine the metric uniquely.
The second comment is related to possible acausalities and problems with the Cauchy development of a constant-time hypersurface. Indeed, there are works claiming that a departure from TEGR, as for instance in f ( T ) gravity, with the subsequent local Lorentz violation, will lead to the above problems [32]. In order to examine whether one also has these problems in the present scenario of F T,T ( G ) gravity, he would need to perform a very complicated analysis, extending the characteristics method of [32] for this case, although at first sight one does expect to indeed find them. Nevertheless, even if this proves to be the case, it does not mean that the theory has to be ruled out, since one could still handle f ( T ) gravity (and similarly F T,T ( G ) one) as an effective theory, in the regime of validity of which the extra degrees of freedom can be removed or be excited in a healthy way (alternatively one could reformulate the theory using Lagrange multipliers) [32]. However, there is a possibility that these problems might be related to the restricting use of the Weitzenb¨ck connection, since the formulation o of TEGR and its modifications using other connections (still in the 'teleparallel class') does not seem to be problematic, and thus, the general formulation of F T,T ( G ) gravity that was presented in [28] might be free of the above disadvantages. These issues definitely need further investigation, and the discussion is still open in the literature.
## III. F T,T ( G ) COSMOLOGY
In this section we apply F T,T ( G ) gravity in a cosmological framework. Firstly, we add the matter sector along the gravitational one, that is we start by the total action
$$S _ { t o t } = \frac { 1 } { 2 \kappa ^ { 2 } } \int d ^ { 4 } x \, e \, F ( T, T _ { G } ) \, + S _ { m } \,, \quad \ \ ( 1 9 ) \\. \quad \ \sim \quad. \quad. \quad. \quad.$$
where S m ν corresponds to a matter energy-momentum tensor Θ µ and κ 2 = 8 πG is the four-dimensional New-
ton's constant. Secondly, in order to investigate the cosmological implications of the above action, we consider a spatially flat cosmological ansatz
$$d s ^ { 2 } = - N ^ { 2 } ( t ) d t ^ { 2 } + a ^ { 2 } ( t ) \delta _ { \hat { i } \hat { j } } d x ^ { \hat { i } } d x ^ { \hat { j } } \,, \quad ( 2 0 ) \quad \text{$\frac{P^{\alpha} \infty$} } _ { \theta \infty }$$
where a t ( ) is the scale factor and N t ( ) is the lapse function (the hat indices run in the three spatial coordinates). This metric arises from the diagonal vierbein
$$e ^ { a } _ { \ \mu } = \text{diag} ( N ( t ), a ( t ), a ( t ), a ( t ) ) \quad \ \ ( 2 1 )$$
through (5), while the dual vierbein is e µ a = diag( N -1 ( ) t , a -1 ( ) t , a -1 ( ) t , a -1 ( )), t and its determinant e = N t a t ( ) ( ) 3 .
Considering as usual N t ( ) = 1 and inserting the vierbein (21) into relations (8) and (12), we find
$$T = 6 \frac { \dot { a } ^ { 2 } } { a ^ { 2 } } = 6 H ^ { 2 } \quad \ \ ( 2 2 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
T _ { \cdot \, 2 \, \dots } }$$
$$T _ { G } = 2 4 \frac { \dot { a } ^ { 2 } } { a ^ { 2 } } \, \frac { \ddot { a } } { a } = 2 4 H ^ { 2 } ( \dot { H } + H ^ { 2 } ), \quad \ \ ( 2 3 ) \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
\text{here $H=\frac{\dot{a} } { a }$ is the Hubble parameter and dots denote} \quad \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \$$
where H = ˙ a a is the Hubble parameter and dots denote differentiation with respect to t . Additionally, inserting (21) into the general equations of motion (16), after some algebra we obtain the Friedmann equations
$$F - 1 2 H ^ { 2 } F _ { T } - T _ { G } F _ { T _ { G } } + 2 4 H ^ { 3 } \dot { F _ { T _ { G } } } = 2 \kappa ^ { 2 } \rho \quad ( 2 4 ) \quad 6 H$$
$$F & - 4 ( \dot { H } + 3 H ^ { 2 } ) F _ { T } - 4 H \dot { F } _ { T } & 2 ( \dot { \cdot } \\ - & T _ { G } F _ { T _ { G } } + \frac { 2 } { 3 H } T _ { G } \dot { F } _ { T _ { G } } + 8 H ^ { 2 } \ddot { F } _ { T _ { G } } = - 2 \kappa ^ { 2 } p, \ ( 2 5 ) \\ & \quad \, \quad.$$
where the right hand sides arise from the independent variation of the matter action, considering it to correspond to a perfect fluid with energy density ρ and pressure p (it is Θ tt = ρ , Θ ˆˆ ij = p a 2 δ ˆˆ ij , Θ ˆ i ˆ i = 3 ). p In the above expressions it is ˙ F T = F TT ˙ T + F TT G ˙ T G , ˙ F T G = F TT G ˙ T + F T G G T ˙ T G , ¨ F T G = F TTT G ˙ T 2 + 2 F TT G G T ˙ TT ˙ G + F T G G G T T ˙ T 2 G + F TT G ¨ + T F T G G T ¨ T G , with F TT , F TT G , ... denoting multiple partial differentiations of F with respect to T , T G . Finally, ˙ T , ¨ and T ˙ T G , ¨ T G are obtained by differentiating (22) and (23) respectively with respect to time.
Let us make a comment here on the derivation of the above Friedmann equations. We mention that we followed the robust way, that is we first performed the general variation of the action resulting to the general equations of motion (16), and then we inserted the cosmological ansatz (21), obtaining (24) and (25). This procedure in principle does not give the same results with the shortcut procedure where one first inserts the cosmological ansatz (21) in the action and then performs variation with respect to N and a , since variation and ansatz-insertion do not commute in general, especially in theories with higher-order derivatives [33, 34]. This shortcut method is a sort of minisuperspace procedure since the (potential) additional degrees of freedom other than those contained in the scale factor are frozen. However, as we show in the Appendix, following the shortcut procedure in the cosmological application of the scenario at hand leads exactly to the two Friedmann equations (24) and (25) of the robust procedure.
Setting F T,T ( G ) = -T in equations (24), (25), we get the standard cosmological equations of General Relativity without a cosmological constant. For F T,T ( G ) = F T ( ) we get
$$F - 1 2 H ^ { 2 } F _ { T } = 2 \kappa ^ { 2 } \rho$$
$$F - 4 ( \dot { H } + 3 H ^ { 2 } ) F _ { T } - 4 H \dot { F } _ { T } = - 2 \kappa ^ { 2 } p \,, \quad ( 2 7 )$$
which are recognized as the standard equations of F T ( ) gravity. However, note that due to the various conventions adopted in the literature in the definitions of the Riemann tensor, the torsion tensor and the Minkowski metric, which may differ by a total sign, our function F T ( ) may correspond to F ( -T ) in some other works (for instance [14]).
In order to parametrize the deviation of the theory F T,T ( G ) from GR, we write F T,T ( G ) = -T + ( f T, T G ). Thus, the modification of GR (for instance the effective dark energy component) is included in the function f . Equations (24), (25) are then written as
$$\cdot ^ { 2 4 } \quad 6 H ^ { 2 } + f - 1 2 H ^ { 2 } f _ { T } - T _ { G } f _ { T _ { G } } + 2 4 H ^ { 3 } \dot { f _ { T _ { G } } } = 2 \kappa ^ { 2 } \rho \ ( 2 8 )$$
$$2 ( 2 \dot { H } + 3 H ^ { 2 } ) & + f - 4 ( \dot { H } + 3 H ^ { 2 } ) f _ { T } - 4 H \dot { f } _ { T } - T _ { G } f _ { T _ { G } } \\ & + \frac { 2 } { 3 H } T _ { G } \dot { f } _ { T _ { G } } + 8 H ^ { 2 } \ddot { f } _ { T _ { G } } = - 2 \kappa ^ { 2 } p \,. \quad ( 2 9 )$$
The Friedmann equations (28), (29) can be rewritten in the usual form
$$H ^ { 2 } \ = \ \frac { \kappa ^ { 2 } } { 3 } ( \rho + \rho _ { D E } )$$
$$\dot { H } \ = \ \dot { - \frac { \kappa ^ { 2 } } { 2 } } ( \rho + p + \rho _ { D E } + p _ { D E } ), \quad \ \ ( 3 1 )$$
where the energy density and pressure of the effective dark energy sector are defined as
$$\text{d} \\ \text{ct} \\ \rho _ { D E } = - \frac { 1 } { 2 \kappa ^ { 2 } } ( f - 1 2 H ^ { 2 } f _ { T } - T _ { G } f _ { T _ { G } } + 2 4 H ^ { 3 } f _ { T _ { G } } ) \, ( 3 2 ) \\ \text{e} \\ \rho _ { D E } = \frac { 1 } { 2 \kappa ^ { 2 } } \left [ f - 4 ( \dot { H } + 3 H ^ { 2 } ) f _ { T } - 4 H \dot { f } _ { T } - T _ { G } f _ { T _ { G } } \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\
\text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{a} \\ \text{\emph{and} } } \, \text{(3)}$$
In terms of the initial function F , we can write ρ DE , p DE as
$$1$$
$$\text{ with } \quad \infty \\ \text{$>\cos$} _ { \text{forms} } \quad \rho _ { D E } = & \frac { 1 } { 2 \kappa ^ { 2 } } ( 6 H ^ { 2 } - F + 1 2 H ^ { 2 } F _ { T } + T _ { G } F _ { T _ { G } } - 2 4 H ^ { 3 } \dot { F } _ { T _ { G } } ) \ ( 3 4 ) \\ \text{$ and } \quad \text{$p_D E } = & \frac { 1 } { 2 \kappa ^ { 2 } } \Big { [ } - 2 ( 2 \dot { H } + 3 H ^ { 2 } ) + F - 4 ( \dot { H } + 3 H ^ { 2 } ) F _ { T } \\ \text{This} \quad \quad \quad - 4 H \dot { F } _ { T } - T _ { G } F _ { T _ { G } } + \frac { 2 } { 3 H } T _ { G } F _ { T _ { G } } ^ { \dot { \cdot } } + 8 H ^ { 2 } F _ { T _ { G } } ^ { \ddot { \cdot } } \Big { ] } ( 3 5 )$$
Since the standard matter is conserved independently, ˙ ρ + 3 H ρ ( + ) = 0, we obtain from (32), (33) that the p dark energy density and pressure also satisfy the usual evolution equation
$$\dot { \rho } _ { D E } + 3 H ( \rho _ { D E } + p _ { D E } ) = 0 \,. \quad \quad ( 3 6 )$$
Finally, we can define the dark energy equation-of-state parameter as
$$w _ { D E } = \frac { p _ { D E } } { \rho _ { D E } } \,.$$
## IV. SPECIFIC CASES
In the previous section we extracted the Friedmann equations of general F T,T ( G ) cosmology, and we defined the effective dark energy sector. Thus, in this section we proceed to the investigation of some specific F T,T ( G ) cases, focusing on the evolution of observables such as the various density parameters Ω i = 8 πGρ / i (3 H 2 ) and the dark energy equation-of-state parameter w DE .
$$\mathbf A. \quad F ( T, T _ { G } ) = - T + \beta _ { 1 } \sqrt { T ^ { 2 } + \beta _ { 2 } T _ { G } } + \alpha _ { 1 } T ^ { 2 } + \alpha _ { 2 } T \sqrt { | T _ { G } | } \quad ^ { d } _ { A l l \ n a _ { 1 } }.$$
Since T G contains quartic torsion terms, it will in general and approximately be of the same order with T 2 . Therefore, T and √ T 2 + β T 2 G are of the same order, and thus, if one of them contributes during the evolution the other will contribute too. Therefore, it would be very interesting to consider modifications of the form F T,T ( G ) = -T + β 1 √ T 2 + β T 2 G , which are expected to play an important role at late times. Note that the couplings β , β 1 2 are dimensionless, and so, no new mass scale enters at late times. Nevertheless, in order to describe the early-times cosmology, one should additionally include higher order corrections like T 2 . Since the scalar T G is of the same order with T 2 , it should be also included. However, since T G is topological in four dimensions it cannot be included as it is, and therefore we use the term T √ | T G | which is also of the same order with T 2 and non-trivial. Thus, the total function F is taken to be
$$F ( T, T _ { G } ) = - T + \beta _ { 1 } \sqrt { T ^ { 2 } + \beta _ { 2 } T _ { G } } + \alpha _ { 1 } T ^ { 2 } + \alpha _ { 2 } T \sqrt { | T _ { G } | } \,. \quad \text{ see th} \\ ( 3 8 ) \quad \text{How} \\ \text{In summary, when the above function is used as an ac-} \quad \text{model}$$
In summary, when the above function is used as an action, it gives rise to a gravitational theory that can describe both inflation and late-times acceleration in a unified way.
In order to examine the cosmological evolution of a universe governed by the above unified action, we perform a numerical elaboration of the Friedman equations (30), (31), with ρ DE , p DE given by equations (34), (35), under the ansatz (38). In Fig. 1 we present the earlytimes, inflationary solutions for four parameter choices. As we observe, inflationary, de-Sitter exponential expan-
/s116
FIG. 1: Four inflationary solutions for the ansatz F T,T ( G ) = α T 1 2 + α T 2 √ | T G | -T + β 1 √ T 2 + β T 2 G , corresponding to a) α 1 = -2 8 . , α 2 = 8 , β 1 = 0 001 . , β 2 = 1 (black-solid), b) α 1 = -2 , α 2 = 8 , β 1 = 0 001 . , β 2 = 1 (reddashed), c) α 1 = 8 , α 2 = 8 , β 1 = 0 001 . , β 2 = 1 (blue-dotted), d) α 1 = 20 , α 2 = 5 , β 1 = 0 001 . , β 2 = 1 (green-dashed-dotted). All parameters are in Planck units.
sions can be easily obtained (with the exponent of the expansion determined by the model parameters), although there is not an explicit cosmological constant term in the action, which is an advantage of the scenario. This was expected, since one can easily extract analytical solutions of the Friedmann equations (30), (31) with H ≈ const (in which case T and T G as also constants).
Let us now focus on the late-times evolution. In Fig. 2 we depict the evolution of the matter and effective dark energy density parameters, as well as the behavior of the dark energy equation-of-state parameter, for a specific choice of the model parameters.
As we see, we can obtain the observed behavior, where Ω m decreases, resulting to its current value of Ω m 0 ≈ 0 3, . while Ω DE = 1 -Ω m increases. Concerning w DE , we can see that in this example it lies in the quintessence regime.
However, as it is usual in modified gravity [35], the model at hand can describe the phantom regime too, for a region of the parameter space, which is an additional advantage. In particular, in Fig. 3 we depict the cosmological evolution for a parameter choice that leads w DE to the phantom regime, while the density parameters maintain their observed behavior. Similarly, note that the scenario can also exhibit the phantom-divide crossing [3] too. Finally, note that one can use dynamical-systems methods in order to examine in a systematic way the latetimes cosmological behavior of the scenario at hand, independently of the initial conditions of the universe [36].
/s119
FIG. 2: Upper graph: The evolution of the dark energy density parameter Ω DE (black-solid) and the matter density parameter Ω m (red-dashed), as a function of the redshift z , for the ansatz F T,T ( G ) = α T 1 2 + α T 2 √ | T G |-T + β 1 √ T 2 + β T 2 G with α 1 = 0 001 . , α 2 = 0 001 . , β 1 = 2 5 . , β 2 = 1 5 . . Lower graph: The evolution of the corresponding dark energy equation-of-state parameter w DE . All parameters are in units where the present Hubble parameter is H 0 = 1 , and we have imposed Ω m 0 ≈ 0 3 . , Ω DE 0 ≈ 0 7 . at present.
/s119
FIG. 3: Upper graph: The evolution of the dark energy density parameter Ω DE (black-solid) and the matter density parameter Ω m (red-dashed), as a function of the redshift z , for the ansatz F T,T ( G ) = α T 1 2 + α T 2 √ | T G | -T + β 1 √ T 2 + β T 2 G , with α 1 = 0 001 . , α 2 = 0 001 . , β 1 = 2 6 . , β 2 = 2 . Lower graph: The evolution of the corresponding dark energy equation-of-state parameter w DE . All parameters are in units where the present Hubble parameter is H 0 = 1 , and we have imposed Ω m 0 ≈ 0 3 . , Ω DE 0 ≈ 0 7 . at present.
$$\mathbf B. \quad F ( T, T _ { G } ) = - T + f ( T ^ { 2 } + \beta _ { 2 } T _ { G } )$$
One can go beyond the simple model of the previous paragraph. In particular, since as we already mentioned T G contains quartic torsion terms, it will in general and approximately be of the same order with T 2 . Therefore, it would be interesting to consider modifications of the form F T,T ( G ) = -T + ( f T 2 + β T 2 G ). The involved building block is an extension of the simple T , and thus, it can significantly improve the detailed cosmological behavior of a suitable reconstructed F T ( ). The general equations (28), (29) in this case become
$$\ddot { \cdot } \quad 6 H ^ { 2 } + f - ( 2 4 H ^ { 2 } T + \beta _ { 2 } T _ { G } ) f ^ { \prime } + 2 4 \beta _ { 2 } H ^ { 3 } ( 2 T \dot { T } + \beta _ { 2 } \dot { T } _ { G } ) f ^ { \prime \prime } \\ \overbrace { \longrightarrow } \, \infty$$
$$& 2 ( 2 \dot { H } + 3 H ^ { 2 } ) + f - [ 8 ( \dot { H } + 3 H ^ { 2 } ) T + 8 H \dot { T } + \beta _ { 2 } T _ { G } ] f ^ { \prime } \\ & \quad \ t y \, d e n _ { \real ^ { \prime } } \\ & \underline { t y \, p a _ { \real ^ { \prime } } } ^ { \ } ( 2 T \dot { T } + \beta _ { 2 } \dot { T } _ { G } ) + 8 \beta _ { 2 } H ^ { 2 } ( 2 T \dot { T } + \beta _ { 2 } \dot { T } _ { G } ) ^ { \, \cdot } ) \, \right \} f ^ { \prime \prime } \\ & \underline { z, \, f o r } ^ { \ } ( 2 T \dot { T } + \beta _ { 2 } \dot { T } _ { G } ) ^ { 2 } f ^ { \prime \prime \prime } = - 2 \kappa ^ { 2 } p \,, \ ( 4 0 )$$
where f , f ′ ′′ , f ′′′ denote the derivatives of the function f and are evaluated at T 2 + β T 2 G .
As a representative example we choose the case F T,T ( G ) = -T + β 1 ( T 2 + β T 2 G )+ β 3 ( T 2 + β T 4 G ) 2 , that is keeping up to fourth-order torsion terms (one could easily proceed to the investigation of other ansatzes in this class and to the detailed description of a unified picture of inflation and late-times acceleration). As expected, the higher-order torsion terms are significant at early times, and thus they can easily drive inflation. In Fig. 4 we show the early-times, inflationary solutions for five parameter choices, changing in particular the value of β 4 in order to see the effect of T G on the evolution (the value of β 2 is irrelevant since the linear T G term does not have any effect, since T G , similarly to G , is topological invariant).
As we observe, inflationary evolution, that is de-Sitter exponential expansions can be easily obtained, and the expansion-exponent is determined by the model parameters. The significant advantage is that the exponential expansion is obtained without an explicit cosmological constant term in the action. Again, this was expected since we can easily extract analytical solutions of the Friedmann equations (39), (40) with H ≈ const (in which case T and T G as also constants). Additionally, note that in this case the inflation realization is more efficient comparing to the model of the previous subsection, since it leads to more e-foldings in less time, as expected since now higher-order torsion terms are considered.
In the above analysis we showed that f ( T, T G ) cosmology can be very efficient in describing the evolution of the universe at the background level. However, before considering any cosmological model as a candidate for the description of nature it is necessary to perform a detailed investigation of its perturbations, namely to examine whether the obtained solutions are stable. Furthermore,
FIG. 4: Five inflationary solutions for the ansatz F T,T ( G ) = -T + β 1 ( T 2 + β T 2 G ) + β 3 ( T 2 + β T 4 G ) 2 , corresponding to a) β 1 = -0 01 . , β 2 = 1 , β 3 = -1 , β 4 = -2 (black-solid), b) β 1 = -0 1 . , β 2 = 1 , β 3 = -2 , β 4 = -2 (red-dashed), c) β 1 = -0 01 . , β 2 = 1 , β 3 = -1 , β 4 = -5 (blue-dotted), d) β 1 = -0 01 . , β 2 = 1 , β 3 = -6 , β 4 = -6 (green-dashed-dotted), e) β 1 = -0 01 . , β 2 = 1 , β 3 = -10 , β 4 = -10 (yellow-dasheddotted-dotted). All parameters are in Planck units.
especially in theories with local Lorentz invariance violation, new degrees of freedom are introduced, the behavior of which is not guaranteed that is stable (for instance this is the case in the initial version of Hoˇava-Lifshitz gravity r [37], in the initial version of de Rham-Gabadadze-Tolley massive gravity [38], etc), and this makes the perturbation analysis of such theories even more imperative. Although such a detailed and complete analysis of the cosmological perturbations of f ( T, T G ) gravity is necessary, its various complications and lengthy calculations make it more convenient to be examined in a separate project [39]. However, for the moment we would like to mention that in the case of simple f ( T ) gravity, the perturbations of which have been examined in detail [15, 17], one does obtain instabilities, but there are many classes of f ( T ) ansantzes and/or parameter-space regions, where the perturbations are well-behaved. This is a good indication that we could expect to find a similar behavior in f ( T, T G ) gravity too, although we need to indeed verify this under the detailed perturbation analysis.
## V. CONCLUSIONS
In this work we investigated the cosmological applications of F T,T ( G ) gravity, which is a modified gravity based on the torsion scalar T and the teleparallel equivalent of the Gauss-Bonnet combination T G . F T,T ( G ) gravity is different from both the simple F T ( ) theory, as well as from the curvature modification F R,G ( ), and thus it is a novel class of gravitational modification. First, we extracted the general Friedmann equations and we defined the effective dark energy sector consisting of torsional combinations. Then, choosing specific F T,T ( G ) ansatzes we performed a detailed study of various observables, such as the matter and dark energy density parameters and the dark energy equation-of-state parameters.
Amongst the huge number of possible ansatzes, an interesting option is the construction of terms of the same order as T or T 2 using T G , for instance new combinations of the form T + α √ | T G | or T 2 + βT G can participate in the F T,T ( G ) function. The resulting cosmology leads to interesting behaviors. Firstly, the scenario can describe the inflationary regime, without an inflaton field. Secondly, at late times it provides an effective dark energy sector which can drive the acceleration of the universe, along with the correct evolution of the density parameters, without the need of a cosmological constant. Furthermore, the dark energy equation-of-state parameter can be quintessence or phantom-like, or experiences the phantom-divide crossing, depending on the parameters of the model. Another possible ansatz is the F T,T ( G ) = -T + f ( T 2 + β T 2 G ), the simplest application of which can also easily lead to inflationary behavior. These features make the proposed modified gravity a good candidate for the description of Nature.
## Acknowledgments
The research of ENS is implemented within the framework of the Operational Program 'Education and Lifelong Learning' (Actions Beneficiary: General Secretariat for Research and Technology), and is co-financed by the European Social Fund (ESF) and the Greek State.
## Appendix A: Shortcut procedure for the extraction of the field equations of F T,T ( G ) cosmology
In this Appendix we follow the shortcut procedure in order to derive the field equations of F T,T ( G ) cosmology. In particular, instead of performing the variation of the action (19) in terms of the general vierbein, obtaining the general field equations (16), and then insert into them the cosmological vierbein ansatz (21), we will first insert the cosmological vierbein ansatz into the action and then perform the variation in terms of the scale factor a t ( ) and the lapse function N t ( ). Although in principle the shortcut procedure is not guaranteed that it will give the same results as the first robust method [33, 34], especially when the action involves higher-order derivatives, in this specific example it proves that we do obtain the same results indeed.
Under the cosmological ansatz (21), namely
$$e ^ { a } _ { \ \mu } = \text{diag} ( N ( t ), a ( t ), a ( t ), a ( t ) ), \quad \text{(A1)}$$
the scalars T and T G become
$$T = 6 \frac { \dot { a } ^ { 2 } } { N ^ { 2 } a ^ { 2 } } = 6 H ^ { 2 }$$
$$= 2 4 H ^ { 2 } \Big ( \frac { \dot { H } } { N } + H ^ { 2 } \Big ). \\ \text{insertion into the total acti}$$
$$T & = 6 \frac { \dot { a } ^ { 2 } } { N ^ { 2 } a ^ { 2 } } = 6 H ^ { 2 } & & ( \mathbb { A } 2 ) & & \\ T _ { G } & = 2 4 \frac { \dot { a } ^ { 2 } } { N ^ { 2 } a ^ { 2 } } \Big { ( } \frac { \ddot { a } } { N ^ { 2 } a } - \frac { \dot { N } \dot { a } } { N ^ { 3 } a } \Big { ) } & & \text{and} \\ & = 2 4 H ^ { 2 } \Big { ( } \frac { \dot { H } } { N } + H ^ { 2 } \Big { ) }. & & ( \mathbb { A } 3 ) & & \cdot$$
Therefore, insertion into the total action (19) gives
$$S _ { t o t } & = \frac { 1 } { 2 \kappa ^ { 2 } } \int d t \, N a ^ { 3 } \, F \left ( 6 H ^ { 2 }, \, 2 4 H ^ { 2 } \left ( \frac { \dot { H } } { N } + H ^ { 2 } \right ) \right ) \, + \, S _ { m } \,. \quad \begin{array} { c } \ln s \\ \text{$fetch} \, e \\ \text{$(A4)} \end{array} \quad \text{$form} \, \\ \intertext { T o t me now form to function of $f(\,\Lambda\,\Lambda$ with transaction} \,.$$
Let us now perform the variation of (A4) with respect to N and a . Since δ N H = -H δN N , we obtain
$$\begin{smallmatrix}. \end{smallmatrix}$$
$$& \dots \\ & \delta _ { N } T = - 1 2 H ^ { 2 } \frac { \delta N } { N } \\ & \delta _ { N } T _ { G } = - 9 6 H ^ { 2 } \left [ \left ( \frac { \dot { H } } { N } + H ^ { 2 } - \frac { H \dot { N } } { 4 N ^ { 2 } } \right ) \frac { \delta N } { N } + \frac { H } { 4 N ^ { 2 } } ( \delta N ) ^ { \cdot } \right ]. \\ & \text{Similarlv since } \delta _ { \cdot } H = \frac { ( \delta a ) ^ { \cdot } } { \cdot } - H \frac { \delta a } { \cdot } \text{ we acquire}$$
Similarly, since δ a H = ( δa ) /squaresmallsolid Na -H δa a , we acquire
$$\underset { \begin{array} { c } { \text{minary, since } \, \varrho _ { a } \, n \, = \, \frac { 1 } { N _ { a } } - n \, \frac { 1 } { a } }, \, \text{we acquire} \end{array} } } \\ \delta _ { a } T = \frac { 1 2 H } { N _ { a } } \left [ \left ( \delta a \right ) ^ { \cdot } - N H \delta a \right ] \\ \delta _ { a } T _ { G } = \frac { 2 4 H } { N _ { a } } \left [ \frac { H } { N } \left ( \delta a \right ) ^ { \cdot \cdot } + \left ( \frac { 2 \dot { H } } { N } + 2 H ^ { 2 } - \frac { H \dot { N } } { N ^ { 2 } } \right ) \left ( \delta a \right ) ^ { \cdot } \quad \text{Ad} \quad \text{morg} \\ - 3 N H \left ( \frac { \dot { H } } { N } + H ^ { 2 } \right ) \delta a \right ]. \quad \text{em} \\ \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \cdot \colon \\ \end{array}$$
Therefore, variation of the gravitational part of the action (A4) with respect to N and a gives
$$\begin{array} { c c c } \cdot & \cdot & \cdot & \cdot \\ \delta _ { N } S = \frac { 1 } { 2 \kappa ^ { 2 } } \int d t \, a ^ { 3 } \left [ F - 1 2 H ^ { 2 } F _ { T } + \frac { 2 4 } { a ^ { 3 } } \left ( \frac { a ^ { 3 } H ^ { 3 } } { N } F _ { T _ { G } } \right ) & \\ & - 9 6 H ^ { 2 } \left ( \frac { \dot { H } } { N } + H ^ { 2 } - \frac { H \dot { N } } { 4 N ^ { 2 } } \right ) F _ { T _ { G } } \right ] \delta N \ ( A 5 ) & \\ & & & \text{where} \end{array}$$
$$\delta _ { a } S = & \frac { 3 } { 2 \kappa ^ { 2 } } \int d t \, N a ^ { 2 } \left \{ F - 4 H ^ { 2 } F _ { T } - 2 4 H ^ { 2 } \left ( \frac { \dot { H } } { N } + H ^ { 2 } \right ) F _ { T _ { G } } \quad \begin{array} { c } \text{where} \,. \\ \text{$\ddots$} \\ F _ { T _ { G } T _ { G } ^ { \prime } } \end{array} \\ - & \frac { 4 } { a ^ { 2 } N } \left [ a ^ { 2 } H F _ { T } + 2 a ^ { 2 } H \left ( \frac { 2 \dot { H } } { N } + 2 H ^ { 2 } - \frac { H \dot { N } } { N ^ { 2 } } \right ) F _ { T _ { G } } \right ] \begin{array} { c } \text{differef} \\ \text{are obl} \\ \text{time,} \end{array} \\ + & \frac { 8 } { a ^ { 2 } N } \left ( \frac { a ^ { 2 } H ^ { 2 } } { N } F _ { T _ { G } } \right ) \end{array} \right \} \delta a, \quad ( A 6 ) \quad \text{As} \quad \text{and} \ ( A \\ \text{coincid} \\ \text{where} \ F _ { T } \equiv \partial F / \partial T \text{ and } F _ { T _ { G } } \equiv \partial F / \partial T _ { G }.$$
where F T ≡ ∂F/∂T and F T G ≡ ∂F/∂T G .
Additionally, variation of S m gives
$$\delta S _ { m } = \frac { 1 } { 2 } \int d ^ { 4 } x \, e \, \Theta ^ { \mu \nu } \delta g _ { \mu \nu }, \\ \iota = \text{dependent part is}$$
and its time-dependent part is
$$\delta S _ { m } = - \int d t \, N ^ { 2 } a ^ { 3 } \Theta ^ { t t } \delta N + \int d t \, N a ^ { 2 } \Theta ^ { \hat { i } } _ { \hat { i } } \delta a \,, \quad ( \mathbf A 7 )$$
where hat indices run in the three spatial coordinates.
In summary, taking into account the total action variation, and setting as usual N = 1 in the end, the obtained field equations, that is the Friedmann equations, take the form
$$F - 1 2 H ^ { 2 } F _ { T } & - 9 6 H ^ { 2 } ( \dot { H } + H ^ { 2 } ) F _ { T _ { G } } \\ + \frac { 2 4 } { a ^ { 3 } } ( a ^ { 3 } H ^ { 3 } F _ { T _ { G } } ) & = 2 \kappa ^ { 2 } \Theta ^ { t t } \quad \ ( A 8 )$$
$$F - 4 H ^ { 2 } F _ { T } - 2 4 H ^ { 2 } ( \dot { H } + H ^ { 2 } ) F _ { T _ { G } } \\ - \frac { 4 } { a ^ { 2 } } \left [ a ^ { 2 } H F _ { T } + 4 a ^ { 2 } H ( \dot { H } + H ^ { 2 } ) F _ { T _ { G } } \right ] ^ { \cdot } \\ + \frac { 8 } { a ^ { 2 } } \left ( a ^ { 2 } H ^ { 2 } F _ { T _ { G } } \right ) ^ { \cdot } = - \frac { 2 } { 3 } \kappa ^ { 2 } \Theta ^ { \hat { i } } _ { \hat { i } }. \quad \text{(A9)} \\ \text{Additionally,} \quad \text{if} \ \ we \ \text{ consider} \ \ the \ \ matter \ \ energy-}$$
Lastly, we can re-organize the terms, performing the involved time derivatives, resulting in the end to
Additionally, if we consider the matter energymomentum tensor to correspond to a perfect fluid of energy density ρ and pressure p , we insert in the above field equations Θ tt = ρ , Θ ˆˆ ij = p a 2 δ ˆˆ ij , Θ ˆ i ˆ i = 3 . p
$$F - 1 2 H ^ { 2 } F _ { T } - T _ { G } F _ { T _ { G } } + 2 4 H ^ { 3 } F _ { T _ { G } } ^ { \cdot } = 2 \kappa ^ { 2 } \rho \quad ( \mathbf A 1 0 )$$
$$F & - 4 ( \dot { H } + 3 H ^ { 2 } ) F _ { T } - 4 H \dot { F } _ { T } \\ & - T _ { G } F _ { T _ { G } } + \frac { 2 } { 3 H } T _ { G } \dot { F } _ { T _ { G } } + 8 H ^ { 2 } \ddot { F } _ { T _ { G } } = - 2 \kappa ^ { 2 } p, ( \mathbb { A } 1 1 )$$
where ˙ F T = F TT ˙ T + F TT G ˙ T G , ˙ F T G = F TT G ˙ T + F T G G T ˙ T G , ¨ F T G = F TTT G ˙ T 2 +2 F TT G G T ˙ TT ˙ G + F T G G T T G ˙ T 2 G + F TT G ¨ + T F T G G T ¨ T G , with F TT , F TT G , ... denoting multiple partial differentiations of F with respect to T , T G . Here, ˙ T , ¨ T are obtained by differentiating T = 6 H 2 with respect to time, while ˙ T G , ¨ T G by differentiating T G = 24 H 2 ( ˙ H + H 2 ).
As we observe, the two Friedmann equations (A10) and (A11), derived with the above shortcut procedure, coincide with the two Friedmann equations (24) and (25) derived with the robust procedure in sections II and III.
Phys. D 15 , 1753 (2006).
- [3] Y. -F. Cai, E. N. Saridakis, M. R. Setare and J. -Q. Xia, Phys. Rept. 493 , 1 (2010).
- [4] S. Capozziello and M. De Laurentis, Phys. Rept. 509 , 167 (2011).
- [5] V. Sahni and A. Starobinsky, Int. J. Mod. Phys. D 15 , 2105 (2006).
- [6] A. Einstein 1928, Sitz. Preuss. Akad. Wiss. p. 217; ibid p. 224; A. Unzicker and T. Case [arXiv:physics/0503046].
- [7] K. Hayashi and T. Shirafuji, Phys. Rev. D 19 , 3524 (1979) [Addendum-ibid. D 24 , 3312 (1982)].
- [8] J. W. Maluf, J. Math. Phys. 35 (1994) 335; H. I. Arcos and J. G. Pereira, Int. J. Mod. Phys. D 13 , 2193 (2004).
- [9] R. Aldrovandi and J. G. Pereira, Teleparallel Gravity: An Introduction , Springer, Dordrecht (2013).
- [10] J. W. Maluf, Annalen Phys. 525 , 339 (2013).
- [11] A. De Felice and S. Tsujikawa, Living Rev. Rel. 13 , 3 (2010).
- [12] S. 'i. Nojiri and S. D. Odintsov, Phys. Rept. 505 , 59 (2011).
- [13] R. Ferraro and F. Fiorini, Phys. Rev. D 75 , 084031 (2007); R. Ferraro, F. Fiorini, Phys. Rev. D78 , 124019 (2008); G. R. Bengochea and R. Ferraro, Phys. Rev. D 79 , 124019 (2009).
- [14] E. V. Linder, Phys. Rev. D 81 , 127301 (2010).
- [15] S. H. Chen, J. B. Dent, S. Dutta and E. N. Saridakis, Phys. Rev. D 83 , 023508 (2011); J. B. Dent, S. Dutta, E. N. Saridakis, JCAP 1101 , 009 (2011).
- [16] Y. Zhang, H. Li, Y. Gong, Z. -H. Zhu, JCAP 1107 , 015 (2011); T. P. Sotiriou, B. Li and J. D. Barrow, Phys. Rev. D 83 , 104030 (2011); Y. -F. Cai, S. -H. Chen, J. B. Dent, S. Dutta, E. N. Saridakis, Class. Quant. Grav. 28 , 2150011 (2011); M. Sharif, S. Rani, Mod. Phys. Lett. A26 , 1657 (2011); S. Capozziello, V. F. Cardone, H. Farajollahi and A. Ravanpak, Phys. Rev. D 84 , 043527 (2011); C. -Q. Geng, C. -C. Lee, E. N. Saridakis, Y. -P. Wu, Phys. Lett. B704 , 384 (2011); H. Wei, Phys. Lett. B 712 , 430 (2012); C. -Q. Geng, C. -C. Lee, E. N. Saridakis, JCAP 1201 , 002 (2012); Y. -P. Wu and C. -Q. Geng, Phys. Rev. D 86 , 104058 (2012); C. G. Bohmer, T. Harko and F. S. N. Lobo, Phys. Rev. D 85 , 044033 (2012); K. Karami and A. Abdolmaleki, JCAP 1204 , 007 (2012); C. Xu, E. N. Saridakis and G. Leon, JCAP 1207 , 005 (2012); K. Bamba, R. Myrzakulov, S. 'i. Nojiri and S. D. Odintsov, Phys. Rev. D 85 , 104036 (2012); N. Tamanini and C. G. Boehmer, Phys. Rev. D 86 , 044009 (2012); M. E. Rodrigues, M. J. S. Houndjo, D. Saez-Gomez and F. Rahaman, Phys. Rev. D 86 , 104059 (2012); K. Bamba, J. de Haro and S. D. Odintsov, JCAP 1302 , 008 (2013); M. Jamil, D. Momeni and R. Myrzakulov, Eur. Phys. J. C 72 , 2267 (2012); J. -T. Li, C. -C. Lee and C. -Q. Geng, Eur. Phys. J. C 73 , 2315 (2013); A. Aviles, A. Bravetti, S. Capozziello and O. Luongo, Phys. Rev. D 87 , 064025 (2013); K. Bamba, S. 'i. Nojiri and S. D. Odintsov, arXiv:1304.6191 [gr-qc]; G. Otalora, JCAP 1307 , 044 (2013); J. Amoros, J. de Haro and S. D. Odintsov, Phys. Rev. D 87 , 104037 (2013); G. Otalora, Phys. Rev. D 88 , 063505 (2013); C. -Q. Geng, J. -A. Gu and C. -C. Lee, Phys. Rev. D 88 , 024030 (2013); M. E. Rodrigues, I. G. Salako, M. J. S. Houndjo and J. Tossa, Int. J. Mod. Phys. D 23 (2014) 1, 1450004; K. Bamba, S. Capozziello, M. De Laurentis, S. 'i. Nojiri and D. Sez-Gmez, Phys. Lett. B 727 , 194
- (2013); K. Bamba, S. 'i. Nojiri and S. D. Odintsov, Phys. Lett. B 731 , 257 (2014); G. Otalora, arXiv:1402.2256 [gr-qc]; A. Paliathanasis, S. Basilakos, E. N. Saridakis, S. Capozziello, K. Atazadeh, F. Darabi and M. Tsamparlis, arXiv:1402.5935 [gr-qc]; G. G. L. Nashed, arXiv:1403.6937 [gr-qc]; S. Chattopadhyay, arXiv:1403.8116 [gr-qc]; V. Fayaz, H. Hossienkhani, A. Farmany, M. Amirabadi and N. Azimi, Astrophys. Space Sci. 351 , 299 (2014).
- [17] B. Li, T. P. Sotiriou and J. D. Barrow, Phys. Rev. D 83 , 104017 (2011); Y. P. Wu and C. Q. Geng, JHEP 1211 , 142 (2012); K. Izumi and Y. C. Ong, JCAP 1306 , 029 (2013).
- [18] P. Wu, H. W. Yu, Phys. Lett. B693 , 415 (2010); G. R. Bengochea, Phys. Lett. B695 , 405 (2011); L. Iorio and E. N. Saridakis, Mon. Not. Roy. Astron. Soc. 427 , 1555 (2012); S. Nesseris, S. Basilakos, E. N. Saridakis and L. Perivolaropoulos, Phys. Rev. D 88 , 103010 (2013).
- [19] T. Wang, Phys. Rev. D84 , 024042 (2011); R. -X. Miao, M. Li and Y. -G. Miao, JCAP 1111 , 033 (2011); C. G. Boehmer, A. Mussa and N. Tamanini, Class. Quant. Grav. 28 , 245020 (2011); R. Ferraro, F. Fiorini, Phys. Rev. D 84 , 083518 (2011); M. H. Daouda, M. E. Rodrigues and M. J. S. Houndjo, Eur. Phys. J. C 71 , 1817 (2011); M. H. Daouda, M. E. Rodrigues and M. J. S. Houndjo, Eur. Phys. J. C 72 , 1890 (2012); P. A. Gonzalez, E. N. Saridakis and Y. Vasquez, JHEP 1207 , 053 (2012); S. Capozziello, P. A. Gonzalez, E. N. Saridakis and Y. Vasquez, JHEP 1302 , 039 (2013); K. Atazadeh and M. Mousavi, Eur. Phys. J. C 72 , 2272 (2012).
- [20] D. Boulware and S. Deser, Phys. Rev. Lett. 55 , 2656 (1985); J. T. Wheeler, Nucl. Phys. B 268 , 737 (1986).
- [21] I. Antoniadis, J. Rizos and K. Tamvakis, Nucl. Phys. B 415 , 497 (1994); P. Kanti, J. Rizos and K. Tamvakis, Phys. Rev. D 59 , 083512 (1999); N. E. Mavromatos and J. Rizos, Phys. Rev. D 62 , 124004 (2000); S. 'i. Nojiri, S. D. Odintsov and M. Sasaki, Phys. Rev. D 71 , 123509 (2005).
- [22] S. 'i. Nojiri and S. D. Odintsov, Phys. Lett. B 631 , 1 (2005).
- [23] A. De Felice and S. Tsujikawa, Phys. Lett. B 675 , 1 (2009).
- [24] S. C. Davis, arXiv:0709.4453 [hep-th]; B. Eynard and N. Orantin, arXiv:0705.0958 [math-ph]; A. De Felice and S. Tsujikawa, Phys. Rev. D 80 , 063516 (2009); A. Jawad, S. Chattopadhyay and A. Pasqua, Eur. Phys. J. Plus 128 , 88 (2013).
- [25] P. D. Mannheim and D. Kazanas, Astrophys. J. 342 , 635 (1989); E. E. Flanagan, Phys. Rev. D 74 , 023002 (2006); N. Deruelle, M. Sasaki, Y. Sendouda and A. Youssef, JCAP 1103 , 040 (2011); D. Grumiller, M. Irakleidou, I. Lovrekovic and R. McNees, Phys. Rev. Lett. 112 , 111102 (2014).
- [26] D. Lovelock, J. Math. Phys. 12 , 498 (1971).
- [27] N. Deruelle and L. Farina-Busto, Phys. Rev. D 41 , 3696 (1990).
- [28] G. Kofinas and E. N. Saridakis, Phys. Rev. D 90 , 084044 (2014), [arXiv:1404.2249 [gr-qc]].
- [29] F. Mueller-Hoissen and J. Nitsch, Phys. Rev. D 28 , 718 (1983).
- [30] A. Mardones and J. Zanelli, Class. Quant. Grav. 8 , 1545 (1991); O. Chandia and J. Zanelli, Phys. Rev. D 55 , 7580 (1997).
- [31] T. Harko, F. S. N. Lobo, G. Otalora and E. N. Saridakis, Phys. Rev. D 89 , 124036 (2014); T. Harko, F. S. N. Lobo, G. Otalora and E. N. Saridakis, arXiv:1405.0519 [gr-qc].
- [32] Y. C. Ong, K. Izumi, J. M. Nester and P. Chen, Phys. Rev. D 88 , 024019 (2013); K. Izumi, J. A. Gu and Y. C. Ong, Phys. Rev. D 89 , 084025 (2014).
- [33] S. Deser, J. Franklin and B. Tekin, Class. Quant. Grav. 21 , 5295 (2004).
- [34] S. Weinberg, Cosmology , Oxford University Press Inc., New York (2008).
- [35] S. Nojiri and E. N. Saridakis, Astrophys. Space Sci. 347 , 221 (2013).
- [36] G. Kofinas, G. Leon and E. N. Saridakis, Class. Quant. Grav. 31 , 175011 (2014).
- [37] C. Bogdanos and E. N. Saridakis, Class. Quant. Grav. 27 , 075005 (2010).
- [38] A. De Felice, A. E. Gumrukcuoglu and S. Mukohyama, Phys. Rev. Lett. 109 , 171101 (2012).
- [39] G. Kofinas and E. N. Saridakis, in preparation. | 10.1103/PhysRevD.90.084045 | [
"Georgios Kofinas",
"Emmanuel N. Saridakis"
] | 2014-08-01T09:15:43+00:00 | 2014-10-24T14:44:53+00:00 | [
"gr-qc",
"astro-ph.CO",
"hep-th"
] | Cosmological applications of $F(T,T_G)$ gravity | We investigate the cosmological applications of $F(T,T_G)$ gravity, which is
a novel modified gravitational theory based on the torsion invariant $T$ and
the teleparallel equivalent of the Gauss-Bonnet term $T_{G}$. $F(T,T_{G})$
gravity differs from both $F(T)$ theories as well as from $F(R,G)$ class of
curvature modified gravity, and thus its corresponding cosmology proves to be
very interesting. In particular, it provides a unified description of the
cosmological history from early-times inflation to late-times
self-acceleration, without the inclusion of a cosmological constant. Moreover,
the dark energy equation-of-state parameter can be quintessence or
phantom-like, or experience the phantom-divide crossing, depending on the
parameters of the model. |
1408.0108v1 | ## Pressure-induced phase transition for single crystalline LaO0.5F0.5BiSe2
Masaya Fujioka 1,a) , Masashi Tanaka , Saleem J. Denholme , Takuma Yamaki 1 1 1,2 , Hiroyuki Takeya , Takahide Yamaguchi , and Yoshihiko Takano 1 1 1,2
1 National Institute for Materials Science, 1-2-1 Sengen, Tsukuba, Ibaraki 305-0047, Japan
2 University of Tsukuba, 1-1-1Tennodai, Tsukuba, Ibaraki 305-0001, Japan
We have demonstrated a pressure-induced phase transition from a lowT c phase to a highT c phase in a single crystal of the superconductor LaO0.5F0.5BiSe2. The highT c phase appears at 2.16 GPa and the maximum superconducting transition temperature ( T c ) is observed at 6.7 K under 2.44 GPa. Although the anisotropy ( ) for the lowγ T c phase is estimated to be 20, it is reduced by around half (9.3) in the highT c phase. This tendency is the same for the BiS2 system. The T c of LaO0.5F0.5BiSe2 has continued to increase up to the maximum pressure of this study (2.44 GPa). Therefore applied further pressure has the potential to induce a much higher T c in this system.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
a) Author to whom correspondence should be addressed. Electronic mail: [email protected]
Recently, a series of BiS2-based superconductor such as Bi4O4S3 1 , LnO1-xFxBiS2 (Ln = La, Ce, Pr, Nd, Yb) 2-8 and Sr 1-x FxBiS2 9,10 were discovered. These compounds have a layered structure composed of superconducting BiS2 layer and charge reservoir blocking layers. This structure is in common with the cuprate superconductors 11 and Fe-based superconductors 12 . The most attractive point of LnO1-xFxBiS2 is the pressure induced phase transition from a lowT c phase to a highT c phase 2, 13-16 . For instance, the T c of LaO0.5F0.5BiS2, which was synthesized by a conventional solid state reaction, is obtained at only 3 K. On the other hand, the T c largely increases above 10 K by using high pressure synthesis. Furthermore, even if the sample is prepared by using a conventional solid state reaction method, high pressure measurements can enhance the T c above 10 K 16 . Very recently, we have reported the pressure induced phase transition for the single crystalline PrO0.5F0.5BiS2 17 . From this study, it was found that the semiconducting-like behavior in lowT c phase changes to the metallic behavior and the γ is reduced by around half after the phase transition.
The modification of superconducting and blocking layers is one of the promising approaches to discover new superconducting materials 18 . Polycrystalline LaO0.5F0.5BiSe2 was discovered by the replacement of the BiS2 superconducting layers in LaO1-xFxBiS2 to the BiSe2 layers 19 . In such a material whether the pressure induced phase transition can be observed or not is a point of interest. Also it will provide useful information to know the mechanism of emergence for the highT c phase. In previous research, we have succeeded in preparing single crystalline LaO0.5F0.5BiSe2 and performing structural analysis of this compound 20 . According to our previous study on PrO0.5F0.5BiS2 17 , it was found that applying uniaxial pressure to single crystals effectively induces the highT c phase. Also, measurements using single crystals are suitable to investigate the intrinsic properties of these materials. In this research, we investigated the pressure induced phase transition of single crystalline LaO0.5F0.5BiSe2.
The single crystals were prepared by the CsCl flux method. The details of characterization are shown in ref. 20. All described fluorine content in this article is the nominal amount. X-ray diffraction (XRD)
measurement showed that the single crystals were highly oriented to the c -axis as shown in Fig.1. The c lattice parameter was estimated to be 1.414(4) nm. Electrical resistivity was measured by a physical properties measurement system (PPMS) under varying pressures up to a maximum of 2.44 GPa. The measurement was performed by a standard four-probe method from 300 K to 2 K in a piston-cylindertype pressure cell. The measured sample was formed into rectangles with dimensions of around 1.3 × 0.4 × 0.02 mm . Since the thickness (20 μm) is smaller compared to the other dimensions, therefore the 2 actual applied pressure should be almost uniaxial along the c -axis, despite the fact that we are using a hydrostatic pressure technique. This relationship between sample configuration and anisotropic pressure has been demonstrated previously in ref.21. The resistivity measurements were performed under several magnetic fields with directions both parallel to the ab plane ( H ab // ) and c axis ( H c // ), under 1.17 and 2.44 GPa.
The temperature dependence of resistivity for LaO0.5F0.5BiSe2 under various pressures is shown in figure 2 (a) and (b). The data points at ambient pressure were noisy due to poor contact resistance, but was improved by applied pressure. In this study, T c onset and T c zero were regarded as described in figure 2 (b). The resistivity at ambient pressure and 0.76 GPa starts to decrease at 3.4 K and a second drop is observed at 2.4 K. Although the zero resistivity was not obtained at ambient pressure, T c zero appeared at 2.2 K under 0.76 GPa. Additionally, a small hump at around 40 K is observed at ambient pressure and 0.76 GPa. This hump was also confirmed in our previous report 22 . When increasing pressure up to 1.17 GPa, it completely disappears. However, even though the pressure increases up to 2.16 GPa, T c zero does not increase above 2.7 K. On the other hand, at 2.16 GPa, the resistivity starts to drop at 6.3 K and shows a step like behavior. This means that some of parts in the sample form the highT c phase. For further pressure up to 2.44 GPa, the T c onset clearly appears at 6.7 K and the T c zero suddenly increases up to 5 K. From this figure, it is expected that the drop of resistivity at around 3 K corresponds to the lowT c phase, and the highT c phase is obtained at around 7 K. However, under ambient pressure and 0.76 GPa,
another drop of resistivity is also observed at 2 K. This may be due to the inhomogeneous fluorine concentration, or a local distortion for the extreme thinness of the sample.
In this measurement, we confirmed the discontinuous increase in T c of LaO0.5F0.5BiSe2, as was also observed with the BiS2 system. Therefore, regardless of whether the superconducting layers are made up of sulfur or selenium, a pressure induced phase transition occurs. Furthermore, in the highT c phase, the BiS2 and BiSe2 systems show similar behavior. Namely, the resistivity in the normal conducting state of the highT c phase gradually increases with increasing applied pressure 17 . On the other hand, in the lowT c phase, although the BiS2 system shows semiconducting-like behavior, the metallic behavior is observed in the BiSe2 system.
The temperature dependences of resistivity under magnetic field along the c -axis and the ab plane were measured as shown in figure 3 (a)-(d). When the magnetic field is parallel to the c axis, superconductivity is drastically suppressed with increasing magnetic field. This is typical behavior observed in superconductors with a layered structure. Figure 4 shows the upper critical field ( H c2 ) versus temperature for the low- and highT c phase. To estimate the H c2 , 90 % of resistivity at T c onset is adopted as a criterion. In this article, H c2 obtained from magnetic field H ab // and H c // are described as H c2 // ab and H c2 // c respectively. In addition, the γ , the coherence length at 0 K along the c axis ( ξc (0)) and the ab -plane ( ξab (0)) are estimated from figure 4 by using following formula: γ = H c2 // ab / H c2 // c , H c2 // c = Φ0/2π ξab 2 (0) and H c2 // ab = Φ0/2π ξab (0) ξc (0), where Φ0 is flux quantum. Obtained these superconducting parameters in low- and highT c phase are summarized in table I.
Although the γ for the lowT c phase is estimated to be 20, it is reduced by around half (9.3) in the highT c phase. This tendency is the same as in the BiS2 system 19 . As mentioned above, the BiS2 and the BiSe2 systems showed very similar behavior under high pressure. It is suggested that these materials exhibit the same mechanism for the pressure induced phase transition. In the previous study of LaO0.5F0.5BiS2, a pressure induced structural transition from tetragonal phase ( P4/nmm ) to monoclinic
phase ( P21/m ) was suggested from XRD analysis under high pressure 16 . Such a kind of structural transition is one of the possible explanations for the pressure induced phase transition of LaO0.5F0.5BiSe2, since it has the same structure as LaO0.5F0.5BiS2 in lowT c phase. Currently, high-pressure XRD measurements for the BiSe2 system have not yet been performed. Therefore, a detailed investigation for the structure of BiS2 and BiSe2 system may provide useful information for understanding the mechanism behind the highT c phase.
Within recent days, a paper about LaO0.5F0.5BiSe2 was submitted to arXiv 23 . it shows that the results of the resistivity measurements under high pressure are slightly different from our results. Although the pressure induced phase transition is also shown in that paper, in the lowT c phase, the T c gradually decreases with increasing applied pressure 23 . This different behavior in lowT c phase may be due to the difference of the fluorine concentration between our samples and the reported samples.
In summary, we revealed that the T c of LaO0.5F0.5BiSe2 discontinuously increases. Although our sample does not show zero resistivity at ambient pressure, by applying pressure up to 2.44 GPa, maximum T c onset and T c zero were observed at 6.7 K and 5 K. The resistivity of both low- and highT c phases shows metallic behavior. This is very different from what was seen in the BiS2 system. The γ extremely decreases from 20 to 9.3 after the phase transition, and the resistivity of the normal conducting state in highT c phase gradually increases with increasing applied pressure which is in accordance with the BiS2 system. In this current stage, the optimal T c of LaO0.5F0.5BiSe2 was not observed even at the maximum pressure obtained during this study. Therefore applied further pressure has the potential to induce a much higher T c in this system.
This work was supported in part by the Japan Science and Technology Agency through Strategic International Collaborative Research Program (SICORP-EU-Japan) and Advanced Low Carbon Technology R&D Program (ALCA) of the Japan Science and Technology Agency.
## Reference
| 1 Y. Mizuguchi, H. Fujihisa, Y. Gotoh, K. Suzuki, H. Usui, K. Kuroki, S. Demura, Y.Takano, H. Izawa, |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| and O. Miura, Phys.Rev.B. 86 , 220510 (2012). |
| 2 Y. Mizuguchi, S. Demura, K. Deguchi, Y. Takano, H. Fujihisa, Y. Gotoh, H. Izawa, and O. Miura, J. |
| Phys. Soc. Jpn. 81 , 114725 (2012). |
| 3 J. Xing, S. Li, X. Ding, H. Yang, and H.H.Wen, Phys. Rev. B. 86 , 214518 ( 2012). |
| 4 S. Demura, K. Deguchi, Y. Mizuguchi, K. Sato, R. Honjyo, A. Yamashita, T. Yamaki, H. Hara, T. |
| Watanabe, S. J. Denholme, M. Fujioka, H. Okazaki, T. Ozaki, O. Miura, T. Yamaguchi, H. Takeya, and |
| Y. Takano, arXiv:1311.4267 (2013). |
| 5 R. Jha, A. Kumar, S. K. Singh, and V. P. S. Awana, J. Sup. Novel Mag. 26 , 499 (2013). |
| 6 S. Demura, Y. Mizuguchi, K. Deguchi, H. Okazaki, H. Hara, T. Watanabe, S. J. Denholme, M. Fujioka, T. Ozaki, H. Fujihisa, Y. Gotoh, O. Miura, T. Yamaguchi, H. Takeya, and Y. Takano, J. Phys. Soc. Jpn. |
| 82 , 033708 (2013). |
| 7 D. Yazici, K. Huang, B. D. White, A. H. Chang, A. J. Friedman, and M. B. Maple, Philos. Mag. 93 , 673 (2013). |
| 8 K. Deguchi, Y. Takano, Y. Mizuguchi, Sci. Technol. Adv. Mater. 13 , 054303 (2012) |
| 9 X. Lin, XNi, B. Chen, X. Xu, X. Yang, J. Dai, Y. Li, X. Yang, Y. Luo, Q. Tao, G. Cao, and Z. Xu, |
| Phys. Rev. B 87 , 020504 (2013). |
| 10 H. Sakai, D. Kotajima, K. Saito, H. Wadati, Y. Wakisaka, M. Mizumaki, K. Nitta, Y. Tokura, and S. |
| Ishiwata, J. Phys. Soc. Jpn. 83 , 014709 (2014). |
| 11 J. G. Bednorz and K. A. Müller, Z. Phys. B 64 , 189 (1986). |
| 12 Y. Kamihara, T. Watanabe, M. Hirano, and H. Hosono, J. Am. Chem. Soc. 130 , 3296 (2008). |
| 13 K. Deguchi, Y. Mizuguchi, S. Demura, H. Hara, T. Watanabe, S. J. Denholme, M. Fujioka, H. |
|--------------------------------------------------------------------------------------------------------|
| Okazaki, T. Ozaki, H. Takeya, T. Yamaguchi, O. Miura, and Y. Takano, Europhys. Lett. 101 , 17004 |
| (2013). |
| 14 Y. Mizuguchi, T. Hiroi, J. Kajitani, H. Takatsu, H. Kadowaki, and O. Miura, J. Phys. Soc. Jpn. 83 , |
| 053704 (2014). |
| 15 J. Kajitani, K. Deguchi, T. Hiroi, A. Omachi, S. Demura, Y. Takano, O. Miura, and Y. Mizuguchi, J. |
| Phys. Soc. Jpn. 83 , 065002 (2014). |
| 16 T. Tomita, M. Ebata, H. Soeda, H. Takahashi, H. Fujihisa, Y. Gotoh, Y. Mizuguchi, H. Izawa, O. |
| Miura, S. Demura, K. Deguchi, and Y. Takano, J. Phys. Soc. Jpn. 83 , 063704 (2014). |
| 17 M. Fujioka, M. Nagao, S. J. Denholme, M. Tanaka, H. Takeya, T. Yamaguchi and Y. Takano, |
| arXiv:1406.3888. (Appl. Phys. Lett., accepted) |
| 18 M. Fujioka, Wiley Encyclopedia of Electrical and Electronics Engineering. 1-30, (2014). |
| 19 A. Krzton-Maziopa, Z. Guguchia, E. Pomjakushina, V. Pomjakushin, R. Khasanov, H. Luetkens, P.K. |
| Biswas, A. Amato, H. Keller, K. Conder: J. Phys.:Condens. Matter 26 (2014) 215702 |
| 20 M. Tanaka, M. Nagao, Y. Matsushita, M. Fujioka, S. J. Denholme, T. Yamaguchi, H. Takeya and Y. |
| Takano, arXiv:1406.0734. (J. Solid State Chem., accepted ) |
| 21 F. Nakamura, T. Goko, J. Hori, Y. Uno, N. Kikugawa, and T. Fujita, Phys. Rev. B. 61 , 107 (2000). |
| 22 M. Nagao, M. Tanaka, S. Watauchi, I. Tanaka and Y. Takano, arXiv:1406.3888 (2014). |
| 23 J. Liu, S. Li, Y. Li, X. Zhu and H. H. Wen, arXive:1407.5939 (2014). |
## FIG. 1
XRD patterns of LaO0.5F0.5BiSe2. All diffraction peaks are assigned to the (00l) indices.
## FIG. 2
- (a): Resistivity versus temperature from 300 K to 2 K for LaO0.5F0.5BiSe2 under varying pressure. (b): The expanded view around T c .
## FIG. 3
Resistivity versus temperature at 1.17 and 2.24 GPa under magnetic field with the different directions, which are parallel with ab plane ( H ab // ) and c axis ( H c // ).
## FIG.4
Upper critical field versus temperature for the lowT c (black) and highT c (red) phases. Solid circles denote the H c2 // ab . Open circles denote H c2 // c . The dashed lines denote the straight-line approximation.
TABLE I. Superconducting parameters for La(O0.5F0.5)BiSe2 under 1.17 (lowT c phase) and 2.44 GPa (highT c phase).
| Pressure (GPa) | d H c2 //ab /d T (T/K) | d H c2 //c /d T (T/K) | H c2 //ab (0) (T) | H c2 //c (0) (T) | ξ ab (0) (nm) | ξ c (0) (nm) | γ (0) |
|------------------|--------------------------|-------------------------|---------------------|--------------------|-----------------|----------------|---------|
| 1.17 | -1.94 | -0.01 | 5.5 | 0.6 | 23.4 | 2.56 | 20 |
| 2.44 | --3.39 | -0.59 | 20.6 | 3.4 | 9.83 | 1.63 | 9.3 |
Fig. 1
Fig. 2
Fig. 3.
Fig. 4.
 | 10.1209/0295-5075/108/47007 | [
"Masaya Fujioka",
"Masashi Tanaka",
"Saleem J. Denholme",
"Takuma Yamaki",
"Hiroyuki Takeya",
"Takahide Yamaguchi",
"Yoshihiko Takano"
] | 2014-08-01T09:19:28+00:00 | 2014-08-01T09:19:28+00:00 | [
"cond-mat.supr-con"
] | Pressure-induced phase transition for single crystalline LaO0.5F0.5BiSe2 | We have demonstrated a pressure-induced phase transition from a low-Tc phase
to a high-Tc phase in a single crystal of the superconductor LaO0.5F0.5BiSe2.
The high-Tc phase appears at 2.16 GPa and the maximum superconducting
transition temperature (Tc) is observed at 6.7 K under 2.44 GPa. Although the
anisotropy ({\gamma}) for the low-Tc phase is estimated to be 20, it is reduced
by around half (9.3) in the high-Tc phase. This tendency is the same for the
BiS2 system. The Tc of LaO0.5F0.5BiSe2 has continued to increase up to the
maximum pressure of this study (2.44 GPa). Therefore applied further pressure
has the potential to induce a much higher Tc in this system. |
1408.0109v1 | ## Trees with Large Neighborhood Total Domination Number
Michael A. Henning ∗ and Kirsti Wash †
Department of Pure and Applied Mathematics University of Johannesburg Auckland Park, 2006, South Africa Email: [email protected] Email: [email protected]
## Abstract
In this paper, we continue the study of neighborhood total domination in graphs first studied by Arumugam and Sivagnanam [Opuscula Math. 31 (2011), 519-531]. A neighborhood total dominating set, abbreviated NTD-set, in a graph G is a dominating set S in G with the property that the subgraph induced by the open neighborhood of the set S has no isolated vertex. The neighborhood total domination number, denoted by γ nt ( G ), is the minimum cardinality of a NTD-set of G . Every total dominating set is a NTD-set, implying that γ G ( ) ≤ γ nt ( G ) ≤ γ t ( G ), where γ G ( ) and γ t ( G ) denote the domination and total domination numbers of G , respectively. Arumugam and Sivagnanam posed the problem of characterizing the connected graphs G of order n ≥ 3 achieving the largest possible neighborhood total domination number, namely γ nt ( G ) = /ceilingleft n/ 2 . /ceilingright A partial solution to this problem was presented by Henning and Rad [Discrete Applied Mathematics 161 (2013), 2460-2466] who showed that 5-cycles and subdivided stars are the only such graphs achieving equality in the bound when n is odd. In this paper, we characterize the extremal trees achieving equality in the bound when n is even. As a consequence of this tree characterization, a characterization of the connected graphs achieving equality in the bound when n is even can be obtained noting that every spanning tree of such a graph belongs to our family of extremal trees.
Keywords: Domination; Total domination; Neighborhood total domination.
AMS subject classification: 05C69
∗ Research supported in part by the South African National Research Foundation and the University of Johannesburg
† Research supported in part by the University of Johannesburg
## 1 Introduction
In this paper we continue the study of a parameter, called the neighborhood total domination number, that is squeezed between arguably the two most important domination parameters, namely the domination number and the total domination number. A dominating set in a graph G is a set S of vertices of G such that every vertex in V ( G ) \ S is adjacent to at least one vertex in S . The domination number of G , denoted by γ G ( ), is the minimum cardinality of a dominating set of G . A total dominating set , abbreviated a TD-set, of a graph G with no isolated vertex is a set S of vertices of G such that every vertex in V ( G ) is adjacent to at least one vertex in S . The total domination number of G , denoted by γ t ( G ), is the minimum cardinality of a TD-set of G . The literature on the subject of domination parameters in graphs up to the year 1997 has been surveyed and detailed in the two books [5, 6]. Total domination is now well studied in graph theory. For a recent book on the topic, see [10]. A survey of total domination in graphs can also be found in [7].
Arumugam and Sivagnanam [1] introduced and studied the concept of neighborhood total domination in graphs. A neighbor of a vertex v is a vertex different from v that is adjacent to v . The neighborhood of a set S is the set of all neighbors of vertices in S . A neighborhood total dominating set , abbreviated NTD-set, in a graph G is a dominating set S in G with the property that the subgraph induced by the open neighborhood of the set S has no isolated vertex. The neighborhood total domination number of G , denoted by γ nt ( G ), is the minimum cardinality of a NTD-set of G . A NTD-set of G of cardinality γ nt ( G ) is called a γ nt ( G )-set .
Every TD-set is a NTD-set, while every NTD-set is a dominating set. Hence the neighborhood total domination number is bounded below by the domination number and above by the total domination number as first observed by Arumugam and Sivagnanam in [1].
Observation 1 ([1, 8]) If G is a graph with no isolated vertex, then γ G ( ) ≤ γ nt ( G ) ≤ γ t ( G ) .
## 1.1 Terminology and Notation
For notation and graph theory terminology not defined herein, we refer the reader to [5]. Let G be a graph with vertex set V ( G ) of order n = | V ( G ) | and edge set E G ( ) of size m = | E G ( ) , | and let v be a vertex in V . We denote the degree of v in G by d G ( v ). The minimum degree among the vertices of G is denoted by δ G ( ). A vertex of degree one is called a leaf and its neighbor a support vertex . We denote the set of leaves in G by L G ( ), and the set of support vertices by S G ( ). A support vertex adjacent to two or more leaves is a strong support vertex . For a set S ⊆ V , the subgraph induced by S is denoted by G S [ ]. A 2packing in G is a set of vertices that are pairwise at distance at least 3 apart in G .
A cycle and path on n vertices are denoted by C n and P n , respectively. A star on n ≥ 2 vertices is a tree with a vertex of degree n -1 and is denoted by K 1 ,n -1 . A double star is a
tree containing exactly two vertices that are not leaves (which are necessarily adjacent). A subdivided star is a graph obtained from a star on at least two vertices by subdividing each edge exactly once. The subdivided star obtained from a star K 1 4 , , for example, is shown in Figure 1. We note that the smallest two subdivided stars are the paths P 3 and P 5 . Let F be the family of all subdivided stars. Let F ∈ F . If F = P 3 , we select a leaf of F and call it the link vertex of F , while if F = P 3 , the link vertex of F is the central vertex of F .
/negationslash
Figure 1: A subdivided star.
The open neighborhood of v is the set N G ( v ) = { u ∈ V | uv ∈ E } and the closed neighborhood of v is N G [ v ] = { v } ∪ N G ( v ). For a set S ⊆ V , its open neighborhood is the set N G ( S ) = ⋃ v ∈ S N G ( v ), and its closed neighborhood is the set N G [ S ] = N G ( S ) ∪ S . If the graph G is clear from the context, we simply write d( v ), N v ( ), N v [ ], N S ( ) and N S [ ] rather than d G ( v ), N G ( v ), N G [ v ], N G ( S ) and N G [ S ], respectively. As observed in [8] a NTD-set in G is a set S of vertices such that N S [ ] = V and G N S [ ( )] contains no isolated vertex.
/negationslash
A rooted tree distinguishes one vertex r called the root . For each vertex v = r of T , the parent of v is the neighbor of v on the unique ( r, v )-path, while a child of v is any other neighbor of v . A descendant of v is a vertex u such that the unique ( r, u )-path contains v . Let C v ( ) and D v ( ) denote the set of children and descendants, respectively, of v , and let D v [ ] = D v ( ) ∪ { v } . The maximal subtree at v is the subtree of T induced by D v [ ], and is denoted by T v .
## 2 Known Results
The following upper bound on the neighborhood total domination number of a connected graph in terms of its order is established in [8].
Theorem 2 ([8]) If G is a connected graph of order n ≥ 3 , then γ nt ( G ) ≤ ( n +1) 2 / .
In this paper we consider the following problem posed by Arumugam and Sivagnanam [1] to characterize the connected graphs of largest possible neighborhood total domination number.
Problem 1 ([1]) Characterize the connected graphs G of order n for which γ nt ( G ) = /ceilingleft n/ 2 /ceilingright .
A partial solution to this problem was presented by Henning and Rad [8] who provided the following characterization in the case when n is odd.
/negationslash
Theorem 3 ([8]) Let G = C 5 be a connected graph of order n ≥ 3 . If γ nt ( G ) = ( n +1) 2 / , then G ∈ F .
As first observed in [8], a characterization in the case when n is even and the minimum degree is at least 2 follows readily from a result on the restrained domination number of a graph due to Domke, Hattingh, Henning and Markus [4]. Let B , B , . . . , B 1 2 5 be the five graphs shown in Figure 2.
/negationslash
Theorem 4 ([8]) Let G = C 5 be a connected graph of order n ≥ 4 with δ G ( ) ≥ 2 . If γ nt ( G ) = n/ 2 , then G ∈ { B , B , B , B 1 2 3 4 , B 5 } .
## 3 The Family T of Trees
In this section we define a family of trees T as follows. Let T 0 be an arbitrary tree. Let T 1 be the tree obtained from T 0 by the following operation: for each vertex x ∈ V ( T 0 ), either add a new vertex and an edge joining it to x or add a new path P 3 and an edge joining its central vertex to x . Let T be the family of all trees T that can be obtained from T 1 by performing the following operation:
- · Choose a set of leaves, L 1 , in T 1 , that form a 2-packing (possibly L 1 = ∅ ). For each vertex v ∈ L 1 , add k ≥ 0 vertex-disjoint copies of P 2 and join v to exactly one end of each added copy of P 2 . We refer to these k added copies of P 2 as appended P 2 s associated with x .
Figure 3: A tree in the family T .
A tree in the family T is illustrated in Figure 3. For ease of reference, we introduce some terminology for a tree T ∈ T . We use the standard notation [ k ] = { 1 2 , , . . . , k } . First note that given a tree T ∈ T , a tree T 0 used to construct the tree T may not be unique. That
is, in some cases we may be able to choose two distinct trees T 0 and T ′ 0 such that T is obtained from either T 0 or T ′ 0 by performing different combinations of the above operations. Therefore, we refer to T 0 as an underlying tree of T , and we refer to T 1 as the corresponding base tree of T 0 .
The vertex set V ( T 1 ) of T 1 can be partitioned into sets V , . . . , V 1 /lscript such that each V i contains exactly one vertex of T 0 and T V [ i ] ∈ { P , K 2 1 3 , } for each i ∈ [ /lscript ]. We say that T V [ i ] is a P 2 -unit of T 1 if T V [ i ] = P 2 and T V [ i ] is a star-unit otherwise.
If x ∈ L 1 belongs to a P 2 -unit of T 1 , then an appended P 2 associated with x we call a Type-1 appended P 2 , while if x ∈ L 1 belongs to a star-unit of T 1 , then an appended P 2 associated with x we call a Type-2 appended P 2 .
For each vertex v that is the central vertex of a star-unit of T 1 , we denote the two leaf neighbors of v in T 1 that do not belong to the underlying tree T 0 by a v and b v . If a v ∈ L 1 , then a v has appended P 2 's in T and, by construction, b v remains a leaf in T (since L 1 is a 2-packing). In this case, we say that v and b v are blocked vertices . Similarly, if b v has appended P 2 's in T , then v and a v are blocked vertices. If a v and b v are both leaves of T , then only v is a blocked vertex. We shall adopt the convention that if one of a v or b v is a blocked vertex of T 1 , then renaming vertices if necessary, b v is the blocked vertex.
## 4 Main Result
By Theorem 2, every connected graph G of order n ≥ 3 satisfies γ nt ( G ) ≤ ( n +1) 2. If / T is a tree of order n ≥ 3 and γ nt ( T ) = ( n +1) 2, then by Theorem 3, / T is a subdivided star. Our aim in this paper is to characterize the trees T of order n ≥ 4 satisfying γ nt ( T ) = n/ 2. We shall prove the following result.
Theorem 5 Let T be a tree of order n ≥ 4 . If γ nt ( T ) = n/ 2 , then T ∈ T .
Proof. We proceed by induction on the order n ≥ 4 of a tree T satisfying γ nt ( T ) = n/ 2. If n = 4, then either T = P 4 or T = K 1 3 , . In both cases, γ nt ( T ) = 2 = n/ 2. If T = P 4 (respectively, T = K 1 3 , ), then T ∈ T with P 2 (respectively, K 1 ) as the unique underlying tree and the tree T itself as the corresponding base tree. This establishes the base case. Let n ≥ 6 and assume that if T ′ is a tree of order n ′ where 4 ≤ n < n ′ satisfying γ nt ( T ) = n / ′ 2, then T ′ ∈ T . Let T be a tree of order n satisfying γ nt ( T ) = n/ 2. Our aim is to show that T ∈ T . For this purpose, we introduce some additional notation.
For a subtree T ′ of the tree T that belongs to the family T , we adopt the following notation in our proof. Let T ′ 0 be an underlying tree of T ′ with corresponding base tree T ′ 1 . For each vertex x ∈ V ( T ′ 1 ), we let N x = N T ′ ( x ) \ V ( T ′ 1 ), and so N x consists of all neighbors of x in T ′ that do not belong to the base tree T ′ 1 . Further, we let L x consist of all leaves of T ′ at distance 2 from x that do not belong to the base tree T ′ 1 . Necessarily, a vertex in N x is a support vertex of T ′ that belongs to a P 2 appended to x , while a vertex in L x is a leaf of T ′ that belongs to a P 2 appended to x .
Let A be the vertex set of the underlying tree T ′ 0 ; that is, A = V ( T ′ 0 ). Let B be the set of vertices in the base tree T ′ 1 that do not belong to the underlying tree T ′ 0 ; that is, B = V ( T ′ 1 ) \ V ( T ′ 0 ). Further, let B 1 be the set of all central vertices of star-units of T ′ 1 . Let C = V ( T ′ ) \ V ( T ′ 1 ) be the set of vertices of T ′ that belong to a Type-1 or Type-2 appended P 2 . We note that ( A,B,C ) is a partition of the vertex set V ( T ′ ), where possibly C = ∅ . Let C 1 (respectively, C 2 ) be the set of all leaves (respectively, support vertices) of T ′ that do not belong to the base tree T ′ 1 . We note that ( C , C 1 2 ) is a partition of the set C . Let
$$D ^ { \prime } = A \cup B _ { 1 } \cup C _ { 1 }.$$
Then the set D ′ is a NTD-set of T ′ (recall that n ′ ≥ 4). Since | D ′ | = n / ′ 2 = γ nt ( T ′ ), the set D ′ is therefore a γ nt ( T ′ )-set.
/negationslash
For each vertex x ∈ A , we let A x be the set of neighbors of x in A that have degree 2 in T ′ and belong to a P 2 -unit in T ′ 1 . Let B x be the set of all vertices in B that are neighbors of vertices in A x and let C x be the set of all vertices of C 2 that are neighbors of vertices in B x . Further, let D x be the set of all vertices of C 1 that are neighbors of vertices in C x . We note that each vertex in C x is a support vertex of T ′ that belongs to a Type-1 appended P 2 , while each vertex in D x is a leaf of T ′ that belongs to a Type-1 appended P 2 . We note that | A x | = | B x | and | C x | = | D x | , although possibly A x = ∅ (in which case B x = ). Further we ∅ let A 1 x be the set of vertices in A x that are support vertices in T ′ and we let B 1 x be the set of leaf-neighbors of vertices in A x . Possibly, A 1 x = ∅ . We note that | A 1 x | = | B 1 x | . If A x = ∅ and A x = A 1 x , then B x is the set B 1 x of leaves of T ′ (and in this case C x = D x = ). ∅
We now return to our proof of Theorem 5. If T is a star, then γ nt ( T ) = 2 < n/ 2, a contradiction. If T is a double star, then the two vertices that are not leaves form a NTDset, implying that γ nt ( T ) = 2 < n/ 2, a contradiction. Therefore, diam( T ) ≥ 4. Let P be a longest path in T and suppose that P is an ( r, u )-path. Necessarily, r and u are leaves in T . We now root the tree T at the vertex r . Let v be the parent of u , and let w be the parent of v in the rooted tree T . Among all such paths P , we may assume that P is chosen so that d T ( v ) is minimum. Thus if P ′ is an arbitrary longest path in T and P ′ is an ( r , u ′ ′ )-path with v ′ the neighbor of u ′ on P ′ , then d T ( v ′ ) ≥ d T ( v ).
We proceed further with the following claim.
$$\text{Claim } \mathbf A \ I f \, d _ { T } ( v ) = 2, \, t h e n \ T \in \mathcal { T }.$$
Proof of Claim A. Suppose that d T ( v ) = 2. Let T ′ = T - { u, v } have order n ′ , and so n ′ = n -2 ≥ 4. Since n is even, so too is n ′ . By Theorem 2, γ nt ( T ′ ) ≤ n / ′ 2. Let D ∗ be a γ nt ( T ′ )-set. If w ∈ D ∗ , let D = D ∗ ∪ { v } . If w / D ∈ ∗ , let D = D ∗ ∪ { u } . In both cases, the set D is a NTD-set of T , and so
$$\frac { n } { 2 } = \gamma _ { \text{nt} } ( T ) \leq | D | = | D ^ { * } | + 1 \leq \frac { n ^ { \prime } } { 2 } + 1 = \frac { n } { 2 }.$$
Hence we must have equality throughout the above inequality chain. In particular, this implies that γ nt ( T ′ ) = n / ′ 2. Applying the inductive hypothesis to the tree T ′ , we have
T ′ ∈ T . Adopting our earlier notation, let D ′ = A ∪ B 1 ∪ C 1 and recall that D ′ is a γ nt ( T ′ )-set. We now consider the parent, w , of the vertex v in the rooted tree T . If w ∈ A , then T ∈ T with T A [ ∪{ } v ] as an underlying tree of T and T A [ ∪ B ∪{ u, v } ] as the corresponding base tree. If w ∈ B and w is not a blocked vertex, then T ∈ T with T ′ 0 as an underlying tree of T and T ′ 1 as the corresponding base tree. Therefore, we may assume that either w ∈ B and w is a blocked vertex or w ∈ C , for otherwise T ∈ T as desired. We proceed further by considering the following three cases.
Case 1. w ∈ B and w is a blocked vertex. Thus, w is a blocked vertex contained in a star-unit of T ′ 1 . Let x be the vertex of A that belongs to the star-unit containing w and let y be the central vertex of the star-unit. If w ∈ B 1 (and so, w = y ), then the set
$$( D ^ { \prime } \, \sum \, ( A _ { x } ^ { 1 } \cup \{ x \} ) ) \cup ( B _ { x } ^ { 1 } \cup \{ v \} )$$
is a NTD-set of T of size | D ′ | + | B 1 x | - | A 1 x | = | D ′ | = n / ′ 2 = n/ 2 -1, implying that γ nt ( T ) < n/ 2, a contradiction. Hence, w / B ∈ 1 and w is therefore a leaf-neighbor of y in the star-unit that contains it. Recall that a y and b y denote the two leaf-neighbors of y in the star-unit that do not belong to A . Since w is a blocked vertex, by convention we have w = b y . We note that at least one Type-2 P 2 is appended to a y in order for b y to be a blocked vertex. If | A | ≥ 2, then the set
$$( D ^ { \prime } \, \smallsetminus \, ( A _ { x } \cup D _ { x } \cup \{ x \} ) ) \cup ( B _ { x } \cup C _ { x } \cup \{ u \} )$$
is a NTD-set of T of size | D ′ | +( | B x | - | A x | ) + ( | C x | - | D x | ) = | D ′ | , a contradiction. Hence, A consists only of the vertex x . Thus, T ∈ T with T [ { v, w } ] as an underlying tree of T and T [ { u, v, w, x, y, a y } ] as the corresponding base tree.
Case 2. w ∈ C and w belongs to a Type1 appended P 2 . Suppose firstly that w is a leaf of T ′ , and so w ∈ C 1 . Let x be the neighbor of w that belongs to C 2 , let y be the neighbor of x that belongs to B and let z be the neighbor of y that belongs to A . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \sum \, ( A _ { z } ^ { 1 } \cup \{ w, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ u, x \} )$$
is a NTD-set of T of size | D ′ | + | B 1 z | - | A 1 z | = | D ′ | , a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case, A = A 1 z ∪{ } z , C 2 = N y and C 1 = L y . Thus, T ∈ T with T N [ y ∪{ } y ] as an underlying tree of T and T C [ ∪ { y, z } ] as the corresponding base tree.
Suppose secondly that w is a support vertex of T ′ , and so w ∈ C 2 . Let x be the leafneighbor of w in T ′ . Let y be the neighbor of w that belongs to B and let z be the neighbor of y that belongs to A . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \sum \, ( A _ { z } ^ { 1 } \cup \{ x, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ v, w \} )$$
is a NTD-set of T of size | D ′ | + | B 1 z | - | A 1 z | = | D ′ | , a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case,
A = A 1 z ∪ { z } , C 2 = N y and C 1 = L y . Thus, T ∈ T with T N [ y ∪ { v, y } ] as an underlying tree of T and T C [ ∪ { u, v, y, z } ] as the corresponding base tree.
Case 3. w ∈ C and w belongs to a Type2 appended P 2 . Suppose firstly that w is a leaf of T ′ , and so w ∈ C 1 . Let x be the neighbor of w that belongs to C 2 . Let a y be the neighbor of x that belongs to B and let y be the central vertex of the star-unit that contains a y . We note that b y is a leaf in T ′ . Let z be the neighbor of y that belongs to A . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \sum \left ( A _ { z } ^ { 1 } \cup \{ w, y, z \} \right ) ) \cup ( B _ { z } ^ { 1 } \cup \{ u, x, b _ { y } \} )$$
is a NTD-set of T of size | D ′ | , a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case, A = A 1 z ∪{ } z and C 2 = N a y . Thus, T ∈ T with T C [ 2 ∪ { a y } ] as an underlying tree of T and T C [ ∪ { y, a y , b y , z } ] as the corresponding base tree.
Suppose secondly that w is a support vertex of T ′ , and so w ∈ C 2 . Let x be the leafneighbor of w in T ′ . Let a y be the neighbor of w that belongs to B and let y be the central vertex of the star-unit that contains a y . Let z be the neighbor of y that belongs to A . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \searrow ( A _ { z } ^ { 1 } \cup \{ x, y, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ v, w, b _ { y } \} )$$
is a NTD-set of T of size | D ′ | , a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case, A = A 1 z ∪{ } z and C 2 = N a y . Thus, T ∈ T with T C [ 2 ∪{ v, a y } ] as an underlying tree of T and T C [ ∪{ u, v, y, a y , b y , z } ] as the corresponding base tree. In all three cases above, we have that T ∈ T . This completes the proof of Claim A. ( ✷ )
/negationslash
By Claim A, we may assume that d T ( v ) ≥ 3, for otherwise T ∈ T as desired. By our choice of the path P , every child of w that is not a leaf has degree at least as large as d T ( v ). Let x be the parent of w in T . Since diam( T ) ≥ 4, we note that x = r , and so d T ( x ) ≥ 2. Let w have /lscript ≥ 0 leaf-neighbors and k ≥ 1 children that are support vertices. Let W be the set consisting of the vertex w and its k children that are support vertices. Then, | W | = k +1 and, as observed earlier, every vertex in W \ { w } has degree at least d T ( v ) ≥ 3. Let the subtree, T w , of T rooted at w have order n w , and so n w ≥ 3 k + /lscript +1. Let T ′ = T -V ( T w ) be the tree obtained from T by deleting the vertices in the subtree T w of T rooted at w . Let T ′ have order n ′ . Then, n ′ ≥ 2 and n ′ = n -n w .
## Claim B If n ′ = 2 , then T ∈ T .
Proof of Claim B. Suppose that n ′ = 2. Then, n ≥ 3 k + /lscript +3 and the set W ∪ { x } is a NTD-set of T ′ , and so n/ 2 = γ nt ( T ) ≤ | W | +1 = k +2 ≤ k +( k + /lscript +3) 2 / ≤ n/ 2. Hence we must have equality throughout this inequality chain, implying that k = 1, /lscript = 0, n w = 4 and n = 6. Thus, T ∈ T with T [ { w,x } ] as the underlying tree of T and T itself as the corresponding base tree. ✷
By Claim B, we may assume that n ′ ≥ 3, for otherwise T ∈ T as desired. Applying Theorem 2 and Theorem 3 to the tree T ′ , we have that γ nt ( T ′ ) ≤ ( n ′ +1) 2, with equality / if and only if T ′ is a subdivided star.
$$\text{Claim } C \ T ^ { \prime } \in \mathcal { T }, \, d _ { T } ( w ) = 2, \, a n d \ d _ { T } ( v ) = 3.$$
Proof of Claim C. We show firstly that γ nt ( T ′ ) ≤ n / ′ 2. Suppose, to the contrary, that γ nt ( T ′ ) = ( n ′ + 1) / 2 and T ′ is a subdivided star. Let y be the link vertex of T ′ , and let Y 1 and Y 2 be the set of vertices at distance 1 and 2, respectively, from y in T ′ . Select an arbitrary vertex y 2 ∈ Y 2 and let y 1 be the common neighbor of y and y 2 , and so yy y 1 2 is a path in T ′ . Renaming vertices if necessary, we may assume that x ∈ { y, y 1 , y 2 } . If x = y , let Y = Y 2 . If x = y 1 , let Y = ( Y 2 \{ y 2 } ) ∪{ } x . If x = y 2 , let Y = ( Y 1 \{ y 1 } ) ∪{ } y . In all three cases, | Y | = ( n ′ -1) / 2 and the set W ∪ Y is a NTD-set of T . Recall that n w ≥ 3 k + /lscript +1 and n ′ = n -n w . Hence,
$$\L \L e, \quad & \gamma _ { \text{nt} } ( T ) & \leq \quad | Y | + | W | \\ & = \quad \frac { n ^ { \prime } - 1 } { 2 } + k + 1 \\ & \leq \quad \frac { n - 3 k - \ell - 2 } { 2 } + k + 1 \\ & = \quad \frac { n - k - \ell } { 2 } \\ & \leq \quad \frac { n - 1 } { 2 }, \\ \text{efore, } \gamma _ { \text{nt} } ( T ^ { \prime } ) & \leq n ^ { \prime } / 2. \text{ Every } \gamma _ { \text{nt} } ( T ^ { \prime } ) \text{-set can be } e \text{.}$$
a contradiction. Therefore, γ nt ( T ′ ) ≤ n / ′ 2. Every γ nt ( T ′ )-set can be extended to a NTD-set of T by adding to it the set W . Hence,
$$\frac { n } { 2 } = \gamma _ { \text{nt} } ( T ) \leq \gamma _ { \text{nt} } ( T ^ { \prime } ) + | W | \leq \frac { n ^ { \prime } } { 2 } + k + 1 \leq \frac { n - k - \ell + 1 } { 2 } \leq \frac { n } { 2 }.$$
Consequently, we must have equality throughout this inequality chain, implying that k = 1, /lscript = 0, d T ( w ) = 2, d T ( v ) = 3, and γ nt ( T ′ ) = n / ′ 2. Applying the inductive hypothesis to the tree T ′ of (even) order n ′ ≥ 4, we deduce that T ′ ∈ T . ✷
By Claim C, d T ( w ) = 2 and d T ( v ) = 3. Thus, N w ( ) = { v, x } . Let u 1 and u 2 be the two children of v where u = u 1 . By Claim C, T ′ ∈ T . Adopting our earlier notation, let T ′ have order n ′ . In this case, n ′ = n -4. Further, let D ′ = A ∪ B 1 ∪ C 1 and recall that D ′ is a γ nt ( T ′ )-set. We now consider the parent, x , of the vertex w in the rooted tree T . If x ∈ A , then T ∈ T with T A [ ∪ { w } ] as an underlying tree of T and T A [ ∪ B ∪ N v [ ]] as the corresponding base tree. Hence we may assume that x ∈ B ∪ C , for otherwise T ∈ T as desired.
Claim D If x ∈ B , then T ∈ T .
Proof of Claim D. Suppose that x ∈ B . We consider two subclaims.
Claim D.1 If x belongs to a P 2 -unit in T ′ 1 , then T ∈ T .
Proof of Claim D.1 Suppose that x belongs to a P 2 -unit in T ′ 1 . Let y be the neighbor of x that belongs to A . If the vertex y has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \sum \, ( A _ { y } ^ { 1 } \cup \{ y \} ) ) \cup ( B _ { y } ^ { 1 } \cup \{ v, w \} )$$
is a NTD-set of T of size | D ′ | + 1 + ( | B 1 y | - | A 1 y | ) = | D ′ | + 1 = n / ′ 2 + 1 = n/ 2 -1, a contradiction. Hence, A = { y } or every neighbor of y that belongs to A is a support vertex of degree 2 in T ′ . In this case, A = A 1 y ∪ { y } , C 2 = N x and C 1 = L x . Thus, T ∈ T with T N [ x ∪{ w,x } ] as an underlying tree of T and T C [ ∪{ u , u 1 2 , v, w, x, y } ] as the corresponding base tree. ( ✷ )
Claim D.2 If x belongs to a star-unit in T ′ 1 , then T ∈ T .
Proof of Claim D.2. Suppose that x belongs to a star-unit in T ′ 1 . Let z be the vertex of A that belongs to the star-unit containing x and let y be the central vertex of the star-unit. If x ∈ B 1 (and so, x = y ), then the set
$$( D ^ { \prime } \, \sum \, ( A _ { z } ^ { 1 } \cup \{ z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ v, w \} )$$
is a NTD-set of T of size | D ′ | +1 = n/ 2 -1, a contradiction. Hence, x / B ∈ 1 and x is therefore a leaf-neighbor in its star-unit. Recall that a y and b y denote the two leaf-neighbors of y in the star-unit that do not belong to A . By convention the vertex b y is a leaf in T ′ and the vertex a y has /lscript ≥ 0 Type-2 P 2 's appended to it.
Suppose x = a y . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \sum \, ( A _ { z } ^ { 1 } \cup \{ y, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ b _ { y }, v, w \} )$$
is a NTD-set of T of size | D ′ | + 1, a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case A = A 1 z ∪ { z } , C 2 = N a y and C 1 = L a y . Thus, T ∈ T with T C [ 2 ∪{ w,a y } ] as an underlying tree of T and T C [ ∪{ a , b y y , u 1 , u 2 , v, w, y, z } ] as the corresponding base tree.
Suppose that x = b y . If a y is a leaf of T ′ , then renaming a y and b y , we may assume that x = a y . In this case, we have shown that T ∈ T . Hence we may assume that a y has at least one Type-2 P 2 appended to it. If | A | ≥ 2, then the set
$$( D ^ { \prime } \, \smallsetminus \, ( A _ { z } \cup D _ { z } \cup \{ z \} ) ) \cup ( B _ { z } \cup C _ { z } \cup \{ v, w \} )$$
is a NTD-set of T of size | D ′ | + 1, a contradiction. Hence, A = { z } . Thus, T ∈ T with T [ { b y , w } ] as an underlying tree of T and T [ { a , b y y , u 1 , u 2 , v, w, y, z } ] as the corresponding base tree. This completes the proof of Claim D.2. ( ✷ )
Claim D now follows from Claim D.1 and Claim D.2. ✷
By Claim D, we may assume that x ∈ C , for otherwise T ∈ T as desired.
Claim E If x belongs to a Type1 appended P 2 , then T ∈ T .
Proof of Claim E. Suppose that x belongs to a Type-1 appended P 2 . Suppose firstly that x is a leaf of T ′ , and so x ∈ C 1 . Let y 2 be the neighbor of x that belongs to C 2 , let y be the neighbor of y 1 that belongs to B and let z be the neighbor of y that belongs to A . If y has degree at least 3 in T ′ , then | N y | ≥ 2 and the set
$$( D ^ { \prime } \, \smallsetminus \, ( A _ { z } ^ { 1 } \cup L _ { y } \cup \{ z \} ) ) \cup ( B _ { z } ^ { 1 } \cup ( N _ { y } \, \smallsetminus \, \{ y _ { 1 } \} ) \cup \{ v, w, y \} )$$
is a NTD-set of T of size | D ′ | +( | B 1 z |-| A 1 z | )+( | N y |-| L y | )+3 -2 = | D ′ | +1, a contradiction. Hence, y has degree 2 in T ′ . If | A | ≥ 2, then the set
$$( D ^ { \prime } \, \searrow \, ( A _ { z } \cup D _ { z } \cup \{ z \} ) ) \cup ( B _ { x } \cup C _ { x } \cup \{ v, w, y \} )$$
is a NTD-set of T of size | D ′ | +( | B x |-| A x | )+( | C x |-| D x | )+3 -2 = | D ′ | +1, a contradiction. Hence, A consists only of the vertex z . Therefore, T is obtained from the path u vwxy yz 1 1 by adding a new vertex u 2 and the edge u v 2 . Thus, T ∈ T with T [ { w,x } ] as an underlying tree of T and T [ { u , u 1 2 , v, w, x, y 1 } ] as the corresponding base tree.
Suppose secondly that x is a support vertex of T ′ , and so x ∈ C 2 . Let x 1 be the leafneighbor of x in T ′ . Let y be the neighbor of x that belongs to B and let z be the neighbor of y that belongs to A . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \sum \, ( A _ { z } ^ { 1 } \cup \{ x _ { 1 }, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ v, w, x \} )$$
is a NTD-set of T of size | D ′ | + 1, a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case, A = A 1 z ∪ { z } , C 2 = N y and C 1 = L y . Thus, T ∈ T with T N [ y ∪ { w,y } ] as an underlying tree of T and T C [ ∪{ u , u 1 2 , v, w, y, z } ] as the corresponding base tree. ✷
By Claim E, we may assume that x belongs to a Type-2 appended P 2 , for otherwise T ∈ T as desired.
Claim F The vertex x is a support vertex of T ′ .
Proof of Claim F. Suppose to the contrary that x is a leaf of T ′ , and so x ∈ C 1 . Let x 1 be the neighbor of x that belongs to C 2 . Let a y be the neighbor of x 1 that belongs to B and let y be the central vertex of the star-unit that contains a y . We note that b y is a leaf in T ′ . Let z be the neighbor of y that belongs to A . Then the set
$$( D ^ { \prime } \, \searrow \, ( A _ { z } ^ { 1 } \cup \{ x, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ v, w, a _ { y } \} )$$
is a NTD-set of T of size | D ′ | +1, a contradiction. ✷
We now return to the proof of Theorem 5 one last time. By Claim F, the vertex x is a support vertex of T ′ , and so x ∈ C 2 . Let x 1 be the leaf-neighbor of x in T ′ . Let a y be
the neighbor of x that belongs to B and let y be the central vertex of the star-unit that contains a y . Let z be the neighbor of y that belongs to A . If the vertex z has a neighbor in A that is not a support vertex of degree 2 in T ′ , then the set
$$( D ^ { \prime } \, \smallsetminus \, ( A _ { z } ^ { 1 } \cup \{ x _ { 1 }, y, z \} ) ) \cup ( B _ { z } ^ { 1 } \cup \{ v, w, x, b _ { y } \} )$$
is a NTD-set of T of size | D ′ | + 1, a contradiction. Hence, A = { z } or every neighbor of z that belongs to A is a support vertex of degree 2 in T ′ . In this case, A = A 1 z ∪ { z } and C 2 = N a y . Thus, T ∈ T with T C [ 2 ∪ { w,a y } ] as an underlying tree of T and T C [ ∪{ u , u 1 2 , v, w, y, a y , b y , z } ] as the corresponding base tree. This completes the proof of Theorem 5. ✷
## 5 Closing Remark
As a consequence of our tree characterization provided in Theorem 5, we remark that a complete solution to the Arumugam-Sivagnanam Problem 1 can be obtained as follows. Let G be a connected graph of (even) order n ≥ 4 satisfying γ nt ( G ) = n/ 2 and consider an arbitrary spanning tree T of G . By Theorem 2, γ nt ( T ) ≤ n/ 2. Every NTD-set of T is an NTD-set of G , implying that n/ 2 = γ nt ( G ) ≤ γ nt ( T ) ≤ n/ 2. Consequently, γ nt ( T ) = n/ 2. Thus, by Theorem 5, T ∈ T . This is true for every spanning tree T of the graph G . An exhaustive case analysis of the allowable edges that can be added to trees in the family T without lowering their neighborhood total domination number produces the connected graphs G of order n ≥ 4 satisfying γ nt ( G ) = n/ 2. Since our detailed case analysis of the resulting such graphs exceeds the length of the current paper, we omit the details here which can be found in [9].
## References
- [1] S. Arumugam, C. Sivagnanam, Neighborhood total domination in graphs. Opuscula Mathematica 31 (2011), 519-531.
- [2] R. C. Brigham, J. R. Carrington, and R. P. Vitray, Connected graphs with maximum total domination number. J. Combin. Comput. Combin. Math. 34 (2000), 81-96.
- [3] E. J. Cockayne, R. M. Dawes, and S. T. Hedetniemi, Total domination in graphs. Networks 10 (1980), 211-219.
- [4] G. Domke, J. H. Hattingh, M. A. Henning, and L. Markus, Restrained domination in graphs with minimum degree two. J. Combin. Math. Combin. Comput. 35 (2000), 239-254.
- [5] T. W. Haynes, S. T. Hedetniemi, and P. J. Slater, Fundamentals of Domination in Graphs , Marcel Dekker, Inc. New York, 1998.
- [6] T. W. Haynes, S. T. Hedetniemi, and P. J. Slater (eds), Domination in Graphs: Advanced Topics , Marcel Dekker, Inc. New York, 1998.
- [7] M. A. Henning, Recent results on total domination in graphs: A survey. Discrete Math . 309 (2009), 32-63.
- [8] M. A. Henning and N. J. Rad, Bounds on neighborhood total domination in graphs. Discrete Applied Math. 161 (2013), 2460-2466.
- [9] M. A. Henning and K. Wash, Graphs with large neighborhood total domination number, mansucript.
- [10] M. A. Henning and A. Yeo, Total domination in graphs (Springer Monographs in Mathematics) 2013. ISBN: 978-1-4614-6524-9 (Print) 978-1-4614-6525-6 (Online). | null | [
"Michael A. Henning",
"Kirsti Wash"
] | 2014-08-01T09:31:40+00:00 | 2014-08-01T09:31:40+00:00 | [
"math.CO",
"05C69"
] | Trees with Large Neighborhood Total Domination Number | In this paper, we continue the study of neighborhood total domination in
graphs first studied by Arumugam and Sivagnanam [Opuscula Math. 31 (2011),
519--531]. A neighborhood total dominating set, abbreviated NTD-set, in a graph
$G$ is a dominating set $S$ in $G$ with the property that the subgraph induced
by the open neighborhood of the set $S$ has no isolated vertex. The
neighborhood total domination number, denoted by $\gnt(G)$, is the minimum
cardinality of a NTD-set of $G$. Every total dominating set is a NTD-set,
implying that $\gamma(G) \le \gnt(G) \le \gt(G)$, where $\gamma(G)$ and
$\gt(G)$ denote the domination and total domination numbers of $G$,
respectively. Arumugam and Sivagnanam posed the problem of characterizing the
connected graphs $G$ of order $n \ge 3$ achieving the largest possible
neighborhood total domination number, namely $\gnt(G) = \lceil n/2 \rceil$. A
partial solution to this problem was presented by Henning and Rad [Discrete
Applied Mathematics 161 (2013), 2460--2466] who showed that $5$-cycles and
subdivided stars are the only such graphs achieving equality in the bound when
$n$ is odd. In this paper, we characterize the extremal trees achieving
equality in the bound when $n$ is even. As a consequence of this tree
characterization, a characterization of the connected graphs achieving equality
in the bound when $n$ is even can be obtained noting that every spanning tree
of such a graph belongs to our family of extremal trees. |
1408.0110v1 | ## A Two-Queue Polling Model with Two Priority Levels in the First Queue ∗ †
M.A.A. Boon ‡ [email protected]
I.J.B.F. Adan † [email protected]
O.J. Boxma † [email protected]
May, 2008
## Abstract
In this paper we consider a single-server cyclic polling system consisting of two queues. Between visits to successive queues, the server is delayed by a random switchover time. Two types of customers arrive at the first queue: high and low priority customers. For this situation the following service disciplines are considered: gated, globally gated, and exhaustive. We study the cycle time distribution, the waiting times for each customer type, the joint queue length distribution at polling epochs, and the steady-state marginal queue length distributions for each customer type.
Keywords: Polling, priority levels, queue lengths, waiting times
## 1 Introduction
A polling model is a single-server system in which the server visits n queues Q , . . . , Q 1 n in cyclic order. Customers that arrive at Q i are referred to as type i customers. The special feature of the model considered in the present paper is that, within a customer type, we distinguish high and low priority customers. More specifically, we study a polling system which consists of two queues, Q 1 and Q 2 . The first of these queues contains customers of two priority classes, high ( H ) and low ( L ). The exhaustive, gated and globally gated service disciplines are studied.
∗ The research was done in the framework of the BSIK/BRICKS project, and of the European Network of Excellence Euro-FGI.
† The present paper is an adapted and extended version of [3].
‡ Eurandom and Department of Mathematics and Computer Science, Eindhoven University of Technology, P.O. Box 513, 5600MB Eindhoven, The Netherlands
Our motivation to study a polling model with priorities is that the performance of a polling system can be improved through the introduction of priorities. In production environments, e.g., one could give highest priority to jobs with a service requirement below a certain threshold level. This might decrease the mean waiting time of an arbitrary customer without having to purchase additional resources [24]. Priority polling models also can be used to study traffic intersections where conflicting traffic flows face a green light simultaneously; e.g. traffic which takes a left turn may have to give right of way to conflicting traffic that moves straight on, even if the traffic light is green for both traffic flows. Another application is discussed in [9], where a priority polling model is used to study scheduling of surgery procedures in medical emergency rooms. In the computer science community the Bluetooth and 802.11 protocols are frequently modelled as polling systems, cf. [17, 18, 19, 27]. Many scheduling policies that have been considered or implemented in these protocols involve different priority levels in order to improve Quality-of-Service (QoS) for traffic that is very sensitive to delays or loss of data, such as Voice over Wireless IP. The 802.11e amendment defines a set of QoS enhancements for wireless LAN applications by differentiating between high priority traffic, like streaming multimedia, and low priority traffic, like web browsing and email traffic.
Although there is quite an extensive amount of literature available on polling systems, only very few papers treat priorities in polling models. Most of these papers only provide approximations or focus on pseudo-conservation laws. In [24] exact mean waiting time results are obtained using the Mean Value Analysis (MVA) framework for polling systems, developed in [26]. The MVA framework can only be used to find the first moment of the waiting time distribution for each customer type, and the mean residual cycle time. The main contribution of the present paper is the derivation of Laplace Stieltjes Transforms (LSTs) of the distributions of the marginal waiting times for each customer type; in particular it turns out to be possible to obtain exact expressions for the waiting time distributions of both high and low priority customers at a queue of a polling system. Probability Generating Functions (PGFs) are derived for the joint queue length distribution at polling epochs, and for the steady-state marginal queue length distribution of the number of customers at an arbitrary epoch.
The present paper is structured as follows: Section 2 gathers known results of nonpriority polling models which are relevant for the present study. Sections 3 (gated), 4 (globally gated), and 5 (exhaustive) give new results on the priority polling model. In each of the sections we successively discuss the joint queue length distribution at polling epochs, the cycle time distribution, the marginal queue length distributions and waiting time distributions. The mean waiting times are given at the end of each section. A numerical example is presented in Section 6 to illustrate some of the improvements that can be obtained by introducing prioritisation in a polling system.
## 2 Notation and description of the nonpriority polling model
The model that is considered in this section, is a nonpriority polling model with two queues ( Q 1 and Q 2 ). We consider three service disciplines: gated, globally gated, and exhaustive. The gated service discipline states that during a visit to Q i , the server serves only those type i customers who are present at the polling epoch. All type i customers that arrive during this visit will be served in the next cycle. In this respect, a cycle is the time between two successive visit beginnings to a queue. The exhaustive service discipline states that when the server arrives at Q i , all type i customers are served until no type i customer is present in the system. We also consider the globally gated service discipline, which means that during a cycle only those customers will be served that were present at the beginning of that cycle.
Customers of type i arrive at Q i according to a Poisson process with arrival rate λ i ( i = 1 2) , . Service times can follow any distribution, and we assume that a customer's service time is independent of other service times and independent of the arrival processes. The LST of the distribution of the generic service time B i of type i customers is denoted by β i ( ) · . The fraction of time that the server is serving customers of type i equals ρ i := λ E B i ( i ) . Switches of the server from Q i to Q i +1 (all indices modulo 2), require a switch-over time S i . The LST of this switch-over time distribution is denoted by σ i ( ) · . The fraction of time that the server is working (i.e., not switching) is ρ := ρ 1 + ρ 2 . We assume that ρ < 1 , which is a necessary and sufficient condition for the steady state distributions of cycle times, queue lengths and waiting times to exist.
[22] studied this model, but without switch-over times and only with the exhaustive service discipline. [11] analysed this polling system for any number of queues, and for both gated and exhaustive service disciplines. [12] obtained results for a polling system with switchover times (but only exhaustive service) by relating the PGFs of the joint queue length distributions at visit beginnings, visit endings, service beginnings and service endings. [20] was the first to point out the relation between polling systems and Multitype Branching Processes with immigration in each state. His results can be applied to polling models in which each queue satisfies the following property:
Property 2.1 If the server arrives at Q i to find k i customers there, then during the course of the server's visit, each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having probability generating function h i ( z , . . . , z 1 n ) , which can be any n -dimensional probability generating function.
We use this property, and the relation to Multitype Branching Processes, to find results for our polling system with two queues, two priorities in the first queue, and gated, globally gated, and exhaustive service discipline. Notice that, unlike the gated and exhaustive service disciplines, the globally gated service discipline does not satisfy Property 2.1. But the results obtained by Resing also hold for a more general class of polling systems, namely
those which satisfy the following (weaker) property that is formulated in [4]:
Property 2.2 If there are k i customers present at Q i at the beginning (or the end) of a visit to Q π i ( ) , with π i ( ) ∈ { 1 , . . . , n } , then during the course of the visit to Q i , each of these k i customers will effectively be replaced in an i.i.d. manner by a random population having probability generating function h i ( z , . . . , z 1 n ) , which can be any n -dimensional probability generating function.
Globally gated and gated are special cases of the synchronised gated service discipline, which states that only customers in Q i will be served that were present at the moment that the server reaches the 'parent queue' of Q i : Q π i ( ) . For gated service, π i ( ) = i , for globally gated service, π i ( ) = 1 . The synchronised gated service discipline is discussed in [16], but no observation is made that this discipline is a member of the class of polling systems satisfying Property 2.2 which means that results as obtained in [20] can be extended to this model.
[5] combined the results of [20] and [12] to find a relation between the PGFs of the marginal queue length distribution for polling systems with and without switch-over times, expressed in the Fuhrmann-Cooper queue length decomposition form [13].
## 2.1 Joint queue length distribution at polling epochs
glyph[negationslash]
The probability generating function h i ( z , . . . , z 1 n ) which is mentioned in Property 2.1 depends on the service discipline. In a polling system with two queues and gated service we have h i ( z , z 1 2 ) = β i ( λ 1 (1 -z 1 ) + λ 2 (1 -z 2 )) . For exhaustive service this PGF becomes h i ( z , z 1 2 ) = π i ( ∑ j = i λ j (1 -z j )) , where π i ( ) · is the LST of a busy period (BP) distribution in an M/G/ 1 system with only type i customers, so it is the root of the equation π i ( ω ) = β i ( ω + λ i (1 -π i ( ω ))) . We choose the beginning of a visit to Q 1 as start of a cycle. In order to find the joint queue length distribution at the beginning of a cycle, we relate the numbers of customers in each queue at the beginning of a cycle to those at the beginning of the previous cycle. Customers always enter the system during a switch-over time, or during a visit period. The first group is called immigration , whereas a customer from the second group is called offspring of the customer that is served at the moment of his arrival. We define the immigration PGF for each switch-over time and the offspring PGF for each visit period analogous to [20]. The immigration PGFs are:
$$g ^ { ( 2 ) } ( z _ { 1 }, z _ { 2 } ) & = \sigma _ { 2 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ), \\ g ^ { ( 1 ) } ( z _ { 1 }, z _ { 2 } ) & = \sigma _ { 1 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - h _ { 2 } ( z _ { 1 }, z _ { 2 } ) ) ).$$
g (2) ( z , z 1 2 ) is the PGF of the joint distribution of type 1 and 2 customers that arrive during S 2 . For S 1 things are slightly more complicated, since type 2 customers arriving during S 1 may be served before the end of the cycle, and generate offspring. g (1) ( z , z 1 2 ) is the joint PGF of the type 1 and 2 customers present at the end of the cycle that either arrived during
S 1 , or are offspring of type 2 customers that arrived during S 1 . The total immigration PGF is the product of these two PGFs:
$$g ( z _ { 1 }, z _ { 2 } ) = \prod _ { i = 1 } ^ { 2 } g ^ { ( i ) } ( z _ { 1 }, z _ { 2 } ) = g ^ { ( 1 ) } ( z _ { 1 }, z _ { 2 } ) g ^ { ( 2 ) } ( z _ { 1 }, z _ { 2 } ).$$
We define the offspring PGFs for each visit period in a similar manner:
$$f ^ { ( 2 ) } ( z _ { 1 }, z _ { 2 } ) & = h _ { 2 } ( z _ { 1 }, z _ { 2 } ), \\ f ^ { ( 1 ) } ( z _ { 1 }, z _ { 2 } ) & = h _ { 1 } ( z _ { 1 }, h _ { 2 } ( z _ { 1 }, z _ { 2 } ) ).$$
The term for Q 1 is again slightly more complicated than the term for Q 2 , since type 2 customers arriving during a server visit to Q 1 may be served before the end of the cycle, and generate offspring.
[20] shows that the following recursive expression holds for the joint queue length PGF at the beginning of a cycle (starting with a visit to Q 1 ):
$$P _ { 1 } ( z _ { 1 }, z _ { 2 } ) = g ( z _ { 1 }, z _ { 2 } ) P _ { 1 } \left ( f ^ { ( 1 ) } ( z _ { 1 }, z _ { 2 } ), f ^ { ( 2 ) } ( z _ { 1 }, z _ { 2 } ) \right ).$$
This expression can be used to compute moments of the joint queue length distribution. Alternatively, iteration of this expression yields the following closed form expression for P 1 ( z , z 1 2 ) :
$$P _ { 1 } ( z _ { 1 }, z _ { 2 } ) = \prod _ { n = 0 } ^ { \infty } g ( f _ { n } ( z _ { 1 }, z _ { 2 } ) ),$$
where we use the following recursive definition for f n ( z , z 1 2 ) , n = 0 1 2 , , , . . . :
$$f _ { n } ( z _ { 1 }, z _ { 2 } ) & = ( f ^ { ( 1 ) } ( f _ { n - 1 } ( z _ { 1 }, z _ { 2 } ) ), f ^ { ( 2 ) } ( f _ { n - 1 } ( z _ { 1 }, z _ { 2 } ) ) ), \\ f _ { 0 } ( z _ { 1 }, z _ { 2 } ) & = ( z _ { 1 }, z _ { 2 } ).$$
[20] proves that this infinite product converges if and only if ρ < 1 .
We can relate the joint queue length distribution at other polling epochs to P 1 ( z , z 1 2 ) . We denote the PGF of the joint queue length distribution at a visit beginning to Q i by V b i ( ) · , so P 1 ( ) = · V b 1 ( ) · . The PGF of the joint queue length distribution at a visit completion to Q i is denoted by V c i ( ) · . The following relations hold:
$$V _ { b _ { 1 } } ( z _ { 1 }, z _ { 2 } ) & = V _ { c _ { 2 } } ( z _ { 1 }, z _ { 2 } ) \sigma _ { 2 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ) \\ & = V _ { b _ { 2 } } ( z _ { 1 }, h _ { 2 } ( z _ { 1 }, z _ { 2 } ) ) \sigma _ { 2 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ) \\ & = V _ { b _ { 2 } } ( z _ { 1 }, f ^ { ( 2 ) } ( z _ { 1 }, z _ { 2 } ) ) g ^ { ( 2 ) } ( z _ { 1 }, z _ { 2 } ), & ( 2. 2 ) \\ V _ { b _ { 2 } } ( z _ { 1 }, z _ { 2 } ) & = V _ { c _ { 1 } } ( z _ { 1 }, z _ { 2 } ) \sigma _ { 1 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ) \\ & = V _ { b _ { 1 } } ( h _ { 1 } ( z _ { 1 }, z _ { 2 } ), z _ { 2 } ) \sigma _ { 1 } ( \lambda _ { 1 } ( 1 - z _ { 1 } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ). & ( 2. 3 )$$
## 2.2 Cycle time
The cycle time, starting at a visit beginning to Q 1 , is the sum of the visit times to Q 1 and Q 2 , and the two switch-over times which are independent of the visit times. Since type 2 customers who arrive during the visit to Q 1 or the switch from Q 1 to Q 2 will be served during the visit to Q 2 , it can be shown that the LST of the distribution of the cycle time C 1 , γ 1 ( ) · , is related to P 1 ( ) · as follows:
$$\gamma _ { 1 } ( \omega ) = \sigma _ { 1 } ( \omega + \lambda _ { 2 } ( 1 - \phi _ { 2 } ( \omega ) ) ) \, \sigma _ { 2 } ( \omega ) \, P _ { 1 } ( \phi _ { 1 } ( \omega + \lambda _ { 2 } ( 1 - \phi _ { 2 } ( \omega ) ) ), \phi _ { 2 } ( \omega ) ), \quad ( 2. 4 )$$
where φ i ( ) · is the LST of the distribution of the time that the server spends at Q i due to the presence of one type i customer there. For gated service φ i ( ) = · β i ( ) · , for exhaustive service φ i ( ) = · π i ( ) · . A proof of (2.4) can be found in [8].
In some cases it is convenient to choose a different starting point for a cycle, for example when analysing a polling system with exhaustive service. If we define C ∗ 1 to be the time between two successive visit completions to Q 1 , the LST of its distribution, γ ∗ 1 ( ) · , is:
$$\gamma _ { 1 } ^ { * } ( \omega ) = & \sigma _ { 1 } ( \omega + \lambda _ { 1 } ( 1 - \phi _ { 1 } ( \omega ) ) + \lambda _ { 2 } ( 1 - \phi _ { 2 } ( \omega + \lambda _ { 1 } ( 1 - \phi _ { 1 } ( \omega ) ) ) ) ) \\ & \cdot \sigma _ { 2 } ( \omega + \lambda _ { 1 } ( 1 - \phi _ { 1 } ( \omega ) ) ) \, V _ { c _ { 1 } } ( \phi _ { 1 } ( \omega ), \phi _ { 2 } ( \omega + \lambda _ { 1 } ( 1 - \phi _ { 1 } ( \omega ) ) ) ),$$
with V c 1 ( z , z 1 2 ) = P 1 ( h 1 ( z , z 1 2 ) , z 2 ) .
## 2.3 Marginal queue lengths and waiting times
We denote the PGF of the steady-state marginal queue length distribution of Q 1 at the visit beginning by ˜ V b 1 ( z ) = V b 1 ( z, 1) . Analogously we define ˜ V b 2 ( ) · , V ˜ c 1 ( ) · , and ˜ V c 2 ( ) · . It is shown in [5] that the steady-state marginal queue length of Q i can be decomposed into two parts: the queue length of the corresponding M/G/ 1 queue with only type i customers, and the queue length at an arbitrary epoch during the intervisit period of Q i , denoted by N i I | . [5] show that by virtue of PASTA, N i I | has the same distribution as the number of type i customers seen by an arbitrary type i customer arriving during an intervisit period, which equals
$$E ( z ^ { N _ { i | I } } ) = \frac { E ( z ^ { N _ { i | I } _ { b e g i n } } ) - E ( z ^ { N _ { i | I } _ { e n d } } ) } { ( 1 - z ) ( E ( N _ { i | I _ { e n d } } ) - E ( N _ { i | I _ { b e g i n } } ) ) },$$
where N i I | begin is the number of type i customers at the beginning of an intervisit period I i , and N i I | end is the number of type i customers at the end of I i . Since the beginning of an intervisit period coincides with the completion of a visit to Q i , and the end of an intervisit period coincides with the beginning of a visit, we know the PGFs for the distributions of these random variables: ˜ V c i ( ) · and ˜ V b i ( ) · . This leads to the following expression for the PGF of the steady-state queue length distribution of Q i at an arbitrary epoch, E z [ N i ] :
$$E [ z ^ { N _ { i } } ] = \frac { ( 1 - \rho _ { i } ) ( 1 - z ) \beta _ { i } ( \lambda _ { i } ( 1 - z ) ) } { \beta _ { i } ( \lambda _ { i } ( 1 - z ) ) - z } \cdot \frac { \widetilde { V } _ { c _ { i } } ( z ) - \widetilde { V } _ { b _ { i } } ( z ) } { ( 1 - z ) ( E ( N _ { i | I _ { e n d } } ) - E ( N _ { i | I _ { b e g i n } } ) ) }.$$
[14] show that the distributional form of Little's law can be used to find the LST of the marginal waiting time distribution: E z ( N i ) = E ( e -λ i (1 -z )( W i + B i ) ) , hence E ( e -ωW i ) = E [(1 -ω λ i ) N i ] /β i ( ω ) . This can be substituted into (2.6):
$$\bar { \ } _ { \mu \nu } ^ { - } \quad \lambda _ { i } \, \varphi ^ { 2 } \quad \, \int _ { I \, \nu \nu \nu } \, \stackrel { \sim } { \sim } \, \longrightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \longrightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \leftarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \leftarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \rightarrow\, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow \, \rightarrow.$$
The interpretation of this formula is that the waiting time of a type i customer in a polling model is the sum of two independent random variables: the waiting time of a customer in an M/G/ 1 queue with only type i customers, W i M/G/ | 1 , and the remaining intervisit time for a customer that arrives at an arbitrary epoch during the intervisit time of Q i .
For gated service, the number of type i customers at the beginning of a visit to Q i is exactly the number of type i customers that arrived during the previous cycle, starting at Q i . In terms of PGFs: ˜ V b i ( z ) = γ i ( λ i (1 -z )) . The number of type i customers at the end of a visit to Q i are exactly those type i customers that arrived during this visit. In terms of PGFs: ˜ V c i ( z ) = γ i ( λ i (1 -β i ( λ i (1 -z )))) . We can rewrite E N ( i I | end ) -E N ( i I | begin ) as λ E I i ( i ) , because this is the number of type i customers that arrive during an intervisit time. In Section 2.4 we show that λ E I i ( i ) = λ i (1 -ρ i ) E C ( ) . Using these expressions we can rewrite Equation (2.7) for gated service to:
$$E [ \mathrm e ^ { - \omega W _ { i } } ] = \frac { ( 1 - \rho _ { i } ) \omega } { \omega - \lambda _ { i } ( 1 - \beta _ { i } ( \omega ) ) } \cdot \frac { \gamma _ { i } ( \lambda _ { i } ( 1 - \beta _ { i } ( \omega ) ) ) - \gamma _ { i } ( \omega ) } { ( 1 - \rho _ { i } ) \omega E ( C ) }.$$
For exhaustive service, ˜ V c i ( z ) = 1 , because Q i is empty at the end of a visit to Q i . The number of type i customers at the beginning of a visit to Q i in an exhaustive polling system is equal to the number of type i customers that arrived during the previous intervisit time of Q i . Hence, ˜ V b i ( z ) = ˜ I i ( λ i (1 -z )) , where ˜ I i ( ) · is the LST of the intervisit time distribution for Q i . Substitution of ˜ I i ( ω ) = ˜ V b i (1 -ω λ i ) in (2.7) leads to the following expression for the LST of the steady-state waiting time distribution of a type i customer in an exhaustive polling system:
$$E [ \mathrm e ^ { - \omega W _ { i } } ] = \frac { ( 1 - \rho _ { i } ) \omega } { \omega - \lambda _ { i } ( 1 - \beta _ { i } ( \omega ) ) } \cdot \frac { 1 - \widetilde { I } _ { i } ( \omega ) } { \omega E ( I _ { i } ) }.$$
To the best of our knowledge, the following result is new.
Proposition 2.3 Let the cycle time C ∗ i be the time between two successive visit completions to Q i . The LST of the cycle time distribution is given by (2.5). An equivalent expression for E [ e -ωW i ] if Q i is served exhaustively, is:
$$\cdot \quad \cdot \quad \cdot & \quad \cdot \\ & E [ e ^ { - \omega W _ { i } } ] = \frac { 1 - \gamma _ { i } ^ { * } ( \omega - \lambda _ { i } ( 1 - \beta _ { i } ( \omega ) ) ) } { ( \omega - \lambda _ { i } ( 1 - \beta _ { i } ( \omega ) ) ) E ( C ) } \\ & = E [ e ^ { - ( \omega - \lambda _ { i } ( 1 - \beta _ { i } ( \omega ) ) ) C _ { i, r e s } ^ { * } } ],$$
where C ∗ i, res is the residual length of C ∗ i .
## Proof:
The cycle time is the length of an intervisit period I i plus the length of a visit V i , which is the time required to serve all type i customers that have arrived during I i , and their type i descendants. Hence, the following equation holds:
$$\gamma _ { i } ^ { * } ( \omega ) = \widetilde { I } _ { i } ( \omega + \lambda _ { i } ( 1 - \pi _ { i } ( \omega ) ) ).$$
We use this equation to find the inverse relation:
$$\widetilde { I } _ { i } ( \omega + \lambda _ { i } ( 1 - \pi _ { i } ( \omega ) ) ) & = \gamma _ { i } ^ { * } ( \omega ) \\ & = \gamma _ { i } ^ { * } ( \omega + \lambda _ { i } ( 1 - \pi _ { i } ( \omega ) ) - \lambda _ { i } ( 1 - \pi _ { i } ( \omega ) ) ) \\ & = \gamma _ { i } ^ { * } ( \omega + \lambda _ { i } ( 1 - \pi _ { i } ( \omega ) ) - \lambda _ { i } ( 1 - \beta _ { i } ( \omega + \lambda _ { i } ( 1 - \pi _ { i } ( \omega ) ) ) ) ).$$
If we substitute s := ω + λ i (1 -π i ( ω )) , we find
$$\widetilde { I } _ { i } ( s ) = \gamma _ { i } ^ { * } ( s - \lambda _ { i } ( 1 - \beta _ { i } ( s ) ) ).$$
$$\text{Substitution of (2.12) into (2.9) gives (2.10). }$$
Remark 2.4 We can write (2.11) and (2.12) as follows:
$$\gamma _ { i } ^ { * } ( \omega ) = \widetilde { I } _ { i } ( \psi ( \omega ) ), \quad \widetilde { I } _ { i } ( s ) = \gamma _ { i } ^ { * } ( \phi ( s ) ),$$
where φ ( ) · equals the Laplace exponent of the Lévy process ∑ N t ( ) j =1 B i,j -t , with N t ( ) a Poisson process with intensity λ i , and with ψ ω ( ) = ω + λ i (1 -π i ( ω )) , which is known to be the inverse of φ ( ) · .
## 2.4 Moments
The focus of this paper is on LST and PGF of distribution functions, not on their moments. Moments can be obtained by differentiation, and are also discussed in [24]. In this subsection we will only mention some results that will be used later.
First we will derive the mean cycle time E C ( ) . Unlike higher moments of the cycle time, the mean does not depend on where the cycle starts: E C ( ) = E S ( 1 )+ E S ( 2 ) 1 -ρ . This can easily be seen, because 1 -ρ is the fraction of time that the server is not working, but switching. The total switch-over time is E S ( 1 ) + E S ( 2 ) .
The expected length of a visit to Q i is E V ( i ) = ρ E C i ( ) . The mean length of an intervisit period for Q i is E I ( i ) = (1 -ρ i ) E C ( ) . Notice that these expectations do not depend on the service discipline used. The expected number of type i customers at polling moments does depend on the service discipline. For gated service the expected number of type i customers at the beginning of a visit to Q i is λ E C i ( ) . For exhaustive service this is λ E I i ( i ) . The
expected number of type i customers at the beginning of a visit to Q i +1 is λ i ( E V ( i )+ E S ( i )) for gated service, and λ E S i ( i ) for exhaustive service.
Moments of the waiting time distribution for a type i customer at an arbitrary epoch can be derived from the LSTs given by (2.8), (2.9) and (2.10). We only present the first moment:
Gated:
$$E ( W _ { i } ) = ( 1 + \rho _ { i } ) \frac { E ( C _ { i } ^ { 2 } ) } { 2 E ( C ) }, \quad \quad \quad ( 2. 1 3 )$$
Exhaustive:
$$( 2. 1 4 )$$
$$E ( W _ { i } ) & = \frac { E ( I _ { i } ^ { 2 } ) } { 2 E ( I _ { i } ) } + \frac { \rho _ { i } } { 1 - \rho _ { i } } \frac { E ( B _ { i } ^ { 2 } ) } { 2 E ( B _ { i } ) }, \\ & = ( 1 - \rho _ { i } ) \frac { E ( C _ { i } ^ { * 2 } ) } { 2 E ( C ) }.$$
Notice that the start of C i is the beginning of a visit to Q i , whereas the start of C ∗ i is the end of a visit. Equations (2.13) and (2.14) are in agreement with Equations (4.1) and (4.2) in [6]. Although at first sight these might seem nice, closed formulas, it should be noted that the expected residual cycle time and the expected residual intervisit time are not easy to determine, requiring the solution of a large set of equations. MVA is an efficient technique to compute mean waiting times, the mean residual cycle time, and also the mean residual intervisit time. We refer to [26] for an MVA framework for polling models.
## 3 Gated service
In this section we study the gated service discipline for a polling system with two queues and two priority classes in the first queue: high ( H ) and low ( L ) priority customers. All type H and L customers that are present at the moment when the server arrives at Q 1 , will be served during the server's visit to Q 1 . First all type H customers will be served, then all type L customers. Type H customers arrive at Q 1 according to a Poisson process with intensity λ H , and have a service requirement B H with LST β H ( ) · . Type L customers arrive at Q 1 with intensity λ L , and have a service requirement B L with LST β L ( ) · . If we do not distinguish between high and low priority customers, we can still use the results from Section 2 if we regard the system as a polling system with two queues where customers in Q 1 arrive according to a Poisson process with intensity λ 1 := λ H + λ L and have service requirement B 1 with LST β 1 ( ) = · λ H λ 1 β H ( ) + · λ L λ 1 β L ( ) · .
We follow the same approach as in Section 2. First we study the joint queue length distribution at polling epochs, then the cycle time distribution, followed by the marginal queue length distribution and waiting time distribution. The last subsection provides the first moment of these distributions.
## 3.1 Joint queue length distribution at polling epochs
Equations (2.2) and (2.3) give the PGFs of the joint queue length distribution at visit beginnings, V b i ( z , z 1 2 ) . A type 1 customer entering the system is a type H customer with probability λ H /λ 1 , and a type L customer with probability λ /λ L 1 . We can express the PGF of the joint queue length distribution in the polling system with priorities, V b i ( · , · , · ) , in terms of the PGF of the joint queue length distribution in the polling system without priorities, V b i ( · , · ) .
## Lemma 3.1
$$V _ { b _ { i } } ( z _ { H }, z _ { L }, z _ { 2 } ) = V _ { b _ { i } } \left ( \frac { \lambda _ { H } z _ { H } + \lambda _ { L } z _ { L } } { \lambda _ { 1 } }, z _ { 2 } \right ).$$
## Proof:
Let X H be the number of high priority customers present in Q 1 at the beginning of a visit to Q i , i = 1 2 , . Similarly define X L to be the number of low priority customers present in Q 1 at the beginning of a visit to Q i . Let X 1 = X H + X L . Since the type H L / customers in Q 1 are exactly those H L / customers that arrived since the previous visit beginning at Q i , we know that
$$P ( X _ { H } = i, X _ { L } = k - i | X _ { 1 } = k ) = \binom { k } { i } \left ( \frac { \lambda _ { H } } { \lambda _ { 1 } } \right ) ^ { i } \left ( \frac { \lambda _ { L } } { \lambda _ { 1 } } \right ) ^ { k - i }.$$
Hence
Finally,
$$V _ { b _ { i } } ( z _ { H }, z _ { L }, z _ { 2 } ) & = \sum _ { i = 0 } ^ { \infty } \sum _ { j = 0 } ^ { \infty } \left ( \frac { \lambda _ { H } z _ { H } + \lambda _ { L } z _ { L } } { \lambda _ { 1 } } \right ) ^ { i } z _ { 2 } ^ { j } P ( X _ { 1 } = i, X _ { 2 } = j ) \\ & = V _ { b _ { i } } \left ( \frac { 1 } { \lambda _ { 1 } } ( \lambda _ { H } z _ { H } + \lambda _ { L } z _ { L } ), z _ { 2 } \right ).$$
$$E [ z _ { H } ^ { X _ { H } } z _ { L } ^ { X _ { L } } | X _ { 1 } = k ] & = \sum _ { i = 0 } ^ { \infty } \sum _ { j = 0 } ^ { \infty } z _ { H } ^ { i } z _ { L } ^ { j } P ( X _ { H } = i, X _ { L } = j | X _ { 1 } = k ) \\ & = \left ( \frac { \lambda _ { H } z _ { H } + \lambda _ { L } z _ { L } } { \lambda _ { 1 } } \right ) ^ { k }.$$
glyph[square]
## 3.2 Cycle time
The LST of the cycle time distribution is still given by (2.4) if we define λ 1 := λ H + λ L and β 1 ( ) · := λ H λ 1 β H ( ) + · λ L λ 1 β L ( ) · , because the cycle time does not depend on the order of service.
Equation (2.4) is valid for polling systems with queues having any branching type service discipline. In the present section we can derive an alternative, shorter expression for γ 1 ( ) · by explicitly using the fact that Q 1 receives gated service. The type 1 (i.e. both H and L ) customers present at the visit beginning to Q 1 are those that arrived during the previous cycle: P 1 ( z, 1) = γ 1 ( λ 1 (1 -z )) . By setting ω = λ 1 (1 -z ) , this leads to the following expression for the LST of the distribution of C 1 if service in Q 1 is gated:
$$\gamma _ { 1 } ( \omega ) = P _ { 1 } ( 1 - \frac { \omega } { \lambda _ { 1 } }, 1 ).$$
## 3.3 Marginal queue lengths and waiting times
We first determine the LST of the waiting time distribution for a type L customer, using the fact that this customer will not be served until the next cycle (starting at Q 1 ). The time from the start of the cycle until the arrival will be called 'past cycle time', denoted by C 1 P . The residual cycle time will be denoted by C 1 R . The waiting time of a type L customer is composed of C 1 R , the service times of all high priority customers that arrived during C 1 P + C 1 R , and the service times of all low priority customers that have arrived during C 1 P . Let N H ( T ) be the number of high priority customers that have arrived during time interval T , and equivalently define N L ( T ) .
## Theorem 3.2
$$E \left [ \mathrm e ^ { - \omega W _ { L } } \right ] = & \frac { \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) - \gamma _ { 1 } ( \omega + \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) } { ( \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) E ( C ) }.$$
## Proof:
$$E \left [ e ^ { - \omega W _ { L } } \right ] & = E \left [ e ^ { - \omega ( C _ { 1 R } + \sum _ { i = 1 } ^ { N H ^ { ( C _ { 1 P } + C _ { 1 R } ) } B _ { H, i } + \sum _ { i = 1 } ^ { N _ { L } ( C _ { 1 P } ) } B _ { L, i } ) } } \right ] \\ & = \int _ { t = 0 } ^ { \infty } \int _ { u = 0 } ^ { \infty } \sum _ { m = 0 } ^ { \infty } E \left [ e ^ { - \omega \sum _ { i = 1 } ^ { m } B _ { H, i } } \right ] E \left [ e ^ { - \omega \sum _ { i = 1 } ^ { n } B _ { L, i } } \right ] \\ & \quad \cdot \mathrm e ^ { - \omega u } \frac { ( \lambda _ { H } ( t + u ) ) ^ { m } } { m! } \mathrm e ^ { - \lambda _ { H } ( t + u ) } \frac { ( \lambda _ { L } t ) ^ { n } } { n! } \mathrm e ^ { - \lambda _ { L } t } \mathrm d P ( C _ { 1 P } < t, C _ { 1 R } < u )$$
$$& = \int _ { t = 0 } ^ { \infty } \int _ { u = 0 } ^ { \infty } \text{e} ^ { - t ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) } \text{e} ^ { - u ( \omega + \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) } \text{d} P ( C _ { 1 P } < t, C _ { 1 R } < u ) \\ & = \frac { \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) - \gamma _ { 1 } ( \omega + \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) } { ( \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) E ( C ) }. \\ - \quad. & \quad. & \quad. & \quad. & \quad. & \quad. & \quad. & \quad. & \quad.$$
$$\begin{array} { l } & & \cdot e ^ { - \omega u } \frac { ( \lambda _ { H } ( t + u ) ) ^ { m } } { m! } e ^ { - \lambda _ { H } ( t + u ) } \frac { ( \lambda _ { L } t ) ^ { n } } { n! } \mathrm e ^ { - \lambda _ { L } t } \mathrm d P ( C _ { 1 P } < t, C _ { 1 R } < u ) \\ & & \\ & = \int _ { t = 0 } ^ { \infty } \int _ { u = 0 } ^ { \infty } \mathrm e ^ { - t ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) } \mathrm e ^ { - u ( \omega + \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) } \mathrm d P ( C _ { 1 P } < t, C _ { 1 R } < u ) \\ & = \frac { \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) - \gamma _ { 1 } ( \omega + \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) } { ( \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) E ( C ) }. \end{array}$$
For the last step in the derivation of (3.3) we used
$$E [ \mathrm e ^ { - \omega _ { P } C _ { 1 P } - \omega _ { R } C _ { 1 R } } ] = \frac { E [ \mathrm e ^ { - \omega _ { P } C _ { 1 } } ] - E [ \mathrm e ^ { - \omega _ { R } C _ { 1 } } ] } { ( \omega _ { R } - \omega _ { P } ) E ( C ) },$$
which is obtained in [7].
glyph[square]
Remark 3.3 The Fuhrmann-Cooper decomposition [13] still holds for the waiting time of type L customers, because (3.3) can be rewritten into
$$E \left [ e ^ { - \omega W _ { L } } \right ] = & \frac { ( 1 - \rho _ { L } ) \omega } { \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) } \\ & \cdot \frac { \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) - \gamma _ { 1 } ( \omega + \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) } { ( 1 - \rho _ { L } ) \omega E ( C ) }. \quad ( 3. 4 )$$
We recognise the first term on the right-hand side of (3.4) as the LST of the waiting time distribution of an M/G/ 1 queue with only type L customers. An interpretation of the other two terms on the right-hand side can be found when regarding the polling system as a polling system with three queues ( Q ,Q ,Q H L 2 ) and no switch-over time between Q H and Q L . The service discipline of this equivalent system is synchronised gated, which is a more general version of gated. The gates for queues Q H and Q L are set simultaneously when the server arrives at Q H , but the gate for Q 2 is still set when the server arrives at Q 2 . In the following paragraphs we show that the second and third term on the right-hand side of (3.4) together can be interpreted as E [ ( 1 -ω λ L ) N L I | ] , where N L I | is the number of type L customers at a random epoch during the intervisit period of Q L .
The expression for the LST of the distribution of the number of type L customers at an arbitrary epoch is determined by first converting the waiting time LST to sojourn time LST, i.e., multiplying expression (3.4) with β L ( ω ) . Second, we apply the distributional form of Little's law [14] to (3.4). This law can be applied because the required conditions are fulfilled for each customer class (H, L, and 2): the customers enter the system in a Poisson stream, every customer enters the system and leaves the system one at a time in order of arrival, and for any time t the entry process into the system of customers after time t and the time spent in the system by any customer arriving before time t are independent. The result is:
$$E \left [ z ^ { N _ { L } } \right ] = \frac { ( 1 - \rho _ { L } ) ( 1 - z ) \beta _ { L } ( \lambda _ { L } ( 1 - z ) ) } { \beta _ { L } ( \lambda _ { L } ( 1 - z ) ) - z } \cdot \frac { \widetilde { V } _ { c _ { L } } ( z ) - \widetilde { V } _ { b _ { L } } ( z ) } { ( 1 - z ) ( E ( N _ { L | I _ { e n d } } ) - E ( N _ { L | I _ { b e q i n } } ) ) }. \quad ( 3. 5 )$$
In this equation ˜ V b L ( z ) denotes the PGF of the distribution of the number of type L customers at the beginning of a visit to Q L , and ˜ V c L ( z ) denotes the PGF at the completion of a visit to Q L :
$$\widetilde { V } _ { b _ { L } } ( z ) & = V _ { b _ { 1 } } ( \beta _ { H } ( \lambda _ { L } ( 1 - z ) ), z, 1 ) \\ & = \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \lambda _ { L } ( 1 - z ) ) ) + \lambda _ { L } ( 1 - z ) ), \\ \widetilde { V } _ { c _ { L } } ( z ) & = V _ { b _ { 1 } } ( \beta _ { H } ( \lambda _ { L } ( 1 - z ) ), \beta _ { L } ( \lambda _ { L } ( 1 - z ) ), 1 ) \\ & = \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \lambda _ { L } ( 1 - z ) ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \lambda _ { L } ( 1 - z ) ) ) ).$$
The last term in (3.5) is the PGF of the distribution of the number of type L customers at an arbitrary epoch during the intervisit period of Q L , E z [ N L I | ] . Substitution of ω := λ L (1 -z ) in (3.5), and using ( E N ( L I | end ) -E N ( L I | begin )) = λ E I L ( L ) , shows that the second and third term at the right-hand side of (3.4) together indeed equal E [ ( 1 -ω λ L ) N L I | ] .
The derivation of the LSTs of W H and W 2 is similar and leads to the following expressions:
$$E \left [ \mathrm e ^ { - \omega W _ { H } } \right ] = & \frac { ( 1 - \rho _ { H } ) \omega } { \omega - \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) } \cdot \frac { \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) - \gamma _ { 1 } ( \omega ) } { \omega - \lambda _ { H } ( 1 - \rho _ { H } ) \omega E ( C ) },$$
$$E \left [ e ^ { - \omega W _ { 2 } } \right ] = & \frac { ( 1 - \rho _ { 2 } ) \omega } { \omega - \lambda _ { 2 } ( 1 - \beta _ { 2 } ( \omega ) ) } \cdot \frac { \gamma _ { 2 } ( \lambda _ { 2 } ( 1 - \beta _ { 2 } ( \omega ) ) ) - \gamma _ { 2 } ( \omega ) } { ( 1 - \rho _ { 2 } ) \omega E ( C ) }.$$
Remark 3.4 Equations (3.6) and (3.7) are equivalent to the LST of W i in a nonpriority polling system (2.8), which illustrates that the Fuhrmann-Cooper decomposition also holds for the waiting time distributions of high priority customers in Q 1 and type 2 customers in a polling system with gated service.
Application of the distributional form of Little's law to these expressions results in:
$$E \left [ z ^ { N _ { H } } \right ] & = \frac { ( 1 - \rho _ { H } ) ( 1 - z ) \beta _ { H } ( \lambda _ { H } ( 1 - z ) ) } { \beta _ { H } ( \lambda _ { H } ( 1 - z ) ) - z } \cdot \frac { \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \lambda _ { H } ( 1 - z ) ) ) ) - \gamma _ { 1 } ( \lambda _ { H } ( 1 - z ) ) } { \lambda _ { H } ( 1 - \rho _ { H } ) ( 1 - z ) E ( C ) }, \\ E \left [ z ^ { N _ { 2 } } \right ] & = \frac { ( 1 - \rho _ { 2 } ) ( 1 - z ) \beta _ { 2 } ( \lambda _ { 2 } ( 1 - z ) ) } { \beta _ { 2 } ( \lambda _ { 2 } ( 1 - z ) ) - z } \cdot \frac { \gamma _ { 2 } ( \lambda _ { 2 } ( 1 - \beta _ { 2 } ( \lambda _ { 2 } ( 1 - z ) ) ) ) - \gamma _ { 2 } ( \lambda _ { 2 } ( 1 - z ) ) } { \lambda _ { 2 } ( 1 - \rho _ { 2 } ) ( 1 - z ) E ( C ) }.$$
Remark 3.5 If the service discipline in Q 2 is not gated, but another branching type service discipline that satisfies Property 2.1, (3.7) should be replaced by the more general expression (2.7).
## 3.4 Moments
As mentioned in Section 2.4, we do not focus on moments in this paper, and we only mention the mean waiting times of type H and L customers. For a type H customer, it is immediately clear that E W ( H ) = (1 + ρ H ) E C ( 1 , res ) . The mean waiting time for a type L customer can be obtained by differentiating (3.3). This results in:
$$E ( W _ { L } ) = ( 1 + 2 \rho _ { H } + \rho _ { L } ) E ( C _ { 1, r e s } ).$$
These formulas can also be obtained using MVA, as shown in [24].
## 4 Globally gated service
In this section we discuss a polling model with two queues ( Q , Q 1 2 ) and two priority classes ( H and L ) in Q 1 with globally gated service. For this service discipline, only customers that were present when the server started its visit to Q 1 are served. This feature makes the model exactly the same as a nonpriority polling model with three queues ( Q ,Q ,Q H L 2 ) . Although this system does not satisfy Property 2.1, it does satisfy Property 2.2 which implies that we can still follow the same approach as in the previous sections.
## 4.1 Joint queue length distribution at polling epochs
We define the beginning of a visit to Q 1 as the start of a cycle, since this is the moment that determines which customers will be served during the next visits to the queues. Arriving customers will always be served in the next cycle, so the three ( i = H,L, 2) offspring PGFs are:
$$f ^ { ( i ) } ( z _ { H }, z _ { L }, z _ { 2 } ) & = h _ { i } ( z _ { H }, z _ { L }, z _ { 2 } ) \\ & = \beta _ { i } ( \lambda _ { H } ( 1 - z _ { H } ) + \lambda _ { L } ( 1 - z _ { L } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ),$$
The two ( i = 1 2) , immigration functions are:
$$g ^ { ( i ) } ( z _ { H }, z _ { L }, z _ { 2 } ) = \sigma _ { i } ( \lambda _ { H } ( 1 - z _ { H } ) + \lambda _ { L } ( 1 - z _ { L } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ),$$
Using these definitions, the formula for the PGF of the joint queue length distribution at the beginning of a cycle is similar to the one found in Section 2:
$$P _ { 1 } ( z _ { H }, z _ { L }, z _ { 2 } ) = \prod _ { n = 0 } ^ { \infty } g ( f _ { n } ( z _ { H }, z _ { L }, z _ { 2 } ) ).$$
Notice that in a system with globally gated service it is possible to express the joint queue length distribution at the beginning of a cycle in terms of the cycle time LST, since all customers that are present at the beginning of a cycle are exactly all of the customers that have arrived during the previous cycle:
$$P _ { 1 } ( z _ { H }, z _ { L }, z _ { 2 } ) = \gamma _ { 1 } ( \lambda _ { H } ( 1 - z _ { H } ) + \lambda _ { L } ( 1 - z _ { L } ) + \lambda _ { 2 } ( 1 - z _ { 2 } ) ).$$
## 4.2 Cycle time
Since only those customers that are present at the start of a cycle, starting at Q 1 , will be served during this cycle, the LST of the cycle time distribution is
$$\gamma _ { 1 } ( \omega ) = \sigma _ { 1 } ( \omega ) \sigma _ { 2 } ( \omega ) P _ { 1 } ( \beta _ { H } ( \omega ), \beta _ { L } ( \omega ), \beta _ { 2 } ( \omega ) ).$$
Substitution of (4.2) into this expression gives us the following relation:
$$& \gamma _ { 1 } ( \omega ) = \sigma _ { 1 } ( \omega ) \sigma _ { 2 } ( \omega ) \\ & \cdot \gamma _ { 1 } ( \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) + \lambda _ { 2 } ( 1 - \beta _ { 2 } ( \omega ) ) ).$$
[7] show that this relation leads to the following expression for the cycle time LST:
$$\gamma _ { 1 } ( \omega ) = \prod _ { i = 0 } ^ { \infty } \sigma ( \delta ^ { ( i ) } ( \omega ) ),$$
where σ ( ) = · σ 1 ( ) · σ 2 ( ) · , and δ ( ) i ( ω ) is recursively defined as follows:
$$\delta ^ { ( 0 ) } ( \omega ) & = \omega, \\ \delta ^ { ( i ) } ( \omega ) & = \delta ( \delta ^ { ( i - 1 ) } ( \omega ) ), \quad \ i = 1, 2, 3, \dots, \\ \delta ( \omega ) & = \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) + \lambda _ { 2 } ( 1 - \beta _ { 2 } ( \omega ) ).$$
## 4.3 Marginal queue lengths and waiting times
For type H and L customers, the expressions for E ( e -ωW H ) and E ( e -ωW L ) are exactly the same as the ones found in Section 3.3, but with γ 1 ( ) · as defined in (4.3).
The expression for E ( e -ωW 2 ) can be obtained with the method used in Section 3.3:
$$\ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e pr o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ ep r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e pr o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e vc { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e pro c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } \\ \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c < \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ ev c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n } & \ e v c { \ e p r o c o n }$$
We can use the distributional form of Little's law to determine the LST of the marginal queue length distribution of Q 2 :
$$E \left [ z ^ { N _ { 2 } } \right ] = & \sigma _ { 1 } ( \lambda _ { 2 } ( 1 - z ) ) \frac { ( 1 - \rho _ { 2 } ) ( 1 - z ) \beta _ { 2 } ( \lambda _ { 2 } ( 1 - z ) ) } { \beta _ { 2 } ( \lambda _ { 2 } ( 1 - z ) ) - z } \\ & \cdot \frac { \gamma _ { 1 } \left ( \sum _ { i = H, L, 2 } \lambda _ { i } ( 1 - \beta _ { i } ( \lambda _ { 2 } ( 1 - z ) ) ) \right ) - \gamma _ { 1 } \left ( \lambda _ { 2 } ( 1 - z ) + \sum _ { i = H, L } \lambda _ { i } ( 1 - \beta _ { i } ( \lambda _ { 2 } ( 1 - z ) ) ) \right ) } { \lambda _ { 2 } ( 1 - \rho _ { 2 } ) ( 1 - z ) E ( C ) }.$$
Remark 4.1 The Fuhrmann-Cooper queue length decomposition also holds for all customer classes in a polling system with globally gated service.
.
## 4.4 Moments
The expressions for E W ( H ) and E W ( L ) from Section 3.4 also hold in a globally gated polling system, but with a different mean residual cycle time. We only provide the mean waiting time of type 2 customers:
$$E ( W _ { 2 } ) = E ( S _ { 1 } ) + ( 1 + 2 \rho _ { H } + 2 \rho _ { L } + \rho _ { 2 } ) E ( C _ { 1, r e s } ).$$
## 5 Exhaustive service
In this section we study the same polling model as in the previous two sections, but the two queues are served exhaustively. The section has the same structure as the other sections, so we start with the derivation of the LST of the joint queue length distribution at polling epochs, followed by the LST of the cycle time distribution. LSTs of the marginal queue length distributions and waiting time distributions are provided in the next subsection. In the last part of the section the mean waiting time of each customer type is studied.
It should be noted that, although we assume that both Q 1 and Q 2 are served exhaustively, a model in which Q 2 is served according to another branching type service discipline, requires only minor adaptations.
## 5.1 Joint queue length distribution at polling epochs
We can derive the joint queue length distribution at the beginning of a cycle for a polling system with two queues and two priority classes in Q 1 , P 1 ( z H , z L , z 2 ) , directly from (2.1) for P 1 ( z , z 1 2 ) . Similar to the proof of Lemma 3.1, we can prove that
$$P _ { 1 } ( z _ { H }, z _ { L }, z _ { 2 } ) = P _ { 1 } \left ( \frac { 1 } { \lambda _ { 1 } } ( \lambda _ { H } z _ { H } + \lambda _ { L } z _ { L } ), z _ { 2 } \right ).$$
The same holds for V b 2 ( · , · , · ) and visit completion epochs V c i ( · , · , · ) , for i = 1 2 , .
## 5.2 Cycle time
For the cycle time starting with a visit to Q 1 , (2.4) is still valid. However, when studying the waiting time of a specific customer type in an exhaustively served queue, it is convenient to consider the completion of a visit to Q 1 as the start of a cycle. Hence, in this section the notation C ∗ 1 , or the LST of its distribution, γ ∗ 1 ( ) · , refers to the cycle time starting at the completion of a visit to Q 1 . Equation (2.5) gives the LST of the distribution of C ∗ 1 .
Using the fact that customers in Q 1 are served exhaustively, we can find an alternative, compact expression for γ ∗ 1 ( ) · . The type 1 (i.e. both type H and L customers) customers at
the beginning of a visit to Q 1 are exactly those type 1 customers that have arrived during the previous intervisit time: P 1 ( z, 1) = ˜ I 1 ( λ 1 (1 -z )) . Hence, by setting ω = λ 1 (1 -z ) , we get ˜ I 1 ( ω ) = P 1 (1 -ω λ 1 , 1) , and thus by (2.11),
$$\gamma _ { 1 } ^ { * } ( \omega ) = P _ { 1 } ( \pi _ { 1 } ( \omega ) - \frac { \omega } { \lambda _ { 1 } }, 1 ).$$
## 5.3 Marginal queue lengths and waiting times
Analysis of the model with exhaustive service requires a different approach. The key observation, made by [13], is that a nonpriority polling system from the viewpoint of a type i customer is an M/G/ 1 queue with multiple server vacations. This implies that the Fuhrmann-Cooper decomposition can be used, even though the intervisit times are strongly dependent on the visit times. The M/G/ 1 queue with priorities and vacations can be analysed by modelling the system as a special version of the nonpriority M/G/ 1 queue with multiple server vacations, and then applying the results from Fuhrmann and Cooper. This approach has been used by [15] who used the concept of delay cycles , and also by [21] who used level crossing analysis ; see also [23]. We apply Kella and Yechiali's approach to the polling model under consideration to find the waiting time LST for type H and L customers. In [15] systems with single and multiple vacations, preemptive resume and nonpreemptive service are considered. In the present paper we do not consider preemptive resume, so we only use results from the case labelled as NPMV (nonpreemptive, multiple vacations) in [15]. We consider the system from the viewpoint of a type H and type L customer separately to derive E [ e -ωW H ] and E [ e -ωW L ] .
From the viewpoint of a type H customer and as far as waiting times are concerned, a polling system is a nonpriority single server system with multiple vacations. The vacation can either be the intervisit period I 1 , or the service of a type L customer. The LSTs of these two types of vacations are:
$$E [ \mathrm e ^ { - \omega I _ { 1 } } ] & = P _ { 1 } ( 1 - \omega / \lambda _ { 1 }, 1 ), \\ E [ \mathrm e ^ { - \omega B _ { L } } ] & = \beta _ { L } ( \omega ).$$
Equation (5.2) follows immediately from the fact that the number of type 1 (i.e. both H and L) customers at the beginning of a visit to Q 1 is the number of type 1 customers that have arrived during the previous intervisit period: P 1 ( z, 1) = E [ e -( λ 1 (1 -z )) I 1 ] .
We now use the concept of delay cycles, introduced in [15], to find the waiting time LST of a type H customer. The key observation is that an arrival of a tagged type H customer will always take place within either an I H cycle, or an L H cycle. An I H cycle is a cycle that starts with an intervisit period for Q 1 , followed by the service of all type H customers that have arrived during the intervisit period, and ends at the moment that no type H customers are left in the system. Notice that at the start of the intervisit period, no type H customers were present in the system either. An L H cycle is a similar cycle, but starts
with the service of a type L customer. This cycle also ends at the moment that no type H customers are left in the system.
The fraction of time that the system is in an L H cycle is ρ L 1 -ρ H , because type L customers arrive with intensity λ L . Each of these customers will start an L H cycle and the length of an L H cycle equals E B ( L ) 1 -ρ H :
$$\psi _ { \nu - \rho _ { H } } ^ { \nu - \rho _ { H } } E ( L _ { H } \text{ cycle} ) & = E ( B _ { L } ) + \lambda _ { H } E ( B _ { L } ) E ( B P _ { H } ) \\ & = E ( B _ { L } ) + \lambda _ { H } E ( B _ { L } ) \frac { E ( B _ { H } ) } { 1 - \rho _ { H } } \\ & = ( 1 + \frac { \rho _ { H } } { 1 - \rho _ { H } } ) E ( B _ { L } ) = \frac { E ( B _ { L } ) } { 1 - \rho _ { H } }, \\ \cdots \text{is the mean length of a busy period of true } H \text{ customers}$$
where E ( BP H ) is the mean length of a busy period of type H customers.
The fraction of time that the system is in an I H cycle, is 1 -ρ L 1 -ρ H = 1 -ρ 1 1 -ρ H . This result can also be obtained by using the argument that the fraction of time that the system is in an intervisit period is the fraction of time that the server is not serving Q 1 , which is equal to 1 -ρ 1 . A cycle which starts with such an intervisit period and stops when all type H customers that arrived during the intervisit period and their type H descendants have been served, has mean length E I ( 1 )+ λ H E I ( 1 ) E ( BP H ) = E I ( 1 ) 1 -ρ H . This also leads to the conclusion that 1 -ρ 1 1 -ρ H is the fraction of time that the system is in an I H cycle. A customer arriving during an I H cycle views the system as a nonpriority M/G/ 1 queue with multiple server vacations I 1 ; a customer arriving during an L H cycle views the system as a nonpriority M/G/ 1 queue with multiple server vacations B L .
[13] showed that the waiting time of a customer in an M/G/ 1 queue with server vacations is the sum of two independent quantities: the waiting time of a customer in a corresponding M/G/ 1 queue without vacations, and the residual vacation time. Hence, the LST of the waiting time distribution of a type H customer is:
$$E [ e ^ { - \omega W _ { H } } ] = \frac { ( 1 - \rho _ { H } ) \omega } { \omega - \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) } \cdot \left [ \frac { 1 - \rho _ { 1 } } { 1 - \rho _ { H } } \cdot \frac { 1 - \widetilde { I } _ { 1 } ( \omega ) } { \omega E ( I _ { 1 } ) } + \frac { \rho _ { L } } { 1 - \rho _ { H } } \cdot \frac { 1 - \beta _ { L } ( \omega ) } { \omega E ( B _ { L } ) } \right ]. \quad ( 5. 3 )$$
Equation (5.3) is in accordance with the more general equation in Section 4.1 in [15].
Remark 5.1 The LST of the distribution of the waiting time of a high priority customer in a two priority M/G/ 1 queue without vacations is
$$E [ \mathrm e ^ { - \omega W _ { H | M / G / 1 } } ] = \frac { ( 1 - \rho _ { 1 } ) \omega + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) } { \omega - \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) },$$
see, e.g., Equation (3.85) in [10], Chapter III.3. Equation (5.4) can be rewritten to (5.3), with 1 -˜ I 1 ( ω ) ωE I ( 1 ) replaced by 1. Hence, the waiting time distribution of a high priority customer in a two priority M/G/ 1 queue equals the waiting time distribution of a customer in a nonpriority M/G/ 1 queue with only type H customers, where the server goes on a vacation B L with probability ρ L 1 -ρ H .
Remark 5.2 Substitution of (2.12) in (5.3) expresses E [ e -ωW H ] in terms of the LST of the cycle time distribution starting at a visit completion to Q 1 , γ ∗ 1 ( ) · :
$$E [ e ^ { - \omega W _ { H } } ] = \frac { 1 - \gamma _ { 1 } ^ { * } ( \omega - \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) - \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) ) + \lambda _ { L } ( 1 - \beta _ { L } ( \omega ) ) E ( C ) } { ( \omega - \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) ) E ( C ) }. \quad ( 5. 5 )$$
The concept of cycles is not really needed to model the system from the perspective of a type L customer, because for a type L customer the system merely consists of I HL cycles. An I HL cycle is the same as an I H cycle, discussed in the previous paragraphs, except that it ends when no type H or L customers are left in the system. So the system can be modelled as a nonpriority M/G/ 1 queue with server vacations. The vacation is the intervisit time I 1 , plus the service times of all type H customers that have arrived during that intervisit time and their type H descendants. We will denote this extended intervisit time by I ∗ with LST
1
$$\widetilde { I } _ { 1 } ^ { * } ( \omega ) = \widetilde { I } _ { 1 } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ).$$
The mean length of I ∗ 1 equals E I ( ∗ 1 ) = E I ( 1 ) 1 -ρ H .
We also have to take into account that a busy period of type L customers might be interrupted by the arrival of type H customers. Therefore the alternative system that we are considering will not contain regular type L customers, but customers still arriving with arrival rate λ L , whose service time equals the service time of a type L customer in the original model, plus the service times of all type H customers that arrive during this service time, and all of their type H descendants. The LST of the distribution of this extended service time B ∗ L is
$$\beta _ { L } ^ { * } ( \omega ) = \beta _ { L } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ).$$
This extended service time is often called completion time in the literature. In this alternative system, the mean service time of these customers equals E B ( ∗ L ) = E B ( L ) 1 -ρ H . The fraction of time that the system is serving these customers is ρ ∗ L = ρ L 1 -ρ H = 1 -1 -ρ 1 1 -ρ H .
Now we use the results from the M/G/ 1 queue with server vacations (starting with the Fuhrmann-Cooper decomposition) to determine the LST of the waiting time distribution for type L customers:
$$E [ e ^ { - \omega W _ { L } } ] = & \frac { ( 1 - \rho _ { L } ^ { * } ) \omega } { \omega - \lambda _ { L } ( 1 - \beta _ { L } ^ { * } ( \omega ) ) } \cdot \frac { 1 - \widetilde { I } _ { 1 } ^ { * } ( \omega ) } { \omega E ( I _ { 1 } ^ { * } ) } \\ = & \frac { ( 1 - \rho _ { 1 } ) ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) } { \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) ) } \cdot \frac { 1 - \widetilde { I } _ { 1 } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) } { ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) E ( I _ { 1 } ) }. \\ \dots \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdot \quad \cdots$$
The last term of (5.6) is the LST of the distribution of the residual intervisit time, plus the time that it takes to serve all type H customers and their type H descendants that arrive during this residual intervisit time. The first term of (5.6) is the LST of the waiting time distribution of a low-priority customer in an M/G/ 1 queue with two priorities, without vacations (see e.g. (3.76) in [10], Chapter III.3).
Remark 5.3 The M/G/ 1 queue with two priorities can be viewed as a nonpriority M/G/ 1 queue with vacations, if we consider the waiting time of type L customers. We only need to rewrite the first term of (5.6):
$$\Lambda _ { \ } \cdots \cdots \cdots \\ E [ e ^ { - \omega W _ { L | M / G / 1 } } ] = & \frac { ( 1 - \rho _ { 1 } ) ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) } { \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) } \\ = & \frac { ( 1 - \rho _ { L } ^ { * } ) \omega } { \omega - \lambda _ { L } ( 1 - \beta _ { L } ^ { * } ( \omega ) ) } \cdot \frac { 1 - \rho _ { 1 } } { 1 - \rho _ { L } ^ { * } } \cdot \frac { \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) } { \omega } \\ = & E [ e ^ { - \omega W _ { L | M / G / 1 } ^ { * } } ] \cdot \left [ ( 1 - \rho _ { H } ) + \rho _ { H } \frac { 1 - \pi _ { H } ( \omega ) } { \omega E ( B P _ { H } ) } \right ], \\. \quad - \Lambda _ { \ } \cdots W _ { * } ^ { * } \quad \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \end{$$
where E e [ -ωW ∗ L M/G/ | 1 ] is the LST of the waiting time distribution of a customer in an M/G/ 1 queue where customers arrive at intensity λ L and have service requirement LST β L ( ω + λ H (1 -π H ( ω ))) . So with probability 1 -ρ H the waiting time of a customer is the waiting time in an M/G/ 1 queue with no vacations, and with probability ρ H the waiting time of a customer is the sum of the waiting time in an M/G/ 1 queue and the residual length of a vacation, which is a busy period of type H customers.
Remark 5.4 Substitution of (2.12) in (5.6) leads to a different expression for E [ e -ωW L ] :
$$E [ \mathrm e ^ { - \omega W _ { L } } ] & = \frac { 1 - \gamma _ { 1 } ^ { * } ( \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) ) ) } { ( \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) ) ) E ( C ) } \\ & = E [ \mathrm e ^ { - ( \omega - \lambda _ { L } ( 1 - \beta _ { L } ( \omega + \lambda _ { H } ( 1 - \pi _ { H } ( \omega ) ) ) ) ) C _ { 1, r e s } ^ { * } } ].$$
The waiting time of type 2 customers is not affected at all by the fact that Q 1 contains multiple classes of customers, so (2.9) is still valid for E ( e -ωW 2 ) .
We will refrain from mentioning the PGFs of the marginal queue length distributions here, because they can be obtained by applying the distributional form of Little's law as we have done before.
## 5.4 Moments
The mean waiting times for high and low priority customers can be found by differentiation of (5.3) and (5.6):
$$E ( W _ { H } ) & = \frac { \rho _ { H } E ( B _ { H, r e s } ) + \rho _ { L } E ( B _ { L, r e s } ) } { 1 - \rho _ { H } } + \frac { 1 - \rho _ { 1 } } { 1 - \rho _ { H } } E ( I _ { 1, r e s } ), \\ E ( W _ { L } ) & = \frac { \rho _ { H } E ( B _ { H, r e s } ) + \rho _ { L } E ( B _ { L, r e s } ) } { ( 1 - \rho _ { H } ) ( 1 - \rho _ { 1 } ) } + \frac { 1 } { 1 - \rho _ { H } } E ( I _ { 1, r e s } ).$$
Differentiation of (5.5) and (5.7) leads to alternative expressions, that can also be found in [24].
$$E ( W _ { H } ) & = \frac { ( 1 - \rho _ { 1 } ) ^ { 2 } } { 1 - \rho _ { H } } \frac { E ( C _ { 1 } ^ { * 2 } ) } { 2 E ( C ) }, \\ E ( W _ { L } ) & = \frac { ( 1 - \rho _ { 1 } ) ^ { 2 } } { ( 1 - \rho _ { H } ) ( 1 - \rho _ { 1 } ) } \frac { E ( C _ { 1 } ^ { * 2 } ) } { 2 E ( C ) } \\ & = \left ( 1 - \frac { \rho _ { L } } { 1 - \rho _ { H } } \right ) \frac { E ( C _ { 1 } ^ { * 2 } ) } { 2 E ( C ) }.$$
## 6 Example
Consider a polling system with two queues, and assume exponential service times and switch-over times. Suppose that λ 1 = 6 10 , λ 2 = 2 10 , E ( B 1 ) = E B ( 2 ) = 1 , E ( S 1 ) = E S ( 2 ) = 1 . The workload of this polling system is ρ = 8 10 . This example is extensively discussed in [26] where MVA was used to compute mean waiting times and mean residual cycle times for the gated and exhaustive service disciplines.
In this example we show that the performance of this system can be improved by giving higher priority to jobs with smaller service times. We define a threshold t and divide the jobs into two classes: jobs with a service time less than t receive high priority, the other jobs receive low priority. In Figures 1 and 2 the mean waiting times of customers in Q 1 are shown as a function of the threshold t . The following four cases are distinguished:
- · the mean waiting time of the low priority customers in Q 1 (indicated as 'Type L');
- · the mean waiting time of the high priority customers in Q 1 (indicated as 'Type H');
- · a weighted average of the above two mean waiting times: λ L λ 1 E W ( L ) + λ H λ 1 E W ( H ) (indicated as 'Type 1 with priorities'). This can be interpreted as the mean waiting time of an arbitrary customer in Q 1 ;
- · the mean waiting time of an arbitrary customer in Q 1 if no priority rules would be applied to this queue (indicated as 'Type 1 no priorities'). In this situation there is no such thing as high and low priority customers, so the mean waiting time does not depend on t , and has already been computed in [26].
The figures show that a unique optimal threshold exists that minimises the mean weighted waiting time for customers in Q 1 . This value depends on the service discipline used and is discussed in [24]. In this example the optimal threshold is 1 for gated, and 1.38 for exhaustive. Figure 1 confirms that the mean waiting times for type H and L customers in the gated model only differ by a constant value: E W ( L ) -E W ( H ) = ρ E C 1 ( 1 , res ) . For globally gated service no figure is included, because we again have E W ( L ) -E W ( H ) =
ρ E C 1 ( 1 , res ) . The mean residual cycle time is different from the one in the gated model, but this does not affect the optimal threshold which is still t = 1 .
In the exhaustive model we have the following relation:
$$E ( W _ { L } ) - E ( W _ { H } ) = \frac { \rho _ { 1 } ( 1 - \rho _ { 1 } ) } { 1 - \rho _ { H } } E ( C _ { 1, r e s } ^ { * } ).$$
If we increase threshold t , the fraction of customers in Q 1 that receive high priority grows, and so does their mean service time. This means that ρ H increases as t increases, so E W ( L ) -E W ( H ) gets bigger, which can be seen in Figure 2. Notice that E W ( H ) E W ( L ) = 1 -ρ 1 , so it does not depend on t .
Figure 1: Mean waiting time of customers in Q 1 in the gated polling system, versus threshold t .
It is interesting to also consider the variance, or rather the standard deviation of the waiting time. Figures 3 and 4 show the standard deviation of the type H and L customers versus the threshold t . The figures also show the standard deviation of an arbitrary customer in Q 1 , with and without priorities. The figures indicate that the waiting times in the gated system have smaller standard deviations than in the exhaustive case. In this example, the introduction of priorities affects the standard deviation of an arbitrary type 1 customer only slightly. However, it is interesting to zoom in to investigate the influence of threshold t . Figure 5 contains zoomed versions of Figures 3 and 4 and indicates that the threshold t that minimises the overall mean waiting time of type 1 customers in the priority system does not minimise the standard deviation. In fact, changing threshold t affects the entire service time distributions B H and B L , which results in two local minima for the standard deviation as function of threshold t .
Figure 2: Mean waiting time of customers in Q 1 in the exhaustive polling system, versus threshold t .
Figure 3: Standard deviation of the waiting time of customers in Q 1 in the gated polling system, versus threshold t .
## 7 Possible extensions and future research
The polling system studied in the present paper leaves many possibilities for extensions or variations. In this section we discuss some of them.
Multiple queues and priority levels. Probably the most obvious extension of the model under consideration, is a polling system with any number of queues and any number of priority levels in each queue. In recent research [2], we have discovered that such a polling
Figure 4: Standard deviation of the waiting time of customers in Q 1 in the exhaustive polling system, versus threshold t .
Figure 5: Zoomed versions of Figures 3 (left) and 4 (right).
model can be analysed in detail. Each queue can have its own service discipline, either exhaustive or (synchronised) gated.
Preemptive resume. In the present paper, the service of low priority customers is not interrupted by the arrival of a high priority customer. If we allow for service interruptions, these would only take place in a queue with exhaustive service, since (globally) gated service forces high priority customers to wait behind the gate. We note that allowing service interruptions does not affect the joint queue length distributions at polling instants, nor the cycle time. Also the waiting time of low priority customers is unaffected (but they might have a longer sojourn time ). It only affects the waiting time of high priority customers, because they do not have to wait for a residual service time of a low priority customer. The LST of the waiting time distribution of a high priority customer if service is preemptive resume, is:
$$E [ \text{e} ^ { - \omega W _ { H } } ] = \frac { ( 1 - \rho _ { H } ) \omega } { \omega - \lambda _ { H } ( 1 - \beta _ { H } ( \omega ) ) } \cdot \left [ \frac { 1 - \rho _ { 1 } } { 1 - \rho _ { H } } \cdot \frac { 1 - \widetilde { I } _ { 1 } ( \omega ) } { \omega E ( I _ { 1 } ) } + \frac { \rho _ { L } } { 1 - \rho _ { H } } \right ].$$
Mixed gated/exhaustive service. In the present paper, customers in Q 1 receive either exhaustive or (globally) gated service. One may consider serving each priority level according to a different service discipline. In [1], high priority customers receive exhaustive service, whereas low priority customers receive gated service. This gives high priority customers an additional advantage, but it turns out that for low priority customers this strategy may be better than, e.g., gated service for all priority levels. A mixture of globally gated service for low priority customers and exhaustive service for high priority customers can be analysed similarly.
The 'opposite' strategy, where low priority customers are served exhaustively and high priority customers are served according to the gated service discipline is easier to analyse, since we can model it as a nonpriority polling model with Q 1 replaced by two queues, Q H and Q L , containing the type H and type L customers and having gated and exhaustive service respectively.
Partially gated. A variant of the gated service discipline is partially gated service: every customer, type H or L , standing in front of the gate is served during a visit with a fixed probability p , and is not served with probability 1 -p . The probability p might even depend on the customer type. Whether a rejected customer is eligible for service in the next cycle, or leaves the system, does not matter. Both situations can be analysed.
Different polling sequences. We assume that the server alternates between Q 1 and Q 2 . A different way of introducing priorities to a polling system is by increasing the frequency of visits to a queue within a cycle. One can, e.g., decide to visit Q 1 two consecutive times if gated service is used. Or one can think of a system where the server switches to Q j after completing a visit to Q i with probability p ij .
Large setup times. [25] establishes fluid limits for polling systems with any branching type service discipline and deterministic switch-over times tending to infinity. The scaled waiting time distribution is shown to converge to a uniform distribution with bounds that can be computed explicitly. The results are relevant to applications in production systems, where large setup times are common. These fluid limits can also be computed for the polling model that is discussed in the present paper and give explicit insight in when each of the discussed service disciplines is optimal.
## References
- [1] M. A. A. Boon and I. J. B. F. Adan. Mixed gated/exhaustive service in a polling model with priorities. Eurandom report 2008-045, submitted for publication, 2008.
- [2] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A polling model with multiple priority levels. Eurandom report 2008-029, submitted for publication, 2008.
- [3] M. A. A. Boon, I. J. B. F. Adan, and O. J. Boxma. A two-queue polling model with two priority levels in the first queue. ValueTools 2008 (Third International Conference on Performance Evaluation Methodologies and Tools, Athens, Greece, October 20-24, 2008) , 2008.
- [4] S. C. Borst. Polling Systems , volume 115 of CWI Tracts . 1996.
- [5] S. C. Borst and O. J. Boxma. Polling models with and without switchover times. Operations Research , 45(4):536 - 543, 1997.
- [6] O. J. Boxma. Workloads and waiting times in single-server systems with multiple customer classes. Queueing Systems , 5:185-214, 1989.
- [7] O. J. Boxma, H. Levy, and U. Yechiali. Cyclic reservation schemes for efficient operation of multiple-queue single-server systems. Annals of Operations Research , 35(3): 187-208, 1992.
- [8] O. J. Boxma, J. Bruin, and B. H. Fralix. Waiting times in polling systems with various service disciplines. Eurandom report 2008-019, submitted for publication, 2008.
- [9] M. Cicin-Sain, C. E. M. Pearce, and J. Sunde. On the application of a polling model with non-zero walk times and priority processing to a medical emergency-room environment. Proceedings of the 23rd International Conference on Information Technology Interfaces, 2001 , 1:49-56, 2001.
- [10] J. W. Cohen. The Single Server Queue . North-Holland, Amsterdam, revised edition, 1982.
- [11] R. B. Cooper and G. Murray. Queues served in cyclic order. The Bell System Technical Journal , 48(3):675-689, 1969.
- [12] M. Eisenberg. Queues with periodic service and changeover time. Operations Research , 20(2):440-451, 1972.
- [13] S. W. Fuhrmann and R. B. Cooper. Stochastic decompositions in the M/G/ 1 queue with generalized vacations. Operations Research , 33(5):1117-1129, 1985.
- [14] J. Keilson and L. D. Servi. The distributional form of Little's Law and the FuhrmannCooper decomposition. Operations Research Letters , 9(4):239-247, 1990.
- [15] O. Kella and U. Yechiali. Priorities in M/G/ 1 queue with server vacations. Naval Research Logistics , 35:23-34, 1988.
- [16] A. Khamisy, E. Altman, and M. Sidi. Polling systems with synchronization constraints. Annals of Operations Research , 35:231 - 267, 1992.
| [17] | R. Y. W. Lam, V. C. M. Leung, and H. C. B. Chan. Polling-based protocols for packet voice transport over IEEE 802.11 wireless local area networks. IEEE transactions on wireless communications , 13:22-29, 2006. |
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [18] | D. Miorandi and A. Zanella. Performance evaluation of bluetooth polling schemes: An analytical approach. Mobile Networks and Applications , 9:63-72, 2004. |
| [19] | Q. Ni. Performance analysis and enhancements for IEEE 802.11e wireless networks. IEEE Network , 19:21-27, 2005. |
| [20] | J. A. C. Resing. Polling systems and multitype branching processes. Queueing Sys- tems , 13:409 - 426, 1993. |
| [21] | J. G. Shanthikumar. Level crossing analysis of priority queues and a conservation identity for vacation models. Naval Research Logistics , 36:797-806, 1989. |
| [22] | L. Takács. Two queues attended by a single server. Operations Research , 16(3):639- 650, 1968. |
| [23] | H. Takagi. Queueing Analysis: A Foundation Of Performance Evaluation , volume 1: Vacation and priority systems, part 1. North-Holland, Amsterdam, 1991. |
| [24] | A. Wierman, E. M. M. Winands, and O. J. Boxma. Scheduling in polling systems. Performance Evaluation , 64:1009-1028, 2007. |
| [25] | E. M. M. Winands. Polling, Production & Priorities . PhD thesis, Eindhoven Univer- sity of Technology, 2007. |
| [26] | E. M. M. Winands, I. J. B. F. Adan, and G.-J. van Houtum. Mean value analysis for polling systems. Queueing Systems , 54:35-44, 2006. |
| [27] | R. A. Yaiz and G. Heijenk. Polling best effort traffic in bluetooth. Wireless Personal Communications , 23:195-206, 2002. | | 10.1007/s10626-009-0072-9 | [
"Marko Boon",
"Ivo Adan",
"Onno Boxma"
] | 2014-08-01T09:31:44+00:00 | 2014-08-01T09:31:44+00:00 | [
"math.PR",
"cs.PF"
] | A Two-Queue Polling Model with Two Priority Levels in the First Queue | In this paper we consider a single-server cyclic polling system consisting of
two queues. Between visits to successive queues, the server is delayed by a
random switch-over time. Two types of customers arrive at the first queue: high
and low priority customers. For this situation the following service
disciplines are considered: gated, globally gated, and exhaustive. We study the
cycle time distribution, the waiting times for each customer type, the joint
queue length distribution at polling epochs, and the steady-state marginal
queue length distributions for each customer type. |
1408.0111v1 | International Journal of Bifurcation and Chaos c © World Scientific Publishing Company
## NEW APPROACH TO MODELING SYMBIOSIS IN BIOLOGICAL AND SOCIAL SYSTEMS
## V.I. YUKALOV
Department of Management, Technology and Economics,
ETH Z¨ urich, Swiss Federal Institute of Technology, Z¨rich CH-8092, Switzerland u and Bogolubov Laboratory of Theoretical Physics, Joint Institute for Nuclear Research, Dubna 141980, Russia [email protected]
## E.P. YUKALOVA
Department of Management, Technology and Economics, ETH Z¨ urich, Swiss Federal Institute of Technology, Z¨rich CH-8092, Switzerland u and
Laboratory of Information Technologies, Joint Institute for Nuclear Research, Dubna 141980, Russia [email protected]
## D. SORNETTE
Department of Management, Technology and Economics, ETH Z¨ urich, Swiss Federal Institute of Technology, Z¨rich CH-8092, Switzerland u and
Swiss Finance Institute, c/o University of Geneva, 40 blvd. Du Pont d'Arve, CH 1211 Geneva 4, Switzerland [email protected]
Received (to be inserted by publisher)
We suggest a novel approach to treating symbiotic relations between biological species or social entities. The main idea is the characterisation of symbiotic relations of coexisting species through their mutual influence on their respective carrying capacities, taking into account that this influence can be quite strong and requires a nonlinear functional framework. We distinguish three variants of mutual influence, representing the main types of relations between species: (i) passive symbiosis, when the mutual carrying capacities are influenced by other species without their direct interactions; (ii) active symbiosis, when the carrying capacities are transformed by interacting species; and (iii) mixed symbiosis, when the carrying capacity of one species is influenced by direct interactions, while that of the other species is not. The approach allows us to describe all kinds of symbiosis, mutualism, commensalism, and parasitism within a unified scheme. The case of two symbiotic species is analysed in detail, demonstrating several dynamical regimes of coexistence, unbounded growth of both populations, growth of one and elimination
## 2 V.I. Yukalov, E.P. Yukalova, D. Sornette
of the other population, convergence to evolutionary stable states, and everlasting population oscillations. The change of the dynamical regimes occurs by varying the system parameters characterising the destruction or creation of the mutual carrying capacities. The regime changes are associated with several dynamical system bifurcations.
Keywords : Mathematical models of symbiosis, nonlinear differential equations, dynamics of coexisting species, functional carrying capacity, dynamical system bifurcations, supercritical Hopf bifurcation
## 1. Introduction
Symbiosis is one of the most widespread phenomenon in nature. Actually, practically all existing species enjoy some kind of symbiotic relations. As examples, we can start from ourselves, as human beings, whose bodies are in symbiotic relations with ten thousand or more bacterial species (National Institute of Health, USA, http://www.nih.gov/news/health/jun2012/nhgri-13.htm) and around 10 14 different microorganisms. Other well known examples include the association between plant roots and fungi, between coral organisms and various types of algae, between cattle egrets and cattle, between alive beings and different bacteria and viruses. Numerous other examples can be found in the literature [Boucher, 1988; Douglas, 1994; Sapp, 1994; Ahmadjian & Paracer, 2000; Townsend et al., 2002; Yukalov et al., 2012a].
Symbiotic relations are not restricted only to biological species, but may be noticed in a variety of economic, financial, and other relations in social systems. For example, as a variant of symbiosis one can treat the interconnections between economics and arts, between basic and applied science, between culture and language, between banks and firms, between different enterprises, between firm owners and hired personal, and so on. Many more examples are discussed in the following publications [Von Hippel, 1988; Grossman & Helpman, 1991; Richard, 1993; Graedel & Allenby, 2003; Yukalov et al., 2012a].
Coexistence of different species, such as predators and preys, is usually described by the evolution equations of the Lotka-Volterra type [Lotka, 1925], where the species directly interact with each other. Such equations are not valid for describing symbiosis since, in symbiotic relations, the species do not eat or kill each other, but influence their mutual livelihoods [Boucher, 1988; Douglas, 1994; Sapp, 1994; Ahmadjian & Paracer, 2000; Townsend et al., 2002; Yukalov et al., 2012a,b].
From the mathematical point of view, the replicator equations characterizing trait groups, e.g., cooperators, defectors, and punishers, are also of the Lotka-Volterra type, as they consider direct interactions. This also concerns the public-goods games for the spatially structured trait-group coexistence on networks [Perc & Szolnoki, 2010, 2012; Szolnoki & Perc, 2013a,b; Perc et al., 2013], as well as the utility-rate equations [Yukalov et al., 2013]. Such equations do not seem to be applicable for describing symbiotic relations.
The special feature of symbiotic relations is that the coexisting species interact with each other mainly through changing the carrying capacities of each other [Boucher, 1988; Douglas, 1994; Sapp, 1994; Ahmadjian & Paracer, 2000; Townsend et al., 2002; Yukalov et al., 2012a]. Therefore, for the correct description of symbiosis, it is necessary to consider the species carrying capacities as functionals of the species population fractions. In the previous publications [Yukalov et al., 2012a,b], the species carrying capacity functionals were considered as polynomial expansions in powers of population fractions, with taking into account only the lowest orders of these expansions, which resulted in linear or bilinear approximations, depending on the symbiosis type. Such lowest-order approximations presuppose that the symbiotic interactions are sufficiently weak, only slightly varying the mutual carrying capacities. The formal use of the linear or bilinear approximations in some cases leads to artificial finite-time singularity or finite-time population death. This defect could be avoided by employing a nonlinear form for the carrying capacities.
It is the aim of the present paper to formulate the evolution equations for coexisting symbiotic species interacting through the influence on the carrying capacities of each other, keeping in mind that this influence can be arbitrarily strong. This implies the use of a nonlinear form for the carrying capacity functional. We follow the idea used for the generalization of the evolution equation for a single population [Yukalov et al., 2014], where some artificial singularities could be eliminated by a nonlinear carrying-capacity functional. But now, we consider several symbiotic coexisting species, which makes the principal difference from the single-species evolution.
In Sec. 2, we formulate the main idea of the approach for describing symbiosis, not as a direct interaction of different species as in the Lotka-Volterra equation but, through the mutual influence on the carrying capacities of each other. We distinguish three types of the mutual influence characterizing passive symbiosis, active symbiosis, and mixed-type symbiosis. The origin of the problems spoiling the linear or bilinear approximations is explained. In Sec. 3, we introduce the generalized formulation for the symbiotic equations with nonlinear carrying-capacity functionals. We stress that this formulation allows one to treat symbiotic relations of arbitrary strength and of any type, such as mutualism, commensalism, and parasitism. In the following sections, we give a detailed analysis of the dynamics and of the evolutionary stable states for
each kind of the symbiotic relations characterizing passive symbiosis (Sec. 4), active symbiosis (Sec. 5), and mixed symbiosis (Sec. 6) for the cases of mutualism and parasitism. All possible dynamical regimes are investigated, occurring as a result of bifurcations. Of special interest is a supercritical Hopf bifurcation happening in the case of mixed symbiosis. Section 7 summarizes the results for commensalism that is a marginal case between mutualism and parasitism. Section 8 concludes.
## 2. Modeling Symbiosis by Mutual Influence on Carrying Capacities
## 2.1. General structure of equations
Suppose several species, enumerated as i = 1 2 , , . . . , S , coexist, being in mutual symbiosis with each other. It is always admissible to reduce the consideration to dimensionless units, as has been thoroughly explained in the previous articles [Yukalov et al., 2012a,b]. So, in what follows, we shall deal with dimensionless quantities, such as the species fractions x i = x i ( ) t depending on dimensionless time t ≥ 0. The species can proliferate, with the inverse of the proliferation rates characterizing their typical lifetimes. Generally, in applications of dynamical theory, the time scales of the connected equations could be different [Desroches et al., 2012]. However, in the case of symbiosis, one has to keep in mind that the relations between the species, by definition, are assumed to last sufficiently long to be treated as genuinely symbiotic [Boucher, 1988; Douglas, 1994; Sapp, 1994; Ahmadjian & Paracer, 2000; Townsend et al., 2002; Yukalov et al., 2012a]. While this does not cover all symbiotic relationships, such as those between longlived humans and very short-lived bacterias for instance, we will restrict our considerations to the class of symbiotic relationships in which the lifetimes of the involved species are comparable. This corresponds to the situations where these species compete for the corresponding carrying capacities y i . Since the meaning of symbiotic relations is the variation of the mutual carrying capacities, the latter have to be functionals of the population fractions:
$$y _ { i } = y _ { i } ( x _ { 1 }, x _ { 2 }, \dots, x _ { S } ) \.$$
We consider the society, composed of the symbiotic species, as being closed, so that the carrying capacities are not subject to variations caused by external forces, but are only influenced by the mutual interactions of the coexisting species. Therefore the population dynamics is completely defined by the type of symbiotic relations between the species. In the other case, when external forces would be present, the society dynamics would also be governed by such external forces and would strongly depend on the kind of chosen forces [Leonov & Kuznetsov, 2007; Pongvuthithum & Likasiri, 2010].
The evolution equation for an i -th species takes the form
$$\frac { d x _ { i } } { d t } = x _ { i } - \ \frac { x _ { i } ^ { 2 } } { y _ { i } }$$
where x i and y i are non-negative. In particular, for the case of two species, x 1 ≡ x and x 2 ≡ z , we have
$$\frac { d x ( t ) } { d t } = x ( t ) - \, \frac { x ^ { 2 } ( t ) } { y _ { 1 } ( x, z ) } \,, \quad \frac { d z ( t ) } { d t } = z ( t ) - \, \frac { z ^ { 2 } ( t ) } { y _ { 2 } ( x, z ) } \,.$$
To proceed further, it is necessary to specify the expressions for y i . It is possible to distinguish three types of symbiosis, depending on the process controlling the variations of the mutual carrying capacities.
## 2.2. Passive weak symbiosis
To clearly characterize the difference between the symbiosis types, we start with the case of weak symbiosis, when the mutual influence on the carrying capacities is not strong, so that the carrying-capacity functionals can be approximated by power-law expansions over the species fractions, limiting ourselves by the lowest orders of such expansions. In what follows, we consider the case of two symbiotic species.
Probably the most often met type of symbiosis is when the species influence the mutual carrying capacities just by the existence of the species themselves, resulting in the change on the mutual livelihoods caused by the species vital activity. For instance, most land ecosystems rely on symbiosis between the plants
that extract carbon from the air and mycorrhizal fungi extracting minerals from the ground. If the mutual influence is weak, the corresponding carrying capacities can be modeled by the linear approximation
$$y _ { 1 } ( x, z ) \simeq 1 + b _ { 1 } z \, \quad y _ { 2 } ( x, z ) \simeq 1 + g _ { 1 } x$$
in which b 1 and g 1 are the parameters characterizing the productive or destructive influence of the related species on their counterparts. This type of symbiosis can be termed passive, since the species do not directly interact in the process of varying the livelihoods of their neighbors, in the sense that the impacts of species abundance on carrying capacities are linear.
## 2.3. Active weak symbiosis
If in the process of influencing the livelihoods of each other the species directly interact, then their carrying capacities are approximated by the bilinear expressions
$$y _ { 1 } ( x, z ) \simeq 1 + b _ { 2 } x z \, \quad y _ { 2 } ( x, z ) \simeq 1 + g _ { 2 } x z$$
assuming that their interactions are sufficiently weak. The parameters b 2 and g 2 again can be interpreted as production or destruction coefficients, according to the production or destruction affecting the related carrying capacities. Examples of this type of symbiosis could be the relations between different firms producing goods in close collaboration with each other, or the relation between basic and applied sciences.
## 2.4. Mixed weak symbiosis
The intermediate type of symbiosis is when one of the species, in the process of influencing the carrying capacity, interacts with the other species, while the latter acts on the carrying capacity of the neighbor just by means of its vital activity, without explicit interactions. This type of symbiosis is common for many biological and social systems, when one of them is a subsystem of the larger one. Thus, such relations exist between the country gross domestic product and the level of science, or between culture and language. In the case of weak influence of this type, the carrying capacities are represented as the expansions
$$y _ { 1 } ( x, z ) \simeq 1 + b _ { 2 } x z \, \quad y _ { 2 } ( x, z ) \simeq 1 + g _ { 1 } x \.$$
## 3. Arbitrarily Strong Influence on Livelihoods of Symbiotic Species
When one or both of the species are parasites, the corresponding parameters b i or g i are negative. Hence the effective carrying capacity y i can become zero or negative. Then, with the approximations (4), (5) or (6), the evolution equations (3) can result in finite-time singularities of the population fraction or in the disappearance of the solutions, as is found in the previous publications [Yukalov et al., 2012a,b]. Such a situation looks artificial, being just the result of the linear or bilinear approximations involved. In order to avoid that carrying capacities can become zero and negative, it is necessary to employ a more elaborated expression for the carrying-capacity functionals.
## 3.1. Passive nonlinear symbiosis
In order to be able to consider mutual symbiotic relations of arbitrary strength, it is necessary to generalize the carrying capacities. The latter can be treated as expansions in powers of the species fractions. In the case of weak symbiosis, it has been possible to limit oneself to the first terms of such expansions. However, for generalizing the applicability of the approach, it is necessary to define the effective sums of such expansions. The effective summation of power series can be done by means of the self-similar approximation theory [Yukalov, 1990, 1991, 1992; Yukalov & Yukalova, 1996; Gluzman & Yukalov, 1997]. Under the condition of obtaining an effective sum that does not change its sign for the variables defined on the whole real axis, one needs to resort to the exponential approximants [Yukalov & Gluzman, 1998; Gluzman & Yukalov, 1998a,b,c; Yukalov & Gluzman, 1999; Gluzman et al., 2003]. Limiting ourselves by the simplest form of such an exponential approximation, for the case of expansion (4), we have the effective sums
$$y _ { 1 } ( x, z ) = e ^ { b z } \,, \quad y _ { 2 } ( x, z ) = e ^ { g x } \,.$$
The parameters b and g , depending on their signs, characterize the creative or destructive influence of the species on the carrying capacities of their coexisting neighbors.
## 3.2. Active nonlinear symbiosis
Similarly involving the method of self-similar exponential approximants to perform the summation for the previous case of passive symbiosis, starting from the terms (5), we obtain the nonlinear carrying capacities
$$y _ { 1 } ( x, z ) = e ^ { b x z } \, \quad y _ { 2 } ( x, z ) = e ^ { g x z }$$
with the same interpretation of the symbiotic parameters b and g .
## 3.3. Mixed nonlinear symbiosis
In the case of the mixed symbiosis, with the carrying capacities starting from terms (6), we get the effective summation resulting in the nonlinear expressions
$$y _ { 1 } ( x, z ) = e ^ { b x z } \, \quad y _ { 2 } ( x, z ) = e ^ { q x } \.$$
In this way, we obtain the generalizations for the carrying capacities that are applicable to the mutual symbiotic relations of arbitrary strength.
## 3.4. Variants of symbiotic coexistence
It is worth stressing that the suggested approach allows us to treat all known variants of symbiosis, which is regulated by the values of the symbiotic parameters b and g . Thus, when both these parameters are positive, this corresponds to mutualism, which is a relationship between different species where both of them derive mutual benefit:
$$b > 0 \, \quad g > 0 \quad ( m u t u a l i s m ) \.$$
When one of the species benefits from the coexistence with the other species, while the other one is neutral, getting neither profit nor harm, this relationship corresponds to commensalism, defined by one of the conditions
$$\begin{smallmatrix} b > 0 &, & g = 0 & ; \\ b = 0$$
Finally, if at least one of the coexisting species is harmful to the other one, this is typical of parasitism that is characterized by the validity of one of the conditions
$$\begin{array} {$$
Varying the symbiotic parameters b and g results in a variety of bifurcations between different dynamical regimes. Below, we study these bifurcations employing the general methods of dynamical theory [Thompson et al., 1994; Kuznetsov, 1995; Chen et al., 2003; Leonov & Kuznetsov, 2013].
## 4. Passive Nonlinear Symbiosis
Equations (3), with the carrying capacities (7) acquire the form
$$\frac { d x } { d t } = x - x ^ { 2 } e ^ { -$$
with the parameters g ∈ -∞ ∞ ( , ) and b ∈ -∞ ∞ ( , ), and with the initial conditions x 0 = x (0), z 0 = z (0). We are looking for non-negative solutions x t ( ) ≥ 0 and z t ( ) ≥ 0 to the system of these differential equations (13).
We may note that system (13) is symmetric with respect to the change b ←→ g , x 0 ←→ z 0 , and x t ( ) ←→ z t ( ).
The overall phase portrait for the case of the passive symbiosis will be displayed below.
## 4.1. Existence of evolutionary stable states
Depending on the signs of the parameters g and b , the system of equations (13) possesses different numbers of stationary states (fixed points) { x , z ∗ ∗ } . For any values of the parameters, there always exist three trivial fixed points, { x ∗ = 0 , z ∗ = 0 , } { x ∗ = 1 , z ∗ = 0 , and } { x ∗ = 0 , z ∗ = 1 , which are unstable for all } g and b . ∗ ∗
Nontrivial fixed points { x = 0 , z = 0 } are the solutions to the equations:
/negationslash
/negationslash
$$x ^ { * } = e ^ { b z ^ { * } } \, \quad z ^$$
The characteristic exponents, defining the stability of the stationary solutions, are given by the expression
$$\lambda _ { 1, 2 } = - 1 \pm \sqrt { b g x ^ {$$
where x ∗ and z ∗ are the fixed points defined by Eqs. (14), which can also be represented as
$$x ^ { * } = \exp ( b e ^ { g x ^ { * } } ) \,, \quad z ^ { * } = \exp ( g e ^ { b z ^ { * } } ) \,.$$
Analysing the existence and stability of the fixed points, we find that, when b ∈ (0 , ∞ ) and g ∈ (0 , ∞ ), there exists a line g = g c ( b ), with respect to which two possibilities can occur:
- · If 0 < g < g c ( b ), then Eqs. (14) have two solutions { x , z ∗ 1 ∗ 1 } and { x , z ∗ 2 ∗ 2 } , such that 1 < x ∗ 1 < x ∗ 2 and 1 < z ∗ 1 < z ∗ 2 . Numerical investigation of (14) and (15) shows that the lower fixed point { x , z ∗ 1 ∗ 1 } is stable, while the higher fixed point { x , z ∗ 2 ∗ 2 } is unstable.
- · If g > g c ( b ), then Eqs. (14) do not have solutions, hence Eqs. (13) do not possess stationary states. When b = 1 /e , then g c ( b ) = 1 /e and x ∗ = z ∗ = . e
If either b ≤ 0 and g > 0, or b > 0 and g ≤ 0, then there exists only one stationary solution { x , z ∗ ∗ } , which is a stable fixed point characterized by the corresponding characteistic exponents (15) with Re λ 1 2 , < 0, which follows from the inequalities λ λ 1 2 = 1 -bgx z ∗ ∗ > 0 and -( λ 1 + λ 2 ) = 2 > 0.
Note that if b ≤ 0 and g > 0, then x ∗ < 1 and z ∗ > 1, while if b > 0 and g ≤ 0, then x ∗ > 1 and z ∗ < 1. When b < 0 and g < 0, there can exist up to three fixed points, such that x ∗ < 1 and z ∗ < 1. For b ≤ -e , there exist two lines g 1 = g 1 ( b ) < 0 and g 2 = g 2 ( b ) < 0, for which g 1 ( -e ) = g 2 ( -e ) = -e . The following two possibilities can happen:
- · If b < -e and g 1 ( b ) < g < g 2 ( b ), then Eqs. (14) have 3 solutions. Numerical analysis shows that two fixed points, { x , z ∗ 1 ∗ 1 } and { x , z ∗ 2 ∗ 2 } , are stable, while the third fixed point, { x , z ∗ 3 ∗ 3 } , is unstable.
- · If either - ≤ e b < 0 and g < 0, or b < -e and g < g 1 ( b ), or b < -e and g 2 ( b ) < g < 0, then Eqs. (14) have only one solution, which is a stable fixed point.
In the limiting cases, if g → 0, then z ∗ → 1 and x ∗ → e b . If b → 0, then x ∗ → 1 and z ∗ → e g . If b → -∞ and g > 0 is fixed, then x ∗ → 0 and z ∗ → 1. When g → -∞ and b > 0 is ∗ ∗
fixed, then z → 0 and x → 1.
If b /lessmuch -1, and g /lessmuch -1, then, depending on the relation between the parameters, it may be that either x ∗ → 0 and z ∗ → 1, or x ∗ → 1 and z ∗ → 0, or x ∗ → 0 and z ∗ → 0, but at finite parameter values, one always has finite x ∗ = 0 and z ∗ = 0.
/negationslash
/negationslash
Figure 1a clarifies the regions of the stable fixed-point existence in the plane b -g . The region of existence for b, g < 0 is detailed in Fig. 1b.
## 4.2. Dynamics of populations under mutualism ( b > 0 , g > 0 )
There exist two types of dynamical behavior: (i) Unbounded growth of populations or (ii) convergence to a stationary state .
## 8 V.I. Yukalov, E.P. Yukalova, D. Sornette
## (i) Unbounded growth of populations
When 0 < b < ∞ and g > g c ( b ) > 0, then Eqs. (14) do not have solutions, hence Eqs. (13) do not have stationary states. For any choice of the initial conditions { x , z 0 0 } , solutions x t , z ( ) ( ) t →∞ , as t →∞ . The corresponding behavior of x t ( ) and z t ( ) is shown in Fig.2a.
## (ii) Convergence to stationary states
If 0 < b < ∞ and 0 < g < g c ( b ), there exist two solutions to Eqs. (14), such that 1 < x ∗ 1 < x ∗ 2 and 1 < z ∗ 1 < z ∗ 2 . Numerical analysis shows that the lower solution { x , z ∗ 1 ∗ 1 } is stable, while { x , z ∗ 2 ∗ 2 } is unstable. Around the stable fixed point, there exists a finite basin of attraction, so that if the initial conditions { x , z 0 0 } belong to it, then x t ( ) → x ∗ 1 , and z t ( ) → z ∗ 1 , as t →∞ . But if the initial conditions do not belong to the basin of attraction, the species fractions rise to infinity for t →∞ .
Figure 2b demonstrates the behavior or solutions for g slightly above the boundary ( g > g c ( b )) and slightly below it ( g < g c ( b )). Below the boundary g c = g c ( b ), there exists a region of parameters b, g , such that x t ( ) and z t ( ) converge to a stationary state, provided that the initial conditions are inside the basin of attraction. Figures 2c and 2d illustrate the behaviour of x t ( ) and z t ( ) for the same choice of the parameters b, g , but for different initial conditions.
## 4.3. Dynamics of populations with one parasitic species (either b < 0 , g > 0 or b > 0 , g < 0 )
Only one regime exists, when the populations tend to their stationary states , with the attraction basin being the whole region of x , z 0 0 .
Recall that there is a symmetry in Eqs. (13), such that under the replacement b ←→ g and x 0 ←→ z 0 , we have x t ( ) ←→ z t ( ) and x ∗ ←→ z ∗ . Therefore, it is sufficient to consider only one case, say, when b < 0 and g > 0.
When b < 0 and g > 0, Eqs. (14) have a single solution { x ∗ < ,z 1 ∗ > 1 , which is a stable fixed point. } Conversely, when b > 0 and g < 0, then x ∗ > 1 and z ∗ < 1. This tells us that the species population coexisting with a parasite is suppressed.
The populations converge to their stationary points irrespectively of the choice of the initial conditions. The convergence can be either monotonic or non-monotonic, as is demonstrated in Figs. 3 and 4.
## 4.4. Dynamics of populations with two parasitic species ( b < 0 , g < 0 )
Depending on the symbiotic parameters, there can exist either (i) a single stationary state or (ii) bistability with two stationary states .
When b < 0 and g < 0, then Eqs. (14) have either a single solution { x , z ∗ ∗ } , which is a stable fixed point, or three solutions, among which two solutions, { x ∗ 1 2 , , z ∗ 1 2 , } , are stable fixed points and the third, { x , z ∗ 3 ∗ 3 } , is a saddle. In all the cases, x ∗ < 1 and z ∗ < 1, which means that two parasitic species cannot develop large populations.
## (i) Single stationary state
For b, g ≤ -e , there exist two lines, g 1 ( b ) and g 2 ( b ), such that g 1 ( -e ) = g 2 ( -e ) = -e and g 1 ( b ) < g 2 ( b ) < 0. If either -e < b < 0 and g < 0, or b < -e and g 2 ( b ) < g < 0, or b < -e and g < g 1 ( b ), then there exists a single solution to Eqs. (14), which is a stable fixed point.
## (ii) Bistability with two stationary states .
If b < -e and g 1 ( b ) < g < g 2 ( b ), there exist three solutions to Eqs. (14). Two solutions are stable fixed points and the third solution is a saddle. The bifurcation point corresponds to b = g = -e . At this point, x ∗ = z ∗ = 1 /e .
The populations x t ( ) and z t ( ) tend monotonically or non-monotonically to their stable stationary states, from above or from below, as is shown in Figs. 5 and 6. In the region of the symbiotic parameters b, g < 0, where a single stable fixed point exists, x t ( ) → x ∗ , z t ( ) → z ∗ , as t → ∞ , irrespectively of the initial conditions.
In the region of the parameters b and g , where two stable fixed point exist, the population convergence depends on the choice of initial conditions. For t →∞ , the population { x t , z ( ) ( ) t } tend either to { x , z ∗ 1 ∗ 1 } or to { x , z ∗ 2 ∗ 2 } , depending on the initial conditions { x , z 0 0 } being in the attraction basin of the related fixed point.
On the line -e < b = g < 0, there exists a single stationary state { x ∗ = z ∗ } that is a stable fixed point. On the line b = g < -e , there are three fixed points. Two fixed points are stable, so that x ∗ 1 = z ∗ 2 and z ∗ 1 = x ∗ 2 . The third fixed point, { x ∗ 3 = z ∗ 3 } is unstable. For b = g →-∞ , we have x ∗ 1 → 0, z ∗ 1 → 1, x ∗ 2 → 1, z ∗ 2 → 0, and x ∗ 3 = z ∗ 3 → 0.
## 4.5. Phase portrait for passive nonlinear symbiosis
Fig. 7 provides an overview of the different regimes analysed in this section concerned with the analysis of equation (13).
Panels (a) and (b) illustrate the regime of mutualism, in which the two species benefit from each other. Panel (a) represents the situation of sufficiently symmetric mutualism, in which the long-term behaviour is characterised by an exponential growth for both species. Note that asymmetric initial conditions lead to a non-monotonous behaviour of the species population that is initially too large, which has to shrink first before growing again in synergy with the other species. Panel (b) corresponds to the situation of large mutualism asymmetries. In this case, the two population need to be above a certain threshold in order to reach the regime of unbounded growth. Otherwise, their populations are trapped and converge to a steady state.
Panel (c) illustrates the dynamics of a very asymmetric situation where one species augments the carrying capacity of the other, while the later has a negative effect on the carrying capacity of the former. In this case, the dynamics of the two species population converges to a stable fixed point, a steady state characterising a compromise in the destructive interactions between the two species.
In the situation shown in panel (d) in which both species tend to destroy the carrying capacity of the other, a saddle node separates two symmetrical stable fixed points, where one species in general profits much more than the other. This is an example of a spontaneous symmetry breaking, in which the two stable fixed points are exactly symmetric under the transformation x ←→ z . The selection of one or the other stable fixed points depends on the initial conditions, as usual in spontaneous symmetry breaking. A slight initial advantage of x above z is sufficient to consolidate into a very large asymptotic population difference. Such behaviours are reminiscent to many real-life situations in which a slight initial favourable situation becomes entrenched in a very strong prominent role. Our analysis shows that such a situation occurs generically in the case of passive symbiosis when the two species are competing destructively. It is tempting to interpret real-life geopolitical and economic situations in particular as embodiment of such a scenario.
## 5. Active Nonlinear Symbiosis
This case is described by the system of equations
$$\frac { d x } { d t } = x - x ^ { 2 } e ^ { - b x z } \,, \quad \frac { d z } { d t } = z - z ^ { 2 } e ^ { - g x z } \,, \quad \dots \quad \dots$$
with the symbiotic parameters g ∈ -∞ ∞ ( , ), b ∈ -∞ ∞ ( , ), and the initial conditions x 0 = x (0), z 0 = z (0). Again, only non-negative solutions x t ( ) ≥ 0 and z t ( ) ≥ 0 are of interest. Note that the system (16) is symmetric with respect to the replacement b ←→ g , x 0 ←→ z 0 , and x t ( ) ←→ z t ( ).
## 5.1. Existence of evolutionary stable states
Similarly to the previous case, there always exist three trivial fixed points, { x ∗ = 0 , z ∗ = 0 , } { x ∗ = 1 , z ∗ = 0 , and } { x ∗ = 0 , z ∗ = 1 , which are unstable for any } g and b .
Nontrivial fixed points { x ∗ = 0 , z ∗ = 0 }
/negationslash
/negationslash
$$x ^ { * } = e ^ { b x ^ { * } z ^ { * } } \, \quad z ^ { * } = e ^ { g x ^ { * } z ^ { * } } \.$$
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdot \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \colon \\ \neq 0, z ^ { * } \neq 0 \} \, \text{are the solutions to the equations:} \\ x ^ { * } = e ^ { b x ^ { * } z ^ { * } } \,, \quad \ \ z ^ { * } = e ^ { g x ^ { * } z ^ { * } } \,.$$
- 10 V.I. Yukalov, E.P. Yukalova, D. Sornette
These Eqs. (17) can be represented as
$$x ^ { * } = \exp ( b ( x ^ { * } ) ^ { 1 + g / b } ) \,, \quad z ^ { * } = \exp ( g ( z ^ { * } ) ^ { 1 + b / g } ) \,.$$
The characteristic exponents are given by the equations
$$\lambda _ { 1 } = - 1 \, \quad \lambda _ { 2 } = - 1 + ( b + g ) x ^ { * } z ^ { * }$$
where x ∗ and z ∗ are the solutions to Eqs. (17). From here, it follows that the fixed points are stable for all b + g < 0.
The following situations can occur:
- · If b + g > 1 /e , then Eqs. (17), or (18), do not have solutions.
- · If 0 < b + g < 1 /e , then Eqs. (17) or (18) have two solutions { x , z ∗ 1 ∗ 1 } and { x , z ∗ 2 ∗ 2 } . Here, when b > 0, g > 0, then 1 < x ∗ 1 < x ∗ 2 and 1 < z ∗ 1 < z ∗ 2 . When b < 0 and g > 0, then 1 > x ∗ 1 > x ∗ 2 and 1 < z ∗ 1 < z ∗ 2 . If b > 0 and g < 0, then 1 < x ∗ 1 < x ∗ 2 , but 1 > z ∗ 1 > z ∗ 2 . Numerical investigation shows that the fixed point { x , z ∗ 1 ∗ 1 } is stable, while the second fixed point { x , z ∗ 2 ∗ 2 } is a saddle.
- · If b + g < 0, then there exists only one solution to Eqs. (17) or (18) that is a stable fixed point.
The region of the existence of the stable fixed-point in the plane b -g is presented in Fig. 8.
When 0 < b + g < 1 /e , the stable fixed point possesses a finite basin of attraction. If b + g ≤ 0, then the basin of attraction is the whole region { x 0 ≥ 0 , z 0 ≥ } 0 .
## 5.2. Population dynamics under b + g > 1 /e
In this case, Eqs. (17) or (18) do not have solutions, which means that there are no fixed points. There can happen two types of solutions: (i) Unbounded growth of mutualistic populations or (ii) Unbounded growth of a parasitic population and dying out of the host population .
- (i) Unbounded growth of mutualistic populations
In the case of mutualism, when b > 0 and g > 0, both populations grow so that x t ( ) → ∞ and z t ( ) →∞ , as t →∞ .
- (ii) Unbounded growth of parasitic population and dying out of host population
When one of the species is parasitic, the host population dies out. If b < 0, but g > 0, then x t ( ) → 0 and z t ( ) →∞ , as t →∞ . Conversely, if b > 0, but g < 0, then x t ( ) →∞ , while z t ( ) → 0, as t →∞ .
The population dynamics for the case b + g > 1 /e is presented in Fig. 9. Because of the symmetry of Eqs. (16), it is sufficient to consider only the cases when b > 0, g > 0 and b < 0, g > 0.
## 5.3. Population dynamics under b + g < 1 /e
There exists only one stable fixed point, so that the population dynamics depends on whether the initial conditions are inside the attraction basin or not. Respectively, there can happen three kinds of behavior: (i) Convergence to a stationary state ; (ii) Unbounded growth of both populations ; (iii) Unbounded growth of parasitic population and dying out of host population .
## (i) Convergence to stationary state
When 0 < b + g < 1 /e and the initial conditions { x , z 0 0 } are in the basin of attraction of the fixed point { x , z ∗ ∗ } , then the populations x t ( ) → x ∗ and z t ( ) → z ∗ , as t →∞ .
If b + g ≤ 0, then the basin of attraction is the whole region of x 0 ≥ 0 and z 0 ≥ 0, that is, for any choice of the initial conditions { x , z 0 0 } the solutions { x t , z ( ) ( ) t } → { x , z ∗ ∗ } , as t →∞ .
## (ii) Unbounded population growth
When 0 < b + g < 1 /e and b, g > 0, there exists a finite basin of attraction, so that if the initial conditions { x , z 0 0 } are outside of the attraction basin, then the populations { x t , z ( ) ( ) t } unboundedly grow with increasing time t →∞ .
- (iii) Unbounded growth of parasitic population and dying out of host population
When 0 < b + g < 1 /e , with b < 0 but g > 0, and initial conditions { x , z 0 0 } are outside of the attraction basin, then for t →∞ , one of the species is dying out, x t ( ) → 0, while another one experiences unbounded growth z t ( ) →∞ . Conversely, if b > 0, but g < 0, then x t ( ) →∞ , while z t ( ) → 0, as t →∞ .
Figure 10 demonstrates different types of the population convergence to a stable stationary state { x , z ∗ ∗ } .
## 5.4. Phase portrait for active nonlinear symbiosis
Figure 11 provides an overview of the different regimes analysed in this section concerned with the analysis of equation (16). Qualitatively, the nature of the different regimes are similar to those discussed with respect to the phase portrait shown in Fig. 7 summarising the different regime for passive symbiosis described by equation (13).
## 6. Mixed Nonlinear Symbiosis
The system of equations describing this case is
$$\frac { d x } { d t } = x - x ^ { 2 } e ^ { - b x z } \, \quad \ \frac { d z } { d t } = z - z ^ { 2 } e ^ { - g x }$$
with the symbiotic parameters g ∈ -∞ ∞ ( , ), b ∈ -∞ ∞ ( , ), and the initial conditions x 0 = x (0), z 0 = z (0). As usual, only non-negative solutions x t ( ) ≥ 0 and z t ( ) ≥ 0 are of interest.
Note that contrary to Eqs. (13) and (16), the system of equations (20) is not symmetric. The carrying capacity of the population x t ( ) is formed in the process of interactions between the coexisting species. In contrast, the carrying capacity of the population z t ( ) is influenced only by the population x t ( ). Therefore, we may call the population x t ( ) active , but the population z t ( ) passive .
## 6.1. Existence of evolutionary stable states
Similarly to the previous cases, there always exist 3 trivial fixed points, { x ∗ = 0 , z ∗ = 0 , } { x ∗ = 1 , z ∗ = 0 , } and { x ∗ = 0 , z ∗ = 1 , which are unstable for all } b, g ∈ -∞ ∞ ( , ).
Nontrivial fixed points { x ∗ = 0 , z ∗ = 0 } are the solutions to the equations:
/negationslash
/negationslash
$$x ^ { * } = e ^ { b x ^ { * } z ^ { * } } \, \quad z ^ { * } = e ^ { g x ^ { * } }$$
which can be transformed into
$$x ^ { * } = \exp ( b x ^ { * } e ^ { g x ^ { * } } ) \,, \quad z ^ { * } = \exp ( g z ^ { b z ^ { * } / g } ) \,.$$
The characteristic exponents, defining the stability of the stationary states, are given by the equations
$$\lambda _ { 1, 2 } = \frac { 1 } { 2 } \left [ b x ^ { * } z ^ { * } - 2 \pm x ^ { * } \sqrt { b z ^ { * } ( 4 g + b z ^ { * } ) } \right ] \,,$$
The following cases can occur:
- · When b > 0, there exists a boundary g = g c ( b ), such that if g < g c ( b ), then there can exist up to three fixed points, but only one of them being stable.
- · If either 0 < b < 1 /e and g > g c ( b ) > 0, or b > 1 /e and g ≥ 0, then Eqs. (21) do not have solutions, hence, there are no fixed points.
- · For b > 1 /e and g c ( b ) < g < 0, there exists only one unstable fixed point.
- · If 0 < b < 1 /e and 0 ≤ g < g c ( b ), there is one stable and one unstable fixed points.
- · When b ≤ 0 and g ∈ -∞ ∞ ( , ), there exists a single fixed point that is stable. For b < 0 and g > 0, we have x ∗ < ,z 1 ∗ > 1, while when b < 0 and g < 0, then x ∗ < ,z 1 ∗ < 1.
- · For 0 ≤ b ≤ b 0 ≈ 0 47, . there exists an additional line g 0 ( b ), such that g 0 (0) = 0 and g 0 ( b 0 ) = g c ( b 0 ) ≈ -0 075706. If either 0 . < b < b 0 and g < g 0 ( b ) or b ≥ b 0 and g < g c ( b ), there is a single fixed point that is stable.
## 12 V.I. Yukalov, E.P. Yukalova, D. Sornette
- · When either 0 < b < 1 /e and g 0 ( b ) < g < 0, or 1 /e ≤ b < b 0 and g 0 ( b ) < g < g c ( b ), then Eqs. (21) have three solutions, but only one of them is a stable fixed point.
In the limiting case, we have g c (1 /e ) = 0. When b → +0, then g c ( b ) →∞ . If b →∞ , then g c ( b ) →-∞ . On the boundary { b ∈ (0 , b 0 ) , g = g 0 ( b ) } , two solutions, corresponding to unstable fixed points, coincide and disappear as soon as g ≤ g 0 ( b ).
The region of the existence of the fixed-point in the plane b -g is presented in Fig. 12.
The dynamics of the symbiotic populations strongly depends on whether the influence of the passive species z t ( ) on the active species x t ( ) is mutualistic or parasitic, which is described by their interaction symbiotic parameter b . Therefore, these two cases will be treated separately.
## 6.2. Dynamics of populations with mutualistic passive species ( b > 0 )
Depending on the symbiotic parameters b and g , there are three types of dynamic behavior: (i) Unbounded growth of populations ; (ii) everlasting oscillations , and (iii) convergence to a stationary state .
## (i) Unbounded growth of populations
When either 0 < b < 1 /e and g > g c ( b ) > 0, or b > 1 /e and g ≥ 0, then Eqs. (20) do not have fixed points. Populations x t ( ) →∞ and z t ( ) →∞ , either monotonically or non-monotonically, as t →∞ . The logarithmic behaviour of diverging solutions x t ( ) and z t ( ) is shown in Figs. 13a and 13b.
When 0 < b < 1 /e and 0 ≤ g < g c ( b ), there are two fixed points, but only one of them is stable. In this case, there exists a finite basin of attraction for the stable fixed point. If the initial conditions { x , z 0 0 } are outside of the attraction basin, the populations x t ( ) and z t ( ) diverge, as t →∞ .
## (ii) Everlasting oscillations
When b > 1 /e and g c ( b ) < g < 0, then Eqs. (21) have only one solution { x , z ∗ ∗ } , which is an unstable focus, with complex characteristic exponents, such that λ 2 = λ ∗ 1 and Re λ 1 2 , > 0. In this region of the parameters b and g , there exists a limit cycle, and the populations x t ( ) and z t ( ) oscillate without convergence for all t > 0.
When g →-0, then the amplitude of oscillations drastically increases, but remains finite. On the half line, b > 1 /e and g = 0, solutions x t ( ) and z t ( ) diverge, as t →∞ .
The dynamics of populations x t ( ) and z t ( ) are shown in Figs. 13c,d, 14a,b, 15c,d, and 16c,d. Figure 17 presents the logarithmic behavior of the populations x t ( ), z t ( ) for the fixed b = 0 4 and varying . g , such that either g c ( b ) < g < 0 or g 0 ( b ) < g < g c ( b ).
## (iii) Convergence to stationary states
When b > 0 and g < g c ( b ), there exists one stable fixed point { x , z ∗ ∗ } .
When 0 < b < 1 /e and 0 < g < g c ( b ), then there exists a finite basin of attraction for the fixed point.
If the initial conditions
{
x , z
0
0
}
are inside the basin of attraction, then x t
( )
→
x
∗
and z t
( )
→
z
∗
,
as
t
→∞
.
If either 0 < b < 1 /e and g ≤ 0, or b > 1 /e and g < g c ( b ) < 0, then the basin of attraction is the whole region of { x 0 ≥ 0 , z 0 ≥ } 0 . In that case, for any initial conditions, x t ( ) → x ∗ and z t ( ) → z ∗ , as t →∞ .
There are two possible ways of convergence to a stationary state, either with oscillations, when the fixed point is a focus, or without oscillations, when the fixed point is a node.
When b > b 0 and g < g c ( b ), and g is in the vicinity of g = g c ( b ), then x t ( ) → x ∗ and z t ( ) → z ∗ with oscillations. The corresponding behaviour is shown in Figs. 14c,d, 15c,d (solid lines), and Figs. 16c,d (dashed lines).
When 0 < b < 1 /e and 0 < g < g c ( b ) and the initial conditions { x , z 0 0 } are inside the attraction basin of the fixed point, then x t ( ) → x ∗ , z t ( ) → z ∗ without explicit oscillations, though the convergence can be either monotonic or non-monotonic.
If either 0 < b < 1 /e and g ≤ 0, or 1 /e < b < b 0 and g < g c ( b ), or b > b 0 and g /lessmuch g c ( b ), then x t ( ) → x ∗ and z t ( ) → z ∗ without oscillations.
Examples of convergence without oscillations are given in Figs. 15 and 16.
The bifurcation line g = g c ( b ) < 0 for b > b 0 is the line of a supercritical Hopf bifurcation. It separates the regions where the real parts of the complex characteristic exponents have different signs. When b > b 0 and g < g c ( b ) < 0, then the characteristic exponents of the stable fixed point are complex, with the negative Lyapunov exponents Re λ 1 2 , < 0. When b > b 0 and g c ( b ) < g < 0, then the stable focus transforms into an unstable focus, with positive Lyapunov exponents Re λ 1 2 , > 0. At the same time, there appears a stable limit cycle. On the bifurcation line, where b > b 0 and g = g c ( b ) the Lyapunov exponents of the focus are zero, Re λ 1 2 , = 0, as it should be under a Hopf bifurcation [Kuznetsov, 1995; Chen et al., 2003; Cobiaga & Reartes, 2013].
A very interesting behaviour is associated with the transition across the line g c ( b ), when 1 /e < b < b 0 . In the region where either 0 < b < 1 /e and g 0 < g < 0, or 1 /e < b < b 0 and g 0 ( b ) < g < g c ( b ), there are three fixed points, a stable node, a saddle, and an unstable focus. In the region b > 1 /e and g > g c ( b ), there is one unstable focus and a limit cycle. When approaching the boundary g c ( b ), moving from one region to the other, the stable node and saddle become close to each other and on the boundary they coincide, while disappearing to the right from this line g c ( b ). The unstable focus safely moves through the boundary to the region where a limit cycle appears.
## 6.3. Dynamics of populations with parasitic passive species ( b < 0 )
There is only one regime of convergence to stationary states .
When b ≤ 0 and g ∈ ( -∞ ∞ , ), there exists just one solution to Eqs. (21), or (22), and it is a stable fixed point. The attraction basin is the whole region of the initial conditions { x , z 0 0 } , so that, for any initial condition, populations x t ( ) → x ∗ and z t ( ) → z ∗ , as t →∞ .
The corresponding behaviour of the populations is presented in Fig. 16.
## 6.4. Phase portrait for mixed nonlinear symbiosis
The phase portraits for the case of the mixed symbiosis described by equation (20), under different symbiotic parameters, are presented in Figs. 18 and 19.
Fig. 18 for g > 0 shows three different regimes that are qualitatively similar to those shown for the passive symbiosis cases in panels (a)-(c) of Fig. 7.
Fig. 19 corresponds to the situation where b > 0 and g < 0, so that the species x tends to destroy the carrying capacity of the species z , while the latter tends to augment nonlinearly the carrying capacity of the former. As a consequence of the asymmetry of the equations and of this pair of parameters, either convergent oscillations to a stable fixed point or oscillatory solutions occur.
## 7. Commensalism as Marginal Type of Symbiosis (either b = 0 , or g = 0 )
## 7.1. Independent species ( b = 0 and g = 0 )
This is the extreme case, when the species are actually independent of each other. If b = 0 and g = 0, then the systems of the evolution equations turn into two independent logistic equations
$$\frac { d x } { d t } = x - x ^ { 2 } \,, \quad \frac { d z } { d t } = z - z ^ { 2 } \,,$$
with the initial conditions x 0 = x (0) and z 0 = z (0).
Solutions to these equations are known:
$$x ( t ) = \frac { x _ { 0 } } { x _ { 0 } - ( x _ { 0 } - 1 ) e ^ { - t } } \, \quad \ z ( t ) = \frac { z _ { 0 } } { z _ { 0 } - ( z _ { 0 } - 1 ) e ^ { - t } } \.$$
That is, x t ( ) → x ∗ = 1 and z t ( ) → z ∗ = 1, as t →∞ .
14 V.I. Yukalov, E.P. Yukalova, D. Sornette
/negationslash
## 7.2. Commensalism under b = 0 , g = 0
/negationslash
When b = 0 and g = 0 in equation (20), this can be treated as a limiting case of either passive or mixed symbiosis. Then the system of equations (13), or (20), turns into
$$\frac { d x } { d t } = x - x ^ { 2 } \, \quad \frac { d z } { d t } = z - z ^ { 2 } e ^ { - g x ( t ) } \.$$
The solution x t ( ) to the first equation of (26) is given by the first equation in (25). The stable set of fixed points is defined by the expressions
$$x ^ { * } = 1 \, \quad z ^ { * } = e ^ { g }$$
which exist for all g ∈ ( -∞ ∞ , ). Populations { x t , z ( ) ( ) t } → { x , z ∗ ∗ } monotonically either from above or from below, depending on the given initial conditions.
/negationslash
## 7.3. Commensalism under b = 0 , g = 0
/negationslash
When b = 0 and g = 0 in equation (20), this is the limiting case of either active or mixed symbiosis. The system of equations (16), or (20), becomes
$$\frac { d x } { d t } = x - x ^ { 2 } e ^ { - b x z } \,, \quad \frac { d z } { d t } = z - z ^ { 2 } \,.$$
The solution z t ( ) to the second equation of (27) is given by the second expression in (25). The fixed point z ∗ = 1 is stable, while the fixed point z ∗ = 0 is unstable.
For the first equation in (27), the trivial fixed point x ∗ = 0 is also unstable. Nontrivial fixed points x ∗ = 0 are the solutions to the equation
/negationslash
$$x ^ { * } = e ^ { b x ^ { * } } \.$$
When b ≤ 0 there exists a single fixed point x ∗ ≤ 1 that is stable. Then, for any initial conditions, x t ( ) → x ∗ and z t ( ) → z ∗ = 1, as t →∞ .
If 0 < b < 1 /e , there exist two solutions, but only one solution, such that 1 < x ∗ < e , is stable, possessing a finite basin of attraction.
When b > 1 /e , there are no fixed points for x t ( ), hence x t ( ) →∞ , though z t ( ) → 1, as t →∞ .
Dynamics of the populations x t ( ) and z t ( ) in the case of commensalism, described by Eqs. (24), (26), and (27), is demonstrated in Fig. 20.
## 8. Summary of Main Symbiotic Behaviors
For the convenience of the reader, we summarize here the main types of symbiotic behaviors for the considered cases of symbiosis, classifying the population dynamics with respect to the related symbiotic parameters.
## 8.1. Dynamics under passive symbiosis
The following types of population behavior can happen:
- · Unbounded growth for
$$0 < b < \infty \, \quad \ g > g _ { c } ( b ) > 0 \.$$
- · Convergence to stationary states , if the initial conditions are inside the attraction basin, and unbounded growth , when the initial conditions are outside the attraction basin, which occurs for
$$0 < b < \infty \, \quad \ 0 < g < g _ { c } ( b ) \.$$
- · Convergence to stationary states for arbitrary initial conditions, when either
$$b < 0 \, \quad \ g > 0$$
or
$$b > 0 \, \quad \ g < 0 \.$$
- · Convergence to stationary states in the presence of bistability , when
$$b < 0 \, \quad \ g < 0 \.$$
## 8.2. Dynamics under active symbiosis
The following regimes of population dynamics exist:
- · Unbounded growth if either
or
$$b + g > \frac { 1 } { e } \,, \quad b > 0 \,, \quad g > 0 \,,$$
$$b + g < \frac { 1 } { e } \,, \quad b > 0 \,, \quad g > 0 \,,$$
and initial conditions are outside of the attraction basin.
- · Dying out of the host species and unbounded proliferation of parasitic species , when either
or
$$b < 0 \, \quad g > \frac { 1 } { e } + | b |$$
or
$$b > \frac { 1 } { e } + | g | \, \quad g < 0$$
$$b < 0 \, \quad | b | < g < \frac { 1 } { e } + | b |$$
and initial conditions are outside of the attraction basin, or
$$g < 0 \, \quad \left | g \right | < b < \frac { 1 } { e } + \left | g \$$
and initial conditions are outside of the attraction basin.
- · Convergence to stationary states for the initial conditions inside the attraction basin if
$$b + g \leq \frac { 1 } { e } \.$$
## 8.3. Dynamics under mixed symbiosis
There can exist the following regimes of population dynamics:
- · Unbounded growth when either
or
$$0 < b < \frac { 1 } { e } \, \quad g > g _ { c } ( b ) > 0$$
$$b > \frac { 1 } { e } \,, \quad g \geq 0 \,. \quad \quad \quad$$
- · Convergence to stationary states for the initial conditions inside the attraction basin and unbounded growth for the initial conditions outside the attraction basin, when
$$0 < b < \frac { 1 } { e } \, \quad 0 \leq g < g _ { c } ( b ) \.$$
16 V.I. Yukalov, E.P. Yukalova, D. Sornette
- · Convergence to stationary states for all initial conditions, if either
$$b > \frac { 1 } { e } \, \quad g < g _ { c } ( b ) < 0$$
or or
$$b \leq 0 \, \quad - \infty < g < \infty \.$$
- · Everlasting oscillations under the condition
$$b > \frac { 1 } { e } \, \quad g _ { c } ( b ) < g < 0 \.$$
## 9. Conclusion
A novel approach to treating symbiotic relations between biological or social species has been suggested. The principal idea of the approach is the characterization of symbiotic relations of coexisting species through the carrying capacities of each other. Taking into account that the mutual influence can be quite strong, the carrying capacities are modeled by nonlinear functionals. We opt for the exponential form of this functional, since such a form naturally appears as an effective sum of a series, summed in a self-similar way, under the condition of semi-positivity.
We distinguish three variants of mutual influence, depending on the type of relations between the species. In the case of passive symbiosis , the mutual carrying capacities are influenced by other species without their direct interactions. In active symbiosis , the carrying capacities are influenced by interacting species. And mixed symbiosis describes the situation when the carrying capacity of one species is influenced by direct interactions, while that of the other species is not.
The approach allows us to describe all kinds of symbiosis, that is, mutualism, commensalism, and parasitism . The case of two symbiotic species is analyzed in detail. Depending on the symbiotic parameters, characterizing the destruction or creation of the mutual carrying capacities, that is, describing mutualistic or parasitic species, several dynamical regimes of coexistence are possible: unbounded growth of both populations, growth of one and the elimination of the other population, convergence to evolutionary stable states, and everlasting population oscillations.
The main difference of the described symbiosis with nonlinear functional carrying capacities, compared with the model of [Yukalov et al., 2012a,b] considered earlier of symbiosis with carrying capacities in the linear or bilinear approximations, is the absence of finite-time singularities and of an abrupt death of populations. The latter have appeared in the previous works [Yukalov et al., 2012a,b] owing to the artificial change of sign of the carrying capacities, when they were crossing zero. The nonlinear carrying capacities, employed in the present paper, are semi-positive defined, which ensures that the crossing-zero problem is avoided.
Among various bifurcations, when the dynamic regimes of the population evolution qualitatively changes, the most interesting ones are the two bifurcations occurring for the case of mixed symbiosis, with the coexistence of two parasitic species, when crossing the bifurcation line g c ( b ). One is the supercritical Hopf bifurcation, when a stable focus becomes unstable and a limit cycle arises. The other is the coalescence of a stable node with a saddle, with their disappearance and the appearance of a limit cycle.
$$0 < b < \frac { 1 } { e } \,, \quad g \leq 0 \,,$$
## References
Ahmadjian, V. & Paracer, S. [2000] An Introduction to Bilogical Associations Boucher, D. [1988] The Biology of Mutualism: Ecology and Evolution (Oxford University, New York).
Chen, G., Hill, D.J. & Yu, X.H. [2003] Bifurcation Control: Theory and Applications
(Oxford University, Oxford). (Springer, Berlin).
Cobiaga, R, $ Reartes, W. [2013] 'A new approach in the search for periodic orbits', Int. J. Bifur. Chaos 23 , 1350186.
Desroches, M., Guckenheimer, J., Krauskopf, B., Kuehn, C., Osinga, H. M. & Wechselberger, M. [2012] 'Mixed-mode oscillations with multiple time scales', SIAM Review 54 , 211-288.
Douglas, A. E. [1994] Symbiotic Interactions (Oxford University, Oxford).
Gluzman, S. & Yukalov, V. I. [1997] 'Algebraic self-similar renormalization in the theory of critical phenomena', Phys. Rev. E 55 , 3983-3999.
Gluzman, S. & Yukalov, V. I. [1998a] 'Resummation method for analyzing time series', Mod. Phys. Lett. B 12 , 61-74.
Gluzman, S. & Yukalov, V. I. [1998b] 'Renormalization group analysis of October market crashes', Mod. Phys. Lett. B 12 , 75-84.
Gluzman, S. & Yukalov, V. I. [1998c] 'Booms and crashes in self-similar markets', Mod. Phys. Lett. B 12 , 575-587.
Gluzman, S., Sornette, D. & Yukalov, V. I. [2003] 'Reconstructing generalized exponential laws by selfsimilar exponential approximants', Int. J. Mod. Phys. C 14 , 509-527.
Graedel, T. & Allenby, B. [2003] Industrial Ecology (Prentice Hall, Englewood Cliffs).
Grossman, G. M. & Helpman, E. [1991] Innovation and Growth in the Global Economy (MIT, Massachusetts).
Kuznetsov, Y. A. [1995] Elements of Applied Bifurcation Theory (Springer, Berlin).
Leonov, G. A. & Kuznetsov, N. V. [2007] 'Time-varying linearization and the Perron effect', Int. J. Bifur. Chaos 17 , 1079-1107.
- Leonov, G. A. & Kuznetsov, N. V. [2013] 'Hidden attractors in dynamical systems', Int. J. Bifur. Chaos 23 , 1330002.
- Lotka, A. J. [1925] Elements of Physical Biology (Williams and Wilkins, Baltimore).
- Perc, M. & Szolnoki, A. [2010] 'Coevolutionary games - a mini review', Biosystems 99 , 109-125.
- Perc, M. & Szolnoki, A. [2012] 'Self-organization of punishment in structured populations', New J, Phys. 14 , 043013.
Perc, M., Gomez-Gardenes, Szolnoki, A., Floria, L. M. & Moreno, J. [2013] 'Evolutionary dynamics of group interactions on structural populations: a review' J. Roy. Soc. Interface 10 , 20120997.
Pongvuthithum, R. & Likasiri, C. [2010] 'Analytical discussions on species extinction in competitive communities due to habitat destruction', Ecol. Model. 221 , 2634-2641.
Richard, R. R. [1993] National Innovation Systems: A Comparative Analysis (Oxford University, Oxford).
Szolnoki, A. & Perc, M. [2013a] 'Effectiveness of conditional punishment for the evolution of public coop- eration',
J. Theor. Biol.
325
,
34-41.
Szolnoki, A. & Perc, M. [2013b] 'Information sharing promotes prosocial behavior', New J. Phys. 15 , 053010.
Sapp, J. [1994] Evolution by Association: A History of Symbiosis (Oxford University, Oxford).
Thompson, J. M., Stewart, H. B. & Ueda, Y. [1994] 'Safe, explosive, and dangerous bifurcations in dissipative dynamical systems', Phys. Rev. E 49 , 1019-1027.
Townsend, C. R., Begon, M. & Harper, J. D. [2002] Ecology: Individuals, Populations and Communities (Blackwell Science, Oxford).
Von Hippel, E. [1988] The Sources of Innovation (Oxford University, Oxford).
Yukalov, V. I. [1990] 'Self-similar approximations for strongly interacting systems', Physica A 167 , 833860.
Yukalov, V. I. [1991] 'Method of self-similar approximations', J. Math. Phys. 32 , 1235-1239.
Yukalov, V. I. [1992] 'Stability conditions for method of self-similar approximations', J. Math. Phys. 33 , 3994-4001.
Yukalov, V. I. & Yukalova, E.P. [1996] 'Temporal dynamics in perturbation theory', Physica A 225 , 336-362.
Yukalov, V. I. & Gluzman, S. [1998] 'Self-similar exponential approximants', Phys. Rev. E 58 , 1359-1382. Yukalov, V. I. & Gluzman, S. [1999] 'Weighted fixed points in self-similar analysis of time series', Int. J. Mod. Phys. B 13 , 1463-1476.
Yukalov, V. I., Yukalova, E. P. & Sornette, D. [2012a] 'Modeling symbiosis by interactions through species carrying capacities', Physica D 241 , 1270-1289.
Yukalov, V. I., Yukalova, E. P. & Sornette, D. [2012b] 'Extreme events in population dynamics with functional carrying capacity', Eur. Phys. J. Spec. Top. 205 , 313-354.
Yukalov, V. I., Yukalova, E. P. & Sornette, D. [2013] 'Utility rate equations of group population dynamics in biological and social systems', PLOS One 8 , e83225.
- Yukalov, V. I., Yukalova, E. P. & Sornette, D. [2014] 'Population dynamics with nonlinear delayed carrying capacity', Int. J. Bifur. Chaos 24 , 1450021.
Fig. 1. (a) The regions of existence of stationary states for passive symbiosis in the plane b -g . When b > 0 and 0 < g < g c ( b ), there exist two fixed points, but only one is stable. If b ≤ 0 and g > 0, or b > 0 and g ≤ 0, there exists a single fixed point that is stable. If b, g < 0, there exist up to three fixed points, but not more then two of them are stable. (b) The region of fixed-point existence under mutual parasitism, when b, g < 0. For either -e < b < 0 and g < 0, or for b < -e and g < g 1 ( b ), or for b < -e and g 2 ( b ) < g < 0, there exists only one fixed point that is stable. For b < -e and g 1 ( b ) < g < g 2 ( b ), there exist three fixed points, but only two of them are stable.
30
25
20
15
10
5
0
0
5
4
3
2
1
0
t
(a)
t
(c)
7
6
5
4
3
2
1
0
t
0
15
30
45
60
75
90
z(t)
4
z = 12.042205
0
z = 12.042204
0
0
10
20
30
40
50
60
Fig. 2. Dynamics of populations in the case of mutualistic passive symbiosis for different symbiotic parameters b > 0 and g > 0, and different initial conditions: (a) For b = 1, g = 0 5 . > g c ( b ) ≈ 0 0973, . and x 0 = 1, z 0 = 0 2, populations . x t ( ) (solid line) and z t ( ) (dashed line) monotonically increase, as t → ∞ ; (b) For the same b = 1, as in Fig. 2a, with the initial conditions x 0 = 6 and z 0 = 0 25, for different . g taken slightly below and above the critical line g = g c ( b ). Below the critical line, when g = 0 0972 . < g c = 0 0973, . the population x t ( ) tends to its stable fixed point x ∗ = 5 672 and the population . z t ( ) tends monotonically from below to z ∗ = 1 735. Both populations are shown by solid lines. Above the critical line, when . g = 0 0976 . > g c , both populations, shown by dashed lines, tend to infinity, as t → ∞ ; (c) Dynamics of the population x t ( ) for the symbiotic parameters b = 0 15 and . g = 0 7 . < g c = 0 765, with the initial condition . x 0 = 2, but for different initial conditions z 0 . The population x t ( ) tends non-monotonically to its stable fixed point x ∗ = 1 567, when . z 0 is taken from the basin of attraction of this point: x t ( ) → x ∗ for z 0 = 12 (solid line), z 0 = 12 04 (dashed line), . z 0 = 12 042204 (dashed-dotted . line), and x t ( ) → ∞ , as t → ∞ , when z 0 = 12 042205 (dotted line); . (d) Dynamics of the population z t ( ) for the same parameters b, g and the same initial conditions, as in Fig. 2c. The population converges to a stationary state, when the initial conditions are inside the attraction basin, and diverges, if the initial conditions are outside of this basin.
x(t)
1
2
x(t)
3
5
6
x(t)
z(t)
(b)
t
Fig. 3. Dynamics of populations under passive symbiosis with one parasitic species. Influence of the symbiotic parameter g > 0 on the behaviour of the populations x t , z ( ) ( ), for the fixed t b = -1, and the initial conditions x 0 = 3 and z 0 = 1. Different lines correspond to the varying parameter g : For g = 1 (dashed-dotted line) the stable fixed point is { x ∗ = 0 270 . , z ∗ = 1 31 . } ; for g = 10 (dashed line), the fixed point is { x ∗ = 0 089 . , z ∗ = 2 42 ; and for . } g = 100 (solid line), the stationary point is { x ∗ = 0 014 . , z ∗ = 4 24 . } . (a) Population x t ( ) tends monotonically from above to the corresponding stable stationary state, as t →∞ ; (b) Population z t ( ) tends non-monotonically from below to the corresponding stable stationary state, as t →∞ .
t
Fig. 4. Dynamics of populations under passive symbiosis with one parasitic species. Influence of the initial condition z 0 on the behavior of solutions for the fixed b = -0 1, . g = 100, and x 0 = 3. The corresponding stable fixed point is { x ∗ = 0 0335 . , z ∗ = 33 49 . } . (a) Population x t ( ) tends monotonically, as t →∞ , from above to the stable stationary state x ∗ for z 0 = 50 (solid line) and for z 0 = 0 5 (dashed line); (b) Population . z t ( ) tends, as t →∞ , non-monotonically from above to the stable stationary state z ∗ for z 0 = 50 (solid line) and non-monotonically from below to z ∗ for z 0 = 0 5 (dashed line). .
Fig. 5. Dynamics of populations under passive symbiosis with two parasitic species. Influence of the symbiotic parameters b < 0 and g < 0 under the fixed initial conditions { x 0 = 2 , z 0 = 1 . (a) Dynamics of } x t ( ) for b = -0 1 . and different parameters g . The population x t ( ) monotonically tends to its stationary state: { x ∗ = 0 924 . , z ∗ = 0 794 . } for g = -0 25 . (solid line); { x ∗ = 0 963 . , z ∗ = 0 382 . } for g = -1 (dashed line); and { x ∗ = 0 992 . , z ∗ = 0 084 . } for g = -2 5 (dashed-dotted . line). (b) Dynamics of z t ( ) for the same, as above, parameters b = -0 1 and different . g . Population z t ( ) monotonically, or non-monotonically, from above tends to the corresponding stationary states. (c) Dynamics of x t ( ) for g = -1 and different parameters b . The population x t ( ) monotonically tends from above to its stationary state: { x ∗ = 0 904 . , z ∗ = 0 405 . } for b = -0 25 (solid line); . { x ∗ = 0 105 . , z ∗ = 0 899 . } for b = -2 5 (dashed line); and . { x ∗ = 0 454 . × 10 -4 , z ∗ = 0 99996 . } for b = -10 (dashed-dotted line). (d) Dynamics of z t ( ) for the same, as in Fig. 5c, parameters g = -1 and different b . Population z t ( ) converges to the corresponding stationary states, either monotonically or non-monotonically.
Fig. 6. Dynamics of populations under passive symbiosis with two parasitic species. Influence of initial conditions { x , z 0 0 } on the behaviour of the parasitic populations with b = -1 and g = -2. The corresponding stable fixed point is { x ∗ = 0 825 . , z ∗ = 0 192 . (a) Dynamics of . } x t ( ) for x 0 = 1 5 . > x ∗ and different z 0 . Population x t ( ) converges to the stationary state x ∗ : monotonically for z 0 = 0 1 . < z ∗ (solid line); non-monotonically for z 0 = 5 (dashed line); and non-monotonically for z 0 = 10 > z ∗ (dashed-dotted line); (b) Dynamics of z t ( ) for the same, as in Fig. 6a, initial condition x 0 = 1 5 and different . z 0 . Population z t ( ) tends to the stationary state z ∗ : non-monotonically for z 0 = 0 1 (solid line); monotonically for . z 0 = 5 (dashed line); and monotonically for z 0 = 10 (dashed-dotted line). (c) Dynamics of x t ( ) for x 0 = 0 1 . < x ∗ and different z 0 . Population x t ( ) converges to the stationary state x ∗ : monotonically for z 0 = 0 15 (solid line); for . z 0 = 0 5 (dashed line); and . z 0 = 1 5 (dashed-dotted line); while non-monotonically for . z 0 = 10 (dotted line). (d) Dynamics of z t ( ) for the same, as in Fig. 6c, initial condition x 0 = 0 1 and different . z 0 . Population z t ( ) tends to the stationary state z ∗ : non-monotonically for z 0 = 0 1 . (solid line); and z 0 = 0 5 (dashed line); but monotonically for . z 0 = 1 5 (dashed-dotted line); and . z 0 = 10 (dotted line).
Fig. 7. Phase portrait for passive symbiosis, with the symbiotic parameters b and g in qualitatively different regions: (a) Phase portrait for b = 0 5 and . g = 0 3, where . g > g c ( b ) /similarequal 0 263. . The parameters are in the region, where no fixed points exist for the system of equations (13). (b) Phase portrait for b = 0 5 and 0 . < g = 0 2 . < g c ( b ) /similarequal 0 263. The parameters are in . the region of b, g , where two fixed points exist. The first fixed point { x ∗ 1 = 2 16019 . , z ∗ 1 = 1 54039 . } is a stable node, with the Lyapunov exponents λ 1 = -1 57685, . λ 2 = -0 42315, while the second point . { x ∗ 2 = 6 66791 . , z ∗ 2 = 3 7946 . } is a saddle, with the Lyapunov exponents λ 1 = -2 59067, . λ 2 = 0 59067. (c) Phase portrait for . b = 0 5 and . g = -0 2. The parameters are in the . region of b, g , where only one fixed point exists, which is a stable focus { x ∗ = 1 45336 . , z ∗ 1 = 0 74776 . } , with the characteristic exponents λ 1 = - -1 0 32966 , . i λ 2 = -1 + 0 32966 . (d) Phase portrait for . i b = g = -3. The parameters are in the bistability region of b, g , where three fixed points exist, two of them being stable and one, unstable. Here, the first stable fixed point is the node { x ∗ 1 = 0 88474 . , z ∗ 1 = 0 13612 . } , with the Lyapunov exponents λ 1 = -1 90242, . λ 2 = -0 0975818. The second stable . fixed point, due to symmetry, is the node { x ∗ 2 = z ∗ 1 , z ∗ 2 = x ∗ 1 } , with the same Lyapunov exponents. And the third fixed point { x ∗ 3 = z ∗ 3 = 0 34997 . } is the saddle, with the Lyapunov exponents λ 1 = -2 04991, . λ 2 = 0 0499089. .
## 26 REFERENCES
Fig. 8. The regions of existence of the fixed-point for Eqs. (16) in the plane b -g . When b + g > 1 /e , then there are no fixed points. If 0 < b + g < 1 /e , then there exist two fixed points, one of them being stable and another, unstable. If b + g ≤ 0, then there exists a single fixed point that is stable.
Fig. 9. Dynamics of populations under b + g > 1 /e , with the initial conditions x 0 = 0 01 and . z 0 = 5 for different symbiotic parameters: (a) Logarithmic behavior of mutualistic populations for b = 2 and g = 1. Both populations grow, as t →∞ , with ln x t ( ) → ∞ increasing monotonically, while ln z t ( ) → ∞ , non-monotonically. (b) Logarithmic behavior of the populations, when one of them is parasitic, for b = -0 5 and . g = 1. At t →∞ , the host population dies out, ln x t ( ) →-∞ , that is, x t ( ) → 0, and the parasitic population non-monotonically increases, ln z t ( ) →∞ . (c) Dynamics of the host population x t ( ), for the same parameters b = -0 5 and . g = 1, demonstrating that x t ( ) → 0 dies out, as t →∞ , in a non-monotonic way. (d) Dynamics of the parasitic population z t ( ), for the same parameters b = -0 5 and . g = 1, showing the details of the non-monotonic increase of z t ( ) →∞ , as t →∞ .
Fig. 10. Population dynamics for 0 < b + g < 1 /e , with the initial conditions x 0 = 0 01 and . z 0 = 5. (a) For b = 0 25 . and g = 0 1, the population . x t ( ) → x ∗ = 1 668 monotonically from below, and population . z t ( ) → z ∗ = z ∗ = 1 227 non-. monotonically from above. (b) For b = -0 75 and . g = 1, the population x t ( ) → x ∗ = 0 342, nonmonotonically from below, and . population z t ( ) → z ∗ = 4 177, non-monotonically from above. (c) For . b = -1 and g = -5, the population x t ( ) → x ∗ = 0 788, . monotonically from below, and population z t ( ) → z ∗ = 0 303 monotonically from above. .
Fig. 11. Phase portrait for active symbiosis, with the symbiosis parameters b and g from qualitatively different regions: (a) Phase portrait for b = 0 1 and . g = 0 3, where . b + g > 1 /e . The parameters are in the region, where there are no fixed points. (b) Phase portrait for b = 0 2 and . g = 0 1, with 0 . < b + g c ( b ) < /e 1 . The parameters are in the region of b, g , where two fixed points exist. The first fixed point { x ∗ 1 = 1 38579 . , z ∗ 1 = 1 17719 . } is the stable node, with the Lyapunov exponents λ 1 = -1, λ 2 = -1 72586, . and the second point { x ∗ 2 = 3 27906 . , z ∗ 2 = 1 81082 . } is a saddle, with the Lyapunov exponents λ 1 = -1, λ 2 = 0 781337. (c) Phase portrait for . b = -0 5 and . g = -1. The parameters are in the region of b, g , where only one fixed point exists, which is the stable node { x ∗ = 0 78509 . , z ∗ = 0 61637 . } , with the Lyapunov exponents λ 1 = -1, λ 2 = -1 72586. .
## 30 REFERENCES
Fig. 12. Regions of existence of the fixed-point for mixed symbiosis. For either 0 < b < 1 /e and g > g c ( b ), or b > 1 /e and g ≥ 0, Eqs. (21) do not have solutions, hence, there are no fixed points. For 0 < b < 1 /e and 0 < g < g c ( b ), Eqs. (21) have two solutions, but only one fixed point is stable. For b > 1 /e and g c ( b ) < g < 0, there exists one unstable fixed point. When either 0 < b < 1 /e and g 0 ( b ) < g < 0, or 1 /e < b < b 0 ≈ 0 47 and . g 0 ( b ) < g < g c ( b ), then there are three fixed points, but only one of them is stable. When either 0 < b < b 0 and g < g 0 ( b ), or b ≥ b 0 and g < g c ( b ), then there exists a single fixed point that is stable. When b ≤ 0 and g ∈ ( -∞ ∞ , ), then the unique solution to Eqs. (21) is a stable fixed point.
ln x
14
12
10
8
6
4
2
0
0
5
10
15
20
t
10
ln z
7.5
5
2.5
0
-2.5
-5
0
5
10
15
20
(b)
t
z(t)
1
0.8
0.6
0.4
0.2
0
t
0
50
100
150
200
Fig. 13. Dynamics of populations under mixed symbiosis for the symbiotic parameters, when unbounded growth changes to everlasting oscillations. The symbiotic parameter of the active species is fixed, b = 0 5 . > /e 1 , while that of the passive species varies. For the given b , the change of the behavior occurs on the line g = 0 that is higher than the Hopf bifurcation point g c ( b ) = -0 083065. The initial conditions are . { x 0 = 5 , z 0 = 0 01 . } . (a) Logarithmic behaviour of the active population x t ( ) for g = 0 05, where there are no fixed points. (b) Logarithmic behaviour of the passive population . z t ( ) for g = 0 05. (c) Active . species population x t ( ) oscillates without convergence for g = -0 05 . > g c ( b ) = -0 083065. (d) Passive species population . z t ( ) oscillates without convergence for the same g = -0 05. .
(d)
(a)
Fig. 14. Dynamics of populations under mixed symbiosis for the symbiotic parameters, when everlasting oscillations change to the oscillating convergence to a a stable focus. The symbiotic parameter of the active species is fixed, b = 0 5 . > 1 /e , with the Hopf bifurcation point g c ( b ) = -0 083065. The initial conditions are the same as in Fig. 13, . { x 0 = 5 , z 0 = 0 01 . } . (a) Active species population x t ( ) oscillates with a small amplitude, as t →∞ , when g = -0 083 . > g c ( b ) is slightly larger than the Hopf bifurcation point. The characteristic exponents for the unstable focus are λ 1 = 0 0018+0 479 . . i and λ 2 = λ ∗ 1 . (b) Passive species population z t ( ) oscillates, as t →∞ , when g = -0 083 . > g c ( b ) is slightly larger than the Hopf bifurcation point. (c) Active species population x t ( ) converges with oscillations to its stable stationary state x ∗ = 7 368, when . g = -0 0831 . < g c ( b ) is slightly lower than the Hopf bifurcation point. The characteristic exponents for the stable focus are λ 1 = -0 0014+0 475 . . i and λ 2 = λ ∗ 1 . (d) Passive species population z t ( ) converges oscillating to its stable stationary state z ∗ = 0 542, when . g = -0 0831 . < g c ( b ) is slightly lower than the Hopf bifurcation point.
Fig. 15. Population dynamics under mixed symbiosis for varying symbiotic parameters, with the initial conditions { x 0 = 5 , z 0 = 0 01 . } . (a) Active species population dynamics for the fixed b = 0 25 . < /e 1 , when g c ( b ) = 0 1645 and . g 0 ( b ) = -0 026564, . for different passive species symbiotic parameters: g = -2 5 . < g 0 ( b ) (solid line), when the population x t ( ) tends to x ∗ = 1 02; . g = -0 2 (dashed line), when the population . x t ( ) → x ∗ = 1 28; 0 . < g = 0 164 . < g c ( b ) (dotted line), when the population x t ( ) → x ∗ = 2 03; and . g = 0 2 . > g c ( b ) (dashed-dotted line), when x t ( ) → ∞ , as t → ∞ . (b) Passive species population dynamics for b = 0 25 and the same initial conditions, with the varying symbiotic parameter . g of the passive species: g = -2 5 . (solid line), when z t ( ) → z ∗ = 0 0781; . g = -0 2 . (dashed line), when z t ( ) → z ∗ = 0 774; . g = 0 164 (dotted line), when . z t ( ) → z ∗ = 1 39; and . g = 0 2 . > g c ( b ) (dashed-dotted line), when x t ( ) →∞ , as t →∞ . (c) Active species population dynamics under the fixed b = 2 > b 0 ≈ 0 47, . with g c ( b ) = -0 271, . for different g : g = -2 5 . (dotted line), when x t ( ) → x ∗ = 1 14; . g = -1 (dashed-dotted line), with x t ( ) → x ∗ = 1 81; . g = -0 35 . < g c ( b ) (solid line), when x t ( ) → x ∗ = 5 28 with a few . oscillations; and g = -0 2 . > g c ( b ) (dashed line), when x t ( ) oscillates without convergence, as t → ∞ . (d) Passive species population dynamics for b = 2 and the same initial conditions, with the varying symbiotic parameter g : g = -2 5 (dotted . line), when z t ( ) → z ∗ = 0 0577; . g = -1 (dashed-dotted line), with z t ( ) → z ∗ = 0 164; . g = -0 35 . < g c ( b ) (solid line), when z t ( ) → z ∗ = 0 157 with a few oscillations, and . g = -0 2 . > g c ( b ) (dashed line), with z t ( ) oscillating without convergence, as t →∞ .
Fig. 16. Population dynamics under mixed symbiosis for varying symbiotic parameters, with the initial conditions { x 0 = 0 01 . , z 0 = 5 . (a) Active species population dynamics under the fixed } b = -0 25 and different . g : g = 5 (solid line), when x t ( ) → x ∗ = 0 421; . g = 2 (dashed line), with x t ( ) → x ∗ = 0 604; . g = -1 (dotted line), when x t ( ) → x ∗ = 0 912; and . g = -2 (dashed-dotted line), with x t ( ) → x ∗ = 0 987. (b) Passive species population dynamics under the fixed . b = -0 25 and different . g : g = 5 (solid line), with z t ( ) → z ∗ = 8 21 non-monotonically from below; . g = 2 (dashed line), when z t ( ) → z ∗ = 3 34 . non-monotonically from above; g = -1 (dotted line), when z t ( ) → z ∗ = 0 402; and . g = -2 (dashed-dotted line ), when z t ( ) → z ∗ = 0 0517 monotonically from above. (c) Active species population dynamics under the fixed . g = -0 5 and different . b : b = -2 (solid line), when x t ( ) → x ∗ = 0 474; . b = 0 (dotted line), with x t ( ) → x ∗ = 1 monotonically from below; b = 2 (dashed line), when g c ( b ) = -0 271 . > g , and x t ( ) → x ∗ = 3 43 with a few oscillations; . b = 20 (dashed-dotted line), when g c ( b ) = -0 5823 . < g < 0, and solution x t ( ) oscillates without convergence, as t → ∞ . (d) Passive species population dynamics under the fixed g = -0 5 and different . b : b = -2 (solid line), when z t ( ) → z ∗ = 0 789; . b = 0 (dotted line), with z t ( ) → z ∗ = 0 607 monotonically from above; . b = 2 (dashed line), when z t ( ) → z ∗ = 0 1796 with a few oscillations; and . b = 20 (dashed-dotted line), when z t ( ) oscillates without convergence, as t →∞ .
t
t
Fig. 17. Logarithmic behaviour of populations x t ( ) (solid line) and z t ( ) (dashed-dotted line) for b = 0 4, and the initial . conditions { x 0 = 5 , z 0 = 0 01 . } , when g c ( b ) ≈ -0 02942408 and . g 0 ( b ) ≈ -0 05524965. (a) Everlasting oscillations of populations . for g c ( b ) < g = -0 0001 . < 0. (b) Everlasting oscillations of populations for g 0 ( b ) < g = -0 029 . < g c ( b ).
Fig. 18. Phase portrait for mixed symbiosis, with the symbiotic parameters b and g from qualitatively different regions: (a) Phase portrait for the symbiotic parameters, where there are no fixed points. The parameters are b = 0 3 and . g = 0 1 . > g c ( b ). Here g c ( b ) ≈ 0 0817. (b) Phase portrait for the parameters . b = 0 1 and . g = 0 5 . < g c ( b ), with g c ( b ) ≈ 0 673, where there are . two fixed points. The first fixed point { x ∗ 1 = 1 27133 . , z ∗ 1 = 1 8882 . } is stable, with the Lyapunov exponents λ 1 = -1 28863 . and λ 2 = -0 471306. . The second fixed point { x ∗ 2 = 2 60324 . , z ∗ 2 = 3 67525 . } is a saddle, with the Lyapunov exponents λ 1 = -1 73578 and . λ 2 = 0 69254. (c) Phase portrait for the parameters . b = -0 5 and . g = 1, where there is a single fixed point { x ∗ = 0 588548 . , z ∗ = 1 80137 . } that is a stable focus, with the characteristic exponents λ 1 = -1 26505 . -0 49167 . i and λ 2 = λ ∗ 1 ).
Fig. 19. Phase portrait for mixed symbiosis, with the symbiotic parameters b > 0 and g < 0 from qualitatively different regions. (a) Phase portrait for b = 0 5 and . g = -0 1 . < g c ( b ) < 0, with g c ( b ) ≈ -0 083056, in the region, where there is a . single fixed point { x ∗ = 3 1801 . , z ∗ = 0 7276 . } that is a stable focus, with the characteristic exponents λ 1 = -0 4215 . -0 1825 . i and λ 2 = λ ∗ 1 . (b) Phase portrait for the same b = 0 5, but with . g c ( b ) < g = -0 083 . < 0. In this region, there exist a single fixed point { x ∗ = 8 8369 . , z ∗ = 0 49315 . } , which is an unstable focus, with the characteristic exponents λ 1 = 0 08947 . -0 5945 , . i λ 2 = λ ∗ 1 , and a limit cycle. (c) Phase portrait for b = 0 4 and . g = -0 054, when . g c ( b ) ≈ -0 02943 and . g 0 ( b ) ≈ -0 05524965, . so that g 0 ( b ) < g < g c ( b ) < 0. The parameters are in the region of b > 0 , g < 0, where three fixed points exist. One of them, { x ∗ 1 = 2 15176 . , z ∗ 1 = 0 890302 . } is a stable node, with the Lyapunov exponents λ 1 = -0 85719 and . λ 2 = -0 37654. . The two other fixed points are unstable. The point { x ∗ 2 = 8 08875 . , z ∗ 2 = 0 646106 . } is a saddle, with the Lyapunov exponents λ 1 = -0 37834 and . λ 2 = 0 468814. And . { x ∗ 3 = 13 6002 . , z ∗ 3 = 0 479787 . } is an unstable focus, with the characteristic exponents λ 1 = 0 305044 . -0 462324 . i and λ 2 = λ ∗ 1 .
Fig. 20. Dynamics of populations under commensalism, characterized by the degenerate systems of equations (24), (26), and (27). Initial conditions are { x 0 = 5 , z 0 = 0 01 . } . (a) Dynamics of the population x t ( ) for different b and g = 0: For b = 0 (dotted line), x t ( ) → x ∗ = 1; for b = 0 5 . > 1 /e (dashed-dotted line), x t ( ) → ∞ ; for b = 0 3 . < 1 /e (dashed line), x t ( ) → x ∗ = 1 63; . and for b = -1 (solid line), x t ( ) → x ∗ = 0 567, as . t →∞ . (b) Dynamics of the population z t ( ) for different g and b = 0: For g = 0 (dotted line), z t ( ) → z ∗ = 1; for g = 0 5 (dashed-dotted line), . z t ( ) → z ∗ = e g = 1 65; and for . g = -0 5 (solid . line), z t ( ) → z ∗ = 0 607, as . t →∞ .
 | 10.1142/S021812741450117X | [
"V. I. Yukalov",
"E. P. Yukalova",
"D. Sornette"
] | 2014-08-01T09:32:58+00:00 | 2014-08-01T09:32:58+00:00 | [
"q-bio.PE",
"physics.bio-ph"
] | New Approach to Modeling Symbiosis in Biological and Social Systems | We suggest a novel approach to treating symbiotic relations between
biological species or social entities. The main idea is the characterisation of
symbiotic relations of coexisting species through their mutual influence on
their respective carrying capacities, taking into account that this influence
can be quite strong and requires a nonlinear functional framework. We
distinguish three variants of mutual influence, representing the main types of
relations between species: (i) passive symbiosis, when the mutual carrying
capacities are influenced by other species without their direct interactions;
(ii) active symbiosis, when the carrying capacities are transformed by
interacting species; and (iii) mixed symbiosis, when the carrying capacity of
one species is influenced by direct interactions, while that of the other
species is not. The approach allows us to describe all kinds of symbiosis,
mutualism, commensalism, and parasitism within a unified scheme. The case of
two symbiotic species is analysed in detail, demonstrating several dynamical
regimes of coexistence, unbounded growth of both populations, growth of one and
elimination of the other population, convergence to evolutionary stable states,
and everlasting population oscillations. The change of the dynamical regimes
occurs by varying the system parameters characterising the destruction or
creation of the mutual carrying capacities. The regime changes are associated
with several dynamical system bifurcations. |
1408.0112v1 | ## The linear tearing instability in three dimensional, toroidal gyrokinetic simulations.
W.A. Hornsby, P. Migliano, R. Bucholz, L. Kroenert, A.G. Peeters Theoretical Physics V, Dept. of Physics, Universitaet Bayreuth, Bayreuth, Germany, D-95447 ∗
## D.Zarzoso, E. Poli
Max-Planck-Institut f¨r Plasmaphysik, Boltzmannstrasse 2, D-85748 Garching bei M¨nchen, Germany u u
## F.J. Casson
CCFE, Culham Science Centre, Abingdon, Oxon, OX14 3DB, UK (Dated: August 4, 2014)
Linear gyro-kinetic simulations of the classical tearing mode in three-dimensional toroidal geometry were performed using the global gyro kinetic turbulence code, GKW . The results were benchmarked against a cylindrical ideal MHD and analytical theory calculations. The stability, growth rate and frequency of the mode were investigated by varying the current profile, collisionality and the pressure gradients. Both collision-less and semi-collisional tearing modes were found with a smooth transition between the two. A residual, finite, rotation frequency of the mode even in the absense of a pressure gradient is observed which is attributed to toroidal finite Larmor-radius effects. When a pressure gradient is present at low collisionality, the mode rotates at the expected electron diamagnetic frequency. However the island rotation reverses direction at high collisionality. The growth rate is found to follow a η 1 / 7 scaling with collisional resistivity in the semi-collisional regime, closely following the semi-collisional scaling found by Fitzpatrick. The stability of the mode closely follows the stability using resistive MHD theory, however a modification due to toroidal coupling and pressure effects is seen.
∗ [email protected]
FIG. 1. Contour plots of (left) the parallel-radial mode structure of A ‖ and (right) the electrostatic potential, φ for a m = 2, n = 1 tearing mode. The vertical dashed line denotes the position of the q = 2 rational surface.
## I. INTRODUCTION
A current density profile in a plasma can lead to instabilities that are able to change the topology of the magnetic field via the process of magnetic reconnection [1]. Resistive instabilities, and in particular tearing instabilities [2-4] are found in a wide variety of astrophysical and laboratory situations [5].
In a magnetically confined tokamak plasma, reconnecting instabilities can form magnetic islands. This has a detrimental effect on the plasma confinement caused by the introduction of a radial component of the magnetic field [6]. The tearing mode can trigger a disruption, something which would be catastrophic to the ITER tokamak and therefore the tearing mode, and specifically, the neoclassical tearing mode (NTM) [7, 8] is expected to be the limiting factor on its operational plasma β [10].
Much work has been performed numerically in studying tearing mode stability in both cylindrical and toroidal geometry [11], using the Magnetohydrodynamic (MHD) framework. However for large current and future tokamaks a fully kinetic description of the physics in the resonant layer is needed for both the linear and non-linear regimes.
Linear theory is generally considered to be valid when the generated magnetic island has a width that is smaller than the singular layer. Above this width, nonlinear effects slow the growth of the island to an algebraic scaling [12] and eventually cause the island to saturate [13]. Recent work studying the effects of electromagnetic turbulence on the evolution of the tearing mode indicates a turbulent modification of the resonant layer, extending the suitability of linear theory to larger island sizes[14], while it has also been seen that a magnetic island can have a profound effect on turbulence and transport [15, 16].
Within the singular layer (Parallel wave-vector of the mode, k || = 0) the assumptions of ideal MHD break down and magnetic reconnection may take place. For a collisionless mode the mechanism of reconnection is the electron inertia, where the singular layer width, and in turn the growth rate, are related closely to the electron skin depth [17]. When collisions become significant, it is plasma resistivity which determines the singular layer width, producing a classical collisional tearing [3] or, more relevant for present day tokamaks, a semi-collisional mode [18, 19]. The mode frequency, and in particular, its direction is vital in predicting the nonlinear stabity of the NTM. Specifically the sign of the mode frequency, whether the mode rotates in the ion or electron diamagnetic direction, determines whether the polarisation current has a stabilising or destabilising effect [9, 23] particularly when the magnetic island is small [24].
In this work the linear mode stability, growth rate and frequency is studied for the first time in three-dimensional toroidal geometry using the gyro-kinetic framework of equations. Parameters appropriate to modern and future Tokamak experiments are used. Gyrokinetics has been highly successful when applied to the study of drift waves,
turbulence and transport but its use in the study of large scale MHD instabilities is still in its infancy. Recent work has studied two dimensional magnetic reconnection in a highly magnetised system [25-27] and the ideal kink instability [28].
The paper is organised as follows. In Sec.II we describe the equations solved, while in Sec. III we outline how the tearing mode is implemented within the gyrokinetic framework. Sec. IV outlines the parameters used, and the resolution requirements. Sec. V and VI presents the scaling of the tearing mode growth rate and mode frequency with collisionality, and with the variation of the background density, temperature and current profiles.
## II. GYROKINETIC FRAMEWORK
The self-consistent treatment of the tearing mode requires a radial profile in geometry and thermodynamic quantities. We use here the global version of the gyrokinetic code, GKW [29]. This is advancement on the already widely used flux-tube variant [30].
The code solves the gyrokinetic set of equations. The full details can be found in [30] and references found therein. Here we outline the basic set of equations that are solved and in the next section the modification and assumptions used in driving the tearing instability.
The deltaf approximation is used. The distribution function is split into a background F and a perturbed distribution f . The final equation for the perturbed distribution function f , for each species, s , can be written in the form
$$\frac { \partial g } { \partial t } + ( v _ { \| } \mathbf b + \mathbf v _ { D } ) \cdot \nabla f - \frac { \mu B } { m } \frac { \mathbf B \cdot \nabla B } { B ^ { 2 } } \frac { \partial f } { \partial v _ { \| } } = S,$$
where S is the source term which is determined by the analytically known, background distribution function, µ is the magnetic moment, v || is the velocity along the magnetic field, B is the magnetic field strength, m and Z are the particle mass and charge number respectively. Here, g = f +( Ze/T v ) ‖ 〈 A ‖ 〉 F M is used to absorb the time derivative of the parallel vector potential ∂A /∂t ‖ which enters the equations through Amp`res law. e
The velocities in Eq. (1) are from left to right: the parallel motion along the unperturbed field ( v ‖ b ), the drift motion
[ mv 2 ]
due to the inhomogeneous field ( v D = 1 Ze ‖ B + µ B ×∇ B B 2 ), and the motion due to the perturbed electromagnetic field ( v χ = b ×∇ χ B , where χ = 〈 φ 〉 -v || 〈 A || 〉 ). The latter is the combination of the E × B velocity ( v E = b ×∇〈 〉 φ /B ) and the parallel motion along the perturbed field line ( v δB = -b ×∇ v ‖ 〈 A ‖ 〉 /B ). Here, the angled brackets denote gyro-averaged quantities.
The background is assumed to be a shifted Maxwellian ( F M ), with particle density ( n r ( )) and temperature ( T r ( )) and toroidal flow velocity ( ω φ ( r ))
$$F _ { M s } = \frac { n _ { s } } { \pi ^ { 3 / 2 } v _ { t h } ^ { 3 } } \exp \left [ - \frac { ( v _ { \| } - ( R B _ { t } / B ) \omega _ { \phi } ) ^ { 2 } + 2 \mu B / m } { v _ { t h } ^ { 2 } } \right ],$$
which determines the source term,
$$S = - ( \mathbf v _ { \chi } ) \cdot \left [ \frac { \nabla n } { n } + \left ( \frac { v _ { \| } ^ { 2 } } { v _ { \text{th} } ^ { 2 } } + \frac { ( \mu B ) } { T } - \frac { 3 } { 2 } \right ) \frac { \nabla T } { T }$$
$$+ \frac { m v _ { \| } } { T } \frac { R B _ { t } } { B } \nabla \omega _ { \phi } \Big { ] } F _ { M } - \frac { Z e } { T } [ v _ { \| } \mathbf b + \mathbf v _ { D } ] \cdot \nabla \langle \phi \rangle F _ { M }.$$
The thermal velocity v th ≡ √ 2 T/m , and the major radius ( R ) are use to normalise the length and time scales. Using standard gyro-kinetic ordering, the length scale of perturbations along the field line ( R ∇ ≈ ‖ 1) are significantly longer than those perpendicular to the field ( R ∇ ⊥ ≈ 1 /ρ ∗ ). Here, ρ ∗ = ρ /R i is the normalised ion Larmor radius (where ρ i = m v i th /eB and v th = √ 2 T /m i i ).
The electrostatic potential is calculated from the gyro-kinetic quasineutrality equation,
$$\sum _ { s } Z _ { s } e \int _ { \langle f \rangle ^ { \dagger } d ^ { 3 } \mathbf v } \cdot \\ \sum _ { s } \frac { Z _ { s } ^ { 2 } e ^ { 2 } } { T _ { s } } \int ( \langle \langle \phi \rangle \rangle ^ { \dagger } - \phi ) F _ { M s } ( \mathbf v ) d ^ { 3 } \mathbf v = 0$$
where the first term represents the perturbed charge density and the second the polarisation density, which is only calculated from the local Maxwellian. The dagger operator represents the conjugate gyro-average operator. Similarly the parallel vector potential is calculated via Amp`res law, e
$$\cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdot$$
The gyro-average is then calculated as a numerical average over a ring with a fixed radius equal to the Larmor radius using a 32 point interpolation defined by,
$$\langle G \rangle ( \mathbf X ) = \frac { 1 } { 2 \pi } \oint \mathrm d \alpha \, G ( \mathbf X + \rho )$$
where α is the gyro-angle, X is the position of the gyro-center and ρ is the gyro-radius. This gyro-average is used in both the evolution equation of the distribution function, as well as in the quasineutrality and Amp´re equations and e on both the electron and ion species. The nonlinearity ( v χ · ∇ g ) is neglected in this study and its effects on magnetic island evolution and saturation will be left for a future publication.
GKW uses straight field line Hamada [32] coordinates ( s, ζ, ψ ) where s is the coordinate along the magnetic field and ζ is the generalised toroidal angle and ψ = r/R ref is the normalised radial coordinate. For circular concentric surfaces [31], the transformation of poloidal and toroidal angle to these coordinates is given by [30] ( s, ζ ) = ( θ/ 2 π, [ qθ -φ / ] 2 π ). The wave vector of the island is k ρ I ζ i = 2 πnρ , ∗ where n is the toroidal mode number. GKW uses a Fourier representation in the binormal direction, perpendicular to the magnetic field. The radial and parallel directions are treated using a high order finite difference scheme so as to include global profile effects utilising Dirichelet boundary conditions in the radial direction, and open field line boundaries in the parallel direction. An example of the radial profiles used is seen in the middle panel of Fig. 2.
The collision operator is particularly important to the growth and development of the tearing mode, as it can be resistive in nature. In GKW the full linearised Landau collision operator with momentum and energy conserving terms is implemented. However here, unless stated otherwise, we utilise only the pitch-angle scattering part. The differential part of the operator has the following form [33]
$$C ( f _ { a } ) = \sum _ { b } \frac { 1 } { v \sin \theta } \frac { \partial } { \partial \theta } \left [ \sin \theta D _ { \theta \theta } ^ { a / b } \frac { 1 } { v } \frac { \partial f _ { a } } { \partial \theta } \right ].$$
Here the sum is over all species b and θ denotes the particle pitch-angle ( v || = v cos θ ).
The coefficients can be obtained from the literature [33] and written in normalised form, suppressing the subscript N for the normalised quantities:
$$D _ { \theta \theta } ^ { a / b } = \sum _ { b } \frac { \Gamma ^ { a / b } } { 4 v _ { a } } \left [ \left ( 2 - \frac { 1 } { v _ { b } ^ { 2 } } \right ) \text{erf} ( v _ { b } ) + \frac { 1 } { v _ { b } } \text{erf} ^ { \prime } ( v _ { b } ) \right ],$$
where erf and erf ′ are the standard definition of the error function and its derivative. Finally, the normalised collision frequency, Γ a/b is given by 2 2 4 a/b
Γ a/b = R ref n Z Z e b a b ln Λ 4 πglyph[epsilon1] 2 0 m v 2 a 4 tha , n b is the scattering species number density, Z is the relative charge of the species and ln Λ is the Coulomb logarithm. v a and v b are the velocities of the scattered and scattering species respectively.
## III. TEARING MODE IMPLEMENTATION
The tearing mode instability is driven by a non-homogeneous current density. In our implementation this is introduced by applying an electron flow profile in the equilibrium. The electron flow velocity is calculated selfconsistently from the imposed q-profile analogous to the method used in [18] for a kinetic calculation in slab geometry.
We assume that the background current is carried by the electrons, J = -n v e e e , i.e. that the electron flow velocity v e is larger than the ion flow and that it is a flux function. The current gradient is therefore related to the gradient in the electron flow, ∂u /∂ψ e , this profile is introduced to the code where ∇ ω φ is written in equation 4.
We assume v e to be significantly smaller than the electron thermal velocity, thus the only term in Eq. 4 of interest is, ∇ F Me = -2 v || v th ∇ u F e Me .
FIG. 2. The radial profiles of (Top) the parallel vector potential as calculated by GKW and the ideal MHD solution in cylindrical geometry calculated using the shooting method. The shift in the eigenmode is compatible with previous results when comparing the cyclindrical to toroidal eigenfunction.[11] (Middle top) The safety factor (q),magnetic shear (ˆ) and, when s present, density gradient ( R/L n ) profiles (Middle bottom) the radial second derivative, ∂ A /∂ψ 2 || 2 , indicating the position of the resistive layer. (Bottom) are the electrostatic potential ( φ ) and perturbed ion density ( n i ) profiles.
The electron profile is related to the q-profile via Amp´res law, e ∫ glyph[vector] B · ds = µ 0 ∫ jd A 2 , which in circular geometry and assuming a low aspect ratio, becomes,
$$2 \pi r \mu _ { 0 } B _ { p 0 } F ( r ) = 2 \pi \mu _ { 0 } \int _ { 0 } ^ { r } r ^ { \prime } d r ^ { \prime } j ( r ^ { \prime } ),$$
where the function F r ( ) = 1 / 2 π ∫ dθ/ (1 + glyph[epsilon1] cos θ ) is approximated to be close to unity and subscript zeros represent constant values. We have used the definition q = 1 2 π ∫ rB t RB p = rB t 0 R B 0 p 0 F r ( ) and therefore the poloidal magnetic field, B p 0 = B t 0 R 0 F r ( ) r q . The gradient of the background current is given by the expression,
$$\frac { d j } { d \psi } = \frac { B _ { t 0 } } { \mu _ { 0 } R _ { 0 } } \frac { d } { d \psi } \left [ \frac { 1 } { \psi } \frac { d } { d \psi } \left [ \frac { \psi ^ { 2 } } { q } \right ] \right ]$$
In this paper we make use of the Wesson analytic form of the current profile [36] which is defined by the expression,
$$j = j _ { 0 } \left ( 1 - \psi ^ { 2 } \left ( \frac { R } { a } \right ) ^ { 2 } \right ) ^ { \nu }$$
which, in turn, gives a q -profile of the form,
$$q = q _ { a } \frac { r ^ { 2 } / a ^ { 2 } } { 1 - ( 1 - r ^ { 2 } / a ^ { 2 } ) ^ { \nu + 1 } }$$
where q a is the safety factor at ψ = a/R . This is related to the q on the axis, q 0 , by q a /q 0 = ν +1, where ν is an integer that determines that peaking of the current gradient.
The density and temperature profiles have the radial form,
$$\text{pomosive one} \, \text{and} \, \text{in}, \\ \frac { \partial n _ { s } } { \partial \psi } & = \frac { 1 } { 2 } \frac { R } { L _ { n s } } ( \tanh \left ( x - x _ { 0 } + \Delta x \right ) / w - \\ \tanh \left ( x - x _ { 0 } + \Delta x \right ) / w \right ) \\ \frac { \partial T _ { s } } { \partial \psi } & = \frac { 1 } { 2 } \frac { R } { L _ { T s } } ( \tanh \left ( x - x _ { 0 } + \Delta x \right ) / w - \\ \tanh \left ( x - x _ { 0 } + \Delta x \right ) / w \right ) \\ \wedge \Delta \, D / T - \frac { 1 } { 2 } - \left ( D / T \wedge A T / A t \right ) \, \text{as to how to use with} \, \text{in} \, \text{and} \, \text{in}.$$
where R/L n = -( R/n ∂n/∂ψ ) and R/L T = -( R/T ∂T/∂ψ ) are the logarithmic density and temperature gradients at the reference radius, x 0 , ∆ x is the profile width and w is the rising width.
## IV. PARAMETERS
In this section we study the linear mode structure, a two-dimensional example of which is plotted in Fig. 1, showing the radially elognated eigenfunction of the parallel vector potential (left panel) and the electrostatic potential ( φ ) which is highly localised around the singular layer at the q = 2 rational surface (dashed line). The growth rates and mode rotation frequencies are calculated for the following parameters unless stated otherwise in the text:
| Simulation parameters. | Simulation parameters. |
|--------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------|
| Aspect ratio, R/a Electron beta, β e Current peaking Mass ratio, m i /m e q at edge, q a Mode number, k ζ ρ i ρ ∗ = ρ i /R T i = T e | 3 10 - 3 (0 . 1%) 1 1836 2.99 0.0255 0.002815 |
| parameter, ν | |
| max( v || /µ ) | 4/8 |
Care must be taken in resolving the relevant scale lengths in each of the domain directions. The number of grid points in the poloidal, parallel velocity and µ directions were, N s = 32, N vp = 64, N µ = 16 respectively which were found to give converged growth rates to within a couple of percent. A single toroidal mode is considered, namely with the n = 1 mode number, the number of resonant poloidal modes within the domain is determined by the q -profile ( q = m/n ); as such the possibilty of mode coupling effects remain, particularly the toroidal coupling of modes with varying poloidal mode numbers (m) which is known to have a destabilizing effect [38]. The radial resolution required is dependent on the physics of the resonant layer. In the collisionless tearing mode the relevant scale length is the electron skin depth, δ e = c/ω pe , where ω pe = √ n e /m glyph[epsilon1] e 2 e 0 is the electron plasma frequency and c is the speed of light. The skin depth is, δ e a = ρ ∗ √ mi me √ β e R a . The β e is the electron β defined by β e = n T / B / µ e e ( 2 0 2 0 ), where n e and T e are equilibrium density and temperature and B 0 is the magnetic field strength at the outboard midplane. For collisional modes, the resistivity defines the width of the layer. Unless otherwise stated, we have used, N x = 512 radial grid points between ψ l = 0 03 and . ψ h = 0 3 gives us three grid points within the skin depth for a normalised gyro-radius of, . ρ ∗ = 0 002815 ( . ∼ 1 / 180) and a β of 0 1%, in the collisionless case without a background pressure gradient. . Increasing collisionality and including a background pressure gradient has the effect of increasing the resonant layer width and with it the number of grid points within the layer. A hydrogen mass ratio plasma is studied due to a slightly more relaxed skin-depth resolution requirement over a deuterium mass ratio plasma while still maintaining applicability to experimental conditions.
In Fig. 2 an example of the radial eigenfunctions are plotted and compared with the result from an MHD shooting calculation performed in the cylindrical tokamak limit ( glyph[epsilon1] → 0). The safety factor and magnetic shear profiles used in this calculation are found in the second panel. The shift in the peak of the parallel vector potential with respect to the cylindrical calculation is consistent with previous work performed using an ideal MHD code [11]. Plotted is also the radial eigenfunction for a simulation using an aspect ratio of R/a = 10, closer to the cylindrical limit, which shows that the eigenfunction tends toward this cylindrical form as expected. The radial density and geometry profiles used are shown in middle panel. The third panel of Fig. 2 shows the second derivative of the radial profile of the vector potential. This shows clearly the position of the singular layer, the position where ideal MHD breaks down
FIG. 3. (top) Stability of the classical tearing mode varying the current peaking parameter, ν = q a /q 0 -1 and the safety factor on at the plasma edge, q a , normalised collisionality, ν ∗ = 1 0. . The lines correspond to the m = 2 , n = 1 stability boundaries as found by Wesson et.al [36]. Solid circles denote an unstable mode, while crosses denote stability. (bottom) The radial mode profiles for a coupled mode with q a = 3 5 and . ν = 1. Inlaid in the top panel are the profiles of the first (dashed line) and second (solid line) radial derivatives of A || close to the q = 2 rational surface.
and a discontinuity in the derivative is produced. The bottom panel also shows the radial profile of the electrostatic potential ( φ ), showing the highly localised electric field at the rational surface, and the perturbed ion density profile ( n i ).
## V. TEARING MODE STABILITY.
The upper panel of Fig. 3 shows the stability of the tearing mode as a function of the current peaking parameter, ν and the safety factor at the plasma edge, q a . This is analogous to the diagram shown in [36, 42], which shows the stability of the n = 1, m = 2 mode in cyclindrical geometry, n denoting the toroidal mode number, while m is the poloidal mode number.
The analysis in [36] considered a single m = 2, n = 1 mode, the outlines of which are also plotted in overlay (black lines). However we are unable to decompose the modes in this manner and consider, for example a m = 3, n = 1 mode in isolation. The different coloured points denote the dominant mode within a particular simulation determined by the amplitude of the mode at the relevant rational surface.
It is evident that there is good agreement with previous work, particularly when there exists only an m = 2, n = 1
mode within the domain. However, the results are complicated by the toroidal coupling of modes. Toroidal coupling has the effect of destabilising modes that would otherwise be stable [38, 39], for example in lower panel of Fig. 3 we see the radial eigenstructure of a combined m = 2 , n = 1 and a m = 3 , n = 1 mode, the latter of which would otherwise be stable. The point at q a = 4, ν = 2 has only a q = 3 rational surface within the domain and is found to be stable. This is further manifested in the growth rate where this is plotted if Fig. 4 for the combined m = 2 3 mode showing , a general increase over the pure m = 2 , n = 1 mode.
The growth rate of the tearing mode is a function of the well known parameter [3],
$$\Delta ^ { \prime } & = \frac { 1 } { A _ { | | } } \frac { \partial A _ { | | } } { \partial r } \Big | _ { r _ { s } ^ { - } } ^ { r _ { s } ^ { + } }$$
across the singular layer, whose position is denoted by r s and upper and lower boundaries by r + s and r -s . This parameter represents the discontinuity in ∂A /∂r || and measures whether mode growth is energetically favourable (∆ ′ > 0 for the mode to grow). As the growth rate of the mode is directly proportional to ∆ , measuring the growth ′ rate allows us to study the mode stability. As such the above difference in growth rate between the coupled tearing mode and the pure m = 2 , n = 1 shows that the toroidal coupling in this case has a destabilising effect (Increasing ∆ ), increasing the growth rate by a factor of 2. ′
It can be seen that points along the line q 0 = 1 are stable to the tearing mode. For the collisionality used in the figure ( ν ∗ ∼ 1 0, . S = 5 10 ), a toroidal MHD analysis (Fig.8 in [42]) predicts that points along this line would . 4 indeed be stable, and the results from GKW are consistent with this, however, the mode is stabilised at a much lower Lundqvist number, S than is predicted in [42]. S is defined as the ratio of the Alven time ( τ A = a √ µ n m /B 0 i i ) and the resistive time scale τ R = µ a /η 0 2 , where η = m ν e ei / n e ( e 2 ).
## VI. COLLISIONALITY EFFECTS ON GROWTH RATE AND ROTATION.
Fig. 4 shows the growth rate of the tearing mode as a function of the normalised collisionality (normalised to the trapping-detrapping rate, ν N = ν ei q/glyph[epsilon1] 3 / 2 ), corresponding to a Ludquist number, S, range between 10 12 and 2 × 10 . 3 A scan with no background density gradient (Black circles) and with a background gradient scale length of R/L n = 1 0 (Red circles) is presented. . Firstly, at low collisionality the collisionless tearing mode is observed, their growth rates are plotted as horizontal dashed lines which are the low collisionality asymptotic values. These asymptotic values were checked for convergence by doubling the radial resolution ( n x = 1024), the growth rate changed by less than 3% from the value using n x = 512.
As the collisionality is increased (and as such the resistivity) we see the expected increase in the mode growth rate. The (blue dashed) line represents the condition γ = ν ei and marks the boundary between the collisionless and semicollisional mode regimes, at this point collisions limit the electron response, which allows them to be accelerated, and broadens the resonant layer width. The semi-collisional theory only holds in the limit when γ < ν ei and the transition between semi-collisional and collisionless modes is clearly seen in our simulations. The growth rate obtained deviates significantly from the collisionless rate once the growth rate is greater than the electron-ion collision frequency.
Plotted are the analytic scalings for the resistive (Green dashes, η 3 / 5 ) and the semi-collisional tearing mode (Black dashes, η 1 / 3 ) obtained using a kinetic treatment by Drake and Lee [18]. However both of these give significantly stronger scalings than our calculated values. Good agreement, particularly when a density gradient is present, is found when we consider the semi-collisional scaling at high ∆ ′ as given by the three fluid, two dimensional slab calculation by Fitzpatrick [19]. This predicts a scaling of the growth rate with η 1 / 7 (Light grey dashes). This corresponds to regime III in Fig.1 of [19] and was also found in a semi-collisional study of m = 1 modes [20]. The visco-resistive scaling as calculated by Porcelli ( η 5 / 6 ) [37] was also considered, but the scaling is found to be much too strong.
The three fluid theory [19] utilises some ordering assumptions in its derivation; firstly that the electron beta is of the order of the mass-ratio ( √ β e ∼ √ m /m e i ), secondly we are in the low collisionality limit and finally, that all length scales are larger then the electron gyro-radius, both of which also hold in our calculations. This model was also derived without a background pressure gradient, however the scaling from our result seems largely invariant to this, as seen in the further two curves in Fig. 5. The η 1 / 7 scaling found here requires a large ∆ ′ in its derivation. This requirement, in turn, invalidates the constantψ approximation. To achieve a constant perturbed magnetic flux across the singular layer, diffusive processes must act to smooth out any perturbations, thus the growth rate of the mode must be slower than the time scale of the diffusive process or the magnetic island must be very narrow [21]. A rough estimate, using the resistive growth rate, states that the growth rate τ A γ glyph[lessmuch] S -1 / 3 for the constantψ approximation to hold. This equality is never really satisfied in the present simulations. In Fig 3 the radial profile of ∂A /∂ψ || shows that through the singular layer A || can not be considered constant. Direct calculation of ∆ ′ in this case is difficult in toroidal
-3
FIG. 4. The (left) growth rates and (right) mode frequencies of an m = 2 , n = 1 tearing mode with aspect ratio R/a = 3 in a hydrogen plasma. These have been calculated for purely electron-ion pitch angle collision operator with no background pressure gradient (black circles) and with a background density gradient (red circles). The left hand panel also shows the analytical result derived by Drake and Lee for a collisional tearing mode ( γ ∝ ν 3 / 5 ei , green dashes) and semi-collisional mode( γ ∝ ν 1 / 3 ei ,black dashed line).
geometry where the resonant layer width is not precisely defined, as such it can be merely estimated qualitatively. The kinetic calculation of [18] utilises the constantψ approximation, as such, with the parameters considered here, a scaling with η 1 / 3 is not expected (Of note, an assumption of ∆ ′ → ∞ is utilised in [20] for an m = 1 perturbation, where the constantψ approximation can not be made).
The right hand panel of Fig. 4 shows the frequency of the tearing mode as a function of the normalised collisionality. We note that the tearing mode has a small but finite rotation frequency in the absence of a background density or temperature gradient. Kinetic analysis of the classical tearing mode [17, 18] in slab geometry has shown that, in the absence of equilibrium pressure gradients, the mode has no frequency ( ω = 0) which is in contrast to our calculated values. Our calculation is a more complete description, performed in three dimensional geometry, and thus includes trapping and curvature drift effects. By artificially switching off the terms related to particle drifts in the gyro kinetic equation, it can be seen that this residual frequency is indeed a toroidal effect. When curvature effects are removed, the mode frequency is found to be essentially zero (Right hand panel of Fig 4). At high collisionalities, (i.e ν ∗ > 1) the frequency begins to decrease and eventually changes sign, rotating in the ion diamagnetic direction, something not predicted by previous analyses.
Presented in Fig. 5 is a collisionality scan (over the same range of parameters as Fig. 4) showing the growth rate and mode frequency in the presence of three different combinations of background density ( R/L n ) and temperature gradients ( R/L T ). The same scaling is seen as in Fig. 4, however it is apparent that at high collisionality the mode starts to stabilise, apparent by the reduction of the growth rate.
Our result shows that the presence of larger pressure gradients causes a stabilisation of the mode at lower collisionalities. This is further evident in Fig. 6 where the growth rate and mode frequency is shown as a function of the equilibrium density gradient at fixed collisionality. Initially here the density gradient has a destabilising effect, causing the growth rate to increase. At higher gradients ( R/L n > 1 0), the mode begins to stabilize. . There are two key parameters in determining the nature of the tearing instability when considering the effects of equilibrium pressure gradients [40, 43], which are noted for having a stabilising effect on the mode as they produce currents outside the resonant layer. The currents shield the singular layer from the magnetic perturbation, preventing reconnection and thus
*
ei
FIG. 5. The (top) growth rates and (bottom) mode frequencies of an m = 2 , n = 1 tearing mode as a function of the normalised collision frequency at the rational surface in the presence of a background temperature and density gradients. Horizontal dashed lines (top) represent the collisionless growth rates, while solid lines (bottom) represent the analytic mode frequencies as calculated by ω = ω n ∗ +0 5 . ω T ∗ in the collisionless limit. Dot-dashed lines are the corresponding analytical values for the semi-collisional frequency, ω = ω ∗ n +5 4 / ω ∗ T .
stabilising the TM [40]. This effect is a function of the normalised beta, ˆ = β β / e 2( L /R s ) 2 ( R/L n ) 2 where L s = Rq/s ˆ is the magnetic shear length, and a second parameter, a normalised collisionality, C = 0 51( . L /L s n ) 2 ( ν ei /ω ∗ e )( m /m e i ) which reduces to 0 51( . δ /ρ c i ) 2 where δ c is the semi-collisional resonant layer width. In the simulations presented it is possible that δ c ∼ ρ i ([43] assume that ρ i > δ c ).
It has been shown analytically [40] that as the parameter ˆ approaches unity the tearing mode becomes entirely β stable. The results presented here have values significantly lower, ( ˆ β ∼ 0 05( . R/L n ) 2 where ˆ = 0 65 at the s . q = 2 rational surface) but the stabilising effects of pressure gradients still become apparent. Analytical work has shown that toroidal geometry has a stabilising effect on the tearing mode[41], however, at a low beta, as is used in this work, these effects will be small
The mode frequency of the tearing mode is plotted in Fig. 5 in the presence of a density and temperature gradient as a function of collisionality along with the corresponding collisionless asymptotes, while in Fig. 6 as a function of density/temperature gradient at fixed collisionality. Kinetic analysis of the mode shows that it rotates at the electron diamagnetic frequency related to the density and temperature gradient at the resonant layer when they are present. In GKW units the diamagnetic frequency is given by ω ∗ e = -( R/L n )( k th ρ i ) / 2 = -0 0128 . v thi /R , for R/L n = 1 0 and . R/L T = 0 0. . When a background temperature gradient is also considered then, in the collisionless limit, the mode frequency is given by the expression, ω = ω ∗ n + 1 2 / ω ∗ T [18], where ω ∗ T = -1 / 2( k ρ θ i ) R/L T which is the electron diamagnetic frequency associated with the temperature gradient, these prediced values are also plotted and their scalings have been plotted in the right hand panel of Fig. 6. In both cases showing a good agreement. We also see
n
T
FIG. 6. The growth rate (left) and frequency (right) of the mode as a function of the equilibrium density gradient at the resonant surface ( R/L n , black) or equilibrium temperature gradients ( R/L T , red). The solid grey line is the electron diamagnetic frequency when considering only R/L n while red is the Drake and Lee prediction of the collisionless mode frequency ω ∗ n +0 5 . ω ∗ T .
that the residual frequency as previously mentioned, is significantly smaller than the electron diamagnetic frequency when the mode evolves in the presence of pressure gradients producing the so called drift-tearing mode.
Plotted in the bottom panel of Fig. 5 are the mode frequencies with (horizontal solid lines) the corresponding diamagnetic frequency as given by the above expression, giving good agreement in the collisionless limit. It is also found that the frequency never reaches the Drake and Lee semi-collisionless expression of, ω = ω ∗ n +5 4 / ω ∗ T which are also plotted as horizontal dot-dashed lines, although a qualitative agreement as a function of the pressure gradient is seen i.e. with a larger background pressure gradient a larger maximal frequency is seen. It is also noted that the collisionality threshold at which the mode changes the sign of its rotation is a function of the pressure gradient, with a higher threshold seen at higher background gradients. While the mode start to be stabilised at a lower collisionality, the opposite relation.
## VII. CONCLUSIONS
Using the global version of the gyrokinetic code, GKW, the tearing mode has been studied in the linear regime for experimentally relevant paramerters in three dimensional, toroidal geometry for the first time. The collisionality, equilibrium temperature, density and current gradients were varied and their effects on the mode stability and frequency were analysed. The main results can be summarised as follows:
- · The tearing mode growth rate scales with the resistivity close to the η 1 / 7 scaling as calculated by Fitzpatrick [19] in the semi-collisional, high ∆ ′ regime as opposed to the semi-collisional scaling of η 1 / 3 found in the kinetic treatment of Drake and Lee.
- · The stability of the mode follows closely the stability calculated in cylindrical geometry performed by Wesson et. al. [42]. However, our analysis differs in that multiple rational surfaces may be present within the domain and so allows double tearing modes and toroidal coupling of modes, a process which is known to be destabilising, as such more modes are excited in our global toroidal treatment.
- · The mode is seen to rotate at the electron diamagnetic frequency when a pressure gradient is present, as is characteristic for the drift-tearing mode. However, this is a function of the collisionality and the sign of the rotation frequency is seen to change at a sufficienty high collisionality.
- · A residual non-zero, mode frequency, is found for the classical tearing mode in three dimensional toroidal geometry, even when equilibrium pressure gradients are not included. Suppressing toroidal drift effects recovers a zero mode frequency.
- · Pressure gradient stabilisation of the mode is apparent, even though β e which determines the effective stabilisation, is small.
Linear mode evolution is valid only when the generated magnetic island is small compared to the resonant layer width, which in these simulations were smaller than the ion gyroradius. However, the mode frequency is important for the non-linear evolution of the magnetic island and in particular the polarisation current drive of the tearing mode, and its neoclassical modification, the Neoclassical tearing mode, particularly when the magnetic island is small [24].
## ACKNOWLEDGMENTS
A part of this work was carried out using the HELIOS supercomputer system at Computational Simulation Centre of International Fusion Energy Research Centre (IFERC-CSC), Aomori, Japan, under the Broader Approach collaboration between Euratom and Japan, implemented by Fusion for Energy and JAEA.
The authors would like to thank the Lorentz Center, Leiden for their support. Useful and productive conversations with C.S. Chang, C. Hegna, G. Huismanns and other attendees of the meeting, 'Modelling Kinetic Aspects of Global MHD Modes' are gratefully acknowledged.
- [1] D. Biskamp Magnetic reconnection in plasmas. 3rd Edition Cambridge University Press (2005)
- [2] W. A. Newcomb, Annals of Physics 10 232-267 (1960)
- [3] H. P. Furth, J. Killeen, M. N. Rosenbluth, Phys. Fluids 6 459 (1963)
- [4] H. P. Furth, M. N. Rosenbluth, H. Selberg, Phys. Fluids 16 1054 (1973)
- [5] E.G. Zweibel and M. Yamada, Annu. Rev. Astron. Astrophys. 47 291 (2009)
- [6] F. L. Waelbroeck, Nucl. Fusion 49 104025 (2009)
- [7] R. Carreras, R.D. Hazeltine, M. Kotschenreuther, Phys. Fluids 29 899 (1986)
- [8] C.C. Hegna, Phys. Plasmas 5 1767 (1998)
- [9] H.R. Wilson, J.W. Connor, R.J. Hastie, and C.C. Hegna, Phys. Plasmas 3 248 (1996)
- [10] O. Sauter et. al , Phys. Plasmas 4 1654 (1997)
- [11] Y. Nishimura, J. D. Callen, C. C. Hegna, Phys. Plasmas 5 4292 (1998)
- [12] P. H. Rutherford, Phys. Fluids 16 1903 (1973)
- [13] R.J. Hastie, F. Militello and F. Porcelli, Phys. Rev Lett. 95 065001 (2005)
- [14] W. A. Hornsby et al. (Submitted) arXiv:1403.1520
- [15] E. Poli, A. Bottino and A.G. Peeters, Nucl. Fusion 49 , 075010 (2009)
- [16] W.A. Hornsby et.al., Euro. Phys. Lett. 91 45001 (2010)
- [17] R. D. Hazeltine, D. Dobrott, T. S. Wang, Phys Fluids 18 , 1778 (1975)
- [18] J. F. Drake, Y. C. Lee, Phys. Fluids 20 , 1341 (1977)
- [19] R. Fitzpatrick, Phys. Plasmas 17 , 042101 (2010)
- [20] A. Y. Aydemir, Phys. Fluids B. 3 3025 (1991)
- [21] F.L. Waelbroeck, Phys. Rev. Lett. 70 3259 (1993)
- [22] T. S. Hahm and L. Chen, Phys. Fluids 29 1891 (1986)
- [23] R. Fitzpatrick, F. L. Waelbroeck, and F. Militello, Phys. Plasmas, 13 122507 (2006)
- [24] E. Poli, A. Bergmann and A. G. Peeters, Phys. Rev. Lett. 94 205001 (2005)
- [25] R. Numata, W. Dorland, G. G. Howes, N. F. Loureiro, B. N. Rogers, T. Tatuno, Phys. Plasmas 18 , 112106 (2011)
- [26] B. N. Rogers, S. Kobayashi, P. Ricci, W. Dorland, J. Drake et al. , Phys. Plasmas 14 , 092110 (2007)
- [27] W. Wan, Y. Chen, S. E. Parker, Phys. Plasmas 12 012311 (2005)
- [28] A. Mishchenko and A. Zocco, Phys. Plasmas 19 , 122104 (2012)
- [29] A.G. Peeters et al (To be submitted)
- [30] A.G. Peeters, Y. Camenen, F.J. Casson, W.A. Hornsby, A.P. Snodin, D. Strintzi, and G. Szepesi, Comp. Phys. Comm. 180 , 2649 (2009)
- [31] X. Lapillonne, S. Brunner, T. Dannert, S. Jolliet, A. Marinoni, L. Villard, T. Gorler, F. Jenko, and F. Merz, Phys. Plasmas, 16 , 032308, (2009).
- [32] S. Hamada, Kakuyugo Kenkyu 1 , 542 (1958)
- [33] C.F.F. Karney, Comp. Phys. Reports 4 (1986) 183
- [34] R. Fitzpatrick, P. G. Watson and F. L. Waelbroeck, Phys. Plasmas 12 082510 (2005)
- [35] I. Katanuma, T. Kamimura, Phys. Fluids 23 2500 (1980)
- [36] J. Wesson, Tokamaks (Cambridge University Press, Cambridge, 1987)
- [37] F. Porcelli, Phys. Fluids 30 6 (1987)
- [38] B. Carreras, H. R. Hicks and D. K. Lee, Phys Fluids 24 1 (1981)
- [39] J.W.Connor, S.C.Cowley, R.J. Hastie, T.C. Hender, A.Hood and T.J.Martin, Phys. Fluids 31 577 (1988)
- [40] J. F. Drake, T. M. Antonsen Jr., A. B. Hassam and N. T. Gladd, Phys. Fluids 26 2509 (1983)
- [41] A.H. Glasser, J.M. Greene and J.L. Johnson, Phys. Fluids 18 875 (1975)
- [42] R.J. Hastie, A. Sykes, M. Turner and J.A. Wesson, Nucl. Fusion, 17 3 (1977)
- [43] J.W. Connor, R.J. Hastie and A. Zocco, Plasma. Phys. Contol. Fusion 54 035003 (2012) | 10.1063/1.4907900 | [
"William Hornsby",
"Pierluigi Migliano",
"Rico Bucholz",
"Lukas Kroenert",
"Arthur Peeters",
"David Zarzoso",
"Emanuele Poli",
"Francis Casson"
] | 2014-08-01T09:42:06+00:00 | 2014-08-01T09:42:06+00:00 | [
"physics.plasm-ph"
] | The linear tearing instability in three dimensional, toroidal gyrokinetic simulations | Linear gyro-kinetic simulations of the classical tearing mode in
three-dimensional toroidal geometry were performed using the global gyro
kinetic turbulence code, GKW . The results were benchmarked against a
cylindrical ideal MHD and analytical theory calculations. The stability, growth
rate and frequency of the mode were investigated by varying the current
profile, collisionality and the pressure gradients. Both collision-less and
semi-collisional tearing modes were found with a smooth transition between the
two. A residual, finite, rotation frequency of the mode even in the absense of
a pressure gradient is observed which is attributed to toroidal finite
Larmor-radius effects. When a pressure gradient is present at low
collisionality, the mode rotates at the expected electron diamagnetic
frequency. However the island rotation reverses direction at high
collisionality. The growth rate is found to follow a $\eta^{1/7}$ scaling with
collisional resistivity in the semi-collisional regime, closely following the
semi-collisional scaling found by Fitzpatrick. The stability of the mode
closely follows the stability using resistive MHD theory, however a
modification due to toroidal coupling and pressure effects is seen. |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.