
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
390. Elimination Game (Test Cases ) | elimination-game | 0 | 1 | # Intuition\n We are trying to find the last remaining number in a sequence of numbers from 1 to n after applying a specific elimination algorithm. \n The algorithm involves repeatedly removing numbers alternately from left to right and from right to left until only one number remains. \n\n# Approach\nWe use a recursive approach to solve this problem efficiently.\n 1. If n is equal to 1, we return 1 as the base case since there\'s only one number remaining.\n 2. For n > 1, we calculate half_n by dividing n by 2.\n 3. We make a recursive call to the lastRemaining function with half_n as the new input. This call calculates the position of the last remaining number in the range from 1 to half_n.\n 4. We calculate the final result using the formula: 2 * (half_n + 1 - result_of_recursive_call). This formula effectively calculates the position of the last remaining number in the original range from 1 to n based on the result of the recursive call.\n\n# Complexity\n- Time complexity: The time complexity of this solution is O(log n) because with each recursive call, we reduce the size of the problem by half.\n- Space complexity: The space complexity is O(log n) as well, due to the recursive call stack.\n\n class Solution:\n def lastRemaining(self, n: int) -> int:\n if n == 1:\n return 1\n \n # Calculate half of n\n half_n = n // 2\n \n # Recursively calculate the position of the last remaining number\n return 2 * (half_n + 1 - self.lastRemaining(half_n))\n | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
O(log(n)) py sol. | elimination-game | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:O(log(n))\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n if n == 1:\n return 1\n res = 0\n ptr1, ptr2 = 1, n\n itr = 1\n offset = 1\n while ptr1 < ptr2:\n offset *= 1 if itr == 1 else 2\n if itr % 2 != 0:\n ptr2 -= offset if (ptr2 - ptr1) % (offset*2) == 0 else 0\n ptr1 += offset\n else:\n ptr1 += offset if (ptr2 - ptr1) % (offset * 2) == 0 else 0\n ptr2 -= offset\n\n if ptr1 > ptr2:\n res = (ptr2 + offset) if itr % 2 != 0 else (ptr1 - offset)\n elif ptr1 == ptr2:\n res = ptr1\n itr += 1\n return res\n\n \n \n``` | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
391: Time 95.62%, Solution with step by step explanation | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize the area of all the rectangles to 0 and create a set to keep track of the corners of the rectangles.\n```\narea = 0\ncorners = set()\n```\n2. Iterate over each rectangle in the input list and do the following:\na. Add the area of the rectangle to the total area.\nb. Check if each corner of the rectangle is unique. If it is, add it to the set of corners. If it is not, remove it from the set of corners.\n```\nfor x1, y1, x2, y2 in rectangles:\n area += (x2 - x1) * (y2 - y1)\n for corner in [(x1, y1), (x1, y2), (x2, y1), (x2, y2)]:\n if corner in corners:\n corners.remove(corner)\n else:\n corners.add(corner)\n```\n3. Check if all corners of the rectangles are unique. If they are not, return False.\n```\nif len(corners) != 4:\n return False\n```\n4. Find the coordinates of the union rectangle by finding the minimum and maximum x and y coordinates of all the corners.\n```\nx1, y1 = float("inf"), float("inf")\nx2, y2 = float("-inf"), float("-inf")\nfor x, y in corners:\n x1 = min(x1, x)\n y1 = min(y1, y)\n x2 = max(x2, x)\n y2 = max(y2, y)\n```\n5. Calculate the area of the union rectangle.\n```\nunion_area = (x2 - x1) * (y2 - y1)\n```\n6. Check if the total area of all the rectangles is equal to the area of the union rectangle. If it is not, return False.\n```\nif area != union_area:\n return False\n```\n7. Check if the total number of corners is equal to the sum of the areas of the rectangles divided by the area of a single rectangle. If it is not, return False.\n```\nreturn area == (x2 - x1) * (y2 - y1)\n```\n8. If all the above conditions are satisfied, return True.\n# Complexity\n- Time complexity:\n95.62%\n\n- Space complexity:\n43.3%\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n # calculate the area of all the rectangles\n area = 0\n corners = set()\n for x1, y1, x2, y2 in rectangles:\n area += (x2 - x1) * (y2 - y1)\n # check if each corner is unique\n for corner in [(x1, y1), (x1, y2), (x2, y1), (x2, y2)]:\n if corner in corners:\n corners.remove(corner)\n else:\n corners.add(corner)\n # check if all corners are unique\n if len(corners) != 4:\n return False\n # calculate the area of the union rectangle\n x1, y1 = float("inf"), float("inf")\n x2, y2 = float("-inf"), float("-inf")\n for x, y in corners:\n x1 = min(x1, x)\n y1 = min(y1, y)\n x2 = max(x2, x)\n y2 = max(y2, y)\n union_area = (x2 - x1) * (y2 - y1)\n # check if the total area of all the rectangles is equal to the area of the union rectangle\n if area != union_area:\n return False\n # check if the total number of corners is equal to the sum of the areas of the rectangles divided by the area of a single rectangle\n return area == (x2 - x1) * (y2 - y1)\n\n``` | 4 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
[Python] Fast and clear solution with explanation | perfect-rectangle | 0 | 1 | We need to check two things:\n- the external corners must appear only once, and the ones inside have to be an even number (we filter them with xor).\n- the total area of all the rectangles together, has to be equal to the area created by the external corners\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n \n area = 0\n corners = set()\n a = lambda: (Y-y) * (X-x)\n \n for x, y, X, Y in rectangles:\n area += a()\n corners ^= {(x,y), (x,Y), (X,y), (X,Y)}\n\n if len(corners) != 4: return False\n x, y = min(corners, key=lambda x: x[0] + x[1])\n X, Y = max(corners, key=lambda x: x[0] + x[1])\n return a() == area\n``` | 47 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Python3 short + Very Easy with comments O(N) | perfect-rectangle | 0 | 1 | ```\ndef isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n # simple problem\n # Check if area of each adds up to the final one\n # If not no solution but if it does then you need to make sure the number of corners are 4 only.\n # If the corners are more than that that means some corners do not match with other ones to fit end to end\n area = 0\n corners = set()\n a = lambda: (Y - y) * (X - x)\n c = lambda k: k[0] + k[1]\n \n for x, y, X, Y in rectangles:\n area += a()\n corners ^= {(x, Y), (X, y), (x, y), (X, Y)}\n \n if len(corners) != 4:\n return False\n x, y = min(corners, key = c)\n X, Y = max(corners, key = c)\n return area == a()\n``` | 4 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
python solution | perfect-rectangle | 0 | 1 | ```\nclass Solution(object):\n def isRectangleCover(self, rectangles):\n """\n :type rectangles: List[List[int]]\n :rtype: bool\n """\n hs = set()\n area = 0\n for rec in rectangles:\n top_left = (rec[0], rec[1])\n top_right = (rec[0], rec[3])\n bottom_left = (rec[2], rec[1])\n bottom_right = (rec[2], rec[3])\n area += (rec[2] - rec[0]) * (rec[3] - rec[1])\n for i in [top_left, top_right, bottom_left, bottom_right]:\n if i not in hs:\n hs.add(i)\n else:\n hs.remove(i)\n if len(hs) != 4:\n return False\n hs = sorted(hs)\n first = hs.pop(0)\n last = hs.pop()\n return area == (last[0] - first[0]) * (last[1] - first[1])\n``` | 20 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
O(n) solution | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe idea for this problem is to check if a set of rectangles can be covered by a single rectangle.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nTo do this, we can use the following steps:\n\n- If the input list of rectangles is empty, return False.\n- If the input list has a single rectangle, return True.\n- Initialize variables to store the minimum and maximum x and y coordinates of the rectangles, and the area of the rectangles.\n- Iterate over the rectangles and update the minimum and maximum x and y coordinates and the area of the rectangles.\n- Initialize a set to store the points of the rectangles.\n- Iterate over the rectangles again and add the points to the set. If a point is already in the set, remove it. Otherwise, add it to the set.\n- Return True if the area of the rectangles is equal to the area of the bounding rectangle and the set of points is equal to the four corner points of the bounding rectangle, otherwise return False.\n\n# Complexity\n- Time complexity: $O(n)$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nWe need to perform a single pass through the input list of rectangles.\n\n\n- Space complexity: $O(n)$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nWe need to store the points of the rectangles in a set, which takes $O(n)$ space.\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n if not rectangles:\n return False\n if len(rectangles) == 1:\n return True\n x1 = y1 = float(\'inf\')\n x2 = y2 = float(\'-inf\')\n area = 0\n points = set()\n for x, y, xx, yy in rectangles:\n x1 = min(x1, x)\n y1 = min(y1, y)\n x2 = max(x2, xx)\n y2 = max(y2, yy)\n area += (xx - x) * (yy - y)\n p1 = (x, y)\n p2 = (xx, y)\n p3 = (xx, yy)\n p4 = (x, yy)\n for p in (p1, p2, p3, p4):\n if p in points:\n points.remove(p)\n else:\n points.add(p)\n return area == (x2 - x1) * (y2 - y1) and points == {(x1, y1), (x1, y2), (x2, y1), (x2, y2)}\n\n``` | 3 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Think of few Conditions, only a perfect rectangle passes | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n Think of few Conditions, only a perfect rectangle passes\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n Idea : Rectangle is perfect then it follows below conditions.\n 1. Area of larger rectangle = Sum of smaller rectangles (eleminates overlap rectgles)\n 2. All edge points appear twice or even number of times\n\n Check this condns if it follows, then its perfect rectangle\n\n# Complexity\n- Time complexity: $$O(n)$$ \n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$ \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n ""\n # Idea : Rectangle is perfect then it follows below condns \n 1. Area of larger rectangle = Sum of smaller rectangles (eleminates overlap rectgles)\n 2. All edge points appear twice or even number of times\n\n Check this condns if it follows, then its perfect rectangle\n ""\n\n def area(X,x,Y,y):\n return (X-x)*(Y-y)\n \n total_area=0\n seen_cords=set()\n for x,y,X,Y in rectangles:\n total_area+=area(X,x,Y,y)\n for a,b in [(x,y),(X,y),(x,Y),(X,Y)]:\n if (a,b) in seen_cords:\n seen_cords.remove((a,b))\n else:\n seen_cords.add((a,b))\n if len(seen_cords)!=4:\n return False\n x,y = min(seen_cords, key=lambda x: x[0]+x[1])\n X,Y = max(seen_cords, key=lambda x: x[0]+x[1])\n Area=area(X,x,Y,y)\n return Area==total_area\n\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Full logic solution, beats 65%, 7% | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nbased on below assumption:\n1. the area of the new rectangle == the summary of all rectangles.\n2. only has 4 conners\n3. for each point that isn\'t a conner, it has 2 or 4 connections.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n points = collections.defaultdict(list)\n n = len(rectangles)\n area = 0\n\n for i in range(n):\n x, y, a, b = rectangles[i]\n points[(x, y)].append(i)\n points[(a, b)].append(i)\n points[(x, b)].append(i)\n points[(a, y)].append(i)\n area += (a-x) * (b-y)\n\n conners = []\n for k, v in points.items():\n if len(v) == 1:\n conners.append(k)\n elif len(v) not in (2, 4):\n return False\n\n if len(conners) != 4:\n return False\n\n mini, maxi = min(conners, key=lambda x:(x[0], x[1])), max(conners, key=lambda x:(x[0], x[1]))\n\n return area == (maxi[0] - mini[0]) * (maxi[1] - mini[1])\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
😚Python3🐽391. Perfect Rectangle🤿Geometry Math🕌 | perfect-rectangle | 0 | 1 | \n\n# Intuition\nGeometry, Math, Line Sweep\n\n# Approach\ncount overlapping situation of each dot\n\n# Complexity\n- Time complexity:\n$$O(n)$$\n\n- Space complexity:\n$$O(n)$$\n\n# Code\n```\nclass Solution:\n\tdef isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n \'\'\'Return bool can it be a rectangle or not\'\'\'\n # list, set and Counter of all coordinates\n cos_all = [(co[0], co[1]) for co in rectangles] + \\\n [(co[0], co[3]) for co in rectangles] + \\\n [(co[2], co[1]) for co in rectangles] + \\\n [(co[2], co[3]) for co in rectangles]\n cos_all_counter = Counter(cos_all) # a dict\n co_set = set(cos_all)\n \n # sum square of all rect literally\n sum_square = sum([(co[2] - co[0]) * (co[3] - co[1]) for co in rectangles])\n \n # Get all vertexes by nexted list comprehension\n xs = sorted([co for cos in rectangles for co in (cos[0], cos[2])])\n ys = sorted([co for cos in rectangles for co in (cos[1], cos[3])])\n left_down = xs[0], ys[0]\n left_up = xs[0], ys[-1]\n right_down = xs[-1], ys[0]\n right_up = xs[-1], ys[-1]\n vertexes = {left_down, left_up, right_down, right_up}\n del xs, ys\n\n # Compare total_square with sum_square\n total_square = (right_up[0] - left_down[0]) * (right_up[1] - left_down[1])\n if total_square != sum_square:\n return False\n\n # return False if vertexes doesn\'t exist\n if not (left_down in co_set and \n left_up in co_set and\n right_down in co_set and\n right_up in co_set\n ):\n return False\n\n # check overlapping situation for vertexes and non-vertexes\n for co in cos_all_counter:\n # vertexes but not single\n if co in vertexes:\n if cos_all_counter[co] != 1:\n return False\n # not vertexes but odd\n elif cos_all_counter[co] % 2 != 0:\n return False\n\n return True\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Python, O(n), Easy Explanation, Diagrams, Breakdown by Code Section | perfect-rectangle | 0 | 1 | (read on a standalone page [here](https://hakanalpay.com/leetcode/391-perfect-rectangle))\n\n### Problem Insight:\n\n1. The combined area of all small rectangles should equal the area of the large rectangle.\n\n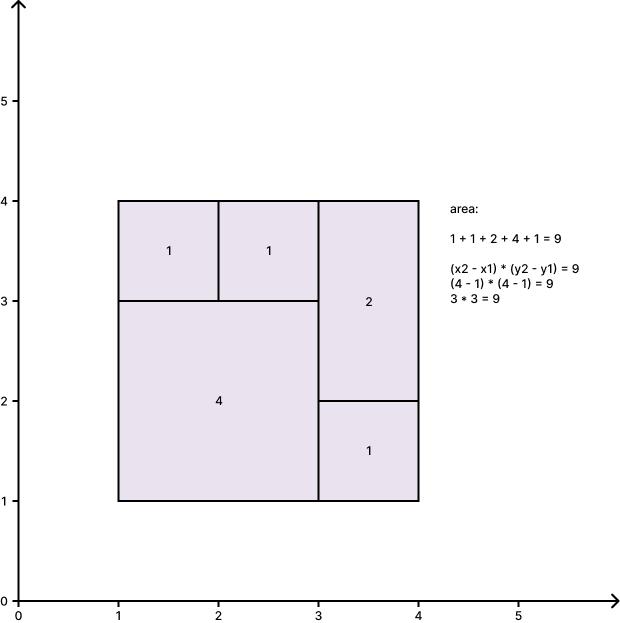\n\n\n2. The corners of the large rectangle should appear only once, while all other points where rectangles meet should appear an even number of times.\n\n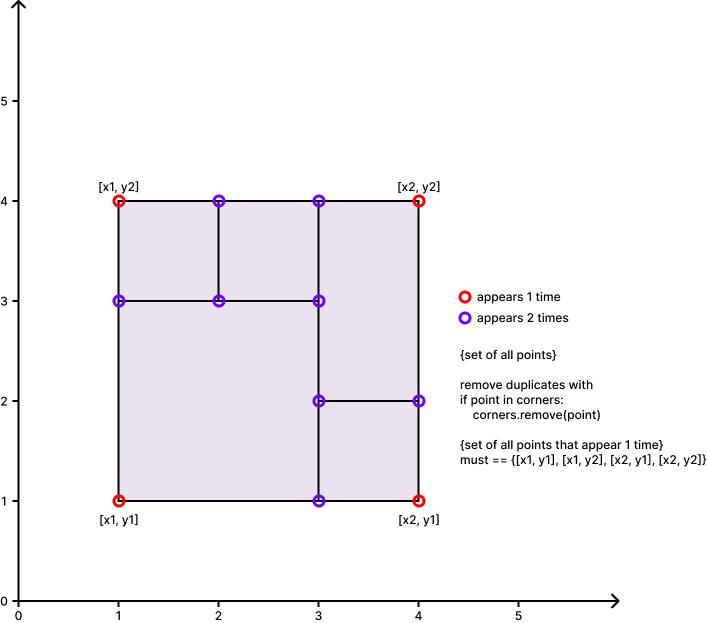\n\n\n### Solution Breakdown:\n\n1. **Initialization**:\n ```python\n x1, y1 = float(\'inf\'), float(\'inf\')\n x2, y2 = float(\'-inf\'), float(\'-inf\')\n corners = set()\n area = 0\n ```\n - `x1`, `y1`: Bottom-left corner of the large rectangle.\n - `x2`, `y2`: Top-right corner of the large rectangle.\n - `corners`: A set to store the corners of all rectangles.\n - `area`: To store the total area covered by all small rectangles.\n\n2. **Iterate over each rectangle**:\n ```python\n for rect in rectangles:\n ```\n For each rectangle, the code does the following:\n\n a. **Updates the potential corners of the large rectangle**:\n ```python\n x1 = min(rect[0], x1)\n y1 = min(rect[1], y1)\n x2 = max(rect[2], x2)\n y2 = max(rect[3], y2)\n ```\n - This updates the minimum values for the bottom-left corner and the maximum values for the top-right corner.\n\n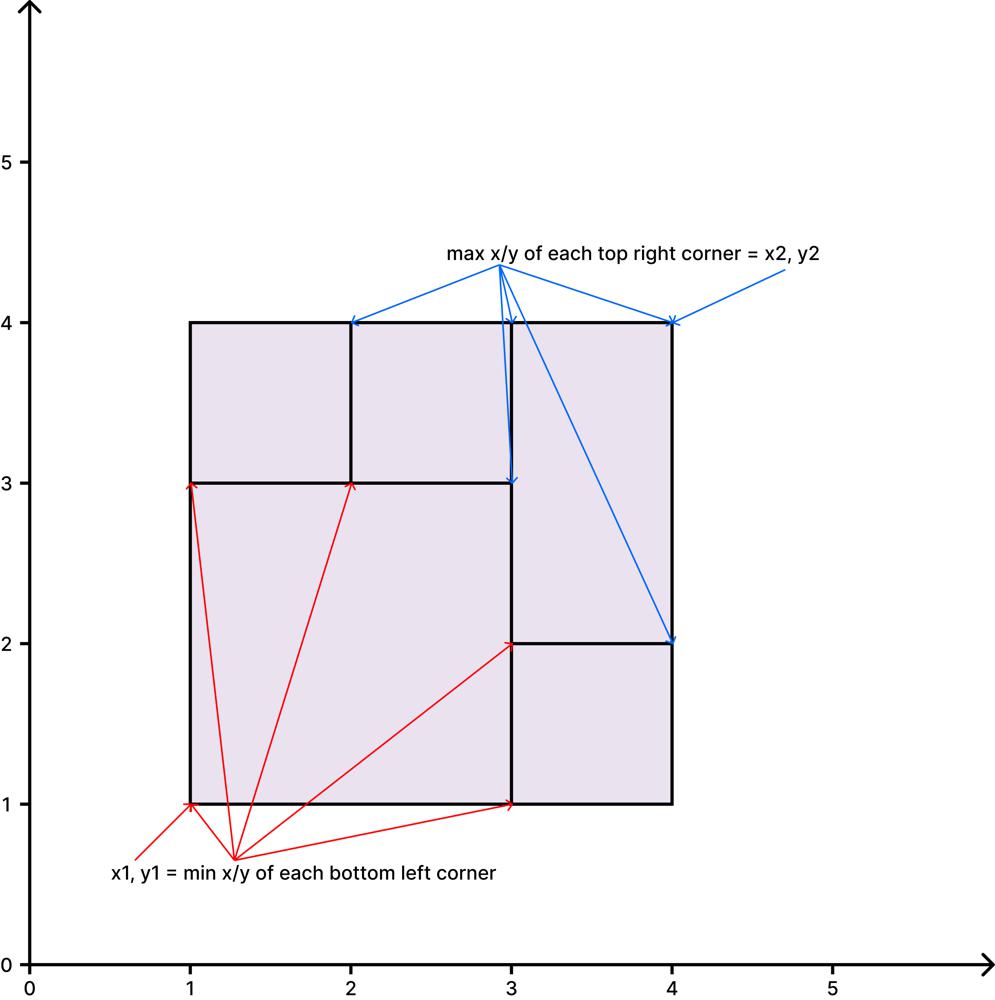\n\n\nb. **Updates the total area**:\n - Adds the area of the current rectangle to the total area.\n```python\narea += (rect[2] - rect[0]) * (rect[3] - rect[1])\n```\n\nc. **Handles the corners of the current rectangle**:\n- The four corners of the current rectangle are created as tuples.\n- The loop checks each corner: \n - If the corner is already in the `corners` set, it is removed.\n - If it\'s not, it\'s added to the set. \n- This ensures that corners appearing twice are eliminated from the set.\n ```\n for point in [(rect[0], rect[1]), (rect[0], rect[3]), (rect[2], rect[3]), (rect[2], rect[1])]:\n if point in corners:\n corners.remove(point)\n else:\n corners.add(point)\n ```\n\n3. **Final Checks**:\n\n a. **Check the four corners of the large rectangle**:\n ```python\n if {(x1, y1), (x1, y2), (x2, y1), (x2, y2)} != corners:\n return False\n ```\n - This checks if the set contains only the four corners of the large rectangle. If there are other corners left in the set, or if any of these four corners are missing, it returns `False`.\n\n b. **Check the area**:\n ```python\n return area == (x2 - x1) * (y2 - y1)\n ```\n - Ensures that the combined area of all small rectangles equals the area of the large rectangle.\n\n### Summary:\n\nIn this Python solution, we utilize the properties of sets and the efficiency and clarity of tuples to determine if the given rectangles can form a large rectangle without overlaps or gaps. The logic is similar to [hu19\'s Java solution](https://leetcode.com/problems/perfect-rectangle/solutions/87181/really-easy-understanding-solution-o-n-java/), but the use of tuples makes the code more concise and readable.\n\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n if not rectangles:\n return False\n\n x1, y1 = float(\'inf\'), float(\'inf\')\n x2, y2 = float(\'-inf\'), float(\'-inf\')\n corners = set()\n area = 0\n\n for rect in rectangles:\n x1 = min(rect[0], x1)\n y1 = min(rect[1], y1)\n x2 = max(rect[2], x2)\n y2 = max(rect[3], y2)\n \n area += (rect[2] - rect[0]) * (rect[3] - rect[1])\n \n for point in [(rect[0], rect[1]), (rect[0], rect[3]), (rect[2], rect[3]), (rect[2], rect[1])]:\n if point in corners:\n corners.remove(point)\n else:\n corners.add(point)\n\n if {(x1, y1), (x1, y2), (x2, y1), (x2, y2)} != corners:\n return False\n\n return area == (x2 - x1) * (y2 - y1)\n\n```\n\n### Time Complexity:\n\n1. **Iterating over each rectangle**:\n ```python\n for rect in rectangles:\n ```\n This loop iterates `n` times, where `n` is the number of rectangles. Within this loop:\n\n a. **Updating the potential corners of the large rectangle and the total area**:\n These operations are \\(O(1)\\) for each rectangle.\n \n b. **Handling the corners of the current rectangle**:\n ```python\n for point in [(rect[0], rect[1]), (rect[0], rect[3]), (rect[2], rect[3]), (rect[2], rect[1])]:\n ```\n This loop iterates 4 times (a constant time). Inside this loop, adding a point to a set or removing a point from a set are both \\(O(1)\\) operations.\n\n Thus, the operations inside the main loop are \\(O(1)\\), making the overall time complexity of the main loop \\(O(n)\\).\n\n2. **Final Checks**:\n Checking the four corners of the large rectangle and checking the area are both \\(O(1)\\) operations.\n\nCombining the above, the overall time complexity is \\(O(n)\\).\n\n### Space Complexity:\n\n1. **Storing the corners**:\n ```python\n corners = set()\n ```\n In the worst case, if every rectangle is disjoint from the others, there would be 4 corners for each rectangle, so the space required would be \\(O(4n)\\) or \\(O(n)\\).\n\n2. **Other variables**: `x1`, `x2`, `y1`, `y2`, and `area` all occupy constant space, \\(O(1)\\).\n\nThus, the overall space complexity is \\(O(n)\\).\n\nIn conclusion, both the time complexity and the space complexity of the Python solution are \\(O(n)\\).\n\n### Acknowledgements\n\nThanks to [hu19](https://leetcode.com/hu19/) for his solution :)\n | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Clean Python Sweel Line O(N log N) | perfect-rectangle | 0 | 1 | In this solution I wanted to practice sweep line algorithm. Even though most solutions count corners, this solution beats 20% of them. The idea is to sweep the plane from left to right with an imaginary line parallel to y axis.\n\n1. We create a list of "events" that will occur with this imaginary line. \n1.1. When the sweep line encounters a new rectangle we need to add a new interval covered by this rectangle, corresponding tuples are marked with True field(third in the tuple). Events where we would need to remove corresponding interval are marked with False. \n1.2. Zero-th element of the tuple is the x-coordinate of the event so we can sort them in order.\n1.3. First element of the tuple is the y-coordinate of the rectangle so that when we process a set of events occuring at the same x we can maintain interval arrays sorted and do inserts to them in O(1).\n1.4. Last element of the tuple is the index of the rectangle in the array of rectangles so that we can retrieve the top and bottom y coordinates.\n2. We sort events by x coordinate, thus allowing sweep from left to right.\n3. The first encounter of the sweep line would be the leftmost borders of leftmost rectangles. Each of these rectangles projects to an interval on the said line. Processing of this first encounter happens in `if len(yrange) == 1` operator. There we simply check that the set of added intervals when merged gives a single continuous range. If there are other errors such as overlapping intervals they will reveal themselves later.\n4. As we process all other events we follow a simple algorithm: for each value of x we accumulate all the added intervals (because of the newly encountered rectangles) and all the deleted intervals. Then we merge the corresponding sets to bring them to a unified form (see https://leetcode.com/problems/merge-intervals/ ). The merging can be done in O(n) because arrays are sorted(follows from events tuple array being sorted). These unified forms should simply be equal for each value of x. \n5. At the maximum x we make sure that all deleted rectangles are equal to the rectangle\'s yrange.\n\n# Code\n```\ndef isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n\tevents = []\n\tfor i, r in enumerate(rectangles):\n\t\tevents += [(r[0], r[1], True, i), (r[2], r[1], False, i)]\n\tevents.sort()\n\n\ti = 0\n\n\tyrange = []\n\twhile i < len(events):\n\t\tx = events[i][0]\n\t\tadd_intervals = []\n\t\tdel_intervals = []\n\t\twhile i < len(events) and events[i][0] == x:\n\t\t\t\tr = rectangles[events[i][3]]\n\t\t\t\tinterval = [r[1], r[3]]\n\t\t\t\tif events[i][2]:\n\t\t\t\t\tadd_intervals.append(interval)\n\t\t\t\telse:\n\t\t\t\t\tdel_intervals.append(interval)\n\t\t\t\ti = i + 1\n\t\tif yrange == []:\n\t\t\tself.merge_ints(add_intervals, yrange)\n\t\t\tif len(yrange) != 1:\n\t\t\t\treturn False\n\t\t\tcontinue\n\t\tadd_merged = []\n\t\tdel_merged = []\n\t\tif (not self.merge_ints(add_intervals, add_merged) or\n\t\t\t\tnot self.merge_ints(del_intervals, del_merged) or\n\t\t\t\t(i != len(events) and del_merged != add_merged) or\n\t\t\t\t(i == len(events) and del_merged != yrange)):\n\t\t\treturn False\n\n\treturn True\n\ndef merge_ints(self, intervals: List[List[int]], merged: List[List[int]]) -> bool:\n\tfor interval in intervals:\n\t\t\tif not merged or merged[-1][1] < interval[0]:\n\t\t\t\tmerged.append([interval[0], interval[1]])\n\t\t\telif merged[-1][1] == interval[0]:\n\t\t\t\tmerged[-1][1] = max(merged[-1][1], interval[1])\n\t\t\telse:\n\t\t\t\treturn False\n\treturn True\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Solution | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n X1, Y1 = float(\'inf\'), float(\'inf\')\n X2, Y2 = -float(\'inf\'), -float(\'inf\')\n \n points = set()\n actual_area = 0\n for x1, y1, x2, y2 in rectangles:\n # \u8BA1\u7B97\u5B8C\u7F8E\u77E9\u5F62\u7684\u7406\u8BBA\u9876\u70B9\u5750\u6807\n X1, Y1 = min(X1, x1), min(Y1, y1)\n X2, Y2 = max(X2, x2), max(Y2, y2)\n # \u7D2F\u52A0\u5C0F\u77E9\u5F62\u7684\u9762\u79EF\n actual_area += (x2 - x1) * (y2 - y1)\n # \u8BB0\u5F55\u6700\u7EC8\u5F62\u6210\u7684\u56FE\u5F62\u4E2D\u7684\u9876\u70B9\n p1, p2 = (x1, y1), (x1, y2)\n p3, p4 = (x2, y1), (x2, y2)\n for p in [p1, p2, p3, p4]:\n if p in points: points.remove(p)\n else: points.add(p)\n # \u5224\u65AD\u9762\u79EF\u662F\u5426\u76F8\u540C\n expected_area = (X2 - X1) * (Y2 - Y1)\n if actual_area != expected_area:\n return False\n # \u5224\u65AD\u6700\u7EC8\u7559\u4E0B\u7684\u9876\u70B9\u4E2A\u6570\u662F\u5426\u4E3A 4\n if len(points) != 4: return False\n # \u5224\u65AD\u7559\u4E0B\u7684 4 \u4E2A\u9876\u70B9\u662F\u5426\u662F\u5B8C\u7F8E\u77E9\u5F62\u7684\u9876\u70B9\n if (X1, Y1) not in points: return False\n if (X1, Y2) not in points: return False\n if (X2, Y1) not in points: return False\n if (X2, Y2) not in points: return False\n # \u9762\u79EF\u548C\u9876\u70B9\u90FD\u5BF9\u5E94\uFF0C\u8BF4\u660E\u77E9\u5F62\u7B26\u5408\u9898\u610F\n return True\n \n\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Perfect Rectangle | perfect-rectangle | 0 | 1 | # Intuition\nAll rectangles form an exact rectangle cover if:\n1. The area of the rectangle cover is equal to the area of all rectangles.\n2. Any point should appear even times as (a corner of a small triangle), otherwise there will be overlaps or gaps. So we can maintain a set to store the corner points. If the number of a point is even, this point will be removed from the set. At last, there should be only 4 points in the set.\n3. The 4 points should be exactly the 4 corners of the rectangle cover.\n\n# Complexity\n- Time complexity:\n$$O(n)$$\n\n- Space complexity:\n$$O(n)$$\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n points = set()\n X1, Y1 = float(\'inf\'), float(\'inf\')\n X2, Y2 = -float(\'inf\'), -float(\'inf\')\n\n for x1, y1, x2, y2 in rectangles:\n X1 = min(x1, X1)\n Y1 = min(y1, Y1)\n X2 = max(x2, X2)\n Y2 = max(y2, Y2)\n \n size = (X2 - X1) * (Y2 - Y1)\n actual_size = 0\n\n for x1, y1, x2, y2 in rectangles:\n p_list = [(x1, y1), (x2, y1), (x1, y2), (x2, y2)]\n for p in p_list:\n if p not in points:\n points.add(p)\n else:\n points.remove(p)\n actual_size += (x2 - x1) * (y2 - y1)\n \n if actual_size != size:\n return False\n \n if len(points) != 4:\n return False\n\n if ((X1, Y1) not in points) or ((X1, Y2) not in points) or ((X2, Y1) not in points) or ((X2, Y2) not in points):\n return False\n \n return True\n\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Python solution | Beats 100% | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rects: List[List[int]]) -> bool:\n area = 0\n corners = {}\n for x1, y1, x2, y2 in rects:\n area += (x2-x1)*(y2-y1)\n for corner in (x1, y1), (x1, y2), (x2, y1), (x2, y2):\n if corner not in corners:\n corners[corner] = True\n else:\n del corners[corner]\n \n if len(corners) != 4:\n return False\n\n c = set(corners.keys())\n x1, y1 = min(c)\n x2, y2 = max(c)\n\n return area == (x2-x1)*(y2-y1) and c == {(x1, y1), (x1, y2), (x2, y1), (x2, y2)}\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Geometry and set | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n # the idea is to count overlap points, if there are 4 non-overlap points and \n # there is no overlap odd numbers of points, we can check the area of all rectangles\n # with the 4 unique points formed rectangles.\n area, count = 0, defaultdict(int)\n for x, y, a, b in rectangles:\n for pointX, pointY in [[x, y], [a, b], [x, b], [a, y]]:\n count[(pointX, pointY)] += 1\n area += (a - x) * (b - y)\n s =set()\n for item, v in count.items():\n if v == 1:\n s.add(item)\n if v > 2 and v % 2 == 1: # case 48\n return False\n if len(s) != 4:\n return False\n\n max_x, max_y, min_x, min_y = -inf, -inf, inf, inf\n for x, y in s:\n max_x = max(max_x, x)\n min_x = min(min_x, x)\n max_y = max(max_y, y)\n min_y = min(min_y, y)\n return area == (max_y - min_y) * (max_x - min_x)\n# using set:\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n # the idea is to count overlap points, if there are 4 non-overlap points and \n # there is no overlap odd numbers of points, we can check the area of all rectangles\n # with the 4 unique points formed rectangles.\n area, s = 0, set()\n for x, y, a, b in rectangles:\n for pointX, pointY in [[x, y], [a, b], [x, b], [a, y]]:\n if (pointX, pointY) in s:\n s.remove((pointX, pointY))\n else:\n s.add((pointX, pointY))\n area += (a - x) * (b - y)\n if len(s) != 4: return False\n\n max_x, max_y, min_x, min_y = -inf, -inf, inf, inf\n for x, y in s:\n max_x = max(max_x, x)\n min_x = min(min_x, x)\n max_y = max(max_y, y)\n min_y = min(min_y, y)\n return area == (max_y - min_y) * (max_x - min_x)\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
(Python) Exact Cover Rectangle | perfect-rectangle | 0 | 1 | # Intuition\nTo check if the given rectangles form an exact cover of a rectangular region, we need to make sure that:\n\n1. All rectangles together completely cover the rectangular region.\n2. No part of the rectangular region is covered twice or more.\n# Approach\nWe can keep track of the area of the union of all rectangles, as well as the area of each individual rectangle. If the sum of individual rectangles\' areas is equal to the area of the union, and there is no overlap between any pair of rectangles, then the rectangles form an exact cover of a rectangular region.\n\nTo check for overlap, we can use a set to keep track of all points that are covered by more than one rectangle. If at any point we find a point that is already in the set, it means that there is overlap, and we can return false.\n# Complexity\n- Time complexity:\nO(nlogn), where n is the number of rectangles. This is because we need to sort the rectangles by their x and y coordinates.\n- Space complexity:\nO(n), to store the set of overlapping points.\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n def check_rectangle(rect):\n nonlocal vertices\n for vertex in rect:\n if vertex not in vertices:\n vertices.add(vertex)\n else:\n vertices.remove(vertex)\n \n return True\n\n vertices = set()\n area = 0\n \n for rect in rectangles:\n area += (rect[2] - rect[0]) * (rect[3] - rect[1])\n if not check_rectangle([(rect[0], rect[1]), (rect[0], rect[3]), (rect[2], rect[3]), (rect[2], rect[1])]):\n return False\n \n if len(vertices) != 4:\n return False\n \n x1, y1 = min(vertices)\n x2, y2 = max(vertices)\n return area == (x2 - x1) * (y2 - y1)\n\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Solution | perfect-rectangle | 1 | 1 | ```C++ []\n#define MOD 113\n#define P 31\n\nclass Solution {\n int corners[MOD];\n int sum = 0;\n inline long long area(const vector<int> &r) {\n return (long long)(r[2] - r[0]) * (r[3] - r[1]);\n }\n inline void add(const pair<int, int> &p) {\n int& v = corners[((p.first * P + p.second) % MOD + MOD) % MOD];\n v ^= 1;\n sum += (v == 1 ? 1 : -1);\n }\npublic:\n bool isRectangleCover(const vector<vector<int>>& rectangles) {\n long long sum_area = 0;\n int x0 = 1e5, y0 = 1e5, x1 = -1e5, y1 = -1e5;\n\n for (const auto &r : rectangles) {\n sum_area += area(r);\n x0 = (x0 < r[0] ? x0 : r[0]);\n y0 = (y0 < r[1] ? y0 : r[1]);\n x1 = (x1 > r[2] ? x1 : r[2]);\n y1 = (y1 > r[3] ? y1 : r[3]);\n add({r[0], r[1]});\n add({r[2], r[3]});\n add({r[0], r[3]});\n add({r[2], r[1]});\n }\n add({x0, y0});\n add({x1, y0});\n add({x0, y1});\n add({x1, y1});\n // cout << x0 << " " << y0 << " " << x1 << " " << y1 << "\\n";\n return area({x0, y0, x1, y1}) == sum_area && sum == 0;\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def isRectangleCover(self, rectangles: list[list[int]]) -> bool:\n area = 0\n corners = set()\n\n for x, y, a, b in rectangles:\n area += (b - y) * (a - x)\n corners ^= {(x, y), (x, b), (a, y), (a, b)}\n\n if len(corners) != 4: return False\n \n x, y = min(corners)\n a, b = max(corners)\n return (b - y) * (a - x) == area\n```\n\n```Java []\nclass Solution {\n public boolean isRectangleCover(int[][] rectangles) {\n if (rectangles == null || rectangles.length == 0 || rectangles[0].length == 0) {\n return false;\n }\n Set<int[]> set = new TreeSet<>((int[] a, int[] b) -> {\n if (a[3] <= b[1]) {\n return -1;\n } else if (a[1] >= b[3]) {\n return 1;\n } else if (a[2] <= b[0]) {\n return -1;\n } else if (a[0] >= b[2]) {\n return 1;\n } else return 0;\n });\n int area = 0;\n int up = Integer.MIN_VALUE;\n int down = Integer.MAX_VALUE;\n int left = Integer.MAX_VALUE;\n int right = Integer.MIN_VALUE;\n \n for (int[] rect : rectangles) {\n area += (rect[2] - rect[0]) * (rect[3] - rect[1]);\n up = Math.max(up, rect[3]);\n right = Math.max(right, rect[2]);\n down = Math.min(down, rect[1]);\n left = Math.min(left, rect[0]);\n if (!set.add(rect)) {\n return false;\n }\n }\n if (!(((up - down) * (right - left)) == area)) return false;\n return true;\n }\n}\n```\n | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Python approach | perfect-rectangle | 0 | 1 | # Intuition\nThe main point here is to compare the corner and area. The area is the same as the rectangle area, which will pass. The second point is the corner, and if we meet the corner once, we record the corner. If we meet it the second time, we delete the corner. The similar continues; if we meet the corner the third time, we record. Ultimately, we will check if it only left four corners, the four corners of a rectangle. More details will be aside from the code.\n\n# Complexity\n- Time complexity:\nO(N)\n\n- Space complexity:\nO(N)\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n \n area = 0\n corners = set()\n a = lambda: (Y-y) * (X-x)\n \n for x, y, X, Y in rectangles:\n # check the area\n area += a()\n # check the corner\n corners ^= {(x,y), (x,Y), (X,y), (X,Y)}\n\n # compare the results\n if len(corners) != 4: return False\n x, y = min(corners, key=lambda x: x[0] + x[1])\n X, Y = max(corners, key=lambda x: x[0] + x[1])\n return a() == area\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Python (Simple Maths) | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles):\n total, ans = 0, set()\n\n for i,j,k,l in rectangles:\n total += (l-j)*(k-i)\n ans ^= {(i,j),(i,l),(k,l),(k,j)}\n\n if len(ans) != 4:\n return False\n\n x,y = min(ans, key = lambda x: x[0] + x[1])\n X,Y = max(ans, key = lambda x: x[0] + x[1])\n\n return (X-x)*(Y-y) == total\n\n \n \n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Perfect Rectangle-Solution | perfect-rectangle | 0 | 1 | # Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n corner=set()\n c=lambda k:k[0]+k[1]\n a = lambda: (Y-y) * (X-x)\n area=0\n for x, y, X, Y in rectangles:\n area += a()\n corner ^= {(x, Y), (X, y), (x, y), (X, Y)}\n \n if len(corner) != 4:\n return False\n x, y = min(corner, key = c)\n X, Y = max(corner, key = c)\n return area == a()\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
PYTHON 90% FASTER EASY SOLUTION | perfect-rectangle | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n corners=set()\n c=lambda k:k[0]+k[1]\n a = lambda: (Y-y) * (X-x)\n area=0\n for x, y, X, Y in rectangles:\n area += a()\n corners ^= {(x, Y), (X, y), (x, y), (X, Y)}\n \n if len(corners) != 4:\n return False\n x, y = min(corners, key = c)\n X, Y = max(corners, key = c)\n return area == a()\n``` | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
Python Solution (fast) | perfect-rectangle | 0 | 1 | \n\n```\nclass Solution:\n def isRectangleCover(self, rectangles: List[List[int]]) -> bool:\n X1, Y1 = float(\'inf\'), float(\'inf\')\n X2, Y2 = -float(\'inf\'), -float(\'inf\')\n points = set()\n actual_area = 0\n for x1, y1, x2, y2 in rectangles:\n \n X1, Y1 = min(X1, x1), min(Y1, y1)\n X2, Y2 = max(X2, x2), max(Y2, y2)\n \n actual_area += (x2 - x1) * (y2 - y1)\n \n p1, p2 = (x1, y1), (x1, y2)\n p3, p4 = (x2, y1), (x2, y2)\n for p in [p1, p2, p3, p4]:\n if p in points: points.remove(p)\n else: points.add(p)\n \n expected_area = (X2 - X1) * (Y2 - Y1)\n if actual_area != expected_area:\n return False\n\n if len(points) != 4: return False\n\n if (X1, Y1) not in points: return False\n if (X1, Y2) not in points: return False\n if (X2, Y1) not in points: return False\n if (X2, Y2) not in points: return False\n\n return True\n```\n\nMore LeetCode solutions of mine at https://github.com/aurimas13/SolutionsToProblems | 0 | Given an array `rectangles` where `rectangles[i] = [xi, yi, ai, bi]` represents an axis-aligned rectangle. The bottom-left point of the rectangle is `(xi, yi)` and the top-right point of it is `(ai, bi)`.
Return `true` _if all the rectangles together form an exact cover of a rectangular region_.
**Example 1:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[3,2,4,4\],\[1,3,2,4\],\[2,3,3,4\]\]
**Output:** true
**Explanation:** All 5 rectangles together form an exact cover of a rectangular region.
**Example 2:**
**Input:** rectangles = \[\[1,1,2,3\],\[1,3,2,4\],\[3,1,4,2\],\[3,2,4,4\]\]
**Output:** false
**Explanation:** Because there is a gap between the two rectangular regions.
**Example 3:**
**Input:** rectangles = \[\[1,1,3,3\],\[3,1,4,2\],\[1,3,2,4\],\[2,2,4,4\]\]
**Output:** false
**Explanation:** Because two of the rectangles overlap with each other.
**Constraints:**
* `1 <= rectangles.length <= 2 * 104`
* `rectangles[i].length == 4`
* `-105 <= xi, yi, ai, bi <= 105` | null |
🗓️ Daily LeetCode Challenge September, Day 22 | C++, C, Python3, Kotlin | is-subsequence | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nChecking One String character wise in the other.\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n# Code\n**C++**\n```\nclass Solution {\npublic:\n bool isSubsequence(string s, string t) {\n int length = s.size();\n int c = 0;\n\n // edge case 1\n if (length == 0){\n return true;\n }\n\n for (int i = 0; i < t.size(); i++){\n if (s[c] == t[i]){\n c++;\n }\n }\n\n if (c == length) return true;\n return false;\n }\n};\n}\n```\n**C**\n```\nbool isSubsequence(char * s, char * t){\n int length = strlen(s);\n if (length == 0) return true;\n int c = 0;\n\n for (int i = 0; i < strlen(t); i++){\n if (t[i] == s[c]) c++;\n }\n\n if (c == length) return true;\n return false;\n}\n```\n**Python3**\n```\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n s = list(s)\n length = len(s)\n\n c = 0\n for i in t:\n try:\n if i == s[c]:\n c += 1\n except:\n continue\n if c == length:\n return True\n return False\n \n```\n**Kotlin**\n```\nclass Solution {\n fun isSubsequence(s: String, t: String): Boolean {\n val length = s.length\n\n // Edge Case 1\n if (length == 0) return true\n\n var c = 0\n\n for (i in 0..(t.length))\n {\n try{\n if (t[i] == s[c])\n {\n c++\n }\n }\n finally{\n continue\n }\n }\n\n if (c == length) return true\n return false\n }\n}\n``` | 1 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
✅ 93.76% Two Pointers & DP | is-subsequence | 1 | 1 | # Explanation of the "Is Subsequence" Problem and Solutions\n\n## Introduction & Problem Statement\n\nGiven two strings, `s` and `t`, the challenge is to determine if `s` is a subsequence of `t`. A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.\n\n## Key Concepts:\n\n### What Makes This Problem Unique?\n\n1. **String Constraints**: \n - The length of `s` can range from 0 to 100.\n - The length of `t` can vary between 0 and 10,000.\n - Both `s` and `t` consist only of lowercase English letters.\n\n2. **Solution Techniques**: \n This problem can be approached using various techniques, including iterative (two-pointers) methods and dynamic programming.\n\n---\n\n# Strategy to Solve the Problem:\n\n## Live Coding Two Pointers\nhttps://youtu.be/gg7hnmSmhkw?si=Bqtwz-8skqwiP8YJ\n\n### Two Pointers Approach:\n\nThe two-pointers technique is an iterative approach that uses two indices, one for each string. The idea is to traverse the longer string `t` and whenever a character matches the current character of string `s`, the index for `s` is moved to the right.\n\n#### Key Data Structures:\n\n- `i` and `j`: Two pointers initialized to 0. `i` is used for string `s` and `j` for string `t`.\n\n#### Enhanced Breakdown:\n\n1. **Traverse and Match**:\n - Traverse string `t` using pointer `j`.\n - If the current character of `t` matches the current character of `s`, increment `i`.\n - Continue until the end of string `t` or until all characters of `s` are found in `t`.\n\n2. **Check Subsequence**:\n - At the end of traversal, if `i` is equal to the length of `s`, then `s` is a subsequence of `t`.\n\n#### Complexity Analysis:\n\n**Time Complexity**: \n- The algorithm traverses the string `t` once, resulting in a time complexity of $$ O(\\text{len}(t)) $$.\n\n**Space Complexity**: \n- Constant space is used, leading to a space complexity of $$ O(1) $$.\n\n# Code Two Pointers\n``` Python []\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n i, j = 0, 0\n while i < len(s) and j < len(t):\n if s[i] == t[j]:\n i += 1\n j += 1\n return i == len(s)\n```\n``` Go []\nfunc isSubsequence(s string, t string) bool {\n i, j := 0, 0\n for i < len(s) && j < len(t) {\n if s[i] == t[j] {\n i++\n }\n j++\n }\n return i == len(s)\n}\n```\n``` Rust []\nimpl Solution {\n pub fn is_subsequence(s: String, t: String) -> bool {\n let mut i = 0;\n let mut j = 0;\n let s_chars: Vec<char> = s.chars().collect();\n let t_chars: Vec<char> = t.chars().collect();\n \n while i < s.len() && j < t.len() {\n if s_chars[i] == t_chars[j] {\n i += 1;\n }\n j += 1;\n }\n i == s.len()\n }\n}\n```\n``` C++ []\nclass Solution {\npublic:\n bool isSubsequence(std::string s, std::string t) {\n int i = 0, j = 0;\n while (i < s.size() && j < t.size()) {\n if (s[i] == t[j]) {\n i++;\n }\n j++;\n }\n return i == s.size();\n }\n};\n```\n``` Java []\npublic class Solution {\n public boolean isSubsequence(String s, String t) {\n int i = 0, j = 0;\n while (i < s.length() && j < t.length()) {\n if (s.charAt(i) == t.charAt(j)) {\n i++;\n }\n j++;\n }\n return i == s.length();\n }\n}\n```\n``` JavaScript []\n/**\n * @param {string} s\n * @param {string} t\n * @return {boolean}\n */\nvar isSubsequence = function(s, t) {\n let i = 0, j = 0;\n while (i < s.length && j < t.length) {\n if (s[i] === t[j]) {\n i++;\n }\n j++;\n }\n return i === s.length;\n }\n```\n``` PHP []\nclass Solution {\n public function isSubsequence($s, $t) {\n $i = 0;\n $j = 0;\n while ($i < strlen($s) && $j < strlen($t)) {\n if ($s[$i] == $t[$j]) {\n $i++;\n }\n $j++;\n }\n return $i == strlen($s);\n }\n}\n```\n``` C# []\npublic class Solution {\n public bool IsSubsequence(string s, string t) {\n int i = 0, j = 0;\n while (i < s.Length && j < t.Length) {\n if (s[i] == t[j]) {\n i++;\n }\n j++;\n }\n return i == s.Length;\n }\n}\n```\n\n---\n\n### Dynamic Programming Approach:\n\nFor the dynamic programming solution, the idea is to preprocess string `t` to understand the next occurrence of every character after each position. This approach is particularly useful when there are numerous subsequences to be checked against `t`, as it can check each subsequence in linear time.\n\n#### Key Data Structures:\n\n- `nxt`: A list of dictionaries to store the next occurrence of every character after each position in `t`.\n\n#### Enhanced Breakdown:\n\n1. **Preprocess string `t`**:\n - Create a list of dictionaries `nxt` to store the next occurrence of every character after each position in `t`.\n - Traverse string `t` in reverse. For each position, copy the next position\'s dictionary and update the current character\'s next occurrence.\n\n2. **Check Subsequence**:\n - Traverse string `s` and for each character, check its next occurrence in `t` using the `nxt` list.\n - If any character of `s` doesn\'t have a next occurrence in `t`, return False. Otherwise, continue.\n\n#### Complexity Analysis:\n\n**Time Complexity** (for checking one subsequence `s`): \n- The algorithm traverses the string `s` once, resulting in a time complexity of $$ O(\\text{len}(s)) $$.\n\n**Space Complexity**: \n- The algorithm creates a list of dictionaries `nxt` of size $$ \\text{len}(t) $$, leading to a space complexity of $$ O(\\text{len}(t)) $$.\n\n\n# Code Dynamic Programming\n``` Python []\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n nxt = [{} for _ in range(len(t) + 1)]\n for i in range(len(t) - 1, -1, -1):\n nxt[i] = nxt[i + 1].copy()\n nxt[i][t[i]] = i + 1\n \n i = 0\n for c in s:\n if c in nxt[i]:\n i = nxt[i][c]\n else:\n return False\n return True\n```\n\n## Performance\n\n| Language | Execution Time (ms) | Memory Usage | Technique |\n|------------|---------------------|--------------|-----------|\n| Rust | 0 | 2.1 MB | Two Pointers |\n| Go | 1 | 2 MB | Two Pointers |\n| Java | 1 | 40.5 MB | Two Pointers |\n| C++ | 3 | 6.7 MB | Two Pointers |\n| PHP | 6 | 19 MB | Two Pointers |\n| JavaScript | 37 | 41.1 MB | Two Pointers |\n| Python3 | 34 | 16.2 MB | Two Pointers |\n| Python3 (DP) | 43 | 19.7 MB | DP |\n| C# | 64 | 37.9 MB | Two Pointers |\n\n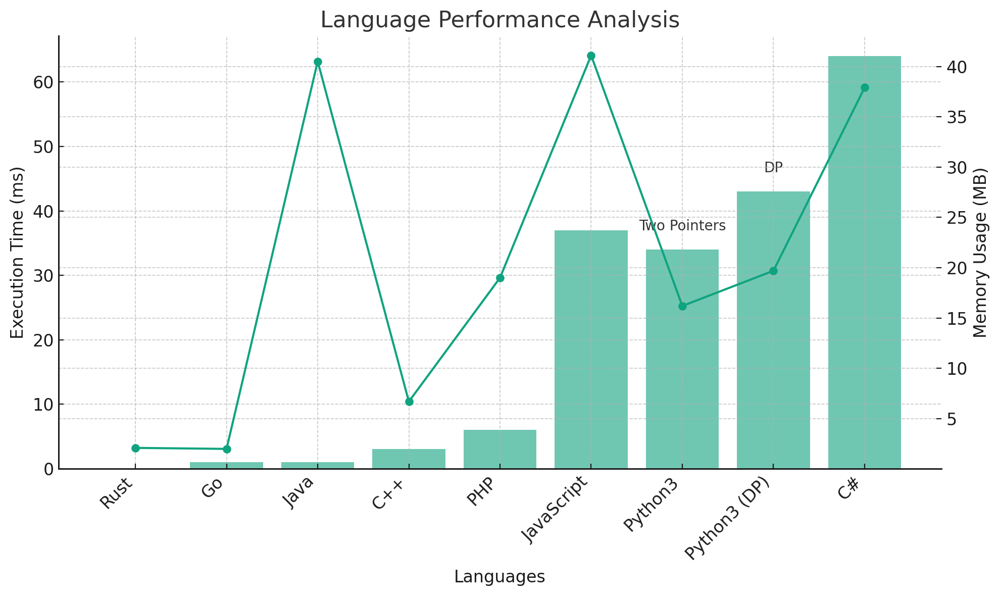\n\n\n## Conclusion\n\nBoth strategies provided here tackle the problem effectively. The two-pointers approach is straightforward and intuitive, making it easy to implement and understand. The dynamic programming approach, on the other hand, is more sophisticated but offers the advantage of efficiently checking multiple subsequences against a single string `t`. Depending on the scenario, one can choose the appropriate strategy to solve the problem. | 84 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
isSubsequence Solution in Python3 | is-subsequence | 0 | 1 | \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nInside the "isSubsequence" method, there are two variables, \'s_index\' and \'t_index,\' both initially set to 0. These variables will be used to keep track of the positions within the strings \'s\' and \'t.\'\n\nThe main part of the code is a while loop that runs as long as \'s_index\' is less than the length of string \'s\' and \'t_index\' is less than the length of string \'t.\' Inside the loop, it checks if the character at the current \'s_index\' position in string \'s\' is equal to the character at the current \'t_index\' position in string \'t.\' If they are equal, it increments \'s_index\' by 1 to move to the next character in string \'s.\' In any case, it increments \'t_index\' by 1 to move to the next character in string \'t.\'\n\nAfter the loop, the method checks if \'s_index\' is equal to the length of string \'s.\' If they are equal, it means that all characters of \'s\' have been found in the same order within \'t,\' and the method returns True, indicating that \'s\' is a subsequence of \'t.\' Otherwise, it returns False, indicating that \'s\' is not a subsequence of \'t.\'\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n s_index = t_index = 0\n\n while s_index < len(s) and t_index < len(t):\n if s[s_index] == t[t_index]:\n s_index += 1\n t_index += 1\n \n return s_index == len(s)\n``` | 1 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
【Video】How I think about a solution - O(t) time, O(1) space - Python, JavaScript, Java, C++ | is-subsequence | 1 | 1 | This artcle starts with "How I think about a solution". In other words, that is my thought process to solve the question. This article explains how I get to my solution instead of just posting solution codes or out of blue algorithms. I hope this aricle is helpful for someone.\n\n# Intuition\nCheck both strings one by one.\n\n---\n\n# Solution Video\n\nIn the video, the steps of approach below are visualized using diagrams and drawings. I\'m sure you understand the solution easily!\n\nhttps://youtu.be/ILymZPILqDs\n\n\u25A0 Timeline\n`0:00` Read the question of Is Subsequence\n`1:26` Explain a basic idea to solve Is Subsequence\n`4:04` Coding\n`5:28` Time Complexity & Space Complexity \n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 2,437\nMy initial goal is 10,000\nThank you for your support!\n\n---\n\n# Approach\n\n**How I think about a solution:**\n\nSimply, all we have to do is just to count characters for each string `s` and `t` and check if `t` has all characters of `s`, but problem is there is an order to find the characters.\n\n```\nInput: s = "abc", t = "ahbgdc"\n```\nIn this case, we need to find `a` in `t` at first. The next character we must find is `b` at the position after `a`, the last character is `c` at the position after `b`. That is kind of a challenging part of this question. It might be tough to use simple `HashMap` or `Set` because they don\'t have order of data.\n\nThat\'s why I just started thinking it with a very simple example like this.\n```\nInput: s = "abc", t = "abc"\n```\nIn this case, if we check each character one by one in the both strings from beginning, we can return `true` and this simple example gave me a hint to solve this question.\n\nI realized that if I have the same index number as length of `s` after I iterate though all characters, I can prove that I have subsequence in `t`. \n\nTo prove that, I also check a simple `false` case like this.\n```\nInput: s = "abc", t = "abd"\n```\nIn this case, when I iterate thorugh both strings from beginning, I stopped at index `2` in `s` which means I didn\'t find the last character `c` in `t`, so this is a `false` case because `index number for s(2)` is not equal to `length of s(3)`. I couldn\'t get to `the last position of s`. \n\n`The last position` means `the last index number + 1` because index usually starts from `0` and counting length of string starts from `1`.\n\nFrom my thought process above, I tried to iterate thorough both strings from beginning at the same time. \n\nLet\'s recap what I said with this example.\n```\nInput: s = "abc", t = "ahbgdc"\n```\n\n```\ntarget: a\ns index: 0\nt index: 0\n```\nThe first target is `a`. Luckily, the first character of `t` is also `a`. \n\n```\nfound: a\nNow I can think inputs like this Input: s = "bc", t = "hbgdc"\n\nafter the above,\n\ns index: 1\nt index: 1\n```\n\nThen, the next target is `b` but the next character of `t` is `h`, so now \n```\ntarget: b\n\nfound: a\nNow I can think inputs like this Input: s = "bc", t = "bgdc"\n\nafter the above,\n\ns index: 1\nt index: 2\n\n```\n\nThe next character of `t` is `b`, I found `b` in `t`.\n```\ntarget: b\n\nfound: ab\nNow I can think inputs like this Input: s = "c", t = "gdc"\n\nafter the above,\n\ns index: 2\nt index: 3\n```\n\nThe next and next next character in `t` are `g` and `d`, so just increment `t index` from `3` to `5`.\n\nFinally, I reached the last character in `t` and found `c`\n\n```\ntarget: c\n\nfound abc\nNow I can think inputs like this Input: s = "", t = ""\n\nafter the above,\n\ns index: 3\nt index: 6\n```\n\nAfter the process, all I have to do is just to check if `s index(3)` is equal to `length of s(3)`.\n\n```\nOutput: true\n```\n\nThat\'s how I think about my solution. Let\'s see a real algorithm below.\n\n\n**Algorithm Overview:**\n\n1. Initialize two pointers, `s_idx` and `t_idx`, to 0 to represent the starting positions of the strings `s` and `t` respectively.\n2. Iterate through the characters of both strings `s` and `t`, comparing characters at the corresponding positions.\n3. If a matching character is found, move the pointer in `s` forward.\n4. Always move the pointer in `t` forward.\n5. Check if all characters in `s` have been matched in `t`.\n6. Return `True` if `s` is a subsequence of `t`, `False` otherwise.\n\n**Detailed Explanation:**\n\n1. Set `s_idx` and `t_idx` to 0, indicating the starting positions of `s` and `t` respectively.\n\n2. Iterate through the characters of `s` and `t` using a while loop until either all characters in `s` have been matched or we reach the end of `t`.\n\n a. Check if the characters at `s_idx` in `s` and `t_idx` in `t` are equal.\n\n b. If they are equal, increment `s_idx` to move to the next character in `s`.\n\n c. Always increment `t_idx` to move forward in `t`.\n\n3. After the loop, check if all characters in `s` have been matched. If `s_idx` is equal to the length of `s`, then `s` is a subsequence of `t`.\n\n a. Return `True` if `s` is a subsequence of `t`.\n\n b. Return `False` if `s` is not a subsequence of `t`.\n\n\n---\n\n\n# Complexity\n- Time complexity: O(t)\n`t` is length of input string `t`.\n\n- Space complexity: O(1)\n\n\n```python []\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n s_idx = t_idx = 0\n\n while s_idx < len(s) and t_idx < len(t):\n if s[s_idx] == t[t_idx]:\n s_idx += 1\n t_idx += 1\n \n return s_idx == len(s)\n```\n```javascript []\n/**\n * @param {string} s\n * @param {string} t\n * @return {boolean}\n */\nvar isSubsequence = function(s, t) {\n let sIdx = 0;\n let tIdx = 0;\n\n while (sIdx < s.length && tIdx < t.length) {\n if (s[sIdx] === t[tIdx]) {\n sIdx++;\n }\n tIdx++;\n }\n\n return sIdx === s.length; \n};\n```\n```java []\nclass Solution {\n public boolean isSubsequence(String s, String t) {\n int sIdx = 0;\n int tIdx = 0;\n\n while (sIdx < s.length() && tIdx < t.length()) {\n if (s.charAt(sIdx) == t.charAt(tIdx)) {\n sIdx++;\n }\n tIdx++;\n }\n\n return sIdx == s.length(); \n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n bool isSubsequence(string s, string t) {\n int sIdx = 0;\n int tIdx = 0;\n\n while (sIdx < s.length() && tIdx < t.length()) {\n if (s[sIdx] == t[tIdx]) {\n sIdx++;\n }\n tIdx++;\n }\n\n return sIdx == s.length(); \n }\n};\n```\n\n---\n\nThank you for reading such a long article.\n\n\u2B50\uFE0F Please upvote it if you learned something and don\'t forget to subsctibe to my channel!\n\nMy next post for daily coding challenge on Sep 23, 2023\nhttps://leetcode.com/problems/longest-string-chain/solutions/4080044/how-we-think-about-a-solution-beats-9749-python-javascript-java-c/\n\nHave a nice day!\n | 41 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
easy 100% solution | is-subsequence | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n l=[[0 for i in range(len(t)+1) ] for j in range(len(s)+1)]\n for i in range(len(s)):\n for j in range(len(t)):\n if s[i]==t[j]:\n l[i+1][j+1]=l[i][j]+1\n else:\n l[i+1][j+1]=max(l[i][j+1],l[i+1][j])\n if len(s)==l[len(s)][len(t)]:\n return True\n else:\n return False\n\n``` | 1 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
5 Liner Solution in Java, Python,C++ ||Beats 100%||Easy To Understand | is-subsequence | 1 | 1 | ***Please upvote to motivate me in my quest of documenting all leetcode solutions. HAPPY CODING:)\nAny suggestions and improvements are always welcome*.**\n___________________\n_________________\n***Q392. Is Subsequence***\n____________________________________________________________________________________________________________________\n____________________________________________________________________________________________________________________\n\u2705 **Python Code** :\n```\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n for c in s:\n i = t.find(c)\n if i == -1: return False\n else: t = t[i+1:]\n return True\n```\n____________________________________________________________________________________________________________________\n____________________________________________________________________________________________________________________\n\n\u2705 **Java Code** :\n```\nclass Solution {\n public boolean isSubsequence(String s, String t) {\n int i = 0, j = 0;\n while(i < s.length() && j < t.length()){\n if(s.charAt(i) == t.charAt(j)) i++;\n j++;\n }\n return i == s.length();\n }\n}\n```\n\n____________________________________________________________________________________________________________________\n____________________________________________________________________________________________________________________\n\u2705 **C++ Code** :\n```\nclass Solution {\npublic:\n bool isSubsequence(string s, string t) {\n int i = 0, j = 0;\n while(i < s.length() && j < t.length()){\n if(s[i] == t[j]) i++;\n j++;\n }\n return i == s.length(); \n }\n};\n```\n____________________________________________________________________________________________________________________\n____________________________________________________________________________________________________________________\nIf you like the solution, please upvote \uD83D\uDD3C\nFor any questions, or discussions, comment below. \uD83D\uDC47\uFE0F\n | 69 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
Python short and clean. Functional programming. | is-subsequence | 0 | 1 | # Approach for original question:\nStandard two-pointer approach.\n\n# Complexity\n- Time complexity: $$O(m + n)$$\n\n- Space complexity: $$O(1)$$\n\nwhere,\n`m is length of t`,\n`n is length of s`.\n\n# Code\nImperative multi-liner:\n```python\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n i = 0\n for x in t:\n if i >= len(s): return True\n i += (s[i] == x)\n return i >= len(s)\n\n\n```\n\nDeclarative and Functional 1-liner:\n```python\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n return len(s) in accumulate(t, lambda i, x: i + (s[i] == x), initial=0)\n\n\n```\n\nShorter 1-liner:\n```python\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n return (t_ := iter(t)) and all(c in t_ for c in s)\n\n\n```\n\n---\n\n# Approach for the follow-up:\nBinarySearch approach.\n1. Pre-process `t` into a mapping from character `x` to list of all idexes `x` appears in `t`. Call this `idxs` map.\n\n2. For every `ch` in `s` binary search on `idxs[ch]` to find an `idx` which satisfies the subsequence constraint.\n\n3. If a valid `idx` is found for each `ch` in `s`, return `True`.\n\n# Complexity\n- Time complexity: $$O(m + n \\cdot log_2(m))$$\n\n- Space complexity: $$O(m)$$\n\nwhere,\n`m is length of t`,\n`n is length of s`.\n\n# Code\nImperative:\n```python\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n idxs = defaultdict(list)\n for i, x in enumerate(t): idxs[x].append(i)\n\n i = 0\n for ch in s:\n idx = bisect_left(idxs[ch], i)\n if idx >= len(idxs[ch]): return False\n i = idxs[ch][idx] + 1\n return True\n\n\n```\n\nDeclarative and Functional:\n```python\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n get_or = lambda xs, i, default: xs[i] if i < len(xs) else default\n idxs = reduce(lambda a, x: a[x[1]].append(x[0]) or a, enumerate(t), defaultdict(list))\n picked_idxs = accumulate(s, lambda a, x: get_or(idxs[x], bisect_left(idxs[x], a), inf) + 1, initial=0)\n return inf not in picked_idxs\n\n\n``` | 1 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
C++|Easy Explanation|Beats 100%🚀|Two Pointer | is-subsequence | 1 | 1 | # Approach\n\n# -Short Explanation\nThis code efficiently checks if one string is a subsequence of another by iterating through both strings and incrementing the pointers and a counter variable as characters are matched. It returns true if s is a subsequence of t, and false otherwise.\n\n---\n\n\n# -Step By Step Explanation\n\n- Initialization: Two pointers, p1 and p2, are initialized to the beginning of s and t respectively. The variables n1 and n2 store the lengths of the two strings, and common keeps track of the number of matching characters between s and t.\n\n- Iteration: The code enters a while loop that continues until one of the following conditions is met:\n\n - p1 reaches the end of s (meaning all characters in s have been matched in t), or\n - p2 reaches the end of t (indicating there are no more characters left in t to examine), or\n - common becomes equal to n1 (indicating that all characters in s have been matched).\n\n- Character Comparison: Inside the loop, the code compares the character at the current position of p1 in s with the character at the current position of p2 in t.\n\n- Matching Characters: If the characters match, it means a character from s has been found in t. In this case, both common and the pointers p1 and p2 are incremented to move to the next characters in both strings.\n\n- Non-Matching Characters: If the characters do not match, the code simply increments p2 to continue searching for the character from s in t without changing the position in s.\n\n- Termination: After the loop, the code checks if common is equal to n1. If they are equal, it means that all characters in s have been successfully matched in t, which implies that s is a subsequence of t. In this case, the function returns true.\n\n- Failure to Match: If common is not equal to n1, it means that not all characters in s could be matched in t, and the function returns false to indicate that s is not a subsequence of t.\n\n\n\n# Complexity\n- Time complexity:\nO(min(s.size(),t.size()));\n\n- Space complexity:\nO(1)\n```C++ []\nclass Solution {\npublic:\n bool isSubsequence(string s, string t) {\n int p1=0,p2=0;\n int n1 = s.size(), n2=t.size();\n int common=0;\n while(p1<n1 && p2<n2 && common!=n1){\n if(s[p1]==t[p2]){\n common++;\n p1++,p2++;\n }\n else p2++;\n }\n return common==n1;\n }\n};\n```\n```java []\nclass Solution {\n public boolean isSubsequence(String s, String t) {\n int p1 = 0, p2 = 0;\n int n1 = s.length(), n2 = t.length();\n int common = 0;\n while (p1 < n1 && p2 < n2 && common != n1) {\n if (s.charAt(p1) == t.charAt(p2)) {\n common++;\n p1++;\n }\n p2++;\n }\n return common == n1;\n }\n}\n\n```\n```python []\nclass Solution:\n def isSubsequence(self, s: str, t: str) -> bool:\n p1, p2 = 0, 0\n n1, n2 = len(s), len(t)\n common = 0\n while p1 < n1 and p2 < n2 and common != n1:\n if s[p1] == t[p2]:\n common += 1\n p1 += 1\n p2 += 1\n \n return common == n1\n\n```\n | 2 | Given two strings `s` and `t`, return `true` _if_ `s` _is a **subsequence** of_ `t`_, or_ `false` _otherwise_.
A **subsequence** of a string is a new string that is formed from the original string by deleting some (can be none) of the characters without disturbing the relative positions of the remaining characters. (i.e., `"ace "` is a subsequence of `"abcde "` while `"aec "` is not).
**Example 1:**
**Input:** s = "abc", t = "ahbgdc"
**Output:** true
**Example 2:**
**Input:** s = "axc", t = "ahbgdc"
**Output:** false
**Constraints:**
* `0 <= s.length <= 100`
* `0 <= t.length <= 104`
* `s` and `t` consist only of lowercase English letters.
**Follow up:** Suppose there are lots of incoming `s`, say `s1, s2, ..., sk` where `k >= 109`, and you want to check one by one to see if `t` has its subsequence. In this scenario, how would you change your code? | null |
393: Time 93.77%, Solution with step by step explanation | utf-8-validation | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize a counter variable count to keep track of how many continuation bytes are expected.\n```\ncount = 0\n```\n2. Iterate through each integer in the input data list data.\n```\nfor num in data:\n```\n3. If the count is 0, check how many leading 1\'s there are in the current integer to determine how many bytes are expected for the current character. If the first few bits of the current integer do not match any valid UTF-8 patterns or if the first bit of the current integer is a 1 (indicating that it is not the start of a character), return False.\n```\nif count == 0:\n if (num >> 5) == 0b110:\n count = 1\n elif (num >> 4) == 0b1110:\n count = 2\n elif (num >> 3) == 0b11110:\n count = 3\n elif (num >> 7) != 0:\n return False\n```\n4. If the count is not 0, check if the current integer is a continuation byte (i.e. the first two bits are 10). If not, return False. Subtract 1 from the count since a continuation byte has been encountered.\n```\nelse:\n if (num >> 6) != 0b10:\n return False\n count -= 1\n```\n5. After iterating through all the integers, if the count is still not 0, it is invalid. Return False.\n```\nreturn count == 0\n```\nOverall, the solution works by iterating through each integer in the input data list and checking if it is a valid start byte or continuation byte for a UTF-8 character. The count variable is used to keep track of how many continuation bytes are expected for the current character. If the input data list contains a valid sequence of bytes for a UTF-8 character, the count variable should end up at 0 after all the integers have been processed.\n\n# Complexity\n- Time complexity:\nThe solution involves iterating through each integer in the input data list exactly once. Within the iteration, the bitwise operations used to check the number of leading 1\'s and the continuation bytes take constant time. Therefore, the time complexity of the solution is O(n), where n is the length of the input data list.\n\n- Space complexity:\nThe solution uses a constant amount of extra space to store the counter variable. Therefore, the space complexity of the solution is O(1).\n\n# Code\n```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n # Initialize a counter variable\n count = 0\n \n # Iterate through each integer in the input data list\n for num in data:\n # If the count is 0, check how many leading 1\'s there are in the current integer\n if count == 0:\n if (num >> 5) == 0b110:\n count = 1\n elif (num >> 4) == 0b1110:\n count = 2\n elif (num >> 3) == 0b11110:\n count = 3\n elif (num >> 7) != 0:\n return False\n # If the count is not 0, check if the current integer is a continuation byte\n else:\n if (num >> 6) != 0b10:\n return False\n count -= 1\n \n # If the count is still not 0 after iterating through all the integers, it is invalid\n return count == 0\n\n``` | 4 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
393: Time 93.77%, Solution with step by step explanation | utf-8-validation | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize a counter variable count to keep track of how many continuation bytes are expected.\n```\ncount = 0\n```\n2. Iterate through each integer in the input data list data.\n```\nfor num in data:\n```\n3. If the count is 0, check how many leading 1\'s there are in the current integer to determine how many bytes are expected for the current character. If the first few bits of the current integer do not match any valid UTF-8 patterns or if the first bit of the current integer is a 1 (indicating that it is not the start of a character), return False.\n```\nif count == 0:\n if (num >> 5) == 0b110:\n count = 1\n elif (num >> 4) == 0b1110:\n count = 2\n elif (num >> 3) == 0b11110:\n count = 3\n elif (num >> 7) != 0:\n return False\n```\n4. If the count is not 0, check if the current integer is a continuation byte (i.e. the first two bits are 10). If not, return False. Subtract 1 from the count since a continuation byte has been encountered.\n```\nelse:\n if (num >> 6) != 0b10:\n return False\n count -= 1\n```\n5. After iterating through all the integers, if the count is still not 0, it is invalid. Return False.\n```\nreturn count == 0\n```\nOverall, the solution works by iterating through each integer in the input data list and checking if it is a valid start byte or continuation byte for a UTF-8 character. The count variable is used to keep track of how many continuation bytes are expected for the current character. If the input data list contains a valid sequence of bytes for a UTF-8 character, the count variable should end up at 0 after all the integers have been processed.\n\n# Complexity\n- Time complexity:\nThe solution involves iterating through each integer in the input data list exactly once. Within the iteration, the bitwise operations used to check the number of leading 1\'s and the continuation bytes take constant time. Therefore, the time complexity of the solution is O(n), where n is the length of the input data list.\n\n- Space complexity:\nThe solution uses a constant amount of extra space to store the counter variable. Therefore, the space complexity of the solution is O(1).\n\n# Code\n```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n # Initialize a counter variable\n count = 0\n \n # Iterate through each integer in the input data list\n for num in data:\n # If the count is 0, check how many leading 1\'s there are in the current integer\n if count == 0:\n if (num >> 5) == 0b110:\n count = 1\n elif (num >> 4) == 0b1110:\n count = 2\n elif (num >> 3) == 0b11110:\n count = 3\n elif (num >> 7) != 0:\n return False\n # If the count is not 0, check if the current integer is a continuation byte\n else:\n if (num >> 6) != 0b10:\n return False\n count -= 1\n \n # If the count is still not 0 after iterating through all the integers, it is invalid\n return count == 0\n\n``` | 4 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Python3 | DP | Memoization | Neat Solution | O(n) | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n n = len(data)\n l = [2**i for i in range(7, -1, -1)]\n \n def isXByteSeq(pos, X):\n f = data[pos]\n rem = data[pos+1:pos+X]\n ret = (f&l[X]) == 0\n for i in range(X):\n ret &= (f&l[i]) != 0\n for num in rem:\n ret &= (num&l[0]) != 0\n ret &= (num&l[1]) == 0\n return ret\n \n @cache\n def res(pos = 0):\n ret = False\n if pos == n:\n ret = True\n if pos + 3 < n:\n ret |= isXByteSeq(pos, 4) and res(pos + 4)\n if pos + 2 < n:\n ret |= isXByteSeq(pos, 3) and res(pos + 3)\n if pos + 1 < n:\n ret |= isXByteSeq(pos, 2) and res(pos + 2)\n if pos < n:\n ret |= isXByteSeq(pos, 0) and res(pos + 1)\n return ret\n \n return res()\n``` | 4 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Python3 | DP | Memoization | Neat Solution | O(n) | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n n = len(data)\n l = [2**i for i in range(7, -1, -1)]\n \n def isXByteSeq(pos, X):\n f = data[pos]\n rem = data[pos+1:pos+X]\n ret = (f&l[X]) == 0\n for i in range(X):\n ret &= (f&l[i]) != 0\n for num in rem:\n ret &= (num&l[0]) != 0\n ret &= (num&l[1]) == 0\n return ret\n \n @cache\n def res(pos = 0):\n ret = False\n if pos == n:\n ret = True\n if pos + 3 < n:\n ret |= isXByteSeq(pos, 4) and res(pos + 4)\n if pos + 2 < n:\n ret |= isXByteSeq(pos, 3) and res(pos + 3)\n if pos + 1 < n:\n ret |= isXByteSeq(pos, 2) and res(pos + 2)\n if pos < n:\n ret |= isXByteSeq(pos, 0) and res(pos + 1)\n return ret\n \n return res()\n``` | 4 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
O(N) O(N) - Naïve solution :) - No bit manipulation | utf-8-validation | 0 | 1 | A very simple solution with both time and space complexity being `O(N)`.\n\n**Approach**\n* The basic idea is that we need a binary representation of the integers so create a list of binary representations.\n* Next, we iterate through this list and check if the current binary string represents a 1-byte or a 2-byte or a 3-byte or a 4-byte data.\n* If the current string represents a `1`-byte data we move to the next string\n* If the current string represents a `k`-byte data where we `k=2,3,4`, we also check if we have at least `1,2,3` additional bytes next to it respectively. If it does, we check these bytes first two characters to be `10` and increment the loop variable `i` accordingly.\n* If none of the above checks is true for the current string, the `else` case, it is an invalid UTF-8 representation and we return `False`.\n* At the end of the loop we return True since it has gone through all the numbers at this point which verifies the array to be a valid UTF-8 encoding.\n```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n\t # a list to store binary representation of the numbers\n sequence = []\n\t\t# get binary representation of all the numbers\n for d in data:\n sequence.append("{0:08b}".format(d))\n \n i = 0\n n = len(sequence)\n while i < n:\n if sequence[i][0] == \'0\': # 1-byte check\n i += 1\n continue\n if sequence[i][:3] == \'110\' and n-i>=1: # 2-byte check\n if sequence[i+1][:2] == \'10\':\n i += 2\n continue\n if sequence[i][:4] == \'1110\' and n-i>=2: # 3-byte check\n if sequence[i+1][:2] == \'10\' and sequence[i+2][:2] == \'10\':\n i += 3\n continue\n if sequence[i][:5] == \'11110\' and n-i>=3: # 4-byte check\n if sequence[i+1][:2] == \'10\' and sequence[i+2][:2] == \'10\' and sequence[i+3][:2] == \'10\':\n i += 4\n continue\n else:\n return False\n return True\n``` | 4 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
O(N) O(N) - Naïve solution :) - No bit manipulation | utf-8-validation | 0 | 1 | A very simple solution with both time and space complexity being `O(N)`.\n\n**Approach**\n* The basic idea is that we need a binary representation of the integers so create a list of binary representations.\n* Next, we iterate through this list and check if the current binary string represents a 1-byte or a 2-byte or a 3-byte or a 4-byte data.\n* If the current string represents a `1`-byte data we move to the next string\n* If the current string represents a `k`-byte data where we `k=2,3,4`, we also check if we have at least `1,2,3` additional bytes next to it respectively. If it does, we check these bytes first two characters to be `10` and increment the loop variable `i` accordingly.\n* If none of the above checks is true for the current string, the `else` case, it is an invalid UTF-8 representation and we return `False`.\n* At the end of the loop we return True since it has gone through all the numbers at this point which verifies the array to be a valid UTF-8 encoding.\n```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n\t # a list to store binary representation of the numbers\n sequence = []\n\t\t# get binary representation of all the numbers\n for d in data:\n sequence.append("{0:08b}".format(d))\n \n i = 0\n n = len(sequence)\n while i < n:\n if sequence[i][0] == \'0\': # 1-byte check\n i += 1\n continue\n if sequence[i][:3] == \'110\' and n-i>=1: # 2-byte check\n if sequence[i+1][:2] == \'10\':\n i += 2\n continue\n if sequence[i][:4] == \'1110\' and n-i>=2: # 3-byte check\n if sequence[i+1][:2] == \'10\' and sequence[i+2][:2] == \'10\':\n i += 3\n continue\n if sequence[i][:5] == \'11110\' and n-i>=3: # 4-byte check\n if sequence[i+1][:2] == \'10\' and sequence[i+2][:2] == \'10\' and sequence[i+3][:2] == \'10\':\n i += 4\n continue\n else:\n return False\n return True\n``` | 4 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Python3 || 10 lines, binary pad, w/explanation || T/M: 95%/97% | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n \n count = 0 # Keep a tally of non-first bytes required\n \n for byte in data: # Pad out bytes to nine digits and ignore the 1st 1\n byte|= 256 # Ex: 35 = 0b100101 --> 35|256 = 0b1_00100101\n\t\t\t\n # Check for bad bytes.\n if (byte >> 3 == 0b1_11111 or # One of first five digits must be a 1\n (byte >> 6 == 0b1_10)^(count>0)): # Non-first byte can happen if and only if the current count !=0.\n return False\n # Update counts after new byte. (1-byte -> no change\n\t\t\t\t\t\t\t\t\t\t\t\t\t# to count required because count == 0.)\n if byte >> 5 == 0b1_110 : count = 1 # 2-byte first byte\n elif byte >> 4 == 0b1_1110: count = 2 # 3-byte first byte\n elif byte >> 4 == 0b1_1111: count = 3 # 4-byte first byte\n elif byte >> 6 == 0b1_10 : count-= 1 # non-first bytes\n\n return not count # Check for zero-count at EOL | 3 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Python3 || 10 lines, binary pad, w/explanation || T/M: 95%/97% | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n \n count = 0 # Keep a tally of non-first bytes required\n \n for byte in data: # Pad out bytes to nine digits and ignore the 1st 1\n byte|= 256 # Ex: 35 = 0b100101 --> 35|256 = 0b1_00100101\n\t\t\t\n # Check for bad bytes.\n if (byte >> 3 == 0b1_11111 or # One of first five digits must be a 1\n (byte >> 6 == 0b1_10)^(count>0)): # Non-first byte can happen if and only if the current count !=0.\n return False\n # Update counts after new byte. (1-byte -> no change\n\t\t\t\t\t\t\t\t\t\t\t\t\t# to count required because count == 0.)\n if byte >> 5 == 0b1_110 : count = 1 # 2-byte first byte\n elif byte >> 4 == 0b1_1110: count = 2 # 3-byte first byte\n elif byte >> 4 == 0b1_1111: count = 3 # 4-byte first byte\n elif byte >> 6 == 0b1_10 : count-= 1 # non-first bytes\n\n return not count # Check for zero-count at EOL | 3 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Simple Python Solution || O(n) Complexity | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n l = []\n \n for i in range(len(data)):\n l.append(bin(data[i])[2:])\n if(len(l[i]) < 8):\n l[i] = \'0\'*(8-len(l[i]))+l[i]\n curr = 0\n byte = 0\n flag = True\n for i in range(len(l)):\n if(byte == 0):\n j = 0\n while(j < len(l[i]) and l[i][j] == \'1\'):\n byte +=1\n j += 1\n flag = True\n elif(byte > 0):\n if(flag):\n byte -= 1\n flag = False\n if l[i][:2] != \'10\':\n return False\n byte -= 1\n if byte > 4:\n return False\n if(byte > 0 and len(l) == 1):\n return False\n if(byte > 0):\n return False\n return True\n``` | 1 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Simple Python Solution || O(n) Complexity | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n l = []\n \n for i in range(len(data)):\n l.append(bin(data[i])[2:])\n if(len(l[i]) < 8):\n l[i] = \'0\'*(8-len(l[i]))+l[i]\n curr = 0\n byte = 0\n flag = True\n for i in range(len(l)):\n if(byte == 0):\n j = 0\n while(j < len(l[i]) and l[i][j] == \'1\'):\n byte +=1\n j += 1\n flag = True\n elif(byte > 0):\n if(flag):\n byte -= 1\n flag = False\n if l[i][:2] != \'10\':\n return False\n byte -= 1\n if byte > 4:\n return False\n if(byte > 0 and len(l) == 1):\n return False\n if(byte > 0):\n return False\n return True\n``` | 1 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Easy python solution | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n unicode=[]\n for i in range(len(data)):\n x=bin(data[i]).replace("0b", "")\n if len(x)<8:\n x=\'0\'*(8-len(x))+x\n unicode.append(x)\n curr=None\n cont=0\n for i in range(len(unicode)):\n if cont>0:\n if unicode[i][:2]!=\'10\':\n return False\n cont-=1\n elif cont==0 and unicode[i][:2]==\'10\':\n return False\n else:\n for j in range(5):\n if unicode[i][j]==\'0\':\n if j==0:\n curr=1\n else:\n curr=j\n cont=j-1\n break\n else:\n print("ok2")\n return False\n if cont>0:\n return False\n return True\n``` | 1 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Easy python solution | utf-8-validation | 0 | 1 | ```\nclass Solution:\n def validUtf8(self, data: List[int]) -> bool:\n unicode=[]\n for i in range(len(data)):\n x=bin(data[i]).replace("0b", "")\n if len(x)<8:\n x=\'0\'*(8-len(x))+x\n unicode.append(x)\n curr=None\n cont=0\n for i in range(len(unicode)):\n if cont>0:\n if unicode[i][:2]!=\'10\':\n return False\n cont-=1\n elif cont==0 and unicode[i][:2]==\'10\':\n return False\n else:\n for j in range(5):\n if unicode[i][j]==\'0\':\n if j==0:\n curr=1\n else:\n curr=j\n cont=j-1\n break\n else:\n print("ok2")\n return False\n if cont>0:\n return False\n return True\n``` | 1 | Given an integer array `data` representing the data, return whether it is a valid **UTF-8** encoding (i.e. it translates to a sequence of valid UTF-8 encoded characters).
A character in **UTF8** can be from **1 to 4 bytes** long, subjected to the following rules:
1. For a **1-byte** character, the first bit is a `0`, followed by its Unicode code.
2. For an **n-bytes** character, the first `n` bits are all one's, the `n + 1` bit is `0`, followed by `n - 1` bytes with the most significant `2` bits being `10`.
This is how the UTF-8 encoding would work:
Number of Bytes | UTF-8 Octet Sequence
| (binary)
--------------------+-----------------------------------------
1 | 0xxxxxxx
2 | 110xxxxx 10xxxxxx
3 | 1110xxxx 10xxxxxx 10xxxxxx
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
`x` denotes a bit in the binary form of a byte that may be either `0` or `1`.
**Note:** The input is an array of integers. Only the **least significant 8 bits** of each integer is used to store the data. This means each integer represents only 1 byte of data.
**Example 1:**
**Input:** data = \[197,130,1\]
**Output:** true
**Explanation:** data represents the octet sequence: 11000101 10000010 00000001.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
**Example 2:**
**Input:** data = \[235,140,4\]
**Output:** false
**Explanation:** data represented the octet sequence: 11101011 10001100 00000100.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
**Constraints:**
* `1 <= data.length <= 2 * 104`
* `0 <= data[i] <= 255` | All you have to do is follow the rules. For a given integer, obtain its binary representation in the string form and work with the rules given in the problem. An integer can either represent the start of a UTF-8 character, or a part of an existing UTF-8 character. There are two separate rules for these two scenarios in the problem. If an integer is a part of an existing UTF-8 character, simply check the 2 most significant bits of in the binary representation string. They should be 10. If the integer represents the start of a UTF-8 character, then the first few bits would be 1 followed by a 0. The number of initial bits (most significant) bits determines the length of the UTF-8 character.
Note: The array can contain multiple valid UTF-8 characters. String manipulation will work fine here. But, it is too slow. Can we instead use bit manipulation to do the validations instead of string manipulations? We can use bit masking to check how many initial bits are set for a given number. We only need to work with the 8 least significant bits as mentioned in the problem.
mask = 1 << 7
while mask & num:
n_bytes += 1
mask = mask >> 1
Can you use bit-masking to perform the second validation as well i.e. checking if the most significant bit is 1 and the second most significant bit a 0? To check if the most significant bit is a 1 and the second most significant bit is a 0, we can make use of the following two masks.
mask1 = 1 << 7
mask2 = 1 << 6
if not (num & mask1 and not (num & mask2)):
return False |
Python solution based on stack | decode-string | 0 | 1 | # Intuition\nThis problem is a pretty classic stack problem. You can see examples of postfix or prefix problems its just similar to that.\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nstep 1: first loop over string and push until you get a closing square bracket.\nstep 2: then pop out and append to the end of tempresult string until you get an integer. \nstep 3: since the integer or numeric value can be bigger than single digit pop out more until there is no number on top of stack.\nstep 4: finally just multiply or increase occurences of tempresult string based on the integer. \nstep 5: push the result into stack again for handling case of bracket inside bracket. \nstep 6: Enjoy !!\n\n# Complexity\n- Time complexity: O(n) where n is length of string.\n <!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n) for the stack used.\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n stack = []\n for char in s:\n if char == "]":\n val = stack.pop()\n item = ""\n while stack and not str(val).isnumeric():\n item = val + item if val != "[" else item\n val = stack.pop()\n\n number = val\n while stack and str(stack[-1]).isnumeric():\n number = stack.pop() + number\n print(number, item)\n [stack.append(item) for _ in range(int(number))]\n else:\n stack.append(char)\n \n return "".join(stack)\n \n\n\n``` | 2 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
394. Decode String | decode-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n # 1. Keep adding to stack untill you get ]\n # 2. When ] is found, dont add ] to stack, instead pop all characters until [ is found, pop [ too\n # 3. Then keep popping till we have digits, keep adding to k\n # 4. Multiply digit * string popped , and add this new string to stack\n\n stack=[]\n for i in range(len(s)):\n if s[i] != \']\':\n stack.append(s[i]) # 1\n else:\n substr=\'\'\n while stack and stack[-1]!= \'[\': # 2\n substr=stack.pop() + substr\n \n stack.pop() # 2. Popping [\n k =\'\'\n while stack and stack[-1].isdigit(): # 3\n k = stack.pop() + k\n \n stack.append( int(k) * substr ) # 4\n \n return \'\'.join(stack) # stack elements will be joined together directly without any characters in between\n\n\n\n\n``` | 1 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
394: Solution with step by step explanation | decode-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize the stack and the current string:\n```\nstack = []\ncurr_str = ""\n```\nThe stack is used to keep track of the current number and string that are being processed. The curr_str variable will store the current string that is being decoded.\n\n2. Initialize the current number to 0:\n```\ncurr_num = 0\n```\nThe curr_num variable is used to keep track of the current number that is being processed.\n\n3. Iterate through each character of the string:\n```\nfor c in s:\n```\nThis loop will iterate through each character of the given string s.\n\n4. If the character is a digit, update the current number:\n```\nif c.isdigit():\n curr_num = curr_num * 10 + int(c)\n```\nIf the current character is a digit, it is part of a number that needs to be decoded. The curr_num variable is updated by multiplying the current number by 10 and adding the value of the current digit.\n\n5. If the character is an opening bracket, push the current number and current string onto the stack:\n```\nelif c == "[":\n stack.append(curr_num)\n stack.append(curr_str)\n curr_num = 0\n curr_str = ""\n```\nIf the current character is an opening bracket, it means that a new string is to be decoded. The curr_num and curr_str variables are pushed onto the stack, and are reset to their initial values.\n\n6. If the character is a closing bracket, repeat the popped characters and push the result back onto the stack:\n```\nelif c == "]":\n prev_str = stack.pop()\n prev_num = stack.pop()\n curr_str = prev_str + curr_str * prev_num\n```\nIf the current character is a closing bracket, it means that a string needs to be repeated. The prev_str and prev_num variables are popped from the stack and the curr_str variable is updated by concatenating the previous string with the current string repeated prev_num times.\n\n7. If the character is a letter, append it to the current string:\n```\nelse:\n curr_str += c\n```\nIf the current character is a letter, it is part of the string that needs to be decoded. The current character is appended to the curr_str variable.\n\n8. Pop any remaining characters from the stack and concatenate them to the final result:\n```\nwhile stack:\n curr_str = stack.pop() + curr_str\n```\nAfter the loop has finished, there may be remaining characters in the stack that need to be added to the final result. The remaining characters are popped from the stack and concatenated to the beginning of the curr_str variable.\n\n9. Return the final decoded string:\n```\nreturn curr_str\n```\nThe final decoded string is returned.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n # Initialize the stack and the current string\n stack = []\n curr_str = ""\n # Initialize the current number to 0\n curr_num = 0\n \n # Iterate through each character of the string\n for c in s:\n # If the character is a digit, update the current number\n if c.isdigit():\n curr_num = curr_num * 10 + int(c)\n # If the character is an opening bracket, push the current number and current string onto the stack\n elif c == "[":\n stack.append(curr_num)\n stack.append(curr_str)\n # Reset the current number and current string\n curr_num = 0\n curr_str = ""\n # If the character is a closing bracket, repeat the popped characters and push the result back onto the stack\n elif c == "]":\n prev_str = stack.pop()\n prev_num = stack.pop()\n curr_str = prev_str + curr_str * prev_num\n # If the character is a letter, append it to the current string\n else:\n curr_str += c\n \n # Pop any remaining characters from the stack and concatenate them to the final result\n while stack:\n curr_str = stack.pop() + curr_str\n \n return curr_str\n\n``` | 32 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
Beginner friendly solution using STACKS (most efficient) | decode-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIdea here is to use a stack.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe initialize an empty stack to store characters.\n\nWe iterate through each character in the given string.\n\nIf the current character is not \']\', we push it onto the stack.\n\nIf the current character is \']\', we start the decoding process:\n-->We pop characters from the stack until we encounter a \'[\'. These characters represent a substring that needs to be repeated.\n-->After popping the substring, we pop the next characters from the stack until we reach a digit. These characters represent the number that specifies the repetition count.\n-->We reverse the extracted number and convert it to an integer.\n-->We multiply the substring by the repetition count and push the result back onto the stack.\n\nOnce we have processed all the characters in the input string, we join the remaining characters in the stack to obtain the final decoded string. Since the characters were pushed onto the stack in reverse order, we reverse each substring before joining them to maintain the original order.\n\n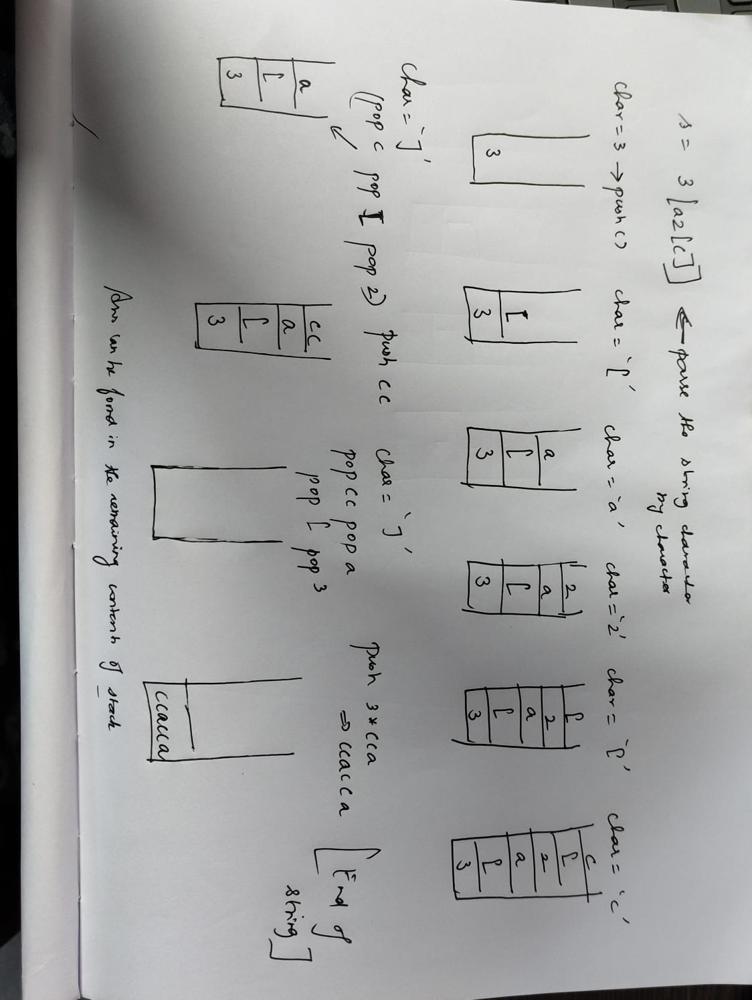\n\n\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n\n stack=[]\n\n for c in s:\n if c!=\']\':\n stack.append(c)\n else:\n res=\'\'\n while stack[-1]!=\'[\':\n res+=stack.pop()\n stack.pop()\n n=\'\'\n while len(stack)!=0 and stack[-1].isdigit()==True:\n n+=stack.pop()\n stack.append(res*int(n[::-1]))\n\n return \'\'.join([word[::-1] for word in stack])\n\n\n \n \n``` | 14 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
single stack solution | decode-string | 0 | 1 | # Intuition\nsingle stack solution\n\n# Approach\ndetail in comment of code\n\n# Complexity\n- Time complexity:\nO(2N)\n\n- Space complexity:\nO(N)\n\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n stack=[]\n for char in s:\n if char != \']\':\n stack.append(char)\n # kick off decode after meeting ]\n else:\n temp_str=""\n # get letter in []\n while stack[-1] != \'[\':\n stack_top=stack.pop()\n temp_str = stack_top + temp_str\n # pop up [\n stack.pop()\n\n # get digital string\n digital=""\n while stack and stack[-1].isdigit():\n stack_top=stack.pop()\n digital = stack_top + digital\n # add decoded string into stack\n stack.append(int(digital)*temp_str)\n #combine all letters in stack(list) \n return "".join(stack)\n\n \n\n\n\n``` | 2 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
394. Decode String | decode-string | 0 | 1 | # Intuition\nThe algorithm iterates through `s`, keeping track of the current number and current substring using the data structure stack. It performs either a push or pop operation on the stack based on the character encountered.\n\n# Approach\n- When a digit is encountered, it is used to update the current number. \n- When an open bracket `[` is encountered, the current substring and number are pushed onto the stack, and the current values are reset. \n- When a closing bracket `]` is encountered, the previous substring and number are popped from the stack, and the current substring is updated by repeating it the specified number of times. \n- For other characters, they are appended to the current substring.\n\n# Complexity\n- Time complexity: The algorithm iterates through each character in the input string once, so the time complexity is O(n), where n is the length of the input string.\n\n- Space complexity: The space complexity is determined by the stack. In the worst case, the stack could contain all characters in the input string (e.g., if the input string is `10[a]`). Therefore, the space complexity is O(n), where n is the length of the input string.\n\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n cur_num = 0\n cur_str = ""\n stack = []\n\n for char in s:\n if char.isdigit():\n cur_num = cur_num * 10 + int(char)\n elif char == "[":\n stack.append((cur_str, cur_num))\n cur_num = 0\n cur_str = ""\n elif char == "]":\n prev_str, cur_num = stack.pop()\n cur_str = prev_str + cur_str * cur_num\n cur_num = 0\n else:\n cur_str += char\n return cur_str\n``` | 1 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
CodeDominar Solution | decode-string | 0 | 1 | # Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n nums = "0123456789"\n stack = []\n for char in s:\n #print(stack)\n if char == \']\':\n temp_s = \'\'\n num=\'\'\n while stack[-1] != \'[\':\n temp_s = stack.pop()+temp_s\n stack.pop()\n while stack and stack[-1] in nums:\n num+= stack.pop()\n num = int(num[::-1])\n while num:\n stack.append(temp_s)\n num-=1\n else:\n stack.append(char)\n l = "".join(map(str,stack))\n return l\n``` | 3 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
[ Python ] | Simple & Clean Code | Easy Sol. using Stack | decode-string | 0 | 1 | - One of the Best problems to learn how to use stack.\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n st = []\n num = 0\n res = \'\'\n\n for ch in s:\n if ch.isnumeric():\n num = num * 10 + int(ch)\n elif ch == \'[\':\n st.append(res)\n st.append(num)\n res = \'\'\n num = 0\n elif ch == \']\':\n cnt = st.pop()\n prev = st.pop()\n res = prev + cnt * res\n else:\n res += ch\n return res\n\n``` | 14 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
Python | Easy to Understand | Stack | decode-string | 0 | 1 | ```\nclass Solution:\n def decodeString(self, s: str) -> str:\n \'\'\'\n 1.Use a stack and keep appending to the stack until you come across the first closing bracket(\']\')\n 2.When you come across the first closing bracket start popping until you encounter an opening bracket(\'[\')),basically iterate unit the top of the stack is not an opening bracket and simultaneously keep on appending it to a seperate variable here its substr\n 3.Once that is done iterate unitl the stack is empty and if the top of the stack is a digit and append the popped values to a seperate string variable here its n\n 4.Once this is done append n and substr , we do this so that we get the repeated substring\n 5.Finally return the stack in a string format using .join\n \n \'\'\'\n stack = []\n for i in range(len(s)):\n if s[i]!="]":\n stack.append(s[i])\n else:\n substr = ""\n while stack[-1]!="[":\n c = stack.pop()\n substr = c + substr\n stack.pop()\n n = ""\n while stack and stack[-1].isdigit():\n nums = stack.pop()\n n = nums + n\n stack.append(int(n)*substr)\n return "".join(stack)\n``` | 2 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
Explained Python Solution using single stack | decode-string | 0 | 1 | \nExplanation:\nSolved using stack\n1. Possible inputs are - \'[\' , \']\', alphabet(s) or numbers. Lets talk about each one by one.\n\n2. We will start for loop for traversing through each element of \'s\'. If we encounter a number, it will be handled by checking isdigit() condition. curNum10+int(c) helps in storing the number in curnum ,when the number is more than single digit.\n\n3.When we encounter a character, we will start it adding to a string named curString. The character can be single or multiple. curString+=c will keep the character string.\n\n4.The easy part is over.Now, when we encounter \'[\' it means thats a start of a new substring, meaning the previous substring (if there was one) has already been traversed and handled. So , we will append the current curString and curNum to stack and, reset our curString as empty string and curNum as 0 to use in further porcessing as we have a open bracket which means start of a new substring.\n\n5.Finally when we encounter a close bracket \']\', it certainely means we have reached where our substring is complete, now we have to find a way to calculate it. Thats when we go back to stack to find what we have stored there which will help us in calculating the current substring. In the stack we will find a number on top which is popped and then a previous string which we will need to add with the curstringnum, and everything will be stored in curString after calculation. \n\n6.The calculated curstring will be returned as answer if \'s\' is over else it will be again appended to stack when an open bracket is encountered. And the above process will be repeated per condition.\n\n\n```\n\nclass Solution(object):\n def decodeString(self, s):\n stack = []; curNum = 0; curString = \'\'\n for c in s:\n if c == \'[\':\n stack.append(curString)\n stack.append(curNum)\n curString = \'\'\n curNum = 0\n elif c == \']\':\n num = stack.pop()\n prevString = stack.pop()\n curString = prevString + num*curString\n elif c.isdigit(): # curNum*10+int(c) is helpful in keep track of more than 1 digit number\n curNum = curNum*10 + int(c)\n else:\n curString += c\n return curString\n```\t\t | 68 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
🐍 98% faster || With and without Stack || Cleane & Concise 📌📌 | decode-string | 0 | 1 | ## IDEA :\n**Using stack** to store the previously stored string and the number which we have to use instantly after bracket(if any) gets closed.\n\'\'\'\n\n\tclass Solution:\n def decodeString(self, s: str) -> str:\n \n res,num = "",0\n st = []\n for c in s:\n if c.isdigit():\n num = num*10+int(c) \n elif c=="[":\n st.append(res)\n st.append(num)\n res=""\n num=0\n elif c=="]":\n pnum = st.pop()\n pstr = st.pop()\n res = pstr + pnum*res\n else:\n res+=c\n \n return res\n\t\t\n****\n### IDEA :\n**Using RECURSION :**\n\'\'\'\n\t\n\tclass Solution:\n def decodeString(self, s: str) -> str: \n def dfs(s,p):\n res = ""\n i,num = p,0\n while i<len(s):\n asc = (ord(s[i])-48)\n if 0<=asc<=9: # can also be written as if s[i].isdigit()\n num=num*10+asc\n elif s[i]=="[":\n local,pos = dfs(s,i+1)\n res+=local*num\n i=pos\n num=0\n elif s[i]=="]":\n return res,i\n else:\n res+=s[i]\n i+=1\n return res,i\n \n return dfs(s,0)[0]\n\t\t\n***Thanks*** and feel free to ask if you have any doubt!! \uD83E\uDD17\n**Upvote** if you found interesting !!\uD83E\uDD1E | 36 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
Parse with Stack | O(n) | Faster than 100% | Fluent | decode-string | 0 | 1 | # Intuition\r\n<!-- Describe your first thoughts on how to solve this problem. -->\r\nThe problem can be seen as a stack problem because the ordering of the closed brackets and opening ones is analogous to the `LIFO` princile of stacks. \r\n\r\n\r\n\r\n> I know I know LeetCode\'s Runtime is biased :)\r\n\r\n\r\n# Approach\r\n<!-- Describe your approach to solving the problem. -->\r\nWhenever we find opening brackets(`[`) we append the characters after it and until a digit is found, and the digit before it to the stack. That means as a tuple in Python.\r\n\r\nWhenever we find closing brackets(`]`) we will pop the last element in the stack. And update our running current string `cur`.\r\n\r\n> Well, how do we keep track of both the characters in between `[` and `]` and the integer with which we are going to multiply the former with?\r\n\r\nThat is a good question actually. We will keep checking whether the character at hand is one of the brackets, or whether it is a digit, or it is a lower case English letter.\r\n\r\n# Complexity\r\n- Time complexity: $$O(n)$$\r\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\r\n\r\n- Space complexity: $$O(n)$$\r\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\r\n\r\n# Code\r\n```\r\nclass Solution:\r\n def decodeString(self, s: str) -> str:\r\n stack = []\r\n cur = ""\r\n k = 0\r\n for c in s:\r\n if c == "[":\r\n stack.append((cur, k))\r\n cur, k = "", 0 # reset global vars\r\n elif c == "]":\r\n enc, n = stack.pop()\r\n cur = enc + n * cur \r\n elif c.isdigit():\r\n k = k * 10 + int(c) # for two and three digit numbers\r\n else:\r\n cur += c # track the lower case letters\r\n return cur\r\n``` | 12 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
Using of Stacks Simple Solution.. | decode-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nBasically the opening and closing brackets plays a crucial role in this problemm.. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFirstly we should insert the possible elements inside of our stack till we encounter any closing brackets the moment we got that we traverse back and then delete the elements in the stack we will be having a number and a character...\nBut they mentioned always a number comes after the character 3[a] \n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(N)\nLinear Time \n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(N)\nStack..\n# Code\n```\nclass Solution:\n def decodeString(self, s: str) -> str:\n stack=[]\n for i in s:\n if(i=="]"):\n #we have encountered a closing brackets..\n stri=""\n while stack[0]!="[":\n stri=stack.pop(0)+stri\n stack.pop(0)\n #we are extracting the possible character from the elements which are included in the stack..\n k=""\n while stack and stack[0].isdigit():\n k=stack.pop(0)+k\n stack.insert(0,int(k)*stri)\n else:\n stack.insert(0,i)\n stack.reverse()\n return ("".join(stack))\n``` | 3 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
Decode String | decode-string | 0 | 1 | ```class Solution:\n def decodeString(self, s: str) -> str:\n stack = []\n curString = \'\'\n curNum = 0\n for c in s:\n if c == \'[\':\n stack.append(curString)\n stack.append(curNum)\n curString = \'\'\n curNum = 0\n elif c == \']\':\n num = stack.pop()\n prevString = stack.pop()\n curString = prevString + num * curString\n elif c.isdigit():\n curNum = curNum * 10 + int(c)\n else:\n curString += c\n return curString | 3 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
[0ms][1LINER][100%][Fastest Solution Explained] O(n)time complexity O(n)space complexity | decode-string | 1 | 1 | \n(Note: This is part of a series of Leetcode solution explanations. If you like this solution or find it useful, ***please upvote*** this post.)\n***Take care brother, peace, love!***\n\n```\n```\n\nThe best result for the code below is ***0ms / 3.27MB*** (beats 99.04% / 90.42%).\n\n```\n\nclass Solution {\n int i = 0;\npublic String decodeString(String s) {\n StringBuilder sb = new StringBuilder();\n int count = 0;\n String tmp_string = "";\n \n while (i < s.length()) {\n char c = s.charAt(i);\n i++;\n \n if (c == \'[\') {\n tmp_string = decodeString(s); // do subproblem\n for (int j = 0; j < count; j++) {\n sb.append(tmp_string);\n }\n count = 0; // reset counter\n } else if (c == \']\') { // subproblem complete\n break;\n } else if (Character.isAlphabetic(c)) {\n sb.append(c);\n } else {\n count = count * 10 + c - \'0\';\n }\n }\n \n return sb.toString();\n}\n}\n\n```\n\n```\n```\n\n```\n```\n\n***"Open your eyes. Expect us." - \uD835\uDCD0\uD835\uDCF7\uD835\uDCF8\uD835\uDCF7\uD835\uDD02\uD835\uDCF6\uD835\uDCF8\uD835\uDCFE\uD835\uDCFC***\n\n\n | 2 | Given an encoded string, return its decoded string.
The encoding rule is: `k[encoded_string]`, where the `encoded_string` inside the square brackets is being repeated exactly `k` times. Note that `k` is guaranteed to be a positive integer.
You may assume that the input string is always valid; there are no extra white spaces, square brackets are well-formed, etc. Furthermore, you may assume that the original data does not contain any digits and that digits are only for those repeat numbers, `k`. For example, there will not be input like `3a` or `2[4]`.
The test cases are generated so that the length of the output will never exceed `105`.
**Example 1:**
**Input:** s = "3\[a\]2\[bc\] "
**Output:** "aaabcbc "
**Example 2:**
**Input:** s = "3\[a2\[c\]\] "
**Output:** "accaccacc "
**Example 3:**
**Input:** s = "2\[abc\]3\[cd\]ef "
**Output:** "abcabccdcdcdef "
**Constraints:**
* `1 <= s.length <= 30`
* `s` consists of lowercase English letters, digits, and square brackets `'[]'`.
* `s` is guaranteed to be **a valid** input.
* All the integers in `s` are in the range `[1, 300]`. | null |
DIvide and conquer method --easy to understand-- | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nSolve this problem by dividing the list at the point that has frequency less thn \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import defaultdict\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n x=self.recursion(s,k)\n if x>=k:\n return x\n else:\n \n return 0\n\n def recursion(self,s,k):\n if len(s)<=1 :\n return len(s)\n flag=True\n for i in range(len(s)):\n if s.count(s[i])<k:\n flag=False\n break\n \n if flag:\n return len(s)\n left=(self.recursion(s[:i],k))\n right=(self.recursion(s[i+1:],k))\n if left>right:\n return (left)\n return (right)\n\n``` | 9 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python Short & Simple Recursive Solution | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | ```\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n if len(s) == 0 or k > len(s):\n return 0\n c = Counter(s)\n sub1, sub2 = "", ""\n for i, letter in enumerate(s):\n if c[letter] < k:\n sub1 = self.longestSubstring(s[:i], k)\n sub2 = self.longestSubstring(s[i+1:], k)\n break\n else:\n return len(s)\n return max(sub1, sub2)\n```\n**Like it? please upvote...** | 59 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
395: Solution with step by step explanation | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. First, we check if the length of the string is less than k. If so, we can immediately return 0, since no substring of the string can have a frequency of each character greater than or equal to k.\n\n2. Next, we count the frequency of each character in the string using a dictionary. We can do this by iterating through each character in the string, and adding 1 to the corresponding dictionary value each time we encounter the character.\n\n3. We then find the index of the first character in the string that has a frequency less than k. If all characters have a frequency greater than or equal to k, we can immediately return the length of the string.\n\n4. If we have found a character with a frequency less than k, we split the string into two parts: the substring before the current index, and the substring after the current index. We then recursively call the longestSubstring function on each substring to find the longest substring in each part.\n\n5. Finally, we return the maximum length of the two substrings found in step 4.\n\n# Complexity\n- Time complexity:\nThe time complexity of this solution is O(n log n), where n is the length of the input string. This is because we recursively split the string into smaller and smaller substrings until we reach substrings of length 1. At each level of recursion, we iterate through the string to count the frequency of each character, which takes O(n) time. Since we do this for each level of recursion, the total time complexity is O(n log n).\n\n- Space complexity:\nThe space complexity of this solution is O(n), since we use a dictionary to store the frequency of each character in the string.\n\n# Code\n```\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n # If the length of the string is less than k, return 0\n if len(s) < k:\n return 0\n \n # Count the frequency of each character in the string\n char_freq = {}\n for char in s:\n if char not in char_freq:\n char_freq[char] = 1\n else:\n char_freq[char] += 1\n \n # Find the index of the first character with a frequency less than k\n for i, char in enumerate(s):\n if char_freq[char] < k:\n # Split the string into two parts and recursively find the longest substring in each part\n left = self.longestSubstring(s[:i], k)\n right = self.longestSubstring(s[i+1:], k)\n # Return the maximum length of the two substrings\n return max(left, right)\n \n # If all characters have a frequency greater than or equal to k, return the length of the string\n return len(s)\n\n``` | 12 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
python/sliding windows | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | # Intuition\nits not the best solution i just went through all windows\n# Approach\nsliding window \n# Complexity\n- Time complexity:\no(n^2) \n- Space complexity:\n16mb\n# Code\n```\n# class Solution:\n# def longestSubstring(self, s: str, k: int) -> int:\n# longest=0\n# for l in range(len(s)):\n# r=l\n# count=Counter(s[l:r+1])\n# while r<len(s):\n# repeat=True\n# for c in count:\n# if count[c]<k:\n# repeat=False\n# break\n# if repeat:\n# longest=max(longest,len(s[l:r+1]))\n# r+=1\n# if r<len(s):\n# count[s[r]]=count.get(s[r],0)+1\n# return longest\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n if len(s) < k:\n return 0\n count = Counter(s)\n for i, c in enumerate(s):\n if count[c] < k:\n left = self.longestSubstring(s[:i], k)\n right = self.longestSubstring(s[i+1:], k)\n return max(left, right)\n\n return len(s)\n\n \n``` | 1 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python by dict and recursion [w/ Comment] | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | Python sol by dictioanry and recursion\n\n---\n\n**Implementation**:\n\n```\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n \n if k > len(s):\n \n # k is too large, larger than the length of s\n # Quick response for invalid k\n return 0\n \n \n # just for the convenience of self-recursion\n f = self.longestSubstring\n \n ## dictionary\n # key: unique character\n # value: occurrence\n char_occ_dict = collections.Counter(s)\n \n # Scan each unique character and check occurrence\n for character, occurrence in char_occ_dict.items():\n \n if occurrence < k:\n \n # If occurrence of current character is less than k,\n # find possible longest substring without current character in recursion\n \n return max( f(sub_string, k) for sub_string in s.split(character) )\n \n # -------------------------------\n \n # If occurrences of all characters are larger than or equal to k\n # the length of s is the answer exactly\n \n return len(s)\n```\n\n---\n\nReference:\n\n[1] [Python official docs about dictionary](https://docs.python.org/3/tutorial/datastructures.html#dictionaries)\n\n[2] [Python official docs about built-in specialized dictionary collections.Counter()](https://docs.python.org/3/library/collections.html?highlight=counter#collections.Counter) | 24 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python3 - Silly Recursion + String ops + Counter 91.92% | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | # Intuition\nYou can\'t cross (read \'use\') letters appearing less than k times, so split on those letters and recurse.\n\n# Code\n```\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n for ch, co in Counter(s).items():\n if co < k:\n s=s.replace(ch, \'|\')\n if \'|\' not in s:\n return len(s)\n else:\n return max([self.longestSubstring(x, k) for x in s.split(\'|\')])\n\n``` | 1 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python, short and clean | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | The idea is that any characters in the string that do not satisfy the requirement break the string in multiple parts that do not contain these characters, and for each part we should check the requirement again. There are similar solutions (not many), though most use string methods like split or count, which keep some important details hidden. Here I am also using Counter for short code but it\'s just replacing a usual dictionary and a single obvious loop to calculate counts of letters. \n\nConcerning complexity, it is indeed formally O(N), like it was mentioned in another solution despite recursion, because at each level of recursion we look at maximum 2N characters, and there can be not more than 26 levels of recursion, because we remove at least one character from 26 possible characters each time we move to the next level.\n\n```\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n cnt = collections.Counter(s)\n st = 0\n maxst = 0\n for i, c in enumerate(s):\n if cnt[c] < k:\n maxst = max(maxst, self.longestSubstring(s[st:i], k))\n st = i + 1\n return len(s) if st == 0 else max(maxst, self.longestSubstring(s[st:], k))\n``` | 27 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python O(n) Sliding window Solution based on template | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | \nSolved using template from https://leetcode.com/problems/minimum-window-substring/discuss/26808/here-is-a-10-line-template-that-can-solve-most-substring-problemsa\n\nTime Complexity: O(26n)\nSpace Complexity: O(26) - Store character frequency array\n\nRuntime: 280 ms\nMemory Usage: 13.6 MB - less than 99%\n\n``` python\ndef longestSubstring(self, s, k):\n count = 0\n for i in range(1, 27):\n count = max(count, self.helper(s, k, i))\n return count\n\ndef helper(self, s, k, numUniqueTarget):\n start = end = numUnique = numNoLessThanK = count = 0\n chMap = [0]*128\n\n while end < len(s):\n if chMap[ord(s[end])] == 0: numUnique += 1\n chMap[ord(s[end])] += 1\n if chMap[ord(s[end])] == k: numNoLessThanK += 1\n end += 1\n \n while numUnique > numUniqueTarget:\n if chMap[ord(s[start])] == k: numNoLessThanK -= 1\n chMap[ord(s[start])] -= 1\n if chMap[ord(s[start])] == 0: numUnique -= 1\n start += 1\n \n if numUnique == numNoLessThanK: count = max(count, end-start)\n \n return count\n``` | 19 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
easy sliding window approach | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | \tclass Solution:\n\t\tdef longestSubstring(self, s: str, k: int) -> int:\n\n\t\t\t# number of unique characters available\n\t\t\tmax_chars = len(set(s))\n\t\t\tn = len(s)\n\t\t\tans = 0\n\n\t\t\t# for all char from 1 to max_chars \n\t\t\tfor available_char in range(1,max_chars+1):\n\n\t\t\t\th = {}\n\t\t\t\ti = j = 0\n\n\n\t\t\t\t# simple sliding window approach\n\t\t\t\twhile(j < n):\n\n\t\t\t\t\tif(s[j] not in h):\n\t\t\t\t\t\th[s[j]] = 0\n\t\t\t\t\th[s[j]] += 1\n\n\t\t\t\t\t# if len of h is less than no of available chars\n\t\t\t\t\tif(len(h) < available_char):\n\t\t\t\t\t\tj += 1\n\n\t\t\t\t\t# if equal then check all have values >=k\n\t\t\t\t\telif(len(h) == available_char):\n\t\t\t\t\t\tcount = 0\n\t\t\t\t\t\tfor x in h.values():\n\t\t\t\t\t\t\tif(x >= k):\n\t\t\t\t\t\t\t\tcount += 1\n\t\t\t\t\t\tif(count == available_char):\n\t\t\t\t\t\t\tans = max(ans,j - i + 1)\n\t\t\t\t\t\tj += 1\n\n\t\t\t\t\t# if greater than remove from starting\n\t\t\t\t\telse:\n\t\t\t\t\t\twhile(len(h) != available_char):\n\t\t\t\t\t\t\th[s[i]] -= 1\n\t\t\t\t\t\t\tif(h[s[i]] == 0):\n\t\t\t\t\t\t\t\tdel h[s[i]]\n\t\t\t\t\t\t\ti += 1\n\t\t\t\t\t\tj += 1\n\n\t\t\treturn ans\n\n | 4 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python3 + divide and conquer | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | \n```\nfrom collections import Counter\n\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n\t\n if len(s) < k: return 0\n\t\t\n\t\tc = Counter(s)\n st = 0\n for p, v in enumerate(s):\n \n if c[v] < k:\n \n return max(self.longestSubstring(s[st:p],k), self.longestSubstring(s[p+1:],k))\n \n return len(s)\n``` | 12 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python Recursive divide and conquer beats 80% | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | \n```\n\n def rec(self,s,k):\n #s += \'0\' will lead to infinite loop\n # eg "aaa0" will always be checked, s[0:3]->s[0:3] \n #so on\n hmap = defaultdict(int);\n for c in s : hmap[c]+= 1\n p ,res = -1,0\n for i in range(0,len(s)):\n if( hmap[s[i]] < k ):\n res = max(res,self.rec(s[p+1:i],k))\n p = i\n\n if( p > -1 ):\n res = max(res,self.rec(s[p+1:len(s)],k))\n \n if( p == -1 ): return len(s);\n else: return res \n \n def longestSubstring(self, s: str, k: int) -> int:\n return self.rec(s,k)\n``` | 3 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Faster than 97.6%. Recursion | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | \n\n```\nclass Solution:\n def rec(self, s, k):\n c = Counter(s)\n\n if pattern := "|".join(filter(lambda x: c[x] < k, c)):\n if arr := list(filter(lambda x: len(x) >= k, re.split(pattern, s))):\n \n return max(map(lambda x: self.rec(x, k), arr))\n \n return 0\n \n return len(s)\n \n def longestSubstring(self, s: str, k: int) -> int:\n return self.rec(s, k)\n```\nPlease, upvote, if you like the solution | 3 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python 4-lines - 44ms (51%) - Counter + Split | longest-substring-with-at-least-k-repeating-characters | 0 | 1 | How about the following solution. You can make it without splits by passing the ranges... But it looks simple and passes the test cases...\n\n```\nfrom collections import Counter\n\nclass Solution:\n def longestSubstring(self, s: str, k: int) -> int:\n for char, count in Counter(s).items():\n if count < k:\n return max(self.longestSubstring(s, k) for s in s.split(char))\n return len(s)\n``` | 8 | Given a string `s` and an integer `k`, return _the length of the longest substring of_ `s` _such that the frequency of each character in this substring is greater than or equal to_ `k`.
**Example 1:**
**Input:** s = "aaabb ", k = 3
**Output:** 3
**Explanation:** The longest substring is "aaa ", as 'a' is repeated 3 times.
**Example 2:**
**Input:** s = "ababbc ", k = 2
**Output:** 5
**Explanation:** The longest substring is "ababb ", as 'a' is repeated 2 times and 'b' is repeated 3 times.
**Constraints:**
* `1 <= s.length <= 104`
* `s` consists of only lowercase English letters.
* `1 <= k <= 105` | null |
Python solution || Beats - 96% | rotate-function | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n # res=[]\n # for _ in range(len(nums)):\n # lst=[]\n # for i in range(len(nums)):\n # lst.append(i*nums[i])\n # res.append(sum(lst))\n # nums.insert(0,nums.pop())\n # return max(res)\n n=len(nums)\n s=sum(nums)\n temp=sum(i*nums[i] for i in range(n))\n maxi=temp\n for i in range(1,n):\n temp+=s-n*nums[n-i]\n maxi=max(maxi,temp)\n return maxi\n``` | 1 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
easy-solution | well-explained | dp | Python3 | clean-code✅ | rotate-function | 0 | 1 | ***Please give an upvote if you like the solution**\n\n#6Companies30days #ReviseWithArsh Challenge 2023\nDay1\nQ4. You are given an integer array nums of length n. Return maximum length of Rotation Function.*\n\n# Approach\nDynamic Programming\n\n# Complexity\n- Time complexity: O(n)\n\n# Code\n**Python3:**\n```\nclass Solution(object):\n def maxRotateFunction(self, nums: List[int])-> int: \n s=sum(nums)\n\n d=sum(elem * idx for idx, elem in enumerate(nums)) #first find our number 1: dynamic programming solution\n sol = d\n for pivot in range(len(nums)-1,-1,-1): # pivot: we move backwards\n d+=s-len(nums)*nums[pivot] # get next d value\n sol=max(d,sol)\n return sol\n \n``` | 2 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
✅ Mathematics || Easy to understand || Javascript || Java || Python3 || Go | rotate-function | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIt\'s a math problem. I draw a graph to show the process. The code is concise. Hope it\'s helpful.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Javascript\n```javascript\n/**\n * @param {number[]} nums\n * @return {number}\n */\nvar maxRotateFunction = function(nums) {\n const n = nums.length;\n let totalSum = 0;\n let perRoundSum = 0;\n\n for (let i = 0; i < n; i++) {\n totalSum += nums[i];\n perRoundSum += i * nums[i];\n }\n\n let answer = perRoundSum;\n\n for (let i = 1; i < n; i++) {\n const rotatedNum = nums[n - i];\n perRoundSum = perRoundSum - (rotatedNum * (n - 1)) + (totalSum - rotatedNum);\n answer = Math.max(answer, perRoundSum);\n }\n\n return answer;\n};\n```\n\n# Java\n```java\nclass Solution {\n public int maxRotateFunction(int[] nums) {\n int n = nums.length;\n int totalSum = 0;\n int perRoundSum = 0;\n \n for (int i = 0; i < n; i++) {\n totalSum += nums[i];\n perRoundSum += i * nums[i];\n }\n\n int answer = perRoundSum;\n\n for (int i = 1; i < n; i++) {\n int rotatedNum = nums[n - i];\n perRoundSum = perRoundSum - (rotatedNum * (n - 1)) + (totalSum - rotatedNum);\n answer = Math.max(answer, perRoundSum);\n }\n\n return answer;\n }\n}\n```\n\n\n# Python3\n```python\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n n: int = len(nums)\n total: int = 0\n per_round: int = 0\n\n for i in range(n):\n total += nums[i]\n per_round += i * nums[i]\n\n answer: int = per_round\n\n for i in range(1, n):\n rotated: int = nums[n - i]\n per_round = per_round - (rotated * (n - 1)) + (total - rotated)\n answer = max(answer, per_round)\n \n return answer\n```\n\n# Go\n```golang\nfunc maxRotateFunction(nums []int) int {\n n := len(nums)\n totalSum := 0\n perRoundSum := 0\n\n for i, v := range nums {\n totalSum += v\n perRoundSum += i * v\n }\n\n answer := perRoundSum\n\n for i := 1; i < n; i++ {\n rotatedNum := nums[n - i]\n perRoundSum = perRoundSum - (rotatedNum * (n - 1)) + (totalSum - rotatedNum)\n if perRoundSum > answer {\n answer = perRoundSum\n }\n }\n\n return answer\n}\n``` | 1 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
396: Solution with step by step explanation | rotate-function | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Calculate the sum of all elements in the array, and store it in a variable "total_sum".\n2. Calculate the initial value of F(0) using a loop that iterates through the array and multiplies each element by its index, then add all the products. Store the result in a variable "current_sum".\n3. Initialize a variable "max_sum" to "current_sum".\n4. Iterate through the array starting from index 1 to n-1:\na. Calculate the new value of F(i) by subtracting the sum of all elements from the last element, then add (n-1) times the last element. The formula is: F(i) = F(i-1) + total_sum - n * nums[n-i]\nb. Update the "current_sum" variable to the new value of F(i).\nc. Update the "max_sum" variable if "current_sum" is greater than "max_sum".\n5. Return the value of "max_sum".\n\n# Complexity\n- Time complexity:\nThe time complexity of this solution is O(n), where n is the length of the input array. This is because the solution involves a single iteration through the input array to calculate the initial value of F(0), and then another iteration through the array to calculate the remaining values of F(i). The time complexity of each iteration is O(n), since we need to perform n multiplication and addition operations for each element in the array.\n\n- Space complexity:\nThe space complexity of this solution is O(1), since we only need to store a constant number of variables regardless of the size of the input array. Specifically, we need to store the length of the input array (n), the total sum of all elements in the array (total_sum), the current value of F(i) (current_sum), and the maximum value of F(i) seen so far (max_sum).\n\n# Code\n```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n n = len(nums)\n total_sum = sum(nums) # Calculate the sum of all elements in the array\n \n current_sum = sum(i * nums[i] for i in range(n)) # Calculate the initial value of F(0)\n max_sum = current_sum\n \n # Iterate through the array starting from index 1 to n-1\n for i in range(1, n):\n current_sum += total_sum - n * nums[n-i] # Calculate the new value of F(i)\n max_sum = max(max_sum, current_sum) # Update the max_sum variable if necessary\n \n return max_sum\n\n``` | 5 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
Derive formula O(n) DP python | rotate-function | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n * If we rotate by 1 elements, then it increases F[i-1] by sum of all values in the array. For example\n * F(0) = (0 * 4) + (1 * 3) + (2 * 2) + (3 * 6)\n * when we rotate by 1, what changes?\n * at F[0], 4 was multiplied by 0 but now by 1\n * at F[0], 3 was multiplied by 1 but now 2 and so on \n * so total increment is 4+3+2+6\n * other factor is, every rotation, we are loosing the last multiplication from previous result\n * i.e, at F[0], last one was 3*6, but F[1], it becomes 0*6\n * That means, F[1] = F[0] + total_sum - n * nums[n-i]\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n n = len(nums)\n total = sum(nums)\n F = [0] * n\n for i, v in enumerate(nums):\n F[0] += v*i\n \n for i in range(1, n):\n F[i] = F[i-1] + total - n*nums[n-i]\n return max(F)\n\n\n``` | 2 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
One line solution | rotate-function | 0 | 1 | ```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n return (s_nums := sum(nums), max(accumulate(reversed(nums), lambda s, n: s+s_nums-len(nums)*n, initial = sum(i*n for i, n in enumerate(nums)))))[1]\n```\n> More readable\n```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n sum_nums = sum(nums)\n rot_sum_nums = sum(i*num for i, num in enumerate(nums))\n ans = rot_sum_nums\n for num in reversed(nums):\n rot_sum_nums += sum_nums - len(nums) * num \n ans = max(rot_sum_nums, ans)\n return ans\n``` | 0 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
Python3 O(N) (T < 99%) | rotate-function | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nEvery rotation, each element\'s k is increased by 1, and with the highest one being reduced to 0. So we can obtain the sum for the next rotation by adding the sum of the original list (which effectively increases every k by 1), then removing n * element with the highest k. The highest k will be the last element in the beginning, while shifting forward every iteration.\n\n# Complexity\n- Time complexity:\nO(n)\n- Space complexity:\nO(1)\n# Code\n```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n s = sum(nums) // sum\n n = len(nums) // length of array\n rs = sum([i * nums[i] for i in range(n)]) // initial rotated sum\n\n ans = rs // default case: initial r-sum\n\n for i in range(n-1, 0, -1): // go through all the rotations\n // we can stop before 0 since it will just loop around\n \n // increase every element by 1, reduce element i to 0\n rs = rs + s - n * nums[i] \n if rs > ans: // check if we got a new solution\n ans = rs\n\n return ans\n``` | 0 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
Simple 6 line solution beats 99%, O(n), O(1) | rotate-function | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nEvery time it rotates, last value becomes a[j] * (n-1) to a[j] * 0.\nwhich makes sum -= a[j] * (n-1)\nand every other sum increases a[i]. whick makes sum += Sum(nums) - a[j]\n\n# Complexity\n- Time complexity:\nO(n)\n- Space complexity:\nO(1)\n# Code\n```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n sm = sum(nums)\n f0 = sum(num * i for i, num in enumerate(nums))\n mx = cur = f0\n for j in range(1, len(nums)):\n cur += sm - nums[-j] * (len(nums))\n mx = max(mx, cur)\n return mx\n``` | 0 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
PYTHON | rotate-function | 0 | 1 | ```\nclass Solution:\n def maxRotateFunction(self, nums: List[int]) -> int:\n f=[]\n k=0\n for i in range(len(nums)):\n k+=i*nums[i]\n f.append(k)\n nums=nums[::-1]\n s=sum(nums)\n for i in range(len(nums)):\n nums_pop=nums[i]\n p=f[-1]+(s-nums_pop)-(nums_pop*(len(nums)-1))\n f.append(p)\n return max(f)\n \n``` | 0 | You are given an integer array `nums` of length `n`.
Assume `arrk` to be an array obtained by rotating `nums` by `k` positions clock-wise. We define the **rotation function** `F` on `nums` as follow:
* `F(k) = 0 * arrk[0] + 1 * arrk[1] + ... + (n - 1) * arrk[n - 1].`
Return _the maximum value of_ `F(0), F(1), ..., F(n-1)`.
The test cases are generated so that the answer fits in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[4,3,2,6\]
**Output:** 26
**Explanation:**
F(0) = (0 \* 4) + (1 \* 3) + (2 \* 2) + (3 \* 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 \* 6) + (1 \* 4) + (2 \* 3) + (3 \* 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 \* 2) + (1 \* 6) + (2 \* 4) + (3 \* 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 \* 3) + (1 \* 2) + (2 \* 6) + (3 \* 4) = 0 + 2 + 12 + 12 = 26
So the maximum value of F(0), F(1), F(2), F(3) is F(3) = 26.
**Example 2:**
**Input:** nums = \[100\]
**Output:** 0
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `-100 <= nums[i] <= 100` | null |
397: Solution with step by step explanation | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nThe solution uses dynamic programming and memoization to avoid repeating subproblems.\n\nThe main function, integerReplacement, initializes a memoization dictionary and calls the recursive helper function with the input n and the memoization dictionary. It then returns the result of the helper function.\n\nThe helper function is the recursive function that actually solves the problem. It has three cases:\n\n1. Base case: if n is 1, return 0. This is the stopping condition for the recursion.\n2. Check if the result is already memoized in the memo dictionary. If it is, return the memoized value.\n3. If n is even, divide it by 2 and make a recursive call to the helper function with n/2. Store the result in the memo dictionary.\n4. If n is odd, make two recursive calls for n+1 and n-1 and return the minimum of the two values plus 1. Store the result in the memo dictionary.\n\nThe helper function returns the memoized result, which is the minimum number of operations needed for n to become 1.\n\n# Complexity\n- Time complexity:\nThe time complexity of the solution is O(log n) because we are dividing the input n by 2 at each recursive call, which means that the number of recursive calls is proportional to log n.\n\n- Space complexity:\nThe space complexity of the solution is also O(log n) because we are using a memoization dictionary to store the intermediate results of the recursive calls. The size of the dictionary is proportional to the number of recursive calls, which is also proportional to log n.\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n # Initialize the memoization dictionary\n memo = {}\n # Call the recursive function\n return self.helper(n, memo)\n\n def helper(self, n, memo):\n # Base case: if n is 1, return 0\n if n == 1:\n return 0\n # Check if the result is already memoized\n if n in memo:\n return memo[n]\n # If n is even, divide it by 2 and make a recursive call\n if n % 2 == 0:\n memo[n] = 1 + self.helper(n // 2, memo)\n # If n is odd, make two recursive calls for n+1 and n-1 and return the minimum of the two values\n else:\n memo[n] = 1 + min(self.helper(n + 1, memo), self.helper(n - 1, memo))\n # Return the memoized result\n return memo[n]\n\n``` | 6 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Easy understand python solution with explanation || Beats 91 % of the python solution. | integer-replacement | 0 | 1 | # Intuition\nAs the problem statement states that we have only two operations that we could make, In one operation where it is an even number we are allowed to reduce it n//2, But the real con=mplexity of the problem lies in the odd number where we have to **choose the minimum of the eitheir options.** So it spretty intuitive that we go for each one and find what is the minimum of them.\n\n# Approach\nSo my approach is that we cache the computations we are making to avoid the time complexity jumping off. And use recursion for considering the both cases. \n\n# Complexity\n- Time complexity:\nTime Complexity becomes O(logn) with base 2\n\n- Space complexity:\nO(n)\nfor caching\n Hope this helps\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n dp={}\n dp[0]=0\n dp[1]=0\n moves=0\n def recur(n):\n if n in dp:\n return dp[n]\n if n%2==0:\n dp[n]=1+recur(n//2)\n else:\n dp[n]=1+min(recur(n-1),recur(n+1))\n return dp[n]\n return recur(n)\n``` | 2 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
SIMPLE PYTHON SOLUTION | integer-replacement | 0 | 1 | ```\nclass Solution:\n def dp(self,n):\n if n<1:\n return float("infinity")\n if n==1:\n return 0\n if n%2==0:\n return self.dp(n//2)+1\n else:\n x=self.dp(n+1)+1\n y=self.dp(n-1)+1\n return min(x,y)\n def integerReplacement(self, n: int) -> int:\n return self.dp(n)\n``` | 2 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Simple python3 solution | 30 ms - faster than 99% solutions | integer-replacement | 0 | 1 | <!-- # Intuition -->\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n<!-- # Approach -->\n<!-- Describe your approach to solving the problem. -->\n\n## Approach\nPicture of the need for memoization\n\n\n\n# Complexity\n- Time complexity: $$O(log(n))$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(log(n))$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n``` python3 []\nfrom functools import cache\n\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n @cache\n def dp(k):\n if k == 1:\n return 0\n if k % 2 == 0:\n return 1 + dp(k // 2)\n return 1 + min(dp(k - 1), dp(k + 1))\n \n return dp(n)\n\n``` | 1 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
easy peasy python [comments] bit manipulation | integer-replacement | 0 | 1 | \tdef integerReplacement(self, n):\n # Basically, There are four cases in the trailing digits:\n # 00 01 10 11 which represents n % 4 == 0, 1, 2, 3\n # For any odd number, it has remaining of 1 or 3 after mod with 4. If it\'s 1, decrease it, if it\'s 3 increase it.\n # if last two digits are 011(3), then add, because 011+1 == 100, hence a bit is removed, so better?\n # but if it was 011111, then 011111+1 = 100000, more bits are removed?\n # hence, adding is always better than or equal to subtracting\n # if it is 01 then remove, 01-1 = 0.\n # n == 3 is a special case, when n == 3, decrementing by 1 gives less replacement, even 3%4 == 3\n # 3-1 = 2, 2//2 = 1, hence 2 replacement\n # but if I do 3+1 = 4, 4//2 = 2, 2//2 = 1, three operations\n\t\t\n\t\t\n cnt = 0\n while n != 1:\n if n % 2 == 0:\n n = n //2\n elif n % 4 == 1 or n == 3:\n n -= 1\n else:\n n += 1\n cnt += 1\n \n return cnt | 25 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
beats 62% | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nif the next bit is 1 choose +1, else choose -1\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n output = 0\n while n > 1:\n if n & 1:\n if n == 3:\n n = n - 1\n elif n >> 1 & 1:\n n += 1\n else:\n n -= 1\n else:\n n = n // 2\n output += 1\n\n return output\n \n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Python solution | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n steps = 0\n if n == 1:\n return 0\n while n > 2:\n if n %2 == 0:\n n = n//2\n steps = steps +1\n else:\n temp1 = n + 1\n temp2 = n - 1\n if temp1 != 4 and temp2 != 3:\n if (temp1 / 2) %2 == 0 and (temp2/2) %2 == 0:\n n = n - 1\n elif (temp1 / 2) %2 == 0 and (temp2/2) %2 != 0:\n n = n + 1\n elif (temp1 / 2) %2 != 0 and (temp2/2) %2 == 0:\n n = n - 1\n else:\n n = n -1\n steps = steps + 1\n else:\n n = 2\n steps = steps +1\n steps = steps + 1\n return steps\n\n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Easy Python Solution | integer-replacement | 0 | 1 | # Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n memo = {}\n def getAnswer(number, steps):\n if number == 1: return steps\n if (number, steps) in memo: return memo[(number, steps)]\n else:\n if number % 2 == 1:\n memo[(number, steps)] = min(getAnswer(number + 1, steps + 1), \n getAnswer(number - 1, steps + 1))\n else: memo[(number, steps)] = getAnswer(number // 2, steps + 1)\n return memo[(number, steps)]\n\n return getAnswer(n, 0)\n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
iterative bit manipulation method, no recursion or DP | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nlooking at binary represnation of n, it\'s pretty clear what is the shortest way to reduce it to 1, and that depend only on the last 2 elast segnificant bits\n\n01 -> reduce 1\n00 -> devide by 2\n10 -> devide by 2\n11 -> unless n is 3, is will be better to just add 1 and that will convert the many 1s into 0 at one operation\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nlog(n). becasue b < 2^32 that is just O(1)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n\n res = 0\n\n while n > 1:\n if n == 3:\n res += 2\n break\n # lower 2 bits\n lsb2 = n & 0x3\n\n # if lsb is 0 divide by 2\n if not (lsb2 & 0x1):\n n = n >> 1 \n # is 1 if lsb and next bit is 0 -> substract 1 and divide\n if not lsb2 ^ 0x1:\n n -= 1\n if not lsb2 ^ 0x3:\n n = n + 1\n\n res += 1\n\n return res\n\n\n \n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Python 1 liner | integer-replacement | 0 | 1 | # Intuition\n There is no need of intuition , very easy problem.\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n c = 0\n while(n != 1):\n if(n % 2 == 0):\n n //= 2\n c+=1\n else:\n if(n==3):\n return c+2\n k=bin(n+1)\n l=bin(n-1)\n k=k.count(\'1\')\n l=l.count(\'1\')\n if(k>l):\n n=(n-1)//2\n else:\n n=(n+1)//2\n c+=2\n return c\n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Easy Python Solution | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n def rec(n):\n if n==1:\n return 0\n if n%2==0:\n return 1+rec(n//2)\n elif n%2!=0:\n return 1+min(rec(n+1),rec(n-1))\n return rec(n)\n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Python Math | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n\n# Code\n```\nclass Solution:\n @cache\n def integerReplacement(self, n: int) -> int:\n if n == 1:\n return 0\n if n == 3:\n return 2\n if n % 2 == 0:\n return self.integerReplacement( n // 2 ) + 1\n if n % 4 == 3:\n return self.integerReplacement( n + 1 ) + 1\n if n % 4 == 1:\n return self.integerReplacement( n - 1 ) + 1\n\n\n\n \n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
using recursion | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n def replace(n,c):\n if n==1:\n return c\n else: \n if n%2==0:\n return replace(n/2,c+1)\n else:\n return min(replace(n+1,c+1),replace(n-1,c+1))\n return replace(n,0)\n \n\n\n\n \n\n \n \n\n \n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Easy solution using Recursion || python3 | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n def integer(n,count):\n if n==1:\n return count\n elif n%2==0:\n return integer(n//2,count+1)\n elif(n%2!=0):\n return min(integer(n+1,count+1),integer(n-1,count+1))\n return integer(n,0)\n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Using Recursion | integer-replacement | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def integerReplacement(self, n: int) -> int:\n def replace(n,count):\n if(n==1):\n return count\n elif(n%2==0):\n return replace(n//2,count+1)\n \n else:\n return min(replace(n-1,count+1),replace(n+1,count+1))\n return replace(n,0)\n \n \n\n\n \n``` | 0 | Given a positive integer `n`, you can apply one of the following operations:
1. If `n` is even, replace `n` with `n / 2`.
2. If `n` is odd, replace `n` with either `n + 1` or `n - 1`.
Return _the minimum number of operations needed for_ `n` _to become_ `1`.
**Example 1:**
**Input:** n = 8
**Output:** 3
**Explanation:** 8 -> 4 -> 2 -> 1
**Example 2:**
**Input:** n = 7
**Output:** 4
**Explanation:** 7 -> 8 -> 4 -> 2 -> 1
or 7 -> 6 -> 3 -> 2 -> 1
**Example 3:**
**Input:** n = 4
**Output:** 2
**Constraints:**
* `1 <= n <= 231 - 1` | null |
✅97.87%🔥python3/C/C#/C++/Java🔥Randomized Index Selection for Target Values in an Array🔥 | random-pick-index | 1 | 1 | \n\n\n```Python3 []\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.indices = defaultdict(list)\n for i, num in enumerate(nums):\n self.indices[num].append(i)\n\n def pick(self, target: int) -> int:\n return random.choice(self.indices[target])\n\n```\n```Python []\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.indices = defaultdict(list)\n for i, num in enumerate(nums):\n self.indices[num].append(i)\n\n def pick(self, target: int) -> int:\n return random.choice(self.indices[target])\n\n```\n```C# []\npublic class Solution\n{\n private Dictionary<int, List<int>> indices;\n\n public Solution(int[] nums)\n {\n indices = new Dictionary<int, List<int>>();\n for (int i = 0; i < nums.Length; i++)\n {\n if (!indices.ContainsKey(nums[i]))\n {\n indices[nums[i]] = new List<int>();\n }\n indices[nums[i]].Add(i);\n }\n }\n\n public int Pick(int target)\n {\n Random random = new Random();\n List<int> targetIndices = indices.ContainsKey(target) ? indices[target] : new List<int>();\n \n int randomIndex = random.Next(0, targetIndices.Count);\n \n return targetIndices[randomIndex];\n }\n}\n```\n```C []\ntypedef struct {\n int* nums;\n int numsSize;\n} Solution;\n\nSolution* solutionCreate(int* nums, int numsSize) {\n Solution* obj = (Solution*)malloc(sizeof(Solution));\n obj->nums = (int*)malloc(numsSize * sizeof(int));\n obj->numsSize = numsSize;\n \n for (int i = 0; i < numsSize; i++) {\n obj->nums[i] = nums[i];\n }\n \n return obj;\n}\n\nint solutionPick(Solution* obj, int target) {\n int count = 0;\n int result = -1;\n \n for (int i = 0; i < obj->numsSize; i++) {\n if (obj->nums[i] == target) {\n count++;\n if (rand() % count == 0) {\n result = i;\n }\n }\n }\n \n return result;\n}\n\nvoid solutionFree(Solution* obj) {\n free(obj->nums);\n free(obj);\n}\n```\n```C++ []\nclass Solution {\nprivate:\n std::unordered_map<int, std::vector<int>> indices;\n\npublic:\n Solution(std::vector<int>& nums) {\n for (int i = 0; i < nums.size(); ++i) {\n indices[nums[i]].push_back(i);\n }\n }\n\n int pick(int target) {\n std::random_device rd;\n std::mt19937 gen(rd());\n\n if (indices.find(target) != indices.end()) {\n std::vector<int>& targetIndices = indices[target];\n std::uniform_int_distribution<int> dist(0, targetIndices.size() - 1);\n int randomIndex = dist(gen);\n return targetIndices[randomIndex];\n }\n\n return -1;\n }\n};\n```\n```Java []\npublic class Solution {\n private Map<Integer, List<Integer>> indices = new HashMap<>();\n\n public Solution(int[] nums) {\n for (int i = 0; i < nums.length; i++) {\n if (!indices.containsKey(nums[i])) {\n indices.put(nums[i], new ArrayList<>());\n }\n indices.get(nums[i]).add(i);\n }\n }\n\n public int pick(int target) {\n Random random = new Random();\n\n if (indices.containsKey(target)) {\n List<Integer> targetIndices = indices.get(target);\n int randomIndex = random.nextInt(targetIndices.size());\n return targetIndices.get(randomIndex);\n }\n\n return -1;\n }\n}\n```\n | 26 | Given an integer array `nums` with possible **duplicates**, randomly output the index of a given `target` number. You can assume that the given target number must exist in the array.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the array `nums`.
* `int pick(int target)` Picks a random index `i` from `nums` where `nums[i] == target`. If there are multiple valid i's, then each index should have an equal probability of returning.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick "\]
\[\[\[1, 2, 3, 3, 3\]\], \[3\], \[1\], \[3\]\]
**Output**
\[null, 4, 0, 2\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3, 3, 3\]);
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
solution.pick(1); // It should return 0. Since in the array only nums\[0\] is equal to 1.
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
**Constraints:**
* `1 <= nums.length <= 2 * 104`
* `-231 <= nums[i] <= 231 - 1`
* `target` is an integer from `nums`.
* At most `104` calls will be made to `pick`. | null |
Beat 100%, O(1) Solution | random-pick-index | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nTake the advantage of hashmap and randint O(1) attribute\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nUse hashmap with list to store candidate numbers, and random pick target from the target list.\n\n# Complexity\n- Time complexity:\n- O(1)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n- O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.hashmap = defaultdict(list)\n for i, v in enumerate(nums):\n self.hashmap[v].append(i)\n\n def pick(self, target: int) -> int:\n indexes = self.hashmap[target]\n length = len(indexes)\n index = randint(0, length-1)\n return indexes[index]\n \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(nums)\n# param_1 = obj.pick(target)\n``` | 1 | Given an integer array `nums` with possible **duplicates**, randomly output the index of a given `target` number. You can assume that the given target number must exist in the array.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the array `nums`.
* `int pick(int target)` Picks a random index `i` from `nums` where `nums[i] == target`. If there are multiple valid i's, then each index should have an equal probability of returning.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick "\]
\[\[\[1, 2, 3, 3, 3\]\], \[3\], \[1\], \[3\]\]
**Output**
\[null, 4, 0, 2\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3, 3, 3\]);
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
solution.pick(1); // It should return 0. Since in the array only nums\[0\] is equal to 1.
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
**Constraints:**
* `1 <= nums.length <= 2 * 104`
* `-231 <= nums[i] <= 231 - 1`
* `target` is an integer from `nums`.
* At most `104` calls will be made to `pick`. | null |
Python 3 Reservoir Sampling, O(n) Time & O(1) Space | random-pick-index | 0 | 1 | Reservoir sampling is particularly helpful when the size of the array `nums` is unknown (e.g. when we have a **stream** of numbers).\nThe [solution](https://leetcode.com/problems/linked-list-random-node/solution/) to LC 382 (Linked List Random Node) gives a more detailed & clear explanation (and the proof) on the mathematics behind reservoir sampling.\nTime complexity for `init()`: `O(1)`; for `pick()`: `O(n)`\nSpace complexity: `O(1)` (constant)\nPlease upvote if you find this solution helpful.\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n # Reservoir Sampling (which can handle the linked list with unknown size), time complexity O(n) (init: O(1), pick: O(n)), space complextiy O(1)\n self.nums = nums\n\n def pick(self, target: int) -> int:\n # https://docs.python.org/3/library/random.html\n count = 0\n chosen_index = None\n for i in range(len(self.nums)):\n if self.nums[i] != target:\n continue\n count += 1\n if count == 1:\n chosen_index = i\n elif random.random() < 1 / count:\n chosen_index = i\n return chosen_index\n``` | 6 | Given an integer array `nums` with possible **duplicates**, randomly output the index of a given `target` number. You can assume that the given target number must exist in the array.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the array `nums`.
* `int pick(int target)` Picks a random index `i` from `nums` where `nums[i] == target`. If there are multiple valid i's, then each index should have an equal probability of returning.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick "\]
\[\[\[1, 2, 3, 3, 3\]\], \[3\], \[1\], \[3\]\]
**Output**
\[null, 4, 0, 2\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3, 3, 3\]);
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
solution.pick(1); // It should return 0. Since in the array only nums\[0\] is equal to 1.
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
**Constraints:**
* `1 <= nums.length <= 2 * 104`
* `-231 <= nums[i] <= 231 - 1`
* `target` is an integer from `nums`.
* At most `104` calls will be made to `pick`. | null |
Python Easy Solution Ever !!! 🔥🔥🔥 Reservoir Sampling | random-pick-index | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.index_map = {} # Dictionary to store indices of elements\n for i, num in enumerate(nums):\n if num not in self.index_map:\n self.index_map[num] = []\n self.index_map[num].append(i)\n \n\n def pick(self, target: int) -> int:\n indices = self.index_map[target]\n return random.choice(indices)\n\n``` | 1 | Given an integer array `nums` with possible **duplicates**, randomly output the index of a given `target` number. You can assume that the given target number must exist in the array.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the array `nums`.
* `int pick(int target)` Picks a random index `i` from `nums` where `nums[i] == target`. If there are multiple valid i's, then each index should have an equal probability of returning.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick "\]
\[\[\[1, 2, 3, 3, 3\]\], \[3\], \[1\], \[3\]\]
**Output**
\[null, 4, 0, 2\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3, 3, 3\]);
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
solution.pick(1); // It should return 0. Since in the array only nums\[0\] is equal to 1.
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
**Constraints:**
* `1 <= nums.length <= 2 * 104`
* `-231 <= nums[i] <= 231 - 1`
* `target` is an integer from `nums`.
* At most `104` calls will be made to `pick`. | null |
easy peasy python reservoir sampling | random-pick-index | 0 | 1 | \tdef __init__(self, nums: List[int]):\n self.nums = nums\n\n def pick(self, target: int) -> int:\n cnt = idx = 0\n for i, num in enumerate(self.nums):\n if num != target:\n continue\n if cnt == 0:\n idx = i\n cnt = 1\n else:\n # this random will already give me numbers\n # between 0 and cnt inclusive\n # so for 2nd number I am getting random number 0 and 1\n # so each having a probability of 1/2\n # similarly for three numbers it will be 1/3\n rnd = random.randint(0, cnt)\n if (rnd == cnt):\n idx = i\n cnt += 1\n \n return idx | 13 | Given an integer array `nums` with possible **duplicates**, randomly output the index of a given `target` number. You can assume that the given target number must exist in the array.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the array `nums`.
* `int pick(int target)` Picks a random index `i` from `nums` where `nums[i] == target`. If there are multiple valid i's, then each index should have an equal probability of returning.
**Example 1:**
**Input**
\[ "Solution ", "pick ", "pick ", "pick "\]
\[\[\[1, 2, 3, 3, 3\]\], \[3\], \[1\], \[3\]\]
**Output**
\[null, 4, 0, 2\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3, 3, 3\]);
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
solution.pick(1); // It should return 0. Since in the array only nums\[0\] is equal to 1.
solution.pick(3); // It should return either index 2, 3, or 4 randomly. Each index should have equal probability of returning.
**Constraints:**
* `1 <= nums.length <= 2 * 104`
* `-231 <= nums[i] <= 231 - 1`
* `target` is an integer from `nums`.
* At most `104` calls will be made to `pick`. | null |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.