
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Easiest python solution, faster than 95% | ransom-note | 0 | 1 | ```\nclass Solution:\n def canConstruct(self, ransomNote, magazine):\n for i in set(ransomNote):\n if magazine.count(i) < ransomNote.count(i):\n return False\n return True\n | 50 | Given two strings `ransomNote` and `magazine`, return `true` _if_ `ransomNote` _can be constructed by using the letters from_ `magazine` _and_ `false` _otherwise_.
Each letter in `magazine` can only be used once in `ransomNote`.
**Example 1:**
**Input:** ransomNote = "a", magazine = "b"
**Output:** false
**Example 2:**
**Input:** ransomNote = "aa", magazine = "ab"
**Output:** false
**Example 3:**
**Input:** ransomNote = "aa", magazine = "aab"
**Output:** true
**Constraints:**
* `1 <= ransomNote.length, magazine.length <= 105`
* `ransomNote` and `magazine` consist of lowercase English letters. | null |
easy and clean Python3 code | ransom-note | 0 | 1 | # Code\n```\nclass Solution:\n def canConstruct(self, ransomNote: str, magazine: str) -> bool:\n for charr in set(ransomNote):\n if ransomNote.count(charr)>magazine.count(charr):return False\n return True\n``` | 3 | Given two strings `ransomNote` and `magazine`, return `true` _if_ `ransomNote` _can be constructed by using the letters from_ `magazine` _and_ `false` _otherwise_.
Each letter in `magazine` can only be used once in `ransomNote`.
**Example 1:**
**Input:** ransomNote = "a", magazine = "b"
**Output:** false
**Example 2:**
**Input:** ransomNote = "aa", magazine = "ab"
**Output:** false
**Example 3:**
**Input:** ransomNote = "aa", magazine = "aab"
**Output:** true
**Constraints:**
* `1 <= ransomNote.length, magazine.length <= 105`
* `ransomNote` and `magazine` consist of lowercase English letters. | null |
384: Solution with step by step explanation | shuffle-an-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n- In the __init__ method, we initialize two instance variables: self.nums and self.original. self.nums is the input array, and self.original is a copy of it. We create the copy so that we can reset the array later.\n\n- In the reset method, we reset the self.nums array to its original state by copying the self.original array into it.\n\n- In the shuffle method, we shuffle the array by iterating over each element of the array and swapping it with a randomly selected element from the remaining elements of the array.\n\n- We start by setting n to the length of the array.\n\n- We then iterate over each index i from 0 to n-1.\n\n- For each index i, we choose a random index j from i to n-1 using random.randrange(i, n).\n\n- We then swap the element at index i with the element at index j using self.nums[i], self.nums[j] = self.nums[j], self.nums[i].\n\n- Finally, we return the shuffled array self.nums.\n\nThis solution has a time complexity of O(n), which is optimal since we need to visit each element of the array at least once to shuffle it.\n\n# Complexity\n- Time complexity:\n69.60%\n\n- Space complexity:\n58.20%\n\n# Code\n```\nclass Solution:\n def __init__(self, nums: List[int]):\n self.nums = nums\n self.original = list(nums)\n\n def reset(self) -> List[int]:\n self.nums = list(self.original)\n return self.nums\n\n def shuffle(self) -> List[int]:\n n = len(self.nums)\n for i in range(n):\n # Choose a random index j from i to n-1\n j = random.randrange(i, n)\n # Swap nums[i] and nums[j]\n self.nums[i], self.nums[j] = self.nums[j], self.nums[i]\n return self.nums\n``` | 5 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Python code | Reset without storing the original array | shuffle-an-array | 0 | 1 | \n```\nRead a lot a solution, but everywhere the original array\nis stored seperately and returned when reset is called.\n\nI tried to reset the array we suffled,\nhowever many times we shuffle it, below is the \naccepted solution, it is slow, beats only 10% but it \nis the full solution in my view.\n```\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.nums = nums\n self.index = [i for i in range(0,len(nums))]\n\n def reset(self) -> List[int]:\n n = len(self.nums)\n nums2 = [0 for _ in range(0,n) ]\n for i in range(0,n):\n nums2[self.index[i]] = self.nums[i]\n self.index = [i for i in range(0,n)]\n self.nums = nums2\n return self.nums\n\n def shuffle(self) -> List[int]:\n n = len(self.nums)\n nums2 = [ 0 for _ in range(0,n) ]\n index2 = [0 for _ in range(0,n) ]\n filled = []\n i = 0\n while(i < n):\n r = randint( 0,n-1)\n if( r not in filled):\n filled.append(r);\n nums2[r] = self.nums[i]\n index2[r] = self.index[i] \n i+=1\n self.nums = nums2 ;\n self.index = index2 \n return self.nums\n \n``` | 2 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Beats 72.88% of Python3 with Explanation | shuffle-an-array | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\n- In the `__init__` method we will create two instances one is `self.nums` which is input Array given to us and second is `self.original` which is copy of original input array.\n\n- In the reset method we will just return the `self.original` which is input array given to us. \n\n- In the shuffle method we will iterate thorough the array and we will take random index j which will range from `i` to `len(nums)` and we will swap elements in i th and j th index and we will return the array. \n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n #given arr\n self.nums = nums\n #copy of given array to return at time of reset\n self.original = list(nums)\n\n def reset(self) -> List[int]:\n #return original array that we stored earlier\n return self.original\n\n def shuffle(self) -> List[int]:\n for i in range(len(self.nums)):\n # Choose a random index j from i to n-1\n j = random.randrange(i, len(self.nums))\n # Swap nums[i] and nums[j]\n self.nums[i], self.nums[j] = self.nums[j], self.nums[i]\n return self.nums\n``` | 1 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
{ Python } | Best Optimal Approach ✔ | shuffle-an-array | 0 | 1 | \tclass Solution:\n\t\tdef __init__(self, nums: List[int]):\n\t\t\tself.arr = nums[:] # Deep Copy, Can also use Shallow Copy concept!\n\t\t\t# self.arr = nums # Shallow Copy would be something like this!\n\n\t\tdef reset(self) -> List[int]:\n\t\t\treturn self.arr\n\n\t\tdef shuffle(self) -> List[int]:\n\t\t\tans = self.arr[:]\n\t\t\tfor i in range(len(ans)):\n\t\t\t\tswp_num = random.randrange(i, len(ans)) # Fisher-Yates Algorithm\n\t\t\t\tans[i], ans[swp_num] = ans[swp_num], ans[i]\n\t\t\treturn ans\nIf you have any questions, please ask me, and if you like this approach, please **vote it up**! | 9 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Python | shuffle-an-array | 0 | 1 | # Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n O(1)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n O(n)\n# Code\n```\nclass Solution:\n def __init__(self, nums: List[int]):\n self.original = nums\n self.nums = nums.copy()\n\n # O(1)\n def reset(self) -> List[int]:\n return self.original\n\n # O(1)\n def shuffle(self) -> List[int]:\n random.shuffle(self.nums)\n return self.nums\n``` | 0 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Fisher-Yates shuffle algorithm; Runtime 134 ms - TC beats 72.98% | shuffle-an-array | 1 | 1 | # Code\n```python\nimport random\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.nums=nums\n self.original=nums.copy()\n self.n=len(nums)\n\n def shuffle_list(self,lst):\n \n #Fisher-Yates shuffle algorithm\n for i in range(self.n - 1, 0, -1):\n j = random.randint(0, i)\n lst[i], lst[j] = lst[j], lst[i] \n \n \n\n def reset(self) -> List[int]:\n return self.original\n \n def shuffle(self) -> List[int]:\n self.shuffle_list(self.nums)\n return self.nums \n\n\n``` | 0 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Easy solution using random.shuffle() | shuffle-an-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport random\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.nums = nums\n \n\n def reset(self) -> List[int]:\n return self.nums\n \n\n def shuffle(self) -> List[int]:\n newL = self.nums.copy()\n random.shuffle(newL)\n return newL\n\n \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(nums)\n# param_1 = obj.reset()\n# param_2 = obj.shuffle()\n``` | 0 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
python3 random | shuffle-an-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.original = nums\n self.nums = nums\n self.len = len(nums)\n\n def reset(self) -> List[int]:\n self.nums = self.original\n return self.nums\n\n def shuffle(self) -> List[int]:\n ans = [0] * self.len\n duplicates = set()\n for i in range(self.len):\n nextIndex = random.randint(0, self.len - 1)\n while nextIndex in duplicates:\n nextIndex = random.randint(0, self.len - 1)\n duplicates.add(nextIndex)\n ans[i] = self.nums[nextIndex]\n \n self.nums = ans\n return ans\n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(nums)\n# param_1 = obj.reset()\n# param_2 = obj.shuffle()\n``` | 0 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Simple solution without using random (99.92%) | shuffle-an-array | 0 | 1 | # Code\n```\n# by ilotoki0804\n\nfrom itertools import permutations\n\nclass Solution:\n def __init__(self, nums: List[int]):\n self.numbers = nums\n self.permutated_iter = permutations(nums)\n\n def reset(self) -> List[int]:\n return self.numbers\n\n def shuffle(self) -> List[int]:\n try:\n return next(self.permutated_iter)\n except StopIteration:\n self.permutated_iter = permutations(self.numbers)\n return next(self.permutated_iter)\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(nums)\n# param_1 = obj.reset()\n# param_2 = obj.shuffle()\n``` | 0 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
Simplest sol using random for shuflling | shuffle-an-array | 0 | 1 | # Complexity\n- Time complexity: O(n)\n\n# Code\n```\nclass Solution:\n\n def __init__(self, nums: List[int]):\n self.nums = nums\n self.original = list(nums)\n \n\n def reset(self) -> List[int]:\n self.nums = list(self.original)\n return self.nums\n \n\n def shuffle(self) -> List[int]:\n n = len(self.nums)\n for i in range(n):\n j = random.randrange(i,n)\n self.nums[i], self.nums[j] = self.nums[j], self.nums[i]\n return self.nums\n \n\n\n# Your Solution object will be instantiated and called as such:\n# obj = Solution(nums)\n# param_1 = obj.reset()\n# param_2 = obj.shuffle()\n``` | 0 | Given an integer array `nums`, design an algorithm to randomly shuffle the array. All permutations of the array should be **equally likely** as a result of the shuffling.
Implement the `Solution` class:
* `Solution(int[] nums)` Initializes the object with the integer array `nums`.
* `int[] reset()` Resets the array to its original configuration and returns it.
* `int[] shuffle()` Returns a random shuffling of the array.
**Example 1:**
**Input**
\[ "Solution ", "shuffle ", "reset ", "shuffle "\]
\[\[\[1, 2, 3\]\], \[\], \[\], \[\]\]
**Output**
\[null, \[3, 1, 2\], \[1, 2, 3\], \[1, 3, 2\]\]
**Explanation**
Solution solution = new Solution(\[1, 2, 3\]);
solution.shuffle(); // Shuffle the array \[1,2,3\] and return its result.
// Any permutation of \[1,2,3\] must be equally likely to be returned.
// Example: return \[3, 1, 2\]
solution.reset(); // Resets the array back to its original configuration \[1,2,3\]. Return \[1, 2, 3\]
solution.shuffle(); // Returns the random shuffling of array \[1,2,3\]. Example: return \[1, 3, 2\]
**Constraints:**
* `1 <= nums.length <= 50`
* `-106 <= nums[i] <= 106`
* All the elements of `nums` are **unique**.
* At most `104` calls **in total** will be made to `reset` and `shuffle`. | The solution expects that we always use the original array to shuffle() else some of the test cases fail. (Credits; @snehasingh31) |
385: Time 92.59% and Space 97.53%, Solution with step by step explanation | mini-parser | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. We start by checking if the input string s starts with a [. If it doesn\'t, then it must be a single integer, so we create a NestedInteger object with that value and return it.\n\n```\nif s[0] != \'[\':\n return NestedInteger(int(s))\n```\n2. If the input string does start with a [, we create an empty stack to keep track of NestedInteger objects and sublists as we parse the input string.\n```\nstack = []\n```\n3. We then loop through each character in the input string, using enumerate to keep track of the index of the current character.\n```\nfor i, c in enumerate(s):\n```\n4. If we encounter an opening bracket [, we push a new empty NestedInteger object onto the stack and set the starting index for the next element to be parsed.\n```\nif c == \'[\':\n stack.append(NestedInteger())\n start = i + 1\n```\n5. If we encounter a comma ,, we check if there was a number between the previous comma or opening bracket and this one. If there was, we create a new NestedInteger object with that value and add it to the NestedInteger object on the top of the stack. We then update the starting index for the next element to be parsed.\n```\nelif c == \',\':\n if i > start:\n num = int(s[start:i])\n stack[-1].add(NestedInteger(num))\n start = i + 1\n```\n6. If we encounter a closing bracket ], we pop the top NestedInteger object from the stack and check if there was a number between the previous comma or opening bracket and this one. If there was, we create a new NestedInteger object with that value and add it to the popped NestedInteger object. If there are still NestedInteger objects on the stack, we add the popped NestedInteger to the one on top. Otherwise, we return the popped NestedInteger. We then update the starting index for the next element to be parsed.\n\n```\nelif c == \']\':\n popped = stack.pop()\n if i > start:\n num = int(s[start:i])\n popped.add(NestedInteger(num))\n if stack:\n stack[-1].add(popped)\n else:\n return popped\n start = i + 1\n```\n7. After the loop is finished, we should have only one NestedInteger object left on the stack. We return this object as the final deserialized result.\n```\nreturn stack[-1]\n```\n# Complexity\n- Time complexity:\n92.59%\n\n- Space complexity:\n97.53%\n\n# Code\n```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n # If s doesn\'t start with a \'[\', it must be a single integer, so create a NestedInteger object with that value\n if s[0] != \'[\':\n return NestedInteger(int(s))\n\n # Create an empty stack to keep track of NestedInteger objects and sublists as we parse the input string\n stack = []\n\n # Loop through each character in the string\n for i, c in enumerate(s):\n if c == \'[\':\n # If we encounter an opening bracket, push a new empty NestedInteger object onto the stack and set the starting index for the next element\n stack.append(NestedInteger())\n start = i + 1\n elif c == \',\':\n # If we encounter a comma, check if there was a number between the previous comma or opening bracket and this one.\n # If there was, create a new NestedInteger object with that value and add it to the NestedInteger object on the top of the stack\n if i > start:\n num = int(s[start:i])\n stack[-1].add(NestedInteger(num))\n # Update the starting index for the next element to be parsed\n start = i + 1\n elif c == \']\':\n # If we encounter a closing bracket, pop the top NestedInteger object from the stack and check if there was a number between the previous comma or opening bracket and this one.\n # If there was, create a new NestedInteger object with that value and add it to the popped NestedInteger object\n popped = stack.pop()\n if i > start:\n num = int(s[start:i])\n popped.add(NestedInteger(num))\n # If there are still NestedInteger objects on the stack, add the popped NestedInteger to the one on top. Otherwise, return the popped NestedInteger\n if stack:\n stack[-1].add(popped)\n else:\n return popped\n # Update the starting index for the next element to be parsed\n start = i + 1\n\n``` | 9 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Python Solution just 6 lines || Easy to understand approach || Using eval | mini-parser | 0 | 1 | ```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n\t\t# eval("[1,2,3]") => [1,2,3] it\'ll convert string of list to list\n return self.find(eval(s))\n \n def find(self,s):\n\t\t# if our elment s is type of int we\'ll return new NestedInteger of that value\n if type(s) == type(1):\n return NestedInteger(s)\n\t\t\t\n\t\t# create a new object that will contain our elements of type NestedInteger\n n = NestedInteger()\n \n\t\tfor x in s:\n\t\t\t# traverse the list s and recursively find all nestedIntegers and add them in container n\n\t\t\t# recursion will handle multiple nested lists\n n.add(self.find(x))\n return n\n``` | 4 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
used stack, beats 62.45%, 65% | mini-parser | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n# Code\n```\n# """\n# This is the interface that allows for creating nested lists.\n# You should not implement it, or speculate about its implementation\n# """\n#class NestedInteger:\n# def __init__(self, value=None):\n# """\n# If value is not specified, initializes an empty list.\n# Otherwise initializes a single integer equal to value.\n# """\n#\n# def isInteger(self):\n# """\n# @return True if this NestedInteger holds a single integer, rather than a nested list.\n# :rtype bool\n# """\n#\n# def add(self, elem):\n# """\n# Set this NestedInteger to hold a nested list and adds a nested integer elem to it.\n# :rtype void\n# """\n#\n# def setInteger(self, value):\n# """\n# Set this NestedInteger to hold a single integer equal to value.\n# :rtype void\n# """\n#\n# def getInteger(self):\n# """\n# @return the single integer that this NestedInteger holds, if it holds a single integer\n# Return None if this NestedInteger holds a nested list\n# :rtype int\n# """\n#\n# def getList(self):\n# """\n# @return the nested list that this NestedInteger holds, if it holds a nested list\n# Return None if this NestedInteger holds a single integer\n# :rtype List[NestedInteger]\n# """\n\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n nest = None\n digits = ""\n nests = []\n\n if \'[\' not in s:\n return NestedInteger(int(s))\n\n for i in range(len(s)):\n if s[i] == \'[\':\n if nest:\n nests.append(nest)\n nest = NestedInteger()\n elif s[i] == \']\':\n if len(digits) > 0:\n nest.add(NestedInteger(int(digits)))\n digits = \'\'\n if i == len(s) - 1:\n return nest\n old = nests.pop()\n old.add(nest)\n nest = old\n elif s[i] == \',\':\n if len(digits):\n nest.add(NestedInteger(int(digits)))\n digits = ""\n else:\n digits = digits + s[i]\n \n \n \n``` | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Python || Clean Recursive Solution | mini-parser | 0 | 1 | ```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n s = \'[\' + s + \']\'\n\n n = len(s)\n\n def parse(i: int) -> tuple[int, NestedInteger]:\n out = NestedInteger()\n num = \'\'\n\n while i < n and s[i] != \']\':\n if s[i].isdigit() or s[i] == \'-\':\n num += s[i]\n elif s[i] == \',\':\n if num:\n out.add(NestedInteger(int(num)))\n num = \'\'\n else:\n i, tmp = parse(i + 1)\n out.add(tmp)\n\n i += 1\n\n if num:\n out.add(NestedInteger(int(num)))\n\n return i, out\n\n return parse(1)[1].getList()[0]\n``` | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Beats 100.00% of users with Python3 | mini-parser | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nWhen we encounter an opening bracket [, we create a new NestedInteger and push it onto a stack.\n\nWhen we encounter a closing bracket ], we finish constructing the current NestedInteger and pop it from the stack.\n\nWhile processing numbers and commas, we build the numbers and add them to the current NestedInteger.\n\nWe continue this process until we\'ve read the entire input string.\n\nAt the end, we\'re left with a single NestedInteger object, which represents the entire nested structure.\n\nOur approach w uses a stack to manage the nesting level and creates NestedInteger objects as we parse the input string. The final NestedInteger object represents the complete nested list. \n\n# Complexity\n- Time complexity: **O(n)** where n is the length of the input string.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: **O(n + d)** where n is the length of the input string and d is the maximum depth of nesting.\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# """\n# This is the interface that allows for creating nested lists.\n# You should not implement it, or speculate about its implementation\n# """\n#class NestedInteger:\n# def __init__(self, value=None):\n# """\n# If value is not specified, initializes an empty list.\n# Otherwise initializes a single integer equal to value.\n# """\n#\n# def isInteger(self):\n# """\n# @return True if this NestedInteger holds a single integer, rather than a nested list.\n# :rtype bool\n# """\n#\n# def add(self, elem):\n# """\n# Set this NestedInteger to hold a nested list and adds a nested integer elem to it.\n# :rtype void\n# """\n#\n# def setInteger(self, value):\n# """\n# Set this NestedInteger to hold a single integer equal to value.\n# :rtype void\n# """\n#\n# def getInteger(self):\n# """\n# @return the single integer that this NestedInteger holds, if it holds a single integer\n# Return None if this NestedInteger holds a nested list\n# :rtype int\n# """\n#\n# def getList(self):\n# """\n# @return the nested list that this NestedInteger holds, if it holds a nested list\n# Return None if this NestedInteger holds a single integer\n# :rtype List[NestedInteger]\n# """\n\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n if not s:\n return None\n \n stack = []\n current = None\n num = ""\n \n for char in s:\n if char == \'[\':\n if current:\n stack.append(current)\n current = NestedInteger()\n elif char == \']\':\n if num:\n current.add(NestedInteger(int(num)))\n num = ""\n if stack:\n top = stack.pop()\n top.add(current)\n current = top\n elif char == \',\':\n if num:\n current.add(NestedInteger(int(num)))\n num = ""\n else:\n num += char\n \n if num:\n return NestedInteger(int(num))\n \n return current\n\n# Example usage\n# serialized = "[123,[456,[789]]]"\n# solution = Solution()\n# result = solution.deserialize(serialized)\n# print(result.getList()[0].getInteger()) # Output: 123\n# print(result.getList()[1].getList()[0].getInteger()) # Output: 456\n# print(result.getList()[1].getList()[1].getList()[0].getInteger())\n# Output: 789\n# print(result) # Output: [123,[456,[789]]]\n\n``` | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Python code along with Algorithm | mini-parser | 0 | 1 | # Approach\nUsing Stack and DFS(Depth-first search)\n\nSince the input is a string, which is not much helpful for our stack approach\nFirst we will convert the string into an array with the following condition:\n- The $$]$$, $$[$$, and the integers (represented as string) should be added as a sepearte element to the array\n- All \'$$,$$\' should be ignored\ne.g. "[123,[345,654]]" $$\\rightarrow$$ $$[$$ \' [ \', \'123\', \'[\', \'345\', \'654\', \']\', \']\' $$]$$\n\n#### convert string to array algorithm\n```\nCONVERT(string):\n Step 1: Declare an array \'arr\' and a variable \'cache\'\n Step 2: For each individual character \'ele\' in string\n Step 2.1: if ele is "[": add ele to arr\n Step 2.2: else if ele is "]":\n Step 2.2.1: First add cache to the arr, then assign cache = ""\n Step 2.2.2: Add ele to the arr\n Step 2.3: else if ele is ",":\n Step 2.3.1: Add the cache to the arr, then assign cache = ""\n Step 2.4: else: add ele to the cache\n Step 3: if cache is not empty string: add cache to the arr\n Step 4: Return arr\n```\nThe next approach is very simple\n```\nStep 1: string_arr = CONVERT(s) and declare a stack = []\nStep 2: if length(string_arr) = 1: s is just an integer\n Step 2.1: Return NestedInteger(int(string_arr[0]))\nStep 3: For each element \'ele\' in string_arr:\n Step 3.1: if ele not equals to \']\': add to the stack\n Step 3.2: else:\n Step 3.2.1: Keeping poping from stack and save it to \'temp\' array until \'[\' is encountered:\n Step 3.2.2: create a NestedInteger object \'temp_ans\' and add the element of temp array to temp_ans using .add function\n Step 3.2.3: Add temp_ans to stack\nStep 4: Return stack[0]\n\n```\n> check out the Python code for implementation, there may be some obvious pitfalls while implementing the idea\n# Code\n```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n def convert(string):\n arr = []\n cache =""\n for ele in string:\n if ele == "[":\n arr.append(ele)\n elif ele == "]":\n if cache:\n arr.append(cache)\n arr.append(ele)\n cache = ""\n elif ele == ",":\n if cache:\n arr.append(cache)\n cache = ""\n else:\n cache += ele\n if cache:\n arr.append(cache)\n return arr\n string_arr = convert(s)\n stack = []\n ans = None\n # print(string_arr)\n\n if len(string_arr) == 1:\n return NestedInteger(int(string_arr[0])) \n for i in range(len(string_arr)):\n ele = string_arr[i]\n if ele != \']\':\n stack.append(ele)\n else:\n temp = []\n while(stack[-1] != \'[\'):\n poped = stack.pop(-1)\n temp = [poped] + temp\n stack.pop(-1)\n temp_ans = NestedInteger()\n for t in temp:\n if type(t) == type("1"):\n temp_ans.add(NestedInteger( int(t)) )\n else:\n temp_ans.add(t)\n stack.append(temp_ans)\n \n return stack[0]\n \n``` | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Solution | mini-parser | 1 | 1 | ```C++ []\nclass Solution {\nprivate:\n NestedInteger dfs(string& s, int& i) {\n NestedInteger res;\n int n(s.size());\n for ( ;i < n; ++i) {\n if (s[i] == \',\') continue;\n if (s[i] == \'[\') res.add(dfs(s,++i));\n else if (s[i]==\']\') break;\n else {\n int sgn(0);\n if (s[i]==\'-\') sgn = s[i++];\n int m(s[i]-\'0\');\n while (i+1 < n && isdigit(s[i+1])) m = m*10+(s[++i]-\'0\');\n res.add(NestedInteger(sgn?-m:m));\n }\n }\n return res;\n }\npublic:\n NestedInteger deserialize(string s) {\n int i(0);\n return dfs(s,i).getList()[0];\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n if s[0] != \'[\':\n return NestedInteger(int(s))\n word = \'\'\n\n output = NestedInteger()\n parents = [output]\n word = \'\'\n for char in s[1:-1]:\n if char in {\'[\', \',\', \']\'}:\n if word:\n parents[-1].add(NestedInteger(int(word)))\n word = \'\'\n if char == \'[\':\n newlist = NestedInteger()\n parents[-1].add(newlist)\n parents.append(newlist)\n elif char == \']\':\n parents.pop()\n else:\n word += char\n if word:\n parents[-1].add(NestedInteger(int(word)))\n return output\n```\n\n```Java []\nclass Solution {\n public NestedInteger deserialize(String s) {\n return run(s, 0, new int[1]).getList().get(0);\n }\n NestedInteger run(String s, int idx, int[] nextidx) {\n\n int i = idx;\n \n NestedInteger newni = new NestedInteger();\n boolean neg = false;\n while(i < s.length()) {\n\n char c = s.charAt(i);\n\n if(isInteger(c)) {\n int v = 0;\n while(i < s.length() && isInteger(s.charAt(i))) {\n c = s.charAt(i);\n v = v * 10 + c - \'0\';\n i++;\n }\n i--;\n if(neg) {\n v = v * -1;\n }\n neg = false;\n NestedInteger ni = new NestedInteger(v);\n newni.add(ni);\n } else if (c == \',\') {\n\n } else if (c == \'[\') {\n newni.add(run(s, i + 1, nextidx));\n i = nextidx[0];\n } else if (c == \']\') {\n nextidx[0] = i;\n return newni;\n } else {\n neg = true;\n }\n i++;\n }\n return newni;\n }\n boolean isInteger(char c) {\n return c >= \'0\' && c <= \'9\';\n }\n}\n```\n | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
O(n) SOlution | mini-parser | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe idea for this problem is to use a recursive approach to deserialize the string representation of a nested integer. \n# Approach\n<!-- Describe your approach to solving the problem. -->\n- If the input string is empty, return an empty nested integer.\n- If the first character of the input string is not \'[\', return a nested integer with the value of the input string converted to an integer.\n- If the input string has a length of 2 or less, return an empty nested integer.\n- Initialize a result nested integer and a start index to 1.\n- Iterate over the input string starting from index 1.\n- If the current character is a \',\' or the last character of the string and the count of open brackets is 0, deserialize the sub-string from the start index to the current index, add it to the result nested integer and update the start index to the current index + 1.\n- If the current character is a \'[\', increment the count of open brackets.\n- If the current character is a \']\', decrement the count of open brackets.\n- Return the result nested integer.\n# Complexity\n- Time complexity: $O(n)$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nWe need to perform a single pass through the input string.\n- Space complexity: $O(n)$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nWe need to store the intermediate results in the call stack, which takes $O(n)$ space.\n# Code\n```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n if not s:\n return NestedInteger()\n if s[0] != \'[\':\n return NestedInteger(int(s))\n if len(s) <= 2:\n return NestedInteger()\n start, cnt = 1, 0\n res = NestedInteger()\n for i in range(1, len(s)):\n if cnt == 0 and (s[i] == \',\' or i == len(s) - 1):\n res.add(self.deserialize(s[start:i]))\n start = i + 1\n elif s[i] == \'[\':\n cnt += 1\n elif s[i] == \']\':\n cnt -= 1\n return res\n\n``` | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
python solution with index-memoization | mini-parser | 0 | 1 | ## What\'s special:\n\n- Manipulate index is cheaper (regarding time&space complexity) than substring\n- Recur between `[]` but creating a `ci` (closing index) to quickly find where the `[]` ends and jump to that index \n\n## Code\n\n```python\nclass Solution:\n s: str\n ci: dict[int, int] # V is ind of close parenthesis of opening parenthesis K\n\n def deserialize(self, s: str) -> NestedInteger:\n # prepare ci\n self.s = s\n self.ci = ci = {} # closing indices of keys\n ps: list[int] = [] # stack of parentheses\' pos\n for i, ch in enumerate(s):\n if ch == "[":\n ps.append(i)\n elif ch == "]":\n oi = ps.pop() # opening index\n ci[oi] = i\n\n # work\n return self.recur(0, len(s) - 1).getList()[0]\n\n def recur(self, start, end) -> NestedInteger:\n # both start and end are inclusive\n ni = NestedInteger()\n s = self.s\n if start + 1 == end and s[start] == "[" and s[end] == "]":\n ni.add(NestedInteger())\n return ni\n i = start\n ns = i # number start\n while i <= end:\n if s[i] == "[":\n ni.add(self.recur(i + 1, self.ci[i] - 1))\n ns = i = self.ci[i] + 1\n elif s[i] == ",":\n if i != ns:\n ni.add(NestedInteger(int(s[ns:i])))\n ns = i = i + 1\n else:\n i += 1\n if ns <= end:\n ni.add(NestedInteger(int(s[ns : end + 1])))\n return ni\n```\n\n\n## TL;DR\n\nPlease upvote if you like to see more solutions like this. | 0 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
[Python3] a concise recursive solution | mini-parser | 0 | 1 | \n```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n if not s: return NestedInteger()\n if not s.startswith("["): return NestedInteger(int(s)) # integer \n ans = NestedInteger()\n s = s[1:-1] # strip outer "[" and "]"\n if s: \n ii = op = 0 \n for i in range(len(s)): \n if s[i] == "[": op += 1\n if s[i] == "]": op -= 1\n if s[i] == "," and op == 0: \n ans.add(self.deserialize(s[ii:i]))\n ii = i+1\n ans.add(self.deserialize(s[ii:i+1]))\n return ans \n``` | 2 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Elegant Python One Pass Solution (using stack) | mini-parser | 0 | 1 | ```\nclass Solution:\n def deserialize(self, s: str) -> NestedInteger:\n stack = []\n integerStr = \'\'\n \n for c in s:\n if c == \'[\':\n stack.append(NestedInteger())\n elif c == \']\':\n if len(integerStr)>0:\n stack[-1].add(NestedInteger(int(integerStr)))\n integerStr = \'\'\n poppedList = stack.pop()\n if len(stack)==0:\n return poppedList\n stack[-1].add(poppedList)\n elif c == \',\':\n if len(integerStr)>0:\n stack[-1].add(NestedInteger(int(integerStr)))\n integerStr = \'\'\n else:\n integerStr += c\n \n return NestedInteger(int(s))\n``` | 1 | Given a string s represents the serialization of a nested list, implement a parser to deserialize it and return _the deserialized_ `NestedInteger`.
Each element is either an integer or a list whose elements may also be integers or other lists.
**Example 1:**
**Input:** s = "324 "
**Output:** 324
**Explanation:** You should return a NestedInteger object which contains a single integer 324.
**Example 2:**
**Input:** s = "\[123,\[456,\[789\]\]\] "
**Output:** \[123,\[456,\[789\]\]\]
**Explanation:** Return a NestedInteger object containing a nested list with 2 elements:
1. An integer containing value 123.
2. A nested list containing two elements:
i. An integer containing value 456.
ii. A nested list with one element:
a. An integer containing value 789
**Constraints:**
* `1 <= s.length <= 5 * 104`
* `s` consists of digits, square brackets `"[] "`, negative sign `'-'`, and commas `','`.
* `s` is the serialization of valid `NestedInteger`.
* All the values in the input are in the range `[-106, 106]`. | null |
Elegent, intuitive recursive O(n) solution | lexicographical-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nI use pre-order traversal and treat this like a DFS problem, where we first add 1, then it\'s *10, and if N < value * 10, then we move on to adding + 1.\n\n# Complexity\n- Time complexity:\n O(N), goes through each number once\n- Space complexity:\n O(N), recursion stack can only get as deep as it\'s N\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n #1 always comes first, and we fill in all the ones that exist,\n #if it gets greater than n, then we finish\n ans = []\n \n def recursive(value):\n if len(ans) >= n:\n return\n ans.append(value)\n if (value * 10) <= n:\n recursive(value * 10)\n if value + 1 <= n and int(str(value)[-1]) < 9:\n recursive(value + 1)\n recursive(1)\n\n return ans\n\n``` | 1 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
386: Time 99.87% and Space 93.99%, Solution with step by step explanation | lexicographical-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize an empty list res to store the result and a variable cur to start from 1.\n```\nres = []\ncur = 1\n```\n2. Loop through the range n times, where n is the upper limit of the numbers to generate.\n```\nfor i in range(n):\n```\n3. Append the current number cur to the result list.\n```\nres.append(cur)\n```\n4. If the current number times 10 is less than or equal to n, move to the next level by multiplying cur by 10.\n```\nif cur * 10 <= n:\n cur *= 10\n```\n5. If the current number times 10 is greater than n, move to the next number at the current level by adding 1 to cur.\n```\nelse:\n # If we\'ve reached the end of a level, divide by 10 to go back up one level\n if cur >= n:\n cur //= 10\n cur += 1\n```\n6. Skip over any trailing zeroes (e.g. if cur is 19, skip over 190, 191, 192, etc.) by dividing cur by 10 until the last digit is not 0.\n```\nwhile cur % 10 == 0:\n cur //= 10\n```\n7. Return the result list res.\n```\nreturn res\n```\nThis algorithm generates all the numbers in the range [1, n] in lexicographical order, and runs in O(n) time complexity and uses O(1) extra space.\n\n# Complexity\n- Time complexity:\n99.87%\n\n- Space complexity:\n93.99%\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n res = []\n cur = 1\n for i in range(n):\n # Add the current number to the result\n res.append(cur)\n # If the current number times 10 is less than or equal to n, move to the next level\n if cur * 10 <= n:\n cur *= 10\n # Otherwise, move to the next number at the current level\n else:\n # If we\'ve reached the end of a level, divide by 10 to go back up one level\n if cur >= n:\n cur //= 10\n cur += 1\n # Skip over any trailing zeroes (e.g. if cur = 19, skip over 190, 191, 192, etc.)\n while cur % 10 == 0:\n cur //= 10\n return res\n\n``` | 12 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Easy | Python3 Solution | lexicographical-numbers | 0 | 1 | \n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n lst=[str(i) for i in range(1,n+1)]\n lst.sort()\n return [int(i) for i in lst]\n \n``` | 3 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Python 3 - Simple DFS with Explanation | lexicographical-numbers | 0 | 1 | # Intuition\nWhenever any lexicographical solution is asked, the first thing that should come to your mind should be DFS on Trees.\n\n(A more [flashy one liner](https://leetcode.com/problems/lexicographical-numbers/solutions/3773772/python-3-disgusting-1-liner-use-at-end-of-interview/))\n# Approach\nWe start from the digit "1", and try placing every possible digit in front of it in ascending order. Then we try placing every possible digit in front of all the previously generated numbers, and so on, till we get a number that is greater than n.\n\n1. Initialize an ```ans``` array to store the results.\n2. Create a dfs function, which will first append a number to the list, and then start by placing every other digit in front of it.\nThe way we do that is by multiplying the current number by 10, and adding whatever digit we want in front of it.\n\nEg - To place a 2 in front of 34, we do ```34 * 10 = 340```, and then we add 2 ```340 + 2 = 342``` to get the desired number.\n3. We then check if this new number is still lesser than whatever our ```n``` was. If yes, we start a dfs on it. \n- Note- The inner loop places all digits from 0-9, whereas the outer loop only places digits from 1-9, as that is what the question statement requires.\n# Complexity\n- Time complexity:\nO(N), since we are generating every number up to N at most.\n- Space complexity:\nO(N) to store the numbers, and O(log(N)) for the recursive call stack in the worst case. \n\n# Code-\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n ans = []\n\n def dfs(num):\n ans.append(num)\n\n for i in range(0, 10):\n if (n2 := 10 * num + i) <= n:\n dfs(n2)\n\n for i in range(1, 10):\n if i <= n:\n dfs(i)\n\n return ans\n\n\n``` | 1 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Easy Python Code | lexicographical-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\ncreating a list of string(i) for integers i in range(1,n)\nsorting them in lexicographical order.\nconverting the list of strings into list of integers \nreturning the list\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nBeats 88% of the python coders\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n l=[]\n for i in range(1,n+1):\n l.append(str(i))\n l.sort()\n l2=[int(i) for i in l]\n return l2\n``` | 1 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Easy Solution O(N) Time O(1) Space || Beats 90% || Examples and Thought Process | lexicographical-numbers | 0 | 1 | To solve this problem, it\u2019s less about data structure knowledge and applying them, it\u2019s more about understanding what is \u201Clexicographical order?\u201D If you do understand what that means the problem becomes easy.\n\n## What is lexicographical order?\n\nPeople online say it\u2019s like alphabetical order but applied with numbers. Let\u2019s go over some alphabetical examples that made me understand then translate that into numbers. This example is only to showcase \u201Clexicographical order,\u201D not an example for the actual problem.\n\n```json\na, aa, aaa, aab, aac\u2026aaz, ab\u2026az, b\u2026\n```\n\n\u201Ca\u201D is the smallest letter, so we keep on going with it until we reach \u201Cz,\u201D which I like to call the \u201Cmax letter\u201D we can go up to.\n\nOnce we hit this \u201Cmax letter\u201D we want to increment the next letter. In this example, specifically at \u201Caaz,\u201D we reached the max letter, so we want to increment the next letter which is the \u201C**a**\u201D in \u201Ca**a**z.\u201D So we drop the z and keep going with this process. Once we hit \u201Caz,\u201D we do the samething and finally we reach \u201Cb!\u201D\n\nSo now we can translate this into numbers:\n\n- the \u201Cmax letter\u201D in this case will be the number 9\n- the number 0 is the smallest number\n\n## Examples\n\nGreat, so now we know what lexicographical order means and are able to translate the process into numbers, lets go through some examples to maybe showcase how we can code this by going through it by hand.\n\n##### Example 1\n\n- Input = 9\n- Output:\n\n```json\n[1, 2, 3, 4, 5, 6, 7, 8, 9]\n```\n\nWith 1 digit inputs it doesn\u2019t look like it\u2019s in lexicographical order, but when we reach 2+ digits it does.\n\n##### Example 2\n\n- Input = 19\n- Output:\n\n```json\n[1, 10...19, 2, 3, 4, 5, 6, 7, 8, 9]\n```\n\nWe\u2019ve reached our input, 19, this is a standard case. Once we hit our max number, 9, for that digit, we want to move onto that \u201C**1**\u201D in \u201C**1**9\u201D and increment that.\n\n##### Example 3\n\n- Input = 10\n- Output:\n\n```json\n[1, 10, 2, 3, 4, 5, 6, 7, 8, 9]\n```\n\nInteresting, we\u2019ve reached out input but haven\u2019t reached the max number, but we still had to move onto that \u201C**1**\u201D in \u201C**1**0\u201D to make it a 2. We\u2019re going through it by hand, but just something to note on how we might code it.\n\n##### Example 4:\n\n- Input = 200\n- Output:\n\n```json\n[1, 10, 100..109, 11, 110......199, 2, 20, 200, 3, 30, 31......]\n```\n\nAs you can see here, we keep on adding the smallest number, 0, to the end of our current number and never go over our input, this is so we have a list that has a range of 0 to N.\n\nThere\u2019s also an interesting case, the 199. It already has two digits with two max numbers, so that means we would have to drop both and increment the \u201C**1**\u201D in \u201C**1**99\u201D so we can get to 2 and move on lexicographically.\n\nNow that we have gone through some examples, specifically examples that showcase how our code and algorithm, lets go ahead and take what we\u2019ve learned and finally implement.\n\n## Implement\n\n```python\ndef lexicalOrder(n):\n\tcurNum = 1\n res = []\n\n for i in range(0, n):\n res.append(curNum)\n if curNum * 10 <= n:\n curNum * 10\n else:\n while((curNum % 10) == 9 or curNum == n):\n curNum = curNum // 10\n curNum += 1\n \n return res\n```\n\n## Thought Process Behind Implementation\n(Best to first look at the code below the text to get context)\n\nI\u2019m usually brainwashed to use `i` as a value to append into a list but in this case it wouldn\u2019t work for lexicographical order. So I created a `int curNum` that would be this number we could append and modify.\n\nSo we\u2019re basically using the for loop to be a counter of how many iterations we\u2019re at, which should be up to `n` iterations to satisfy a list of numbers `[1, n]`\n\nIt\u2019s also given at each iteration we\u2019re going to append our `curNum`.\n\n```python\n\tcurNum = 1\n res = []\n\n for i in range(0, n):\n\t\t\tres.append(curNum)\n```\n\nThis is our intuition from Example 4, where we keep adding the smallest number, 0, as long as we don\u2019t go over our input `n`\n\n```python\n if curNum * 10 <= n:\n curNum * 10\n```\n\nIf we can\u2019t keep adding our smallest number, we\u2019ll just keep incrementing our current number we\u2019re at.\n\n```python\n else:\n ...\n ...\n curNum += 1\n```\n\nBut once we\u2019re at the point where we reached our max number, we need to move onto the next number to increment.\n\nTo identify if our number has reached its max, 9, we can do modulo division extract the ones placed digit. Just like Example 2.\n\nIf it is 9, we want to integer divide our `curNum` by 10 so we can remove the 9 and keep incrementing.\n\nThere will also be a case where our `curNum` has reached `n` in that case it will have the same outcome as if we\u2019ve reached 9.\n\nIn Example 4 we\u2019ve identified there would be numbers like 199, 1999, etc. So that\u2019s why there\u2019s a `while` loop to compensate for those cases of `curNum`.\n\n```python\n else:\n while((curNum % 10) == 9 or curNum == n):\n curNum = curNum // 10\n curNum += 1\n```\n\n## Review Complexity\n\n**Time O(n)**\n\nWe\u2019re iterating `n` times within the for loop. In every iteration, we\u2019re storing a correct and already lexicographical result into the list. There is a while which loops as many \u201C9\u201D there are in the number, but that shouldn\u2019t be an issue to change our time complexity.\n\n**Extra Space O(1)**\n\nWe\u2019re not using any extra data structures to solve this problem, we\u2019re only using extra variables such as `curNum`. We created a list to store our result, but that\u2019s not considered extra space, it\u2019s necessary. \n\n## Conclusion\n\nHope this helps if you were stuck or just wanted to undestand it from another perspective. This was from my perspective and my own understanding so it might be confusing if you don\u2019t get me haha, I\u2019m sure there are other explanations and solutions that are better for you in that case. | 3 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Python oneliner | lexicographical-numbers | 0 | 1 | ```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n return sorted([x for x in range(1,n+1)],key=lambda x: str(x))\n``` | 2 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
DFS | lexicographical-numbers | 0 | 1 | # Intuition\nWe use DFS to traverse the tree of all possible numbers. We start with 1, and then we try to append 0-9 to the end of it. If the number is less than or equal to N, we append it to the result and then recursively call the function on it. We do this for all numbers from 1 to 9.\n\n# Approach\n - Initialize a list to store the result.\n - Define a function to do DFS.\n - Append the number to the result.\n - For each digit from 0 to 9:\n - If the number * 10 + digit is less than or equal to N:\n - Call the function on the number * 10 + digit.\n - For each number from 1 to 9:\n - If the number is less than or equal to N:\n - Call the function on the number.\n - Return the result.\n\n# Complexity\n- Time complexity: O(n)\n\n- Space complexity: O(1)\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, N: int) -> List[int]:\n ret = []\n\n def dfs(n):\n ret.append(n)\n\n for i in range(0, 10):\n if n * 10 + i <= N:\n dfs(n * 10 + i)\n\n for i in range(1, 10):\n if i <= N:\n dfs(i)\n\n return ret\n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
merged sorted lists | lexicographical-numbers | 0 | 1 | Not the fastest solution (actually it\'s like 7% percentile or something) but I think it\'s an easy solution to think about. \n\nWe can think of the final result as a merged list of all the lists of numbers with the same number of digits:\n```\none = [1, 2, 3, 4, 5, 6, 7, 8, 9]\ntwo = [100, 101, 102, 103, ...]\nthree = [1000, 1001, 1002, ...]\n...\n```\nWe need to merge these sorted lists based on the lexicographical order. We don\'t have to store all the values in each list, we just need the current value. Since the number of digits is maxed at 4, we\'re using O(1) space. Also for the same reason comparing two numbers is O(1). Note that each list is capped at `10 ** (num_digits + 1) - 1` or `n - 1`.\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n def smaller(a, a_digit, b, b_digit):\n if a_digit < b_digit:\n b = b // 10 ** (b_digit - a_digit)\n return a <= b\n else:\n a = a // 10 ** (a_digit - b_digit)\n return a < b\n\n import math\n num_digits = int(math.log10(n)) + 1\n res = []\n cands = [(1 * 10 ** d, d + 1) for d in range(num_digits)]\n limits = [min(1 * 10 ** (d + 1), n + 1) for d in range(num_digits)]\n while len(res) < n:\n min_idx = -1\n min_val = None\n min_digit = None\n for idx, (cand, cand_digit) in enumerate(cands):\n if cand >= limits[idx]:\n continue\n if min_val is None or smaller(cand, cand_digit, min_val, min_digit):\n min_val = cand\n min_digit = cand_digit\n min_idx = idx\n res.append(min_val)\n cands[min_idx] = (min_val + 1, min_digit)\n \n return res\n\n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Python, runtime O(n), memory O(1) | lexicographical-numbers | 0 | 1 | ```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n ans = [1]\n stack = [1]\n cur = 1\n while stack:\n if cur*10 <= n:\n stack.append(0)\n cur = cur*10\n elif cur+1 <= n and stack[-1] < 9:\n stack.append(stack.pop()+1)\n cur += 1\n else:\n stack.pop()\n cur //= 10\n while stack and stack[-1] == 9:\n stack.pop()\n cur //= 10\n if stack and cur+1 <= n:\n stack.append(stack.pop()+1)\n cur += 1\n if cur:\n ans.append(cur)\n return ans\n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Python Solution | lexicographical-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n ret = [1]\n while len(ret) < n:\n if ret[-1] == n:\n if ret[-1] % 10 != 0:\n ret.append(ret[-1] + 10 - ret[-1] % 10)\n while ret[-1] % 10 == 0:\n ret[-1] //= 10\n else:\n ret.append(n // 10 + 1)\n else:\n if ret[-1] * 10 <= n:\n ret.append(ret[-1] * 10)\n else:\n ret.append(ret[-1] + 1)\n while ret[-1] % 10 == 0:\n ret[-1] //= 10\n return ret\n \n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
one liner python code | lexicographical-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n return sorted(sorted(list(range(1,n+1))),key=str)\n \n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
1-liner python | lexicographical-numbers | 0 | 1 | # Intuition\nsorted will use lexicographical sort order for string\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n return sorted([a for a in range(1,n+1)], key=lambda x: str(x))\n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Python DFS | lexicographical-numbers | 0 | 1 | # Approach\nDFS\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1) without counting return array\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n res = []\n def dfs(operand, n):\n for i in range(0, 10):\n if operand == 1 and i == 9:\n continue\n if operand+i <= n:\n res.append(operand+i)\n if (operand+i) * 10 <= n:\n dfs((operand+i)*10, n)\n dfs(1, n)\n return res\n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Python| Very simple solutions!! | lexicographical-numbers | 0 | 1 | # Intuition\nThis can be easly done by follwing Basic list concept(s)\n\n# Approach\nFollow Fundamentals for Array/List\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n ranging = [list(str(x)) for x in range(1, n+1)]\n int_list = list()\n for i in ranging:\n int_list.append(list(map(int, i)))\n\n lexicographical_sorted = sorted(int_list)\n final = [int("".join(str(y) for y in x)) for x in lexicographical_sorted]\n return final\n \n\n \n \n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Most Easiest Solution in Python>>>Two line code......(^_^) | lexicographical-numbers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lexicalOrder(self, n: int) -> List[int]:\n p=[]\n for i in range(1,n+1):\n p.append(i)\n p.sort(key=str) # convert list element to string and then sort.\n return p\n``` | 0 | Given an integer `n`, return all the numbers in the range `[1, n]` sorted in lexicographical order.
You must write an algorithm that runs in `O(n)` time and uses `O(1)` extra space.
**Example 1:**
**Input:** n = 13
**Output:** \[1,10,11,12,13,2,3,4,5,6,7,8,9\]
**Example 2:**
**Input:** n = 2
**Output:** \[1,2\]
**Constraints:**
* `1 <= n <= 5 * 104` | null |
Simple solution with using Queue and HashTable DS | first-unique-character-in-a-string | 0 | 1 | # Intuition\nThe description of task requires to find **the first unique character** in string, that has **no repetitions**.\n\n---\n\n1. **Naive brut force**:\n\nIterate over all chars in string => check the **frequency** of a current count, and compare like `freq = cache[s[i]]; freq == 1`\n\nThis will lead us to **O(n^2) + O(n)**, thus this isn\'t an efficient algorithm.\n\n2. **Hash table**:\nIf you haven\'t already familiar with [Hash table](https://en.wikipedia.org/wiki/Hash_table), click to the link to know more!\n``` \n# Pseudocode\ncache = hashtable()\nfor index in rangeof s:\n char = s[index]\n cache[char] = cache[char] ? Infinity : index\n# find the min index, that\'ll be or Infinity or an int\n```\nTime and space complexity are improved to **O(n) + O(n)**.\n\n3. **Hash table with Queue DS**\n\nIf you haven\'t already familiar with [Queue DS](https://en.wikipedia.org/wiki/Queue_(abstract_data_type)), let\'s have a look a little closer in the article (follow the link).\n```\n# Pseudocode\ncache = hashtable() + count the freq of any char\nq = deque() or queue() # deque is more appropriate, because of O(1)\n\nfor char in s:\n add char into q\n if the freq of this char > 1:\n pop it\n else if freq of this char == 1:\n remove the index\n```\nTime and space complexity are the same as in **hash table section**.\n\n# Approach\n1. count the freq of any char, using `Counter` and store it to `c`\n2. initialize a `deque`\n3. initialize an `ans` variable \n4. iterate over all symbols in `s`\n5. add curr element in `q`\n6. if the freq of this `freq >= 1`, pop it and increment the `ans`\n7. otherwise check, if the `freq == 1`, this means, that you\'ve found the `ans`\n8. in bad case **all** the chars have the **pair**, so the `ans == -1`\n\n# Complexity\n- Time complexity: **O(n)**\n\n- Space complexity: **O(n)**\n\n# Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n c = Counter(s)\n q = deque()\n ans = 0\n \n for char in s:\n q.append(char)\n if c[q[0]] > 1:\n while q and c[q[0]] > 1:\n q.popleft()\n ans += 1\n elif c[q[0]] == 1:\n return ans \n return -1 \n``` | 1 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
simple solution for beginners | first-unique-character-in-a-string | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i in range(len(s)):\n if s.count(s[i])==1:\n return i\n return -1\n\n``` | 2 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
5 Lines of Code in Two Methods | first-unique-character-in-a-string | 0 | 1 | \n\n# 1. Count the first occurence one and break loop\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i,c in enumerate(s):\n if s.count(c)==1:\n return i\n break\n return -1\n #please upvote me it would encourage me alot\n\n```\n# 2. Using Hashtable and Set\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n dic={}\n seen=set()\n for ind,let in enumerate(s):\n if let not in seen:\n dic[let]=ind\n seen.add(let)\n elif let in dic:\n del dic[let]\n return min(dic.values()) if dic else -1\n\n //please upvote me it would encourage me alot\n\n```\n# please upvote me it would encourage me alot\n | 43 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Very Easy || 100% || Fully Explained || Java, C++, Python, JavaScript, Python3 | first-unique-character-in-a-string | 1 | 1 | # **Java Solution:**\n```\nclass Solution {\n public int firstUniqChar(String s) {\n // Base case...\n if(s.length() == 0) return -1;\n // To keep track of the count of each character, we initialize an int[]store with size 26...\n int[] store = new int[26];\n // Traverse string to keep track number of times each character in the string appears...\n for(char ch : s.toCharArray()){\n store[ch - \'a\']++; // To access the store[] element representative of each character, we subtract \u2018a\u2019 from that character...\n }\n // Traverse string again to find a character that appears exactly one time, return it\u2019s index...\n for(int idx = 0; idx < s.length(); idx++){\n if(store[s.charAt(idx) - \'a\'] == 1){\n return idx;\n }\n }\n return -1; // if no character appeared exactly once...\n }\n}\n```\n\n# **C++ Solution:**\n```\nclass Solution {\npublic:\n int firstUniqChar(string s) {\n map<char, int> hmap;\n for (int idx{}; idx < s.size(); idx++) {\n // Everytime the character appears in the string, add one to its count\n hmap[s[idx]]++;\n }\n // Traverse the string from the beginning...\n for (int idx{}; idx < s.size(); idx++) {\n // If the count of the char is equal to 1, it is the first distinct character in the list.\n if (hmap[s[idx]] == 1)\n return idx;\n } \n return -1; // if no character appeared exactly once...\n }\n};\n```\n\n# **Python/Python3 Solution:**\n```\nclass Solution(object):\n def firstUniqChar(self, s):\n hset = collections.Counter(s);\n # Traverse the string from the beginning...\n for idx in range(len(s)):\n # If the count is equal to 1, it is the first distinct character in the list.\n if hset[s[idx]] == 1:\n return idx\n return -1 # If no character appeared exactly once...\n```\n \n# **JavaScript Solution:**\n```\nvar firstUniqChar = function(s) {\n for (let idx = 0; idx < s.length; idx++){\n // If same...\n if(s.indexOf(s[idx]) === s.lastIndexOf(s[idx])){\n // return the index of that unique character\n return idx\n } else {\n return -1 // If no character appeared exactly once...\n }\n }\n};\n```\n**I am working hard for you guys...\nPlease upvote if you found any help with this code...** | 73 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Python || 3 diff way || 99% beats | first-unique-character-in-a-string | 0 | 1 | **If you got help from this,... Plz Upvote .. it encourage me**\n# Code\n> # HashMap\n```\n# HASHMAP\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n d = {}\n for char in s:\n d[char] = d.get(char,0) + 1\n \n for i , char in enumerate(s):\n if d[char] == 1:\n return i\n return -1\n\n\n```\n\n> # String\n``` \n# String\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i in range(len(s)):\n if s[i] not in s[i+1:] and s[i] not in s[:i] :\n return i\n return -1\n\n\n```\n\n> # Count\n```\n# Count\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i in range(len(s)):\n if s.count(s[i]) == 1:\n return i\n return -1\n``` | 9 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Python Easy Solution || Hashmap | first-unique-character-in-a-string | 0 | 1 | # Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n dic=dict()\n for i in s:\n if i in dic:\n dic[i]+=1\n else:\n dic[i]=1\n for i in dic:\n if dic[i]==1:\n return s.index(i)\n return -1\n \n``` | 1 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Python3 ✅✅✅|| Faster than 93.83% ⏭ || Memory beats 83.08% 🧠 | first-unique-character-in-a-string | 0 | 1 | 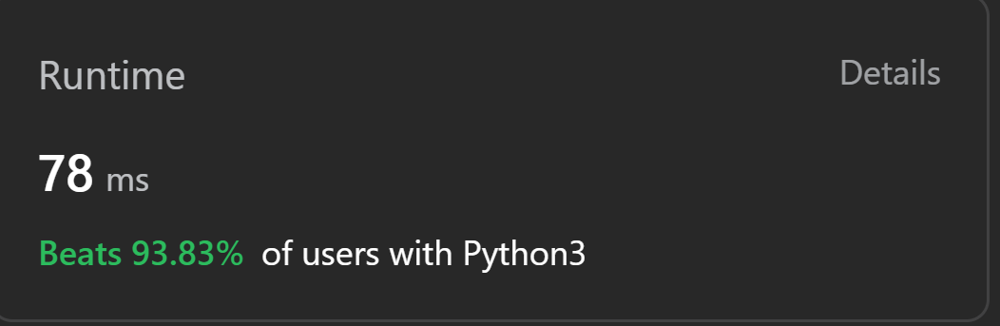\n\n\n\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. get frequency of `s`\n2. go over frequency\n - if that letter has a frequency of 1, return index of that letter\n3. if you passed through none of that, return -1\n\n# Complexity\n- Time complexity: O(2n\xB2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:???\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import defaultdict as dd\nclass Solution:\n def getFreq(self, s):\n freq = dd(lambda: 0)\n for c in s:\n freq[c] += 1\n return freq\n def firstUniqChar(self, s: str) -> int:\n freq = self.getFreq(s)\n for c in freq:\n if freq[c] == 1:\n return s.index(c)\n return -1\n``` | 1 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
[ Python ] ✅✅ Simple Python Solution With Two Approach 🥳✌👍 | first-unique-character-in-a-string | 0 | 1 | # If You like the Solution, Don\'t Forget To UpVote Me, Please UpVote! \uD83D\uDD3C\uD83D\uDE4F\n# Approach 1: - Iterative \n\tclass Solution:\n\t\tdef firstUniqChar(self, s: str) -> int:\n\n\t\t\tfor i in range(len(s)):\n\n\t\t\t\tif s[i] not in s[:i] and s[i] not in s[i+1:]:\n\n\t\t\t\t\treturn i\n\n\t\t\treturn -1\n\n# Approach 2: - HashMap or Dictionary \n# Runtime: 137 ms, faster than 71.83% of Python3 online submissions for First Unique Character in a String.\n# Memory Usage: 14.2 MB, less than 18.33% of Python3 online submissions for First Unique Character in a String.\n\n\tclass Solution:\n\t\tdef firstUniqChar(self, s: str) -> int:\n\n\t\t\tfrequency = {}\n\n\t\t\tfor char in s:\n\n\t\t\t\tif char not in frequency:\n\t\t\t\t\tfrequency[char] = 1\n\t\t\t\telse:\n\t\t\t\t\tfrequency[char] = frequency[char] + 1\n\n\t\t\tfor index in range(len(s)):\n\n\t\t\t\tif frequency[s[index]] == 1:\n\t\t\t\t\treturn index\n\n\t\t\treturn -1\n\n# Thank You \uD83E\uDD73\u270C\uD83D\uDC4D | 48 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Python, using Counter | first-unique-character-in-a-string | 0 | 1 | ```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n counter = Counter(s)\n for i, c in enumerate(s):\n if counter[c] == 1:\n return i\n \n return -1\n``` | 4 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Simple Python Solution with hashmap | first-unique-character-in-a-string | 0 | 1 | ```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n hashmap = {}\n for c in s:\n hashmap[c] = hashmap.get(c, 0) + 1\n \n for i, c in enumerate(s):\n if hashmap[c] == 1:\n return i\n \n return -1\n\nTime: O(n)\nSpace: O(n)\n``` | 3 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Easy Python solution | first-unique-character-in-a-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i in range(len(s)):\n if s.count(s[i]) == 1:\n return i\n return -1 \n``` | 1 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Beats : 54.37% [36/145 Top Interview Question] | first-unique-character-in-a-string | 0 | 1 | # Intuition\n*my intuition would be to iterate through the string and for each character, check if it appears only once in the string. If so, return its index. If no such character is found, return -1. This would involve two nested loops, resulting in a time complexity of O(n^2), where n is the length of the input string. However, there may be a more efficient solution that involves using a hash table or dictionary to store the frequency count of each character in the string and then iterating through the string again to find the first unique character. This would result in a time complexity of O(n), where n is the length of the input string.*\n\n# Approach\nThis code is a Python implementation of a solution to find the index of the first unique character in a given string. \n\nThe `Solution` class has a method called `firstUniqChar` that takes a single argument, which is a string (`s`). The method returns an integer representing the index of the first unique character in the input string, or -1 if all characters in the string are repeated.\n\nThe `hashMap` variable is an empty dictionary used to store the count of each character in the input string. The `for` loop iterates through each character in the input string and updates the count in the `hashMap` dictionary. The `get` method of the dictionary is used to retrieve the current count of the character, and if the character is not yet in the dictionary, the default value of 0 is used. \n\nThe second `for` loop iterates through each character in the input string and checks whether its count in the `hashMap` dictionary is equal to 1. If it is, then the index of the character is returned as the first occurrence of a unique character. If there is no unique character in the input string, the method returns -1.\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(n)\n\nThe `time complexity` of the `firstUniqChar` method is `O(n)`, where n is the length of the input string. \n\nThe `space complexity` is also `O(n)`, because the `hashMap` dictionary can contain up to n key-value pairs, one for each character in the string.\n\n# Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n hashMap = {}\n for char in s: hashMap[char] = hashMap.get(char, 0) + 1\n for i, char in enumerate(s):\n if hashMap[char] == 1:\n return i\n return -1\n``` | 2 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
3 Line code Python3 easy and neat solution | first-unique-character-in-a-string | 0 | 1 | # Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i,j in(Counter(s).items()):\n if j == 1: return s.index(i)\n return -1\n``` | 3 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Easy and simple || First Unique Character in a String | first-unique-character-in-a-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n for i in s:\n if s.count(i)==1:\n return s.index(i)\n else:\n return -1\n``` | 3 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Best PYTHON Solution beats 99%!!!! | first-unique-character-in-a-string | 0 | 1 | The best easy solution beats 99%.\nPlease upvote if you like it.\n\n# Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n if 1 not in Counter(s).values():\n return -1\n for i,j in Counter(s).items():\n if j==1:\n return s.index(i)\n\n``` | 4 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Beats 90% | CodeDominar Solution | first-unique-character-in-a-string | 0 | 1 | # Code\n```\nclass Solution:\n def firstUniqChar(self, s: str) -> int:\n d=dict()\n for c in s:\n d[c] = d.get(c,0)+1\n for i,c in enumerate(s):\n if d[c] == 1:\n return i\n return -1\n``` | 4 | Given a string `s`, _find the first non-repeating character in it and return its index_. If it does not exist, return `-1`.
**Example 1:**
**Input:** s = "leetcode"
**Output:** 0
**Example 2:**
**Input:** s = "loveleetcode"
**Output:** 2
**Example 3:**
**Input:** s = "aabb"
**Output:** -1
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of only lowercase English letters. | null |
Python easy stack | longest-absolute-file-path | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nkeep track longest range\nassume level = 1,2,3,1,2,3,5,1,1\nex. 1 => 1,2 => 1,2,3 => 1 => 1,2 => 1,2,3 => 1,2,3,5 => 1 => 1\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n lines = input.split("\\n")\n stack = [] # [level, cum_size]\n ans = 0\n for line in lines:\n if not stack:\n level = line.count("\\t")\n stack.append([level, len(line) - level])\n \n else:\n level = line.count("\\t")\n while stack and stack[-1][0] >= level:\n stack.pop()\n \n offset = stack[-1][1] + 1 if stack else 0\n stack.append([level, offset + len(line) - level])\n \n if "." in line:\n ans = max(ans, stack[-1][1])\n \n return ans\n \n``` | 1 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
388: Time 100%, Solution with step by step explanation | longest-absolute-file-path | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. First, we split the input string s into individual paths using the newline character \\n as the delimiter. We store these paths in the paths list.\n\n2. Next, we initialize a stack with a single value of 0. We use this to keep track of the length of each directory path in the file system.\n\n3. We also initialize the variable ans to 0, which we will use to store the length of the longest absolute path to a file.\n\n4. For each path in the paths list, we split it into a list of directory and file names using the tab character \\t as the delimiter. The last element in this list is the name of the file or directory.\n\n5. We determine the depth of the current path by subtracting 1 from the length of the directory list.\n\n6. We then check if the current path is a file or a directory. If it\'s a file (i.e., it contains a period), we update the ans variable by taking the maximum of its current value and the length of the current directory path in the stack (i.e., stack[-1]) plus the length of the file name.\n\n7. If the current path is a directory, we push its length onto the stack. We calculate this length by adding the length of the directory name plus 1 (for the forward slash separator).\n\n8. Before processing the next path, we check if there are any directories in the stack that are deeper than the current directory. If so, we pop them off the stack.\n\n9. Finally, we return the ans variable, which contains the length of the longest absolute path to a file in the file system.\n\n# Complexity\n- Time complexity:\n100%\n\n- Space complexity:\n63.3%\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, s: str) -> int:\n paths = s.split(\'\\n\')\n stack, ans = [0], 0 # initialize the stack with 0 to handle the case when there\'s no directory\n for path in paths:\n p = path.split(\'\\t\')\n depth, name = len(p) - 1, p[-1]\n while len(stack) > depth + 1: # pop directories that are deeper than the current one\n stack.pop()\n if \'.\' in name: # if it\'s a file, update the answer\n ans = max(ans, stack[-1] + len(name))\n else: # if it\'s a directory, push its length to the stack\n stack.append(stack[-1] + len(name) + 1)\n return ans\n\n``` | 9 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python 3 | Stack | Explanation | longest-absolute-file-path | 0 | 1 | ### Intuition\n- Directories has a hierarchy type of relation, so we can use stack to simulate the process.\n### Explanations\n- For each dir or file, we store 3 things in stack\n\t- current total length (including parent and \'/\'), depth (how many \'\\t\' to reach this subdir)\n- If `stack` is empty, we add new tuple\n- If deepest dir or file in stack (`stack[-1]`) is at the same or deeper depth of current `path`\n\t- pop stack until `stack[-1]` (or empty stack) is shallower than depth of `path`\n- Add tuple and cumulate the total length\n- If `name` has `.` then it\'s a file path and we can compare it with `ans` to get the longest.\n### Implementation\n```\nclass Solution:\n def lengthLongestPath(self, s: str) -> int:\n paths, stack, ans = s.split(\'\\n\'), [], 0\n for path in paths:\n p = path.split(\'\\t\')\n depth, name = len(p) - 1, p[-1]\n l = len(name)\n while stack and stack[-1][1] >= depth: stack.pop()\n if not stack: stack.append((l, depth))\n else: stack.append((l+stack[-1][0], depth))\n if \'.\' in name: ans = max(ans, stack[-1][0] + stack[-1][1]) \n return ans\n``` | 27 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python | Stack | 9 Lines | Simple | longest-absolute-file-path | 0 | 1 | ```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n input = input.split(\'\\n\')\n path, ans, total = [], 0, 0\n for line in input:\n tabs = line.count(\'\\t\')\n while len(path) > tabs: total -= path.pop()\n path.append(len(line) - tabs)\n total += path[-1]\n if \'.\' in line: ans = max(ans, total + len(path) - 1)\n return ans\n```\nThe basic idea is to create a stack containing the lengths of each of the path components along with a running total of the component lengths. Depth in the filepath is based on how many tab characters per line. \n\nTo traverse back up the file path, keep popping off the stack until the depth is same as the number of path components. The `.` in the line means a file was found. Take the total length of components and add the missing `\\` characters (number of components - 1) to get the path length. `ans` is the maximum of these candidates. | 2 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Easiest solution with full explanation : ) | longest-absolute-file-path | 1 | 1 | \n### Problem Explanation:\n\nImagine a file system that stores both files and directories, represented in a textual format. Directories may contain subdirectories and files. The goal is to find the length of the longest absolute path to a file in the file system.\n\n### File System Representation:\n\nThe file system is represented as a string with a specific format. Directories and files are separated by newline characters (`\\n`), and indentation (tabs `\\t`) is used to denote the hierarchy. For example:\n\n```\ndir\n subdir1\n file1.ext\n subdir2\n file.ext\n```\n\nHere, "dir" is the root directory, containing "subdir1" and "subdir2". "subdir1" contains "file1.ext", and "subdir2" contains "file.ext".\n\n### Absolute Path:\n\nEvery file and directory has a unique absolute path, which is the order of directories that must be opened to reach the file or directory itself, all concatenated by \'/\'s. Using the above example, the absolute path to "file.ext" is "dir/subdir2/file.ext".\n\n### Approach:\n\nTo find the length of the longest absolute path, you can follow these steps:\n\n1. **Split Lines:**\n - Split the input string into lines to process each line individually.\n\n2. **Process Each Line:**\n - Iterate through each line in the input.\n - Remove leading tabs to determine the depth of the file or directory.\n - Check if the line represents a file (contains a dot \'.\').\n\n3. **Update Path Lengths:**\n - Maintain a data structure (e.g., a map) to store the length of the path at each depth.\n - Update the path length for each directory and file.\n\n4. **Find Maximum Length:**\n - Track the maximum length encountered while processing the lines.\n\n5. **Return Result:**\n - The maximum length represents the length of the longest absolute path to a file.\n\n### Example Walkthrough:\n\nConsider the input: \n```\ndir\n subdir1\n file1.ext\n subdir2\n file.ext\n```\n\n1. **Split Lines:**\n - Split the input into lines: ["dir", " subdir1", " file1.ext", " subdir2", " file.ext"].\n\n2. **Process Each Line:**\n - For each line, remove leading tabs to determine the depth:\n - "dir" (depth 0), "subdir1" (depth 1), "file1.ext" (depth 2), "subdir2" (depth 1), "file.ext" (depth 2).\n - Identify files based on the presence of a dot \'.\'.\n\n3. **Update Path Lengths:**\n - Use a map to store path lengths at each depth.\n - Update the path length for each directory and file.\n\n4. **Find Maximum Length:**\n - Track the maximum length encountered while processing the lines.\n\n5. **Return Result:**\n - The maximum length is the length of the longest absolute path to a file.\n\n### Conclusion:\n\nBy systematically processing each line, tracking path lengths, and identifying files, you can find the length of the longest absolute path in the given file system representation. This approach ensures correctness by considering the hierarchical structure of the file system.\n\n```java []\nclass Solution {\n public int lengthLongestPath(String input) {\n String[] lines = input.split("\\n");\n int maxLength = 0;\n HashMap<Integer, Integer> pathLengths = new HashMap<>(); // depth: length\n\n for (String line : lines) {\n String name = line.replaceAll("\\t", "");\n int depth = line.length() - name.length();\n boolean isFile = name.contains(".");\n\n if (isFile) {\n maxLength = Math.max(maxLength, pathLengths.get(depth) + name.length());\n } else {\n pathLengths.put(depth + 1, pathLengths.getOrDefault(depth, 0) + name.length() + 1); // 1 for the \'/\'\n }\n }\n\n return maxLength;\n }\n}\n```\n```python []\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n lines = input.split(\'\\n\')\n max_length = 0\n path_lengths = {0: 0} # depth: length\n\n for line in lines:\n name = line.lstrip(\'\\t\')\n depth = len(line) - len(name)\n is_file = \'.\' in name\n\n if is_file:\n max_length = max(max_length, path_lengths[depth] + len(name))\n else:\n path_lengths[depth + 1] = path_lengths[depth] + len(name) + 1 # 1 for the \'/\'\n \n return max_length\n```\n```C++ []\nclass Solution {\npublic:\n int lengthLongestPath(string input) {\n vector<string> lines;\n istringstream iss(input);\n string line;\n while (getline(iss, line, \'\\n\')) {\n lines.push_back(line);\n }\n\n int maxLength = 0;\n unordered_map<int, int> pathLengths; // depth: length\n\n for (const string& line : lines) {\n string name = line.substr(line.find_first_not_of(\'\\t\'));\n int depth = line.length() - name.length();\n bool isFile = (name.find(\'.\') != string::npos);\n\n if (isFile) {\n maxLength = max(maxLength, pathLengths[depth] + name.length());\n } else {\n pathLengths[depth + 1] = pathLengths[depth] + name.length() + 1; // 1 for the \'/\'\n }\n }\n\n return maxLength;\n }\n};\n```\n | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Simple Solution Using Stack | longest-absolute-file-path | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n commands = input.split("\\n") \n print(commands)\n\n pwd = []\n longest = 0\n for cmd in commands:\n depth = cmd.count(\'\\t\')\n name = cmd.replace(\'\\t\', \'\')\n # print(name, depth)\n \n while len(pwd) > depth:\n pwd.pop()\n pwd.append(name)\n \n if \'.\' in pwd[-1]:\n absolutePath = \'/\'.join(pwd)\n # print("path", absolutePath)\n longest = max(longest, len(absolutePath))\n \n return longest\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Intuitive Python Solution: Stack-based Approach | longest-absolute-file-path | 0 | 1 | # Approach\nUse a stack to store the current path. Length of stack represents the current level of nesting.\n\nPop off the top of the stack while the level of nesting is greater than the current component\'s level of nesting (indicated by the number of tabs).\n\n# Complexity\nTime complexity: O(n)\nSpace complexity: O(n)\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, inp: str) -> int:\n longest_file_path = 0\n components = inp.split(\'\\n\')\n\n curr_path = [] # stores the lengths of the current path components so Far\n for comp in components:\n t_count = comp.count(\'\\t\')\n # pop off unused files + subdirectory components while necessary\n while curr_path and len(curr_path) > t_count:\n curr_path.pop()\n\n curr_path.append(len(comp) - t_count) # each tab char counts as a length of 1\n if comp.find(\'.\') != -1: # is a file\n longest_file_path = max(longest_file_path, sum(curr_path) + len(curr_path) - 1) # len(curr_path) - 1 is the number of \'/\' to join the current path components\n \n return longest_file_path\n\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python3 Solution | longest-absolute-file-path | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIt uses a stack t keep track of the current layer depth and the size of the path.\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def __init__(self):\n self.stack = []\n self.stack_size = 0\n\n def is_file(self, word: str):\n return \'.\' in word\n \n def push(self, dir: str):\n self.stack.append(dir)\n self.stack_size += len(dir)\n \n def pop_func(self):\n dir = self.stack.pop()\n self.stack_size -= len(dir)\n return dir\n \n def cur_level(self):\n return len(self.stack)\n\n def lengthLongestPath(self, input: str) -> int:\n layers = input.split(\'\\n\')\n res = 0\n for layer in layers:\n layer_level = layer.count(\'\\t\')\n while self.cur_level() > layer_level:\n popped = self.pop_func()\n print(self.cur_level(), layer_level)\n \n if self.cur_level() != layer_level:\n print("???")\n\n layer = layer.strip(\'\\t\')\n if self.is_file(layer):\n res = max(res, self.stack_size + len(layer))\n else:\n self.push(layer + "\\\\" )\n\n \n return res\n \n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python Iterative DFS Solution | 91.52% Runtime | longest-absolute-file-path | 0 | 1 | ```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n \n new_input = input.split("\\n")\n input_levels = []\n \n # Get level of each file/dir\n for d in new_input:\n input_levels.append(len(d.split("\\t")) - 1)\n\n max_len = 0\n stack = [[0, 0, 0, False]]\n \n while stack:\n curr_dir_idx, curr_level, curr_len, is_file = stack.pop()\n \n if curr_len > max_len and is_file:\n max_len = curr_len\n continue\n \n if curr_dir_idx >= len(new_input):\n continue\n \n for i in range(curr_dir_idx, len(input_levels)):\n tmp_level = input_levels[i]\n \n # Break if encountered parent directory\n if curr_dir_idx != 0 and curr_level > tmp_level:\n break\n \n # Add next levels to stack\n if tmp_level == curr_level and i < len(new_input):\n \n new_dir = new_input[i].split("\\t")[-1]\n tmp_is_file = True if "." in new_dir else False \n\n # If parent directory exclude forward slash from length\n if curr_dir_idx == 0:\n stack.append([i + 1, tmp_level + 1, len(new_dir), tmp_is_file])\n else:\n stack.append([i + 1, tmp_level + 1, curr_len + len(new_dir) + 1, tmp_is_file])\n \n return max_len\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
(Python3) 30ms Beats 96.49 - Readable code - Monotonic stack | longest-absolute-file-path | 0 | 1 | # Code\n```\nEntry = namedtuple("Entry", ["line", "depth", "length"])\n\n\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n result = 0\n stack = []\n\n def consume(depth):\n if not stack or depth > stack[-1].depth:\n return\n\n name, _, length = stack.pop()\n if "." in name:\n nonlocal result\n result = max(result, length)\n\n while stack and stack[-1].depth >= depth:\n stack.pop()\n\n for line in input.splitlines():\n name = line.lstrip("\\t")\n depth = len(line) - len(name)\n consume(depth)\n par_length = stack[-1].length + 1 if stack else 0\n stack.append(Entry(name, depth, par_length + len(name)))\n \n consume(0)\n return result\n \n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python with Tuple Stack | O(N) | longest-absolute-file-path | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\n1. **Initialization**\n - Initialize `maxLen` to 0 to store the length of the longest path to a file.\n - Initialize `stack` with a dummy root tuple `(0, 0)` to facilitate length calculations.\n\n2. **Split the Input**\n - Split the input string by newline characters (`\\n`) to obtain a list of paths (files and directories).\n\n3. **Iterate Through Paths**\n - For each path, perform the following steps:\n 1. **Calculate Level**: Count the number of tabs (`\\t`) to determine the "level" (depth) of the directory or file.\n 2. **Extract Name**: Remove the tabs to get the actual name of the directory or file.\n 3. **Adjust Stack**: Pop elements from the stack until it reflects the correct parent directory for the current entry.\n 4. **Calculate Current Length**: Update the length of the path up to the current directory or file.\n 5. **Check for File**: If the current name contains a dot (`.`), it\'s a file. Update `maxLen` if this path is longer than the current `maxLen`.\n 6. **Push to Stack**: If it\'s a directory, push the new total length and the length of the directory\'s name onto the stack.\n\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n paths = input.split(\'\\n\')\n maxLen = 0\n stack = [(0, 0)] # Stack to keep track of (length_so_far, current_name_length)\n\n for path in paths:\n level = path.count(\'\\t\')\n name = path.lstrip(\'\\t\')\n\n # Pop elements from stack to go up to the correct directory level\n while level + 1 < len(stack):\n stack.pop()\n\n # Calculate current length\n curLen = stack[-1][0] + len(name) + 1 # +1 for the \'/\' between names\n\n if \'.\' in name:\n maxLen = max(maxLen, curLen - 1) # -1 because the root doesn\'t need a \'/\'\n else:\n stack.append((curLen, len(name)))\n\n return maxLen\n\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python3 approach (beats 88%) | longest-absolute-file-path | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\n1. Split the input into a list of paths based on the line breaks.\n2. Set three variables, path, slashes, and max_len. Path will initially be set to the first file/directory in the list, and will store the current path. Slashes will be empty at first, and will store the indices in the path where there are slashes. Max_len will initially be equal to the length of the first element (if it\'s a file) or 0 (if it\'s a directory), and will store the length of the longest path to a file.\n3. Iterate through the input list. For each file or directory, check how many levels deep it is by counting the number of blank spaces at the start. If it\'s fewer levels than the previous file, we remove files/directories from our path by removing the last slash and all subsequent characters, until the number of slashes is one less than the required depth.\n4. If the depth of the current file or directory is 0 (it is top-level), then we simply set path equal to it. Otherwise, once we\'re done deleting characters, we add "/[file or directory name]" to the path, and add the appropriate index to slashes.\n5. If the path we have now is to a file, we check whether it\'s greater than the value we had for max_len, and if so, we set max_len equal to it.\n6. Once we\'ve iterated through the whole input, we can return max_len.\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, inp: str) -> int:\n dests = inp.split(\'\\n\')\n\n path = dests[0]\n slashes = []\n max_len = len(path) if "." in path else 0\n\n for i in range(1,len(dests)):\n d = dests[i]\n depth = 0\n\n while d[0] == "\t":\n depth += 1\n d = d[1:]\n \n while slashes and depth <= len(slashes):\n path = path[:slashes.pop()]\n\n if depth > 0:\n slashes.append(len(path))\n path += "/" + d\n \n else:\n path = d\n\n if "." in path:\n max_len = max(max_len,len(path))\n\n return max_len\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Monotonic Stack | With the detailed understanding | Python Easiest Solution | longest-absolute-file-path | 0 | 1 | \n# Approach\nI have solved it through monotonic stack. \n\nFirstly, seeking for the new line character to check if our extension file is in the further subfolder or not. For this, I have written a check \n```\nif input[i] == "\\n":\n if "\\t" * len(self.stack) == input[i + 1 : i + 1 + len(self.stack)]:\n i += 1 + len(self.stack)\n```\n\nIf the condition becomes false then it means `.extension file` is not is this sub directory. We have to get out of this directory. For this purpose I have made a member fuction:\n```\ndef maintain_stack (self, length):\n self.stack = self.stack[ : length]\n```\nIt will maintain the stack to the possible length of reaching towards extension file.\n\nSecondly, if the current element is not newline character which means it is a name of some directory or file. We\'ll append it to the monotonic stack\n```\ndef push_item (self, i, input, s = ""): \n while i < len(input) and input[i] != "\\n":\n s += input[i]\n i += 1\n self.stack.append(s)\n return i\n```\n\nLastly, If our extension file will be found then first path to the file extension has been recorded by the monotonic stack and then compare to the `longest_path` and initialize length if the current path is maximized.\n\n\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int: \n self.stack = list()\n longest_path = 0\n i = 0\n while i < len(input):\n if input[i] == "\\n":\n if "\\t" * len(self.stack) == input[i + 1 : i + 1 + len(self.stack)]:\n i += 1 + len(self.stack)\n else:\n length = input[i + 1 : i + 1 + len(self.stack)].count("\\t")\n self.maintain_stack (length)\n\n else:\n i = self.push_item (i, input)\n if "." in self.stack[-1]: \n longest_path = max(longest_path, self.count_length ())\n \n return longest_path\n\n def maintain_stack (self, length):\n self.stack = self.stack[ : length]\n \n def push_item (self, i, input, s = ""): \n while i < len(input) and input[i] != "\\n":\n s += input[i]\n i += 1\n self.stack.append(s)\n return i\n\n def count_length (self, length = 0): \n for x in self.stack:\n if x == "\\t": length += 1\n else: length += len(x)\n length += len(self.stack) - 1\n self.stack.pop()\n return length\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
[Python3] [Stack] Simple but fast with Stack | longest-absolute-file-path | 0 | 1 | # Code\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n lines = input.split(\'\\n\')\n s = []\n total_names_length = 0\n max_length = 0\n current_level = 0\n for line_index in range(len(lines)):\n current_line = lines[line_index]\n # Count the number of tabs at the beginning of the line\n tabs_count = current_line.rfind(\'\\t\') + 1\n name = current_line[tabs_count:]\n is_file = name.find(\'.\') != -1\n # If the current number of tabs < current_level, then we are moving outside of a directory\n if tabs_count < current_level:\n for _ in range(len(s) - tabs_count):\n removed = s.pop()\n total_names_length -= len(removed)\n current_level -= 1\n if not is_file:\n # Add current directory to the stack\n s.append(name)\n total_names_length += len(name)\n current_level += 1\n else:\n # Calculate the total path length (len(s) indicates the number of slashes needed to separate the names)\n total_absolute_path_length = len(s) + total_names_length + len(name)\n max_length = max(max_length, total_absolute_path_length)\n return max_length\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Solution | longest-absolute-file-path | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int lengthLongestPath(string str) {\n str.push_back(\'\\n\');\n vector<int> dp = {0};\n int res = 0;\n for (int i = 0; i < str.size(); ++i) {\n int t = 0;\n while (str[i] == \'\\t\') {\n ++t;\n ++i;\n }\n int len = 0;\n bool file = false;\n while (str[i] != \'\\n\') {\n file |= str[i] == \'.\';\n ++len;\n ++i;\n }\n if (!file) {\n if (dp.size() <= t+1) dp.push_back(100000);\n dp[t+1] = len+1+dp[t];\n continue;\n }\n int cur = dp[t]+len;\n res = max(res, cur);\n }\n return res;\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def lengthLongestPath(self, s: str) -> int:\n paths = s.split(\'\\n\')\n stack, ans = [0], 0\n for path in paths:\n p = path.split(\'\\t\')\n depth, name = len(p) - 1, p[-1]\n while len(stack) > depth + 1:\n stack.pop()\n if \'.\' in name:\n ans = max(ans, stack[-1] + len(name))\n else:\n stack.append(stack[-1] + len(name) + 1)\n return ans\n```\n\n```Java []\nclass Solution {\n int ans = 0;\n public int lengthLongestPath(String input) {\n int[] fileLenths = new int[input.length()];\n for(String fileDirName: input.split("\\n")) {\n int dirLevel = dirLevel(fileDirName);\n fileDirName = fileDirName.substring(dirLevel);\n fileLenths[dirLevel] = (dirLevel > 0 ? fileLenths[dirLevel-1] + 1: 0) + fileDirName.length();\n if(fileDirName.contains(".")) {\n ans = Math.max(ans, fileLenths[dirLevel]);\n }\n }\n return ans;\n }\n int dirLevel(String dirName) {\n int count = 0;\n int i = 0;\n while(dirName.charAt(i++) == \'\\t\') count++;\n return count;\n }\n}\n```\n | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
[Python] Count the number of '\t'; Explained | longest-absolute-file-path | 0 | 1 | We can count the number of \'\\t\' in each file/folder string.\nThe number of \'\\t\' can represent the level or depth of a folder or file\n\nFor example,\n`\'dir\'`, has 0 \'\\t\' ,and it is on level 0\n`\'\\tsubdir1\'`, has 1 \'\\t\', and it is on level 1\n\nBased on the folder level (i.e., the count of \'\\t\') we can track the current full path length using a stack (see the details in code).\n\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n self.ans = 0\n\t\t# use a stack to track the deepth of a path\n self.folder_stack = []\n\t\t# current folder level in stack, inital value is -1\n self.current_fd_level = -1\n self.current_path_len = 0\n file_path = input.split(\'\\n\')\n \n for t_path in file_path:\n # count the number of \'\\t\' for each file/foder name\n # we can get the current folder level based on the count\n idx = 0\n while idx < len(t_path) and t_path[idx] == \'\\t\':\n idx += 1\n \n t_fd_level = idx\n if t_fd_level <= self.current_fd_level:\n # pop out the previous folder\n while self.current_fd_level >= t_fd_level:\n t_fd = self.folder_stack.pop()\n self.current_path_len -= (len(t_fd) + 1)\n self.current_fd_level -= 1\n \n self.process_file_path(t_path[idx:], t_fd_level)\n \n return self.ans\n \n def process_file_path(self, file_folder_name, level):\n if len(file_folder_name.split(\'.\')) >= 2:\n # this is a file\n t_file_path_len = self.current_path_len + len(file_folder_name)\n if t_file_path_len > self.ans:\n self.ans = t_file_path_len\n else:\n self.folder_stack.append(file_folder_name)\n self.current_path_len += (len(file_folder_name) + 1)\n self.current_fd_level = level\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
O(n) Solution | longest-absolute-file-path | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe idea for this problem is to use a dictionary to store the length of the current path and a variable to store the maximum length of a file path.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nTo do this, we can use the following steps:\n- Initialize the maximum length of a file path to 0 and a dictionary to store the length of the current path, with the key 0 and value 0.\n- Iterate over the lines of the input string.\n- Strip the leading tabs from the current line to get the name of the file or directory.\n- Calculate the depth of the current file or directory by subtracting the length of the name from the length of the line.\n- If the current file is a file (it has a \'.\' in its name), update the maximum length of a file path by taking the maximum of the current maximum and the length of the current path at the current depth plus the length of the name.\n- If the current file is a directory, update the length of the current path at the next depth by adding the length of the name and 1 (for the \'/\' character).\n- Return the maximum length of a file path.\n# Complexity\n- Time complexity: $O(n)$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nWe need to perform a single pass through the input string.\n- Space complexity: $O(n)$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nWe need to store the length of the current path in a dictionary, which takes $O(n)$ space.\n# Code\n```\nclass Solution:\n def lengthLongestPath(self, input: str) -> int:\n maxLen = 0\n pathLen = {0:0}\n for line in input.splitlines():\n name = line.lstrip(\'\\t\')\n depth = len(line) - len(name)\n if \'.\' in name:\n maxLen = max(maxLen, pathLen[depth] + len(name))\n else:\n pathLen[depth+1] = pathLen[depth] + len(name) + 1\n return maxLen\n``` | 0 | Suppose we have a file system that stores both files and directories. An example of one system is represented in the following picture:
Here, we have `dir` as the only directory in the root. `dir` contains two subdirectories, `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and subdirectory `subsubdir1`. `subdir2` contains a subdirectory `subsubdir2`, which contains a file `file2.ext`.
In text form, it looks like this (with ⟶ representing the tab character):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
If we were to write this representation in code, it will look like this: `"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext "`. Note that the `'\n'` and `'\t'` are the new-line and tab characters.
Every file and directory has a unique **absolute path** in the file system, which is the order of directories that must be opened to reach the file/directory itself, all concatenated by `'/'s`. Using the above example, the **absolute path** to `file2.ext` is `"dir/subdir2/subsubdir2/file2.ext "`. Each directory name consists of letters, digits, and/or spaces. Each file name is of the form `name.extension`, where `name` and `extension` consist of letters, digits, and/or spaces.
Given a string `input` representing the file system in the explained format, return _the length of the **longest absolute path** to a **file** in the abstracted file system_. If there is no file in the system, return `0`.
**Note** that the testcases are generated such that the file system is valid and no file or directory name has length 0.
**Example 1:**
**Input:** input = "dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext "
**Output:** 20
**Explanation:** We have only one file, and the absolute path is "dir/subdir2/file.ext " of length 20.
**Example 2:**
**Input:** input = "dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext "
**Output:** 32
**Explanation:** We have two files:
"dir/subdir1/file1.ext " of length 21
"dir/subdir2/subsubdir2/file2.ext " of length 32.
We return 32 since it is the longest absolute path to a file.
**Example 3:**
**Input:** input = "a "
**Output:** 0
**Explanation:** We do not have any files, just a single directory named "a ".
**Constraints:**
* `1 <= input.length <= 104`
* `input` may contain lowercase or uppercase English letters, a new line character `'\n'`, a tab character `'\t'`, a dot `'.'`, a space `' '`, and digits.
* All file and directory names have **positive** length. | null |
Python 3 || Sorting | find-the-difference | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n s=sorted(s)\n t=sorted(t)\n i=0\n j=0\n while i<len(s) and j<len(t):\n if s[i]!=t[j]:\n return t[j]\n i+=1\n j+=1\n \n return t[-1]\n \n \n``` | 2 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
[Py , Java , C++ , C# , JS] ✅ MAP |🔥100% | find-the-difference | 1 | 1 | ```python []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n char_count = {}\n \n # Count characters in string t\n for char in t:\n if char in char_count:\n char_count[char] += 1\n else:\n char_count[char] = 1\n \n # Subtract characters in string s\n for char in s:\n char_count[char] -= 1\n if char_count[char] == 0:\n del char_count[char]\n \n # The remaining character in char_count is the difference\n return list(char_count.keys())[0]\n```\n```java []\n Map<Character, Integer> m = new HashMap<>();\n\n for (char e : t.toCharArray()) {\n m.put(e, m.getOrDefault(e, 0) + 1);\n }\n\n for (char e : s.toCharArray()) {\n m.put(e, m.get(e) - 1);\n if (m.get(e) == 0) {\n m.remove(e);\n }\n }\n\n char res = \'\\0\'; // Initialize with a default value\n for (char e : m.keySet()) {\n res = e;\n }\n\n return res;\n```\n```C++ []\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n unordered_map< char , int> m;\n\n for(auto e : t) m[e]++;\n for(auto e : s) {\n m[e]--;\n if(m[e] == 0) m.erase(e);\n }\n char res = \'-1\';\n for(auto e : m) res = e.first;\n return res;\n\n }\n};\n```\n```C# []\npublic class Solution {\n public char FindTheDifference(string s, string t) {\n Dictionary<char, int> charCount = new Dictionary<char, int>();\n\n foreach (char c in t) {\n if (charCount.ContainsKey(c)) {\n charCount[c]++;\n } else {\n charCount[c] = 1;\n }\n }\n\n foreach (char c in s) {\n if (charCount.ContainsKey(c)) {\n charCount[c]--;\n if (charCount[c] == 0) {\n charCount.Remove(c);\n }\n }\n }\n\n char result = \'\\0\'; // Default value for char\n foreach (var kvp in charCount) {\n result = kvp.Key;\n }\n\n return result;\n }\n}\n```\n```JavaScript []\nconst charCount = {};\n\n // Count characters in string t\n for (const char of t) {\n charCount[char] = (charCount[char] || 0) + 1;\n }\n\n // Subtract characters in string s\n for (const char of s) {\n charCount[char] = (charCount[char] || 0) - 1;\n if (charCount[char] === 0) {\n delete charCount[char];\n }\n }\n\n // The remaining character in charCount is the added character\n for (const char in charCount) {\n return char;\n }\n\n return \'\'; // Default return if no difference is found\n```\n | 1 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
✅94.54%🔥Efficient Algorithms for Finding the Added Letter in a Shuffled String🔥 | find-the-difference | 1 | 1 | # Problem\n\n#### The problem you\'re describing is known as "Find the Difference." You are given two strings, s and t, with the following characteristics:\n##### 1. String t is generated by randomly shuffling string s.\n##### 2.An additional letter is added to t at a random position.\n#### You need to find and return the letter that was added to t.\n---\n\n# Solution\n\n#### 1. It first checks if s is longer than t. If so, it means that an extra letter is present in s, so it loops through the characters in s.\n\n#### 2. For each character i in s, it checks if the count of i in s is greater than the count of i in t. If this condition is met, it means that i is the extra letter that was added to s, so it returns i and breaks out of the loop.\n\n#### 3. If s is not longer than t, it means that t is longer than s, so it checks the other way around. It loops through the characters in t.\n\n#### 4.For each character i in t, it checks if the count of i in t is greater than the count of i in s. If this condition is met, it means that i is the extra letter that was added to t, so it returns i and breaks out of the loop.\n\n---\n# Code\n\n```Python3 []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n if len(s)> len(t):\n for i in s:\n if s.count(i)>t.count(i):\n return(i)\n break\n if len(t)>len(s):\n for i in t:\n if t.count(i)>s.count(i):\n return(i)\n break\n```\n```python []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n if len(s)> len(t):\n for i in s:\n if s.count(i)>t.count(i):\n return(i)\n break\n if len(t)>len(s):\n for i in t:\n if t.count(i)>s.count(i):\n return(i)\n break\n```\n```C# []\npublic class Solution {\n public char FindTheDifference(string s, string t) {\n if (s.Length > t.Length) {\n foreach (char c in s) {\n if (s.Count(ch => ch == c) > t.Count(ch => ch == c)) {\n return c;\n }\n }\n }\n \n if (t.Length > s.Length) {\n foreach (char c in t) {\n if (t.Count(ch => ch == c) > s.Count(ch => ch == c)) {\n return c;\n }\n }\n }\n\n return \' \'; // Return a default value or handle the case when no difference is found.\n }\n}\n\n```\n```C++ []\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n char result = 0;\n for (char c : s) {\n result ^= c; \n }\n \n for (char c : t) {\n result ^= c; \n }\n \n return result;\n }\n};\n\n```\n```Java []\npublic class Solution {\n public char findTheDifference(String s, String t) {\n char result = 0; \n for (char c : s.toCharArray()) {\n result ^= c; \n }\n for (char c : t.toCharArray()) {\n result ^= c; \n }\n \n return result;\n }\n}\n\n```\n```C []\nchar findTheDifference(char *s, char *t) {\n char result = 0; \n while (*s != \'\\0\') {\n result ^= *s;\n s++;\n }\n while (*t != \'\\0\') {\n result ^= *t;\n t++;\n }\n \n return result;\n}\n\n```\n```javascript []\nvar findTheDifference = function(s, t) {\n let result = 0; \n for (let i = 0; i < s.length; i++) {\n result ^= s.charCodeAt(i);\n }\n for (let i = 0; i < t.length; i++) {\n result ^= t.charCodeAt(i);\n }\n return String.fromCharCode(result); \n};\n\n```\n\n | 25 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Simple Python Solution O(n^2) | find-the-difference | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n l1=list(s)\n l2=list(t)\n for i in l2:\n if i in l1:\n l1.remove(i)\n else:\n return i \n``` | 0 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
【Video】How we think about a solution - Python, JavaScript, Java, C++ | find-the-difference | 1 | 1 | Welcome to my article! This artcle starts with "How we think about a solution". In other words, that is my thought process to solve the question. This article explains how I get to my solution instead of just posting solution codes or out of blue algorithms. I hope this aricle is helpful for someone.\n\n# Intuition\nCount characters of t and subtract characters of s from characters of s\n\n---\n\n# Solution Video\n\nhttps://youtu.be/843PSCaBPVg\n\n\u25A0 Timeline of the video\n`0:00` Read the question of Find the Difference\n`0:32` How we think about a solution\n`1:46` Demonstrate solution with an example.\n`3:27` Coding\n`5:01` Time Complexity and Space Complexity\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 2,464\nMy initial goal is 10,000\nThank you for your support!\n\nBy the way, the answers of spot the difference on the thumbnail above are\n\n\n\nDid you find them?\n\n---\n\n# Approach\n\n**How we think about a solution:**\n\nSince `t` is +1 longer than `s`, so seems like we can use subtraction. But problem is `t` is shuffled `s` + 1 character. \n\n```\nInput: s = "abcd", t = "badec"\n```\nAt first, I thought I need to count both strings, but I realized that I only count numbers of characters in string `t`, because `t` is longer than `s`. So all we have to do after counting `t` is to subtract each character of `s` from results from `t`.\n\nLet\'s see how it works\n\nCount each character in string `t` with `HashMap`\n\n```\ncount = { "a": 1, "b": 1, "c": 1, "d": 1, "e": 1 }\n```\nThen, Let\'s subtract `-1` if we have the same key from string `s`. One important thing is that if numbers of count are zero, delete key/value from HashMap, becuase in the end we want to use only leftover of key.\n```\ns = "abcd"\n\ntarget = "a" in count = { "a": 1, "b": 1, "c": 1, "d": 1, "e": 1 }\nresult: count = { "b": 1, "c": 1, "d": 1, "e": 1 }\n\ntarget = "b" in count = { "b": 1, "c": 1, "d": 1, "e": 1 }\nresult: count = { "c": 1, "d": 1, "e": 1 }\n\ntarget = "c" in count = { "c": 1, "d": 1, "e": 1 }\nresult: count = { "d": 1, "e": 1 }\n\ntarget = "d" in count = { "d": 1, "e": 1 }\nresult: count = { "e": 1 }\n```\nIn the end, we get `count = { "e": 1 }` , so just return `key`.\n\nI hope you can understand how to think about a solution. Let\'s see a real algorithm.\n\n**Algorithm Overview:**\n\n1. Initialize a dictionary to store character counts.\n2. Count characters in string `t`.\n3. Subtract counts for characters in string `s`.\n4. Find the remaining character in the dictionary (the difference character).\n5. Return the difference character.\n\n**Detailed Explanation:**\n\n1. **Initialize a Dictionary:**\n - Create an empty dictionary called `count`. This dictionary will be used to store the count of each character in the second string `t`.\n\n2. **Count Characters in String `t`:**\n - Iterate through each character `c` in string `t`.\n - For each character `c`, increment its count in the `count` dictionary using `count.get(c, 0) + 1`. If the character is not already in the dictionary, initialize its count to 1.\n\n3. **Count Characters in String `s` and Subtract Counts:**\n - Iterate through each character `c` in string `s`.\n - For each character `c`, decrement its count in the `count` dictionary by 1.\n - If the count of the character `c` becomes 0, remove the entry for `c` from the dictionary.\n\n4. **Find the Remaining Character:**\n - The remaining character in the `count` dictionary is the difference character between `s` and `t`.\n\n5. **Return the Difference Character:**\n - Convert the remaining character to a list of keys using `list(count.keys())`.\n - Return the first (and only) element in the list, which is the difference character.\n\n---\n\n# Complexity\n- Time complexity: O(s + t)\n`s` is length of `s` and `t` is length of `t`\n\n- Space complexity: O(t)\nFor `HashMap`, `t` is length of `t`\n\n```python []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n # Initialize a dictionary to store character counts\n count = {}\n\n # Count characters in string t\n for c in t:\n count[c] = count.get(c, 0) + 1\n\n # Subtract counts for characters in string s\n for c in s:\n count[c] -= 1\n if count[c] == 0:\n del count[c]\n\n # The remaining character in the dictionary is the difference\n return list(count.keys())[0]\n```\n```javascript []\n/**\n * @param {string} s\n * @param {string} t\n * @return {character}\n */\nvar findTheDifference = function(s, t) {\n const count = new Map();\n \n for (const char of t) {\n count.set(char, (count.get(char) || 0) + 1);\n }\n \n for (const char of s) {\n count.set(char, count.get(char) - 1);\n if (count.get(char) === 0) {\n count.delete(char);\n }\n }\n \n return Array.from(count.keys())[0]; \n};\n```\n```java []\nclass Solution {\n public char findTheDifference(String s, String t) {\n Map<Character, Integer> count = new HashMap<>();\n \n for (char c : t.toCharArray()) {\n count.put(c, count.getOrDefault(c, 0) + 1);\n }\n \n for (char c : s.toCharArray()) {\n count.put(c, count.get(c) - 1);\n if (count.get(c) == 0) {\n count.remove(c);\n }\n }\n \n return (char) count.keySet().toArray()[0]; \n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n std::unordered_map<char, int> count;\n \n for (char c : t) {\n count[c]++;\n }\n \n for (char c : s) {\n count[c]--;\n if (count[c] == 0) {\n count.erase(c);\n }\n }\n \n return count.begin()->first; \n }\n};\n```\n\n\n---\n\n\n# Bonus code\n\n### Solution 2\nIn reality, I\'ve never seen people solving the questions with XOR solutions in real interviews, but there are a few ways to solve the question. I think this is O(len(s)+len(t)) time and O(1) space.\n\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n res = 0\n \n # XOR all characters in s and t\n for char in s + t:\n res ^= ord(char)\n \n # Convert the XOR result back to character\n return chr(res)\n```\n\n### Solution 3\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n for c in t:\n if t.count(c) > s.count(c):\n return(c)\n```\n\n\n---\n\n\n\nThank you for reading my post. \u2B50\uFE0FPlease upvote it and don\'t forget to subscribe to my channel!\n\nMy next post for daily coding challenge on Sep 26th, 2023\nhttps://leetcode.com/problems/remove-duplicate-letters/solutions/4091060/how-we-think-about-a-solution-stack-python-javascript-java-c/ | 30 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Python | easy solution | find-the-difference | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n ht={}\n hs={}\n for char in s:\n hs[char]=hs.get(char,0)+1\n for char in t:\n ht[char]=ht.get(char,0)+1\n for char in ht:\n if char not in hs or ht[char] > hs[char]:\n return char\n \n``` | 1 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Python shortest 1-liner. Functional programming. | find-the-difference | 0 | 1 | # Approach\nSimilar to [136. Single Number](https://leetcode.com/problems/single-number/description/) and it\'s [solution](https://leetcode.com/problems/single-number/solutions/3215764/python-shortest-1-liner-functional-programming/).\n\n# Complexity\n- Time complexity: $$O(m + n)$$\n\n- Space complexity: $$O(1)$$\n\n# Code\n```python\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n return chr(reduce(xor, map(ord, chain(s, t))))\n\n\n``` | 1 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
✅96.54%🔥Efficient Algorithms for Finding the Added Letter in a Shuffled String🔥 | find-the-difference | 1 | 1 | # Problem\n\n#### The problem you\'re describing is known as "Find the Difference." You are given two strings, s and t, with the following characteristics:\n##### 1. String t is generated by randomly shuffling string s.\n##### 2.An additional letter is added to t at a random position.\n#### You need to find and return the letter that was added to t.\n---\n\n# Solution\n\n#### 1. It first checks if s is longer than t. If so, it means that an extra letter is present in s, so it loops through the characters in s.\n\n#### 2. For each character i in s, it checks if the count of i in s is greater than the count of i in t. If this condition is met, it means that i is the extra letter that was added to s, so it returns i and breaks out of the loop.\n\n#### 3. If s is not longer than t, it means that t is longer than s, so it checks the other way around. It loops through the characters in t.\n\n#### 4.For each character i in t, it checks if the count of i in t is greater than the count of i in s. If this condition is met, it means that i is the extra letter that was added to t, so it returns i and breaks out of the loop.\n\n---\n# Code\n\n```Python3 []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n if len(s)> len(t):\n for i in s:\n if s.count(i)>t.count(i):\n return(i)\n break\n if len(t)>len(s):\n for i in t:\n if t.count(i)>s.count(i):\n return(i)\n break\n```\n```python []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n if len(s)> len(t):\n for i in s:\n if s.count(i)>t.count(i):\n return(i)\n break\n if len(t)>len(s):\n for i in t:\n if t.count(i)>s.count(i):\n return(i)\n break\n```\n```C# []\npublic class Solution {\n public char FindTheDifference(string s, string t) {\n if (s.Length > t.Length) {\n foreach (char c in s) {\n if (s.Count(ch => ch == c) > t.Count(ch => ch == c)) {\n return c;\n }\n }\n }\n \n if (t.Length > s.Length) {\n foreach (char c in t) {\n if (t.Count(ch => ch == c) > s.Count(ch => ch == c)) {\n return c;\n }\n }\n }\n\n return \' \'; // Return a default value or handle the case when no difference is found.\n }\n}\n\n```\n```C++ []\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n char result = 0;\n for (char c : s) {\n result ^= c; \n }\n \n for (char c : t) {\n result ^= c; \n }\n \n return result;\n }\n};\n\n```\n```Java []\npublic class Solution {\n public char findTheDifference(String s, String t) {\n char result = 0; \n for (char c : s.toCharArray()) {\n result ^= c; \n }\n for (char c : t.toCharArray()) {\n result ^= c; \n }\n \n return result;\n }\n}\n\n```\n```C []\nchar findTheDifference(char *s, char *t) {\n char result = 0; \n while (*s != \'\\0\') {\n result ^= *s;\n s++;\n }\n while (*t != \'\\0\') {\n result ^= *t;\n t++;\n }\n \n return result;\n}\n\n```\n```javascript []\nvar findTheDifference = function(s, t) {\n let result = 0; \n for (let i = 0; i < s.length; i++) {\n result ^= s.charCodeAt(i);\n }\n for (let i = 0; i < t.length; i++) {\n result ^= t.charCodeAt(i);\n }\n return String.fromCharCode(result); \n};\n\n```\n\n | 5 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Python Easy Bitwise Solution - 25/09/2023 | find-the-difference | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n # s and t \n # t is generated by shuffling s + one more letter at random position\n # return the new letter\n # using bitwise operation \n # XOR of both strings will return in the additional character\n\n c = 0\n for cs in s: c^= ord(cs)\n for ct in t: c^= ord(ct)\n return chr(c)\n\n``` | 0 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Python3 with hash map | find-the-difference | 0 | 1 | I used Counter from collections method to make the hash map.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n**O**(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n**O**(n+m)\nWhere, n = length of string **t**\nm = length of string **s**\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n s_ = Counter(s)\n t_ = Counter(t)\n\n for i in t_:\n if i not in s_:\n return i\n elif s_[i] != t_[i]:\n return i\n\n``` | 0 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Easy to understand using single for loop (PYTHON 3) | find-the-difference | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n for x in t:\n if x not in s:\n return x \n s=s.replace(x,"",1)\n``` | 1 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
✔Best Bit Manipulation 📈|| Easy to understand ✨|| #Beginner😇😎 | find-the-difference | 1 | 1 | # Intuition\n- The code aims to find the extra character (the difference) that is present in string `t `but not in string `s`. It does this by XORing all the characters in both strings, and the result will be the extra character.\n\n# Approach\n1. Initialize a variable `r` to `0`. This variable will be used to store the XOR result of all characters in both strings.\n1. Loop through each character c in string `s`, and for each character, XOR it with the current value of `r`. This will effectively cancel out all the common characters between `s` and `t`, leaving only the extra character from `t`.\n1. Loop through each character `c `in string `t`, and for each character, XOR it with the current value of` r`.\n1. The final value of `r `will be the ASCII value of the extra character in string `t`.\n\n# Complexity\n- Time complexity:\n - The code has two loops that iterate through each character in both strings `s` and `t`. **`Therefore, the time complexity is O(N)`**, where N is the maximum of the lengths of strings s and t.\n\n- Space complexity:\n - The code uses only a constant amount of extra space for the variable `r`, regardless of the input sizes. **`Therefore, the space complexity is O(1)`**.\n\n# PLEASE UPVOTE IF HELPFUL\u2764\uD83D\uDE0D\n\n# Code\n```\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n\n \n char r=0;\n for(char c:s) r ^=c;\n for(char c:t) r ^=c;\n return r;\n }\n};\n```\n# C++ SIMPLE SOLUTION\n```\n int a = 0;\n int b = 0;\n for (char c : s)\n a += c;\n for (char c : t)\n b += c;\n \n return b - a; //extra letter ascii\n```\n# JAVA\n```\npublic class Solution {\n public char findTheDifference(String s, String t) {\n char r = 0;\n for (char c : s.toCharArray()) {\n r ^= c;\n }\n for (char c : t.toCharArray()) {\n r ^= c;\n }\n return r;\n }\n}\n\n```\n# PYTHON\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n r = 0\n for c in s:\n r ^= ord(c)\n for c in t:\n r ^= ord(c)\n return chr(r)\n\n```\n# JAVASCRIPT\n```\nvar findTheDifference = function(s, t) {\n let r = 0;\n for (let i = 0; i < s.length; i++) {\n r ^= s.charCodeAt(i);\n }\n for (let i = 0; i < t.length; i++) {\n r ^= t.charCodeAt(i);\n }\n return String.fromCharCode(r);\n};\n\n```\n# PLEASE UPVOTE IF HELPFUL\u2764\uD83D\uDE0D | 14 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
✔Bit Manipulation 📈|| Easy to understand ✨|| #Beginner😇😎 | find-the-difference | 1 | 1 | # Intuition\n- The code aims to find the extra character (the difference) that is present in string `t `but not in string `s`. It does this by XORing all the characters in both strings, and the result will be the extra character.\n\n# Approach\n1. Initialize a variable `r` to `0`. This variable will be used to store the XOR result of all characters in both strings.\n1. Loop through each character c in string `s`, and for each character, XOR it with the current value of `r`. This will effectively cancel out all the common characters between `s` and `t`, leaving only the extra character from `t`.\n1. Loop through each character `c `in string `t`, and for each character, XOR it with the current value of` r`.\n1. The final value of `r `will be the ASCII value of the extra character in string `t`.\n\n# Complexity\n- Time complexity:\n - The code has two loops that iterate through each character in both strings `s` and `t`. **`Therefore, the time complexity is O(N)`**, where N is the maximum of the lengths of strings s and t.\n\n- Space complexity:\n - The code uses only a constant amount of extra space for the variable `r`, regardless of the input sizes. **`Therefore, the space complexity is O(1)`**.\n\n# PLEASE UPVOTE IF HELPFUL\u2764\uD83D\uDE0D\n\n# Code\n```\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n\n \n char r=0;\n for(char c:s) r ^=c;\n for(char c:t) r ^=c;\n return r;\n }\n};\n```\n# C++ SIMPLE SOLUTION\n```\n int a = 0;\n int b = 0;\n for (char c : s)\n a += c;\n for (char c : t)\n b += c;\n \n return b - a; //extra letter ascii\n```\n# JAVA\n```\npublic class Solution {\n public char findTheDifference(String s, String t) {\n char r = 0;\n for (char c : s.toCharArray()) {\n r ^= c;\n }\n for (char c : t.toCharArray()) {\n r ^= c;\n }\n return r;\n }\n}\n\n```\n# PYTHON\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n r = 0\n for c in s:\n r ^= ord(c)\n for c in t:\n r ^= ord(c)\n return chr(r)\n\n```\n# JAVASCRIPT\n```\nvar findTheDifference = function(s, t) {\n let r = 0;\n for (let i = 0; i < s.length; i++) {\n r ^= s.charCodeAt(i);\n }\n for (let i = 0; i < t.length; i++) {\n r ^= t.charCodeAt(i);\n }\n return String.fromCharCode(r);\n};\n\n```\n# PLEASE UPVOTE IF HELPFUL\u2764\uD83D\uDE0D | 5 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
C++/Python frequencies vs XOR vs Sum||0ms Beats 100%||Math explains | find-the-difference | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nCount the frequencies of alphabets in s & t. find the different alphbet.\n# Approach\n<!-- Describe your approach to solving the problem. -->\n[Please turn English subtitles if neccessary]\n[https://youtu.be/79AP8uMpO5E?si=Ty4FAbc05I00yYE5](https://youtu.be/79AP8uMpO5E?si=Ty4FAbc05I00yYE5)\n2nd approach uses just XOR thanks the hint from @mochy\n# How XOR works?\nConvert the characters to integers. To be more precisely, Use the facts in the language of algebra (Math)\n```\n(a^b)^c=a^(b^c) (associative)\na^b=b^a (commutative) \nand x^x=0, \n```\nthe same alphabet will be canceled out pairwise, and the rest is the answer. \n\n3rd approach is just one line and uses sum/accumulate! And that is a `+` variant from the `^`second approach. It should be noted that the integers satisfy the associative and commutative rules. And x-x=0.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$O(2n+26)=O(n)$ vs $O(n)$ \n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(2*26)=O(1) vs O(1)\n# Code\n```\nclass Solution {\npublic:\n vector<int> freq(string& s){\n vector<int> f(26, 0);\n for (char c: s)\n f[c-\'a\']++;\n return f;\n }\n char findTheDifference(string s, string t) {\n vector<int> sN=freq(s), tN=freq(t);\n for(char c=\'a\'; c<=\'z\'; c++)\n if (sN[c-\'a\']!=tN[c-\'a\'])\n return c;\n return \'X\';\n }\n};\n```\n# Code using XOR\n```\nclass Solution {\npublic:\n int XOR(string& s){\n int f=0;\n for (char c: s)\n f^=c;\n return f;\n }\n char findTheDifference(string s, string t) {\n int sN=XOR(s), tN=XOR(t);\n return (char)sN^tN;\n }\n};\n```\n# Python Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n def XOR(s):\n f=0\n for c in s:\n f^=ord(c)\n return f\n return chr(XOR(s)^XOR(t))\n \n```\n# Code using sum\n```Python []\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n return chr(sum(map(ord, t)) - sum(map(ord, s)))\n \n```\n```C++ []\n\nclass Solution {\npublic:\n char findTheDifference(string s, string t) {\n return (char)(accumulate(t.begin(), t.end(), 0)-accumulate(s.begin(), s.end(), 0));\n }\n};\n``` | 7 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Beats 99.15% of Solution- Find the Difference | find-the-difference | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n if len(s)>len(t):\n for i in s:\n if s.count(i)>t.count(i):\n return(i)\n break\n if len(t)>len(s):\n for i in t:\n if t.count(i)>s.count(i):\n return(i)\n break\n``` | 0 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Easy Python Solution | find-the-difference | 0 | 1 | ```\ndef findTheDifference(self, s: str, t: str) -> str:\n for i in t:\n if s.count(i) != t.count(i):\n return i\n``` | 72 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
NOOB CODE : | find-the-difference | 0 | 1 | # Intuition\nCounting the no. of each char\n\n# Approach\nFirst, the function checks if the length of string s is 0. If it is, it returns the entire string t. This is because, in this case, there are no characters in s to compare with t, so the extra character in t is the difference.\n\nTwo empty lists ls and lt are initialized. These lists are used to store the characters of strings s and t, respectively.\n\nThe function then iterates over each character in string s and appends it to the list ls, and similarly for string t, it appends characters to the list lt. Essentially, it converts the strings into lists of characters.\n\nBoth lists ls and lt are sorted in ascending order. Sorting the lists is not strictly necessary for finding the difference, but it helps in comparing characters efficiently.\n\nThe function then iterates over the characters in ls using a for loop.\n\nInside the loop, it checks if the count of the current character ls[i] in ls is not equal to the count of the same character lt[i] in lt. If they are not equal, it means that the character in s occurs fewer times than in t, indicating that this character is the extra character in t. In this case, it returns lt[i].\n\nIf the counts are equal, it checks if lt[i+1] is equal to lt[-1]. This is done to find the character that occurs one more time in t than in s. If this condition is true, it means that lt[i] is the last occurrence of the extra character in t, so it returns lt[-1].\n\n# Complexity\n- Time complexity: **O(len(t) * log(len(t)))**\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: **O(len(s) + len(t))**\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n ls=[]\n lt=[]\n if(len(s)==0):\n return(t)\n p=0\n for i in range(0,len(s)):\n ls.append(s[i])\n for i in range(0,len(t)):\n lt.append(t[i])\n ls.sort()\n lt.sort()\n for i in range(0,len(ls)):\n if(ls.count(ls[i])!=lt.count(lt[i])):\n return(lt[i])\n else:\n if(lt[i+1]==lt[-1]):\n return(lt[-1])\n\n``` | 3 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Using Counter,Sorting,Count Approaches | find-the-difference | 0 | 1 | # 1. Using Sort Algorithm\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n \ts, t = sorted(s), sorted(t)\n \tfor i in range(len(t))\n \t\tif t[i] not in s[i]:\n\t\t\t\treturn t[i]\n```\n\n# 2. Using Count\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n \tfor i in t:\n \t\tif s.count(i) != t.count(i): return i\n```\n\n# 3. Using Counter:\n```\nfrom collections import Counter\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n \treturn list(Counter(t) - Counter(s))[0]\n```\n# please upvote me it would encourage me alot\n | 11 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Easy For Python Beginners | find-the-difference | 0 | 1 | \n\n# Approach\n1.iterating Over t \n2.if count of the character in t not equal to it\'s count in s\n "THEN WE CAN RETURN THAT character"\n\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n if len(s)==0:\n return t\n\n for i in t:\n if s.count(i)!=t.count(i):\n return i\n \n \n``` | 2 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
Friendly approach for beginners : time complexity O(n) | find-the-difference | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findTheDifference(self, s: str, t: str) -> str:\n for alpha in (t):\n if s.count(alpha) != t.count(alpha):\n return alpha\n\n #below line fails if s="a" and t="aa"\n # if alpha not in s :\n # result+=alpha\n # return result \n``` | 2 | You are given two strings `s` and `t`.
String `t` is generated by random shuffling string `s` and then add one more letter at a random position.
Return the letter that was added to `t`.
**Example 1:**
**Input:** s = "abcd ", t = "abcde "
**Output:** "e "
**Explanation:** 'e' is the letter that was added.
**Example 2:**
**Input:** s = " ", t = "y "
**Output:** "y "
**Constraints:**
* `0 <= s.length <= 1000`
* `t.length == s.length + 1`
* `s` and `t` consist of lowercase English letters. | null |
390: Time 92.4%, Solution with step by step explanation | elimination-game | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize variables:\n\n - left as True to indicate that we start with left-to-right elimination\n - remaining as n to keep track of the remaining numbers\n - step as 1 to keep track of the step size\n - head as 1 to keep track of the head of the remaining numbers\n2. Loop while remaining is greater than 1:\n\n - If we\'re going from left to right or from right to left with an odd number of remaining elements, or from right to left with an even number of remaining elements, then we need to update the head by adding the current step size to it.\n - Double the step size.\n - Divide the remaining elements by 2 to discard the removed numbers.\n - Flip the left flag to alternate between left-to-right and right-to-left elimination.\n3. Return the head of the remaining numbers.\n\nEssentially, the algorithm simulates the elimination process and keeps track of the head of the remaining numbers. At each iteration, it updates the head by adding the step size if we\'re going from left to right or from right to left with an odd number of remaining elements or from right to left with an even number of remaining elements. The step size is doubled at each iteration to reflect the fact that we\'re removing every other number. Finally, the remaining elements are divided by 2 to discard the removed numbers. The left flag is flipped at each iteration to alternate between left-to-right and right-to-left elimination.\n\n# Complexity\n- Time complexity:\n92.4%\n\n- Space complexity:\n62.6%\n\n# Code\n```\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n left = True # flag to keep track of left-to-right or right-to-left elimination\n remaining = n # keep track of the remaining numbers\n step = 1 # keep track of the step size\n head = 1 # keep track of the head of the remaining numbers\n while remaining > 1:\n # if we\'re going from left to right or from right to left with an odd number of remaining elements\n # or from right to left with an even number of remaining elements, then we need to update the head\n if left or remaining % 2 == 1:\n head += step\n step *= 2 # double the step size\n remaining //= 2 # divide the remaining elements by 2\n left = not left # flip the flag\n\n return head\n\n``` | 7 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Python O(log(n)) solution | elimination-game | 0 | 1 | # Intuition\nAt each step we remove half of the numbers so in total we will do `log(n)` step.\n\n# Approach\nIf at level `i` we have the numbers of the form: `2 ^ i * k + m` then at the level `i + 1` we will have numbers of the form: `2 ^ (i + 1) * k + m` or `2 ^ (i + 1) * k + 2 ^ i + m` depending on the removed number in the latest step.\nFor example if at level `i = 3` we proceed from left ro right and the first number is `14` and all of the number are in the form : `8k + 6` then in the next step, all of the numbers will be in the form `16k + 6` (not containing `14`).\nIn the last step we can conclude the remained number from `2 ^ (log(n))k + m`.\n\n# Complexity\n- Time complexity:\n`O(log(n))` because of the number of steps.\n\n- Space complexity:\n`O(1)`\n\n# Code\n*tip: use shift (`<<`) operator for the powers.\n```\nfrom math import log2, floor\n\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n if n == 1:\n return 1\n c = floor(log2(n))\n m = 0 # 2^i * k + m remains\n p = 1\n for i in range(1, c):\n p <<= 1\n if i % 2 == 0:\n first = m if m > 0 else p\n if first % (2 * p) == m:\n m += p\n else:\n last = ((n - m) // p) * p + m\n if last % (2 * p) == m:\n m += p\n return m if m > 0 else 2 * p\n``` | 2 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Python > 95% Time, O(logN) and Constant Memory, Commented and Explained | elimination-game | 0 | 1 | ```\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n N = n # number of remaining numbers\n fwd = True # flag for forward/backward elimination\n m = 2 # elimination step/interval\n s = 0 # elimination base\n\n while N > 1:\n if fwd or N % 2 == 1: \n s += m // 2\n m *= 2\n N = N // 2\n fwd = not fwd # reverse the pass direction\n return s+1\n```\n\n# Solution Explanation\nFor this problem, we begin by identifying some patterns in the elimination.\nUsing **zero-based indexing**, let\'s consider the pattern of elimination to be simulated by the following bit of logic:\n```\nfor i in range(n):\n\tif (i - s) % m == 0:\n\t\t# eliminate\n\t\t# first elimination pass forward, s=0 and m=2\n```\n\nBut first, let\'s consider a few things: 1) elimination steps 2) elimination base 3) direction of elimination, and 4) number of remaining numbers left to eliminate\n\n1) Pattern Interval/Step:\n\t* Described by variable `m` in the soln. code - the intervals/distance between the eliminated numbers\n\t* **The interval/step doubles after every pass of elimination `m *= 2`**\n\t* The first pass of elimination is described by the solution of numbers `i`, such that `i % 2 == 0` \n\n2) Elimination Base Update/Shift - (Normalizing the Pattern)\n\t* Described by `s` in the soln. code - It normalizes the pattern to zero base\n\t* From 1), we see that we are left with a pattern of numbers that are all separated by a fixed interval/step of `m` beginning with an elimination base. `s` will only ever increase in magnitude as we eliminate numbers, a tightening of boundaries from both ends of the range of N.\n\t* So we can describe the whole pattern of numbers to be eliminated with `(i - s) % m == 0` for some `s`\n\t* After the first pass, we can see that next pass of numbers would eliminate numbers with a fixed step of `m = 4` or `(i - s) % 4 == 0` for some `s`\n\n3) Direction of Elimination\n\t* Described by variable `fwd` in the soln. code\n\t* Forward: the minimum *remaining* element is eliminated, AKA elimination base is eliminated\n\t* Backward: the minimum *remaining* element *may not* be eliminated (more on this to follow)\n\n4) Numbers Remaining to Eliminate\n\t* Described by variable `N` in the soln. code\n\t* **Odd** number of numbers remaining `N # odd`\n\t\t* Note: This elimination pattern looks the same, regardless of pass direction. Min and max remaining numbers are eliminated, we know that the minimum remaining number (elim. pattern base `s`) will be shifted up by a half step, such that `s += m // 2`. \n\t* **Even** number of numbers remaining `N # even`\n\t\t* This elimination pattern will differ between a foward and backward pass by a half-step, `m // 2`.\n\t\t\t* Foward: If there are an even count of numbers remaining, and it is a forward pass, the base of the elimination pattern will eliminated such that we\'d shift the base of the elimination pattern up by half-step, `s += m // 2`\n\t\t\t* Backward: If there are an even count of numbers remaining, and it is a backward pass, then the base of elimination pattern will be left unchanged for the next pass, a forward pass (because we will not end up eliminating the base in the backward pass). The only update in this situation is the doubling of the step size, `m *= 2`.\n\nSo the above code simulates the . We will only need O(logN) passes, since we are effectively eliminating half the possible numbers every time. This is simulated by the updates `N = N // 2` in the soln. code.\nMemory is constant.\n\nWe are left with the final elimination pattern for a single number, which will be described by the base, `s` here. We return `s+1` because we use **zero-based** indexing for the code.\n\n\n | 11 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Easiest solution with full explanation | elimination-game | 0 | 1 | \n### Problem Explanation:\n\nYou have a list `arr` of all integers in the range [1, n] sorted in strictly increasing order. The task is to apply a specific algorithm on `arr` that involves removing numbers alternately from left to right and right to left until only one number remains. The goal is to find and return the last remaining number.\n\n### Algorithm Steps:\n\n1. **Remove from Left to Right:**\n - Starting from the left, remove the first number and every other number afterward until reaching the end of the list.\n\n2. **Remove from Right to Left:**\n - Repeat the process, but this time from right to left, removing the rightmost number and every other number from the remaining numbers.\n\n3. **Repeat Steps:**\n - Keep repeating the steps, alternating left to right and right to left, until a single number remains.\n\n### Example Walkthrough:\n\nLet\'s take an example with `n = 9`.\n\n1. **Initial List:** [1, 2, 3, 4, 5, 6, 7, 8, 9]\n2. **Remove from Left to Right:** [2, 4, 6, 8]\n3. **Remove from Right to Left:** [2, 6]\n4. **Remove from Left to Right:** [6]\n5. **Last Remaining Number:** 6\n\n### Approach:\n\nThe solution involves simulating the process described in the algorithm. Key points:\n\n- Keep track of whether the removal is from left to right or right to left.\n- Update the head (the first number in the remaining list) and the step (the interval between consecutive numbers to be removed).\n- Continue the process until only one number remains.\n\n### Conclusion:\n\nBy simulating the described algorithm, you can find the last remaining number efficiently. The approach takes into account the left-to-right and right-to-left alternation, updating the head and step accordingly. This ensures correctness in determining the last number remaining in the list.\n\n\n```python []\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n left_to_right = True\n remaining = n\n step = 1\n head = 1\n\n while remaining > 1:\n if left_to_right or remaining % 2 == 1:\n head += step\n\n remaining //= 2\n step *= 2\n left_to_right = not left_to_right\n\n return head\n```\n```C++ []\nclass Solution {\npublic:\n int lastRemaining(int n) {\n bool left_to_right = true;\n int remaining = n;\n int step = 1;\n int head = 1;\n\n while (remaining > 1) {\n if (left_to_right || remaining % 2 == 1) {\n head += step;\n }\n\n remaining /= 2;\n step *= 2;\n left_to_right = !left_to_right;\n }\n\n return head;\n }\n};\n```\n | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Intuition: Just observe starting element 😉 | elimination-game | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n Head changes when we go from (left to right) or (right to left when we have odd number of digits remaining) otherwise it remains same.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n Just track starting element because starting element is our answer when we have only one number left \uD83D\uDE09!!\n\n# Complexity\n- Time complexity: $$O(Logn)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(1)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n """\n Intuition: Just observe starting element\n Ex1. 1 2 3 4 5 (left to right) Head = 1\n # - 2 4 (right to left) (total nof digits =2) (even) Head = 2\n # - 2 (Ans) Head = 4\n Ans = 4\n\n Ex2. 1 2 3 4 5 6 (left to right) Head = 1\n # - 2 4 6 (right to left) (total nof digits=3) (odd) Head = 2\n # - 4 (Ans) Head = 4\n\n Head changes when we go from (left to right) or (right to left when if we have odd number of digits remaining).\n\n """\n from_left=True\n head=1\n step=1\n remaining=n\n while remaining>1:\n if from_left or remaining%2==1:\n head+=step\n step*=2\n remaining//=2\n from_left= not from_left\n return head\n\n\n\n\n \n \n \n \n``` | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
2 pointers. beats 88%, 55% | elimination-game | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nUsed 2 pointers keep track of the starting and the ending point. and moves one pointer according to the gap between start and end.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(logn)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n# Code\n```\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n if n == 1:\n return 1\n\n l, r = 1, n\n seed = 1\n while l < r:\n l += seed\n if l == r:\n return l\n r = r if (r-l) % (seed*2) == 0 else r - seed\n seed *= 2\n if l == r:\n return l\n r -= seed\n if l == r:\n return l\n l = l if (r-l) % (seed*2) == 0 else l + seed\n seed *= 2\n \n return l\n \n``` | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Easy Way to Think (Python) | elimination-game | 0 | 1 | \nKeep tracking the first element.\nIf ```from_left``` is ```True``` or the number of the list is odd. Then we should update the first element.\n```gap``` is the number we should add to make the first element to the second element in the current list.\n```n``` is the number of element in the list.\n\n# Code\n```python\nclass Solution:\n def lastRemaining(self, n: int) -> int:\n from_left=True\n res,gap=1,1\n while n>1:\n if from_left or n%2: res+=gap\n gap*=2\n n//=2\n from_left=not from_left\n return res\n``` | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Easy explanation | Arithmetic progression | Math | Python | Recursion | elimination-game | 0 | 1 | # Approach\nAt each step we will use formula of `nth` term of AP. `n` will be half of what prevous `n` was. This is because for each iteration we are eliminating the 1st number. So after emimination process, half the elements will remain. \nFor example:\n```\n1st iteration: [1,2,3,4]\n2nd iteration: [2,4]\n```\nThis is why we are only considring n/2 for n terms because we want to know the 2nd last term which will be eliminated in current AP.\n\nThe formula of AP will give us the 2nd last term which we want to eliminate, so we can add a `flag` value to that 2nd last term to get the term from which we will start our next iteration of elimination(it could be left to right or right to left). The value of `flag` will be `previous d / 2` and the value of `d` (for this iteration) will be `-2 * previous d`. We are using `-` here because when we start the elimination process from right to left, the difference in the AP series will be negative and it will be positive if we start from left to right. If we hit `n = 1`, we know that there is only one term left and we can return that.\n\n# Code\n```\nclass Solution(object):\n def lastRemaining(self, n):\n def eliminate(n, a, d):\n if n==1:\n return a\n return eliminate(n//2, a+(n//2 -1)*d + d//2, -d*2)\n return eliminate(n,1,2)\n \n``` | 0 | You have a list `arr` of all integers in the range `[1, n]` sorted in a strictly increasing order. Apply the following algorithm on `arr`:
* Starting from left to right, remove the first number and every other number afterward until you reach the end of the list.
* Repeat the previous step again, but this time from right to left, remove the rightmost number and every other number from the remaining numbers.
* Keep repeating the steps again, alternating left to right and right to left, until a single number remains.
Given the integer `n`, return _the last number that remains in_ `arr`.
**Example 1:**
**Input:** n = 9
**Output:** 6
**Explanation:**
arr = \[1, 2, 3, 4, 5, 6, 7, 8, 9\]
arr = \[2, 4, 6, 8\]
arr = \[2, 6\]
arr = \[6\]
**Example 2:**
**Input:** n = 1
**Output:** 1
**Constraints:**
* `1 <= n <= 109` | null |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.