
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Python 3 (two lines) (beats 100%) (16 ms) (With Explanation) | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | - Start from letter z (two digit numbers) and work backwords to avoid any confusion or inteference with one digit numbers. After replacing all two digit (hashtag based) numbers, we know that the remaining numbers will be simple one digit replacements.\n- Note that ord(\'a\') is 97 which means that chr(97) is \'a\'. This allows us to easily create a character based on its number in the alphabet. For example, \'a\' is the first letter in the alphabet. It has an index of 1 and chr(96 + 1) is \'a\'.\n\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n for i in range(26,0,-1): s = s.replace(str(i)+\'#\'*(i>9),chr(96+i))\n return s\n \n\t\t\n\t\t\n- Junaid Mansuri\n- Chicago, IL | 138 | There are `n` people and `40` types of hats labeled from `1` to `40`.
Given a 2D integer array `hats`, where `hats[i]` is a list of all hats preferred by the `ith` person.
Return _the number of ways that the `n` people wear different hats to each other_.
Since the answer may be too large, return it modulo `109 + 7`.
**Example 1:**
**Input:** hats = \[\[3,4\],\[4,5\],\[5\]\]
**Output:** 1
**Explanation:** There is only one way to choose hats given the conditions.
First person choose hat 3, Second person choose hat 4 and last one hat 5.
**Example 2:**
**Input:** hats = \[\[3,5,1\],\[3,5\]\]
**Output:** 4
**Explanation:** There are 4 ways to choose hats:
(3,5), (5,3), (1,3) and (1,5)
**Example 3:**
**Input:** hats = \[\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\]\]
**Output:** 24
**Explanation:** Each person can choose hats labeled from 1 to 4.
Number of Permutations of (1,2,3,4) = 24.
**Constraints:**
* `n == hats.length`
* `1 <= n <= 10`
* `1 <= hats[i].length <= 40`
* `1 <= hats[i][j] <= 40`
* `hats[i]` contains a list of **unique** integers. | Scan from right to left, in each step of the scanning check whether there is a trailing "#" 2 indexes away. |
Easy Soln | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | # Code\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n i=0\n st=""\n while i<len(s):\n if i+2<len(s) and s[i+2]=="#":\n st+=chr(96+int(s[i:i+2]))\n i+=2\n else:\n st+=chr(96+int(s[i]))\n i+=1\n return st\n \n``` | 1 | You are given a string `s` formed by digits and `'#'`. We want to map `s` to English lowercase characters as follows:
* Characters (`'a'` to `'i'`) are represented by (`'1'` to `'9'`) respectively.
* Characters (`'j'` to `'z'`) are represented by (`'10#'` to `'26#'`) respectively.
Return _the string formed after mapping_.
The test cases are generated so that a unique mapping will always exist.
**Example 1:**
**Input:** s = "10#11#12 "
**Output:** "jkab "
**Explanation:** "j " -> "10# " , "k " -> "11# " , "a " -> "1 " , "b " -> "2 ".
**Example 2:**
**Input:** s = "1326# "
**Output:** "acz "
**Constraints:**
* `1 <= s.length <= 1000`
* `s` consists of digits and the `'#'` letter.
* `s` will be a valid string such that mapping is always possible. | Think of it as a graph problem. We need to find a topological order on the dependency graph. Build two graphs, one for the groups and another for the items. |
Easy Soln | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | # Code\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n i=0\n st=""\n while i<len(s):\n if i+2<len(s) and s[i+2]=="#":\n st+=chr(96+int(s[i:i+2]))\n i+=2\n else:\n st+=chr(96+int(s[i]))\n i+=1\n return st\n \n``` | 1 | There are `n` people and `40` types of hats labeled from `1` to `40`.
Given a 2D integer array `hats`, where `hats[i]` is a list of all hats preferred by the `ith` person.
Return _the number of ways that the `n` people wear different hats to each other_.
Since the answer may be too large, return it modulo `109 + 7`.
**Example 1:**
**Input:** hats = \[\[3,4\],\[4,5\],\[5\]\]
**Output:** 1
**Explanation:** There is only one way to choose hats given the conditions.
First person choose hat 3, Second person choose hat 4 and last one hat 5.
**Example 2:**
**Input:** hats = \[\[3,5,1\],\[3,5\]\]
**Output:** 4
**Explanation:** There are 4 ways to choose hats:
(3,5), (5,3), (1,3) and (1,5)
**Example 3:**
**Input:** hats = \[\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\]\]
**Output:** 24
**Explanation:** Each person can choose hats labeled from 1 to 4.
Number of Permutations of (1,2,3,4) = 24.
**Constraints:**
* `n == hats.length`
* `1 <= n <= 10`
* `1 <= hats[i].length <= 40`
* `1 <= hats[i][j] <= 40`
* `hats[i]` contains a list of **unique** integers. | Scan from right to left, in each step of the scanning check whether there is a trailing "#" 2 indexes away. |
Just replace 26 times - STUPID Python solution | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | \n# Code\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n s = s.replace(\'10#\',\'j\').replace(\'11#\',\'k\').replace(\'12#\',\'l\').replace(\'13#\',\'m\').replace(\'14#\',\'n\').replace(\'15#\',\'o\')\n s = s.replace(\'16#\',\'p\').replace(\'17#\',\'q\').replace(\'18#\',\'r\').replace(\'19#\',\'s\').replace(\'20#\',\'t\').replace(\'21#\',\'u\')\n s = s.replace(\'22#\',\'v\').replace(\'23#\',\'w\').replace(\'24#\',\'x\').replace(\'25#\',\'y\').replace(\'26#\',\'z\')\n s = s.replace(\'1\',\'a\').replace(\'2\',\'b\').replace(\'3\',\'c\').replace(\'4\',\'d\').replace(\'5\',\'e\').replace(\'6\',\'f\').replace(\'7\',\'g\')\n s = s.replace(\'8\',\'h\').replace(\'9\',\'i\')\n return s\n```\n\nAN "Actual" Solution:\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n for i in range(26,0,-1):\n s = s.replace(str(i)+"#", chr(ord("a")+i-1)) if i>9 else s.replace(str(i), chr(ord("a")+i-1))\n return s\n``` | 4 | You are given a string `s` formed by digits and `'#'`. We want to map `s` to English lowercase characters as follows:
* Characters (`'a'` to `'i'`) are represented by (`'1'` to `'9'`) respectively.
* Characters (`'j'` to `'z'`) are represented by (`'10#'` to `'26#'`) respectively.
Return _the string formed after mapping_.
The test cases are generated so that a unique mapping will always exist.
**Example 1:**
**Input:** s = "10#11#12 "
**Output:** "jkab "
**Explanation:** "j " -> "10# " , "k " -> "11# " , "a " -> "1 " , "b " -> "2 ".
**Example 2:**
**Input:** s = "1326# "
**Output:** "acz "
**Constraints:**
* `1 <= s.length <= 1000`
* `s` consists of digits and the `'#'` letter.
* `s` will be a valid string such that mapping is always possible. | Think of it as a graph problem. We need to find a topological order on the dependency graph. Build two graphs, one for the groups and another for the items. |
Just replace 26 times - STUPID Python solution | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | \n# Code\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n s = s.replace(\'10#\',\'j\').replace(\'11#\',\'k\').replace(\'12#\',\'l\').replace(\'13#\',\'m\').replace(\'14#\',\'n\').replace(\'15#\',\'o\')\n s = s.replace(\'16#\',\'p\').replace(\'17#\',\'q\').replace(\'18#\',\'r\').replace(\'19#\',\'s\').replace(\'20#\',\'t\').replace(\'21#\',\'u\')\n s = s.replace(\'22#\',\'v\').replace(\'23#\',\'w\').replace(\'24#\',\'x\').replace(\'25#\',\'y\').replace(\'26#\',\'z\')\n s = s.replace(\'1\',\'a\').replace(\'2\',\'b\').replace(\'3\',\'c\').replace(\'4\',\'d\').replace(\'5\',\'e\').replace(\'6\',\'f\').replace(\'7\',\'g\')\n s = s.replace(\'8\',\'h\').replace(\'9\',\'i\')\n return s\n```\n\nAN "Actual" Solution:\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n for i in range(26,0,-1):\n s = s.replace(str(i)+"#", chr(ord("a")+i-1)) if i>9 else s.replace(str(i), chr(ord("a")+i-1))\n return s\n``` | 4 | There are `n` people and `40` types of hats labeled from `1` to `40`.
Given a 2D integer array `hats`, where `hats[i]` is a list of all hats preferred by the `ith` person.
Return _the number of ways that the `n` people wear different hats to each other_.
Since the answer may be too large, return it modulo `109 + 7`.
**Example 1:**
**Input:** hats = \[\[3,4\],\[4,5\],\[5\]\]
**Output:** 1
**Explanation:** There is only one way to choose hats given the conditions.
First person choose hat 3, Second person choose hat 4 and last one hat 5.
**Example 2:**
**Input:** hats = \[\[3,5,1\],\[3,5\]\]
**Output:** 4
**Explanation:** There are 4 ways to choose hats:
(3,5), (5,3), (1,3) and (1,5)
**Example 3:**
**Input:** hats = \[\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\]\]
**Output:** 24
**Explanation:** Each person can choose hats labeled from 1 to 4.
Number of Permutations of (1,2,3,4) = 24.
**Constraints:**
* `n == hats.length`
* `1 <= n <= 10`
* `1 <= hats[i].length <= 40`
* `1 <= hats[i][j] <= 40`
* `hats[i]` contains a list of **unique** integers. | Scan from right to left, in each step of the scanning check whether there is a trailing "#" 2 indexes away. |
[Python] Simple and easy solution | 96% faster | help of ascii code | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | ```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n ans = ""\n i = len(s)-1\n while i>=0:\n if s[i]=="#":\n ans = ans + chr(int(s[i-2:i])+96)\n i=i-2\n else:\n ans = ans + chr(int(s[i])+96)\n i -= 1\n return ans[::-1]\n \n```\n\n1. comment if you face any problem understanding the solution.\n1. upvote if you find it helpful | 29 | You are given a string `s` formed by digits and `'#'`. We want to map `s` to English lowercase characters as follows:
* Characters (`'a'` to `'i'`) are represented by (`'1'` to `'9'`) respectively.
* Characters (`'j'` to `'z'`) are represented by (`'10#'` to `'26#'`) respectively.
Return _the string formed after mapping_.
The test cases are generated so that a unique mapping will always exist.
**Example 1:**
**Input:** s = "10#11#12 "
**Output:** "jkab "
**Explanation:** "j " -> "10# " , "k " -> "11# " , "a " -> "1 " , "b " -> "2 ".
**Example 2:**
**Input:** s = "1326# "
**Output:** "acz "
**Constraints:**
* `1 <= s.length <= 1000`
* `s` consists of digits and the `'#'` letter.
* `s` will be a valid string such that mapping is always possible. | Think of it as a graph problem. We need to find a topological order on the dependency graph. Build two graphs, one for the groups and another for the items. |
[Python] Simple and easy solution | 96% faster | help of ascii code | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | ```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n ans = ""\n i = len(s)-1\n while i>=0:\n if s[i]=="#":\n ans = ans + chr(int(s[i-2:i])+96)\n i=i-2\n else:\n ans = ans + chr(int(s[i])+96)\n i -= 1\n return ans[::-1]\n \n```\n\n1. comment if you face any problem understanding the solution.\n1. upvote if you find it helpful | 29 | There are `n` people and `40` types of hats labeled from `1` to `40`.
Given a 2D integer array `hats`, where `hats[i]` is a list of all hats preferred by the `ith` person.
Return _the number of ways that the `n` people wear different hats to each other_.
Since the answer may be too large, return it modulo `109 + 7`.
**Example 1:**
**Input:** hats = \[\[3,4\],\[4,5\],\[5\]\]
**Output:** 1
**Explanation:** There is only one way to choose hats given the conditions.
First person choose hat 3, Second person choose hat 4 and last one hat 5.
**Example 2:**
**Input:** hats = \[\[3,5,1\],\[3,5\]\]
**Output:** 4
**Explanation:** There are 4 ways to choose hats:
(3,5), (5,3), (1,3) and (1,5)
**Example 3:**
**Input:** hats = \[\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\]\]
**Output:** 24
**Explanation:** Each person can choose hats labeled from 1 to 4.
Number of Permutations of (1,2,3,4) = 24.
**Constraints:**
* `n == hats.length`
* `1 <= n <= 10`
* `1 <= hats[i].length <= 40`
* `1 <= hats[i][j] <= 40`
* `hats[i]` contains a list of **unique** integers. | Scan from right to left, in each step of the scanning check whether there is a trailing "#" 2 indexes away. |
Decrypt String from Alphabet to Integer Mapping | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | python 3\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n out = []\n res=[]\n i= 0 \n while i <len(s)-2: \n if s[i+2] == "#":\n out.append(s[i:i+2]+"#")\n i+=3\n else:\n out.append(s[i])\n i+=1\n out.append(s[i:])\n for i in out :\n if "#"in i :\n res.append(chr(ord("a")+(int(i[:-1])-1)))\n else:\n for j in i:\n res.append(chr(ord("a")+int(j)-1))\n return "".join(res)\n```\n\nO(N)\nsol\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n res=[]\n i= 0 \n while i <len(s): \n if i + 2 < len(s) and s[i+2] == "#" :\n res.append(chr(int(s[i:i + 2]) + 96)) \n i+=3\n \n else:\n res.append(chr(96+int(s[i])))\n i+=1\n\n return "".join(res)\n \n``` | 1 | You are given a string `s` formed by digits and `'#'`. We want to map `s` to English lowercase characters as follows:
* Characters (`'a'` to `'i'`) are represented by (`'1'` to `'9'`) respectively.
* Characters (`'j'` to `'z'`) are represented by (`'10#'` to `'26#'`) respectively.
Return _the string formed after mapping_.
The test cases are generated so that a unique mapping will always exist.
**Example 1:**
**Input:** s = "10#11#12 "
**Output:** "jkab "
**Explanation:** "j " -> "10# " , "k " -> "11# " , "a " -> "1 " , "b " -> "2 ".
**Example 2:**
**Input:** s = "1326# "
**Output:** "acz "
**Constraints:**
* `1 <= s.length <= 1000`
* `s` consists of digits and the `'#'` letter.
* `s` will be a valid string such that mapping is always possible. | Think of it as a graph problem. We need to find a topological order on the dependency graph. Build two graphs, one for the groups and another for the items. |
Decrypt String from Alphabet to Integer Mapping | decrypt-string-from-alphabet-to-integer-mapping | 0 | 1 | python 3\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n out = []\n res=[]\n i= 0 \n while i <len(s)-2: \n if s[i+2] == "#":\n out.append(s[i:i+2]+"#")\n i+=3\n else:\n out.append(s[i])\n i+=1\n out.append(s[i:])\n for i in out :\n if "#"in i :\n res.append(chr(ord("a")+(int(i[:-1])-1)))\n else:\n for j in i:\n res.append(chr(ord("a")+int(j)-1))\n return "".join(res)\n```\n\nO(N)\nsol\n```\nclass Solution:\n def freqAlphabets(self, s: str) -> str:\n res=[]\n i= 0 \n while i <len(s): \n if i + 2 < len(s) and s[i+2] == "#" :\n res.append(chr(int(s[i:i + 2]) + 96)) \n i+=3\n \n else:\n res.append(chr(96+int(s[i])))\n i+=1\n\n return "".join(res)\n \n``` | 1 | There are `n` people and `40` types of hats labeled from `1` to `40`.
Given a 2D integer array `hats`, where `hats[i]` is a list of all hats preferred by the `ith` person.
Return _the number of ways that the `n` people wear different hats to each other_.
Since the answer may be too large, return it modulo `109 + 7`.
**Example 1:**
**Input:** hats = \[\[3,4\],\[4,5\],\[5\]\]
**Output:** 1
**Explanation:** There is only one way to choose hats given the conditions.
First person choose hat 3, Second person choose hat 4 and last one hat 5.
**Example 2:**
**Input:** hats = \[\[3,5,1\],\[3,5\]\]
**Output:** 4
**Explanation:** There are 4 ways to choose hats:
(3,5), (5,3), (1,3) and (1,5)
**Example 3:**
**Input:** hats = \[\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\],\[1,2,3,4\]\]
**Output:** 24
**Explanation:** Each person can choose hats labeled from 1 to 4.
Number of Permutations of (1,2,3,4) = 24.
**Constraints:**
* `n == hats.length`
* `1 <= n <= 10`
* `1 <= hats[i].length <= 40`
* `1 <= hats[i][j] <= 40`
* `hats[i]` contains a list of **unique** integers. | Scan from right to left, in each step of the scanning check whether there is a trailing "#" 2 indexes away. |
Simple explanation with Prefix Sum in Python3 / TypeScript | xor-queries-of-a-subarray | 0 | 1 | # Intuition\nLet\'s briefly explain what the problem is:\n- there\'s a list of `arr`, that has as particular item as an **interval** `[left, right]`\n- our goal is to find **a XOR prefix** from `left` to `right` according to `queries` list \n\nThe first idea we could come up with is to iterate over `queries` and **brute force** a particular interval. This\'ll be a result of **TLE**, because of large amount of data (since it leads to **TC** more than **O(N^2)**).\n\nTo avoid **useless computations** lets define a **Prefix of XOR\'s**.\n\n```\n# For particular [left, right] we could find an accumulated XOR as\n\nXOR[i] = prefix[left] ^ prefix[right + 1]\n\n# We include right + 1 to cover all parts of a particular interval.\n# Thus we should initialize a Prefix XOR\'s with [0, arr[i]] \n```\n\n# Approach\n1. define `ans` to store a result\n2. define `prefix` with `[0, arr[i]]` \n3. fill the `prefix` as `prefix[i] ^ arr[i]`\n4. iterate over `queries` and find a **calculated XOR** at each step\n5. return `ans`\n\n# Complexity\n- Time complexity: **O(N + K)**, where `N` - size of `arr` and `K` - size of `queries` \n\n- Space complexity: **O(N + K)**, the same for storing\n\n# Code in Python3\n```\nclass Solution:\n def xorQueries(self, arr: List[int], queries: List[List[int]]) -> List[int]:\n ans = []\n prefix = [0, arr[0]]\n\n for i in range(1, len(arr)): \n prefix.append(prefix[i] ^ arr[i])\n\n for left, right in queries: \n ans.append(prefix[left] ^ prefix[right + 1])\n\n return ans\n```\n# Code in TypeScript\n```\nfunction xorQueries(arr: number[], queries: number[][]): number[] {\n const ans = []\n const prefix = [0, arr[0]]\n\n for (let i = 1; i < arr.length; i++)\n prefix.push(prefix[i] ^ arr[i])\n\n for (const [left, right] of queries)\n ans.push(prefix[left] ^ prefix[right + 1])\n\n return ans\n};\n``` | 1 | You are given an array `arr` of positive integers. You are also given the array `queries` where `queries[i] = [lefti, righti]`.
For each query `i` compute the **XOR** of elements from `lefti` to `righti` (that is, `arr[lefti] XOR arr[lefti + 1] XOR ... XOR arr[righti]` ).
Return an array `answer` where `answer[i]` is the answer to the `ith` query.
**Example 1:**
**Input:** arr = \[1,3,4,8\], queries = \[\[0,1\],\[1,2\],\[0,3\],\[3,3\]\]
**Output:** \[2,7,14,8\]
**Explanation:**
The binary representation of the elements in the array are:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
The XOR values for queries are:
\[0,1\] = 1 xor 3 = 2
\[1,2\] = 3 xor 4 = 7
\[0,3\] = 1 xor 3 xor 4 xor 8 = 14
\[3,3\] = 8
**Example 2:**
**Input:** arr = \[4,8,2,10\], queries = \[\[2,3\],\[1,3\],\[0,0\],\[0,3\]\]
**Output:** \[8,0,4,4\]
**Constraints:**
* `1 <= arr.length, queries.length <= 3 * 104`
* `1 <= arr[i] <= 109`
* `queries[i].length == 2`
* `0 <= lefti <= righti < arr.length` | Simulate the process. Return to refill the container once you meet a plant that needs more water than you have. |
Python3 | Bit Manipulation Trick O(N + M) Time and O(N) Space Solution! | xor-queries-of-a-subarray | 0 | 1 | ```\nclass Solution:\n #Let n = len(arr) and m = len(queries)!\n #Time-Complexity: O(n + m)\n #Space-Complexity: O(n)\n def xorQueries(self, arr: List[int], queries: List[List[int]]) -> List[int]:\n #Approach: To get prefix exclusive or from L to R indices, you can first get prefix exclusive\n #ors from index 0 to last index position in-bouds! Then, to get exclusive or using elements\n #from arr from L to R, then take prefix[L-1] ^ prefix[R] -> (arr[0] ^ arr[1] ^...^arr[L-1]) ^\n #(arr[0] ^ arr[1] ^...^arr[R]) -> the pairs of arr[0] to arr[L-1] will exclusive or to 0 ->\n #chain of 0 exclusive ors -> the result is arr[L] ^ arr[L+1] ^...^arr[R]!\n \n #initialize prefix exclusive or with first element of input array!\n prefix_or = [arr[0]]\n for i in range(1, len(arr)):\n prefix_or.append(prefix_or[i-1] ^ arr[i])\n #intialize answer!\n ans = []\n for L, R in queries:\n L_one_less = None\n if(L == 0):\n ans.append(prefix_or[R])\n continue\n L_one_less = prefix_or[L-1]\n sub_res = prefix_or[R]\n res = L_one_less ^ sub_res\n ans.append(res)\n return ans | 0 | You are given an array `arr` of positive integers. You are also given the array `queries` where `queries[i] = [lefti, righti]`.
For each query `i` compute the **XOR** of elements from `lefti` to `righti` (that is, `arr[lefti] XOR arr[lefti + 1] XOR ... XOR arr[righti]` ).
Return an array `answer` where `answer[i]` is the answer to the `ith` query.
**Example 1:**
**Input:** arr = \[1,3,4,8\], queries = \[\[0,1\],\[1,2\],\[0,3\],\[3,3\]\]
**Output:** \[2,7,14,8\]
**Explanation:**
The binary representation of the elements in the array are:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
The XOR values for queries are:
\[0,1\] = 1 xor 3 = 2
\[1,2\] = 3 xor 4 = 7
\[0,3\] = 1 xor 3 xor 4 xor 8 = 14
\[3,3\] = 8
**Example 2:**
**Input:** arr = \[4,8,2,10\], queries = \[\[2,3\],\[1,3\],\[0,0\],\[0,3\]\]
**Output:** \[8,0,4,4\]
**Constraints:**
* `1 <= arr.length, queries.length <= 3 * 104`
* `1 <= arr[i] <= 109`
* `queries[i].length == 2`
* `0 <= lefti <= righti < arr.length` | Simulate the process. Return to refill the container once you meet a plant that needs more water than you have. |
Python Solution using Prefix XOR||O(N+Q)|/O(N+Q)||🐍✔ | xor-queries-of-a-subarray | 0 | 1 | \n\n# Complexity\n- Time complexity:\nO(N+Q)\n- Space complexity:\nO(N+Q)\n# Code\n```\nclass Solution:\n def xorQueries(self, arr: List[int], queries: List[List[int]]) -> List[int]:\n pxor = [0] * (len(arr)+1)\n n=len(arr)\n for i in range(n):\n pxor[i]=pxor[i-1]^arr[i]#taking prefix xor ;O(N) time \n return [pxor[j] ^ pxor[i-1] for i, j in queries]#returning each query ; O(N+Q)\n \n```\nIf you like the solution, please upvote, thank you!\uD83D\uDE2C | 1 | You are given an array `arr` of positive integers. You are also given the array `queries` where `queries[i] = [lefti, righti]`.
For each query `i` compute the **XOR** of elements from `lefti` to `righti` (that is, `arr[lefti] XOR arr[lefti + 1] XOR ... XOR arr[righti]` ).
Return an array `answer` where `answer[i]` is the answer to the `ith` query.
**Example 1:**
**Input:** arr = \[1,3,4,8\], queries = \[\[0,1\],\[1,2\],\[0,3\],\[3,3\]\]
**Output:** \[2,7,14,8\]
**Explanation:**
The binary representation of the elements in the array are:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
The XOR values for queries are:
\[0,1\] = 1 xor 3 = 2
\[1,2\] = 3 xor 4 = 7
\[0,3\] = 1 xor 3 xor 4 xor 8 = 14
\[3,3\] = 8
**Example 2:**
**Input:** arr = \[4,8,2,10\], queries = \[\[2,3\],\[1,3\],\[0,0\],\[0,3\]\]
**Output:** \[8,0,4,4\]
**Constraints:**
* `1 <= arr.length, queries.length <= 3 * 104`
* `1 <= arr[i] <= 109`
* `queries[i].length == 2`
* `0 <= lefti <= righti < arr.length` | Simulate the process. Return to refill the container once you meet a plant that needs more water than you have. |
Python3 O(N) solution with prefix xor (95.34% Runtime) | xor-queries-of-a-subarray | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nUtilize accumulatd XOR to compute XOR in range [i, j] in constant time\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- Update the given array "arr" to contain accumulated XOR result (prefix)\n- Then for query [i, j] you can immeidately calculate ans[i] which is arr[j] ^ arr[i-1]\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\nIf this solution is similar to yours or helpful, upvote me if you don\'t mind\n```\nclass Solution:\n def xorQueries(self, arr: List[int], queries: List[List[int]]) -> List[int]:\n l = len(arr)\n for i in range(1, l):\n arr[i] = arr[i] ^ arr[i-1]\n\n lq = len(queries)\n ans = [0] * lq\n\n for i in range(lq):\n i1, i2 = queries[i]\n\n if i1 > 0:\n ans[i] = arr[i2] ^ arr[i1-1]\n else:\n ans[i] = arr[i2]\n\n return ans\n``` | 0 | You are given an array `arr` of positive integers. You are also given the array `queries` where `queries[i] = [lefti, righti]`.
For each query `i` compute the **XOR** of elements from `lefti` to `righti` (that is, `arr[lefti] XOR arr[lefti + 1] XOR ... XOR arr[righti]` ).
Return an array `answer` where `answer[i]` is the answer to the `ith` query.
**Example 1:**
**Input:** arr = \[1,3,4,8\], queries = \[\[0,1\],\[1,2\],\[0,3\],\[3,3\]\]
**Output:** \[2,7,14,8\]
**Explanation:**
The binary representation of the elements in the array are:
1 = 0001
3 = 0011
4 = 0100
8 = 1000
The XOR values for queries are:
\[0,1\] = 1 xor 3 = 2
\[1,2\] = 3 xor 4 = 7
\[0,3\] = 1 xor 3 xor 4 xor 8 = 14
\[3,3\] = 8
**Example 2:**
**Input:** arr = \[4,8,2,10\], queries = \[\[2,3\],\[1,3\],\[0,0\],\[0,3\]\]
**Output:** \[8,0,4,4\]
**Constraints:**
* `1 <= arr.length, queries.length <= 3 * 104`
* `1 <= arr[i] <= 109`
* `queries[i].length == 2`
* `0 <= lefti <= righti < arr.length` | Simulate the process. Return to refill the container once you meet a plant that needs more water than you have. |
SIMPLE PYTHON SOLUTION USING BFS TRAVERSAL | get-watched-videos-by-your-friends | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n dct=defaultdict(lambda :0)\n n=len(friends)\n st=[(id,0)]\n visited=[0]*n\n visited[id]=1\n while st:\n x,d=st.pop(0)\n for i in friends[x]:\n if visited[i]==0 and d+1<=level:\n if d+1==level:\n for j in watchedVideos[i]:\n dct[j]+=1\n st.append((i,d+1))\n visited[i]=1\n lst=sorted(dct,key=lambda x: (dct[x],x))\n return lst\n\n\n``` | 1 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
SIMPLE PYTHON SOLUTION USING BFS TRAVERSAL | get-watched-videos-by-your-friends | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n dct=defaultdict(lambda :0)\n n=len(friends)\n st=[(id,0)]\n visited=[0]*n\n visited[id]=1\n while st:\n x,d=st.pop(0)\n for i in friends[x]:\n if visited[i]==0 and d+1<=level:\n if d+1==level:\n for j in watchedVideos[i]:\n dct[j]+=1\n st.append((i,d+1))\n visited[i]=1\n lst=sorted(dct,key=lambda x: (dct[x],x))\n return lst\n\n\n``` | 1 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Python 3 || 6 lines, bfs, Counter || T/S: 93% / 78% | get-watched-videos-by-your-friends | 0 | 1 | Here\'s the plan:\n- We keep track of the nodes not visited in our *bfs* with `unseen`.\n- The first `row` in our *bfs* is `id`. We construct each subsequent `row` using the current`row`.\n- We we arrive at the *level*`row`, we use a counter to do the required sort.\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]],\n friends: List[List[int]], id: int, level: int) -> List[str]:\n\n unseen = set(range(len(watchedVideos))) - (row:={id})\n\n for _ in range(level):\n unseen-= row\n row = set(chain(*[friends[r] for r in row])) & unseen\n\n ctr = Counter(chain(*[watchedVideos[r] for r in row]))\n return sorted(ctr.keys(), key = lambda x: (ctr[x],x)) \n```\n[https://leetcode.com/problems/get-watched-videos-by-your-friends/submissions/1114681551/](http://)\n\n\nI could be wrong, but I think that time complexity is *O*(*NM*) and space complexity is *O*(*NM*), in which *N* ~ `len(friends)` and *M* ~ the count of all movies. | 5 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Python 3 || 6 lines, bfs, Counter || T/S: 93% / 78% | get-watched-videos-by-your-friends | 0 | 1 | Here\'s the plan:\n- We keep track of the nodes not visited in our *bfs* with `unseen`.\n- The first `row` in our *bfs* is `id`. We construct each subsequent `row` using the current`row`.\n- We we arrive at the *level*`row`, we use a counter to do the required sort.\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]],\n friends: List[List[int]], id: int, level: int) -> List[str]:\n\n unseen = set(range(len(watchedVideos))) - (row:={id})\n\n for _ in range(level):\n unseen-= row\n row = set(chain(*[friends[r] for r in row])) & unseen\n\n ctr = Counter(chain(*[watchedVideos[r] for r in row]))\n return sorted(ctr.keys(), key = lambda x: (ctr[x],x)) \n```\n[https://leetcode.com/problems/get-watched-videos-by-your-friends/submissions/1114681551/](http://)\n\n\nI could be wrong, but I think that time complexity is *O*(*NM*) and space complexity is *O*(*NM*), in which *N* ~ `len(friends)` and *M* ~ the count of all movies. | 5 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
🤯 [Python] Easy Logic | BFS using Deque + Set + Defaultdict | Codeplug | get-watched-videos-by-your-friends | 0 | 1 | **Upvote if it helped :)**\n\n# Intuition\nWe need to visit the nearest neighbours when we talk about level, this suggests that we should be using BFS with queue.\n\n# Approach\nWe reduce the level as we iterate and when the level is 1, we count all the videos watched by friends at that level using a defaultdict.\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n videos = defaultdict(int)\n q = deque([id])\n visited = set([id])\n\n while level > 0:\n for _ in range(len(q)):\n person = q.popleft()\n\n for friend in friends[person]:\n if friend not in visited:\n visited.add(friend)\n q.append(friend)\n\n if level == 1:\n for vid in watchedVideos[friend]:\n videos[vid] += 1\n \n level -= 1\n\n return sorted(list(videos.keys()), key = lambda k: (videos[k], k))\n``` | 1 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
🤯 [Python] Easy Logic | BFS using Deque + Set + Defaultdict | Codeplug | get-watched-videos-by-your-friends | 0 | 1 | **Upvote if it helped :)**\n\n# Intuition\nWe need to visit the nearest neighbours when we talk about level, this suggests that we should be using BFS with queue.\n\n# Approach\nWe reduce the level as we iterate and when the level is 1, we count all the videos watched by friends at that level using a defaultdict.\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n videos = defaultdict(int)\n q = deque([id])\n visited = set([id])\n\n while level > 0:\n for _ in range(len(q)):\n person = q.popleft()\n\n for friend in friends[person]:\n if friend not in visited:\n visited.add(friend)\n q.append(friend)\n\n if level == 1:\n for vid in watchedVideos[friend]:\n videos[vid] += 1\n \n level -= 1\n\n return sorted(list(videos.keys()), key = lambda k: (videos[k], k))\n``` | 1 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Simple Python3 Solution | Easy to understand | get-watched-videos-by-your-friends | 0 | 1 | # Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n d = deque() # deque for bfs\n videos = [] # videos on searched level\n\n d.appendleft((0, id)) \n visited = {id} # mem visited nodes\n\n while d:\n lvl, i = d.pop()\n\n if lvl == level:\n videos.append(watchedVideos[i])\n else:\n for val in friends[i]:\n if val not in visited:\n d.appendleft((lvl + 1, val))\n visited.add(val)\n\n freq = defaultdict(int)\n\n for val in videos:\n for video in val:\n freq[video] += 1\n\n h = []\n\n for key, val in freq.items():\n heapq.heappush(h, (val, key))\n\n res = []\n\n while h:\n _, key = heapq.heappop(h)\n res.append(key)\n\n return res\n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Simple Python3 Solution | Easy to understand | get-watched-videos-by-your-friends | 0 | 1 | # Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n d = deque() # deque for bfs\n videos = [] # videos on searched level\n\n d.appendleft((0, id)) \n visited = {id} # mem visited nodes\n\n while d:\n lvl, i = d.pop()\n\n if lvl == level:\n videos.append(watchedVideos[i])\n else:\n for val in friends[i]:\n if val not in visited:\n d.appendleft((lvl + 1, val))\n visited.add(val)\n\n freq = defaultdict(int)\n\n for val in videos:\n for video in val:\n freq[video] += 1\n\n h = []\n\n for key, val in freq.items():\n heapq.heappush(h, (val, key))\n\n res = []\n\n while h:\n _, key = heapq.heappop(h)\n res.append(key)\n\n return res\n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Python | BFS | get-watched-videos-by-your-friends | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n """\n BFS:\n Start with\n - queue containing id\n Perform level (k) times of level order BFS traversals\n At the end of BFS, the queue should contain all level k acquantainces\n Iterate through the queue and count the frequency of each video watched (use hashmap to count)\n Return list of watched videos sorted by frequency\n """\n N = len(watchedVideos)\n queue = deque([id])\n visited = set([id])\n for _ in range(level):\n for _ in range(len(queue)):\n curr_id = queue.popleft()\n for friend_id in friends[curr_id]:\n if friend_id in visited:\n continue\n visited.add(friend_id)\n queue.append(friend_id)\n \n view_count = Counter()\n for person_id in queue:\n for video in watchedVideos[person_id]:\n view_count[video] += 1\n \n return sorted(view_count, key=lambda x: (view_count[x], x)) # Sort by views first, then lexographically\n\n # Time Complexity: O(N * M) at worst case as we may need to traverse all N friend nodes and add M videos, M is max videos of a person\n # Space Complexity: O(N + M) for queue and M possible videos\n\n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Python | BFS | get-watched-videos-by-your-friends | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n """\n BFS:\n Start with\n - queue containing id\n Perform level (k) times of level order BFS traversals\n At the end of BFS, the queue should contain all level k acquantainces\n Iterate through the queue and count the frequency of each video watched (use hashmap to count)\n Return list of watched videos sorted by frequency\n """\n N = len(watchedVideos)\n queue = deque([id])\n visited = set([id])\n for _ in range(level):\n for _ in range(len(queue)):\n curr_id = queue.popleft()\n for friend_id in friends[curr_id]:\n if friend_id in visited:\n continue\n visited.add(friend_id)\n queue.append(friend_id)\n \n view_count = Counter()\n for person_id in queue:\n for video in watchedVideos[person_id]:\n view_count[video] += 1\n \n return sorted(view_count, key=lambda x: (view_count[x], x)) # Sort by views first, then lexographically\n\n # Time Complexity: O(N * M) at worst case as we may need to traverse all N friend nodes and add M videos, M is max videos of a person\n # Space Complexity: O(N + M) for queue and M possible videos\n\n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Python3 Clean BFS Solution | get-watched-videos-by-your-friends | 0 | 1 | \n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, wv: List[List[str]], fnds: List[List[int]], id: int, level: int) -> List[str]:\n \n \n n=len(wv)\n adj=defaultdict(list)\n \n for i in range(n):\n for x in fnds[i]:\n adj[i].append(x)\n \n \n q=deque([id])\n seen=set([id])\n h=0\n \n while q:\n for i in range(len(q)):\n curr=q.popleft()\n for child in adj[curr]:\n if child not in seen:\n seen.add(child)\n q.append(child)\n \n h+=1\n if h==level:\n break\n \n \n count=Counter()\n for friend in q:\n for video in wv[friend]:\n count[video]+=1\n \n return sorted(count.keys(), key=lambda x:(count[x],x))\n \n \n \n \n \n \n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Python3 Clean BFS Solution | get-watched-videos-by-your-friends | 0 | 1 | \n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, wv: List[List[str]], fnds: List[List[int]], id: int, level: int) -> List[str]:\n \n \n n=len(wv)\n adj=defaultdict(list)\n \n for i in range(n):\n for x in fnds[i]:\n adj[i].append(x)\n \n \n q=deque([id])\n seen=set([id])\n h=0\n \n while q:\n for i in range(len(q)):\n curr=q.popleft()\n for child in adj[curr]:\n if child not in seen:\n seen.add(child)\n q.append(child)\n \n h+=1\n if h==level:\n break\n \n \n count=Counter()\n for friend in q:\n for video in wv[friend]:\n count[video]+=1\n \n return sorted(count.keys(), key=lambda x:(count[x],x))\n \n \n \n \n \n \n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Python - BFS + sorting | get-watched-videos-by-your-friends | 0 | 1 | # Intuition\nThink of this as graph problem where each person is graph node, do the simple BFS and count levels, measure frequency of values on target level. Sort the way it is explained in problem statement.\nI did level start from 1 so I don\'t need to use L+1 in comparisons to children (node to) level!\n\n# Complexity\n- Time complexity:\n$$O(nV)$$ - n is number of nodes in graph, V is number of videos watched by each of nodes\n\n- Space complexity:\n$$O(n)$$\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], root: int, level: int) -> List[str]:\n seen, qu, count, L = {root}, [root], Counter(), 1\n while qu:\n new_qu = []\n for node in qu:\n for to in friends[node]:\n if to not in seen and L <= level: \n new_qu.append(to)\n seen.add(to)\n if L == level: count += Counter(watchedVideos[to])\n L += 1\n qu = new_qu\n\n return sorted(count, key=lambda x: (count[x], x))\n \n\n \n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Python - BFS + sorting | get-watched-videos-by-your-friends | 0 | 1 | # Intuition\nThink of this as graph problem where each person is graph node, do the simple BFS and count levels, measure frequency of values on target level. Sort the way it is explained in problem statement.\nI did level start from 1 so I don\'t need to use L+1 in comparisons to children (node to) level!\n\n# Complexity\n- Time complexity:\n$$O(nV)$$ - n is number of nodes in graph, V is number of videos watched by each of nodes\n\n- Space complexity:\n$$O(n)$$\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], root: int, level: int) -> List[str]:\n seen, qu, count, L = {root}, [root], Counter(), 1\n while qu:\n new_qu = []\n for node in qu:\n for to in friends[node]:\n if to not in seen and L <= level: \n new_qu.append(to)\n seen.add(to)\n if L == level: count += Counter(watchedVideos[to])\n L += 1\n qu = new_qu\n\n return sorted(count, key=lambda x: (count[x], x))\n \n\n \n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Solution | get-watched-videos-by-your-friends | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n\tvector<string> watchedVideosByFriends(vector<vector<string>>& watchedVideos, vector<vector<int>>& friends, int id, int level) \n\t{\n\t\tint size_of_friends = friends.size();\n\t\tint oth_param = -1;\n\t\tint clr_var = 0;\n int ctrl_flag = -1;\n\n\t\tvector<string> my_v1;\n\t\tqueue<int> my_q1;\n\n\t\tvector<int> visited(size_of_friends, oth_param);\n\t\tmy_q1.push(id);\n\t\tvisited[id] = clr_var;\n\n\t\tfor (; !my_q1.empty(); my_q1.pop())\n {\n\t\t\tint var_1 = my_q1.front();\n\n\t\t\tfor(auto v:friends[var_1])\n\t\t\t{\n\t\t\t\tif(ctrl_flag != visited[v])\n\t\t\t\t{\n\t\t\t\t\t continue;\n\t\t\t\t}\n\t\t\t\tvisited[v] = visited[var_1] +1 ;\n\t\t\t\tmy_q1.push(v);\n\t\t\t}\n\t\t}\n\t\tunordered_map<string,int> table;\n\n\t\tfor(int i=0;i<visited.size();i++)\n\t\t{\n\t\t\tif(visited[i]==level)\n\t\t\t{\n\t\t\t\tfor(auto x:watchedVideos[i])\n\t\t\t\t{\n\t\t\t\t\ttable[x]+=1;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tvector<pair<int,string>> my_v2;\n\n\t\tfor(auto v:table){\n\t\t\tmy_v2.push_back({v.second,v.first});\n\t\t}\n\t\tsort(my_v2.begin(),my_v2.end());\n\t\tfor(auto x:my_v2){\n\t\t\tmy_v1.push_back(x.second);\n\t\t}\n\t\treturn my_v1;\n\t}\n};\n```\n\n```Python3 []\nimport collections\n\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n bfs,visited={id},{id}\n for _ in range(level):\n bfs={j for i in bfs for j in friends[i] if j not in visited}\n visited|=bfs\n freq=collections.Counter([v for idx in bfs for v in watchedVideos[idx]])\n return sorted(freq.keys(),key=lambda x:(freq[x],x))\n```\n\n```Java []\nclass Solution {\n public List<String> watchedVideosByFriends(List<List<String>> watchedVideos, int[][] friends, int id, int level) {\n LinkedList<Integer> queue = new LinkedList<Integer>();\n queue.offer(id);\n int layer = -1;\n int[] levels = new int[friends.length];\n Arrays.fill(levels, -1);\n while (!queue.isEmpty()) {\n layer++;\n int size = queue.size();\n for (int i = 0; i < size; i++) {\n int person = queue.poll();\n levels[person] = layer;\n queue.offer(person);\n }\n for (int i = 0; i < size; i++) {\n int person = queue.poll();\n for (int j = 0; j < friends[person].length; j++) {\n if (levels[friends[person][j]] == -1) {\n queue.offer(friends[person][j]);\n }\n }\n }\n if (layer == level) {\n break;\n }\n }\n List<Integer> personList = new ArrayList<Integer>();\n for (int i = 0; i < levels.length; i++) {\n if (levels[i] == level) {\n personList.add(i);\n }\n }\n if (personList.size() == 0) {\n return new ArrayList<String>();\n }\n Map<String, Integer> frequencyMap = new HashMap<String, Integer>();\n for (Integer person : personList) {\n for (String video : watchedVideos.get(person)) {\n frequencyMap.put(video, \n frequencyMap.getOrDefault(video, 0) + 1);\n }\n }\n Map<Integer, Set<String>> reverseMap = \n new TreeMap<Integer, Set<String>>();\n for (String video : frequencyMap.keySet()) {\n reverseMap.putIfAbsent(frequencyMap.get(video), \n new TreeSet<String>());\n reverseMap.get(frequencyMap.get(video)).add(video);\n }\n List<String> resultList = new ArrayList<String>();\n for (Integer frequency : reverseMap.keySet()) {\n for (String video : reverseMap.get(frequency)) {\n resultList.add(video);\n }\n }\n return resultList;\n }\n}\n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Solution | get-watched-videos-by-your-friends | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n\tvector<string> watchedVideosByFriends(vector<vector<string>>& watchedVideos, vector<vector<int>>& friends, int id, int level) \n\t{\n\t\tint size_of_friends = friends.size();\n\t\tint oth_param = -1;\n\t\tint clr_var = 0;\n int ctrl_flag = -1;\n\n\t\tvector<string> my_v1;\n\t\tqueue<int> my_q1;\n\n\t\tvector<int> visited(size_of_friends, oth_param);\n\t\tmy_q1.push(id);\n\t\tvisited[id] = clr_var;\n\n\t\tfor (; !my_q1.empty(); my_q1.pop())\n {\n\t\t\tint var_1 = my_q1.front();\n\n\t\t\tfor(auto v:friends[var_1])\n\t\t\t{\n\t\t\t\tif(ctrl_flag != visited[v])\n\t\t\t\t{\n\t\t\t\t\t continue;\n\t\t\t\t}\n\t\t\t\tvisited[v] = visited[var_1] +1 ;\n\t\t\t\tmy_q1.push(v);\n\t\t\t}\n\t\t}\n\t\tunordered_map<string,int> table;\n\n\t\tfor(int i=0;i<visited.size();i++)\n\t\t{\n\t\t\tif(visited[i]==level)\n\t\t\t{\n\t\t\t\tfor(auto x:watchedVideos[i])\n\t\t\t\t{\n\t\t\t\t\ttable[x]+=1;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tvector<pair<int,string>> my_v2;\n\n\t\tfor(auto v:table){\n\t\t\tmy_v2.push_back({v.second,v.first});\n\t\t}\n\t\tsort(my_v2.begin(),my_v2.end());\n\t\tfor(auto x:my_v2){\n\t\t\tmy_v1.push_back(x.second);\n\t\t}\n\t\treturn my_v1;\n\t}\n};\n```\n\n```Python3 []\nimport collections\n\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n bfs,visited={id},{id}\n for _ in range(level):\n bfs={j for i in bfs for j in friends[i] if j not in visited}\n visited|=bfs\n freq=collections.Counter([v for idx in bfs for v in watchedVideos[idx]])\n return sorted(freq.keys(),key=lambda x:(freq[x],x))\n```\n\n```Java []\nclass Solution {\n public List<String> watchedVideosByFriends(List<List<String>> watchedVideos, int[][] friends, int id, int level) {\n LinkedList<Integer> queue = new LinkedList<Integer>();\n queue.offer(id);\n int layer = -1;\n int[] levels = new int[friends.length];\n Arrays.fill(levels, -1);\n while (!queue.isEmpty()) {\n layer++;\n int size = queue.size();\n for (int i = 0; i < size; i++) {\n int person = queue.poll();\n levels[person] = layer;\n queue.offer(person);\n }\n for (int i = 0; i < size; i++) {\n int person = queue.poll();\n for (int j = 0; j < friends[person].length; j++) {\n if (levels[friends[person][j]] == -1) {\n queue.offer(friends[person][j]);\n }\n }\n }\n if (layer == level) {\n break;\n }\n }\n List<Integer> personList = new ArrayList<Integer>();\n for (int i = 0; i < levels.length; i++) {\n if (levels[i] == level) {\n personList.add(i);\n }\n }\n if (personList.size() == 0) {\n return new ArrayList<String>();\n }\n Map<String, Integer> frequencyMap = new HashMap<String, Integer>();\n for (Integer person : personList) {\n for (String video : watchedVideos.get(person)) {\n frequencyMap.put(video, \n frequencyMap.getOrDefault(video, 0) + 1);\n }\n }\n Map<Integer, Set<String>> reverseMap = \n new TreeMap<Integer, Set<String>>();\n for (String video : frequencyMap.keySet()) {\n reverseMap.putIfAbsent(frequencyMap.get(video), \n new TreeSet<String>());\n reverseMap.get(frequencyMap.get(video)).add(video);\n }\n List<String> resultList = new ArrayList<String>();\n for (Integer frequency : reverseMap.keySet()) {\n for (String video : reverseMap.get(frequency)) {\n resultList.add(video);\n }\n }\n return resultList;\n }\n}\n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Python3 - BFS + Hash Table | get-watched-videos-by-your-friends | 0 | 1 | # Code\n```\nfrom collections import Counter\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n graph, visited, dist = {}, [], []\n n, mx = len(watchedVideos), float("inf")\n\n for i in range(n):\n graph[i] = [] \n visited.append(0)\n dist.append(mx)\n\n for i in range(n):\n for neighbor in friends[i]:\n graph[i].append(neighbor)\n graph[neighbor].append(i)\n\n queue, idx = [id], 0\n visited[id], dist[id], total = 1, 0, []\n while idx < len(queue):\n src = queue[idx]\n idx += 1\n for neighbor in graph[src]:\n if not visited[neighbor]:\n visited[neighbor] = 1\n queue.append(neighbor)\n dist[neighbor] = dist[src] + 1\n\n for i in range(n):\n if dist[i] == level:\n total += watchedVideos[i]\n\n freq, unique, combined = Counter(total), set(), {}\n for i in freq.keys():\n unique.add(freq[i])\n if combined.get(freq[i]) == None:\n combined[freq[i]] = [i]\n else:\n combined[freq[i]].append(i)\n\n for i in combined.keys():\n combined[i].sort()\n unique, ans = list(unique), []\n unique.sort()\n\n for i in unique:\n ans += combined[i]\n return ans\n\n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Python3 - BFS + Hash Table | get-watched-videos-by-your-friends | 0 | 1 | # Code\n```\nfrom collections import Counter\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n graph, visited, dist = {}, [], []\n n, mx = len(watchedVideos), float("inf")\n\n for i in range(n):\n graph[i] = [] \n visited.append(0)\n dist.append(mx)\n\n for i in range(n):\n for neighbor in friends[i]:\n graph[i].append(neighbor)\n graph[neighbor].append(i)\n\n queue, idx = [id], 0\n visited[id], dist[id], total = 1, 0, []\n while idx < len(queue):\n src = queue[idx]\n idx += 1\n for neighbor in graph[src]:\n if not visited[neighbor]:\n visited[neighbor] = 1\n queue.append(neighbor)\n dist[neighbor] = dist[src] + 1\n\n for i in range(n):\n if dist[i] == level:\n total += watchedVideos[i]\n\n freq, unique, combined = Counter(total), set(), {}\n for i in freq.keys():\n unique.add(freq[i])\n if combined.get(freq[i]) == None:\n combined[freq[i]] = [i]\n else:\n combined[freq[i]].append(i)\n\n for i in combined.keys():\n combined[i].sort()\n unique, ans = list(unique), []\n unique.sort()\n\n for i in unique:\n ans += combined[i]\n return ans\n\n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
BFS & Hashmap | get-watched-videos-by-your-friends | 0 | 1 | # Approach\nFind level level of friends by BFS.\nThen count the occurences of each movie.\nSort by frequency then name.\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, w: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n S = {id}\n q = [id]\n\n for _ in range(level):\n p = q\n q = []\n\n for u in p:\n for v in friends[u]:\n if v not in S:\n q.append(v)\n S.add(v)\n \n L = []\n\n for i in q:\n L.extend(w[i])\n \n D = Counter(L)\n return [x[0] for x in sorted(D.items(), key = itemgetter(1, 0))]\n\n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
BFS & Hashmap | get-watched-videos-by-your-friends | 0 | 1 | # Approach\nFind level level of friends by BFS.\nThen count the occurences of each movie.\nSort by frequency then name.\n\n# Code\n```\nclass Solution:\n def watchedVideosByFriends(self, w: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n S = {id}\n q = [id]\n\n for _ in range(level):\n p = q\n q = []\n\n for u in p:\n for v in friends[u]:\n if v not in S:\n q.append(v)\n S.add(v)\n \n L = []\n\n for i in q:\n L.extend(w[i])\n \n D = Counter(L)\n return [x[0] for x in sorted(D.items(), key = itemgetter(1, 0))]\n\n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Simple to understand Python code with comments and explanation. | get-watched-videos-by-your-friends | 0 | 1 | \n# Code\n```python\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n #Here is what I think:\n # - Find all friends in level k\n # - Count the frequency of each video\n # - Sort the videos based on freq\n # First let us build k_level friends\n # Level 0 friends include myself\n level_friends = [id]\n visited = set()\n visited.add(id)\n for i in range(level):\n next_level_friends = []\n for friend in level_friends:\n # We are doing a BFS to find the next level of friends\n for ff in friends[friend]:\n # To eliminate duplicate processing\n if ff not in visited:\n visited.add(ff)\n next_level_friends.append(ff)\n level_friends = next_level_friends\n # Now we should find the freq of each video\n freq = {}\n for person in level_friends:\n # We increment the video freq count for each video watched\n for video in watchedVideos[person]:\n freq[video] = freq.get(video, 0)+1\n # Now lets make a list of videos and their freq. Since we want to sort based on freq, put freq first\n ar = []\n for k,v in freq.items():\n ar.append([v,k])\n ar.sort()\n ans = []\n for cnt, video in ar:\n ans.append(video)\n return ans\n \n \n\n``` | 0 | There are `n` people, each person has a unique _id_ between `0` and `n-1`. Given the arrays `watchedVideos` and `friends`, where `watchedVideos[i]` and `friends[i]` contain the list of watched videos and the list of friends respectively for the person with `id = i`.
Level **1** of videos are all watched videos by your friends, level **2** of videos are all watched videos by the friends of your friends and so on. In general, the level `k` of videos are all watched videos by people with the shortest path **exactly** equal to `k` with you. Given your `id` and the `level` of videos, return the list of videos ordered by their frequencies (increasing). For videos with the same frequency order them alphabetically from least to greatest.
**Example 1:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 1
**Output:** \[ "B ", "C "\]
**Explanation:**
You have id = 0 (green color in the figure) and your friends are (yellow color in the figure):
Person with id = 1 -> watchedVideos = \[ "C "\]
Person with id = 2 -> watchedVideos = \[ "B ", "C "\]
The frequencies of watchedVideos by your friends are:
B -> 1
C -> 2
**Example 2:**
**Input:** watchedVideos = \[\[ "A ", "B "\],\[ "C "\],\[ "B ", "C "\],\[ "D "\]\], friends = \[\[1,2\],\[0,3\],\[0,3\],\[1,2\]\], id = 0, level = 2
**Output:** \[ "D "\]
**Explanation:**
You have id = 0 (green color in the figure) and the only friend of your friends is the person with id = 3 (yellow color in the figure).
**Constraints:**
* `n == watchedVideos.length == friends.length`
* `2 <= n <= 100`
* `1 <= watchedVideos[i].length <= 100`
* `1 <= watchedVideos[i][j].length <= 8`
* `0 <= friends[i].length < n`
* `0 <= friends[i][j] < n`
* `0 <= id < n`
* `1 <= level < n`
* if `friends[i]` contains `j`, then `friends[j]` contains `i` | Check all squares in the matrix and find the largest one. |
Simple to understand Python code with comments and explanation. | get-watched-videos-by-your-friends | 0 | 1 | \n# Code\n```python\nclass Solution:\n def watchedVideosByFriends(self, watchedVideos: List[List[str]], friends: List[List[int]], id: int, level: int) -> List[str]:\n #Here is what I think:\n # - Find all friends in level k\n # - Count the frequency of each video\n # - Sort the videos based on freq\n # First let us build k_level friends\n # Level 0 friends include myself\n level_friends = [id]\n visited = set()\n visited.add(id)\n for i in range(level):\n next_level_friends = []\n for friend in level_friends:\n # We are doing a BFS to find the next level of friends\n for ff in friends[friend]:\n # To eliminate duplicate processing\n if ff not in visited:\n visited.add(ff)\n next_level_friends.append(ff)\n level_friends = next_level_friends\n # Now we should find the freq of each video\n freq = {}\n for person in level_friends:\n # We increment the video freq count for each video watched\n for video in watchedVideos[person]:\n freq[video] = freq.get(video, 0)+1\n # Now lets make a list of videos and their freq. Since we want to sort based on freq, put freq first\n ar = []\n for k,v in freq.items():\n ar.append([v,k])\n ar.sort()\n ans = []\n for cnt, video in ar:\n ans.append(video)\n return ans\n \n \n\n``` | 0 | You are given the array `paths`, where `paths[i] = [cityAi, cityBi]` means there exists a direct path going from `cityAi` to `cityBi`. _Return the destination city, that is, the city without any path outgoing to another city._
It is guaranteed that the graph of paths forms a line without any loop, therefore, there will be exactly one destination city.
**Example 1:**
**Input:** paths = \[\[ "London ", "New York "\],\[ "New York ", "Lima "\],\[ "Lima ", "Sao Paulo "\]\]
**Output:** "Sao Paulo "
**Explanation:** Starting at "London " city you will reach "Sao Paulo " city which is the destination city. Your trip consist of: "London " -> "New York " -> "Lima " -> "Sao Paulo ".
**Example 2:**
**Input:** paths = \[\[ "B ", "C "\],\[ "D ", "B "\],\[ "C ", "A "\]\]
**Output:** "A "
**Explanation:** All possible trips are:
"D " -> "B " -> "C " -> "A ".
"B " -> "C " -> "A ".
"C " -> "A ".
"A ".
Clearly the destination city is "A ".
**Example 3:**
**Input:** paths = \[\[ "A ", "Z "\]\]
**Output:** "Z "
**Constraints:**
* `1 <= paths.length <= 100`
* `paths[i].length == 2`
* `1 <= cityAi.length, cityBi.length <= 10`
* `cityAi != cityBi`
* All strings consist of lowercase and uppercase English letters and the space character. | Do BFS to find the kth level friends. Then collect movies saw by kth level friends and sort them accordingly. |
Python3 clean Solution beats 💯 100% with Proof 🔥 | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Code\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n if s == s[::-1]: return 0 \n n = len(s)\n dp = [[0] * n for _ in range(n)]\n for i in range(n-1,-1,-1):\n dp[i][i] = 1\n for j in range(i+1,n):\n if s[i] == s[j]:dp[i][j] = dp[i+1][j-1]+2\n else: dp[i][j] = max(dp[i+1][j], dp[i][j-1])\n return n-dp[0][n-1]\n```\n# Proof \n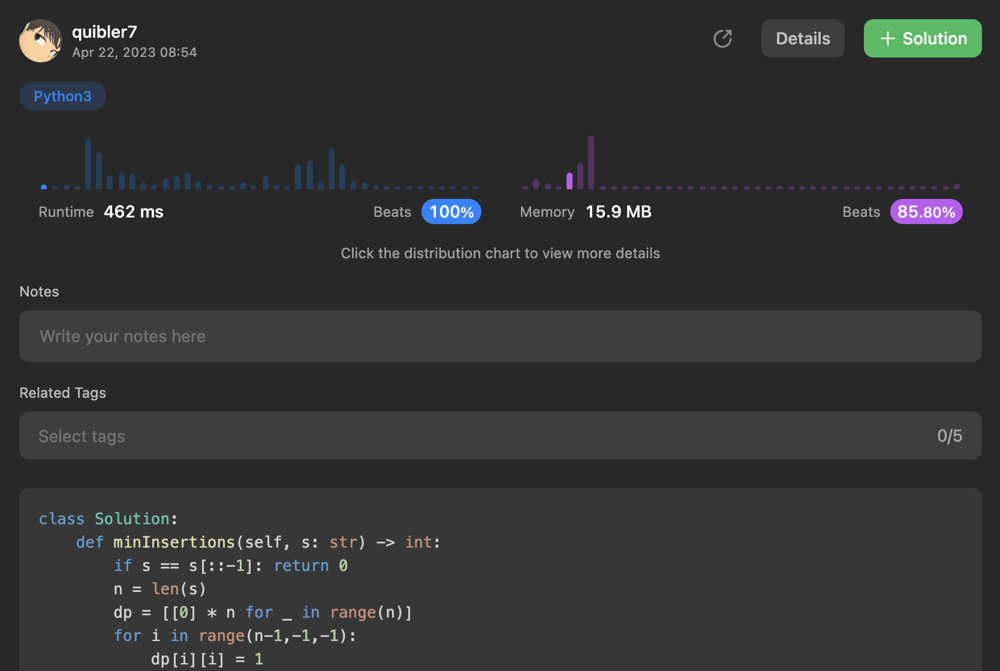\n | 3 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
Python3 clean Solution beats 💯 100% with Proof 🔥 | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Code\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n if s == s[::-1]: return 0 \n n = len(s)\n dp = [[0] * n for _ in range(n)]\n for i in range(n-1,-1,-1):\n dp[i][i] = 1\n for j in range(i+1,n):\n if s[i] == s[j]:dp[i][j] = dp[i+1][j-1]+2\n else: dp[i][j] = max(dp[i+1][j], dp[i][j-1])\n return n-dp[0][n-1]\n```\n# Proof \n\n | 3 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
[ Python ] ✅✅ Simple Python Solution Using Dynamic Programming🥳✌👍 | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # If You like the Solution, Don\'t Forget To UpVote Me, Please UpVote! \uD83D\uDD3C\uD83D\uDE4F\n# Runtime: 1317 ms, faster than 27.39% of Python3 online submissions for Minimum Insertion Steps to Make a String Palindrome.\n# Memory Usage: 16 MB, less than 67.55% of Python3 online submissions for Minimum Insertion Steps to Make a String Palindrome.\n\n\tclass Solution:\n\t\tdef minInsertions(self, s: str) -> int:\n\n\t\t\tdef LeastCommonSubsequence(string, reverse_string, row, col):\n\n\t\t\t\tdp = [[0 for _ in range(col + 1)] for _ in range(row + 1)]\n\n\t\t\t\tfor r in range(1, row + 1):\n\t\t\t\t\tfor c in range(1, col + 1):\n\n\t\t\t\t\t\tif string[r - 1] == reverse_string[c - 1]:\n\n\t\t\t\t\t\t\tdp[r][c] = dp[r - 1][c - 1] + 1\n\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tdp[r][c] = max(dp[r - 1][c] , dp[r][c - 1])\n\n\t\t\t\treturn dp[row][col]\n\n\t\t\tlength = len(s)\n\n\t\t\tresult = length - LeastCommonSubsequence(s , s[::-1] , length , length)\n\n\t\t\treturn result\n\t\t\t\n# Thank You \uD83E\uDD73\u270C\uD83D\uDC4D | 1 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
[ Python ] ✅✅ Simple Python Solution Using Dynamic Programming🥳✌👍 | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # If You like the Solution, Don\'t Forget To UpVote Me, Please UpVote! \uD83D\uDD3C\uD83D\uDE4F\n# Runtime: 1317 ms, faster than 27.39% of Python3 online submissions for Minimum Insertion Steps to Make a String Palindrome.\n# Memory Usage: 16 MB, less than 67.55% of Python3 online submissions for Minimum Insertion Steps to Make a String Palindrome.\n\n\tclass Solution:\n\t\tdef minInsertions(self, s: str) -> int:\n\n\t\t\tdef LeastCommonSubsequence(string, reverse_string, row, col):\n\n\t\t\t\tdp = [[0 for _ in range(col + 1)] for _ in range(row + 1)]\n\n\t\t\t\tfor r in range(1, row + 1):\n\t\t\t\t\tfor c in range(1, col + 1):\n\n\t\t\t\t\t\tif string[r - 1] == reverse_string[c - 1]:\n\n\t\t\t\t\t\t\tdp[r][c] = dp[r - 1][c - 1] + 1\n\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tdp[r][c] = max(dp[r - 1][c] , dp[r][c - 1])\n\n\t\t\t\treturn dp[row][col]\n\n\t\t\tlength = len(s)\n\n\t\t\tresult = length - LeastCommonSubsequence(s , s[::-1] , length , length)\n\n\t\t\treturn result\n\t\t\t\n# Thank You \uD83E\uDD73\u270C\uD83D\uDC4D | 1 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
Ex-Amazon explains a solution with a video, Python, JavaScript, Java and C++ | minimum-insertion-steps-to-make-a-string-palindrome | 1 | 1 | # My youtube channel - KeetCode(Ex-Amazon)\nI create 155 videos for leetcode questions as of April 24, 2023. I believe my channel helps you prepare for the coming technical interviews. Please subscribe my channel!\n\n### Please subscribe my channel - KeetCode(Ex-Amazon) from here.\n\n**I created a video for this question. I believe you can understand easily with visualization.** \n\n**My youtube channel - KeetCode(Ex-Amazon)**\nThere is my channel link under picture in LeetCode profile.\nhttps://leetcode.com/niits/\n\n\n\n\n# Intuition\nUse 1D dynamic programming to store minimum steps\n\n# Approach\n1. Get the length of the input string s and store it in a variable n.\n\n2. Create a list dp of length n filled with zeros to store the dynamic programming values.\n\n3. Loop through the indices of the string s from n - 2 to 0 in reverse order using for i in range(n - 2, -1, -1):.\n\n4. Inside the outer loop, initialize a variable prev to 0 to keep track of the previous dynamic programming value.\n\n5. Loop through the indices of the string s from i + 1 to n using for j in range(i + 1, n):.\n\n6. Inside the inner loop, store the current dynamic programming value in a temporary variable temp for future reference.\n\n7. Check if the characters at indices i and j in the string s are the same using if s[i] == s[j]:.\n\n8. If the characters are the same, update the dynamic programming value at index j in the dp list with the previous dynamic programming value prev.\n\n9. If the characters are different, update the dynamic programming value at index j in the dp list with the minimum of the dynamic programming values at index j and j-1 in the dp list, incremented by 1.\n\n10. Update the prev variable with the temporary variable temp.\n\n11. After the inner loop completes, the dynamic programming values in the dp list represent the minimum number of insertions needed to make s a palindrome.\n\n12. Return the dynamic programming value at index n-1 in the dp list as the final result. This represents the minimum number of insertions needed to make the entire string s a palindrome.\n\n\n---\n\n\n**If you don\'t understand the algorithm, let\'s check my video solution.\nThere is my channel link under picture in LeetCode profile.**\nhttps://leetcode.com/niits/\n\n\n---\n\n# Complexity\n- Time complexity: O(n^2)\nn is the length of the input string \'s\'. This is because there are two nested loops. The outer loop runs from n-2 to 0, and the inner loop runs from i+1 to n-1. In the worst case, the inner loop iterates n-1 times for each value of i, resulting in a total of (n-2) + (n-3) + ... + 1 = n(n-1)/2 iterations. Therefore, the overall time complexity is O(n^2).\n\n- Space complexity: O(n)\nn is the length of the input string \'s\'. This is because the code uses an array \'dp\' of size n to store the minimum number of insertions required at each position in \'s\'. Hence, the space complexity is linear with respect to the length of the input string.\n\n# Python\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n n = len(s)\n dp = [0] * n\n\n for i in range(n - 2, -1, -1):\n prev = 0\n\n for j in range(i + 1, n):\n temp = dp[j]\n\n if s[i] == s[j]:\n dp[j] = prev\n else:\n dp[j] = min(dp[j], dp[j-1]) + 1\n \n prev = temp\n \n return dp[n-1]\n```\n# JavaScript\n```\n/**\n * @param {string} s\n * @return {number}\n */\nvar minInsertions = function(s) {\n const n = s.length;\n const dp = new Array(n).fill(0);\n\n for (let i = n - 2; i >= 0; i--) {\n let prev = 0;\n\n for (let j = i + 1; j < n; j++) {\n const temp = dp[j];\n\n if (s[i] === s[j]) {\n dp[j] = prev;\n } else {\n dp[j] = Math.min(dp[j], dp[j-1]) + 1;\n }\n\n prev = temp;\n }\n }\n\n return dp[n-1]; \n};\n```\n# Java\n```\nclass Solution {\n public int minInsertions(String s) {\n int n = s.length();\n int[] dp = new int[n];\n\n for (int i = n - 2; i >= 0; i--) {\n int prev = 0;\n\n for (int j = i + 1; j < n; j++) {\n int temp = dp[j];\n\n if (s.charAt(i) == s.charAt(j)) {\n dp[j] = prev;\n } else {\n dp[j] = Math.min(dp[j], dp[j-1]) + 1;\n }\n\n prev = temp;\n }\n }\n\n return dp[n-1]; \n }\n}\n```\n# C++\n```\nclass Solution {\npublic:\n int minInsertions(string s) {\n int n = s.length();\n vector<int> dp(n, 0);\n\n for (int i = n - 2; i >= 0; i--) {\n int prev = 0;\n\n for (int j = i + 1; j < n; j++) {\n int temp = dp[j];\n\n if (s[i] == s[j]) {\n dp[j] = prev;\n } else {\n dp[j] = min(dp[j], dp[j-1]) + 1;\n }\n\n prev = temp;\n }\n }\n\n return dp[n-1]; \n }\n};\n``` | 1 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
Ex-Amazon explains a solution with a video, Python, JavaScript, Java and C++ | minimum-insertion-steps-to-make-a-string-palindrome | 1 | 1 | # My youtube channel - KeetCode(Ex-Amazon)\nI create 155 videos for leetcode questions as of April 24, 2023. I believe my channel helps you prepare for the coming technical interviews. Please subscribe my channel!\n\n### Please subscribe my channel - KeetCode(Ex-Amazon) from here.\n\n**I created a video for this question. I believe you can understand easily with visualization.** \n\n**My youtube channel - KeetCode(Ex-Amazon)**\nThere is my channel link under picture in LeetCode profile.\nhttps://leetcode.com/niits/\n\n\n\n\n# Intuition\nUse 1D dynamic programming to store minimum steps\n\n# Approach\n1. Get the length of the input string s and store it in a variable n.\n\n2. Create a list dp of length n filled with zeros to store the dynamic programming values.\n\n3. Loop through the indices of the string s from n - 2 to 0 in reverse order using for i in range(n - 2, -1, -1):.\n\n4. Inside the outer loop, initialize a variable prev to 0 to keep track of the previous dynamic programming value.\n\n5. Loop through the indices of the string s from i + 1 to n using for j in range(i + 1, n):.\n\n6. Inside the inner loop, store the current dynamic programming value in a temporary variable temp for future reference.\n\n7. Check if the characters at indices i and j in the string s are the same using if s[i] == s[j]:.\n\n8. If the characters are the same, update the dynamic programming value at index j in the dp list with the previous dynamic programming value prev.\n\n9. If the characters are different, update the dynamic programming value at index j in the dp list with the minimum of the dynamic programming values at index j and j-1 in the dp list, incremented by 1.\n\n10. Update the prev variable with the temporary variable temp.\n\n11. After the inner loop completes, the dynamic programming values in the dp list represent the minimum number of insertions needed to make s a palindrome.\n\n12. Return the dynamic programming value at index n-1 in the dp list as the final result. This represents the minimum number of insertions needed to make the entire string s a palindrome.\n\n\n---\n\n\n**If you don\'t understand the algorithm, let\'s check my video solution.\nThere is my channel link under picture in LeetCode profile.**\nhttps://leetcode.com/niits/\n\n\n---\n\n# Complexity\n- Time complexity: O(n^2)\nn is the length of the input string \'s\'. This is because there are two nested loops. The outer loop runs from n-2 to 0, and the inner loop runs from i+1 to n-1. In the worst case, the inner loop iterates n-1 times for each value of i, resulting in a total of (n-2) + (n-3) + ... + 1 = n(n-1)/2 iterations. Therefore, the overall time complexity is O(n^2).\n\n- Space complexity: O(n)\nn is the length of the input string \'s\'. This is because the code uses an array \'dp\' of size n to store the minimum number of insertions required at each position in \'s\'. Hence, the space complexity is linear with respect to the length of the input string.\n\n# Python\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n n = len(s)\n dp = [0] * n\n\n for i in range(n - 2, -1, -1):\n prev = 0\n\n for j in range(i + 1, n):\n temp = dp[j]\n\n if s[i] == s[j]:\n dp[j] = prev\n else:\n dp[j] = min(dp[j], dp[j-1]) + 1\n \n prev = temp\n \n return dp[n-1]\n```\n# JavaScript\n```\n/**\n * @param {string} s\n * @return {number}\n */\nvar minInsertions = function(s) {\n const n = s.length;\n const dp = new Array(n).fill(0);\n\n for (let i = n - 2; i >= 0; i--) {\n let prev = 0;\n\n for (let j = i + 1; j < n; j++) {\n const temp = dp[j];\n\n if (s[i] === s[j]) {\n dp[j] = prev;\n } else {\n dp[j] = Math.min(dp[j], dp[j-1]) + 1;\n }\n\n prev = temp;\n }\n }\n\n return dp[n-1]; \n};\n```\n# Java\n```\nclass Solution {\n public int minInsertions(String s) {\n int n = s.length();\n int[] dp = new int[n];\n\n for (int i = n - 2; i >= 0; i--) {\n int prev = 0;\n\n for (int j = i + 1; j < n; j++) {\n int temp = dp[j];\n\n if (s.charAt(i) == s.charAt(j)) {\n dp[j] = prev;\n } else {\n dp[j] = Math.min(dp[j], dp[j-1]) + 1;\n }\n\n prev = temp;\n }\n }\n\n return dp[n-1]; \n }\n}\n```\n# C++\n```\nclass Solution {\npublic:\n int minInsertions(string s) {\n int n = s.length();\n vector<int> dp(n, 0);\n\n for (int i = n - 2; i >= 0; i--) {\n int prev = 0;\n\n for (int j = i + 1; j < n; j++) {\n int temp = dp[j];\n\n if (s[i] == s[j]) {\n dp[j] = prev;\n } else {\n dp[j] = min(dp[j], dp[j-1]) + 1;\n }\n\n prev = temp;\n }\n }\n\n return dp[n-1]; \n }\n};\n``` | 1 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
Short simple python solution using DP | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Code\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n dp=[[-1]*501 for _ in range(501)]\n def dfs(i,j):\n if i>j or i==j:\n return 0\n if dp[i][j]!=-1:\n return dp[i][j]\n if s[i]==s[j]:\n dp[i][j]=dfs(i+1,j-1)\n else:\n dp[i][j]=min(dfs(i,j-1),dfs(i+1,j))+1\n return dp[i][j]\n return dfs(0,len(s)-1)\n``` | 1 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
Short simple python solution using DP | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Code\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n dp=[[-1]*501 for _ in range(501)]\n def dfs(i,j):\n if i>j or i==j:\n return 0\n if dp[i][j]!=-1:\n return dp[i][j]\n if s[i]==s[j]:\n dp[i][j]=dfs(i+1,j-1)\n else:\n dp[i][j]=min(dfs(i,j-1),dfs(i+1,j))+1\n return dp[i][j]\n return dfs(0,len(s)-1)\n``` | 1 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
python 3 - top down dp | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Intuition\nLogic is straightforward.\n\nstate variable = left, right\nDo all combination of left and right -> DP should be used.\nIf s[left] == s[right], skip both left and right. Else, add either s[left] or s[right] and repeat the process.\n\n# Approach\ntop-down dp\n\n# Complexity\n- Time complexity:\nO(n^2) -> dp on all states.\n\n- Space complexity:\nO(n^2) -> cache size\n\n# Code\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n\n @lru_cache(None)\n def dp(l, r): # return min step\n if l >= r:\n return 0\n \n if s[l] == s[r]:\n return dp(l+1, r-1)\n\n else: # add left or right\n t1 = dp(l+1, r) + 1\n t2 = dp(l, r-1) + 1\n return min(t1, t2)\n \n return dp(0, len(s) - 1)\n``` | 1 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
python 3 - top down dp | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Intuition\nLogic is straightforward.\n\nstate variable = left, right\nDo all combination of left and right -> DP should be used.\nIf s[left] == s[right], skip both left and right. Else, add either s[left] or s[right] and repeat the process.\n\n# Approach\ntop-down dp\n\n# Complexity\n- Time complexity:\nO(n^2) -> dp on all states.\n\n- Space complexity:\nO(n^2) -> cache size\n\n# Code\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n\n @lru_cache(None)\n def dp(l, r): # return min step\n if l >= r:\n return 0\n \n if s[l] == s[r]:\n return dp(l+1, r-1)\n\n else: # add left or right\n t1 = dp(l+1, r) + 1\n t2 = dp(l, r-1) + 1\n return min(t1, t2)\n \n return dp(0, len(s) - 1)\n``` | 1 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
Python Top Down Memoization Solution | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | ```\neg: leetcode \nWe try to insert at both ends if not equal\n\n1. Insert to the right and match \'l\', cost is 1 then check remaining string : 1 + rec(i+1,j)\n2. Insert to left and match \'e\' , cost is 1 then check the remaining string : 1+rec(i,j-1)\n3. if the ends are the same character , no cost : rec(i+1,j) \n```\n\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n @lru_cache(None)\n def rec(i,j):\n if(i>=j ) : return 0\n elif(s[i]==s[j]): return rec(i+1,j-1) \n else: return 1+ min( rec(i+1,j) , rec(i,j-1))\n return rec(0,len(s)-1)\n\n``` | 1 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
Python Top Down Memoization Solution | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | ```\neg: leetcode \nWe try to insert at both ends if not equal\n\n1. Insert to the right and match \'l\', cost is 1 then check remaining string : 1 + rec(i+1,j)\n2. Insert to left and match \'e\' , cost is 1 then check the remaining string : 1+rec(i,j-1)\n3. if the ends are the same character , no cost : rec(i+1,j) \n```\n\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n @lru_cache(None)\n def rec(i,j):\n if(i>=j ) : return 0\n elif(s[i]==s[j]): return rec(i+1,j-1) \n else: return 1+ min( rec(i+1,j) , rec(i,j-1))\n return rec(0,len(s)-1)\n\n``` | 1 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
Python easy 7-liner | DP | Top-down & Bottom-up | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Code\n\n***Top Down***\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n @lru_cache(None)\n def dp(i, j):\n if i >= j:\n return 0\n\n if s[i] == s[j]:\n return dp(i+1, j-1)\n else:\n return 1+min(dp(i+1, j), dp(i, j-1))\n\n return dp(0, len(s)-1)\n```\n\n***Bottom-up***\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n n = len(s)\n dp = [[0 for _ in range(n)] for _ in range(2)]\n i = 0\n for i in range(n-2, -1, -1):\n for j in range(i+1, n):\n if s[i] == s[j]:\n dp[i%2][j] = dp[(i+1)%2][j-1]\n else:\n dp[i%2][j] = 1+min(dp[(i+1)%2][j], dp[i%2][j-1])\n\n return dp[i%2][n-1]\n```\nNote: To reduce space complexity, matrix of 2xn is used here. Same can be achieved using nxn matrix which is easy to interpret.\n\nOR (same as above)\n\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n n = len(s)\n dp = [[0 for _ in range(n)] for _ in range(2)]\n \n i = 0\n for i in range(n-2, -1, -1):\n for j in range(i+1, n):\n dp[i%2][j] = dp[(i+1)%2][j-1] if s[i] == s[j] else 1+min(dp[(i+1)%2][j], dp[i%2][j-1])\n \n return dp[i%2][n-1]\n```\n | 1 | Given a string `s`. In one step you can insert any character at any index of the string.
Return _the minimum number of steps_ to make `s` palindrome.
A **Palindrome String** is one that reads the same backward as well as forward.
**Example 1:**
**Input:** s = "zzazz "
**Output:** 0
**Explanation:** The string "zzazz " is already palindrome we do not need any insertions.
**Example 2:**
**Input:** s = "mbadm "
**Output:** 2
**Explanation:** String can be "mbdadbm " or "mdbabdm ".
**Example 3:**
**Input:** s = "leetcode "
**Output:** 5
**Explanation:** Inserting 5 characters the string becomes "leetcodocteel ".
**Constraints:**
* `1 <= s.length <= 500`
* `s` consists of lowercase English letters. | Check if each coordinate of each artifact has been excavated. How can we do this quickly without iterating over the dig array every time? Consider marking all excavated cells in a 2D boolean array. |
Python easy 7-liner | DP | Top-down & Bottom-up | minimum-insertion-steps-to-make-a-string-palindrome | 0 | 1 | # Code\n\n***Top Down***\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n @lru_cache(None)\n def dp(i, j):\n if i >= j:\n return 0\n\n if s[i] == s[j]:\n return dp(i+1, j-1)\n else:\n return 1+min(dp(i+1, j), dp(i, j-1))\n\n return dp(0, len(s)-1)\n```\n\n***Bottom-up***\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n n = len(s)\n dp = [[0 for _ in range(n)] for _ in range(2)]\n i = 0\n for i in range(n-2, -1, -1):\n for j in range(i+1, n):\n if s[i] == s[j]:\n dp[i%2][j] = dp[(i+1)%2][j-1]\n else:\n dp[i%2][j] = 1+min(dp[(i+1)%2][j], dp[i%2][j-1])\n\n return dp[i%2][n-1]\n```\nNote: To reduce space complexity, matrix of 2xn is used here. Same can be achieved using nxn matrix which is easy to interpret.\n\nOR (same as above)\n\n```\nclass Solution:\n def minInsertions(self, s: str) -> int:\n n = len(s)\n dp = [[0 for _ in range(n)] for _ in range(2)]\n \n i = 0\n for i in range(n-2, -1, -1):\n for j in range(i+1, n):\n dp[i%2][j] = dp[(i+1)%2][j-1] if s[i] == s[j] else 1+min(dp[(i+1)%2][j], dp[i%2][j-1])\n \n return dp[i%2][n-1]\n```\n | 1 | Given an binary array `nums` and an integer `k`, return `true` _if all_ `1`_'s are at least_ `k` _places away from each other, otherwise return_ `false`.
**Example 1:**
**Input:** nums = \[1,0,0,0,1,0,0,1\], k = 2
**Output:** true
**Explanation:** Each of the 1s are at least 2 places away from each other.
**Example 2:**
**Input:** nums = \[1,0,0,1,0,1\], k = 2
**Output:** false
**Explanation:** The second 1 and third 1 are only one apart from each other.
**Constraints:**
* `1 <= nums.length <= 105`
* `0 <= k <= nums.length`
* `nums[i]` is `0` or `1` | Is dynamic programming suitable for this problem ? If we know the longest palindromic sub-sequence is x and the length of the string is n then, what is the answer to this problem? It is n - x as we need n - x insertions to make the remaining characters also palindrome. |
Easy Python Solution || Let's Decompress Run-Length Encoded List....... | decompress-run-length-encoded-list | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem involves decompressing a run-length encoded list. Run-length encoding represents consecutive elements with the same value as a single pair of value and frequency. The goal is to reconstruct the original list.\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- We iterate through pairs of elements in the input list.\n- For each pair, the first element is the frequency, and the second element is the value.\n- We append the value to the decompressed list \'frequency\' times.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nThe time complexity is O(n), where n is the length of the input list. This is because we iterate through each pair of elements once.\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nThe space complexity is also O(n), where n is the length of the input list. The additional space is used to store the decompressed list.\n# Code\n```\nclass Solution:\n def decompressRLElist(self, nums: List[int]) -> List[int]:\n # Initialize an empty list to store the decompressed elements\n decompressed = []\n \n # Iterate through pairs of elements in the input list\n for i in range(len(nums)//2):\n # Extract the frequency and value from the pair\n frequency = nums[2*i]\n value = nums[2*i+1]\n \n # Append the value to the decompressed list \'frequency\' times\n decompressed += [value]*frequency\n \n # Return the final decompressed list\n return decompressed\n\n```\n\n---\n# I hope this helped you. If so, please do upvote me.\n\n---\n\n | 3 | We are given a list `nums` of integers representing a list compressed with run-length encoding.
Consider each adjacent pair of elements `[freq, val] = [nums[2*i], nums[2*i+1]]` (with `i >= 0`). For each such pair, there are `freq` elements with value `val` concatenated in a sublist. Concatenate all the sublists from left to right to generate the decompressed list.
Return the decompressed list.
**Example 1:**
**Input:** nums = \[1,2,3,4\]
**Output:** \[2,4,4,4\]
**Explanation:** The first pair \[1,2\] means we have freq = 1 and val = 2 so we generate the array \[2\].
The second pair \[3,4\] means we have freq = 3 and val = 4 so we generate \[4,4,4\].
At the end the concatenation \[2\] + \[4,4,4\] is \[2,4,4,4\].
**Example 2:**
**Input:** nums = \[1,1,2,3\]
**Output:** \[1,3,3\]
**Constraints:**
* `2 <= nums.length <= 100`
* `nums.length % 2 == 0`
* `1 <= nums[i] <= 100` | Use dynamic programming. Let dp[i] be the number of ways to solve the problem for the subtree of node i. Imagine you are trying to fill an array with the order of traversal, dp[i] equals the multiplications of the number of ways to distribute the subtrees of the children of i on the array using combinatorics, multiplied bu their dp values. |
Python 😎😀😎 || Faster than 97.88% & Memory beats 98.41% | decompress-run-length-encoded-list | 0 | 1 | Plz upvote if you find this helpful and I\'ll upvote your comment or your posts! : )\n# Code\n```\nclass Solution:\n def decompressRLElist(self, nums: List[int]) -> List[int]:\n generated = [] # just a starter array\n for i in range(0, len(nums), 2): # skip by 2 because...\n freq = nums[i]\n val = nums[i+1] # that\'s why\n generated += [val] * freq # shortcut to get freq vals\n return generated\n```\n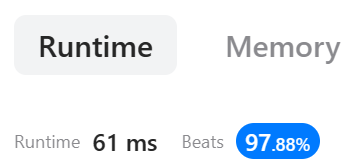\n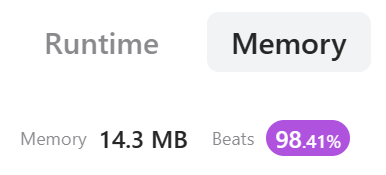\n | 14 | We are given a list `nums` of integers representing a list compressed with run-length encoding.
Consider each adjacent pair of elements `[freq, val] = [nums[2*i], nums[2*i+1]]` (with `i >= 0`). For each such pair, there are `freq` elements with value `val` concatenated in a sublist. Concatenate all the sublists from left to right to generate the decompressed list.
Return the decompressed list.
**Example 1:**
**Input:** nums = \[1,2,3,4\]
**Output:** \[2,4,4,4\]
**Explanation:** The first pair \[1,2\] means we have freq = 1 and val = 2 so we generate the array \[2\].
The second pair \[3,4\] means we have freq = 3 and val = 4 so we generate \[4,4,4\].
At the end the concatenation \[2\] + \[4,4,4\] is \[2,4,4,4\].
**Example 2:**
**Input:** nums = \[1,1,2,3\]
**Output:** \[1,3,3\]
**Constraints:**
* `2 <= nums.length <= 100`
* `nums.length % 2 == 0`
* `1 <= nums[i] <= 100` | Use dynamic programming. Let dp[i] be the number of ways to solve the problem for the subtree of node i. Imagine you are trying to fill an array with the order of traversal, dp[i] equals the multiplications of the number of ways to distribute the subtrees of the children of i on the array using combinatorics, multiplied bu their dp values. |
Decompress run length encoded list | decompress-run-length-encoded-list | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n\n\n# Code\n```\nclass Solution:\n def decompressRLElist(self, nums: List[int]) -> List[int]:\n res=[]\n for i in range(0,len(nums),2):\n freq=nums[i]\n val=nums[i+1]\n res+=[val]*freq\n return res\n \n``` | 2 | We are given a list `nums` of integers representing a list compressed with run-length encoding.
Consider each adjacent pair of elements `[freq, val] = [nums[2*i], nums[2*i+1]]` (with `i >= 0`). For each such pair, there are `freq` elements with value `val` concatenated in a sublist. Concatenate all the sublists from left to right to generate the decompressed list.
Return the decompressed list.
**Example 1:**
**Input:** nums = \[1,2,3,4\]
**Output:** \[2,4,4,4\]
**Explanation:** The first pair \[1,2\] means we have freq = 1 and val = 2 so we generate the array \[2\].
The second pair \[3,4\] means we have freq = 3 and val = 4 so we generate \[4,4,4\].
At the end the concatenation \[2\] + \[4,4,4\] is \[2,4,4,4\].
**Example 2:**
**Input:** nums = \[1,1,2,3\]
**Output:** \[1,3,3\]
**Constraints:**
* `2 <= nums.length <= 100`
* `nums.length % 2 == 0`
* `1 <= nums[i] <= 100` | Use dynamic programming. Let dp[i] be the number of ways to solve the problem for the subtree of node i. Imagine you are trying to fill an array with the order of traversal, dp[i] equals the multiplications of the number of ways to distribute the subtrees of the children of i on the array using combinatorics, multiplied bu their dp values. |
Python Solution | Beginners Friendly | Explained | decompress-run-length-encoded-list | 0 | 1 | 1. Create an empty list `res`.\n2. Iterate in the Range of floor division of length of the `nums` by `2` (`range(len(nums)//2)`)\n3. Create two variables and assign them the values of `nums[2*i]` and `nums[(2*i)+1` respectively\n4. Iterate again in the range of `freq + 1`.\n5. At last Condition the value in the loop that `j>=1` and then append the `val` number of times the `freq` is. \n\n```\nclass Solution:\n def decompressRLElist(self, nums: List[int]) -> List[int]:\n res =[]\n for i in range(len(nums)//2):\n freq,val = nums[2*i] , nums[(2*i)+1]\n for j in range(freq+1):\n if j >=1 :\n res.append(val)\n return res\n \n```\n\n**Upvote if you like the solution.** | 6 | We are given a list `nums` of integers representing a list compressed with run-length encoding.
Consider each adjacent pair of elements `[freq, val] = [nums[2*i], nums[2*i+1]]` (with `i >= 0`). For each such pair, there are `freq` elements with value `val` concatenated in a sublist. Concatenate all the sublists from left to right to generate the decompressed list.
Return the decompressed list.
**Example 1:**
**Input:** nums = \[1,2,3,4\]
**Output:** \[2,4,4,4\]
**Explanation:** The first pair \[1,2\] means we have freq = 1 and val = 2 so we generate the array \[2\].
The second pair \[3,4\] means we have freq = 3 and val = 4 so we generate \[4,4,4\].
At the end the concatenation \[2\] + \[4,4,4\] is \[2,4,4,4\].
**Example 2:**
**Input:** nums = \[1,1,2,3\]
**Output:** \[1,3,3\]
**Constraints:**
* `2 <= nums.length <= 100`
* `nums.length % 2 == 0`
* `1 <= nums[i] <= 100` | Use dynamic programming. Let dp[i] be the number of ways to solve the problem for the subtree of node i. Imagine you are trying to fill an array with the order of traversal, dp[i] equals the multiplications of the number of ways to distribute the subtrees of the children of i on the array using combinatorics, multiplied bu their dp values. |
Python/JS/Go/C++ O( m*n ) Integral Image // DP [ w/ Explanation ] | matrix-block-sum | 0 | 1 | O( m*n ) sol. based on integral image technique ( 2D DP ).\n\n---\n\n**Explanation on integral image**:\n\nHere we use the technique of **integral image**, which is introduced to **speed up block computation**.\n\nAlso, this technique is practical and common in the field of matrix operation and image processing such as [filtering](https://docs.opencv.org/master/d4/d86/group__imgproc__filter.html#gad533230ebf2d42509547d514f7d3fbc3) and feature extraction.\n\nBlock sum formula on integral image.\n **Block-sum** of **red rectangle** = **block-sum of D - block-sum of B - block-sum of C + block-sum of A**\n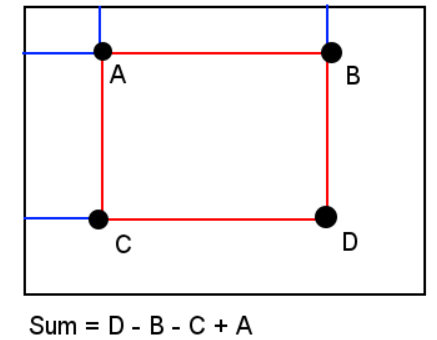\n\n---\n\n**Example** of integral image ( focus on the purple block ).\n\n\n\n\n\n---\n\n**Implementation**:\n\n**Python**:\n\n```\nclass Solution:\n def matrixBlockSum(self, mat: List[List[int]], K: int) -> List[List[int]]:\n \n h, w = len(mat), len( mat[0])\n integral_image = [ [ 0 for y in range(w) ] for x in range(h) ]\n \n\n # building integral image to speed up block sum computation\n for y in range(0, h):\n summation = 0\n \n for x in range(0, w):\n summation += mat[y][x]\n integral_image[y][x] = summation\n \n if y > 0:\n integral_image[y][x] += integral_image[y-1][x]\n \n \n \n # compute block sum by looking-up integral image\n output_image = [ [ 0 for y in range(w) ] for x in range(h) ]\n \n for y in range(h):\n for x in range(w):\n \n min_row, max_row = max( 0, y-K), min( h-1, y+K)\n min_col, max_col = max( 0, x-K), min( w-1, x+K)\n \n output_image[y][x] = integral_image[max_row][max_col]\n \n if min_row > 0:\n output_image[y][x] -= integral_image[min_row-1][max_col]\n \n if min_col > 0:\n output_image[y][x] -= integral_image[max_row][min_col-1]\n \n if min_col > 0 and min_row > 0:\n output_image[y][x] += integral_image[min_row-1][min_col-1]\n \n return output_image\n```\n\n---\n\n**Javascript**:\n\n```\nvar matrixBlockSum = function(mat, k) {\n \n let [h, w] = [ mat.length, mat[0].length ];\n \n let integralImg = new Array(h).fill(0).map( () => new Array(w).fill(0) );\n let outputImg = new Array(h).fill(0).map( () => new Array(w).fill(0) );\n \n \n // building integral image to speed up block sum computation\n for( let y = 0 ; y < h ; y++){\n let pixelSum = 0;\n \n for( let x = 0 ; x < w ;x++){\n pixelSum += mat[y][x];\n integralImg[y][x] = pixelSum;\n \n if( y > 0 ){ \n integralImg[y][x] += integralImg[y-1][x];\n }\n }\n }\n \n \n // compute block sum by looking-up integral image\n for( let y = 0 ; y < h ; y++){\n \n let [minRow, maxRow] = [ Math.max(0, y-k), Math.min(h-1, y+k)];\n \n for( let x = 0 ; x < w ;x++){\n \n let [minCol, maxCol] = [ Math.max(0, x-k), Math.min(w-1, x+k)];\n \n outputImg[y][x] = integralImg[maxRow][maxCol];\n \n if( minRow > 0 ){\n outputImg[y][x] -= integralImg[minRow-1][maxCol];\n }\n \n if( minCol > 0 ){\n outputImg[y][x] -= integralImg[maxRow][minCol-1];\n }\n \n if( (minRow > 0) && (minCol > 0) ){\n outputImg[y][x] += integralImg[minRow-1][minCol-1];\n }\n \n \n }\n }\n \n return outputImg;\n \n \n};\n```\n\n---\n\n**C++**\n\n```\nclass Solution {\npublic:\n vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {\n\n const int h = mat.size(), w = mat[0].size();\n \n vector< vector<int> > integralImg = vector< vector<int> >(h, vector< int >(w, 0) );\n vector< vector<int> > outputImg = vector< vector<int> >(h, vector< int >(w, 0) );\n \n \n // building integral image to speed up block sum computation\n for( int y = 0 ; y < h ; y++){\n int pixelSum = 0;\n \n for( int x = 0 ; x < w ;x++){\n pixelSum += mat[y][x];\n integralImg[y][x] = pixelSum;\n \n if( y > 0 ){ \n integralImg[y][x] += integralImg[y-1][x];\n }\n }\n }\n \n \n // compute block sum by looking-up integral image\n for( int y = 0 ; y < h ; y++){\n \n const int minRow = max(0, y-k), maxRow = min(h-1, y+k);\n \n for( int x = 0 ; x < w ;x++){\n \n const int minCol = max(0, x-k), maxCol = min(w-1, x+k);\n \n outputImg[y][x] = integralImg[maxRow][maxCol];\n \n if( minRow > 0 ){\n outputImg[y][x] -= integralImg[minRow-1][maxCol];\n }\n \n if( minCol > 0 ){\n outputImg[y][x] -= integralImg[maxRow][minCol-1];\n }\n \n if( (minRow > 0) && (minCol > 0) ){\n outputImg[y][x] += integralImg[minRow-1][minCol-1];\n }\n }\n }\n \n return outputImg; \n }\n};\n```\n\n---\n\n**Go**:\n\n```\nfunc create2DArray( h, w int) [][]int{\n \n matrix := make( [][]int, h )\n row := make( []int, h * w)\n \n for y := 0 ; y < h ; y++{\n matrix[ y ] = row[ y*w : (y+1)*w ] \n }\n \n return matrix\n}\n\n\nfunc max(x, y int) int {\n if x > y {\n return x\n }else{\n return y\n }\n}\n\nfunc min(x, y int) int {\n if x < y {\n return x\n }else{\n return y\n }\n}\n\n\n\nfunc matrixBlockSum(mat [][]int, k int) [][]int {\n \n h, w := len(mat), len(mat[0])\n \n integralImg := create2DArray(h, w)\n outputImg := create2DArray(h, w)\n \n \n \n // building integral image to speed up block sum computation\n for y := 0 ; y < h ; y++{\n pixelSum := 0;\n \n for x := 0 ; x < w ;x++{\n pixelSum += mat[y][x];\n integralImg[y][x] = pixelSum;\n \n if y > 0 { \n integralImg[y][x] += integralImg[y-1][x];\n }\n }\n }\n \n \n // compute block sum by looking-up integral image\n for y := 0 ; y < h ; y++{\n \n minRow := max(0, y-k)\n maxRow := min(h-1, y+k)\n \n for x := 0 ; x < w ;x++ {\n \n minCol := max(0, x-k)\n maxCol := min(w-1, x+k)\n \n outputImg[y][x] = integralImg[maxRow][maxCol];\n \n if( minRow > 0 ){\n outputImg[y][x] -= integralImg[minRow-1][maxCol];\n }\n \n if( minCol > 0 ){\n outputImg[y][x] -= integralImg[maxRow][minCol-1];\n }\n \n if( (minRow > 0) && (minCol > 0) ){\n outputImg[y][x] += integralImg[minRow-1][minCol-1];\n }\n }\n }\n \n return outputImg; \n \n\n}\n```\n\n---\n\nShare another implementation with update function in bottom-up\n\n<details>\n\t<summary> Click to show source code</summary>\n\n```\nclass Solution:\n def matrixBlockSum(self, mat: List[List[int]], K: int) -> List[List[int]]:\n \n h, w = len(mat), len( mat[0])\n integral_image = [ [ 0 for y in range(w) ] for x in range(h) ]\n \n #-----------------------------------------\n def update(x, y):\n \n # add current pixel\n result = mat[y][x]\n \n if x:\n # add integral image of left pixel\n result += integral_image[y][x-1]\n \n if y:\n # add integral image of top pixel\n result += integral_image[y-1][x]\n\n if x and y:\n # remove repeated part of top-left pixel\n result -= integral_image[y-1][x-1]\n \n return result\n \n # ----------------------------------------\n # building integral image to speed up block sum computation\n for y in range(0, h):\n for x in range(0, w):\n integral_image[y][x] = update(x, y)\n \n \n \n # compute block sum by looking-up integral image\n output_image = [ [ 0 for y in range(w) ] for x in range(h) ]\n \n for y in range(h):\n for x in range(w):\n \n min_row, max_row = max( 0, y-K), min( h-1, y+K)\n min_col, max_col = max( 0, x-K), min( w-1, x+K)\n \n output_image[y][x] = integral_image[max_row][max_col]\n \n if min_row > 0:\n output_image[y][x] -= integral_image[min_row-1][max_col]\n \n if min_col > 0:\n output_image[y][x] -= integral_image[max_row][min_col-1]\n \n if min_col > 0 and min_row > 0:\n output_image[y][x] += integral_image[min_row-1][min_col-1]\n \n return output_image\n```\n\n</details>\n\n---\n\n**Implentation** with integral image building in top-down DP \n\n<details>\n\t<summary> Click to show source code</summary>\n\t\n```\nclass Solution:\n def matrixBlockSum(self, mat: List[List[int]], K: int) -> List[List[int]]:\n \n h, w = len(mat), len( mat[0])\n integral_image = [ [ 0 for y in range(w) ] for x in range(h) ]\n \n #-----------------------------------------\n def build_integral_image(x, y):\n \n if (x < 0) or (y < 0):\n \n ## base case:\n # zero for those pixels out of valid boundary\n return 0\n \n if integral_image[y][x]:\n ## base case:\n # direcly look-up table\n return integral_image[y][x]\n \n ## general cases\n # comptue and update integral image at (x, y)\n \n integral_image[y][x] = mat[y][x] + build_integral_image(x, y-1) + build_integral_image(x-1, y) - build_integral_image(x-1, y-1)\n \n return integral_image[y][x]\n \n # ----------------------------------------\n # building integral image to speed up block sum computation\n build_integral_image(w-1, h-1)\n \n \n # compute block sum by looking-up integral image\n output_image = [ [ 0 for y in range(w) ] for x in range(h) ]\n \n for y in range(h):\n for x in range(w):\n \n min_row, max_row = max( 0, y-K), min( h-1, y+K)\n min_col, max_col = max( 0, x-K), min( w-1, x+K)\n \n output_image[y][x] = integral_image[max_row][max_col]\n \n if min_row > 0:\n output_image[y][x] -= integral_image[min_row-1][max_col]\n \n if min_col > 0:\n output_image[y][x] -= integral_image[max_row][min_col-1]\n \n if min_col > 0 and min_row > 0:\n output_image[y][x] += integral_image[min_row-1][min_col-1]\n \n return output_image\n```\n\n</details>\n\n---\n\nRelated leetcode challenge:\n[Leetcode #304 Range Sum Query 2D - Immutable](https://leetcode.com/problems/range-sum-query-2d-immutable/)\n\n[Leetcode #303 Range Sum Query - Immutable](https://leetcode.com/problems/range-sum-query-immutable/)\n\n---\n\nReference:\n[Integral Image in wikipedia](https://en.wikipedia.org/wiki/Summed-area_table)\n\n---\n\nFurther reading:\n[1] [Integral Image in OpenCV API](https://docs.opencv.org/master/d5/de6/group__cudaarithm__reduce.html#ga07e5104eba4bf45212ac9dbc5bf72ba6)\n\n[2] [ImageJ: Integral Image Filter](https://imagej.net/Integral_Image_Filters)\n\n---\n\nThanks for your reading.\n\nWish you have a nice day.\n\nMeow~\uD83D\uDE3A | 165 | Given a `m x n` matrix `mat` and an integer `k`, return _a matrix_ `answer` _where each_ `answer[i][j]` _is the sum of all elements_ `mat[r][c]` _for_:
* `i - k <= r <= i + k,`
* `j - k <= c <= j + k`, and
* `(r, c)` is a valid position in the matrix.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\], k = 1
**Output:** \[\[12,21,16\],\[27,45,33\],\[24,39,28\]\]
**Example 2:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\], k = 2
**Output:** \[\[45,45,45\],\[45,45,45\],\[45,45,45\]\]
**Constraints:**
* `m == mat.length`
* `n == mat[i].length`
* `1 <= m, n, k <= 100`
* `1 <= mat[i][j] <= 100` | null |
Python, Two Approaches: Easy-to-understand w Explanation | matrix-block-sum | 0 | 1 | ### Approach 1: Brute Force\n\nThis is by far the simplest and shortest solution. How it works:\n\n- Loop through each ```(x, y)``` coordinate in the resultant array ```result```.\n- At each ```result[x][y]```, get the appropriate subarray from the matrix ```mat```. I.e., for each ```(x, y)``` in ```result```, get the subarray ```mat[x-k:x+k+1][y-k:y+k+1]```. Then we need to factor in the matrix length and breadth:\n\n```python\ndef getSubarray(mat: List[List[int]], x: int, y: int, k: int) -> List[List[int]]:\n\t"""\n\tPython pseudocode to obtain the following: mat[x-k:x+k+1][y-k:y+k+1].\n\tIf x - k < 0 --> Use index x = 0 instead\n\tIf y - k < 0 --> Use index y = 0 instead\n\tIf x + k >= len(mat) --> Use index x = len(mat)-1 instead\n\tIf y + k >- len(mat[0]) --> Use index y = len(mat[0])-1 instead\n\t"""\n\t# We can shorten this to:\n\treturn mat[max(x-k, 0):min(x+k+1, len(mat)][max(y-k, 0):min(y+k+1, len(mat[0])]\n```\n\n- Compute the sum of the entire subarray and save into ```result[x][y]```.\n\n```python\ndef sumOfSubarray(arr: List[List[int]]) -> int:\n\t"""\n\tPython pseudocode to calculate the sum of all the elements in the given array.\n\tresult = 0\n\tfor i in range(len(arr)):\n\t\tfor j in range(len(arr[0])):\n\t\t\tresult += arr[i][j]\n\treturn result\n\t"""\n\t# We can shorten this to:\n\treturn sum(sum(arr[i]) for i in range(len(arr)))\n```\n\nThat\'s all. You can probably optimise the runtime using sliding window technique, but this approach is the easiest to come up with.\n\n```python\nclass Solution:\n def matrixBlockSum(self, mat: List[List[int]], k: int) -> List[List[int]]:\n m, n = len(mat), len(mat[0])\n result = [[0 for _ in range(n)] for _ in range(m)]\n for i in range(m):\n for j in range(n):\n result[i][j] = sum(sum(mat[x][max(0, j-k):min(n, j+k+1)])\n for x in range(max(0, i-k), min(m, i+k+1)))\n return result\n```\n\nTime Complexity: O(mnk^2), due to the nested sum functions.\nSpace Complexity: O(1) auxillary space.\nResult: Almost 2s runtime, 15MB used space. Not great, obviously.\n\n---\n\n### Approach 2: Prefix Sum\n\n[This blog](https://computersciencesource.wordpress.com/2010/09/03/computer-vision-the-integral-image/) describes the algorithm quite well. Essentially the algorithm consists of the following:\n\n- On our first pass through the matrix ```mat```, we obtain the cumulative sum of the elements above and to the left of the current element, including the element itself.\n\nI.e., for each ```(x, y)``` in ```mat```, we obtain ```sumOfSubarray(mat[:x+1][:y+1])``` (refer to the pseudocode above). The reason why we can do this in one pass is because of DP:\n\n```python\ndef prefixSum(mat: List[List[int]]) -> List[List[int]]:\n\t"""\n\tPython pseudocode to obtain the prefix sum of the given array via DP.\n\t"""\n\tresult = mat[:][:] # essentially copies the array\n\tfor i in range(len(mat)):\n\t\tfor j in range(len(mat[0])):\n\t\t\tresult[i][j] += (result[i-1][j] if i > 0 else 0) + \\ # add prefix sum of (i-1, j), if it exists\n\t\t\t\t\t\t\t(result[i][j-1] if j > 0 else 0) + \\ # add prefix sum of (i, j-1), if it exists\n\t\t\t\t\t\t\t(result[i-1][j-1] if i > 0 and j > 0 else 0) # subtract prefix sum of (i-1, j-1), if it exists\n\treturn result\n```\n\n- Calculate the block sum at each ```(x, y)``` using the prefix sum.\n\nThe prefix sum is optimal for this task because we can actually **calculate the block sum from the prefix sum in O(1) time**, according to the formula ```S(D) + S(A) - S(B) - S(C)```. (Again, refer to [this blog](https://computersciencesource.wordpress.com/2010/09/03/computer-vision-the-integral-image/) for a more detailed explanation.) This ensures our code runs within O(mn) time, even at the cost of having to loop through the matrix again.\n\nAgain, we need to account for the matrix borders. Similar to approach 1, we can just replace all nonexistent matrix coordinates with 0, since the matrix ```mat``` only contains positive integers (```1 <= mat[i][j] <= 100```).\n\n```python\nclass Solution:\n def matrixBlockSum(self, mat: List[List[int]], k: int) -> List[List[int]]:\n m, n = len(mat), len(mat[0])\n\t\t\n\t\t# Calculate the prefix sum\n prefix = mat[:][:] # essentially copies the entire array\n for i in range(m):\n for j in range(n):\n prefix[i][j] += (prefix[i-1][j] if i > 0 else 0) + \\ # add prefix sum of (i-1, j) if it exists\n (prefix[i][j-1] if j > 0 else 0) - \\ # add prefix sum of (i, j-1) if it exists\n (prefix[i-1][j-1] if i > 0 and j > 0 else 0) # subtract prefix sum of (i-1, j-1) if it exists\n\t\t\n\t\t# Calculate the block sum from the prefix sum\n result = [[0 for _ in range(n)] for _ in range(m)]\n for i in range(m):\n for j in range(n):\n result[i][j] = prefix[min(i+k, m-1)][min(j+k, n-1)] + \\ # S(D), bounded by m x n\n (prefix[i-k-1][j-k-1] if i-k > 0 and j-k > 0 else 0) - \\ # S(A), if it exists\n (prefix[i-k-1][min(j+k, n-1)] if i-k > 0 else 0) - \\ # S(B), if it exists\n (prefix[min(i+k, m-1)][j-k-1] if j-k > 0 else 0) # S(C), if it exists\n return result\n\t\t# we could technically shorten the block sum calculation into one line of code, but that is super unreadable\n```\n\nTime Complexity: O(mn), since the calculations performed in the nested loops are of O(1) time complexity.\nSpace Complexity: O(mn) auxillary space, due to the prefix sum matrix.\n\n---\n\n### Final Result\n\n\n\nPlease upvote if this has helped you! Appreciate any comments as well :)\n | 12 | Given a `m x n` matrix `mat` and an integer `k`, return _a matrix_ `answer` _where each_ `answer[i][j]` _is the sum of all elements_ `mat[r][c]` _for_:
* `i - k <= r <= i + k,`
* `j - k <= c <= j + k`, and
* `(r, c)` is a valid position in the matrix.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\], k = 1
**Output:** \[\[12,21,16\],\[27,45,33\],\[24,39,28\]\]
**Example 2:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\], k = 2
**Output:** \[\[45,45,45\],\[45,45,45\],\[45,45,45\]\]
**Constraints:**
* `m == mat.length`
* `n == mat[i].length`
* `1 <= m, n, k <= 100`
* `1 <= mat[i][j] <= 100` | null |
Python3 || Beats 99.61% || DFS | sum-of-nodes-with-even-valued-grandparent | 0 | 1 | \n# Please UPVOTE\uD83D\uDE0A\n\n# Python3\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def sumEvenGrandparent(self, root: TreeNode) -> int:\n def dfs(root,dad,gp):\n if not root:\n return 0\n x=0\n if(gp%2==0):\n x=root.val\n x+=dfs(root.left,root.val,dad)\n x+=dfs(root.right,root.val,dad)\n return x\n\n return dfs(root,1,1)\n``` | 20 | Given the `root` of a binary tree, return _the sum of values of nodes with an **even-valued grandparent**_. If there are no nodes with an **even-valued grandparent**, return `0`.
A **grandparent** of a node is the parent of its parent if it exists.
**Example 1:**
**Input:** root = \[6,7,8,2,7,1,3,9,null,1,4,null,null,null,5\]
**Output:** 18
**Explanation:** The red nodes are the nodes with even-value grandparent while the blue nodes are the even-value grandparents.
**Example 2:**
**Input:** root = \[1\]
**Output:** 0
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `1 <= Node.val <= 100` | null |
✔💖Easiest Solution in Python || Step by step explanation | sum-of-nodes-with-even-valued-grandparent | 0 | 1 | # Approach\n**Step 1:** Create a variable **sum** which will store the sum of all the nodes which are having their grandparents wih even value.\n\n**Step 2:** Check if the root node their is their, if it is then move ahead else return 0.\n\n**Step 3:** Now check if the current node value is even, and if it is even then it means we have to addup the values of grandchildren of that current node into our sum variable. So for that we will check each for the each possible grandchildren of that current node. And as we know that there can be only 4 grandchildren possible for each node, so we will check for each of them one by one and if they are present then we will add up their value to our sum.\n\n**Step 4:** We have to recursively call each and every node using left and right of each node. At last we will return value of sum. \n\n#### PLEASE UPVOTE\u2B06 IF THIS SOLUTION HELPS YOU SOMEHOW\uD83C\uDF1F\n\n# Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n sum=0\n def sumEvenGrandparent(self, root: TreeNode) -> int:\n if not root:\n return 0\n if root.val%2==0:\n if root.left and root.left.left:\n self.sum+=root.left.left.val\n if root.left and root.left.right:\n self.sum+=root.left.right.val\n if root.right and root.right.left:\n self.sum+=root.right.left.val\n if root.right and root.right.right:\n self.sum+=root.right.right.val\n self.sumEvenGrandparent(root.left)\n self.sumEvenGrandparent(root.right)\n return self.sum\n``` | 3 | Given the `root` of a binary tree, return _the sum of values of nodes with an **even-valued grandparent**_. If there are no nodes with an **even-valued grandparent**, return `0`.
A **grandparent** of a node is the parent of its parent if it exists.
**Example 1:**
**Input:** root = \[6,7,8,2,7,1,3,9,null,1,4,null,null,null,5\]
**Output:** 18
**Explanation:** The red nodes are the nodes with even-value grandparent while the blue nodes are the even-value grandparents.
**Example 2:**
**Input:** root = \[1\]
**Output:** 0
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `1 <= Node.val <= 100` | null |
Recursive | Time Complexity - O(N) | sum-of-nodes-with-even-valued-grandparent | 0 | 1 | Please upvote if you like the solution .\n\n```\nclass Solution:\n def sumEvenGrandparent(self, root: TreeNode) -> int:\n def helper(grandparent, parent, node):\n if not node:return\n if grandparent and grandparent.val%2 == 0:self.ans += node.val\n helper(parent, node, node.left)\n helper(parent, node, node.right)\n \n self.ans = 0\n helper(None, None, root)\n return self.ans\n``` | 2 | Given the `root` of a binary tree, return _the sum of values of nodes with an **even-valued grandparent**_. If there are no nodes with an **even-valued grandparent**, return `0`.
A **grandparent** of a node is the parent of its parent if it exists.
**Example 1:**
**Input:** root = \[6,7,8,2,7,1,3,9,null,1,4,null,null,null,5\]
**Output:** 18
**Explanation:** The red nodes are the nodes with even-value grandparent while the blue nodes are the even-value grandparents.
**Example 2:**
**Input:** root = \[1\]
**Output:** 0
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `1 <= Node.val <= 100` | null |
✅ 🔥 Python3 || ⚡easy solution | distinct-echo-substrings | 0 | 1 | ```\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n text_values = [ord(char) - 97 for char in text]\n hash_map = {}\n powers_of_26 = [1]\n \n\n for i in range(1, len(text) + 1):\n powers_of_26.append(powers_of_26[i - 1] * 26)\n \n\n for substring_length in range(1, len(text_values) // 2 + 1):\n current_hash = 0\n for k in range(0, substring_length):\n current_hash = current_hash * 26 + text_values[k]\n hash_map[(0, substring_length)] = current_hash\n \n for start_index in range(1, len(text_values) - substring_length + 1):\n\n current_hash -= text_values[start_index - 1] * powers_of_26[substring_length - 1]\n current_hash = current_hash * 26 + text_values[start_index + substring_length - 1]\n hash_map[(start_index, start_index + substring_length)] = current_hash\n\n distinct_substrings = set()\n \n\n for pair in hash_map:\n first_pair = pair\n second_pair = (pair[1], pair[1] + (first_pair[1] - first_pair[0]))\n if first_pair in hash_map and second_pair in hash_map and hash_map[first_pair] == hash_map[second_pair]:\n distinct_substrings.add((first_pair[1] - first_pair[0], hash_map[first_pair]))\n \n return len(distinct_substrings)\n\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Simple Python Code (1231ms) | distinct-echo-substrings | 0 | 1 | # Approach\n\n\n# Complexity\n- Time complexity:\n$$O(n^2)$$\nbeats ~ 70%\n\n- Space complexity:\n$$O(n)$$\nbeats ~ 31%\n\n# Code\n```\nimport math\nclass Solution:\n def distinctEchoSubstrings(self, text) :\n n = len(text)\n m = 0\n max_n = math.floor(n/2)\n substrs = set()\n for i in range(1, max_n+1) :\n for j in range(n-i-m) :\n substr = text[j:j+2*i]\n if substr[0:i] == substr[i:] :\n substrs.add(substr)\n m += 1\n return len(substrs)\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Python3 rolling hash O(n^2) Python3 | distinct-echo-substrings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n text_arr = [ord(val)-97 for val in text]\n hash_map = {}\n pow_arr = [1]\n for i in range(1,len(text)+1):\n pow_arr.append(pow_arr[i-1]*26)\n \n\n for substr_len in range(1,len(text_arr)//2 + 1):\n cur_hash = 0\n for k in range(0,substr_len):\n cur_hash = cur_hash*26+text_arr[k]\n hash_map[(0,substr_len)] = cur_hash\n for start_ind in range(1,len(text_arr)-substr_len+1):\n cur_hash -= text_arr[start_ind-1]*pow_arr[substr_len-1]\n cur_hash = cur_hash*26 + text_arr[start_ind+substr_len-1]\n hash_map[(start_ind, start_ind+substr_len)] = cur_hash\n\n\n substr_set = set()\n for pair in hash_map:\n first_pair = pair\n second_pair = (pair[1],pair[1]+(first_pair[1]-first_pair[0]))\n if first_pair in hash_map and second_pair in hash_map and hash_map[first_pair] == hash_map[second_pair]:\n substr_set.add((first_pair[1]-first_pair[0], hash_map[first_pair]))\n \n return len(substr_set)\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
My attempt towards an O(n) solution | distinct-echo-substrings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWhenever there exists a substring that meets the condition, the leading char in the second half must have been seen previously.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nAs we traverse the text char by char, recall where the same char exists before, and check if the suffix starting from those two positions matches.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nBest scenario: Not much duplicates (abcdefghij) -> O(n)\nWorst scenario: Too many duplicates (aaaaaaaaaa) -> O(n**2/2)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n# Code\n```\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n seenCharAt = defaultdict(list)\n res = set()\n for i, char in enumerate(text):\n if char in seenCharAt:\n for prevPos in seenCharAt[char]:\n suffixLen = i - prevPos\n if text[prevPos:i] == text[i:i+suffixLen]:\n res.add(text[prevPos:i+suffixLen])\n seenCharAt[char].append(i)\n return len(res)\n\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Solution | distinct-echo-substrings | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int distinctEchoSubstrings(string text) {\n unordered_set<string> result;\n int l = text.length() - 1;\n for (int i = 0; i < l; ++i) {\n const auto& substr_len = KMP(text, i, &result);\n if (substr_len != numeric_limits<int>::max()) {\n l = min(l, i + substr_len);\n }\n }\n return result.size();\n }\nprivate:\n int KMP(const string& text, int l, unordered_set<string> *result) {\n vector<int> prefix(text.length() - l, -1);\n int j = -1;\n for (int i = 1; i < prefix.size(); ++i) {\n while (j > -1 && text[l + j + 1] != text[l + i]) {\n j = prefix[j];\n }\n if (text[l + j + 1] == text[l + i]) {\n ++j;\n }\n prefix[i] = j;\n if ((j + 1) && (i + 1) % ((i + 1) - (j + 1)) == 0 &&\n (i + 1) / ((i + 1) - (j + 1)) % 2 == 0) {\n result->emplace(text.substr(l, i + 1));\n }\n }\n return (prefix.back() + 1 && (prefix.size() % (prefix.size() - (prefix.back() + 1)) == 0))\n ? (prefix.size() - (prefix.back() + 1))\n : numeric_limits<int>::max();\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n d = {}\n visited = set()\n ans = 0\n if all([t == text[0] for t in text]):\n return len(text) //2\n for (i, s) in enumerate(text):\n if s not in d:\n d[s] = [i]\n else:\n for k in d[s]:\n if text[k:i] == text[i:(2 * i - k)]:\n visited.add(text[k:i])\n break\n d[s].append(i)\n return len(visited)\n```\n\n```Java []\nclass Solution {\n public int distinctEchoSubstrings(String text) {\n Set<Long> st = new HashSet<>();\n RollingHash rh = new RollingHash(text);\n for(int i = 0; i < text.length(); i++){\n for(int j = i; j < text.length(); j++){\n if( (j-i+1) % 2 == 0){\n int mid = (i+1)+(j+1-(i+1))/2;\n if(rh.get(i+1, mid) == rh.get(mid+1, j+1)){\n st.add(rh.get(i+1, j+1));\n }\n }\n }\n }\n return st.size();\n }\n}\nclass RollingHash{\n int n;\n int base = 31;\n long[] p;\n long[] h;\n \n public RollingHash(String text){\n n = text.length();\n p = new long[n+2];\n h = new long[n+2];\n \n p[0] = 1;\n \n for(int i = 1; i <= n; i++){\n p[i] = p[i-1]*base;\n h[i] = h[i-1]*base + text.charAt(i-1);\n }\n }\n public long get(int l, int r){\n return h[r]-h[l-1]*p[r-l+1];\n } \n} \n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Fast | Python Solution | distinct-echo-substrings | 0 | 1 | # Code\n```\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n n = len(text)\n\t\t\n def helper(size):\n base = 1 << 5\n M = 10 ** 9 + 7\n a = pow(base, size, M)\n t = 0\n vis = defaultdict(set)\n vis_pattern = set()\n ans = 0\n for i in range(n):\n t = (base * t + ord(text[i]) - ord(\'a\')) % M\n if i >= size:\n t -= a * (ord(text[i - size]) - ord(\'a\'))\n t %= M\n if t not in vis_pattern and (i - size * 2 + 1) in vis[t]:\n ans += 1\n vis_pattern.add(t)\n if i >= size - 1:\n vis[t].add(i - size + 1)\n return ans\n\n return sum(helper(size) for size in range(1, n//2+1))\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Python - O(N^2) - easy to understand | distinct-echo-substrings | 0 | 1 | # Approach\necho substring is a + a. so for each text[i] for i from 0 -> len(text) -1 and for j from i -> len(text). get prefix = text[i: j + 1], suffix = text[j + 1: j + 1 + len(prefix)]. if prefix == suffix: ans.add(prefix)\n\nthen return len(ans)\n# Complexity\n- Time complexity:\nO(n^2)\n\n- Space complexity:\nO(n)\n\n# Code\n```\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n ans = set()\n\n for i in range(len(text)):\n for j in range(i, len(text)):\n prefix = text[i : j + 1]\n suffix = text[j + 1: j + 1 + len(prefix)]\n\n if prefix == suffix: \n ans.add(prefix)\n\n # print(ans) \n return len(ans)\n\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
[Python] Solution | distinct-echo-substrings | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n count=0\n dic=dict()\n for i in range(len(text)):\n a=i\n b=a+1\n for j in range(len(text[i:])):\n if text[a:b]==text[b:len(text[a:b])+b]:\n if not text[a:b] in dic:\n count+=1\n dic[text[a:b]]=0\n b+=1\n \n return count \n\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Python Hashing + Memo Solution | Easy to Understand | Faster than 60% | distinct-echo-substrings | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\n```dp[start][end]``` contains the hashing value of substring ```text[start: end + 1]```\n\nIf ```text[start: start + substrLen]``` is equal to ```text[start + substrLen: start + substrLen * 2]```, we will have ```dp[start][start + substrLen-1] == dp[start + substrLen][start + substrLen * 2 - 1]```\n\nNow the things will be very simple. We just need to iterate in dp to find the differnet hash value with this condition.\n\n# Complexity\n- Time complexity: $$O(n^2)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n^2)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```python []\nclass Solution:\n def distinctEchoSubstrings(self, text: str) -> int:\n if len(set(text)) == 1:\n return len(text) // 2\n nums = [ord(char) - ord(\'a\') + 1 for char in text]\n hashMemo = [[0] * len(text) for _ in text]\n hashMod, ans = 10 ** 10 + 7, set()\n for start in range(len(nums)):\n hashMemo[start][start] = nums[start]\n for end in range(start + 1, len(nums)):\n hashMemo[start][end] = (hashMemo[start][end - 1] * 26 + nums[end]) % hashMod\n for start in range(len(nums)):\n for substrLen in range(1, (len(nums) - start) // 2 + 1):\n if hashMemo[start][start + substrLen - 1] == hashMemo[start + substrLen][start + substrLen * 2 - 1]:\n ans.add(hashMemo[start][start + substrLen - 1])\n return len(ans)\n``` | 0 | You have the four functions: You are given an instance of the class FizzBuzz that has four functions: fizz, buzz, fizzbuzz and number. The same instance of FizzBuzz will be passed to four different threads: Modify the given class to output the series [1, 2, "Fizz", 4, "Buzz", ...] where the ith token (1-indexed) of the series is: Implement the FizzBuzz class: | null |
Simple Python solution | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | \n# Code\n```\nclass Solution:\n def nz(self, num):\n return not str(num).count(\'0\')\n def getNoZeroIntegers(self, n: int) -> List[int]:\n for i in range(1, n):\n if self.nz(i) and self.nz(n-i):\n return [i, n-i]\n``` | 2 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
91.52% 25ms Python3 One-liner and detailed version | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> List[int]:\n for i in range(n-1, -1, -1):\n if \'0\' not in str(i) and \'0\' not in str(n - i):\n return [i, n-i ]\n\n #Oneliner\n\n return next([i, n-i] for i in range(n-1, -1, -1) if \'0\' not in str(i) and \'0\' not in str(n-i))\n``` | 1 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
Python Easy Solution Faster Than 98.86% | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | ```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> List[int]:\n def check(num):\n while num>0:\n if num%10==0:\n return False\n num//=10\n return True\n for i in range(1,n):\n t=n-i\n if check(t) and check(i):\n return [i,t]\n```\n\n**Upvote if you like the solution or ask if there is any query** | 2 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
convert-integer-to-the-sum-of-two-no-zero-integers | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | # Code\n```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> List[int]:\n for i in range(n-1,-1,-1):\n if str(i).count("0")==0 and str(n-i).count("0")==0:\n return [i,n-i]\n\n \n``` | 0 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
easy cod python | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> List[int]:\n a=[]\n for i in range(1,n):\n if "0" not in str(i) and \'0\' not in str(n-i):\n a.append(i)\n a.append(n-i)\n break\n return a\n\n\n \n``` | 0 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
easy 5 line solution | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nsince we need a no-zero integer eliminate all numbers having 0 in decimal representation from 1 to (n-1) and simply use 2 nested for loops to find a & b\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n> find all numbers from 1 till (n-1)\n> eliminate all numbers having zero in decimal representation\n> reverse array & iterate to find number b\n> iterate the same array to find number a, using nested for loop\n> keep checking if we found the a & b for condition (a + b = n)\n> return a & b if condition satisfy\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> List[int]:\n # form an array of no-zero integers between 1 - (n-1), eliminate the rest \n n1 = [ i for i in range(1, n) if \'0\' not in str(i)]\n \n # use two nested for loops to find a & b\n for i in n1[::-1]:\n for j in n1:\n if i + j == n:\n return [i, j]\n``` | 0 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
Python. Finding zero in a string | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | In the for loop we only work with half the numbers (`n//2+1`). Although in fact you only need 112 (`range(1, 113)`) - I counted \uD83D\uDE00\n\nCasting a number to a string and searching for the zero character in it turned out to be faster than checking the remainder of division by 10\n\n# Code\n```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> list[int]:\n for i in range(1, n//2+1):\n if \'0\' in str(n-i) or \'0\' in str(i):\n continue\n return [i, n-i]\n return []\n```\n\n# Alternative code\n\n```\nclass Solution:\n def _not_zero(self, n: int) -> bool:\n while n > 0:\n if n % 10 != 0:\n n //= 10\n else:\n return False\n return True\n\n def getNoZeroIntegers(self, n: int) -> list[int]:\n for i in range(1, n//2+1):\n if self._not_zero(n-i) and self._not_zero(i):\n return [i, n-i]\n return []\n``` | 0 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
Simple Python3: Beats 91% solutions, 3 lines code | convert-integer-to-the-sum-of-two-no-zero-integers | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\n1. Convert potential integers to strings and check if they contain \'0\'\n2. If not, then return the first instance\n\n# Code\n```\nclass Solution:\n def getNoZeroIntegers(self, n: int) -> List[int]:\n for i in range(1, n):\n if str(i).count(\'0\') == 0 and str(n-i).count(\'0\') == 0:\n return [i, n-i]\n\n\n``` | 0 | **No-Zero integer** is a positive integer that **does not contain any `0`** in its decimal representation.
Given an integer `n`, return _a list of two integers_ `[a, b]` _where_:
* `a` and `b` are **No-Zero integers**.
* `a + b = n`
The test cases are generated so that there is at least one valid solution. If there are many valid solutions, you can return any of them.
**Example 1:**
**Input:** n = 2
**Output:** \[1,1\]
**Explanation:** Let a = 1 and b = 1.
Both a and b are no-zero integers, and a + b = 2 = n.
**Example 2:**
**Input:** n = 11
**Output:** \[2,9\]
**Explanation:** Let a = 2 and b = 9.
Both a and b are no-zero integers, and a + b = 9 = n.
Note that there are other valid answers as \[8, 3\] that can be accepted.
**Constraints:**
* `2 <= n <= 104` | null |
Odd_Even.py | minimum-flips-to-make-a-or-b-equal-to-c | 0 | 1 | # Code\n```\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n ans=0\n while a or b or c:\n x,y,z=a%2,b%2,c%2\n print(x,y,z)\n if z==0:ans+=(x+y)\n elif x==0 and y==0:ans+=1\n a,b,c=a//2,b//2,c//2\n return ans\n```\n\n | 4 | Given 3 positives numbers `a`, `b` and `c`. Return the minimum flips required in some bits of `a` and `b` to make ( `a` OR `b` == `c` ). (bitwise OR operation).
Flip operation consists of change **any** single bit 1 to 0 or change the bit 0 to 1 in their binary representation.
**Example 1:**
**Input:** a = 2, b = 6, c = 5
**Output:** 3
**Explanation:** After flips a = 1 , b = 4 , c = 5 such that (`a` OR `b` == `c`)
**Example 2:**
**Input:** a = 4, b = 2, c = 7
**Output:** 1
**Example 3:**
**Input:** a = 1, b = 2, c = 3
**Output:** 0
**Constraints:**
* `1 <= a <= 10^9`
* `1 <= b <= 10^9`
* `1 <= c <= 10^9` | null |
Odd_Even.py | minimum-flips-to-make-a-or-b-equal-to-c | 0 | 1 | # Code\n```\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n ans=0\n while a or b or c:\n x,y,z=a%2,b%2,c%2\n print(x,y,z)\n if z==0:ans+=(x+y)\n elif x==0 and y==0:ans+=1\n a,b,c=a//2,b//2,c//2\n return ans\n```\n\n | 4 | You are given an integer array `target` and an integer `n`.
You have an empty stack with the two following operations:
* **`"Push "`**: pushes an integer to the top of the stack.
* **`"Pop "`**: removes the integer on the top of the stack.
You also have a stream of the integers in the range `[1, n]`.
Use the two stack operations to make the numbers in the stack (from the bottom to the top) equal to `target`. You should follow the following rules:
* If the stream of the integers is not empty, pick the next integer from the stream and push it to the top of the stack.
* If the stack is not empty, pop the integer at the top of the stack.
* If, at any moment, the elements in the stack (from the bottom to the top) are equal to `target`, do not read new integers from the stream and do not do more operations on the stack.
Return _the stack operations needed to build_ `target` following the mentioned rules. If there are multiple valid answers, return **any of them**.
**Example 1:**
**Input:** target = \[1,3\], n = 3
**Output:** \[ "Push ", "Push ", "Pop ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Pop the integer on the top of the stack. s = \[1\].
Read 3 from the stream and push it to the stack. s = \[1,3\].
**Example 2:**
**Input:** target = \[1,2,3\], n = 3
**Output:** \[ "Push ", "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Read 3 from the stream and push it to the stack. s = \[1,2,3\].
**Example 3:**
**Input:** target = \[1,2\], n = 4
**Output:** \[ "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Since the stack (from the bottom to the top) is equal to target, we stop the stack operations.
The answers that read integer 3 from the stream are not accepted.
**Constraints:**
* `1 <= target.length <= 100`
* `1 <= n <= 100`
* `1 <= target[i] <= n`
* `target` is strictly increasing. | Check the bits one by one whether they need to be flipped. |
Python solution | minimum-flips-to-make-a-or-b-equal-to-c | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n A=bin(a)[2:]\n B=bin(b)[2:]\n C=bin(c)[2:]\n count=0\n lenAlenB=max(len(A),len(B))\n lenC=max(lenAlenB,len(C))\n i=0\n A=int(bin(a)[2:])\n B=int(bin(b)[2:])\n C=int(bin(c)[2:])\n while i< lenC:\n digitA=A%10 \n digitB=B%10\n digitC=C%10 \n if int(digitA or digitB) != digitC:\n if digitC==1:\n count=count+1\n else:\n count=count+digitA + digitB \n i=i+1\n A=A//10\n B=B//10\n C=C//10\n return count\n``` | 1 | Given 3 positives numbers `a`, `b` and `c`. Return the minimum flips required in some bits of `a` and `b` to make ( `a` OR `b` == `c` ). (bitwise OR operation).
Flip operation consists of change **any** single bit 1 to 0 or change the bit 0 to 1 in their binary representation.
**Example 1:**
**Input:** a = 2, b = 6, c = 5
**Output:** 3
**Explanation:** After flips a = 1 , b = 4 , c = 5 such that (`a` OR `b` == `c`)
**Example 2:**
**Input:** a = 4, b = 2, c = 7
**Output:** 1
**Example 3:**
**Input:** a = 1, b = 2, c = 3
**Output:** 0
**Constraints:**
* `1 <= a <= 10^9`
* `1 <= b <= 10^9`
* `1 <= c <= 10^9` | null |
Python solution | minimum-flips-to-make-a-or-b-equal-to-c | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n A=bin(a)[2:]\n B=bin(b)[2:]\n C=bin(c)[2:]\n count=0\n lenAlenB=max(len(A),len(B))\n lenC=max(lenAlenB,len(C))\n i=0\n A=int(bin(a)[2:])\n B=int(bin(b)[2:])\n C=int(bin(c)[2:])\n while i< lenC:\n digitA=A%10 \n digitB=B%10\n digitC=C%10 \n if int(digitA or digitB) != digitC:\n if digitC==1:\n count=count+1\n else:\n count=count+digitA + digitB \n i=i+1\n A=A//10\n B=B//10\n C=C//10\n return count\n``` | 1 | You are given an integer array `target` and an integer `n`.
You have an empty stack with the two following operations:
* **`"Push "`**: pushes an integer to the top of the stack.
* **`"Pop "`**: removes the integer on the top of the stack.
You also have a stream of the integers in the range `[1, n]`.
Use the two stack operations to make the numbers in the stack (from the bottom to the top) equal to `target`. You should follow the following rules:
* If the stream of the integers is not empty, pick the next integer from the stream and push it to the top of the stack.
* If the stack is not empty, pop the integer at the top of the stack.
* If, at any moment, the elements in the stack (from the bottom to the top) are equal to `target`, do not read new integers from the stream and do not do more operations on the stack.
Return _the stack operations needed to build_ `target` following the mentioned rules. If there are multiple valid answers, return **any of them**.
**Example 1:**
**Input:** target = \[1,3\], n = 3
**Output:** \[ "Push ", "Push ", "Pop ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Pop the integer on the top of the stack. s = \[1\].
Read 3 from the stream and push it to the stack. s = \[1,3\].
**Example 2:**
**Input:** target = \[1,2,3\], n = 3
**Output:** \[ "Push ", "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Read 3 from the stream and push it to the stack. s = \[1,2,3\].
**Example 3:**
**Input:** target = \[1,2\], n = 4
**Output:** \[ "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Since the stack (from the bottom to the top) is equal to target, we stop the stack operations.
The answers that read integer 3 from the stream are not accepted.
**Constraints:**
* `1 <= target.length <= 100`
* `1 <= n <= 100`
* `1 <= target[i] <= n`
* `target` is strictly increasing. | Check the bits one by one whether they need to be flipped. |
[Python] Simple and intuitive bit manipulation 🤙 | 1 line | minimum-flips-to-make-a-or-b-equal-to-c | 0 | 1 | # Intuition\n\n\nThere are only three scenarios that require flipping.\n\n- c == 1\n - if a == 0 and b == 0: flip a or b to 1\n- c == 0\n - if a == 1: flip a to 0\n - if b == 1: flip b to 0\n\n\n# Code\n```\n# c == 1 and a == 0 and b == 0\n# means c and not(a) and not(b) \n# The flip count is how many "1" in bin(c & ~a & ~b)\nbin(c & ~a & ~b).count("1")\n\n# c == 0 and a == 1\n# means not(c) and a\nbin(~c & a).count("1")\n\n# c == 0 and b == 1\n# means not(c) and b\nbin(~c & b).count("1")\n```\n```\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n return bin(c & ~a & ~b).count("1") + bin(~c & a).count("1") + bin(~c & b).count("1")\n\n``` | 1 | Given 3 positives numbers `a`, `b` and `c`. Return the minimum flips required in some bits of `a` and `b` to make ( `a` OR `b` == `c` ). (bitwise OR operation).
Flip operation consists of change **any** single bit 1 to 0 or change the bit 0 to 1 in their binary representation.
**Example 1:**
**Input:** a = 2, b = 6, c = 5
**Output:** 3
**Explanation:** After flips a = 1 , b = 4 , c = 5 such that (`a` OR `b` == `c`)
**Example 2:**
**Input:** a = 4, b = 2, c = 7
**Output:** 1
**Example 3:**
**Input:** a = 1, b = 2, c = 3
**Output:** 0
**Constraints:**
* `1 <= a <= 10^9`
* `1 <= b <= 10^9`
* `1 <= c <= 10^9` | null |
[Python] Simple and intuitive bit manipulation 🤙 | 1 line | minimum-flips-to-make-a-or-b-equal-to-c | 0 | 1 | # Intuition\n\n\nThere are only three scenarios that require flipping.\n\n- c == 1\n - if a == 0 and b == 0: flip a or b to 1\n- c == 0\n - if a == 1: flip a to 0\n - if b == 1: flip b to 0\n\n\n# Code\n```\n# c == 1 and a == 0 and b == 0\n# means c and not(a) and not(b) \n# The flip count is how many "1" in bin(c & ~a & ~b)\nbin(c & ~a & ~b).count("1")\n\n# c == 0 and a == 1\n# means not(c) and a\nbin(~c & a).count("1")\n\n# c == 0 and b == 1\n# means not(c) and b\nbin(~c & b).count("1")\n```\n```\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n return bin(c & ~a & ~b).count("1") + bin(~c & a).count("1") + bin(~c & b).count("1")\n\n``` | 1 | You are given an integer array `target` and an integer `n`.
You have an empty stack with the two following operations:
* **`"Push "`**: pushes an integer to the top of the stack.
* **`"Pop "`**: removes the integer on the top of the stack.
You also have a stream of the integers in the range `[1, n]`.
Use the two stack operations to make the numbers in the stack (from the bottom to the top) equal to `target`. You should follow the following rules:
* If the stream of the integers is not empty, pick the next integer from the stream and push it to the top of the stack.
* If the stack is not empty, pop the integer at the top of the stack.
* If, at any moment, the elements in the stack (from the bottom to the top) are equal to `target`, do not read new integers from the stream and do not do more operations on the stack.
Return _the stack operations needed to build_ `target` following the mentioned rules. If there are multiple valid answers, return **any of them**.
**Example 1:**
**Input:** target = \[1,3\], n = 3
**Output:** \[ "Push ", "Push ", "Pop ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Pop the integer on the top of the stack. s = \[1\].
Read 3 from the stream and push it to the stack. s = \[1,3\].
**Example 2:**
**Input:** target = \[1,2,3\], n = 3
**Output:** \[ "Push ", "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Read 3 from the stream and push it to the stack. s = \[1,2,3\].
**Example 3:**
**Input:** target = \[1,2\], n = 4
**Output:** \[ "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Since the stack (from the bottom to the top) is equal to target, we stop the stack operations.
The answers that read integer 3 from the stream are not accepted.
**Constraints:**
* `1 <= target.length <= 100`
* `1 <= n <= 100`
* `1 <= target[i] <= n`
* `target` is strictly increasing. | Check the bits one by one whether they need to be flipped. |
Java+ Python Solution || comparing the Each bit of the binary number | minimum-flips-to-make-a-or-b-equal-to-c | 1 | 1 | # Approach\nFirst converted all three numbers from decimal to binary and padded the elements which are less in length than binary number of max length among three, After converting checking the each bit of a , b with c based on that we will get the minimum number of changes. \n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n```java []\nclass Solution {\n public int minFlips(int a, int b, int c) {\n int res=0;\n int maxDecimal = Math.max(a, Math.max(b, c));\n String a1= Integer.toBinaryString(a);\n String b1= Integer.toBinaryString(b);\n String c1= Integer.toBinaryString(c);\n int maxBinaryLength = Integer.toBinaryString(maxDecimal).length();\n a1 = padWithLeadingZeros(a1, maxBinaryLength);\n b1 = padWithLeadingZeros(b1, maxBinaryLength);\n c1 = padWithLeadingZeros(c1, maxBinaryLength);\n for(int i=0;i<c1.toCharArray().length;i++){\n if(c1.toCharArray()[i]==\'0\'){\n if(a1.toCharArray()[i]!=\'0\')\n res+=1;\n if(b1.toCharArray()[i]!=\'0\')\n res+=1;\n }\n else if(c1.toCharArray()[i]==\'1\'){\n if(a1.toCharArray()[i]==\'0\' && b1.toCharArray()[i]==\'0\')\n res+=1;\n }\n }\n return res;\n }\n private static String padWithLeadingZeros(String binary, int length) {\n int paddingLength = length - binary.length();\n StringBuilder paddedBinary = new StringBuilder();\n\n for (int i = 0; i < paddingLength; i++) {\n paddedBinary.append(\'0\');\n }\n\n paddedBinary.append(binary);\n return paddedBinary.toString();\n }\n}\n```\n```python []\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n def padding(s,l):\n arr=[]\n for i in range(l-len(s)):\n arr.append(\'0\')\n arr.append(s)\n return "".join(arr)\n res=0\n maxi=max(a,b,c)\n a1=bin(a)[2:]\n b1=bin(b)[2:]\n c1=bin(c)[2:]\n maxlength= len(bin(maxi)[2:])\n a1=padding(a1,maxlength)\n b1=padding(b1,maxlength)\n c1=padding(c1,maxlength)\n for i in range(len(c1)):\n if(c1[i]==\'0\'):\n if(a1[i]!=\'0\'):\n res+=1\n if(b1[i]!=\'0\'):\n res+=1\n elif(c1[i]==\'1\'):\n if(a1[i]==\'0\' and b1[i]==\'0\'):\n res+=1\n return res\n```\n<!-- Describe your approach to solving the problem. --> | 1 | Given 3 positives numbers `a`, `b` and `c`. Return the minimum flips required in some bits of `a` and `b` to make ( `a` OR `b` == `c` ). (bitwise OR operation).
Flip operation consists of change **any** single bit 1 to 0 or change the bit 0 to 1 in their binary representation.
**Example 1:**
**Input:** a = 2, b = 6, c = 5
**Output:** 3
**Explanation:** After flips a = 1 , b = 4 , c = 5 such that (`a` OR `b` == `c`)
**Example 2:**
**Input:** a = 4, b = 2, c = 7
**Output:** 1
**Example 3:**
**Input:** a = 1, b = 2, c = 3
**Output:** 0
**Constraints:**
* `1 <= a <= 10^9`
* `1 <= b <= 10^9`
* `1 <= c <= 10^9` | null |
Java+ Python Solution || comparing the Each bit of the binary number | minimum-flips-to-make-a-or-b-equal-to-c | 1 | 1 | # Approach\nFirst converted all three numbers from decimal to binary and padded the elements which are less in length than binary number of max length among three, After converting checking the each bit of a , b with c based on that we will get the minimum number of changes. \n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n```java []\nclass Solution {\n public int minFlips(int a, int b, int c) {\n int res=0;\n int maxDecimal = Math.max(a, Math.max(b, c));\n String a1= Integer.toBinaryString(a);\n String b1= Integer.toBinaryString(b);\n String c1= Integer.toBinaryString(c);\n int maxBinaryLength = Integer.toBinaryString(maxDecimal).length();\n a1 = padWithLeadingZeros(a1, maxBinaryLength);\n b1 = padWithLeadingZeros(b1, maxBinaryLength);\n c1 = padWithLeadingZeros(c1, maxBinaryLength);\n for(int i=0;i<c1.toCharArray().length;i++){\n if(c1.toCharArray()[i]==\'0\'){\n if(a1.toCharArray()[i]!=\'0\')\n res+=1;\n if(b1.toCharArray()[i]!=\'0\')\n res+=1;\n }\n else if(c1.toCharArray()[i]==\'1\'){\n if(a1.toCharArray()[i]==\'0\' && b1.toCharArray()[i]==\'0\')\n res+=1;\n }\n }\n return res;\n }\n private static String padWithLeadingZeros(String binary, int length) {\n int paddingLength = length - binary.length();\n StringBuilder paddedBinary = new StringBuilder();\n\n for (int i = 0; i < paddingLength; i++) {\n paddedBinary.append(\'0\');\n }\n\n paddedBinary.append(binary);\n return paddedBinary.toString();\n }\n}\n```\n```python []\nclass Solution:\n def minFlips(self, a: int, b: int, c: int) -> int:\n def padding(s,l):\n arr=[]\n for i in range(l-len(s)):\n arr.append(\'0\')\n arr.append(s)\n return "".join(arr)\n res=0\n maxi=max(a,b,c)\n a1=bin(a)[2:]\n b1=bin(b)[2:]\n c1=bin(c)[2:]\n maxlength= len(bin(maxi)[2:])\n a1=padding(a1,maxlength)\n b1=padding(b1,maxlength)\n c1=padding(c1,maxlength)\n for i in range(len(c1)):\n if(c1[i]==\'0\'):\n if(a1[i]!=\'0\'):\n res+=1\n if(b1[i]!=\'0\'):\n res+=1\n elif(c1[i]==\'1\'):\n if(a1[i]==\'0\' and b1[i]==\'0\'):\n res+=1\n return res\n```\n<!-- Describe your approach to solving the problem. --> | 1 | You are given an integer array `target` and an integer `n`.
You have an empty stack with the two following operations:
* **`"Push "`**: pushes an integer to the top of the stack.
* **`"Pop "`**: removes the integer on the top of the stack.
You also have a stream of the integers in the range `[1, n]`.
Use the two stack operations to make the numbers in the stack (from the bottom to the top) equal to `target`. You should follow the following rules:
* If the stream of the integers is not empty, pick the next integer from the stream and push it to the top of the stack.
* If the stack is not empty, pop the integer at the top of the stack.
* If, at any moment, the elements in the stack (from the bottom to the top) are equal to `target`, do not read new integers from the stream and do not do more operations on the stack.
Return _the stack operations needed to build_ `target` following the mentioned rules. If there are multiple valid answers, return **any of them**.
**Example 1:**
**Input:** target = \[1,3\], n = 3
**Output:** \[ "Push ", "Push ", "Pop ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Pop the integer on the top of the stack. s = \[1\].
Read 3 from the stream and push it to the stack. s = \[1,3\].
**Example 2:**
**Input:** target = \[1,2,3\], n = 3
**Output:** \[ "Push ", "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Read 3 from the stream and push it to the stack. s = \[1,2,3\].
**Example 3:**
**Input:** target = \[1,2\], n = 4
**Output:** \[ "Push ", "Push "\]
**Explanation:** Initially the stack s is empty. The last element is the top of the stack.
Read 1 from the stream and push it to the stack. s = \[1\].
Read 2 from the stream and push it to the stack. s = \[1,2\].
Since the stack (from the bottom to the top) is equal to target, we stop the stack operations.
The answers that read integer 3 from the stream are not accepted.
**Constraints:**
* `1 <= target.length <= 100`
* `1 <= n <= 100`
* `1 <= target[i] <= n`
* `target` is strictly increasing. | Check the bits one by one whether they need to be flipped. |
Python3 Solution || DFS Approach | number-of-operations-to-make-network-connected | 0 | 1 | # Complexity\n- Time complexity:\nO(E+V)\n\n- Space complexity:\nO(V)\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n adj=defaultdict(list)\n for ele1,ele2 in connections:\n adj[ele1].append(ele2)\n adj[ele2].append(ele1)\n self.cables=0\n def dfs(i,visited,adj,parent):\n if(i in visited):\n self.cables+=1\n return\n visited.add(i)\n for child in adj[i]:\n if child!=parent:\n dfs(child,visited,adj,i)\n c=0\n visited=set()\n for i in range(n):\n if i not in visited:\n c+=1\n dfs(i,visited,adj,-1)\n if(self.cables//2>=c-1):\n return c-1\n return -1\n\n``` | 2 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Python3 Solution || DFS Approach | number-of-operations-to-make-network-connected | 0 | 1 | # Complexity\n- Time complexity:\nO(E+V)\n\n- Space complexity:\nO(V)\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n adj=defaultdict(list)\n for ele1,ele2 in connections:\n adj[ele1].append(ele2)\n adj[ele2].append(ele1)\n self.cables=0\n def dfs(i,visited,adj,parent):\n if(i in visited):\n self.cables+=1\n return\n visited.add(i)\n for child in adj[i]:\n if child!=parent:\n dfs(child,visited,adj,i)\n c=0\n visited=set()\n for i in range(n):\n if i not in visited:\n c+=1\n dfs(i,visited,adj,-1)\n if(self.cables//2>=c-1):\n return c-1\n return -1\n\n``` | 2 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Python union find solution | number-of-operations-to-make-network-connected | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nUse Union find to count the redundant connections and connected clusters.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(nlog(n))\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n count = 0 # number of redundant connections\n network = [i for i in range(n)]\n\n def find(x):\n if network[x] != x:\n network[x] = find(network[x])\n return network[x]\n \n def union(a, b):\n # return True if 2 nodes are already connected.\n root_a = find(a)\n root_b = find(b)\n network[root_a] = root_b\n return True if root_a == root_b else False\n \n for link in connections:\n if union(link[0], link[1]):\n count += 1\n\n # count the number of connected clusters\n a = len(set([find(i) for i in range(n)]))\n return -1 if a - 1 > count else a - 1\n``` | 5 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Python union find solution | number-of-operations-to-make-network-connected | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nUse Union find to count the redundant connections and connected clusters.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(nlog(n))\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n count = 0 # number of redundant connections\n network = [i for i in range(n)]\n\n def find(x):\n if network[x] != x:\n network[x] = find(network[x])\n return network[x]\n \n def union(a, b):\n # return True if 2 nodes are already connected.\n root_a = find(a)\n root_b = find(b)\n network[root_a] = root_b\n return True if root_a == root_b else False\n \n for link in connections:\n if union(link[0], link[1]):\n count += 1\n\n # count the number of connected clusters\n a = len(set([find(i) for i in range(n)]))\n return -1 if a - 1 > count else a - 1\n``` | 5 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Simple solution with using Depth-First Search in Python3 | number-of-operations-to-make-network-connected | 0 | 1 | # Intuition\nThe problem description is the following:\n- there\'s an **undirected graph** with `n` nodes and `connections` edges\n- our goal is to find **the minimum amount of connections we should switch** in order to make all the network **connected**\n\n**PS: there\'re at least two valid solutions.** The first one is **Union-Find** (Prim\'s or Kruskal Algorithm), but we\'ll focus on at simplified approach of finding [connected components](https://en.wikipedia.org/wiki/Component_(graph_theory)). \n\n```\n# Example\nn = 4 # vertices\nconnections = [[0,1],[0,2],[1,2]] # edges\n\n# This can looks like\n# (0) - (1)\n# \\ /\n# (2)\n# (3)\n\n# The vertice (3) isn\'t connected with any other vertices.\n# Connected component represents a chain of edges, where you\n# can travel from one node to another.\n# 0-1-2 and 3 are two connected components (vertice 3 we can treat\n# as a valid one, even if it doesn\'t have any edges) \n\n# The answer is the number of connected components - 1,\n# because we want to define a number of edges to reconnect\n\n```\n\n# Approach\n1. check in advance, if the count of nodes `n - 1 == len(connections)` and return `-1` if it\'s not.\n2. create an `adjList`\n3. initialize an `ans = -1` and set of visited nodes `seen`\n4. define `dfs` function to treat all of the nodes after the first as a part of **connected component**\n5. iterate over all count of nodes `n` and count the amount of connected components\n6. return `ans`\n\n# Complexity\n- Time complexity: **O(n + m)**, to iterate over `connections` and in range of `n`\n\n- Space complexity: **O(n + m)**, the same, but for storing vertices and edges in `adjList`\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: list[list[int]]) -> int:\n if n - 1 > len(connections):\n return -1\n\n adjList = [[] for _ in range(n)]\n \n for u, v in connections: \n adjList[u].append(v)\n adjList[v].append(u)\n \n ans = -1\n seen = set()\n\n def dfs(node):\n for n in adjList[node]:\n if n not in seen:\n seen.add(n)\n dfs(n)\n\n for i in range(n):\n if i not in seen:\n seen.add(i)\n ans += 1\n dfs(i)\n\n return ans\n``` | 1 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Simple solution with using Depth-First Search in Python3 | number-of-operations-to-make-network-connected | 0 | 1 | # Intuition\nThe problem description is the following:\n- there\'s an **undirected graph** with `n` nodes and `connections` edges\n- our goal is to find **the minimum amount of connections we should switch** in order to make all the network **connected**\n\n**PS: there\'re at least two valid solutions.** The first one is **Union-Find** (Prim\'s or Kruskal Algorithm), but we\'ll focus on at simplified approach of finding [connected components](https://en.wikipedia.org/wiki/Component_(graph_theory)). \n\n```\n# Example\nn = 4 # vertices\nconnections = [[0,1],[0,2],[1,2]] # edges\n\n# This can looks like\n# (0) - (1)\n# \\ /\n# (2)\n# (3)\n\n# The vertice (3) isn\'t connected with any other vertices.\n# Connected component represents a chain of edges, where you\n# can travel from one node to another.\n# 0-1-2 and 3 are two connected components (vertice 3 we can treat\n# as a valid one, even if it doesn\'t have any edges) \n\n# The answer is the number of connected components - 1,\n# because we want to define a number of edges to reconnect\n\n```\n\n# Approach\n1. check in advance, if the count of nodes `n - 1 == len(connections)` and return `-1` if it\'s not.\n2. create an `adjList`\n3. initialize an `ans = -1` and set of visited nodes `seen`\n4. define `dfs` function to treat all of the nodes after the first as a part of **connected component**\n5. iterate over all count of nodes `n` and count the amount of connected components\n6. return `ans`\n\n# Complexity\n- Time complexity: **O(n + m)**, to iterate over `connections` and in range of `n`\n\n- Space complexity: **O(n + m)**, the same, but for storing vertices and edges in `adjList`\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: list[list[int]]) -> int:\n if n - 1 > len(connections):\n return -1\n\n adjList = [[] for _ in range(n)]\n \n for u, v in connections: \n adjList[u].append(v)\n adjList[v].append(u)\n \n ans = -1\n seen = set()\n\n def dfs(node):\n for n in adjList[node]:\n if n not in seen:\n seen.add(n)\n dfs(n)\n\n for i in range(n):\n if i not in seen:\n seen.add(i)\n ans += 1\n dfs(i)\n\n return ans\n``` | 1 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Python Readable - Simple Intuition | number-of-operations-to-make-network-connected | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n1. Scope the problem -> Find the min moves needed to connect all nodes.\n2. What kind of problem is this? Graph Problem. Think DFS BFS Union-Find.\n3. How to connect node? Remove 1 wire and use it on another\n3. How do I know if its unsolvable? To connect n nodes, you need n-1 wires.\n\nRecognise that this is union-find because UF is good for things like\n- Anything with connections/loops in graph\n- finding if 1 node can lead to all paths\n\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n if len(connections) < n-1: return -1\n\n parent = [i for i in range(n)]\n rank = [1] * (n)\n\n def find(x):\n if parent[x] != x:\n parent[x] = find(parent[x])\n return parent[x]\n\n def union(x, y):\n p1, p2 = find(x), find(y)\n if p1 == p2: return\n\n if p1 > p2:\n parent[p2] = p1\n rank[p1] += rank[p2]\n else:\n parent[p1] = p2\n rank[p2] += rank[p1]\n \n unconnected = n-1\n for a,b in connections:\n if find(a) == find(b): continue\n unconnected -= 1\n union(a, b)\n\n return unconnected\n```\n\n# Complexity\n- Time complexity: O(E*(log*N) + N) = O(E + N)\n-> E = connections \n-> N = nodes\n-> Interesting to note (log\\*N) is not (logN). \n\n*log\\*N is called an interative logarithm, which is basically amortized O(1) time complexity. Learnt something new today!*\n\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N) where n is no. nodes\n<!-- Add your space complexity here, e.g. $$O(n)$$ --> | 1 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Python Readable - Simple Intuition | number-of-operations-to-make-network-connected | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n1. Scope the problem -> Find the min moves needed to connect all nodes.\n2. What kind of problem is this? Graph Problem. Think DFS BFS Union-Find.\n3. How to connect node? Remove 1 wire and use it on another\n3. How do I know if its unsolvable? To connect n nodes, you need n-1 wires.\n\nRecognise that this is union-find because UF is good for things like\n- Anything with connections/loops in graph\n- finding if 1 node can lead to all paths\n\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n if len(connections) < n-1: return -1\n\n parent = [i for i in range(n)]\n rank = [1] * (n)\n\n def find(x):\n if parent[x] != x:\n parent[x] = find(parent[x])\n return parent[x]\n\n def union(x, y):\n p1, p2 = find(x), find(y)\n if p1 == p2: return\n\n if p1 > p2:\n parent[p2] = p1\n rank[p1] += rank[p2]\n else:\n parent[p1] = p2\n rank[p2] += rank[p1]\n \n unconnected = n-1\n for a,b in connections:\n if find(a) == find(b): continue\n unconnected -= 1\n union(a, b)\n\n return unconnected\n```\n\n# Complexity\n- Time complexity: O(E*(log*N) + N) = O(E + N)\n-> E = connections \n-> N = nodes\n-> Interesting to note (log\\*N) is not (logN). \n\n*log\\*N is called an interative logarithm, which is basically amortized O(1) time complexity. Learnt something new today!*\n\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N) where n is no. nodes\n<!-- Add your space complexity here, e.g. $$O(n)$$ --> | 1 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Python Solution O(E) | Adj List + BFS/DFS + Connected Components | number-of-operations-to-make-network-connected | 0 | 1 | 1. Using BFS\n```\ndef makeConnected(self, n: int, connections: List[List[int]]) -> int:\n #check if possible , should have atleast n-1 edges\n if(len(connections) < n-1 ):\n return -1 \n\n #build adjacency list, bidirectional edges\n graph = { i:[] for i in range(0,n)}\n for item in connections:\n graph[item[0]].append(item[1])\n graph[item[1]].append(item[0])\n\n # find number of connected components using bfs \n visited = [ 0 for _ in range(0,n)]\n comp_count = 0 # number of connected components\n for i in range(0,n):\n if(visited[i]==0 ):\n visited[i] = 1\n comp_count += 1\n dq = deque([i]);\n while(len(dq)>0):\n curNode = dq.popleft();\n for item in graph[curNode]:\n if(visited[item] == 0 ):\n visited[item] = 1\n dq.append(item);\n \n return comp_count-1\n\n```\n2.Using DFS\n```\ndef makeConnected(self, n: int, connections: List[List[int]]) -> int:\n #check if possible , should have atleast n-1 edges\n if(len(connections) < n-1 ):\n return -1 \n\n #build adjacency list, bidirectional edges\n graph = { i:[] for i in range(0,n)}\n for item in connections:\n graph[item[0]].append(item[1])\n graph[item[1]].append(item[0])\n \n\n # find number of connected components using dfs \n def dfs(graph,i,visited):\n visited[i] = 1\n for item in graph[i]:\n if(visited[item]==0):\n dfs(graph,item,visited);\n return;\n visited = [ 0 for _ in range(0,n)]\n comp_count = 0 # number of connected components\n for i in range(0,n):\n if(visited[i]==0 ):\n comp_count += 1\n dfs(graph,i,visited)\n \n return comp_count-1\n```\n\n\n | 1 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Python Solution O(E) | Adj List + BFS/DFS + Connected Components | number-of-operations-to-make-network-connected | 0 | 1 | 1. Using BFS\n```\ndef makeConnected(self, n: int, connections: List[List[int]]) -> int:\n #check if possible , should have atleast n-1 edges\n if(len(connections) < n-1 ):\n return -1 \n\n #build adjacency list, bidirectional edges\n graph = { i:[] for i in range(0,n)}\n for item in connections:\n graph[item[0]].append(item[1])\n graph[item[1]].append(item[0])\n\n # find number of connected components using bfs \n visited = [ 0 for _ in range(0,n)]\n comp_count = 0 # number of connected components\n for i in range(0,n):\n if(visited[i]==0 ):\n visited[i] = 1\n comp_count += 1\n dq = deque([i]);\n while(len(dq)>0):\n curNode = dq.popleft();\n for item in graph[curNode]:\n if(visited[item] == 0 ):\n visited[item] = 1\n dq.append(item);\n \n return comp_count-1\n\n```\n2.Using DFS\n```\ndef makeConnected(self, n: int, connections: List[List[int]]) -> int:\n #check if possible , should have atleast n-1 edges\n if(len(connections) < n-1 ):\n return -1 \n\n #build adjacency list, bidirectional edges\n graph = { i:[] for i in range(0,n)}\n for item in connections:\n graph[item[0]].append(item[1])\n graph[item[1]].append(item[0])\n \n\n # find number of connected components using dfs \n def dfs(graph,i,visited):\n visited[i] = 1\n for item in graph[i]:\n if(visited[item]==0):\n dfs(graph,item,visited);\n return;\n visited = [ 0 for _ in range(0,n)]\n comp_count = 0 # number of connected components\n for i in range(0,n):\n if(visited[i]==0 ):\n comp_count += 1\n dfs(graph,i,visited)\n \n return comp_count-1\n```\n\n\n | 1 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Python3 Solution | number-of-operations-to-make-network-connected | 0 | 1 | \n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n parent=list(range(n))\n self.count=n\n self.redundant=0\n def find(x):\n if x!=parent[x]:\n parent[x]=find(parent[x])\n\n return parent[x]\n\n def union(x,y):\n rootx=find(x)\n rooty=find(y)\n\n if rootx !=rooty:\n parent[rootx]=rooty\n self.count-=1\n\n else:\n self.redundant+=1\n\n for x,y in connections:\n union(x,y)\n\n if self.redundant >=self.count-1:\n return self.count-1\n\n else:\n return -1 \n``` | 1 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Python3 Solution | number-of-operations-to-make-network-connected | 0 | 1 | \n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n parent=list(range(n))\n self.count=n\n self.redundant=0\n def find(x):\n if x!=parent[x]:\n parent[x]=find(parent[x])\n\n return parent[x]\n\n def union(x,y):\n rootx=find(x)\n rooty=find(y)\n\n if rootx !=rooty:\n parent[rootx]=rooty\n self.count-=1\n\n else:\n self.redundant+=1\n\n for x,y in connections:\n union(x,y)\n\n if self.redundant >=self.count-1:\n return self.count-1\n\n else:\n return -1 \n``` | 1 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Simple 🐍python solution using DFS ✔ | number-of-operations-to-make-network-connected | 0 | 1 | \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nConnected components concept in graph theory.\n\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n graph = {}\n\n for i in range(n):\n graph[i] = []\n \n for (u,v) in connections:\n graph[u].append(v)\n graph[v].append(u)\n \n if len(connections) < n - 1:\n return -1\n\n def dfs(graph, node, visited):\n visited.add(node)\n summ = 0\n\n for child in graph[node]:\n if child not in visited:\n dfs(graph,child,visited)\n\n ans = []; summ=0\n visited = set()\n for i in range(n):\n if i not in visited:\n summ += 1\n dfs(graph,i,visited)\n\n return summ-1\n``` | 1 | There are `n` computers numbered from `0` to `n - 1` connected by ethernet cables `connections` forming a network where `connections[i] = [ai, bi]` represents a connection between computers `ai` and `bi`. Any computer can reach any other computer directly or indirectly through the network.
You are given an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected.
Return _the minimum number of times you need to do this in order to make all the computers connected_. If it is not possible, return `-1`.
**Example 1:**
**Input:** n = 4, connections = \[\[0,1\],\[0,2\],\[1,2\]\]
**Output:** 1
**Explanation:** Remove cable between computer 1 and 2 and place between computers 1 and 3.
**Example 2:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\],\[1,3\]\]
**Output:** 2
**Example 3:**
**Input:** n = 6, connections = \[\[0,1\],\[0,2\],\[0,3\],\[1,2\]\]
**Output:** -1
**Explanation:** There are not enough cables.
**Constraints:**
* `1 <= n <= 105`
* `1 <= connections.length <= min(n * (n - 1) / 2, 105)`
* `connections[i].length == 2`
* `0 <= ai, bi < n`
* `ai != bi`
* There are no repeated connections.
* No two computers are connected by more than one cable. | Find the number of occurrences of each element in the array using a hash map. Iterate through the hash map and check if there is a repeated value. |
Simple 🐍python solution using DFS ✔ | number-of-operations-to-make-network-connected | 0 | 1 | \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nConnected components concept in graph theory.\n\n\n# Code\n```\nclass Solution:\n def makeConnected(self, n: int, connections: List[List[int]]) -> int:\n graph = {}\n\n for i in range(n):\n graph[i] = []\n \n for (u,v) in connections:\n graph[u].append(v)\n graph[v].append(u)\n \n if len(connections) < n - 1:\n return -1\n\n def dfs(graph, node, visited):\n visited.add(node)\n summ = 0\n\n for child in graph[node]:\n if child not in visited:\n dfs(graph,child,visited)\n\n ans = []; summ=0\n visited = set()\n for i in range(n):\n if i not in visited:\n summ += 1\n dfs(graph,i,visited)\n\n return summ-1\n``` | 1 | Given an array of integers `arr`.
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
Let's define `a` and `b` as follows:
* `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
* `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
Note that **^** denotes the **bitwise-xor** operation.
Return _the number of triplets_ (`i`, `j` and `k`) Where `a == b`.
**Example 1:**
**Input:** arr = \[2,3,1,6,7\]
**Output:** 4
**Explanation:** The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
**Example 2:**
**Input:** arr = \[1,1,1,1,1\]
**Output:** 10
**Constraints:**
* `1 <= arr.length <= 300`
* `1 <= arr[i] <= 108` | As long as there are at least (n - 1) connections, there is definitely a way to connect all computers. Use DFS to determine the number of isolated computer clusters. |
Python || Top Down DP | minimum-distance-to-type-a-word-using-two-fingers | 0 | 1 | Assume board as a grid of m*n and store corrdinates of each char in a dictionary.\nuse top down dp and memoize it.\nTime Complexity - O(len(word)*m^2*n^2) where m and n are rows and columns of keyboard\n\n```\nclass Solution:\n def minimumDistance(self, word: str) -> int:\n n=len(word)\n graph={}\n i,j=0,0\n for c in ascii_uppercase:\n graph[c]=(i,j)\n j=(j+1)%6\n if j==0:\n i+=1\n @cache\n def dp(idx,fi,fj,si,sj):\n if idx==n:\n return 0\n #use first finger\n ii,jj=graph[word[idx]]\n ans=dp(idx+1,ii,jj,si,sj)+(0 if fi==-1 and fj==-1 else abs(ii-fi)+abs(jj-fj))\n #use second finger\n ans=min(ans,dp(idx+1,fi,fj,ii,jj)+(0 if si==-1 and sj==-1 else abs(ii-si)+abs(jj-sj)))\n return ans\n return dp(0,-1,-1,-1,-1)\n``` | 1 | You have a keyboard layout as shown above in the **X-Y** plane, where each English uppercase letter is located at some coordinate.
* For example, the letter `'A'` is located at coordinate `(0, 0)`, the letter `'B'` is located at coordinate `(0, 1)`, the letter `'P'` is located at coordinate `(2, 3)` and the letter `'Z'` is located at coordinate `(4, 1)`.
Given the string `word`, return _the minimum total **distance** to type such string using only two fingers_.
The **distance** between coordinates `(x1, y1)` and `(x2, y2)` is `|x1 - x2| + |y1 - y2|`.
**Note** that the initial positions of your two fingers are considered free so do not count towards your total distance, also your two fingers do not have to start at the first letter or the first two letters.
**Example 1:**
**Input:** word = "CAKE "
**Output:** 3
**Explanation:** Using two fingers, one optimal way to type "CAKE " is:
Finger 1 on letter 'C' -> cost = 0
Finger 1 on letter 'A' -> cost = Distance from letter 'C' to letter 'A' = 2
Finger 2 on letter 'K' -> cost = 0
Finger 2 on letter 'E' -> cost = Distance from letter 'K' to letter 'E' = 1
Total distance = 3
**Example 2:**
**Input:** word = "HAPPY "
**Output:** 6
**Explanation:** Using two fingers, one optimal way to type "HAPPY " is:
Finger 1 on letter 'H' -> cost = 0
Finger 1 on letter 'A' -> cost = Distance from letter 'H' to letter 'A' = 2
Finger 2 on letter 'P' -> cost = 0
Finger 2 on letter 'P' -> cost = Distance from letter 'P' to letter 'P' = 0
Finger 1 on letter 'Y' -> cost = Distance from letter 'A' to letter 'Y' = 4
Total distance = 6
**Constraints:**
* `2 <= word.length <= 300`
* `word` consists of uppercase English letters. | Use a stack to store the characters, when there are k same characters, delete them. To make it more efficient, use a pair to store the value and the count of each character. |
Python || Top Down DP | minimum-distance-to-type-a-word-using-two-fingers | 0 | 1 | Assume board as a grid of m*n and store corrdinates of each char in a dictionary.\nuse top down dp and memoize it.\nTime Complexity - O(len(word)*m^2*n^2) where m and n are rows and columns of keyboard\n\n```\nclass Solution:\n def minimumDistance(self, word: str) -> int:\n n=len(word)\n graph={}\n i,j=0,0\n for c in ascii_uppercase:\n graph[c]=(i,j)\n j=(j+1)%6\n if j==0:\n i+=1\n @cache\n def dp(idx,fi,fj,si,sj):\n if idx==n:\n return 0\n #use first finger\n ii,jj=graph[word[idx]]\n ans=dp(idx+1,ii,jj,si,sj)+(0 if fi==-1 and fj==-1 else abs(ii-fi)+abs(jj-fj))\n #use second finger\n ans=min(ans,dp(idx+1,fi,fj,ii,jj)+(0 if si==-1 and sj==-1 else abs(ii-si)+abs(jj-sj)))\n return ans\n return dp(0,-1,-1,-1,-1)\n``` | 1 | Given an undirected tree consisting of `n` vertices numbered from `0` to `n-1`, which has some apples in their vertices. You spend 1 second to walk over one edge of the tree. _Return the minimum time in seconds you have to spend to collect all apples in the tree, starting at **vertex 0** and coming back to this vertex._
The edges of the undirected tree are given in the array `edges`, where `edges[i] = [ai, bi]` means that exists an edge connecting the vertices `ai` and `bi`. Additionally, there is a boolean array `hasApple`, where `hasApple[i] = true` means that vertex `i` has an apple; otherwise, it does not have any apple.
**Example 1:**
**Input:** n = 7, edges = \[\[0,1\],\[0,2\],\[1,4\],\[1,5\],\[2,3\],\[2,6\]\], hasApple = \[false,false,true,false,true,true,false\]
**Output:** 8
**Explanation:** The figure above represents the given tree where red vertices have an apple. One optimal path to collect all apples is shown by the green arrows.
**Example 2:**
**Input:** n = 7, edges = \[\[0,1\],\[0,2\],\[1,4\],\[1,5\],\[2,3\],\[2,6\]\], hasApple = \[false,false,true,false,false,true,false\]
**Output:** 6
**Explanation:** The figure above represents the given tree where red vertices have an apple. One optimal path to collect all apples is shown by the green arrows.
**Example 3:**
**Input:** n = 7, edges = \[\[0,1\],\[0,2\],\[1,4\],\[1,5\],\[2,3\],\[2,6\]\], hasApple = \[false,false,false,false,false,false,false\]
**Output:** 0
**Constraints:**
* `1 <= n <= 105`
* `edges.length == n - 1`
* `edges[i].length == 2`
* `0 <= ai < bi <= n - 1`
* `hasApple.length == n` | Use dynamic programming. dp[i][j][k]: smallest movements when you have one finger on i-th char and the other one on j-th char already having written k first characters from word. |
SImple DP in python3 | minimum-distance-to-type-a-word-using-two-fingers | 0 | 1 | # Code\n```\nclass Solution:\n def minimumDistance(self, word: str) -> int:\n def place(l):\n a = ord(l) - ord(\'A\')\n return (a//6,a%6)\n places = {a:place(a) for a in \'ABCDEFGHIJKLMNOPQRSTUVWXYZ\'}\n def dist(a,b):\n if a == None:\n return 0\n return abs(place(a)[0] - place(b)[0])+abs(place(a)[1] - place(b)[1])\n @cache\n def dp(i,j,k):\n if k == len(word)-1:\n return 0\n else:\n return min(dist(i,word[k+1])+dp(word[k+1],j,k+1),dist(j,word[k+1])+dp(i,word[k+1],k+1))\n return dp(None,None,-1)\n\n \n\n \n``` | 0 | You have a keyboard layout as shown above in the **X-Y** plane, where each English uppercase letter is located at some coordinate.
* For example, the letter `'A'` is located at coordinate `(0, 0)`, the letter `'B'` is located at coordinate `(0, 1)`, the letter `'P'` is located at coordinate `(2, 3)` and the letter `'Z'` is located at coordinate `(4, 1)`.
Given the string `word`, return _the minimum total **distance** to type such string using only two fingers_.
The **distance** between coordinates `(x1, y1)` and `(x2, y2)` is `|x1 - x2| + |y1 - y2|`.
**Note** that the initial positions of your two fingers are considered free so do not count towards your total distance, also your two fingers do not have to start at the first letter or the first two letters.
**Example 1:**
**Input:** word = "CAKE "
**Output:** 3
**Explanation:** Using two fingers, one optimal way to type "CAKE " is:
Finger 1 on letter 'C' -> cost = 0
Finger 1 on letter 'A' -> cost = Distance from letter 'C' to letter 'A' = 2
Finger 2 on letter 'K' -> cost = 0
Finger 2 on letter 'E' -> cost = Distance from letter 'K' to letter 'E' = 1
Total distance = 3
**Example 2:**
**Input:** word = "HAPPY "
**Output:** 6
**Explanation:** Using two fingers, one optimal way to type "HAPPY " is:
Finger 1 on letter 'H' -> cost = 0
Finger 1 on letter 'A' -> cost = Distance from letter 'H' to letter 'A' = 2
Finger 2 on letter 'P' -> cost = 0
Finger 2 on letter 'P' -> cost = Distance from letter 'P' to letter 'P' = 0
Finger 1 on letter 'Y' -> cost = Distance from letter 'A' to letter 'Y' = 4
Total distance = 6
**Constraints:**
* `2 <= word.length <= 300`
* `word` consists of uppercase English letters. | Use a stack to store the characters, when there are k same characters, delete them. To make it more efficient, use a pair to store the value and the count of each character. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.