
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4578/comments | https://api.github.com/repos/huggingface/datasets/issues/4578/events | https://github.com/huggingface/datasets/issues/4578 | 1,286,086,400 | I_kwDODunzps5MqB8A | 4,578 | [Multi Configs] Use directories to differentiate between subsets/configurations | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 3 | 2022-06-27T16:55:11Z | 2023-06-14T15:43:05Z | null | null | Currently to define several subsets/configurations of your dataset, you need to use a dataset script.
However it would be nice to have a no-code way to to this.
For example we could specify different configurations of a dataset (for example, if a dataset contains different languages) with one directory per configuration.
These structures are not supported right now, but would be nice to have:
```
my_dataset_repository/
├── README.md
├── en/
│ ├── train.csv
│ └── test.csv
└── fr/
├── train.csv
└── test.csv
```
Or with one directory per split:
```
my_dataset_repository/
├── README.md
├── en/
│ ├── train/
│ │ ├── shard_0.csv
│ │ └── shard_1.csv
│ └── test/
│ ├── shard_0.csv
│ └── shard_1.csv
└── fr/
├── train/
│ ├── shard_0.csv
│ └── shard_1.csv
└── test/
├── shard_0.csv
└── shard_1.csv
```
cc @stevhliu @albertvillanova
This can be specified in the README as YAML with
```
configs:
- config_name: en
data_dir: en
- config_name: fr
data_dir: fr
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 5,
"heart": 9,
"hooray": 0,
"laugh": 0,
"rocket": 5,
"total_count": 19,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4578/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4578/timeline | null | null | null | null | false | [
"I want to be able to create folders in a model.",
"How to set new split names, instead of train/test/validation? For example, I have a local dataset, consists of several subsets, named \"A\", \"B\", and \"C\". How can I create a huggingface dataset, with splits A/B/C ?\r\n\r\nThe document in https://huggingface.co/docs/datasets/dataset_script only tells me how to create datasets with subsets that is hosted on another server. How to do it if my datasets are local?",
"> The document in https://huggingface.co/docs/datasets/dataset_script only tells me how to create datasets with subsets that is hosted on another server. How to do it if my datasets are local?\r\n\r\nIt works the same - you just need to use local paths instead of URLs"
] |
https://api.github.com/repos/huggingface/datasets/issues/2290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2290/comments | https://api.github.com/repos/huggingface/datasets/issues/2290/events | https://github.com/huggingface/datasets/pull/2290 | 871,145,817 | MDExOlB1bGxSZXF1ZXN0NjI2MjEyNTIz | 2,290 | Bbaw egyptian | [] | closed | false | null | 9 | 2021-04-29T15:27:58Z | 2021-05-06T17:25:25Z | 2021-05-06T17:25:25Z | null | This is the "hieroglyph corpus" that I could unfortunately not contribute during the marathon. I re-extracted it again now, so that it is in the state as used in my paper (seee documentation). I hope it satiesfies your requirements and wish every scientist out their loads of fun deciphering a 5.000 years old language :-) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2290/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2290.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2290",
"merged_at": "2021-05-06T17:25:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2290.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2290"
} | true | [
"Hi @phiwi,\r\n\r\nThanks for contributing this nice dataset. If you have any blocking problem or question, do not hesitate to ask here. We are pleased to help you.\r\n\r\nCould you please first synchronize with our master branch? From your branch `bbaw_egyptian`, type:\r\n```\r\ngit fetch upstream master\r\ngit merge upstream/master\r\n```",
"Thanks ! Can you check that you have `black==21.4b0` and run `make style` again ? This should fix the \"check_code_quality\" CI issue",
"Reformatted with black.",
"Hi @phiwi, there are still some minor problems in relation with the tags you used in the dataset card (README.md).\r\n\r\nHere you can find the output of the metadata validator:\r\n```\r\nWARNING:root:❌ Failed to validate 'datasets/bbaw_egyptian/README.md':\r\nCould not validate the metada, found the following errors:\r\n* field 'size_categories':\r\n\t['100K<n<1000K'] are not registered tags for 'size_categories', reference at https://github.com/huggingface/datasets/tree/master/src/datasets/utils/resources/size_categories.json\r\n* field 'task_ids':\r\n\t['machine translation'] are not registered tags for 'task_ids', reference at https://github.com/huggingface/datasets/tree/master/src/datasets/utils/resources/tasks.json\r\n* field 'languages':\r\n\t['eg'] are not registered tags for 'languages', reference at https://github.com/huggingface/datasets/tree/master/src/datasets/utils/resources/languages.json\r\n\r\n``` ",
"@albertvillanova corrected :-)",
"Thanks, @phiwi. Now all tests should pass green.\r\n\r\nHowever, I think there is still an issue with the language code:\r\n- the code for the Ancient Egyptian is not `ar-EG`\r\n- there is no ISO 639-1 code for the Ancient Egyptian\r\n- there is an ISO 639-2 code: `egy`; but this code will not pass the validation test because it is not in the list of valid codes\r\n\r\nI am not sure what to do in this case... Maybe @lhoestq has an idea? Maybe adding the code to the list? https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/languages.json",
"I have just checked that in the [list of valid codes](https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/languages.json) there are already ISO 639-2 codes. Therefore, I would suggest you to add it to the list:\r\n```\r\n\"egy\": \"Egyptian (Ancient)\",\r\n```\r\nand change it in the dataset card.",
"Done.",
"Hope, everything is okay right now."
] |
https://api.github.com/repos/huggingface/datasets/issues/898 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/898/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/898/comments | https://api.github.com/repos/huggingface/datasets/issues/898/events | https://github.com/huggingface/datasets/pull/898 | 752,148,284 | MDExOlB1bGxSZXF1ZXN0NTI4NTI4MDY1 | 898 | Adding SQA dataset | [] | closed | false | null | 2 | 2020-11-27T10:29:18Z | 2020-12-15T12:54:40Z | 2020-12-15T12:54:19Z | null | As discussed in #880
Seems like automatic dummy-data generation doesn't work if the builder is a `ArrowBasedBuilder`, do you think you could take a look @lhoestq ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/898/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/898/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/898.diff",
"html_url": "https://github.com/huggingface/datasets/pull/898",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/898.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/898"
} | true | [
"This dataset seems to have around 1000 configs. Therefore when creating the dummy data we end up with hundreds of MB of dummy data which we don't want to add in the repo.\r\nLet's make this PR on hold for now and find a solution after the sprint of next week",
"Closing in favor of #1566 "
] |
https://api.github.com/repos/huggingface/datasets/issues/5885 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5885/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5885/comments | https://api.github.com/repos/huggingface/datasets/issues/5885/events | https://github.com/huggingface/datasets/pull/5885 | 1,720,954,440 | PR_kwDODunzps5RFjTL | 5,885 | Modify `is_remote_filesystem` to return True for FUSE-mounted paths | [] | open | false | null | 5 | 2023-05-23T01:04:54Z | 2023-05-25T08:50:48Z | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5885/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5885/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5885.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5885",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5885.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5885"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5885). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq would you or another maintainer be able to review please? :)",
"Why you do need to support FUSE mounted paths ?\r\n\r\n`datasets` uses data that live on disk for fast lookups - FUSE mounted disks would lead to poor performance and I wouldn't recomment using it.",
"Fuse is commonly used to mount remote file systems (e.g. S3, DBFS) as a local directory. Since it's slower than using an actual local device, it's better to treat it as remote to reduce latency.",
"I think people would be confused if they don't have the same dataset behavior depending on the disk type.\r\n\r\nIf they want to use a remote bucket they should use the remote URI instead, e.g. `s3://...`. Advancements on this are tracked at #5281 "
] |
https://api.github.com/repos/huggingface/datasets/issues/1656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1656/comments | https://api.github.com/repos/huggingface/datasets/issues/1656/events | https://github.com/huggingface/datasets/pull/1656 | 775,645,356 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjg0NDI3 | 1,656 | assin 2 dataset: add instances and data splits info | [] | closed | false | null | 0 | 2020-12-29T00:57:51Z | 2020-12-30T16:50:56Z | 2020-12-30T16:50:56Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1656/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1656.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1656",
"merged_at": "2020-12-30T16:50:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1656.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1656"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/322 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/322/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/322/comments | https://api.github.com/repos/huggingface/datasets/issues/322/events | https://github.com/huggingface/datasets/pull/322 | 647,483,850 | MDExOlB1bGxSZXF1ZXN0NDQxNTAyMjc2 | 322 | output nested dict in get_nearest_examples | [] | closed | false | null | 0 | 2020-06-29T15:47:47Z | 2020-07-02T08:33:33Z | 2020-07-02T08:33:32Z | null | As we are using a columnar format like arrow as the backend for datasets, we expect to have a dictionary of columns when we slice a dataset like in this example:
```python
my_examples = dataset[0:10]
print(type(my_examples))
# >>> dict
print(my_examples["my_column"][0]
# >>> this is the first element of the column 'my_column'
```
Therefore I wanted to keep this logic when calling `get_nearest_examples` that returns the top 10 nearest examples:
```python
dataset.add_faiss_index(column="embeddings")
scores, examples = dataset.get_nearest_examples("embeddings", query=my_numpy_embedding)
print(type(examples))
# >>> dict
```
Previously it was returning a list[dict]. It was the only place that was using this output format.
To make it work I had to implement `__getitem__(key)` where `key` is a list.
This is different from `.select` because `.select` is a dataset transform (it returns a new dataset object) while `__getitem__` is an extraction method (it returns python dictionaries). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/322/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/322/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/322.diff",
"html_url": "https://github.com/huggingface/datasets/pull/322",
"merged_at": "2020-07-02T08:33:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/322.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/322"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2041 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2041/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2041/comments | https://api.github.com/repos/huggingface/datasets/issues/2041/events | https://github.com/huggingface/datasets/pull/2041 | 830,180,803 | MDExOlB1bGxSZXF1ZXN0NTkxNzMyNzMw | 2,041 | Doc2dial update data_infos and data_loaders | [] | closed | false | null | 0 | 2021-03-12T14:39:29Z | 2021-03-16T11:09:20Z | 2021-03-16T11:09:20Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2041/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2041/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2041.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2041",
"merged_at": "2021-03-16T11:09:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2041.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2041"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/3689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3689/comments | https://api.github.com/repos/huggingface/datasets/issues/3689/events | https://github.com/huggingface/datasets/pull/3689 | 1,127,422,478 | PR_kwDODunzps4yPnp7 | 3,689 | Fix streaming for servers not supporting HTTP range requests | [] | closed | false | null | 10 | 2022-02-08T15:41:05Z | 2022-02-10T16:51:25Z | 2022-02-10T16:51:25Z | null | Some servers do not support HTTP range requests, whereas this is required to stream some file formats (like ZIP).
~~This PR implements a workaround for those cases, by download the files locally in a temporary directory (cleaned up by the OS once the process is finished).~~
This PR raises custom error explaining that streaming is not possible because data host server does not support HTTP range requests.
Fix #3677. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3689/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3689/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3689.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3689",
"merged_at": "2022-02-10T16:51:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3689.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3689"
} | true | [
"Does it mean that huge files might end up being downloaded? It would go against the purpose of streaming, I think. At least, this fallback should be an option that could be disabled",
"Yes, it is against the purpose of streaming, but streaming is not possible if the server does not allow HTTP range requests.\n\nWe have two options: either we download the file or we throw an error.",
"I think we simply cannot fallback to downloading the file if streaming fails without the user being aware of it. Some options: \r\n- make the fallback optional (using an env var? or a function param)\r\n- use the fallback only if the dataset size is under some threshold (provided we have the data in the DatasetInfo) -> it's the option I use in `datasets-preview-backend` ([here](https://github.com/huggingface/datasets-preview-backend/blob/48ac19e49c19809763e8d640986bf2c3d792faed/src/datasets_preview_backend/models/typed_row.py#L40) and [here](https://github.com/huggingface/datasets-preview-backend/blob/aa86c5493b275c9e2dbae7dab7bd469da5773a41/src/datasets_preview_backend/models/split.py#L31-L37))\r\n- throw an exception and let the user decide what to do\r\n",
"IMO in general we should throw an exception and ask the user to not use streaming mode in that case.\r\n\r\nYour second point is also interesting but I feel like it could be confusing for users sometimes: it doesn't feel natural that the streaming-ability should depend on the size of the file.",
"Sure, I think we should just throw an exception\r\n",
"Current behavior is already throwing an Exception:\r\n```\r\nValueError: Cannot seek streaming HTTP file\r\n```\r\n\r\nWe could customize the exception class and/or the exception message.",
"I'm not sure we really need to change anything. I opened the issue https://github.com/huggingface/datasets/issues/3677 because discovery was streamable and is not anymore (according to my test suite in https://github.com/huggingface/datasets-preview-backend): I was not sure if it was due to some regression in the library, or to some change in the dataset itself.",
"I'm wondering why it worked before and it is no longer working...",
"> We could customize the exception class and/or the exception message.\r\n\r\nYup a message that says that the host doesn't support streaming because it doesn't support HTTP Range requests would be useful !",
"DONE, @lhoestq. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3923/comments | https://api.github.com/repos/huggingface/datasets/issues/3923/events | https://github.com/huggingface/datasets/pull/3923 | 1,169,773,869 | PR_kwDODunzps40d9YU | 3,923 | Add methods to IterableDatasetDict | [] | closed | false | null | 5 | 2022-03-15T14:46:03Z | 2022-07-06T15:40:20Z | 2022-03-15T16:45:06Z | null | Following the new methods added in #3826 and https://github.com/huggingface/datasets/pull/3862 I added several methods to IterableDatasetDict:
- map
- filter
- shuffle
- with_format
- cast
- cast_column
- remove_columns
- rename_column
- rename_columns
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3923/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3923.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3923",
"merged_at": "2022-03-15T16:45:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3923.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3923"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3923). All of your documentation changes will be reflected on that endpoint.",
"Is this feature stale or needs any help to it ? If so I can quickly send a PR. Thanks\r\n\r\nCC : @lhoestq, @albertvillanova ",
"These features have been merged and are already available, thanks :)",
"Hello @lhoestq, I see that `IterableDataset` doesn't allow features like `take`, `len`, `slice` which can enable a lot of stuffs. Is it worth an addition ? Or is it intended that they didn't have those features ?",
"IterableDataset objects don't have `len` or `slice` because they can be possibly unbounded (you don't know in advance how many items they contain). Though IterableDataset.take and IterableDataset.skip do exist."
] |
https://api.github.com/repos/huggingface/datasets/issues/1773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1773/comments | https://api.github.com/repos/huggingface/datasets/issues/1773/events | https://github.com/huggingface/datasets/issues/1773 | 792,708,160 | MDU6SXNzdWU3OTI3MDgxNjA= | 1,773 | bug in loading datasets | [] | closed | false | null | 3 | 2021-01-24T02:53:45Z | 2021-09-06T08:54:46Z | 2021-08-04T18:13:01Z | null | Hi,
I need to load a dataset, I use these commands:
```
from datasets import load_dataset
dataset = load_dataset('csv', data_files={'train': 'sick/train.csv',
'test': 'sick/test.csv',
'validation': 'sick/validation.csv'})
print(dataset['validation'])
```
the dataset in sick/train.csv are simple csv files representing the data. I am getting this error, do you have an idea how I can solve this? thank you @lhoestq
```
Using custom data configuration default
Downloading and preparing dataset csv/default-61468fc71a743ec1 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /julia/cache_home_2/datasets/csv/default-61468fc71a743ec1/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2...
Traceback (most recent call last):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 485, in incomplete_dir
yield tmp_dir
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 527, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 604, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 959, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/tqdm-4.49.0-py3.7.egg/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/julia/cache_home_2/modules/datasets_modules/datasets/csv/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2/csv.py", line 129, in _generate_tables
for batch_idx, df in enumerate(csv_file_reader):
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1029, in __next__
return self.get_chunk()
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1079, in get_chunk
return self.read(nrows=size)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 1052, in read
index, columns, col_dict = self._engine.read(nrows)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/pandas-1.2.0-py3.7-linux-x86_64.egg/pandas/io/parsers.py", line 2056, in read
data = self._reader.read(nrows)
File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 783, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 1 fields in line 37, saw 2
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "write_sick.py", line 19, in <module>
'validation': 'sick/validation.csv'})
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/load.py", line 612, in load_dataset
ignore_verifications=ignore_verifications,
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 534, in download_and_prepare
self._save_info()
File "/julia/libs/anaconda3/envs/success/lib/python3.7/contextlib.py", line 130, in __exit__
self.gen.throw(type, value, traceback)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/site-packages/datasets-1.2.0-py3.7.egg/datasets/builder.py", line 491, in incomplete_dir
shutil.rmtree(tmp_dir)
File "/julia/libs/anaconda3/envs/success/lib/python3.7/shutil.py", line 498, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File "/julia/libs/anaconda3/envs/success/lib/python3.7/shutil.py", line 496, in rmtree
os.rmdir(path)
OSError: [Errno 39] Directory not empty: '/julia/cache_home_2/datasets/csv/default-61468fc71a743ec1/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2.incomplete'
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1773/timeline | null | completed | null | null | false | [
"Looks like an issue with your csv file. Did you use the right delimiter ?\r\nApparently at line 37 the CSV reader from pandas reads 2 fields instead of 1.",
"Note that you can pass any argument you would pass to `pandas.read_csv` as kwargs to `load_dataset`. For example you can do\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset('csv', data_files=data_files, sep=\"\\t\")\r\n```\r\n\r\nfor example to use a tab separator.\r\n\r\nYou can see the full list of arguments here: https://github.com/huggingface/datasets/blob/master/src/datasets/packaged_modules/csv/csv.py\r\n\r\n(I've not found the list in the documentation though, we definitely must add them !)",
"You can try to convert the file to (CSV UTF-8)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2200 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2200/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2200/comments | https://api.github.com/repos/huggingface/datasets/issues/2200/events | https://github.com/huggingface/datasets/issues/2200 | 854,449,656 | MDU6SXNzdWU4NTQ0NDk2NTY= | 2,200 | _prepare_split will overwrite DatasetBuilder.info.features | [] | closed | false | null | 2 | 2021-04-09T11:47:13Z | 2021-06-04T10:37:35Z | 2021-06-04T10:37:35Z | null | Hi, here is my issue:
I initialized a Csv datasetbuilder with specific features:
```
def get_dataset_features(data_args):
features = {}
if data_args.text_features:
features.update({text_feature: hf_features.Value("string") for text_feature in data_args.text_features.strip().split(",")})
if data_args.num_features:
features.update({text_feature: hf_features.Value("float32") for text_feature in data_args.num_features.strip().split(",")})
if data_args.label_classes:
features["label"] = hf_features.ClassLabel(names=data_args.label_classes.strip().split(","))
else:
features["label"] = hf_features.Value("float32")
return hf_features.Features(features)
datasets = load_dataset(extension,
data_files=data_files,
sep=data_args.delimiter,
header=data_args.header,
column_names=data_args.column_names.split(",") if data_args.column_names else None,
features=get_dataset_features(data_args=data_args))
```
The `features` is printout as below before `builder_instance.as_dataset` is called:
```
{'label': ClassLabel(num_classes=2, names=['unacceptable', 'acceptable'], names_file=None, id=None), 'notated': Value(dtype='string', id=None), 'sentence': Value(dtype='string', id=None), 'src_code': Value(dtype='string', id=None)}
````
But after the `builder_instance.as_dataset` is called for Csv dataset builder, the `features` is changed to:
```
{'label': Value(dtype='int64', id=None), 'notated': Value(dtype='string', id=None), 'sentence': Value(dtype='string', id=None), 'src_code': Value(dtype='string', id=None)}
```
After digged into the code, I releazed that in `ArrowBasedBuilder._prepare_split`, the DatasetBuilder's info's features will be overwrited by `ArrowWriter`'s `_features`.
But `ArrowWriter` is initailized without passing `features`.
So my concern is:
It's this overwrite must be done, or, should it be an option to pass features in `_prepare_split` function? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2200/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2200/timeline | null | completed | null | null | false | [
"Hi ! This might be related to #2153 \r\n\r\nYou're right the ArrowWriter should be initialized with `features=self.info.features` ! Good catch\r\nI'm opening a PR to fix this and also to figure out how it was not caught in the tests\r\n\r\nEDIT: opened #2201",
"> Hi ! This might be related to #2153\r\n> \r\n> You're right the ArrowWriter should be initialized with `features=self.info.features` ! Good catch\r\n> I'm opening a PR to fix this and also to figure out how it was not caught in the tests\r\n> \r\n> EDIT: opened #2201\r\n\r\nGlad to hear that! Thank you for your fix, I'm new to huggingface, it's a fantastic project 😁"
] |
https://api.github.com/repos/huggingface/datasets/issues/73 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/73/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/73/comments | https://api.github.com/repos/huggingface/datasets/issues/73/events | https://github.com/huggingface/datasets/pull/73 | 616,417,845 | MDExOlB1bGxSZXF1ZXN0NDE2NTMyMTg1 | 73 | JSON script | [] | closed | false | null | 5 | 2020-05-12T07:11:22Z | 2020-05-18T06:50:37Z | 2020-05-18T06:50:36Z | null | Add a JSONS script to read JSON datasets from files. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/73/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/73/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/73.diff",
"html_url": "https://github.com/huggingface/datasets/pull/73",
"merged_at": "2020-05-18T06:50:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/73.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/73"
} | true | [
"The tests for the Wikipedia dataset do not pass anymore with the error:\r\n```\r\nTo be able to use this dataset, you need to install the following dependencies ['mwparserfromhell'] using 'pip install mwparserfromhell' for instance'\r\n```",
"This was an issue on master. You can just rebase from master.",
"Perfect! Indeed, it worked^^ Thanks @lhoestq ",
"Currently the dummy_data tests are always green because in a PR the dataset is not yet synchronized with aws. This PR fixes this: https://github.com/huggingface/nlp/pull/140 . \r\n\r\nCould you test `json` locally or wait until the PR: https://github.com/huggingface/nlp/pull/140 is merged ? :-) ",
"Ok, I will wait #140 to be merged and then rebase :) "
] |
https://api.github.com/repos/huggingface/datasets/issues/451 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/451/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/451/comments | https://api.github.com/repos/huggingface/datasets/issues/451/events | https://github.com/huggingface/datasets/pull/451 | 667,210,468 | MDExOlB1bGxSZXF1ZXN0NDU3OTIxNDMx | 451 | Fix csv/json/txt cache dir | [] | closed | false | null | 4 | 2020-07-28T16:30:51Z | 2020-07-29T13:57:23Z | 2020-07-29T13:57:22Z | null | The cache dir for csv/json/txt datasets was always the same. This is an issue because it should be different depending on the data files provided by the user.
To fix that, I added a line that use the hash of the data files provided by the user to define the cache dir.
This should fix #444 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/451/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/451/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/451.diff",
"html_url": "https://github.com/huggingface/datasets/pull/451",
"merged_at": "2020-07-29T13:57:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/451.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/451"
} | true | [
"I think this is the way to go but I’m afraid this might be a little slow. I was thinking that we could use a high quality very fast non crypto hash like xxhash for these stuff (hashing data files)",
"Yep good idea, I'll take a look",
"I tested the hashing speed [here](https://colab.research.google.com/drive/1hlhP84kLIHmOzMRQN1h8x10hKWpXXyud?usp=sharing).\r\nI was able to get 8x speed with `xxhashlib` (42ms vs 345ms for 100MiB of data).\r\nWhat do you think @thomwolf ?",
"I added xxhash and some tests"
] |
https://api.github.com/repos/huggingface/datasets/issues/2655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2655/comments | https://api.github.com/repos/huggingface/datasets/issues/2655/events | https://github.com/huggingface/datasets/issues/2655 | 945,382,723 | MDU6SXNzdWU5NDUzODI3MjM= | 2,655 | Allow the selection of multiple columns at once | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2021-07-15T13:30:45Z | 2021-07-23T15:40:57Z | null | null | **Is your feature request related to a problem? Please describe.**
Similar to pandas, it would be great if we could select multiple columns at once.
**Describe the solution you'd like**
```python
my_dataset = ... # Has columns ['idx', 'sentence', 'label']
idx, label = my_dataset[['idx', 'label']]
```
**Describe alternatives you've considered**
we can do `[dataset[col] for col in ('idx', 'label')]`
**Additional context**
This is of course very minor.
| {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2655/timeline | null | null | null | null | false | [
"Hi! I was looking into this and hope you can clarify a point. Your my_dataset variable would be of type DatasetDict which means the alternative you've described (dict comprehension) is what makes sense. \r\nIs there a reason why you wouldn't want to convert my_dataset to a pandas df if you'd like to use it like one? Please let me know if I'm missing something.",
"Hi! Sorry for the delay.\r\n\r\nIn this case, the dataset would be a `datasets.Dataset` and we want to select multiple columns, the `idx` and `label` columns for example.\r\n\r\nMy issue is that my dataset is too big for memory if I load everything into pandas."
] |
https://api.github.com/repos/huggingface/datasets/issues/5430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5430/comments | https://api.github.com/repos/huggingface/datasets/issues/5430/events | https://github.com/huggingface/datasets/issues/5430 | 1,535,856,503 | I_kwDODunzps5bi093 | 5,430 | Support Apache Beam >= 2.44.0 | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2023-01-17T06:42:12Z | 2023-01-17T16:12:18Z | null | null | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5430/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5430/timeline | null | null | null | null | false | [
"Some of the shard files now have 0 number of rows.\r\n\r\nWe have opened an issue in the Apache Beam repo:\r\n- https://github.com/apache/beam/issues/25041"
] |
https://api.github.com/repos/huggingface/datasets/issues/2265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2265/comments | https://api.github.com/repos/huggingface/datasets/issues/2265/events | https://github.com/huggingface/datasets/pull/2265 | 867,490,646 | MDExOlB1bGxSZXF1ZXN0NjIzMTUyOTg5 | 2,265 | Update black | [] | closed | false | null | 0 | 2021-04-26T09:35:09Z | 2021-04-26T09:47:48Z | 2021-04-26T09:47:47Z | null | Latest black version 21.4b0 requires to reformat most dataset scripts and also the core code of the lib.
This makes the CI currently fail on master | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2265/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2265",
"merged_at": "2021-04-26T09:47:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2265"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4785 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4785/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4785/comments | https://api.github.com/repos/huggingface/datasets/issues/4785/events | https://github.com/huggingface/datasets/pull/4785 | 1,327,225,826 | PR_kwDODunzps48k8y4 | 4,785 | Require torchaudio<0.12.0 in docs | [] | closed | false | null | 1 | 2022-08-03T13:32:00Z | 2022-08-03T15:07:43Z | 2022-08-03T14:52:16Z | null | This PR adds to docs the requirement of torchaudio<0.12.0 to avoid RuntimeError.
Subsequent to PR:
- #4777 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4785/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4785/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4785.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4785",
"merged_at": "2022-08-03T14:52:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4785.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4785"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1504 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1504/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1504/comments | https://api.github.com/repos/huggingface/datasets/issues/1504/events | https://github.com/huggingface/datasets/pull/1504 | 763,697,231 | MDExOlB1bGxSZXF1ZXN0NTM4MDczMzcw | 1,504 | Add SentiWS dataset for pos-tagging and sentiment-scoring (German) | [] | closed | false | null | 2 | 2020-12-12T12:17:53Z | 2020-12-15T18:32:38Z | 2020-12-15T18:32:38Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1504/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1504/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1504.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1504",
"merged_at": "2020-12-15T18:32:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1504.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1504"
} | true | [
"Hi @lhoestq @yjernite, requesting you to review this for any changes needed. Thanks! :)",
"Hi @lhoestq , I have updated the PR"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/1712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1712/comments | https://api.github.com/repos/huggingface/datasets/issues/1712/events | https://github.com/huggingface/datasets/pull/1712 | 782,313,097 | MDExOlB1bGxSZXF1ZXN0NTUxODkxMDk4 | 1,712 | Silicone | [] | closed | false | null | 6 | 2021-01-08T18:24:18Z | 2021-01-21T14:12:37Z | 2021-01-21T10:31:11Z | null | My collaborators and I within the Affective Computing team at Telecom Paris would like to push our spoken dialogue dataset for publication. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1712/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1712/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1712.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1712",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1712.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1712"
} | true | [
"When should we expect to see our dataset appear in the search dropdown at huggingface.co?",
"Hi @eusip,\r\n\r\n> When should we expect to see our dataset appear in the search dropdown at huggingface.co?\r\n\r\nwhen this PR is merged.",
"Thanks!",
"I've implemented all the changes requested by @lhoestq but I made the mistake of trying to change the remote branch name. \r\n\r\nHopefully the changes are seen on your end as both branches `silicone` and `main` should be up-to-date.",
"It looks like the PR includes changes about many other files than the ones for Silicone (+30,000 line changes)\r\n\r\nMaybe you can try to create another branch and another PR ?",
"> It looks like the PR includes changes about many other files than the ones for Silicone (+30,000 line changes)\r\n> \r\n> Maybe you can try to create another branch and another PR ?\r\n\r\nSure. I will make a new pull request."
] |
https://api.github.com/repos/huggingface/datasets/issues/4406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4406/comments | https://api.github.com/repos/huggingface/datasets/issues/4406/events | https://github.com/huggingface/datasets/pull/4406 | 1,248,626,622 | PR_kwDODunzps44ePLU | 4,406 | Improve language tag for PIAF dataset | [] | closed | false | null | 0 | 2022-05-25T19:41:55Z | 2022-05-27T14:51:23Z | 2022-05-27T14:51:23Z | null | Hi,
As pointed out by @lhoestq in this discussion (https://huggingface.co/datasets/asi/wikitext_fr/discussions/1), it is not yet possible to edit datasets outside of a namespace with the Hub PR feature and that you have to go through GitHub.
This modification should allow better referencing since only the xx language tags are currently taken into account and not the xx-xx. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4406/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4406/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4406.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4406",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4406.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4406"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3927/comments | https://api.github.com/repos/huggingface/datasets/issues/3927/events | https://github.com/huggingface/datasets/pull/3927 | 1,170,016,465 | PR_kwDODunzps40ewN2 | 3,927 | Update main readme | [] | closed | false | null | 2 | 2022-03-15T18:09:59Z | 2022-03-29T10:13:47Z | 2022-03-29T10:08:20Z | null | The main readme was still focused on text datasets - I extended it by mentioning that we also support image and audio datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3927/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3927.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3927",
"merged_at": "2022-03-29T10:08:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3927.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3927"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"What do you think @albertvillanova ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/1529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1529/comments | https://api.github.com/repos/huggingface/datasets/issues/1529/events | https://github.com/huggingface/datasets/pull/1529 | 764,748,410 | MDExOlB1bGxSZXF1ZXN0NTM4NjY4MjU4 | 1,529 | Ro sent | [] | closed | false | null | 8 | 2020-12-13T01:55:02Z | 2021-03-19T10:32:43Z | 2021-03-19T10:32:42Z | null | Movies reviews dataset for Romanian language. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1529/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1529/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1529.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1529",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1529.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1529"
} | true | [
"Hi @iliemihai, it looks like this PR holds changes from your previous PR #1493 .\r\nWould you mind removing them from the branch please ?",
"@SBrandeis I am sorry. Yes I will remove them. Thank you :D ",
"Hi @lhoestq @SBrandeis @iliemihai\r\n\r\nIs this still in progress or can I take over this one?\r\n\r\nThanks,\r\nGunjan",
"Hi,\r\nWhile trying to add this dataset, I found some potential issues. \r\nThe homepage mentioned is : https://github.com/katakonst/sentiment-analysis-tensorflow/tree/master/datasets/ro/, where the dataset is different from the URLs: https://raw.githubusercontent.com/dumitrescustefan/Romanian-Transformers/examples/examples/sentiment_analysis/ro/train.csv. It is unclear which dataset is \"correct\". I checked the total examples (train+test) in both places and they do not match.",
"We should use the data from dumitrescustefan and set the homepage to his repo IMO, since he's first author of the paper of the dataset.",
"Hi @lhoestq,\r\n\r\nCool, I'll get working on it.\r\n\r\nThanks",
"Hi @lhoestq, \r\n\r\nThis PR can be closed.",
"Closing in favor of #2011 \r\nThanks again for adding it !"
] |
https://api.github.com/repos/huggingface/datasets/issues/1382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1382/comments | https://api.github.com/repos/huggingface/datasets/issues/1382/events | https://github.com/huggingface/datasets/pull/1382 | 760,325,077 | MDExOlB1bGxSZXF1ZXN0NTM1MTc1NzMx | 1,382 | adding UNPC | [] | closed | false | null | 1 | 2020-12-09T13:21:41Z | 2020-12-09T17:53:06Z | 2020-12-09T17:53:06Z | null | Adding United Nations Parallel Corpus
http://opus.nlpl.eu/UNPC.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1382/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1382.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1382",
"merged_at": "2020-12-09T17:53:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1382.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1382"
} | true | [
"merging since the CI just had a connection error"
] |
https://api.github.com/repos/huggingface/datasets/issues/6044 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6044/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6044/comments | https://api.github.com/repos/huggingface/datasets/issues/6044/events | https://github.com/huggingface/datasets/pull/6044 | 1,808,057,906 | PR_kwDODunzps5Vr7jr | 6,044 | Rename "pattern" to "path" in YAML data_files configs | [] | closed | false | null | 10 | 2023-07-17T15:41:16Z | 2023-07-19T16:59:55Z | 2023-07-19T16:48:06Z | null | To make it easier to understand for users.
They can use "path" to specify a single path, <s>or "paths" to use a list of paths.</s>
Glob patterns are still supported though
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6044/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6044/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6044.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6044",
"merged_at": "2023-07-19T16:48:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6044.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6044"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006543 / 0.011353 (-0.004809) | 0.004085 / 0.011008 (-0.006924) | 0.083989 / 0.038508 (0.045481) | 0.074733 / 0.023109 (0.051623) | 0.310839 / 0.275898 (0.034941) | 0.333540 / 0.323480 (0.010060) | 0.005566 / 0.007986 (-0.002419) | 0.003461 / 0.004328 (-0.000868) | 0.065194 / 0.004250 (0.060943) | 0.057007 / 0.037052 (0.019954) | 0.325633 / 0.258489 (0.067144) | 0.351665 / 0.293841 (0.057824) | 0.030561 / 0.128546 (-0.097985) | 0.008579 / 0.075646 (-0.067068) | 0.287457 / 0.419271 (-0.131815) | 0.063554 / 0.043533 (0.020021) | 0.309182 / 0.255139 (0.054043) | 0.327809 / 0.283200 (0.044609) | 0.034470 / 0.141683 (-0.107213) | 1.452098 / 1.452155 (-0.000057) | 1.527130 / 1.492716 (0.034414) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.241736 / 0.018006 (0.223729) | 0.552432 / 0.000490 (0.551943) | 0.004085 / 0.000200 (0.003885) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027290 / 0.037411 (-0.010121) | 0.081250 / 0.014526 (0.066724) | 0.094739 / 0.176557 (-0.081818) | 0.150424 / 0.737135 (-0.586711) | 0.095488 / 0.296338 (-0.200851) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.377245 / 0.215209 (0.162036) | 3.781021 / 2.077655 (1.703366) | 1.820092 / 1.504120 (0.315972) | 1.654420 / 1.541195 (0.113225) | 1.751256 / 1.468490 (0.282766) | 0.475161 / 4.584777 (-4.109616) | 3.603462 / 3.745712 (-0.142251) | 5.437837 / 5.269862 (0.167975) | 3.305598 / 4.565676 (-1.260079) | 0.055856 / 0.424275 (-0.368419) | 0.007259 / 0.007607 (-0.000348) | 0.454205 / 0.226044 (0.228161) | 4.544157 / 2.268929 (2.275229) | 2.296776 / 55.444624 (-53.147848) | 1.951017 / 6.876477 (-4.925459) | 2.128759 / 2.142072 (-0.013313) | 0.590354 / 4.805227 (-4.214873) | 0.129974 / 6.500664 (-6.370690) | 0.059506 / 0.075469 (-0.015963) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.285866 / 1.841788 (-0.555921) | 19.419446 / 8.074308 (11.345138) | 13.985108 / 10.191392 (3.793716) | 0.146803 / 0.680424 (-0.533620) | 0.018176 / 0.534201 (-0.516025) | 0.392345 / 0.579283 (-0.186938) | 0.405394 / 0.434364 (-0.028970) | 0.454649 / 0.540337 (-0.085688) | 0.633075 / 1.386936 (-0.753861) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006497 / 0.011353 (-0.004855) | 0.004092 / 0.011008 (-0.006916) | 0.064908 / 0.038508 (0.026400) | 0.073494 / 0.023109 (0.050385) | 0.382227 / 0.275898 (0.106329) | 0.407320 / 0.323480 (0.083840) | 0.005653 / 0.007986 (-0.002332) | 0.003500 / 0.004328 (-0.000829) | 0.064570 / 0.004250 (0.060320) | 0.058733 / 0.037052 (0.021681) | 0.385702 / 0.258489 (0.127213) | 0.426463 / 0.293841 (0.132622) | 0.031073 / 0.128546 (-0.097473) | 0.008710 / 0.075646 (-0.066936) | 0.071378 / 0.419271 (-0.347893) | 0.050141 / 0.043533 (0.006608) | 0.377769 / 0.255139 (0.122630) | 0.395016 / 0.283200 (0.111816) | 0.025158 / 0.141683 (-0.116525) | 1.470503 / 1.452155 (0.018348) | 1.532742 / 1.492716 (0.040026) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.214249 / 0.018006 (0.196243) | 0.583580 / 0.000490 (0.583090) | 0.004027 / 0.000200 (0.003828) | 0.000104 / 0.000054 (0.000050) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030186 / 0.037411 (-0.007226) | 0.086927 / 0.014526 (0.072401) | 0.102060 / 0.176557 (-0.074497) | 0.156281 / 0.737135 (-0.580855) | 0.100825 / 0.296338 (-0.195514) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419942 / 0.215209 (0.204733) | 4.183797 / 2.077655 (2.106142) | 2.205079 / 1.504120 (0.700959) | 2.071219 / 1.541195 (0.530024) | 2.194047 / 1.468490 (0.725557) | 0.478768 / 4.584777 (-4.106009) | 3.584864 / 3.745712 (-0.160848) | 3.371635 / 5.269862 (-1.898227) | 2.022134 / 4.565676 (-2.543542) | 0.056553 / 0.424275 (-0.367722) | 0.007231 / 0.007607 (-0.000376) | 0.493158 / 0.226044 (0.267113) | 4.934370 / 2.268929 (2.665441) | 2.699593 / 55.444624 (-52.745031) | 2.396371 / 6.876477 (-4.480105) | 2.438052 / 2.142072 (0.295979) | 0.589578 / 4.805227 (-4.215649) | 0.147234 / 6.500664 (-6.353430) | 0.062049 / 0.075469 (-0.013420) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.318246 / 1.841788 (-0.523542) | 19.829025 / 8.074308 (11.754717) | 14.314825 / 10.191392 (4.123433) | 0.168309 / 0.680424 (-0.512115) | 0.018596 / 0.534201 (-0.515605) | 0.397540 / 0.579283 (-0.181743) | 0.421280 / 0.434364 (-0.013084) | 0.479917 / 0.540337 (-0.060421) | 0.643494 / 1.386936 (-0.743442) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008349 / 0.011353 (-0.003004) | 0.005362 / 0.011008 (-0.005646) | 0.100777 / 0.038508 (0.062269) | 0.078719 / 0.023109 (0.055609) | 0.398105 / 0.275898 (0.122207) | 0.444189 / 0.323480 (0.120709) | 0.006834 / 0.007986 (-0.001152) | 0.004642 / 0.004328 (0.000314) | 0.076284 / 0.004250 (0.072034) | 0.062738 / 0.037052 (0.025685) | 0.409532 / 0.258489 (0.151043) | 0.447218 / 0.293841 (0.153377) | 0.052996 / 0.128546 (-0.075550) | 0.012977 / 0.075646 (-0.062669) | 0.347687 / 0.419271 (-0.071585) | 0.068076 / 0.043533 (0.024543) | 0.394526 / 0.255139 (0.139387) | 0.434110 / 0.283200 (0.150910) | 0.041719 / 0.141683 (-0.099963) | 1.759109 / 1.452155 (0.306955) | 1.866049 / 1.492716 (0.373333) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.287633 / 0.018006 (0.269627) | 0.611540 / 0.000490 (0.611051) | 0.005388 / 0.000200 (0.005188) | 0.000096 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027394 / 0.037411 (-0.010017) | 0.089796 / 0.014526 (0.075270) | 0.106931 / 0.176557 (-0.069625) | 0.173560 / 0.737135 (-0.563575) | 0.106948 / 0.296338 (-0.189391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.575156 / 0.215209 (0.359947) | 5.674170 / 2.077655 (3.596516) | 2.463090 / 1.504120 (0.958971) | 2.128245 / 1.541195 (0.587050) | 2.118982 / 1.468490 (0.650492) | 0.876976 / 4.584777 (-3.707801) | 5.238229 / 3.745712 (1.492517) | 4.548788 / 5.269862 (-0.721074) | 2.905243 / 4.565676 (-1.660433) | 0.090750 / 0.424275 (-0.333525) | 0.008266 / 0.007607 (0.000659) | 0.693305 / 0.226044 (0.467260) | 7.126970 / 2.268929 (4.858041) | 3.152131 / 55.444624 (-52.292494) | 2.532118 / 6.876477 (-4.344359) | 2.678442 / 2.142072 (0.536369) | 0.932745 / 4.805227 (-3.872483) | 0.196290 / 6.500664 (-6.304374) | 0.074082 / 0.075469 (-0.001387) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.599636 / 1.841788 (-0.242152) | 23.271435 / 8.074308 (15.197127) | 19.696709 / 10.191392 (9.505317) | 0.222668 / 0.680424 (-0.457756) | 0.029088 / 0.534201 (-0.505113) | 0.492477 / 0.579283 (-0.086806) | 0.580578 / 0.434364 (0.146214) | 0.558852 / 0.540337 (0.018514) | 0.762083 / 1.386936 (-0.624853) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009021 / 0.011353 (-0.002332) | 0.005011 / 0.011008 (-0.005997) | 0.076504 / 0.038508 (0.037996) | 0.077303 / 0.023109 (0.054193) | 0.480660 / 0.275898 (0.204762) | 0.493944 / 0.323480 (0.170464) | 0.006339 / 0.007986 (-0.001646) | 0.004302 / 0.004328 (-0.000026) | 0.076228 / 0.004250 (0.071978) | 0.060805 / 0.037052 (0.023753) | 0.477539 / 0.258489 (0.219050) | 0.496799 / 0.293841 (0.202958) | 0.049495 / 0.128546 (-0.079052) | 0.013333 / 0.075646 (-0.062313) | 0.087217 / 0.419271 (-0.332055) | 0.061451 / 0.043533 (0.017918) | 0.485169 / 0.255139 (0.230030) | 0.487348 / 0.283200 (0.204149) | 0.035874 / 0.141683 (-0.105809) | 1.829137 / 1.452155 (0.376982) | 1.906151 / 1.492716 (0.413435) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304526 / 0.018006 (0.286520) | 0.627499 / 0.000490 (0.627009) | 0.003786 / 0.000200 (0.003586) | 0.000098 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035512 / 0.037411 (-0.001899) | 0.096684 / 0.014526 (0.082158) | 0.111879 / 0.176557 (-0.064678) | 0.171489 / 0.737135 (-0.565647) | 0.112175 / 0.296338 (-0.184164) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.604791 / 0.215209 (0.389582) | 6.089137 / 2.077655 (4.011482) | 2.883237 / 1.504120 (1.379117) | 2.561109 / 1.541195 (1.019914) | 2.542400 / 1.468490 (1.073910) | 0.852828 / 4.584777 (-3.731949) | 5.236812 / 3.745712 (1.491100) | 4.756429 / 5.269862 (-0.513432) | 2.885660 / 4.565676 (-1.680016) | 0.095643 / 0.424275 (-0.328632) | 0.008403 / 0.007607 (0.000796) | 0.727707 / 0.226044 (0.501663) | 7.428002 / 2.268929 (5.159074) | 3.816051 / 55.444624 (-51.628573) | 2.971057 / 6.876477 (-3.905420) | 2.915965 / 2.142072 (0.773893) | 1.006553 / 4.805227 (-3.798674) | 0.201840 / 6.500664 (-6.298824) | 0.080795 / 0.075469 (0.005326) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.794951 / 1.841788 (-0.046837) | 23.624556 / 8.074308 (15.550248) | 21.856195 / 10.191392 (11.664802) | 0.253043 / 0.680424 (-0.427381) | 0.031201 / 0.534201 (-0.503000) | 0.461641 / 0.579283 (-0.117642) | 0.577789 / 0.434364 (0.143425) | 0.569197 / 0.540337 (0.028860) | 0.780111 / 1.386936 (-0.606825) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007646 / 0.011353 (-0.003707) | 0.004750 / 0.011008 (-0.006258) | 0.097981 / 0.038508 (0.059473) | 0.088989 / 0.023109 (0.065880) | 0.377732 / 0.275898 (0.101834) | 0.406805 / 0.323480 (0.083325) | 0.006389 / 0.007986 (-0.001597) | 0.003854 / 0.004328 (-0.000474) | 0.073977 / 0.004250 (0.069727) | 0.066497 / 0.037052 (0.029444) | 0.371498 / 0.258489 (0.113009) | 0.417352 / 0.293841 (0.123511) | 0.036326 / 0.128546 (-0.092220) | 0.009876 / 0.075646 (-0.065770) | 0.330142 / 0.419271 (-0.089130) | 0.062423 / 0.043533 (0.018890) | 0.369375 / 0.255139 (0.114236) | 0.406048 / 0.283200 (0.122848) | 0.026564 / 0.141683 (-0.115119) | 1.713295 / 1.452155 (0.261140) | 1.797493 / 1.492716 (0.304777) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231889 / 0.018006 (0.213882) | 0.512497 / 0.000490 (0.512007) | 0.000390 / 0.000200 (0.000190) | 0.000069 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033978 / 0.037411 (-0.003433) | 0.100117 / 0.014526 (0.085592) | 0.112460 / 0.176557 (-0.064097) | 0.179936 / 0.737135 (-0.557200) | 0.114277 / 0.296338 (-0.182061) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.461320 / 0.215209 (0.246111) | 4.563180 / 2.077655 (2.485526) | 2.249474 / 1.504120 (0.745354) | 2.100450 / 1.541195 (0.559255) | 2.231080 / 1.468490 (0.762590) | 0.567907 / 4.584777 (-4.016870) | 4.117233 / 3.745712 (0.371521) | 4.943159 / 5.269862 (-0.326703) | 3.112299 / 4.565676 (-1.453377) | 0.065500 / 0.424275 (-0.358775) | 0.008407 / 0.007607 (0.000800) | 0.545928 / 0.226044 (0.319883) | 5.508058 / 2.268929 (3.239129) | 2.834645 / 55.444624 (-52.609980) | 2.440328 / 6.876477 (-4.436148) | 2.680483 / 2.142072 (0.538410) | 0.697191 / 4.805227 (-4.108036) | 0.176646 / 6.500664 (-6.324018) | 0.073608 / 0.075469 (-0.001861) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.451865 / 1.841788 (-0.389922) | 22.752595 / 8.074308 (14.678287) | 15.543338 / 10.191392 (5.351946) | 0.214644 / 0.680424 (-0.465780) | 0.022050 / 0.534201 (-0.512151) | 0.463898 / 0.579283 (-0.115385) | 0.481691 / 0.434364 (0.047327) | 0.549715 / 0.540337 (0.009378) | 0.773595 / 1.386936 (-0.613341) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007541 / 0.011353 (-0.003812) | 0.004715 / 0.011008 (-0.006293) | 0.076782 / 0.038508 (0.038274) | 0.086242 / 0.023109 (0.063133) | 0.458053 / 0.275898 (0.182155) | 0.503097 / 0.323480 (0.179617) | 0.006262 / 0.007986 (-0.001724) | 0.003882 / 0.004328 (-0.000447) | 0.075669 / 0.004250 (0.071419) | 0.066004 / 0.037052 (0.028952) | 0.469439 / 0.258489 (0.210950) | 0.529744 / 0.293841 (0.235903) | 0.037228 / 0.128546 (-0.091319) | 0.009794 / 0.075646 (-0.065852) | 0.082464 / 0.419271 (-0.336808) | 0.058797 / 0.043533 (0.015264) | 0.452069 / 0.255139 (0.196930) | 0.488246 / 0.283200 (0.205046) | 0.029324 / 0.141683 (-0.112359) | 1.742237 / 1.452155 (0.290082) | 1.839676 / 1.492716 (0.346959) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228106 / 0.018006 (0.210100) | 0.491632 / 0.000490 (0.491142) | 0.004993 / 0.000200 (0.004793) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035413 / 0.037411 (-0.001999) | 0.104617 / 0.014526 (0.090091) | 0.121948 / 0.176557 (-0.054609) | 0.186233 / 0.737135 (-0.550902) | 0.121574 / 0.296338 (-0.174764) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.473849 / 0.215209 (0.258640) | 4.788312 / 2.077655 (2.710657) | 2.470535 / 1.504120 (0.966415) | 2.270393 / 1.541195 (0.729198) | 2.361096 / 1.468490 (0.892606) | 0.556184 / 4.584777 (-4.028593) | 4.216852 / 3.745712 (0.471140) | 3.901718 / 5.269862 (-1.368143) | 2.355209 / 4.565676 (-2.210467) | 0.066708 / 0.424275 (-0.357567) | 0.008709 / 0.007607 (0.001102) | 0.571714 / 0.226044 (0.345669) | 5.663150 / 2.268929 (3.394221) | 3.025769 / 55.444624 (-52.418855) | 2.652554 / 6.876477 (-4.223923) | 2.750555 / 2.142072 (0.608483) | 0.681536 / 4.805227 (-4.123691) | 0.157187 / 6.500664 (-6.343477) | 0.073533 / 0.075469 (-0.001936) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.604630 / 1.841788 (-0.237158) | 22.735629 / 8.074308 (14.661321) | 16.762347 / 10.191392 (6.570955) | 0.175514 / 0.680424 (-0.504910) | 0.021497 / 0.534201 (-0.512704) | 0.461438 / 0.579283 (-0.117845) | 0.476184 / 0.434364 (0.041820) | 0.571048 / 0.540337 (0.030710) | 0.747086 / 1.386936 (-0.639850) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006889 / 0.011353 (-0.004464) | 0.004241 / 0.011008 (-0.006767) | 0.084542 / 0.038508 (0.046034) | 0.080484 / 0.023109 (0.057374) | 0.309356 / 0.275898 (0.033458) | 0.338548 / 0.323480 (0.015068) | 0.004904 / 0.007986 (-0.003082) | 0.005220 / 0.004328 (0.000892) | 0.065501 / 0.004250 (0.061251) | 0.062095 / 0.037052 (0.025043) | 0.317332 / 0.258489 (0.058843) | 0.364797 / 0.293841 (0.070956) | 0.030492 / 0.128546 (-0.098054) | 0.008991 / 0.075646 (-0.066656) | 0.288274 / 0.419271 (-0.130998) | 0.052582 / 0.043533 (0.009049) | 0.310838 / 0.255139 (0.055699) | 0.346304 / 0.283200 (0.063104) | 0.027968 / 0.141683 (-0.113715) | 1.509727 / 1.452155 (0.057573) | 1.577410 / 1.492716 (0.084694) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.269725 / 0.018006 (0.251719) | 0.627685 / 0.000490 (0.627195) | 0.000419 / 0.000200 (0.000219) | 0.000060 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031022 / 0.037411 (-0.006389) | 0.081858 / 0.014526 (0.067332) | 0.099477 / 0.176557 (-0.077080) | 0.162981 / 0.737135 (-0.574154) | 0.101987 / 0.296338 (-0.194351) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.386297 / 0.215209 (0.171088) | 3.845321 / 2.077655 (1.767666) | 1.834446 / 1.504120 (0.330326) | 1.699730 / 1.541195 (0.158536) | 1.764342 / 1.468490 (0.295852) | 0.486423 / 4.584777 (-4.098354) | 3.527595 / 3.745712 (-0.218117) | 4.137034 / 5.269862 (-1.132827) | 2.590457 / 4.565676 (-1.975219) | 0.057598 / 0.424275 (-0.366677) | 0.007318 / 0.007607 (-0.000289) | 0.460775 / 0.226044 (0.234730) | 4.627576 / 2.268929 (2.358647) | 2.402566 / 55.444624 (-53.042059) | 2.011392 / 6.876477 (-4.865085) | 2.223915 / 2.142072 (0.081842) | 0.623217 / 4.805227 (-4.182011) | 0.148875 / 6.500664 (-6.351789) | 0.059799 / 0.075469 (-0.015671) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.290768 / 1.841788 (-0.551020) | 20.455083 / 8.074308 (12.380775) | 13.469846 / 10.191392 (3.278454) | 0.170329 / 0.680424 (-0.510095) | 0.018409 / 0.534201 (-0.515792) | 0.394356 / 0.579283 (-0.184927) | 0.422685 / 0.434364 (-0.011679) | 0.476241 / 0.540337 (-0.064096) | 0.662682 / 1.386936 (-0.724254) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006724 / 0.011353 (-0.004629) | 0.004508 / 0.011008 (-0.006500) | 0.065304 / 0.038508 (0.026796) | 0.080243 / 0.023109 (0.057133) | 0.384545 / 0.275898 (0.108647) | 0.415234 / 0.323480 (0.091754) | 0.006361 / 0.007986 (-0.001624) | 0.004193 / 0.004328 (-0.000135) | 0.065940 / 0.004250 (0.061689) | 0.063633 / 0.037052 (0.026581) | 0.392799 / 0.258489 (0.134310) | 0.443618 / 0.293841 (0.149777) | 0.031134 / 0.128546 (-0.097412) | 0.009058 / 0.075646 (-0.066588) | 0.071051 / 0.419271 (-0.348221) | 0.049096 / 0.043533 (0.005563) | 0.379526 / 0.255139 (0.124387) | 0.403370 / 0.283200 (0.120171) | 0.026378 / 0.141683 (-0.115305) | 1.457879 / 1.452155 (0.005724) | 1.562890 / 1.492716 (0.070174) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304416 / 0.018006 (0.286410) | 0.626046 / 0.000490 (0.625557) | 0.000469 / 0.000200 (0.000269) | 0.000057 / 0.000054 (0.000002) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032979 / 0.037411 (-0.004433) | 0.086769 / 0.014526 (0.072243) | 0.108188 / 0.176557 (-0.068369) | 0.163077 / 0.737135 (-0.574058) | 0.106276 / 0.296338 (-0.190062) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.406922 / 0.215209 (0.191713) | 4.052828 / 2.077655 (1.975174) | 2.084802 / 1.504120 (0.580682) | 1.927263 / 1.541195 (0.386069) | 1.956078 / 1.468490 (0.487587) | 0.480110 / 4.584777 (-4.104667) | 3.553022 / 3.745712 (-0.192691) | 3.554450 / 5.269862 (-1.715411) | 2.082681 / 4.565676 (-2.482995) | 0.056711 / 0.424275 (-0.367564) | 0.007374 / 0.007607 (-0.000234) | 0.480555 / 0.226044 (0.254510) | 4.795851 / 2.268929 (2.526923) | 2.606675 / 55.444624 (-52.837949) | 2.249964 / 6.876477 (-4.626512) | 2.274234 / 2.142072 (0.132162) | 0.571767 / 4.805227 (-4.233461) | 0.133312 / 6.500664 (-6.367352) | 0.061703 / 0.075469 (-0.013766) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.354308 / 1.841788 (-0.487479) | 20.959352 / 8.074308 (12.885044) | 14.158420 / 10.191392 (3.967028) | 0.197959 / 0.680424 (-0.482465) | 0.018412 / 0.534201 (-0.515789) | 0.394307 / 0.579283 (-0.184976) | 0.402455 / 0.434364 (-0.031909) | 0.463314 / 0.540337 (-0.077024) | 0.621050 / 1.386936 (-0.765886) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007179 / 0.011353 (-0.004174) | 0.004318 / 0.011008 (-0.006690) | 0.085209 / 0.038508 (0.046701) | 0.089989 / 0.023109 (0.066880) | 0.328188 / 0.275898 (0.052290) | 0.346027 / 0.323480 (0.022547) | 0.005711 / 0.007986 (-0.002275) | 0.003703 / 0.004328 (-0.000625) | 0.065419 / 0.004250 (0.061169) | 0.065354 / 0.037052 (0.028301) | 0.314531 / 0.258489 (0.056042) | 0.354357 / 0.293841 (0.060516) | 0.030918 / 0.128546 (-0.097628) | 0.008632 / 0.075646 (-0.067015) | 0.286817 / 0.419271 (-0.132455) | 0.065267 / 0.043533 (0.021735) | 0.310918 / 0.255139 (0.055779) | 0.330497 / 0.283200 (0.047298) | 0.035695 / 0.141683 (-0.105988) | 1.471101 / 1.452155 (0.018947) | 1.538658 / 1.492716 (0.045942) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254314 / 0.018006 (0.236308) | 0.591413 / 0.000490 (0.590923) | 0.006082 / 0.000200 (0.005882) | 0.000091 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031843 / 0.037411 (-0.005568) | 0.089968 / 0.014526 (0.075442) | 0.101838 / 0.176557 (-0.074718) | 0.164401 / 0.737135 (-0.572734) | 0.103785 / 0.296338 (-0.192554) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.380486 / 0.215209 (0.165277) | 3.798868 / 2.077655 (1.721213) | 1.824645 / 1.504120 (0.320525) | 1.660804 / 1.541195 (0.119610) | 1.784793 / 1.468490 (0.316303) | 0.487222 / 4.584777 (-4.097555) | 3.560580 / 3.745712 (-0.185132) | 5.392662 / 5.269862 (0.122800) | 3.295327 / 4.565676 (-1.270350) | 0.057699 / 0.424275 (-0.366576) | 0.007559 / 0.007607 (-0.000048) | 0.459655 / 0.226044 (0.233611) | 4.587583 / 2.268929 (2.318654) | 2.304845 / 55.444624 (-53.139779) | 1.966433 / 6.876477 (-4.910044) | 2.254591 / 2.142072 (0.112519) | 0.582978 / 4.805227 (-4.222250) | 0.133455 / 6.500664 (-6.367210) | 0.061924 / 0.075469 (-0.013546) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.275685 / 1.841788 (-0.566103) | 20.814545 / 8.074308 (12.740237) | 13.753567 / 10.191392 (3.562175) | 0.164076 / 0.680424 (-0.516348) | 0.018768 / 0.534201 (-0.515433) | 0.390991 / 0.579283 (-0.188293) | 0.404417 / 0.434364 (-0.029947) | 0.457522 / 0.540337 (-0.082815) | 0.624654 / 1.386936 (-0.762282) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007435 / 0.011353 (-0.003918) | 0.004255 / 0.011008 (-0.006754) | 0.066134 / 0.038508 (0.027626) | 0.086035 / 0.023109 (0.062925) | 0.364688 / 0.275898 (0.088790) | 0.403895 / 0.323480 (0.080415) | 0.005868 / 0.007986 (-0.002117) | 0.003634 / 0.004328 (-0.000694) | 0.065803 / 0.004250 (0.061553) | 0.065113 / 0.037052 (0.028061) | 0.370057 / 0.258489 (0.111568) | 0.412634 / 0.293841 (0.118793) | 0.031660 / 0.128546 (-0.096886) | 0.008699 / 0.075646 (-0.066947) | 0.070618 / 0.419271 (-0.348654) | 0.050814 / 0.043533 (0.007281) | 0.362320 / 0.255139 (0.107181) | 0.383863 / 0.283200 (0.100663) | 0.027980 / 0.141683 (-0.113703) | 1.486389 / 1.452155 (0.034234) | 1.595534 / 1.492716 (0.102817) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.300991 / 0.018006 (0.282985) | 0.565265 / 0.000490 (0.564775) | 0.000400 / 0.000200 (0.000200) | 0.000053 / 0.000054 (-0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034942 / 0.037411 (-0.002470) | 0.092498 / 0.014526 (0.077972) | 0.106737 / 0.176557 (-0.069819) | 0.165400 / 0.737135 (-0.571735) | 0.107809 / 0.296338 (-0.188529) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412156 / 0.215209 (0.196947) | 4.116747 / 2.077655 (2.039092) | 2.199612 / 1.504120 (0.695492) | 2.049310 / 1.541195 (0.508115) | 2.174342 / 1.468490 (0.705852) | 0.482794 / 4.584777 (-4.101983) | 3.561344 / 3.745712 (-0.184368) | 3.465935 / 5.269862 (-1.803926) | 2.076595 / 4.565676 (-2.489081) | 0.056242 / 0.424275 (-0.368033) | 0.007371 / 0.007607 (-0.000236) | 0.489135 / 0.226044 (0.263091) | 4.895691 / 2.268929 (2.626763) | 2.626936 / 55.444624 (-52.817688) | 2.306658 / 6.876477 (-4.569818) | 2.421705 / 2.142072 (0.279633) | 0.599547 / 4.805227 (-4.205680) | 0.133627 / 6.500664 (-6.367037) | 0.063830 / 0.075469 (-0.011639) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.383039 / 1.841788 (-0.458748) | 21.005346 / 8.074308 (12.931038) | 14.911083 / 10.191392 (4.719691) | 0.190995 / 0.680424 (-0.489429) | 0.018510 / 0.534201 (-0.515691) | 0.396346 / 0.579283 (-0.182937) | 0.411496 / 0.434364 (-0.022868) | 0.470972 / 0.540337 (-0.069366) | 0.615670 / 1.386936 (-0.771266) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007249 / 0.011353 (-0.004104) | 0.004261 / 0.011008 (-0.006747) | 0.100645 / 0.038508 (0.062137) | 0.078522 / 0.023109 (0.055413) | 0.423526 / 0.275898 (0.147628) | 0.439541 / 0.323480 (0.116061) | 0.005812 / 0.007986 (-0.002173) | 0.003615 / 0.004328 (-0.000713) | 0.075908 / 0.004250 (0.071658) | 0.062490 / 0.037052 (0.025437) | 0.414941 / 0.258489 (0.156452) | 0.447267 / 0.293841 (0.153426) | 0.035127 / 0.128546 (-0.093419) | 0.009642 / 0.075646 (-0.066004) | 0.354093 / 0.419271 (-0.065179) | 0.060970 / 0.043533 (0.017437) | 0.418579 / 0.255139 (0.163440) | 0.427972 / 0.283200 (0.144772) | 0.025838 / 0.141683 (-0.115845) | 1.778349 / 1.452155 (0.326194) | 1.845965 / 1.492716 (0.353249) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227304 / 0.018006 (0.209298) | 0.571833 / 0.000490 (0.571343) | 0.001328 / 0.000200 (0.001128) | 0.000071 / 0.000054 (0.000017) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031343 / 0.037411 (-0.006068) | 0.096400 / 0.014526 (0.081875) | 0.106881 / 0.176557 (-0.069676) | 0.175449 / 0.737135 (-0.561686) | 0.108751 / 0.296338 (-0.187588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.480204 / 0.215209 (0.264995) | 4.622063 / 2.077655 (2.544408) | 2.211505 / 1.504120 (0.707385) | 2.065154 / 1.541195 (0.523959) | 2.159446 / 1.468490 (0.690956) | 0.584571 / 4.584777 (-4.000206) | 4.392449 / 3.745712 (0.646737) | 4.790166 / 5.269862 (-0.479695) | 2.840615 / 4.565676 (-1.725062) | 0.070845 / 0.424275 (-0.353430) | 0.009112 / 0.007607 (0.001505) | 0.580251 / 0.226044 (0.354207) | 5.660311 / 2.268929 (3.391382) | 2.836136 / 55.444624 (-52.608489) | 2.412859 / 6.876477 (-4.463618) | 2.556710 / 2.142072 (0.414637) | 0.691946 / 4.805227 (-4.113282) | 0.160123 / 6.500664 (-6.340541) | 0.072593 / 0.075469 (-0.002876) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.547339 / 1.841788 (-0.294448) | 21.724793 / 8.074308 (13.650485) | 16.315304 / 10.191392 (6.123912) | 0.188733 / 0.680424 (-0.491690) | 0.022109 / 0.534201 (-0.512092) | 0.481623 / 0.579283 (-0.097660) | 0.464316 / 0.434364 (0.029952) | 0.557953 / 0.540337 (0.017615) | 0.756023 / 1.386936 (-0.630913) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008637 / 0.011353 (-0.002716) | 0.005286 / 0.011008 (-0.005723) | 0.091387 / 0.038508 (0.052879) | 0.114092 / 0.023109 (0.090983) | 0.457547 / 0.275898 (0.181649) | 0.506878 / 0.323480 (0.183398) | 0.006849 / 0.007986 (-0.001137) | 0.004255 / 0.004328 (-0.000073) | 0.079556 / 0.004250 (0.075306) | 0.077729 / 0.037052 (0.040677) | 0.454094 / 0.258489 (0.195605) | 0.515812 / 0.293841 (0.221971) | 0.038271 / 0.128546 (-0.090275) | 0.010110 / 0.075646 (-0.065536) | 0.094254 / 0.419271 (-0.325017) | 0.065392 / 0.043533 (0.021860) | 0.459749 / 0.255139 (0.204610) | 0.489829 / 0.283200 (0.206629) | 0.040393 / 0.141683 (-0.101290) | 1.810414 / 1.452155 (0.358259) | 1.913212 / 1.492716 (0.420496) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236898 / 0.018006 (0.218891) | 0.513118 / 0.000490 (0.512628) | 0.004432 / 0.000200 (0.004232) | 0.000115 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035074 / 0.037411 (-0.002337) | 0.102384 / 0.014526 (0.087858) | 0.117326 / 0.176557 (-0.059231) | 0.182596 / 0.737135 (-0.554539) | 0.116384 / 0.296338 (-0.179955) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.514544 / 0.215209 (0.299335) | 5.152930 / 2.077655 (3.075275) | 2.624477 / 1.504120 (1.120357) | 2.363209 / 1.541195 (0.822014) | 2.436060 / 1.468490 (0.967570) | 0.592523 / 4.584777 (-3.992254) | 4.209668 / 3.745712 (0.463956) | 6.284372 / 5.269862 (1.014511) | 3.667303 / 4.565676 (-0.898374) | 0.067017 / 0.424275 (-0.357259) | 0.008607 / 0.007607 (0.001000) | 0.600840 / 0.226044 (0.374796) | 5.992630 / 2.268929 (3.723701) | 3.114532 / 55.444624 (-52.330093) | 2.693242 / 6.876477 (-4.183235) | 2.767187 / 2.142072 (0.625115) | 0.687591 / 4.805227 (-4.117636) | 0.158477 / 6.500664 (-6.342187) | 0.075504 / 0.075469 (0.000034) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.605039 / 1.841788 (-0.236749) | 21.524730 / 8.074308 (13.450422) | 17.014643 / 10.191392 (6.823251) | 0.201580 / 0.680424 (-0.478843) | 0.023028 / 0.534201 (-0.511173) | 0.483801 / 0.579283 (-0.095482) | 0.490221 / 0.434364 (0.055857) | 0.589292 / 0.540337 (0.048955) | 0.758532 / 1.386936 (-0.628404) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008080 / 0.011353 (-0.003273) | 0.004859 / 0.011008 (-0.006149) | 0.101895 / 0.038508 (0.063387) | 0.091168 / 0.023109 (0.068059) | 0.378914 / 0.275898 (0.103016) | 0.417172 / 0.323480 (0.093692) | 0.006314 / 0.007986 (-0.001672) | 0.004069 / 0.004328 (-0.000259) | 0.076566 / 0.004250 (0.072315) | 0.070986 / 0.037052 (0.033934) | 0.380935 / 0.258489 (0.122446) | 0.417131 / 0.293841 (0.123290) | 0.036343 / 0.128546 (-0.092203) | 0.009996 / 0.075646 (-0.065650) | 0.346386 / 0.419271 (-0.072886) | 0.063162 / 0.043533 (0.019630) | 0.372620 / 0.255139 (0.117481) | 0.404902 / 0.283200 (0.121702) | 0.028217 / 0.141683 (-0.113466) | 1.793875 / 1.452155 (0.341721) | 1.836284 / 1.492716 (0.343568) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223830 / 0.018006 (0.205823) | 0.503643 / 0.000490 (0.503153) | 0.004957 / 0.000200 (0.004757) | 0.000107 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035455 / 0.037411 (-0.001957) | 0.108015 / 0.014526 (0.093489) | 0.116887 / 0.176557 (-0.059669) | 0.188174 / 0.737135 (-0.548961) | 0.117217 / 0.296338 (-0.179121) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.471681 / 0.215209 (0.256472) | 4.694509 / 2.077655 (2.616855) | 2.369539 / 1.504120 (0.865419) | 2.176839 / 1.541195 (0.635644) | 2.300536 / 1.468490 (0.832045) | 0.575689 / 4.584777 (-4.009088) | 4.232765 / 3.745712 (0.487053) | 4.766775 / 5.269862 (-0.503087) | 2.864667 / 4.565676 (-1.701010) | 0.069390 / 0.424275 (-0.354885) | 0.008822 / 0.007607 (0.001214) | 0.559620 / 0.226044 (0.333576) | 5.580401 / 2.268929 (3.311472) | 2.920293 / 55.444624 (-52.524331) | 2.552166 / 6.876477 (-4.324311) | 2.795890 / 2.142072 (0.653818) | 0.687863 / 4.805227 (-4.117364) | 0.159129 / 6.500664 (-6.341535) | 0.073475 / 0.075469 (-0.001994) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.505892 / 1.841788 (-0.335896) | 24.127650 / 8.074308 (16.053342) | 16.758238 / 10.191392 (6.566846) | 0.200555 / 0.680424 (-0.479869) | 0.021596 / 0.534201 (-0.512605) | 0.480668 / 0.579283 (-0.098615) | 0.483528 / 0.434364 (0.049164) | 0.571241 / 0.540337 (0.030903) | 0.790547 / 1.386936 (-0.596390) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007997 / 0.011353 (-0.003356) | 0.004842 / 0.011008 (-0.006166) | 0.077190 / 0.038508 (0.038681) | 0.092765 / 0.023109 (0.069656) | 0.457475 / 0.275898 (0.181577) | 0.523914 / 0.323480 (0.200434) | 0.006349 / 0.007986 (-0.001637) | 0.003902 / 0.004328 (-0.000427) | 0.075860 / 0.004250 (0.071609) | 0.069708 / 0.037052 (0.032656) | 0.459612 / 0.258489 (0.201123) | 0.555028 / 0.293841 (0.261187) | 0.036854 / 0.128546 (-0.091692) | 0.010078 / 0.075646 (-0.065568) | 0.083871 / 0.419271 (-0.335400) | 0.061221 / 0.043533 (0.017689) | 0.435737 / 0.255139 (0.180598) | 0.509700 / 0.283200 (0.226500) | 0.038091 / 0.141683 (-0.103592) | 1.777161 / 1.452155 (0.325006) | 1.859603 / 1.492716 (0.366886) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250020 / 0.018006 (0.232014) | 0.486198 / 0.000490 (0.485708) | 0.007080 / 0.000200 (0.006880) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038163 / 0.037411 (0.000751) | 0.110812 / 0.014526 (0.096286) | 0.122489 / 0.176557 (-0.054068) | 0.188215 / 0.737135 (-0.548920) | 0.122375 / 0.296338 (-0.173963) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.484534 / 0.215209 (0.269325) | 4.828654 / 2.077655 (2.751000) | 2.545102 / 1.504120 (1.040982) | 2.368867 / 1.541195 (0.827672) | 2.458042 / 1.468490 (0.989552) | 0.576372 / 4.584777 (-4.008404) | 4.814033 / 3.745712 (1.068321) | 6.175972 / 5.269862 (0.906110) | 4.033422 / 4.565676 (-0.532254) | 0.068544 / 0.424275 (-0.355731) | 0.008906 / 0.007607 (0.001299) | 0.581767 / 0.226044 (0.355723) | 5.808623 / 2.268929 (3.539695) | 3.120312 / 55.444624 (-52.324313) | 2.774834 / 6.876477 (-4.101642) | 2.770413 / 2.142072 (0.628340) | 0.692715 / 4.805227 (-4.112512) | 0.158883 / 6.500664 (-6.341782) | 0.075894 / 0.075469 (0.000425) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.631250 / 1.841788 (-0.210538) | 24.693250 / 8.074308 (16.618942) | 17.434790 / 10.191392 (7.243398) | 0.196456 / 0.680424 (-0.483968) | 0.022505 / 0.534201 (-0.511696) | 0.474788 / 0.579283 (-0.104495) | 0.500947 / 0.434364 (0.066583) | 0.553596 / 0.540337 (0.013259) | 0.737767 / 1.386936 (-0.649169) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006629 / 0.011353 (-0.004724) | 0.004115 / 0.011008 (-0.006894) | 0.083934 / 0.038508 (0.045426) | 0.074952 / 0.023109 (0.051843) | 0.313069 / 0.275898 (0.037171) | 0.345878 / 0.323480 (0.022398) | 0.006034 / 0.007986 (-0.001952) | 0.003413 / 0.004328 (-0.000916) | 0.065130 / 0.004250 (0.060880) | 0.057363 / 0.037052 (0.020310) | 0.314483 / 0.258489 (0.055994) | 0.352626 / 0.293841 (0.058785) | 0.031325 / 0.128546 (-0.097221) | 0.008577 / 0.075646 (-0.067069) | 0.288137 / 0.419271 (-0.131135) | 0.053651 / 0.043533 (0.010118) | 0.313006 / 0.255139 (0.057867) | 0.338668 / 0.283200 (0.055468) | 0.023709 / 0.141683 (-0.117974) | 1.481209 / 1.452155 (0.029054) | 1.559801 / 1.492716 (0.067085) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211543 / 0.018006 (0.193537) | 0.452185 / 0.000490 (0.451696) | 0.003177 / 0.000200 (0.002977) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028821 / 0.037411 (-0.008591) | 0.083290 / 0.014526 (0.068765) | 0.097478 / 0.176557 (-0.079079) | 0.153506 / 0.737135 (-0.583629) | 0.097054 / 0.296338 (-0.199284) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.385847 / 0.215209 (0.170638) | 3.835629 / 2.077655 (1.757974) | 1.880938 / 1.504120 (0.376819) | 1.711848 / 1.541195 (0.170653) | 1.785099 / 1.468490 (0.316609) | 0.486256 / 4.584777 (-4.098521) | 3.629026 / 3.745712 (-0.116686) | 3.321578 / 5.269862 (-1.948283) | 2.024314 / 4.565676 (-2.541363) | 0.058097 / 0.424275 (-0.366179) | 0.007724 / 0.007607 (0.000117) | 0.458293 / 0.226044 (0.232249) | 4.581314 / 2.268929 (2.312386) | 2.314379 / 55.444624 (-53.130246) | 1.966089 / 6.876477 (-4.910387) | 2.203824 / 2.142072 (0.061752) | 0.611581 / 4.805227 (-4.193647) | 0.149166 / 6.500664 (-6.351498) | 0.059825 / 0.075469 (-0.015644) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235546 / 1.841788 (-0.606242) | 19.747439 / 8.074308 (11.673131) | 14.628383 / 10.191392 (4.436991) | 0.193074 / 0.680424 (-0.487350) | 0.020327 / 0.534201 (-0.513874) | 0.397051 / 0.579283 (-0.182232) | 0.418491 / 0.434364 (-0.015873) | 0.462055 / 0.540337 (-0.078282) | 0.637524 / 1.386936 (-0.749412) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007069 / 0.011353 (-0.004284) | 0.004106 / 0.011008 (-0.006902) | 0.065818 / 0.038508 (0.027310) | 0.077101 / 0.023109 (0.053991) | 0.363323 / 0.275898 (0.087425) | 0.399463 / 0.323480 (0.075983) | 0.005540 / 0.007986 (-0.002446) | 0.003480 / 0.004328 (-0.000849) | 0.065176 / 0.004250 (0.060926) | 0.060867 / 0.037052 (0.023815) | 0.365763 / 0.258489 (0.107273) | 0.407789 / 0.293841 (0.113949) | 0.032018 / 0.128546 (-0.096528) | 0.008550 / 0.075646 (-0.067096) | 0.071750 / 0.419271 (-0.347521) | 0.050625 / 0.043533 (0.007092) | 0.361434 / 0.255139 (0.106295) | 0.384799 / 0.283200 (0.101599) | 0.026104 / 0.141683 (-0.115579) | 1.496093 / 1.452155 (0.043938) | 1.592909 / 1.492716 (0.100193) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185794 / 0.018006 (0.167787) | 0.453379 / 0.000490 (0.452890) | 0.004365 / 0.000200 (0.004165) | 0.000092 / 0.000054 (0.000038) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031666 / 0.037411 (-0.005746) | 0.088323 / 0.014526 (0.073798) | 0.104602 / 0.176557 (-0.071954) | 0.159827 / 0.737135 (-0.577308) | 0.103725 / 0.296338 (-0.192614) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413509 / 0.215209 (0.198300) | 4.126071 / 2.077655 (2.048416) | 2.137088 / 1.504120 (0.632968) | 1.981034 / 1.541195 (0.439839) | 2.063660 / 1.468490 (0.595170) | 0.478798 / 4.584777 (-4.105979) | 3.642801 / 3.745712 (-0.102911) | 3.428994 / 5.269862 (-1.840867) | 2.031902 / 4.565676 (-2.533774) | 0.056244 / 0.424275 (-0.368032) | 0.007365 / 0.007607 (-0.000242) | 0.484371 / 0.226044 (0.258327) | 4.838537 / 2.268929 (2.569608) | 2.559497 / 55.444624 (-52.885127) | 2.251863 / 6.876477 (-4.624614) | 2.339227 / 2.142072 (0.197155) | 0.607228 / 4.805227 (-4.198000) | 0.133877 / 6.500664 (-6.366787) | 0.062049 / 0.075469 (-0.013420) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.350389 / 1.841788 (-0.491399) | 20.060359 / 8.074308 (11.986051) | 14.305675 / 10.191392 (4.114283) | 0.165642 / 0.680424 (-0.514782) | 0.018206 / 0.534201 (-0.515994) | 0.396907 / 0.579283 (-0.182376) | 0.431896 / 0.434364 (-0.002468) | 0.475778 / 0.540337 (-0.064559) | 0.644688 / 1.386936 (-0.742248) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009048 / 0.011353 (-0.002305) | 0.005787 / 0.011008 (-0.005221) | 0.111617 / 0.038508 (0.073109) | 0.087603 / 0.023109 (0.064494) | 0.446481 / 0.275898 (0.170583) | 0.491726 / 0.323480 (0.168247) | 0.007052 / 0.007986 (-0.000934) | 0.004481 / 0.004328 (0.000152) | 0.084331 / 0.004250 (0.080081) | 0.072006 / 0.037052 (0.034953) | 0.454238 / 0.258489 (0.195749) | 0.496749 / 0.293841 (0.202908) | 0.049027 / 0.128546 (-0.079520) | 0.014005 / 0.075646 (-0.061641) | 0.372550 / 0.419271 (-0.046722) | 0.071414 / 0.043533 (0.027881) | 0.459432 / 0.255139 (0.204293) | 0.467332 / 0.283200 (0.184133) | 0.037539 / 0.141683 (-0.104144) | 1.869179 / 1.452155 (0.417024) | 1.983641 / 1.492716 (0.490925) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.265426 / 0.018006 (0.247419) | 0.672527 / 0.000490 (0.672037) | 0.001152 / 0.000200 (0.000953) | 0.000181 / 0.000054 (0.000127) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032967 / 0.037411 (-0.004445) | 0.103023 / 0.014526 (0.088497) | 0.115978 / 0.176557 (-0.060578) | 0.191698 / 0.737135 (-0.545438) | 0.117867 / 0.296338 (-0.178471) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.602208 / 0.215209 (0.386999) | 6.147784 / 2.077655 (4.070129) | 2.768933 / 1.504120 (1.264813) | 2.415619 / 1.541195 (0.874424) | 2.456159 / 1.468490 (0.987669) | 0.836270 / 4.584777 (-3.748507) | 5.447754 / 3.745712 (1.702042) | 7.751825 / 5.269862 (2.481963) | 4.591892 / 4.565676 (0.026215) | 0.108269 / 0.424275 (-0.316006) | 0.009626 / 0.007607 (0.002019) | 0.719260 / 0.226044 (0.493216) | 7.313442 / 2.268929 (5.044514) | 3.490739 / 55.444624 (-51.953885) | 2.743543 / 6.876477 (-4.132934) | 3.035071 / 2.142072 (0.892999) | 1.042791 / 4.805227 (-3.762436) | 0.217080 / 6.500664 (-6.283584) | 0.084286 / 0.075469 (0.008817) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.655427 / 1.841788 (-0.186361) | 25.386536 / 8.074308 (17.312228) | 21.740666 / 10.191392 (11.549274) | 0.246388 / 0.680424 (-0.434036) | 0.029723 / 0.534201 (-0.504478) | 0.491537 / 0.579283 (-0.087746) | 0.603495 / 0.434364 (0.169131) | 0.573938 / 0.540337 (0.033600) | 0.981875 / 1.386936 (-0.405061) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009664 / 0.011353 (-0.001689) | 0.006446 / 0.011008 (-0.004562) | 0.085113 / 0.038508 (0.046605) | 0.094533 / 0.023109 (0.071424) | 0.498388 / 0.275898 (0.222490) | 0.540127 / 0.323480 (0.216647) | 0.007316 / 0.007986 (-0.000670) | 0.004252 / 0.004328 (-0.000077) | 0.086292 / 0.004250 (0.082041) | 0.067956 / 0.037052 (0.030903) | 0.507664 / 0.258489 (0.249175) | 0.554324 / 0.293841 (0.260483) | 0.050107 / 0.128546 (-0.078439) | 0.014277 / 0.075646 (-0.061370) | 0.098838 / 0.419271 (-0.320433) | 0.066053 / 0.043533 (0.022521) | 0.491090 / 0.255139 (0.235951) | 0.537432 / 0.283200 (0.254232) | 0.035937 / 0.141683 (-0.105746) | 1.820715 / 1.452155 (0.368561) | 1.996268 / 1.492716 (0.503552) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.300859 / 0.018006 (0.282852) | 0.610958 / 0.000490 (0.610468) | 0.000474 / 0.000200 (0.000274) | 0.000098 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036372 / 0.037411 (-0.001039) | 0.109115 / 0.014526 (0.094589) | 0.122802 / 0.176557 (-0.053755) | 0.187092 / 0.737135 (-0.550044) | 0.123432 / 0.296338 (-0.172906) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.646979 / 0.215209 (0.431770) | 6.577713 / 2.077655 (4.500058) | 3.004606 / 1.504120 (1.500486) | 2.661183 / 1.541195 (1.119989) | 2.726717 / 1.468490 (1.258227) | 0.889497 / 4.584777 (-3.695280) | 5.485055 / 3.745712 (1.739343) | 4.852043 / 5.269862 (-0.417819) | 3.177392 / 4.565676 (-1.388285) | 0.099796 / 0.424275 (-0.324479) | 0.009868 / 0.007607 (0.002261) | 0.819919 / 0.226044 (0.593874) | 7.911255 / 2.268929 (5.642326) | 3.839877 / 55.444624 (-51.604747) | 3.088663 / 6.876477 (-3.787813) | 3.371184 / 2.142072 (1.229112) | 1.072762 / 4.805227 (-3.732466) | 0.224536 / 6.500664 (-6.276128) | 0.083415 / 0.075469 (0.007946) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.754426 / 1.841788 (-0.087361) | 25.546690 / 8.074308 (17.472382) | 22.998252 / 10.191392 (12.806860) | 0.258019 / 0.680424 (-0.422405) | 0.030104 / 0.534201 (-0.504097) | 0.518406 / 0.579283 (-0.060877) | 0.605753 / 0.434364 (0.171389) | 0.599630 / 0.540337 (0.059292) | 0.819042 / 1.386936 (-0.567894) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5302 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5302/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5302/comments | https://api.github.com/repos/huggingface/datasets/issues/5302/events | https://github.com/huggingface/datasets/pull/5302 | 1,464,778,901 | PR_kwDODunzps5DuJJp | 5,302 | Improve `use_auth_token` docstring and deprecate `use_auth_token` in `download_and_prepare` | [] | closed | false | null | 1 | 2022-11-25T17:09:21Z | 2022-12-09T14:20:15Z | 2022-12-09T14:17:20Z | null | Clarify in the docstrings what happens when `use_auth_token` is `None` and deprecate the `use_auth_token` param in `download_and_prepare`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5302/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5302/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5302.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5302",
"merged_at": "2022-12-09T14:17:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5302.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5302"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3810 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3810/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3810/comments | https://api.github.com/repos/huggingface/datasets/issues/3810/events | https://github.com/huggingface/datasets/pull/3810 | 1,158,202,093 | PR_kwDODunzps4z4WUW | 3,810 | Update version of xcopa dataset | [] | closed | false | null | 0 | 2022-03-03T09:58:25Z | 2022-03-03T10:44:30Z | 2022-03-03T10:44:29Z | null | Note that there was a version update of the `xcopa` dataset: https://github.com/cambridgeltl/xcopa/releases
We updated our loading script, but we did not bump a new version number:
- #3254
This PR updates our loading script version from `1.0.0` to `1.1.0`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3810/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3810/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3810.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3810",
"merged_at": "2022-03-03T10:44:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3810.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3810"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/782 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/782/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/782/comments | https://api.github.com/repos/huggingface/datasets/issues/782/events | https://github.com/huggingface/datasets/pull/782 | 733,316,463 | MDExOlB1bGxSZXF1ZXN0NTEzMTE2MTM0 | 782 | Fix metric deletion when attribuets are missing | [] | closed | false | null | 0 | 2020-10-30T16:16:10Z | 2020-10-30T16:47:53Z | 2020-10-30T16:47:52Z | null | When you call `del` on a metric we want to make sure that the arrow attributes are not already deleted.
I just added `if hasattr(...)` to make sure it doesn't crash | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/782/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/782/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/782.diff",
"html_url": "https://github.com/huggingface/datasets/pull/782",
"merged_at": "2020-10-30T16:47:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/782.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/782"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3745/comments | https://api.github.com/repos/huggingface/datasets/issues/3745/events | https://github.com/huggingface/datasets/pull/3745 | 1,141,520,953 | PR_kwDODunzps4y__m2 | 3,745 | Add mIoU metric | [] | closed | false | null | 3 | 2022-02-17T15:52:17Z | 2022-03-08T13:20:26Z | 2022-03-08T13:20:26Z | null | This PR adds the mean Intersection-over-Union metric to the library, useful for tasks like semantic segmentation.
It is entirely based on mmseg's [implementation](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/core/evaluation/metrics.py).
I've removed any PyTorch dependency, and rely on Numpy only. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3745/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3745/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3745.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3745",
"merged_at": "2022-03-08T13:20:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3745.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3745"
} | true | [
"Hmm the doctest failed again - maybe the full result needs to be on one single line",
"cc @lhoestq for the final review",
"Cool ! Feel free to merge if it's all good for you"
] |
https://api.github.com/repos/huggingface/datasets/issues/4395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4395/comments | https://api.github.com/repos/huggingface/datasets/issues/4395/events | https://github.com/huggingface/datasets/pull/4395 | 1,245,436,486 | PR_kwDODunzps44TrBA | 4,395 | Add Pascal VOC dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 6 | 2022-05-23T16:34:05Z | 2022-10-03T09:39:08Z | 2022-10-03T09:36:56Z | null | This PR adds the Pascal VOC dataset in the same way TFDS has it added. I believe we can iterate on this dataset and in future versions include more data, such as segmentation masks, but for now I think it is a good idea to just add it the same way as TFDS to get a solid first version out there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4395/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4395",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4395"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Some CI fails are unrelated to your PR and fixed on master, feel free to merge master into your branch :)",
"Thanks @nateraw for the addition of this dataset.\r\n\r\nI would suggest to transfer it to the Hugging Face Hub, under a \"pascal\" organization namespace: \"pascal/voc\".\r\n\r\nWhat do you think?",
"FYI I think this dataset is also available at (internal) https://huggingface.co/datasets/HuggingFaceM4/pascal_voc",
"@lhoestq @albertvillanova what do you think best path forward is? No idea when I'll get to looking at this again, but would be nice to know plan so when I find time I can just get it done in one sitting. ",
"My (not strong) opinion on this:\r\n- as we are removing dataset scripts from GitHub, this dataset should be created directly on the Hub\r\n- I proposed doing it under some kind of \"official\" org namespace, like pascal or pascal2; other suggestions are welcome\r\n- the link given by @lhoestq might serve as inspiration for your implementation (I think yours misses data about action classification): their implementation comprises tasks: classification/detection, segmentation, action classification, person layout; it misses other tasks though\r\n\r\nWhat do you think?"
] |
https://api.github.com/repos/huggingface/datasets/issues/5992 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5992/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5992/comments | https://api.github.com/repos/huggingface/datasets/issues/5992/events | https://github.com/huggingface/datasets/pull/5992 | 1,776,460,964 | PR_kwDODunzps5UAk3C | 5,992 | speedup | [] | closed | false | null | 1 | 2023-06-27T09:17:58Z | 2023-06-27T09:23:07Z | 2023-06-27T09:18:04Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5992/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5992/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5992.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5992",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5992.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5992"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5992). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/2555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2555/comments | https://api.github.com/repos/huggingface/datasets/issues/2555/events | https://github.com/huggingface/datasets/pull/2555 | 931,585,485 | MDExOlB1bGxSZXF1ZXN0Njc5MDU4ODM3 | 2,555 | Fix code_search_net keys | [] | closed | false | null | 1 | 2021-06-28T13:40:23Z | 2021-09-02T08:24:43Z | 2021-06-28T14:10:35Z | null | There were duplicate keys in the `code_search_net` dataset, as reported in https://github.com/huggingface/datasets/issues/2552
I fixed the keys (it was an addition of the file and row indices, which was causing collisions)
Fix #2552. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2555/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2555/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2555.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2555",
"merged_at": "2021-06-28T14:10:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2555.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2555"
} | true | [
"Fix #2552."
] |
https://api.github.com/repos/huggingface/datasets/issues/4765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4765/comments | https://api.github.com/repos/huggingface/datasets/issues/4765/events | https://github.com/huggingface/datasets/pull/4765 | 1,321,787,428 | PR_kwDODunzps48S2rM | 4,765 | Fix version in map_nested docstring | [] | closed | false | null | 1 | 2022-07-29T05:44:32Z | 2022-07-29T11:51:25Z | 2022-07-29T11:38:36Z | null | After latest release, `map_nested` docstring needs being updated with the right version for versionchanged and versionadded. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4765/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4765.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4765",
"merged_at": "2022-07-29T11:38:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4765.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4765"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4296 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4296/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4296/comments | https://api.github.com/repos/huggingface/datasets/issues/4296/events | https://github.com/huggingface/datasets/pull/4296 | 1,229,554,645 | PR_kwDODunzps43foZ- | 4,296 | Fix URL query parameters in compression hop path when streaming | [] | open | false | null | 1 | 2022-05-09T11:18:22Z | 2022-07-06T15:19:53Z | null | null | Fix #3488. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4296/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4296/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4296.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4296",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4296.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4296"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4296). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/3359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3359/comments | https://api.github.com/repos/huggingface/datasets/issues/3359/events | https://github.com/huggingface/datasets/pull/3359 | 1,068,638,213 | PR_kwDODunzps4vQtI0 | 3,359 | Add The Pile Free Law subset | [] | closed | false | null | 3 | 2021-12-01T16:46:04Z | 2021-12-06T10:12:17Z | 2021-12-01T17:30:44Z | null | Add:
- Free Law subset of The Pile: "free_law" config
Close bigscience-workshop/data_tooling#75.
CC: @StellaAthena | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3359/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3359.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3359",
"merged_at": "2021-12-01T17:30:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3359.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3359"
} | true | [
"@albertvillanova Is there a specific reason you’re adding the Pile under “the” instead of under “pile”? That does not appear to be consistent with other datasets.",
"Hi @StellaAthena,\r\n\r\nI asked myself the same question, but at the end I decided to be consistent with previously added Pile subsets:\r\n- #2817\r\n\r\nI guess the reason is to stress that the definite article is always used before the name of the dataset (your site says: \"The Pile. An 800GB Dataset of Diverse Text for Language Modeling\"). Other datasets are not usually preceded by the definite article, like \"the SQuAD\" or \"the GLUE\" or \"the Common Voice\"...\r\n\r\nCC: @lhoestq ",
"> I guess the reason is to stress that the definite article is always used before the name of the dataset (your site says: \"The Pile. An 800GB Dataset of Diverse Text for Language Modeling\").\r\n\r\nYes that's because of this that it starts with \"the\""
] |
https://api.github.com/repos/huggingface/datasets/issues/3241 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3241/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3241/comments | https://api.github.com/repos/huggingface/datasets/issues/3241/events | https://github.com/huggingface/datasets/pull/3241 | 1,048,461,852 | PR_kwDODunzps4uRzHa | 3,241 | Swap descriptions of v1 and raw-v1 configs of WikiText dataset and fix metadata | [] | closed | false | null | 0 | 2021-11-09T10:54:15Z | 2022-02-14T15:46:00Z | 2021-11-09T13:49:28Z | null | Fix #3237, fix #795. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3241/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3241/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3241.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3241",
"merged_at": "2021-11-09T13:49:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3241.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3241"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/16 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/16/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/16/comments | https://api.github.com/repos/huggingface/datasets/issues/16/events | https://github.com/huggingface/datasets/pull/16 | 605,661,462 | MDExOlB1bGxSZXF1ZXN0NDA4MDIyMTUz | 16 | create our own DownloadManager | [] | closed | false | null | 4 | 2020-04-23T16:08:07Z | 2021-05-05T18:25:24Z | 2020-04-25T21:25:10Z | null | I tried to create our own - and way simpler - download manager, by replacing all the complicated stuff with our own `cached_path` solution.
With this implementation, I tried `dataset = nlp.load('squad')` and it seems to work fine.
For the implementation, what I did exactly:
- I copied the old download manager
- I removed all the dependences to the old `download` files
- I replaced all the download + extract calls by calls to `cached_path`
- I removed unused parameters (extract_dir, compute_stats) (maybe compute_stats could be re-added later if we want to compute stats...)
- I left some functions unimplemented for now. We will probably have to implement them because they are used by some datasets scripts (download_kaggle_data, iter_archive) or because we may need them at some point (download_checksums, _record_sizes_checksums)
Let me know if you think that this is going the right direction or if you have remarks.
Note: I didn't write any test yet as I wanted to read your remarks first | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/16/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/16/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/16.diff",
"html_url": "https://github.com/huggingface/datasets/pull/16",
"merged_at": "2020-04-25T21:25:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/16.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/16"
} | true | [
"Looks great to me! ",
"The new download manager is ready. I removed the old folder and I fixed a few remaining dependencies.\r\nI tested it on squad and a few others from the dataset folder and it works fine.\r\n\r\nThe only impact of these changes is that it breaks the `download_and_prepare` script that was used to register the checksums when we create a dataset, as the checksum logic is not implemented.\r\n\r\nLet me know if you have remarks",
"Ok merged it (a bit fast for you to update the copyright, now I see that. but it's ok, we'll do a pass on these doc/copyright before releasing anyway)",
"Actually two additional things here @lhoestq (I merged too fast sorry, let's make a new PR for additional developments):\r\n- I think we can remove some dependencies now (e.g. `promises`) in setup.py, can you have a look?\r\n- also, I think we can remove the boto3 dependency like here: https://github.com/huggingface/transformers/pull/3968"
] |
https://api.github.com/repos/huggingface/datasets/issues/3250 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3250/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3250/comments | https://api.github.com/repos/huggingface/datasets/issues/3250/events | https://github.com/huggingface/datasets/pull/3250 | 1,050,541,348 | PR_kwDODunzps4uYmkr | 3,250 | Add ETHICS dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2021-11-11T03:45:34Z | 2022-10-03T09:37:25Z | 2022-10-03T09:37:25Z | null | This PR adds the ETHICS dataset, including all 5 sub-datasets.
From https://arxiv.org/abs/2008.02275 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3250/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3250/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3250.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3250",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3250.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3250"
} | true | [
"Thanks for your contribution, @ssss1029. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/6058 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6058/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6058/comments | https://api.github.com/repos/huggingface/datasets/issues/6058/events | https://github.com/huggingface/datasets/issues/6058 | 1,815,131,397 | I_kwDODunzps5sMLUF | 6,058 | laion-coco download error | [] | closed | false | null | 1 | 2023-07-21T04:24:15Z | 2023-07-22T01:42:06Z | 2023-07-22T01:42:06Z | null | ### Describe the bug
The full trace:
```
/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/load.py:1744: FutureWarning: 'ignore_verifications' was de
precated in favor of 'verification_mode' in version 2.9.1 and will be removed in 3.0.0.
You can remove this warning by passing 'verification_mode=no_checks' instead.
warnings.warn(
Downloading and preparing dataset parquet/laion--laion-coco to /home/bian/.cache/huggingface/datasets/laion___parquet/laion--
laion-coco-cb4205d7f1863066/0.0.0/bcacc8bdaa0614a5d73d0344c813275e590940c6ea8bc569da462847103a1afd...
Downloading data: 100%|█| 1.89G/1.89G [04:57<00:00,
Downloading data files: 100%|█| 1/1 [04:59<00:00, 2
Extracting data files: 100%|█| 1/1 [00:00<00:00, 13
Generating train split: 0 examples [00:00, ? examples/s]<_io.BufferedReader
name='/home/bian/.cache/huggingface/datasets/downlo
ads/26d7a016d25bbd9443115cfa3092136e8eb2f1f5bcd4154
0cb9234572927f04c'>
Traceback (most recent call last):
File "/home/bian/data/ZOC/download_laion_coco.py", line 4, in <module>
dataset = load_dataset("laion/laion-coco", ignore_verifications=True)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/load.py", line 1791, in load_dataset
builder_instance.download_and_prepare(
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 891, in download_and_prepare
self._download_and_prepare(
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 986, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 1748, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/builder.py", line 1842, in _prepare_split_single
generator = self._generate_tables(**gen_kwargs)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/packaged_modules/parquet/parquet.py", line 67, in
_generate_tables
parquet_file = pq.ParquetFile(f)
File "/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/pyarrow/parquet/core.py", line 323, in __init__
self.reader.open(
File "pyarrow/_parquet.pyx", line 1227, in pyarrow._parquet.ParquetReader.open
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file
.
```
I have carefully followed the instructions in #5264 but still get the same error.
Other helpful information:
```
ds = load_dataset("parquet", data_files=
...: "https://huggingface.co/datasets/laion/l
...: aion-coco/resolve/d22869de3ccd39dfec1507
...: f7ded32e4a518dad24/part-00000-2256f782-1
...: 26f-4dc6-b9c6-e6757637749d-c000.snappy.p
...: arquet")
Found cached dataset parquet (/home/bian/.cache/huggingface/datasets/parquet/default-a02eea00aeb08b0e/0.0.0/bb8ccf89d9ee38581ff5e51506d721a9b37f14df8090dc9b2d8fb4a40957833f)
100%|██████████████| 1/1 [00:00<00:00, 4.55it/s]
```
### Steps to reproduce the bug
```
from datasets import load_dataset
dataset = load_dataset("laion/laion-coco", ignore_verifications=True/False)
```
### Expected behavior
Properly load Laion-coco dataset
### Environment info
datasets==2.11.0 torch==1.12.1 python 3.10 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6058/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6058/timeline | null | completed | null | null | false | [
"This can also mean one of the files was not downloaded correctly.\r\n\r\nWe log an erroneous file's name before raising the reader's error, so this is how you can find the problematic file. Then, you should delete it and call `load_dataset` again.\r\n\r\n(I checked all the uploaded files, and they seem to be valid Parquet files, so I don't think this is a bug on their side)\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2750/comments | https://api.github.com/repos/huggingface/datasets/issues/2750/events | https://github.com/huggingface/datasets/issues/2750 | 958,984,730 | MDU6SXNzdWU5NTg5ODQ3MzA= | 2,750 | Second concatenation of datasets produces errors | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2021-08-03T10:47:04Z | 2022-01-19T14:23:43Z | 2022-01-19T14:19:05Z | null | Hi,
I am need to concatenate my dataset with others several times, and after I concatenate it for the second time, the features of features (e.g. tags names) are collapsed. This hinders, for instance, the usage of tokenize function with `data.map`.
```
from datasets import load_dataset, concatenate_datasets
data = load_dataset('trec')['train']
concatenated = concatenate_datasets([data, data])
concatenated_2 = concatenate_datasets([concatenated, concatenated])
print('True features of features:', concatenated.features)
print('\nProduced features of features:', concatenated_2.features)
```
outputs
```
True features of features: {'label-coarse': ClassLabel(num_classes=6, names=['DESC', 'ENTY', 'ABBR', 'HUM', 'NUM', 'LOC'], names_file=None, id=None), 'label-fine': ClassLabel(num_classes=47, names=['manner', 'cremat', 'animal', 'exp', 'ind', 'gr', 'title', 'def', 'date', 'reason', 'event', 'state', 'desc', 'count', 'other', 'letter', 'religion', 'food', 'country', 'color', 'termeq', 'city', 'body', 'dismed', 'mount', 'money', 'product', 'period', 'substance', 'sport', 'plant', 'techmeth', 'volsize', 'instru', 'abb', 'speed', 'word', 'lang', 'perc', 'code', 'dist', 'temp', 'symbol', 'ord', 'veh', 'weight', 'currency'], names_file=None, id=None), 'text': Value(dtype='string', id=None)}
Produced features of features: {'label-coarse': Value(dtype='int64', id=None), 'label-fine': Value(dtype='int64', id=None), 'text': Value(dtype='string', id=None)}
```
I am using `datasets` v.1.11.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2750/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2750/timeline | null | completed | null | null | false | [
"@albertvillanova ",
"Hi @Aktsvigun, thanks for reporting.\r\n\r\nI'm investigating this.",
"Hi @albertvillanova ,\r\nany update on this? Can I probably help in some way?",
"Hi @Aktsvigun! We are planning to address this issue before our next release, in a couple of weeks at most. 😅 \r\n\r\nIn the meantime, if you would like to contribute, feel free to open a Pull Request. You are welcome. Here you can find more information: [How to contribute to Datasets?](CONTRIBUTING.md)",
"I can't reproduce the bug on master. I believe this issue was fixed by https://github.com/huggingface/datasets/pull/3551."
] |
https://api.github.com/repos/huggingface/datasets/issues/1481 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1481/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1481/comments | https://api.github.com/repos/huggingface/datasets/issues/1481/events | https://github.com/huggingface/datasets/pull/1481 | 762,579,658 | MDExOlB1bGxSZXF1ZXN0NTM3MTEwOTM1 | 1,481 | Fix ADD_NEW_DATASET to avoid rebasing once pushed | [] | closed | false | null | 0 | 2020-12-11T16:27:49Z | 2021-01-07T10:10:20Z | 2021-01-07T10:10:20Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1481/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1481/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1481.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1481",
"merged_at": "2021-01-07T10:10:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1481.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1481"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/4243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4243/comments | https://api.github.com/repos/huggingface/datasets/issues/4243/events | https://github.com/huggingface/datasets/pull/4243 | 1,217,689,909 | PR_kwDODunzps425Gkn | 4,243 | WIP: Initial shades loading script and readme | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2022-04-27T17:45:43Z | 2022-10-03T09:36:35Z | 2022-10-03T09:36:35Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4243/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4243",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4243"
} | true | [
"Thanks for your contribution, @shayne-longpre.\r\n\r\nAre you still interested in adding this dataset? As we are transferring the dataset scripts from this GitHub repo, we would recommend you to add this to the Hugging Face Hub: https://huggingface.co/datasets"
] |
https://api.github.com/repos/huggingface/datasets/issues/3946 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3946/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3946/comments | https://api.github.com/repos/huggingface/datasets/issues/3946/events | https://github.com/huggingface/datasets/pull/3946 | 1,171,239,287 | PR_kwDODunzps40i1L3 | 3,946 | Add newline to text dataset builder for controlling universal newlines mode | [] | open | false | null | 2 | 2022-03-16T16:11:11Z | 2022-07-06T15:19:51Z | null | null | Fix #3804. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3946/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3946/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3946.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3946",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3946.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3946"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3946). All of your documentation changes will be reflected on that endpoint.",
"The failing CI test has nothing to do with this PR."
] |
https://api.github.com/repos/huggingface/datasets/issues/536 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/536/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/536/comments | https://api.github.com/repos/huggingface/datasets/issues/536/events | https://github.com/huggingface/datasets/pull/536 | 687,378,332 | MDExOlB1bGxSZXF1ZXN0NDc0ODE0NzY1 | 536 | Fingerprint | [] | closed | false | null | 1 | 2020-08-27T16:27:09Z | 2020-08-31T14:20:40Z | 2020-08-31T14:20:39Z | null | This PR is a continuation of #513 , in which many in-place functions were introduced or updated (cast_, flatten_) etc.
However the caching didn't handle these changes. Indeed the caching took into account only the previous cache file name of the table, and not the possible in-place transforms of the table.
To fix that, I added the concept of dataset fingerprint, that is updated after each transform (in place or not), and stored inside the table metadata.
When a dataset is created, an initial fingerprint is computed. If the dataset is memory-mapped, then the fingerprint generator doesn't read the table and only looks at the filename. However if the table is in-memory, then the fingerprint generator reads the content of the table using a batched non-crypto hashing.
I added a utility class to compute hashes of arbitrary python objects in `fingerprint.py` : `Hasher`. The API is close to standard hashing tools (`.update`, `.hexdigest`). It also supports custom hashing functions depending on object types using a registry like pickle. I added a custom hashing function to hash a `pa.Table` in a batched way, and also for `nlp.DatasetInfo` to leverage its json serialization feature.
Note about this PR:
This is a draft PR because #513 needs to be merged first.
The diff that is shown is for branches fingerprint -> indices (and not master, for now) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/536/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/536/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/536.diff",
"html_url": "https://github.com/huggingface/datasets/pull/536",
"merged_at": "2020-08-31T14:20:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/536.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/536"
} | true | [
"I changed the way I implemented fingerprint updates to use decorator functions.\r\n\r\nI also added a new attribute called `_inplace_history` that stores the in-place history of transforms (like cast_, rename_columns, etc.). This history is useful to replay the changes that were done in-place when unpickling a dataset that is memory mapped from a file.\r\n\r\nLet me know what you think @thomwolf "
] |
https://api.github.com/repos/huggingface/datasets/issues/4557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4557/comments | https://api.github.com/repos/huggingface/datasets/issues/4557/events | https://github.com/huggingface/datasets/pull/4557 | 1,283,473,889 | PR_kwDODunzps46TGZK | 4,557 | Add evaluation metadata to wmt16 | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 3 | 2022-06-24T09:04:23Z | 2022-09-23T09:36:32Z | 2022-09-23T09:36:32Z | null | Just to confirm: we should add this metadata via GitHub and not Hub PRs for canonical datasets right? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4557/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4557/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4557.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4557",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4557.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4557"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4557). All of your documentation changes will be reflected on that endpoint.",
"> Just to confirm: we should add this metadata via GitHub and not Hub PRs for canonical datasets right?\r\n\r\nyes :)",
"As discussed with @lewtun, we are closing this PR, because it requires first the task names to be aligned between AutoTrain and datasets."
] |
https://api.github.com/repos/huggingface/datasets/issues/2375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2375/comments | https://api.github.com/repos/huggingface/datasets/issues/2375/events | https://github.com/huggingface/datasets/pull/2375 | 894,655,157 | MDExOlB1bGxSZXF1ZXN0NjQ2OTg2NTcw | 2,375 | Dataset Streaming | [] | closed | false | null | 0 | 2021-05-18T18:20:00Z | 2021-06-23T16:35:02Z | 2021-06-23T16:35:01Z | null | # Dataset Streaming
## API
Current API is
```python
from datasets import load_dataset
# Load an IterableDataset without downloading data
snli = load_dataset("snli", streaming=True)
# Access examples by streaming data
print(next(iter(snli["train"])))
# {'premise': 'A person on a horse jumps over a broken down airplane.',
# 'hypothesis': 'A person is training his horse for a competition.',
# 'label': 1}
```
I already implemented a few methods:
- IterableDataset.map: apply transforms on-the-fly to the examples
- IterableDataset.shuffle: shuffle the data _a la_ TFDS, i.e. with a shuffling buffer
- IterableDataset.with_format: set the format to `"torch"` to get a `torch.utils.data.IterableDataset`
- merge_datasets: merge two iterable datasets by alternating one or the other (you can specify the probabilities)
I would love to have your opinion on the API design :)
## Implementation details
### Streaming
Data streaming is done using `fsspec` which has nice caching features.
To make dataset streaming work I extend the `open` function of dataset scripts to support opening remote files without downloading them entirely. It also works with remote compressed archives (currently only zip is supported):
```python
# Get a file-like object by streaming data from a remote file
open("https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt")
# Get a file-like object by streaming data from a remote compressed archive by using the hop separator "::"
open("zip://snli_1.0_train.txt::https://nlp.stanford.edu/projects/snli/snli_1.0.zip")
```
I also extend the `os.path.join` function to support navigation in remote compressed archives, since it has to deal with the `"::"` separator. This separator is used by `fsspec`.
Finally I also added a retry mechanism in case the connection fails during data streaming.
### Transforms
An IterableDataset wraps an ExamplesIterable instance. There are different subclasses depending on the transforms we want to apply:
- ExamplesIterable: the basic one
- MappedExamplesIterable: an iterable with a `map` function applied on the fly
- BufferShuffledExamplesIterable: an iterable with a shuffling buffer
- CyclingMultiSourcesExamplesIterable: alternates between several ExamplesIterable
- RandomlyCyclingMultiSourcesExamplesIterable: randomly alternates between several ExamplesIterable
### DatasetBuilder
I use the same builders as usual. I just added a new method `_get_examples_iterable_for_split` to get an ExamplesIterable for a given split. Currently only the GeneratorBasedBuilder and the ArrowBasedBuilder implement it.
The BeamBasedBuilder doesn't implement it yet.
It means that datasets like wikipedia and natural_questions can't be loaded as IterableDataset for now.
## Other details
<S>I may have to do some changes in many dataset script to use `download` instead of `download_and_extract` when extraction is not needed. This will avoid errors for streaming.</s>
EDIT: Actually I just check for the extension of the file to do extraction only if needed.
EDIT2: It's not possible to stream from .tar.gz files without downloading the file completely. For now I raise an error if one want to get a streaming dataset based on .tar.gz files.
## TODO
usual stuff:
- [x] make streaming dependency "aiohttp" optional: `pip install datasets[streaming]`
- [x] tests
- [x] docs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 6,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2375/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2375",
"merged_at": "2021-06-23T16:35:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2375"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3506 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3506/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3506/comments | https://api.github.com/repos/huggingface/datasets/issues/3506/events | https://github.com/huggingface/datasets/pull/3506 | 1,091,166,595 | PR_kwDODunzps4wZpot | 3,506 | Allows DatasetDict.filter to have batching option | [] | closed | false | null | 0 | 2021-12-30T15:22:22Z | 2022-01-04T10:24:28Z | 2022-01-04T10:24:27Z | null | - Related to: #3244
- Fixes: #3503
We extends `.filter( ... batched: bool)` support to DatasetDict. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3506/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3506/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3506.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3506",
"merged_at": "2022-01-04T10:24:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3506.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3506"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1555/comments | https://api.github.com/repos/huggingface/datasets/issues/1555/events | https://github.com/huggingface/datasets/pull/1555 | 765,681,607 | MDExOlB1bGxSZXF1ZXN0NTM5MDMzMzIw | 1,555 | Added Opus TedTalks | [] | closed | false | null | 2 | 2020-12-13T22:29:33Z | 2020-12-18T09:44:43Z | 2020-12-18T09:44:43Z | null | Dataset : http://opus.nlpl.eu/TedTalks.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1555/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1555/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1555.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1555",
"merged_at": "2020-12-18T09:44:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1555.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1555"
} | true | [
"@lhoestq I saw some common changes you made on the other PR's (Similar Opus Datasets). I fixed those changes here. Can you please review it once ? \r\nThanks.",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5415/comments | https://api.github.com/repos/huggingface/datasets/issues/5415/events | https://github.com/huggingface/datasets/issues/5415 | 1,526,904,861 | I_kwDODunzps5bArgd | 5,415 | RuntimeError: Sharding is ambiguous for this dataset | [] | closed | false | null | 0 | 2023-01-10T07:36:11Z | 2023-01-18T14:09:04Z | 2023-01-18T14:09:03Z | null | ### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
1415 fpath = path_join(self._output_dir, fname)
1416
-> 1417 num_input_shards = _number_of_shards_in_gen_kwargs(split_generator.gen_kwargs)
1418 if num_input_shards <= 1 and num_proc is not None:
1419 logger.warning(
.../huggingface/datasets/src/datasets/utils/sharding.py in _number_of_shards_in_gen_kwargs(gen_kwargs)
10 lists_lengths = {key: len(value) for key, value in gen_kwargs.items() if isinstance(value, list)}
11 if len(set(lists_lengths.values())) > 1:
---> 12 raise RuntimeError(
13 (
14 "Sharding is ambiguous for this dataset: "
RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key samples_paths has length 6
- key ids has length 7
- key verification_ids has length 6
To fix this, check the 'gen_kwargs' and make sure to use lists only for data sources, and use tuples otherwise. In the end there should only be one single list, or several lists with the same length.
```
This behavior was introduced when implementing multiprocessing by PR:
- #5107
### Steps to reproduce the bug
```python
ds = load_dataset("ami", "microphone-single", split="train", revision="2d7620bb7c3f1aab9f329615c3bdb598069d907a")
```
### Expected behavior
No error raised.
### Environment info
Since datasets 2.7.0 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5415/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/775 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/775/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/775/comments | https://api.github.com/repos/huggingface/datasets/issues/775/events | https://github.com/huggingface/datasets/pull/775 | 732,287,504 | MDExOlB1bGxSZXF1ZXN0NTEyMjUyODI3 | 775 | Properly delete metrics when a process is killed | [] | closed | false | null | 0 | 2020-10-29T12:52:07Z | 2020-10-29T14:01:20Z | 2020-10-29T14:01:19Z | null | Tests are flaky when using metrics in distributed setup.
There is because of one test that make sure that using two possibly incompatible metric computation (same exp id) either works or raises the right error.
However if the error is raised, all the processes of the metric are killed, and the open files (arrow + lock files) are not closed correctly. This causes PermissionError on Windows when deleting the temporary directory.
To fix that I added a `finally` clause in the function passed to multiprocess to properly close the files when the process exits. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/775/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/775/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/775.diff",
"html_url": "https://github.com/huggingface/datasets/pull/775",
"merged_at": "2020-10-29T14:01:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/775.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/775"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2634/comments | https://api.github.com/repos/huggingface/datasets/issues/2634/events | https://github.com/huggingface/datasets/pull/2634 | 942,805,621 | MDExOlB1bGxSZXF1ZXN0Njg4NDk2Mzc2 | 2,634 | Inject ASR template for lj_speech dataset | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-05T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/6",
"id": 6836458,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/6/labels",
"node_id": "MDk6TWlsZXN0b25lNjgzNjQ1OA==",
"number": 6,
"open_issues": 0,
"state": "closed",
"title": "1.10",
"updated_at": "2021-07-21T15:36:49Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/6"
} | 0 | 2021-07-13T06:04:54Z | 2021-07-13T09:05:09Z | 2021-07-13T09:05:09Z | null | Related to: #2565, #2633.
cc: @lewtun | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2634/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2634/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2634.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2634",
"merged_at": "2021-07-13T09:05:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2634.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2634"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2208 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2208/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2208/comments | https://api.github.com/repos/huggingface/datasets/issues/2208/events | https://github.com/huggingface/datasets/pull/2208 | 855,343,835 | MDExOlB1bGxSZXF1ZXN0NjEzMTAxMzMw | 2,208 | Remove Python2 leftovers | [] | closed | false | null | 1 | 2021-04-11T16:08:03Z | 2021-04-14T22:05:36Z | 2021-04-14T13:40:51Z | null | This PR removes Python2 leftovers since this project aims for Python3.6+ (and as of 2020 Python2 is no longer officially supported) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2208/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2208/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2208.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2208",
"merged_at": "2021-04-14T13:40:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2208.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2208"
} | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5677/comments | https://api.github.com/repos/huggingface/datasets/issues/5677/events | https://github.com/huggingface/datasets/issues/5677 | 1,644,828,606 | I_kwDODunzps5iChe- | 5,677 | Dataset.map() crashes when any column contains more than 1000 empty dictionaries | [] | closed | false | null | 0 | 2023-03-29T00:01:31Z | 2023-07-07T14:01:14Z | 2023-07-07T14:01:14Z | null | ### Describe the bug
`Dataset.map()` crashes any time any column contains more than `writer_batch_size` (default 1000) empty dictionaries, regardless of whether the column is being operated on. The error does not occur if the dictionaries are non-empty.
### Steps to reproduce the bug
Example:
```
import datasets
def add_one(example):
example["col2"] += 1
return example
n = 1001 # crashes
# n = 999 # works
ds = datasets.Dataset.from_dict({"col1": [{}] * n, "col2": [1] * n})
ds = ds.map(add_one, writer_batch_size=1000)
```
### Expected behavior
Above code should not crash
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- PyArrow version: 9.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5677/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5677/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4483/comments | https://api.github.com/repos/huggingface/datasets/issues/4483/events | https://github.com/huggingface/datasets/issues/4483 | 1,269,253,840 | I_kwDODunzps5Lp0bQ | 4,483 | Dataset.map throws pyarrow.lib.ArrowNotImplementedError when converting from list of empty lists | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-06-13T10:47:52Z | 2022-06-14T13:34:14Z | 2022-06-14T13:34:14Z | null | ## Describe the bug
Dataset.map throws pyarrow.lib.ArrowNotImplementedError: Unsupported cast from int64 to null using function cast_null when converting from a type of 'empty lists' to 'lists with some type'.
This appears to be due to the interaction of arrow internals and some assumptions made by datasets.
The bug appeared when binarizing some labels, and then adding a dataset which had all these labels absent (to force the model to not label empty strings such with anything)
Particularly the fact that this only happens in batched mode is strange.
## Steps to reproduce the bug
```python
import numpy as np
ds = Dataset.from_dict(
{
"text": ["the lazy dog jumps over the quick fox", "another sentence"],
"label": [[], []],
}
)
def mapper(features):
features['label'] = [
[0,0,0] for l in features['label']
]
return features
ds_mapped = ds.map(mapper,batched=True)
```
## Expected results
Not crashing
## Actual results
```
../.venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:2346: in map
return self._map_single(
../.venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:532: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../.venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:499: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../.venv/lib/python3.8/site-packages/datasets/fingerprint.py:458: in wrapper
out = func(self, *args, **kwargs)
../.venv/lib/python3.8/site-packages/datasets/arrow_dataset.py:2751: in _map_single
writer.write_batch(batch)
../.venv/lib/python3.8/site-packages/datasets/arrow_writer.py:503: in write_batch
arrays.append(pa.array(typed_sequence))
pyarrow/array.pxi:230: in pyarrow.lib.array
???
pyarrow/array.pxi:110: in pyarrow.lib._handle_arrow_array_protocol
???
../.venv/lib/python3.8/site-packages/datasets/arrow_writer.py:198: in __arrow_array__
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
../.venv/lib/python3.8/site-packages/datasets/table.py:1675: in wrapper
return func(array, *args, **kwargs)
../.venv/lib/python3.8/site-packages/datasets/table.py:1812: in cast_array_to_feature
casted_values = _c(array.values, feature.feature)
../.venv/lib/python3.8/site-packages/datasets/table.py:1675: in wrapper
return func(array, *args, **kwargs)
../.venv/lib/python3.8/site-packages/datasets/table.py:1843: in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
../.venv/lib/python3.8/site-packages/datasets/table.py:1675: in wrapper
return func(array, *args, **kwargs)
../.venv/lib/python3.8/site-packages/datasets/table.py:1752: in array_cast
return array.cast(pa_type)
pyarrow/array.pxi:915: in pyarrow.lib.Array.cast
???
../.venv/lib/python3.8/site-packages/pyarrow/compute.py:376: in cast
return call_function("cast", [arr], options)
pyarrow/_compute.pyx:542: in pyarrow._compute.call_function
???
pyarrow/_compute.pyx:341: in pyarrow._compute.Function.call
???
pyarrow/error.pxi:144: in pyarrow.lib.pyarrow_internal_check_status
???
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
> ???
E pyarrow.lib.ArrowNotImplementedError: Unsupported cast from int64 to null using function cast_null
pyarrow/error.pxi:121: ArrowNotImplementedError
```
## Workarounds
* Not using batched=True
* Using an np.array([],dtype=float) or similar instead of [] in the input
* Naming the output column differently from the input column
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.2
- Platform: Ubuntu
- Python version: 3.8
- PyArrow version: 8.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4483/timeline | null | completed | null | null | false | [
"Hi @sanderland ! Thanks for reporting :) This is a bug, I opened a PR to fix it. We'll do a new release soon\r\n\r\nIn the meantime you can fix it by specifying in advance that the \"label\" are integers:\r\n```python\r\nimport numpy as np\r\n\r\nds = Dataset.from_dict(\r\n {\r\n \"text\": [\"the lazy dog jumps over the quick fox\", \"another sentence\"],\r\n \"label\": [[], []],\r\n }\r\n)\r\n# explicitly say that the \"label\" type is int64, even though it contains only null values\r\nds = ds.cast_column(\"label\", Sequence(Value(\"int64\")))\r\n\r\ndef mapper(features):\r\n features['label'] = [\r\n [0,0,0] for l in features['label']\r\n ]\r\n return features\r\n\r\nds_mapped = ds.map(mapper,batched=True)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/2934 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2934/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2934/comments | https://api.github.com/repos/huggingface/datasets/issues/2934/events | https://github.com/huggingface/datasets/issues/2934 | 999,477,413 | I_kwDODunzps47ktCl | 2,934 | to_tf_dataset keeps a reference to the open data somewhere, causing issues on windows | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-09-17T15:26:53Z | 2021-10-13T09:03:23Z | 2021-10-13T09:03:23Z | null | To reproduce:
```python
import datasets as ds
import weakref
import gc
d = ds.load_dataset("mnist", split="train")
ref = weakref.ref(d._data.table)
tfd = d.to_tf_dataset("image", batch_size=1, shuffle=False, label_cols="label")
del tfd, d
gc.collect()
assert ref() is None, "Error: there is at least one reference left"
```
This causes issues because the table holds a reference to an open arrow file that should be closed. So on windows it's not possible to delete or move the arrow file afterwards.
Moreover the CI test of the `to_tf_dataset` method isn't able to clean up the temporary arrow files because of this.
cc @Rocketknight1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2934/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2934/timeline | null | completed | null | null | false | [
"I did some investigation and, as it seems, the bug stems from [this line](https://github.com/huggingface/datasets/blob/8004d7c3e1d74b29c3e5b0d1660331cd26758363/src/datasets/arrow_dataset.py#L325). The lifecycle of the dataset from the linked line is bound to one of the returned `tf.data.Dataset`. So my (hacky) solution involves wrapping the linked dataset with `weakref.proxy` and adding a custom `__del__` to `tf.python.data.ops.dataset_ops.TensorSliceDataset` (this is the type of a dataset that is returned by `tf.data.Dataset.from_tensor_slices`; this works for TF 2.x, but I'm not sure `tf.python.data.ops.dataset_ops` is a valid path for TF 1.x) that deletes the linked dataset, which is assigned to the dataset object as a property. Will open a draft PR soon!",
"Thanks a lot for investigating !"
] |
https://api.github.com/repos/huggingface/datasets/issues/3629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3629/comments | https://api.github.com/repos/huggingface/datasets/issues/3629/events | https://github.com/huggingface/datasets/pull/3629 | 1,113,971,575 | PR_kwDODunzps4xkCZA | 3,629 | Fix Hub repos update when there's a new release | [] | closed | false | null | 0 | 2022-01-25T14:39:45Z | 2022-01-25T14:55:46Z | 2022-01-25T14:55:46Z | null | It was not listing the full list of datasets correctly
cc @SBrandeis this is why it failed for 1.18.0
We should be good now ! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3629/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3629/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3629.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3629",
"merged_at": "2022-01-25T14:55:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3629.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3629"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/340/comments | https://api.github.com/repos/huggingface/datasets/issues/340/events | https://github.com/huggingface/datasets/pull/340 | 650,533,920 | MDExOlB1bGxSZXF1ZXN0NDQ0MDA2Nzcy | 340 | Update cfq.py | [] | closed | false | null | 1 | 2020-07-03T11:23:19Z | 2020-07-03T12:33:50Z | 2020-07-03T12:33:50Z | null | Make the dataset name consistent with in the paper: Compositional Freebase Question => Compositional Freebase Questions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/340/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/340",
"merged_at": "2020-07-03T12:33:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/340"
} | true | [
"Thanks @brainshawn for this update"
] |
https://api.github.com/repos/huggingface/datasets/issues/3749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3749/comments | https://api.github.com/repos/huggingface/datasets/issues/3749/events | https://github.com/huggingface/datasets/pull/3749 | 1,142,156,678 | PR_kwDODunzps4zCKqg | 3,749 | Add tqdm arguments | [] | closed | false | null | 6 | 2022-02-18T01:34:46Z | 2022-03-08T09:38:48Z | 2022-03-08T09:38:48Z | null | In this PR, tqdm arguments can be passed to the map() function and such, in order to be more flexible. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3749/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3749/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3749.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3749",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3749.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3749"
} | true | [
"Hi ! Thanks this will be very useful :)\r\n\r\nIt looks like there are some changes in the github diff that are not related to your contribution, can you try fixing this by merging `master` into your PR, or create a new PR from an updated version of `master` ?",
"I have already solved the conflict on this latest version. This is my first time sending PR, if there's anything I need to adjust just let me know~",
"Thanks, most changes are gone :)\r\nIt still seems to include changes though - do you mind try creating a new branch from upstream/master and create a new PR please ?",
"Yeah sure, I'll try to send a new PR today!",
"Please forward to [#3850](https://github.com/huggingface/datasets/pull/3850)",
"Thanks ! Closing this one in favor of https://github.com/huggingface/datasets/pull/3850/files"
] |
https://api.github.com/repos/huggingface/datasets/issues/1643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1643/comments | https://api.github.com/repos/huggingface/datasets/issues/1643/events | https://github.com/huggingface/datasets/issues/1643 | 775,280,046 | MDU6SXNzdWU3NzUyODAwNDY= | 1,643 | Dataset social_bias_frames 404 | [] | closed | false | null | 1 | 2020-12-28T08:35:34Z | 2020-12-28T08:38:07Z | 2020-12-28T08:38:07Z | null | ```
>>> from datasets import load_dataset
>>> dataset = load_dataset("social_bias_frames")
...
Downloading and preparing dataset social_bias_frames/default
...
~/.pyenv/versions/3.7.6/lib/python3.7/site-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag)
484 )
485 elif response is not None and response.status_code == 404:
--> 486 raise FileNotFoundError("Couldn't find file at {}".format(url))
487 raise ConnectionError("Couldn't reach {}".format(url))
488
FileNotFoundError: Couldn't find file at https://homes.cs.washington.edu/~msap/social-bias-frames/SocialBiasFrames_v2.tgz
```
[Here](https://homes.cs.washington.edu/~msap/social-bias-frames/) we find button `Download data` with the correct URL for the data: https://homes.cs.washington.edu/~msap/social-bias-frames/SBIC.v2.tgz | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1643/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1643/timeline | null | completed | null | null | false | [
"I see, master is already fixed in https://github.com/huggingface/datasets/commit/9e058f098a0919efd03a136b9b9c3dec5076f626"
] |
https://api.github.com/repos/huggingface/datasets/issues/4417 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4417/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4417/comments | https://api.github.com/repos/huggingface/datasets/issues/4417/events | https://github.com/huggingface/datasets/issues/4417 | 1,251,933,091 | I_kwDODunzps5Knvuj | 4,417 | how to convert a dict generator into a huggingface dataset. | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | 18 | 2022-05-29T16:28:27Z | 2022-09-16T14:44:19Z | 2022-09-16T14:44:19Z | null | ### Link
_No response_
### Description
Hey there, I have used seqio to get a well distributed mixture of samples from multiple dataset. However the resultant output from seqio is a python generator dict, which I cannot produce back into huggingface dataset.
The generator contains all the samples needed for training the model but I cannot convert it into a huggingface dataset.
The code looks like this:
```
for ex in seqio_data:
print(ex[“text”])
```
I need to convert the seqio_data (generator) into huggingface dataset.
the complete seqio code goes here:
```
import functools
import seqio
import tensorflow as tf
import t5.data
from datasets import load_dataset
from t5.data import postprocessors
from t5.data import preprocessors
from t5.evaluation import metrics
from seqio import FunctionDataSource, utils
TaskRegistry = seqio.TaskRegistry
def gen_dataset(split, shuffle=False, seed=None, column="text", dataset_params=None):
dataset = load_dataset(**dataset_params)
if shuffle:
if seed:
dataset = dataset.shuffle(seed=seed)
else:
dataset = dataset.shuffle()
while True:
for item in dataset[str(split)]:
yield item[column]
def dataset_fn(split, shuffle_files, seed=None, dataset_params=None):
return tf.data.Dataset.from_generator(
functools.partial(gen_dataset, split, shuffle_files, seed, dataset_params=dataset_params),
output_signature=tf.TensorSpec(shape=(), dtype=tf.string, name=dataset_name)
)
@utils.map_over_dataset
def target_to_key(x, key_map, target_key):
"""Assign the value from the dataset to target_key in key_map"""
return {**key_map, target_key: x}
dataset_name = 'oscar-corpus/OSCAR-2109'
subset= 'mr'
dataset_params = {"path": dataset_name, "language":subset, "use_auth_token":True}
dataset_shapes = None
TaskRegistry.add(
"oscar_marathi_corpus",
source=seqio.FunctionDataSource(
dataset_fn=functools.partial(dataset_fn, dataset_params=dataset_params),
splits=("train", "validation"),
caching_permitted=False,
num_input_examples=dataset_shapes,
),
preprocessors=[
functools.partial(
target_to_key, key_map={
"targets": None,
}, target_key="targets")],
output_features={"targets": seqio.Feature(vocabulary=seqio.PassThroughVocabulary, add_eos=False, dtype=tf.string, rank=0)},
metric_fns=[]
)
dataset = seqio.get_mixture_or_task("oscar_marathi_corpus").get_dataset(
sequence_length=None,
split="train",
shuffle=True,
num_epochs=1,
shard_info=seqio.ShardInfo(index=0, num_shards=10),
use_cached=False,
seed=42
)
for _, ex in zip(range(5), dataset):
print(ex['targets'].numpy().decode())
```
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4417/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4417/timeline | null | completed | null | null | false | [
"@albertvillanova @lhoestq , could you please help me on this issue. ",
"Hi ! As mentioned on the [forum](https://discuss.huggingface.co/t/how-to-wrap-a-generator-with-hf-dataset/18464), the simplest for now would be to define a [dataset script](https://huggingface.co/docs/datasets/dataset_script) which can contain your generator. But we can also explore adding something like `ds = Dataset.from_iterable(seqio_dataset)`",
"@lhoestq , hey i did as you instructed, but sadly i cannot get pass through the download_manager, as i dont have anything to download. i was skipping the ` def _split_generators(self, dl_manager):` function. but i cannot get around it. I get a `NotImplementedError: `\r\n\r\nthe following is my code for the same: \r\n\r\n\r\n\r\n```\r\nimport datasets \r\nimport functools\r\nimport glob \r\nfrom datasets import load_from_disk\r\nimport seqio\r\nimport tensorflow as tf\r\nimport t5.data\r\nfrom datasets import load_dataset\r\nfrom t5.data import postprocessors\r\nfrom t5.data import preprocessors\r\nfrom t5.evaluation import metrics\r\nfrom seqio import FunctionDataSource, utils\r\n\r\nTaskRegistry = seqio.TaskRegistry\r\n\r\ndata_path = glob.glob(\"/home/stephen/Desktop/MEGA_CORPUS/COMBINED_CORPUS/*\", recursive=False)\r\n\r\n\r\ndef gen_dataset(split, shuffle=False, seed=None, column=\"text\", dataset_path=None):\r\n dataset = load_from_disk(dataset_path)\r\n if shuffle:\r\n if seed:\r\n dataset = dataset.shuffle(seed=seed)\r\n else:\r\n dataset = dataset.shuffle()\r\n while True:\r\n for item in dataset[str(split)]:\r\n yield item[column]\r\n\r\n\r\ndef dataset_fn(split, shuffle_files, seed=None, dataset_path=None):\r\n return tf.data.Dataset.from_generator(\r\n functools.partial(gen_dataset, split, shuffle_files, seed, dataset_path=dataset_path),\r\n output_signature=tf.TensorSpec(shape=(), dtype=tf.string, name=dataset_path)\r\n )\r\n\r\[email protected]_over_dataset\r\ndef target_to_key(x, key_map, target_key):\r\n \"\"\"Assign the value from the dataset to target_key in key_map\"\"\"\r\n return {**key_map, target_key: x}\r\n\r\n\r\n_CITATION = \"Not ready yet\"\r\n_DESCRIPTION = \"a custom seqio based mixed samples on a given temperature value, that again returns a dataset in HF dataset format well samples on the Mixture temperature\"\r\n_HOMEPAGE = \"ldcil.org\"\r\n\r\nclass CustomSeqio(datasets.GeneratorBasedBuilder):\r\n\r\n def _info(self):\r\n return datasets.DatasetInfo(\r\n description=_DESCRIPTION,\r\n features=datasets.Features(\r\n {\r\n \"text\": datasets.Value(\"string\"),\r\n }\r\n ),\r\n homepage=\"https://ldcil.org\",\r\n citation=_CITATION,)\r\n\r\ndef generate_examples(self):\r\n seqio_train_list = []\r\n for lang in data_path:\r\n dataset_name = lang.split(\"/\")[-1]\r\n dataset_shapes = None \r\n\r\n TaskRegistry.add(\r\n str(dataset_name),\r\n source=seqio.FunctionDataSource(\r\n dataset_fn=functools.partial(dataset_fn, dataset_path=lang),\r\n splits=(\"train\", \"test\"),\r\n caching_permitted=False,\r\n num_input_examples=dataset_shapes,\r\n ),\r\n preprocessors=[\r\n functools.partial(\r\n target_to_key, key_map={\r\n \"targets\": None,\r\n }, target_key=\"targets\")],\r\n output_features={\"targets\": seqio.Feature(vocabulary=seqio.PassThroughVocabulary, add_eos=False, dtype=tf.string, rank=0)},\r\n metric_fns=[]\r\n )\r\n\r\n seqio_train_dataset = seqio.get_mixture_or_task(dataset_name).get_dataset(\r\n sequence_length=None,\r\n split=\"train\",\r\n shuffle=True,\r\n num_epochs=1,\r\n shard_info=seqio.ShardInfo(index=0, num_shards=10),\r\n use_cached=False,\r\n seed=42)\r\n seqio_train_list.append(seqio_train_dataset)\r\n \r\n lang_name_list = []\r\n for lang in data_path:\r\n lang_name = lang.split(\"/\")[-1]\r\n lang_name_list.append(lang_name)\r\n\r\n seqio_mixture = seqio.MixtureRegistry.add(\r\n \"seqio_mixture\",\r\n lang_name_list,\r\n default_rate=0.7)\r\n \r\n seqio_mixture_dataset = seqio.get_mixture_or_task(\"seqio_mixture\").get_dataset(\r\n sequence_length=None,\r\n split=\"train\",\r\n shuffle=True,\r\n num_epochs=1,\r\n shard_info=seqio.ShardInfo(index=0, num_shards=10),\r\n use_cached=False,\r\n seed=42)\r\n\r\n for id, ex in enumerate(seqio_mixture_dataset):\r\n yield id, {\"text\": ex[\"targets\"].numpy().decode()}\r\n```\r\n\r\nand i load it by:\r\n\r\n`seqio_mixture = load_dataset(\"seqio_loader\")`",
"@lhoestq , just to make things clear ... \r\n\r\nthe following is my original code, thats not in the HF dataset loading script: \r\n\r\n```\r\nimport functools\r\nimport seqio\r\nimport tensorflow as tf\r\nimport t5.data\r\nfrom datasets import load_from_disk\r\nfrom t5.data import postprocessors\r\nfrom t5.data import preprocessors\r\nfrom t5.evaluation import metrics\r\nfrom seqio import FunctionDataSource, utils\r\nimport glob \r\n\r\nTaskRegistry = seqio.TaskRegistry\r\n\r\n\r\n\r\ndef gen_dataset(split, shuffle=False, seed=None, column=\"text\", dataset_path=None):\r\n dataset = load_from_disk(dataset_path)\r\n if shuffle:\r\n if seed:\r\n dataset = dataset.shuffle(seed=seed)\r\n else:\r\n dataset = dataset.shuffle()\r\n while True:\r\n for item in dataset[str(split)]:\r\n yield item[column]\r\n\r\n\r\ndef dataset_fn(split, shuffle_files, seed=None, dataset_path=None):\r\n return tf.data.Dataset.from_generator(\r\n functools.partial(gen_dataset, split, shuffle_files, seed, dataset_path=dataset_path),\r\n output_signature=tf.TensorSpec(shape=(), dtype=tf.string, name=dataset_path)\r\n )\r\n\r\n\r\[email protected]_over_dataset\r\ndef target_to_key(x, key_map, target_key):\r\n \"\"\"Assign the value from the dataset to target_key in key_map\"\"\"\r\n return {**key_map, target_key: x}\r\n\r\ndata_path = glob.glob(\"/home/stephen/Desktop/MEGA_CORPUS/COMBINED_CORPUS/*\", recursive=False)\r\n\r\nseqio_train_list = []\r\n\r\nfor lang in data_path:\r\n dataset_name = lang.split(\"/\")[-1]\r\n dataset_shapes = None \r\n\r\n TaskRegistry.add(\r\n str(dataset_name),\r\n source=seqio.FunctionDataSource(\r\n dataset_fn=functools.partial(dataset_fn, dataset_path=lang),\r\n splits=(\"train\", \"test\"),\r\n caching_permitted=False,\r\n num_input_examples=dataset_shapes,\r\n ),\r\n preprocessors=[\r\n functools.partial(\r\n target_to_key, key_map={\r\n \"targets\": None,\r\n }, target_key=\"targets\")],\r\n output_features={\"targets\": seqio.Feature(vocabulary=seqio.PassThroughVocabulary, add_eos=False, dtype=tf.string, rank=0)},\r\n metric_fns=[]\r\n )\r\n\r\n seqio_train_dataset = seqio.get_mixture_or_task(dataset_name).get_dataset(\r\n sequence_length=None,\r\n split=\"train\",\r\n shuffle=True,\r\n num_epochs=1,\r\n shard_info=seqio.ShardInfo(index=0, num_shards=10),\r\n use_cached=False,\r\n seed=42)\r\n seqio_train_list.append(seqio_train_dataset)\r\n\r\nlang_name_list = []\r\nfor lang in data_path:\r\n lang_name = lang.split(\"/\")[-1]\r\n lang_name_list.append(lang_name)\r\n\r\nseqio_mixture = seqio.MixtureRegistry.add(\r\n \"seqio_mixture\",\r\n lang_name_list,\r\n default_rate=0.7\r\n)\r\n\r\nseqio_mixture_dataset = seqio.get_mixture_or_task(\"seqio_mixture\").get_dataset(\r\n sequence_length=None,\r\n split=\"train\",\r\n shuffle=True,\r\n num_epochs=1,\r\n shard_info=seqio.ShardInfo(index=0, num_shards=10),\r\n use_cached=False,\r\n seed=42)\r\n\r\nfor _, ex in zip(range(15), seqio_mixture_dataset):\r\n print(ex[\"targets\"].numpy().decode())\r\n```\r\n\r\nwhere the seqio_mixture_dataset is the generator that i wanted to be wrapped in HF dataset. \r\n\r\nalso additionally, could you please tell me how do i set the `default_rate=0.7` args where `seqio_mixture` is defined to be made as a custom option in the HF load_dataset() method,\r\n\r\nmaybe like this: \r\n`seqio_mixture_dataset = datasets.load_dataset(\"seqio_loader\",temperature=0.5)`",
"I like the idea of having `Dataset.from_iterable(iterable)` in the API. The only problem is that we also want to make this part cachable, which is tricky if `iterable` is a generator. \r\n\r\nSome resources on this issue:\r\n* https://github.com/uqfoundation/dill/issues/311\r\n* https://stackoverflow.com/questions/7180212/why-cant-generators-be-pickled\r\n* https://github.com/tonyroberts/generator_tools - python package for pickling generators; pickles bytecode, so it creates version-specific dumps",
"For the caching maybe we can have `Dataset.from_generator` as TF and pickle+hash the generator function (not the generator object itself) ?\r\n\r\nAnd then keep `Dataset.from_iterable` fo pickable objects like lists",
"@lhoestq, @mariosasko do you too have any examples where the dataset is a generator and needs to be wrapped into hf dataset ? ",
"@lhoestq, following to my previous question ... what possibly could be done in this [link1](https://github.com/huggingface/datasets/issues/4417#issuecomment-1146627404) [link2](https://github.com/huggingface/datasets/issues/4417#issuecomment-1146627593) case? do you have any ideas? ",
"@lhoestq +1 for the `Dataset.from_generator` idea.\r\n\r\nHaving thought about it, let's avoid adding `Dataset.from_iterable` to the API since dictionaries are technically iteralbles (\"iterable\" is a broad term in Python), and we already provide `Dataset.from_dict`. And for lists maybe we can add `Dataset.from_list` similar to `pa.Table.from_pylist`. WDYT?\r\n",
"Hi @StephennFernandes!\r\n\r\nTo fix the issues in the copied code, rename `generate_examples` to` _generate_examples` and add one level of indentation as this is a method of `GeneratorBasedBuilder` and define `_split_generators` as follows (again as a method of `GeneratorBasedBuilder):\r\n```python\r\n def _split_generators(self, dl_manager):\r\n return [\r\n datasets.SplitGenerator(\r\n name=datasets.Split.TRAIN,\r\n gen_kwargs={},\r\n ),\r\n ]\r\n```\r\n\r\nAnd if you are feeling extra adventurous, you can try to use ArrowWriter to directly create a cache file:\r\n```python\r\nfrom datasets import Dataset\r\nfrom datasets.arrow_writer import ArrowWriter\r\n\r\nwriter = ArrowWriter(path=\"path/to/cache_file.arrow\", writer_batch_size=1000)\r\n\r\nwith writer:\r\n for ex in generator:\r\n writer.write(ex) \r\n writer.finalize()\r\n\r\ndset = Dataset.from_file(\"path/to/cache_file.arrow\")\r\n```\r\n\r\n",
"I have a problem which I think is very similar: I would like to \"stream\" data to a HF Array (memory-mapped) Dataset, where the final size of the dataset is unknown, but could be much larger than what fits into memory.\r\nWhat I want to end up with is an Array Dataset which I can open using `Dataset.load_from_disk(dataset_path=\"somename\")` and use e.g. as the training set. \r\n\r\nFor this I would have thought there should be an API which allows me to open/create the dataset (and define the features etc), then write examples to the dataset, but I could not find a way to do this. \r\n\r\nI tried doing this and it looks like it works, but it feels very hacky and I am not sure if this might fail to update some of the fields in the json files which may turn out to be important:\r\n```\r\nfrom datasets import Dataset, Features, ClassLabel, Sequence, Value\r\nfrom datasets.arrow_writer import ArrowWriter \r\n# 1) define the features\r\nfeatures = Features(dict(\r\n id=Value(dtype=\"string\"),\r\n tokens=Sequence(feature=Value(dtype=\"string\")),\r\n ner_tags=Sequence(feature=ClassLabel(names=['O', 'B-corporation', 'I-corporation', 'B-creative-work', 'I-creative-work', 'B-group', 'I-group', 'B-location', 'I-location', 'B-person', 'I-person', 'B-product', 'I-product'])),\r\n))\r\n# 2) create empty dataset for examples with these features and store to disk\r\nempty = dict(\r\n id = [],\r\n tokens = [],\r\n ner_tags = [],\r\n)\r\nds = Dataset.from_dict(empty, features=features)\r\nds.save_to_disk(dataset_path=\"debug_ds1\")\r\n\r\n# 3) directly write all the examples to the arrow dataset \r\nwith ArrowWriter(path=\"debug_ds1/dataset.arrow\") as writer: \r\n writer.write(dict(id=0, tokens=[\"a\", \"b\"], ner_tags=[0, 0])) \r\n writer.write(dict(id=1, tokens=[\"x\", \"y\"], ner_tags=[1, 0])) \r\n writer.finalize() \r\n \r\nds2 = Dataset.load_from_disk(dataset_path=\"debug_ds1\")\r\nlen(ds2)\r\n```\r\nIs there a cleaner/proper way to do this?\r\n\r\nI like the sound of `Dataset.from_iterable` or `Dataset.from_generator` (should not from iterable be able to handle from generator too as all generators are iterables?) but how would I define the features for me examples there? ",
"Hi @johann-petrak! You can pass the features directly to ArrowWriter's initializer like so `ArrowWriter(..., features=features)`.\r\n\r\nAnd the reason why I prefer `Dataset.from_generator` over `Dataset.from_iterable` is mentioned in one of my previous comments.",
"@mariosasko so at the moment we still have to create a fake `Dataset` first and then use `ArrowWriter` to write an actual dataset? I'm using the latest version of `datasets` on pypi but my final file is always empty. Is there anything wrong with the code below?\r\n\r\n```python\r\n total = 0\r\n with ArrowWriter(path=str(final_data_path), features=features) as writer:\r\n for batch in loader:\r\n for traj in batch:\r\n for generator in question_generators:\r\n for xi in generator(traj):\r\n # print(f\"Question: {xi.question}, answer: {xi.answer}\")\r\n total += 1\r\n writer.write(\r\n {\r\n \"id\": f\"qa_{total}\",\r\n \"question\": xi.question,\r\n \"answer\": xi.answer,\r\n }\r\n )\r\n writer.finalize()\r\n print(f\"Total #questions = {total}\") # this prints 402\r\n```",
"This works for me if I then (actually I also close the writer: `writer.close()`) open the Arrow file as a dataset using `ds=Dataset.from_file(final_data_path)` then `ds.save_to_disk(somedir)`. The Dataset created that way contains the expected examples.",
"Oh thanks. That did the trick I believe. Shouldn't ArrowWriter have a context manager that does these operations?",
"You can just use `Dataset.from_file` to get your dataset, no need to do an extra `save_to_disk` somewhere else ;)",
"I was thinking that `save_to_disk` is necessary when one wants to re-use that dataset as a proper HF dataset later, no?\r\nAt least what I wanted to achieve is create a dataset that can be opened like any other local or remote dataset. ",
"`save_to_disk`/`load_from_disk` is indeed more general, e.g. it supports datasets that consist in several files, and saves some extra info in a dataset_info.json file (description, citation, split sizes, etc.)\r\n\r\nIf you have one single file it's fine to simply do `.from_file()`"
] |
https://api.github.com/repos/huggingface/datasets/issues/803 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/803/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/803/comments | https://api.github.com/repos/huggingface/datasets/issues/803/events | https://github.com/huggingface/datasets/pull/803 | 736,818,917 | MDExOlB1bGxSZXF1ZXN0NTE1OTY1ODE2 | 803 | fix: typos in tutorial to map KILT and TriviaQA | [] | closed | false | null | 0 | 2020-11-05T10:42:00Z | 2020-11-10T09:08:07Z | 2020-11-10T09:08:07Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/803/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/803/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/803.diff",
"html_url": "https://github.com/huggingface/datasets/pull/803",
"merged_at": "2020-11-10T09:08:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/803.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/803"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5930/comments | https://api.github.com/repos/huggingface/datasets/issues/5930/events | https://github.com/huggingface/datasets/issues/5930 | 1,745,184,395 | I_kwDODunzps5oBWaL | 5,930 | loading private custom dataset script - authentication error | [] | closed | false | null | 1 | 2023-06-07T06:58:23Z | 2023-06-15T14:49:21Z | 2023-06-15T14:49:20Z | null | ### Describe the bug
Train model with my custom dataset stored in HuggingFace and loaded with the loading script requires authentication but I am not sure how ?
I am logged in in the terminal, in the browser. I receive this error:
/python3.8/site-packages/datasets/utils/file_utils.py", line 566, in get_from_cache
raise ConnectionError(f"Couldn't reach {url} ({repr(head_error)})")
ConnectionError: Couldn't reach https://huggingface.co/datasets/fkov/s/blob/main/data/s/train/labels `(ConnectionError('Unauthorized for URL `https://huggingface.co/datasets/fkov/s/blob/main/data/s/train/labels. Please use the parameter `**`use_auth_token=True`**` after logging in with `**`huggingface-cli login`**`'))
when I added: `use_auth_token=True` and logged in via terminal then I received error:
or the same error in different format:
raise ConnectionError(f"`Couldn't reach {url} (error {response.status_code}`)")
ConnectionError: Couldn't reach https://huggingface.co/datasets/fkov/s/blob/main/data/s/train/labels (`error 401`)
### Steps to reproduce the bug
1. cloned transformers library locally:
https://huggingface.co/docs/transformers/v4.15.0/examples :
> git clone https://github.com/huggingface/transformers
> cd transformers
> pip install .
> cd /transformers/examples/pytorch/audio-classification
> pip install -r requirements.txt
2. created **loading script**
> https://huggingface.co/docs/datasets/dataset_script added next to dataset:
3. uploaded **private custom dataset** with loading script to HuggingFace
> https://huggingface.co/docs/datasets/dataset_script
4. added dataset loading script to **local directory** in the above cloned transformers library:
> cd /transformers/examples/pytorch/audio-classification
5. logged in to HuggingFace on local terminal with :
> **huggingface-cli login**
6. run the model with the custom dataset stored on HuggingFace with code: https://github.com/huggingface/transformers/blob/main/examples/pytorch/audio-classification/README.md
cd /transformers/examples/pytorch/audio-classification
> python run_audio_classification.py \
> --model_name_or_path facebook/wav2vec2-base \
> --output_dir l/users/flck/outputs/wav2vec2-base-s \
> --overwrite_output_dir \
> --dataset_name s \
> --dataset_config_name s \
> --remove_unused_columns False \
> --do_train \
> --do_eval \
> --fp16 \
> --learning_rate 3e-5 \
> --max_length_seconds 1 \
> --attention_mask False \
> --warmup_ratio 0.1 \
> --num_train_epochs 5 \
> --per_device_train_batch_size 32 \
> --gradient_accumulation_steps 4 \
> --per_device_eval_batch_size 32 \
> --dataloader_num_workers 4 \
> --logging_strategy steps \
> --logging_steps 10 \
> --evaluation_strategy epoch \
> --save_strategy epoch \
> --load_best_model_at_end True \
> --metric_for_best_model accuracy \
> --save_total_limit 3 \
> --seed 0 \
> --push_to_hub \
> **--use_auth_token=True**
### Expected behavior
Be able to train a model the https://github.com/huggingface/transformers/blob/main/examples/pytorch/audio-classification/ run_audio_classification.py with private custom dataset stored on HuggingFace.
### Environment info
- datasets version: 2.12.0
- `transformers` version: 4.30.0.dev0
- Platform: Linux-5.4.204-ql-generic-12.0-19-x86_64-with-glibc2.17
- Python version: 3.8.12
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1+cu117 (True)
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.1
[pip3] torchaudio==2.0.2
[conda] numpy 1.24.3 pypi_0 pypi
[conda] torch 2.0.1 pypi_0 pypi
[conda] torchaudio 2.0.2 pypi_0 pypi
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5930/timeline | null | completed | null | null | false | [
"This issue seems to have been resolved, so I'm closing it."
] |
https://api.github.com/repos/huggingface/datasets/issues/2576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2576/comments | https://api.github.com/repos/huggingface/datasets/issues/2576/events | https://github.com/huggingface/datasets/pull/2576 | 934,986,761 | MDExOlB1bGxSZXF1ZXN0NjgxOTc5MTA1 | 2,576 | Add mC4 | [] | closed | false | null | 0 | 2021-07-01T15:51:25Z | 2021-07-02T14:50:56Z | 2021-07-02T14:50:55Z | null | AllenAI is now hosting the processed C4 and mC4 dataset in this repo: https://huggingface.co/datasets/allenai/c4
Thanks a lot to them !
In this PR I added the mC4 dataset builder. It supports 108 languages
You can load it with
```python
from datasets import load_dataset
en_mc4 = load_dataset("mc4", "en")
fr_mc4 = load_dataset("mc4", "fr")
en_and_fr_mc4 = load_dataset("mc4", languages=["en", "fr"])
```
It also supports streaming, if you don't want to download hundreds of GB of data:
```python
en_mc4 = load_dataset("mc4", "en", streaming=True)
```
Regarding the dataset_infos.json, I will add them once I have them.
Also we can work on the dataset card at that will be at https://huggingface.co/datasets/mc4
For now I just added a link to https://huggingface.co/datasets/allenai/c4 as well as a few sections | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2576/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2576.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2576",
"merged_at": "2021-07-02T14:50:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2576.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2576"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4269 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4269/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4269/comments | https://api.github.com/repos/huggingface/datasets/issues/4269/events | https://github.com/huggingface/datasets/pull/4269 | 1,223,865,145 | PR_kwDODunzps43Nzwh | 4,269 | Add license and point of contact to big_patent dataset | [] | closed | false | null | 1 | 2022-05-03T09:24:07Z | 2022-05-06T08:38:09Z | 2022-05-03T11:16:19Z | null | Update metadata of big_patent dataset with:
- license
- point of contact | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4269/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4269/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4269.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4269",
"merged_at": "2022-05-03T11:16:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4269.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4269"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/6047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6047/comments | https://api.github.com/repos/huggingface/datasets/issues/6047/events | https://github.com/huggingface/datasets/pull/6047 | 1,809,627,947 | PR_kwDODunzps5VxRLA | 6,047 | Bump dev version | [] | closed | false | null | 3 | 2023-07-18T10:15:39Z | 2023-07-18T10:28:01Z | 2023-07-18T10:15:52Z | null | workaround to fix an issue with transformers CI
https://github.com/huggingface/transformers/pull/24867#discussion_r1266519626 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6047/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6047",
"merged_at": "2023-07-18T10:15:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6047"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6047). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006384 / 0.011353 (-0.004969) | 0.003872 / 0.011008 (-0.007136) | 0.083454 / 0.038508 (0.044946) | 0.069120 / 0.023109 (0.046011) | 0.312573 / 0.275898 (0.036675) | 0.345814 / 0.323480 (0.022334) | 0.005729 / 0.007986 (-0.002257) | 0.003225 / 0.004328 (-0.001103) | 0.063950 / 0.004250 (0.059700) | 0.053998 / 0.037052 (0.016946) | 0.316492 / 0.258489 (0.058003) | 0.350738 / 0.293841 (0.056897) | 0.030770 / 0.128546 (-0.097776) | 0.008474 / 0.075646 (-0.067173) | 0.286989 / 0.419271 (-0.132282) | 0.052473 / 0.043533 (0.008940) | 0.314361 / 0.255139 (0.059222) | 0.335170 / 0.283200 (0.051970) | 0.022885 / 0.141683 (-0.118798) | 1.465430 / 1.452155 (0.013275) | 1.527799 / 1.492716 (0.035083) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209377 / 0.018006 (0.191371) | 0.455583 / 0.000490 (0.455094) | 0.003352 / 0.000200 (0.003152) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026284 / 0.037411 (-0.011127) | 0.080710 / 0.014526 (0.066185) | 0.091741 / 0.176557 (-0.084816) | 0.147602 / 0.737135 (-0.589534) | 0.091173 / 0.296338 (-0.205166) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.386592 / 0.215209 (0.171383) | 3.856665 / 2.077655 (1.779011) | 1.835745 / 1.504120 (0.331625) | 1.671814 / 1.541195 (0.130619) | 1.711224 / 1.468490 (0.242734) | 0.484704 / 4.584777 (-4.100073) | 3.649239 / 3.745712 (-0.096473) | 3.784051 / 5.269862 (-1.485810) | 2.241195 / 4.565676 (-2.324482) | 0.056613 / 0.424275 (-0.367662) | 0.007140 / 0.007607 (-0.000467) | 0.464585 / 0.226044 (0.238540) | 4.616537 / 2.268929 (2.347609) | 2.371969 / 55.444624 (-53.072656) | 1.977754 / 6.876477 (-4.898723) | 2.083385 / 2.142072 (-0.058687) | 0.582330 / 4.805227 (-4.222897) | 0.132744 / 6.500664 (-6.367920) | 0.059822 / 0.075469 (-0.015647) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.259566 / 1.841788 (-0.582221) | 18.990166 / 8.074308 (10.915858) | 13.992069 / 10.191392 (3.800677) | 0.160001 / 0.680424 (-0.520423) | 0.018622 / 0.534201 (-0.515579) | 0.392921 / 0.579283 (-0.186362) | 0.418225 / 0.434364 (-0.016139) | 0.471252 / 0.540337 (-0.069086) | 0.653227 / 1.386936 (-0.733709) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006641 / 0.011353 (-0.004712) | 0.003738 / 0.011008 (-0.007271) | 0.064053 / 0.038508 (0.025545) | 0.069467 / 0.023109 (0.046357) | 0.360625 / 0.275898 (0.084727) | 0.394291 / 0.323480 (0.070811) | 0.005236 / 0.007986 (-0.002750) | 0.003304 / 0.004328 (-0.001024) | 0.064078 / 0.004250 (0.059827) | 0.054605 / 0.037052 (0.017552) | 0.374567 / 0.258489 (0.116078) | 0.411227 / 0.293841 (0.117386) | 0.031614 / 0.128546 (-0.096933) | 0.008323 / 0.075646 (-0.067324) | 0.070616 / 0.419271 (-0.348656) | 0.050077 / 0.043533 (0.006544) | 0.362229 / 0.255139 (0.107090) | 0.388310 / 0.283200 (0.105110) | 0.024053 / 0.141683 (-0.117630) | 1.508913 / 1.452155 (0.056759) | 1.562140 / 1.492716 (0.069423) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230172 / 0.018006 (0.212165) | 0.449363 / 0.000490 (0.448873) | 0.002374 / 0.000200 (0.002174) | 0.000097 / 0.000054 (0.000043) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029813 / 0.037411 (-0.007598) | 0.087298 / 0.014526 (0.072772) | 0.096712 / 0.176557 (-0.079845) | 0.152864 / 0.737135 (-0.584271) | 0.098204 / 0.296338 (-0.198135) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.408664 / 0.215209 (0.193455) | 4.075068 / 2.077655 (1.997414) | 2.096365 / 1.504120 (0.592245) | 1.936096 / 1.541195 (0.394901) | 1.961872 / 1.468490 (0.493382) | 0.483383 / 4.584777 (-4.101394) | 3.686926 / 3.745712 (-0.058787) | 4.798824 / 5.269862 (-0.471037) | 2.652279 / 4.565676 (-1.913398) | 0.056695 / 0.424275 (-0.367580) | 0.007592 / 0.007607 (-0.000016) | 0.484710 / 0.226044 (0.258665) | 4.842153 / 2.268929 (2.573225) | 2.636828 / 55.444624 (-52.807796) | 2.243666 / 6.876477 (-4.632811) | 2.375972 / 2.142072 (0.233899) | 0.578544 / 4.805227 (-4.226683) | 0.132579 / 6.500664 (-6.368085) | 0.061287 / 0.075469 (-0.014182) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.360287 / 1.841788 (-0.481501) | 19.464110 / 8.074308 (11.389802) | 14.530875 / 10.191392 (4.339483) | 0.149479 / 0.680424 (-0.530944) | 0.018471 / 0.534201 (-0.515730) | 0.395399 / 0.579283 (-0.183884) | 0.412897 / 0.434364 (-0.021467) | 0.465194 / 0.540337 (-0.075144) | 0.611752 / 1.386936 (-0.775184) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008986 / 0.011353 (-0.002367) | 0.005104 / 0.011008 (-0.005905) | 0.108371 / 0.038508 (0.069863) | 0.091655 / 0.023109 (0.068546) | 0.430183 / 0.275898 (0.154285) | 0.481387 / 0.323480 (0.157907) | 0.006662 / 0.007986 (-0.001324) | 0.004681 / 0.004328 (0.000353) | 0.089325 / 0.004250 (0.085075) | 0.065096 / 0.037052 (0.028044) | 0.435021 / 0.258489 (0.176532) | 0.478635 / 0.293841 (0.184794) | 0.047628 / 0.128546 (-0.080918) | 0.013496 / 0.075646 (-0.062150) | 0.389661 / 0.419271 (-0.029611) | 0.082260 / 0.043533 (0.038727) | 0.474165 / 0.255139 (0.219026) | 0.464877 / 0.283200 (0.181677) | 0.039784 / 0.141683 (-0.101899) | 1.874694 / 1.452155 (0.422539) | 1.980183 / 1.492716 (0.487467) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254044 / 0.018006 (0.236038) | 0.631495 / 0.000490 (0.631005) | 0.000628 / 0.000200 (0.000428) | 0.000086 / 0.000054 (0.000032) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038773 / 0.037411 (0.001362) | 0.103681 / 0.014526 (0.089156) | 0.125081 / 0.176557 (-0.051476) | 0.198345 / 0.737135 (-0.538790) | 0.122217 / 0.296338 (-0.174121) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.611677 / 0.215209 (0.396468) | 6.220790 / 2.077655 (4.143135) | 2.729858 / 1.504120 (1.225739) | 2.351944 / 1.541195 (0.810749) | 2.449137 / 1.468490 (0.980647) | 0.896842 / 4.584777 (-3.687935) | 5.537491 / 3.745712 (1.791778) | 8.480182 / 5.269862 (3.210320) | 5.251404 / 4.565676 (0.685728) | 0.100449 / 0.424275 (-0.323826) | 0.009008 / 0.007607 (0.001401) | 0.750060 / 0.226044 (0.524016) | 7.390940 / 2.268929 (5.122011) | 3.478256 / 55.444624 (-51.966369) | 2.883597 / 6.876477 (-3.992880) | 3.082256 / 2.142072 (0.940183) | 1.114339 / 4.805227 (-3.690889) | 0.225389 / 6.500664 (-6.275275) | 0.083972 / 0.075469 (0.008503) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.741522 / 1.841788 (-0.100266) | 25.674700 / 8.074308 (17.600392) | 24.324412 / 10.191392 (14.133020) | 0.257878 / 0.680424 (-0.422546) | 0.038384 / 0.534201 (-0.495817) | 0.508302 / 0.579283 (-0.070981) | 0.612979 / 0.434364 (0.178615) | 0.584366 / 0.540337 (0.044029) | 0.881115 / 1.386936 (-0.505821) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009114 / 0.011353 (-0.002239) | 0.005333 / 0.011008 (-0.005675) | 0.094944 / 0.038508 (0.056436) | 0.099178 / 0.023109 (0.076068) | 0.529813 / 0.275898 (0.253915) | 0.551282 / 0.323480 (0.227802) | 0.006442 / 0.007986 (-0.001543) | 0.004283 / 0.004328 (-0.000045) | 0.084257 / 0.004250 (0.080007) | 0.067557 / 0.037052 (0.030504) | 0.514733 / 0.258489 (0.256244) | 0.568200 / 0.293841 (0.274359) | 0.050969 / 0.128546 (-0.077577) | 0.014495 / 0.075646 (-0.061151) | 0.097089 / 0.419271 (-0.322182) | 0.063142 / 0.043533 (0.019609) | 0.513327 / 0.255139 (0.258188) | 0.520593 / 0.283200 (0.237394) | 0.036824 / 0.141683 (-0.104859) | 1.954875 / 1.452155 (0.502720) | 1.976307 / 1.492716 (0.483591) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.304070 / 0.018006 (0.286063) | 0.611073 / 0.000490 (0.610583) | 0.005027 / 0.000200 (0.004827) | 0.000113 / 0.000054 (0.000059) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037993 / 0.037411 (0.000582) | 0.115876 / 0.014526 (0.101350) | 0.118087 / 0.176557 (-0.058469) | 0.186437 / 0.737135 (-0.550699) | 0.129883 / 0.296338 (-0.166456) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.658292 / 0.215209 (0.443083) | 6.618257 / 2.077655 (4.540602) | 3.203786 / 1.504120 (1.699667) | 2.858714 / 1.541195 (1.317519) | 2.940974 / 1.468490 (1.472484) | 0.856238 / 4.584777 (-3.728538) | 5.427708 / 3.745712 (1.681996) | 4.810048 / 5.269862 (-0.459813) | 3.120006 / 4.565676 (-1.445671) | 0.098098 / 0.424275 (-0.326177) | 0.010077 / 0.007607 (0.002470) | 0.790890 / 0.226044 (0.564845) | 7.956679 / 2.268929 (5.687750) | 3.955710 / 55.444624 (-51.488914) | 3.446419 / 6.876477 (-3.430057) | 3.541228 / 2.142072 (1.399156) | 1.013420 / 4.805227 (-3.791808) | 0.213741 / 6.500664 (-6.286923) | 0.080857 / 0.075469 (0.005388) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.813265 / 1.841788 (-0.028522) | 25.965199 / 8.074308 (17.890891) | 21.892761 / 10.191392 (11.701369) | 0.257843 / 0.680424 (-0.422580) | 0.029388 / 0.534201 (-0.504813) | 0.510609 / 0.579283 (-0.068674) | 0.626579 / 0.434364 (0.192215) | 0.576865 / 0.540337 (0.036528) | 0.826610 / 1.386936 (-0.560326) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1076 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1076/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1076/comments | https://api.github.com/repos/huggingface/datasets/issues/1076/events | https://github.com/huggingface/datasets/pull/1076 | 756,584,328 | MDExOlB1bGxSZXF1ZXN0NTMyMTExNDU5 | 1,076 | quac quac / coin coin | [] | closed | false | null | 1 | 2020-12-03T20:55:29Z | 2020-12-04T16:36:39Z | 2020-12-04T09:15:20Z | null | Add QUAC (Question Answering in Context)
I linearized most of the dictionnaries to lists.
Referenced to the authors' datasheet for the dataset card.
🦆🦆🦆
Coin coin | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1076/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1076/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1076.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1076",
"merged_at": "2020-12-04T09:15:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1076.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1076"
} | true | [
"pan"
] |
https://api.github.com/repos/huggingface/datasets/issues/4594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4594/comments | https://api.github.com/repos/huggingface/datasets/issues/4594/events | https://github.com/huggingface/datasets/issues/4594 | 1,288,070,023 | I_kwDODunzps5MxmOH | 4,594 | load_from_disk suggests incorrect fix when used to load DatasetDict | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-06-29T01:40:01Z | 2022-06-29T04:03:44Z | 2022-06-29T04:03:44Z | null | Edit: Please feel free to remove this issue. The problem was not the error message but the fact that the DatasetDict.load_from_disk does not support loading nested splits, i.e. if one of the splits is itself a DatasetDict. If nesting splits is an antipattern, perhaps the load_from_disk function can throw a warning indicating that? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4594/timeline | null | not_planned | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3098 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3098/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3098/comments | https://api.github.com/repos/huggingface/datasets/issues/3098/events | https://github.com/huggingface/datasets/pull/3098 | 1,028,210,790 | PR_kwDODunzps4tSRSZ | 3,098 | Push to hub capabilities for `Dataset` and `DatasetDict` | [] | closed | false | null | 9 | 2021-10-17T04:12:44Z | 2021-12-08T16:04:50Z | 2021-11-24T11:25:36Z | null | This PR implements a `push_to_hub` method on `Dataset` and `DatasetDict`. This does not currently work in `IterableDatasetDict` nor `IterableDataset` as those are simple dicts and I would like your opinion on how you would like to implement this before going ahead and doing it.
This implementation needs to be used with the following `huggingface_hub` branch in order to work correctly: https://github.com/huggingface/huggingface_hub/pull/415
### Implementation
The `push_to_hub` API is entirely based on HTTP requests rather than a git-based workflow:
- This allows pushing changes without firstly cloning the repository, which reduces the time in half for the `push_to_hub` method.
- Collaboration, as well as the system of branches/merges/rebases is IMO less straightforward than for models and spaces. In the situation where such collaboration is needed, I would *heavily* advocate for the `Repository` helper of the `huggingface_hub` to be used instead of the `push_to_hub` method which will always be, by design, limiting in that regard (even if based on a git-workflow instead of HTTP requests)
In order to overcome the limit of 5GB files set by the HTTP requests, dataset sharding is used.
### Testing
The test suite implemented here makes use of the moon-staging instead of the production setup. As several repositories are created and deleted, it is better to use the staging.
It does not require setting an environment variable or any kind of special attention but introduces a new decorator `with_staging_testing` which patches global variables to use the staging endpoint instead of the production endpoint.
### Examples
The tests cover a lot of examples and behavior. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 3,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3098/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3098/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3098.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3098",
"merged_at": "2021-11-24T11:25:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3098.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3098"
} | true | [
"Thank you for your reviews! I should have addressed all of your comments, and I added a test to ensure that `private` datasets work correctly too. I have merged the changes in `huggingface_hub`, so the `main` branch can be installed now; and I will release v0.1.0 soon.\r\n\r\nAs blockers for this PR:\r\n- It's still waiting for #3027 to be addressed as the folder name will dictate the split name\r\n- The `self.split` name is set to `None` when the dataset dict is instantiated as follows:\r\n```py\r\nds = Dataset.from_dict({\"x\": [1, 2, 3], \"y\": [4, 5, 6]})\r\nlocal_ds = DatasetDict({\"random\": ds})\r\n\r\nlocal_ds['random'].split # returns None\r\n```\r\nIn order to remove the `split=key` I would need to know of a different way to test here as it relies on the above as a surefire way of constructing a `DatasetDict`.\r\n- Finally, the `threading` parameter is flaky on moon-staging which results in many errors server side. I propose to leave it as an argument instead of having it having it set to `True` so that users may toggle it according to their wish. ",
"Currently it looks like it only saves the last split.\r\nIndeed when writing the data of one split, it deletes all the other files from the other splits\r\n```python\r\n>>> dataset.push_to_hub(\"lhoestq/squad_titles\", shard_size=50<<10) \r\nPushing split train to the Hub.\r\nPushing dataset shards to the dataset hub: 100%|█| 31/31 [00:22<00:00, 1.38\r\nPushing split validation to the Hub.\r\nThe repository already exists: the `private` keyword argument will be ignored.\r\nDeleting unused files from dataset repository: 100%|█| 31/31 [00:14<00:00, \r\nPushing dataset shards to the dataset hub: 100%|█| 4/4 [00:03<00:00, 1.18it\r\n```\r\nNote the \"Deleting\" part.",
"I think this PR should fix #3035, so feel free to link it. ",
"Thank you for your comments! I have rebased on `master` to have PR #3221. I've updated all tests to reflect the `-` instead of the `_` in the filenames.\r\n\r\n@lhoestq, I have fixed the issue with splits and added a corresponding test.\r\n\r\n@mariosasko I have not updated the `load_dataset` method to work differently, so I don't expect #3035 to be resolved with `push_to_hub`.\r\n\r\nOnly remaining issues before merging:\r\n- Take a good look at the `threading` and if that's something we want to keep.\r\n- As mentioned above:\r\n>The self.split name is set to None when the dataset dict is instantiated as follows:\r\n> ```\r\n> ds = Dataset.from_dict({\"x\": [1, 2, 3], \"y\": [4, 5, 6]})\r\n> local_ds = DatasetDict({\"random\": ds})\r\n> \r\n> local_ds['random'].split # returns None\r\n> ```\r\nI need to understand how to build a `DatasetDict` from some `Dataset` objects to be able to leverage the `split` parameter in `DatasetDict.push_to_hub`",
"Cool thanks ! And indeed this won't solve https://github.com/huggingface/datasets/issues/3035 yet\r\n\r\n> I need to understand how to build a DatasetDict from some Dataset objects to be able to leverage the split parameter in DatasetDict.push_to_hub\r\n\r\nYou can use the key in the DatasetDict instead of the `split` attribute",
"What do you think about bumping the minimum version of pyarrow to 3.0.0 ? This is the minimum required version to write parquet files, which is needed for push_to_hub. That's why our pyarrow 1 CI is failing.\r\n\r\nI think it's fine since it's been available for a long time (january 2021) and it's also the version that is installed on Google Colab.",
"Pushing pyarrow to 3.0.0 is fine for me. I don’t think we need to keep a lot of backward support for pyarrow.",
"Hi.\r\nI published in the forum about my experience with `DatasetDict.push_to_hub()`: here is my [post.](https://discuss.huggingface.co/t/save-datasetdict-to-huggingface-hub/12075/4)\r\nOn my side, there is a problem as my train and validation `Datasets` are concatenated when I do a `load_dataset()` from the `DatasetDict` I pushed to the HF datasets hub.",
"Hi ! Let me respond here as well in case other people have the same issues and come here:\r\n\r\n`push_to_hub` was introduced in `datasets` 1.16, and to be able to properly load a dataset with separated splits you need to have `datasets>=1.16.0` as well. \r\n\r\nOld version of `datasets` used to concatenate everything in the `train` split."
] |
https://api.github.com/repos/huggingface/datasets/issues/2148 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2148/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2148/comments | https://api.github.com/repos/huggingface/datasets/issues/2148/events | https://github.com/huggingface/datasets/issues/2148 | 844,700,910 | MDU6SXNzdWU4NDQ3MDA5MTA= | 2,148 | Add configurable options to `seqeval` metric | [] | closed | false | null | 1 | 2021-03-30T15:04:06Z | 2021-04-15T13:49:46Z | 2021-04-15T13:49:46Z | null | Right now `load_metric("seqeval")` only works in the default mode of evaluation (equivalent to conll evaluation).
However, seqeval library [supports](https://github.com/chakki-works/seqeval#support-features) different evaluation schemes (IOB1, IOB2, etc.), which can be plugged in just by supporting additional kwargs in `Seqeval._compute`
https://github.com/huggingface/datasets/blob/85cf7ff920c90ca2e12bedca12b36d2a043c3da2/metrics/seqeval/seqeval.py#L109
Things that would be relevant are, for example, supporting `mode="strict", scheme=IOB2` to count only full entity match as a true positive and omit partial matches.
The only problem I see is that the spirit of `metrics` seems to not require additional imports from user. `seqeval` only supports schemes as objects, without any string aliases.
It can be solved naively with mapping like `{"IOB2": seqeval.scheme.IOB2}`. Or just left as is and require user to explicitly import scheme from `seqeval` if he wants to configure it past the default implementation.
If that makes sense, I am happy to implement the change. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2148/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2148/timeline | null | completed | null | null | false | [
"Hi @marrodion. \r\n\r\nThanks for pointing this out. It would be great to incorporate this metric-specific enhancement.\r\n\r\nAnother possibility would be to require the user to input the scheme as a string `mode=\"strict\", scheme=\"IOB2\"` and then dynamically import the corresponding module using Python `importlib`:\r\n```python\r\nif scheme:\r\n scheme = importlib.import_module(f\"seqeval.scheme.{scheme}\")\r\n```\r\n\r\nFeel free to create a Pull Request to make this contribution."
] |
https://api.github.com/repos/huggingface/datasets/issues/1099 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1099/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1099/comments | https://api.github.com/repos/huggingface/datasets/issues/1099/events | https://github.com/huggingface/datasets/pull/1099 | 756,993,540 | MDExOlB1bGxSZXF1ZXN0NTMyNDQyODEw | 1,099 | Add tamilmixsentiment data | [] | closed | false | null | 0 | 2020-12-04T10:34:07Z | 2020-12-06T06:32:22Z | 2020-12-05T16:48:33Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1099/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1099/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1099.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1099",
"merged_at": "2020-12-05T16:48:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1099.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1099"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/2722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2722/comments | https://api.github.com/repos/huggingface/datasets/issues/2722/events | https://github.com/huggingface/datasets/issues/2722 | 954,446,053 | MDU6SXNzdWU5NTQ0NDYwNTM= | 2,722 | Missing cache file | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-07-28T03:52:07Z | 2022-03-21T08:27:51Z | 2022-03-21T08:27:51Z | null | Strangely missing cache file after I restart my program again.
`glue_dataset = datasets.load_dataset('glue', 'sst2')`
`FileNotFoundError: [Errno 2] No such file or directory: /Users/chris/.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96d6053ad/dataset_info.json'`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2722/timeline | null | completed | null | null | false | [
"This could be solved by going to the glue/ directory and delete sst2 directory, then load the dataset again will help you redownload the dataset.",
"Hi ! Not sure why this file was missing, but yes the way to fix this is to delete the sst2 directory and to reload the dataset"
] |
https://api.github.com/repos/huggingface/datasets/issues/1453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1453/comments | https://api.github.com/repos/huggingface/datasets/issues/1453/events | https://github.com/huggingface/datasets/pull/1453 | 761,188,657 | MDExOlB1bGxSZXF1ZXN0NTM1ODkyNTM5 | 1,453 | Adding ethos dataset clean | [] | closed | false | null | 2 | 2020-12-10T12:13:21Z | 2020-12-14T15:00:46Z | 2020-12-14T10:31:24Z | null | I addressed the comments on the PR1318 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1453/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1453/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1453.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1453",
"merged_at": "2020-12-14T10:31:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1453.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1453"
} | true | [
"> Thanks !\r\n\r\nThanks as well for your hard work 😊!!",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5572/comments | https://api.github.com/repos/huggingface/datasets/issues/5572/events | https://github.com/huggingface/datasets/issues/5572 | 1,597,257,624 | I_kwDODunzps5fNDeY | 5,572 | Datasets 2.10.0 does not reuse the dataset cache | [] | closed | false | null | 0 | 2023-02-23T17:28:11Z | 2023-02-23T18:03:55Z | 2023-02-23T18:03:55Z | null | ### Describe the bug
download_mode="reuse_dataset_if_exists" will always consider that a dataset doesn't exist.
Specifically, upon losing an internet connection trying to load a dataset for a second time in ten seconds, a connection error results, showing a breakpoint of:
```
File ~/jupyterlab/.direnv/python-3.9.6/lib/python3.9/site-packages/datasets/load.py:1174, in dataset_module_factory(path, revision, download_config, download_mode, dynamic_modules_path, data_dir, data_files, **download_kwargs)
1165 except Exception as e: # noqa: catch any exception of hf_hub and consider that the dataset doesn't exist
1166 if isinstance(
1167 e,
1168 (
(...)
1172 ),
1173 ):
-> 1174 raise ConnectionError(f"Couldn't reach '{path}' on the Hub ({type(e).__name__})")
1175 elif "404" in str(e):
1176 msg = f"Dataset '{path}' doesn't exist on the Hub"
ConnectionError: Couldn't reach 'lsb/tenk' on the Hub (ConnectionError)
```
This has been around since at least v2.0.
### Steps to reproduce the bug
```
from datasets import load_dataset
import numpy as np
tenk = load_dataset("lsb/tenk") # ten thousand integers
print(np.average(tenk['train']['a'])) # prints 4999.5
### now disconnect your internet
tenk_too = load_dataset("lsb/tenk", download_mode="reuse_dataset_if_exists")
# Raises ConnectionError: Couldn't reach 'lsb/tenk' on the Hub (ConnectionError)
```
### Expected behavior
I expected that I would be able to reuse the dataset I just downloaded.
### Environment info
- `datasets` version: 2.10.0
- Platform: macOS-13.1-arm64-arm-64bit
- Python version: 3.9.6
- PyArrow version: 7.0.0
- Pandas version: 1.5.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5572/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5572/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2949/comments | https://api.github.com/repos/huggingface/datasets/issues/2949/events | https://github.com/huggingface/datasets/pull/2949 | 1,001,026,680 | PR_kwDODunzps4r90Pt | 2,949 | Introduce web and wiki config in triviaqa dataset | [] | closed | false | null | 3 | 2021-09-20T14:17:23Z | 2021-10-05T13:20:52Z | 2021-10-01T15:39:29Z | null | The TriviaQA paper suggests that the two subsets (Wikipedia and Web)
should be treated differently. There are also different leaderboards
for the two sets on CodaLab. For that reason, introduce additional
builder configs in the trivia_qa dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2949/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2949/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2949.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2949",
"merged_at": "2021-10-01T15:39:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2949.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2949"
} | true | [
"I just made the dummy data smaller :)\r\nOnce github refreshes the change I think we can merge !",
"Thank you so much for reviewing and accepting my pull request!! :)\r\n\r\nI created these rather large dummy data sets to cover all different cases for the row structure. E.g. in the web configuration, it's possible that a row has evidence from wikipedia (\"EntityPages\") and the web (\"SearchResults\"). But it also might happen that either EntityPages or SearchResults is empty. Probably, I will add this thought to the dataset description in the future.",
"Ok I see ! Yes feel free to mention it in the dataset card, this can be useful.\r\n\r\nFor the dummy data though we can keep the small ones, as the tests are mainly about testing the parsing from the dataset script rather than the actual content of the dataset."
] |
https://api.github.com/repos/huggingface/datasets/issues/539 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/539/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/539/comments | https://api.github.com/repos/huggingface/datasets/issues/539/events | https://github.com/huggingface/datasets/issues/539 | 688,323,602 | MDU6SXNzdWU2ODgzMjM2MDI= | 539 | [Dataset] `NonMatchingChecksumError` due to an update in the LinCE benchmark data | [] | closed | false | null | 3 | 2020-08-28T19:55:51Z | 2020-09-03T16:34:02Z | 2020-09-03T16:34:01Z | null | Hi,
There is a `NonMatchingChecksumError` error for the `lid_msaea` (language identification for Modern Standard Arabic - Egyptian Arabic) dataset from the LinCE benchmark due to a minor update on that dataset.
How can I update the checksum of the library to solve this issue? The error is below and it also appears in the [nlp viewer](https://huggingface.co/nlp/viewer/?dataset=lince&config=lid_msaea):
```python
import nlp
nlp.load_dataset('lince', 'lid_msaea')
```
Output:
```
NonMatchingChecksumError: ['https://ritual.uh.edu/lince/libaccess/eyJ1c2VybmFtZSI6ICJodWdnaW5nZmFjZSBubHAiLCAidXNlcl9pZCI6IDExMSwgImVtYWlsIjogImR1bW15QGVtYWlsLmNvbSJ9/lid_msaea.zip']
Traceback:
File "/home/sasha/streamlit/lib/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__dict__)
File "/home/sasha/nlp-viewer/run.py", line 196, in <module>
dts, fail = get(str(option.id), str(conf_option.name) if conf_option else None)
File "/home/sasha/streamlit/lib/streamlit/caching.py", line 591, in wrapped_func
return get_or_create_cached_value()
File "/home/sasha/streamlit/lib/streamlit/caching.py", line 575, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/home/sasha/nlp-viewer/run.py", line 150, in get
builder_instance.download_and_prepare()
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/builder.py", line 432, in download_and_prepare
download_config.force_download = download_mode == FORCE_REDOWNLOAD
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/builder.py", line 469, in _download_and_prepare
File "/home/sasha/.local/share/virtualenvs/lib-ogGKnCK_/lib/python3.7/site-packages/nlp/utils/info_utils.py", line 36, in verify_checksums
raise NonMatchingChecksumError(str(bad_urls))
```
Thank you in advance!
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/539/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/539/timeline | null | completed | null | null | false | [
"Hi @gaguilar \r\n\r\nIf you want to take care of this, it very simple, you just need to regenerate the `dataset_infos.json` file as indicated [in the doc](https://huggingface.co/nlp/share_dataset.html#adding-metadata) by [installing from source](https://huggingface.co/nlp/installation.html#installing-from-source) and running the following command from the root of the repo:\r\n```bash\r\npython nlp-cli test ./datasets/lince --save_infos --all_configs\r\n```\r\nAnd then you can open a pull-request with the updated json file.\r\n\r\nOtherwise we'll do it sometime this week.",
"Hi @thomwolf \r\n\r\nThanks for the details! I just created a PR with the updated `dataset_infos.json` file (#550).",
"Thanks for updating the json file. Closing this one"
] |
https://api.github.com/repos/huggingface/datasets/issues/3522 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3522/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3522/comments | https://api.github.com/repos/huggingface/datasets/issues/3522/events | https://github.com/huggingface/datasets/issues/3522 | 1,093,807,586 | I_kwDODunzps5BMi3i | 3,522 | wmt19 is broken (zh-en) | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 1 | 2022-01-04T22:33:45Z | 2022-05-06T16:27:37Z | 2022-05-06T16:27:37Z | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("wmt19", 'zh-en')
```
## Expected results
The dataset should download.
## Actual results
`ConnectionError: Couldn't reach ftp://cwmt-wmt:[email protected]/parallel/casia2015.zip`
## Environment info
- `datasets` version: 1.15.1
- Platform: Linux
- Python version: 3.8
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3522/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3522/timeline | null | completed | null | null | false | [
"This issue is not reproducible."
] |
https://api.github.com/repos/huggingface/datasets/issues/1426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1426/comments | https://api.github.com/repos/huggingface/datasets/issues/1426/events | https://github.com/huggingface/datasets/pull/1426 | 760,735,763 | MDExOlB1bGxSZXF1ZXN0NTM1NTE3NDc4 | 1,426 | init commit for MultiReQA for third PR with all issues fixed | [] | closed | false | null | 2 | 2020-12-09T22:57:41Z | 2020-12-11T13:37:08Z | 2020-12-11T13:37:08Z | null | 3rd PR w.r.t. PR #1349 with all the issues fixed. As #1349 had uploaded other files along with the multi_re_qa dataset | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1426/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1426/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1426.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1426",
"merged_at": "2020-12-11T13:37:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1426.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1426"
} | true | [
"good dataset card as well :) ",
"@lhoestq Thank you :) "
] |
https://api.github.com/repos/huggingface/datasets/issues/72 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/72/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/72/comments | https://api.github.com/repos/huggingface/datasets/issues/72/events | https://github.com/huggingface/datasets/pull/72 | 616,225,010 | MDExOlB1bGxSZXF1ZXN0NDE2Mzc4Mjg4 | 72 | [README dummy data tests] README to better understand how the dummy data structure works | [] | closed | false | null | 0 | 2020-05-11T22:19:03Z | 2020-05-11T22:26:03Z | 2020-05-11T22:26:01Z | null | In this PR a README.md is added to tests to shine more light on how the dummy data structure works. I try to explain the different possible cases. IMO the best way to understand the logic is to checkout the dummy data structure of the different datasets I mention in the README.md since those are the "edge cases".
@mariamabarham @thomwolf @lhoestq @jplu - I'd be happy to checkout the dummy data structure and get some feedback on possible improvements. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/72/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/72/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/72.diff",
"html_url": "https://github.com/huggingface/datasets/pull/72",
"merged_at": "2020-05-11T22:26:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/72.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/72"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/535 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/535/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/535/comments | https://api.github.com/repos/huggingface/datasets/issues/535/events | https://github.com/huggingface/datasets/pull/535 | 686,238,315 | MDExOlB1bGxSZXF1ZXN0NDczODM3Njg0 | 535 | Benchmarks | [] | closed | false | null | 0 | 2020-08-26T11:21:26Z | 2020-08-27T08:40:00Z | 2020-08-27T08:39:59Z | null | Adding some benchmarks with DVC/CML
To add a new tracked benchmark:
- create a new python benchmarking script in `./benchmarks/`. The script can use the utilities in `./benchmarks/utils.py` and should output a JSON file with results in `./benchmarks/results/`.
- add a new pipeline stage in [dvc.yaml](./dvc.yaml) with the name of your new benchmark.
That's it | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/535/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/535/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/535.diff",
"html_url": "https://github.com/huggingface/datasets/pull/535",
"merged_at": "2020-08-27T08:39:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/535.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/535"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | [] | closed | false | null | 6 | 2022-02-01T17:55:04Z | 2022-02-02T10:52:25Z | 2022-02-02T10:52:25Z | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with sampling_rate=32000
!wget https://file-examples-com.github.io/uploads/2017/11/file_example_MP3_700KB.mp3
import torchaudio
audio_path = "file_example_MP3_700KB.mp3"
audio_path2 = audio_path.replace(".mp3", "_resampled.mp3")
resample = torchaudio.transforms.Resample(32000, 16000) # create a new file with sampling_rate=16000
torchaudio.save(audio_path2, resample(torchaudio.load(audio_path)[0]), 16000)
```
Then we can see an issue here when decoding:
```python
from datasets import Dataset, Audio
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[0] # decode the first audio file sets the resampler orig_freq to 32000
print(dataset .features["audio"]._resampler.orig_freq)
# 32000
print(dataset[0]["audio"]["array"].shape) # here decoding is fine
# (1308096,)
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[1] # decode the second audio file sets the resampler orig_freq to 16000
print(dataset .features["audio"]._resampler.orig_freq)
# 16000
print(dataset[0]["audio"]["array"].shape) # here decoding uses orig_freq=16000 instead of 32000
# (2616192,)
```
The value of `orig_freq` doesn't change no matter what file needs to be decoded
cc @patrickvonplaten @anton-l @cahya-wirawan @albertvillanova
The issue seems to be here in `Audio.decode_mp3`:
https://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/features/audio.py#L176-L180 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null | completed | null | null | false | [
"Thanks @lhoestq for finding the reason of incorrect resampling. This issue affects all languages which have sound files with different sampling rates such as Turkish and Luganda.",
"@cahya-wirawan - do you know how many languages have different sampling rates in Common Voice? I'm quite surprised to see this for multiple languages actually",
"@cahya-wirawan, I can reproduce the problem for Common Voice 7 for Turkish. Here a script you can use:\r\n\r\n\r\n```python\r\n#!/usr/bin/env python3\r\nfrom datasets import load_dataset\r\nimport torchaudio\r\nfrom io import BytesIO\r\nfrom datasets import Audio\r\nfrom collections import Counter\r\nimport sys\r\n\r\nds_name = str(sys.argv[1])\r\nlang = str(sys.argv[2])\r\n\r\nds = load_dataset(ds_name, lang, split=\"train\", use_auth_token=True)\r\nds = ds.cast_column(\"audio\", Audio(decode=False))\r\n\r\nall_sampling_rates = []\r\n\r\n\r\ndef print_sampling_rate(x):\r\n x, sr = torchaudio.load(BytesIO(x[\"audio\"][\"bytes\"]), format=\"mp3\")\r\n all_sampling_rates.append(sr)\r\n\r\nds.map(print_sampling_rate)\r\n\r\n\r\nprint(Counter(all_sampling_rates))\r\n```\r\n\r\ncan be run with:\r\n\r\n```bash\r\npython run.py mozilla-foundation/common_voice_7_0 tr\r\n```\r\n\r\nFor CV 6.1 all samples seem to have the same audio",
"It actually shows that many more samples are in 32kHz format than it 48kHz which is unexpected. Thanks a lot for flagging! Will contact Common Voice about this as well",
"I only checked the CV 7.0 for Turkish, Luganda and Indonesian, they have audio files with difference sampling rates, and all of them are affected by this issue. Percentage of incorrect resampling as follow, Turkish: 9.1%, Luganda: 88.2% and Indonesian: 64.1%.\r\nI checked it using the original CV files. I check the original sampling rates and the length of audio array of each files and compare it with the length of audio array (and the sampling rate which is always 48kHz) from mozilla-foundation/common_voice_7_0 datasets. if the length of audio array from dataset is not equal to 48kHz/original sampling rate * length of audio array of the original audio file then it is affected,",
"Ok wow, thanks a lot for checking this - you've found a pretty big bug :sweat_smile: It seems like **a lot** more datasets are actually affected than I original thought. We'll try to solve this as soon as possible and make an announcement tomorrow."
] |
https://api.github.com/repos/huggingface/datasets/issues/3304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3304/comments | https://api.github.com/repos/huggingface/datasets/issues/3304/events | https://github.com/huggingface/datasets/issues/3304 | 1,059,130,494 | I_kwDODunzps4_IQx- | 3,304 | Dataset object has no attribute `to_tf_dataset` | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-11-20T12:03:59Z | 2021-11-21T07:07:25Z | 2021-11-21T07:07:25Z | null | I am following HuggingFace Course. I am at Fine-tuning a model.
Link: https://huggingface.co/course/chapter3/2?fw=tf
I use tokenize_function and `map` as mentioned in the course to process data.
`# define a tokenize function`
`def Tokenize_function(example):`
` return tokenizer(example['sentence'], truncation=True)`
`# tokenize entire data`
`tokenized_data = raw_data.map(Tokenize_function, batched=True)`
I get Dataset object at this point. When I try converting this to a TF dataset object as mentioned in the course, it throws the following error.
`# convert to TF dataset`
`train_data = tokenized_data["train"].to_tf_dataset( `
` columns = ['attention_mask', 'input_ids', 'token_type_ids'], `
` label_cols = ['label'], `
` shuffle = True, `
` collate_fn = data_collator, `
` batch_size = 8 `
`)`
Output:
`---------------------------------------------------------------------------`
`AttributeError Traceback (most recent call last)`
`/tmp/ipykernel_42/103099799.py in <module>`
` 1 # convert to TF dataset`
`----> 2 train_data = tokenized_data["train"].to_tf_dataset( \`
` 3 columns = ['attention_mask', 'input_ids', 'token_type_ids'], \`
` 4 label_cols = ['label'], \`
` 5 shuffle = True, \`
`AttributeError: 'Dataset' object has no attribute 'to_tf_dataset'`
When I look for `dir(tokenized_data["train"])`, there is no method or attribute in the name of `to_tf_dataset`.
Why do I get this error? And how to clear this?
Please help me. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3304/timeline | null | completed | null | null | false | [
"The issue is due to the older version of transformers and datasets. It has been resolved by upgrading their versions.\r\n\r\n```\r\n# upgrade transformers and datasets to latest versions\r\n!pip install --upgrade transformers\r\n!pip install --upgrade datasets\r\n```\r\n\r\nRegards!"
] |
https://api.github.com/repos/huggingface/datasets/issues/669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/669/comments | https://api.github.com/repos/huggingface/datasets/issues/669/events | https://github.com/huggingface/datasets/issues/669 | 708,857,595 | MDU6SXNzdWU3MDg4NTc1OTU= | 669 | How to skip a example when running dataset.map | [] | closed | false | null | 3 | 2020-09-25T11:17:53Z | 2022-06-17T21:45:03Z | 2020-10-05T16:28:13Z | null | in processing func, I process examples and detect some invalid examples, which I did not want it to be added into train dataset. However I did not find how to skip this recognized invalid example when doing dataset.map. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/669/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/669/timeline | null | completed | null | null | false | [
"Hi @xixiaoyao,\r\nDepending on what you want to do you can:\r\n- use a first step of `filter` to filter out the invalid examples: https://huggingface.co/docs/datasets/processing.html#filtering-rows-select-and-filter\r\n- or directly detect the invalid examples inside the callable used with `map` and return them unchanged or even remove them at the same time if you are using `map` in batched mode. Here is an example where we use `map` in batched mode to add new rows on the fly but you can also use it to remove examples on the fly (that's what `filter` actually do under-the-hood): https://huggingface.co/docs/datasets/processing.html#augmenting-the-dataset",
"Closing this one.\r\nFeel free to re-open if you have other questions",
"Letting finders-of-this-thread know that the new link is: https://huggingface.co/docs/datasets/process#data-augmentation\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5705/comments | https://api.github.com/repos/huggingface/datasets/issues/5705/events | https://github.com/huggingface/datasets/issues/5705 | 1,653,500,383 | I_kwDODunzps5ijmnf | 5,705 | Getting next item from IterableDataset took forever. | [] | closed | false | null | 2 | 2023-04-04T09:16:17Z | 2023-04-05T23:35:41Z | 2023-04-05T23:35:41Z | null | ### Describe the bug
I have a large dataset, about 500GB. The format of the dataset is parquet.
I then load the dataset and try to get the first item
```python
def get_one_item():
dataset = load_dataset("path/to/datafiles", split="train", cache_dir=".", streaming=True)
dataset = dataset.filter(lambda example: example['text'].startswith('Ar'))
print(next(iter(dataset)))
```
However, this function never finish. I waited ~10mins, the function was still running so I killed the process. I'm now using `line_profiler` to profile how long it would take to return one item. I'll be patient and wait for as long as it needs.
I suspect the filter operation is the reason why it took so long. Can I get some possible reasons behind this?
### Steps to reproduce the bug
Unfortunately without my data files, there is no way to reproduce this bug.
### Expected behavior
With `IteralbeDataset`, I expect the first item to be returned instantly.
### Environment info
- datasets version: 2.11.0
- python: 3.7.12 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5705/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5705/timeline | null | completed | null | null | false | [
"Hi! It can take some time to iterate over Parquet files as big as yours, convert the samples to Python, and find the first one that matches a filter predicate before yielding it...",
"Thanks @mariosasko, I figured it was the filter operation. I'm closing this issue because it is not a bug, it is the expected beheaviour."
] |
https://api.github.com/repos/huggingface/datasets/issues/3148 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3148/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3148/comments | https://api.github.com/repos/huggingface/datasets/issues/3148/events | https://github.com/huggingface/datasets/issues/3148 | 1,033,685,208 | I_kwDODunzps49nMjY | 3,148 | Streaming with num_workers != 0 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 4 | 2021-10-22T15:07:17Z | 2022-07-04T12:14:58Z | 2022-07-04T12:14:58Z | null | ## Describe the bug
When using dataset streaming with pytorch DataLoader, the setting num_workers to anything other than 0 causes the code to freeze forever before yielding the first batch.
The code owner is likely @lhoestq
## Steps to reproduce the bug
For your convenience, we've prepped a colab notebook that reproduces the bug
https://colab.research.google.com/drive/1Mgl0oTZSNIE3UeGl_oX9wPCOIxRg19h1?usp=sharing
```python
!pip install datasets==1.14.0
should_freeze_forever = True
# ^-- set this to True in order to freeze forever, set to False in order to work normally
import torch
from datasets import load_dataset
data = load_dataset("oscar", "unshuffled_deduplicated_bn", split="train", streaming=True)
data = data.map(lambda x: {"text": x["text"], "orig": f"oscar[{x['id']}]"}, batched=True)
data = data.shuffle(100, seed=1337)
data = data.with_format("torch")
loader = torch.utils.data.DataLoader(data, batch_size=2, num_workers=2 if should_freeze_forever else 0)
# v-- the code should freeze forever at this line
for i, row in enumerate(loader):
print(row)
if i > 10: break
print("DONE!")
```
## Expected results
The code should not freeze forever with num_workers=2
## Actual results
The code freezes forever with num_workers=2
## Environment info
- `datasets` version: 1.14.0 (also found in previous versions)
- Platform: google colab (also locally)
- Python version: 3.7, (also 3.8)
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3148/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3148/timeline | null | completed | null | null | false | [
"I can confirm that I was able to reproduce the bug. This seems odd given that #3423 reports duplicate data retrieval when `num_workers` and `streaming` are used together, which is obviously different from what is reported here. ",
"Any update? A possible solution is to have multiple arrow files as shards, and handle them like what webdatasets does.\r\n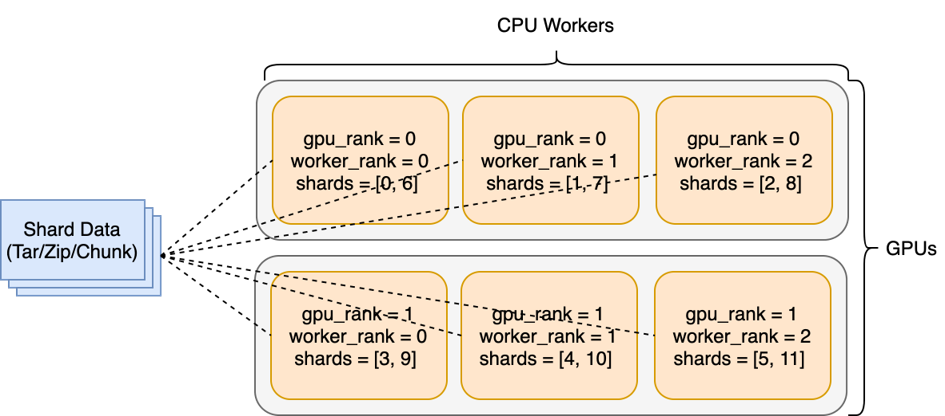\r\n\r\nPytorch's new dataset RFC is supporting sharding now, which may helps avoid duplicate data under streaming mode. (https://github.com/pytorch/pytorch/blob/master/torch/utils/data/datapipes/iter/grouping.py#L13)\r\n",
"Hi ! Thanks for the insights :) Note that in streaming mode there're usually no arrow files. The data are streamed from TAR, ZIP, text, etc. files directly from the web. Though for sharded datasets we can definitely adopt a similar strategy !",
"fixed by #4375 "
] |
https://api.github.com/repos/huggingface/datasets/issues/2199 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2199/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2199/comments | https://api.github.com/repos/huggingface/datasets/issues/2199/events | https://github.com/huggingface/datasets/pull/2199 | 854,417,318 | MDExOlB1bGxSZXF1ZXN0NjEyMzY0ODU3 | 2,199 | Fix backward compatibility in Dataset.load_from_disk | [] | closed | false | null | 3 | 2021-04-09T11:01:10Z | 2021-04-09T15:57:05Z | 2021-04-09T15:57:05Z | null | Fix backward compatibility when loading from disk an old dataset saved to disk with indices using key "_indices_data_files".
Related to #2195. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2199/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2199/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2199.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2199",
"merged_at": "2021-04-09T15:57:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2199.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2199"
} | true | [
"Hi @lhoestq, could you please check if this makes sense? Thanks.",
"What about using `_indices_data_files` field in save_to_disk instead of `_indices_files` ?\r\nThis way future datasets can also be reloaded from older versions of the lib\r\n\r\n`_indices_files` was introduced in a recent PR and was not released",
"Yes, I have seen it is not released yet...\r\n\r\nYou are right! It was your awesome PR on Tables which renamed this. If there is no particular reason for this renaming, yes, we could switch it back to the previous `_indices_data_files`. ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2138 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2138/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2138/comments | https://api.github.com/repos/huggingface/datasets/issues/2138/events | https://github.com/huggingface/datasets/pull/2138 | 843,508,402 | MDExOlB1bGxSZXF1ZXN0NjAyODc4NzU2 | 2,138 | Add CER metric | [] | closed | false | null | 0 | 2021-03-29T15:52:27Z | 2021-04-06T16:16:11Z | 2021-04-06T07:14:38Z | null | Add Character Error Rate (CER) metric that is used in evaluation in ASR. I also have written unittests (hopefully thorough enough) but I'm not sure how to integrate them into the existed codebase.
```python
from cer import CER
cer = CER()
class TestCER(unittest.TestCase):
def test_cer_case_senstive(self):
refs = ['White House']
preds = ['white house']
# S = 2, D = 0, I = 0, N = 11, CER = 2 / 11
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.1818181818) < 1e-6)
def test_cer_whitespace(self):
refs = ['were wolf']
preds = ['werewolf']
# S = 0, D = 0, I = 1, N = 9, CER = 1 / 9
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.1111111) < 1e-6)
refs = ['werewolf']
preds = ['weae wolf']
# S = 1, D = 1, I = 0, N = 8, CER = 0.25
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.25) < 1e-6)
# consecutive whitespaces case 1
refs = ['were wolf']
preds = ['were wolf']
# S = 0, D = 0, I = 0, N = 9, CER = 0
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.0) < 1e-6)
# consecutive whitespaces case 2
refs = ['were wolf']
preds = ['were wolf']
# S = 0, D = 0, I = 0, N = 9, CER = 0
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.0) < 1e-6)
def test_cer_sub(self):
refs = ['werewolf']
preds = ['weaewolf']
# S = 1, D = 0, I = 0, N = 8, CER = 0.125
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.125) < 1e-6)
def test_cer_del(self):
refs = ['werewolf']
preds = ['wereawolf']
# S = 0, D = 1, I = 0, N = 8, CER = 0.125
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.125) < 1e-6)
def test_cer_insert(self):
refs = ['werewolf']
preds = ['wereolf']
# S = 0, D = 0, I = 1, N = 8, CER = 0.125
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.125) < 1e-6)
def test_cer_equal(self):
refs = ['werewolf']
char_error_rate = cer.compute(predictions=refs, references=refs)
self.assertEqual(char_error_rate, 0.0)
def test_cer_list_of_seqs(self):
refs = ['werewolf', 'I am your father']
char_error_rate = cer.compute(predictions=refs, references=refs)
self.assertEqual(char_error_rate, 0.0)
refs = ['werewolf', 'I am your father', 'doge']
preds = ['werxwolf', 'I am your father', 'doge']
# S = 1, D = 0, I = 0, N = 28, CER = 1 / 28
char_error_rate = cer.compute(predictions=preds, references=refs)
self.assertTrue(abs(char_error_rate - 0.03571428) < 1e-6)
def test_cer_unicode(self):
ref = [u'我能吞下玻璃而不伤身体']
pred = [u' 能吞虾玻璃而 不霜身体啦']
# S = 3, D = 2, I = 0, N = 11
# CER = 5 / 11
char_error_rate = cer.compute(predictions=pred, references=ref)
self.assertTrue(abs(char_error_rate - 0.4545454545) < 1e-6)
ref = [u'我能吞', u'下玻璃而不伤身体']
pred = [u'我 能 吞 下 玻 璃', u'而不伤身体']
# S = 0, D = 5, I = 0, N = 11
# CER = 5 / 11
char_error_rate = cer.compute(predictions=pred, references=ref)
self.assertTrue(abs(char_error_rate - 0.454545454545) < 1e-6)
ref = [u'我能吞下玻璃而不伤身体']
char_error_rate = cer.compute(predictions=ref, references=ref)
self.assertFalse(char_error_rate, 0.0)
def test_cer_empty(self):
ref = ''
pred = 'Hypothesis'
with self.assertRaises(ValueError):
char_error_rate = cer.compute(predictions=pred, references=ref)
if __name__ == '__main__':
unittest.main()
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2138/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2138/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2138.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2138",
"merged_at": "2021-04-06T07:14:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2138.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2138"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3678/comments | https://api.github.com/repos/huggingface/datasets/issues/3678/events | https://github.com/huggingface/datasets/pull/3678 | 1,123,402,426 | PR_kwDODunzps4yCt91 | 3,678 | Add code example in wikipedia card | [] | closed | false | null | 0 | 2022-02-03T18:09:02Z | 2022-02-21T09:14:56Z | 2022-02-04T13:21:39Z | null | Close #3292. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3678/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3678/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3678.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3678",
"merged_at": "2022-02-04T13:21:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3678.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3678"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1087/comments | https://api.github.com/repos/huggingface/datasets/issues/1087/events | https://github.com/huggingface/datasets/pull/1087 | 756,794,430 | MDExOlB1bGxSZXF1ZXN0NTMyMjc5NDI3 | 1,087 | Add Big Patent dataset | [] | closed | false | null | 2 | 2020-12-04T04:37:30Z | 2020-12-06T17:21:00Z | 2020-12-06T17:20:59Z | null | * More info on the dataset: https://evasharma.github.io/bigpatent/
* There's another raw version of the dataset available from tfds. However, they're quite large so I don't have the resources to fully test all the configs for that version yet. We'll try to add it later. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1087/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1087",
"merged_at": "2020-12-06T17:20:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1087"
} | true | [
"@lhoestq reduced the dummy data size to around 19MB in total and added the dataset card.",
"@lhoestq so I ended up removing all the nested JSON objects in the gz datafile and keep only one object with minimal content: `{\"publication_number\": \"US-8230922-B2\", \"abstract\": \"dummy abstract\", \"application_number\": \"US-201113163519-A\", \"description\": \"dummy description\"}`. \r\n\r\nThey're reduced to 35KB in total (2.5KB per domain and 17.5KB for all domains), hopefully, they're small enough."
] |
https://api.github.com/repos/huggingface/datasets/issues/1824 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1824/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1824/comments | https://api.github.com/repos/huggingface/datasets/issues/1824/events | https://github.com/huggingface/datasets/pull/1824 | 802,048,281 | MDExOlB1bGxSZXF1ZXN0NTY4MjU3MTU3 | 1,824 | Add OSCAR dataset card | [] | closed | false | null | 3 | 2021-02-05T10:30:26Z | 2021-05-05T18:24:14Z | 2021-02-08T11:30:33Z | null | I started adding the dataset card for OSCAR !
For now it's just basic info for all the different configurations in `Dataset Structure`.
In particular the Data Splits section tells how may samples there are for each config. The Data Instances section show an example for each config, and it also shows the size in MB. Since the Data Instances section is very long the user has to click to expand the info. I was able to generate it thanks to the tools made by @madlag and @yjernite :D
Cc @pjox could you help me with the other sections ? (Dataset Description, Dataset Creation, Considerations for Using the Data, Additional Information)
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1824/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1824/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1824.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1824",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1824.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1824"
} | true | [
"Hi @lhoestq! When are you planning to release the version with this dataset?\r\n\r\nBTW: What a huge README file :astonished:",
"Next week !",
"Closing in favor of #1833"
] |
https://api.github.com/repos/huggingface/datasets/issues/1085 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1085/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1085/comments | https://api.github.com/repos/huggingface/datasets/issues/1085/events | https://github.com/huggingface/datasets/pull/1085 | 756,704,563 | MDExOlB1bGxSZXF1ZXN0NTMyMjExNTA4 | 1,085 | add mutual friends conversational dataset | [] | closed | false | null | 1 | 2020-12-04T00:48:21Z | 2020-12-16T15:58:31Z | 2020-12-16T15:58:30Z | null | Mutual friends dataset
WIP
TODO:
- scenario_kbs (bug with pyarrow conversion)
- download from codalab checksums bug | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1085/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1085/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1085.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1085",
"merged_at": "2020-12-16T15:58:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1085.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1085"
} | true | [
"Ready for review"
] |
https://api.github.com/repos/huggingface/datasets/issues/3647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3647/comments | https://api.github.com/repos/huggingface/datasets/issues/3647/events | https://github.com/huggingface/datasets/pull/3647 | 1,117,383,675 | PR_kwDODunzps4xvGDQ | 3,647 | Fix `add_column` on datasets with indices mapping | [] | closed | false | null | 2 | 2022-01-28T13:06:29Z | 2022-01-28T15:35:58Z | 2022-01-28T15:35:58Z | null | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3647/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"merged_at": "2022-01-28T15:35:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3647"
} | true | [
"Sure, let's include this in today's release.",
"Cool ! The windows CI should be fixed on master now, feel free to merge :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5392/comments | https://api.github.com/repos/huggingface/datasets/issues/5392/events | https://github.com/huggingface/datasets/pull/5392 | 1,512,712,529 | PR_kwDODunzps5GS2DF | 5,392 | Fix Colab notebook link | [] | closed | false | null | 2 | 2022-12-28T11:44:53Z | 2023-01-03T15:36:14Z | 2023-01-03T15:27:31Z | null | Fix notebook link to open in Colab. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5392/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5392/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5392.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5392",
"merged_at": "2023-01-03T15:27:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5392.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5392"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011196 / 0.011353 (-0.000157) | 0.006039 / 0.011008 (-0.004969) | 0.122497 / 0.038508 (0.083989) | 0.043884 / 0.023109 (0.020774) | 0.372982 / 0.275898 (0.097084) | 0.444229 / 0.323480 (0.120749) | 0.009489 / 0.007986 (0.001503) | 0.004612 / 0.004328 (0.000284) | 0.093921 / 0.004250 (0.089670) | 0.052698 / 0.037052 (0.015646) | 0.372327 / 0.258489 (0.113838) | 0.426586 / 0.293841 (0.132745) | 0.046755 / 0.128546 (-0.081792) | 0.014848 / 0.075646 (-0.060799) | 0.410474 / 0.419271 (-0.008798) | 0.058206 / 0.043533 (0.014674) | 0.367051 / 0.255139 (0.111912) | 0.389950 / 0.283200 (0.106750) | 0.120857 / 0.141683 (-0.020826) | 1.795195 / 1.452155 (0.343040) | 1.823938 / 1.492716 (0.331222) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215199 / 0.018006 (0.197192) | 0.482420 / 0.000490 (0.481930) | 0.001834 / 0.000200 (0.001634) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034483 / 0.037411 (-0.002928) | 0.135503 / 0.014526 (0.120977) | 0.149991 / 0.176557 (-0.026565) | 0.198482 / 0.737135 (-0.538653) | 0.153556 / 0.296338 (-0.142783) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.504492 / 0.215209 (0.289283) | 4.950949 / 2.077655 (2.873294) | 2.251186 / 1.504120 (0.747067) | 2.049195 / 1.541195 (0.508000) | 2.123325 / 1.468490 (0.654835) | 0.865651 / 4.584777 (-3.719126) | 4.652297 / 3.745712 (0.906585) | 4.417260 / 5.269862 (-0.852602) | 2.362390 / 4.565676 (-2.203287) | 0.098845 / 0.424275 (-0.325430) | 0.014675 / 0.007607 (0.007068) | 0.608048 / 0.226044 (0.382003) | 6.063863 / 2.268929 (3.794935) | 2.753041 / 55.444624 (-52.691583) | 2.340961 / 6.876477 (-4.535516) | 2.511934 / 2.142072 (0.369862) | 0.989297 / 4.805227 (-3.815930) | 0.195770 / 6.500664 (-6.304894) | 0.076027 / 0.075469 (0.000558) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.479617 / 1.841788 (-0.362170) | 18.917860 / 8.074308 (10.843552) | 18.219594 / 10.191392 (8.028202) | 0.218494 / 0.680424 (-0.461930) | 0.037207 / 0.534201 (-0.496994) | 0.571543 / 0.579283 (-0.007741) | 0.527884 / 0.434364 (0.093520) | 0.658661 / 0.540337 (0.118324) | 0.755449 / 1.386936 (-0.631487) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008762 / 0.011353 (-0.002591) | 0.006019 / 0.011008 (-0.004989) | 0.118756 / 0.038508 (0.080248) | 0.039584 / 0.023109 (0.016474) | 0.400127 / 0.275898 (0.124229) | 0.468114 / 0.323480 (0.144634) | 0.006771 / 0.007986 (-0.001215) | 0.004689 / 0.004328 (0.000360) | 0.087274 / 0.004250 (0.083023) | 0.055548 / 0.037052 (0.018496) | 0.419901 / 0.258489 (0.161412) | 0.459516 / 0.293841 (0.165675) | 0.044197 / 0.128546 (-0.084349) | 0.014162 / 0.075646 (-0.061484) | 0.409634 / 0.419271 (-0.009638) | 0.058668 / 0.043533 (0.015135) | 0.404758 / 0.255139 (0.149619) | 0.431562 / 0.283200 (0.148363) | 0.122361 / 0.141683 (-0.019322) | 1.726597 / 1.452155 (0.274442) | 1.798977 / 1.492716 (0.306260) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250831 / 0.018006 (0.232825) | 0.489811 / 0.000490 (0.489321) | 0.000490 / 0.000200 (0.000290) | 0.000071 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035666 / 0.037411 (-0.001745) | 0.134899 / 0.014526 (0.120374) | 0.153156 / 0.176557 (-0.023401) | 0.202409 / 0.737135 (-0.534726) | 0.157350 / 0.296338 (-0.138989) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.522464 / 0.215209 (0.307254) | 5.204449 / 2.077655 (3.126794) | 2.617410 / 1.504120 (1.113290) | 2.406246 / 1.541195 (0.865052) | 2.494487 / 1.468490 (1.025997) | 0.834923 / 4.584777 (-3.749854) | 4.794186 / 3.745712 (1.048474) | 2.617939 / 5.269862 (-2.651922) | 1.648310 / 4.565676 (-2.917367) | 0.109785 / 0.424275 (-0.314490) | 0.015217 / 0.007607 (0.007610) | 0.682970 / 0.226044 (0.456926) | 6.853894 / 2.268929 (4.584966) | 3.277150 / 55.444624 (-52.167475) | 2.832502 / 6.876477 (-4.043975) | 2.984874 / 2.142072 (0.842802) | 1.005307 / 4.805227 (-3.799921) | 0.200623 / 6.500664 (-6.300041) | 0.076852 / 0.075469 (0.001383) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.556656 / 1.841788 (-0.285131) | 19.088978 / 8.074308 (11.014669) | 16.946406 / 10.191392 (6.755014) | 0.204419 / 0.680424 (-0.476004) | 0.021456 / 0.534201 (-0.512745) | 0.523603 / 0.579283 (-0.055680) | 0.530067 / 0.434364 (0.095703) | 0.604058 / 0.540337 (0.063721) | 0.731531 / 1.386936 (-0.655405) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3914 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3914/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3914/comments | https://api.github.com/repos/huggingface/datasets/issues/3914/events | https://github.com/huggingface/datasets/pull/3914 | 1,168,777,880 | PR_kwDODunzps40aq2r | 3,914 | Use templates for doc-builidng jobs | [] | closed | false | null | 2 | 2022-03-14T18:53:06Z | 2022-03-17T15:02:59Z | 2022-03-17T15:02:58Z | null | This PR updates the jobs for all doc-building related things by using the templates introduced on `doc-builder`. By putting those once there, we make sure every repo gets the latest fixes on the doc-building github actions :-)
Note: all libraries must share the same docker image for those doc-building jobs. For now, all the one used (`huggingface/transformers-doc-builder`) contains all extra steps of the datasets install for docbuling (mainly libsndfile) but if in the future some additional steps are necessary on top of `pip install -e .[dev]`, this docker image will need to be updated with the extra deps. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3914/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3914/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3914.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3914",
"merged_at": "2022-03-17T15:02:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3914.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3914"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3914). All of your documentation changes will be reflected on that endpoint.",
"You can ignore the CI failures btw, they're unrelated to this PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/4548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4548/comments | https://api.github.com/repos/huggingface/datasets/issues/4548/events | https://github.com/huggingface/datasets/issues/4548 | 1,282,218,096 | I_kwDODunzps5MbRhw | 4,548 | Metadata.jsonl for Imagefolder is ignored if it's in a parent directory to the splits directories/do not have "{split}_" prefix | [] | closed | false | null | 1 | 2022-06-23T10:58:57Z | 2022-06-30T10:15:32Z | 2022-06-30T10:15:32Z | null | If data contains a single `metadata.jsonl` file for several splits, it won't be included in a dataset's `data_files` and therefore ignored.
This happens when a directory is structured like as follows:
```
train/
file_1.jpg
file_2.jpg
test/
file_3.jpg
file_4.jpg
metadata.jsonl
```
or like as follows:
```
train_file_1.jpg
train_file_2.jpg
test_file_3.jpg
test_file_4.jpg
metadata.jsonl
```
The same for HF repos.
because it's ignored by the patterns [here](https://github.com/huggingface/datasets/blob/master/src/datasets/data_files.py#L29)
@lhoestq @mariosasko Do you think it's better to add this functionality in `data_files.py` or just specifically in imagefolder/audiofolder code? In `data_files.py` would me more general but I don't know if there are any other cases when that might be needed.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4548/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4548/timeline | null | completed | null | null | false | [
"I agree it would be nice to support this. It doesn't fit really well in the current data_files.py, where files of each splits are separated in different folder though, maybe we have to modify a bit the logic here. \r\n\r\nOne idea would be to extend `get_patterns_in_dataset_repository` and `get_patterns_locally` to additionally check for `metadata.json`, but feel free to comment if you have better ideas (I feel like we're reaching the limits of what the current implementation IMO, so we could think of a different way of resolving the data files if necessary)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5174 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5174/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5174/comments | https://api.github.com/repos/huggingface/datasets/issues/5174/events | https://github.com/huggingface/datasets/pull/5174 | 1,427,216,416 | PR_kwDODunzps5Bv3rh | 5,174 | Preserve None in list type cast in PyArrow 10 | [] | closed | false | null | 1 | 2022-10-28T12:48:30Z | 2022-10-28T13:15:33Z | 2022-10-28T13:13:18Z | null | The `ListArray` type in PyArrow 10.0.0 supports the `mask` parameter, which allows us to preserve Nones in nested lists in `cast` instead of replacing them with empty lists.
Fix https://github.com/huggingface/datasets/issues/3676 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5174/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5174/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5174.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5174",
"merged_at": "2022-10-28T13:13:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5174.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5174"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4116 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4116/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4116/comments | https://api.github.com/repos/huggingface/datasets/issues/4116/events | https://github.com/huggingface/datasets/pull/4116 | 1,194,926,459 | PR_kwDODunzps41wCEO | 4,116 | Pretty print dataset info files | [] | closed | false | null | 5 | 2022-04-06T17:40:48Z | 2022-04-08T11:28:01Z | 2022-04-08T11:21:53Z | null | Adds indentation to the `dataset_infos.json` file when saving for nicer diffs.
(suggested by @julien-c)
This PR also updates the info files of the GH datasets. Note that this change adds more than **10 MB** to the repo size (the total file size before the change: 29.672298 MB, after: 41.666475 MB), so I'm not sure this change is a good idea.
`src/datasets/info.py` is the only relevant file for reviewers.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4116/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4116/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4116.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4116",
"merged_at": "2022-04-08T11:21:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4116.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4116"
} | true | [
"maybe just do it from now on no? (i.e. not for existing `dataset_infos.json` files)",
"_The documentation is not available anymore as the PR was closed or merged._",
"> maybe just do it from now on no? (i.e. not for existing dataset_infos.json files)\r\n\r\nYes, or do this only for datasets created with `push_to_hub` to (always) keep the GH datasets small? \r\n",
"yep sounds good too on my side! ",
"I reverted the change to avoid the size increase and added the `pretty_print` flag, which pretty-prints the JSON, and that flag is only True for datasets created with `push_to_hub`. "
] |
https://api.github.com/repos/huggingface/datasets/issues/2854 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2854/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2854/comments | https://api.github.com/repos/huggingface/datasets/issues/2854/events | https://github.com/huggingface/datasets/pull/2854 | 983,726,084 | MDExOlB1bGxSZXF1ZXN0NzIzMjU3NDg5 | 2,854 | Fix caching when moving script | [] | closed | false | null | 1 | 2021-08-31T10:58:35Z | 2021-08-31T13:13:36Z | 2021-08-31T13:13:36Z | null | When caching the result of a `map` function, the hash that is computed depends on many properties of this function, such as all the python objects it uses, its code and also the location of this code.
Using the full path of the python script for the location of the code makes the hash change if a script like `run_mlm.py` is moved.
I changed this by simply using the base name of the script instead of the full path.
Note that this change also affects the hash of the code used from imported modules, but I think it's fine. Indeed it hashes the code of the imported modules anyway, so the location of the python files of the imported modules doesn't matter when computing the hash.
Close https://github.com/huggingface/datasets/issues/2825 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2854/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2854/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2854.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2854",
"merged_at": "2021-08-31T13:13:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2854.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2854"
} | true | [
"Merging since the CI failure is unrelated to this PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/1273 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1273/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1273/comments | https://api.github.com/repos/huggingface/datasets/issues/1273/events | https://github.com/huggingface/datasets/pull/1273 | 758,935,768 | MDExOlB1bGxSZXF1ZXN0NTM0MDE4MjQ2 | 1,273 | Created wiki_movies dataset. | [] | closed | false | null | 5 | 2020-12-07T23:38:54Z | 2020-12-14T13:56:49Z | 2020-12-14T13:56:49Z | null | First PR (ever). Hopefully this movies dataset is useful to others! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1273/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1273/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1273.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1273",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1273.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1273"
} | true | [
"looks like your PR includes changes about many other files than the ones for wiki_movies\r\n\r\nCan you create another branch and another PR please ?",
"I'm happy to. What's the best way to do that (sorry, I'm new to PRs etc.)?",
"Sure !\r\n\r\nFirst please save your new dataset files somewhere.\r\nThen you can do in this order:\r\n```\r\ngit checkout master\r\ngit fetch upstream\r\ngit rebase upstream/master\r\ngit push\r\ngit checkout -b my-new-branch-name\r\n```\r\nThis will create a new branch from the updated master branch.\r\nThen you can re-add your files and commit + push them\r\n\r\nOnce it's done you should be able to create a new PR using your new branch :) ",
"Done!",
"closing in favor of #1485 "
] |
https://api.github.com/repos/huggingface/datasets/issues/1154 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1154/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1154/comments | https://api.github.com/repos/huggingface/datasets/issues/1154/events | https://github.com/huggingface/datasets/pull/1154 | 757,651,669 | MDExOlB1bGxSZXF1ZXN0NTMyOTk2MDQ3 | 1,154 | Opus sardware | [] | closed | false | null | 0 | 2020-12-05T10:38:02Z | 2020-12-05T17:05:45Z | 2020-12-05T17:05:45Z | null | Added Opus sardware dataset for machine translation English to Sardinian.
for more info : http://opus.nlpl.eu/sardware.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1154/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1154/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1154.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1154",
"merged_at": "2020-12-05T17:05:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1154.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1154"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2662/comments | https://api.github.com/repos/huggingface/datasets/issues/2662/events | https://github.com/huggingface/datasets/pull/2662 | 946,470,815 | MDExOlB1bGxSZXF1ZXN0NjkxNjM5MjU5 | 2,662 | Load Dataset from the Hub (NO DATASET SCRIPT) | [] | closed | false | null | 5 | 2021-07-16T17:21:58Z | 2021-08-25T14:53:01Z | 2021-08-25T14:18:08Z | null | ## Load the data from any Dataset repository on the Hub
This PR adds support for loading datasets from any dataset repository on the hub, without requiring any dataset script.
As a user it's now possible to create a repo and upload some csv/json/text/parquet files, and then be able to load the data in one line. Here is an example with the `allenai/c4` repository that contains a lot of compressed json lines files:
```python
from datasets import load_dataset
data_files = {"train": "en/c4-train.*.json.gz"}
c4 = load_dataset("allenai/c4", data_files=data_files, split="train", streaming=True)
print(c4.n_shards)
# 1024
print(next(iter(c4)))
# {'text': 'Beginners BBQ Class Takin...'}
```
By default it loads all the files, but as shown in the example you can choose the ones you want with unix style patterns.
Of course it's still possible to use dataset scripts since they offer the most flexibility.
## Implementation details
It uses `huggingface_hub` to list the files in a dataset repository.
If you provide a path to a local directory instead of a repository name, it works the same way but it uses `glob`.
Depending on the data files available, or passed in the `data_files` parameter, one of the available builders will be used among the csv, json, text and parquet builders.
Because of this, it's not possible to load both csv and json files at once. In this case you have to load them separately and then concatenate the two datasets for example.
## TODO
- [x] tests
- [x] docs
- [x] when huggingface_hub gets a new release, update the CI and the setup.py
Close https://github.com/huggingface/datasets/issues/2629 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 5,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2662/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2662.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2662",
"merged_at": "2021-08-25T14:18:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2662.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2662"
} | true | [
"This is ready for review now :)\r\n\r\nI would love to have some feedback on the changes in load.py @albertvillanova. There are many changes so if you have questions let me know, especially on the `resolve_data_files` functions and on the changes in `prepare_module`.\r\n\r\nAnd @thomwolf if you want to take a look at the documentation, feel free to share your suggestions :)",
"I took your comments into account thanks !\r\nAnd I made `aiohttp` a required dependency :)",
"Just updated the documentation :)\r\n[share_datasets.html](https://45532-250213286-gh.circle-artifacts.com/0/docs/_build/html/share_dataset.html)\r\n\r\nLet me know if you have some comments",
"Merging this one :) \r\n\r\nWe can try to integrate the changes in the docs to #2718 @stevhliu !",
"Baked this into the [docs](https://44335-250213286-gh.circle-artifacts.com/0/docs/_build/html/loading.html#hugging-face-hub) already, let me know if there is anything else I should add! :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2991 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2991/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2991/comments | https://api.github.com/repos/huggingface/datasets/issues/2991/events | https://github.com/huggingface/datasets/issues/2991 | 1,012,174,823 | I_kwDODunzps48VI_n | 2,991 | add docmentation for the `Unix style pattern` matching feature that can be leverage for `data_files` into `load_dataset` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2021-09-30T13:22:01Z | 2021-09-30T13:22:01Z | null | null | Unless I'm mistaken, it seems that in the new documentation it is no longer mentioned that you can use Unix style pattern matching in the `data_files` argument of the `load_dataset` method.
This feature was mentioned [here](https://huggingface.co/docs/datasets/loading_datasets.html#from-a-community-dataset-on-the-hugging-face-hub) in the previous documentation.
I'd love to hear your opinion @lhoestq , @albertvillanova and @stevhliu | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2991/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2991/timeline | null | null | null | null | false | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.