
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4553/comments | https://api.github.com/repos/huggingface/datasets/issues/4553/events | https://github.com/huggingface/datasets/pull/4553 | 1,282,779,560 | PR_kwDODunzps46Q1q7 | 4,553 | Stop dropping columns in to_tf_dataset() before we load batches | [] | closed | false | null | 4 | 2022-06-23T18:21:05Z | 2022-07-04T19:00:13Z | 2022-07-04T18:49:01Z | null | `to_tf_dataset()` dropped unnecessary columns before loading batches from the dataset, but this is causing problems when using a transform, because the dropped columns might be needed to compute the transform. Since there's no real way to check which columns the transform might need, we skip dropping columns and instead drop keys from the batch after we load it.
cc @amyeroberts and https://github.com/huggingface/notebooks/pull/202 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4553/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4553.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4553",
"merged_at": "2022-07-04T18:49:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4553.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4553"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq Rebasing fixed the test failures, so this should be ready to review now! There's still a failure on Win but it seems unrelated.",
"Gentle ping @lhoestq ! This is a simple fix (dropping columns after loading a batch from the dataset rather than with `.remove_columns()` to make sure we don't break transforms), and tests are green so we're ready for review!",
"@lhoestq Test is in!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5024 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5024/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5024/comments | https://api.github.com/repos/huggingface/datasets/issues/5024/events | https://github.com/huggingface/datasets/pull/5024 | 1,385,947,624 | PR_kwDODunzps4_mZ3J | 5,024 | Fix string features of xcsr dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2022-09-26T11:55:36Z | 2022-09-28T07:56:18Z | 2022-09-28T07:54:19Z | null | This PR fixes string features of `xcsr` dataset to avoid character splitting.
Fix #5023.
CC: @yangxqiao, @yuchenlin | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5024/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5024/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5024.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5024",
"merged_at": "2022-09-28T07:54:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5024.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5024"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5804 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5804/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5804/comments | https://api.github.com/repos/huggingface/datasets/issues/5804/events | https://github.com/huggingface/datasets/pull/5804 | 1,688,285,666 | PR_kwDODunzps5PX0Dk | 5,804 | Set dev version | [] | closed | false | null | 3 | 2023-04-28T10:10:01Z | 2023-04-28T10:18:51Z | 2023-04-28T10:10:29Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5804/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5804/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5804.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5804",
"merged_at": "2023-04-28T10:10:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5804.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5804"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5804). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006448 / 0.011353 (-0.004905) | 0.004440 / 0.011008 (-0.006568) | 0.097837 / 0.038508 (0.059328) | 0.027754 / 0.023109 (0.004645) | 0.306462 / 0.275898 (0.030564) | 0.332454 / 0.323480 (0.008975) | 0.004984 / 0.007986 (-0.003001) | 0.004703 / 0.004328 (0.000375) | 0.075213 / 0.004250 (0.070962) | 0.036524 / 0.037052 (-0.000529) | 0.310149 / 0.258489 (0.051659) | 0.346392 / 0.293841 (0.052552) | 0.031012 / 0.128546 (-0.097534) | 0.011598 / 0.075646 (-0.064049) | 0.323066 / 0.419271 (-0.096206) | 0.042945 / 0.043533 (-0.000588) | 0.302286 / 0.255139 (0.047147) | 0.327813 / 0.283200 (0.044614) | 0.092540 / 0.141683 (-0.049143) | 1.532893 / 1.452155 (0.080739) | 1.556676 / 1.492716 (0.063960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195126 / 0.018006 (0.177120) | 0.399623 / 0.000490 (0.399133) | 0.003176 / 0.000200 (0.002976) | 0.000068 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023612 / 0.037411 (-0.013799) | 0.097794 / 0.014526 (0.083268) | 0.104665 / 0.176557 (-0.071891) | 0.167145 / 0.737135 (-0.569990) | 0.108769 / 0.296338 (-0.187570) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437818 / 0.215209 (0.222608) | 4.354896 / 2.077655 (2.277242) | 2.092832 / 1.504120 (0.588712) | 1.957630 / 1.541195 (0.416435) | 2.033135 / 1.468490 (0.564645) | 0.702316 / 4.584777 (-3.882461) | 3.448035 / 3.745712 (-0.297678) | 1.906762 / 5.269862 (-3.363100) | 1.253274 / 4.565676 (-3.312402) | 0.082486 / 0.424275 (-0.341789) | 0.012442 / 0.007607 (0.004835) | 0.532096 / 0.226044 (0.306052) | 5.366580 / 2.268929 (3.097652) | 2.441904 / 55.444624 (-53.002720) | 2.112116 / 6.876477 (-4.764361) | 2.185471 / 2.142072 (0.043398) | 0.797905 / 4.805227 (-4.007322) | 0.149811 / 6.500664 (-6.350853) | 0.066507 / 0.075469 (-0.008962) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.206300 / 1.841788 (-0.635487) | 13.620851 / 8.074308 (5.546543) | 14.190666 / 10.191392 (3.999274) | 0.142343 / 0.680424 (-0.538081) | 0.016867 / 0.534201 (-0.517334) | 0.381557 / 0.579283 (-0.197726) | 0.373935 / 0.434364 (-0.060429) | 0.437856 / 0.540337 (-0.102481) | 0.525235 / 1.386936 (-0.861701) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006598 / 0.011353 (-0.004755) | 0.004487 / 0.011008 (-0.006522) | 0.077582 / 0.038508 (0.039073) | 0.028008 / 0.023109 (0.004899) | 0.341602 / 0.275898 (0.065704) | 0.377105 / 0.323480 (0.053625) | 0.004999 / 0.007986 (-0.002986) | 0.004791 / 0.004328 (0.000462) | 0.076418 / 0.004250 (0.072167) | 0.038347 / 0.037052 (0.001295) | 0.343196 / 0.258489 (0.084707) | 0.382459 / 0.293841 (0.088618) | 0.030597 / 0.128546 (-0.097950) | 0.011579 / 0.075646 (-0.064067) | 0.085876 / 0.419271 (-0.333396) | 0.043241 / 0.043533 (-0.000292) | 0.343754 / 0.255139 (0.088615) | 0.380689 / 0.283200 (0.097489) | 0.096015 / 0.141683 (-0.045668) | 1.464419 / 1.452155 (0.012264) | 1.574010 / 1.492716 (0.081294) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.156433 / 0.018006 (0.138427) | 0.403179 / 0.000490 (0.402690) | 0.002415 / 0.000200 (0.002215) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024946 / 0.037411 (-0.012465) | 0.100568 / 0.014526 (0.086042) | 0.106440 / 0.176557 (-0.070117) | 0.158457 / 0.737135 (-0.578678) | 0.110774 / 0.296338 (-0.185564) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.434734 / 0.215209 (0.219525) | 4.343874 / 2.077655 (2.266220) | 2.059759 / 1.504120 (0.555639) | 1.855124 / 1.541195 (0.313930) | 1.908567 / 1.468490 (0.440077) | 0.695283 / 4.584777 (-3.889494) | 3.347724 / 3.745712 (-0.397988) | 2.979498 / 5.269862 (-2.290364) | 1.532040 / 4.565676 (-3.033636) | 0.083021 / 0.424275 (-0.341254) | 0.012522 / 0.007607 (0.004915) | 0.540934 / 0.226044 (0.314890) | 5.385690 / 2.268929 (3.116762) | 2.507409 / 55.444624 (-52.937216) | 2.160537 / 6.876477 (-4.715939) | 2.269195 / 2.142072 (0.127123) | 0.804718 / 4.805227 (-4.000509) | 0.152432 / 6.500664 (-6.348232) | 0.068783 / 0.075469 (-0.006686) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294698 / 1.841788 (-0.547090) | 14.152792 / 8.074308 (6.078484) | 14.233132 / 10.191392 (4.041740) | 0.143655 / 0.680424 (-0.536768) | 0.016844 / 0.534201 (-0.517357) | 0.380246 / 0.579283 (-0.199037) | 0.381730 / 0.434364 (-0.052633) | 0.456838 / 0.540337 (-0.083499) | 0.543677 / 1.386936 (-0.843259) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008586 / 0.011353 (-0.002767) | 0.005886 / 0.011008 (-0.005122) | 0.114522 / 0.038508 (0.076014) | 0.040966 / 0.023109 (0.017857) | 0.366655 / 0.275898 (0.090757) | 0.408765 / 0.323480 (0.085285) | 0.006822 / 0.007986 (-0.001164) | 0.004508 / 0.004328 (0.000180) | 0.084715 / 0.004250 (0.080465) | 0.054007 / 0.037052 (0.016954) | 0.380500 / 0.258489 (0.122011) | 0.410377 / 0.293841 (0.116536) | 0.041040 / 0.128546 (-0.087507) | 0.013940 / 0.075646 (-0.061707) | 0.398456 / 0.419271 (-0.020816) | 0.059315 / 0.043533 (0.015782) | 0.353640 / 0.255139 (0.098501) | 0.388682 / 0.283200 (0.105482) | 0.121744 / 0.141683 (-0.019939) | 1.729306 / 1.452155 (0.277151) | 1.824768 / 1.492716 (0.332052) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228806 / 0.018006 (0.210800) | 0.492790 / 0.000490 (0.492300) | 0.010815 / 0.000200 (0.010615) | 0.000372 / 0.000054 (0.000318) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031750 / 0.037411 (-0.005662) | 0.127160 / 0.014526 (0.112635) | 0.136717 / 0.176557 (-0.039839) | 0.205590 / 0.737135 (-0.531545) | 0.142596 / 0.296338 (-0.153742) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.486419 / 0.215209 (0.271210) | 4.858572 / 2.077655 (2.780918) | 2.173867 / 1.504120 (0.669747) | 1.934619 / 1.541195 (0.393424) | 2.104185 / 1.468490 (0.635695) | 0.837913 / 4.584777 (-3.746864) | 4.552192 / 3.745712 (0.806480) | 2.565040 / 5.269862 (-2.704822) | 1.808499 / 4.565676 (-2.757178) | 0.103283 / 0.424275 (-0.320993) | 0.015040 / 0.007607 (0.007433) | 0.602325 / 0.226044 (0.376281) | 6.038655 / 2.268929 (3.769727) | 2.759789 / 55.444624 (-52.684835) | 2.330990 / 6.876477 (-4.545487) | 2.404111 / 2.142072 (0.262038) | 1.011637 / 4.805227 (-3.793590) | 0.202142 / 6.500664 (-6.298522) | 0.079496 / 0.075469 (0.004026) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.429543 / 1.841788 (-0.412245) | 18.052409 / 8.074308 (9.978101) | 16.989154 / 10.191392 (6.797762) | 0.208981 / 0.680424 (-0.471443) | 0.020490 / 0.534201 (-0.513711) | 0.502746 / 0.579283 (-0.076537) | 0.491769 / 0.434364 (0.057405) | 0.581970 / 0.540337 (0.041632) | 0.695816 / 1.386936 (-0.691120) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008449 / 0.011353 (-0.002904) | 0.006633 / 0.011008 (-0.004375) | 0.088638 / 0.038508 (0.050130) | 0.040013 / 0.023109 (0.016904) | 0.413108 / 0.275898 (0.137210) | 0.446310 / 0.323480 (0.122830) | 0.006515 / 0.007986 (-0.001471) | 0.006223 / 0.004328 (0.001894) | 0.089823 / 0.004250 (0.085573) | 0.052029 / 0.037052 (0.014977) | 0.407263 / 0.258489 (0.148774) | 0.449416 / 0.293841 (0.155576) | 0.041810 / 0.128546 (-0.086736) | 0.014604 / 0.075646 (-0.061042) | 0.103728 / 0.419271 (-0.315543) | 0.058212 / 0.043533 (0.014679) | 0.408936 / 0.255139 (0.153797) | 0.436727 / 0.283200 (0.153528) | 0.124344 / 0.141683 (-0.017339) | 1.752112 / 1.452155 (0.299957) | 1.859104 / 1.492716 (0.366387) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.231172 / 0.018006 (0.213166) | 0.502974 / 0.000490 (0.502485) | 0.005586 / 0.000200 (0.005386) | 0.000137 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034097 / 0.037411 (-0.003314) | 0.133780 / 0.014526 (0.119254) | 0.142321 / 0.176557 (-0.034236) | 0.199807 / 0.737135 (-0.537329) | 0.150073 / 0.296338 (-0.146266) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.515658 / 0.215209 (0.300449) | 5.129783 / 2.077655 (3.052129) | 2.534767 / 1.504120 (1.030648) | 2.352468 / 1.541195 (0.811274) | 2.430708 / 1.468490 (0.962218) | 0.850087 / 4.584777 (-3.734690) | 4.529622 / 3.745712 (0.783910) | 2.451986 / 5.269862 (-2.817876) | 1.569568 / 4.565676 (-2.996109) | 0.102907 / 0.424275 (-0.321368) | 0.014420 / 0.007607 (0.006813) | 0.635124 / 0.226044 (0.409080) | 6.260496 / 2.268929 (3.991568) | 3.094984 / 55.444624 (-52.349640) | 2.780629 / 6.876477 (-4.095847) | 2.947620 / 2.142072 (0.805548) | 1.002397 / 4.805227 (-3.802830) | 0.200502 / 6.500664 (-6.300162) | 0.076577 / 0.075469 (0.001107) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.505958 / 1.841788 (-0.335829) | 18.364986 / 8.074308 (10.290678) | 16.707214 / 10.191392 (6.515822) | 0.210976 / 0.680424 (-0.469447) | 0.022077 / 0.534201 (-0.512124) | 0.516174 / 0.579283 (-0.063109) | 0.502469 / 0.434364 (0.068105) | 0.626790 / 0.540337 (0.086453) | 0.747230 / 1.386936 (-0.639706) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1124 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1124/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1124/comments | https://api.github.com/repos/huggingface/datasets/issues/1124/events | https://github.com/huggingface/datasets/pull/1124 | 757,186,983 | MDExOlB1bGxSZXF1ZXN0NTMyNjA0NzY3 | 1,124 | Add Xitsonga Ner | [] | closed | false | null | 1 | 2020-12-04T15:27:44Z | 2020-12-06T18:31:35Z | 2020-12-06T18:31:35Z | null | Clean Xitsonga Ner PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1124/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1124/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1124.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1124",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1124.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1124"
} | true | [
"looks like this PR includes changes about many files other than the ones related to xitsonga NER\r\n\r\ncould you create another branch and another PR please ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/952/comments | https://api.github.com/repos/huggingface/datasets/issues/952/events | https://github.com/huggingface/datasets/pull/952 | 754,357,270 | MDExOlB1bGxSZXF1ZXN0NTMwMjcxMTQz | 952 | Add orange sum | [] | closed | false | null | 0 | 2020-12-01T12:33:34Z | 2020-12-01T15:44:00Z | 2020-12-01T15:44:00Z | null | Add OrangeSum a french abstractive summarization dataset.
Paper: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/952/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/952.diff",
"html_url": "https://github.com/huggingface/datasets/pull/952",
"merged_at": "2020-12-01T15:44:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/952.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/952"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4597/comments | https://api.github.com/repos/huggingface/datasets/issues/4597/events | https://github.com/huggingface/datasets/issues/4597 | 1,288,672,007 | I_kwDODunzps5Mz5MH | 4,597 | Streaming issue for financial_phrasebank | [
{
"color": "8B51EF",
"default": false,
"description": "",
"id": 4069435429,
"name": "hosted-on-google-drive",
"node_id": "LA_kwDODunzps7yjqgl",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hosted-on-google-drive"
}
] | closed | false | null | 3 | 2022-06-29T12:45:43Z | 2022-07-01T09:29:36Z | 2022-07-01T09:29:36Z | null | ### Link
https://huggingface.co/datasets/financial_phrasebank/viewer/sentences_allagree/train
### Description
As reported by a community member using [AutoTrain Evaluate](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions/5#62bc217436d0e5d316a768f0), there seems to be a problem streaming this dataset:
```
Server error
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with ConnectionError
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4597/timeline | null | completed | null | null | false | [
"cc @huggingface/datasets: it seems like https://www.researchgate.net/ is flaky for datasets hosting (I put the \"hosted-on-google-drive\" tag since it's the same kind of issue I think)",
"Let's see if their license allows hosting their data on the Hub.",
"License is Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported (CC BY-NC-SA 3.0).\r\n\r\nWe can host their data on the Hub."
] |
https://api.github.com/repos/huggingface/datasets/issues/5361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | https://api.github.com/repos/huggingface/datasets/issues/5361/events | https://github.com/huggingface/datasets/issues/5361 | 1,497,153,889 | I_kwDODunzps5ZPMFh | 5,361 | How concatenate `Audio` elements using batch mapping | [] | closed | false | null | 3 | 2022-12-14T18:13:55Z | 2023-07-21T14:30:51Z | 2023-07-21T14:30:51Z | null | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batch), 3)
dataset = dataset.map(mapper_function, batch=True, batch_size=24)
print(dataset)
# Expected output:
# Dataset({
# features: ['path', 'audio'],
# num_rows: 8
# })
```
I tried to construct `result={}` dictionary inside the mapper function, I just found it will not work because it needs `byte` also needed :((
I'd appreciate if your share any use cases similar to my problem or any solutions really. Thanks!
cc: @lhoestq
### Steps to reproduce the bug
1. load audio dataset
2. try to merge every k audios and return as one
### Expected behavior
Merged dataset with a fewer rows. If we merge every 3 rows, then `n // 3` number of examples.
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5361/timeline | null | completed | null | null | false | [
"You can try something like this ?\r\n```python\r\ndef mapper_function(batch):\r\n return {\"concatenated_audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset = dataset.map(\r\n mapper_function,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.features),\r\n)\r\n```",
"Thanks for the snippet!\r\n\r\nOne more question. I wonder why those two mappers are working so different that one taking 4 sec while other taking over 1 min :\r\n\r\n```python\r\n%%time\r\ndef mapper_function1(batch):\r\n # list_audio\r\n return {\r\n \"audio\": [\r\n {\r\n \"array\": np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]]),\r\n \"sampling_rate\": 16_000,\r\n }\r\n ]\r\n }\r\n\r\ndataset.map(\r\n mapper_function1,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.features),\r\n)\r\n\r\n# 100%\r\n# 135/135 [01:13<00:00, 1.93ba/s]\r\n# CPU times: user 1min 10s, sys: 3.21 s, total: 1min 13s\r\n# Wall time: 1min 13s\r\n# Dataset({\r\n# features: ['audio'],\r\n# num_rows: 135\r\n# })\r\n\r\n# --------------------------------\r\n%%time\r\ndef mapper_function2(batch):\r\n # list_audio\r\n return {\"audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset.map(\r\n mapper_function2,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.features),\r\n)\r\n\r\n# 100%\r\n# 135/135 [00:03<00:00, 40.69ba/s]\r\n# CPU times: user 1.88 s, sys: 1.48 s, total: 3.36 s\r\n# Wall time: 4.8 s\r\n# Dataset({\r\n# features: ['audio'],\r\n# num_rows: 135\r\n# })\r\n```\r\n",
"In the first one you get a dataset with an Audio type, and in the second one you get a dataset with a sequence of floats type.\r\n\r\nThe Audio type encodes the data as WAV to save disk space, so it takes more time to create.\r\nThe Audio type is automatically inferred because you modify the column \"audio\" which was already an Audio type. If you name it to something else, type inference will use a type struct with array and sampling rate fields."
] |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | [] | closed | false | null | 6 | 2023-03-03T09:52:08Z | 2023-03-29T01:44:05Z | 2023-03-24T12:44:25Z | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
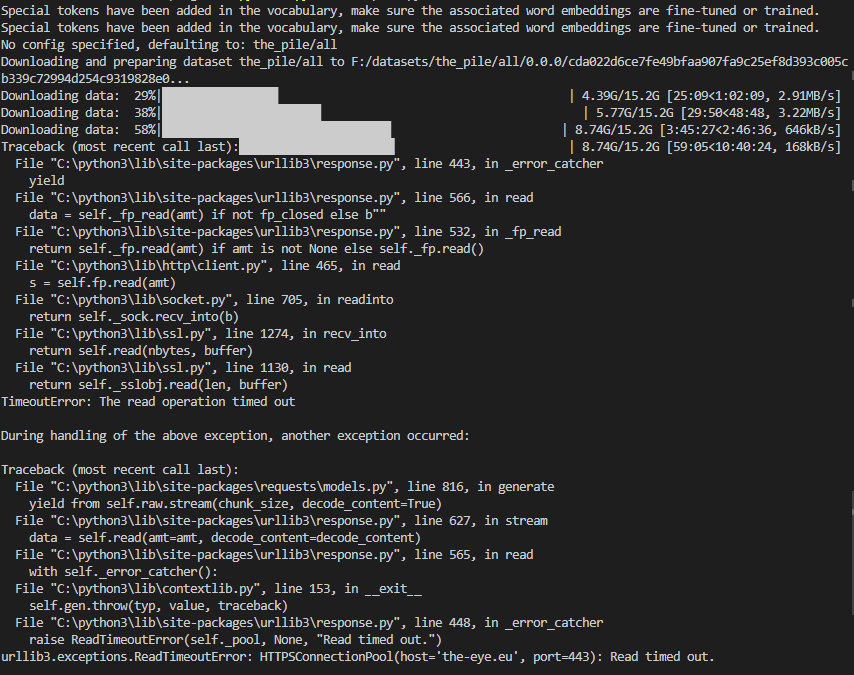
Here are the downloaded files:
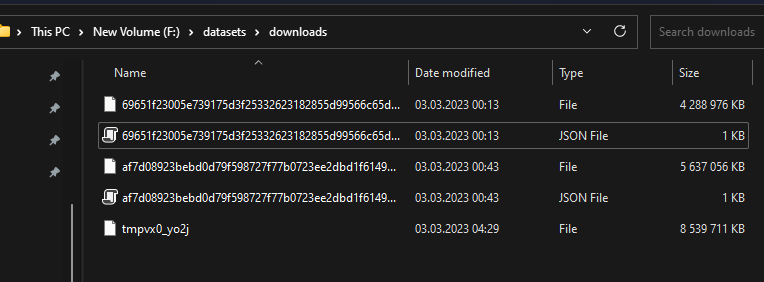
They should be all 14GB like here (https://the-eye.eu/public/AI/pile/train/).
Alternatively, can I somehow download the files by myself and use the datasets preparing script?
### Steps to reproduce the bug
dataset = load_dataset('the_pile', split='train', cache_dir='F:\datasets')
### Expected behavior
The files should be downloaded correctly.
### Environment info
- `datasets` version: 2.10.1
- Platform: Windows-10-10.0.22623-SP0
- Python version: 3.10.5
- PyArrow version: 9.0.0
- Pandas version: 1.4.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5604/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5604/timeline | null | completed | null | null | false | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\datasets', download_config=DownloadConfig(resume_download=True))\r\n```\r\n\r\n",
"@mariosasko , I used your suggestion but its not saving anything , just stops and runs from the same point .\r\nbelow is the script to download and save on disk .\r\n\r\n```\r\nfrom datasets import load_dataset, DownloadConfig\r\n\r\n\r\n#load the Pile dataset from Hugging Face Datasets\r\n#dataset = load_dataset('the_pile')\r\ndataset = load_dataset('the_pile', split='train', cache_dir='datasets', download_config=DownloadConfig(resume_download=True))\r\n\r\n\r\n# save each file in the dataset to disk\r\nfor i, example in enumerate(dataset['train']):\r\n filename = f'pile_file_{i}.json'\r\n with open(filename, 'w') as f:\r\n f.write(str(example))\r\n\r\nprint(\"Finished saving Pile dataset files to disk.\")\r\n```\r\n",
"@mariosasko , it shows nothing in dataset folder\r\n\r\n```\r\n du -sh /mnt/nlp/hugging_face/*\r\n20K /mnt/nlp/hugging_face/datasets\r\n4.0K /mnt/nlp/hugging_face/download_pile.py\r\n```\r\n",
"@mariosasko \r\n\r\n```\r\nroot@d20f0ab8f4f8:/mnt/hugging_face# python3 download_pile.py\r\nNo config specified, defaulting to: the_pile/all\r\nDownloading and preparing dataset the_pile/all to /mnt/hugging_face/datasets/the_pile/all/0.0.0/6fadc480ecb32470826cbf5900a9558b791ce55d5e9a0fdc8ad653e7b64bb349...\r\nDownloading data files: 0%| | 0/3 [00:00<?, ?it/s]\r\n\r\n\r\n\r\n\r\n\r\nDownloading data: 70%|████████████████████████████████████████████████████████████████████▊ | 10.7G/15.2G [12:09<11:53, 6.36MB/s]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 15.2G/15.2G [22:15<00:00, 7.25MB/s]\r\nDownloading data: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 15.2G/15.2G [46:17<00:00, 5.48MB/s]\r\nDownloading data: 40%|██████████████████████████████████████▏ | 6.07G/15.3G [50:49<1:17:02, 1.99MB/s]\r\nTraceback (most recent call last):██████████████████████████▊ | 6.07G/15.3G [50:49<25:35:23, 99.9kB/s]\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 444, in _error_catcher\r\n yield\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 567, in read\r\n data = self._fp_read(amt) if not fp_closed else b\"\"\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 525, in _fp_read\r\n data = self._fp.read(chunk_amt)\r\n File \"/usr/lib/python3.8/http/client.py\", line 459, in read\r\n n = self.readinto(b)\r\n File \"/usr/lib/python3.8/http/client.py\", line 503, in readinto\r\n n = self.fp.readinto(b)\r\n File \"/usr/lib/python3.8/socket.py\", line 669, in readinto\r\n return self._sock.recv_into(b)\r\n File \"/usr/lib/python3.8/ssl.py\", line 1241, in recv_into\r\n return self.read(nbytes, buffer)\r\n File \"/usr/lib/python3.8/ssl.py\", line 1099, in read\r\n return self._sslobj.read(len, buffer)\r\nConnectionResetError: [Errno 104] Connection reset by peer\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.8/dist-packages/requests/models.py\", line 816, in generate\r\n yield from self.raw.stream(chunk_size, decode_content=True)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 628, in stream\r\n data = self.read(amt=amt, decode_content=decode_content)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 593, in read\r\n raise IncompleteRead(self._fp_bytes_read, self.length_remaining)\r\n File \"/usr/lib/python3.8/contextlib.py\", line 131, in __exit__\r\n self.gen.throw(type, value, traceback)\r\n File \"/usr/local/lib/python3.8/dist-packages/urllib3/response.py\", line 461, in _error_catcher\r\n raise ProtocolError(\"Connection broken: %r\" % e, e)\r\nurllib3.exceptions.ProtocolError: (\"Connection broken: ConnectionResetError(104, 'Connection reset by peer')\", ConnectionResetError(104, 'Connection reset by peer'))\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"download_pile.py\", line 6, in <module>\r\n dataset = load_dataset('the_pile', split='train', cache_dir='datasets', download_config=DownloadConfig(resume_download=True))\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/load.py\", line 1782, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 872, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 1649, in _download_and_prepare\r\n super()._download_and_prepare(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/builder.py\", line 945, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/datasets/the_pile/6fadc480ecb32470826cbf5900a9558b791ce55d5e9a0fdc8ad653e7b64bb349/the_pile.py\", line 192, in _split_generators\r\n data_dir = dl_manager.download(_DATA_URLS[self.config.name])\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/download/download_manager.py\", line 427, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 443, in map_nested\r\n mapped = [\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 444, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True, None))\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 363, in _single_map_nested\r\n mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 363, in <listcomp>\r\n mapped = [_single_map_nested((function, v, types, None, True, None)) for v in pbar]\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/py_utils.py\", line 346, in _single_map_nested\r\n return function(data_struct)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/download/download_manager.py\", line 453, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 182, in cached_path\r\n output_path = get_from_cache(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 575, in get_from_cache\r\n http_get(\r\n File \"/usr/local/lib/python3.8/dist-packages/datasets/utils/file_utils.py\", line 379, in http_get\r\n for chunk in response.iter_content(chunk_size=1024):\r\n File \"/usr/local/lib/python3.8/dist-packages/requests/models.py\", line 818, in generate\r\n raise ChunkedEncodingError(e)\r\nrequests.exceptions.ChunkedEncodingError: (\"Connection broken: ConnectionResetError(104, 'Connection reset by peer')\", ConnectionResetError(104, 'Connection reset by peer'))\r\n```\r\n",
"Users with slow internet speed are doomed (4MB/s). The dataset downloads fine at minimum speed 10MB/s.\n\nAlso, when the train splits were generated and then I removed the downloads folder to save up disk space, it started redownloading the whole dataset. Is there any way to use the already generated splits instead?",
"@sentialx @mariosasko , anytime on my above script , am I downloading and saving dataset correctly . Please suggest :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2418/comments | https://api.github.com/repos/huggingface/datasets/issues/2418/events | https://github.com/huggingface/datasets/pull/2418 | 904,051,497 | MDExOlB1bGxSZXF1ZXN0NjU1MjM2OTEz | 2,418 | add utf-8 while reading README | [] | closed | false | null | 2 | 2021-05-27T18:12:28Z | 2021-06-04T09:55:01Z | 2021-06-04T09:55:00Z | null | It was causing tests to fail in Windows (see #2416). In Windows, the default encoding is CP1252 which is unable to decode the character byte 0x9d | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2418/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2418.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2418",
"merged_at": "2021-06-04T09:55:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2418.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2418"
} | true | [
"Can you please add encoding to this line as well to fix the issue (and maybe replace `path.open(...)` with `open(path, ...)`)?\r\nhttps://github.com/huggingface/datasets/blob/7bee4be44706a59b084b9b69c4cd00f73ee72f76/src/datasets/utils/metadata.py#L58",
"Sure, in fact even I was thinking of adding this in order to maintain the consistency!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2977 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2977/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2977/comments | https://api.github.com/repos/huggingface/datasets/issues/2977/events | https://github.com/huggingface/datasets/issues/2977 | 1,009,378,692 | I_kwDODunzps48KeWE | 2,977 | Impossible to load compressed csv | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-09-28T07:18:54Z | 2021-10-01T15:53:16Z | 2021-10-01T15:53:15Z | null | ## Describe the bug
It is not possible to load from a compressed csv anymore.
## Steps to reproduce the bug
```python
load_dataset('csv', data_files=['/path/to/csv.bz2'])
```
## Problem and possible solution
This used to work, but the commit that broke it is [this one](https://github.com/huggingface/datasets/commit/ad489d4597381fc2d12c77841642cbeaecf7a2e0#diff-6f60f8d0552b75be8b3bfd09994480fd60dcd4e7eb08d02f721218c3acdd2782).
`pandas` usually gets the compression information from the filename itself (which was previously directly passed). Now, since it gets a file descriptor, it might be good to auto-infer the compression or let the user pass the `compression` kwarg to `load_dataset` (or maybe warn the user if the file ends with a commonly known compression scheme?).
## Environment info
- `datasets` version: 1.10.0 (and over)
- Platform: Linux-5.8.0-45-generic-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2977/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2977/timeline | null | completed | null | null | false | [
"Hi @Valahaar, thanks for reporting and for your investigation about the source cause.\r\n\r\nYou are right and that commit prevents `pandas` from inferring the compression. On the other hand, @lhoestq did that change to support loading that dataset in streaming mode. \r\n\r\nI'm fixing it."
] |
https://api.github.com/repos/huggingface/datasets/issues/784 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/784/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/784/comments | https://api.github.com/repos/huggingface/datasets/issues/784/events | https://github.com/huggingface/datasets/issues/784 | 733,700,463 | MDU6SXNzdWU3MzM3MDA0NjM= | 784 | Issue with downloading Wikipedia data for low resource language | [] | closed | false | null | 5 | 2020-10-31T11:40:00Z | 2022-02-09T17:50:16Z | 2020-11-25T15:42:13Z | null | Hi, I tried to download Sundanese and Javanese wikipedia data with the following snippet
```
jv_wiki = datasets.load_dataset('wikipedia', '20200501.jv', beam_runner='DirectRunner')
su_wiki = datasets.load_dataset('wikipedia', '20200501.su', beam_runner='DirectRunner')
```
And I get the following error for these two languages:
Javanese
```
FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/jvwiki/20200501/dumpstatus.json
```
Sundanese
```
FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/suwiki/20200501/dumpstatus.json
```
I found from https://github.com/huggingface/datasets/issues/577#issuecomment-688435085 that for small languages, they are directly downloaded and parsed from the Wikipedia dump site, but both of `https://dumps.wikimedia.org/jvwiki/20200501/dumpstatus.json` and `https://dumps.wikimedia.org/suwiki/20200501/dumpstatus.json` are no longer valid.
Any suggestions on how to handle this issue? Thanks! | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/784/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/784/timeline | null | completed | null | null | false | [
"Hello, maybe you could ty to use another date for the wikipedia dump (see the available [dates](https://dumps.wikimedia.org/jvwiki) here for `jv`) ?",
"@lhoestq\r\n\r\nI've tried `load_dataset('wikipedia', '20200501.zh', beam_runner='DirectRunner')` and got the same `FileNotFoundError` as @SamuelCahyawijaya.\r\n\r\nAlso, using another date (e.g. `load_dataset('wikipedia', '20201120.zh', beam_runner='DirectRunner')`) will give the following error message.\r\n\r\n```\r\nValueError: BuilderConfig 20201120.zh not found. Available: ['20200501.aa', '20200501.ab', '20200501.ace', '20200501.ady', '20200501.af', '20200501.ak', '20200501.als', '20200501.am', '20200501.an', '20200501.ang', '20200501.ar', '20200501.arc', '20200501.arz', '20200501.as', '20200501.ast', '20200501.atj', '20200501.av', '20200501.ay', '20200501.az', '20200501.azb', '20200501.ba', '20200501.bar', '20200501.bat-smg', '20200501.bcl', '20200501.be', '20200501.be-x-old', '20200501.bg', '20200501.bh', '20200501.bi', '20200501.bjn', '20200501.bm', '20200501.bn', '20200501.bo', '20200501.bpy', '20200501.br', '20200501.bs', '20200501.bug', '20200501.bxr', '20200501.ca', '20200501.cbk-zam', '20200501.cdo', '20200501.ce', '20200501.ceb', '20200501.ch', '20200501.cho', '20200501.chr', '20200501.chy', '20200501.ckb', '20200501.co', '20200501.cr', '20200501.crh', '20200501.cs', '20200501.csb', '20200501.cu', '20200501.cv', '20200501.cy', '20200501.da', '20200501.de', '20200501.din', '20200501.diq', '20200501.dsb', '20200501.dty', '20200501.dv', '20200501.dz', '20200501.ee', '20200501.el', '20200501.eml', '20200501.en', '20200501.eo', '20200501.es', '20200501.et', '20200501.eu', '20200501.ext', '20200501.fa', '20200501.ff', '20200501.fi', '20200501.fiu-vro', '20200501.fj', '20200501.fo', '20200501.fr', '20200501.frp', '20200501.frr', '20200501.fur', '20200501.fy', '20200501.ga', '20200501.gag', '20200501.gan', '20200501.gd', '20200501.gl', '20200501.glk', '20200501.gn', '20200501.gom', '20200501.gor', '20200501.got', '20200501.gu', '20200501.gv', '20200501.ha', '20200501.hak', '20200501.haw', '20200501.he', '20200501.hi', '20200501.hif', '20200501.ho', '20200501.hr', '20200501.hsb', '20200501.ht', '20200501.hu', '20200501.hy', '20200501.ia', '20200501.id', '20200501.ie', '20200501.ig', '20200501.ii', '20200501.ik', '20200501.ilo', '20200501.inh', '20200501.io', '20200501.is', '20200501.it', '20200501.iu', '20200501.ja', '20200501.jam', '20200501.jbo', '20200501.jv', '20200501.ka', '20200501.kaa', '20200501.kab', '20200501.kbd', '20200501.kbp', '20200501.kg', '20200501.ki', '20200501.kj', '20200501.kk', '20200501.kl', '20200501.km', '20200501.kn', '20200501.ko', '20200501.koi', '20200501.krc', '20200501.ks', '20200501.ksh', '20200501.ku', '20200501.kv', '20200501.kw', '20200501.ky', '20200501.la', '20200501.lad', '20200501.lb', '20200501.lbe', '20200501.lez', '20200501.lfn', '20200501.lg', '20200501.li', '20200501.lij', '20200501.lmo', '20200501.ln', '20200501.lo', '20200501.lrc', '20200501.lt', '20200501.ltg', '20200501.lv', '20200501.mai', '20200501.map-bms', '20200501.mdf', '20200501.mg', '20200501.mh', '20200501.mhr', '20200501.mi', '20200501.min', '20200501.mk', '20200501.ml', '20200501.mn', '20200501.mr', '20200501.mrj', '20200501.ms', '20200501.mt', '20200501.mus', '20200501.mwl', '20200501.my', '20200501.myv', '20200501.mzn', '20200501.na', '20200501.nah', '20200501.nap', '20200501.nds', '20200501.nds-nl', '20200501.ne', '20200501.new', '20200501.ng', '20200501.nl', '20200501.nn', '20200501.no', '20200501.nov', '20200501.nrm', '20200501.nso', '20200501.nv', '20200501.ny', '20200501.oc', '20200501.olo', '20200501.om', '20200501.or', '20200501.os', '20200501.pa', '20200501.pag', '20200501.pam', '20200501.pap', '20200501.pcd', '20200501.pdc', '20200501.pfl', '20200501.pi', '20200501.pih', '20200501.pl', '20200501.pms', '20200501.pnb', '20200501.pnt', '20200501.ps', '20200501.pt', '20200501.qu', '20200501.rm', '20200501.rmy', '20200501.rn', '20200501.ro', '20200501.roa-rup', '20200501.roa-tara', '20200501.ru', '20200501.rue', '20200501.rw', '20200501.sa', '20200501.sah', '20200501.sat', '20200501.sc', '20200501.scn', '20200501.sco', '20200501.sd', '20200501.se', '20200501.sg', '20200501.sh', '20200501.si', '20200501.simple', '20200501.sk', '20200501.sl', '20200501.sm', '20200501.sn', '20200501.so', '20200501.sq', '20200501.sr', '20200501.srn', '20200501.ss', '20200501.st', '20200501.stq', '20200501.su', '20200501.sv', '20200501.sw', '20200501.szl', '20200501.ta', '20200501.tcy', '20200501.te', '20200501.tet', '20200501.tg', '20200501.th', '20200501.ti', '20200501.tk', '20200501.tl', '20200501.tn', '20200501.to', '20200501.tpi', '20200501.tr', '20200501.ts', '20200501.tt', '20200501.tum', '20200501.tw', '20200501.ty', '20200501.tyv', '20200501.udm', '20200501.ug', '20200501.uk', '20200501.ur', '20200501.uz', '20200501.ve', '20200501.vec', '20200501.vep', '20200501.vi', '20200501.vls', '20200501.vo', '20200501.wa', '20200501.war', '20200501.wo', '20200501.wuu', '20200501.xal', '20200501.xh', '20200501.xmf', '20200501.yi', '20200501.yo', '20200501.za', '20200501.zea', '20200501.zh', '20200501.zh-classical', '20200501.zh-min-nan', '20200501.zh-yue', '20200501.zu']\r\n```\r\n\r\nI am pretty sure that `https://dumps.wikimedia.org/enwiki/20201120/dumpstatus.json` exists.",
"Thanks for reporting I created a PR to make the custom config work (language=\"zh\", date=\"20201120\").",
"@lhoestq Thanks!",
"For posterity, here's how I got the data I needed: I needed Bengali, so I had to check which dumps are available here: https://dumps.wikimedia.org/bnwiki/ , then I ran:\r\n```\r\nload_dataset(\"wikipedia\", language=\"bn\", date=\"20211101\",\r\n beam_runner=\"DirectRunner\")\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/3382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3382/comments | https://api.github.com/repos/huggingface/datasets/issues/3382/events | https://github.com/huggingface/datasets/pull/3382 | 1,071,293,299 | PR_kwDODunzps4vZT2K | 3,382 | #3337 Add typing overloads to Dataset.__getitem__ for mypy | [] | closed | false | null | 2 | 2021-12-04T20:54:49Z | 2021-12-14T10:28:55Z | 2021-12-14T10:28:55Z | null | Add typing overloads to Dataset.__getitem__ for mypy
Fixes #3337
**Iterable**
Iterable from `collections` cannot have a type, so you can't do `Iterable[int]` for example. `typing` has a Generic version that builds upon the one from `collections`.
**Flake8**
I had to add `# noqa: F811`, this is a bug from Flake8.
datasets uses flake8==3.7.9 which released in October 2019 if I update flake8 (4.0.1), I no longer get these errors, but I did not want to make the update without your approval. (It also triggers other errors like no args in f-strings.) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3382/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3382.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3382",
"merged_at": "2021-12-14T10:28:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3382.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3382"
} | true | [
"Locally the `make quality` passes with the same dependencies. I would suggest upgrading flake8. (I can take care of it in another PR)\r\ncc @lhoestq ",
"Thank you for fixing flake8! I think we are ready to merge then. "
] |
https://api.github.com/repos/huggingface/datasets/issues/788 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/788/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/788/comments | https://api.github.com/repos/huggingface/datasets/issues/788/events | https://github.com/huggingface/datasets/issues/788 | 734,136,124 | MDU6SXNzdWU3MzQxMzYxMjQ= | 788 | failed to reuse cache | [] | closed | false | null | 0 | 2020-11-02T02:42:36Z | 2020-11-02T12:26:15Z | 2020-11-02T12:26:15Z | null | I packed the `load_dataset ` in a function of class, and cached data in a directory. But when I import the class and use the function, the data still have to be downloaded again. The information (Downloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.28 GiB, post-processed: Unknown size, total: 1.82 GiB) to ******) which logged to terminal shows the path is right to the cache directory, but the files still have to be downloaded again. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/788/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/788/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3786 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3786/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3786/comments | https://api.github.com/repos/huggingface/datasets/issues/3786/events | https://github.com/huggingface/datasets/issues/3786 | 1,150,233,067 | I_kwDODunzps5Ejynr | 3,786 | Bug downloading Virus scan warning page from Google Drive URLs | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-02-25T09:32:23Z | 2022-03-03T09:25:59Z | 2022-02-25T11:56:35Z | null | ## Describe the bug
Recently, some issues were reported with URLs from Google Drive, where we were downloading the Virus scan warning page instead of the data file itself.
See:
- #3758
- #3773
- #3784
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3786/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3786/timeline | null | completed | null | null | false | [
"Once the PR merged into master and until our next `datasets` library release, you can get this fix by installing our library from the GitHub master branch:\r\n```shell\r\npip install git+https://github.com/huggingface/datasets#egg=datasets\r\n```\r\nThen, if you had previously tried to load the data and got the checksum error, you should force the redownload of the data (before the fix, you just downloaded and cached the virus scan warning page, instead of the data file):\r\n```shell\r\nload_dataset(\"...\", download_mode=\"force_redownload\")\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/4781 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4781/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4781/comments | https://api.github.com/repos/huggingface/datasets/issues/4781/events | https://github.com/huggingface/datasets/pull/4781 | 1,326,114,161 | PR_kwDODunzps48hOie | 4,781 | Fix label renaming and add a battery of tests | [] | closed | false | null | 12 | 2022-08-02T16:42:07Z | 2022-09-12T11:27:06Z | 2022-09-12T11:24:45Z | null | This PR makes some changes to label renaming in `to_tf_dataset()`, both to fix some issues when users input something we weren't expecting, and also to make it easier to deprecate label renaming in future, if/when we want to move this special-casing logic to a function in `transformers`.
The main changes are:
- Label renaming now only happens when the `auto_rename_labels` argument is set. For backward compatibility, this defaults to `True` for now.
- If the user requests "label" but the data collator renames that column to "labels", the label renaming logic will now handle that case correctly.
- Added a battery of tests to make this more reliable in future.
- Adds an optimization to loading in `to_tf_dataset()` for unshuffled datasets (uses slicing instead of a list of indices)
Fixes #4772 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4781/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4781/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4781.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4781",
"merged_at": "2022-09-12T11:24:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4781.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4781"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Why don't we deprecate label renaming already instead ?",
"I think it'll break a lot of workflows if we deprecate it now! There isn't really a non-deprecated workflow yet - once we've added the `auto_rename_labels` option, then we can have `prepare_tf_dataset` on the `transformers` side use that, and then we can consider setting the default option to `False`, or beginning to deprecate it somehow.",
"I'm worried it's a bit of a waste of time to continue working on this behavior that shouldn't be here in the first place. Do you have a plan in mind ?",
"@lhoestq Broadly! The plan is:\r\n\r\n1) Create the `auto_rename_labels` flag with this PR and skip label renaming if it isn't set. Leave it as `True` for backward compatibility.\r\n2) Add the label renaming logic to `model.prepare_tf_dataset` in `transformers`. That method calls `to_tf_dataset()` right now. Once the label renaming logic is moved there, `model.prepare_tf_dataset` will set `auto_rename_labels=False` when calling `to_tf_dataset()`, and do label renaming itself.\r\n\r\nAfter step 2, `auto_rename_labels` is now only necessary for backward compatibility when users use `to_tf_dataset` directly. I want to leave it alone for a while because the `model.prepare_tf_dataset` workflow is very new. However, once it is established, we can deprecate `auto_rename_labels` and then finally remove it from the `datasets` code and keep it in `transformers` where it belongs.",
"I see ! Could it be possible to not add `auto_rename_labels` at all, since you want to remove it at the end ? Something roughly like this:\r\n1. show a warning in `to_tf_dataset` whevener a label is renamed automatically, saying that in the next major release this will be removed\r\n1. add the label renaming logic in `transformers` (to not have the warning)\r\n1. after some time, do a major release 3.0.0 and remove label renaming completely in `to_tf_dataset`\r\n\r\nWhat do you think ? cc @LysandreJik in case you have an opinion on this process.",
"@lhoestq I think that plan is mostly good, but if we make the change to `datasets` first then all users will keep getting deprecation warnings until we update the method in `transformers` and release a new version. \r\n\r\nI think we can follow your plan, but make the change to `transformers` first and wait for a new release before changing `datasets` - that way there are no visible warnings or API changes for users using `prepare_tf_dataset`. It also gives us more time to update the docs and try to move people to `prepare_tf_dataset` so they aren't confused by this!",
"Sounds good to me ! To summarize:\r\n1. add the label renaming logic in `transformers` + release\r\n1. show a warning in `to_tf_dataset` whevener a label is renamed automatically, saying that in the next major release this will be removed + minor release\r\n1. after some time, do a major release 3.0.0 and remove label renaming completely in `to_tf_dataset`",
"Yep, that's the plan! ",
"@lhoestq Are you okay with me merging this for now? ",
"Can you remove `auto_rename_labels` ? I don't think it's a good idea to add it if the plan is to remove it later",
"Right now, the `auto_rename_labels` behaviour happens in all cases! Making it an option is the first step in the process of disabling it (and moving the functionality to `transformers`) and then finally deprecating it."
] |
https://api.github.com/repos/huggingface/datasets/issues/3461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3461/comments | https://api.github.com/repos/huggingface/datasets/issues/3461/events | https://github.com/huggingface/datasets/pull/3461 | 1,085,007,346 | PR_kwDODunzps4wFzDP | 3,461 | Fix links in metrics description | [] | closed | false | null | 0 | 2021-12-20T16:56:19Z | 2021-12-20T17:14:52Z | 2021-12-20T17:14:51Z | null | Remove Markdown syntax for links in metrics description, as it is not properly rendered.
Related to #3437. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3461/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3461/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3461.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3461",
"merged_at": "2021-12-20T17:14:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3461.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3461"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1031/comments | https://api.github.com/repos/huggingface/datasets/issues/1031/events | https://github.com/huggingface/datasets/pull/1031 | 755,844,004 | MDExOlB1bGxSZXF1ZXN0NTMxNDgyMzEy | 1,031 | add crows_pairs | [] | closed | false | null | 2 | 2020-12-03T05:05:11Z | 2020-12-03T18:29:52Z | 2020-12-03T18:29:39Z | null | This PR adds CrowS-Pairs datasets.
More info:
https://github.com/nyu-mll/crows-pairs/
https://arxiv.org/pdf/2010.00133.pdf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1031/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1031.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1031",
"merged_at": "2020-12-03T18:29:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1031.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1031"
} | true | [
"looks good now :) wdyt @yjernite ?",
"Looks good to merge for me, can edit the dataset card later if required. Merging"
] |
https://api.github.com/repos/huggingface/datasets/issues/5509 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5509/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5509/comments | https://api.github.com/repos/huggingface/datasets/issues/5509/events | https://github.com/huggingface/datasets/pull/5509 | 1,574,177,320 | PR_kwDODunzps5JbH-u | 5,509 | Add a static `__all__` to `__init__.py` for typecheckers | [] | open | false | null | 2 | 2023-02-07T11:42:40Z | 2023-02-08T17:48:24Z | null | null | This adds a static `__all__` field to `__init__.py`, allowing typecheckers to know which symbols are accessible from `datasets` at runtime. In particular [Pyright](https://github.com/microsoft/pylance-release/issues/2328#issuecomment-1029381258) seems to rely on this. At this point I have added all (modulo oversight) the symbols mentioned in the Reference part of [the docs](https://huggingface.co/docs/datasets), but that could be adjusted. As a side effect, only these symbols will be imported by `from datasets import *`, which may or may not be a good thing (and if it isn't, that's easy to fix).
Another option would be to add a pyi stub, but I think `__all__` should be the most pythonic solution.
This should fix #3841. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5509/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5509/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5509.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5509",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5509.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5509"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5509). All of your documentation changes will be reflected on that endpoint.",
"Hi! I've commented on the original issue to provide some context. Feel free to share your opinion there."
] |
https://api.github.com/repos/huggingface/datasets/issues/5807 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5807/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5807/comments | https://api.github.com/repos/huggingface/datasets/issues/5807/events | https://github.com/huggingface/datasets/pull/5807 | 1,688,977,237 | PR_kwDODunzps5PaKRE | 5,807 | Support parallelized downloading in load_dataset with Spark | [] | closed | false | null | 3 | 2023-04-28T18:34:32Z | 2023-05-25T16:54:14Z | 2023-05-25T16:54:14Z | null | As proposed in https://github.com/huggingface/datasets/issues/5798, this adds support to parallelized downloading in `load_dataset` with Spark, which can speed up the process by distributing the workload to worker nodes.
Parallelizing dataset processing is not supported in this PR. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5807/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5807/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5807.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5807",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5807.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5807"
} | true | [
"Hi @lhoestq or other maintainers, this is ready for review, could you please take a look?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5807). All of your documentation changes will be reflected on that endpoint.",
"Per the discussion in #5798, will implement with `joblibspark` instead."
] |
https://api.github.com/repos/huggingface/datasets/issues/290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/290/comments | https://api.github.com/repos/huggingface/datasets/issues/290/events | https://github.com/huggingface/datasets/issues/290 | 641,978,286 | MDU6SXNzdWU2NDE5NzgyODY= | 290 | ConnectionError - Eli5 dataset download | [] | closed | false | null | 2 | 2020-06-19T13:40:33Z | 2020-06-20T13:22:24Z | 2020-06-20T13:22:24Z | null | Hi, I have a problem with downloading Eli5 dataset. When typing `nlp.load_dataset('eli5')`, I get ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/eli5/LFQA_reddit/1.0.0/explain_like_im_five-train_eli5.arrow
I would appreciate if you could help me with this issue. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/290/timeline | null | completed | null | null | false | [
"It should ne fixed now, thanks for reporting this one :)\r\nIt was an issue on our google storage.\r\n\r\nLet me now if you're still facing this issue.",
"It works now, thanks for prompt help!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5893 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5893/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5893/comments | https://api.github.com/repos/huggingface/datasets/issues/5893/events | https://github.com/huggingface/datasets/pull/5893 | 1,722,519,056 | PR_kwDODunzps5RK40K | 5,893 | Load cached dataset as iterable | [] | closed | false | null | 8 | 2023-05-23T17:40:35Z | 2023-06-01T11:58:24Z | 2023-06-01T11:51:29Z | null | To be used to train models it allows to load an IterableDataset from the cached Arrow file.
See https://github.com/huggingface/datasets/issues/5481 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5893/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5893/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5893.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5893",
"merged_at": "2023-06-01T11:51:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5893.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5893"
} | true | [
"@lhoestq Could you please look into that and review?",
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq I refactored the code. Could you please check is it what you requested?",
"@lhoestq Thanks for a review. Excellent tips. All tips applied. ",
"I think there is just PythonFormatter that needs to be imported in the test file and we should be good to merge",
"@lhoestq that is weird. I have linter error when I do it.",
"@lhoestq Now it should work properly.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006152 / 0.011353 (-0.005201) | 0.004169 / 0.011008 (-0.006839) | 0.097968 / 0.038508 (0.059460) | 0.028325 / 0.023109 (0.005216) | 0.308958 / 0.275898 (0.033060) | 0.341832 / 0.323480 (0.018352) | 0.005098 / 0.007986 (-0.002887) | 0.004721 / 0.004328 (0.000393) | 0.075067 / 0.004250 (0.070817) | 0.040514 / 0.037052 (0.003462) | 0.308355 / 0.258489 (0.049866) | 0.351063 / 0.293841 (0.057222) | 0.025261 / 0.128546 (-0.103285) | 0.008483 / 0.075646 (-0.067163) | 0.321219 / 0.419271 (-0.098052) | 0.058258 / 0.043533 (0.014725) | 0.312572 / 0.255139 (0.057433) | 0.330667 / 0.283200 (0.047467) | 0.091047 / 0.141683 (-0.050635) | 1.536541 / 1.452155 (0.084387) | 1.606566 / 1.492716 (0.113850) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.213234 / 0.018006 (0.195228) | 0.494801 / 0.000490 (0.494311) | 0.003764 / 0.000200 (0.003564) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023653 / 0.037411 (-0.013758) | 0.097176 / 0.014526 (0.082650) | 0.102961 / 0.176557 (-0.073595) | 0.164285 / 0.737135 (-0.572851) | 0.107586 / 0.296338 (-0.188753) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421402 / 0.215209 (0.206193) | 4.195828 / 2.077655 (2.118174) | 1.884664 / 1.504120 (0.380544) | 1.679750 / 1.541195 (0.138556) | 1.719725 / 1.468490 (0.251235) | 0.552290 / 4.584777 (-4.032486) | 3.386337 / 3.745712 (-0.359375) | 1.771527 / 5.269862 (-3.498334) | 1.133327 / 4.565676 (-3.432349) | 0.067911 / 0.424275 (-0.356364) | 0.012572 / 0.007607 (0.004965) | 0.518004 / 0.226044 (0.291960) | 5.192381 / 2.268929 (2.923453) | 2.316032 / 55.444624 (-53.128592) | 1.993264 / 6.876477 (-4.883212) | 2.071009 / 2.142072 (-0.071063) | 0.655062 / 4.805227 (-4.150165) | 0.135488 / 6.500664 (-6.365177) | 0.067273 / 0.075469 (-0.008196) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.217731 / 1.841788 (-0.624056) | 13.812927 / 8.074308 (5.738619) | 13.137886 / 10.191392 (2.946494) | 0.143102 / 0.680424 (-0.537322) | 0.016884 / 0.534201 (-0.517317) | 0.370106 / 0.579283 (-0.209178) | 0.392349 / 0.434364 (-0.042015) | 0.424501 / 0.540337 (-0.115837) | 0.509830 / 1.386936 (-0.877106) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006210 / 0.011353 (-0.005142) | 0.004215 / 0.011008 (-0.006793) | 0.076129 / 0.038508 (0.037621) | 0.027825 / 0.023109 (0.004716) | 0.403973 / 0.275898 (0.128075) | 0.441089 / 0.323480 (0.117609) | 0.005420 / 0.007986 (-0.002566) | 0.004870 / 0.004328 (0.000542) | 0.075558 / 0.004250 (0.071308) | 0.039464 / 0.037052 (0.002411) | 0.404329 / 0.258489 (0.145840) | 0.447213 / 0.293841 (0.153372) | 0.025877 / 0.128546 (-0.102669) | 0.008660 / 0.075646 (-0.066987) | 0.081849 / 0.419271 (-0.337422) | 0.044551 / 0.043533 (0.001018) | 0.379102 / 0.255139 (0.123963) | 0.403104 / 0.283200 (0.119905) | 0.094754 / 0.141683 (-0.046929) | 1.460772 / 1.452155 (0.008617) | 1.569531 / 1.492716 (0.076815) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183923 / 0.018006 (0.165917) | 0.420708 / 0.000490 (0.420219) | 0.002091 / 0.000200 (0.001891) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026180 / 0.037411 (-0.011231) | 0.101529 / 0.014526 (0.087003) | 0.108739 / 0.176557 (-0.067818) | 0.160702 / 0.737135 (-0.576433) | 0.111739 / 0.296338 (-0.184600) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.448671 / 0.215209 (0.233462) | 4.469287 / 2.077655 (2.391632) | 2.244335 / 1.504120 (0.740215) | 2.107495 / 1.541195 (0.566301) | 2.224763 / 1.468490 (0.756272) | 0.554006 / 4.584777 (-4.030771) | 3.390109 / 3.745712 (-0.355603) | 1.744189 / 5.269862 (-3.525673) | 1.008515 / 4.565676 (-3.557161) | 0.067904 / 0.424275 (-0.356371) | 0.012243 / 0.007607 (0.004636) | 0.557635 / 0.226044 (0.331590) | 5.610383 / 2.268929 (3.341454) | 2.687326 / 55.444624 (-52.757298) | 2.405262 / 6.876477 (-4.471214) | 2.527300 / 2.142072 (0.385227) | 0.662282 / 4.805227 (-4.142945) | 0.136225 / 6.500664 (-6.364439) | 0.068136 / 0.075469 (-0.007334) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.310791 / 1.841788 (-0.530997) | 14.370381 / 8.074308 (6.296072) | 14.122675 / 10.191392 (3.931283) | 0.152302 / 0.680424 (-0.528122) | 0.016624 / 0.534201 (-0.517577) | 0.359395 / 0.579283 (-0.219888) | 0.392131 / 0.434364 (-0.042233) | 0.423796 / 0.540337 (-0.116542) | 0.511387 / 1.386936 (-0.875549) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5489 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5489/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5489/comments | https://api.github.com/repos/huggingface/datasets/issues/5489/events | https://github.com/huggingface/datasets/pull/5489 | 1,565,761,705 | PR_kwDODunzps5I_WPH | 5,489 | Pin dill lower version | [] | closed | false | null | 2 | 2023-02-01T09:33:42Z | 2023-02-02T07:48:09Z | 2023-02-02T07:40:43Z | null | Pin `dill` lower version compatible with `datasets`.
Related to:
- #5487
- #288
Note that the required `dill._dill` module was introduced in dill-2.8.0, however we have heuristically tested that datasets can only be installed with dill>=3.0.0 (otherwise pip hangs indefinitely while preparing metadata for multiprocess-0.70.7)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5489/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5489/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5489.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5489",
"merged_at": "2023-02-02T07:40:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5489.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5489"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008798 / 0.011353 (-0.002554) | 0.005313 / 0.011008 (-0.005695) | 0.099234 / 0.038508 (0.060726) | 0.033935 / 0.023109 (0.010826) | 0.306610 / 0.275898 (0.030712) | 0.373151 / 0.323480 (0.049671) | 0.008305 / 0.007986 (0.000320) | 0.004647 / 0.004328 (0.000319) | 0.079984 / 0.004250 (0.075733) | 0.042546 / 0.037052 (0.005493) | 0.355105 / 0.258489 (0.096616) | 0.332769 / 0.293841 (0.038928) | 0.037708 / 0.128546 (-0.090839) | 0.012141 / 0.075646 (-0.063505) | 0.365338 / 0.419271 (-0.053933) | 0.048875 / 0.043533 (0.005343) | 0.301771 / 0.255139 (0.046632) | 0.323301 / 0.283200 (0.040101) | 0.099116 / 0.141683 (-0.042566) | 1.463948 / 1.452155 (0.011793) | 1.563006 / 1.492716 (0.070290) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.219799 / 0.018006 (0.201793) | 0.524126 / 0.000490 (0.523636) | 0.003899 / 0.000200 (0.003699) | 0.000092 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028361 / 0.037411 (-0.009050) | 0.111386 / 0.014526 (0.096860) | 0.125749 / 0.176557 (-0.050807) | 0.167026 / 0.737135 (-0.570109) | 0.132082 / 0.296338 (-0.164257) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.385046 / 0.215209 (0.169837) | 3.933129 / 2.077655 (1.855475) | 1.823395 / 1.504120 (0.319276) | 1.646468 / 1.541195 (0.105273) | 1.658835 / 1.468490 (0.190344) | 0.708300 / 4.584777 (-3.876477) | 4.001478 / 3.745712 (0.255766) | 2.221773 / 5.269862 (-3.048089) | 1.597925 / 4.565676 (-2.967751) | 0.088699 / 0.424275 (-0.335577) | 0.013575 / 0.007607 (0.005968) | 0.520577 / 0.226044 (0.294533) | 5.044313 / 2.268929 (2.775385) | 2.239862 / 55.444624 (-53.204763) | 2.060394 / 6.876477 (-4.816083) | 2.060684 / 2.142072 (-0.081389) | 0.844862 / 4.805227 (-3.960365) | 0.190321 / 6.500664 (-6.310343) | 0.071595 / 0.075469 (-0.003875) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.400048 / 1.841788 (-0.441740) | 15.684159 / 8.074308 (7.609851) | 14.369298 / 10.191392 (4.177906) | 0.164874 / 0.680424 (-0.515550) | 0.033219 / 0.534201 (-0.500982) | 0.449176 / 0.579283 (-0.130107) | 0.456560 / 0.434364 (0.022196) | 0.517978 / 0.540337 (-0.022359) | 0.635467 / 1.386936 (-0.751469) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007263 / 0.011353 (-0.004089) | 0.005451 / 0.011008 (-0.005558) | 0.078785 / 0.038508 (0.040277) | 0.032656 / 0.023109 (0.009546) | 0.346384 / 0.275898 (0.070486) | 0.390778 / 0.323480 (0.067299) | 0.005848 / 0.007986 (-0.002137) | 0.004565 / 0.004328 (0.000236) | 0.077903 / 0.004250 (0.073652) | 0.048659 / 0.037052 (0.011606) | 0.368629 / 0.258489 (0.110140) | 0.401632 / 0.293841 (0.107791) | 0.038516 / 0.128546 (-0.090030) | 0.011895 / 0.075646 (-0.063752) | 0.089185 / 0.419271 (-0.330086) | 0.049875 / 0.043533 (0.006342) | 0.344771 / 0.255139 (0.089632) | 0.378237 / 0.283200 (0.095038) | 0.099184 / 0.141683 (-0.042498) | 1.505058 / 1.452155 (0.052903) | 1.555330 / 1.492716 (0.062614) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.209132 / 0.018006 (0.191126) | 0.479928 / 0.000490 (0.479438) | 0.005923 / 0.000200 (0.005723) | 0.000113 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029187 / 0.037411 (-0.008224) | 0.117026 / 0.014526 (0.102500) | 0.131834 / 0.176557 (-0.044722) | 0.172797 / 0.737135 (-0.564339) | 0.129098 / 0.296338 (-0.167240) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.450214 / 0.215209 (0.235005) | 4.323950 / 2.077655 (2.246295) | 2.210100 / 1.504120 (0.705980) | 2.058733 / 1.541195 (0.517538) | 1.968191 / 1.468490 (0.499701) | 0.694918 / 4.584777 (-3.889859) | 4.176559 / 3.745712 (0.430846) | 2.118211 / 5.269862 (-3.151651) | 1.410652 / 4.565676 (-3.155024) | 0.093606 / 0.424275 (-0.330669) | 0.013729 / 0.007607 (0.006122) | 0.528463 / 0.226044 (0.302418) | 5.311766 / 2.268929 (3.042837) | 2.522981 / 55.444624 (-52.921644) | 2.177191 / 6.876477 (-4.699285) | 2.211448 / 2.142072 (0.069375) | 0.824334 / 4.805227 (-3.980893) | 0.166642 / 6.500664 (-6.334022) | 0.062774 / 0.075469 (-0.012695) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.367573 / 1.841788 (-0.474215) | 15.913637 / 8.074308 (7.839328) | 13.397411 / 10.191392 (3.206019) | 0.162599 / 0.680424 (-0.517825) | 0.020325 / 0.534201 (-0.513876) | 0.438745 / 0.579283 (-0.140538) | 0.449892 / 0.434364 (0.015528) | 0.556226 / 0.540337 (0.015888) | 0.672661 / 1.386936 (-0.714275) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3885 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3885/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3885/comments | https://api.github.com/repos/huggingface/datasets/issues/3885/events | https://github.com/huggingface/datasets/pull/3885 | 1,165,102,209 | PR_kwDODunzps40O00Z | 3,885 | Fix some shuffle docs | [] | closed | false | null | 1 | 2022-03-10T11:29:15Z | 2022-03-10T14:16:29Z | 2022-03-10T14:16:28Z | null | Following #3842 some docs were still outdated (with `buffer_size` as the first argument) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3885/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3885/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3885.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3885",
"merged_at": "2022-03-10T14:16:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3885.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3885"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3885). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5238 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5238/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5238/comments | https://api.github.com/repos/huggingface/datasets/issues/5238/events | https://github.com/huggingface/datasets/pull/5238 | 1,448,211,251 | PR_kwDODunzps5C2L9h | 5,238 | Make `Version` hashable | [] | closed | false | null | 1 | 2022-11-14T14:52:55Z | 2022-11-14T15:30:02Z | 2022-11-14T15:27:35Z | null | Add `__hash__` to the `Version` class to make it hashable (and remove the unneeded methods), as `Version("0.0.0")` is the default value of `BuilderConfig.version` and the default fields of a dataclass need to be hashable in Python 3.11.
Fix https://github.com/huggingface/datasets/issues/5230 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5238/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5238/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5238.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5238",
"merged_at": "2022-11-14T15:27:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5238.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5238"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/75 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/75/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/75/comments | https://api.github.com/repos/huggingface/datasets/issues/75/events | https://github.com/huggingface/datasets/pull/75 | 616,520,163 | MDExOlB1bGxSZXF1ZXN0NDE2NjE0MzU1 | 75 | WIP adding metrics | [] | closed | false | null | 1 | 2020-05-12T09:52:00Z | 2020-05-13T07:44:12Z | 2020-05-13T07:44:10Z | null | Adding the following metrics as identified by @mariamabarham:
1. BLEU: BiLingual Evaluation Understudy: https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py, https://github.com/chakki-works/sumeval/blob/master/sumeval/metrics/bleu.py (multilingual)
2. GLEU: Google-BLEU: https://github.com/cnap/gec-ranking/blob/master/scripts/compute_gleu
3. Sacrebleu: https://pypi.org/project/sacrebleu/1.4.8/ (pypi package), https://github.com/mjpost/sacrebleu (github implementation)
4. ROUGE: Recall-Oriented Understudy for Gisting Evaluation: https://github.com/google-research/google-research/tree/master/rouge, https://github.com/chakki-works/sumeval/blob/master/sumeval/metrics/rouge.py (multilingual)
5. Seqeval: https://github.com/chakki-works/seqeval (github implementation), https://pypi.org/project/seqeval/0.0.12/ (pypi package)
6. Coval: coreference evaluation package for the CoNLL and ARRAU datasets https://github.com/ns-moosavi/coval
7. SQuAD v1 evaluation script
8. SQuAD V2 evaluation script: https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/
9. GLUE
10. XNLI
Not now:
1. Perplexity: https://github.com/allenai/allennlp/blob/master/allennlp/training/metrics/perplexity.py
2. Spearman: https://github.com/allenai/allennlp/blob/master/allennlp/training/metrics/spearman_correlation.py
3. F1_measure: https://github.com/allenai/allennlp/blob/master/allennlp/training/metrics/f1_measure.py
4. Pearson_corelation: https://github.com/allenai/allennlp/blob/master/allennlp/training/metrics/pearson_correlation.py
5. AUC: https://github.com/allenai/allennlp/blob/master/allennlp/training/metrics/auc.py
6. Entropy: https://github.com/allenai/allennlp/blob/master/allennlp/training/metrics/entropy.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/75/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/75/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/75.diff",
"html_url": "https://github.com/huggingface/datasets/pull/75",
"merged_at": "2020-05-13T07:44:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/75.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/75"
} | true | [
"It's all about my metric stuff so I'll probably merge it unless you want to have a look.\r\n\r\nTook the occasion to remove the old doc and requirements.txt"
] |
https://api.github.com/repos/huggingface/datasets/issues/647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/647/comments | https://api.github.com/repos/huggingface/datasets/issues/647/events | https://github.com/huggingface/datasets/issues/647 | 704,734,764 | MDU6SXNzdWU3MDQ3MzQ3NjQ= | 647 | Cannot download dataset_info.json | [] | closed | false | null | 4 | 2020-09-19T01:35:15Z | 2020-09-21T08:28:42Z | 2020-09-21T08:28:42Z | null | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text/default-53ee3045f07ba8ca/0.0.0/dataset_info.json
```
I tried to open this link manually, but I cannot access this file. How can I download this file and pass it through `dataset.load_dataset()` manually?
Versions:
Python version 3.7.3
PyTorch version 1.6.0
TensorFlow version 2.3.0
datasets version: 1.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/647/timeline | null | completed | null | null | false | [
"Thanks for reporting !\r\nWe should add support for servers without internet connection indeed\r\nI'll do that early next week",
"Thanks, @lhoestq !\r\nPlease let me know when it is available. ",
"Right now the recommended way is to create the dataset on a server with internet connection and then to save it and copy the serialized dataset to the server without internet connection.",
"#652 should allow you to load text/json/csv/pandas datasets without an internet connection **IF** you've the dataset script locally.\r\n\r\nExample: \r\nIf you have `datasets/text/text.py` locally, then you can do `load_dataset(\"./datasets/text\", data_files=...)`"
] |
https://api.github.com/repos/huggingface/datasets/issues/904 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/904/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/904/comments | https://api.github.com/repos/huggingface/datasets/issues/904/events | https://github.com/huggingface/datasets/pull/904 | 752,372,743 | MDExOlB1bGxSZXF1ZXN0NTI4NzA5NTUx | 904 | Very detailed step-by-step on how to add a dataset | [] | closed | false | null | 1 | 2020-11-27T16:45:21Z | 2020-11-30T09:56:27Z | 2020-11-30T09:56:26Z | null | Add very detailed step-by-step instructions to add a new dataset to the library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/904/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/904/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/904.diff",
"html_url": "https://github.com/huggingface/datasets/pull/904",
"merged_at": "2020-11-30T09:56:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/904.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/904"
} | true | [
"Awesome! Thanks @lhoestq "
] |
https://api.github.com/repos/huggingface/datasets/issues/2518 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2518/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2518/comments | https://api.github.com/repos/huggingface/datasets/issues/2518/events | https://github.com/huggingface/datasets/pull/2518 | 924,654,100 | MDExOlB1bGxSZXF1ZXN0NjczMjU5Nzg1 | 2,518 | Add task templates for tydiqa and xquad | [] | closed | false | null | 1 | 2021-06-18T08:06:34Z | 2021-06-18T15:01:17Z | 2021-06-18T14:50:33Z | null | This PR adds question-answering templates to the remaining datasets that are linked to a model on the Hub.
Notes:
* I could not test the tydiqa implementation since I don't have enough disk space 😢 . But I am confident the template works :)
* there exist other datasets like `fquad` and `mlqa` which are candidates for question-answering templates, but some work is needed to handle the ordering of nested column described in #2434
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2518/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2518/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2518.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2518",
"merged_at": "2021-06-18T14:50:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2518.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2518"
} | true | [
"Just tested TydiQA and it works fine :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3090/comments | https://api.github.com/repos/huggingface/datasets/issues/3090/events | https://github.com/huggingface/datasets/pull/3090 | 1,027,100,371 | PR_kwDODunzps4tPEtH | 3,090 | Update BibTeX entry | [] | closed | false | null | 0 | 2021-10-15T05:39:27Z | 2021-10-15T07:35:57Z | 2021-10-15T07:35:57Z | null | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3090/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3090.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3090",
"merged_at": "2021-10-15T07:35:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3090.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3090"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/179/comments | https://api.github.com/repos/huggingface/datasets/issues/179/events | https://github.com/huggingface/datasets/issues/179 | 622,525,410 | MDU6SXNzdWU2MjI1MjU0MTA= | 179 | [Feature request] separate split name and split instructions | [] | closed | false | null | 2 | 2020-05-21T14:10:51Z | 2020-05-22T13:31:08Z | 2020-05-22T13:31:07Z | null | Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was built in stages, adding new examples at each stage
Would it be possible to have two separate fields in the Split class, a name /instruction and a unique ID that is used as the key in the builder's split_dict ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/179/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/179/timeline | null | completed | null | null | false | [
"If your dataset is a collection of sub-datasets, you should probably consider having one config per sub-dataset. For example for Glue, we have sst2, mnli etc.\r\nIf you want to have multiple train sets (for example one per stage). The easiest solution would be to name them `nlp.Split(\"train_stage1\")`, `nlp.Split(\"train_stage2\")`, etc. or something like that.",
"Thanks for the tip! I ended up setting up three different versions of the dataset with their own configs.\r\n\r\nfor the named splits, I was trying with `nlp.Split(\"train-stage1\")`, which fails. Changing to `nlp.Split(\"train_stage1\")` works :) I looked for examples of what works in the code comments, it may be worth adding some examples of valid/invalid names in there?"
] |
https://api.github.com/repos/huggingface/datasets/issues/1182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1182/comments | https://api.github.com/repos/huggingface/datasets/issues/1182/events | https://github.com/huggingface/datasets/pull/1182 | 757,804,877 | MDExOlB1bGxSZXF1ZXN0NTMzMTA5Nzgx | 1,182 | ADD COVID-QA dataset | [] | closed | false | null | 2 | 2020-12-05T23:31:56Z | 2020-12-28T13:23:14Z | 2020-12-07T14:23:27Z | null | This PR adds the COVID-QA dataset, a question answering dataset consisting of 2,019 question/answer pairs annotated by volunteer biomedical experts on scientific articles related to COVID-19
Link to the paper: https://openreview.net/forum?id=JENSKEEzsoU
Link to the dataset/repo: https://github.com/deepset-ai/COVID-QA | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1182/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1182/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1182.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1182",
"merged_at": "2020-12-07T14:23:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1182.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1182"
} | true | [
"merging since the CI is fixed on master",
"Wow, thanks for including this dataset from my side as well!"
] |
https://api.github.com/repos/huggingface/datasets/issues/917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/917/comments | https://api.github.com/repos/huggingface/datasets/issues/917/events | https://github.com/huggingface/datasets/pull/917 | 753,391,591 | MDExOlB1bGxSZXF1ZXN0NTI5NDc5MTIy | 917 | Addition of Concode Dataset | [] | closed | false | null | 8 | 2020-11-30T11:20:59Z | 2020-12-29T02:55:36Z | 2020-12-29T02:55:36Z | null | ##Overview
Concode Dataset contains pairs of Nl Queries and the corresponding Code.(Contextual Code Generation)
Reference Links
Paper Link = https://arxiv.org/pdf/1904.09086.pdf
Github Link =https://github.com/microsoft/CodeXGLUE/tree/main/Text-Code/text-to-code | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/917/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/917/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/917.diff",
"html_url": "https://github.com/huggingface/datasets/pull/917",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/917.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/917"
} | true | [
"Testing command doesn't work\r\n###trace\r\n-- Docs: https://docs.pytest.org/en/stable/warnings.html\r\n========================================================= short test summary info ========================================================== \r\nERROR tests/test_dataset_common.py - absl.testing.parameterized.NoTestsError: parameterized test decorators did not generate any tests. Ma...\r\n====================================================== 2 warnings, 1 error in 54.23s ======================================================= \r\nERROR: not found: G:\\Work Related\\hf\\datasets\\tests\\test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_concode\r\n(no name 'G:\\\\Work Related\\\\hf\\\\datasets\\\\tests\\\\test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_concode' in any of [<Module test_dataset_common.py>])\r\n",
"Hello @lhoestq Test checks are passing in my local, but the commit fails in ci. Any idea onto why? \r\n#### Dummy Dataset Test \r\n====================================================== 1 passed, 6 warnings in 7.14s ======================================================= \r\n#### Real Dataset Test \r\n====================================================== 1 passed, 6 warnings in 25.54s ====================================================== ",
"Hello @lhoestq, Have a look, I've changed the file according to the reviews. Thanks!",
"@reshinthadithyan that's a great start! You will also need to add a Dataset card, following the instructions given [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#manually-tag-the-dataset-and-write-the-dataset-card)",
"> @reshinthadithyan that's a great start! You will also need to add a Dataset card, following the instructions given [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#manually-tag-the-dataset-and-write-the-dataset-card)\r\n\r\nHello @yjernite I'm facing issues in using the datasets-tagger Refer #1 in datasets-tagger. Thanks",
"> > @reshinthadithyan that's a great start! You will also need to add a Dataset card, following the instructions given [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#manually-tag-the-dataset-and-write-the-dataset-card)\r\n> \r\n> Hello @yjernite I'm facing issues in using the datasets-tagger Refer #1 in datasets-tagger. Thanks\r\n\r\nHi @reshinthadithyan ! Did you try with the latest version of the tagger? What issues are you facing?\r\n\r\nWe're also relaxed the dataset requirement for now, you'll only add to add the tags :) ",
"Could you work on another branch when adding different datasets ?\r\nThe idea is to have one PR per dataset",
"Thanks ! The github diff looks all clean now :) \r\nTo fix the CI you just need to rebase from master\r\n\r\nDon't forget to add the tags of the dataset card. It's the yaml part at the top of the dataset card\r\nMore infor here : https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#tag-the-dataset-and-write-the-dataset-card\r\n\r\nThe issue you had with the tagger should be fixed now by https://github.com/huggingface/datasets-tagging/pull/5\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2340/comments | https://api.github.com/repos/huggingface/datasets/issues/2340/events | https://github.com/huggingface/datasets/pull/2340 | 882,370,824 | MDExOlB1bGxSZXF1ZXN0NjM1OTExNzIx | 2,340 | More consistent copy logic | [] | closed | false | null | 0 | 2021-05-09T14:17:33Z | 2021-05-11T08:58:33Z | 2021-05-11T08:58:33Z | null | Use `info.copy()` instead of `copy.deepcopy(info)`.
`Features.copy` now creates a deep copy. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2340/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2340",
"merged_at": "2021-05-11T08:58:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2340"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/57 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/57/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/57/comments | https://api.github.com/repos/huggingface/datasets/issues/57/events | https://github.com/huggingface/datasets/pull/57 | 614,261,638 | MDExOlB1bGxSZXF1ZXN0NDE0ODUzMDM5 | 57 | Better cached path | [] | closed | false | null | 2 | 2020-05-07T18:36:00Z | 2020-05-08T13:20:30Z | 2020-05-08T13:20:28Z | null | ### Changes:
- The `cached_path` no longer returns None if the file is missing/the url doesn't work. Instead, it can raise `FileNotFoundError` (missing file), `ConnectionError` (no cache and unreachable url) or `ValueError` (parsing error)
- Fix requests to firebase API that doesn't handle HEAD requests...
- Allow custom download in datasets script: it allows to use `tf.io.gfile.copy` for example, to download from google storage. I added an example: the `boolq` script | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/57/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/57/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/57.diff",
"html_url": "https://github.com/huggingface/datasets/pull/57",
"merged_at": "2020-05-08T13:20:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/57.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/57"
} | true | [
"I should have read this PR before doing my own: https://github.com/huggingface/nlp/pull/62 :D \r\nwill close mine. Looks great :-) ",
"> Awesome, this is really nice!\r\n> \r\n> By the way, we should improve the `cached_path` method of the `transformers` repo similarly, don't you think (@patrickvonplaten in particular).\r\n\r\nYeah, we should do the same in `transformers` I think - will note it down."
] |
https://api.github.com/repos/huggingface/datasets/issues/381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/381/comments | https://api.github.com/repos/huggingface/datasets/issues/381/events | https://github.com/huggingface/datasets/issues/381 | 655,277,119 | MDU6SXNzdWU2NTUyNzcxMTk= | 381 | NLp | [] | closed | false | null | 0 | 2020-07-11T20:50:14Z | 2020-07-11T20:50:39Z | 2020-07-11T20:50:39Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/381/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/381/timeline | null | completed | null | null | false | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/1803 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1803/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1803/comments | https://api.github.com/repos/huggingface/datasets/issues/1803/events | https://github.com/huggingface/datasets/issues/1803 | 798,243,904 | MDU6SXNzdWU3OTgyNDM5MDQ= | 1,803 | Querying examples from big datasets is slower than small datasets | [] | closed | false | null | 8 | 2021-02-01T11:08:23Z | 2021-08-04T18:11:01Z | 2021-08-04T18:10:42Z | null | After some experiments with bookcorpus I noticed that querying examples from big datasets is slower than small datasets.
For example
```python
from datasets import load_dataset
b1 = load_dataset("bookcorpus", split="train[:1%]")
b50 = load_dataset("bookcorpus", split="train[:50%]")
b100 = load_dataset("bookcorpus", split="train[:100%]")
%timeit _ = b1[-1]
# 12.2 µs ± 70.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
%timeit _ = b50[-1]
# 92.5 µs ± 1.24 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit _ = b100[-1]
# 177 µs ± 3.13 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
It looks like the time to fetch the example increases with the size of the dataset.
This is maybe due to the use of the Arrow streaming format to store the data on disk. I guess pyarrow needs to iterate through the file as a stream to find the queried sample.
Maybe switching to the Arrow IPC file format could help fixing this issue.
Indeed according to the [documentation](https://arrow.apache.org/docs/format/Columnar.html?highlight=arrow1#ipc-file-format), it's identical to the streaming format except that it contains the memory offsets of each sample, which could fix the issue:
> We define a “file format” supporting random access that is build with the stream format. The file starts and ends with a magic string ARROW1 (plus padding). What follows in the file is identical to the stream format. At the end of the file, we write a footer containing a redundant copy of the schema (which is a part of the streaming format) plus memory offsets and sizes for each of the data blocks in the file. This enables random access any record batch in the file. See File.fbs for the precise details of the file footer.
cc @gaceladri since it can help speed up your training when this one is fixed. | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1803/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1803/timeline | null | completed | null | null | false | [
"Hello, @lhoestq / @gaceladri : We have been seeing similar behavior with bigger datasets, where querying time increases. Are you folks aware of any solution that fixes this problem yet? ",
"Hi ! I'm pretty sure that it can be fixed by using the Arrow IPC file format instead of the raw streaming format but I haven't tested yet.\r\nI'll take a look at it soon and let you know",
"My workaround is to shard the dataset into splits in my ssd disk and feed the data in different training sessions. But it is a bit of a pain when we need to reload the last training session with the rest of the split with the Trainer in transformers.\r\n\r\nI mean, when I split the training and then reloads the model and optimizer, it not gets the correct global_status of the optimizer, so I need to hardcode some things. I'm planning to open an issue in transformers and think about it.\r\n```\r\nfrom datasets import load_dataset\r\n\r\nbook_corpus = load_dataset(\"bookcorpus\", split=\"train[:25%]\")\r\nwikicorpus = load_dataset(\"wikicorpus\", split=\"train[:25%]\")\r\nopenwebtext = load_dataset(\"openwebtext\", split=\"train[:25%]\")\r\n\r\nbig_dataset = datasets.concatenate_datasets([wikicorpus, openwebtext, book_corpus])\r\nbig_dataset.shuffle(seed=42)\r\nbig_dataset = big_dataset.map(encode, batched=True, num_proc=20, load_from_cache_file=True, writer_batch_size=5000)\r\nbig_dataset.set_format(type='torch', columns=[\"text\", \"input_ids\", \"attention_mask\", \"token_type_ids\"])\r\n\r\n\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./linear_bert\",\r\n overwrite_output_dir=True,\r\n per_device_train_batch_size=71,\r\n save_steps=500,\r\n save_total_limit=10,\r\n logging_first_step=True,\r\n logging_steps=100,\r\n gradient_accumulation_steps=9,\r\n fp16=True,\r\n dataloader_num_workers=20,\r\n warmup_steps=24000,\r\n learning_rate=0.000545205002870214,\r\n adam_epsilon=1e-6,\r\n adam_beta2=0.98,\r\n weight_decay=0.01,\r\n max_steps=138974, # the total number of steps after concatenating 100% datasets\r\n max_grad_norm=1.0,\r\n)\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n data_collator=data_collator,\r\n train_dataset=big_dataset,\r\n tokenizer=tokenizer))\r\n```\r\n\r\nI do one training pass with the total steps of this shard and I use len(bbig)/batchsize to stop the training (hardcoded in the trainer.py) when I pass over all the examples in this split.\r\n\r\nNow Im working, I will edit the comment with a more elaborated answer when I left the work.",
"I just tested and using the Arrow File format doesn't improve the speed... This will need further investigation.\r\n\r\nMy guess is that it has to iterate over the record batches or chunks of a ChunkedArray in order to retrieve elements.\r\n\r\nHowever if we know in advance in which chunk the element is, and at what index it is, then we can access it instantaneously. But this requires dealing with the chunked arrays instead of the pyarrow Table directly which is not practical.",
"I have a dataset with about 2.7 million rows (which I'm loading via `load_from_disk`), and I need to fetch around 300k (particular) rows of it, by index. Currently this is taking a really long time (~8 hours). I tried sharding the large dataset but overall it doesn't change how long it takes to fetch the desired rows.\r\n\r\nI actually have enough RAM that I could fit the large dataset in memory. Would having the large dataset in memory speed up querying? To find out, I tried to load (a column of) the large dataset into memory like this:\r\n```\r\ncolumn_data = large_ds['column_name']\r\n```\r\nbut in itself this takes a really long time.\r\n\r\nI'm pretty stuck - do you have any ideas what I should do? ",
"Hi ! Feel free to post a message on the [forum](https://discuss.huggingface.co/c/datasets/10). I'd be happy to help you with this.\r\n\r\nIn your post on the forum, feel free to add more details about your setup:\r\nWhat are column names and types of your dataset ?\r\nHow was the dataset constructed ?\r\nIs the dataset shuffled ?\r\nIs the dataset tokenized ?\r\nAre you on a SSD or an HDD ?\r\n\r\nI'm sure we can figure something out.\r\nFor example on my laptop I can access the 6 millions articles from wikipedia in less than a minute.",
"Thanks @lhoestq, I've [posted on the forum](https://discuss.huggingface.co/t/fetching-rows-of-a-large-dataset-by-index/4271?u=abisee).",
"Fixed by #2122."
] |
https://api.github.com/repos/huggingface/datasets/issues/38 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/38/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/38/comments | https://api.github.com/repos/huggingface/datasets/issues/38/events | https://github.com/huggingface/datasets/issues/38 | 611,677,656 | MDU6SXNzdWU2MTE2Nzc2NTY= | 38 | [Checksums] Error for some datasets | [] | closed | false | null | 3 | 2020-05-04T08:00:16Z | 2020-05-04T09:48:20Z | 2020-05-04T09:48:20Z | null | The checksums command works very nicely for `squad`. But for `crime_and_punish` and `xnli`,
the same bug happens:
When running:
```
python nlp-cli nlp-cli test xnli --save_checksums
```
leads to:
```
File "nlp-cli", line 33, in <module>
service.run()
File "/home/patrick/python_bin/nlp/commands/test.py", line 61, in run
ignore_checksums=self._ignore_checksums,
File "/home/patrick/python_bin/nlp/builder.py", line 383, in download_and_prepare
self._download_and_prepare(dl_manager=dl_manager, download_config=download_config)
File "/home/patrick/python_bin/nlp/builder.py", line 627, in _download_and_prepare
dl_manager=dl_manager, max_examples_per_split=download_config.max_examples_per_split,
File "/home/patrick/python_bin/nlp/builder.py", line 431, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/patrick/python_bin/nlp/datasets/xnli/8bf4185a2da1ef2a523186dd660d9adcf0946189e7fa5942ea31c63c07b68a7f/xnli.py", line 95, in _split_generators
dl_dir = dl_manager.download_and_extract(_DATA_URL)
File "/home/patrick/python_bin/nlp/utils/download_manager.py", line 246, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/home/patrick/python_bin/nlp/utils/download_manager.py", line 186, in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
File "/home/patrick/python_bin/nlp/utils/download_manager.py", line 166, in _record_sizes_checksums
self._recorded_sizes_checksums[url] = get_size_checksum(path)
File "/home/patrick/python_bin/nlp/utils/checksums_utils.py", line 81, in get_size_checksum
with open(path, "rb") as f:
TypeError: expected str, bytes or os.PathLike object, not tuple
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/38/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/38/timeline | null | completed | null | null | false | [
"@lhoestq - could you take a look? It's not very urgent though!",
"Fixed with 06882b4\r\n\r\nNow your command works :)\r\nNote that you can also do\r\n```\r\nnlp-cli test datasets/nlp/xnli --save_checksums\r\n```\r\nSo that it will save the checksums directly in the right directory.",
"Awesome!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2707/comments | https://api.github.com/repos/huggingface/datasets/issues/2707/events | https://github.com/huggingface/datasets/issues/2707 | 950,812,945 | MDU6SXNzdWU5NTA4MTI5NDU= | 2,707 | 404 Not Found Error when loading LAMA dataset | [] | closed | false | null | 3 | 2021-07-22T15:52:33Z | 2021-07-26T14:29:07Z | 2021-07-26T14:29:07Z | null | The [LAMA](https://huggingface.co/datasets/viewer/?dataset=lama) probing dataset is not available for download:
Steps to Reproduce:
1. `from datasets import load_dataset`
2. `dataset = load_dataset('lama', 'trex')`.
Results:
`FileNotFoundError: Couldn't find file locally at lama/lama.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.2/datasets/lama/lama.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/lama/lama.py` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2707/timeline | null | completed | null | null | false | [
"Hi @dwil2444! I was able to reproduce your error when I downgraded to v1.1.2. Updating to the latest version of Datasets fixed the error for me :)",
"Hi @dwil2444, thanks for reporting.\r\n\r\nCould you please confirm which `datasets` version you were using and if the problem persists after you update it to the latest version: `pip install -U datasets`?\r\n\r\nThanks @stevhliu for the hint to fix this! ;)",
"@stevhliu @albertvillanova updating to the latest version of datasets did in fact fix this issue. Thanks a lot for your help!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2476/comments | https://api.github.com/repos/huggingface/datasets/issues/2476/events | https://github.com/huggingface/datasets/pull/2476 | 917,686,662 | MDExOlB1bGxSZXF1ZXN0NjY3MTg3OTk1 | 2,476 | Add TimeDial | [] | closed | false | null | 1 | 2021-06-10T18:33:07Z | 2021-07-30T12:57:54Z | 2021-07-30T12:57:54Z | null | Dataset: https://github.com/google-research-datasets/TimeDial
To-Do: Update README.md and add YAML tags | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2476/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2476/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2476.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2476",
"merged_at": "2021-07-30T12:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2476.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2476"
} | true | [
"Hi @lhoestq,\r\nI've pushed the updated README and tags. Let me know if anything is missing/needs some improvement!\r\n\r\n~PS. I don't know why it's not triggering the build~"
] |
https://api.github.com/repos/huggingface/datasets/issues/4423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4423/comments | https://api.github.com/repos/huggingface/datasets/issues/4423/events | https://github.com/huggingface/datasets/pull/4423 | 1,253,326,023 | PR_kwDODunzps44trdP | 4,423 | Add new dataset MMChat | [] | closed | false | null | 2 | 2022-05-31T04:45:07Z | 2022-06-11T12:40:52Z | 2022-06-11T12:31:42Z | null | Hi, I am adding a new dataset MMChat.
It seems that all tests are passed | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4423/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4423/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4423.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4423",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4423.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4423"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! As for https://github.com/huggingface/datasets/pull/4431 please also update the licensing section in https://huggingface.co/datasets/silver/mmchat ;)\r\n\r\nThen if it's fine for you feel free to close this PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/2480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2480/comments | https://api.github.com/repos/huggingface/datasets/issues/2480/events | https://github.com/huggingface/datasets/issues/2480 | 918,678,578 | MDU6SXNzdWU5MTg2Nzg1Nzg= | 2,480 | Set download/extracted paths configurable | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2021-06-11T12:20:24Z | 2021-06-15T14:23:49Z | null | null | As discussed with @stas00 and @lhoestq, setting these paths configurable may allow to overcome disk space limitation on different partitions/drives.
TODO:
- [x] Set configurable extracted datasets path: #2487
- [x] Set configurable downloaded datasets path: #2488
- [ ] Set configurable "incomplete" datasets path? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2480/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2480/timeline | null | null | null | null | false | [
"For example to be able to send uncompressed and temp build files to another volume/partition, so that the user gets the minimal disk usage on their primary setup - and ends up with just the downloaded compressed data + arrow files, but outsourcing the huge files and building to another partition. e.g. on JZ there is a special partition for fast data, but it's also volatile, so only temp files should go there.\r\n\r\nThink of it as `TMPDIR` so we need the equivalent for `datasets`."
] |
https://api.github.com/repos/huggingface/datasets/issues/4789 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4789/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4789/comments | https://api.github.com/repos/huggingface/datasets/issues/4789/events | https://github.com/huggingface/datasets/pull/4789 | 1,328,409,253 | PR_kwDODunzps48o3Kk | 4,789 | Update doc upload_dataset.mdx | [] | closed | false | null | 1 | 2022-08-04T10:24:00Z | 2022-09-09T16:37:10Z | 2022-09-09T16:34:58Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4789/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4789/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4789.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4789",
"merged_at": "2022-09-09T16:34:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4789.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4789"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/292/comments | https://api.github.com/repos/huggingface/datasets/issues/292/events | https://github.com/huggingface/datasets/pull/292 | 642,897,797 | MDExOlB1bGxSZXF1ZXN0NDM3Nzk4NTM2 | 292 | Update metadata for x_stance dataset | [] | closed | false | null | 3 | 2020-06-22T09:13:26Z | 2020-06-23T08:07:24Z | 2020-06-23T08:07:24Z | null | Thank you for featuring the x_stance dataset in your library. This PR updates some metadata:
- Citation: Replace preprint with proceedings
- URL: Use a URL with long-term availability
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/292/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/292.diff",
"html_url": "https://github.com/huggingface/datasets/pull/292",
"merged_at": "2020-06-23T08:07:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/292.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/292"
} | true | [
"Great! Thanks @jvamvas for these updates.\r\n",
"I have fixed a warning. The remaining test failure is due to an unrelated dataset.",
"We just fixed the other dataset on master. Could you rebase from master and push to rerun the CI ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/4481 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4481/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4481/comments | https://api.github.com/repos/huggingface/datasets/issues/4481/events | https://github.com/huggingface/datasets/pull/4481 | 1,269,187,792 | PR_kwDODunzps45jIRi | 4,481 | Fix iwslt2017 | [] | closed | false | null | 4 | 2022-06-13T09:51:21Z | 2022-10-26T09:09:31Z | 2022-06-13T10:40:18Z | null | The files were moved to google drive, I hosted them on the Hub instead (ok according to the license)
I also updated the `datasets_infos.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4481/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4481/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4481.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4481",
"merged_at": "2022-06-13T10:40:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4481.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4481"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI fails are just abut missing tags in the dataset card, merging !",
"FYI, \r\n\r\nThe checksums have not been edited from the changes of .tgz to .zip files, and as a result a `ExpectedMoreDownloadedFiles` error occurs. Updating them in the `dataset_infos.json` should fix the error. ",
"Thanks for reporting and sorry for the delay, I opened https://huggingface.co/datasets/iwslt2017/discussions/2 to fix this"
] |
https://api.github.com/repos/huggingface/datasets/issues/2580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2580/comments | https://api.github.com/repos/huggingface/datasets/issues/2580/events | https://github.com/huggingface/datasets/pull/2580 | 935,767,421 | MDExOlB1bGxSZXF1ZXN0NjgyNjI2MTkz | 2,580 | Fix Counter import | [] | closed | false | null | 0 | 2021-07-02T13:21:48Z | 2021-07-02T14:37:47Z | 2021-07-02T14:37:46Z | null | Import from `collections` instead of `typing`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2580/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2580.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2580",
"merged_at": "2021-07-02T14:37:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2580.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2580"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1553/comments | https://api.github.com/repos/huggingface/datasets/issues/1553/events | https://github.com/huggingface/datasets/pull/1553 | 765,670,083 | MDExOlB1bGxSZXF1ZXN0NTM5MDI4MzM3 | 1,553 | added air_dialogue | [] | closed | false | null | 0 | 2020-12-13T21:59:02Z | 2020-12-23T11:20:40Z | 2020-12-23T11:20:39Z | null | UPDATE2 (3797ce5): Updated for multi-configs
UPDATE (7018082): manually created the dummy_datasets. All tests were cleared locally. Pushed it to origin/master
DRAFT VERSION (57fdb20): (_no longer draft_)
Uploaded the air_dialogue database.
dummy_data creation was failing in local, since the original downloaded file has some nested folders. Pushing it since the tests with real data was cleared. Will re-check & update via manually creating some dummy_data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1553/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1553/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1553.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1553",
"merged_at": "2020-12-23T11:20:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1553.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1553"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/723 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/723/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/723/comments | https://api.github.com/repos/huggingface/datasets/issues/723/events | https://github.com/huggingface/datasets/issues/723 | 718,926,723 | MDU6SXNzdWU3MTg5MjY3MjM= | 723 | Adding pseudo-labels to datasets | [] | closed | false | null | 8 | 2020-10-11T21:05:45Z | 2021-08-03T05:11:51Z | 2021-08-03T05:11:51Z | null | I recently [uploaded pseudo-labels](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/precomputed_pseudo_labels.md) for CNN/DM, XSUM and WMT16-en-ro to s3, and thom mentioned I should add them to this repo.
Since pseudo-labels are just a large model's generations on an existing dataset, what is the right way to structure this contribution.
I read https://huggingface.co/docs/datasets/add_dataset.html, but it doesn't really cover this type of contribution.
I could, for example, make a new directory, `xsum_bart_pseudolabels` for each set of pseudolabels or add some sort of parametrization to `xsum.py`: https://github.com/huggingface/datasets/blob/5f4c6e830f603830117877b8990a0e65a2386aa6/datasets/xsum/xsum.py
What do you think @lhoestq ?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/723/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/723/timeline | null | completed | null | null | false | [
"Nice ! :)\r\nIt's indeed the first time we have such contributions so we'll have to figure out the appropriate way to integrate them.\r\nCould you add details on what they could be used for ?\r\n",
"They can be used as training data for a smaller model.",
"Sounds just like a regular dataset to me then, no?",
"A new configuration for those datasets should do the job then.\r\nNote that until now datasets like xsum only had one configuration. It means that users didn't have to specify the configuration name when loading the dataset. If we add new configs, users that update the lib will have to update their code to specify the default/standard configuration name (not the one with pseudo labels).",
"Could also be a `user-namespace` dataset maybe?",
"Oh yes why not. I'm more in favor of this actually since pseudo labels are things that users (not dataset authors in general) can compute by themselves and share with the community",
"\r\n\r\nI assume I should (for example) rename the xsum dir, change the URL, and put the modified dir somewhere in S3?",
"You can use the `datasets-cli` to upload the folder with your version of xsum with the pseudo labels.\r\n\r\n```\r\ndatasets-cli upload_dataset path/to/xsum\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/693 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/693/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/693/comments | https://api.github.com/repos/huggingface/datasets/issues/693/events | https://github.com/huggingface/datasets/pull/693 | 712,822,200 | MDExOlB1bGxSZXF1ZXN0NDk2MjQxMjUw | 693 | Rachel ker add dataset/mlsum | [] | closed | false | null | 1 | 2020-10-01T13:01:10Z | 2020-10-01T17:01:13Z | 2020-10-01T17:01:13Z | null | . | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/693/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/693/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/693.diff",
"html_url": "https://github.com/huggingface/datasets/pull/693",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/693.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/693"
} | true | [
"It looks like an outdated PR (we've already added mlsum). Closing it"
] |
https://api.github.com/repos/huggingface/datasets/issues/5793 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5793/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5793/comments | https://api.github.com/repos/huggingface/datasets/issues/5793/events | https://github.com/huggingface/datasets/issues/5793 | 1,684,777,320 | I_kwDODunzps5ka6lo | 5,793 | IterableDataset.with_format("torch") not working | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | null | 1 | 2023-04-26T10:50:23Z | 2023-06-13T15:57:06Z | 2023-06-13T15:57:06Z | null | ### Describe the bug
After calling the with_format("torch") method on an IterableDataset instance, the data format is unchanged.
### Steps to reproduce the bug
```python
from datasets import IterableDataset
def gen():
for i in range(4):
yield {"a": [i] * 4}
dataset = IterableDataset.from_generator(gen).with_format("torch")
next(iter(dataset))
```
### Expected behavior
`{"a": torch.tensor([0, 0, 0, 0])}` is expected, but `{"a": [0, 0, 0, 0]}` is observed.
### Environment info
```bash
platform==ubuntu 22.04.01
python==3.10.9
datasets==2.11.0
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5793/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5793/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting, I'm working on it ;)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5019 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5019/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5019/comments | https://api.github.com/repos/huggingface/datasets/issues/5019/events | https://github.com/huggingface/datasets/pull/5019 | 1,384,673,718 | PR_kwDODunzps4_iq9b | 5,019 | Update swiss judgment prediction | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 4 | 2022-09-24T13:28:57Z | 2022-09-28T07:13:39Z | 2022-09-28T05:48:50Z | null | Hi,
I updated the dataset to include additional data made available recently. When I test it locally, it seems to work. However, I get the following error with the dummy data creation:
`Dummy data generation done but dummy data test failed since splits ['train', 'validation', 'test'] have 0 examples for config 'fr'`. Do you know why this could be the case?
Cheers,
Joel | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5019/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5019/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5019.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5019",
"merged_at": "2022-09-28T05:48:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5019.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5019"
} | true | [
"Thank you very much for the detailed review @albertvillanova!\r\n\r\nI updated the PR with the requested changes. ",
"At the end, I had to manually fix the conflict, so that CI tests are launched.\r\n\r\nPLEASE NOTE: you should first pull to incorporate the previous commit\r\n```shell\r\ngit pull\r\n```",
"_The documentation is not available anymore as the PR was closed or merged._",
"Thank you very much for the detailed feedback and your time @albertvillanova! \r\nYes, thanks. My other datasets are already on the hub: https://huggingface.co/joelito\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1998 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1998/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1998/comments | https://api.github.com/repos/huggingface/datasets/issues/1998/events | https://github.com/huggingface/datasets/pull/1998 | 823,723,960 | MDExOlB1bGxSZXF1ZXN0NTg2MTE4NTQ4 | 1,998 | Add -DOCSTART- note to dataset card of conll-like datasets | [] | closed | false | null | 1 | 2021-03-06T19:08:29Z | 2021-03-11T02:20:07Z | 2021-03-11T02:20:07Z | null | Closes #1983 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1998/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1998/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1998.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1998",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1998.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1998"
} | true | [
"Nice catch! Yes I didn't check the actual data, instead I was just looking for the `if line.startswith(\"-DOCSTART-\")` pattern."
] |
https://api.github.com/repos/huggingface/datasets/issues/1231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1231/comments | https://api.github.com/repos/huggingface/datasets/issues/1231/events | https://github.com/huggingface/datasets/pull/1231 | 758,121,398 | MDExOlB1bGxSZXF1ZXN0NTMzMzQzMzAz | 1,231 | Add Urdu Sentiment Corpus (USC) | [] | closed | false | null | 0 | 2020-12-07T03:25:20Z | 2020-12-07T18:05:16Z | 2020-12-07T16:43:23Z | null | @lhoestq opened a clean PR containing only relevant files.
old PR #1140 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1231/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1231",
"merged_at": "2020-12-07T16:43:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1231"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5824 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5824/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5824/comments | https://api.github.com/repos/huggingface/datasets/issues/5824/events | https://github.com/huggingface/datasets/pull/5824 | 1,697,152,148 | PR_kwDODunzps5P1rIZ | 5,824 | Fix incomplete docstring for `BuilderConfig` | [] | closed | false | null | 2 | 2023-05-05T07:34:28Z | 2023-05-05T12:39:14Z | 2023-05-05T12:31:54Z | null | Fixes #5820
Also fixed a couple of typos I spotted | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5824/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5824/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5824.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5824",
"merged_at": "2023-05-05T12:31:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5824.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5824"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007658 / 0.011353 (-0.003695) | 0.005497 / 0.011008 (-0.005511) | 0.097142 / 0.038508 (0.058633) | 0.034602 / 0.023109 (0.011493) | 0.304191 / 0.275898 (0.028293) | 0.329103 / 0.323480 (0.005624) | 0.005936 / 0.007986 (-0.002049) | 0.004324 / 0.004328 (-0.000004) | 0.073387 / 0.004250 (0.069137) | 0.049657 / 0.037052 (0.012604) | 0.301352 / 0.258489 (0.042863) | 0.343095 / 0.293841 (0.049254) | 0.036767 / 0.128546 (-0.091779) | 0.012438 / 0.075646 (-0.063208) | 0.333804 / 0.419271 (-0.085468) | 0.064557 / 0.043533 (0.021024) | 0.302397 / 0.255139 (0.047258) | 0.319739 / 0.283200 (0.036540) | 0.119264 / 0.141683 (-0.022418) | 1.465309 / 1.452155 (0.013155) | 1.578194 / 1.492716 (0.085478) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.256552 / 0.018006 (0.238545) | 0.555344 / 0.000490 (0.554854) | 0.004845 / 0.000200 (0.004645) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027215 / 0.037411 (-0.010197) | 0.107071 / 0.014526 (0.092545) | 0.116343 / 0.176557 (-0.060213) | 0.172646 / 0.737135 (-0.564490) | 0.123366 / 0.296338 (-0.172973) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.411421 / 0.215209 (0.196212) | 4.126028 / 2.077655 (2.048373) | 1.975826 / 1.504120 (0.471706) | 1.784404 / 1.541195 (0.243210) | 1.848697 / 1.468490 (0.380207) | 0.686400 / 4.584777 (-3.898377) | 3.677649 / 3.745712 (-0.068063) | 2.077787 / 5.269862 (-3.192075) | 1.310912 / 4.565676 (-3.254764) | 0.083980 / 0.424275 (-0.340295) | 0.012183 / 0.007607 (0.004575) | 0.506969 / 0.226044 (0.280924) | 5.094730 / 2.268929 (2.825802) | 2.419790 / 55.444624 (-53.024834) | 2.106592 / 6.876477 (-4.769884) | 2.244309 / 2.142072 (0.102237) | 0.814312 / 4.805227 (-3.990915) | 0.167872 / 6.500664 (-6.332792) | 0.065339 / 0.075469 (-0.010130) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.193314 / 1.841788 (-0.648474) | 14.980621 / 8.074308 (6.906313) | 14.352452 / 10.191392 (4.161060) | 0.164531 / 0.680424 (-0.515893) | 0.017432 / 0.534201 (-0.516769) | 0.422193 / 0.579283 (-0.157090) | 0.410047 / 0.434364 (-0.024317) | 0.497011 / 0.540337 (-0.043326) | 0.581395 / 1.386936 (-0.805541) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007214 / 0.011353 (-0.004139) | 0.005449 / 0.011008 (-0.005559) | 0.074320 / 0.038508 (0.035812) | 0.034261 / 0.023109 (0.011152) | 0.378265 / 0.275898 (0.102367) | 0.414419 / 0.323480 (0.090939) | 0.005804 / 0.007986 (-0.002182) | 0.004205 / 0.004328 (-0.000124) | 0.073266 / 0.004250 (0.069015) | 0.050444 / 0.037052 (0.013392) | 0.372999 / 0.258489 (0.114510) | 0.436032 / 0.293841 (0.142191) | 0.035432 / 0.128546 (-0.093114) | 0.012581 / 0.075646 (-0.063065) | 0.085777 / 0.419271 (-0.333495) | 0.046902 / 0.043533 (0.003369) | 0.378732 / 0.255139 (0.123593) | 0.401746 / 0.283200 (0.118547) | 0.113398 / 0.141683 (-0.028285) | 1.463851 / 1.452155 (0.011696) | 1.566387 / 1.492716 (0.073670) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261246 / 0.018006 (0.243240) | 0.546730 / 0.000490 (0.546241) | 0.005245 / 0.000200 (0.005045) | 0.000103 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029441 / 0.037411 (-0.007970) | 0.111834 / 0.014526 (0.097308) | 0.122411 / 0.176557 (-0.054145) | 0.171288 / 0.737135 (-0.565847) | 0.130338 / 0.296338 (-0.166001) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.433405 / 0.215209 (0.218196) | 4.315790 / 2.077655 (2.238135) | 2.121934 / 1.504120 (0.617814) | 1.924123 / 1.541195 (0.382928) | 2.029077 / 1.468490 (0.560587) | 0.710245 / 4.584777 (-3.874532) | 3.844393 / 3.745712 (0.098681) | 3.576580 / 5.269862 (-1.693281) | 1.930985 / 4.565676 (-2.634691) | 0.092186 / 0.424275 (-0.332090) | 0.012307 / 0.007607 (0.004700) | 0.533722 / 0.226044 (0.307677) | 5.324447 / 2.268929 (3.055519) | 2.615451 / 55.444624 (-52.829174) | 2.282310 / 6.876477 (-4.594167) | 2.319847 / 2.142072 (0.177774) | 0.849364 / 4.805227 (-3.955864) | 0.172722 / 6.500664 (-6.327942) | 0.064721 / 0.075469 (-0.010748) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.289942 / 1.841788 (-0.551846) | 15.875062 / 8.074308 (7.800754) | 14.784682 / 10.191392 (4.593290) | 0.144432 / 0.680424 (-0.535991) | 0.017703 / 0.534201 (-0.516498) | 0.424357 / 0.579283 (-0.154926) | 0.419078 / 0.434364 (-0.015286) | 0.489331 / 0.540337 (-0.051006) | 0.585284 / 1.386936 (-0.801652) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1690/comments | https://api.github.com/repos/huggingface/datasets/issues/1690/events | https://github.com/huggingface/datasets/pull/1690 | 779,441,631 | MDExOlB1bGxSZXF1ZXN0NTQ5NDEwOTgw | 1,690 | Fast start up | [] | closed | false | null | 0 | 2021-01-05T19:07:53Z | 2021-01-06T14:20:59Z | 2021-01-06T14:20:58Z | null | Currently if optional dependencies such as tensorflow, torch, apache_beam, faiss and elasticsearch are installed, then it takes a long time to do `import datasets` since it imports all of these heavy dependencies.
To make a fast start up for `datasets` I changed that so that they are not imported when `datasets` is being imported. On my side it changed the import time of `datasets` from 5sec to 0.5sec, which is enjoyable.
To be able to check if optional dependencies are available without importing them I'm using `importlib_metadata`, which is part of the standard lib in python>=3.8 and was backported. The difference with `importlib` is that it also enables to get the versions of the libraries without importing them.
I added this dependency in `setup.py`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 3,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1690/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1690/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1690.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1690",
"merged_at": "2021-01-06T14:20:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1690.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1690"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1061 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1061/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1061/comments | https://api.github.com/repos/huggingface/datasets/issues/1061/events | https://github.com/huggingface/datasets/pull/1061 | 756,362,661 | MDExOlB1bGxSZXF1ZXN0NTMxOTE5ODA0 | 1,061 | add labr dataset | [] | closed | false | null | 0 | 2020-12-03T16:38:57Z | 2020-12-03T18:25:44Z | 2020-12-03T18:25:44Z | null | Arabic Book Reviews dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1061/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1061/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1061.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1061",
"merged_at": "2020-12-03T18:25:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1061.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1061"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2355/comments | https://api.github.com/repos/huggingface/datasets/issues/2355/events | https://github.com/huggingface/datasets/pull/2355 | 890,484,408 | MDExOlB1bGxSZXF1ZXN0NjQzNDk5NTIz | 2,355 | normalized TOCs and titles in data cards | [] | closed | false | null | 3 | 2021-05-12T20:59:59Z | 2021-05-14T13:23:12Z | 2021-05-14T13:23:12Z | null | I started fixing some of the READMEs that were failing the tests introduced by @gchhablani but then realized that there were some consistent differences between earlier and newer versions of some of the titles (e.g. Data Splits vs Data Splits Sample Size, Supported Tasks vs Supported Tasks and Leaderboards). We also had different versions of the Table of Content
This PR normalizes all of them to the newer version | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2355/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2355.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2355",
"merged_at": "2021-05-14T13:23:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2355.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2355"
} | true | [
"Oh right! I'd be in favor of still having the same TOC across the board, we can either leave it as is or add a `[More Info Needed]` `Contributions` Section wherever it's currently missing, wdyt?",
"(I thought those were programmatically updated based on git history :D )",
"Merging for now to avoid conflict since there are so many changes but let's figure out the contributions section next ;) "
] |
https://api.github.com/repos/huggingface/datasets/issues/3503 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3503/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3503/comments | https://api.github.com/repos/huggingface/datasets/issues/3503/events | https://github.com/huggingface/datasets/issues/3503 | 1,090,472,735 | I_kwDODunzps5A_0sf | 3,503 | Batched in filter throws error | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2021-12-29T12:01:04Z | 2022-01-04T10:24:27Z | 2022-01-04T10:24:27Z | null | I hope this is really a bug, I could not find it among the open issues
## Describe the bug
using `batched=False` in DataSet.filter throws error
```python
TypeError: filter() got an unexpected keyword argument 'batched'
```
but in the docs it is lister as an argument.
## Steps to reproduce the bug
```python
task = "mnli"
max_length = 128
tokenizer = AutoTokenizer.from_pretrained("./pretrained_models/pretrained_models_drozd/sl250.m.gsic.titech.ac.jp:8000/21.11.17_06.30.32_roberta-base_a0057/checkpoints/smpl_400M/hf/")
dataset = load_dataset("glue", task)
task_to_keys = {
"cola": ("sentence", None),
"mnli": ("premise", "hypothesis"),
"mnli-mm": ("premise", "hypothesis"),
"mrpc": ("sentence1", "sentence2"),
"qnli": ("question", "sentence"),
"qqp": ("question1", "question2"),
"rte": ("sentence1", "sentence2"),
"sst2": ("sentence", None),
"stsb": ("sentence1", "sentence2"),
"wnli": ("sentence1", "sentence2"),
}
##### tokenization_parameters
sentence1_key, sentence2_key = task_to_keys[task]
def preprocess_function(examples, max_length):
if sentence2_key is None:
return tokenizer(
examples[sentence1_key], truncation=True, max_length=max_length
)
return tokenizer(
examples[sentence1_key],
examples[sentence2_key],
truncation=False,
padding="max_length",
max_length=max_length,
)
encoded_dataset = dataset.map(
lambda x: preprocess_function(x, max_length=max_length), batched=False
)
encoded_dataset.filter(lambda x: len(x['input_ids']) <= max_length, batched=False)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.1, 1.17.0
- Platform: ubuntu
- Python version: 3.8.12
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3503/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3503/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4375/comments | https://api.github.com/repos/huggingface/datasets/issues/4375/events | https://github.com/huggingface/datasets/pull/4375 | 1,241,921,147 | PR_kwDODunzps44IMCS | 4,375 | Support DataLoader with num_workers > 0 in streaming mode | [] | closed | false | null | 7 | 2022-05-19T15:00:31Z | 2022-07-04T16:05:14Z | 2022-06-10T20:47:27Z | null | ### Issue
It's currently not possible to properly stream a dataset using multiple `torch.utils.data.DataLoader` workers:
- the `TorchIterableDataset` can't be pickled and passed to the subprocesses: https://github.com/huggingface/datasets/issues/3950
- streaming extension is failing: https://github.com/huggingface/datasets/issues/3951
- `fsspec` doesn't work out of the box in subprocesses
### Solution in this PR
I fixed these to enable passing an `IterableDataset` to a `torch.utils.data.DataLoader` with `num_workers > 0`.
I also had to shard the `IterableDataset` to give each worker a shard, otherwise data would be duplicated. This is implemented in `TorchIterableDataset.__iter__` and uses the new `IterableDataset._iter_shard(shard_idx)` method
I also had to do a few changes the patching that enable streaming in dataset scripts:
- the patches are now always applied - not just for streaming mode. They're applied when a builder is instantiated
- I improved it to also check for renamed modules or attributes (ex: pandas vs pd)
- I grouped all the patches of pathlib.Path into a class `xPath`, so that `Path` outside of dataset scripts stay unchanged - otherwise I didn't change the content of the extended Path methods for streaming
- I fixed a bug with the `pd.read_csv` patch, opening the file in "rb" mode was missing and causing some datasets to not work in streaming mode, and compression inference was missing
### A few details regarding `fsspec` in multiprocessing
From https://github.com/fsspec/filesystem_spec/pull/963#issuecomment-1131709948 :
> Non-async instances might be safe in the forked child, if they hold no open files/sockets etc.; I'm not sure any implementations pass this test!
> If any async instance has been created, the newly forked processes must:
> 1. discard references to locks, threads and event loops and make new ones
> 2. not use any async fsspec instances from the parent process
> 3. clear all class instance caches
Therefore in a DataLoader's worker, I clear the reference to the loop and thread (1). We should be fine for 2 and 3 already since we don't use fsspec class instances from the parent process.
Fix https://github.com/huggingface/datasets/issues/3950
Fix https://github.com/huggingface/datasets/issues/3951
TODO:
- [x] fix tests | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4375/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4375",
"merged_at": "2022-06-10T20:47:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4375"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright this is finally ready for review ! It's quite long I'm sorry, but it's not easy to disentangle everything ^^'\r\n\r\nThe main additions are in\r\n- src/datasets/formatting/dataset_wrappers/torch_iterable_dataset.py\r\n- src/datasets/iterable_dataset.py\r\n- src/datasets/utils/patching.py",
"Added some comments and an error when lists have different lengths for sharding :)",
"Let's resolve the merge conflict and the CI error (if it's related to the changes), and I can review the PR again.",
"Feel free to review again :) The CI fail is unrelated to this PR and will be fixed by https://github.com/huggingface/datasets/pull/4472 (the hub now returns 401 instead of 404 for unauthenticated requests to non-existing repos)",
"CI failures are unrelated to this PR - merging :)\r\n\r\n(CI fails are a mix of pip install fails and Hub fails)",
"@lhoestq you're our hero :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/639/comments | https://api.github.com/repos/huggingface/datasets/issues/639/events | https://github.com/huggingface/datasets/pull/639 | 704,217,963 | MDExOlB1bGxSZXF1ZXN0NDg5MTgxOTY3 | 639 | Update glue QQP checksum | [] | closed | false | null | 0 | 2020-09-18T09:08:15Z | 2020-09-18T11:37:08Z | 2020-09-18T11:37:07Z | null | Fix #638 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/639/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/639.diff",
"html_url": "https://github.com/huggingface/datasets/pull/639",
"merged_at": "2020-09-18T11:37:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/639.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/639"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/533/comments | https://api.github.com/repos/huggingface/datasets/issues/533/events | https://github.com/huggingface/datasets/pull/533 | 685,585,914 | MDExOlB1bGxSZXF1ZXN0NDczMjg4OTgx | 533 | Fix ArrayXD for pyarrow 0.17.1 by using non fixed length list arrays | [] | closed | false | null | 0 | 2020-08-25T15:32:44Z | 2020-08-26T08:02:24Z | 2020-08-26T08:02:23Z | null | It should fix the CI problems in #513 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/533/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/533/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/533.diff",
"html_url": "https://github.com/huggingface/datasets/pull/533",
"merged_at": "2020-08-26T08:02:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/533.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/533"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5856 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5856/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5856/comments | https://api.github.com/repos/huggingface/datasets/issues/5856/events | https://github.com/huggingface/datasets/issues/5856 | 1,709,218,242 | I_kwDODunzps5l4JnC | 5,856 | Error loading natural_questions | [] | closed | false | null | 2 | 2023-05-15T02:46:04Z | 2023-06-05T09:11:19Z | 2023-06-05T09:11:18Z | null | ### Describe the bug
When try to load natural_questions through datasets == 2.12.0 with python == 3.8.9:
```python
import datasets
datasets.load_dataset('natural_questions',beam_runner='DirectRunner')
```
It failed with following info:
`pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs`
### Steps to reproduce the bug
In python console:
```python
import datasets
datasets.load_dataset('natural_questions',beam_runner='DirectRunner')
```
Then the trace is:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/nlp/.cache/pypoetry/virtualenvs/drg-W3LF4Ol9-py3.8/lib/python3.8/site-packages/datasets/load.py", line 1797, in load_dataset
builder_instance.download_and_prepare(
File "/home/nlp/.cache/pypoetry/virtualenvs/drg-W3LF4Ol9-py3.8/lib/python3.8/site-packages/datasets/builder.py", line 890, in download_and_prepare
self._download_and_prepare(
File "/home/nlp/.cache/pypoetry/virtualenvs/drg-W3LF4Ol9-py3.8/lib/python3.8/site-packages/datasets/builder.py", line 2019, in _download_and_prepare
num_examples, num_bytes = beam_writer.finalize(metrics.query(m_filter))
File "/home/nlp/.cache/pypoetry/virtualenvs/drg-W3LF4Ol9-py3.8/lib/python3.8/site-packages/datasets/arrow_writer.py", line 694, in finalize
shard_num_bytes, _ = parquet_to_arrow(source, destination)
File "/home/nlp/.cache/pypoetry/virtualenvs/drg-W3LF4Ol9-py3.8/lib/python3.8/site-packages/datasets/arrow_writer.py", line 737, in parquet_to_arrow
for record_batch in parquet_file.iter_batches():
File "pyarrow/_parquet.pyx", line 1323, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
```
### Expected behavior
load natural_question questions
### Environment info
```
- `datasets` version: 2.12.0
- Platform: Linux-3.10.0-1160.42.2.el7.x86_64-x86_64-with-glibc2.2.5
- Python version: 3.8.9
- Huggingface_hub version: 0.14.1
- PyArrow version: 11.0.0
- Pandas version: 2.0.1
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5856/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5856/timeline | null | completed | null | null | false | [
"Hi! You can avoid this error by using the preprocessed version:\r\n```python\r\nimport datasets\r\nds = datasets.load_dataset('natural_questions')\r\n```\r\n\r\nPS: Once we finish https://github.com/huggingface/datasets/pull/5364, this error will no longer be a problem.",
"> Hi! You can avoid this error by using the preprocessed version:\r\n> \r\n> ```python\r\n> import datasets\r\n> ds = datasets.load_dataset('natural_questions')\r\n> ```\r\n> \r\n> PS: Once we finish #5364, this error will no longer be a problem.\r\n\r\nThanks, wish #5364 finish early"
] |
https://api.github.com/repos/huggingface/datasets/issues/4899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4899/comments | https://api.github.com/repos/huggingface/datasets/issues/4899/events | https://github.com/huggingface/datasets/pull/4899 | 1,352,031,286 | PR_kwDODunzps492uTO | 4,899 | Re-add code and und language tags | [] | closed | false | null | 1 | 2022-08-26T09:48:57Z | 2022-08-26T10:27:18Z | 2022-08-26T10:24:20Z | null | This PR fixes the removal of 2 language tags done by:
- #4882
The tags are:
- "code": this is not a IANA tag but needed
- "und": this is one of the special scoped tags removed by 0d53202b9abce6fd0358cb00d06fcfd904b875af
- used in "mc4" and "udhr" datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4899/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4899.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4899",
"merged_at": "2022-08-26T10:24:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4899.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4899"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5625/comments | https://api.github.com/repos/huggingface/datasets/issues/5625/events | https://github.com/huggingface/datasets/issues/5625 | 1,618,971,855 | I_kwDODunzps5gf4zP | 5,625 | Allow "jsonl" data type signifier | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2023-03-10T13:21:48Z | 2023-03-11T10:35:39Z | null | null | ### Feature request
`load_dataset` currently does not accept `jsonl` as type but only `json`.
### Motivation
I was working with one of the `run_translation` scripts and used my own datasets (`.jsonl`) as train_dataset. But the default code did not work because
```
FileNotFoundError: Couldn't find a dataset script at jsonl\jsonl.py or any data file in the same directory. Couldn't find 'jsonl' on the Hugging Face Hub either: FileNotFoundError: Dataset 'jsonl' doesn't exist on the Hub. If the repo is private or gated, make sure to log in with `huggingface-cli login`.
```
The reason is because the script has these lines to extract the data type by its extension. Therefore, the derived type is `jsonl` which is not recognized by datasets as the error above shows.
https://github.com/huggingface/transformers/blob/ade26bf9912f69e2110137443e4406d7dbe253e7/examples/pytorch/translation/run_translation.py#L342-L356
I suppose you could argue that this is the script's fault (in which case I'll do a PR over at `transformers`) but it makes sense to me to add `jsonl` as an alias to `json` in `datasets`.
### Your contribution
At the moment I cannot work on this. I think it can be as "easy" as having an alias for json, namely jsonl. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5625/timeline | null | null | null | null | false | [
"You can use \"json\" instead. It doesn't work by extension names, but rather by dataset builder names, e.g. \"text\", \"imagefolder\", etc. I don't think the example in `transformers` is correct because of that",
"Yes, I understand the reasoning but this issue is to propose that the example in transformers (while incorrect) \"makes sense\" in terms of user expectation. So the question is whether it would be possible to add \"aliases\" for common types (like \"json\" and \"text\") based on common extensions (like jsonl and txt)?"
] |
https://api.github.com/repos/huggingface/datasets/issues/3305 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3305/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3305/comments | https://api.github.com/repos/huggingface/datasets/issues/3305/events | https://github.com/huggingface/datasets/pull/3305 | 1,059,161,000 | PR_kwDODunzps4uzZWv | 3,305 | asserts replaced with exception for ``fingerprint.py``, ``search.py``, ``arrow_writer.py`` and ``metric.py`` | [] | closed | false | null | 0 | 2021-11-20T14:51:23Z | 2021-11-22T18:24:32Z | 2021-11-22T17:08:13Z | null | Addresses #3171
Fixes exception for ``fingerprint.py``, ``search.py``, ``arrow_writer.py`` and ``metric.py`` and modified tests | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3305/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3305/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3305.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3305",
"merged_at": "2021-11-22T17:08:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3305.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3305"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2696/comments | https://api.github.com/repos/huggingface/datasets/issues/2696/events | https://github.com/huggingface/datasets/pull/2696 | 949,901,726 | MDExOlB1bGxSZXF1ZXN0Njk0NTMwODg3 | 2,696 | Add support for disable_progress_bar on Windows | [] | closed | false | null | 1 | 2021-07-21T16:34:53Z | 2021-07-26T13:31:14Z | 2021-07-26T09:38:37Z | null | This PR is a continuation of #2667 and adds support for `utils.disable_progress_bar()` on Windows when using multiprocessing. This [answer](https://stackoverflow.com/a/6596695/14095927) on SO explains it nicely why the current approach (with calling `utils.is_progress_bar_enabled()` inside `Dataset._map_single`) would not work on Windows. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2696/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2696/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2696.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2696",
"merged_at": "2021-07-26T09:38:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2696.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2696"
} | true | [
"The CI failure seems unrelated to this PR (probably has something to do with Transformers)."
] |
https://api.github.com/repos/huggingface/datasets/issues/5466 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5466/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5466/comments | https://api.github.com/repos/huggingface/datasets/issues/5466/events | https://github.com/huggingface/datasets/pull/5466 | 1,557,584,845 | PR_kwDODunzps5Ij-z1 | 5,466 | remove pathlib.Path with URIs | [] | closed | false | null | 5 | 2023-01-26T03:25:45Z | 2023-01-26T17:08:57Z | 2023-01-26T16:59:11Z | null | Pathlib will convert "//" to "/" which causes retry errors when downloading from cloud storage | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5466/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5466/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5466.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5466",
"merged_at": "2023-01-26T16:59:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5466.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5466"
} | true | [
"Thanks !\r\n`os.path.join` will use a backslash `\\` on windows which will also fail. You can use this instead in `load_from_disk`:\r\n```python\r\nfrom .filesystems import is_remote_filesystem\r\n\r\nis_local = not is_remote_filesystem(fs)\r\npath_join = os.path.join if is_local else posixpath.join\r\n```",
"Thank you ! I did a minor change to not have to define a new function and I ran the CI. If it's green we can merge :)",
"_The documentation is not available anymore as the PR was closed or merged._",
"> \r\n\r\n\r\n\r\n> Thank you ! I did a minor change to not have to define a new function and I ran the CI. If it's green we can merge :)\r\n\r\nlol it's a battle of +1 imports or +1 functions. LGTM, I was editing fast and swapped which branch gets os vs Path. Should be ok now 🤙",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012043 / 0.011353 (0.000690) | 0.006585 / 0.011008 (-0.004423) | 0.149007 / 0.038508 (0.110499) | 0.039514 / 0.023109 (0.016405) | 0.403893 / 0.275898 (0.127995) | 0.431252 / 0.323480 (0.107772) | 0.009218 / 0.007986 (0.001233) | 0.006108 / 0.004328 (0.001779) | 0.114666 / 0.004250 (0.110416) | 0.044962 / 0.037052 (0.007910) | 0.411592 / 0.258489 (0.153103) | 0.461561 / 0.293841 (0.167721) | 0.059958 / 0.128546 (-0.068589) | 0.029047 / 0.075646 (-0.046599) | 0.456000 / 0.419271 (0.036728) | 0.060744 / 0.043533 (0.017211) | 0.415816 / 0.255139 (0.160677) | 0.430488 / 0.283200 (0.147289) | 0.122477 / 0.141683 (-0.019205) | 1.862910 / 1.452155 (0.410755) | 1.974698 / 1.492716 (0.481981) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.257230 / 0.018006 (0.239224) | 0.606854 / 0.000490 (0.606364) | 0.006175 / 0.000200 (0.005975) | 0.000099 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030533 / 0.037411 (-0.006879) | 0.130702 / 0.014526 (0.116177) | 0.143781 / 0.176557 (-0.032775) | 0.183272 / 0.737135 (-0.553863) | 0.151267 / 0.296338 (-0.145071) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.637422 / 0.215209 (0.422213) | 6.503535 / 2.077655 (4.425880) | 2.630387 / 1.504120 (1.126267) | 2.281180 / 1.541195 (0.739985) | 2.354341 / 1.468490 (0.885851) | 1.306497 / 4.584777 (-3.278280) | 5.837184 / 3.745712 (2.091472) | 3.257198 / 5.269862 (-2.012663) | 2.050681 / 4.565676 (-2.514995) | 0.146415 / 0.424275 (-0.277860) | 0.015386 / 0.007607 (0.007779) | 0.790146 / 0.226044 (0.564102) | 8.056137 / 2.268929 (5.787209) | 3.383566 / 55.444624 (-52.061059) | 2.707620 / 6.876477 (-4.168856) | 2.714857 / 2.142072 (0.572785) | 1.520847 / 4.805227 (-3.284380) | 0.266028 / 6.500664 (-6.234636) | 0.091422 / 0.075469 (0.015953) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.656148 / 1.841788 (-0.185640) | 18.833393 / 8.074308 (10.759085) | 21.360824 / 10.191392 (11.169432) | 0.227608 / 0.680424 (-0.452816) | 0.049018 / 0.534201 (-0.485183) | 0.593418 / 0.579283 (0.014135) | 0.656690 / 0.434364 (0.222326) | 0.709171 / 0.540337 (0.168833) | 0.828226 / 1.386936 (-0.558710) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010112 / 0.011353 (-0.001241) | 0.006761 / 0.011008 (-0.004247) | 0.146723 / 0.038508 (0.108215) | 0.038451 / 0.023109 (0.015342) | 0.524267 / 0.275898 (0.248369) | 0.609484 / 0.323480 (0.286004) | 0.008502 / 0.007986 (0.000516) | 0.006964 / 0.004328 (0.002635) | 0.111396 / 0.004250 (0.107146) | 0.056839 / 0.037052 (0.019787) | 0.514649 / 0.258489 (0.256160) | 0.604212 / 0.293841 (0.310372) | 0.061410 / 0.128546 (-0.067137) | 0.020396 / 0.075646 (-0.055250) | 0.505026 / 0.419271 (0.085754) | 0.067280 / 0.043533 (0.023747) | 0.522249 / 0.255139 (0.267110) | 0.559484 / 0.283200 (0.276284) | 0.120943 / 0.141683 (-0.020740) | 2.124323 / 1.452155 (0.672169) | 2.153397 / 1.492716 (0.660681) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216614 / 0.018006 (0.198608) | 0.594181 / 0.000490 (0.593692) | 0.004079 / 0.000200 (0.003879) | 0.000117 / 0.000054 (0.000063) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036925 / 0.037411 (-0.000486) | 0.131322 / 0.014526 (0.116797) | 0.148542 / 0.176557 (-0.028015) | 0.196045 / 0.737135 (-0.541090) | 0.156867 / 0.296338 (-0.139472) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.669722 / 0.215209 (0.454513) | 6.858856 / 2.077655 (4.781202) | 3.093969 / 1.504120 (1.589849) | 2.667385 / 1.541195 (1.126190) | 2.797192 / 1.468490 (1.328702) | 1.334759 / 4.584777 (-3.250018) | 6.024861 / 3.745712 (2.279149) | 3.257779 / 5.269862 (-2.012083) | 2.202816 / 4.565676 (-2.362860) | 0.147617 / 0.424275 (-0.276658) | 0.015451 / 0.007607 (0.007844) | 0.887015 / 0.226044 (0.660970) | 8.371288 / 2.268929 (6.102360) | 3.807451 / 55.444624 (-51.637173) | 3.079483 / 6.876477 (-3.796994) | 3.103321 / 2.142072 (0.961249) | 1.520272 / 4.805227 (-3.284955) | 0.273079 / 6.500664 (-6.227585) | 0.088613 / 0.075469 (0.013143) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.818913 / 1.841788 (-0.022875) | 19.274269 / 8.074308 (11.199960) | 19.871784 / 10.191392 (9.680392) | 0.250388 / 0.680424 (-0.430036) | 0.030562 / 0.534201 (-0.503638) | 0.560566 / 0.579283 (-0.018717) | 0.664701 / 0.434364 (0.230337) | 0.714513 / 0.540337 (0.174176) | 0.827227 / 1.386936 (-0.559710) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3724/comments | https://api.github.com/repos/huggingface/datasets/issues/3724/events | https://github.com/huggingface/datasets/issues/3724 | 1,138,827,681 | I_kwDODunzps5D4SGh | 3,724 | Bug while streaming CSV dataset with pandas 1.4 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-02-15T15:16:19Z | 2022-02-15T16:55:44Z | 2022-02-15T16:55:44Z | null | ## Describe the bug
If we upgrade to pandas `1.4`, the patching of the pandas module is no longer working
```
AttributeError: '_PatchedModuleObj' object has no attribute '__version__'
```
## Steps to reproduce the bug
```
pip install pandas==1.4
```
```python
from datasets import load_dataset
ds = load_dataset("lvwerra/red-wine", split="train", streaming=True)
item = next(iter(ds))
item
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3724/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3209/comments | https://api.github.com/repos/huggingface/datasets/issues/3209/events | https://github.com/huggingface/datasets/issues/3209 | 1,044,505,771 | I_kwDODunzps4-QeSr | 3,209 | Unpin keras once TF fixes its release | [] | closed | false | null | 0 | 2021-11-04T09:15:32Z | 2021-11-05T10:57:37Z | 2021-11-05T10:57:37Z | null | Related to:
- #3208 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3209/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3209/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2834 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2834/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2834/comments | https://api.github.com/repos/huggingface/datasets/issues/2834/events | https://github.com/huggingface/datasets/pull/2834 | 978,309,749 | MDExOlB1bGxSZXF1ZXN0NzE4OTE5NjQ0 | 2,834 | Fix IndexError by ignoring empty RecordBatch | [] | closed | false | null | 0 | 2021-08-24T17:06:13Z | 2021-08-24T17:21:18Z | 2021-08-24T17:21:18Z | null | We need to ignore the empty record batches for the interpolation search to work correctly when querying arrow tables
Close #2833
cc @SaulLu | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2834/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2834/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2834.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2834",
"merged_at": "2021-08-24T17:21:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2834.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2834"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4974 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4974/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4974/comments | https://api.github.com/repos/huggingface/datasets/issues/4974/events | https://github.com/huggingface/datasets/pull/4974 | 1,371,682,020 | PR_kwDODunzps4-4Iri | 4,974 | [GH->HF] Part 2: Remove all dataset scripts from github | [] | closed | false | null | 6 | 2022-09-13T16:01:12Z | 2022-10-03T17:09:39Z | 2022-10-03T17:07:32Z | null | Now that all the datasets live on the Hub we can remove the /datasets directory that contains all the dataset scripts of this repository
- [x] Needs https://github.com/huggingface/datasets/pull/4973 to be merged first
- [x] and PR to be enabled on the Hub for non-namespaced datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4974/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4974/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4974.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4974",
"merged_at": "2022-10-03T17:07:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4974.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4974"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"So this means metrics will be deleted from this repo in favor of the \"evaluate\" library? Maybe you guys could just redirect metrics to that library.",
"We are deprecating the metrics in `datasets` indeed and suggest users to switch to `evaluate` (via a warning message)\r\n\r\nWe'll keep the current metrics as they are for now, but they'll be completely removed at one point",
"I guess this is ready to merge ?\r\n\r\nIt should break nothing except one rare case:\r\n\r\nIf someone is using an old version of `datasets` to try to load a recent dataset. Indeed in that case it fetches the `main` branch on github to see if it exists. But since we're removing all the datasets, forward fetching won't work anymore.\r\n\r\ne.g. if someone uses \"imagenet-1k\" with a version of `datasets` that didn't have it at that time. I checked on kibana and one single user would be affected with 4k downloads/months. It should still work for them though thanks to the `datasets` cache\r\n\r\nBut if they delete their cache, the workaround is... 🥁 update `datasets` 😅",
"Let's merge this on monday if we can, to make sure contributors who wanted to merge their dataset PRs here could do it",
"Alright, merging !"
] |
https://api.github.com/repos/huggingface/datasets/issues/5829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5829/comments | https://api.github.com/repos/huggingface/datasets/issues/5829/events | https://github.com/huggingface/datasets/issues/5829 | 1,699,958,189 | I_kwDODunzps5lU02t | 5,829 | (mach-o file, but is an incompatible architecture (have 'arm64', need 'x86_64')) | [] | closed | false | null | 2 | 2023-05-08T10:07:14Z | 2023-06-30T11:39:14Z | 2023-05-09T00:46:42Z | null | ### Describe the bug
M2 MBP can't run
```python
from datasets import load_dataset
jazzy = load_dataset("nomic-ai/gpt4all-j-prompt-generations", revision='v1.2-jazzy')
```
### Steps to reproduce the bug
1. Use M2 MBP
2. Python 3.10.10 from pyenv
3. Run
```
from datasets import load_dataset
jazzy = load_dataset("nomic-ai/gpt4all-j-prompt-generations", revision='v1.2-jazzy')
```
### Expected behavior
Be able to run normally
### Environment info
```
from datasets import load_dataset
jazzy = load_dataset("nomic-ai/gpt4all-j-prompt-generations", revision='v1.2-jazzy')
```
OSX: 13.2
CPU: M2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5829/timeline | null | completed | null | null | false | [
"Can you paste the error stack trace?",
"That is weird. I can't reproduce it again after reboot.\r\n```python\r\nIn [2]: import platform\r\n\r\nIn [3]: platform.platform()\r\nOut[3]: 'macOS-13.2-arm64-arm-64bit'\r\n\r\nIn [4]: from datasets import load_dataset\r\n ...:\r\n ...: jazzy = load_dataset(\"nomic-ai/gpt4all-j-prompt-generations\", revision='v1.2-jazzy')\r\nFound cached dataset parquet (/Users/sarit/.cache/huggingface/datasets/nomic-ai___parquet/nomic-ai--gpt4all-j-prompt-generations-a3b62015e2e52043/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec)\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 63.25it/s]\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/2789 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2789/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2789/comments | https://api.github.com/repos/huggingface/datasets/issues/2789/events | https://github.com/huggingface/datasets/pull/2789 | 967,361,934 | MDExOlB1bGxSZXF1ZXN0NzA5NTQwMzY5 | 2,789 | Updated dataset description of DaNE | [] | closed | false | null | 1 | 2021-08-11T19:58:48Z | 2021-08-12T16:10:59Z | 2021-08-12T16:06:01Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2789/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2789/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2789.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2789",
"merged_at": "2021-08-12T16:06:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2789.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2789"
} | true | [
"Thanks for finishing it @albertvillanova "
] |
https://api.github.com/repos/huggingface/datasets/issues/5542 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5542/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5542/comments | https://api.github.com/repos/huggingface/datasets/issues/5542/events | https://github.com/huggingface/datasets/pull/5542 | 1,588,633,724 | PR_kwDODunzps5KLjMl | 5,542 | Avoid saving sparse ChunkedArrays in pyarrow tables | [] | closed | false | null | 2 | 2023-02-17T01:52:38Z | 2023-02-17T19:20:49Z | 2023-02-17T11:12:32Z | null | Fixes https://github.com/huggingface/datasets/issues/5541 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5542/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5542/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5542.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5542",
"merged_at": "2023-02-17T11:12:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5542.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5542"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008452 / 0.011353 (-0.002901) | 0.004500 / 0.011008 (-0.006508) | 0.100103 / 0.038508 (0.061595) | 0.029395 / 0.023109 (0.006286) | 0.297740 / 0.275898 (0.021842) | 0.359132 / 0.323480 (0.035652) | 0.007045 / 0.007986 (-0.000941) | 0.003415 / 0.004328 (-0.000913) | 0.076389 / 0.004250 (0.072138) | 0.036612 / 0.037052 (-0.000440) | 0.308773 / 0.258489 (0.050284) | 0.345701 / 0.293841 (0.051860) | 0.033230 / 0.128546 (-0.095317) | 0.011463 / 0.075646 (-0.064183) | 0.322382 / 0.419271 (-0.096890) | 0.041194 / 0.043533 (-0.002339) | 0.300685 / 0.255139 (0.045546) | 0.323076 / 0.283200 (0.039876) | 0.087330 / 0.141683 (-0.054353) | 1.508661 / 1.452155 (0.056506) | 1.531776 / 1.492716 (0.039059) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.188391 / 0.018006 (0.170385) | 0.400102 / 0.000490 (0.399612) | 0.002006 / 0.000200 (0.001806) | 0.000075 / 0.000054 (0.000021) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023232 / 0.037411 (-0.014179) | 0.097313 / 0.014526 (0.082787) | 0.106244 / 0.176557 (-0.070313) | 0.141180 / 0.737135 (-0.595955) | 0.107871 / 0.296338 (-0.188468) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418610 / 0.215209 (0.203400) | 4.162243 / 2.077655 (2.084588) | 1.884300 / 1.504120 (0.380180) | 1.694197 / 1.541195 (0.153002) | 1.727740 / 1.468490 (0.259250) | 0.692129 / 4.584777 (-3.892648) | 3.364230 / 3.745712 (-0.381482) | 1.871507 / 5.269862 (-3.398355) | 1.261520 / 4.565676 (-3.304156) | 0.083258 / 0.424275 (-0.341017) | 0.012479 / 0.007607 (0.004872) | 0.528802 / 0.226044 (0.302757) | 5.281029 / 2.268929 (3.012100) | 2.402222 / 55.444624 (-53.042403) | 2.064954 / 6.876477 (-4.811522) | 2.027044 / 2.142072 (-0.115029) | 0.813124 / 4.805227 (-3.992103) | 0.149397 / 6.500664 (-6.351267) | 0.065032 / 0.075469 (-0.010437) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.239192 / 1.841788 (-0.602595) | 13.529913 / 8.074308 (5.455605) | 14.253251 / 10.191392 (4.061859) | 0.165145 / 0.680424 (-0.515278) | 0.028367 / 0.534201 (-0.505834) | 0.395121 / 0.579283 (-0.184162) | 0.405372 / 0.434364 (-0.028992) | 0.472201 / 0.540337 (-0.068137) | 0.560620 / 1.386936 (-0.826316) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006368 / 0.011353 (-0.004985) | 0.004542 / 0.011008 (-0.006466) | 0.076361 / 0.038508 (0.037853) | 0.026893 / 0.023109 (0.003784) | 0.341210 / 0.275898 (0.065312) | 0.378377 / 0.323480 (0.054898) | 0.004833 / 0.007986 (-0.003153) | 0.003358 / 0.004328 (-0.000970) | 0.075516 / 0.004250 (0.071265) | 0.038841 / 0.037052 (0.001788) | 0.342230 / 0.258489 (0.083741) | 0.384317 / 0.293841 (0.090476) | 0.031874 / 0.128546 (-0.096672) | 0.011651 / 0.075646 (-0.063995) | 0.085816 / 0.419271 (-0.333455) | 0.042389 / 0.043533 (-0.001144) | 0.340678 / 0.255139 (0.085539) | 0.367441 / 0.283200 (0.084241) | 0.089748 / 0.141683 (-0.051935) | 1.487358 / 1.452155 (0.035203) | 1.615049 / 1.492716 (0.122333) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220933 / 0.018006 (0.202926) | 0.397162 / 0.000490 (0.396673) | 0.002336 / 0.000200 (0.002136) | 0.000069 / 0.000054 (0.000015) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025004 / 0.037411 (-0.012407) | 0.100877 / 0.014526 (0.086351) | 0.110624 / 0.176557 (-0.065932) | 0.152042 / 0.737135 (-0.585094) | 0.112951 / 0.296338 (-0.183388) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441071 / 0.215209 (0.225862) | 4.419471 / 2.077655 (2.341817) | 2.082976 / 1.504120 (0.578856) | 1.884023 / 1.541195 (0.342828) | 1.950590 / 1.468490 (0.482100) | 0.706104 / 4.584777 (-3.878673) | 3.329825 / 3.745712 (-0.415887) | 1.868850 / 5.269862 (-3.401011) | 1.178785 / 4.565676 (-3.386892) | 0.083910 / 0.424275 (-0.340365) | 0.012296 / 0.007607 (0.004689) | 0.542998 / 0.226044 (0.316953) | 5.429944 / 2.268929 (3.161015) | 2.502285 / 55.444624 (-52.942339) | 2.150507 / 6.876477 (-4.725970) | 2.170492 / 2.142072 (0.028420) | 0.813410 / 4.805227 (-3.991817) | 0.152310 / 6.500664 (-6.348354) | 0.066999 / 0.075469 (-0.008470) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.290839 / 1.841788 (-0.550949) | 14.089491 / 8.074308 (6.015183) | 13.704922 / 10.191392 (3.513530) | 0.130089 / 0.680424 (-0.550335) | 0.017000 / 0.534201 (-0.517201) | 0.381173 / 0.579283 (-0.198110) | 0.389271 / 0.434364 (-0.045093) | 0.461700 / 0.540337 (-0.078637) | 0.556428 / 1.386936 (-0.830508) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4703/comments | https://api.github.com/repos/huggingface/datasets/issues/4703/events | https://github.com/huggingface/datasets/pull/4703 | 1,307,844,097 | PR_kwDODunzps47kABf | 4,703 | Make cast in `from_pandas` more robust | [] | closed | false | null | 1 | 2022-07-18T11:55:49Z | 2022-07-22T11:17:42Z | 2022-07-22T11:05:24Z | null | Make the cast in `from_pandas` more robust (as it was done for the packaged modules in https://github.com/huggingface/datasets/pull/4364)
This should be useful in situations like [this one](https://discuss.huggingface.co/t/loading-custom-audio-dataset-and-fine-tuning-model/8836/4). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4703/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4703",
"merged_at": "2022-07-22T11:05:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4703"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2294 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2294/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2294/comments | https://api.github.com/repos/huggingface/datasets/issues/2294/events | https://github.com/huggingface/datasets/issues/2294 | 872,136,075 | MDU6SXNzdWU4NzIxMzYwNzU= | 2,294 | Slow #0 when using map to tokenize. | [] | open | false | null | 3 | 2021-04-30T08:00:33Z | 2021-05-04T11:00:11Z | null | null | Hi, _datasets_ is really amazing! I am following [run_mlm_no_trainer.py](url) to pre-train BERT, and it uses `tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
)` to tokenize by multiprocessing. However, I have found that when `num_proc`>1,the process _#0_ is much slower than others.
It looks like this:

It takes more than 12 hours for #0, while others just about half an hour. Could anyone tell me it is normal or not, and is there any methods to speed up it?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2294/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2294/timeline | null | null | null | null | false | [
"Hi ! Have you tried other values for `preprocessing_num_workers` ? Is it always process 0 that is slower ?\r\nThere are no difference between process 0 and the others except that it processes the first shard of the dataset.",
"Hi, I have found the reason of it. Before using the map function to tokenize the data, I concatenate the wikipedia and bookcorpus first, like this:\r\n```if args.dataset_name1 is not None:\r\n dataset1 = load_dataset(args.dataset_name1, args.dataset_config_name1, split=\"train\")\r\n dataset1 = dataset1.remove_columns('title')\r\n if args.dataset_name2 is not None:\r\n dataset2 = load_dataset(args.dataset_name2, args.dataset_config_name2,split=\"train\")\r\n assert dataset1.features.type == dataset2.features.type, str(dataset1.features.type)+';'+str(dataset2.features.type)\r\n datasets12 = concatenate_datasets([dataset1, dataset2], split='train')\r\n```\r\nWhen I just use one datasets, e.g. wikipedia, the problem seems no longer exist:\r\n\r\n\r\nBookcorpus has more row numbers than Wikipedia, however, it takes much more time to process each batch of wiki than that of bookcorpus. When we first concatenate two datasets and then use _map_ to process the concatenated datasets, e.g. `num_proc=5`, process 0 has to process all of the wikipedia data, causing the problem that #0 takes a longer time to finish the job. \r\n\r\nThe problem is caused by the different characteristic of different datasets. One solution might be using _map_ first to process two datasets seperately, then concatenate the tokenized and processed datasets before input to the `Dataloader`.\r\n\r\n",
"That makes sense ! You can indeed use `map` on both datasets separately and then concatenate.\r\nAnother option is to concatenate, then shuffle, and then `map`."
] |
https://api.github.com/repos/huggingface/datasets/issues/1274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1274/comments | https://api.github.com/repos/huggingface/datasets/issues/1274/events | https://github.com/huggingface/datasets/pull/1274 | 758,943,174 | MDExOlB1bGxSZXF1ZXN0NTM0MDI0MTQx | 1,274 | oclar-dataset | [] | closed | false | null | 1 | 2020-12-07T23:56:45Z | 2020-12-09T15:36:08Z | 2020-12-09T15:36:08Z | null | Opinion Corpus for Lebanese Arabic Reviews (OCLAR) corpus is utilizable for Arabic sentiment classification on reviews, including hotels, restaurants, shops, and others. : [homepage](http://archive.ics.uci.edu/ml/datasets/Opinion+Corpus+for+Lebanese+Arabic+Reviews+%28OCLAR%29#) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1274/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1274.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1274",
"merged_at": "2020-12-09T15:36:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1274.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1274"
} | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/3682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3682/comments | https://api.github.com/repos/huggingface/datasets/issues/3682/events | https://github.com/huggingface/datasets/pull/3682 | 1,124,434,330 | PR_kwDODunzps4yGFml | 3,682 | adding told-br for toxic/abusive hatespeech detection | [] | closed | false | null | 2 | 2022-02-04T17:18:29Z | 2022-02-07T03:23:24Z | 2022-02-04T17:36:40Z | null | Hey,
I'm adding our dataset from our paper published at AACL 2020. Feel free to ask for modifications.
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3682/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3682.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3682",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3682.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3682"
} | true | [
"Sorry for using multiple github accounts, I didn't notice I was using my professional account to commit/push. Please consider this @JAugusto97 account as the correct one.",
"Will remake the PR with the correct github account."
] |
https://api.github.com/repos/huggingface/datasets/issues/862 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/862/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/862/comments | https://api.github.com/repos/huggingface/datasets/issues/862/events | https://github.com/huggingface/datasets/pull/862 | 744,906,131 | MDExOlB1bGxSZXF1ZXN0NTIyNTUzMzY1 | 862 | Update head requests | [] | closed | false | null | 0 | 2020-11-17T16:49:06Z | 2020-11-18T14:43:53Z | 2020-11-18T14:43:50Z | null | Get requests and Head requests didn't have the same parameters. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/862/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/862/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/862",
"merged_at": "2020-11-18T14:43:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/862"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4805 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4805/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4805/comments | https://api.github.com/repos/huggingface/datasets/issues/4805/events | https://github.com/huggingface/datasets/issues/4805 | 1,332,653,531 | I_kwDODunzps5Pbq3b | 4,805 | Wrong example in opus_gnome dataset card | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-08-09T03:21:27Z | 2022-08-09T11:52:05Z | 2022-08-09T11:52:05Z | null | ## Describe the bug
I found that [the example on opus_gone dataset ](https://github.com/huggingface/datasets/tree/main/datasets/opus_gnome#dataset-summary) doesn't work.
## Steps to reproduce the bug
```python
load_dataset("gnome", lang1="it", lang2="pl")
```
`"gnome"` should be `"opus_gnome"`
## Expected results
```bash
100%
1/1 [00:00<00:00, 42.09it/s]
DatasetDict({
train: Dataset({
features: ['id', 'translation'],
num_rows: 8368
})
})
```
## Actual results
```bash
Couldn't find 'gnome' on the Hugging Face Hub either: FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/main/datasets/gnome/gnome.py
```
## Environment info
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-120-generic-x86_64-with-glibc2.27
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4805/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4805/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/348/comments | https://api.github.com/repos/huggingface/datasets/issues/348/events | https://github.com/huggingface/datasets/pull/348 | 652,158,308 | MDExOlB1bGxSZXF1ZXN0NDQ1MjgwNjk3 | 348 | Add OSCAR dataset | [] | closed | false | null | 20 | 2020-07-07T09:22:07Z | 2021-05-03T22:07:08Z | 2021-02-09T10:19:19Z | null | I don't know if tests pass, when I run them it tries to download the whole corpus which is around 3.5TB compressed and I don't have that kind of space. I'll really need some help with it 😅
Thanks! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 4,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/348/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/348.diff",
"html_url": "https://github.com/huggingface/datasets/pull/348",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/348.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/348"
} | true | [
"@pjox I think the tests don't pass because you haven't provided any dummy data (`dummy_data.zip`).\r\n\r\n ",
"> @pjox I think the tests don't pass because you haven't provided any dummy data (`dummy_data.zip`).\r\n\r\nBut can I do the dummy data without running `python nlp-cli test datasets/<your-dataset-folder> --save_infos --all_configs` first? 🤔 ",
"You make a good point! Do you know how big is it uncompressed?",
"Between 7T and 9T I think.",
"Hi ! I've been busy but I plan to compute the missing metadata soon !\r\nLooking forward to be able to load a memory mapped version of OSCAR :) ",
"> Hi ! I've been busy but I plan to compute the missing metadata soon !\r\n> Looking forward to be able to load a memory mapped version of OSCAR :)\r\n\r\nAmazing! Thanks! 😄 ",
"Hi there, are there any plans to complete this issue soon? I'm planning to use this dataset on a project. Let me know if there's anything I can do to help to finish this 🤗 ",
"Yes it will be added soon :) \r\nRecently the OSCAR data files were moved to another host. We just need to update the script and compute the dataset_infos.json (it will probably take a few days).",
"@lhoestq I've seen in oscar.py that it isn't a dataset script with manual download way. Is that correct? \r\nSome time ago, @pjox had some troubles with his servers providing that dataset 'cause it's really huge. Providing it on an automatic download way seems to be a little bit dangerous for me 😄 ",
"Now thanks to @pjox 's help OSCAR is hosted on HF's S3, which is probably more robust that the previous servers :)\r\n\r\nAlso small update on my side:\r\nI launched the computation of the dataset_infos.json file, it will take a few days.",
"Now it seems to be a good plan for me 🤗 ",
"But is there a plan to provide the OSCAR's unshuffled version too?",
"The one we have on S3 is currently the unshuffled version",
"I've thought that you won't provide the unshuffled version 'cause this comment on oscar.py:\r\n\r\n`# TODO(oscar): Implement unshuffled OSCAR`\r\n\r\n",
"That TODO is normal, I haven't touched the python script in months (I haven't had the time, sorry), but I guess @lhoestq fixed the paths if he's already working on the metadata. In any case from now on, only the unshuffled versions of OSCAR will be distributed through the hf/datasets library as in any case it is the version most people use to train language models.\r\n\r\nIf for any reason, you need the shuffled version it will always be available on the [OSCAR website](https://oscar-corpus.com).\r\n\r\nAlso future versions of OSCAR will be unshuffled only.",
"Should we close this PR now that the other one was merged?",
"Sure.\r\nClosing since #1694 is merged",
"@lhoestq just a little detail, is the Oscar version that HF offers the same one that was available on INRIA? By that I mean, have you done any further filtering or removing of data inside it? Thanks a lot! ",
"Hello @jchwenger, this is exactly the same (unshuffled) version that's available at Inria. Sadly no further filtering is provided, but after the latest OSCAR audit (https://arxiv.org/abs/2103.12028) we're already working on future versions of OSCAR that will be \"filtered\" and that will be available on the OSCAR website and hopefully here as well.",
"@pjox brilliant, in my case I was hoping it would be unfiltered, good news!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3248 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3248/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3248/comments | https://api.github.com/repos/huggingface/datasets/issues/3248/events | https://github.com/huggingface/datasets/pull/3248 | 1,050,171,082 | PR_kwDODunzps4uXZzU | 3,248 | Stream from Google Drive and other hosts | [] | closed | false | null | 3 | 2021-11-10T18:32:32Z | 2021-11-30T16:03:43Z | 2021-11-12T17:18:11Z | null | Streaming from Google Drive is a bit more challenging than the other host we've been supporting:
- the download URL must be updated to add the confirm token obtained by HEAD request
- it requires to use cookies to keep the connection alive
- the URL doesn't tell any information about whether the file is compressed or not
Therefore I did two things:
- I added a step for URL and headers/cookies preparation in the StreamingDownloadManager
- I added automatic compression type inference by reading the [magic number](https://en.wikipedia.org/wiki/List_of_file_signatures)
This allows to do do fancy things like
```python
from datasets.utils.streaming_download_manager import StreamingDownloadManager, xopen, xjoin, xglob
# zip file containing a train.tsv file
url = "https://drive.google.com/uc?export=download&id=1k92sUfpHxKq8PXWRr7Y5aNHXwOCNUmqh"
extracted = StreamingDownloadManager().download_and_extract(url)
for inner_file in xglob(xjoin(extracted, "*.tsv")):
with xopen(inner_file) as f:
# streaming starts here
for line in f:
print(line)
```
This should make around 80 datasets streamable. It concerns those hosted on Google Drive but also any dataset for which the URL doesn't give any information about compression. Here is the full list:
```
amazon_polarity, ami, arabic_billion_words, ascent_kb, asset, big_patent, billsum, capes, cmrc2018, cnn_dailymail,
code_x_glue_cc_code_completion_token, code_x_glue_cc_code_refinement, code_x_glue_cc_code_to_code_trans,
code_x_glue_tt_text_to_text, conll2002, craigslist_bargains, dbpedia_14, docred, ehealth_kd, emo, euronews, germeval_14,
gigaword, grail_qa, great_code, has_part, head_qa, health_fact, hope_edi, id_newspapers_2018,
igbo_english_machine_translation, irc_disentangle, jfleg, jnlpba, journalists_questions, kor_ner, linnaeus, med_hop, mrqa,
mt_eng_vietnamese, multi_news, norwegian_ner, offcombr, offenseval_dravidian, para_pat, peoples_daily_ner, pn_summary,
poleval2019_mt, pubmed_qa, qangaroo, reddit_tifu, refresd, ro_sts_parallel, russian_super_glue, samsum, sberquad, scielo,
search_qa, species_800, spider, squad_adversarial, tamilmixsentiment, tashkeela, ted_talks_iwslt, trec, turk, turkish_ner,
twi_text_c3, universal_morphologies, web_of_science, weibo_ner, wiki_bio, wiki_hop, wiki_lingua, wiki_summary, wili_2018,
wisesight1000, wnut_17, yahoo_answers_topics, yelp_review_full, yoruba_text_c3
```
Some of them may not work if the host doesn't support HTTP range requests for example
Fix https://github.com/huggingface/datasets/issues/2742
Fix https://github.com/huggingface/datasets/issues/3188 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3248/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3248/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3248.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3248",
"merged_at": "2021-11-12T17:18:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3248.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3248"
} | true | [
"I just tried some datasets and noticed that `spider` is not working for some reason (the compression type is not recognized), resulting in FileNotFoundError. I can take a look tomorrow",
"I'm fixing the remaining files based on TAR archives",
"THANKS A LOT"
] |
https://api.github.com/repos/huggingface/datasets/issues/5196 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5196/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5196/comments | https://api.github.com/repos/huggingface/datasets/issues/5196/events | https://github.com/huggingface/datasets/pull/5196 | 1,434,401,646 | PR_kwDODunzps5CH439 | 5,196 | Use hfh hf_hub_url function | [] | closed | false | null | 9 | 2022-11-03T10:08:09Z | 2022-12-06T11:38:17Z | 2022-11-09T07:15:12Z | null | Small refactoring to use `hf_hub_url` function from `huggingface_hub`.
This PR also creates the `hub` module that will contain all `huggingface_hub` functionalities relevant to `datasets`.
This is a necessary stage before implementing the use of the `hfh` caching system (which uses its `hf_hub_url` under the hood).
EDIT:
~~Finally, we use our `config.HUB_DATASETS_URL` when using `hfh.hf_hub_url`~~
There is a breaking change: the `hfh` `hf_hub_url` function uses
- `hfh` `HUGGINGFACE_CO_URL_TEMPLATE` URL template, different from the `datasets` `config.HUB_DATASETS_URL`
- also, `hfh` `DEFAULT_REVISION`, instead of `datasets` `config.HUB_DEFAULT_VERSION` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5196/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5196/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5196.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5196",
"merged_at": "2022-11-09T07:15:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5196.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5196"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5196). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq I think we should first agree if `datasets` can introduce the breaking change of ignoring `config.HUB_DATASETS_URL`: some users may have override this.\r\n\r\nIf so, I then would suggest to initiate a deprecation cycle.",
"After a discussion with the rest of the datasets team, we agreed we can introduce the breaking change of ignoring `config.HUB_DATASETS_URL`: this will have minimal impact, only for **private Hubs**. We will address eventual possible impacts in the future.\r\n\r\nAdditionally, we also ignore `config.HUB_DEFAULT_VERSION`.\r\n\r\nSee explanation in this PR description: https://github.com/huggingface/datasets/pull/5196#issue-1434401646",
"I'm trying to upgrade datasets to 2.7.0 in https://github.com/huggingface/datasets-server, and the tests fail due to this change. I think it's a breaking change (that was not listed in https://github.com/huggingface/datasets/releases/tag/2.7.0) since code that previously worked (by setting `datasets.config.HUB_DATASETS_URL = CI_HUB_DATASETS_URL` for example) does not work anymore.\r\n\r\nI'm not sure what is the correct way to set up the tests; besides setting the env var \"HF_ENDPOINT\" before launching the tests (which, I think, is not a good way to do: the tests should not depend on the environment).",
"OK, I re-read this thread, and https://github.com/huggingface/datasets/pull/5196#issuecomment-1307430175 explicitely states that `config.HUB_DATASETS_URL` (as well as `config.HUB_DEFAULT_VERSION`) is now ignored. I was expecting the breaking changes to be listed in the release notes: https://github.com/huggingface/datasets/releases/tag/2.7.0.",
"> I'm not sure what is the correct way to set up the tests; besides setting the env var \"HF_ENDPOINT\" before launching the tests (which, I think, is not a good way to do: the tests should not depend on the environment).\r\n\r\nI think the current workaround of settings an env variable before launching the tests is \"not so bad\" when considering the fact that env variables are evaluated at import time in `huggingface_hub` (and most probable `datasets` as well). I think that when refactoring this in huggingface_hub (https://github.com/huggingface/huggingface_hub/issues/1172) I'll opt for instantiating a `Settings` object (or `Constants`) that contains all the settings variables. This way it will not be possible to import attributes individually + tests would be easier. As I see it, it would be similar to [what `Pydantic` does](https://pydantic-docs.helpmanual.io/usage/settings/) even though we most probably don't want Pydantic as a root dependency just for that. ",
"You can use fixtures in your tests:\r\n```python\r\nCI_HUB_ENDPOINT = \"https://hub-ci.huggingface.co\"\r\nCI_HUB_DATASETS_URL = CI_HUB_ENDPOINT + \"/datasets/{repo_id}/resolve/{revision}/{path}\"\r\nCI_HFH_HUGGINGFACE_CO_URL_TEMPLATE = CI_HUB_ENDPOINT + \"/{repo_id}/resolve/{revision}/{filename}\"\r\n\r\[email protected]\r\ndef ci_hfh_hf_hub_url(monkeypatch):\r\n monkeypatch.setattr(\r\n \"huggingface_hub.file_download.HUGGINGFACE_CO_URL_TEMPLATE\", CI_HFH_HUGGINGFACE_CO_URL_TEMPLATE\r\n )\r\n\r\[email protected]\r\ndef ci_hub_config(monkeypatch):\r\n monkeypatch.setattr(\"datasets.config.HF_ENDPOINT\", CI_HUB_ENDPOINT)\r\n monkeypatch.setattr(\"datasets.config.HUB_DATASETS_URL\", CI_HUB_DATASETS_URL)\r\n```\r\n\r\nand use `@pytest.fixture(autouse=True)` if you want to always use the CI endpoints.\r\n\r\nAnd when `huggingface-hub` and `datasets` change the way we can set the endpoint, we'll just need to update the fixtures.\r\nI think ultimately you'll only have to change the `huggingface-hub` endpoint settings\r\n",
"OK.\r\n\r\nIn fact, in datasets-server we set `config.HUB_DATASETS_URL` (https://github.com/huggingface/datasets-server/blob/35a30dbcd687b26db1f02502ea8305f70c064473/workers/splits/src/splits/config.py#L26) at config time, before starting the workers. It's not an issue with how to launch the tests, but with the app in itself.\r\n\r\nI understand that for now, the only way to fix this is to setup `HF_ENDPOINT` in the env when launching the app (currently, we set the endpoint with `COMMON_HF_ENDPOINT`, a custom env var I set to be sure not to have side-effects)",
"> You can use fixtures in your tests:\r\n\r\nThanks, used in https://github.com/huggingface/datasets-server/pull/644."
] |
https://api.github.com/repos/huggingface/datasets/issues/4450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4450/comments | https://api.github.com/repos/huggingface/datasets/issues/4450/events | https://github.com/huggingface/datasets/pull/4450 | 1,261,878,324 | PR_kwDODunzps45Kzwh | 4,450 | Update README.md of fquad | [] | closed | false | null | 1 | 2022-06-06T13:52:41Z | 2022-06-06T14:51:49Z | 2022-06-06T14:43:03Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4450/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4450.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4450",
"merged_at": "2022-06-06T14:43:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4450.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4450"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1586/comments | https://api.github.com/repos/huggingface/datasets/issues/1586/events | https://github.com/huggingface/datasets/pull/1586 | 768,864,502 | MDExOlB1bGxSZXF1ZXN0NTQxMTY0MDc2 | 1,586 | added irc disentangle dataset | [] | closed | false | null | 5 | 2020-12-16T13:25:58Z | 2021-01-29T10:28:53Z | 2021-01-29T10:28:53Z | null | added irc disentanglement dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1586/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1586.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1586",
"merged_at": "2021-01-29T10:28:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1586.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1586"
} | true | [
"@lhoestq sorry, this was the only way I was able to fix the pull request ",
"@lhoestq Thank you for the feedback. I wondering whether I should be passing an 'id' field in the dictionary since the 'connections' reference the 'id' of the linked messages. This 'id' would just be the same as the id_ that is in the yielded tuple.",
"Yes indeed it would be cool to have the ids in the dictionary. This way the dataset can be shuffled and all without losing information about the connections. Can you add it if you don't mind ?",
"Thanks :) could you also add the ids in the dictionary since they're useful for the connection links ?",
"Thanks !\r\nAlso it looks like the dummy_data.zip were regenerated and are now back to being too big (300KB each).\r\nCan you reduce their sizes ? You can actually just revert to the ones you had before the last commit"
] |
https://api.github.com/repos/huggingface/datasets/issues/4902 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4902/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4902/comments | https://api.github.com/repos/huggingface/datasets/issues/4902/events | https://github.com/huggingface/datasets/issues/4902 | 1,352,469,196 | I_kwDODunzps5QnQrM | 4,902 | Name the default config `default` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | 1 | 2022-08-26T16:16:22Z | 2023-07-24T21:15:31Z | 2023-07-24T21:15:31Z | null | Currently, if a dataset has no configuration, a default configuration is created from the dataset name.
For example, for a dataset loaded from the hub repository, such as https://huggingface.co/datasets/user/dataset (repo id is `user/dataset`), the default configuration will be `user--dataset`.
It might be easier to handle to set it to `default`, or another reserved word. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4902/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4902/timeline | null | completed | null | null | false | [
"Addressed in #5331."
] |
https://api.github.com/repos/huggingface/datasets/issues/4989 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4989/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4989/comments | https://api.github.com/repos/huggingface/datasets/issues/4989/events | https://github.com/huggingface/datasets/issues/4989 | 1,376,832,233 | I_kwDODunzps5SEMrp | 4,989 | Running add_column() seems to corrupt existing sequence-type column info | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-09-17T17:42:05Z | 2022-09-19T12:54:54Z | 2022-09-19T12:54:54Z | null | I have a dataset that contains a column ("foo") that is a sequence type of length 4. So when I run .to_pandas() on it, the resulting dataframe correctly contains 4 columns - foo_0, foo_1, foo_2, foo_3. So the 1st row of the dataframe might look like:
ds = load_dataset(...)
df = ds.to_pandas()
df:
foo_0 | foo_1 | foo_2 | foo_3
0.0 | 1.0 | 2.0 | 3.0
If I run .add_column("new_col", data) on the dataset, and then .to_pandas() on the resulting new dataset, the resulting dataframe contains only 2 columns - foo, new_col. The values in column foo are lists of length 4, the 4 elements that should have been split into separate columns. Dataframe 1st row would be:
ds = load_dataset(...)
new_ds = ds.add_column("new_col", data)
df = new_ds.to_pandas()
df:
foo | new_col
[0.0, 1.0, 2.0, 3.0] | new_val
I've explored the 2 datasets in a debugger and haven't noticed any changes to any attributes related to the foo column, but I can't determine why the dataframes are so different. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4989/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4989/timeline | null | completed | null | null | false | [
"Nevermind, I was incorrect."
] |
https://api.github.com/repos/huggingface/datasets/issues/5083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5083/comments | https://api.github.com/repos/huggingface/datasets/issues/5083/events | https://github.com/huggingface/datasets/issues/5083 | 1,399,842,514 | I_kwDODunzps5Tb-bS | 5,083 | Support numpy/torch/tf/jax formatting for IterableDataset | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
},
{
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues",
"id": 3761482852,
"name": "good second issue",
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue"
}
] | open | false | null | 0 | 2022-10-06T15:14:58Z | 2023-02-17T14:10:01Z | null | null | Right now `IterableDataset` doesn't do any formatting.
In particular this code should return a numpy array:
```python
from datasets import load_dataset
ds = load_dataset("imagenet-1k", split="train", streaming=True).with_format("np")
print(next(iter(ds))["image"])
```
Right now it returns a PIL.Image.
Setting `streaming=False` does return a numpy array after #5072 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5083/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5083/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4915 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4915/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4915/comments | https://api.github.com/repos/huggingface/datasets/issues/4915/events | https://github.com/huggingface/datasets/issues/4915 | 1,356,009,042 | I_kwDODunzps5Q0w5S | 4,915 | FileNotFoundError while downloading wikipedia dataset for any language | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 5 | 2022-08-30T16:15:46Z | 2022-12-04T22:20:33Z | null | null | ## Describe the bug
Hi, I am currently trying to download wikipedia dataset using
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner'). However, I end up in getting filenotfound error. I get this error for any language I try to download.
Environment:
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("wikipedia", language="aa", date="20220401", split="train",beam_runner='DirectRunner')
```
## Expected results
to load the dataset
## Actual results
I am pasting the error trace here:
Downloading builder script: 35.9kB [00:00, ?B/s]
Downloading metadata: 30.4kB [00:00, 1.94MB/s]
Using custom data configuration 20220401.aa-date=20220401,language=aa
Downloading and preparing dataset wikipedia/20220401.aa to C:\Users\Shilpa\.cache\huggingface\datasets\wikipedia\20220401.aa-date=20220401,language=aa\2.0.0\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559...
Downloading data: 100%|████████████████████████████████████████████████████████████| 11.1k/11.1k [00:00<00:00, 712kB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.82s/it]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████| 1/1 [00:00<?, ?it/s]
Downloading data: 100%|███████████████████████████████████████████████████████████| 35.6k/35.6k [00:00<00:00, 84.3kB/s]
Downloading data files: 100%|████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.93s/it]
Traceback (most recent call last):
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1571, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "G:\Python3.7\lib\site-packages\apache_beam\io\iobase.py", line 1193, in process
self.writer = self.sink.open_writer(init_result, str(uuid.uuid4()))
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 202, in open_writer
return FileBasedSinkWriter(self, writer_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 419, in __init__
self.temp_handle = self.sink.open(temp_shard_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\parquetio.py", line 553, in open
self._file_handle = super().open(temp_path)
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 139, in open
temp_path, self.mime_type, self.compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filesystems.py", line 224, in create
return filesystem.create(path, mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 163, in create
return self._path_open(path, 'wb', mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 140, in _path_open
raw_file = io.open(path, mode)
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\Shilpa\\.cache\\huggingface\\datasets\\wikipedia\\20220401.aa-date=20220401,language=aa\\2.0.0\\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559.incomplete\\beam-temp-wikipedia-train-880233e8287e11edaf9d3ca067f2714e\\20a05238-6106-4420-a713-4eca6dd5959a.wikipedia-train'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "G:/abc/temp.py", line 32, in <module>
beam_runner='DirectRunner')
File "G:\Python3.7\lib\site-packages\datasets\load.py", line 1751, in load_dataset
use_auth_token=use_auth_token,
File "G:\Python3.7\lib\site-packages\datasets\builder.py", line 705, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "G:\Python3.7\lib\site-packages\datasets\builder.py", line 1394, in _download_and_prepare
pipeline_results = pipeline.run()
File "G:\Python3.7\lib\site-packages\apache_beam\pipeline.py", line 574, in run
return self.runner.run_pipeline(self, self._options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\direct\direct_runner.py", line 131, in run_pipeline
return runner.run_pipeline(pipeline, options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 201, in run_pipeline
options)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 212, in run_via_runner_api
return self.run_stages(stage_context, stages)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 443, in run_stages
runner_execution_context, bundle_context_manager, bundle_input)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 776, in _execute_bundle
bundle_manager))
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 1000, in _run_bundle
data_input, data_output, input_timers, expected_timer_output)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\fn_runner.py", line 1309, in process_bundle
result_future = self._worker_handler.control_conn.push(process_bundle_req)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\portability\fn_api_runner\worker_handlers.py", line 380, in push
response = self.worker.do_instruction(request)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\sdk_worker.py", line 598, in do_instruction
getattr(request, request_type), request.instruction_id)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\sdk_worker.py", line 635, in process_bundle
bundle_processor.process_bundle(instruction_id))
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 1004, in process_bundle
element.data)
File "G:\Python3.7\lib\site-packages\apache_beam\runners\worker\bundle_processor.py", line 227, in process_encoded
self.output(decoded_value)
File "apache_beam\runners\worker\operations.py", line 526, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam\runners\worker\operations.py", line 528, in apache_beam.runners.worker.operations.Operation.output
File "apache_beam\runners\worker\operations.py", line 237, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 324, in apache_beam.runners.worker.operations.GeneralPurposeConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 905, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 623, in apache_beam.runners.common.SimpleInvoker.invoke_process
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1491, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1581, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "apache_beam\runners\common.py", line 1694, in apache_beam.runners.common._OutputHandler._write_value_to_tag
File "apache_beam\runners\worker\operations.py", line 240, in apache_beam.runners.worker.operations.SingletonElementConsumerSet.receive
File "apache_beam\runners\worker\operations.py", line 907, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\worker\operations.py", line 908, in apache_beam.runners.worker.operations.DoOperation.process
File "apache_beam\runners\common.py", line 1419, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 1507, in apache_beam.runners.common.DoFnRunner._reraise_augmented
File "apache_beam\runners\common.py", line 1417, in apache_beam.runners.common.DoFnRunner.process
File "apache_beam\runners\common.py", line 837, in apache_beam.runners.common.PerWindowInvoker.invoke_process
File "apache_beam\runners\common.py", line 981, in apache_beam.runners.common.PerWindowInvoker._invoke_process_per_window
File "apache_beam\runners\common.py", line 1571, in apache_beam.runners.common._OutputHandler.handle_process_outputs
File "G:\Python3.7\lib\site-packages\apache_beam\io\iobase.py", line 1193, in process
self.writer = self.sink.open_writer(init_result, str(uuid.uuid4()))
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 202, in open_writer
return FileBasedSinkWriter(self, writer_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 419, in __init__
self.temp_handle = self.sink.open(temp_shard_path)
File "G:\Python3.7\lib\site-packages\apache_beam\io\parquetio.py", line 553, in open
self._file_handle = super().open(temp_path)
File "G:\Python3.7\lib\site-packages\apache_beam\options\value_provider.py", line 193, in _f
return fnc(self, *args, **kwargs)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filebasedsink.py", line 139, in open
temp_path, self.mime_type, self.compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\filesystems.py", line 224, in create
return filesystem.create(path, mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 163, in create
return self._path_open(path, 'wb', mime_type, compression_type)
File "G:\Python3.7\lib\site-packages\apache_beam\io\localfilesystem.py", line 140, in _path_open
raw_file = io.open(path, mode)
RuntimeError: FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\Shilpa\\.cache\\huggingface\\datasets\\wikipedia\\20220401.aa-date=20220401,language=aa\\2.0.0\\aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559.incomplete\\beam-temp-wikipedia-train-880233e8287e11edaf9d3ca067f2714e\\20a05238-6106-4420-a713-4eca6dd5959a.wikipedia-train' [while running 'train/Save to parquet/Write/WriteImpl/WriteBundles']
## Environment info
Python: 3.7.6
Windows 10 Pro
datasets :2.4.0
apache_beam: 2.41.0
mwparserfromhell: 0.6.4
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4915/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4915/timeline | null | reopened | null | null | false | [
"Hi @Shilpac20,\r\n\r\nAs explained in the Wikipedia dataset card: https://huggingface.co/datasets/wikipedia\r\n> You can find the full list of languages and dates [here](https://dumps.wikimedia.org/backup-index.html).\r\n\r\nThis means that, before passing a specific date, you should first make sure it is available online, as Wikimedia only keeps last X months (depending on the size of the corresponding language dump)): e.g. to see which dates \"aa\" Wikipedia is available online, see https://dumps.wikimedia.org/aawiki/ (as of today 2022-08-31, the available dates are from [20220401](https://dumps.wikimedia.org/aawiki/20220401/) to [20220820](https://dumps.wikimedia.org/aawiki/20220820/)).",
"Hi, the date that I have specified \"20220401\" is available for the language \"aa\". The error persists for any other available dates as present in https://dumps.wikimedia.org/aawiki/. The error is mainly due to apache beam not able to write the downloaded files. Any help on this?",
"I see, sorry, I misread your issue.\r\n\r\nWe are investigating this.",
"I am struggling with basically the same issue. I am trying to download the German Wikipedia dump.\r\n\r\nAs per the [documentation](https://huggingface.co/datasets/wikipedia), `\"20220301.de\"` should be available as a pre-processed dataset.\r\n\r\nIssuing the command mentioned in the documentation cited above\r\n\r\n from datasets import load_dataset\r\n load_dataset(\"wikipedia\", \"20220301.de\")\r\n\r\nraises the following `FileNotFound` error\r\n\r\n FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/dewiki/20220301/dumpstatus.json\r\n\r\nUsing the ([undocumented](https://huggingface.co/docs/datasets/v1.2.1/package_reference/loading_methods.html#datasets.load_dataset)?) call to `load_dataset()` with `language` and `date` parameters\r\n\r\n load_dataset(\"wikipedia\", language=\"de\", date=\"20220301\", beam_runner=\"DirectRunner\")\r\n\r\nproduces the same error.\r\n\r\nEDIT: as I am using `datasets` v2.7.1, I should be looking at [that version's documentation](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/loading_methods#datasets.load_dataset)! It is mentioned there, that additional `kwargs` are \"passed to the [BuilderConfig](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/builder_classes#datasets.BuilderConfig) and used in the [DatasetBuilder](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/builder_classes#datasets.DatasetBuilder)\". So I guess that is how `language` and `date` are used.\r\n\r\nAs I can see a folder `20221130` on `https://dumps.wikimedia.org/dewiki/`, I also tried\r\n\r\n from datasets import load_dataset\r\n load_dataset(\"wikipedia\", \"20221130.de\")\r\n\r\nwhich throws another error:\r\n\r\n ValueError: BuilderConfig 20221120.de not found. Available: ['20220301.aa', ... '20220301.de', ...\r\n\r\nbasically telling me that the dataset I originally requested (`'20220301.de'`) is available...\r\n\r\nIt seems that `load_dataset` is not handling the vanishing older dumps for Wikipedia correctly?",
"I am able to start downloading the dataset when trying anything with the recent dumps for 20221201. But obviously, those are the big wiki dumps and I need the smaller preloaded version.\r\n\r\nI am now getting some error when the files show up in my cache but it will say FileNotFoundError at the end of the download for some reason. The cache directory to the datasets\\wikipedia\\date.bn\\ had something in it, then when the error came up it disappeared. \r\n\r\nIt is easy to test with the langauge \"bn\" because the amount of files is low.\r\n\r\ndataset = load_dataset('wikipedia', date=\"20221201\", language=\"bn\", split='train', beam_runner='DirectRunner')"
] |
https://api.github.com/repos/huggingface/datasets/issues/5028 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5028/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5028/comments | https://api.github.com/repos/huggingface/datasets/issues/5028/events | https://github.com/huggingface/datasets/issues/5028 | 1,386,272,533 | I_kwDODunzps5SoNcV | 5,028 | passing parameters to the method passed to Dataset.from_generator() | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2022-09-26T15:20:06Z | 2022-10-03T13:00:00Z | 2022-10-03T13:00:00Z | null | Big thanks for providing dataset creation via a generator.
I want to ask whether there is any way that parameters can be passed to the method Dataset.from_generator() method, like as follows.
```
from datasets import Dataset
def gen(param1):
for idx in len(custom_dataset):
yield custom_dataset[idx] + param1
ds = Dataset.from_generator(gen(param1))
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5028/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5028/timeline | null | completed | null | null | false | [
"Hi! Yes, you can either use the `gen_kwargs` param in `Dataset.from_generator` (`ds = Dataset.from_generator(gen, gen_kwargs={\"param1\": val})`) or wrap the generator function with `functools.partial`\r\n(`ds = Dataset.from_generator(functools.partial(gen, param1=\"val\"))`) to pass custom parameters to it.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4652/comments | https://api.github.com/repos/huggingface/datasets/issues/4652/events | https://github.com/huggingface/datasets/issues/4652 | 1,296,697,498 | I_kwDODunzps5NSgia | 4,652 | Add Sentence Compression Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2022-07-07T02:13:46Z | 2022-07-14T02:11:48Z | 2022-07-14T02:11:48Z | null | ## Adding a Dataset
- **Name:** *Sentence Compression*
- **Description:** *Large corpus of uncompressed and compressed sentences from news articles.*
- **Paper:** *https://www.aclweb.org/anthology/D13-1155/*
- **Data:** *https://github.com/google-research-datasets/sentence-compression/tree/master/data*
- **Motivation:** *Dataset for training and evaluating models of conversational response*
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4652/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4652/timeline | null | completed | null | null | false | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/sentence-compression)."
] |
https://api.github.com/repos/huggingface/datasets/issues/3440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3440/comments | https://api.github.com/repos/huggingface/datasets/issues/3440/events | https://github.com/huggingface/datasets/issues/3440 | 1,081,528,426 | I_kwDODunzps5AdtBq | 3,440 | datasets keeps reading from cached files, although I disabled it | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-12-15T21:26:22Z | 2022-02-24T09:12:22Z | 2022-02-24T09:12:22Z | null | ## Describe the bug
Hi,
I am trying to avoid dataset library using cached files, I get the following bug when this tried to read the cached files. I tried to do the followings:
```
from datasets import set_caching_enabled
set_caching_enabled(False)
```
also force redownlaod:
```
download_mode='force_redownload'
```
but none worked so far, this is on a cluster and on some of the machines this reads from the cached files, I really appreciate any idea on how to fully remove caching @lhoestq
many thanks
```
File "run_clm.py", line 496, in <module>
main()
File "run_clm.py", line 419, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 943, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/transformers/trainer.py", line 1445, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 172, in evaluate
output = self.eval_loop(
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 241, in eval_loop
metrics = self.compute_pet_metrics(eval_datasets, model, self.extra_info[metric_key_prefix], task=task)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 268, in compute_pet_metrics
centroids = self._compute_per_token_train_centroids(model, task=task)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 353, in _compute_per_token_train_centroids
data = get_label_samples(self.get_per_task_train_dataset(task), label)
File "/users/dara/codes/fewshot/debug/fewshot/third_party/trainers/trainer.py", line 350, in get_label_samples
return dataset.filter(lambda example: int(example['labels']) == label)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 470, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/fingerprint.py", line 406, in wrapper
out = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2519, in filter
indices = self.map(
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2036, in map
return self._map_single(
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 503, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 470, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/fingerprint.py", line 406, in wrapper
out = func(self, *args, **kwargs)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2248, in _map_single
return Dataset.from_file(cache_file_name, info=info, split=self.split)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 654, in from_file
return cls(
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 593, in __init__
self.info.features = self.info.features.reorder_fields_as(inferred_features)
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/features/features.py", line 1092, in reorder_fields_as
return Features(recursive_reorder(self, other))
File "/users/dara/conda/envs/multisuccess/lib/python3.8/site-packages/datasets/features/features.py", line 1081, in recursive_reorder
raise ValueError(f"Keys mismatch: between {source} and {target}" + stack_position)
ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'candidates_ids': Sequence(feature=Value(dtype='null', id=None), length=-1, id=None), 'labels': Value(dtype='int64', id=None), 'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None), 'input_ids': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None), 'extra_fields': {}, 'task': Value(dtype='string', id=None)}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: linux
- Python version: 3.8.12
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3440/timeline | null | completed | null | null | false | [
"Hi ! What version of `datasets` are you using ? Can you also provide the logs you get before it raises the error ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/6083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6083/comments | https://api.github.com/repos/huggingface/datasets/issues/6083/events | https://github.com/huggingface/datasets/pull/6083 | 1,824,832,348 | PR_kwDODunzps5WkgAI | 6,083 | set dev version | [] | closed | false | null | 3 | 2023-07-27T17:10:41Z | 2023-07-27T17:22:05Z | 2023-07-27T17:11:01Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6083/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6083/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6083.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6083",
"merged_at": "2023-07-27T17:11:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6083.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6083"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6083). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006049 / 0.011353 (-0.005304) | 0.003698 / 0.011008 (-0.007310) | 0.080614 / 0.038508 (0.042106) | 0.060955 / 0.023109 (0.037846) | 0.337119 / 0.275898 (0.061221) | 0.369544 / 0.323480 (0.046064) | 0.004681 / 0.007986 (-0.003305) | 0.002892 / 0.004328 (-0.001436) | 0.062907 / 0.004250 (0.058657) | 0.049235 / 0.037052 (0.012183) | 0.338842 / 0.258489 (0.080353) | 0.371172 / 0.293841 (0.077331) | 0.027016 / 0.128546 (-0.101530) | 0.007940 / 0.075646 (-0.067706) | 0.260902 / 0.419271 (-0.158369) | 0.044566 / 0.043533 (0.001034) | 0.342354 / 0.255139 (0.087215) | 0.359829 / 0.283200 (0.076629) | 0.020801 / 0.141683 (-0.120881) | 1.444111 / 1.452155 (-0.008044) | 1.515595 / 1.492716 (0.022879) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.183446 / 0.018006 (0.165439) | 0.437071 / 0.000490 (0.436581) | 0.003124 / 0.000200 (0.002924) | 0.000067 / 0.000054 (0.000013) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023760 / 0.037411 (-0.013651) | 0.072812 / 0.014526 (0.058286) | 0.082790 / 0.176557 (-0.093766) | 0.146330 / 0.737135 (-0.590805) | 0.084469 / 0.296338 (-0.211870) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.395215 / 0.215209 (0.180006) | 3.953023 / 2.077655 (1.875369) | 1.914268 / 1.504120 (0.410148) | 1.710195 / 1.541195 (0.169001) | 1.782594 / 1.468490 (0.314104) | 0.503651 / 4.584777 (-4.081126) | 3.039656 / 3.745712 (-0.706056) | 4.364691 / 5.269862 (-0.905171) | 2.597762 / 4.565676 (-1.967915) | 0.057384 / 0.424275 (-0.366891) | 0.006419 / 0.007607 (-0.001188) | 0.467214 / 0.226044 (0.241169) | 4.661425 / 2.268929 (2.392497) | 2.341957 / 55.444624 (-53.102667) | 1.977598 / 6.876477 (-4.898878) | 2.178005 / 2.142072 (0.035933) | 0.588492 / 4.805227 (-4.216735) | 0.124972 / 6.500664 (-6.375692) | 0.060902 / 0.075469 (-0.014567) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.243092 / 1.841788 (-0.598695) | 18.369971 / 8.074308 (10.295663) | 13.939700 / 10.191392 (3.748308) | 0.149275 / 0.680424 (-0.531149) | 0.016873 / 0.534201 (-0.517328) | 0.334245 / 0.579283 (-0.245038) | 0.353832 / 0.434364 (-0.080532) | 0.382720 / 0.540337 (-0.157617) | 0.534634 / 1.386936 (-0.852302) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005933 / 0.011353 (-0.005420) | 0.003695 / 0.011008 (-0.007313) | 0.063457 / 0.038508 (0.024949) | 0.062347 / 0.023109 (0.039238) | 0.412370 / 0.275898 (0.136472) | 0.450399 / 0.323480 (0.126920) | 0.004627 / 0.007986 (-0.003358) | 0.002822 / 0.004328 (-0.001507) | 0.063819 / 0.004250 (0.059569) | 0.049154 / 0.037052 (0.012101) | 0.428196 / 0.258489 (0.169707) | 0.464109 / 0.293841 (0.170268) | 0.026967 / 0.128546 (-0.101579) | 0.007876 / 0.075646 (-0.067770) | 0.068479 / 0.419271 (-0.350793) | 0.041080 / 0.043533 (-0.002453) | 0.399817 / 0.255139 (0.144678) | 0.426900 / 0.283200 (0.143701) | 0.019931 / 0.141683 (-0.121752) | 1.461642 / 1.452155 (0.009487) | 1.529314 / 1.492716 (0.036598) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230256 / 0.018006 (0.212249) | 0.423442 / 0.000490 (0.422952) | 0.002492 / 0.000200 (0.002292) | 0.000072 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025798 / 0.037411 (-0.011613) | 0.077361 / 0.014526 (0.062836) | 0.088454 / 0.176557 (-0.088102) | 0.142137 / 0.737135 (-0.594998) | 0.088213 / 0.296338 (-0.208125) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417656 / 0.215209 (0.202447) | 4.157095 / 2.077655 (2.079440) | 2.132863 / 1.504120 (0.628743) | 1.967220 / 1.541195 (0.426025) | 2.020505 / 1.468490 (0.552015) | 0.496835 / 4.584777 (-4.087942) | 2.989251 / 3.745712 (-0.756462) | 2.849315 / 5.269862 (-2.420546) | 1.848941 / 4.565676 (-2.716736) | 0.057307 / 0.424275 (-0.366968) | 0.006825 / 0.007607 (-0.000782) | 0.489103 / 0.226044 (0.263059) | 4.904776 / 2.268929 (2.635847) | 2.593914 / 55.444624 (-52.850710) | 2.253384 / 6.876477 (-4.623093) | 2.426384 / 2.142072 (0.284312) | 0.592467 / 4.805227 (-4.212760) | 0.126122 / 6.500664 (-6.374542) | 0.063160 / 0.075469 (-0.012309) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.313020 / 1.841788 (-0.528768) | 18.343984 / 8.074308 (10.269676) | 13.763060 / 10.191392 (3.571668) | 0.146312 / 0.680424 (-0.534111) | 0.016980 / 0.534201 (-0.517221) | 0.339572 / 0.579283 (-0.239711) | 0.351310 / 0.434364 (-0.083054) | 0.397616 / 0.540337 (-0.142721) | 0.536879 / 1.386936 (-0.850057) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009979 / 0.011353 (-0.001374) | 0.005024 / 0.011008 (-0.005984) | 0.096566 / 0.038508 (0.058058) | 0.081181 / 0.023109 (0.058072) | 0.398415 / 0.275898 (0.122517) | 0.513971 / 0.323480 (0.190491) | 0.006716 / 0.007986 (-0.001269) | 0.004350 / 0.004328 (0.000022) | 0.071418 / 0.004250 (0.067168) | 0.065002 / 0.037052 (0.027949) | 0.424791 / 0.258489 (0.166302) | 0.442369 / 0.293841 (0.148528) | 0.054540 / 0.128546 (-0.074007) | 0.014067 / 0.075646 (-0.061580) | 0.368930 / 0.419271 (-0.050341) | 0.082468 / 0.043533 (0.038935) | 0.419875 / 0.255139 (0.164736) | 0.508308 / 0.283200 (0.225108) | 0.050411 / 0.141683 (-0.091272) | 1.582271 / 1.452155 (0.130116) | 1.842033 / 1.492716 (0.349317) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290427 / 0.018006 (0.272420) | 0.594736 / 0.000490 (0.594246) | 0.007058 / 0.000200 (0.006858) | 0.000149 / 0.000054 (0.000095) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027085 / 0.037411 (-0.010326) | 0.087626 / 0.014526 (0.073101) | 0.094299 / 0.176557 (-0.082257) | 0.160169 / 0.737135 (-0.576966) | 0.101474 / 0.296338 (-0.194864) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.545845 / 0.215209 (0.330636) | 5.674389 / 2.077655 (3.596734) | 2.489065 / 1.504120 (0.984945) | 2.166674 / 1.541195 (0.625479) | 2.166925 / 1.468490 (0.698434) | 0.791244 / 4.584777 (-3.793533) | 4.944878 / 3.745712 (1.199165) | 4.121628 / 5.269862 (-1.148234) | 2.701262 / 4.565676 (-1.864415) | 0.087609 / 0.424275 (-0.336666) | 0.006945 / 0.007607 (-0.000662) | 0.668478 / 0.226044 (0.442434) | 6.552813 / 2.268929 (4.283885) | 3.164698 / 55.444624 (-52.279927) | 2.447333 / 6.876477 (-4.429144) | 2.608271 / 2.142072 (0.466198) | 0.954202 / 4.805227 (-3.851025) | 0.187730 / 6.500664 (-6.312934) | 0.063229 / 0.075469 (-0.012240) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.461042 / 1.841788 (-0.380746) | 21.601409 / 8.074308 (13.527101) | 18.553604 / 10.191392 (8.362212) | 0.234571 / 0.680424 (-0.445853) | 0.027119 / 0.534201 (-0.507082) | 0.423448 / 0.579283 (-0.155835) | 0.556397 / 0.434364 (0.122033) | 0.493958 / 0.540337 (-0.046379) | 0.711345 / 1.386936 (-0.675591) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008637 / 0.011353 (-0.002716) | 0.014450 / 0.011008 (0.003442) | 0.084135 / 0.038508 (0.045627) | 0.080513 / 0.023109 (0.057403) | 0.557941 / 0.275898 (0.282042) | 0.563199 / 0.323480 (0.239719) | 0.006475 / 0.007986 (-0.001510) | 0.004407 / 0.004328 (0.000078) | 0.088537 / 0.004250 (0.084287) | 0.060871 / 0.037052 (0.023819) | 0.593077 / 0.258489 (0.334588) | 0.615572 / 0.293841 (0.321732) | 0.050157 / 0.128546 (-0.078389) | 0.014313 / 0.075646 (-0.061333) | 0.091784 / 0.419271 (-0.327487) | 0.065649 / 0.043533 (0.022116) | 0.532569 / 0.255139 (0.277430) | 0.580775 / 0.283200 (0.297575) | 0.036434 / 0.141683 (-0.105249) | 2.080051 / 1.452155 (0.627896) | 1.907430 / 1.492716 (0.414713) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.297763 / 0.018006 (0.279757) | 0.670408 / 0.000490 (0.669918) | 0.000467 / 0.000200 (0.000267) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030297 / 0.037411 (-0.007114) | 0.100310 / 0.014526 (0.085784) | 0.113158 / 0.176557 (-0.063398) | 0.149599 / 0.737135 (-0.587536) | 0.102620 / 0.296338 (-0.193718) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.616588 / 0.215209 (0.401379) | 6.572262 / 2.077655 (4.494608) | 2.830748 / 1.504120 (1.326628) | 2.478441 / 1.541195 (0.937246) | 2.573017 / 1.468490 (1.104527) | 0.844154 / 4.584777 (-3.740623) | 5.161625 / 3.745712 (1.415913) | 4.541114 / 5.269862 (-0.728748) | 2.907804 / 4.565676 (-1.657872) | 0.097044 / 0.424275 (-0.327231) | 0.008692 / 0.007607 (0.001085) | 0.806640 / 0.226044 (0.580595) | 7.620521 / 2.268929 (5.351593) | 3.587100 / 55.444624 (-51.857524) | 2.901319 / 6.876477 (-3.975157) | 3.091288 / 2.142072 (0.949215) | 1.056109 / 4.805227 (-3.749118) | 0.209860 / 6.500664 (-6.290804) | 0.079575 / 0.075469 (0.004106) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.966194 / 1.841788 (0.124407) | 28.040515 / 8.074308 (19.966207) | 25.848647 / 10.191392 (15.657255) | 0.255472 / 0.680424 (-0.424951) | 0.036154 / 0.534201 (-0.498046) | 0.515168 / 0.579283 (-0.064115) | 0.696092 / 0.434364 (0.261728) | 0.602712 / 0.540337 (0.062374) | 0.781091 / 1.386936 (-0.605845) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4521 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4521/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4521/comments | https://api.github.com/repos/huggingface/datasets/issues/4521/events | https://github.com/huggingface/datasets/issues/4521 | 1,274,919,437 | I_kwDODunzps5L_boN | 4,521 | Datasets method `.map` not hashing | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2022-06-17T11:31:10Z | 2022-08-04T12:08:16Z | 2022-06-28T13:23:05Z | null | ## Describe the bug
Datasets method `.map` not hashing, even with an empty no-op function
## Steps to reproduce the bug
```python
from datasets import load_dataset
# download 9MB dummy dataset
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean")
def prepare_dataset(batch):
return(batch)
ds = ds.map(
prepare_dataset,
num_proc=1,
desc="preprocess train dataset",
)
```
## Expected results
Hashed and cached dataset preprocessing
## Actual results
Does not hash properly:
```
Parameter 'function'=<function prepare_dataset at 0x7fccb68e9280> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.3.dev0
- Platform: Linux-5.11.0-1028-gcp-x86_64-with-glibc2.31
- Python version: 3.9.12
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
cc @lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4521/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4521/timeline | null | completed | null | null | false | [
"Fix posted: https://github.com/huggingface/datasets/issues/4506#issuecomment-1157417219",
"Didn't realize it's a bug when I asked the question yesterday! Free free to post an answer if you are sure the cause has been addressed.\r\n\r\nhttps://stackoverflow.com/questions/72664827/can-pickle-dill-foo-but-not-lambda-x-foox",
"Thank @nalzok . That works for me:\r\n\r\n`pip install \"dill<0.3.5\"`"
] |
https://api.github.com/repos/huggingface/datasets/issues/1562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1562/comments | https://api.github.com/repos/huggingface/datasets/issues/1562/events | https://github.com/huggingface/datasets/pull/1562 | 765,981,749 | MDExOlB1bGxSZXF1ZXN0NTM5MTc5ODc3 | 1,562 | Add dataset COrpus of Urdu News TExt Reuse (COUNTER). | [] | closed | false | null | 3 | 2020-12-14T06:32:48Z | 2020-12-21T13:14:46Z | 2020-12-21T13:14:46Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1562/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1562",
"merged_at": "2020-12-21T13:14:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1562"
} | true | [
"Just a small revision from simon's review: 20KB for the dummy_data.zip is fine, you can keep them this way.",
"Also the CI is failing because of an error `tests/test_file_utils.py::TempSeedTest::test_tensorflow` that is not related to your dataset and is fixed on master. You can ignore it",
"merging since the Ci is fixed on master"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/2644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2644/comments | https://api.github.com/repos/huggingface/datasets/issues/2644/events | https://github.com/huggingface/datasets/issues/2644 | 944,254,748 | MDU6SXNzdWU5NDQyNTQ3NDg= | 2,644 | Batched `map` not allowed to return 0 items | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 6 | 2021-07-14T09:58:19Z | 2021-07-26T14:55:15Z | 2021-07-26T14:55:15Z | null | ## Describe the bug
I'm trying to use `map` to filter a large dataset by selecting rows that match an expensive condition (files referenced by one of the columns need to exist in the filesystem, so we have to `stat` them). According to [the documentation](https://huggingface.co/docs/datasets/processing.html#augmenting-the-dataset), `a batch mapped function can take as input a batch of size N and return a batch of size M where M can be greater or less than N and can even be zero`.
However, when the returned batch has a size of zero (neither item in the batch fulfilled the condition), we get an `index out of bounds` error. I think that `arrow_writer.py` is [trying to infer the returned types using the first element returned](https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_writer.py#L100), but no elements were returned in this case.
For this error to happen, I'm returning a dictionary that contains empty lists for the keys I want to keep, see below. If I return an empty dictionary instead (no keys), then a different error eventually occurs.
## Steps to reproduce the bug
```python
def select_rows(examples):
# `key` is a column name that exists in the original dataset
# The following line simulates no matches found, so we return an empty batch
result = {'key': []}
return result
filtered_dataset = dataset.map(
select_rows,
remove_columns = dataset.column_names,
batched = True,
num_proc = 1,
desc = "Selecting rows with images that exist"
)
```
The code above immediately triggers the exception. If we use the following instead:
```python
def select_rows(examples):
# `key` is a column name that exists in the original dataset
result = {'key': []} # or defaultdict or whatever
# code to check for condition and append elements to result
# some_items_found will be set to True if there were any matching elements in the batch
return result if some_items_found else {}
```
Then it _seems_ to work, but it eventually fails with some sort of schema error. I believe it may happen when an empty batch is followed by a non-empty one, but haven't set up a test to verify it.
In my opinion, returning a dictionary with empty lists and valid column names should be accepted as a valid result with zero items.
## Expected results
The dataset would be filtered and only the matching fields would be returned.
## Actual results
An exception is encountered, as described. Using a workaround makes it fail further along the line.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.1.dev0
- Platform: Linux-5.4.0-53-generic-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2644/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting. Indeed it looks like type inference makes it fail. We should probably just ignore this step until a non-empty batch is passed.",
"Sounds good! Do you want me to propose a PR? I'm quite busy right now, but if it's not too urgent I could take a look next week.",
"Sure if you're interested feel free to open a PR :)\r\n\r\nYou can also ping me anytime if you have questions or if I can help !",
"Sorry to ping you, @lhoestq, did you have a chance to take a look at the proposed PR? Thank you!",
"Yes and it's all good, thank you :)\r\n\r\nFeel free to close this issue if it's good for you",
"Everything's good, thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/916/comments | https://api.github.com/repos/huggingface/datasets/issues/916/events | https://github.com/huggingface/datasets/pull/916 | 753,376,643 | MDExOlB1bGxSZXF1ZXN0NTI5NDY3MTkx | 916 | Add Swedish NER Corpus | [] | closed | false | null | 2 | 2020-11-30T10:59:51Z | 2020-12-02T03:10:50Z | 2020-12-02T03:10:49Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/916/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/916",
"merged_at": "2020-12-02T03:10:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/916"
} | true | [
"Yes the use of configs is optional",
"@abhishekkrthakur we want to keep track of the information that is and isn't in the dataset cards so we're asking everyone to use the full template :) If there is some information in there that you really can't find or don't feel qualified to add, you can just leave the `[More Information Needed]` text"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/5090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5090/comments | https://api.github.com/repos/huggingface/datasets/issues/5090/events | https://github.com/huggingface/datasets/issues/5090 | 1,401,102,407 | I_kwDODunzps5TgyBH | 5,090 | Review sync issues from GitHub to Hub | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-10-07T12:31:56Z | 2022-10-08T07:07:36Z | 2022-10-08T07:07:36Z | null | ## Describe the bug
We have discovered that sometimes there were sync issues between GitHub and Hub datasets, after a merge commit to main branch.
For example:
- this merge commit: https://github.com/huggingface/datasets/commit/d74a9e8e4bfff1fed03a4cab99180a841d7caf4b
- was not properly synced with the Hub: https://github.com/huggingface/datasets/actions/runs/3002495269/jobs/4819769684
```
[main 9e641de] Add Papers with Code ID to scifact dataset (#4941)
Author: Albert Villanova del Moral <[email protected]>
1 file changed, 42 insertions(+), 14 deletions(-)
push failed !
GitCommandError(['git', 'push'], 1, b'remote: ---------------------------------------------------------- \nremote: Sorry, your push was rejected during YAML metadata verification: \nremote: - Error: "license" does not match any of the allowed types \nremote: ---------------------------------------------------------- \nremote: Please find the documentation at: \nremote: https://huggingface.co/docs/hub/models-cards#model-card-metadata \nremote: ---------------------------------------------------------- \nTo [https://huggingface.co/datasets/scifact.git\n](https://huggingface.co/datasets/scifact.git/n) ! [remote rejected] main -> main (pre-receive hook declined)\nerror: failed to push some refs to \'[https://huggingface.co/datasets/scifact.git\](https://huggingface.co/datasets/scifact.git/)'', b'')
```
We are reviewing sync issues in previous commits to recover them and repushing to the Hub.
TODO: Review
- [x] #4941
- scifact
- [x] #4931
- scifact
- [x] #4753
- wikipedia
- [x] #4554
- wmt17, wmt19, wmt_t2t
- Fixed with "Release 2.4.0" commit: https://github.com/huggingface/datasets/commit/401d4c4f9b9594cb6527c599c0e7a72ce1a0ea49
- https://huggingface.co/datasets/wmt17/commit/5c0afa83fbbd3508ff7627c07f1b27756d1379ea
- https://huggingface.co/datasets/wmt19/commit/b8ad5bf1960208a376a0ab20bc8eac9638f7b400
- https://huggingface.co/datasets/wmt_t2t/commit/b6d67191804dd0933476fede36754a436b48d1fc
- [x] #4607
- [x] #4416
- lccc
- Fixed with "Release 2.3.0" commit: https://huggingface.co/datasets/lccc/commit/8b1f8cf425b5653a0a4357a53205aac82ce038d1
- [x] #4367
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5090/timeline | null | completed | null | null | false | [
"Nice!!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1748/comments | https://api.github.com/repos/huggingface/datasets/issues/1748/events | https://github.com/huggingface/datasets/pull/1748 | 788,431,642 | MDExOlB1bGxSZXF1ZXN0NTU2OTQ0NDEx | 1,748 | add Stuctured Argument Extraction for Korean dataset | [] | closed | false | null | 0 | 2021-01-18T17:14:19Z | 2021-09-17T16:53:18Z | 2021-01-19T11:26:58Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1748/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1748/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1748",
"merged_at": "2021-01-19T11:26:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1748"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/4946 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4946/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4946/comments | https://api.github.com/repos/huggingface/datasets/issues/4946/events | https://github.com/huggingface/datasets/pull/4946 | 1,364,692,069 | PR_kwDODunzps4-g0Hz | 4,946 | Introduce regex check when pushing as well | [] | closed | false | null | 2 | 2022-09-07T13:45:58Z | 2022-09-13T10:19:01Z | 2022-09-13T10:16:34Z | null | Closes https://github.com/huggingface/datasets/issues/4945 by adding a regex check when pushing to hub.
Let me know if this is helpful and if it's the fix you would have in mind for the issue and I'm happy to contribute tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4946/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4946/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4946.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4946",
"merged_at": "2022-09-13T10:16:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4946.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4946"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Let me take over this PR if you don't mind"
] |
https://api.github.com/repos/huggingface/datasets/issues/889 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/889/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/889/comments | https://api.github.com/repos/huggingface/datasets/issues/889/events | https://github.com/huggingface/datasets/pull/889 | 751,115,691 | MDExOlB1bGxSZXF1ZXN0NTI3NjkwODE2 | 889 | Optional per-dataset default config name | [] | closed | false | null | 3 | 2020-11-25T21:02:30Z | 2020-11-30T17:27:33Z | 2020-11-30T17:27:27Z | null | This PR adds a `DEFAULT_CONFIG_NAME` class attribute to `DatasetBuilder`. This allows a dataset to have a specified default config name when a dataset has more than one config but the user does not specify it. For example, after defining `DEFAULT_CONFIG_NAME = "combined"` in PolyglotNER, a user can now do the following:
```python
ds = load_dataset("polyglot_ner")
```
which is equivalent to,
```python
ds = load_dataset("polyglot_ner", "combined")
```
In effect (for this particular dataset configuration), this means that if the user doesn't specify a language, they are given the combined dataset including all languages.
Since it doesn't always make sense to have a default config, this feature is opt-in. If `DEFAULT_CONFIG_NAME` is not defined and a user does not pass a config for a dataset with multiple configs available, a ValueError is raised like usual.
Let me know what you think about this approach @lhoestq @thomwolf and I'll add some documentation and define a default for some of our existing datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/889/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/889/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/889.diff",
"html_url": "https://github.com/huggingface/datasets/pull/889",
"merged_at": "2020-11-30T17:27:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/889.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/889"
} | true | [
"I like the idea ! And the approach is right imo\r\n\r\nNote that by changing this we will have to add a way for users to get the config lists of a dataset. In the current user workflow, the user could see the list of the config when the missing config error is raised but now it won't be the case because of the default config.",
"Maybe let's add a test in the test_builder.py test script ?",
"@lhoestq Okay great, I added a test as well as two new inspect functions: `get_dataset_config_names` and `get_dataset_infos` (the latter is something I've been wanting anyway). As a quick hack, you can also just pass a random config name (e.g. an empty string) to `load_dataset` to get the config names in the error msg as before. Also added a couple paragraphs to the adding new datasets doc.\r\n\r\nI'll send a separate PR incorporating this in existing datasets so we can get this merged before our sprint on Monday.\r\n\r\nAny ideas on the failing tests? I'm having trouble making sense of it. **Edit**: nvm, it was master."
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.