
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2564/comments | https://api.github.com/repos/huggingface/datasets/issues/2564/events | https://github.com/huggingface/datasets/issues/2564 | 932,389,639 | MDU6SXNzdWU5MzIzODk2Mzk= | 2,564 | concatenate_datasets for iterable datasets | [] | closed | false | null | 2 | 2021-06-29T08:59:41Z | 2022-06-28T21:15:04Z | 2022-06-28T21:15:04Z | null | Currently `concatenate_datasets` only works for map-style `Dataset`.
It would be nice to have it work for `IterableDataset` objects as well.
It would simply chain the iterables of the iterable datasets. | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2564/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2564/timeline | null | completed | null | null | false | [
"It is probably worth noting here that the [documentation](https://huggingface.co/docs/datasets/process#concatenate) is misleading (indicating that it does work for IterableDatasets):\r\n\r\n> You can also mix several datasets together by taking alternating examples from each one to create a new dataset. This is known as interleaving, and you can use it with [interleave_datasets()](https://huggingface.co/docs/datasets/v2.2.1/en/package_reference/main_classes#datasets.interleave_datasets). **Both [interleave_datasets()](https://huggingface.co/docs/datasets/v2.2.1/en/package_reference/main_classes#datasets.interleave_datasets) and [concatenate_datasets()](https://huggingface.co/docs/datasets/v2.2.1/en/package_reference/main_classes#datasets.concatenate_datasets) will work with regular [Dataset](https://huggingface.co/docs/datasets/v2.2.1/en/package_reference/main_classes#datasets.Dataset) and [IterableDataset](https://huggingface.co/docs/datasets/v2.2.1/en/package_reference/main_classes#datasets.IterableDataset) objects**. Refer to the [Stream](https://huggingface.co/docs/datasets/stream#interleave) section for an example of how it’s used. ",
"Thanks for the heads up, I'll fix that"
] |
https://api.github.com/repos/huggingface/datasets/issues/1278 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1278/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1278/comments | https://api.github.com/repos/huggingface/datasets/issues/1278/events | https://github.com/huggingface/datasets/pull/1278 | 758,988,465 | MDExOlB1bGxSZXF1ZXN0NTM0MDYwNDY5 | 1,278 | Craigslist bargains | [] | closed | false | null | 2 | 2020-12-08T01:45:55Z | 2020-12-09T00:46:15Z | 2020-12-09T00:46:15Z | null | `craigslist_bargains` dataset from [here](https://worksheets.codalab.org/worksheets/0x453913e76b65495d8b9730d41c7e0a0c/) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1278/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1278/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1278.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1278",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1278.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1278"
} | true | [
"Seeing this in the CircleCI builds, this is what I was originally getting before I started messing around with the download URLS to try to fix this:\r\n\r\n`FileNotFoundError: [Errno 2] No such file or directory: '/tmp/tmpwvji917g/extracted/d6185140afb24ad8fee67392100a478269cba286b0d88915a137fdf88872de14/dummy_data/train__VARIABLE_MISUSE__SStuB.txt-00001-of-00300'`\r\n\r\nCould this be because of the files in my `dummy_data.zip`? I had to manually create it, and it looked like the test was looking for the following files, so I created the `.zip` with this structure:\r\n\r\n```\r\nArchive: dummy_data.zip\r\n creating: dummy_data/\r\n inflating: dummy_data/blobtest \r\n inflating: dummy_data/parsed.jsontrain \r\n inflating: dummy_data/parsed.jsonvalidation \r\n```",
"Going to close this out and link to a new (cleaner) PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/3442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3442/comments | https://api.github.com/repos/huggingface/datasets/issues/3442/events | https://github.com/huggingface/datasets/pull/3442 | 1,081,862,747 | PR_kwDODunzps4v7oBZ | 3,442 | Extend text to support yielding lines, paragraphs or documents | [] | closed | false | null | 5 | 2021-12-16T07:33:17Z | 2021-12-20T16:59:10Z | 2021-12-20T16:39:18Z | null | Add `config.row` option to `text` module to allow yielding lines (default, current case), paragraphs or documents.
Feel free to comment on the name of the config parameter `row`:
- Currently, the docs state datasets are made of rows and columns
- Other names I considered: `example`, `item` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3442/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3442/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3442.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3442",
"merged_at": "2021-12-20T16:39:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3442.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3442"
} | true | [
"The parameter can also be named `split_by` with values \"line\", \"paragraph\" or \"document\" (no 's' at the end)",
"> The parameter can also be named `split_by` with values \"line\", \"paragraph\" or \"document\" (no 's' at the end)\r\n\r\n@lhoestq @mariosasko I would avoid the term `split` in this context and keep it only for \"train\", \"validation\" and \"test\" splits.\r\n- https://huggingface.co/docs/datasets/process.html#split\r\n > datasets.Dataset.train_test_split() creates train and test splits, if your dataset doesn’t already have them.\r\n- https://huggingface.co/docs/datasets/process.html#process-multiple-splits\r\n > Many datasets have splits that you can process simultaneously with datasets.DatasetDict.map().\r\n\r\nPlease note that in the documentation, one of the terms more frequently used in this context is **\"row\"**:\r\n- https://huggingface.co/docs/datasets/access.html#features-and-columns\r\n > A dataset is a table of rows and typed columns.\r\n\r\n > Return the number of rows and columns with the following standard attributes:\r\n > dataset.num_columns\r\n > 4\r\n > dataset.num_rows\r\n > 3668\r\n\r\n- https://huggingface.co/docs/datasets/access.html#rows-slices-batches-and-columns\r\n > Get several rows of your dataset at a time with slice notation or a list of indices:\r\n- https://huggingface.co/docs/datasets/process.html#map\r\n > This function can even create new rows and columns.\r\n\r\nOther of the terms more frequently used in the docs (in the code as well) is **\"example\"**:\r\n- https://huggingface.co/docs/datasets/process.html#map\r\n > It allows you to apply a processing function to each example in a dataset, independently or in batches.\r\n- https://huggingface.co/docs/datasets/process.html#batch-processing\r\n > datasets.Dataset.map() also supports working with batches of examples.\r\n- https://huggingface.co/docs/datasets/process.html#split-long-examples\r\n > When your examples are too long, you may want to split them\r\n- https://huggingface.co/docs/datasets/process.html#data-augmentation\r\n > With batch processing, you can even augment your dataset with additional examples.\r\n\r\nLess frequently used: **\"item\"**:\r\n- https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.add_item\r\n > Add item to Dataset.\r\n\r\nOther term used in the docs (although less frequently) is **\"sample\"**. The advantage of this word is that it is also a verb, so we can use the parameter: \"sample_by\" (if you insist on using a verb instead of a noun).\r\n\r\nIn summary, these proposals:\r\n- config.row\r\n- config.example\r\n- config.item\r\n- config.sample\r\n- config.sample_by",
"I like `sample_by`. Another idea I had was `separate_by`.\r\n\r\nIt could also be `sampling`, `sampling_method`, `separation_method`.\r\n\r\nNot a big fan of the proposed nouns alone since they are very generic, that's why I tried to have something more specific.\r\n\r\nI also agree that we actually should avoid `split` to avoid any confusion",
"Thanks for the analysis of the used terms. I also like `sample_by` (`separate_by` is good too).",
"Thank you !! :D "
] |
https://api.github.com/repos/huggingface/datasets/issues/1401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1401/comments | https://api.github.com/repos/huggingface/datasets/issues/1401/events | https://github.com/huggingface/datasets/pull/1401 | 760,525,949 | MDExOlB1bGxSZXF1ZXN0NTM1MzQyOTY2 | 1,401 | Add reasoning_bg | [] | closed | false | null | 4 | 2020-12-09T17:30:49Z | 2020-12-17T16:50:43Z | 2020-12-17T16:50:42Z | null | Adding reading comprehension dataset for Bulgarian language | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1401/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1401/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1401.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1401",
"merged_at": "2020-12-17T16:50:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1401.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1401"
} | true | [
"Hi @saradhix have you had the chance to reduce the size of the dummy data ?\r\n\r\nFeel free to ping me when it's done so we can merge :) ",
"@lhoestq I have reduced the size of the dummy data manually and pushed the changes.",
"The CI errors are not related to your dataset.\r\nThey're fixed on master, you can ignore them",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/3089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3089/comments | https://api.github.com/repos/huggingface/datasets/issues/3089/events | https://github.com/huggingface/datasets/issues/3089 | 1,026,973,360 | I_kwDODunzps49Nl6w | 3,089 | JNLPBA Dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-10-15T01:16:02Z | 2021-10-22T08:23:57Z | 2021-10-22T08:23:57Z | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
## Expected results
The dataset loading script for this dataset is incorrect. This is a biomedical dataset used for named entity recognition. The entities in the [script](https://github.com/huggingface/datasets/blob/master/datasets/jnlpba/jnlpba.py#L81-L83) are: O, B, and I. The correct entities from the original data file are:
['O',
'B-DNA',
'I-DNA',
'B-RNA',
'I-RNA',
'B-cell_line',
'I-cell_line',
'B-cell_type',
'I-cell_type',
'B-protein',
'I-protein']
## Actual results
The dataset loader script needs to include the following NER names:
['O',
'B-DNA',
'I-DNA',
'B-RNA',
'I-RNA',
'B-cell_line',
'I-cell_line',
'B-cell_type',
'I-cell_type',
'B-protein',
'I-protein']
And the [data](https://github.com/huggingface/datasets/blob/master/datasets/jnlpba/jnlpba.py#L46) that is being pulled has been modified from the original dataset and does not include the original NER tags.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform:
- Python version:
- PyArrow version:
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3089/timeline | null | completed | null | null | false | [
"# Steps to reproduce\r\n\r\nTo reproduce:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\ndataset = load_dataset('jnlpba')\r\n\r\ndataset['train'].features['ner_tags']\r\n```\r\nOutput:\r\n```python\r\nSequence(feature=ClassLabel(num_classes=3, names=['O', 'B', 'I'], names_file=None, id=None), length=-1, id=None)\r\n```\r\n\r\n",
"Since I cannot create a branch here is the updated code:\r\n\r\n```python\r\n\r\n# coding=utf-8\r\n# Copyright 2020 HuggingFace Datasets Authors.\r\n#\r\n# Licensed under the Apache License, Version 2.0 (the \"License\");\r\n# you may not use this file except in compliance with the License.\r\n# You may obtain a copy of the License at\r\n#\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n#\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\n\r\n# Lint as: python3\r\n\"\"\"Introduction to the Bio-Entity Recognition Task at JNLPBA\"\"\"\r\n\r\nimport os\r\n\r\nimport datasets\r\n\r\n\r\nlogger = datasets.logging.get_logger(__name__)\r\n\r\n\r\n_CITATION = \"\"\"\\\r\n@inproceedings{kim2004introduction,\r\n title={Introduction to the bio-entity recognition task at JNLPBA},\r\n author={Kim, Jin-Dong and Ohta, Tomoko and Tsuruoka, Yoshimasa and Tateisi, Yuka and Collier, Nigel},\r\n booktitle={Proceedings of the international joint workshop on natural language processing in biomedicine and its applications},\r\n pages={70--75},\r\n year={2004},\r\n organization={Citeseer}\r\n}\r\n\"\"\"\r\n\r\n_DESCRIPTION = \"\"\"\\\r\nThe data came from the GENIA version 3.02 corpus (Kim et al., 2003). This was formed from a controlled search\r\non MEDLINE using the MeSH terms \u0018human\u0019, \u0018blood cells\u0019 and \u0018transcription factors\u0019. From this search 2,000 abstracts\r\nwere selected and hand annotated according to a small taxonomy of 48 classes based on a chemical classification.\r\nAmong the classes, 36 terminal classes were used to annotate the GENIA corpus.\r\n\"\"\"\r\n\r\n_HOMEPAGE = \"http://www.geniaproject.org/shared-tasks/bionlp-jnlpba-shared-task-2004\"\r\n_TRAIN_URL = \"http://www.nactem.ac.uk/GENIA/current/Shared-tasks/JNLPBA/Train/Genia4ERtraining.tar.gz\"\r\n_VAL_URL = 'http://www.nactem.ac.uk/GENIA/current/Shared-tasks/JNLPBA/Evaluation/Genia4ERtest.tar.gz'\r\n\r\n\r\n_URLS = {\r\n \"train\": _TRAIN_URL,\r\n \"val\": _VAL_URL,\r\n}\r\n\r\n_TRAIN_DIRECTORY = \"Genia4ERtraining\"\r\n_VAL_DIRECTORY = \"Genia4ERtest\"\r\n\r\n_TRAIN_FILE = \"Genia4ERtask1.iob2\"\r\n_VAL_FILE = \"Genia4EReval1.iob2\"\r\n\r\n\r\nclass JNLPBAConfig(datasets.BuilderConfig):\r\n \"\"\"BuilderConfig for JNLPBA\"\"\"\r\n\r\n def __init__(self, **kwargs):\r\n \"\"\"BuilderConfig for JNLPBA.\r\n Args:\r\n **kwargs: keyword arguments forwarded to super.\r\n \"\"\"\r\n super(JNLPBAConfig, self).__init__(**kwargs)\r\n\r\n\r\nclass JNLPBA(datasets.GeneratorBasedBuilder):\r\n \"\"\"JNLPBA dataset.\"\"\"\r\n\r\n BUILDER_CONFIGS = [\r\n JNLPBAConfig(name=\"jnlpba\", version=datasets.Version(\"1.0.0\"), description=\"JNLPBA dataset\"),\r\n ]\r\n\r\n def _info(self):\r\n return datasets.DatasetInfo(\r\n description=_DESCRIPTION,\r\n features=datasets.Features(\r\n {\r\n \"id\": datasets.Value(\"string\"),\r\n \"tokens\": datasets.Sequence(datasets.Value(\"string\")),\r\n \"ner_tags\": datasets.Sequence(\r\n datasets.features.ClassLabel(\r\n names=[\r\n 'O',\r\n 'B-DNA',\r\n 'I-DNA', \r\n 'B-RNA',\r\n 'I-RNA',\r\n 'B-cell_line',\r\n 'I-cell_line',\r\n 'B-cell_type',\r\n 'I-cell_type',\r\n 'B-protein',\r\n 'I-protein',\r\n ]\r\n )\r\n ),\r\n }\r\n ),\r\n supervised_keys=None,\r\n homepage=_HOMEPAGE,\r\n citation=_CITATION,\r\n )\r\n\r\n def _split_generators(self, dl_manager):\r\n downloaded_files = dl_manager.download_and_extract(_URLS)\r\n \r\n return [\r\n datasets.SplitGenerator(name=datasets.Split.TRAIN, \r\n gen_kwargs={\"filepath\": os.path.join(downloaded_files['train'], _TRAIN_FILE)}),\r\n datasets.SplitGenerator(name=datasets.Split.VALIDATION, \r\n gen_kwargs={\"filepath\": os.path.join(downloaded_files['val'], _VAL_FILE)})\r\n ]\r\n \r\n\r\n def _generate_examples(self, filepath):\r\n logger.info(\"⏳ Generating examples from = %s\", filepath)\r\n with open(filepath, encoding=\"utf-8\") as f:\r\n guid = 0\r\n tokens = []\r\n ner_tags = []\r\n for line in f:\r\n if line.startswith('###'):\r\n continue\r\n if line == '' or line == '\\n':\r\n if tokens:\r\n yield guid, {\r\n \"id\": str(guid),\r\n \"tokens\": tokens,\r\n \"ner_tags\": ner_tags,\r\n }\r\n guid += 1\r\n tokens = []\r\n ner_tags = []\r\n else:\r\n # tokens are tab separated\r\n splits = line.split(\"\\t\")\r\n #print(splits)\r\n #print(len(splits))\r\n if len(splits) < 2:\r\n splits = splits[0].split()\r\n tokens.append(splits[0])\r\n ner_tags.append(splits[1].rstrip())\r\n # last example\r\n yield guid, {\r\n \"id\": str(guid),\r\n \"tokens\": tokens,\r\n \"ner_tags\": ner_tags,\r\n }\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/4111 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4111/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4111/comments | https://api.github.com/repos/huggingface/datasets/issues/4111/events | https://github.com/huggingface/datasets/pull/4111 | 1,194,660,699 | PR_kwDODunzps41vJCt | 4,111 | Update security policy | [] | closed | false | null | 1 | 2022-04-06T13:59:51Z | 2022-04-07T09:46:30Z | 2022-04-07T09:40:27Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4111/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4111/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4111.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4111",
"merged_at": "2022-04-07T09:40:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4111.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4111"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/847 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/847/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/847/comments | https://api.github.com/repos/huggingface/datasets/issues/847/events | https://github.com/huggingface/datasets/issues/847 | 742,179,495 | MDU6SXNzdWU3NDIxNzk0OTU= | 847 | multiprocessing in dataset map "can only test a child process" | [] | closed | false | null | 9 | 2020-11-13T06:01:04Z | 2022-10-05T12:22:51Z | 2022-10-05T12:22:51Z | null | Using a dataset with a single 'text' field and a fast tokenizer in a jupyter notebook.
```
def tokenizer_fn(example):
return tokenizer.batch_encode_plus(example['text'])
ds_tokenized = text_dataset.map(tokenizer_fn, batched=True, num_proc=6, remove_columns=['text'])
```
```
---------------------------------------------------------------------------
RemoteTraceback Traceback (most recent call last)
RemoteTraceback:
"""
Traceback (most recent call last):
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/multiprocess/pool.py", line 119, in worker
result = (True, func(*args, **kwds))
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 156, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/datasets/fingerprint.py", line 163, in wrapper
out = func(self, *args, **kwargs)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/datasets/arrow_dataset.py", line 1510, in _map_single
for i in pbar:
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/tqdm/notebook.py", line 228, in __iter__
for obj in super(tqdm_notebook, self).__iter__(*args, **kwargs):
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/tqdm/std.py", line 1186, in __iter__
self.close()
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/tqdm/notebook.py", line 251, in close
super(tqdm_notebook, self).close(*args, **kwargs)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/tqdm/std.py", line 1291, in close
fp_write('')
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/tqdm/std.py", line 1288, in fp_write
self.fp.write(_unicode(s))
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/wandb/sdk/lib/redirect.py", line 91, in new_write
cb(name, data)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/wandb/sdk/wandb_run.py", line 598, in _console_callback
self._backend.interface.publish_output(name, data)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/wandb/sdk/interface/interface.py", line 146, in publish_output
self._publish_output(o)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/wandb/sdk/interface/interface.py", line 151, in _publish_output
self._publish(rec)
File "/home/jovyan/share/users/tlaurent/invitae-bert/ve/lib/python3.6/site-packages/wandb/sdk/interface/interface.py", line 431, in _publish
if self._process and not self._process.is_alive():
File "/usr/lib/python3.6/multiprocessing/process.py", line 134, in is_alive
assert self._parent_pid == os.getpid(), 'can only test a child process'
AssertionError: can only test a child process
"""
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/847/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/847/timeline | null | completed | null | null | false | [
"It looks like an issue with wandb/tqdm here.\r\nWe're using the `multiprocess` library instead of the `multiprocessing` builtin python package to support various types of mapping functions. Maybe there's some sort of incompatibility.\r\n\r\nCould you make a minimal script to reproduce or a google colab ?",
"hi facing the same issue here - \r\n\r\n`AssertionError: Caught AssertionError in DataLoader worker process 0.\r\nOriginal Traceback (most recent call last):\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 996, in emit\r\n stream.write(msg)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/lib/redirect.py\", line 100, in new_write\r\n cb(name, data)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/wandb_run.py\", line 723, in _console_callback\r\n self._backend.interface.publish_output(name, data)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/interface/interface.py\", line 153, in publish_output\r\n self._publish_output(o)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/interface/interface.py\", line 158, in _publish_output\r\n self._publish(rec)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/interface/interface.py\", line 456, in _publish\r\n if self._process and not self._process.is_alive():\r\n File \"/usr/lib/python3.6/multiprocessing/process.py\", line 134, in is_alive\r\n assert self._parent_pid == os.getpid(), 'can only test a child process'\r\nAssertionError: can only test a child process\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/worker.py\", line 198, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py\", line 44, in fetch\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py\", line 44, in <listcomp>\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"<ipython-input-8-a4d9a08d114e>\", line 20, in __getitem__\r\n return_token_type_ids=True\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py\", line 2405, in encode_plus\r\n **kwargs,\r\n File \"/usr/local/lib/python3.6/dist-packages/transformers/tokenization_utils_base.py\", line 2125, in _get_padding_truncation_strategies\r\n \"Truncation was not explicitly activated but `max_length` is provided a specific value, \"\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 1320, in warning\r\n self._log(WARNING, msg, args, **kwargs)\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 1444, in _log\r\n self.handle(record)\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 1454, in handle\r\n self.callHandlers(record)\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 1516, in callHandlers\r\n hdlr.handle(record)\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 865, in handle\r\n self.emit(record)\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 1000, in emit\r\n self.handleError(record)\r\n File \"/usr/lib/python3.6/logging/__init__.py\", line 917, in handleError\r\n sys.stderr.write('--- Logging error ---\\n')\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/lib/redirect.py\", line 100, in new_write\r\n cb(name, data)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/wandb_run.py\", line 723, in _console_callback\r\n self._backend.interface.publish_output(name, data)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/interface/interface.py\", line 153, in publish_output\r\n self._publish_output(o)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/interface/interface.py\", line 158, in _publish_output\r\n self._publish(rec)\r\n File \"/usr/local/lib/python3.6/dist-packages/wandb/sdk/interface/interface.py\", line 456, in _publish\r\n if self._process and not self._process.is_alive():\r\n File \"/usr/lib/python3.6/multiprocessing/process.py\", line 134, in is_alive\r\n assert self._parent_pid == os.getpid(), 'can only test a child process'\r\nAssertionError: can only test a child process`\r\n",
"It looks like this warning : \r\n\"Truncation was not explicitly activated but max_length is provided a specific value, \"\r\nis not handled well by wandb.\r\n\r\nThe error occurs when calling the tokenizer.\r\nMaybe you can try to specify `truncation=True` when calling the tokenizer to remove the warning ?\r\nOtherwise I don't know why wandb would fail on a warning. Maybe one of its logging handlers have some issues with the logging of tokenizers. Maybe @n1t0 knows more about this ?",
"I'm having a similar issue but when I try to do multiprocessing with the `DataLoader`\r\n\r\nCode to reproduce:\r\n\r\n```\r\nfrom datasets import load_dataset\r\n\r\nbook_corpus = load_dataset('bookcorpus', 'plain_text', cache_dir='/home/ad/Desktop/bookcorpus', split='train[:1%]')\r\nbook_corpus = book_corpus.map(encode, batched=True, num_proc=20, load_from_cache_file=True, batch_size=5000)\r\nbook_corpus.set_format(type='torch', columns=['text', \"input_ids\", \"attention_mask\", \"token_type_ids\"])\r\n\r\nfrom transformers import DataCollatorForWholeWordMask\r\nfrom transformers import Trainer, TrainingArguments\r\n\r\ndata_collator = DataCollatorForWholeWordMask(\r\n tokenizer=tokenizer, mlm=True, mlm_probability=0.15)\r\n\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./mobile_linear_att_8L_128_128_03layerdrop_shared\",\r\n overwrite_output_dir=True,\r\n num_train_epochs=1,\r\n per_device_train_batch_size=64,\r\n save_steps=50,\r\n save_total_limit=2,\r\n logging_first_step=True,\r\n warmup_steps=100,\r\n logging_steps=50,\r\n gradient_accumulation_steps=1,\r\n fp16=True,\r\n **dataloader_num_workers=10**,\r\n)\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n data_collator=data_collator,\r\n train_dataset=book_corpus,\r\n tokenizer=tokenizer)\r\n\r\ntrainer.train()\r\n```\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nAssertionError Traceback (most recent call last)\r\n<timed eval> in <module>\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/transformers/trainer.py in train(self, model_path, trial)\r\n 869 self.control = self.callback_handler.on_epoch_begin(self.args, self.state, self.control)\r\n 870 \r\n--> 871 for step, inputs in enumerate(epoch_iterator):\r\n 872 \r\n 873 # Skip past any already trained steps if resuming training\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/dataloader.py in __next__(self)\r\n 433 if self._sampler_iter is None:\r\n 434 self._reset()\r\n--> 435 data = self._next_data()\r\n 436 self._num_yielded += 1\r\n 437 if self._dataset_kind == _DatasetKind.Iterable and \\\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/dataloader.py in _next_data(self)\r\n 1083 else:\r\n 1084 del self._task_info[idx]\r\n-> 1085 return self._process_data(data)\r\n 1086 \r\n 1087 def _try_put_index(self):\r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/dataloader.py in _process_data(self, data)\r\n 1109 self._try_put_index()\r\n 1110 if isinstance(data, ExceptionWrapper):\r\n-> 1111 data.reraise()\r\n 1112 return data\r\n 1113 \r\n\r\n~/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/_utils.py in reraise(self)\r\n 426 # have message field\r\n 427 raise self.exc_type(message=msg)\r\n--> 428 raise self.exc_type(msg)\r\n 429 \r\n 430 \r\n\r\nAssertionError: Caught AssertionError in DataLoader worker process 0.\r\nOriginal Traceback (most recent call last):\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py\", line 198, in _worker_loop\r\n data = fetcher.fetch(index)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py\", line 44, in fetch\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py\", line 44, in <listcomp>\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1087, in __getitem__\r\n format_kwargs=self._format_kwargs,\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 1074, in _getitem\r\n format_kwargs=format_kwargs,\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 890, in _convert_outputs\r\n v = map_nested(command, v, **map_nested_kwargs)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/utils/py_utils.py\", line 225, in map_nested\r\n return function(data_struct)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/datasets/arrow_dataset.py\", line 851, in command\r\n return torch.tensor(x, **format_kwargs)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/warnings.py\", line 101, in _showwarnmsg\r\n _showwarnmsg_impl(msg)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/warnings.py\", line 30, in _showwarnmsg_impl\r\n file.write(text)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/lib/redirect.py\", line 100, in new_write\r\n cb(name, data)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/wandb_run.py\", line 723, in _console_callback\r\n self._backend.interface.publish_output(name, data)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py\", line 153, in publish_output\r\n self._publish_output(o)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py\", line 158, in _publish_output\r\n self._publish(rec)\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py\", line 456, in _publish\r\n if self._process and not self._process.is_alive():\r\n File \"/home/ad/anaconda3/envs/tfm/lib/python3.6/multiprocessing/process.py\", line 134, in is_alive\r\n assert self._parent_pid == os.getpid(), 'can only test a child process'\r\nAssertionError: can only test a child process\r\n```\r\n\r\nAs a workaround I have commented line 456 and 457 in `/home/ad/anaconda3/envs/tfm/lib/python3.6/site-packages/wandb/sdk/interface/interface.py`",
"Isn't it more the pytorch warning on the use of non-writable memory for tensor that trigger this here @lhoestq? (since it seems to be a warning triggered in `torch.tensor()`",
"Yep this time this is a warning from pytorch that causes wandb to not work properly.\r\nCould this by a wandb issue ?",
"Hi @timothyjlaurent @gaceladri \r\nIf you're running `transformers` from `master` you can try setting the env var `WAND_DISABLE=true` (from https://github.com/huggingface/transformers/pull/9896) and try again ?\r\nThis issue might be related to https://github.com/huggingface/transformers/issues/9623 ",
"I have commented the lines that cause my code break. I'm now seeing my reports on Wandb and my code does not break. I am training now, so I will check probably in 6 hours. I suppose that setting wandb disable will work as well.",
"This seems to be a bug in `wandb` (see https://github.com/wandb/wandb/issues/1994)."
] |
https://api.github.com/repos/huggingface/datasets/issues/1035 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1035/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1035/comments | https://api.github.com/repos/huggingface/datasets/issues/1035/events | https://github.com/huggingface/datasets/pull/1035 | 755,947,097 | MDExOlB1bGxSZXF1ZXN0NTMxNTczMTc3 | 1,035 | add wiki_hop | [] | closed | false | null | 1 | 2020-12-03T07:32:26Z | 2020-12-03T16:43:40Z | 2020-12-03T16:41:12Z | null | This PR adds the WikiHop dataset from the QAngaroo multi hop reading comprehension datasets
More info:
http://qangaroo.cs.ucl.ac.uk/index.html
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1035/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1035/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1035.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1035",
"merged_at": "2020-12-03T16:41:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1035.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1035"
} | true | [
"Also the dummy data files are quite big (500KB)\r\nIf you could reduce that that would be nice (just look at the files inside and remove unecessary chunks of texts)\r\nin general dummy data are just a few KB and we suggest to not get higher than 50KB\r\n\r\nHaving light dummy data makes the repo faster to clone"
] |
https://api.github.com/repos/huggingface/datasets/issues/4339 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4339/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4339/comments | https://api.github.com/repos/huggingface/datasets/issues/4339/events | https://github.com/huggingface/datasets/pull/4339 | 1,234,496,289 | PR_kwDODunzps43v0WT | 4,339 | Dataset loader for the MSLR2022 shared task | [] | closed | false | null | 9 | 2022-05-12T21:23:41Z | 2022-07-18T17:19:27Z | 2022-07-18T16:58:34Z | null | This PR adds a dataset loader for the [MSLR2022 Shared Task](https://github.com/allenai/mslr-shared-task). Both the MS^2 and Cochrane datasets can be loaded with this dataloader:
```python
from datasets import load_dataset
ms2 = load_dataset("mslr2022", "ms2")
cochrane = load_dataset("mslr2022", "cochrane")
```
Usage looks like:
```python
>>> ms2 = load_dataset("mslr2022", "ms2", split="validation")
>>> ms2.keys()
dict_keys(['review_id', 'pmid', 'title', 'abstract', 'target', 'background', 'reviews_info'])
>>> ms2[0].target
'Conclusions SC therapy is effective for PAH in pre clinical studies .\nThese results may help to st and ardise pre clinical animal studies and provide a theoretical basis for clinical trial design in the future .'
```
I have tested this works with the following command:
```bash
datasets-cli test datasets/mslr2022 --save_infos --all_configs
```
However I have having a little trouble generating the dummy data
```bash
datasets-cli dummy_data datasets/mslr2022 --auto_generate
```
errors out with the following stack trace:
```
Couldn't generate dummy file 'datasets/mslr2022/dummy/ms2/1.0.0/dummy_data/mslr_data.tar.gz/mslr_data/ms2/convert_to_cochrane.py'. Ignore that if this file is not useful for dummy data.
Traceback (most recent call last):
File "/Users/johngiorgi/.pyenv/versions/datasets/bin/datasets-cli", line 11, in <module>
load_entry_point('datasets', 'console_scripts', 'datasets-cli')()
File "/Users/johngiorgi/Documents/dev/datasets/src/datasets/commands/datasets_cli.py", line 39, in main
service.run()
File "/Users/johngiorgi/Documents/dev/datasets/src/datasets/commands/dummy_data.py", line 319, in run
keep_uncompressed=self._keep_uncompressed,
File "/Users/johngiorgi/Documents/dev/datasets/src/datasets/commands/dummy_data.py", line 361, in _autogenerate_dummy_data
dataset_builder._prepare_split(split_generator, check_duplicate_keys=False)
File "/Users/johngiorgi/Documents/dev/datasets/src/datasets/builder.py", line 1146, in _prepare_split
desc=f"Generating {split_info.name} split",
File "/Users/johngiorgi/.pyenv/versions/3.7.13/envs/datasets/lib/python3.7/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/Users/johngiorgi/.cache/huggingface/modules/datasets_modules/datasets/mslr2022/b4becd2f52cf18255d4934d7154c2a1127fb393371b87b3c1fc2c8b35a777cea/mslr2022.py", line 149, in _generate_examples
reviews_info_df = pd.read_csv(reviews_info_filepath, index_col=0)
File "/Users/johngiorgi/.pyenv/versions/3.7.13/envs/datasets/lib/python3.7/site-packages/pandas/util/_decorators.py", line 311, in wrapper
return func(*args, **kwargs)
File "/Users/johngiorgi/.pyenv/versions/3.7.13/envs/datasets/lib/python3.7/site-packages/pandas/io/parsers/readers.py", line 586, in read_csv
return _read(filepath_or_buffer, kwds)
File "/Users/johngiorgi/.pyenv/versions/3.7.13/envs/datasets/lib/python3.7/site-packages/pandas/io/parsers/readers.py", line 488, in _read
return parser.read(nrows)
File "/Users/johngiorgi/.pyenv/versions/3.7.13/envs/datasets/lib/python3.7/site-packages/pandas/io/parsers/readers.py", line 1047, in read
index, columns, col_dict = self._engine.read(nrows)
File "/Users/johngiorgi/.pyenv/versions/3.7.13/envs/datasets/lib/python3.7/site-packages/pandas/io/parsers/c_parser_wrapper.py", line 224, in read
chunks = self._reader.read_low_memory(nrows)
File "pandas/_libs/parsers.pyx", line 801, in pandas._libs.parsers.TextReader.read_low_memory
File "pandas/_libs/parsers.pyx", line 857, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 843, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1925, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: EOF inside string starting at row 2
```
I think this may have to do with unusual line terminators in the original data. When I open it in VSCode, it complains:
```
The file 'dev-inputs.csv' contains one or more unusual line terminator characters, like Line Separator (LS) or Paragraph Separator (PS).
It is recommended to remove them from the file. This can be configured via `editor.unusualLineTerminators`.
```
Tagging the organizers of the shared task in case they want to sanity check this or add any info to the model card :) @lucylw @jayded
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4339/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4339/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4339.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4339",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4339.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4339"
} | true | [
"I think the underlying issue is in https://github.com/huggingface/datasets/blob/c0ed6fdc29675b3565b01b77fde5ab5d9d8b60ec/src/datasets/commands/dummy_data.py#L124 - where `CSV`s are considered to be in the same class of file as text, jsonl, and tsv.\r\n\r\nI think this is an error because CSVs can have newlines within the rows of a file. I'm happy to make a PR to change how this handling works, or make the change within this PR. \r\n\r\nWe should figure out:\r\n1. Does this dummy data need to be generated more than once? (It looks like no)\r\n2. Should this be fixed generally? (needs a HF person to weigh in here)\r\n3. What is the right way for such a fix to exist permanently here; the [Contributing document](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md) doesn't provide guidance on any tests. Writing a test is several times more effort than fixing the underlying issue. (again needs a HF person)",
"Would someone from HF mind taking a look at this PR? (@lhoestq)",
"Hi ! Sorry for the delay in responding :)\r\n\r\nI don't think there's a big need to fix this in the general case for now, feel free to just generate the dummy data for this specific dataset :)\r\n\r\nThe `datasets-cli dummy_data datasets/mslr2022` command should tell you what dummy files to generate. In each dummy file you just need to include enough data to generate 4 or 5 examples",
"_The documentation is not available anymore as the PR was closed or merged._",
"Awesome! Generated the dummy data and the tests now pass. @jayded thanks for your help! If you and @lucylw are happy with this I think it's ready to be merged. @lhoestq this is ready for another look :)",
"Hi @lhoestq, is there anything blocking this from being merged that I can address?",
"Hi @JohnGiorgi ! Thanks for the changes, it looks all good now :)\r\n\r\nI think this dataset can be under the AllenAI page here: https://huggingface.co/allenai What do you think ?\r\nFeel free to create a new dataset repository on huggingface.co and upload your files (dataset script, readme, etc.)\r\n\r\nOnce the dataset is under the AllenAI org, we can close this PR\r\n",
"> Hi @JohnGiorgi ! Thanks for the changes, it looks all good now :)\r\n> \r\n> I think this dataset can be under the AllenAI page here: https://huggingface.co/allenai What do you think ? Feel free to create a new dataset repository on huggingface.co and upload your files (dataset script, readme, etc.)\r\n> \r\n> Once the dataset is under the AllenAI org, we can close this PR\r\n\r\nSweet! It is uploaded here: https://huggingface.co/datasets/allenai/mslr2022",
"Nice ! Thanks :)\r\n\r\nI think we can close this PR then.\r\n\r\nI noticed that the dataset preview is not available on this dataset, this is because we require datasets to work in streaming mode to show a preview. However TAR archives don't work well in streaming mode (you can't know in advance what files are inside a TAR archive without reading it completely). This can be fixed by using a ZIP archive instead.\r\n\r\nLet me know if you have questions or if I can help."
] |
https://api.github.com/repos/huggingface/datasets/issues/3404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3404/comments | https://api.github.com/repos/huggingface/datasets/issues/3404/events | https://github.com/huggingface/datasets/issues/3404 | 1,073,657,561 | I_kwDODunzps4__rbZ | 3,404 | Optimize ZIP format inference | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2021-12-07T18:44:49Z | 2021-12-14T17:08:41Z | 2021-12-14T17:08:41Z | null | **Is your feature request related to a problem? Please describe.**
When hundreds of ZIP files are present in a dataset, format inference takes too long.
See: https://github.com/bigscience-workshop/data_tooling/issues/232#issuecomment-986685497
**Describe the solution you'd like**
Iterate over a maximum number of files.
CC: @lhoestq
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3404/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3404/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/963 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/963/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/963/comments | https://api.github.com/repos/huggingface/datasets/issues/963/events | https://github.com/huggingface/datasets/pull/963 | 754,451,234 | MDExOlB1bGxSZXF1ZXN0NTMwMzQ5NjQ4 | 963 | add CODAH dataset | [] | closed | false | null | 0 | 2020-12-01T14:37:05Z | 2020-12-02T13:45:58Z | 2020-12-02T13:21:25Z | null | Adding CODAH dataset.
More info:
https://github.com/Websail-NU/CODAH | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/963/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/963/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/963.diff",
"html_url": "https://github.com/huggingface/datasets/pull/963",
"merged_at": "2020-12-02T13:21:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/963.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/963"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/730/comments | https://api.github.com/repos/huggingface/datasets/issues/730/events | https://github.com/huggingface/datasets/issues/730 | 721,073,812 | MDU6SXNzdWU3MjEwNzM4MTI= | 730 | Possible caching bug | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 7 | 2020-10-14T02:02:34Z | 2022-11-22T01:45:54Z | 2020-10-29T09:36:01Z | null | The following code with `test1.txt` containing just "🤗🤗🤗":
```
dataset = datasets.load_dataset('text', data_files=['test1.txt'], split="train", encoding="latin_1")
print(dataset[0])
dataset = datasets.load_dataset('text', data_files=['test1.txt'], split="train", encoding="utf-8")
print(dataset[0])
```
produces this output:
```
Downloading and preparing dataset text/default-15600e4d83254059 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/arne/.cache/huggingface/datasets/text/default-15600e4d83254059/0.0.0/52cefbb2b82b015d4253f1aeb1e6ee5591124a6491e834acfe1751f765925155...
Dataset text downloaded and prepared to /home/arne/.cache/huggingface/datasets/text/default-15600e4d83254059/0.0.0/52cefbb2b82b015d4253f1aeb1e6ee5591124a6491e834acfe1751f765925155. Subsequent calls will reuse this data.
{'text': 'ð\x9f¤\x97ð\x9f¤\x97ð\x9f¤\x97'}
Using custom data configuration default
Reusing dataset text (/home/arne/.cache/huggingface/datasets/text/default-15600e4d83254059/0.0.0/52cefbb2b82b015d4253f1aeb1e6ee5591124a6491e834acfe1751f765925155)
{'text': 'ð\x9f¤\x97ð\x9f¤\x97ð\x9f¤\x97'}
```
Just changing the order (and deleting the temp files):
```
dataset = datasets.load_dataset('text', data_files=['test1.txt'], split="train", encoding="utf-8")
print(dataset[0])
dataset = datasets.load_dataset('text', data_files=['test1.txt'], split="train", encoding="latin_1")
print(dataset[0])
```
produces this:
```
Using custom data configuration default
Downloading and preparing dataset text/default-15600e4d83254059 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/arne/.cache/huggingface/datasets/text/default-15600e4d83254059/0.0.0/52cefbb2b82b015d4253f1aeb1e6ee5591124a6491e834acfe1751f765925155...
Dataset text downloaded and prepared to /home/arne/.cache/huggingface/datasets/text/default-15600e4d83254059/0.0.0/52cefbb2b82b015d4253f1aeb1e6ee5591124a6491e834acfe1751f765925155. Subsequent calls will reuse this data.
{'text': '🤗🤗🤗'}
Using custom data configuration default
Reusing dataset text (/home/arne/.cache/huggingface/datasets/text/default-15600e4d83254059/0.0.0/52cefbb2b82b015d4253f1aeb1e6ee5591124a6491e834acfe1751f765925155)
{'text': '🤗🤗🤗'}
```
Is it intended that the cache path does not depend on the config entries?
tested with datasets==1.1.2 and python==3.8.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/730/timeline | null | completed | null | null | false | [
"Thanks for reporting. That's a bug indeed.\r\nApparently only the `data_files` parameter is taken into account right now in `DatasetBuilder._create_builder_config` but it should also be the case for `config_kwargs` (or at least the instantiated `builder_config`)",
"Hi, does this bug be fixed? when I load JSON files, I get the same errors by the command \r\n`!python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/`\r\n\r\nchange the dateset to load json by refering to https://huggingface.co/docs/datasets/loading.html\r\n`dataset = datasets.load_dataset('json', data_files=args.dataset)`\r\n\r\nErrors:\r\n`Downloading and preparing dataset json/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/json/default-c1e124ad488911b8/0.0.0/45636811569ec4a6630521c18235dfbbab83b7ab572e3393c5ba68ccabe98264...\r\n`",
"```ds = load_dataset(\"csv\", data_files={'train': 'train.csv', 'test': 'test.csv'})```\r\n\r\nGives the output\r\n```Using custom data configuration default-5c8ae7c208631aca```\r\n\r\nand the code hangs there.",
"> `ds = load_dataset(\"csv\", data_files={'train': 'train.csv', 'test': 'test.csv'})`\r\n> \r\n> Gives the output `Using custom data configuration default-5c8ae7c208631aca`\r\n> \r\n> and the code hangs there.\r\n\r\nHave you solved it? I met this problem too!",
"Can you Ctrl+C to kill the process and share the stacktrace here ? It should show at which location in the code it was hanging",
"I had the same issue and solved it by downgrading the datasets version from 2.7.0 -> 2.6.1\r\npip install -q datasets==2.6.1",
"> I had the same issue and solved it by downgrading the datasets version from 2.7.0 -> 2.6.1 pip install -q datasets==2.6.1\r\n\r\nThanks, it works for me"
] |
https://api.github.com/repos/huggingface/datasets/issues/2995 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2995/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2995/comments | https://api.github.com/repos/huggingface/datasets/issues/2995/events | https://github.com/huggingface/datasets/pull/2995 | 1,013,143,868 | PR_kwDODunzps4sjThd | 2,995 | Fix trivia_qa unfiltered | [] | closed | false | null | 1 | 2021-10-01T09:53:43Z | 2021-10-01T10:04:11Z | 2021-10-01T10:04:10Z | null | Fix https://github.com/huggingface/datasets/issues/2993 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2995/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2995/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2995.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2995",
"merged_at": "2021-10-01T10:04:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2995.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2995"
} | true | [
"CI fails due to missing tags, but they will be added in https://github.com/huggingface/datasets/pull/2949"
] |
https://api.github.com/repos/huggingface/datasets/issues/3358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3358/comments | https://api.github.com/repos/huggingface/datasets/issues/3358/events | https://github.com/huggingface/datasets/issues/3358 | 1,068,623,216 | I_kwDODunzps4_seVw | 3,358 | add new field, and get errors | [] | closed | false | null | 2 | 2021-12-01T16:35:38Z | 2021-12-02T02:26:22Z | 2021-12-02T02:26:22Z | null | after adding new field **tokenized_examples["example_id"]**, and get errors below,
I think it is due to changing data to tensor, and **tokenized_examples["example_id"]** is string list
**all fields**
```
***************** train_dataset 1: Dataset({
features: ['attention_mask', 'end_positions', 'example_id', 'input_ids', 'start_positions', 'token_type_ids'],
num_rows: 87714
})
```
**Errors**
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 705, in convert_to_tensors
tensor = as_tensor(value)
ValueError: too many dimensions 'str'
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3358/timeline | null | completed | null | null | false | [
"Hi, \r\n\r\ncould you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests? ",
"> Hi,\r\n> \r\n> could you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests?\r\n\r\nok."
] |
https://api.github.com/repos/huggingface/datasets/issues/2243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2243/comments | https://api.github.com/repos/huggingface/datasets/issues/2243/events | https://github.com/huggingface/datasets/issues/2243 | 862,909,389 | MDU6SXNzdWU4NjI5MDkzODk= | 2,243 | Map is slow and processes batches one after another | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2021-04-20T14:58:20Z | 2021-05-03T17:54:33Z | 2021-05-03T17:54:32Z | null | ## Describe the bug
I have a somewhat unclear bug to me, where I can't figure out what the problem is. The code works as expected on a small subset of my dataset (2000 samples) on my local machine, but when I execute the same code with a larger dataset (1.4 million samples) this problem occurs. Thats why I can't give exact steps to reproduce, I'm sorry.
I process a large dataset in a two step process. I first call map on a dataset I load from disk and create a new dataset from it. This works like expected and `map` uses all workers I started it with. Then I process the dataset created by the first step, again with `map`, which is really slow and starting only one or two process at a time. Number of processes is the same for both steps.
pseudo code:
```python
ds = datasets.load_from_disk("path")
new_dataset = ds.map(work, batched=True, ...) # fast uses all processes
final_dataset = new_dataset.map(work2, batched=True, ...) # slow starts one process after another
```
## Expected results
Second stage should be as fast as the first stage.
## Versions
Paste the output of the following code:
- Datasets: 1.5.0
- Python: 3.8.8 (default, Feb 24 2021, 21:46:12)
- Platform: Linux-5.4.0-60-generic-x86_64-with-glibc2.10
Do you guys have any idea? Thanks a lot! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2243/timeline | null | completed | null | null | false | [
"Hi @villmow, thanks for reporting.\r\n\r\nCould you please try with the Datasets version 1.6? We released it yesterday and it fixes some issues about the processing speed. You can see the fix implemented by @lhoestq here: #2122.\r\n\r\nOnce you update Datasets, please confirm if the problem persists.",
"Hi @albertvillanova, thanks for the reply. I just tried the new version and the problem still persists. \r\n\r\nDo I need to rebuild the saved dataset (which I load from disk) with the 1.6.0 version of datasets? My script loads this dataset and creates new datasets from it. I tried it without rebuilding.\r\n\r\nSee this short video of what happens. It does not create all processes at the same time:\r\n\r\nhttps://user-images.githubusercontent.com/2743060/115720139-0da3a500-a37d-11eb-833a-9bbacc70868d.mp4\r\n\r\n",
"There can be a bit of delay between the creations of the processes but this delay should be the same for both your `map` calls. We should look into this.\r\nAlso if you hav some code that reproduces this issue on google colab that'd be really useful !\r\n\r\nRegarding the speed differences:\r\nThis looks like a similar issue as https://github.com/huggingface/datasets/issues/1992 who is experiencing the same speed differences between processes.\r\nThis is a known bug that we are investigating. As of now I've never managed to reproduce it on my machine so it's pretty hard for me to find where this issue comes from.\r\n",
"Upgrade to 1.6.1 solved my problem somehow. I did not change any of my code, but now it starts all processes around the same time.",
"Nice ! I'm glad this works now.\r\nClosing for now, but feel free to re-open if you experience this issue again."
] |
https://api.github.com/repos/huggingface/datasets/issues/4956 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4956/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4956/comments | https://api.github.com/repos/huggingface/datasets/issues/4956/events | https://github.com/huggingface/datasets/pull/4956 | 1,366,475,160 | PR_kwDODunzps4-m5NU | 4,956 | Fix TF tests for 2.10 | [] | closed | false | null | 1 | 2022-09-08T14:39:10Z | 2022-09-08T15:16:51Z | 2022-09-08T15:14:44Z | null | Fixes #4953 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4956/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4956/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4956.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4956",
"merged_at": "2022-09-08T15:14:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4956.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4956"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5765/comments | https://api.github.com/repos/huggingface/datasets/issues/5765/events | https://github.com/huggingface/datasets/issues/5765 | 1,671,388,824 | I_kwDODunzps5jn16Y | 5,765 | ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['text'] | [] | open | false | null | 4 | 2023-04-17T15:00:50Z | 2023-04-25T13:50:45Z | null | null | ### Describe the bug
Following is my code that I am trying to run, but facing an error (have attached the whole error below):
My code:
```
from collections import OrderedDict
import warnings
import flwr as fl
import torch
import numpy as np
import random
from torch.utils.data import DataLoader
from datasets import load_dataset, load_metric
from transformers import AutoTokenizer, DataCollatorWithPadding
from transformers import AutoModelForSequenceClassification
from transformers import AdamW
#from transformers import tokenized_datasets
warnings.filterwarnings("ignore", category=UserWarning)
# DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
DEVICE = "cpu"
CHECKPOINT = "distilbert-base-uncased" # transformer model checkpoint
def load_data():
"""Load IMDB data (training and eval)"""
raw_datasets = load_dataset("yhavinga/imdb_dutch")
raw_datasets = raw_datasets.shuffle(seed=42)
# remove unnecessary data split
del raw_datasets["unsupervised"]
tokenizer = AutoTokenizer.from_pretrained(CHECKPOINT)
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True)
# random 100 samples
population = random.sample(range(len(raw_datasets["train"])), 100)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets["train"] = tokenized_datasets["train"].select(population)
tokenized_datasets["test"] = tokenized_datasets["test"].select(population)
# tokenized_datasets = tokenized_datasets.remove_columns("text")
# tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets = tokenized_datasets.remove_columns("attention_mask")
tokenized_datasets = tokenized_datasets.remove_columns("input_ids")
tokenized_datasets = tokenized_datasets.remove_columns("label")
tokenized_datasets = tokenized_datasets.remove_columns("text_en")
# tokenized_datasets = tokenized_datasets.remove_columns(raw_datasets["train"].column_names)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
batch_size=32,
collate_fn=data_collator,
)
testloader = DataLoader(
tokenized_datasets["test"], batch_size=32, collate_fn=data_collator
)
return trainloader, testloader
def train(net, trainloader, epochs):
optimizer = AdamW(net.parameters(), lr=5e-4)
net.train()
for _ in range(epochs):
for batch in trainloader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
outputs = net(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
def test(net, testloader):
metric = load_metric("accuracy")
loss = 0
net.eval()
for batch in testloader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
with torch.no_grad():
outputs = net(**batch)
logits = outputs.logits
loss += outputs.loss.item()
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
loss /= len(testloader.dataset)
accuracy = metric.compute()["accuracy"]
return loss, accuracy
def main():
net = AutoModelForSequenceClassification.from_pretrained(
CHECKPOINT, num_labels=2
).to(DEVICE)
trainloader, testloader = load_data()
# Flower client
class IMDBClient(fl.client.NumPyClient):
def get_parameters(self, config):
return [val.cpu().numpy() for _, val in net.state_dict().items()]
def set_parameters(self, parameters):
params_dict = zip(net.state_dict().keys(), parameters)
state_dict = OrderedDict({k: torch.Tensor(v) for k, v in params_dict})
net.load_state_dict(state_dict, strict=True)
def fit(self, parameters, config):
self.set_parameters(parameters)
print("Training Started...")
train(net, trainloader, epochs=1)
print("Training Finished.")
return self.get_parameters(config={}), len(trainloader), {}
def evaluate(self, parameters, config):
self.set_parameters(parameters)
loss, accuracy = test(net, testloader)
return float(loss), len(testloader), {"accuracy": float(accuracy)}
# Start client
fl.client.start_numpy_client(server_address="localhost:8080", client=IMDBClient())
if __name__ == "__main__":
main()
```
Error:
```
Traceback (most recent call last):
File "client_2.py", line 136, in <module>
main()
File "client_2.py", line 132, in main
fl.client.start_numpy_client(server_address="localhost:8080", client=IMDBClient())
File "/home/saurav/.local/lib/python3.8/site-packages/flwr/client/app.py", line 208, in start_numpy_client
start_client(
File "/home/saurav/.local/lib/python3.8/site-packages/flwr/client/app.py", line 142, in start_client
client_message, sleep_duration, keep_going = handle(
File "/home/saurav/.local/lib/python3.8/site-packages/flwr/client/grpc_client/message_handler.py", line 68, in handle
return _fit(client, server_msg.fit_ins), 0, True
File "/home/saurav/.local/lib/python3.8/site-packages/flwr/client/grpc_client/message_handler.py", line 157, in _fit
fit_res = client.fit(fit_ins)
File "/home/saurav/.local/lib/python3.8/site-packages/flwr/client/app.py", line 252, in _fit
results = self.numpy_client.fit(parameters, ins.config) # type: ignore
File "client_2.py", line 122, in fit
train(net, trainloader, epochs=1)
File "client_2.py", line 76, in train
for batch in trainloader:
File "/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 652, in __next__
data = self._next_data()
File "/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 692, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 52, in fetch
return self.collate_fn(data)
File "/home/saurav/.local/lib/python3.8/site-packages/transformers/data/data_collator.py", line 221, in __call__
batch = self.tokenizer.pad(
File "/home/saurav/.local/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 2713, in pad
raise ValueError(
ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['text']
```
### Steps to reproduce the bug
Run the above code.
### Expected behavior
Don't know, doing it for the first time.
### Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 11.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5765/timeline | null | null | null | null | false | [
"You need to remove the `text` and `text_en` columns before passing the dataset to the `DataLoader` to avoid this error:\r\n```python\r\ntokenized_datasets = tokenized_datasets.remove_columns([\"text\", \"text_en\"])\r\n```\r\n",
"Thanks @mariosasko. Now I am getting this error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"client_2.py\", line 138, in <module>\r\n main()\r\n File \"client_2.py\", line 134, in main\r\n fl.client.start_numpy_client(server_address=\"localhost:8080\", client=IMDBClient())\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/flwr/client/app.py\", line 208, in start_numpy_client\r\n start_client(\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/flwr/client/app.py\", line 142, in start_client\r\n client_message, sleep_duration, keep_going = handle(\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/flwr/client/grpc_client/message_handler.py\", line 68, in handle\r\n return _fit(client, server_msg.fit_ins), 0, True\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/flwr/client/grpc_client/message_handler.py\", line 157, in _fit\r\n fit_res = client.fit(fit_ins)\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/flwr/client/app.py\", line 252, in _fit\r\n results = self.numpy_client.fit(parameters, ins.config) # type: ignore\r\n File \"client_2.py\", line 124, in fit\r\n train(net, trainloader, epochs=1)\r\n File \"client_2.py\", line 78, in train\r\n for batch in trainloader:\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py\", line 652, in __next__\r\n data = self._next_data()\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/dataloader.py\", line 692, in _next_data\r\n data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py\", line 49, in fetch\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py\", line 49, in <listcomp>\r\n data = [self.dataset[idx] for idx in possibly_batched_index]\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1525, in __getitem__\r\n return self._getitem(\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1517, in _getitem\r\n pa_subtable = query_table(self._data, key, indices=self._indices if self._indices is not None else None)\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/datasets/formatting/formatting.py\", line 373, in query_table\r\n pa_subtable = _query_table_with_indices_mapping(table, key, indices=indices)\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/datasets/formatting/formatting.py\", line 55, in _query_table_with_indices_mapping\r\n return _query_table(table, key)\r\n File \"/home/saurav/.local/lib/python3.8/site-packages/datasets/formatting/formatting.py\", line 79, in _query_table\r\n return table.fast_slice(key % table.num_rows, 1)\r\nZeroDivisionError: integer division or modulo by zero\r\n```\r\n\r\nThis is my code:\r\n\r\n```\r\nfrom collections import OrderedDict\r\nimport warnings\r\n\r\nimport flwr as fl\r\nimport torch\r\nimport numpy as np\r\n\r\nimport random\r\nfrom torch.utils.data import DataLoader\r\n\r\nfrom datasets import load_dataset, load_metric\r\n\r\nfrom transformers import AutoTokenizer, DataCollatorWithPadding\r\nfrom transformers import AutoModelForSequenceClassification\r\nfrom transformers import AdamW\r\n#from transformers import tokenized_datasets\r\n\r\n\r\nwarnings.filterwarnings(\"ignore\", category=UserWarning)\r\n# DEVICE = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\r\n\r\nDEVICE = \"cpu\"\r\n\r\nCHECKPOINT = \"distilbert-base-uncased\" # transformer model checkpoint\r\n\r\n\r\ndef load_data():\r\n \"\"\"Load IMDB data (training and eval)\"\"\"\r\n raw_datasets = load_dataset(\"yhavinga/imdb_dutch\")\r\n raw_datasets = raw_datasets.shuffle(seed=42)\r\n\r\n # remove unnecessary data split\r\n del raw_datasets[\"unsupervised\"]\r\n\r\n tokenizer = AutoTokenizer.from_pretrained(CHECKPOINT)\r\n\r\n def tokenize_function(examples):\r\n return tokenizer(examples[\"text\"], truncation=True)\r\n\r\n # random 100 samples\r\n population = random.sample(range(len(raw_datasets[\"train\"])), 100)\r\n\r\n tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)\r\n tokenized_datasets[\"train\"] = tokenized_datasets[\"train\"].select(population)\r\n tokenized_datasets[\"test\"] = tokenized_datasets[\"test\"].select(population)\r\n\r\n # tokenized_datasets = tokenized_datasets.remove_columns(\"text\")\r\n # tokenized_datasets = tokenized_datasets.rename_column(\"label\", \"labels\")\r\n\r\n tokenized_datasets = tokenized_datasets.remove_columns(\"attention_mask\")\r\n tokenized_datasets = tokenized_datasets.remove_columns(\"input_ids\")\r\n tokenized_datasets = tokenized_datasets.remove_columns(\"label\")\r\n # tokenized_datasets = tokenized_datasets.remove_columns(\"text_en\")\r\n\r\n # tokenized_datasets = tokenized_datasets.remove_columns(raw_datasets[\"train\"].column_names)\r\n \r\n tokenized_datasets = tokenized_datasets.remove_columns([\"text\", \"text_en\"])\r\n \r\n data_collator = DataCollatorWithPadding(tokenizer=tokenizer)\r\n trainloader = DataLoader(\r\n tokenized_datasets[\"train\"],\r\n shuffle=True,\r\n batch_size=32,\r\n collate_fn=data_collator,\r\n )\r\n\r\n testloader = DataLoader(\r\n tokenized_datasets[\"test\"], batch_size=32, collate_fn=data_collator\r\n )\r\n\r\n return trainloader, testloader\r\n\r\n\r\ndef train(net, trainloader, epochs):\r\n optimizer = AdamW(net.parameters(), lr=5e-4)\r\n net.train()\r\n for _ in range(epochs):\r\n for batch in trainloader:\r\n batch = {k: v.to(DEVICE) for k, v in batch.items()}\r\n outputs = net(**batch)\r\n loss = outputs.loss\r\n loss.backward()\r\n optimizer.step()\r\n optimizer.zero_grad()\r\n\r\n\r\ndef test(net, testloader):\r\n metric = load_metric(\"accuracy\")\r\n loss = 0\r\n net.eval()\r\n for batch in testloader:\r\n batch = {k: v.to(DEVICE) for k, v in batch.items()}\r\n with torch.no_grad():\r\n outputs = net(**batch)\r\n logits = outputs.logits\r\n loss += outputs.loss.item()\r\n predictions = torch.argmax(logits, dim=-1)\r\n metric.add_batch(predictions=predictions, references=batch[\"labels\"])\r\n loss /= len(testloader.dataset)\r\n accuracy = metric.compute()[\"accuracy\"]\r\n return loss, accuracy\r\n\r\n\r\ndef main():\r\n net = AutoModelForSequenceClassification.from_pretrained(\r\n CHECKPOINT, num_labels=2\r\n ).to(DEVICE)\r\n\r\n trainloader, testloader = load_data()\r\n\r\n # Flower client\r\n class IMDBClient(fl.client.NumPyClient):\r\n def get_parameters(self, config):\r\n return [val.cpu().numpy() for _, val in net.state_dict().items()]\r\n\r\n def set_parameters(self, parameters):\r\n params_dict = zip(net.state_dict().keys(), parameters)\r\n state_dict = OrderedDict({k: torch.Tensor(v) for k, v in params_dict})\r\n net.load_state_dict(state_dict, strict=True)\r\n\r\n def fit(self, parameters, config):\r\n self.set_parameters(parameters)\r\n print(\"Training Started...\")\r\n train(net, trainloader, epochs=1)\r\n print(\"Training Finished.\")\r\n return self.get_parameters(config={}), len(trainloader), {}\r\n\r\n def evaluate(self, parameters, config):\r\n self.set_parameters(parameters)\r\n loss, accuracy = test(net, testloader)\r\n return float(loss), len(testloader), {\"accuracy\": float(accuracy)}\r\n\r\n # Start client\r\n fl.client.start_numpy_client(server_address=\"localhost:8080\", client=IMDBClient())\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n```",
"Please also remove/comment these lines:\r\n```python\r\ntokenized_datasets = tokenized_datasets.remove_columns(\"attention_mask\")\r\ntokenized_datasets = tokenized_datasets.remove_columns(\"input_ids\")\r\ntokenized_datasets = tokenized_datasets.remove_columns(\"label\")\r\n```",
"Thanks @mariosasko .\r\n\r\nNow, I am trying out this [tutorial](https://flower.dev/docs/quickstart-huggingface.html) which basically trains distil-BERT with IMDB dataset (very similar to this [tutorial](https://huggingface.co/docs/transformers/main/tasks/sequence_classification)). But I don't know why my accuracy isn't increasing even after training for a significant amount of time and also by using the entire dataset. Below I have attached `client.py` file:\r\n\r\n`client.py`:\r\n\r\n```\r\nfrom collections import OrderedDict\r\nimport warnings\r\n\r\nimport flwr as fl\r\nimport torch\r\nimport numpy as np\r\n\r\nimport random\r\nfrom torch.utils.data import DataLoader\r\n\r\nfrom datasets import load_dataset, load_metric\r\n\r\nfrom transformers import AutoTokenizer, DataCollatorWithPadding\r\nfrom transformers import AutoModelForSequenceClassification\r\nfrom transformers import AdamW\r\n\r\nwarnings.filterwarnings(\"ignore\", category=UserWarning)\r\n\r\nDEVICE = \"cuda:1\"\r\n\r\nCHECKPOINT = \"distilbert-base-uncased\" # transformer model checkpoint\r\n\r\n\r\ndef load_data():\r\n \"\"\"Load IMDB data (training and eval)\"\"\"\r\n raw_datasets = load_dataset(\"imdb\")\r\n raw_datasets = raw_datasets.shuffle(seed=42)\r\n\r\n # remove unnecessary data split\r\n del raw_datasets[\"unsupervised\"]\r\n\r\n tokenizer = AutoTokenizer.from_pretrained(CHECKPOINT)\r\n\r\n def tokenize_function(examples):\r\n return tokenizer(examples[\"text\"], truncation=True)\r\n\r\n tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)\r\n\r\n tokenized_datasets = tokenized_datasets.remove_columns(\"text\")\r\n tokenized_datasets = tokenized_datasets.rename_column(\"label\", \"labels\")\r\n\r\n data_collator = DataCollatorWithPadding(tokenizer=tokenizer)\r\n trainloader = DataLoader(\r\n tokenized_datasets[\"train\"],\r\n shuffle=True,\r\n batch_size=32,\r\n collate_fn=data_collator,\r\n )\r\n\r\n testloader = DataLoader(\r\n tokenized_datasets[\"test\"], batch_size=32, collate_fn=data_collator\r\n )\r\n\r\n return trainloader, testloader\r\n\r\n\r\ndef train(net, trainloader, epochs):\r\n optimizer = AdamW(net.parameters(), lr=5e-5)\r\n net.train()\r\n for i in range(epochs):\r\n print(\"Epoch: \", i+1)\r\n j = 1\r\n print(\"####################### The length of the trainloader is: \", len(trainloader)) \r\n for batch in trainloader:\r\n print(\"####################### The batch number is: \", j)\r\n batch = {k: v.to(DEVICE) for k, v in batch.items()}\r\n outputs = net(**batch)\r\n loss = outputs.loss\r\n loss.backward()\r\n optimizer.step()\r\n optimizer.zero_grad()\r\n j += 1\r\n\r\n\r\ndef test(net, testloader):\r\n metric = load_metric(\"accuracy\")\r\n loss = 0\r\n net.eval()\r\n for batch in testloader:\r\n batch = {k: v.to(DEVICE) for k, v in batch.items()}\r\n with torch.no_grad():\r\n outputs = net(**batch)\r\n logits = outputs.logits\r\n loss += outputs.loss.item()\r\n predictions = torch.argmax(logits, dim=-1)\r\n metric.add_batch(predictions=predictions, references=batch[\"labels\"])\r\n loss /= len(testloader.dataset)\r\n accuracy = metric.compute()[\"accuracy\"]\r\n return loss, accuracy\r\n\r\n\r\ndef main():\r\n net = AutoModelForSequenceClassification.from_pretrained(\r\n CHECKPOINT, num_labels=2\r\n ).to(DEVICE)\r\n\r\n trainloader, testloader = load_data()\r\n\r\n # Flower client\r\n class IMDBClient(fl.client.NumPyClient):\r\n def get_parameters(self, config):\r\n return [val.cpu().numpy() for _, val in net.state_dict().items()]\r\n\r\n def set_parameters(self, parameters):\r\n params_dict = zip(net.state_dict().keys(), parameters)\r\n state_dict = OrderedDict({k: torch.Tensor(v) for k, v in params_dict})\r\n net.load_state_dict(state_dict, strict=True)\r\n\r\n def fit(self, parameters, config):\r\n self.set_parameters(parameters)\r\n print(\"Training Started...\")\r\n train(net, trainloader, epochs=1)\r\n print(\"Training Finished.\")\r\n return self.get_parameters(config={}), len(trainloader), {}\r\n\r\n def evaluate(self, parameters, config):\r\n self.set_parameters(parameters)\r\n loss, accuracy = test(net, testloader)\r\n print({\"loss\": float(loss), \"accuracy\": float(accuracy)})\r\n return float(loss), len(testloader), {\"loss\": float(loss), \"accuracy\": float(accuracy)}\r\n\r\n # Start client\r\n fl.client.start_numpy_client(server_address=\"localhost:5040\", client=IMDBClient())\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n```\r\n\r\nCan I get any help, please?"
] |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | [] | closed | false | null | 3 | 2023-03-03T15:46:31Z | 2023-03-03T21:57:18Z | 2023-03-03T21:50:17Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"merged_at": "2023-03-03T21:50:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5605"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Are you sure it's safe to remove? https://github.com/huggingface/datasets/pull/3866",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009520 / 0.011353 (-0.001833) | 0.005319 / 0.011008 (-0.005690) | 0.099372 / 0.038508 (0.060863) | 0.036173 / 0.023109 (0.013064) | 0.295752 / 0.275898 (0.019853) | 0.362882 / 0.323480 (0.039402) | 0.008442 / 0.007986 (0.000456) | 0.004225 / 0.004328 (-0.000103) | 0.076645 / 0.004250 (0.072394) | 0.044198 / 0.037052 (0.007146) | 0.311948 / 0.258489 (0.053459) | 0.342963 / 0.293841 (0.049122) | 0.038613 / 0.128546 (-0.089933) | 0.012127 / 0.075646 (-0.063519) | 0.334427 / 0.419271 (-0.084844) | 0.048309 / 0.043533 (0.004776) | 0.297046 / 0.255139 (0.041907) | 0.314562 / 0.283200 (0.031363) | 0.105797 / 0.141683 (-0.035886) | 1.460967 / 1.452155 (0.008812) | 1.500907 / 1.492716 (0.008190) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216185 / 0.018006 (0.198179) | 0.438924 / 0.000490 (0.438435) | 0.001210 / 0.000200 (0.001011) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026193 / 0.037411 (-0.011219) | 0.105888 / 0.014526 (0.091363) | 0.115812 / 0.176557 (-0.060744) | 0.158748 / 0.737135 (-0.578387) | 0.121514 / 0.296338 (-0.174824) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399837 / 0.215209 (0.184628) | 3.996992 / 2.077655 (1.919338) | 1.784964 / 1.504120 (0.280844) | 1.591078 / 1.541195 (0.049883) | 1.666424 / 1.468490 (0.197934) | 0.711450 / 4.584777 (-3.873327) | 3.787814 / 3.745712 (0.042102) | 2.056776 / 5.269862 (-3.213085) | 1.332163 / 4.565676 (-3.233514) | 0.085755 / 0.424275 (-0.338520) | 0.012033 / 0.007607 (0.004426) | 0.511500 / 0.226044 (0.285455) | 5.098999 / 2.268929 (2.830071) | 2.288261 / 55.444624 (-53.156364) | 1.947483 / 6.876477 (-4.928994) | 1.987838 / 2.142072 (-0.154234) | 0.852241 / 4.805227 (-3.952986) | 0.164781 / 6.500664 (-6.335883) | 0.061825 / 0.075469 (-0.013644) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.202253 / 1.841788 (-0.639534) | 14.632608 / 8.074308 (6.558300) | 13.331320 / 10.191392 (3.139928) | 0.157944 / 0.680424 (-0.522480) | 0.029284 / 0.534201 (-0.504917) | 0.446636 / 0.579283 (-0.132647) | 0.437009 / 0.434364 (0.002645) | 0.521883 / 0.540337 (-0.018455) | 0.606687 / 1.386936 (-0.780249) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007528 / 0.011353 (-0.003825) | 0.005274 / 0.011008 (-0.005734) | 0.073524 / 0.038508 (0.035016) | 0.033893 / 0.023109 (0.010784) | 0.335432 / 0.275898 (0.059534) | 0.379981 / 0.323480 (0.056501) | 0.005954 / 0.007986 (-0.002031) | 0.004126 / 0.004328 (-0.000203) | 0.072891 / 0.004250 (0.068641) | 0.046517 / 0.037052 (0.009465) | 0.337241 / 0.258489 (0.078752) | 0.385562 / 0.293841 (0.091721) | 0.036410 / 0.128546 (-0.092136) | 0.012246 / 0.075646 (-0.063401) | 0.085974 / 0.419271 (-0.333298) | 0.049665 / 0.043533 (0.006133) | 0.330919 / 0.255139 (0.075780) | 0.352041 / 0.283200 (0.068841) | 0.103751 / 0.141683 (-0.037931) | 1.468851 / 1.452155 (0.016696) | 1.565380 / 1.492716 (0.072663) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260431 / 0.018006 (0.242425) | 0.444554 / 0.000490 (0.444064) | 0.016055 / 0.000200 (0.015855) | 0.000283 / 0.000054 (0.000228) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029130 / 0.037411 (-0.008281) | 0.112002 / 0.014526 (0.097476) | 0.120769 / 0.176557 (-0.055788) | 0.169345 / 0.737135 (-0.567790) | 0.129609 / 0.296338 (-0.166730) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.432211 / 0.215209 (0.217002) | 4.293008 / 2.077655 (2.215353) | 2.071291 / 1.504120 (0.567171) | 1.859322 / 1.541195 (0.318127) | 1.971434 / 1.468490 (0.502943) | 0.704042 / 4.584777 (-3.880735) | 3.791696 / 3.745712 (0.045983) | 3.142632 / 5.269862 (-2.127230) | 1.735151 / 4.565676 (-2.830525) | 0.086203 / 0.424275 (-0.338072) | 0.012542 / 0.007607 (0.004935) | 0.534870 / 0.226044 (0.308826) | 5.326042 / 2.268929 (3.057113) | 2.547960 / 55.444624 (-52.896664) | 2.212730 / 6.876477 (-4.663747) | 2.296177 / 2.142072 (0.154105) | 0.840311 / 4.805227 (-3.964917) | 0.168353 / 6.500664 (-6.332311) | 0.065949 / 0.075469 (-0.009520) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.255589 / 1.841788 (-0.586199) | 14.947344 / 8.074308 (6.873036) | 13.253721 / 10.191392 (3.062329) | 0.162349 / 0.680424 (-0.518075) | 0.017579 / 0.534201 (-0.516622) | 0.420758 / 0.579283 (-0.158525) | 0.430030 / 0.434364 (-0.004334) | 0.524669 / 0.540337 (-0.015669) | 0.623920 / 1.386936 (-0.763016) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1389/comments | https://api.github.com/repos/huggingface/datasets/issues/1389/events | https://github.com/huggingface/datasets/pull/1389 | 760,402,224 | MDExOlB1bGxSZXF1ZXN0NTM1MjM5OTYy | 1,389 | add amazon polarity dataset | [] | closed | false | null | 5 | 2020-12-09T14:58:21Z | 2020-12-11T11:45:39Z | 2020-12-11T11:41:01Z | null | This corresponds to the amazon (binary dataset) requested in https://github.com/huggingface/datasets/issues/353 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1389/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1389/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1389.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1389",
"merged_at": "2020-12-11T11:41:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1389.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1389"
} | true | [
"`amazon_polarity` is probably a subset of `amazon_us_reviews` but I am not entirely sure about that.\r\nI guess `amazon_polarity` will help in reproducing results of papers using this dataset since even if it is a subset from `amazon_us_reviews`, it is not trivial how to extract `amazon_polarity` from `amazon_us_reviews`, especially since `amazon_us_reviews` was released after `amazon_polarity`. ",
"do you know what the problem would be ? should I pull the master before ? @lhoestq ",
"The error just appeared on master. I will try to fix it today.\r\nYou can ignore them since it's not related to the dataset you added",
"merging since the CI is fixed on master",
"Great thanks for the help. "
] |
https://api.github.com/repos/huggingface/datasets/issues/5490 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5490/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5490/comments | https://api.github.com/repos/huggingface/datasets/issues/5490/events | https://github.com/huggingface/datasets/pull/5490 | 1,565,842,327 | PR_kwDODunzps5I_nz- | 5,490 | Do not add index column by default when exporting to CSV | [] | closed | false | null | 2 | 2023-02-01T10:20:55Z | 2023-02-09T09:29:08Z | 2023-02-09T09:22:23Z | null | As pointed out by @merveenoyan, default behavior of `Dataset.to_csv` adds the index as an additional column without name.
This PR changes the default behavior, so that now the index column is not written.
To add the index column, now you need to pass `index=True` and also `index_label=<name of the index colum>` to name that column.
CC: @merveenoyan | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5490/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5490/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5490.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5490",
"merged_at": "2023-02-09T09:22:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5490.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5490"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008581 / 0.011353 (-0.002772) | 0.004519 / 0.011008 (-0.006490) | 0.099721 / 0.038508 (0.061213) | 0.029217 / 0.023109 (0.006107) | 0.298229 / 0.275898 (0.022331) | 0.332605 / 0.323480 (0.009125) | 0.006880 / 0.007986 (-0.001106) | 0.003324 / 0.004328 (-0.001005) | 0.078143 / 0.004250 (0.073892) | 0.034262 / 0.037052 (-0.002790) | 0.304162 / 0.258489 (0.045673) | 0.342351 / 0.293841 (0.048510) | 0.033387 / 0.128546 (-0.095159) | 0.011397 / 0.075646 (-0.064249) | 0.321527 / 0.419271 (-0.097744) | 0.040886 / 0.043533 (-0.002647) | 0.299968 / 0.255139 (0.044829) | 0.322484 / 0.283200 (0.039285) | 0.083832 / 0.141683 (-0.057851) | 1.482241 / 1.452155 (0.030086) | 1.548438 / 1.492716 (0.055721) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191002 / 0.018006 (0.172996) | 0.403423 / 0.000490 (0.402933) | 0.002493 / 0.000200 (0.002293) | 0.000074 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023720 / 0.037411 (-0.013691) | 0.100806 / 0.014526 (0.086281) | 0.105314 / 0.176557 (-0.071242) | 0.141490 / 0.737135 (-0.595645) | 0.108695 / 0.296338 (-0.187644) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.412250 / 0.215209 (0.197041) | 4.124830 / 2.077655 (2.047175) | 1.851948 / 1.504120 (0.347828) | 1.651597 / 1.541195 (0.110403) | 1.712486 / 1.468490 (0.243996) | 0.696634 / 4.584777 (-3.888143) | 3.304220 / 3.745712 (-0.441492) | 1.862776 / 5.269862 (-3.407086) | 1.159452 / 4.565676 (-3.406224) | 0.082930 / 0.424275 (-0.341345) | 0.012586 / 0.007607 (0.004979) | 0.524499 / 0.226044 (0.298455) | 5.249235 / 2.268929 (2.980307) | 2.293187 / 55.444624 (-53.151437) | 1.950101 / 6.876477 (-4.926376) | 2.008274 / 2.142072 (-0.133799) | 0.811641 / 4.805227 (-3.993586) | 0.148785 / 6.500664 (-6.351879) | 0.064461 / 0.075469 (-0.011008) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.232227 / 1.841788 (-0.609561) | 13.235896 / 8.074308 (5.161588) | 13.837420 / 10.191392 (3.646028) | 0.135586 / 0.680424 (-0.544838) | 0.028935 / 0.534201 (-0.505266) | 0.397064 / 0.579283 (-0.182220) | 0.393814 / 0.434364 (-0.040549) | 0.480450 / 0.540337 (-0.059887) | 0.561159 / 1.386936 (-0.825777) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006696 / 0.011353 (-0.004657) | 0.004528 / 0.011008 (-0.006480) | 0.077335 / 0.038508 (0.038827) | 0.027181 / 0.023109 (0.004072) | 0.345379 / 0.275898 (0.069481) | 0.372544 / 0.323480 (0.049064) | 0.006808 / 0.007986 (-0.001178) | 0.003284 / 0.004328 (-0.001045) | 0.077379 / 0.004250 (0.073129) | 0.039954 / 0.037052 (0.002901) | 0.348094 / 0.258489 (0.089605) | 0.382315 / 0.293841 (0.088474) | 0.031694 / 0.128546 (-0.096852) | 0.011714 / 0.075646 (-0.063933) | 0.086425 / 0.419271 (-0.332846) | 0.041778 / 0.043533 (-0.001754) | 0.342161 / 0.255139 (0.087022) | 0.363798 / 0.283200 (0.080599) | 0.091315 / 0.141683 (-0.050368) | 1.462066 / 1.452155 (0.009912) | 1.541417 / 1.492716 (0.048700) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235840 / 0.018006 (0.217834) | 0.397096 / 0.000490 (0.396606) | 0.004597 / 0.000200 (0.004397) | 0.000079 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024296 / 0.037411 (-0.013115) | 0.099167 / 0.014526 (0.084641) | 0.108257 / 0.176557 (-0.068299) | 0.143434 / 0.737135 (-0.593701) | 0.111933 / 0.296338 (-0.184406) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440306 / 0.215209 (0.225096) | 4.374065 / 2.077655 (2.296410) | 2.072653 / 1.504120 (0.568533) | 1.864829 / 1.541195 (0.323635) | 1.927970 / 1.468490 (0.459479) | 0.710118 / 4.584777 (-3.874659) | 3.391216 / 3.745712 (-0.354496) | 1.888847 / 5.269862 (-3.381015) | 1.178740 / 4.565676 (-3.386936) | 0.083950 / 0.424275 (-0.340325) | 0.012567 / 0.007607 (0.004960) | 0.540557 / 0.226044 (0.314513) | 5.437621 / 2.268929 (3.168692) | 2.531165 / 55.444624 (-52.913460) | 2.181450 / 6.876477 (-4.695027) | 2.209108 / 2.142072 (0.067035) | 0.814236 / 4.805227 (-3.990991) | 0.153000 / 6.500664 (-6.347664) | 0.066769 / 0.075469 (-0.008700) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.301057 / 1.841788 (-0.540731) | 14.066786 / 8.074308 (5.992478) | 13.641455 / 10.191392 (3.450063) | 0.138838 / 0.680424 (-0.541586) | 0.016733 / 0.534201 (-0.517468) | 0.391823 / 0.579283 (-0.187460) | 0.390817 / 0.434364 (-0.043547) | 0.487682 / 0.540337 (-0.052656) | 0.581134 / 1.386936 (-0.805802) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5406/comments | https://api.github.com/repos/huggingface/datasets/issues/5406/events | https://github.com/huggingface/datasets/issues/5406 | 1,519,140,544 | I_kwDODunzps5ajD7A | 5,406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | [] | open | false | null | 11 | 2023-01-04T15:10:04Z | 2023-06-21T18:45:38Z | null | null | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadata of those datasets to a format that is not supported in 2.6.1 and 2.7.0
This change is required or those datasets won't be supported by the Hugging Face Hub.
Therefore if you encounter this error or if you're using `datasets` 2.6.1 or 2.7.0, we encourage you to update to a newer version.
For example, versions 2.6.2 and 2.7.1 patch this issue.
```python
pip install -U datasets
```
All the datasets affected are the ones with a ClassLabel feature type and YAML "dataset_info" metadata. More info [here](https://github.com/huggingface/datasets/issues/5275).
We apologize for the inconvenience. | {
"+1": 10,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5406/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5406/timeline | null | null | null | null | false | [
"I still get this error on 2.9.0\r\n<img width=\"1925\" alt=\"image\" src=\"https://user-images.githubusercontent.com/7208470/215597359-2f253c76-c472-4612-8099-d3a74d16eb29.png\">\r\n",
"Hi ! I just tested locally and or colab and it works fine for 2.9 on `sst2`.\r\n\r\nAlso the code that is shown in your stack trace is not present in the 2.9 source code - so I'm wondering how you installed `datasets` that could cause this ? (you can check by searching for `[0:{label_ids[-1] + 1}]` in the [2.9 codebase](https://github.dev/huggingface/datasets/tree/b5672a956d5de864e6f5550e493527d962d6ae55) - it doesn't find anything)\r\n\r\nAnyway you can try uninstalling `datasets` and install it again",
"For what it's worth, I've also gotten this error on 2.9.0, and I've tried uninstalling an reinstalling\r\n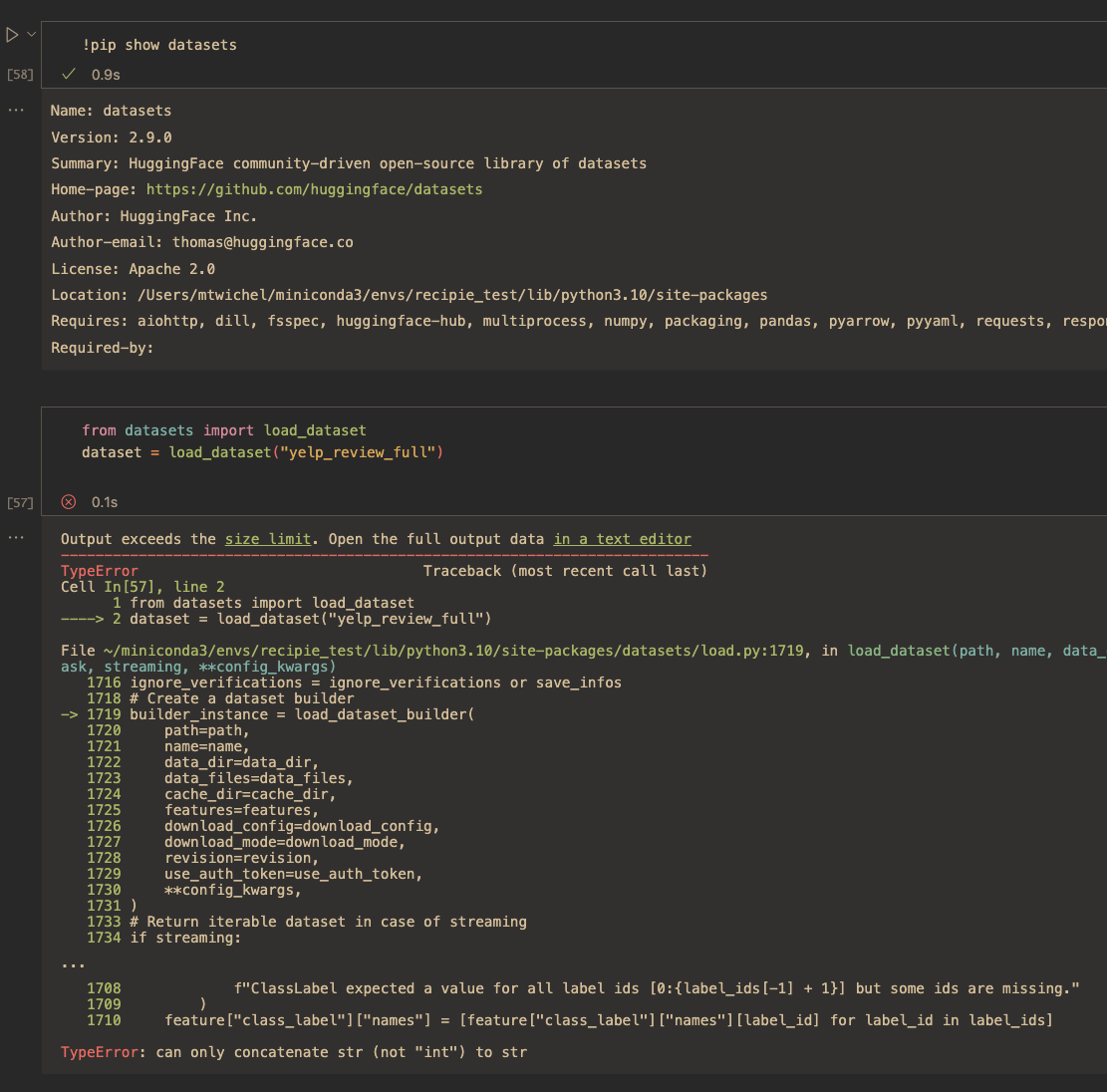\r\n\r\nI'm very new to this package (I was following this tutorial: https://huggingface.co/docs/transformers/training), so there's a good chance I was doing something wrong 😅 but thought I'd pass along the feedback",
"@ntrpnr @mtwichel Did you install `datasets` with conda ?\r\n\r\nI suspect that `datasets` 2.9 on conda still have this issue for some reason. When I install `datasets` with `pip` I don't have this error.",
"> @ntrpnr @mtwichel Did you install datasets with conda ?\r\n\r\nI did yeah, I wonder if that's the issue",
"I just checked on conda at https://anaconda.org/HuggingFace/datasets/files\r\n\r\nand everything looks fine, I got\r\n```python\r\n\r\nf\"ClassLabel expected a value for all label ids [0:{int(label_ids[-1]) + 1}] but some ids are missing.\"\r\n```\r\nas expected in features.py line 1760 (notice the \"int()\") to not have the TypeError.\r\n\r\nFrom where on conda did you install `datasets` ? You should use the `HuggingFace` official channel\r\n\r\nedit: the conda-forge one [here](https://anaconda.org/conda-forge/datasets/files) seems ok as well",
"Could you also try this in your notebook ? In case your python kernel doesn't match the `pip` environment in your shell\r\n```python\r\nimport datasets; datasets.__version__\r\n```\r\nand\r\n```\r\n!which python\r\n```\r\n```python\r\nimport sys; sys.executable\r\n```",
"Mmmm, just a potential clue:\r\n\r\nWhere are you running your Python code? Is it the Spyder IDE?\r\n\r\nI have recently seen some users reporting conflicting Python environments while using Spyder...\r\n\r\nMaybe related:\r\n- #5487",
"Other potential clue:\r\n- Had you already imported `datasets` before pip-updating it? You should first update datasets, before importing it. Otherwise, you need to restart the kernel after updating it.",
"I installed `datasets` with Conda using `conda install datasets` and got this issue.\r\n\r\nThen I tried to reinstall using\r\n`\r\nconda install -c huggingface -c conda-forge datasets\r\n`\r\nThe issue is now fixed.",
"I'm still getting this error on 2.13.0"
] |
https://api.github.com/repos/huggingface/datasets/issues/824 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/824/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/824/comments | https://api.github.com/repos/huggingface/datasets/issues/824/events | https://github.com/huggingface/datasets/issues/824 | 739,896,526 | MDU6SXNzdWU3Mzk4OTY1MjY= | 824 | Discussion using datasets in offline mode | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | closed | false | null | 8 | 2020-11-10T13:10:51Z | 2022-02-15T10:32:36Z | 2022-02-15T10:32:36Z | null | `datasets.load_dataset("csv", ...)` breaks if you have no connection (There is already this issue https://github.com/huggingface/datasets/issues/761 about it). It seems to be the same for metrics too.
I create this ticket to discuss a bit and gather what you have in mind or other propositions.
Here are some points to open discussion:
- if you want to prepare your code/datasets on your machine (having internet connexion) but run it on another offline machine (not having internet connexion), it won't work as is, even if you have all files locally on this machine.
- AFAIK, you can make it work if you manually put the python files (csv.py for example) on this offline machine and change your code to `datasets.load_dataset("MY_PATH/csv.py", ...)`. But it would be much better if you could run ths same code without modification if files are available locally.
- I've also been considering the requirement of downloading Python code and execute on your machine to use datasets. This can be an issue in a professional context. Downloading a CSV/H5 file is acceptable, downloading an executable script can open many security issues. We certainly need a mechanism to at least "freeze" the dataset code you retrieved once so that you can review it if you want and then be sure you use this one everywhere and not a version dowloaded from internet.
WDYT? (thks)
| {
"+1": 8,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/824/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/824/timeline | null | completed | null | null | false | [
"No comments ?",
"I think it would be very cool. I'm currently working on a cluster from Compute Canada, and I have internet access only when I'm not in the nodes where I run the scripts. So I was expecting to be able to use the wmt14 dataset until I realized I needed internet connection even if I downloaded the data already. I'm going to try option 2 you mention for now though! Thanks ;)",
"Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.\r\n\r\n@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?",
"here is my way to load a dataset offline, but it **requires** an online machine\r\n1. (online machine)\r\n```\r\nimport datasets\r\ndata = datasets.load_dataset(...)\r\ndata.save_to_disk(/YOUR/DATASET/DIR)\r\n```\r\n2. copy the dir from online to the offline machine\r\n3. (offline machine)\r\n```\r\nimport datasets\r\ndata = datasets.load_from_disk(/SAVED/DATA/DIR)\r\n```\r\n\r\nHTH.",
"> here is my way to load a dataset offline, but it **requires** an online machine\n> \n> 1. (online machine)\n> \n> ```\n> \n> import datasets\n> \n> data = datasets.load_dataset(...)\n> \n> data.save_to_disk(/YOUR/DATASET/DIR)\n> \n> ```\n> \n> 2. copy the dir from online to the offline machine\n> \n> 3. (offline machine)\n> \n> ```\n> \n> import datasets\n> \n> data = datasets.load_from_disk(/SAVED/DATA/DIR)\n> \n> ```\n> \n> \n> \n> HTH.\n\n",
"I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.\r\n\r\nLet me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :) \r\n\r\nI already note the \"freeze\" modules option, to prevent local modules updates. It would be a cool feature.\r\n\r\n----------\r\n\r\n> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?\r\n\r\nIndeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.\r\nFor example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do\r\n```python\r\nload_dataset(\"./my_dataset\")\r\n```\r\nand the dataset script will generate your dataset once and for all.\r\n\r\n----------\r\n\r\nAbout I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.\r\ncf #1724 ",
"The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)\r\nYou can now use them offline\r\n```python\r\ndatasets = load_dataset('text', data_files=data_files)\r\n```\r\n\r\nWe'll do a new release soon",
"Already fixed by:\r\n- #1726"
] |
https://api.github.com/repos/huggingface/datasets/issues/1812 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1812/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1812/comments | https://api.github.com/repos/huggingface/datasets/issues/1812/events | https://github.com/huggingface/datasets/pull/1812 | 799,379,178 | MDExOlB1bGxSZXF1ZXN0NTY2MDMxODIy | 1,812 | Add CIFAR-100 Dataset | [] | closed | false | null | 2 | 2021-02-02T15:22:59Z | 2021-02-08T11:10:18Z | 2021-02-08T10:39:06Z | null | Adding CIFAR-100 Dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1812/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1812/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1812.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1812",
"merged_at": "2021-02-08T10:39:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1812.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1812"
} | true | [
"Hi @lhoestq,\r\nI have updated with the changes from the review.",
"Thanks for approving :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4135 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4135/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4135/comments | https://api.github.com/repos/huggingface/datasets/issues/4135/events | https://github.com/huggingface/datasets/pull/4135 | 1,198,307,610 | PR_kwDODunzps416-Rn | 4,135 | Support streaming xtreme dataset for PAN-X config | [] | closed | false | null | 1 | 2022-04-09T06:19:48Z | 2022-05-06T08:39:40Z | 2022-04-11T06:54:14Z | null | Support streaming xtreme dataset for PAN-X config. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4135/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4135/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4135.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4135",
"merged_at": "2022-04-11T06:54:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4135.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4135"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1315 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1315/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1315/comments | https://api.github.com/repos/huggingface/datasets/issues/1315/events | https://github.com/huggingface/datasets/pull/1315 | 759,548,706 | MDExOlB1bGxSZXF1ZXN0NTM0NTM1NjM4 | 1,315 | add yelp_review_full | [] | closed | false | null | 0 | 2020-12-08T15:38:27Z | 2020-12-09T15:55:49Z | 2020-12-09T15:55:49Z | null | This corresponds to the Yelp-5 requested in https://github.com/huggingface/datasets/issues/353
I included the dataset card. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1315/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1315/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1315.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1315",
"merged_at": "2020-12-09T15:55:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1315.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1315"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2397/comments | https://api.github.com/repos/huggingface/datasets/issues/2397/events | https://github.com/huggingface/datasets/pull/2397 | 899,427,378 | MDExOlB1bGxSZXF1ZXN0NjUxMTMxMTY0 | 2,397 | Fix number of classes in indic_glue sna.bn dataset | [] | closed | false | null | 2 | 2021-05-24T08:18:55Z | 2021-05-25T16:32:16Z | 2021-05-25T16:32:16Z | null | As read in the [paper](https://www.aclweb.org/anthology/2020.findings-emnlp.445.pdf), Table 11. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 1,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2397/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2397",
"merged_at": "2021-05-25T16:32:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2397"
} | true | [
"@lhoestq there are many things missing in the README.md file, but this correction is right despite not passing the validation tests...",
"Yes indeed. We run the validation in all modified readme because we think that it is the time when contributors are the most likely to fix a dataset card - or it will never be done"
] |
https://api.github.com/repos/huggingface/datasets/issues/3541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3541/comments | https://api.github.com/repos/huggingface/datasets/issues/3541/events | https://github.com/huggingface/datasets/issues/3541 | 1,095,033,828 | I_kwDODunzps5BROPk | 3,541 | Support 7-zip compressed data files | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2022-01-06T07:11:03Z | 2022-07-19T10:18:30Z | null | null | **Is your feature request related to a problem? Please describe.**
We should support 7-zip compressed data files:
- [x] in `extract`:
- #4672
- [ ] in `iter_archive`: for streaming mode
both in streaming and non-streaming modes.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3541/timeline | null | null | null | null | false | [
"This should also resolve: https://github.com/huggingface/datasets/issues/3185."
] |
https://api.github.com/repos/huggingface/datasets/issues/2130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2130/comments | https://api.github.com/repos/huggingface/datasets/issues/2130/events | https://github.com/huggingface/datasets/issues/2130 | 843,111,936 | MDU6SXNzdWU4NDMxMTE5MzY= | 2,130 | wikiann dataset is missing columns | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 5 | 2021-03-29T08:23:00Z | 2021-08-27T14:44:18Z | 2021-08-27T14:44:18Z | null | Hi
Wikiann dataset needs to have "spans" columns, which is necessary to be able to use this dataset, but this column is missing from huggingface datasets, could you please have a look? thank you @lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2130/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2130/timeline | null | completed | null | null | false | [
"Here please find TFDS format of this dataset: https://www.tensorflow.org/datasets/catalog/wikiann\r\nwhere there is a span column, this is really necessary to be able to use the data, and I appreciate your help @lhoestq ",
"Hi !\r\nApparently you can get the spans from the NER tags using `tags_to_spans` defined here:\r\n\r\nhttps://github.com/tensorflow/datasets/blob/c7096bd38e86ed240b8b2c11ecab9893715a7d55/tensorflow_datasets/text/wikiann/wikiann.py#L81-L126\r\n\r\nIt would be nice to include the `spans` field in this dataset as in TFDS. This could be a good first issue for new contributors !\r\n\r\nThe objective is to use `tags_to_spans` in the `_generate_examples` method [here](https://github.com/huggingface/nlp/blob/c98e4b8f23e3770c401c6d9326e243e1ffd599ec/datasets/wikiann/wikiann.py#L292-L316) to create he `spans` for each example.",
"Hi @lhoestq \r\nthank you very much for the help, it would be very nice to have it included, here is the full code, one need to also convert tags to string first:\r\n\r\n```\r\nimport datasets \r\nfrom datasets import load_dataset\r\n\r\ndef tags_to_spans(tags):\r\n \"\"\"Convert tags to spans.\"\"\"\r\n spans = set()\r\n span_start = 0\r\n span_end = 0\r\n active_conll_tag = None\r\n for index, string_tag in enumerate(tags):\r\n # Actual BIO tag.\r\n bio_tag = string_tag[0]\r\n assert bio_tag in [\"B\", \"I\", \"O\"], \"Invalid Tag\"\r\n conll_tag = string_tag[2:]\r\n if bio_tag == \"O\":\r\n # The span has ended.\r\n if active_conll_tag:\r\n spans.add((active_conll_tag, (span_start, span_end)))\r\n active_conll_tag = None\r\n # We don't care about tags we are\r\n # told to ignore, so we do nothing.\r\n continue\r\n elif bio_tag == \"B\":\r\n # We are entering a new span; reset indices and active tag to new span.\r\n if active_conll_tag:\r\n spans.add((active_conll_tag, (span_start, span_end)))\r\n active_conll_tag = conll_tag\r\n span_start = index\r\n span_end = index\r\n elif bio_tag == \"I\" and conll_tag == active_conll_tag:\r\n # We're inside a span.\r\n span_end += 1\r\n else:\r\n # This is the case the bio label is an \"I\", but either:\r\n # 1) the span hasn't started - i.e. an ill formed span.\r\n # 2) We have IOB1 tagging scheme.\r\n # We'll process the previous span if it exists, but also include this\r\n # span. This is important, because otherwise, a model may get a perfect\r\n # F1 score whilst still including false positive ill-formed spans.\r\n if active_conll_tag:\r\n spans.add((active_conll_tag, (span_start, span_end)))\r\n active_conll_tag = conll_tag\r\n span_start = index\r\n span_end = index\r\n # Last token might have been a part of a valid span.\r\n if active_conll_tag:\r\n spans.add((active_conll_tag, (span_start, span_end)))\r\n # Return sorted list of spans\r\n return sorted(list(spans), key=lambda x: x[1][0])\r\n\r\ndataset = load_dataset('wikiann', 'en', split=\"train\")\r\nner_tags = {\r\n 0:\"O\",\r\n 1:\"B-PER\",\r\n 2:\"I-PER\",\r\n 3:\"B-ORG\",\r\n 4:\"I-ORG\",\r\n 5:\"B-LOC\",\r\n 6:\"I-LOC\"\r\n}\r\n\r\ndef get_spans(tokens, tags):\r\n \"\"\"Convert tags to textspans.\"\"\"\r\n spans = tags_to_spans(tags)\r\n text_spans = [\r\n x[0] + \": \" + \" \".join([tokens[i]\r\n for i in range(x[1][0], x[1][1] + 1)])\r\n for x in spans\r\n ]\r\n if not text_spans:\r\n text_spans = [\"None\"]\r\n return text_spans\r\n\r\n\r\nfor i, d in enumerate(dataset):\r\n tokens = d['tokens']\r\n tags = d['ner_tags']\r\n tags = [ner_tags[i] for i in tags]\r\n spans = get_spans(tokens, tags)\r\n print(\"spans \", spans)\r\n print(d)\r\n if i > 10:\r\n break; \r\n```\r\nI am not sure how to contribute to the repository and how things work, could you let me know how one can access the datasets to be able to contribute to the repository? Maybe I could do it then\r\nthanks \r\n",
"Cool ! Let me give you some context:\r\n\r\n#### Contribution guide\r\n\r\nYou can find the contribution guide here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md\r\n\r\nIt explains how to set up your dev environment in a few steps.\r\n\r\n#### Dataset loading\r\n\r\nEach Dataset is defined by a Table that have many rows (one row = one example) and columns (one column = one feature).\r\nTo change how a dataset is constructed, you have to modify its dataset script that you can find here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/master/datasets/wikiann/wikiann.py\r\n\r\nIt includes everything needed to load the WikiANN dataset.\r\nYou can load locally a modified version of `wikiann.py` with `load_dataset(\"path/to/wikiann.py\")`.\r\n\r\n#### Define a new column\r\n\r\nEach column has a name and a type. You can see how the features of WikiANN are defined here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/c98e4b8f23e3770c401c6d9326e243e1ffd599ec/datasets/wikiann/wikiann.py#L245-L263\r\n\r\nIdeally we would have one additional feature \"spans\":\r\n```python\r\n \"spans\": datasets.Sequence(datasets.Value(\"string\")),\r\n```\r\n\r\n#### Compute the content of each row\r\n\r\nTo build the WikiANN rows, the _generate_examples method from [here](https://github.com/huggingface/nlp/blob/c98e4b8f23e3770c401c6d9326e243e1ffd599ec/datasets/wikiann/wikiann.py#L292-L316) is used. This function `yield` one python dictionary for each example:\r\n```python\r\nyield guid_index, {\"tokens\": tokens, \"ner_tags\": ner_tags, \"langs\": langs}\r\n```\r\n\r\nThe objective would be to return instead something like\r\n```python\r\nspans = spans = get_spans(tokens, tags)\r\nyield guid_index, {\"tokens\": tokens, \"ner_tags\": ner_tags, \"langs\": langs, \"spans\": spans}\r\n```\r\n\r\nLet me know if you have questions !",
"The PR was merged. Issue should be closed.\r\n\r\nCC: @lhoestq "
] |
https://api.github.com/repos/huggingface/datasets/issues/273 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/273/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/273/comments | https://api.github.com/repos/huggingface/datasets/issues/273/events | https://github.com/huggingface/datasets/pull/273 | 638,968,054 | MDExOlB1bGxSZXF1ZXN0NDM0NjM0MzU4 | 273 | update cos_e to add cos_e v1.0 | [] | closed | false | null | 0 | 2020-06-15T16:03:22Z | 2020-06-16T08:25:54Z | 2020-06-16T08:25:52Z | null | This PR updates the cos_e dataset to add v1.0 as requested here #163
@nazneenrajani | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/273/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/273/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/273.diff",
"html_url": "https://github.com/huggingface/datasets/pull/273",
"merged_at": "2020-06-16T08:25:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/273.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/273"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5922 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5922/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5922/comments | https://api.github.com/repos/huggingface/datasets/issues/5922/events | https://github.com/huggingface/datasets/issues/5922 | 1,736,898,953 | I_kwDODunzps5nhvmJ | 5,922 | Length of table does not accurately reflect the split | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | 2 | 2023-06-01T18:56:26Z | 2023-06-02T16:13:31Z | 2023-06-02T16:13:31Z | null | ### Describe the bug
I load a Huggingface Dataset and do `train_test_split`. I'm expecting the underlying table for the dataset to also be split, but it's not.
### Steps to reproduce the bug

### Expected behavior
The expected behavior is when `len(hf_dataset["train"].data)` should match the length of the train split, and not be the entire unsplit dataset.
### Environment info
datasets 2.10.1
python 3.10.11 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5922/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5922/timeline | null | completed | null | null | false | [
"As already replied by @lhoestq (private channel):\r\n> `.train_test_split` (as well as `.shard`, `.select`) doesn't create a new arrow table to save time and disk space. Instead, it uses an indices mapping on top of the table that locate which examples are part of train or test.",
"This is an optimization that we don't plan to \"fix\", so I'm closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/4828 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4828/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4828/comments | https://api.github.com/repos/huggingface/datasets/issues/4828/events | https://github.com/huggingface/datasets/pull/4828 | 1,336,040,168 | PR_kwDODunzps49B_vb | 4,828 | Support PIL Image objects in `add_item`/`add_column` | [] | open | false | null | 2 | 2022-08-11T14:25:45Z | 2023-02-23T14:01:47Z | null | null | Fix #4796
PS: We should also improve the type inference in `OptimizedTypeSequence` to make it possible to also infer the complex types (only `Image` currently) in nested arrays (e.g. `[[pil_image], [pil_image, pil_image]]` or `[{"img": pil_image}`]), but I plan to address this in a separate PR. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4828/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4828/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4828.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4828",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4828.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4828"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4828). All of your documentation changes will be reflected on that endpoint.",
"Hey @mariosasko could we please merge this? I'm still getting the original error at #4796 ."
] |
https://api.github.com/repos/huggingface/datasets/issues/1204 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1204/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1204/comments | https://api.github.com/repos/huggingface/datasets/issues/1204/events | https://github.com/huggingface/datasets/pull/1204 | 757,939,475 | MDExOlB1bGxSZXF1ZXN0NTMzMjA2MzE3 | 1,204 | adding meta_woz dataset | [] | closed | false | null | 0 | 2020-12-06T14:34:13Z | 2020-12-16T15:05:25Z | 2020-12-16T15:05:24Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1204/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1204/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1204.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1204",
"merged_at": "2020-12-16T15:05:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1204.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1204"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/3907 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3907/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3907/comments | https://api.github.com/repos/huggingface/datasets/issues/3907/events | https://github.com/huggingface/datasets/pull/3907 | 1,168,575,998 | PR_kwDODunzps40Z_vd | 3,907 | Update README.md for SQuAD metric | [] | closed | false | null | 1 | 2022-03-14T15:52:31Z | 2022-03-15T17:04:20Z | 2022-03-15T17:04:19Z | null | Putting "Values from popular papers" as a subsection of "Output values" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3907/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3907/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3907.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3907",
"merged_at": "2022-03-15T17:04:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3907.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3907"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3907). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/1862 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1862/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1862/comments | https://api.github.com/repos/huggingface/datasets/issues/1862/events | https://github.com/huggingface/datasets/pull/1862 | 805,722,293 | MDExOlB1bGxSZXF1ZXN0NTcxMjc2ODAx | 1,862 | Fix writing GPU Faiss index | [] | closed | false | null | 0 | 2021-02-10T17:32:03Z | 2021-02-10T18:17:48Z | 2021-02-10T18:17:47Z | null | As reported in by @corticalstack there is currently an error when we try to save a faiss index on GPU.
I fixed that by checking the index `getDevice()` method before calling `index_gpu_to_cpu`
Close #1859 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1862/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1862/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1862",
"merged_at": "2021-02-10T18:17:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1862"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5247/comments | https://api.github.com/repos/huggingface/datasets/issues/5247/events | https://github.com/huggingface/datasets/pull/5247 | 1,451,297,749 | PR_kwDODunzps5DAhto | 5,247 | Set dev version | [] | closed | false | null | 1 | 2022-11-16T10:17:31Z | 2022-11-16T10:22:20Z | 2022-11-16T10:17:50Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5247/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5247.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5247",
"merged_at": "2022-11-16T10:17:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5247.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5247"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5247). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5681/comments | https://api.github.com/repos/huggingface/datasets/issues/5681/events | https://github.com/huggingface/datasets/issues/5681 | 1,645,630,784 | I_kwDODunzps5iFlVA | 5,681 | Add information about patterns search order to the doc about structuring repo | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 2 | 2023-03-29T11:44:49Z | 2023-04-03T18:31:11Z | 2023-04-03T18:31:11Z | null | Following [this](https://github.com/huggingface/datasets/issues/5650) issue I think we should add a note about the order of patterns that is used to find splits, see [my comment](https://github.com/huggingface/datasets/issues/5650#issuecomment-1488412527). Also we should reference this page in pages about packaged loaders.
I have a déjà vu that it had already been discussed as some point but I don't remember.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5681/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5681/timeline | null | completed | null | null | false | [
"Good idea, I think I've seen this a couple of times before too on the forums. I can work on this :)",
"Closed in #5693 "
] |
https://api.github.com/repos/huggingface/datasets/issues/2495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2495/comments | https://api.github.com/repos/huggingface/datasets/issues/2495/events | https://github.com/huggingface/datasets/issues/2495 | 920,170,030 | MDU6SXNzdWU5MjAxNzAwMzA= | 2,495 | JAX formatting | [] | closed | false | null | 0 | 2021-06-14T08:32:07Z | 2021-06-21T16:15:49Z | 2021-06-21T16:15:49Z | null | We already support pytorch, tensorflow, numpy, pandas and arrow dataset formatting. Let's add jax as well | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2495/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5722/comments | https://api.github.com/repos/huggingface/datasets/issues/5722/events | https://github.com/huggingface/datasets/issues/5722 | 1,659,837,510 | I_kwDODunzps5i7xxG | 5,722 | Distributed Training Error on Customized Dataset | [] | closed | false | null | 1 | 2023-04-09T11:04:59Z | 2023-07-24T14:50:46Z | 2023-07-24T14:50:46Z | null | Hi guys, recently I tried to use `datasets` to train a dual encoder.
I finish my own datasets according to the nice [tutorial](https://huggingface.co/docs/datasets/v2.11.0/en/dataset_script)
Here are my code:
```python
class RetrivalDataset(datasets.GeneratorBasedBuilder):
"""CrossEncoder dataset."""
BUILDER_CONFIGS = [RetrivalConfig(name="DuReader")]
# DEFAULT_CONFIG_NAME = "DuReader"
def _info(self):
return datasets.DatasetInfo(
features=datasets.Features(
{
"id": datasets.Value("string"),
"question": datasets.Value("string"),
"documents": Sequence(datasets.Value("string")),
}
),
supervised_keys=None,
)
def _split_generators(self, dl_manager):
"""Returns SplitGenerators."""
train_file = self.config.data_dir + self.config.train_file
valid_file = self.config.data_dir + self.config.valid_file
logger.info(f"Training on {self.config.train_file}")
logger.info(f"Evaluating on {self.config.valid_file}")
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN, gen_kwargs={"file_path": train_file}
),
datasets.SplitGenerator(
name=datasets.Split.VALIDATION, gen_kwargs={"file_path": valid_file}
),
]
def _generate_examples(self, file_path):
with jsonlines.open(file_path, "r") as f:
for record in f:
label = record["label"]
question = record["question"]
# dual encoder
all_documents = record["all_documents"]
positive_paragraph = all_documents.pop(label)
all_documents = [positive_paragraph] + all_documents
u_id = "{}_#_{}".format(
md5_hash(question + "".join(all_documents)),
"".join(random.sample(string.ascii_letters + string.digits, 7)),
)
item = {
"question": question,
"documents": all_documents,
"id": u_id,
}
yield u_id, item
```
It works well on single GPU, but got errors as follows when used DDP:
```python
Detected mismatch between collectives on ranks. Rank 1 is running collective: CollectiveFingerPrint(OpType=BARRIER), but Rank 0 is running collective: CollectiveFingerPrint(OpType=ALLGATHER_COALESCED)
```
Here are my train script on a two A100 mechine:
```bash
export TORCH_DISTRIBUTED_DEBUG=DETAIL
export TORCH_SHOW_CPP_STACKTRACES=1
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=INIT,COLL,ENV
nohup torchrun --nproc_per_node 2 train.py experiments/de-big.json >logs/de-big.log 2>&1&
```
I am not sure if this error below related to my dataset code when use DDP. And I notice the PR(#5369 ), but I don't know when and where should I used the function(`split_dataset_by_node`) .
@lhoestq hope you could help me?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5722/timeline | null | completed | null | null | false | [
"Hmm the error doesn't seem related to data loading.\r\n\r\nRegarding `split_dataset_by_node`: it's generally used to split an iterable dataset (e.g. when streaming) in pytorch DDP. It's not needed if you use a regular dataset since the pytorch DataLoader already assigns a subset of the dataset indices to each node."
] |
https://api.github.com/repos/huggingface/datasets/issues/2887 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2887/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2887/comments | https://api.github.com/repos/huggingface/datasets/issues/2887/events | https://github.com/huggingface/datasets/pull/2887 | 992,576,305 | MDExOlB1bGxSZXF1ZXN0NzMwODg4MTU3 | 2,887 | #2837 Use cache folder for lockfile | [] | closed | false | null | 1 | 2021-09-09T19:55:56Z | 2021-10-05T17:58:22Z | 2021-10-05T17:58:22Z | null | Fixes #2837
Use a cache folder directory to store the FileLock.
The issue was that the lock file was in a readonly folder.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2887/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2887/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2887.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2887",
"merged_at": "2021-10-05T17:58:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2887.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2887"
} | true | [
"The CI fail about the meteor metric is unrelated to this PR "
] |
https://api.github.com/repos/huggingface/datasets/issues/1798 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1798/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1798/comments | https://api.github.com/repos/huggingface/datasets/issues/1798/events | https://github.com/huggingface/datasets/pull/1798 | 797,766,818 | MDExOlB1bGxSZXF1ZXN0NTY0Njk2NjE1 | 1,798 | Add Arabic sarcasm dataset | [] | closed | false | null | 1 | 2021-01-31T17:38:55Z | 2021-02-10T20:39:13Z | 2021-02-03T10:35:54Z | null | This MIT license dataset: https://github.com/iabufarha/ArSarcasm
Via https://sites.google.com/view/ar-sarcasm-sentiment-detection/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1798/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1798/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1798.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1798",
"merged_at": "2021-02-03T10:35:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1798.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1798"
} | true | [
"@lhoestq thanks for the comments - I believe these are now addressed. I re-generated the datasets_info.json and dummy data"
] |
https://api.github.com/repos/huggingface/datasets/issues/3495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3495/comments | https://api.github.com/repos/huggingface/datasets/issues/3495/events | https://github.com/huggingface/datasets/issues/3495 | 1,089,983,632 | I_kwDODunzps5A99SQ | 3,495 | Add VoxLingua107 | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 0 | 2021-12-28T15:51:43Z | 2021-12-28T15:51:43Z | null | null | ## Adding a Dataset
- **Name:** VoxLingua107
- **Description:** VoxLingua107 is a speech dataset for training spoken language identification models.
- **Paper:** https://arxiv.org/abs/2011.12998
- **Data:** http://bark.phon.ioc.ee/voxlingua107/
- **Motivation:** 107 languages, totaling 6628 hours for the train split.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3495/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2451 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2451/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2451/comments | https://api.github.com/repos/huggingface/datasets/issues/2451/events | https://github.com/huggingface/datasets/pull/2451 | 913,263,340 | MDExOlB1bGxSZXF1ZXN0NjYzMzIwNDY1 | 2,451 | Mention that there are no answers in adversarial_qa test set | [] | closed | false | null | 0 | 2021-06-07T08:13:57Z | 2021-06-07T08:34:14Z | 2021-06-07T08:34:13Z | null | As mention in issue https://github.com/huggingface/datasets/issues/2447, there are no answers in the test set | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2451/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2451/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2451.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2451",
"merged_at": "2021-06-07T08:34:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2451.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2451"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/245 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/245/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/245/comments | https://api.github.com/repos/huggingface/datasets/issues/245/events | https://github.com/huggingface/datasets/issues/245 | 631,985,108 | MDU6SXNzdWU2MzE5ODUxMDg= | 245 | SST-2 test labels are all -1 | [] | closed | false | null | 10 | 2020-06-05T21:41:42Z | 2021-12-08T00:47:32Z | 2020-06-06T16:56:41Z | null | I'm trying to test a model on the SST-2 task, but all the labels I see in the test set are -1.
```
>>> import nlp
>>> glue = nlp.load_dataset('glue', 'sst2')
>>> glue
{'train': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 67349), 'validation': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 872), 'test': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 1821)}
>>> list(l['label'] for l in glue['test'])
[-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/245/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/245/timeline | null | completed | null | null | false | [
"this also happened to me with `nlp.load_dataset('glue', 'mnli')`",
"Yes, this is because the test sets for glue are hidden so the labels are\nnot publicly available. You can read the glue paper for more details.\n\nOn Sat, 6 Jun 2020 at 18:16, Jack Morris <[email protected]> wrote:\n\n> this also happened to me with nlp.load_datasets('glue', 'mnli')\n>\n> —\n> You are receiving this because you are subscribed to this thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/issues/245#issuecomment-640083980>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABYDIHMVQD2EDX2HTZUXG5DRVJTWRANCNFSM4NVG3AKQ>\n> .\n>\n",
"Thanks @thomwolf!",
"@thomwolf shouldn't this be visible in the .info and/or in the .features?",
"It should be in the datasets card (the README.md and on the hub) in my opinion. What do you think @yjernite?",
"I checked both before I got to looking at issues, so that would be fine as well.\r\n\r\nSome additional thoughts on this: Is there a specific reason why the \"test\" split even has a \"label\" column if it isn't tagged. Shouldn't there just not be any. Seems more transparent",
"I'm a little confused with the data size.\r\n`sst2` dataset is referenced to `Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank` and the link of the dataset in the paper is https://nlp.stanford.edu/sentiment/index.html which is often shown in GLUE/SST2 reference.\r\nFrom the original data, the standard train/dev/test splits split is 6920/872/1821 for binary classification. \r\nWhy in GLUE/SST2 the train/dev/test split is 67,349/872/1,821 ? \r\n\r\n",
"> I'm a little confused with the data size.\r\n> `sst2` dataset is referenced to `Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank` and the link of the dataset in the paper is https://nlp.stanford.edu/sentiment/index.html which is often shown in GLUE/SST2 reference.\r\n> From the original data, the standard train/dev/test splits split is 6920/872/1821 for binary classification.\r\n> Why in GLUE/SST2 the train/dev/test split is 67,349/872/1,821 ?\r\n\r\nHave you figured out this problem? AFAIK, the original sst-2 dataset is totally different from the GLUE/sst-2. Do you think so?",
"@yc1999 Sorry, I didn't solve this conflict. In the end, I just use a local data file provided by the previous work I followed(for consistent comparison), not use `datasets` package.\r\n\r\nRelated information: https://github.com/thunlp/OpenAttack/issues/146#issuecomment-766323571",
"@yc1999 I find that the original SST-2 dataset (6,920/872/1,821) can be loaded from https://huggingface.co/datasets/gpt3mix/sst2 or built with SST data and the scripts in https://github.com/prrao87/fine-grained-sentiment/tree/master/data/sst.\r\nThe GLUE/SST-2 dataset (67,349/872/1,821) should be a completely different version.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5724/comments | https://api.github.com/repos/huggingface/datasets/issues/5724/events | https://github.com/huggingface/datasets/issues/5724 | 1,659,938,135 | I_kwDODunzps5i8KVX | 5,724 | Error after shuffling streaming IterableDatasets with downloaded dataset | [] | closed | false | null | 1 | 2023-04-09T16:58:44Z | 2023-04-20T20:37:30Z | 2023-04-20T20:37:30Z | null | ### Describe the bug
I downloaded the C4 dataset, and used streaming IterableDatasets to read it. Everything went normal until I used `dataset = dataset.shuffle(seed=42, buffer_size=10_000)` to shuffle the dataset. Shuffled dataset will throw the following error when it is used by `next(iter(dataset))`:
```
File "/data/miniconda3/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 937, in __iter__
for key, example in ex_iterable:
File "/data/miniconda3/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 627, in __iter__
for x in self.ex_iterable:
File "/data/miniconda3/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 138, in __iter__
yield from self.generate_examples_fn(**kwargs_with_shuffled_shards)
File "/data/miniconda3/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 763, in wrapper
for key, table in generate_tables_fn(**kwargs):
File "/data/miniconda3/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py", line 101, in _generate_tables
batch = f.read(self.config.chunksize)
File "/data/miniconda3/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py", line 372, in read_with_retries
out = read(*args, **kwargs)
File "/data/miniconda3/lib/python3.9/gzip.py", line 300, in read
return self._buffer.read(size)
File "/data/miniconda3/lib/python3.9/_compression.py", line 68, in readinto
data = self.read(len(byte_view))
File "/data/miniconda3/lib/python3.9/gzip.py", line 487, in read
if not self._read_gzip_header():
File "/data/miniconda3/lib/python3.9/gzip.py", line 435, in _read_gzip_header
raise BadGzipFile('Not a gzipped file (%r)' % magic)
gzip.BadGzipFile: Not a gzipped file (b've')
```
I found that there is no problem to use the dataset in this way without shuffling. Also, use `dataset = datasets.load_dataset('c4', 'en', split='train', streaming=True)`, which will download the dataset on-the-fly instead of loading from the local file, will also not have problems even after shuffle.
### Steps to reproduce the bug
1. Download C4 dataset from https://huggingface.co/datasets/allenai/c4
2.
```
import datasets
dataset = datasets.load_dataset('/path/to/your/data/dir', 'en', streaming=True, split='train')
dataset = dataset.shuffle(buffer_size=10_000, seed=42)
next(iter(dataset))
```
### Expected behavior
`next(iter(dataset))` should give me a sample from the dataset
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.4.32-1-tlinux4-0001-x86_64-with-glibc2.28
- Python version: 3.9.16
- Huggingface_hub version: 0.13.1
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5724/timeline | null | completed | null | null | false | [
"Moving `\"en\"` to the end of the path instead of passing it as a config name should fix the error:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('/path/to/your/data/dir/en', streaming=True, split='train')\r\ndataset = dataset.shuffle(buffer_size=10_000, seed=42)\r\nnext(iter(dataset))\r\n```\r\n\r\nPS: https://github.com/huggingface/datasets/pull/5331, once merged, will allow us to define C4's configs in its README, making downloading it much more user-friendly."
] |
https://api.github.com/repos/huggingface/datasets/issues/5809 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5809/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5809/comments | https://api.github.com/repos/huggingface/datasets/issues/5809/events | https://github.com/huggingface/datasets/issues/5809 | 1,689,797,293 | I_kwDODunzps5kuEKt | 5,809 | wiki_dpr details for Open Domain Question Answering tasks | [] | closed | false | null | 1 | 2023-04-30T06:12:04Z | 2023-07-21T14:11:00Z | 2023-07-21T14:11:00Z | null | Hey guys!
Thanks for creating the wiki_dpr dataset!
I am currently trying to combine wiki_dpr and my own datasets. but I don't know how to make the embedding value the same way as wiki_dpr.
As an experiment, I embeds the text of id="7" of wiki_dpr, but this result was very different from wiki_dpr. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5809/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5809/timeline | null | completed | null | null | false | [
"Hi ! I don't remember exactly how it was done, but maybe you have to embed `f\"{title}<sep>{text}\"` ?\r\n\r\nUsing a HF tokenizer it corresponds to doing\r\n```python\r\ntokenized = tokenizer(titles, texts)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/2439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2439/comments | https://api.github.com/repos/huggingface/datasets/issues/2439/events | https://github.com/huggingface/datasets/pull/2439 | 908,511,983 | MDExOlB1bGxSZXF1ZXN0NjU5MTkzMDE3 | 2,439 | Better error message when trying to access elements of a DatasetDict without specifying the split | [] | closed | false | null | 0 | 2021-06-01T17:04:32Z | 2021-06-15T16:03:23Z | 2021-06-07T08:54:35Z | null | As mentioned in #2437 it'd be nice to to have an indication to the users when they try to access an element of a DatasetDict without specifying the split name.
cc @thomwolf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2439/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2439.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2439",
"merged_at": "2021-06-07T08:54:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2439.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2439"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2238 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2238/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2238/comments | https://api.github.com/repos/huggingface/datasets/issues/2238/events | https://github.com/huggingface/datasets/pull/2238 | 861,518,291 | MDExOlB1bGxSZXF1ZXN0NjE4MTY5NzM5 | 2,238 | NLU evaluation data | [] | closed | false | null | 0 | 2021-04-19T16:47:20Z | 2021-04-23T15:32:05Z | 2021-04-23T15:32:05Z | null | New intent classification dataset from https://github.com/xliuhw/NLU-Evaluation-Data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2238/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2238/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2238.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2238",
"merged_at": "2021-04-23T15:32:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2238.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2238"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4268 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4268/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4268/comments | https://api.github.com/repos/huggingface/datasets/issues/4268/events | https://github.com/huggingface/datasets/issues/4268 | 1,223,331,964 | I_kwDODunzps5I6pB8 | 4,268 | error downloading bigscience-catalogue-lm-data/lm_en_wiktionary_filtered | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 10 | 2022-05-02T20:34:25Z | 2022-05-06T15:53:30Z | 2022-05-03T11:23:48Z | null | ## Describe the bug
Error generated when attempting to download dataset
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("bigscience-catalogue-lm-data/lm_en_wiktionary_filtered")
```
## Expected results
A clear and concise description of the expected results.
## Actual results
```
ExpectedMoreDownloadedFiles Traceback (most recent call last)
[<ipython-input-62-4ac5cf959477>](https://localhost:8080/#) in <module>()
1 from datasets import load_dataset
2
----> 3 dataset = load_dataset("bigscience-catalogue-lm-data/lm_en_wiktionary_filtered")
3 frames
[/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py](https://localhost:8080/#) in verify_checksums(expected_checksums, recorded_checksums, verification_name)
31 return
32 if len(set(expected_checksums) - set(recorded_checksums)) > 0:
---> 33 raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))
34 if len(set(recorded_checksums) - set(expected_checksums)) > 0:
35 raise UnexpectedDownloadedFile(str(set(recorded_checksums) - set(expected_checksums)))
ExpectedMoreDownloadedFiles: {'/home/leandro/catalogue_data/datasets/lm_en_wiktionary_filtered/data/file-01.jsonl.gz', '/home/leandro/catalogue_data/datasets/lm_en_wiktionary_filtered/data/file-01.jsonl.gz.lock'}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4268/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4268/timeline | null | completed | null | null | false | [
"It would help a lot to be able to preview the dataset - I'd like to see if the pronunciations are in the dataset, eg. for [\"word\"](https://en.wiktionary.org/wiki/word),\r\n\r\nPronunciation\r\n([Received Pronunciation](https://en.wikipedia.org/wiki/Received_Pronunciation)) [IPA](https://en.wiktionary.org/wiki/Wiktionary:International_Phonetic_Alphabet)([key](https://en.wiktionary.org/wiki/Appendix:English_pronunciation)): /wɜːd/\r\n([General American](https://en.wikipedia.org/wiki/General_American)) [enPR](https://en.wiktionary.org/wiki/Appendix:English_pronunciation): wûrd, [IPA](https://en.wiktionary.org/wiki/Wiktionary:International_Phonetic_Alphabet)([key](https://en.wiktionary.org/wiki/Appendix:English_pronunciation)): /wɝd/",
"Hi @i-am-neo, thanks for reporting.\r\n\r\nNormally this dataset should be private and not accessible for public use. @cakiki, @lvwerra, any reason why is it public? I see many other Wikimedia datasets are also public.\r\n\r\nAlso note that last commit \"Add metadata\" (https://huggingface.co/datasets/bigscience-catalogue-lm-data/lm_en_wiktionary_filtered/commit/dc2f458dab50e00f35c94efb3cd4009996858609) introduced buggy data files (`data/file-01.jsonl.gz.lock`, `data/file-01.jsonl.gz.lock.lock`). The same bug appears in other datasets as well.\r\n\r\n@i-am-neo, please note that in the near future we are planning to make public all datasets used for the BigScience project (at least all of them whose license allows to do that). Once public, they will be accessible for all the NLP community.",
"Ah this must be a bug introduced at creation time since the repos were created programmatically; I'll go ahead and make them private; sorry about that!",
"All datasets are private now. \r\n\r\nRe:that bug I think we're currently avoiding it by avoiding verifications. (i.e. `ignore_verifications=True`)",
"Thanks a lot, @cakiki.\r\n\r\n@i-am-neo, I'm closing this issue for now because the dataset is not publicly available yet. Just stay tuned, as we will soon release all the BigScience open-license datasets. ",
"Thanks for letting me know, @albertvillanova @cakiki.\r\nAny chance of having a subset alpha version in the meantime? \r\nI only need two dicts out of wiktionary: 1) phoneme(as key): word, and 2) word(as key): its phonemes.\r\n\r\nWould like to use it for a mini-poc [Robust ASR](https://github.com/huggingface/transformers/issues/13162#issuecomment-1096881290) decoding, cc @patrickvonplaten. \r\n\r\n(Patrick, possible to email you so as not to litter github with comments? I have some observations after experiments training hubert on some YT AMI-like data (11.44% wer). Also wonder if a robust ASR is on your/HG's roadmap). Thanks!",
"Hey @i-am-neo,\r\n\r\nCool to hear that you're working on Robust ASR! Feel free to drop me a mail :-)",
"@i-am-neo This particular subset of the dataset was taken from the [CirrusSearch dumps](https://dumps.wikimedia.org/other/cirrussearch/current/)\r\nYou're specifically after the [enwiktionary-20220425-cirrussearch-content.json.gz](https://dumps.wikimedia.org/other/cirrussearch/current/enwiktionary-20220425-cirrussearch-content.json.gz) file",
"thanks @cakiki ! <del>I could access the gz file yesterday (but neglected to tuck it away somewhere safe), and today the link is throwing a 404. Can you help? </del> Never mind, got it!",
"thanks @patrickvonplaten. will do - getting my observations together."
] |
https://api.github.com/repos/huggingface/datasets/issues/214 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/214/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/214/comments | https://api.github.com/repos/huggingface/datasets/issues/214/events | https://github.com/huggingface/datasets/pull/214 | 626,641,549 | MDExOlB1bGxSZXF1ZXN0NDI0NTk1NjIx | 214 | [arrow_dataset.py] add new filter function | [] | closed | false | null | 13 | 2020-05-28T16:21:40Z | 2020-05-29T11:43:29Z | 2020-05-29T11:32:20Z | null | The `.map()` function is super useful, but can IMO a bit tedious when filtering certain examples.
I think, filtering out examples is also a very common operation people would like to perform on datasets.
This PR is a proposal to add a `.filter()` function in the same spirit than the `.map()` function.
Here is a sample code you can play around with:
```python
ds = nlp.load_dataset("squad", split="validation[:10%]")
def remove_under_idx_5(example, idx):
return idx < 5
def only_keep_examples_with_is_in_context(example):
return "is" in example["context"]
result_keep_only_first_5 = ds.filter(remove_under_idx_5, with_indices=True, load_from_cache_file=False)
result_keep_examples_with_is_in_context = ds.filter(only_keep_examples_with_is_in_context, load_from_cache_file=False)
print("Original number of examples: {}".format(len(ds)))
print("First five examples number of examples: {}".format(len(result_keep_only_first_5)))
print("Is in context examples number of examples: {}".format(len(result_keep_examples_with_is_in_context)))
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/214/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/214/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/214.diff",
"html_url": "https://github.com/huggingface/datasets/pull/214",
"merged_at": "2020-05-29T11:32:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/214.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/214"
} | true | [
"I agree that a `.filter` method would be VERY useful and appreciated. I'm not a big fan of using `flatten_nested` as it completely breaks down the structure of the example and it may create bugs. Right now I think it may not work for nested structures. Maybe there's a simpler way that we've not figured out yet.",
"Instead of flattening everything and rebuilding the example, maybe we can try to access the examples like this:\r\n```python\r\nfor i in range(num_examples):\r\n example = map_nested(lambda x: x[i], batch)\r\n # ... then test to keep it or not\r\n```",
"> Instead of flattening everything and rebuilding the example, maybe we can try to access the examples like this:\r\n> \r\n> ```python\r\n> for i in range(num_examples):\r\n> example = map_nested(lambda x: x[i], batch)\r\n> # ... then test to keep it or not\r\n> ```\r\n\r\nAwesome I'll check it out :-) ",
"> Instead of flattening everything and rebuilding the example, maybe we can try to access the examples like this:\r\n> \r\n> ```python\r\n> for i in range(num_examples):\r\n> example = map_nested(lambda x: x[i], batch)\r\n> # ... then test to keep it or not\r\n> ```\r\n\r\nAwesome this function is definitely much nicer!",
"Actually I just realized that `map_nested` might not work either as it applies the function at the very last list of the structure. However we can imagine that a single example has also a list in its structure:\r\n```python\r\none_example = {\r\n \"title\": \"blabla\",\r\n \"paragraphs\": [\r\n \"p1\", \"p2\", ...\r\n ]\r\n}\r\n```",
"We'll probably have to take into account the `dset._data.schema` to extract the examples from the batch.",
"> Actually I just realized that `map_nested` might not work either as it applies the function at the very last list of the structure. However we can imagine that a single example has also a list in its structure:\r\n> \r\n> ```python\r\n> one_example = {\r\n> \"title\": \"blabla\",\r\n> \"paragraphs\": [\r\n> \"p1\", \"p2\", ...\r\n> ]\r\n> }\r\n> ```\r\n\r\nThey both work. I'm using it on trivia_qa which is pretty nested. If you use the option `dict_only=True` I think it's fine.",
"> We'll probably have to take into account the `dset._data.schema` to extract the examples from the batch.\r\n\r\nWhy? ",
"Actually it's fine. I guess this is going to be yet another thing to be unit-tested just to make sure ^^",
"Yes, I will need to add tests and documentation! \r\n@thomwolf - would a function like this be ok? It abstracts `.map()` a bit which might be hard to understand. ",
"I tried on some datasets with nested structure and it works fine ! Great work :D \r\n",
"Awesome :-), I will add documentation and some simple unittests",
"Ok merging!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4223 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4223/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4223/comments | https://api.github.com/repos/huggingface/datasets/issues/4223/events | https://github.com/huggingface/datasets/pull/4223 | 1,216,107,082 | PR_kwDODunzps42z0YV | 4,223 | Add Accuracy Metric Card | [] | closed | false | null | 1 | 2022-04-26T15:10:46Z | 2022-05-03T14:27:45Z | 2022-05-03T14:20:47Z | null | - adds accuracy metric card
- updates docstring in accuracy.py
- adds .json file with metric card and docstring information | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4223/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4223/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4223.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4223",
"merged_at": "2022-05-03T14:20:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4223.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4223"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1962 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1962/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1962/comments | https://api.github.com/repos/huggingface/datasets/issues/1962/events | https://github.com/huggingface/datasets/pull/1962 | 818,089,156 | MDExOlB1bGxSZXF1ZXN0NTgxNDQwNzM4 | 1,962 | Fix unused arguments | [] | closed | false | null | 3 | 2021-02-28T02:47:07Z | 2021-03-11T02:18:17Z | 2021-03-03T16:37:50Z | null | Noticed some args in the codebase are not used, so managed to find all such occurrences with Pylance and fix them. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1962/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1962/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1962.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1962",
"merged_at": "2021-03-03T16:37:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1962.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1962"
} | true | [
"@lhoestq Re-added the arg. The ConnectionError in CI seems unrelated to this PR (the same test fails on master as well).",
"Thanks !\r\nI'm re-running the CI, maybe this was an issue with circleCI",
"Looks all good now, merged :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/6036 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6036/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6036/comments | https://api.github.com/repos/huggingface/datasets/issues/6036/events | https://github.com/huggingface/datasets/pull/6036 | 1,805,138,898 | PR_kwDODunzps5ViKc4 | 6,036 | Deprecate search API | [] | open | false | null | 8 | 2023-07-14T16:22:09Z | 2023-07-21T19:53:51Z | null | null | The Search API only supports Faiss and ElasticSearch as vector stores, is somewhat difficult to maintain (e.g., it still doesn't support ElasticSeach 8.0, difficult testing, ...), does not have the best design (adds a bunch of methods to the `Dataset` class that are only useful after creating an index), the usage doesn't seem to be significant and is not integrated with the Hub. Since we have no plans/bandwidth to improve it and better alternatives such as `langchain` and `docarray` exist, I think it should be deprecated (and eventually removed).
If we decide to deprecate/remove it, the following usage instances need to be addressed:
* [Course](https://github.com/huggingface/course/blob/0018bb434204d9750a03592cb0d4e846093218d8/chapters/en/chapter5/6.mdx#L342 ) and [Blog](https://github.com/huggingface/blog/blob/4897c6f73d4492a0955ade503281711d01840e09/image-search-datasets.md?plain=1#L252) - calling the FAISS API directly should be OK in these instances as it's pretty simple to use for basic scenarios. Alternatively, we can use `langchain`, but this adds an extra dependency
* [Transformers](https://github.com/huggingface/transformers/blob/50726f9ea7afc6113da617f8f4ca1ab264a5e28a/src/transformers/models/rag/retrieval_rag.py#L183) - we can use the FAISS API directly and store the index as a separate attribute (and instead of building the `wiki_dpr` index each time the dataset is generated, we can generate it once and push it to the Hub repo, and then read it from there
cc @huggingface/datasets @LysandreJik for the opinion | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6036/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6036/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6036.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6036",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6036.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6036"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005746 / 0.011353 (-0.005607) | 0.003461 / 0.011008 (-0.007548) | 0.078672 / 0.038508 (0.040164) | 0.056800 / 0.023109 (0.033691) | 0.312853 / 0.275898 (0.036955) | 0.346715 / 0.323480 (0.023235) | 0.004516 / 0.007986 (-0.003469) | 0.002872 / 0.004328 (-0.001457) | 0.061264 / 0.004250 (0.057013) | 0.046606 / 0.037052 (0.009553) | 0.320080 / 0.258489 (0.061591) | 0.350390 / 0.293841 (0.056550) | 0.026445 / 0.128546 (-0.102101) | 0.007710 / 0.075646 (-0.067936) | 0.259519 / 0.419271 (-0.159752) | 0.043935 / 0.043533 (0.000402) | 0.320015 / 0.255139 (0.064876) | 0.339799 / 0.283200 (0.056599) | 0.018638 / 0.141683 (-0.123044) | 1.463393 / 1.452155 (0.011239) | 1.496977 / 1.492716 (0.004261) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.185175 / 0.018006 (0.167168) | 0.420734 / 0.000490 (0.420245) | 0.002569 / 0.000200 (0.002369) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022335 / 0.037411 (-0.015077) | 0.071686 / 0.014526 (0.057161) | 0.079906 / 0.176557 (-0.096650) | 0.140386 / 0.737135 (-0.596749) | 0.079712 / 0.296338 (-0.216627) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.392643 / 0.215209 (0.177434) | 3.917934 / 2.077655 (1.840279) | 1.906808 / 1.504120 (0.402688) | 1.729564 / 1.541195 (0.188369) | 1.751533 / 1.468490 (0.283043) | 0.496810 / 4.584777 (-4.087967) | 3.047405 / 3.745712 (-0.698307) | 4.361766 / 5.269862 (-0.908095) | 2.660845 / 4.565676 (-1.904832) | 0.056951 / 0.424275 (-0.367324) | 0.006277 / 0.007607 (-0.001330) | 0.466357 / 0.226044 (0.240312) | 4.660457 / 2.268929 (2.391529) | 2.328590 / 55.444624 (-53.116034) | 1.986140 / 6.876477 (-4.890337) | 2.096182 / 2.142072 (-0.045891) | 0.581685 / 4.805227 (-4.223542) | 0.123643 / 6.500664 (-6.377021) | 0.060286 / 0.075469 (-0.015183) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237024 / 1.841788 (-0.604763) | 17.778533 / 8.074308 (9.704225) | 13.202205 / 10.191392 (3.010813) | 0.141301 / 0.680424 (-0.539123) | 0.016453 / 0.534201 (-0.517748) | 0.329173 / 0.579283 (-0.250110) | 0.349945 / 0.434364 (-0.084419) | 0.375319 / 0.540337 (-0.165018) | 0.530394 / 1.386936 (-0.856542) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005863 / 0.011353 (-0.005489) | 0.003578 / 0.011008 (-0.007430) | 0.062719 / 0.038508 (0.024211) | 0.056192 / 0.023109 (0.033082) | 0.422812 / 0.275898 (0.146914) | 0.454316 / 0.323480 (0.130836) | 0.004446 / 0.007986 (-0.003540) | 0.002808 / 0.004328 (-0.001521) | 0.062819 / 0.004250 (0.058569) | 0.046243 / 0.037052 (0.009190) | 0.445858 / 0.258489 (0.187369) | 0.463750 / 0.293841 (0.169909) | 0.027504 / 0.128546 (-0.101042) | 0.007897 / 0.075646 (-0.067749) | 0.068248 / 0.419271 (-0.351024) | 0.041921 / 0.043533 (-0.001612) | 0.413314 / 0.255139 (0.158175) | 0.441619 / 0.283200 (0.158419) | 0.019246 / 0.141683 (-0.122437) | 1.457069 / 1.452155 (0.004914) | 1.524168 / 1.492716 (0.031452) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237785 / 0.018006 (0.219779) | 0.418455 / 0.000490 (0.417965) | 0.002301 / 0.000200 (0.002101) | 0.000065 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025630 / 0.037411 (-0.011781) | 0.076673 / 0.014526 (0.062147) | 0.084877 / 0.176557 (-0.091680) | 0.137528 / 0.737135 (-0.599607) | 0.085261 / 0.296338 (-0.211077) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419040 / 0.215209 (0.203831) | 4.183022 / 2.077655 (2.105368) | 2.157852 / 1.504120 (0.653732) | 1.966177 / 1.541195 (0.424982) | 2.019612 / 1.468490 (0.551122) | 0.497415 / 4.584777 (-4.087362) | 3.102873 / 3.745712 (-0.642839) | 4.526336 / 5.269862 (-0.743525) | 2.991503 / 4.565676 (-1.574174) | 0.057235 / 0.424275 (-0.367040) | 0.006735 / 0.007607 (-0.000872) | 0.498255 / 0.226044 (0.272211) | 4.957364 / 2.268929 (2.688435) | 2.632643 / 55.444624 (-52.811981) | 2.249788 / 6.876477 (-4.626688) | 2.289134 / 2.142072 (0.147062) | 0.583581 / 4.805227 (-4.221646) | 0.126046 / 6.500664 (-6.374618) | 0.062966 / 0.075469 (-0.012504) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.295215 / 1.841788 (-0.546573) | 18.554020 / 8.074308 (10.479711) | 13.683273 / 10.191392 (3.491881) | 0.132266 / 0.680424 (-0.548158) | 0.016376 / 0.534201 (-0.517825) | 0.334495 / 0.579283 (-0.244788) | 0.347106 / 0.434364 (-0.087258) | 0.387531 / 0.540337 (-0.152806) | 0.525745 / 1.386936 (-0.861191) |\n\n</details>\n</details>\n\n\n",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6036). All of your documentation changes will be reflected on that endpoint.",
"I don't think `transformers` should have any dataset indexing code. So before deprecating I'd be in favor of finding a suitable replacement. Not sure about the stats of the RAG model that uses `datasets` indexing though",
"The RAG downloads stats are decent (over 20k downloads last month).\r\n\r\nI think it's suboptimal to maintain an API that only a single model uses. One option is to put this code into a separate lib. However, `langchain` and `docarray` already provide a unified interface to vector stores, so I don't see this as an impactful project. Considering how specific this model is, I think we should go with the simplest solution and combine an index with a dataset in Transformers (this wouldn't require too much code).",
"What about migrating to the [datasets-server](https://github.com/huggingface/datasets-server) search feature instead? Would make more sense from a product perspective ",
"I don't think it's a good idea:\r\n- using datasets-server would require to upload the data and to not control the indexing, whereas the current feature is about using a local index that you control\r\n- faiss indexes are vector indexes that are not supported by datasets-server, and they are also very customised. For instance RAG uses DPR embeddings and cosine similarity\r\n- FTS is only done for the first 5GB of data for now in datasets-server\r\n\r\nI think a better option would be to integrate with open source search tools such as docarray.\r\nAnd if we want to make the datasets-server search available in python we can build an integration in docarray and/or in huggingface_hub.",
"`llama_index` is another popular tool in this space.\r\n\r\n@lhoestq \r\n> I think a better option would be to integrate with open source search tools such as docarray.\r\nAnd if we want to make the datasets-server search available in python we can build an integration in docarray and/or in huggingface_hub.\r\n\r\nI don't think these integrations would be popular unless we integrate them with the Hub \"UI-wise\" (e.g., through a widget), so they can wait IMO. Also, FAISS supports `fsspec` already with the callback reader/writer, so this doesn't require a specific integration. ",
"After discussing it a bit with @lhoestq, do we need to deprecate the search API? While I understand it's imperfect, it looks like this will result in significant work to update it everywhere, so I'd favor keeping it until there's an obviously better alternative; this way we can focus on different things in the meantime."
] |
https://api.github.com/repos/huggingface/datasets/issues/5360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5360/comments | https://api.github.com/repos/huggingface/datasets/issues/5360/events | https://github.com/huggingface/datasets/issues/5360 | 1,496,947,177 | I_kwDODunzps5ZOZnp | 5,360 | IterableDataset returns duplicated data using PyTorch DDP | [] | closed | false | null | 11 | 2022-12-14T16:06:19Z | 2023-06-15T09:51:13Z | 2023-01-16T13:33:33Z | null | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5360/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5360/timeline | null | completed | null | null | false | [
"If you use huggingface trainer, you will find the trainer has wrapped a `IterableDatasetShard` to avoid duplication.\r\nSee:\r\nhttps://github.com/huggingface/transformers/blob/dfd818420dcbad68e05a502495cf666d338b2bfb/src/transformers/trainer.py#L835\r\n",
"If you want to support it by datasets natively, maybe we also need to change the code in `transformers` ?",
"Opened https://github.com/huggingface/transformers/issues/20770 to discuss this :)",
"Maybe something like this then ?\r\n```python\r\nfrom datasets.distributed import split_dataset_by_node\r\nds = split_dataset_by_node(ds, rank=rank, world_size=world_size)\r\n```\r\n\r\nFor map-style datasets the implementation is trivial (it can simply use `.shard()`).\r\n\r\nFor iterable datasets we would need to implement a new ExamplesIterable that would only iterate on a subset of the (possibly shuffled and re-shuffled after each epoch) list of shards, based on the rank and world size.",
"My plan is to skip examples by default to not end up with duplicates.\r\n\r\nAnd if a dataset has a number of shards that is a factor of the world size, then I'd make it more optimized by distributing the shards evenly across nodes instead.",
"Opened a PR here: https://github.com/huggingface/datasets/pull/5369\r\n\r\nfeel free to play with it and share your feedbacks :)",
"@lhoestq I add shuffle after split_dataset_by_node, duplicated data still exist. \r\nFor example, we have a directory named `mock_pretraining_data`, which has three files, `part-00000`, `part-00002`,`part-00002`. \r\nText in `part-00000` is like this: \r\n{\"id\": 0}\r\n{\"id\": 1}\r\n{\"id\": 2}\r\n{\"id\": 3}\r\n{\"id\": 4}\r\n{\"id\": 5}\r\n{\"id\": 6}\r\n{\"id\": 7}\r\n{\"id\": 8}\r\n{\"id\": 9}\r\n\r\nand `part-00001`\r\n{\"id\": 10}\r\n{\"id\": 11}\r\n{\"id\": 12}\r\n{\"id\": 13}\r\n{\"id\": 14}\r\n{\"id\": 15}\r\n{\"id\": 16}\r\n{\"id\": 17}\r\n{\"id\": 18}\r\n{\"id\": 19}\r\n\r\nand `part-00002`\r\n{\"id\": 20}\r\n{\"id\": 21}\r\n{\"id\": 22}\r\n{\"id\": 23}\r\n{\"id\": 24}\r\n{\"id\": 25}\r\n{\"id\": 26}\r\n{\"id\": 27}\r\n{\"id\": 28}\r\n{\"id\": 29}\r\n\r\nAnd code in `test_dist.py` like this,\r\n```python\r\nimport torch\r\nfrom torch.utils.data import Dataset, DataLoader\r\nfrom datasets import load_dataset\r\nimport os\r\nfrom transformers import AutoTokenizer, NezhaForPreTraining\r\nfrom transformers import AdamW, get_linear_schedule_with_warmup\r\nimport torch.nn.functional as F\r\nimport torch.nn as nn\r\nimport torch.distributed as dist\r\nfrom datasets.distributed import split_dataset_by_node\r\nfrom torch.nn.parallel import DistributedDataParallel as DDP\r\n\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = '5,6,7'\r\n\r\ndist.init_process_group(\"nccl\")\r\nlocal_rank = int(os.environ['LOCAL_RANK'])\r\nworld_size = torch.distributed.get_world_size()\r\ndevice = torch.device('cuda', local_rank)\r\ndata_dir = './'\r\n\r\ndef load_trainset(train_path):\r\n dataset = load_dataset('json', data_dir=os.path.join(data_dir, train_path), split='train', streaming=True)\r\n return dataset\r\n\r\ndef collate_fn(examples):\r\n input_ids = []\r\n for example in examples:\r\n input_ids.append(example['id'])\r\n return torch.LongTensor(input_ids).to(device)\r\n\r\n\r\ndataset = load_trainset('mock_pretraining_data')\r\ndataset = split_dataset_by_node(dataset, rank=local_rank, world_size=world_size).shuffle(buffer_size=512)\r\n# train_sampler = torch.utils.data.distributed.DistributedSampler(dataset)\r\nbatch_size = 3\r\nprint('batch_size: {}'.format(batch_size))\r\ntrain_dataloader = DataLoader(dataset, batch_size=batch_size, collate_fn=collate_fn)\r\n\r\nfor x in train_dataloader:\r\n print({'rank': local_rank, 'id': x})\r\n```\r\nrun `python -m torch.distributed.launch --nproc_per_node=3 test_dist.py`\r\nThe output is\r\n```\r\n{'rank': 1, 'id': tensor([12, 15, 14], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([16, 10, 18], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([17, 13, 19], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([11], device='cuda:1')}\r\n{'rank': 0, 'id': tensor([0, 2, 9], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([4, 8, 1], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([5, 3, 6], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([7], device='cuda:0')}\r\n{'rank': 2, 'id': tensor([13, 15, 14], device='cuda:2')}\r\n{'rank': 2, 'id': tensor([19, 17, 18], device='cuda:2')}\r\n{'rank': 2, 'id': tensor([12, 16, 11], device='cuda:2')}\r\n{'rank': 2, 'id': tensor([10], device='cuda:2')}\r\n```\r\n`part-00001` is loaded twice, `part-00002` isn't loaded.\r\n\r\nIf I run `python -m torch.distributed.launch --nproc_per_node=2 test_dist.py`\r\nThe output is weirder,many numbers appear twice\r\n```\r\n{'rank': 1, 'id': tensor([26, 8, 13], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([22, 19, 20], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([12, 28, 11], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([24, 2, 14], device='cuda:1')}\r\n{'rank': 1, 'id': tensor([ 6, 27, 3], device='cuda:1')}\r\n{'rank': 0, 'id': tensor([ 8, 25, 1], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([20, 4, 12], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([14, 29, 5], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([ 7, 18, 23], device='cuda:0')}\r\n{'rank': 0, 'id': tensor([19, 17, 11], device='cuda:0')}\r\n``` ",
"Hi ! Thanks for reporting, you need to pass `seed=` to `shuffle()` or the processes won't use the same seed to shuffle the shards order before assigning each shard to a node.\r\n\r\nThe issue is that the workers are not using the same seed to shuffle the shards before splitting the shards list by node.",
"Opened https://github.com/huggingface/datasets/issues/5696",
"I have the same issue\r\n```\r\nds['train'] = load_dataset(streaming=True)\r\nds['train'] = split_dataset_by_node(ds['train'], rank=int(os.environ[\"RANK\"]), world_size=int(os.environ[\"WORLD_SIZE\"]))\r\nvectorized_datasets = ds.map(\r\n prepare_dataset,\r\n remove_columns=raw_datasets_features,\r\n).with_format(\"torch\")\r\n\r\nvectorized_datasets[\"train\"] = vectorized_datasets[\"train\"].shuffle(\r\n buffer_size=500,\r\n seed=42,\r\n)\r\n\r\ndef prepare_dataset(batch):\r\n ....\r\n print(f\"sentence: {batch['sentence']}, target_text: {batch['target_text']}\")\r\n return batch\r\n```\r\nWhen using split_dataset_by_node(), the data being read is indeed different for each GPU ID.\r\n\r\n```\r\ntrainer = Trainer(\r\n model=model,\r\n data_collator=data_collator,\r\n args=training_args,\r\n compute_metrics=compute_metrics,\r\n train_dataset=vectorized_datasets[\"train\"] if training_args.do_train else None,\r\n eval_dataset=vectorized_datasets[\"eval\"] if training_args.do_eval else None,\r\n tokenizer=processor,\r\n callbacks=[ShuffleCallback()],\r\n )\r\n...\r\ntrain_result = trainer.train(resume_from_checkpoint=checkpoint)\r\n```\r\nHowever, when I execute trainer.train(), the data being read is different from what I expected.\r\nBecause I print the batch value in prepare_dataset() , I observe that the data is the same for each GPU ID.\r\n\r\nHow should I handle this issue?\r\n\r\n\r\n",
"There are two ways an iterable dataset can be split by node:\r\n1. if the number of shards is a factor of number of GPUs: in that case the shards are evenly distributed per GPU\r\n2. otherwise, each GPU iterate on the data and at the end keeps 1 sample out of n(GPUs) - skipping the others.\r\n\r\nIn case 2. it's therefore possible to have the same examples passed to `prepare_dataset` for each GPU.\r\n\r\nThis doesn't sound optimized though, because it runs the preprocessing on samples that won't be used in the end.\r\n\r\nCould you open a new issue so that we can discuss about this and find a solution ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/632/comments | https://api.github.com/repos/huggingface/datasets/issues/632/events | https://github.com/huggingface/datasets/pull/632 | 702,358,124 | MDExOlB1bGxSZXF1ZXN0NDg3NjQ5OTQ2 | 632 | Fix typos in the loading datasets docs | [] | closed | false | null | 1 | 2020-09-16T00:27:41Z | 2020-09-21T16:31:11Z | 2020-09-16T06:52:44Z | null | This PR fixes two typos in the loading datasets docs, one of them being a broken link to the `load_dataset` function. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/632/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/632.diff",
"html_url": "https://github.com/huggingface/datasets/pull/632",
"merged_at": "2020-09-16T06:52:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/632.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/632"
} | true | [
"thanks!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2575/comments | https://api.github.com/repos/huggingface/datasets/issues/2575/events | https://github.com/huggingface/datasets/pull/2575 | 934,876,496 | MDExOlB1bGxSZXF1ZXN0NjgxODg0OTgy | 2,575 | Add C4 | [] | closed | false | null | 0 | 2021-07-01T13:58:08Z | 2021-07-02T14:50:23Z | 2021-07-02T14:50:23Z | null | The old code for the C4 dataset was to generate the C4 with Apache Beam, as in Tensorflow Datasets.
However AllenAI is now hosting the processed C4 dataset in this repo: https://huggingface.co/datasets/allenai/c4
Thanks a lot to them for their amazing work !
In this PR I changed the script to download and prepare the data directly from this repo.
It has 4 variants: en, en.noblocklist, en.noclean, realnewslike
You can load it with
```python
from datasets import load_dataset
c4 = load_dataset("c4", "en")
```
It also supports streaming, if you don't want to download hundreds of GB of data:
```python
c4 = load_dataset("c4", "en", streaming=True)
```
Regarding the dataset_infos.json, I haven't added the infos for en.noclean. I will add them once I have them.
Also we can work on the dataset card at https://huggingface.co/datasets/c4
For now I just added a link to https://huggingface.co/datasets/allenai/c4 as well as a few sections | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2575/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2575/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2575.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2575",
"merged_at": "2021-07-02T14:50:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2575.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2575"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/990 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/990/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/990/comments | https://api.github.com/repos/huggingface/datasets/issues/990/events | https://github.com/huggingface/datasets/pull/990 | 755,097,798 | MDExOlB1bGxSZXF1ZXN0NTMwODc1NDYx | 990 | Add E2E NLG | [] | closed | false | null | 0 | 2020-12-02T09:25:12Z | 2020-12-03T13:08:05Z | 2020-12-03T13:08:04Z | null | Adding the E2E NLG dataset.
More info here : http://www.macs.hw.ac.uk/InteractionLab/E2E/
### Checkbox
- [x] Create the dataset script `/datasets/my_dataset/my_dataset.py` using the template
- [x] Fill the `_DESCRIPTION` and `_CITATION` variables
- [x] Implement `_infos()`, `_split_generators()` and `_generate_examples()`
- [x] Make sure that the `BUILDER_CONFIGS` class attribute is filled with the different configurations of the dataset and that the `BUILDER_CONFIG_CLASS` is specified if there is a custom config class.
- [x] Generate the metadata file `dataset_infos.json` for all configurations
- [x] Generate the dummy data `dummy_data.zip` files to have the dataset script tested and that they don't weigh too much (<50KB)
- [x] Add the dataset card `README.md` using the template and at least fill the tags
- [x] Both tests for the real data and the dummy data pass.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/990/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/990/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/990.diff",
"html_url": "https://github.com/huggingface/datasets/pull/990",
"merged_at": "2020-12-03T13:08:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/990.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/990"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1032 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1032/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1032/comments | https://api.github.com/repos/huggingface/datasets/issues/1032/events | https://github.com/huggingface/datasets/pull/1032 | 755,858,785 | MDExOlB1bGxSZXF1ZXN0NTMxNDk2MTU2 | 1,032 | IIT B English to Hindi machine translation dataset | [] | closed | false | null | 5 | 2020-12-03T05:18:45Z | 2021-01-10T08:44:51Z | 2021-01-10T08:44:15Z | null | Adding IIT Bombay English-Hindi Corpus dataset
more info : http://www.cfilt.iitb.ac.in/iitb_parallel/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1032/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1032/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1032.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1032",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1032.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1032"
} | true | [
"Please note that this dataset is actually behind a form that one needs to fill. However, the link is direct. I'm not sure what should the approach be in this case.",
"also pinging @thomwolf \r\nThe dataset webpage returns a form when trying to download the dataset (form here : http://www.cfilt.iitb.ac.in/iitb_parallel/dataset.html).\r\nHowever the url we get with the form can be used for the dataset script.\r\nShould we ask the authors or use the urls this way ?",
"> also pinging @thomwolf\r\n> The dataset webpage returns a form when trying to download the dataset (form here : http://www.cfilt.iitb.ac.in/iitb_parallel/dataset.html).\r\n> However the url we get with the form can be used for the dataset script.\r\n> Should we ask the authors or use the urls this way ?\r\n\r\nI had discussion on this with @thomwolf . We have already sent email to author of this dataset.",
"Hi @spatil6 !\r\nAny news from the authors ?",
"IIT B folks will add this dataset to repo."
] |
https://api.github.com/repos/huggingface/datasets/issues/1638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1638/comments | https://api.github.com/repos/huggingface/datasets/issues/1638/events | https://github.com/huggingface/datasets/pull/1638 | 774,869,184 | MDExOlB1bGxSZXF1ZXN0NTQ1Njg5ODQ5 | 1,638 | Add id_puisi dataset | [] | closed | false | null | 0 | 2020-12-26T12:41:55Z | 2020-12-30T16:34:17Z | 2020-12-30T16:34:17Z | null | Puisi (poem) is an Indonesian poetic form. The dataset contains 7223 Indonesian puisi with its title and author. :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1638/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1638/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1638.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1638",
"merged_at": "2020-12-30T16:34:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1638.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1638"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/77 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/77/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/77/comments | https://api.github.com/repos/huggingface/datasets/issues/77/events | https://github.com/huggingface/datasets/pull/77 | 616,674,601 | MDExOlB1bGxSZXF1ZXN0NDE2NzQwMjAz | 77 | New datasets | [] | closed | false | null | 0 | 2020-05-12T13:51:59Z | 2020-05-12T14:02:16Z | 2020-05-12T14:02:15Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/77/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/77/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/77.diff",
"html_url": "https://github.com/huggingface/datasets/pull/77",
"merged_at": "2020-05-12T14:02:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/77.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/77"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5410/comments | https://api.github.com/repos/huggingface/datasets/issues/5410/events | https://github.com/huggingface/datasets/pull/5410 | 1,521,168,032 | PR_kwDODunzps5GvnJH | 5,410 | Map-style Dataset to IterableDataset | [] | closed | false | null | 22 | 2023-01-05T18:12:17Z | 2023-02-01T18:11:45Z | 2023-02-01T16:36:01Z | null | Added `ds.to_iterable()` to get an iterable dataset from a map-style arrow dataset.
It also has a `num_shards` argument to split the dataset before converting to an iterable dataset. Sharding is important to enable efficient shuffling and parallel loading of iterable datasets.
TODO:
- [x] tests
- [x] docs
Fix https://github.com/huggingface/datasets/issues/5265 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5410/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5410/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5410",
"merged_at": "2023-02-01T16:36:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5410"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009812 / 0.011353 (-0.001540) | 0.005290 / 0.011008 (-0.005719) | 0.099728 / 0.038508 (0.061220) | 0.036712 / 0.023109 (0.013602) | 0.305924 / 0.275898 (0.030026) | 0.349844 / 0.323480 (0.026365) | 0.008353 / 0.007986 (0.000368) | 0.004464 / 0.004328 (0.000135) | 0.075329 / 0.004250 (0.071079) | 0.046146 / 0.037052 (0.009094) | 0.304197 / 0.258489 (0.045708) | 0.354245 / 0.293841 (0.060404) | 0.039270 / 0.128546 (-0.089276) | 0.012496 / 0.075646 (-0.063151) | 0.334390 / 0.419271 (-0.084882) | 0.049428 / 0.043533 (0.005896) | 0.297318 / 0.255139 (0.042179) | 0.315646 / 0.283200 (0.032447) | 0.106746 / 0.141683 (-0.034937) | 1.443562 / 1.452155 (-0.008593) | 1.546022 / 1.492716 (0.053305) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.303419 / 0.018006 (0.285413) | 0.536971 / 0.000490 (0.536481) | 0.001335 / 0.000200 (0.001135) | 0.000088 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030484 / 0.037411 (-0.006927) | 0.110043 / 0.014526 (0.095518) | 0.125265 / 0.176557 (-0.051291) | 0.171410 / 0.737135 (-0.565725) | 0.128978 / 0.296338 (-0.167361) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398354 / 0.215209 (0.183145) | 3.984180 / 2.077655 (1.906526) | 1.781134 / 1.504120 (0.277014) | 1.589656 / 1.541195 (0.048462) | 1.704192 / 1.468490 (0.235702) | 0.682271 / 4.584777 (-3.902506) | 3.731504 / 3.745712 (-0.014208) | 2.243520 / 5.269862 (-3.026342) | 1.511334 / 4.565676 (-3.054343) | 0.084243 / 0.424275 (-0.340032) | 0.012261 / 0.007607 (0.004654) | 0.507499 / 0.226044 (0.281454) | 5.066037 / 2.268929 (2.797109) | 2.246107 / 55.444624 (-53.198517) | 1.921032 / 6.876477 (-4.955444) | 2.144111 / 2.142072 (0.002039) | 0.845233 / 4.805227 (-3.959995) | 0.165392 / 6.500664 (-6.335272) | 0.064201 / 0.075469 (-0.011268) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.217649 / 1.841788 (-0.624138) | 15.890487 / 8.074308 (7.816179) | 14.772039 / 10.191392 (4.580647) | 0.192901 / 0.680424 (-0.487523) | 0.029119 / 0.534201 (-0.505082) | 0.442904 / 0.579283 (-0.136380) | 0.451035 / 0.434364 (0.016671) | 0.520788 / 0.540337 (-0.019550) | 0.623588 / 1.386936 (-0.763348) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007452 / 0.011353 (-0.003901) | 0.005426 / 0.011008 (-0.005582) | 0.096488 / 0.038508 (0.057980) | 0.033575 / 0.023109 (0.010465) | 0.375688 / 0.275898 (0.099790) | 0.412393 / 0.323480 (0.088913) | 0.006050 / 0.007986 (-0.001936) | 0.004424 / 0.004328 (0.000095) | 0.073102 / 0.004250 (0.068852) | 0.052672 / 0.037052 (0.015620) | 0.379352 / 0.258489 (0.120862) | 0.436065 / 0.293841 (0.142224) | 0.036594 / 0.128546 (-0.091952) | 0.012380 / 0.075646 (-0.063266) | 0.332899 / 0.419271 (-0.086373) | 0.048859 / 0.043533 (0.005326) | 0.373215 / 0.255139 (0.118076) | 0.386990 / 0.283200 (0.103791) | 0.105166 / 0.141683 (-0.036517) | 1.490762 / 1.452155 (0.038607) | 1.611310 / 1.492716 (0.118593) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.333142 / 0.018006 (0.315136) | 0.537137 / 0.000490 (0.536647) | 0.000452 / 0.000200 (0.000252) | 0.000063 / 0.000054 (0.000009) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030368 / 0.037411 (-0.007043) | 0.109608 / 0.014526 (0.095083) | 0.124220 / 0.176557 (-0.052336) | 0.162834 / 0.737135 (-0.574301) | 0.128037 / 0.296338 (-0.168302) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440991 / 0.215209 (0.225782) | 4.400825 / 2.077655 (2.323170) | 2.158768 / 1.504120 (0.654648) | 1.968158 / 1.541195 (0.426963) | 2.085115 / 1.468490 (0.616625) | 0.710757 / 4.584777 (-3.874020) | 3.835441 / 3.745712 (0.089729) | 2.204118 / 5.269862 (-3.065744) | 1.378909 / 4.565676 (-3.186767) | 0.089149 / 0.424275 (-0.335126) | 0.013066 / 0.007607 (0.005459) | 0.539165 / 0.226044 (0.313121) | 5.414176 / 2.268929 (3.145248) | 2.677020 / 55.444624 (-52.767604) | 2.328334 / 6.876477 (-4.548143) | 2.518933 / 2.142072 (0.376860) | 0.840902 / 4.805227 (-3.964325) | 0.170365 / 6.500664 (-6.330299) | 0.063909 / 0.075469 (-0.011561) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237205 / 1.841788 (-0.604583) | 15.678776 / 8.074308 (7.604468) | 14.118576 / 10.191392 (3.927184) | 0.167236 / 0.680424 (-0.513188) | 0.018177 / 0.534201 (-0.516024) | 0.426680 / 0.579283 (-0.152603) | 0.425126 / 0.434364 (-0.009238) | 0.501755 / 0.540337 (-0.038582) | 0.592754 / 1.386936 (-0.794182) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008708 / 0.011353 (-0.002645) | 0.004462 / 0.011008 (-0.006546) | 0.100159 / 0.038508 (0.061651) | 0.029543 / 0.023109 (0.006434) | 0.304056 / 0.275898 (0.028158) | 0.367098 / 0.323480 (0.043618) | 0.007049 / 0.007986 (-0.000937) | 0.003294 / 0.004328 (-0.001034) | 0.076954 / 0.004250 (0.072703) | 0.036850 / 0.037052 (-0.000202) | 0.307556 / 0.258489 (0.049067) | 0.348327 / 0.293841 (0.054486) | 0.033520 / 0.128546 (-0.095026) | 0.011312 / 0.075646 (-0.064334) | 0.317588 / 0.419271 (-0.101684) | 0.040196 / 0.043533 (-0.003337) | 0.298330 / 0.255139 (0.043191) | 0.333821 / 0.283200 (0.050622) | 0.086584 / 0.141683 (-0.055099) | 1.480205 / 1.452155 (0.028050) | 1.520975 / 1.492716 (0.028259) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.186641 / 0.018006 (0.168635) | 0.414420 / 0.000490 (0.413930) | 0.003021 / 0.000200 (0.002821) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022953 / 0.037411 (-0.014458) | 0.097338 / 0.014526 (0.082812) | 0.104985 / 0.176557 (-0.071572) | 0.139208 / 0.737135 (-0.597927) | 0.108031 / 0.296338 (-0.188307) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.417969 / 0.215209 (0.202759) | 4.173189 / 2.077655 (2.095534) | 1.862813 / 1.504120 (0.358693) | 1.653226 / 1.541195 (0.112031) | 1.725917 / 1.468490 (0.257426) | 0.701038 / 4.584777 (-3.883739) | 3.350500 / 3.745712 (-0.395213) | 1.913156 / 5.269862 (-3.356705) | 1.267597 / 4.565676 (-3.298079) | 0.082197 / 0.424275 (-0.342078) | 0.012499 / 0.007607 (0.004892) | 0.520173 / 0.226044 (0.294128) | 5.219981 / 2.268929 (2.951053) | 2.306029 / 55.444624 (-53.138595) | 1.948169 / 6.876477 (-4.928307) | 2.013160 / 2.142072 (-0.128912) | 0.813325 / 4.805227 (-3.991902) | 0.149729 / 6.500664 (-6.350935) | 0.065492 / 0.075469 (-0.009977) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.194163 / 1.841788 (-0.647625) | 13.739562 / 8.074308 (5.665254) | 13.881988 / 10.191392 (3.690596) | 0.138180 / 0.680424 (-0.542244) | 0.029031 / 0.534201 (-0.505170) | 0.387858 / 0.579283 (-0.191425) | 0.395171 / 0.434364 (-0.039193) | 0.446349 / 0.540337 (-0.093988) | 0.527073 / 1.386936 (-0.859863) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006504 / 0.011353 (-0.004849) | 0.004564 / 0.011008 (-0.006444) | 0.099108 / 0.038508 (0.060599) | 0.027420 / 0.023109 (0.004311) | 0.340712 / 0.275898 (0.064814) | 0.391613 / 0.323480 (0.068133) | 0.004977 / 0.007986 (-0.003009) | 0.003375 / 0.004328 (-0.000953) | 0.076403 / 0.004250 (0.072152) | 0.036650 / 0.037052 (-0.000402) | 0.341948 / 0.258489 (0.083459) | 0.392065 / 0.293841 (0.098224) | 0.031802 / 0.128546 (-0.096745) | 0.011659 / 0.075646 (-0.063987) | 0.320099 / 0.419271 (-0.099173) | 0.041615 / 0.043533 (-0.001918) | 0.342125 / 0.255139 (0.086986) | 0.372833 / 0.283200 (0.089633) | 0.089032 / 0.141683 (-0.052650) | 1.486691 / 1.452155 (0.034536) | 1.567326 / 1.492716 (0.074610) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.193123 / 0.018006 (0.175117) | 0.404062 / 0.000490 (0.403573) | 0.003460 / 0.000200 (0.003260) | 0.000079 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024565 / 0.037411 (-0.012846) | 0.098958 / 0.014526 (0.084432) | 0.108701 / 0.176557 (-0.067855) | 0.142567 / 0.737135 (-0.594569) | 0.111048 / 0.296338 (-0.185290) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474549 / 0.215209 (0.259340) | 4.753776 / 2.077655 (2.676121) | 2.435528 / 1.504120 (0.931409) | 2.234491 / 1.541195 (0.693297) | 2.269474 / 1.468490 (0.800984) | 0.695636 / 4.584777 (-3.889141) | 3.367816 / 3.745712 (-0.377896) | 1.854828 / 5.269862 (-3.415034) | 1.159729 / 4.565676 (-3.405948) | 0.082267 / 0.424275 (-0.342008) | 0.012483 / 0.007607 (0.004876) | 0.578490 / 0.226044 (0.352446) | 5.814490 / 2.268929 (3.545561) | 2.893310 / 55.444624 (-52.551314) | 2.540555 / 6.876477 (-4.335922) | 2.573705 / 2.142072 (0.431633) | 0.800545 / 4.805227 (-4.004682) | 0.151306 / 6.500664 (-6.349358) | 0.067925 / 0.075469 (-0.007544) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.294645 / 1.841788 (-0.547142) | 13.641842 / 8.074308 (5.567534) | 14.015200 / 10.191392 (3.823808) | 0.128829 / 0.680424 (-0.551595) | 0.016870 / 0.534201 (-0.517331) | 0.389137 / 0.579283 (-0.190146) | 0.388384 / 0.434364 (-0.045980) | 0.447711 / 0.540337 (-0.092627) | 0.540637 / 1.386936 (-0.846299) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.012282 / 0.011353 (0.000929) | 0.006328 / 0.011008 (-0.004680) | 0.129666 / 0.038508 (0.091158) | 0.039403 / 0.023109 (0.016294) | 0.375464 / 0.275898 (0.099566) | 0.463167 / 0.323480 (0.139687) | 0.010329 / 0.007986 (0.002344) | 0.005111 / 0.004328 (0.000782) | 0.108727 / 0.004250 (0.104476) | 0.047156 / 0.037052 (0.010103) | 0.381869 / 0.258489 (0.123380) | 0.441936 / 0.293841 (0.148095) | 0.054750 / 0.128546 (-0.073796) | 0.019809 / 0.075646 (-0.055837) | 0.436389 / 0.419271 (0.017118) | 0.066585 / 0.043533 (0.023052) | 0.402108 / 0.255139 (0.146969) | 0.424571 / 0.283200 (0.141371) | 0.118326 / 0.141683 (-0.023357) | 1.870175 / 1.452155 (0.418020) | 1.878720 / 1.492716 (0.386004) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.012863 / 0.018006 (-0.005144) | 0.528670 / 0.000490 (0.528181) | 0.006057 / 0.000200 (0.005857) | 0.000124 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030091 / 0.037411 (-0.007320) | 0.136143 / 0.014526 (0.121618) | 0.148931 / 0.176557 (-0.027626) | 0.179578 / 0.737135 (-0.557558) | 0.144528 / 0.296338 (-0.151810) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.594080 / 0.215209 (0.378871) | 6.029101 / 2.077655 (3.951446) | 2.443084 / 1.504120 (0.938964) | 2.123949 / 1.541195 (0.582754) | 2.183021 / 1.468490 (0.714531) | 1.235453 / 4.584777 (-3.349324) | 5.585121 / 3.745712 (1.839408) | 3.208510 / 5.269862 (-2.061351) | 2.090334 / 4.565676 (-2.475342) | 0.150353 / 0.424275 (-0.273922) | 0.016787 / 0.007607 (0.009180) | 0.797561 / 0.226044 (0.571516) | 7.756291 / 2.268929 (5.487363) | 3.283638 / 55.444624 (-52.160986) | 2.527441 / 6.876477 (-4.349036) | 2.590765 / 2.142072 (0.448692) | 1.446818 / 4.805227 (-3.358409) | 0.250563 / 6.500664 (-6.250101) | 0.077919 / 0.075469 (0.002450) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.612022 / 1.841788 (-0.229765) | 18.363316 / 8.074308 (10.289008) | 22.578570 / 10.191392 (12.387178) | 0.232801 / 0.680424 (-0.447623) | 0.048232 / 0.534201 (-0.485969) | 0.549518 / 0.579283 (-0.029766) | 0.624663 / 0.434364 (0.190299) | 0.674745 / 0.540337 (0.134408) | 0.803489 / 1.386936 (-0.583447) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009872 / 0.011353 (-0.001481) | 0.006593 / 0.011008 (-0.004415) | 0.139248 / 0.038508 (0.100740) | 0.035708 / 0.023109 (0.012598) | 0.551335 / 0.275898 (0.275437) | 0.544995 / 0.323480 (0.221515) | 0.007085 / 0.007986 (-0.000900) | 0.004742 / 0.004328 (0.000413) | 0.095823 / 0.004250 (0.091572) | 0.051674 / 0.037052 (0.014621) | 0.463405 / 0.258489 (0.204916) | 0.640392 / 0.293841 (0.346551) | 0.055242 / 0.128546 (-0.073304) | 0.022602 / 0.075646 (-0.053044) | 0.419171 / 0.419271 (-0.000100) | 0.062986 / 0.043533 (0.019453) | 0.503683 / 0.255139 (0.248544) | 0.568719 / 0.283200 (0.285519) | 0.113906 / 0.141683 (-0.027777) | 1.825248 / 1.452155 (0.373094) | 1.985667 / 1.492716 (0.492951) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237478 / 0.018006 (0.219472) | 0.528861 / 0.000490 (0.528371) | 0.008507 / 0.000200 (0.008307) | 0.000158 / 0.000054 (0.000103) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033536 / 0.037411 (-0.003875) | 0.144202 / 0.014526 (0.129677) | 0.139472 / 0.176557 (-0.037084) | 0.184540 / 0.737135 (-0.552596) | 0.147818 / 0.296338 (-0.148520) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.671654 / 0.215209 (0.456445) | 6.616368 / 2.077655 (4.538713) | 2.805634 / 1.504120 (1.301514) | 2.482890 / 1.541195 (0.941695) | 2.547686 / 1.468490 (1.079195) | 1.289169 / 4.584777 (-3.295608) | 5.551436 / 3.745712 (1.805724) | 5.228500 / 5.269862 (-0.041362) | 2.456706 / 4.565676 (-2.108970) | 0.148556 / 0.424275 (-0.275720) | 0.015290 / 0.007607 (0.007683) | 0.837090 / 0.226044 (0.611045) | 8.373561 / 2.268929 (6.104632) | 3.663910 / 55.444624 (-51.780714) | 2.927117 / 6.876477 (-3.949360) | 2.976785 / 2.142072 (0.834712) | 1.501618 / 4.805227 (-3.303609) | 0.263321 / 6.500664 (-6.237343) | 0.082644 / 0.075469 (0.007175) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.707419 / 1.841788 (-0.134368) | 18.371117 / 8.074308 (10.296809) | 22.015154 / 10.191392 (11.823762) | 0.232066 / 0.680424 (-0.448357) | 0.027149 / 0.534201 (-0.507052) | 0.544450 / 0.579283 (-0.034833) | 0.605134 / 0.434364 (0.170770) | 0.656063 / 0.540337 (0.115725) | 0.788121 / 1.386936 (-0.598815) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008952 / 0.011353 (-0.002401) | 0.005592 / 0.011008 (-0.005416) | 0.101138 / 0.038508 (0.062630) | 0.035573 / 0.023109 (0.012464) | 0.295959 / 0.275898 (0.020060) | 0.365347 / 0.323480 (0.041867) | 0.008136 / 0.007986 (0.000150) | 0.004479 / 0.004328 (0.000150) | 0.078806 / 0.004250 (0.074556) | 0.045180 / 0.037052 (0.008127) | 0.321687 / 0.258489 (0.063198) | 0.345874 / 0.293841 (0.052033) | 0.038720 / 0.128546 (-0.089826) | 0.012534 / 0.075646 (-0.063112) | 0.335571 / 0.419271 (-0.083700) | 0.049048 / 0.043533 (0.005515) | 0.294756 / 0.255139 (0.039617) | 0.327496 / 0.283200 (0.044296) | 0.109181 / 0.141683 (-0.032502) | 1.417068 / 1.452155 (-0.035087) | 1.455473 / 1.492716 (-0.037244) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267774 / 0.018006 (0.249768) | 0.538546 / 0.000490 (0.538056) | 0.001755 / 0.000200 (0.001555) | 0.000090 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026839 / 0.037411 (-0.010572) | 0.105862 / 0.014526 (0.091336) | 0.118278 / 0.176557 (-0.058279) | 0.157926 / 0.737135 (-0.579209) | 0.124700 / 0.296338 (-0.171638) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.399060 / 0.215209 (0.183851) | 3.991409 / 2.077655 (1.913754) | 1.763569 / 1.504120 (0.259449) | 1.579602 / 1.541195 (0.038407) | 1.652928 / 1.468490 (0.184438) | 0.692962 / 4.584777 (-3.891815) | 3.784635 / 3.745712 (0.038922) | 3.249341 / 5.269862 (-2.020521) | 1.815711 / 4.565676 (-2.749966) | 0.084384 / 0.424275 (-0.339891) | 0.012546 / 0.007607 (0.004939) | 0.521397 / 0.226044 (0.295352) | 5.075824 / 2.268929 (2.806895) | 2.258353 / 55.444624 (-53.186272) | 1.925220 / 6.876477 (-4.951256) | 2.002821 / 2.142072 (-0.139252) | 0.830507 / 4.805227 (-3.974720) | 0.165845 / 6.500664 (-6.334819) | 0.063905 / 0.075469 (-0.011565) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.198726 / 1.841788 (-0.643061) | 14.804448 / 8.074308 (6.730139) | 12.855167 / 10.191392 (2.663775) | 0.167932 / 0.680424 (-0.512492) | 0.028643 / 0.534201 (-0.505558) | 0.441224 / 0.579283 (-0.138059) | 0.434924 / 0.434364 (0.000560) | 0.516188 / 0.540337 (-0.024150) | 0.605017 / 1.386936 (-0.781919) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007031 / 0.011353 (-0.004322) | 0.005157 / 0.011008 (-0.005851) | 0.086943 / 0.038508 (0.048434) | 0.031377 / 0.023109 (0.008268) | 0.334810 / 0.275898 (0.058912) | 0.368590 / 0.323480 (0.045110) | 0.005973 / 0.007986 (-0.002013) | 0.004173 / 0.004328 (-0.000155) | 0.067033 / 0.004250 (0.062783) | 0.054070 / 0.037052 (0.017018) | 0.332232 / 0.258489 (0.073743) | 0.384982 / 0.293841 (0.091141) | 0.034023 / 0.128546 (-0.094524) | 0.011301 / 0.075646 (-0.064345) | 0.295644 / 0.419271 (-0.123628) | 0.045589 / 0.043533 (0.002056) | 0.330739 / 0.255139 (0.075600) | 0.352841 / 0.283200 (0.069642) | 0.104829 / 0.141683 (-0.036854) | 1.329360 / 1.452155 (-0.122794) | 1.437956 / 1.492716 (-0.054760) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.299187 / 0.018006 (0.281181) | 0.563407 / 0.000490 (0.562917) | 0.004179 / 0.000200 (0.003979) | 0.000114 / 0.000054 (0.000060) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027405 / 0.037411 (-0.010006) | 0.097498 / 0.014526 (0.082972) | 0.114265 / 0.176557 (-0.062292) | 0.146823 / 0.737135 (-0.590313) | 0.117948 / 0.296338 (-0.178391) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.378756 / 0.215209 (0.163547) | 3.774804 / 2.077655 (1.697150) | 1.804149 / 1.504120 (0.300029) | 1.626312 / 1.541195 (0.085117) | 1.731111 / 1.468490 (0.262620) | 0.633493 / 4.584777 (-3.951284) | 3.488220 / 3.745712 (-0.257492) | 3.064710 / 5.269862 (-2.205151) | 1.690647 / 4.565676 (-2.875029) | 0.076093 / 0.424275 (-0.348182) | 0.010820 / 0.007607 (0.003213) | 0.465091 / 0.226044 (0.239046) | 4.676842 / 2.268929 (2.407913) | 2.297381 / 55.444624 (-53.147244) | 1.960355 / 6.876477 (-4.916122) | 1.983742 / 2.142072 (-0.158330) | 0.739525 / 4.805227 (-4.065702) | 0.152663 / 6.500664 (-6.348001) | 0.057316 / 0.075469 (-0.018153) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.104721 / 1.841788 (-0.737067) | 14.577171 / 8.074308 (6.502863) | 13.680402 / 10.191392 (3.489010) | 0.182234 / 0.680424 (-0.498190) | 0.018853 / 0.534201 (-0.515348) | 0.426194 / 0.579283 (-0.153089) | 0.429202 / 0.434364 (-0.005162) | 0.543125 / 0.540337 (0.002788) | 0.645887 / 1.386936 (-0.741049) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010055 / 0.011353 (-0.001298) | 0.005576 / 0.011008 (-0.005432) | 0.100059 / 0.038508 (0.061551) | 0.038535 / 0.023109 (0.015425) | 0.297538 / 0.275898 (0.021640) | 0.368117 / 0.323480 (0.044637) | 0.008540 / 0.007986 (0.000555) | 0.004469 / 0.004328 (0.000141) | 0.075801 / 0.004250 (0.071551) | 0.046604 / 0.037052 (0.009552) | 0.307242 / 0.258489 (0.048753) | 0.343949 / 0.293841 (0.050108) | 0.039353 / 0.128546 (-0.089194) | 0.012446 / 0.075646 (-0.063200) | 0.334628 / 0.419271 (-0.084643) | 0.051628 / 0.043533 (0.008095) | 0.298726 / 0.255139 (0.043587) | 0.316010 / 0.283200 (0.032810) | 0.120564 / 0.141683 (-0.021119) | 1.459396 / 1.452155 (0.007241) | 1.493682 / 1.492716 (0.000965) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011702 / 0.018006 (-0.006304) | 0.570261 / 0.000490 (0.569771) | 0.003760 / 0.000200 (0.003560) | 0.000091 / 0.000054 (0.000037) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028806 / 0.037411 (-0.008605) | 0.112150 / 0.014526 (0.097625) | 0.123140 / 0.176557 (-0.053417) | 0.173055 / 0.737135 (-0.564080) | 0.130060 / 0.296338 (-0.166279) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398216 / 0.215209 (0.183007) | 3.978677 / 2.077655 (1.901022) | 1.754229 / 1.504120 (0.250109) | 1.561892 / 1.541195 (0.020697) | 1.679138 / 1.468490 (0.210648) | 0.690254 / 4.584777 (-3.894523) | 3.817698 / 3.745712 (0.071986) | 2.177854 / 5.269862 (-3.092008) | 1.361860 / 4.565676 (-3.203816) | 0.084108 / 0.424275 (-0.340167) | 0.012640 / 0.007607 (0.005033) | 0.504385 / 0.226044 (0.278341) | 5.034103 / 2.268929 (2.765174) | 2.254032 / 55.444624 (-53.190593) | 1.910439 / 6.876477 (-4.966038) | 2.003515 / 2.142072 (-0.138558) | 0.839747 / 4.805227 (-3.965480) | 0.165654 / 6.500664 (-6.335010) | 0.063483 / 0.075469 (-0.011986) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.187521 / 1.841788 (-0.654267) | 15.381121 / 8.074308 (7.306812) | 14.579418 / 10.191392 (4.388026) | 0.199221 / 0.680424 (-0.481202) | 0.029335 / 0.534201 (-0.504866) | 0.443159 / 0.579283 (-0.136124) | 0.447772 / 0.434364 (0.013408) | 0.545071 / 0.540337 (0.004733) | 0.650494 / 1.386936 (-0.736442) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007675 / 0.011353 (-0.003677) | 0.005364 / 0.011008 (-0.005644) | 0.097921 / 0.038508 (0.059413) | 0.033645 / 0.023109 (0.010536) | 0.404818 / 0.275898 (0.128920) | 0.429983 / 0.323480 (0.106503) | 0.006106 / 0.007986 (-0.001879) | 0.005281 / 0.004328 (0.000953) | 0.073762 / 0.004250 (0.069512) | 0.053065 / 0.037052 (0.016012) | 0.400657 / 0.258489 (0.142168) | 0.447743 / 0.293841 (0.153902) | 0.036782 / 0.128546 (-0.091765) | 0.012593 / 0.075646 (-0.063054) | 0.332825 / 0.419271 (-0.086446) | 0.049424 / 0.043533 (0.005891) | 0.400397 / 0.255139 (0.145258) | 0.414794 / 0.283200 (0.131594) | 0.106555 / 0.141683 (-0.035128) | 1.466917 / 1.452155 (0.014762) | 1.571351 / 1.492716 (0.078635) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.254337 / 0.018006 (0.236331) | 0.568360 / 0.000490 (0.567870) | 0.000445 / 0.000200 (0.000245) | 0.000059 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031044 / 0.037411 (-0.006367) | 0.112282 / 0.014526 (0.097756) | 0.127205 / 0.176557 (-0.049352) | 0.166551 / 0.737135 (-0.570584) | 0.130520 / 0.296338 (-0.165818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442906 / 0.215209 (0.227697) | 4.430218 / 2.077655 (2.352563) | 2.287251 / 1.504120 (0.783132) | 2.112345 / 1.541195 (0.571150) | 2.240952 / 1.468490 (0.772462) | 0.713800 / 4.584777 (-3.870977) | 3.884161 / 3.745712 (0.138449) | 2.166901 / 5.269862 (-3.102960) | 1.374490 / 4.565676 (-3.191187) | 0.087548 / 0.424275 (-0.336727) | 0.012369 / 0.007607 (0.004761) | 0.540783 / 0.226044 (0.314739) | 5.396187 / 2.268929 (3.127258) | 2.779636 / 55.444624 (-52.664988) | 2.434220 / 6.876477 (-4.442257) | 2.508180 / 2.142072 (0.366107) | 0.852470 / 4.805227 (-3.952757) | 0.171266 / 6.500664 (-6.329398) | 0.065463 / 0.075469 (-0.010006) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.241720 / 1.841788 (-0.600067) | 15.332568 / 8.074308 (7.258260) | 13.688723 / 10.191392 (3.497331) | 0.145150 / 0.680424 (-0.535273) | 0.017694 / 0.534201 (-0.516507) | 0.426078 / 0.579283 (-0.153205) | 0.441189 / 0.434364 (0.006825) | 0.540284 / 0.540337 (-0.000054) | 0.657548 / 1.386936 (-0.729388) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008604 / 0.011353 (-0.002749) | 0.004566 / 0.011008 (-0.006442) | 0.099607 / 0.038508 (0.061099) | 0.029628 / 0.023109 (0.006519) | 0.300481 / 0.275898 (0.024583) | 0.342596 / 0.323480 (0.019116) | 0.007003 / 0.007986 (-0.000982) | 0.003408 / 0.004328 (-0.000920) | 0.079076 / 0.004250 (0.074826) | 0.034104 / 0.037052 (-0.002948) | 0.303856 / 0.258489 (0.045367) | 0.348729 / 0.293841 (0.054888) | 0.033752 / 0.128546 (-0.094794) | 0.011497 / 0.075646 (-0.064149) | 0.321568 / 0.419271 (-0.097704) | 0.041472 / 0.043533 (-0.002061) | 0.303396 / 0.255139 (0.048257) | 0.331121 / 0.283200 (0.047921) | 0.086203 / 0.141683 (-0.055480) | 1.476995 / 1.452155 (0.024840) | 1.539428 / 1.492716 (0.046712) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215810 / 0.018006 (0.197803) | 0.414292 / 0.000490 (0.413802) | 0.000388 / 0.000200 (0.000188) | 0.000058 / 0.000054 (0.000004) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023441 / 0.037411 (-0.013970) | 0.098463 / 0.014526 (0.083938) | 0.105435 / 0.176557 (-0.071121) | 0.139736 / 0.737135 (-0.597399) | 0.109467 / 0.296338 (-0.186872) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418244 / 0.215209 (0.203035) | 4.160693 / 2.077655 (2.083039) | 1.878895 / 1.504120 (0.374775) | 1.679338 / 1.541195 (0.138143) | 1.730384 / 1.468490 (0.261894) | 0.688603 / 4.584777 (-3.896174) | 3.393542 / 3.745712 (-0.352170) | 1.901337 / 5.269862 (-3.368525) | 1.447269 / 4.565676 (-3.118408) | 0.083003 / 0.424275 (-0.341272) | 0.012574 / 0.007607 (0.004967) | 0.526363 / 0.226044 (0.300318) | 5.275159 / 2.268929 (3.006230) | 2.323642 / 55.444624 (-53.120982) | 1.982929 / 6.876477 (-4.893548) | 2.014081 / 2.142072 (-0.127991) | 0.809466 / 4.805227 (-3.995761) | 0.149038 / 6.500664 (-6.351626) | 0.064394 / 0.075469 (-0.011075) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.207439 / 1.841788 (-0.634349) | 13.691048 / 8.074308 (5.616740) | 13.880965 / 10.191392 (3.689573) | 0.148553 / 0.680424 (-0.531871) | 0.028397 / 0.534201 (-0.505804) | 0.391818 / 0.579283 (-0.187465) | 0.407181 / 0.434364 (-0.027183) | 0.481163 / 0.540337 (-0.059175) | 0.570689 / 1.386936 (-0.816247) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006361 / 0.011353 (-0.004992) | 0.004520 / 0.011008 (-0.006488) | 0.097679 / 0.038508 (0.059171) | 0.027223 / 0.023109 (0.004113) | 0.407966 / 0.275898 (0.132068) | 0.439868 / 0.323480 (0.116388) | 0.004625 / 0.007986 (-0.003360) | 0.004039 / 0.004328 (-0.000289) | 0.074548 / 0.004250 (0.070298) | 0.034957 / 0.037052 (-0.002095) | 0.412762 / 0.258489 (0.154273) | 0.449716 / 0.293841 (0.155875) | 0.031272 / 0.128546 (-0.097274) | 0.011598 / 0.075646 (-0.064049) | 0.320922 / 0.419271 (-0.098349) | 0.041250 / 0.043533 (-0.002283) | 0.411439 / 0.255139 (0.156300) | 0.429722 / 0.283200 (0.146523) | 0.087161 / 0.141683 (-0.054522) | 1.512573 / 1.452155 (0.060418) | 1.569385 / 1.492716 (0.076668) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.222612 / 0.018006 (0.204606) | 0.409086 / 0.000490 (0.408596) | 0.004246 / 0.000200 (0.004046) | 0.000083 / 0.000054 (0.000028) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024324 / 0.037411 (-0.013087) | 0.099055 / 0.014526 (0.084530) | 0.106809 / 0.176557 (-0.069748) | 0.141275 / 0.737135 (-0.595860) | 0.109426 / 0.296338 (-0.186913) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469736 / 0.215209 (0.254527) | 4.686900 / 2.077655 (2.609246) | 2.413392 / 1.504120 (0.909272) | 2.217366 / 1.541195 (0.676171) | 2.266957 / 1.468490 (0.798467) | 0.698647 / 4.584777 (-3.886129) | 3.389317 / 3.745712 (-0.356395) | 1.862315 / 5.269862 (-3.407546) | 1.160931 / 4.565676 (-3.404746) | 0.082829 / 0.424275 (-0.341446) | 0.012627 / 0.007607 (0.005020) | 0.568027 / 0.226044 (0.341983) | 5.683220 / 2.268929 (3.414291) | 2.865701 / 55.444624 (-52.578924) | 2.522401 / 6.876477 (-4.354076) | 2.542395 / 2.142072 (0.400323) | 0.801224 / 4.805227 (-4.004003) | 0.149946 / 6.500664 (-6.350718) | 0.065447 / 0.075469 (-0.010023) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.283756 / 1.841788 (-0.558032) | 13.903662 / 8.074308 (5.829354) | 13.238389 / 10.191392 (3.046997) | 0.142304 / 0.680424 (-0.538120) | 0.016922 / 0.534201 (-0.517279) | 0.377797 / 0.579283 (-0.201487) | 0.382460 / 0.434364 (-0.051904) | 0.464645 / 0.540337 (-0.075692) | 0.556270 / 1.386936 (-0.830666) |\n\n</details>\n</details>\n\n\n",
"> I think this would be more of a Conceptual Guide doc since this is more explanatory and compares the differences between a Dataset and an IterableDataset\r\n\r\nsounds good to me !\r\n\r\n> There are definitely places in the docs where we can add a nice and link to this doc though to build up the user's understanding of this topic. For example, in the Know your dataset [tutorial](https://huggingface.co/docs/datasets/access), we only introduce the regular Dataset object and not the IterableDataset. We can add a section there for IterableDataset and then link to this doc that explains the difference between the two 🙂\r\n\r\ngood idea, thanks :)",
"I'll open a PR to add a section on `IterableDataset`'s in the tutorial, and once you're done editing this doc I can give it a final polish! 😄 ",
"I moved the doc page to conceptual guides and took your suggestions into account :)\r\n\r\nI think this is ready for final review now",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009890 / 0.011353 (-0.001463) | 0.005156 / 0.011008 (-0.005852) | 0.099493 / 0.038508 (0.060984) | 0.036671 / 0.023109 (0.013562) | 0.304686 / 0.275898 (0.028788) | 0.339070 / 0.323480 (0.015590) | 0.008466 / 0.007986 (0.000481) | 0.005863 / 0.004328 (0.001534) | 0.075082 / 0.004250 (0.070832) | 0.045926 / 0.037052 (0.008874) | 0.303157 / 0.258489 (0.044668) | 0.363710 / 0.293841 (0.069870) | 0.038497 / 0.128546 (-0.090049) | 0.012063 / 0.075646 (-0.063583) | 0.334463 / 0.419271 (-0.084808) | 0.048161 / 0.043533 (0.004628) | 0.300431 / 0.255139 (0.045292) | 0.330344 / 0.283200 (0.047145) | 0.105509 / 0.141683 (-0.036174) | 1.475242 / 1.452155 (0.023087) | 1.550624 / 1.492716 (0.057908) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245749 / 0.018006 (0.227743) | 0.575091 / 0.000490 (0.574601) | 0.001556 / 0.000200 (0.001357) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030447 / 0.037411 (-0.006964) | 0.110982 / 0.014526 (0.096456) | 0.126760 / 0.176557 (-0.049797) | 0.173375 / 0.737135 (-0.563760) | 0.128799 / 0.296338 (-0.167539) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.392861 / 0.215209 (0.177651) | 3.911231 / 2.077655 (1.833576) | 1.757413 / 1.504120 (0.253293) | 1.563287 / 1.541195 (0.022093) | 1.658678 / 1.468490 (0.190188) | 0.677244 / 4.584777 (-3.907533) | 3.754917 / 3.745712 (0.009205) | 3.779417 / 5.269862 (-1.490444) | 1.993159 / 4.565676 (-2.572517) | 0.084425 / 0.424275 (-0.339850) | 0.012500 / 0.007607 (0.004893) | 0.501788 / 0.226044 (0.275743) | 5.003173 / 2.268929 (2.734244) | 2.273547 / 55.444624 (-53.171077) | 1.909766 / 6.876477 (-4.966711) | 1.968287 / 2.142072 (-0.173785) | 0.834895 / 4.805227 (-3.970332) | 0.165312 / 6.500664 (-6.335352) | 0.062202 / 0.075469 (-0.013267) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203080 / 1.841788 (-0.638708) | 15.158284 / 8.074308 (7.083976) | 14.174484 / 10.191392 (3.983092) | 0.171540 / 0.680424 (-0.508883) | 0.028604 / 0.534201 (-0.505597) | 0.438379 / 0.579283 (-0.140904) | 0.429447 / 0.434364 (-0.004917) | 0.540979 / 0.540337 (0.000642) | 0.630322 / 1.386936 (-0.756614) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007600 / 0.011353 (-0.003753) | 0.005400 / 0.011008 (-0.005608) | 0.097983 / 0.038508 (0.059475) | 0.033407 / 0.023109 (0.010297) | 0.384429 / 0.275898 (0.108531) | 0.415880 / 0.323480 (0.092400) | 0.006085 / 0.007986 (-0.001900) | 0.004330 / 0.004328 (0.000002) | 0.074654 / 0.004250 (0.070403) | 0.053076 / 0.037052 (0.016024) | 0.383958 / 0.258489 (0.125469) | 0.427289 / 0.293841 (0.133448) | 0.036710 / 0.128546 (-0.091836) | 0.012400 / 0.075646 (-0.063246) | 0.332712 / 0.419271 (-0.086560) | 0.058390 / 0.043533 (0.014857) | 0.377747 / 0.255139 (0.122608) | 0.398997 / 0.283200 (0.115798) | 0.117370 / 0.141683 (-0.024313) | 1.464211 / 1.452155 (0.012057) | 1.596465 / 1.492716 (0.103749) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212989 / 0.018006 (0.194983) | 0.554968 / 0.000490 (0.554479) | 0.004305 / 0.000200 (0.004105) | 0.000116 / 0.000054 (0.000061) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029167 / 0.037411 (-0.008244) | 0.109156 / 0.014526 (0.094631) | 0.122575 / 0.176557 (-0.053982) | 0.163058 / 0.737135 (-0.574077) | 0.127431 / 0.296338 (-0.168908) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.445395 / 0.215209 (0.230185) | 4.447534 / 2.077655 (2.369879) | 2.259186 / 1.504120 (0.755066) | 2.082956 / 1.541195 (0.541761) | 2.259126 / 1.468490 (0.790636) | 0.692271 / 4.584777 (-3.892506) | 3.795759 / 3.745712 (0.050047) | 3.603000 / 5.269862 (-1.666862) | 1.948556 / 4.565676 (-2.617120) | 0.084589 / 0.424275 (-0.339687) | 0.012751 / 0.007607 (0.005144) | 0.544783 / 0.226044 (0.318738) | 5.452278 / 2.268929 (3.183349) | 2.809467 / 55.444624 (-52.635157) | 2.479297 / 6.876477 (-4.397180) | 2.587756 / 2.142072 (0.445683) | 0.832258 / 4.805227 (-3.972970) | 0.167424 / 6.500664 (-6.333240) | 0.066064 / 0.075469 (-0.009405) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262719 / 1.841788 (-0.579069) | 15.917869 / 8.074308 (7.843561) | 13.879301 / 10.191392 (3.687909) | 0.187712 / 0.680424 (-0.492712) | 0.018175 / 0.534201 (-0.516026) | 0.425840 / 0.579283 (-0.153443) | 0.426164 / 0.434364 (-0.008200) | 0.527465 / 0.540337 (-0.012872) | 0.629478 / 1.386936 (-0.757458) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009064 / 0.011353 (-0.002289) | 0.004824 / 0.011008 (-0.006184) | 0.100869 / 0.038508 (0.062361) | 0.030803 / 0.023109 (0.007694) | 0.350880 / 0.275898 (0.074982) | 0.423816 / 0.323480 (0.100336) | 0.007581 / 0.007986 (-0.000405) | 0.003642 / 0.004328 (-0.000686) | 0.077682 / 0.004250 (0.073432) | 0.039856 / 0.037052 (0.002803) | 0.366097 / 0.258489 (0.107608) | 0.409226 / 0.293841 (0.115385) | 0.033698 / 0.128546 (-0.094848) | 0.011730 / 0.075646 (-0.063916) | 0.321683 / 0.419271 (-0.097588) | 0.041794 / 0.043533 (-0.001739) | 0.351175 / 0.255139 (0.096036) | 0.374328 / 0.283200 (0.091128) | 0.091833 / 0.141683 (-0.049850) | 1.507082 / 1.452155 (0.054927) | 1.543289 / 1.492716 (0.050572) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010670 / 0.018006 (-0.007337) | 0.429674 / 0.000490 (0.429184) | 0.003246 / 0.000200 (0.003046) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025015 / 0.037411 (-0.012397) | 0.102155 / 0.014526 (0.087629) | 0.107010 / 0.176557 (-0.069546) | 0.144265 / 0.737135 (-0.592870) | 0.110635 / 0.296338 (-0.185703) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.414211 / 0.215209 (0.199002) | 4.125582 / 2.077655 (2.047928) | 1.997856 / 1.504120 (0.493736) | 1.847676 / 1.541195 (0.306481) | 1.994100 / 1.468490 (0.525610) | 0.694975 / 4.584777 (-3.889802) | 3.373629 / 3.745712 (-0.372083) | 2.863255 / 5.269862 (-2.406606) | 1.565723 / 4.565676 (-2.999953) | 0.082539 / 0.424275 (-0.341736) | 0.012650 / 0.007607 (0.005043) | 0.522989 / 0.226044 (0.296945) | 5.205720 / 2.268929 (2.936792) | 2.352292 / 55.444624 (-53.092332) | 2.080467 / 6.876477 (-4.796010) | 2.231014 / 2.142072 (0.088942) | 0.811252 / 4.805227 (-3.993975) | 0.149171 / 6.500664 (-6.351493) | 0.065207 / 0.075469 (-0.010262) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.203137 / 1.841788 (-0.638651) | 14.244903 / 8.074308 (6.170595) | 14.454368 / 10.191392 (4.262976) | 0.139090 / 0.680424 (-0.541334) | 0.028738 / 0.534201 (-0.505463) | 0.396394 / 0.579283 (-0.182889) | 0.407207 / 0.434364 (-0.027156) | 0.478036 / 0.540337 (-0.062302) | 0.568488 / 1.386936 (-0.818448) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006878 / 0.011353 (-0.004475) | 0.004636 / 0.011008 (-0.006372) | 0.099118 / 0.038508 (0.060610) | 0.028076 / 0.023109 (0.004967) | 0.416097 / 0.275898 (0.140199) | 0.451722 / 0.323480 (0.128242) | 0.005364 / 0.007986 (-0.002622) | 0.003506 / 0.004328 (-0.000822) | 0.075791 / 0.004250 (0.071541) | 0.041373 / 0.037052 (0.004321) | 0.416358 / 0.258489 (0.157869) | 0.458440 / 0.293841 (0.164599) | 0.031870 / 0.128546 (-0.096676) | 0.011751 / 0.075646 (-0.063896) | 0.321748 / 0.419271 (-0.097524) | 0.041780 / 0.043533 (-0.001752) | 0.425037 / 0.255139 (0.169898) | 0.444169 / 0.283200 (0.160969) | 0.093145 / 0.141683 (-0.048538) | 1.472151 / 1.452155 (0.019996) | 1.542942 / 1.492716 (0.050226) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224287 / 0.018006 (0.206281) | 0.415303 / 0.000490 (0.414813) | 0.003180 / 0.000200 (0.002980) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026377 / 0.037411 (-0.011035) | 0.106222 / 0.014526 (0.091696) | 0.113873 / 0.176557 (-0.062684) | 0.143255 / 0.737135 (-0.593880) | 0.112642 / 0.296338 (-0.183697) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.444149 / 0.215209 (0.228940) | 4.421434 / 2.077655 (2.343779) | 2.082198 / 1.504120 (0.578078) | 1.879909 / 1.541195 (0.338715) | 1.968526 / 1.468490 (0.500036) | 0.697230 / 4.584777 (-3.887546) | 3.430800 / 3.745712 (-0.314912) | 1.893353 / 5.269862 (-3.376509) | 1.173271 / 4.565676 (-3.392406) | 0.082636 / 0.424275 (-0.341639) | 0.012357 / 0.007607 (0.004750) | 0.544008 / 0.226044 (0.317964) | 5.465472 / 2.268929 (3.196543) | 2.530017 / 55.444624 (-52.914608) | 2.178462 / 6.876477 (-4.698014) | 2.279570 / 2.142072 (0.137498) | 0.804890 / 4.805227 (-4.000337) | 0.152091 / 6.500664 (-6.348573) | 0.069442 / 0.075469 (-0.006027) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.256722 / 1.841788 (-0.585065) | 14.554131 / 8.074308 (6.479823) | 13.499913 / 10.191392 (3.308521) | 0.144350 / 0.680424 (-0.536074) | 0.016977 / 0.534201 (-0.517224) | 0.378836 / 0.579283 (-0.200447) | 0.392004 / 0.434364 (-0.042360) | 0.468423 / 0.540337 (-0.071914) | 0.584711 / 1.386936 (-0.802225) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008542 / 0.011353 (-0.002811) | 0.004552 / 0.011008 (-0.006456) | 0.100543 / 0.038508 (0.062035) | 0.029717 / 0.023109 (0.006608) | 0.301948 / 0.275898 (0.026050) | 0.360211 / 0.323480 (0.036731) | 0.006881 / 0.007986 (-0.001105) | 0.003433 / 0.004328 (-0.000896) | 0.077760 / 0.004250 (0.073510) | 0.037069 / 0.037052 (0.000017) | 0.314084 / 0.258489 (0.055595) | 0.347759 / 0.293841 (0.053918) | 0.033255 / 0.128546 (-0.095291) | 0.011487 / 0.075646 (-0.064160) | 0.323873 / 0.419271 (-0.095399) | 0.041203 / 0.043533 (-0.002330) | 0.298397 / 0.255139 (0.043258) | 0.327174 / 0.283200 (0.043974) | 0.088892 / 0.141683 (-0.052791) | 1.560114 / 1.452155 (0.107959) | 1.532475 / 1.492716 (0.039759) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226080 / 0.018006 (0.208074) | 0.467492 / 0.000490 (0.467003) | 0.002198 / 0.000200 (0.001998) | 0.000074 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023627 / 0.037411 (-0.013784) | 0.096696 / 0.014526 (0.082170) | 0.106196 / 0.176557 (-0.070360) | 0.140496 / 0.737135 (-0.596639) | 0.108859 / 0.296338 (-0.187480) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422335 / 0.215209 (0.207126) | 4.214879 / 2.077655 (2.137224) | 1.865866 / 1.504120 (0.361747) | 1.660914 / 1.541195 (0.119719) | 1.691869 / 1.468490 (0.223379) | 0.688164 / 4.584777 (-3.896613) | 3.432708 / 3.745712 (-0.313004) | 1.856852 / 5.269862 (-3.413010) | 1.243685 / 4.565676 (-3.321991) | 0.081552 / 0.424275 (-0.342723) | 0.012491 / 0.007607 (0.004884) | 0.524331 / 0.226044 (0.298287) | 5.255090 / 2.268929 (2.986162) | 2.269705 / 55.444624 (-53.174919) | 1.936722 / 6.876477 (-4.939755) | 2.018958 / 2.142072 (-0.123114) | 0.800658 / 4.805227 (-4.004569) | 0.148665 / 6.500664 (-6.351999) | 0.064210 / 0.075469 (-0.011259) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.235422 / 1.841788 (-0.606365) | 14.156755 / 8.074308 (6.082447) | 14.005916 / 10.191392 (3.814524) | 0.150983 / 0.680424 (-0.529441) | 0.028500 / 0.534201 (-0.505701) | 0.393013 / 0.579283 (-0.186270) | 0.408191 / 0.434364 (-0.026173) | 0.481017 / 0.540337 (-0.059320) | 0.581711 / 1.386936 (-0.805225) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006950 / 0.011353 (-0.004403) | 0.004575 / 0.011008 (-0.006434) | 0.076702 / 0.038508 (0.038194) | 0.028050 / 0.023109 (0.004941) | 0.342916 / 0.275898 (0.067018) | 0.378861 / 0.323480 (0.055381) | 0.005315 / 0.007986 (-0.002671) | 0.004822 / 0.004328 (0.000494) | 0.075560 / 0.004250 (0.071310) | 0.040441 / 0.037052 (0.003388) | 0.344284 / 0.258489 (0.085795) | 0.386519 / 0.293841 (0.092678) | 0.032122 / 0.128546 (-0.096424) | 0.011843 / 0.075646 (-0.063803) | 0.085798 / 0.419271 (-0.333473) | 0.043027 / 0.043533 (-0.000506) | 0.342910 / 0.255139 (0.087771) | 0.366618 / 0.283200 (0.083418) | 0.094766 / 0.141683 (-0.046917) | 1.492981 / 1.452155 (0.040827) | 1.566994 / 1.492716 (0.074278) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.166083 / 0.018006 (0.148076) | 0.409315 / 0.000490 (0.408826) | 0.003189 / 0.000200 (0.002989) | 0.000127 / 0.000054 (0.000072) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024753 / 0.037411 (-0.012658) | 0.099112 / 0.014526 (0.084586) | 0.106668 / 0.176557 (-0.069889) | 0.142562 / 0.737135 (-0.594573) | 0.110648 / 0.296338 (-0.185690) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.452668 / 0.215209 (0.237459) | 4.501188 / 2.077655 (2.423534) | 2.086197 / 1.504120 (0.582077) | 1.873955 / 1.541195 (0.332761) | 1.935610 / 1.468490 (0.467120) | 0.708290 / 4.584777 (-3.876487) | 3.426986 / 3.745712 (-0.318726) | 2.805852 / 5.269862 (-2.464009) | 1.516918 / 4.565676 (-3.048759) | 0.084067 / 0.424275 (-0.340208) | 0.012776 / 0.007607 (0.005169) | 0.548853 / 0.226044 (0.322809) | 5.488198 / 2.268929 (3.219270) | 2.704464 / 55.444624 (-52.740161) | 2.377817 / 6.876477 (-4.498660) | 2.366152 / 2.142072 (0.224079) | 0.818192 / 4.805227 (-3.987035) | 0.152649 / 6.500664 (-6.348015) | 0.066914 / 0.075469 (-0.008555) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.273803 / 1.841788 (-0.567985) | 14.071633 / 8.074308 (5.997325) | 13.655586 / 10.191392 (3.464194) | 0.149471 / 0.680424 (-0.530953) | 0.016745 / 0.534201 (-0.517456) | 0.386850 / 0.579283 (-0.192434) | 0.393595 / 0.434364 (-0.040769) | 0.480396 / 0.540337 (-0.059942) | 0.573708 / 1.386936 (-0.813228) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008173 / 0.011353 (-0.003180) | 0.004461 / 0.011008 (-0.006547) | 0.100284 / 0.038508 (0.061776) | 0.028900 / 0.023109 (0.005791) | 0.293639 / 0.275898 (0.017741) | 0.359450 / 0.323480 (0.035971) | 0.007567 / 0.007986 (-0.000418) | 0.003434 / 0.004328 (-0.000894) | 0.077913 / 0.004250 (0.073663) | 0.036313 / 0.037052 (-0.000740) | 0.308484 / 0.258489 (0.049995) | 0.347575 / 0.293841 (0.053734) | 0.033367 / 0.128546 (-0.095179) | 0.011508 / 0.075646 (-0.064138) | 0.323490 / 0.419271 (-0.095782) | 0.042285 / 0.043533 (-0.001248) | 0.295696 / 0.255139 (0.040557) | 0.332475 / 0.283200 (0.049276) | 0.089980 / 0.141683 (-0.051703) | 1.461851 / 1.452155 (0.009697) | 1.493030 / 1.492716 (0.000314) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191068 / 0.018006 (0.173062) | 0.396768 / 0.000490 (0.396278) | 0.002355 / 0.000200 (0.002155) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023117 / 0.037411 (-0.014294) | 0.096155 / 0.014526 (0.081630) | 0.102424 / 0.176557 (-0.074132) | 0.142148 / 0.737135 (-0.594987) | 0.105954 / 0.296338 (-0.190384) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421227 / 0.215209 (0.206018) | 4.200403 / 2.077655 (2.122748) | 1.899410 / 1.504120 (0.395290) | 1.684091 / 1.541195 (0.142896) | 1.698084 / 1.468490 (0.229594) | 0.696195 / 4.584777 (-3.888582) | 3.364116 / 3.745712 (-0.381596) | 1.899133 / 5.269862 (-3.370728) | 1.281405 / 4.565676 (-3.284272) | 0.082958 / 0.424275 (-0.341317) | 0.012433 / 0.007607 (0.004826) | 0.521856 / 0.226044 (0.295812) | 5.217626 / 2.268929 (2.948698) | 2.309228 / 55.444624 (-53.135396) | 1.956828 / 6.876477 (-4.919648) | 2.018964 / 2.142072 (-0.123108) | 0.816855 / 4.805227 (-3.988373) | 0.152867 / 6.500664 (-6.347798) | 0.064764 / 0.075469 (-0.010705) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.219020 / 1.841788 (-0.622768) | 13.509058 / 8.074308 (5.434750) | 13.637826 / 10.191392 (3.446434) | 0.156620 / 0.680424 (-0.523804) | 0.028518 / 0.534201 (-0.505683) | 0.399138 / 0.579283 (-0.180146) | 0.399931 / 0.434364 (-0.034433) | 0.482902 / 0.540337 (-0.057435) | 0.574089 / 1.386936 (-0.812847) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006232 / 0.011353 (-0.005121) | 0.004467 / 0.011008 (-0.006542) | 0.075494 / 0.038508 (0.036986) | 0.026891 / 0.023109 (0.003782) | 0.356603 / 0.275898 (0.080705) | 0.371977 / 0.323480 (0.048497) | 0.004709 / 0.007986 (-0.003276) | 0.003230 / 0.004328 (-0.001099) | 0.074338 / 0.004250 (0.070088) | 0.035588 / 0.037052 (-0.001464) | 0.349554 / 0.258489 (0.091065) | 0.389672 / 0.293841 (0.095831) | 0.031524 / 0.128546 (-0.097022) | 0.011493 / 0.075646 (-0.064153) | 0.084584 / 0.419271 (-0.334688) | 0.041945 / 0.043533 (-0.001588) | 0.341057 / 0.255139 (0.085918) | 0.367876 / 0.283200 (0.084677) | 0.090113 / 0.141683 (-0.051569) | 1.507104 / 1.452155 (0.054949) | 1.567810 / 1.492716 (0.075094) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210939 / 0.018006 (0.192933) | 0.392600 / 0.000490 (0.392110) | 0.002188 / 0.000200 (0.001988) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024294 / 0.037411 (-0.013118) | 0.100325 / 0.014526 (0.085799) | 0.104027 / 0.176557 (-0.072530) | 0.141189 / 0.737135 (-0.595947) | 0.107438 / 0.296338 (-0.188901) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443314 / 0.215209 (0.228105) | 4.429612 / 2.077655 (2.351957) | 2.129275 / 1.504120 (0.625156) | 1.940016 / 1.541195 (0.398821) | 2.008975 / 1.468490 (0.540485) | 0.695434 / 4.584777 (-3.889343) | 3.355137 / 3.745712 (-0.390575) | 2.606262 / 5.269862 (-2.663600) | 1.451283 / 4.565676 (-3.114394) | 0.082875 / 0.424275 (-0.341400) | 0.012398 / 0.007607 (0.004791) | 0.544262 / 0.226044 (0.318218) | 5.450829 / 2.268929 (3.181900) | 2.582074 / 55.444624 (-52.862550) | 2.220037 / 6.876477 (-4.656439) | 2.232473 / 2.142072 (0.090401) | 0.802094 / 4.805227 (-4.003134) | 0.150188 / 6.500664 (-6.350476) | 0.066543 / 0.075469 (-0.008926) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.269098 / 1.841788 (-0.572690) | 13.764780 / 8.074308 (5.690472) | 13.461490 / 10.191392 (3.270098) | 0.143841 / 0.680424 (-0.536583) | 0.016687 / 0.534201 (-0.517514) | 0.388548 / 0.579283 (-0.190736) | 0.385229 / 0.434364 (-0.049135) | 0.478966 / 0.540337 (-0.061371) | 0.570355 / 1.386936 (-0.816581) |\n\n</details>\n</details>\n\n\n",
"I took your comments into account :)\r\n\r\n> Regarding the docs, I think it would be better to add this info as notes/tips/sections to the existing docs (Process/Stream; e.g. a tip under Dataset.shuffle that explains how to make this operation more performant by using to_iterable + shuffle, etc.) rather than introducing a new doc page.\r\n\r\nI added a paragraph in the Dataset.shuffle docstring, and a note in the Process doc page",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010906 / 0.011353 (-0.000447) | 0.005995 / 0.011008 (-0.005014) | 0.120183 / 0.038508 (0.081675) | 0.042166 / 0.023109 (0.019057) | 0.350945 / 0.275898 (0.075046) | 0.433055 / 0.323480 (0.109575) | 0.009093 / 0.007986 (0.001107) | 0.004695 / 0.004328 (0.000366) | 0.090362 / 0.004250 (0.086112) | 0.051402 / 0.037052 (0.014350) | 0.368677 / 0.258489 (0.110188) | 0.410926 / 0.293841 (0.117086) | 0.044471 / 0.128546 (-0.084075) | 0.014051 / 0.075646 (-0.061595) | 0.397765 / 0.419271 (-0.021507) | 0.057227 / 0.043533 (0.013694) | 0.357587 / 0.255139 (0.102448) | 0.377470 / 0.283200 (0.094270) | 0.119482 / 0.141683 (-0.022201) | 1.719799 / 1.452155 (0.267645) | 1.758228 / 1.492716 (0.265511) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.224385 / 0.018006 (0.206379) | 0.505070 / 0.000490 (0.504580) | 0.004863 / 0.000200 (0.004663) | 0.000379 / 0.000054 (0.000324) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030366 / 0.037411 (-0.007046) | 0.130481 / 0.014526 (0.115955) | 0.136429 / 0.176557 (-0.040128) | 0.182263 / 0.737135 (-0.554872) | 0.142871 / 0.296338 (-0.153468) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.467623 / 0.215209 (0.252414) | 4.665522 / 2.077655 (2.587868) | 2.130885 / 1.504120 (0.626766) | 1.903810 / 1.541195 (0.362615) | 2.019077 / 1.468490 (0.550587) | 0.820868 / 4.584777 (-3.763909) | 4.543118 / 3.745712 (0.797406) | 2.491541 / 5.269862 (-2.778321) | 1.585377 / 4.565676 (-2.980299) | 0.101850 / 0.424275 (-0.322426) | 0.014737 / 0.007607 (0.007129) | 0.597241 / 0.226044 (0.371197) | 5.938445 / 2.268929 (3.669516) | 2.695799 / 55.444624 (-52.748825) | 2.286890 / 6.876477 (-4.589587) | 2.363064 / 2.142072 (0.220991) | 0.986670 / 4.805227 (-3.818557) | 0.194407 / 6.500664 (-6.306257) | 0.074767 / 0.075469 (-0.000702) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.420630 / 1.841788 (-0.421158) | 17.537702 / 8.074308 (9.463394) | 16.521804 / 10.191392 (6.330412) | 0.173622 / 0.680424 (-0.506802) | 0.033944 / 0.534201 (-0.500257) | 0.520461 / 0.579283 (-0.058822) | 0.541283 / 0.434364 (0.106919) | 0.651906 / 0.540337 (0.111569) | 0.771724 / 1.386936 (-0.615212) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008448 / 0.011353 (-0.002905) | 0.005893 / 0.011008 (-0.005115) | 0.087995 / 0.038508 (0.049487) | 0.038602 / 0.023109 (0.015493) | 0.400048 / 0.275898 (0.124150) | 0.436998 / 0.323480 (0.113518) | 0.006414 / 0.007986 (-0.001572) | 0.004478 / 0.004328 (0.000149) | 0.086444 / 0.004250 (0.082194) | 0.056535 / 0.037052 (0.019483) | 0.402066 / 0.258489 (0.143577) | 0.458730 / 0.293841 (0.164889) | 0.041622 / 0.128546 (-0.086924) | 0.014014 / 0.075646 (-0.061632) | 0.101382 / 0.419271 (-0.317889) | 0.056986 / 0.043533 (0.013453) | 0.404527 / 0.255139 (0.149388) | 0.428105 / 0.283200 (0.144906) | 0.118321 / 0.141683 (-0.023361) | 1.716940 / 1.452155 (0.264785) | 1.834683 / 1.492716 (0.341967) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.252917 / 0.018006 (0.234910) | 0.485950 / 0.000490 (0.485461) | 0.000489 / 0.000200 (0.000289) | 0.000066 / 0.000054 (0.000011) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035023 / 0.037411 (-0.002388) | 0.139055 / 0.014526 (0.124529) | 0.144165 / 0.176557 (-0.032392) | 0.189559 / 0.737135 (-0.547577) | 0.153213 / 0.296338 (-0.143126) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.505069 / 0.215209 (0.289860) | 5.024620 / 2.077655 (2.946965) | 2.429469 / 1.504120 (0.925349) | 2.186210 / 1.541195 (0.645015) | 2.275971 / 1.468490 (0.807481) | 0.829432 / 4.584777 (-3.755345) | 4.518600 / 3.745712 (0.772888) | 2.466418 / 5.269862 (-2.803443) | 1.558910 / 4.565676 (-3.006767) | 0.102017 / 0.424275 (-0.322258) | 0.015191 / 0.007607 (0.007584) | 0.619092 / 0.226044 (0.393048) | 6.241105 / 2.268929 (3.972176) | 3.044213 / 55.444624 (-52.400411) | 2.630194 / 6.876477 (-4.246282) | 2.723685 / 2.142072 (0.581613) | 0.994018 / 4.805227 (-3.811210) | 0.198722 / 6.500664 (-6.301942) | 0.075812 / 0.075469 (0.000343) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.545497 / 1.841788 (-0.296291) | 18.305250 / 8.074308 (10.230942) | 16.035275 / 10.191392 (5.843883) | 0.209339 / 0.680424 (-0.471085) | 0.020903 / 0.534201 (-0.513298) | 0.499909 / 0.579283 (-0.079374) | 0.488775 / 0.434364 (0.054411) | 0.581990 / 0.540337 (0.041653) | 0.697786 / 1.386936 (-0.689150) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.011706 / 0.011353 (0.000353) | 0.008406 / 0.011008 (-0.002602) | 0.130887 / 0.038508 (0.092379) | 0.037468 / 0.023109 (0.014359) | 0.385043 / 0.275898 (0.109145) | 0.458837 / 0.323480 (0.135357) | 0.013400 / 0.007986 (0.005414) | 0.004885 / 0.004328 (0.000557) | 0.107156 / 0.004250 (0.102905) | 0.046958 / 0.037052 (0.009906) | 0.419314 / 0.258489 (0.160825) | 0.456061 / 0.293841 (0.162220) | 0.058859 / 0.128546 (-0.069687) | 0.016682 / 0.075646 (-0.058965) | 0.428401 / 0.419271 (0.009129) | 0.062908 / 0.043533 (0.019376) | 0.370902 / 0.255139 (0.115763) | 0.433897 / 0.283200 (0.150697) | 0.125672 / 0.141683 (-0.016011) | 1.818279 / 1.452155 (0.366124) | 1.935767 / 1.492716 (0.443050) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011928 / 0.018006 (-0.006078) | 0.591995 / 0.000490 (0.591506) | 0.008416 / 0.000200 (0.008216) | 0.000122 / 0.000054 (0.000067) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029640 / 0.037411 (-0.007772) | 0.121044 / 0.014526 (0.106518) | 0.141840 / 0.176557 (-0.034716) | 0.195856 / 0.737135 (-0.541280) | 0.146460 / 0.296338 (-0.149879) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.591838 / 0.215209 (0.376629) | 5.817309 / 2.077655 (3.739654) | 2.411864 / 1.504120 (0.907744) | 2.098517 / 1.541195 (0.557323) | 2.214609 / 1.468490 (0.746119) | 1.217542 / 4.584777 (-3.367235) | 5.658394 / 3.745712 (1.912682) | 5.155807 / 5.269862 (-0.114055) | 2.797313 / 4.565676 (-1.768363) | 0.141309 / 0.424275 (-0.282967) | 0.014462 / 0.007607 (0.006855) | 0.772274 / 0.226044 (0.546230) | 7.547357 / 2.268929 (5.278429) | 3.150178 / 55.444624 (-52.294446) | 2.500130 / 6.876477 (-4.376347) | 2.572036 / 2.142072 (0.429964) | 1.434498 / 4.805227 (-3.370729) | 0.257355 / 6.500664 (-6.243309) | 0.087491 / 0.075469 (0.012022) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.483899 / 1.841788 (-0.357889) | 17.990741 / 8.074308 (9.916433) | 20.398965 / 10.191392 (10.207573) | 0.239529 / 0.680424 (-0.440895) | 0.046118 / 0.534201 (-0.488083) | 0.528349 / 0.579283 (-0.050934) | 0.614333 / 0.434364 (0.179969) | 0.653621 / 0.540337 (0.113284) | 0.794654 / 1.386936 (-0.592282) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008732 / 0.011353 (-0.002621) | 0.006432 / 0.011008 (-0.004576) | 0.090811 / 0.038508 (0.052303) | 0.030154 / 0.023109 (0.007045) | 0.407885 / 0.275898 (0.131987) | 0.452457 / 0.323480 (0.128977) | 0.006966 / 0.007986 (-0.001020) | 0.006449 / 0.004328 (0.002120) | 0.094439 / 0.004250 (0.090188) | 0.050628 / 0.037052 (0.013576) | 0.401815 / 0.258489 (0.143326) | 0.451814 / 0.293841 (0.157973) | 0.047456 / 0.128546 (-0.081090) | 0.019019 / 0.075646 (-0.056628) | 0.112941 / 0.419271 (-0.306331) | 0.057677 / 0.043533 (0.014145) | 0.406160 / 0.255139 (0.151021) | 0.434469 / 0.283200 (0.151269) | 0.110515 / 0.141683 (-0.031167) | 1.601393 / 1.452155 (0.149238) | 1.745581 / 1.492716 (0.252865) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.280264 / 0.018006 (0.262258) | 0.630074 / 0.000490 (0.629585) | 0.006900 / 0.000200 (0.006700) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027338 / 0.037411 (-0.010073) | 0.114772 / 0.014526 (0.100246) | 0.130436 / 0.176557 (-0.046121) | 0.168990 / 0.737135 (-0.568145) | 0.135842 / 0.296338 (-0.160496) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.666739 / 0.215209 (0.451530) | 6.212953 / 2.077655 (4.135298) | 2.781716 / 1.504120 (1.277596) | 2.369975 / 1.541195 (0.828781) | 2.338807 / 1.468490 (0.870317) | 1.174138 / 4.584777 (-3.410639) | 5.420297 / 3.745712 (1.674585) | 4.972669 / 5.269862 (-0.297192) | 2.214294 / 4.565676 (-2.351382) | 0.135429 / 0.424275 (-0.288846) | 0.013877 / 0.007607 (0.006270) | 0.750805 / 0.226044 (0.524761) | 7.145429 / 2.268929 (4.876500) | 3.215081 / 55.444624 (-52.229544) | 2.598307 / 6.876477 (-4.278170) | 2.690479 / 2.142072 (0.548406) | 1.344673 / 4.805227 (-3.460554) | 0.241536 / 6.500664 (-6.259128) | 0.075544 / 0.075469 (0.000074) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.473595 / 1.841788 (-0.368192) | 17.372237 / 8.074308 (9.297929) | 18.586588 / 10.191392 (8.395196) | 0.209300 / 0.680424 (-0.471124) | 0.030878 / 0.534201 (-0.503323) | 0.509131 / 0.579283 (-0.070152) | 0.617884 / 0.434364 (0.183520) | 0.633721 / 0.540337 (0.093383) | 0.727624 / 1.386936 (-0.659312) |\n\n</details>\n</details>\n\n\n",
"Took your last comments into account !\r\n\r\n> so maybe a better title for it would be \"Optimize processing\" (or \"Working with datasets at scale\" as I mentioned earlier on Slack)\r\n\r\nI think the content would be slightly different, e.g. focus more on multiprocessing/sharding or what data formats to use. This can be a complementary page IMO\r\n\r\n> PS: I think it would be a good idea to add links to the Guide pages for better discoverability and to somewhat \"justify their presence in the docs\" (from the tutorial/how-to pages to the guides; some guides are not referenced at all)\r\n\r\nAdded a link in the how-to stream page. We may want to include it in the tutorial at one point at well - right now none of the tutorials mention streaming",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009167 / 0.011353 (-0.002186) | 0.005345 / 0.011008 (-0.005663) | 0.098302 / 0.038508 (0.059794) | 0.035649 / 0.023109 (0.012540) | 0.295597 / 0.275898 (0.019699) | 0.358843 / 0.323480 (0.035364) | 0.008011 / 0.007986 (0.000025) | 0.004229 / 0.004328 (-0.000100) | 0.075123 / 0.004250 (0.070872) | 0.046098 / 0.037052 (0.009046) | 0.310581 / 0.258489 (0.052092) | 0.343230 / 0.293841 (0.049389) | 0.038318 / 0.128546 (-0.090229) | 0.011954 / 0.075646 (-0.063693) | 0.331056 / 0.419271 (-0.088216) | 0.052875 / 0.043533 (0.009342) | 0.302758 / 0.255139 (0.047619) | 0.340596 / 0.283200 (0.057396) | 0.113676 / 0.141683 (-0.028007) | 1.448272 / 1.452155 (-0.003883) | 1.498008 / 1.492716 (0.005291) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.240524 / 0.018006 (0.222518) | 0.555823 / 0.000490 (0.555333) | 0.003143 / 0.000200 (0.002943) | 0.000098 / 0.000054 (0.000044) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027764 / 0.037411 (-0.009647) | 0.105006 / 0.014526 (0.090480) | 0.120550 / 0.176557 (-0.056007) | 0.167052 / 0.737135 (-0.570084) | 0.124521 / 0.296338 (-0.171818) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401758 / 0.215209 (0.186549) | 3.989629 / 2.077655 (1.911974) | 1.767307 / 1.504120 (0.263187) | 1.579451 / 1.541195 (0.038257) | 1.637642 / 1.468490 (0.169152) | 0.702524 / 4.584777 (-3.882253) | 3.714326 / 3.745712 (-0.031386) | 2.131829 / 5.269862 (-3.138033) | 1.487410 / 4.565676 (-3.078267) | 0.084901 / 0.424275 (-0.339374) | 0.012292 / 0.007607 (0.004685) | 0.505211 / 0.226044 (0.279166) | 5.074479 / 2.268929 (2.805551) | 2.243068 / 55.444624 (-53.201556) | 1.880199 / 6.876477 (-4.996278) | 2.003757 / 2.142072 (-0.138315) | 0.870719 / 4.805227 (-3.934508) | 0.167626 / 6.500664 (-6.333039) | 0.062024 / 0.075469 (-0.013445) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.192969 / 1.841788 (-0.648819) | 14.830812 / 8.074308 (6.756504) | 14.331178 / 10.191392 (4.139786) | 0.199222 / 0.680424 (-0.481202) | 0.029292 / 0.534201 (-0.504909) | 0.440427 / 0.579283 (-0.138857) | 0.437893 / 0.434364 (0.003529) | 0.547155 / 0.540337 (0.006818) | 0.645255 / 1.386936 (-0.741681) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007465 / 0.011353 (-0.003888) | 0.005386 / 0.011008 (-0.005622) | 0.073609 / 0.038508 (0.035100) | 0.033550 / 0.023109 (0.010440) | 0.341730 / 0.275898 (0.065832) | 0.371518 / 0.323480 (0.048038) | 0.005986 / 0.007986 (-0.001999) | 0.004264 / 0.004328 (-0.000065) | 0.073749 / 0.004250 (0.069498) | 0.051452 / 0.037052 (0.014399) | 0.347385 / 0.258489 (0.088896) | 0.392284 / 0.293841 (0.098444) | 0.036981 / 0.128546 (-0.091566) | 0.012431 / 0.075646 (-0.063216) | 0.086421 / 0.419271 (-0.332850) | 0.053014 / 0.043533 (0.009481) | 0.336660 / 0.255139 (0.081521) | 0.359155 / 0.283200 (0.075956) | 0.107666 / 0.141683 (-0.034017) | 1.424324 / 1.452155 (-0.027830) | 1.543027 / 1.492716 (0.050310) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.260862 / 0.018006 (0.242855) | 0.552057 / 0.000490 (0.551567) | 0.000449 / 0.000200 (0.000249) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029184 / 0.037411 (-0.008227) | 0.108799 / 0.014526 (0.094274) | 0.125136 / 0.176557 (-0.051421) | 0.157436 / 0.737135 (-0.579699) | 0.126333 / 0.296338 (-0.170005) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.424054 / 0.215209 (0.208845) | 4.227847 / 2.077655 (2.150192) | 2.051102 / 1.504120 (0.546983) | 1.848651 / 1.541195 (0.307457) | 1.922728 / 1.468490 (0.454238) | 0.705903 / 4.584777 (-3.878874) | 3.800977 / 3.745712 (0.055265) | 2.099345 / 5.269862 (-3.170517) | 1.342919 / 4.565676 (-3.222757) | 0.086128 / 0.424275 (-0.338147) | 0.012539 / 0.007607 (0.004932) | 0.528767 / 0.226044 (0.302723) | 5.299989 / 2.268929 (3.031061) | 2.534280 / 55.444624 (-52.910345) | 2.229532 / 6.876477 (-4.646945) | 2.326704 / 2.142072 (0.184632) | 0.838533 / 4.805227 (-3.966694) | 0.168446 / 6.500664 (-6.332218) | 0.065158 / 0.075469 (-0.010311) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.250091 / 1.841788 (-0.591697) | 14.988651 / 8.074308 (6.914343) | 13.655103 / 10.191392 (3.463711) | 0.165079 / 0.680424 (-0.515345) | 0.017829 / 0.534201 (-0.516372) | 0.425903 / 0.579283 (-0.153381) | 0.419771 / 0.434364 (-0.014593) | 0.534309 / 0.540337 (-0.006028) | 0.635563 / 1.386936 (-0.751373) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010569 / 0.011353 (-0.000784) | 0.005790 / 0.011008 (-0.005218) | 0.118626 / 0.038508 (0.080118) | 0.040455 / 0.023109 (0.017346) | 0.342309 / 0.275898 (0.066411) | 0.411828 / 0.323480 (0.088349) | 0.008824 / 0.007986 (0.000839) | 0.005426 / 0.004328 (0.001098) | 0.088740 / 0.004250 (0.084489) | 0.050042 / 0.037052 (0.012990) | 0.352350 / 0.258489 (0.093861) | 0.396030 / 0.293841 (0.102189) | 0.043385 / 0.128546 (-0.085162) | 0.013805 / 0.075646 (-0.061841) | 0.396489 / 0.419271 (-0.022783) | 0.055667 / 0.043533 (0.012135) | 0.336165 / 0.255139 (0.081026) | 0.372912 / 0.283200 (0.089713) | 0.115343 / 0.141683 (-0.026340) | 1.656412 / 1.452155 (0.204257) | 1.708993 / 1.492716 (0.216277) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.011650 / 0.018006 (-0.006357) | 0.444415 / 0.000490 (0.443926) | 0.003985 / 0.000200 (0.003785) | 0.000136 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031718 / 0.037411 (-0.005693) | 0.119640 / 0.014526 (0.105114) | 0.138519 / 0.176557 (-0.038037) | 0.188847 / 0.737135 (-0.548288) | 0.137891 / 0.296338 (-0.158448) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.447540 / 0.215209 (0.232331) | 4.577189 / 2.077655 (2.499534) | 2.106992 / 1.504120 (0.602872) | 1.889631 / 1.541195 (0.348436) | 1.972256 / 1.468490 (0.503766) | 0.778209 / 4.584777 (-3.806568) | 4.430279 / 3.745712 (0.684567) | 2.401226 / 5.269862 (-2.868636) | 1.481251 / 4.565676 (-3.084425) | 0.094244 / 0.424275 (-0.330031) | 0.013961 / 0.007607 (0.006354) | 0.570962 / 0.226044 (0.344917) | 5.809224 / 2.268929 (3.540295) | 2.663290 / 55.444624 (-52.781334) | 2.201228 / 6.876477 (-4.675249) | 2.319240 / 2.142072 (0.177168) | 0.938340 / 4.805227 (-3.866887) | 0.185546 / 6.500664 (-6.315118) | 0.069087 / 0.075469 (-0.006382) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.448597 / 1.841788 (-0.393191) | 17.188573 / 8.074308 (9.114265) | 16.197532 / 10.191392 (6.006140) | 0.194064 / 0.680424 (-0.486360) | 0.033694 / 0.534201 (-0.500507) | 0.507585 / 0.579283 (-0.071699) | 0.505470 / 0.434364 (0.071106) | 0.623270 / 0.540337 (0.082932) | 0.729964 / 1.386936 (-0.656972) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008529 / 0.011353 (-0.002824) | 0.005705 / 0.011008 (-0.005304) | 0.085594 / 0.038508 (0.047086) | 0.038377 / 0.023109 (0.015268) | 0.384221 / 0.275898 (0.108323) | 0.414678 / 0.323480 (0.091199) | 0.006195 / 0.007986 (-0.001791) | 0.004549 / 0.004328 (0.000221) | 0.082710 / 0.004250 (0.078460) | 0.054899 / 0.037052 (0.017847) | 0.404017 / 0.258489 (0.145528) | 0.450309 / 0.293841 (0.156468) | 0.040620 / 0.128546 (-0.087926) | 0.013774 / 0.075646 (-0.061872) | 0.099231 / 0.419271 (-0.320041) | 0.057183 / 0.043533 (0.013650) | 0.390806 / 0.255139 (0.135667) | 0.419334 / 0.283200 (0.136134) | 0.116449 / 0.141683 (-0.025234) | 1.709124 / 1.452155 (0.256969) | 1.812769 / 1.492716 (0.320052) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.225206 / 0.018006 (0.207199) | 0.440530 / 0.000490 (0.440040) | 0.002982 / 0.000200 (0.002782) | 0.000102 / 0.000054 (0.000048) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032256 / 0.037411 (-0.005155) | 0.127086 / 0.014526 (0.112560) | 0.138133 / 0.176557 (-0.038424) | 0.176168 / 0.737135 (-0.560968) | 0.146072 / 0.296338 (-0.150267) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474374 / 0.215209 (0.259165) | 4.785106 / 2.077655 (2.707452) | 2.319344 / 1.504120 (0.815225) | 2.075239 / 1.541195 (0.534045) | 2.179231 / 1.468490 (0.710741) | 0.832124 / 4.584777 (-3.752653) | 4.376302 / 3.745712 (0.630590) | 3.966837 / 5.269862 (-1.303024) | 1.820230 / 4.565676 (-2.745446) | 0.100692 / 0.424275 (-0.323583) | 0.014748 / 0.007607 (0.007141) | 0.568702 / 0.226044 (0.342657) | 5.771548 / 2.268929 (3.502619) | 2.747431 / 55.444624 (-52.697193) | 2.448482 / 6.876477 (-4.427994) | 2.497206 / 2.142072 (0.355133) | 0.960842 / 4.805227 (-3.844385) | 0.192855 / 6.500664 (-6.307809) | 0.072494 / 0.075469 (-0.002975) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.474542 / 1.841788 (-0.367245) | 17.344804 / 8.074308 (9.270496) | 15.336082 / 10.191392 (5.144690) | 0.200134 / 0.680424 (-0.480290) | 0.020728 / 0.534201 (-0.513473) | 0.488854 / 0.579283 (-0.090429) | 0.490781 / 0.434364 (0.056418) | 0.626288 / 0.540337 (0.085950) | 0.721130 / 1.386936 (-0.665806) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008542 / 0.011353 (-0.002811) | 0.004624 / 0.011008 (-0.006384) | 0.100749 / 0.038508 (0.062241) | 0.029587 / 0.023109 (0.006478) | 0.298680 / 0.275898 (0.022782) | 0.359659 / 0.323480 (0.036180) | 0.007001 / 0.007986 (-0.000984) | 0.003398 / 0.004328 (-0.000930) | 0.078654 / 0.004250 (0.074404) | 0.036440 / 0.037052 (-0.000612) | 0.313245 / 0.258489 (0.054756) | 0.342776 / 0.293841 (0.048936) | 0.033195 / 0.128546 (-0.095352) | 0.011500 / 0.075646 (-0.064146) | 0.323957 / 0.419271 (-0.095314) | 0.039878 / 0.043533 (-0.003655) | 0.298189 / 0.255139 (0.043050) | 0.325488 / 0.283200 (0.042289) | 0.087276 / 0.141683 (-0.054407) | 1.480846 / 1.452155 (0.028691) | 1.507016 / 1.492716 (0.014300) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.189570 / 0.018006 (0.171564) | 0.406407 / 0.000490 (0.405917) | 0.003062 / 0.000200 (0.002862) | 0.000073 / 0.000054 (0.000019) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022865 / 0.037411 (-0.014546) | 0.096103 / 0.014526 (0.081578) | 0.106462 / 0.176557 (-0.070094) | 0.140888 / 0.737135 (-0.596247) | 0.108172 / 0.296338 (-0.188167) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.415951 / 0.215209 (0.200742) | 4.172187 / 2.077655 (2.094532) | 1.842210 / 1.504120 (0.338090) | 1.636997 / 1.541195 (0.095802) | 1.706078 / 1.468490 (0.237588) | 0.695825 / 4.584777 (-3.888952) | 3.337354 / 3.745712 (-0.408358) | 1.877880 / 5.269862 (-3.391982) | 1.153882 / 4.565676 (-3.411794) | 0.082923 / 0.424275 (-0.341352) | 0.012814 / 0.007607 (0.005207) | 0.521793 / 0.226044 (0.295748) | 5.275980 / 2.268929 (3.007051) | 2.279230 / 55.444624 (-53.165394) | 1.941777 / 6.876477 (-4.934700) | 1.981297 / 2.142072 (-0.160775) | 0.809669 / 4.805227 (-3.995558) | 0.148753 / 6.500664 (-6.351911) | 0.064909 / 0.075469 (-0.010560) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.226757 / 1.841788 (-0.615031) | 13.717354 / 8.074308 (5.643046) | 12.925885 / 10.191392 (2.734493) | 0.137926 / 0.680424 (-0.542498) | 0.028788 / 0.534201 (-0.505413) | 0.396654 / 0.579283 (-0.182630) | 0.401931 / 0.434364 (-0.032432) | 0.460515 / 0.540337 (-0.079823) | 0.537903 / 1.386936 (-0.849033) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006757 / 0.011353 (-0.004596) | 0.004474 / 0.011008 (-0.006534) | 0.076571 / 0.038508 (0.038063) | 0.027580 / 0.023109 (0.004471) | 0.348231 / 0.275898 (0.072333) | 0.398403 / 0.323480 (0.074923) | 0.005089 / 0.007986 (-0.002897) | 0.004676 / 0.004328 (0.000347) | 0.076444 / 0.004250 (0.072194) | 0.038508 / 0.037052 (0.001456) | 0.348515 / 0.258489 (0.090026) | 0.401456 / 0.293841 (0.107615) | 0.031630 / 0.128546 (-0.096916) | 0.011698 / 0.075646 (-0.063949) | 0.085805 / 0.419271 (-0.333467) | 0.041962 / 0.043533 (-0.001570) | 0.343415 / 0.255139 (0.088276) | 0.383001 / 0.283200 (0.099801) | 0.090231 / 0.141683 (-0.051452) | 1.488114 / 1.452155 (0.035960) | 1.569039 / 1.492716 (0.076323) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.261751 / 0.018006 (0.243745) | 0.411354 / 0.000490 (0.410865) | 0.015103 / 0.000200 (0.014903) | 0.000262 / 0.000054 (0.000208) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025423 / 0.037411 (-0.011988) | 0.101334 / 0.014526 (0.086808) | 0.108835 / 0.176557 (-0.067722) | 0.143995 / 0.737135 (-0.593140) | 0.111751 / 0.296338 (-0.184588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.446507 / 0.215209 (0.231298) | 4.461543 / 2.077655 (2.383888) | 2.104648 / 1.504120 (0.600528) | 1.895900 / 1.541195 (0.354706) | 1.985481 / 1.468490 (0.516991) | 0.699029 / 4.584777 (-3.885748) | 3.371064 / 3.745712 (-0.374648) | 1.883445 / 5.269862 (-3.386416) | 1.166150 / 4.565676 (-3.399527) | 0.082639 / 0.424275 (-0.341636) | 0.012605 / 0.007607 (0.004998) | 0.544860 / 0.226044 (0.318815) | 5.513223 / 2.268929 (3.244294) | 2.570661 / 55.444624 (-52.873963) | 2.206066 / 6.876477 (-4.670411) | 2.256346 / 2.142072 (0.114273) | 0.801142 / 4.805227 (-4.004085) | 0.150412 / 6.500664 (-6.350252) | 0.067742 / 0.075469 (-0.007727) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303477 / 1.841788 (-0.538310) | 14.287767 / 8.074308 (6.213458) | 13.525563 / 10.191392 (3.334171) | 0.148202 / 0.680424 (-0.532222) | 0.016868 / 0.534201 (-0.517333) | 0.380729 / 0.579283 (-0.198555) | 0.388177 / 0.434364 (-0.046187) | 0.477410 / 0.540337 (-0.062927) | 0.569343 / 1.386936 (-0.817593) |\n\n</details>\n</details>\n\n\n",
"> PS: I think it would be a good idea to add links to the Guide pages for better discoverability and to somewhat \"justify their presence in the docs\" (from the tutorial/how-to pages to the guides; some guides are not referenced at all)\r\n\r\nJust merged #5485, which references this new doc! Will look for other pages in the docs where it'd make sense to add them :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | 3 | 2023-03-01T12:58:18Z | 2023-03-02T13:30:41Z | 2023-03-02T03:47:00Z | null | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Dataset.from_list([])
ds.add_item({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: [],
>>> num_rows: 0
>>> })
ds = ds.add_item({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: ['a', 'b'],
>>> num_rows: 1
>>> })
```
### Feature request
Call for in-place dataset update functions, that update the existing `Dataset` in place without creating a new copy. The interface is supposed to keep the same style as PyTorch, such as the in-place version of a `function` is named `function_`. For example, the in-pace version of `add_item`, i.e., `add_item_`, immediately updates the `Dataset`.
```python
from datasets import Dataset
ds = Dataset.from_list([])
ds.add_item({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: [],
>>> num_rows: 0
>>> })
ds.add_item_({'a': [1, 2, 3], 'b': 4})
print(ds)
>>> Dataset({
>>> features: ['a', 'b'],
>>> num_rows: 1
>>> })
```
### Related Functions
* `.map`
* `.filter`
* `.add_item` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | null | null | false | [
"We won't support in-place modifications since `datasets` is based on the Apache Arrow format which doesn't support in-place modifications.\r\n\r\nIn your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nNote that datasets loaded from disk (memory mapped) are not loaded in memory, and therefore the new dataset actually use the same buffers as the old one.",
"Thank you for your detailed reply.\r\n\r\n> In your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nI understand this, but it still copies the old dataset to create the new one, is this correct? So maybe it is not memory-consuming, but time-consuming?",
"Indeed, and because of that it is more efficient to add multiple rows at once instead of one by one, using `concatenate_datasets` for example."
] |
https://api.github.com/repos/huggingface/datasets/issues/2694 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2694/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2694/comments | https://api.github.com/repos/huggingface/datasets/issues/2694/events | https://github.com/huggingface/datasets/pull/2694 | 949,844,722 | MDExOlB1bGxSZXF1ZXN0Njk0NDg0NTcy | 2,694 | fix: 🐛 change string format to allow copy/paste to work in bash | [] | closed | false | null | 0 | 2021-07-21T15:30:40Z | 2021-07-22T10:41:47Z | 2021-07-22T10:41:47Z | null | Before: copy/paste resulted in an error because the square bracket
characters `[]` are special characters in bash | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2694/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2694/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2694.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2694",
"merged_at": "2021-07-22T10:41:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2694.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2694"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1700/comments | https://api.github.com/repos/huggingface/datasets/issues/1700/events | https://github.com/huggingface/datasets/pull/1700 | 781,333,589 | MDExOlB1bGxSZXF1ZXN0NTUxMDc1NTg2 | 1,700 | Update Curiosity dialogs DatasetCard | [] | closed | false | null | 0 | 2021-01-07T13:59:27Z | 2021-01-12T18:51:32Z | 2021-01-12T18:51:32Z | null | Update Curiosity dialogs DatasetCard
There are some entries in the data fields section yet to be filled. There is little information regarding those fields. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1700/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1700/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1700.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1700",
"merged_at": "2021-01-12T18:51:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1700.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1700"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4459 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4459/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4459/comments | https://api.github.com/repos/huggingface/datasets/issues/4459/events | https://github.com/huggingface/datasets/pull/4459 | 1,264,636,481 | PR_kwDODunzps45UFc8 | 4,459 | Add and fix language tags for udhr dataset | [] | closed | false | null | 1 | 2022-06-08T12:03:42Z | 2022-06-08T12:36:24Z | 2022-06-08T12:27:13Z | null | Related to #4362. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4459/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4459/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4459.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4459",
"merged_at": "2022-06-08T12:27:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4459.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4459"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2973 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2973/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2973/comments | https://api.github.com/repos/huggingface/datasets/issues/2973/events | https://github.com/huggingface/datasets/pull/2973 | 1,007,894,592 | PR_kwDODunzps4sTRvk | 2,973 | Fix JSON metadata of masakhaner dataset | [] | closed | false | null | 0 | 2021-09-27T09:09:08Z | 2021-09-27T12:59:59Z | 2021-09-27T12:59:59Z | null | Fix #2971. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2973/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2973/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2973.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2973",
"merged_at": "2021-09-27T12:59:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2973.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2973"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/445/comments | https://api.github.com/repos/huggingface/datasets/issues/445/events | https://github.com/huggingface/datasets/issues/445 | 666,836,658 | MDU6SXNzdWU2NjY4MzY2NTg= | 445 | DEFAULT_TOKENIZER import error in sacrebleu | [] | closed | false | null | 1 | 2020-07-28T07:31:30Z | 2020-07-28T12:58:56Z | 2020-07-28T12:58:56Z | null | Latest Version 0.3.0
When loading the metric "sacrebleu" there is an import error due to the wrong path

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/445/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/445/timeline | null | completed | null | null | false | [
"This issue was resolved by #447 "
] |
https://api.github.com/repos/huggingface/datasets/issues/2879 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2879/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2879/comments | https://api.github.com/repos/huggingface/datasets/issues/2879/events | https://github.com/huggingface/datasets/issues/2879 | 990,257,404 | MDU6SXNzdWU5OTAyNTc0MDQ= | 2,879 | In v1.4.1, all TIMIT train transcripts are "Would such an act of refusal be useful?" | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2021-09-07T18:53:45Z | 2021-09-08T16:55:19Z | 2021-09-08T09:12:28Z | null | ## Describe the bug
Using version 1.4.1 of `datasets`, TIMIT transcripts are all the same.
## Steps to reproduce the bug
I was following this tutorial
- https://huggingface.co/blog/fine-tune-wav2vec2-english
But here's a distilled repro:
```python
!pip install datasets==1.4.1
from datasets import load_dataset
timit = load_dataset("timit_asr", cache_dir="./temp")
unique_transcripts = set(timit["train"]["text"])
print(unique_transcripts)
assert len(unique_transcripts) > 1
```
## Expected results
Expected the correct TIMIT data. Or an error saying that this version of `datasets` can't produce it.
## Actual results
Every train transcript was "Would such an act of refusal be useful?" Every test transcript was "The bungalow was pleasantly situated near the shore."
## Environment info
- `datasets` version: 1.4.1
- Platform: Darwin-18.7.0-x86_64-i386-64bit
- Python version: 3.7.9
- PyTorch version (GPU?): 1.9.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: tried both
- Using distributed or parallel set-up in script?: no
-
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2879/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2879/timeline | null | completed | null | null | false | [
"Hi @rcgale, thanks for reporting.\r\n\r\nPlease note that this bug was fixed on `datasets` version 1.5.0: https://github.com/huggingface/datasets/commit/a23c73e526e1c30263834164f16f1fdf76722c8c#diff-f12a7a42d4673bb6c2ca5a40c92c29eb4fe3475908c84fd4ce4fad5dc2514878\r\n\r\nIf you update `datasets` version, that should work.\r\n\r\nOn the other hand, would it be possible for @patrickvonplaten to update the [blog post](https://huggingface.co/blog/fine-tune-wav2vec2-english) with the correct version of `datasets`?",
"I just proposed a change in the blog post.\r\n\r\nI had assumed there was a data format change that broke a previous version of the code, since presumably @patrickvonplaten tested the tutorial with the version they explicitly referenced. But that fix you linked suggests a problem in the code, which surprised me.\r\n\r\nI still wonder, though, is there a way for downloads to be invalidated server-side? If the client can announce its version during a download request, perhaps the server could reject known incompatibilities? It would save much valuable time if `datasets` raised an informative error on a known problem (\"Error: the requested data set requires `datasets>=1.5.0`.\"). This kind of API versioning is a prudent move anyhow, as there will surely come a time when you'll need to make a breaking change to data.",
"Also, thank you for a quick and helpful reply!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1013 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1013/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1013/comments | https://api.github.com/repos/huggingface/datasets/issues/1013/events | https://github.com/huggingface/datasets/pull/1013 | 755,493,075 | MDExOlB1bGxSZXF1ZXN0NTMxMTkzMTcy | 1,013 | Adding CS restaurants dataset | [] | closed | false | null | 0 | 2020-12-02T18:02:30Z | 2020-12-02T18:25:20Z | 2020-12-02T18:25:19Z | null | This PR adds the CS restaurants dataset; this is a re-opening of a previous PR with a chaotic commit history. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1013/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1013/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1013.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1013",
"merged_at": "2020-12-02T18:25:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1013.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1013"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5113 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5113/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5113/comments | https://api.github.com/repos/huggingface/datasets/issues/5113/events | https://github.com/huggingface/datasets/pull/5113 | 1,409,207,607 | PR_kwDODunzps5Az0Ei | 5,113 | Fix filter indices when batched | [] | closed | false | null | 3 | 2022-10-14T11:30:03Z | 2022-10-24T06:21:09Z | 2022-10-14T12:11:44Z | null | This PR fixes a bug introduced by:
- #5030
Fix #5112. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5113/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5113/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5113.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5113",
"merged_at": "2022-10-14T12:11:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5113.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5113"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think a patch release will be necessary.",
"I'm also fixing https://github.com/huggingface/datasets/issues/5111 which will lalso require a patch release"
] |
https://api.github.com/repos/huggingface/datasets/issues/2212 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2212/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2212/comments | https://api.github.com/repos/huggingface/datasets/issues/2212/events | https://github.com/huggingface/datasets/issues/2212 | 855,999,133 | MDU6SXNzdWU4NTU5OTkxMzM= | 2,212 | Can't reach "https://storage.googleapis.com/illuin/fquad/train.json.zip" when trying to load fquad dataset | [] | open | false | null | 4 | 2021-04-12T13:49:56Z | 2021-05-17T22:17:06Z | null | null | I'm trying to load the [fquad dataset](https://huggingface.co/datasets/fquad) by running:
```Python
fquad = load_dataset("fquad")
```
which produces the following error:
```
Using custom data configuration default
Downloading and preparing dataset fquad/default (download: 3.14 MiB, generated: 6.62 MiB, post-processed: Unknown size, total: 9.76 MiB) to /root/.cache/huggingface/datasets/fquad/default/0.1.0/778dc2c85813d05ddd0c17087294d5f8f24820752340958070876b677af9f061...
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
<ipython-input-48-a2721797e23b> in <module>()
----> 1 fquad = load_dataset("fquad")
11 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries, use_auth_token)
614 raise FileNotFoundError("Couldn't find file at {}".format(url))
615 _raise_if_offline_mode_is_enabled(f"Tried to reach {url}")
--> 616 raise ConnectionError("Couldn't reach {}".format(url))
617
618 # Try a second time
ConnectionError: Couldn't reach https://storage.googleapis.com/illuin/fquad/train.json.zip
```
Does anyone know why that is and how to fix it? | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2212/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2212/timeline | null | null | null | null | false | [
"Hi ! Apparently the data are not available from this url anymore. We'll replace it with the new url when it's available",
"I saw this on their website when we request to download the dataset:\r\n\r\n\r\nCan we still request them link for the dataset and make a PR? @lhoestq @yjernite ",
"I've contacted Martin (first author of the fquad paper) regarding a possible new url. Hopefully we can get one soon !",
"They now made a website to force people who want to use the dataset for commercial purposes to seek a commercial license from them ..."
] |
https://api.github.com/repos/huggingface/datasets/issues/1437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1437/comments | https://api.github.com/repos/huggingface/datasets/issues/1437/events | https://github.com/huggingface/datasets/pull/1437 | 760,891,879 | MDExOlB1bGxSZXF1ZXN0NTM1NjQwODE0 | 1,437 | Add Indosum dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 2 | 2020-12-10T05:02:00Z | 2022-10-03T09:38:54Z | 2022-10-03T09:38:54Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1437/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1437/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1437.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1437",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1437.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1437"
} | true | [
"Hi @prasastoadi have you had a chance to take a look at my suggestions ?\r\n\r\nFeel free to ping ;e if you have questions or when you're ready for a review",
"Thanks for your contribution, @prasastoadi. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/3909 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3909/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3909/comments | https://api.github.com/repos/huggingface/datasets/issues/3909/events | https://github.com/huggingface/datasets/issues/3909 | 1,168,578,058 | I_kwDODunzps5FpxYK | 3,909 | Error loading file audio when downloading the Common Voice dataset directly from the Hub | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 8 | 2022-03-14T15:53:50Z | 2023-03-02T15:31:27Z | 2023-03-02T15:31:26Z | null | ## Describe the bug
When loading the Common_Voice dataset, by downloading it directly from the Hugging Face hub, some files can not be opened.
## Steps to reproduce the bug
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "it", split="test")
#test_dataset = load_dataset('csv', data_files = {'test': '/workspace/Dataset/Common_Voice/cv-corpus80/it/test.csv'})
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("joorock12/wav2vec2-large-xlsr-italian")
model = Wav2Vec2ForCTC.from_pretrained("joorock12/wav2vec2-large-xlsr-italian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\'\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
```
## Expected results
The common voice dataset downloaded and correctly loaded whit the use of the hugging face datasets library.
## Actual results
The error is:
```python
0ex [00:00, ?ex/s]
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-48-ef87f4129e6e> in <module>
7 return batch
8
----> 9 test_dataset = test_dataset.map(speech_file_to_array_fn)
/opt/conda/lib/python3.8/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)
2107
2108 if num_proc is None or num_proc == 1:
-> 2109 return self._map_single(
2110 function=function,
2111 with_indices=with_indices,
/opt/conda/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
516 self: "Dataset" = kwargs.pop("self")
517 # apply actual function
--> 518 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
519 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
520 for dataset in datasets:
/opt/conda/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
483 }
484 # apply actual function
--> 485 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
486 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
487 # re-apply format to the output
/opt/conda/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
411 # Call actual function
412
--> 413 out = func(self, *args, **kwargs)
414
415 # Update fingerprint of in-place transforms + update in-place history of transforms
/opt/conda/lib/python3.8/site-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, disable_tqdm, desc, cache_only)
2465 if not batched:
2466 for i, example in enumerate(pbar):
-> 2467 example = apply_function_on_filtered_inputs(example, i, offset=offset)
2468 if update_data:
2469 if i == 0:
/opt/conda/lib/python3.8/site-packages/datasets/arrow_dataset.py in apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples, offset)
2372 if with_rank:
2373 additional_args += (rank,)
-> 2374 processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
2375 if update_data is None:
2376 # Check if the function returns updated examples
/opt/conda/lib/python3.8/site-packages/datasets/arrow_dataset.py in decorated(item, *args, **kwargs)
2067 )
2068 # Use the LazyDict internally, while mapping the function
-> 2069 result = f(decorated_item, *args, **kwargs)
2070 # Return a standard dict
2071 return result.data if isinstance(result, LazyDict) else result
<ipython-input-48-ef87f4129e6e> in speech_file_to_array_fn(batch)
3 def speech_file_to_array_fn(batch):
4 batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
----> 5 speech_array, sampling_rate = torchaudio.load(batch["path"])
6 batch["speech"] = resampler(speech_array).squeeze().numpy()
7 return batch
/opt/conda/lib/python3.8/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file common_voice_it_17415776.mp3 ```
## Environment info
- `datasets` version: 1.18.4
- Platform: Linux-5.4.0-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyArrow version: 7.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3909/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3909/timeline | null | completed | null | null | false | [
"Hi ! It could an issue with torchaudio, which version of torchaudio are you using ? Can you also try updating `datasets` to 2.0.0 and see if it works ?",
"I _might_ have a similar issue. I'm trying to use the librispeech_asr dataset and read it with soundfile.\r\n\r\n```python\r\nfrom datasets import load_dataset, load_metric\r\nfrom transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor\r\nimport soundfile as sf\r\n\r\nlibrispeech_eval = load_dataset(\"librispeech_asr\", \"clean\", split=\"test\") # change to \"other\" for other test dataset\r\nwer = load_metric(\"wer\")\r\n\r\nmodel = Speech2TextForConditionalGeneration.from_pretrained(\"facebook/s2t-small-librispeech-asr\").to(\"cuda\")\r\nprocessor = Speech2TextProcessor.from_pretrained(\"facebook/s2t-small-librispeech-asr\", do_upper_case=True)\r\n\r\ndef map_to_array(batch):\r\n speech, _ = sf.read(batch[\"file\"])\r\n batch[\"speech\"] = speech\r\n return batch\r\n\r\nlibrispeech_eval = librispeech_eval.map(map_to_array)\r\n\r\ndef map_to_pred(batch):\r\n features = processor(batch[\"speech\"], sampling_rate=16000, padding=True, return_tensors=\"pt\")\r\n input_features = features.input_features.to(\"cuda\")\r\n attention_mask = features.attention_mask.to(\"cuda\")\r\n\r\n gen_tokens = model.generate(input_ids=input_features, attention_mask=attention_mask)\r\n batch[\"transcription\"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)\r\n return batch\r\n\r\nresult = librispeech_eval.map(map_to_pred, batched=True, batch_size=8, remove_columns=[\"speech\"])\r\n\r\nprint(\"WER:\", wer(predictions=result[\"transcription\"], references=result[\"text\"]))\r\n```\r\n\r\nThe code is taken directly from \"https://huggingface.co/facebook/s2t-small-librispeech-asr\".\r\n\r\nThe short error code is \"RuntimeError: Error opening '6930-75918-0000.flac': System error.\" (it can't find the first file), and I agree, I can't find the file either. The dataset has downloaded correctly (it says), but on the location, there are only \".arrow\" files, no \".flac\" files.\r\n\r\n**Error message:**\r\n\r\n```python\r\nRuntimeError Traceback (most recent call last)\r\nInput In [15], in <cell line: 16>()\r\n 13 batch[\"speech\"] = speech\r\n 14 return batch\r\n---> 16 librispeech_eval = librispeech_eval.map(map_to_array)\r\n 18 def map_to_pred(batch):\r\n 19 features = processor(batch[\"speech\"], sampling_rate=16000, padding=True, return_tensors=\"pt\")\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\arrow_dataset.py:1953, in Dataset.map(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)\r\n 1950 disable_tqdm = not logging.is_progress_bar_enabled()\r\n 1952 if num_proc is None or num_proc == 1:\r\n-> 1953 return self._map_single(\r\n 1954 function=function,\r\n 1955 with_indices=with_indices,\r\n 1956 with_rank=with_rank,\r\n 1957 input_columns=input_columns,\r\n 1958 batched=batched,\r\n 1959 batch_size=batch_size,\r\n 1960 drop_last_batch=drop_last_batch,\r\n 1961 remove_columns=remove_columns,\r\n 1962 keep_in_memory=keep_in_memory,\r\n 1963 load_from_cache_file=load_from_cache_file,\r\n 1964 cache_file_name=cache_file_name,\r\n 1965 writer_batch_size=writer_batch_size,\r\n 1966 features=features,\r\n 1967 disable_nullable=disable_nullable,\r\n 1968 fn_kwargs=fn_kwargs,\r\n 1969 new_fingerprint=new_fingerprint,\r\n 1970 disable_tqdm=disable_tqdm,\r\n 1971 desc=desc,\r\n 1972 )\r\n 1973 else:\r\n 1975 def format_cache_file_name(cache_file_name, rank):\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\arrow_dataset.py:519, in transmit_tasks.<locals>.wrapper(*args, **kwargs)\r\n 517 self: \"Dataset\" = kwargs.pop(\"self\")\r\n 518 # apply actual function\r\n--> 519 out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n 520 datasets: List[\"Dataset\"] = list(out.values()) if isinstance(out, dict) else [out]\r\n 521 for dataset in datasets:\r\n 522 # Remove task templates if a column mapping of the template is no longer valid\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\arrow_dataset.py:486, in transmit_format.<locals>.wrapper(*args, **kwargs)\r\n 479 self_format = {\r\n 480 \"type\": self._format_type,\r\n 481 \"format_kwargs\": self._format_kwargs,\r\n 482 \"columns\": self._format_columns,\r\n 483 \"output_all_columns\": self._output_all_columns,\r\n 484 }\r\n 485 # apply actual function\r\n--> 486 out: Union[\"Dataset\", \"DatasetDict\"] = func(self, *args, **kwargs)\r\n 487 datasets: List[\"Dataset\"] = list(out.values()) if isinstance(out, dict) else [out]\r\n 488 # re-apply format to the output\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\fingerprint.py:458, in fingerprint_transform.<locals>._fingerprint.<locals>.wrapper(*args, **kwargs)\r\n 452 kwargs[fingerprint_name] = update_fingerprint(\r\n 453 self._fingerprint, transform, kwargs_for_fingerprint\r\n 454 )\r\n 456 # Call actual function\r\n--> 458 out = func(self, *args, **kwargs)\r\n 460 # Update fingerprint of in-place transforms + update in-place history of transforms\r\n 462 if inplace: # update after calling func so that the fingerprint doesn't change if the function fails\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\arrow_dataset.py:2318, in Dataset._map_single(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, disable_tqdm, desc, cache_only)\r\n 2316 if not batched:\r\n 2317 for i, example in enumerate(pbar):\r\n-> 2318 example = apply_function_on_filtered_inputs(example, i, offset=offset)\r\n 2319 if update_data:\r\n 2320 if i == 0:\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\arrow_dataset.py:2218, in Dataset._map_single.<locals>.apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples, offset)\r\n 2216 if with_rank:\r\n 2217 additional_args += (rank,)\r\n-> 2218 processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)\r\n 2219 if update_data is None:\r\n 2220 # Check if the function returns updated examples\r\n 2221 update_data = isinstance(processed_inputs, (Mapping, pa.Table))\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\datasets\\arrow_dataset.py:1913, in Dataset.map.<locals>.decorate.<locals>.decorated(item, *args, **kwargs)\r\n 1909 decorated_item = (\r\n 1910 Example(item, features=self.features) if not batched else Batch(item, features=self.features)\r\n 1911 )\r\n 1912 # Use the LazyDict internally, while mapping the function\r\n-> 1913 result = f(decorated_item, *args, **kwargs)\r\n 1914 # Return a standard dict\r\n 1915 return result.data if isinstance(result, LazyDict) else result\r\n\r\nInput In [15], in map_to_array(batch)\r\n 11 def map_to_array(batch):\r\n---> 12 speech, _ = sf.read(batch[\"file\"])\r\n 13 batch[\"speech\"] = speech\r\n 14 return batch\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\soundfile.py:256, in read(file, frames, start, stop, dtype, always_2d, fill_value, out, samplerate, channels, format, subtype, endian, closefd)\r\n 170 def read(file, frames=-1, start=0, stop=None, dtype='float64', always_2d=False,\r\n 171 fill_value=None, out=None, samplerate=None, channels=None,\r\n 172 format=None, subtype=None, endian=None, closefd=True):\r\n 173 \"\"\"Provide audio data from a sound file as NumPy array.\r\n 174 \r\n 175 By default, the whole file is read from the beginning, but the\r\n (...)\r\n 254 \r\n 255 \"\"\"\r\n--> 256 with SoundFile(file, 'r', samplerate, channels,\r\n 257 subtype, endian, format, closefd) as f:\r\n 258 frames = f._prepare_read(start, stop, frames)\r\n 259 data = f.read(frames, dtype, always_2d, fill_value, out)\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\soundfile.py:629, in SoundFile.__init__(self, file, mode, samplerate, channels, subtype, endian, format, closefd)\r\n 626 self._mode = mode\r\n 627 self._info = _create_info_struct(file, mode, samplerate, channels,\r\n 628 format, subtype, endian)\r\n--> 629 self._file = self._open(file, mode_int, closefd)\r\n 630 if set(mode).issuperset('r+') and self.seekable():\r\n 631 # Move write position to 0 (like in Python file objects)\r\n 632 self.seek(0)\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\soundfile.py:1183, in SoundFile._open(self, file, mode_int, closefd)\r\n 1181 else:\r\n 1182 raise TypeError(\"Invalid file: {0!r}\".format(self.name))\r\n-> 1183 _error_check(_snd.sf_error(file_ptr),\r\n 1184 \"Error opening {0!r}: \".format(self.name))\r\n 1185 if mode_int == _snd.SFM_WRITE:\r\n 1186 # Due to a bug in libsndfile version <= 1.0.25, frames != 0\r\n 1187 # when opening a named pipe in SFM_WRITE mode.\r\n 1188 # See http://github.com/erikd/libsndfile/issues/77.\r\n 1189 self._info.frames = 0\r\n\r\nFile C:\\ProgramData\\Miniconda3\\envs\\noise_cancel\\lib\\site-packages\\soundfile.py:1357, in _error_check(err, prefix)\r\n 1355 if err != 0:\r\n 1356 err_str = _snd.sf_error_number(err)\r\n-> 1357 raise RuntimeError(prefix + _ffi.string(err_str).decode('utf-8', 'replace'))\r\n\r\nRuntimeError: Error opening '6930-75918-0000.flac': System error.\r\n```\r\n\r\n**Package versions:**\r\n```python\r\npython: 3.9\r\ntransformers: 4.17.0\r\ndatasets: 2.0.0\r\nSoundFile: 0.10.3.post1\r\n```\r\n",
"Hi ! In `datasets` 2.0 can access the audio array with `librispeech_eval[0][\"audio\"][\"array\"]` already, no need to use `map_to_array`. See our documentation on [how to process audio data](https://huggingface.co/docs/datasets/audio_process) :)\r\n\r\ncc @patrickvonplaten we will need to update the readme at [facebook/s2t-small-librispeech-asr](https://huggingface.co/facebook/s2t-small-librispeech-asr) as well as https://huggingface.co/docs/transformers/model_doc/speech_to_text",
"Thanks!\r\n\r\nAnd sorry for posting this problem in what turned on to be an unrelated thread.\r\n\r\nI rewrote the code, and the model works. The WER is 0.137 however, so I'm not sure if I have missed a step. I will look further into that at a later point. The transcriptions look good through manual inspection.\r\n\r\nThe rewritten code:\r\n```python\r\nfrom datasets import load_dataset, load_metric\r\nfrom transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor, Wav2Vec2Processor\r\n\r\nlibrispeech_eval = load_dataset(\"librispeech_asr\", \"clean\", split=\"test\") # change to \"other\" for other test dataset\r\nwer = load_metric(\"wer\")\r\n\r\nmodel = Speech2TextForConditionalGeneration.from_pretrained(\"facebook/s2t-small-librispeech-asr\").to(\"cuda\")\r\nprocessor = Speech2TextProcessor.from_pretrained(\"facebook/s2t-small-librispeech-asr\", do_upper_case=True)\r\n\r\ndef map_to_pred(batch):\r\n audio = batch[\"audio\"]\r\n features = processor(audio[\"array\"], sampling_rate=audio[\"sampling_rate\"], padding=True, return_tensors=\"pt\")\r\n input_features = features.input_features.to(\"cuda\")\r\n attention_mask = features.attention_mask.to(\"cuda\")\r\n\r\n gen_tokens = model.generate(input_features=input_features, attention_mask=attention_mask)\r\n batch[\"transcription\"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)\r\n return batch\r\n\r\nresult = librispeech_eval.map(map_to_pred)#, batched=True, batch_size=8)\r\n\r\nprint(\"WER:\", wer.compute(predictions=result[\"transcription\"], references=result[\"text\"]))\r\n```",
"I think the issue comes from the fact that you set `batched=False` while `map_to_pred` still returns a list of strings for \"transcription\". You can fix it by adding `[0]` at the end of this line to get the string:\r\n```python\r\nbatch[\"transcription\"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)[0]\r\n```",
"Updating as many model cards now as I can find",
"https://github.com/huggingface/transformers/pull/16611",
"We no longer use `torchaudio` for decoding MP3 files, and the problem with model cards has been addressed, so I'm closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/3138 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3138/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3138/comments | https://api.github.com/repos/huggingface/datasets/issues/3138/events | https://github.com/huggingface/datasets/issues/3138 | 1,033,379,997 | I_kwDODunzps49mCCd | 3,138 | More fine-grained taxonomy of error types | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | open | false | null | 1 | 2021-10-22T09:35:29Z | 2022-09-20T13:04:42Z | null | null | **Is your feature request related to a problem? Please describe.**
Exceptions like `FileNotFoundError` can be raised by different parts of the code, and it's hard to detect which one did
**Describe the solution you'd like**
Give a specific exception type for every group of similar errors
**Describe alternatives you've considered**
Rely on the error message, using regex
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3138/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3138/timeline | null | null | null | null | false | [
"related: #4995\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1486 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1486/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1486/comments | https://api.github.com/repos/huggingface/datasets/issues/1486/events | https://github.com/huggingface/datasets/pull/1486 | 762,790,102 | MDExOlB1bGxSZXF1ZXN0NTM3MzAxODY2 | 1,486 | hate speech 18 dataset | [] | closed | false | null | 2 | 2020-12-11T19:22:14Z | 2020-12-14T19:43:18Z | 2020-12-14T19:43:18Z | null | This is again a PR instead of #1339, because something went wrong there. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1486/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1486/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1486.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1486",
"merged_at": "2020-12-14T19:43:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1486.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1486"
} | true | [
"The error `tests/test_file_utils.py::TempSeedTest::test_tensorflow` just appeared because of tensorflow's update.\r\nOnce it's fixed on master we'll be free to merge this one",
"It's fixed on master now :) \r\n\r\nmerging this once"
] |
https://api.github.com/repos/huggingface/datasets/issues/3587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3587/comments | https://api.github.com/repos/huggingface/datasets/issues/3587/events | https://github.com/huggingface/datasets/issues/3587 | 1,106,719,182 | I_kwDODunzps5B9zHO | 3,587 | No module named 'fsspec.archive' | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-01-18T10:17:01Z | 2022-08-11T09:57:54Z | 2022-01-18T10:33:10Z | null | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 61, in <module>
from .arrow_writer import ArrowWriter, OptimizedTypedSequence
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/arrow_writer.py", line 28, in <module>
from .features import (
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/features/__init__.py", line 2, in <module>
from .audio import Audio
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/features/audio.py", line 7, in <module>
from ..utils.streaming_download_manager import xopen
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 18, in <module>
from ..filesystems import COMPRESSION_FILESYSTEMS
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/filesystems/__init__.py", line 6, in <module>
from . import compression
File "/home/shuchen/miniconda3/envs/hf/lib/python3.9/site-packages/datasets/filesystems/compression.py", line 5, in <module>
from fsspec.archive import AbstractArchiveFileSystem
ModuleNotFoundError: No module named 'fsspec.archive'
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3587/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3587/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/347/comments | https://api.github.com/repos/huggingface/datasets/issues/347/events | https://github.com/huggingface/datasets/issues/347 | 652,106,567 | MDU6SXNzdWU2NTIxMDY1Njc= | 347 | 'cp950' codec error from load_dataset('xtreme', 'tydiqa') | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 10 | 2020-07-07T08:14:23Z | 2020-09-07T14:51:45Z | 2020-09-07T14:51:45Z | null | 
I guess the error is related to python source encoding issue that my PC is trying to decode the source code with wrong encoding-decoding tools, perhaps :
https://www.python.org/dev/peps/pep-0263/
I guess the error was triggered by the code " module = importlib.import_module(module_path)" at line 57 in the source code: nlp/src/nlp/load.py / (https://github.com/huggingface/nlp/blob/911d5596f9b500e39af8642fe3d1b891758999c7/src/nlp/load.py#L51)
Any ideas?
p.s. tried the same code on colab, that runs perfectly
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/347/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/347/timeline | null | completed | null | null | false | [
"This is probably a Windows issue, we need to specify the encoding when `load_dataset()` reads the original CSV file.\r\nTry to find the `open()` statement called by `load_dataset()` and add an `encoding='utf-8'` parameter.\r\nSee issues #242 and #307 ",
"It should be in `xtreme.py:L755`:\r\n```python\r\n if self.config.name == \"tydiqa\" or self.config.name.startswith(\"MLQA\") or self.config.name == \"SQuAD\":\r\n with open(filepath) as f:\r\n data = json.load(f)\r\n```\r\n\r\nCould you try to add the encoding parameter:\r\n```python\r\nopen(filepath, encoding='utf-8')\r\n```",
"Hello @jerryIsHere :) Did it work ?\r\nIf so we may change the dataset script to force the utf-8 encoding",
"@lhoestq sorry for being that late, I found 4 copy of xtreme.py. I did the changes as what has been told to all of them.\r\nThe problem is not solved",
"Could you provide a better error message so that we can make sure it comes from the opening of the `tydiqa`'s json files ?\r\n",
"@lhoestq \r\nThe error message is same as before:\r\nException has occurred: UnicodeDecodeError\r\n'cp950' codec can't decode byte 0xe2 in position 111: illegal multibyte sequence\r\n File \"D:\\python\\test\\test.py\", line 3, in <module>\r\n dataset = load_dataset('xtreme', 'tydiqa')\r\n\r\n\r\n\r\nI said that I found 4 copy of xtreme.py and add the 「, encoding='utf-8'」 parameter to the open() function\r\nthese python script was found under this directory\r\nC:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python37\\Lib\\site-packages\\nlp\\datasets\\xtreme\r\n",
"Hi there !\r\nI encountered the same issue with the IMDB dataset on windows. It threw an error about charmap not being able to decode a symbol during the first time I tried to download it. I checked on a remote linux machine I have, and it can't be reproduced.\r\nI added ```encoding='UTF-8'``` to both lines that have ```open``` in ```imdb.py``` (108 and 114) and it worked for me.\r\nThank you !",
"> Hi there !\r\n> I encountered the same issue with the IMDB dataset on windows. It threw an error about charmap not being able to decode a symbol during the first time I tried to download it. I checked on a remote linux machine I have, and it can't be reproduced.\r\n> I added `encoding='UTF-8'` to both lines that have `open` in `imdb.py` (108 and 114) and it worked for me.\r\n> Thank you !\r\n\r\nHello !\r\nGlad you managed to fix this issue on your side.\r\nDo you mind opening a PR for IMDB ?",
"> This is probably a Windows issue, we need to specify the encoding when `load_dataset()` reads the original CSV file.\r\n> Try to find the `open()` statement called by `load_dataset()` and add an `encoding='utf-8'` parameter.\r\n> See issues #242 and #307\r\n\r\nSorry for not responding for about a month.\r\nI have just found that it is necessary to change / add the environment variable as what was told in #242.\r\nEverything works after I add the new environment variable and restart my PC.\r\n\r\nI think the encoding issue for windows isn't limited to the open() function call specific to few dataset, but actually in the entire library, depends on the machine / os you use.",
"Since #481 we shouldn't have other issues with encodings as they need to be set to \"utf-8\" be default.\r\n\r\nClosing this one, but feel free to re-open if you gave other questions"
] |
https://api.github.com/repos/huggingface/datasets/issues/27 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/27/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/27/comments | https://api.github.com/repos/huggingface/datasets/issues/27/events | https://github.com/huggingface/datasets/pull/27 | 610,230,476 | MDExOlB1bGxSZXF1ZXN0NDExNzA5OTc0 | 27 | [Cleanup] Removes all files in testing except test_dataset_common | [] | closed | false | null | 0 | 2020-04-30T16:45:21Z | 2020-04-30T17:39:25Z | 2020-04-30T17:39:23Z | null | As far as I know, all files in `tests` were old `tfds test files` so I removed them. We can still look them up on the other library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/27/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/27/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/27.diff",
"html_url": "https://github.com/huggingface/datasets/pull/27",
"merged_at": "2020-04-30T17:39:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/27.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/27"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1616/comments | https://api.github.com/repos/huggingface/datasets/issues/1616/events | https://github.com/huggingface/datasets/pull/1616 | 772,074,229 | MDExOlB1bGxSZXF1ZXN0NTQzNDEwNDc1 | 1,616 | added TurkishMovieSentiment dataset | [] | closed | false | null | 1 | 2020-12-21T11:03:16Z | 2020-12-24T07:08:41Z | 2020-12-23T16:50:06Z | null | This PR adds the **TurkishMovieSentiment: This dataset contains turkish movie reviews.**
- **Homepage:** [https://www.kaggle.com/mustfkeskin/turkish-movie-sentiment-analysis-dataset/tasks](https://www.kaggle.com/mustfkeskin/turkish-movie-sentiment-analysis-dataset/tasks)
- **Point of Contact:** [Mustafa Keskin](https://www.linkedin.com/in/mustfkeskin/) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1616/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1616.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1616",
"merged_at": "2020-12-23T16:50:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1616.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1616"
} | true | [
"> I just generated the dataset_infos.json file\r\n> \r\n> Thanks for adding this one !\r\n\r\nThank you very much for your support."
] |
https://api.github.com/repos/huggingface/datasets/issues/5364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5364/comments | https://api.github.com/repos/huggingface/datasets/issues/5364/events | https://github.com/huggingface/datasets/pull/5364 | 1,498,360,628 | PR_kwDODunzps5Fiss1 | 5,364 | Support for writing arrow files directly with BeamWriter | [] | open | false | null | 4 | 2022-12-15T12:38:05Z | 2023-01-25T15:49:25Z | null | null | Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5364/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5364.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5364",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5364.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5364"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5364). All of your documentation changes will be reflected on that endpoint.",
"Deleting `BeamPipeline` and `upload_local_to_remote` would break the existing Beam scripts, so I reverted this change.\r\n\r\nFrom what I understand, we need these components in our scripts for the pattern:\r\n```python\r\nif not pipeline.is_local():\r\n dl_manager.ship_files_with_pipeline()\r\n```\r\n\r\nI plan to address this in a subsequent PR by (implicitly) downloading the files directly to the remote storage of the non-local runners.",
"I got `AttributeError: 'Pipeline' object has no attribute 'is_local'` when running\r\n```python\r\nload_dataset(\"wikipedia\", language=\"af\", date=\"20230101\", beam_runner=\"DirectRunner\")\r\n```\r\n```python\r\n~/.cache/huggingface/modules/datasets_modules/datasets/wikipedia/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559/wikipedia.py in _split_generators(self, dl_manager, pipeline)\r\n 965 # Use dictionary since testing mock always returns the same result.\r\n 966 downloaded_files = dl_manager.download({\"xml\": xml_urls})\r\n--> 967 if not pipeline.is_local():\r\n 968 downloaded_files = dl_manager.ship_files_with_pipeline(downloaded_files, pipeline)\r\n 969 \r\n\r\nAttributeError: 'Pipeline' object has no attribute 'is_local'\r\n```",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010649 / 0.011353 (-0.000704) | 0.006116 / 0.011008 (-0.004892) | 0.115568 / 0.038508 (0.077060) | 0.041704 / 0.023109 (0.018595) | 0.360459 / 0.275898 (0.084561) | 0.425679 / 0.323480 (0.102200) | 0.008992 / 0.007986 (0.001006) | 0.006321 / 0.004328 (0.001993) | 0.090223 / 0.004250 (0.085973) | 0.049877 / 0.037052 (0.012824) | 0.382447 / 0.258489 (0.123958) | 0.406567 / 0.293841 (0.112726) | 0.045138 / 0.128546 (-0.083409) | 0.014203 / 0.075646 (-0.061444) | 0.388897 / 0.419271 (-0.030375) | 0.057176 / 0.043533 (0.013644) | 0.358729 / 0.255139 (0.103590) | 0.386086 / 0.283200 (0.102887) | 0.119221 / 0.141683 (-0.022462) | 1.731574 / 1.452155 (0.279419) | 1.744103 / 1.492716 (0.251386) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230380 / 0.018006 (0.212373) | 0.493690 / 0.000490 (0.493201) | 0.005150 / 0.000200 (0.004950) | 0.000097 / 0.000054 (0.000042) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030771 / 0.037411 (-0.006641) | 0.123196 / 0.014526 (0.108671) | 0.134097 / 0.176557 (-0.042459) | 0.190442 / 0.737135 (-0.546693) | 0.138416 / 0.296338 (-0.157923) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.469763 / 0.215209 (0.254554) | 4.682847 / 2.077655 (2.605192) | 2.076717 / 1.504120 (0.572597) | 1.843721 / 1.541195 (0.302527) | 1.923486 / 1.468490 (0.454996) | 0.817680 / 4.584777 (-3.767097) | 4.482409 / 3.745712 (0.736697) | 3.898695 / 5.269862 (-1.371167) | 2.078291 / 4.565676 (-2.487386) | 0.100285 / 0.424275 (-0.323990) | 0.014761 / 0.007607 (0.007154) | 0.611261 / 0.226044 (0.385217) | 5.926919 / 2.268929 (3.657990) | 2.685080 / 55.444624 (-52.759544) | 2.232179 / 6.876477 (-4.644298) | 2.305576 / 2.142072 (0.163504) | 0.993729 / 4.805227 (-3.811498) | 0.194491 / 6.500664 (-6.306173) | 0.074176 / 0.075469 (-0.001293) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.388592 / 1.841788 (-0.453196) | 17.146945 / 8.074308 (9.072636) | 15.989570 / 10.191392 (5.798178) | 0.200147 / 0.680424 (-0.480277) | 0.034009 / 0.534201 (-0.500192) | 0.517531 / 0.579283 (-0.061753) | 0.533966 / 0.434364 (0.099602) | 0.637024 / 0.540337 (0.096687) | 0.749166 / 1.386936 (-0.637770) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008240 / 0.011353 (-0.003113) | 0.006139 / 0.011008 (-0.004869) | 0.112258 / 0.038508 (0.073750) | 0.039001 / 0.023109 (0.015891) | 0.449467 / 0.275898 (0.173569) | 0.483422 / 0.323480 (0.159942) | 0.006176 / 0.007986 (-0.001810) | 0.006340 / 0.004328 (0.002012) | 0.083105 / 0.004250 (0.078855) | 0.047002 / 0.037052 (0.009950) | 0.458564 / 0.258489 (0.200075) | 0.513704 / 0.293841 (0.219863) | 0.041359 / 0.128546 (-0.087188) | 0.014515 / 0.075646 (-0.061131) | 0.392599 / 0.419271 (-0.026673) | 0.055222 / 0.043533 (0.011690) | 0.446956 / 0.255139 (0.191817) | 0.469194 / 0.283200 (0.185994) | 0.118212 / 0.141683 (-0.023471) | 1.682647 / 1.452155 (0.230492) | 1.780076 / 1.492716 (0.287360) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.259124 / 0.018006 (0.241117) | 0.507559 / 0.000490 (0.507069) | 0.001080 / 0.000200 (0.000880) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031969 / 0.037411 (-0.005442) | 0.126997 / 0.014526 (0.112471) | 0.139593 / 0.176557 (-0.036963) | 0.182735 / 0.737135 (-0.554400) | 0.145871 / 0.296338 (-0.150468) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.530894 / 0.215209 (0.315685) | 5.284979 / 2.077655 (3.207324) | 2.592886 / 1.504120 (1.088766) | 2.407202 / 1.541195 (0.866007) | 2.434079 / 1.468490 (0.965589) | 0.829382 / 4.584777 (-3.755395) | 4.481710 / 3.745712 (0.735998) | 3.912280 / 5.269862 (-1.357581) | 1.962291 / 4.565676 (-2.603386) | 0.101840 / 0.424275 (-0.322435) | 0.014528 / 0.007607 (0.006921) | 0.639956 / 0.226044 (0.413911) | 6.414685 / 2.268929 (4.145756) | 3.240290 / 55.444624 (-52.204334) | 2.795208 / 6.876477 (-4.081269) | 2.912122 / 2.142072 (0.770050) | 0.992188 / 4.805227 (-3.813039) | 0.200701 / 6.500664 (-6.299964) | 0.074235 / 0.075469 (-0.001234) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.455075 / 1.841788 (-0.386712) | 17.186669 / 8.074308 (9.112361) | 15.404357 / 10.191392 (5.212965) | 0.168267 / 0.680424 (-0.512157) | 0.020774 / 0.534201 (-0.513427) | 0.502603 / 0.579283 (-0.076680) | 0.506500 / 0.434364 (0.072136) | 0.624245 / 0.540337 (0.083907) | 0.735529 / 1.386936 (-0.651407) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1627/comments | https://api.github.com/repos/huggingface/datasets/issues/1627/events | https://github.com/huggingface/datasets/issues/1627 | 773,960,255 | MDU6SXNzdWU3NzM5NjAyNTU= | 1,627 | `Dataset.map` disable progress bar | [] | closed | false | null | 2 | 2020-12-23T17:53:42Z | 2023-02-08T02:37:47Z | 2020-12-26T19:57:17Z | null | I can't find anything to turn off the `tqdm` progress bars while running a preprocessing function using `Dataset.map`. I want to do akin to `disable_tqdm=True` in the case of `transformers`. Is there something like that? | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1627/timeline | null | completed | null | null | false | [
"Progress bar can be disabled like this:\r\n```python\r\nfrom datasets.utils.logging import set_verbosity_error\r\nset_verbosity_error()\r\n```\r\n\r\nThere is this line in `Dataset.map`:\r\n```python\r\nnot_verbose = bool(logger.getEffectiveLevel() > WARNING)\r\n```\r\n\r\nSo any logging level higher than `WARNING` turns off the progress bar.",
"From the linked issues above, an up-to-date solution is:\r\n\r\n```python\r\nfrom datasets.utils.logging import disable_progress_bar\r\ndisable_progress_bar()\r\n```\r\n\r\nhttps://github.com/huggingface/datasets/blob/c6e08fcfc3a04e53430c26fa7c07da4cb18d977d/src/datasets/utils/logging.py#L233-L236"
] |
https://api.github.com/repos/huggingface/datasets/issues/5983 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5983/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5983/comments | https://api.github.com/repos/huggingface/datasets/issues/5983/events | https://github.com/huggingface/datasets/pull/5983 | 1,770,578,804 | PR_kwDODunzps5TtDdy | 5,983 | replaced PathLike as a variable for save_to_disk for dataset_path wit… | [] | open | false | null | 0 | 2023-06-23T00:57:05Z | 2023-06-23T00:57:05Z | null | null | …h str like that of load_from_disk | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5983/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5983/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5983.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5983",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5983.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5983"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1368/comments | https://api.github.com/repos/huggingface/datasets/issues/1368/events | https://github.com/huggingface/datasets/pull/1368 | 760,222,616 | MDExOlB1bGxSZXF1ZXN0NTM1MDkwMjM0 | 1,368 | Re-adding narrativeqa dataset | [] | closed | false | null | 4 | 2020-12-09T10:53:09Z | 2020-12-11T13:30:59Z | 2020-12-11T13:30:59Z | null | An update of #309. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1368/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1368/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/1368.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1368",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1368.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1368"
} | true | [
"@lhoestq I think I've fixed the dummy data - it finally passes! I'll add the model card now.",
"@lhoestq - pretty happy with it now",
"> Awesome thank you !\r\n> \r\n> Could you try to reduce the size of the dummy_data.zip file before we merge ? (it's 300KB right now)\r\n> \r\n> To do so feel free to take a look inside it and remove all the unnecessary files and chunks of text, to only keep a few examples. The idea is to have a zip file that is only a few KB\r\n\r\nAh, it only contains 1 example for each split. I think the problem is that I include an entire story (like in the full dataset). We can probably get away with a summarised version.",
"> Nice thank you, can you make it even lighter if possible ? Something round 10KB would be awesone\r\n> We try to keep the repo light so that it doesn't take ages to clone. So we have to make sure the dummy data are as small as possible for every single dataset.\r\n\r\nHave trimmed a little more out of each example now."
] |
https://api.github.com/repos/huggingface/datasets/issues/4245 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4245/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4245/comments | https://api.github.com/repos/huggingface/datasets/issues/4245/events | https://github.com/huggingface/datasets/pull/4245 | 1,217,959,400 | PR_kwDODunzps426AUR | 4,245 | Add code examples for DatasetDict | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 1 | 2022-04-27T22:52:22Z | 2022-04-29T18:19:34Z | 2022-04-29T18:13:03Z | null | This PR adds code examples for `DatasetDict` in the API reference :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4245/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4245/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4245.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4245",
"merged_at": "2022-04-29T18:13:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4245.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4245"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5855 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5855/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5855/comments | https://api.github.com/repos/huggingface/datasets/issues/5855/events | https://github.com/huggingface/datasets/issues/5855 | 1,708,784,943 | I_kwDODunzps5l2f0v | 5,855 | `to_tf_dataset` consumes too much memory | [] | closed | false | null | 6 | 2023-05-14T01:22:29Z | 2023-06-08T16:32:52Z | 2023-06-08T16:32:52Z | null | ### Describe the bug
Hi, I'm using `to_tf_dataset` to convert a _large_ dataset to `tf.data.Dataset`. I observed that the data loading *before* training took a lot of time and memory, even with `batch_size=1`.
After some digging, i believe the reason lies in the shuffle behavior. The [source code](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/tf_utils.py#L185) uses `len(dataset)` as the `buffer_size`, which may load all the data into the memory, and the [tf.data doc](https://www.tensorflow.org/guide/data#randomly_shuffling_input_data) also states that "While large buffer_sizes shuffle more thoroughly, they can take a lot of memory, and significant time to fill".
### Steps to reproduce the bug
```python
from datasets import Dataset
def gen(): # some large data
for i in range(50000000):
yield {"data": i}
ds = Dataset.from_generator(gen, cache_dir="./huggingface")
tf_ds = ds.to_tf_dataset(
batch_size=64,
shuffle=False, # no shuffle
drop_remainder=False,
prefetch=True,
)
# fast and memory friendly 🤗
for batch in tf_ds:
...
tf_ds_shuffle = ds.to_tf_dataset(
batch_size=64,
shuffle=True,
drop_remainder=False,
prefetch=True,
)
# slow and memory hungry for simple iteration 😱
for batch in tf_ds_shuffle:
...
```
### Expected behavior
Shuffling should not load all the data into the memory. Would adding a `buffer_size` parameter in the `to_tf_dataset` API alleviate the problem?
### Environment info
- `datasets` version: 2.11.0
- Platform: Linux-5.17.1-051701-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- Huggingface_hub version: 0.13.4
- PyArrow version: 11.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5855/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5855/timeline | null | completed | null | null | false | [
"Cc @amyeroberts @Rocketknight1 \r\n\r\nIndded I think it's because it does something like this under the hood when there's no multiprocessing:\r\n\r\n```python\r\ntf_dataset = tf_dataset.shuffle(len(dataset))\r\n```\r\n\r\nPS: with multiprocessing it appears to be different:\r\n\r\n```python\r\nindices = np.arange(len(dataset))\r\nif shuffle:\r\n np.random.shuffle(indices)\r\n```",
"Hi @massquantity, the dataset being shuffled there is not the full dataset. If you look at [the line above](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/tf_utils.py#L182), the dataset is actually just a single indices array at that point, and that array is the only thing that gets fully loaded into memory and shuffled. We then load samples from the dataset by applying a transform function to the shuffled dataset, which fetches samples based on the indices it receives.\r\n\r\nIf your dataset is **really** gigantic, then this index tensor might be a memory issue, but since it's just an int64 tensor it will only use 1GB of memory per 125 million samples.\r\n\r\nStill, if you're encountering memory issues, there might be another cause here - can you share some code to reproduce the error, or does it depend on some internal/proprietary dataset?",
"Hi @Rocketknight1, you're right and I also noticed that only indices are used in shuffling. My data has shape (50000000, 10), but really the problem doesn't relate to a specific dataset. Simply running the following code costs me 10GB of memory.\r\n\r\n```python\r\nfrom datasets import Dataset\r\n\r\ndef gen():\r\n for i in range(50000000):\r\n yield {\"data\": i}\r\n\r\nds = Dataset.from_generator(gen, cache_dir=\"./huggingface\")\r\n\r\ntf_ds = ds.to_tf_dataset(\r\n batch_size=1,\r\n shuffle=True,\r\n drop_remainder=False,\r\n prefetch=True,\r\n)\r\ntf_ds = iter(tf_ds)\r\nnext(tf_ds)\r\n# {'data': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>}\r\n```\r\n\r\nI just realized maybe it was an issue from tensorflow (I'm using tf 2.12). So I tried the following code, and it used 10GB of memory too.\r\n```python\r\nimport numpy as np\r\nimport tensorflow as tf\r\n\r\ndata_size = 50000000\r\ntf_dataset = tf.data.Dataset.from_tensor_slices(np.arange(data_size))\r\ntf_dataset = iter(tf_dataset.shuffle(data_size))\r\nnext(tf_dataset)\r\n# <tf.Tensor: shape=(), dtype=int64, numpy=24774043>\r\n```\r\n\r\nBy the way, as @lhoestq mentioned, multiprocessing uses numpy shuffling, and it uses less than 1 GB of memory:\r\n```python\r\ntf_ds_mp = ds.to_tf_dataset(\r\n batch_size=1,\r\n shuffle=True,\r\n drop_remainder=False,\r\n prefetch=True,\r\n num_workers=2,\r\n)\r\n```",
"Thanks for that reproduction script - I've confirmed the same issue is occurring for me. Investigating it now!",
"Update: The memory usage is occurring in creation of the index and shuffle buffer. You can reproduce it very simply with:\r\n\r\n```python\r\nimport tensorflow as tf\r\nindices = tf.range(50_000_000, dtype=tf.int64)\r\ndataset = tf.data.Dataset.from_tensor_slices(indices)\r\ndataset = dataset.shuffle(len(dataset))\r\nprint(next(iter(dataset))\r\n```\r\nWhen I wrote this code I thought `tf.data` had an optimization for shuffling an entire tensor that wouldn't create the entire shuffle buffer, but evidently it's just creating the enormous buffer in memory. I'll see if I can find a more efficient way to do this - we might end up moving everything to the `numpy` multiprocessing path to avoid it.",
"I opened a PR to fix this - will continue the discussion there!"
] |
https://api.github.com/repos/huggingface/datasets/issues/984 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/984/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/984/comments | https://api.github.com/repos/huggingface/datasets/issues/984/events | https://github.com/huggingface/datasets/pull/984 | 755,009,916 | MDExOlB1bGxSZXF1ZXN0NTMwODAzNzgw | 984 | committing Whoa file | [] | closed | false | null | 2 | 2020-12-02T07:07:46Z | 2020-12-02T16:15:29Z | 2020-12-02T15:40:58Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/984/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/984.diff",
"html_url": "https://github.com/huggingface/datasets/pull/984",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/984.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/984"
} | true | [
"can't find the Whoa file since there' nothing left",
"The classic `rm -rf` command - nice one"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3328 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3328/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3328/comments | https://api.github.com/repos/huggingface/datasets/issues/3328/events | https://github.com/huggingface/datasets/pull/3328 | 1,065,015,262 | PR_kwDODunzps4vFTpW | 3,328 | Quick fix error formatting | [] | closed | false | null | 0 | 2021-11-27T11:47:48Z | 2021-11-29T13:32:42Z | 2021-11-29T13:32:42Z | null | While working on a dataset, I got the error
```
TypeError: Provided `function` which is applied to all elements of table returns a `dict` of types {[type(x) for x in processed_inputs.values()]}. When using `batched=True`, make sure provided `function` returns a `dict` of types like `{allowed_batch_return_types}`.
```
This PR should fix the formatting of this error | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3328/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3328/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3328.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3328",
"merged_at": "2021-11-29T13:32:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3328.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3328"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4472 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4472/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4472/comments | https://api.github.com/repos/huggingface/datasets/issues/4472/events | https://github.com/huggingface/datasets/pull/4472 | 1,267,488,523 | PR_kwDODunzps45drcb | 4,472 | Fix 401 error for unauthticated requests to non-existing repos | [] | closed | false | null | 1 | 2022-06-10T12:38:11Z | 2022-06-10T13:05:11Z | 2022-06-10T12:55:57Z | null | The hub now returns 401 instead of 404 for unauthenticated requests to non-existing repos.
This PR add support for the 401 error and fixes the CI fails on `master` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4472/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4472/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4472.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4472",
"merged_at": "2022-06-10T12:55:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4472.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4472"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2020/comments | https://api.github.com/repos/huggingface/datasets/issues/2020/events | https://github.com/huggingface/datasets/pull/2020 | 826,961,126 | MDExOlB1bGxSZXF1ZXN0NTg4OTE3MjYx | 2,020 | Remove unnecessary docstart check in conll-like datasets | [] | closed | false | null | 0 | 2021-03-10T02:20:16Z | 2021-03-11T13:33:37Z | 2021-03-11T13:33:37Z | null | Related to this PR: #1998
Additionally, this PR adds the docstart note to the conll2002 dataset card ([link](https://raw.githubusercontent.com/teropa/nlp/master/resources/corpora/conll2002/ned.train) to the raw data with `DOCSTART` lines).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2020/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2020.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2020",
"merged_at": "2021-03-11T13:33:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2020.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2020"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3631/comments | https://api.github.com/repos/huggingface/datasets/issues/3631/events | https://github.com/huggingface/datasets/issues/3631 | 1,114,833,662 | I_kwDODunzps5CcwL- | 3,631 | Labels conflict when loading a local CSV file. | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-01-26T10:00:33Z | 2022-02-11T23:02:31Z | 2022-02-11T23:02:31Z | null | ## Describe the bug
I am trying to load a local CSV file with a separate file containing label names. It is successfully loaded for the first time, but when I try to load it again, there is a conflict between provided labels and the cached dataset info. Disabling caching globally and/or using `download_mode="force_redownload"` did not help.
## Steps to reproduce the bug
```python
load_dataset('csv', data_files='data/my_data.csv',
features=Features(text=Value(dtype='string'),
label=ClassLabel(names_file='data/my_data_labels.txt')))
```
`my_data.csv` file has the following structure:
```
text,label
"example1",0
"example2",1
...
```
and the `my_data_labels.txt` looks like this:
```
label1
label2
...
```
## Expected results
Successfully loaded dataset.
## Actual results
```python
File "/usr/local/lib/python3.8/site-packages/datasets/load.py", line 1706, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 766, in as_dataset
datasets = utils.map_nested(
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 261, in map_nested
mapped = [
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 262, in <listcomp>
_single_map_nested((function, obj, types, None, True))
File "/usr/local/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 197, in _single_map_nested
return function(data_struct)
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 797, in _build_single_dataset
ds = self._as_dataset(
File "/usr/local/lib/python3.8/site-packages/datasets/builder.py", line 872, in _as_dataset
return Dataset(fingerprint=fingerprint, **dataset_kwargs)
File "/usr/local/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 638, in __init__
inferred_features = Features.from_arrow_schema(arrow_table.schema)
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1242, in from_arrow_schema
return Features.from_dict(metadata["info"]["features"])
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1271, in from_dict
obj = generate_from_dict(dic)
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1076, in generate_from_dict
return {key: generate_from_dict(value) for key, value in obj.items()}
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1076, in <dictcomp>
return {key: generate_from_dict(value) for key, value in obj.items()}
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 1083, in generate_from_dict
return class_type(**{k: v for k, v in obj.items() if k in field_names})
File "<string>", line 7, in __init__
File "/usr/local/lib/python3.8/site-packages/datasets/features/features.py", line 776, in __post_init__
raise ValueError("Please provide either names or names_file but not both.")
ValueError: Please provide either names or names_file but not both.
```
## Environment info
- `datasets` version: 1.18.0
- Python version: 3.8.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3631/timeline | null | completed | null | null | false | [
"Hi @pichljan, thanks for reporting.\r\n\r\nThis should be fixed. I'm looking at it. "
] |
https://api.github.com/repos/huggingface/datasets/issues/3482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3482/comments | https://api.github.com/repos/huggingface/datasets/issues/3482/events | https://github.com/huggingface/datasets/pull/3482 | 1,088,317,921 | PR_kwDODunzps4wQqE1 | 3,482 | Fix duplicate keys in NewsQA | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 2 | 2021-12-24T11:01:59Z | 2022-09-23T12:57:10Z | 2022-09-23T12:57:10Z | null | * Fix duplicate keys in NewsQA when loading from CSV files.
* Fix s/narqa/newsqa/ in the download manually error message.
* Make the download manually error message show nicely when printed. Otherwise, is hard to read due to spacing issues.
* Fix the format of the license text.
* Reformat the code to make it simpler. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3482/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3482.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3482",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3482.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3482"
} | true | [
"Flaky tests?",
"Thanks for your contribution, @bryant1410.\r\n\r\nI think the fix of the duplicate key in this PR was superseded by:\r\n- #3696\r\n\r\nI'm closing this because we are moving all dataset scripts from GitHub to the Hugging Face Hub."
] |
https://api.github.com/repos/huggingface/datasets/issues/5161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5161/comments | https://api.github.com/repos/huggingface/datasets/issues/5161/events | https://github.com/huggingface/datasets/issues/5161 | 1,422,371,748 | I_kwDODunzps5Ux6uk | 5,161 | Dataset can’t cache model’s outputs | [] | closed | false | null | 1 | 2022-10-25T12:19:00Z | 2022-11-03T16:12:52Z | 2022-11-03T16:12:51Z | null | ### Describe the bug
Hi,
I try to cache some outputs of teacher model( Knowledge Distillation ) by using map function of Dataset library, while every time I run my code, I still recompute all the sequences. I tested Bert Model like this, I got different hash every single run, so any idea to deal with this?
### Steps to reproduce the bug
1. run below code
2. get different hash
```
from transformers import BertModel
from transformers import AutoTokenizer
import torch
token = ['hello']
model = BertModel.from_pretrained("bert-base-uncased").eval()
tok = AutoTokenizer.from_pretrained("bert-base-uncased")
def abcd():
with torch.no_grad():
out = model(**tok(token,return_tensors='pt'))[0]
# out = tok(token)
return out
from datasets.fingerprint import Hasher
my_func = abcd
print(Hasher.hash(my_func))
print(abcd())
```
### Expected behavior
I wanna cache all the model output
### Environment info
datasets:2.5.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5161/timeline | null | completed | null | null | false | [
"Addressed in https://github.com/huggingface/datasets/pull/5191 (torch.Tensor objects now produce deterministic hashes)"
] |
https://api.github.com/repos/huggingface/datasets/issues/175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/175/comments | https://api.github.com/repos/huggingface/datasets/issues/175/events | https://github.com/huggingface/datasets/issues/175 | 621,929,428 | MDU6SXNzdWU2MjE5Mjk0Mjg= | 175 | [Manual data dir] Error message: nlp.load_dataset('xsum') -> TypeError | [] | closed | false | null | 0 | 2020-05-20T17:00:32Z | 2020-05-20T18:18:50Z | 2020-05-20T18:18:50Z | null | v 0.1.0 from pip
```python
import nlp
xsum = nlp.load_dataset('xsum')
```
Issue is `dl_manager.manual_dir`is `None`
```python
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-42-8a32f066f3bd> in <module>
----> 1 xsum = nlp.load_dataset('xsum')
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
515 download_mode=download_mode,
516 ignore_verifications=ignore_verifications,
--> 517 save_infos=save_infos,
518 )
519
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, dl_manager, **download_and_prepare_kwargs)
361 verify_infos = not save_infos and not ignore_verifications
362 self._download_and_prepare(
--> 363 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
364 )
365 # Sync info
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
397 split_dict = SplitDict(dataset_name=self.name)
398 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 399 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
400 # Checksums verification
401 if verify_infos:
~/miniconda3/envs/nb/lib/python3.7/site-packages/nlp/datasets/xsum/5c5fca23aaaa469b7a1c6f095cf12f90d7ab99bcc0d86f689a74fd62634a1472/xsum.py in _split_generators(self, dl_manager)
102 with open(dl_path, "r") as json_file:
103 split_ids = json.load(json_file)
--> 104 downloaded_path = os.path.join(dl_manager.manual_dir, "xsum-extracts-from-downloads")
105 return [
106 nlp.SplitGenerator(
~/miniconda3/envs/nb/lib/python3.7/posixpath.py in join(a, *p)
78 will be discarded. An empty last part will result in a path that
79 ends with a separator."""
---> 80 a = os.fspath(a)
81 sep = _get_sep(a)
82 path = a
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/175/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3344/comments | https://api.github.com/repos/huggingface/datasets/issues/3344/events | https://github.com/huggingface/datasets/pull/3344 | 1,067,567,603 | PR_kwDODunzps4vNJwd | 3,344 | Add ArrayXD docs | [] | closed | false | null | 0 | 2021-11-30T18:53:31Z | 2021-12-01T20:16:03Z | 2021-12-01T19:35:32Z | null | Documents support for dynamic first dimension in `ArrayXD` from #2891, and explain the `ArrayXD` feature in general.
Let me know if I'm missing anything @lhoestq :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3344/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3344/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3344.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3344",
"merged_at": "2021-12-01T19:35:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3344.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3344"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/79 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/79/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/79/comments | https://api.github.com/repos/huggingface/datasets/issues/79/events | https://github.com/huggingface/datasets/pull/79 | 616,785,613 | MDExOlB1bGxSZXF1ZXN0NDE2ODI5NzMy | 79 | [Convert] add new pattern | [] | closed | false | null | 0 | 2020-05-12T16:16:51Z | 2020-05-12T16:17:10Z | 2020-05-12T16:17:09Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/79/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/79/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/79.diff",
"html_url": "https://github.com/huggingface/datasets/pull/79",
"merged_at": "2020-05-12T16:17:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/79.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/79"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5226 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5226/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5226/comments | https://api.github.com/repos/huggingface/datasets/issues/5226/events | https://github.com/huggingface/datasets/issues/5226 | 1,444,385,148 | I_kwDODunzps5WF5F8 | 5,226 | Q: Memory release when removing the column? | [] | closed | false | null | 3 | 2022-11-10T18:35:27Z | 2022-11-29T15:10:10Z | 2022-11-29T15:10:10Z | null | ### Describe the bug
How do I release memory when I use methods like `.remove_columns()` or `clear()` in notebooks?
```python
from datasets import load_dataset
common_voice = load_dataset("mozilla-foundation/common_voice_11_0", "ja", use_auth_token=True)
# check memory -> RAM Used (GB): 0.704 / Total (GB) 33.670
common_voice = common_voice.remove_columns(column_names=common_voice.column_names['train'])
common_voice.clear()
# check memory -> RAM Used (GB): 0.705 / Total (GB) 33.670
```
I tried `gc.collect()` but did not help
### Steps to reproduce the bug
1. load dataset
2. remove all the columns
3. check memory is reduced or not
[link to reproduce](https://www.kaggle.com/code/bayartsogtya/huggingface-dataset-memory-issue/notebook?scriptVersionId=110630567)
### Expected behavior
Memory released when I remove the column
### Environment info
- `datasets` version: 2.1.0
- Platform: Linux-5.15.65+-x86_64-with-debian-bullseye-sid
- Python version: 3.7.12
- PyArrow version: 8.0.0
- Pandas version: 1.3.5 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5226/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5226/timeline | null | completed | null | null | false | [
"Hi ! Datasets are memory mapped from your disk, i.e. they're not loaded in RAM. This is possible thanks to the Arrow data format.\r\n\r\nTherefore the column you remove is not in RAM, so removing it doesn't cause the RAM to decrease.",
"Thanks for the explanation! @lhoestq \r\nI wonder since it is memory mapped, can we reduce or remove this memory map?",
"Yes you can `del common_voice` for example or wait for it to be garbage collected"
] |
https://api.github.com/repos/huggingface/datasets/issues/738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/738/comments | https://api.github.com/repos/huggingface/datasets/issues/738/events | https://github.com/huggingface/datasets/pull/738 | 723,033,923 | MDExOlB1bGxSZXF1ZXN0NTA0NjkxNjM4 | 738 | Replace seqeval code with original classification_report for simplicity | [] | closed | false | null | 3 | 2020-10-16T08:51:45Z | 2021-01-21T16:07:15Z | 2020-10-19T10:31:12Z | null | Recently, the original seqeval has enabled us to get per type scores and overall scores as a dictionary.
This PR replaces the current code with the original function(`classification_report`) to simplify it.
Also, the original code has been updated to fix #352.
- Related issue: https://github.com/chakki-works/seqeval/pull/38
```python
from datasets import load_metric
metric = load_metric("seqeval")
y_true = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
y_pred = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
metric.compute(predictions=y_pred, references=y_true)
# Output: {'MISC': {'precision': 0.0, 'recall': 0.0, 'f1': 0, 'number': 1}, 'PER': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1}, 'overall_precision': 0.5, 'overall_recall': 0.5, 'overall_f1': 0.5, 'overall_accuracy': 0.8}
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/738/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/738/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/738.diff",
"html_url": "https://github.com/huggingface/datasets/pull/738",
"merged_at": "2020-10-19T10:31:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/738.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/738"
} | true | [
"Hello,\r\n\r\nI ran https://github.com/huggingface/transformers/blob/master/examples/token-classification/run.sh\r\n\r\nAnd received this error:\r\n```\r\n100%|██████████| 407/407 [21:37<00:00, 3.44s/it]Traceback (most recent call last):\r\n File \"run_ner.py\", line 445, in <module>\r\n main()\r\n File \"run_ner.py\", line 398, in main\r\n results = trainer.evaluate()\r\n File \"/data/2021/transformers/src/transformers/trainer.py\", line 1470, in evaluate\r\n metric_key_prefix=metric_key_prefix,\r\n File \"/data/2021/transformers/src/transformers/trainer.py\", line 1622, in prediction_loop\r\n metrics = self.compute_metrics(EvalPrediction(predictions=preds, label_ids=label_ids))\r\n File \"run_ner.py\", line 345, in compute_metrics\r\n results = metric.compute(predictions=true_predictions, references=true_labels)\r\n File \"/usr/local/lib/python3.6/dist-packages/datasets/metric.py\", line 398, in compute\r\n output = self._compute(predictions=predictions, references=references, **kwargs)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/metrics/seqeval/81eda1ff004361d4fa48754a446ec69bb7aa9cf4d14c7215f407d1475941c5ff/seqeval.py\", line 97, in _compute\r\n report = classification_report(y_true=references, y_pred=predictions, suffix=suffix, output_dict=True)\r\nTypeError: classification_report() got an unexpected keyword argument 'output_dict'\r\n```\r\n\r\nI'm still trying multiple things to see if I can work around this, but I thought it might be useful to mention it here.\r\n\r\n```\r\nName: transformers\r\nVersion: 4.3.0.dev0\r\n\r\nName: datasets\r\nVersion: 1.2.1\r\n```",
"Hi, can you try to update your local installation of `seqeval` ?\r\n\r\n```\r\npip install --upgrade seqeval\r\n```",
"@lhoestq thanks for the reply. Indeed it was some issue with my setup. I removed the \"transformers\" and \"datasets\" (that I had previously installed from the source code), cleared the cache and installed everything again. It works great now!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2011 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2011/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2011/comments | https://api.github.com/repos/huggingface/datasets/issues/2011/events | https://github.com/huggingface/datasets/pull/2011 | 825,621,952 | MDExOlB1bGxSZXF1ZXN0NTg3Njk4MTAx | 2,011 | Add RoSent Dataset | [] | closed | false | null | 0 | 2021-03-09T09:40:08Z | 2021-03-11T18:00:52Z | 2021-03-11T18:00:52Z | null | This PR adds a Romanian sentiment analysis dataset. This PR also closes pending PR #1529.
I had to add an `original_id` feature because the dataset files have repeated IDs. I can remove them if needed. I have also added `id` which is unique.
Let me know in case of any issues. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2011/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2011/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2011.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2011",
"merged_at": "2021-03-11T18:00:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2011.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2011"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-01-19T13:36:50Z | 2022-01-28T15:35:57Z | 2022-01-28T15:35:57Z | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousand rows, create a new dataset with these and also add a new column to it:
> dataset2 = dataset.select(list(range(1000)))
> final_dataset = dataset2.add_column('colB', list(range(1000)))
This gives an error
>ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
So it looks like even though it is a dataset with 1000 rows, it "remembers" the shape of the one it was sliced from.
## Actual results
```
ArrowInvalid Traceback (most recent call last)
<ipython-input-138-e806860f3ce3> in <module>
----> 1 final_dataset = dataset2.add_column('colB', list(range(1000)))
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
468 }
469 # apply actual function
--> 470 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
471 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
472 # re-apply format to the output
~/.local/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
404 # Call actual function
405
--> 406 out = func(self, *args, **kwargs)
407
408 # Update fingerprint of in-place transforms + update in-place history of transforms
~/.local/lib/python3.8/site-packages/datasets/arrow_dataset.py in add_column(self, name, column, new_fingerprint)
3343 column_table = InMemoryTable.from_pydict({name: column})
3344 # Concatenate tables horizontally
-> 3345 table = ConcatenationTable.from_tables([self._data, column_table], axis=1)
3346 # Update features
3347 info = self.info.copy()
~/.local/lib/python3.8/site-packages/datasets/table.py in from_tables(cls, tables, axis)
729 table_blocks = to_blocks(table)
730 blocks = _extend_blocks(blocks, table_blocks, axis=axis)
--> 731 return cls.from_blocks(blocks)
732
733 @property
~/.local/lib/python3.8/site-packages/datasets/table.py in from_blocks(cls, blocks)
668 @classmethod
669 def from_blocks(cls, blocks: TableBlockContainer) -> "ConcatenationTable":
--> 670 blocks = cls._consolidate_blocks(blocks)
671 if isinstance(blocks, TableBlock):
672 table = blocks
~/.local/lib/python3.8/site-packages/datasets/table.py in _consolidate_blocks(cls, blocks)
664 return cls._merge_blocks(blocks, axis=0)
665 else:
--> 666 return cls._merge_blocks(blocks)
667
668 @classmethod
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in <listcomp>(.0)
650 merged_blocks += list(block_group)
651 else: # both
--> 652 merged_blocks = [cls._merge_blocks(row_block, axis=1) for row_block in blocks]
653 if all(len(row_block) == 1 for row_block in merged_blocks):
654 merged_blocks = cls._merge_blocks(
~/.local/lib/python3.8/site-packages/datasets/table.py in _merge_blocks(cls, blocks, axis)
647 for is_in_memory, block_group in groupby(blocks, key=lambda x: isinstance(x, InMemoryTable)):
648 if is_in_memory:
--> 649 block_group = [InMemoryTable(cls._concat_blocks(list(block_group), axis=axis))]
650 merged_blocks += list(block_group)
651 else: # both
~/.local/lib/python3.8/site-packages/datasets/table.py in _concat_blocks(blocks, axis)
626 else:
627 for name, col in zip(table.column_names, table.columns):
--> 628 pa_table = pa_table.append_column(name, col)
629 return pa_table
630 else:
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.append_column()
~/.local/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.add_column()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/.local/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Added column's length must match table's length. Expected length 2000 but got length 1000
```
A solution provided by @mariosasko is to use `dataset2.flatten_indices()` after the `select()` and before attempting to add the new column:
> dataset = Dataset.from_dict({'colA': list(range(2000))})
> dataset2 = dataset.select(list(range(1000)))
> dataset2 = dataset2.flatten_indices()
> final_dataset = dataset2.add_column('colB', list(range(1000)))
which works.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.13.2 (note: also checked with version 1.17.0, still the same error)
- Platform: Ubuntu 20.04.3
- Python version: 3.8.10
- PyArrow version: 6.0.0
| {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | completed | null | null | false | [
"similar #3611 "
] |
https://api.github.com/repos/huggingface/datasets/issues/595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/595/comments | https://api.github.com/repos/huggingface/datasets/issues/595/events | https://github.com/huggingface/datasets/issues/595 | 696,892,304 | MDU6SXNzdWU2OTY4OTIzMDQ= | 595 | `Dataset`/`DatasetDict` has no attribute 'save_to_disk' | [] | closed | false | null | 2 | 2020-09-09T15:01:52Z | 2020-09-09T16:20:19Z | 2020-09-09T16:20:18Z | null | Hi,
As the title indicates, both `Dataset` and `DatasetDict` classes don't seem to have the `save_to_disk` method. While the file [`arrow_dataset.py`](https://github.com/huggingface/nlp/blob/34bf0b03bfe03e7f77b8fec1cd48f5452c4fc7c1/src/nlp/arrow_dataset.py) in the repo here has the method, the file `arrow_dataset.py` which is saved after `pip install nlp -U` in my `conda` environment DOES NOT contain the `save_to_disk` method. I even tried `pip install git+https://github.com/huggingface/nlp.git ` and still no luck. Do I need to install the library in another way? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/595/timeline | null | completed | null | null | false | [
"`pip install git+https://github.com/huggingface/nlp.git` should have done the job.\r\n\r\nDid you uninstall `nlp` before installing from github ?",
"> Did you uninstall `nlp` before installing from github ?\r\n\r\nI did not. I created a new environment and installed `nlp` directly from `github` and it worked!\r\n\r\nThanks.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5895 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5895/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5895/comments | https://api.github.com/repos/huggingface/datasets/issues/5895/events | https://github.com/huggingface/datasets/issues/5895 | 1,725,467,252 | I_kwDODunzps5m2Ip0 | 5,895 | The dir name and split strings are confused when loading ArmelR/stack-exchange-instruction dataset | [] | closed | false | null | 2 | 2023-05-25T09:39:06Z | 2023-05-29T02:32:12Z | 2023-05-29T02:32:12Z | null | ### Describe the bug
When I load the ArmelR/stack-exchange-instruction dataset, I encounter a bug that may be raised by confusing the dir name string and the split string about the dataset.
When I use the script "datasets.load_dataset('ArmelR/stack-exchange-instruction', data_dir="data/finetune", split="train", use_auth_token=True)", it fails. But it succeeds when I add the "streaming = True" parameter.
The website of the dataset is https://huggingface.co/datasets/ArmelR/stack-exchange-instruction/ .
The traceback logs are as below:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/load.py", line 1797, in load_dataset
builder_instance.download_and_prepare(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/builder.py", line 890, in download_and_prepare
self._download_and_prepare(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/builder.py", line 985, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/builder.py", line 1706, in _prepare_split
split_info = self.info.splits[split_generator.name]
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/splits.py", line 530, in __getitem__
instructions = make_file_instructions(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/arrow_reader.py", line 112, in make_file_instructions
name2filenames = {
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/arrow_reader.py", line 113, in <dictcomp>
info.name: filenames_for_dataset_split(
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/naming.py", line 70, in filenames_for_dataset_split
prefix = filename_prefix_for_split(dataset_name, split)
File "/home/xxx/miniconda3/envs/code/lib/python3.9/site-packages/datasets/naming.py", line 54, in filename_prefix_for_split
if os.path.basename(name) != name:
File "/home/xxx/miniconda3/envs/code/lib/python3.9/posixpath.py", line 142, in basename
p = os.fspath(p)
TypeError: expected str, bytes or os.PathLike object, not NoneType
### Steps to reproduce the bug
1. import datasets library function: ```from datasets import load_dataset```
2. load dataset: ```ds=load_dataset('ArmelR/stack-exchange-instruction', data_dir="data/finetune", split="train", use_auth_token=True)```
### Expected behavior
The dataset can be loaded successfully without the streaming setting.
### Environment info
Linux,
python=3.9
datasets=2.12.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5895/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5895/timeline | null | completed | null | null | false | [
"Thanks for reporting, @DongHande.\r\n\r\nI think the issue is caused by the metadata in the dataset card: in the header of the `README.md`, they state that the dataset has 4 splits (\"finetune\", \"reward\", \"rl\", \"evaluation\"). \r\n```yaml\r\n splits:\r\n - name: finetune\r\n num_bytes: 6674567576\r\n num_examples: 3000000\r\n - name: reward\r\n num_bytes: 6674341521\r\n num_examples: 3000000\r\n - name: rl\r\n num_bytes: 6679279968\r\n num_examples: 3000000\r\n - name: evaluation\r\n num_bytes: 4022714493\r\n num_examples: 1807695\r\n```\r\n\r\n\r\nI guess the user wanted to define these as configs, instead of splits. This is not yet supported for no-script datasets, but will be soon supported. See:\r\n- #5331\r\n\r\nI think we should contact the dataset author to inform about the issue with the split names, as you already did: https://huggingface.co/datasets/ArmelR/stack-exchange-instruction/discussions/1\r\nLet's continue the discussion there!",
"Thank you! It has been fixed. "
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.