
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3566/comments | https://api.github.com/repos/huggingface/datasets/issues/3566/events | https://github.com/huggingface/datasets/pull/3566 | 1,100,155,902 | PR_kwDODunzps4w2Tcc | 3,566 | Add initial electricity time series dataset | [] | closed | false | null | 2 | 2022-01-12T10:21:32Z | 2022-02-15T13:31:48Z | 2022-02-15T13:31:48Z | null | Here is an initial prototype time series dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3566/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3566.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3566",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3566.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3566"
} | true | [
"@kashif Some commits on the PR branch are not authored by you, so could you please open a new PR and not use rebase this time :)? You can copy and paste the dataset dir to the new branch. \r\n\r\n",
"making a new PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/5433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5433/comments | https://api.github.com/repos/huggingface/datasets/issues/5433/events | https://github.com/huggingface/datasets/issues/5433 | 1,536,017,901 | I_kwDODunzps5bjcXt | 5,433 | Support latest Docker image in CI benchmarks | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 3 | 2023-01-17T09:06:08Z | 2023-01-18T06:29:08Z | 2023-01-18T06:29:08Z | null | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5433/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5433/timeline | null | completed | null | null | false | [
"Sorry, it was us:[^1] https://github.com/iterative/cml/pull/1317 & https://github.com/iterative/cml/issues/1319#issuecomment-1385599559; should be fixed with [v0.18.17](https://github.com/iterative/cml/releases/tag/v0.18.17).\r\n\r\n[^1]: More or less, see https://github.com/yargs/yargs/issues/873.",
"Opened https://github.com/huggingface/datasets/pull/5436 unpinning again the container image.",
"Hi @0x2b3bfa0, thanks a lot for the investigation, the context about the the root cause and for fixing it!!\r\n\r\nWe are reviewing your PR to unpin the container image."
] |
https://api.github.com/repos/huggingface/datasets/issues/2746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2746/comments | https://api.github.com/repos/huggingface/datasets/issues/2746/events | https://github.com/huggingface/datasets/issues/2746 | 958,551,619 | MDU6SXNzdWU5NTg1NTE2MTk= | 2,746 | Cannot load `few-nerd` dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 6 | 2021-08-02T22:18:57Z | 2021-11-16T08:51:34Z | 2021-08-03T19:45:43Z | null | ## Describe the bug
Cannot load `few-nerd` dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('few-nerd', 'supervised')
```
## Actual results
Executing above code will give the following error:
```
Using the latest cached version of the module from /Users/Mehrad/.cache/huggingface/modules/datasets_modules/datasets/few-nerd/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53 (last modified on Wed Jun 2 11:34:25 2021) since it couldn't be found locally at /Users/Mehrad/Documents/GitHub/genienlp/few-nerd/few-nerd.py, or remotely (FileNotFoundError).
Downloading and preparing dataset few_nerd/supervised (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /Users/Mehrad/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53...
Traceback (most recent call last):
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/datasets/builder.py", line 693, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/datasets/builder.py", line 1107, in _prepare_split
disable=bool(logging.get_verbosity() == logging.NOTSET),
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/Users/Mehrad/.cache/huggingface/modules/datasets_modules/datasets/few-nerd/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53/few-nerd.py", line 196, in _generate_examples
with open(filepath, encoding="utf-8") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/Users/Mehrad/.cache/huggingface/datasets/downloads/supervised/train.json'
```
The bug is probably in identifying and downloading the dataset. If I download the json splits directly from [link](https://github.com/nbroad1881/few-nerd/tree/main/uncompressed) and put them under the downloads directory, they will be processed into arrow format correctly.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Python version: 3.8
- PyArrow version: 1.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2746/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2746/timeline | null | completed | null | null | false | [
"Hi @Mehrad0711,\r\n\r\nI'm afraid there is no \"canonical\" Hugging Face dataset named \"few-nerd\".\r\n\r\nThere are 2 kinds of datasets hosted at the Hugging Face Hub:\r\n- canonical datasets (their identifier contains no slash \"/\"): we, the Hugging Face team, supervise their implementation and we make sure they work correctly by means of our test suite\r\n- community datasets (their identifier contains a slash \"/\", where before the slash it is the username or the organization name): those datasets are uploaded to the Hub by the community, and we, the Hugging Face team, do not supervise them; it is the responsibility of the user/organization implementing them properly if they want them to be used by other users.\r\n\r\nIn this specific case, there is no \"canonical\" dataset named \"few-nerd\". On the other hand, there are two \"community\" datasets named \"few-nerd\":\r\n- [\"nbroad/few-nerd\"](https://huggingface.co/datasets/nbroad/few-nerd)\r\n- [\"dfki-nlp/few-nerd\"](https://huggingface.co/datasets/dfki-nlp/few-nerd)\r\n\r\nIf they were properly implemented, you should be able to load them this way:\r\n```python\r\n# \"nbroad/few-nerd\" community dataset\r\nds = load_dataset(\"nbroad/few-nerd\", \"supervised\")\r\n\r\n# \"dfki-nlp/few-nerd\" community dataset\r\nds = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\n```\r\n\r\nHowever, they are not correctly implemented and both of them give errors:\r\n- \"nbroad/few-nerd\":\r\n ```\r\n TypeError: expected str, bytes or os.PathLike object, not dict\r\n ```\r\n- \"dfki-nlp/few-nerd\":\r\n ```\r\n ConnectionError: Couldn't reach https://cloud.tsinghua.edu.cn/f/09265750ae6340429827/?dl=1\r\n ```\r\n\r\nYou could try to contact their users/organizations to inform them about their bugs and ask them if they are planning to fix them. Alternatively you could try to implement your own script for this dataset.",
"Thanks @albertvillanova for your detailed explanation! I will resort to my own scripts for now. ",
"Hello, @Mehrad0711; Hi, @albertvillanova !\r\nI am the maintainer of the `dfki/few-nerd\" dataset script, sorry for the very late reply and hope this message finds you well!\r\nWe should use\r\n```\r\ndataset = load_dataset(\"dfki-nlp/few-nerd\", name=\"supervised\")\r\n```\r\ninstead of not specifying the \"name\" argument, where name is from `[\"supervised\", \"inter\", \"intra\"]`. Otherwise the method just treats \"supervised\" as `split`, which we reserve after specifying the name, since for each name, there are three splits: train, dev and test.\r\n\r\nAlso we use Tsinghua server source to download data files since it is the official source referred in the paper where the dataset is released (even though it is cc-by-sa-4.0 licensed, means we can copy the data anywhere after mentioning the license\r\n). Sometimes the server just runs down due to high pressure, kinda weird (we encountered the same server problem serveral times a month when we conducted experiments on Few-NERD XD). I tried the script just now and it works perfectly!\r\n```\r\n>> dataset\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 131767\r\n })\r\n validation: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 18824\r\n })\r\n test: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 37648\r\n })\r\n})\r\n>>> dataset[\"train\"]\r\nDataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 131767\r\n})\r\n>>> dataset[\"train\"][0]\r\n{'id': '0', 'tokens': ['Paul', 'International', 'airport', '.'], 'ner_tags': [0, 0, 0, 0], 'fine_ner_tags': [0, 0, 0, 0]}\r\n```\r\nAnyways if you cannot stand the pain with the server and its slow download speed, you can also download the `dfki/few-nerd.py` script from HF and change the `_URLs` to your personal drive (after you once successfully download the data and upload to your cloud drive), and then load the .py script locally.\r\n\r\nHope this reply can still be any help. If you still have problems with it, feel free to ask here and I am glad to help!\r\nBest wishes.",
"Hi @chen-yuxuan, thanks for your answer.\r\n\r\nJust a few comments:\r\n\r\n- Please, note that as we use `datasets.load_dataset` implementation, we can pass the configuration name as the second positional argument (no need to pass explicitly `name=`) and it downloads the 3 splits:\r\n```python\r\n In [4]: ds = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.5k/11.5k [00:00<00:00, 2.85MB/s]\r\nDownloading and preparing dataset few_nerd/supervised to .cache\\huggingface\\datasets\\dfki-nlp___few_nerd\\supervised\\0.0.0\\e40882b71f037a4a1f232025899170fbe8113cd2f4a26dddd2add7222a077255...\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14.6M/14.6M [01:16<00:00, 190kB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.9M/11.9M [01:14<00:00, 160kB/s]\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12.0M/12.0M [01:04<00:00, 186kB/s]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [03:58<00:00, 79.45s/it]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 3.11it/s]\r\n```\r\n\r\n- On the other hand, please note that your script does not work on Windows machines, because you call `open()` without passing the encoding parameter:\r\n```\r\n~\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\dfki-nlp___few-nerd\\e40882b71f037a4a1f232025899170fbe8113cd2f4a26dddd2add7222a077255\\few-nerd.py in <genexpr>(.0)\r\n 276 assert filepath[-4:] == \".txt\"\r\n 277\r\n--> 278 num_lines = sum(1 for _ in open(filepath))\r\n 279 id = 0\r\n 280\r\n\r\n.venv\\lib\\encodings\\cp1252.py in decode(self, input, final)\r\n 21 class IncrementalDecoder(codecs.IncrementalDecoder):\r\n 22 def decode(self, input, final=False):\r\n---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]\r\n 24\r\n 25 class StreamWriter(Codec,codecs.StreamWriter):\r\n\r\nUnicodeDecodeError: 'charmap' codec can't decode byte 0x8d in position 5238: character maps to <undefined>\r\n```\r\n\r\nIf you would like your script to be usable on Windows machines, you should pass `encoding=\"utf-8\"` to every `open()` function:\r\n- line 278: `num_lines = sum(1 for _ in open(filepath, encoding=\"utf-8\"))`\r\n- line 281: `with open(filepath, \"r\", encoding=\"utf-8\")`",
"Thank you @albertvillanova for your detailed feedback!\r\n\r\n> no need to pass explicitly `name=`\r\n\r\nGood catch! I thought `split` stands before `name` in the argument list... but now it is all clear to me, sounds cool! Thanks for the explanation.\r\n\r\nAnyways in our old code it still looks bit confusing if we only want one split but the function downloads all, so to allow efficient downloading, I optimized the code a bit so that only the specified split data is downloaded. now we get\r\n```\r\n>>> x = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\nDownloading and preparing dataset few_nerd/supervised to /home/user/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/8e7ab598946cd5b395dcec6ea239123c8dff5b58b8e1c03b0c595b540248a885...\r\nDownloading: 100%|███████████████████████████████████████████████████████████████████| 14.6M/14.6M [01:01<00:00, 238kB/s]\r\n100%|██████████████████████████████████████████████████████████████████████| 3359329/3359329 [00:12<00:00, 275462.84it/s]\r\n100%|████████████████████████████████████████████████████████████████████████| 482037/482037 [00:01<00:00, 278633.64it/s]\r\n100%|████████████████████████████████████████████████████████████████████████| 958765/958765 [00:03<00:00, 267472.83it/s]\r\nDataset few_nerd downloaded and prepared to /home/user/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/8e7ab598946cd5b395dcec6ea239123c8dff5b58b8e1c03b0c595b540248a885. Subsequent calls will reuse this data.\r\n```\r\nwhere only one progress bar indicates downloading, and the three others just indicate pre-processing for the train, dev, test set.\r\n\r\nFor the encoding issue, I have made corresponding changes for the two lines you pointed out. However, I have no windows machine at hand, I would really appreciate it if you could help test on your end.\r\n\r\nAll the updates are uploaded to HF under `dfki-nlp` account where I am working for. \r\nThank you again for your kind help!\r\n",
"Hi @chen-yuxuan,\r\n\r\nI have tested on Windows and now it works perfectly, after the fixing of the encoding issue:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"dfki-nlp/few-nerd\", \"supervised\")\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11.5k/11.5k [00:00<?, ?B/s]\r\nDownloading and preparing dataset few_nerd/supervised to C:\\Users\\username\\.cache\\huggingface\\datasets\\dfki-nlp___few_nerd\\supervised\\0.0.0\\e1ceeaee82073fea12206e4461c7cfcd67e68c8f3ebeca179bddcacee00c4511...\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3359329/3359329 [00:25<00:00, 129427.23it/s]\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 482037/482037 [00:03<00:00, 134513.66it/s]\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 958765/958765 [00:06<00:00, 143152.35it/s]\r\nDataset few_nerd downloaded and prepared to C:\\Users\\username\\.cache\\huggingface\\datasets\\dfki-nlp___few_nerd\\supervised\\0.0.0\\e1ceeaee82073fea12206e4461c7cfcd67e68c8f3ebeca179bddcacee00c4511. Subsequent calls will reuse this data.765 [00:06<00:00, 139045.03it/s]\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 174.71it/s]\r\n\r\nIn [3]: ds\r\nOut[3]:\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 131767\r\n })\r\n validation: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 18824\r\n })\r\n test: Dataset({\r\n features: ['id', 'tokens', 'ner_tags', 'fine_ner_tags'],\r\n num_rows: 37648\r\n })\r\n})\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/5341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5341/comments | https://api.github.com/repos/huggingface/datasets/issues/5341/events | https://github.com/huggingface/datasets/pull/5341 | 1,484,376,644 | PR_kwDODunzps5Exohx | 5,341 | Remove tasks.json | [] | closed | false | null | 1 | 2022-12-08T11:04:35Z | 2022-12-09T12:26:21Z | 2022-12-09T12:23:20Z | null | After discussions in https://github.com/huggingface/datasets/pull/5335 we should remove this file that is not used anymore. We should update https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts instead. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5341/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5341",
"merged_at": "2022-12-09T12:23:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5341"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3467 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3467/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3467/comments | https://api.github.com/repos/huggingface/datasets/issues/3467/events | https://github.com/huggingface/datasets/pull/3467 | 1,085,870,665 | PR_kwDODunzps4wIoqd | 3,467 | Push dataset infos.json to Hub | [] | closed | false | null | 1 | 2021-12-21T14:07:13Z | 2021-12-21T17:00:10Z | 2021-12-21T17:00:09Z | null | When doing `push_to_hub`, the feature types are lost (see issue https://github.com/huggingface/datasets/issues/3394).
This PR fixes this by also pushing a `dataset_infos.json` file to the Hub, that stores the feature types.
Other minor changes:
- renamed the `___` separator to `--`, since `--` is now disallowed in a name in the back-end.
I tested this feature with datasets like conll2003 that has feature types like `ClassLabel` that were previously lost.
Close https://github.com/huggingface/datasets/issues/3394
I would like to include this in today's release (though not mandatory), so feel free to comment/suggest changes | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3467/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3467/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3467.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3467",
"merged_at": "2021-12-21T17:00:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3467.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3467"
} | true | [
"The change from `___` to `--` was allowed by https://github.com/huggingface/moon-landing/pull/1657"
] |
https://api.github.com/repos/huggingface/datasets/issues/1826 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1826/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1826/comments | https://api.github.com/repos/huggingface/datasets/issues/1826/events | https://github.com/huggingface/datasets/pull/1826 | 802,074,744 | MDExOlB1bGxSZXF1ZXN0NTY4Mjc4OTI2 | 1,826 | Print error message with filename when malformed CSV | [] | closed | false | null | 0 | 2021-02-05T11:07:59Z | 2021-02-09T17:39:27Z | 2021-02-09T17:39:27Z | null | Print error message specifying filename when malformed CSV file.
Close #1821 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1826/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1826/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1826.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1826",
"merged_at": "2021-02-09T17:39:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1826.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1826"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1311/comments | https://api.github.com/repos/huggingface/datasets/issues/1311/events | https://github.com/huggingface/datasets/pull/1311 | 759,514,819 | MDExOlB1bGxSZXF1ZXN0NTM0NTA3NjM1 | 1,311 | Add OPUS Bible Corpus (102 Languages) | [] | closed | false | null | 1 | 2020-12-08T14:57:08Z | 2020-12-09T15:30:57Z | 2020-12-09T15:30:56Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1311/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1311/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1311.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1311",
"merged_at": "2020-12-09T15:30:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1311.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1311"
} | true | [
"@lhoestq done"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/1974 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1974/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1974/comments | https://api.github.com/repos/huggingface/datasets/issues/1974/events | https://github.com/huggingface/datasets/pull/1974 | 820,122,223 | MDExOlB1bGxSZXF1ZXN0NTgzMTE5MDI0 | 1,974 | feat(docs): navigate with left/right arrow keys | [] | closed | false | null | 0 | 2021-03-02T15:24:50Z | 2021-03-04T10:44:12Z | 2021-03-04T10:42:48Z | null | Enables docs navigation with left/right arrow keys. It can be useful for the ones who navigate with keyboard a lot.
More info : https://github.com/sphinx-doc/sphinx/pull/2064
You can try here : https://29353-250213286-gh.circle-artifacts.com/0/docs/_build/html/index.html | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1974/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1974/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1974.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1974",
"merged_at": "2021-03-04T10:42:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1974.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1974"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/120 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/120/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/120/comments | https://api.github.com/repos/huggingface/datasets/issues/120/events | https://github.com/huggingface/datasets/issues/120 | 618,737,783 | MDU6SXNzdWU2MTg3Mzc3ODM= | 120 | 🐛 `map` not working | [] | closed | false | null | 1 | 2020-05-15T06:43:08Z | 2020-05-15T07:02:38Z | 2020-05-15T07:02:38Z | null | I'm trying to run a basic example (mapping function to add a prefix).
[Here is the colab notebook I'm using.](https://colab.research.google.com/drive/1YH4JCAy0R1MMSc-k_Vlik_s1LEzP_t1h?usp=sharing)
```python
import nlp
dataset = nlp.load_dataset('squad', split='validation[:10%]')
def test(sample):
sample['title'] = "test prefix @@@ " + sample["title"]
return sample
print(dataset[0]['title'])
dataset.map(test)
print(dataset[0]['title'])
```
Output :
> Super_Bowl_50
Super_Bowl_50
Expected output :
> Super_Bowl_50
test prefix @@@ Super_Bowl_50 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/120/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/120/timeline | null | completed | null | null | false | [
"I didn't assign the output 🤦♂️\r\n\r\n```python\r\ndataset.map(test)\r\n```\r\n\r\nshould be :\r\n\r\n```python\r\ndataset = dataset.map(test)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/5077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5077/comments | https://api.github.com/repos/huggingface/datasets/issues/5077/events | https://github.com/huggingface/datasets/pull/5077 | 1,398,080,859 | PR_kwDODunzps5AOs9L | 5,077 | Fix passed download_config in HubDatasetModuleFactoryWithoutScript | [] | closed | false | null | 1 | 2022-10-05T16:42:36Z | 2022-10-06T05:31:22Z | 2022-10-06T05:29:06Z | null | Fix passed `download_config` in `HubDatasetModuleFactoryWithoutScript`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5077/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5077/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5077.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5077",
"merged_at": "2022-10-06T05:29:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5077.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5077"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/637/comments | https://api.github.com/repos/huggingface/datasets/issues/637/events | https://github.com/huggingface/datasets/pull/637 | 703,539,909 | MDExOlB1bGxSZXF1ZXN0NDg4NjMwNzk4 | 637 | Add MATINF | [] | closed | false | null | 0 | 2020-09-17T12:24:53Z | 2020-09-17T13:23:18Z | 2020-09-17T13:23:17Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/637/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/637.diff",
"html_url": "https://github.com/huggingface/datasets/pull/637",
"merged_at": "2020-09-17T13:23:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/637.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/637"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/6033 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6033/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6033/comments | https://api.github.com/repos/huggingface/datasets/issues/6033/events | https://github.com/huggingface/datasets/issues/6033 | 1,804,482,051 | I_kwDODunzps5rjjYD | 6,033 | `map` function doesn't fully utilize `input_columns`. | [] | closed | false | null | 0 | 2023-07-14T08:49:28Z | 2023-07-14T09:16:04Z | 2023-07-14T09:16:04Z | null | ### Describe the bug
I wanted to select only some columns of data.
And I thought that's why the argument `input_columns` exists.
What I expected is like this:
If there are ["a", "b", "c", "d"] columns, and if I set `input_columns=["a", "d"]`, the data will have only ["a", "d"] columns.
But it doesn't select columns.
It preserves existing columns.
The main cause is `update` function of `dictionary` type `transformed_batch`.
https://github.com/huggingface/datasets/blob/682d21e94ab1e64c11b583de39dc4c93f0101c5a/src/datasets/iterable_dataset.py#L687-L691
`transformed_batch` gets all the columns by `transformed_batch = dict(batch)`.
Even `function_args` selects `input_columns`, `update` preserves columns other than `input_columns`.
I think it should take a new dictionary with columns in `input_columns` like this:
```
# transformed_batch = dict(batch)
# transformed_batch.update(self.function(*function_args, **self.fn_kwargs)
# This is what I think correct.
transformed_batch = self.function(*function_args, **self.fn_kwargs)
```
Let me know how to use `input_columns`.
### Steps to reproduce the bug
Described all above.
### Expected behavior
Described all above.
### Environment info
datasets: 2.12
python: 3.8 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6033/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6033/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1163 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1163/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1163/comments | https://api.github.com/repos/huggingface/datasets/issues/1163/events | https://github.com/huggingface/datasets/pull/1163 | 757,711,340 | MDExOlB1bGxSZXF1ZXN0NTMzMDM4Mzc3 | 1,163 | Added memat : Xhosa-English parallel corpora | [] | closed | false | null | 2 | 2020-12-05T16:08:50Z | 2020-12-07T10:40:24Z | 2020-12-07T10:40:24Z | null | Added memat : Xhosa-English parallel corpora
for more info : http://opus.nlpl.eu/memat.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1163/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1163/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1163.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1163",
"merged_at": "2020-12-07T10:40:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1163.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1163"
} | true | [
"The `RemoteDatasetTest` CI fail is fixed on master so it's fine",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/5908 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5908/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5908/comments | https://api.github.com/repos/huggingface/datasets/issues/5908/events | https://github.com/huggingface/datasets/issues/5908 | 1,728,653,935 | I_kwDODunzps5nCSpv | 5,908 | Unbearably slow sorting on big mapped datasets | [] | open | false | null | 6 | 2023-05-27T11:08:32Z | 2023-06-13T17:45:10Z | null | null | ### Describe the bug
For me, with ~40k lines, sorting took 3.5 seconds on a flattened dataset (including the flatten operation) and 22.7 seconds on a mapped dataset (right after sharding), which is about x5 slowdown. Moreover, it seems like it slows down exponentially with bigger datasets (wasn't able to sort 700k lines at all, with flattening takes about a minute).
### Steps to reproduce the bug
```Python
from datasets import load_dataset
import time
dataset = load_dataset("xnli", "en", split="train")
dataset = dataset.shard(10, 0)
print(len(dataset))
t = time.time()
# dataset = dataset.flatten_indices() # uncomment this line and it's fast
dataset = dataset.sort("label", reverse=True, load_from_cache_file=False)
print(f"finished in {time.time() - t:.4f} seconds")
```
### Expected behavior
Expect sorting to take the same or less time than flattening and then sorting.
### Environment info
- `datasets` version: 2.12.1.dev0 (same with 2.12.0 too)
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.10.10
- Huggingface_hub version: 0.14.1
- PyArrow version: 12.0.0
- Pandas version: 2.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5908/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5908/timeline | null | null | null | null | false | [
"Hi ! `shard` currently returns a slow dataset by default, with examples evenly distributed in the dataset.\r\n\r\nYou can get a fast dataset using `contiguous=True` (which should be the default imo):\r\n\r\n```python\r\ndataset = dataset.shard(10, 0, contiguous=True)\r\n```\r\n\r\nThis way you don't need to flatten_indices() and sort should be fast as well",
"@lhoestq \r\n\r\n> contiguous=True (which should be the default imo)\r\n\r\nFor `IterableDataset`, it's not possible to implement contiguous sharding without knowing the number of examples in advance, so setting the default value to `contiguous=True` would result in an inconsistency between `Dataset` and `IterableDataset` (when we add `IterableDataset.shard`)",
"Actually sharded iterable datasets are made of sub iterables that generally yield contiguous data no ? So in a way it's possible to shard an iterable dataset contiguously.\r\n\r\nIf the dataset is made of one shard it's indeed not possible to shard it contiguously though",
"> Actually sharded iterable datasets are made of sub iterables that generally yield contiguous data no ? So in a way it's possible to shard an iterable dataset contiguously.\r\n\r\nBut sharding an iterable dataset by sharding its `gen_kwargs` would still yield approximate shards(not equal to `Dataset.shard`), no? ",
"Yes indeed !",
"I understand the issue doesn't exist with non-mapped datasets, but if flattening is so much more efficient than sorting the indices, that's an issue in itself.\n\nThere are plenty of issues people posted for which the root cause turns out to be the same. It seems like mapped datasets are terribly inefficient. I think I saw some issue like that somewhere (about the mapped datasets in general), but can't find it now.\n\nMaybe indices should be flattened before any additional processing, then."
] |
https://api.github.com/repos/huggingface/datasets/issues/2207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2207/comments | https://api.github.com/repos/huggingface/datasets/issues/2207/events | https://github.com/huggingface/datasets/issues/2207 | 855,267,383 | MDU6SXNzdWU4NTUyNjczODM= | 2,207 | making labels consistent across the datasets | [] | closed | false | null | 2 | 2021-04-11T10:03:56Z | 2022-06-01T16:23:08Z | 2022-06-01T16:21:10Z | null | Hi
For accessing the labels one can type
```
>>> a.features['label']
ClassLabel(num_classes=3, names=['entailment', 'neutral', 'contradiction'], names_file=None, id=None)
```
The labels however are not consistent with the actual labels sometimes, for instance in case of XNLI, the actual labels are 0,1,2, but if one try to access as above they are entailment, neutral,contradiction,
it would be great to have the labels consistent.
thanks
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2207/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2207/timeline | null | completed | null | null | false | [
"Hi ! The ClassLabel feature type encodes the labels as integers.\r\nThe integer corresponds to the index of the label name in the `names` list of the ClassLabel.\r\nHere that means that the labels are 'entailment' (0), 'neutral' (1), 'contradiction' (2).\r\n\r\nYou can get the label names back by using `a.features['label'].int2str(i)`.\r\n",
"Hi! You can also easily reorder the label with the [`Dataset.align_labels_with_mapping`](https://huggingface.co/docs/datasets/master/en/process#align) method."
] |
https://api.github.com/repos/huggingface/datasets/issues/5729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5729/comments | https://api.github.com/repos/huggingface/datasets/issues/5729/events | https://github.com/huggingface/datasets/pull/5729 | 1,661,929,923 | PR_kwDODunzps5N_pvI | 5,729 | Fix nondeterministic sharded data split order | [] | closed | false | null | 3 | 2023-04-11T07:34:20Z | 2023-04-26T15:12:25Z | 2023-04-26T15:05:12Z | null | This PR makes the order of the split names deterministic. Before it was nondeterministic because we were iterating over `set` elements.
Fix #5728. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5729/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5729/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5729.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5729",
"merged_at": "2023-04-26T15:05:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5729.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5729"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The error in the CI was unrelated to this PR. I have merged main branch once that has been fixed.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006954 / 0.011353 (-0.004399) | 0.004947 / 0.011008 (-0.006061) | 0.086564 / 0.038508 (0.048056) | 0.031167 / 0.023109 (0.008058) | 0.262285 / 0.275898 (-0.013613) | 0.295753 / 0.323480 (-0.027727) | 0.005389 / 0.007986 (-0.002596) | 0.004130 / 0.004328 (-0.000198) | 0.065127 / 0.004250 (0.060877) | 0.042511 / 0.037052 (0.005458) | 0.263497 / 0.258489 (0.005008) | 0.307456 / 0.293841 (0.013615) | 0.031338 / 0.128546 (-0.097209) | 0.011023 / 0.075646 (-0.064623) | 0.295625 / 0.419271 (-0.123647) | 0.045813 / 0.043533 (0.002280) | 0.259369 / 0.255139 (0.004230) | 0.279325 / 0.283200 (-0.003875) | 0.099748 / 0.141683 (-0.041934) | 1.252572 / 1.452155 (-0.199583) | 1.347069 / 1.492716 (-0.145647) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.249726 / 0.018006 (0.231720) | 0.556882 / 0.000490 (0.556392) | 0.008237 / 0.000200 (0.008037) | 0.000294 / 0.000054 (0.000239) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026879 / 0.037411 (-0.010533) | 0.105141 / 0.014526 (0.090615) | 0.115473 / 0.176557 (-0.061084) | 0.172989 / 0.737135 (-0.564147) | 0.120433 / 0.296338 (-0.175906) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400022 / 0.215209 (0.184812) | 3.965402 / 2.077655 (1.887747) | 1.805257 / 1.504120 (0.301138) | 1.610136 / 1.541195 (0.068941) | 1.661162 / 1.468490 (0.192672) | 0.695311 / 4.584777 (-3.889466) | 3.753757 / 3.745712 (0.008045) | 2.060609 / 5.269862 (-3.209253) | 1.333251 / 4.565676 (-3.232426) | 0.085790 / 0.424275 (-0.338485) | 0.012256 / 0.007607 (0.004649) | 0.502133 / 0.226044 (0.276088) | 5.040979 / 2.268929 (2.772051) | 2.310919 / 55.444624 (-53.133705) | 2.010534 / 6.876477 (-4.865943) | 2.132961 / 2.142072 (-0.009111) | 0.837636 / 4.805227 (-3.967592) | 0.169838 / 6.500664 (-6.330826) | 0.065003 / 0.075469 (-0.010466) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.218674 / 1.841788 (-0.623114) | 14.696076 / 8.074308 (6.621768) | 14.559492 / 10.191392 (4.368100) | 0.167761 / 0.680424 (-0.512663) | 0.017747 / 0.534201 (-0.516454) | 0.421624 / 0.579283 (-0.157659) | 0.414086 / 0.434364 (-0.020278) | 0.501398 / 0.540337 (-0.038940) | 0.596099 / 1.386936 (-0.790837) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007230 / 0.011353 (-0.004123) | 0.005345 / 0.011008 (-0.005664) | 0.073739 / 0.038508 (0.035231) | 0.033440 / 0.023109 (0.010330) | 0.339790 / 0.275898 (0.063892) | 0.367857 / 0.323480 (0.044377) | 0.005927 / 0.007986 (-0.002058) | 0.004279 / 0.004328 (-0.000049) | 0.074247 / 0.004250 (0.069996) | 0.048971 / 0.037052 (0.011918) | 0.340235 / 0.258489 (0.081746) | 0.380521 / 0.293841 (0.086680) | 0.035322 / 0.128546 (-0.093225) | 0.012416 / 0.075646 (-0.063230) | 0.086060 / 0.419271 (-0.333212) | 0.049331 / 0.043533 (0.005799) | 0.342871 / 0.255139 (0.087732) | 0.355673 / 0.283200 (0.072473) | 0.111976 / 0.141683 (-0.029707) | 1.462530 / 1.452155 (0.010375) | 1.550336 / 1.492716 (0.057620) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.266560 / 0.018006 (0.248554) | 0.550886 / 0.000490 (0.550396) | 0.001069 / 0.000200 (0.000869) | 0.000085 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028701 / 0.037411 (-0.008711) | 0.110535 / 0.014526 (0.096010) | 0.122846 / 0.176557 (-0.053711) | 0.176395 / 0.737135 (-0.560740) | 0.128653 / 0.296338 (-0.167685) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.431693 / 0.215209 (0.216484) | 4.283691 / 2.077655 (2.206036) | 2.013967 / 1.504120 (0.509847) | 1.823914 / 1.541195 (0.282719) | 1.872055 / 1.468490 (0.403565) | 0.703318 / 4.584777 (-3.881459) | 3.783412 / 3.745712 (0.037699) | 2.950147 / 5.269862 (-2.319715) | 1.826159 / 4.565676 (-2.739518) | 0.086897 / 0.424275 (-0.337379) | 0.012512 / 0.007607 (0.004905) | 0.526730 / 0.226044 (0.300685) | 5.263871 / 2.268929 (2.994943) | 2.552163 / 55.444624 (-52.892462) | 2.276216 / 6.876477 (-4.600261) | 2.419934 / 2.142072 (0.277862) | 0.848235 / 4.805227 (-3.956993) | 0.170405 / 6.500664 (-6.330259) | 0.064979 / 0.075469 (-0.010491) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.276780 / 1.841788 (-0.565008) | 15.100829 / 8.074308 (7.026521) | 15.117531 / 10.191392 (4.926139) | 0.147129 / 0.680424 (-0.533295) | 0.017806 / 0.534201 (-0.516395) | 0.422975 / 0.579283 (-0.156308) | 0.430286 / 0.434364 (-0.004078) | 0.501405 / 0.540337 (-0.038932) | 0.596810 / 1.386936 (-0.790126) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3343/comments | https://api.github.com/repos/huggingface/datasets/issues/3343/events | https://github.com/huggingface/datasets/pull/3343 | 1,067,505,507 | PR_kwDODunzps4vM8yB | 3,343 | Better error message when download fails | [] | closed | false | null | 0 | 2021-11-30T17:38:50Z | 2021-12-01T11:27:59Z | 2021-12-01T11:27:58Z | null | From our discussions in https://github.com/huggingface/datasets/issues/3269 and https://github.com/huggingface/datasets/issues/3282 it would be nice to have better messages if a download fails.
In particular the error now shows:
- the error from the HEAD request if there's one
- otherwise the response code of the HEAD request
I also added an error to tell users to pass `use_auth_token` when the Hugging Face Hub returns 401 (Unauthorized).
While paying around with this I also fixed a minor issue with the `force_download` parameter that was not always taken into account | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3343/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3343/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3343.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3343",
"merged_at": "2021-12-01T11:27:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3343.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3343"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1609/comments | https://api.github.com/repos/huggingface/datasets/issues/1609/events | https://github.com/huggingface/datasets/issues/1609 | 771,421,881 | MDU6SXNzdWU3NzE0MjE4ODE= | 1,609 | Not able to use 'jigsaw_toxicity_pred' dataset | [] | closed | false | null | 2 | 2020-12-19T17:35:48Z | 2020-12-22T16:42:24Z | 2020-12-22T16:42:23Z | null | When trying to use jigsaw_toxicity_pred dataset, like this in a [colab](https://colab.research.google.com/drive/1LwO2A5M2X5dvhkAFYE4D2CUT3WUdWnkn?usp=sharing):
```
from datasets import list_datasets, list_metrics, load_dataset, load_metric
ds = load_dataset("jigsaw_toxicity_pred")
```
I see below error:
> FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
280 raise FileNotFoundError(
281 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 282 combined_path, github_file_path, file_path
283 )
284 )
FileNotFoundError: Couldn't find file locally at jigsaw_toxicity_pred/jigsaw_toxicity_pred.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1609/timeline | null | completed | null | null | false | [
"Hi @jassimran,\r\nThe `jigsaw_toxicity_pred` dataset has not been released yet, it will be available with version 2 of `datasets`, coming soon.\r\nYou can still access it by installing the master (unreleased) version of datasets directly :\r\n`pip install git+https://github.com/huggingface/datasets.git@master`\r\nPlease let me know if this helps",
"Thanks.That works for now."
] |
https://api.github.com/repos/huggingface/datasets/issues/1136 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1136/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1136/comments | https://api.github.com/repos/huggingface/datasets/issues/1136/events | https://github.com/huggingface/datasets/pull/1136 | 757,341,607 | MDExOlB1bGxSZXF1ZXN0NTMyNzM0MzQ4 | 1,136 | minor change in description in paws-x.py and updated dataset_infos | [] | closed | false | null | 0 | 2020-12-04T19:17:49Z | 2020-12-06T18:02:57Z | 2020-12-06T18:02:57Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1136/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1136/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1136.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1136",
"merged_at": "2020-12-06T18:02:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1136.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1136"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/715/comments | https://api.github.com/repos/huggingface/datasets/issues/715/events | https://github.com/huggingface/datasets/pull/715 | 714,690,192 | MDExOlB1bGxSZXF1ZXN0NDk3NzMwMDQ2 | 715 | Use python read for text dataset | [] | closed | false | null | 7 | 2020-10-05T09:47:55Z | 2020-10-05T13:13:18Z | 2020-10-05T13:13:17Z | null | As mentioned in #622 the pandas reader used for text dataset doesn't work properly when there are \r characters in the text file.
Instead I switched to pure python using `open` and `read`.
From my benchmark on a 100MB text file, it's the same speed as the previous pandas reader. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 3,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/715/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/715/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/715.diff",
"html_url": "https://github.com/huggingface/datasets/pull/715",
"merged_at": "2020-10-05T13:13:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/715.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/715"
} | true | [
"One thing though, could we try to read the files in parallel?",
"We could but I'm not sure this would help a lot since the bottleneck is the drive IO if the files are big enough.\r\nIt could make sense for very small files.",
"Looks like windows is not a big fan of this approach\r\nI'm working on a fix",
"I remember issue https://github.com/huggingface/datasets/issues/546 where this was kinda requested (but maybe IO would bottleneck). What do you think?",
"I think it's worth testing multiprocessing. It could also be something we add to our speed benchmarks",
"> I remember issue #546 where this was kinda requested (but maybe IO would bottleneck). What do you think?\r\n\r\nIt still would be interesting I think, especially in scenarios where IO is less of an issue (SSDs particularly) and where there are many smaller files. Wrapping this function in a `pool.map` is perhaps an easy thing to try. ",
"Merging this one for now for the patch release"
] |
https://api.github.com/repos/huggingface/datasets/issues/725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/725/comments | https://api.github.com/repos/huggingface/datasets/issues/725/events | https://github.com/huggingface/datasets/pull/725 | 718,985,641 | MDExOlB1bGxSZXF1ZXN0NTAxMjUxODI1 | 725 | pretty print dataset objects | [] | closed | false | null | 2 | 2020-10-12T02:03:46Z | 2020-10-23T16:24:35Z | 2020-10-23T09:00:46Z | null | Currently, if I do:
```
from datasets import load_dataset
load_dataset("wikihow", 'all', data_dir="/hf/pegasus-datasets/wikihow/")
```
I get:
```
DatasetDict({'train': Dataset(features: {'text': Value(dtype='string', id=None),
'headline': Value(dtype='string', id=None), 'title': Value(dtype='string',
id=None)}, num_rows: 157252), 'validation': Dataset(features: {'text':
Value(dtype='string', id=None), 'headline': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None)}, num_rows: 5599), 'test':
Dataset(features: {'text': Value(dtype='string', id=None), 'headline':
Value(dtype='string', id=None), 'title': Value(dtype='string', id=None)},
num_rows: 5577)})
```
This is not very readable.
Can we either have a better `__repr__` or have a custom method to nicely pprint the dataset object?
Here is my very simple attempt. With this PR, it produces:
```
DatasetDict({
train: Dataset({
features: ['text', 'headline', 'title'],
num_rows: 157252
})
validation: Dataset({
features: ['text', 'headline', 'title'],
num_rows: 5599
})
test: Dataset({
features: ['text', 'headline', 'title'],
num_rows: 5577
})
})
```
I did omit the data types on purpose to make it more readable, but it shouldn't be too difficult to integrate those too.
note that this PR also fixes the inconsistency in output that in master misses enclosing `{}` for Dataset, but it is there for `DatasetDict` - or perhaps it was by design.
I'm totally not attached to this format, just wanting something more readable. One approach could be to serialize to `json.dumps` or something similar. It'd make the indentation simpler.
Thank you. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/725/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/725.diff",
"html_url": "https://github.com/huggingface/datasets/pull/725",
"merged_at": "2020-10-23T09:00:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/725.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/725"
} | true | [
"Great, as you found it useful I improved the code a bit to automate indentation in the parent class, so that the child repr doesn't need to guess the indentation level, while repr'ing nicely on its own.\r\n\r\n- do we want indent=4 or 2?\r\n- do we want `{` ... `}` or w/o?\r\n\r\ncurrently it's indent4 and w/ curly braces, so it looks:\r\n\r\n```\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['text', 'headline', 'title'],\r\n num_rows: 157252\r\n })\r\n validation: Dataset({\r\n features: ['text', 'headline', 'title'],\r\n num_rows: 5599\r\n })\r\n test: Dataset({\r\n features: ['text', 'headline', 'title'],\r\n num_rows: 5577\r\n })\r\n})\r\n```\r\njust child:\r\n```\r\nDataset({\r\n features: ['text', 'headline', 'title'],\r\n num_rows: 5577\r\n})\r\n```\r\n\r\n",
"Yes! A lot better indeed!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2483/comments | https://api.github.com/repos/huggingface/datasets/issues/2483/events | https://github.com/huggingface/datasets/pull/2483 | 918,871,712 | MDExOlB1bGxSZXF1ZXN0NjY4MjU1Mjg1 | 2,483 | Use gc.collect only when needed to avoid slow downs | [] | closed | false | null | 2 | 2021-06-11T15:09:30Z | 2021-06-18T19:25:06Z | 2021-06-11T15:31:36Z | null | In https://github.com/huggingface/datasets/commit/42320a110d9d072703814e1f630a0d90d626a1e6 we added a call to gc.collect to resolve some issues on windows (see https://github.com/huggingface/datasets/pull/2482)
However calling gc.collect too often causes significant slow downs (the CI run time doubled).
So I just moved the gc.collect call to the exact place where it's actually needed: when post-processing a dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2483/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2483.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2483",
"merged_at": "2021-06-11T15:31:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2483.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2483"
} | true | [
"I continue thinking that the origin of the issue has to do with tqdm (and not with Arrow): this issue only arises for version 4.50.0 (and later) of tqdm, not for previous versions of tqdm.\r\n\r\nMy guess is that tqdm made a change from version 4.50.0 that does not properly release the iterable. ",
"FR"
] |
https://api.github.com/repos/huggingface/datasets/issues/1234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1234/comments | https://api.github.com/repos/huggingface/datasets/issues/1234/events | https://github.com/huggingface/datasets/pull/1234 | 758,229,304 | MDExOlB1bGxSZXF1ZXN0NTMzNDM0ODkz | 1,234 | Added ade_corpus_v2, with 3 configs for relation extraction and classification task | [] | closed | false | null | 3 | 2020-12-07T07:05:14Z | 2020-12-14T17:49:14Z | 2020-12-14T17:49:14Z | null | Adverse Drug Reaction Data: ADE-Corpus-V2 dataset added configs for different tasks with given data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1234/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1234",
"merged_at": "2020-12-14T17:49:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1234"
} | true | [
"@lhoestq I have added the tags they are in separate files for 3 different configs",
"@lhoestq thanks for the review I added your suggested changes.",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/4811 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4811/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4811/comments | https://api.github.com/repos/huggingface/datasets/issues/4811/events | https://github.com/huggingface/datasets/issues/4811 | 1,333,043,421 | I_kwDODunzps5PdKDd | 4,811 | Bug in function validate_type for Python >= 3.9 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-08-09T10:25:21Z | 2022-08-12T13:27:05Z | 2022-08-12T13:27:05Z | null | ## Describe the bug
The function `validate_type` assumes that the type `typing.Optional[str]` is automatically transformed to `typing.Union[str, NoneType]`.
```python
In [4]: typing.Optional[str]
Out[4]: typing.Union[str, NoneType]
```
However, this is not the case for Python 3.9:
```python
In [3]: typing.Optional[str]
Out[3]: typing.Optional[str]
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4811/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4811/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1708/comments | https://api.github.com/repos/huggingface/datasets/issues/1708/events | https://github.com/huggingface/datasets/issues/1708 | 781,631,455 | MDU6SXNzdWU3ODE2MzE0NTU= | 1,708 | <html dir="ltr" lang="en" class="focus-outline-visible"><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> | [] | closed | false | null | 0 | 2021-01-07T21:45:24Z | 2021-01-08T09:00:01Z | 2021-01-08T09:00:01Z | null | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1708/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1708/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/6002 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6002/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6002/comments | https://api.github.com/repos/huggingface/datasets/issues/6002/events | https://github.com/huggingface/datasets/pull/6002 | 1,786,053,060 | PR_kwDODunzps5UhP-Z | 6,002 | Add KLUE-MRC metrics | [] | closed | false | null | 1 | 2023-07-03T12:11:10Z | 2023-07-09T11:57:20Z | 2023-07-09T11:57:20Z | null | ## Metrics for KLUE-MRC (Korean Language Understanding Evaluation — Machine Reading Comprehension)
Adding metrics for [KLUE-MRC](https://huggingface.co/datasets/klue).
KLUE-MRC is very similar to SQuAD 2.0 but has a slightly different format which is why I added metrics for KLUE-MRC.
Specifically, in the case of [LM Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness), it leverages the scoring script of SQuAD to evaluate SQuAD 2.0 and KorQuAD. But the script isn't suitable for KLUE-MRC because KLUE-MRC is a bit different from SQuAD 2.0. And this is why I added the scoring script for KLUE-MRC.
- [x] All tests passed
- [x] Added a metric card (referred the metric card of SQuAD 2.0)
- [x] Compatibility test with [LM Eval Harness](https://github.com/EleutherAI/lm-evaluation-harness) passed
### References
- [KLUE: Korean Language Understanding Evaluation](https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/file/98dce83da57b0395e163467c9dae521b-Paper-round2.pdf)
- [KLUE on Hugging Face Datasets](https://huggingface.co/datasets/klue)
- #2416 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6002/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6002/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6002.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6002",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6002.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6002"
} | true | [
"The metrics API in `datasets` is deprecated as of version 2.0, and `evaulate` is our new library for metrics. You can add a new metric to it by following [these steps](https://huggingface.co/docs/evaluate/creating_and_sharing)."
] |
https://api.github.com/repos/huggingface/datasets/issues/4321 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4321/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4321/comments | https://api.github.com/repos/huggingface/datasets/issues/4321/events | https://github.com/huggingface/datasets/pull/4321 | 1,233,273,351 | PR_kwDODunzps43ryW7 | 4,321 | Adding dataset enwik8 | [] | closed | false | null | 2 | 2022-05-11T23:25:02Z | 2022-06-01T14:27:30Z | 2022-06-01T14:04:06Z | null | Because I regularly work with enwik8, I would like to contribute the dataset loader 🤗 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4321/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4321/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4321.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4321",
"merged_at": "2022-06-01T14:04:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4321.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4321"
} | true | [
"@lhoestq Thank you for the great feedback! Looks like all tests are passing now :)",
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2967 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2967/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2967/comments | https://api.github.com/repos/huggingface/datasets/issues/2967/events | https://github.com/huggingface/datasets/issues/2967 | 1,007,194,837 | I_kwDODunzps48CJLV | 2,967 | Adding vision-and-language datasets (e.g., VQA, VCR) to Datasets | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2021-09-25T20:58:15Z | 2021-10-03T20:34:22Z | 2021-10-03T20:34:22Z | null | **Is your feature request related to a problem? Please describe.**
Would you like to add any vision-and-language datasets (e.g., VQA, VCR) to Huggingface Datasets?
**Describe the solution you'd like**
N/A
**Describe alternatives you've considered**
N/A
**Additional context**
This is Da Yin at UCLA. Recently, we have published an EMNLP 2021 paper about geo-diverse visual commonsense reasoning (https://arxiv.org/abs/2109.06860). We propose a new dataset called GD-VCR, a vision-and-language dataset to evaluate how well V&L models perform on scenarios involving geo-location-specific commonsense. We hope to have our V&L dataset incorporated into Huggingface to further promote our project, but I haven't seen much V&L datasets in the current package. Is it possible to add V&L datasets, and if so, how should we prepare for the loading? Thank you very much!
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2967/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2967/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3363/comments | https://api.github.com/repos/huggingface/datasets/issues/3363/events | https://github.com/huggingface/datasets/pull/3363 | 1,068,824,340 | PR_kwDODunzps4vRVCl | 3,363 | Update URL of Jeopardy! dataset | [] | closed | false | null | 2 | 2021-12-01T20:08:10Z | 2022-10-06T13:45:49Z | 2021-12-03T12:35:01Z | null | Updates the URL of the Jeopardy! dataset.
Fix #3361 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3363/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3363.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3363",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3363.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3363"
} | true | [
"Closing this PR in favor of #3266.",
"I think you should also close this branch"
] |
https://api.github.com/repos/huggingface/datasets/issues/2202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2202/comments | https://api.github.com/repos/huggingface/datasets/issues/2202/events | https://github.com/huggingface/datasets/pull/2202 | 854,501,109 | MDExOlB1bGxSZXF1ZXN0NjEyNDM2ODMx | 2,202 | Add classes GenerateMode, DownloadConfig and Version to the documentation | [] | closed | false | null | 0 | 2021-04-09T12:58:19Z | 2021-04-12T17:58:00Z | 2021-04-12T17:57:59Z | null | Add documentation for classes `GenerateMode`, `DownloadConfig` and `Version`.
Update the docstring of `load_dataset` to create cross-reference links to the classes.
Related to #2187. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2202/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2202/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2202.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2202",
"merged_at": "2021-04-12T17:57:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2202.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2202"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3903 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3903/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3903/comments | https://api.github.com/repos/huggingface/datasets/issues/3903/events | https://github.com/huggingface/datasets/pull/3903 | 1,167,521,627 | PR_kwDODunzps40WnkI | 3,903 | Add Biwi Kinect Head Pose dataset. | [] | closed | false | null | 17 | 2022-03-13T08:59:21Z | 2022-05-31T17:02:19Z | 2022-05-31T12:15:58Z | null | This PR adds the Biwi Kinect Head Pose dataset.
Dataset Request : Add Biwi Kinect Head Pose Database [#3822](https://github.com/huggingface/datasets/issues/3822)
The Biwi Kinect Head Pose Database is acquired with the Microsoft Kinect sensor, a structured IR light device.It contains 15K images of 20 people with 6 females and 14 males where 4 people were recorded twice.
For each frame, there is :
- a depth image, (.bin file)
- a corresponding rgb image (both 640x480 pixels),
- annotation ( present inside a .txt file)
The ground truth is the 3D location of the head and its rotation.
The dataset structure is as follows :
```
- 01.obj
- 01
- frame_00003_depth.bin
- frame_00003_pose.txt
- frame_00003_rgb.png
.
.
.
- 02.obj
- 02
- frame_00003_depth.bin
- frame_00003_pose.txt
- frame_00003_rgb.png
.
.
.
```
Preview of frame_00003_pose.txt :
```
0.988397 0.0731349 0.133128
-0.0441539 0.976945 -0.208876
-0.145334 0.200575 0.968838
126.665 40.4515 876.198
```
I have used the following dataset features :
```
features=datasets.Features(
{
"person_id": datasets.Value("string"),
"frame_number": datasets.Value("string"),
"depth_image": datasets.Value("string"),
"rgb_image": datasets.Image(),
"3D_head_center": datasets.Array2D(shape=(3, 3), dtype="float"),
"3D_head_rotation": datasets.Value("float"),
}
```
I am giving the path to the depth_image here.
I need some inputs for the following :
1. For each person, the dataset has the following additional information :
```
For each sequence, the corresponding .obj file represents a head template deformed to match the neutral face of that specific person. [*.obj file]
In each folder, two .cal files contain calibration information for the depth and the color camera, e.g., the intrinsic camera matrix of the depth camera and the global rotation and translation to the rgb camera.
```
Wanted to know how we can represent these features ?
2. For _generate_examples , do I parse the directories and fetch the required information ? This would mean reading the .txt file to obtain the "3D_head_center" and "3D_head_rotation" details. We could precompute the features information and have a metadata file and use the metadata file to yield information in _generate_examples ? Wanted your thoughts for the best approach for this ?
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3903/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3903/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3903.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3903",
"merged_at": "2022-05-31T12:15:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3903.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3903"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the detailed explanation of the structure!\r\n\r\n1. IMO it makes the most sense to yield one example for each person (so the total of 24 examples), so the features dict should be similar to this:\r\n \r\n ```python\r\n features = Features({\r\n \"rgb\": Sequence(Image()), # for the png frames\r\n \"rgb_cal\": {\"intrisic_mat\": Array2D(shape=(3, 3), dtype=\"float32\"), \"extrinsic_mat\": {\"rotation\": Array2D(shape=(3, 3), dtype=\"float32\"), \"translation\": Sequence(Value(\"float32\", length=3)}},\r\n \"depth\": Sequence(Value(\"string\")), # for the depth frames\r\n \"depth_cal\": the same as \"rgb_cal\",\r\n \"head_pose_gt\": Sequence({\"center\": Sequence(Value(\"float32\", length=3), \"rotation\": Array2D(shape=(3, 3), dtype=\"float32\")}),\r\n \"head_template\": Value(\"string\"), # for the person's obj file\r\n\r\n })\r\n ```\r\n We can add a \"Data Processing\" section to the card to explain how to parse the files.\r\n\r\n\r\n2. Yes, it's ok to parse the files as long as it doesn't take too much time/memory (e.g., it's ok to parse the `*_pose.txt` or `*.cal` files, but it's better to leave the `*_depth.bin` or `*.obj` files unprocessed and yield the paths to them)",
"Thanks for the suggestions @mariosasko, yielding one example for each person would make things much easier.\r\nOkay. I'll look at parsing the files and then displaying the information.",
"Added the following : \r\n- Features, I have included sequence_number and subject_id along with the features you had suggested.\r\n- Tested loading of the dataset along with dummy_data and full_data tests.\r\n- Created the dataset_infos.json file.\r\n\r\nTo-Do :\r\n- [x] Update Dataset Cards with more details.\r\n- [x] \"Data Processing\" section\r\n\r\nAny inputs on what to include in the \"Data Processing\" section ?\r\n",
"@mariosasko Please could you review this when you get time. Thank you.",
"In the Data Processing section, I've added example code for a compressed binary depth image file. Updated the Readme as well. ",
"@mariosasko / @lhoestq , Please could you review this when you get time. Thank you.",
"Created an issue here: https://github.com/huggingface/datasets/issues/4152",
"Got it. Thanks for the comments. I've collapsed the C++ code in the readme and added the suggestions.",
"Hi ! The `AttributeError ` bug has been fixed, feel free to merge `master` into your branch ;)",
"I haven't been able to figure out why CI is failing, the error shown is : \r\n\r\n```\r\nE ValueError: The following issues have been found in the dataset cards:\r\nE README Parsing:\r\nE list index out of range\r\nE The following issues have been found in the dataset cards:\r\nE README Validation:\r\nE list index out of range\r\n```\r\n\r\nAny inputs would be helpful.",
"I think it's because there are tabulations in the c++ code, can you replace them with regular spaces please ?\r\n\r\n(then in another PR we can maybe fix the Readme parser to support text indented with tabulations)",
"@lhoestq , initially the idea was to have one example = one image with an additional field mentioning the frame_number. But each subject, we had a head template, calibration information for the depth and the color camera which was common to all the examples for that subject. Also, the images were continuous frames.\r\n@mariosasko suggested this structure and it made sense to group the images together for a particular subject.",
"> Don't you think it would be more practical to have one example = one image in this dataset ?\r\n\r\nHaving one example = one image would be good but since we have a head template, calibration information for the depth and the color camera which is common to all the images for that subject and the images being continuous frames, I think it makes sense to group the images together for each subject. This will make the feature representation easier.\r\n\r\n",
"Ok I see, sounds good then. Users can still separate the images if they want to",
"The CI fails are unrelated to this PR and fixed on master, merging !",
"Great. Thanks @lhoestq , I think we can close this issue now. ( #3822 )"
] |
https://api.github.com/repos/huggingface/datasets/issues/3945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3945/comments | https://api.github.com/repos/huggingface/datasets/issues/3945/events | https://github.com/huggingface/datasets/pull/3945 | 1,171,222,257 | PR_kwDODunzps40ixmc | 3,945 | Fix comet metric | [] | closed | false | null | 4 | 2022-03-16T15:56:47Z | 2022-03-22T15:10:12Z | 2022-03-22T15:05:30Z | null | The COMET metric has been broken for a while since big breaking changes happened. We did not catch them in the CI because the slow test mocks the download_model function that was changed.
This PR fixes the metric, updates the download_model mock and updates the doctest. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3945/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3945/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3945.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3945",
"merged_at": "2022-03-22T15:05:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3945.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3945"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Finally I'm done updating the dependencies ^^'\r\n\r\ncc @sashavor can you review my changes in the metric card please ?",
"Looks good to me! Just fixed a tiny typo :wink: ",
"Thanks !"
] |
https://api.github.com/repos/huggingface/datasets/issues/1949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1949/comments | https://api.github.com/repos/huggingface/datasets/issues/1949/events | https://github.com/huggingface/datasets/issues/1949 | 816,986,936 | MDU6SXNzdWU4MTY5ODY5MzY= | 1,949 | Enable Fast Filtering using Arrow Dataset | [] | open | false | null | 2 | 2021-02-26T02:53:37Z | 2021-02-26T19:18:29Z | null | null | Hi @lhoestq,
As mentioned in Issue #1796, I would love to work on enabling fast filtering/mapping. Can you please share the expectations? It would be great if you could point me to the relevant methods/files involved. Or the docs or maybe an overview of `arrow_dataset.py`. I only ask this because I am having trouble getting started ;-;
Any help would be appreciated.
Thanks,
Gunjan | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1949/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1949/timeline | null | null | null | null | false | [
"Hi @gchhablani :)\r\nThanks for proposing your help !\r\n\r\nI'll be doing a refactor of some parts related to filtering in the scope of https://github.com/huggingface/datasets/issues/1877\r\nSo I would first wait for this refactor to be done before working on the filtering. In particular because I plan to make things simpler to manipulate.\r\n\r\nYour feedback on this refactor would also be appreciated since it also aims at making the core code more accessible (basically my goal is that no one's ever \"having troubles getting started\" ^^)\r\n\r\nThis will be available in a few days, I will be able to give you more details at that time if you don't mind waiting a bit !",
"Sure! I don't mind waiting. I'll check the refactor and try to understand what you're trying to do :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5393/comments | https://api.github.com/repos/huggingface/datasets/issues/5393/events | https://github.com/huggingface/datasets/pull/5393 | 1,512,908,613 | PR_kwDODunzps5GTg0a | 5,393 | Finish deprecating the fs argument | [] | closed | false | null | 6 | 2022-12-28T15:33:17Z | 2023-01-18T12:42:33Z | 2023-01-18T12:35:32Z | null | See #5385 for some discussion on this
The `fs=` arg was depcrecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in `2.8.0` (to be removed in `3.0.0`). There are a few other places where the `fs=` arg was still used (functions/methods in `datasets.info` and `datasets.load`). This PR adds a similar behavior, warnings and the `storage_options=` arg to these functions and methods.
One question: should the "deprecated" / "added" versions be `2.8.1` for the docs/warnings on these? Right now I'm going with "fs was deprecated in 2.8.0" but "storage_options= was added in 2.8.1" where appropriate.
@mariosasko | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5393/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5393/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5393.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5393",
"merged_at": "2023-01-18T12:35:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5393.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5393"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the deprecation. Some minor suggested fixes below...\r\n> \r\n> Also note that the corresponding tests should be updated as well.\r\n\r\nThanks for the suggestions/typo fixes. I updated the failing test - passing locally now",
"Nice thanks !\r\n\r\nI believe you also need to update `_load_info` and `_save_info` in `builder.py` - they're still passing `fs=self._fs` instead of `storage_options=self._fs.storage_options`\r\n\r\nThis should remove the remaining warnings in the CI such as \r\n\r\n```python\r\ntests/test_builder.py::test_builder_with_filesystem_download_and_prepare_reload\r\ntests/test_load.py::test_load_dataset_local[False]\r\ntests/test_load.py::test_load_dataset_local[True]\r\ntests/test_load.py::test_load_dataset_zip_csv[csv_path-False]\r\ntests/test_load.py::test_load_dataset_then_move_then_reload\r\n /opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/site-packages/datasets/info.py:344: FutureWarning: 'fs' was deprecated in favor of 'storage_options' in version 2.9.0 and will be removed in 3.0.0.\r\n You can remove this warning by passing 'storage_options=fs.storage_options' instead.\r\n```",
"re: docstring, I assume passing in `storage_options=s3.storage_options` is correct/necessary to pass the secrets?",
"what about \r\nhttps://github.com/huggingface/datasets/blob/5b793dd8c43bf6e85f165238becb3c64f6cd3ed0/src/datasets/filesystems/__init__.py#L43-L54\r\nleave as is? Is this function no longer necessary?",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008877 / 0.011353 (-0.002475) | 0.004725 / 0.011008 (-0.006283) | 0.100738 / 0.038508 (0.062230) | 0.030251 / 0.023109 (0.007141) | 0.301483 / 0.275898 (0.025585) | 0.374161 / 0.323480 (0.050681) | 0.007225 / 0.007986 (-0.000761) | 0.003654 / 0.004328 (-0.000674) | 0.078400 / 0.004250 (0.074149) | 0.035786 / 0.037052 (-0.001267) | 0.309744 / 0.258489 (0.051255) | 0.355834 / 0.293841 (0.061994) | 0.034344 / 0.128546 (-0.094202) | 0.011584 / 0.075646 (-0.064062) | 0.321462 / 0.419271 (-0.097810) | 0.041201 / 0.043533 (-0.002332) | 0.298808 / 0.255139 (0.043669) | 0.332626 / 0.283200 (0.049426) | 0.089131 / 0.141683 (-0.052552) | 1.477888 / 1.452155 (0.025734) | 1.530365 / 1.492716 (0.037649) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.191647 / 0.018006 (0.173640) | 0.424339 / 0.000490 (0.423849) | 0.002941 / 0.000200 (0.002741) | 0.000075 / 0.000054 (0.000020) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023442 / 0.037411 (-0.013969) | 0.097264 / 0.014526 (0.082738) | 0.105655 / 0.176557 (-0.070901) | 0.145055 / 0.737135 (-0.592081) | 0.108750 / 0.296338 (-0.187588) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422925 / 0.215209 (0.207716) | 4.216022 / 2.077655 (2.138367) | 1.876441 / 1.504120 (0.372322) | 1.665115 / 1.541195 (0.123920) | 1.711105 / 1.468490 (0.242615) | 0.701820 / 4.584777 (-3.882957) | 3.389319 / 3.745712 (-0.356393) | 1.909868 / 5.269862 (-3.359994) | 1.270482 / 4.565676 (-3.295195) | 0.083680 / 0.424275 (-0.340595) | 0.012347 / 0.007607 (0.004740) | 0.531076 / 0.226044 (0.305031) | 5.344045 / 2.268929 (3.075117) | 2.310897 / 55.444624 (-53.133728) | 1.971953 / 6.876477 (-4.904524) | 2.113748 / 2.142072 (-0.028325) | 0.823766 / 4.805227 (-3.981462) | 0.150864 / 6.500664 (-6.349800) | 0.066263 / 0.075469 (-0.009206) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253190 / 1.841788 (-0.588598) | 13.757887 / 8.074308 (5.683579) | 13.888195 / 10.191392 (3.696803) | 0.137285 / 0.680424 (-0.543139) | 0.029151 / 0.534201 (-0.505050) | 0.387402 / 0.579283 (-0.191881) | 0.401673 / 0.434364 (-0.032691) | 0.450474 / 0.540337 (-0.089863) | 0.533757 / 1.386936 (-0.853179) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006919 / 0.011353 (-0.004434) | 0.004655 / 0.011008 (-0.006353) | 0.096946 / 0.038508 (0.058438) | 0.028697 / 0.023109 (0.005588) | 0.420020 / 0.275898 (0.144122) | 0.460193 / 0.323480 (0.136713) | 0.005189 / 0.007986 (-0.002796) | 0.003425 / 0.004328 (-0.000904) | 0.074900 / 0.004250 (0.070649) | 0.041844 / 0.037052 (0.004792) | 0.421538 / 0.258489 (0.163049) | 0.468497 / 0.293841 (0.174656) | 0.032573 / 0.128546 (-0.095973) | 0.011731 / 0.075646 (-0.063916) | 0.320221 / 0.419271 (-0.099050) | 0.042113 / 0.043533 (-0.001420) | 0.422757 / 0.255139 (0.167618) | 0.445372 / 0.283200 (0.162172) | 0.090300 / 0.141683 (-0.051383) | 1.458598 / 1.452155 (0.006443) | 1.550060 / 1.492716 (0.057344) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235489 / 0.018006 (0.217483) | 0.418207 / 0.000490 (0.417718) | 0.002511 / 0.000200 (0.002311) | 0.000080 / 0.000054 (0.000025) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025603 / 0.037411 (-0.011808) | 0.100237 / 0.014526 (0.085711) | 0.108617 / 0.176557 (-0.067939) | 0.148417 / 0.737135 (-0.588719) | 0.110163 / 0.296338 (-0.186176) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.474804 / 0.215209 (0.259595) | 4.745370 / 2.077655 (2.667715) | 2.417819 / 1.504120 (0.913699) | 2.209892 / 1.541195 (0.668697) | 2.263296 / 1.468490 (0.794806) | 0.695537 / 4.584777 (-3.889240) | 3.381028 / 3.745712 (-0.364684) | 2.952271 / 5.269862 (-2.317591) | 1.507041 / 4.565676 (-3.058636) | 0.083334 / 0.424275 (-0.340941) | 0.012554 / 0.007607 (0.004947) | 0.578861 / 0.226044 (0.352817) | 5.795241 / 2.268929 (3.526313) | 2.858544 / 55.444624 (-52.586080) | 2.516270 / 6.876477 (-4.360207) | 2.557350 / 2.142072 (0.415278) | 0.801799 / 4.805227 (-4.003428) | 0.151579 / 6.500664 (-6.349085) | 0.068765 / 0.075469 (-0.006704) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.279935 / 1.841788 (-0.561853) | 14.049065 / 8.074308 (5.974757) | 13.972703 / 10.191392 (3.781311) | 0.140551 / 0.680424 (-0.539873) | 0.016831 / 0.534201 (-0.517370) | 0.383886 / 0.579283 (-0.195397) | 0.385661 / 0.434364 (-0.048703) | 0.444525 / 0.540337 (-0.095813) | 0.532197 / 1.386936 (-0.854739) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/6090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6090/comments | https://api.github.com/repos/huggingface/datasets/issues/6090/events | https://github.com/huggingface/datasets/issues/6090 | 1,825,865,043 | I_kwDODunzps5s1H1T | 6,090 | FilesIterable skips all the files after a hidden file | [] | open | false | null | 0 | 2023-07-28T07:25:57Z | 2023-07-28T07:25:57Z | null | null | ### Describe the bug
When initializing `FilesIterable` with a list of file paths using `FilesIterable.from_paths`, it will discard all the files after a hidden file.
The problem is in [this line](https://github.com/huggingface/datasets/blob/88896a7b28610ace95e444b94f9a4bc332cc1ee3/src/datasets/download/download_manager.py#L233C26-L233C26) where `return` should be replaced by `continue`.
### Steps to reproduce the bug
https://colab.research.google.com/drive/1SQlxs4y_LSo1Q89KnFoYDSyyKEISun_J#scrollTo=93K4_blkW-8-
### Expected behavior
The script should print all the files except the hidden one.
### Environment info
- `datasets` version: 2.14.1
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- PyArrow version: 9.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6090/timeline | null | null | null | null | false | [
"Thanks for reporting. We've merged a PR with a fix."
] |
https://api.github.com/repos/huggingface/datasets/issues/6010 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6010/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6010/comments | https://api.github.com/repos/huggingface/datasets/issues/6010/events | https://github.com/huggingface/datasets/issues/6010 | 1,793,838,152 | I_kwDODunzps5q68xI | 6,010 | Improve `Dataset`'s string representation | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2023-07-07T16:38:03Z | 2023-07-16T13:00:18Z | null | null | Currently, `Dataset.__repr__` outputs a dataset's column names and the number of rows. We could improve it by printing its features and the first few rows.
We should also implement `_repr_html_` to have a rich HTML representation in notebooks/Streamlit. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6010/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6010/timeline | null | null | null | null | false | [
"I want to take a shot at this if possible ",
"Yes, feel free to work on this.\r\n\r\nYou can check the PyArrow Table `__repr__` and Polars DataFrame `__repr__`/`_repr_html_` implementations for some pointers/ideas."
] |
https://api.github.com/repos/huggingface/datasets/issues/1049 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1049/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1049/comments | https://api.github.com/repos/huggingface/datasets/issues/1049/events | https://github.com/huggingface/datasets/pull/1049 | 756,157,602 | MDExOlB1bGxSZXF1ZXN0NTMxNzQ3NDY0 | 1,049 | Add siswati ner corpus | [] | closed | false | null | 0 | 2020-12-03T12:36:00Z | 2020-12-03T17:27:02Z | 2020-12-03T17:26:55Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1049/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1049/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1049.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1049",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1049.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1049"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/4325 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4325/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4325/comments | https://api.github.com/repos/huggingface/datasets/issues/4325/events | https://github.com/huggingface/datasets/issues/4325 | 1,233,812,191 | I_kwDODunzps5Jinrf | 4,325 | Dataset Viewer issue for strombergnlp/offenseval_2020, strombergnlp/polstance | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 4 | 2022-05-12T10:59:08Z | 2022-05-13T10:57:15Z | 2022-05-13T10:57:02Z | null | ### Link
https://huggingface.co/datasets/strombergnlp/offenseval_2020/viewer/ar/train
### Description
The viewer isn't running for these two datasets. I left it overnight because a wait sometimes helps things get loaded, and the error messages have all gone, but the datasets are still turning up blank in viewer. Maybe it needs a bit more time.
* https://huggingface.co/datasets/strombergnlp/polstance/viewer/PolStance/train
* https://huggingface.co/datasets/strombergnlp/offenseval_2020/viewer/ar/train
While offenseval_2020 is gated w. prompt, the other gated previews I have run fine in Viewer, e.g. https://huggingface.co/datasets/strombergnlp/shaj , so I'm a bit stumped!
### Owner
Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4325/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4325/timeline | null | completed | null | null | false | [
"Not sure if it's related... I was going to raise an issue for https://huggingface.co/datasets/domenicrosati/TruthfulQA which also has the same issue... https://huggingface.co/datasets/domenicrosati/TruthfulQA/viewer/domenicrosati--TruthfulQA/train \r\n\r\n",
"Yes, it's related. The backend behind the dataset viewer is currently under too much load, and these datasets are still in the jobs queue. We're actively working on this issue, and we expect to fix the issue permanently soon. Thanks for your patience 🙏 ",
"Thanks @severo and no worries! - a suggestion for a UI usability thing maybe is to indicate that the dataset processing is in the job queue (rather than no data?)",
"Thanks, these are working great now (including @domenicrosati 's, afaics!)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4864 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4864/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4864/comments | https://api.github.com/repos/huggingface/datasets/issues/4864/events | https://github.com/huggingface/datasets/issues/4864 | 1,344,410,043 | I_kwDODunzps5QIhG7 | 4,864 | Allow pathlib PoxisPath in Dataset.read_json | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 6 | 2022-08-19T12:59:17Z | 2023-03-12T11:25:49Z | null | null | **Is your feature request related to a problem? Please describe.**
```
from pathlib import Path
from datasets import Dataset
ds = Dataset.read_json(Path('data.json'))
```
causes an error
```
AttributeError: 'PosixPath' object has no attribute 'decode'
```
**Describe the solution you'd like**
It should be able to accept PosixPath and read the json from inside. | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4864/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4864/timeline | null | null | null | null | false | [
"This same error will occur using `ds = datasets.load_dataset('json', data_files=['test.jsonl'])`",
"@cccntu I want to make a quick fix for this, but I am struggling to find where the json dataset builder is. Do you know?",
"@vvvm23 I think you mean think:\r\n```python\r\nds = datasets.load_dataset('json', data_files=[Path('test.jsonl')])\r\n```\r\nAnd the place you want to modify is here:\r\n```\r\nutils/file_utils.py:64, in is_remote_url(url_or_filename)\r\n 63 def is_remote_url(url_or_filename: str) -> bool:\r\n---> 64 parsed = urlparse(url_or_filename)\r\n 65 return parsed.scheme in (\"http\", \"https\", \"s3\", \"gs\", \"hdfs\", \"ftp\")\r\n```\r\n\r\nProbably just need to check first if `url_or_filename` is [PathLike](https://docs.python.org/3/library/os.html#os.PathLike) and return False early.\r\n\r\nBtw, I tried installing from main, and ran my code above and got a different error. Probably because the API have changed.\r\n`AttributeError: module 'datasets' has no attribute 'read_json'`\r\n",
"> @vvvm23 I think you mean think:\r\n\r\nYou are correct, thanks!\r\n\r\n> Probably just need to check first if url_or_filename is [PathLike](https://docs.python.org/3/library/os.html#os.PathLike) and return False early.\r\n\r\nIs PathLike sufficient, or should I check the file exists here? Or is that handled later?",
"I think here we just want to avoid passing Path to urlparse. A simpler solution is to add a str() call and convert the input to string before passing to the next step. No need to check anything.",
"Above PR should do your first suggestion. Hope that works for you, as I am going on holiday and won't be able to change much :wink: "
] |
https://api.github.com/repos/huggingface/datasets/issues/4987 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4987/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4987/comments | https://api.github.com/repos/huggingface/datasets/issues/4987/events | https://github.com/huggingface/datasets/pull/4987 | 1,376,006,477 | PR_kwDODunzps4_GlIu | 4,987 | Embed image/audio data in dl_and_prepare parquet | [] | closed | false | null | 1 | 2022-09-16T14:09:27Z | 2022-09-16T16:24:47Z | 2022-09-16T16:22:35Z | null | Embed the bytes of the image or audio files in the Parquet files directly, instead of having a "path" that points to a local file.
Indeed Parquet files are often used to share data or to be used by workers that may not have access to the local files. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4987/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4987/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4987.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4987",
"merged_at": "2022-09-16T16:22:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4987.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4987"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3921 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3921/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3921/comments | https://api.github.com/repos/huggingface/datasets/issues/3921/events | https://github.com/huggingface/datasets/pull/3921 | 1,169,749,338 | PR_kwDODunzps40d4Mk | 3,921 | Fix NonMatchingChecksumError in CRD3 dataset | [] | closed | false | null | 2 | 2022-03-15T14:27:14Z | 2022-03-15T15:54:27Z | 2022-03-15T15:54:26Z | null | Fix #3051 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3921/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3921/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3921.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3921",
"merged_at": "2022-03-15T15:54:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3921.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3921"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3921). All of your documentation changes will be reflected on that endpoint.",
"Unrelated test failure. This PR can be merged."
] |
https://api.github.com/repos/huggingface/datasets/issues/2409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2409/comments | https://api.github.com/repos/huggingface/datasets/issues/2409/events | https://github.com/huggingface/datasets/pull/2409 | 903,441,398 | MDExOlB1bGxSZXF1ZXN0NjU0Njk3NjA0 | 2,409 | Add HF_ prefix to env var MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES | [] | closed | false | null | 14 | 2021-05-27T09:07:00Z | 2021-06-08T16:00:55Z | 2021-05-27T09:33:41Z | null | As mentioned in https://github.com/huggingface/datasets/pull/2399 the env var should be prefixed by HF_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2409/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2409/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2409.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2409",
"merged_at": "2021-05-27T09:33:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2409.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2409"
} | true | [
"I thought the renaming was suggested only for the env var, and not for the config variable... As you think is better! ;)",
"I think it's better if they match, so that users understand directly that they're directly connected",
"Well, if you're not concerned about back-compat here, perhaps it could be renamed and shortened too ;)\r\n\r\nI'd suggest one of:\r\n\r\n* `HF_DATASETS_IN_MEMORY_MAX_SIZE`\r\n* `HF_DATASETS_MAX_IN_MEMORY_SIZE`\r\n\r\nthe itention is to:\r\n1. make it consistent with all the other `datasets` env vars which all start with `HF_DATASETS_`, e.g.:\r\n```\r\nHF_DATASETS_CACHE\r\nHF_DATASETS_OFFLINE \r\n```\r\n2. allow to recode in the future to support 1M, 4K, 1T and not just bytes - bytes is not a great choice for this type of variable since it will be at least X Mbytes for most reasonable uses.\r\n\r\nAnd I agree with @albertvillanova that the config variable name shouldn't have the HF prefix - it's preaching to the choir - the user already knows it's a local variable. \r\n\r\nThe only reason we prefix env vars, is because they are used outside of the software.\r\n\r\nBut I do see a good point of you trying to make things consistent too. How about this:\r\n\r\n`config.IN_MEMORY_MAX_SIZE` (or whatever the final env var will be minus `HF_DATASETS_` prefix).\r\n\r\nThis is of course just my opinion.\r\n\r\n",
"Thanks for the comment :)\r\nI like both propositions, and I agree this would be better in order to allow support for 1M, 1T etc. \r\nRegarding the prefix of the variable in config.py I don't have a strong opinion. I just added it for consistency with the other variables that default to the env variables like HF_DATASETS_CACHE. However I agree this would be nice to have shorter names so I'm not against removing the prefix either. Since the feature is relatively new, I think we can still allow ourself to rename it",
"Awesome, \r\n\r\nLet's use then:\r\n\r\n- `HF_DATASETS_IN_MEMORY_MAX_SIZE` for the env var\r\n- `config.IN_MEMORY_MAX_SIZE` for config.\r\n\r\nand for now bytes will be documented as the only option and down the road add support for K/M/G.\r\n\r\n@albertvillanova, does that sound good to you?",
"Great!!! 🤗 ",
"Did I miss a PR with this change?\r\n\r\nI want to make sure to add it to transformers tests to avoid the overheard of rebuilding the datasets.\r\n\r\nThank you!",
"@stas00 I'm taking on this now that I have finally finished the collaborative training experiment. Sorry for the delay.",
"Yes, of course! Thank you for taking care of it, @albertvillanova ",
"Actually, why is this feature on by default? \r\n\r\nUsers are very unlikely to understand what is going on or to know where to look. Should it at the very least emit a warning that this was done w/o asking the user to do so and how to turn it off?\r\n\r\nIMHO, this feature should be enabled explicitly by those who want it and not be On by default. This is an optimization that benefits only select users and is a burden on the rest.\r\n\r\nIn my line of dev/debug work (multiple short runs that have to be very fast) now I have to remember to disable this feature explicitly on every machine I work :(\r\n",
"Having the dataset in memory is nice to get the speed but I agree that the lack of caching for dataset in memory is an issue. By default we always had caching on.\r\nHere the issue is that in-memory datasets are still not able to use the cache - we should fix this asap IMO.\r\n\r\nHere is the PR that fixes this: https://github.com/huggingface/datasets/pull/2329",
"But why do they have to be datasets in memory in the first place? Why not just have the default that all datasets are normal and are cached which seems to be working solidly. And only enable in memory datasets explicitly if the user chooses to and then it doesn't matter if it's cached on not for the majority of the users who will not make this choice.\r\n\r\nI mean the definition of in-memory-datasets is very arbitrary - why 250MB and not 5GB? It's very likely that the user will want to set this threshold based on their RAM availability. So while doing that they can enable the in-memory-datasets. Unless I'm missing something here.\r\n\r\nThe intention here is that things work well in general out of the box, and further performance optimizations are available to those who know what they are doing.\r\n",
"This is just for speed improvements, especially for data exploration/experiments in notebooks. Ideally it shouldn't have changed anything regarding caching behavior in the first place (i.e. have the caching enabled by default).\r\n\r\nThe 250MB limit has also been chosen to not create unexpected high memory usage on small laptops.",
"Won't it be more straight-forward to create a performance optimization doc and share all these optimizations there? That way the user will be in the knowing and will be able to get faster speeds if their RAM is large. \r\n\r\nIt is hard for me to tell the average size of a dataset an average user will have, but my gut feeling is that many NLP datasets are larger than 250MB. Please correct me if I'm wrong.\r\n\r\nBut at the same time what you're saying is that once https://github.com/huggingface/datasets/pull/2329 is completed and merged, the in-memory-datasets will be cached too. So if I wait long enough the whole issue will go away altogether, correct?"
] |
https://api.github.com/repos/huggingface/datasets/issues/194 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/194/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/194/comments | https://api.github.com/repos/huggingface/datasets/issues/194/events | https://github.com/huggingface/datasets/pull/194 | 624,854,897 | MDExOlB1bGxSZXF1ZXN0NDIzMTgyNDM5 | 194 | Add Dataset: Qanta | [] | closed | false | null | 3 | 2020-05-26T12:44:35Z | 2020-05-26T16:58:17Z | 2020-05-26T13:16:20Z | null | Fixes dummy data for #169 @EntilZha | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/194/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/194/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/194.diff",
"html_url": "https://github.com/huggingface/datasets/pull/194",
"merged_at": "2020-05-26T13:16:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/194.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/194"
} | true | [
"@lhoestq - the config name is rather special here: *E.g.* `mode=first,char_skip=25`. It includes `=` and `,` - will that be a problem for windows folders, you think? \r\n\r\nApart from that good to merge for me.",
"It's ok to have `=` and `,`.\r\nWindows doesn't like things like `?`, `:`, `/` etc.\r\n\r\nI'll add some lines to raise an error if the config name is invalid.",
"Thanks for fixing things up! I'm curious to take a look at the zip files now to know the format for future reference."
] |
https://api.github.com/repos/huggingface/datasets/issues/1230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1230/comments | https://api.github.com/repos/huggingface/datasets/issues/1230/events | https://github.com/huggingface/datasets/pull/1230 | 758,119,342 | MDExOlB1bGxSZXF1ZXN0NTMzMzQxNTg0 | 1,230 | Add Urdu fake news dataset | [] | closed | false | null | 1 | 2020-12-07T03:19:50Z | 2020-12-07T18:04:55Z | 2020-12-07T16:57:54Z | null | @lhoestq opened a clean PR containing only relevant files.
old PR #1125 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1230/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1230.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1230",
"merged_at": "2020-12-07T16:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1230.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1230"
} | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/3806 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3806/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3806/comments | https://api.github.com/repos/huggingface/datasets/issues/3806/events | https://github.com/huggingface/datasets/pull/3806 | 1,157,505,826 | PR_kwDODunzps4z2FeI | 3,806 | Fix Spanish data file URL in wiki_lingua dataset | [] | closed | false | null | 0 | 2022-03-02T17:43:42Z | 2022-03-03T08:38:17Z | 2022-03-03T08:38:16Z | null | This PR fixes the URL for Spanish data file.
Previously, Spanish had the same URL as Vietnamese data file. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3806/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3806/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3806.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3806",
"merged_at": "2022-03-03T08:38:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3806.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3806"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/6084 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6084/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6084/comments | https://api.github.com/repos/huggingface/datasets/issues/6084/events | https://github.com/huggingface/datasets/issues/6084 | 1,824,896,761 | I_kwDODunzps5sxbb5 | 6,084 | Changing pixel values of images in the Winoground dataset | [] | open | false | null | 0 | 2023-07-27T17:55:35Z | 2023-07-27T17:55:35Z | null | null | Hi, as I followed the instructions, with lasted "datasets" version:
"
from datasets import load_dataset
examples = load_dataset('facebook/winoground', use_auth_token=<YOUR USER ACCESS TOKEN>)
"
I got slightly different datasets in colab and in my hpc environment. Specifically, the pixel values of images are slightly different.
I thought it was due to the package version difference, but today's morning I found out that my winoground dataset in colab became the same with the one in my hpc environment. The dataset in colab can produce the correct result but now it is gone as well.
Can you help me with this? What causes the datasets to have the wrong pixel values? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6084/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6084/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/156/comments | https://api.github.com/repos/huggingface/datasets/issues/156/events | https://github.com/huggingface/datasets/issues/156 | 620,263,687 | MDU6SXNzdWU2MjAyNjM2ODc= | 156 | SyntaxError with WMT datasets | [] | closed | false | null | 7 | 2020-05-18T14:38:18Z | 2020-07-23T16:41:55Z | 2020-07-23T16:41:55Z | null | The following snippet produces a syntax error:
```
import nlp
dataset = nlp.load_dataset('wmt14')
print(dataset['train'][0])
```
```
Traceback (most recent call last):
File "/home/tom/.local/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 3326, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-8-3206959998b9>", line 3, in <module>
dataset = nlp.load_dataset('wmt14')
File "/home/tom/.local/lib/python3.6/site-packages/nlp/load.py", line 505, in load_dataset
builder_cls = import_main_class(module_path, dataset=True)
File "/home/tom/.local/lib/python3.6/site-packages/nlp/load.py", line 56, in import_main_class
module = importlib.import_module(module_path)
File "/usr/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 665, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 678, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/tom/.local/lib/python3.6/site-packages/nlp/datasets/wmt14/c258d646f4f5870b0245f783b7aa0af85c7117e06aacf1e0340bd81935094de2/wmt14.py", line 21, in <module>
from .wmt_utils import Wmt, WmtConfig
File "/home/tom/.local/lib/python3.6/site-packages/nlp/datasets/wmt14/c258d646f4f5870b0245f783b7aa0af85c7117e06aacf1e0340bd81935094de2/wmt_utils.py", line 659
<<<<<<< HEAD
^
SyntaxError: invalid syntax
```
Python version:
`3.6.9 (default, Apr 18 2020, 01:56:04) [GCC 8.4.0]`
Running on Ubuntu 18.04, via a Jupyter notebook | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/156/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/156/timeline | null | completed | null | null | false | [
"Jeez - don't know what happened there :D Should be fixed now! \r\n\r\nThanks a lot for reporting this @tomhosking !",
"Hi @patrickvonplaten!\r\n\r\nI'm now getting the below error:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-28-3206959998b9> in <module>\r\n 1 import nlp\r\n 2 \r\n----> 3 dataset = nlp.load_dataset('wmt14')\r\n 4 print(dataset['train'][0])\r\n\r\n~/.local/lib/python3.6/site-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)\r\n 507 # Instantiate the dataset builder\r\n 508 builder_instance = builder_cls(\r\n--> 509 cache_dir=cache_dir, name=name, version=version, data_dir=data_dir, data_files=data_files, **config_kwargs,\r\n 510 )\r\n 511 \r\n\r\nTypeError: Can't instantiate abstract class Wmt with abstract methods _subsets\r\n```\r\n\r\n",
"To correct this error I think you need the master branch of `nlp`. Can you try to install `nlp` with. `WMT` was not included at the beta release of the library. \r\n\r\nCan you try:\r\n`pip install git+https://github.com/huggingface/nlp.git`\r\n\r\nand check again? ",
"That works, thanks :)\r\n\r\nThe WMT datasets are listed in by `list_datasets()` in the beta release on pypi - it would be good to only show datasets that are actually supported by that version?",
"Usually, the idea is that a dataset can be added without releasing a new version. The problem in the case of `WMT` was that some \"core\" code of the library had to be changed as well. \r\n\r\n@thomwolf @lhoestq @julien-c - How should we go about this. If we add a dataset that also requires \"core\" code changes, how do we handle the versioning? The moment a dataset is on AWS it will actually be listed with `list_datasets()` in all earlier versions...\r\n\r\nIs there a way to somehow insert the `pip version` to the HfApi() and get only the datasets that were available for this version (at the date of the release of the version) @julien-c ? ",
"We plan to have something like a `requirements.txt` per dataset to prevent user from loading dataset with old version of `nlp` or any other libraries. Right now the solution is just to keep `nlp` up to date when you want to load a dataset that leverages the latests features of `nlp`.\r\n\r\nFor datasets that are on AWS but that use features that are not released yet we should be able to filter those from the `list_dataset` as soon as we have the `requirements.txt` feature on (filter datasets that need a future version of `nlp`).\r\n\r\nShall we rename this issue to be more explicit about the problem ?\r\nSomething like `Specify the minimum version of the nlp library required for each dataset` ?",
"Closing this one.\r\nFeel free to re-open if you have other questions :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/568/comments | https://api.github.com/repos/huggingface/datasets/issues/568/events | https://github.com/huggingface/datasets/issues/568 | 691,638,656 | MDU6SXNzdWU2OTE2Mzg2NTY= | 568 | `metric.compute` throws `ArrowInvalid` error | [] | closed | false | null | 3 | 2020-09-03T04:56:57Z | 2020-10-05T16:33:53Z | 2020-10-05T16:33:53Z | null | I get the following error with `rouge.compute`. It happens only with distributed training, and it occurs randomly I can't easily reproduce it. This is using `nlp==0.4.0`
```
File "/home/beltagy/trainer.py", line 92, in validation_step
rouge_scores = rouge.compute(predictions=generated_str, references=gold_str, rouge_types=['rouge2', 'rouge1', 'rougeL'])
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/metric.py", line 224, in compute
self.finalize(timeout=timeout)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/metric.py", line 213, in finalize
self.data = Dataset(**reader.read_files(node_files))
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/arrow_reader.py", line 217, in read_files
dataset_kwargs = self._read_files(files=files, info=self._info, original_instructions=original_instructions)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/arrow_reader.py", line 162, in _read_files
pa_table: pa.Table = self._get_dataset_from_filename(f_dict)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/nlp/arrow_reader.py", line 276, in _get_dataset_from_filename
f = pa.ipc.open_stream(mmap)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/pyarrow/ipc.py", line 173, in open_stream
return RecordBatchStreamReader(source)
File "/home/beltagy/miniconda3/envs/allennlp/lib/python3.7/site-packages/pyarrow/ipc.py", line 64, in __init__
self._open(source)
File "pyarrow/ipc.pxi", line 469, in pyarrow.lib._RecordBatchStreamReader._open
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Tried reading schema message, was null or length 0
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/568/timeline | null | completed | null | null | false | [
"Hmm might be related to what we are solving in #564",
"Could you try to update to `datasets>=1.0.0` (we changed the name of the library) and try again ?\r\nIf is was related to the distributed setup settings it must be fixed.\r\nIf it was related to empty metric inputs it's going to be fixed in #654 ",
"Closing this one as it was fixed in #654 \r\nFeel free to re-open if you have other questions"
] |
https://api.github.com/repos/huggingface/datasets/issues/3311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3311/comments | https://api.github.com/repos/huggingface/datasets/issues/3311/events | https://github.com/huggingface/datasets/issues/3311 | 1,060,387,957 | I_kwDODunzps4_NDx1 | 3,311 | Add WebSRC | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 0 | 2021-11-22T16:58:33Z | 2021-11-22T16:58:33Z | null | null | ## Adding a Dataset
- **Name:** WebSRC
- **Description:** WebSRC is a novel Web-based Structural Reading Comprehension dataset. It consists of 0.44M question-answer pairs, which are collected from 6.5K web pages with corresponding HTML source code, screenshots and metadata.
- **Paper:** https://arxiv.org/abs/2101.09465
- **Data:** https://x-lance.github.io/WebSRC/dashboard.html#
- **Motivation:** Currently adding MarkupLM to HuggingFace Transformers, which achieves SOTA on this dataset.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3311/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3311/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5602/comments | https://api.github.com/repos/huggingface/datasets/issues/5602/events | https://github.com/huggingface/datasets/pull/5602 | 1,607,054,110 | PR_kwDODunzps5LJGfa | 5,602 | Return dict structure if columns are lists - to_tf_dataset | [] | open | false | null | 19 | 2023-03-02T15:51:12Z | 2023-04-12T15:54:53Z | null | null | This PR introduces new logic to `to_tf_dataset` affecting the returned data structure, enabling a dictionary structure to be returned, even if only one feature column is selected.
If the passed in `columns` or `label_cols` to `to_tf_dataset` are a list, they are returned as a dictionary, respectively. If they are a string, the tensor is returned.
An outline of the behaviour:
```
dataset,to_tf_dataset(columns=["col_1"], label_cols="col_2")
# ({'col_1': col_1}, col_2}
dataset,to_tf_dataset(columns="col1", label_cols="col_2")
# (col1, col2)
dataset,to_tf_dataset(columns="col1")
# col1
dataset,to_tf_dataset(columns=["col_1"], labels=["col_2"])
# ({'col1': tensor}, {'col2': tensor}}
dataset,to_tf_dataset(columns="col_1", labels=["col_2"])
# (col1, {'col2': tensor}}
```
## Motivation
Currently, when calling `to_tf_dataset`, the returned dataset will always return a tuple structure if a single feature column is used. This can cause issues when calling `model.fit` on models which train without labels e.g. [TFVitMAEForPreTraining](https://github.com/huggingface/transformers/blob/b6f47b539377ac1fd845c7adb4ccaa5eb514e126/src/transformers/models/vit_mae/modeling_vit_mae.py#L849). Specifically, [this line](https://github.com/huggingface/transformers/blob/d9e28d91a8b2d09b51a33155d3a03ad9fcfcbd1f/src/transformers/modeling_tf_utils.py#L1521) where it's assumed the input `x` is a dictionary if there is no label.
## Example
Previous behaviour
```python
In [1]: import tensorflow as tf
...: from datasets import load_dataset
...:
...:
...: def transform(batch):
...: def _transform_img(img):
...: img = img.convert("RGB")
...: img = tf.keras.utils.img_to_array(img)
...: img = tf.image.resize(img, (224, 224))
...: img /= 255.0
...: img = tf.transpose(img, perm=[2, 0, 1])
...: return img
...: batch['pixel_values'] = [_transform_img(pil_img) for pil_img in batch['img']]
...: return batch
...:
...:
...: def collate_fn(examples):
...: pixel_values = tf.stack([example["pixel_values"] for example in examples])
...: return {"pixel_values": pixel_values}
...:
...:
...: dataset = load_dataset('cifar10')['train']
...: dataset = dataset.with_transform(transform)
...: dataset.to_tf_dataset(batch_size=8, columns=['pixel_values'], collate_fn=collate_fn)
Out[1]: <PrefetchDataset element_spec=TensorSpec(shape=(None, 3, 224, 224), dtype=tf.float32, name=None)>
```
New behaviour
```python
In [1]: import tensorflow as tf
...: from datasets import load_dataset
...:
...:
...: def transform(batch):
...: def _transform_img(img):
...: img = img.convert("RGB")
...: img = tf.keras.utils.img_to_array(img)
...: img = tf.image.resize(img, (224, 224))
...: img /= 255.0
...: img = tf.transpose(img, perm=[2, 0, 1])
...: return img
...: batch['pixel_values'] = [_transform_img(pil_img) for pil_img in batch['img']]
...: return batch
...:
...:
...: def collate_fn(examples):
...: pixel_values = tf.stack([example["pixel_values"] for example in examples])
...: return {"pixel_values": pixel_values}
...:
...:
...: dataset = load_dataset('cifar10')['train']
...: dataset = dataset.with_transform(transform)
...: dataset.to_tf_dataset(batch_size=8, columns=['pixel_values'], collate_fn=collate_fn)
Out[1]: <PrefetchDataset element_spec={'pixel_values': TensorSpec(shape=(None, 3, 224, 224), dtype=tf.float32, name=None)}>
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5602/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5602/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5602.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5602",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5602.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5602"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5602). All of your documentation changes will be reflected on that endpoint.",
"This is a great PR! Thinking about the UX though, maybe we could do it without the extra argument? Before this PR, the logic in `to_tf_dataset` was that if the user passed a single column name in either `columns` or `label_cols`, we converted it to a length-1 list. Then, later in the code, we convert output dicts with only one key to naked Tensors.\r\n\r\nWould it be easier if we removed the argument, but instead treated the cases differently? Passing a column name as a string could yield a single naked Tensor in the output as before, but passing a list of length 1 would yield a full dict? That way if you wanted dict output with a single key you could just say `columns=[col_name]`.\r\n\r\n(I'm not totally convinced this is a good idea yet, it just seems like it might be more intuitive)",
"@Rocketknight1 Happy to implement it that way - it's certainly cleaner to not have another arg. In this case, am I right in saying we'd effectively set `return_dict` [here](https://github.com/huggingface/datasets/blob/6569014a9948eab7d031a3587405e64ba92d6c59/src/datasets/arrow_dataset.py#L410) - where columns are made into a list if they were a string? \r\n\r\nThere only concern I have is this changes the default behaviour, which might break things for people who were happily using `columns=[\"my_col_str\"]` before. \r\n\r\n\r\n",
"@amyeroberts That's correct! Probably the simplest way to implement it would be to just add the flag there.\r\n\r\nAnd yeah, I'm aware this might be a slightly breaking change, but we've mostly tried to move users to `prepare_tf_dataset` in `transformers` at this point, so hopefully as long as that method doesn't break then most users won't be negatively affected by the change.",
"@lhoestq @Rocketknight1 - I've remove the `return_dict` argument and implemented @Rocketknight1 's suggestion. LMK what you think :) ",
"@lhoestq Of course :) I've opened a draft PR here for the updates needed in transformers examples and docs to keep the returned data structure consistent: https://github.com/huggingface/transformers/pull/21935. Note: even with the different structure, `model.fit` can still successfully be called. \r\n\r\nFor the [link you shared](https://github.com/huggingface/datasets/pull/url) - for me it returns a 404 error. Is there another link I could follow to see how to run the transformers CI with this branch? \r\n\r\nCurrently looking into the failing tests 😭 ",
"Oh sorry - I fixed the URL: https://github.com/huggingface/transformers/commit/4eb55bbd593adf2e49362613ee32a11ddc4a854d",
"The error shows `There appear to be 80 leaked shared_memory objects to clean up at shutdown`. IIRC to_tf_dataset does some shared memory stuff for multiprocessing - maybe @Rocketknight1 you know what's going on ?",
"@lhoestq That warning appears anytime you interrupt a process using Python `SharedMemory` objects - it's only a problem if you still get the error when the process finishes normally! Our implementation of `to_tf_dataset` should clean things up properly.",
"Ok, not sure why it fails then :/",
"Hmm, will investigate! Sorry, I misread - I thought that warning was coming up in the context of another error",
"IMO outputing different types based on nuances in the input could confuse users.\r\n\r\nAlso, in the ideal scenario,`to_tf_function` should return a `tf.data.Dataset` that iterates over the underlying Arrow data and yields (unprocessed) dicts of TF tensors, and all the model-specific code should live in Transformers (e.g., in `prepare_tf_dataset`). So the goal would be to make `to_tf_dataset` more user-friendly, not more complex :).",
"I think we agree @mariosasko :) \r\n\r\n> Also, in the ideal scenario,to_tf_function should return a tf.data.Dataset that iterates over the underlying Arrow data and yields (unprocessed) dicts of TF tensors\r\n\r\nThis I'll leave for another PR as it's outside the scope of this one and @Rocketknight1 will have far more knowledge and ideas about what is possible\r\n\r\n> all the model-specific code should live in Transformers (e.g., in prepare_tf_dataset\r\n\r\nAgreed! This PR isn't really a model specific change - although it was highlighted when trying to train a model. We definitely want to move model specific things out of datasets as much as possible. \r\n\r\n> IMO outputing different types based on nuances in the input could confuse users.\r\n> So the goal would be to make to_tf_dataset more user-friendly, not more complex :).\r\n\r\nThe aim was to move more towards being able to return the dict of TF tensors you suggest, whilst maintaining backwards compatibility. Personally, I found it surprising to be returned a tuple structure when I was using `to_tf_dataset`. The aim was to make `to_tf_dataset` more user friendly, but I agree that it has the potential to be confusing. \r\n\r\nFor context, the thought process behind this design was to: \r\n* Not add even more arguments to `to_tf_dataset`. \r\n* Have a feature selection -> return type logic in keeping with `datasets` e.g. `dataset['train'][:10]['feat1']` returns a list of values, whereas `dataset['train'][:10]['feat1', 'feat2']` returns a dictionary. \r\n\r\nVery happy to add any suggestions or changes you might have about how to make this design better! :) \r\n",
"Hi ! Anything blocking here ? I'b be happy to help",
"Hi @lhoestq - sorry this hasn't been very active for the past ~1.5 weeks. There's nothing specific blocking, other than not being able to replicate without running on CI, and still need to test a bit more to narrow down the issue. I should have time tomorrow to pick it up again :) ",
"@lhoestq @Rocketknight1 Friendly ping for a review :) ",
"Awesome ! What about showing a warning that this change is about to happen in the next version of `datasets`, and then apply this change in a subsequent major release ? This way folks at twitter won't hate us: https://github.com/twitter/the-algorithm/blob/138bb519975407d4ea0dc1478d897d451ef05dab/trust_and_safety_models/toxicity/data/mb_generator.py#L142-L148",
"@lhoestq Sounds good! How would you like this warning to happen? I could open a PR to add a warning message within `to_tf_dataset`?",
"Yup sounds good :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4098 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4098/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4098/comments | https://api.github.com/repos/huggingface/datasets/issues/4098/events | https://github.com/huggingface/datasets/pull/4098 | 1,193,245,522 | PR_kwDODunzps41qXjo | 4,098 | Proposing WikiSplit metric card | [] | closed | false | null | 3 | 2022-04-05T14:36:34Z | 2022-10-11T09:10:21Z | 2022-04-05T15:42:28Z | null | Pinging @lhoestq to ensure that my distinction between the dataset and the metric are clear :sweat_smile: | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4098/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4098/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4098.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4098",
"merged_at": "2022-04-05T15:42:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4098.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4098"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"A quick Github tip ;) To avoid running N times the CI, you can push all the changes at once: go to Files Changed tab, and on each suggestion there's a \"add to commit batch\" and then you can do one commit for all the suggestions you want to approve ;)",
"Oh thanks for the tip!! Haha I was wondering why it was running a bunch of\ntimes :P\n\nOn Tue, Apr 5, 2022 at 11:44 AM Quentin Lhoest ***@***.***>\nwrote:\n\n> A quick Github tip ;) To avoid running N times the CI, you can push all\n> the changes at once: go to Files Changed tab, and on each suggestion\n> there's a \"add to commit batch\" and then you can do one commit for all the\n> suggestions you want to approve ;)\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/pull/4098#issuecomment-1088894515>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ADMMIIRZYNVFJRWRWW4VJY3VDRNUBANCNFSM5SS7L5HA>\n> .\n> You are receiving this because you modified the open/close state.Message\n> ID: ***@***.***>\n>\n\n\n-- \nSasha Luccioni, PhD\nPostdoctoral Researcher (Mila, Université de Montréal)\nChercheure postdoctorale (Mila, Université de Montréal)\nhttps://www.sashaluccioni.com/\n [image: Image result for universite de montreal logo]\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3743/comments | https://api.github.com/repos/huggingface/datasets/issues/3743/events | https://github.com/huggingface/datasets/pull/3743 | 1,141,176,011 | PR_kwDODunzps4y-2Do | 3,743 | initial monash time series forecasting repository | [] | closed | false | null | 3 | 2022-02-17T10:51:31Z | 2022-03-21T09:54:41Z | 2022-03-21T09:50:16Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3743/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3743/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3743.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3743",
"merged_at": "2022-03-21T09:50:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3743.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3743"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI fails are unrelated to this PR, merging !",
"thanks 🙇🏽 "
] |
https://api.github.com/repos/huggingface/datasets/issues/5781 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5781/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5781/comments | https://api.github.com/repos/huggingface/datasets/issues/5781/events | https://github.com/huggingface/datasets/issues/5781 | 1,679,580,460 | I_kwDODunzps5kHF0s | 5,781 | Error using `load_datasets` | [] | closed | false | null | 2 | 2023-04-22T15:10:44Z | 2023-05-02T23:41:25Z | 2023-05-02T23:41:25Z | null | ### Describe the bug
I tried to load a dataset using the `datasets` library in a conda jupyter notebook and got the below error.
```
ImportError: dlopen(/Users/gilbertyoung/miniforge3/envs/review_sense/lib/python3.8/site-packages/scipy/sparse/linalg/_isolve/_iterative.cpython-38-darwin.so, 0x0002): Library not loaded: @rpath/liblapack.3.dylib
Referenced from: <65B094A2-59D7-31AC-A966-4DB9E11D2A15> /Users/gilbertyoung/miniforge3/envs/review_sense/lib/python3.8/site-packages/scipy/sparse/linalg/_isolve/_iterative.cpython-38-darwin.so
Reason: tried: '/Users/gilbertyoung/miniforge3/envs/review_sense/lib/python3.8/site-packages/scipy/sparse/linalg/_isolve/liblapack.3.dylib' (no such file), '/Users/gilbertyoung/miniforge3/envs/review_sense/lib/python3.8/site-packages/scipy/sparse/linalg/_isolve/../../../../../../liblapack.3.dylib' (no such file), '/Users/gilbertyoung/miniforge3/envs/review_sense/lib/python3.8/site-packages/scipy/sparse/linalg/_isolve/liblapack.3.dylib' (no such file), '/Users/gilbertyoung/miniforge3/envs/review_sense/lib/python3.8/site-packages/scipy/sparse/linalg/_isolve/../../../../../../liblapack.3.dylib' (no such file), '/Users/gilbertyoung/miniforge3/envs/review_sense/bin/../lib/liblapack.3.dylib' (no such file), '/Users/gilbertyoung/miniforge3/envs/review_sense/bin/../lib/liblapack.3.dylib' (no such file), '/usr/local/lib/liblapack.3.dylib' (no such file), '/usr/lib/liblapack.3.dylib' (no such file, not in dyld cache)
```
### Steps to reproduce the bug
Run the `load_datasets` function
### Expected behavior
I expected the dataset to be loaded into my notebook.
### Environment info
name: review_sense
channels:
- apple
- conda-forge
dependencies:
- python=3.8
- pip>=19.0
- jupyter
- tensorflow-deps
#- scikit-learn
#- scipy
- pandas
- pandas-datareader
- matplotlib
- pillow
- tqdm
- requests
- h5py
- pyyaml
- flask
- boto3
- ipykernel
- seaborn
- pip:
- tensorflow-macos==2.9
- tensorflow-metal==0.5.0
- bayesian-optimization
- gym
- kaggle
- huggingface_hub
- datasets
- numpy
- huggingface
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5781/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5781/timeline | null | completed | null | null | false | [
"It looks like an issue with your installation of scipy, can you try reinstalling it ?",
"Sorry for the late reply, but that worked @lhoestq . Thanks for the assist."
] |
https://api.github.com/repos/huggingface/datasets/issues/2454 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2454/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2454/comments | https://api.github.com/repos/huggingface/datasets/issues/2454/events | https://github.com/huggingface/datasets/pull/2454 | 913,883,631 | MDExOlB1bGxSZXF1ZXN0NjYzODUyODU1 | 2,454 | Rename config and environment variable for in memory max size | [] | closed | false | null | 1 | 2021-06-07T19:21:08Z | 2021-06-07T20:43:46Z | 2021-06-07T20:43:46Z | null | As discussed in #2409, both config and environment variable have been renamed.
cc: @stas00, huggingface/transformers#12056 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2454/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2454/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2454.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2454",
"merged_at": "2021-06-07T20:43:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2454.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2454"
} | true | [
"Thank you for the rename, @albertvillanova!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3181 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3181/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3181/comments | https://api.github.com/repos/huggingface/datasets/issues/3181/events | https://github.com/huggingface/datasets/issues/3181 | 1,039,682,097 | I_kwDODunzps49-Eox | 3,181 | `None` converted to `"None"` when loading a dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 9 | 2021-10-29T15:23:53Z | 2021-12-11T01:16:40Z | 2021-12-09T14:26:57Z | null | ## Describe the bug
When loading a dataset `None` values of the type `NoneType` are converted to `'None'` of the type `str`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
qasper = load_dataset("qasper", split="train", download_mode="reuse_cache_if_exists")
print(qasper[60]["full_text"]["section_name"])
```
When installing version 1.1.40, the output is
`[None, 'Introduction', 'Benchmark Datasets', ...]`
When installing from the master branch, the output is
`['None', 'Introduction', 'Benchmark Datasets', ...]`
Notice how the first element was changed from `NoneType` to `str`.
## Expected results
`None` should stay as is.
## Actual results
`None` is converted to a string.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: master
- Platform: Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3181/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3181/timeline | null | completed | null | null | false | [
"Hi @eladsegal, thanks for reporting.\r\n\r\n@mariosasko I saw you are already working on this, but maybe my comment will be useful to you.\r\n\r\nAll values are casted to their corresponding feature type (including `None` values). For example if the feature type is `Value(\"bool\")`, `None` is casted to `False`.\r\n\r\nIt is true that strings were an exception, but this was recently fixed by @lhoestq (see #3158).",
"Thanks for reporting.\r\n\r\nThis is actually a breaking change that I think can cause issues when users preprocess their data. String columns used to be nullable. Maybe we can correct https://github.com/huggingface/datasets/pull/3158 to keep the None values and avoid this breaking change ?\r\n\r\nEDIT: the other types (bool, int, etc) can also become nullable IMO",
"So what would be the best way to handle a feature that can have a null value in some of the instances? So far I used `None`.\r\nUsing the empty string won't be a good option, as it can be an actual value in the data and is not the same as not having a value at all.",
"Hi @eladsegal,\r\n\r\nUse `None`. As @albertvillanova correctly pointed out, this change in conversion was introduced (by mistake) in #3158. To avoid it, install the earlier revision with:\r\n```\r\npip install git+https://github.com/huggingface/datasets.git@8107844ec0e7add005db0585c772ee20adc01a5e\r\n```\r\n\r\nI'm making all the feature types nullable as we speak, and the fix will be merged probably early next week.",
"Hi @mariosasko, is there an estimation as to when this issue will be fixed?",
"https://github.com/huggingface/datasets/pull/3195 fixed it, we'll do a new release soon :)\r\n\r\nFor now feel free to install `datasets` from the master branch",
"Thanks, but unfortunately looks like it isn't fixed yet 😢 \r\n[notebook for 1.14.0](https://colab.research.google.com/drive/1SV3sFXPJMWSQgbm4pr9Y1Q8OJ4JYKcDo?usp=sharing)\r\n[notebook for master](https://colab.research.google.com/drive/145wDpuO74MmsuI0SVLcI1IswG6aHpyhi?usp=sharing)",
"Oh, sorry. I deleted the fix by accident when I was resolving a merge conflict. Let me fix this real quick.",
"Thank you, it works! 🎊 "
] |
https://api.github.com/repos/huggingface/datasets/issues/5916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5916/comments | https://api.github.com/repos/huggingface/datasets/issues/5916/events | https://github.com/huggingface/datasets/pull/5916 | 1,732,456,392 | PR_kwDODunzps5RskTb | 5,916 | Unpin responses | [] | closed | false | null | 4 | 2023-05-30T14:59:48Z | 2023-05-30T18:03:10Z | 2023-05-30T17:53:29Z | null | Fix #5906 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5916/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5916",
"merged_at": "2023-05-30T17:53:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5916"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006113 / 0.011353 (-0.005239) | 0.004195 / 0.011008 (-0.006813) | 0.098103 / 0.038508 (0.059595) | 0.027970 / 0.023109 (0.004860) | 0.300992 / 0.275898 (0.025094) | 0.335402 / 0.323480 (0.011922) | 0.005079 / 0.007986 (-0.002906) | 0.003516 / 0.004328 (-0.000813) | 0.077311 / 0.004250 (0.073061) | 0.037863 / 0.037052 (0.000810) | 0.302638 / 0.258489 (0.044149) | 0.346554 / 0.293841 (0.052713) | 0.025218 / 0.128546 (-0.103328) | 0.008630 / 0.075646 (-0.067017) | 0.319748 / 0.419271 (-0.099523) | 0.049182 / 0.043533 (0.005650) | 0.306233 / 0.255139 (0.051094) | 0.331040 / 0.283200 (0.047840) | 0.089203 / 0.141683 (-0.052480) | 1.496104 / 1.452155 (0.043949) | 1.567878 / 1.492716 (0.075162) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.215774 / 0.018006 (0.197768) | 0.436810 / 0.000490 (0.436320) | 0.000307 / 0.000200 (0.000107) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024102 / 0.037411 (-0.013310) | 0.095459 / 0.014526 (0.080933) | 0.106564 / 0.176557 (-0.069992) | 0.169894 / 0.737135 (-0.567241) | 0.109152 / 0.296338 (-0.187186) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429066 / 0.215209 (0.213857) | 4.297385 / 2.077655 (2.219730) | 2.054854 / 1.504120 (0.550734) | 1.846844 / 1.541195 (0.305649) | 1.840807 / 1.468490 (0.372317) | 0.553193 / 4.584777 (-4.031584) | 3.366788 / 3.745712 (-0.378924) | 1.727337 / 5.269862 (-3.542525) | 0.994357 / 4.565676 (-3.571319) | 0.067790 / 0.424275 (-0.356485) | 0.012002 / 0.007607 (0.004395) | 0.533335 / 0.226044 (0.307291) | 5.341341 / 2.268929 (3.072412) | 2.543581 / 55.444624 (-52.901043) | 2.220374 / 6.876477 (-4.656103) | 2.321656 / 2.142072 (0.179583) | 0.654408 / 4.805227 (-4.150819) | 0.134693 / 6.500664 (-6.365971) | 0.066926 / 0.075469 (-0.008544) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.209463 / 1.841788 (-0.632325) | 13.568221 / 8.074308 (5.493913) | 13.965418 / 10.191392 (3.774026) | 0.145049 / 0.680424 (-0.535375) | 0.016936 / 0.534201 (-0.517265) | 0.371587 / 0.579283 (-0.207696) | 0.386363 / 0.434364 (-0.048001) | 0.437137 / 0.540337 (-0.103201) | 0.514779 / 1.386936 (-0.872157) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006245 / 0.011353 (-0.005108) | 0.004232 / 0.011008 (-0.006776) | 0.075682 / 0.038508 (0.037174) | 0.027858 / 0.023109 (0.004749) | 0.425325 / 0.275898 (0.149427) | 0.466732 / 0.323480 (0.143253) | 0.005240 / 0.007986 (-0.002745) | 0.003506 / 0.004328 (-0.000823) | 0.075294 / 0.004250 (0.071044) | 0.041677 / 0.037052 (0.004624) | 0.426552 / 0.258489 (0.168063) | 0.469452 / 0.293841 (0.175611) | 0.025443 / 0.128546 (-0.103104) | 0.008526 / 0.075646 (-0.067120) | 0.082190 / 0.419271 (-0.337081) | 0.040906 / 0.043533 (-0.002626) | 0.428406 / 0.255139 (0.173267) | 0.446795 / 0.283200 (0.163595) | 0.093837 / 0.141683 (-0.047846) | 1.518639 / 1.452155 (0.066484) | 1.620214 / 1.492716 (0.127498) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223259 / 0.018006 (0.205253) | 0.425077 / 0.000490 (0.424588) | 0.001980 / 0.000200 (0.001780) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025813 / 0.037411 (-0.011599) | 0.103062 / 0.014526 (0.088536) | 0.108958 / 0.176557 (-0.067598) | 0.161591 / 0.737135 (-0.575544) | 0.112130 / 0.296338 (-0.184209) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.472843 / 0.215209 (0.257634) | 4.713281 / 2.077655 (2.635626) | 2.458216 / 1.504120 (0.954096) | 2.272467 / 1.541195 (0.731273) | 2.324456 / 1.468490 (0.855965) | 0.554686 / 4.584777 (-4.030091) | 3.445079 / 3.745712 (-0.300634) | 3.451896 / 5.269862 (-1.817966) | 1.431065 / 4.565676 (-3.134612) | 0.067868 / 0.424275 (-0.356407) | 0.012093 / 0.007607 (0.004486) | 0.573571 / 0.226044 (0.347526) | 5.820452 / 2.268929 (3.551523) | 2.934858 / 55.444624 (-52.509767) | 2.602719 / 6.876477 (-4.273758) | 2.645999 / 2.142072 (0.503927) | 0.660688 / 4.805227 (-4.144540) | 0.137490 / 6.500664 (-6.363174) | 0.068311 / 0.075469 (-0.007158) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.321709 / 1.841788 (-0.520079) | 14.592346 / 8.074308 (6.518038) | 14.520748 / 10.191392 (4.329356) | 0.132689 / 0.680424 (-0.547735) | 0.016422 / 0.534201 (-0.517779) | 0.370071 / 0.579283 (-0.209212) | 0.397091 / 0.434364 (-0.037273) | 0.431979 / 0.540337 (-0.108358) | 0.509965 / 1.386936 (-0.876971) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006182 / 0.011353 (-0.005171) | 0.004153 / 0.011008 (-0.006855) | 0.095715 / 0.038508 (0.057207) | 0.032457 / 0.023109 (0.009347) | 0.314961 / 0.275898 (0.039063) | 0.353696 / 0.323480 (0.030216) | 0.005256 / 0.007986 (-0.002729) | 0.004870 / 0.004328 (0.000541) | 0.072442 / 0.004250 (0.068192) | 0.046102 / 0.037052 (0.009050) | 0.324410 / 0.258489 (0.065921) | 0.366861 / 0.293841 (0.073020) | 0.027088 / 0.128546 (-0.101458) | 0.008572 / 0.075646 (-0.067075) | 0.325988 / 0.419271 (-0.093284) | 0.049494 / 0.043533 (0.005961) | 0.311221 / 0.255139 (0.056082) | 0.359720 / 0.283200 (0.076521) | 0.095101 / 0.141683 (-0.046581) | 1.472821 / 1.452155 (0.020667) | 1.516157 / 1.492716 (0.023441) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210456 / 0.018006 (0.192450) | 0.439440 / 0.000490 (0.438950) | 0.003764 / 0.000200 (0.003564) | 0.000087 / 0.000054 (0.000033) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024076 / 0.037411 (-0.013335) | 0.104886 / 0.014526 (0.090360) | 0.114164 / 0.176557 (-0.062393) | 0.167289 / 0.737135 (-0.569847) | 0.116457 / 0.296338 (-0.179882) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.400039 / 0.215209 (0.184830) | 3.973243 / 2.077655 (1.895588) | 1.801991 / 1.504120 (0.297871) | 1.592017 / 1.541195 (0.050822) | 1.612564 / 1.468490 (0.144074) | 0.527475 / 4.584777 (-4.057302) | 3.676246 / 3.745712 (-0.069466) | 1.806423 / 5.269862 (-3.463438) | 1.176921 / 4.565676 (-3.388756) | 0.065902 / 0.424275 (-0.358373) | 0.012245 / 0.007607 (0.004638) | 0.490883 / 0.226044 (0.264838) | 4.905270 / 2.268929 (2.636341) | 2.218694 / 55.444624 (-53.225930) | 1.903074 / 6.876477 (-4.973403) | 1.979505 / 2.142072 (-0.162567) | 0.644415 / 4.805227 (-4.160812) | 0.142433 / 6.500664 (-6.358231) | 0.063564 / 0.075469 (-0.011905) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.193756 / 1.841788 (-0.648032) | 14.673103 / 8.074308 (6.598795) | 13.410951 / 10.191392 (3.219559) | 0.159175 / 0.680424 (-0.521249) | 0.017076 / 0.534201 (-0.517125) | 0.388880 / 0.579283 (-0.190403) | 0.409974 / 0.434364 (-0.024390) | 0.454494 / 0.540337 (-0.085844) | 0.556873 / 1.386936 (-0.830063) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006107 / 0.011353 (-0.005246) | 0.004433 / 0.011008 (-0.006575) | 0.073892 / 0.038508 (0.035384) | 0.032386 / 0.023109 (0.009277) | 0.370339 / 0.275898 (0.094441) | 0.388996 / 0.323480 (0.065516) | 0.005438 / 0.007986 (-0.002548) | 0.003875 / 0.004328 (-0.000454) | 0.073867 / 0.004250 (0.069617) | 0.048350 / 0.037052 (0.011298) | 0.380328 / 0.258489 (0.121839) | 0.411373 / 0.293841 (0.117532) | 0.028183 / 0.128546 (-0.100363) | 0.008924 / 0.075646 (-0.066723) | 0.082484 / 0.419271 (-0.336787) | 0.047321 / 0.043533 (0.003788) | 0.371702 / 0.255139 (0.116563) | 0.380535 / 0.283200 (0.097335) | 0.100772 / 0.141683 (-0.040911) | 1.475038 / 1.452155 (0.022883) | 1.564293 / 1.492716 (0.071577) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.214589 / 0.018006 (0.196583) | 0.437193 / 0.000490 (0.436703) | 0.003676 / 0.000200 (0.003476) | 0.000094 / 0.000054 (0.000040) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027991 / 0.037411 (-0.009421) | 0.111154 / 0.014526 (0.096628) | 0.120365 / 0.176557 (-0.056191) | 0.173601 / 0.737135 (-0.563535) | 0.126244 / 0.296338 (-0.170094) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.442848 / 0.215209 (0.227639) | 4.398336 / 2.077655 (2.320681) | 2.217058 / 1.504120 (0.712938) | 2.011155 / 1.541195 (0.469960) | 2.123086 / 1.468490 (0.654596) | 0.525857 / 4.584777 (-4.058920) | 3.730191 / 3.745712 (-0.015521) | 3.517680 / 5.269862 (-1.752181) | 1.557940 / 4.565676 (-3.007736) | 0.066309 / 0.424275 (-0.357967) | 0.011788 / 0.007607 (0.004181) | 0.548506 / 0.226044 (0.322462) | 5.483615 / 2.268929 (3.214687) | 2.663784 / 55.444624 (-52.780840) | 2.325744 / 6.876477 (-4.550732) | 2.344179 / 2.142072 (0.202106) | 0.644217 / 4.805227 (-4.161010) | 0.141546 / 6.500664 (-6.359118) | 0.063730 / 0.075469 (-0.011739) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.296032 / 1.841788 (-0.545756) | 14.903729 / 8.074308 (6.829421) | 14.505409 / 10.191392 (4.314017) | 0.170478 / 0.680424 (-0.509946) | 0.017876 / 0.534201 (-0.516325) | 0.401047 / 0.579283 (-0.178236) | 0.417855 / 0.434364 (-0.016509) | 0.472138 / 0.540337 (-0.068200) | 0.570859 / 1.386936 (-0.816077) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008495 / 0.011353 (-0.002858) | 0.005322 / 0.011008 (-0.005686) | 0.125471 / 0.038508 (0.086962) | 0.034604 / 0.023109 (0.011495) | 0.419831 / 0.275898 (0.143933) | 0.415707 / 0.323480 (0.092227) | 0.007471 / 0.007986 (-0.000515) | 0.005441 / 0.004328 (0.001112) | 0.095412 / 0.004250 (0.091162) | 0.053865 / 0.037052 (0.016812) | 0.375257 / 0.258489 (0.116768) | 0.438114 / 0.293841 (0.144273) | 0.046183 / 0.128546 (-0.082363) | 0.013663 / 0.075646 (-0.061984) | 0.438317 / 0.419271 (0.019045) | 0.065665 / 0.043533 (0.022133) | 0.387640 / 0.255139 (0.132501) | 0.431350 / 0.283200 (0.148150) | 0.112841 / 0.141683 (-0.028842) | 1.778639 / 1.452155 (0.326484) | 1.891948 / 1.492716 (0.399232) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.284371 / 0.018006 (0.266365) | 0.598247 / 0.000490 (0.597758) | 0.013674 / 0.000200 (0.013474) | 0.000483 / 0.000054 (0.000428) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032437 / 0.037411 (-0.004974) | 0.120547 / 0.014526 (0.106021) | 0.129845 / 0.176557 (-0.046711) | 0.203455 / 0.737135 (-0.533680) | 0.140039 / 0.296338 (-0.156300) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.596549 / 0.215209 (0.381340) | 6.138766 / 2.077655 (4.061111) | 2.515506 / 1.504120 (1.011386) | 2.124472 / 1.541195 (0.583277) | 2.160812 / 1.468490 (0.692322) | 0.898965 / 4.584777 (-3.685812) | 5.588152 / 3.745712 (1.842440) | 2.717580 / 5.269862 (-2.552282) | 1.683641 / 4.565676 (-2.882036) | 0.108045 / 0.424275 (-0.316230) | 0.014089 / 0.007607 (0.006481) | 0.749567 / 0.226044 (0.523523) | 7.518051 / 2.268929 (5.249123) | 3.198238 / 55.444624 (-52.246386) | 2.575156 / 6.876477 (-4.301321) | 2.725818 / 2.142072 (0.583745) | 1.149338 / 4.805227 (-3.655889) | 0.220443 / 6.500664 (-6.280221) | 0.081452 / 0.075469 (0.005983) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.624462 / 1.841788 (-0.217325) | 18.204963 / 8.074308 (10.130655) | 21.379169 / 10.191392 (11.187777) | 0.248520 / 0.680424 (-0.431903) | 0.030121 / 0.534201 (-0.504080) | 0.499542 / 0.579283 (-0.079741) | 0.599783 / 0.434364 (0.165419) | 0.597642 / 0.540337 (0.057305) | 0.681948 / 1.386936 (-0.704988) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008431 / 0.011353 (-0.002921) | 0.006143 / 0.011008 (-0.004865) | 0.107531 / 0.038508 (0.069023) | 0.036308 / 0.023109 (0.013199) | 0.480555 / 0.275898 (0.204657) | 0.556407 / 0.323480 (0.232927) | 0.007614 / 0.007986 (-0.000372) | 0.004749 / 0.004328 (0.000421) | 0.105734 / 0.004250 (0.101484) | 0.051619 / 0.037052 (0.014567) | 0.514821 / 0.258489 (0.256332) | 0.562143 / 0.293841 (0.268302) | 0.042957 / 0.128546 (-0.085589) | 0.015142 / 0.075646 (-0.060505) | 0.143161 / 0.419271 (-0.276111) | 0.061910 / 0.043533 (0.018377) | 0.496923 / 0.255139 (0.241784) | 0.556302 / 0.283200 (0.273102) | 0.136700 / 0.141683 (-0.004983) | 1.886184 / 1.452155 (0.434029) | 2.004087 / 1.492716 (0.511371) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235530 / 0.018006 (0.217523) | 0.600796 / 0.000490 (0.600306) | 0.009074 / 0.000200 (0.008874) | 0.000203 / 0.000054 (0.000149) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.036345 / 0.037411 (-0.001066) | 0.126112 / 0.014526 (0.111586) | 0.143369 / 0.176557 (-0.033188) | 0.211381 / 0.737135 (-0.525755) | 0.151095 / 0.296338 (-0.145243) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.695022 / 0.215209 (0.479813) | 6.685981 / 2.077655 (4.608326) | 3.104521 / 1.504120 (1.600401) | 2.758323 / 1.541195 (1.217128) | 2.706286 / 1.468490 (1.237796) | 0.941182 / 4.584777 (-3.643595) | 5.715839 / 3.745712 (1.970127) | 5.089636 / 5.269862 (-0.180226) | 2.594739 / 4.565676 (-1.970937) | 0.112621 / 0.424275 (-0.311655) | 0.014001 / 0.007607 (0.006394) | 0.812990 / 0.226044 (0.586945) | 8.060890 / 2.268929 (5.791961) | 3.832506 / 55.444624 (-51.612119) | 3.148051 / 6.876477 (-3.728425) | 3.110096 / 2.142072 (0.968023) | 1.105050 / 4.805227 (-3.700178) | 0.219835 / 6.500664 (-6.280829) | 0.078600 / 0.075469 (0.003131) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.707551 / 1.841788 (-0.134237) | 19.238194 / 8.074308 (11.163885) | 22.167076 / 10.191392 (11.975684) | 0.233458 / 0.680424 (-0.446966) | 0.025131 / 0.534201 (-0.509070) | 0.525241 / 0.579283 (-0.054042) | 0.649666 / 0.434364 (0.215303) | 0.602941 / 0.540337 (0.062603) | 0.718472 / 1.386936 (-0.668464) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5475/comments | https://api.github.com/repos/huggingface/datasets/issues/5475/events | https://github.com/huggingface/datasets/issues/5475 | 1,559,030,149 | I_kwDODunzps5c7OmF | 5,475 | Dataset scan time is much slower than using native arrow | [] | closed | false | null | 3 | 2023-01-27T01:32:25Z | 2023-01-30T16:17:11Z | 2023-01-30T16:17:11Z | null | ### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that explains this phenomenon?
### Steps to reproduce the bug
https://colab.research.google.com/drive/11EtHDaGAf1DKCpvYnAPJUW-LFfAcDzHY?usp=sharing
### Expected behavior
I expect scan times to be on par with using pyarrow directly.
### Environment info
standard colab environment | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5475/timeline | null | completed | null | null | false | [
"Hi ! In your code you only iterate on the Arrow buffers - you don't actually load the data as python objects. For a fair comparison, you can modify your code using:\r\n```diff\r\n- for _ in range(0, len(table), bsz):\r\n- _ = {k:table[k][_ : _ + bsz] for k in cols}\r\n+ for _ in range(0, len(table), bsz):\r\n+ _ = {k:table[k][_ : _ + bsz].to_pylist() for k in cols}\r\n```\r\n\r\nI re-ran your code and got a speed ratio of 1.00x and 1.02x",
"Ah I see, datasets is implicitly making this conversion. Thanks for pointing that out!\r\n\r\nIf it's not too much, I would also suggest updating some of your docs with the same `.to_pylist()` conversion in the code snippet that follows [here](https://huggingface.co/course/chapter5/4?fw=pt#:~:text=let%E2%80%99s%20run%20a%20little%20speed%20test%20by%20iterating%20over%20all%20the%20elements%20in%20the%20PubMed%20Abstracts%20dataset%3A).",
"This code snippet shows `datasets` code that reads the Arrow data as python objects already, there is no need to add to_pylist. Or were you thinking about something else ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/5234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5234/comments | https://api.github.com/repos/huggingface/datasets/issues/5234/events | https://github.com/huggingface/datasets/pull/5234 | 1,447,999,062 | PR_kwDODunzps5C1diq | 5,234 | fix: dataset path should be absolute | [] | closed | false | null | 3 | 2022-11-14T12:47:40Z | 2022-12-07T23:49:22Z | 2022-12-07T23:46:34Z | null | cache_file_name depends on dataset's path.
A simple way where this could cause a problem:
```
import os
import datasets
def add_prefix(example):
example["text"] = "Review: " + example["text"]
return example
ds = datasets.load_from_disk("a/relative/path")
os.chdir("/tmp")
ds_1 = ds.map(add_prefix)
```
while it may feel that the `chdir` is quite constructed, there are many scenarios when the current working dir can/will change... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5234/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5234",
"merged_at": "2022-12-07T23:46:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5234"
} | true | [
"Good catch thanks ! Have you tried to use the absolue path in `MemoryMappedTable.__init__` in `table.py`?\r\n\r\nI think it can fix issues with relative paths at more levels than just fixing it `load_from_disk`. If it works I think it would be a more robust fix to this issue",
"@lhoestq right, that actually fixed it indeed. I've pushed the changes (one-liner). lemme know if there's anything else you need for this fix",
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5772 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5772/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5772/comments | https://api.github.com/repos/huggingface/datasets/issues/5772/events | https://github.com/huggingface/datasets/pull/5772 | 1,675,033,510 | PR_kwDODunzps5OreXV | 5,772 | Fix JSON builder when missing keys in first row | [] | closed | false | null | 2 | 2023-04-19T14:32:57Z | 2023-04-21T06:45:13Z | 2023-04-21T06:35:27Z | null | Until now, the JSON builder only considered the keys present in the first element of the list:
- Either explicitly: by passing index 0 in `dataset[0].keys()`
- Or implicitly: `pa.Table.from_pylist(dataset)`, where "schema (default None): If not passed, will be inferred from the first row of the mapping values"
This PR fixes the bug by considering the union of the keys present in all the rows.
Fix #5726. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5772/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5772/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5772.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5772",
"merged_at": "2023-04-21T06:35:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5772.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5772"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009262 / 0.011353 (-0.002091) | 0.006157 / 0.011008 (-0.004851) | 0.125960 / 0.038508 (0.087451) | 0.036213 / 0.023109 (0.013104) | 0.399331 / 0.275898 (0.123433) | 0.453597 / 0.323480 (0.130117) | 0.006990 / 0.007986 (-0.000995) | 0.007320 / 0.004328 (0.002991) | 0.100321 / 0.004250 (0.096070) | 0.048870 / 0.037052 (0.011818) | 0.396284 / 0.258489 (0.137795) | 0.475619 / 0.293841 (0.181778) | 0.052329 / 0.128546 (-0.076217) | 0.019564 / 0.075646 (-0.056083) | 0.430942 / 0.419271 (0.011670) | 0.063224 / 0.043533 (0.019692) | 0.391717 / 0.255139 (0.136578) | 0.448342 / 0.283200 (0.165142) | 0.114055 / 0.141683 (-0.027628) | 1.793204 / 1.452155 (0.341049) | 1.895151 / 1.492716 (0.402435) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.283699 / 0.018006 (0.265693) | 0.597194 / 0.000490 (0.596704) | 0.007143 / 0.000200 (0.006944) | 0.000602 / 0.000054 (0.000548) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034761 / 0.037411 (-0.002651) | 0.124555 / 0.014526 (0.110030) | 0.149126 / 0.176557 (-0.027430) | 0.220335 / 0.737135 (-0.516801) | 0.153109 / 0.296338 (-0.143229) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.620210 / 0.215209 (0.405001) | 6.229937 / 2.077655 (4.152282) | 2.615203 / 1.504120 (1.111083) | 2.239337 / 1.541195 (0.698143) | 2.262138 / 1.468490 (0.793648) | 1.196498 / 4.584777 (-3.388279) | 5.609932 / 3.745712 (1.864220) | 3.031347 / 5.269862 (-2.238515) | 2.025530 / 4.565676 (-2.540146) | 0.139828 / 0.424275 (-0.284447) | 0.015476 / 0.007607 (0.007869) | 0.768964 / 0.226044 (0.542920) | 7.728677 / 2.268929 (5.459748) | 3.336407 / 55.444624 (-52.108217) | 2.700055 / 6.876477 (-4.176422) | 2.765223 / 2.142072 (0.623151) | 1.409073 / 4.805227 (-3.396155) | 0.246849 / 6.500664 (-6.253815) | 0.081231 / 0.075469 (0.005762) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.593836 / 1.841788 (-0.247952) | 18.020525 / 8.074308 (9.946216) | 21.766822 / 10.191392 (11.575430) | 0.258615 / 0.680424 (-0.421809) | 0.026895 / 0.534201 (-0.507306) | 0.529823 / 0.579283 (-0.049460) | 0.623470 / 0.434364 (0.189106) | 0.628171 / 0.540337 (0.087833) | 0.745249 / 1.386936 (-0.641687) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008624 / 0.011353 (-0.002729) | 0.006317 / 0.011008 (-0.004691) | 0.097315 / 0.038508 (0.058807) | 0.035217 / 0.023109 (0.012108) | 0.440197 / 0.275898 (0.164299) | 0.473863 / 0.323480 (0.150383) | 0.006722 / 0.007986 (-0.001264) | 0.006444 / 0.004328 (0.002116) | 0.102056 / 0.004250 (0.097806) | 0.047142 / 0.037052 (0.010089) | 0.452476 / 0.258489 (0.193986) | 0.487619 / 0.293841 (0.193778) | 0.052456 / 0.128546 (-0.076090) | 0.018735 / 0.075646 (-0.056911) | 0.114656 / 0.419271 (-0.304616) | 0.062577 / 0.043533 (0.019044) | 0.444471 / 0.255139 (0.189332) | 0.494264 / 0.283200 (0.211065) | 0.117112 / 0.141683 (-0.024571) | 1.848965 / 1.452155 (0.396810) | 1.984008 / 1.492716 (0.491292) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290494 / 0.018006 (0.272488) | 0.588415 / 0.000490 (0.587925) | 0.000459 / 0.000200 (0.000259) | 0.000080 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032873 / 0.037411 (-0.004538) | 0.131139 / 0.014526 (0.116614) | 0.140268 / 0.176557 (-0.036289) | 0.204561 / 0.737135 (-0.532574) | 0.147443 / 0.296338 (-0.148895) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.636899 / 0.215209 (0.421690) | 6.236139 / 2.077655 (4.158484) | 2.801468 / 1.504120 (1.297348) | 2.398808 / 1.541195 (0.857613) | 2.493150 / 1.468490 (1.024659) | 1.228845 / 4.584777 (-3.355932) | 5.675874 / 3.745712 (1.930162) | 3.084939 / 5.269862 (-2.184922) | 2.061310 / 4.565676 (-2.504367) | 0.142285 / 0.424275 (-0.281990) | 0.014972 / 0.007607 (0.007365) | 0.786599 / 0.226044 (0.560555) | 7.876036 / 2.268929 (5.607107) | 3.476136 / 55.444624 (-51.968489) | 2.847922 / 6.876477 (-4.028555) | 3.040326 / 2.142072 (0.898253) | 1.448538 / 4.805227 (-3.356690) | 0.257230 / 6.500664 (-6.243434) | 0.085137 / 0.075469 (0.009668) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.668173 / 1.841788 (-0.173615) | 18.668520 / 8.074308 (10.594212) | 20.535542 / 10.191392 (10.344150) | 0.244580 / 0.680424 (-0.435844) | 0.026364 / 0.534201 (-0.507837) | 0.531753 / 0.579283 (-0.047530) | 0.616578 / 0.434364 (0.182214) | 0.618906 / 0.540337 (0.078569) | 0.738785 / 1.386936 (-0.648151) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4928/comments | https://api.github.com/repos/huggingface/datasets/issues/4928/events | https://github.com/huggingface/datasets/pull/4928 | 1,360,941,172 | PR_kwDODunzps4-Ubi4 | 4,928 | Add ability to read-write to SQL databases. | [] | closed | false | null | 14 | 2022-09-03T19:09:08Z | 2022-10-03T16:34:36Z | 2022-10-03T16:32:28Z | null | Fixes #3094
Add ability to read/write to SQLite files and also read from any SQL database supported by SQLAlchemy.
I didn't add SQLAlchemy as a dependence as it is fairly big and it remains optional.
I also recorded a Loom to showcase the feature.
https://www.loom.com/share/f0e602c2de8a46f58bca4b43333d541f | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 2,
"heart": 4,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4928/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4928",
"merged_at": "2022-10-03T16:32:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4928"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Ah CI runs with `pandas=1.3.5` which doesn't return the number of row inserted.",
"wow this is super cool!",
"@lhoestq I'm getting error in integration tests, not sure if it's related to my PR. Any help would be appreciated :) \r\n\r\n```\r\nif not self._is_valid_token(token):\r\n> raise ValueError(\"Invalid token passed!\")\r\nE ValueError: Invalid token passed!\r\n```",
"I just relaunched the tests, it should be fixed now",
"Thanks a lot for working on this!\r\n\r\nI have some concerns with the current design:\r\n* Besides SQLite, the loader should also work with the other engines supported by SQLAlchemy. (A better name for it in the current state would be `sqlite` :))\r\n* It should support arbitrary queries/table names - only the latter currently works.\r\n* Exposing this loader as a packaged builder (`load_dataset(\"sql\", ...)`) is not a good idea for the following reasons:\r\n * Considering the scenario where a table with the same name is present in multiple files is very unlikely, the data files resolution is not needed here. And if we remove that, what the name of the default split should be? \"train\"?\r\n * `load_dataset(\"sql\", ...)` also implies that streaming should work, but that's not the case. And I don't think we can change that, considering how hard it is to make SQLite files streamable.\r\n\r\nAll this makes me think we shouldn't expose this builder as a packaged module and, instead, limit the API to `Dataset.from_sql`/`Dataset.to_sql` (with the signatures matching the ones in pandas as much as possible; regarding this, note that SQLAlchemy connections are not hashable/picklable, which is required for caching, but I think it's OK only to allow URI strings as connections to bypass that (Dask has the same limitation).\r\n\r\nWDYT?",
"Hi @mariosasko thank you for your review.\r\n\r\nI agree that `load_dataset('sql',...)` is a bit weird and I would be happy to remove it. To be honest, I only added it when I saw that it was the preferred way in `loading.mdx`. \r\n\r\nI agree that the `SELECT` should be a parameters as well. I'll add it.\r\n\r\nSo far, only `Dataset.to_sql` explicitly supports any SQLAlchemy Connexion, I'm pretty sure that `Dataset.from_sql` would work with a Connexion as well, but it would break the typing from the parent class which is `path_or_paths: NestedDataStructureLike[PathLike]`. I would prefer not to break this API Contract.\r\n\r\n\r\nI will have time to work on this over the weekend. Please let me know what you think if I do the following:\r\n* Remove `load_dataset('sql', ...)` and edit the documentation to use `to_sql, from_sql`.\r\n* Tentatively make `Dataset.from_sql` typing work with SQLAlchemy Connexion.\r\n* Add support for custom queries (Default would be `SELECT * FROM {table_name}`).\r\n\r\nCheers!",
"Perhaps after we merge https://github.com/huggingface/datasets/pull/4957 (**Done!**), you can subclass `AbstractDatasetInputStream` instead of `AbstractDatasetReader` to not break the contract with the connection object. Also, let's avoid having the default value for the query/table (you can set it to `None` in the builder and raise an error in the builder config's `__post_init__` if it's not provided). Other than that, sounds good!",
"@Dref360 I've made final changes/refinements to align the SQL API with Pandas/Dask. Let me know what you think.\r\n",
"Thank you so much! I was missing a lot of things sorry about that.\r\nLGTM",
"I think we can merge if the tests pass. \r\n\r\nOne last thing I would like to get your opinion on - currently, if SQLAlchemy is not installed, the missing dependency error will be thrown inside `pandas.read_sql`. Do you think we should be the ones throwing this error, e.g. after the imports in `packaged_modules/sql/sql.py` if `SQLALCHEMY_AVAILABLE` is `False` (note that this would mean making `sqlalchemy` a required dependency for the docs to be able to add `SqlConfig` to the package reference)?",
"> One last thing I would like to get your opinion on - currently, if SQLAlchemy is not installed, the missing dependency error will be thrown inside pandas.read_sql\r\n\r\nIs sqlalchemy always required for pd.read_sql ? If so, I think we can raise the error on our side.\r\nBut sqlalchemy should still be an optional dependency for `datasets` IMO",
"@lhoestq \r\n> Is sqlalchemy always required for pd.read_sql ? If so, I think we can raise the error on our side.\r\n\r\nIn our case, it's always required as we only support database URIs.\r\n\r\n> But sqlalchemy should still be an optional dependency for datasets IMO\r\n\r\nYes, it will remain optional for datasets but will be required for building the docs (as is`s3fs`, for instance). ",
"Ok I see ! Sounds good :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5098 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5098/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5098/comments | https://api.github.com/repos/huggingface/datasets/issues/5098/events | https://github.com/huggingface/datasets/issues/5098 | 1,404,058,518 | I_kwDODunzps5TsDuW | 5,098 | Classes label error when loading symbolic links using imagefolder | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
},
{
"color": "DF8D62",
"default": false,
"description": "",
"id": 4614514401,
"name": "hacktoberfest",
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest"
}
] | closed | false | null | 3 | 2022-10-11T06:10:58Z | 2022-11-14T14:40:20Z | 2022-11-14T14:40:20Z | null | **Is your feature request related to a problem? Please describe.**
Like this: #4015
When there are **symbolic links** to pictures in the data folder, the parent folder name of the **real file** will be used as the class name instead of the parent folder of the symbolic link itself. Can you give an option to decide whether to enable symbolic link tracking?
This is inconsistent with the `torchvision.datasets.ImageFolder` behavior.
For example:
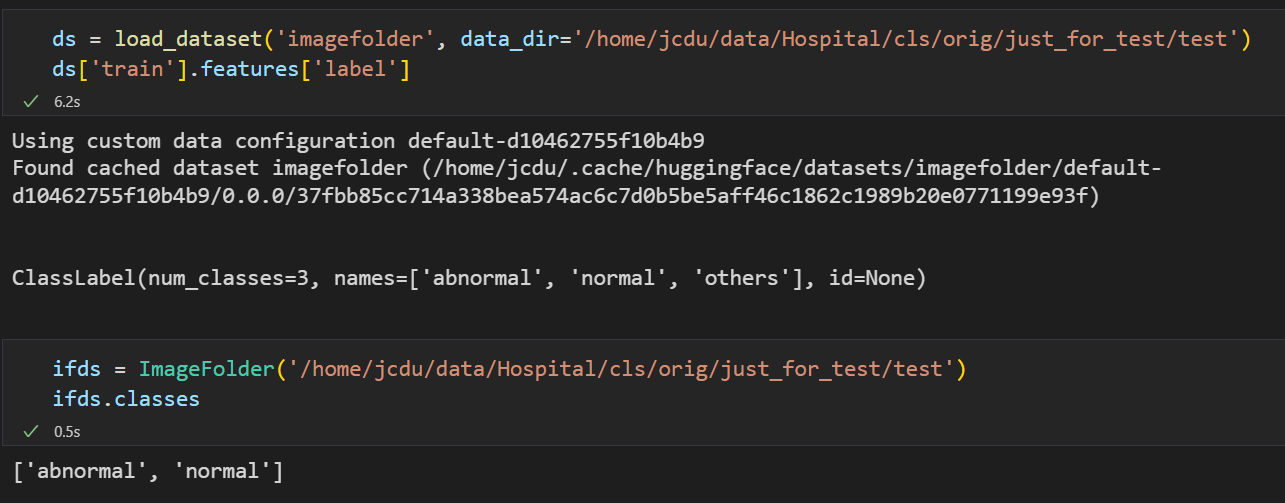

It use `others` in green circle as class label but not `abnormal`, I wish `load_dataset` not use the real file parent as label.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context about the feature request here.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5098/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5098/timeline | null | completed | null | null | false | [
"It can be solved temporarily by remove `resolve` in \r\nhttps://github.com/huggingface/datasets/blob/bef23be3d9543b1ca2da87ab2f05070201044ddc/src/datasets/data_files.py#L278",
"Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `Path(os.path.abspath(filepath))`.",
"> Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `Path(os.path.abspath(filepath))`.\r\n\r\nThanks for your reply!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1807 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1807/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1807/comments | https://api.github.com/repos/huggingface/datasets/issues/1807/events | https://github.com/huggingface/datasets/pull/1807 | 798,823,591 | MDExOlB1bGxSZXF1ZXN0NTY1NTczNzU5 | 1,807 | Adding an aggregated dataset for the GEM benchmark | [] | closed | false | null | 1 | 2021-02-02T00:39:53Z | 2021-02-02T22:48:41Z | 2021-02-02T18:06:58Z | null | This dataset gathers modified versions of several other conditional text generation datasets which together make up the shared task for the Generation Evaluation and Metrics workshop (think GLUE for text generation)
The changes from the original datasets are detailed in the Dataset Cards on the GEM website, which are linked to in this dataset card.
cc @sebastianGehrmann
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1807/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1807/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1807.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1807",
"merged_at": "2021-02-02T18:06:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1807.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1807"
} | true | [
"Nice !"
] |
https://api.github.com/repos/huggingface/datasets/issues/6072 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6072/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6072/comments | https://api.github.com/repos/huggingface/datasets/issues/6072/events | https://github.com/huggingface/datasets/pull/6072 | 1,822,123,560 | PR_kwDODunzps5WbWFN | 6,072 | Fix fsspec storage_options from load_dataset | [] | closed | false | null | 6 | 2023-07-26T10:44:23Z | 2023-07-27T12:51:51Z | 2023-07-27T12:42:57Z | null | close https://github.com/huggingface/datasets/issues/6071 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6072/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6072/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6072.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6072",
"merged_at": "2023-07-27T12:42:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6072.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6072"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007617 / 0.011353 (-0.003736) | 0.004580 / 0.011008 (-0.006428) | 0.100913 / 0.038508 (0.062405) | 0.087703 / 0.023109 (0.064594) | 0.424159 / 0.275898 (0.148261) | 0.467195 / 0.323480 (0.143715) | 0.006890 / 0.007986 (-0.001096) | 0.003765 / 0.004328 (-0.000564) | 0.077513 / 0.004250 (0.073262) | 0.064889 / 0.037052 (0.027837) | 0.422349 / 0.258489 (0.163860) | 0.477391 / 0.293841 (0.183550) | 0.036025 / 0.128546 (-0.092522) | 0.009939 / 0.075646 (-0.065707) | 0.342409 / 0.419271 (-0.076862) | 0.061568 / 0.043533 (0.018035) | 0.431070 / 0.255139 (0.175931) | 0.462008 / 0.283200 (0.178809) | 0.027480 / 0.141683 (-0.114203) | 1.802271 / 1.452155 (0.350116) | 1.861336 / 1.492716 (0.368620) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.255806 / 0.018006 (0.237800) | 0.507969 / 0.000490 (0.507479) | 0.010060 / 0.000200 (0.009860) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032286 / 0.037411 (-0.005125) | 0.104468 / 0.014526 (0.089942) | 0.112707 / 0.176557 (-0.063850) | 0.181285 / 0.737135 (-0.555850) | 0.113180 / 0.296338 (-0.183158) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.449265 / 0.215209 (0.234056) | 4.465941 / 2.077655 (2.388287) | 2.177889 / 1.504120 (0.673769) | 1.969864 / 1.541195 (0.428669) | 2.077502 / 1.468490 (0.609011) | 0.561607 / 4.584777 (-4.023170) | 4.281873 / 3.745712 (0.536161) | 4.975352 / 5.269862 (-0.294510) | 2.907121 / 4.565676 (-1.658555) | 0.070205 / 0.424275 (-0.354070) | 0.009164 / 0.007607 (0.001557) | 0.581921 / 0.226044 (0.355876) | 5.538667 / 2.268929 (3.269739) | 2.798853 / 55.444624 (-52.645771) | 2.314015 / 6.876477 (-4.562462) | 2.584836 / 2.142072 (0.442763) | 0.672333 / 4.805227 (-4.132894) | 0.153828 / 6.500664 (-6.346836) | 0.069757 / 0.075469 (-0.005712) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.559670 / 1.841788 (-0.282118) | 23.994639 / 8.074308 (15.920331) | 16.856160 / 10.191392 (6.664768) | 0.195555 / 0.680424 (-0.484869) | 0.021586 / 0.534201 (-0.512615) | 0.469295 / 0.579283 (-0.109989) | 0.481582 / 0.434364 (0.047218) | 0.588667 / 0.540337 (0.048329) | 0.734347 / 1.386936 (-0.652589) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009614 / 0.011353 (-0.001739) | 0.004616 / 0.011008 (-0.006392) | 0.077223 / 0.038508 (0.038715) | 0.103074 / 0.023109 (0.079965) | 0.447834 / 0.275898 (0.171936) | 0.524696 / 0.323480 (0.201216) | 0.007120 / 0.007986 (-0.000866) | 0.003890 / 0.004328 (-0.000438) | 0.076406 / 0.004250 (0.072156) | 0.073488 / 0.037052 (0.036436) | 0.466221 / 0.258489 (0.207732) | 0.532206 / 0.293841 (0.238365) | 0.037596 / 0.128546 (-0.090950) | 0.010029 / 0.075646 (-0.065617) | 0.084313 / 0.419271 (-0.334959) | 0.060088 / 0.043533 (0.016555) | 0.437792 / 0.255139 (0.182653) | 0.512850 / 0.283200 (0.229650) | 0.032424 / 0.141683 (-0.109259) | 1.762130 / 1.452155 (0.309975) | 1.946097 / 1.492716 (0.453381) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250774 / 0.018006 (0.232768) | 0.506869 / 0.000490 (0.506379) | 0.008232 / 0.000200 (0.008032) | 0.000164 / 0.000054 (0.000110) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037779 / 0.037411 (0.000368) | 0.111933 / 0.014526 (0.097407) | 0.122385 / 0.176557 (-0.054172) | 0.190372 / 0.737135 (-0.546763) | 0.122472 / 0.296338 (-0.173866) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488502 / 0.215209 (0.273293) | 4.878114 / 2.077655 (2.800459) | 2.504144 / 1.504120 (1.000024) | 2.321077 / 1.541195 (0.779883) | 2.416797 / 1.468490 (0.948307) | 0.583582 / 4.584777 (-4.001195) | 4.277896 / 3.745712 (0.532184) | 3.874780 / 5.269862 (-1.395082) | 2.540099 / 4.565676 (-2.025577) | 0.068734 / 0.424275 (-0.355541) | 0.009158 / 0.007607 (0.001550) | 0.578401 / 0.226044 (0.352357) | 5.763354 / 2.268929 (3.494426) | 3.167771 / 55.444624 (-52.276853) | 2.675220 / 6.876477 (-4.201257) | 2.920927 / 2.142072 (0.778855) | 0.673948 / 4.805227 (-4.131280) | 0.157908 / 6.500664 (-6.342756) | 0.071672 / 0.075469 (-0.003797) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.635120 / 1.841788 (-0.206668) | 24.853480 / 8.074308 (16.779172) | 17.162978 / 10.191392 (6.971586) | 0.209577 / 0.680424 (-0.470847) | 0.030110 / 0.534201 (-0.504091) | 0.546970 / 0.579283 (-0.032313) | 0.581912 / 0.434364 (0.147548) | 0.571460 / 0.540337 (0.031123) | 0.823411 / 1.386936 (-0.563525) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006674 / 0.011353 (-0.004679) | 0.004198 / 0.011008 (-0.006810) | 0.084859 / 0.038508 (0.046351) | 0.076065 / 0.023109 (0.052955) | 0.316065 / 0.275898 (0.040167) | 0.352097 / 0.323480 (0.028617) | 0.005610 / 0.007986 (-0.002376) | 0.003600 / 0.004328 (-0.000729) | 0.064921 / 0.004250 (0.060671) | 0.054493 / 0.037052 (0.017441) | 0.318125 / 0.258489 (0.059636) | 0.370183 / 0.293841 (0.076342) | 0.031141 / 0.128546 (-0.097405) | 0.008755 / 0.075646 (-0.066891) | 0.288241 / 0.419271 (-0.131030) | 0.052379 / 0.043533 (0.008846) | 0.328147 / 0.255139 (0.073008) | 0.347548 / 0.283200 (0.064348) | 0.024393 / 0.141683 (-0.117290) | 1.480646 / 1.452155 (0.028492) | 1.575867 / 1.492716 (0.083151) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.268978 / 0.018006 (0.250971) | 0.586470 / 0.000490 (0.585980) | 0.003190 / 0.000200 (0.002990) | 0.000081 / 0.000054 (0.000026) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030595 / 0.037411 (-0.006816) | 0.083037 / 0.014526 (0.068511) | 0.103706 / 0.176557 (-0.072850) | 0.164104 / 0.737135 (-0.573031) | 0.104536 / 0.296338 (-0.191802) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.382274 / 0.215209 (0.167065) | 3.811878 / 2.077655 (1.734223) | 1.840098 / 1.504120 (0.335978) | 1.670949 / 1.541195 (0.129754) | 1.763755 / 1.468490 (0.295264) | 0.479526 / 4.584777 (-4.105251) | 3.544443 / 3.745712 (-0.201269) | 3.263004 / 5.269862 (-2.006858) | 2.092801 / 4.565676 (-2.472875) | 0.057167 / 0.424275 (-0.367108) | 0.007450 / 0.007607 (-0.000157) | 0.463731 / 0.226044 (0.237686) | 4.624630 / 2.268929 (2.355701) | 2.327078 / 55.444624 (-53.117546) | 1.977734 / 6.876477 (-4.898743) | 2.237152 / 2.142072 (0.095079) | 0.573210 / 4.805227 (-4.232018) | 0.132095 / 6.500664 (-6.368569) | 0.060283 / 0.075469 (-0.015186) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.243404 / 1.841788 (-0.598384) | 20.306778 / 8.074308 (12.232470) | 14.561660 / 10.191392 (4.370268) | 0.170826 / 0.680424 (-0.509598) | 0.018574 / 0.534201 (-0.515627) | 0.392367 / 0.579283 (-0.186916) | 0.402918 / 0.434364 (-0.031446) | 0.476629 / 0.540337 (-0.063708) | 0.653709 / 1.386936 (-0.733227) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006562 / 0.011353 (-0.004791) | 0.004092 / 0.011008 (-0.006916) | 0.065951 / 0.038508 (0.027443) | 0.078090 / 0.023109 (0.054981) | 0.369679 / 0.275898 (0.093781) | 0.411442 / 0.323480 (0.087962) | 0.005646 / 0.007986 (-0.002339) | 0.003537 / 0.004328 (-0.000791) | 0.066024 / 0.004250 (0.061773) | 0.058947 / 0.037052 (0.021895) | 0.389219 / 0.258489 (0.130730) | 0.414200 / 0.293841 (0.120359) | 0.030372 / 0.128546 (-0.098174) | 0.008631 / 0.075646 (-0.067015) | 0.071692 / 0.419271 (-0.347580) | 0.048035 / 0.043533 (0.004502) | 0.376960 / 0.255139 (0.121821) | 0.389847 / 0.283200 (0.106648) | 0.023940 / 0.141683 (-0.117743) | 1.487633 / 1.452155 (0.035479) | 1.561680 / 1.492716 (0.068964) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.301467 / 0.018006 (0.283461) | 0.544159 / 0.000490 (0.543669) | 0.000408 / 0.000200 (0.000208) | 0.000055 / 0.000054 (0.000001) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030939 / 0.037411 (-0.006472) | 0.087432 / 0.014526 (0.072906) | 0.103263 / 0.176557 (-0.073293) | 0.154551 / 0.737135 (-0.582585) | 0.104631 / 0.296338 (-0.191707) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422348 / 0.215209 (0.207139) | 4.206003 / 2.077655 (2.128348) | 2.212619 / 1.504120 (0.708499) | 2.049616 / 1.541195 (0.508421) | 2.139093 / 1.468490 (0.670603) | 0.489647 / 4.584777 (-4.095130) | 3.523291 / 3.745712 (-0.222422) | 3.277657 / 5.269862 (-1.992205) | 2.111353 / 4.565676 (-2.454324) | 0.057597 / 0.424275 (-0.366679) | 0.007675 / 0.007607 (0.000068) | 0.493068 / 0.226044 (0.267023) | 4.939493 / 2.268929 (2.670565) | 2.695995 / 55.444624 (-52.748630) | 2.374904 / 6.876477 (-4.501573) | 2.600110 / 2.142072 (0.458038) | 0.586306 / 4.805227 (-4.218921) | 0.134137 / 6.500664 (-6.366527) | 0.061897 / 0.075469 (-0.013572) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.330628 / 1.841788 (-0.511160) | 20.557964 / 8.074308 (12.483656) | 14.251632 / 10.191392 (4.060240) | 0.148772 / 0.680424 (-0.531652) | 0.018383 / 0.534201 (-0.515817) | 0.392552 / 0.579283 (-0.186731) | 0.403959 / 0.434364 (-0.030405) | 0.462154 / 0.540337 (-0.078184) | 0.608832 / 1.386936 (-0.778104) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007659 / 0.011353 (-0.003694) | 0.004500 / 0.011008 (-0.006508) | 0.100379 / 0.038508 (0.061871) | 0.079731 / 0.023109 (0.056622) | 0.381788 / 0.275898 (0.105890) | 0.416524 / 0.323480 (0.093044) | 0.004446 / 0.007986 (-0.003539) | 0.003752 / 0.004328 (-0.000577) | 0.074956 / 0.004250 (0.070706) | 0.062885 / 0.037052 (0.025832) | 0.383849 / 0.258489 (0.125360) | 0.433906 / 0.293841 (0.140065) | 0.036079 / 0.128546 (-0.092468) | 0.009927 / 0.075646 (-0.065719) | 0.343879 / 0.419271 (-0.075393) | 0.061055 / 0.043533 (0.017523) | 0.376703 / 0.255139 (0.121564) | 0.428111 / 0.283200 (0.144911) | 0.028667 / 0.141683 (-0.113016) | 1.777755 / 1.452155 (0.325600) | 1.878283 / 1.492716 (0.385567) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.220829 / 0.018006 (0.202823) | 0.506406 / 0.000490 (0.505916) | 0.005550 / 0.000200 (0.005350) | 0.000123 / 0.000054 (0.000069) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034928 / 0.037411 (-0.002483) | 0.103873 / 0.014526 (0.089347) | 0.114352 / 0.176557 (-0.062204) | 0.188218 / 0.737135 (-0.548918) | 0.117343 / 0.296338 (-0.178995) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.459148 / 0.215209 (0.243939) | 4.582092 / 2.077655 (2.504437) | 2.275603 / 1.504120 (0.771483) | 2.058155 / 1.541195 (0.516960) | 2.163886 / 1.468490 (0.695396) | 0.573033 / 4.584777 (-4.011744) | 4.414891 / 3.745712 (0.669178) | 7.280433 / 5.269862 (2.010572) | 4.119414 / 4.565676 (-0.446262) | 0.067432 / 0.424275 (-0.356843) | 0.008687 / 0.007607 (0.001080) | 0.556029 / 0.226044 (0.329984) | 5.557192 / 2.268929 (3.288264) | 2.921596 / 55.444624 (-52.523028) | 2.520249 / 6.876477 (-4.356228) | 2.778965 / 2.142072 (0.636893) | 0.684765 / 4.805227 (-4.120462) | 0.159228 / 6.500664 (-6.341436) | 0.074015 / 0.075469 (-0.001454) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.534470 / 1.841788 (-0.307318) | 23.630693 / 8.074308 (15.556385) | 17.058142 / 10.191392 (6.866750) | 0.200909 / 0.680424 (-0.479515) | 0.021637 / 0.534201 (-0.512564) | 0.467417 / 0.579283 (-0.111866) | 0.460456 / 0.434364 (0.026092) | 0.541131 / 0.540337 (0.000793) | 0.728560 / 1.386936 (-0.658376) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007625 / 0.011353 (-0.003727) | 0.004495 / 0.011008 (-0.006513) | 0.076373 / 0.038508 (0.037865) | 0.085260 / 0.023109 (0.062151) | 0.475778 / 0.275898 (0.199880) | 0.504604 / 0.323480 (0.181124) | 0.006733 / 0.007986 (-0.001253) | 0.003751 / 0.004328 (-0.000578) | 0.074993 / 0.004250 (0.070743) | 0.064704 / 0.037052 (0.027652) | 0.490072 / 0.258489 (0.231583) | 0.507560 / 0.293841 (0.213719) | 0.036765 / 0.128546 (-0.091781) | 0.009955 / 0.075646 (-0.065692) | 0.082452 / 0.419271 (-0.336820) | 0.057131 / 0.043533 (0.013598) | 0.467664 / 0.255139 (0.212525) | 0.482143 / 0.283200 (0.198943) | 0.025396 / 0.141683 (-0.116287) | 1.807587 / 1.452155 (0.355433) | 1.853355 / 1.492716 (0.360639) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.250543 / 0.018006 (0.232537) | 0.495685 / 0.000490 (0.495196) | 0.000415 / 0.000200 (0.000215) | 0.000063 / 0.000054 (0.000008) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.035795 / 0.037411 (-0.001616) | 0.105954 / 0.014526 (0.091428) | 0.120158 / 0.176557 (-0.056399) | 0.181714 / 0.737135 (-0.555422) | 0.121242 / 0.296338 (-0.175097) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.488241 / 0.215209 (0.273032) | 4.866916 / 2.077655 (2.789262) | 2.531530 / 1.504120 (1.027410) | 2.360642 / 1.541195 (0.819448) | 2.457320 / 1.468490 (0.988830) | 0.571224 / 4.584777 (-4.013553) | 4.339042 / 3.745712 (0.593330) | 3.672812 / 5.269862 (-1.597050) | 2.364535 / 4.565676 (-2.201142) | 0.067004 / 0.424275 (-0.357271) | 0.009019 / 0.007607 (0.001412) | 0.563751 / 0.226044 (0.337707) | 5.664917 / 2.268929 (3.395989) | 3.043316 / 55.444624 (-52.401308) | 2.682722 / 6.876477 (-4.193755) | 2.863482 / 2.142072 (0.721409) | 0.666171 / 4.805227 (-4.139056) | 0.151862 / 6.500664 (-6.348802) | 0.071199 / 0.075469 (-0.004271) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.601880 / 1.841788 (-0.239907) | 23.069073 / 8.074308 (14.994765) | 16.918377 / 10.191392 (6.726985) | 0.173614 / 0.680424 (-0.506810) | 0.021843 / 0.534201 (-0.512358) | 0.470531 / 0.579283 (-0.108753) | 0.471152 / 0.434364 (0.036788) | 0.550968 / 0.540337 (0.010631) | 0.718869 / 1.386936 (-0.668067) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007530 / 0.011353 (-0.003823) | 0.004151 / 0.011008 (-0.006858) | 0.098490 / 0.038508 (0.059982) | 0.086955 / 0.023109 (0.063846) | 0.362133 / 0.275898 (0.086235) | 0.391402 / 0.323480 (0.067922) | 0.006274 / 0.007986 (-0.001712) | 0.003711 / 0.004328 (-0.000618) | 0.073519 / 0.004250 (0.069269) | 0.066170 / 0.037052 (0.029118) | 0.379057 / 0.258489 (0.120568) | 0.398132 / 0.293841 (0.104291) | 0.033936 / 0.128546 (-0.094610) | 0.009977 / 0.075646 (-0.065670) | 0.323766 / 0.419271 (-0.095505) | 0.078615 / 0.043533 (0.035082) | 0.352403 / 0.255139 (0.097264) | 0.386607 / 0.283200 (0.103407) | 0.036579 / 0.141683 (-0.105103) | 1.691899 / 1.452155 (0.239745) | 1.819396 / 1.492716 (0.326680) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216888 / 0.018006 (0.198882) | 0.465781 / 0.000490 (0.465291) | 0.006197 / 0.000200 (0.005997) | 0.000086 / 0.000054 (0.000031) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032870 / 0.037411 (-0.004542) | 0.096026 / 0.014526 (0.081500) | 0.111093 / 0.176557 (-0.065464) | 0.185982 / 0.737135 (-0.551154) | 0.106967 / 0.296338 (-0.189371) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441567 / 0.215209 (0.226358) | 4.353813 / 2.077655 (2.276158) | 2.176034 / 1.504120 (0.671914) | 1.969631 / 1.541195 (0.428437) | 2.048821 / 1.468490 (0.580330) | 0.549144 / 4.584777 (-4.035633) | 4.016166 / 3.745712 (0.270453) | 3.764249 / 5.269862 (-1.505613) | 2.293995 / 4.565676 (-2.271681) | 0.065227 / 0.424275 (-0.359048) | 0.008303 / 0.007607 (0.000695) | 0.513783 / 0.226044 (0.287738) | 5.247617 / 2.268929 (2.978689) | 2.782114 / 55.444624 (-52.662510) | 2.342776 / 6.876477 (-4.533701) | 2.621569 / 2.142072 (0.479497) | 0.679336 / 4.805227 (-4.125891) | 0.152061 / 6.500664 (-6.348603) | 0.070294 / 0.075469 (-0.005175) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.471778 / 1.841788 (-0.370010) | 22.714904 / 8.074308 (14.640596) | 15.607991 / 10.191392 (5.416599) | 0.172592 / 0.680424 (-0.507832) | 0.021799 / 0.534201 (-0.512402) | 0.462740 / 0.579283 (-0.116543) | 0.490885 / 0.434364 (0.056521) | 0.552997 / 0.540337 (0.012660) | 0.763784 / 1.386936 (-0.623152) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007466 / 0.011353 (-0.003886) | 0.004322 / 0.011008 (-0.006686) | 0.074331 / 0.038508 (0.035823) | 0.085315 / 0.023109 (0.062206) | 0.409284 / 0.275898 (0.133386) | 0.464584 / 0.323480 (0.141104) | 0.005651 / 0.007986 (-0.002335) | 0.003577 / 0.004328 (-0.000751) | 0.070250 / 0.004250 (0.066000) | 0.059780 / 0.037052 (0.022727) | 0.419668 / 0.258489 (0.161179) | 0.462984 / 0.293841 (0.169143) | 0.034159 / 0.128546 (-0.094387) | 0.008999 / 0.075646 (-0.066647) | 0.076302 / 0.419271 (-0.342969) | 0.052274 / 0.043533 (0.008741) | 0.425938 / 0.255139 (0.170799) | 0.430399 / 0.283200 (0.147200) | 0.025017 / 0.141683 (-0.116666) | 1.680697 / 1.452155 (0.228542) | 1.774677 / 1.492716 (0.281960) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.291514 / 0.018006 (0.273508) | 0.461175 / 0.000490 (0.460685) | 0.023061 / 0.000200 (0.022861) | 0.000120 / 0.000054 (0.000065) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033950 / 0.037411 (-0.003462) | 0.100032 / 0.014526 (0.085506) | 0.118308 / 0.176557 (-0.058249) | 0.183601 / 0.737135 (-0.553535) | 0.116936 / 0.296338 (-0.179402) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.478779 / 0.215209 (0.263570) | 4.709505 / 2.077655 (2.631850) | 2.457442 / 1.504120 (0.953322) | 2.213737 / 1.541195 (0.672542) | 2.340642 / 1.468490 (0.872152) | 0.567187 / 4.584777 (-4.017590) | 3.923061 / 3.745712 (0.177349) | 3.752989 / 5.269862 (-1.516873) | 2.324028 / 4.565676 (-2.241649) | 0.064471 / 0.424275 (-0.359804) | 0.008845 / 0.007607 (0.001238) | 0.547447 / 0.226044 (0.321402) | 5.599435 / 2.268929 (3.330506) | 2.980547 / 55.444624 (-52.464077) | 2.754908 / 6.876477 (-4.121569) | 2.832978 / 2.142072 (0.690906) | 0.635059 / 4.805227 (-4.170168) | 0.153478 / 6.500664 (-6.347187) | 0.067146 / 0.075469 (-0.008323) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.555588 / 1.841788 (-0.286200) | 22.828906 / 8.074308 (14.754597) | 16.211008 / 10.191392 (6.019616) | 0.168009 / 0.680424 (-0.512415) | 0.021966 / 0.534201 (-0.512235) | 0.464872 / 0.579283 (-0.114411) | 0.460429 / 0.434364 (0.026065) | 0.530498 / 0.540337 (-0.009839) | 0.705020 / 1.386936 (-0.681916) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005964 / 0.011353 (-0.005389) | 0.003644 / 0.011008 (-0.007364) | 0.079607 / 0.038508 (0.041099) | 0.058387 / 0.023109 (0.035278) | 0.312226 / 0.275898 (0.036328) | 0.349206 / 0.323480 (0.025726) | 0.004715 / 0.007986 (-0.003271) | 0.002869 / 0.004328 (-0.001460) | 0.061668 / 0.004250 (0.057417) | 0.045694 / 0.037052 (0.008642) | 0.313516 / 0.258489 (0.055027) | 0.357543 / 0.293841 (0.063702) | 0.027179 / 0.128546 (-0.101367) | 0.007961 / 0.075646 (-0.067686) | 0.262473 / 0.419271 (-0.156798) | 0.045588 / 0.043533 (0.002055) | 0.313102 / 0.255139 (0.057963) | 0.368686 / 0.283200 (0.085486) | 0.020556 / 0.141683 (-0.121127) | 1.447258 / 1.452155 (-0.004897) | 1.527319 / 1.492716 (0.034602) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199417 / 0.018006 (0.181411) | 0.422155 / 0.000490 (0.421665) | 0.004972 / 0.000200 (0.004772) | 0.000073 / 0.000054 (0.000018) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023539 / 0.037411 (-0.013872) | 0.073055 / 0.014526 (0.058529) | 0.083631 / 0.176557 (-0.092926) | 0.145923 / 0.737135 (-0.591212) | 0.083820 / 0.296338 (-0.212518) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.396305 / 0.215209 (0.181096) | 3.967065 / 2.077655 (1.889410) | 2.101109 / 1.504120 (0.596989) | 1.958817 / 1.541195 (0.417622) | 2.037894 / 1.468490 (0.569404) | 0.496955 / 4.584777 (-4.087822) | 3.078948 / 3.745712 (-0.666764) | 3.363655 / 5.269862 (-1.906207) | 2.087659 / 4.565676 (-2.478018) | 0.057171 / 0.424275 (-0.367104) | 0.006410 / 0.007607 (-0.001197) | 0.470535 / 0.226044 (0.244491) | 4.715259 / 2.268929 (2.446330) | 2.355510 / 55.444624 (-53.089114) | 2.025270 / 6.876477 (-4.851207) | 2.210401 / 2.142072 (0.068329) | 0.580538 / 4.805227 (-4.224689) | 0.125068 / 6.500664 (-6.375596) | 0.059871 / 0.075469 (-0.015598) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.245468 / 1.841788 (-0.596320) | 18.322042 / 8.074308 (10.247734) | 13.609726 / 10.191392 (3.418334) | 0.143623 / 0.680424 (-0.536801) | 0.017068 / 0.534201 (-0.517133) | 0.330758 / 0.579283 (-0.248525) | 0.339946 / 0.434364 (-0.094418) | 0.377861 / 0.540337 (-0.162476) | 0.524593 / 1.386936 (-0.862343) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006049 / 0.011353 (-0.005304) | 0.003737 / 0.011008 (-0.007271) | 0.062816 / 0.038508 (0.024308) | 0.063768 / 0.023109 (0.040658) | 0.362001 / 0.275898 (0.086103) | 0.395251 / 0.323480 (0.071772) | 0.004823 / 0.007986 (-0.003163) | 0.002881 / 0.004328 (-0.001447) | 0.061987 / 0.004250 (0.057737) | 0.049950 / 0.037052 (0.012898) | 0.362442 / 0.258489 (0.103953) | 0.399321 / 0.293841 (0.105480) | 0.027616 / 0.128546 (-0.100930) | 0.007965 / 0.075646 (-0.067681) | 0.068584 / 0.419271 (-0.350687) | 0.044700 / 0.043533 (0.001168) | 0.361011 / 0.255139 (0.105872) | 0.386007 / 0.283200 (0.102807) | 0.024621 / 0.141683 (-0.117061) | 1.441497 / 1.452155 (-0.010657) | 1.533145 / 1.492716 (0.040429) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.223446 / 0.018006 (0.205440) | 0.411147 / 0.000490 (0.410657) | 0.001821 / 0.000200 (0.001621) | 0.000081 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025661 / 0.037411 (-0.011751) | 0.077838 / 0.014526 (0.063313) | 0.086148 / 0.176557 (-0.090408) | 0.140386 / 0.737135 (-0.596750) | 0.088793 / 0.296338 (-0.207546) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.425209 / 0.215209 (0.210000) | 4.250723 / 2.077655 (2.173068) | 2.403437 / 1.504120 (0.899317) | 2.283584 / 1.541195 (0.742390) | 2.326870 / 1.468490 (0.858380) | 0.504781 / 4.584777 (-4.079996) | 3.017042 / 3.745712 (-0.728670) | 4.643068 / 5.269862 (-0.626794) | 2.535710 / 4.565676 (-2.029967) | 0.058520 / 0.424275 (-0.365755) | 0.006766 / 0.007607 (-0.000841) | 0.500664 / 0.226044 (0.274620) | 5.017073 / 2.268929 (2.748145) | 2.668661 / 55.444624 (-52.775963) | 2.335486 / 6.876477 (-4.540991) | 2.486518 / 2.142072 (0.344445) | 0.598795 / 4.805227 (-4.206432) | 0.126395 / 6.500664 (-6.374269) | 0.063154 / 0.075469 (-0.012315) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.358059 / 1.841788 (-0.483728) | 18.615724 / 8.074308 (10.541416) | 13.670934 / 10.191392 (3.479542) | 0.134650 / 0.680424 (-0.545774) | 0.016941 / 0.534201 (-0.517260) | 0.335215 / 0.579283 (-0.244068) | 0.356118 / 0.434364 (-0.078246) | 0.393109 / 0.540337 (-0.147228) | 0.534165 / 1.386936 (-0.852771) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | [] | closed | false | null | 4 | 2023-03-01T12:53:08Z | 2023-04-19T10:19:37Z | 2023-03-02T11:12:11Z | null | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wrapper
return func(array, *args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 2132, in cast_array_to_feature
raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
TypeError: Couldn't cast array of type
struct<type: string, action: string, datetime: timestamp[s], author: string, title: string, description: string, comment_id: int64, comment: string, labels: list<item: string>>
to
{'type': Value(dtype='string', id=None), 'action': Value(dtype='string', id=None), 'datetime': Value(dtype='timestamp[s]', id=None), 'author': Value(dtype='string', id=None), 'title': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'comment_id': Value(dtype='int64', id=None), 'comment': Value(dtype='string', id=None)}
```
But I can succesfully load a subset of the dataset, for example this works:
```python
ds = load_dataset('bigcode-data/the-stack-gh-issues', split="train", data_files=[f"data/data-{x}.jsonl" for x in range(10)])
```
and `ds.features` returns:
```
{'repo': Value(dtype='string', id=None),
'org': Value(dtype='string', id=None),
'issue_id': Value(dtype='int64', id=None),
'issue_number': Value(dtype='int64', id=None),
'pull_request': {'user_login': Value(dtype='string', id=None),
'repo': Value(dtype='string', id=None),
'number': Value(dtype='int64', id=None)},
'events': [{'type': Value(dtype='string', id=None),
'action': Value(dtype='string', id=None),
'datetime': Value(dtype='timestamp[s]', id=None),
'author': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None),
'description': Value(dtype='string', id=None),
'comment_id': Value(dtype='int64', id=None),
'comment': Value(dtype='string', id=None)}]}
```
So I'm not sure if there's an issue with just some of the files. Grateful if you have any suggestions to fix the issue.
Side note:
I saw this related [issue](https://github.com/huggingface/datasets/issues/3637) and tried to write a loading script to have `events` as a `Sequence` and not `list` [here](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues/blob/main/loading.py) (the script was renamed). It worked with a subset locally but doesn't for the remote dataset it can't find https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues/resolve/main/data.
### Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset('bigcode-data/the-stack-gh-issues', split="train")
```
### Expected behavior
Load the entire dataset succesfully.
### Environment info
- `datasets` version: 2.10.1
- Platform: Linux-4.19.0-23-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.12
- PyArrow version: 9.0.0
- Pandas version: 1.3.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | null | null | false | [
"Apparently some JSON objects have a `\"labels\"` field. Since this field is not present in every object, you must specify all the fields types in the README.md\r\n\r\nEDIT: actually specifying the feature types doesn’t solve the issue, it raises an error because “labels” is missing in the data",
"We've updated the dataset to remove the extra `labels` field from some files, closing this issue. Thanks!",
"A similar error occurs in the Pile dataset (EleutherAI/the_pile)\r\n\r\nLoading the dataset produces the following error.\r\n\r\n```\r\nTypeError: Couldn't cast array of type\r\nstruct<file: string, id: string>\r\nto\r\n{'id': Value(dtype='string', id=None)}\r\n```\r\n",
"I think this was fixed in https://huggingface.co/datasets/EleutherAI/the_pile/discussions/11"
] |
https://api.github.com/repos/huggingface/datasets/issues/1649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1649/comments | https://api.github.com/repos/huggingface/datasets/issues/1649/events | https://github.com/huggingface/datasets/pull/1649 | 775,544,487 | MDExOlB1bGxSZXF1ZXN0NTQ2MjAzMjE1 | 1,649 | Update README.md | [] | closed | false | null | 0 | 2020-12-28T19:05:00Z | 2020-12-29T10:50:58Z | 2020-12-29T10:43:03Z | null | Added information in the dataset card | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1649/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1649.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1649",
"merged_at": "2020-12-29T10:43:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1649.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1649"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2458 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2458/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2458/comments | https://api.github.com/repos/huggingface/datasets/issues/2458/events | https://github.com/huggingface/datasets/issues/2458 | 915,199,693 | MDU6SXNzdWU5MTUxOTk2OTM= | 2,458 | Revert default in-memory for small datasets | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"closed_at": "2021-06-08T18:51:04Z",
"closed_issues": 2,
"created_at": "2021-04-20T16:49:16Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-06-08T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/4",
"id": 6680642,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/4/labels",
"node_id": "MDk6TWlsZXN0b25lNjY4MDY0Mg==",
"number": 4,
"open_issues": 0,
"state": "closed",
"title": "1.8",
"updated_at": "2021-06-08T18:51:37Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/4"
} | 1 | 2021-06-08T15:51:41Z | 2021-06-08T18:57:11Z | 2021-06-08T17:55:43Z | null | Users are reporting issues and confusion about setting default in-memory to True for small datasets.
We see 2 clear use cases of Datasets:
- the "canonical" way, where you can work with very large datasets, as they are memory-mapped and cached (after every transformation)
- some edge cases (speed benchmarks, interactive/exploratory analysis,...), where default in-memory can explicitly be enabled, and no caching will be done
After discussing with @lhoestq we have agreed to:
- revert this feature (implemented in #2182)
- explain in the docs how to optimize speed/performance by setting default in-memory
cc: @stas00 https://github.com/huggingface/datasets/pull/2409#issuecomment-856210552 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2458/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2458/timeline | null | completed | null | null | false | [
"cc: @krandiash (pinged in reverted PR)."
] |
https://api.github.com/repos/huggingface/datasets/issues/178 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/178/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/178/comments | https://api.github.com/repos/huggingface/datasets/issues/178/events | https://github.com/huggingface/datasets/pull/178 | 621,979,849 | MDExOlB1bGxSZXF1ZXN0NDIwOTMyMDI5 | 178 | [Manual data] improve error message for manual data in general | [] | closed | false | null | 0 | 2020-05-20T18:10:45Z | 2020-05-20T18:18:52Z | 2020-05-20T18:18:50Z | null | `nlp.load("xsum")` now leads to the following error message:

I guess the manual download instructions for `xsum` can also be improved. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/178/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/178/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/178.diff",
"html_url": "https://github.com/huggingface/datasets/pull/178",
"merged_at": "2020-05-20T18:18:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/178.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/178"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1678/comments | https://api.github.com/repos/huggingface/datasets/issues/1678/events | https://github.com/huggingface/datasets/pull/1678 | 777,567,920 | MDExOlB1bGxSZXF1ZXN0NTQ3ODI4MTMy | 1,678 | Switchboard Dialog Act Corpus added under `datasets/swda` | [] | closed | false | null | 8 | 2021-01-03T03:53:41Z | 2021-01-08T18:09:21Z | 2021-01-05T10:06:35Z | null | Switchboard Dialog Act Corpus
Intro:
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Details:
[homepage](http://compprag.christopherpotts.net/swda.html)
[repo](https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/)
I believe this is an important dataset to have since there is no dataset related to dialogue act added.
I didn't find any formatting for pull request. I hope all this information is enough.
For any support please contact me. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1678/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1678/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1678.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1678",
"merged_at": "2021-01-05T10:06:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1678.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1678"
} | true | [
"@lhoestq Thank you for your detailed comments! I fixed everything you suggested.\r\n\r\nPlease let me know if I'm missing anything else.",
"It looks like the Transcript and Utterance objects are missing, maybe we can mention it in the README ? Or just add them ? @gmihaila @bhavitvyamalik ",
"Hi @lhoestq,\r\nI'm working on this to add the full dataset",
"> It looks like the Transcript and Utterance objects are missing, maybe we can mention it in the README ? Or just add them ? @gmihaila @bhavitvyamalik\r\n\r\n@lhoestq Any info on how to add them?",
"@gmihaila, instead of using the current repo you should look into [this](https://github.com/cgpotts/swda). You can use the `csv` files uploaded in this repo (`swda.zip`) to access other fields and include them in this dataset. It has one dependency too, `swda.py`, you can download that separately and include it in your dataset's folder to be imported while reading the `csv` files.\r\n\r\nAlmost all the attributes of `Transcript` and `Utterance` objects are of the type str, int, or list. As far as `trees` attribute is concerned in utterance object you can simply parse it as string and user can maybe later convert it to nltk.tree object",
"@bhavitvyamalik Thank you for the clarification! \r\n\r\nI didn't use [that](https://github.com/cgpotts/swda) because it doesn't have the splits. I think in combination with [what I used](https://github.com/NathanDuran/Switchboard-Corpus) would help.\r\n\r\nLet me know if I can help! I can make those changes if you don't have the time.",
"I'm a bit busy for the next 2 weeks. I'll be able to complete it by end of January only. Maybe you can start with it and I'll help you?\r\nAlso, I looked into the official train/val/test splits and not all the files are there in the repo I used so I think either we'll have to skip them or put all of that into just train",
"Yes, I can start working on it and ask you to do a code review.\r\n\r\nYes, not all files are there. I'll try to find papers that have the correct and full splits, if not, I'll do like you suggested.\r\n\r\nThank you again for your help @bhavitvyamalik !"
] |
https://api.github.com/repos/huggingface/datasets/issues/1917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1917/comments | https://api.github.com/repos/huggingface/datasets/issues/1917/events | https://github.com/huggingface/datasets/issues/1917 | 812,390,178 | MDU6SXNzdWU4MTIzOTAxNzg= | 1,917 | UnicodeDecodeError: windows 10 machine | [] | closed | false | null | 1 | 2021-02-19T22:13:05Z | 2021-02-19T22:41:11Z | 2021-02-19T22:40:28Z | null | Windows 10
Php 3.6.8
when running
```
import datasets
oscar_am = datasets.load_dataset("oscar", "unshuffled_deduplicated_am")
print(oscar_am["train"][0])
```
I get the following error
```
file "C:\PYTHON\3.6.8\lib\encodings\cp1252.py", line 23, in decode
return codecs.charmap_decode(input,self.errors,decoding_table)[0]
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 58: character maps to <undefined>
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1917/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1917/timeline | null | completed | null | null | false | [
"upgraded to php 3.9.2 and it works!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5071/comments | https://api.github.com/repos/huggingface/datasets/issues/5071/events | https://github.com/huggingface/datasets/pull/5071 | 1,397,301,270 | PR_kwDODunzps5AMG3g | 5,071 | Support DEFAULT_CONFIG_NAME when no BUILDER_CONFIGS | [] | closed | false | null | 2 | 2022-10-05T06:28:39Z | 2022-10-06T14:43:12Z | 2022-10-06T14:40:26Z | null | This PR supports defining a default config name, even if no predefined allowed config names are set.
Fix #5070.
CC: @stas00 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5071/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5071/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5071.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5071",
"merged_at": "2022-10-06T14:40:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5071.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5071"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Super, thanks a lot for adding this support, Albert!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5646/comments | https://api.github.com/repos/huggingface/datasets/issues/5646/events | https://github.com/huggingface/datasets/pull/5646 | 1,627,838,762 | PR_kwDODunzps5MOqjj | 5,646 | Allow self as key in `Features` | [] | closed | false | null | 3 | 2023-03-16T16:17:03Z | 2023-03-16T17:21:58Z | 2023-03-16T17:14:50Z | null | Fix #5641 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5646/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5646/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5646.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5646",
"merged_at": "2023-03-16T17:14:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5646.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5646"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009980 / 0.011353 (-0.001373) | 0.006643 / 0.011008 (-0.004366) | 0.140722 / 0.038508 (0.102214) | 0.036693 / 0.023109 (0.013584) | 0.430019 / 0.275898 (0.154121) | 0.463218 / 0.323480 (0.139738) | 0.006977 / 0.007986 (-0.001008) | 0.006488 / 0.004328 (0.002160) | 0.099385 / 0.004250 (0.095134) | 0.047160 / 0.037052 (0.010108) | 0.431440 / 0.258489 (0.172951) | 0.500232 / 0.293841 (0.206391) | 0.057968 / 0.128546 (-0.070578) | 0.020197 / 0.075646 (-0.055449) | 0.438269 / 0.419271 (0.018998) | 0.071149 / 0.043533 (0.027617) | 0.428502 / 0.255139 (0.173363) | 0.486861 / 0.283200 (0.203661) | 0.119855 / 0.141683 (-0.021828) | 1.875372 / 1.452155 (0.423218) | 1.955055 / 1.492716 (0.462339) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.243468 / 0.018006 (0.225462) | 0.547842 / 0.000490 (0.547352) | 0.004885 / 0.000200 (0.004685) | 0.000144 / 0.000054 (0.000089) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031555 / 0.037411 (-0.005856) | 0.125869 / 0.014526 (0.111343) | 0.137816 / 0.176557 (-0.038741) | 0.206581 / 0.737135 (-0.530555) | 0.142976 / 0.296338 (-0.153362) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.624773 / 0.215209 (0.409564) | 6.154861 / 2.077655 (4.077206) | 2.504586 / 1.504120 (1.000466) | 1.989118 / 1.541195 (0.447923) | 2.092280 / 1.468490 (0.623790) | 1.240108 / 4.584777 (-3.344669) | 5.584893 / 3.745712 (1.839181) | 3.075369 / 5.269862 (-2.194492) | 2.174285 / 4.565676 (-2.391391) | 0.141555 / 0.424275 (-0.282720) | 0.016099 / 0.007607 (0.008492) | 0.720543 / 0.226044 (0.494498) | 7.489000 / 2.268929 (5.220071) | 3.239189 / 55.444624 (-52.205435) | 2.525772 / 6.876477 (-4.350704) | 2.773514 / 2.142072 (0.631441) | 1.410084 / 4.805227 (-3.395143) | 0.259252 / 6.500664 (-6.241412) | 0.082573 / 0.075469 (0.007104) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.458186 / 1.841788 (-0.383602) | 17.503738 / 8.074308 (9.429430) | 20.817682 / 10.191392 (10.626290) | 0.231221 / 0.680424 (-0.449203) | 0.032550 / 0.534201 (-0.501651) | 0.559020 / 0.579283 (-0.020263) | 0.592987 / 0.434364 (0.158623) | 0.602661 / 0.540337 (0.062324) | 0.731912 / 1.386936 (-0.655024) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009543 / 0.011353 (-0.001810) | 0.006953 / 0.011008 (-0.004055) | 0.087651 / 0.038508 (0.049143) | 0.031717 / 0.023109 (0.008608) | 0.437813 / 0.275898 (0.161915) | 0.468448 / 0.323480 (0.144968) | 0.007378 / 0.007986 (-0.000607) | 0.005170 / 0.004328 (0.000842) | 0.102286 / 0.004250 (0.098035) | 0.043643 / 0.037052 (0.006591) | 0.458788 / 0.258489 (0.200299) | 0.519891 / 0.293841 (0.226050) | 0.052875 / 0.128546 (-0.075671) | 0.020518 / 0.075646 (-0.055128) | 0.112675 / 0.419271 (-0.306597) | 0.066390 / 0.043533 (0.022858) | 0.423037 / 0.255139 (0.167898) | 0.420345 / 0.283200 (0.137146) | 0.119221 / 0.141683 (-0.022462) | 1.632244 / 1.452155 (0.180090) | 1.829585 / 1.492716 (0.336869) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.242312 / 0.018006 (0.224305) | 0.547592 / 0.000490 (0.547102) | 0.006520 / 0.000200 (0.006320) | 0.000185 / 0.000054 (0.000131) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.032204 / 0.037411 (-0.005207) | 0.113320 / 0.014526 (0.098794) | 0.135667 / 0.176557 (-0.040889) | 0.194360 / 0.737135 (-0.542775) | 0.127934 / 0.296338 (-0.168404) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.648134 / 0.215209 (0.432925) | 6.470574 / 2.077655 (4.392920) | 2.799121 / 1.504120 (1.295001) | 2.160450 / 1.541195 (0.619255) | 2.261648 / 1.468490 (0.793158) | 1.244660 / 4.584777 (-3.340117) | 5.694636 / 3.745712 (1.948923) | 5.316191 / 5.269862 (0.046329) | 2.764551 / 4.565676 (-1.801126) | 0.152225 / 0.424275 (-0.272051) | 0.015959 / 0.007607 (0.008351) | 0.833606 / 0.226044 (0.607562) | 8.099765 / 2.268929 (5.830836) | 3.523005 / 55.444624 (-51.921620) | 2.855126 / 6.876477 (-4.021351) | 2.730849 / 2.142072 (0.588776) | 1.434351 / 4.805227 (-3.370876) | 0.251963 / 6.500664 (-6.248701) | 0.085718 / 0.075469 (0.010249) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.722466 / 1.841788 (-0.119322) | 17.846981 / 8.074308 (9.772673) | 21.578684 / 10.191392 (11.387292) | 0.239987 / 0.680424 (-0.440437) | 0.029189 / 0.534201 (-0.505012) | 0.543181 / 0.579283 (-0.036102) | 0.626527 / 0.434364 (0.192163) | 0.614334 / 0.540337 (0.073997) | 0.745934 / 1.386936 (-0.641002) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007395 / 0.011353 (-0.003958) | 0.004965 / 0.011008 (-0.006043) | 0.096376 / 0.038508 (0.057868) | 0.033243 / 0.023109 (0.010134) | 0.299990 / 0.275898 (0.024092) | 0.336287 / 0.323480 (0.012807) | 0.005528 / 0.007986 (-0.002458) | 0.004003 / 0.004328 (-0.000326) | 0.072820 / 0.004250 (0.068569) | 0.042867 / 0.037052 (0.005815) | 0.296719 / 0.258489 (0.038230) | 0.337313 / 0.293841 (0.043472) | 0.036809 / 0.128546 (-0.091738) | 0.012239 / 0.075646 (-0.063407) | 0.332351 / 0.419271 (-0.086921) | 0.050449 / 0.043533 (0.006916) | 0.301483 / 0.255139 (0.046344) | 0.316673 / 0.283200 (0.033474) | 0.102526 / 0.141683 (-0.039157) | 1.415429 / 1.452155 (-0.036726) | 1.544381 / 1.492716 (0.051665) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.211158 / 0.018006 (0.193152) | 0.434718 / 0.000490 (0.434228) | 0.003386 / 0.000200 (0.003186) | 0.000078 / 0.000054 (0.000024) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027945 / 0.037411 (-0.009466) | 0.108743 / 0.014526 (0.094217) | 0.119771 / 0.176557 (-0.056785) | 0.178667 / 0.737135 (-0.558468) | 0.123718 / 0.296338 (-0.172620) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.413908 / 0.215209 (0.198699) | 4.136828 / 2.077655 (2.059174) | 1.932547 / 1.504120 (0.428427) | 1.715389 / 1.541195 (0.174194) | 1.791679 / 1.468490 (0.323189) | 0.692715 / 4.584777 (-3.892062) | 3.741807 / 3.745712 (-0.003905) | 2.066274 / 5.269862 (-3.203587) | 1.314106 / 4.565676 (-3.251570) | 0.087191 / 0.424275 (-0.337084) | 0.012866 / 0.007607 (0.005259) | 0.510012 / 0.226044 (0.283968) | 5.116419 / 2.268929 (2.847490) | 2.408562 / 55.444624 (-53.036063) | 2.002044 / 6.876477 (-4.874433) | 2.121868 / 2.142072 (-0.020204) | 0.837141 / 4.805227 (-3.968086) | 0.166596 / 6.500664 (-6.334068) | 0.063190 / 0.075469 (-0.012279) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.204152 / 1.841788 (-0.637636) | 14.739793 / 8.074308 (6.665485) | 14.403469 / 10.191392 (4.212077) | 0.165781 / 0.680424 (-0.514642) | 0.017826 / 0.534201 (-0.516375) | 0.423527 / 0.579283 (-0.155756) | 0.431410 / 0.434364 (-0.002954) | 0.499422 / 0.540337 (-0.040915) | 0.596116 / 1.386936 (-0.790820) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007365 / 0.011353 (-0.003988) | 0.005165 / 0.011008 (-0.005844) | 0.073403 / 0.038508 (0.034895) | 0.032542 / 0.023109 (0.009433) | 0.339304 / 0.275898 (0.063406) | 0.371892 / 0.323480 (0.048412) | 0.005544 / 0.007986 (-0.002442) | 0.004108 / 0.004328 (-0.000221) | 0.073750 / 0.004250 (0.069500) | 0.045613 / 0.037052 (0.008561) | 0.366159 / 0.258489 (0.107670) | 0.389864 / 0.293841 (0.096023) | 0.036006 / 0.128546 (-0.092540) | 0.012402 / 0.075646 (-0.063244) | 0.085137 / 0.419271 (-0.334135) | 0.048485 / 0.043533 (0.004952) | 0.334172 / 0.255139 (0.079033) | 0.353168 / 0.283200 (0.069969) | 0.099393 / 0.141683 (-0.042290) | 1.460584 / 1.452155 (0.008429) | 1.518601 / 1.492716 (0.025885) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.227352 / 0.018006 (0.209346) | 0.444211 / 0.000490 (0.443721) | 0.000410 / 0.000200 (0.000210) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029517 / 0.037411 (-0.007894) | 0.115557 / 0.014526 (0.101031) | 0.125855 / 0.176557 (-0.050701) | 0.175214 / 0.737135 (-0.561922) | 0.129324 / 0.296338 (-0.167014) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.429783 / 0.215209 (0.214574) | 4.301159 / 2.077655 (2.223504) | 2.084939 / 1.504120 (0.580819) | 1.887781 / 1.541195 (0.346586) | 2.045712 / 1.468490 (0.577222) | 0.693319 / 4.584777 (-3.891458) | 3.788595 / 3.745712 (0.042883) | 2.087080 / 5.269862 (-3.182781) | 1.325247 / 4.565676 (-3.240429) | 0.085919 / 0.424275 (-0.338356) | 0.012710 / 0.007607 (0.005103) | 0.533432 / 0.226044 (0.307387) | 5.339468 / 2.268929 (3.070540) | 2.578351 / 55.444624 (-52.866273) | 2.224905 / 6.876477 (-4.651572) | 2.301064 / 2.142072 (0.158992) | 0.839622 / 4.805227 (-3.965605) | 0.166523 / 6.500664 (-6.334141) | 0.065254 / 0.075469 (-0.010215) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.262223 / 1.841788 (-0.579565) | 15.042523 / 8.074308 (6.968215) | 14.542719 / 10.191392 (4.351327) | 0.142230 / 0.680424 (-0.538194) | 0.017610 / 0.534201 (-0.516591) | 0.422357 / 0.579283 (-0.156926) | 0.417785 / 0.434364 (-0.016579) | 0.491990 / 0.540337 (-0.048348) | 0.585835 / 1.386936 (-0.801101) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4232/comments | https://api.github.com/repos/huggingface/datasets/issues/4232/events | https://github.com/huggingface/datasets/pull/4232 | 1,216,659,444 | PR_kwDODunzps421qz4 | 4,232 | adding new tag to tasks.json and modified for existing datasets | [] | closed | false | null | 2 | 2022-04-27T01:21:09Z | 2022-05-03T14:23:56Z | 2022-05-03T14:16:39Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4232/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4232/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4232.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4232",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4232.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4232"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"closing in favor of https://github.com/huggingface/datasets/pull/4244"
] |
https://api.github.com/repos/huggingface/datasets/issues/5043 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5043/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5043/comments | https://api.github.com/repos/huggingface/datasets/issues/5043/events | https://github.com/huggingface/datasets/pull/5043 | 1,391,141,773 | PR_kwDODunzps4_3uzy | 5,043 | Fix `flatten_indices` with empty indices mapping | [] | closed | false | null | 1 | 2022-09-29T16:17:28Z | 2022-09-30T15:46:39Z | 2022-09-30T15:44:25Z | null | Fix #5038 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5043/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5043/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5043.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5043",
"merged_at": "2022-09-30T15:44:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5043.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5043"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4192 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4192/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4192/comments | https://api.github.com/repos/huggingface/datasets/issues/4192/events | https://github.com/huggingface/datasets/issues/4192 | 1,210,692,554 | I_kwDODunzps5IKbPK | 4,192 | load_dataset can't load local dataset,Unable to find ... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 4 | 2022-04-21T08:28:58Z | 2022-04-25T16:51:57Z | 2022-04-22T07:39:53Z | null |
Traceback (most recent call last):
File "/home/gs603/ahf/pretrained/model.py", line 48, in <module>
dataset = load_dataset("json",data_files="dataset/dataset_infos.json")
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1675, in load_dataset
**config_kwargs,
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1496, in load_dataset_builder
data_files=data_files,
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1155, in dataset_module_factory
download_mode=download_mode,
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 800, in get_module
data_files = DataFilesDict.from_local_or_remote(patterns, use_auth_token=self.downnload_config.use_auth_token)
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 582, in from_local_or_remote
if not isinstance(patterns_for_key, DataFilesList)
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 544, in from_local_or_remote
data_files = resolve_patterns_locally_or_by_urls(base_path, patterns, allowed_extensions)
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 194, in resolve_patterns_locally_or_by_urls
for path in _resolve_single_pattern_locally(base_path, pattern, allowed_extensions):
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/data_files.py", line 144, in _resolve_single_pattern_locally
raise FileNotFoundError(error_msg)
FileNotFoundError: Unable to find '/home/gs603/ahf/pretrained/dataset/dataset_infos.json' at /home/gs603/ahf/pretrained


the code is in the model.py,why I can't use the load_dataset function to load my local dataset? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4192/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4192/timeline | null | completed | null | null | false | [
"Hi! :)\r\n\r\nI believe that should work unless `dataset_infos.json` isn't actually a dataset. For Hugging Face datasets, there is usually a file named `dataset_infos.json` which contains metadata about the dataset (eg. the dataset citation, license, description, etc). Can you double-check that `dataset_infos.json` isn't just metadata please?",
"Hi @ahf876828330, \r\n\r\nAs @stevhliu pointed out, the proper way to load a dataset is not trying to load its metadata file.\r\n\r\nIn your case, as the dataset script is local, you should better point to your local loading script:\r\n```python\r\ndataset = load_dataset(\"dataset/opus_books.py\")\r\n```\r\n\r\nPlease, feel free to re-open this issue if the previous code snippet does not work for you.",
"> Hi! :)\r\n> \r\n> I believe that should work unless `dataset_infos.json` isn't actually a dataset. For Hugging Face datasets, there is usually a file named `dataset_infos.json` which contains metadata about the dataset (eg. the dataset citation, license, description, etc). Can you double-check that `dataset_infos.json` isn't just metadata please?\r\n\r\nYes,you are right!So if I have a metadata dataset local,How can I turn it to a dataset that can be used by the load_dataset() function?Are there some examples?",
"The metadata file isn't a dataset so you can't turn it into one. You should try @albertvillanova's code snippet above (now merged in the docs [here](https://huggingface.co/docs/datasets/master/en/loading#local-loading-script)), which uses your local loading script `opus_books.py` to:\r\n\r\n1. Download the actual dataset. \r\n2. Once the dataset is downloaded, `load_dataset` will load it for you."
] |
https://api.github.com/repos/huggingface/datasets/issues/1532 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1532/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1532/comments | https://api.github.com/repos/huggingface/datasets/issues/1532/events | https://github.com/huggingface/datasets/pull/1532 | 764,772,184 | MDExOlB1bGxSZXF1ZXN0NTM4NjgxODcz | 1,532 | adding hate-speech-and-offensive-language | [] | closed | false | null | 1 | 2020-12-13T02:16:31Z | 2020-12-17T18:36:54Z | 2020-12-17T18:10:05Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1532/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1532/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1532.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1532",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1532.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1532"
} | true | [
"made suggested changes and a new PR created here : https://github.com/huggingface/datasets/pull/1597"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/5627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5627/comments | https://api.github.com/repos/huggingface/datasets/issues/5627/events | https://github.com/huggingface/datasets/issues/5627 | 1,619,336,609 | I_kwDODunzps5ghR2h | 5,627 | Unable to load AutoTrain-generated dataset from the hub | [] | open | false | null | 2 | 2023-03-10T17:25:58Z | 2023-03-11T15:44:42Z | null | null | ### Describe the bug
DatasetGenerationError: An error occurred while generating the dataset -> ValueError: Couldn't cast ... because column names don't match
```
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
_fingerprint: string
_format_columns: list<item: string>
child 0, item: string
_format_kwargs: struct<>
_format_type: null
_indexes: struct<>
_output_all_columns: bool
_split: null
to
{'citation': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'features': {'image': {'_type': Value(dtype='string', id=None)}, 'target': {'names': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), '_type': Value(dtype='string', id=None)}}, 'homepage': Value(dtype='string', id=None), 'license': Value(dtype='string', id=None), 'splits': {'train': {'name': Value(dtype='string', id=None), 'num_bytes': Value(dtype='int64', id=None), 'num_examples': Value(dtype='int64', id=None), 'dataset_name': Value(dtype='null', id=None)}}}
because column names don't match
```
### Steps to reproduce the bug
Steps to reproduce:
1. `pip install datasets==2.10.1`
2. Attempt to load (private dataset). Note that I'm authenticated via ` huggingface-cli login`
```
from datasets import load_dataset
# load dataset
dataset = "ijmiller2/autotrain-data-betterbin-vision-10000"
dataset = load_dataset(dataset)
```
Here's the full traceback:
```Downloading and preparing dataset json/ijmiller2--autotrain-data-betterbin-vision-10000 to /Users/ian/.cache/huggingface/datasets/ijmiller2___json/ijmiller2--autotrain-data-betterbin-vision-10000-2eae034a9ff8a1a9/0.0.0/0f7e3662623656454fcd2b650f34e886a7db4b9104504885bd462096cc7a9f51...
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 2383.80it/s]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 505.95it/s]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/builder.py:1874, in ArrowBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
1868 writer = writer_class(
1869 features=writer._features,
1870 path=fpath.replace("SSSSS", f"{shard_id:05d}").replace("JJJJJ", f"{job_id:05d}"),
1871 storage_options=self._fs.storage_options,
1872 embed_local_files=embed_local_files,
1873 )
-> 1874 writer.write_table(table)
1875 num_examples_progress_update += len(table)
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/arrow_writer.py:568, in ArrowWriter.write_table(self, pa_table, writer_batch_size)
567 pa_table = pa_table.combine_chunks()
--> 568 pa_table = table_cast(pa_table, self._schema)
569 if self.embed_local_files:
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/table.py:2312, in table_cast(table, schema)
2311 if table.schema != schema:
-> 2312 return cast_table_to_schema(table, schema)
2313 elif table.schema.metadata != schema.metadata:
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/table.py:2270, in cast_table_to_schema(table, schema)
2269 if sorted(table.column_names) != sorted(features):
-> 2270 raise ValueError(f"Couldn't cast\n{table.schema}\nto\n{features}\nbecause column names don't match")
2271 arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
_fingerprint: string
_format_columns: list<item: string>
child 0, item: string
_format_kwargs: struct<>
_format_type: null
_indexes: struct<>
_output_all_columns: bool
_split: null
to
{'citation': Value(dtype='string', id=None), 'description': Value(dtype='string', id=None), 'features': {'image': {'_type': Value(dtype='string', id=None)}, 'target': {'names': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), '_type': Value(dtype='string', id=None)}}, 'homepage': Value(dtype='string', id=None), 'license': Value(dtype='string', id=None), 'splits': {'train': {'name': Value(dtype='string', id=None), 'num_bytes': Value(dtype='int64', id=None), 'num_examples': Value(dtype='int64', id=None), 'dataset_name': Value(dtype='null', id=None)}}}
because column names don't match
The above exception was the direct cause of the following exception:
DatasetGenerationError Traceback (most recent call last)
Input In [8], in <cell line: 6>()
4 # load dataset
5 dataset = "ijmiller2/autotrain-data-betterbin-vision-10000"
----> 6 dataset = load_dataset(dataset)
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/load.py:1782, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, verification_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, num_proc, **config_kwargs)
1779 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1781 # Download and prepare data
-> 1782 builder_instance.download_and_prepare(
1783 download_config=download_config,
1784 download_mode=download_mode,
1785 verification_mode=verification_mode,
1786 try_from_hf_gcs=try_from_hf_gcs,
1787 num_proc=num_proc,
1788 )
1790 # Build dataset for splits
1791 keep_in_memory = (
1792 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1793 )
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/builder.py:872, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, verification_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, num_proc, storage_options, **download_and_prepare_kwargs)
870 if num_proc is not None:
871 prepare_split_kwargs["num_proc"] = num_proc
--> 872 self._download_and_prepare(
873 dl_manager=dl_manager,
874 verification_mode=verification_mode,
875 **prepare_split_kwargs,
876 **download_and_prepare_kwargs,
877 )
878 # Sync info
879 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/builder.py:967, in DatasetBuilder._download_and_prepare(self, dl_manager, verification_mode, **prepare_split_kwargs)
963 split_dict.add(split_generator.split_info)
965 try:
966 # Prepare split will record examples associated to the split
--> 967 self._prepare_split(split_generator, **prepare_split_kwargs)
968 except OSError as e:
969 raise OSError(
970 "Cannot find data file. "
971 + (self.manual_download_instructions or "")
972 + "\nOriginal error:\n"
973 + str(e)
974 ) from None
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/builder.py:1749, in ArrowBasedBuilder._prepare_split(self, split_generator, file_format, num_proc, max_shard_size)
1747 job_id = 0
1748 with pbar:
-> 1749 for job_id, done, content in self._prepare_split_single(
1750 gen_kwargs=gen_kwargs, job_id=job_id, **_prepare_split_args
1751 ):
1752 if done:
1753 result = content
File ~/anaconda3/envs/betterbin/lib/python3.8/site-packages/datasets/builder.py:1892, in ArrowBasedBuilder._prepare_split_single(self, gen_kwargs, fpath, file_format, max_shard_size, job_id)
1890 if isinstance(e, SchemaInferenceError) and e.__context__ is not None:
1891 e = e.__context__
-> 1892 raise DatasetGenerationError("An error occurred while generating the dataset") from e
1894 yield job_id, True, (total_num_examples, total_num_bytes, writer._features, num_shards, shard_lengths)
DatasetGenerationError: An error occurred while generating the dataset
```
### Expected behavior
I'm ultimately trying to generate my own performance metrics on validation data (before putting an endpoint into production) and so was hoping to load all or at least the validation subset from the hub.
I'm expecting the `load_dataset()` function to work as shown in the documentation [here](https://huggingface.co/docs/datasets/loading#hugging-face-hub):
```python
dataset = load_dataset(
"lhoestq/custom_squad",
revision="main" # tag name, or branch name, or commit hash
)
```
### Environment info
- `datasets` version: 2.10.1
- Platform: macOS-13.2.1-arm64-arm-64bit
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.4 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5627/timeline | null | null | null | null | false | [
"The AutoTrain format is not supported right now. I think it would require a dedicated dataset builder",
"Okay, good to know. Thanks for the reply. For now I will just have to\nmanage the split manually before training, because I can’t find any way of\npulling out file indices or file names from the autogenerated split. The\nfile names field of the image dataset (loaded directly from arrow file) is\nmissing, just fyi (for anyone else this might be relevant too).\n\nOn Fri, Mar 10, 2023 at 7:02 PM Quentin Lhoest ***@***.***>\nwrote:\n\n> The AutoTrain format is not supported right now. I think it would require\n> a dedicated dataset builder\n>\n> —\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/datasets/issues/5627#issuecomment-1464734308>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ACBJ4F5A353MCZ76OGRJ6CTW3PFI7ANCNFSM6AAAAAAVWXNUTE>\n> .\n> You are receiving this because you authored the thread.Message ID:\n> ***@***.***>\n>\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3766 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3766/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3766/comments | https://api.github.com/repos/huggingface/datasets/issues/3766/events | https://github.com/huggingface/datasets/pull/3766 | 1,145,829,289 | PR_kwDODunzps4zOujH | 3,766 | Fix head_qa data URL | [] | closed | false | null | 0 | 2022-02-21T13:52:50Z | 2022-02-21T14:39:20Z | 2022-02-21T14:39:19Z | null | Fix #3758. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3766/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3766/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3766.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3766",
"merged_at": "2022-02-21T14:39:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3766.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3766"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4473/comments | https://api.github.com/repos/huggingface/datasets/issues/4473/events | https://github.com/huggingface/datasets/pull/4473 | 1,267,555,994 | PR_kwDODunzps45d5-R | 4,473 | Add SST-2 dataset | [] | closed | false | null | 5 | 2022-06-10T13:37:26Z | 2022-06-13T14:11:34Z | 2022-06-13T14:01:09Z | null | Add SST-2 dataset.
Currently it is part of GLUE benchmark.
This PR adds it as a standalone dataset.
CC: @julien-c | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4473/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4473/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4473.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4473",
"merged_at": "2022-06-13T14:01:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4473.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4473"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"on the hub this dataset is referenced as `sst-2` not `sst2` – is there a canonical orthography? If not, could we name it `sst-2`?",
"@julien-c, we normally do not use hyphens for dataset names: whenever the original dataset name contains a hyphen, we usually:\r\n- either suppress it: CoNLL-2000 (`conll2000`), CORD-19 (`cord19`)\r\n- or replace it with underscore: CC-News (`cc_news`), SQuAD-es (`squad_es`)\r\n\r\nThere are some exceptions though... (I wonder why)\r\n\r\nI think, the reason is there was a 1-to-1 relation with the corresponding Python module name.\r\n\r\nI personally find confusing not having a rule and using both hyphens and underscores indistinctly: you never know which is the right orthography.\r\n\r\nWhichever the decision we make, I would prefer to be applied consistently.\r\n\r\nAlso note that we already implemented this dataset as part of GLUE: https://github.com/huggingface/datasets/blob/master/datasets/glue/glue.py#L163\r\n- dataset name: `glue`\r\n- config name: `sst2`\r\n\r\nOn the other hand, let's see how other libraries name it:\r\n- torchtext: `SST2` https://pytorch.org/text/stable/datasets.html#sst2\r\n- OpenAI CLIP: `rendered-sst2` https://github.com/openai/CLIP/blob/main/data/rendered-sst2.md\r\n- Kaggle: `SST2` https://www.kaggle.com/datasets/atulanandjha/stanford-sentiment-treebank-v2-sst2/version/22\r\n- TensorFlow Datasets: `glue/sst2` https://www.tensorflow.org/datasets/catalog/glue#gluesst2",
"Ok, another option is to open PRs against the models in https://huggingface.co/models?datasets=sst-2 to change their dataset reference to `sst2`\r\n\r\n(BTW some models refer to `sst2` already – but they're less popular: https://huggingface.co/models?datasets=sst2)",
"OK, I'm taking care of the subsequent PRs on models to align with this dataset name."
] |
https://api.github.com/repos/huggingface/datasets/issues/1199 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1199/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1199/comments | https://api.github.com/repos/huggingface/datasets/issues/1199/events | https://github.com/huggingface/datasets/pull/1199 | 757,909,237 | MDExOlB1bGxSZXF1ZXN0NTMzMTg0Nzk3 | 1,199 | Turkish NER dataset, script works fine, couldn't generate dummy data | [] | closed | false | null | 2 | 2020-12-06T12:00:03Z | 2020-12-16T16:13:24Z | 2020-12-16T16:13:24Z | null | I've written the script (Turkish_NER.py) that includes dataset. The dataset is a zip inside another zip, and it's extracted as .DUMP file. However, after preprocessing I only get .arrow file. After I ran the script with no error messages, I get .arrow file of dataset, LICENSE and dataset_info.json. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1199/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1199/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1199.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1199",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1199.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1199"
} | true | [
"the .DUMP file looks like a txt with one example per line so adding `--match_text_files *.DUMP --n_lines 50` to the dummy generation command might work .",
"We can close this PR since a new PR was open at #1268 "
] |
https://api.github.com/repos/huggingface/datasets/issues/4803 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4803/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4803/comments | https://api.github.com/repos/huggingface/datasets/issues/4803/events | https://github.com/huggingface/datasets/issues/4803 | 1,332,079,562 | I_kwDODunzps5PZevK | 4,803 | Support `pipeline` argument in inspect.py functions | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2022-08-08T16:01:24Z | 2022-08-08T16:01:24Z | null | null | **Is your feature request related to a problem? Please describe.**
The `wikipedia` dataset requires a `pipeline` argument to build the list of splits:
https://huggingface.co/datasets/wikipedia/blob/main/wikipedia.py#L937
But this is currently not supported in `get_dataset_config_info`:
https://github.com/huggingface/datasets/blob/main/src/datasets/inspect.py#L373-L375
which is called by other functions, e.g. `get_dataset_split_names`.
**Additional context**
The dataset viewer is not working out-of-the-box on `wikipedia` for this reason:
https://huggingface.co/datasets/wikipedia/viewer
<img width="637" alt="Capture d’écran 2022-08-08 à 12 01 16" src="https://user-images.githubusercontent.com/1676121/183461838-5330783b-0269-4ba7-a999-314cde2023d8.png">
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4803/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4803/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1780 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1780/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1780/comments | https://api.github.com/repos/huggingface/datasets/issues/1780/events | https://github.com/huggingface/datasets/pull/1780 | 793,882,132 | MDExOlB1bGxSZXF1ZXN0NTYxNDkxNTgy | 1,780 | Update SciFact URL | [] | closed | false | null | 7 | 2021-01-26T02:49:06Z | 2021-01-28T18:48:00Z | 2021-01-28T10:19:45Z | null | Hi,
I'm following up this [issue](https://github.com/huggingface/datasets/issues/1717). I'm the SciFact dataset creator, and I'm trying to update the SciFact data url in your repo. Thanks again for adding the dataset!
Basically, I'd just like to change the `_URL` to `"https://scifact.s3-us-west-2.amazonaws.com/release/latest/data.tar.gz"`. I changed `scifact.py` appropriately and tried running
```
python datasets-cli test datasets/scifact --save_infos --all_configs
```
which I was hoping would update the `dataset_infos.json` for SciFact. But for some reason the code still seems to be looking for the old version of the dataset. Full stack trace below. I've tried to clear all my Huggingface-related caches, and I've `git grep`'d to make sure that the old path to the dataset isn't floating around somewhere. So I'm not sure why this is happening?
Can you help me switch the download URL?
```
(datasets) $ python datasets-cli test datasets/scifact --save_infos --all_configs
Checking datasets/scifact/scifact.py for additional imports.
Found main folder for dataset datasets/scifact/scifact.py at /Users/dwadden/.cache/huggingface/modules/datasets_modules/datasets/scifact
Found specific version folder for dataset datasets/scifact/scifact.py at /Users/dwadden/.cache/huggingface/modules/datasets_modules/datasets/scifact/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534
Found script file from datasets/scifact/scifact.py to /Users/dwadden/.cache/huggingface/modules/datasets_modules/datasets/scifact/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534/scifact.py
Found dataset infos file from datasets/scifact/dataset_infos.json to /Users/dwadden/.cache/huggingface/modules/datasets_modules/datasets/scifact/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534/dataset_infos.json
Found metadata file for dataset datasets/scifact/scifact.py at /Users/dwadden/.cache/huggingface/modules/datasets_modules/datasets/scifact/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534/scifact.json
Loading Dataset Infos from /Users/dwadden/.cache/huggingface/modules/datasets_modules/datasets/scifact/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534
Testing builder 'corpus' (1/2)
Generating dataset scifact (/Users/dwadden/.cache/huggingface/datasets/scifact/corpus/1.0.0/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534)
Downloading and preparing dataset scifact/corpus (download: 2.72 MiB, generated: 7.63 MiB, post-processed: Unknown size, total: 10.35 MiB) to /Users/dwadden/.cache/huggingface/datasets/scifact/corpus/1.0.0/2b43b4e125ce3369da7d6353961d9d315e6593f24cc7bbe9ede5e5c911d11534...
Downloading took 0.0 min
Checksum Computation took 0.0 min
Traceback (most recent call last):
File "/Users/dwadden/proj/datasets/datasets-cli", line 36, in <module>
service.run()
File "/Users/dwadden/proj/datasets/src/datasets/commands/test.py", line 139, in run
builder.download_and_prepare(
File "/Users/dwadden/proj/datasets/src/datasets/builder.py", line 562, in download_and_prepare
self._download_and_prepare(
File "/Users/dwadden/proj/datasets/src/datasets/builder.py", line 622, in _download_and_prepare
verify_checksums(
File "/Users/dwadden/proj/datasets/src/datasets/utils/info_utils.py", line 32, in verify_checksums
raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))
datasets.utils.info_utils.ExpectedMoreDownloadedFiles: {'https://ai2-s2-scifact.s3-us-west-2.amazonaws.com/release/2020-05-01/data.tar.gz'}
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1780/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1780/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1780.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1780",
"merged_at": "2021-01-28T10:19:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1780.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1780"
} | true | [
"Hi ! The error you get is the result of some verifications the library is doing when loading a dataset that already has some metadata in the dataset_infos.json. You can ignore the verifications with \r\n```\r\npython datasets-cli test datasets/scifact --save_infos --all_configs --ignore_verifications\r\n```\r\nThis will update the dataset_infos.json :)",
"Nice, I ran that command and `dataset_infos` seems to have been updated appropriately; I added this to the PR. But when I try to load the dataset it still seems like it's getting a path to the old URL somehow. I `pip install -e`'d my fork of the repo, so I'm not sure why `load_dataset` is still looking for the old version of the file. Stack trace below.\r\n\r\n```\r\nIn [1]: import datasets\r\n\r\nIn [2]: ds = datasets.load_dataset(\"scifact\", \"claims\")\r\nDownloading: 7.34kB [00:00, 2.58MB/s]\r\nDownloading: 3.38kB [00:00, 1.36MB/s]\r\nDownloading and preparing dataset scifact/claims (download: 2.72 MiB, generated: 258.64 KiB, post-processed: Unknown size, total: 2.97 MiB) to /Users/dwadden/.cache/huggingface/datasets/scifact/claims/1.0.0/2bb675b2003716a061a4d8ce27fab32ab7f6d010016bab08ffaccea3c14ec6e7...\r\n---------------------------------------------------------------------------\r\nConnectionError Traceback (most recent call last)\r\n<ipython-input-2-9a50b954d89a> in <module>\r\n----> 1 ds = datasets.load_dataset(\"scifact\", \"claims\")\r\n\r\n~/proj/datasets/src/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, save_infos, script_version, **config_kwargs)\r\n 672\r\n 673 # Download and prepare data\r\n--> 674 builder_instance.download_and_prepare(\r\n 675 download_config=download_config,\r\n 676 download_mode=download_mode,\r\n\r\n~/proj/datasets/src/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)\r\n 560 logger.warning(\"HF google storage unreachable. Downloading and preparing it from source\")\r\n 561 if not downloaded_from_gcs:\r\n--> 562 self._download_and_prepare(\r\n 563 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n 564 )\r\n\r\n~/proj/datasets/src/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)\r\n 616 split_dict = SplitDict(dataset_name=self.name)\r\n 617 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)\r\n--> 618 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n 619\r\n 620 # Checksums verification\r\n\r\n~/.cache/huggingface/modules/datasets_modules/datasets/scifact/2bb675b2003716a061a4d8ce27fab32ab7f6d010016bab08ffaccea3c14ec6e7/scifact.py in _split_generators(self, dl_manager)\r\n 92 # dl_manager is a datasets.download.DownloadManager that can be used to\r\n 93 # download and extract URLs\r\n---> 94 dl_dir = dl_manager.download_and_extract(_URL)\r\n 95\r\n 96 if self.config.name == \"corpus\":\r\n\r\n~/proj/datasets/src/datasets/utils/download_manager.py in download_and_extract(self, url_or_urls)\r\n 256 extracted_path(s): `str`, extracted paths of given URL(s).\r\n 257 \"\"\"\r\n--> 258 return self.extract(self.download(url_or_urls))\r\n 259\r\n 260 def get_recorded_sizes_checksums(self):\r\n\r\n~/proj/datasets/src/datasets/utils/download_manager.py in download(self, url_or_urls)\r\n 177\r\n 178 start_time = datetime.now()\r\n--> 179 downloaded_path_or_paths = map_nested(\r\n 180 download_func,\r\n 181 url_or_urls,\r\n\r\n~/proj/datasets/src/datasets/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, types)\r\n 223 # Singleton\r\n 224 if not isinstance(data_struct, dict) and not isinstance(data_struct, types):\r\n--> 225 return function(data_struct)\r\n 226\r\n 227 disable_tqdm = bool(logger.getEffectiveLevel() > INFO)\r\n\r\n~/proj/datasets/src/datasets/utils/file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)\r\n 348 if is_remote_url(url_or_filename):\r\n 349 # URL, so get it from the cache (downloading if necessary)\r\n--> 350 output_path = get_from_cache(\r\n 351 url_or_filename,\r\n 352 cache_dir=cache_dir,\r\n\r\n~/proj/datasets/src/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries)\r\n 631 elif response is not None and response.status_code == 404:\r\n 632 raise FileNotFoundError(\"Couldn't find file at {}\".format(url))\r\n--> 633 raise ConnectionError(\"Couldn't reach {}\".format(url))\r\n 634\r\n 635 # Try a second time\r\n\r\nConnectionError: Couldn't reach https://ai2-s2-scifact.s3-us-west-2.amazonaws.com/release/2020-05-01/data.tar.gz\r\n```",
"Hi ! This may be because you need to point `load_dataset` to the path of the dataset script that has the updated url:\r\n```python\r\nload_dataset(\"./datasets/scifact\", \"claims\")\r\n```\r\n\r\nIf you don't use a path to the updated script, then the old one is used by deffault",
"Nice, I did\r\n```\r\nload_dataset(\"./datasets/scifact\", \"claims\")\r\n```\r\nand it worked. ",
"One more question about the way the code is being preprocessed. The way I've formatted the data, each entry is a claim, which may be associated with multiple evidence documents (similar to FEVER):\r\n```\r\n# My way\r\n{'id': 70,\r\n 'claim': 'Activation of PPM1D suppresses p53 function.',\r\n 'evidence': {'5956380': [{'sentences': [5, 6], 'label': 'SUPPORT'}],\r\n '4414547': [{'sentences': [5], 'label': 'SUPPORT'}]},\r\n 'cited_doc_ids': [5956380, 4414547]}\r\n```\r\n\r\nIn the Hugginface data, each entry is a single claim / evidence document pair. So, the above entry is converted into two separate entries, like so:\r\n```\r\n# huggingface\r\n[{'cited_doc_ids': [5956380, 4414547],\r\n 'claim': 'Activation of PPM1D suppresses p53 function.',\r\n 'evidence_doc_id': '5956380',\r\n 'evidence_label': 'SUPPORT',\r\n 'evidence_sentences': [5, 6],\r\n 'id': 70},\r\n {'cited_doc_ids': [5956380, 4414547],\r\n 'claim': 'Activation of PPM1D suppresses p53 function.',\r\n 'evidence_doc_id': '4414547',\r\n 'evidence_label': 'SUPPORT',\r\n 'evidence_sentences': [5],\r\n 'id': 70}]\r\n```\r\n\r\nWas this done by design? If not, would you mind if I modify the Huggingface code so that it more closely matches the format that people will get if they download the data from the SciFact repo?",
"Yes if you think the format is not convenient for training or evaluation we can change it.\r\nAlso I think we're doing something similar for FEVER: one example = one (claim, sentence) pair.\r\n\r\nLet's merge this PR first and then feel free to open a new PR to change the format :) ",
"Thanks for merging!\r\n\r\nI don't have super-strong feelings one way or the other in terms of the data, I think it's probably fine. I may revisit later."
] |
https://api.github.com/repos/huggingface/datasets/issues/4071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4071/comments | https://api.github.com/repos/huggingface/datasets/issues/4071/events | https://github.com/huggingface/datasets/issues/4071 | 1,187,587,683 | I_kwDODunzps5GySZj | 4,071 | Loading issue for xuyeliu/notebookCDG dataset | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 1 | 2022-03-31T06:36:29Z | 2022-03-31T08:17:01Z | 2022-03-31T08:16:16Z | null | ## Dataset viewer issue for '*xuyeliu/notebookCDG*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/xuyeliu/notebookCDG)*
*Couldn't load the xuyeliu/notebookCDG with provided scripts: *
```
from datasets import load_dataset
dataset = load_dataset("xuyeliu/notebookCDG/dataset_notebook.pkl")
```
I get an error message as follows:
FileNotFoundError: Couldn't find a dataset script at /home/code_documentation/code/xuyeliu/notebookCDG/notebookCDG.py or any data file in the same directory. Couldn't find 'xuyeliu/notebookCDG' on the Hugging Face Hub either: FileNotFoundError: Unable to resolve any data file that matches ['**train*'] in dataset repository xuyeliu/notebookCDG with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'blp', 'bmp', 'dib', 'bufr', 'cur', 'pcx', 'dcx', 'dds', 'ps', 'eps', 'fit', 'fits', 'fli', 'flc', 'ftc', 'ftu', 'gbr', 'gif', 'grib', 'h5', 'hdf', 'png', 'apng', 'jp2', 'j2k', 'jpc', 'jpf', 'jpx', 'j2c', 'icns', 'ico', 'im', 'iim', 'tif', 'tiff', 'jfif', 'jpe', 'jpg', 'jpeg', 'mpg', 'mpeg', 'msp', 'pcd', 'pxr', 'pbm', 'pgm', 'ppm', 'pnm', 'psd', 'bw', 'rgb', 'rgba', 'sgi', 'ras', 'tga', 'icb', 'vda', 'vst', 'webp', 'wmf', 'emf', 'xbm', 'xpm', 'zip']
Am I the one who added this dataset ? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4071/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4071/timeline | null | completed | null | null | false | [
"Hi @Jun-jie-Huang,\r\n\r\nAs the error message says, \".pkl\" data files are not supported.\r\n\r\nIf you would like to share your dataset on the Hub, you would need:\r\n- either to create a Python loading script, that loads the data in any format\r\n- or to transform your data files to one of the supported formats (listed in the error message above: CSV, JSON, Parquet, TXT,...)\r\n\r\nYou can find the details in our docs: \r\n- How to share a dataset: https://huggingface.co/docs/datasets/share\r\n- How to create a dataset loading script: https://huggingface.co/docs/datasets/dataset_script\r\n\r\nFeel free to re-open this issue and ping us if you need further assistance."
] |
https://api.github.com/repos/huggingface/datasets/issues/2396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2396/comments | https://api.github.com/repos/huggingface/datasets/issues/2396/events | https://github.com/huggingface/datasets/issues/2396 | 899,016,308 | MDU6SXNzdWU4OTkwMTYzMDg= | 2,396 | strange datasets from OSCAR corpus | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 2 | 2021-05-23T13:06:02Z | 2021-06-17T13:54:37Z | null | null | 

From the [official site ](https://oscar-corpus.com/), the Yue Chinese dataset should have 2.2KB data.
7 training instances is obviously not a right number.
As I can read Yue Chinese, I call tell the last instance is definitely not something that would appear on Common Crawl.
And even if you don't read Yue Chinese, you can tell the first six instance are problematic.
(It is embarrassing, as the 7 training instances look exactly like something from a pornographic novel or flitting messages in a chat of a dating app)
It might not be the problem of the huggingface/datasets implementation, because when I tried to download the dataset from the official site, I found out that the zip file is corrupted.
I will try to inform the host of OSCAR corpus later.
Awy a remake about this dataset in huggingface/datasets is needed, perhaps after the host of the dataset fixes the issue.
> Hi @jerryIsHere , sorry for the late response! Sadly this is normal, the problem comes form fasttext's classifier which we used to create the original corpus. In general the classifier is not really capable of properly recognizing Yue Chineese so the file ends un being just noise from Common Crawl. Some of these problems with OSCAR were already discussed [here](https://arxiv.org/pdf/2103.12028.pdf) but we are working on explicitly documenting the problems by language on our website. In fact, could please you open an issue on [our repo](https://github.com/oscar-corpus/oscar-website/issues) as well so that we can track it?
Thanks a lot, the new post is here:
https://github.com/oscar-corpus/oscar-website/issues/11 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2396/timeline | null | null | null | null | false | [
"Hi ! Thanks for reporting\r\ncc @pjox is this an issue from the data ?\r\n\r\nAnyway we should at least mention that OSCAR could contain such contents in the dataset card, you're totally right @jerryIsHere ",
"Hi @jerryIsHere , sorry for the late response! Sadly this is normal, the problem comes form fasttext's classifier which we used to create the original corpus. In general the classifier is not really capable of properly recognizing Yue Chineese so the file ends un being just noise from Common Crawl. Some of these problems with OSCAR were already discussed [here](https://arxiv.org/pdf/2103.12028.pdf) but we are working on explicitly documenting the problems by language on our website. In fact, could please you open an issue on [our repo](https://github.com/oscar-corpus/oscar-website/issues) as well so that we can track it?"
] |
https://api.github.com/repos/huggingface/datasets/issues/2374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2374/comments | https://api.github.com/repos/huggingface/datasets/issues/2374/events | https://github.com/huggingface/datasets/pull/2374 | 894,579,364 | MDExOlB1bGxSZXF1ZXN0NjQ2OTIyMjkw | 2,374 | add `desc` to `tqdm` in `Dataset.map()` | [] | closed | false | null | 5 | 2021-05-18T16:44:29Z | 2021-05-27T15:44:04Z | 2021-05-26T14:59:21Z | null | Fixes #2330. Please let me know if anything is also required in this | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2374/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2374.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2374",
"merged_at": "2021-05-26T14:59:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2374.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2374"
} | true | [
"Once this is merged, let's update `transformers` examples to use this new code. As currently all those tqdm bars are who knows what they are....\r\n\r\nhttps://github.com/huggingface/transformers/issues/11797",
"Sure @stas00! Once this is merged let's discuss what all changes can be done on `transformers` side",
"@bhavitvyamalik, as it has been merged would you like to tackle https://github.com/huggingface/transformers/issues/11797?\r\n",
"Definitely @stas00. From what I could gather, you guys want more meaningful `.map` calls for all examples [here](https://github.com/huggingface/transformers/tree/master/examples/pytorch)?",
"That's exactly right, @bhavitvyamalik \r\n\r\nPerhaps the best approach is to do one example, see that other maintainers agree on it. and then replicate to other."
] |
https://api.github.com/repos/huggingface/datasets/issues/767 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/767/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/767/comments | https://api.github.com/repos/huggingface/datasets/issues/767/events | https://github.com/huggingface/datasets/issues/767 | 730,771,610 | MDU6SXNzdWU3MzA3NzE2MTA= | 767 | Add option for named splits when using ds.train_test_split | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2020-10-27T19:59:44Z | 2020-11-10T14:05:21Z | null | null | ### Feature Request 🚀
Can we add a way to name your splits when using the `.train_test_split` function?
In almost every use case I've come across, I have a `train` and a `test` split in my `DatasetDict`, and I want to create a `validation` split. Therefore, its kinda useless to get a `test` split back from `train_test_split`, as it'll just overwrite my real `test` split that I intended to keep.
### Workaround
this is my hack for dealin with this, for now :slightly_smiling_face:
```python
from datasets import load_dataset
ds = load_dataset('imdb')
ds['train'], ds['validation'] = ds['train'].train_test_split(.1).values()
```
| {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/767/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/767/timeline | null | null | null | null | false | [
"Yes definitely we should give more flexibility to control the name of the splits outputted by `train_test_split`.\r\n\r\nRelated is the very interesting feedback from @bramvanroy on how we should improve this method: https://discuss.huggingface.co/t/how-to-split-main-dataset-into-train-dev-test-as-datasetdict/1090/5\r\n\r\nAnd in particular that it should advantageously be able to split in 3 splits as well instead of just 2 like we copied from sklearn."
] |
https://api.github.com/repos/huggingface/datasets/issues/3288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3288/comments | https://api.github.com/repos/huggingface/datasets/issues/3288/events | https://github.com/huggingface/datasets/pull/3288 | 1,056,145,703 | PR_kwDODunzps4up6S5 | 3,288 | Allow datasets with indices table when concatenating along axis=1 | [] | closed | false | null | 0 | 2021-11-17T13:41:28Z | 2021-11-17T15:41:12Z | 2021-11-17T15:41:11Z | null | Calls `flatten_indices` on the datasets with indices table in `concatenate_datasets` to fix issues when concatenating along `axis=1`.
cc @lhoestq: I decided to flatten all the datasets instead of flattening all the datasets except the largest one in the end. The latter approach fails on the following example:
```python
a = Dataset.from_dict({"a": [10, 20, 30, 40]})
b = Dataset.from_dict({"b": [10, 20, 30, 40, 50, 60]}) # largest dataset
a = a.select([1, 2, 3])
b = b.select([1, 2, 3])
concatenate_datasets([a, b], axis=1) # fails at line concat_tables(...) because the real length of b's data is 6 and a's length is 3 after flattening (was 4 before flattening)
```
Also, it requires additional re-ordering of indices to prepare them for working with the indices table of the largest dataset. IMO not worth when we save only one `flatten_indices` call. (feel free to check the code of that approach at https://github.com/huggingface/datasets/commit/6acd10481c70950dcfdbfd2bab0bf0c74ad80bcb if you are interested)
Fixes #3273
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3288/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3288.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3288",
"merged_at": "2021-11-17T15:41:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3288.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3288"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/692 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/692/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/692/comments | https://api.github.com/repos/huggingface/datasets/issues/692/events | https://github.com/huggingface/datasets/pull/692 | 712,818,968 | MDExOlB1bGxSZXF1ZXN0NDk2MjM4NzIw | 692 | Update README.md | [] | closed | false | null | 4 | 2020-10-01T12:57:22Z | 2020-10-02T11:01:59Z | 2020-10-02T11:01:59Z | null | {
"+1": 0,
"-1": 4,
"confused": 2,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/692/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/692/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/692.diff",
"html_url": "https://github.com/huggingface/datasets/pull/692",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/692.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/692"
} | true | [
"Hacktoberfest spam",
"To enhance its readability.....not Hacktoberfest spam",
"How is adding a punctuation to the end of a sentence justified as \"To enhance its readability\". \r\nConsidering that this is not your first \"README enhancement '' please don't spam the open source community with useless PR to get a free T-Shirt it just hurts the maintainers.\r\n\r\n//Joey",
"closed as spam"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/5751 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5751/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5751/comments | https://api.github.com/repos/huggingface/datasets/issues/5751/events | https://github.com/huggingface/datasets/pull/5751 | 1,668,333,316 | PR_kwDODunzps5OVMuT | 5,751 | Consistent ArrayXD Python formatting + better NumPy/Pandas formatting | [] | closed | false | null | 4 | 2023-04-14T14:13:59Z | 2023-04-20T14:43:20Z | 2023-04-20T14:40:34Z | null | Return a list of lists instead of a list of NumPy arrays when converting the variable-shaped `ArrayXD` to Python. Additionally, improve the NumPy conversion by returning a numeric NumPy array when the offsets are equal or a NumPy object array when they aren't, and allow converting the variable-shaped `ArrayXD` to Pandas.
(Reported in https://github.com/huggingface/datasets/issues/5719#issuecomment-1507579671) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5751/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5751/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5751.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5751",
"merged_at": "2023-04-20T14:40:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5751.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5751"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.010459 / 0.011353 (-0.000894) | 0.007009 / 0.011008 (-0.003999) | 0.153885 / 0.038508 (0.115377) | 0.037308 / 0.023109 (0.014199) | 0.431931 / 0.275898 (0.156033) | 0.452940 / 0.323480 (0.129461) | 0.008572 / 0.007986 (0.000586) | 0.007479 / 0.004328 (0.003150) | 0.093835 / 0.004250 (0.089584) | 0.050172 / 0.037052 (0.013120) | 0.428855 / 0.258489 (0.170366) | 0.517814 / 0.293841 (0.223974) | 0.058558 / 0.128546 (-0.069988) | 0.019550 / 0.075646 (-0.056096) | 0.449837 / 0.419271 (0.030566) | 0.069710 / 0.043533 (0.026177) | 0.444163 / 0.255139 (0.189024) | 0.469003 / 0.283200 (0.185803) | 0.114665 / 0.141683 (-0.027018) | 1.822415 / 1.452155 (0.370261) | 1.956360 / 1.492716 (0.463644) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237489 / 0.018006 (0.219483) | 0.556947 / 0.000490 (0.556457) | 0.006988 / 0.000200 (0.006789) | 0.000499 / 0.000054 (0.000444) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.037047 / 0.037411 (-0.000364) | 0.133973 / 0.014526 (0.119447) | 0.137072 / 0.176557 (-0.039485) | 0.201520 / 0.737135 (-0.535615) | 0.144177 / 0.296338 (-0.152161) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.694853 / 0.215209 (0.479644) | 6.805746 / 2.077655 (4.728091) | 2.717864 / 1.504120 (1.213744) | 2.360529 / 1.541195 (0.819335) | 2.384403 / 1.468490 (0.915913) | 1.337512 / 4.584777 (-3.247265) | 5.734090 / 3.745712 (1.988378) | 5.344909 / 5.269862 (0.075047) | 2.906218 / 4.565676 (-1.659458) | 0.160148 / 0.424275 (-0.264127) | 0.015159 / 0.007607 (0.007551) | 0.871356 / 0.226044 (0.645312) | 8.550965 / 2.268929 (6.282037) | 3.613522 / 55.444624 (-51.831103) | 2.868508 / 6.876477 (-4.007969) | 2.912263 / 2.142072 (0.770190) | 1.652548 / 4.805227 (-3.152680) | 0.274117 / 6.500664 (-6.226547) | 0.085911 / 0.075469 (0.010442) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.624798 / 1.841788 (-0.216989) | 18.413303 / 8.074308 (10.338995) | 21.742854 / 10.191392 (11.551462) | 0.255937 / 0.680424 (-0.424487) | 0.029492 / 0.534201 (-0.504709) | 0.541932 / 0.579283 (-0.037351) | 0.638594 / 0.434364 (0.204230) | 0.607427 / 0.540337 (0.067090) | 0.763046 / 1.386936 (-0.623890) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.020543 / 0.011353 (0.009190) | 0.006079 / 0.011008 (-0.004929) | 0.100558 / 0.038508 (0.062050) | 0.039474 / 0.023109 (0.016365) | 0.468889 / 0.275898 (0.192991) | 0.477731 / 0.323480 (0.154251) | 0.006999 / 0.007986 (-0.000987) | 0.005845 / 0.004328 (0.001516) | 0.110022 / 0.004250 (0.105772) | 0.056885 / 0.037052 (0.019833) | 0.447296 / 0.258489 (0.188807) | 0.489007 / 0.293841 (0.195166) | 0.055086 / 0.128546 (-0.073460) | 0.020623 / 0.075646 (-0.055024) | 0.129599 / 0.419271 (-0.289672) | 0.064316 / 0.043533 (0.020784) | 0.446681 / 0.255139 (0.191542) | 0.488897 / 0.283200 (0.205698) | 0.119121 / 0.141683 (-0.022562) | 1.836248 / 1.452155 (0.384093) | 2.002456 / 1.492716 (0.509740) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.249344 / 0.018006 (0.231338) | 0.544320 / 0.000490 (0.543830) | 0.000459 / 0.000200 (0.000259) | 0.000088 / 0.000054 (0.000034) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.038771 / 0.037411 (0.001359) | 0.129527 / 0.014526 (0.115002) | 0.144681 / 0.176557 (-0.031876) | 0.208237 / 0.737135 (-0.528898) | 0.149502 / 0.296338 (-0.146836) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.668457 / 0.215209 (0.453248) | 6.729550 / 2.077655 (4.651895) | 2.741076 / 1.504120 (1.236956) | 2.394737 / 1.541195 (0.853542) | 2.415242 / 1.468490 (0.946752) | 1.322334 / 4.584777 (-3.262442) | 5.787454 / 3.745712 (2.041742) | 3.309847 / 5.269862 (-1.960015) | 2.199181 / 4.565676 (-2.366495) | 0.170740 / 0.424275 (-0.253535) | 0.015095 / 0.007607 (0.007487) | 0.864157 / 0.226044 (0.638112) | 8.701858 / 2.268929 (6.432929) | 3.617966 / 55.444624 (-51.826658) | 2.847144 / 6.876477 (-4.029332) | 3.011391 / 2.142072 (0.869319) | 1.595466 / 4.805227 (-3.209762) | 0.284010 / 6.500664 (-6.216654) | 0.091054 / 0.075469 (0.015585) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.702404 / 1.841788 (-0.139384) | 19.427130 / 8.074308 (11.352822) | 21.900446 / 10.191392 (11.709053) | 0.244088 / 0.680424 (-0.436336) | 0.027428 / 0.534201 (-0.506773) | 0.552226 / 0.579283 (-0.027057) | 0.653102 / 0.434364 (0.218738) | 0.635379 / 0.540337 (0.095042) | 0.771842 / 1.386936 (-0.615094) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006547 / 0.011353 (-0.004806) | 0.004569 / 0.011008 (-0.006439) | 0.097782 / 0.038508 (0.059274) | 0.028157 / 0.023109 (0.005048) | 0.319017 / 0.275898 (0.043119) | 0.340758 / 0.323480 (0.017278) | 0.005078 / 0.007986 (-0.002907) | 0.003343 / 0.004328 (-0.000985) | 0.074194 / 0.004250 (0.069944) | 0.037918 / 0.037052 (0.000866) | 0.310298 / 0.258489 (0.051809) | 0.349441 / 0.293841 (0.055600) | 0.030375 / 0.128546 (-0.098171) | 0.011527 / 0.075646 (-0.064119) | 0.320499 / 0.419271 (-0.098773) | 0.042639 / 0.043533 (-0.000894) | 0.312182 / 0.255139 (0.057043) | 0.329058 / 0.283200 (0.045858) | 0.085517 / 0.141683 (-0.056165) | 1.532603 / 1.452155 (0.080448) | 1.583996 / 1.492716 (0.091279) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.208286 / 0.018006 (0.190280) | 0.418696 / 0.000490 (0.418206) | 0.007051 / 0.000200 (0.006851) | 0.000409 / 0.000054 (0.000354) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024055 / 0.037411 (-0.013356) | 0.098420 / 0.014526 (0.083894) | 0.104785 / 0.176557 (-0.071771) | 0.163618 / 0.737135 (-0.573517) | 0.110006 / 0.296338 (-0.186332) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418756 / 0.215209 (0.203547) | 4.179557 / 2.077655 (2.101902) | 1.881708 / 1.504120 (0.377588) | 1.683393 / 1.541195 (0.142198) | 1.731909 / 1.468490 (0.263419) | 0.696674 / 4.584777 (-3.888103) | 3.384167 / 3.745712 (-0.361545) | 3.173479 / 5.269862 (-2.096382) | 1.620019 / 4.565676 (-2.945658) | 0.082850 / 0.424275 (-0.341426) | 0.012396 / 0.007607 (0.004789) | 0.519743 / 0.226044 (0.293699) | 5.208480 / 2.268929 (2.939552) | 2.312917 / 55.444624 (-53.131708) | 1.963486 / 6.876477 (-4.912991) | 2.084553 / 2.142072 (-0.057519) | 0.805486 / 4.805227 (-3.999742) | 0.153429 / 6.500664 (-6.347235) | 0.069451 / 0.075469 (-0.006018) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197185 / 1.841788 (-0.644603) | 14.341005 / 8.074308 (6.266696) | 14.476162 / 10.191392 (4.284770) | 0.157372 / 0.680424 (-0.523052) | 0.016444 / 0.534201 (-0.517757) | 0.383721 / 0.579283 (-0.195562) | 0.380800 / 0.434364 (-0.053564) | 0.441137 / 0.540337 (-0.099200) | 0.524778 / 1.386936 (-0.862158) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006728 / 0.011353 (-0.004625) | 0.004536 / 0.011008 (-0.006472) | 0.076266 / 0.038508 (0.037757) | 0.028133 / 0.023109 (0.005024) | 0.351072 / 0.275898 (0.075174) | 0.375823 / 0.323480 (0.052344) | 0.005166 / 0.007986 (-0.002819) | 0.004717 / 0.004328 (0.000388) | 0.076130 / 0.004250 (0.071880) | 0.041354 / 0.037052 (0.004301) | 0.345904 / 0.258489 (0.087415) | 0.384119 / 0.293841 (0.090278) | 0.030759 / 0.128546 (-0.097787) | 0.011659 / 0.075646 (-0.063988) | 0.085269 / 0.419271 (-0.334002) | 0.042161 / 0.043533 (-0.001372) | 0.340806 / 0.255139 (0.085667) | 0.366832 / 0.283200 (0.083632) | 0.092187 / 0.141683 (-0.049495) | 1.520035 / 1.452155 (0.067880) | 1.603856 / 1.492716 (0.111140) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.237763 / 0.018006 (0.219757) | 0.413406 / 0.000490 (0.412916) | 0.000415 / 0.000200 (0.000215) | 0.000060 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026095 / 0.037411 (-0.011317) | 0.105775 / 0.014526 (0.091249) | 0.108452 / 0.176557 (-0.068105) | 0.160014 / 0.737135 (-0.577122) | 0.112385 / 0.296338 (-0.183953) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.437327 / 0.215209 (0.222118) | 4.374949 / 2.077655 (2.297294) | 2.090292 / 1.504120 (0.586172) | 1.885946 / 1.541195 (0.344752) | 1.946768 / 1.468490 (0.478278) | 0.704124 / 4.584777 (-3.880653) | 3.394994 / 3.745712 (-0.350718) | 1.905189 / 5.269862 (-3.364673) | 1.182300 / 4.565676 (-3.383376) | 0.082920 / 0.424275 (-0.341355) | 0.012781 / 0.007607 (0.005174) | 0.535467 / 0.226044 (0.309423) | 5.362799 / 2.268929 (3.093870) | 2.504825 / 55.444624 (-52.939799) | 2.180458 / 6.876477 (-4.696019) | 2.317750 / 2.142072 (0.175677) | 0.811182 / 4.805227 (-3.994045) | 0.151654 / 6.500664 (-6.349010) | 0.067925 / 0.075469 (-0.007544) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.290746 / 1.841788 (-0.551042) | 14.799309 / 8.074308 (6.725001) | 14.439722 / 10.191392 (4.248330) | 0.144358 / 0.680424 (-0.536066) | 0.016688 / 0.534201 (-0.517513) | 0.392907 / 0.579283 (-0.186376) | 0.383109 / 0.434364 (-0.051255) | 0.450069 / 0.540337 (-0.090269) | 0.532534 / 1.386936 (-0.854402) |\n\n</details>\n</details>\n\n\n",
"I turned it into a draft to fix the failing tests, but CI is now green, so there is no good reason for it :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/627/comments | https://api.github.com/repos/huggingface/datasets/issues/627/events | https://github.com/huggingface/datasets/pull/627 | 701,411,661 | MDExOlB1bGxSZXF1ZXN0NDg2ODcxMTg2 | 627 | fix (#619) MLQA features names | [] | closed | false | null | 0 | 2020-09-14T20:41:59Z | 2020-11-02T21:04:32Z | 2020-09-16T06:54:11Z | null | Fixed the features names as suggested in (#619) in the `_generate_examples` and `_info` methods in the MLQA loading script and also changed the names in the `dataset_infos.json` file. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/627/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/627.diff",
"html_url": "https://github.com/huggingface/datasets/pull/627",
"merged_at": "2020-09-16T06:54:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/627.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/627"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3714 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3714/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3714/comments | https://api.github.com/repos/huggingface/datasets/issues/3714/events | https://github.com/huggingface/datasets/issues/3714 | 1,136,105,530 | I_kwDODunzps5Dt5g6 | 3,714 | tatoeba_mt: File not found error and key error | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 1 | 2022-02-13T16:35:45Z | 2022-02-13T20:44:04Z | 2022-02-13T20:44:04Z | null | ## Dataset viewer issue for 'tatoeba_mt'
**Link:** https://huggingface.co/datasets/Helsinki-NLP/tatoeba_mt
My data loader script does not seem to work.
The files are part of the local repository but cannot be found. An example where it should work is the subset for "afr-eng".
Another problem is that I do not have validation data for all subsets and I don't know how to properly check whether validation exists in the configuration before I try to download it. An example is the subset for "afr-deu".
Am I the one who added this dataset ? Yes
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3714/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3714/timeline | null | completed | null | null | false | [
"Looks like I solved my problems ..."
] |
https://api.github.com/repos/huggingface/datasets/issues/4292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4292/comments | https://api.github.com/repos/huggingface/datasets/issues/4292/events | https://github.com/huggingface/datasets/pull/4292 | 1,228,216,788 | PR_kwDODunzps43bhrp | 4,292 | Add API code examples for remaining main classes | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 1 | 2022-05-06T18:15:31Z | 2022-05-25T18:05:13Z | 2022-05-25T17:56:36Z | null | This PR adds API code examples for the remaining functions in the Main classes. I wasn't too familiar with some of the functions (`decode_batch`, `decode_column`, `decode_example`, etc.) so please feel free to add an example of usage and I can fill in the rest :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4292/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4292.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4292",
"merged_at": "2022-05-25T17:56:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4292.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4292"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | [] | open | false | null | 4 | 2023-03-05T05:27:15Z | 2023-07-13T18:48:05Z | null | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_disk` and then use `load_from_disk` to load the filtered version.
The performance of these two approaches is wildly different:
* Using `load_dataset` takes about 20 seconds to load the dataset, and a few seconds to re-filter (thanks to the brilliant filter/map caching)
* Using `load_from_disk` takes 14 minutes! And the second time I tried, the session just crashed (on a machine with 32GB of RAM)
I don't know if you'd call this a bug, but it seems like there shouldn't need to be two methods to load from disk, or that they should not take such wildly different amounts of time, or that one should not crash. Or maybe that the docs could offer some guidance about when to pick which method and why two methods exist, or just how do most people do it?
Something I couldn't work out from reading the docs was this: can I modify a dataset from the hub, save it (locally) and use `load_dataset` to load it? This [post seemed to suggest that the answer is no](https://discuss.huggingface.co/t/save-and-load-datasets/9260).
### Steps to reproduce the bug
See above
### Expected behavior
Load times should be about the same.
### Environment info
- `datasets` version: 2.9.0
- Platform: Linux-5.10.102.1-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | null | null | false | [
"Hi! We've recently made some improvements to `save_to_disk`/`list_to_disk` (100x faster in some scenarios), so it would help if you could install `datasets` directly from `main` (`pip install git+https://github.com/huggingface/datasets.git`) and re-run the \"benchmark\".",
"Great to hear! I'll give it a try when I've got a moment.",
"@mariosasko is that fix released to pip in the meantime? Asking cause im facing still the same issue (regarding loading images from local paths):\r\n```\r\ndataset = load_dataset(\"csv\", cache_dir=\"cache\", data_files=[\"/STORAGE/DATA/mijam/vit/code/list_filtered.csv\"], num_proc=16, split=\"train\").cast_column(\"image\", Image())\r\ndataset = dataset.class_encode_column(\"label\")\r\n```\r\nquite fast. \r\n\r\nThen I do `save_to_disk()` and some time later:\r\n```\r\ndataset = load_from_disk('/STORAGE/DATA/mijam/accel/saved_arrow_big')\r\n```\r\nreally slow. In theory it should be quicked since it only loads arrow files, no conversions and so on.\r\n",
"@mjamroz I assume your CSV file stores image file paths. This means `save_to_disk` needs to embed the image bytes resulting in a much bigger Arrow file (than the initial one). Maybe specifying `num_shards` to make the Arrow files smaller can help (large Arrow files on some systems take a long time to load)."
] |
https://api.github.com/repos/huggingface/datasets/issues/1765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1765/comments | https://api.github.com/repos/huggingface/datasets/issues/1765/events | https://github.com/huggingface/datasets/issues/1765 | 791,553,065 | MDU6SXNzdWU3OTE1NTMwNjU= | 1,765 | Error iterating over Dataset with DataLoader | [] | closed | false | null | 6 | 2021-01-21T22:56:45Z | 2022-10-28T02:16:38Z | 2021-01-23T03:44:14Z | null | I have a Dataset that I've mapped a tokenizer over:
```
encoded_dataset.set_format(type='torch',columns=['attention_mask','input_ids','token_type_ids'])
encoded_dataset[:1]
```
```
{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
'input_ids': tensor([[ 101, 178, 1198, 1400, 1714, 22233, 21365, 4515, 8618, 1113,
102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
When I try to iterate as in the docs, I get errors:
```
dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_sampler=32)
next(iter(dataloader))
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-05180ba8aa35> in <module>()
1 dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_sampler=32)
----> 2 next(iter(dataloader))
3 frames
/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py in __init__(self, loader)
411 self._timeout = loader.timeout
412 self._collate_fn = loader.collate_fn
--> 413 self._sampler_iter = iter(self._index_sampler)
414 self._base_seed = torch.empty((), dtype=torch.int64).random_(generator=loader.generator).item()
415 self._persistent_workers = loader.persistent_workers
TypeError: 'int' object is not iterable
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1765/timeline | null | completed | null | null | false | [
"Instead of:\r\n```python\r\ndataloader = torch.utils.data.DataLoader(encoded_dataset, batch_sampler=32)\r\n```\r\nIt should be:\r\n```python\r\ndataloader = torch.utils.data.DataLoader(encoded_dataset, batch_size=32)\r\n```\r\n\r\n`batch_sampler` accepts a Sampler object or an Iterable, so you get an error.",
"@mariosasko I thought that would fix it, but now I'm getting a different error:\r\n\r\n```\r\n/usr/local/lib/python3.6/dist-packages/datasets/arrow_dataset.py:851: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:141.)\r\n return torch.tensor(x, **format_kwargs)\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-20-3af1d82bf93a> in <module>()\r\n 1 dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_size=32)\r\n----> 2 next(iter(dataloader))\r\n\r\n5 frames\r\n/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/collate.py in default_collate(batch)\r\n 53 storage = elem.storage()._new_shared(numel)\r\n 54 out = elem.new(storage)\r\n---> 55 return torch.stack(batch, 0, out=out)\r\n 56 elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \\\r\n 57 and elem_type.__name__ != 'string_':\r\n\r\nRuntimeError: stack expects each tensor to be equal size, but got [7] at entry 0 and [10] at entry 1\r\n```\r\n\r\nAny thoughts what this means?I Do I need padding?",
"Yes, padding is an answer. \r\n\r\nThis can be solved easily by passing a callable to the collate_fn arg of DataLoader that adds padding. ",
"Padding was the fix, thanks!",
"dataloader = torch.utils.data.DataLoader(encoded_dataset, batch_size=4)\r\nbatch = next(iter(dataloader))\r\n\r\ngetting \r\nValueError: cannot reshape array of size 8192 into shape (1,512,4)\r\n\r\nI had put padding as 2048 for encoded_dataset\r\nkindly help",
"data_loader_val = torch.utils.data.DataLoader(val_dataset, batch_size=32, shuffle=True, drop_last=False, num_workers=0)\r\ndataiter = iter(data_loader_val)\r\nimages, _ = next(dataiter)\r\n\r\ngetting -> TypeError: 'list' object is not callable\r\n\r\nCannot iterate through the data. Kindly suggest."
] |
https://api.github.com/repos/huggingface/datasets/issues/6014 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6014/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6014/comments | https://api.github.com/repos/huggingface/datasets/issues/6014/events | https://github.com/huggingface/datasets/issues/6014 | 1,798,213,816 | I_kwDODunzps5rLpC4 | 6,014 | Request to Share/Update Dataset Viewer Code | [] | open | false | null | 6 | 2023-07-11T06:36:09Z | 2023-07-12T14:18:49Z | null | null |
Overview:
The repository (huggingface/datasets-viewer) was recently archived and when I tried to run the code, there was the error message "AttributeError: module 'datasets.load' has no attribute 'prepare_module'". I could not resolve the issue myself due to lack of documentation of that attribute.
Request:
I kindly request the sharing of the code responsible for the dataset preview functionality or help with resolving the error. The dataset viewer on the Hugging Face website is incredibly useful since it is compatible with different types of inputs. It allows users to find datasets that meet their needs more efficiently. If needed, I am willing to contribute to the project by testing, documenting, and providing feedback on the dataset viewer code.
Thank you for considering this request, and I look forward to your response. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6014/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6014/timeline | null | null | null | null | false | [
"Hi ! The huggingface/dataset-viewer code was not maintained anymore because we switched to a new dataset viewer that is deployed available for each dataset the Hugging Face website.\r\n\r\nWhat are you using this old repository for ?",
"I think these parts are outdated:\r\n\r\n* https://github.com/huggingface/datasets-viewer/blob/8efad8eae313a891f713469983bf4c744786f26e/run.py#L126-L131\r\n* https://github.com/huggingface/datasets-viewer/blob/8efad8eae313a891f713469983bf4c744786f26e/run.py#L145-L150\r\n\r\nTo make the viewer work, the first one should be replaced with the following:\r\n```python\r\ndataset_module = datasets.load.dataset_module_factory(path)\r\nbuilder_cls = datasets.load.import_main_class(dataset_module.module_path)\r\nconfs = builder_cls.BUILDER_CONFIGS\r\n```\r\nAnd the second one:\r\n```python\r\ndataset_module = datasets.load.dataset_module_factory(path)\r\nbuilder_cls = datasets.load.import_main_class(dataset_module.module_path)\r\nif conf:\r\n builder_instance = builder_cls(name=conf, cache_dir=path if path_to_datasets is not None else None)\r\nelse:\r\n builder_instance = builder_cls(cache_dir=path if path_to_datasets is not None else None)\r\n```\r\n\r\nBut as @lhoestq suggested, it's better to use the `datasets-server` API nowadays to [fetch the rows](https://huggingface.co/docs/datasets-server/rows).",
"> The dataset viewer on the Hugging Face website is incredibly useful\r\n\r\n@mariosasko i think @lilyorlilypad wants to run the new dataset-viewer, not the old one",
"> wants to run the new dataset-viewer, not the old one\r\n\r\nThanks for the clarification for me. I do want to run the new dataset-viewer. ",
"It should be possible to run it locally using the HF datasets-server API (docs [here](https://huggingface.co/docs/datasets-server)) but the front end part is not open source (yet ?)\r\n\r\nThe back-end is open source though if you're interested: https://github.com/huggingface/datasets-server\r\nIt automatically converts datasets on HF to Parquet, which is the format we use to power the viewer.",
"the new frontend would probably be hard to open source, as is, as it's quite intertwined with the Hub's code.\r\n\r\nHowever, at some point it would be amazing to have a community-driven open source implementation of a frontend to datasets-server! "
] |
https://api.github.com/repos/huggingface/datasets/issues/791 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/791/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/791/comments | https://api.github.com/repos/huggingface/datasets/issues/791/events | https://github.com/huggingface/datasets/pull/791 | 734,656,518 | MDExOlB1bGxSZXF1ZXN0NTE0MTg0MzU5 | 791 | add amazon reviews | [] | closed | false | null | 3 | 2020-11-02T16:42:57Z | 2020-11-03T20:15:06Z | 2020-11-03T16:43:57Z | null | Adds the Amazon US Reviews dataset as requested in #353. Converted from [TensorFlow Datasets](https://www.tensorflow.org/datasets/catalog/amazon_us_reviews). cc @clmnt @sshleifer | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/791/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/791/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/791.diff",
"html_url": "https://github.com/huggingface/datasets/pull/791",
"merged_at": "2020-11-03T16:43:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/791.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/791"
} | true | [
"@patrickvonplaten Yeah this is adapted from tfds so a lot is just how they wrote the code. Addressed your comments and also simplified the weird `AmazonUSReviewsConfig` definition. Will merge once tests pass.",
"Thanks for checking this one :) \r\nLooks good to me \r\n\r\nJust one question : is there a particular reason to use `names=[\"Y\", \"N\"]` in this order ? Usually the positive label is at index 1 and the negative one at index 0 for binary classification",
"> is there a particular reason to use `names=[\"Y\", \"N\"]` in this order ? Usually the positive label is at index 1 and the negative one at index 0 for binary classification\r\n\r\nHmm that's a good point. I'll submit a quick fix.\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3015 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3015/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3015/comments | https://api.github.com/repos/huggingface/datasets/issues/3015/events | https://github.com/huggingface/datasets/pull/3015 | 1,015,130,845 | PR_kwDODunzps4so0GX | 3,015 | Extend support for streaming datasets that use glob.glob | [] | closed | false | null | 0 | 2021-10-04T12:42:37Z | 2021-10-05T13:46:39Z | 2021-10-05T13:46:38Z | null | This PR extends the support in streaming mode for datasets that use `glob`, by patching the function `glob.glob`.
Related to #2880, #2876, #2874 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3015/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3015/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3015.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3015",
"merged_at": "2021-10-05T13:46:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3015.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3015"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1020/comments | https://api.github.com/repos/huggingface/datasets/issues/1020/events | https://github.com/huggingface/datasets/pull/1020 | 755,601,450 | MDExOlB1bGxSZXF1ZXN0NTMxMjgyODQy | 1,020 | Add Setswana NER | [] | closed | false | null | 0 | 2020-12-02T20:52:07Z | 2020-12-03T14:56:14Z | 2020-12-03T14:56:14Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1020/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1020.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1020",
"merged_at": "2020-12-03T14:56:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1020.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1020"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/3472 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3472/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3472/comments | https://api.github.com/repos/huggingface/datasets/issues/3472/events | https://github.com/huggingface/datasets/pull/3472 | 1,086,908,508 | PR_kwDODunzps4wMEwA | 3,472 | Fix `str(Path(...))` conversion in streaming on Linux | [] | closed | false | null | 0 | 2021-12-22T15:06:03Z | 2021-12-22T16:52:53Z | 2021-12-22T16:52:52Z | null | Fix `str(Path(...))` conversion in streaming on Linux. This should fix the streaming of the `beans` and `cats_vs_dogs` datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3472/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3472/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3472.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3472",
"merged_at": "2021-12-22T16:52:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3472.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3472"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2702/comments | https://api.github.com/repos/huggingface/datasets/issues/2702/events | https://github.com/huggingface/datasets/pull/2702 | 950,448,159 | MDExOlB1bGxSZXF1ZXN0Njk0OTkyOTc1 | 2,702 | Update BibTeX entry | [] | closed | false | null | 0 | 2021-07-22T09:04:39Z | 2021-07-22T09:17:39Z | 2021-07-22T09:17:38Z | null | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2702/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2702/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2702.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2702",
"merged_at": "2021-07-22T09:17:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2702.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2702"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4475/comments | https://api.github.com/repos/huggingface/datasets/issues/4475/events | https://github.com/huggingface/datasets/pull/4475 | 1,267,798,451 | PR_kwDODunzps45eufw | 4,475 | Improve error message for missing pacakges from inside dataset script | [] | closed | false | null | 3 | 2022-06-10T16:59:36Z | 2022-10-06T13:46:26Z | 2022-06-13T13:16:43Z | null | Improve the error message for missing packages from inside a dataset script:
With this change, the error message for missing packages for `bigbench` looks as follows:
```
ImportError: To be able to use bigbench, you need to install the following dependencies:
- 'bigbench' using 'pip install "bigbench @ https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz"'
```
And this is how it looked before:
```
ImportError: To be able to use bigbench, you need to install the following dependencies['bigbench', 'bigbench', 'bigbench', 'bigbench'] using 'pip install "bigbench @ https://storage.googleapis.com/public_research_data/bigbench/bigbench-0.0.1.tar.gz" bigbench bigbench bigbench' for instance'
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4475/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4475.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4475",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4475.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4475"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I opened a PR before I noticed yours ^^' You can find it here: https://github.com/huggingface/datasets/pull/4484\r\n\r\nThe only comment I have regarding your message is that it possibly shows several `pip install` commands, whereas one can run one single `pip install` command with the list of missing dependencies, which is maybe simpler.\r\n\r\nLet me know which one your prefer",
"Closing in favor of #4484. "
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.