
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3421/comments | https://api.github.com/repos/huggingface/datasets/issues/3421/events | https://github.com/huggingface/datasets/pull/3421 | 1,077,966,571 | PR_kwDODunzps4vuvJK | 3,421 | Adding mMARCO dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 7 | 2021-12-13T00:56:43Z | 2022-10-03T09:37:15Z | 2022-10-03T09:37:15Z | null | Adding mMARCO (v1.1) to HF datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3421/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3421.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3421",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3421.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3421"
} | true | [
"Hi @albertvillanova we've made a major overhaul of the loading script including all configurations we're making available. Could you please review it again?",
"@albertvillanova :ping_pong: ",
"Thanks @lhbonifacio for adding this dataset.\r\nHi there, i got an error about mmarco:\r\nConnectionError: Couldn't reach 'unicamp-dl/mmarco' on the Hub (ConnectionError)\r\ncode:\r\n`from datasets import list_datasets, load_dataset\r\ndataset = load_dataset('unicamp-dl/mmarco', language='portuguese')`\r\n\r\nAny help will be appreciated!",
"Hi @catqaq, we updated the loading script. Now you can load the datasets with:\r\n\r\n```python\r\ndataset = load_dataset('unicamp-dl/mmarco', 'portuguese')\r\n```\r\n\r\nYou can check the list of supported languages and usage examples in [this link](https://huggingface.co/datasets/unicamp-dl/mmarco). Feel free to contact us if you have any issues.",
"\r\n\r\n\r\n> \r\n\r\n\r\n\r\n> Hi @catqaq, we updated the loading script. Now you can load the datasets with:\r\n> \r\n> ```python\r\n> dataset = load_dataset('unicamp-dl/mmarco', 'portuguese')\r\n> ```\r\n> \r\n> You can check the list of supported languages and usage examples in [this link](https://huggingface.co/datasets/unicamp-dl/mmarco). Feel free to contact us if you have any issues.\r\n\r\nThanks for your quick updates. So, how can i get the fixed version, install from the source? It seems that the merging is blocked.",
"@catqaq you can load mMARCO using the namespace `unicamp-dl/mmarco` while this PR remains under review.",
"Thanks for your contribution, @lhbonifacio and @hugoabonizio. And sorry for the late response.\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nAs you already created this dataset under your organization namespace (https://huggingface.co/datasets/unicamp-dl/mmarco), I think we can safely close this PR.\r\n\r\nWe would suggest you complete your dataset card with the YAML tags, to make it searchable and discoverable.\r\n\r\nPlease, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/3447 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3447/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3447/comments | https://api.github.com/repos/huggingface/datasets/issues/3447/events | https://github.com/huggingface/datasets/issues/3447 | 1,082,539,790 | I_kwDODunzps5Ahj8O | 3,447 | HF_DATASETS_OFFLINE=1 didn't stop datasets.builder from downloading | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2021-12-16T18:51:13Z | 2022-02-17T14:16:27Z | 2022-02-17T14:16:27Z | null | ## Describe the bug
According to https://huggingface.co/docs/datasets/loading_datasets.html#loading-a-dataset-builder, setting HF_DATASETS_OFFLINE to 1 should make datasets to "run in full offline mode". It didn't work for me. At the very beginning, datasets still tried to download "custom data configuration" for JSON, despite I have run the program once and cached all data into the same --cache_dir.
"Downloading" is not an issue when running with local disk, but crashes often with cloud storage because (1) multiply GPU processes try to access the same file, AND (2) FileLocker fails to synchronize all processes, due to storage throttling. 99% of times, when the main process releases FileLocker, the file is not actually ready for access in cloud storage and thus triggers "FileNotFound" errors for all other processes. Well, another way to resolve the problem is to investigate super reliable cloud storage, but that's out of scope here.
## Steps to reproduce the bug
```
export HF_DATASETS_OFFLINE=1
python run_clm.py --model_name_or_path=models/gpt-j-6B --train_file=trainpy.v2.train.json --validation_file=trainpy.v2.eval.json --cache_dir=datacache/trainpy.v2
```
## Expected results
datasets should stop all "downloading" behavior but reuse the cached JSON configuration. I think the problem here is part of the cache directory path, "default-471372bed4b51b53", is randomly generated, and it could change if some parameters changed. And I didn't find a way to use a fixed path to ensure datasets to reuse cached data every time.
## Actual results
The logging shows datasets are still downloading into "datacache/trainpy.v2/json/default-471372bed4b51b53/0.0.0/c2d554c3377ea79c7664b93dc65d0803b45e3279000f993c7bfd18937fd7f426".
```
12/16/2021 10:25:59 - WARNING - datasets.builder - Using custom data configuration default-471372bed4b51b53
12/16/2021 10:25:59 - INFO - datasets.builder - Generating dataset json (datacache/trainpy.v2/json/default-471372bed4b51b53/0.0.0/c2d554c3377ea79c7664b93dc65d0803b45e3279000f993c7bfd18937fd7f426)
Downloading and preparing dataset json/default to datacache/trainpy.v2/json/default-471372bed4b51b53/0.0.0/c2d554c3377ea79c7664b93dc65d0803b45e3279000f993c7bfd18937fd7f426...
100%|██████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 17623.13it/s]
12/16/2021 10:25:59 - INFO - datasets.utils.download_manager - Downloading took 0.0 min
12/16/2021 10:26:00 - INFO - datasets.utils.download_manager - Checksum Computation took 0.0 min
100%|███████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 1206.99it/s]
12/16/2021 10:26:00 - INFO - datasets.utils.info_utils - Unable to verify checksums.
12/16/2021 10:26:00 - INFO - datasets.builder - Generating split train
12/16/2021 10:26:01 - INFO - datasets.builder - Generating split validation
12/16/2021 10:26:02 - INFO - datasets.utils.info_utils - Unable to verify splits sizes.
Dataset json downloaded and prepared to datacache/trainpy.v2/json/default-471372bed4b51b53/0.0.0/c2d554c3377ea79c7664b93dc65d0803b45e3279000f993c7bfd18937fd7f426. Subsequent calls will reuse this data.
100%|█████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 53.54it/s]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.1
- Platform: Linux
- Python version: 3.8.10
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3447/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3447/timeline | null | completed | null | null | false | [
"Hi ! Indeed it says \"downloading and preparing\" but in your case it didn't need to download anything since you used local files (it would have thrown an error otherwise). I think we can improve the logging to make it clearer in this case",
"@lhoestq Thank you for explaining. I am sorry but I was not clear about my intention. I didn't want to kill internet traffic; I wanted to kill all write activity. In other words, you can imagine that my storage has only read access but crashes on write.\r\n\r\nWhen run_clm.py is invoked with the same parameters, the hash in the cache directory \"datacache/trainpy.v2/json/default-471372bed4b51b53/0.0.0/...\" doesn't change, and my job can load cached data properly. This is great.\r\n\r\nUnfortunately, when params change (which happens sometimes), the hash changes and the old cache is invalid. datasets builder would create a new cache directory with the new hash and create JSON builder there, even though every JSON builder is the same. I didn't find a way to avoid such behavior.\r\n\r\nThis problem can be resolved when using datasets.map() for tokenizing and grouping text. This function allows me to specify output filenames with --cache_file_names, so that the cached files are always valid.\r\n\r\nThis is the code that I used to freeze cache filenames for tokenization. I wish I could do the same to datasets.load_dataset()\r\n```\r\n tokenized_datasets = raw_datasets.map(\r\n tokenize_function,\r\n batched=True,\r\n num_proc=data_args.preprocessing_num_workers,\r\n remove_columns=column_names,\r\n load_from_cache_file=not data_args.overwrite_cache,\r\n desc=\"Running tokenizer on dataset\",\r\n cache_file_names={k: os.path.join(model_args.cache_dir, f'{k}-tokenized') for k in raw_datasets},\r\n )\r\n```",
"Hi ! `load_dataset` may re-generate your dataset if some parameters changed indeed. If you want to freeze a dataset loaded with `load_dataset`, I think the best solution is just to save it somewhere on your disk with `.save_to_disk(my_dataset_dir)` and reload it with `load_from_disk(my_dataset_dir)`. This way you will be able to reload the dataset without having to run `load_dataset`"
] |
https://api.github.com/repos/huggingface/datasets/issues/2645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2645/comments | https://api.github.com/repos/huggingface/datasets/issues/2645/events | https://github.com/huggingface/datasets/issues/2645 | 944,374,284 | MDU6SXNzdWU5NDQzNzQyODQ= | 2,645 | load_dataset processing failed with OS error after downloading a dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-07-14T12:23:53Z | 2021-07-15T09:34:02Z | 2021-07-15T09:34:02Z | null | ## Describe the bug
After downloading a dataset like opus100, there is a bug that
OSError: Cannot find data file.
Original error:
dlopen: cannot load any more object with static TLS
## Steps to reproduce the bug
```python
from datasets import load_dataset
this_dataset = load_dataset('opus100', 'af-en')
```
## Expected results
there is no error when running load_dataset.
## Actual results
Specify the actual results or traceback.
Traceback (most recent call last):
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 652, in _download_and_prep
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 989, in _prepare_split
example = self.info.features.encode_example(record)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/features.py", line 952, in encode_example
example = cast_to_python_objects(example)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/features.py", line 219, in cast_to_python_ob
return _cast_to_python_objects(obj)[0]
File "/home/anaconda3/lib/python3.6/site-packages/datasets/features.py", line 165, in _cast_to_python_o
import torch
File "/home/anaconda3/lib/python3.6/site-packages/torch/__init__.py", line 188, in <module>
_load_global_deps()
File "/home/anaconda3/lib/python3.6/site-packages/torch/__init__.py", line 141, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/home/anaconda3/lib/python3.6/ctypes/__init__.py", line 348, in __init__
self._handle = _dlopen(self._name, mode)
OSError: dlopen: cannot load any more object with static TLS
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "download_hub_opus100.py", line 9, in <module>
this_dataset = load_dataset('opus100', language_pair)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/load.py", line 748, in load_dataset
use_auth_token=use_auth_token,
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 575, in download_and_prepa
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 658, in _download_and_prep
+ str(e)
OSError: Cannot find data file.
Original error:
dlopen: cannot load any more object with static TLS
## Environment info
- `datasets` version: 1.8.0
- Platform: Linux-3.13.0-32-generic-x86_64-with-debian-jessie-sid
- Python version: 3.6.6
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2645/timeline | null | completed | null | null | false | [
"Hi ! It looks like an issue with pytorch.\r\n\r\nCould you try to run `import torch` and see if it raises an error ?",
"> Hi ! It looks like an issue with pytorch.\r\n> \r\n> Could you try to run `import torch` and see if it raises an error ?\r\n\r\nIt works. Thank you!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2928/comments | https://api.github.com/repos/huggingface/datasets/issues/2928/events | https://github.com/huggingface/datasets/pull/2928 | 997,941,506 | PR_kwDODunzps4r0yUb | 2,928 | Update BibTeX entry | [] | closed | false | null | 0 | 2021-09-16T08:39:20Z | 2021-09-16T12:35:34Z | 2021-09-16T12:35:34Z | null | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2928/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2928",
"merged_at": "2021-09-16T12:35:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2928"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5825 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5825/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5825/comments | https://api.github.com/repos/huggingface/datasets/issues/5825/events | https://github.com/huggingface/datasets/issues/5825 | 1,697,327,483 | I_kwDODunzps5lKyl7 | 5,825 | FileNotFound even though exists | [] | open | false | null | 3 | 2023-05-05T09:49:55Z | 2023-05-07T17:43:46Z | null | null | ### Describe the bug
I'm trying to download https://huggingface.co/datasets/bigscience/xP3/resolve/main/ur/xp3_facebook_flores_spa_Latn-urd_Arab_devtest_ab-spa_Latn-urd_Arab.jsonl which works fine in my webbrowser, but somehow not with datasets. Am I doing sth wrong?
```
Downloading builder script: 100%
2.82k/2.82k [00:00<00:00, 64.2kB/s]
Downloading readme: 100%
12.6k/12.6k [00:00<00:00, 585kB/s]
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
[<ipython-input-2-4b45446a91d5>](https://localhost:8080/#) in <cell line: 4>()
2 lang = "ur"
3 fname = "xp3_facebook_flores_spa_Latn-urd_Arab_devtest_ab-spa_Latn-urd_Arab.jsonl"
----> 4 dataset = load_dataset("bigscience/xP3", data_files=f"{lang}/{fname}")
6 frames
[/usr/local/lib/python3.10/dist-packages/datasets/data_files.py](https://localhost:8080/#) in _resolve_single_pattern_locally(base_path, pattern, allowed_extensions)
291 if allowed_extensions is not None:
292 error_msg += f" with any supported extension {list(allowed_extensions)}"
--> 293 raise FileNotFoundError(error_msg)
294 return sorted(out)
295
FileNotFoundError: Unable to find 'https://huggingface.co/datasets/bigscience/xP3/resolve/main/ur/xp3_facebook_flores_spa_Latn-urd_Arab_devtest_ab-spa_Latn-urd_Arab.jsonl' at /content/https:/huggingface.co/datasets/bigscience/xP3/resolve/main
```
### Steps to reproduce the bug
```
!pip install -q datasets
from datasets import load_dataset
lang = "ur"
fname = "xp3_facebook_flores_spa_Latn-urd_Arab_devtest_ab-spa_Latn-urd_Arab.jsonl"
dataset = load_dataset("bigscience/xP3", data_files=f"{lang}/{fname}")
```
### Expected behavior
Correctly downloads
### Environment info
latest versions | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5825/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5825/timeline | null | null | null | null | false | [
"Hi! \r\n\r\nThis would only work if `bigscience/xP3` was a no-code dataset, but it isn't (it has a Python builder script).\r\n\r\nBut this should work: \r\n```python\r\nload_dataset(\"json\", data_files=\"https://huggingface.co/datasets/bigscience/xP3/resolve/main/ur/xp3_facebook_flores_spa_Latn-urd_Arab_devtest_ab-spa_Latn-urd_Arab.jsonl\")\r\n```\r\n\r\n",
"I see, it's not compatible w/ regex right?\r\ne.g.\r\n`load_dataset(\"json\", data_files=\"https://huggingface.co/datasets/bigscience/xP3/resolve/main/ur/*\")`",
"> I see, it's not compatible w/ regex right? e.g. `load_dataset(\"json\", data_files=\"https://huggingface.co/datasets/bigscience/xP3/resolve/main/ur/*\")`\r\n\r\nIt should work for patterns that \"reference\" the local filesystem, but to make this work with the Hub, we must implement https://github.com/huggingface/datasets/issues/5281 first.\r\n\r\nIn the meantime, you can fetch these glob files with `HfFileSystem` and pass them as a list to `load_dataset`:\r\n```python\r\nfrom datasets import load_dataset\r\nfrom huggingface_hub import HfFileSystem, hf_hub_url # `HfFileSystem` requires the latest version of `huggingface_hub`\r\n\r\nfs = HfFileSystem()\r\nglob_files = fs.glob(\"datasets/bigscience/xP3/ur/*\")\r\n# convert fsspec URLs to HTTP URLs\r\nresolved_paths = [fs.resolve_path(file) for file in glob_files]\r\ndata_files = [hf_hub_url(resolved_path.repo_id, resolved_path.path_in_repo, repo_type=resolved_path.repo_type) for resolved_path in resolved_paths]\r\n\r\nds = load_dataset(\"json\", data_files=data_files)\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/3275 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3275/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3275/comments | https://api.github.com/repos/huggingface/datasets/issues/3275/events | https://github.com/huggingface/datasets/pull/3275 | 1,053,698,898 | PR_kwDODunzps4uiN9t | 3,275 | Force data files extraction if download_mode='force_redownload' | [] | closed | false | null | 0 | 2021-11-15T14:00:24Z | 2021-11-15T14:45:23Z | 2021-11-15T14:45:23Z | null | Avoids weird issues when redownloading a dataset due to cached data not being fully updated.
With this change, issues #3122 and https://github.com/huggingface/datasets/issues/2956 (not a fix, but a workaround) can be fixed as follows:
```python
dset = load_dataset(..., download_mode="force_redownload")
``` | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3275/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3275/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3275.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3275",
"merged_at": "2021-11-15T14:45:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3275.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3275"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2047/comments | https://api.github.com/repos/huggingface/datasets/issues/2047/events | https://github.com/huggingface/datasets/pull/2047 | 830,626,430 | MDExOlB1bGxSZXF1ZXN0NTkyMTI2NzQ3 | 2,047 | Multilingual dIalogAct benchMark (miam) | [] | closed | false | null | 4 | 2021-03-12T23:02:55Z | 2021-03-23T10:36:34Z | 2021-03-19T10:47:13Z | null | My collaborators (@EmileChapuis, @PierreColombo) and I within the Affective Computing team at Telecom Paris would like to anonymously publish the miam dataset. It is assocated with a publication currently under review. We will update the dataset with full citations once the review period is over. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2047/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2047",
"merged_at": "2021-03-19T10:47:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2047"
} | true | [
"Hello. All aforementioned changes have been made. I've also re-run black on miam.py. :-)",
"I will run isort again. Hopefully it resolves the current check_code_quality test failure.",
"Once the review period is over, feel free to open a PR to add all the missing information ;)",
"Hi! I will follow up right now with one more pull request as I have new anonymous citation information to include."
] |
https://api.github.com/repos/huggingface/datasets/issues/630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/630/comments | https://api.github.com/repos/huggingface/datasets/issues/630/events | https://github.com/huggingface/datasets/issues/630 | 701,636,350 | MDU6SXNzdWU3MDE2MzYzNTA= | 630 | Text dataset not working with large files | [] | closed | false | null | 11 | 2020-09-15T06:02:36Z | 2020-09-25T22:21:43Z | 2020-09-25T22:21:43Z | null | ```
Traceback (most recent call last):
File "examples/language-modeling/run_language_modeling.py", line 333, in <module>
main()
File "examples/language-modeling/run_language_modeling.py", line 262, in main
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
File "examples/language-modeling/run_language_modeling.py", line 144, in get_dataset
dataset = load_dataset("text", data_files=file_path, split='train+test')
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/load.py", line 611, in load_dataset
ignore_verifications=ignore_verifications,
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/builder.py", line 469, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/builder.py", line 546, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/ksjae/.local/lib/python3.7/site-packages/datasets/builder.py", line 888, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/home/ksjae/.local/lib/python3.7/site-packages/tqdm/std.py", line 1129, in __iter__
for obj in iterable:
File "/home/ksjae/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.py", line 104, in _generate_tables
convert_options=self.config.convert_options,
File "pyarrow/_csv.pyx", line 714, in pyarrow._csv.read_csv
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
```
**pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries (try to increase block size?)**
It gives the same message for both 200MB, 10GB .tx files but not for 700MB file.
Can't upload due to size & copyright problem. sorry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/630/timeline | null | completed | null | null | false | [
"Seems like it works when setting ```block_size=2100000000``` or something arbitrarily large though.",
"Can you give us some stats on the data files you use as inputs?",
"Basically ~600MB txt files(UTF-8) * 59. \r\ncontents like ```안녕하세요, 이것은 예제로 한번 말해보는 텍스트입니다. 그냥 이렇다고요.<|endoftext|>\\n```\r\n\r\nAlso, it gets stuck for a loooong time at ```Testing the mapped function outputs```, for more than 12 hours(currently ongoing)",
"It gets stuck while doing `.map()` ? Are you using multiprocessing ?\r\nIf you could provide a code snippet it could be very useful",
"From transformers/examples/language-modeling/run-language-modeling.py :\r\n```\r\ndef get_dataset(\r\n args: DataTrainingArguments,\r\n tokenizer: PreTrainedTokenizer,\r\n evaluate: bool = False,\r\n cache_dir: Optional[str] = None,\r\n):\r\n file_path = args.eval_data_file if evaluate else args.train_data_file\r\n if True:\r\n dataset = load_dataset(\"text\", data_files=glob.glob(file_path), split='train', use_threads=True, \r\n ignore_verifications=True, save_infos=True, block_size=104857600)\r\n dataset = dataset.map(lambda ex: tokenizer(ex[\"text\"], add_special_tokens=True,\r\n truncation=True, max_length=args.block_size), batched=True)\r\n dataset.set_format(type='torch', columns=['input_ids'])\r\n return dataset\r\n if args.line_by_line:\r\n return LineByLineTextDataset(tokenizer=tokenizer, file_path=file_path, block_size=args.block_size)\r\n else:\r\n return TextDataset(\r\n tokenizer=tokenizer,\r\n file_path=file_path,\r\n block_size=args.block_size,\r\n overwrite_cache=args.overwrite_cache,\r\n cache_dir=cache_dir,\r\n )\r\n```\r\n\r\nNo, I'm not using multiprocessing.",
"I am not able to reproduce on my side :/\r\n\r\nCould you send the version of `datasets` and `pyarrow` you're using ?\r\nCould you try to update the lib and try again ?\r\nOr do you think you could try to reproduce it on google colab ?",
"Huh, weird. It's fixed on my side too.\r\nBut now ```Caching processed dataset``` is taking forever - how can I disable it? Any flags?",
"Right after `Caching processed dataset`, your function is applied to the dataset and there's a progress bar that shows how much time is left. How much time does it take for you ?\r\n\r\nAlso caching isn't supposed to slow down your processing. But if you still want to disable it you can do `.map(..., load_from_cache_file=False)`",
"Ah, it’s much faster now(Takes around 15~20min). \r\nBTW, any way to set default tensor output as plain tensors with distributed training? The ragged tensors are incompatible with tpustrategy :(",
"> Ah, it’s much faster now(Takes around 15~20min).\r\n\r\nGlad to see that it's faster now. What did you change exactly ?\r\n\r\n> BTW, any way to set default tensor output as plain tensors with distributed training? The ragged tensors are incompatible with tpustrategy :(\r\n\r\nOh I didn't know about that. Feel free to open an issue to mention that.\r\nI guess what you can do for now is set the dataset format to numpy instead of tensorflow, and use a wrapper of the dataset that converts the numpy arrays to tf tensors.\r\n\r\n",
">>> Glad to see that it's faster now. What did you change exactly ?\r\nI don't know, it just worked...? Sorry I couldn't be more helpful.\r\n\r\nSetting with numpy array is a great idea! Thanks."
] |
https://api.github.com/repos/huggingface/datasets/issues/1983 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1983/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1983/comments | https://api.github.com/repos/huggingface/datasets/issues/1983/events | https://github.com/huggingface/datasets/issues/1983 | 821,746,008 | MDU6SXNzdWU4MjE3NDYwMDg= | 1,983 | The size of CoNLL-2003 is not consistant with the official release. | [] | closed | false | null | 4 | 2021-03-04T04:41:34Z | 2022-10-05T13:13:26Z | 2022-10-05T13:13:26Z | null | Thanks for the dataset sharing! But when I use conll-2003, I meet some questions.
The statistics of conll-2003 in this repo is :
\#train 14041 \#dev 3250 \#test 3453
While the official statistics is:
\#train 14987 \#dev 3466 \#test 3684
Wish for your reply~ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1983/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1983/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nif you inspect the raw data, you can find there are 946 occurrences of `-DOCSTART- -X- -X- O` in the train split and `14041 + 946 = 14987`, which is exactly the number of sentences the authors report. `-DOCSTART-` is a special line that acts as a boundary between two different documents and is filtered out in our implementation.\r\n\r\n@lhoestq What do you think about including these lines? ([Link](https://github.com/flairNLP/flair/issues/1097) to a similar issue in the flairNLP repo)",
"We should mention in the Conll2003 dataset card that these lines have been removed indeed.\r\n\r\nIf some users are interested in using these lines (maybe to recombine documents ?) then we can add a parameter to the conll2003 dataset to include them.\r\n\r\nBut IMO the default config should stay the current one (without the `-DOCSTART-` stuff), so that you can directly train NER models without additional preprocessing. Let me know what you think",
"@lhoestq Yes, I agree adding a small note should be sufficient.\r\n\r\nCurrently, NLTK's `ConllCorpusReader` ignores the `-DOCSTART-` lines so I think it's ok if we do the same. If there is an interest in the future to use these lines, then we can include them.",
"I added a mention of this in conll2003's dataset card:\r\nhttps://github.com/huggingface/datasets/blob/fc9796920da88486c3b97690969aabf03d6b4088/datasets/conll2003/README.md#conll2003\r\n\r\nEdit: just saw your PR @mariosasko (noticed it too late ^^)\r\nLet me take a look at it :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5894 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5894/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5894/comments | https://api.github.com/repos/huggingface/datasets/issues/5894/events | https://github.com/huggingface/datasets/pull/5894 | 1,724,774,910 | PR_kwDODunzps5RSjot | 5,894 | Force overwrite existing filesystem protocol | [] | closed | false | null | 2 | 2023-05-24T21:41:53Z | 2023-05-25T06:52:08Z | 2023-05-25T06:42:33Z | null | Fix #5876 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5894/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5894/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5894.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5894",
"merged_at": "2023-05-25T06:42:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5894.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5894"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009139 / 0.011353 (-0.002214) | 0.005634 / 0.011008 (-0.005374) | 0.129587 / 0.038508 (0.091079) | 0.038298 / 0.023109 (0.015189) | 0.428149 / 0.275898 (0.152251) | 0.443744 / 0.323480 (0.120264) | 0.007501 / 0.007986 (-0.000485) | 0.005999 / 0.004328 (0.001671) | 0.100796 / 0.004250 (0.096546) | 0.053236 / 0.037052 (0.016184) | 0.423868 / 0.258489 (0.165379) | 0.460110 / 0.293841 (0.166269) | 0.041255 / 0.128546 (-0.087291) | 0.013790 / 0.075646 (-0.061856) | 0.438398 / 0.419271 (0.019127) | 0.063086 / 0.043533 (0.019553) | 0.414826 / 0.255139 (0.159687) | 0.460652 / 0.283200 (0.177453) | 0.121223 / 0.141683 (-0.020460) | 1.754430 / 1.452155 (0.302275) | 1.900037 / 1.492716 (0.407320) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.027222 / 0.018006 (0.009216) | 0.617666 / 0.000490 (0.617176) | 0.022443 / 0.000200 (0.022243) | 0.000820 / 0.000054 (0.000766) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.030397 / 0.037411 (-0.007014) | 0.125732 / 0.014526 (0.111206) | 0.149805 / 0.176557 (-0.026752) | 0.234048 / 0.737135 (-0.503087) | 0.143108 / 0.296338 (-0.153231) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.631189 / 0.215209 (0.415980) | 6.182871 / 2.077655 (4.105216) | 2.635730 / 1.504120 (1.131610) | 2.231429 / 1.541195 (0.690235) | 2.438360 / 1.468490 (0.969870) | 0.861170 / 4.584777 (-3.723607) | 5.785984 / 3.745712 (2.040272) | 2.758358 / 5.269862 (-2.511504) | 1.678095 / 4.565676 (-2.887582) | 0.105961 / 0.424275 (-0.318314) | 0.013659 / 0.007607 (0.006052) | 0.762943 / 0.226044 (0.536898) | 7.774399 / 2.268929 (5.505471) | 3.319027 / 55.444624 (-52.125598) | 2.700248 / 6.876477 (-4.176229) | 3.008581 / 2.142072 (0.866509) | 1.122522 / 4.805227 (-3.682705) | 0.214832 / 6.500664 (-6.285832) | 0.085281 / 0.075469 (0.009811) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.647610 / 1.841788 (-0.194177) | 18.178316 / 8.074308 (10.104008) | 21.199177 / 10.191392 (11.007785) | 0.247063 / 0.680424 (-0.433361) | 0.030443 / 0.534201 (-0.503758) | 0.512527 / 0.579283 (-0.066757) | 0.640758 / 0.434364 (0.206394) | 0.639986 / 0.540337 (0.099649) | 0.760113 / 1.386936 (-0.626823) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008293 / 0.011353 (-0.003060) | 0.005360 / 0.011008 (-0.005648) | 0.102932 / 0.038508 (0.064424) | 0.037457 / 0.023109 (0.014347) | 0.444114 / 0.275898 (0.168216) | 0.512855 / 0.323480 (0.189375) | 0.007030 / 0.007986 (-0.000956) | 0.004954 / 0.004328 (0.000625) | 0.095757 / 0.004250 (0.091507) | 0.051239 / 0.037052 (0.014187) | 0.471118 / 0.258489 (0.212629) | 0.517764 / 0.293841 (0.223923) | 0.041953 / 0.128546 (-0.086593) | 0.013748 / 0.075646 (-0.061898) | 0.118089 / 0.419271 (-0.301182) | 0.060159 / 0.043533 (0.016626) | 0.466011 / 0.255139 (0.210872) | 0.489180 / 0.283200 (0.205980) | 0.123250 / 0.141683 (-0.018433) | 1.714738 / 1.452155 (0.262584) | 1.838571 / 1.492716 (0.345855) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.267792 / 0.018006 (0.249785) | 0.624313 / 0.000490 (0.623824) | 0.007315 / 0.000200 (0.007115) | 0.000136 / 0.000054 (0.000082) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033751 / 0.037411 (-0.003661) | 0.122819 / 0.014526 (0.108293) | 0.148270 / 0.176557 (-0.028286) | 0.198581 / 0.737135 (-0.538554) | 0.144845 / 0.296338 (-0.151494) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.620631 / 0.215209 (0.405422) | 6.224665 / 2.077655 (4.147010) | 2.856592 / 1.504120 (1.352473) | 2.525089 / 1.541195 (0.983894) | 2.600198 / 1.468490 (1.131708) | 0.872038 / 4.584777 (-3.712739) | 5.571650 / 3.745712 (1.825937) | 5.907643 / 5.269862 (0.637782) | 2.348770 / 4.565676 (-2.216906) | 0.111665 / 0.424275 (-0.312610) | 0.013886 / 0.007607 (0.006278) | 0.762154 / 0.226044 (0.536109) | 7.792686 / 2.268929 (5.523758) | 3.601122 / 55.444624 (-51.843503) | 2.939412 / 6.876477 (-3.937064) | 2.973430 / 2.142072 (0.831358) | 1.065016 / 4.805227 (-3.740211) | 0.221701 / 6.500664 (-6.278963) | 0.088157 / 0.075469 (0.012688) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.771061 / 1.841788 (-0.070727) | 18.826926 / 8.074308 (10.752618) | 21.283830 / 10.191392 (11.092438) | 0.239233 / 0.680424 (-0.441191) | 0.026159 / 0.534201 (-0.508042) | 0.487074 / 0.579283 (-0.092209) | 0.623241 / 0.434364 (0.188877) | 0.600506 / 0.540337 (0.060169) | 0.691271 / 1.386936 (-0.695665) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",
"default": false,
"description": "Vision datasets",
"id": 3608941089,
"name": "vision",
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision"
}
] | open | false | null | 5 | 2022-01-16T21:42:25Z | 2022-03-18T10:44:42Z | null | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:** [link to the dataset paper if available](https://arxiv.org/abs/2106.05735)
- **Data:** http://medicaldecathlon.com/
- **Motivation:** Hugging Face seeks to democratize ML for society. One of the growing niches within ML is the ML + Medicine community. Key data sets will help increase the supply of HF resources for starting an initial community.
(cc @osanseviero @abidlabs )
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | null | null | false | [
"Hello! I have recently been involved with a medical image segmentation project myself and was going through the `The Medical Segmentation Decathlon Dataset` as well. \r\nI haven't yet had experience adding datasets to this repository yet but would love to get started. Should I take this issue?\r\nIf yes, I've got two questions -\r\n1. There are 10 different datasets available, so are all datasets to be added in a single PR, or one at a time? \r\n2. Since it's a competition, masks for the test-set are not available. How is that to be tackled? Sorry if it's a silly question, I have recently started exploring `datasets`.",
"Hi! Sure, feel free to take this issue. You can self-assign the issue by commenting `#self-assign`.\r\n\r\nTo answer your questions:\r\n1. It makes the most sense to add each one as a separate config, so one dataset script with 10 configs in a single PR.\r\n2. Just set masks in the test set to `None`.\r\n\r\nNote that the images/masks in this dataset are in NIfTI format, which our `Image` feature currently doesn't support, so I think it's best to yield the paths to the images/masks in the script and add a preprocessing section to the card where we explain how to load/process the images/masks with `nibabel` (I can help with that). \r\n\r\n",
"> Note that the images/masks in this dataset are in NIfTI format, which our `Image` feature currently doesn't support, so I think it's best to yield the paths to the images/masks in the script and add a preprocessing section to the card where we explain how to load/process the images/masks with `nibabel` (I can help with that).\r\n\r\nGotcha, thanks. Will start working on the issue and let you know in case of any doubt.",
"#self-assign",
"This is great! There is a first model on the HUb that uses this dataset! https://huggingface.co/MONAI/example_spleen_segmentation"
] |
https://api.github.com/repos/huggingface/datasets/issues/817 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/817/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/817/comments | https://api.github.com/repos/huggingface/datasets/issues/817/events | https://github.com/huggingface/datasets/issues/817 | 739,145,369 | MDU6SXNzdWU3MzkxNDUzNjk= | 817 | Add MRQA dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2020-11-09T15:52:19Z | 2020-12-04T15:44:42Z | 2020-12-04T15:44:41Z | null | ## Adding a Dataset
- **Name:** MRQA
- **Description:** Collection of different (subsets of) QA datasets all converted to the same format to evaluate out-of-domain generalization (the datasets come from different domains, distributions, etc.). Some datasets are used for training and others are used for evaluation. This dataset was collected as part of MRQA 2019's shared task
- **Paper:** https://arxiv.org/abs/1910.09753
- **Data:** https://github.com/mrqa/MRQA-Shared-Task-2019
- **Motivation:** Out-of-domain generalization is becoming (has become) a de-factor evaluation for NLU systems
Instructions to add a new dataset can be found [here](https://huggingface.co/docs/datasets/share_dataset.html). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/817/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/817/timeline | null | completed | null | null | false | [
"Done! cf #1117 and #1022"
] |
https://api.github.com/repos/huggingface/datasets/issues/915 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/915/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/915/comments | https://api.github.com/repos/huggingface/datasets/issues/915/events | https://github.com/huggingface/datasets/issues/915 | 753,118,481 | MDU6SXNzdWU3NTMxMTg0ODE= | 915 | Shall we change the hashing to encoding to reduce potential replicated cache files? | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | open | false | null | 2 | 2020-11-30T03:50:46Z | 2020-12-24T05:11:49Z | null | null | Hi there. For now, we are using `xxhash` to hash the transformations to fingerprint and we will save a copy of the processed dataset to disk if there is a new hash value. However, there are some transformations that are idempotent or commutative to each other. I think that encoding the transformation chain as the fingerprint may help in those cases, for example, use `base64.urlsafe_b64encode`. In this way, before we want to save a new copy, we can decode the transformation chain and normalize it to prevent omit potential reuse. As the main targets of this project are the really large datasets that cannot be loaded entirely in memory, I believe it would save a lot of time if we can avoid some write.
If you have interest in this, I'd love to help :). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/915/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/915/timeline | null | null | null | null | false | [
"This is an interesting idea !\r\nDo you have ideas about how to approach the decoding and the normalization ?",
"@lhoestq\r\nI think we first need to save the transformation chain to a list in `self._fingerprint`. Then we can\r\n- decode all the current saved datasets to see if there is already one that is equivalent to the transformation we need now.\r\n- or, calculate all the possible hash value of the current chain for comparison so that we could continue to use hashing.\r\nIf we find one, we can adjust the list in `self._fingerprint` to it.\r\n\r\nAs for the transformation reordering rules, we can just start with some manual rules, like two sort on the same column should merge to one, filter and select can change orders.\r\n\r\nAnd for encoding and decoding, we can just manually specify `sort` is 0, `shuffling` is 2 and create a base-n number or use some general algorithm like `base64.urlsafe_b64encode`.\r\n\r\nBecause we are not doing lazy evaluation now, we may not be able to normalize the transformation to its minimal form. If we want to support that, we can provde a `Sequential` api and let user input a list or transformation, so that user would not use the intermediate datasets. This would look like tf.data.Dataset."
] |
https://api.github.com/repos/huggingface/datasets/issues/4327 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4327/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4327/comments | https://api.github.com/repos/huggingface/datasets/issues/4327/events | https://github.com/huggingface/datasets/issues/4327 | 1,233,840,020 | I_kwDODunzps5JiueU | 4,327 | `wikipedia` pre-processed datasets | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-05-12T11:25:42Z | 2022-08-31T08:26:57Z | 2022-08-31T08:26:57Z | null | ## Describe the bug
[Wikipedia](https://huggingface.co/datasets/wikipedia) dataset readme says that certain subsets are preprocessed. However it seems like they are not available. When I try to load them it takes a really long time, and it seems like it's processing them.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("wikipedia", "20220301.en")
```
## Expected results
To load the dataset
## Actual results
Takes a very long time to load (after downloading)
After `Downloading data files: 100%`. It takes hours and gets killed.
Tried `wikipedia.simple` and it got processed after ~30mins. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4327/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4327/timeline | null | completed | null | null | false | [
"Hi @vpj, thanks for reporting.\r\n\r\nI'm sorry, but I can't reproduce your bug: I load \"20220301.simple\"in 9 seconds:\r\n```shell\r\ntime python -c \"from datasets import load_dataset; load_dataset('wikipedia', '20220301.simple')\"\r\n\r\nDownloading and preparing dataset wikipedia/20220301.simple (download: 228.58 MiB, generated: 224.18 MiB, post-processed: Unknown size, total: 452.76 MiB) to .../.cache/huggingface/datasets/wikipedia/20220301.simple/2.0.0/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559...\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.66k/1.66k [00:00<00:00, 1.02MB/s]\r\nDownloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 235M/235M [00:02<00:00, 82.8MB/s]\r\nDataset wikipedia downloaded and prepared to .../.cache/huggingface/datasets/wikipedia/20220301.simple/2.0.0/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 290.75it/s]\r\n\r\nreal\t0m9.693s\r\nuser\t0m6.002s\r\nsys\t0m3.260s\r\n```\r\n\r\nCould you please check your environment info, as requested when opening this issue?\r\n```\r\n## Environment info\r\n<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->\r\n- `datasets` version:\r\n- Platform:\r\n- Python version:\r\n- PyArrow version:\r\n```\r\nMaybe you are using an old version of `datasets`...",
"Downloading and processing `wikipedia simple` dataset completed in under 11sec on M1 Mac. Could you please check `dataset` version as mentioned by @albertvillanova? Also check system specs, if system is under load processing could take some time I guess."
] |
https://api.github.com/repos/huggingface/datasets/issues/1707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1707/comments | https://api.github.com/repos/huggingface/datasets/issues/1707/events | https://github.com/huggingface/datasets/pull/1707 | 781,507,545 | MDExOlB1bGxSZXF1ZXN0NTUxMjE5MDk2 | 1,707 | Added generated READMEs for datasets that were missing one. | [] | closed | false | null | 1 | 2021-01-07T18:10:06Z | 2021-01-18T14:32:33Z | 2021-01-18T14:32:33Z | null | This is it: we worked on a generator with Yacine @yjernite , and we generated dataset cards for all missing ones (161), with all the information we could gather from datasets repository, and using dummy_data to generate examples when possible.
Code is available here for the moment: https://github.com/madlag/datasets_readme_generator .
We will move it to a Hugging Face repository and to https://huggingface.co/datasets/card-creator/ later.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1707/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1707.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1707",
"merged_at": "2021-01-18T14:32:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1707.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1707"
} | true | [
"Looks like we need to trim the ones with too many configs, will look into it tomorrow!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3951 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3951/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3951/comments | https://api.github.com/repos/huggingface/datasets/issues/3951/events | https://github.com/huggingface/datasets/issues/3951 | 1,171,568,814 | I_kwDODunzps5F1Liu | 3,951 | Forked streaming datasets try to `open` data urls rather than use network | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-03-16T21:21:02Z | 2022-06-10T20:47:26Z | 2022-06-10T20:47:26Z | null | ## Describe the bug
Building on #3950, if you bypass the pickling problem you still can't use the dataset. Somehow something gets confused and the forked processes try to `open` urls rather than anything else.
## Steps to reproduce the bug
```python
from multiprocessing import freeze_support
import transformers
from transformers import Trainer, AutoModelForCausalLM, TrainingArguments
import datasets
import torch.utils.data
# work around #3950
class TorchIterableDataset(datasets.IterableDataset, torch.utils.data.IterableDataset):
pass
def _ensure_format(v: datasets.IterableDataset) -> datasets.IterableDataset:
return TorchIterableDataset(v._ex_iterable, v.info, v.split, "torch", v._shuffling)
if __name__ == '__main__':
freeze_support()
ds = datasets.load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True)
ds = _ensure_format(ds)
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
Trainer(model, train_dataset=ds, args=TrainingArguments("out", max_steps=1000, dataloader_num_workers=4)).train()
```
## Expected results
I'd expect the dataset to load the url correctly and produce examples.
## Actual results
```
warnings.warn(
***** Running training *****
Num examples = 8000
Num Epochs = 9223372036854775807
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 1000
0%| | 0/1000 [00:00<?, ?it/s]Traceback (most recent call last):
File "/Users/dlwh/src/mistral/src/stream_fork_crash.py", line 22, in <module>
Trainer(model, train_dataset=ds, args=TrainingArguments("out", max_steps=1000, dataloader_num_workers=4)).train()
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/transformers/trainer.py", line 1339, in train
for step, inputs in enumerate(epoch_iterator):
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 521, in __next__
data = self._next_data()
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1203, in _next_data
return self._process_data(data)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 1229, in _process_data
data.reraise()
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/_utils.py", line 434, in reraise
raise exception
FileNotFoundError: Caught FileNotFoundError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/_utils/worker.py", line 287, in _worker_loop
data = fetcher.fetch(index)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/_utils/fetch.py", line 32, in fetch
data.append(next(self.dataset_iter))
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 497, in __iter__
for key, example in self._iter():
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 494, in _iter
yield from ex_iterable
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/datasets/iterable_dataset.py", line 87, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/Users/dlwh/.cache/huggingface/modules/datasets_modules/datasets/oscar/84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2/oscar.py", line 358, in _generate_examples
with gzip.open(open(filepath, "rb"), "rt", encoding="utf-8") as f:
FileNotFoundError: [Errno 2] No such file or directory: 'https://s3.amazonaws.com/datasets.huggingface.co/oscar/1.0/unshuffled/deduplicated/en/en_part_1.txt.gz'
Error in atexit._run_exitfuncs:
Traceback (most recent call last):
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/multiprocessing/popen_fork.py", line 27, in poll
pid, sts = os.waitpid(self.pid, flag)
File "/Users/dlwh/.conda/envs/mistral/lib/python3.8/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 6932) is killed by signal: Terminated: 15.
0%| | 0/1000 [00:02<?, ?it/s]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.0.0
- Platform: macOS-12.2-arm64-arm-64bit
- Python version: 3.8.12
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3951/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3951/timeline | null | completed | null | null | false | [
"Thanks for reporting this second issue as well. We definitely want to make streaming datasets fully working in a distributed setup and with the best performance. Right now it only supports single process.\r\n\r\nIn this issue it seems that the streaming capabilities that we offer to dataset builders are not transferred to the forked process (so it fails to open remote files and start streaming data from them). In particular `open` is supposed to be mocked by our `xopen` function that is an extended open that supports remote files. Let me try to fix this"
] |
https://api.github.com/repos/huggingface/datasets/issues/3007 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3007/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3007/comments | https://api.github.com/repos/huggingface/datasets/issues/3007/events | https://github.com/huggingface/datasets/pull/3007 | 1,014,775,450 | PR_kwDODunzps4sns-n | 3,007 | Correct a typo | [] | closed | false | null | 0 | 2021-10-04T06:15:47Z | 2021-10-04T09:27:57Z | 2021-10-04T09:27:57Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3007/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3007/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3007.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3007",
"merged_at": "2021-10-04T09:27:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3007.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3007"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4560/comments | https://api.github.com/repos/huggingface/datasets/issues/4560/events | https://github.com/huggingface/datasets/pull/4560 | 1,283,558,873 | PR_kwDODunzps46TY9n | 4,560 | Add evaluation metadata to imagenet-1k | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 2 | 2022-06-24T10:12:41Z | 2022-09-23T09:39:53Z | 2022-09-23T09:37:03Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4560/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4560/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4560.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4560",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4560.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4560"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"As discussed with @lewtun, we are closing this PR, because it requires first the task names to be aligned between AutoTrain and datasets."
] |
https://api.github.com/repos/huggingface/datasets/issues/2282 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2282/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2282/comments | https://api.github.com/repos/huggingface/datasets/issues/2282/events | https://github.com/huggingface/datasets/pull/2282 | 870,900,332 | MDExOlB1bGxSZXF1ZXN0NjI2MDEyMzM3 | 2,282 | Initialize imdb dataset from don't stop pretraining paper | [] | closed | false | null | 0 | 2021-04-29T11:17:56Z | 2021-04-29T11:43:51Z | 2021-04-29T11:43:51Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2282/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2282/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2282.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2282",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2282.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2282"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/4981 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4981/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4981/comments | https://api.github.com/repos/huggingface/datasets/issues/4981/events | https://github.com/huggingface/datasets/issues/4981 | 1,375,086,773 | I_kwDODunzps5R9ii1 | 4,981 | Can't create a dataset with `float16` features | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 7 | 2022-09-15T21:03:24Z | 2023-03-22T21:40:09Z | null | null | ## Describe the bug
I can't create a dataset with `float16` features.
I understand from the traceback that this is a `pyarrow` error, but I don't see anywhere in the `datasets` documentation about how to successfully do this. Is it actually supported? I've tried older versions of `pyarrow` as well with the same exact error.
The bug seems to arise from `datasets` casting the values to `double` and then `pyarrow` doesn't know how to convert those back to `float16`... does that sound right? Is there a way to bypass this since it's not necessary in the `numpy` and `torch` cases?
Thanks!
## Steps to reproduce the bug
All of the following raise the following error with the same exact (as far as I can tell) traceback:
```python
ArrowNotImplementedError: Unsupported cast from double to halffloat using function cast_half_float
```
```python
from datasets import Dataset, Features, Value
Dataset.from_dict({"x": [0.0, 1.0, 2.0]}, features=Features(x=Value("float16")))
import numpy as np
Dataset.from_dict({"x": np.arange(3, dtype=np.float16)}, features=Features(x=Value("float16")))
import torch
Dataset.from_dict({"x": torch.arange(3).to(torch.float16)}, features=Features(x=Value("float16")))
```
## Expected results
A dataset with `float16` features is successfully created.
## Actual results
```python
---------------------------------------------------------------------------
ArrowNotImplementedError Traceback (most recent call last)
Cell In [14], line 1
----> 1 Dataset.from_dict({"x": [1.0, 2.0, 3.0]}, features=Features(x=Value("float16")))
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/arrow_dataset.py:870, in Dataset.from_dict(cls, mapping, features, info, split)
865 mapping = features.encode_batch(mapping)
866 mapping = {
867 col: OptimizedTypedSequence(data, type=features[col] if features is not None else None, col=col)
868 for col, data in mapping.items()
869 }
--> 870 pa_table = InMemoryTable.from_pydict(mapping=mapping)
871 if info.features is None:
872 info.features = Features({col: ts.get_inferred_type() for col, ts in mapping.items()})
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/table.py:750, in InMemoryTable.from_pydict(cls, *args, **kwargs)
734 @classmethod
735 def from_pydict(cls, *args, **kwargs):
736 """
737 Construct a Table from Arrow arrays or columns
738
(...)
748 :class:`datasets.table.Table`:
749 """
--> 750 return cls(pa.Table.from_pydict(*args, **kwargs))
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/table.pxi:3648, in pyarrow.lib.Table.from_pydict()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/table.pxi:5174, in pyarrow.lib._from_pydict()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/array.pxi:343, in pyarrow.lib.asarray()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/array.pxi:231, in pyarrow.lib.array()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/array.pxi:110, in pyarrow.lib._handle_arrow_array_protocol()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py:197, in TypedSequence.__arrow_array__(self, type)
192 # otherwise we can finally use the user's type
193 elif type is not None:
194 # We use cast_array_to_feature to support casting to custom types like Audio and Image
195 # Also, when trying type "string", we don't want to convert integers or floats to "string".
196 # We only do it if trying_type is False - since this is what the user asks for.
--> 197 out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
198 return out
199 except (TypeError, pa.lib.ArrowInvalid) as e: # handle type errors and overflows
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/table.py:1683, in _wrap_for_chunked_arrays.<locals>.wrapper(array, *args, **kwargs)
1681 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
1682 else:
-> 1683 return func(array, *args, **kwargs)
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/table.py:1853, in cast_array_to_feature(array, feature, allow_number_to_str)
1851 return array_cast(array, get_nested_type(feature), allow_number_to_str=allow_number_to_str)
1852 elif not isinstance(feature, (Sequence, dict, list, tuple)):
-> 1853 return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
1854 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{feature}")
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/table.py:1683, in _wrap_for_chunked_arrays.<locals>.wrapper(array, *args, **kwargs)
1681 return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
1682 else:
-> 1683 return func(array, *args, **kwargs)
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/datasets/table.py:1762, in array_cast(array, pa_type, allow_number_to_str)
1760 if pa.types.is_null(pa_type) and not pa.types.is_null(array.type):
1761 raise TypeError(f"Couldn't cast array of type {array.type} to {pa_type}")
-> 1762 return array.cast(pa_type)
1763 raise TypeError(f"Couldn't cast array of type\n{array.type}\nto\n{pa_type}")
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/array.pxi:919, in pyarrow.lib.Array.cast()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/compute.py:389, in cast(arr, target_type, safe, options)
387 else:
388 options = CastOptions.safe(target_type)
--> 389 return call_function("cast", [arr], options)
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/_compute.pyx:560, in pyarrow._compute.call_function()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/_compute.pyx:355, in pyarrow._compute.Function.call()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/error.pxi:144, in pyarrow.lib.pyarrow_internal_check_status()
File ~/scratch/scratch-env-39/.venv/lib/python3.9/site-packages/pyarrow/error.pxi:121, in pyarrow.lib.check_status()
ArrowNotImplementedError: Unsupported cast from double to halffloat using function cast_half_float
```
## Environment info
- `datasets` version: 2.4.0
- Platform: macOS-12.5.1-arm64-arm-64bit
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.4
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4981/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4981/timeline | null | null | null | null | false | [
"Hi @dconathan, thanks for reporting.\r\n\r\nWe rely on Arrow as a backend, and as far as I know currently support for `float16` in Arrow is not fully implemented in Python (C++), hence the `ArrowNotImplementedError` you get.\r\n\r\nSee, e.g.: https://arrow.apache.org/docs/status.html?highlight=float16#data-types",
"Thanks for the link…. didn’t realize arrow didn’t support it yet. Should it be removed from https://huggingface.co/docs/datasets/v2.4.0/en/package_reference/main_classes#datasets.Value until Arrow supports it?",
"Yes, you are right: maybe we should either remove it from our docs or add a comment explaining the issue.\r\n\r\nThe thing is that in Arrow it is partially supported: you can create `float16` values, but you can't cast them from/to other types. And current implementation of `Value` always tries to perform a cast from `float64` to `float16`.",
"Maybe we can just add a note in the `Value` documentation ?",
"Would you accept a PR to fix this? @lhoestq Do you have an idea of how hard it would be to fix?",
"I think the issue comes mostly from pyarrow not supporting `float16` completely.\r\n\r\nFor example you stil can't cast from/to `float16`\r\n```python\r\nimport numpy as np\r\nimport pyarrow as pa\r\n\r\npa.array(range(5)).cast(pa.float16())\r\n# ArrowNotImplementedError: Unsupported cast from int64 to halffloat using function cast_half_float\r\npa.array(range(5), pa.float32()).cast(pa.float16())\r\n# ArrowNotImplementedError: Unsupported cast from float to halffloat using function cast_half_float\r\npa.array(range(5), pa.float16())\r\n# ArrowTypeError: Expected np.float16 instance\r\npa.array(np.arange(5, dtype=np.float16())).cast(pa.float32())\r\n# ArrowNotImplementedError: Unsupported cast from halffloat to float using function cast_float\r\n```",
"Hmm it seems like we can either:\r\n1. try to fix pyarrow upstream\r\n2. half-support float16 with some workaround to make sure we don't ever do casting internally\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/3888 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3888/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3888/comments | https://api.github.com/repos/huggingface/datasets/issues/3888/events | https://github.com/huggingface/datasets/issues/3888 | 1,165,435,529 | I_kwDODunzps5FdyKJ | 3,888 | IterableDataset columns and feature types | [
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
},
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | open | false | null | 8 | 2022-03-10T16:19:12Z | 2022-11-29T11:39:24Z | null | null | Right now, an IterableDataset (e.g. when streaming a dataset) doesn't require to know the list of columns it contains, nor their types: `my_iterable_dataset.features` may be `None`
However it's often interesting to know the column types and types. This helps knowing what's inside your dataset without having to manually check a few examples, and this is useful to prepare a processing pipeline or to train models.
Here are a few cases that lead to `features` being `None`:
1. when loading a dataset with `load_dataset` on CSV, JSON Lines, etc. files: type inference is only done when iterating over the dataset
2. when calling `map`, because we don't know in advance what's the output of the user's function passed to `map`
3. when calling `rename_columns`, `remove_columns`, etc. because they rely on `map`
Things we can consider, for each point above:
1.a infer the type automatically from the first samples on the dataset using prefetching, when the dataset builder doesn't provide the `features`
2.a allow the user to specify the `features` as an argument to `map` (this would be consistent with the non-streaming API)
2.b prefetch the first output value to infer the type
3.a don't rely on `map` directly and reuse the previous `features` and rename/remove the corresponding ones
The thing is that prefetching can take a few seconds, while the operations above are instantaneous since no data are downloaded. Therefore I'm not sure whether this solution may be worth it. Maybe prefetching could also be done when explicitly asked by the user
cc @mariosasko @albertvillanova | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3888/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3888/timeline | null | null | null | null | false | [
"#self-assign",
"@alvarobartt I've assigned you the issue since I'm not actively working on it.",
"Cool thanks @mariosasko I'll try to fix it in the upcoming days, thanks!",
"@lhoestq so in order to address what’s not completed in this issue, do you think it makes sense to add a param `features` to `IterableDataset.map` so that the output features right after the `map` are defined there? ",
"Yes that would be ideal IMO, thanks again for the help :)",
"@lhoestq cool then if you agree I can work on that! I’ll also update the docs accordingly once done, thanks!",
"I've already started with a PR as a draft @lhoestq, should we also try to look for a way to explicitly request pre-fetching right after a map operation is applied, so that the features are inferred if the user says explicitly so? Thanks!",
"> should we also try to look for a way to explicitly request pre-fetching right after a map operation is applied, so that the features are inferred if the user says explicitly so?\r\n\r\nRight now one can use `ds = ds._resolve_features()` do to so. It can be used after `map` or `load_dataset` if the features are not known. Maybe we can make this method public ?"
] |
https://api.github.com/repos/huggingface/datasets/issues/3562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3562/comments | https://api.github.com/repos/huggingface/datasets/issues/3562/events | https://github.com/huggingface/datasets/pull/3562 | 1,098,341,351 | PR_kwDODunzps4wwa44 | 3,562 | Allow multiple task templates of the same type | [] | closed | false | null | 0 | 2022-01-10T20:32:07Z | 2022-01-11T14:16:47Z | 2022-01-11T14:16:47Z | null | Add support for multiple task templates of the same type. Fixes (partially) #2520.
CC: @lewtun | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3562/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3562",
"merged_at": "2022-01-11T14:16:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3562"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/6030 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6030/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6030/comments | https://api.github.com/repos/huggingface/datasets/issues/6030/events | https://github.com/huggingface/datasets/pull/6030 | 1,803,864,744 | PR_kwDODunzps5Vd0ZG | 6,030 | fixed typo in comment | [] | closed | false | null | 2 | 2023-07-13T22:49:57Z | 2023-07-14T14:21:58Z | 2023-07-14T14:13:38Z | null | This mistake was a bit confusing, so I thought it was worth sending a PR over. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6030/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6030/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/6030.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6030",
"merged_at": "2023-07-14T14:13:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6030.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6030"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005855 / 0.011353 (-0.005498) | 0.003556 / 0.011008 (-0.007452) | 0.079430 / 0.038508 (0.040922) | 0.056754 / 0.023109 (0.033645) | 0.311718 / 0.275898 (0.035820) | 0.346731 / 0.323480 (0.023251) | 0.004414 / 0.007986 (-0.003571) | 0.002835 / 0.004328 (-0.001493) | 0.062138 / 0.004250 (0.057888) | 0.044259 / 0.037052 (0.007206) | 0.314681 / 0.258489 (0.056192) | 0.359802 / 0.293841 (0.065961) | 0.026684 / 0.128546 (-0.101862) | 0.008023 / 0.075646 (-0.067623) | 0.260148 / 0.419271 (-0.159123) | 0.043734 / 0.043533 (0.000202) | 0.312081 / 0.255139 (0.056942) | 0.340004 / 0.283200 (0.056805) | 0.019559 / 0.141683 (-0.122124) | 1.488758 / 1.452155 (0.036604) | 1.510828 / 1.492716 (0.018111) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.181376 / 0.018006 (0.163370) | 0.441726 / 0.000490 (0.441236) | 0.001722 / 0.000200 (0.001522) | 0.000066 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023760 / 0.037411 (-0.013651) | 0.071847 / 0.014526 (0.057321) | 0.082642 / 0.176557 (-0.093915) | 0.145555 / 0.737135 (-0.591580) | 0.084554 / 0.296338 (-0.211784) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.401688 / 0.215209 (0.186479) | 4.000994 / 2.077655 (1.923339) | 2.047109 / 1.504120 (0.542989) | 1.891874 / 1.541195 (0.350679) | 1.970599 / 1.468490 (0.502109) | 0.500646 / 4.584777 (-4.084131) | 3.006623 / 3.745712 (-0.739089) | 4.248359 / 5.269862 (-1.021503) | 2.613946 / 4.565676 (-1.951730) | 0.057921 / 0.424275 (-0.366354) | 0.006407 / 0.007607 (-0.001200) | 0.470676 / 0.226044 (0.244631) | 4.722280 / 2.268929 (2.453352) | 2.448530 / 55.444624 (-52.996095) | 2.175841 / 6.876477 (-4.700635) | 2.352287 / 2.142072 (0.210214) | 0.589049 / 4.805227 (-4.216179) | 0.125145 / 6.500664 (-6.375519) | 0.060829 / 0.075469 (-0.014640) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.189225 / 1.841788 (-0.652563) | 16.753085 / 8.074308 (8.678777) | 13.086512 / 10.191392 (2.895120) | 0.132371 / 0.680424 (-0.548052) | 0.016933 / 0.534201 (-0.517268) | 0.328258 / 0.579283 (-0.251025) | 0.344074 / 0.434364 (-0.090290) | 0.374042 / 0.540337 (-0.166296) | 0.515307 / 1.386936 (-0.871629) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005963 / 0.011353 (-0.005390) | 0.003484 / 0.011008 (-0.007525) | 0.062618 / 0.038508 (0.024110) | 0.057217 / 0.023109 (0.034108) | 0.426760 / 0.275898 (0.150862) | 0.464422 / 0.323480 (0.140942) | 0.005276 / 0.007986 (-0.002709) | 0.002872 / 0.004328 (-0.001456) | 0.062636 / 0.004250 (0.058385) | 0.045953 / 0.037052 (0.008900) | 0.433221 / 0.258489 (0.174732) | 0.475087 / 0.293841 (0.181246) | 0.027217 / 0.128546 (-0.101329) | 0.007965 / 0.075646 (-0.067681) | 0.067749 / 0.419271 (-0.351522) | 0.041235 / 0.043533 (-0.002298) | 0.425424 / 0.255139 (0.170285) | 0.453390 / 0.283200 (0.170190) | 0.020217 / 0.141683 (-0.121466) | 1.436354 / 1.452155 (-0.015801) | 1.492372 / 1.492716 (-0.000345) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.226896 / 0.018006 (0.208889) | 0.411935 / 0.000490 (0.411445) | 0.000356 / 0.000200 (0.000156) | 0.000054 / 0.000054 (-0.000000) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024705 / 0.037411 (-0.012706) | 0.076232 / 0.014526 (0.061706) | 0.086949 / 0.176557 (-0.089608) | 0.141867 / 0.737135 (-0.595269) | 0.088199 / 0.296338 (-0.208140) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.419748 / 0.215209 (0.204539) | 4.198597 / 2.077655 (2.120942) | 2.338477 / 1.504120 (0.834357) | 2.195741 / 1.541195 (0.654547) | 2.278145 / 1.468490 (0.809655) | 0.502365 / 4.584777 (-4.082412) | 2.987773 / 3.745712 (-0.757939) | 2.896526 / 5.269862 (-2.373336) | 1.841610 / 4.565676 (-2.724067) | 0.058032 / 0.424275 (-0.366243) | 0.006470 / 0.007607 (-0.001137) | 0.496969 / 0.226044 (0.270925) | 4.960984 / 2.268929 (2.692056) | 2.648615 / 55.444624 (-52.796009) | 2.286846 / 6.876477 (-4.589631) | 2.320176 / 2.142072 (0.178104) | 0.600550 / 4.805227 (-4.204678) | 0.125652 / 6.500664 (-6.375012) | 0.062177 / 0.075469 (-0.013292) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.293063 / 1.841788 (-0.548725) | 18.294204 / 8.074308 (10.219896) | 13.720502 / 10.191392 (3.529110) | 0.146480 / 0.680424 (-0.533944) | 0.016965 / 0.534201 (-0.517236) | 0.330137 / 0.579283 (-0.249146) | 0.352051 / 0.434364 (-0.082313) | 0.381754 / 0.540337 (-0.158584) | 0.517935 / 1.386936 (-0.869001) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2896 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2896/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2896/comments | https://api.github.com/repos/huggingface/datasets/issues/2896/events | https://github.com/huggingface/datasets/pull/2896 | 993,613,113 | MDExOlB1bGxSZXF1ZXN0NzMxNzcwMTE3 | 2,896 | add multi-proc in `to_csv` | [] | closed | false | null | 2 | 2021-09-10T21:35:09Z | 2021-10-28T05:47:33Z | 2021-10-26T16:00:42Z | null | This PR extends the multi-proc method used in #2747 for`to_json` to `to_csv` as well.
Results on my machine post benchmarking on `ascent_kb` dataset (giving ~45% improvement when compared to num_proc = 1):
```
Time taken on 1 num_proc, 10000 batch_size 674.2055702209473
Time taken on 4 num_proc, 10000 batch_size 425.6553490161896
Time taken on 1 num_proc, 50000 batch_size 623.5897650718689
Time taken on 4 num_proc, 50000 batch_size 380.0402421951294
Time taken on 4 num_proc, 100000 batch_size 361.7168130874634
```
This is a WIP as writing tests is pending for this PR.
I'm also exploring [this](https://arrow.apache.org/docs/python/csv.html#incremental-writing) approach for which I'm using `pyarrow-5.0.0`.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2896/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2896/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2896.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2896",
"merged_at": "2021-10-26T16:00:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2896.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2896"
} | true | [
"I think you can just add a test `test_dataset_to_csv_multiproc` in `tests/io/test_csv.py` and we'll be good",
"Hi @lhoestq, \r\nI've added `test_dataset_to_csv` apart from `test_dataset_to_csv_multiproc` as no test was there to check generated CSV file when `num_proc=1`. Please let me know if anything is also required! "
] |
https://api.github.com/repos/huggingface/datasets/issues/4350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4350/comments | https://api.github.com/repos/huggingface/datasets/issues/4350/events | https://github.com/huggingface/datasets/pull/4350 | 1,235,505,104 | PR_kwDODunzps43zKIV | 4,350 | Add a new metric: CTC_Consistency | [] | closed | false | null | 1 | 2022-05-13T17:31:19Z | 2022-05-19T10:23:04Z | 2022-05-19T10:23:03Z | null | Add CTC_Consistency metric
Do I also need to modify the `test_metric_common.py` file to make it run on test? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4350/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4350",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4350"
} | true | [
"Thanks for your contribution, @YEdenZ.\r\n\r\nPlease note that our old `metrics` module is in the process of being incorporated to a separate library called `evaluate`: https://github.com/huggingface/evaluate\r\n\r\nTherefore, I would ask you to transfer your PR to that repository. Thank you."
] |
https://api.github.com/repos/huggingface/datasets/issues/5413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5413/comments | https://api.github.com/repos/huggingface/datasets/issues/5413/events | https://github.com/huggingface/datasets/issues/5413 | 1,524,591,837 | I_kwDODunzps5a32zd | 5,413 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers | [] | closed | false | null | 1 | 2023-01-08T17:01:52Z | 2023-01-26T09:27:21Z | 2023-01-26T09:27:21Z | null | ### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 5499, in _concatenate_map_style_datasets
table = concat_tables([dset._data for dset in dsets], axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1778, in concat_tables
return ConcatenationTable.from_tables(tables, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1483, in from_tables
blocks = _extend_blocks(blocks, table_blocks, axis=axis)
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/table.py", line 1477, in _extend_blocks
result[i].extend(row_blocks)
IndexError: list index out of range
```
### Steps to reproduce the bug
dataset = concatenate_datasets([dataset1, dataset2], axis = 1)
### Expected behavior
The datasets are correctly concatenated.
### Environment info
datasets==2.8.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5413/timeline | null | completed | null | null | false | [
"Hi ! Thanks for reporting :)\r\n\r\nI managed to reproduce the hub using\r\n```python\r\n\r\nfrom datasets import concatenate_datasets, Dataset, load_from_disk\r\n\r\nDataset.from_dict({\"a\": range(9)}).save_to_disk(\"tmp/ds1\")\r\nds1 = load_from_disk(\"tmp/ds1\")\r\nds1 = concatenate_datasets([ds1, ds1])\r\n\r\nDataset.from_dict({\"b\": range(6)}).save_to_disk(\"tmp/ds2\")\r\nds2 = load_from_disk(\"tmp/ds2\")\r\nds2 = concatenate_datasets([ds2, ds2, ds2])\r\n\r\nconcatenate_datasets([ds1, ds2], axis=1)\r\n```\r\nand I get\r\n```python\r\nTraceback (most recent call last): \r\n File \"test.py\", line 98, in <module>\r\n dds = concatenate_datasets([ds1, ds2], axis=1)\r\n File \"/Users/.../datasets/combine.py\", line 182, in concatenate_datasets\r\n return _concatenate_map_style_datasets(dsets, info=info, split=split, axis=axis)\r\n File \"/Users/.../datasets/arrow_dataset.py\", line 5499, in _concatenate_map_style_datasets\r\n table = concat_tables([dset._data for dset in dsets], axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1778, in concat_tables\r\n return ConcatenationTable.from_tables(tables, axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1483, in from_tables\r\n blocks = _extend_blocks(blocks, table_blocks, axis=axis)\r\n File \"/Users/.../datasets/table.py\", line 1477, in _extend_blocks\r\n result[i].extend(row_blocks)\r\nIndexError: list index out of range\r\n```\r\n\r\nIt appears to happen when the two datasets have a number of shards that is not the same"
] |
https://api.github.com/repos/huggingface/datasets/issues/1797 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1797/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1797/comments | https://api.github.com/repos/huggingface/datasets/issues/1797/events | https://github.com/huggingface/datasets/issues/1797 | 797,357,901 | MDU6SXNzdWU3OTczNTc5MDE= | 1,797 | Connection error | [] | closed | false | null | 1 | 2021-01-30T07:32:45Z | 2021-08-04T18:09:37Z | 2021-08-04T18:09:37Z | null | Hi
I am hitting to the error, help me and thanks.
`train_data = datasets.load_dataset("xsum", split="train")`
`ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/xsum/xsum.py` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1797/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1797/timeline | null | completed | null | null | false | [
"Hi ! For future references let me add a link to our discussion here : https://github.com/huggingface/datasets/issues/759#issuecomment-770684693\r\n\r\nLet me know if you manage to fix your proxy issue or if we can do something on our end to help you :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4800 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4800/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4800/comments | https://api.github.com/repos/huggingface/datasets/issues/4800/events | https://github.com/huggingface/datasets/pull/4800 | 1,331,288,128 | PR_kwDODunzps48yIss | 4,800 | support LargeListArray in pyarrow | [] | open | false | null | 17 | 2022-08-08T03:58:46Z | 2022-10-20T16:34:04Z | null | null | ```python
import numpy as np
import datasets
a = np.zeros((5000000, 768))
res = datasets.Dataset.from_dict({'embedding': a})
'''
File '/home/wenjiaxin/anaconda3/envs/data/lib/python3.8/site-packages/datasets/arrow_writer.py', line 178, in __arrow_array__
out = numpy_to_pyarrow_listarray(data)
File "/home/wenjiaxin/anaconda3/envs/data/lib/python3.8/site-packages/datasets/features/features.py", line 1173, in numpy_to_pyarrow_listarray
offsets = pa.array(np.arange(n_offsets + 1) * step_offsets, type=pa.int32())
File "pyarrow/array.pxi", line 312, in pyarrow.lib.array
File "pyarrow/array.pxi", line 83, in pyarrow.lib._ndarray_to_array
File "pyarrow/error.pxi", line 100, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Integer value 2147483904 not in range: -2147483648 to 2147483647
'''
```
Loading a large numpy array currently raises the error above as the type of offsets is `int32`.
And pyarrow has supported [LargeListArray](https://arrow.apache.org/docs/python/generated/pyarrow.LargeListArray.html) for this case.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4800/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4800/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4800.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4800",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4800.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4800"
} | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4800). All of your documentation changes will be reflected on that endpoint.",
"Hi, thanks for working on this! Can you run `make style` at the repo root to fix the code quality error in CI and add a test?",
"Hi, I have fixed the code quality error and added a test",
"It seems that CI fails due to the lack of memory for allocating a large array, while I pass the test locally.",
"Also, the current implementation of the NumPy-to-PyArrow conversion creates a lot of copies, which is not ideal for large arrays.\r\n\r\nWe can improve performance significantly if we rewrite this part:\r\nhttps://github.com/huggingface/datasets/blob/83f695c14507a3a38e9f4d84612cf49e5f50c153/src/datasets/features/features.py#L1322-L1323\r\n\r\nas\r\n```python\r\n values = pa.array(arr.ravel(), type=type) \r\n```",
"@xwwwwww Feel free to ignore https://github.com/huggingface/datasets/pull/4800#issuecomment-1212280549 and revert the changes you've made to address it. \r\n\r\nWithout copying the array, this would be possible:\r\n```python\r\narr = np.array([\r\n [1, 2, 3],\r\n [4, 5, 6]\r\n])\r\n\r\ndset = Dataset.from_dict({\"data\": [arr]})\r\n\r\narr[0][0] = 100 # this change would be reflected in dset's PyArrow table -> a breaking change and also probably unexpected by the user \r\n```",
"> @xwwwwww Feel free to ignore [#4800 (comment)](https://github.com/huggingface/datasets/pull/4800#issuecomment-1212280549) and revert the changes you've made to address it.\r\n> \r\n> Without copying the array, this would be possible:\r\n> \r\n> ```python\r\n> arr = np.array([\r\n> [1, 2, 3],\r\n> [4, 5, 6]\r\n> ])\r\n> \r\n> dset = Dataset.from_dict({\"data\": [arr]})\r\n> \r\n> arr[0][0] = 100 # this change would be reflected in dset's PyArrow table -> a breaking change and also probably unexpected by the user \r\n> ```\r\n\r\nOh, that makes sense.",
"passed tests in ubuntu while failed in windows",
"@mariosasko Hi, do you have any clue about this failure in windows?",
"Perhaps we can skip the added test on Windows then.\r\n\r\nNot sure if this can help, but the ERR tool available on Windows outputs the following for the returned error code `-1073741819`:\r\n```\r\n# for decimal -1073741819 / hex 0xc0000005\r\n ISCSI_ERR_SETUP_NETWORK_NODE iscsilog.h\r\n# Failed to setup initiator portal. Error status is given in\r\n# the dump data.\r\n STATUS_ACCESS_VIOLATION ntstatus.h\r\n# The instruction at 0x%p referenced memory at 0x%p. The\r\n# memory could not be %s.\r\n USBD_STATUS_DEV_NOT_RESPONDING usb.h\r\n# as an HRESULT: Severity: FAILURE (1), FACILITY_NONE (0x0), Code 0x5\r\n# for decimal 5 / hex 0x5\r\n WINBIO_FP_TOO_FAST winbio_err.h\r\n# Move your finger more slowly on the fingerprint reader.\r\n# as an HRESULT: Severity: FAILURE (1), FACILITY_NULL (0x0), Code 0x5\r\n ERROR_ACCESS_DENIED winerror.h\r\n# Access is denied.\r\n# 5 matches found for \"-1073741819\"\r\n```",
"What's the proper way to skip the added test in windows?\r\nI tried `if platform.system() == 'Linux'`, but the CI test seems stuck",
"@mariosasko Hi, any idea about this :)",
"Hi again! We want to skip the test on Windows but not on Linux. You can use this decorator to do so: \r\n```python\r\[email protected](os.name == \"nt\" and (os.getenv(\"CIRCLECI\") == \"true\" or os.getenv(\"GITHUB_ACTIONS\") == \"true\"), reason=\"The Windows CI runner does not have enough RAM to run this test\")\r\[email protected](...)\r\ndef test_large_array_xd_with_np(...):\r\n ...\r\n```",
"> Hi again! We want to skip the test on Windows but not on Linux. You can use this decorator to do so:\r\n> \r\n> ```python\r\n> @pytest.mark.skipif(os.name == \"nt\" and (os.getenv(\"CIRCLECI\") == \"true\" or os.getenv(\"GITHUB_ACTIONS\") == \"true\"), reason=\"The Windows CI runner does not have enough RAM to run this test\")\r\n> @pytest.mark.parametrize(...)\r\n> def test_large_array_xd_with_np(...):\r\n> ...\r\n> ```\r\n\r\nCI on windows still stucks :(",
"@mariosasko Hi, could you please take a look at this issue",
"@mariosasko Hi, all checks have passed, and we are finally ready to merge this PR :)",
"@lhoestq @albertvillanova Perhaps other maintainers can take a look and merge this PR :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4184 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4184/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4184/comments | https://api.github.com/repos/huggingface/datasets/issues/4184/events | https://github.com/huggingface/datasets/pull/4184 | 1,208,592,669 | PR_kwDODunzps42cB2j | 4,184 | [Librispeech] Add 'all' config | [] | closed | false | null | 27 | 2022-04-19T16:27:56Z | 2022-08-29T06:35:57Z | 2022-04-22T09:45:17Z | null | Add `"all"` config to Librispeech
Closed #4179 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4184/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4184/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4184.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4184",
"merged_at": "2022-04-22T09:45:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4184.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4184"
} | true | [
"Fix https://github.com/huggingface/datasets/issues/4179",
"_The documentation is not available anymore as the PR was closed or merged._",
"Just that I understand: With this change, simply doing `load_dataset(\"librispeech_asr\")` is possible and returns the whole dataset?\r\n\r\nAnd to get the subsets, I do sth like:\r\n```python\r\nds = load_dataset(\"librispeech_asr\")\r\ntrain_ds = ds[\"train\"]\r\ndev_clean_ds = ds[\"dev-clean\"]\r\ndev_other_ds = ds[\"dev-other\"]\r\ntest_clean_ds = ds[\"test-clean\"]\r\ntest_other_ds = ds[\"test-other\"]\r\n```\r\n?\r\n",
"> Just that I understand: With this change, simply doing `load_dataset(\"librispeech_asr\")` is possible and returns the whole dataset?\r\n> \r\n> And to get the subsets, I do sth like:\r\n> \r\n> ```python\r\n> ds = load_dataset(\"librispeech_asr\")\r\n> train_ds = ds[\"train\"]\r\n> dev_clean_ds = ds[\"dev-clean\"]\r\n> dev_other_ds = ds[\"dev-other\"]\r\n> test_clean_ds = ds[\"test-clean\"]\r\n> test_other_ds = ds[\"test-other\"]\r\n> ```\r\n> \r\n> ?\r\n\r\nYou could do:\r\n\r\n\r\n```python\r\nds = load_dataset(\"librispeech_asr\", \"all\") # <- note that we have to pass a config\r\ntrain_ds = ds[\"train\"]\r\ndev_clean_ds = ds[\"dev-clean\"]\r\ndev_other_ds = ds[\"dev-other\"]\r\ntest_clean_ds = ds[\"test-clean\"]\r\ntest_other_ds = ds[\"test-other\"]\r\n```",
"So, `load_dataset(\"librispeech_asr\")` is not possible, it must be `load_dataset(\"librispeech_asr\", \"all\")`?\r\n\r\nWhy is that?\r\n\r\nThe docs say:\r\n```\r\nname: `str` name, optional configuration for the dataset that affects the data generated on disk. Different\r\n `builder_config`s will have their own subdirectories and versions.\r\n If not provided, uses the first configuration in self.BUILDER_CONFIGS\r\n```\r\nhttps://github.com/huggingface/datasets/blob/cd3ce34ab1604118351e1978d26402de57188901/src/datasets/builder.py#L228\r\n\r\nOr maybe you could just define `DEFAULT_CONFIG_NAME`?\r\n",
"> If not provided, uses the first configuration in self.BUILDER_CONFIGS\r\n\r\nOh crap this is outdated documentation. No it doesn't take the first config by default.\r\n\r\nEDIT: opened a PR to fix this: https://github.com/huggingface/datasets/pull/4186",
"> No it doesn't take the first config by default.\r\n\r\nBut defining `DEFAULT_CONFIG_NAME` would work?\r\n\r\nSo should we define `DEFAULT_CONFIG_NAME = \"all\"` here as well? I think this is a reasonable default config.\r\n\r\nDon't most datasets have some default config?\r\n",
"> But defining DEFAULT_CONFIG_NAME would work?\r\n>\r\n> So should we define DEFAULT_CONFIG_NAME = \"all\" here as well? I think this is a reasonable default config.\r\n\r\nYes that would work, and I also find it reasonable to do it :)\r\n\r\n> Don't most datasets have some default config?\r\n\r\nMost datasets only have one configuration, so the single configuration is the default one. Then other datasets gave several configurations, and whether they have a default one is decided case-by-case.\r\n\r\ne.g. `glue` is a benchmark and doesn't have a default task, one must choose which task of `glue` they want to use explicitely.",
"Thanks a lot for the feedback! \r\n\r\nUsing `\"all\"` now as the default config. I changed the layout a bit so that there is not a single \"train\", but instead we have multiple \"train.clean.100\", \"train.clean.360\", \"train.other.500\". This way we don't even need to do filtering and it's also cleaner IMO.\r\n\r\n@albertz - you should now be able to do the following:\r\n\r\n```python\r\nload_dataset(\"librispeech_asr\") # <- run this once to download, prepare dataset and cache everything\r\n\r\n# The following operations will be very fast since all the downloading and processing is already cached\r\ntrain_1 = load_dataset(\"librispeech_asr\", split=\"train.clean.100\")\r\nprint(train_1)\r\ntrain_2 = load_dataset(\"librispeech_asr\", split=\"train.clean.100+train.clean.360\")\r\nprint(train_2)\r\ntrain_full = load_dataset(\"librispeech_asr\", split=\"train.clean.100+train.clean.360+train.other.500\")\r\nprint(train_full)\r\ndev_clean_ds = load_dataset(\"librispeech_asr\", split=\"validation.clean\")\r\nprint(dev_clean_ds)\r\ndev_other_ds = load_dataset(\"librispeech_asr\", split=\"validation.other\")\r\nprint(dev_other_ds)\r\ntest_clean_ds = load_dataset(\"librispeech_asr\", split=\"test.clean\")\r\nprint(test_clean_ds)\r\ntest_other_ds = load_dataset(\"librispeech_asr\", split=\"test.other\")\r\nprint(test_other_ds)\r\n```\r\n\r\n\r\n",
"Think this way we have the best of both worlds. Also @lhoestq, I think we could highlight better in the docs that it's possible to combine different splits. We do this actually quite a lot for speech. For Common Voice many people include \"validation\" in the training if the data is too small, e.g.: https://github.com/huggingface/transformers/blob/ff06b177917384137af2d9585697d2d76c40cdfc/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L147\r\n\r\nShould we maybe add a short section to the loading tutorial here: https://huggingface.co/docs/datasets/v2.1.0/en/loading#hugging-face-hub ? (Happy to do it)",
"Is there any advantage or difference in calling `load_dataset` multiple times for each split? Or why not just call `load_dataset` once and then access each split?\r\n\r\nNote in our case, we cannot really use the caching mechanism because we have a recipe pipeline used by multiple users (and I think a common cache dir for all users might end up in problems) and we basically would use `load_dataset(\"librispeech_asr\").save_to_disk(...)` and then later `load_from_disk(...)`. (See here: https://github.com/rwth-i6/i6_core/pull/253)\r\n\r\nSo with `load_from_disk`, we cannot really provide the split this way, so we anyway would do sth like:\r\n```python\r\nds = datasets.load_from_disk(...)\r\ntrain = ds[\"train\"]\r\n```\r\nOr with your latest proposal, it would look like:\r\n```python\r\nds = datasets.load_from_disk(...)\r\ntrain_ds = datasets.concatenate_datasets(\r\n [ds[\"train.clean.100\"], ds[\"train.clean.360\"], ds[\"train.other.500\"]])\r\n```\r\nright?\r\n",
"> Is there any advantage or difference in calling `load_dataset` multiple times for each split? Or why not just call `load_dataset` once and then access each split?\r\n> \r\n> Note in our case, we cannot really use the caching mechanism because we have a recipe pipeline used by multiple users (and I think a common cache dir for all users might end up in problems) and we basically would use `load_dataset(\"librispeech_asr\").save_to_disk(...)` and then later `load_from_disk(...)`. (See here: [rwth-i6/i6_core#253](https://github.com/rwth-i6/i6_core/pull/253))\r\n> \r\n> So with `load_from_disk`, we cannot really provide the split this way, so we anyway would do sth like:\r\n> \r\n> ```python\r\n> ds = datasets.load_from_disk(...)\r\n> train = ds[\"train\"]\r\n> ```\r\n> \r\n> Or with your latest proposal, it would look like:\r\n> \r\n> ```python\r\n> ds = datasets.load_from_disk(...)\r\n> train_ds = datasets.concatenate_datasets(\r\n> [ds[\"train.clean.100\"], ds[\"train.clean.360\"], ds[\"train.other.500\"]])\r\n> ```\r\n> \r\n> right?\r\n\r\nI see the use case! The only advantage by calling `datasets` multiple times is that one can easily \"merge\" splits with `\"+\"`, but yeah you can do the exact same with `concatenate`.\r\n\r\n@lhoestq what do you think is the best approach with `load_from_disk`? \r\n\r\n@albertz, you could also define the `cache_dir` when doing `load_dataset(...)` which will then put all the relevant `arrow` files int the cache dir that you defined, e.g.:\r\n\r\n```python\r\nload_dataset(\"librispeech_asr\", cache_dir=\"/easy/to/access/directory\")\r\n```",
"@albertz, I took a read through https://github.com/rwth-i6/i6_core/pull/253 . \r\n\r\nI think the best would be the following:\r\n\r\n1. Do `ds = load_dataset(..., cache_dir=\"/dir/that/is/easy/to/access\")` <- having merged this PR, this will save all the original `.flac` files in the `cache_dir`\r\n2. Do `ds.save_to_disk(\"local/path\")` this should then only save the `arrow.format` with a `path` string to the audio files which are located in `cache_dir` <- this won't require a lot of memory after https://github.com/huggingface/datasets/pull/4184#discussion_r854132740 is fixed and can be done for each person individually.\r\n3. `ds = datasets.load_from_disk(\"local/path\")` can the be used. An object of `ds` will then have a `path` variable that links to the original audio files in the `cache_dir`. You can change these audio files then easily to `.mp3. You could do this with the `.map(...)` function, e.g. define a function that maps through all audio files, load them and then save them on disk afterward.",
"@lhoestq - I think this one is good to go",
"> @albertz, I took a read through [rwth-i6/i6_core#253](https://github.com/rwth-i6/i6_core/pull/253) .\r\n> \r\n> I think the best would be the following:\r\n> \r\n> 1. Do `ds = load_dataset(..., cache_dir=\"/dir/that/is/easy/to/access\")` <- having merged this PR, this will save all the original `.flac` files in the `cache_dir`\r\n> 2. Do `ds.save_to_disk(\"local/path\")` this should then only save the `arrow.format` with a `path` string to the audio files which are located in `cache_dir` <- this won't require a lot of memory after [[Librispeech] Add 'all' config #4184 (comment)](https://github.com/huggingface/datasets/pull/4184#discussion_r854132740) is fixed and can be done for each person individually.\r\n> 3. `ds = datasets.load_from_disk(\"local/path\")` can the be used. An object of `ds` will then have a `path` variable that links to the original audio files in the `cache_dir`. You can change these audio files then easily to `.mp3. You could do this with the `.map(...)` function, e.g. define a function that maps through all audio files, load them and then save them on disk afterward.\r\n\r\nOh, so you say that our current implementation in https://github.com/rwth-i6/i6_core/pull/253 is broken? Because our cache dir is just some temp directory which will be removed afterwards, and we just store what we get out of `save_to_disk`. I think it would be good to clarify that in the doc of `save_to_disk`, that this is not enough and can depend on files from the cache dir. (@dthulke)\r\n\r\nSo, you say we anyway need to share the cache dir among users? But we would want to make sure that after the initial download and preparation of the data, this is set to readonly, because we want to make sure that other people will not modify the data in any way. Right?\r\n\r\nBut then, we don't really need the `save_to_disk` and `load_from_disk` at all, right?\r\n",
"@albertz \r\n\r\n> Oh, so you say that our current implementation in https://github.com/rwth-i6/i6_core/pull/253 is broken? Because our cache dir is just some temp directory which will be removed afterwards, and we just store what we get out of save_to_disk. I think it would be good to clarify that in the doc of save_to_disk, that this is not enough and can depend on files from the cache dir. (@dthulke)\r\n\r\nOh, I wasn't aware that audio files are handled this way. Then we should have the cache directory as an additional job output, so that we keep the audio files. \r\n\r\n> So, you say we anyway need to share the cache dir among users?\r\n\r\nNo, the cache dir can still be a directory in the job output folder. Then the audio paths in the corresponding dataset column correspond to the flac files in that directory. This way the \"output\" of the job is contained into the job directory and we don't write files to a global cache directory that is independent of the sisyphus graph.\r\n\r\nIf we want to share the audio data between different users, we can just link to a central instance of the job (similar to how we do it with the `DownloadLibriSpeechCorpusJob`).",
"@dthulke - that's a good point actually! So you can do both things:\r\n\r\n1. Convert all audio files to bytes. Bytes can be saved by `arrow` so in this case you can do `save_to_disk(...)`, but then you cannot really inspect the audio files locally as they'll just be saved within a large arrow file (this actually used to be the default case but we're changing this now). The problem of this is summarized here a bit: https://github.com/huggingface/datasets/issues/3663 . You can still do this if you'd like, e.g. you could do:\r\n\r\n```python\r\nds = load_dataset(\"librispeech_asr\")\r\n\r\ndef read_file(batch):\r\n with open(batch[\"file\"], \"r\") as f:\r\n batch[\"bytes\"] = f.read() \r\n return batch\r\n\r\nds = ds.map(read_file)\r\nds.save_to_disk(\"/path\") <- the saved arrow object will now contain everything you need\r\n```\r\n\r\nhowever this is not recommend - it's should be much easier to just save the path to the downloaded audio files.\r\n\r\n2. Not convert audio files to bytes, but just leave them in their original file format. Then only the path to the original files will be save in arrow. This will be the default case. This means that when you do `load_dataset(...)` both the orginal audio data and the arrow file will be saved in the `cache_dir` (which can be saved locally for every user or in a shared cache - we actually use a shared cache quite a bit at Hugging Face). When do you do `save_to_disk(...)` now only the `path` will be saved in `arrow` format (after this PR is merged, you'll see that the `arrow files should be very light weight` meaning that `save_to_disk(...)` can be done for every user, but has a dependency on the `cache_dir` (because the audio files live there).\r\n\r\n=> Now what you could do as well would be to simply move all the audio files to the folder you want (the `save_to_disk(...)` folder) and then change the path of every sample to this folder (maybe with `map(...)`) and then this folder would be self contained. I do however think it's better to just specific a `cache_dir` and re-use `load_dataset(...)` every time instead of `load_from_disk` or `save_to_disk(...)`. Note that you can even pass the relevant cache files to `load_dataset(...)` here: https://huggingface.co/docs/datasets/v2.1.0/en/package_reference/loading_methods#datasets.load_dataset.data_files in which case you can be 100% sure that nothing is redownloaded. \r\n\r\nWe discussed storing audio files quite a bit, e.g. see: https://github.com/huggingface/datasets/issues/3663 and had (too many) changes around this topic recently, but we've come to the conclusion that the best is to leave the audio format in the format it was originally (`.flac` for Librispeech) so that the user can easily inspect it / understand the data. Arrow cannot save data is `.flac` so we'll just save a path to the original data. Curious to hear your guys opinion on this as well.",
"So what I would suggest here is to do the following:\r\n\r\n1. Do `load_dataset(..., cache_dir=/a/read-only/folder)`\r\n2. \r\n- Either just re-use `load_dataset(..., cache_dir=...)` which should always re-use the data in the `cache_dir` since the hash of the url matches - so there should never be any duplicated downloading \r\n\r\nor \r\n\r\n- If you want to store the files in MP3 locally, first convert the files to MP3 in the read-only folder, then take do `ds.save_to_disk(/some/path)` which will save the correct path to the read-only folder to MP3 and then you can easily re-use the small arrow dataset that is saved in `/some/path`",
"> So what I would suggest here is to do the following:\r\n> \r\n> 1. Do `load_dataset(..., cache_dir=/a/read-only/folder)`\r\n> \r\n> * Either just re-use `load_dataset(..., cache_dir=...)` which should always re-use the data in the `cache_dir` since the hash of the url matches - so there should never be any duplicated downloading\r\n> \r\n> or\r\n> \r\n> * If you want to store the files in MP3 locally, first convert the files to MP3 in the read-only folder, then take do `ds.save_to_disk(/some/path)` which will save the correct path to the read-only folder to MP3 and then you can easily re-use the small arrow dataset that is saved in `/some/path`\r\n\r\nAlso relevant here: https://github.com/huggingface/datasets/issues/3663",
"I also added some documentation about how `save_to_disk` handles audio files here: https://github.com/huggingface/datasets/pull/4193",
"> > So, you say we anyway need to share the cache dir among users?\r\n> \r\n> No, the cache dir can still be a directory in the job output folder.\r\n\r\n@dthulke But this is what I mean. When we share the job output folder, it means we share the cache dir among users.\r\n\r\nI wonder if `load_dataset(..., cache_dir=job_output_cache_dir)` is always save to do then, that it really would not modify the `job_output_cache_dir`.\r\n\r\nWe could enforce that by making the `job_output_cache_dir` read-only afterwards. We currently don't do this.\r\n\r\n@patrickvonplaten @dthulke But in any case, we actually prefer the data content to be inside the dataset (the arrow files). Lots of small files would be very problematic for our cache manager. We have one main copy of the data on NFS, but accessing the NFS directly by all computing nodes is not feasible, so the cache manager will have copies of the files on the nodes. So it means, whenever we access some file, we query the cache manager DB whether the file is already cached somewhere (some other computing node) and if so, it copies it from the other computing node and not from NFS. This works very well when there are not too many files (but the files can be big). So, we want to have only a few but big files. Even for NFS access this is much better.\r\n\r\nI also commented in #3663.\r\n",
"Hey @albertz @dthulke,\r\n\r\nThanks a lot for your input! \r\n\r\nWe've discussed quite a bit with @lhoestq and we think the best approach is the following:\r\n\r\n\r\na)\r\n`load_dataset(...)` will not store both bytes and the files because this would mean that 3x the size of the dataset would often be needed (1. the compressed `tar.gz` file, 2. the extracted file b, 3. the raw bytes in arrow format). \r\n\r\nFor canonical datasets like librispeech and common voice I think we want to keep the dataset filenames because of i) no breaking changes and ii) reasons explained in #3663\r\n\r\nHowever it's also trivial to write your own datasetset downloading script of librispeech and just not extract the folder e.g. this line: https://huggingface.co/datasets/common_voice/blob/main/common_voice.py#L671\r\n\r\nAnd then it'll be allowed to save the bytes and the dataset will be self-contained out-of-the-box when using `load_dataset(...)`\r\n\r\nb) Now, one major problem that you guys uncovered is that `save_to_disk(...)` is currently not necessarily saving a dataset to be self-contained. We will change that asap. This means that after we've corrected this when you do download the canonical librispeech dataset the following will work:\r\n\r\n```python\r\nds = load_dataset(\"....\") # <- here we have a dependency on the filepathes\r\nds[0][\"audio\"][\"bytes\"] # <- will not work\r\n\r\nds.save_to_disk(\"/local/path\") # <- now we want to have a self-contained dataset in arrow format, so we load the files into bytes and save it in arrow format\r\n\r\n# now you can delete everything besides \"/local/path\"\r\n\r\nds = load_from_disk(\"/local/path\") # <- this will work\r\n```\r\n\r\nSo either option a) where you define your own librispeech data downloading script (you guys could just sign up here: https://huggingface.co/join) and upload a dataset loading script in private mode so that no one can see it and you would always store the audio as bytes or b) where you first load then save to disk then delete cache would work. \r\n\r\nHope that fits in your vision :-)\r\n\r\ncc @lhoestq @mariosasko ",
"@patrickvonplaten sounds like a good approach to me. For b) this could even be configurable with a parameter like `embed_external_files` as you have for `push_to_hub` (if people prefer to keep separate audio files).\r\n",
"> However it's also trivial to write your own datasetset downloading script of librispeech and just not extract the folder\r\n\r\nI don't exactly understand. In all cases, we need to extract it to prepare the dataset, or not? No matter if we want to store the raw bytes inside the dataset or leaving them as local files. Just in the first case, we can safely delete the extracted files after the dataset preparation.\r\n\r\n> `save_to_disk(...)` is currently not necessarily saving a dataset to be self-contained. We will change that asap.\r\n\r\nFor us, this sounds exactly like what we want.\r\n\r\nBut regarding not introducing breaking changes, wouldn't this maybe also break some setups for users who don't expect this new behavior?\r\n",
"@albertz I would suggest to move the discussion on implementation details on our side to the following issue: rwth-i6/i6_core/issues/257",
"I like the idea of adding `embed_external_files` and set it to True by default to `save_to_disk`.\r\nIt's indeed a kind of breaking change since some users will get bigger Arrow files when updating the lib, but the advantages are nice:\r\n1. I like the idea of having it self contained, in case you want to delete your cache\r\n2. users also upload these Arrow files to cloud storage via the `fs` parameter, and in this case they would expect to upload a self-contained dataset\r\n3. consistency with `push_to_hub`\r\n\r\nIf it sounds good to you I'll open an issue to discuss this and track the advancements",
"Closed #4179."
] |
https://api.github.com/repos/huggingface/datasets/issues/4408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4408/comments | https://api.github.com/repos/huggingface/datasets/issues/4408/events | https://github.com/huggingface/datasets/pull/4408 | 1,248,687,574 | PR_kwDODunzps44ecNI | 4,408 | Update imagenet gate | [] | closed | false | null | 1 | 2022-05-25T20:32:19Z | 2022-05-25T20:45:11Z | 2022-05-25T20:36:47Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4408/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4408.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4408",
"merged_at": "2022-05-25T20:36:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4408.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4408"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1446 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1446/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1446/comments | https://api.github.com/repos/huggingface/datasets/issues/1446/events | https://github.com/huggingface/datasets/pull/1446 | 761,060,323 | MDExOlB1bGxSZXF1ZXN0NTM1Nzg1NDk1 | 1,446 | Add Bing Coronavirus Query Set | [] | closed | false | null | 0 | 2020-12-10T09:20:46Z | 2020-12-11T17:03:08Z | 2020-12-11T17:03:07Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1446/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1446/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1446.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1446",
"merged_at": "2020-12-11T17:03:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1446.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1446"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/5155 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5155/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5155/comments | https://api.github.com/repos/huggingface/datasets/issues/5155/events | https://github.com/huggingface/datasets/pull/5155 | 1,421,278,748 | PR_kwDODunzps5BcCYr | 5,155 | TextConfig: added "errors" | [] | closed | false | null | 3 | 2022-10-24T18:56:52Z | 2022-11-03T13:38:13Z | 2022-11-03T13:35:35Z | null | This patch adds the ability to set the `errors` option of `open` for loading text datasets. I needed it because some data I had scraped had bad bytes in it, so I needed `errors='ignore'`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5155/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5155/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5155.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5155",
"merged_at": "2022-11-03T13:35:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5155.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5155"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for adding this ! You can fix the CI by formatting your code using the `make style` command :)",
"[**@lhoestq**](https://github.com/lhoestq) commented on [Oct 27, 2022, 4:08 PM GMT+3:30](https://github.com/huggingface/datasets/pull/5155#issuecomment-1293464680 \"2022-10-27T12:38:04Z - Replied by Github Reply Comments\"):\r\n> Thanks for adding this ! You can fix the CI by formatting your code using the `make style` command :)\r\n\r\nI ran this and force pushed the changes."
] |
https://api.github.com/repos/huggingface/datasets/issues/2171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2171/comments | https://api.github.com/repos/huggingface/datasets/issues/2171/events | https://github.com/huggingface/datasets/pull/2171 | 851,090,662 | MDExOlB1bGxSZXF1ZXN0NjA5NTY4MDcw | 2,171 | Fixed the link to wikiauto training data. | [] | closed | false | null | 3 | 2021-04-06T07:13:11Z | 2021-04-06T16:05:42Z | 2021-04-06T16:05:09Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2171/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2171/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2171.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2171",
"merged_at": "2021-04-06T16:05:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2171.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2171"
} | true | [
"Also you can ignore the CI failing on `docs`, this has been fixed on master :)",
"@lhoestq I need to update other stuff on GEM later today too, so will merge this one and remove columns in the next PR!",
"Ok !"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/1357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1357/comments | https://api.github.com/repos/huggingface/datasets/issues/1357/events | https://github.com/huggingface/datasets/pull/1357 | 760,023,525 | MDExOlB1bGxSZXF1ZXN0NTM0OTIzMzA4 | 1,357 | Youtube caption corrections | [] | closed | false | null | 10 | 2020-12-09T05:52:34Z | 2020-12-15T18:12:56Z | 2020-12-15T18:12:56Z | null | This PR adds a new dataset of YouTube captions, error and corrections. This dataset was created in just the last week, as inspired by this sprint! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1357/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1357/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1357.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1357",
"merged_at": "2020-12-15T18:12:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1357.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1357"
} | true | [
"Sorry about forgetting flake8.\r\nRather than use up the circleci resources on a new push with only formatting changes, I will wait to push until the results from all tests finish and/or any feedback comes in... probably tomorrow for me.",
"\r\nSo... my normal work is with mercurial and seem to have clearly forked this up using git... :(\r\n\r\nWhat I did is after calling:\r\n```\r\ngit fetch upstream\r\ngit rebase upstream/master\r\n```\r\n\r\nI then I attempt to pull in my most recent changes UI commit changes based on @lhoestq's feedback with:\r\n```\r\ngit pull\r\n``` \r\n... which I now suspect undid the above fetch and rebase. Will look into fixing later today when I have more time. Sorry!\r\n",
"My dummy data seems quite large as a single row is composed of tokens/labels for an entire youtube video, with at least one row required for each file, which in this case 1 file per 13 youtube channels.\r\n\r\nTo make it smaller I passed `--n_lines 1` to reduce about 5x.\r\n\r\nI then manually reduced size of the particularly long youtube lectures to get the size to about 30KB. However, after recompressing into a zip, and running dummy data test I got the following error:\r\n`FAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_youtube_caption_corrections - OSError: Cannot find data file. `, despite file being there, which I haven't had a chance yet to debug.",
"I wrote a small script to generate a smaller json file for the dummy_data, with the hope that I could resolve the pytest error noted above (in case related to a manual typo I could have introduce), however the test contains to fail locally... here's to hoping it can pass on remote!",
"Sorry for delayed comments here. Last commit made two changes:\r\n- Increased the valency of the labels from just True/False to more categories to describe the various types of diffs encountered. This required some rewrite of the README\r\n- Reduced the number of remote files to be downloaded from 13 to 4, by combining all 13 of the channel-specific files together, and the splitting them up in a way to meet Github file size requirements. This also reduces size of the dummy-data.",
"@lhoestq, thank you for the great feedback, especially given how busy you guys are now! \r\n\r\nI checked out GitHub release tags and looks cool. I have added the version tag to the url, instead of the commit sha as originally suggested, with the hope that it serves the same purpose of pinning the content to this url. Please let me know if I have misunderstood.\r\n\r\nIn regard to dynamically changing the number of files downloaded by first downloading a JSON listing the files, I love that idea. But I am a little confused, as I was thinking that any changes to the dataset itself would require a new PR with an updated `dataset_infos.json`, e.g. `num_examples` would increase. \r\n\r\nIf the purpose of this is not to permit dynamic (without a PR needed) growth of the number of files, but instead to provide stability to the consumers of the dataset, maybe I continued use the release tags, maintaining access to old releases could serve this purpose? I am still learning about these release tags... ",
"For dynamic datasets, i.e. datasets that evolve over time, we support custom configurations: they are configurations that are not part of the BUILDER_CONFIGS or in the dataset_infos.json\r\n\r\nFor example for wikipedia, you can use the latest wiki dump by specifying `date=` inside `load_dataset()`. A configuration is created on the fly for this date and is used to build the dataset using the latest data.\r\n\r\nTherefore we don't need to have PRs to update the script for each wikipedia release.\r\n\r\nOne downside though is that we don't have metadata in advance such as the size of the dataset.\r\n\r\nI think this could be a nice addition for the youtube caption dataset in the future to be have a system of releases and be able to load the version we want easily. What do you think ?",
"\r\n\r\n\r\n\r\n> For dynamic datasets, i.e. datasets that evolve over time, we support custom configurations: they are configurations that are not part of the BUILDER_CONFIGS or in the dataset_infos.json\r\n> \r\n \r\n> I think this could be a nice addition for the youtube caption dataset in the future to be have a system of releases and be able to load the version we want easily. What do you think ?\r\n\r\nThank you for the suggestion! This sounds great! I will take a look at the some datasets that do this, and would love to give it a try in the future, if I continue to grow the captions dataset in a meaningful way. \r\n\r\nAppreciate all the help on this. It has been a really great experience for me. :)",
"Excited to merge! And sorry to be such a github n00b, but from what I've quickly read, I don't 'Close pull request', but rather the next steps are action taken on your end... Please let me know if there is some action to be taken at my end first. :/",
"Alright merging this one then :) "
] |
https://api.github.com/repos/huggingface/datasets/issues/3318 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3318/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3318/comments | https://api.github.com/repos/huggingface/datasets/issues/3318/events | https://github.com/huggingface/datasets/pull/3318 | 1,062,369,717 | PR_kwDODunzps4u9m-k | 3,318 | Finish transition to PyArrow 3.0.0 | [] | closed | false | null | 0 | 2021-11-24T12:30:14Z | 2021-11-24T15:35:05Z | 2021-11-24T15:35:04Z | null | Finish transition to PyArrow 3.0.0 that was started in #3098. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3318/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3318/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3318.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3318",
"merged_at": "2021-11-24T15:35:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3318.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3318"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2609/comments | https://api.github.com/repos/huggingface/datasets/issues/2609/events | https://github.com/huggingface/datasets/pull/2609 | 939,616,682 | MDExOlB1bGxSZXF1ZXN0Njg1ODA3MTMz | 2,609 | Fix potential DuplicatedKeysError | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-05T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/6",
"id": 6836458,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/6/labels",
"node_id": "MDk6TWlsZXN0b25lNjgzNjQ1OA==",
"number": 6,
"open_issues": 0,
"state": "closed",
"title": "1.10",
"updated_at": "2021-07-21T15:36:49Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/6"
} | 1 | 2021-07-08T08:38:04Z | 2021-07-12T14:13:16Z | 2021-07-09T16:42:08Z | null | Fix potential DiplicatedKeysError by ensuring keys are unique.
We should promote as a good practice, that the keys should be programmatically generated as unique, instead of read from data (which might be not unique). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2609/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2609.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2609",
"merged_at": "2021-07-09T16:42:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2609.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2609"
} | true | [
"Finally, I'm splitting this PR."
] |
https://api.github.com/repos/huggingface/datasets/issues/1487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1487/comments | https://api.github.com/repos/huggingface/datasets/issues/1487/events | https://github.com/huggingface/datasets/pull/1487 | 762,794,921 | MDExOlB1bGxSZXF1ZXN0NTM3MzA2MTEx | 1,487 | added conv_ai_3 dataset | [] | closed | false | null | 4 | 2020-12-11T19:26:26Z | 2020-12-28T09:38:40Z | 2020-12-28T09:38:39Z | null | Dataset : https://github.com/aliannejadi/ClariQ/
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1487/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1487",
"merged_at": "2020-12-28T09:38:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1487"
} | true | [
"@lhoestq Thank you for suggesting changes. I fixed all the changes you suggested. Can you please review it again? ",
"@lhoestq Thank you for reviewing and suggesting changes. I made the requested changes. Can you please review it again?",
"Thanks @lhoestq for reviewing it again. I made the required changes. Can you please have a look ?",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/1089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1089/comments | https://api.github.com/repos/huggingface/datasets/issues/1089/events | https://github.com/huggingface/datasets/pull/1089 | 756,823,690 | MDExOlB1bGxSZXF1ZXN0NTMyMzA0MDM2 | 1,089 | add sharc_modified | [] | closed | false | null | 0 | 2020-12-04T05:49:49Z | 2020-12-04T10:41:30Z | 2020-12-04T10:31:44Z | null | Adding modified ShARC dataset https://github.com/nikhilweee/neural-conv-qa | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1089/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1089.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1089",
"merged_at": "2020-12-04T10:31:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1089.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1089"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2876 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2876/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2876/comments | https://api.github.com/repos/huggingface/datasets/issues/2876/events | https://github.com/huggingface/datasets/pull/2876 | 990,001,079 | MDExOlB1bGxSZXF1ZXN0NzI4NjU3MDc2 | 2,876 | Extend support for streaming datasets that use pathlib.Path.glob | [] | closed | false | null | 2 | 2021-09-07T13:43:45Z | 2021-09-10T09:50:49Z | 2021-09-10T09:50:48Z | null | This PR extends the support in streaming mode for datasets that use `pathlib`, by patching the method `pathlib.Path.glob`.
Related to #2874, #2866.
CC: @severo | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2876/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2876/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2876.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2876",
"merged_at": "2021-09-10T09:50:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2876.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2876"
} | true | [
"I am thinking that ideally we should call `fs.glob()` instead...",
"Thanks, @lhoestq: the idea of adding the mock filesystem is to avoid network calls and reduce testing time ;) \r\n\r\nI have added `rglob` as well and fixed some bugs."
] |
https://api.github.com/repos/huggingface/datasets/issues/5994 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5994/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5994/comments | https://api.github.com/repos/huggingface/datasets/issues/5994/events | https://github.com/huggingface/datasets/pull/5994 | 1,776,829,004 | PR_kwDODunzps5UB1cA | 5,994 | Fix select_columns columns order | [] | closed | false | null | 4 | 2023-06-27T12:32:46Z | 2023-06-27T15:40:47Z | 2023-06-27T15:32:43Z | null | Fix the order of the columns in dataset.features when the order changes with `dataset.select_columns()`.
I also fixed the same issue for `dataset.flatten()`
Close https://github.com/huggingface/datasets/issues/5993 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5994/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5994/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5994.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5994",
"merged_at": "2023-06-27T15:32:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5994.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5994"
} | true | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005969 / 0.011353 (-0.005384) | 0.003687 / 0.011008 (-0.007321) | 0.100843 / 0.038508 (0.062335) | 0.036912 / 0.023109 (0.013803) | 0.312389 / 0.275898 (0.036491) | 0.370335 / 0.323480 (0.046855) | 0.003434 / 0.007986 (-0.004552) | 0.003710 / 0.004328 (-0.000619) | 0.076899 / 0.004250 (0.072648) | 0.053647 / 0.037052 (0.016594) | 0.324825 / 0.258489 (0.066336) | 0.367711 / 0.293841 (0.073870) | 0.028079 / 0.128546 (-0.100467) | 0.008326 / 0.075646 (-0.067320) | 0.312342 / 0.419271 (-0.106930) | 0.047423 / 0.043533 (0.003890) | 0.321063 / 0.255139 (0.065924) | 0.336508 / 0.283200 (0.053308) | 0.019973 / 0.141683 (-0.121710) | 1.529334 / 1.452155 (0.077179) | 1.573746 / 1.492716 (0.081030) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.210849 / 0.018006 (0.192843) | 0.418798 / 0.000490 (0.418309) | 0.007347 / 0.000200 (0.007147) | 0.000070 / 0.000054 (0.000016) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022718 / 0.037411 (-0.014694) | 0.098400 / 0.014526 (0.083874) | 0.106590 / 0.176557 (-0.069967) | 0.168460 / 0.737135 (-0.568675) | 0.108401 / 0.296338 (-0.187938) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.443066 / 0.215209 (0.227857) | 4.416658 / 2.077655 (2.339003) | 2.088844 / 1.504120 (0.584724) | 1.879564 / 1.541195 (0.338369) | 1.933815 / 1.468490 (0.465325) | 0.565085 / 4.584777 (-4.019692) | 3.412440 / 3.745712 (-0.333273) | 1.754686 / 5.269862 (-3.515175) | 1.024576 / 4.565676 (-3.541100) | 0.067909 / 0.424275 (-0.356366) | 0.011054 / 0.007607 (0.003447) | 0.534748 / 0.226044 (0.308703) | 5.351457 / 2.268929 (3.082529) | 2.517368 / 55.444624 (-52.927256) | 2.182762 / 6.876477 (-4.693715) | 2.238205 / 2.142072 (0.096133) | 0.672962 / 4.805227 (-4.132265) | 0.136098 / 6.500664 (-6.364566) | 0.066534 / 0.075469 (-0.008935) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.281241 / 1.841788 (-0.560547) | 13.872881 / 8.074308 (5.798573) | 13.161023 / 10.191392 (2.969631) | 0.130011 / 0.680424 (-0.550412) | 0.016759 / 0.534201 (-0.517442) | 0.359802 / 0.579283 (-0.219481) | 0.392577 / 0.434364 (-0.041787) | 0.427742 / 0.540337 (-0.112595) | 0.522241 / 1.386936 (-0.864695) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005985 / 0.011353 (-0.005368) | 0.003705 / 0.011008 (-0.007304) | 0.077699 / 0.038508 (0.039191) | 0.035686 / 0.023109 (0.012577) | 0.420356 / 0.275898 (0.144458) | 0.476753 / 0.323480 (0.153273) | 0.003510 / 0.007986 (-0.004475) | 0.002807 / 0.004328 (-0.001521) | 0.077151 / 0.004250 (0.072901) | 0.046420 / 0.037052 (0.009368) | 0.391781 / 0.258489 (0.133292) | 0.461128 / 0.293841 (0.167287) | 0.027847 / 0.128546 (-0.100699) | 0.008322 / 0.075646 (-0.067324) | 0.082768 / 0.419271 (-0.336503) | 0.042629 / 0.043533 (-0.000904) | 0.405745 / 0.255139 (0.150606) | 0.430797 / 0.283200 (0.147598) | 0.019832 / 0.141683 (-0.121851) | 1.556208 / 1.452155 (0.104054) | 1.612166 / 1.492716 (0.119450) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.230633 / 0.018006 (0.212626) | 0.401667 / 0.000490 (0.401178) | 0.000776 / 0.000200 (0.000576) | 0.000069 / 0.000054 (0.000014) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024959 / 0.037411 (-0.012452) | 0.100560 / 0.014526 (0.086034) | 0.109175 / 0.176557 (-0.067382) | 0.159919 / 0.737135 (-0.577217) | 0.112810 / 0.296338 (-0.183528) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.460601 / 0.215209 (0.245392) | 4.620039 / 2.077655 (2.542385) | 2.257900 / 1.504120 (0.753780) | 2.039192 / 1.541195 (0.497997) | 2.064451 / 1.468490 (0.595961) | 0.557887 / 4.584777 (-4.026890) | 3.356100 / 3.745712 (-0.389612) | 1.703578 / 5.269862 (-3.566284) | 1.024984 / 4.565676 (-3.540693) | 0.067602 / 0.424275 (-0.356673) | 0.011450 / 0.007607 (0.003842) | 0.563230 / 0.226044 (0.337186) | 5.632150 / 2.268929 (3.363221) | 2.698701 / 55.444624 (-52.745924) | 2.363218 / 6.876477 (-4.513259) | 2.363997 / 2.142072 (0.221925) | 0.671260 / 4.805227 (-4.133967) | 0.136166 / 6.500664 (-6.364499) | 0.067094 / 0.075469 (-0.008375) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.303030 / 1.841788 (-0.538757) | 14.137277 / 8.074308 (6.062969) | 13.937631 / 10.191392 (3.746239) | 0.162626 / 0.680424 (-0.517798) | 0.016687 / 0.534201 (-0.517514) | 0.363657 / 0.579283 (-0.215626) | 0.392021 / 0.434364 (-0.042343) | 0.427275 / 0.540337 (-0.113062) | 0.512192 / 1.386936 (-0.874744) |\n\n</details>\n</details>\n\n\n",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.005974 / 0.011353 (-0.005378) | 0.003947 / 0.011008 (-0.007061) | 0.098604 / 0.038508 (0.060096) | 0.036947 / 0.023109 (0.013838) | 0.311844 / 0.275898 (0.035946) | 0.375243 / 0.323480 (0.051763) | 0.003453 / 0.007986 (-0.004533) | 0.003834 / 0.004328 (-0.000495) | 0.077943 / 0.004250 (0.073692) | 0.052956 / 0.037052 (0.015904) | 0.320812 / 0.258489 (0.062323) | 0.373963 / 0.293841 (0.080122) | 0.028382 / 0.128546 (-0.100164) | 0.008525 / 0.075646 (-0.067121) | 0.311306 / 0.419271 (-0.107965) | 0.047029 / 0.043533 (0.003496) | 0.309933 / 0.255139 (0.054794) | 0.335114 / 0.283200 (0.051915) | 0.019629 / 0.141683 (-0.122054) | 1.569771 / 1.452155 (0.117617) | 1.585899 / 1.492716 (0.093182) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.216565 / 0.018006 (0.198559) | 0.426717 / 0.000490 (0.426228) | 0.003609 / 0.000200 (0.003409) | 0.000077 / 0.000054 (0.000023) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.023079 / 0.037411 (-0.014332) | 0.096954 / 0.014526 (0.082428) | 0.105398 / 0.176557 (-0.071158) | 0.165433 / 0.737135 (-0.571703) | 0.109703 / 0.296338 (-0.186636) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.456227 / 0.215209 (0.241018) | 4.529857 / 2.077655 (2.452202) | 2.214054 / 1.504120 (0.709934) | 2.029716 / 1.541195 (0.488521) | 2.081175 / 1.468490 (0.612685) | 0.563642 / 4.584777 (-4.021135) | 3.355393 / 3.745712 (-0.390320) | 1.765938 / 5.269862 (-3.503924) | 1.039062 / 4.565676 (-3.526615) | 0.067952 / 0.424275 (-0.356323) | 0.011044 / 0.007607 (0.003437) | 0.556935 / 0.226044 (0.330890) | 5.588167 / 2.268929 (3.319239) | 2.667217 / 55.444624 (-52.777407) | 2.337383 / 6.876477 (-4.539094) | 2.429590 / 2.142072 (0.287517) | 0.676972 / 4.805227 (-4.128256) | 0.135782 / 6.500664 (-6.364882) | 0.066323 / 0.075469 (-0.009146) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.237358 / 1.841788 (-0.604429) | 13.910492 / 8.074308 (5.836184) | 13.227275 / 10.191392 (3.035883) | 0.146857 / 0.680424 (-0.533567) | 0.016991 / 0.534201 (-0.517210) | 0.363637 / 0.579283 (-0.215646) | 0.392462 / 0.434364 (-0.041902) | 0.450009 / 0.540337 (-0.090329) | 0.536077 / 1.386936 (-0.850859) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006067 / 0.011353 (-0.005286) | 0.003851 / 0.011008 (-0.007158) | 0.078462 / 0.038508 (0.039954) | 0.036221 / 0.023109 (0.013112) | 0.389195 / 0.275898 (0.113297) | 0.428710 / 0.323480 (0.105230) | 0.004645 / 0.007986 (-0.003341) | 0.002973 / 0.004328 (-0.001355) | 0.078299 / 0.004250 (0.074048) | 0.047076 / 0.037052 (0.010024) | 0.375673 / 0.258489 (0.117184) | 0.432352 / 0.293841 (0.138511) | 0.028212 / 0.128546 (-0.100334) | 0.008475 / 0.075646 (-0.067172) | 0.083902 / 0.419271 (-0.335369) | 0.046699 / 0.043533 (0.003166) | 0.364502 / 0.255139 (0.109363) | 0.389792 / 0.283200 (0.106592) | 0.025266 / 0.141683 (-0.116417) | 1.517458 / 1.452155 (0.065303) | 1.543634 / 1.492716 (0.050918) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.236479 / 0.018006 (0.218472) | 0.411528 / 0.000490 (0.411038) | 0.005213 / 0.000200 (0.005013) | 0.000091 / 0.000054 (0.000036) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.025764 / 0.037411 (-0.011647) | 0.103174 / 0.014526 (0.088648) | 0.110609 / 0.176557 (-0.065948) | 0.164630 / 0.737135 (-0.572506) | 0.114863 / 0.296338 (-0.181475) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.457155 / 0.215209 (0.241946) | 4.550675 / 2.077655 (2.473021) | 2.350473 / 1.504120 (0.846353) | 2.204919 / 1.541195 (0.663724) | 2.076724 / 1.468490 (0.608234) | 0.563107 / 4.584777 (-4.021670) | 3.390669 / 3.745712 (-0.355043) | 1.741111 / 5.269862 (-3.528751) | 1.033268 / 4.565676 (-3.532408) | 0.068400 / 0.424275 (-0.355875) | 0.011607 / 0.007607 (0.004000) | 0.561944 / 0.226044 (0.335900) | 5.620224 / 2.268929 (3.351296) | 2.705241 / 55.444624 (-52.739384) | 2.344520 / 6.876477 (-4.531957) | 2.386119 / 2.142072 (0.244046) | 0.681583 / 4.805227 (-4.123644) | 0.137272 / 6.500664 (-6.363392) | 0.069217 / 0.075469 (-0.006252) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.322690 / 1.841788 (-0.519098) | 14.464953 / 8.074308 (6.390645) | 14.269350 / 10.191392 (4.077958) | 0.158879 / 0.680424 (-0.521545) | 0.016722 / 0.534201 (-0.517479) | 0.360299 / 0.579283 (-0.218984) | 0.391609 / 0.434364 (-0.042755) | 0.420507 / 0.540337 (-0.119831) | 0.512822 / 1.386936 (-0.874114) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007106 / 0.011353 (-0.004247) | 0.005224 / 0.011008 (-0.005784) | 0.127563 / 0.038508 (0.089055) | 0.055067 / 0.023109 (0.031958) | 0.418660 / 0.275898 (0.142761) | 0.487891 / 0.323480 (0.164411) | 0.005712 / 0.007986 (-0.002274) | 0.004585 / 0.004328 (0.000256) | 0.090994 / 0.004250 (0.086743) | 0.071837 / 0.037052 (0.034784) | 0.446957 / 0.258489 (0.188468) | 0.475966 / 0.293841 (0.182125) | 0.038062 / 0.128546 (-0.090484) | 0.010056 / 0.075646 (-0.065590) | 0.406796 / 0.419271 (-0.012475) | 0.066542 / 0.043533 (0.023009) | 0.413676 / 0.255139 (0.158537) | 0.448624 / 0.283200 (0.165424) | 0.030332 / 0.141683 (-0.111351) | 1.895307 / 1.452155 (0.443152) | 1.904411 / 1.492716 (0.411694) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.221246 / 0.018006 (0.203240) | 0.461288 / 0.000490 (0.460799) | 0.005957 / 0.000200 (0.005757) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029255 / 0.037411 (-0.008156) | 0.131299 / 0.014526 (0.116773) | 0.135814 / 0.176557 (-0.040742) | 0.201342 / 0.737135 (-0.535793) | 0.141748 / 0.296338 (-0.154591) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.463936 / 0.215209 (0.248727) | 4.709621 / 2.077655 (2.631966) | 2.093844 / 1.504120 (0.589724) | 1.897963 / 1.541195 (0.356768) | 1.927865 / 1.468490 (0.459375) | 0.610879 / 4.584777 (-3.973898) | 4.481370 / 3.745712 (0.735658) | 2.112235 / 5.269862 (-3.157627) | 1.203349 / 4.565676 (-3.362327) | 0.074828 / 0.424275 (-0.349447) | 0.013121 / 0.007607 (0.005514) | 0.580894 / 0.226044 (0.354849) | 5.801872 / 2.268929 (3.532943) | 2.579950 / 55.444624 (-52.864674) | 2.251569 / 6.876477 (-4.624908) | 2.421305 / 2.142072 (0.279232) | 0.760938 / 4.805227 (-4.044289) | 0.169554 / 6.500664 (-6.331110) | 0.077499 / 0.075469 (0.002030) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.410419 / 1.841788 (-0.431368) | 17.442331 / 8.074308 (9.368023) | 15.782183 / 10.191392 (5.590791) | 0.180649 / 0.680424 (-0.499775) | 0.021790 / 0.534201 (-0.512411) | 0.511040 / 0.579283 (-0.068243) | 0.510472 / 0.434364 (0.076108) | 0.607141 / 0.540337 (0.066804) | 0.724794 / 1.386936 (-0.662142) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007280 / 0.011353 (-0.004073) | 0.004712 / 0.011008 (-0.006296) | 0.089225 / 0.038508 (0.050717) | 0.053157 / 0.023109 (0.030048) | 0.431949 / 0.275898 (0.156051) | 0.478128 / 0.323480 (0.154648) | 0.006181 / 0.007986 (-0.001804) | 0.003387 / 0.004328 (-0.000941) | 0.083741 / 0.004250 (0.079490) | 0.071610 / 0.037052 (0.034557) | 0.414698 / 0.258489 (0.156209) | 0.484422 / 0.293841 (0.190581) | 0.034988 / 0.128546 (-0.093558) | 0.009831 / 0.075646 (-0.065816) | 0.089644 / 0.419271 (-0.329628) | 0.057053 / 0.043533 (0.013520) | 0.413144 / 0.255139 (0.158005) | 0.445464 / 0.283200 (0.162264) | 0.026109 / 0.141683 (-0.115574) | 1.842899 / 1.452155 (0.390745) | 1.923774 / 1.492716 (0.431057) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.245051 / 0.018006 (0.227045) | 0.460444 / 0.000490 (0.459954) | 0.000444 / 0.000200 (0.000244) | 0.000067 / 0.000054 (0.000012) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.034835 / 0.037411 (-0.002577) | 0.130078 / 0.014526 (0.115553) | 0.147012 / 0.176557 (-0.029544) | 0.203097 / 0.737135 (-0.534038) | 0.149636 / 0.296338 (-0.146702) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.521664 / 0.215209 (0.306455) | 5.283865 / 2.077655 (3.206210) | 2.456701 / 1.504120 (0.952581) | 2.266059 / 1.541195 (0.724864) | 2.295387 / 1.468490 (0.826897) | 0.613200 / 4.584777 (-3.971577) | 4.526107 / 3.745712 (0.780394) | 2.047327 / 5.269862 (-3.222535) | 1.261063 / 4.565676 (-3.304614) | 0.070402 / 0.424275 (-0.353873) | 0.014128 / 0.007607 (0.006521) | 0.620929 / 0.226044 (0.394884) | 6.109127 / 2.268929 (3.840198) | 3.081406 / 55.444624 (-52.363218) | 2.658224 / 6.876477 (-4.218253) | 2.671974 / 2.142072 (0.529902) | 0.744081 / 4.805227 (-4.061146) | 0.161498 / 6.500664 (-6.339166) | 0.075148 / 0.075469 (-0.000321) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.585640 / 1.841788 (-0.256148) | 17.884321 / 8.074308 (9.810013) | 15.938937 / 10.191392 (5.747545) | 0.220818 / 0.680424 (-0.459605) | 0.021452 / 0.534201 (-0.512749) | 0.499747 / 0.579283 (-0.079536) | 0.512318 / 0.434364 (0.077954) | 0.562853 / 0.540337 (0.022515) | 0.678512 / 1.386936 (-0.708424) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2984 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2984/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2984/comments | https://api.github.com/repos/huggingface/datasets/issues/2984/events | https://github.com/huggingface/datasets/issues/2984 | 1,010,484,326 | I_kwDODunzps48OsRm | 2,984 | Exceeded maximum rows when reading large files | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-09-29T04:49:22Z | 2021-10-12T06:05:42Z | 2021-10-12T06:05:42Z | null | ## Describe the bug
A clear and concise description of what the bug is.
When using `load_dataset` with json files, if the files are too large, there will be "Exceeded maximum rows" error.
## Steps to reproduce the bug
```python
dataset = load_dataset('json', data_files=data_files) # data files have 3M rows in a single file
```
## Expected results
No error
## Actual results
```
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
134 with open(file, encoding="utf-8") as f:
--> 135 dataset = json.load(f)
136 except json.JSONDecodeError:
~/anaconda3/envs/python/lib/python3.9/json/__init__.py in load(fp, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
292 """
--> 293 return loads(fp.read(),
294 cls=cls, object_hook=object_hook,
~/anaconda3/envs/python/lib/python3.9/json/__init__.py in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
345 parse_constant is None and object_pairs_hook is None and not kw):
--> 346 return _default_decoder.decode(s)
347 if cls is None:
~/anaconda3/envs/python/lib/python3.9/json/decoder.py in decode(self, s, _w)
339 if end != len(s):
--> 340 raise JSONDecodeError("Extra data", s, end)
341 return obj
JSONDecodeError: Extra data: line 2 column 1 (char 20321)
During handling of the above exception, another exception occurred:
ArrowInvalid Traceback (most recent call last)
<ipython-input-20-ab3718a6482f> in <module>
----> 1 dataset = load_dataset('json', data_files=data_files)
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
841
842 # Download and prepare data
--> 843 builder_instance.download_and_prepare(
844 download_config=download_config,
845 download_mode=download_mode,
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
606 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
607 if not downloaded_from_gcs:
--> 608 self._download_and_prepare(
609 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
610 )
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
684 try:
685 # Prepare split will record examples associated to the split
--> 686 self._prepare_split(split_generator, **prepare_split_kwargs)
687 except OSError as e:
688 raise OSError(
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/builder.py in _prepare_split(self, split_generator)
1153 generator = self._generate_tables(**split_generator.gen_kwargs)
1154 with ArrowWriter(features=self.info.features, path=fpath) as writer:
-> 1155 for key, table in utils.tqdm(
1156 generator, unit=" tables", leave=False, disable=bool(logging.get_verbosity() == logging.NOTSET)
1157 ):
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
135 dataset = json.load(f)
136 except json.JSONDecodeError:
--> 137 raise e
138 raise ValueError(
139 f"Not able to read records in the JSON file at {file}. "
~/anaconda3/envs/python/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py in _generate_tables(self, files)
114 while True:
115 try:
--> 116 pa_table = paj.read_json(
117 BytesIO(batch), read_options=paj.ReadOptions(block_size=block_size)
118 )
~/anaconda3/envs/python/lib/python3.9/site-packages/pyarrow/_json.pyx in pyarrow._json.read_json()
~/anaconda3/envs/python/lib/python3.9/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/anaconda3/envs/python/lib/python3.9/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Exceeded maximum rows
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Linux
- Python version: 3.9
- PyArrow version: 4.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2984/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2984/timeline | null | completed | null | null | false | [
"Hi @zijwang, thanks for reporting this issue.\r\n\r\nYou did not mention which `datasets` version you are using, but looking at the code in the stack trace, it seems you are using an old version.\r\n\r\nCould you please update `datasets` (`pip install -U datasets`) and check if the problem persists?"
] |
https://api.github.com/repos/huggingface/datasets/issues/2730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2730/comments | https://api.github.com/repos/huggingface/datasets/issues/2730/events | https://github.com/huggingface/datasets/issues/2730 | 955,987,834 | MDU6SXNzdWU5NTU5ODc4MzQ= | 2,730 | Update CommonVoice with new release | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | 3 | 2021-07-29T15:59:59Z | 2021-08-07T16:19:19Z | null | null | ## Adding a Dataset
- **Name:** CommonVoice mid-2021 release
- **Description:** more data in CommonVoice: Languages that have increased the most by percentage are Thai (almost 20x growth, from 12 hours to 250 hours), Luganda (almost 9x growth, from 8 to 80), Esperanto (7x growth, from 100 to 840), and Tamil (almost 8x, from 24 to 220).
- **Paper:** https://discourse.mozilla.org/t/common-voice-2021-mid-year-dataset-release/83812
- **Data:** https://commonvoice.mozilla.org/en/datasets
- **Motivation:** More data and more varied. I think we just need to add configs in the existing dataset script.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2730/timeline | null | null | null | null | false | [
"cc @patrickvonplaten?",
"Does anybody know if there is a bundled link, which would allow direct data download instead of manual? \r\nSomething similar to: `https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/ab.tar.gz` ? cc @patil-suraj \r\n",
"Also see: https://github.com/common-voice/common-voice-bundler/issues/15"
] |
https://api.github.com/repos/huggingface/datasets/issues/2806 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2806/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2806/comments | https://api.github.com/repos/huggingface/datasets/issues/2806/events | https://github.com/huggingface/datasets/pull/2806 | 971,625,449 | MDExOlB1bGxSZXF1ZXN0NzEzMzM5NDUw | 2,806 | Fix streaming tar files from canonical datasets | [] | closed | false | null | 5 | 2021-08-16T11:10:28Z | 2021-10-13T09:04:03Z | 2021-10-13T09:04:02Z | null | Previous PR #2800 implemented support to stream remote tar files when passing the parameter `data_files`: they required a glob string `"*"`.
However, this glob string creates an error when streaming canonical datasets (with a `join` after the `open`).
This PR fixes this issue and allows streaming tar files both from:
- canonical datasets scripts and
- data files.
This PR also adds support for compressed tar files: `.tar.gz`, `.tar.bz2`,...
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2806/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2806/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2806.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2806",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2806.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2806"
} | true | [
"In case it's relevant for this PR, I'm finding that I cannot stream the `bookcorpus` dataset (using the `master` branch of `datasets`), which is a `.tar.bz2` file:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nbooks_dataset_streamed = load_dataset(\"bookcorpus\", split=\"train\", streaming=True)\r\n# Throws a 404 HTTP error\r\nnext(iter(books_dataset_streamed))\r\n```\r\n\r\nThe full stack trace is:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nClientResponseError Traceback (most recent call last)\r\n<ipython-input-11-5ebbbe110b13> in <module>()\r\n----> 1 next(iter(books_dataset_streamed))\r\n\r\n11 frames\r\n/usr/local/lib/python3.7/dist-packages/datasets/iterable_dataset.py in __iter__(self)\r\n 339 \r\n 340 def __iter__(self):\r\n--> 341 for key, example in self._iter():\r\n 342 if self.features:\r\n 343 # we encode the example for ClassLabel feature types for example\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/iterable_dataset.py in _iter(self)\r\n 336 else:\r\n 337 ex_iterable = self._ex_iterable\r\n--> 338 yield from ex_iterable\r\n 339 \r\n 340 def __iter__(self):\r\n\r\n/usr/local/lib/python3.7/dist-packages/datasets/iterable_dataset.py in __iter__(self)\r\n 76 \r\n 77 def __iter__(self):\r\n---> 78 for key, example in self.generate_examples_fn(**self.kwargs):\r\n 79 yield key, example\r\n 80 \r\n\r\n/root/.cache/huggingface/modules/datasets_modules/datasets/bookcorpus/44662c4a114441c35200992bea923b170e6f13f2f0beb7c14e43759cec498700/bookcorpus.py in _generate_examples(self, directory)\r\n 98 for txt_file in files:\r\n 99 with open(txt_file, mode=\"r\", encoding=\"utf-8\") as f:\r\n--> 100 for line in f:\r\n 101 yield _id, {\"text\": line.strip()}\r\n 102 _id += 1\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/implementations/http.py in read(self, length)\r\n 496 else:\r\n 497 length = min(self.size - self.loc, length)\r\n--> 498 return super().read(length)\r\n 499 \r\n 500 async def async_fetch_all(self):\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/spec.py in read(self, length)\r\n 1481 # don't even bother calling fetch\r\n 1482 return b\"\"\r\n-> 1483 out = self.cache._fetch(self.loc, self.loc + length)\r\n 1484 self.loc += len(out)\r\n 1485 return out\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/caching.py in _fetch(self, start, end)\r\n 374 ):\r\n 375 # First read, or extending both before and after\r\n--> 376 self.cache = self.fetcher(start, bend)\r\n 377 self.start = start\r\n 378 elif start < self.start:\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/asyn.py in wrapper(*args, **kwargs)\r\n 86 def wrapper(*args, **kwargs):\r\n 87 self = obj or args[0]\r\n---> 88 return sync(self.loop, func, *args, **kwargs)\r\n 89 \r\n 90 return wrapper\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/asyn.py in sync(loop, func, timeout, *args, **kwargs)\r\n 67 raise FSTimeoutError\r\n 68 if isinstance(result[0], BaseException):\r\n---> 69 raise result[0]\r\n 70 return result[0]\r\n 71 \r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/asyn.py in _runner(event, coro, result, timeout)\r\n 23 coro = asyncio.wait_for(coro, timeout=timeout)\r\n 24 try:\r\n---> 25 result[0] = await coro\r\n 26 except Exception as ex:\r\n 27 result[0] = ex\r\n\r\n/usr/local/lib/python3.7/dist-packages/fsspec/implementations/http.py in async_fetch_range(self, start, end)\r\n 535 # range request outside file\r\n 536 return b\"\"\r\n--> 537 r.raise_for_status()\r\n 538 if r.status == 206:\r\n 539 # partial content, as expected\r\n\r\n/usr/local/lib/python3.7/dist-packages/aiohttp/client_reqrep.py in raise_for_status(self)\r\n 1003 status=self.status,\r\n 1004 message=self.reason,\r\n-> 1005 headers=self.headers,\r\n 1006 )\r\n 1007 \r\n\r\nClientResponseError: 404, message='Not Found', url=URL('https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2/books_large_p1.txt')\r\n```\r\n\r\nLet me know if this is unrelated and I'll open a separate issue :)\r\n\r\nEnvironment info:\r\n\r\n```\r\n- `datasets` version: 1.11.1.dev0\r\n- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic\r\n- Python version: 3.7.11\r\n- PyArrow version: 3.0.0\r\n```",
"@lewtun: `.tar.compression-extension` files are not supported yet. That is the objective of this PR.",
"> @lewtun: `.tar.compression-extension` files are not supported yet. That is the objective of this PR.\r\n\r\nthanks for the context and the great work on the streaming features (right now i'm writing the streaming section of the HF course, so am acting like a beta tester 😄)",
"@lewtun this PR fixes previous issue with xjoin:\r\n\r\nGiven:\r\n```python\r\nxjoin(\r\n \"https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2\",\r\n \"books_large_p1.txt\"\r\n)\r\n```\r\n\r\n- Before it gave: \r\n `\"https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2/books_large_p1.txt\"`\r\n thus raising the 404 error\r\n\r\n- Now it gives:\r\n `tar://books_large_p1.txt::https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2`\r\n (this is the expected format for `fsspec`) and additionally passes the parameter `compression=\"bz2\"`.\r\n See: https://github.com/huggingface/datasets/pull/2806/files#diff-97bb2d08db65ce3b679aefc43cadad76d053c1e58ecc315e49b80873d0fbdabeR15",
"closing in favor of #3066 "
] |
https://api.github.com/repos/huggingface/datasets/issues/1488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1488/comments | https://api.github.com/repos/huggingface/datasets/issues/1488/events | https://github.com/huggingface/datasets/pull/1488 | 762,860,679 | MDExOlB1bGxSZXF1ZXN0NTM3MzY1ODUz | 1,488 | Adding NELL | [] | closed | false | null | 2 | 2020-12-11T20:25:25Z | 2021-01-07T08:37:07Z | 2020-12-21T14:45:00Z | null | NELL is a knowledge base and knowledge graph along with sentences used to create the KB. See http://rtw.ml.cmu.edu/rtw/ for more details. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1488/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1488.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1488",
"merged_at": "2020-12-21T14:44:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1488.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1488"
} | true | [
"hi @lhoestq, I wanted to push another change to this branch b/c I found a bug in the parsing. I need to swap arg1 and arg2. I tried to git push -u origin nell but it didn't work. So I tried to do git push --force -u origin nell which seems to work, but nothing is happening to this branch. I think this is because it's closed. Do I need to open another PR?\r\n\r\nThe change should be below in _generate_examples:\r\n best_arg1 = row[9]\r\n best_arg2 = row[8]\r\n",
"Hi @ontocord !\r\n\r\nYup the easiest thing to do is to open a new PR with a title like \"Fix NELL dataset argument order\". If it's a simple fix we can look at it pretty fast :) "
] |
https://api.github.com/repos/huggingface/datasets/issues/1333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1333/comments | https://api.github.com/repos/huggingface/datasets/issues/1333/events | https://github.com/huggingface/datasets/pull/1333 | 759,687,836 | MDExOlB1bGxSZXF1ZXN0NTM0NjQ4OTI4 | 1,333 | Add Tanzil Dataset | [] | closed | false | null | 0 | 2020-12-08T18:45:15Z | 2020-12-10T11:17:56Z | 2020-12-10T11:14:43Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1333/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1333/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1333.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1333",
"merged_at": "2020-12-10T11:14:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1333.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1333"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/855 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/855/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/855/comments | https://api.github.com/repos/huggingface/datasets/issues/855/events | https://github.com/huggingface/datasets/pull/855 | 743,690,839 | MDExOlB1bGxSZXF1ZXN0NTIxNTQ2Njkx | 855 | Fix kor nli csv reader | [] | closed | false | null | 0 | 2020-11-16T09:53:41Z | 2020-11-16T13:59:14Z | 2020-11-16T13:59:12Z | null | The kor_nli dataset had an issue with the csv reader that was not able to parse the lines correctly. Some lines were merged together for some reason.
I fixed that by iterating through the lines directly instead of using a csv reader.
I also changed the feature names to match the other NLI datasets (i.e. use "premise", "hypothesis", "label" features)
Fix #821 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/855/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/855/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/855.diff",
"html_url": "https://github.com/huggingface/datasets/pull/855",
"merged_at": "2020-11-16T13:59:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/855.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/855"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2847 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2847/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2847/comments | https://api.github.com/repos/huggingface/datasets/issues/2847/events | https://github.com/huggingface/datasets/pull/2847 | 981,589,693 | MDExOlB1bGxSZXF1ZXN0NzIxNjA3OTA0 | 2,847 | fix regex to accept negative timezone | [] | closed | false | null | 0 | 2021-08-27T20:54:05Z | 2021-09-13T20:39:50Z | 2021-09-07T09:34:23Z | null | fix #2846 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2847/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2847/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2847.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2847",
"merged_at": "2021-09-07T09:34:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2847.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2847"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/773/comments | https://api.github.com/repos/huggingface/datasets/issues/773/events | https://github.com/huggingface/datasets/issues/773 | 731,684,153 | MDU6SXNzdWU3MzE2ODQxNTM= | 773 | Adding CC-100: Monolingual Datasets from Web Crawl Data | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 4 | 2020-10-28T18:20:41Z | 2022-01-26T13:22:54Z | 2020-12-14T10:20:07Z | null | ## Adding a Dataset
- **Name:** CC-100: Monolingual Datasets from Web Crawl Data
- **Description:** https://twitter.com/alex_conneau/status/1321507120848625665
- **Paper:** https://arxiv.org/abs/1911.02116
- **Data:** http://data.statmt.org/cc-100/
- **Motivation:** A large scale multi-lingual language modeling dataset. Text is de-duplicated and filtered by how "Wikipedia-like" it is, hopefully helping avoid some of the worst parts of the common crawl.
Instructions to add a new dataset can be found [here](https://huggingface.co/docs/datasets/share_dataset.html).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/773/timeline | null | completed | null | null | false | [
"cc @aconneau ;) ",
"These dataset files are no longer available. https://data.statmt.org/cc-100/ files provided in this link are no longer available. Can anybody fix that issue?\r\n@abhishekkrthakur @yjernite ",
"Hi ! Can you open an issue to report this problem ? This will help keep track of the fix :)",
"Ok"
] |
https://api.github.com/repos/huggingface/datasets/issues/3337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3337/comments | https://api.github.com/repos/huggingface/datasets/issues/3337/events | https://github.com/huggingface/datasets/issues/3337 | 1,066,232,936 | I_kwDODunzps4_jWxo | 3,337 | Typing of Dataset.__getitem__ could be improved. | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-11-29T16:20:11Z | 2021-12-14T10:28:54Z | 2021-12-14T10:28:54Z | null | ## Describe the bug
The newly added typing for Dataset.__getitem__ is Union[Dict, List]. This makes tools like mypy a bit awkward to use as we need to check the type manually. We could use type overloading to make this easier. [Documentation](https://docs.python.org/3/library/typing.html#typing.overload)
## Steps to reproduce the bug
Let's have a file `test.py`
```python
from typing import List, Dict, Any
from datasets import Dataset
ds = Dataset.from_dict({
'a': [1,2,3],
'b': ["1", "2", "3"]
})
one_colum: List[str] = ds['a']
some_index: Dict[Any, Any] = ds[1]
```
## Expected results
Running `mypy test.py` should not give any error.
## Actual results
```
test.py:10: error: Incompatible types in assignment (expression has type "Union[Dict[Any, Any], List[Any]]", variable has type "List[str]")
test.py:11: error: Incompatible types in assignment (expression has type "Union[Dict[Any, Any], List[Any]]", variable has type "Dict[Any, Any]")
Found 2 errors in 1 file (checked 1 source file)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.13.3
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.8
- PyArrow version: 6.0.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3337/timeline | null | completed | null | null | false | [
"Hi ! Thanks for the suggestion, I didn't know about this decorator.\r\n\r\nIf you are interesting in contributing, feel free to open a pull request to add the overload methods for each typing combination :) To assign you to this issue, you can comment `#self-assign` in this thread.\r\n\r\n`Dataset.__getitem__` is defined right here: https://github.com/huggingface/datasets/blob/e6f1352fe19679de897f3d962e616936a17094f5/src/datasets/arrow_dataset.py#L1840",
"#self-assign"
] |
https://api.github.com/repos/huggingface/datasets/issues/6 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6/comments | https://api.github.com/repos/huggingface/datasets/issues/6/events | https://github.com/huggingface/datasets/issues/6 | 600,330,836 | MDU6SXNzdWU2MDAzMzA4MzY= | 6 | Error when citation is not given in the DatasetInfo | [] | closed | false | null | 3 | 2020-04-15T14:14:54Z | 2020-04-29T09:23:22Z | 2020-04-29T09:23:22Z | null | The following error is raised when the `citation` parameter is missing when we instantiate a `DatasetInfo`:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/dev/jplu/datasets/src/nlp/info.py", line 338, in __repr__
citation_pprint = _indent('"""{}"""'.format(self.citation.strip()))
AttributeError: 'NoneType' object has no attribute 'strip'
```
I propose to do the following change in the `info.py` file. The method:
```python
def __repr__(self):
splits_pprint = _indent("\n".join(["{"] + [
" '{}': {},".format(k, split.num_examples)
for k, split in sorted(self.splits.items())
] + ["}"]))
features_pprint = _indent(repr(self.features))
citation_pprint = _indent('"""{}"""'.format(self.citation.strip()))
return INFO_STR.format(
name=self.name,
version=self.version,
description=self.description,
total_num_examples=self.splits.total_num_examples,
features=features_pprint,
splits=splits_pprint,
citation=citation_pprint,
homepage=self.homepage,
supervised_keys=self.supervised_keys,
# Proto add a \n that we strip.
license=str(self.license).strip())
```
Becomes:
```python
def __repr__(self):
splits_pprint = _indent("\n".join(["{"] + [
" '{}': {},".format(k, split.num_examples)
for k, split in sorted(self.splits.items())
] + ["}"]))
features_pprint = _indent(repr(self.features))
## the strip is done only is the citation is given
citation_pprint = self.citation
if self.citation:
citation_pprint = _indent('"""{}"""'.format(self.citation.strip()))
return INFO_STR.format(
name=self.name,
version=self.version,
description=self.description,
total_num_examples=self.splits.total_num_examples,
features=features_pprint,
splits=splits_pprint,
citation=citation_pprint,
homepage=self.homepage,
supervised_keys=self.supervised_keys,
# Proto add a \n that we strip.
license=str(self.license).strip())
```
And now it is ok. @thomwolf are you ok with this fix? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6/timeline | null | completed | null | null | false | [
"Yes looks good to me.\r\nNote that we may refactor quite strongly the `info.py` to make it a lot simpler (it's very complicated for basically a dictionary of info I think)",
"No, problem ^^ It might just be a temporary fix :)",
"Fixed."
] |
https://api.github.com/repos/huggingface/datasets/issues/2748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2748/comments | https://api.github.com/repos/huggingface/datasets/issues/2748/events | https://github.com/huggingface/datasets/pull/2748 | 958,889,041 | MDExOlB1bGxSZXF1ZXN0NzAyMDg4NTk4 | 2,748 | Generate metadata JSON for wikihow dataset | [] | closed | false | null | 0 | 2021-08-03T08:55:40Z | 2021-08-03T10:17:51Z | 2021-08-03T10:17:51Z | null | Related to #2743. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2748/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2748/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2748",
"merged_at": "2021-08-03T10:17:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2748"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1205 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1205/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1205/comments | https://api.github.com/repos/huggingface/datasets/issues/1205/events | https://github.com/huggingface/datasets/pull/1205 | 757,942,403 | MDExOlB1bGxSZXF1ZXN0NTMzMjA4NDI1 | 1,205 | add lst20 with manual download | [] | closed | false | null | 2 | 2020-12-06T14:49:10Z | 2020-12-09T16:33:10Z | 2020-12-09T16:33:10Z | null | passed on local:
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_lst20
```
Not sure how to test:
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_lst20
```
```
LST20 Corpus is a dataset for Thai language processing developed by National Electronics and Computer Technology Center (NECTEC), Thailand.
It offers five layers of linguistic annotation: word boundaries, POS tagging, named entities, clause boundaries, and sentence boundaries.
At a large scale, it consists of 3,164,002 words, 288,020 named entities, 248,181 clauses, and 74,180 sentences, while it is annotated with
16 distinct POS tags. All 3,745 documents are also annotated with one of 15 news genres. Regarding its sheer size, this dataset is
considered large enough for developing joint neural models for NLP.
Manually download at https://aiforthai.in.th/corpus.php
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1205/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1205/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1205.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1205",
"merged_at": "2020-12-09T16:33:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1205.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1205"
} | true | [
"The pytest suite doesn't allow manual downloads so we just make sure that the `datasets-cli test` command to run without errors instead",
"@lhoestq Changes made. Thank you for the review. I've made some same mistakes for https://github.com/huggingface/datasets/pull/1253 too. Will fix them before review."
] |
https://api.github.com/repos/huggingface/datasets/issues/5883 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5883/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5883/comments | https://api.github.com/repos/huggingface/datasets/issues/5883/events | https://github.com/huggingface/datasets/pull/5883 | 1,719,527,597 | PR_kwDODunzps5RAkYi | 5,883 | Fix string-encoding, make `batch_size` optional, and minor improvements in `Dataset.to_tf_dataset` | [] | closed | false | null | 29 | 2023-05-22T11:51:07Z | 2023-06-08T11:09:03Z | 2023-06-06T16:49:15Z | null | ## What's in this PR?
This PR addresses some minor fixes and general improvements in the `to_tf_dataset` method of `datasets.Dataset`, to convert a 🤗HuggingFace Dataset as a TensorFlow Dataset.
The main bug solved in this PR comes with the string-encoding, since for safety purposes the internal conversion of `numpy.arrays` when `dtype` is unicode/string, is to convert it into `numpy.bytes`, more information in the docstring of https://github.com/tensorflow/tensorflow/blob/388d952114e59a1aeda440ed4737b29f8b7c6e8a/tensorflow/python/ops/script_ops.py#L210. That's triggered when using `tensorflow.numpy_function` as it's applying another type cast besides the one that `datasets` does, so the casting is applied at least twice per entry/batch. So this means that the definition of the `numpy.unicode_` dtype when the data in the batch is a string, is ignored, and replaced by `numpy.bytes_`.
Besides that, some other minor things have been fixed:
* Made `batch_size` an optional parameter in `to_tf_dataset`
* Map the `tensorflow` output dtypes just once, and not in every `tf.function` call during `map`
* Keep `numpy` formatting in the `datasets.Dataset` if already formatted like it, no need to format it again as `numpy`
* Docstring indentation in `dataset_to_tf` and `multiprocess_dataset_to_tf`
## What's missing in this PR?
I can include some integration tests if needed, to validate that `batch_size` is optional, and that the tensors in the TF-Dataset can be looped over with no issues as before. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5883/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5883/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5883.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5883",
"merged_at": "2023-06-06T16:49:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5883.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5883"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"To showcase the current issue, here's a Colab Gist, that shows that the `imdb` dataset cannot be read/iterated, since one or more samples contain a non-ascii character that is being converted to `numpy.bytes_`, and so on fails.\r\n\r\nColab Gist at https://gist.github.com/alvarobartt/1746959d1abb9a33e0c593f3bd82a2fb\r\n\r\nAlso, here's a quick sample of what's happening:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"imdb\", split=\"train\")\r\ntfds = ds.to_tf_dataset(batch_size=16)\r\nfor batch in tfds:\r\n print(batch)\r\n>>> UnicodeEncodeError: 'ascii' codec can't encode character '\\xe9' in position 0: ordinal not in range(128)\r\n```\r\n\r\nA more detailed version of it:\r\n\r\n```python\r\nfrom datasets import Dataset\r\n\r\nds = Dataset.from_dict(\r\n {\r\n \"a\": [1],\r\n \"b\": [\"é\"],\r\n }\r\n)\r\ntfds = ds.to_tf_dataset(batch_size=1)\r\nfor batch in tfds:\r\n print(batch)\r\n>>> UnicodeEncodeError: 'ascii' codec can't encode character '\\xe9' in position 0: ordinal not in range(128)\r\n```\r\n\r\nThe original issue comes from https://github.com/tensorflow/tensorflow/blob/388d952114e59a1aeda440ed4737b29f8b7c6e8a/tensorflow/python/ops/script_ops.py#LL234C4-L234C4, which could easily be solved by replacing that line with `return result.astype(np.unicode_)` but they are mentioning that it may lead to issues.\r\n\r\nEven the following fails in `numpy`:\r\n\r\n```python\r\nimport numpy as np\r\n\r\nx = np.array([\"é\"]).astype(np.bytes_)\r\n```",
"cc. @lhoestq :hugs:",
"cc @Rocketknight1 ",
"> Nice ! Could you add some tests to make sure that batch_size=None works as expected ?\r\n\r\nSure, I'll add the tests for everything, including the string-encoding issue to make sure it's solved!",
"Thanks for the review @lhoestq and @Rocketknight1! I do understand that processing it in batches is always more efficient than processing it one-by-one, it was just to make `batch_size` optional. What we can do is default it to a certain batch size e.g. 16 as before, and that's it, but I think it can still remain optional.",
"@Rocketknight1 then I'll add the integration tests for the optional `batch_size` as well as for the encoding of non-ASCII compatible characters 😄 Do we set the default `batch_size` to 16 instead of `None`?",
"@alvarobartt I think 16 is a reasonable default, yep!",
"I think default should be None, not 16.\r\nUsers won't expect to have it batched by default.",
"Then I'll leave it as is, and add the unit/integration tests, thanks @Rocketknight1 and @lhoestq ",
"Hi @Rocketknight1 @lhoestq! So the string-encoding issue is already solved, but I've got one doubt about the `batch_size` being optional in the multiprocessing approach, since in that case I assume the `batch_size` should be mandatory, for the moment I'm assuming it is/should be mandatory, but let me know if you want me to add a check to disallow `batch_size=None` when `num_workers>1`. Thanks!",
"> To showcase the current issue, here's a Colab Gist, that shows that the `imdb` dataset cannot be read/iterated, since one or more samples contain a non-ascii character that is being converted to `numpy.bytes_`, and so on fails.\r\n> \r\n> Colab Gist at https://gist.github.com/alvarobartt/1746959d1abb9a33e0c593f3bd82a2fb\r\n\r\nI've used the Colab shared above for testing purposes, and it works fine, plus the unit/integration tests are passing. I've also trained a `KerasNLP` model with incoming data from 🤗`datasets` with no issue at all!",
"> in the multiprocessing approach, since in that case I assume the batch_size should be mandatory,\r\n\r\nNo I think they're quite orthogonal, no need to have it mandatory",
"> No I think they're quite orthogonal, no need to have it mandatory\r\n\r\nBut it will break if `batch_size=None` as the multiprocessing approach will aim to prepare batches and distribute those to every worker, and assuming `batch_size=1` when `batch_size=None` I guess is not a good assumption, right?",
"Ah I see. Multiprocessing should support batch_size=None indeed. If you have ideas you can do it in this PR, or raise a NotImplementedError and we can see later",
"Sure @lhoestq, I can add a `NotImplementedError` for the moment, and prepare the next PR straight-away to tackle the multiprocessing approach with `batch_size=None`, but not sure if that may eventually collide with @Rocketknight1 PR at https://github.com/huggingface/datasets/pull/5863",
"Yes, let me merge the PR at #5863 after this one, and then we can open another to improve the behaviour with multiprocessing and `batch_size=None`!",
"Sure @Rocketknight1 makes complete sense to me! Do you want me to add the `raise NotImplementedError` and then we merge this PR? Or you prefer to directly merge the current?",
"`raise NotImplementedError` for now with an error telling the user that multiprocessing needs them to specify a batch size, I think!",
"Since you recently approved @Rocketknight1, are we ready to merge? Thanks 🤗",
"Ah actually it looks like `minimal_tf_collate_fn` doesn't support batch_size=None",
"Hi @lhoestq so I didn't include the call to `collate_fn`, as we won't need to collate the incoming data e.g. \"str\" should remain a \"str\" not a [\"str\"], and the `minimal_collate_fn` was indeed putting everything into a list, so the output was not un-batched, but batched with size 1",
"What if the user passes a collate_fn ? The torch DataLoader still applies it if batch_size=None for example.\r\n\r\nDoes my last change look of to you ? If so I think we can merge",
"> What if the user passes a collate_fn ? The torch DataLoader still applies it if batch_size=None for example.\r\n> \r\n> Does my last change look of to you ? If so I think we can merge\r\n\r\nI think we're good, since it won't batch it under the scenario of `str` being provided instead of `List[str]`, and the unit/integration tests are passing, so I'm OK to merge. Maybe we can double check with Matt? cc @Rocketknight1 ",
"Yes, and sorry for the delay! I'm happy to merge.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006555 / 0.011353 (-0.004798) | 0.004521 / 0.011008 (-0.006487) | 0.096633 / 0.038508 (0.058125) | 0.032859 / 0.023109 (0.009750) | 0.294632 / 0.275898 (0.018734) | 0.325140 / 0.323480 (0.001660) | 0.005676 / 0.007986 (-0.002310) | 0.005252 / 0.004328 (0.000924) | 0.074349 / 0.004250 (0.070099) | 0.045836 / 0.037052 (0.008784) | 0.302919 / 0.258489 (0.044430) | 0.340686 / 0.293841 (0.046845) | 0.028398 / 0.128546 (-0.100148) | 0.008942 / 0.075646 (-0.066704) | 0.326994 / 0.419271 (-0.092278) | 0.049556 / 0.043533 (0.006023) | 0.293883 / 0.255139 (0.038744) | 0.316522 / 0.283200 (0.033322) | 0.097385 / 0.141683 (-0.044298) | 1.405334 / 1.452155 (-0.046821) | 1.521529 / 1.492716 (0.028812) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.212269 / 0.018006 (0.194263) | 0.445692 / 0.000490 (0.445203) | 0.004930 / 0.000200 (0.004730) | 0.000093 / 0.000054 (0.000039) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026907 / 0.037411 (-0.010504) | 0.108607 / 0.014526 (0.094081) | 0.116806 / 0.176557 (-0.059751) | 0.178428 / 0.737135 (-0.558707) | 0.122326 / 0.296338 (-0.174012) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.404211 / 0.215209 (0.189002) | 4.045374 / 2.077655 (1.967719) | 1.877237 / 1.504120 (0.373117) | 1.706276 / 1.541195 (0.165081) | 1.750610 / 1.468490 (0.282120) | 0.522331 / 4.584777 (-4.062446) | 3.742286 / 3.745712 (-0.003426) | 1.791285 / 5.269862 (-3.478577) | 1.043872 / 4.565676 (-3.521805) | 0.065176 / 0.424275 (-0.359099) | 0.011821 / 0.007607 (0.004214) | 0.507374 / 0.226044 (0.281329) | 5.088803 / 2.268929 (2.819875) | 2.282742 / 55.444624 (-53.161882) | 1.950737 / 6.876477 (-4.925740) | 2.042262 / 2.142072 (-0.099810) | 0.636525 / 4.805227 (-4.168702) | 0.140837 / 6.500664 (-6.359827) | 0.063223 / 0.075469 (-0.012246) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.188070 / 1.841788 (-0.653718) | 14.622681 / 8.074308 (6.548372) | 13.247988 / 10.191392 (3.056596) | 0.165858 / 0.680424 (-0.514566) | 0.017476 / 0.534201 (-0.516725) | 0.391973 / 0.579283 (-0.187310) | 0.433326 / 0.434364 (-0.001038) | 0.467163 / 0.540337 (-0.073175) | 0.568359 / 1.386936 (-0.818577) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006076 / 0.011353 (-0.005276) | 0.004439 / 0.011008 (-0.006570) | 0.074496 / 0.038508 (0.035988) | 0.031396 / 0.023109 (0.008287) | 0.372237 / 0.275898 (0.096339) | 0.403412 / 0.323480 (0.079932) | 0.005430 / 0.007986 (-0.002555) | 0.003846 / 0.004328 (-0.000483) | 0.074403 / 0.004250 (0.070153) | 0.045398 / 0.037052 (0.008346) | 0.394133 / 0.258489 (0.135644) | 0.421769 / 0.293841 (0.127928) | 0.027936 / 0.128546 (-0.100610) | 0.008962 / 0.075646 (-0.066685) | 0.083158 / 0.419271 (-0.336113) | 0.044863 / 0.043533 (0.001331) | 0.393834 / 0.255139 (0.138695) | 0.391537 / 0.283200 (0.108337) | 0.097971 / 0.141683 (-0.043712) | 1.496632 / 1.452155 (0.044477) | 1.585511 / 1.492716 (0.092795) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.010094 / 0.018006 (-0.007913) | 0.437811 / 0.000490 (0.437321) | 0.000963 / 0.000200 (0.000763) | 0.000084 / 0.000054 (0.000029) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028864 / 0.037411 (-0.008547) | 0.112480 / 0.014526 (0.097954) | 0.120938 / 0.176557 (-0.055619) | 0.170888 / 0.737135 (-0.566247) | 0.125903 / 0.296338 (-0.170435) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.426716 / 0.215209 (0.211507) | 4.238380 / 2.077655 (2.160725) | 2.052889 / 1.504120 (0.548769) | 1.871043 / 1.541195 (0.329848) | 1.890405 / 1.468490 (0.421915) | 0.522059 / 4.584777 (-4.062718) | 3.813331 / 3.745712 (0.067619) | 2.891651 / 5.269862 (-2.378210) | 1.323836 / 4.565676 (-3.241841) | 0.065124 / 0.424275 (-0.359151) | 0.011498 / 0.007607 (0.003891) | 0.525102 / 0.226044 (0.299057) | 5.245190 / 2.268929 (2.976261) | 2.531149 / 55.444624 (-52.913476) | 2.197323 / 6.876477 (-4.679153) | 2.197314 / 2.142072 (0.055241) | 0.633423 / 4.805227 (-4.171804) | 0.140248 / 6.500664 (-6.360416) | 0.064432 / 0.075469 (-0.011037) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.270639 / 1.841788 (-0.571149) | 14.856678 / 8.074308 (6.782369) | 14.337631 / 10.191392 (4.146239) | 0.195319 / 0.680424 (-0.485105) | 0.017628 / 0.534201 (-0.516573) | 0.393984 / 0.579283 (-0.185299) | 0.421987 / 0.434364 (-0.012376) | 0.459245 / 0.540337 (-0.081092) | 0.557786 / 1.386936 (-0.829150) |\n\n</details>\n</details>\n\n\n",
"Will you eventually need help with your PR @Rocketknight1? I'll be happy to help if needed 😄 ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007577 / 0.011353 (-0.003776) | 0.004960 / 0.011008 (-0.006048) | 0.113622 / 0.038508 (0.075114) | 0.037981 / 0.023109 (0.014872) | 0.355312 / 0.275898 (0.079414) | 0.393384 / 0.323480 (0.069904) | 0.006575 / 0.007986 (-0.001411) | 0.005941 / 0.004328 (0.001612) | 0.085976 / 0.004250 (0.081726) | 0.053784 / 0.037052 (0.016732) | 0.369358 / 0.258489 (0.110869) | 0.399402 / 0.293841 (0.105561) | 0.032155 / 0.128546 (-0.096391) | 0.010448 / 0.075646 (-0.065199) | 0.389009 / 0.419271 (-0.030263) | 0.057377 / 0.043533 (0.013844) | 0.354968 / 0.255139 (0.099829) | 0.382404 / 0.283200 (0.099204) | 0.111056 / 0.141683 (-0.030627) | 1.807986 / 1.452155 (0.355832) | 1.866070 / 1.492716 (0.373354) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.244439 / 0.018006 (0.226432) | 0.491942 / 0.000490 (0.491452) | 0.001910 / 0.000200 (0.001710) | 0.000112 / 0.000054 (0.000058) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031024 / 0.037411 (-0.006387) | 0.129674 / 0.014526 (0.115148) | 0.142974 / 0.176557 (-0.033583) | 0.213568 / 0.737135 (-0.523568) | 0.147794 / 0.296338 (-0.148545) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.480333 / 0.215209 (0.265124) | 4.792901 / 2.077655 (2.715246) | 2.233145 / 1.504120 (0.729025) | 2.036291 / 1.541195 (0.495096) | 2.109631 / 1.468490 (0.641140) | 0.624546 / 4.584777 (-3.960231) | 4.543511 / 3.745712 (0.797799) | 3.961345 / 5.269862 (-1.308517) | 1.903634 / 4.565676 (-2.662042) | 0.076584 / 0.424275 (-0.347691) | 0.014590 / 0.007607 (0.006983) | 0.593195 / 0.226044 (0.367151) | 5.928740 / 2.268929 (3.659811) | 2.781164 / 55.444624 (-52.663460) | 2.364303 / 6.876477 (-4.512173) | 2.510139 / 2.142072 (0.368067) | 0.770886 / 4.805227 (-4.034341) | 0.167995 / 6.500664 (-6.332669) | 0.076622 / 0.075469 (0.001153) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.402398 / 1.841788 (-0.439390) | 17.921233 / 8.074308 (9.846925) | 17.036738 / 10.191392 (6.845346) | 0.168997 / 0.680424 (-0.511427) | 0.020259 / 0.534201 (-0.513941) | 0.465322 / 0.579283 (-0.113962) | 0.500435 / 0.434364 (0.066071) | 0.546846 / 0.540337 (0.006509) | 0.658130 / 1.386936 (-0.728806) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007624 / 0.011353 (-0.003729) | 0.005265 / 0.011008 (-0.005744) | 0.086886 / 0.038508 (0.048377) | 0.038235 / 0.023109 (0.015126) | 0.463969 / 0.275898 (0.188071) | 0.502451 / 0.323480 (0.178971) | 0.006285 / 0.007986 (-0.001701) | 0.004525 / 0.004328 (0.000197) | 0.086557 / 0.004250 (0.082307) | 0.052414 / 0.037052 (0.015362) | 0.482167 / 0.258489 (0.223678) | 0.513684 / 0.293841 (0.219843) | 0.032929 / 0.128546 (-0.095618) | 0.010249 / 0.075646 (-0.065397) | 0.093377 / 0.419271 (-0.325895) | 0.054114 / 0.043533 (0.010582) | 0.466116 / 0.255139 (0.210977) | 0.488977 / 0.283200 (0.205777) | 0.115446 / 0.141683 (-0.026237) | 1.762912 / 1.452155 (0.310757) | 1.874191 / 1.492716 (0.381475) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.012666 / 0.018006 (-0.005341) | 0.485962 / 0.000490 (0.485473) | 0.002621 / 0.000200 (0.002421) | 0.000128 / 0.000054 (0.000074) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033661 / 0.037411 (-0.003751) | 0.135395 / 0.014526 (0.120869) | 0.147230 / 0.176557 (-0.029326) | 0.205847 / 0.737135 (-0.531288) | 0.151496 / 0.296338 (-0.144842) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.514097 / 0.215209 (0.298887) | 5.134093 / 2.077655 (3.056438) | 2.496775 / 1.504120 (0.992655) | 2.268078 / 1.541195 (0.726883) | 2.342153 / 1.468490 (0.873663) | 0.623130 / 4.584777 (-3.961647) | 4.601787 / 3.745712 (0.856075) | 3.414249 / 5.269862 (-1.855613) | 1.849603 / 4.565676 (-2.716073) | 0.078350 / 0.424275 (-0.345925) | 0.013785 / 0.007607 (0.006178) | 0.638783 / 0.226044 (0.412739) | 6.378356 / 2.268929 (4.109427) | 3.072867 / 55.444624 (-52.371757) | 2.668123 / 6.876477 (-4.208354) | 2.693905 / 2.142072 (0.551833) | 0.764583 / 4.805227 (-4.040644) | 0.166854 / 6.500664 (-6.333810) | 0.076883 / 0.075469 (0.001414) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.502003 / 1.841788 (-0.339784) | 18.674205 / 8.074308 (10.599897) | 16.837759 / 10.191392 (6.646367) | 0.176995 / 0.680424 (-0.503428) | 0.020126 / 0.534201 (-0.514075) | 0.464480 / 0.579283 (-0.114803) | 0.516477 / 0.434364 (0.082113) | 0.549818 / 0.540337 (0.009481) | 0.659927 / 1.386936 (-0.727009) |\n\n</details>\n</details>\n\n\n",
"@alvarobartt Yes, I'll ping you for a review once it's ready!"
] |
https://api.github.com/repos/huggingface/datasets/issues/410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/410/comments | https://api.github.com/repos/huggingface/datasets/issues/410/events | https://github.com/huggingface/datasets/pull/410 | 659,242,871 | MDExOlB1bGxSZXF1ZXN0NDUxMTEzMTI3 | 410 | 20newsgroup | [] | closed | false | null | 0 | 2020-07-17T13:07:57Z | 2020-07-20T07:05:29Z | 2020-07-20T07:05:28Z | null | Add 20Newsgroup dataset.
#353 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/410/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/410/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/410.diff",
"html_url": "https://github.com/huggingface/datasets/pull/410",
"merged_at": "2020-07-20T07:05:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/410.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/410"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4835 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4835/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4835/comments | https://api.github.com/repos/huggingface/datasets/issues/4835/events | https://github.com/huggingface/datasets/pull/4835 | 1,336,994,835 | PR_kwDODunzps49FJg9 | 4,835 | Fix documentation card of ethos dataset | [] | closed | false | null | 1 | 2022-08-12T09:51:06Z | 2022-08-12T13:13:55Z | 2022-08-12T12:59:39Z | null | Fix documentation card of ethos dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4835/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4835/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4835.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4835",
"merged_at": "2022-08-12T12:59:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4835.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4835"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/6059 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6059/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6059/comments | https://api.github.com/repos/huggingface/datasets/issues/6059/events | https://github.com/huggingface/datasets/issues/6059 | 1,816,537,176 | I_kwDODunzps5sRihY | 6,059 | Provide ability to load label mappings from file | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 0 | 2023-07-22T02:04:19Z | 2023-07-22T02:04:19Z | null | null | ### Feature request
My task is classification of a dataset containing a large label set that includes a hierarchy. Even ignoring the hierarchy I'm not able to find an example using `datasets` where the label names aren't hard-coded. This works find for classification of a handful of labels but ideally there would be a way of loading the name/id mappings required for `datasets.features.ClassLabel` from a file.
It is possible to pass a file to ClassLabel but I cannot see an easy way of using this with `GeneratorBasedBuilder` since `self._info` is called before the `dl_manager` is constructed so even if my dataset contains say `label_mappings.json` there's no way of loading it in order to construct the `datasets.DatasetInfo`
I can see other uses to accessing the `download_manager` from `self._info` - i.e. if the files contain a schema (i.e. `arrow` or `parquet` files) the `datasets.DatasetInfo` could be inferred.
The workaround that was suggested in the forum is to generate a `.py` file from the `label_mappings.json` and import it.
```
class TestDatasetBuilder(datasets.GeneratorBasedBuilder):
VERSION = datasets.Version("1.0.0")
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=datasets.Features(
{
"text": datasets.Value("string"),
"label": datasets.features.ClassLabel(names=["label_1", "label_2"]),
}
),
task_templates=[TextClassification(text_column="text", label_column="label")],
)
def _split_generators(self, dl_manager):
train_path = dl_manager.download_and_extract(_TRAIN_DOWNLOAD_URL)
test_path = dl_manager.download_and_extract(_TEST_DOWNLOAD_URL)
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": train_path}),
datasets.SplitGenerator(name=datasets.Split.TEST, gen_kwargs={"filepath": test_path}),
]
def _generate_examples(self, filepath):
"""Generate AG News examples."""
with open(filepath, encoding="utf-8") as csv_file:
csv_reader = csv.DictReader(csv_file)
for id_, row in enumerate(csv_reader):
yield id_, row
```
### Motivation
Allow `datasets.DatasetInfo` to be generated based on the contents of the dataset.
### Your contribution
I'm willing to work on a PR with guidence. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6059/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6059/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1276 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1276/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1276/comments | https://api.github.com/repos/huggingface/datasets/issues/1276/events | https://github.com/huggingface/datasets/pull/1276 | 758,965,936 | MDExOlB1bGxSZXF1ZXN0NTM0MDQyODYy | 1,276 | add One Million Posts Corpus | [] | closed | false | null | 1 | 2020-12-08T00:50:08Z | 2020-12-11T18:28:18Z | 2020-12-11T18:28:18Z | null | - **Name:** One Million Posts Corpus
- **Description:** The “One Million Posts” corpus is an annotated data set consisting of user comments posted to an Austrian newspaper website (in German language).
- **Paper:** https://dl.acm.org/doi/10.1145/3077136.3080711
- **Data:** https://github.com/OFAI/million-post-corpus
- **Motivation:** Big German (real-life) dataset containing different annotations around forum moderation with expert annotations.
### Checkbox
- [X] Create the dataset script `/datasets/my_dataset/my_dataset.py` using the template
- [X] Fill the `_DESCRIPTION` and `_CITATION` variables
- [X] Implement `_infos()`, `_split_generators()` and `_generate_examples()`
- [X] Make sure that the `BUILDER_CONFIGS` class attribute is filled with the different configurations of the dataset and that the `BUILDER_CONFIG_CLASS` is specified if there is a custom config class.
- [X] Generate the metadata file `dataset_infos.json` for all configurations
- [X] Generate the dummy data `dummy_data.zip` files to have the dataset script tested and that they don't weigh too much (<50KB)
- [X] Add the dataset card `README.md` using the template : fill the tags and the various paragraphs
- [X] Both tests for the real data and the dummy data pass.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1276/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1276/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1276.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1276",
"merged_at": "2020-12-11T18:28:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1276.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1276"
} | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/1100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1100/comments | https://api.github.com/repos/huggingface/datasets/issues/1100/events | https://github.com/huggingface/datasets/pull/1100 | 756,998,433 | MDExOlB1bGxSZXF1ZXN0NTMyNDQ2ODc1 | 1,100 | Urdu fake news | [] | closed | false | null | 0 | 2020-12-04T10:41:20Z | 2020-12-04T11:19:00Z | 2020-12-04T11:19:00Z | null | Added Bend the Truth urdu fake news dataset. More inforation <a href="https://github.com/MaazAmjad/Datasets-for-Urdu-news">here</a>. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1100/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1100/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1100.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1100",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1100.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1100"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4969 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4969/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4969/comments | https://api.github.com/repos/huggingface/datasets/issues/4969/events | https://github.com/huggingface/datasets/pull/4969 | 1,369,334,740 | PR_kwDODunzps4-wPOk | 4,969 | Fix data URL and metadata of vivos dataset | [] | closed | false | null | 1 | 2022-09-12T06:12:34Z | 2022-09-12T07:16:15Z | 2022-09-12T07:14:19Z | null | After contacting the authors of the VIVOS dataset to report that their data server is down, we have received a reply from Hieu-Thi Luong that their data is now hosted on Zenodo: https://doi.org/10.5281/zenodo.7068130
This PR updates their data URL and some metadata (homepage, citation and license).
Fix #4936. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4969/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4969/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4969.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4969",
"merged_at": "2022-09-12T07:14:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4969.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4969"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2663/comments | https://api.github.com/repos/huggingface/datasets/issues/2663/events | https://github.com/huggingface/datasets/issues/2663 | 946,552,273 | MDU6SXNzdWU5NDY1NTIyNzM= | 2,663 | [`to_json`] add multi-proc sharding support | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2021-07-16T19:41:50Z | 2021-09-13T13:56:37Z | 2021-09-13T13:56:37Z | null | As discussed on slack it appears that `to_json` is quite slow on huge datasets like OSCAR.
I implemented sharded saving, which is much much faster - but the tqdm bars all overwrite each other, so it's hard to make sense of the progress, so if possible ideally this multi-proc support could be implemented internally in `to_json` via `num_proc` argument. I guess `num_proc` will be the number of shards?
I think the user will need to use this feature wisely, since too many processes writing to say normal style HD is likely to be slower than one process.
I'm not sure whether the user should be responsible to concatenate the shards at the end or `datasets`, either way works for my needs.
The code I was using:
```
from multiprocessing import cpu_count, Process, Queue
[...]
filtered_dataset = concat_dataset.map(filter_short_documents, batched=True, batch_size=256, num_proc=cpu_count())
DATASET_NAME = "oscar"
SHARDS = 10
def process_shard(idx):
print(f"Sharding {idx}")
ds_shard = filtered_dataset.shard(SHARDS, idx, contiguous=True)
# ds_shard = ds_shard.shuffle() # remove contiguous=True above if shuffling
print(f"Saving {DATASET_NAME}-{idx}.jsonl")
ds_shard.to_json(f"{DATASET_NAME}-{idx}.jsonl", orient="records", lines=True, force_ascii=False)
queue = Queue()
processes = [Process(target=process_shard, args=(idx,)) for idx in range(SHARDS)]
for p in processes:
p.start()
for p in processes:
p.join()
```
Thank you!
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2663/timeline | null | completed | null | null | false | [
"Hi @stas00, \r\nI want to work on this issue and I was thinking why don't we use `imap` [in this loop](https://github.com/huggingface/datasets/blob/440b14d0dd428ae1b25881aa72ba7bbb8ad9ff84/src/datasets/io/json.py#L99)? This way, using offset (which is being used to slice the pyarrow table) we can convert pyarrow table to `json` using multiprocessing. I've a small code snippet for some clarity:\r\n```\r\nresult = list(\r\n pool.imap(self._apply_df, [(offset, batch_size) for offset in range(0, len(self.dataset), batch_size)])\r\n )\r\n```\r\n`_apply_df` is a function which will return `batch.to_pandas().to_json(path_or_buf=None, orient=\"records\", lines=True)` which is basically json version of the batched pyarrow table. Later on we can concatenate it to form json file? \r\n\r\nI think the only downside here is to write file from `imap` output (output would be a list and we'll need to iterate over it and write in a file) which might add a little overhead cost. What do you think about this?",
"Followed up in https://github.com/huggingface/datasets/pull/2747"
] |
https://api.github.com/repos/huggingface/datasets/issues/2351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2351/comments | https://api.github.com/repos/huggingface/datasets/issues/2351/events | https://github.com/huggingface/datasets/pull/2351 | 889,584,953 | MDExOlB1bGxSZXF1ZXN0NjQyNzI5NDIz | 2,351 | simpllify faiss index save | [] | closed | false | null | 0 | 2021-05-12T03:54:10Z | 2021-05-17T13:41:41Z | 2021-05-17T13:41:41Z | null | Fixes #2350
In some cases, Faiss GPU index objects do not have neither "device" nor "getDevice". Possibly this happens when some part of the index is computed on CPU.
In particular, this would happen with the index `OPQ16_128,IVF512,PQ32` (issue #2350). I did check it, but it is likely that `OPQ` or `PQ` transforms cause it.
I propose, instead of using the index object to get the device, to infer it form the `FaissIndex.device` field as it is done in `.add_vectors`. Here we assume that `.device` always corresponds to the index placement and it seems reasonable. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2351/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2351.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2351",
"merged_at": "2021-05-17T13:41:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2351.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2351"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1268 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1268/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1268/comments | https://api.github.com/repos/huggingface/datasets/issues/1268/events | https://github.com/huggingface/datasets/pull/1268 | 758,871,252 | MDExOlB1bGxSZXF1ZXN0NTMzOTY0OTQ4 | 1,268 | new pr for Turkish NER | [] | closed | false | null | 3 | 2020-12-07T21:40:26Z | 2020-12-09T13:45:05Z | 2020-12-09T13:45:05Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1268/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1268/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1268.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1268",
"merged_at": "2020-12-09T13:45:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1268.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1268"
} | true | [
"Can you run `make style` to fix the code format ?\r\n\r\nAlso it looks like the file `file_downloaded/TWNERTC_TC_Coarse Grained NER_DomainIndependent_NoiseReduction.zip/TWNERTC_TC_Coarse Grained NER_DomainIndependent_NoiseReduction.DUMP` is missing inside the dummy_data.zip\r\n\r\n\r\n(note that `TWNERTC_TC_Coarse Grained NER_DomainIndependent_NoiseReduction.zip` is a directory name, not an actual zip file)",
"Hi Quentin, thank you for your patience with me. I've fixed the preprocessing pipeline, got this very weird error that Yacine told me to push. I've pushed it and after I'll find out that it will work, I will have my final pr on styling.",
"looks like you removed the dataset script file in your latest commit, is it expected ?"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3271/comments | https://api.github.com/repos/huggingface/datasets/issues/3271/events | https://github.com/huggingface/datasets/pull/3271 | 1,053,482,919 | PR_kwDODunzps4uhgi1 | 3,271 | Decode audio from remote | [] | closed | false | null | 0 | 2021-11-15T10:25:56Z | 2021-11-16T11:35:58Z | 2021-11-16T11:35:58Z | null | Currently the Audio feature type can only decode local audio files, not remote files.
To fix this I replaced `open` with our `xopen` functoin that is compatible with remote files in audio.py
cc @albertvillanova @mariosasko | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3271/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3271.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3271",
"merged_at": "2021-11-16T11:35:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3271.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3271"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2725/comments | https://api.github.com/repos/huggingface/datasets/issues/2725/events | https://github.com/huggingface/datasets/pull/2725 | 955,020,776 | MDExOlB1bGxSZXF1ZXN0Njk4ODMwNjYw | 2,725 | Pass use_auth_token to request_etags | [] | closed | false | null | 0 | 2021-07-28T16:13:29Z | 2021-07-28T16:38:02Z | 2021-07-28T16:38:02Z | null | Fix #2724. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2725/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2725.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2725",
"merged_at": "2021-07-28T16:38:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2725.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2725"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4663/comments | https://api.github.com/repos/huggingface/datasets/issues/4663/events | https://github.com/huggingface/datasets/pull/4663 | 1,299,298,693 | PR_kwDODunzps47H19n | 4,663 | Add text decorators | [] | closed | false | null | 1 | 2022-07-08T17:51:48Z | 2022-07-18T18:33:14Z | 2022-07-18T18:20:49Z | null | This PR adds some decoration to text about different modalities to make it more obvious separate guides exist for audio, vision, and text. The goal is to make it easier for users to discover these guides!

TODO:
- [x] Open PR to support new Tailwind classes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4663/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4663.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4663",
"merged_at": "2022-07-18T18:20:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4663.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4663"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3478 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3478/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3478/comments | https://api.github.com/repos/huggingface/datasets/issues/3478/events | https://github.com/huggingface/datasets/pull/3478 | 1,087,860,180 | PR_kwDODunzps4wPMWq | 3,478 | Extend support for streaming datasets that use os.walk | [] | closed | false | null | 1 | 2021-12-23T16:42:55Z | 2021-12-24T10:50:20Z | 2021-12-24T10:50:19Z | null | This PR extends the support in streaming mode for datasets that use `os.walk`, by patching that function.
This PR adds support for streaming mode to datasets:
1. autshumato
1. code_x_glue_cd_code_to_text
1. code_x_glue_tc_nl_code_search_adv
1. nchlt
CC: @severo | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3478/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3478/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3478.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3478",
"merged_at": "2021-12-24T10:50:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3478.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3478"
} | true | [
"Nice. I'll update the dataset viewer once merged, and test on these four datasets"
] |
https://api.github.com/repos/huggingface/datasets/issues/1429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1429/comments | https://api.github.com/repos/huggingface/datasets/issues/1429/events | https://github.com/huggingface/datasets/pull/1429 | 760,737,818 | MDExOlB1bGxSZXF1ZXN0NTM1NTE5MjY5 | 1,429 | extract rar files | [] | closed | false | null | 0 | 2020-12-09T23:01:10Z | 2020-12-18T15:03:37Z | 2020-12-18T15:03:37Z | null | Unfortunately, I didn't find any native python libraries for extracting rar files. The user has to manually install `sudo apt-get install unrar`. Discussion with @yjernite is in the slack channel. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1429/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1429/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1429",
"merged_at": "2020-12-18T15:03:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1429"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2463 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2463/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2463/comments | https://api.github.com/repos/huggingface/datasets/issues/2463/events | https://github.com/huggingface/datasets/pull/2463 | 915,454,788 | MDExOlB1bGxSZXF1ZXN0NjY1MjY3NTA2 | 2,463 | Fix proto_qa download link | [] | closed | false | null | 0 | 2021-06-08T20:23:16Z | 2021-06-10T12:49:56Z | 2021-06-10T08:31:10Z | null | Fixes #2459
Instead of updating the path, this PR fixes a commit hash as suggested by @lhoestq. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2463/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2463/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2463.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2463",
"merged_at": "2021-06-10T08:31:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2463.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2463"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4174 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4174/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4174/comments | https://api.github.com/repos/huggingface/datasets/issues/4174/events | https://github.com/huggingface/datasets/pull/4174 | 1,205,575,941 | PR_kwDODunzps42SnJS | 4,174 | Fix when map function modifies input in-place | [] | closed | false | null | 1 | 2022-04-15T13:23:15Z | 2022-04-15T14:52:07Z | 2022-04-15T14:45:58Z | null | When `function` modifies input in-place, the guarantee that columns in `remove_columns` are contained in `input` doesn't hold true anymore. Therefore we need to relax way we pop elements by checking if that column exists. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4174/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4174/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4174.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4174",
"merged_at": "2022-04-15T14:45:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4174.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4174"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/191/comments | https://api.github.com/repos/huggingface/datasets/issues/191/events | https://github.com/huggingface/datasets/pull/191 | 624,394,936 | MDExOlB1bGxSZXF1ZXN0NDIyODI3MDMy | 191 | [Squad es] add dataset_infos | [] | closed | false | null | 0 | 2020-05-25T16:35:52Z | 2020-05-25T16:39:59Z | 2020-05-25T16:39:58Z | null | @mariamabarham - was still about to upload this. Should have waited with my comment a bit more :D | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/191/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/191/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/191.diff",
"html_url": "https://github.com/huggingface/datasets/pull/191",
"merged_at": "2020-05-25T16:39:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/191.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/191"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/180/comments | https://api.github.com/repos/huggingface/datasets/issues/180/events | https://github.com/huggingface/datasets/pull/180 | 622,556,861 | MDExOlB1bGxSZXF1ZXN0NDIxMzk5Nzg2 | 180 | Add hall of fame | [] | closed | false | null | 0 | 2020-05-21T14:53:48Z | 2020-05-22T16:35:16Z | 2020-05-22T16:35:14Z | null | powered by https://github.com/sourcerer-io/hall-of-fame | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/180/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/180.diff",
"html_url": "https://github.com/huggingface/datasets/pull/180",
"merged_at": "2020-05-22T16:35:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/180.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/180"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2143/comments | https://api.github.com/repos/huggingface/datasets/issues/2143/events | https://github.com/huggingface/datasets/pull/2143 | 844,313,228 | MDExOlB1bGxSZXF1ZXN0NjAzNTc0NjI0 | 2,143 | task casting via load_dataset | [] | closed | false | null | 0 | 2021-03-30T10:00:42Z | 2021-06-11T13:20:41Z | 2021-06-11T13:20:36Z | null | wip
not satisfied with the API, it means as a dataset implementer I need to write a function with boilerplate and write classes for each `<dataset><task>` "facet". | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2143/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2143/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2143.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2143",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2143.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2143"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4048 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4048/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4048/comments | https://api.github.com/repos/huggingface/datasets/issues/4048/events | https://github.com/huggingface/datasets/issues/4048 | 1,183,804,576 | I_kwDODunzps5Gj2yg | 4,048 | Split size error on `amazon_us_reviews` / `PC_v1_00` dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | 3 | 2022-03-28T18:12:04Z | 2022-04-08T12:29:30Z | 2022-04-08T12:29:30Z | null | ## Describe the bug
When downloading this subset as of 3-28-2022 you will encounter a split size error after the dataset is extracted. The extracted dataset has roughly ~6m rows while the split expects <1m.
Upon digging a little deeper, I downloaded the raw files from `https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_us_PC_v1_00.tsv.gz` and extracted them. A line count via `wc -l` confirms the ~6m number that we see and the data looks valid at a glance (I did not check for duplicate rows). My guess is this file has either been updated in place or there is a bug in the dataset metadata.
Happy to submit a PR and fix this up if turns out to be a metadata issue but wanted to get some other :eyes: on it first.
## Steps to reproduce the bug
```python
load_dataset('amazon_us_reviews', 'PC_v1_00')
```
## Expected results
Dataset is downloaded and extracted successfully.
## Actual results
An split size exception is thrown.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.0.0
- Platform: Linux-5.10.16.3-microsoft-standard-WSL2-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4048/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4048/timeline | null | completed | null | null | false | [
"Follow-up: I have confirmed there are no duplicate lines via `sort amazon_reviews_us_PC_v1_00.tsv | uniq -cd` after extracting the raw file.",
"Hi @trentonstrong, thanks for reporting!\r\n\r\nI confirm that loading this dataset configuration throws a `NonMatchingSplitsSizesError`:\r\n```\r\nNonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=350242049, num_examples=785730, dataset_name='amazon_us_reviews'), 'recorded': SplitInfo(name='train', num_bytes=3982712078, num_examples=6908554, dataset_name='amazon_us_reviews')}]\r\n```\r\n\r\nAlso thank you for your offer to fix this. You can find information about how to update the metadata JSON file here: https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#automatically-add-code-metadata\r\n```shell\r\ndatasets-cli test datasets/amazon_us_reviews --save_infos --all_configs\r\n```\r\nPlease, feel free to open a PR with this fix. And do not hesitate to ping me if you need any help.",
"No sweat. Will get it patched up ASAP."
] |
https://api.github.com/repos/huggingface/datasets/issues/4512 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4512/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4512/comments | https://api.github.com/repos/huggingface/datasets/issues/4512/events | https://github.com/huggingface/datasets/pull/4512 | 1,273,378,129 | PR_kwDODunzps45xEDN | 4,512 | Add links to vision tasks scripts in ADD_NEW_DATASET template | [] | closed | false | null | 2 | 2022-06-16T10:35:35Z | 2022-07-08T14:07:50Z | 2022-07-08T13:56:23Z | null | Add links to vision dataset scripts in the ADD_NEW_DATASET template. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4512/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4512/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4512.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4512",
"merged_at": "2022-07-08T13:56:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4512.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4512"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI failure is unrelated to the PR's changes. Merging."
] |
https://api.github.com/repos/huggingface/datasets/issues/3686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3686/comments | https://api.github.com/repos/huggingface/datasets/issues/3686/events | https://github.com/huggingface/datasets/issues/3686 | 1,127,137,290 | I_kwDODunzps5DLsAK | 3,686 | `Translation` features cannot be `flatten`ed | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-02-08T11:33:48Z | 2022-03-18T17:28:13Z | 2022-03-18T17:28:13Z | null | ## Describe the bug
(`Dataset.flatten`)[https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_dataset.py#L1265] fails for columns with feature (`Translation`)[https://github.com/huggingface/datasets/blob/3edbeb0ec6519b79f1119adc251a1a6b379a2c12/src/datasets/features/translation.py#L8]
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train[:10]")
print(dataset.features)
# {'translation': Translation(languages=['en', 'fr'], id=None)}
print(dataset[0])
# {'translation': {'en': 'Vaccination against hepatitis C is not yet available.', 'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
dataset.flatten()
```
## Expected results
`dataset.flatten` should flatten the `Translation` column as if it were a dict of `Value("string")`
```python
dataset[0]
# {'translation.en': 'Vaccination against hepatitis C is not yet available.', 'translation.fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.' }
dataset.features
# {'translation.en': Value("string"), 'translation.fr': Value("string")}
```
## Actual results
```python
In [31]: dset.flatten()
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-31-bb88eb5276ee> in <module>
----> 1 dset.flatten()
[...]\site-packages\datasets\fingerprint.py in wrapper(*args, **kwargs)
411 # Call actual function
412
--> 413 out = func(self, *args, **kwargs)
414
415 # Update fingerprint of in-place transforms + update in-place history of transforms
[...]\site-packages\datasets\arrow_dataset.py in flatten(self, new_fingerprint, max_depth)
1294 break
1295 dataset.info.features = self.features.flatten(max_depth=max_depth)
-> 1296 dataset._data = update_metadata_with_features(dataset._data, dataset.features)
1297 logger.info(f'Flattened dataset from depth {depth} to depth {1 if depth + 1 < max_depth else "unknown"}.')
1298 dataset._fingerprint = new_fingerprint
[...]\site-packages\datasets\arrow_dataset.py in update_metadata_with_features(table, features)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
[...]\site-packages\datasets\arrow_dataset.py in <dictcomp>(.0)
534 def update_metadata_with_features(table: Table, features: Features):
535 """To be used in dataset transforms that modify the features of the dataset, in order to update the features stored in the metadata of its schema."""
--> 536 features = Features({col_name: features[col_name] for col_name in table.column_names})
537 if table.schema.metadata is None or b"huggingface" not in table.schema.metadata:
538 pa_metadata = ArrowWriter._build_metadata(DatasetInfo(features=features))
KeyError: 'translation.en'
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.7.10
- PyArrow version: 3.0.0
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3686/timeline | null | completed | null | null | false | [
"Thanks for reporting, @SBrandeis! Some additional feature types that don't behave as expected when flattened: `Audio`, `Image` and `TranslationVariableLanguages`"
] |
https://api.github.com/repos/huggingface/datasets/issues/3835 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3835/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3835/comments | https://api.github.com/repos/huggingface/datasets/issues/3835/events | https://github.com/huggingface/datasets/issues/3835 | 1,161,029,205 | I_kwDODunzps5FM-ZV | 3,835 | The link given on the gigaword does not work | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-03-07T07:56:42Z | 2022-03-15T12:30:23Z | 2022-03-15T12:30:23Z | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3835/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3835/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2022-02-02T18:33:29Z | 2022-07-19T13:36:24Z | 2022-07-19T13:36:24Z | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
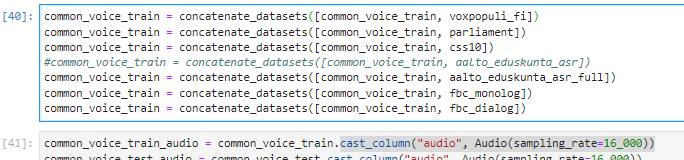
but get error:
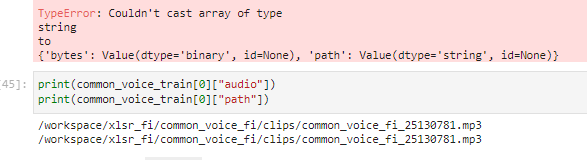
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
- PyArrow version:
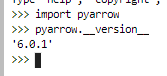
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3668/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3668/timeline | null | completed | null | null | false | [
"Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.\r\n\r\nIf you manage to share a reproducible code example that would be perfect",
"Hi,\r\n\r\nI think my team mate got this solved. Clolsing it for now and will reopen if I experience this again.\r\nThanks :) ",
"Hi @R4ZZ3,\r\n\r\nIf it is not too much of a bother, can you please help me how to resolve this error? I am exactly getting the same error where I am going as per the documentation guideline:\r\n\r\n`my_audio_dataset = my_audio_dataset.cast_column(\"audio_paths\", Audio())`\r\n\r\nwhere `\"audio_paths\"` is a dataset column (feature) having strings of absolute paths to mp3 files of the dataset.\r\n\r\n",
"I was having the same issue with this code:\r\n\r\n```\r\ndataset = dataset.map(\r\n lambda batch: {\"full_path\" : os.path.join(self.data_path, batch[\"path\"])},\r\n num_procs = 4\r\n)\r\nmy_audio_dataset = dataset.cast_column(\"full_path\", Audio(sampling_rate=16_000))\r\n```\r\n\r\nRemoving the \"num_procs\" argument fixed it somehow.\r\nUsing a mac with m1 chip",
"Hi @Hubert-Bonisseur, I think this will be fixed by https://github.com/huggingface/datasets/pull/4614"
] |
https://api.github.com/repos/huggingface/datasets/issues/3432 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3432/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3432/comments | https://api.github.com/repos/huggingface/datasets/issues/3432/events | https://github.com/huggingface/datasets/pull/3432 | 1,079,910,769 | PR_kwDODunzps4v1NGS | 3,432 | Correctly indent builder config in dataset script docs | [] | closed | false | null | 0 | 2021-12-14T15:39:47Z | 2021-12-14T17:35:17Z | 2021-12-14T17:35:17Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3432/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3432/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3432.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3432",
"merged_at": "2021-12-14T17:35:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3432.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3432"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4218 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4218/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4218/comments | https://api.github.com/repos/huggingface/datasets/issues/4218/events | https://github.com/huggingface/datasets/pull/4218 | 1,214,748,226 | PR_kwDODunzps42vTA0 | 4,218 | Make code for image downloading from image urls cacheable | [] | closed | false | null | 1 | 2022-04-25T16:17:59Z | 2022-04-26T17:00:24Z | 2022-04-26T13:38:26Z | null | Fix #4199 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4218/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4218/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4218.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4218",
"merged_at": "2022-04-26T13:38:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4218.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4218"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/242/comments | https://api.github.com/repos/huggingface/datasets/issues/242/events | https://github.com/huggingface/datasets/issues/242 | 631,733,683 | MDU6SXNzdWU2MzE3MzM2ODM= | 242 | UnicodeDecodeError when downloading GLUE-MNLI | [] | closed | false | null | 2 | 2020-06-05T16:30:01Z | 2020-06-09T16:06:47Z | 2020-06-08T08:45:03Z | null | When I run
```python
dataset = nlp.load_dataset('glue', 'mnli')
```
I get an encoding error (could it be because I'm using Windows?) :
```python
# Lots of error log lines later...
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\std.py in __iter__(self)
1128 try:
-> 1129 for obj in iterable:
1130 yield obj
~\Miniconda3\envs\nlp\lib\site-packages\nlp\datasets\glue\5256cc2368cf84497abef1f1a5f66648522d5854b225162148cb8fc78a5a91cc\glue.py in _generate_examples(self, data_file, split, mrpc_files)
529
--> 530 for n, row in enumerate(reader):
531 if is_cola_non_test:
~\Miniconda3\envs\nlp\lib\csv.py in __next__(self)
110 self.fieldnames
--> 111 row = next(self.reader)
112 self.line_num = self.reader.line_num
~\Miniconda3\envs\nlp\lib\encodings\cp1252.py in decode(self, input, final)
22 def decode(self, input, final=False):
---> 23 return codecs.charmap_decode(input,self.errors,decoding_table)[0]
24
UnicodeDecodeError: 'charmap' codec can't decode byte 0x9d in position 6744: character maps to <undefined>
```
Anyway this can be solved by specifying to decode in UTF when reading the csv file. I am proposing a PR if that's okay. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/242/timeline | null | completed | null | null | false | [
"It should be good now, thanks for noticing and fixing it ! I would say that it was because you are on windows but not 100% sure",
"On Windows Python supports Unicode almost everywhere, but one of the notable exceptions is open() where it uses the locale encoding schema. So platform independent python scripts would always set the encoding='utf-8' in calls to open explicitly. \r\nIn the meantime: since Python 3.7 Windows users can set the default encoding for everything including open() to Unicode by setting this environment variable: set PYTHONUTF8=1 (details can be found in [PEP 540](https://www.python.org/dev/peps/pep-0540/))\r\n\r\nFor me this fixed the problem described by the OP."
] |
https://api.github.com/repos/huggingface/datasets/issues/2613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2613/comments | https://api.github.com/repos/huggingface/datasets/issues/2613/events | https://github.com/huggingface/datasets/pull/2613 | 940,759,852 | MDExOlB1bGxSZXF1ZXN0Njg2Nzg0MzY0 | 2,613 | Use ndarray.item instead of ndarray.tolist | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-05T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/6",
"id": 6836458,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/6/labels",
"node_id": "MDk6TWlsZXN0b25lNjgzNjQ1OA==",
"number": 6,
"open_issues": 0,
"state": "closed",
"title": "1.10",
"updated_at": "2021-07-21T15:36:49Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/6"
} | 0 | 2021-07-09T13:19:35Z | 2021-07-12T14:12:57Z | 2021-07-09T13:50:05Z | null | This PR follows up on #2612 to use `numpy.ndarray.item` instead of `numpy.ndarray.tolist` as the latter is somewhat confusing to the developer (even though it works).
Judging from the `numpy` docs, `ndarray.item` is closer to what we want: https://numpy.org/doc/stable/reference/generated/numpy.ndarray.item.html#numpy-ndarray-item
PS. Sorry for the duplicate work here. I should have read the numpy docs more carefully in #2612
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2613/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2613.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2613",
"merged_at": "2021-07-09T13:50:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2613.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2613"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1937 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1937/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1937/comments | https://api.github.com/repos/huggingface/datasets/issues/1937/events | https://github.com/huggingface/datasets/issues/1937 | 815,163,943 | MDU6SXNzdWU4MTUxNjM5NDM= | 1,937 | CommonGen dataset page shows an error OSError: [Errno 28] No space left on device | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 2 | 2021-02-24T06:47:33Z | 2021-02-26T11:10:06Z | 2021-02-26T11:10:06Z | null | The page of the CommonGen data https://huggingface.co/datasets/viewer/?dataset=common_gen shows

| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1937/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1937/timeline | null | completed | null | null | false | [
"Facing the same issue for [Squad](https://huggingface.co/datasets/viewer/?dataset=squad) and [TriviaQA](https://huggingface.co/datasets/viewer/?dataset=trivia_qa) datasets as well.",
"We just fixed the issue, thanks for reporting !"
] |
https://api.github.com/repos/huggingface/datasets/issues/4247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4247/comments | https://api.github.com/repos/huggingface/datasets/issues/4247/events | https://github.com/huggingface/datasets/issues/4247 | 1,218,320,882 | I_kwDODunzps5Inhny | 4,247 | The data preview of XGLUE | [] | closed | false | null | 3 | 2022-04-28T07:30:50Z | 2022-04-29T08:23:28Z | 2022-04-28T16:08:03Z | null | It seems that something wrong with the data previvew of XGLUE | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4247/timeline | null | completed | null | null | false | [
"\r\n",
"Thanks for reporting @czq1999.\r\n\r\nNote that the dataset viewer uses the dataset in streaming mode and that not all datasets support streaming yet.\r\n\r\nThat is the case for XGLUE dataset (as the error message points out): this must be refactored to support streaming. ",
"Fixed, thanks @albertvillanova !\r\n\r\nhttps://huggingface.co/datasets/xglue\r\n\r\n<img width=\"824\" alt=\"Capture d’écran 2022-04-29 à 10 23 14\" src=\"https://user-images.githubusercontent.com/1676121/165909391-9f98d98a-665a-4e57-822d-8baa2dc9b7c9.png\">\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/1351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1351/comments | https://api.github.com/repos/huggingface/datasets/issues/1351/events | https://github.com/huggingface/datasets/pull/1351 | 759,902,770 | MDExOlB1bGxSZXF1ZXN0NTM0ODI0NTcw | 1,351 | added craigslist_bargians | [] | closed | false | null | 0 | 2020-12-09T01:02:31Z | 2020-12-10T14:14:34Z | 2020-12-10T14:14:34Z | null | `craigslist_bargains` data set from [here](https://worksheets.codalab.org/worksheets/0x453913e76b65495d8b9730d41c7e0a0c/)
(Cleaned up version of #1278) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1351/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1351.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1351",
"merged_at": "2020-12-10T14:14:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1351.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1351"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2761 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2761/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2761/comments | https://api.github.com/repos/huggingface/datasets/issues/2761/events | https://github.com/huggingface/datasets/issues/2761 | 961,568,287 | MDU6SXNzdWU5NjE1NjgyODc= | 2,761 | Error loading C4 realnewslike dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 4 | 2021-08-05T08:16:58Z | 2021-08-08T19:44:34Z | 2021-08-08T19:44:34Z | null | ## Describe the bug
Error loading C4 realnewslike dataset. Validation part mismatch
## Steps to reproduce the bug
```python
raw_datasets = load_dataset('c4', 'realnewslike', cache_dir=model_args.cache_dir)
## Expected results
success on data loading
## Actual results
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15.3M/15.3M [00:00<00:00, 28.1MB/s]Traceback (most recent call last):
File "run_mlm_tf.py", line 794, in <module>
main()
File "run_mlm_tf.py", line 425, in main
raw_datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir) File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py", line 843, in load_dataset
builder_instance.download_and_prepare(
File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py", line 608, in download_and_prepare
self._download_and_prepare(
File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py", line 698, in _download_and_prepare verify_splits(self.info.splits, split_dict) File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='validation', num_bytes=38165657946, num_examples=13799838, dataset_name='c4'), 'recorded': SplitInfo(name='validation', num_bytes=37875873, num_examples=13863, dataset_name='c4')}]
## Environment info
- `datasets` version: 1.10.2
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 4.0.1 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2761/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2761/timeline | null | completed | null | null | false | [
"Hi @danshirron, \r\n`c4` was updated few days back by @lhoestq. The new configs are `['en', 'en.noclean', 'en.realnewslike', 'en.webtextlike'].` You'll need to remove any older version of this dataset you previously downloaded and then run `load_dataset` again with new configuration.",
"@bhavitvyamalik @lhoestq , just tried the above and got:\r\n>>> a=datasets.load_dataset('c4','en.realnewslike')\r\nDownloading: 3.29kB [00:00, 1.66MB/s] \r\nDownloading: 2.40MB [00:00, 12.6MB/s] \r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py\", line 819, in load_dataset\r\n builder_instance = load_dataset_builder(\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py\", line 701, in load_dataset_builder\r\n builder_instance: DatasetBuilder = builder_cls(\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py\", line 1049, in __init__\r\n super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py\", line 268, in __init__\r\n self.config, self.config_id = self._create_builder_config(\r\n File \"/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py\", line 360, in _create_builder_config\r\n raise ValueError(\r\nValueError: BuilderConfig en.realnewslike not found. Available: ['en', 'realnewslike', 'en.noblocklist', 'en.noclean']\r\n>>> \r\n\r\ndatasets version is 1.11.0\r\n",
"I think I had an older version of datasets installed and that's why I commented the old configurations in my last comment, my bad! I re-checked and updated it to latest version (`datasets==1.11.0`) and it's showing `available configs: ['en', 'realnewslike', 'en.noblocklist', 'en.noclean']`. \r\n\r\nI tried `raw_datasets = load_dataset('c4', 'realnewslike')` and the download started. Make sure you don't have any old copy of this dataset and you download it fresh using the latest version of datasets. Sorry for the mix up!",
"It works. I probably had some issue with the cache. after cleaning it im able to download the dataset. Thanks"
] |
https://api.github.com/repos/huggingface/datasets/issues/5524 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5524/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5524/comments | https://api.github.com/repos/huggingface/datasets/issues/5524/events | https://github.com/huggingface/datasets/pull/5524 | 1,580,219,454 | PR_kwDODunzps5JvbMw | 5,524 | [INVALID PR] | [] | closed | false | null | 1 | 2023-02-10T19:35:50Z | 2023-02-10T19:51:45Z | 2023-02-10T19:49:12Z | null | Hi to whoever is reading this! 🤗
## What's in this PR?
~~Basically, I've removed the 🤗`datasets` installation as `python -m pip install ".[quality]" in the `check_code_quality` job in `.github/workflows/ci.yaml`, as we don't need to install the whole package to run the CI, unless that's done on purpose e.g. to check that the Python package installation succeeds before running the tests over the matrix of os?~~
~~So I just wanted to check whether the time was reduced doing this (which I assume it will), plus whether this is something that can be improved, or just discarded in case you're also using that step to make sure that the package can be installed.~~
## What's missing?
~~I was just wondering whether you consider replacing `isort` and `flake8` with `ruff` (if possible), since it's way faster, more information at [`ruff`](https://github.com/charliermarsh/ruff). Before creating this PR the average time of the `check_code_quality` job was around 40s.~~
## Edit
Sorry for the inconvenience this may have caused, didn't realise that the config is defined in `setup.cfg` and `pyproject.toml`, so running those without installing the Python package leads to failure, my bad 😞
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5524/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5524/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5524.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5524",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5524.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5524"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5541/comments | https://api.github.com/repos/huggingface/datasets/issues/5541/events | https://github.com/huggingface/datasets/issues/5541 | 1,588,633,555 | I_kwDODunzps5esJ_T | 5,541 | Flattening indices in selected datasets is extremely inefficient | [] | closed | false | null | 3 | 2023-02-17T01:52:24Z | 2023-02-22T13:15:20Z | 2023-02-17T11:12:33Z | null | ### Describe the bug
If we perform a `select` (or `shuffle`, `train_test_split`, etc.) operation on a dataset , we end up with a dataset with an `indices_table`. Currently, flattening such dataset consumes a lot of memory and the resulting flat dataset contains ChunkedArrays with as many chunks as there are rows. This is extremely inefficient and slows down the operations on the flat dataset, e.g., saving/loading the dataset to disk becomes really slow.
Perhaps more importantly, loading the dataset back from disk basically loads the whole table into RAM, as it cannot take advantage of memory mapping.
### Steps to reproduce the bug
The following script reproduces the issue:
```python
import gc
import os
import psutil
import tempfile
import time
from datasets import Dataset
DATASET_SIZE = 5000000
def profile(func):
def wrapper(*args, **kwargs):
mem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
start = time.time()
# Run function here
out = func(*args, **kwargs)
end = time.time()
mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
print(f"{func.__name__} -- RAM memory used: {mem_after - mem_before} MB -- Total time: {end - start:.6f} s")
return out
return wrapper
def main():
ds = Dataset.from_list([{'col': i} for i in range(DATASET_SIZE)])
print(f"Num chunks for original ds: {ds.data['col'].num_chunks}")
with tempfile.TemporaryDirectory() as tmpdir:
path1 = os.path.join(tmpdir, 'ds1')
print("Original ds save/load")
profile(ds.save_to_disk)(path1)
ds_loaded = profile(Dataset.load_from_disk)(path1)
print(f"Num chunks for original ds after reloading: {ds_loaded.data['col'].num_chunks}")
print("")
ds_select = ds.select(reversed(range(len(ds))))
print(f"Num chunks for selected ds: {ds_select.data['col'].num_chunks}")
del ds
del ds_loaded
gc.collect()
# This would happen anyway when we call save_to_disk
ds_select = profile(ds_select.flatten_indices)()
print(f"Num chunks for selected ds after flattening: {ds_select.data['col'].num_chunks}")
print("")
path2 = os.path.join(tmpdir, 'ds2')
print("Selected ds save/load")
profile(ds_select.save_to_disk)(path2)
del ds_select
gc.collect()
ds_select_loaded = profile(Dataset.load_from_disk)(path2)
print(f"Num chunks for selected ds after reloading: {ds_select_loaded.data['col'].num_chunks}")
if __name__ == '__main__':
main()
```
Sample result:
```
Num chunks for original ds: 1
Original ds save/load
save_to_disk -- RAM memory used: 0.515625 MB -- Total time: 0.253888 s
load_from_disk -- RAM memory used: 42.765625 MB -- Total time: 0.015176 s
Num chunks for original ds after reloading: 5000
Num chunks for selected ds: 1
flatten_indices -- RAM memory used: 4852.609375 MB -- Total time: 46.116774 s
Num chunks for selected ds after flattening: 5000000
Selected ds save/load
save_to_disk -- RAM memory used: 1326.65625 MB -- Total time: 42.309825 s
load_from_disk -- RAM memory used: 2085.953125 MB -- Total time: 11.659137 s
Num chunks for selected ds after reloading: 5000000
```
### Expected behavior
Saving/loading the dataset should be much faster and consume almost no extra memory thanks to pyarrow memory mapping.
### Environment info
- `datasets` version: 2.9.1.dev0
- Platform: macOS-13.1-arm64-arm-64bit
- Python version: 3.10.8
- PyArrow version: 11.0.0
- Pandas version: 1.5.3 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5541/timeline | null | completed | null | null | false | [
"Running the script above on the branch https://github.com/huggingface/datasets/pull/5542 results in the expected behaviour:\r\n```\r\nNum chunks for original ds: 1\r\nOriginal ds save/load\r\nsave_to_disk -- RAM memory used: 0.671875 MB -- Total time: 0.255265 s\r\nload_from_disk -- RAM memory used: 42.796875 MB -- Total time: 0.014899 s\r\nNum chunks for original ds after reloading: 5000\r\n\r\nNum chunks for selected ds: 1\r\nflatten_indices -- RAM memory used: 42.546875 MB -- Total time: 23.735089 s\r\nNum chunks for selected ds after flattening: 5000\r\n\r\nSelected ds save/load\r\nsave_to_disk -- RAM memory used: 0.0 MB -- Total time: 0.287112 s\r\nload_from_disk -- RAM memory used: 38.84375 MB -- Total time: 0.014772 s\r\nNum chunks for selected ds after reloading: 5000\r\n```",
"Wouahouh super cool @marioga thanks a lot!",
"We just released `datasets==2.10.0` with this big improvement, thanks again @marioga "
] |
https://api.github.com/repos/huggingface/datasets/issues/5385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5385/comments | https://api.github.com/repos/huggingface/datasets/issues/5385/events | https://github.com/huggingface/datasets/issues/5385 | 1,508,535,532 | I_kwDODunzps5Z6mzs | 5,385 | Is `fs=` deprecated in `load_from_disk()` as well? | [] | closed | false | null | 3 | 2022-12-22T21:00:45Z | 2023-01-23T10:50:05Z | 2023-01-23T10:50:04Z | null | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the same thing shouldn't also apply to `datasets.load.load_from_disk()` as well ?
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/load.py#L1779
### Steps to reproduce the bug
n/a
### Expected behavior
n/a
### Environment info
n/a | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5385/timeline | null | completed | null | null | false | [
"Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR? ",
"> Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR?\r\n\r\nYeah I can do that sometime next week. Should the storage_options be a new arg here? I’ll look around for anywhere else where fs is an arg.",
"Closed by #5393."
] |
https://api.github.com/repos/huggingface/datasets/issues/2653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2653/comments | https://api.github.com/repos/huggingface/datasets/issues/2653/events | https://github.com/huggingface/datasets/issues/2653 | 945,102,321 | MDU6SXNzdWU5NDUxMDIzMjE= | 2,653 | Add SD task for SUPERB | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"closed_at": "2021-09-02T05:34:03Z",
"closed_issues": 2,
"created_at": "2021-07-09T05:49:00Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-07-30T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/7",
"id": 6931350,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/7/labels",
"node_id": "MDk6TWlsZXN0b25lNjkzMTM1MA==",
"number": 7,
"open_issues": 0,
"state": "closed",
"title": "1.11",
"updated_at": "2021-09-02T05:34:03Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/7"
} | 2 | 2021-07-15T07:51:40Z | 2021-08-04T17:03:52Z | 2021-08-04T17:03:52Z | null | Include the SD (Speaker Diarization) task as described in the [SUPERB paper](https://arxiv.org/abs/2105.01051) and `s3prl` [instructions](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#sd-speaker-diarization).
Steps:
- [x] Generate the LibriMix corpus
- [x] Prepare the corpus for diarization
- [x] Upload these files to the superb-data repo
- [x] Transcribe the corresponding s3prl processing of these files into our superb loading script
- [ ] README: tags + description sections
Related to #2619.
cc: @lewtun
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2653/timeline | null | completed | null | null | false | [
"Note that this subset requires us to:\r\n\r\n* generate the LibriMix corpus from LibriSpeech\r\n* prepare the corpus for diarization\r\n\r\nAs suggested by @lhoestq we should perform these steps locally and add the prepared data to this public repo on the Hub: https://huggingface.co/datasets/superb/superb-data\r\n\r\nThen we can use the URLs for the files to load the data in `superb`'s dataset loading script.\r\n\r\nFor consistency, I suggest we name the folders in `superb-data` in the same way as the configs in the dataset loading script - e.g. use `sd` for speech diarization in both places :)",
"@lewtun @lhoestq: \r\n\r\nI have already generated the LibriMix corpus and prepared the corpus for diarization. The output is 3 dirs (train, dev, test), each one containing 6 files: reco2dur rttm segments spk2utt utt2spk wav.scp\r\n\r\nNext steps:\r\n- Upload these files to the superb-data repo\r\n- Transcribe the corresponding s3prl processing of these files into our superb loading script\r\n\r\nNote that processing of these files is a bit more intricate than usual datasets: https://github.com/s3prl/s3prl/blob/master/s3prl/downstream/diarization/dataset.py#L233\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/8 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8/comments | https://api.github.com/repos/huggingface/datasets/issues/8/events | https://github.com/huggingface/datasets/pull/8 | 601,783,243 | MDExOlB1bGxSZXF1ZXN0NDA0OTg0NDUz | 8 | Fix issue 6: error when the citation is missing in the DatasetInfo | [] | closed | false | null | 0 | 2020-04-17T08:04:26Z | 2020-04-29T09:27:11Z | 2020-04-20T13:24:12Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/8.diff",
"html_url": "https://github.com/huggingface/datasets/pull/8",
"merged_at": "2020-04-20T13:24:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/8.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/8"
} | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/1356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1356/comments | https://api.github.com/repos/huggingface/datasets/issues/1356/events | https://github.com/huggingface/datasets/pull/1356 | 759,994,457 | MDExOlB1bGxSZXF1ZXN0NTM0ODk3OTQ1 | 1,356 | Add StackOverflow StackSample dataset | [] | closed | false | null | 5 | 2020-12-09T04:59:51Z | 2020-12-21T14:48:21Z | 2020-12-21T14:48:21Z | null | This PR adds the StackOverflow StackSample dataset from Kaggle: https://www.kaggle.com/stackoverflow/stacksample
Ran through all of the steps. However, since my dataset requires manually downloading the data, I was unable to run the pytest on the real dataset (the dummy data pytest passed). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1356/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1356",
"merged_at": "2020-12-21T14:48:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1356"
} | true | [
"@lhoestq Thanks for the review and suggestions! I've added your comments and pushed the changes. I'm having issues with the dummy data still. When I run the dummy data test\r\n\r\n```bash\r\nRUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_so_stacksample\r\n```\r\nI get this error: \r\n\r\n```\r\n___________________________________________ LocalDatasetTest.test_load_dataset_all_configs_so_stacksample ____________________________________________\r\n\r\nself = <tests.test_dataset_common.LocalDatasetTest testMethod=test_load_dataset_all_configs_so_stacksample>, dataset_name = 'so_stacksample'\r\n\r\n @slow\r\n def test_load_dataset_all_configs(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True)\r\n\r\ntests/test_dataset_common.py:237: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:198: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n\r\nFAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_so_stacksample - AssertionError: False is not true\r\n```\r\n\r\nI tried formatting the data similar to other datasets, but I think I don't have my csv's in the zip folder with the proper name. I also ran the command that's supposed to outline the exact steps I need to perform to get them into the correct format, but I followed them and they don't seem to be working still :/. Any help would be greatly appreciated!\r\n",
"Ok I found the issue with the dummy data.\r\nIt's currently failing because it's not generating a single example using the dummy csv file.\r\nThat's because there's only only line in the dummy csv file, and this line is skipped using the `next()` call used to ignore the headers of the csv.\r\n\r\nTo fix the dummy data you must add headers to the dummy csv files.",
"Also can you make sure that all the original CSV files have headers ? i.e. check that their first line is just the column names",
"> Ok I found the issue with the dummy data.\r\n> It's currently failing because it's not generating a single example using the dummy csv file.\r\n> That's because there's only only line in the dummy csv file, and this line is skipped using the `next()` call used to ignore the headers of the csv.\r\n> \r\n> To fix the dummy data you must add headers to the dummy csv files.\r\n\r\nOh man, I bamboozled myself! Thank you @lhoestq for catching that! I've updated the dummy csv's to include headers and also confirmed that they all have headers, so I am not throwing away any information with that `next()` call. When I run the test locally for the dummy data it passes, so hopefully it is good to go :D",
"merging since the Ci is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/4694 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4694/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4694/comments | https://api.github.com/repos/huggingface/datasets/issues/4694/events | https://github.com/huggingface/datasets/issues/4694 | 1,306,958,380 | I_kwDODunzps5N5pos | 4,694 | Distributed data parallel training for streaming datasets | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 6 | 2022-07-17T01:29:43Z | 2023-04-26T18:21:09Z | null | null | ### Feature request
Any documentations for the the `load_dataset(streaming=True)` for (multi-node multi-GPU) DDP training?
### Motivation
Given a bunch of data files, it is expected to split them onto different GPUs. Is there a guide or documentation?
### Your contribution
Does it requires manually split on data files for each worker in `DatasetBuilder._split_generator()`? What is`IterableDatasetShard` expected to do? | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4694/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4694/timeline | null | null | null | null | false | [
"Hi ! According to https://huggingface.co/docs/datasets/use_with_pytorch#stream-data you can use the pytorch DataLoader with `num_workers>0` to distribute the shards across your workers (it uses `torch.utils.data.get_worker_info()` to get the worker ID and select the right subsets of shards to use)\r\n\r\n<s> EDIT: here is a code example </s>\r\n```python\r\n# ds = ds.with_format(\"torch\")\r\n# dataloader = DataLoader(ds, num_workers=num_workers)\r\n```\r\n\r\nEDIT: `with_format(\"torch\")` is not required, now you can just do\r\n```python\r\ndataloader = DataLoader(ds, num_workers=num_workers)\r\n```",
"@cyk1337 does streaming datasets with multi-gpu works for you? I am testing on one node with multiple gpus, but this is freezing, https://github.com/huggingface/datasets/issues/5123 \r\nIn case you could make this work, could you share with me your data-loading codes?\r\nthank you",
"+1",
"This has been implemented in `datasets` 2.8:\r\n```python\r\nfrom datasets.distributed import split_dataset_by_node\r\n\r\nds = split_dataset_by_node(ds, rank=rank, world_size=world_size)\r\n```\r\n\r\ndocs: https://huggingface.co/docs/datasets/use_with_pytorch#distributed",
"i'm having hanging issues with this when using DDP and allocating the datasets with `split_dataset_by_node` 🤔\r\n\r\n--- \r\n### edit\r\nI don't want to pollute this thread, but for the sake of following up, I observed hanging close to the final iteration of the dataloader. I think this was happening on the final shard. First, I removed the final shard and things worked. Then (including all shards), I reordered the list of shards: `load_dataset('json', data_files=reordered, streaming=True)` and no hang. \r\n\r\nI won't open an issue yet bc I am not quite sure about this observation.",
"@wconnell would you mind opening a different bug issue and giving more details?\r\nhttps://github.com/huggingface/datasets/issues/new?assignees=&labels=&template=bug-report.yml\r\n\r\nThanks."
] |
https://api.github.com/repos/huggingface/datasets/issues/3129 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3129/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3129/comments | https://api.github.com/repos/huggingface/datasets/issues/3129/events | https://github.com/huggingface/datasets/pull/3129 | 1,032,234,167 | PR_kwDODunzps4tezlA | 3,129 | Support Audio feature for TAR archives in sequential access | [] | closed | false | null | 7 | 2021-10-21T08:56:51Z | 2021-11-17T17:42:08Z | 2021-11-17T17:42:07Z | null | Add Audio feature support for TAR archived files in sequential access.
Fix #3128. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3129/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3129/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3129.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3129",
"merged_at": "2021-11-17T17:42:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3129.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3129"
} | true | [
"Also do you think we can adapt `cast_column` to keep the same value for this new parameter when the user only wants to change the sampling rate ?",
"Thanks for your comments, @lhoestq, I will address them afterwards.\r\n\r\nBut, I think it is more important/urgent first address the current blocking non-passing test: https://github.com/huggingface/datasets/runs/4143579241?check_suite_focus=true\r\n- I am thinking of a way of solving it, but if you have any hint, it will be more than welcome! 😅 \r\n\r\nBasically:\r\n```\r\n{'audio': '/tmp/pytest-of-runner/pytest-0/popen-gw1/test_dataset_with_audio_featur1/data/test_audio_44100.wav'}\r\n``` \r\nbecomes\r\n```\r\n{'audio': {'bytes': None, 'path': '/tmp/pytest-of-runner/pytest-0/popen-gw1/test_dataset_with_audio_featur1/data/test_audio_44100.wav'}}\r\n```\r\nafter a `map`, which is what was stored in the Arrow file. However we expect it remains invariant after this `map`.",
"@lhoestq, @mariosasko I finally proposed another implementation different from my last one:\r\n- Before: store Audio always a struct<path: string, bytes: binary>, where bytes can be None\r\n- Now, depending on the examples, either store Audio as a struct (as before), or as a string.\r\n\r\nPlease note that the main motivation for this change was the issue mentioned above: https://github.com/huggingface/datasets/pull/3129#issuecomment-964347056\r\n",
"Until here we had the assumption that a Features object always has an associated, deterministic, pyarrow schema. This is useful to ensure that we are able to concatenate two datasets that have the same features for example.\r\n\r\nBy breaking this assumption for the Audio type, how can we ensure that we can concatenate two audio datasets if one has Audio as a struct and the other a string ?",
"Oh I noticed that the Audio feature type has a private attribute `_storage_dtype`, so the assumption still holds, since they are now different feature types depending on the this attribute :)\r\n(i mean different from the python equal operator point of view)",
"I think this PR is ready, @lhoestq, @mariosasko. ",
"Nit: We should also mention the new storage structure in the `Features` docstring [here](https://github.com/huggingface/datasets/blob/b29fb550c31de337b952035a7584147e0f18c0cf/src/datasets/features/features.py#L966) for users to know what type of value to return in their dataset scripts (we also have a link to that docstring in the `ADD_NEW_DATASET` template)."
] |
https://api.github.com/repos/huggingface/datasets/issues/4169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4169/comments | https://api.github.com/repos/huggingface/datasets/issues/4169/events | https://github.com/huggingface/datasets/issues/4169 | 1,203,995,869 | I_kwDODunzps5Hw4Td | 4,169 | Timit_asr dataset cannot be previewed recently | [] | closed | false | null | 5 | 2022-04-14T03:28:31Z | 2023-02-03T04:54:57Z | 2022-05-06T16:06:51Z | null | ## Dataset viewer issue for '*timit_asr*'
**Link:** *https://huggingface.co/datasets/timit_asr*
Issue: The timit-asr dataset cannot be previewed recently.
Am I the one who added this dataset ? Yes-No
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4169/timeline | null | completed | null | null | false | [
"Thanks for reporting. The bug has already been detected, and we hope to fix it soon.",
"TIMIT is now a dataset that requires manual download, see #4145 \r\n\r\nTherefore it might take a bit more time to fix it",
"> TIMIT is now a dataset that requires manual download, see #4145\r\n> \r\n> Therefore it might take a bit more time to fix it\r\n\r\nThank you for your quickly response. Exactly, I also found the manual download issue in the morning. But when I used *list_datasets()* to check the available datasets, *'timit_asr'* is still in the list. So I am a little bit confused. If *'timit_asr'* need to be manually downloaded, does that mean we can **not** automatically download it **any more** in the future?",
"Yes exactly. If you try to load the dataset it will ask you to download it manually first, and to pass the downloaded and extracted data like `load_dataset(\"timir_asr\", data_dir=\"path/to/extracted/data\")`\r\n\r\nThe URL we were using was coming from a host that doesn't have the permission to redistribute the data, and the dataset owners (LDC) notified us about it.",
"I downloaded the timit_asr data and unzipped. But I can't run my code. Could you resolve this problem for me? Thanks\r\n\r\n import soundfile as sf\r\n import torch\r\n from datasets import load_dataset\r\n dataset = load_dataset(\"timit_asr\", data_dir=\"/Users/nguyenvannham/Documents/test_case/data\")\r\n \r\n \r\n Generating train split: 0 examples [00:00, ? examples/s]\r\n\r\nGenerating train split: 0 examples [00:00, ? examples/s]Traceback (most recent call last):\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/builder.py\", line 1571, in _prepare_split_single\r\n for key, record in generator:\r\n\r\n File \"/Users/nguyenvannham/.cache/huggingface/modules/datasets_modules/datasets/timit_asr/43f9448dd5db58e95ee48a277f466481b151f112ea53e27f8173784da9254fb2/timit_asr.py\", line 138, in _generate_examples\r\n with txt_path.open(encoding=\"utf-8\") as op:\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/pathlib.py\", line 1252, in open\r\n return io.open(self, mode, buffering, encoding, errors, newline,\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/pathlib.py\", line 1120, in _opener\r\n return self._accessor.open(self, flags, mode)\r\n\r\nFileNotFoundError: [Errno 2] No such file or directory: '/Users/nguyenvannham/Documents/test_case/data/train/DR1/FCJF0/SA1.WAV.TXT'\r\n\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n\r\n File \"/var/folders/t9/l8d3rwpn1k33_gjtqs732lzc0000gn/T/ipykernel_3891/1203313828.py\", line 1, in <module>\r\n dataset = load_dataset(\"timit_asr\", data_dir=\"/Users/nguyenvannham/Documents/test_case/data\")\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/load.py\", line 1758, in load_dataset\r\n builder_instance.download_and_prepare(\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/builder.py\", line 860, in download_and_prepare\r\n self._download_and_prepare(\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/builder.py\", line 1612, in _download_and_prepare\r\n super()._download_and_prepare(\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/builder.py\", line 953, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/builder.py\", line 1450, in _prepare_split\r\n for job_id, done, content in self._prepare_split_single(\r\n\r\n File \"/opt/anaconda3/envs/audio/lib/python3.9/site-packages/datasets/builder.py\", line 1607, in _prepare_split_single\r\n raise DatasetGenerationError(\"An error occurred while generating the dataset\") from e\r\n\r\nDatasetGenerationError: An error occurred while generating the dataset"
] |
https://api.github.com/repos/huggingface/datasets/issues/4576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4576/comments | https://api.github.com/repos/huggingface/datasets/issues/4576/events | https://github.com/huggingface/datasets/pull/4576 | 1,285,698,576 | PR_kwDODunzps46aSN_ | 4,576 | Include `metadata.jsonl` in resolved data files | [] | closed | false | null | 5 | 2022-06-27T12:01:29Z | 2022-07-01T12:44:55Z | 2022-06-30T10:15:32Z | null | Include `metadata.jsonl` in resolved data files.
Fix #4548
@lhoestq ~~https://github.com/huggingface/datasets/commit/d94336d30eef17fc9abc67f67fa1c139661f4e75 adds support for metadata files placed at the root, and https://github.com/huggingface/datasets/commit/4d20618ea7a19bc143ddc5fdff9d79e671fcbb95 accounts for nested metadata files also, but this results in more complex code. Let me know which one of these two approaches you prefer.~~ Maybe https://github.com/huggingface/datasets/commit/d94336d30eef17fc9abc67f67fa1c139661f4e75 is good enough for now (for the sake of simplicity). https://github.com/huggingface/datasets/commit/4d20618ea7a19bc143ddc5fdff9d79e671fcbb95 breaks the imagefolder tests due to duplicates in the resolved metadata files. One way to fix this would be to resolve the metadata pattern only on parent directories, but this adds even more logic to `_get_data_files_patterns`, so not sure if this is what we should do. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4576/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4576.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4576",
"merged_at": "2022-06-30T10:15:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4576.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4576"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I still don't know if the way we implemented data files resolution could support the metadata.jsonl file without bad side effects for the other packaged builders. In particular here if you have a folder of csv/parquet/whatever files and a metadata.jsonl file, it would return \r\n```\r\nsplit: patterns_dict[split] + [METADATA_PATTERN]\r\n```\r\nwhich is a bit unexpected and can lead to errors.\r\n\r\nMaybe this logic can be specific to imagefolder somehow ? This could be an additional pattern `[\"metadata.jsonl\", \"**/metadata.jsonl\"]` just for imagefolder, that is only used when `data_files=` is not specified by the user.\r\n\r\nI guess it's ok to have patterns that lead to duplicate metadata.jsonl files for imagefolder, since the imagefolder logic only considers the closest metadata file for each image.\r\n\r\nWhat do you think ?",
"Yes, that's indeed the problem. My solution in https://github.com/huggingface/datasets/commit/4d20618ea7a19bc143ddc5fdff9d79e671fcbb95 that accounts for that (include metadata files only if image files are present; not ideal): https://github.com/huggingface/datasets/blob/4d20618ea7a19bc143ddc5fdff9d79e671fcbb95/src/datasets/data_files.py#L119-L125.\r\nPerhaps a cleaner approach would be to check for metadata files after the packaged module type is inferred as `imagefolder` and append metadata files to already resolved data files (if there are any). WDYT?",
"@lhoestq \r\n\r\n> Perhaps a cleaner approach would be to check for metadata files after the packaged module type is inferred as imagefolder and append metadata files to already resolved data files (if there are any). WDYT?\r\n\r\nI decided to go with this approach.\r\n\r\n Not sure if you meant the same thing with this comment:\r\n\r\n> Maybe this logic can be specific to imagefolder somehow ? This could be an additional pattern [\"metadata.jsonl\", \"**/metadata.jsonl\"] just for imagefolder, that is only used when data_files= is not specified by the user.\r\n\r\n\r\nIt adds more code but is easy to follow IMO.\r\n",
"The CI still struggles but you can merge since at least one of the two WIN CI succeeded"
] |
https://api.github.com/repos/huggingface/datasets/issues/4675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4675/comments | https://api.github.com/repos/huggingface/datasets/issues/4675/events | https://github.com/huggingface/datasets/issues/4675 | 1,302,193,649 | I_kwDODunzps5NneXx | 4,675 | Unable to use dataset with PyTorch dataloader | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 1 | 2022-07-12T15:04:04Z | 2022-07-14T14:17:46Z | null | null | ## Describe the bug
When using `.with_format("torch")`, an arrow table is returned and I am unable to use it by passing it to a PyTorch DataLoader: please see the code below.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torch.utils.data import DataLoader
ds = load_dataset(
"para_crawl",
name="enfr",
cache_dir="/tmp/test/",
split="train",
keep_in_memory=True,
)
dataloader = DataLoader(ds.with_format("torch"), num_workers=32)
print(next(iter(dataloader)))
```
Is there something I am doing wrong? The documentation does not say much about the behavior of `.with_format()` so I feel like I am a bit stuck here :-/
Thanks in advance for your help!
## Expected results
The code should run with no error
## Actual results
```
AttributeError: 'str' object has no attribute 'dtype'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-4.18.0-348.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.4
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4675/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4675/timeline | null | null | null | null | false | [
"Hi! `para_crawl` has a single column of type `Translation`, which stores translation dictionaries. These dictionaries can be stored in a NumPy array but not in a PyTorch tensor since PyTorch only supports numeric types. In `datasets`, the conversion to `torch` works as follows: \r\n1. convert PyArrow table to NumPy arrays \r\n2. convert NumPy arrays to Torch tensors. \r\n\r\nThe 2nd step is problematic for your case as `datasets` attempts to convert the array of dictionaries to a PyTorch tensor. One way to fix this is to use the [preprocessing logic](https://github.com/huggingface/transformers/blob/8581a798c0a48fca07b29ce2ca2ef55adcae8c7e/examples/pytorch/translation/run_translation.py#L440-L458) from the Transformers translation script. And on our side, I think we can replace a NumPy array of dicts with a dict of NumPy array if the feature type is `Translation`/`TranslationVariableLanguages` (one array for each language) to get the official PyTorch error message for strings in such case."
] |
https://api.github.com/repos/huggingface/datasets/issues/5454 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5454/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5454/comments | https://api.github.com/repos/huggingface/datasets/issues/5454/events | https://github.com/huggingface/datasets/issues/5454 | 1,552,890,419 | I_kwDODunzps5cjzoz | 5,454 | Save and resume the state of a DataLoader | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | open | false | null | 2 | 2023-01-23T10:58:54Z | 2023-01-24T01:45:48Z | null | null | It would be nice when using `datasets` with a PyTorch DataLoader to be able to resume a training from a DataLoader state (e.g. to resume a training that crashed)
What I have in mind (but lmk if you have other ideas or comments):
For map-style datasets, this requires to have a PyTorch Sampler state that can be saved and reloaded per node and worker.
For iterable datasets, this requires to save the state of the dataset iterator, which includes:
- the current shard idx and row position in the current shard
- the epoch number
- the rng state
- the shuffle buffer
Right now you can already resume the data loading of an iterable dataset by using `IterableDataset.skip` but it takes a lot of time because it re-iterates on all the past data until it reaches the resuming point.
cc @stas00 @sgugger | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5454/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5454/timeline | null | null | null | null | false | [
"Something that'd be nice to have is \"manual update of state\". One of the learning from training LLMs is the ability to skip some batches whenever we notice huge spike might be handy.",
"Your outline spec is very sound and clear, @lhoestq - thank you!\r\n\r\n@thomasw21, indeed that would be a wonderful extra feature. In Megatron-Deepspeed we manually drained the dataloader for the range we wanted. I wasn't very satisfied with the way we did it, since its behavior would change if you were to do multiple range skips. I think it should remember all the ranges it skipped and not just skip the last range - since otherwise the data is inconsistent (but we probably should discuss this in a separate issue not to derail this much bigger one)."
] |
https://api.github.com/repos/huggingface/datasets/issues/5811 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5811/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5811/comments | https://api.github.com/repos/huggingface/datasets/issues/5811/events | https://github.com/huggingface/datasets/issues/5811 | 1,689,919,046 | I_kwDODunzps5kuh5G | 5,811 | load_dataset: TypeError: 'NoneType' object is not callable, on local dataset filename changes | [] | open | false | null | 1 | 2023-04-30T13:27:17Z | 2023-05-05T17:44:03Z | null | null | ### Describe the bug
I've adapted Databrick's [train_dolly.py](/databrickslabs/dolly/blob/master/train_dolly.py) to train using a local dataset, which has been working. Upon changing the filenames of the `.json` & `.py` files in my local dataset directory, `dataset = load_dataset(path_or_dataset)["train"]` throws the error:
```python
2023-04-30 09:10:52 INFO [training.trainer] Loading dataset from dushowxa-characters
Traceback (most recent call last):
File "/data/dushowxa-dolly/train_dushowxa.py", line 26, in <module>
load_training_dataset()
File "/data/dushowxa-dolly/training/trainer.py", line 89, in load_training_dataset
dataset = load_dataset(path_or_dataset)["train"]
File "/data/dushowxa-dolly/.venv/lib/python3.10/site-packages/datasets/load.py", line 1773, in load_dataset
builder_instance = load_dataset_builder(
File "/data/dushowxa-dolly/.venv/lib/python3.10/site-packages/datasets/load.py", line 1528, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
TypeError: 'NoneType' object is not callable
```
The local dataset filenames were of the form `dushowxa-characters/expanse-dushowxa-characters.json` and are now of the form `dushowxa-characters/dushowxa-characters.json` (the word `expanse-` was removed from the filenames). Is this perhaps a dataset caching issue?
I have attempted to manually clear caches, but to no effect:
```sh
rm -rfv ~/.cache/huggingface/datasets/*
rm -rfv ~/.cache/huggingface/modules/*
```
### Steps to reproduce the bug
Run `python3 train_dushowxa.py` (adapted from Databrick's [train_dolly.py](/databrickslabs/dolly/blob/master/train_dolly.py)).
### Expected behavior
Training succeeds as before local dataset filenames were changed.
### Environment info
Ubuntu 22.04, Python 3.10.6, venv
```python
accelerate>=0.16.0,<1
click>=8.0.4,<9
datasets>=2.10.0,<3
deepspeed>=0.9.0,<1
transformers[torch]>=4.28.1,<5
langchain>=0.0.139
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5811/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5811/timeline | null | null | null | null | false | [
"This error means a `DatasetBuilder` subclass that generates the dataset could not be found inside the script, so make sure `dushowxa-characters/dushowxa-characters.py `is a valid dataset script (assuming `path_or_dataset` is `dushowxa-characters`)\r\n\r\nAlso, we should improve the error to make it more obvious what the problem is."
] |
https://api.github.com/repos/huggingface/datasets/issues/2302 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2302/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2302/comments | https://api.github.com/repos/huggingface/datasets/issues/2302/events | https://github.com/huggingface/datasets/pull/2302 | 873,961,435 | MDExOlB1bGxSZXF1ZXN0NjI4NjIzMDQ3 | 2,302 | Add SubjQA dataset | [] | closed | false | null | 4 | 2021-05-02T14:51:20Z | 2021-05-10T09:21:19Z | 2021-05-10T09:21:19Z | null | Hello datasetters 🙂!
Here's an interesting dataset about extractive question-answering on _subjective_ product / restaurant reviews. It's quite challenging for models fine-tuned on SQuAD and provides a nice example of domain adaptation (i.e. fine-tuning a SQuAD model on this domain gives better performance).
I found a bug in the start/end indices that I've proposed a fix for here: https://github.com/megagonlabs/SubjQA/pull/2
Unfortunately, the dataset creators are unresponsive, so for now I am using my fork as the source. Will update the URL if/when the creators respond. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2302/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2302/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2302.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2302",
"merged_at": "2021-05-10T09:21:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2302.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2302"
} | true | [
"I'm not sure why the windows test fails, but looking at the logs it looks like some caching issue on one of the metrics ... maybe re-run and 🤞 ?",
"Hi @lewtun, thanks for adding this dataset!\r\n\r\nIf the dataset is going to be referenced heavily, I think it's worth spending some time to make the dataset card really great :) To start, the information that is currently in the `Data collection` paragraph should probably be organized in the `Dataset Creation` section.\r\n\r\nHere's a link to the [relevant section of the guide](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md#dataset-creation), let me know if you have any questions!",
"> If the dataset is going to be referenced heavily, I think it's worth spending some time to make the dataset card really great :) To start, the information that is currently in the `Data collection` paragraph should probably be organized in the `Dataset Creation` section.\r\n\r\ngreat idea @yjernite! i've added some extra information / moved things as you suggest and will wrap up the rest tomorrow :)",
"hi @yjernite and @lhoestq, i've fleshed out the dataset card and think this is now ready for another round of review!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2147 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2147/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2147/comments | https://api.github.com/repos/huggingface/datasets/issues/2147/events | https://github.com/huggingface/datasets/pull/2147 | 844,687,831 | MDExOlB1bGxSZXF1ZXN0NjAzOTA3NjM4 | 2,147 | Render docstring return type as inline | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | 0 | 2021-03-30T14:55:43Z | 2021-03-31T13:11:05Z | 2021-03-31T13:11:05Z | null | This documentation setting will avoid having the return type in a separate line under `Return type`.
See e.g. current docs for `Dataset.to_csv`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2147/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2147/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2147.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2147",
"merged_at": "2021-03-31T13:11:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2147.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2147"
} | true | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.