
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Simple DFS solution | coloring-a-border | 0 | 1 | ```\nclass Solution:\n def colorBorder(self, grid: List[List[int]], row: int, col: int, color: int) -> List[List[int]]:\n old_color, n, m = grid[row][col], len(grid)-1, len(grid[0])-1\n stack = [(row, col)]\n visited = set(stack)\n while stack: \n i, j = stack.pop()\n if i in {0, n} or j in {0, m} or any(grid[x][y] != old_color and (x, y) not in visited for x, y in [(i-1, j), (i, j-1), (i, j+1), (i+1, j)]):\n grid[i][j] = color\n for x, y in (i-1, j), (i, j-1), (i, j+1), (i+1, j): \n if 0 <= x <= n and 0 <= y <= m and grid[x][y] == old_color and (x, y) not in visited:\n stack.append((x, y))\n visited.add((x, y))\n return grid\n``` | 0 | You are given an `m x n` integer matrix `grid`, and three integers `row`, `col`, and `color`. Each value in the grid represents the color of the grid square at that location.
Two squares belong to the same **connected component** if they have the same color and are next to each other in any of the 4 directions.
The **border of a connected component** is all the squares in the connected component that are either **4-directionally** adjacent to a square not in the component, or on the boundary of the grid (the first or last row or column).
You should color the **border** of the **connected component** that contains the square `grid[row][col]` with `color`.
Return _the final grid_.
**Example 1:**
**Input:** grid = \[\[1,1\],\[1,2\]\], row = 0, col = 0, color = 3
**Output:** \[\[3,3\],\[3,2\]\]
**Example 2:**
**Input:** grid = \[\[1,2,2\],\[2,3,2\]\], row = 0, col = 1, color = 3
**Output:** \[\[1,3,3\],\[2,3,3\]\]
**Example 3:**
**Input:** grid = \[\[1,1,1\],\[1,1,1\],\[1,1,1\]\], row = 1, col = 1, color = 2
**Output:** \[\[2,2,2\],\[2,1,2\],\[2,2,2\]\]
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j], color <= 1000`
* `0 <= row < m`
* `0 <= col < n` | null |
[Python3] barebones DFS, code also explains the requirements | coloring-a-border | 0 | 1 | ```\n# border: < 4 neighbors\nclass Solution:\n def colorBorder(self, grid: List[List[int]], row: int, col: int, color: int) -> List[List[int]]:\n def in_bounds(r, c):\n return 0 <= r < len(grid) and 0 <= c < len(grid[0])\n\n\n def neighbors(r, c):\n nbrs = []\n if in_bounds(r - 1, c) and grid[r - 1][c] == orig_color:\n nbrs.append((r - 1, c))\n if in_bounds(r + 1, c) and grid[r + 1][c] == orig_color:\n nbrs.append((r + 1, c))\n if in_bounds(r, c - 1) and grid[r][c - 1] == orig_color:\n nbrs.append((r, c - 1))\n if in_bounds(r, c + 1) and grid[r][c + 1] == orig_color:\n nbrs.append((r, c + 1))\n return nbrs\n\n\n def explore(r, c):\n if (r, c) in visited:\n return\n\n visited.add((r, c))\n\n nbrs = neighbors(r, c)\n if len(nbrs) < 4:\n border.add((r, c))\n\n for nr, nc in nbrs:\n explore(nr, nc)\n\n orig_color = grid[row][col]\n visited = set()\n border = set()\n\n explore(row, col)\n\n for r, c in border:\n grid[r][c] = color\n\n return grid\n``` | 0 | You are given an `m x n` integer matrix `grid`, and three integers `row`, `col`, and `color`. Each value in the grid represents the color of the grid square at that location.
Two squares belong to the same **connected component** if they have the same color and are next to each other in any of the 4 directions.
The **border of a connected component** is all the squares in the connected component that are either **4-directionally** adjacent to a square not in the component, or on the boundary of the grid (the first or last row or column).
You should color the **border** of the **connected component** that contains the square `grid[row][col]` with `color`.
Return _the final grid_.
**Example 1:**
**Input:** grid = \[\[1,1\],\[1,2\]\], row = 0, col = 0, color = 3
**Output:** \[\[3,3\],\[3,2\]\]
**Example 2:**
**Input:** grid = \[\[1,2,2\],\[2,3,2\]\], row = 0, col = 1, color = 3
**Output:** \[\[1,3,3\],\[2,3,3\]\]
**Example 3:**
**Input:** grid = \[\[1,1,1\],\[1,1,1\],\[1,1,1\]\], row = 1, col = 1, color = 2
**Output:** \[\[2,2,2\],\[2,1,2\],\[2,2,2\]\]
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j], color <= 1000`
* `0 <= row < m`
* `0 <= col < n` | null |
Python DFS | coloring-a-border | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n+v) where v is the linear operation for checking visited list and n is for checking through n points.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n) for a visited list\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def colorBorder(self, grid: List[List[int]], row: int, col: int, color: int) -> List[List[int]]:\n\n rows, cols = len(grid), len(grid[0])\n visited = set()\n prev_color = grid[row][col]\n\n def dfs(row, col):\n # addind the node in visited\n visited.add((row, col))\n\n # explore four adjucent node\n for dr, dc in [(1, 0), (0, 1), (-1, 0), (0, -1)]:\n new_row, new_col = row + dr, col + dc\n\n # check if the new node is already visited or not\n if (new_row, new_col) not in visited:\n\n # check if the new node is out of range or not\n if (0 <= new_row < rows) and (0 <= new_col < cols):\n\n # check if the new node has the same color or not\n if grid[new_row][new_col]==prev_color:\n\n # do dfs on new node\n dfs(new_row, new_col)\n \n # If the node is not same color then it is a border node. Change the color \n else:\n grid[row][col] = color\n \n # if new node out of range, then it is a border node. Change the color\n else:\n grid[row][col] = color\n \n # start the bfs from the given point\n dfs(row, col)\n\n \n return grid\n``` | 0 | You are given an `m x n` integer matrix `grid`, and three integers `row`, `col`, and `color`. Each value in the grid represents the color of the grid square at that location.
Two squares belong to the same **connected component** if they have the same color and are next to each other in any of the 4 directions.
The **border of a connected component** is all the squares in the connected component that are either **4-directionally** adjacent to a square not in the component, or on the boundary of the grid (the first or last row or column).
You should color the **border** of the **connected component** that contains the square `grid[row][col]` with `color`.
Return _the final grid_.
**Example 1:**
**Input:** grid = \[\[1,1\],\[1,2\]\], row = 0, col = 0, color = 3
**Output:** \[\[3,3\],\[3,2\]\]
**Example 2:**
**Input:** grid = \[\[1,2,2\],\[2,3,2\]\], row = 0, col = 1, color = 3
**Output:** \[\[1,3,3\],\[2,3,3\]\]
**Example 3:**
**Input:** grid = \[\[1,1,1\],\[1,1,1\],\[1,1,1\]\], row = 1, col = 1, color = 2
**Output:** \[\[2,2,2\],\[2,1,2\],\[2,2,2\]\]
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j], color <= 1000`
* `0 <= row < m`
* `0 <= col < n` | null |
Python solution BFS | coloring-a-border | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nApplying Breadth First Search. The idea is we will take a point and then we will find out if this point is our point of interest. After that, we will look points which is \'one\' distance from the first point. We can say this layer 1. In our case, there are total four points as such. Top, bottom, right and left points of the main point. We will check the top point and see if it is desired point or not. Then checke the bottom then right and then left. Layer 1 is complete. Then we will go for layer 2. We will check the 4 neighbors of Top point. And it continues.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nMaintain a list called components to list down the points that needs to be checked sequntially. And then apply checking on the points from the component list.\n\n# Complexity\n- Time complexity: Although it looks like a $$O(n^3)$$ [while loop for components, inside for loop for neighbors, inside checking the neighbors in visited set] but really the computation is way less. because the for loop only checks four neighbour so instead of $$O(n * n * n)$$ it becomes $$O(n * 4 * n)$$ which is $$O(n^2)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$ \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nCorrect me if I am wrong.\n\n# Code\n```\nclass Solution:\n def colorBorder(self, grid: List[List[int]], row: int, col: int, color: int) -> List[List[int]]:\n rows, cols = len(grid), len(grid[0])\n # co-ordinate that we visited\n visited = set()\n # co-ordinates that we need to visit\n components = [(row, col)]\n prev_color = grid[row][col]\n\n def bfs(row, col):\n visited.add((row, col))\n\n # checking four neighbors of the point\n for dr, dc in [(1, 0), (0, 1), (-1, 0), (0, -1)]:\n new_row, new_col = row + dr, col + dc\n if (new_row, new_col) not in visited:\n if (0<=new_row<rows) and (0<=new_col<cols):\n # add to the components if the neighboring point is not in perimeter of the matrix\n components.append((new_row, new_col))\n if grid[new_row][new_col] != prev_color:\n # if the color doesn\'t match, means the new point is not connected component. so we don\'t need to visit this point anymore.\n components.pop(-1)\n # because colors doesn\'t match that means this is a border\n grid[row][col] = color\n\n else:\n # permimeter of the matrix, border by definition\n grid[row][col] = color\n\n # looping through components and do bfs for each point\n i = 0\n while i < len(components):\n bfs(*components[i])\n i += 1\n\n return grid\n\n \n``` | 0 | You are given an `m x n` integer matrix `grid`, and three integers `row`, `col`, and `color`. Each value in the grid represents the color of the grid square at that location.
Two squares belong to the same **connected component** if they have the same color and are next to each other in any of the 4 directions.
The **border of a connected component** is all the squares in the connected component that are either **4-directionally** adjacent to a square not in the component, or on the boundary of the grid (the first or last row or column).
You should color the **border** of the **connected component** that contains the square `grid[row][col]` with `color`.
Return _the final grid_.
**Example 1:**
**Input:** grid = \[\[1,1\],\[1,2\]\], row = 0, col = 0, color = 3
**Output:** \[\[3,3\],\[3,2\]\]
**Example 2:**
**Input:** grid = \[\[1,2,2\],\[2,3,2\]\], row = 0, col = 1, color = 3
**Output:** \[\[1,3,3\],\[2,3,3\]\]
**Example 3:**
**Input:** grid = \[\[1,1,1\],\[1,1,1\],\[1,1,1\]\], row = 1, col = 1, color = 2
**Output:** \[\[2,2,2\],\[2,1,2\],\[2,2,2\]\]
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j], color <= 1000`
* `0 <= row < m`
* `0 <= col < n` | null |
Python top down dp | uncrossed-lines | 0 | 1 | # Intuition\nBasically attempt to join the string in each steps, then try out not joining\n\n# Code\n```\nclass Solution:\n def maxUncrossedLines(self, nums1: List[int], nums2: List[int]) -> int:\n @lru_cache(None)\n def max_lines(i, j):\n if i == len(nums1) or j == len(nums2):\n return 0\n else:\n res = max(max_lines(i+1, j), max_lines(i, j+1))\n if nums1[i] == nums2[j]:\n res = max(res, 1+ max_lines(i+1, j+1))\n return res\n \n return max_lines(0,0)\n``` | 3 | You are given two integer arrays `nums1` and `nums2`. We write the integers of `nums1` and `nums2` (in the order they are given) on two separate horizontal lines.
We may draw connecting lines: a straight line connecting two numbers `nums1[i]` and `nums2[j]` such that:
* `nums1[i] == nums2[j]`, and
* the line we draw does not intersect any other connecting (non-horizontal) line.
Note that a connecting line cannot intersect even at the endpoints (i.e., each number can only belong to one connecting line).
Return _the maximum number of connecting lines we can draw in this way_.
**Example 1:**
**Input:** nums1 = \[1,4,2\], nums2 = \[1,2,4\]
**Output:** 2
**Explanation:** We can draw 2 uncrossed lines as in the diagram.
We cannot draw 3 uncrossed lines, because the line from nums1\[1\] = 4 to nums2\[2\] = 4 will intersect the line from nums1\[2\]=2 to nums2\[1\]=2.
**Example 2:**
**Input:** nums1 = \[2,5,1,2,5\], nums2 = \[10,5,2,1,5,2\]
**Output:** 3
**Example 3:**
**Input:** nums1 = \[1,3,7,1,7,5\], nums2 = \[1,9,2,5,1\]
**Output:** 2
**Constraints:**
* `1 <= nums1.length, nums2.length <= 500`
* `1 <= nums1[i], nums2[j] <= 2000` | null |
Dynamic Programming || beginner friendly | uncrossed-lines | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n```\n 0 1 2 3\n0 0 0 0 0\n1 0 1 1 1\n2 0 1 1 2\n3 0 1 2 2\n```\n# Approach\n<!-- Describe your approach to solving the problem. -->\n```\n 0 1 2 3\n0 +--+--+--+\n | | | |\n1 +--+--+--+\n | |\u2196 |\u2196 |\n2 +--+\u2196 | + |\n | | + |\u2196 |\n3 +--+--+\u2196 | \n | | | + |\n +--+--+--+ \n\n\n 0 1 2 3\n0 + 0 0 0\n | | | |\n1 + 0 1 1\n | |\u2196|\u2196|\n2 + 0 1+1+\n | |+|\u2196|\n3 + 0 1 2+\n | | |+|\n + + + + \n\n\n\n```\n- Initialize a 2D array dp of size (n+1) x (m+1) to 0.\n- Loop through the indices i and j of nums1 and nums2 respectively, from 0 to n and m:\n1. If nums1[i-1] == nums2[j-1], set dp[i][j] = dp[i-1][j-1] + 1.\n1. b. Otherwise, set dp[i][j] = max(dp[i-1][j], dp[i][j-1]).\n- Return dp[n][m].\n\n# Complexity\n- Time complexity: O (nm)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O (nm)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maxUncrossedLines(self, nums1: List[int], nums2: List[int]) -> int:\n n , m = len(nums1) , len(nums2)\n dp = [[0] * (m + 1) for _ in range(n + 1)]\n\n for i in range(1 , n + 1) :\n for j in range( 1 , m + 1) :\n if nums1[i - 1] == nums2[j - 1] :\n dp[i][j] = dp[i - 1][j - 1] + 1\n else :\n dp[i][j] = max(dp[i - 1][j] , dp[i][j - 1])\n return dp[n][m]\n``` | 3 | You are given two integer arrays `nums1` and `nums2`. We write the integers of `nums1` and `nums2` (in the order they are given) on two separate horizontal lines.
We may draw connecting lines: a straight line connecting two numbers `nums1[i]` and `nums2[j]` such that:
* `nums1[i] == nums2[j]`, and
* the line we draw does not intersect any other connecting (non-horizontal) line.
Note that a connecting line cannot intersect even at the endpoints (i.e., each number can only belong to one connecting line).
Return _the maximum number of connecting lines we can draw in this way_.
**Example 1:**
**Input:** nums1 = \[1,4,2\], nums2 = \[1,2,4\]
**Output:** 2
**Explanation:** We can draw 2 uncrossed lines as in the diagram.
We cannot draw 3 uncrossed lines, because the line from nums1\[1\] = 4 to nums2\[2\] = 4 will intersect the line from nums1\[2\]=2 to nums2\[1\]=2.
**Example 2:**
**Input:** nums1 = \[2,5,1,2,5\], nums2 = \[10,5,2,1,5,2\]
**Output:** 3
**Example 3:**
**Input:** nums1 = \[1,3,7,1,7,5\], nums2 = \[1,9,2,5,1\]
**Output:** 2
**Constraints:**
* `1 <= nums1.length, nums2.length <= 500`
* `1 <= nums1[i], nums2[j] <= 2000` | null |
Clean Python DP | uncrossed-lines | 0 | 1 | # Code\n```\nclass Solution:\n def maxUncrossedLines(self, nums1: List[int], nums2: List[int]) -> int:\n\n n = len(nums1)\n dic = defaultdict(list)\n for i,num in enumerate(nums2):\n dic[num].append(i)\n \n @lru_cache(None)\n def rec(i=0, i_max=-1):\n\n if i==n:\n return 0\n \n num = nums1[i]\n i2 = bisect_left(dic[num], i_max+1)\n if i2<len(dic[num]):\n return max(1+rec(i+1, dic[num][i2]), rec(i+1, i_max))\n \n return rec(i+1, i_max)\n \n return rec()\n``` | 1 | You are given two integer arrays `nums1` and `nums2`. We write the integers of `nums1` and `nums2` (in the order they are given) on two separate horizontal lines.
We may draw connecting lines: a straight line connecting two numbers `nums1[i]` and `nums2[j]` such that:
* `nums1[i] == nums2[j]`, and
* the line we draw does not intersect any other connecting (non-horizontal) line.
Note that a connecting line cannot intersect even at the endpoints (i.e., each number can only belong to one connecting line).
Return _the maximum number of connecting lines we can draw in this way_.
**Example 1:**
**Input:** nums1 = \[1,4,2\], nums2 = \[1,2,4\]
**Output:** 2
**Explanation:** We can draw 2 uncrossed lines as in the diagram.
We cannot draw 3 uncrossed lines, because the line from nums1\[1\] = 4 to nums2\[2\] = 4 will intersect the line from nums1\[2\]=2 to nums2\[1\]=2.
**Example 2:**
**Input:** nums1 = \[2,5,1,2,5\], nums2 = \[10,5,2,1,5,2\]
**Output:** 3
**Example 3:**
**Input:** nums1 = \[1,3,7,1,7,5\], nums2 = \[1,9,2,5,1\]
**Output:** 2
**Constraints:**
* `1 <= nums1.length, nums2.length <= 500`
* `1 <= nums1[i], nums2[j] <= 2000` | null |
Solution | escape-a-large-maze | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<vector<int>> dirs = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}}; \n \n bool isEscapePossible(vector<vector<int>>& blocked, vector<int>& source, vector<int>& target) {\n unordered_set<long long> visited_s;\n unordered_set<long long> visited_t;\n for (auto& block : blocked) {\n if (abs(source[0] - block[0]) + abs(source[1] - block[1]) <= 200)\n visited_s.insert(((long long)block[0] << 32) + block[1]);\n if (abs(target[0] - block[0]) + abs(target[1] - block[1]) <= 200)\n visited_t.insert(((long long)block[0] << 32) + block[1]);\n }\n return bfs(source, target, visited_s, visited_s.size()) &&\n bfs(target, source, visited_t, visited_t.size());\n }\n bool bfs(vector<int>& source, vector<int>& target, \n unordered_set<long long>& visited, int blocks) {\n queue<pair<int, int>> q;\n q.push({source[0], source[1]});\n while (!q.empty() && q.size() <= blocks) {\n int x = q.front().first;\n int y = q.front().second;\n q.pop();\n if (x == target[0] && y == target[1])\n return true;\n for (auto& dir : dirs) {\n int next_x = x + dir[0];\n int next_y = y + dir[1];\n if (next_x < 0 || next_x > 999999 || next_y < 0 || next_y > 999999\n || visited.find(((long long)next_x << 32) + next_y) != visited.end())\n continue;\n q.push({next_x, next_y});\n visited.insert(((long long)next_x << 32) + next_y);\n }\n }\n return !q.empty();\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n \n escapeDist = len(blocked)\n \n def dfs(s, t, blocked):\n nonlocal escapeDist\n stk = [s]\n blocked.add(tuple(s))\n while len(stk) != 0:\n x, y = stk.pop()\n if (abs(s[0]-x) + abs(s[1]-y) >= escapeDist):\n return True\n neighbours = [(x+1, y), (x-1, y), (x, y+1), (x, y-1)]\n for n in neighbours:\n if n[0] > -1 and n[0] < 1000000 and n[1] > -1 and n[1] < 1000000 and n not in blocked:\n stk.append(n)\n blocked.add(n)\n return (t[0], t[1]) in blocked\n \n blocked = {(a[0], a[1]) for a in blocked}\n return dfs(source, target, set(blocked)) and dfs(target, source, set(blocked))\n```\n\n```Java []\nclass Solution {\n \n int[]source;\n int[]target;\n int xmin;\n int xmax;\n int ymin;\n int ymax;\n HashSet<Node>blocks;\n HashSet<Node>been;\n LinkedList<Integer>vertical;\n LinkedList<Integer>horizontal;\n int[][]neigh={{-1,-1},{-1,0},{-1,1},{0,-1},{0,1},{1,-1},{1,0},{1,1}};\n int[][]ds={{-1,0},{1,0},{0,-1},{0,1}};\n int[][]want;\n \n public boolean isEscapePossible(int[][] blocked, int[] source, int[] target) {\n this.source=target;\n this.target=target;\n blocks=new HashSet();\n been=new HashSet();\n vertical=new LinkedList();\n horizontal=new LinkedList();\n \n int xmirror=source[0]<=target[0]?1:-1;\n int ymirror=source[1]<=target[1]?1:-1;\n \n source[0]*=xmirror;\n source[1]*=ymirror;\n target[0]*=xmirror;\n target[1]*=ymirror;\n \n xmin=xmirror==1?0:(-1000000+1);\n xmax=xmirror==1?(1000000-1):0;\n ymin=ymirror==1?0:(-1000000+1);\n ymax=ymirror==1?(1000000-1):0;\n \n for(int[]b:blocked){\n int x=(b[0]*=xmirror),y=(b[1]*=ymirror);\n blocks.add(new Node(x,y));\n if(y==source[1])horizontal.offer(x);\n if(x==target[0])vertical.offer(y);\n }\n Collections.sort(horizontal);\n Collections.sort(vertical);\n \n want=new int[][]{{source[0]+1,target[0]-1,source[1],source[1]},{target[0],target[0],source[1],target[1]}};\n \n return dfs(source[0],source[1],true); \n }\n private boolean dfs(int x,int y,boolean jump){\n if(x==target[0]&&y==target[1])return true;\n if(jump){\n if(x!=target[0]){\n ceil(horizontal,x);\n if(horizontal.isEmpty()||horizontal.peek()>target[0]){\n want[0][0]=want[0][1]+1;//means disabled\n want[1][2]=y+1;\n return dfs(target[0],y,true);\n }\n else{\n int nx=horizontal.peek()-1;\n been.add(new Node(nx,y));\n want[0][0]=nx+1;\n return dfs(nx,y,false);\n }\n }\n else{\n ceil(vertical,y);\n if(vertical.isEmpty()||vertical.peek()>target[1])\n return true;\n else{\n int ny=vertical.peek()-1;\n been.add(new Node(x,ny));\n want[1][2]=ny+1;\n return dfs(x,ny,false);\n }\n }\n }\n for(int[]d:ds){\n int nx=x+d[0], ny=y+d[1];\n Node node=new Node(nx,ny);\n if(nx>=xmin&&nx<=xmax&&ny>=ymin&&ny<=ymax\n &&!blocks.contains(node)&&!been.contains(node)\n &&hasBlockedNeighbor(nx,ny)){\n been.add(node);\n if(readyToJump(nx,ny)&&dfs(nx,ny,true))return true;\n if(dfs(nx,ny,false))return true;\n }\n }\n return false;\n }\n private void ceil(LinkedList<Integer>list,int n){\n while(!list.isEmpty()&&list.peek()<n)list.poll();\n }\n private boolean hasBlockedNeighbor(int x,int y){\n for(int[]ngh:neigh){\n if(blocks.contains(new Node(x+ngh[0],y+ngh[1])))\n return true;\n }\n return false;\n }\n private boolean readyToJump(int x,int y){\n if(x>=want[0][0]&&x<=want[0][1]&&y>=want[0][2]&&y<=want[0][3]){\n want[0][0]=x+1;\n return true;\n }\n if(x>=want[1][0]&&x<=want[1][1]&&y>=want[1][2]&&y<=want[1][3]){\n want[1][2]=y+1;\n return true;\n }\n return false;\n } \n}\nclass Node {\n int x;\n int y;\n public Node(int xx,int yy){\n x=xx;\n y=yy;\n }\n \n public int hashCode(){\n return x+20773*y;\n }\n public boolean equals(Object obj){\n if(obj instanceof Node){\n Node n=(Node)obj;\n return x==n.x&&y==n.y;\n }\n return false;\n }\n}\n``` | 1 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Clean Python | High Speed | O(n) time, O(1) space | Beats 96.9% | escape-a-large-maze | 0 | 1 | # Code\n\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n blocked = set(map(tuple, blocked))\n \n def fn(x, y, tx, ty): \n """Return True if (x, y) is not looped from (tx, ty)."""\n seen = {(x, y)}\n queue = [(x, y)]\n level = 0 \n while queue: \n level += 1\n if level > 200: return True \n newq = []\n for x, y in queue: \n if (x, y) == (tx, ty): return True \n for xx, yy in (x-1, y), (x, y-1), (x, y+1), (x+1, y): \n if 0 <= xx < 1e6 and 0 <= yy < 1e6 and (xx, yy) not in blocked and (xx, yy) not in seen: \n seen.add((xx, yy))\n newq.append((xx, yy))\n queue = newq\n return False \n \n return fn(*source, *target) and fn(*target, *source)\n```\n\n\n# Faster Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n blocked = set(map(tuple, blocked))\n \n def dfs(sx, sy, tx, ty): \n """Return True if (x, y) is not looped from (tx, ty)."""\n seen = {(sx, sy)}\n stack = [(sx, sy)]\n while stack: \n x, y = stack.pop()\n if abs(x - sx) + abs(y - sy) > 200 or (x, y) == (tx, ty): return True \n for xx, yy in (x-1, y), (x, y-1), (x, y+1), (x+1, y): \n if 0 <= xx < 1e6 and 0 <= yy < 1e6 and (xx, yy) not in blocked and (xx, yy) not in seen: \n seen.add((xx, yy))\n stack.append((xx, yy))\n return False \n \n return dfs(*source, *target) and dfs(*target, *source)\n``` | 1 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Faster than 99.22% | escape-a-large-maze | 0 | 1 | # Approach\nsee code comments - it\'s tweaked depth-first search\n\nThe basic heuristic is: there are at most 200 blocks. If I can get 200 steps away from the start/source then there must be a hole where we can slip through and reach the target.\n\nThe only tricky part is that you have to run the search in both directions: from source to target AND (!) from target to source.\nOtherwise the heuristic fails because the walls may be around the target, not the source (I believe test 29 is such a case).\n\nBy the way: breadth-first search works as well but it is slower because you need longer to get at least 200 steps away from home.\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n # it\'s always possible to reach to destination unless\n # the start in enclosed by those 200 blocked cells (and the borders of the grid)\n # if I can walk more than 200 steps away from the start\n # then no such enclosing exists\n\n # corner case: if source and target are on the same side of such an enclosing,\n # then you reach the target\n\n # why 200 ?\n # imagine you start at (0,0) then there could be\n # a super short wall at (0,1) and long wall at (1,0)-(1,199)\n # (plus the borders of the grid)\n\n blocks = set([ (x, y) for x, y in blocked ])\n\n def deeper(sx, sy, tx, ty):\n todo = [ (sx, sy) ]\n seen = set()\n while todo:\n next = todo.pop()\n if next in seen:\n continue\n seen.add(next)\n\n if next in blocks:\n continue\n\n x, y = next\n # escaped\n if x == tx and y == ty:\n return True\n\n # there must be a hole\n dx = abs(x - sx)\n dy = abs(y - sy)\n if dx + dy > 200:\n return True\n\n if x > 0:\n todo.append((x - 1, y))\n if y > 0:\n todo.append((x, y - 1))\n if x < 999_999:\n todo.append((x + 1, y))\n if y < 999_999:\n todo.append((x, y + 1))\n\n # couldn\'t escape the blocked walls\n return False\n\n # run search in both directions\n sx, sy = source\n tx, ty = target\n return deeper(sx,sy, tx,ty) and deeper(tx,ty, sx,sy)\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Python A*, early return for circumventing blockade | escape-a-large-maze | 0 | 1 | # Intuition\nUse A* to search for the target starting from the source.\n\nFor A*, we use a priority-queue/min-heap to determine when to visit nodes. The value to compare against in the priority-queue should be the actual cost so far to reach plus the estimated cost.\n\nThe estimated cost needs to be admissible, so we\'ll use manhattan distance as we can only travel in four directions. The estimated cost is not less than the minimum possible cost to reach the target.\n\nActual cost is the distance so we\'ve traveled so far.\n\nIf we\'ve reached some search threshold, we know we can\'t be blocked because there are only 200 blocked spaces so we can always go around it. I think if we\'ve traveled greater than 200 distance, we know that a blockade can\'t block us because the blockade can only be 200 cells long. We can travel 201 cells, then go around the blockage. I think this covers edge cases, too, near walls.\n\n# Approach\nA* probably isn\'t necessary. I didn\'t see the constraints of the problem until I hit the TLE! Then, I realized that we needed a way to determine if we were completely blocked by the blockade, including with walls. Then, I realized that you know the blockade can\'t enclose you if you\'ve moved beyond a certain distance. \n\nOthers use an area maximum; you can also use max distance in up, left, right, or down direction; you can also use manhattan distance. I used all three and they\'re all comparable in runtime.\n\nAnyways, you don\'t need A* for this problem. But it was a good refresher in case I needed to use it for an actual maze solving problem.\n\nNote: I could spend time optimizing things a bit, but the Big O runtime wouldn\'t change, so I\'ll just leave the code as is for readability.\n\n# Complexity\n- Time complexity: I think the time complexity is on the order of $$O(b^2)$$ where `b = number of blocks`. \n\n- Space complexity: $$O(b^2)$$.\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport heapq\n\n\nclass Solution:\n\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n source_escape = self._isEscapePossible(blocked, source, target)\n if source_escape == -1:\n return False\n target_escape = self._isEscapePossible(blocked, target, source)\n if target_escape == -1:\n return False\n return True\n\n\n def _isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n\n visited = set()\n queue = []\n\n def distance(node1, node2):\n return abs(node1[0] - node2[0]) + abs(node1[1] - node2[1])\n\n rows = 1_000_000\n cols = 1_000_000\n _directions = [(-1, 0), (1, 0), (0, -1), (0, 1)]\n\n blocked = set((x,y) for x, y in blocked)\n def get_neighbors(me):\n r, c = me\n for dr, dc in _directions:\n nr = r + dr\n nc = c + dc\n if (0 <= nr < rows) and (0 <= nc < cols) and (nr, nc) not in blocked:\n yield (nr, nc) \n\n source = tuple(source)\n target = tuple(target)\n\n start = (0 + distance(source, target), 0, source)\n heapq.heappush(queue, start)\n visited.add(source)\n\n while queue:\n cost, dist, node = heapq.heappop(queue)\n if node == target:\n return 1\n\n # area threshold\n #if len(visited) > 20000:\n # return 0\n\n # distance up, down, left, or right threshold\n #if max(abs(source[0]-node[0]), abs(source[1]-node[1])) > 200:\n # return 0\n\n # manhattan distance threshold\n if distance(source, node) > 200:\n return 0\n\n for neighbor in get_neighbors(node):\n if neighbor not in visited:\n visited.add(neighbor)\n neighbor_dist = dist + 1\n item = (neighbor_dist + distance(neighbor, target), neighbor_dist, neighbor)\n heapq.heappush(queue, item)\n return -1\n \n\n\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Python 3 FT 100%: TC O(B log(B)), SC O(B): "Detour" Union-Find | escape-a-large-maze | 0 | 1 | After seeing some other solutions, there are definitely simpler ones that will let you succeed without TLE, but with worse $O(B^2)$ complexity for $B$ blocked cells\n1. "escape region:" \n * if we can\'t reach target from source, that means a wall of blocked cells separates them.\n * a wall of B cells can contain only order B^2 cells\n * so if you can reach order B^2 cells from source and target then they can\'t be separated by a wall\n * obvious issue: you need a specific threshold for the order B^2. You\'ll have to guess with a lenient fudge factor like 4*B^2; there\'s not enough time in an interview to derive the maximum area formula\n2. "escape radius:"\n * average case improvement of "escape region" and no tricky formula\n * if two points are reachable from each other, any wall that surrounds them must have at least twice as many cells\n * so run BFS from the source and target and see if you can reach a point at L1 distance B away. If you can, the boundary clearly can\'t enclose them.\n * so if you find target while doing BFS from source, return True\n * if you can reach a point at distance B from both source and target, also return True because no wall can exist that seals source/target away from the rest of the grid\n * otherwise one or both are sealed off in a tiny region by a wall away from the other\n\nBoth of these are O(B^2) algorithms.\n\n**But if you want B log(B), strap yourself in.**\n\nNOTE: I don\'t recommend this for an in-person interview, it\'s just too long. By the time I fixed all the edge cases and came up with a "detour loop" that didn\'t have like 20 edge cases it took me the better part of THREE HOURS.\n\nBut it\'s really cool and beats the complexity of other solutions so I figured I\'d share it.\n\nI write it because this is what I came up with, and only read the "escape region/radius" solutions later.\n\n# Intuition\n\n## Overal Idea\nThe general idea is we start by drawing the simplest path from `source` to `target`. If we find blocked cells in our way, we detour around them to get to a later cell on the simple path.\n* if there are no blocked cells on the path, the simple path is viable. Return True.\n* if we can detour around all blocked cells to get back on the path, then return True because we\'ve shown a path exists:\n * advance straight to first blockage\n * detour around it\n * advance straight to next blockage\n * detour around it\n* if we *can\'t* detour around all blockages, then the target is blocked off from the source. So return False\n\n## More Details\n\nWithout loss of generality, make the source be above the target - reachability doesn\'t depend on the direction. Just connectivity.\n\nNow draw an "elbow path" between them:\n```\n s\n |\n |\n |\n -- -- -- -- t\n```\nso we\n1. descend the rows\n2. then move over the columns\n(note: t may be to the left of `source`; the code handles this with the `sign` variable)\n\nIf there are no blocked cells on this path, an O(B) check, then we return True immediately.\n\nIf thre *are* blocked cells on the path, we have to go around them to get back on the elbow path.\n\n*We have to detour*.\n\nWe know if we can detour around a blocked cell if\n* we can find cells on the perimeter of blocked cells\n* and there\'s a path among those cells to a later point on the elbow path\n\nThat way we would know we an follow the elbow path to a cell on the perimeter, then detour around to a later point on the perimeter.\n\n# Approach\n\nThe code is pretty well documented IMO, but there\'s some pointers\n* to know if we have blockages, I make `down_i` and `over_j` lists with i/j coordinates along the elbow path. If both are empty then there are no blocked cells on the elbow path.\n* to get the "perimeter" of blocked cells, I find all open cells that are EIGHT-adjacent to a blocked cell. The ascii art below explains why we need 8-adj: to make a perimeter path around diagonal walls and corners, we need a cell to the left/right, above/below, and BOTH (a diagonal cell). In this simple example we clearly need 8-adj to get around blocked cell B2:\n```\nO----O B3 # 4-adj path around B2 means we have to look at\n| # the 8-adj perimeter of {B1, B2, B3, ..}\nO B2\n\nB1 \n```\n* to know what segments of the perimeter connect to each other, I use Union-Find which is linear in the number of perimeter cells, and the number of perimeter cells in linear in the number of blocked cells\n* to quickly skip from one part of a perimeter to the farthest reachable part of the perimeter, I modify the Union-Find algorithm to also track the farthest point along the path in the cluster\n* I spent a LOT of time simplifying the final "jump to farthest loop:"\n * we start at distance 0 along the elbow path: the source\n * when we find a blocked cell farther than we\'ve gotten so far, let its distane by `d`. We have to be able to walk around the perimeter to a farther point on the elbow path to detour\n * so back up one cell (guaranteed to be open), find its UF root, and find the farthest cell in that cluster. That\'s where we detour to\n * if the distance of that farthest perimeter cell is less than `d`, we can\'t detour around the blockage.\n * otherwise store the distance of the cell we detoured to as `best`\n * repeat for all blocked cells until we find something we can\'t detour around, or until we\'ve detoured past all obstacles\n* **we iterate over blocked cells on the path in order**. This way we can jump to the next blockage without having to iterate over all the empty O(1e6) cells in the middle\n# Complexity\n- Time complexity: $O(B \\log(B))$ for $B$ bocked cells. Asymtotically the slowest part is sorting the obstacles in the elbow path by their distance along the path.\n\n- Space complexity: $O(B)$. We have hashsets of blocked cells and perimeter cells, lists of blocked indices on the elbow path, and a bunch of keys and values for Union-Find hashmaps. All are $O(B)$. Sorting with quicksort only takes $O(\\log(B))$ memory.\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n # COOL PROBLEM\n # Hard, but cool. How can we do BFS without actually doing BFS??\n\n # The general idea:\n # Start by conceptually making an "elbow path" from source to target\n # 1. move up/down rows from (si, sj) to (ti, sj)\n # 2. then move left/right along cols from (ti, sj) to (ti, tj)\n #\n # If we find no obstacles along this path then we just found a valid path. Return True.\n #\n # Otherwise we have source - obstacle1 - obstacle 2 - .. - target\n # If for each obstacle we can detour around to the other side of the obstacle on a later\n # part of the elbow path. So we\'ll track the latest cell of the elbow path for each UF cluster.\n #\n # If we can\'t jump to a later part of the path, then that means the rest of the path\n # is blocked by an obtacle. Therefore there is no path and we return False.\n #\n # We don\'t need to know the actual elbow path, just the fact that one exists is enough.\n \n N = 10**6 # allowed coordinates are [0, N)\n\n si, sj = source\n ti, tj = target\n\n if si > ti: # wlog let source have lower i coordinate\n si, sj, ti, tj = ti, tj, si, sj\n\n lo = min(sj, tj)\n hi = max(sj, tj)\n sign = 1 if tj > sj else -1\n down_i = [i for (i, j) in blocked if j == sj and si < i <= ti]\n over_j = [j for (i, j) in blocked if i == ti and lo < j < hi]\n\n print(f"{down_i=}")\n print(f"{over_j=}")\n\n if not down_i and not over_j: return True\n\n bset = {(i, j) for (i, j) in blocked}\n\n\n # get all open cells that are 8-adj to blocked cells\n boundary = set()\n for bi, bj in blocked:\n for di,dj in [(-1, -1), (-1, 0), (-1, +1), (0, -1), (0, +1), (1, -1), (1, 0), (1, +1)]:\n i, j = bi+di, bj+dj\n if 0 <= i < N and 0 <= j < N and (i,j) not in bset:\n boundary.add((i, j))\n\n # run 4-adj UF to find so we can find boundary cells that are reachable from one another\n parent = {}\n size = defaultdict(lambda: 1) # dflt size is 1 for isolated cluster\n latest = {} # latest cell on elbow path in each cluster\n \n def onPath(ij: tuple[int, int]) -> bool:\n if si <= ij[0] <= ti and ij[1] == sj:\n return True # on down path\n\n if ij[0] == ti and lo <= ij[1] <= hi:\n return True\n\n return False\n\n def dist(ij: tuple[int, int]) -> int:\n """For ij on the elbow path, returns the distance of ij along the path."""\n return abs(ij[0]-si) + abs(ij[1]-sj)\n\n\n def find(ij: tuple[int, int]) -> tuple[int, int]:\n if ij not in parent:\n return ij\n\n parent[ij] = (ans := find(parent[ij]))\n return ans\n\n def union(ij: tuple[int, int], xy = tuple[int, int]) -> None:\n rij = find(ij)\n rxy = find(xy)\n\n if rij == rxy:\n return\n\n if size[rij] < size[rxy]:\n rij, rxy = rxy, rij\n\n # update latest\n candidates = [latest.get(rij), latest.get(rxy)]\n if onPath(ij): candidates.append(ij)\n if onPath(xy): candidates.append(xy)\n l = max((c for c in candidates if c is not None), key=dist, default=None)\n\n size[rij] += size[rxy]\n latest[rij] = l\n del size[rxy]\n parent[rxy] = rij\n\n for bi, bj in boundary:\n for di, dj in [(-1, 0), (0, -1)]:\n ij = (bi+di, bj+dj)\n if ij in boundary:\n union((bi, bj), ij)\n\n # start at (si, sj). For each obstacle we encounter, jump via some path implied by UF to\n # the "other side" of the elbow path on the obstacle\n\n down_i.sort()\n over_j.sort(reverse=tj < sj) # in the order we\'ll encounter them in the path\n sign = 1 if tj > sj else -1\n\n # for each obstacle at ij, back up one and jump to farthest\n best = 0 # farthest we\'ve gotten along elbow route thus far\n for i in down_i:\n print(f"obstacle at {i}, {sj}")\n d = dist((i, sj))\n \n if d < best:\n continue # already jumped past this\n\n # encountered new obstacle to jump past\n rij = find((i-1, sj)) \n lij = latest.get(rij, rij)\n dlij = dist(lij)\n if dlij <= d:\n # couldn\'t detour around obstacle to get farther, so we\'re stuck\n return False\n\n best = dlij\n\n for j in over_j:\n d = dist((ti, j))\n \n if d < best:\n continue # already jumped past this\n\n # encountered new obstacle to jump past\n rij = find((ti, j-sign)) \n lij = latest.get(rij, rij)\n dlij = dist(lij)\n if dlij <= d:\n # couldn\'t detour around obstacle to get farther, so we\'re stuck\n return False\n\n best = dlij\n\n \n \n # successfully detoured past all obstacles\n return True\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Python 3: Simple BFS Solution | escape-a-large-maze | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n \n # furthest src/target can travel is at maximum 200\n blocked = set(map(tuple, blocked))\n def bfs(sx, sy, tx, ty):\n q = deque()\n q.append((sx, sy))\n visited = set()\n visited.add((sx, sy))\n directions = [(1,0),(0,1),(-1,0),(0,-1)]\n level = 0\n while q:\n level += 1\n if level > 200 :\n return True\n for _ in range(len(q)):\n x, y = q.popleft()\n if (x, y) == (tx, ty):\n return True\n for dx, dy in directions:\n nx, ny = x + dx, y + dy\n if (nx, ny) not in visited and nx in range(1000000) and ny in range(1000000) and (nx, ny) not in blocked:\n visited.add((nx, ny))\n q.append((nx, ny))\n return False\n\n \n\n \n return bfs(*source, *target) and bfs(*target, *source)\n \n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
[Python] O(N) Easy Explanation | escape-a-large-maze | 0 | 1 | Since maximum length of square is 200, we just check if we can visit that far without being blocked.\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n dx = [0,0,-1,1]\n dy = [1,-1,0,0]\n MAX = 200\n N = 10**6 \n # Three cases to block \n # either make sq around target or source, solution- since limit on size of blocks max side of rec that can be blocked is MAX\n # or parition gird into two such that soruce and target seprate, solution just check if we can reach target before max \n def dfs(sy,sx,ty,tx,y,x,vis):\n if abs(y-sy)>MAX or abs(x-sx)>MAX or (x==tx and y==ty): \n # print(y,x)\n return True\n vis.add((y,x))\n for k in range(4):\n i,j = y+dy[k],x+dx[k]\n if i>=0 and j>=0 and i<N and j<N and (i,j) not in vis:\n if dfs(sy,sx,ty,tx,i,j,vis): return True\n return False\n res = []\n r = [source,target]\n for i,(x,y) in enumerate(r):\n vis = set(map(lambda x:(x[1],x[0]) , blocked))\n res.append(dfs(y,x,r[i^1][1],r[i^1][0],y,x,vis))\n return all(res)\n\n\n\n \n\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Optimized DFS Approach | Escape Distance | O(B^2) T and S | Commented and Explained | escape-a-large-maze | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe two ways to phrase the question are if a route is blocked or if a route is open. We can check this with one function using alternate styles of return, which is a focus in this implementation for those still learning that style of return. This allows for generator style functionality in returns, speeding up submissions on leetcode and elsewhere. \n\nTo approach the problem, we know that the length of our blocked array is relative to the manhattan distance of an open route between source and some point (if we escape the blocked neighborhood, we can get anywhere). \n\nWith this in mind, we start by first getting the non-unique size of our blocked list, then converting our blocked list to a set of tuples for the points in the list. After that, the approach is carried out to solve the problem. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFor any possible route between two points we cacn consider it to either be blocked or open, which we use a flip flag defaulted to True to consider which case we are working on at the time. We will be considering two points and are given a blocked listing within the maxe to use at the start of it. Our progression then is \n\n- set up a stack using the first point passed as a list\n- set up a visited set using a tuple of first point \n- add the first point passed to blocked points \n- while you have stack \n - pop off a point \n - if manhattan distance between this point and p1 is gte our escape distance or this point is our target \n - return False if doing is_blocked else True \n - otherwise, get neighbors in N4 of this point \n - for neighbor in N4 \n - if valid point and not in blocked or visited\n - add to stack, blocked, and visited \n- return True if flip else False \n\nTo set up our algorithm, return False if blocked from source to Target, otherwise return whether or not the path is open from target to source \n\n# Complexity\n- Time complexity : O(B^2) \n - We loop over blocked for as much as 200 points \n - We carry out a dfs for at most 40000 unique points (visited and blocked contribute to this, ensuring minimal stack space as well) \n - We do dfs at most 2 times for up to 40000 points, which is our blocked distance squared (the number of points within escape distance)\n - So, we run in O(B^2) to process the stack space \n\n- Space complexity : O(B^2) \n - Due to stack space considerations, we at most use up to O(B^2) in the stack inside is blocked\n - We save on space by requiring only unique points via visited with no repeats \n\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n # get escape distance \n self.escape_distance = len(blocked)\n # set up blocked as set of tuples \n blocked = {tuple(point) for point in blocked}\n\n # set up is_blocked function passing two points, blocked, and which type of check\n def is_blocked(p1, p2, blocked, flip=True) :\n # set up initial stack \n stack = [p1]\n # set up visited \n visited = set()\n visited.add(tuple(p1))\n # add p1 to blocked \n blocked.add(tuple(p1))\n # while you have a stack \n while stack :\n # pop one off the top \n x, y = stack.pop()\n # check mhd. If at or above escape distance, or if this is the target, return False, not blocked\n if (abs(p1[0]-x) + abs(p1[1]-y) >= self.escape_distance) or (x == p2[0] and y == p2[1]) :\n return False if flip else True\n # get 4 directional neighbors \n N4 = [(x+1, y), (x-1, y), (x, y+1), (x, y-1)]\n # loop over each \n for N_i in N4 :\n # if valid point and not blocked -> append to consider it and add to blocked\n if ((0 <= N_i[0] < 1e6) and (0 <= N_i[1] < 1e6)) and ((N_i not in blocked) and (N_i not in visited)) :\n stack.append(N_i)\n blocked.add(N_i)\n visited.add(N_i)\n # return True if never escape distance or reached target \n return True if flip else False\n \n # return False if blocked source to target else return not is blocked target to source \n return False if is_blocked(source, target, set(blocked)) else is_blocked(target, source, set(blocked), False)\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
DFS solution Python | escape-a-large-maze | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem is asking to determine if it\'s possible to escape a blocked grid by starting at the source point and reaching the target point. The approach I\'m thinking of using is using breadth-first search (BFS) to check if the source point can reach the target point.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nMy approach is to use BFS to check if the source point can reach the target point. I will use a queue to keep track of all the points that need to be visited and a set to keep track of all the points that have been visited. I will also use a set to store all the blocked points. If at any point the number of seen points exceeds 20000, I will return True as it is not possible to escape from a blocked grid if the number of seen points exceeds 20000.\n\n\n# Complexity\n- Time complexity: $$O(b + n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nwhere b is the number of blocked points and n is the number of points visited.\n\n- Space complexity: $$O(b + n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nwhere b is the number of blocked points and n is the number of points visited.\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n blocked = set(map(tuple, blocked))\n return self.bfs(blocked, source, target) and self.bfs(blocked, target, source)\n\n def bfs(self, blocked, source, target):\n q = collections.deque([tuple(source)])\n seen = set(q)\n while q:\n if len(seen) > 20000:\n return True\n x, y = q.popleft()\n if [x, y] == target:\n return True\n for dx, dy in ((1, 0), (-1, 0), (0, 1), (0, -1)):\n nx, ny = x + dx, y + dy\n if 0 <= nx < 10 ** 6 and 0 <= ny < 10 ** 6 and (nx, ny) not in blocked and (nx, ny) not in seen:\n seen.add((nx, ny))\n q.append((nx, ny))\n return False\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
BFS from source and target to see if we can reach a point > 200 unit | escape-a-large-maze | 0 | 1 | ```\nclass Solution:\n def isEscapePossible(self, blocked: List[List[int]], source: List[int], target: List[int]) -> bool:\n """\n the blocked is only of length 200\n we cannot reach from source to target if either the source is bounded/completely \n isolated by points in blocked or the target is bounded/isolated by blocked points\n hence, we need to run bfs twice. One from source and one time from target\n if we are able to reach a point which is 200 manhattan distance away from the source,\n hence we can confirm that source is not blocked\n we repeat the same process for target\n """\n m, n = 1000000, 1000000\n blocked = {tuple(item) for item in blocked}\n def is_valid(i, j):\n return 0 <= i < m and 0 <= j < n\n \n def get_neighbors(i, j):\n return [(i+1,j), (i-1,j), (i,j+1), (i,j-1)]\n \n def get_distance(pt1, pt2):\n dist = abs(pt2[1] - pt1[1]) + abs(pt2[0] - pt1[0])\n return dist\n\n def bfs(point, dest):\n que = deque([point])\n visited = {point}\n while len(que):\n i,j = que.popleft()\n\n if (i,j) == dest:\n return True\n if dist(point, (i,j)) >= 200:\n return True\n\n for nei in get_neighbors(i,j):\n x, y = nei\n if is_valid(x, y) and (x, y) not in blocked and (x,y) not in visited:\n visited.add((x,y))\n que.append((x,y))\n\n \n a = bfs(tuple(source), tuple(target))\n b = bfs(tuple(target), tuple(source))\n return a and b\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Python (Simple BFS) | escape-a-large-maze | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isEscapePossible(self, blocked, source, target):\n if not blocked:\n return True\n\n n = len(blocked)\n\n def dfs(start,end,visited):\n stack = [start]\n\n while stack:\n i, j = stack.pop(0)\n\n if abs(start[0]-i) + abs(start[1]-j) >= n or [i,j] == end:\n return True\n\n for ni,nj in [(i-1,j),(i+1,j),(i,j-1),(i,j+1)]:\n if 0 <= ni < 10**6 and 0 <= nj < 10**6 and [ni,nj] not in blocked and (ni,nj) not in visited:\n stack.append((ni,nj))\n visited.add((ni,nj))\n\n return False\n\n return dfs(source,target,set(source)) and dfs(target,source,set(target))\n\n\n\n\n\n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Layz guy only explore as much as needed with BFS algorithm | escape-a-large-maze | 0 | 1 | # Intuition\nLayz guy only explore as much as needed with BFS algorithm\n\n# Approach\nBFS\n\n\n\n# Code\n```\n#https://leetcode.com/problems/escape-a-large-maze/solutions/282849/python-bfs-and-dfs-the-whole-problem-is-broken/?orderBy=most_votes\nclass Solution: \n def isEscapePossible(self, blocked, source, target):\n MAX_BLOCK_AREA = 200 * (200-1) / 2\n blocked = {tuple(p) for p in blocked}\n\n def bfs(source, target):\n q, seen = [source], {tuple(source)}\n for x0, y0 in q:\n for i, j in [[0, 1], [1, 0], [-1, 0], [0, -1]]:\n x, y = x0 + i, y0 + j\n if 0 <= x < 10**6 and 0 <= y < 10**6 and (x, y) not in seen and (x, y) not in blocked:\n if [x, y] == target: return True\n q.append([x, y])\n seen.add((x, y))\n if len(q) > MAX_BLOCK_AREA: return True \n return False\n return bfs(source, target) and bfs(target, source)\n \n``` | 0 | There is a 1 million by 1 million grid on an XY-plane, and the coordinates of each grid square are `(x, y)`.
We start at the `source = [sx, sy]` square and want to reach the `target = [tx, ty]` square. There is also an array of `blocked` squares, where each `blocked[i] = [xi, yi]` represents a blocked square with coordinates `(xi, yi)`.
Each move, we can walk one square north, east, south, or west if the square is **not** in the array of `blocked` squares. We are also not allowed to walk outside of the grid.
Return `true` _if and only if it is possible to reach the_ `target` _square from the_ `source` _square through a sequence of valid moves_.
**Example 1:**
**Input:** blocked = \[\[0,1\],\[1,0\]\], source = \[0,0\], target = \[0,2\]
**Output:** false
**Explanation:** The target square is inaccessible starting from the source square because we cannot move.
We cannot move north or east because those squares are blocked.
We cannot move south or west because we cannot go outside of the grid.
**Example 2:**
**Input:** blocked = \[\], source = \[0,0\], target = \[999999,999999\]
**Output:** true
**Explanation:** Because there are no blocked cells, it is possible to reach the target square.
**Constraints:**
* `0 <= blocked.length <= 200`
* `blocked[i].length == 2`
* `0 <= xi, yi < 106`
* `source.length == target.length == 2`
* `0 <= sx, sy, tx, ty < 106`
* `source != target`
* It is guaranteed that `source` and `target` are not blocked. | null |
Python Super Easy | valid-boomerang | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isBoomerang(self, points: List[List[int]]) -> bool:\n x1, y1 = points[0][0], points[0][1]\n x2, y2 = points[1][0], points[1][1]\n x3, y3 = points[2][0], points[2][1]\n # slope between 1 and 2\n slope12 = 0\n if x2 - x1 == 0:\n slope12 = 90\n else:\n slope12 = (y2 - y1) / (x2 - x1)\n \n # slope between 1 and 3\n slope13 = 0\n if x3 - x1 == 0:\n slope13 = 90\n else:\n slope13 = (y3 - y1) / (x3 - x1)\n \n # slope between 2 and 3\n slope23 = 0\n if x3 - x2 == 0:\n slope23 = 90\n else:\n slope23 = (y3 - y2) / (x3 - x2)\n\n if slope12 == slope13 or slope12 == slope23 or slope13 == slope23:\n return False\n return True\n\n``` | 1 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
[Python 3] Triangle Area | valid-boomerang | 0 | 1 | **Concept:** We need to check if the 3 points are in a straight line or not.\nMath: We can find the area of the triangle formed by the three points and check if the area is non-zero.\n**DO UPVOTE IF YOU FOUND IT HELPFUL.**\n\n\n```\nclass Solution:\n def isBoomerang(self, points: List[List[int]]) -> bool:\n x1, y1 = points[0]\n x2, y2 = points[1]\n x3, y3 = points[2]\n \n area = abs(x1*(y2-y3) + x2*(y3-y1) + x3*(y1-y2))/2\n return area != 0\n``` | 18 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
Compare slopes python | valid-boomerang | 0 | 1 | To avoid division by zero instead of comparing (delta y1)/(delta x1) != (delta y2)/(delta x2), cross multiply: (delta y1) * (delta x2) != (delta y2) * (delta x1)\n\n```\nclass Solution:\n def isBoomerang(self, points: List[List[int]]) -> bool:\n a,b,c=points\n return (b[1]-a[1])*(c[0]-b[0]) != (c[1]-b[1])*(b[0]-a[0])\n``` | 3 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
Python, math solution, checking slopes | valid-boomerang | 0 | 1 | ```\nclass Solution:\n def isBoomerang(self, points: List[List[int]]) -> bool:\n (x0, y0), (x1, y1), (x2, y2) = points\n return (y2 - y1) * (x0 - x1) != (x2 - x1) * (y0 - y1)\n``` | 8 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
Production code. | valid-boomerang | 0 | 1 | # Code\n```\nimport dataclasses\nimport typing as tp\nfrom math import isclose\n\n\[email protected]\nclass Point:\n x: int\n y: int\n\n\nclass Solution:\n def isBoomerang(self, points: tp.List[tp.List[int]]) -> bool:\n return self._is_boomerang(points)\n\n @staticmethod\n def _get_area_under_the_segment(\n first_point: Point,\n second_point: Point\n ) -> float:\n delta_x = abs(first_point.x - second_point.x)\n return delta_x * (first_point.y + second_point.y) / 2\n\n def _is_boomerang(self, points: tp.List[tp.List[int]]) -> bool:\n points = sorted(\n [Point(*points[i]) for i in range(3)],\n key=lambda point: point.x\n )\n area: float = 0.0\n area += self._get_area_under_the_segment(points[1], points[0])\n area += self._get_area_under_the_segment(points[1], points[2])\n area -= self._get_area_under_the_segment(points[0], points[2])\n return not isclose(area, 0.0)\n\n``` | 0 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
Python Geometry Solution | valid-boomerang | 0 | 1 | \n\n\n# Complexity\n- Time complexity: O(1)\n\n- Space complexity: O(1)\n\n# Code\n```\nclass Solution(object):\n def isBoomerang(self, p):\n x1, y1, x2, y2, x3, y3 = p[0][0], p[0][1], p[1][0], p[1][1], p[2][0], p[2][1]\n return x1 * (y2 - y3) + x2 * (y3 - y1) + x3 * (y1 - y2) != 0\n``` | 0 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
PYTHON SIMPLE | valid-boomerang | 0 | 1 | # Code\n```\nclass Solution:\n def isBoomerang(self, points: List[List[int]]) -> bool:\n a,b,c=points\n return (b[1]-a[1])*(c[0]-b[0]) != (c[1]-b[1])*(b[0]-a[0])\n \n \n \n``` | 0 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
area of triangle in coordinate geometry | valid-boomerang | 0 | 1 | # Intuition\nCheck if area of the triangle is greater than 0\n\n# Approach\nhttps://www.cuemath.com/geometry/area-of-triangle-in-coordinate-geometry/\n\n\n# Complexity\n- Time complexity:\nO(1)\n\n- Space complexity:\nO(1)\n# Code\n```\nclass Solution:\n def isBoomerang(self, points: List[List[int]]) -> bool:\n xa, ya = points[0]\n xb, yb = points[1]\n xc, yc = points[2]\n\n area = 0.5 * abs((xb - xa) * (yc - ya) - (xc - xa) * (yb - ya))\n\n return area != 0\n``` | 0 | Given an array `points` where `points[i] = [xi, yi]` represents a point on the **X-Y** plane, return `true` _if these points are a **boomerang**_.
A **boomerang** is a set of three points that are **all distinct** and **not in a straight line**.
**Example 1:**
**Input:** points = \[\[1,1\],\[2,3\],\[3,2\]\]
**Output:** true
**Example 2:**
**Input:** points = \[\[1,1\],\[2,2\],\[3,3\]\]
**Output:** false
**Constraints:**
* `points.length == 3`
* `points[i].length == 2`
* `0 <= xi, yi <= 100` | null |
Python3 DFS/ Recursive DFS | binary-search-tree-to-greater-sum-tree | 0 | 1 | \n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n - DFS - \n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def bstToGst(self, root: TreeNode) -> TreeNode:\n if not root: return None\n stack, val, curr = [], 0, root\n while curr or stack:\n while curr:\n stack.append(curr)\n curr = curr.right\n curr = stack.pop()\n val += curr.val \n curr.val = val\n curr = curr.left\n return root \n```\n - Recursive DFS -\n``` \n def dfs(node, val):\n if node.right:\n val = dfs(node.right, val)\n val += node.val\n node.val = val\n if node.left:\n val = dfs(node.left, val)\n return val\n dfs(root, 0)\n return root\n``` | 1 | Given the `root` of a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus the sum of all keys greater than the original key in BST.
As a reminder, a _binary search tree_ is a tree that satisfies these constraints:
* The left subtree of a node contains only nodes with keys **less than** the node's key.
* The right subtree of a node contains only nodes with keys **greater than** the node's key.
* Both the left and right subtrees must also be binary search trees.
**Example 1:**
**Input:** root = \[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8\]
**Output:** \[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8\]
**Example 2:**
**Input:** root = \[0,null,1\]
**Output:** \[1,null,1\]
**Constraints:**
* The number of nodes in the tree is in the range `[1, 100]`.
* `0 <= Node.val <= 100`
* All the values in the tree are **unique**.
**Note:** This question is the same as 538: [https://leetcode.com/problems/convert-bst-to-greater-tree/](https://leetcode.com/problems/convert-bst-to-greater-tree/) | null |
Python || 91.95% Faster || DP || 3 solutions | minimum-score-triangulation-of-polygon | 0 | 1 | ```\n#Recursive\n#Time Complexity: Exponential\n#Space Complexity: O(n)\nclass Solution1:\n def minScoreTriangulation(self, values: List[int]) -> int:\n def solve(i, j):\n if i+1 == j:\n return 0\n m = float(\'inf\')\n for k in range(i+1, j):\n m = min(m, values[i] * (values[j]*values[k]) + solve(i, k) + solve(k, j))\n return m\n return solve(0, len(values)-1)\n \n#Memoization (Top-Down)\n#Time Complexity: O(n^2)\n#Space Complexity: O(n^2) + O(n)\nclass Solution2:\n def minScoreTriangulation(self, values: List[int]) -> int:\n def solve(i, j):\n if i+1 == j:\n return 0\n if dp[i][j] != -1:\n return dp[i][j]\n m = float(\'inf\')\n for k in range(i+1, j):\n m = min(m, values[i] * (values[j]*values[k]) + solve(i, k) + solve(k, j))\n dp[i][j] = m\n return dp[i][j]\n \n n = len(values)\n dp = [[-1 for j in range(n)] for i in range(n)]\n return solve(0, n-1)\n\n#Tabulation (Bottom-Up)\n#Time Complexity: O(n^2)\n#Space Complexity: O(n^2)\nclass Solution:\n def minScoreTriangulation(self, values: List[int]) -> int:\n n = len(values)\n dp = [[0 for j in range(n)] for i in range(n)]\n for i in range(n-1, -1, -1):\n for j in range(i+2, n):\n m = float(\'inf\')\n for k in range(i+1, j):\n m = min(m, values[i]*values[j]*values[k] + dp[i][k] + dp[k][j])\n dp[i][j] = m\n return dp[0][n-1]\n```\n**An upvote will be encouraging** | 1 | You have a convex `n`\-sided polygon where each vertex has an integer value. You are given an integer array `values` where `values[i]` is the value of the `ith` vertex (i.e., **clockwise order**).
You will **triangulate** the polygon into `n - 2` triangles. For each triangle, the value of that triangle is the product of the values of its vertices, and the total score of the triangulation is the sum of these values over all `n - 2` triangles in the triangulation.
Return _the smallest possible total score that you can achieve with some triangulation of the polygon_.
**Example 1:**
**Input:** values = \[1,2,3\]
**Output:** 6
**Explanation:** The polygon is already triangulated, and the score of the only triangle is 6.
**Example 2:**
**Input:** values = \[3,7,4,5\]
**Output:** 144
**Explanation:** There are two triangulations, with possible scores: 3\*7\*5 + 4\*5\*7 = 245, or 3\*4\*5 + 3\*4\*7 = 144.
The minimum score is 144.
**Example 3:**
**Input:** values = \[1,3,1,4,1,5\]
**Output:** 13
**Explanation:** The minimum score triangulation has score 1\*1\*3 + 1\*1\*4 + 1\*1\*5 + 1\*1\*1 = 13.
**Constraints:**
* `n == values.length`
* `3 <= n <= 50`
* `1 <= values[i] <= 100` | null |
[Python] Sliding window with detailed expalanation | moving-stones-until-consecutive-ii | 0 | 1 | ```python\nclass Solution:\n def numMovesStonesII(self, stones: list[int]) -> list[int]:\n """\n 1. For the higher bound, it is determined by either moving the leftmost\n to the right side, or by moving the rightmost to the left side:\n 1.1 If moving leftmost to the right side, the available moving\n positions are A[n - 1] - A[1] + 1 - (n - 1) = \n A[n - 1] - A[1] - n + 2\n 1.2 If moving rightmost to the left side, the available moving\n positions are A[n - 2] - A[0] + 1 - (n - 1) = \n A[n - 2] - A[0] - n + 2.\n 2. For the lower bound, we could use sliding window to find a window\n that contains the most consecutive stones (A[i] - A[i - 1] = 1):\n 2.1 Generally the moves we need are the same as the number of\n missing stones in the current window.\n 2.3 When the window is already consecutive and contains all the\n n - 1 stones, we need at least 2 steps to move the last stone\n into the current window. For example, 1,2,3,4,10:\n 2.3.1 We need to move 1 to 6 first as we are not allowed to\n move 10 to 5 as it will still be an endpoint stone.\n 2.3.2 Then we need to move 10 to 5 and now the window becomes\n 2,3,4,5,6.\n """\n A, N = sorted(stones), len(stones)\n maxMoves = max(A[N - 1] - A[1] - N + 2, A[N - 2] - A[0] - N + 2)\n minMoves = N\n\n # Calculate minimum moves through sliding window.\n start = 0\n for end in range(N):\n while A[end] - A[start] + 1 > N:\n start += 1\n\n if end - start + 1 == N - 1 and A[end] - A[start] + 1 == N - 1:\n # Case: N - 1 stones with N - 1 positions.\n minMoves = min(minMoves, 2)\n else:\n minMoves = min(minMoves, N - (end - start + 1))\n\n return [minMoves, maxMoves]\n``` | 4 | There are some stones in different positions on the X-axis. You are given an integer array `stones`, the positions of the stones.
Call a stone an **endpoint stone** if it has the smallest or largest position. In one move, you pick up an **endpoint stone** and move it to an unoccupied position so that it is no longer an **endpoint stone**.
* In particular, if the stones are at say, `stones = [1,2,5]`, you cannot move the endpoint stone at position `5`, since moving it to any position (such as `0`, or `3`) will still keep that stone as an endpoint stone.
The game ends when you cannot make any more moves (i.e., the stones are in three consecutive positions).
Return _an integer array_ `answer` _of length_ `2` _where_:
* `answer[0]` _is the minimum number of moves you can play, and_
* `answer[1]` _is the maximum number of moves you can play_.
**Example 1:**
**Input:** stones = \[7,4,9\]
**Output:** \[1,2\]
**Explanation:** We can move 4 -> 8 for one move to finish the game.
Or, we can move 9 -> 5, 4 -> 6 for two moves to finish the game.
**Example 2:**
**Input:** stones = \[6,5,4,3,10\]
**Output:** \[2,3\]
**Explanation:** We can move 3 -> 8 then 10 -> 7 to finish the game.
Or, we can move 3 -> 7, 4 -> 8, 5 -> 9 to finish the game.
Notice we cannot move 10 -> 2 to finish the game, because that would be an illegal move.
**Constraints:**
* `3 <= stones.length <= 104`
* `1 <= stones[i] <= 109`
* All the values of `stones` are **unique**. | null |
100 T and S | Commented and Explained With Examples | moving-stones-until-consecutive-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nAt the base of this problem is a linear scan. This is because we are trying to achieve the pairing of minimum number of moves and maximum number of moves. As such, we are trying to sort the move value space and scan over it linearly. This can be achieved with a few key insights from the problem that keep it at a medium level. \n\nFirst, we have a list size lower bound of 3. This is actually dreadfully important for one of our key edge cases that make this easily solvable so don\'t discard such things when they come up! \n\nSecond, we have that all the stone values are unique. \n\nThird, we have that all the stone values are positive integers from 1 to 10^9. This is important both as an insight into the fact that we are working with only positive values, and that we are working with a very large value space compared to a much relatively smaller value ordination (there are 10^9 values for the stones, but only 10^4 positions at most for them) \n\nWe are also provided with a helpful hint \n>For the minimum, how many cows are already in place? For the maximum, we have to lose either the gap A[1] - A[0] or A[N-1] - A[N-2] (where N = A.length), but every other space can be occupied ? \n\nWe turn first to the idea of the maximum, where we have a gap we will need to lose of either between the first and second position or ultimate and penultimate position. \n\nIf we consider a list of 3 items, our minimum, what is our minimum values to get our minimal return? Not to spoil anything, but it is 1, 2, 3 \n\nThis is key to the problem, since there are no spaces provided between the values, so our return should be [0, 0] \n\nBy realizing the impact of this the approach follows below. Try to work out for a few values and sizes to get the feel for it and you\'ll likely find an understanding either intuitively or by action. I recommend working with small list sizes and trying to generate [0, 1], [0, 2], [1, 2], and [2, 2] with only 3 or so items. It\'ll be difficult, but worth it for the understanding pay off. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe original ordering of the stones is not valid compared to their ordinal positioning, and since we know we have a size limit much less than a value limit, we start by sorting. \n\nThen, we want to know how much space we have to work witin, so get the size of your listing (how many stones do you have regardless of how much they are worth?) \n\nThen, we need to calculate the two largest costs, move penultimate and move ultimate (final in the code) \n\nMove penultimate is the cost of swapping the stones at the second to last spot and the first spot, minus the cost of the number of stones you have (Since you moved over the whole thing!) plus 2 to deal with the fact that they are unique\n\nMove ultimate is the cost of swapping the stones at the last spot and second spot, minus the cost of the number of stones you have plus 2 to deal with the fact that they are unique\n\nIf either of these is 0, the other must be locked in as most moves, as most moves will be the max of these two options (try to convince yourself of why that is the case! This relates to the idea of the list sizings, and is really clearly seen with a list of size 3)\n\nIf either is 0, \n- min legal moves is min of 2 and most moves \n- return min legal moves and most moves \n\nOtherwise we now must consider how many max legal moves are there really? \n\nSet max legal moves to 0 \nSet starting index to 0 \nenumerate index and stone in stones \n- while stones at starting index lte stone - stone length \n - increment starting index \n- our max legal moves here is the max of itself (so it preserves good discoveries) and index - starting index + 1 (+1 for the fact we use 0 indexing) \n- but, it cannot get too big! Remember, we already found the actual max, so don\'t let anything in here fool you! Set max legal moves as such to min(max(max_legal_moves, index - starting_index + 1), max_moves) \n- this keeps our newly found max legal less than our actual max moves \n\nWhen done enumerating return length - max legal moves, max moves \n\n# Complexity\n- Time complexity : O(S log S + S)\n - O(S log S) to sort the stones \n - O(S) to loop over (while loop is incindental, as it can only run as many times as the length of stones as well in total, so it does not add to this) \n\n- Space complexity : O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nNo additional space utilized \n\n# Code\n```\nclass Solution:\n \'\'\'\n Test cases walk through \n Given 7, 4, 9 prove 1, 2 6, 5, 4, 3, 10, prove 2, 3 \n\n Sort stones -> 4, 7, 9 3, 4, 5, 6, 10 \n Stone length -> 3 5\n Move penultimate = 7 - 4 - 3 + 2 = 2 6-3-5+2 = 0 \n Move final = 9 - 7 - 3 + 2 = 1 10-4-5+2 = 3 \n Neither is 0, so we cannot return for sure Move penultimate is 0, so move final is assured \n This means we can return [min(2, 3), 3] -> [2, 3]\n\n Max legal moves is 0 For completeness, max legal moves is 0, max moves is 3 \n starting index is 0 starting index is 0 \n\n Enumeration Enumeration\n index is 0, stone is 4 index is 0, stone is 3 \n stones[0] lte 4 - 3 ? No, skip while loop stones[0] lte 3 - 5 ? No, skip while \n max legal moves is min of (max of self and 0 - 0 + 1, most moves) max legal moves is min of (max of self and 0 - 0 + 1), max moves -> max legal moves is 1 \n -> max legal moves is 1 \n\n index is 1, stone is 7 index is 1, stone is 4 \n stones[0] <= 7 - 3 ? Yes, enter while stones[0] lte 4 - 5 ? No, skip while \n starting index is now 1 max legal moves is min of (max of self and 1 - 0 + 1), max moves -> max legal moves is 2\n stones[1] <= 7 - 3 ? No, skip while \n max legal moves -> min(max of self and 1 - 1 + 1), max_moves \n -> max legal moves is 1 index is 2, stone is 5 \n stones[0] lte 5 - 5 ? No skip while \n index is 2, stone is 9 max legal moves is min of (max of self and 2 - 0 + 1), max_moves -> max legal moves is 3 \n stones[1] <= 9 - 3 ? No, skip while \n max legal moves is min(max of self and 2-1 + 1), max_moves\n -> max legal moves is 2 index is 3, stone is 6 \n End enumeration stones[0] lte 6 - 5 ? No skip while \n max legal moves is min (max of self and 3 - 0 + 1), max_moves -> max legal moves is 3 \n Return [3 - 2, 2] -> [1, 2] checks out \n index is 4, stones is 10 \n stones[0] lte 10 - 5 ? Yes, enter while \n starting index is 1 \n stones[1] lte 10 - 5 ? Yes, enter while \n starting index is 2 \n stones[2] lte 10 - 5 ? Yes, enter while \n starting index is 3 \n max legal moves is min (max of self and 4 - 3 + 1), max moves -> max legal moves is 3 \n End enumeration\n\n Return [5 - 3, 3] -> [2, 3]\n \'\'\'\n def numMovesStonesII(self, stones: List[int]) -> List[int] :\n # order does not need to be maintained, so sorting is optimal \n stones.sort()\n # want to work within stone physical space since 10^9 >> 10^4 (stone weight vs length)\n stone_length = len(stones)\n # what is the cost of moving the second to last stone and the 0th stone? \n move_penultimate = stones[-2] - stones[0] - stone_length + 2 \n # what is the cost of moving the last stone and the 1st stone? \n move_final = stones[-1] - stones[1] - stone_length + 2 \n # in both of these, the cost is the positional exchange in stones along the stone length + 2 for the two stones moving \n # our most moves possible are the max of these two \n most_moves = max(move_penultimate, move_final)\n # since the stones are unique, if either is 0, the one that we have must be max legal moves \n # if move penultimate is 0, that means that the second largest stone less the least stone less the length + 2 is 0 \n # this means that the largest stone, which must be at least one larger than the largest, less the second to least stone which is at least one larger than the least stone less the length + 2 is move final \n # our minimal length is 3 \n # let a, b, c be stones in order \n # b - a - 3 + 2 = 0 -> b = a + 1 move penultimate \n # c - b - 3 + 2 = 0 -> b = c - 1 move final \n # c - 1 = a + 1 -> c = a + 2 \n # all stones must be at least 1 to 10^9 and are unique \n # so at minimum a is 1, b is 2 and c is 3 \n # in this case, move final is also 0 so we get 0, 0 \n # if a = 4, b = 5, c = 7 \n # 5 - 4 - 3 + 2 = 0 move penultimate is 0 \n # 7 - 5 - 3 + 2 -> 1 move ultimate is 1 \n # min legal moves is min of 2 and 1 -> min legal moves is 1 -> 1, 1 is returned \n # from this it can be seen that the movement of c relative to b impacts the return here when one is 0, and that if either is 0 it does not preclude the other. However it does entail a relation to 2 as most that min could become \n # this is because if most moves is greater than 2, we could always do the move alternate that was 0 in two steps. This is what locks in to place the ability to use 2 here as the min argument. \n if move_penultimate == 0 or move_final == 0 : \n min_legal_moves = min(2, most_moves)\n return [min_legal_moves, most_moves]\n # how many legal moves are there in sorted order? \n max_legal_moves = 0 \n # starting from 0th index \n starting_index = 0\n # enumerate each stone and index \n for index, stone in enumerate(stones) :\n # while the stone at starting index is lte this stone minus stone length (cost of a move) \n while stones[starting_index] <= stone - stone_length : \n # increment \n starting_index += 1\n # max legal moves is then set to maxima of self and indexed difference with 1 for 0 based indexing \n max_legal_moves = min(max(max_legal_moves, index - starting_index + 1), most_moves) \n # return length - max legal moves when in sorted order (your minimal move state) and most moves in sorted order \n return [stone_length - max_legal_moves, most_moves]\n``` | 0 | There are some stones in different positions on the X-axis. You are given an integer array `stones`, the positions of the stones.
Call a stone an **endpoint stone** if it has the smallest or largest position. In one move, you pick up an **endpoint stone** and move it to an unoccupied position so that it is no longer an **endpoint stone**.
* In particular, if the stones are at say, `stones = [1,2,5]`, you cannot move the endpoint stone at position `5`, since moving it to any position (such as `0`, or `3`) will still keep that stone as an endpoint stone.
The game ends when you cannot make any more moves (i.e., the stones are in three consecutive positions).
Return _an integer array_ `answer` _of length_ `2` _where_:
* `answer[0]` _is the minimum number of moves you can play, and_
* `answer[1]` _is the maximum number of moves you can play_.
**Example 1:**
**Input:** stones = \[7,4,9\]
**Output:** \[1,2\]
**Explanation:** We can move 4 -> 8 for one move to finish the game.
Or, we can move 9 -> 5, 4 -> 6 for two moves to finish the game.
**Example 2:**
**Input:** stones = \[6,5,4,3,10\]
**Output:** \[2,3\]
**Explanation:** We can move 3 -> 8 then 10 -> 7 to finish the game.
Or, we can move 3 -> 7, 4 -> 8, 5 -> 9 to finish the game.
Notice we cannot move 10 -> 2 to finish the game, because that would be an illegal move.
**Constraints:**
* `3 <= stones.length <= 104`
* `1 <= stones[i] <= 109`
* All the values of `stones` are **unique**. | null |
Solution | moving-stones-until-consecutive-ii | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<int> numMovesStonesII(vector<int>& A) {\n sort(A.begin(), A.end());\n int i = 0, n = A.size(), low = n;\n int high = max(A[n - 1] - n + 2 - A[1], A[n - 2] - A[0] - n + 2);\n for (int j = 0; j < n; ++j) {\n while (A[j] - A[i] >= n) ++i;\n if (j - i + 1 == n - 1 && A[j] - A[i] == n - 2)\n low = min(low, 2);\n else\n low = min(low, n - (j - i + 1));\n }\n return {low, high};\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def numMovesStonesII(self, s: List[int]) -> List[int]:\n s.sort()\n n = len(s)\n d1 = s[-2] - s[0] - n + 2\n d2 = s[-1] - s[1] - n + 2\n max_move = max(d1, d2)\n if d1 == 0 or d2 == 0:\n return [min(2, max_move), max_move]\n max_cnt = left = 0\n for right, x in enumerate(s):\n while s[left] <= x - n:\n left += 1\n max_cnt = max(max_cnt, right - left + 1)\n return [n - max_cnt, max_move]\n```\n\n```Java []\n\tclass Solution {\n\t\tpublic int[] numMovesStonesII(int[] stones) {\n\t\t\tint n = stones.length;\n\t\t\t int[] ans = new int[2];\n\t\t\t int i = 0, j = 0, wsize, scount, minMoves = Integer.MAX_VALUE;\n\t\t\tArrays.sort(stones);\n\t\t\t while (j < n) {\n\t\t\t\twsize = stones[j] - stones[i] + 1;\n\t\t\t\tscount = j - i + 1;\n\n\t\t\t\tif (wsize > n) {\n\t\t\t\t\ti++;\n\t\t\t\t\tcontinue;\n\t\t\t\t}\n\t\t\t\tif (wsize == n - 1 && scount == n - 1)\n\t\t\t\t\tminMoves = Math.min(minMoves, 2);\n\n\t\t\t\telse minMoves = Math.min(minMoves, n - scount);\n\n\t\t\t\tj++;\n\t\t\t}\n\t\t\tans[0] = minMoves;\n\t\t\tint maxMoves = 0;\n\t\t\t if (stones[1] == stones[0] + 1 || stones[n - 1] == stones[n - 2] + 1)\n\t\t\t\tmaxMoves = stones[n - 1] - stones[0] + 1 - n;\n\t\t\telse \n\t\t\t\tmaxMoves = Math.max(((stones[n - 1] - stones[1]) - (n - 1) + 1), ((stones[n - 2] - stones[0]) - (n - 1) + 1));\n\t\t\tans[1] = maxMoves;\n\t\t\treturn ans;\n\t\t}\n\t}\n``` | 0 | There are some stones in different positions on the X-axis. You are given an integer array `stones`, the positions of the stones.
Call a stone an **endpoint stone** if it has the smallest or largest position. In one move, you pick up an **endpoint stone** and move it to an unoccupied position so that it is no longer an **endpoint stone**.
* In particular, if the stones are at say, `stones = [1,2,5]`, you cannot move the endpoint stone at position `5`, since moving it to any position (such as `0`, or `3`) will still keep that stone as an endpoint stone.
The game ends when you cannot make any more moves (i.e., the stones are in three consecutive positions).
Return _an integer array_ `answer` _of length_ `2` _where_:
* `answer[0]` _is the minimum number of moves you can play, and_
* `answer[1]` _is the maximum number of moves you can play_.
**Example 1:**
**Input:** stones = \[7,4,9\]
**Output:** \[1,2\]
**Explanation:** We can move 4 -> 8 for one move to finish the game.
Or, we can move 9 -> 5, 4 -> 6 for two moves to finish the game.
**Example 2:**
**Input:** stones = \[6,5,4,3,10\]
**Output:** \[2,3\]
**Explanation:** We can move 3 -> 8 then 10 -> 7 to finish the game.
Or, we can move 3 -> 7, 4 -> 8, 5 -> 9 to finish the game.
Notice we cannot move 10 -> 2 to finish the game, because that would be an illegal move.
**Constraints:**
* `3 <= stones.length <= 104`
* `1 <= stones[i] <= 109`
* All the values of `stones` are **unique**. | null |
Clean Python | 8 Lines | High Speed | O(n) time, O(1) space | Beats 96.9% | With Explanation | moving-stones-until-consecutive-ii | 0 | 1 | # Intuition & Approach\n\n## Lower Bound\nAs I mentioned in my video last week,\nin case of `n` stones,\nwe need to find a consecutive `n` positions and move the stones in.\n\nThis idea led the solution with sliding windows.\n\nSlide a window of size `N`, and find how many stones are already in this window.\nWe want moves other stones into this window.\nFor each missing stone, we need at least one move.\n\nGenerally, the number of missing stones and the moves we need are the same.\nOnly one corner case in this problem, we need to move the endpoint to no endpoint.\n\nFor case `1,2,4,5,10`\n1 move needed from `10` to `3`.\n\nFor case `1,2,3,4,10`\n2 move needed from `1` to `6`, then from `10` to `5`.\n\n\n## Upper Bound\nWe try to move all stones to leftmost or rightmost.\nFor example of to rightmost.\nWe move the `A[0]` to `A[1] + 1`.\nThen each time, we pick the stone of left endpoint, move it to the next empty position.\nDuring this process, the position of leftmost stones increment 1 by 1 each time.\nUntil the leftmost is at `A[n - 1] - n + 1`.\n\n# Complexity\n#### Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n- Time of quick sorting `O(NlogN)`\n- Time of sliding window `O(N)`\n#### Space complexity: `O(1)`\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def numMovesStonesII(self, A):\n A.sort()\n i, n, low = 0, len(A), len(A)\n high = max(A[-1] - n + 2 - A[1], A[-2] - A[0] - n + 2)\n for j in range(n):\n while A[j] - A[i] >= n: i += 1\n if j - i + 1 == n - 1 and A[j] - A[i] == n - 2: low = min(low, 2)\n else: low = min(low, n - (j - i + 1))\n return [low, high]\n``` | 0 | There are some stones in different positions on the X-axis. You are given an integer array `stones`, the positions of the stones.
Call a stone an **endpoint stone** if it has the smallest or largest position. In one move, you pick up an **endpoint stone** and move it to an unoccupied position so that it is no longer an **endpoint stone**.
* In particular, if the stones are at say, `stones = [1,2,5]`, you cannot move the endpoint stone at position `5`, since moving it to any position (such as `0`, or `3`) will still keep that stone as an endpoint stone.
The game ends when you cannot make any more moves (i.e., the stones are in three consecutive positions).
Return _an integer array_ `answer` _of length_ `2` _where_:
* `answer[0]` _is the minimum number of moves you can play, and_
* `answer[1]` _is the maximum number of moves you can play_.
**Example 1:**
**Input:** stones = \[7,4,9\]
**Output:** \[1,2\]
**Explanation:** We can move 4 -> 8 for one move to finish the game.
Or, we can move 9 -> 5, 4 -> 6 for two moves to finish the game.
**Example 2:**
**Input:** stones = \[6,5,4,3,10\]
**Output:** \[2,3\]
**Explanation:** We can move 3 -> 8 then 10 -> 7 to finish the game.
Or, we can move 3 -> 7, 4 -> 8, 5 -> 9 to finish the game.
Notice we cannot move 10 -> 2 to finish the game, because that would be an illegal move.
**Constraints:**
* `3 <= stones.length <= 104`
* `1 <= stones[i] <= 109`
* All the values of `stones` are **unique**. | null |
[Python3] sliding window | moving-stones-until-consecutive-ii | 0 | 1 | \n```\nclass Solution:\n def numMovesStonesII(self, stones: List[int]) -> List[int]:\n stones.sort()\n high = max(stones[-1] - stones[1], stones[-2] - stones[0]) - (len(stones) - 2)\n \n ii, low = 0, inf\n for i in range(len(stones)): \n while stones[i] - stones[ii] >= len(stones): ii += 1\n if i - ii + 1 == stones[i] - stones[ii] + 1 == len(stones) - 1: low = min(low, 2)\n else: low = min(low, len(stones) - (i - ii + 1))\n return [low, high]\n``` | 0 | There are some stones in different positions on the X-axis. You are given an integer array `stones`, the positions of the stones.
Call a stone an **endpoint stone** if it has the smallest or largest position. In one move, you pick up an **endpoint stone** and move it to an unoccupied position so that it is no longer an **endpoint stone**.
* In particular, if the stones are at say, `stones = [1,2,5]`, you cannot move the endpoint stone at position `5`, since moving it to any position (such as `0`, or `3`) will still keep that stone as an endpoint stone.
The game ends when you cannot make any more moves (i.e., the stones are in three consecutive positions).
Return _an integer array_ `answer` _of length_ `2` _where_:
* `answer[0]` _is the minimum number of moves you can play, and_
* `answer[1]` _is the maximum number of moves you can play_.
**Example 1:**
**Input:** stones = \[7,4,9\]
**Output:** \[1,2\]
**Explanation:** We can move 4 -> 8 for one move to finish the game.
Or, we can move 9 -> 5, 4 -> 6 for two moves to finish the game.
**Example 2:**
**Input:** stones = \[6,5,4,3,10\]
**Output:** \[2,3\]
**Explanation:** We can move 3 -> 8 then 10 -> 7 to finish the game.
Or, we can move 3 -> 7, 4 -> 8, 5 -> 9 to finish the game.
Notice we cannot move 10 -> 2 to finish the game, because that would be an illegal move.
**Constraints:**
* `3 <= stones.length <= 104`
* `1 <= stones[i] <= 109`
* All the values of `stones` are **unique**. | null |
Python Solution. Pretty intuitive. | robot-bounded-in-circle | 0 | 1 | My first time posting a solution on Leetcode and I think the solution was unique so really proud of it.\n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFirst of sorry for bad English.\nPretty Intuitive Solution.\nTook help from the hint given for the question to check if the circle is forming or not.\n<!-- # Approach -->\n<!-- Describe your approach to solving the problem. -->\n\n<!-- # Complexity\n- Time complexity: -->\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n<!-- - Space complexity: -->\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isRobotBounded(self, instructions: str) -> bool:\n initial_pos = curr_pos = [0, 0]\n directions = {\n \'N\': [0, 1],\n \'S\': [0, -1],\n \'E\': [1, 0],\n \'W\': [-1, 0]\n }\n nesw = [\'N\', \'E\', \'S\', \'W\']\n dir = \'N\'\n for i in range(len(instructions)):\n if instructions[i] == \'G\':\n curr_pos = [x + y for x, y in zip(curr_pos, directions[dir])]\n elif instructions[i] == \'L\':\n dir = nesw[(nesw.index(dir) - 1) % len(nesw)]\n elif instructions[i] == \'R\':\n dir = nesw[(nesw.index(dir) + 1) % len(nesw)]\n return initial_pos == curr_pos or dir != \'N\'\n```\nUpvote pls thx. | 6 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
Python Simple Fastest Solution Explained (video + code) | robot-bounded-in-circle | 0 | 1 | [](https://www.youtube.com/watch?v=xgJh5HPCi3A)\nhttps://www.youtube.com/watch?v=xgJh5HPCi3A\n```\nclass Solution:\n def isRobotBounded(self, instructions: str) -> bool:\n direction = (0,1)\n start = [0,0]\n \n for x in instructions:\n if x == \'G\':\n start[0] += direction[0]\n start[1] += direction[1]\n elif x == \'L\':\n direction = (-direction[1], direction[0])\n elif x == \'R\':\n direction = (direction[1], -direction[0])\n \n return start == [0,0] or direction != (0,1)\n``` | 37 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
Python | Simple Solution using Dict | No Maths | robot-bounded-in-circle | 0 | 1 | Hello, I have a simpler solution that involves less of maths and more of logical thinking. \n\n```\n\tdef isRobotBounded(self, instructions: str) -> bool:\n curr_dir = \'N\'\n curr_pos = [0,0]\n directions = {\'N\':[0,1], \'E\':[1,0], \'W\':[-1,0], \'S\':[0,-1]}\n change_dir = {\n \'N\':{\'L\':\'W\', \'R\':\'E\'},\n \'E\':{\'L\':\'N\', \'R\':\'S\'},\n \'W\':{\'L\':\'S\', \'R\':\'N\'},\n \'S\':{\'L\':\'E\', \'R\':\'W\'}\n }\n for instruction in instructions:\n if instruction == \'G\':\n curr_pos[1] += directions[curr_dir][1]\n curr_pos[0] += directions[curr_dir][0]\n else:\n curr_dir=change_dir[curr_dir][instruction]\n if curr_dir != \'N\' or curr_pos == [0,0]:\n return True\n else:\n return False\n```\n\n\nHope it helps! | 3 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
Python3 | robot-bounded-in-circle | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def isRobotBounded(self, instructions: str) -> bool:\n x, y, dx, dy = 0, 0, 0, 1\n for ins in instructions:\n if ins == \'G\':\n x, y = x + dx, y + dy\n elif ins == \'L\':\n dx, dy = -dy, dx\n elif ins == \'R\':\n dx, dy = dy, -dx\n return (x, y) == (0, 0) or (dx, dy) != (0, 1)\n\n``` | 1 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
⬆️✅🔥 100% | 0 MS | EASY | CONCISE | PROOF 🔥⬆️✅ | robot-bounded-in-circle | 1 | 1 | # UPVOTE PLS\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n public boolean isRobotBounded(String I) {\n int x=0,y=0,i=0,l=I.length(),D[][]={{0,1},{1,0},{0,-1},{-1,0}};\n for(int j=0;j<l;j++){ char ch=I.charAt(j);\n if(ch==\'L\') i=(i+3)%4;\n else if(ch==\'R\') i=(i+1)%4;\n else {\n x+=D[i][0];y+=D[i][1];\n }\n }return x==0 && y==0 || i>0;\n }\n``` | 2 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
🐍 python simple solution with explanation; O(N) | robot-bounded-in-circle | 0 | 1 | # Approach\nOne naive solution would be to run the instruction infinite time to see if there is a cycle. But obviously, it is not efficient.\n\nLet\'s look carefully! The robot always goes back to the initial point unless it looks towards north at the end of the movement and that point is not the initial point. That\'s is all we have to check which we do using `dir==\'n\' and (x!=0 or y!=0)`. The rest of the code is just to follow the instruction and find the location and direction at the end of the movement. \n\n# Complexity\n- Time complexity: O(N)\n- Space complexity: O(1)\n\n# Code\n```\nclass Solution:\n def isRobotBounded(self, instructions: str) -> bool:\n\n dir=\'n\'\n turn_left = {\'n\':\'w\', \'w\':\'s\', \'s\':\'e\', \'e\':\'n\'}\n turn_right = {\'n\':\'e\', \'w\':\'n\', \'s\':\'w\', \'e\':\'s\'}\n x = 0\n y = 0\n for i in instructions:\n if i==\'L\':\n dir = turn_left[dir]\n elif i==\'R\':\n dir = turn_right[dir]\n else:\n if dir==\'n\':\n y+=1\n if dir==\'s\':\n y-=1 \n if dir==\'w\':\n x-=1\n if dir==\'e\':\n x+=1\n if dir==\'n\' and (x!=0 or y!=0):\n return False\n return True\n``` | 1 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
✔️ [Python3] LINEAR (≧∇≦)/❤, Explained | robot-bounded-in-circle | 0 | 1 | The robot stays in the circle only if at the end of instructions the angle between the final heading vector and the initial vector is not equal to 0. Only one exclusion is the case when the final position is the initial position. In this case, the final heading is not important, because it doesn\'t matter where the robot moves, it will always return to the start point. To find angle between two vectors we could use formula `cos(angle) = a dot b / |a| * |b|`. But in our case, the robot can have just 4 different directions, so comparing the initial and final headings will be enough.\n\nWhy the angle between two directions is important? The robot executes instructions forever, so if at the end of the first run it looks in the same directions and it\'s not in the starting position that means the distance from the start will increase constantly as the robot will repeat THE SAME moves over and over again. If the angle is different that means that the robot will spin within a certain bounded area.\n\nTime: **O(n)** - for instructions\nSpace: **O(1)** - nothing stored\n\n```\nclass Solution:\n def isRobotBounded(self, instructions: str) -> bool:\n dirs = ((0, 1), (1, 0), (0, -1), (-1, 0))\n pos, head = (0, 0), 0\n\t\t\n for ch in instructions:\n if ch == "G":\n pos = (pos[0] + dirs[head][0], pos[1] + dirs[head][1])\n elif ch == "L":\n head = (head - 1) % 4\n else:\n head = (head + 1) % 4\n\n return pos == (0, 0) or head != 0\n``` | 2 | On an infinite plane, a robot initially stands at `(0, 0)` and faces north. Note that:
* The **north direction** is the positive direction of the y-axis.
* The **south direction** is the negative direction of the y-axis.
* The **east direction** is the positive direction of the x-axis.
* The **west direction** is the negative direction of the x-axis.
The robot can receive one of three instructions:
* `"G "`: go straight 1 unit.
* `"L "`: turn 90 degrees to the left (i.e., anti-clockwise direction).
* `"R "`: turn 90 degrees to the right (i.e., clockwise direction).
The robot performs the `instructions` given in order, and repeats them forever.
Return `true` if and only if there exists a circle in the plane such that the robot never leaves the circle.
**Example 1:**
**Input:** instructions = "GGLLGG "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (0, 2). Direction: South.
"G ": move one step. Position: (0, 1). Direction: South.
"G ": move one step. Position: (0, 0). Direction: South.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (0, 2) --> (0, 1) --> (0, 0).
Based on that, we return true.
**Example 2:**
**Input:** instructions = "GG "
**Output:** false
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"G ": move one step. Position: (0, 2). Direction: North.
Repeating the instructions, keeps advancing in the north direction and does not go into cycles.
Based on that, we return false.
**Example 3:**
**Input:** instructions = "GL "
**Output:** true
**Explanation:** The robot is initially at (0, 0) facing the north direction.
"G ": move one step. Position: (0, 1). Direction: North.
"L ": turn 90 degrees anti-clockwise. Position: (0, 1). Direction: West.
"G ": move one step. Position: (-1, 1). Direction: West.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 1). Direction: South.
"G ": move one step. Position: (-1, 0). Direction: South.
"L ": turn 90 degrees anti-clockwise. Position: (-1, 0). Direction: East.
"G ": move one step. Position: (0, 0). Direction: East.
"L ": turn 90 degrees anti-clockwise. Position: (0, 0). Direction: North.
Repeating the instructions, the robot goes into the cycle: (0, 0) --> (0, 1) --> (-1, 1) --> (-1, 0) --> (0, 0).
Based on that, we return true.
**Constraints:**
* `1 <= instructions.length <= 100`
* `instructions[i]` is `'G'`, `'L'` or, `'R'`. | null |
SIMPLE PYTHON SOLUTION | flower-planting-with-no-adjacent | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nBFS TRAVERSAL\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def gardenNoAdj(self, n: int, paths: List[List[int]]) -> List[int]:\n lst=[[0]*4 for i in range(n)]\n visited=[0]*(n+1)\n adj=[[] for i in range(n+1)]\n for i,j in paths:\n adj[i].append(j)\n adj[j].append(i)\n visited[0]=1\n ans=[0]*n\n for i in range(1,n+1):\n st=[i]\n while st:\n x=st.pop(0)\n ans[x-1]=lst[x-1].index(0)+1\n for i in adj[x]:\n if visited[i]==0:\n st.append(i)\n visited[i]=1\n lst[i-1][ans[x-1]-1]=1\n return ans\n \n\n \n``` | 1 | You have `n` gardens, labeled from `1` to `n`, and an array `paths` where `paths[i] = [xi, yi]` describes a bidirectional path between garden `xi` to garden `yi`. In each garden, you want to plant one of 4 types of flowers.
All gardens have **at most 3** paths coming into or leaving it.
Your task is to choose a flower type for each garden such that, for any two gardens connected by a path, they have different types of flowers.
Return _**any** such a choice as an array_ `answer`_, where_ `answer[i]` _is the type of flower planted in the_ `(i+1)th` _garden. The flower types are denoted_ `1`_,_ `2`_,_ `3`_, or_ `4`_. It is guaranteed an answer exists._
**Example 1:**
**Input:** n = 3, paths = \[\[1,2\],\[2,3\],\[3,1\]\]
**Output:** \[1,2,3\]
**Explanation:**
Gardens 1 and 2 have different types.
Gardens 2 and 3 have different types.
Gardens 3 and 1 have different types.
Hence, \[1,2,3\] is a valid answer. Other valid answers include \[1,2,4\], \[1,4,2\], and \[3,2,1\].
**Example 2:**
**Input:** n = 4, paths = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,1,2\]
**Example 3:**
**Input:** n = 4, paths = \[\[1,2\],\[2,3\],\[3,4\],\[4,1\],\[1,3\],\[2,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `1 <= n <= 104`
* `0 <= paths.length <= 2 * 104`
* `paths[i].length == 2`
* `1 <= xi, yi <= n`
* `xi != yi`
* Every garden has **at most 3** paths coming into or leaving it. | null |
Python || 94.80% Faster || Backtracking || Easy | flower-planting-with-no-adjacent | 0 | 1 | ```\nclass Solution:\n def gardenNoAdj(self, n: int, paths: List[List[int]]) -> List[int]:\n graph=defaultdict(list)\n for u,v in paths:\n graph[u].append(v)\n graph[v].append(u)\n color=[0]*(n+1)\n self.solve(1,n,graph,color)\n return color[1:]\n \n def safe(self,node,col,n,graph,color):\n for k in graph[node]:\n if color[k]==col:\n return False\n return True\n \n def solve(self,node,n,graph,color):\n if node==n+1:\n return True\n for i in range(1,5):\n if self.safe(node,i,n,graph,color):\n color[node]=i\n if self.solve(node+1,n,graph,color):\n return True\n color[node]=0\n return False\n```\n**An upvote will be encouraging** | 1 | You have `n` gardens, labeled from `1` to `n`, and an array `paths` where `paths[i] = [xi, yi]` describes a bidirectional path between garden `xi` to garden `yi`. In each garden, you want to plant one of 4 types of flowers.
All gardens have **at most 3** paths coming into or leaving it.
Your task is to choose a flower type for each garden such that, for any two gardens connected by a path, they have different types of flowers.
Return _**any** such a choice as an array_ `answer`_, where_ `answer[i]` _is the type of flower planted in the_ `(i+1)th` _garden. The flower types are denoted_ `1`_,_ `2`_,_ `3`_, or_ `4`_. It is guaranteed an answer exists._
**Example 1:**
**Input:** n = 3, paths = \[\[1,2\],\[2,3\],\[3,1\]\]
**Output:** \[1,2,3\]
**Explanation:**
Gardens 1 and 2 have different types.
Gardens 2 and 3 have different types.
Gardens 3 and 1 have different types.
Hence, \[1,2,3\] is a valid answer. Other valid answers include \[1,2,4\], \[1,4,2\], and \[3,2,1\].
**Example 2:**
**Input:** n = 4, paths = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,1,2\]
**Example 3:**
**Input:** n = 4, paths = \[\[1,2\],\[2,3\],\[3,4\],\[4,1\],\[1,3\],\[2,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `1 <= n <= 104`
* `0 <= paths.length <= 2 * 104`
* `paths[i].length == 2`
* `1 <= xi, yi <= n`
* `xi != yi`
* Every garden has **at most 3** paths coming into or leaving it. | null |
Python 3 || 5 lines, sets, w/ with comments || T/M: 97% / 95% | flower-planting-with-no-adjacent | 0 | 1 | ```\nclass Solution:\n def gardenNoAdj(self, n: int, paths: List[List[int]]) -> List[int]:\n\n d, ans = defaultdict(list), [0]*(n+1)\n \n for a, b in paths: d[a].append(b) ; d[b].append(a) # construct graph\n \n for i in range(1,n+1): # determine available flowers\n ans[i] = ({1,2,3,4}-{ans[node] for node in d[i]}).pop()\n \n return ans[1:] # return ans, one-indexed\n```\n[https://leetcode.com/problems/flower-planting-with-no-adjacent/submissions/868708173/](http://)\n\nI could be wrong, but I think that time is *O*(*N*) and space is *O*(*N*). | 7 | You have `n` gardens, labeled from `1` to `n`, and an array `paths` where `paths[i] = [xi, yi]` describes a bidirectional path between garden `xi` to garden `yi`. In each garden, you want to plant one of 4 types of flowers.
All gardens have **at most 3** paths coming into or leaving it.
Your task is to choose a flower type for each garden such that, for any two gardens connected by a path, they have different types of flowers.
Return _**any** such a choice as an array_ `answer`_, where_ `answer[i]` _is the type of flower planted in the_ `(i+1)th` _garden. The flower types are denoted_ `1`_,_ `2`_,_ `3`_, or_ `4`_. It is guaranteed an answer exists._
**Example 1:**
**Input:** n = 3, paths = \[\[1,2\],\[2,3\],\[3,1\]\]
**Output:** \[1,2,3\]
**Explanation:**
Gardens 1 and 2 have different types.
Gardens 2 and 3 have different types.
Gardens 3 and 1 have different types.
Hence, \[1,2,3\] is a valid answer. Other valid answers include \[1,2,4\], \[1,4,2\], and \[3,2,1\].
**Example 2:**
**Input:** n = 4, paths = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,1,2\]
**Example 3:**
**Input:** n = 4, paths = \[\[1,2\],\[2,3\],\[3,4\],\[4,1\],\[1,3\],\[2,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `1 <= n <= 104`
* `0 <= paths.length <= 2 * 104`
* `paths[i].length == 2`
* `1 <= xi, yi <= n`
* `xi != yi`
* Every garden has **at most 3** paths coming into or leaving it. | null |
Linear solution, 93% speed | flower-planting-with-no-adjacent | 0 | 1 | \n```\nclass Solution:\n def gardenNoAdj(self, n: int, paths: List[List[int]]) -> List[int]:\n neighbors = defaultdict(set)\n for a, b in paths:\n neighbors[a].add(b)\n neighbors[b].add(a)\n ans = [0] * n\n for i in range(1, n + 1):\n available = {1, 2, 3, 4}\n for neighbor in neighbors[i]:\n if ans[neighbor - 1] in available:\n available.remove(ans[neighbor - 1])\n ans[i - 1] = available.pop()\n return ans\n``` | 2 | You have `n` gardens, labeled from `1` to `n`, and an array `paths` where `paths[i] = [xi, yi]` describes a bidirectional path between garden `xi` to garden `yi`. In each garden, you want to plant one of 4 types of flowers.
All gardens have **at most 3** paths coming into or leaving it.
Your task is to choose a flower type for each garden such that, for any two gardens connected by a path, they have different types of flowers.
Return _**any** such a choice as an array_ `answer`_, where_ `answer[i]` _is the type of flower planted in the_ `(i+1)th` _garden. The flower types are denoted_ `1`_,_ `2`_,_ `3`_, or_ `4`_. It is guaranteed an answer exists._
**Example 1:**
**Input:** n = 3, paths = \[\[1,2\],\[2,3\],\[3,1\]\]
**Output:** \[1,2,3\]
**Explanation:**
Gardens 1 and 2 have different types.
Gardens 2 and 3 have different types.
Gardens 3 and 1 have different types.
Hence, \[1,2,3\] is a valid answer. Other valid answers include \[1,2,4\], \[1,4,2\], and \[3,2,1\].
**Example 2:**
**Input:** n = 4, paths = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,1,2\]
**Example 3:**
**Input:** n = 4, paths = \[\[1,2\],\[2,3\],\[3,4\],\[4,1\],\[1,3\],\[2,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `1 <= n <= 104`
* `0 <= paths.length <= 2 * 104`
* `paths[i].length == 2`
* `1 <= xi, yi <= n`
* `xi != yi`
* Every garden has **at most 3** paths coming into or leaving it. | null |
6-9 | flower-planting-with-no-adjacent | 0 | 1 | # Code\n```\nclass Solution:\n def gardenNoAdj(self, n: int, paths: List[List[int]]) -> List[int]:\n graph = [[] for _ in range(n)]\n for x, y in paths:\n graph[x - 1].append(y - 1)\n graph[y - 1].append(x - 1)\n\n res = [0] * n\n\n for i in range(n):\n used_flowers = {res[j] for j in graph[i] if res[j] > 0}\n for flower in range(1, 5):\n if flower not in used_flowers:\n res[i] = flower\n break\n\n return res\n``` | 0 | You have `n` gardens, labeled from `1` to `n`, and an array `paths` where `paths[i] = [xi, yi]` describes a bidirectional path between garden `xi` to garden `yi`. In each garden, you want to plant one of 4 types of flowers.
All gardens have **at most 3** paths coming into or leaving it.
Your task is to choose a flower type for each garden such that, for any two gardens connected by a path, they have different types of flowers.
Return _**any** such a choice as an array_ `answer`_, where_ `answer[i]` _is the type of flower planted in the_ `(i+1)th` _garden. The flower types are denoted_ `1`_,_ `2`_,_ `3`_, or_ `4`_. It is guaranteed an answer exists._
**Example 1:**
**Input:** n = 3, paths = \[\[1,2\],\[2,3\],\[3,1\]\]
**Output:** \[1,2,3\]
**Explanation:**
Gardens 1 and 2 have different types.
Gardens 2 and 3 have different types.
Gardens 3 and 1 have different types.
Hence, \[1,2,3\] is a valid answer. Other valid answers include \[1,2,4\], \[1,4,2\], and \[3,2,1\].
**Example 2:**
**Input:** n = 4, paths = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,1,2\]
**Example 3:**
**Input:** n = 4, paths = \[\[1,2\],\[2,3\],\[3,4\],\[4,1\],\[1,3\],\[2,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `1 <= n <= 104`
* `0 <= paths.length <= 2 * 104`
* `paths[i].length == 2`
* `1 <= xi, yi <= n`
* `xi != yi`
* Every garden has **at most 3** paths coming into or leaving it. | null |
project6-9 | flower-planting-with-no-adjacent | 0 | 1 | # Code\n```\nclass Solution:\n def gardenNoAdj(self, n: int, paths: List[List[int]]) -> List[int]:\n graph = [[] for _ in range(n)]\n for x, y in paths:\n graph[x - 1].append(y - 1)\n graph[y - 1].append(x - 1)\n\n res = [0] * n\n\n for i in range(n):\n used_flowers = {res[j] for j in graph[i] if res[j] > 0}\n for flower in range(1, 5):\n if flower not in used_flowers:\n res[i] = flower\n break\n\n return res\n``` | 0 | You have `n` gardens, labeled from `1` to `n`, and an array `paths` where `paths[i] = [xi, yi]` describes a bidirectional path between garden `xi` to garden `yi`. In each garden, you want to plant one of 4 types of flowers.
All gardens have **at most 3** paths coming into or leaving it.
Your task is to choose a flower type for each garden such that, for any two gardens connected by a path, they have different types of flowers.
Return _**any** such a choice as an array_ `answer`_, where_ `answer[i]` _is the type of flower planted in the_ `(i+1)th` _garden. The flower types are denoted_ `1`_,_ `2`_,_ `3`_, or_ `4`_. It is guaranteed an answer exists._
**Example 1:**
**Input:** n = 3, paths = \[\[1,2\],\[2,3\],\[3,1\]\]
**Output:** \[1,2,3\]
**Explanation:**
Gardens 1 and 2 have different types.
Gardens 2 and 3 have different types.
Gardens 3 and 1 have different types.
Hence, \[1,2,3\] is a valid answer. Other valid answers include \[1,2,4\], \[1,4,2\], and \[3,2,1\].
**Example 2:**
**Input:** n = 4, paths = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,1,2\]
**Example 3:**
**Input:** n = 4, paths = \[\[1,2\],\[2,3\],\[3,4\],\[4,1\],\[1,3\],\[2,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `1 <= n <= 104`
* `0 <= paths.length <= 2 * 104`
* `paths[i].length == 2`
* `1 <= xi, yi <= n`
* `xi != yi`
* Every garden has **at most 3** paths coming into or leaving it. | null |
[Python] Easy DP with Visualization and examples | partition-array-for-maximum-sum | 0 | 1 | \nHow to approach:\n\nAssume we only look ***back*** for dividing groups\n\nTake an example to see how to calculate and roll over:\n\n\nThen the states and transition function is as below:\n-\tFirst is to calculate a result for all cases:\n```\ncurr = [] # current sub-list\nfor m in range(k): # in total m cases\n\tcurr += dp[i][j-m-1] + max(arr[(j-m):(j+i)]) * (m+1)\n```\ndp[i][j-m-1] : is to use the previous dp result for the previous sum\narr[(j-m):(j+i)] : by looking back m+1 numbers to find the max and repeat m+1 times\n\n-\tThen is to choose the max result\n```\ndp[i][j] = max(curr)\n```\n\n- Since index i in not necessary, we only need j (index of arr), and m (index of k), the script is as below:\n```\nclass Solution:\n def maxSumAfterPartitioning(self, arr: List[int], k: int) -> int:\n n = len(arr)\n dp = [0]*n\n \n # handle the first k indexes differently\n for j in range(k): dp[j]=max(arr[:j+1])*(j+1)\n \n # we can get rid of index i by running i times\n for j in range(k,n):\n curr = []\n for m in range(k):\n curr.append(dp[j-m-1] + max(arr[(j-m):(j+1)]) * (m+1))\n dp[j] = max(curr)\n\n return dp[-1]\n``` | 74 | Given an integer array `arr`, partition the array into (contiguous) subarrays of length **at most** `k`. After partitioning, each subarray has their values changed to become the maximum value of that subarray.
Return _the largest sum of the given array after partitioning. Test cases are generated so that the answer fits in a **32-bit** integer._
**Example 1:**
**Input:** arr = \[1,15,7,9,2,5,10\], k = 3
**Output:** 84
**Explanation:** arr becomes \[15,15,15,9,10,10,10\]
**Example 2:**
**Input:** arr = \[1,4,1,5,7,3,6,1,9,9,3\], k = 4
**Output:** 83
**Example 3:**
**Input:** arr = \[1\], k = 1
**Output:** 1
**Constraints:**
* `1 <= arr.length <= 500`
* `0 <= arr[i] <= 109`
* `1 <= k <= arr.length` | null |
Python || 91.42% Faster || DP || Memo + Tabulation | partition-array-for-maximum-sum | 0 | 1 | ```\n#Recursion \n#Time Complexity: O(Exponential)\n#Space Complexity: O(n)\nclass Solution1:\n def maxSumAfterPartitioning(self, arr: List[int], k: int) -> int:\n def solve(ind):\n if ind==n:\n return 0\n l=0\n maxi=-maxsize\n maxAns=-maxsize\n for j in range(ind,min(n,ind+k)):\n l+=1\n maxi=max(maxi,arr[j])\n s=maxi*l+solve(j+1)\n maxAns=max(maxAns,s)\n return maxAns\n n=len(arr)\n return solve(0)\n\n#Memoization (Top-Down)\n#Time Complexity: O(n*k)\n#Space Complexity: O(n) + O(n)\nclass Solution2:\n def maxSumAfterPartitioning(self, arr: List[int], k: int) -> int:\n def solve(ind):\n if ind==n:\n return 0\n if dp[ind]!=-1:\n return dp[ind]\n l=0\n maxi=-maxsize\n maxAns=-maxsize\n for j in range(ind,min(n,ind+k)):\n l+=1\n maxi=max(maxi,arr[j])\n s=maxi*l+solve(j+1)\n maxAns=max(maxAns,s)\n dp[ind]=maxAns\n return dp[ind]\n n=len(arr)\n dp=[-1]*n\n return solve(0)\n \n#Tabulation (Bottom-Up)\n#Time Complexity: O(n*k)\n#Space Complexity: O(n)\nclass Solution:\n def maxSumAfterPartitioning(self, arr: List[int], k: int) -> int:\n n=len(arr)\n dp=[-1]*(n+1)\n dp[n]=0\n for ind in range(n-1,-1,-1):\n l=0\n maxi=-maxsize\n maxAns=-maxsize\n for j in range(ind,min(n,ind+k)):\n l+=1\n maxi=max(maxi,arr[j])\n s=maxi*l+dp[j+1]\n maxAns=max(maxAns,s)An upvotew will be encouraging\n dp[ind]=maxAns \n return dp[0]\n```\n**An upvotew will be encouraging** | 2 | Given an integer array `arr`, partition the array into (contiguous) subarrays of length **at most** `k`. After partitioning, each subarray has their values changed to become the maximum value of that subarray.
Return _the largest sum of the given array after partitioning. Test cases are generated so that the answer fits in a **32-bit** integer._
**Example 1:**
**Input:** arr = \[1,15,7,9,2,5,10\], k = 3
**Output:** 84
**Explanation:** arr becomes \[15,15,15,9,10,10,10\]
**Example 2:**
**Input:** arr = \[1,4,1,5,7,3,6,1,9,9,3\], k = 4
**Output:** 83
**Example 3:**
**Input:** arr = \[1\], k = 1
**Output:** 1
**Constraints:**
* `1 <= arr.length <= 500`
* `0 <= arr[i] <= 109`
* `1 <= k <= arr.length` | null |
Minimal explanation, 2 approaches | partition-array-for-maximum-sum | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIt is intuitively a recursion and dynamic programming based problem.\nYou have to check for all possible cases with common sub-problems.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nJust read the recursive code, you will get it.\n\n\n# Complexity\n- Time complexity: $$O(n*k)$$ for both approaches\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$ for iterative, extra $$O(n)$$ for stack space in recursive.\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code (recursive - memoized)\n```\nclass Solution:\n def maxSumAfterPartitioning(self, arr: List[int], k: int) -> int:\n n = len(arr)\n dp = [-1]*n\n\n def recur(i):\n if i == n:\n return 0\n \n max_elm = -1 # max element in segment\n max_score = -1 # overall max score\n segment_len = 0 # this is obvious\n\n if dp[i] != -1:\n return dp[i]\n\n for j in range(i,min(i+k,n)):\n # We iterate from i to minimum of i+k or n\n # in spirit of checking all cases\n segment_len += 1\n max_elm = max(max_elm, arr[j])\n score = segment_len*max_elm + recur(j+1)\n # the recursive stack here goes till the end of \n # arr each time it is called, \n # hence the // sub-problems //\n max_score = max(max_score,score)\n\n # dp array fills up from the last, hence\n # the first element of dp array is the ans.\n dp[i] = max_score\n return dp[i]\n\n return recur(0)\n```\n\n# Code (iterative - tabulated)\n```\nclass Solution:\n def maxSumAfterPartitioning(self, arr: List[int], k: int) -> int:\n n = len(arr)\n dp = [0]*(n+1)\n\n for i in range(n-1,-1,-1):\n # the order of filling \n # the dp array is same\n max_elm = -1\n max_score = -1\n segment_len = 0\n\n for j in range(i,min(i+k,n)):\n # again we simply take the "k" cases here\n # and take the best among them.\n segment_len += 1\n max_elm = max(max_elm,arr[j])\n score = segment_len*max_elm + dp[j+1]\n max_score = max(max_score,score)\n # IF YOU ARE READING THIS HAVE A BOMB DAY BUDDY!!!\n dp[i] = max_score\n\n return dp[0]\n\n``` | 1 | Given an integer array `arr`, partition the array into (contiguous) subarrays of length **at most** `k`. After partitioning, each subarray has their values changed to become the maximum value of that subarray.
Return _the largest sum of the given array after partitioning. Test cases are generated so that the answer fits in a **32-bit** integer._
**Example 1:**
**Input:** arr = \[1,15,7,9,2,5,10\], k = 3
**Output:** 84
**Explanation:** arr becomes \[15,15,15,9,10,10,10\]
**Example 2:**
**Input:** arr = \[1,4,1,5,7,3,6,1,9,9,3\], k = 4
**Output:** 83
**Example 3:**
**Input:** arr = \[1\], k = 1
**Output:** 1
**Constraints:**
* `1 <= arr.length <= 500`
* `0 <= arr[i] <= 109`
* `1 <= k <= arr.length` | null |
双指针slide window | longest-duplicate-substring | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nDefine left and right double pointers, treat the area of double pointers as a sliding window, at first the sliding window contains only the leftmost element in the string, judge when the element exists in the remaining substring, if it exists, move the right pointer one position to the right, so that the sliding window contains two elements, continue to judge, if it still exists, continue to perform the above operation.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n# Code\n```\nclass Solution:\n def longestDupSubstring(self, s: str) -> str:\n left = 0\n right = 1\n res = ""\n n = len(s)\n while right<n:\n if s[left:right] in s[left+1:]:\n if right - left > len(res):\n res = s[left:right]\n right+=1\n continue\n left+=1\n if left == right:\n right+=1\n return res\n``` | 2 | Given a string `s`, consider all _duplicated substrings_: (contiguous) substrings of s that occur 2 or more times. The occurrences may overlap.
Return **any** duplicated substring that has the longest possible length. If `s` does not have a duplicated substring, the answer is `" "`.
**Example 1:**
**Input:** s = "banana"
**Output:** "ana"
**Example 2:**
**Input:** s = "abcd"
**Output:** ""
**Constraints:**
* `2 <= s.length <= 3 * 104`
* `s` consists of lowercase English letters. | null |
Simplest Python Solution || Easily Understandable | last-stone-weight | 0 | 1 | \n# Code\n```\nclass Solution:\n def lastStoneWeight(self, stones: List[int]) -> int:\n \n while len(stones) > 1:\n stones.sort()\n m1=max(stones)\n stones.remove(m1)\n m2=max(stones)\n stones.remove(m2)\n \n if m1 < m2:\n m2 = m2 - m1\n stones.append(m2)\n \n elif m2 < m1:\n m1 = m1 - m2\n stones.append(m1)\n \n if len(stones) == 0:\n return 0\n return stones[0]\n``` | 1 | You are given an array of integers `stones` where `stones[i]` is the weight of the `ith` stone.
We are playing a game with the stones. On each turn, we choose the **heaviest two stones** and smash them together. Suppose the heaviest two stones have weights `x` and `y` with `x <= y`. The result of this smash is:
* If `x == y`, both stones are destroyed, and
* If `x != y`, the stone of weight `x` is destroyed, and the stone of weight `y` has new weight `y - x`.
At the end of the game, there is **at most one** stone left.
Return _the weight of the last remaining stone_. If there are no stones left, return `0`.
**Example 1:**
**Input:** stones = \[2,7,4,1,8,1\]
**Output:** 1
**Explanation:**
We combine 7 and 8 to get 1 so the array converts to \[2,4,1,1,1\] then,
we combine 2 and 4 to get 2 so the array converts to \[2,1,1,1\] then,
we combine 2 and 1 to get 1 so the array converts to \[1,1,1\] then,
we combine 1 and 1 to get 0 so the array converts to \[1\] then that's the value of the last stone.
**Example 2:**
**Input:** stones = \[1\]
**Output:** 1
**Constraints:**
* `1 <= stones.length <= 30`
* `1 <= stones[i] <= 1000` | One thing's for sure, we will only flip a zero if it extends an existing window of 1s. Otherwise, there's no point in doing it, right? Think Sliding Window! Since we know this problem can be solved using the sliding window construct, we might as well focus in that direction for hints. Basically, in a given window, we can never have > K zeros, right? We don't have a fixed size window in this case. The window size can grow and shrink depending upon the number of zeros we have (we don't actually have to flip the zeros here!). The way to shrink or expand a window would be based on the number of zeros that can still be flipped and so on. |
Easiest Solution || One Pass || O(1) memory | remove-all-adjacent-duplicates-in-string | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def removeDuplicates(self, s: str) -> str:\n idx =0\n while(idx+1<len(s)):\n if(s[idx]==s[idx+1]):\n s= s[:idx]+s[idx+2:]\n if idx > 0:\n idx -= 1\n else:\n idx += 1\n return s\n``` | 1 | You are given a string `s` consisting of lowercase English letters. A **duplicate removal** consists of choosing two **adjacent** and **equal** letters and removing them.
We repeatedly make **duplicate removals** on `s` until we no longer can.
Return _the final string after all such duplicate removals have been made_. It can be proven that the answer is **unique**.
**Example 1:**
**Input:** s = "abbaca "
**Output:** "ca "
**Explanation:**
For example, in "abbaca " we could remove "bb " since the letters are adjacent and equal, and this is the only possible move. The result of this move is that the string is "aaca ", of which only "aa " is possible, so the final string is "ca ".
**Example 2:**
**Input:** s = "azxxzy "
**Output:** "ay "
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of lowercase English letters. | null |
Python || Easy Solution || Stack | remove-all-adjacent-duplicates-in-string | 0 | 1 | # Code\n```\nclass Solution:\n def removeDuplicates(self, s: str) -> str:\n lis=[s[0]]\n for i in range(1,len(s)):\n if len(lis)==0 or lis[len(lis)-1]!=s[i]:\n lis.append(s[i])\n else:\n lis=lis[:len(lis)-1] \n s="".join(lis)\n return s \n \n``` | 1 | You are given a string `s` consisting of lowercase English letters. A **duplicate removal** consists of choosing two **adjacent** and **equal** letters and removing them.
We repeatedly make **duplicate removals** on `s` until we no longer can.
Return _the final string after all such duplicate removals have been made_. It can be proven that the answer is **unique**.
**Example 1:**
**Input:** s = "abbaca "
**Output:** "ca "
**Explanation:**
For example, in "abbaca " we could remove "bb " since the letters are adjacent and equal, and this is the only possible move. The result of this move is that the string is "aaca ", of which only "aa " is possible, so the final string is "ca ".
**Example 2:**
**Input:** s = "azxxzy "
**Output:** "ay "
**Constraints:**
* `1 <= s.length <= 105`
* `s` consists of lowercase English letters. | null |
Python 3 || 8 lines, w/comments || T/S: 97% / 94% | longest-string-chain | 0 | 1 | \n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n \n d = defaultdict(int) # The keys for d are words. The values \n # are the # of predecessors of that word\n for word in sorted(words,key = len):\n n, d[word] = len(word), 1\n\n for i in range(n): # Check which larger words are predecessors\n w = word[:i] + word[i+1:] # and determine the max length path\n\n if w in d:\n d[word] = max(d[word], d[w] + 1)\n\n return max(d.values()) \n```\n[https://leetcode.com/problems/longest-string-chain/submissions/1056706538/?envType=daily-question&envId=2023-09-23](http://)\n\n\n\nI could be wrong, but I think that time complexity is *O*(*MN*) and space complexity is *O*(*MN*), in which *N* ~ `len(words)` *M* ~ maximum length of elements in`words`. | 6 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
Well commented Python code. Sort + dp | longest-string-chain | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n # store { word : maxlen } in dp\n # word will be used to track predecessor later on\n dp = {}\n W = sorted(words, key = len) \n # sorting based on length\n\n for w in W:\n dp[w] = 1\n # initialize\n for i in range(len(w)):\n # for each position of w, skip one\n # (to find its possible predecessor)\n # and check if it is available in dp.\n prv = w[:i] + w[i+1:]\n if prv in dp:\n # predecessor of w was found!!\n # update dp value\n dp[w] = max(dp[prv] + 1, dp[w])\n \n # return max of all possible values in dp\n return max(dp.values())\n\n``` | 2 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
Python3 | DP | Sorting | Time -> 96.22% | Space -> 93.85% | Solution | longest-string-chain | 0 | 1 | # Code\n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n res = 1\n words.sort(key=lambda x:len(x))\n dp = {word:1 for word in words}\n\n for i in range(1,len(words)):\n w = words[i]\n for j in range(len(w)):\n if w[:j]+w[j+1:] in dp:\n dp[w] = max(dp[w], 1 + dp[w[:j]+w[j+1:]])\n res = max(res,dp[w])\n\n return res\n\n```\n# Complexity\n- Time complexity: $$O(n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n# Upvote :)\n\n | 2 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
Python3 Solution | longest-string-chain | 0 | 1 | \n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n dp={}\n for word in sorted(words,key=len):\n temp=[0]\n n=len(word)\n for i in range(n):\n if word[:i]+word[i+1:] in dp:\n temp.append(dp[word[:i]+word[i+1:]])\n dp[word]=max(temp)+1\n return max(dp.values()) \n``` | 2 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
Easy Top Down Approach (Commented Code) with Examples | longest-string-chain | 1 | 1 | \n# Code\n```\nclass Solution:\n def isSubsequence(self,s,t):\n n1=len(s)\n n2=len(t)\n i=n1-1\n j=n2-1\n while i>=0 and j>=0:\n if s[i]==t[j]:\n i-=1\n j-=1\n else:\n j-=1\n return True if i==-1 else False \n\n\n def longestStrChain(self, words: List[str]) -> int:\n # sorting respect to length of each word\n arr=sorted(words,key=lambda x: len(x))\n # print(arr)\n n=len(arr)\n dp=[[-1]*(n-1) for _ in range(n)]\n\n def dfs(i,prevInd): # Just like LIS but with few extra conditions\n if i==n-1:\n # previous string has to be current string\'s subsequence but there is also one more thing written. we can only add one character to make the chain. thats why we are checking if previous and current string has 1 character difference\n\n # had to add prevInx==-1 for a situation when there is only 1 string present in the list. for ex: ["a"] o/p = 1\n if (len(arr[i])-len(arr[prevInd])==1 and self.isSubsequence(arr[prevInd],arr[i])) or prevInd==-1:\n return 1\n else : return 0\n \n if dp[i][prevInd]!=-1:\n return dp[i][prevInd]\n\n # just like the base case all the conditions in this if statement is same but here is an edge case.\n\n # what about the first element. it won\'t take it as for first string in the arr its previous element index would be -1, which is invalid, so just to take the first element into my account i am letting this one string pass all the other conditions i mentioned on the base case. to do this i added if prevInd is -1 then i can take that \n take=1+dfs(i+1,i) if (len(arr[i])-len(arr[prevInd])==1 and self.isSubsequence(arr[prevInd],arr[i])) or prevInd==-1 else 0\n\n # 1.if i am not taking any string that means that string was not fit for making a chain so i will move to next index but my previous element with whoom i was compairing would remain same.\n\n # 2.for example: [xb, xgv, xcb] \n # here if i take xb and move to next index my current will become xgv and my prev will become xb\n\n # 3.but since xgv is not fit to make a chain i am moving my pointer to the next element which is xcb which can make chain with xb.\n\n # 4.so my previous which is xb remained same for not take conditions\n not_take=dfs(i+1,prevInd)\n\n dp[i][prevInd]=max(take,not_take)\n return dp[i][prevInd]\n\n return dfs(0,-1)\n``` | 2 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
【Video】How we think about a solution - Beats 97.49% - Python, JavaScript, Java, C++ | longest-string-chain | 1 | 1 | This artcle starts with "How we think about a solution". In other words, that is my thought process to solve the question. This article explains how I get to my solution instead of just posting solution codes or out of blue algorithms. I hope this aricle is helpful for someone.\n\n# Intuition\nSort all words by length of the words\n\n---\n\n# Solution Video\n\nIn the video, the steps of approach below are visualized using diagrams and drawings. I\'m sure you understand the solution easily!\n\nhttps://youtu.be/NJzV2nE8KjI\n\n\u25A0 Timeline\n`0:00` Read the question of Longest String Chain\n`0:57` How we think about a solution\n`4:01` Explain how to solve Longest String Chain with a concrete example\n`7:19` Coding\n`11:20` Time Complexity and Space Complexity\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 2,446\nMy initial goal is 10,000\nThank you for your support!\n\n---\n\n# Approach\n\n## How we think about a solution\nAccording to the description, we can create another word `wordB` from `wordA` by adding one letter anywhere in `wordA`, so seems like it\'s easy for us to solve the question with `sorting` because the differece between `wordA` and `wordB` is just one letter. I thought `sorting` might make the question easy to compare words.\n\nQuestion is that what do you sort all input data by? each character in all words? My answer is `to sort by length of input words`. \n\nI have 3 reasons.\n\n1. **Increased Potential for Efficient Solutions**:\n Sorting the words by their length allows us to process the words starting from the shortest, potentially leading to more efficient algorithms as we can prioritize shorter words first.\n\n2. **Enables Preprocessing**:\n Since we are sure that `wordB` is +1 longer than `wordA` and `wordB` has one different letter from `wordA`, if we take off one letter from `wordB` one by one, we can create all predecessors of `wordB` which are all possible `wordA`. For example,\n\n```\nwordB = "abc"\n\nwordA should be\ntake off "a" \u2192 "bc"\ntake off "b" \u2192 "ac"\ntake off "c" \u2192 "ab"\n```\n\nSo we have 3 possible predecessor candidates.\n\nOne more important thing why we should sort by length is that now we check `abc` which is `length of 3`. That means we already finished checking `the max chain length unitl length of 2` because we sorted by length of input words. In other words, We should have the results for all possible words until length of 2. `all possible words` means all words coming from input list `words`. That is the third reason to sort by length of words.\n\nIn this case, we need to keep all the previous results. What strategy do you use to keep the results?\n\nMy answer is `Dynamic Programming`. More precisely use `HashMap`.\n\nWe can only use words from input list `words`, so keys of `Hashmap` should be words from input list `words`. Each value stands for max chain length for each word.\n\nLet\'s see what I said with \n```\nwordB = "abc"\n\nwordA should be\ntake off "a" \u2192 "bc"\ntake off "b" \u2192 "ac"\ntake off "c" \u2192 "ab"\n```\nCurrent `wordB` is `abc` and we have 3 possible predecessor candidates. Let\'s say we have the results until length of 2 like this\n```\nhash = {\'bc\': 1, \'ab\': 2}\n```\nIn this case, we check `bc`, `ac`, `ab` one by one.\n\nFirst of all, we should add `abc` with `1` because word `abc` itself is at least one chain.\n\n```\nhash = {\'bc\': 1, \'ab\': 2, \'abc\': 1}\n```\n\nThen check `bc`. We have the result of `bc` which is 1, so compare like this\n```\nhash[wordB] = max(hash[wordB], hash["bc"] + 1)\n```\n`hash[wordB]` is current result so far and `hash["bc"]` is the previous result `1`, `+1` is for adding some character. This time, a chain should be `+1` longer than from previous word. Now `hash[wordB] = 2`\n\nNext, check `ac` but we don\'t have the result for `ac` which means `ac` is not listed in input list `words`.\n\nAt last, check `ab` and we have the result of `ab` which is `2`, so\n\n```\nNow, hash[wordB] = 2\n\nhash[wordB] = max(hash[wordB], hash["ab"] + 1)\n\u2193\nhash[wordB] = max(2, 2 + 1)\n\u2193\nhash[wordB] = 3\n```\n\nIn the end, `hash` has the max chain length for each valid word. So all we have to do is just take max of chains from `hash`.\n\nSeems like `sorting` and `dynamic programming` strategy works. Let\'s see a real algorithm.\n\n## Algorithm Overview\n1. Create a dictionary `chains` to store the maximum chain length for each word.\n2. Sort the words in the input list by their lengths.\n3. Iterate through the sorted words and calculate the maximum chain length for each word.\n4. Return the maximum chain length found.\n\n## Detailed Explanation\n1. Initialize an empty dictionary `chains` to store the maximum chain length for each word.\n\n2. Sort the words in the input list (`words`) by their lengths using the `sorted` function and assign the result to `sorted_words`.\n\n3. Iterate through each word in the sorted list (`sorted_words`):\n\n a. For each word, initialize the chain length for that word in the `chains` dictionary to 1, representing the chain with just the word itself.\n \n b. For each index `i` in the range of the length of the current word:\n \n i. Generate the predecessor of the current word by removing the character at index `i` using slicing (`word[:i] + word[i+1:]`), and assign it to `pred`.\n \n ii. Check if the predecessor `pred` is already in the `chains` dictionary:\n \n - If it is, update the chain length for the current word (`chains[word]`) to the maximum of its current chain length and the chain length of the predecessor incremented by 1 (`chains[pred] + 1`).\n \n - If it\'s not, continue to the next iteration.\n \n4. Return the maximum chain length found by taking the maximum value from the values in the `chains` dictionary using the `max` function. This represents the longest string chain.\n\n5. The function returns the maximum chain length.\n\n\n---\n\n\n\n# Complexity\n- Time complexity: O(n log n + len(words) * 16) \u2192 `O(n log n)`\n - the first part of `O(n log n)` comes from `sorting`, where `n` is the number of words (which can be at most 1000)\n\n - `len(words) * 16` comes from for loop. `len(words)` is `n` and `16` comes from one of constraints and can be removed, so part of `len(words) * 16` should be `n`.\n - Since `O(n log n)` dominates time, overall time complexity is `O(n log n)`\n\n- Space complexity: O(n)\n`n` is the number of words\n\n\n```python []\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n chains = {} # Stores the max chain length for each word\n sorted_words = sorted(words, key=len) # Sort words by length\n\n for word in sorted_words:\n chains[word] = 1 # Initialize the chain length for the current word\n \n for i in range(len(word)):\n # word = abc, i = 0, word[:i] = "" + word[i+1:] = "bc" = "bc"\n # word = abc, i = 1, word[:i] = "a" + word[i+1:] = "c" = "ac"\n # word = abc, i = 2, word[:i] = "ab" + word[i+1:] = "" = "ab"\n pred = word[:i] + word[i+1:] # Generate predecessor by removing one character\n if pred in chains:\n chains[word] = max(chains[word], chains[pred] + 1)\n\n return max(chains.values())\n```\n```javascript []\n/**\n * @param {string[]} words\n * @return {number}\n */\nvar longestStrChain = function(words) {\n const chains = new Map(); // Stores the max chain length for each word\n const sortedWords = words.slice().sort((a, b) => a.length - b.length); // Sort words by length\n\n for (const word of sortedWords) {\n chains.set(word, 1); // Initialize the chain length for the current word\n\n for (let i = 0; i < word.length; i++) {\n const pred = word.slice(0, i) + word.slice(i + 1); // Generate predecessor by removing one character\n if (chains.has(pred)) {\n chains.set(word, Math.max(chains.get(word) || 0, chains.get(pred) + 1));\n }\n }\n }\n\n return Math.max(...Array.from(chains.values())); // Return the maximum chain length \n};\n```\n```java []\nclass Solution {\n public int longestStrChain(String[] words) {\n Map<String, Integer> chains = new HashMap<>(); // Stores the max chain length for each word\n String[] sortedWords = Arrays.copyOf(words, words.length);\n Arrays.sort(sortedWords, (a, b) -> a.length() - b.length()); // Sort words by length\n\n for (String word : sortedWords) {\n chains.put(word, 1); // Initialize the chain length for the current word\n\n for (int i = 0; i < word.length(); i++) {\n String pred = word.substring(0, i) + word.substring(i + 1); // Generate predecessor by removing one character\n if (chains.containsKey(pred)) {\n chains.put(word, Math.max(chains.getOrDefault(word, 0), chains.get(pred) + 1));\n }\n }\n }\n\n int maxChainLength = chains.values().stream().mapToInt(Integer::intValue).max().orElse(0);\n return maxChainLength; \n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n int longestStrChain(vector<string>& words) {\n std::unordered_map<std::string, int> chains; // Stores the max chain length for each word\n std::vector<std::string> sortedWords = words;\n std::sort(sortedWords.begin(), sortedWords.end(), [](const std::string& a, const std::string& b) {\n return a.length() < b.length(); // Sort words by length\n });\n\n for (const std::string& word : sortedWords) {\n chains[word] = 1; // Initialize the chain length for the current word\n\n for (int i = 0; i < word.length(); i++) {\n std::string pred = word.substr(0, i) + word.substr(i + 1); // Generate predecessor by removing one character\n if (chains.find(pred) != chains.end()) {\n chains[word] = std::max(chains[word], chains[pred] + 1);\n }\n }\n }\n\n int maxChainLength = 0;\n for (const auto& entry : chains) {\n maxChainLength = std::max(maxChainLength, entry.second);\n }\n\n return maxChainLength; \n }\n};\n```\n\n\n---\n\n\nThank you for reading such a long post. Please upvote it and don\'t forget to subscribe to my channel!\n\nMy next post for daily coding challenge on Sep 24th, 2023\nhttps://leetcode.com/problems/champagne-tower/solutions/4082622/video-how-we-think-about-a-solution-dp-solution-with-1d-and-2d-python-javascript-java-and-c/\n\nHave a nice day! | 32 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
LIS type solution and DFS solution with memo | longest-string-chain | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nSame as Longest common subsequence. We sort the list of words by length. If we can include the previous word then we add the longest chain at that previous word to current word.\n\nWe can check longest chain (backwards) for each word\n# Approach I\n<!-- Describe your approach to solving the problem. -->\n1) Write can Add function. If we can make large word form smaller word\n2) We check the length of longest chain backwards\n3) return the max ans\n\n# Approach II\n1) Do dfs on each word.\n2) Base case when the word becomes and empty string ""\n3) return the max\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n**2)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n# Code\n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n words.sort()\n def canAdd(small, large):\n if len(small) + 1 != len(large): return False\n for i in range(len(large)):\n newWord = large[:i] + large[i+1:]\n if newWord == small: return True\n return False\n words.sort(key = lambda x: len(x))\n dp = [1]*len(words)\n ans = 1\n for i in range(len(words)):\n for j in range(i):\n if canAdd(words[j], words[i]):\n dp[i] = max(dp[i], 1 + dp[j])\n ans = max(ans, dp[i])\n return ans\n #second approach\n def longestStrChain(self, words: List[str]) -> int:\n set_words = set(words)\n @cache\n def solve(word):\n if word == "":\n return 0\n currMax = 1\n for i in range(len(word)):\n newWord = word[:i] + word[i + 1:]\n if newWord in set_words:\n currMax = max(currMax, 1 + solve(newWord))\n return currMax\n ans = 1\n #skip the words with length 1\n for word in [ele for ele in words if len(words) > 1]:\n ans = max(ans, solve(word))\n return ans\n \n``` | 1 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
longestStrChain is Solution in Python3 | longest-string-chain | 0 | 1 | \n# Approach\n\nlet\'s break down the longestStrChain function step by step:\n\n1. dp = {}: We initialize an empty dictionary called dp to store information about the longest chain for each word.\n\n2. for w in sorted(words, key=len):: We loop through the input list words, but we process them in sorted order by their length (shortest to longest). This is helpful for our dynamic programming approach.\n\n3. dp[w] = max(dp.get(w[:i] + w[i + 1:], 0) + 1 for i in range(len(w))): For each word w, we calculate the length of the longest chain that can be formed with it.\n\n- dp.get(w[:i] + w[i + 1:], 0): We check if there is a shorter word that can form a chain with w. To do this, we remove one character at a time from w and see if the resulting shorter word is in our dp dictionary. If it is, we retrieve the length of the chain associated with that shorter word; otherwise, we assume a chain length of 0.\n\n- + "+ 1": We add 1 to the chain length because w itself can be part of the chain.\n\n- + for i in range(len(w)): We repeat this process for all possible shorter words by removing one character at a time from w.\n\n- + dp[w] = max(...): We assign the maximum chain length found for word w to the dp dictionary.\n\n4. return max(dp.values()): Finally, after processing all the words, we return the maximum chain length found among all the words. This represents the longest word chain that can be formed with the input words.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n * m)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n dp = {}\n for w in sorted(words, key=len): dp[w] = max(dp.get(w[:i] + w[i + 1:], 0) + 1 for i in range(len(w)))\n return max(dp.values())\n```\n\n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n dp = {}\n for w in sorted(words, key=len):\n dp[w] = max(dp.get(w[:i] + w[i + 1:], 0) + 1 for i in range(len(w)))\n return max(dp.values())\n``` | 1 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
DFS tree traversal using Reg-Ex || Python ✅ | longest-string-chain | 0 | 1 | # Intuition\nA simple DFS approach.\n\n---\n\n\n# Approach\n- Building a DFS tree for every word in `words` array. \n\n- And storing the maximum no of elements for every word in words in `ma` if the number of elements is greater than the count `c`.\n\n---\n> Not an optimal approach as it contains regex comparisions and recursion, But it works.\n---\n# Complexity\n- Time complexity:\n$$O(n*2^n)$$\n\n- Space complexity:\n$$O(n)$$\n\n---\n\n\n# Code\n```python []\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n words.sort(key=lambda x: len(x))\n d = defaultdict(list)\n\n for i in words:\n d[len(i)].append(i)\n\n @functools.lru_cache(None)\n def trav(dic_ind, s, c):\n nonlocal ma\n if ma<c:\n ma=c\n if dic_ind not in d:\n return \n for i in d[dic_ind]:\n if re.search("[a-z]*" + (\'[a-z]*\').join(s) + \'[a-z]*\', i) :\n trav(dic_ind + 1, i ,c+1)\n\n ma = -1\n for i in d.keys():\n trav(i,"",0)\n return ma\n``` | 1 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
✅ 95.46% DP & Memo | longest-string-chain | 1 | 1 | # Interview Guide: "Longest String Chain" Problem\n\n## Problem Understanding\n\nThe "Longest String Chain" problem presents you with an array of words. The objective is to identify the lengthiest chain of words where every word in the chain acts as a predecessor to the subsequent word. A word, say `A`, stands as a predecessor to another word, `B`, if you can inject just a single letter at any position in `A`, without altering the sequence of its other characters, to match it to `B`.\n\n### Key Points to Ponder:\n\n1. **Grasp the Boundaries**\n Start by thoroughly comprehending the constraints of the problem. Words in the array can be as few as 1 or as many as 1000. Each word\'s length can range between 1 to 16 characters. Understanding these limits can guide your solution\'s design and efficiency.\n\n2. **Diverse Pathways**\n Multiple avenues can be explored to crack this problem, such as:\n - Dynamic Programming\n - Depth-First Search (DFS) with Memoization\n\n Every approach carries its own time and space complexity. Thus, select wisely, keeping the constraints in mind.\n\n3. **Be Wary of Edge Cases**\n If you notice words that don\'t adhere to the lowercase English letters rule or exceed the mentioned lengths, they can be potential edge cases to consider.\n\n4. **Narrate Your Thought Journey**\n As you unravel the problem, always articulate your thought process and the rationale behind picking a certain methodology. Shed light on any trade-offs you\'re contemplating in terms of computational time and space.\n\n5. **Test and Validate**\n Once you\'ve drafted a solution, validate it with different test cases, especially edge cases, to ensure its robustness.\n\n### Conclusion\n\nThe "Longest String Chain" problem is a classic example of challenges that examine your string manipulation and optimization skills. Being adept at various solution techniques and understanding the nuances can not only help you solve the problem efficiently but also make a strong impression in technical discussions or interviews. Your ability to understand, analyze, and optimize will set you apart.\n\n---\n\n# Strategy to Solve the Problem:\n\n## Live Coding Special\nhttps://youtu.be/EiQpUgUghzY?si=leq4DHTH6WC7iiSB\n\n## Approach: Dynamic Programming\n\nTackling the "Longest String Chain" puzzle requires a blend of systematic organization and methodical computation. Our primary weapon of choice for this challenge is Dynamic Programming, a strategy that breaks problems down into smaller, more manageable sub-problems. The beauty of this approach lies in its ability to remember past results, which significantly speeds up computing the final solution.\n\n### Key Data Structures:\n\n- `dp`: A dictionary, acting like our memory vault, that remembers the longest chain length we can achieve for each word.\n\n### Detailed Breakdown:\n\n1. **Setting the Stage - Organizing Words**:\n - Imagine you\'re arranging dominoes; the smallest pieces first, growing to the largest. Similarly, we start by sorting our words from shortest to longest. This ensures that when we\'re looking at a word, any potential \'parent\' word (a word it could have evolved from) has already been evaluated.\n\n2. **Constructing Chains**:\n - For every word, we assume it to be a unique entity and assign a chain length of 1. This is our base scenario, the minimal chain.\n - Now, we dive deep into each word. By omitting one character at a time, we attempt to form a predecessor word. If this predecessor exists in our `dp` (our memory vault), it means our current word could have evolved from it. Using the transition function, we then update our current word\'s chain length based on the predecessor\'s length.\n\n**Why the Transition Function?** \nIn dynamic programming, transition functions act like bridges, connecting sub-problems to construct the bigger picture. Here, it helps us decide if the chain length of the current word should be updated based on its predecessor. It\'s the heart of our solution, ensuring we always have the longest chain possible.\n\n### Complexity Commentary:\n\n**Time Complexity**: \n- Our method involves scanning through our sorted list of words. For each word, it evaluates all possible words it could have evolved from. This double traversal gives rise to a time complexity of $$ O(n \\times m) $$, where $$ n $$ denotes the total number of words and $$ m $$ signifies the average word length.\n\n**Space Complexity**: \n- Our `dp` dictionary occupies space based on the number of words, giving us a space complexity of $$ O(n) $$.\n\n\n# Code Dynamic Programming\n``` Python []\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n words.sort(key=len)\n dp = {}\n max_chain = 0\n for word in words:\n dp[word] = 1\n for i in range(len(word)):\n prev_word = word[:i] + word[i+1:]\n if prev_word in dp:\n dp[word] = max(dp[word], dp[prev_word] + 1)\n max_chain = max(max_chain, dp[word])\n return max_chain\n```\n``` Go []\nfunc longestStrChain(words []string) int {\n sort.Slice(words, func(i, j int) bool {\n return len(words[i]) < len(words[j])\n })\n dp := make(map[string]int)\n max_chain := 0\n for _, word := range words {\n dp[word] = 1\n for i := 0; i < len(word); i++ {\n prev_word := word[:i] + word[i+1:]\n if val, exists := dp[prev_word]; exists {\n dp[word] = max(dp[word], val + 1)\n }\n }\n max_chain = max(max_chain, dp[word])\n }\n return max_chain\n}\n\nfunc max(a, b int) int {\n if a > b {\n return a\n }\n return b\n}\n```\n``` Rust []\nuse std::collections::HashMap;\n\nimpl Solution {\n pub fn longest_str_chain(words: Vec<String>) -> i32 {\n let mut words = words;\n words.sort_by_key(|a| a.len());\n let mut dp: HashMap<String, i32> = HashMap::new();\n let mut max_chain = 0;\n for word in &words {\n dp.insert(word.clone(), 1);\n for i in 0..word.len() {\n let prev_word = format!("{}{}", &word[..i], &word[i+1..]);\n if let Some(val) = dp.get(&prev_word) {\n dp.insert(word.clone(), std::cmp::max(dp[word], val + 1));\n }\n }\n max_chain = std::cmp::max(max_chain, dp[word]);\n }\n max_chain\n }\n}\n```\n``` C++ []\nclass Solution {\npublic:\n int longestStrChain(std::vector<std::string>& words) {\n std::sort(words.begin(), words.end(), [](const std::string& a, const std::string& b) {\n return a.size() < b.size();\n });\n \n std::unordered_map<std::string, int> dp;\n int max_chain = 0;\n for (const auto& word : words) {\n dp[word] = 1;\n for (int i = 0; i < word.size(); ++i) {\n std::string prev_word = word.substr(0, i) + word.substr(i + 1);\n if (dp.find(prev_word) != dp.end()) {\n dp[word] = std::max(dp[word], dp[prev_word] + 1);\n }\n }\n max_chain = std::max(max_chain, dp[word]);\n }\n return max_chain;\n }\n};\n```\n``` Java []\npublic class Solution {\n public int longestStrChain(String[] words) {\n Arrays.sort(words, (a, b) -> a.length() - b.length());\n HashMap<String, Integer> dp = new HashMap<>();\n int max_chain = 0;\n for (String word : words) {\n dp.put(word, 1);\n for (int i = 0; i < word.length(); i++) {\n String prev_word = word.substring(0, i) + word.substring(i + 1);\n if (dp.containsKey(prev_word)) {\n dp.put(word, Math.max(dp.get(word), dp.get(prev_word) + 1));\n }\n }\n max_chain = Math.max(max_chain, dp.get(word));\n }\n return max_chain;\n }\n}\n```\n``` PHP []\nclass Solution {\n function longestStrChain($words) {\n usort($words, function($a, $b) {\n return strlen($a) - strlen($b);\n });\n $dp = [];\n $max_chain = 0;\n foreach ($words as $word) {\n $dp[$word] = 1;\n for ($i = 0; $i < strlen($word); $i++) {\n $prev_word = substr($word, 0, $i) . substr($word, $i + 1);\n if (isset($dp[$prev_word])) {\n $dp[$word] = max($dp[$word], $dp[$prev_word] + 1);\n }\n }\n $max_chain = max($max_chain, $dp[$word]);\n }\n return $max_chain;\n }\n}\n```\n``` JavaScritp []\nvar longestStrChain = function(words) {\n words.sort((a, b) => a.length - b.length);\n const dp = {};\n let max_chain = 0;\n for (const word of words) {\n dp[word] = 1;\n for (let i = 0; i < word.length; i++) {\n const prev_word = word.slice(0, i) + word.slice(i + 1);\n if (prev_word in dp) {\n dp[word] = Math.max(dp[word], dp[prev_word] + 1);\n }\n }\n max_chain = Math.max(max_chain, dp[word]);\n }\n return max_chain;\n};\n```\n``` C# []\npublic class Solution {\n public int LongestStrChain(string[] words) {\n Array.Sort(words, (a, b) => a.Length.CompareTo(b.Length));\n Dictionary<string, int> dp = new Dictionary<string, int>();\n int max_chain = 0;\n foreach (var word in words) {\n dp[word] = 1;\n for (int i = 0; i < word.Length; i++) {\n string prev_word = word.Remove(i, 1);\n if (dp.ContainsKey(prev_word)) {\n dp[word] = Math.Max(dp[word], dp[prev_word] + 1);\n }\n }\n max_chain = Math.Max(max_chain, dp[word]);\n }\n return max_chain;\n }\n}\n```\n\n---\n\n## Memoization with DFS Approach:\n\nThis approach uses DFS to explore the potential chains starting from each word. To optimize the solution, the results of expensive recursive calls are cached using memoization.\n\n### Key Data Structures:\n\n- `memo`: A dictionary to cache the results of DFS calls for each word.\n\n### Enhanced Breakdown:\n\n1. **DFS Exploration**:\n - For each word, recursively explore its potential predecessors by removing one character at a time.\n - Cache the result of the DFS exploration for each word to avoid redundant calculations.\n\n2. **Check Maximum Chain Length**:\n - After exploring all potential chains starting from a word, store the maximum chain length found in the `memo` dictionary.\n\n### Complexity Analysis:\n\n**Time Complexity**: \n- The algorithm explores each word once and, for each word, checks all its potential predecessors. Due to memoization, repeated calculations are avoided. The time complexity is $$ O(n \\times m) $$.\n\n**Space Complexity**: \n- The space complexity is $$ O(n) $$ due to the storage requirements of the `memo` dictionary and the `word_set`.\n\n\n## Code Memoization with DFS\n``` Python []\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n word_set = set(words)\n memo = {}\n\n def dfs(word):\n if word not in word_set:\n return 0\n\n if word in memo:\n return memo[word]\n\n max_chain = 1\n for i in range(len(word)):\n next_word = word[:i] + word[i+1:]\n max_chain = max(max_chain, 1 + dfs(next_word))\n\n memo[word] = max_chain\n return max_chain\n\n return max(dfs(word) for word in words)\n```\n\n## Performance\n\n| Language | Time (ms) | Memory (MB) | Solution Technique |\n|-------------|----------:|------------:|-----------------------|\n| Go | 21 | 6.8 | DP |\n| Rust | 28 | 2.5 | DP |\n| Java | 39 | 44.5 | DP |\n| PHP | 42 | 19.3 | DP |\n| C++ | 58 | 17.0 | DP |\n| C# | 96 | 56.8 | DP |\n| Python3 | 112 | 16.7 | DP |\n| Python3 | 147 | 20.2 | Memoization with DFS |\n| JavaScript | 167 | 63.4 | DP |\n\n\n\n\n## Summary\n\nAll strategies provided above tackle the problem effectively. The dynamic programming approach offers a systematic way of computing the chain lengths, making it intuitive and efficient. On the other hand, the DFS with memoization approach provides a depth-first exploration of the problem, optimized by caching results. Depending on the nature of the input and specific use cases, one can choose the appropriate strategy to solve the problem. | 85 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
[Python] LIS Variation | Easy to Understand | Tabulation Approach | longest-string-chain | 0 | 1 | ```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n words = sorted(list(set(words)), key=len)\n dp = [1] * len(words)\n \n for i in range(0, len(words)):\n for j in range(0, i):\n \n wordA = words[i]\n wordB = words[j]\n \n if len(wordA) - 1 == len(wordB):\n for k in range(len(wordA)):\n if wordB in (wordA[:k] + wordA[k+1:]):\n dp[i] = max(dp[i], dp[j] + 1)\n \n return max(dp)\n``` | 1 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
longest possible word chain | longest-string-chain | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nMy initial thoughts on how to solve this problem were to:\n\n1. Sort the words by length to consider shorter words first.\n2. Use dynamic programming to iteratively calculate the longest chain length for each word by considering its possible predecessors.\n3. Keep track of the maximum chain length found during the process.\n5. Return the maximum chain length as the result.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Sort the list of words based on their lengths in ascending order.\n2. Initialize a dictionary to store the longest chain length for each word, setting all initial lengths to 1.\n3. Use dynamic programming to iterate through each word, considering all possible predecessors by removing one letter at a time.\n4. Update the chain length for each word based on its predecessors, keeping track of the maximum chain length found.\n5. Return the maximum chain length as the result.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nThe time complexity is O(N * M^2), where N is the number of words in the input list words, and M is the maximum length of a word in the list.\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\nThe space complexity of this code is O(N * M), where N is the number of words in the input list words, and M is the maximum length of a word in the list.\n\n# Code\n```\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n words.sort(key=len)\n \n longest_chain = {}\n \n for word in words:\n longest_chain[word] = 1\n \n for word in words:\n for i in range(len(word)):\n prev_word = word[:i] + word[i+1:]\n if prev_word in longest_chain:\n longest_chain[word] = max(longest_chain[word], longest_chain[prev_word] + 1)\n \n max_length = max(longest_chain.values())\n \n return max_length\n\n``` | 1 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
Rabin-Karp rolling hash algo [Optimized complexity][O(W * L)] | longest-string-chain | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nUsing of Rabin-Karp algorithm can reduce generation all hashes of predecessors for linear time.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nOriginal Rabin-Karp Rolling Hash formula:\n$$hash(S) = S_1 \\cdot P^{k - 1} + S_2 \\cdot P^{k - 2}+ ... + S_{k - 1} \\cdot P + S_k\\ [mod\\ M]$$\nWhere $$P$$ is some primary number, that is greater of any symbol code of $$S$$ and $$M$$ is some big number to avoid collisions.\n\nTaking hash of $$S$$ without symbol $$S_i$$:\n$$hash(S[:i] + S[i+1:]) = (S_1 \\cdot P^{k - 1} + S_2 \\cdot P^{k - 2}+ ... + S_{i-1} \\cdot P^{k-i+1}) / P+ S_{i+1} \\cdot P ^ {k-i-1} + ... + S_{k - 1} \\cdot P + S_k = hash(S[:i]) \\cdot P^{k-i} + hash(S[i+1:]) = hash(S[:i]) \\cdot P^{k-i} + hash(S) - hash(S[:i + 1]) \\cdot P^{k-i} = hash(S) + (hash(S[:i]) - hash(S[:i + 1])) \\cdot P^{k-i} \\ [mod\\ M]$$\n\nEach $$hash(S[:i])$$ can be calculated from $$hash(S[:i-1])$$ for $$O(1)$$ time, and the powers of $$P$$ could be precomputed at the program start.\n\n\n# Complexity\n- Time complexity: $$O(W \\cdot L)$$: function $$roll\\_all\\_sequences(word)$$ generates hashes of all predecessors of $$word$$ for $$O(L)$$ instead of $$O(L^2)$$, where $$L$$ is the length of $$word$$. So, the overall complexity for the task can be improved from $$O(W \\cdot L^2)$$ to $$O(W \\cdot L)$$.\n- Space complexity: $$O(W)$$\n\n# Code\n```\nP = 29 # All char codes will be in the range from 1 to 26, so P is enough\nMOD = 2 ** 60\n\n\n# precalculation of powers of P\nMAX_P_POW = 20\nP_POW = [1] * MAX_P_POW\nfor i in range(1, MAX_P_POW):\n P_POW[i] = (P_POW[i - 1] * P) % MOD\n\n\n# Rabin-Karp Rolling Hash\ndef roll(word):\n result = 0\n for char in word:\n result = (result * P + ord(char) - ord(\'a\') + 1) % MOD\n return result\n\n\n# Hash generator of all predecessors of a word\ndef roll_all_sequences(word):\n original_hash = roll(word)\n \n prev_hash = 0\n\n for i, char in enumerate(word):\n cur_hash = (prev_hash * P + ord(char) - ord(\'a\') + 1) % MOD\n yield (original_hash + (prev_hash - cur_hash) * P_POW[len(word) - i - 1]) % MOD\n prev_hash = cur_hash\n\n\nclass Solution:\n def longestStrChain(self, words: List[str]) -> int:\n # calculating mappings from hashes of words to words\n hashes2words = {roll(word): word for word in words}\n\n # dynamic programming magic\n @cache\n def depth(word):\n result = 1\n for cur_hash in roll_all_sequences(word):\n cur_word = hashes2words.get(cur_hash)\n if cur_word is not None:\n result = max(result, 1 + depth(cur_word))\n return result\n\n return max(depth(word) for word in words)\n\n``` | 1 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
🚀 97.50% || DP Recursive & Iterative || Commented Code🚀 | longest-string-chain | 1 | 1 | # Problem Description\nGiven an **array** of words, each composed of **lowercase** English letters.\n\nA word `wordA` is considered a **predecessor** of another word `wordB` if and only if we can **insert** exactly **one** letter anywhere in `wordA`, **without changing** the **order** of the other characters, to make it equal to `wordB`.\n\nFor instance, `abc` is a **predecessor** of `abac` since we can insert `a` after the `b` in `abc` to get `abac`. However, `cba` is **not** a **predecessor** of `bcad` as **rearrangement** is needed.\n\nA word **chain** is defined as a **sequence** of words `[word1, word2, ..., wordk]` where `k` is **greater** than or **equal** to `1`, and each word in the sequence is a **predecessor** of the next word.\n\nThe task is to **determine** the length of the **longest** possible word chain that can be formed using words chosen from the given list of words.\n\n---\n\n# Dynamic Programming\n\n\n\n**Dynamic Programming** is a powerful technique that involves **caching** pre-computed results, thereby **eliminating** the need for redundant computations and significantly **optimizing** time complexity.\nThere are **two primary approaches** to Dynamic Programming:\n\n## Recursive Approach (Top-Down)\nWe can think of Recursive Approach as **breaking** hard bricks into **small** rocks. but, how this apply to our problem ?\nWe can **break** our **complex problem** into **easier** ones. for each word search for all of its possible predecessors. If one exist, then seach also for its all possible predecessors until we reach a base case. \n\n## Iterative Approach (Bottom-Up)\nWe can think of Iterative Approach as **building** high building from small bricks. but, how this also apply to our problem ?\nWe can **solve** our **complex problem** by solving **easier** ones first and build until we reach our complex problem. We can start by words of length `1` and search for their predecessors and then words of length `2` then `3` so on.\n\n---\n# Intuition\nHello There\uD83D\uDE00\nLet\'s take a look on our today\'s interesting problem\uD83D\uDE80\n\n- In our today\'s problem we have **two** important requirements:\n - A chain if consist of **multiple** words each one is a predecessor for the one before it.\n - We want to find the **longest** chain.\n\n- If we sat a little and thought about this problem we can conclude some points.\uD83D\uDE33\n - For each word, we want to try each **possible** **predecessor** of it.\n - See if the predecessor **exists** in our words list then try also each predecessor of it and so on.\n\nLet\'s see an example:\uD83D\uDE80\nWith words list = `["a", "d", "b","aa", "ab", "da", "aba", "ada"]`\nLet\'s see what can we do for word `ada`\n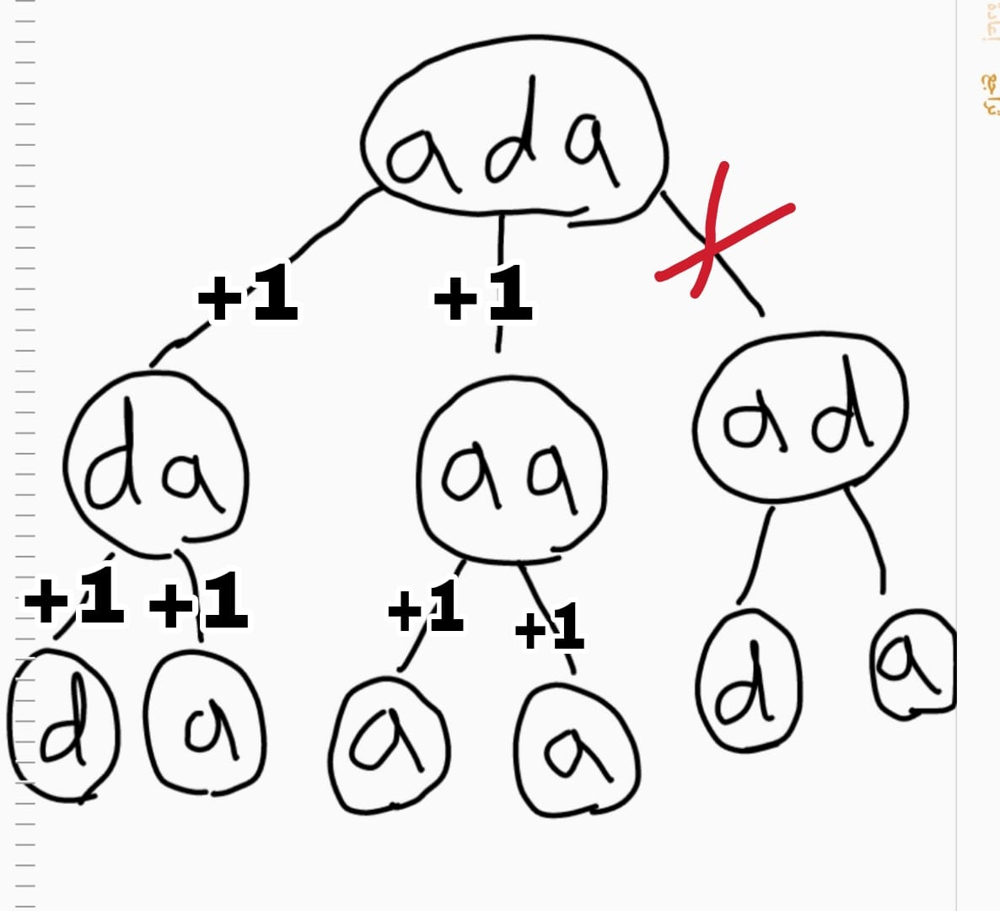\nwe can see that `2` out of `3` predecessor exist in our words list which are `da` and `aa` so we will continue our chain to look for furthur predecessor. and we can see that the longest chain if we make `ada` is the last word in it is `3`.\uD83E\uDD2F\n\nNow, let\'s see what can we do for word `aba`\n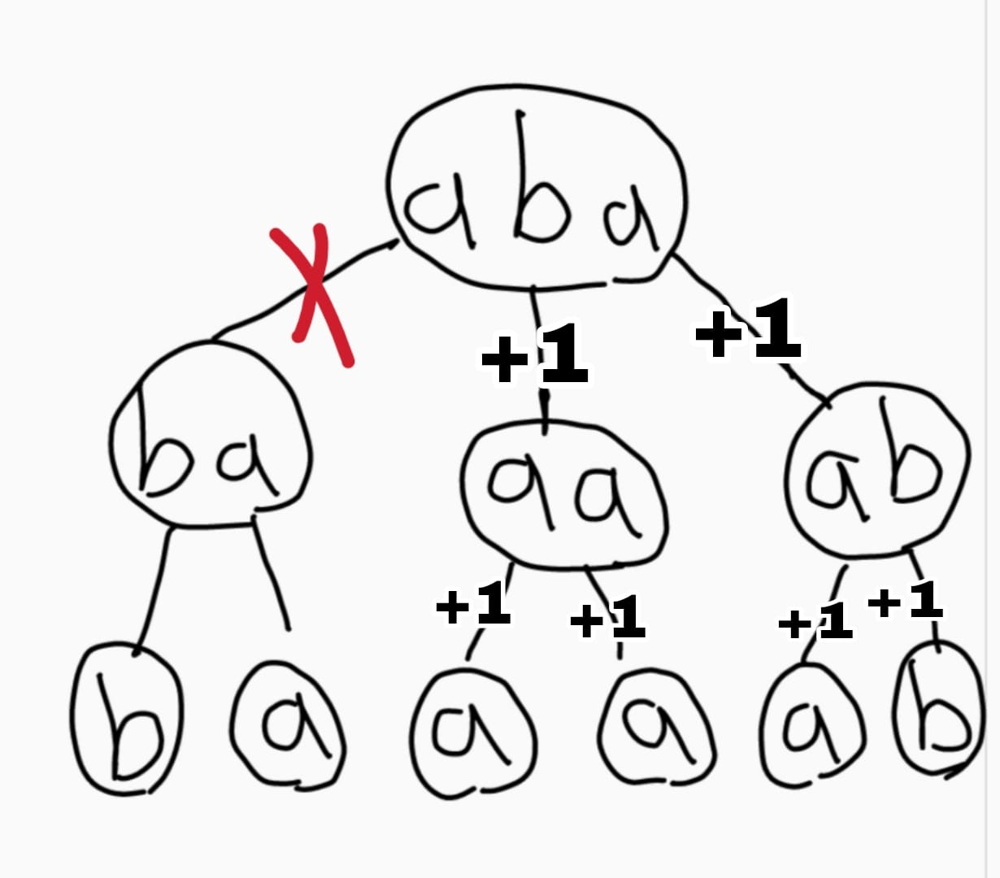\nwe can see that `2` out of `3` predecessor exist in our words list which are `ab` and `aa` so we will continue our chain to look for furthur predecessor. and we can see that the longest chain if we make `aba` is the last word in it is `3`.\uD83E\uDD2F\n\nInteresting, I think we are catching something.\uD83E\uDD29\nYes, Our approach is the right one but we will have to **repeat** many steps like we saw in the two examples each of them need to calculate the largest chain for word `aa`.\uD83D\uDE14\n\nHere comes the **hero** of the day **Dynamic Programming**.\uD83D\uDC31\u200D\uD83C\uDFCD\uD83D\uDC31\u200D\uD83C\uDFCD\nWhat will we do is once we calculated the largest chain for any string we will **cache** it in a `hashmap` for that string so we don\'t have to recalculate it again.\n\nThis will **reduce** the time needed to solve our problem. and the two approached of Dynamic Programming are the same the main difference that one is starting from the larger word and search for all of its predecessors (Top-Down) and the other builds our `hashmap` from the shorter words (Bottom-Up).\n\nAnd this is the solution for our today problem I hope that you understood it\uD83D\uDE80\uD83D\uDE80\n\n---\n\n\n# Proposed Solutions\n## 1. Recursive Approach (Top-Down)\n### Approach\n1. Create two empty dictionaries: `chain_lengths` to store chain lengths (DP) and `word_set` to track word existence.\n2. Calculate Chain Length:\n - If the word is **not** in `word_set`, return `0` (word doesn\'t exist in the set).\n - If the chain length for the word is already **calculated**, return the stored chain length (DP).\n - **Iterate** through each character in the word:\n - Create a new word by **removing** the current character.\n - Recur and calculate chain length for the **new** word.\n - Update chain_length.\n - Return the final chain_length.\n3. Longest Word Chain:\n - Add the word to the `word_set` and mark it as existing.\n - Initialize `max_chain_length` to `-1` (no chain found yet).\n - Iterate through each word in the input list:\n - **Calculate** the chain length for the current word.\n - Update `max_chain_length`.\n - Return the final `max_chain_length`.\n\n### Complexity\n- **Time complexity:** $$O(N * M)$$\nSince we are iterating over all the `N` words and in each word we try all possible predecessor by removing one character a time then the time complexity is `O(N * M)`.\nWhere `N` is the **number** of words in our array and `M` is the **length** of the word.\nremember that we eleminated redundant calls by using `DP`.\n- **Space complexity:** $$O(N)$$\nWe store two `HashMaps` each of size `N` then the space we are storing is `2 * N` then the space complexity it `O(N)`.\n\n---\n\n\n## 2. Iterative Approach (Bottom-Up)\n### Approach\n1. **Sort** the words in the input vector based on their **lengths** in ascending order.\n2. Initialize a map called `longestChainLength` to store the **longest** chain length for each word.\n3. Initialize a variable `maxChainLength` to -1 to (no chain found yet).\n4. Iterate through **each word** in the sorted list of words:\n - Initialize the **chain length** for the current word as `1` (The word itself).\n6. remove **one character** at a time and check if the resulting word exists.\n7. If the resulted word **exists** in the map:\n - **Update** the chain length.\n - **Update** the maximum chain length seen so far.\n8. **Return** Maximum Chain Length.\n\n### Complexity\n- **Time complexity:** $$O(N * (log(N) + M))$$\nSince we are sorting the array of words then iterating over all the `N` words and in each word we try all possible predecessor by removing one character a time then the time complexity is `O(N * log(N) + N * M)`.\nWhere `N` is the **number** of words in our array and `M` is the **length** of the word.\nremember that we eleminated redundant calls by using `DP`;`\n- **Space complexity:** $$O(N)$$\nWe store one `HashMaps` of size `N` then the space we are storing is `N` then the space complexity it `O(N)`.\n\n---\n\n\n# Code\n## 1. Recursive Approach (Top-Down)\n```C++ []\nclass Solution {\nprivate:\n unordered_map<string, int> chain_lengths;\n unordered_map<string, bool> word_set;\n\n int calculateChainLength(const string &word) {\n // If the word doesn\'t exist in the set\n if (word_set.find(word) == word_set.end())\n return 0;\n\n // If chain length for the word is already calculated\n if (chain_lengths.find(word) != chain_lengths.end())\n return chain_lengths[word];\n\n int chain_length = 1;\n\n // Try removing one character at a time from the word and calculate chain length\n for (int i = 0; i < word.size(); i++) {\n string new_word = word.substr(0, i) + word.substr(i + 1);\n chain_length = max(chain_length, 1 + calculateChainLength(new_word));\n }\n\n chain_lengths[word] = chain_length;\n return chain_length;\n }\n\npublic:\n int longestStrChain(vector<string> &words) {\n for (const auto &word : words) {\n word_set[word] = true;\n }\n\n int max_chain_length = -1;\n\n // Calculate the maximum chain length for each word\n for (const auto &word : words) {\n max_chain_length = max(max_chain_length, calculateChainLength(word));\n }\n\n return max_chain_length;\n }\n};\n```\n```Java []\nclass Solution {\n private Map<String, Integer> chainLengths = new HashMap<>();\n private Map<String, Boolean> wordSet = new HashMap<>();\n\n private int calculateChainLength(String word) {\n // If the word doesn\'t exist in the set\n if (!wordSet.containsKey(word) || !wordSet.get(word))\n return 0;\n\n // If chain length for the word is already calculated\n if (chainLengths.containsKey(word))\n return chainLengths.get(word);\n\n int chainLength = 1;\n\n // Try removing one character at a time from the word and calculate chain length\n for (int i = 0; i < word.length(); i++) {\n String newWord = word.substring(0, i) + word.substring(i + 1);\n chainLength = Math.max(chainLength, 1 + calculateChainLength(newWord));\n }\n\n chainLengths.put(word, chainLength);\n return chainLength;\n }\n\n public int longestStrChain(String[] words) {\n for (String word : words) {\n wordSet.put(word, true);\n }\n\n int maxChainLength = -1;\n\n // Calculate the maximum chain length for each word\n for (String word : words) {\n maxChainLength = Math.max(maxChainLength, calculateChainLength(word));\n }\n\n return maxChainLength;\n }\n}\n```\n```Python []\nclass Solution:\n def __init__(self):\n self.chain_lengths = {}\n self.word_set = {}\n\n def calculate_chain_length(self, word) -> int:\n # If the word doesn\'t exist in the set\n if word not in self.word_set or not self.word_set[word]:\n return 0\n\n # If chain length for the word is already calculated\n if word in self.chain_lengths:\n return self.chain_lengths[word]\n\n chain_length = 1\n\n # Try removing one character at a time from the word and calculate chain length\n for i in range(len(word)):\n new_word = word[:i] + word[i + 1:]\n chain_length = max(chain_length, 1 + self.calculate_chain_length(new_word))\n\n self.chain_lengths[word] = chain_length\n return chain_length\n\n def longestStrChain(self, words) -> int:\n for word in words:\n self.word_set[word] = True\n\n max_chain_length = -1\n\n # Calculate the maximum chain length for each word\n for word in words:\n max_chain_length = max(max_chain_length, self.calculate_chain_length(word))\n\n return max_chain_length\n```\n\n## 2. Iterative Approach (Bottom-Up) \n```C++ []\nclass Solution {\npublic:\n\n int longestStrChain(vector<string>& words) {\n // Sort the words by their lengths\n sort(words.begin(), words.end(), [](const string& a, const string& b) {\n return a.length() < b.length();\n });\n\n // Map to store the longest chain length for each word\n unordered_map<string, int> longestChainLength;\n\n // Initialize the answer\n int maxChainLength = -1;\n\n for(auto &word: words){\n // Initialize the chain length for the current word\n longestChainLength[word] = 1;\n\n // Try removing one character at a time from the word and check if the resulting word exists\n for(int i = 0 ; i < word.size() ; i++){\n string reducedWord = word.substr(0, i) + word.substr(i + 1) ;\n\n // If the reduced word exists in the map\n if(longestChainLength.find(reducedWord) != longestChainLength.end())\n // Update the chain length for the current word\n longestChainLength[word] = max(longestChainLength[word], longestChainLength[reducedWord] + 1) ;\n }\n\n // Update the maximum chain length seen so far\n maxChainLength = max(maxChainLength, longestChainLength[word]) ;\n }\n\n return maxChainLength;\n }\n};\n```\n```Java []\nclass Solution {\n public int longestStrChain(String[] words) {\n // Sort the words by their lengths\n Arrays.sort(words, (a, b) -> Integer.compare(a.length(), b.length()));\n\n // Map to store the longest chain length for each word\n Map<String, Integer> longestChainLength = new HashMap<>();\n\n // Initialize the answer\n int maxChainLength = -1;\n\n for (String word : words) {\n // Initialize the chain length for the current word\n longestChainLength.put(word, 1);\n\n // Try removing one character at a time from the word and check if the resulting word exists\n for (int i = 0; i < word.length(); i++) {\n String reducedWord = word.substring(0, i) + word.substring(i + 1);\n\n // If the reduced word exists in the map\n if (longestChainLength.containsKey(reducedWord))\n // Update the chain length for the current word\n longestChainLength.put(word, Math.max(longestChainLength.get(word), longestChainLength.get(reducedWord) + 1));\n }\n\n // Update the maximum chain length seen so far\n maxChainLength = Math.max(maxChainLength, longestChainLength.get(word));\n }\n\n return maxChainLength;\n }\n}\n```\n```Python []\nclass Solution:\n def longestStrChain(self, words) -> int:\n # Sort the words by their lengths\n words.sort(key=len)\n\n # Dictionary to store the longest chain length for each word\n longest_chain_length = {}\n\n # Initialize the answer\n max_chain_length = -1\n\n for word in words:\n # Initialize the chain length for the current word\n longest_chain_length[word] = 1\n\n # Try removing one character at a time from the word and check if the resulting word exists\n for i in range(len(word)):\n reduced_word = word[:i] + word[i + 1:]\n\n # If the reduced word exists in the dictionary\n if reduced_word in longest_chain_length:\n # Update the chain length for the current word\n longest_chain_length[word] = max(longest_chain_length[word], longest_chain_length[reduced_word] + 1)\n\n # Update the maximum chain length seen so far\n max_chain_length = max(max_chain_length, longest_chain_length[word])\n\n return max_chain_length\n```\n\n\n---\n\n\n\n\n\n\n\n\n\n | 33 | You are given an array of `words` where each word consists of lowercase English letters.
`wordA` is a **predecessor** of `wordB` if and only if we can insert **exactly one** letter anywhere in `wordA` **without changing the order of the other characters** to make it equal to `wordB`.
* For example, `"abc "` is a **predecessor** of `"abac "`, while `"cba "` is not a **predecessor** of `"bcad "`.
A **word chain** is a sequence of words `[word1, word2, ..., wordk]` with `k >= 1`, where `word1` is a **predecessor** of `word2`, `word2` is a **predecessor** of `word3`, and so on. A single word is trivially a **word chain** with `k == 1`.
Return _the **length** of the **longest possible word chain** with words chosen from the given list of_ `words`.
**Example 1:**
**Input:** words = \[ "a ", "b ", "ba ", "bca ", "bda ", "bdca "\]
**Output:** 4
**Explanation**: One of the longest word chains is \[ "a ", "ba ", "bda ", "bdca "\].
**Example 2:**
**Input:** words = \[ "xbc ", "pcxbcf ", "xb ", "cxbc ", "pcxbc "\]
**Output:** 5
**Explanation:** All the words can be put in a word chain \[ "xb ", "xbc ", "cxbc ", "pcxbc ", "pcxbcf "\].
**Example 3:**
**Input:** words = \[ "abcd ", "dbqca "\]
**Output:** 1
**Explanation:** The trivial word chain \[ "abcd "\] is one of the longest word chains.
\[ "abcd ", "dbqca "\] is not a valid word chain because the ordering of the letters is changed.
**Constraints:**
* `1 <= words.length <= 1000`
* `1 <= words[i].length <= 16`
* `words[i]` only consists of lowercase English letters. | null |
easisest python solution, beats 87/93% | height-checker | 0 | 1 | \n# Code\n```\nclass Solution:\n def heightChecker(self, heights: List[int]) -> int:\n h = sorted(heights)\n ans = 0\n for i in range(0, len(heights)):\n if h[i] != heights[i]:\n ans += 1\n return ans\n``` | 1 | A school is trying to take an annual photo of all the students. The students are asked to stand in a single file line in **non-decreasing order** by height. Let this ordering be represented by the integer array `expected` where `expected[i]` is the expected height of the `ith` student in line.
You are given an integer array `heights` representing the **current order** that the students are standing in. Each `heights[i]` is the height of the `ith` student in line (**0-indexed**).
Return _the **number of indices** where_ `heights[i] != expected[i]`.
**Example 1:**
**Input:** heights = \[1,1,4,2,1,3\]
**Output:** 3
**Explanation:**
heights: \[1,1,4,2,1,3\]
expected: \[1,1,1,2,3,4\]
Indices 2, 4, and 5 do not match.
**Example 2:**
**Input:** heights = \[5,1,2,3,4\]
**Output:** 5
**Explanation:**
heights: \[5,1,2,3,4\]
expected: \[1,2,3,4,5\]
All indices do not match.
**Example 3:**
**Input:** heights = \[1,2,3,4,5\]
**Output:** 0
**Explanation:**
heights: \[1,2,3,4,5\]
expected: \[1,2,3,4,5\]
All indices match.
**Constraints:**
* `1 <= heights.length <= 100`
* `1 <= heights[i] <= 100` | Which conditions have to been met in order to be impossible to form the target string? If there exists a character in the target string which doesn't exist in the source string then it will be impossible to form the target string. Assuming we are in the case which is possible to form the target string, how can we assure the minimum number of used subsequences of source? For each used subsequence try to match the leftmost character of the current subsequence with the leftmost character of the target string, if they match then erase both character otherwise erase just the subsequence character whenever the current subsequence gets empty, reset it to a new copy of subsequence and increment the count, do this until the target sequence gets empty. Finally return the count. |
Python simple and easy to understand code. Faster than 92.67% 39ms runtime | height-checker | 0 | 1 | \n# Approach\n<!-- Describe your approach to solving the problem. -->\nsimply sort heights in increasing order and store in expected, then use list comprehension for get a list when heights[i] != expected[i], after that just return the length of that list.\n\n\n# Code\n```\nclass Solution:\n def heightChecker(self, heights: List[int]) -> int:\n expected = sorted(heights)\n l = len(expected)\n lst = [i for i in range(l) if heights[i]!=expected[i]]\n return (len(lst))\n``` | 4 | A school is trying to take an annual photo of all the students. The students are asked to stand in a single file line in **non-decreasing order** by height. Let this ordering be represented by the integer array `expected` where `expected[i]` is the expected height of the `ith` student in line.
You are given an integer array `heights` representing the **current order** that the students are standing in. Each `heights[i]` is the height of the `ith` student in line (**0-indexed**).
Return _the **number of indices** where_ `heights[i] != expected[i]`.
**Example 1:**
**Input:** heights = \[1,1,4,2,1,3\]
**Output:** 3
**Explanation:**
heights: \[1,1,4,2,1,3\]
expected: \[1,1,1,2,3,4\]
Indices 2, 4, and 5 do not match.
**Example 2:**
**Input:** heights = \[5,1,2,3,4\]
**Output:** 5
**Explanation:**
heights: \[5,1,2,3,4\]
expected: \[1,2,3,4,5\]
All indices do not match.
**Example 3:**
**Input:** heights = \[1,2,3,4,5\]
**Output:** 0
**Explanation:**
heights: \[1,2,3,4,5\]
expected: \[1,2,3,4,5\]
All indices match.
**Constraints:**
* `1 <= heights.length <= 100`
* `1 <= heights[i] <= 100` | Which conditions have to been met in order to be impossible to form the target string? If there exists a character in the target string which doesn't exist in the source string then it will be impossible to form the target string. Assuming we are in the case which is possible to form the target string, how can we assure the minimum number of used subsequences of source? For each used subsequence try to match the leftmost character of the current subsequence with the leftmost character of the target string, if they match then erase both character otherwise erase just the subsequence character whenever the current subsequence gets empty, reset it to a new copy of subsequence and increment the count, do this until the target sequence gets empty. Finally return the count. |
Python | Sort | Faster than 98.86% | height-checker | 0 | 1 | The idea here is to sort the given array and then compare the sorted array with the given array. \n\n```\nclass Solution:\n def heightChecker(self, heights: List[int]) -> int:\n sort_heights = sorted(heights)\n return sum([0 if heights[i] == sort_heights[i] else 1 for i in range(len(heights))])\n```\n\n\n\nPlease upvote if you like my solution. Thanks!\n | 10 | A school is trying to take an annual photo of all the students. The students are asked to stand in a single file line in **non-decreasing order** by height. Let this ordering be represented by the integer array `expected` where `expected[i]` is the expected height of the `ith` student in line.
You are given an integer array `heights` representing the **current order** that the students are standing in. Each `heights[i]` is the height of the `ith` student in line (**0-indexed**).
Return _the **number of indices** where_ `heights[i] != expected[i]`.
**Example 1:**
**Input:** heights = \[1,1,4,2,1,3\]
**Output:** 3
**Explanation:**
heights: \[1,1,4,2,1,3\]
expected: \[1,1,1,2,3,4\]
Indices 2, 4, and 5 do not match.
**Example 2:**
**Input:** heights = \[5,1,2,3,4\]
**Output:** 5
**Explanation:**
heights: \[5,1,2,3,4\]
expected: \[1,2,3,4,5\]
All indices do not match.
**Example 3:**
**Input:** heights = \[1,2,3,4,5\]
**Output:** 0
**Explanation:**
heights: \[1,2,3,4,5\]
expected: \[1,2,3,4,5\]
All indices match.
**Constraints:**
* `1 <= heights.length <= 100`
* `1 <= heights[i] <= 100` | Which conditions have to been met in order to be impossible to form the target string? If there exists a character in the target string which doesn't exist in the source string then it will be impossible to form the target string. Assuming we are in the case which is possible to form the target string, how can we assure the minimum number of used subsequences of source? For each used subsequence try to match the leftmost character of the current subsequence with the leftmost character of the target string, if they match then erase both character otherwise erase just the subsequence character whenever the current subsequence gets empty, reset it to a new copy of subsequence and increment the count, do this until the target sequence gets empty. Finally return the count. |
Python with explanation. Rolling sum. | grumpy-bookstore-owner | 0 | 1 | The way I approached this problem was to split it into 2 smaller problems. \n\nThe first involves counting how many customers are already satisfied, i.e. those where the shopkeeper is not grumpy. I also set any slots with already satisfied customers to 0, so that we will be left with only the currently unsatisfied customers in the list.\n\nFor the second part, the array now only contains customers who will not be satisfied. We are able to make X adjacent times \u201Chappy\u201D, so we want to find the subarray of length X that has the most customers. We can just keep a rolling sum of the last X customers in the array, and then the best solution is the max the rolling sum ever was.\n\nFinally we return the sum of the 2 parts: the customers who were already satisfied, and the maximum number who can be made satisfied by stopping the shop keeper from being grumpy for X time.\n\nNote that both parts can be combined into a single loop, but I felt this way was probably easier for understanding, and both are still ```O(n)``` time. I\'ll shortly include code for how to merge it all together.\n\n```\nclass Solution:\n def maxSatisfied(self, customers: List[int], grumpy: List[int], X: int) -> int:\n \n # Part 1 requires counting how many customers\n # are already satisfied, and removing them\n # from the customer list.\n already_satisfied = 0\n for i in range(len(grumpy)):\n if grumpy[i] == 0: #He\'s happy\n already_satisfied += customers[i]\n customers[i] = 0\n \n # Part 2 requires finding the optinal number\n # of unhappy customers we can make happy.\n best_we_can_make_satisfied = 0\n current_satisfied = 0\n for i, customers_at_time in enumerate(customers):\n current_satisfied += customers_at_time # Add current to rolling total\n if i >= X: # We need to remove some from the rolling total\n current_satisfied -= customers[i - X]\n best_we_can_make_satisfied = max(best_we_can_make_satisfied, current_satisfied)\n \n # The answer is the sum of the solutions for the 2 parts.\n return already_satisfied + best_we_can_make_satisfied\n``` | 153 | There is a bookstore owner that has a store open for `n` minutes. Every minute, some number of customers enter the store. You are given an integer array `customers` of length `n` where `customers[i]` is the number of the customer that enters the store at the start of the `ith` minute and all those customers leave after the end of that minute.
On some minutes, the bookstore owner is grumpy. You are given a binary array grumpy where `grumpy[i]` is `1` if the bookstore owner is grumpy during the `ith` minute, and is `0` otherwise.
When the bookstore owner is grumpy, the customers of that minute are not satisfied, otherwise, they are satisfied.
The bookstore owner knows a secret technique to keep themselves not grumpy for `minutes` consecutive minutes, but can only use it once.
Return _the maximum number of customers that can be satisfied throughout the day_.
**Example 1:**
**Input:** customers = \[1,0,1,2,1,1,7,5\], grumpy = \[0,1,0,1,0,1,0,1\], minutes = 3
**Output:** 16
**Explanation:** The bookstore owner keeps themselves not grumpy for the last 3 minutes.
The maximum number of customers that can be satisfied = 1 + 1 + 1 + 1 + 7 + 5 = 16.
**Example 2:**
**Input:** customers = \[1\], grumpy = \[0\], minutes = 1
**Output:** 1
**Constraints:**
* `n == customers.length == grumpy.length`
* `1 <= minutes <= n <= 2 * 104`
* `0 <= customers[i] <= 1000`
* `grumpy[i]` is either `0` or `1`. | Sort the elements by distance. In case of a tie, sort them by the index of the worker. After that, if there are still ties, sort them by the index of the bike.
Can you do this in less than O(nlogn) time, where n is the total number of pairs between workers and bikes? Loop the sorted elements and match each pair of worker and bike if the given worker and bike where not used. |
Sliding window + Explaination | grumpy-bookstore-owner | 1 | 1 | The code starts by calculating the total number of customers satisfied when the owner is not grumpy.\n\nNext, a sliding window approach is used to iterate through all possible time periods of length "minutes". For each window, the total number of satisfied customers is calculated by subtracting the unsatisfied customers during grumpy periods (gSum) from the current window\'s customer sum (curSum) and adding the previously calculated total number of satisfied customers (totalSum). The maximum number of satisfied customers across all windows is recorded and returned at the end.\n\nThe sliding window technique is efficient because it avoids recalculating the sum of customers for each new window. Instead, it subtracts the departing customer(s) from the current window and adds the arriving customer(s) to the current window. The grumpy period is taken into account by subtracting the unsatisfied customers during grumpy periods from the total customer sum.\n```\nclass Solution {\n public int maxSatisfied(int[] customers, int[] grumpy, int minutes) {\n \n int i=0,j=0,curSum=0,totalSum=0,gSum=0,max=-1;\n for(int k=0;k<customers.length;k++){ // calculate total no of customers satisfied\n if(grumpy[k] == 0) \n totalSum += customers[k];\n }\n\n // you will be maintaining two sum, one is currSum means total sum of window\n // another sum is gSum which means total window sum when owner is not grumpy\n while(j < customers.length){ \n curSum += customers[j]; // \n if(grumpy[j] == 0)\n gSum += customers[j];\n \n //every time you slide the window, update max\n if(j-i+1 == minutes){\n max = Math.max(max,totalSum-gSum+curSum);\n curSum -= customers[i]; // update current window sum\n if(grumpy[i] == 0) //update currenst gSum \n gSum -= customers[i];\n i++;\n }\n j++;\n }\n return max;\n }\n}\n``` | 2 | There is a bookstore owner that has a store open for `n` minutes. Every minute, some number of customers enter the store. You are given an integer array `customers` of length `n` where `customers[i]` is the number of the customer that enters the store at the start of the `ith` minute and all those customers leave after the end of that minute.
On some minutes, the bookstore owner is grumpy. You are given a binary array grumpy where `grumpy[i]` is `1` if the bookstore owner is grumpy during the `ith` minute, and is `0` otherwise.
When the bookstore owner is grumpy, the customers of that minute are not satisfied, otherwise, they are satisfied.
The bookstore owner knows a secret technique to keep themselves not grumpy for `minutes` consecutive minutes, but can only use it once.
Return _the maximum number of customers that can be satisfied throughout the day_.
**Example 1:**
**Input:** customers = \[1,0,1,2,1,1,7,5\], grumpy = \[0,1,0,1,0,1,0,1\], minutes = 3
**Output:** 16
**Explanation:** The bookstore owner keeps themselves not grumpy for the last 3 minutes.
The maximum number of customers that can be satisfied = 1 + 1 + 1 + 1 + 7 + 5 = 16.
**Example 2:**
**Input:** customers = \[1\], grumpy = \[0\], minutes = 1
**Output:** 1
**Constraints:**
* `n == customers.length == grumpy.length`
* `1 <= minutes <= n <= 2 * 104`
* `0 <= customers[i] <= 1000`
* `grumpy[i]` is either `0` or `1`. | Sort the elements by distance. In case of a tie, sort them by the index of the worker. After that, if there are still ties, sort them by the index of the bike.
Can you do this in less than O(nlogn) time, where n is the total number of pairs between workers and bikes? Loop the sorted elements and match each pair of worker and bike if the given worker and bike where not used. |
Python 3 || 6 lines, w/example || T/M: 100% /88% | grumpy-bookstore-owner | 0 | 1 | ```\nclass Solution:\n def maxSatisfied(self, customers: List[int], grumpy: List[int], minutes: int) -> int:\n\n # Example: customers = [1,0,2,7,5]\n # grumpy = [0,1,1,0,1]\n # minutes = 3\n # \n z = list(map(mul, customers, grumpy)) # z = [1*0,0*1,2*1,7*0,5*1] = [0,0,2,0,5]\n\n ans = score = sum(customers) - sum(z[minutes:]) # ans = score = sum([1,0,2,7,5]) - sum([0,5]) = 10\n\n for i in range(len(grumpy) - minutes): # i score ans\n score+= z[i+minutes] - z[i] # \u2013\u2013\u2013 \u2013\u2013\u2013\u2013\u2013\u2013\u2013\u2013\u2013\u2013\u2013 \u2013\u2013\u2013\n ans = max(ans, score) # 10\n # 0 10+0-0 10\n return ans # 1 10+5-0 15 <--return\n```\n[https://leetcode.com/problems/grumpy-bookstore-owner/submissions/1007973320/](http://)\n\nI could be wrong, but I think that time complexity is *O*(*N*) and space complexity is *O*(*N*).\n | 4 | There is a bookstore owner that has a store open for `n` minutes. Every minute, some number of customers enter the store. You are given an integer array `customers` of length `n` where `customers[i]` is the number of the customer that enters the store at the start of the `ith` minute and all those customers leave after the end of that minute.
On some minutes, the bookstore owner is grumpy. You are given a binary array grumpy where `grumpy[i]` is `1` if the bookstore owner is grumpy during the `ith` minute, and is `0` otherwise.
When the bookstore owner is grumpy, the customers of that minute are not satisfied, otherwise, they are satisfied.
The bookstore owner knows a secret technique to keep themselves not grumpy for `minutes` consecutive minutes, but can only use it once.
Return _the maximum number of customers that can be satisfied throughout the day_.
**Example 1:**
**Input:** customers = \[1,0,1,2,1,1,7,5\], grumpy = \[0,1,0,1,0,1,0,1\], minutes = 3
**Output:** 16
**Explanation:** The bookstore owner keeps themselves not grumpy for the last 3 minutes.
The maximum number of customers that can be satisfied = 1 + 1 + 1 + 1 + 7 + 5 = 16.
**Example 2:**
**Input:** customers = \[1\], grumpy = \[0\], minutes = 1
**Output:** 1
**Constraints:**
* `n == customers.length == grumpy.length`
* `1 <= minutes <= n <= 2 * 104`
* `0 <= customers[i] <= 1000`
* `grumpy[i]` is either `0` or `1`. | Sort the elements by distance. In case of a tie, sort them by the index of the worker. After that, if there are still ties, sort them by the index of the bike.
Can you do this in less than O(nlogn) time, where n is the total number of pairs between workers and bikes? Loop the sorted elements and match each pair of worker and bike if the given worker and bike where not used. |
Sliding Window Rolling sum Python 3 | grumpy-bookstore-owner | 0 | 1 | ```\nclass Solution:\n def maxSatisfied(self, customers: List[int], grumpy: List[int], minutes: int) -> int:\n satisfied=0\n n=len(grumpy)\n satisfied=sum([customers[i]*(1-grumpy[i]) for i in range(n)])\n max_satisfied=satisfied\n for i in range(n):\n if grumpy[i]==1: satisfied+=customers[i] \n if i>=minutes:\n if grumpy[i-minutes]==1: satisfied-=customers[i-minutes]\n max_satisfied=max(satisfied,max_satisfied)\n return max_satisfied\n\t\t``` | 2 | There is a bookstore owner that has a store open for `n` minutes. Every minute, some number of customers enter the store. You are given an integer array `customers` of length `n` where `customers[i]` is the number of the customer that enters the store at the start of the `ith` minute and all those customers leave after the end of that minute.
On some minutes, the bookstore owner is grumpy. You are given a binary array grumpy where `grumpy[i]` is `1` if the bookstore owner is grumpy during the `ith` minute, and is `0` otherwise.
When the bookstore owner is grumpy, the customers of that minute are not satisfied, otherwise, they are satisfied.
The bookstore owner knows a secret technique to keep themselves not grumpy for `minutes` consecutive minutes, but can only use it once.
Return _the maximum number of customers that can be satisfied throughout the day_.
**Example 1:**
**Input:** customers = \[1,0,1,2,1,1,7,5\], grumpy = \[0,1,0,1,0,1,0,1\], minutes = 3
**Output:** 16
**Explanation:** The bookstore owner keeps themselves not grumpy for the last 3 minutes.
The maximum number of customers that can be satisfied = 1 + 1 + 1 + 1 + 7 + 5 = 16.
**Example 2:**
**Input:** customers = \[1\], grumpy = \[0\], minutes = 1
**Output:** 1
**Constraints:**
* `n == customers.length == grumpy.length`
* `1 <= minutes <= n <= 2 * 104`
* `0 <= customers[i] <= 1000`
* `grumpy[i]` is either `0` or `1`. | Sort the elements by distance. In case of a tie, sort them by the index of the worker. After that, if there are still ties, sort them by the index of the bike.
Can you do this in less than O(nlogn) time, where n is the total number of pairs between workers and bikes? Loop the sorted elements and match each pair of worker and bike if the given worker and bike where not used. |
AC readable Python, 9 lines | grumpy-bookstore-owner | 0 | 1 | ```\ndef maxSatisfied(self, customers: List[int], grumpy: List[int], X: int) -> int:\n\tm = s = tmp = 0\n\tfor i in range(len(customers)):\n\t\tif not grumpy[i]: \n\t\t\ts += customers[i] # sum of satisfied customers\n\t\t\tcustomers[i] = 0 \n\t\telse: tmp += customers[i] # sum of grumpy customers \n\t\tif i>=X: tmp -= customers[i-X] # remove the leftmost element to keep the sliding window with # of X\n\t\tm = max(m, tmp) # max # of satisfied grumpy customers with a secret technique\n\treturn s+m\n``` | 12 | There is a bookstore owner that has a store open for `n` minutes. Every minute, some number of customers enter the store. You are given an integer array `customers` of length `n` where `customers[i]` is the number of the customer that enters the store at the start of the `ith` minute and all those customers leave after the end of that minute.
On some minutes, the bookstore owner is grumpy. You are given a binary array grumpy where `grumpy[i]` is `1` if the bookstore owner is grumpy during the `ith` minute, and is `0` otherwise.
When the bookstore owner is grumpy, the customers of that minute are not satisfied, otherwise, they are satisfied.
The bookstore owner knows a secret technique to keep themselves not grumpy for `minutes` consecutive minutes, but can only use it once.
Return _the maximum number of customers that can be satisfied throughout the day_.
**Example 1:**
**Input:** customers = \[1,0,1,2,1,1,7,5\], grumpy = \[0,1,0,1,0,1,0,1\], minutes = 3
**Output:** 16
**Explanation:** The bookstore owner keeps themselves not grumpy for the last 3 minutes.
The maximum number of customers that can be satisfied = 1 + 1 + 1 + 1 + 7 + 5 = 16.
**Example 2:**
**Input:** customers = \[1\], grumpy = \[0\], minutes = 1
**Output:** 1
**Constraints:**
* `n == customers.length == grumpy.length`
* `1 <= minutes <= n <= 2 * 104`
* `0 <= customers[i] <= 1000`
* `grumpy[i]` is either `0` or `1`. | Sort the elements by distance. In case of a tie, sort them by the index of the worker. After that, if there are still ties, sort them by the index of the bike.
Can you do this in less than O(nlogn) time, where n is the total number of pairs between workers and bikes? Loop the sorted elements and match each pair of worker and bike if the given worker and bike where not used. |
PYTHON SOL | GREEDY | WELL EXPLAINED | SIMPLE | EFFICIENT APPROACH | | previous-permutation-with-one-swap | 0 | 1 | # EXPLANATION\n```\nWe need to find the next smaller permutation of arr is exists \n\nSo for this we think greedily i.e. we must replace the index having value x such that there exists a smaller value y having index > index of x and index of x must be as right as possible\n\nWhat I mean is say arr = [3,1,9,3,4,5,6]\nHere 9 is the rightmost number having a number smaller than 9 on its right\n\nBut there are [3,4,5,6] smaller than 9 on its right\nSo we need to think greedy again and we must swap 9 with right most item smaller than 9 on its right i.e. 6 to make arr = [3,1,6,3,4,5,9] \n\n```\n# CODE\n\n```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]: \n n = len(arr)\n for i in range(n-2,-1,-1):\n if arr[i] > arr[i+1]:\n for j in range(n-1,i,-1):\n if arr[j] < arr[i] and (j == i-1 or arr[j] != arr[j-1]):\n arr[i],arr[j] = arr[j],arr[i]\n return arr\n return arr | 2 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
python O(n) time, O(1) space with explanation | previous-permutation-with-one-swap | 0 | 1 | I would suggest doing this question first:\n\n[31. Next Permutation](/https://leetcode.com/problems/next-permutation/ )\n\n[this will help understand what a next permutatin even is](https://www.nayuki.io/page/next-lexicographical-permutation-algorithmttp://)\n\nalso a note about the word "non-decreasing" and why I didn\'t say "increasing". non-decreasing accounts for duplicates. e.g [1, 1, 1, 2] is non-decreasing not increasing.\n\n\nexample:\n\n\t[3, 1, 1, 3]\n \nremember that we want the largest perm that is smaller than the current one. So what is that (forget the algorithm, just what is it?)\n\nwell, if you naively check all possiblites that ignore duplicates(which is O(n! x n) btw):\n\n\t[3, 3, 1, 1]\n\t[1, 1, 3, 3]\n\t[1, 3, 1, 3] -> winner\n\nso to find the largest one that\'s smaller than the current one is to swap the first non-decreasing number (moving from right to left) with the largest number(that\'s smaller than it) to the right of where that lands. (you can see what this means more clearly if you draw a simple graph plotting [3 1 1 3] vs [1 3 1 3]...vs the other possiblites\n\nso:\n\n\t\t r\n\t\t l\n\t3, 1, 1, 3\n\t\n\tour left pointer ends up at 1 (nums[1] < nums[0])\n\tbecause it\'s first non-decreasing comparison we see.\n\tif there was another 3 to the left of it, we would choose the left most of that (skip dups).\n\t\n\t\t\t r\n\t l\n\t\t3, 1, 1, 3\n\n\t\tso k = left - 1 (as the while loop just goes to the number +1 from it)\n\t\twe now need to swap k with the largest number that\'s smaller than nums[k]\n\t\ton the right.\n\n\t\t r\n\t k l\n\t\t3, 1, 1, 3 \n\n\t\t r\n\t k l\n\t\t3, 1, 1, 3\n\t\t\n\t\tfrom right to left:\n\t\t\t3 was >= than nums[k](3) so skip\n\t\t\t1 is a duplciate so skip so we end up at nums[1]\n\n\t\tswap nums[k] with nums[r]\n\t\t\n\t\t\t r\n\t k l\n\t\t1, 3, 1, 3\n\t\t\n\t\nso the code:\n\n\n\tclass Solution:\n\t\t def prevPermOpt1(self, nums: List[int]) -> List[int]:\n\t\t\tn = len(nums)-1\n\t\t\tleft = n\n\n // find first non-decreasing number\n while left >= 0 and nums[left] >= nums[left-1]:\n left -= 1\n \n\t\t// if this hits, it means we have the smallest possible perm \n if left <= 0:\n return nums\n\t\t\n\t\t// the while loop above lands us at +1, so k is the actual value\n k = left - 1\n \n // find the largest number that\'s smaller than k \n // while skipping duplicates\n right = n\n while right >= left:\n if nums[right] < nums[k] and nums[right] != nums[right-1]:\n nums[k], nums[right] = nums[right], nums[k]\n return nums\n \n right -= 1\n \n return nums | 3 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Python3 easy O(N) solution explained | previous-permutation-with-one-swap | 0 | 1 | ```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n # find the first pair of values that is NOT in increasing order\n i = len(arr) - 1\n while i > 0 and arr[i-1] <= arr[i]:\n i -= 1\n if i > 0:\n # if you find such a pair\n # find the largest number to the right of arr[i-1]\n # that is also smaller than arr[i-1]\n k = i\n for j in range(i, len(arr)):\n if arr[i-1] > arr[j] > arr[k]:\n k = j\n # swap the values of arr[i-1] and arr[k]\n arr[i-1], arr[k] = arr[k], arr[i-1]\n return arr\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Python easy sol... | previous-permutation-with-one-swap | 0 | 1 | # Code\n```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n for i in range(len(arr)-1,0,-1):\n if arr[i]<arr[i-1]:\n ind=i-1\n break\n else:\n return arr\n m=ind+1\n for i in range(ind+1,len(arr)):\n if arr[m]<arr[i] and arr[ind]>arr[i]:\n m=i\n arr[m],arr[ind]=arr[ind],arr[m]\n return arr\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
[Python] Greedy + priority queue | previous-permutation-with-one-swap | 0 | 1 | # Intuition\n- Find the last index `i with (0 <= i < arr.length -1)` where `arr[i] > arr[i + 1]` (That mean where the array is not sorted non-decreasinly).\n- Swap it with `max(arr[i + 1 ~ arr.length - 1])` that is less than `arr[i]`.\n\n\n# Code\n```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n n = len(arr)\n pq = [(-arr[-1], n - 1)]\n for i in range(n - 2, -1, -1):\n if arr[i] > arr[i + 1]:\n while pq and -pq[0][0] >= arr[i]:\n heappop(pq)\n _, j = pq[0]\n arr[i], arr[j] = arr[j], arr[i]\n break\n heappush(pq, (-arr[i], i))\n return arr\n\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
PYTHON SOLUTION USING STACK | previous-permutation-with-one-swap | 0 | 1 | ```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n stack=[len(arr)-1]\n for i in range(len(arr)-2,-1,-1):\n if stack and arr[stack[-1]]<arr[i]:\n while stack and arr[stack[-1]]<arr[i]:\n popped_index=stack.pop()\n arr[i],arr[popped_index]=arr[popped_index],arr[i]\n return arr\n else:\n while stack and arr[stack[-1]]==arr[i]:\n stack.pop()\n stack.append(i)\n return arr\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Solution | previous-permutation-with-one-swap | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<int> prevPermOpt1(vector<int>& A) {\n int n = A.size();\n int i = n - 2;\n while (i >= 0 && A[i] <= A[i+1]) i--;\n if (i < 0) return A;\n int j = n - 1;\n while (j > i && A[j] >= A[i]) j--;\n while (A[j] == A[j-1]) j--;\n swap(A[i], A[j]);\n return A;\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n for i in range(len(arr)-2,-1,-1):\n if arr[i] > arr[i+1]:\n j = bisect_right(arr[i+1:], arr[i]-1) + i\n while arr[j] == arr[j-1]: j -= 1\n arr[i], arr[j] = arr[j], arr[i]\n break\n return arr\n```\n\n```Java []\nclass Solution {\n public int[] prevPermOpt1(int[] A) {\n int i = A.length - 2, max_ = -1;\n while(i >= 0 && A[i] <= A[i+1])\n --i;\n if(i >= 0){\n\t\t\tmax_ = i + 1;\n\t\t\tfor(int j=max_ + 1; j < A.length; ++j)\n\t\t\t\tif(A[max_] < A[j] && A[j] < A[i])\n\t\t\t\t\tmax_ = j;\n\t\t\tint temp = A[max_];\n\t\t\tA[max_] = A[i];\n\t\t\tA[i] = temp;\n\t\t}\n return A;\n }\n}\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Fix first violation of ordering | previous-permutation-with-one-swap | 0 | 1 | # Intuition\nThink it as an integer, where each digit can be arbitrary large.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nTo find the predecessor of the given number with ordering constraint, we\'d like to tweak the left digit of first violation from right to left with the rightmost largest that doesn\'t exceed the left digit.\n\nIf we neglect the first violation and fix a higher significant digit, since the left digit are going to be filled with smaller digit, the fixed value is less than optimal since it is smaller at left digit.\n\nSay there are more than one equal right digits, if we didn\'t exchange the last one with last digit, it would end up smaller at the first original right digit.\n\nFinally, if we pick a right digit that is smaller than max., then the exchanged left digit is not largest, which did not satisfy "largest" lexigraphically smaller number. \n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n for i in range(len(arr)-1, 0, -1):\n if arr[i-1] > arr[i]:\n Max = -1\n\n for j in range(i, len(arr)):\n if Max < arr[j] < arr[i-1]:\n pos = j\n Max = arr[j]\n \n arr[i-1], arr[pos] = arr[pos], arr[i-1]\n return arr\n \n return arr\n\n\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
[Python3] 7 - Lines (Beats 100%, Binary Search, O(n+log(n))) | previous-permutation-with-one-swap | 0 | 1 | 1) Find the first decreasing number from the end\n2) Since up to this point all numbers are non-decreasing we can binary search the closest number\n3) If the number repeats, find the left-most one\n# Code\n```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n for i in range(len(arr)-2,-1,-1): # Start from the end\n if arr[i] > arr[i+1]: # Find the first decreasing number\n j = bisect_right(arr, arr[i]-1, i+1) - 1 # Binary search the closest number\n while arr[j] == arr[j-1]: j -= 1 # Find the left-most of repeating numbers\n arr[i], arr[j] = arr[j], arr[i] # Swap\n break\n return arr\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Greedy and Two Pointers | dpm07 | previous-permutation-with-one-swap | 0 | 1 | """\nSImple Strarigy:\n\nif left side of array (last 2 ele are NOT sorted) make them sort,\nif already sorted cycle the array to right ie. big_elememt to last and shift rest accordingly \n"""\n\n\n\n```\n\nclass Solution:\n\t"""\n\tGreedy Algo O(n)\n\n\twe start by finding the largest index i such that arr[i] > arr[i + 1] \n\t(if there is no such index, then the given array is already lexicographically smallest permutation and we return it as is). \n\n\tThen we find the largest index j such that arr[j] < arr[i], and swap arr[i] and arr[j]. \n\tSince we want to make the lexicographically previous permutation with only one swap, \n\n\twe need to make sure that the swap decreases the value of the permutation by the largest amount possible. \n\n\tTo do this, we choose the largest possible j such that arr[j] < arr[i] and j > i, and we make sure that j is as small as possible (i.e., we look for the largest possible j such that arr[j] < arr[i] and j is the smallest possible index with that property). \n\n\tThis is why we include the loop that skips over equal elements at the end.\n\t"""\n\n\tdef prevPermOpt1(self, arr: List[int]) -> List[int]:\n\t\tn = len(arr)\n\t\ti = n - 2\n\n\t\twhile i >= 0 and arr[i] <= arr[i + 1]:\n\t\t\ti -= 1\n\n\t\tif i == -1:\n\t\t\treturn arr\n\n\t\tj = n - 1\n\n\t\twhile arr[j] >= arr[i] or (j > i and arr[j - 1] == arr[j]):\n\t\t\tj -= 1\n\n\t\t# while j > i and arr[j - 1] == arr[j]:\n\t\t# \tj -= 1\n\n\t\tarr[i], arr[j] = arr[j], arr[i]\n\n\t\treturn arr\n\nclass Solution1:\n\t"""\n\tTwo Pointer Solution\n\n\tleft pointer moves towards the left until it finds the first element that is smaller than its previous element\n\n\t`k`:\n\twhich is the index of the element that needs to be swapped with another element to get the previous permutation with one swap.\n\n\t"""\n\n\tdef prevPermOpt1(self, nums: List[int]) -> List[int]:\n\t\tn = len(nums) - 1\n\t\t\n\t\tleft = n\n\n\t\twhile left >= 0 and nums[left] >= nums[left - 1]:\n\t\t\tleft -= 1\n\t\t\n\t\tif left <= 0:\n\t\t\treturn nums\n\t\t\n\t\tk = left - 1\n\t\t\n\t\tright = n\n\t\twhile right >= left:\n\t\t\tif nums[right] < nums[k] and nums[right] != nums[right - 1]:\n\t\t\t\tnums[k], nums[right] = nums[right], nums[k]\n\t\t\t\treturn nums\n\t\t\n\t\t\tright -= 1\n\n\t\treturn nums\n\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Clean Python | High Speed | O(n) time, O(1) space | Beats 98.9% | previous-permutation-with-one-swap | 0 | 1 | # Code\n```\nclass Solution: \n def prevPermOpt1(self, A: List[int]) -> List[int]:\n end_A = [A.pop()]\n length = len(A)\n while A:\n a = A.pop()\n # find if the largest number less than a in end_A\n next_largest = float("-Infinity")\n next_largest_idx = -1\n for i, num in enumerate(end_A):\n if num > next_largest and num < a:\n next_largest = num\n next_largest_idx = i\n if next_largest_idx >= 0:\n return A + [next_largest] + end_A[:next_largest_idx] + [a] + end_A[next_largest_idx+1:]\n \n end_A = [a] + end_A\n return end_A\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
Python 3 step solution, Rise, Replacement and Swap! | previous-permutation-with-one-swap | 0 | 1 | # Intuition\nOnce you have solved next largest permutation, this one would strike immediately\n# Approach\n1) find the last fall as you u traverse from left to right or first rise when traversing from right to left. \n2) Once you got the rise, find the index and value of the next smallest integer to the rise.\n3) swap \n# Complexity\n- Time complexity:\n$$O(N)$$\n- Space complexity:\n$$O(1)$$ i think\n# Code\n```\nclass Solution:\n def prevPermOpt1(self, arr: List[int]) -> List[int]:\n\n for i in range(len(arr)-1,0,-1):\n if arr[i-1] > arr[i]:\n break\n m= [arr[i],i] #found the rise\n\n #now finding the replacement\n for j in range(i,len(arr)):\n if arr[j] < arr[i-1] and arr[j] > m[0]:\n m[0] = arr[j]\n m[1] = j\n \n #Now the Swap\n arr[m[1]] = arr[i-1]\n arr[i-1] = m[0]\n return arr\n``` | 0 | Given an array of positive integers `arr` (not necessarily distinct), return _the_ _lexicographically_ _largest permutation that is smaller than_ `arr`, that can be **made with exactly one swap**. If it cannot be done, then return the same array.
**Note** that a _swap_ exchanges the positions of two numbers `arr[i]` and `arr[j]`
**Example 1:**
**Input:** arr = \[3,2,1\]
**Output:** \[3,1,2\]
**Explanation:** Swapping 2 and 1.
**Example 2:**
**Input:** arr = \[1,1,5\]
**Output:** \[1,1,5\]
**Explanation:** This is already the smallest permutation.
**Example 3:**
**Input:** arr = \[1,9,4,6,7\]
**Output:** \[1,7,4,6,9\]
**Explanation:** Swapping 9 and 7.
**Constraints:**
* `1 <= arr.length <= 104`
* `1 <= arr[i] <= 104` | If we have integer values in the array then we just need to subtract the target those integer values, so we reduced the problem. Similarly if we have non integer values we have two options to put them flor(value) or ceil(value) = floor(value) + 1, so the idea is to just subtract floor(value). Now the problem is different for each position we can sum just add 0 or 1 in order to sum the target, minimizing the deltas. This can be solved with DP. |
82% TC easy python solution | distant-barcodes | 0 | 1 | ```\ndef rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n\tc = Counter(barcodes)\n\theap = []\n\tfor i in c:\n\t\theappush(heap, (-c[i], i))\n\tans = []\n\tprev = -1\n\twhile(heap):\n\t\tcount, t = heappop(heap)\n\t\tif(prev != t):\n\t\t\tans.append(t)\n\t\t\tprev = t\n\t\t\tif(count+1): heappush(heap, (count+1, t))\n\t\telse:\n\t\t\tcount2, t2 = heappop(heap)\n\t\t\tans.append(t2)\n\t\t\tprev = t2\n\t\t\tif(count2+1): heappush(heap, (count2+1, t2))\n\t\t\theappush(heap, (count, t))\n\treturn ans\n``` | 2 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
[Python] Counter & Heap Solution with detailed comments! | distant-barcodes | 0 | 1 | ```python\ndef rearrangeBarcodes(barcodes):\n\n\t# Our result to return\n\tresult = []\n\t\n\t# Get the counts\n\tcounts = collections.Counter(barcodes)\n\t\n\t# Create a max-heap based on count\n\theap = [[-v, k] for k, v in counts.items()]\n\t\n\t# Heapify the heap\n\theapq.heapify(heap)\n\t\n\t# Get the first item\n\titem = heapq.heappop(heap)\n\n\twhile heap:\n\t\tresult.append(item[1])\n\t\titem[0] += 1 # "Decrease" the count (remember our count is negative for min-heap, that\'s why we add)\n\t\t\n\t\t"""\n\t\t\'heapreplace\' will pop the next item onto the heap, then push the old item!\n\t\tIts the secret weapon for this solution.\n\t\tWe heappop if we don\'t want to push \'item\' back onto the heap.\n\t\t"""\n\t\titem = heapq.heapreplace(heap, [item[0], item[-1]]) if item[0] < 0 else heapq.heappop(heap)\n\n\t# Because I do a `heappop` outside of the while loop, we should append the last element!\n\tresult.append(item[1])\n\n\treturn result\n``` | 8 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
[Python] O(n) using Dictionary | distant-barcodes | 0 | 1 | Approach:\nInspired from the method proposed by [rock](https://leetcode.com/problems/distant-barcodes/discuss/300394/JavaPython-3-2-easy-codes-w-comments-O(nlogn)-and-O(n)-respectively.)\n1. Obtain the frequencies of the barcodes\n2. Fill the alternative indices of the result array with the code with maximum frequency\n3. Fill the rest of the result array with the other codes\n\n```\nclass Solution:\n def rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n\t\t# Build the frequency dictionary\n freq_map = collections.defaultdict(int)\n maxFreq = 0\n for code in barcodes:\n freq_map[code] += 1\n if freq_map[code] > freq_map[maxFreq]:\n maxFreq = code\n \n n = len(barcodes)\n idx = 0\n res = [0]*n\n \n\t\t# Fill in the result array with the code with maximum frequency\n idx = 0\n for v in range(freq_map[maxFreq]):\n res[idx] = maxFreq\n idx += 2\n \n del freq_map[maxFreq]\n \n\t\t# Fill the rest of the codes in the result array\n for k,v in freq_map.items():\n for _ in range(v):\n if idx >= n:\n idx = 1\n res[idx] = k\n idx += 2\n \n return res\n```\n\nTime complexity: O(n)\nSpace complexity: O(n) | 9 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
Easy python solution using heap (priority queue) | distant-barcodes | 0 | 1 | # Intuition\nCount the freq of each type of bar and store in a `dict`. next push the items of the dict into a `heap`. finally pop from the max heap and append to an output list. if the popped element is same as the last element of the `output` then pop again and append that element. after popping change the counter to `count-1` and pushback to the heap. repeat until all the barcode has count `0`. \n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(n)\n\n# Code\n```py\nclass Solution:\n def rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n mapper = {} \n for bar in barcodes : \n if bar not in mapper : \n mapper[bar] = 0 \n mapper[bar] += 1 \n\n heap = []\n for val, count in mapper.items() : \n heappush(heap, (-count, val))\n\n output = []\n while heap : \n count, val = heappop(heap)\n if count == 0 : \n continue \n \n if not output : \n output.append(val)\n heappush(heap, (count+1, val))\n \n elif val != output[-1] :\n output.append(val)\n heappush(heap, (count+1, val))\n \n elif val == output[-1] :\n new_count, new_val = heappop(heap)\n output.append(new_val)\n heappush(heap, (new_count+1, new_val))\n heappush(heap, (count, val))\n\n return output\n``` | 0 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
Simpe python3 solution | Heap + Greedy | distant-barcodes | 0 | 1 | # Complexity\n- Time complexity: $$O(n \\cdot \\log(n))$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n``` python3 []\nimport heapq\n\nclass Solution:\n def rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n h = [\n [-cnt, elem]\n for elem, cnt in Counter(barcodes).items()\n ]\n heapq.heapify(h)\n\n result = []\n prev = None\n\n while h:\n cnt_a, a = heapq.heappop(h)\n if a != prev:\n prev = a\n result.append(a)\n if cnt_a != -1:\n heapq.heappush(h, [cnt_a + 1, a])\n else:\n cnt_b, b = heapq.heappop(h)\n prev = b\n result.append(b)\n if cnt_b != -1:\n heapq.heappush(h, [cnt_b + 1, b])\n heapq.heappush(h, [cnt_a, a])\n \n return result\n\n``` | 0 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
Explained in Detail and With Unit Tests | distant-barcodes | 0 | 1 | ## Follow Vaclav Kosar for more software and machine learning at https://vaclavkosar.com/\n\n\n```\nfrom collections import Counter\nfrom heapq import heappush, heappop\nfrom typing import List\n\n\nclass Solution:\n def rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n """\n The barcodes is a list of integer numbers.\n Rearrange the numbers so that no two adjacent numberes are equal.\n Return the solution, which is guaranteed to exist.\n\n\n # Examples Including Edge Cases\n\n >>> check([51,83,51,40,51,40,51,40,83,40,83,83,51,40,40,51,51,51,40,40,40,83,51,51,40,51,51,40,40,51,51,40,51,51,51,40,83,40,40,83,51,51,51,40,40,40,51,51,83,83,40,51,51,40,40,40,51,40,83,40,83,40,83,40,51,51,40,51,51,51,51,40,51,83,51,83,51,51,40,51,40,51,40,51,40,40,51,51,51,40,51,83,51,51,51,40,51,51,40,40])\n\n # In this case, we have to be careful about not being left with some last numbers 8. We have to be able to distribute them in.\n # Example solution: [7, 5, 8, 7, 5, 8, 7, 5, 7, 5]\n >>> check([7, 7, 7, 8, 5, 7, 5, 5, 5, 8])\n\n # This is a simple case.\n # Example solution [1, 2, 1, 2]\n >>> check([1, 1, 2, 2])\n\n # Many 1s Example\n # In this case, we have to make sure that all 1s are separated.\n # Example solution: [1, 2, 1, 2, 1, 3, 1, 3]\n >>> check([1, 1, 1, 1, 2, 2, 3, 3])\n\n\n # This case is complicated for the right order. We have to start with the most common number first.\n # Example solution: [1, 2, 1]\n >>> check([2, 1, 1])\n\n\n # Reasoning about Solution Approaches To Find The Best One Of The Correct Once\n\n It is not possible to do this if there is more than half of one identical number in the array.\n Otherwise, we can simply always be odd-even mixing two different numbers next to each other.\n\n Brute force would be on each new number to iterate across others and try to find non-equal.\n Faster is use some sort or bucketing.\n\n The sort itself with odd from start and even from the end won\'t work,\n because if we have suffient number of items in the middle this strategy will fail.\n For example [1, 1, 2, 2, 2, 3, 3, 3] -> [1, 3, 1, 3, 2, 3, 2, 2]\n\n So instead we need bucketing with counting.\n Count all numbers, then iteratively mix two different buckets, until non are left.\n This will be O(N) time and O(N) space.\n\n A round-robin iteration over the buckets in a round is not enough, because if we have a number that is there many times, it fill fail:\n\n Another approach is to have 2 indexes that are the most common and mix those.\n The two indexes is wrong idea, because if you don\'t prioritize the most common numbers,\n you are not solving the problem recursively and the rules that you expect stop holding.\n In this case you may be using less common numbers first, and end up with some numbers left without ability to mix them.\n You could remix ditribute them back to the existing result, because those were not used at the beginning, but it is complex.\n\n The correct approach is to make sure we are using up the most common numbers at all times.\n We can do that with keeping sort with a heap.\n We mix them in even-odd making sure we never append the same numbers.\n\n Inspiration: https://leetcode.com/problems/distant-barcodes/solutions/2497111/82-tc-easy-python-solution/\n\n\n # Risks\n\n Not using all the numbers.\n The two indexes could conflict in various way. They must not use the same counter, they must not overflow.\n Pushing back to sorted heap too early, making impossible to find the second most common number.\n """\n\n # Count the numbers into a counter dictionary.\n counter = Counter(barcodes)\n heap = []\n for i in counter:\n # insert sorted from the highest count to the lowest\n heappush(heap, (-counter[i], i))\n\n result = []\n previously_appended_result_number = -1\n while heap:\n # Get the currently most common number.\n negative_count_1, number_1 = heappop(heap)\n\n # Check if we pushed this the most common number just previously.\n if previously_appended_result_number != number_1:\n\n # Append to the result and remember the last number.\n result.append(number_1)\n previously_appended_result_number = number_1\n\n # If there is count left, sort it back to the sorted heap.\n if negative_count_1 + 1:\n heappush(heap, (negative_count_1 + 1, number_1))\n\n else:\n # Get the second most common number instead.\n negative_count_2, number_2 = heappop(heap)\n\n # Append to the result and remember the last number.\n result.append(number_2)\n previously_appended_result_number = number_2\n\n # If there is count left, sort it back to the sorted heap.\n if negative_count_2 + 1:\n heappush(heap, (negative_count_2 + 1, number_2))\n\n # Return the most common number back to sorted heap, making it the most common again.\n heappush(heap, (negative_count_1, number_1))\n\n return result\n\n\ndef check(barcodes: List[int]):\n solution = Solution().rearrangeBarcodes(barcodes)\n assert list(sorted(solution)) == list(sorted(barcodes))\n previous = None\n for n in solution:\n if previous is not None:\n assert n != previous\n\n previous = n\n\n return None\n\n``` | 0 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
✅heap solution || Python | distant-barcodes | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n d={}\n for i in barcodes:\n d[i]=d.get(i,0)+1\n l=[]\n for a,b in d.items():\n l.append([-1*b,a])\n heapify(l)\n # print(l)\n ans=[]\n while(len(ans)!=len(barcodes)):\n a,b=l[0]\n heappop(l)\n # print(l)\n f=0\n if(len(l)>0):\n f=1\n c,d=l[0]\n heappop(l)\n ans.append(b)\n if(f):ans.append(d)\n a+=1\n if(f):c+=1\n if(a!=0):heappush(l,[a,b])\n if(f and c!=0):heappush(l,[c,d])\n return ans\n``` | 0 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
[Python3] Good enough | distant-barcodes | 0 | 1 | ``` Python3 []\nclass Solution:\n def rearrangeBarcodes(self, barcodes: List[int]) -> List[int]:\n mapping = Counter(barcodes)\n heap = []\n\n for k,v in mapping.items():\n heapq.heappush(heap, (-v, k))\n \n final = []\n\n while heap:\n temp = None\n if final and final[-1]==heap[0][1]:\n temp = heapq.heappop(heap)\n\n pop = heapq.heappop(heap)\n final.append(pop[1])\n if pop[0]!=-1:\n heapq.heappush(heap, (pop[0]+1,pop[1]))\n\n if temp:\n heapq.heappush(heap, temp)\n\n return final\n``` | 0 | In a warehouse, there is a row of barcodes, where the `ith` barcode is `barcodes[i]`.
Rearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists.
**Example 1:**
**Input:** barcodes = \[1,1,1,2,2,2\]
**Output:** \[2,1,2,1,2,1\]
**Example 2:**
**Input:** barcodes = \[1,1,1,1,2,2,3,3\]
**Output:** \[1,3,1,3,1,2,1,2\]
**Constraints:**
* `1 <= barcodes.length <= 10000`
* `1 <= barcodes[i] <= 10000` | A binary number plus its complement will equal 111....111 in binary. Also, N = 0 is a corner case. |
Simple Python Solution with explanation 🔥 || beats 96.5% | lexicographically-smallest-equivalent-string | 0 | 1 | # Approach\n\n* Create two maps `char_group` and `char_map` to track characters which are equivalent:\n \n \n\n `char_group` is a map of groups of characters which are equivalent, eg: \'a\', \'d\', \'e\' are equivalent with group_id as 0.\n\n \n 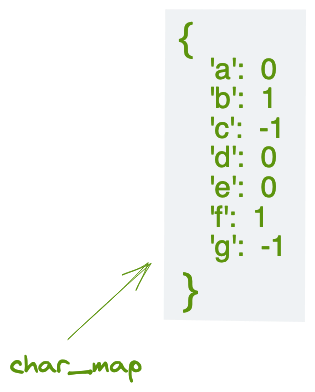\n\n `char_map`: is a map of characters to the equivalent group it belongs, eg: \'a\', \'d\', \'e\' belong to group_id 0. If the character doesn\'t belong to any group, the default value is -1.\n\n* Sort `char_group` lexicographically (since we need only the smallest lexicographic character, we can optimise this by selecting only the smallest character).\n\n* For `basestr` for each character check using `char_map` which equivalent group the character belongs to and select the smallest lexicographic character (0th index since we have sorted this).\n\n\n# Complexity\n`n` => len(s1)\n`m` => len(baseStr)\n\n- Time complexity:\n$$O(m + n*26 + 26*26)$$ => $$O(m + n)$$\n\n- Space complexity:\n$$O(m + (26 + 26*26))$$ => $$O(m))$$\n\n `char_map` and `char_group` are considered constant since `char_map` and `char_group` can have 26 max keys, and for each key in `char_group` it can have value of list of max 26 members\n\n# Code\n``` python []\nclass Solution:\n def smallestEquivalentString(self, s1: str, s2: str, baseStr: str) -> str:\n char_group = {}\n idx = 0\n char_map = {chr(97 + i): -1 for i in range(26)}\n\n for i in range(len(s1)):\n if s1[i] == s2[i]:\n continue\n\n if char_map[s1[i]] == -1 and char_map[s2[i]] == -1:\n char_map[s1[i]] = char_map[s2[i]] = idx\n char_group[idx] = [s2[i], s1[i]]\n idx += 1\n elif char_map[s1[i]] == -1:\n char_map[s1[i]] = char_map[s2[i]]\n char_group[char_map[s2[i]]].append(s1[i])\n elif char_map[s2[i]] == -1:\n char_map[s2[i]] = char_map[s1[i]]\n char_group[char_map[s1[i]]].append(s2[i])\n elif char_map[s1[i]] != char_map[s2[i]]:\n for c in char_group[char_map[s2[i]]]:\n char_map[c] = char_map[s1[i]]\n char_group[char_map[s1[i]]].append(c)\n\n # sort each group\n for k in char_group.keys():\n char_group[k].sort()\n\n ans = ""\n for c in baseStr:\n if char_map[c] == -1:\n ans += c\n else:\n ans += char_group[char_map[c]][0]\n\n return ans\n\n\n``` | 8 | You are given two strings of the same length `s1` and `s2` and a string `baseStr`.
We say `s1[i]` and `s2[i]` are equivalent characters.
* For example, if `s1 = "abc "` and `s2 = "cde "`, then we have `'a' == 'c'`, `'b' == 'd'`, and `'c' == 'e'`.
Equivalent characters follow the usual rules of any equivalence relation:
* **Reflexivity:** `'a' == 'a'`.
* **Symmetry:** `'a' == 'b'` implies `'b' == 'a'`.
* **Transitivity:** `'a' == 'b'` and `'b' == 'c'` implies `'a' == 'c'`.
For example, given the equivalency information from `s1 = "abc "` and `s2 = "cde "`, `"acd "` and `"aab "` are equivalent strings of `baseStr = "eed "`, and `"aab "` is the lexicographically smallest equivalent string of `baseStr`.
Return _the lexicographically smallest equivalent string of_ `baseStr` _by using the equivalency information from_ `s1` _and_ `s2`.
**Example 1:**
**Input:** s1 = "parker ", s2 = "morris ", baseStr = "parser "
**Output:** "makkek "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[m,p\], \[a,o\], \[k,r,s\], \[e,i\].
The characters in each group are equivalent and sorted in lexicographical order.
So the answer is "makkek ".
**Example 2:**
**Input:** s1 = "hello ", s2 = "world ", baseStr = "hold "
**Output:** "hdld "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[h,w\], \[d,e,o\], \[l,r\].
So only the second letter 'o' in baseStr is changed to 'd', the answer is "hdld ".
**Example 3:**
**Input:** s1 = "leetcode ", s2 = "programs ", baseStr = "sourcecode "
**Output:** "aauaaaaada "
**Explanation:** We group the equivalent characters in s1 and s2 as \[a,o,e,r,s,c\], \[l,p\], \[g,t\] and \[d,m\], thus all letters in baseStr except 'u' and 'd' are transformed to 'a', the answer is "aauaaaaada ".
**Constraints:**
* `1 <= s1.length, s2.length, baseStr <= 1000`
* `s1.length == s2.length`
* `s1`, `s2`, and `baseStr` consist of lowercase English letters. | Given a data structure that answers queries of the type to find the minimum in a range of an array (Range minimum query (RMQ) sparse table) in O(1) time. How can you solve this problem? For each starting index do a binary search with an RMQ to find the ending possible position. |
MOST OPTIMIZED PYTHON SOLUTION || CLASS BASED STRUCTURE | lexicographically-smallest-equivalent-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Disjoint:\n def __init__(self,n):\n self.size=[1]*n\n self.parent=[i for i in range(n)]\n\n def findUPar(self,node):\n if node==self.parent[node]:\n return node\n self.parent[node]=self.findUPar(self.parent[node])\n return self.parent[node]\n\n def union(self,u,v):\n ulp_u=self.findUPar(u)\n ulp_v=self.findUPar(v)\n if ulp_u==ulp_v:\n return\n if ulp_u<ulp_v:\n self.parent[ulp_v]=ulp_u\n elif ulp_u>ulp_v:\n self.parent[ulp_u]=ulp_v\n \n\nclass Solution:\n def smallestEquivalentString(self, s1: str, s2: str, baseStr: str) -> str:\n disjoint=Disjoint(26)\n n=len(s1)\n for i in range(n):\n # print(s1[i],s2[i],ord(s1[i])-97,ord(s2[i])-97)\n disjoint.union(ord(s1[i])-97,ord(s2[i])-97)\n \n st=""\n for i in range(26):\n disjoint.findUPar(i)\n # print(disjoint.parent)\n\n for i in baseStr:\n x=disjoint.findUPar(ord(i)-97)\n st+=chr(x+97)\n return st\n``` | 5 | You are given two strings of the same length `s1` and `s2` and a string `baseStr`.
We say `s1[i]` and `s2[i]` are equivalent characters.
* For example, if `s1 = "abc "` and `s2 = "cde "`, then we have `'a' == 'c'`, `'b' == 'd'`, and `'c' == 'e'`.
Equivalent characters follow the usual rules of any equivalence relation:
* **Reflexivity:** `'a' == 'a'`.
* **Symmetry:** `'a' == 'b'` implies `'b' == 'a'`.
* **Transitivity:** `'a' == 'b'` and `'b' == 'c'` implies `'a' == 'c'`.
For example, given the equivalency information from `s1 = "abc "` and `s2 = "cde "`, `"acd "` and `"aab "` are equivalent strings of `baseStr = "eed "`, and `"aab "` is the lexicographically smallest equivalent string of `baseStr`.
Return _the lexicographically smallest equivalent string of_ `baseStr` _by using the equivalency information from_ `s1` _and_ `s2`.
**Example 1:**
**Input:** s1 = "parker ", s2 = "morris ", baseStr = "parser "
**Output:** "makkek "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[m,p\], \[a,o\], \[k,r,s\], \[e,i\].
The characters in each group are equivalent and sorted in lexicographical order.
So the answer is "makkek ".
**Example 2:**
**Input:** s1 = "hello ", s2 = "world ", baseStr = "hold "
**Output:** "hdld "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[h,w\], \[d,e,o\], \[l,r\].
So only the second letter 'o' in baseStr is changed to 'd', the answer is "hdld ".
**Example 3:**
**Input:** s1 = "leetcode ", s2 = "programs ", baseStr = "sourcecode "
**Output:** "aauaaaaada "
**Explanation:** We group the equivalent characters in s1 and s2 as \[a,o,e,r,s,c\], \[l,p\], \[g,t\] and \[d,m\], thus all letters in baseStr except 'u' and 'd' are transformed to 'a', the answer is "aauaaaaada ".
**Constraints:**
* `1 <= s1.length, s2.length, baseStr <= 1000`
* `s1.length == s2.length`
* `s1`, `s2`, and `baseStr` consist of lowercase English letters. | Given a data structure that answers queries of the type to find the minimum in a range of an array (Range minimum query (RMQ) sparse table) in O(1) time. How can you solve this problem? For each starting index do a binary search with an RMQ to find the ending possible position. |
Python3 Simple Depth-First Search | lexicographically-smallest-equivalent-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis is obviously an undirected graph question at first glance, so we will connect the characters first. Also, to avoid repeating search when constructing smallest ```baseStr```, we will find the smallest character for each character first and store them inside a dictionary ```smallest```. We will use DFS to traverse the adjacent characters.\n\nHow do we do that? We can iterate from \'a\' to \'z\' using an iterator, lets say ```i``` and if ```i``` is in the graph, then set the smallest character for all the adjacent characters to ```i```. This works because we iterate the characters in ascending order. Thus, the adjacent nodes will be set to the smallest character in the relationship\n\n# Code\n```\nclass Solution:\n def smallestEquivalentString(self, s1: str, s2: str, baseStr: str) -> str:\n equiv = defaultdict(set)\n smallest = defaultdict(str)\n\n for c1, c2 in zip(s1, s2):\n if c1 == c2: continue\n equiv[c1].add(c2)\n equiv[c2].add(c1)\n \n def setMinChar(curr, minCh):\n if curr in smallest: return\n smallest[curr] = minCh\n for eq in equiv[curr]:\n setMinChar(eq, minCh)\n\n for c in [chr(ord(\'a\') + i) for i in range(26)]:\n if c in equiv:\n if c in smallest: continue\n setMinChar(c, c)\n return \'\'.join([smallest[c] if c in smallest else c for c in baseStr])\n``` | 7 | You are given two strings of the same length `s1` and `s2` and a string `baseStr`.
We say `s1[i]` and `s2[i]` are equivalent characters.
* For example, if `s1 = "abc "` and `s2 = "cde "`, then we have `'a' == 'c'`, `'b' == 'd'`, and `'c' == 'e'`.
Equivalent characters follow the usual rules of any equivalence relation:
* **Reflexivity:** `'a' == 'a'`.
* **Symmetry:** `'a' == 'b'` implies `'b' == 'a'`.
* **Transitivity:** `'a' == 'b'` and `'b' == 'c'` implies `'a' == 'c'`.
For example, given the equivalency information from `s1 = "abc "` and `s2 = "cde "`, `"acd "` and `"aab "` are equivalent strings of `baseStr = "eed "`, and `"aab "` is the lexicographically smallest equivalent string of `baseStr`.
Return _the lexicographically smallest equivalent string of_ `baseStr` _by using the equivalency information from_ `s1` _and_ `s2`.
**Example 1:**
**Input:** s1 = "parker ", s2 = "morris ", baseStr = "parser "
**Output:** "makkek "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[m,p\], \[a,o\], \[k,r,s\], \[e,i\].
The characters in each group are equivalent and sorted in lexicographical order.
So the answer is "makkek ".
**Example 2:**
**Input:** s1 = "hello ", s2 = "world ", baseStr = "hold "
**Output:** "hdld "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[h,w\], \[d,e,o\], \[l,r\].
So only the second letter 'o' in baseStr is changed to 'd', the answer is "hdld ".
**Example 3:**
**Input:** s1 = "leetcode ", s2 = "programs ", baseStr = "sourcecode "
**Output:** "aauaaaaada "
**Explanation:** We group the equivalent characters in s1 and s2 as \[a,o,e,r,s,c\], \[l,p\], \[g,t\] and \[d,m\], thus all letters in baseStr except 'u' and 'd' are transformed to 'a', the answer is "aauaaaaada ".
**Constraints:**
* `1 <= s1.length, s2.length, baseStr <= 1000`
* `s1.length == s2.length`
* `s1`, `s2`, and `baseStr` consist of lowercase English letters. | Given a data structure that answers queries of the type to find the minimum in a range of an array (Range minimum query (RMQ) sparse table) in O(1) time. How can you solve this problem? For each starting index do a binary search with an RMQ to find the ending possible position. |
Python | Union Find | Easy and Simple Solution | lexicographically-smallest-equivalent-string | 0 | 1 | \n# Code\n```\nfrom collections import defaultdict\nclass Solution:\n def smallestEquivalentString(self, s1: str, s2: str, baseStr: str) -> str:\n parent = defaultdict(str)\n for c in \'abcdefghijklmnopqrstuvwxyz\':\n parent[c] = c \n def find(v):\n if parent[v] != v:\n parent[v] = find(parent[v])\n return parent[v]\n def union(v,w):\n pv, pw = find(v), find(w)\n if pv < pw:\n parent[pw] = pv\n else:\n parent[pv] = pw \n for v, w in zip(s1, s2):\n union(v, w)\n res = []\n for c in baseStr:\n res.append(find(c))\n return "".join(res)\n``` | 2 | You are given two strings of the same length `s1` and `s2` and a string `baseStr`.
We say `s1[i]` and `s2[i]` are equivalent characters.
* For example, if `s1 = "abc "` and `s2 = "cde "`, then we have `'a' == 'c'`, `'b' == 'd'`, and `'c' == 'e'`.
Equivalent characters follow the usual rules of any equivalence relation:
* **Reflexivity:** `'a' == 'a'`.
* **Symmetry:** `'a' == 'b'` implies `'b' == 'a'`.
* **Transitivity:** `'a' == 'b'` and `'b' == 'c'` implies `'a' == 'c'`.
For example, given the equivalency information from `s1 = "abc "` and `s2 = "cde "`, `"acd "` and `"aab "` are equivalent strings of `baseStr = "eed "`, and `"aab "` is the lexicographically smallest equivalent string of `baseStr`.
Return _the lexicographically smallest equivalent string of_ `baseStr` _by using the equivalency information from_ `s1` _and_ `s2`.
**Example 1:**
**Input:** s1 = "parker ", s2 = "morris ", baseStr = "parser "
**Output:** "makkek "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[m,p\], \[a,o\], \[k,r,s\], \[e,i\].
The characters in each group are equivalent and sorted in lexicographical order.
So the answer is "makkek ".
**Example 2:**
**Input:** s1 = "hello ", s2 = "world ", baseStr = "hold "
**Output:** "hdld "
**Explanation:** Based on the equivalency information in s1 and s2, we can group their characters as \[h,w\], \[d,e,o\], \[l,r\].
So only the second letter 'o' in baseStr is changed to 'd', the answer is "hdld ".
**Example 3:**
**Input:** s1 = "leetcode ", s2 = "programs ", baseStr = "sourcecode "
**Output:** "aauaaaaada "
**Explanation:** We group the equivalent characters in s1 and s2 as \[a,o,e,r,s,c\], \[l,p\], \[g,t\] and \[d,m\], thus all letters in baseStr except 'u' and 'd' are transformed to 'a', the answer is "aauaaaaada ".
**Constraints:**
* `1 <= s1.length, s2.length, baseStr <= 1000`
* `s1.length == s2.length`
* `s1`, `s2`, and `baseStr` consist of lowercase English letters. | Given a data structure that answers queries of the type to find the minimum in a range of an array (Range minimum query (RMQ) sparse table) in O(1) time. How can you solve this problem? For each starting index do a binary search with an RMQ to find the ending possible position. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.