
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Unpredicted Logic Python | substrings-of-size-three-with-distinct-characters | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countGoodSubstrings(self, s: str) -> int:\n count=0\n for i in range(len(s)-2):\n if len(set(s[i:(i+3)]))==3:\n count+=1\n return count\n``` | 3 | You are given a binary string `binary`. A **subsequence** of `binary` is considered **good** if it is **not empty** and has **no leading zeros** (with the exception of `"0 "`).
Find the number of **unique good subsequences** of `binary`.
* For example, if `binary = "001 "`, then all the **good** subsequences are `[ "0 ", "0 ", "1 "]`, so the **unique** good subsequences are `"0 "` and `"1 "`. Note that subsequences `"00 "`, `"01 "`, and `"001 "` are not good because they have leading zeros.
Return _the number of **unique good subsequences** of_ `binary`. Since the answer may be very large, return it **modulo** `109 + 7`.
A **subsequence** is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
**Example 1:**
**Input:** binary = "001 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "0 ", "0 ", "1 "\].
The unique good subsequences are "0 " and "1 ".
**Example 2:**
**Input:** binary = "11 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "1 ", "1 ", "11 "\].
The unique good subsequences are "1 " and "11 ".
**Example 3:**
**Input:** binary = "101 "
**Output:** 5
**Explanation:** The good subsequences of binary are \[ "1 ", "0 ", "1 ", "10 ", "11 ", "101 "\].
The unique good subsequences are "0 ", "1 ", "10 ", "11 ", and "101 ".
**Constraints:**
* `1 <= binary.length <= 105`
* `binary` consists of only `'0'`s and `'1'`s. | Try using a set to find out the number of distinct characters in a substring. |
Python 3 Simple and linear time. | substrings-of-size-three-with-distinct-characters | 0 | 1 | Iterative over string and increase the counter if all characters of length 3 string are different.\n\n```\n def countGoodSubstrings(self, s: str) -> int:\n ans=0\n for i in range(len(s)-2):\n if len(set(s[i:i+3]))==3:\n ans+=1\n return ans\n``` | 32 | A string is **good** if there are no repeated characters.
Given a string `s`, return _the number of **good substrings** of length **three** in_ `s`.
Note that if there are multiple occurrences of the same substring, every occurrence should be counted.
A **substring** is a contiguous sequence of characters in a string.
**Example 1:**
**Input:** s = "xyzzaz "
**Output:** 1
**Explanation:** There are 4 substrings of size 3: "xyz ", "yzz ", "zza ", and "zaz ".
The only good substring of length 3 is "xyz ".
**Example 2:**
**Input:** s = "aababcabc "
**Output:** 4
**Explanation:** There are 7 substrings of size 3: "aab ", "aba ", "bab ", "abc ", "bca ", "cab ", and "abc ".
The good substrings are "abc ", "bca ", "cab ", and "abc ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters. | Set each water cell to be 0. The height of each cell is limited by its closest water cell. Perform a multi-source BFS with all the water cells as sources. |
Python 3 Simple and linear time. | substrings-of-size-three-with-distinct-characters | 0 | 1 | Iterative over string and increase the counter if all characters of length 3 string are different.\n\n```\n def countGoodSubstrings(self, s: str) -> int:\n ans=0\n for i in range(len(s)-2):\n if len(set(s[i:i+3]))==3:\n ans+=1\n return ans\n``` | 32 | You are given a binary string `binary`. A **subsequence** of `binary` is considered **good** if it is **not empty** and has **no leading zeros** (with the exception of `"0 "`).
Find the number of **unique good subsequences** of `binary`.
* For example, if `binary = "001 "`, then all the **good** subsequences are `[ "0 ", "0 ", "1 "]`, so the **unique** good subsequences are `"0 "` and `"1 "`. Note that subsequences `"00 "`, `"01 "`, and `"001 "` are not good because they have leading zeros.
Return _the number of **unique good subsequences** of_ `binary`. Since the answer may be very large, return it **modulo** `109 + 7`.
A **subsequence** is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
**Example 1:**
**Input:** binary = "001 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "0 ", "0 ", "1 "\].
The unique good subsequences are "0 " and "1 ".
**Example 2:**
**Input:** binary = "11 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "1 ", "1 ", "11 "\].
The unique good subsequences are "1 " and "11 ".
**Example 3:**
**Input:** binary = "101 "
**Output:** 5
**Explanation:** The good subsequences of binary are \[ "1 ", "0 ", "1 ", "10 ", "11 ", "101 "\].
The unique good subsequences are "0 ", "1 ", "10 ", "11 ", and "101 ".
**Constraints:**
* `1 <= binary.length <= 105`
* `binary` consists of only `'0'`s and `'1'`s. | Try using a set to find out the number of distinct characters in a substring. |
Python || Sliding Window || 95.01% Faster || 5 Lines | substrings-of-size-three-with-distinct-characters | 0 | 1 | ```\nclass Solution:\n def countGoodSubstrings(self, s: str) -> int:\n c,n=0,len(s)\n for i in range(n-2):\n t=set(s[i:i+3])\n if len(t)==3:\n c+=1\n return c\n``` | 4 | A string is **good** if there are no repeated characters.
Given a string `s`, return _the number of **good substrings** of length **three** in_ `s`.
Note that if there are multiple occurrences of the same substring, every occurrence should be counted.
A **substring** is a contiguous sequence of characters in a string.
**Example 1:**
**Input:** s = "xyzzaz "
**Output:** 1
**Explanation:** There are 4 substrings of size 3: "xyz ", "yzz ", "zza ", and "zaz ".
The only good substring of length 3 is "xyz ".
**Example 2:**
**Input:** s = "aababcabc "
**Output:** 4
**Explanation:** There are 7 substrings of size 3: "aab ", "aba ", "bab ", "abc ", "bca ", "cab ", and "abc ".
The good substrings are "abc ", "bca ", "cab ", and "abc ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters. | Set each water cell to be 0. The height of each cell is limited by its closest water cell. Perform a multi-source BFS with all the water cells as sources. |
Python || Sliding Window || 95.01% Faster || 5 Lines | substrings-of-size-three-with-distinct-characters | 0 | 1 | ```\nclass Solution:\n def countGoodSubstrings(self, s: str) -> int:\n c,n=0,len(s)\n for i in range(n-2):\n t=set(s[i:i+3])\n if len(t)==3:\n c+=1\n return c\n``` | 4 | You are given a binary string `binary`. A **subsequence** of `binary` is considered **good** if it is **not empty** and has **no leading zeros** (with the exception of `"0 "`).
Find the number of **unique good subsequences** of `binary`.
* For example, if `binary = "001 "`, then all the **good** subsequences are `[ "0 ", "0 ", "1 "]`, so the **unique** good subsequences are `"0 "` and `"1 "`. Note that subsequences `"00 "`, `"01 "`, and `"001 "` are not good because they have leading zeros.
Return _the number of **unique good subsequences** of_ `binary`. Since the answer may be very large, return it **modulo** `109 + 7`.
A **subsequence** is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
**Example 1:**
**Input:** binary = "001 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "0 ", "0 ", "1 "\].
The unique good subsequences are "0 " and "1 ".
**Example 2:**
**Input:** binary = "11 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "1 ", "1 ", "11 "\].
The unique good subsequences are "1 " and "11 ".
**Example 3:**
**Input:** binary = "101 "
**Output:** 5
**Explanation:** The good subsequences of binary are \[ "1 ", "0 ", "1 ", "10 ", "11 ", "101 "\].
The unique good subsequences are "0 ", "1 ", "10 ", "11 ", and "101 ".
**Constraints:**
* `1 <= binary.length <= 105`
* `binary` consists of only `'0'`s and `'1'`s. | Try using a set to find out the number of distinct characters in a substring. |
Python3 Solution | O(N) Time Complexity using sliding window | substrings-of-size-three-with-distinct-characters | 0 | 1 | Approach:\nSlidding Window Technique:\n1. At each ith position slice the string from i to i + 3 and count the letters\n2. If there is a substring with all elements with count one, then the substring will be counted else the substring will be skipped\n3. Then finally return the number of substrings that are good in the given criteria.\n\n```\ndef countGoodSubstrings(self, s: str) -> int:\n\ti = 0\n\tnumberOfSubstring = 0\n\twhile i + 3 <= len(s):\n\t\tfirst3 = s[i:i+3]\n\t\tcountFirst3 = Counter(first3)\n\t\tisOne = True\n\t\tfor letter in countFirst3:\n\t\t\tif countFirst3[letter] != 1:\n\t\t\t\tisOne = False\n\t\tif isOne:\n\t\t\tnumberOfSubstring +=1\n\t\ti +=1\n\treturn numberOfSubstring | 1 | A string is **good** if there are no repeated characters.
Given a string `s`, return _the number of **good substrings** of length **three** in_ `s`.
Note that if there are multiple occurrences of the same substring, every occurrence should be counted.
A **substring** is a contiguous sequence of characters in a string.
**Example 1:**
**Input:** s = "xyzzaz "
**Output:** 1
**Explanation:** There are 4 substrings of size 3: "xyz ", "yzz ", "zza ", and "zaz ".
The only good substring of length 3 is "xyz ".
**Example 2:**
**Input:** s = "aababcabc "
**Output:** 4
**Explanation:** There are 7 substrings of size 3: "aab ", "aba ", "bab ", "abc ", "bca ", "cab ", and "abc ".
The good substrings are "abc ", "bca ", "cab ", and "abc ".
**Constraints:**
* `1 <= s.length <= 100`
* `s` consists of lowercase English letters. | Set each water cell to be 0. The height of each cell is limited by its closest water cell. Perform a multi-source BFS with all the water cells as sources. |
Python3 Solution | O(N) Time Complexity using sliding window | substrings-of-size-three-with-distinct-characters | 0 | 1 | Approach:\nSlidding Window Technique:\n1. At each ith position slice the string from i to i + 3 and count the letters\n2. If there is a substring with all elements with count one, then the substring will be counted else the substring will be skipped\n3. Then finally return the number of substrings that are good in the given criteria.\n\n```\ndef countGoodSubstrings(self, s: str) -> int:\n\ti = 0\n\tnumberOfSubstring = 0\n\twhile i + 3 <= len(s):\n\t\tfirst3 = s[i:i+3]\n\t\tcountFirst3 = Counter(first3)\n\t\tisOne = True\n\t\tfor letter in countFirst3:\n\t\t\tif countFirst3[letter] != 1:\n\t\t\t\tisOne = False\n\t\tif isOne:\n\t\t\tnumberOfSubstring +=1\n\t\ti +=1\n\treturn numberOfSubstring | 1 | You are given a binary string `binary`. A **subsequence** of `binary` is considered **good** if it is **not empty** and has **no leading zeros** (with the exception of `"0 "`).
Find the number of **unique good subsequences** of `binary`.
* For example, if `binary = "001 "`, then all the **good** subsequences are `[ "0 ", "0 ", "1 "]`, so the **unique** good subsequences are `"0 "` and `"1 "`. Note that subsequences `"00 "`, `"01 "`, and `"001 "` are not good because they have leading zeros.
Return _the number of **unique good subsequences** of_ `binary`. Since the answer may be very large, return it **modulo** `109 + 7`.
A **subsequence** is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
**Example 1:**
**Input:** binary = "001 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "0 ", "0 ", "1 "\].
The unique good subsequences are "0 " and "1 ".
**Example 2:**
**Input:** binary = "11 "
**Output:** 2
**Explanation:** The good subsequences of binary are \[ "1 ", "1 ", "11 "\].
The unique good subsequences are "1 " and "11 ".
**Example 3:**
**Input:** binary = "101 "
**Output:** 5
**Explanation:** The good subsequences of binary are \[ "1 ", "0 ", "1 ", "10 ", "11 ", "101 "\].
The unique good subsequences are "0 ", "1 ", "10 ", "11 ", and "101 ".
**Constraints:**
* `1 <= binary.length <= 105`
* `binary` consists of only `'0'`s and `'1'`s. | Try using a set to find out the number of distinct characters in a substring. |
sort & greedy vs Frequency &2 pointers||71 ms Beats 100% | minimize-maximum-pair-sum-in-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nHere are 2 different approaches. \nOne is using sort & greedy; using python 1 line & C++ to implement.\nOther is using frequency & 2 pointers, C & C++ solutions which are really fast & beat 100%.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nSuppose `nums` is sorted, either by `sort` or by frequency counting & 2-pointers.\nChoose the pairs `(nums[0], nums[n-1])`,$\\cdots$,`(nums[i], nums[n-1-i])`,$\\cdots$,`(nums[n/2-1], nums[n/2])`. Take the maximun among them which is the answer.\n\n# Why Gready works in this way?\nOne can prove it by induction on $n=2k$ which is formal. Here is a brief sketch of proof for $k=2, n=4$.\nLet $x_o\\leq x_1\\leq x_2\\leq x_3$. There are 3 different ways to arrange the pairs:\n$$\nL_0:(x_0, x_1), (x_2, x_3) \\to l_0=x_2+x_3 \\\\\nL_1:(x_0, x_2), (x_1, x_3) \\to l_1=\\max(x_0+x_2,x_1+x_3)\\\\\nL_2:(x_0, x_3), (x_1, x_2) \\to l_2=\\max(x_0+x_3,x_1+x_2)\n$$\nOne obtains $l_2\\leq l_1 \\leq l_0.$\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n\\log n)$$ vs $O(n+10^5)=O(n)$\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$O(1)$ vs $O(10^5)=O(1) $\n# 1st approach Python 1 line\n```python []\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n return nums.sort() or max(nums[i]+nums[-1-i] for i in range((len(nums)>>1)+1))\n``` \n```C++ []\n\nclass Solution {\npublic:\n int minPairSum(vector<int>& nums) {\n sort(nums.begin(), nums.end());\n int n=nums.size();\n int maxP=0;\n for(int i=0; i<n/2; i++)\n maxP=max(maxP, nums[i]+nums[n-1-i]);\n return maxP;\n }\n};\n```\n# C++ code using freq & 2 pointers 71 ms Beats 100.00%\n```C++ []\n#pragma GCC optimize("O3")\nclass Solution {\npublic:\n int minPairSum(vector<int>& nums) {\n int freq[100001]={0};\n #pragma unroll\n for(int x: nums )\n freq[x]++;\n int l=0, r=100000, maxP=0, pairN=1, rN=0, lN=0;\n #pragma unroll\n while (l < r) {\n #pragma unroll\n while (lN < pairN) {\n lN += freq[l++];\n }\n #pragma unroll\n while (rN < pairN) {\n rN += freq[r--];\n }\n maxP = max(maxP, l+r);\n pairN++;\n }\n return maxP;\n }\n};\n```\n\n```C []\n#pragma GCC optimize("O3")\n\nint minPairSum(int* nums, int n){\n int freq[100001]={0};\n int l=100000, r=1;\n #pragma unroll\n for(register i=0; i<n; i++){\n int x=nums[i];\n freq[x]++;\n if (l>x) l=x;\n if (r<x) r=x;\n }\n int maxP=0, rN=0, lN=0, k=n>>1;\n #pragma unroll\n for(register int pairN=1; pairN<=k; pairN++){\n #pragma unroll\n while (lN < pairN) lN += freq[l++];\n \n #pragma unroll\n while (rN < pairN) rN += freq[r--];\n if (l+r>maxP) maxP=l+r;\n }\n return maxP;\n}\n```\n\n\n | 11 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
Python [beats 99.59%]sort, split list in half, zip lower half and reversed of upper half, return max | minimize-maximum-pair-sum-in-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nI believe many other posts has covered the general method of how to solve this. the ideas is to pair up the smallest number with the largest, 2nd smallest with 2nd largest and so on.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nsort the list in nlogn time. split the list in half and reverse one of the halved list. merge the list and take the maximum pair sum.\n\nthe key difference here is that we use a zipped list comprehensive for faster speed in python compared to using a for loop.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(nlogn)\nBeats 99.59%\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n\n# Code\n```\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n nums.sort()\n return max([x+y for x,y in zip(nums[:len(nums)//2],nums[len(nums)//2:][::-1])])\n \n``` | 7 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
faster than 92.7 percent of python solutions in one line | minimize-maximum-pair-sum-in-array | 0 | 1 | # Intuition\n\nThe intuition behind this solution is to pair the largest and smallest elements in the sorted array. By doing so, we aim to maximize the sum of pairs.\n\n# Approach\nhis code uses the zip function to pair the smallest and largest numbers in the sorted list of nums. The [::-1] slice reverses the second half of the list so that the largest numbers are paired with the smallest numbers. The max function then returns the maximum sum of each pair.\n# Time complexity:\n\n**"O(nlogn)"**\n\nThe dominant factor is the sorting operation.\n\n# Space complexity:\n\n**O(1)**\n\nThe space complexity is constant as the algorithm uses only a constant amount of extra space.\n\n\n```\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n return max(a + b for a, b in zip(sorted(nums)[:int(len(nums)//2)], sorted(nums)[int(len(nums)/2):][::-1]))\n\n```\n\n\n | 4 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
【Video】Give me u minutes - How we think about a solution | minimize-maximum-pair-sum-in-array | 1 | 1 | # Intuition\nSort input array.\n\n---\n\n# Solution Video\n\nhttps://youtu.be/DzzjWJdhNhI\n\n\u25A0 Timeline of the video\n\n`0:04` Explain how we can solve Minimize Maximum Pair Sum in Array\n`2:21` Check with other pair combinations\n`4:12` Let\'s see another example!\n`5:37` Find Common process of the two examples\n`6:45` Coding\n`7:55` Time Complexity and Space Complexity\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 3,130\nMy first goal is 10,000 (It\'s far from done \uD83D\uDE05)\nThank you for your support!\n\n**My channel reached 3,000 subscribers these days. Thank you so much for your support!**\n\n---\n\n\n# Approach\n\n## How we think about a solution\n\nWe need to meet these two condtion\n\n\n---\n\n1. Each element of nums is in exactly one pair\n2. The maximum pair sum is minimized.\n\n---\n\nLet\'s think about this input\n```\nInput: [63, 71, 12, 80, 38, 21, 92, 15]\n```\nSince we return minimized maximum pair sum, we create minimum pair of each number, then find the minimized maximum pair sum.\n\nLet\'s start with the biggest number.\n\nIf we use `92`, how do you create minimized maximum pair sum? It\'s simple. Just pairing `92` with the smallest number in the input array.\n\n```\n(92, 12) \n\nrest of numbers\n[63, 71, 80, 38, 21, 15]\n```\nThe next biggest number is `80`. how do you create minimized maximum pair sum? We pair `80` with `15`.\n\nThey are pair of the second biggest number and second smallest number.\n```\n(92, 12) \n(80, 15)\n\nrest of numbers\n[63, 71, 38, 21]\n```\nHow about `71`. If we want to create minimized maximum pair sum, we should choose `21` in the rest of numbers.\n```\n(92, 12) \n(80, 15)\n(71, 21)\n\nrest of numbers\n[63, 38]\n```\nThen we pair `63` and `38`\n```\n(92, 12) = 104\n(80, 15) = 95\n(71, 21) = 92\n(63, 38) = 101\n```\nThese 4 numbers are possible minimized maximum pair sum.\n\nAll we have to do is to return maximum value of the 4 pairs.\n\n```\nOutput: 104\n```\n\nWhat if we create `(80, 12)`?\n```\n(80, 12) = 92\n(92, 15) = 107\n(71, 21) = 92\n(63, 38) = 101\n```\nminimum maximum is now `107` which is greater than `104`. This is not answer.\n\nHow about `(92, 80)`? minimum maximum is now `172` which is greater than `104`. This is not answer.\n\n```\n(92, 80) = 172\n(71, 12) = 83\n(63, 15) = 78\n(38, 21) = 59\n```\n\nHow about `(21, 12)`? minimum maximum is now `134` which is greater than `104`. This is not answer.\n\n```\n(21, 12) = 33\n(92, 15) = 107\n(80, 38) = 118\n(71, 63) = 134\n```\nWe have more other patterns but we cannot create minimum maximum number which is less than `104`.\n\n---\n\n\n### Let\'s see other example quickly\n\nLet\'s see simpler example.\n```\nInput: [1, 70, 80, 100]\n```\n\n```\n(100, 1) = 101\n(80, 70) = 150\n```\nminimum maximum is `150`. We swap the numbers.\n```\n(100, 80) = 180\n(1, 70) = 70\n```\nminimum maximum is `180` which is greater than `150`. This is not answer. \n\n```\n(100, 70) = 170\n(80, 1) = 81\n```\nminimum maximum is `170` which is greater than `150`. This is not answer. \n\nThere are 3 more pair combinations but they just reverse of pairs. For example, `(1, 100)` is equal to `(100, 1)`, so let me skip explanation.\n```\nOutput: 150\n```\n\nLook at these answer pair combinations.\n```\n(92, 12) = 104\n(80, 15) = 95\n(71, 21) = 92\n(63, 38) = 101\n```\n```\n(100, 1) = 101\n(80, 70) = 150\n```\nThe common process of these two is that we pair the biggest number and the smallest number at first. Next, we pair the second biggest number and the second smallest number...\n\nThat\'s why, seems like sorting input array is big help to solve this question.\n\nThen we create pairs with current biggest and smallest number and take maximum value of all pairs.\n\n\n---\n\n\u2B50\uFE0F Points\n\nSort input array and create pairs of current biggest and smallest number. Then take maximum number of all pairs.\n\n---\n\nI felt like this question is tricky. but it\'s very straightforward question.\nLet\'s see a real algorithm!\n\n1. **Sort the array:**\n ```python\n nums.sort()\n ```\n Sorts the input array `nums` in ascending order. Sorting is crucial for pairing smaller and larger numbers efficiently.\n\n2. **Initialize variables:**\n ```python\n n = len(nums)\n min_max_sum = 0\n ```\n Sets `n` to the length of the sorted array and initializes `min_max_sum` to 0. `min_max_sum` will keep track of the maximum pair sum as we iterate through the array.\n\n3. **Iterate through pairs:**\n ```python\n for i in range(n // 2):\n min_max_sum = max(min_max_sum, nums[i] + nums[n - 1 - i])\n ```\n Iterates through the first half of the sorted array. For each iteration, calculates the sum of the current pair `(nums[i], nums[n - 1 - i])`. Updates `min_max_sum` to be the maximum of its current value and the calculated sum.\n\n4. **Return the result:**\n ```python\n return min_max_sum\n ```\n After iterating through all possible pairs, returns the final value of `min_max_sum`.\n\n\n# Complexity\n- Time complexity: $$O(n log n)$$\n\n\n- Space complexity: $$O(log n)$$ or $$O(n)$$\n\n Depends on language you use\n\n\n```python []\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n nums.sort()\n\n n = len(nums)\n min_max_sum = 0\n\n for i in range(n // 2):\n min_max_sum = max(min_max_sum, nums[i] + nums[n - 1 - i])\n\n return min_max_sum \n```\n```javascript []\nvar minPairSum = function(nums) {\n nums.sort((a, b) => a - b);\n\n let n = nums.length;\n let minMaxSum = 0;\n\n for (let i = 0; i < n / 2; i++) {\n minMaxSum = Math.max(minMaxSum, nums[i] + nums[n - 1 - i]);\n }\n\n return minMaxSum; \n};\n```\n```java []\nclass Solution {\n public int minPairSum(int[] nums) {\n Arrays.sort(nums);\n\n int n = nums.length;\n int minMaxSum = 0;\n\n for (int i = 0; i < n / 2; i++) {\n minMaxSum = Math.max(minMaxSum, nums[i] + nums[n - 1 - i]);\n }\n\n return minMaxSum; \n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n int minPairSum(vector<int>& nums) {\n sort(nums.begin(), nums.end());\n\n int n = nums.size();\n int minMaxSum = 0;\n\n for (int i = 0; i < n / 2; i++) {\n minMaxSum = max(minMaxSum, nums[i] + nums[n - 1 - i]);\n }\n\n return minMaxSum; \n }\n};\n```\n\n---\n\nThank you for reading my post.\n\u2B50\uFE0F Please upvote it and don\'t forget to subscribe to my channel!\n\n\u25A0 Subscribe URL\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\n\u25A0 Twitter\nhttps://twitter.com/CodingNinjaAZ\n\n### My next daily coding challenge post and video.\n\npost\nhttps://leetcode.com/problems/frequency-of-the-most-frequent-element/solutions/4300895/video-give-me-10-minutes-how-we-think-about-a-solution/\n\nvideo\nhttps://youtu.be/MbCFzt4v1uE\n\n\u25A0 Timeline of the video\n\n`0:00` Read the question of Frequency of the Most Frequent Element\n`1:11` Explain a basic idea to solve Frequency of the Most Frequent Element\n`11:48` Coding\n`14:21` Summarize the algorithm of Frequency of the Most Frequent Element\n\n### My previous daily coding challenge post and video.\n\npost\nhttps://leetcode.com/problems/find-unique-binary-string/solutions/4293749/video-give-me-7-minutes-how-we-think-about-a-solution/\n\nvideo\nhttps://youtu.be/tJ_Eu2S4334\n\n\u25A0 Timeline of the video\n\n`0:04` Explain a key point of the question\n`1:39` Why you need to iterate through input array with len(nums) + 1?\n`2:25` Coding\n`3:56` Explain part of my solution code.\n`3:08` What if we have a lot of the same numbers in input array?\n`6:11` Time Complexity and Space Complexity | 26 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
Python3 Solution | minimize-maximum-pair-sum-in-array | 0 | 1 | \n```\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n nums.sort()\n n=len(nums)\n ans=0\n for idx in range(n):\n ans=max(ans,nums[idx]+nums[n-idx-1])\n return ans \n``` | 3 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
✅☑[C++/Java/Python/JavaScript] || Easy Solution || EXPLAINED🔥 | minimize-maximum-pair-sum-in-array | 1 | 1 | # PLEASE UPVOTE IF IT HELPED\n\n---\n\n\n# Approaches\n**(Also explained in the code)**\n1. **Function Purpose:**\n\n - `minPairSum` function finds the maximum sum obtained by pairing elements from a given vector of integers.\n1. **Sorting:**\n\n - The input vector nums is sorted in non-decreasing order using `sort(nums.begin(), nums.end())`. Sorting is essential to ensure that we pair the smallest and largest elements to get the maximum sum.\n1. **Pointers Initialization:**\n\n - `i` and `j` are initialized to the start and end indices of the sorted vector, respectively.\n1. **Maximum Sum Tracking:**\n\n - `maxi` variable stores the maximum sum found during the traversal of the vector.\n1. **Traversing the Vector:**\n\n - A while loop is used to traverse the sorted vector from both ends (`i` starting from the beginning and `j` starting from the end) simultaneously.\n1. **Pair Sum Calculation:**\n\n - The sum of the pair of elements pointed by `i` and `j` is calculated using `nums[i] + nums[j]`.\n1. **Maximum Sum Update:**\n\n - `maxi` is updated by comparing the current sum with the existing maximum sum using `max()` function.\n1. **Pointer Movement:**\n\n - Pointers `i` and `j` are moved towards each other (`i++` and `j--`) to consider the next pair of elements.\n1. **Return:**\n\n - The function returns the maximum pair sum (`maxi`) found after traversing the entire vector.\n\n\n\n# Complexity\n- *Time complexity:*\n $$O(nlogn)$$\n \n\n- *Space complexity:*\n $$O(logn)$$\n \n\n\n# Code\n```C++ []\n// ---------------------WITH WHILE LOOP-----------------------\n\n\nclass Solution {\npublic:\n // Function to find the minimum pair sum from a given vector of integers\n int minPairSum(vector<int>& nums) {\n // Sorting the input vector in non-decreasing order\n sort(nums.begin(), nums.end());\n \n // Getting the size of the input vector\n int n = nums.size();\n \n // Initializing pointers i and j for traversing from both ends of the sorted vector\n int i = 0, j = n - 1;\n \n // Variable to store the maximum sum found so far\n int maxi = INT_MIN;\n\n // Loop to find the minimum pair sum by traversing the sorted vector\n while (i < j) {\n // Calculating the sum of the pair of elements pointed by i and j\n int sum = nums[i] + nums[j];\n \n // Updating the maximum sum found so far\n maxi = max(sum, maxi);\n \n // Moving pointers to the next pair of elements\n i++;\n j--;\n }\n \n // Returning the maximum pair sum found\n return maxi;\n }\n};\n\n// ---------------------WITH FOR LOOP-----------------------\n\nclass Solution {\npublic:\n int minPairSum(vector<int>& nums) {\n sort(nums.begin(), nums.end());\n \n int maxSum = 0;\n for (int i = 0; i < nums.size() / 2; i++) {\n maxSum = max(maxSum, nums[i] + nums[nums.size() - 1 - i]);\n }\n \n return maxSum;\n }\n};\n\n```\n\n```C []\n\nvoid swap(int *a, int *b) {\n int temp = *a;\n *a = *b;\n *b = temp;\n}\n\n// Function to perform sorting (using selection sort here)\nvoid sort(int arr[], int n) {\n for (int i = 0; i < n - 1; i++) {\n int min_index = i;\n for (int j = i + 1; j < n; j++) {\n if (arr[j] < arr[min_index]) {\n min_index = j;\n }\n }\n swap(&arr[i], &arr[min_index]);\n }\n}\n\n// Function to find the minimum pair sum from a given array of integers\nint minPairSum(int nums[], int n) {\n // Sorting the input array in non-decreasing order\n sort(nums, n);\n \n // Initializing pointers i and j for traversing from both ends of the sorted array\n int i = 0, j = n - 1;\n \n // Variable to store the maximum sum found so far\n int maxi = INT_MIN;\n\n // Loop to find the minimum pair sum by traversing the sorted array\n while (i < j) {\n // Calculating the sum of the pair of elements pointed by i and j\n int sum = nums[i] + nums[j];\n \n // Updating the maximum sum found so far\n maxi = (sum > maxi) ? sum : maxi;\n \n // Moving pointers to the next pair of elements\n i++;\n j--;\n }\n \n // Returning the maximum pair sum found\n return maxi;\n}\n\n\n\n```\n```Java []\n\n\nclass Solution {\n public int minPairSum(int[] nums) {\n // Sorting the input array in non-decreasing order\n Arrays.sort(nums);\n \n // Getting the length of the input array\n int n = nums.length;\n \n // Initializing pointers i and j for traversing from both ends of the sorted array\n int i = 0, j = n - 1;\n \n // Variable to store the maximum sum found so far\n int maxi = Integer.MIN_VALUE;\n\n // Loop to find the minimum pair sum by traversing the sorted array\n while (i < j) {\n // Calculating the sum of the pair of elements pointed by i and j\n int sum = nums[i] + nums[j];\n \n // Updating the maximum sum found so far\n maxi = Math.max(sum, maxi);\n \n // Moving pointers to the next pair of elements\n i++;\n j--;\n }\n \n // Returning the maximum pair sum found\n return maxi;\n }\n}\n\n\n\n```\n```python3 []\nclass Solution:\n def minPairSum(self, nums):\n # Sorting the input list in non-decreasing order\n nums.sort()\n \n # Getting the length of the input list\n n = len(nums)\n \n # Initializing pointers i and j for traversing from both ends of the sorted list\n i, j = 0, n - 1\n \n # Variable to store the maximum sum found so far\n maxi = float(\'-inf\')\n\n # Loop to find the minimum pair sum by traversing the sorted list\n while i < j:\n # Calculating the sum of the pair of elements pointed by i and j\n pair_sum = nums[i] + nums[j]\n \n # Updating the maximum sum found so far\n maxi = max(pair_sum, maxi)\n \n # Moving pointers to the next pair of elements\n i += 1\n j -= 1\n \n # Returning the maximum pair sum found\n return maxi\n\n\n\n```\n```javascript []\nfunction minPairSum(nums) {\n // Sorting the input array in non-decreasing order\n nums.sort((a, b) => a - b);\n \n // Getting the length of the input array\n const n = nums.length;\n \n // Initializing pointers i and j for traversing from both ends of the sorted array\n let i = 0;\n let j = n - 1;\n \n // Variable to store the maximum sum found so far\n let maxi = Number.MIN_SAFE_INTEGER;\n\n // Loop to find the minimum pair sum by traversing the sorted array\n while (i < j) {\n // Calculating the sum of the pair of elements pointed by i and j\n const sum = nums[i] + nums[j];\n \n // Updating the maximum sum found so far\n maxi = Math.max(sum, maxi);\n \n // Moving pointers to the next pair of elements\n i++;\n j--;\n }\n \n // Returning the maximum pair sum found\n return maxi;\n}\n\n\n\n```\n\n---\n\n\n\n# PLEASE UPVOTE IF IT HELPED\n\n---\n---\n\n\n--- | 2 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
Python (Simple Two Pointers) | minimize-maximum-pair-sum-in-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minPairSum(self, nums):\n n, max_val = len(nums), 0\n\n nums.sort()\n\n i,j = 0,n-1\n\n while i<j:\n max_val = max(max_val,nums[i]+nums[j])\n i += 1\n j -= 1\n\n return max_val\n\n \n``` | 2 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
Harmonious Pairing: Unveiling the Summit of Minimized Pairs! 🌈✨ | minimize-maximum-pair-sum-in-array | 0 | 1 | # Intuition\nTo minimize the maximum pair sum, a possible approach is to pair the smallest numbers with the largest numbers. By doing so, the maximum sum would be minimized, as adding smaller numbers to larger ones typically results in smaller total sums.\n\n# Approach\n1. Sort the given array of numbers.\n2. Use two pointers, one starting from the beginning (left pointer) and the other from the end (right pointer) of the sorted array.\n3. While the left pointer is less than the right pointer:\n 1. Calculate the sum of the pair formed by elements at the left and right pointers.\n 2. Update the maximum pair sum by comparing it with the current sum.\n 3. Move the pointers inward (increment the left pointer and decrement the right pointer).\n 4. Return the maximum pair sum found.\n# Complexity\nTime complexity: Sorting the array takes O(n log n) time, where n is the number of elements in the array. The iteration through the sorted array takes linear time, so overall time complexity is O(n log n).\n\nSpace complexity: The space complexity is O(1) since the algorithm uses only a constant amount of extra space for variables like pointers and maximum pair sum storage.\n\n# Code\n``` Python []\nclass Solution(object):\n def minPairSum(self, nums):\n nums.sort() # Sort the array\n left, right = 0, len(nums) - 1\n max_pair_sum = float(\'-inf\')\n\n while left < right:\n pair_sum = nums[left] + nums[right]\n max_pair_sum = max(max_pair_sum, pair_sum)\n left += 1\n right -= 1\n\n return max_pair_sum\n```\n```C++ []\nclass Solution { \npublic:\n int minPairSum(vector<int>& nums) {\n std::sort(nums.begin(), nums.end()); // Sort the array\n\n int left = 0, right = nums.size() - 1;\n int maxPairSum = INT_MIN;\n\n while (left < right) {\n int pairSum = nums[left] + nums[right];\n maxPairSum = std::max(maxPairSum, pairSum);\n left++;\n right--;\n }\n\n return maxPairSum;\n \n }\n};\n```\n``` Python []\nclass Solution(object):\n def minPairSum(self, nums):\n max_num = max(nums)\n min_num = min(nums)\n\n freq = [0] * (max_num - min_num + 1)\n\n for num in nums:\n freq[num - min_num] += 1\n\n left = min_num\n right = max_num\n max_pair_sum = float(\'-inf\')\n\n while left <= right:\n while freq[left - min_num] > 0 and freq[right - min_num] > 0:\n pair_sum = left + right\n max_pair_sum = max(max_pair_sum, pair_sum)\n freq[left - min_num] -= 1\n freq[right - min_num] -= 1\n\n while freq[left - min_num] == 0 and left <= right:\n left += 1\n while freq[right - min_num] == 0 and left <= right:\n right -= 1\n\n return max_pair_sum\n```\n```C++ []\n#include <iostream>\n#include <vector>\n#include <climits>\nusing namespace std;\n\nclass Solution {\npublic:\n int minPairSum(vector<int>& nums) {\n int max_num = INT_MIN;\n int min_num = INT_MAX;\n\n for (int num : nums) {\n max_num = max(max_num, num);\n min_num = min(min_num, num);\n }\n\n vector<int> freq(max_num - min_num + 1, 0);\n\n for (int num : nums) {\n freq[num - min_num]++;\n }\n\n int left = min_num;\n int right = max_num;\n int max_pair_sum = INT_MIN;\n\n while (left <= right) {\n while (freq[left - min_num] > 0 && freq[right - min_num] > 0) {\n int pair_sum = left + right;\n max_pair_sum = max(max_pair_sum, pair_sum);\n freq[left - min_num]--;\n freq[right - min_num]--;\n }\n\n while (freq[left - min_num] == 0 && left <= right) {\n left++;\n }\n while (freq[right - min_num] == 0 && left <= right) {\n right--;\n }\n }\n\n return max_pair_sum;\n }\n};\n```\n | 13 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
OneLine Python3 | minimize-maximum-pair-sum-in-array | 0 | 1 | \n\n# Approach\nThis is my Python solution with one line\n\n# Complexity\n- Time complexity:\nO(n*log(n))\n\n- Space complexity:\nO(1)\n\n# Code\n```\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n return max([l + r for l, r in zip(sorted(nums)[:len(nums)//2], sorted(nums)[-1:len(nums)//2-1:-1])])\n``` | 1 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
😮1-Liner.py🤯 | minimize-maximum-pair-sum-in-array | 0 | 1 | # Intuition\n- something like sorting can hrlp\n\n# Approach\n- 2 -Pointer\n\n# Complexity\n- Time complexity:\n $$O(n)$$ \n\n- Space complexity:\n $$O(1)$$ \n\n# Code\n```py\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n return nums.sort() or max((nums[i]+nums[-(i+1)]) for i in range(len(nums)//2+1))\n```\n\n | 6 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
Python one line | minimize-maximum-pair-sum-in-array | 0 | 1 | ```python []\nclass Solution:\n def minPairSum(self, nums: List[int]) -> int:\n return (x := sorted(nums)) and max(x[-i - 1] + x[i] for i in range(len(x) >> 1))\n\n``` | 7 | The **pair sum** of a pair `(a,b)` is equal to `a + b`. The **maximum pair sum** is the largest **pair sum** in a list of pairs.
* For example, if we have pairs `(1,5)`, `(2,3)`, and `(4,4)`, the **maximum pair sum** would be `max(1+5, 2+3, 4+4) = max(6, 5, 8) = 8`.
Given an array `nums` of **even** length `n`, pair up the elements of `nums` into `n / 2` pairs such that:
* Each element of `nums` is in **exactly one** pair, and
* The **maximum pair sum** is **minimized**.
Return _the minimized **maximum pair sum** after optimally pairing up the elements_.
**Example 1:**
**Input:** nums = \[3,5,2,3\]
**Output:** 7
**Explanation:** The elements can be paired up into pairs (3,3) and (5,2).
The maximum pair sum is max(3+3, 5+2) = max(6, 7) = 7.
**Example 2:**
**Input:** nums = \[3,5,4,2,4,6\]
**Output:** 8
**Explanation:** The elements can be paired up into pairs (3,5), (4,4), and (6,2).
The maximum pair sum is max(3+5, 4+4, 6+2) = max(8, 8, 8) = 8.
**Constraints:**
* `n == nums.length`
* `2 <= n <= 105`
* `n` is **even**.
* `1 <= nums[i] <= 105` | null |
🐍 {python} || 100% faster || well-explained || Simple approach | get-biggest-three-rhombus-sums-in-a-grid | 0 | 1 | Don\'t leave the idea of question and if you want more explaination or any example please feel free to ask !!\n## IDEA :\n\uD83D\uDC49 Firstly we will determine all the four vertices of rhombus.\n\uD83D\uDC49 Then we will pass that rhombus to calc function to calculate the score(perimeter).\n\uD83D\uDC49 "expand" flag is used to determine upto what time rhombus will expand then again it will get shrink.\n\uD83D\uDC49 Store that perimeter in heap\n\uD83D\uDC49 length of heap will always be three\n\uD83D\uDC49 Return heap after sorting in reverse order.\n\n\'\'\'\n\t\n\tclass Solution:\n def getBiggestThree(self, grid: List[List[int]]) -> List[int]:\n \n def calc(l,r,u,d):\n sc=0\n c1=c2=(l+r)//2\n expand=True\n for row in range(u,d+1):\n if c1==c2:\n sc+=grid[row][c1]\n else:\n sc+=grid[row][c1]+grid[row][c2]\n \n if c1==l:\n expand=False\n \n if expand:\n c1-=1\n c2+=1\n else:\n c1+=1\n c2-=1\n return sc\n \n \n m=len(grid)\n n=len(grid[0])\n heap=[]\n for i in range(m):\n for j in range(n):\n l=r=j\n d=i\n while l>=0 and r<=n-1 and d<=m-1:\n sc=calc(l,r,i,d)\n l-=1\n r+=1\n d+=2\n if len(heap)<3:\n if sc not in heap:\n heapq.heappush(heap,sc)\n else:\n if sc not in heap and sc>heap[0]:\n heapq.heappop(heap)\n heapq.heappush(heap,sc)\n \n heap.sort(reverse=True)\n return heap\n\nThank You\nif you liked please **Upvote** !! | 6 | You are given an `m x n` integer matrix `grid`.
A **rhombus sum** is the sum of the elements that form **the** **border** of a regular rhombus shape in `grid`. The rhombus must have the shape of a square rotated 45 degrees with each of the corners centered in a grid cell. Below is an image of four valid rhombus shapes with the corresponding colored cells that should be included in each **rhombus sum**:
Note that the rhombus can have an area of 0, which is depicted by the purple rhombus in the bottom right corner.
Return _the biggest three **distinct rhombus sums** in the_ `grid` _in **descending order**__. If there are less than three distinct values, return all of them_.
**Example 1:**
**Input:** grid = \[\[3,4,5,1,3\],\[3,3,4,2,3\],\[20,30,200,40,10\],\[1,5,5,4,1\],\[4,3,2,2,5\]\]
**Output:** \[228,216,211\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 20 + 3 + 200 + 5 = 228
- Red: 200 + 2 + 10 + 4 = 216
- Green: 5 + 200 + 4 + 2 = 211
**Example 2:**
**Input:** grid = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[20,9,8\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 4 + 2 + 6 + 8 = 20
- Red: 9 (area 0 rhombus in the bottom right corner)
- Green: 8 (area 0 rhombus in the bottom middle)
**Example 3:**
**Input:** grid = \[\[7,7,7\]\]
**Output:** \[7\]
**Explanation:** All three possible rhombus sums are the same, so return \[7\].
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j] <= 105` | Brute force and check if it is possible for a sorted array to start from each position. |
Python - prefixes sums and heap | get-biggest-three-rhombus-sums-in-a-grid | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe basically do lots of addition, so let\'s do some of it ahead of time\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nCreate prefix sums of the diagonals. Keep track of best sums in a heap. For each point in the grid, we create the largest rhombus we can from that point, calculate the sum using the prefixes and add to our heap. If the heap is longer than 3, we pop. Return the sorted heap at the end.\n\n# Complexity\n- Time complexity: O(mn*min(m,n))\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(mn)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport heapq\nclass Solution:\n def getBiggestThree(self, grid: List[List[int]]) -> List[int]:\n n = len(grid)\n m = len(grid[0])\n left_prefix = [[0]*m for _ in range(n)]\n for j in range(m):\n left_prefix[0][j] = grid[0][j]\n for i in range(1, n):\n for j in range(m):\n if j + 1 < m:\n left_prefix[i][j] = grid[i][j] + left_prefix[i-1][j+1]\n else:\n left_prefix[i][j] = grid[i][j]\n\n right_prefix = [[0]*m for _ in range(n)]\n for j in range(m):\n right_prefix[0][j] = grid[0][j]\n for i in range(1, n):\n for j in range(m):\n if j - 1 >= 0:\n right_prefix[i][j] = grid[i][j] + right_prefix[i-1][j-1]\n else:\n right_prefix[i][j] = grid[i][j]\n heap = []\n for i in range(n):\n for j in range(m):\n offset = 0\n while j - offset>= 0 and j + offset < m and i + 2*(offset) < n:\n if offset == 0:\n temp = grid[i][j]\n else:\n temp = left_prefix[i+offset][j-offset] - left_prefix[i][j] + grid[i][j] + right_prefix[i+offset][j+offset] - right_prefix[i][j] + right_prefix[i+2*offset][j]-right_prefix[i+offset][j-offset] + left_prefix[i+2*offset][j] - left_prefix[i+offset][j+offset] - grid[i+2*offset][j]\n if temp not in heap:\n heapq.heappush(heap, temp)\n if len(heap) > 3:\n heapq.heappop(heap)\n offset+=1\n heap.sort(key = lambda x: -x)\n return heap\n\n \n\n``` | 0 | You are given an `m x n` integer matrix `grid`.
A **rhombus sum** is the sum of the elements that form **the** **border** of a regular rhombus shape in `grid`. The rhombus must have the shape of a square rotated 45 degrees with each of the corners centered in a grid cell. Below is an image of four valid rhombus shapes with the corresponding colored cells that should be included in each **rhombus sum**:
Note that the rhombus can have an area of 0, which is depicted by the purple rhombus in the bottom right corner.
Return _the biggest three **distinct rhombus sums** in the_ `grid` _in **descending order**__. If there are less than three distinct values, return all of them_.
**Example 1:**
**Input:** grid = \[\[3,4,5,1,3\],\[3,3,4,2,3\],\[20,30,200,40,10\],\[1,5,5,4,1\],\[4,3,2,2,5\]\]
**Output:** \[228,216,211\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 20 + 3 + 200 + 5 = 228
- Red: 200 + 2 + 10 + 4 = 216
- Green: 5 + 200 + 4 + 2 = 211
**Example 2:**
**Input:** grid = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[20,9,8\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 4 + 2 + 6 + 8 = 20
- Red: 9 (area 0 rhombus in the bottom right corner)
- Green: 8 (area 0 rhombus in the bottom middle)
**Example 3:**
**Input:** grid = \[\[7,7,7\]\]
**Output:** \[7\]
**Explanation:** All three possible rhombus sums are the same, so return \[7\].
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j] <= 105` | Brute force and check if it is possible for a sorted array to start from each position. |
Prefix sum, Python 3, stupid code | get-biggest-three-rhombus-sums-in-a-grid | 0 | 1 | # Intuition\nBrute force.\n\n# Approach\nThis is a space-wasteful implementation, but coding-friendly. See the code below.\n\n# Code\n```\nimport heapq\nclass Solution:\n def getBiggestThree(self, grid: List[List[int]]) -> List[int]:\n ROW, COL = len(grid), len(grid[0])\n # prefix sums in two diagonal directions\n ls1 = {i: [0]*ROW for i in range(0-(COL-1), (ROW-1)-0+1)} # \\, up to bottom, indexed by r-c\n ls2 = {i: [0]*ROW for i in range(0, (ROW-1)+(COL-1)+1)} # /, up to bottom, indexed by r+c\n for r in range(ROW):\n for c in range(COL):\n v = grid[r][c] if r==0 else grid[r][c] + ls1[r-c][r-1]\n ls1[r-c][r] = v\n v = grid[r][c] if r==0 else grid[r][c] + ls2[r+c][r-1]\n ls2[r+c][r] = v\n def rhombusSum(center_r, center_c, size):\n if size == 0:\n return grid[center_r][center_c]\n up = (center_r - size, center_c)\n bottom = (center_r + size, center_c)\n left = (center_r, center_c - size)\n right = (center_r, center_c + size)\n # up\n # o\n # "/": ls2 e4 / \\ e1 "\\": ls1\n # / \\ \n # left o o right\n # \\ / \n # "\\": ls1 e3 \\ / e2 "/": ls2\n # o\n # bottom\n ####################################\n # prefix sum lists for the egdes\n e1 = ls1[up[0] - up[1]]\n e2 = ls2[right[0] + right[1]]\n e3 = ls1[bottom[0] - bottom[1]]\n e4 = ls2[left[0] + left[1]]\n # sum of edges (one edge includes one vertice)\n s = 0\n s += e1[right[0]] - e1[up[0]]\n s += e2[bottom[0]] - e2[right[0]]\n s += (e3[bottom[0]-1] if bottom[0]>=1 else 0) - (e3[left[0]-1] if left[0]>=1 else 0)\n s += (e4[left[0]-1] if left[0]>=1 else 0) - (e4[up[0]-1] if up[0]>=1 else 0)\n return s\n # a heap of fixed size 3\n sums = []\n heapq.heapify(sums)\n seen = set()\n for r in range(ROW):\n for c in range(COL):\n for size in range(min([r, c, ROW-1-r, COL-1-c]) + 1):\n r_sum = rhombusSum(r, c, size)\n if r_sum in seen:\n continue\n seen.add(r_sum)\n heapq.heappush(sums, r_sum)\n if len(sums) > 3:\n _ = heapq.heappop(sums)\n res = []\n while sums:\n res.append(heapq.heappop(sums))\n res.reverse()\n return res\n```\n\n# Complexity\n- Time complexity:\n$$O(n^3)$$\n\n- Space complexity:\n$$O(n^3)$$ | 0 | You are given an `m x n` integer matrix `grid`.
A **rhombus sum** is the sum of the elements that form **the** **border** of a regular rhombus shape in `grid`. The rhombus must have the shape of a square rotated 45 degrees with each of the corners centered in a grid cell. Below is an image of four valid rhombus shapes with the corresponding colored cells that should be included in each **rhombus sum**:
Note that the rhombus can have an area of 0, which is depicted by the purple rhombus in the bottom right corner.
Return _the biggest three **distinct rhombus sums** in the_ `grid` _in **descending order**__. If there are less than three distinct values, return all of them_.
**Example 1:**
**Input:** grid = \[\[3,4,5,1,3\],\[3,3,4,2,3\],\[20,30,200,40,10\],\[1,5,5,4,1\],\[4,3,2,2,5\]\]
**Output:** \[228,216,211\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 20 + 3 + 200 + 5 = 228
- Red: 200 + 2 + 10 + 4 = 216
- Green: 5 + 200 + 4 + 2 = 211
**Example 2:**
**Input:** grid = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[20,9,8\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 4 + 2 + 6 + 8 = 20
- Red: 9 (area 0 rhombus in the bottom right corner)
- Green: 8 (area 0 rhombus in the bottom middle)
**Example 3:**
**Input:** grid = \[\[7,7,7\]\]
**Output:** \[7\]
**Explanation:** All three possible rhombus sums are the same, so return \[7\].
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j] <= 105` | Brute force and check if it is possible for a sorted array to start from each position. |
Python3, clean and commented code, Using Prefix Sum | get-biggest-three-rhombus-sums-in-a-grid | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nMain idea to have a prefix sum in both diagonal directions (left and rigth) for full Grid. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFirst, we will prepare prefix sum arrays for both diagonal directions(left and right), these would further leveraged during calculation of every rhombus boundary cells values sum.\n\nAfter above step, we will iterate over all cells in grid, for each cell we will try to make every possibel rhombus, including that single cell also, and then we will append area of each rhombus in an hashmap(to store only unique values). Here, cretivity is mainly is using prefix sum arrays in calculating boundary sum. \n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nif grid is (m x n)\n$$O(m^2*n)$$\n\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(m^2*n)$$\n\n\n\n# Code\n```\nclass Solution:\n def getBiggestThree(self, grid: List[List[int]]) -> List[int]:\n m = len(grid)\n n = len(grid[0])\n\n all_area = set() \n\n # making diagonal prefix sum\n right_pfsum = [[grid[i][j] for j in range(n)] for i in range(m)]\n left_pfsum = [[grid[i][j] for j in range(n)] for i in range(m)]\n\n # for j in range(n):\n # right_pfsum[0][j] = grid[0][j]\n # left_pfsum[0][j] = grid[0][j]\n \n # for i in range(m):\n # right_pfsum[i][0] = grid[i][0]\n # left_pfsum[i][n-1] = grid[i][n-1]\n \n # populate right prefix sum\n for i in range(1, m):\n for j in range(1, n):\n right_pfsum[i][j] += right_pfsum[i-1][j-1]\n \n for i in range(1, m):\n for j in range(n-2, -1, -1):\n left_pfsum[i][j] += left_pfsum[i-1][j+1]\n\n\n for i in range(m):\n for j in range(n):\n all_area.add(grid[i][j])\n if i <= m-3:\n d = 2\n while(True):\n bottom_x, bottom_y = i+d, j\n if bottom_x >= m:\n break\n\n left_x, left_y = (i + d//2), j-d//2\n right_x, right_y = (i + d//2), j+d//2\n\n if left_y < 0:\n break\n if right_y >= n:\n break\n \n top_right = left_pfsum[i-1][j+1] if (i-1)>=0 and (j+1)<n else 0\n top_left = right_pfsum[i-1][j-1] if (i-1)>=0 and (j-1)>=0 else 0\n\n sum_left = left_pfsum[left_x][left_y] - top_right\n sum_right = right_pfsum[right_x][right_y] - top_left\n\n # right_up = left_pfsum[right_x-1][right_y+1] if (right_x-1)>=0 and (right_y+1)<n else 0\n # left_up = right_pfsum[left_x-1][left_y-1] if (left_x-1)>=0 and (left_y-1)>=0 else 0\n\n b_sum_left = right_pfsum[bottom_x][bottom_y] - right_pfsum[left_x][left_y]\n b_sum_right = left_pfsum[bottom_x][bottom_y] - left_pfsum[right_x][right_y]\n\n t_sum = sum_left + sum_right + b_sum_left + b_sum_right - grid[i][j] - grid[bottom_x][bottom_y]\n all_area.add(t_sum)\n d += 2\n \n all_area = sorted(list(all_area), reverse = True)\n return all_area[:3]\n\n\n \n\n\n\n\n``` | 0 | You are given an `m x n` integer matrix `grid`.
A **rhombus sum** is the sum of the elements that form **the** **border** of a regular rhombus shape in `grid`. The rhombus must have the shape of a square rotated 45 degrees with each of the corners centered in a grid cell. Below is an image of four valid rhombus shapes with the corresponding colored cells that should be included in each **rhombus sum**:
Note that the rhombus can have an area of 0, which is depicted by the purple rhombus in the bottom right corner.
Return _the biggest three **distinct rhombus sums** in the_ `grid` _in **descending order**__. If there are less than three distinct values, return all of them_.
**Example 1:**
**Input:** grid = \[\[3,4,5,1,3\],\[3,3,4,2,3\],\[20,30,200,40,10\],\[1,5,5,4,1\],\[4,3,2,2,5\]\]
**Output:** \[228,216,211\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 20 + 3 + 200 + 5 = 228
- Red: 200 + 2 + 10 + 4 = 216
- Green: 5 + 200 + 4 + 2 = 211
**Example 2:**
**Input:** grid = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[20,9,8\]
**Explanation:** The rhombus shapes for the three biggest distinct rhombus sums are depicted above.
- Blue: 4 + 2 + 6 + 8 = 20
- Red: 9 (area 0 rhombus in the bottom right corner)
- Green: 8 (area 0 rhombus in the bottom middle)
**Example 3:**
**Input:** grid = \[\[7,7,7\]\]
**Output:** \[7\]
**Explanation:** All three possible rhombus sums are the same, so return \[7\].
**Constraints:**
* `m == grid.length`
* `n == grid[i].length`
* `1 <= m, n <= 50`
* `1 <= grid[i][j] <= 105` | Brute force and check if it is possible for a sorted array to start from each position. |
Bit Mask | minimum-xor-sum-of-two-arrays | 1 | 1 | We have a tight constraint here: n <= 14. Thus, we can just try all combinations.\n\nFor each position `i` in the first array, we\'ll try all elements in the second array that haven\'t been chosen before. We can use a bit mask to represent the chosen elements. \n\nTo avoid re-computing the same subproblem, we memoise the result for each bit mask.\n\n> Thanks [LazyCoder16](https://leetcode.com/LazyCoder16) for pointing out that we do not need to memoise for `i`.\n\n**C++**\n```cpp\nint dp[16384] = {[0 ... 16383] = INT_MAX};\nint minimumXORSum(vector<int>& a, vector<int>& b, int i = 0, int mask = 0) {\n if (i >= a.size())\n return 0;\n if (dp[mask] == INT_MAX)\n for (int j = 0; j < b.size(); ++j)\n if (!(mask & (1 << j)))\n dp[mask] = min(dp[mask], (a[i] ^ b[j]) + minimumXORSum(a, b, i + 1, mask + (1 << j)));\n return dp[mask];\n}\n```\n**Java**\n```java\nint dfs(int[] dp, int[] a, int[] b, int i, int mask) {\n if (i >= a.length)\n return 0;\n if (dp[mask] == Integer.MAX_VALUE)\n for (int j = 0; j < b.length; ++j)\n if ((mask & (1 << j)) == 0)\n dp[mask] = Math.min(dp[mask], (a[i] ^ b[j]) + dfs(dp, a, b, i + 1, mask + (1 << j)));\n return dp[mask];\n}\npublic int minimumXORSum(int[] nums1, int[] nums2) {\n int dp[] = new int[1 << nums2.length];\n Arrays.fill(dp, Integer.MAX_VALUE);\n return dfs(dp, nums1, nums2, 0, 0);\n}\n```\n**Python 3**\nNote that here we are inferring `i` by counting bits in `mask`. We can pass `i` as an argument, but it will increase the size of the LRU cache.\n\nThe `min` construction is a courtesy of [lee215](https://leetcode.com/lee215).\n\n> Note that `@cahce` was introduced in Python 3.9, and it\'s a shorthand for `@lru_cache(maxsize=None)`\n\n```python\nclass Solution:\n def minimumXORSum(self, a: List[int], b: List[int]) -> int:\n @cache\n def dp(mask: int) -> int:\n i = bin(mask).count("1")\n if i >= len(a):\n return 0\n return min((a[i] ^ b[j]) + dp(mask + (1 << j)) \n for j in range(len(b)) if mask & (1 << j) == 0)\n return dp(0)\n``` | 109 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Minimum XOR Sum of Two Arrays | minimum-xor-sum-of-two-arrays | 0 | 1 | You are given two integer arrays `nums1` and `nums2` of length n.\n\nThe XOR sum of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1]) (0-indexed)`.\n\nFor example, the XOR sum of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4.`\nRearrange the elements of nums2 such that the resulting XOR sum is minimized.\n\nReturn the XOR sum after the rearrangement.\n\n \n\nExample 1:\n\nInput: `nums1` = [1,2], `nums2` = [2,3]\nOutput: 2\nExplanation: Rearrange nums2 so that it becomes [3,2].\nThe XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.\nExample 2:\n\nInput: nums1 = [1,0,3], nums2 = [5,3,4]\nOutput: 8\nExplanation: Rearrange nums2 so that it becomes [5,4,3]. \nThe XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.\n \n\n# Constraints:\n\nn == nums1.length\nn == nums2.length\n1 <= n <= 14\n0 <= nums1[i], nums2[i] <= 107\n\n# Intuition\nThe intuition behind the minimumXORSum function is to find a permutation of the list b such that the sum of the XOR of a[i] and b[i] is as small as possible. This is a combinatorial optimization problem, and it\u2019s solved using dynamic programming and bit manipulation.\n\nHere\u2019s the intuition step by step:\n\nProblem Understanding: The problem is asking to pair each element in list a with an element in list b such that the sum of the XOR of the pairs is minimized.\n\nBitmasking: To keep track of which elements in b have already been paired, a bitmask is used. Each bit in the mask represents whether an element in b is used or not.\n\nDynamic Programming: The dp function is used to recursively find the optimal pairing. It calculates the XOR of a[i] and b[j] and adds it to the result of the recursive call dp(mask + (1 << j)). It returns the minimum value among these. The @cache decorator is used to memoize the function, reducing the time complexity.\n\nBase Case and Recursive Case: If the number of set bits in the mask is greater than or equal to the length of list a, the function returns 0. This is the base case of the recursion. For each index j in the range of the length of list b, if the j-th bit in the mask is not set, it calculates the XOR of a[i] and b[j] and adds it to the result of the recursive call dp(mask + (1 << j)). It returns the minimum value among these. This is the recursive case.\n\nFinal Result: Finally, the function minimumXORSum calls the dp function with an initial mask of 0 and returns its result. This result is the minimum possible sum of XOR operations between two lists of integers, a and b.\n\nIn essence, this function is trying to find the best way to pair the elements in a and b to minimize the total XOR sum. It uses dynamic programming to avoid redundant calculations and bit manipulation to efficiently track which elements have been used. This is a common approach in combinatorial optimization problems12\n\n# Approach\nThe function uses a technique called dynamic programming with bit masking. The idea is to find a permutation of the list b such that the sum of the XOR of a[i] and b[i] is as small as possible. A bitmask is used to keep track of which elements in b have already been paired. The dp function is used to recursively find the optimal pairing. The @cache decorator is used to memoize the function, reducing the time complexity.\n\n# Complexity\n- Time complexity:\nThe time complexity of this function is `O(n2\u22C52n)`\n\n- Space complexity:\nThe space complexity of this function is `O(2n)`\n due to the memoization. The cache stores a result for each possible state of the mask, which can have 2n\n possible states\n\n\n\n\n# Code\n```\nclass Solution:\n def minimumXORSum(self, a: List[int], b: List[int]) -> int:\n n = len(a)\n precomputed = [[a[i] ^ b[j] for j in range(n)] for i in range(n)]\n @cache\n def dp(mask: int) -> int:\n i = bin(mask).count("1")\n if i >= n:\n return 0\n return min(precomputed[i][j] + dp(mask | (1 << j)) \n for j in range(n) if mask & (1 << j) == 0)\n return dp(0)\n``` | 0 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Polynomial Complexity C++ and Python Faster than 100% Minimum-cost Max-flow problem | minimum-xor-sum-of-two-arrays | 0 | 1 | Source connects to all points in num1 and sink connects to all points in num2 with flow is 1 and weight is 0. This problem is changed into a minimum cost max flow problem. \n\nPolynomial Complexity $O(VElog(V))$, which is $O(n^3log(n))$\n# Code\n# Python\n```\nINF = 10**10\n\nclass Edge:\n def __init__(self, from_vertex: int, to_vertex: int, capacity: int, cost: int, flow: int) -> None:\n self.from_vertex = from_vertex\n self.to_vertex = to_vertex\n self.capacity = capacity\n self.cost = cost\n self.flow = flow\n\nclass MinCostMaxFlow:\n def __init__(self, total_vertices: int, source: int, sink: int):\n self.total_vertices = total_vertices\n self.source = source\n self.sink = sink\n self.edges = []\n self.graph = [[] for _ in range(total_vertices)]\n self.distances = [INF] * total_vertices\n self.flow_values = [0] * total_vertices\n self.previous = [-1] * total_vertices\n\n def add_edge(self, from_vertex: int, to_vertex: int, capacity: int, cost: int) -> None:\n self.edges.append(Edge(from_vertex, to_vertex, capacity, cost, 0))\n self.edges.append(Edge(to_vertex, from_vertex, 0, -cost, 0))\n self.graph[from_vertex].append(len(self.edges) - 2)\n self.graph[to_vertex].append(len(self.edges) - 1)\n\n def find_augmenting_path(self) -> bool:\n self.flow_values = [0] * self.total_vertices\n self.previous = [-1] * self.total_vertices\n self.distances = [INF] * self.total_vertices\n self.distances[self.source] = 0\n self.flow_values[self.source] = INF\n\n priority_queue = [(0, self.source)] # (distance, vertex)\n\n while priority_queue:\n dist_u, u = heappop(priority_queue)\n if dist_u > self.distances[u]: # Ignore outdated distances\n continue\n for edge_index in self.graph[u]:\n edge = self.edges[edge_index]\n v = edge.to_vertex\n if edge.capacity - edge.flow > 0:\n new_distance = self.distances[u] + edge.cost\n if new_distance < self.distances[v]:\n self.distances[v] = new_distance\n self.previous[v] = edge_index\n self.flow_values[v] = min(self.flow_values[u], edge.capacity - edge.flow)\n heappush(priority_queue, (self.distances[v], v))\n\n return self.previous[self.sink] != -1\n\n def compute(self) -> Tuple[int, int]:\n max_flow, min_cost = 0, 0\n while self.find_augmenting_path():\n flow = self.flow_values[self.sink]\n max_flow += flow\n min_cost += flow * self.distances[self.sink]\n current_vertex = self.sink\n while current_vertex != self.source:\n edge_index = self.previous[current_vertex]\n self.edges[edge_index].flow += flow\n self.edges[edge_index ^ 1].flow -= flow\n current_vertex = self.edges[edge_index].from_vertex\n return max_flow, min_cost\n\nclass Solution:\n def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:\n n = len(nums1)\n source = 2 * n\n sink = source + 1\n network = MinCostMaxFlow(2 * n + 2, source, sink)\n \n # Connect source to all vertices in nums1\n for i in range(n):\n network.add_edge(source, i, 1, 0)\n \n # Connect all pairs of vertices between nums1 and nums2 with cost as their XOR value\n for i in range(n):\n for j in range(n):\n cost = nums1[i] ^ nums2[j]\n network.add_edge(i, j + n, 1, cost)\n \n # Connect all vertices in nums2 to sink\n for i in range(n):\n network.add_edge(i + n, sink, 1, 0)\n \n _, min_cost = network.compute()\n return min_cost\n\n```\n# C++ code\n```\nconst int INF = numeric_limits<int>::max();\n\nclass Edge {\npublic:\n int from_vertex, to_vertex, capacity, cost, flow;\n Edge(int from_vertex, int to_vertex, int capacity, int cost, int flow)\n : from_vertex(from_vertex), to_vertex(to_vertex), capacity(capacity), cost(cost), flow(flow) {}\n};\n\nclass MinCostMaxFlow {\nprivate:\n int total_vertices, source, sink;\n vector<Edge> edges;\n vector<vector<int>> graph;\n vector<int> distances, flow_values, previous;\n\npublic:\n MinCostMaxFlow(int total_vertices, int source, int sink)\n : total_vertices(total_vertices), source(source), sink(sink),\n graph(total_vertices), distances(total_vertices, INF),\n flow_values(total_vertices, 0), previous(total_vertices, -1) {}\n\n void add_edge(int from_vertex, int to_vertex, int capacity, int cost) {\n edges.emplace_back(from_vertex, to_vertex, capacity, cost, 0);\n edges.emplace_back(to_vertex, from_vertex, 0, -cost, 0);\n graph[from_vertex].push_back(edges.size() - 2);\n graph[to_vertex].push_back(edges.size() - 1);\n }\n\n bool find_augmenting_path() {\n fill(flow_values.begin(), flow_values.end(), 0);\n fill(previous.begin(), previous.end(), -1);\n fill(distances.begin(), distances.end(), INF);\n distances[source] = 0;\n flow_values[source] = INF;\n\n using pii = pair<int, int>; // (distance, vertex)\n priority_queue<pii, vector<pii>, greater<pii>> priority_queue;\n priority_queue.emplace(0, source);\n\n while (!priority_queue.empty()) {\n int dist_u, u;\n tie(dist_u, u) = priority_queue.top();\n priority_queue.pop();\n if (dist_u > distances[u]) continue;\n for (int edge_index : graph[u]) {\n Edge& edge = edges[edge_index];\n int v = edge.to_vertex;\n if (edge.capacity - edge.flow > 0) {\n int new_distance = distances[u] + edge.cost;\n if (new_distance < distances[v]) {\n distances[v] = new_distance;\n previous[v] = edge_index;\n flow_values[v] = min(flow_values[u], edge.capacity - edge.flow);\n priority_queue.emplace(distances[v], v);\n }\n }\n }\n }\n\n return previous[sink] != -1;\n }\n\n pair<int, int> compute() {\n int max_flow = 0, min_cost = 0;\n while (find_augmenting_path()) {\n int flow = flow_values[sink];\n max_flow += flow;\n min_cost += flow * distances[sink];\n int current_vertex = sink;\n while (current_vertex != source) {\n int edge_index = previous[current_vertex];\n edges[edge_index].flow += flow;\n edges[edge_index ^ 1].flow -= flow;\n current_vertex = edges[edge_index].from_vertex;\n }\n }\n return {max_flow, min_cost};\n }\n};\n\nclass Solution {\npublic:\n int minimumXORSum(vector<int>& nums1, vector<int>& nums2) {\n int n = nums1.size();\n int source = 2 * n;\n int sink = source + 1;\n MinCostMaxFlow network(2 * n + 2, source, sink);\n \n // Connect source to all vertices in nums1\n for (int i = 0; i < n; ++i) {\n network.add_edge(source, i, 1, 0);\n }\n \n // Connect all pairs of vertices between nums1 and nums2 with cost as their XOR value\n for (int i = 0; i < n; ++i) {\n for (int j = 0; j < n; ++j) {\n int cost = nums1[i] ^ nums2[j];\n network.add_edge(i, j + n, 1, cost);\n }\n }\n \n // Connect all vertices in nums2 to sink\n for (int i = 0; i < n; ++i) {\n network.add_edge(i + n, sink, 1, 0);\n }\n \n int _, min_cost;\n tie(_, min_cost) = network.compute();\n return min_cost;\n }\n};\n\n``` | 0 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Python | Bit masking | DP | minimum-xor-sum-of-two-arrays | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import defaultdict\nclass Solution:\n def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:\n\n l=0\n state=0\n for i in nums1:\n state+=2**l\n l+=1\n \n dp=defaultdict(int)\n\n @lru_cache(None)\n def sol(ind,state):\n\n if not state:\n return 0 \n \n elif dp[(ind,state)]:\n return dp[(ind,state)]\n\n ret=1000000000\n for i in range(l):\n if state & 1<<i:\n tt=(nums1[ind] ^ nums2[i]) + sol(ind+1,state ^ 1<<i)\n ret=min(ret,tt)\n dp[(ind,state)]=ret\n return ret\n \n final=sol(0,state)\n return final\n\n``` | 0 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Top Down Recursive | Commented and Explained | minimum-xor-sum-of-two-arrays | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. --> \nSince we only have 14 for the size of the nums, we can do an exhaustive comparison of 14 states to process these overall. This is similar in nature to a backtracking approach, but where instead we simply enumerate all possible states of comparison (2^14). As some results will be repeated, we cache our findings to speed up the process. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nGet length of nums1, which is our overall nums length as numsL \n\nSet up a dynamic processing function with a cache for faster processing \nThe function is passed a sublist of nums2 to consider. When passed in \n- get length of the sublist. If length is 0, return 0. \n- Otherwise, get the nums1 index nums1_i as nums length - nums2 sublist length \n- From this find num1 as nums1 at n1_i \n- build a possible values array \n- loop over n2_i (nums2 indices) in range length of nums2 sub list \n - get the result of xor of num1 with nums2 sublist at n2_i added to the result of a dp call using the current sublist without the n2_ith element\n - append this result to the possible values array \n- return the smallest of the possible values array \n\nTo complete the program, pass *nums2 to dp and return the result of that call. \n\n# Complexity\n- Time complexity : O(N^2)\n - N is the size of our nums lists \n - N is processed over \n - within which, N work is also done \n - Overall is N^2 \n\n- Space complexity : O(N^2)\n - As the processing calls are stored on system stack, O(N^2)\n\n# Code\n```\nclass Solution:\n def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:\n numsL = len(nums1)\n\n # cache results for dp for faster look up \n @cache\n def dp(*nums2_sublist) :\n # get length of current sublist of nums2 \n nums2sL = len(nums2_sublist)\n \n # if length of current is 0 -> at end, return 0 \n if nums2sL == 0 :\n return 0\n\n # otherwise, index in nums1 is length of nums1 minus length of nums2 sub list \n n1_i = numsL - nums2sL\n num1 = nums1[n1_i]\n\n # build over time \n possible_values = []\n # loop in range of the current sublist \n for n2_i in range(nums2sL) : \n # append the calculated xor value for current num1 and the nums2 sublists n2_ith value, then add the dp using list up to not including here\n # with the list from here forwards as the unpacking set subslist to pass to next dp processing \n possible_values.append((num1^nums2_sublist[n2_i]) + dp(*nums2_sublist[:n2_i], *nums2_sublist[n2_i+1:]))\n # at each phase, when done return min of possible values \n return min(possible_values)\n\n # return dp processing nums 2 \n return dp(*nums2)\n``` | 0 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Two fast and very short solutions in Python: DP vs Hungarian | minimum-xor-sum-of-two-arrays | 0 | 1 | # Solution 1: Dynamic Programming with Bitmask\n<!-- Describe your approach to solving the problem. -->\nThis problem can be solved as the classic traveling salesperson problem (TSP), which can be solved in $$O(N^2 2^N)$$ in dynamic programming, faster than the brute-force $$O(N!)$$ backtracking for large $$N$$.\n\nThis solution implemented the algorithm by using memoization and bitmask in a few lines of Python code. The runtime is faster than 75%.\n\n# Complexity\n- Time complexity: $$O(N^2 2^N)$$ \n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(N 2^N)$$ \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:\n @cache\n def dp(i, used):\n if i >= n:\n return 0\n return min(((v ^ nums1[i]) + dp(i+1, used | (1 << j))) \n for j, v in enumerate(nums2) if (1 << j) & used == 0)\n n = len(nums2)\n return dp(0, 0) \n```\n\n# Shorter Version\nIn fact, the DP can also be shorten as one-line as follows. However, the implementation is less efficient than the previous one. \n\n```\nclass Solution:\n def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:\n @cache\n def dp(i, used):\n return min(((v^nums1[i]) + dp(i+1, used | (1 << j))\n for j, v in enumerate(nums2) if (1 << j) & used == 0), default=0)\n return dp(0, 0) \n```\n\n# Soluton 2: Hungarian Method\nThis problem is a classic [assignment_problem](https://en.wikipedia.org/wiki/Assignment_problem) that can be solved with the Hungarian method. The algorithm is difficult to implement but Python users can just call the built-in [scipy.optimize.linear_sum_assignment](https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.optimize.linear_sum_assignment.html) function. Only 3 lines of code have to do, and the runtime is faster than 88%. Happy cheating!\n\n# Complexity: \n* Time Complexity: $$O(N^3)$$\n\n# Code\n```\nimport numpy as np\nfrom scipy.optimize import linear_sum_assignment\n\nclass Solution:\n def minimumXORSum(self, nums1: List[int], nums2: List[int]) -> int:\n cost = np.array([[v ^ u for u in nums2] for v in nums1])\n row_idx, col_idx = linear_sum_assignment(cost)\n return cost[row_idx, col_idx].sum() | 0 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Python (Simple DP + Bitmask) | minimum-xor-sum-of-two-arrays | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minimumXORSum(self, nums1, nums2):\n n = len(nums1)\n\n @lru_cache(None)\n def dfs(i,mask):\n if i == n:\n return 0\n\n total = float("inf")\n\n for j in range(n):\n if mask & (1<<j) == 0:\n total = min(total,(nums1[i]^nums2[j]) + dfs(i+1,(1<<j)|mask))\n\n return total\n\n return dfs(0,0)\n\n\n \n \n\n``` | 0 | You are given two integer arrays `nums1` and `nums2` of length `n`.
The **XOR sum** of the two integer arrays is `(nums1[0] XOR nums2[0]) + (nums1[1] XOR nums2[1]) + ... + (nums1[n - 1] XOR nums2[n - 1])` (**0-indexed**).
* For example, the **XOR sum** of `[1,2,3]` and `[3,2,1]` is equal to `(1 XOR 3) + (2 XOR 2) + (3 XOR 1) = 2 + 0 + 2 = 4`.
Rearrange the elements of `nums2` such that the resulting **XOR sum** is **minimized**.
Return _the **XOR sum** after the rearrangement_.
**Example 1:**
**Input:** nums1 = \[1,2\], nums2 = \[2,3\]
**Output:** 2
**Explanation:** Rearrange `nums2` so that it becomes `[3,2]`.
The XOR sum is (1 XOR 3) + (2 XOR 2) = 2 + 0 = 2.
**Example 2:**
**Input:** nums1 = \[1,0,3\], nums2 = \[5,3,4\]
**Output:** 8
**Explanation:** Rearrange `nums2` so that it becomes `[5,4,3]`.
The XOR sum is (1 XOR 5) + (0 XOR 4) + (3 XOR 3) = 4 + 4 + 0 = 8.
**Constraints:**
* `n == nums1.length`
* `n == nums2.length`
* `1 <= n <= 14`
* `0 <= nums1[i], nums2[i] <= 107` | It's optimal to always remove one stone from the biggest 2 piles Note that the limits are small enough for simulation |
Easy and Clean Python Solution ✔ | check-if-word-equals-summation-of-two-words | 0 | 1 | Python3 Solution\n\n# Code\n```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n x=[\'a\',\'b\',\'c\',\'d\',\'e\',\'f\',\'g\',\'h\',\'i\',\'j\',\'k\',\'l\',\'m\',\'n\',\'o\',\'p\',\'q\',\'r\',\'s\',\'t\',\'u\',\'v\',\'w\',\'x\',\'y\',\'z\']\n a=""\n for i in firstWord:\n a=a+str(x.index(i))\n \n b=""\n for i in secondWord:\n b=b+str(x.index(i))\n\n c=""\n for i in targetWord:\n c=c+str(x.index(i))\n if int(a)+int(b)==int(c):\n return True\n return False\n``` | 1 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Frightening One Liner Python | check-if-word-equals-summation-of-two-words | 0 | 1 | \n\n# Approach\nI\'ve just done useless and hard to read one liner\n\nUpvote if you want to see worse one\n\n**Check it out!!**\n\n*(It\'s just for fun)* \'-\'\n# Code\n```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n return sum([{\'a\':0, \'b\':1, \'c\':2, \'d\':3, \'e\':4, \'f\':5, \'g\':6, \'h\':7, \'i\':8, \'j\':9}[firstWord[i]]*(10**(len(firstWord)-i-1)) for i in range(len(firstWord))]) + sum([{\'a\':0, \'b\':1, \'c\':2, \'d\':3, \'e\':4, \'f\':5, \'g\':6, \'h\':7, \'i\':8, \'j\':9}[secondWord[j]]*(10**(len(secondWord)-j-1)) for j in range(len(secondWord))]) == sum([{\'a\':0, \'b\':1, \'c\':2, \'d\':3, \'e\':4, \'f\':5, \'g\':6, \'h\':7, \'i\':8, \'j\':9}[targetWord[k]]*(10**(len(targetWord)-1-k)) for k in range(len(targetWord))])\n\n``` | 3 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python simple and clean solution | check-if-word-equals-summation-of-two-words | 0 | 1 | **Python :**\n\n```\ndef isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n\tfirstNum, secondNum, targetNum = "", "", ""\n\n\tfor char in firstWord:\n\t\tfirstNum += str(ord(char) - ord(\'a\'))\n\n\tfor char in secondWord:\n\t\tsecondNum += str(ord(char) - ord(\'a\'))\n\n\tfor char in targetWord:\n\t\ttargetNum += str(ord(char) - ord(\'a\'))\n\n\treturn int(firstNum) + int(secondNum) == int(targetNum)\n```\n\n**Like it ? please upvote !** | 11 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Minus 49 | check-if-word-equals-summation-of-two-words | 0 | 1 | Replace letters with corresponding numbers, and then use a standard string-to-number conversion.\n\n> `\'a\' - \'0\' == 49`.\n\n**C++**\n```cpp\nbool isSumEqual(string first, string second, string target) {\n auto op = [](string &s) { for(auto &ch : s) ch -= 49; return s; };\n return stoi(op(first)) + stoi(op(second)) == stoi(op(target));\n}\n```\n\n**Python 3**\n```python\nclass Solution:\n def isSumEqual(self, first: str, second: str, target: str) -> bool:\n def op(s: str): return "".join(chr(ord(ch) - 49) for ch in s)\n return int(op(first)) + int(op(second)) == int(op(target))\n``` | 20 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python Simple Solution | check-if-word-equals-summation-of-two-words | 0 | 1 | \n```\ndef isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n numeric_total = lambda s: int(\'\'.join([str(ord(letter) - ord(\'a\')) for letter in s]))\n return numeric_total(firstWord) + numeric_total(secondWord) == numeric_total(targetWord)\n```\n\nAlternatively, the first line can be made into a separate function that returns the total. | 22 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Check if word equals summation of two words | check-if-word-equals-summation-of-two-words | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n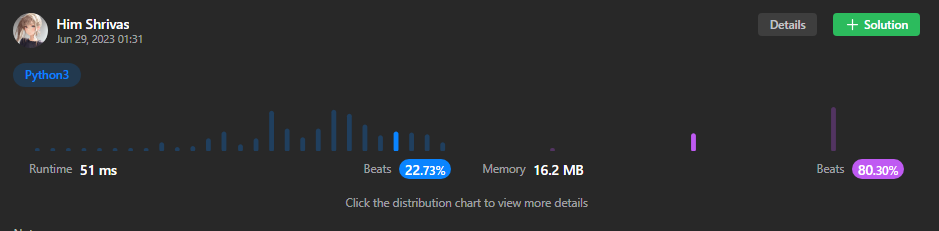\n\n# Code\n```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n count_first=\'\'\n count_sec=\'\'\n count_target=\'\'\n for i in firstWord:\n count_first+=str(ord(i)-97) \n for i in secondWord:\n count_sec+=str(ord(i)-97)\n for i in targetWord:\n count_target+=str(ord(i)-97)\n if int(count_first)+int(count_sec)==int(count_target):\n return True\n return False\n\n``` | 2 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python3 | Time: O(n) | Space: O(1) | Clear. Explanation! | check-if-word-equals-summation-of-two-words | 0 | 1 | # **Solution**\nCreate a dictionary `mapping` that translates a letter into a number.\n\nThe `decoding` function converts a string to a number.\n\n## **How *lambda* works**\nWe use the `lambda` keyword to declare an anonymous function, which is why we refer to them as "lambda functions". An anonymous function refers to a function declared with no name. \n\nThis code:\n```\nlambda i:mapping[i]\n```\n\nEquivalent to this code:\n```\ndef func(i):\n\treturn mapping[i]\n```\n\nYou can read more about anonymous functions at *[this link](https://stackabuse.com/lambda-functions-in-python/)*.\n\n## **How *map* works**\nMap performs the specified function for each item in the list.\n\nExample:\n```\nlist( map(int, [\'1\',\'2\']) ) #[1, 2]\n```\n\n*[More examples.](https://www.tutorialsteacher.com/python/python-map-function)*\n\n## **How *join* works**\nThe `join()` method takes all items in an iterable and joins them into one string.\n```\n\' - \'.join([\'a\',\'b\',\'c\']) # \'a - b - c\'\n```\n\n*[Python Join](https://www.programiz.com/python-programming/methods/string/join)*\n\n## **Code**\n```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n mapping = {\n \'a\':\'0\', \'b\':\'1\', \'c\':\'2\', \'d\':\'3\', \'e\':\'4\', \'f\':\'5\', \'g\':\'6\', \'h\':\'7\', \'i\':\'8\', \'j\':\'9\'\n }\n \n def decoding(s):\n nonlocal mapping\n return int(\'\'.join(list(map((lambda i:mapping[i]),list(s)))))\n \n return decoding(firstWord) + decoding(secondWord) == decoding(targetWord)\n```\n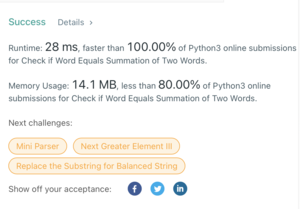\n\n\n | 10 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Easy Python Solution | check-if-word-equals-summation-of-two-words | 0 | 1 | ```\ndef isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n s1=self.helper(firstWord) \n s2=self.helper(secondWord)\n s3=self.helper(targetWord)\n return s1+s2==s3\n \n def helper(self, word):\n s=0\n for i in range(len(word)):\n s=s*10+ord(word[i])-97\n return s\n```\n\nShorter Version:\n```\ndef isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n return (self.helper(firstWord)+self.helper(secondWord)==self.helper(targetWord))\n \n def helper(self, word):\n s=0\n for i in range(len(word)):\n s=s*10+ord(word[i])-97\n return s\n``` | 2 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python solution Faster than >97% of submissions | check-if-word-equals-summation-of-two-words | 0 | 1 | \n\t\tdictm = {\'a\': \'0\', \'b\': \'1\', \'c\': \'2\', \'d\': \'3\', \'e\': \'4\', \'f\': \'5\', \'g\': \'6\', \'h\': \'7\', \'i\': \'8\', \'j\': \'9\'}\n\n s1 = \'\'.join([dictm[i] for i in firstWord])\n s2 = \'\'.join([dictm[i] for i in secondWord])\n s3 = \'\'.join([dictm[i] for i in targetWord])\n\n return (int(s1) + int(s2)) == int(s3)\n | 6 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python3 easy understanding (ord) solution beat 90.30% 25ms | check-if-word-equals-summation-of-two-words | 0 | 1 | \n\n# Complexity\n- Time complexity: O(n) n is the total length of the three input strings.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n) n is the total length of the three input strings.\n<!-- Add your space compl exity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n firstnumval = secondnumval = targetnumval = \'\'\n for i in firstWord: firstnumval += str(ord(i) - 97)\n for i in secondWord: secondnumval += str(ord(i) - 97)\n for i in targetWord: targetnumval += str(ord(i) - 97)\n return int(firstnumval) + int(secondnumval) == int(targetnumval)\n \n\n``` | 2 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python 3 Simple Solution in O(n) | check-if-word-equals-summation-of-two-words | 0 | 1 | **Approach:**\n\nConsider three strings ans, ans1 and ans2 which stores the corresponding values of characters of firstWord, secondWord and targetWord respectively. After converting the strings to integer, just check the difference of ans and ans1 is equal to ans2 or not.\n\n```\ndef isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n ans=""\n ans1=""\n for i in firstWord:\n ans+=str(ord(i)-97)\n for i in secondWord:\n ans1+=str(ord(i)-97)\n ans2=""\n for i in targetWord:\n ans2+=str(ord(i)-97)\n final=int(ans)+int(ans1)\n return int(ans2)==final\n``` | 5 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python || simple using ascii conversion | check-if-word-equals-summation-of-two-words | 0 | 1 | We will convert each letter to its ascii form and them subtract it from ascii value of "a". \nWe store all the values in a list and then concatinate it to form an integer.\nwe will then check if the required condition holds true.\n\nNote: This only works because we know we s[i]<="j" so **(ascii value of s[i] - acii value of "a") is always a single digit.**\n\n```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n a, b, c = [],[],[]\n a_,b_,c_="","",""\n base = ord("a")\n \n def getList(l,s):\n for i in s:\n l.append(ord(i)-base)\n return l\n \n def getString(x,l):\n for i in l:\n x += str(i)\n return x\n \n a = getList(a,firstWord)\n b = getList(b,secondWord)\n c = getList(c,targetWord)\n \n a_ = getString(a_,a)\n b_ = getString(b_,b)\n c_ = getString(c_,c)\n \n return(( int(a_)+int(b_)) == int(c_))\n``` | 4 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Check if Word Equals Summation of Two Words | check-if-word-equals-summation-of-two-words | 0 | 1 | ```\nclass Solution:\n def isSumEqual(self, firstWord: str, secondWord: str, targetWord: str) -> bool:\n wordList = [firstWord, secondWord, targetWord]\n sumList = []\n for word in wordList:\n sumList.append(self.calcSum(word))\n return sumList[0]+sumList[1]==sumList[2]\n def calcSum(self, word):\n s = ""\n for letter in word:\n s+=str(ord(letter)-97)\n return int(s)\n``` | 1 | The **letter value** of a letter is its position in the alphabet **starting from 0** (i.e. `'a' -> 0`, `'b' -> 1`, `'c' -> 2`, etc.).
The **numerical value** of some string of lowercase English letters `s` is the **concatenation** of the **letter values** of each letter in `s`, which is then **converted** into an integer.
* For example, if `s = "acb "`, we concatenate each letter's letter value, resulting in `"021 "`. After converting it, we get `21`.
You are given three strings `firstWord`, `secondWord`, and `targetWord`, each consisting of lowercase English letters `'a'` through `'j'` **inclusive**.
Return `true` _if the **summation** of the **numerical values** of_ `firstWord` _and_ `secondWord` _equals the **numerical value** of_ `targetWord`_, or_ `false` _otherwise._
**Example 1:**
**Input:** firstWord = "acb ", secondWord = "cba ", targetWord = "cdb "
**Output:** true
**Explanation:**
The numerical value of firstWord is "acb " -> "021 " -> 21.
The numerical value of secondWord is "cba " -> "210 " -> 210.
The numerical value of targetWord is "cdb " -> "231 " -> 231.
We return true because 21 + 210 == 231.
**Example 2:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aab "
**Output:** false
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aab " -> "001 " -> 1.
We return false because 0 + 0 != 1.
**Example 3:**
**Input:** firstWord = "aaa ", secondWord = "a ", targetWord = "aaaa "
**Output:** true
**Explanation:**
The numerical value of firstWord is "aaa " -> "000 " -> 0.
The numerical value of secondWord is "a " -> "0 " -> 0.
The numerical value of targetWord is "aaaa " -> "0000 " -> 0.
We return true because 0 + 0 == 0.
**Constraints:**
* `1 <= firstWord.length,` `secondWord.length,` `targetWord.length <= 8`
* `firstWord`, `secondWord`, and `targetWord` consist of lowercase English letters from `'a'` to `'j'` **inclusive**. | Build the result character by character. At each step, you choose a character from one of the two strings. If the next character of the first string is larger than that of the second string, or vice versa, it's optimal to use the larger one. If both are equal, think of a criteria that lets you decide which string to consume the next character from. You should choose the next character from the larger string. |
Python Elegant & Short | Maximize or Minimize | maximum-value-after-insertion | 0 | 1 | # Complexity\n- Time complexity: $$O(n)$$\n- Space complexity: $$O(n)$$\n\n# Code\n```\nclass Solution:\n def maxValue(self, n: str, x: int) -> str:\n x = str(x)\n\n if n.startswith(\'-\'):\n return \'-\' + self.minimize(n[1:], x)\n\n return self.maximize(n, x)\n\n @staticmethod\n def maximize(num: str, x: str) -> str:\n for i, d in enumerate(num):\n if x > d:\n return num[:i] + x + num[i:]\n\n return num + x\n\n @staticmethod\n def minimize(num: str, x: str) -> str:\n for i, d in enumerate(num):\n if x < d:\n return num[:i] + x + num[i:]\n\n return num + x\n\n``` | 2 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
[Python 3] Find insertion position || 93ms | maximum-value-after-insertion | 0 | 1 | ```python3 []\nclass Solution:\n def maxValue(self, n: str, x: int) -> str:\n isNegative, x, L, i = n[0] == \'-\', str(x), len(n), 0\n \n while i < L:\n if not isNegative and x > n[i]: break\n elif isNegative and x < n[i]: break\n i += 1\n \n return n[:i] + x + n[i:]\n``` | 2 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
Python3 Easy understanding | maximum-value-after-insertion | 0 | 1 | \n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maxValue(self, n: str, x: int) -> str:\n if n[0] != "-":\n for i in range(len(n)):\n if int(n[i]) < x:\n return n[:i] + str(x) + n[i:]\n else:\n for i in range(1, len(n)):\n if int(n[i]) > x:\n return n[:i] + str(x) + n[i:]\n return n + str(x)\n``` | 3 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
Python 3 || 12 lines, w/examples || T/M: 100% / 61% | maximum-value-after-insertion | 0 | 1 | ```\nclass Solution:\n def maxValue(self, n: str, x: int) -> str:\n # Example: n = "673", x = 6\n x = str(x) # n = "73", x = "6" \n \n if n[0].isdigit(): # ch\n for ch in n: # \u2013\u2013\u2013\n if ch < x: # "6"\n n = n.replace(ch,x+ch, 1) # "7"\n return n # "3" \u2013\u2013> n = n.replace("3","63", 1)\n # = "6763"\n return n+x\n # Example: n = "-13", x = "4"\n for ch in n[1:]: \n if ch > x: # ch\n n = n.replace(ch,x+ch, 1) # \u2013\u2013\u2013\n return n # "1"\n # "3"\n\n return n+x # \u2013\u2013> n + x = "-134"\n```\n[https://leetcode.com/problems/maximum-value-after-insertion/submissions/939608436/](http://)\n\n\nI could be wrong, but I think that time complexity is *O*(*N*) and space complexity is *O*(*N*).\n | 4 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
75% TC and 98% SC easy python solution | maximum-value-after-insertion | 0 | 1 | ```\ndef maxValue(self, n: str, x: int) -> str:\n\tif(n[0] == "-"):\n\t\ti = 1\n\t\twhile(i < len(n) and int(n[i]) <= x):\n\t\t\ti += 1\n\telse:\n\t\ti = 0\n\t\twhile(i < len(n) and int(n[i]) >= x):\n\t\t\ti += 1\n\treturn n[:i]+str(x)+n[i:]\n``` | 5 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
Python || simple O(N) iteration | maximum-value-after-insertion | 0 | 1 | If the number is greater than 0 we will iterate from index 0 if the target is greater than the current element we will add it before that.\n\nElse if the number is less than 0 we will iterate from index 0 if target is less than the current we will replace add it there.\n\nWe will also keep a flag to check if we have placed the taget number or not if the flag was not striked in the end we will simply add the target number in the end.\n\n```\nclass Solution:\n def maxValue(self, n: str, x: int) -> str:\n if int(n)>0:\n ans = ""\n flag = False\n for i in range(len(n)):\n if int(n[i])>=x:\n ans += n[i]\n else:\n a = n[:i]\n b = n[i:]\n ans = a+str(x)+b\n \n flag = True\n break\n if not flag:\n ans += str(x)\n else:\n n = n[1:]\n ans = ""\n flag = False\n for i in range(len(n)):\n if int(n[i])<=x:\n ans += n[i]\n else:\n a = n[:i]\n b = n[i:]\n ans = a+str(x)+b\n \n flag = True\n break\n if not flag:\n ans += str(x)\n ans = "-"+ans\n \n return ans\n \n``` | 5 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
Python solution | maximum-value-after-insertion | 0 | 1 | ```\nclass Solution:\n def maxValue(self, n: str, x: int) -> str:\n\n for i in range(len(n)):\n if n[i] == "-":\n continue\n elif "-" in n:\n if int(n[i]) > x:\n return n[:i] + str(x) + n[i:]\n else:\n if int(n[i]) < x:\n return n[:i] + str(x) + n[i:]\n\n return n + str(x)\n``` | 0 | You are given a very large integer `n`, represented as a string, and an integer digit `x`. The digits in `n` and the digit `x` are in the **inclusive** range `[1, 9]`, and `n` may represent a **negative** number.
You want to **maximize** `n`**'s numerical value** by inserting `x` anywhere in the decimal representation of `n`. You **cannot** insert `x` to the left of the negative sign.
* For example, if `n = 73` and `x = 6`, it would be best to insert it between `7` and `3`, making `n = 763`.
* If `n = -55` and `x = 2`, it would be best to insert it before the first `5`, making `n = -255`.
Return _a string representing the **maximum** value of_ `n`_ after the insertion_.
**Example 1:**
**Input:** n = "99 ", x = 9
**Output:** "999 "
**Explanation:** The result is the same regardless of where you insert 9.
**Example 2:**
**Input:** n = "-13 ", x = 2
**Output:** "-123 "
**Explanation:** You can make n one of {-213, -123, -132}, and the largest of those three is -123.
**Constraints:**
* `1 <= n.length <= 105`
* `1 <= x <= 9`
* The digits in `n` are in the range `[1, 9]`.
* `n` is a valid representation of an integer.
* In the case of a negative `n`, it will begin with `'-'`. | The naive solution is to check all possible subsequences. This works in O(2^n). Divide the array into two parts of nearly is equal size. Consider all subsets of one part and make a list of all possible subset sums and sort this list. Consider all subsets of the other part, and for each one, let its sum = x, do binary search to get the nearest possible value to goal - x in the first part. |
🔥 [Python3] Two Heap, beats 98% 🔥 | process-tasks-using-servers | 0 | 1 | ```\nclass Solution:\n def assignTasks(self, servers: List[int], tasks: List[int]) -> List[int]:\n res, unavailable, time = [], [], 0\n available = [(weight, id) for id, weight in enumerate(servers)]\n heapify(available)\n\n for task in tasks:\n while unavailable and unavailable[0][0] == time:\n _, weight, id = heappop(unavailable)\n heappush(available, (weight, id))\n\n if len(available) > 0:\n weight, id = heappop(available)\n heappush(unavailable, (time + task, weight, id))\n res.append(id)\n else:\n finishTime, weight, id = heappop(unavailable)\n heappush(unavailable, (finishTime + task, weight, id))\n res.append(id)\n time +=1\n\n return res\n``` | 8 | You are given two **0-indexed** integer arrays `servers` and `tasks` of lengths `n` and `m` respectively. `servers[i]` is the **weight** of the `ith` server, and `tasks[j]` is the **time needed** to process the `jth` task **in seconds**.
Tasks are assigned to the servers using a **task queue**. Initially, all servers are free, and the queue is **empty**.
At second `j`, the `jth` task is **inserted** into the queue (starting with the `0th` task being inserted at second `0`). As long as there are free servers and the queue is not empty, the task in the front of the queue will be assigned to a free server with the **smallest weight**, and in case of a tie, it is assigned to a free server with the **smallest index**.
If there are no free servers and the queue is not empty, we wait until a server becomes free and immediately assign the next task. If multiple servers become free at the same time, then multiple tasks from the queue will be assigned **in order of insertion** following the weight and index priorities above.
A server that is assigned task `j` at second `t` will be free again at second `t + tasks[j]`.
Build an array `ans` of length `m`, where `ans[j]` is the **index** of the server the `jth` task will be assigned to.
Return _the array_ `ans`.
**Example 1:**
**Input:** servers = \[3,3,2\], tasks = \[1,2,3,2,1,2\]
**Output:** \[2,2,0,2,1,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 2 until second 1.
- At second 1, server 2 becomes free. Task 1 is added and processed using server 2 until second 3.
- At second 2, task 2 is added and processed using server 0 until second 5.
- At second 3, server 2 becomes free. Task 3 is added and processed using server 2 until second 5.
- At second 4, task 4 is added and processed using server 1 until second 5.
- At second 5, all servers become free. Task 5 is added and processed using server 2 until second 7.
**Example 2:**
**Input:** servers = \[5,1,4,3,2\], tasks = \[2,1,2,4,5,2,1\]
**Output:** \[1,4,1,4,1,3,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 1 until second 2.
- At second 1, task 1 is added and processed using server 4 until second 2.
- At second 2, servers 1 and 4 become free. Task 2 is added and processed using server 1 until second 4.
- At second 3, task 3 is added and processed using server 4 until second 7.
- At second 4, server 1 becomes free. Task 4 is added and processed using server 1 until second 9.
- At second 5, task 5 is added and processed using server 3 until second 7.
- At second 6, task 6 is added and processed using server 2 until second 7.
**Constraints:**
* `servers.length == n`
* `tasks.length == m`
* `1 <= n, m <= 2 * 105`
* `1 <= servers[i], tasks[j] <= 2 * 105` | null |
🐍 {Python} || Heap || O(n+mlogn) || easy and well-explained | process-tasks-using-servers | 0 | 1 | ## Idea :\nUsing two heap one to store the available server for any task and other to store the servers busy in completing the task.\n\'\'\'\n\t\n\tclass Solution:\n def assignTasks(self, servers: List[int], tasks: List[int]) -> List[int]:\n \n # sort the servers in order of weight, keeping index \n server_avail = [(w,i) for i,w in enumerate(servers)]\n heapify(server_avail)\n tasks_in_progress = []\n res = []\n st=0\n for j,task in enumerate(tasks):\n #starting time of task\n st = max(st,j)\n \n # if any server is not free then we can take start-time equal to end-time of task\n if not server_avail:\n st = tasks_in_progress[0][0]\n \n # pop the completed task\'s server and push inside the server avail\n while tasks_in_progress and tasks_in_progress[0][0]<=st:\n heapq.heappush(server_avail,heappop(tasks_in_progress)[1])\n \n # append index of used server in res\n res.append(server_avail[0][1])\n \n # push the first available server in "server_avail" heap to "tasks_in_progress" heap\n heapq.heappush(tasks_in_progress,(st+task,heappop(server_avail)))\n \n return res\n\nif any doubt or want more explaination feel free to ask\uD83E\uDD1E\nThank you!!\nif u got helped from this, u can **Upvote** | 6 | You are given two **0-indexed** integer arrays `servers` and `tasks` of lengths `n` and `m` respectively. `servers[i]` is the **weight** of the `ith` server, and `tasks[j]` is the **time needed** to process the `jth` task **in seconds**.
Tasks are assigned to the servers using a **task queue**. Initially, all servers are free, and the queue is **empty**.
At second `j`, the `jth` task is **inserted** into the queue (starting with the `0th` task being inserted at second `0`). As long as there are free servers and the queue is not empty, the task in the front of the queue will be assigned to a free server with the **smallest weight**, and in case of a tie, it is assigned to a free server with the **smallest index**.
If there are no free servers and the queue is not empty, we wait until a server becomes free and immediately assign the next task. If multiple servers become free at the same time, then multiple tasks from the queue will be assigned **in order of insertion** following the weight and index priorities above.
A server that is assigned task `j` at second `t` will be free again at second `t + tasks[j]`.
Build an array `ans` of length `m`, where `ans[j]` is the **index** of the server the `jth` task will be assigned to.
Return _the array_ `ans`.
**Example 1:**
**Input:** servers = \[3,3,2\], tasks = \[1,2,3,2,1,2\]
**Output:** \[2,2,0,2,1,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 2 until second 1.
- At second 1, server 2 becomes free. Task 1 is added and processed using server 2 until second 3.
- At second 2, task 2 is added and processed using server 0 until second 5.
- At second 3, server 2 becomes free. Task 3 is added and processed using server 2 until second 5.
- At second 4, task 4 is added and processed using server 1 until second 5.
- At second 5, all servers become free. Task 5 is added and processed using server 2 until second 7.
**Example 2:**
**Input:** servers = \[5,1,4,3,2\], tasks = \[2,1,2,4,5,2,1\]
**Output:** \[1,4,1,4,1,3,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 1 until second 2.
- At second 1, task 1 is added and processed using server 4 until second 2.
- At second 2, servers 1 and 4 become free. Task 2 is added and processed using server 1 until second 4.
- At second 3, task 3 is added and processed using server 4 until second 7.
- At second 4, server 1 becomes free. Task 4 is added and processed using server 1 until second 9.
- At second 5, task 5 is added and processed using server 3 until second 7.
- At second 6, task 6 is added and processed using server 2 until second 7.
**Constraints:**
* `servers.length == n`
* `tasks.length == m`
* `1 <= n, m <= 2 * 105`
* `1 <= servers[i], tasks[j] <= 2 * 105` | null |
Python Two heaps one queue | process-tasks-using-servers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nSimilar to 1834 Single-Threaded CPU, but instead of just one server, we have multiple servers. Therefore the code structure are similar instead we use while inside the outter while \n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n2 min heap and 1 queue. First min heap store servers that are awaliable to work, second min heap store the servers that are currently occupied. The queue store the tasks that are ready to be done. \n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def assignTasks(self, servers: List[int], tasks: List[int]) -> List[int]:\n\n for i in range(len(servers)):\n servers[i] = [servers[i], i]\n \n serverQueue = servers\n heapq.heapify(serverQueue)\n\n processQueue = []\n heapq.heapify(processQueue)\n\n taskQueue = deque()\n \n cur_time = 0\n i = 0\n res = [0] * len(tasks)\n while i < len(tasks) or taskQueue:\n while i < len(tasks) and cur_time >= i:\n taskQueue.append([i, tasks[i]])\n i += 1\n cur_time == i\n\n while processQueue and processQueue[0][0] <= cur_time:\n time, weight, idx = heapq.heappop(processQueue)\n heapq.heappush(serverQueue, [weight, idx])\n\n \n while taskQueue and serverQueue:\n serverWeight, serverIdx = heapq.heappop(serverQueue)\n taskIdx, processTime = taskQueue.popleft()\n res[taskIdx] = serverIdx\n heapq.heappush(processQueue, [cur_time + processTime, serverWeight, serverIdx])\n \n if processQueue and taskQueue:\n cur_time = processQueue[0][0]\n else:\n cur_time += 1\n \n return res\n\n\n\n \n\n \n \n\n \n\n``` | 0 | You are given two **0-indexed** integer arrays `servers` and `tasks` of lengths `n` and `m` respectively. `servers[i]` is the **weight** of the `ith` server, and `tasks[j]` is the **time needed** to process the `jth` task **in seconds**.
Tasks are assigned to the servers using a **task queue**. Initially, all servers are free, and the queue is **empty**.
At second `j`, the `jth` task is **inserted** into the queue (starting with the `0th` task being inserted at second `0`). As long as there are free servers and the queue is not empty, the task in the front of the queue will be assigned to a free server with the **smallest weight**, and in case of a tie, it is assigned to a free server with the **smallest index**.
If there are no free servers and the queue is not empty, we wait until a server becomes free and immediately assign the next task. If multiple servers become free at the same time, then multiple tasks from the queue will be assigned **in order of insertion** following the weight and index priorities above.
A server that is assigned task `j` at second `t` will be free again at second `t + tasks[j]`.
Build an array `ans` of length `m`, where `ans[j]` is the **index** of the server the `jth` task will be assigned to.
Return _the array_ `ans`.
**Example 1:**
**Input:** servers = \[3,3,2\], tasks = \[1,2,3,2,1,2\]
**Output:** \[2,2,0,2,1,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 2 until second 1.
- At second 1, server 2 becomes free. Task 1 is added and processed using server 2 until second 3.
- At second 2, task 2 is added and processed using server 0 until second 5.
- At second 3, server 2 becomes free. Task 3 is added and processed using server 2 until second 5.
- At second 4, task 4 is added and processed using server 1 until second 5.
- At second 5, all servers become free. Task 5 is added and processed using server 2 until second 7.
**Example 2:**
**Input:** servers = \[5,1,4,3,2\], tasks = \[2,1,2,4,5,2,1\]
**Output:** \[1,4,1,4,1,3,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 1 until second 2.
- At second 1, task 1 is added and processed using server 4 until second 2.
- At second 2, servers 1 and 4 become free. Task 2 is added and processed using server 1 until second 4.
- At second 3, task 3 is added and processed using server 4 until second 7.
- At second 4, server 1 becomes free. Task 4 is added and processed using server 1 until second 9.
- At second 5, task 5 is added and processed using server 3 until second 7.
- At second 6, task 6 is added and processed using server 2 until second 7.
**Constraints:**
* `servers.length == n`
* `tasks.length == m`
* `1 <= n, m <= 2 * 105`
* `1 <= servers[i], tasks[j] <= 2 * 105` | null |
O(mlogn) time | O(n) space | solution explained | process-tasks-using-servers | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe are given m number of tasks with processing time and n number of servers with weights. We have to schedule these tasks and return which task will be assigned to which server.\n\nFor each task arriving at time t:\n- release all busy servers with availability time <= t\n- if free servers are available, pick the one with minimum weight and index and assign it to the task\n- if free server is not available, release the earliest available busy server and assign it to the task\n\nWe need to track the minimum weight in free servers and the earliest available time in busy servers. Use min heap because it returns the min element in O(1) time.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- set res = a list to store the result i.e indices of servers\n- create a min heap for busy servers. For each server the heap will contain availability time, weight, and index i.e the heap will be sorted by availability time\n- create a min heap for free servers. For each server, the heap will contain weight, index, and availability time i.e the heap will be sorted by weight. \nNote: create a list first and then heapify to create a min heap. If *you create min-heap without heapify i.e by pushing elements one by one, the time complexity will be O(nlogn) *\n- Traverse all tasks. For each task index (start time) and value (processing time)\n - if there are busy servers and busy server availability time <= start time of the current task\n - release the busy server by removing it from the busy server heap and adding it to the free server heap \n - if there is a server available\n - pop free server heap to get the minimum weight server\n - assign it to process the task by marking it busy i.e push it to the busy heap \n - add its index to the result list\n - else there is no server available\n - pop busy server heap to get the busy server with minimal availability time\n - assign it to the task i.e push the server with new availability time to the busy heap \n - add its index to result list\n- return result list\n\n# Complexity\n- Time complexity: (free server list + heapify + tasks traversal * heap push pop) \u2192 (n + n + m * log(heap size)) \u2192 (n + n + m * log(n)) \u2192 (mlogn)\n - n = number of servers\n - m = number of tasks\n - the inner while loop will not run n times for each outer loop iteration \u2192 O(1)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(free server heap + busy server heap + result list) \u2192 O(n + n + n) \u2192 O(n)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def assignTasks(self, servers: List[int], tasks: List[int]) -> List[int]:\n res = []\n busy = []\n free = [(weight, i, 0) for i, weight in enumerate(servers)]\n heapify(free)\n for start_time, process_time in enumerate(tasks):\n while busy and busy[0][0] <= start_time:\n free_time, weight, index = heappop(busy)\n heappush(free, (weight, index, free_time))\n if free:\n weight, index, free_time = heappop(free)\n res.append(index)\n heappush(busy, (start_time + process_time, weight, index))\n else:\n free_time, weight, index = heappop(busy)\n res.append(index)\n heappush(busy, (free_time + process_time, weight, index))\n return res\n\n``` | 0 | You are given two **0-indexed** integer arrays `servers` and `tasks` of lengths `n` and `m` respectively. `servers[i]` is the **weight** of the `ith` server, and `tasks[j]` is the **time needed** to process the `jth` task **in seconds**.
Tasks are assigned to the servers using a **task queue**. Initially, all servers are free, and the queue is **empty**.
At second `j`, the `jth` task is **inserted** into the queue (starting with the `0th` task being inserted at second `0`). As long as there are free servers and the queue is not empty, the task in the front of the queue will be assigned to a free server with the **smallest weight**, and in case of a tie, it is assigned to a free server with the **smallest index**.
If there are no free servers and the queue is not empty, we wait until a server becomes free and immediately assign the next task. If multiple servers become free at the same time, then multiple tasks from the queue will be assigned **in order of insertion** following the weight and index priorities above.
A server that is assigned task `j` at second `t` will be free again at second `t + tasks[j]`.
Build an array `ans` of length `m`, where `ans[j]` is the **index** of the server the `jth` task will be assigned to.
Return _the array_ `ans`.
**Example 1:**
**Input:** servers = \[3,3,2\], tasks = \[1,2,3,2,1,2\]
**Output:** \[2,2,0,2,1,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 2 until second 1.
- At second 1, server 2 becomes free. Task 1 is added and processed using server 2 until second 3.
- At second 2, task 2 is added and processed using server 0 until second 5.
- At second 3, server 2 becomes free. Task 3 is added and processed using server 2 until second 5.
- At second 4, task 4 is added and processed using server 1 until second 5.
- At second 5, all servers become free. Task 5 is added and processed using server 2 until second 7.
**Example 2:**
**Input:** servers = \[5,1,4,3,2\], tasks = \[2,1,2,4,5,2,1\]
**Output:** \[1,4,1,4,1,3,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 1 until second 2.
- At second 1, task 1 is added and processed using server 4 until second 2.
- At second 2, servers 1 and 4 become free. Task 2 is added and processed using server 1 until second 4.
- At second 3, task 3 is added and processed using server 4 until second 7.
- At second 4, server 1 becomes free. Task 4 is added and processed using server 1 until second 9.
- At second 5, task 5 is added and processed using server 3 until second 7.
- At second 6, task 6 is added and processed using server 2 until second 7.
**Constraints:**
* `servers.length == n`
* `tasks.length == m`
* `1 <= n, m <= 2 * 105`
* `1 <= servers[i], tasks[j] <= 2 * 105` | null |
Using minheap, the solution can be solved in O(nlogm). | process-tasks-using-servers | 0 | 1 | # Intuition\nWe create two heaps for servers, available and unavailable.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(nlogm)\n\n- Space complexity: O(n)\n\n# Code\n```\nclass Solution:\n def assignTasks(self, servers: List[int], tasks: List[int]) -> List[int]:\n res = []\n avail = [(servers[i], i) for i in range(len(servers))]\n heapq.heapify(avail)\n unavail = []\n t = 0\n for i in range(len(tasks)):\n t = max(t, i)\n\n # forward time if necessary\n if len(avail) == 0:\n t = unavail[0][0]\n \n # check if there are servers in unavail that can be made available\n while unavail and t >= unavail[0][0]:\n time, weight, idx = heapq.heappop(unavail)\n heapq.heappush(avail, (weight, idx))\n \n # now take an available server and assign it some task\n weight, idx = heapq.heappop(avail)\n res.append(idx)\n heapq.heappush(unavail, (t + tasks[i], weight, idx))\n return res\n\n``` | 0 | You are given two **0-indexed** integer arrays `servers` and `tasks` of lengths `n` and `m` respectively. `servers[i]` is the **weight** of the `ith` server, and `tasks[j]` is the **time needed** to process the `jth` task **in seconds**.
Tasks are assigned to the servers using a **task queue**. Initially, all servers are free, and the queue is **empty**.
At second `j`, the `jth` task is **inserted** into the queue (starting with the `0th` task being inserted at second `0`). As long as there are free servers and the queue is not empty, the task in the front of the queue will be assigned to a free server with the **smallest weight**, and in case of a tie, it is assigned to a free server with the **smallest index**.
If there are no free servers and the queue is not empty, we wait until a server becomes free and immediately assign the next task. If multiple servers become free at the same time, then multiple tasks from the queue will be assigned **in order of insertion** following the weight and index priorities above.
A server that is assigned task `j` at second `t` will be free again at second `t + tasks[j]`.
Build an array `ans` of length `m`, where `ans[j]` is the **index** of the server the `jth` task will be assigned to.
Return _the array_ `ans`.
**Example 1:**
**Input:** servers = \[3,3,2\], tasks = \[1,2,3,2,1,2\]
**Output:** \[2,2,0,2,1,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 2 until second 1.
- At second 1, server 2 becomes free. Task 1 is added and processed using server 2 until second 3.
- At second 2, task 2 is added and processed using server 0 until second 5.
- At second 3, server 2 becomes free. Task 3 is added and processed using server 2 until second 5.
- At second 4, task 4 is added and processed using server 1 until second 5.
- At second 5, all servers become free. Task 5 is added and processed using server 2 until second 7.
**Example 2:**
**Input:** servers = \[5,1,4,3,2\], tasks = \[2,1,2,4,5,2,1\]
**Output:** \[1,4,1,4,1,3,2\]
**Explanation:** Events in chronological order go as follows:
- At second 0, task 0 is added and processed using server 1 until second 2.
- At second 1, task 1 is added and processed using server 4 until second 2.
- At second 2, servers 1 and 4 become free. Task 2 is added and processed using server 1 until second 4.
- At second 3, task 3 is added and processed using server 4 until second 7.
- At second 4, server 1 becomes free. Task 4 is added and processed using server 1 until second 9.
- At second 5, task 5 is added and processed using server 3 until second 7.
- At second 6, task 6 is added and processed using server 2 until second 7.
**Constraints:**
* `servers.length == n`
* `tasks.length == m`
* `1 <= n, m <= 2 * 105`
* `1 <= servers[i], tasks[j] <= 2 * 105` | null |
(Warning: No Explanation) [Python] DP + Time to Distance Equivalent Trick | minimum-skips-to-arrive-at-meeting-on-time | 0 | 1 | # Learning\nObserve the **skip & noskip** variable in **Dp** and how it is implemented with dinstance equivant of time to not get into precision error troubles. \nI have provided this solution just because i found my equivalent distance calculate little different than others and it\'s correct.\n**Your task is to check the correctness, Grab a pen and paper!**\n# Complexity\n- Time complexity: O(N^2)\n\n# Code\n```\nclass Solution:\n def minSkips(self, dist: List[int], speed: int, time: int) -> int:\n """\n dp(n , k) calculates minimum time required \n to cross n first roads with k available skips\n """\n @lru_cache(None)\n def dp(n, skips):\n if skips < 0: return inf\n if n <= 0: return 0\n if n == len(dist):\n return dp(n - 1, skips) + dist[n - 1]\n skip = dp(n - 1, skips - 1) + dist[n - 1]\n noskip = ((dp(n - 1, skips) + dist[n - 1] + speed - 1) // speed) * speed \n return min(skip, noskip)\n\n n = len(dist)\n for i in range(n):\n if dp(n , i) <= speed * time: return i\n return -1\n``` | 1 | You are given an integer `hoursBefore`, the number of hours you have to travel to your meeting. To arrive at your meeting, you have to travel through `n` roads. The road lengths are given as an integer array `dist` of length `n`, where `dist[i]` describes the length of the `ith` road in **kilometers**. In addition, you are given an integer `speed`, which is the speed (in **km/h**) you will travel at.
After you travel road `i`, you must rest and wait for the **next integer hour** before you can begin traveling on the next road. Note that you do not have to rest after traveling the last road because you are already at the meeting.
* For example, if traveling a road takes `1.4` hours, you must wait until the `2` hour mark before traveling the next road. If traveling a road takes exactly `2` hours, you do not need to wait.
However, you are allowed to **skip** some rests to be able to arrive on time, meaning you do not need to wait for the next integer hour. Note that this means you may finish traveling future roads at different hour marks.
* For example, suppose traveling the first road takes `1.4` hours and traveling the second road takes `0.6` hours. Skipping the rest after the first road will mean you finish traveling the second road right at the `2` hour mark, letting you start traveling the third road immediately.
Return _the **minimum number of skips required** to arrive at the meeting on time, or_ `-1` _if it is **impossible**_.
**Example 1:**
**Input:** dist = \[1,3,2\], speed = 4, hoursBefore = 2
**Output:** 1
**Explanation:**
Without skipping any rests, you will arrive in (1/4 + 3/4) + (3/4 + 1/4) + (2/4) = 2.5 hours.
You can skip the first rest to arrive in ((1/4 + 0) + (3/4 + 0)) + (2/4) = 1.5 hours.
Note that the second rest is shortened because you finish traveling the second road at an integer hour due to skipping the first rest.
**Example 2:**
**Input:** dist = \[7,3,5,5\], speed = 2, hoursBefore = 10
**Output:** 2
**Explanation:**
Without skipping any rests, you will arrive in (7/2 + 1/2) + (3/2 + 1/2) + (5/2 + 1/2) + (5/2) = 11.5 hours.
You can skip the first and third rest to arrive in ((7/2 + 0) + (3/2 + 0)) + ((5/2 + 0) + (5/2)) = 10 hours.
**Example 3:**
**Input:** dist = \[7,3,5,5\], speed = 1, hoursBefore = 10
**Output:** -1
**Explanation:** It is impossible to arrive at the meeting on time even if you skip all the rests.
**Constraints:**
* `n == dist.length`
* `1 <= n <= 1000`
* `1 <= dist[i] <= 105`
* `1 <= speed <= 106`
* `1 <= hoursBefore <= 107` | Get the LCA of p and q. The answer is the sum of distances between p-LCA and q-LCA |
Memoization in Python within 10 lines | minimum-skips-to-arrive-at-meeting-on-time | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nDynamic programming in the reversed order of the roads. A state in the search space can be defined by `(i, skip)` where `i` is the ith road and `skip` is the remaining number of skips can be applied.\nAt each state, there are three cases to consider: \n\n1. No need to skip: the previous road is passed at an integer hour \n2. Not to skip: waiting for the next integer hour\n3. To skip: begining the next road immediately\n\nUse dynamic programming to find the best choice from Case 2 and Case 3. Take care about the precision issues of floating numbers. \n\n# Complexity\n- Time complexity: $$O(n^2)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n^2)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minSkips(self, dist: List[int], speed: int, hoursBefore: int) -> int:\n @cache\n def dp(i, skip):\n if i == 0: return dist[i] / speed\n t = dp(i-1, skip)\n if isclose(t, round(t)): return t + dist[i] / speed\n ans = ceil(t) + dist[i] / speed\n if skip: ans = min(ans, dp(i-1, skip-1) + dist[i]/speed)\n return ans\n return next((i for i in range(len(dist)) if dp(len(dist)-1, i) <= hoursBefore+0.000000001), -1)\n``` | 0 | You are given an integer `hoursBefore`, the number of hours you have to travel to your meeting. To arrive at your meeting, you have to travel through `n` roads. The road lengths are given as an integer array `dist` of length `n`, where `dist[i]` describes the length of the `ith` road in **kilometers**. In addition, you are given an integer `speed`, which is the speed (in **km/h**) you will travel at.
After you travel road `i`, you must rest and wait for the **next integer hour** before you can begin traveling on the next road. Note that you do not have to rest after traveling the last road because you are already at the meeting.
* For example, if traveling a road takes `1.4` hours, you must wait until the `2` hour mark before traveling the next road. If traveling a road takes exactly `2` hours, you do not need to wait.
However, you are allowed to **skip** some rests to be able to arrive on time, meaning you do not need to wait for the next integer hour. Note that this means you may finish traveling future roads at different hour marks.
* For example, suppose traveling the first road takes `1.4` hours and traveling the second road takes `0.6` hours. Skipping the rest after the first road will mean you finish traveling the second road right at the `2` hour mark, letting you start traveling the third road immediately.
Return _the **minimum number of skips required** to arrive at the meeting on time, or_ `-1` _if it is **impossible**_.
**Example 1:**
**Input:** dist = \[1,3,2\], speed = 4, hoursBefore = 2
**Output:** 1
**Explanation:**
Without skipping any rests, you will arrive in (1/4 + 3/4) + (3/4 + 1/4) + (2/4) = 2.5 hours.
You can skip the first rest to arrive in ((1/4 + 0) + (3/4 + 0)) + (2/4) = 1.5 hours.
Note that the second rest is shortened because you finish traveling the second road at an integer hour due to skipping the first rest.
**Example 2:**
**Input:** dist = \[7,3,5,5\], speed = 2, hoursBefore = 10
**Output:** 2
**Explanation:**
Without skipping any rests, you will arrive in (7/2 + 1/2) + (3/2 + 1/2) + (5/2 + 1/2) + (5/2) = 11.5 hours.
You can skip the first and third rest to arrive in ((7/2 + 0) + (3/2 + 0)) + ((5/2 + 0) + (5/2)) = 10 hours.
**Example 3:**
**Input:** dist = \[7,3,5,5\], speed = 1, hoursBefore = 10
**Output:** -1
**Explanation:** It is impossible to arrive at the meeting on time even if you skip all the rests.
**Constraints:**
* `n == dist.length`
* `1 <= n <= 1000`
* `1 <= dist[i] <= 105`
* `1 <= speed <= 106`
* `1 <= hoursBefore <= 107` | Get the LCA of p and q. The answer is the sum of distances between p-LCA and q-LCA |
[Python] Floating Point Sucks! use distance instead | minimum-skips-to-arrive-at-meeting-on-time | 0 | 1 | \n# Code\n```\nclass Solution:\n def minSkips(self, dist: List[int], sp: int, hb: int) -> int:\n n = len(dist)\n dp = [[0]*(n+1) for i in range(n)] # dp[i][k] - min distance upto i with k sips\n dp[0][0] = math.ceil(dist[0]/sp)*sp\n for k in range(1,n+1): dp[0][k] = dist[0]\n for i in range(1,n): dp[i][0] = math.ceil((dp[i-1][0] + dist[i])/sp)*sp \n for i in range(1,n):\n for k in range(1,n+1):\n dp[i][k] = min(math.ceil((dp[i-1][k] + dist[i])/sp)*sp, dp[i-1][k-1] + dist[i] )\n for k in range(0,len(dist)+1):\n if(dp[n-1][k]/sp <=hb): return k\n return -1\n \n\n\n``` | 0 | You are given an integer `hoursBefore`, the number of hours you have to travel to your meeting. To arrive at your meeting, you have to travel through `n` roads. The road lengths are given as an integer array `dist` of length `n`, where `dist[i]` describes the length of the `ith` road in **kilometers**. In addition, you are given an integer `speed`, which is the speed (in **km/h**) you will travel at.
After you travel road `i`, you must rest and wait for the **next integer hour** before you can begin traveling on the next road. Note that you do not have to rest after traveling the last road because you are already at the meeting.
* For example, if traveling a road takes `1.4` hours, you must wait until the `2` hour mark before traveling the next road. If traveling a road takes exactly `2` hours, you do not need to wait.
However, you are allowed to **skip** some rests to be able to arrive on time, meaning you do not need to wait for the next integer hour. Note that this means you may finish traveling future roads at different hour marks.
* For example, suppose traveling the first road takes `1.4` hours and traveling the second road takes `0.6` hours. Skipping the rest after the first road will mean you finish traveling the second road right at the `2` hour mark, letting you start traveling the third road immediately.
Return _the **minimum number of skips required** to arrive at the meeting on time, or_ `-1` _if it is **impossible**_.
**Example 1:**
**Input:** dist = \[1,3,2\], speed = 4, hoursBefore = 2
**Output:** 1
**Explanation:**
Without skipping any rests, you will arrive in (1/4 + 3/4) + (3/4 + 1/4) + (2/4) = 2.5 hours.
You can skip the first rest to arrive in ((1/4 + 0) + (3/4 + 0)) + (2/4) = 1.5 hours.
Note that the second rest is shortened because you finish traveling the second road at an integer hour due to skipping the first rest.
**Example 2:**
**Input:** dist = \[7,3,5,5\], speed = 2, hoursBefore = 10
**Output:** 2
**Explanation:**
Without skipping any rests, you will arrive in (7/2 + 1/2) + (3/2 + 1/2) + (5/2 + 1/2) + (5/2) = 11.5 hours.
You can skip the first and third rest to arrive in ((7/2 + 0) + (3/2 + 0)) + ((5/2 + 0) + (5/2)) = 10 hours.
**Example 3:**
**Input:** dist = \[7,3,5,5\], speed = 1, hoursBefore = 10
**Output:** -1
**Explanation:** It is impossible to arrive at the meeting on time even if you skip all the rests.
**Constraints:**
* `n == dist.length`
* `1 <= n <= 1000`
* `1 <= dist[i] <= 105`
* `1 <= speed <= 106`
* `1 <= hoursBefore <= 107` | Get the LCA of p and q. The answer is the sum of distances between p-LCA and q-LCA |
Python (Simple DP) | minimum-skips-to-arrive-at-meeting-on-time | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minSkips(self, dist, speed, hoursBefore):\n n = len(dist)\n\n if sum(dist)/speed > hoursBefore: return -1\n\n @lru_cache(None)\n def dfs(i,k):\n if k < 0: return float("inf")\n if i >= n: return 0\n return min(ceil((dfs(i+1,k) + dist[i])/speed)*speed, dist[i] + dfs(i+1,k-1))\n\n for k in range(n+1):\n if dfs(0,k) <= hoursBefore*speed: return k\n\n\n\n\n\n\n \n``` | 0 | You are given an integer `hoursBefore`, the number of hours you have to travel to your meeting. To arrive at your meeting, you have to travel through `n` roads. The road lengths are given as an integer array `dist` of length `n`, where `dist[i]` describes the length of the `ith` road in **kilometers**. In addition, you are given an integer `speed`, which is the speed (in **km/h**) you will travel at.
After you travel road `i`, you must rest and wait for the **next integer hour** before you can begin traveling on the next road. Note that you do not have to rest after traveling the last road because you are already at the meeting.
* For example, if traveling a road takes `1.4` hours, you must wait until the `2` hour mark before traveling the next road. If traveling a road takes exactly `2` hours, you do not need to wait.
However, you are allowed to **skip** some rests to be able to arrive on time, meaning you do not need to wait for the next integer hour. Note that this means you may finish traveling future roads at different hour marks.
* For example, suppose traveling the first road takes `1.4` hours and traveling the second road takes `0.6` hours. Skipping the rest after the first road will mean you finish traveling the second road right at the `2` hour mark, letting you start traveling the third road immediately.
Return _the **minimum number of skips required** to arrive at the meeting on time, or_ `-1` _if it is **impossible**_.
**Example 1:**
**Input:** dist = \[1,3,2\], speed = 4, hoursBefore = 2
**Output:** 1
**Explanation:**
Without skipping any rests, you will arrive in (1/4 + 3/4) + (3/4 + 1/4) + (2/4) = 2.5 hours.
You can skip the first rest to arrive in ((1/4 + 0) + (3/4 + 0)) + (2/4) = 1.5 hours.
Note that the second rest is shortened because you finish traveling the second road at an integer hour due to skipping the first rest.
**Example 2:**
**Input:** dist = \[7,3,5,5\], speed = 2, hoursBefore = 10
**Output:** 2
**Explanation:**
Without skipping any rests, you will arrive in (7/2 + 1/2) + (3/2 + 1/2) + (5/2 + 1/2) + (5/2) = 11.5 hours.
You can skip the first and third rest to arrive in ((7/2 + 0) + (3/2 + 0)) + ((5/2 + 0) + (5/2)) = 10 hours.
**Example 3:**
**Input:** dist = \[7,3,5,5\], speed = 1, hoursBefore = 10
**Output:** -1
**Explanation:** It is impossible to arrive at the meeting on time even if you skip all the rests.
**Constraints:**
* `n == dist.length`
* `1 <= n <= 1000`
* `1 <= dist[i] <= 105`
* `1 <= speed <= 106`
* `1 <= hoursBefore <= 107` | Get the LCA of p and q. The answer is the sum of distances between p-LCA and q-LCA |
Python Bottom-up DP: O(n^2) time & space | 63% time, 78% space | minimum-skips-to-arrive-at-meeting-on-time | 0 | 1 | ```python []\nclass Solution:\n def minSkips(self, dist: List[int], speed: int, hoursBefore: int) -> int:\n n = len(dist)\n # Handle float accuracy error\n eps = 1e-9\n\n dp = [[sys.maxsize] * n for _ in range(n)]\n dp[0][0] = dist[0] / speed\n\n for i in range(1, n):\n for j in range(i + 1):\n if j == 0:\n dp[i][j] = ceil(dp[i - 1][0]) - eps + dist[i] / speed\n else:\n skip = dp[i - 1][j - 1]\n no_skip = ceil(dp[i - 1][j]) - eps\n dp[i][j] = min(skip, no_skip) + dist[i] / speed\n\n for k in range(n):\n if dp[-1][k] <= hoursBefore: return k\n return -1\n``` | 0 | You are given an integer `hoursBefore`, the number of hours you have to travel to your meeting. To arrive at your meeting, you have to travel through `n` roads. The road lengths are given as an integer array `dist` of length `n`, where `dist[i]` describes the length of the `ith` road in **kilometers**. In addition, you are given an integer `speed`, which is the speed (in **km/h**) you will travel at.
After you travel road `i`, you must rest and wait for the **next integer hour** before you can begin traveling on the next road. Note that you do not have to rest after traveling the last road because you are already at the meeting.
* For example, if traveling a road takes `1.4` hours, you must wait until the `2` hour mark before traveling the next road. If traveling a road takes exactly `2` hours, you do not need to wait.
However, you are allowed to **skip** some rests to be able to arrive on time, meaning you do not need to wait for the next integer hour. Note that this means you may finish traveling future roads at different hour marks.
* For example, suppose traveling the first road takes `1.4` hours and traveling the second road takes `0.6` hours. Skipping the rest after the first road will mean you finish traveling the second road right at the `2` hour mark, letting you start traveling the third road immediately.
Return _the **minimum number of skips required** to arrive at the meeting on time, or_ `-1` _if it is **impossible**_.
**Example 1:**
**Input:** dist = \[1,3,2\], speed = 4, hoursBefore = 2
**Output:** 1
**Explanation:**
Without skipping any rests, you will arrive in (1/4 + 3/4) + (3/4 + 1/4) + (2/4) = 2.5 hours.
You can skip the first rest to arrive in ((1/4 + 0) + (3/4 + 0)) + (2/4) = 1.5 hours.
Note that the second rest is shortened because you finish traveling the second road at an integer hour due to skipping the first rest.
**Example 2:**
**Input:** dist = \[7,3,5,5\], speed = 2, hoursBefore = 10
**Output:** 2
**Explanation:**
Without skipping any rests, you will arrive in (7/2 + 1/2) + (3/2 + 1/2) + (5/2 + 1/2) + (5/2) = 11.5 hours.
You can skip the first and third rest to arrive in ((7/2 + 0) + (3/2 + 0)) + ((5/2 + 0) + (5/2)) = 10 hours.
**Example 3:**
**Input:** dist = \[7,3,5,5\], speed = 1, hoursBefore = 10
**Output:** -1
**Explanation:** It is impossible to arrive at the meeting on time even if you skip all the rests.
**Constraints:**
* `n == dist.length`
* `1 <= n <= 1000`
* `1 <= dist[i] <= 105`
* `1 <= speed <= 106`
* `1 <= hoursBefore <= 107` | Get the LCA of p and q. The answer is the sum of distances between p-LCA and q-LCA |
[Python3] top-down dp | minimum-skips-to-arrive-at-meeting-on-time | 0 | 1 | \n```\nclass Solution:\n def minSkips(self, dist: List[int], speed: int, hoursBefore: int) -> int:\n if sum(dist)/speed > hoursBefore: return -1 # impossible \n \n @cache\n def fn(i, k): \n """Return min time (in distance) of traveling first i roads with k skips."""\n if k < 0: return inf # impossible \n if i == 0: return 0 \n return min(ceil((fn(i-1, k) + dist[i-1])/speed) * speed, dist[i-1] + fn(i-1, k-1))\n \n for k in range(len(dist)):\n if fn(len(dist)-1, k) + dist[-1] <= hoursBefore*speed: return k \n``` | 3 | You are given an integer `hoursBefore`, the number of hours you have to travel to your meeting. To arrive at your meeting, you have to travel through `n` roads. The road lengths are given as an integer array `dist` of length `n`, where `dist[i]` describes the length of the `ith` road in **kilometers**. In addition, you are given an integer `speed`, which is the speed (in **km/h**) you will travel at.
After you travel road `i`, you must rest and wait for the **next integer hour** before you can begin traveling on the next road. Note that you do not have to rest after traveling the last road because you are already at the meeting.
* For example, if traveling a road takes `1.4` hours, you must wait until the `2` hour mark before traveling the next road. If traveling a road takes exactly `2` hours, you do not need to wait.
However, you are allowed to **skip** some rests to be able to arrive on time, meaning you do not need to wait for the next integer hour. Note that this means you may finish traveling future roads at different hour marks.
* For example, suppose traveling the first road takes `1.4` hours and traveling the second road takes `0.6` hours. Skipping the rest after the first road will mean you finish traveling the second road right at the `2` hour mark, letting you start traveling the third road immediately.
Return _the **minimum number of skips required** to arrive at the meeting on time, or_ `-1` _if it is **impossible**_.
**Example 1:**
**Input:** dist = \[1,3,2\], speed = 4, hoursBefore = 2
**Output:** 1
**Explanation:**
Without skipping any rests, you will arrive in (1/4 + 3/4) + (3/4 + 1/4) + (2/4) = 2.5 hours.
You can skip the first rest to arrive in ((1/4 + 0) + (3/4 + 0)) + (2/4) = 1.5 hours.
Note that the second rest is shortened because you finish traveling the second road at an integer hour due to skipping the first rest.
**Example 2:**
**Input:** dist = \[7,3,5,5\], speed = 2, hoursBefore = 10
**Output:** 2
**Explanation:**
Without skipping any rests, you will arrive in (7/2 + 1/2) + (3/2 + 1/2) + (5/2 + 1/2) + (5/2) = 11.5 hours.
You can skip the first and third rest to arrive in ((7/2 + 0) + (3/2 + 0)) + ((5/2 + 0) + (5/2)) = 10 hours.
**Example 3:**
**Input:** dist = \[7,3,5,5\], speed = 1, hoursBefore = 10
**Output:** -1
**Explanation:** It is impossible to arrive at the meeting on time even if you skip all the rests.
**Constraints:**
* `n == dist.length`
* `1 <= n <= 1000`
* `1 <= dist[i] <= 105`
* `1 <= speed <= 106`
* `1 <= hoursBefore <= 107` | Get the LCA of p and q. The answer is the sum of distances between p-LCA and q-LCA |
Recursive, Iterative, Generic | egg-drop-with-2-eggs-and-n-floors | 1 | 1 | It may take you a while to come up with an efficient math-based solution. So, for an interview, I would start with a simple recursion - at least you will have something. It can help you see a pattern, and it will be easiser to develop an intuition for an improved solution. \n\nIf you follow-up with an improved solution, and also generalize it for `k` eggs ([887. Super Egg Drop](https://leetcode.com/problems/super-egg-drop/)) - it would be a home run. This is how this progression might look like.\n\n> Fun fact: this problem is decribed in the Wikipedia\'s article for [Dynamic Programming](https://en.wikipedia.org/w/index.php?title=Dynamic_programming).\n\n#### Simple Recursion\nIn the solution below, we drop an egg from each floor and find the number of throws for these two cases:\n- We lost an egg but we reduced the number of floors to `i`.\n\t- Since we only have one egg left, we can just return `i - 1` to check all floors.\n- The egg did not break, and we reduced the number of floors to `n - i`.\n\t- Solve this recursively to get the number of throws for `n - i` floors.\n\nThis way, we find a floor for which the number of throws - maximum from these two cases - is minimal.\n\n**C++**\n```cpp\nint dp[1001] = {};\nclass Solution {\npublic:\nint twoEggDrop(int n) {\n\tif (dp[n] == 0)\n\t\tfor (int i = 1; i <= n; ++i)\n\t\t\tdp[n] = min(dp[n] == 0 ? n : dp[n], 1 + max(i - 1, twoEggDrop(n - i)));\n\treturn dp[n];\n}\n};\n```\n**Java**\n```java\nstatic int[] dp = new int[1001];\npublic int twoEggDrop(int n) {\n if (dp[n] == 0)\n for (int i = 1; i <= n; ++i)\n dp[n] = Math.min(dp[n] == 0 ? n : dp[n], 1 + Math.max(i - 1, twoEggDrop(n - i)));\n return dp[n];\n}\n```\n\n**Python 3**\n```python\nclass Solution:\n @cache\n def twoEggDrop(self, n: int) -> int:\n return min((1 + max(i - 1, self.twoEggDrop(n - i)) for i in range (1, n)), default = 1)\n```\n#### Iterative Computation\nLet\'s take a look at the results from the first solution for different `n`:\n```\n1: 1\n2: 2\n4: 3\n7: 4\n11: 5\n16: 6\n22: 7\n29: 8\n37: 9\n46: 10\n```\nAs you see, with `m` drops, we can test up to 1 + 2 + ... + m floors. \n\n**C++**\n```cpp\nint twoEggDrop(int n) {\n int res = 1;\n while (n - res > 0)\n n -= res++;\n return res; \n}\n```\n... or, using a formula:\n\n**C++**\n```cpp\nint twoEggDrop(int n) {\n int m = 1;\n while (m * (m + 1) / 2 < n)\n ++m;\n return m; \n} \n```\n\n#### Inversion and Generic Solution\nWith the help of the iterative solution above, we see that it\'s easier to solve an inverse problem: given `m` total drops, and `k` eggs, how high can we go?\n\nSo with one egg and `m` drops, we can only test `m` floors.\n\nWith two eggs and `m` drops:\n1. We drop one egg to test one floor.\n2. We add the number of floors we can test with `m - 1` drops and 2 eggs (the egg did not break).\n3. And we add `m - 1 ` floors we can test with the last egg (the egg broke).\n\nThus, the formula is:\n```\ndp[m] = 1 + dp[m - 1] + m - 1;\n```\n... which is in-line with the observation we made for the iterative solution above!\n\nThis can be easily generalized for `k` eggs:\n\n```\ndp[m][k] = 1 + dp[m - 1][k] + dp[m - 1][k - 1];\n```\n\n**C++**\n```cpp\nint dp[1001][3] = {};\nclass Solution {\npublic:\nint twoEggDrop(int n, int k = 2) {\n int m = 0;\n while (dp[m][k] < n) {\n ++m;\n for (int j = 1; j <= k; ++j)\n dp[m][j] = dp[m - 1][j - 1] + dp[m - 1][j] + 1;\n }\n return m; \n}\n};\n```\nAs we only look one step back, we can reduce the memory ussage to O(k): \n\n**C++**\n```cpp\nint twoEggDrop(int n, int k = 2) {\n int dp[3] = {};\n int m = 0;\n while (dp[k] < n) {\n ++m;\n for (int j = k; j > 0; --j)\n dp[j] += dp[j - 1] + 1;\n }\n return m;\n}\n``` | 226 | You are given **two identical** eggs and you have access to a building with `n` floors labeled from `1` to `n`.
You know that there exists a floor `f` where `0 <= f <= n` such that any egg dropped at a floor **higher** than `f` will **break**, and any egg dropped **at or below** floor `f` will **not break**.
In each move, you may take an **unbroken** egg and drop it from any floor `x` (where `1 <= x <= n`). If the egg breaks, you can no longer use it. However, if the egg does not break, you may **reuse** it in future moves.
Return _the **minimum number of moves** that you need to determine **with certainty** what the value of_ `f` is.
**Example 1:**
**Input:** n = 2
**Output:** 2
**Explanation:** We can drop the first egg from floor 1 and the second egg from floor 2.
If the first egg breaks, we know that f = 0.
If the second egg breaks but the first egg didn't, we know that f = 1.
Otherwise, if both eggs survive, we know that f = 2.
**Example 2:**
**Input:** n = 100
**Output:** 14
**Explanation:** One optimal strategy is:
- Drop the 1st egg at floor 9. If it breaks, we know f is between 0 and 8. Drop the 2nd egg starting from floor 1 and going up one at a time to find f within 8 more drops. Total drops is 1 + 8 = 9.
- If the 1st egg does not break, drop the 1st egg again at floor 22. If it breaks, we know f is between 9 and 21. Drop the 2nd egg starting from floor 10 and going up one at a time to find f within 12 more drops. Total drops is 2 + 12 = 14.
- If the 1st egg does not break again, follow a similar process dropping the 1st egg from floors 34, 45, 55, 64, 72, 79, 85, 90, 94, 97, 99, and 100.
Regardless of the outcome, it takes at most 14 drops to determine f.
**Constraints:**
* `1 <= n <= 1000` | Think about how the final string will look like. It will either start with a '0' and be like '010101010..' or with a '1' and be like '10101010..' Try both ways, and check for each way, the number of changes needed to reach it from the given string. The answer is the minimum of both ways. |
[Python3] rotate matrix | determine-whether-matrix-can-be-obtained-by-rotation | 0 | 1 | \n```\nclass Solution:\n def findRotation(self, mat: List[List[int]], target: List[List[int]]) -> bool:\n for _ in range(4): \n if mat == target: return True\n mat = [list(x) for x in zip(*mat[::-1])]\n return False \n``` | 93 | Given two `n x n` binary matrices `mat` and `target`, return `true` _if it is possible to make_ `mat` _equal to_ `target` _by **rotating**_ `mat` _in **90-degree increments**, or_ `false` _otherwise._
**Example 1:**
**Input:** mat = \[\[0,1\],\[1,0\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise to make mat equal target.
**Example 2:**
**Input:** mat = \[\[0,1\],\[1,1\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** false
**Explanation:** It is impossible to make mat equal to target by rotating mat.
**Example 3:**
**Input:** mat = \[\[0,0,0\],\[0,1,0\],\[1,1,1\]\], target = \[\[1,1,1\],\[0,1,0\],\[0,0,0\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise two times to make mat equal target.
**Constraints:**
* `n == mat.length == target.length`
* `n == mat[i].length == target[i].length`
* `1 <= n <= 10`
* `mat[i][j]` and `target[i][j]` are either `0` or `1`. | Let's change the question if we know the maximum size of a bag what is the minimum number of bags you can make note that as the maximum size increases the minimum number of bags decreases so we can binary search the maximum size |
Python - Very detailed explanation of one liner solution (for python beginners) | determine-whether-matrix-can-be-obtained-by-rotation | 0 | 1 | Lets take an example - `mat = [[0,0,0],[0,1,0],[1,1,1]], target = [[1,1,1],[0,1,0],[0,0,0]]`\n\nFirst rotate 90 degree::\n```\n mat = [list(x) for x in zip(*mat[::-1])]\n```\nStart processing above statement from right to left.\n\n**Step 1->** Reverse ---> `mat[::-1] --> [ [1,1,1], [0,1,0], [0,0,0] ]`\n**Step 2->** Unpack so that it can be passed as separate positional arguments to zip function ----> `(*mat[::-1]) -->[1,1,1], [0,1,0], [0,0,0]`\n\t\t\tNotice missing outer square brackets from step1. In step1 this was a single arguments -**[** [1,1,1] [0,1,0] [0,0,0] **]** and after unpacking these are 3 arguments - [1,1,1],[0,1,0],[0,0,0].\n**Step 3 ->** zip it ---->`zip(*mat[::-1]) ---->zip( [1,1,1],[0,1,0],[0,0,0] )`\n\t\t\t\tAs per definition -zip returns an iterator of tuples, where the i-th tuple contains the i-th element from each of the argument sequences or iterables. \n\t\t\t\tso zip( [**1**,1,1],[**0**,1,0],[**0**,0,0] ) takes first column value from all 3 arguments and makes tuple-(1, 0, 0)\n\t\t\t\tthen zip( [1,**1**,1],[0,**1**,0],[0,**0**,0] ) takes 2nd column value from all 3 arguments and makes tuple -(1, 1, 0)\n\t\t\t\tthen zip( [1,1,**1**],[0,1,**0**],[0,0,**0**] ) takes 3rd column value from all 3 arguments and makes tuple -(1, 0, 0)\n\t\t\t\tso complete output ---> (1, 0, 0), (1, 1, 0), (1, 0, 0) . \n\t\t\t\tNotice output of step is 3 tuples.\n\t\t\t\t\n **Step 4 -->** convert output of step 3 into the list--->` [list(x) for x in zip(*mat[::-1])]`--->\n "for loop" executes 3 times for 3 tuples in zip - (1, 0, 0), (1, 1, 0), (1, 0, 0) and converts this into list---> **[** [1,0,0], [1,1,0], [1,0,0] **]**\n Now repeate step 1 to 4, four times to check if given output can be obtained by 90 degree roation or 180 degree roation or 270 degree or 360 degree roation.\n\t After step 4 new value of mat = \t [[1,0,0], [1,1,0], [1,0,0]]. \n\t Lets rotate it one more time:\n\t `mat = [list(x) for x in zip(*mat[::-1])]`\n\t` mat[::-1]`--->[ [1, 0, 0], [1, 1, 0], [1, 0, 0] ]\n\t` zip(*mat[::-1])` --->zip( [1, 0, 0 ], [1, 1, 0], [1, 0, 0] )-->(1, 1, 1), (0, 1, 0), (0, 0, 0)\n` [list(x) for x in zip(*mat[::-1])]` --> [ [ 1, 1,1], [0, 1, 0], [0, 0, 0] ]\n \nthis transforms mat to [ [ 1, 1,1], [0, 1, 0], [0, 0, 0] ] which is equal to given target in problem so return `True`.\n\t \n\t \n\n\n\n\n\n\t \n\t \n\t \n\t \n\t \n\t \n\t \n\t \n\t \n\t \n\t \n\t\n\t \n\t \n\t \n\n\n\n\n\n```\nclass Solution:\n def findRotation(self, mat: List[List[int]], target: List[List[int]]) -> bool:\n for _ in range(4): \n if mat == target: return True\n mat = [list(x) for x in zip(*mat[::-1])]\n return False\n``` | 56 | Given two `n x n` binary matrices `mat` and `target`, return `true` _if it is possible to make_ `mat` _equal to_ `target` _by **rotating**_ `mat` _in **90-degree increments**, or_ `false` _otherwise._
**Example 1:**
**Input:** mat = \[\[0,1\],\[1,0\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise to make mat equal target.
**Example 2:**
**Input:** mat = \[\[0,1\],\[1,1\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** false
**Explanation:** It is impossible to make mat equal to target by rotating mat.
**Example 3:**
**Input:** mat = \[\[0,0,0\],\[0,1,0\],\[1,1,1\]\], target = \[\[1,1,1\],\[0,1,0\],\[0,0,0\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise two times to make mat equal target.
**Constraints:**
* `n == mat.length == target.length`
* `n == mat[i].length == target[i].length`
* `1 <= n <= 10`
* `mat[i][j]` and `target[i][j]` are either `0` or `1`. | Let's change the question if we know the maximum size of a bag what is the minimum number of bags you can make note that as the maximum size increases the minimum number of bags decreases so we can binary search the maximum size |
Comparing indices without rotating the matrix || Python | determine-whether-matrix-can-be-obtained-by-rotation | 0 | 1 | # Complexity\n- Time complexity: O(n2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findRotation(self, mat: List[List[int]], target: List[List[int]]) -> bool:\n n = len(mat)\n count_0, count_90, count_180, count_270 = 0, 0, 0, 0\n\n for i in range(n):\n for j in range(n):\n # imaging rotating the matrix but without actually doing it, and for\n # each 90 degree rotation, take the new indices of the matrix and\n # compare them to the target\n\n # both matrices as they are\n if mat[i][j] == target[i][j]:\n count_0 += 1\n\n # after rotating mat 90 degrees\n if mat[i][j] == target[j][n - i - 1]:\n count_90 += 1\n\n # after rotating mat 180 degrees\n if mat[i][j] == target[n - i - 1][n - j - 1]:\n count_180 += 1\n\n # after rotating mat 270 degrees\n if mat[i][j] == target[n - j - 1][i]:\n count_270 += 1\n\n return n * n in {count_0, count_90, count_180, count_270}\n``` | 3 | Given two `n x n` binary matrices `mat` and `target`, return `true` _if it is possible to make_ `mat` _equal to_ `target` _by **rotating**_ `mat` _in **90-degree increments**, or_ `false` _otherwise._
**Example 1:**
**Input:** mat = \[\[0,1\],\[1,0\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise to make mat equal target.
**Example 2:**
**Input:** mat = \[\[0,1\],\[1,1\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** false
**Explanation:** It is impossible to make mat equal to target by rotating mat.
**Example 3:**
**Input:** mat = \[\[0,0,0\],\[0,1,0\],\[1,1,1\]\], target = \[\[1,1,1\],\[0,1,0\],\[0,0,0\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise two times to make mat equal target.
**Constraints:**
* `n == mat.length == target.length`
* `n == mat[i].length == target[i].length`
* `1 <= n <= 10`
* `mat[i][j]` and `target[i][j]` are either `0` or `1`. | Let's change the question if we know the maximum size of a bag what is the minimum number of bags you can make note that as the maximum size increases the minimum number of bags decreases so we can binary search the maximum size |
Python rotate function | determine-whether-matrix-can-be-obtained-by-rotation | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nHow clockwise rotation works?\n\nGiven a matrix \n```\n[[1, 2, 3], \n [4, 5, 6], \n [7, 8, 9]]\n```\n, it will become \n\n```\n[[7, 4, 1], \n [8, 5, 2], \n [9, 6, 3]]\n```\n\nif rotated 90 degree clockwise.\n\nAs we can see that **the first row of the rotated matrix is the first column of the original matrix in reversed order.**\nTo get column values of a matrix we can use `zip(*matrix)` and to get the reversed order we can use `[::-1]`. \nSo the clockwise rotate function would be\n```python\ndef rotate90_clockwise(mat):\n return [list(x[::-1]) for x in zip(*mat)]\n```\nSimilarily, the counter-clockwise function would be\n```python\ndef rotate90_counterwise(mat):\n return [list(x) for x in zip(*mat)][::-1]\n```\n\n\n# Code\n```python\nclass Solution:\n def findRotation(self, mat: List[List[int]], target: List[List[int]]) -> bool:\n \n def rotate90(mat):\n return [list(x[::-1]) for x in zip(*mat)]\n \n if sum(sum(row) for row in mat) != sum(sum(row) for row in target):\n return False\n\n for _ in range(4):\n mat = rotate90(mat)\n if mat == target:\n return True\n return False\n\n``` | 4 | Given two `n x n` binary matrices `mat` and `target`, return `true` _if it is possible to make_ `mat` _equal to_ `target` _by **rotating**_ `mat` _in **90-degree increments**, or_ `false` _otherwise._
**Example 1:**
**Input:** mat = \[\[0,1\],\[1,0\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise to make mat equal target.
**Example 2:**
**Input:** mat = \[\[0,1\],\[1,1\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** false
**Explanation:** It is impossible to make mat equal to target by rotating mat.
**Example 3:**
**Input:** mat = \[\[0,0,0\],\[0,1,0\],\[1,1,1\]\], target = \[\[1,1,1\],\[0,1,0\],\[0,0,0\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise two times to make mat equal target.
**Constraints:**
* `n == mat.length == target.length`
* `n == mat[i].length == target[i].length`
* `1 <= n <= 10`
* `mat[i][j]` and `target[i][j]` are either `0` or `1`. | Let's change the question if we know the maximum size of a bag what is the minimum number of bags you can make note that as the maximum size increases the minimum number of bags decreases so we can binary search the maximum size |
Fast and easy | determine-whether-matrix-can-be-obtained-by-rotation | 0 | 1 | ```\nclass Solution:\n def findRotation(self, mat: List[List[int]], target: List[List[int]]) -> bool:\n \n def rotate(matrix):\n l,r=0,len(matrix)-1\n\n while l< r:\n for i in range(r-l):\n top,bottom=l,r\n temp=matrix[top][l+i]\n\n matrix[top][l+i]=matrix[bottom-i][l]\n\n matrix[bottom-i][l]=matrix[bottom][r-i]\n\n matrix[bottom][r-i]=matrix[top+i][r]\n\n matrix[top+i][r]=temp\n l+=1\n r-=1\n \n return matrix\n for i in range(4):\n if rotate(mat)==target:\n return True\n else:\n continue\n return False\n \n``` | 0 | Given two `n x n` binary matrices `mat` and `target`, return `true` _if it is possible to make_ `mat` _equal to_ `target` _by **rotating**_ `mat` _in **90-degree increments**, or_ `false` _otherwise._
**Example 1:**
**Input:** mat = \[\[0,1\],\[1,0\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise to make mat equal target.
**Example 2:**
**Input:** mat = \[\[0,1\],\[1,1\]\], target = \[\[1,0\],\[0,1\]\]
**Output:** false
**Explanation:** It is impossible to make mat equal to target by rotating mat.
**Example 3:**
**Input:** mat = \[\[0,0,0\],\[0,1,0\],\[1,1,1\]\], target = \[\[1,1,1\],\[0,1,0\],\[0,0,0\]\]
**Output:** true
**Explanation:** We can rotate mat 90 degrees clockwise two times to make mat equal target.
**Constraints:**
* `n == mat.length == target.length`
* `n == mat[i].length == target[i].length`
* `1 <= n <= 10`
* `mat[i][j]` and `target[i][j]` are either `0` or `1`. | Let's change the question if we know the maximum size of a bag what is the minimum number of bags you can make note that as the maximum size increases the minimum number of bags decreases so we can binary search the maximum size |
Python3 Solution | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | \n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n n=len(nums)\n nums.sort(reverse=True)\n ans=0\n for i in range(n-1):\n if nums[i]>nums[i+1]:\n ans+=i+1\n return ans \n``` | 12 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
[Python] One line Python Solution, better than O(n logn) Time | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nUse Counter(nums) to make nums into a hash table, then sort it by the number, which would also reduce the complexity.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe could make the nums into Counter and sort into an array, we can name it arr. For each element in the arr in the arr, it has [num, cnt]. The num needs to reduce idx times to become the smallest number, where idx is its index in arr. And there\'s cnt numbers, multiple it by cnt. Add them all together, we can get the final answer.\n# Complexity\n- Time complexity:$$O(n + k logk)$$\n<!-- Add your time complexity here, e.g. -->\n\n- Space complexity:$$O(n)$$\n<!-- Add your space complexity here, e.g. -->\nk is the number of different numbers.\nThe time complexity would be much better than $$O(n logn)$$ if there\'re a lot of duplicated numbers\n\n# Code\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n return sum([i*cnt for i, (num, cnt) in enumerate(sorted(Counter(nums).items()))])\n``` | 7 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
✅☑[C++/Java/Python/JavaScript] || Easiest Approach || EXPLAINED🔥 | reduction-operations-to-make-the-array-elements-equal | 1 | 1 | # PLEASE UPVOTE IF IT HELPED\n\n---\n\n\n# Approaches\n**(Also explained in the code)**\n1. **Sorting:**\n\n - The code sorts the input vector nums in non-decreasing order using `sort()`.\n1. **Iterating Through the Sorted Vector:**\n\n - It iterates through the sorted vector and counts the number of unique elements.\n - For each new unique element encountered, it increments the temporary count `temp`.\n1. **Calculating Sum:**\n\n - For each iteration, it adds the `temp` count to the `sum`.\n - `sum` accumulates the total number of operations required for reduction.\n\n\n\n# Complexity\n- *Time complexity:*\n $$O(nlogn)$$\n \n\n- *Space complexity:*\n $$O(1)$$\n \n\n\n# Code\n```C++ []\nclass Solution {\npublic:\n int reductionOperations(vector<int>& nums) {\n sort(nums.begin(), nums.end()); // Sort the input vector \'nums\' in non-decreasing order\n int n = nums.size(); // Get the size of the input vector\n int sum = 0, temp = 0; // Initialize variables to keep track of sum and temporary count\n\n // Iterate through the sorted vector\n for (int i = 1; i < n; i++) {\n // Check if the current element is different from the previous one\n if (nums[i] != nums[i - 1]) {\n temp++; // Increment temporary count for a new unique element\n }\n sum += temp; // Add the temporary count to the sum for each iteration\n }\n\n return sum; // Return the final sum, which represents the number of operations performed\n }\n};\n\n\n\n```\n```C []\n\nint reductionOperations(int* nums, int numsSize) {\n qsort(nums, numsSize, sizeof(int), compare); // Sort the input array \'nums\' in non-decreasing order\n int sum = 0, temp = 0; // Initialize variables to keep track of sum and temporary count\n\n // Iterate through the sorted array\n for (int i = 1; i < numsSize; i++) {\n // Check if the current element is different from the previous one\n if (nums[i] != nums[i - 1]) {\n temp++; // Increment temporary count for a new unique element\n }\n sum += temp; // Add the temporary count to the sum for each iteration\n }\n\n return sum; // Return the final sum, which represents the number of operations performed\n}\n\n// Comparison function for qsort\nint compare(const void* a, const void* b) {\n return (*(int*)a - *(int*)b);\n}\n\n\n\n```\n\n\nclass Solution {\n public int reductionOperations(int[] nums) {\n Arrays.sort(nums); // Sort the input array \'nums\' in non-decreasing order\n int n = nums.length; // Get the size of the input array\n int sum = 0, temp = 0; // Initialize variables to keep track of sum and temporary count\n\n // Iterate through the sorted array\n for (int i = 1; i < n; i++) {\n // Check if the current element is different from the previous one\n if (nums[i] != nums[i - 1]) {\n temp++; // Increment temporary count for a new unique element\n }\n sum += temp; // Add the temporary count to the sum for each iteration\n }\n\n return sum; // Return the final sum, which represents the number of operations performed\n }\n}\n\n\n\n```\n```python3 []\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n nums.sort() # Sort the input list \'nums\' in non-decreasing order\n n = len(nums) # Get the size of the input list\n sum_val = 0\n temp = 0\n\n # Iterate through the sorted list\n for i in range(1, n):\n # Check if the current element is different from the previous one\n if nums[i] != nums[i - 1]:\n temp += 1 # Increment temporary count for a new unique element\n sum_val += temp # Add the temporary count to the sum for each iteration\n\n return sum_val # Return the final sum, which represents the number of operations performed\n\n\n```\n\n```javascript []\nvar reductionOperations = function(nums) {\n nums.sort((a, b) => a - b); // Sort the input array \'nums\' in non-decreasing order\n let sum = 0, temp = 0; // Initialize variables to keep track of sum and temporary count\n\n // Iterate through the sorted array\n for (let i = 1; i < nums.length; i++) {\n // Check if the current element is different from the previous one\n if (nums[i] !== nums[i - 1]) {\n temp++; // Increment temporary count for a new unique element\n }\n sum += temp; // Add the temporary count to the sum for each iteration\n }\n\n return sum; // Return the final sum, which represents the number of operations performed\n};\n\n\n```\n\n---\n\n\n\n# PLEASE UPVOTE IF IT HELPED\n\n---\n---\n\n\n--- | 8 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
Easy Sorting Solution with Dry Run! 🌟 | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nsort the array, count distinct values, and track operations to reduce each element\neg - 1 3 3 5 5\ncount shows the number of distinct elements between the lowest and the current element \ncount , ans , cur = 0 , 0 , nums[0]\ntraversing from the first index \n* 3 != 1 : count = 1 , ans = 1 , cur = 3\n* 3 == 3 : ans = 2 \n* 5 != 3 : count = 2 , ans = 4 , cur = 5\n* 5 == 5 : ans = 6\n\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n nums.sort()\n count , ans , cur = 0 , 0 , nums[0]\n for i in range(1,len(nums)):\n if cur != nums[i] :\n count += 1 \n ans += count \n cur = nums[i]\n else:\n ans += count \n return ans \n``` | 3 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
Efficiently Equalizing Array Elements 😊: Strategy and Complexity Analysis | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Intuition\nGiven an array, we aim to find the number of operations needed to make all elements equal. To do so, we need to strategically reduce larger elements to the smallest element in the array.\n\n# Approach\n1. Count the frequencies of each number: Create a map or dictionary to store the frequencies of each element in the array.\n2. Sort the elements: Sort the array in descending order to start with the largest elements.\n3. Iterate through the sorted array: As we iterate through the sorted array, keep track of the number of operations required to reduce elements.\n - For each element in the sorted array, increment the count of operations needed to make it equal to the smallest element (which will be at the end after sorting).\n - Accumulate the count of operations.\n4. Return the total count of operations: This count represents the minimum number of operations required to make all elements equal.\n# Complexity Analysis\n- Time Complexity:\n - Counting the frequencies of elements takes O(n) time.\n - Sorting the array takes O(n log n) time.\n - Iterating through the sorted array to count operations takes O(n) time.\n - Therefore, the overall time complexity is O(n log n).\n- Space Complexity:\n - Space required to store the frequencies in a map or dictionary is O(n).\n - Sorting the array in place might take O(log n) extra space due to recursive calls in certain sorting algorithms like quicksort.\n - Therefore, the overall space complexity is O(n).\n\n\n\n\n\n# Code\n``` C++ []\n#include <vector>\n#include <map>\n\nclass Solution {\npublic:\n int reductionOperations(std::vector<int>& nums) {\n std::map<int, int> count;\n int operations = 0;\n\n // Count the frequency of each number\n for (int num : nums) {\n count[num]++;\n }\n\n int prevFreq = 0;\n for (auto it = count.rbegin(); it != count.rend(); ++it) {\n operations += prevFreq;\n prevFreq += it->second;\n }\n\n return operations;\n }\n};\n\n```\n``` Python []\nclass Solution(object):\n def reductionOperations(self, nums):\n max_val = max(nums)\n freq = [0] * (max_val + 1)\n\n for num in nums:\n freq[num] += 1\n\n operations = 0\n current = max_val\n\n while True:\n while current > 0 and freq[current] == 0:\n current -= 1\n \n if current == 0:\n break\n\n next_largest = current - 1\n while next_largest > 0 and freq[next_largest] == 0:\n next_largest -= 1\n\n if next_largest == 0:\n break\n \n operations += freq[current]\n freq[next_largest] += freq[current]\n freq[current] = 0\n\n return operations\n``` | 7 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
Easy Python Solution || Beats 99% in Runtime | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Beats 99% in runtime\n\n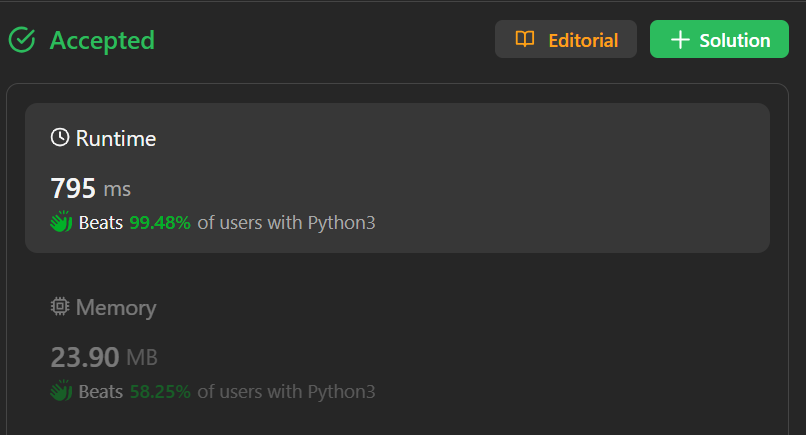\n\n# Intuition\nIf all the elements in the array are to be made equal just by reduction of values, then all elements can only be equal if they are equal to the smallest element.\n\n# Approach\n 1. Sort the array to simplify the reduction process.\n 2. Initialize variables: Declare a `multiplier` variable to track the number of reductions required and set it to -1.\n Also, declare a `count` variable to keep track of the total operations.\n 3. Iterate through the sorted array:\n - For each new element, increment the `count` by the current `multiplier`.\n - Whenever a new variable is encountered, increase the value of the `multiplier` by `1`.\n 4. The total operations needed to make all elements equal is the value of `count`.\n\n# Example\nConsider the array [4, 6, 3, 7, 1]:\n - After sorting: [1, 3, 4, 6, 7].\n \n - Iterating through:\n - For 1, no previous element to compare, so count += 0.\n - For 3, increment multiplier to 0, so count += 0.\n - For 4, increment multiplier to 1, so count += 1.\n - For 6, increment multiplier to 2, so count += 3.\n - For 7, increment multiplier to 3, so count += 6.\n\n The total operations to make all elements equal is 10.\n\n\n\n# Complexity\n\n- Time complexity: O ( n.log n)\n\n- Space complexity: O(1)\n\n# Code\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n \n nums.sort()\n\n visited, count, multiplier = None, 0, -1\n\n for i in nums:\n\n if i!=visited:\n multiplier += 1\n visited = i\n \n count+= multiplier\n\n return count\n\n``` | 2 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
✅ [C++/Python] Clean & Simple Solutions w/ Explanation | Sorting | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Intuition\nThe goal is to make all elements in the array equal by following a set of operations. The operations involve finding the largest value, determining the next largest value smaller than the current largest, and reducing the corresponding element to the next largest value. The task is to calculate the total number of operations required.\n\n# Approach\n1. Sort the array in non-decreasing order.\n2. Iterate through the sorted array from the end.\n3. For each unique value encountered, add the difference between the total length of the array and the current index to the result.\n - This accounts for the number of times the current value needs to be reduced to reach the smallest value.\n - Update the total number of operations accordingly.\n\n# Complexity\n- Time complexity:\n - Sorting the array takes O(n log n) time, where n is the length of the array.\n - Iterating through the array once takes O(n) time.\n - Overall time complexity: O(n log n)\n\n- Space complexity:\n - O(1) (since the sorting is done in-place)\n\n# Code\n\n```python []\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n nums.sort()\n ans = 0\n for i in range(len(nums) - 2, -1, -1):\n if nums[i] != nums[i + 1]:\n ans += len(nums) - (i + 1)\n\n return ans\n```\n```C++ []\nclass Solution {\npublic:\n int reductionOperations(vector<int>& nums) {\n sort(nums.begin(), nums.end());\n int ans = 0;\n for (int i = nums.size() - 2; i >= 0; --i) {\n if (nums[i] != nums[i + 1]) {\n ans += nums.size() - (i + 1);\n }\n }\n return ans;\n }\n};\n```\n****\u2714\uFE0F UP VOTE IF HELPFUL\n | 1 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
Easy Python Solution 🐍 | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Code\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n x=sorted(list(set(nums)))\n j=0\n freq={}\n for i in x:\n freq[i]=j\n j+=1\n ans=0\n for i in nums: ans+=freq[i]\n return ans\n```\n***Hope it helps...!!*** \uD83D\uDE07\u270C\uFE0F | 1 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
[Python] Dynamic Frequency with unique elements | Easy to understand | Approach & Code | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | #### Approach:\n\n1. Made a counter to keep in check the frequency of all elements\n2. Made an array of all unique elements & dropped the last element after dropping it as it\'s our target element\n3. Iterate through the array of `uniqueElements`, and keep adding the frequency of each element in `answer`.\n4. During this, we also keep updating the frequency with last element\'s frequency as we have made the last element as current element in last iteration. (Most important step of the question)\n\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n uniqueElements = list(set(nums))\n frequency = collections.Counter(nums)\n \n uniqueElements.sort(reverse=True)\n uniqueElements.pop()\n \n answer = 0\n for index, num in enumerate(uniqueElements):\n answer += frequency[num]\n \n\t\t\t# frequency update for next upcoming element\n if index + 1 < len(uniqueElements):\n frequency[uniqueElements[index + 1]] += frequency[num]\n \n return answer\n``` | 1 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
This question doesn't test your... | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis question does\'nt test your programming skills.\nIt tests your problem solving skills. \nThat is why I liked this.\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nTake a pen paper and you will find that at each index if it is different than previous index value, all the values before that index will be changed.\n\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(nlogn)---due to sorting\n\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n# Code\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n ans=0\n nums.sort()\n for i in range(len(nums)-2,-1,-1):\n if(nums[i]!=nums[i+1]):\n ans+=(len(nums)-1-i)\n return ans\n\n``` | 1 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
EASY PYTHON SOLUTION | reduction-operations-to-make-the-array-elements-equal | 0 | 1 | \n# Approach\nCount the occurrence of each number and store it in dictionary. Sort the keys as the index of keys will increase its steps to minimum value will increase by one \n\n# Complexity\n- Time complexity: O(N^2)\n\n- Space complexity: O(N)\n\n# Code\n```\nclass Solution:\n def reductionOperations(self, nums: List[int]) -> int:\n cnt=Counter(nums)\n lst=list(cnt.keys())\n lst.sort()\n sm=0\n for i in range(len(lst)):\n sm+=(i*cnt[lst[i]])\n\n return sm\n \n``` | 1 | Given an integer array `nums`, your goal is to make all elements in `nums` equal. To complete one operation, follow these steps:
1. Find the **largest** value in `nums`. Let its index be `i` (**0-indexed**) and its value be `largest`. If there are multiple elements with the largest value, pick the smallest `i`.
2. Find the **next largest** value in `nums` **strictly smaller** than `largest`. Let its value be `nextLargest`.
3. Reduce `nums[i]` to `nextLargest`.
Return _the number of operations to make all elements in_ `nums` _equal_.
**Example 1:**
**Input:** nums = \[5,1,3\]
**Output:** 3
**Explanation:** It takes 3 operations to make all elements in nums equal:
1. largest = 5 at index 0. nextLargest = 3. Reduce nums\[0\] to 3. nums = \[3,1,3\].
2. largest = 3 at index 0. nextLargest = 1. Reduce nums\[0\] to 1. nums = \[1,1,3\].
3. largest = 3 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1\].
**Example 2:**
**Input:** nums = \[1,1,1\]
**Output:** 0
**Explanation:** All elements in nums are already equal.
**Example 3:**
**Input:** nums = \[1,1,2,2,3\]
**Output:** 4
**Explanation:** It takes 4 operations to make all elements in nums equal:
1. largest = 3 at index 4. nextLargest = 2. Reduce nums\[4\] to 2. nums = \[1,1,2,2,2\].
2. largest = 2 at index 2. nextLargest = 1. Reduce nums\[2\] to 1. nums = \[1,1,1,2,2\].
3. largest = 2 at index 3. nextLargest = 1. Reduce nums\[3\] to 1. nums = \[1,1,1,1,2\].
4. largest = 2 at index 4. nextLargest = 1. Reduce nums\[4\] to 1. nums = \[1,1,1,1,1\].
**Constraints:**
* `1 <= nums.length <= 5 * 104`
* `1 <= nums[i] <= 5 * 104` | Consider a trio with nodes u, v, and w. The degree of the trio is just degree(u) + degree(v) + degree(w) - 6. The -6 comes from subtracting the edges u-v, u-w, and v-w, which are counted twice each in the vertex degree calculation. To get the trios (u,v,w), you can iterate on u, then iterate on each w,v such that w and v are neighbors of u and are neighbors of each other. |
Simple Python3 Solution | 99.9% | Sliding Window | Simple And Elegant With Explanation. | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem is to find the minimum number of flips needed to make a given binary string have alternating characters. The solution aims to achieve this by considering two possible alternate patterns: one starting with "0" and the other starting with "1". Then, it iterates through the string while keeping track of the differences between the original string and these two alternate patterns. The goal is to find the minimum number of differences at any position that matches the length of the original string.\n\n---\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Calculate the length of the input string n.\n\n2. Duplicate the input string by concatenating it with itself (s = s + s). This doubling of the string helps handle circular cases more easily.\n\n3. Initialize two alternate patterns, alt1 and alt2, where each character alternates between "0" and "1" (starting with different characters).\n\n4. Initialize variables: res to store the minimum number of flips needed, l to track the left end of the current substring, diff1 and diff2 to track the differences between the substring and the two alternate patterns.\n\n5. Iterate through the string using the variable r as the right end of the substring.\n\n- Update diff1 and diff2 by comparing the current character with the corresponding characters in alt1 and alt2.\n- If the length of the current substring is greater than n, adjust the differences by removing the contribution of the leftmost character (s[l]) from the counts.\n- If the length of the current substring is exactly n, update res with the minimum of the current values of res, diff1, and diff2. This accounts for the possibility of flipping a substring with the minimum differences.\n\n6. Finally, return the value of res, which represents the minimum number of flips needed to create an alternating pattern of characters.\n\n---\n\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\nBeats 88.65% of Python3 Users\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\nBeats 87.33% of Python Users\n\n---\n\n\n# Code\n```\nclass Solution:\n def minFlips(self, s: str) -> int:\n n = len(s)\n s = s + s\n alt1 , alt2 = " " , " "\n\n for i in range(len(s)):\n alt1 += "0" if i % 2 else "1"\n alt2 += "1" if i % 2 else "0"\n\n res = len(s)\n l = 0\n diff1 , diff2 = 0 , 0 \n for r in range(len(s)):\n if s[r] != alt1[r]:\n diff1 +=1\n if s[r] != alt2[r]:\n diff2 +=1\n\n if (r-l+1) > n:\n if s[l] != alt1[l]:\n diff1-=1\n if s[l] != alt2[l]:\n diff2-=1\n l+=1\n\n if (r-l+1) == n:\n res = min(res,diff1,diff2)\n return res\n \n \n``` | 1 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
✔ Python3 Solution | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | # Complexity\n- Time complexity: $$O(n)$$\n- Space complexity: $$O(1)$$\n\n# Code\n```\nclass Solution:\n def minFlips(self, s):\n n = len(s)\n e, o = (n + 1) // 2, n // 2\n x = s[::2].count(\'1\') - s[1::2].count(\'1\')\n ans = min(e - x, o + x)\n if n&1 == 0: return ans\n for i in s:\n x = 2 * int(i) - x\n ans = min(ans, e - x, o + x)\n return ans\n``` | 4 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
[Python] Simple DP (beats 99.52%) | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | * **Type-1** operation doesn\'t count. It will only benefit when the length of s is **odd** (will allow one-time two adjacent positions with same value, e.g. moving the first \'1\' of \'110\' to the end, it will become valid \'101\'.\n* We track 4 DP variables to count the # of Type-2 operations:\n\t* **start_1**: final valid string starting with \'1\', e.g. \'1010\'\n\t* **start_0**: the final valid string starting with \'0\', e.g. \'0101\'\n\t* **start_1_odd**: only works when s with odd length. positions after type-1 operation are the same with start_1\n\t* **start_0_odd**: only works when s with odd length. positions after type-1 operation are the same with start_0\n* **prev**: 0 or 1 (initial val as 0, used to track start_1)\n\t* if current **val** == **prev** (conflict with start_1): 1) flip **start_1** (+=1); 2) for odd length s: perform Type-1 operation move current **start_1** to **start_0_odd**, flip **start_1_odd**\n\t* if current **val** != **prev** (conflict with start_0): 1) flip **start_0** (+=1); 2) perform Type-1 operation for odd length s, move current **start_0** to **start_1_odd**, flip **start_0_odd**\n\t* after each iteration, switch the value of prev, i.e. prev = 1- prev\n* In the end, pick the smallest operations from: start_1, start_0, start_1_odd, start_0_odd\n```\nclass Solution:\n def minFlips(self, s: str) -> int:\n prev = 0\n start_1, start_0, start_1_odd, start_0_odd = 0,0,sys.maxsize,sys.maxsize\n odd = len(s)%2\n for val in s:\n val = int(val)\n if val == prev:\n if odd:\n start_0_odd = min(start_0_odd, start_1)\n start_1_odd += 1\n start_1 += 1\n else:\n if odd:\n start_1_odd = min(start_1_odd, start_0)\n start_0_odd += 1\n start_0 += 1\n prev = 1 - prev\n return min([start_1, start_0, start_1_odd, start_0_odd])\n``` | 8 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
Python || easy sliding window based solutiion | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | * so first of all basic idea is that we add s at the back because for every possible s that is a n length piece\n* we try to see what no changes it req for that we make it 2n length now we make to dummty strings s1 and s2 as only two alternative are available .... one starts with one 10101 and another starts with 01010101 \n* . so now start for loop with i if s1[i]!=s[i] then we want a change so we increase ans1 by + 1 now if we reach n-1 index we have a n lenrtgh string so we check with ans what if we got a min answer so ans1 ans2 and ans are compared and minimum value stored in ans\n* ....now we go to n th index now we remove the first index i=0 from s but we check if that index was earlier if changed \n* then we did ans-=1 so as to nullify its effect in ans so wo a new ans1 and ans2\nfor this n len string from index 1 to n and so on we go to n+1 then we remove 2 nd index element ...and so on and \n* we return ans at end which is min of all iterations\n**if u like the explanation plz do upvote it ..**\n\n```py\nclass Solution(object):\n def minFlips(self, s):\n n=len(s) # we save this length as it is length of window\n s+=s #we add this string because we can have any possibility like s[0]->s[n-1] or s[2]->s[n+1]meaning is that any continous variation with n length ... \n ans=sys.maxint #assiging the answer max possible value as want our answer to be minimum so while comparing min answer will be given \n ans1,ans2=0,0#two answer variables telling amount of changes we require to make it alternative\n s1=""#dummy string like 10010101\n s2=""#dummy string like 01010101\n for i in range(len(s)):\n if i%2==0:\n s1+="1"\n s2+="0"\n else :\n s1+="0"\n s2+="1"\n for i in range(len(s)):\n if s[i]!=s1[i]:#if they dont match we want a change so ++1\n ans1+=1\n if s[i]!=s2[i]:\n ans2+=1\n \n if i>=n:\n if s[i-n]!=s1[i-n]:#now we have gone ahead so removing the intial element but wait if that element needed a change we added ++ earlier but now he is not our part so why we have his ++ so to nullify its ++ we did a -- in string\n ans1-=1\n if s[i-n]!=s2[i-n]:\n ans2-=1\n if i>=n-1#when i reaches n-1 we have n length so we check answer first time and after that we always keep seeing if we get a less answer value and after the loop we get \n ans=min([ans,ans1,ans2])\n return ans \n | 6 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
Python | Sliding Window | Clean code | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | # Complexity\n- Time complexity: O(N)\n\n- Space complexity: O(1)\n- \n# Code\n```\nclass Solution:\n def minFlips(self, s: str) -> int:\n N = len(s)\n s *= 2\n \n valid1 = []\n valid2 = []\n for i in range(len(s)):\n valid1.append("0" if i % 2 == 0 else "1")\n valid2.append("1" if i % 2 == 0 else "0")\n valid1 = "".join(valid1)\n valid2 = "".join(valid2)\n\n flips1 = flips2 = 0\n for i in range(N):\n flips1 += s[i] != valid1[i]\n flips2 += s[i] != valid2[i]\n\n min_flips = min(flips1, flips2) \n for i in range(N, len(s)):\n flips1 += s[i] != valid1[i]\n flips1 -= s[i-N] != valid1[i-N]\n flips2 += s[i] != valid2[i]\n flips2 -= s[i-N] != valid2[i-N]\n min_flips = min(min_flips, flips1, flips2)\n return min_flips\n``` | 0 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
1888. Minimum Number of Flips to Make the Binary String Alternating | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minFlips(self, s: str) -> int:\n n = len(s)\n s = s+s\n alt1=""\n alt2 =""\n for i in range(len(s)):#store\n alt1 += "0" if i%2==0 else "1"\n alt2 += "1" if i%2==0 else "0"\n diff1,diff2 = 0,0\n l = 0\n res = len(s)\n for r in range(len(s)):#iterate\n if s[r]!=alt1[r]:#condition\n diff1 = diff1+1#count\n if s[r]!=alt2[r]:#condition\n diff2 = diff2+1#count\n if (r-l+1)>n:#count\n if s[l]!=alt1[l]:\n diff1 = diff1-1#count\n if s[l]!=alt2[l]:\n diff2 = diff2-1#count\n l = l+1#contract\n if (r-l+1)==n:\n res = min(res,diff1,diff2)#store\n return res\n``` | 0 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
O(n) time | O(1) space | solution explained | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIf the string length is: \n- even, the rotate (type-I) operation will not reduce the number of flips (type-II operation)\n- odd, the rotate operation may reduce the flips. So, we need to perform both operations\n\nFirst, find the flips. If the string is odd, rotate it and check if the rotate operation reduces the flips.\n\nThe alternating binary string can start with\n- 0 (case I) e.g 0101 \n- 1 (case II) e.g 1010\n\nSo, we need to find the minimum flips of the two cases. To find the flips in both cases:\n- traverse the string separately for each case. If the current character is not the expected character according to alternation, increase the flip count by 1 \n- traverse the string once and count even odd position flips\n - for case I, 0\'s are required at the even position and 1\'s at the odd position. We need to flip bits that are not at their position i.e 0\'s at odd positions and 1\'s at even positions\n - for case II, 0\'s are required at the odd position and 1\'s at the even position. We need to flip 0\'s at even position and 1\'s at odd position\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- set n = size of input string\n- set even = a hashmap to count flips required for even position 0\'s (case ii) and even position 1\'s (case i)\n- set odd = a hashmap to count flips required for odd position 0\'s (case i) and odd position 1\'s (case ii)\n- we can also use four variables instead of the two hashmaps but the code is clear this way)\n- traverse the string and count the even-odd position flips. For each index i in the range 0 to n\n - if current position is odd\n - if character is 1, we need to flip it according to case ii because in case ii, 1\'s are required at even position\n - if character is 0, we need to flip it according to case i because in case i, 0\'s are required at even position\n - so increment the count of corresponding character in the odd hashmap\n - else current position is even\n - if character is 1, we need to flip it according to case i because in case i, 1\'s are required at odd position\n - if character is 0, we need to flip it according to case ii because in case ii, 0\'s are required at odd position\n - so increment the count of corresponding character in the even hashmap\n- set res = minimum of case ii flips and case i flips to track the minimum flips\n- if n is odd, we need to perform the rotate operation also. Becasue if odd length string, odd and even position swap after each rotate operation\n- return res\n\n# Complexity\n- Time complexity: O(flip + rotate in case n is odd) \u2192 O(n + n) \u2192 O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(hashmaps) \u2192 O(even + odd) \u2192 O(2 + 2) \u2192 O(1)\n - 2 because each hashmap has two keys i.e 0 and 1\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minFlips(self, s: str) -> int:\n n = len(s)\n even, odd = {\'0\': 0, \'1\': 0}, {\'0\': 0, \'1\': 0}\n for i in range(n):\n if i & 1:\n odd[s[i]] += 1\n else: \n even[s[i]] += 1\n res = min(odd[\'1\'] + even[\'0\'], odd[\'0\'] + even[\'1\'])\n if n & 1: \n for c in s:\n even[c] -= 1\n odd[c] += 1\n even, odd = odd, even\n res = min(res, odd[\'1\'] + even[\'0\'], odd[\'0\'] + even[\'1\'])\n return res\n``` | 0 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
Python Medium Sliding Window | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | ```\nclass Solution:\n def minFlips(self, s: str) -> int:\n s += s\n arr = [int(char) for char in s]\n\n\n def calc(arr):\n N = len(arr) // 2\n\n prefSum = [0]\n ans = float("inf")\n\n for i in range(len(arr)):\n if i % 2 == 0:\n if arr[i] == 0:\n prefSum.append(prefSum[-1] + 1)\n\n else:\n prefSum.append(prefSum[-1])\n\n else:\n if arr[i] == 1:\n prefSum.append(prefSum[-1] + 1)\n\n else:\n prefSum.append(prefSum[-1])\n\n \n if i >= N:\n ans = min(ans, prefSum[i] - prefSum[i - N])\n\n \n\n\n \n return ans\n\n \n r = [char ^ 1 for char in arr]\n return min(calc(arr), calc(r))\n \n``` | 0 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
linear time | minimum-number-of-flips-to-make-the-binary-string-alternating | 0 | 1 | \n# Approach\nsliding window\n# Complexity\n- Time complexity:\nO(N)\n- Space complexity:\nO(1)\n# Code\n```\nclass Solution:\n def minFlips(self, s: str) -> int:\n n = len(s)\n s = s+s\n alt1,alt2 = "",""\n\n for i in range(len(s)):\n alt1 += "0" if i % 2 else "1"\n alt2 += "1" if i % 2 else "0"\n\n res = len(s)\n diff1,diff2 = 0 , 0\n l = 0\n for r in range(len(s)):\n if s[r] != alt1[r]:\n diff1 += 1\n if s[r] != alt2[r]:\n diff2 += 1\n\n if (r-l+1) > n:\n if s[l] != alt1[l]:\n diff1 -= 1\n if s[l] != alt2[l]:\n diff2 -= 1\n l+=1\n\n if (r-l+1) == n:\n res = min(res,diff1,diff2)\n \n return res\n``` | 0 | You are given a binary string `s`. You are allowed to perform two types of operations on the string in any sequence:
* **Type-1: Remove** the character at the start of the string `s` and **append** it to the end of the string.
* **Type-2: Pick** any character in `s` and **flip** its value, i.e., if its value is `'0'` it becomes `'1'` and vice-versa.
Return _the **minimum** number of **type-2** operations you need to perform_ _such that_ `s` _becomes **alternating**._
The string is called **alternating** if no two adjacent characters are equal.
* For example, the strings `"010 "` and `"1010 "` are alternating, while the string `"0100 "` is not.
**Example 1:**
**Input:** s = "111000 "
**Output:** 2
**Explanation**: Use the first operation two times to make s = "100011 ".
Then, use the second operation on the third and sixth elements to make s = "101010 ".
**Example 2:**
**Input:** s = "010 "
**Output:** 0
**Explanation**: The string is already alternating.
**Example 3:**
**Input:** s = "1110 "
**Output:** 1
**Explanation**: Use the second operation on the second element to make s = "1010 ".
**Constraints:**
* `1 <= s.length <= 105`
* `s[i]` is either `'0'` or `'1'`. | Iterate through each point, and keep track of the current point with the smallest Manhattan distance from your current location. |
[Python3] prefix sum & binary search | minimum-space-wasted-from-packaging | 0 | 1 | \n```\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n packages.sort()\n prefix = [0]\n for x in packages: prefix.append(prefix[-1] + x)\n \n ans = inf \n for box in boxes: \n box.sort()\n if packages[-1] <= box[-1]: \n kk = val = 0 \n for x in box: \n k = bisect_right(packages, x)\n val += (k - kk) * x - (prefix[k] - prefix[kk])\n kk = k\n ans = min(ans, val)\n return ans % 1_000_000_007 if ans < inf else -1 \n```\n\nEdited on 6/6/2021\nIt turns out that we don\'t need prefix sum (per @lee215). \n\n```\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n packages.sort()\n \n ans = inf \n for box in boxes: \n box.sort()\n if packages[-1] <= box[-1]: \n kk = val = 0 \n for x in box: \n k = bisect_right(packages, x)\n val += (k - kk) * x\n kk = k\n ans = min(ans, val)\n return (ans - sum(packages)) % 1_000_000_007 if ans < inf else -1 \n``` | 5 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
Python | Binary search | minimum-space-wasted-from-packaging | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import defaultdict\nfrom bisect import bisect_left,bisect_right\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n\n packages.sort()\n\n l=len(packages)\n\n #prefix sum of packages\n pre=[0 for i in range(l)]\n pre[0]=packages[0]\n\n for i in range(1,l):\n pre[i]+=pre[i-1]+packages[i]\n\n #print(\'pre \',pre)\n\n minn=10000000000\n\n #for each supplier\n for i in boxes:\n \n flag=False\n\n #sorting the box of supplier\n i.sort()\n \n #lenght of supplier\n L=len(i)\n\n #wastage of supplier\n wastage=0\n\n last=-1\n\n #for each design of supplier\n for j in i:\n \n ind=bisect_right(packages,j)\n\n if ind<l:\n\n summ=pre[ind]-packages[ind]\n\n elif ind==l:\n\n flag=True\n summ=pre[ind-1]\n \n tt=0\n if last<0:\n tt=ind\n else:\n tt=(ind-last-1)\n summ-=pre[last]\n\n wastage+=((tt*j)-(summ))\n\n last=ind-1\n\n if flag:\n minn=min(minn,wastage)%1000000007\n\n if minn>=1000000000:\n return -1\n return minn%1000000007\n\n\n\n\n\n \n \n \n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
Solution | minimum-space-wasted-from-packaging | 0 | 1 | \n# Code\n```\nfrom typing import List\nfrom math import inf\nfrom itertools import accumulate\nfrom bisect import bisect_right\n\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n MOD = 10**9 + 7\n packages.sort()\n prefix_sum = [0] + list(accumulate(packages))\n min_waste = inf\n\n for supplier in boxes:\n supplier.sort()\n if supplier[-1] < packages[-1]:\n continue\n\n total_waste = 0\n box_idx = 0\n for box_size in supplier:\n idx = bisect_right(packages, box_size, box_idx)\n total_waste += box_size * (idx - box_idx) - (prefix_sum[idx] - prefix_sum[box_idx])\n box_idx = idx\n\n min_waste = min(min_waste, total_waste)\n\n return min_waste % MOD if min_waste < inf else -1\n\n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
Line Sweep w/Early Stopping | Commented and Explained | minimum-space-wasted-from-packaging | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFrom the problem description and examples, we can notice that \n- packages and boxes in their lists are not in order \n- packages can contain duplicates \n- any box list without max package in it is not feasible and can be ignored\n\nFrom this start, our first steps are to \n- get the frequency of package sizes in our package list\n- get the sum of our package sizes \n- determine the maximal package size -> minimal largest package size\n- determine the minimal package size -> maximal package start size \n\nWe have now limited our space to the frequency of unique packcages moving from O(P) to O(p) where p <= P strictly \n\nNow we build a new box list as a list by \n- for box list in boxes \n - sort that box list \n - if box list maximal item >= max package \n - find final index we\'ll care about in box list via right bisection of box list with max package \n - find first index we\'ll care about in box list via left bisection of box list with minimal package \n - append to new box list the box list up until final index + 1 \n - otherwise, continue\n\nIf we do not have a new box list, return -1, it\'s not possible \n\nGet modulo set up otherwise\nThen, our prefix sum is a prefix sum of frequencies of packages summed together by indexing up to max size + 1 \nWe can set it up by filling into an array of max size + 1 the frequency for each package size at its package index \nThen we loop over package indices in range 1 to max package + 1 and update the prefix sum \nNow we have our most ideal space to begin work as now \n- packages are in terms of frequencies instead of individual items \n- prefix sum of package frequency is only to size needed \n- each list in new box list is only as large as needed \n - we could make sure each list is unique, but it afforded no speed up to do so, and as such we may assume that we end up with unique box lists for the most part as well! \n\nWith this in place, we can now confront the sweepline process we will consider \nConsider our wasted space as math.inf \nFor each box list in new box list \n- set up current waste as negative package sum (we used all perfectly!)\n- set previous box and count to 0 \n- for current box in box list \n - if current box is gte max package \n - count = prefix sum at max package - prefix sum of previous box (how many boxes for size max package will we overshoot with total up to previous box) \n - increment current waste by count * current box as amount of added waste \n - break\n - otherwise\n - count is prefix sum of frequency of current box - prefix sum of previous box (how many boxes of current size is different from prior)\n - if prefix sum difference is 0, that means no box of this size \n - otherwise, prefix sum difference gives us the number of these boxes \n - we add that to the current waste as product of count and current box to showcase the useage of this box \n - then move previous box forward to current box \n- after processing box list, set wasted space to minima of self and current waste \n\nreturn wasted space modulo mod \n\n# Approach\nDescribed in intuition above \n\n# Complexity\n- Time complexity : O(P + Diff + B * (sum(b log b)))\n - Takes O(P) twice to get packages to Counter form and to get sum of packages \n - Takes O(p) to get max package \n - Takes O(B) to go over all box lists in boxes \n - within which we do b log b to sort them, where b is their size \n - then, for those we do need to consider, takes O(log b) to get the first and final index \n - at which we then store a list of size b2 - b1 where b2 and b1 are the indices respective within b for final and first index, summarized as the min to max size + 1 \n - we then build a prefix sum of size max package plus 1 O(maxP + 1)\n - and do work for min package to max package + 1 steps O(maxP + 1)\n - we then loop over new_b number of box lists \n - in which we do b2 - b1 boxes at most work \n - \n - In total then O(P + Diff + O(B) * (b log b + log b) + O(new_b) * O(avg_new_b_size)) work \n - b log b dominates log b, so we can simplify there \n - new_b * avg new_b size is at most B * b \n - so B * b log b dominates \n - So O(P + Diff + B * sum of (b log b)) where P is number of packages, B is number of box lists and b is average size of each box list, and Diff is the max package - min package difference\n\n- Space complexity : O(p + B + max_p)\n - O(p) to store package frequencies \n - O(B) to store new box list \n - O(max_p) to store package prefix sum \n - In total O(p + B + max_p)\n\n# Code\n```\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int :\n # n packages in n boxes \n # m packagers who produce boxes of different sizes \n # need -> range of boxes produceable map to producers who produce them \n # box most be greater than or equal to package size \n # packages -> size of the ith package \n # boxes -> ith supplier \n # |\n # v\n # jth sizes available \n # goal is to find best singular box list such that \n # all packages are done \n # minimal waste is produced \n # ideas \n # sort packages -> largest size is limiting factor \n # sort boxes at each supplier -> if largest size is not largest package useable\n # remove from consideration \n # if after removing from consideration, none remain -> return -1 \n # final answer may be large -> use modulo \n # packages can be reduced to frequency packages \n # counter conversion \n packages, package_sum = collections.Counter(packages), sum(packages)\n # get max package and min package \n max_package, min_package = max(packages.keys()), min(packages.keys())\n # only care about the useable ones \n new_box_list = []\n for box_list in boxes : \n box_list.sort()\n if box_list[-1] >= max_package : \n # find actual final index of the max package in box list \n final_index = bisect.bisect_right(box_list, max_package)\n # find actual first index of the min package in box list\n first_index = bisect.bisect_left(box_list, min_package)\n # go only up to there inclusive \n new_box_list.append(box_list[first_index:final_index+1])\n else : \n continue \n\n # but if there are not any, we can quit early \n if len(new_box_list) == 0 : \n return -1\n\n # otherwise, we must solve, so set up mod \n mod = 10**9 + 7\n # Then we now build our prefix sum\n prefix_sum = [0] * (max_package + 1)\n for package in packages : \n prefix_sum[package] = packages[package]\n\n # loop over prefix sum of frequencies to make proper prefix sum \n for index in range(min_package, max_package+1) : \n prefix_sum[index] += prefix_sum[index - 1]\n\n # set up wasted space \n wasted_space = math.inf\n # for box list in new box list \n for box_list in new_box_list :\n # get current waste as negative package sum \n current_waste = -package_sum \n # set up previous box as box 0 \n previous_box = 0 \n # set count to start \n count = 0 \n # loop over boxes by index to stop index \n for current_box in box_list :\n # if this box is too big all others will be as well \n if current_box >= max_package : \n # set count variable prefix sum at max packages - prefix sum of previous box \n count = prefix_sum[max_package] - prefix_sum[previous_box]\n # increase current waste by count * current box as that is the amount of waste generated here\n current_waste += count * current_box\n break\n else : \n # otherwise count is the prefix sum at current minus previous\n count = prefix_sum[current_box] - prefix_sum[previous_box]\n # and the waste goes up by count times current box (waste for using this box)\n current_waste += count * current_box \n # and the previous box updates appropriately \n previous_box = current_box \n # at end update wasted space as needed \n wasted_space = min(wasted_space, current_waste)\n # answer is gauranteed due to earlier work \n return wasted_space % mod \n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
python 3 | line sweep | 100% faster | minimum-space-wasted-from-packaging | 0 | 1 | # Complexity\n- Time complexity:\n$O(n + h + \\sum_{i=0}^{m-1}b_i\\log (b_i))$\n\n- Space complexity:\n$O(h + \\max(b_0, b_1,..., b_{m-1}))$\n\n# Code\n```\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n n, s, high = len(packages), sum(packages), max(packages)\n prefixSum = [0] * (high + 1)\n for package in packages:\n prefixSum[package] += 1\n for i in range(1, high + 1):\n prefixSum[i] += prefixSum[i - 1]\n res = math.inf\n for sizes in boxes:\n sizes.sort()\n if sizes[-1] < high:\n continue\n wasted = -s\n prev = 0\n for size in sizes:\n if size >= high:\n count = prefixSum[high] - prefixSum[prev]\n wasted += count * size\n break\n count = prefixSum[size] - prefixSum[prev]\n wasted += count * size\n prev = size\n res = min(res, wasted)\n return res % 1000000007 if res != math.inf else -1\n\n\n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
Python (Simple Binary Search) | minimum-space-wasted-from-packaging | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minWastedSpace(self, packages, boxes):\n packages.sort()\n\n min_val, mod = float("inf"), 10**9 + 7\n\n for box in boxes:\n box.sort()\n if packages[-1] <= box[-1]:\n j = val = 0\n for x in box:\n i = bisect.bisect_right(packages,x)\n val += (i-j)*x\n j = i\n min_val = min(min_val,val)\n\n return (min_val - sum(packages))%mod if min_val != float("inf") else -1\n\n\n\n\n\n\n\n\n\n\n\n \n \n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
Binary search (right) + prefix sum | minimum-space-wasted-from-packaging | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import defaultdict\nimport sys\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n\n packages.sort()\n wasted_space = 0\n min_wasted_space = sys.maxsize\n \n pre_sum = defaultdict(lambda : 0)\n sums = 0\n for i,p in enumerate(packages):\n sums += p\n pre_sum[i] = sums\n\n for box in boxes:\n # compute wastedspace. \n wasted_space = 0\n box.sort()\n i = 0\n left_marker = 0\n if packages[-1] > box[-1]:\n continue\n while(i < len(box)):\n new_left_marker = bisect.bisect_right(packages,box[i])\n num_packages = new_left_marker - left_marker\n total_space = num_packages*box[i]\n box_space = pre_sum[new_left_marker-1] - pre_sum[left_marker-1]\n wasted_space += (total_space - box_space)\n i += 1\n left_marker = new_left_marker\n\n min_wasted_space = min(wasted_space,min_wasted_space)\n if min_wasted_space == sys.maxsize:\n return -1\n \n return int(min_wasted_space % (math.pow(10,9) + 7))\n\n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
Easiest Solution | minimum-space-wasted-from-packaging | 0 | 1 | \n```\nclass Solution:\n def minWastedSpace(self, P: List[int], B: List[List[int]]) -> int:\n maxp, maxb, n, ans = max(P), max(max(x) for x in B), len(P), math.inf\n if maxb < maxp:\n return -1\n P.sort()\n presum = [0] + list(itertools.accumulate(P))\n for box in B:\n box.sort()\n if box[-1] < maxp:\n continue\n preidx, res = 0, 0\n for b in box:\n if b < P[0]:\n continue\n curidx = bisect.bisect_right(P, b)\n res += (curidx - preidx) * b - (presum[curidx] - presum[preidx])\n if curidx >= n:\n break\n preidx = curidx\n ans = min(ans, res)\n return ans % (10 ** 9 + 7)\n``` | 0 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
[Python 3] Binary Search + Prefix Sum (1576 ms) | minimum-space-wasted-from-packaging | 0 | 1 | ```\nclass Solution:\n def minWastedSpace(self, packages: List[int], boxes: List[List[int]]) -> int:\n # prefix sum to save time\n acc = [0] + [*accumulate(packages)]\n packages.sort()\n\n ans = float(\'inf\')\n for box in boxes:\n tmp = 0\n # deal with smallest box first\n box.sort()\n \n # record number of packages already dealt with\n start = 0\n \n for b in box:\n loc = bisect.bisect(packages, b)\n if loc == 0: continue\n tmp += b * (loc - start) - (acc[loc] - acc[start])\n \n # all are packaged\n if loc == len(packages):\n ans = min(ans, tmp)\n break\n \n start = loc\n \n return ans % (10 **9+7) if ans != float(\'inf\') else -1 | 2 | You have `n` packages that you are trying to place in boxes, **one package in each box**. There are `m` suppliers that each produce boxes of **different sizes** (with infinite supply). A package can be placed in a box if the size of the package is **less than or equal to** the size of the box.
The package sizes are given as an integer array `packages`, where `packages[i]` is the **size** of the `ith` package. The suppliers are given as a 2D integer array `boxes`, where `boxes[j]` is an array of **box sizes** that the `jth` supplier produces.
You want to choose a **single supplier** and use boxes from them such that the **total wasted space** is **minimized**. For each package in a box, we define the space **wasted** to be `size of the box - size of the package`. The **total wasted space** is the sum of the space wasted in **all** the boxes.
* For example, if you have to fit packages with sizes `[2,3,5]` and the supplier offers boxes of sizes `[4,8]`, you can fit the packages of size-`2` and size-`3` into two boxes of size-`4` and the package with size-`5` into a box of size-`8`. This would result in a waste of `(4-2) + (4-3) + (8-5) = 6`.
Return _the **minimum total wasted space** by choosing the box supplier **optimally**, or_ `-1` _if it is **impossible** to fit all the packages inside boxes._ Since the answer may be **large**, return it **modulo** `109 + 7`.
**Example 1:**
**Input:** packages = \[2,3,5\], boxes = \[\[4,8\],\[2,8\]\]
**Output:** 6
**Explanation**: It is optimal to choose the first supplier, using two size-4 boxes and one size-8 box.
The total waste is (4-2) + (4-3) + (8-5) = 6.
**Example 2:**
**Input:** packages = \[2,3,5\], boxes = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** -1
**Explanation:** There is no box that the package of size 5 can fit in.
**Example 3:**
**Input:** packages = \[3,5,8,10,11,12\], boxes = \[\[12\],\[11,9\],\[10,5,14\]\]
**Output:** 9
**Explanation:** It is optimal to choose the third supplier, using two size-5 boxes, two size-10 boxes, and two size-14 boxes.
The total waste is (5-3) + (5-5) + (10-8) + (10-10) + (14-11) + (14-12) = 9.
**Constraints:**
* `n == packages.length`
* `m == boxes.length`
* `1 <= n <= 105`
* `1 <= m <= 105`
* `1 <= packages[i] <= 105`
* `1 <= boxes[j].length <= 105`
* `1 <= boxes[j][k] <= 105`
* `sum(boxes[j].length) <= 105`
* The elements in `boxes[j]` are **distinct**. | Let's note that the maximum power of 3 you'll use in your soln is 3^16 The number can not be represented as a sum of powers of 3 if it's ternary presentation has a 2 in it |
7 lines of code beats 99.52% | check-if-all-the-integers-in-a-range-are-covered | 0 | 1 | # Code\n```\nclass Solution:\n def isCovered(self, matrix: List[List[int]], l: int, r: int) -> bool:\n mat = []\n \n for start, end in matrix:\n mat.extend(list(range(start, end + 1)))\n \n for i in range(l, r + 1):\n if i not in mat:\n return False\n \n return True\n\n``` | 1 | You are given a 2D integer array `ranges` and two integers `left` and `right`. Each `ranges[i] = [starti, endi]` represents an **inclusive** interval between `starti` and `endi`.
Return `true` _if each integer in the inclusive range_ `[left, right]` _is covered by **at least one** interval in_ `ranges`. Return `false` _otherwise_.
An integer `x` is covered by an interval `ranges[i] = [starti, endi]` if `starti <= x <= endi`.
**Example 1:**
**Input:** ranges = \[\[1,2\],\[3,4\],\[5,6\]\], left = 2, right = 5
**Output:** true
**Explanation:** Every integer between 2 and 5 is covered:
- 2 is covered by the first range.
- 3 and 4 are covered by the second range.
- 5 is covered by the third range.
**Example 2:**
**Input:** ranges = \[\[1,10\],\[10,20\]\], left = 21, right = 21
**Output:** false
**Explanation:** 21 is not covered by any range.
**Constraints:**
* `1 <= ranges.length <= 50`
* `1 <= starti <= endi <= 50`
* `1 <= left <= right <= 50` | Think about dynamic programming Define an array dp[nums.length][2], where dp[i][0] is the max subarray sum including nums[i] and without squaring any element. dp[i][1] is the max subarray sum including nums[i] and having only one element squared. |
Python3 | Solved Using Sorting And Prefix Sum O(nlogn) Runtime and O(n) Space! | check-if-all-the-integers-in-a-range-are-covered | 0 | 1 | ```\nclass Solution:\n #Let n = len(ranges)!\n #Time-Complexity: O(nlogn + n * 1 + n * 1) - > O(nlogn)\n #Space-Complexity: O(n), if there are n intervals side by side non overlapping!\n def isCovered(self, ranges: List[List[int]], left: int, right: int) -> bool:\n #Approach: I will iterate through each range 1-d array element in order to \n #find all inclusive ranges that are distinct!\n \n #Then, I will iterate through each and every inclusive range and see if both left and right\n #interval within values are all contained in at least one of such ranges! \n \n #If so, I return T! Otherwise, I return F!\n \n #We can extend the last interval inserted if its end value is off by no more than 1 compared\n #to current interval we are iterating on! -> This way I can utilize prefix sum technique\n #to extend already inserted array!\n \n \n #sort by the start point of each range first!\n ranges.sort(key = lambda x: x[0])\n \n inclusive_arr = []\n \n #initially, add the first interval!\n inclusive_arr.append(ranges[0])\n \n for i in range(1, len(ranges)):\n cur = ranges[i]\n cur_start = cur[0]\n last = inclusive_arr[-1]\n last_end = last[1]\n \n #if current interval start comes before the most recently inserted range\'s end value!\n if(cur_start <= last_end):\n if(cur[1] > last_end):\n inclusive_arr[-1][1] = cur[1]\n continue\n #if current interval end point is encompassed within already existing interval, then\n #simply don\'t modify most recently inserted interval!\n else:\n continue\n else:\n #if current interval\'s start value is no more than 1 greater than most recently\n #inserted interval\'s last value, then we can simply extend the already inserted one!\n if(abs(cur_start - last_end) <= 1):\n inclusive_arr[-1][1] = cur[1]\n continue\n #otherwise, add on a new inclusive array!\n else:\n inclusive_arr.append(cur)\n \n \n \n \n \n #then, we have to check if [left, right] is contained in at least one such interval!\n \n for inc_arr in inclusive_arr:\n inc_start, inc_end = inc_arr[0], inc_arr[1]\n \n if((inc_start <= left <= inc_end) and\n (inc_start <= right <= inc_end)):\n return True\n return False | 0 | You are given a 2D integer array `ranges` and two integers `left` and `right`. Each `ranges[i] = [starti, endi]` represents an **inclusive** interval between `starti` and `endi`.
Return `true` _if each integer in the inclusive range_ `[left, right]` _is covered by **at least one** interval in_ `ranges`. Return `false` _otherwise_.
An integer `x` is covered by an interval `ranges[i] = [starti, endi]` if `starti <= x <= endi`.
**Example 1:**
**Input:** ranges = \[\[1,2\],\[3,4\],\[5,6\]\], left = 2, right = 5
**Output:** true
**Explanation:** Every integer between 2 and 5 is covered:
- 2 is covered by the first range.
- 3 and 4 are covered by the second range.
- 5 is covered by the third range.
**Example 2:**
**Input:** ranges = \[\[1,10\],\[10,20\]\], left = 21, right = 21
**Output:** false
**Explanation:** 21 is not covered by any range.
**Constraints:**
* `1 <= ranges.length <= 50`
* `1 <= starti <= endi <= 50`
* `1 <= left <= right <= 50` | Think about dynamic programming Define an array dp[nums.length][2], where dp[i][0] is the max subarray sum including nums[i] and without squaring any element. dp[i][1] is the max subarray sum including nums[i] and having only one element squared. |
Python simple solution | check-if-all-the-integers-in-a-range-are-covered | 0 | 1 | ```\nclass Solution:\n def isCovered(self, ranges: List[List[int]], left: int, right: int) -> bool:\n ans = 0\n for i in range(left, right+1):\n for x,y in ranges:\n if i in [x for x in range(x,y+1)]:\n ans += 1\n break\n return ans == right-left+1\n``` | 2 | You are given a 2D integer array `ranges` and two integers `left` and `right`. Each `ranges[i] = [starti, endi]` represents an **inclusive** interval between `starti` and `endi`.
Return `true` _if each integer in the inclusive range_ `[left, right]` _is covered by **at least one** interval in_ `ranges`. Return `false` _otherwise_.
An integer `x` is covered by an interval `ranges[i] = [starti, endi]` if `starti <= x <= endi`.
**Example 1:**
**Input:** ranges = \[\[1,2\],\[3,4\],\[5,6\]\], left = 2, right = 5
**Output:** true
**Explanation:** Every integer between 2 and 5 is covered:
- 2 is covered by the first range.
- 3 and 4 are covered by the second range.
- 5 is covered by the third range.
**Example 2:**
**Input:** ranges = \[\[1,10\],\[10,20\]\], left = 21, right = 21
**Output:** false
**Explanation:** 21 is not covered by any range.
**Constraints:**
* `1 <= ranges.length <= 50`
* `1 <= starti <= endi <= 50`
* `1 <= left <= right <= 50` | Think about dynamic programming Define an array dp[nums.length][2], where dp[i][0] is the max subarray sum including nums[i] and without squaring any element. dp[i][1] is the max subarray sum including nums[i] and having only one element squared. |
✅✅✅ Python3 - Faster than 99.63% ✅✅✅ | check-if-all-the-integers-in-a-range-are-covered | 0 | 1 | \n\n```\nclass Solution:\n def isCovered(self, ranges: List[List[int]], left: int, right: int) -> bool:\n cross_off_list = [i for i in range(left, right+1)]\n for rnge in ranges:\n for i in range(rnge[0], rnge[1]+1):\n if i in cross_off_list:\n cross_off_list.remove(i)\n return True if len(cross_off_list) == 0 else False\n```\n**Please upvote if you find it useful.**\n | 1 | You are given a 2D integer array `ranges` and two integers `left` and `right`. Each `ranges[i] = [starti, endi]` represents an **inclusive** interval between `starti` and `endi`.
Return `true` _if each integer in the inclusive range_ `[left, right]` _is covered by **at least one** interval in_ `ranges`. Return `false` _otherwise_.
An integer `x` is covered by an interval `ranges[i] = [starti, endi]` if `starti <= x <= endi`.
**Example 1:**
**Input:** ranges = \[\[1,2\],\[3,4\],\[5,6\]\], left = 2, right = 5
**Output:** true
**Explanation:** Every integer between 2 and 5 is covered:
- 2 is covered by the first range.
- 3 and 4 are covered by the second range.
- 5 is covered by the third range.
**Example 2:**
**Input:** ranges = \[\[1,10\],\[10,20\]\], left = 21, right = 21
**Output:** false
**Explanation:** 21 is not covered by any range.
**Constraints:**
* `1 <= ranges.length <= 50`
* `1 <= starti <= endi <= 50`
* `1 <= left <= right <= 50` | Think about dynamic programming Define an array dp[nums.length][2], where dp[i][0] is the max subarray sum including nums[i] and without squaring any element. dp[i][1] is the max subarray sum including nums[i] and having only one element squared. |
99.99% | python | clean | | check-if-all-the-integers-in-a-range-are-covered | 0 | 1 | ```\nclass Solution:\n def isCovered(self, ranges: List[List[int]], left: int, right: int) -> bool:\n \n \n t=[0]*(60)\n \n for i in ranges:\n \n t[i[0]]+=1\n t[i[1]+1]-=1\n \n for i in range(1,len(t)):\n t[i] += t[i-1]\n \n return min(t[left:right+1])>=1\n \n \n \n \n \n``` | 6 | You are given a 2D integer array `ranges` and two integers `left` and `right`. Each `ranges[i] = [starti, endi]` represents an **inclusive** interval between `starti` and `endi`.
Return `true` _if each integer in the inclusive range_ `[left, right]` _is covered by **at least one** interval in_ `ranges`. Return `false` _otherwise_.
An integer `x` is covered by an interval `ranges[i] = [starti, endi]` if `starti <= x <= endi`.
**Example 1:**
**Input:** ranges = \[\[1,2\],\[3,4\],\[5,6\]\], left = 2, right = 5
**Output:** true
**Explanation:** Every integer between 2 and 5 is covered:
- 2 is covered by the first range.
- 3 and 4 are covered by the second range.
- 5 is covered by the third range.
**Example 2:**
**Input:** ranges = \[\[1,10\],\[10,20\]\], left = 21, right = 21
**Output:** false
**Explanation:** 21 is not covered by any range.
**Constraints:**
* `1 <= ranges.length <= 50`
* `1 <= starti <= endi <= 50`
* `1 <= left <= right <= 50` | Think about dynamic programming Define an array dp[nums.length][2], where dp[i][0] is the max subarray sum including nums[i] and without squaring any element. dp[i][1] is the max subarray sum including nums[i] and having only one element squared. |
Subsets and Splits
No saved queries yet
Save your SQL queries to embed, download, and access them later. Queries will appear here once saved.