
text
stringlengths 7
318k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
439
|
|---|---|---|---|
# Changelog
This documents the main changes to the `candle` crate.
## v0.3.1 - Unreleased
### Added
### Modified
## v0.3.0 - 2023-10-01
### Added
- Added the Mistral 7b v0.1 model
[983](https://github.com/huggingface/candle/pull/983).
- Quantized version of the Mistral model
[1009](https://github.com/huggingface/candle/pull/1009).
- Add the gelu-erf op and activation function
[969](https://github.com/huggingface/candle/pull/969).
- Add the mixformer/phi-v1.5 model
[930](https://github.com/huggingface/candle/pull/930).
- Add the sclice-scatter op
[927](https://github.com/huggingface/candle/pull/927).
- Add the Wuerstchen diffusion model
[911](https://github.com/huggingface/candle/pull/911).
### Modified
- Support for simd128 intrinsics in some quantized vecdots
[982](https://github.com/huggingface/candle/pull/982).
- Optimize the index-select cuda kernel
[976](https://github.com/huggingface/candle/pull/976).
- Self-contained safetensor wrappers
[946](https://github.com/huggingface/candle/pull/946).
## v0.2.2 - 2023-09-18
### Added
- Support for `top_p` sampling
[819](https://github.com/huggingface/candle/pull/819).
- T5 model including decoding
[864](https://github.com/huggingface/candle/pull/864).
- 1-d upsampling
[839](https://github.com/huggingface/candle/pull/839).
### Modified
- Bugfix for conv2d
[820](https://github.com/huggingface/candle/pull/820).
- Support tensor based indexing using `.i`
[842](https://github.com/huggingface/candle/pull/842).
## v0.2.1 - 2023-09-11
### Added
- Add some RNNs (GRU and LSTM) in `candle-nn`
[674](https://github.com/huggingface/candle/pull/674),
[688](https://github.com/huggingface/candle/pull/688).
- gguf v2 support
[725](https://github.com/huggingface/candle/pull/725).
- Quantized llama example in Python using the pyo3 api
[716](https://github.com/huggingface/candle/pull/716).
- `candle-nn` layer for conv2d-transposed
[760](https://github.com/huggingface/candle/pull/760).
- Add the Segment-Anything Model (SAM) as an example
[773](https://github.com/huggingface/candle/pull/773).
- TinyViT backbone for the segment anything example
[787](https://github.com/huggingface/candle/pull/787).
- Shape with holes support
[770](https://github.com/huggingface/candle/pull/770).
### Modified
- Dilations are now supported in conv-transpose2d.
[671](https://github.com/huggingface/candle/pull/671).
- Interactive mode for the quantized model
[690](https://github.com/huggingface/candle/pull/690).
- Faster softmax operation
[747](https://github.com/huggingface/candle/pull/747).
- Faster convolution operations on CPU and CUDA via im2col
[802](https://github.com/huggingface/candle/pull/802).
- Moving some models to a more central location
[796](https://github.com/huggingface/candle/pull/796).
## v0.2.0 - 2023-08-30
### Added
- Add the powf op
[664](https://github.com/huggingface/candle/pull/664).
- Stable Diffusion XL support
[647](https://github.com/huggingface/candle/pull/647).
- Add the conv-transpose2d op
[635](https://github.com/huggingface/candle/pull/635).
- Refactor the VarBuilder api
[627](https://github.com/huggingface/candle/pull/627).
- Add some quantization command
[625](https://github.com/huggingface/candle/pull/625).
- Support more quantized types, e.g. Q2K, Q4K, Q5K...
[586](https://github.com/huggingface/candle/pull/586).
- Add pose estimation to the yolo example
[589](https://github.com/huggingface/candle/pull/589).
- Api to write GGUF files
[585](https://github.com/huggingface/candle/pull/585).
- Support more quantization types
[580](https://github.com/huggingface/candle/pull/580).
- Add EfficientNet as an example Computer Vision model
[572](https://github.com/huggingface/candle/pull/572).
- Add a group parameter to convolutions
[566](https://github.com/huggingface/candle/pull/566).
- New dtype: int64
[563](https://github.com/huggingface/candle/pull/563).
- Handling of the GGUF file format.
[559](https://github.com/huggingface/candle/pull/559).
## v0.1.2 - 2023-08-21
| candle/CHANGELOG.md/0 | {
"file_path": "candle/CHANGELOG.md",
"repo_id": "candle",
"token_count": 1525
} | 16 |
# Chapter 1
| candle/candle-book/src/chapter_1.md/0 | {
"file_path": "candle/candle-book/src/chapter_1.md",
"repo_id": "candle",
"token_count": 4
} | 17 |
# MNIST
So we now have downloaded the MNIST parquet files, let's put them in a simple struct.
```rust,ignore
{{#include ../lib.rs:book_training_3}}
```
The parsing of the file and putting it into single tensors requires the dataset to fit the entire memory.
It is quite rudimentary, but simple enough for a small dataset like MNIST.
| candle/candle-book/src/training/mnist.md/0 | {
"file_path": "candle/candle-book/src/training/mnist.md",
"repo_id": "candle",
"token_count": 93
} | 18 |
use candle_core::quantized::{gguf_file, GgmlDType, QTensor};
use candle_core::{Device, Result};
use clap::{Parser, Subcommand, ValueEnum};
use rayon::prelude::*;
#[derive(ValueEnum, Debug, Clone)]
enum QuantizationMode {
/// The default quantization includes all 2d tensors, except the output tensor which always
/// uses Q6_K.
Llama,
}
impl QuantizationMode {
fn quantize(&self, name: &str, tensor: QTensor, dtype: GgmlDType) -> Result<QTensor> {
match self {
Self::Llama => {
// Same behavior as the llama.cpp quantization.
let should_quantize = name.ends_with(".weight") && tensor.rank() == 2;
if should_quantize {
let tensor = tensor.dequantize(&Device::Cpu)?;
if name == "output.weight" {
QTensor::quantize(&tensor, GgmlDType::Q6K)
} else {
QTensor::quantize(&tensor, dtype)
}
} else {
Ok(tensor)
}
}
}
}
}
#[derive(ValueEnum, Debug, Clone)]
enum Quantization {
#[value(name = "q4_0")]
Q4_0,
#[value(name = "q4_1")]
Q4_1,
#[value(name = "q5_0")]
Q5_0,
#[value(name = "q5_1")]
Q5_1,
#[value(name = "q8_0")]
Q8_0,
#[value(name = "q8_1")]
Q8_1,
Q2k,
Q3k,
Q4k,
Q5k,
Q6k,
Q8k,
F16,
F32,
}
impl Quantization {
fn dtype(&self) -> GgmlDType {
match self {
Quantization::Q4_0 => GgmlDType::Q4_0,
Quantization::Q4_1 => GgmlDType::Q4_1,
Quantization::Q5_0 => GgmlDType::Q5_0,
Quantization::Q5_1 => GgmlDType::Q5_1,
Quantization::Q8_0 => GgmlDType::Q8_0,
Quantization::Q8_1 => GgmlDType::Q8_1,
Quantization::Q2k => GgmlDType::Q2K,
Quantization::Q3k => GgmlDType::Q3K,
Quantization::Q4k => GgmlDType::Q4K,
Quantization::Q5k => GgmlDType::Q5K,
Quantization::Q6k => GgmlDType::Q6K,
Quantization::Q8k => GgmlDType::Q8K,
Quantization::F16 => GgmlDType::F16,
Quantization::F32 => GgmlDType::F32,
}
}
}
#[derive(ValueEnum, Debug, Clone)]
enum Format {
Safetensors,
Npz,
Ggml,
Gguf,
Pth,
Pickle,
}
impl Format {
fn infer<P: AsRef<std::path::Path>>(p: P) -> Option<Self> {
p.as_ref()
.extension()
.and_then(|e| e.to_str())
.and_then(|e| match e {
// We don't infer any format for .bin as it can be used for ggml/gguf or pytorch.
"safetensors" | "safetensor" => Some(Self::Safetensors),
"npz" => Some(Self::Npz),
"pth" | "pt" => Some(Self::Pth),
"ggml" => Some(Self::Ggml),
"gguf" => Some(Self::Gguf),
_ => None,
})
}
}
#[derive(Subcommand, Debug, Clone)]
enum Command {
Ls {
files: Vec<std::path::PathBuf>,
/// The file format to use, if unspecified infer from the file extension.
#[arg(long, value_enum)]
format: Option<Format>,
/// Enable verbose mode.
#[arg(short, long)]
verbose: bool,
},
Quantize {
/// The input file(s), in safetensors format.
in_file: Vec<std::path::PathBuf>,
/// The output file, in gguf format.
#[arg(long)]
out_file: std::path::PathBuf,
/// The quantization schema to apply.
#[arg(long, value_enum)]
quantization: Quantization,
/// Which tensor to quantize.
#[arg(long, value_enum, default_value_t = QuantizationMode::Llama)]
mode: QuantizationMode,
},
Dequantize {
/// The input file, in gguf format.
in_file: std::path::PathBuf,
/// The output file, in safetensors format.
#[arg(long)]
out_file: std::path::PathBuf,
},
}
#[derive(Parser, Debug, Clone)]
struct Args {
#[command(subcommand)]
command: Command,
}
fn run_ls(
file: &std::path::PathBuf,
format: Option<Format>,
verbose: bool,
device: &Device,
) -> Result<()> {
let format = match format {
Some(format) => format,
None => match Format::infer(file) {
Some(format) => format,
None => {
println!(
"{file:?}: cannot infer format from file extension, use the --format flag"
);
return Ok(());
}
},
};
match format {
Format::Npz => {
let tensors = candle_core::npy::NpzTensors::new(file)?;
let mut names = tensors.names();
names.sort();
for name in names {
let shape_dtype = match tensors.get_shape_and_dtype(name) {
Ok((shape, dtype)) => format!("[{shape:?}; {dtype:?}]"),
Err(err) => err.to_string(),
};
println!("{name}: {shape_dtype}")
}
}
Format::Safetensors => {
let tensors = unsafe { candle_core::safetensors::MmapedSafetensors::new(file)? };
let mut tensors = tensors.tensors();
tensors.sort_by(|a, b| a.0.cmp(&b.0));
for (name, view) in tensors.iter() {
let dtype = view.dtype();
let dtype = match candle_core::DType::try_from(dtype) {
Ok(dtype) => format!("{dtype:?}"),
Err(_) => format!("{dtype:?}"),
};
let shape = view.shape();
println!("{name}: [{shape:?}; {dtype}]")
}
}
Format::Pth => {
let mut tensors = candle_core::pickle::read_pth_tensor_info(file, verbose)?;
tensors.sort_by(|a, b| a.name.cmp(&b.name));
for tensor_info in tensors.iter() {
println!(
"{}: [{:?}; {:?}]",
tensor_info.name,
tensor_info.layout.shape(),
tensor_info.dtype,
);
if verbose {
println!(" {:?}", tensor_info);
}
}
}
Format::Pickle => {
let file = std::fs::File::open(file)?;
let mut reader = std::io::BufReader::new(file);
let mut stack = candle_core::pickle::Stack::empty();
stack.read_loop(&mut reader)?;
for (i, obj) in stack.stack().iter().enumerate() {
println!("{i} {obj:?}");
}
}
Format::Ggml => {
let mut file = std::fs::File::open(file)?;
let content = candle_core::quantized::ggml_file::Content::read(&mut file, device)?;
let mut tensors = content.tensors.into_iter().collect::<Vec<_>>();
tensors.sort_by(|a, b| a.0.cmp(&b.0));
for (name, qtensor) in tensors.iter() {
println!("{name}: [{:?}; {:?}]", qtensor.shape(), qtensor.dtype());
}
}
Format::Gguf => {
let mut file = std::fs::File::open(file)?;
let content = gguf_file::Content::read(&mut file)?;
if verbose {
let mut metadata = content.metadata.into_iter().collect::<Vec<_>>();
metadata.sort_by(|a, b| a.0.cmp(&b.0));
println!("metadata entries ({})", metadata.len());
for (key, value) in metadata.iter() {
println!(" {key}: {value:?}");
}
}
let mut tensors = content.tensor_infos.into_iter().collect::<Vec<_>>();
tensors.sort_by(|a, b| a.0.cmp(&b.0));
for (name, info) in tensors.iter() {
println!("{name}: [{:?}; {:?}]", info.shape, info.ggml_dtype);
}
}
}
Ok(())
}
fn run_quantize_safetensors(
in_files: &[std::path::PathBuf],
out_file: std::path::PathBuf,
q: Quantization,
) -> Result<()> {
let mut out_file = std::fs::File::create(out_file)?;
let mut tensors = std::collections::HashMap::new();
for in_file in in_files.iter() {
let in_tensors = candle_core::safetensors::load(in_file, &Device::Cpu)?;
tensors.extend(in_tensors)
}
println!("tensors: {}", tensors.len());
let dtype = q.dtype();
let block_size = dtype.block_size();
let qtensors = tensors
.into_par_iter()
.map(|(name, tensor)| {
let should_quantize = tensor.rank() == 2 && tensor.dim(1)? % block_size == 0;
println!(" quantizing {name} {tensor:?} {should_quantize}");
let tensor = if should_quantize {
QTensor::quantize(&tensor, dtype)?
} else {
QTensor::quantize(&tensor, GgmlDType::F32)?
};
Ok((name, tensor))
})
.collect::<Result<Vec<_>>>()?;
let qtensors = qtensors
.iter()
.map(|(k, v)| (k.as_str(), v))
.collect::<Vec<_>>();
gguf_file::write(&mut out_file, &[], &qtensors)?;
Ok(())
}
fn run_dequantize(
in_file: std::path::PathBuf,
out_file: std::path::PathBuf,
device: &Device,
) -> Result<()> {
let mut in_file = std::fs::File::open(in_file)?;
let content = gguf_file::Content::read(&mut in_file)?;
let mut tensors = std::collections::HashMap::new();
for (tensor_name, _) in content.tensor_infos.iter() {
let tensor = content.tensor(&mut in_file, tensor_name, device)?;
let tensor = tensor.dequantize(device)?;
tensors.insert(tensor_name.to_string(), tensor);
}
candle_core::safetensors::save(&tensors, out_file)?;
Ok(())
}
fn run_quantize(
in_files: &[std::path::PathBuf],
out_file: std::path::PathBuf,
q: Quantization,
qmode: QuantizationMode,
device: &Device,
) -> Result<()> {
if in_files.is_empty() {
candle_core::bail!("no specified input files")
}
if let Some(extension) = out_file.extension() {
if extension == "safetensors" {
candle_core::bail!("the generated file cannot use the safetensors extension")
}
}
if let Some(extension) = in_files[0].extension() {
if extension == "safetensors" {
return run_quantize_safetensors(in_files, out_file, q);
}
}
if in_files.len() != 1 {
candle_core::bail!("only a single in-file can be used when quantizing gguf files")
}
// Open the out file early so as to fail directly on missing directories etc.
let mut out_file = std::fs::File::create(out_file)?;
let mut in_ = std::fs::File::open(&in_files[0])?;
let content = gguf_file::Content::read(&mut in_)?;
println!("tensors: {}", content.tensor_infos.len());
let dtype = q.dtype();
let qtensors = content
.tensor_infos
.par_iter()
.map(|(name, _)| {
println!(" quantizing {name}");
let mut in_file = std::fs::File::open(&in_files[0])?;
let tensor = content.tensor(&mut in_file, name, device)?;
let tensor = qmode.quantize(name, tensor, dtype)?;
Ok((name, tensor))
})
.collect::<Result<Vec<_>>>()?;
let qtensors = qtensors
.iter()
.map(|(k, v)| (k.as_str(), v))
.collect::<Vec<_>>();
let metadata = content
.metadata
.iter()
.map(|(k, v)| (k.as_str(), v))
.collect::<Vec<_>>();
gguf_file::write(&mut out_file, metadata.as_slice(), &qtensors)?;
Ok(())
}
fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = Device::Cpu;
match args.command {
Command::Ls {
files,
format,
verbose,
} => {
let multiple_files = files.len() > 1;
for file in files.iter() {
if multiple_files {
println!("--- {file:?} ---");
}
run_ls(file, format.clone(), verbose, &device)?
}
}
Command::Quantize {
in_file,
out_file,
quantization,
mode,
} => run_quantize(&in_file, out_file, quantization, mode, &device)?,
Command::Dequantize { in_file, out_file } => run_dequantize(in_file, out_file, &device)?,
}
Ok(())
}
| candle/candle-core/examples/tensor-tools.rs/0 | {
"file_path": "candle/candle-core/examples/tensor-tools.rs",
"repo_id": "candle",
"token_count": 6583
} | 19 |
/// Pretty printing of tensors
/// This implementation should be in line with the PyTorch version.
/// https://github.com/pytorch/pytorch/blob/7b419e8513a024e172eae767e24ec1b849976b13/torch/_tensor_str.py
use crate::{DType, Result, Tensor, WithDType};
use half::{bf16, f16};
impl Tensor {
fn fmt_dt<T: WithDType + std::fmt::Display>(
&self,
f: &mut std::fmt::Formatter,
) -> std::fmt::Result {
let device_str = match self.device().location() {
crate::DeviceLocation::Cpu => "".to_owned(),
crate::DeviceLocation::Cuda { gpu_id } => {
format!(", cuda:{}", gpu_id)
}
crate::DeviceLocation::Metal { gpu_id } => {
format!(", metal:{}", gpu_id)
}
};
write!(f, "Tensor[")?;
match self.dims() {
[] => {
if let Ok(v) = self.to_scalar::<T>() {
write!(f, "{v}")?
}
}
[s] if *s < 10 => {
if let Ok(vs) = self.to_vec1::<T>() {
for (i, v) in vs.iter().enumerate() {
if i > 0 {
write!(f, ", ")?;
}
write!(f, "{v}")?;
}
}
}
dims => {
write!(f, "dims ")?;
for (i, d) in dims.iter().enumerate() {
if i > 0 {
write!(f, ", ")?;
}
write!(f, "{d}")?;
}
}
}
write!(f, "; {}{}]", self.dtype().as_str(), device_str)
}
}
impl std::fmt::Debug for Tensor {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
match self.dtype() {
DType::U8 => self.fmt_dt::<u8>(f),
DType::U32 => self.fmt_dt::<u32>(f),
DType::I64 => self.fmt_dt::<i64>(f),
DType::BF16 => self.fmt_dt::<bf16>(f),
DType::F16 => self.fmt_dt::<f16>(f),
DType::F32 => self.fmt_dt::<f32>(f),
DType::F64 => self.fmt_dt::<f64>(f),
}
}
}
/// Options for Tensor pretty printing
pub struct PrinterOptions {
precision: usize,
threshold: usize,
edge_items: usize,
line_width: usize,
sci_mode: Option<bool>,
}
static PRINT_OPTS: std::sync::Mutex<PrinterOptions> =
std::sync::Mutex::new(PrinterOptions::const_default());
impl PrinterOptions {
// We cannot use the default trait as it's not const.
const fn const_default() -> Self {
Self {
precision: 4,
threshold: 1000,
edge_items: 3,
line_width: 80,
sci_mode: None,
}
}
}
pub fn set_print_options(options: PrinterOptions) {
*PRINT_OPTS.lock().unwrap() = options
}
pub fn set_print_options_default() {
*PRINT_OPTS.lock().unwrap() = PrinterOptions::const_default()
}
pub fn set_print_options_short() {
*PRINT_OPTS.lock().unwrap() = PrinterOptions {
precision: 2,
threshold: 1000,
edge_items: 2,
line_width: 80,
sci_mode: None,
}
}
pub fn set_print_options_full() {
*PRINT_OPTS.lock().unwrap() = PrinterOptions {
precision: 4,
threshold: usize::MAX,
edge_items: 3,
line_width: 80,
sci_mode: None,
}
}
struct FmtSize {
current_size: usize,
}
impl FmtSize {
fn new() -> Self {
Self { current_size: 0 }
}
fn final_size(self) -> usize {
self.current_size
}
}
impl std::fmt::Write for FmtSize {
fn write_str(&mut self, s: &str) -> std::fmt::Result {
self.current_size += s.len();
Ok(())
}
}
trait TensorFormatter {
type Elem: WithDType;
fn fmt<T: std::fmt::Write>(&self, v: Self::Elem, max_w: usize, f: &mut T) -> std::fmt::Result;
fn max_width(&self, to_display: &Tensor) -> usize {
let mut max_width = 1;
if let Ok(vs) = to_display.flatten_all().and_then(|t| t.to_vec1()) {
for &v in vs.iter() {
let mut fmt_size = FmtSize::new();
let _res = self.fmt(v, 1, &mut fmt_size);
max_width = usize::max(max_width, fmt_size.final_size())
}
}
max_width
}
fn write_newline_indent(i: usize, f: &mut std::fmt::Formatter) -> std::fmt::Result {
writeln!(f)?;
for _ in 0..i {
write!(f, " ")?
}
Ok(())
}
fn fmt_tensor(
&self,
t: &Tensor,
indent: usize,
max_w: usize,
summarize: bool,
po: &PrinterOptions,
f: &mut std::fmt::Formatter,
) -> std::fmt::Result {
let dims = t.dims();
let edge_items = po.edge_items;
write!(f, "[")?;
match dims {
[] => {
if let Ok(v) = t.to_scalar::<Self::Elem>() {
self.fmt(v, max_w, f)?
}
}
[v] if summarize && *v > 2 * edge_items => {
if let Ok(vs) = t
.narrow(0, 0, edge_items)
.and_then(|t| t.to_vec1::<Self::Elem>())
{
for v in vs.into_iter() {
self.fmt(v, max_w, f)?;
write!(f, ", ")?;
}
}
write!(f, "...")?;
if let Ok(vs) = t
.narrow(0, v - edge_items, edge_items)
.and_then(|t| t.to_vec1::<Self::Elem>())
{
for v in vs.into_iter() {
write!(f, ", ")?;
self.fmt(v, max_w, f)?;
}
}
}
[_] => {
let elements_per_line = usize::max(1, po.line_width / (max_w + 2));
if let Ok(vs) = t.to_vec1::<Self::Elem>() {
for (i, v) in vs.into_iter().enumerate() {
if i > 0 {
if i % elements_per_line == 0 {
write!(f, ",")?;
Self::write_newline_indent(indent, f)?
} else {
write!(f, ", ")?;
}
}
self.fmt(v, max_w, f)?
}
}
}
_ => {
if summarize && dims[0] > 2 * edge_items {
for i in 0..edge_items {
match t.get(i) {
Ok(t) => self.fmt_tensor(&t, indent + 1, max_w, summarize, po, f)?,
Err(e) => write!(f, "{e:?}")?,
}
write!(f, ",")?;
Self::write_newline_indent(indent, f)?
}
write!(f, "...")?;
Self::write_newline_indent(indent, f)?;
for i in dims[0] - edge_items..dims[0] {
match t.get(i) {
Ok(t) => self.fmt_tensor(&t, indent + 1, max_w, summarize, po, f)?,
Err(e) => write!(f, "{e:?}")?,
}
if i + 1 != dims[0] {
write!(f, ",")?;
Self::write_newline_indent(indent, f)?
}
}
} else {
for i in 0..dims[0] {
match t.get(i) {
Ok(t) => self.fmt_tensor(&t, indent + 1, max_w, summarize, po, f)?,
Err(e) => write!(f, "{e:?}")?,
}
if i + 1 != dims[0] {
write!(f, ",")?;
Self::write_newline_indent(indent, f)?
}
}
}
}
}
write!(f, "]")?;
Ok(())
}
}
struct FloatFormatter<S: WithDType> {
int_mode: bool,
sci_mode: bool,
precision: usize,
_phantom: std::marker::PhantomData<S>,
}
impl<S> FloatFormatter<S>
where
S: WithDType + num_traits::Float + std::fmt::Display,
{
fn new(t: &Tensor, po: &PrinterOptions) -> Result<Self> {
let mut int_mode = true;
let mut sci_mode = false;
// Rather than containing all values, this should only include
// values that end up being displayed according to [threshold].
let values = t
.flatten_all()?
.to_vec1()?
.into_iter()
.filter(|v: &S| v.is_finite() && !v.is_zero())
.collect::<Vec<_>>();
if !values.is_empty() {
let mut nonzero_finite_min = S::max_value();
let mut nonzero_finite_max = S::min_value();
for &v in values.iter() {
let v = v.abs();
if v < nonzero_finite_min {
nonzero_finite_min = v
}
if v > nonzero_finite_max {
nonzero_finite_max = v
}
}
for &value in values.iter() {
if value.ceil() != value {
int_mode = false;
break;
}
}
if let Some(v1) = S::from(1000.) {
if let Some(v2) = S::from(1e8) {
if let Some(v3) = S::from(1e-4) {
sci_mode = nonzero_finite_max / nonzero_finite_min > v1
|| nonzero_finite_max > v2
|| nonzero_finite_min < v3
}
}
}
}
match po.sci_mode {
None => {}
Some(v) => sci_mode = v,
}
Ok(Self {
int_mode,
sci_mode,
precision: po.precision,
_phantom: std::marker::PhantomData,
})
}
}
impl<S> TensorFormatter for FloatFormatter<S>
where
S: WithDType + num_traits::Float + std::fmt::Display + std::fmt::LowerExp,
{
type Elem = S;
fn fmt<T: std::fmt::Write>(&self, v: Self::Elem, max_w: usize, f: &mut T) -> std::fmt::Result {
if self.sci_mode {
write!(
f,
"{v:width$.prec$e}",
v = v,
width = max_w,
prec = self.precision
)
} else if self.int_mode {
if v.is_finite() {
write!(f, "{v:width$.0}.", v = v, width = max_w - 1)
} else {
write!(f, "{v:max_w$.0}")
}
} else {
write!(
f,
"{v:width$.prec$}",
v = v,
width = max_w,
prec = self.precision
)
}
}
}
struct IntFormatter<S: WithDType> {
_phantom: std::marker::PhantomData<S>,
}
impl<S: WithDType> IntFormatter<S> {
fn new() -> Self {
Self {
_phantom: std::marker::PhantomData,
}
}
}
impl<S> TensorFormatter for IntFormatter<S>
where
S: WithDType + std::fmt::Display,
{
type Elem = S;
fn fmt<T: std::fmt::Write>(&self, v: Self::Elem, max_w: usize, f: &mut T) -> std::fmt::Result {
write!(f, "{v:max_w$}")
}
}
fn get_summarized_data(t: &Tensor, edge_items: usize) -> Result<Tensor> {
let dims = t.dims();
if dims.is_empty() {
Ok(t.clone())
} else if dims.len() == 1 {
if dims[0] > 2 * edge_items {
Tensor::cat(
&[
t.narrow(0, 0, edge_items)?,
t.narrow(0, dims[0] - edge_items, edge_items)?,
],
0,
)
} else {
Ok(t.clone())
}
} else if dims[0] > 2 * edge_items {
let mut vs: Vec<_> = (0..edge_items)
.map(|i| get_summarized_data(&t.get(i)?, edge_items))
.collect::<Result<Vec<_>>>()?;
for i in (dims[0] - edge_items)..dims[0] {
vs.push(get_summarized_data(&t.get(i)?, edge_items)?)
}
Tensor::cat(&vs, 0)
} else {
let vs: Vec<_> = (0..dims[0])
.map(|i| get_summarized_data(&t.get(i)?, edge_items))
.collect::<Result<Vec<_>>>()?;
Tensor::cat(&vs, 0)
}
}
impl std::fmt::Display for Tensor {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
let po = PRINT_OPTS.lock().unwrap();
let summarize = self.elem_count() > po.threshold;
let to_display = if summarize {
match get_summarized_data(self, po.edge_items) {
Ok(v) => v,
Err(err) => return write!(f, "{err:?}"),
}
} else {
self.clone()
};
match self.dtype() {
DType::U8 => {
let tf: IntFormatter<u8> = IntFormatter::new();
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
DType::U32 => {
let tf: IntFormatter<u32> = IntFormatter::new();
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
DType::I64 => {
let tf: IntFormatter<i64> = IntFormatter::new();
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
DType::BF16 => {
if let Ok(tf) = FloatFormatter::<bf16>::new(&to_display, &po) {
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
}
DType::F16 => {
if let Ok(tf) = FloatFormatter::<f16>::new(&to_display, &po) {
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
}
DType::F64 => {
if let Ok(tf) = FloatFormatter::<f64>::new(&to_display, &po) {
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
}
DType::F32 => {
if let Ok(tf) = FloatFormatter::<f32>::new(&to_display, &po) {
let max_w = tf.max_width(&to_display);
tf.fmt_tensor(self, 1, max_w, summarize, &po, f)?;
writeln!(f)?;
}
}
};
let device_str = match self.device().location() {
crate::DeviceLocation::Cpu => "".to_owned(),
crate::DeviceLocation::Cuda { gpu_id } => {
format!(", cuda:{}", gpu_id)
}
crate::DeviceLocation::Metal { gpu_id } => {
format!(", metal:{}", gpu_id)
}
};
write!(
f,
"Tensor[{:?}, {}{}]",
self.dims(),
self.dtype().as_str(),
device_str
)
}
}
| candle/candle-core/src/display.rs/0 | {
"file_path": "candle/candle-core/src/display.rs",
"repo_id": "candle",
"token_count": 9501
} | 20 |
use super::utils::{
get_scale_min_k4, group_for_dequantization, group_for_quantization, make_q3_quants,
make_qkx1_quants, make_qx_quants, nearest_int,
};
use super::GgmlDType;
use crate::Result;
use byteorder::{ByteOrder, LittleEndian};
use half::f16;
use rayon::prelude::*;
// Default to QK_K 256 rather than 64.
pub const QK_K: usize = 256;
pub const K_SCALE_SIZE: usize = 12;
pub const QK4_0: usize = 32;
pub const QK4_1: usize = 32;
pub const QK5_0: usize = 32;
pub const QK5_1: usize = 32;
pub const QK8_0: usize = 32;
pub const QK8_1: usize = 32;
pub trait GgmlType: Sized + Clone + Send + Sync {
const DTYPE: GgmlDType;
const BLCK_SIZE: usize;
type VecDotType: GgmlType;
// This is only safe for types that include immediate values such as float/int/...
fn zeros() -> Self {
unsafe { std::mem::MaybeUninit::zeroed().assume_init() }
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()>;
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()>;
/// Dot product used as a building block for quantized mat-mul.
/// n is the number of elements to be considered.
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32>;
/// Generic implementation of the dot product without simd optimizations.
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32>;
}
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ4_0 {
pub(crate) d: f16,
pub(crate) qs: [u8; QK4_0 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ4_0>() == 18);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ4_1 {
pub(crate) d: f16,
pub(crate) m: f16,
pub(crate) qs: [u8; QK4_1 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ4_1>() == 20);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ5_0 {
pub(crate) d: f16,
pub(crate) qh: [u8; 4],
pub(crate) qs: [u8; QK5_0 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ5_0>() == 22);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ5_1 {
pub(crate) d: f16,
pub(crate) m: f16,
pub(crate) qh: [u8; 4],
pub(crate) qs: [u8; QK5_1 / 2],
}
const _: () = assert!(std::mem::size_of::<BlockQ5_1>() == 24);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ8_0 {
pub(crate) d: f16,
pub(crate) qs: [i8; QK8_0],
}
const _: () = assert!(std::mem::size_of::<BlockQ8_0>() == 34);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ8_1 {
pub(crate) d: f16,
pub(crate) s: f16,
pub(crate) qs: [i8; QK8_1],
}
const _: () = assert!(std::mem::size_of::<BlockQ8_1>() == 36);
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ2K {
pub(crate) scales: [u8; QK_K / 16],
pub(crate) qs: [u8; QK_K / 4],
pub(crate) d: f16,
pub(crate) dmin: f16,
}
const _: () = assert!(QK_K / 16 + QK_K / 4 + 2 * 2 == std::mem::size_of::<BlockQ2K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ3K {
pub(crate) hmask: [u8; QK_K / 8],
pub(crate) qs: [u8; QK_K / 4],
pub(crate) scales: [u8; 12],
pub(crate) d: f16,
}
const _: () = assert!(QK_K / 8 + QK_K / 4 + 12 + 2 == std::mem::size_of::<BlockQ3K>());
#[derive(Debug, Clone, PartialEq)]
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/k_quants.h#L82
#[repr(C)]
pub struct BlockQ4K {
pub(crate) d: f16,
pub(crate) dmin: f16,
pub(crate) scales: [u8; K_SCALE_SIZE],
pub(crate) qs: [u8; QK_K / 2],
}
const _: () = assert!(QK_K / 2 + K_SCALE_SIZE + 2 * 2 == std::mem::size_of::<BlockQ4K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ5K {
pub(crate) d: f16,
pub(crate) dmin: f16,
pub(crate) scales: [u8; K_SCALE_SIZE],
pub(crate) qh: [u8; QK_K / 8],
pub(crate) qs: [u8; QK_K / 2],
}
const _: () =
assert!(QK_K / 8 + QK_K / 2 + 2 * 2 + K_SCALE_SIZE == std::mem::size_of::<BlockQ5K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ6K {
pub(crate) ql: [u8; QK_K / 2],
pub(crate) qh: [u8; QK_K / 4],
pub(crate) scales: [i8; QK_K / 16],
pub(crate) d: f16,
}
const _: () = assert!(3 * QK_K / 4 + QK_K / 16 + 2 == std::mem::size_of::<BlockQ6K>());
#[derive(Debug, Clone, PartialEq)]
#[repr(C)]
pub struct BlockQ8K {
pub(crate) d: f32,
pub(crate) qs: [i8; QK_K],
pub(crate) bsums: [i16; QK_K / 16],
}
const _: () = assert!(4 + QK_K + QK_K / 16 * 2 == std::mem::size_of::<BlockQ8K>());
impl GgmlType for BlockQ4_0 {
const DTYPE: GgmlDType = GgmlDType::Q4_0;
const BLCK_SIZE: usize = QK4_0;
type VecDotType = BlockQ8_0;
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1525
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
let qk = Self::BLCK_SIZE;
if k % qk != 0 {
crate::bail!("dequantize_row_q4_0: {k} is not divisible by {qk}")
}
let nb = k / qk;
for i in 0..nb {
let d = xs[i].d.to_f32();
for j in 0..(qk / 2) {
let x0 = (xs[i].qs[j] & 0x0F) as i16 - 8;
let x1 = (xs[i].qs[j] >> 4) as i16 - 8;
ys[i * qk + j] = (x0 as f32) * d;
ys[i * qk + j + qk / 2] = (x1 as f32) * d;
}
}
Ok(())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q4_0
let qk = Self::BLCK_SIZE;
let k = xs.len();
if k % qk != 0 {
crate::bail!("{k} is not divisible by {}", qk);
};
let nb = k / qk;
if ys.len() != nb {
crate::bail!("size mismatch {} {} {}", xs.len(), ys.len(), qk,)
}
for (i, ys) in ys.iter_mut().enumerate() {
let mut amax = 0f32;
let mut max = 0f32;
let xs = &xs[i * qk..(i + 1) * qk];
for &x in xs.iter() {
if amax < x.abs() {
amax = x.abs();
max = x;
}
}
let d = max / -8.0;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
for (j, q) in ys.qs.iter_mut().enumerate() {
let x0 = xs[j] * id;
let x1 = xs[qk / 2 + j] * id;
let xi0 = u8::min(15, (x0 + 8.5) as u8);
let xi1 = u8::min(15, (x1 + 8.5) as u8);
*q = xi0 | (xi1 << 4)
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/b5ffb2849d23afe73647f68eec7b68187af09be6/ggml.c#L2361C10-L2361C122
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q4_0_q8_0(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q4_0_q8_0(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q4_0_q8_0(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q4_0_q8_0: {n} is not divisible by {qk}")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let mut sum_i = 0;
for j in 0..qk / 2 {
let v0 = (xs.qs[j] & 0x0F) as i32 - 8;
let v1 = (xs.qs[j] >> 4) as i32 - 8;
sum_i += v0 * ys.qs[j] as i32 + v1 * ys.qs[j + qk / 2] as i32
}
sumf += sum_i as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
}
Ok(sumf)
}
}
impl GgmlType for BlockQ4_1 {
const DTYPE: GgmlDType = GgmlDType::Q4_1;
const BLCK_SIZE: usize = QK4_1;
type VecDotType = BlockQ8_1;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
// ggml_vec_dot_q4_1_q8_1
let qk = QK8_1;
if n % qk != 0 {
crate::bail!("vec_dot_q4_1_q8_1: {n} is not divisible by {qk}")
}
let nb = n / qk;
if nb % 2 != 0 {
crate::bail!("vec_dot_q4_1_q8_1: {n}, nb is not divisible by 2")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let mut sumi = 0i32;
for j in 0..qk / 2 {
let v0 = xs.qs[j] as i32 & 0x0F;
let v1 = xs.qs[j] as i32 >> 4;
sumi += (v0 * ys.qs[j] as i32) + (v1 * ys.qs[j + qk / 2] as i32);
}
sumf += sumi as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
+ f16::to_f32(xs.m) * f16::to_f32(ys.s)
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q4_1
let qk = Self::BLCK_SIZE;
if ys.len() * qk != xs.len() {
crate::bail!("size mismatch {} {} {}", xs.len(), ys.len(), qk,)
}
for (i, ys) in ys.iter_mut().enumerate() {
let xs = &xs[i * qk..(i + 1) * qk];
let mut min = f32::INFINITY;
let mut max = f32::NEG_INFINITY;
for &x in xs.iter() {
min = f32::min(x, min);
max = f32::max(x, max);
}
let d = (max - min) / ((1 << 4) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
ys.m = f16::from_f32(min);
for (j, q) in ys.qs.iter_mut().take(qk / 2).enumerate() {
let x0 = (xs[j] - min) * id;
let x1 = (xs[qk / 2 + j] - min) * id;
let xi0 = u8::min(15, (x0 + 0.5) as u8);
let xi1 = u8::min(15, (x1 + 0.5) as u8);
*q = xi0 | (xi1 << 4);
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1545
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK4_1 != 0 {
crate::bail!("dequantize_row_q4_1: {k} is not divisible by {QK4_1}");
}
let nb = k / QK4_1;
for i in 0..nb {
let d = xs[i].d.to_f32();
let m = xs[i].m.to_f32();
for j in 0..(QK4_1 / 2) {
let x0 = xs[i].qs[j] & 0x0F;
let x1 = xs[i].qs[j] >> 4;
ys[i * QK4_1 + j] = (x0 as f32) * d + m;
ys[i * QK4_1 + j + QK4_1 / 2] = (x1 as f32) * d + m;
}
}
Ok(())
}
}
impl GgmlType for BlockQ5_0 {
const DTYPE: GgmlDType = GgmlDType::Q5_0;
const BLCK_SIZE: usize = QK5_0;
type VecDotType = BlockQ8_0;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = Self::BLCK_SIZE;
if n % Self::BLCK_SIZE != 0 {
crate::bail!("vec_dot_q5_0_q8_0: {n} is not divisible by {qk}")
}
let nb = n / qk;
if nb % 2 != 0 {
crate::bail!("vec_dot_q5_0_q8_0: {n}, nb is not divisible by 2")
}
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(_n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let qh = LittleEndian::read_u32(&xs.qh);
let mut sumi = 0i32;
for j in 0..Self::BLCK_SIZE / 2 {
let xh_0 = (((qh & (1u32 << j)) >> j) << 4) as u8;
let xh_1 = ((qh & (1u32 << (j + 16))) >> (j + 12)) as u8;
let x0 = ((xs.qs[j] & 0x0F) as i32 | xh_0 as i32) - 16;
let x1 = ((xs.qs[j] >> 4) as i32 | xh_1 as i32) - 16;
sumi += (x0 * ys.qs[j] as i32) + (x1 * ys.qs[j + Self::BLCK_SIZE / 2] as i32);
}
sumf += sumi as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q5_0
let k = xs.len();
if ys.len() * Self::BLCK_SIZE != k {
crate::bail!("size mismatch {k} {} {}", ys.len(), Self::BLCK_SIZE)
}
for (i, ys) in ys.iter_mut().enumerate() {
let xs = &xs[i * Self::BLCK_SIZE..(i + 1) * Self::BLCK_SIZE];
let mut amax = 0f32;
let mut max = 0f32;
for &x in xs.iter() {
if amax < x.abs() {
amax = x.abs();
max = x;
}
}
let d = max / -16.;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
let mut qh = 0u32;
for j in 0..Self::BLCK_SIZE / 2 {
let x0 = xs[j] * id;
let x1 = xs[j + Self::BLCK_SIZE / 2] * id;
let xi0 = ((x0 + 16.5) as i8).min(31) as u8;
let xi1 = ((x1 + 16.5) as i8).min(31) as u8;
ys.qs[j] = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
qh |= ((xi0 as u32 & 0x10) >> 4) << j;
qh |= ((xi1 as u32 & 0x10) >> 4) << (j + Self::BLCK_SIZE / 2);
}
LittleEndian::write_u32(&mut ys.qh, qh)
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1566
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK5_0 != 0 {
crate::bail!("dequantize_row_q5_0: {k} is not divisible by {QK5_0}");
}
let nb = k / QK5_0;
for i in 0..nb {
let d = xs[i].d.to_f32();
let qh: u32 = LittleEndian::read_u32(&xs[i].qh);
for j in 0..(QK5_0 / 2) {
let xh_0 = (((qh >> j) << 4) & 0x10) as u8;
let xh_1 = ((qh >> (j + 12)) & 0x10) as u8;
let x0 = ((xs[i].qs[j] & 0x0F) | xh_0) as i32 - 16;
let x1 = ((xs[i].qs[j] >> 4) | xh_1) as i32 - 16;
ys[i * QK5_0 + j] = (x0 as f32) * d;
ys[i * QK5_0 + j + QK5_0 / 2] = (x1 as f32) * d;
}
}
Ok(())
}
}
impl GgmlType for BlockQ5_1 {
const DTYPE: GgmlDType = GgmlDType::Q5_1;
const BLCK_SIZE: usize = QK5_1;
type VecDotType = BlockQ8_1;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = Self::BLCK_SIZE;
if n % Self::BLCK_SIZE != 0 {
crate::bail!("vec_dot_q5_1_q8_1: {n} is not divisible by {qk}")
}
let nb = n / qk;
if nb % 2 != 0 {
crate::bail!("vec_dot_q5_1_q8_1: {n}, nb is not divisible by 2")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let qh = LittleEndian::read_u32(&xs.qh);
let mut sumi = 0i32;
for j in 0..Self::BLCK_SIZE / 2 {
let xh_0 = ((qh >> j) << 4) & 0x10;
let xh_1 = (qh >> (j + 12)) & 0x10;
let x0 = (xs.qs[j] as i32 & 0xF) | xh_0 as i32;
let x1 = (xs.qs[j] as i32 >> 4) | xh_1 as i32;
sumi += (x0 * ys.qs[j] as i32) + (x1 * ys.qs[j + Self::BLCK_SIZE / 2] as i32);
}
sumf += sumi as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
+ f16::to_f32(xs.m) * f16::to_f32(ys.s)
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q5_1
let qk = Self::BLCK_SIZE;
if ys.len() * qk != xs.len() {
crate::bail!("size mismatch {} {} {}", xs.len(), ys.len(), qk,)
}
for (i, ys) in ys.iter_mut().enumerate() {
let xs = &xs[i * qk..(i + 1) * qk];
let mut min = f32::INFINITY;
let mut max = f32::NEG_INFINITY;
for &x in xs.iter() {
min = f32::min(x, min);
max = f32::max(x, max);
}
let d = (max - min) / ((1 << 5) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
ys.m = f16::from_f32(min);
let mut qh = 0u32;
for (j, q) in ys.qs.iter_mut().take(qk / 2).enumerate() {
let x0 = (xs[j] - min) * id;
let x1 = (xs[qk / 2 + j] - min) * id;
let xi0 = (x0 + 0.5) as u8;
let xi1 = (x1 + 0.5) as u8;
*q = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
// get the 5-th bit and store it in qh at the right position
qh |= ((xi0 as u32 & 0x10) >> 4) << j;
qh |= ((xi1 as u32 & 0x10) >> 4) << (j + qk / 2);
}
LittleEndian::write_u32(&mut ys.qh, qh);
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1592
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK5_1 != 0 {
crate::bail!("dequantize_row_q5_1: {k} is not divisible by {QK5_1}");
}
let nb = k / QK5_1;
for i in 0..nb {
let d = xs[i].d.to_f32();
let m = xs[i].m.to_f32();
let qh: u32 = LittleEndian::read_u32(&xs[i].qh);
for j in 0..(QK5_1 / 2) {
let xh_0 = (((qh >> j) << 4) & 0x10) as u8;
let xh_1 = ((qh >> (j + 12)) & 0x10) as u8;
let x0 = (xs[i].qs[j] & 0x0F) | xh_0;
let x1 = (xs[i].qs[j] >> 4) | xh_1;
ys[i * QK5_1 + j] = (x0 as f32) * d + m;
ys[i * QK5_1 + j + QK5_1 / 2] = (x1 as f32) * d + m;
}
}
Ok(())
}
}
impl GgmlType for BlockQ8_0 {
const DTYPE: GgmlDType = GgmlDType::Q8_0;
const BLCK_SIZE: usize = QK8_0;
type VecDotType = BlockQ8_0;
// https://github.com/ggerganov/llama.cpp/blob/468ea24fb4633a0d681f7ac84089566c1c6190cb/ggml.c#L1619
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK8_0 != 0 {
crate::bail!("dequantize_row_q8_0: {k} is not divisible by {QK8_0}");
}
let nb = k / QK8_0;
for i in 0..nb {
let d = xs[i].d.to_f32();
for j in 0..QK8_0 {
ys[i * QK8_0 + j] = xs[i].qs[j] as f32 * d;
}
}
Ok(())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q8_0
let k = xs.len();
if k % Self::BLCK_SIZE != 0 {
crate::bail!("{k} is not divisible by {}", Self::BLCK_SIZE);
};
let nb = k / Self::BLCK_SIZE;
if ys.len() != nb {
crate::bail!(
"size mismatch {} {} {}",
xs.len(),
ys.len(),
Self::BLCK_SIZE
)
}
for (i, ys) in ys.iter_mut().enumerate() {
let mut amax = 0f32;
let xs = &xs[i * Self::BLCK_SIZE..(i + 1) * Self::BLCK_SIZE];
for &x in xs.iter() {
amax = amax.max(x.abs())
}
let d = amax / ((1 << 7) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
for (y, &x) in ys.qs.iter_mut().zip(xs.iter()) {
*y = f32::round(x * id) as i8
}
}
Ok(())
}
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q8_0_q8_0(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q8_0_q8_0(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q8_0_q8_0(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = QK8_0;
if n % QK8_0 != 0 {
crate::bail!("vec_dot_q8_0_q8_0: {n} is not divisible by {qk}")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let sum_i = xs
.qs
.iter()
.zip(ys.qs.iter())
.map(|(&x, &y)| x as i32 * y as i32)
.sum::<i32>();
sumf += sum_i as f32 * f16::to_f32(xs.d) * f16::to_f32(ys.d)
}
Ok(sumf)
}
}
impl GgmlType for BlockQ8_1 {
const DTYPE: GgmlDType = GgmlDType::Q8_1;
const BLCK_SIZE: usize = QK8_1;
type VecDotType = BlockQ8_1;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(_n: usize, _xs: &[Self], _ys: &[Self::VecDotType]) -> Result<f32> {
unimplemented!("no support for vec-dot on Q8_1")
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
// quantize_row_q8_1
let k = xs.len();
if ys.len() * Self::BLCK_SIZE != k {
crate::bail!("size mismatch {k} {} {}", ys.len(), Self::BLCK_SIZE)
}
for (i, ys) in ys.iter_mut().enumerate() {
let mut amax = 0f32;
let xs = &xs[i * Self::BLCK_SIZE..(i + 1) * Self::BLCK_SIZE];
for &x in xs.iter() {
amax = amax.max(x.abs())
}
let d = amax / ((1 << 7) - 1) as f32;
let id = if d != 0f32 { 1. / d } else { 0. };
ys.d = f16::from_f32(d);
let mut sum = 0i32;
for j in 0..Self::BLCK_SIZE / 2 {
let v0 = xs[j] * id;
let v1 = xs[j + Self::BLCK_SIZE / 2] * id;
ys.qs[j] = f32::round(v0) as i8;
ys.qs[j + Self::BLCK_SIZE / 2] = f32::round(v1) as i8;
sum += ys.qs[j] as i32 + ys.qs[j + Self::BLCK_SIZE / 2] as i32;
}
ys.s = f16::from_f32(sum as f32) * ys.d;
}
Ok(())
}
fn to_float(_xs: &[Self], _ys: &mut [f32]) -> Result<()> {
unimplemented!("no support for vec-dot on Q8_1")
}
}
impl GgmlType for BlockQ2K {
const DTYPE: GgmlDType = GgmlDType::Q2K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q2k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q2k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q2k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q2k_q8k: {n} is not divisible by {QK_K}")
}
let mut sumf = 0.0;
for (x, y) in xs.iter().zip(ys.iter()) {
let mut q2: &[_] = &x.qs;
let mut q8: &[_] = &y.qs;
let sc = &x.scales;
let mut summs = 0;
for (bsum, scale) in y.bsums.iter().zip(sc) {
summs += *bsum as i32 * ((scale >> 4) as i32);
}
let dall = y.d * x.d.to_f32();
let dmin = y.d * x.dmin.to_f32();
let mut isum = 0;
let mut is = 0;
for _ in 0..(QK_K / 128) {
let mut shift = 0;
for _ in 0..4 {
let d = (sc[is] & 0xF) as i32;
is += 1;
let mut isuml = 0;
for l in 0..16 {
isuml += q8[l] as i32 * (((q2[l] >> shift) & 3) as i32);
}
isum += d * isuml;
let d = (sc[is] & 0xF) as i32;
is += 1;
isuml = 0;
for l in 16..32 {
isuml += q8[l] as i32 * (((q2[l] >> shift) & 3) as i32);
}
isum += d * isuml;
shift += 2;
// adjust the indexing
q8 = &q8[32..];
}
// adjust the indexing
q2 = &q2[32..];
}
sumf += dall * isum as f32 - dmin * summs as f32;
}
Ok(sumf)
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L279
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
const Q4SCALE: f32 = 15.0;
for (block, x) in group_for_quantization(xs, ys)? {
//calculate scales and mins
let mut mins: [f32; QK_K / 16] = [0.0; QK_K / 16];
let mut scales: [f32; QK_K / 16] = [0.0; QK_K / 16];
for (j, x_scale_slice) in x.chunks(16).enumerate() {
(scales[j], mins[j]) = make_qkx1_quants(3, 5, x_scale_slice);
}
// get max scale and max min and ensure they are >= 0.0
let max_scale = scales.iter().fold(0.0, |max, &val| val.max(max));
let max_min = mins.iter().fold(0.0, |max, &val| val.max(max));
if max_scale > 0.0 {
let iscale = Q4SCALE / max_scale;
for (j, scale) in scales.iter().enumerate().take(QK_K / 16) {
block.scales[j] = nearest_int(iscale * scale) as u8;
}
block.d = f16::from_f32(max_scale / Q4SCALE);
} else {
for j in 0..QK_K / 16 {
block.scales[j] = 0;
}
block.d = f16::from_f32(0.0);
}
if max_min > 0.0 {
let iscale = Q4SCALE / max_min;
for (j, scale) in block.scales.iter_mut().enumerate() {
let l = nearest_int(iscale * mins[j]) as u8;
*scale |= l << 4;
}
block.dmin = f16::from_f32(max_min / Q4SCALE);
} else {
block.dmin = f16::from_f32(0.0);
}
let mut big_l: [u8; QK_K] = [0; QK_K];
for j in 0..QK_K / 16 {
let d = block.d.to_f32() * (block.scales[j] & 0xF) as f32;
if d == 0.0 {
continue;
}
let dm = block.dmin.to_f32() * (block.scales[j] >> 4) as f32;
for ii in 0..16 {
let ll = nearest_int((x[16 * j + ii] + dm) / d).clamp(0, 3);
big_l[16 * j + ii] = ll as u8;
}
}
for j in (0..QK_K).step_by(128) {
for ll in 0..32 {
block.qs[j / 4 + ll] = big_l[j + ll]
| (big_l[j + ll + 32] << 2)
| (big_l[j + ll + 64] << 4)
| (big_l[j + ll + 96] << 6);
}
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L354
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
for (block, y) in group_for_dequantization(xs, ys)? {
let d = block.d.to_f32();
let min = block.dmin.to_f32();
let mut is = 0;
for (y_block, qs) in y.chunks_exact_mut(128).zip(block.qs.chunks_exact(32)) {
// Step by 32 over q.
let mut shift = 0;
let mut y_block_index = 0;
for _j in 0..4 {
let sc = block.scales[is];
is += 1;
let dl = d * (sc & 0xF) as f32;
let ml = min * (sc >> 4) as f32;
for q in &qs[..16] {
let y = dl * ((q >> shift) & 3) as f32 - ml;
y_block[y_block_index] = y;
y_block_index += 1;
}
let sc = block.scales[is];
is += 1;
let dl = d * (sc & 0xF) as f32;
let ml = min * (sc >> 4) as f32;
for q in &qs[16..] {
let y = dl * ((q >> shift) & 3) as f32 - ml;
y_block[y_block_index] = y;
y_block_index += 1;
}
shift += 2;
}
}
}
Ok(())
}
}
impl GgmlType for BlockQ3K {
const DTYPE: GgmlDType = GgmlDType::Q3K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q3k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q3k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q3k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x03030303;
const KMASK2: u32 = 0x0f0f0f0f;
let mut aux8: [i8; QK_K] = [0; QK_K];
let mut aux16: [i16; 8] = [0; 8];
let mut sums: [f32; 8] = [0.0; 8];
let mut aux32: [i32; 8] = [0; 8];
let mut auxs: [u32; 4] = [0; 4];
for (x, y) in xs.iter().zip(ys.iter()) {
let mut q3: &[u8] = &x.qs;
let hmask: &[u8] = &x.hmask;
let mut q8: &[i8] = &y.qs;
aux32.fill(0);
let mut a = &mut aux8[..];
let mut m = 1;
//Like the GGML original this is written this way to enable the compiler to vectorize it.
for _ in 0..QK_K / 128 {
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = (q3_val & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = ((q3_val >> 2) & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = ((q3_val >> 4) & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
a.iter_mut()
.take(32)
.zip(q3)
.for_each(|(a_val, q3_val)| *a_val = ((q3_val >> 6) & 3) as i8);
a.iter_mut()
.take(32)
.zip(hmask)
.for_each(|(a_val, hmask_val)| {
*a_val -= if hmask_val & m != 0 { 0 } else { 4 }
});
a = &mut a[32..];
m <<= 1;
q3 = &q3[32..];
}
a = &mut aux8[..];
LittleEndian::read_u32_into(&x.scales, &mut auxs[0..3]);
let tmp = auxs[2];
auxs[2] = ((auxs[0] >> 4) & KMASK2) | (((tmp >> 4) & KMASK1) << 4);
auxs[3] = ((auxs[1] >> 4) & KMASK2) | (((tmp >> 6) & KMASK1) << 4);
auxs[0] = (auxs[0] & KMASK2) | (((tmp) & KMASK1) << 4);
auxs[1] = (auxs[1] & KMASK2) | (((tmp >> 2) & KMASK1) << 4);
for aux in auxs {
for scale in aux.to_le_bytes() {
let scale = i8::from_be_bytes([scale]);
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += (scale as i32 - 32) * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += (scale as i32 - 32) * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
}
}
let d = x.d.to_f32() * y.d;
for l in 0..8 {
sums[l] += d * aux32[l] as f32;
}
}
Ok(sums.iter().sum())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
for (block, x) in group_for_quantization(xs, ys)? {
let mut scales: [f32; QK_K / 16] = [0.0; QK_K / 16];
for (j, x_scale_slice) in x.chunks_exact(16).enumerate() {
scales[j] = make_q3_quants(x_scale_slice, 4, true);
}
// Get max scale by absolute value.
let mut max_scale: f32 = 0.0;
for &scale in scales.iter() {
if scale.abs() > max_scale.abs() {
max_scale = scale;
}
}
block.scales.fill(0);
if max_scale != 0.0 {
let iscale = -32.0 / max_scale;
for (j, scale) in scales.iter().enumerate() {
let l_val = nearest_int(iscale * scale);
let l_val = l_val.clamp(-32, 31) + 32;
if j < 8 {
block.scales[j] = (l_val & 0xF) as u8;
} else {
block.scales[j - 8] |= ((l_val & 0xF) << 4) as u8;
}
let l_val = l_val >> 4;
block.scales[j % 4 + 8] |= (l_val << (2 * (j / 4))) as u8;
}
block.d = f16::from_f32(1.0 / iscale);
} else {
block.d = f16::from_f32(0.0);
}
let mut l: [i8; QK_K] = [0; QK_K];
for j in 0..QK_K / 16 {
let sc = if j < 8 {
block.scales[j] & 0xF
} else {
block.scales[j - 8] >> 4
};
let sc = (sc | (((block.scales[8 + j % 4] >> (2 * (j / 4))) & 3) << 4)) as i8 - 32;
let d = block.d.to_f32() * sc as f32;
if d != 0.0 {
for ii in 0..16 {
let l_val = nearest_int(x[16 * j + ii] / d);
l[16 * j + ii] = (l_val.clamp(-4, 3) + 4) as i8;
}
}
}
block.hmask.fill(0);
let mut m = 0;
let mut hm = 1;
for ll in l.iter_mut() {
if *ll > 3 {
block.hmask[m] |= hm;
*ll -= 4;
}
m += 1;
if m == QK_K / 8 {
m = 0;
hm <<= 1;
}
}
for j in (0..QK_K).step_by(128) {
for l_val in 0..32 {
block.qs[j / 4 + l_val] = (l[j + l_val]
| (l[j + l_val + 32] << 2)
| (l[j + l_val + 64] << 4)
| (l[j + l_val + 96] << 6))
as u8;
}
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L533
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
const KMASK1: u32 = 0x03030303;
const KMASK2: u32 = 0x0f0f0f0f;
for (block, y) in group_for_dequantization(xs, ys)? {
//Reconstruct the scales
let mut aux = [0; 4];
LittleEndian::read_u32_into(&block.scales, &mut aux[0..3]);
let tmp = aux[2];
aux[2] = ((aux[0] >> 4) & KMASK2) | (((tmp >> 4) & KMASK1) << 4);
aux[3] = ((aux[1] >> 4) & KMASK2) | (((tmp >> 6) & KMASK1) << 4);
aux[0] = (aux[0] & KMASK2) | (((tmp) & KMASK1) << 4);
aux[1] = (aux[1] & KMASK2) | (((tmp >> 2) & KMASK1) << 4);
//Transfer the scales into an i8 array
let scales: &mut [i8] =
unsafe { std::slice::from_raw_parts_mut(aux.as_mut_ptr() as *mut i8, 16) };
let d_all = block.d.to_f32();
let mut m = 1;
let mut is = 0;
// Dequantize both 128 long blocks
// 32 qs values per 128 long block
// Each 16 elements get a scale
for (y, qs) in y.chunks_exact_mut(128).zip(block.qs.chunks_exact(32)) {
let mut shift = 0;
for shift_scoped_y in y.chunks_exact_mut(32) {
for (scale_index, scale_scoped_y) in
shift_scoped_y.chunks_exact_mut(16).enumerate()
{
let dl = d_all * (scales[is] as f32 - 32.0);
for (i, inner_y) in scale_scoped_y.iter_mut().enumerate() {
let new_y = dl
* (((qs[i + 16 * scale_index] >> shift) & 3) as i8
- if (block.hmask[i + 16 * scale_index] & m) == 0 {
4
} else {
0
}) as f32;
*inner_y = new_y;
}
// 16 block finished => advance scale index
is += 1;
}
// 32 block finished => increase shift and m
shift += 2;
m <<= 1;
}
}
}
Ok(())
}
}
impl GgmlType for BlockQ4K {
const DTYPE: GgmlDType = GgmlDType::Q4K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q4k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q4k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q4k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q4k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
let mut utmp: [u32; 4] = [0; 4];
let mut scales: [u8; 8] = [0; 8];
let mut mins: [u8; 8] = [0; 8];
let mut aux8: [i8; QK_K] = [0; QK_K];
let mut aux16: [i16; 8] = [0; 8];
let mut sums: [f32; 8] = [0.0; 8];
let mut aux32: [i32; 8] = [0; 8];
let mut sumf = 0.0;
for (y, x) in ys.iter().zip(xs.iter()) {
let q4 = &x.qs;
let q8 = &y.qs;
aux32.fill(0);
let mut a = &mut aux8[..];
let mut q4 = &q4[..];
for _ in 0..QK_K / 64 {
for l in 0..32 {
a[l] = (q4[l] & 0xF) as i8;
}
a = &mut a[32..];
for l in 0..32 {
a[l] = (q4[l] >> 4) as i8;
}
a = &mut a[32..];
q4 = &q4[32..];
}
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
//extract scales and mins
LittleEndian::write_u32_into(&utmp[0..2], &mut scales);
LittleEndian::write_u32_into(&utmp[2..4], &mut mins);
let mut sumi = 0;
for j in 0..QK_K / 16 {
sumi += y.bsums[j] as i32 * mins[j / 2] as i32;
}
let mut a = &mut aux8[..];
let mut q8 = &q8[..];
for scale in scales {
let scale = scale as i32;
for _ in 0..4 {
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
}
}
let d = x.d.to_f32() * y.d;
for l in 0..8 {
sums[l] += d * aux32[l] as f32;
}
let dmin = x.dmin.to_f32() * y.d;
sumf -= dmin * sumi as f32;
}
Ok(sumf + sums.iter().sum::<f32>())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
for (block, x) in group_for_quantization(xs, ys)? {
let mut mins: [f32; QK_K / 32] = [0.0; QK_K / 32];
let mut scales: [f32; QK_K / 32] = [0.0; QK_K / 32];
for (j, x_scale_slice) in x.chunks_exact(32).enumerate() {
(scales[j], mins[j]) = make_qkx1_quants(15, 5, x_scale_slice);
}
// get max scale and max min and ensure they are >= 0.0
let max_scale = scales.iter().fold(0.0, |max, &val| val.max(max));
let max_min = mins.iter().fold(0.0, |max, &val| val.max(max));
let inv_scale = if max_scale > 0.0 {
63.0 / max_scale
} else {
0.0
};
let inv_min = if max_min > 0.0 { 63.0 / max_min } else { 0.0 };
for j in 0..QK_K / 32 {
let ls = nearest_int(inv_scale * scales[j]).min(63) as u8;
let lm = nearest_int(inv_min * mins[j]).min(63) as u8;
if j < 4 {
block.scales[j] = ls;
block.scales[j + 4] = lm;
} else {
block.scales[j + 4] = (ls & 0xF) | ((lm & 0xF) << 4);
block.scales[j - 4] |= (ls >> 4) << 6;
block.scales[j] |= (lm >> 4) << 6;
}
}
block.d = f16::from_f32(max_scale / 63.0);
block.dmin = f16::from_f32(max_min / 63.0);
let mut l: [u8; QK_K] = [0; QK_K];
for j in 0..QK_K / 32 {
let (sc, m) = get_scale_min_k4(j, &block.scales);
let d = block.d.to_f32() * sc as f32;
if d != 0.0 {
let dm = block.dmin.to_f32() * m as f32;
for ii in 0..32 {
let l_val = nearest_int((x[32 * j + ii] + dm) / d);
l[32 * j + ii] = l_val.clamp(0, 15) as u8;
}
}
}
let q = &mut block.qs;
for j in (0..QK_K).step_by(64) {
for l_val in 0..32 {
let offset_index = (j / 64) * 32 + l_val;
q[offset_index] = l[j + l_val] | (l[j + l_val + 32] << 4);
}
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L735
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
for (block, y) in group_for_dequantization(xs, ys)? {
let d = block.d.to_f32();
let min = block.dmin.to_f32();
let q = &block.qs;
let mut is = 0;
let mut ys_index = 0;
for j in (0..QK_K).step_by(64) {
let q = &q[j / 2..j / 2 + 32];
let (sc, m) = get_scale_min_k4(is, &block.scales);
let d1 = d * sc as f32;
let m1 = min * m as f32;
let (sc, m) = get_scale_min_k4(is + 1, &block.scales);
let d2 = d * sc as f32;
let m2 = min * m as f32;
for q in q {
y[ys_index] = d1 * (q & 0xF) as f32 - m1;
ys_index += 1;
}
for q in q {
y[ys_index] = d2 * (q >> 4) as f32 - m2;
ys_index += 1;
}
is += 2;
}
}
Ok(())
}
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L928
impl GgmlType for BlockQ5K {
const DTYPE: GgmlDType = GgmlDType::Q5K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q5k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q5k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q5k_q8k: {n} is not divisible by {QK_K}")
}
const KMASK1: u32 = 0x3f3f3f3f;
const KMASK2: u32 = 0x0f0f0f0f;
const KMASK3: u32 = 0x03030303;
let mut utmp: [u32; 4] = [0; 4];
let mut scales: [u8; 8] = [0; 8];
let mut mins: [u8; 8] = [0; 8];
let mut aux8: [i8; QK_K] = [0; QK_K];
let mut aux16: [i16; 8] = [0; 8];
let mut sums: [f32; 8] = [0.0; 8];
let mut aux32: [i32; 8] = [0; 8];
let mut sumf = 0.0;
for (y, x) in ys.iter().zip(xs.iter()) {
let q5 = &x.qs;
let hm = &x.qh;
let q8 = &y.qs;
aux32.fill(0);
let mut a = &mut aux8[..];
let mut q5 = &q5[..];
let mut m = 1u8;
for _ in 0..QK_K / 64 {
for l in 0..32 {
a[l] = (q5[l] & 0xF) as i8;
a[l] += if hm[l] & m != 0 { 16 } else { 0 };
}
a = &mut a[32..];
m <<= 1;
for l in 0..32 {
a[l] = (q5[l] >> 4) as i8;
a[l] += if hm[l] & m != 0 { 16 } else { 0 };
}
a = &mut a[32..];
m <<= 1;
q5 = &q5[32..];
}
LittleEndian::read_u32_into(&x.scales, &mut utmp[0..3]);
utmp[3] = ((utmp[2] >> 4) & KMASK2) | (((utmp[1] >> 6) & KMASK3) << 4);
let uaux = utmp[1] & KMASK1;
utmp[1] = (utmp[2] & KMASK2) | (((utmp[0] >> 6) & KMASK3) << 4);
utmp[2] = uaux;
utmp[0] &= KMASK1;
//extract scales and mins
LittleEndian::write_u32_into(&utmp[0..2], &mut scales);
LittleEndian::write_u32_into(&utmp[2..4], &mut mins);
let mut sumi = 0;
for j in 0..QK_K / 16 {
sumi += y.bsums[j] as i32 * mins[j / 2] as i32;
}
let mut a = &mut aux8[..];
let mut q8 = &q8[..];
for scale in scales {
let scale = scale as i32;
for _ in 0..4 {
for l in 0..8 {
aux16[l] = q8[l] as i16 * a[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as i32;
}
q8 = &q8[8..];
a = &mut a[8..];
}
}
let d = x.d.to_f32() * y.d;
for l in 0..8 {
sums[l] += d * aux32[l] as f32;
}
let dmin = x.dmin.to_f32() * y.d;
sumf -= dmin * sumi as f32;
}
Ok(sumf + sums.iter().sum::<f32>())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L793
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
for (block, x) in group_for_quantization(xs, ys)? {
let mut mins: [f32; QK_K / 32] = [0.0; QK_K / 32];
let mut scales: [f32; QK_K / 32] = [0.0; QK_K / 32];
for (j, x_scale_slice) in x.chunks_exact(32).enumerate() {
(scales[j], mins[j]) = make_qkx1_quants(31, 5, x_scale_slice);
}
// get max scale and max min and ensure they are >= 0.0
let max_scale = scales.iter().fold(0.0, |max, &val| val.max(max));
let max_min = mins.iter().fold(0.0, |max, &val| val.max(max));
let inv_scale = if max_scale > 0.0 {
63.0 / max_scale
} else {
0.0
};
let inv_min = if max_min > 0.0 { 63.0 / max_min } else { 0.0 };
for j in 0..QK_K / 32 {
let ls = nearest_int(inv_scale * scales[j]).min(63) as u8;
let lm = nearest_int(inv_min * mins[j]).min(63) as u8;
if j < 4 {
block.scales[j] = ls;
block.scales[j + 4] = lm;
} else {
block.scales[j + 4] = (ls & 0xF) | ((lm & 0xF) << 4);
block.scales[j - 4] |= (ls >> 4) << 6;
block.scales[j] |= (lm >> 4) << 6;
}
}
block.d = f16::from_f32(max_scale / 63.0);
block.dmin = f16::from_f32(max_min / 63.0);
let mut l: [u8; QK_K] = [0; QK_K];
for j in 0..QK_K / 32 {
let (sc, m) = get_scale_min_k4(j, &block.scales);
let d = block.d.to_f32() * sc as f32;
if d == 0.0 {
continue;
}
let dm = block.dmin.to_f32() * m as f32;
for ii in 0..32 {
let ll = nearest_int((x[32 * j + ii] + dm) / d);
l[32 * j + ii] = ll.clamp(0, 31) as u8;
}
}
let qh = &mut block.qh;
let ql = &mut block.qs;
qh.fill(0);
let mut m1 = 1;
let mut m2 = 2;
for n in (0..QK_K).step_by(64) {
let offset = (n / 64) * 32;
for j in 0..32 {
let mut l1 = l[n + j];
if l1 > 15 {
l1 -= 16;
qh[j] |= m1;
}
let mut l2 = l[n + j + 32];
if l2 > 15 {
l2 -= 16;
qh[j] |= m2;
}
ql[offset + j] = l1 | (l2 << 4);
}
m1 <<= 2;
m2 <<= 2;
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L928
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
for (block, y) in group_for_dequantization(xs, ys)? {
let d = block.d.to_f32();
let min = block.dmin.to_f32();
let ql = &block.qs;
let qh = &block.qh;
let mut is = 0;
let mut u1 = 1;
let mut u2 = 2;
let mut ys_index = 0;
for j in (0..QK_K).step_by(64) {
let ql = &ql[j / 2..j / 2 + 32];
let (sc, m) = get_scale_min_k4(is, &block.scales);
let d1 = d * sc as f32;
let m1 = min * m as f32;
let (sc, m) = get_scale_min_k4(is + 1, &block.scales);
let d2 = d * sc as f32;
let m2 = min * m as f32;
for (ql, qh) in ql.iter().zip(qh) {
let to_add = if qh & u1 != 0 { 16f32 } else { 0f32 };
y[ys_index] = d1 * ((ql & 0xF) as f32 + to_add) - m1;
ys_index += 1;
}
for (ql, qh) in ql.iter().zip(qh) {
let to_add = if qh & u2 != 0 { 16f32 } else { 0f32 };
y[ys_index] = d2 * ((ql >> 4) as f32 + to_add) - m2;
ys_index += 1;
}
is += 2;
u1 <<= 2;
u2 <<= 2;
}
}
Ok(())
}
}
impl GgmlType for BlockQ6K {
const DTYPE: GgmlDType = GgmlDType::Q6K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q6k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q6k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q6k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if n % QK_K != 0 {
crate::bail!("vec_dot_q6k_q8k: {n} is not divisible by {QK_K}")
}
let mut aux8 = [0i8; QK_K];
let mut aux16 = [0i16; 8];
let mut sums = [0f32; 8];
let mut aux32 = [0f32; 8];
for (x, y) in xs.iter().zip(ys.iter()) {
let q4 = &x.ql;
let qh = &x.qh;
let q8 = &y.qs;
aux32.fill(0f32);
for j in (0..QK_K).step_by(128) {
let aux8 = &mut aux8[j..];
let q4 = &q4[j / 2..];
let qh = &qh[j / 4..];
for l in 0..32 {
aux8[l] = (((q4[l] & 0xF) | ((qh[l] & 3) << 4)) as i32 - 32) as i8;
aux8[l + 32] =
(((q4[l + 32] & 0xF) | (((qh[l] >> 2) & 3) << 4)) as i32 - 32) as i8;
aux8[l + 64] = (((q4[l] >> 4) | (((qh[l] >> 4) & 3) << 4)) as i32 - 32) as i8;
aux8[l + 96] =
(((q4[l + 32] >> 4) | (((qh[l] >> 6) & 3) << 4)) as i32 - 32) as i8;
}
}
for (j, &scale) in x.scales.iter().enumerate() {
let scale = scale as f32;
let q8 = &q8[16 * j..];
let aux8 = &aux8[16 * j..];
for l in 0..8 {
aux16[l] = q8[l] as i16 * aux8[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as f32
}
let q8 = &q8[8..];
let aux8 = &aux8[8..];
for l in 0..8 {
aux16[l] = q8[l] as i16 * aux8[l] as i16;
}
for l in 0..8 {
aux32[l] += scale * aux16[l] as f32
}
}
let d = x.d.to_f32() * y.d;
for (sum, &a) in sums.iter_mut().zip(aux32.iter()) {
*sum += a * d;
}
}
Ok(sums.iter().sum())
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
if xs.len() != ys.len() * Self::BLCK_SIZE {
crate::bail!(
"quantize_row_q6k: size mismatch {} {} {}",
xs.len(),
ys.len(),
Self::BLCK_SIZE
)
}
let mut l = [0i8; QK_K];
let mut scales = [0f32; QK_K / 16];
let mut x = xs.as_ptr();
let l = l.as_mut_ptr();
unsafe {
for y in ys.iter_mut() {
let mut max_scale = 0f32;
let mut max_abs_scale = 0f32;
for (ib, scale_) in scales.iter_mut().enumerate() {
let scale = make_qx_quants(16, 32, x.add(16 * ib), l.add(16 * ib), 1);
*scale_ = scale;
let abs_scale = scale.abs();
if abs_scale > max_abs_scale {
max_abs_scale = abs_scale;
max_scale = scale
}
}
let iscale = -128f32 / max_scale;
y.d = f16::from_f32(1.0 / iscale);
for (y_scale, scale) in y.scales.iter_mut().zip(scales.iter()) {
*y_scale = nearest_int(iscale * scale).min(127) as i8
}
for (j, &y_scale) in y.scales.iter().enumerate() {
let d = y.d.to_f32() * y_scale as f32;
if d == 0. {
continue;
}
for ii in 0..16 {
let ll = nearest_int(*x.add(16 * j + ii) / d).clamp(-32, 31);
*l.add(16 * j + ii) = (ll + 32) as i8
}
}
let mut ql = y.ql.as_mut_ptr();
let mut qh = y.qh.as_mut_ptr();
for j in (0..QK_K).step_by(128) {
for l_idx in 0..32 {
let q1 = *l.add(j + l_idx) & 0xF;
let q2 = *l.add(j + l_idx + 32) & 0xF;
let q3 = *l.add(j + l_idx + 64) & 0xF;
let q4 = *l.add(j + l_idx + 96) & 0xF;
*ql.add(l_idx) = (q1 | (q3 << 4)) as u8;
*ql.add(l_idx + 32) = (q2 | (q4 << 4)) as u8;
*qh.add(l_idx) = ((*l.add(j + l_idx) >> 4)
| ((*l.add(j + l_idx + 32) >> 4) << 2)
| ((*l.add(j + l_idx + 64) >> 4) << 4)
| ((*l.add(j + l_idx + 96) >> 4) << 6))
as u8;
}
ql = ql.add(64);
qh = qh.add(32);
}
x = x.add(QK_K)
}
}
Ok(())
}
// https://github.com/ggerganov/llama.cpp/blob/8183159cf3def112f6d1fe94815fce70e1bffa12/k_quants.c#L1067
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK_K != 0 {
crate::bail!("dequantize_row_q6k: {k} is not divisible by {QK_K}")
}
for (idx_x, x) in xs.iter().enumerate() {
let d = x.d.to_f32();
let ql = &x.ql;
let qh = &x.qh;
let sc = &x.scales;
for n in (0..QK_K).step_by(128) {
let idx = n / 128;
let ys = &mut ys[idx_x * QK_K + n..];
let sc = &sc[8 * idx..];
let ql = &ql[64 * idx..];
let qh = &qh[32 * idx..];
for l in 0..32 {
let is = l / 16;
let q1 = ((ql[l] & 0xF) | ((qh[l] & 3) << 4)) as i8 - 32;
let q2 = ((ql[l + 32] & 0xF) | (((qh[l] >> 2) & 3) << 4)) as i8 - 32;
let q3 = ((ql[l] >> 4) | (((qh[l] >> 4) & 3) << 4)) as i8 - 32;
let q4 = ((ql[l + 32] >> 4) | (((qh[l] >> 6) & 3) << 4)) as i8 - 32;
ys[l] = d * sc[is] as f32 * q1 as f32;
ys[l + 32] = d * sc[is + 2] as f32 * q2 as f32;
ys[l + 64] = d * sc[is + 4] as f32 * q3 as f32;
ys[l + 96] = d * sc[is + 6] as f32 * q4 as f32;
}
}
}
Ok(())
}
}
impl GgmlType for BlockQ8K {
const DTYPE: GgmlDType = GgmlDType::Q8K;
const BLCK_SIZE: usize = QK_K;
type VecDotType = BlockQ8K;
#[allow(unreachable_code)]
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
#[cfg(target_feature = "avx")]
return super::avx::vec_dot_q8k_q8k(n, xs, ys);
#[cfg(target_feature = "neon")]
return super::neon::vec_dot_q8k_q8k(n, xs, ys);
#[cfg(target_feature = "simd128")]
return super::simd128::vec_dot_q8k_q8k(n, xs, ys);
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
let qk = QK_K;
if n % QK_K != 0 {
crate::bail!("vec_dot_q8k_q8k: {n} is not divisible by {qk}")
}
// Generic implementation.
let mut sumf = 0f32;
for (xs, ys) in xs.iter().zip(ys.iter()) {
let sum_i = xs
.qs
.iter()
.zip(ys.qs.iter())
.map(|(&x, &y)| x as i32 * y as i32)
.sum::<i32>();
sumf += sum_i as f32 * xs.d * ys.d
}
Ok(sumf)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
let k = xs.len();
if k % QK_K != 0 {
crate::bail!("quantize_row_q8k: {k} is not divisible by {QK_K}")
}
for (i, y) in ys.iter_mut().enumerate() {
let mut max = 0f32;
let mut amax = 0f32;
let xs = &xs[i * QK_K..(i + 1) * QK_K];
for &x in xs.iter() {
if amax < x.abs() {
amax = x.abs();
max = x;
}
}
if amax == 0f32 {
y.d = 0f32;
y.qs.fill(0)
} else {
let iscale = -128f32 / max;
for (j, q) in y.qs.iter_mut().enumerate() {
// ggml uses nearest_int with bit magic here, maybe we want the same
// but we would have to test and benchmark it.
let v = (iscale * xs[j]).round();
*q = v.min(127.) as i8
}
for j in 0..QK_K / 16 {
let mut sum = 0i32;
for ii in 0..16 {
sum += y.qs[j * 16 + ii] as i32
}
y.bsums[j] = sum as i16
}
y.d = 1.0 / iscale
}
}
Ok(())
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
let k = ys.len();
if k % QK_K != 0 {
crate::bail!("dequantize_row_q8k: {k} is not divisible by {QK_K}")
}
for (i, x) in xs.iter().enumerate() {
for (j, &q) in x.qs.iter().enumerate() {
ys[i * QK_K + j] = x.d * q as f32
}
}
Ok(())
}
}
// https://github.com/ggerganov/llama.cpp/blob/b5ffb2849d23afe73647f68eec7b68187af09be6/ggml.c#L10605
pub fn matmul<T: GgmlType>(
mkn: (usize, usize, usize),
lhs: &[f32],
rhs_t: &[T],
dst: &mut [f32],
) -> Result<()> {
let (m, k, n) = mkn;
if m * k != lhs.len() {
crate::bail!("unexpected lhs length {} {mkn:?}", lhs.len());
}
let k_in_lhs_blocks = (k + T::BLCK_SIZE - 1) / T::BLCK_SIZE;
let k_in_rhs_blocks = (k + T::VecDotType::BLCK_SIZE - 1) / T::VecDotType::BLCK_SIZE;
// TODO: Do not make this copy if the DotType is f32.
// TODO: Pre-allocate this.
let mut lhs_b = vec![T::VecDotType::zeros(); m * k_in_lhs_blocks];
for row_idx in 0..m {
let lhs_b = &mut lhs_b[row_idx * k_in_lhs_blocks..(row_idx + 1) * k_in_lhs_blocks];
let lhs = &lhs[row_idx * k..(row_idx + 1) * k];
T::VecDotType::from_float(lhs, lhs_b)?
}
let lhs_b = lhs_b.as_slice();
for row_idx in 0..m {
let lhs_row = &lhs_b[row_idx * k_in_lhs_blocks..(row_idx + 1) * k_in_lhs_blocks];
let dst_row = &mut dst[row_idx * n..(row_idx + 1) * n];
let result: Result<Vec<_>> = dst_row
.into_par_iter()
.enumerate()
.with_min_len(128)
.with_max_len(512)
.map(|(col_idx, dst)| {
let rhs_col = &rhs_t[col_idx * k_in_rhs_blocks..(col_idx + 1) * k_in_rhs_blocks];
T::vec_dot(k, rhs_col, lhs_row).map(|value| *dst = value)
})
.collect();
result?;
}
Ok(())
}
impl GgmlType for f32 {
const DTYPE: GgmlDType = GgmlDType::F32;
const BLCK_SIZE: usize = 1;
type VecDotType = f32;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if xs.len() < n {
crate::bail!("size mismatch {} < {n}", xs.len())
}
if ys.len() < n {
crate::bail!("size mismatch {} < {n}", ys.len())
}
let mut res = 0f32;
unsafe { crate::cpu::vec_dot_f32(xs.as_ptr(), ys.as_ptr(), &mut res, n) };
Ok(res)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
ys.copy_from_slice(xs);
Ok(())
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
ys.copy_from_slice(xs);
Ok(())
}
}
impl GgmlType for f16 {
const DTYPE: GgmlDType = GgmlDType::F16;
const BLCK_SIZE: usize = 1;
type VecDotType = f16;
fn vec_dot(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
Self::vec_dot_unopt(n, xs, ys)
}
fn vec_dot_unopt(n: usize, xs: &[Self], ys: &[Self::VecDotType]) -> Result<f32> {
if xs.len() < n {
crate::bail!("size mismatch {} < {n}", xs.len())
}
if ys.len() < n {
crate::bail!("size mismatch {} < {n}", ys.len())
}
let mut res = 0f32;
unsafe { crate::cpu::vec_dot_f16(xs.as_ptr(), ys.as_ptr(), &mut res, n) };
Ok(res)
}
fn from_float(xs: &[f32], ys: &mut [Self]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
// TODO: vectorize
for (x, y) in xs.iter().zip(ys.iter_mut()) {
*y = f16::from_f32(*x)
}
Ok(())
}
fn to_float(xs: &[Self], ys: &mut [f32]) -> Result<()> {
if xs.len() != ys.len() {
crate::bail!("size mismatch {} {}", xs.len(), ys.len());
}
// TODO: vectorize
for (x, y) in xs.iter().zip(ys.iter_mut()) {
*y = x.to_f32()
}
Ok(())
}
}
| candle/candle-core/src/quantized/k_quants.rs/0 | {
"file_path": "candle/candle-core/src/quantized/k_quants.rs",
"repo_id": "candle",
"token_count": 42652
} | 21 |
use candle_core::backend::BackendStorage;
use candle_core::cpu_backend;
use candle_core::test_utils::to_vec1_round;
use candle_core::{CpuStorage, CustomOp1, DType, Device, Error, Layout, Result, Shape, Tensor};
fn fwd<T: num_traits::Float>(v: T, alpha: f64) -> T {
if v.is_sign_positive() {
v
} else {
let alpha = T::from(alpha).unwrap_or(T::nan());
(v.exp() - T::one()) * alpha
}
}
struct Elu {
alpha: f64,
}
impl CustomOp1 for Elu {
fn name(&self) -> &'static str {
"elu"
}
fn cpu_fwd(&self, s: &CpuStorage, l: &Layout) -> Result<(CpuStorage, Shape)> {
let storage = candle_core::map_dtype!(
"elu",
s,
|s| cpu_backend::unary_map(s, l, |v| fwd(v, self.alpha)),
(BF16, F16, F32, F64)
);
Ok((storage, l.shape().clone()))
}
}
#[test]
fn custom_op1_no_backward() -> Result<()> {
let cpu = &Device::Cpu;
let t = Tensor::arange(0u32, 12u32, cpu)?.to_dtype(DType::F32)?;
let t = (t - 5.)?;
let elu_t = t.apply_op1_no_bwd(&Elu { alpha: 1. })?;
assert_eq!(
to_vec1_round(&elu_t, 4)?,
&[-0.9933, -0.9817, -0.9502, -0.8647, -0.6321, 0.0, 1.0, 2.0, 3.0, 4.0, 5.0, 6.0]
);
Ok(())
}
// Define a similar struct as Elu but with backward support.
fn bwd<T: num_traits::Float>(v: T, alpha: f64) -> T {
if v.is_sign_positive() {
T::one()
} else {
let alpha = T::from(alpha).unwrap_or(T::nan());
v.exp() * alpha
}
}
struct EluBackward {
alpha: f64,
}
impl CustomOp1 for EluBackward {
fn name(&self) -> &'static str {
"elu-bwd"
}
fn cpu_fwd(&self, s: &CpuStorage, l: &Layout) -> Result<(CpuStorage, Shape)> {
let storage = candle_core::map_dtype!(
"elu-bwd",
s,
|s| cpu_backend::unary_map(s, l, |v| bwd(v, self.alpha)),
(BF16, F16, F32, F64)
);
Ok((storage, l.shape().clone()))
}
}
struct EluWithBackward(Elu);
impl EluWithBackward {
fn new(alpha: f64) -> Self {
Self(Elu { alpha })
}
}
impl CustomOp1 for EluWithBackward {
fn name(&self) -> &'static str {
"elu"
}
fn cpu_fwd(&self, s: &CpuStorage, l: &Layout) -> Result<(CpuStorage, Shape)> {
self.0.cpu_fwd(s, l)
}
fn bwd(&self, arg: &Tensor, _res: &Tensor, grad_res: &Tensor) -> Result<Option<Tensor>> {
let alpha = self.0.alpha;
let bwd = arg.apply_op1(EluBackward { alpha })?;
Ok(Some(grad_res.mul(&bwd)?))
}
}
#[test]
fn custom_op1_with_backward() -> Result<()> {
let cpu = &Device::Cpu;
let t = candle_core::Var::new(&[-2f32, 0f32, 2f32], cpu)?;
let elu_t = t.apply_op1(EluWithBackward::new(2.))?;
assert_eq!(to_vec1_round(&elu_t, 4)?, &[-1.7293, 0.0, 2.0]);
let grads = elu_t.backward()?;
let grad_x = grads.get(&t).unwrap();
assert_eq!(to_vec1_round(grad_x, 4)?, [0.2707, 1.0, 1.0]);
Ok(())
}
| candle/candle-core/tests/custom_op_tests.rs/0 | {
"file_path": "candle/candle-core/tests/custom_op_tests.rs",
"repo_id": "candle",
"token_count": 1542
} | 22 |
//! Datasets & Dataloaders for Candle
pub mod batcher;
pub mod hub;
pub mod nlp;
pub mod vision;
pub use batcher::Batcher;
| candle/candle-datasets/src/lib.rs/0 | {
"file_path": "candle/candle-datasets/src/lib.rs",
"repo_id": "candle",
"token_count": 45
} | 23 |
// An implementation of LLaMA https://github.com/facebookresearch/llama
//
// This is based on nanoGPT in a similar way to:
// https://github.com/Lightning-AI/lit-llama/blob/main/lit_llama/model.py
//
// The tokenizer config can be retrieved from:
// https://huggingface.co/hf-internal-testing/llama-tokenizer/raw/main/tokenizer.json
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
use anyhow::{bail, Error as E, Result};
use clap::Parser;
use candle::{DType, Device, Tensor};
use candle_transformers::generation::LogitsProcessor;
use cudarc::driver::safe::CudaDevice;
use cudarc::nccl::safe::{Comm, Id};
use hf_hub::{api::sync::Api, Repo, RepoType};
use std::io::Write;
use std::rc::Rc;
mod model;
use model::{Config, Llama};
const MAX_SEQ_LEN: usize = 4096;
const DEFAULT_PROMPT: &str = r"
EDWARD:
I wonder how our princely father 'scaped,
Or whether he be 'scaped away or no
From Clifford's and Northumberland's pursuit:
Had he been ta'en, we should have heard the news;
Had he been slain, we should have heard the news;
Or had he 'scaped, methinks we should have heard
The happy tidings of his good escape.
How fares my brother? why is he so sad?
RICHARD:
I cannot joy, until I be resolved
Where our right valiant father is become.
I saw him in the battle range about;
And watch'd him how he singled Clifford forth.
Methought he bore him in the thickest troop
As doth a lion in a herd of neat;
Or as a bear, encompass'd round with dogs,
Who having pinch'd a few and made them cry,
The rest stand all aloof, and bark at him.
So fared our father with his enemies;
So fled his enemies my warlike father:
Methinks, 'tis prize enough to be his son.
See how the morning opes her golden gates,
And takes her farewell of the glorious sun!
How well resembles it the prime of youth,
Trimm'd like a younker prancing to his love!
EDWARD:
Dazzle mine eyes, or do I see three suns?
RICHARD:
Three glorious suns, each one a perfect sun;
Not separated with the racking clouds,
But sever'd in a pale clear-shining sky.
See, see! they join, embrace, and seem to kiss,
As if they vow'd some league inviolable:
Now are they but one lamp, one light, one sun.
In this the heaven figures some event.
EDWARD:
'Tis wondrous strange, the like yet never heard of.
I think it cites us, brother, to the field,
That we, the sons of brave Plantagenet,
Each one already blazing by our meeds,
Should notwithstanding join our lights together
And over-shine the earth as this the world.
Whate'er it bodes, henceforward will I bear
Upon my target three fair-shining suns.
";
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
#[arg(long)]
num_shards: usize,
#[arg(long)]
rank: Option<usize>,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, default_value_t = 100)]
sample_len: usize,
/// Disable the key-value cache.
#[arg(long)]
no_kv_cache: bool,
/// The initial prompt.
#[arg(long)]
prompt: Option<String>,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
dtype: Option<String>,
}
fn main() -> Result<()> {
use tokenizers::Tokenizer;
let args = Args::parse();
let dtype = match args.dtype.as_deref() {
Some("f16") => DType::F16,
Some("bf16") => DType::BF16,
Some("f32") => DType::F32,
Some(dtype) => bail!("Unsupported dtype {dtype}"),
None => DType::F16,
};
let api = Api::new()?;
let model_id = args
.model_id
.unwrap_or_else(|| "meta-llama/Llama-2-7b-hf".to_string());
println!("loading the model weights from {model_id}");
let revision = args.revision.unwrap_or("main".to_string());
let api = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));
let config_filename = api.get("config.json")?;
let config: Config = serde_json::from_slice(&std::fs::read(config_filename)?)?;
let tokenizer_filename = api.get("tokenizer.json")?;
let filenames = candle_examples::hub_load_safetensors(&api, "model.safetensors.index.json")?;
if args.rank.is_none() {
let children: Vec<_> = (0..args.num_shards)
.map(|rank| {
let mut args: std::collections::VecDeque<_> = std::env::args().collect();
args.push_back("--rank".to_string());
args.push_back(format!("{rank}"));
let name = args.pop_front().unwrap();
std::process::Command::new(name).args(args).spawn().unwrap()
})
.collect();
for mut child in children {
child.wait().unwrap();
}
return Ok(());
}
let i = args.rank.unwrap();
let num_shards = args.num_shards;
let rank = i;
// Primitive IPC
let id = if rank == 0 {
let id = Id::new().unwrap();
std::fs::File::create("nccl_id.txt.tmp")?
.write_all(&id.internal().iter().map(|&i| i as u8).collect::<Vec<_>>())
.unwrap();
std::fs::rename("nccl_id.txt.tmp", "nccl_id.txt")?;
id
} else {
let path = std::path::PathBuf::from("nccl_id.txt");
while !path.exists() {
std::thread::sleep(std::time::Duration::from_secs(1));
}
let data = std::fs::read("nccl_id.txt")?;
let internal: [i8; 128] = data
.into_iter()
.map(|i| i as i8)
.collect::<Vec<_>>()
.try_into()
.unwrap();
let id: Id = Id::uninit(internal);
id
};
let device = CudaDevice::new(i)?;
let comm = Rc::new(Comm::from_rank(device, i, num_shards, id).unwrap());
if rank == 0 {
std::fs::remove_file("nccl_id.txt")?;
}
println!("Rank {rank:?} spawned");
let device = Device::new_cuda(i)?;
let cache = model::Cache::new(dtype, &config, &device)?;
println!("building the model");
let vb = unsafe {
candle_nn::var_builder::ShardedSafeTensors::var_builder(&filenames, dtype, &device)?
};
let llama = Llama::load(vb, &cache, &config, comm)?;
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let prompt = args.prompt.as_ref().map_or(DEFAULT_PROMPT, |p| p.as_str());
let mut tokens = tokenizer
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
println!("starting the inference loop");
let mut logits_processor = LogitsProcessor::new(args.seed, args.temperature, args.top_p);
let mut new_tokens = vec![];
let start_gen = std::time::Instant::now();
let mut index_pos = 0;
for index in 0..args.sample_len {
let start_gen = std::time::Instant::now();
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;
let logits = llama.forward(&input, index_pos)?;
let logits = logits.squeeze(0)?;
index_pos += ctxt.len();
let next_token = logits_processor.sample(&logits)?;
tokens.push(next_token);
new_tokens.push(next_token);
if rank == 0 {
println!("> {:?}", start_gen.elapsed());
println!(
"{} token: {} '{}'",
index + 1,
next_token,
tokenizer.decode(&[next_token], true).map_err(E::msg)?
);
}
}
let dt = start_gen.elapsed();
if rank == 0 {
println!(
"{} tokens generated ({} token/s)\n----\n{}\n----",
args.sample_len,
args.sample_len as f64 / dt.as_secs_f64(),
tokenizer
.decode(new_tokens.as_slice(), true)
.map_err(E::msg)?
);
}
Ok(())
}
| candle/candle-examples/examples/llama_multiprocess/main.rs/0 | {
"file_path": "candle/candle-examples/examples/llama_multiprocess/main.rs",
"repo_id": "candle",
"token_count": 3470
} | 24 |
#![allow(dead_code)]
// https://huggingface.co/facebook/musicgen-small/tree/main
// https://github.com/huggingface/transformers/blob/cd4584e3c809bb9e1392ccd3fe38b40daba5519a/src/transformers/models/musicgen/modeling_musicgen.py
// TODO: Add an offline mode.
// TODO: Add a KV cache.
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
mod encodec_model;
mod musicgen_model;
mod nn;
use musicgen_model::{GenConfig, MusicgenForConditionalGeneration};
use anyhow::{Error as E, Result};
use candle::{DType, Tensor};
use candle_nn::VarBuilder;
use clap::Parser;
use hf_hub::{api::sync::Api, Repo, RepoType};
const DTYPE: DType = DType::F32;
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// The model weight file, in safetensor format.
#[arg(long)]
model: Option<String>,
/// The tokenizer config.
#[arg(long)]
tokenizer: Option<String>,
#[arg(
long,
default_value = "90s rock song with loud guitars and heavy drums"
)]
prompt: String,
}
fn main() -> Result<()> {
use tokenizers::Tokenizer;
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let tokenizer = match args.tokenizer {
Some(tokenizer) => std::path::PathBuf::from(tokenizer),
None => Api::new()?
.model("facebook/musicgen-small".to_string())
.get("tokenizer.json")?,
};
let mut tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;
let tokenizer = tokenizer
.with_padding(None)
.with_truncation(None)
.map_err(E::msg)?;
let model = match args.model {
Some(model) => std::path::PathBuf::from(model),
None => Api::new()?
.repo(Repo::with_revision(
"facebook/musicgen-small".to_string(),
RepoType::Model,
"refs/pr/13".to_string(),
))
.get("model.safetensors")?,
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DTYPE, &device)? };
let config = GenConfig::small();
let mut model = MusicgenForConditionalGeneration::load(vb, config)?;
let tokens = tokenizer
.encode(args.prompt.as_str(), true)
.map_err(E::msg)?
.get_ids()
.to_vec();
println!("tokens: {tokens:?}");
let tokens = Tensor::new(tokens.as_slice(), &device)?.unsqueeze(0)?;
println!("{tokens:?}");
let embeds = model.text_encoder.forward(&tokens)?;
println!("{embeds}");
Ok(())
}
| candle/candle-examples/examples/musicgen/main.rs/0 | {
"file_path": "candle/candle-examples/examples/musicgen/main.rs",
"repo_id": "candle",
"token_count": 1164
} | 25 |
#![allow(unused)]
//! Wrappers around the Python API of Gymnasium (the new version of OpenAI gym)
use candle::{Device, Result, Tensor};
use pyo3::prelude::*;
use pyo3::types::PyDict;
/// The return value for a step.
#[derive(Debug)]
pub struct Step<A> {
pub state: Tensor,
pub action: A,
pub reward: f64,
pub terminated: bool,
pub truncated: bool,
}
impl<A: Copy> Step<A> {
/// Returns a copy of this step changing the observation tensor.
pub fn copy_with_obs(&self, state: &Tensor) -> Step<A> {
Step {
state: state.clone(),
action: self.action,
reward: self.reward,
terminated: self.terminated,
truncated: self.truncated,
}
}
}
/// An OpenAI Gym session.
pub struct GymEnv {
env: PyObject,
action_space: usize,
observation_space: Vec<usize>,
}
fn w(res: PyErr) -> candle::Error {
candle::Error::wrap(res)
}
impl GymEnv {
/// Creates a new session of the specified OpenAI Gym environment.
pub fn new(name: &str) -> Result<GymEnv> {
Python::with_gil(|py| {
let gym = py.import("gymnasium")?;
let make = gym.getattr("make")?;
let env = make.call1((name,))?;
let action_space = env.getattr("action_space")?;
let action_space = if let Ok(val) = action_space.getattr("n") {
val.extract()?
} else {
let action_space: Vec<usize> = action_space.getattr("shape")?.extract()?;
action_space[0]
};
let observation_space = env.getattr("observation_space")?;
let observation_space = observation_space.getattr("shape")?.extract()?;
Ok(GymEnv {
env: env.into(),
action_space,
observation_space,
})
})
.map_err(w)
}
/// Resets the environment, returning the observation tensor.
pub fn reset(&self, seed: u64) -> Result<Tensor> {
let state: Vec<f32> = Python::with_gil(|py| {
let kwargs = PyDict::new(py);
kwargs.set_item("seed", seed)?;
let state = self.env.call_method(py, "reset", (), Some(kwargs))?;
state.as_ref(py).get_item(0)?.extract()
})
.map_err(w)?;
Tensor::new(state, &Device::Cpu)
}
/// Applies an environment step using the specified action.
pub fn step<A: pyo3::IntoPy<pyo3::Py<pyo3::PyAny>> + Clone>(
&self,
action: A,
) -> Result<Step<A>> {
let (state, reward, terminated, truncated) = Python::with_gil(|py| {
let step = self.env.call_method(py, "step", (action.clone(),), None)?;
let step = step.as_ref(py);
let state: Vec<f32> = step.get_item(0)?.extract()?;
let reward: f64 = step.get_item(1)?.extract()?;
let terminated: bool = step.get_item(2)?.extract()?;
let truncated: bool = step.get_item(3)?.extract()?;
Ok((state, reward, terminated, truncated))
})
.map_err(w)?;
let state = Tensor::new(state, &Device::Cpu)?;
Ok(Step {
state,
action,
reward,
terminated,
truncated,
})
}
/// Returns the number of allowed actions for this environment.
pub fn action_space(&self) -> usize {
self.action_space
}
/// Returns the shape of the observation tensors.
pub fn observation_space(&self) -> &[usize] {
&self.observation_space
}
}
| candle/candle-examples/examples/reinforcement-learning/gym_env.rs/0 | {
"file_path": "candle/candle-examples/examples/reinforcement-learning/gym_env.rs",
"repo_id": "candle",
"token_count": 1716
} | 26 |
# candle-stable-diffusion: A Diffusers API in Rust/Candle

_A rusty robot holding a fire torch in its hand_, generated by Stable Diffusion
XL using Rust and [candle](https://github.com/huggingface/candle).
The `stable-diffusion` example is a conversion of
[diffusers-rs](https://github.com/LaurentMazare/diffusers-rs) using candle
rather than libtorch. This implementation supports Stable Diffusion v1.5, v2.1,
as well as Stable Diffusion XL 1.0, and Turbo.
## Getting the weights
The weights are automatically downloaded for you from the [HuggingFace
Hub](https://huggingface.co/) on the first run. There are various command line
flags to use local files instead, run with `--help` to learn about them.
## Running some example.
```bash
cargo run --example stable-diffusion --release --features=cuda,cudnn \
-- --prompt "a cosmonaut on a horse (hd, realistic, high-def)"
```
The final image is named `sd_final.png` by default. The Turbo version is much
faster than previous versions, to give it a try add a `--sd-version turbo` flag,
e.g.:
```bash
cargo run --example stable-diffusion --release --features=cuda,cudnn \
-- --prompt "a cosmonaut on a horse (hd, realistic, high-def)" --sd-version turbo
```
The default scheduler for the v1.5, v2.1 and XL 1.0 version is the Denoising
Diffusion Implicit Model scheduler (DDIM). The original paper and some code can
be found in the [associated repo](https://github.com/ermongroup/ddim).
The default scheduler for the XL Turbo version is the Euler Ancestral scheduler.
### Command-line flags
- `--prompt`: the prompt to be used to generate the image.
- `--uncond-prompt`: the optional unconditional prompt.
- `--sd-version`: the Stable Diffusion version to use, can be `v1-5`, `v2-1`,
`xl`, or `turbo`.
- `--cpu`: use the cpu rather than the gpu (much slower).
- `--height`, `--width`: set the height and width for the generated image.
- `--n-steps`: the number of steps to be used in the diffusion process.
- `--num-samples`: the number of samples to generate.
- `--final-image`: the filename for the generated image(s).
### Using flash-attention
Using flash attention makes image generation a lot faster and uses less memory.
The downside is some long compilation time. You can set the
`CANDLE_FLASH_ATTN_BUILD_DIR` environment variable to something like
`/home/user/.candle` to ensures that the compilation artifacts are properly
cached.
Enabling flash-attention requires both a feature flag, `--feature flash-attn`
and using the command line flag `--use-flash-attn`.
Note that flash-attention-v2 is only compatible with Ampere, Ada, or Hopper GPUs
(e.g., A100/H100, RTX 3090/4090).
## Image to Image Pipeline
...
## FAQ
### Memory Issues
This requires a GPU with more than 8GB of memory, as a fallback the CPU version can be used
with the `--cpu` flag but is much slower.
Alternatively, reducing the height and width with the `--height` and `--width`
flag is likely to reduce memory usage significantly.
| candle/candle-examples/examples/stable-diffusion/README.md/0 | {
"file_path": "candle/candle-examples/examples/stable-diffusion/README.md",
"repo_id": "candle",
"token_count": 917
} | 27 |
# Get the checkpoint from
# https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt
import torch
from safetensors.torch import save_file
data = torch.load("tiny.en.pt")
weights = {}
for k, v in data["model_state_dict"].items():
weights[k] = v.contiguous()
print(k, v.shape, v.dtype)
save_file(weights, "tiny.en.safetensors")
print(data["dims"])
| candle/candle-examples/examples/whisper/extract_weights.py/0 | {
"file_path": "candle/candle-examples/examples/whisper/extract_weights.py",
"repo_id": "candle",
"token_count": 183
} | 28 |
// Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 128>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim128<cutlass::half_t>(params, stream);
}
| candle/candle-flash-attn/kernels/flash_fwd_hdim128_fp16_sm80.cu/0 | {
"file_path": "candle/candle-flash-attn/kernels/flash_fwd_hdim128_fp16_sm80.cu",
"repo_id": "candle",
"token_count": 135
} | 29 |
/******************************************************************************
* Copyright (c) 2023, Tri Dao.
******************************************************************************/
#pragma once
#include "static_switch.h"
#include "flash.h"
#include "flash_fwd_kernel.h"
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Return_softmax>
__global__ void flash_fwd_kernel(Flash_fwd_params params) {
static_assert(!(Is_causal && Is_local)); // If Is_local is true, Is_causal should be false
flash::compute_attn<Kernel_traits, Is_dropout, Is_causal, Is_local, Has_alibi, Is_even_MN, Is_even_K, Return_softmax>(params);
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal>
void run_flash_fwd(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr size_t smem_size = Kernel_traits::kSmemSize;
// printf("smem_size = %d\n", smem_size);
// Work-around for gcc 7. It doesn't like nested BOOL_SWITCH.
// https://github.com/kokkos/kokkos-kernels/issues/349
// https://github.com/HazyResearch/flash-attention/issues/21
const int num_m_block = (params.seqlen_q + Kernel_traits::kBlockM - 1) / Kernel_traits::kBlockM;
dim3 grid(num_m_block, params.b, params.h);
const bool is_even_MN = params.cu_seqlens_q == nullptr && params.cu_seqlens_k == nullptr && params.seqlen_k % Kernel_traits::kBlockN == 0 && params.seqlen_q % Kernel_traits::kBlockM == 0;
const bool is_even_K = params.d == Kernel_traits::kHeadDim;
const bool return_softmax = params.p_ptr != nullptr;
BOOL_SWITCH(is_even_MN, IsEvenMNConst, [&] {
BOOL_SWITCH(is_even_K, IsEvenKConst, [&] {
BOOL_SWITCH((params.window_size_left >= 0 || params.window_size_right >= 0) && !Is_causal, Is_local, [&] {
BOOL_SWITCH(return_softmax, ReturnSoftmaxConst, [&] {
BOOL_SWITCH(params.alibi_slopes_ptr != nullptr, Has_alibi, [&] {
// Will only return softmax if dropout, to reduce compilation time.
// If not IsEvenKConst, we also set IsEvenMNConst to false to reduce number of templates.
// If return_softmax, set IsEvenMNConst to false to reduce number of templates
// If head dim > 128, set IsEvenMNConst to false to reduce number of templates
// If Is_local, set Is_causal to false
auto kernel = &flash_fwd_kernel<Kernel_traits, Is_dropout, Is_causal, Is_local && !Is_causal, Has_alibi, IsEvenMNConst && IsEvenKConst && !Is_local && !ReturnSoftmaxConst && Kernel_traits::kHeadDim <= 128, IsEvenKConst, ReturnSoftmaxConst && Is_dropout>;
// auto kernel = &flash_fwd_kernel<Kernel_traits, false, Is_causal, false, false, true, true, false>;
// printf("IsEvenMNConst = %d, IsEvenKConst = %d, Is_local = %d, Is_causal = %d, ReturnSoftmaxConst = %d, Is_dropout = %d\n", int(IsEvenMNConst), int(IsEvenKConst), int(Is_local), int(Is_causal), int(ReturnSoftmaxConst), int(Is_dropout));
// auto kernel = &flash_fwd_kernel<Kernel_traits, false, Is_causal, false, true, true, false>;
// int ctas_per_sm;
// cudaError status_ = cudaOccupancyMaxActiveBlocksPerMultiprocessor(
// &ctas_per_sm, kernel, Kernel_traits::kNThreads, smem_size);
// printf("smem_size = %d, CTAs per SM = %d\n", int(smem_size), ctas_per_sm);
kernel<<<grid, Kernel_traits::kNThreads, smem_size, stream>>>(params);
});
});
});
});
});
}
template<typename T>
void run_mha_fwd_hdim32(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 32;
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
});
});
}
template<typename T>
void run_mha_fwd_hdim64(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 64;
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
if constexpr(!Is_dropout) {
// Using 8 warps is 18% slower for seqlen=2k, 2 warps is 5% slower
// Using block size (64 x 256) is 27% slower for seqlen=2k
// Using block size (256 x 64) is 85% slower for seqlen=2k, because of register spilling
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
});
});
}
template<typename T>
void run_mha_fwd_hdim96(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 96;
// auto dprops = at::cuda::getCurrentDeviceProperties();
bool is_sm8x = true; // dprops->major == 8 && dprops->minor > 0;
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
// For sm86 or sm89, 64 x 64 is the fastest for causal (because it's square),
if (is_sm8x) {
if constexpr(!Is_causal) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
// These two are always slower
// run_flash_fwd<Flash_fwd_kernel_traits<96, 128, 128, 4, true, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<96, 64, 128, 4, true, T>>(params, stream);
});
});
}
template<typename T>
void run_mha_fwd_hdim128(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 128;
// auto dprops = at::cuda::getCurrentDeviceProperties();
bool is_sm8x = true; // dprops->major == 8 && dprops->minor > 0;
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
if constexpr(!Is_dropout) {
// For sm86 or sm89, 64 x 64 is the fastest for causal (because it's square),
// and 128 x 32 (48 KB smem) is the fastest for non-causal since we get 2 CTAs per SM.
if (is_sm8x) {
if constexpr(!Is_causal) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// Using 8 warps (128 x 128 and 256 x 64) is 28% slower for seqlen=2k
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
// 1st ones are good for H100, A100
// 2nd one is good for A6000 bc we get slightly better occupancy
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
}
});
});
}
template<typename T>
void run_mha_fwd_hdim160(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 160;
// auto dprops = at::cuda::getCurrentDeviceProperties();
bool is_sm8x = true; // dprops->major == 8 && dprops->minor > 0;
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
// For A100, H100, 128 x 32 is the fastest.
// For sm86 or sm89, 64 x 64 is the fastest for causal (because it's square),
// and 128 x 64 with 8 warps is the fastest for non-causal.
if (is_sm8x) {
if constexpr(!Is_causal) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, true, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 128, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 8, false, T>>(params, stream);
});
});
}
template<typename T>
void run_mha_fwd_hdim192(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 192;
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
if constexpr(!Is_dropout) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 128, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 8, false, T>>(params, stream);
});
});
}
template<typename T>
void run_mha_fwd_hdim224(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 224;
int device;
cudaGetDevice(&device);
int max_smem_per_block;
cudaError status_ = cudaDeviceGetAttribute(
&max_smem_per_block, cudaDevAttrMaxSharedMemoryPerBlockOptin, device);
// printf("max_smem_per_block = %d\n", max_smem_per_block);
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
if (max_smem_per_block >= 2 * Headdim * (128 + 2 * 64)) { // 112 KB
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// We can't do 128 x 32 with 8 warps because with headdim 224, kBlockKSmem = 32.
// If we have N = 32, there are only 1024 elements to load at once, where each load
// is 8 elements. This means we can only use 128 threads and not 256 threads.
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
});
});
}
template<typename T>
void run_mha_fwd_hdim256(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 256;
int device;
cudaGetDevice(&device);
int max_smem_per_sm, max_smem_per_block;
cudaError status_ = cudaDeviceGetAttribute(
&max_smem_per_sm, cudaDevAttrMaxSharedMemoryPerMultiprocessor, device);
status_ = cudaDeviceGetAttribute(
&max_smem_per_block, cudaDevAttrMaxSharedMemoryPerBlockOptin, device);
// printf("max_smem_per_sm = %d, max_smem_per_block = %d\n", max_smem_per_sm, max_smem_per_block);
BOOL_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
BOOL_SWITCH(params.is_causal, Is_causal, [&] {
// For A100, we want to run with 128 x 64 (128KB smem).
// For H100 we want to run with 64 x 64 (96KB smem) since then we can get 2 CTAs per SM.
if (max_smem_per_block >= 2 * Headdim * (128 + 2 * 64) && max_smem_per_sm < 4 * Headdim * (64 + 2 * 64)) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// 64 KB
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// 96 KB
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
});
});
}
| candle/candle-flash-attn/kernels/flash_fwd_launch_template.h/0 | {
"file_path": "candle/candle-flash-attn/kernels/flash_fwd_launch_template.h",
"repo_id": "candle",
"token_count": 7583
} | 30 |
#include "cuda_utils.cuh"
#include<stdint.h>
template <typename S, typename T>
__device__ void cast_(
const size_t numel,
const size_t num_dims,
const size_t *info,
const S *inp,
T *out
) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
if (is_contiguous(num_dims, dims, strides)) {
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
out[i] = inp[i];
}
}
else {
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
unsigned strided_i = get_strided_index(i, num_dims, dims, strides);
out[i] = inp[strided_i];
}
}
}
template <typename S, typename T, typename I>
__device__ void cast_through(
const size_t numel,
const size_t num_dims,
const size_t *info,
const S *inp,
T *out
) {
const size_t *dims = info;
const size_t *strides = info + num_dims;
if (is_contiguous(num_dims, dims, strides)) {
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
out[i] = static_cast<T>(static_cast<I>(inp[i]));
}
}
else {
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
unsigned strided_i = get_strided_index(i, num_dims, dims, strides);
out[i] = static_cast<T>(static_cast<I>(inp[strided_i]));
}
}
}
#define CAST_OP(SRC_TYPENAME, DST_TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const size_t numel, \
const size_t num_dims, \
const size_t *info, \
const SRC_TYPENAME *inp, \
DST_TYPENAME *out \
) { \
cast_<SRC_TYPENAME, DST_TYPENAME>(numel, num_dims, info, inp, out); \
} \
#define CAST_THROUGH_OP(SRC_TYPENAME, DST_TYPENAME, INT_TYPENAME, FN_NAME) \
extern "C" __global__ void FN_NAME( \
const size_t numel, \
const size_t num_dims, \
const size_t *info, \
const SRC_TYPENAME *inp, \
DST_TYPENAME *out \
) { \
cast_through<SRC_TYPENAME, DST_TYPENAME, INT_TYPENAME>(numel, num_dims, info, inp, out); \
} \
#if __CUDA_ARCH__ >= 800
CAST_OP(__nv_bfloat16, __nv_bfloat16, cast_bf16_bf16)
CAST_OP(__nv_bfloat16, uint32_t, cast_bf16_u32)
CAST_OP(__nv_bfloat16, float, cast_bf16_f32)
CAST_OP(__nv_bfloat16, double, cast_bf16_f64)
CAST_OP(uint8_t, __nv_bfloat16, cast_u8_bf16)
CAST_OP(uint32_t, __nv_bfloat16, cast_u32_bf16)
CAST_OP(float, __nv_bfloat16, cast_f32_bf16)
CAST_OP(double, __nv_bfloat16, cast_f64_bf16)
CAST_THROUGH_OP(__nv_bfloat16, uint8_t, float, cast_bf16_u8)
CAST_THROUGH_OP(__nv_bfloat16, __half, float, cast_bf16_f16)
CAST_THROUGH_OP(__half, __nv_bfloat16, float, cast_f16_bf16)
#endif
#if __CUDA_ARCH__ >= 530
CAST_OP(__half, __half, cast_f16_f16)
CAST_THROUGH_OP(__half, uint8_t, float, cast_f16_u8)
CAST_OP(__half, uint32_t, cast_f16_u32)
CAST_OP(__half, float, cast_f16_f32)
CAST_OP(__half, double, cast_f16_f64)
CAST_OP(uint8_t, __half, cast_u8_f16 )
CAST_OP(uint32_t, __half, cast_u32_f16)
CAST_OP(float, __half, cast_f32_f16)
CAST_OP(double, __half, cast_f64_f16)
#endif
CAST_OP(uint32_t, uint32_t, cast_u32_u32)
CAST_OP(uint32_t, uint8_t, cast_u32_u8 )
CAST_OP(uint32_t, int64_t, cast_u32_i64 )
CAST_OP(uint32_t, float, cast_u32_f32)
CAST_OP(uint32_t, double, cast_u32_f64)
CAST_OP(uint8_t, uint32_t, cast_u8_u32)
CAST_OP(uint8_t, uint8_t, cast_u8_u8 )
CAST_OP(uint8_t, int64_t, cast_u8_i64 )
CAST_OP(uint8_t, float, cast_u8_f32)
CAST_OP(uint8_t, double, cast_u8_f64)
CAST_OP(int64_t, uint32_t, cast_i64_u32)
CAST_OP(int64_t, uint8_t, cast_i64_u8 )
CAST_OP(int64_t, int64_t, cast_i64_i64 )
CAST_OP(int64_t, float, cast_i64_f32)
CAST_OP(int64_t, double, cast_i64_f64)
CAST_OP(float, uint8_t, cast_f32_u8 )
CAST_OP(float, uint32_t, cast_f32_u32)
CAST_OP(float, int64_t, cast_f32_i64 )
CAST_OP(float, float, cast_f32_f32)
CAST_OP(float, double, cast_f32_f64)
CAST_OP(double, uint8_t, cast_f64_u8 )
CAST_OP(double, uint32_t, cast_f64_u32)
CAST_OP(double, int64_t, cast_f64_i64 )
CAST_OP(double, float, cast_f64_f32)
CAST_OP(double, double, cast_f64_f64)
| candle/candle-kernels/src/cast.cu/0 | {
"file_path": "candle/candle-kernels/src/cast.cu",
"repo_id": "candle",
"token_count": 2161
} | 31 |
#include <metal_stdlib>
using namespace metal;
template<typename TYPENAME, typename INDEX_TYPENAME>
METAL_FUNC void index(
constant size_t &dst_size,
constant size_t &left_size,
constant size_t &src_dim_size,
constant size_t &right_size,
constant size_t &ids_size,
const device TYPENAME *input,
const device INDEX_TYPENAME *input_ids,
device TYPENAME *output,
uint tid [[ thread_position_in_grid ]]
) {
if (tid >= dst_size) {
return;
}
const size_t id_i = (tid / right_size) % ids_size;
const INDEX_TYPENAME input_i = min(input_ids[id_i], (INDEX_TYPENAME)(src_dim_size - 1));
const size_t right_rank_i = tid % right_size;
const size_t left_rank_i = tid / right_size / ids_size;
/*
// Force prevent out of bounds indexing
// since there doesn't seem to be a good way to force crash
// No need to check for zero we're only allowing unsized.
*/
const size_t src_i = left_rank_i * src_dim_size * right_size + input_i * right_size + right_rank_i;
output[tid] = input[src_i];
}
# define INDEX_OP(NAME, INDEX_TYPENAME, TYPENAME) \
kernel void NAME( \
constant size_t &dst_size, \
constant size_t &left_size, \
constant size_t &src_dim_size, \
constant size_t &right_size, \
constant size_t &ids_size, \
const device TYPENAME *input, \
const device INDEX_TYPENAME *input_ids, \
device TYPENAME *output, \
uint tid [[ thread_position_in_grid ]] \
) { \
index<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, ids_size, input, input_ids, output, tid); \
}
template<typename TYPENAME, typename INDEX_TYPENAME>
METAL_FUNC void gather(
constant size_t &dst_size,
constant size_t &left_size,
constant size_t &src_dim_size,
constant size_t &right_size,
constant size_t &ids_size,
const device TYPENAME *input,
const device INDEX_TYPENAME *input_ids,
device TYPENAME *output,
uint tid [[ thread_position_in_grid ]]
) {
if (tid >= dst_size) {
return;
}
const INDEX_TYPENAME input_i = input_ids[tid];
const size_t right_rank_i = tid % right_size;
const size_t left_rank_i = tid / right_size / ids_size;
const size_t src_i = (left_rank_i * src_dim_size + input_i) * right_size + right_rank_i;
output[tid] = input[src_i];
}
# define GATHER_OP(NAME, INDEX_TYPENAME, TYPENAME) \
kernel void NAME( \
constant size_t &dst_size, \
constant size_t &left_size, \
constant size_t &src_dim_size, \
constant size_t &right_size, \
constant size_t &ids_size, \
const device TYPENAME *input, \
const device INDEX_TYPENAME *input_ids, \
device TYPENAME *output, \
uint tid [[ thread_position_in_grid ]] \
) { \
gather<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, ids_size, input, input_ids, output, tid); \
}
template<typename TYPENAME, typename INDEX_TYPENAME>
METAL_FUNC void scatter_add(
constant size_t &dst_size,
constant size_t &left_size,
constant size_t &src_dim_size,
constant size_t &right_size,
constant size_t &dst_dim_size,
const device TYPENAME *input,
const device INDEX_TYPENAME *input_ids,
device TYPENAME *output,
uint tid [[ thread_position_in_grid ]]
) {
if (tid >= dst_size) {
return;
}
const size_t right_rank_i = tid % right_size;
const size_t left_rank_i = tid / right_size;
for (unsigned int j = 0; j < src_dim_size; ++j) {
const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i;
const INDEX_TYPENAME idx = input_ids[src_i];
const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i;
output[dst_i] += input[src_i];
}
}
# define SCATTER_ADD_OP(NAME, INDEX_TYPENAME, TYPENAME) \
kernel void NAME( \
constant size_t &dst_size, \
constant size_t &left_size, \
constant size_t &src_dim_size, \
constant size_t &right_size, \
constant size_t &dst_dim_size, \
const device TYPENAME *input, \
const device INDEX_TYPENAME *input_ids, \
device TYPENAME *output, \
uint tid [[ thread_position_in_grid ]] \
) { \
scatter_add<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, dst_dim_size, input, input_ids, output, tid); \
}
template<typename TYPENAME, typename INDEX_TYPENAME>
METAL_FUNC void index_add(
constant size_t &dst_size,
constant size_t &left_size,
constant size_t &src_dim_size,
constant size_t &right_size,
constant size_t &dst_dim_size,
constant size_t &ids_dim_size,
const device TYPENAME *input,
const device INDEX_TYPENAME *input_ids,
device TYPENAME *output,
uint tid [[ thread_position_in_grid ]]
) {
if (tid >= dst_size) {
return;
}
const size_t right_rank_i = tid % right_size;
const size_t left_rank_i = tid / right_size;
for (unsigned int j = 0; j < ids_dim_size; ++j) {
const INDEX_TYPENAME idx = input_ids[j];
const size_t src_i = (left_rank_i * src_dim_size + j) * right_size + right_rank_i;
const size_t dst_i = (left_rank_i * dst_dim_size + idx) * right_size + right_rank_i;
output[dst_i] += input[src_i];
}
}
# define INDEX_ADD_OP(NAME, INDEX_TYPENAME, TYPENAME) \
kernel void NAME( \
constant size_t &dst_size, \
constant size_t &left_size, \
constant size_t &src_dim_size, \
constant size_t &right_size, \
constant size_t &dst_dim_size, \
constant size_t &ids_dim_size, \
const device TYPENAME *input, \
const device INDEX_TYPENAME *input_ids, \
device TYPENAME *output, \
uint tid [[ thread_position_in_grid ]] \
) { \
index_add<TYPENAME, INDEX_TYPENAME>(dst_size, left_size, src_dim_size, right_size, dst_dim_size, ids_dim_size, input, input_ids, output, tid); \
}
INDEX_OP(is_u32_f32, uint, float)
INDEX_OP(is_u32_f16, uint, half)
GATHER_OP(gather_u32_f32, uint, float)
GATHER_OP(gather_u32_f16, uint, half)
SCATTER_ADD_OP(sa_u32_f32, uint, float)
SCATTER_ADD_OP(sa_u32_f16, uint, half)
#if defined(__HAVE_BFLOAT__)
INDEX_OP(is_u32_bf16, uint32_t, bfloat)
INDEX_OP(is_u8_bf16, uint8_t, bfloat)
INDEX_ADD_OP(ia_i64_bf16, int64_t, bfloat)
INDEX_ADD_OP(ia_u32_bf16, uint32_t, bfloat)
INDEX_ADD_OP(ia_u8_bf16, uint8_t, bfloat)
#endif
INDEX_ADD_OP(ia_u32_f16, uint32_t, half)
INDEX_ADD_OP(ia_u8_f16, uint8_t, half)
INDEX_ADD_OP(ia_i64_f32, int64_t, float)
INDEX_ADD_OP(ia_i64_u8, int64_t, uint8_t)
INDEX_ADD_OP(ia_i64_i64, int64_t, int64_t)
INDEX_ADD_OP(ia_i64_u32, int64_t, uint32_t)
INDEX_ADD_OP(ia_u32_f32, uint32_t, float)
INDEX_ADD_OP(ia_u32_u8, uint32_t, uint8_t)
INDEX_ADD_OP(ia_u32_i64, uint32_t, int64_t)
INDEX_ADD_OP(ia_u32_u32, uint32_t, uint32_t)
INDEX_ADD_OP(ia_u8_f32, uint8_t, float)
INDEX_ADD_OP(ia_u8_u8, uint8_t, uint8_t)
INDEX_ADD_OP(ia_u8_u32, uint8_t, uint32_t)
INDEX_ADD_OP(ia_u8_i64, uint8_t, int64_t)
| candle/candle-metal-kernels/src/indexing.metal/0 | {
"file_path": "candle/candle-metal-kernels/src/indexing.metal",
"repo_id": "candle",
"token_count": 3203
} | 32 |
/// This example contains some simple benchmarks so that it's easy to run them in perf etc.
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use candle::quantized::GgmlType;
use candle::{CpuStorage, Device, Layout, Module, Result, Shape, Tensor, D};
use clap::{Parser, Subcommand};
const CHECK_CONV2D: bool = false;
trait Benchmark {
type PreProcessData;
type RunResult;
fn preprocess() -> Result<Self::PreProcessData>;
fn run_one(_: &Self::PreProcessData) -> Result<Self::RunResult>;
const ITERS: usize;
}
struct Im2Col {
h_k: usize,
w_k: usize,
stride: usize,
dilation: usize,
padding: usize,
}
impl Im2Col {
fn hw_out(&self, h: usize, w: usize) -> (usize, usize) {
let h_out = (h + 2 * self.padding - self.dilation * (self.h_k - 1) - 1) / self.stride + 1;
let w_out = (w + 2 * self.padding - self.dilation * (self.w_k - 1) - 1) / self.stride + 1;
(h_out, w_out)
}
}
impl candle::CustomOp1 for Im2Col {
fn name(&self) -> &'static str {
"im2col"
}
fn cpu_fwd(&self, storage: &CpuStorage, layout: &Layout) -> Result<(CpuStorage, Shape)> {
let &Self {
h_k,
w_k,
stride,
dilation,
padding,
} = self;
let (b, c, h, w) = layout.shape().dims4()?;
let (h_out, w_out) = self.hw_out(h, w);
let slice = storage.as_slice::<f32>()?;
let src = &slice[layout.start_offset()..];
let mut dst = vec![0f32; b * h_out * w_out * c * h_k * w_k];
let (src_s0, src_s1, src_s2, src_s3) = {
let s = layout.stride();
(s[0], s[1], s[2], s[3])
};
// TODO: provide specialized kernels for the common use cases.
// - h_k = w_k = 1
// - padding = 0
// - stride = 1
// - dilation = 1
for b_idx in 0..b {
let src_idx = b_idx * src_s0;
let dst_idx = b_idx * h_out * w_out * c * h_k * w_k;
for h_idx in 0..h_out {
let dst_idx = dst_idx + h_idx * w_out * c * h_k * w_k;
for w_idx in 0..w_out {
let dst_idx = dst_idx + w_idx * c * h_k * w_k;
for c_idx in 0..c {
let dst_idx = dst_idx + c_idx * h_k * w_k;
let src_idx = c_idx * src_s1 + src_idx;
for h_k_idx in 0..h_k {
let src_h = h_idx * stride + h_k_idx * dilation;
if padding != 0 && (src_h < padding || src_h >= h + padding) {
continue;
}
let src_h = src_h - padding;
let src_idx = src_idx + src_h * src_s2;
let dst_idx = dst_idx + h_k_idx * w_k;
for w_k_idx in 0..w_k {
let src_w = w_idx * stride + w_k_idx * dilation;
if padding != 0 && (src_w < padding || src_w >= w + padding) {
continue;
}
let src_w = src_w - padding;
let src_idx = src_idx + src_w * src_s3;
let dst_idx = dst_idx + w_k_idx;
dst[dst_idx] = src[src_idx]
}
}
}
}
}
}
let storage = candle::WithDType::to_cpu_storage_owned(dst);
Ok((storage, (b * h_out * w_out, c * h_k * w_k).into()))
}
}
// Conv1d example as used in whisper.
struct Conv1d;
impl Benchmark for Conv1d {
type PreProcessData = (Tensor, Tensor);
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
let inp = Tensor::randn(0f32, 1., (1, 384, 3000), &Device::Cpu)?;
let w = Tensor::randn(0f32, 1., (384, 384, 3), &Device::Cpu)?;
Ok((inp, w))
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
d.0.conv1d(&d.1, 0, 1, 1, 1)
}
const ITERS: usize = 5;
}
// Conv2d example as used in stable-diffusion.
struct Conv2d;
impl Benchmark for Conv2d {
type PreProcessData = (Tensor, Tensor);
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
let inp = Tensor::randn(0f32, 1., (2, 320, 96, 96), &Device::Cpu)?;
let w = Tensor::randn(0f32, 1., (320, 320, 3, 3), &Device::Cpu)?;
Ok((inp, w))
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
d.0.conv2d(&d.1, 0, 1, 1, 1)
}
const ITERS: usize = 5;
}
// Conv2d example as used in stable-diffusion, im2col implementation.
struct Conv2dIm2Col;
impl Benchmark for Conv2dIm2Col {
type PreProcessData = (Tensor, Tensor);
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
let inp = Tensor::randn(0f32, 1., (2, 320, 96, 96), &Device::Cpu)?;
let w = Tensor::randn(0f32, 1., (320, 320, 3, 3), &Device::Cpu)?;
Ok((inp, w))
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
// d.0.conv2d(&d.1, 0, 1, 1, 1)
let (b, _, h, w) = d.0.dims4()?;
let (_, _, h_k, w_k) = d.1.dims4()?;
let op = Im2Col {
h_k,
w_k,
stride: 1,
dilation: 1,
padding: 0,
};
let (h_out, w_out) = op.hw_out(h, w);
let col = d.0.apply_op1_no_bwd(&op)?;
let res = col.matmul(&d.1.flatten_from(1)?.t()?)?;
let res = res
.reshape((b, h_out, w_out, ()))?
.permute((0, 3, 1, 2))?
.contiguous()?;
if CHECK_CONV2D {
let res2 = d.0.conv2d(&d.1, op.padding, op.stride, op.dilation, 1);
let diff = (&res - res2)?.sqr()?.mean_all()?;
println!("{diff}");
}
Ok(res)
}
const ITERS: usize = 5;
}
struct MatMul;
impl Benchmark for MatMul {
type PreProcessData = (Tensor, Tensor);
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
let lhs = Tensor::randn(0f32, 1., (1024, 1024), &Device::Cpu)?;
let rhs = Tensor::randn(0f32, 1., (1024, 1024), &Device::Cpu)?;
Ok((lhs, rhs))
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
d.0.matmul(&d.1)
}
const ITERS: usize = 100;
}
struct MatVec;
impl Benchmark for MatVec {
type PreProcessData = (Tensor, Tensor);
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
let lhs = Tensor::randn(0f32, 1., (1024 * 4, 1024 * 4), &Device::Cpu)?;
let rhs = Tensor::randn(0f32, 1., (1024 * 4, 1), &Device::Cpu)?;
Ok((lhs, rhs))
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
d.0.matmul(&d.1)
}
const ITERS: usize = 100;
}
// This benchmark is similar to:
// https://github.com/ggerganov/llama.cpp/blob/master/examples/benchmark/benchmark-matmult.cpp
struct QMatMul;
impl Benchmark for QMatMul {
type PreProcessData = (candle::quantized::QMatMul, Tensor);
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
let zeros = vec![candle::quantized::k_quants::BlockQ4_0::zeros(); 4096 * 11008 / 32];
let mm = candle::quantized::QTensor::new(
candle::quantized::QStorage::Cpu(Box::new(zeros)),
(4096, 11008),
)?;
let mm = candle::quantized::QMatMul::from_qtensor(mm)?;
let arg = Tensor::randn(0f32, 1., (128, 11008), &Device::Cpu)?;
Ok((mm, arg))
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
d.0.forward(&d.1)
}
const ITERS: usize = 100;
}
struct Softmax;
impl Benchmark for Softmax {
type PreProcessData = Tensor;
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
// Typical whisper tiny size.
let x = Tensor::randn(0f32, 1., (1, 6, 200, 1500), &Device::Cpu)?;
Ok(x)
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
candle_nn::ops::softmax(d, D::Minus1)
}
const ITERS: usize = 100;
}
struct SoftmaxLastDim;
impl Benchmark for SoftmaxLastDim {
type PreProcessData = Tensor;
type RunResult = Tensor;
fn preprocess() -> Result<Self::PreProcessData> {
// Typical whisper tiny size.
let x = Tensor::randn(0f32, 1., (1, 6, 200, 1500), &Device::Cpu)?;
Ok(x)
}
fn run_one(d: &Self::PreProcessData) -> Result<Self::RunResult> {
candle_nn::ops::softmax_last_dim(d)
}
const ITERS: usize = 100;
}
fn run<B: Benchmark>(iters: Option<usize>) -> Result<()> {
use std::hint::black_box;
let iters = iters.unwrap_or(B::ITERS);
let d = B::preprocess()?;
let start = std::time::Instant::now();
for _iter in 0..iters {
let _res = black_box(B::run_one(black_box(&d))?);
}
println!("{:?}", start.elapsed() / iters as u32);
Ok(())
}
#[derive(Subcommand, Debug, Clone)]
enum Task {
Conv1d,
Conv2d,
Conv2dIm2Col,
Matmul,
Matvec,
Qmatmul,
Softmax,
SoftmaxLastDim,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
pub struct Args {
/// The benchmark to be run.
#[command(subcommand)]
task: Task,
#[arg(long)]
iters: Option<usize>,
}
fn main() -> Result<()> {
let args = Args::parse();
match args.task {
Task::Conv1d => run::<Conv1d>(args.iters)?,
Task::Conv2d => run::<Conv2d>(args.iters)?,
Task::Conv2dIm2Col => run::<Conv2dIm2Col>(args.iters)?,
Task::Matmul => run::<MatMul>(args.iters)?,
Task::Matvec => run::<MatVec>(args.iters)?,
Task::Softmax => run::<Softmax>(args.iters)?,
Task::SoftmaxLastDim => run::<SoftmaxLastDim>(args.iters)?,
Task::Qmatmul => run::<QMatMul>(args.iters)?,
}
Ok(())
}
| candle/candle-nn/examples/cpu_benchmarks.rs/0 | {
"file_path": "candle/candle-nn/examples/cpu_benchmarks.rs",
"repo_id": "candle",
"token_count": 5283
} | 33 |
//! A sequential layer used to chain multiple layers and closures.
use candle::{Module, Result, Tensor};
/// A sequential layer combining multiple other layers.
pub struct Sequential {
layers: Vec<Box<dyn Module>>,
}
/// Creates a new empty sequential layer.
pub fn seq() -> Sequential {
Sequential { layers: vec![] }
}
impl Sequential {
/// The number of sub-layers embedded in this layer.
pub fn len(&self) -> i64 {
self.layers.len() as i64
}
/// Returns true if this layer does not have any sub-layer.
pub fn is_empty(&self) -> bool {
self.layers.is_empty()
}
}
impl Module for Sequential {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs)?
}
Ok(xs)
}
}
impl Sequential {
/// Appends a layer after all the current layers.
#[allow(clippy::should_implement_trait)]
pub fn add<M: Module + 'static>(mut self, layer: M) -> Self {
self.layers.push(Box::new(layer));
self
}
/// Appends a closure after all the current layers.
pub fn add_fn<F>(self, f: F) -> Self
where
F: 'static + Fn(&Tensor) -> Result<Tensor> + Send + Sync,
{
self.add(super::func(f))
}
/// Applies the forward pass and returns the output for each layer.
pub fn forward_all(&self, xs: &Tensor) -> Result<Vec<Tensor>> {
let mut vec = Vec::with_capacity(self.layers.len());
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs)?;
vec.push(xs.clone())
}
Ok(vec)
}
}
| candle/candle-nn/src/sequential.rs/0 | {
"file_path": "candle/candle-nn/src/sequential.rs",
"repo_id": "candle",
"token_count": 705
} | 34 |
//
// WARNING: This file is automatically generated! Please edit onnx.in.proto.
//
// SPDX-License-Identifier: Apache-2.0
syntax = "proto3";
package onnx;
// Overview
//
// ONNX is an open specification that is comprised of the following components:
//
// 1) A definition of an extensible computation graph model.
// 2) Definitions of standard data types.
// 3) Definitions of built-in operators.
//
// This document describes the syntax of models and their computation graphs,
// as well as the standard data types. Together, they are referred to as the ONNX
// Intermediate Representation, or 'IR' for short.
//
// The normative semantic specification of the ONNX IR is found in docs/IR.md.
// Definitions of the built-in neural network operators may be found in docs/Operators.md.
// Notes
//
// Protobuf compatibility
//
// To simplify framework compatibility, ONNX is defined using the subset of protobuf
// that is compatible with both protobuf v2 and v3. This means that we do not use any
// protobuf features that are only available in one of the two versions.
//
// Here are the most notable contortions we have to carry out to work around
// these limitations:
//
// - No 'map' (added protobuf 3.0). We instead represent mappings as lists
// of key-value pairs, where order does not matter and duplicates
// are not allowed.
// Versioning
//
// ONNX versioning is specified in docs/IR.md and elaborated on in docs/Versioning.md
//
// To be compatible with both proto2 and proto3, we will use a version number
// that is not defined by the default value but an explicit enum number.
enum Version {
// proto3 requires the first enum value to be zero.
// We add this just to appease the compiler.
_START_VERSION = 0;
// The version field is always serialized and we will use it to store the
// version that the graph is generated from. This helps us set up version
// control.
// For the IR, we are using simple numbers starting with 0x00000001,
// which was the version we published on Oct 10, 2017.
IR_VERSION_2017_10_10 = 0x0000000000000001;
// IR_VERSION 2 published on Oct 30, 2017
// - Added type discriminator to AttributeProto to support proto3 users
IR_VERSION_2017_10_30 = 0x0000000000000002;
// IR VERSION 3 published on Nov 3, 2017
// - For operator versioning:
// - Added new message OperatorSetIdProto
// - Added opset_import in ModelProto
// - For vendor extensions, added domain in NodeProto
IR_VERSION_2017_11_3 = 0x0000000000000003;
// IR VERSION 4 published on Jan 22, 2019
// - Relax constraint that initializers should be a subset of graph inputs
// - Add type BFLOAT16
IR_VERSION_2019_1_22 = 0x0000000000000004;
// IR VERSION 5 published on March 18, 2019
// - Add message TensorAnnotation.
// - Add quantization annotation in GraphProto to map tensor with its scale and zero point quantization parameters.
IR_VERSION_2019_3_18 = 0x0000000000000005;
// IR VERSION 6 published on Sep 19, 2019
// - Add support for sparse tensor constants stored in model.
// - Add message SparseTensorProto
// - Add sparse initializers
IR_VERSION_2019_9_19 = 0x0000000000000006;
// IR VERSION 7 published on May 8, 2020
// - Add support to allow function body graph to rely on multiple external opreator sets.
// - Add a list to promote inference graph's initializers to global and
// mutable variables. Global variables are visible in all graphs of the
// stored models.
// - Add message TrainingInfoProto to store initialization
// method and training algorithm. The execution of TrainingInfoProto
// can modify the values of mutable variables.
// - Implicitly add inference graph into each TrainingInfoProto's algorithm.
IR_VERSION_2020_5_8 = 0x0000000000000007;
// IR VERSION 8 published on July 30, 2021
// Introduce TypeProto.SparseTensor
// Introduce TypeProto.Optional
// Added a list of FunctionProtos local to the model
// Deprecated since_version and operator status from FunctionProto
IR_VERSION_2021_7_30 = 0x0000000000000008;
// IR VERSION 9 published on May 5, 2023
// Added AttributeProto to FunctionProto so that default attribute values can be set.
// Added FLOAT8E4M3FN, FLOAT8E4M3FNUZ, FLOAT8E5M2, FLOAT8E5M2FNUZ.
IR_VERSION = 0x0000000000000009;
}
// Attributes
//
// A named attribute containing either singular float, integer, string, graph,
// and tensor values, or repeated float, integer, string, graph, and tensor values.
// An AttributeProto MUST contain the name field, and *only one* of the
// following content fields, effectively enforcing a C/C++ union equivalent.
message AttributeProto {
reserved 12, 16 to 19;
reserved "v";
// Note: this enum is structurally identical to the OpSchema::AttrType
// enum defined in schema.h. If you rev one, you likely need to rev the other.
enum AttributeType {
UNDEFINED = 0;
FLOAT = 1;
INT = 2;
STRING = 3;
TENSOR = 4;
GRAPH = 5;
SPARSE_TENSOR = 11;
TYPE_PROTO = 13;
FLOATS = 6;
INTS = 7;
STRINGS = 8;
TENSORS = 9;
GRAPHS = 10;
SPARSE_TENSORS = 12;
TYPE_PROTOS = 14;
}
// The name field MUST be present for this version of the IR.
string name = 1; // namespace Attribute
// if ref_attr_name is not empty, ref_attr_name is the attribute name in parent function.
// In this case, this AttributeProto does not contain data, and it's a reference of attribute
// in parent scope.
// NOTE: This should ONLY be used in function (sub-graph). It's invalid to be used in main graph.
string ref_attr_name = 21;
// A human-readable documentation for this attribute. Markdown is allowed.
string doc_string = 13;
// The type field MUST be present for this version of the IR.
// For 0.0.1 versions of the IR, this field was not defined, and
// implementations needed to use has_field heuristics to determine
// which value field was in use. For IR_VERSION 0.0.2 or later, this
// field MUST be set and match the f|i|s|t|... field in use. This
// change was made to accommodate proto3 implementations.
AttributeType type = 20; // discriminator that indicates which field below is in use
// Exactly ONE of the following fields must be present for this version of the IR
float f = 2; // float
int64 i = 3; // int
bytes s = 4; // UTF-8 string
TensorProto t = 5; // tensor value
GraphProto g = 6; // graph
SparseTensorProto sparse_tensor = 22; // sparse tensor value
// Do not use field below, it's deprecated.
// optional ValueProto v = 12; // value - subsumes everything but graph
TypeProto tp = 14; // type proto
repeated float floats = 7; // list of floats
repeated int64 ints = 8; // list of ints
repeated bytes strings = 9; // list of UTF-8 strings
repeated TensorProto tensors = 10; // list of tensors
repeated GraphProto graphs = 11; // list of graph
repeated SparseTensorProto sparse_tensors = 23; // list of sparse tensors
repeated TypeProto type_protos = 15;// list of type protos
}
// Defines information on value, including the name, the type, and
// the shape of the value.
message ValueInfoProto {
// This field MUST be present in this version of the IR.
string name = 1; // namespace Value
// This field MUST be present in this version of the IR for
// inputs and outputs of the top-level graph.
TypeProto type = 2;
// A human-readable documentation for this value. Markdown is allowed.
string doc_string = 3;
}
// Nodes
//
// Computation graphs are made up of a DAG of nodes, which represent what is
// commonly called a "layer" or "pipeline stage" in machine learning frameworks.
//
// For example, it can be a node of type "Conv" that takes in an image, a filter
// tensor and a bias tensor, and produces the convolved output.
message NodeProto {
repeated string input = 1; // namespace Value
repeated string output = 2; // namespace Value
// An optional identifier for this node in a graph.
// This field MAY be absent in ths version of the IR.
string name = 3; // namespace Node
// The symbolic identifier of the Operator to execute.
string op_type = 4; // namespace Operator
// The domain of the OperatorSet that specifies the operator named by op_type.
string domain = 7; // namespace Domain
// Additional named attributes.
repeated AttributeProto attribute = 5;
// A human-readable documentation for this node. Markdown is allowed.
string doc_string = 6;
}
// Training information
// TrainingInfoProto stores information for training a model.
// In particular, this defines two functionalities: an initialization-step
// and a training-algorithm-step. Initialization resets the model
// back to its original state as if no training has been performed.
// Training algorithm improves the model based on input data.
//
// The semantics of the initialization-step is that the initializers
// in ModelProto.graph and in TrainingInfoProto.algorithm are first
// initialized as specified by the initializers in the graph, and then
// updated by the "initialization_binding" in every instance in
// ModelProto.training_info.
//
// The field "algorithm" defines a computation graph which represents a
// training algorithm's step. After the execution of a
// TrainingInfoProto.algorithm, the initializers specified by "update_binding"
// may be immediately updated. If the targeted training algorithm contains
// consecutive update steps (such as block coordinate descent methods),
// the user needs to create a TrainingInfoProto for each step.
message TrainingInfoProto {
// This field describes a graph to compute the initial tensors
// upon starting the training process. Initialization graph has no input
// and can have multiple outputs. Usually, trainable tensors in neural
// networks are randomly initialized. To achieve that, for each tensor,
// the user can put a random number operator such as RandomNormal or
// RandomUniform in TrainingInfoProto.initialization.node and assign its
// random output to the specific tensor using "initialization_binding".
// This graph can also set the initializers in "algorithm" in the same
// TrainingInfoProto; a use case is resetting the number of training
// iteration to zero.
//
// By default, this field is an empty graph and its evaluation does not
// produce any output. Thus, no initializer would be changed by default.
GraphProto initialization = 1;
// This field represents a training algorithm step. Given required inputs,
// it computes outputs to update initializers in its own or inference graph's
// initializer lists. In general, this field contains loss node, gradient node,
// optimizer node, increment of iteration count.
//
// An execution of the training algorithm step is performed by executing the
// graph obtained by combining the inference graph (namely "ModelProto.graph")
// and the "algorithm" graph. That is, the actual
// input/initializer/output/node/value_info/sparse_initializer list of
// the training graph is the concatenation of
// "ModelProto.graph.input/initializer/output/node/value_info/sparse_initializer"
// and "algorithm.input/initializer/output/node/value_info/sparse_initializer"
// in that order. This combined graph must satisfy the normal ONNX conditions.
// Now, let's provide a visualization of graph combination for clarity.
// Let the inference graph (i.e., "ModelProto.graph") be
// tensor_a, tensor_b -> MatMul -> tensor_c -> Sigmoid -> tensor_d
// and the "algorithm" graph be
// tensor_d -> Add -> tensor_e
// The combination process results
// tensor_a, tensor_b -> MatMul -> tensor_c -> Sigmoid -> tensor_d -> Add -> tensor_e
//
// Notice that an input of a node in the "algorithm" graph may reference the
// output of a node in the inference graph (but not the other way round). Also, inference
// node cannot reference inputs of "algorithm". With these restrictions, inference graph
// can always be run independently without training information.
//
// By default, this field is an empty graph and its evaluation does not
// produce any output. Evaluating the default training step never
// update any initializers.
GraphProto algorithm = 2;
// This field specifies the bindings from the outputs of "initialization" to
// some initializers in "ModelProto.graph.initializer" and
// the "algorithm.initializer" in the same TrainingInfoProto.
// See "update_binding" below for details.
//
// By default, this field is empty and no initializer would be changed
// by the execution of "initialization".
repeated StringStringEntryProto initialization_binding = 3;
// Gradient-based training is usually an iterative procedure. In one gradient
// descent iteration, we apply
//
// x = x - r * g
//
// where "x" is the optimized tensor, "r" stands for learning rate, and "g" is
// gradient of "x" with respect to a chosen loss. To avoid adding assignments
// into the training graph, we split the update equation into
//
// y = x - r * g
// x = y
//
// The user needs to save "y = x - r * g" into TrainingInfoProto.algorithm. To
// tell that "y" should be assigned to "x", the field "update_binding" may
// contain a key-value pair of strings, "x" (key of StringStringEntryProto)
// and "y" (value of StringStringEntryProto).
// For a neural network with multiple trainable (mutable) tensors, there can
// be multiple key-value pairs in "update_binding".
//
// The initializers appears as keys in "update_binding" are considered
// mutable variables. This implies some behaviors
// as described below.
//
// 1. We have only unique keys in all "update_binding"s so that two
// variables may not have the same name. This ensures that one
// variable is assigned up to once.
// 2. The keys must appear in names of "ModelProto.graph.initializer" or
// "TrainingInfoProto.algorithm.initializer".
// 3. The values must be output names of "algorithm" or "ModelProto.graph.output".
// 4. Mutable variables are initialized to the value specified by the
// corresponding initializer, and then potentially updated by
// "initializer_binding"s and "update_binding"s in "TrainingInfoProto"s.
//
// This field usually contains names of trainable tensors
// (in ModelProto.graph), optimizer states such as momentums in advanced
// stochastic gradient methods (in TrainingInfoProto.graph),
// and number of training iterations (in TrainingInfoProto.graph).
//
// By default, this field is empty and no initializer would be changed
// by the execution of "algorithm".
repeated StringStringEntryProto update_binding = 4;
}
// Models
//
// ModelProto is a top-level file/container format for bundling a ML model and
// associating its computation graph with metadata.
//
// The semantics of the model are described by the associated GraphProto's.
message ModelProto {
// The version of the IR this model targets. See Version enum above.
// This field MUST be present.
int64 ir_version = 1;
// The OperatorSets this model relies on.
// All ModelProtos MUST have at least one entry that
// specifies which version of the ONNX OperatorSet is
// being imported.
//
// All nodes in the ModelProto's graph will bind against the operator
// with the same-domain/same-op_type operator with the HIGHEST version
// in the referenced operator sets.
repeated OperatorSetIdProto opset_import = 8;
// The name of the framework or tool used to generate this model.
// This field SHOULD be present to indicate which implementation/tool/framework
// emitted the model.
string producer_name = 2;
// The version of the framework or tool used to generate this model.
// This field SHOULD be present to indicate which implementation/tool/framework
// emitted the model.
string producer_version = 3;
// Domain name of the model.
// We use reverse domain names as name space indicators. For example:
// `com.facebook.fair` or `com.microsoft.cognitiveservices`
//
// Together with `model_version` and GraphProto.name, this forms the unique identity of
// the graph.
string domain = 4;
// The version of the graph encoded. See Version enum below.
int64 model_version = 5;
// A human-readable documentation for this model. Markdown is allowed.
string doc_string = 6;
// The parameterized graph that is evaluated to execute the model.
GraphProto graph = 7;
// Named metadata values; keys should be distinct.
repeated StringStringEntryProto metadata_props = 14;
// Training-specific information. Sequentially executing all stored
// `TrainingInfoProto.algorithm`s and assigning their outputs following
// the corresponding `TrainingInfoProto.update_binding`s is one training
// iteration. Similarly, to initialize the model
// (as if training hasn't happened), the user should sequentially execute
// all stored `TrainingInfoProto.initialization`s and assigns their outputs
// using `TrainingInfoProto.initialization_binding`s.
//
// If this field is empty, the training behavior of the model is undefined.
repeated TrainingInfoProto training_info = 20;
// A list of function protos local to the model.
//
// Name of the function "FunctionProto.name" should be unique within the domain "FunctionProto.domain".
// In case of any conflicts the behavior (whether the model local functions are given higher priority,
// or standard operator sets are given higher priotity or this is treated as error) is defined by
// the runtimes.
//
// The operator sets imported by FunctionProto should be compatible with the ones
// imported by ModelProto and other model local FunctionProtos.
// Example, if same operator set say 'A' is imported by a FunctionProto and ModelProto
// or by 2 FunctionProtos then versions for the operator set may be different but,
// the operator schema returned for op_type, domain, version combination
// for both the versions should be same for every node in the function body.
//
// One FunctionProto can reference other FunctionProto in the model, however, recursive reference
// is not allowed.
repeated FunctionProto functions = 25;
};
// StringStringEntryProto follows the pattern for cross-proto-version maps.
// See https://developers.google.com/protocol-buffers/docs/proto3#maps
message StringStringEntryProto {
string key = 1;
string value = 2;
};
message TensorAnnotation {
string tensor_name = 1;
// <key, value> pairs to annotate tensor specified by <tensor_name> above.
// The keys used in the mapping below must be pre-defined in ONNX spec.
// For example, for 8-bit linear quantization case, 'SCALE_TENSOR', 'ZERO_POINT_TENSOR' will be pre-defined as
// quantization parameter keys.
repeated StringStringEntryProto quant_parameter_tensor_names = 2;
}
// Graphs
//
// A graph defines the computational logic of a model and is comprised of a parameterized
// list of nodes that form a directed acyclic graph based on their inputs and outputs.
// This is the equivalent of the "network" or "graph" in many deep learning
// frameworks.
message GraphProto {
// The nodes in the graph, sorted topologically.
repeated NodeProto node = 1;
// The name of the graph.
string name = 2; // namespace Graph
// A list of named tensor values, used to specify constant inputs of the graph.
// Each initializer (both TensorProto as well SparseTensorProto) MUST have a name.
// The name MUST be unique across both initializer and sparse_initializer,
// but the name MAY also appear in the input list.
repeated TensorProto initializer = 5;
// Initializers (see above) stored in sparse format.
repeated SparseTensorProto sparse_initializer = 15;
// A human-readable documentation for this graph. Markdown is allowed.
string doc_string = 10;
// The inputs and outputs of the graph.
repeated ValueInfoProto input = 11;
repeated ValueInfoProto output = 12;
// Information for the values in the graph. The ValueInfoProto.name's
// must be distinct. It is optional for a value to appear in value_info list.
repeated ValueInfoProto value_info = 13;
// This field carries information to indicate the mapping among a tensor and its
// quantization parameter tensors. For example:
// For tensor 'a', it may have {'SCALE_TENSOR', 'a_scale'} and {'ZERO_POINT_TENSOR', 'a_zero_point'} annotated,
// which means, tensor 'a_scale' and tensor 'a_zero_point' are scale and zero point of tensor 'a' in the model.
repeated TensorAnnotation quantization_annotation = 14;
reserved 3, 4, 6 to 9;
reserved "ir_version", "producer_version", "producer_tag", "domain";
}
// Tensors
//
// A serialized tensor value.
message TensorProto {
enum DataType {
UNDEFINED = 0;
// Basic types.
FLOAT = 1; // float
UINT8 = 2; // uint8_t
INT8 = 3; // int8_t
UINT16 = 4; // uint16_t
INT16 = 5; // int16_t
INT32 = 6; // int32_t
INT64 = 7; // int64_t
STRING = 8; // string
BOOL = 9; // bool
// IEEE754 half-precision floating-point format (16 bits wide).
// This format has 1 sign bit, 5 exponent bits, and 10 mantissa bits.
FLOAT16 = 10;
DOUBLE = 11;
UINT32 = 12;
UINT64 = 13;
COMPLEX64 = 14; // complex with float32 real and imaginary components
COMPLEX128 = 15; // complex with float64 real and imaginary components
// Non-IEEE floating-point format based on IEEE754 single-precision
// floating-point number truncated to 16 bits.
// This format has 1 sign bit, 8 exponent bits, and 7 mantissa bits.
BFLOAT16 = 16;
// Non-IEEE floating-point format based on papers
// FP8 Formats for Deep Learning, https://arxiv.org/abs/2209.05433,
// 8-bit Numerical Formats For Deep Neural Networks, https://arxiv.org/pdf/2206.02915.pdf.
// Operators supported FP8 are Cast, CastLike, QuantizeLinear, DequantizeLinear.
// The computation usually happens inside a block quantize / dequantize
// fused by the runtime.
FLOAT8E4M3FN = 17; // float 8, mostly used for coefficients, supports nan, not inf
FLOAT8E4M3FNUZ = 18; // float 8, mostly used for coefficients, supports nan, not inf, no negative zero
FLOAT8E5M2 = 19; // follows IEEE 754, supports nan, inf, mostly used for gradients
FLOAT8E5M2FNUZ = 20; // follows IEEE 754, supports nan, inf, mostly used for gradients, no negative zero
// Future extensions go here.
}
// The shape of the tensor.
repeated int64 dims = 1;
// The data type of the tensor.
// This field MUST have a valid TensorProto.DataType value
int32 data_type = 2;
// For very large tensors, we may want to store them in chunks, in which
// case the following fields will specify the segment that is stored in
// the current TensorProto.
message Segment {
int64 begin = 1;
int64 end = 2;
}
Segment segment = 3;
// Tensor content must be organized in row-major order.
//
// Depending on the data_type field, exactly one of the fields below with
// name ending in _data is used to store the elements of the tensor.
// For float and complex64 values
// Complex64 tensors are encoded as a single array of floats,
// with the real components appearing in odd numbered positions,
// and the corresponding imaginary component appearing in the
// subsequent even numbered position. (e.g., [1.0 + 2.0i, 3.0 + 4.0i]
// is encoded as [1.0, 2.0 ,3.0 ,4.0]
// When this field is present, the data_type field MUST be FLOAT or COMPLEX64.
repeated float float_data = 4 [packed = true];
// For int32, uint8, int8, uint16, int16, bool, float8, and float16 values
// float16 and float8 values must be bit-wise converted to an uint16_t prior
// to writing to the buffer.
// When this field is present, the data_type field MUST be
// INT32, INT16, INT8, UINT16, UINT8, BOOL, FLOAT16, BFLOAT16, FLOAT8E4M3FN, FLOAT8E4M3FNUZ, FLOAT8E5M2, FLOAT8E5M2FNUZ
repeated int32 int32_data = 5 [packed = true];
// For strings.
// Each element of string_data is a UTF-8 encoded Unicode
// string. No trailing null, no leading BOM. The protobuf "string"
// scalar type is not used to match ML community conventions.
// When this field is present, the data_type field MUST be STRING
repeated bytes string_data = 6;
// For int64.
// When this field is present, the data_type field MUST be INT64
repeated int64 int64_data = 7 [packed = true];
// Optionally, a name for the tensor.
string name = 8; // namespace Value
// A human-readable documentation for this tensor. Markdown is allowed.
string doc_string = 12;
// Serializations can either use one of the fields above, or use this
// raw bytes field. The only exception is the string case, where one is
// required to store the content in the repeated bytes string_data field.
//
// When this raw_data field is used to store tensor value, elements MUST
// be stored in as fixed-width, little-endian order.
// Floating-point data types MUST be stored in IEEE 754 format.
// Complex64 elements must be written as two consecutive FLOAT values, real component first.
// Complex128 elements must be written as two consecutive DOUBLE values, real component first.
// Boolean type MUST be written one byte per tensor element (00000001 for true, 00000000 for false).
//
// Note: the advantage of specific field rather than the raw_data field is
// that in some cases (e.g. int data), protobuf does a better packing via
// variable length storage, and may lead to smaller binary footprint.
// When this field is present, the data_type field MUST NOT be STRING or UNDEFINED
bytes raw_data = 9;
// Data can be stored inside the protobuf file using type-specific fields or raw_data.
// Alternatively, raw bytes data can be stored in an external file, using the external_data field.
// external_data stores key-value pairs describing data location. Recognized keys are:
// - "location" (required) - POSIX filesystem path relative to the directory where the ONNX
// protobuf model was stored
// - "offset" (optional) - position of byte at which stored data begins. Integer stored as string.
// Offset values SHOULD be multiples 4096 (page size) to enable mmap support.
// - "length" (optional) - number of bytes containing data. Integer stored as string.
// - "checksum" (optional) - SHA1 digest of file specified in under 'location' key.
repeated StringStringEntryProto external_data = 13;
// Location of the data for this tensor. MUST be one of:
// - DEFAULT - data stored inside the protobuf message. Data is stored in raw_data (if set) otherwise in type-specified field.
// - EXTERNAL - data stored in an external location as described by external_data field.
enum DataLocation {
DEFAULT = 0;
EXTERNAL = 1;
}
// If value not set, data is stored in raw_data (if set) otherwise in type-specified field.
DataLocation data_location = 14;
// For double
// Complex128 tensors are encoded as a single array of doubles,
// with the real components appearing in odd numbered positions,
// and the corresponding imaginary component appearing in the
// subsequent even numbered position. (e.g., [1.0 + 2.0i, 3.0 + 4.0i]
// is encoded as [1.0, 2.0 ,3.0 ,4.0]
// When this field is present, the data_type field MUST be DOUBLE or COMPLEX128
repeated double double_data = 10 [packed = true];
// For uint64 and uint32 values
// When this field is present, the data_type field MUST be
// UINT32 or UINT64
repeated uint64 uint64_data = 11 [packed = true];
}
// A serialized sparse-tensor value
message SparseTensorProto {
// The sequence of non-default values are encoded as a tensor of shape [NNZ].
// The default-value is zero for numeric tensors, and empty-string for string tensors.
// values must have a non-empty name present which serves as a name for SparseTensorProto
// when used in sparse_initializer list.
TensorProto values = 1;
// The indices of the non-default values, which may be stored in one of two formats.
// (a) Indices can be a tensor of shape [NNZ, rank] with the [i,j]-th value
// corresponding to the j-th index of the i-th value (in the values tensor).
// (b) Indices can be a tensor of shape [NNZ], in which case the i-th value
// must be the linearized-index of the i-th value (in the values tensor).
// The linearized-index can be converted into an index tuple (k_1,...,k_rank)
// using the shape provided below.
// The indices must appear in ascending order without duplication.
// In the first format, the ordering is lexicographic-ordering:
// e.g., index-value [1,4] must appear before [2,1]
TensorProto indices = 2;
// The shape of the underlying dense-tensor: [dim_1, dim_2, ... dim_rank]
repeated int64 dims = 3;
}
// Defines a tensor shape. A dimension can be either an integer value
// or a symbolic variable. A symbolic variable represents an unknown
// dimension.
message TensorShapeProto {
message Dimension {
oneof value {
int64 dim_value = 1;
string dim_param = 2; // namespace Shape
};
// Standard denotation can optionally be used to denote tensor
// dimensions with standard semantic descriptions to ensure
// that operations are applied to the correct axis of a tensor.
// Refer to https://github.com/onnx/onnx/blob/main/docs/DimensionDenotation.md#denotation-definition
// for pre-defined dimension denotations.
string denotation = 3;
};
repeated Dimension dim = 1;
}
// Types
//
// The standard ONNX data types.
message TypeProto {
message Tensor {
// This field MUST NOT have the value of UNDEFINED
// This field MUST have a valid TensorProto.DataType value
// This field MUST be present for this version of the IR.
int32 elem_type = 1;
TensorShapeProto shape = 2;
}
// repeated T
message Sequence {
// The type and optional shape of each element of the sequence.
// This field MUST be present for this version of the IR.
TypeProto elem_type = 1;
};
// map<K,V>
message Map {
// This field MUST have a valid TensorProto.DataType value
// This field MUST be present for this version of the IR.
// This field MUST refer to an integral type ([U]INT{8|16|32|64}) or STRING
int32 key_type = 1;
// This field MUST be present for this version of the IR.
TypeProto value_type = 2;
};
// wrapper for Tensor, Sequence, or Map
message Optional {
// The type and optional shape of the element wrapped.
// This field MUST be present for this version of the IR.
// Possible values correspond to OptionalProto.DataType enum
TypeProto elem_type = 1;
};
message SparseTensor {
// This field MUST NOT have the value of UNDEFINED
// This field MUST have a valid TensorProto.DataType value
// This field MUST be present for this version of the IR.
int32 elem_type = 1;
TensorShapeProto shape = 2;
}
oneof value {
// The type of a tensor.
Tensor tensor_type = 1;
// NOTE: DNN-only implementations of ONNX MAY elect to not support non-tensor values
// as input and output to graphs and nodes. These types are needed to naturally
// support classical ML operators. DNN operators SHOULD restrict their input
// and output types to tensors.
// The type of a sequence.
Sequence sequence_type = 4;
// The type of a map.
Map map_type = 5;
// The type of an optional.
Optional optional_type = 9;
// Type of the sparse tensor
SparseTensor sparse_tensor_type = 8;
}
// An optional denotation can be used to denote the whole
// type with a standard semantic description as to what is
// stored inside. Refer to https://github.com/onnx/onnx/blob/main/docs/TypeDenotation.md#type-denotation-definition
// for pre-defined type denotations.
string denotation = 6;
}
// Operator Sets
//
// OperatorSets are uniquely identified by a (domain, opset_version) pair.
message OperatorSetIdProto {
// The domain of the operator set being identified.
// The empty string ("") or absence of this field implies the operator
// set that is defined as part of the ONNX specification.
// This field MUST be present in this version of the IR when referring to any other operator set.
string domain = 1;
// The version of the operator set being identified.
// This field MUST be present in this version of the IR.
int64 version = 2;
}
// Operator/function status.
enum OperatorStatus {
EXPERIMENTAL = 0;
STABLE = 1;
}
message FunctionProto {
// The name of the function, similar usage of op_type in OperatorProto.
// Combined with FunctionProto.domain, this forms the unique identity of
// the FunctionProto.
string name = 1;
// Deprecated since IR Version 8
// optional int64 since_version = 2;
reserved 2;
reserved "since_version";
// Deprecated since IR Version 8
// optional OperatorStatus status = 3;
reserved 3;
reserved "status";
// The inputs and outputs of the function.
repeated string input = 4;
repeated string output = 5;
// The attribute parameters of the function.
// It is for function parameters without default values.
repeated string attribute = 6;
// The attribute protos of the function.
// It is for function attributes with default values.
// A function attribute shall be represented either as
// a string attribute or an AttributeProto, not both.
repeated AttributeProto attribute_proto = 11;
// The nodes in the function.
repeated NodeProto node = 7;
// A human-readable documentation for this function. Markdown is allowed.
string doc_string = 8;
// The OperatorSets this function body (graph) relies on.
//
// All nodes in the function body (graph) will bind against the operator
// with the same-domain/same-op_type operator with the HIGHEST version
// in the referenced operator sets. This means at most one version can be relied
// for one domain.
//
// The operator sets imported by FunctionProto should be compatible with the ones
// imported by ModelProto. Example, if same operator set say 'A' is imported by FunctionProto
// and ModelProto then versions for the operator set may be different but,
// the operator schema returned for op_type, domain, version combination
// for both the versions should be same.
repeated OperatorSetIdProto opset_import = 9;
// The domain which this function belongs to. Combined with FunctionProto.name, this forms the unique identity of
// the FunctionProto.
string domain = 10;
}
// For using protobuf-lite
option optimize_for = LITE_RUNTIME;
| candle/candle-onnx/src/onnx.proto3/0 | {
"file_path": "candle/candle-onnx/src/onnx.proto3",
"repo_id": "candle",
"token_count": 10183
} | 35 |
# see https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/container.py
from .module import Module
from typing import (
Any,
Dict,
Iterable,
Iterator,
Mapping,
Optional,
overload,
Tuple,
TypeVar,
Union,
)
from collections import OrderedDict, abc as container_abcs
import operator
from itertools import chain, islice
__all__ = ["Sequential", "ModuleList", "ModuleDict"]
T = TypeVar("T", bound=Module)
def _addindent(s_: str, numSpaces: int):
s = s_.split("\n")
# don't do anything for single-line stuff
if len(s) == 1:
return s_
first = s.pop(0)
s = [(numSpaces * " ") + line for line in s]
s = "\n".join(s)
s = first + "\n" + s
return s
class Sequential(Module):
r"""A sequential container.
Modules will be added to it in the order they are passed in the
constructor. Alternatively, an ``OrderedDict`` of modules can be
passed in. The ``forward()`` method of ``Sequential`` accepts any
input and forwards it to the first module it contains. It then
"chains" outputs to inputs sequentially for each subsequent module,
finally returning the output of the last module.
The value a ``Sequential`` provides over manually calling a sequence
of modules is that it allows treating the whole container as a
single module, such that performing a transformation on the
``Sequential`` applies to each of the modules it stores (which are
each a registered submodule of the ``Sequential``).
What's the difference between a ``Sequential`` and a
:class:`candle.nn.ModuleList`? A ``ModuleList`` is exactly what it
sounds like--a list for storing ``Module`` s! On the other hand,
the layers in a ``Sequential`` are connected in a cascading way.
"""
_modules: Dict[str, Module] # type: ignore[assignment]
@overload
def __init__(self, *args: Module) -> None:
...
@overload
def __init__(self, arg: "OrderedDict[str, Module]") -> None:
...
def __init__(self, *args):
super().__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def _get_item_by_idx(self, iterator, idx) -> T:
"""Get the idx-th item of the iterator"""
size = len(self)
idx = operator.index(idx)
if not -size <= idx < size:
raise IndexError("index {} is out of range".format(idx))
idx %= size
return next(islice(iterator, idx, None))
def __getitem__(self, idx: Union[slice, int]) -> Union["Sequential", T]:
if isinstance(idx, slice):
return self.__class__(OrderedDict(list(self._modules.items())[idx]))
else:
return self._get_item_by_idx(self._modules.values(), idx)
def __setitem__(self, idx: int, module: Module) -> None:
key: str = self._get_item_by_idx(self._modules.keys(), idx)
return setattr(self, key, module)
def __delitem__(self, idx: Union[slice, int]) -> None:
if isinstance(idx, slice):
for key in list(self._modules.keys())[idx]:
delattr(self, key)
else:
key = self._get_item_by_idx(self._modules.keys(), idx)
delattr(self, key)
# To preserve numbering
str_indices = [str(i) for i in range(len(self._modules))]
self._modules = OrderedDict(list(zip(str_indices, self._modules.values())))
def __len__(self) -> int:
return len(self._modules)
def __add__(self, other) -> "Sequential":
if isinstance(other, Sequential):
ret = Sequential()
for layer in self:
ret.append(layer)
for layer in other:
ret.append(layer)
return ret
else:
raise ValueError(
"add operator supports only objects " "of Sequential class, but {} is given.".format(str(type(other)))
)
def pop(self, key: Union[int, slice]) -> Module:
v = self[key]
del self[key]
return v
def __iadd__(self, other) -> "Sequential":
if isinstance(other, Sequential):
offset = len(self)
for i, module in enumerate(other):
self.add_module(str(i + offset), module)
return self
else:
raise ValueError(
"add operator supports only objects " "of Sequential class, but {} is given.".format(str(type(other)))
)
def __mul__(self, other: int) -> "Sequential":
if not isinstance(other, int):
raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}")
elif other <= 0:
raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}")
else:
combined = Sequential()
offset = 0
for _ in range(other):
for module in self:
combined.add_module(str(offset), module)
offset += 1
return combined
def __rmul__(self, other: int) -> "Sequential":
return self.__mul__(other)
def __imul__(self, other: int) -> "Sequential":
if not isinstance(other, int):
raise TypeError(f"unsupported operand type(s) for *: {type(self)} and {type(other)}")
elif other <= 0:
raise ValueError(f"Non-positive multiplication factor {other} for {type(self)}")
else:
len_original = len(self)
offset = len(self)
for _ in range(other - 1):
for i in range(len_original):
self.add_module(str(i + offset), self._modules[str(i)])
offset += len_original
return self
def __dir__(self):
keys = super().__dir__()
keys = [key for key in keys if not key.isdigit()]
return keys
def __iter__(self) -> Iterator[Module]:
return iter(self._modules.values())
# NB: We can't really type check this function as the type of input
# may change dynamically (as is tested in
# TestScript.test_sequential_intermediary_types). Cannot annotate
# with Any as TorchScript expects a more precise type
def forward(self, input):
for module in self:
input = module(input)
return input
def append(self, module: Module) -> "Sequential":
r"""Appends a given module to the end.
Args:
module (nn.Module): module to append
"""
self.add_module(str(len(self)), module)
return self
def insert(self, index: int, module: Module) -> "Sequential":
if not isinstance(module, Module):
raise AssertionError("module should be of type: {}".format(Module))
n = len(self._modules)
if not (-n <= index <= n):
raise IndexError("Index out of range: {}".format(index))
if index < 0:
index += n
for i in range(n, index, -1):
self._modules[str(i)] = self._modules[str(i - 1)]
self._modules[str(index)] = module
return self
def extend(self, sequential) -> "Sequential":
for layer in sequential:
self.append(layer)
return self
class ModuleList(Module):
r"""Holds submodules in a list.
:class:`~candle.nn.ModuleList` can be indexed like a regular Python list, but
modules it contains are properly registered, and will be visible by all
:class:`~candle.nn.Module` methods.
Args:
modules (iterable, optional): an iterable of modules to add
Example::
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x
"""
_modules: Dict[str, Module] # type: ignore[assignment]
def __init__(self, modules: Optional[Iterable[Module]] = None) -> None:
super().__init__()
if modules is not None:
self += modules
def _get_abs_string_index(self, idx):
"""Get the absolute index for the list of modules"""
idx = operator.index(idx)
if not (-len(self) <= idx < len(self)):
raise IndexError("index {} is out of range".format(idx))
if idx < 0:
idx += len(self)
return str(idx)
def __getitem__(self, idx: Union[int, slice]) -> Union[Module, "ModuleList"]:
if isinstance(idx, slice):
return self.__class__(list(self._modules.values())[idx])
else:
return self._modules[self._get_abs_string_index(idx)]
def __setitem__(self, idx: int, module: Module) -> None:
idx = self._get_abs_string_index(idx)
return setattr(self, str(idx), module)
def __delitem__(self, idx: Union[int, slice]) -> None:
if isinstance(idx, slice):
for k in range(len(self._modules))[idx]:
delattr(self, str(k))
else:
delattr(self, self._get_abs_string_index(idx))
# To preserve numbering, self._modules is being reconstructed with modules after deletion
str_indices = [str(i) for i in range(len(self._modules))]
self._modules = OrderedDict(list(zip(str_indices, self._modules.values())))
def __len__(self) -> int:
return len(self._modules)
def __iter__(self) -> Iterator[Module]:
return iter(self._modules.values())
def __iadd__(self, modules: Iterable[Module]) -> "ModuleList":
return self.extend(modules)
def __add__(self, other: Iterable[Module]) -> "ModuleList":
combined = ModuleList()
for i, module in enumerate(chain(self, other)):
combined.add_module(str(i), module)
return combined
def __repr__(self):
"""A custom repr for ModuleList that compresses repeated module representations"""
list_of_reprs = [repr(item) for item in self]
if len(list_of_reprs) == 0:
return self._get_name() + "()"
start_end_indices = [[0, 0]]
repeated_blocks = [list_of_reprs[0]]
for i, r in enumerate(list_of_reprs[1:], 1):
if r == repeated_blocks[-1]:
start_end_indices[-1][1] += 1
continue
start_end_indices.append([i, i])
repeated_blocks.append(r)
lines = []
main_str = self._get_name() + "("
for (start_id, end_id), b in zip(start_end_indices, repeated_blocks):
local_repr = f"({start_id}): {b}" # default repr
if start_id != end_id:
n = end_id - start_id + 1
local_repr = f"({start_id}-{end_id}): {n} x {b}"
local_repr = _addindent(local_repr, 2)
lines.append(local_repr)
main_str += "\n " + "\n ".join(lines) + "\n"
main_str += ")"
return main_str
def __dir__(self):
keys = super().__dir__()
keys = [key for key in keys if not key.isdigit()]
return keys
def insert(self, index: int, module: Module) -> None:
r"""Insert a given module before a given index in the list.
Args:
index (int): index to insert.
module (nn.Module): module to insert
"""
for i in range(len(self._modules), index, -1):
self._modules[str(i)] = self._modules[str(i - 1)]
self._modules[str(index)] = module
def append(self, module: Module) -> "ModuleList":
r"""Appends a given module to the end of the list.
Args:
module (nn.Module): module to append
"""
self.add_module(str(len(self)), module)
return self
def pop(self, key: Union[int, slice]) -> Module:
v = self[key]
del self[key]
return v
def extend(self, modules: Iterable[Module]) -> "ModuleList":
r"""Appends modules from a Python iterable to the end of the list.
Args:
modules (iterable): iterable of modules to append
"""
if not isinstance(modules, container_abcs.Iterable):
raise TypeError(
"ModuleList.extend should be called with an " "iterable, but got " + type(modules).__name__
)
offset = len(self)
for i, module in enumerate(modules):
self.add_module(str(offset + i), module)
return self
# remove forward altogether to fallback on Module's _forward_unimplemented
class ModuleDict(Module):
r"""Holds submodules in a dictionary.
:class:`~candle.nn.ModuleDict` can be indexed like a regular Python dictionary,
but modules it contains are properly registered, and will be visible by all
:class:`~candle.nn.Module` methods.
:class:`~candle.nn.ModuleDict` is an **ordered** dictionary that respects
* the order of insertion, and
* in :meth:`~candle.nn.ModuleDict.update`, the order of the merged
``OrderedDict``, ``dict`` (started from Python 3.6) or another
:class:`~candle.nn.ModuleDict` (the argument to
:meth:`~candle.nn.ModuleDict.update`).
Note that :meth:`~candle.nn.ModuleDict.update` with other unordered mapping
types (e.g., Python's plain ``dict`` before Python version 3.6) does not
preserve the order of the merged mapping.
Args:
modules (iterable, optional): a mapping (dictionary) of (string: module)
or an iterable of key-value pairs of type (string, module)
"""
_modules: Dict[str, Module] # type: ignore[assignment]
def __init__(self, modules: Optional[Mapping[str, Module]] = None) -> None:
super().__init__()
if modules is not None:
self.update(modules)
def __getitem__(self, key: str) -> Module:
return self._modules[key]
def __setitem__(self, key: str, module: Module) -> None:
self.add_module(key, module)
def __delitem__(self, key: str) -> None:
del self._modules[key]
def __len__(self) -> int:
return len(self._modules)
def __iter__(self) -> Iterator[str]:
return iter(self._modules)
def __contains__(self, key: str) -> bool:
return key in self._modules
def clear(self) -> None:
"""Remove all items from the ModuleDict."""
self._modules.clear()
def pop(self, key: str) -> Module:
r"""Remove key from the ModuleDict and return its module.
Args:
key (str): key to pop from the ModuleDict
"""
v = self[key]
del self[key]
return v
def keys(self) -> Iterable[str]:
r"""Return an iterable of the ModuleDict keys."""
return self._modules.keys()
def items(self) -> Iterable[Tuple[str, Module]]:
r"""Return an iterable of the ModuleDict key/value pairs."""
return self._modules.items()
def values(self) -> Iterable[Module]:
r"""Return an iterable of the ModuleDict values."""
return self._modules.values()
def update(self, modules: Mapping[str, Module]) -> None:
r"""Update the :class:`~candle.nn.ModuleDict` with the key-value pairs from a
mapping or an iterable, overwriting existing keys.
.. note::
If :attr:`modules` is an ``OrderedDict``, a :class:`~candle.nn.ModuleDict`, or
an iterable of key-value pairs, the order of new elements in it is preserved.
Args:
modules (iterable): a mapping (dictionary) from string to :class:`~candle.nn.Module`,
or an iterable of key-value pairs of type (string, :class:`~candle.nn.Module`)
"""
if not isinstance(modules, container_abcs.Iterable):
raise TypeError(
"ModuleDict.update should be called with an "
"iterable of key/value pairs, but got " + type(modules).__name__
)
if isinstance(modules, (OrderedDict, ModuleDict, container_abcs.Mapping)):
for key, module in modules.items():
self[key] = module
else:
# modules here can be a list with two items
for j, m in enumerate(modules):
if not isinstance(m, container_abcs.Iterable):
raise TypeError(
"ModuleDict update sequence element "
"#" + str(j) + " should be Iterable; is" + type(m).__name__
)
if not len(m) == 2:
raise ValueError(
"ModuleDict update sequence element "
"#" + str(j) + " has length " + str(len(m)) + "; 2 is required"
)
# modules can be Mapping (what it's typed at), or a list: [(name1, module1), (name2, module2)]
# that's too cumbersome to type correctly with overloads, so we add an ignore here
self[m[0]] = m[1] # type: ignore[assignment]
# remove forward altogether to fallback on Module's _forward_unimplemented
| candle/candle-pyo3/py_src/candle/nn/container.py/0 | {
"file_path": "candle/candle-pyo3/py_src/candle/nn/container.py",
"repo_id": "candle",
"token_count": 7618
} | 36 |
use pyo3::exceptions::PyValueError;
use pyo3::prelude::*;
pub fn wrap_err(err: ::candle::Error) -> PyErr {
PyErr::new::<PyValueError, _>(format!("{err:?}"))
}
| candle/candle-pyo3/src/utils.rs/0 | {
"file_path": "candle/candle-pyo3/src/utils.rs",
"repo_id": "candle",
"token_count": 74
} | 37 |
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{embedding, Embedding, LayerNorm, Linear, Module, VarBuilder};
fn linear(size1: usize, size2: usize, bias: bool, vb: VarBuilder) -> Result<Linear> {
let weight = vb.get((size2, size1), "weight")?;
let bias = if bias {
Some(vb.get(size2, "bias")?)
} else {
None
};
Ok(Linear::new(weight, bias))
}
fn layer_norm(size: usize, eps: f64, vb: VarBuilder) -> Result<LayerNorm> {
let weight = vb.get(size, "weight")?;
let bias = vb.get(size, "bias")?;
Ok(LayerNorm::new(weight, bias, eps))
}
fn make_causal_mask(t: usize, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j <= i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), device)?;
Ok(mask)
}
#[derive(Debug)]
pub struct Config {
pub vocab_size: usize,
// max_position_embeddings aka n_positions
pub max_position_embeddings: usize,
// num_hidden_layers aka n_layer
pub num_hidden_layers: usize,
// hidden_size aka n_embd
pub hidden_size: usize,
pub layer_norm_epsilon: f64,
pub n_inner: Option<usize>,
// num_attention_heads aka n_head
pub num_attention_heads: usize,
pub multi_query: bool,
pub use_cache: bool,
}
impl Config {
#[allow(dead_code)]
pub fn starcoder_1b() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 24,
hidden_size: 2048,
layer_norm_epsilon: 1e-5,
n_inner: Some(8192),
num_attention_heads: 16,
multi_query: true,
use_cache: true,
}
}
#[allow(dead_code)]
pub fn starcoder_3b() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 36,
hidden_size: 2816,
layer_norm_epsilon: 1e-5,
n_inner: Some(11264),
num_attention_heads: 22,
multi_query: true,
use_cache: true,
}
}
#[allow(dead_code)]
pub fn starcoder_7b() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 42,
hidden_size: 4096,
layer_norm_epsilon: 1e-5,
n_inner: Some(16384),
num_attention_heads: 32,
multi_query: true,
use_cache: true,
}
}
#[allow(dead_code)]
pub fn starcoder() -> Self {
Self {
vocab_size: 49152,
max_position_embeddings: 8192,
num_hidden_layers: 40,
hidden_size: 6144,
layer_norm_epsilon: 1e-5,
n_inner: Some(24576),
num_attention_heads: 48,
multi_query: true,
use_cache: true,
}
}
}
struct Attention {
c_attn: Linear,
c_proj: Linear,
kv_cache: Option<Tensor>,
use_cache: bool,
embed_dim: usize,
kv_dim: usize,
num_heads: usize,
head_dim: usize,
multi_query: bool,
}
impl Attention {
pub fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let head_dim = hidden_size / cfg.num_attention_heads;
let kv_heads = if cfg.multi_query {
1
} else {
cfg.num_attention_heads
};
let kv_dim = kv_heads * head_dim;
let c_attn = linear(hidden_size, hidden_size + 2 * kv_dim, true, vb.pp("c_attn"))?;
let c_proj = linear(hidden_size, hidden_size, true, vb.pp("c_proj"))?;
Ok(Self {
c_proj,
c_attn,
embed_dim: hidden_size,
kv_cache: None,
use_cache: cfg.use_cache,
kv_dim,
head_dim,
num_heads: cfg.num_attention_heads,
multi_query: cfg.multi_query,
})
}
fn attn(
&self,
query: &Tensor,
key: &Tensor,
value: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
if query.dtype() != DType::F32 {
// If we start supporting f16 models, we may need the upcasting scaling bits.
// https://github.com/huggingface/transformers/blob/a0042379269bea9182c1f87e6b2eee4ba4c8cce8/src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py#L133
candle::bail!("upcasting is not supported {:?}", query.dtype())
}
let scale_factor = 1f64 / (self.head_dim as f64).sqrt();
let initial_query_shape = query.shape();
let key_len = key.dim(D::Minus1)?;
let (query, key, attn_shape, attn_view) = if self.multi_query {
let (b_sz, query_len, _) = query.dims3()?;
let query = query.reshape((b_sz, query_len * self.num_heads, self.head_dim))?;
let attn_shape = (b_sz, query_len, self.num_heads, key_len);
let attn_view = (b_sz, query_len * self.num_heads, key_len);
(query, key.clone(), attn_shape, attn_view)
} else {
let (b_sz, _num_heads, query_len, _head_dim) = query.dims4()?;
let query = query.reshape((b_sz, query_len * self.num_heads, self.head_dim))?;
let key = key.reshape((b_sz * self.num_heads, self.head_dim, key_len))?;
let attn_shape = (b_sz, self.num_heads, query_len, key_len);
let attn_view = (b_sz * self.num_heads, query_len, key_len);
(query, key, attn_shape, attn_view)
};
let attn_weights =
(query.matmul(&key.contiguous()?)? * scale_factor)?.reshape(attn_shape)?;
let attention_mask = attention_mask.broadcast_as(attn_shape)?;
let mask_value =
Tensor::new(f32::NEG_INFINITY, query.device())?.broadcast_as(attn_shape)?;
let attn_weights = attention_mask.where_cond(&attn_weights, &mask_value)?;
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
let value = value.contiguous()?;
let attn_output = if self.multi_query {
attn_weights
.reshape(attn_view)?
.matmul(&value)?
.reshape(initial_query_shape)?
} else {
attn_weights.matmul(&value)?
};
Ok(attn_output)
}
fn forward(&mut self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let qkv = self.c_attn.forward(hidden_states)?;
let (query, key_value) = if self.multi_query {
let query = qkv.i((.., .., ..self.embed_dim))?;
let key_value = qkv.i((.., .., self.embed_dim..self.embed_dim + 2 * self.kv_dim))?;
(query, key_value)
} else {
let mut dims = qkv.dims().to_vec();
dims.pop();
dims.push(self.embed_dim);
dims.push(self.head_dim * 3);
let qkv = qkv.reshape(dims)?.transpose(1, 2)?;
let query = qkv.i((.., .., .., ..self.head_dim))?;
let key_value = qkv.i((.., .., .., self.head_dim..3 * self.head_dim))?;
(query, key_value)
};
let mut key_value = key_value;
if self.use_cache {
if let Some(kv_cache) = &self.kv_cache {
// TODO: we could trim the tensors to MAX_SEQ_LEN so that this would work for
// arbitrarily large sizes.
key_value = Tensor::cat(&[kv_cache, &key_value], D::Minus2)?.contiguous()?;
}
self.kv_cache = Some(key_value.clone())
}
let key = key_value.narrow(D::Minus1, 0, self.head_dim)?;
let value = key_value.narrow(D::Minus1, self.head_dim, self.head_dim)?;
let attn_output = self.attn(&query, &key.t()?, &value, attention_mask)?;
let attn_output = if self.multi_query {
attn_output
} else {
attn_output
.transpose(1, 2)?
.reshape(hidden_states.shape())?
};
let attn_output = self.c_proj.forward(&attn_output)?;
Ok(attn_output)
}
}
struct Mlp {
c_fc: Linear,
c_proj: Linear,
}
impl Mlp {
fn load(inner_dim: usize, vb: VarBuilder, cfg: &Config) -> Result<Self> {
let c_fc = linear(cfg.hidden_size, inner_dim, true, vb.pp("c_fc"))?;
let c_proj = linear(inner_dim, cfg.hidden_size, true, vb.pp("c_proj"))?;
Ok(Self { c_fc, c_proj })
}
fn forward(&mut self, hidden_states: &Tensor) -> Result<Tensor> {
let hidden_states = self.c_fc.forward(hidden_states)?.gelu()?;
let hidden_states = self.c_proj.forward(&hidden_states)?;
Ok(hidden_states)
}
}
// TODO: Add cross-attention?
struct Block {
ln_1: LayerNorm,
attn: Attention,
ln_2: LayerNorm,
mlp: Mlp,
}
impl Block {
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let inner_dim = cfg.n_inner.unwrap_or(4 * hidden_size);
let ln_1 = layer_norm(hidden_size, cfg.layer_norm_epsilon, vb.pp("ln_1"))?;
let attn = Attention::load(vb.pp("attn"), cfg)?;
let ln_2 = layer_norm(hidden_size, cfg.layer_norm_epsilon, vb.pp("ln_2"))?;
let mlp = Mlp::load(inner_dim, vb.pp("mlp"), cfg)?;
Ok(Self {
ln_1,
attn,
ln_2,
mlp,
})
}
fn forward(&mut self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let residual = hidden_states;
let hidden_states = self.ln_1.forward(hidden_states)?;
let attn_outputs = self.attn.forward(&hidden_states, attention_mask)?;
let hidden_states = (&attn_outputs + residual)?;
let residual = &hidden_states;
let hidden_states = self.ln_2.forward(&hidden_states)?;
let hidden_states = self.mlp.forward(&hidden_states)?;
let hidden_states = (&hidden_states + residual)?;
Ok(hidden_states)
}
}
pub struct GPTBigCode {
wte: Embedding,
wpe: Embedding,
blocks: Vec<Block>,
ln_f: LayerNorm,
lm_head: Linear,
bias: Tensor,
config: Config,
}
impl GPTBigCode {
pub fn config(&self) -> &Config {
&self.config
}
pub fn load(vb: VarBuilder, cfg: Config) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let vb_t = vb.pp("transformer");
let wte = embedding(cfg.vocab_size, hidden_size, vb_t.pp("wte"))?;
let wpe = embedding(cfg.max_position_embeddings, hidden_size, vb_t.pp("wpe"))?;
let blocks = (0..cfg.num_hidden_layers)
.map(|i| Block::load(vb_t.pp(&format!("h.{i}")), &cfg))
.collect::<Result<Vec<_>>>()?;
let ln_f = layer_norm(hidden_size, cfg.layer_norm_epsilon, vb_t.pp("ln_f"))?;
let lm_head = linear(hidden_size, cfg.vocab_size, false, vb_t.pp("wte"))?;
let bias = make_causal_mask(cfg.max_position_embeddings, vb.device())?;
Ok(Self {
wte,
wpe,
blocks,
lm_head,
ln_f,
bias,
config: cfg,
})
}
pub fn forward(&mut self, input_ids: &Tensor, past_len: usize) -> Result<Tensor> {
let dev = input_ids.device();
let (b_sz, seq_len) = input_ids.dims2()?;
let key_len = past_len + seq_len;
let attention_mask = self.bias.i((past_len..key_len, ..key_len))?.unsqueeze(0)?;
// MQA models: (batch_size, query_length, n_heads, key_length)
// MHA models: (batch_size, n_heads, query_length, key_length)
let seq_len_dim = if self.config.multi_query { 2 } else { 1 };
let attention_mask = attention_mask.unsqueeze(seq_len_dim)?;
let position_ids = Tensor::arange(past_len as u32, (past_len + seq_len) as u32, dev)?;
let position_ids = position_ids.unsqueeze(0)?.broadcast_as((b_sz, seq_len))?;
let input_embeds = self.wte.forward(input_ids)?;
let position_embeds = self.wpe.forward(&position_ids)?;
let mut hidden_states = (&input_embeds + &position_embeds)?;
for block in self.blocks.iter_mut() {
hidden_states = block.forward(&hidden_states, &attention_mask)?;
}
let hidden_states = self.ln_f.forward(&hidden_states)?;
let hidden_states = hidden_states
.reshape((b_sz, seq_len, self.config.hidden_size))?
.narrow(1, seq_len - 1, 1)?;
let logits = self.lm_head.forward(&hidden_states)?.squeeze(1)?;
Ok(logits)
}
}
| candle/candle-transformers/src/models/bigcode.rs/0 | {
"file_path": "candle/candle-transformers/src/models/bigcode.rs",
"repo_id": "candle",
"token_count": 6402
} | 38 |
//! MobileOne inference implementation based on timm and candle-repvgg
//!
//! See "MobileOne: An Improved One millisecond Mobile Backbone"
//! https://arxiv.org/abs/2206.04040
use candle::{DType, Result, Tensor, D};
use candle_nn::{
batch_norm, conv2d, conv2d_no_bias, linear, ops::sigmoid, BatchNorm, Conv2d, Conv2dConfig,
Func, VarBuilder,
};
struct StageConfig {
blocks: usize,
channels: usize,
}
// The architecture in the paper has 6 stages. The timm implementation uses an equivalent form
// by concatenating the 5th stage (starts with stride 1) to the previous one.
const STAGES: [StageConfig; 5] = [
StageConfig {
blocks: 1,
channels: 64,
},
StageConfig {
blocks: 2,
channels: 64,
},
StageConfig {
blocks: 8,
channels: 128,
},
StageConfig {
blocks: 10,
channels: 256,
},
StageConfig {
blocks: 1,
channels: 512,
},
];
#[derive(Clone)]
pub struct Config {
/// overparameterization factor
k: usize,
/// per-stage channel number multipliers
alphas: [f32; 5],
}
impl Config {
pub fn s0() -> Self {
Self {
k: 4,
alphas: [0.75, 0.75, 1.0, 1.0, 2.0],
}
}
pub fn s1() -> Self {
Self {
k: 1,
alphas: [1.5, 1.5, 1.5, 2.0, 2.5],
}
}
pub fn s2() -> Self {
Self {
k: 1,
alphas: [1.5, 1.5, 2.0, 2.5, 4.0],
}
}
pub fn s3() -> Self {
Self {
k: 1,
alphas: [2.0, 2.0, 2.5, 3.0, 4.0],
}
}
pub fn s4() -> Self {
Self {
k: 1,
alphas: [3.0, 3.0, 3.5, 3.5, 4.0],
}
}
}
// SE blocks are used in the last stages of the s4 variant.
fn squeeze_and_excitation(
in_channels: usize,
squeeze_channels: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
..Default::default()
};
let fc1 = conv2d(in_channels, squeeze_channels, 1, conv2d_cfg, vb.pp("fc1"))?;
let fc2 = conv2d(squeeze_channels, in_channels, 1, conv2d_cfg, vb.pp("fc2"))?;
Ok(Func::new(move |xs| {
let residual = xs;
let xs = xs.mean_keepdim(D::Minus2)?.mean_keepdim(D::Minus1)?;
let xs = sigmoid(&xs.apply(&fc1)?.relu()?.apply(&fc2)?)?;
residual.broadcast_mul(&xs)
}))
}
// fuses a convolutional kernel and a batchnorm layer into a convolutional layer
// based on the _fuse_bn_tensor method in timm
// see https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L602
fn fuse_conv_bn(weights: &Tensor, bn: BatchNorm) -> Result<(Tensor, Tensor)> {
let (gamma, beta) = bn.weight_and_bias().unwrap();
let mu = bn.running_mean();
let sigma = (bn.running_var() + bn.eps())?.sqrt();
let gps = (gamma / sigma)?;
let bias = (beta - mu * &gps)?;
let weights = weights.broadcast_mul(&gps.reshape(((), 1, 1, 1))?)?;
Ok((weights, bias))
}
// A mobileone block has a different training time and inference time architecture.
// The latter is a simple and efficient equivalent transformation of the former
// realized by a structural reparameterization technique, where convolutions
// along with identity branches and batchnorm layers are fused into a single convolution.
#[allow(clippy::too_many_arguments)]
fn mobileone_block(
has_identity: bool,
k: usize,
dim: usize,
stride: usize,
padding: usize,
groups: usize,
kernel: usize,
in_channels: usize,
out_channels: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
stride,
padding,
groups,
..Default::default()
};
let mut w = Tensor::zeros(
(out_channels, in_channels / groups, kernel, kernel),
DType::F32,
vb.device(),
)?;
let mut b = Tensor::zeros(dim, DType::F32, vb.device())?;
// k is the training-time overparameterization factor, larger than 1 only in the s0 variant
for i in 0..k {
let conv_kxk_bn = batch_norm(dim, 1e-5, vb.pp(format!("conv_kxk.{i}.bn")))?;
let conv_kxk = conv2d_no_bias(
in_channels,
out_channels,
kernel,
conv2d_cfg,
vb.pp(format!("conv_kxk.{i}.conv")),
)?;
let (wk, bk) = fuse_conv_bn(conv_kxk.weight(), conv_kxk_bn)?;
w = (w + wk)?;
b = (b + bk)?;
}
if kernel > 1 {
let conv_scale_bn = batch_norm(dim, 1e-5, vb.pp("conv_scale.bn"))?;
let conv_scale = conv2d_no_bias(
in_channels,
out_channels,
1,
conv2d_cfg,
vb.pp("conv_scale.conv"),
)?;
let (mut ws, bs) = fuse_conv_bn(conv_scale.weight(), conv_scale_bn)?;
// resize to 3x3
ws = ws.pad_with_zeros(D::Minus1, 1, 1)?;
ws = ws.pad_with_zeros(D::Minus2, 1, 1)?;
w = (w + ws)?;
b = (b + bs)?;
}
// Use SE blocks if present (last layers of the s4 variant)
let se = squeeze_and_excitation(out_channels, out_channels / 16, vb.pp("attn"));
// read and reparameterize the identity bn into wi and bi
if has_identity {
let identity_bn = batch_norm(dim, 1e-5, vb.pp("identity"))?;
let mut weights: Vec<f32> = vec![0.0; w.elem_count()];
let id = in_channels / groups;
// See https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L809
for i in 0..in_channels {
if kernel > 1 {
weights[i * kernel * kernel + 4] = 1.0;
} else {
weights[i * (id + 1)] = 1.0;
}
}
let weights = &Tensor::from_vec(weights, w.shape(), w.device())?;
let (wi, bi) = fuse_conv_bn(weights, identity_bn)?;
w = (w + wi)?;
b = (b + bi)?;
}
let reparam_conv = Conv2d::new(w, Some(b), conv2d_cfg);
Ok(Func::new(move |xs| {
let mut xs = xs.apply(&reparam_conv)?;
if let Ok(f) = &se {
xs = xs.apply(f)?;
}
xs = xs.relu()?;
Ok(xs)
}))
}
// Get the number of output channels per stage taking into account the multipliers
fn output_channels_per_stage(cfg: &Config, stage: usize) -> usize {
let channels = STAGES[stage].channels as f32;
let alpha = cfg.alphas[stage];
match stage {
0 => std::cmp::min(64, (channels * alpha) as usize),
_ => (channels * alpha) as usize,
}
}
// Each stage is made of blocks. The first layer always downsamples with stride 2.
// All but the first block have a residual connection.
fn mobileone_stage(cfg: &Config, idx: usize, vb: VarBuilder) -> Result<Func<'static>> {
let nblocks = STAGES[idx].blocks;
let mut blocks = Vec::with_capacity(nblocks);
let mut in_channels = output_channels_per_stage(cfg, idx - 1);
for block_idx in 0..nblocks {
let out_channels = output_channels_per_stage(cfg, idx);
let (has_identity, stride) = if block_idx == 0 {
(false, 2)
} else {
(true, 1)
};
// depthwise convolution layer
blocks.push(mobileone_block(
has_identity,
cfg.k,
in_channels,
stride,
1,
in_channels,
3,
in_channels,
in_channels,
vb.pp(block_idx * 2),
)?);
// pointwise convolution layer
blocks.push(mobileone_block(
has_identity,
cfg.k,
out_channels,
1, // stride
0, // padding
1, // groups
1, // kernel
in_channels,
out_channels,
vb.pp(block_idx * 2 + 1),
)?);
in_channels = out_channels;
}
Ok(Func::new(move |xs| {
let mut xs = xs.clone();
for block in blocks.iter() {
xs = xs.apply(block)?
}
Ok(xs)
}))
}
// Build a mobileone model for a given configuration.
fn mobileone_model(
config: &Config,
nclasses: Option<usize>,
vb: VarBuilder,
) -> Result<Func<'static>> {
let cls = match nclasses {
None => None,
Some(nclasses) => {
let outputs = output_channels_per_stage(config, 4);
let linear = linear(outputs, nclasses, vb.pp("head.fc"))?;
Some(linear)
}
};
let stem_dim = output_channels_per_stage(config, 0);
let stem = mobileone_block(false, 1, stem_dim, 2, 1, 1, 3, 3, stem_dim, vb.pp("stem"))?;
let vb = vb.pp("stages");
let stage1 = mobileone_stage(config, 1, vb.pp(0))?;
let stage2 = mobileone_stage(config, 2, vb.pp(1))?;
let stage3 = mobileone_stage(config, 3, vb.pp(2))?;
let stage4 = mobileone_stage(config, 4, vb.pp(3))?;
Ok(Func::new(move |xs| {
let xs = xs
.apply(&stem)?
.apply(&stage1)?
.apply(&stage2)?
.apply(&stage3)?
.apply(&stage4)?
.mean(D::Minus2)?
.mean(D::Minus1)?;
match &cls {
None => Ok(xs),
Some(cls) => xs.apply(cls),
}
}))
}
pub fn mobileone(cfg: &Config, nclasses: usize, vb: VarBuilder) -> Result<Func<'static>> {
mobileone_model(cfg, Some(nclasses), vb)
}
pub fn mobileone_no_final_layer(cfg: &Config, vb: VarBuilder) -> Result<Func<'static>> {
mobileone_model(cfg, None, vb)
}
| candle/candle-transformers/src/models/mobileone.rs/0 | {
"file_path": "candle/candle-transformers/src/models/mobileone.rs",
"repo_id": "candle",
"token_count": 4721
} | 39 |
use candle::{DType, IndexOp, Result, Tensor};
use candle_nn::{layer_norm, LayerNorm, Module, VarBuilder};
#[derive(Debug)]
struct PatchEmbed {
proj: candle_nn::Conv2d,
span: tracing::Span,
}
impl PatchEmbed {
fn new(
in_chans: usize,
embed_dim: usize,
k_size: usize,
stride: usize,
padding: usize,
vb: VarBuilder,
) -> Result<Self> {
let cfg = candle_nn::Conv2dConfig {
stride,
padding,
..Default::default()
};
let proj = candle_nn::conv2d(in_chans, embed_dim, k_size, cfg, vb.pp("proj"))?;
let span = tracing::span!(tracing::Level::TRACE, "patch-embed");
Ok(Self { proj, span })
}
}
impl Module for PatchEmbed {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
xs.apply(&self.proj)?.permute((0, 2, 3, 1))
}
}
// A custom op to make add_decomposed_rel_pos faster. Most of the time is spent on the final
// addition in the case where b = 12, q_h = q_w = 4096, k_h = k_w = 4096
// (attn.reshape((b, q_h, q_w, k_h, k_w))?
// + rel_h.unsqueeze(4)?.broadcast_add(&rel_w.unsqueeze(3)?)?)?
// .reshape((b, q_h * q_w, k_h * k_w))
// Ideally we would perform this operation in place but this is not supported in candle at the
// moment. We should also investigate using f16 rather than f32.
struct Add3(usize, usize, usize, usize, usize);
impl candle::CustomOp3 for Add3 {
fn name(&self) -> &'static str {
"add3"
}
fn cpu_fwd(
&self,
s1: &candle::CpuStorage,
l1: &candle::Layout,
s2: &candle::CpuStorage,
l2: &candle::Layout,
s3: &candle::CpuStorage,
l3: &candle::Layout,
) -> Result<(candle::CpuStorage, candle::Shape)> {
use rayon::prelude::*;
let Add3(b, q_h, q_w, k_h, k_w) = *self;
let s1 = s1.as_slice::<f32>()?;
let s1 = match l1.contiguous_offsets() {
None => candle::bail!("input1 has to be contiguous"),
Some((o1, o2)) => &s1[o1..o2],
};
let s2 = s2.as_slice::<f32>()?;
let s2 = match l2.contiguous_offsets() {
None => candle::bail!("input2 has to be contiguous"),
Some((o1, o2)) => &s2[o1..o2],
};
let s3 = s3.as_slice::<f32>()?;
let s3 = match l3.contiguous_offsets() {
None => candle::bail!("input3 has to be contiguous"),
Some((o1, o2)) => &s3[o1..o2],
};
let mut dst = vec![0f32; b * q_h * q_w * k_h * k_w];
dst.par_chunks_exact_mut(k_h * k_w)
.enumerate()
.for_each(|(b_idx, dst)| {
let s1_idx = b_idx * k_h * k_w;
let s2_idx = b_idx * k_h;
let s3_idx = b_idx * k_w;
for h_idx in 0..k_h {
let s1_idx = s1_idx + h_idx * k_w;
let s2_idx = s2_idx + h_idx;
let dst_idx = h_idx * k_w;
for w_idx in 0..k_w {
let s1_idx = s1_idx + w_idx;
let s3_idx = s3_idx + w_idx;
let dst_idx = dst_idx + w_idx;
dst[dst_idx] = s1[s1_idx] + s2[s2_idx] + s3[s3_idx]
}
}
});
let dst = candle::WithDType::to_cpu_storage_owned(dst);
Ok((dst, (b, q_h * q_w, k_h * k_w).into()))
}
}
#[derive(Debug)]
struct Attention {
qkv: super::Linear,
proj: super::Linear,
num_heads: usize,
scale: f64,
rel_pos_hw: Option<(Tensor, Tensor)>,
span: tracing::Span,
span_matmul: tracing::Span,
span_rel_pos: tracing::Span,
span_softmax: tracing::Span,
}
impl Attention {
fn new(
dim: usize,
num_heads: usize,
qkv_bias: bool,
use_rel_pos: bool,
input_size: (usize, usize),
vb: VarBuilder,
) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "attention");
let span_matmul = tracing::span!(tracing::Level::TRACE, "attn-matmul");
let span_rel_pos = tracing::span!(tracing::Level::TRACE, "attn-rel-pos");
let span_softmax = tracing::span!(tracing::Level::TRACE, "attn-sm");
let qkv = super::linear(vb.pp("qkv"), dim, dim * 3, qkv_bias)?;
let proj = super::linear(vb.pp("proj"), dim, dim, true)?;
let head_dim = dim / num_heads;
let scale = 1. / (head_dim as f64).sqrt();
let rel_pos_hw = if use_rel_pos {
let h = vb.get((2 * input_size.0 - 1, head_dim), "rel_pos_h")?;
let w = vb.get((2 * input_size.1 - 1, head_dim), "rel_pos_w")?;
Some((h, w))
} else {
None
};
Ok(Self {
qkv,
proj,
num_heads,
scale,
rel_pos_hw,
span,
span_matmul,
span_rel_pos,
span_softmax,
})
}
fn add_decomposed_rel_pos(
&self,
attn: Tensor,
q: &Tensor,
(q_h, q_w): (usize, usize),
(k_h, k_w): (usize, usize),
) -> Result<Tensor> {
match &self.rel_pos_hw {
Some((rel_pos_h, rel_pos_w)) => {
let r_h = get_rel_pos(q_h, k_h, rel_pos_h)?;
let r_w = get_rel_pos(q_w, k_w, rel_pos_w)?;
let (b, _, dim) = q.dims3()?;
let r_q = q.reshape((b, q_h, q_w, dim))?;
// rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
let rel_h = r_q.matmul(&r_h.broadcast_left(b)?.t()?.contiguous()?)?;
// rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
let rel_w = r_q
.transpose(1, 2)? // -> bwhc
.contiguous()?
.matmul(&r_w.broadcast_left(b)?.t()?.contiguous()?)? // bwhc,bwck -> bwhk
.transpose(1, 2)?
.contiguous()?;
if attn.device().is_cpu() {
let op = Add3(b, q_h, q_w, k_h, k_w);
attn.apply_op3_no_bwd(&rel_h, &rel_w, &op)
} else {
(attn.reshape((b, q_h, q_w, k_h, k_w))?
+ rel_h.unsqueeze(4)?.broadcast_add(&rel_w.unsqueeze(3)?)?)?
.reshape((b, q_h * q_w, k_h * k_w))
}
}
None => Ok(attn),
}
}
}
fn get_rel_pos(q_size: usize, k_size: usize, rel_pos: &Tensor) -> Result<Tensor> {
let max_rel_dist = 2 * usize::max(q_size, k_size) - 1;
let dev = rel_pos.device();
let rel_pos_resized = if rel_pos.dim(0)? != max_rel_dist {
todo!("interpolation")
} else {
rel_pos
};
let q_coords = Tensor::arange(0u32, q_size as u32, dev)?
.reshape((q_size, 1))?
.to_dtype(DType::F32)?;
let k_coords = Tensor::arange(0u32, k_size as u32, dev)?
.reshape((1, k_size))?
.to_dtype(DType::F32)?;
let q_coords = (q_coords * f64::max(1f64, k_size as f64 / q_size as f64))?;
let k_coords = (k_coords * f64::max(1f64, q_size as f64 / k_size as f64))?;
let relative_coords = (q_coords.broadcast_sub(&k_coords)?
+ (k_size as f64 - 1.) * f64::max(1f64, q_size as f64 / k_size as f64))?;
let (d1, d2) = relative_coords.dims2()?;
let relative_coords = relative_coords.to_dtype(DType::U32)?;
rel_pos_resized
.index_select(&relative_coords.reshape(d1 * d2)?, 0)?
.reshape((d1, d2, ()))
}
impl Module for Attention {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (b, h, w, c) = xs.dims4()?;
let qkv = self
.qkv
.forward(&xs.flatten_to(1)?)?
.reshape((b, h * w, 3, self.num_heads, c / self.num_heads))?
.permute((2, 0, 3, 1, 4))?
.reshape((3, b * self.num_heads, h * w, c / self.num_heads))?;
let q = qkv.i(0)?;
let k = qkv.i(1)?;
let v = qkv.i(2)?;
let attn = {
let _enter = self.span_matmul.enter();
(&q * self.scale)?.matmul(&k.t()?)?
};
let attn = {
let _enter = self.span_rel_pos.enter();
self.add_decomposed_rel_pos(attn, &q, (h, w), (h, w))?
};
let attn = {
let _enter = self.span_softmax.enter();
candle_nn::ops::softmax_last_dim(&attn)?
};
let attn = {
let _enter = self.span_matmul.enter();
attn.matmul(&v)?
};
let attn = attn
.reshape((b, self.num_heads, h, w, c / self.num_heads))?
.permute((0, 2, 3, 1, 4))?
.reshape((b, h * w, c))?;
self.proj.forward(&attn)?.reshape((b, h, w, c))
}
}
#[derive(Debug)]
struct Block {
norm1: LayerNorm,
attn: Attention,
norm2: LayerNorm,
mlp: super::MlpBlock,
window_size: usize,
span: tracing::Span,
}
impl Block {
fn new(
dim: usize,
num_heads: usize,
qkv_bias: bool,
use_rel_pos: bool,
window_size: usize,
input_size: (usize, usize),
vb: VarBuilder,
) -> Result<Self> {
let norm1 = layer_norm(dim, 1e-6, vb.pp("norm1"))?;
let norm2 = layer_norm(dim, 1e-6, vb.pp("norm2"))?;
let input_size_attn = if window_size == 0 {
input_size
} else {
(window_size, window_size)
};
let attn = Attention::new(
dim,
num_heads,
qkv_bias,
use_rel_pos,
input_size_attn,
vb.pp("attn"),
)?;
let mlp = super::MlpBlock::new(dim, dim * 4, candle_nn::Activation::Gelu, vb.pp("mlp"))?;
let span = tracing::span!(tracing::Level::TRACE, "ie-block");
Ok(Self {
norm1,
attn,
norm2,
mlp,
window_size,
span,
})
}
}
fn window_partition(xs: Tensor, window_size: usize) -> Result<(Tensor, (usize, usize))> {
let (b, h, w, c) = xs.dims4()?;
let pad_h = (window_size - h % window_size) % window_size;
let pad_w = (window_size - w % window_size) % window_size;
let xs = if pad_h > 0 {
xs.pad_with_zeros(1, 0, pad_h)?
} else {
xs
};
let xs = if pad_w > 0 {
xs.pad_with_zeros(2, 0, pad_w)?
} else {
xs
};
let (h_p, w_p) = (h + pad_h, w + pad_w);
let windows = xs
.reshape((
b,
h_p / window_size,
window_size,
w_p / window_size,
window_size,
c,
))?
.transpose(2, 3)?
.contiguous()?
.flatten_to(2)?;
Ok((windows, (h_p, w_p)))
}
fn window_unpartition(
windows: Tensor,
window_size: usize,
(h_p, w_p): (usize, usize),
(h, w): (usize, usize),
) -> Result<Tensor> {
let b = windows.dim(0)? / (h_p * w_p / window_size / window_size);
let xs = windows
.reshape((
b,
h_p / window_size,
w_p / window_size,
window_size,
window_size,
windows.elem_count() / b / h_p / w_p,
))?
.transpose(2, 3)?
.contiguous()?
.reshape((b, h_p, w_p, ()))?;
let xs = if h_p > h { xs.narrow(1, 0, h)? } else { xs };
let xs = if w_p > w { xs.narrow(2, 0, w)? } else { xs };
Ok(xs)
}
impl Module for Block {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let shortcut = xs;
let xs = self.norm1.forward(xs)?;
let hw = (xs.dim(1)?, xs.dim(2)?);
let (xs, pad_hw) = if self.window_size > 0 {
window_partition(xs, self.window_size)?
} else {
(xs, (0, 0))
};
let xs = self.attn.forward(&xs)?;
let xs = if self.window_size > 0 {
window_unpartition(xs, self.window_size, pad_hw, hw)?
} else {
xs
};
let xs = (xs + shortcut)?;
&xs + xs.apply(&self.norm2)?.apply(&self.mlp)?
}
}
#[derive(Debug)]
pub struct ImageEncoderViT {
patch_embed: PatchEmbed,
blocks: Vec<Block>,
neck_conv1: candle_nn::Conv2d,
neck_ln1: super::LayerNorm2d,
neck_conv2: candle_nn::Conv2d,
neck_ln2: super::LayerNorm2d,
pos_embed: Option<Tensor>,
span: tracing::Span,
}
impl ImageEncoderViT {
#[allow(clippy::too_many_arguments)]
pub fn new(
img_size: usize,
patch_size: usize,
in_chans: usize,
embed_dim: usize,
depth: usize,
num_heads: usize,
out_chans: usize,
qkv_bias: bool,
use_rel_pos: bool,
use_abs_pos: bool,
window_size: usize,
global_attn_indexes: &[usize],
vb: VarBuilder,
) -> Result<Self> {
let patch_embed = PatchEmbed::new(
in_chans,
embed_dim,
patch_size,
patch_size,
0,
vb.pp("patch_embed"),
)?;
let mut blocks = Vec::with_capacity(depth);
let vb_b = vb.pp("blocks");
for i in 0..depth {
let window_size = if global_attn_indexes.contains(&i) {
0
} else {
window_size
};
let block = Block::new(
embed_dim,
num_heads,
qkv_bias,
use_rel_pos,
window_size,
(img_size / patch_size, img_size / patch_size),
vb_b.pp(i),
)?;
blocks.push(block)
}
let neck_conv1 = candle_nn::conv2d_no_bias(
embed_dim,
out_chans,
1,
Default::default(),
vb.pp("neck.0"),
)?;
let neck_ln1 = super::LayerNorm2d::new(out_chans, 1e-6, vb.pp("neck.1"))?;
let cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let neck_conv2 = candle_nn::conv2d_no_bias(out_chans, out_chans, 3, cfg, vb.pp("neck.2"))?;
let neck_ln2 = super::LayerNorm2d::new(out_chans, 1e-6, vb.pp("neck.3"))?;
let pos_embed = if use_abs_pos {
let p = vb.get(
(1, img_size / patch_size, img_size / patch_size, embed_dim),
"pos_embed",
)?;
Some(p)
} else {
None
};
let span = tracing::span!(tracing::Level::TRACE, "image-encoder-vit");
Ok(Self {
patch_embed,
blocks,
neck_conv1,
neck_ln1,
neck_conv2,
neck_ln2,
pos_embed,
span,
})
}
}
impl Module for ImageEncoderViT {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = self.patch_embed.forward(xs)?;
let mut xs = match &self.pos_embed {
Some(pos_embed) => (xs + pos_embed)?,
None => xs,
};
for block in self.blocks.iter() {
xs = block.forward(&xs)?
}
xs.permute((0, 3, 1, 2))?
.apply(&self.neck_conv1)?
.apply(&self.neck_ln1)?
.apply(&self.neck_conv2)?
.apply(&self.neck_ln2)
}
}
| candle/candle-transformers/src/models/segment_anything/image_encoder.rs/0 | {
"file_path": "candle/candle-transformers/src/models/segment_anything/image_encoder.rs",
"repo_id": "candle",
"token_count": 8848
} | 40 |
//! 2D UNet Denoising Models
//!
//! The 2D Unet models take as input a noisy sample and the current diffusion
//! timestep and return a denoised version of the input.
use super::embeddings::{TimestepEmbedding, Timesteps};
use super::unet_2d_blocks::*;
use crate::models::with_tracing::{conv2d, Conv2d};
use candle::{Result, Tensor};
use candle_nn as nn;
use candle_nn::Module;
#[derive(Debug, Clone, Copy)]
pub struct BlockConfig {
pub out_channels: usize,
/// When `None` no cross-attn is used, when `Some(d)` then cross-attn is used and `d` is the
/// number of transformer blocks to be used.
pub use_cross_attn: Option<usize>,
pub attention_head_dim: usize,
}
#[derive(Debug, Clone)]
pub struct UNet2DConditionModelConfig {
pub center_input_sample: bool,
pub flip_sin_to_cos: bool,
pub freq_shift: f64,
pub blocks: Vec<BlockConfig>,
pub layers_per_block: usize,
pub downsample_padding: usize,
pub mid_block_scale_factor: f64,
pub norm_num_groups: usize,
pub norm_eps: f64,
pub cross_attention_dim: usize,
pub sliced_attention_size: Option<usize>,
pub use_linear_projection: bool,
}
impl Default for UNet2DConditionModelConfig {
fn default() -> Self {
Self {
center_input_sample: false,
flip_sin_to_cos: true,
freq_shift: 0.,
blocks: vec![
BlockConfig {
out_channels: 320,
use_cross_attn: Some(1),
attention_head_dim: 8,
},
BlockConfig {
out_channels: 640,
use_cross_attn: Some(1),
attention_head_dim: 8,
},
BlockConfig {
out_channels: 1280,
use_cross_attn: Some(1),
attention_head_dim: 8,
},
BlockConfig {
out_channels: 1280,
use_cross_attn: None,
attention_head_dim: 8,
},
],
layers_per_block: 2,
downsample_padding: 1,
mid_block_scale_factor: 1.,
norm_num_groups: 32,
norm_eps: 1e-5,
cross_attention_dim: 1280,
sliced_attention_size: None,
use_linear_projection: false,
}
}
}
#[derive(Debug)]
pub(crate) enum UNetDownBlock {
Basic(DownBlock2D),
CrossAttn(CrossAttnDownBlock2D),
}
#[derive(Debug)]
enum UNetUpBlock {
Basic(UpBlock2D),
CrossAttn(CrossAttnUpBlock2D),
}
#[derive(Debug)]
pub struct UNet2DConditionModel {
conv_in: Conv2d,
time_proj: Timesteps,
time_embedding: TimestepEmbedding,
down_blocks: Vec<UNetDownBlock>,
mid_block: UNetMidBlock2DCrossAttn,
up_blocks: Vec<UNetUpBlock>,
conv_norm_out: nn::GroupNorm,
conv_out: Conv2d,
span: tracing::Span,
config: UNet2DConditionModelConfig,
}
impl UNet2DConditionModel {
pub fn new(
vs: nn::VarBuilder,
in_channels: usize,
out_channels: usize,
use_flash_attn: bool,
config: UNet2DConditionModelConfig,
) -> Result<Self> {
let n_blocks = config.blocks.len();
let b_channels = config.blocks[0].out_channels;
let bl_channels = config.blocks.last().unwrap().out_channels;
let bl_attention_head_dim = config.blocks.last().unwrap().attention_head_dim;
let time_embed_dim = b_channels * 4;
let conv_cfg = nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let conv_in = conv2d(in_channels, b_channels, 3, conv_cfg, vs.pp("conv_in"))?;
let time_proj = Timesteps::new(b_channels, config.flip_sin_to_cos, config.freq_shift);
let time_embedding =
TimestepEmbedding::new(vs.pp("time_embedding"), b_channels, time_embed_dim)?;
let vs_db = vs.pp("down_blocks");
let down_blocks = (0..n_blocks)
.map(|i| {
let BlockConfig {
out_channels,
use_cross_attn,
attention_head_dim,
} = config.blocks[i];
// Enable automatic attention slicing if the config sliced_attention_size is set to 0.
let sliced_attention_size = match config.sliced_attention_size {
Some(0) => Some(attention_head_dim / 2),
_ => config.sliced_attention_size,
};
let in_channels = if i > 0 {
config.blocks[i - 1].out_channels
} else {
b_channels
};
let db_cfg = DownBlock2DConfig {
num_layers: config.layers_per_block,
resnet_eps: config.norm_eps,
resnet_groups: config.norm_num_groups,
add_downsample: i < n_blocks - 1,
downsample_padding: config.downsample_padding,
..Default::default()
};
if let Some(transformer_layers_per_block) = use_cross_attn {
let config = CrossAttnDownBlock2DConfig {
downblock: db_cfg,
attn_num_head_channels: attention_head_dim,
cross_attention_dim: config.cross_attention_dim,
sliced_attention_size,
use_linear_projection: config.use_linear_projection,
transformer_layers_per_block,
};
let block = CrossAttnDownBlock2D::new(
vs_db.pp(&i.to_string()),
in_channels,
out_channels,
Some(time_embed_dim),
use_flash_attn,
config,
)?;
Ok(UNetDownBlock::CrossAttn(block))
} else {
let block = DownBlock2D::new(
vs_db.pp(&i.to_string()),
in_channels,
out_channels,
Some(time_embed_dim),
db_cfg,
)?;
Ok(UNetDownBlock::Basic(block))
}
})
.collect::<Result<Vec<_>>>()?;
// https://github.com/huggingface/diffusers/blob/a76f2ad538e73b34d5fe7be08c8eb8ab38c7e90c/src/diffusers/models/unet_2d_condition.py#L462
let mid_transformer_layers_per_block = match config.blocks.last() {
None => 1,
Some(block) => block.use_cross_attn.unwrap_or(1),
};
let mid_cfg = UNetMidBlock2DCrossAttnConfig {
resnet_eps: config.norm_eps,
output_scale_factor: config.mid_block_scale_factor,
cross_attn_dim: config.cross_attention_dim,
attn_num_head_channels: bl_attention_head_dim,
resnet_groups: Some(config.norm_num_groups),
use_linear_projection: config.use_linear_projection,
transformer_layers_per_block: mid_transformer_layers_per_block,
..Default::default()
};
let mid_block = UNetMidBlock2DCrossAttn::new(
vs.pp("mid_block"),
bl_channels,
Some(time_embed_dim),
use_flash_attn,
mid_cfg,
)?;
let vs_ub = vs.pp("up_blocks");
let up_blocks = (0..n_blocks)
.map(|i| {
let BlockConfig {
out_channels,
use_cross_attn,
attention_head_dim,
} = config.blocks[n_blocks - 1 - i];
// Enable automatic attention slicing if the config sliced_attention_size is set to 0.
let sliced_attention_size = match config.sliced_attention_size {
Some(0) => Some(attention_head_dim / 2),
_ => config.sliced_attention_size,
};
let prev_out_channels = if i > 0 {
config.blocks[n_blocks - i].out_channels
} else {
bl_channels
};
let in_channels = {
let index = if i == n_blocks - 1 {
0
} else {
n_blocks - i - 2
};
config.blocks[index].out_channels
};
let ub_cfg = UpBlock2DConfig {
num_layers: config.layers_per_block + 1,
resnet_eps: config.norm_eps,
resnet_groups: config.norm_num_groups,
add_upsample: i < n_blocks - 1,
..Default::default()
};
if let Some(transformer_layers_per_block) = use_cross_attn {
let config = CrossAttnUpBlock2DConfig {
upblock: ub_cfg,
attn_num_head_channels: attention_head_dim,
cross_attention_dim: config.cross_attention_dim,
sliced_attention_size,
use_linear_projection: config.use_linear_projection,
transformer_layers_per_block,
};
let block = CrossAttnUpBlock2D::new(
vs_ub.pp(&i.to_string()),
in_channels,
prev_out_channels,
out_channels,
Some(time_embed_dim),
use_flash_attn,
config,
)?;
Ok(UNetUpBlock::CrossAttn(block))
} else {
let block = UpBlock2D::new(
vs_ub.pp(&i.to_string()),
in_channels,
prev_out_channels,
out_channels,
Some(time_embed_dim),
ub_cfg,
)?;
Ok(UNetUpBlock::Basic(block))
}
})
.collect::<Result<Vec<_>>>()?;
let conv_norm_out = nn::group_norm(
config.norm_num_groups,
b_channels,
config.norm_eps,
vs.pp("conv_norm_out"),
)?;
let conv_out = conv2d(b_channels, out_channels, 3, conv_cfg, vs.pp("conv_out"))?;
let span = tracing::span!(tracing::Level::TRACE, "unet2d");
Ok(Self {
conv_in,
time_proj,
time_embedding,
down_blocks,
mid_block,
up_blocks,
conv_norm_out,
conv_out,
span,
config,
})
}
pub fn forward(
&self,
xs: &Tensor,
timestep: f64,
encoder_hidden_states: &Tensor,
) -> Result<Tensor> {
let _enter = self.span.enter();
self.forward_with_additional_residuals(xs, timestep, encoder_hidden_states, None, None)
}
pub fn forward_with_additional_residuals(
&self,
xs: &Tensor,
timestep: f64,
encoder_hidden_states: &Tensor,
down_block_additional_residuals: Option<&[Tensor]>,
mid_block_additional_residual: Option<&Tensor>,
) -> Result<Tensor> {
let (bsize, _channels, height, width) = xs.dims4()?;
let device = xs.device();
let n_blocks = self.config.blocks.len();
let num_upsamplers = n_blocks - 1;
let default_overall_up_factor = 2usize.pow(num_upsamplers as u32);
let forward_upsample_size =
height % default_overall_up_factor != 0 || width % default_overall_up_factor != 0;
// 0. center input if necessary
let xs = if self.config.center_input_sample {
((xs * 2.0)? - 1.0)?
} else {
xs.clone()
};
// 1. time
let emb = (Tensor::ones(bsize, xs.dtype(), device)? * timestep)?;
let emb = self.time_proj.forward(&emb)?;
let emb = self.time_embedding.forward(&emb)?;
// 2. pre-process
let xs = self.conv_in.forward(&xs)?;
// 3. down
let mut down_block_res_xs = vec![xs.clone()];
let mut xs = xs;
for down_block in self.down_blocks.iter() {
let (_xs, res_xs) = match down_block {
UNetDownBlock::Basic(b) => b.forward(&xs, Some(&emb))?,
UNetDownBlock::CrossAttn(b) => {
b.forward(&xs, Some(&emb), Some(encoder_hidden_states))?
}
};
down_block_res_xs.extend(res_xs);
xs = _xs;
}
let new_down_block_res_xs =
if let Some(down_block_additional_residuals) = down_block_additional_residuals {
let mut v = vec![];
// A previous version of this code had a bug because of the addition being made
// in place via += hence modifying the input of the mid block.
for (i, residuals) in down_block_additional_residuals.iter().enumerate() {
v.push((&down_block_res_xs[i] + residuals)?)
}
v
} else {
down_block_res_xs
};
let mut down_block_res_xs = new_down_block_res_xs;
// 4. mid
let xs = self
.mid_block
.forward(&xs, Some(&emb), Some(encoder_hidden_states))?;
let xs = match mid_block_additional_residual {
None => xs,
Some(m) => (m + xs)?,
};
// 5. up
let mut xs = xs;
let mut upsample_size = None;
for (i, up_block) in self.up_blocks.iter().enumerate() {
let n_resnets = match up_block {
UNetUpBlock::Basic(b) => b.resnets.len(),
UNetUpBlock::CrossAttn(b) => b.upblock.resnets.len(),
};
let res_xs = down_block_res_xs.split_off(down_block_res_xs.len() - n_resnets);
if i < n_blocks - 1 && forward_upsample_size {
let (_, _, h, w) = down_block_res_xs.last().unwrap().dims4()?;
upsample_size = Some((h, w))
}
xs = match up_block {
UNetUpBlock::Basic(b) => b.forward(&xs, &res_xs, Some(&emb), upsample_size)?,
UNetUpBlock::CrossAttn(b) => b.forward(
&xs,
&res_xs,
Some(&emb),
upsample_size,
Some(encoder_hidden_states),
)?,
};
}
// 6. post-process
let xs = self.conv_norm_out.forward(&xs)?;
let xs = nn::ops::silu(&xs)?;
self.conv_out.forward(&xs)
}
}
| candle/candle-transformers/src/models/stable_diffusion/unet_2d.rs/0 | {
"file_path": "candle/candle-transformers/src/models/stable_diffusion/unet_2d.rs",
"repo_id": "candle",
"token_count": 8419
} | 41 |
use candle::{Result, Tensor};
#[derive(Debug, Clone)]
pub struct DDPMWSchedulerConfig {
scaler: f64,
s: f64,
}
impl Default for DDPMWSchedulerConfig {
fn default() -> Self {
Self {
scaler: 1f64,
s: 0.008f64,
}
}
}
pub struct DDPMWScheduler {
init_alpha_cumprod: f64,
init_noise_sigma: f64,
timesteps: Vec<f64>,
pub config: DDPMWSchedulerConfig,
}
impl DDPMWScheduler {
pub fn new(inference_steps: usize, config: DDPMWSchedulerConfig) -> Result<Self> {
let init_alpha_cumprod = (config.s / (1. + config.s) * std::f64::consts::PI)
.cos()
.powi(2);
let timesteps = (0..=inference_steps)
.map(|i| 1. - i as f64 / inference_steps as f64)
.collect::<Vec<_>>();
Ok(Self {
init_alpha_cumprod,
init_noise_sigma: 1.0,
timesteps,
config,
})
}
pub fn timesteps(&self) -> &[f64] {
&self.timesteps
}
fn alpha_cumprod(&self, t: f64) -> f64 {
let scaler = self.config.scaler;
let s = self.config.s;
let t = if scaler > 1. {
1. - (1. - t).powf(scaler)
} else if scaler < 1. {
t.powf(scaler)
} else {
t
};
let alpha_cumprod = ((t + s) / (1. + s) * std::f64::consts::PI * 0.5)
.cos()
.powi(2)
/ self.init_alpha_cumprod;
alpha_cumprod.clamp(0.0001, 0.9999)
}
fn previous_timestep(&self, ts: f64) -> f64 {
let index = self
.timesteps
.iter()
.enumerate()
.map(|(idx, v)| (idx, (v - ts).abs()))
.min_by(|x, y| x.1.total_cmp(&y.1))
.unwrap()
.0;
self.timesteps[index + 1]
}
/// Ensures interchangeability with schedulers that need to scale the denoising model input
/// depending on the current timestep.
pub fn scale_model_input(&self, sample: Tensor, _timestep: usize) -> Tensor {
sample
}
pub fn step(&self, model_output: &Tensor, ts: f64, sample: &Tensor) -> Result<Tensor> {
let prev_t = self.previous_timestep(ts);
let alpha_cumprod = self.alpha_cumprod(ts);
let alpha_cumprod_prev = self.alpha_cumprod(prev_t);
let alpha = alpha_cumprod / alpha_cumprod_prev;
let mu = (sample - model_output * ((1. - alpha) / (1. - alpha_cumprod).sqrt()))?;
let mu = (mu * (1. / alpha).sqrt())?;
let std_noise = mu.randn_like(0., 1.)?;
let std =
std_noise * ((1. - alpha) * (1. - alpha_cumprod_prev) / (1. - alpha_cumprod)).sqrt();
if prev_t == 0. {
Ok(mu)
} else {
mu + std
}
}
pub fn init_noise_sigma(&self) -> f64 {
self.init_noise_sigma
}
}
| candle/candle-transformers/src/models/wuerstchen/ddpm.rs/0 | {
"file_path": "candle/candle-transformers/src/models/wuerstchen/ddpm.rs",
"repo_id": "candle",
"token_count": 1537
} | 42 |
cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| candle/candle-wasm-examples/bert/build-lib.sh/0 | {
"file_path": "candle/candle-wasm-examples/bert/build-lib.sh",
"repo_id": "candle",
"token_count": 48
} | 43 |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Welcome to Candle!</title>
<link data-trunk rel="copy-file" href="tokenizer.json" />
<link data-trunk rel="copy-file" href="model.bin" />
<link data-trunk rel="rust" href="Cargo.toml" data-bin="app" data-type="main" />
<link data-trunk rel="rust" href="Cargo.toml" data-bin="worker" data-type="worker" />
<link rel="stylesheet" href="https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css">
</head>
<body></body>
</html>
| candle/candle-wasm-examples/llama2-c/index.html/0 | {
"file_path": "candle/candle-wasm-examples/llama2-c/index.html",
"repo_id": "candle",
"token_count": 315
} | 44 |
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::log(&format_args!($($t)*).to_string()))
}
| candle/candle-wasm-examples/phi/src/lib.rs/0 | {
"file_path": "candle/candle-wasm-examples/phi/src/lib.rs",
"repo_id": "candle",
"token_count": 183
} | 45 |
//load the candle Whisper decoder wasm module
import init, { Decoder } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "whisper-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class Whisper {
static instance = {};
// Retrieve the Whisper model. When called for the first time,
// this will load the model and save it for future use.
static async getInstance(params) {
const {
weightsURL,
modelID,
tokenizerURL,
mel_filtersURL,
configURL,
quantized,
is_multilingual,
timestamps,
task,
language,
} = params;
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [
weightsArrayU8,
tokenizerArrayU8,
mel_filtersArrayU8,
configArrayU8,
] = await Promise.all([
fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
fetchArrayBuffer(mel_filtersURL),
fetchArrayBuffer(configURL),
]);
this.instance[modelID] = new Decoder(
weightsArrayU8,
tokenizerArrayU8,
mel_filtersArrayU8,
configArrayU8,
quantized,
is_multilingual,
timestamps,
task,
language
);
} else {
self.postMessage({ status: "loading", message: "Model Already Loaded" });
}
return this.instance[modelID];
}
}
self.addEventListener("message", async (event) => {
const {
weightsURL,
modelID,
tokenizerURL,
configURL,
mel_filtersURL,
audioURL,
} = event.data;
try {
self.postMessage({ status: "decoding", message: "Starting Decoder" });
let quantized = false;
if (modelID.includes("quantized")) {
quantized = true;
}
let is_multilingual = false;
if (modelID.includes("multilingual")) {
is_multilingual = true;
}
let timestamps = true;
const decoder = await Whisper.getInstance({
weightsURL,
modelID,
tokenizerURL,
mel_filtersURL,
configURL,
quantized,
is_multilingual,
timestamps,
task: null,
language: null,
});
self.postMessage({ status: "decoding", message: "Loading Audio" });
const audioArrayU8 = await fetchArrayBuffer(audioURL);
self.postMessage({ status: "decoding", message: "Running Decoder..." });
const segments = decoder.decode(audioArrayU8);
// Send the segment back to the main thread as JSON
self.postMessage({
status: "complete",
message: "complete",
output: JSON.parse(segments),
});
} catch (e) {
self.postMessage({ error: e });
}
});
| candle/candle-wasm-examples/whisper/whisperWorker.js/0 | {
"file_path": "candle/candle-wasm-examples/whisper/whisperWorker.js",
"repo_id": "candle",
"token_count": 1215
} | 46 |
Run the tests with:
```bash
RUST_LOG=wasm_bindgen_test_runner wasm-pack test --chrome --headless
```
Or:
```bash
wasm-pack test --chrome
```
If you get an "invalid session id" failure in headless mode, check that logs and
it may well be that your ChromeDriver is not at the same version as your
browser.
| candle/candle-wasm-tests/README.md/0 | {
"file_path": "candle/candle-wasm-tests/README.md",
"repo_id": "candle",
"token_count": 98
} | 47 |
## Privacy
> Last updated: October 4, 2023
Users of HuggingChat are authenticated through their HF user account.
By default, your conversations may be shared with the respective models' authors to improve their training data and model over time. Model authors are the custodians of the data collected by their model, even if it's hosted on our platform.
If you disable data sharing in your settings, your conversations will not be used for any downstream usage (including for research or model training purposes), and they will only be stored to let you access past conversations. You can click on the Delete icon to delete any past conversation at any moment.
🗓 Please also consult huggingface.co's main privacy policy at <https://huggingface.co/privacy>. To exercise any of your legal privacy rights, please send an email to <[email protected]>.
## About available LLMs
The goal of this app is to showcase that it is now possible to build an open source alternative to ChatGPT. 💪
For now (October 2023), it's running:
- [Llama 2 70B](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)
- [CodeLlama 35B](https://about.fb.com/news/2023/08/code-llama-ai-for-coding/)
- [Falcon 180B](https://www.tii.ae/news/technology-innovation-institute-introduces-worlds-most-powerful-open-llm-falcon-180b)
- [Mistral 7B](https://mistral.ai/news/announcing-mistral-7b/)
## Technical details
This app is running in a [Space](https://huggingface.co/docs/hub/spaces-overview), which entails that the code for this UI is publicly visible [inside the Space repo](https://huggingface.co/spaces/huggingchat/chat-ui/tree/main).
**Further development takes place on the [huggingface/chat-ui GitHub repo](https://github.com/huggingface/chat-ui).**
The inference backend is running the optimized [text-generation-inference](https://github.com/huggingface/text-generation-inference) on HuggingFace's Inference API infrastructure.
It is therefore possible to deploy a copy of this app to a Space and customize it (swap model, add some UI elements, or store user messages according to your own Terms and conditions). You can also 1-click deploy your own instance using the [Chat UI Spaces Docker template](https://huggingface.co/new-space?template=huggingchat/chat-ui-template).
We welcome any feedback on this app: please participate to the public discussion at <https://huggingface.co/spaces/huggingchat/chat-ui/discussions>
<a target="_blank" href="https://huggingface.co/spaces/huggingchat/chat-ui/discussions"><img src="https://huggingface.co/datasets/huggingface/badges/raw/main/open-a-discussion-xl.svg" title="open a discussion"></a>
| chat-ui/PRIVACY.md/0 | {
"file_path": "chat-ui/PRIVACY.md",
"repo_id": "chat-ui",
"token_count": 762
} | 48 |
<script lang="ts">
export let title = "";
export let classNames = "";
</script>
<div class="flex items-center rounded-xl bg-gray-100 p-1 text-sm dark:bg-gray-800 {classNames}">
<span
class="mr-2 inline-flex items-center rounded-lg bg-gradient-to-br from-primary-300 px-2 py-1 text-xxs font-medium uppercase leading-3 text-primary-700 dark:from-primary-900 dark:text-primary-400"
>New</span
>
{title}
<div class="ml-auto shrink-0">
<slot />
</div>
</div>
| chat-ui/src/lib/components/AnnouncementBanner.svelte/0 | {
"file_path": "chat-ui/src/lib/components/AnnouncementBanner.svelte",
"repo_id": "chat-ui",
"token_count": 184
} | 49 |
<script lang="ts">
import CarbonStopFilledAlt from "~icons/carbon/stop-filled-alt";
export let classNames = "";
</script>
<button
type="button"
on:click
class="btn flex h-8 rounded-lg border bg-white px-3 py-1 shadow-sm transition-all hover:bg-gray-100 dark:border-gray-600 dark:bg-gray-700 dark:hover:bg-gray-600 {classNames}"
>
<CarbonStopFilledAlt class="-ml-1 mr-1 h-[1.25rem] w-[1.1875rem] text-gray-300" /> Stop generating
</button>
| chat-ui/src/lib/components/StopGeneratingBtn.svelte/0 | {
"file_path": "chat-ui/src/lib/components/StopGeneratingBtn.svelte",
"repo_id": "chat-ui",
"token_count": 170
} | 50 |
<script lang="ts">
export let classNames = "";
</script>
<svg
xmlns="http://www.w3.org/2000/svg"
width="1em"
height="1em"
class={classNames}
fill="none"
viewBox="0 0 26 23"
>
<path
fill="url(#a)"
d="M.93 10.65A10.17 10.17 0 0 1 11.11.48h4.67a9.45 9.45 0 0 1 0 18.89H4.53L1.62 22.2a.38.38 0 0 1-.69-.28V10.65Z"
/>
<path
fill="#000"
fill-rule="evenodd"
d="M11.52 7.4a1.86 1.86 0 1 1-3.72 0 1.86 1.86 0 0 1 3.72 0Zm7.57 0a1.86 1.86 0 1 1-3.73 0 1.86 1.86 0 0 1 3.73 0ZM8.9 12.9a.55.55 0 0 0-.11.35.76.76 0 0 1-1.51 0c0-.95.67-1.94 1.76-1.94 1.09 0 1.76 1 1.76 1.94H9.3a.55.55 0 0 0-.12-.35c-.06-.07-.1-.08-.13-.08s-.08 0-.14.08Zm4.04 0a.55.55 0 0 0-.12.35h-1.51c0-.95.68-1.94 1.76-1.94 1.1 0 1.77 1 1.77 1.94h-1.51a.55.55 0 0 0-.12-.35c-.06-.07-.11-.08-.14-.08-.02 0-.07 0-.13.08Zm-1.89.79c-.02 0-.07-.01-.13-.08a.55.55 0 0 1-.12-.36h-1.5c0 .95.67 1.95 1.75 1.95 1.1 0 1.77-1 1.77-1.95h-1.51c0 .16-.06.28-.12.36-.06.07-.11.08-.14.08Zm4.04 0c-.03 0-.08-.01-.14-.08a.55.55 0 0 1-.12-.36h-1.5c0 .95.67 1.95 1.76 1.95 1.08 0 1.76-1 1.76-1.95h-1.51c0 .16-.06.28-.12.36-.06.07-.11.08-.13.08Zm1.76-.44c0-.16.05-.28.12-.35.06-.07.1-.08.13-.08s.08 0 .14.08c.06.07.11.2.11.35a.76.76 0 0 0 1.51 0c0-.95-.67-1.94-1.76-1.94-1.09 0-1.76 1-1.76 1.94h1.5Z"
clip-rule="evenodd"
/>
<defs>
<radialGradient
id="a"
cx="0"
cy="0"
r="1"
gradientTransform="matrix(0 31.37 -34.85 0 13.08 -9.02)"
gradientUnits="userSpaceOnUse"
>
<stop stop-color="#FFD21E" />
<stop offset="1" stop-color="red" />
</radialGradient>
</defs>
</svg>
| chat-ui/src/lib/components/icons/IconDazzled.svelte/0 | {
"file_path": "chat-ui/src/lib/components/icons/IconDazzled.svelte",
"repo_id": "chat-ui",
"token_count": 916
} | 51 |
import { HF_ACCESS_TOKEN, HF_TOKEN } from "$env/static/private";
import { buildPrompt } from "$lib/buildPrompt";
import type { TextGenerationStreamOutput } from "@huggingface/inference";
import type { Endpoint } from "../endpoints";
import { z } from "zod";
export const endpointLlamacppParametersSchema = z.object({
weight: z.number().int().positive().default(1),
model: z.any(),
type: z.literal("llamacpp"),
url: z.string().url().default("http://127.0.0.1:8080"),
accessToken: z
.string()
.min(1)
.default(HF_TOKEN ?? HF_ACCESS_TOKEN),
});
export function endpointLlamacpp(
input: z.input<typeof endpointLlamacppParametersSchema>
): Endpoint {
const { url, model } = endpointLlamacppParametersSchema.parse(input);
return async ({ conversation }) => {
const prompt = await buildPrompt({
messages: conversation.messages,
webSearch: conversation.messages[conversation.messages.length - 1].webSearch,
preprompt: conversation.preprompt,
model,
});
const r = await fetch(`${url}/completion`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
prompt,
stream: true,
temperature: model.parameters.temperature,
top_p: model.parameters.top_p,
top_k: model.parameters.top_k,
stop: model.parameters.stop,
repeat_penalty: model.parameters.repetition_penalty,
n_predict: model.parameters.max_new_tokens,
}),
});
if (!r.ok) {
throw new Error(`Failed to generate text: ${await r.text()}`);
}
const encoder = new TextDecoderStream();
const reader = r.body?.pipeThrough(encoder).getReader();
return (async function* () {
let stop = false;
let generatedText = "";
let tokenId = 0;
while (!stop) {
// read the stream and log the outputs to console
const out = (await reader?.read()) ?? { done: false, value: undefined };
// we read, if it's done we cancel
if (out.done) {
reader?.cancel();
return;
}
if (!out.value) {
return;
}
if (out.value.startsWith("data: ")) {
let data = null;
try {
data = JSON.parse(out.value.slice(6));
} catch (e) {
return;
}
if (data.content || data.stop) {
generatedText += data.content;
const output: TextGenerationStreamOutput = {
token: {
id: tokenId++,
text: data.content ?? "",
logprob: 0,
special: false,
},
generated_text: data.stop ? generatedText : null,
details: null,
};
if (data.stop) {
stop = true;
reader?.cancel();
}
yield output;
// take the data.content value and yield it
}
}
}
})();
};
}
export default endpointLlamacpp;
| chat-ui/src/lib/server/endpoints/llamacpp/endpointLlamacpp.ts/0 | {
"file_path": "chat-ui/src/lib/server/endpoints/llamacpp/endpointLlamacpp.ts",
"repo_id": "chat-ui",
"token_count": 1156
} | 52 |
import { JSDOM, VirtualConsole } from "jsdom";
export async function searchWebLocal(query: string) {
const abortController = new AbortController();
setTimeout(() => abortController.abort(), 10000);
const htmlString = await fetch("https://www.google.com/search?hl=en&q=" + query, {
signal: abortController.signal,
})
.then((response) => response.text())
.catch();
const virtualConsole = new VirtualConsole();
virtualConsole.on("error", () => {
// No-op to skip console errors.
});
// put the html string into a DOM
const dom = new JSDOM(htmlString ?? "", {
virtualConsole,
});
const { document } = dom.window;
// get all a documents with href tag
const links = document.querySelectorAll("a");
if (!links.length) {
throw new Error(`webpage doesn't have any "a" element`);
}
// take url that start wirth /url?q=
// and do not contain google.com links
// and strip them up to '&sa='
const linksHref = Array.from(links)
.filter((el) => el.href?.startsWith("/url?q=") && !el.href.includes("google.com/"))
.map((el) => {
const link = el.href;
return link.slice("/url?q=".length, link.indexOf("&sa="));
});
// remove duplicate links and map links to the correct object shape
return { organic_results: [...new Set(linksHref)].map((link) => ({ link })) };
}
| chat-ui/src/lib/server/websearch/searchWebLocal.ts/0 | {
"file_path": "chat-ui/src/lib/server/websearch/searchWebLocal.ts",
"repo_id": "chat-ui",
"token_count": 438
} | 53 |
import type { BackendModel } from "$lib/server/models";
export type Model = Pick<
BackendModel,
| "id"
| "name"
| "displayName"
| "websiteUrl"
| "datasetName"
| "promptExamples"
| "parameters"
| "description"
| "modelUrl"
| "datasetUrl"
| "preprompt"
| "multimodal"
| "unlisted"
>;
| chat-ui/src/lib/types/Model.ts/0 | {
"file_path": "chat-ui/src/lib/types/Model.ts",
"repo_id": "chat-ui",
"token_count": 130
} | 54 |
import { base } from "$app/paths";
import { PUBLIC_ORIGIN, PUBLIC_SHARE_PREFIX } from "$env/static/public";
export function getShareUrl(url: URL, shareId: string): string {
return `${PUBLIC_SHARE_PREFIX || `${PUBLIC_ORIGIN || url.origin}${base}`}/r/${shareId}`;
}
| chat-ui/src/lib/utils/getShareUrl.ts/0 | {
"file_path": "chat-ui/src/lib/utils/getShareUrl.ts",
"repo_id": "chat-ui",
"token_count": 99
} | 55 |
import {
PARQUET_EXPORT_DATASET,
PARQUET_EXPORT_HF_TOKEN,
PARQUET_EXPORT_SECRET,
} from "$env/static/private";
import { collections } from "$lib/server/database";
import type { Message } from "$lib/types/Message";
import { error } from "@sveltejs/kit";
import { pathToFileURL } from "node:url";
import { unlink } from "node:fs/promises";
import { uploadFile } from "@huggingface/hub";
import parquet from "parquetjs";
import { z } from "zod";
// Triger like this:
// curl -X POST "http://localhost:5173/chat/admin/export" -H "Authorization: Bearer <PARQUET_EXPORT_SECRET>" -H "Content-Type: application/json" -d '{"model": "OpenAssistant/oasst-sft-6-llama-30b-xor"}'
export async function POST({ request }) {
if (!PARQUET_EXPORT_SECRET || !PARQUET_EXPORT_DATASET || !PARQUET_EXPORT_HF_TOKEN) {
throw error(500, "Parquet export is not configured.");
}
if (request.headers.get("Authorization") !== `Bearer ${PARQUET_EXPORT_SECRET}`) {
throw error(403);
}
const { model } = z
.object({
model: z.string(),
})
.parse(await request.json());
const schema = new parquet.ParquetSchema({
title: { type: "UTF8" },
created_at: { type: "TIMESTAMP_MILLIS" },
updated_at: { type: "TIMESTAMP_MILLIS" },
messages: {
repeated: true,
fields: {
from: { type: "UTF8" },
content: { type: "UTF8" },
score: { type: "INT_8", optional: true },
},
},
});
const fileName = `/tmp/conversations-${new Date().toJSON().slice(0, 10)}-${Date.now()}.parquet`;
const writer = await parquet.ParquetWriter.openFile(schema, fileName);
let count = 0;
console.log("Exporting conversations for model", model);
for await (const conversation of collections.settings.aggregate<{
title: string;
created_at: Date;
updated_at: Date;
messages: Message[];
}>([
{
$match: {
shareConversationsWithModelAuthors: true,
sessionId: { $exists: true },
userId: { $exists: false },
},
},
{
$lookup: {
from: "conversations",
localField: "sessionId",
foreignField: "sessionId",
as: "conversations",
pipeline: [{ $match: { model, userId: { $exists: false } } }],
},
},
{ $unwind: "$conversations" },
{
$project: {
title: "$conversations.title",
created_at: "$conversations.createdAt",
updated_at: "$conversations.updatedAt",
messages: "$conversations.messages",
},
},
])) {
await writer.appendRow({
title: conversation.title,
created_at: conversation.created_at,
updated_at: conversation.updated_at,
messages: conversation.messages.map((message: Message) => ({
from: message.from,
content: message.content,
...(message.score ? { score: message.score } : undefined),
})),
});
++count;
if (count % 1_000 === 0) {
console.log("Exported", count, "conversations");
}
}
console.log("exporting convos with userId");
for await (const conversation of collections.settings.aggregate<{
title: string;
created_at: Date;
updated_at: Date;
messages: Message[];
}>([
{ $match: { shareConversationsWithModelAuthors: true, userId: { $exists: true } } },
{
$lookup: {
from: "conversations",
localField: "userId",
foreignField: "userId",
as: "conversations",
pipeline: [{ $match: { model } }],
},
},
{ $unwind: "$conversations" },
{
$project: {
title: "$conversations.title",
created_at: "$conversations.createdAt",
updated_at: "$conversations.updatedAt",
messages: "$conversations.messages",
},
},
])) {
await writer.appendRow({
title: conversation.title,
created_at: conversation.created_at,
updated_at: conversation.updated_at,
messages: conversation.messages.map((message: Message) => ({
from: message.from,
content: message.content,
...(message.score ? { score: message.score } : undefined),
})),
});
++count;
if (count % 1_000 === 0) {
console.log("Exported", count, "conversations");
}
}
await writer.close();
console.log("Uploading", fileName, "to Hugging Face Hub");
await uploadFile({
file: pathToFileURL(fileName) as URL,
credentials: { accessToken: PARQUET_EXPORT_HF_TOKEN },
repo: {
type: "dataset",
name: PARQUET_EXPORT_DATASET,
},
});
console.log("Upload done");
await unlink(fileName);
return new Response();
}
| chat-ui/src/routes/admin/export/+server.ts/0 | {
"file_path": "chat-ui/src/routes/admin/export/+server.ts",
"repo_id": "chat-ui",
"token_count": 1727
} | 56 |
import { authCondition } from "$lib/server/auth";
import { collections } from "$lib/server/database";
import { error } from "@sveltejs/kit";
import { ObjectId } from "mongodb";
import { z } from "zod";
export async function POST({ params, request, locals }) {
const { score } = z
.object({
score: z.number().int().min(-1).max(1),
})
.parse(await request.json());
const conversationId = new ObjectId(params.id);
const messageId = params.messageId;
const document = await collections.conversations.updateOne(
{
_id: conversationId,
...authCondition(locals),
"messages.id": messageId,
},
{
...(score !== 0
? {
$set: {
"messages.$.score": score,
},
}
: { $unset: { "messages.$.score": "" } }),
}
);
if (!document.matchedCount) {
throw error(404, "Message not found");
}
return new Response();
}
| chat-ui/src/routes/conversation/[id]/message/[messageId]/vote/+server.ts/0 | {
"file_path": "chat-ui/src/routes/conversation/[id]/message/[messageId]/vote/+server.ts",
"repo_id": "chat-ui",
"token_count": 337
} | 57 |
<script lang="ts">
import { page } from "$app/stores";
import { base } from "$app/paths";
import { PUBLIC_ORIGIN } from "$env/static/public";
import type { BackendModel } from "$lib/server/models";
import { useSettingsStore } from "$lib/stores/settings";
import CopyToClipBoardBtn from "$lib/components/CopyToClipBoardBtn.svelte";
import CarbonArrowUpRight from "~icons/carbon/arrow-up-right";
import CarbonLink from "~icons/carbon/link";
const settings = useSettingsStore();
$: if ($settings.customPrompts[$page.params.model] === undefined) {
$settings.customPrompts = {
...$settings.customPrompts,
[$page.params.model]:
$page.data.models.find((el: BackendModel) => el.id === $page.params.model)?.preprompt || "",
};
}
$: hasCustomPreprompt =
$settings.customPrompts[$page.params.model] !==
$page.data.models.find((el: BackendModel) => el.id === $page.params.model)?.preprompt;
$: isActive = $settings.activeModel === $page.params.model;
$: model = $page.data.models.find((el: BackendModel) => el.id === $page.params.model);
</script>
<div class="flex flex-col items-start">
<div class="mb-5 flex flex-col gap-1.5">
<h2 class="text-lg font-semibold md:text-xl">
{$page.params.model}
</h2>
{#if model.description}
<p class=" text-gray-600">
{model.description}
</p>
{/if}
</div>
<div class="flex flex-wrap items-center gap-2 md:gap-4">
<a
href={model.modelUrl || "https://huggingface.co/" + model.name}
target="_blank"
rel="noreferrer"
class="flex items-center truncate underline underline-offset-2"
>
<CarbonArrowUpRight class="mr-1.5 shrink-0 text-xs " />
Model page
</a>
{#if model.datasetName || model.datasetUrl}
<a
href={model.datasetUrl || "https://huggingface.co/datasets/" + model.datasetName}
target="_blank"
rel="noreferrer"
class="flex items-center truncate underline underline-offset-2"
>
<CarbonArrowUpRight class="mr-1.5 shrink-0 text-xs " />
Dataset page
</a>
{/if}
{#if model.websiteUrl}
<a
href={model.websiteUrl}
target="_blank"
class="flex items-center truncate underline underline-offset-2"
rel="noreferrer"
>
<CarbonArrowUpRight class="mr-1.5 shrink-0 text-xs " />
Model website
</a>
{/if}
<CopyToClipBoardBtn
value="{PUBLIC_ORIGIN || $page.url.origin}{base}?model={model.id}"
classNames="!border-none !shadow-none !py-0 !px-1 !rounded-md"
>
<div class="flex items-center gap-1.5 hover:underline">
<CarbonLink />Copy direct link to model
</div>
</CopyToClipBoardBtn>
</div>
<button
class="{isActive
? 'bg-gray-100'
: 'bg-black text-white'} my-8 flex items-center rounded-full px-3 py-1"
disabled={isActive}
name="Activate model"
on:click|stopPropagation={() => {
$settings.activeModel = $page.params.model;
}}
>
{isActive ? "Active model" : "Activate"}
</button>
<div class="flex w-full flex-col gap-2">
<div class="flex w-full flex-row content-between">
<h3 class="mb-1.5 text-lg font-semibold text-gray-800">System Prompt</h3>
{#if hasCustomPreprompt}
<button
class="ml-auto underline decoration-gray-300 hover:decoration-gray-700"
on:click|stopPropagation={() =>
($settings.customPrompts[$page.params.model] = model.preprompt)}
>
Reset
</button>
{/if}
</div>
<textarea
rows="10"
class="w-full resize-none rounded-md border-2 bg-gray-100 p-2"
bind:value={$settings.customPrompts[$page.params.model]}
/>
</div>
</div>
| chat-ui/src/routes/settings/[...model]/+page.svelte/0 | {
"file_path": "chat-ui/src/routes/settings/[...model]/+page.svelte",
"repo_id": "chat-ui",
"token_count": 1483
} | 58 |
{
"$schema": "https://vega.github.io/schema/vega-lite/v4.json",
"data": {
"values": "<DVC_METRIC_DATA>"
},
"title": "<DVC_METRIC_TITLE>",
"mark": {
"type": "line"
},
"encoding": {
"x": {
"field": "<DVC_METRIC_X>",
"type": "quantitative",
"title": "<DVC_METRIC_X_LABEL>"
},
"y": {
"field": "<DVC_METRIC_Y>",
"type": "quantitative",
"title": "<DVC_METRIC_Y_LABEL>",
"scale": {
"zero": false
}
},
"color": {
"field": "rev",
"type": "nominal"
}
}
}
| datasets/.dvc/plots/default.json/0 | {
"file_path": "datasets/.dvc/plots/default.json",
"repo_id": "datasets",
"token_count": 419
} | 59 |
# How to contribute to Datasets?
[](CODE_OF_CONDUCT.md)
Datasets is an open source project, so all contributions and suggestions are welcome.
You can contribute in many different ways: giving ideas, answering questions, reporting bugs, proposing enhancements,
improving the documentation, fixing bugs,...
Many thanks in advance to every contributor.
In order to facilitate healthy, constructive behavior in an open and inclusive community, we all respect and abide by
our [code of conduct](CODE_OF_CONDUCT.md).
## How to work on an open Issue?
You have the list of open Issues at: https://github.com/huggingface/datasets/issues
Some of them may have the label `help wanted`: that means that any contributor is welcomed!
If you would like to work on any of the open Issues:
1. Make sure it is not already assigned to someone else. You have the assignee (if any) on the top of the right column of the Issue page.
2. You can self-assign it by commenting on the Issue page with the keyword: `#self-assign`.
3. Work on your self-assigned issue and eventually create a Pull Request.
## How to create a Pull Request?
If you want to add a dataset see specific instructions in the section [*How to add a dataset*](#how-to-add-a-dataset).
1. Fork the [repository](https://github.com/huggingface/datasets) by clicking on the 'Fork' button on the repository's page. This creates a copy of the code under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone [email protected]:<your Github handle>/datasets.git
cd datasets
git remote add upstream https://github.com/huggingface/datasets.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
**do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
(If datasets was already installed in the virtual environment, remove
it with `pip uninstall datasets` before reinstalling it in editable
mode with the `-e` flag.)
5. Develop the features on your branch.
6. Format your code. Run `black` and `ruff` so that your newly added files look nice with the following command:
```bash
make style
```
7. _(Optional)_ You can also use [`pre-commit`](https://pre-commit.com/) to format your code automatically each time run `git commit`, instead of running `make style` manually.
To do this, install `pre-commit` via `pip install pre-commit` and then run `pre-commit install` in the project's root directory to set up the hooks.
Note that if any files were formatted by `pre-commit` hooks during committing, you have to run `git commit` again .
8. Once you're happy with your contribution, add your changed files and make a commit to record your changes locally:
```bash
git add -u
git commit
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
git fetch upstream
git rebase upstream/main
```
9. Once you are satisfied, push the changes to your fork repo using:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
Go the webpage of your fork on GitHub. Click on "Pull request" to send your to the project maintainers for review.
## How to add a dataset
You can share your dataset on https://huggingface.co/datasets directly using your account, see the documentation:
* [Create a dataset and upload files on the website](https://huggingface.co/docs/datasets/upload_dataset)
* [Advanced guide using the CLI](https://huggingface.co/docs/datasets/share)
## How to contribute to the dataset cards
Improving the documentation of datasets is an ever-increasing effort, and we invite users to contribute by sharing their insights with the community in the `README.md` dataset cards provided for each dataset.
If you see that a dataset card is missing information that you are in a position to provide (as an author of the dataset or as an experienced user), the best thing you can do is to open a Pull Request on the Hugging Face Hub. To do, go to the "Files and versions" tab of the dataset page and edit the `README.md` file. We provide:
* a [template](https://github.com/huggingface/datasets/blob/main/templates/README.md)
* a [guide](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md) describing what information should go into each of the paragraphs
* and if you need inspiration, we recommend looking through a [completed example](https://huggingface.co/datasets/eli5/blob/main/README.md)
If you are a **dataset author**... you know what to do, it is your dataset after all ;) ! We would especially appreciate if you could help us fill in information about the process of creating the dataset, and take a moment to reflect on its social impact and possible limitations if you haven't already done so in the dataset paper or in another data statement.
If you are a **user of a dataset**, the main source of information should be the dataset paper if it is available: we recommend pulling information from there into the relevant paragraphs of the template. We also eagerly welcome discussions on the [Considerations for Using the Data](https://github.com/huggingface/datasets/blob/main/templates/README_guide.md#considerations-for-using-the-data) based on existing scholarship or personal experience that would benefit the whole community.
Finally, if you want more information on the how and why of dataset cards, we strongly recommend reading the foundational works [Datasheets for Datasets](https://arxiv.org/abs/1803.09010) and [Data Statements for NLP](https://www.aclweb.org/anthology/Q18-1041/).
Thank you for your contribution!
## Code of conduct
This project adheres to the HuggingFace [code of conduct](CODE_OF_CONDUCT.md).
By participating, you are expected to abide by this code.
| datasets/CONTRIBUTING.md/0 | {
"file_path": "datasets/CONTRIBUTING.md",
"repo_id": "datasets",
"token_count": 1715
} | 60 |
# Load audio data
You can load an audio dataset using the [`Audio`] feature that automatically decodes and resamples the audio files when you access the examples.
Audio decoding is based on the [`soundfile`](https://github.com/bastibe/python-soundfile) python package, which uses the [`libsndfile`](https://github.com/libsndfile/libsndfile) C library under the hood.
## Installation
To work with audio datasets, you need to have the `audio` dependencies installed.
Check out the [installation](./installation#audio) guide to learn how to install it.
## Local files
You can load your own dataset using the paths to your audio files. Use the [`~Dataset.cast_column`] function to take a column of audio file paths, and cast it to the [`Audio`] feature:
```py
>>> audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
>>> audio_dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': 'path/to/audio_1',
'sampling_rate': 16000}
```
## AudioFolder
You can also load a dataset with an `AudioFolder` dataset builder. It does not require writing a custom dataloader, making it useful for quickly creating and loading audio datasets with several thousand audio files.
## AudioFolder with metadata
To link your audio files with metadata information, make sure your dataset has a `metadata.csv` file. Your dataset structure might look like:
```
folder/train/metadata.csv
folder/train/first_audio_file.mp3
folder/train/second_audio_file.mp3
folder/train/third_audio_file.mp3
```
Your `metadata.csv` file must have a `file_name` column which links audio files with their metadata. An example `metadata.csv` file might look like:
```text
file_name,transcription
first_audio_file.mp3,znowu się duch z ciałem zrośnie w młodocianej wstaniesz wiosnie i możesz skutkiem tych leków umierać wstawać wiek wieków dalej tam były przestrogi jak siekać głowę jak nogi
second_audio_file.mp3,już u źwierzyńca podwojów król zasiada przy nim książęta i panowie rada a gdzie wzniosły krążył ganek rycerze obok kochanek król skinął palcem zaczęto igrzysko
third_audio_file.mp3,pewnie kędyś w obłędzie ubite minęły szlaki zaczekajmy dzień jaki poślemy szukać wszędzie dziś jutro pewnie będzie posłali wszędzie sługi czekali dzień i drugi gdy nic nie doczekali z płaczem chcą jechać dali
```
`AudioFolder` will load audio data and create a `transcription` column containing texts from `metadata.csv`:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder")
>>> # OR by specifying the list of files
>>> dataset = load_dataset("audiofolder", data_files=["path/to/audio_1", "path/to/audio_2", ..., "path/to/audio_n"])
```
You can load remote datasets from their URLs with the data_files parameter:
```py
>>> dataset = load_dataset("audiofolder", data_files=["https://foo.bar/audio_1", "https://foo.bar/audio_2", ..., "https://foo.bar/audio_n"]
>>> # for example, pass SpeechCommands archive:
>>> dataset = load_dataset("audiofolder", data_files="https://s3.amazonaws.com/datasets.huggingface.co/SpeechCommands/v0.01/v0.01_test.tar.gz")
```
Metadata can also be specified as JSON Lines, in which case use `metadata.jsonl` as the name of the metadata file. This format is helpful in scenarios when one of the columns is complex, e.g. a list of floats, to avoid parsing errors or reading the complex values as strings.
To ignore the information in the metadata file, set `drop_metadata=True` in [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder", drop_metadata=True)
```
If you don't have a metadata file, `AudioFolder` automatically infers the label name from the directory name.
If you want to drop automatically created labels, set `drop_labels=True`.
In this case, your dataset will only contain an audio column:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder_without_metadata", drop_labels=True)
```
<Tip>
For more information about creating your own `AudioFolder` dataset, take a look at the [Create an audio dataset](./audio_dataset) guide.
</Tip>
For a guide on how to load any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./loading">general loading guide</a>.
| datasets/docs/source/audio_load.mdx/0 | {
"file_path": "datasets/docs/source/audio_load.mdx",
"repo_id": "datasets",
"token_count": 1529
} | 61 |
# Process
🤗 Datasets provides many tools for modifying the structure and content of a dataset. These tools are important for tidying up a dataset, creating additional columns, converting between features and formats, and much more.
This guide will show you how to:
- Reorder rows and split the dataset.
- Rename and remove columns, and other common column operations.
- Apply processing functions to each example in a dataset.
- Concatenate datasets.
- Apply a custom formatting transform.
- Save and export processed datasets.
For more details specific to processing other dataset modalities, take a look at the <a class="underline decoration-pink-400 decoration-2 font-semibold" href="./audio_process">process audio dataset guide</a>, the <a class="underline decoration-yellow-400 decoration-2 font-semibold" href="./image_process">process image dataset guide</a>, or the <a class="underline decoration-green-400 decoration-2 font-semibold" href="./nlp_process">process text dataset guide</a>.
The examples in this guide use the MRPC dataset, but feel free to load any dataset of your choice and follow along!
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("glue", "mrpc", split="train")
```
<Tip warning={true}>
All processing methods in this guide return a new [`Dataset`] object. Modification is not done in-place. Be careful about overriding your previous dataset!
</Tip>
## Sort, shuffle, select, split, and shard
There are several functions for rearranging the structure of a dataset.
These functions are useful for selecting only the rows you want, creating train and test splits, and sharding very large datasets into smaller chunks.
### Sort
Use [`~Dataset.sort`] to sort column values according to their numerical values. The provided column must be NumPy compatible.
```py
>>> dataset["label"][:10]
[1, 0, 1, 0, 1, 1, 0, 1, 0, 0]
>>> sorted_dataset = dataset.sort("label")
>>> sorted_dataset["label"][:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
>>> sorted_dataset["label"][-10:]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
Under the hood, this creates a list of indices that is sorted according to values of the column.
This indices mapping is then used to access the right rows in the underlying Arrow table.
### Shuffle
The [`~Dataset.shuffle`] function randomly rearranges the column values. You can specify the `generator` parameter in this function to use a different `numpy.random.Generator` if you want more control over the algorithm used to shuffle the dataset.
```py
>>> shuffled_dataset = sorted_dataset.shuffle(seed=42)
>>> shuffled_dataset["label"][:10]
[1, 1, 1, 0, 1, 1, 1, 1, 1, 0]
```
Shuffling takes the list of indices `[0:len(my_dataset)]` and shuffles it to create an indices mapping.
However as soon as your [`Dataset`] has an indices mapping, the speed can become 10x slower.
This is because there is an extra step to get the row index to read using the indices mapping, and most importantly, you aren't reading contiguous chunks of data anymore.
To restore the speed, you'd need to rewrite the entire dataset on your disk again using [`Dataset.flatten_indices`], which removes the indices mapping.
Alternatively, you can switch to an [`IterableDataset`] and leverage its fast approximate shuffling [`IterableDataset.shuffle`]:
```py
>>> iterable_dataset = dataset.to_iterable_dataset(num_shards=128)
>>> shuffled_iterable_dataset = iterable_dataset.shuffle(seed=42, buffer_size=1000)
```
### Select and Filter
There are two options for filtering rows in a dataset: [`~Dataset.select`] and [`~Dataset.filter`].
- [`~Dataset.select`] returns rows according to a list of indices:
```py
>>> small_dataset = dataset.select([0, 10, 20, 30, 40, 50])
>>> len(small_dataset)
6
```
- [`~Dataset.filter`] returns rows that match a specified condition:
```py
>>> start_with_ar = dataset.filter(lambda example: example["sentence1"].startswith("Ar"))
>>> len(start_with_ar)
6
>>> start_with_ar["sentence1"]
['Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
'Arison said Mann may have been one of the pioneers of the world music movement and he had a deep love of Brazilian music .',
'Arts helped coach the youth on an eighth-grade football team at Lombardi Middle School in Green Bay .',
'Around 9 : 00 a.m. EDT ( 1300 GMT ) , the euro was at $ 1.1566 against the dollar , up 0.07 percent on the day .',
"Arguing that the case was an isolated example , Canada has threatened a trade backlash if Tokyo 's ban is not justified on scientific grounds .",
'Artists are worried the plan would harm those who need help most - performers who have a difficult time lining up shows .'
]
```
[`~Dataset.filter`] can also filter by indices if you set `with_indices=True`:
```py
>>> even_dataset = dataset.filter(lambda example, idx: idx % 2 == 0, with_indices=True)
>>> len(even_dataset)
1834
>>> len(dataset) / 2
1834.0
```
Unless the list of indices to keep is contiguous, those methods also create an indices mapping under the hood.
### Split
The [`~Dataset.train_test_split`] function creates train and test splits if your dataset doesn't already have them. This allows you to adjust the relative proportions or an absolute number of samples in each split. In the example below, use the `test_size` parameter to create a test split that is 10% of the original dataset:
```py
>>> dataset.train_test_split(test_size=0.1)
{'train': Dataset(schema: {'sentence1': 'string', 'sentence2': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 3301),
'test': Dataset(schema: {'sentence1': 'string', 'sentence2': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 367)}
>>> 0.1 * len(dataset)
366.8
```
The splits are shuffled by default, but you can set `shuffle=False` to prevent shuffling.
### Shard
🤗 Datasets supports sharding to divide a very large dataset into a predefined number of chunks. Specify the `num_shards` parameter in [`~Dataset.shard`] to determine the number of shards to split the dataset into. You'll also need to provide the shard you want to return with the `index` parameter.
For example, the [imdb](https://huggingface.co/datasets/imdb) dataset has 25000 examples:
```py
>>> from datasets import load_dataset
>>> datasets = load_dataset("imdb", split="train")
>>> print(dataset)
Dataset({
features: ['text', 'label'],
num_rows: 25000
})
```
After sharding the dataset into four chunks, the first shard will only have 6250 examples:
```py
>>> dataset.shard(num_shards=4, index=0)
Dataset({
features: ['text', 'label'],
num_rows: 6250
})
>>> print(25000/4)
6250.0
```
## Rename, remove, cast, and flatten
The following functions allow you to modify the columns of a dataset. These functions are useful for renaming or removing columns, changing columns to a new set of features, and flattening nested column structures.
### Rename
Use [`~Dataset.rename_column`] when you need to rename a column in your dataset. Features associated with the original column are actually moved under the new column name, instead of just replacing the original column in-place.
Provide [`~Dataset.rename_column`] with the name of the original column, and the new column name:
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.rename_column("sentence1", "sentenceA")
>>> dataset = dataset.rename_column("sentence2", "sentenceB")
>>> dataset
Dataset({
features: ['sentenceA', 'sentenceB', 'label', 'idx'],
num_rows: 3668
})
```
### Remove
When you need to remove one or more columns, provide the column name to remove to the [`~Dataset.remove_columns`] function. Remove more than one column by providing a list of column names:
```py
>>> dataset = dataset.remove_columns("label")
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.remove_columns(["sentence1", "sentence2"])
>>> dataset
Dataset({
features: ['idx'],
num_rows: 3668
})
```
Conversely, [`~Dataset.select_columns`] selects one or more columns to keep and removes the rest. This function takes either one or a list of column names:
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.select_columns(['sentence1', 'sentence2', 'idx'])
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'idx'],
num_rows: 3668
})
>>> dataset = dataset.select_columns('idx')
>>> dataset
Dataset({
features: ['idx'],
num_rows: 3668
})
```
### Cast
The [`~Dataset.cast`] function transforms the feature type of one or more columns. This function accepts your new [`Features`] as its argument. The example below demonstrates how to change the [`ClassLabel`] and [`Value`] features:
```py
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
>>> from datasets import ClassLabel, Value
>>> new_features = dataset.features.copy()
>>> new_features["label"] = ClassLabel(names=["negative", "positive"])
>>> new_features["idx"] = Value("int64")
>>> dataset = dataset.cast(new_features)
>>> dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['negative', 'positive'], names_file=None, id=None),
'idx': Value(dtype='int64', id=None)}
```
<Tip>
Casting only works if the original feature type and new feature type are compatible. For example, you can cast a column with the feature type `Value("int32")` to `Value("bool")` if the original column only contains ones and zeros.
</Tip>
Use the [`~Dataset.cast_column`] function to change the feature type of a single column. Pass the column name and its new feature type as arguments:
```py
>>> dataset.features
{'audio': Audio(sampling_rate=44100, mono=True, id=None)}
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> dataset.features
{'audio': Audio(sampling_rate=16000, mono=True, id=None)}
```
### Flatten
Sometimes a column can be a nested structure of several types. Take a look at the nested structure below from the SQuAD dataset:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("squad", split="train")
>>> dataset.features
{'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None),
'context': Value(dtype='string', id=None),
'id': Value(dtype='string', id=None),
'question': Value(dtype='string', id=None),
'title': Value(dtype='string', id=None)}
```
The `answers` field contains two subfields: `text` and `answer_start`. Use the [`~Dataset.flatten`] function to extract the subfields into their own separate columns:
```py
>>> flat_dataset = dataset.flatten()
>>> flat_dataset
Dataset({
features: ['id', 'title', 'context', 'question', 'answers.text', 'answers.answer_start'],
num_rows: 87599
})
```
Notice how the subfields are now their own independent columns: `answers.text` and `answers.answer_start`.
## Map
Some of the more powerful applications of 🤗 Datasets come from using the [`~Dataset.map`] function. The primary purpose of [`~Dataset.map`] is to speed up processing functions. It allows you to apply a processing function to each example in a dataset, independently or in batches. This function can even create new rows and columns.
In the following example, prefix each `sentence1` value in the dataset with `'My sentence: '`.
Start by creating a function that adds `'My sentence: '` to the beginning of each sentence. The function needs to accept and output a `dict`:
```py
>>> def add_prefix(example):
... example["sentence1"] = 'My sentence: ' + example["sentence1"]
... return example
```
Now use [`~Dataset.map`] to apply the `add_prefix` function to the entire dataset:
```py
>>> updated_dataset = small_dataset.map(add_prefix)
>>> updated_dataset["sentence1"][:5]
['My sentence: Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
"My sentence: Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'My sentence: They had published an advertisement on the Internet on June 10 , offering the cargo for sale , he added .',
'My sentence: Around 0335 GMT , Tab shares were up 19 cents , or 4.4 % , at A $ 4.56 , having earlier set a record high of A $ 4.57 .',
]
```
Let's take a look at another example, except this time, you'll remove a column with [`~Dataset.map`]. When you remove a column, it is only removed after the example has been provided to the mapped function. This allows the mapped function to use the content of the columns before they are removed.
Specify the column to remove with the `remove_columns` parameter in [`~Dataset.map`]:
```py
>>> updated_dataset = dataset.map(lambda example: {"new_sentence": example["sentence1"]}, remove_columns=["sentence1"])
>>> updated_dataset.column_names
['sentence2', 'label', 'idx', 'new_sentence']
```
<Tip>
🤗 Datasets also has a [`~Dataset.remove_columns`] function which is faster because it doesn't copy the data of the remaining columns.
</Tip>
You can also use [`~Dataset.map`] with indices if you set `with_indices=True`. The example below adds the index to the beginning of each sentence:
```py
>>> updated_dataset = dataset.map(lambda example, idx: {"sentence2": f"{idx}: " + example["sentence2"]}, with_indices=True)
>>> updated_dataset["sentence2"][:5]
['0: Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
"1: Yucaipa bought Dominick 's in 1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in 1998 .",
"2: On June 10 , the ship 's owners had published an advertisement on the Internet , offering the explosives for sale .",
'3: Tab shares jumped 20 cents , or 4.6 % , to set a record closing high at A $ 4.57 .',
'4: PG & E Corp. shares jumped $ 1.63 or 8 percent to $ 21.03 on the New York Stock Exchange on Friday .'
]
```
### Multiprocessing
Multiprocessing significantly speeds up processing by parallelizing processes on the CPU. Set the `num_proc` parameter in [`~Dataset.map`] to set the number of processes to use:
```py
>>> updated_dataset = dataset.map(lambda example, idx: {"sentence2": f"{idx}: " + example["sentence2"]}, num_proc=4)
```
The [`~Dataset.map`] also works with the rank of the process if you set `with_rank=True`. This is analogous to the `with_indices` parameter. The `with_rank` parameter in the mapped function goes after the `index` one if it is already present.
```py
>>> import torch
>>> from multiprocess import set_start_method
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> from datasets import load_dataset
>>>
>>> # Get an example dataset
>>> dataset = load_dataset("fka/awesome-chatgpt-prompts", split="train")
>>>
>>> # Get an example model and its tokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
>>>
>>> def gpu_computation(example, rank):
... # Move the model on the right GPU if it's not there already
... model.to(f"cuda:{rank or 0}")
...
... # Your big GPU call goes here, for example:
... inputs = tokenizer(texts, padding=True, return_tensors="pt").to(f"cuda:{rank or 0}")
... outputs = model.generate(**inputs)
... example["translated"] = tokenizer.batch_decode(outputs, skip_special_tokens=True)
... return example
>>>
>>> if __name__ == "__main__":
... set_start_method("spawn")
... updated_dataset = dataset.map(
... gpu_computation,
... with_rank=True,
... num_proc=torch.cuda.device_count(), # one process per GPU
... batched=True, # optional
... batch_size=8, # optional
... )
```
The main use-case for rank is to parallelize computation across several GPUs. This requires setting `multiprocess.set_start_method("spawn")`. If you don't you'll receive the following CUDA error:
```bash
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method.
```
### Batch processing
The [`~Dataset.map`] function supports working with batches of examples. Operate on batches by setting `batched=True`. The default batch size is 1000, but you can adjust it with the `batch_size` parameter. Batch processing enables interesting applications such as splitting long sentences into shorter chunks and data augmentation.
#### Split long examples
When examples are too long, you may want to split them into several smaller chunks. Begin by creating a function that:
1. Splits the `sentence1` field into chunks of 50 characters.
2. Stacks all the chunks together to create the new dataset.
```py
>>> def chunk_examples(examples):
... chunks = []
... for sentence in examples["sentence1"]:
... chunks += [sentence[i:i + 50] for i in range(0, len(sentence), 50)]
... return {"chunks": chunks}
```
Apply the function with [`~Dataset.map`]:
```py
>>> chunked_dataset = dataset.map(chunk_examples, batched=True, remove_columns=dataset.column_names)
>>> chunked_dataset[:10]
{'chunks': ['Amrozi accused his brother , whom he called " the ',
'witness " , of deliberately distorting his evidenc',
'e .',
"Yucaipa owned Dominick 's before selling the chain",
' to Safeway in 1998 for $ 2.5 billion .',
'They had published an advertisement on the Interne',
't on June 10 , offering the cargo for sale , he ad',
'ded .',
'Around 0335 GMT , Tab shares were up 19 cents , or',
' 4.4 % , at A $ 4.56 , having earlier set a record']}
```
Notice how the sentences are split into shorter chunks now, and there are more rows in the dataset.
```py
>>> dataset
Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
>>> chunked_dataset
Dataset(schema: {'chunks': 'string'}, num_rows: 10470)
```
#### Data augmentation
The [`~Dataset.map`] function could also be used for data augmentation. The following example generates additional words for a masked token in a sentence.
Load and use the [RoBERTA](https://huggingface.co/roberta-base) model in 🤗 Transformers' [FillMaskPipeline](https://huggingface.co/transformers/main_classes/pipelines#transformers.FillMaskPipeline):
```py
>>> from random import randint
>>> from transformers import pipeline
>>> fillmask = pipeline("fill-mask", model="roberta-base")
>>> mask_token = fillmask.tokenizer.mask_token
>>> smaller_dataset = dataset.filter(lambda e, i: i<100, with_indices=True)
```
Create a function to randomly select a word to mask in the sentence. The function should also return the original sentence and the top two replacements generated by RoBERTA.
```py
>>> def augment_data(examples):
... outputs = []
... for sentence in examples["sentence1"]:
... words = sentence.split(' ')
... K = randint(1, len(words)-1)
... masked_sentence = " ".join(words[:K] + [mask_token] + words[K+1:])
... predictions = fillmask(masked_sentence)
... augmented_sequences = [predictions[i]["sequence"] for i in range(3)]
... outputs += [sentence] + augmented_sequences
...
... return {"data": outputs}
```
Use [`~Dataset.map`] to apply the function over the whole dataset:
```py
>>> augmented_dataset = smaller_dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, batch_size=8)
>>> augmented_dataset[:9]["data"]
['Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'Amrozi accused his brother, whom he called " the witness ", of deliberately withholding his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately suppressing his evidence.',
'Amrozi accused his brother, whom he called " the witness ", of deliberately destroying his evidence.',
"Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion .",
'Yucaipa owned Dominick Stores before selling the chain to Safeway in 1998 for $ 2.5 billion.',
"Yucaipa owned Dominick's before selling the chain to Safeway in 1998 for $ 2.5 billion.",
'Yucaipa owned Dominick Pizza before selling the chain to Safeway in 1998 for $ 2.5 billion.'
]
```
For each original sentence, RoBERTA augmented a random word with three alternatives. The original word `distorting` is supplemented by `withholding`, `suppressing`, and `destroying`.
### Process multiple splits
Many datasets have splits that can be processed simultaneously with [`DatasetDict.map`]. For example, tokenize the `sentence1` field in the train and test split by:
```py
>>> from datasets import load_dataset
# load all the splits
>>> dataset = load_dataset('glue', 'mrpc')
>>> encoded_dataset = dataset.map(lambda examples: tokenizer(examples["sentence1"]), batched=True)
>>> encoded_dataset["train"][0]
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0,
'input_ids': [ 101, 7277, 2180, 5303, 4806, 1117, 1711, 117, 2292, 1119, 1270, 107, 1103, 7737, 107, 117, 1104, 9938, 4267, 12223, 21811, 1117, 2554, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
```
### Distributed usage
When you use [`~Dataset.map`] in a distributed setting, you should also use [torch.distributed.barrier](https://pytorch.org/docs/stable/distributed?highlight=barrier#torch.distributed.barrier). This ensures the main process performs the mapping, while the other processes load the results, thereby avoiding duplicate work.
The following example shows how you can use `torch.distributed.barrier` to synchronize the processes:
```py
>>> from datasets import Dataset
>>> import torch.distributed
>>> dataset1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> if training_args.local_rank > 0:
... print("Waiting for main process to perform the mapping")
... torch.distributed.barrier()
>>> dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})
>>> if training_args.local_rank == 0:
... print("Loading results from main process")
... torch.distributed.barrier()
```
## Concatenate
Separate datasets can be concatenated if they share the same column types. Concatenate datasets with [`concatenate_datasets`]:
```py
>>> from datasets import concatenate_datasets, load_dataset
>>> bookcorpus = load_dataset("bookcorpus", split="train")
>>> wiki = load_dataset("wikipedia", "20220301.en", split="train")
>>> wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
>>> assert bookcorpus.features.type == wiki.features.type
>>> bert_dataset = concatenate_datasets([bookcorpus, wiki])
```
You can also concatenate two datasets horizontally by setting `axis=1` as long as the datasets have the same number of rows:
```py
>>> from datasets import Dataset
>>> bookcorpus_ids = Dataset.from_dict({"ids": list(range(len(bookcorpus)))})
>>> bookcorpus_with_ids = concatenate_datasets([bookcorpus, bookcorpus_ids], axis=1)
```
### Interleave
You can also mix several datasets together by taking alternating examples from each one to create a new dataset. This is known as *interleaving*, which is enabled by the [`interleave_datasets`] function. Both [`interleave_datasets`] and [`concatenate_datasets`] work with regular [`Dataset`] and [`IterableDataset`] objects.
Refer to the [Stream](./stream#interleave) guide for an example of how to interleave [`IterableDataset`] objects.
You can define sampling probabilities for each of the original datasets to specify how to interleave the datasets.
In this case, the new dataset is constructed by getting examples one by one from a random dataset until one of the datasets runs out of samples.
```py
>>> seed = 42
>>> probabilities = [0.3, 0.5, 0.2]
>>> d1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
>>> d3 = Dataset.from_dict({"a": [20, 21, 22]})
>>> dataset = interleave_datasets([d1, d2, d3], probabilities=probabilities, seed=seed)
>>> dataset["a"]
[10, 11, 20, 12, 0, 21, 13]
```
You can also specify the `stopping_strategy`. The default strategy, `first_exhausted`, is a subsampling strategy, i.e the dataset construction is stopped as soon one of the dataset runs out of samples.
You can specify `stopping_strategy=all_exhausted` to execute an oversampling strategy. In this case, the dataset construction is stopped as soon as every samples in every dataset has been added at least once. In practice, it means that if a dataset is exhausted, it will return to the beginning of this dataset until the stop criterion has been reached.
Note that if no sampling probabilities are specified, the new dataset will have `max_length_datasets*nb_dataset samples`.
```py
>>> d1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
>>> d3 = Dataset.from_dict({"a": [20, 21, 22]})
>>> dataset = interleave_datasets([d1, d2, d3], stopping_strategy="all_exhausted")
>>> dataset["a"]
[0, 10, 20, 1, 11, 21, 2, 12, 22, 0, 13, 20]
```
## Format
The [`~Dataset.set_format`] function changes the format of a column to be compatible with some common data formats. Specify the output you'd like in the `type` parameter and the columns you want to format. Formatting is applied on-the-fly.
For example, create PyTorch tensors by setting `type="torch"`:
```py
>>> import torch
>>> dataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
```
The [`~Dataset.with_format`] function also changes the format of a column, except it returns a new [`Dataset`] object:
```py
>>> dataset = dataset.with_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])
```
<Tip>
🤗 Datasets also provides support for other common data formats such as NumPy, Pandas, and JAX. Check out the [Using Datasets with TensorFlow](https://huggingface.co/docs/datasets/master/en/use_with_tensorflow#using-totfdataset) guide for more details on how to efficiently create a TensorFlow dataset.
</Tip>
If you need to reset the dataset to its original format, use the [`~Dataset.reset_format`] function:
```py
>>> dataset.format
{'type': 'torch', 'format_kwargs': {}, 'columns': ['label'], 'output_all_columns': False}
>>> dataset.reset_format()
>>> dataset.format
{'type': 'python', 'format_kwargs': {}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
```
### Format transform
The [`~Dataset.set_transform`] function applies a custom formatting transform on-the-fly. This function replaces any previously specified format. For example, you can use this function to tokenize and pad tokens on-the-fly. Tokenization is only applied when examples are accessed:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
>>> def encode(batch):
... return tokenizer(batch["sentence1"], padding="longest", truncation=True, max_length=512, return_tensors="pt")
>>> dataset.set_transform(encode)
>>> dataset.format
{'type': 'custom', 'format_kwargs': {'transform': <function __main__.encode(batch)>}, 'columns': ['idx', 'label', 'sentence1', 'sentence2'], 'output_all_columns': False}
```
You can also use the [`~Dataset.set_transform`] function to decode formats not supported by [`Features`]. For example, the [`Audio`] feature uses [`soundfile`](https://python-soundfile.readthedocs.io/en/0.11.0/) - a fast and simple library to install - but it does not provide support for less common audio formats. Here is where you can use [`~Dataset.set_transform`] to apply a custom decoding transform on the fly. You're free to use any library you like to decode the audio files.
The example below uses the [`pydub`](http://pydub.com/) package to open an audio format not supported by `soundfile`:
```py
>>> import numpy as np
>>> from pydub import AudioSegment
>>> audio_dataset_amr = Dataset.from_dict({"audio": ["audio_samples/audio.amr"]})
>>> def decode_audio_with_pydub(batch, sampling_rate=16_000):
... def pydub_decode_file(audio_path):
... sound = AudioSegment.from_file(audio_path)
... if sound.frame_rate != sampling_rate:
... sound = sound.set_frame_rate(sampling_rate)
... channel_sounds = sound.split_to_mono()
... samples = [s.get_array_of_samples() for s in channel_sounds]
... fp_arr = np.array(samples).T.astype(np.float32)
... fp_arr /= np.iinfo(samples[0].typecode).max
... return fp_arr
...
... batch["audio"] = [pydub_decode_file(audio_path) for audio_path in batch["audio"]]
... return batch
>>> audio_dataset_amr.set_transform(decode_audio_with_pydub)
```
## Save
Once you are done processing your dataset, you can save and reuse it later with [`~Dataset.save_to_disk`].
Save your dataset by providing the path to the directory you wish to save it to:
```py
>>> encoded_dataset.save_to_disk("path/of/my/dataset/directory")
```
Use the [`load_from_disk`] function to reload the dataset:
```py
>>> from datasets import load_from_disk
>>> reloaded_dataset = load_from_disk("path/of/my/dataset/directory")
```
<Tip>
Want to save your dataset to a cloud storage provider? Read our [Cloud Storage](./filesystems) guide to learn how to save your dataset to AWS or Google Cloud Storage.
</Tip>
## Export
🤗 Datasets supports exporting as well so you can work with your dataset in other applications. The following table shows currently supported file formats you can export to:
| File type | Export method |
|-------------------------|----------------------------------------------------------------|
| CSV | [`Dataset.to_csv`] |
| JSON | [`Dataset.to_json`] |
| Parquet | [`Dataset.to_parquet`] |
| SQL | [`Dataset.to_sql`] |
| In-memory Python object | [`Dataset.to_pandas`] or [`Dataset.to_dict`] |
For example, export your dataset to a CSV file like this:
```py
>>> encoded_dataset.to_csv("path/of/my/dataset.csv")
```
| datasets/docs/source/process.mdx/0 | {
"file_path": "datasets/docs/source/process.mdx",
"repo_id": "datasets",
"token_count": 10210
} | 62 |
# Metric Card for Accuracy
## Metric Description
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'accuracy': 1.0}
```
### Inputs
- **predictions** (`list` of `int`): Predicted labels.
- **references** (`list` of `int`): Ground truth labels.
- **normalize** (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.
- **sample_weight** (`list` of `float`): Sample weights Defaults to None.
### Output Values
- **accuracy**(`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.
Output Example(s):
```python
{'accuracy': 1.0}
```
This metric outputs a dictionary, containing the accuracy score.
#### Values from Popular Papers
Top-1 or top-5 accuracy is often used to report performance on supervised classification tasks such as image classification (e.g. on [ImageNet](https://paperswithcode.com/sota/image-classification-on-imagenet)) or sentiment analysis (e.g. on [IMDB](https://paperswithcode.com/sota/text-classification-on-imdb)).
### Examples
Example 1-A simple example
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
>>> print(results)
{'accuracy': 0.5}
```
Example 2-The same as Example 1, except with `normalize` set to `False`.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)
>>> print(results)
{'accuracy': 3.0}
```
Example 3-The same as Example 1, except with `sample_weight` set.
```python
>>> accuracy_metric = datasets.load_metric("accuracy")
>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])
>>> print(results)
{'accuracy': 0.8778625954198473}
```
## Limitations and Bias
This metric can be easily misleading, especially in the case of unbalanced classes. For example, a high accuracy might be because a model is doing well, but if the data is unbalanced, it might also be because the model is only accurately labeling the high-frequency class. In such cases, a more detailed analysis of the model's behavior, or the use of a different metric entirely, is necessary to determine how well the model is actually performing.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
| datasets/metrics/accuracy/README.md/0 | {
"file_path": "datasets/metrics/accuracy/README.md",
"repo_id": "datasets",
"token_count": 1120
} | 63 |
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" COMET metric.
Requirements:
pip install unbabel-comet
Usage:
```python
from datasets import load_metric
comet_metric = load_metric('metrics/comet/comet.py')
#comet_metric = load_metric('comet')
#comet_metric = load_metric('comet', 'wmt-large-hter-estimator')
source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
hypothesis = ["The fire could be stopped", "Schools and kindergartens were open"]
reference = ["They were able to control the fire.", "Schools and kindergartens opened"]
predictions = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
predictions['scores']
```
"""
import comet # From: unbabel-comet
import torch
import datasets
logger = datasets.logging.get_logger(__name__)
_CITATION = """\
@inproceedings{rei-EtAl:2020:WMT,
author = {Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon},
title = {Unbabel's Participation in the WMT20 Metrics Shared Task},
booktitle = {Proceedings of the Fifth Conference on Machine Translation},
month = {November},
year = {2020},
address = {Online},
publisher = {Association for Computational Linguistics},
pages = {909--918},
}
@inproceedings{rei-etal-2020-comet,
title = "{COMET}: A Neural Framework for {MT} Evaluation",
author = "Rei, Ricardo and
Stewart, Craig and
Farinha, Ana C and
Lavie, Alon",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.213",
pages = "2685--2702",
}
"""
_DESCRIPTION = """\
Crosslingual Optimized Metric for Evaluation of Translation (COMET) is an open-source framework used to train Machine Translation metrics that achieve high levels of correlation with different types of human judgments (HTER, DA's or MQM).
With the release of the framework the authors also released fully trained models that were used to compete in the WMT20 Metrics Shared Task achieving SOTA in that years competition.
See the [README.md] file at https://unbabel.github.io/COMET/html/models.html for more information.
"""
_KWARGS_DESCRIPTION = """
COMET score.
Args:
`sources` (list of str): Source sentences
`predictions` (list of str): candidate translations
`references` (list of str): reference translations
`cuda` (bool): If set to True, runs COMET using GPU
`show_progress` (bool): Shows progress
`model`: COMET model to be used. Will default to `wmt-large-da-estimator-1719` if None.
Returns:
`samples`: List of dictionaries with `src`, `mt`, `ref` and `score`.
`scores`: List of scores.
Examples:
>>> comet_metric = datasets.load_metric('comet')
>>> # comet_metric = load_metric('comet', 'wmt20-comet-da') # you can also choose which model to use
>>> source = ["Dem Feuer konnte Einhalt geboten werden", "Schulen und Kindergärten wurden eröffnet."]
>>> hypothesis = ["The fire could be stopped", "Schools and kindergartens were open"]
>>> reference = ["They were able to control the fire.", "Schools and kindergartens opened"]
>>> results = comet_metric.compute(predictions=hypothesis, references=reference, sources=source)
>>> print([round(v, 2) for v in results["scores"]])
[0.19, 0.92]
"""
@datasets.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class COMET(datasets.Metric):
def _info(self):
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
homepage="https://unbabel.github.io/COMET/html/index.html",
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"sources": datasets.Value("string", id="sequence"),
"predictions": datasets.Value("string", id="sequence"),
"references": datasets.Value("string", id="sequence"),
}
),
codebase_urls=["https://github.com/Unbabel/COMET"],
reference_urls=[
"https://github.com/Unbabel/COMET",
"https://www.aclweb.org/anthology/2020.emnlp-main.213/",
"http://www.statmt.org/wmt20/pdf/2020.wmt-1.101.pdf6",
],
)
def _download_and_prepare(self, dl_manager):
if self.config_name == "default":
self.scorer = comet.load_from_checkpoint(comet.download_model("wmt20-comet-da"))
else:
self.scorer = comet.load_from_checkpoint(comet.download_model(self.config_name))
def _compute(self, sources, predictions, references, gpus=None, progress_bar=False):
if gpus is None:
gpus = 1 if torch.cuda.is_available() else 0
data = {"src": sources, "mt": predictions, "ref": references}
data = [dict(zip(data, t)) for t in zip(*data.values())]
scores, mean_score = self.scorer.predict(data, gpus=gpus, progress_bar=progress_bar)
return {"mean_score": mean_score, "scores": scores}
| datasets/metrics/comet/comet.py/0 | {
"file_path": "datasets/metrics/comet/comet.py",
"repo_id": "datasets",
"token_count": 2168
} | 64 |
# Metric Card for Google BLEU (GLEU)
## Metric Description
The BLEU score has some undesirable properties when used for single
sentences, as it was designed to be a corpus measure. The Google BLEU score, also known as GLEU score, is designed to limit these undesirable properties when used for single sentences.
To calculate this score, all sub-sequences of 1, 2, 3 or 4 tokens in output and target sequence (n-grams) are recorded. The precision and recall, described below, are then computed.
- **precision:** the ratio of the number of matching n-grams to the number of total n-grams in the generated output sequence
- **recall:** the ratio of the number of matching n-grams to the number of total n-grams in the target (ground truth) sequence
The minimum value of precision and recall is then returned as the score.
## Intended Uses
This metric is generally used to evaluate machine translation models. It is especially used when scores of individual (prediction, reference) sentence pairs are needed, as opposed to when averaging over the (prediction, reference) scores for a whole corpus. That being said, it can also be used when averaging over the scores for a whole corpus.
Because it performs better on individual sentence pairs as compared to BLEU, Google BLEU has also been used in RL experiments.
## How to Use
At minimum, this metric takes predictions and references:
```python
>>> sentence1 = "the cat sat on the mat".split()
>>> sentence2 = "the cat ate the mat".split()
>>> google_bleu = datasets.load_metric("google_bleu")
>>> result = google_bleu.compute(predictions=[sentence1], references=[[sentence2]])
>>> print(result)
{'google_bleu': 0.3333333333333333}
```
### Inputs
- **predictions** (list of list of str): list of translations to score. Each translation should be tokenized into a list of tokens.
- **references** (list of list of list of str): list of lists of references for each translation. Each reference should be tokenized into a list of tokens.
- **min_len** (int): The minimum order of n-gram this function should extract. Defaults to 1.
- **max_len** (int): The maximum order of n-gram this function should extract. Defaults to 4.
### Output Values
This metric returns the following in a dict:
- **google_bleu** (float): google_bleu score
The output format is as follows:
```python
{'google_bleu': google_bleu score}
```
This metric can take on values from 0 to 1, inclusive. Higher scores are better, with 0 indicating no matches, and 1 indicating a perfect match.
Note that this score is symmetrical when switching output and target. This means that, given two sentences, `sentence1` and `sentence2`, whatever score is output when `sentence1` is the predicted sentence and `sencence2` is the reference sentence will be the same as when the sentences are swapped and `sentence2` is the predicted sentence while `sentence1` is the reference sentence. In code, this looks like:
```python
sentence1 = "the cat sat on the mat".split()
sentence2 = "the cat ate the mat".split()
google_bleu = datasets.load_metric("google_bleu")
result_a = google_bleu.compute(predictions=[sentence1], references=[[sentence2]])
result_b = google_bleu.compute(predictions=[sentence2], references=[[sentence1]])
print(result_a == result_b)
>>> True
```
#### Values from Popular Papers
### Examples
Example with one reference per sample:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references)
>>> print(round(results["google_bleu"], 2))
0.44
```
Example with multiple references for the first sample:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references)
>>> print(round(results["google_bleu"], 2))
0.61
```
Example with multiple references for the first sample, and with `min_len` adjusted to `2`, instead of the default `1`:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references, min_len=2)
>>> print(round(results["google_bleu"], 2))
0.53
```
Example with multiple references for the first sample, with `min_len` adjusted to `2`, instead of the default `1`, and `max_len` adjusted to `6` instead of the default `4`:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses,references=list_of_references, min_len=2, max_len=6)
>>> print(round(results["google_bleu"], 2))
0.4
```
## Limitations and Bias
## Citation
```bibtex
@misc{wu2016googles,
title={Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation},
author={Yonghui Wu and Mike Schuster and Zhifeng Chen and Quoc V. Le and Mohammad Norouzi and Wolfgang Macherey and Maxim Krikun and Yuan Cao and Qin Gao and Klaus Macherey and Jeff Klingner and Apurva Shah and Melvin Johnson and Xiaobing Liu and Łukasz Kaiser and Stephan Gouws and Yoshikiyo Kato and Taku Kudo and Hideto Kazawa and Keith Stevens and George Kurian and Nishant Patil and Wei Wang and Cliff Young and Jason Smith and Jason Riesa and Alex Rudnick and Oriol Vinyals and Greg Corrado and Macduff Hughes and Jeffrey Dean},
year={2016},
eprint={1609.08144},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Further References
- This Hugging Face implementation uses the [nltk.translate.gleu_score implementation](https://www.nltk.org/_modules/nltk/translate/gleu_score.html) | datasets/metrics/google_bleu/README.md/0 | {
"file_path": "datasets/metrics/google_bleu/README.md",
"repo_id": "datasets",
"token_count": 3361
} | 65 |
# Metric Card for MSE
## Metric Description
Mean Squared Error(MSE) represents the average of the squares of errors -- i.e. the average squared difference between the estimated values and the actual values.
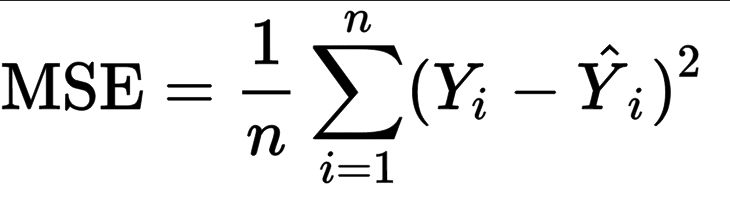
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mse_metric = datasets.load_metric("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mse_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
- `squared` (`bool`): If `True` returns MSE value, if `False` returns RMSE (Root Mean Squared Error). The default value is `True`.
### Output Values
This metric outputs a dictionary, containing the mean squared error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MSE `float` value ranges from `0.0` to `1.0`, with the best value being `0.0`.
Output Example(s):
```python
{'mse': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mse': array([0.41666667, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> from datasets import load_metric
>>> mse_metric = load_metric("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mse_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mse': 0.375}
```
Example with `squared = True`, which returns the RMSE:
```python
>>> from datasets import load_metric
>>> mse_metric = load_metric("mse")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> rmse_result = mse_metric.compute(predictions=predictions, references=references, squared=False)
>>> print(rmse_result)
{'mse': 0.6123724356957945}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> from datasets import load_metric
>>> mse_metric = load_metric("mse", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0, 2], [-1, 2], [8, -5]]
>>> results = mse_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mse': array([0.41666667, 1. ])}
"""
```
## Limitations and Bias
MSE has the disadvantage of heavily weighting outliers -- given that it squares them, this results in large errors weighing more heavily than small ones. It can be used alongside [MAE](https://huggingface.co/metrics/mae), which is complementary given that it does not square the errors.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{willmott2005advantages,
title={Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance},
author={Willmott, Cort J and Matsuura, Kenji},
journal={Climate research},
volume={30},
number={1},
pages={79--82},
year={2005}
}
```
## Further References
- [Mean Squared Error - Wikipedia](https://en.wikipedia.org/wiki/Mean_squared_error)
| datasets/metrics/mse/README.md/0 | {
"file_path": "datasets/metrics/mse/README.md",
"repo_id": "datasets",
"token_count": 1554
} | 66 |
# Metric Card for SARI
## Metric description
SARI (***s**ystem output **a**gainst **r**eferences and against the **i**nput sentence*) is a metric used for evaluating automatic text simplification systems.
The metric compares the predicted simplified sentences against the reference and the source sentences. It explicitly measures the goodness of words that are added, deleted and kept by the system.
SARI can be computed as:
`sari = ( F1_add + F1_keep + P_del) / 3`
where
`F1_add` is the n-gram F1 score for add operations
`F1_keep` is the n-gram F1 score for keep operations
`P_del` is the n-gram precision score for delete operations
The number of n grams, `n`, is equal to 4, as in the original paper.
This implementation is adapted from [Tensorflow's tensor2tensor implementation](https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/sari_hook.py).
It has two differences with the [original GitHub implementation](https://github.com/cocoxu/simplification/blob/master/SARI.py):
1) It defines 0/0=1 instead of 0 to give higher scores for predictions that match a target exactly.
2) It fixes an [alleged bug](https://github.com/cocoxu/simplification/issues/6) in the keep score computation.
## How to use
The metric takes 3 inputs: sources (a list of source sentence strings), predictions (a list of predicted sentence strings) and references (a list of lists of reference sentence strings)
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted."]
predictions=["About 95 you now get in."]
references=[["About 95 species are currently known.","About 95 species are now accepted.","95 species are now accepted."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary with the SARI score:
```
print(sari_score)
{'sari': 26.953601953601954}
```
The range of values for the SARI score is between 0 and 100 -- the higher the value, the better the performance of the model being evaluated, with a SARI of 100 being a perfect score.
### Values from popular papers
The [original paper that proposes the SARI metric](https://aclanthology.org/Q16-1029.pdf) reports scores ranging from 26 to 43 for different simplification systems and different datasets. They also find that the metric ranks all of the simplification systems and human references in the same order as the human assessment used as a comparison, and that it correlates reasonably with human judgments.
More recent SARI scores for text simplification can be found on leaderboards for datasets such as [TurkCorpus](https://paperswithcode.com/sota/text-simplification-on-turkcorpus) and [Newsela](https://paperswithcode.com/sota/text-simplification-on-newsela).
## Examples
Perfect match between prediction and reference:
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 species are currently accepted ."]
references=[["About 95 species are currently accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 100.0}
```
Partial match between prediction and reference:
```python
from datasets import load_metric
sari = load_metric("sari")
sources=["About 95 species are currently accepted ."]
predictions=["About 95 you now get in ."]
references=[["About 95 species are currently known .","About 95 species are now accepted .","95 species are now accepted ."]]
sari_score = sari.compute(sources=sources, predictions=predictions, references=references)
print(sari_score)
{'sari': 26.953601953601954}
```
## Limitations and bias
SARI is a valuable measure for comparing different text simplification systems as well as one that can assist the iterative development of a system.
However, while the [original paper presenting SARI](https://aclanthology.org/Q16-1029.pdf) states that it captures "the notion of grammaticality and meaning preservation", this is a difficult claim to empirically validate.
## Citation
```bibtex
@inproceedings{xu-etal-2016-optimizing,
title = {Optimizing Statistical Machine Translation for Text Simplification},
authors={Xu, Wei and Napoles, Courtney and Pavlick, Ellie and Chen, Quanze and Callison-Burch, Chris},
journal = {Transactions of the Association for Computational Linguistics},
volume = {4},
year={2016},
url = {https://www.aclweb.org/anthology/Q16-1029},
pages = {401--415},
}
```
## Further References
- [NLP Progress -- Text Simplification](http://nlpprogress.com/english/simplification.html)
- [Hugging Face Hub -- Text Simplification Models](https://huggingface.co/datasets?filter=task_ids:text-simplification)
| datasets/metrics/sari/README.md/0 | {
"file_path": "datasets/metrics/sari/README.md",
"repo_id": "datasets",
"token_count": 1355
} | 67 |
# Copyright 2021 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" TER metric as available in sacrebleu. """
import sacrebleu as scb
from packaging import version
from sacrebleu import TER
import datasets
_CITATION = """\
@inproceedings{snover-etal-2006-study,
title = "A Study of Translation Edit Rate with Targeted Human Annotation",
author = "Snover, Matthew and
Dorr, Bonnie and
Schwartz, Rich and
Micciulla, Linnea and
Makhoul, John",
booktitle = "Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers",
month = aug # " 8-12",
year = "2006",
address = "Cambridge, Massachusetts, USA",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2006.amta-papers.25",
pages = "223--231",
}
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
"""
_DESCRIPTION = """\
TER (Translation Edit Rate, also called Translation Error Rate) is a metric to quantify the edit operations that a
hypothesis requires to match a reference translation. We use the implementation that is already present in sacrebleu
(https://github.com/mjpost/sacreBLEU#ter), which in turn is inspired by the TERCOM implementation, which can be found
here: https://github.com/jhclark/tercom.
The implementation here is slightly different from sacrebleu in terms of the required input format. The length of
the references and hypotheses lists need to be the same, so you may need to transpose your references compared to
sacrebleu's required input format. See https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534
See the README.md file at https://github.com/mjpost/sacreBLEU#ter for more information.
"""
_KWARGS_DESCRIPTION = """
Produces TER scores alongside the number of edits and reference length.
Args:
predictions (list of str): The system stream (a sequence of segments).
references (list of list of str): A list of one or more reference streams (each a sequence of segments).
normalized (boolean): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
ignore_punct (boolean): If `True`, applies basic tokenization and normalization to sentences. Defaults to `False`.
support_zh_ja_chars (boolean): If `True`, tokenization/normalization supports processing of Chinese characters,
as well as Japanese Kanji, Hiragana, Katakana, and Phonetic Extensions of Katakana.
Only applies if `normalized = True`. Defaults to `False`.
case_sensitive (boolean): If `False`, makes all predictions and references lowercase to ignore differences in case. Defaults to `False`.
Returns:
'score' (float): TER score (num_edits / sum_ref_lengths * 100)
'num_edits' (int): The cumulative number of edits
'ref_length' (float): The cumulative average reference length
Examples:
Example 1:
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 150.0, 'num_edits': 15, 'ref_length': 10.0}
Example 2:
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... case_sensitive=True)
>>> print(results)
{'score': 62.5, 'num_edits': 5, 'ref_length': 8.0}
Example 3:
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... normalized=True,
... case_sensitive=True)
>>> print(results)
{'score': 57.14285714285714, 'num_edits': 6, 'ref_length': 10.5}
Example 4:
>>> predictions = ["does this sentence match??",
... "what about this sentence?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 0.0, 'num_edits': 0, 'ref_length': 8.0}
Example 5:
>>> predictions = ["does this sentence match??",
... "what about this sentence?",
... "What did the TER metric user say to the developer?"]
>>> references = [["does this sentence match", "does this sentence match!?!"],
... ["wHaT aBoUt ThIs SeNtEnCe?", "wHaT aBoUt ThIs SeNtEnCe?"],
... ["Your jokes are...", "...TERrible"]]
>>> ter = datasets.load_metric("ter")
>>> results = ter.compute(predictions=predictions,
... references=references,
... ignore_punct=True,
... case_sensitive=False)
>>> print(results)
{'score': 100.0, 'num_edits': 10, 'ref_length': 10.0}
"""
@datasets.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class Ter(datasets.Metric):
def _info(self):
if version.parse(scb.__version__) < version.parse("1.4.12"):
raise ImportWarning(
"To use `sacrebleu`, the module `sacrebleu>=1.4.12` is required, and the current version of `sacrebleu` doesn't match this condition.\n"
'You can install it with `pip install "sacrebleu>=1.4.12"`.'
)
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
homepage="http://www.cs.umd.edu/~snover/tercom/",
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": datasets.Value("string", id="sequence"),
"references": datasets.Sequence(datasets.Value("string", id="sequence"), id="references"),
}
),
codebase_urls=["https://github.com/mjpost/sacreBLEU#ter"],
reference_urls=[
"https://github.com/jhclark/tercom",
],
)
def _compute(
self,
predictions,
references,
normalized: bool = False,
ignore_punct: bool = False,
support_zh_ja_chars: bool = False,
case_sensitive: bool = False,
):
references_per_prediction = len(references[0])
if any(len(refs) != references_per_prediction for refs in references):
raise ValueError("Sacrebleu requires the same number of references for each prediction")
transformed_references = [[refs[i] for refs in references] for i in range(references_per_prediction)]
sb_ter = TER(
normalized=normalized,
no_punct=ignore_punct,
asian_support=support_zh_ja_chars,
case_sensitive=case_sensitive,
)
output = sb_ter.corpus_score(predictions, transformed_references)
return {"score": output.score, "num_edits": output.num_edits, "ref_length": output.ref_length}
| datasets/metrics/ter/ter.py/0 | {
"file_path": "datasets/metrics/ter/ter.py",
"repo_id": "datasets",
"token_count": 3966
} | 68 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""To write records into Parquet files."""
import errno
import json
import os
import sys
from pathlib import Path
from typing import Any, Dict, Iterable, List, Optional, Tuple, Union
import fsspec
import numpy as np
import pyarrow as pa
import pyarrow.parquet as pq
from . import config
from .features import Features, Image, Value
from .features.features import (
FeatureType,
_ArrayXDExtensionType,
cast_to_python_objects,
generate_from_arrow_type,
get_nested_type,
list_of_np_array_to_pyarrow_listarray,
numpy_to_pyarrow_listarray,
to_pyarrow_listarray,
)
from .filesystems import is_remote_filesystem
from .info import DatasetInfo
from .keyhash import DuplicatedKeysError, KeyHasher
from .table import array_cast, array_concat, cast_array_to_feature, embed_table_storage, table_cast
from .utils import logging
from .utils import tqdm as hf_tqdm
from .utils.file_utils import hash_url_to_filename
from .utils.py_utils import asdict, first_non_null_value
logger = logging.get_logger(__name__)
type_ = type # keep python's type function
class SchemaInferenceError(ValueError):
pass
class TypedSequence:
"""
This data container generalizes the typing when instantiating pyarrow arrays, tables or batches.
More specifically it adds several features:
- Support extension types like ``datasets.features.Array2DExtensionType``:
By default pyarrow arrays don't return extension arrays. One has to call
``pa.ExtensionArray.from_storage(type, pa.array(data, type.storage_type))``
in order to get an extension array.
- Support for ``try_type`` parameter that can be used instead of ``type``:
When an array is transformed, we like to keep the same type as before if possible.
For example when calling :func:`datasets.Dataset.map`, we don't want to change the type
of each column by default.
- Better error message when a pyarrow array overflows.
Example::
from datasets.features import Array2D, Array2DExtensionType, Value
from datasets.arrow_writer import TypedSequence
import pyarrow as pa
arr = pa.array(TypedSequence([1, 2, 3], type=Value("int32")))
assert arr.type == pa.int32()
arr = pa.array(TypedSequence([1, 2, 3], try_type=Value("int32")))
assert arr.type == pa.int32()
arr = pa.array(TypedSequence(["foo", "bar"], try_type=Value("int32")))
assert arr.type == pa.string()
arr = pa.array(TypedSequence([[[1, 2, 3]]], type=Array2D((1, 3), "int64")))
assert arr.type == Array2DExtensionType((1, 3), "int64")
table = pa.Table.from_pydict({
"image": TypedSequence([[[1, 2, 3]]], type=Array2D((1, 3), "int64"))
})
assert table["image"].type == Array2DExtensionType((1, 3), "int64")
"""
def __init__(
self,
data: Iterable,
type: Optional[FeatureType] = None,
try_type: Optional[FeatureType] = None,
optimized_int_type: Optional[FeatureType] = None,
):
# assert type is None or try_type is None,
if type is not None and try_type is not None:
raise ValueError("You cannot specify both type and try_type")
# set attributes
self.data = data
self.type = type
self.try_type = try_type # is ignored if it doesn't match the data
self.optimized_int_type = optimized_int_type
# when trying a type (is ignored if data is not compatible)
self.trying_type = self.try_type is not None
self.trying_int_optimization = optimized_int_type is not None and type is None and try_type is None
# used to get back the inferred type after __arrow_array__() is called once
self._inferred_type = None
def get_inferred_type(self) -> FeatureType:
"""Return the inferred feature type.
This is done by converting the sequence to an Arrow array, and getting the corresponding
feature type.
Since building the Arrow array can be expensive, the value of the inferred type is cached
as soon as pa.array is called on the typed sequence.
Returns:
FeatureType: inferred feature type of the sequence.
"""
if self._inferred_type is None:
self._inferred_type = generate_from_arrow_type(pa.array(self).type)
return self._inferred_type
@staticmethod
def _infer_custom_type_and_encode(data: Iterable) -> Tuple[Iterable, Optional[FeatureType]]:
"""Implement type inference for custom objects like PIL.Image.Image -> Image type.
This function is only used for custom python objects that can't be direclty passed to build
an Arrow array. In such cases is infers the feature type to use, and it encodes the data so
that they can be passed to an Arrow array.
Args:
data (Iterable): array of data to infer the type, e.g. a list of PIL images.
Returns:
Tuple[Iterable, Optional[FeatureType]]: a tuple with:
- the (possibly encoded) array, if the inferred feature type requires encoding
- the inferred feature type if the array is made of supported custom objects like
PIL images, else None.
"""
if config.PIL_AVAILABLE and "PIL" in sys.modules:
import PIL.Image
non_null_idx, non_null_value = first_non_null_value(data)
if isinstance(non_null_value, PIL.Image.Image):
return [Image().encode_example(value) if value is not None else None for value in data], Image()
return data, None
def __arrow_array__(self, type: Optional[pa.DataType] = None):
"""This function is called when calling pa.array(typed_sequence)"""
if type is not None:
raise ValueError("TypedSequence is supposed to be used with pa.array(typed_sequence, type=None)")
del type # make sure we don't use it
data = self.data
# automatic type inference for custom objects
if self.type is None and self.try_type is None:
data, self._inferred_type = self._infer_custom_type_and_encode(data)
if self._inferred_type is None:
type = self.try_type if self.trying_type else self.type
else:
type = self._inferred_type
pa_type = get_nested_type(type) if type is not None else None
optimized_int_pa_type = (
get_nested_type(self.optimized_int_type) if self.optimized_int_type is not None else None
)
trying_cast_to_python_objects = False
try:
# custom pyarrow types
if isinstance(pa_type, _ArrayXDExtensionType):
storage = to_pyarrow_listarray(data, pa_type)
return pa.ExtensionArray.from_storage(pa_type, storage)
# efficient np array to pyarrow array
if isinstance(data, np.ndarray):
out = numpy_to_pyarrow_listarray(data)
elif isinstance(data, list) and data and isinstance(first_non_null_value(data)[1], np.ndarray):
out = list_of_np_array_to_pyarrow_listarray(data)
else:
trying_cast_to_python_objects = True
out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))
# use smaller integer precisions if possible
if self.trying_int_optimization:
if pa.types.is_int64(out.type):
out = out.cast(optimized_int_pa_type)
elif pa.types.is_list(out.type):
if pa.types.is_int64(out.type.value_type):
out = array_cast(out, pa.list_(optimized_int_pa_type))
elif pa.types.is_list(out.type.value_type) and pa.types.is_int64(out.type.value_type.value_type):
out = array_cast(out, pa.list_(pa.list_(optimized_int_pa_type)))
# otherwise we can finally use the user's type
elif type is not None:
# We use cast_array_to_feature to support casting to custom types like Audio and Image
# Also, when trying type "string", we don't want to convert integers or floats to "string".
# We only do it if trying_type is False - since this is what the user asks for.
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
return out
except (
TypeError,
pa.lib.ArrowInvalid,
pa.lib.ArrowNotImplementedError,
) as e: # handle type errors and overflows
# Ignore ArrowNotImplementedError caused by trying type, otherwise re-raise
if not self.trying_type and isinstance(e, pa.lib.ArrowNotImplementedError):
raise
if self.trying_type:
try: # second chance
if isinstance(data, np.ndarray):
return numpy_to_pyarrow_listarray(data)
elif isinstance(data, list) and data and any(isinstance(value, np.ndarray) for value in data):
return list_of_np_array_to_pyarrow_listarray(data)
else:
trying_cast_to_python_objects = True
return pa.array(cast_to_python_objects(data, only_1d_for_numpy=True))
except pa.lib.ArrowInvalid as e:
if "overflow" in str(e):
raise OverflowError(
f"There was an overflow with type {type_(data)}. Try to reduce writer_batch_size to have batches smaller than 2GB.\n({e})"
) from None
elif self.trying_int_optimization and "not in range" in str(e):
optimized_int_pa_type_str = np.dtype(optimized_int_pa_type.to_pandas_dtype()).name
logger.info(
f"Failed to cast a sequence to {optimized_int_pa_type_str}. Falling back to int64."
)
return out
elif trying_cast_to_python_objects and "Could not convert" in str(e):
out = pa.array(
cast_to_python_objects(data, only_1d_for_numpy=True, optimize_list_casting=False)
)
if type is not None:
out = cast_array_to_feature(out, type, allow_number_to_str=True)
return out
else:
raise
elif "overflow" in str(e):
raise OverflowError(
f"There was an overflow with type {type_(data)}. Try to reduce writer_batch_size to have batches smaller than 2GB.\n({e})"
) from None
elif self.trying_int_optimization and "not in range" in str(e):
optimized_int_pa_type_str = np.dtype(optimized_int_pa_type.to_pandas_dtype()).name
logger.info(f"Failed to cast a sequence to {optimized_int_pa_type_str}. Falling back to int64.")
return out
elif trying_cast_to_python_objects and "Could not convert" in str(e):
out = pa.array(cast_to_python_objects(data, only_1d_for_numpy=True, optimize_list_casting=False))
if type is not None:
out = cast_array_to_feature(out, type, allow_number_to_str=True)
return out
else:
raise
class OptimizedTypedSequence(TypedSequence):
def __init__(
self,
data,
type: Optional[FeatureType] = None,
try_type: Optional[FeatureType] = None,
col: Optional[str] = None,
optimized_int_type: Optional[FeatureType] = None,
):
optimized_int_type_by_col = {
"attention_mask": Value("int8"), # binary tensor
"special_tokens_mask": Value("int8"),
"input_ids": Value("int32"), # typical vocab size: 0-50k (max ~500k, never > 1M)
"token_type_ids": Value(
"int8"
), # binary mask; some (XLNetModel) use an additional token represented by a 2
}
if type is None and try_type is None:
optimized_int_type = optimized_int_type_by_col.get(col, None)
super().__init__(data, type=type, try_type=try_type, optimized_int_type=optimized_int_type)
class ArrowWriter:
"""Shuffles and writes Examples to Arrow files."""
_WRITER_CLASS = pa.RecordBatchStreamWriter
def __init__(
self,
schema: Optional[pa.Schema] = None,
features: Optional[Features] = None,
path: Optional[str] = None,
stream: Optional[pa.NativeFile] = None,
fingerprint: Optional[str] = None,
writer_batch_size: Optional[int] = None,
hash_salt: Optional[str] = None,
check_duplicates: Optional[bool] = False,
disable_nullable: bool = False,
update_features: bool = False,
with_metadata: bool = True,
unit: str = "examples",
embed_local_files: bool = False,
storage_options: Optional[dict] = None,
):
if path is None and stream is None:
raise ValueError("At least one of path and stream must be provided.")
if features is not None:
self._features = features
self._schema = None
elif schema is not None:
self._schema: pa.Schema = schema
self._features = Features.from_arrow_schema(self._schema)
else:
self._features = None
self._schema = None
if hash_salt is not None:
# Create KeyHasher instance using split name as hash salt
self._hasher = KeyHasher(hash_salt)
else:
self._hasher = KeyHasher("")
self._check_duplicates = check_duplicates
self._disable_nullable = disable_nullable
if stream is None:
fs_token_paths = fsspec.get_fs_token_paths(path, storage_options=storage_options)
self._fs: fsspec.AbstractFileSystem = fs_token_paths[0]
self._path = (
fs_token_paths[2][0]
if not is_remote_filesystem(self._fs)
else self._fs.unstrip_protocol(fs_token_paths[2][0])
)
self.stream = self._fs.open(fs_token_paths[2][0], "wb")
self._closable_stream = True
else:
self._fs = None
self._path = None
self.stream = stream
self._closable_stream = False
self.fingerprint = fingerprint
self.disable_nullable = disable_nullable
self.writer_batch_size = writer_batch_size or config.DEFAULT_MAX_BATCH_SIZE
self.update_features = update_features
self.with_metadata = with_metadata
self.unit = unit
self.embed_local_files = embed_local_files
self._num_examples = 0
self._num_bytes = 0
self.current_examples: List[Tuple[Dict[str, Any], str]] = []
self.current_rows: List[pa.Table] = []
self.pa_writer: Optional[pa.RecordBatchStreamWriter] = None
self.hkey_record = []
def __len__(self):
"""Return the number of writed and staged examples"""
return self._num_examples + len(self.current_examples) + len(self.current_rows)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()
def close(self):
# Try closing if opened; if closed: pyarrow.lib.ArrowInvalid: Invalid operation on closed file
if self.pa_writer: # it might be None
try:
self.pa_writer.close()
except Exception: # pyarrow.lib.ArrowInvalid, OSError
pass
if self._closable_stream and not self.stream.closed:
self.stream.close() # This also closes self.pa_writer if it is opened
def _build_writer(self, inferred_schema: pa.Schema):
schema = self.schema
inferred_features = Features.from_arrow_schema(inferred_schema)
if self._features is not None:
if self.update_features: # keep original features it they match, or update them
fields = {field.name: field for field in self._features.type}
for inferred_field in inferred_features.type:
name = inferred_field.name
if name in fields:
if inferred_field == fields[name]:
inferred_features[name] = self._features[name]
self._features = inferred_features
schema: pa.Schema = inferred_schema
else:
self._features = inferred_features
schema: pa.Schema = inferred_features.arrow_schema
if self.disable_nullable:
schema = pa.schema(pa.field(field.name, field.type, nullable=False) for field in schema)
if self.with_metadata:
schema = schema.with_metadata(self._build_metadata(DatasetInfo(features=self._features), self.fingerprint))
else:
schema = schema.with_metadata({})
self._schema = schema
self.pa_writer = self._WRITER_CLASS(self.stream, schema)
@property
def schema(self):
_schema = (
self._schema
if self._schema is not None
else (pa.schema(self._features.type) if self._features is not None else None)
)
if self._disable_nullable and _schema is not None:
_schema = pa.schema(pa.field(field.name, field.type, nullable=False) for field in _schema)
return _schema if _schema is not None else []
@staticmethod
def _build_metadata(info: DatasetInfo, fingerprint: Optional[str] = None) -> Dict[str, str]:
info_keys = ["features"] # we can add support for more DatasetInfo keys in the future
info_as_dict = asdict(info)
metadata = {}
metadata["info"] = {key: info_as_dict[key] for key in info_keys}
if fingerprint is not None:
metadata["fingerprint"] = fingerprint
return {"huggingface": json.dumps(metadata)}
def write_examples_on_file(self):
"""Write stored examples from the write-pool of examples. It makes a table out of the examples and write it."""
if not self.current_examples:
return
# order the columns properly
cols = (
[col for col in self.schema.names if col in self.current_examples[0][0]]
+ [col for col in self.current_examples[0][0].keys() if col not in self.schema.names]
if self.schema
else self.current_examples[0][0].keys()
)
batch_examples = {}
for col in cols:
# We use row[0][col] since current_examples contains (example, key) tuples.
# Morever, examples could be Arrow arrays of 1 element.
# This can happen in `.map()` when we want to re-write the same Arrow data
if all(isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) for row in self.current_examples):
arrays = [row[0][col] for row in self.current_examples]
batch_examples[col] = array_concat(arrays)
else:
batch_examples[col] = [
row[0][col].to_pylist()[0] if isinstance(row[0][col], (pa.Array, pa.ChunkedArray)) else row[0][col]
for row in self.current_examples
]
self.write_batch(batch_examples=batch_examples)
self.current_examples = []
def write_rows_on_file(self):
"""Write stored rows from the write-pool of rows. It concatenates the single-row tables and it writes the resulting table."""
if not self.current_rows:
return
table = pa.concat_tables(self.current_rows)
self.write_table(table)
self.current_rows = []
def write(
self,
example: Dict[str, Any],
key: Optional[Union[str, int, bytes]] = None,
writer_batch_size: Optional[int] = None,
):
"""Add a given (Example,Key) pair to the write-pool of examples which is written to file.
Args:
example: the Example to add.
key: Optional, a unique identifier(str, int or bytes) associated with each example
"""
# Utilize the keys and duplicate checking when `self._check_duplicates` is passed True
if self._check_duplicates:
# Create unique hash from key and store as (key, example) pairs
hash = self._hasher.hash(key)
self.current_examples.append((example, hash))
# Maintain record of keys and their respective hashes for checking duplicates
self.hkey_record.append((hash, key))
else:
# Store example as a tuple so as to keep the structure of `self.current_examples` uniform
self.current_examples.append((example, ""))
if writer_batch_size is None:
writer_batch_size = self.writer_batch_size
if writer_batch_size is not None and len(self.current_examples) >= writer_batch_size:
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
def check_duplicate_keys(self):
"""Raises error if duplicates found in a batch"""
tmp_record = set()
for hash, key in self.hkey_record:
if hash in tmp_record:
duplicate_key_indices = [
str(self._num_examples + index)
for index, (duplicate_hash, _) in enumerate(self.hkey_record)
if duplicate_hash == hash
]
raise DuplicatedKeysError(key, duplicate_key_indices)
else:
tmp_record.add(hash)
def write_row(self, row: pa.Table, writer_batch_size: Optional[int] = None):
"""Add a given single-row Table to the write-pool of rows which is written to file.
Args:
row: the row to add.
"""
if len(row) != 1:
raise ValueError(f"Only single-row pyarrow tables are allowed but got table with {len(row)} rows.")
self.current_rows.append(row)
if writer_batch_size is None:
writer_batch_size = self.writer_batch_size
if writer_batch_size is not None and len(self.current_rows) >= writer_batch_size:
self.write_rows_on_file()
def write_batch(
self,
batch_examples: Dict[str, List],
writer_batch_size: Optional[int] = None,
):
"""Write a batch of Example to file.
Ignores the batch if it appears to be empty,
preventing a potential schema update of unknown types.
Args:
batch_examples: the batch of examples to add.
"""
if batch_examples and len(next(iter(batch_examples.values()))) == 0:
return
features = None if self.pa_writer is None and self.update_features else self._features
try_features = self._features if self.pa_writer is None and self.update_features else None
arrays = []
inferred_features = Features()
cols = (
[col for col in self.schema.names if col in batch_examples]
+ [col for col in batch_examples.keys() if col not in self.schema.names]
if self.schema
else batch_examples.keys()
)
for col in cols:
col_values = batch_examples[col]
col_type = features[col] if features else None
if isinstance(col_values, (pa.Array, pa.ChunkedArray)):
array = cast_array_to_feature(col_values, col_type) if col_type is not None else col_values
arrays.append(array)
inferred_features[col] = generate_from_arrow_type(col_values.type)
else:
col_try_type = try_features[col] if try_features is not None and col in try_features else None
typed_sequence = OptimizedTypedSequence(col_values, type=col_type, try_type=col_try_type, col=col)
arrays.append(pa.array(typed_sequence))
inferred_features[col] = typed_sequence.get_inferred_type()
schema = inferred_features.arrow_schema if self.pa_writer is None else self.schema
pa_table = pa.Table.from_arrays(arrays, schema=schema)
self.write_table(pa_table, writer_batch_size)
def write_table(self, pa_table: pa.Table, writer_batch_size: Optional[int] = None):
"""Write a Table to file.
Args:
example: the Table to add.
"""
if writer_batch_size is None:
writer_batch_size = self.writer_batch_size
if self.pa_writer is None:
self._build_writer(inferred_schema=pa_table.schema)
pa_table = pa_table.combine_chunks()
pa_table = table_cast(pa_table, self._schema)
if self.embed_local_files:
pa_table = embed_table_storage(pa_table)
self._num_bytes += pa_table.nbytes
self._num_examples += pa_table.num_rows
self.pa_writer.write_table(pa_table, writer_batch_size)
def finalize(self, close_stream=True):
self.write_rows_on_file()
# In case current_examples < writer_batch_size, but user uses finalize()
if self._check_duplicates:
self.check_duplicate_keys()
# Re-intializing to empty list for next batch
self.hkey_record = []
self.write_examples_on_file()
# If schema is known, infer features even if no examples were written
if self.pa_writer is None and self.schema:
self._build_writer(self.schema)
if self.pa_writer is not None:
self.pa_writer.close()
self.pa_writer = None
if close_stream:
self.stream.close()
else:
if close_stream:
self.stream.close()
raise SchemaInferenceError("Please pass `features` or at least one example when writing data")
logger.debug(
f"Done writing {self._num_examples} {self.unit} in {self._num_bytes} bytes {self._path if self._path else ''}."
)
return self._num_examples, self._num_bytes
class ParquetWriter(ArrowWriter):
_WRITER_CLASS = pq.ParquetWriter
class BeamWriter:
"""
Shuffles and writes Examples to Arrow files.
The Arrow files are converted from Parquet files that are the output of Apache Beam pipelines.
"""
def __init__(
self,
features: Optional[Features] = None,
schema: Optional[pa.Schema] = None,
path: Optional[str] = None,
namespace: Optional[str] = None,
cache_dir: Optional[str] = None,
):
if features is None and schema is None:
raise ValueError("At least one of features and schema must be provided.")
if path is None:
raise ValueError("Path must be provided.")
if features is not None:
self._features: Features = features
self._schema: pa.Schema = features.arrow_schema
else:
self._schema: pa.Schema = schema
self._features: Features = Features.from_arrow_schema(schema)
self._path = path
self._parquet_path = os.path.splitext(path)[0] # remove extension
self._namespace = namespace or "default"
self._num_examples = None
self._cache_dir = cache_dir or config.HF_DATASETS_CACHE
def write_from_pcollection(self, pcoll_examples):
"""Add the final steps of the beam pipeline: write to parquet files."""
import apache_beam as beam
def inc_num_examples(example):
beam.metrics.Metrics.counter(self._namespace, "num_examples").inc()
# count examples
_ = pcoll_examples | "Count N. Examples" >> beam.Map(inc_num_examples)
# save dataset
return (
pcoll_examples
| "Get values" >> beam.Values()
| "Save to parquet"
>> beam.io.parquetio.WriteToParquet(
self._parquet_path, self._schema, shard_name_template="-SSSSS-of-NNNNN.parquet"
)
)
def finalize(self, metrics_query_result: dict):
"""
Run after the pipeline has finished.
It converts the resulting parquet files to arrow and it completes the info from the pipeline metrics.
Args:
metrics_query_result: `dict` obtained from pipeline_results.metrics().query(m_filter). Make sure
that the filter keeps only the metrics for the considered split, under the namespace `split_name`.
"""
import apache_beam as beam
from .utils import beam_utils
# Beam FileSystems require the system's path separator in the older versions
fs, _, [parquet_path] = fsspec.get_fs_token_paths(self._parquet_path)
parquet_path = str(Path(parquet_path)) if not is_remote_filesystem(fs) else fs.unstrip_protocol(parquet_path)
shards_metadata = list(beam.io.filesystems.FileSystems.match([parquet_path + "*.parquet"])[0].metadata_list)
shards = [metadata.path for metadata in shards_metadata]
num_bytes = sum([metadata.size_in_bytes for metadata in shards_metadata])
shard_lengths = get_parquet_lengths(shards)
# Convert to arrow
if self._path.endswith(".arrow"):
logger.info(f"Converting parquet files {self._parquet_path} to arrow {self._path}")
shards = [
metadata.path
for metadata in beam.io.filesystems.FileSystems.match([parquet_path + "*.parquet"])[0].metadata_list
]
try: # stream conversion
num_bytes = 0
for shard in hf_tqdm(shards, unit="shards"):
with beam.io.filesystems.FileSystems.open(shard) as source:
with beam.io.filesystems.FileSystems.create(
shard.replace(".parquet", ".arrow")
) as destination:
shard_num_bytes, _ = parquet_to_arrow(source, destination)
num_bytes += shard_num_bytes
except OSError as e: # broken pipe can happen if the connection is unstable, do local conversion instead
if e.errno != errno.EPIPE: # not a broken pipe
raise
logger.warning(
"Broken Pipe during stream conversion from parquet to arrow. Using local convert instead"
)
local_convert_dir = os.path.join(self._cache_dir, "beam_convert")
os.makedirs(local_convert_dir, exist_ok=True)
num_bytes = 0
for shard in hf_tqdm(shards, unit="shards"):
local_parquet_path = os.path.join(local_convert_dir, hash_url_to_filename(shard) + ".parquet")
beam_utils.download_remote_to_local(shard, local_parquet_path)
local_arrow_path = local_parquet_path.replace(".parquet", ".arrow")
shard_num_bytes, _ = parquet_to_arrow(local_parquet_path, local_arrow_path)
num_bytes += shard_num_bytes
remote_arrow_path = shard.replace(".parquet", ".arrow")
beam_utils.upload_local_to_remote(local_arrow_path, remote_arrow_path)
# Save metrics
counters_dict = {metric.key.metric.name: metric.result for metric in metrics_query_result["counters"]}
self._num_examples = counters_dict["num_examples"]
self._num_bytes = num_bytes
self._shard_lengths = shard_lengths
return self._num_examples, self._num_bytes
def get_parquet_lengths(sources) -> List[int]:
shard_lengths = []
for source in hf_tqdm(sources, unit="parquet files"):
parquet_file = pa.parquet.ParquetFile(source)
shard_lengths.append(parquet_file.metadata.num_rows)
return shard_lengths
def parquet_to_arrow(source, destination) -> List[int]:
"""Convert parquet file to arrow file. Inputs can be str paths or file-like objects"""
stream = None if isinstance(destination, str) else destination
with ArrowWriter(path=destination, stream=stream) as writer:
parquet_file = pa.parquet.ParquetFile(source)
for record_batch in parquet_file.iter_batches():
pa_table = pa.Table.from_batches([record_batch])
writer.write_table(pa_table)
num_bytes, num_examples = writer.finalize()
return num_bytes, num_examples
| datasets/src/datasets/arrow_writer.py/0 | {
"file_path": "datasets/src/datasets/arrow_writer.py",
"repo_id": "datasets",
"token_count": 14723
} | 69 |
# Copyright 2020 The TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""Download manager interface."""
import enum
import io
import os
import posixpath
import tarfile
import warnings
import zipfile
from datetime import datetime
from functools import partial
from itertools import chain
from typing import Callable, Dict, Generator, List, Optional, Tuple, Union
from .. import config
from ..utils import tqdm as hf_tqdm
from ..utils.deprecation_utils import DeprecatedEnum, deprecated
from ..utils.file_utils import (
cached_path,
get_from_cache,
hash_url_to_filename,
is_relative_path,
stack_multiprocessing_download_progress_bars,
url_or_path_join,
)
from ..utils.info_utils import get_size_checksum_dict
from ..utils.logging import get_logger
from ..utils.py_utils import NestedDataStructure, map_nested, size_str
from ..utils.track import TrackedIterable, tracked_str
from .download_config import DownloadConfig
logger = get_logger(__name__)
BASE_KNOWN_EXTENSIONS = [
"txt",
"csv",
"json",
"jsonl",
"tsv",
"conll",
"conllu",
"orig",
"parquet",
"pkl",
"pickle",
"rel",
"xml",
]
MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL = {
bytes.fromhex("504B0304"): "zip",
bytes.fromhex("504B0506"): "zip", # empty archive
bytes.fromhex("504B0708"): "zip", # spanned archive
bytes.fromhex("425A68"): "bz2",
bytes.fromhex("1F8B"): "gzip",
bytes.fromhex("FD377A585A00"): "xz",
bytes.fromhex("04224D18"): "lz4",
bytes.fromhex("28B52FFD"): "zstd",
}
MAGIC_NUMBER_TO_UNSUPPORTED_COMPRESSION_PROTOCOL = {
b"Rar!": "rar",
}
MAGIC_NUMBER_MAX_LENGTH = max(
len(magic_number)
for magic_number in chain(MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL, MAGIC_NUMBER_TO_UNSUPPORTED_COMPRESSION_PROTOCOL)
)
class DownloadMode(enum.Enum):
"""`Enum` for how to treat pre-existing downloads and data.
The default mode is `REUSE_DATASET_IF_EXISTS`, which will reuse both
raw downloads and the prepared dataset if they exist.
The generations modes:
| | Downloads | Dataset |
|-------------------------------------|-----------|---------|
| `REUSE_DATASET_IF_EXISTS` (default) | Reuse | Reuse |
| `REUSE_CACHE_IF_EXISTS` | Reuse | Fresh |
| `FORCE_REDOWNLOAD` | Fresh | Fresh |
"""
REUSE_DATASET_IF_EXISTS = "reuse_dataset_if_exists"
REUSE_CACHE_IF_EXISTS = "reuse_cache_if_exists"
FORCE_REDOWNLOAD = "force_redownload"
class GenerateMode(DeprecatedEnum):
REUSE_DATASET_IF_EXISTS = "reuse_dataset_if_exists"
REUSE_CACHE_IF_EXISTS = "reuse_cache_if_exists"
FORCE_REDOWNLOAD = "force_redownload"
@property
def help_message(self):
return "Use 'DownloadMode' instead."
def _get_path_extension(path: str) -> str:
# Get extension: train.json.gz -> gz
extension = path.split(".")[-1]
# Remove query params ("dl=1", "raw=true"): gz?dl=1 -> gz
# Remove shards infos (".txt_1", ".txt-00000-of-00100"): txt_1 -> txt
for symb in "?-_":
extension = extension.split(symb)[0]
return extension
def _get_extraction_protocol_with_magic_number(f) -> Optional[str]:
"""read the magic number from a file-like object and return the compression protocol"""
# Check if the file object is seekable even before reading the magic number (to avoid https://bugs.python.org/issue26440)
try:
f.seek(0)
except (AttributeError, io.UnsupportedOperation):
return None
magic_number = f.read(MAGIC_NUMBER_MAX_LENGTH)
f.seek(0)
for i in range(MAGIC_NUMBER_MAX_LENGTH):
compression = MAGIC_NUMBER_TO_COMPRESSION_PROTOCOL.get(magic_number[: MAGIC_NUMBER_MAX_LENGTH - i])
if compression is not None:
return compression
compression = MAGIC_NUMBER_TO_UNSUPPORTED_COMPRESSION_PROTOCOL.get(magic_number[: MAGIC_NUMBER_MAX_LENGTH - i])
if compression is not None:
raise NotImplementedError(f"Compression protocol '{compression}' not implemented.")
def _get_extraction_protocol(path: str) -> Optional[str]:
path = str(path)
extension = _get_path_extension(path)
# TODO(mariosasko): The below check will be useful once we can preserve the original extension in the new cache layout (use the `filename` parameter of `hf_hub_download`)
if (
extension in BASE_KNOWN_EXTENSIONS
or extension in ["tgz", "tar"]
or path.endswith((".tar.gz", ".tar.bz2", ".tar.xz"))
):
return None
with open(path, "rb") as f:
return _get_extraction_protocol_with_magic_number(f)
class _IterableFromGenerator(TrackedIterable):
"""Utility class to create an iterable from a generator function, in order to reset the generator when needed."""
def __init__(self, generator: Callable, *args, **kwargs):
super().__init__()
self.generator = generator
self.args = args
self.kwargs = kwargs
def __iter__(self):
for x in self.generator(*self.args, **self.kwargs):
self.last_item = x
yield x
self.last_item = None
class ArchiveIterable(_IterableFromGenerator):
"""An iterable of (path, fileobj) from a TAR archive, used by `iter_archive`"""
@staticmethod
def _iter_tar(f):
stream = tarfile.open(fileobj=f, mode="r|*")
for tarinfo in stream:
file_path = tarinfo.name
if not tarinfo.isreg():
continue
if file_path is None:
continue
if os.path.basename(file_path).startswith((".", "__")):
# skipping hidden files
continue
file_obj = stream.extractfile(tarinfo)
yield file_path, file_obj
stream.members = []
del stream
@staticmethod
def _iter_zip(f):
zipf = zipfile.ZipFile(f)
for member in zipf.infolist():
file_path = member.filename
if member.is_dir():
continue
if file_path is None:
continue
if os.path.basename(file_path).startswith((".", "__")):
# skipping hidden files
continue
file_obj = zipf.open(member)
yield file_path, file_obj
@classmethod
def _iter_from_fileobj(cls, f) -> Generator[Tuple, None, None]:
compression = _get_extraction_protocol_with_magic_number(f)
if compression == "zip":
yield from cls._iter_zip(f)
else:
yield from cls._iter_tar(f)
@classmethod
def _iter_from_path(cls, urlpath: str) -> Generator[Tuple, None, None]:
compression = _get_extraction_protocol(urlpath)
with open(urlpath, "rb") as f:
if compression == "zip":
yield from cls._iter_zip(f)
else:
yield from cls._iter_tar(f)
@classmethod
def from_buf(cls, fileobj) -> "ArchiveIterable":
return cls(cls._iter_from_fileobj, fileobj)
@classmethod
def from_path(cls, urlpath_or_buf) -> "ArchiveIterable":
return cls(cls._iter_from_path, urlpath_or_buf)
class FilesIterable(_IterableFromGenerator):
"""An iterable of paths from a list of directories or files"""
@classmethod
def _iter_from_paths(cls, urlpaths: Union[str, List[str]]) -> Generator[str, None, None]:
if not isinstance(urlpaths, list):
urlpaths = [urlpaths]
for urlpath in urlpaths:
if os.path.isfile(urlpath):
yield urlpath
else:
for dirpath, dirnames, filenames in os.walk(urlpath):
# in-place modification to prune the search
dirnames[:] = sorted([dirname for dirname in dirnames if not dirname.startswith((".", "__"))])
if os.path.basename(dirpath).startswith((".", "__")):
# skipping hidden directories
continue
for filename in sorted(filenames):
if filename.startswith((".", "__")):
# skipping hidden files
continue
yield os.path.join(dirpath, filename)
@classmethod
def from_paths(cls, urlpaths) -> "FilesIterable":
return cls(cls._iter_from_paths, urlpaths)
class DownloadManager:
is_streaming = False
def __init__(
self,
dataset_name: Optional[str] = None,
data_dir: Optional[str] = None,
download_config: Optional[DownloadConfig] = None,
base_path: Optional[str] = None,
record_checksums=True,
):
"""Download manager constructor.
Args:
data_dir:
can be used to specify a manual directory to get the files from.
dataset_name (`str`):
name of dataset this instance will be used for. If
provided, downloads will contain which datasets they were used for.
download_config (`DownloadConfig`):
to specify the cache directory and other
download options
base_path (`str`):
base path that is used when relative paths are used to
download files. This can be a remote url.
record_checksums (`bool`, defaults to `True`):
Whether to record the checksums of the downloaded files. If None, the value is inferred from the builder.
"""
self._dataset_name = dataset_name
self._data_dir = data_dir
self._base_path = base_path or os.path.abspath(".")
# To record what is being used: {url: {num_bytes: int, checksum: str}}
self._recorded_sizes_checksums: Dict[str, Dict[str, Optional[Union[int, str]]]] = {}
self.record_checksums = record_checksums
self.download_config = download_config or DownloadConfig()
self.downloaded_paths = {}
self.extracted_paths = {}
@property
def manual_dir(self):
return self._data_dir
@property
def downloaded_size(self):
"""Returns the total size of downloaded files."""
return sum(checksums_dict["num_bytes"] for checksums_dict in self._recorded_sizes_checksums.values())
@staticmethod
def ship_files_with_pipeline(downloaded_path_or_paths, pipeline):
"""Ship the files using Beam FileSystems to the pipeline temp dir.
Args:
downloaded_path_or_paths (`str` or `list[str]` or `dict[str, str]`):
Nested structure containing the
downloaded path(s).
pipeline ([`utils.beam_utils.BeamPipeline`]):
Apache Beam Pipeline.
Returns:
`str` or `list[str]` or `dict[str, str]`
"""
from ..utils.beam_utils import upload_local_to_remote
remote_dir = pipeline._options.get_all_options().get("temp_location")
if remote_dir is None:
raise ValueError("You need to specify 'temp_location' in PipelineOptions to upload files")
def upload(local_file_path):
remote_file_path = posixpath.join(
remote_dir, config.DOWNLOADED_DATASETS_DIR, os.path.basename(local_file_path)
)
logger.info(
f"Uploading {local_file_path} ({size_str(os.path.getsize(local_file_path))}) to {remote_file_path}."
)
upload_local_to_remote(local_file_path, remote_file_path)
return remote_file_path
uploaded_path_or_paths = map_nested(
lambda local_file_path: upload(local_file_path),
downloaded_path_or_paths,
)
return uploaded_path_or_paths
def _record_sizes_checksums(self, url_or_urls: NestedDataStructure, downloaded_path_or_paths: NestedDataStructure):
"""Record size/checksum of downloaded files."""
delay = 5
for url, path in hf_tqdm(
list(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())),
delay=delay,
desc="Computing checksums",
):
# call str to support PathLike objects
self._recorded_sizes_checksums[str(url)] = get_size_checksum_dict(
path, record_checksum=self.record_checksums
)
@deprecated("Use `.download`/`.download_and_extract` with `fsspec` URLs instead.")
def download_custom(self, url_or_urls, custom_download):
"""
Download given urls(s) by calling `custom_download`.
Args:
url_or_urls (`str` or `list` or `dict`):
URL or `list` or `dict` of URLs to download and extract. Each URL is a `str`.
custom_download (`Callable[src_url, dst_path]`):
The source URL and destination path. For example
`tf.io.gfile.copy`, that lets you download from Google storage.
Returns:
downloaded_path(s): `str`, The downloaded paths matching the given input
`url_or_urls`.
Example:
```py
>>> downloaded_files = dl_manager.download_custom('s3://my-bucket/data.zip', custom_download_for_my_private_bucket)
```
"""
cache_dir = self.download_config.cache_dir or config.DOWNLOADED_DATASETS_PATH
max_retries = self.download_config.max_retries
def url_to_downloaded_path(url):
return os.path.join(cache_dir, hash_url_to_filename(url))
downloaded_path_or_paths = map_nested(url_to_downloaded_path, url_or_urls)
url_or_urls = NestedDataStructure(url_or_urls)
downloaded_path_or_paths = NestedDataStructure(downloaded_path_or_paths)
for url, path in zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten()):
try:
get_from_cache(
url, cache_dir=cache_dir, local_files_only=True, use_etag=False, max_retries=max_retries
)
cached = True
except FileNotFoundError:
cached = False
if not cached or self.download_config.force_download:
custom_download(url, path)
get_from_cache(
url, cache_dir=cache_dir, local_files_only=True, use_etag=False, max_retries=max_retries
)
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
return downloaded_path_or_paths.data
def download(self, url_or_urls):
"""Download given URL(s).
By default, only one process is used for download. Pass customized `download_config.num_proc` to change this behavior.
Args:
url_or_urls (`str` or `list` or `dict`):
URL or `list` or `dict` of URLs to download. Each URL is a `str`.
Returns:
`str` or `list` or `dict`:
The downloaded paths matching the given input `url_or_urls`.
Example:
```py
>>> downloaded_files = dl_manager.download('https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz')
```
"""
download_config = self.download_config.copy()
download_config.extract_compressed_file = False
if download_config.download_desc is None:
download_config.download_desc = "Downloading data"
download_func = partial(self._download, download_config=download_config)
start_time = datetime.now()
with stack_multiprocessing_download_progress_bars():
downloaded_path_or_paths = map_nested(
download_func,
url_or_urls,
map_tuple=True,
num_proc=download_config.num_proc,
desc="Downloading data files",
)
duration = datetime.now() - start_time
logger.info(f"Downloading took {duration.total_seconds() // 60} min")
url_or_urls = NestedDataStructure(url_or_urls)
downloaded_path_or_paths = NestedDataStructure(downloaded_path_or_paths)
self.downloaded_paths.update(dict(zip(url_or_urls.flatten(), downloaded_path_or_paths.flatten())))
start_time = datetime.now()
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
duration = datetime.now() - start_time
logger.info(f"Checksum Computation took {duration.total_seconds() // 60} min")
return downloaded_path_or_paths.data
def _download(self, url_or_filename: str, download_config: DownloadConfig) -> str:
url_or_filename = str(url_or_filename)
if is_relative_path(url_or_filename):
# append the relative path to the base_path
url_or_filename = url_or_path_join(self._base_path, url_or_filename)
out = cached_path(url_or_filename, download_config=download_config)
out = tracked_str(out)
out.set_origin(url_or_filename)
return out
def iter_archive(self, path_or_buf: Union[str, io.BufferedReader]):
"""Iterate over files within an archive.
Args:
path_or_buf (`str` or `io.BufferedReader`):
Archive path or archive binary file object.
Yields:
`tuple[str, io.BufferedReader]`:
2-tuple (path_within_archive, file_object).
File object is opened in binary mode.
Example:
```py
>>> archive = dl_manager.download('https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz')
>>> files = dl_manager.iter_archive(archive)
```
"""
if hasattr(path_or_buf, "read"):
return ArchiveIterable.from_buf(path_or_buf)
else:
return ArchiveIterable.from_path(path_or_buf)
def iter_files(self, paths: Union[str, List[str]]):
"""Iterate over file paths.
Args:
paths (`str` or `list` of `str`):
Root paths.
Yields:
`str`: File path.
Example:
```py
>>> files = dl_manager.download_and_extract('https://huggingface.co/datasets/beans/resolve/main/data/train.zip')
>>> files = dl_manager.iter_files(files)
```
"""
return FilesIterable.from_paths(paths)
def extract(self, path_or_paths, num_proc="deprecated"):
"""Extract given path(s).
Args:
path_or_paths (path or `list` or `dict`):
Path of file to extract. Each path is a `str`.
num_proc (`int`):
Use multi-processing if `num_proc` > 1 and the length of
`path_or_paths` is larger than `num_proc`.
<Deprecated version="2.6.2">
Pass `DownloadConfig(num_proc=<num_proc>)` to the initializer instead.
</Deprecated>
Returns:
extracted_path(s): `str`, The extracted paths matching the given input
path_or_paths.
Example:
```py
>>> downloaded_files = dl_manager.download('https://storage.googleapis.com/seldon-datasets/sentence_polarity_v1/rt-polaritydata.tar.gz')
>>> extracted_files = dl_manager.extract(downloaded_files)
```
"""
if num_proc != "deprecated":
warnings.warn(
"'num_proc' was deprecated in version 2.6.2 and will be removed in 3.0.0. Pass `DownloadConfig(num_proc=<num_proc>)` to the initializer instead.",
FutureWarning,
)
download_config = self.download_config.copy()
download_config.extract_compressed_file = True
extract_func = partial(self._download, download_config=download_config)
extracted_paths = map_nested(
extract_func,
path_or_paths,
num_proc=download_config.num_proc,
desc="Extracting data files",
)
path_or_paths = NestedDataStructure(path_or_paths)
extracted_paths = NestedDataStructure(extracted_paths)
self.extracted_paths.update(dict(zip(path_or_paths.flatten(), extracted_paths.flatten())))
return extracted_paths.data
def download_and_extract(self, url_or_urls):
"""Download and extract given `url_or_urls`.
Is roughly equivalent to:
```
extracted_paths = dl_manager.extract(dl_manager.download(url_or_urls))
```
Args:
url_or_urls (`str` or `list` or `dict`):
URL or `list` or `dict` of URLs to download and extract. Each URL is a `str`.
Returns:
extracted_path(s): `str`, extracted paths of given URL(s).
"""
return self.extract(self.download(url_or_urls))
def get_recorded_sizes_checksums(self):
return self._recorded_sizes_checksums.copy()
def delete_extracted_files(self):
paths_to_delete = set(self.extracted_paths.values()) - set(self.downloaded_paths.values())
for key, path in list(self.extracted_paths.items()):
if path in paths_to_delete and os.path.isfile(path):
os.remove(path)
del self.extracted_paths[key]
def manage_extracted_files(self):
if self.download_config.delete_extracted:
self.delete_extracted_files()
| datasets/src/datasets/download/download_manager.py/0 | {
"file_path": "datasets/src/datasets/download/download_manager.py",
"repo_id": "datasets",
"token_count": 9779
} | 70 |
# Copyright 2020 The HuggingFace Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import sys
from collections.abc import Mapping
import numpy as np
import pyarrow as pa
from .. import config
from ..utils.py_utils import map_nested
from .formatting import TensorFormatter
class NumpyFormatter(TensorFormatter[Mapping, np.ndarray, Mapping]):
def __init__(self, features=None, **np_array_kwargs):
super().__init__(features=features)
self.np_array_kwargs = np_array_kwargs
def _consolidate(self, column):
if isinstance(column, list):
if column and all(
isinstance(x, np.ndarray) and x.shape == column[0].shape and x.dtype == column[0].dtype for x in column
):
return np.stack(column)
else:
# don't use np.array(column, dtype=object)
# since it fails in certain cases
# see https://stackoverflow.com/q/51005699
out = np.empty(len(column), dtype=object)
out[:] = column
return out
return column
def _tensorize(self, value):
if isinstance(value, (str, bytes, type(None))):
return value
elif isinstance(value, (np.character, np.ndarray)) and np.issubdtype(value.dtype, np.character):
return value
elif isinstance(value, np.number):
return value
default_dtype = {}
if isinstance(value, np.ndarray) and np.issubdtype(value.dtype, np.integer):
default_dtype = {"dtype": np.int64}
elif isinstance(value, np.ndarray) and np.issubdtype(value.dtype, np.floating):
default_dtype = {"dtype": np.float32}
elif config.PIL_AVAILABLE and "PIL" in sys.modules:
import PIL.Image
if isinstance(value, PIL.Image.Image):
return np.asarray(value, **self.np_array_kwargs)
return np.asarray(value, **{**default_dtype, **self.np_array_kwargs})
def _recursive_tensorize(self, data_struct):
# support for torch, tf, jax etc.
if config.TORCH_AVAILABLE and "torch" in sys.modules:
import torch
if isinstance(data_struct, torch.Tensor):
return self._tensorize(data_struct.detach().cpu().numpy()[()])
if hasattr(data_struct, "__array__") and not isinstance(data_struct, (np.ndarray, np.character, np.number)):
data_struct = data_struct.__array__()
# support for nested types like struct of list of struct
if isinstance(data_struct, np.ndarray):
if data_struct.dtype == object:
return self._consolidate([self.recursive_tensorize(substruct) for substruct in data_struct])
if isinstance(data_struct, (list, tuple)):
return self._consolidate([self.recursive_tensorize(substruct) for substruct in data_struct])
return self._tensorize(data_struct)
def recursive_tensorize(self, data_struct: dict):
return map_nested(self._recursive_tensorize, data_struct, map_list=False)
def format_row(self, pa_table: pa.Table) -> Mapping:
row = self.numpy_arrow_extractor().extract_row(pa_table)
row = self.python_features_decoder.decode_row(row)
return self.recursive_tensorize(row)
def format_column(self, pa_table: pa.Table) -> np.ndarray:
column = self.numpy_arrow_extractor().extract_column(pa_table)
column = self.python_features_decoder.decode_column(column, pa_table.column_names[0])
column = self.recursive_tensorize(column)
column = self._consolidate(column)
return column
def format_batch(self, pa_table: pa.Table) -> Mapping:
batch = self.numpy_arrow_extractor().extract_batch(pa_table)
batch = self.python_features_decoder.decode_batch(batch)
batch = self.recursive_tensorize(batch)
for column_name in batch:
batch[column_name] = self._consolidate(batch[column_name])
return batch
| datasets/src/datasets/formatting/np_formatter.py/0 | {
"file_path": "datasets/src/datasets/formatting/np_formatter.py",
"repo_id": "datasets",
"token_count": 1871
} | 71 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""Access datasets."""
import filecmp
import glob
import importlib
import inspect
import json
import os
import posixpath
import shutil
import signal
import time
import warnings
from collections import Counter
from dataclasses import dataclass, field
from pathlib import Path
from typing import Any, Dict, List, Mapping, Optional, Sequence, Tuple, Type, Union
import fsspec
import requests
import yaml
from huggingface_hub import DatasetCard, DatasetCardData, HfApi, HfFileSystem
from . import config
from .arrow_dataset import Dataset
from .builder import BuilderConfig, DatasetBuilder
from .data_files import (
DEFAULT_PATTERNS_ALL,
DataFilesDict,
DataFilesList,
DataFilesPatternsDict,
DataFilesPatternsList,
EmptyDatasetError,
get_data_patterns,
get_metadata_patterns,
sanitize_patterns,
)
from .dataset_dict import DatasetDict, IterableDatasetDict
from .download.download_config import DownloadConfig
from .download.download_manager import DownloadMode
from .download.streaming_download_manager import StreamingDownloadManager, xbasename, xglob, xjoin
from .exceptions import DataFilesNotFoundError, DatasetNotFoundError
from .features import Features
from .fingerprint import Hasher
from .info import DatasetInfo, DatasetInfosDict
from .iterable_dataset import IterableDataset
from .metric import Metric
from .naming import camelcase_to_snakecase, snakecase_to_camelcase
from .packaged_modules import (
_EXTENSION_TO_MODULE,
_MODULE_SUPPORTS_METADATA,
_MODULE_TO_EXTENSIONS,
_PACKAGED_DATASETS_MODULES,
_hash_python_lines,
)
from .splits import Split
from .utils import _datasets_server
from .utils._filelock import FileLock
from .utils.deprecation_utils import deprecated
from .utils.file_utils import (
OfflineModeIsEnabled,
_raise_if_offline_mode_is_enabled,
cached_path,
head_hf_s3,
hf_github_url,
init_hf_modules,
is_relative_path,
relative_to_absolute_path,
url_or_path_join,
)
from .utils.hub import hf_hub_url
from .utils.info_utils import VerificationMode, is_small_dataset
from .utils.logging import get_logger
from .utils.metadata import MetadataConfigs
from .utils.py_utils import get_imports
from .utils.version import Version
logger = get_logger(__name__)
ALL_ALLOWED_EXTENSIONS = list(_EXTENSION_TO_MODULE.keys()) + [".zip"]
def _raise_timeout_error(signum, frame):
raise ValueError(
"Loading this dataset requires you to execute custom code contained in the dataset repository on your local "
"machine. Please set the option `trust_remote_code=True` to permit loading of this dataset."
)
def resolve_trust_remote_code(trust_remote_code: Optional[bool], repo_id: str) -> bool:
"""
Copied and adapted from Transformers
https://github.com/huggingface/transformers/blob/2098d343cc4b4b9d2aea84b3cf1eb5a1e610deff/src/transformers/dynamic_module_utils.py#L589
"""
trust_remote_code = trust_remote_code if trust_remote_code is not None else config.HF_DATASETS_TRUST_REMOTE_CODE
if trust_remote_code is None:
if config.TIME_OUT_REMOTE_CODE > 0:
try:
signal.signal(signal.SIGALRM, _raise_timeout_error)
signal.alarm(config.TIME_OUT_REMOTE_CODE)
while trust_remote_code is None:
answer = input(
f"The repository for {repo_id} contains custom code which must be executed to correctly "
f"load the dataset. You can inspect the repository content at https://hf.co/datasets/{repo_id}.\n"
f"You can avoid this prompt in future by passing the argument `trust_remote_code=True`.\n\n"
f"Do you wish to run the custom code? [y/N] "
)
if answer.lower() in ["yes", "y", "1"]:
trust_remote_code = True
elif answer.lower() in ["no", "n", "0", ""]:
trust_remote_code = False
signal.alarm(0)
except Exception:
# OS which does not support signal.SIGALRM
raise ValueError(
f"The repository for {repo_id} contains custom code which must be executed to correctly "
f"load the dataset. You can inspect the repository content at https://hf.co/datasets/{repo_id}.\n"
f"Please pass the argument `trust_remote_code=True` to allow custom code to be run."
)
else:
# For the CI which might put the timeout at 0
_raise_timeout_error(None, None)
return trust_remote_code
def init_dynamic_modules(
name: str = config.MODULE_NAME_FOR_DYNAMIC_MODULES, hf_modules_cache: Optional[Union[Path, str]] = None
):
"""
Create a module with name `name` in which you can add dynamic modules
such as metrics or datasets. The module can be imported using its name.
The module is created in the HF_MODULE_CACHE directory by default (~/.cache/huggingface/modules) but it can
be overridden by specifying a path to another directory in `hf_modules_cache`.
"""
hf_modules_cache = init_hf_modules(hf_modules_cache)
dynamic_modules_path = os.path.join(hf_modules_cache, name)
os.makedirs(dynamic_modules_path, exist_ok=True)
if not os.path.exists(os.path.join(dynamic_modules_path, "__init__.py")):
with open(os.path.join(dynamic_modules_path, "__init__.py"), "w"):
pass
return dynamic_modules_path
def import_main_class(module_path, dataset=True) -> Optional[Union[Type[DatasetBuilder], Type[Metric]]]:
"""Import a module at module_path and return its main class:
- a DatasetBuilder if dataset is True
- a Metric if dataset is False
"""
module = importlib.import_module(module_path)
if dataset:
main_cls_type = DatasetBuilder
else:
main_cls_type = Metric
# Find the main class in our imported module
module_main_cls = None
for name, obj in module.__dict__.items():
if inspect.isclass(obj) and issubclass(obj, main_cls_type):
if inspect.isabstract(obj):
continue
module_main_cls = obj
obj_module = inspect.getmodule(obj)
if obj_module is not None and module == obj_module:
break
return module_main_cls
class _InitializeConfiguredDatasetBuilder:
"""
From https://stackoverflow.com/questions/4647566/pickle-a-dynamically-parameterized-sub-class
See also ConfiguredDatasetBuilder.__reduce__
When called with the param value as the only argument, returns an
un-initialized instance of the parameterized class. Subsequent __setstate__
will be called by pickle.
"""
def __call__(self, builder_cls, metadata_configs, default_config_name, name):
# make a simple object which has no complex __init__ (this one will do)
obj = _InitializeConfiguredDatasetBuilder()
obj.__class__ = configure_builder_class(
builder_cls, metadata_configs, default_config_name=default_config_name, dataset_name=name
)
return obj
def configure_builder_class(
builder_cls: Type[DatasetBuilder],
builder_configs: List[BuilderConfig],
default_config_name: Optional[str],
dataset_name: str,
) -> Type[DatasetBuilder]:
"""
Dynamically create a builder class with custom builder configs parsed from README.md file,
i.e. set BUILDER_CONFIGS class variable of a builder class to custom configs list.
"""
class ConfiguredDatasetBuilder(builder_cls):
BUILDER_CONFIGS = builder_configs
DEFAULT_CONFIG_NAME = default_config_name
__module__ = builder_cls.__module__ # so that the actual packaged builder can be imported
def __reduce__(self): # to make dynamically created class pickable, see _InitializeParameterizedDatasetBuilder
parent_builder_cls = self.__class__.__mro__[1]
return (
_InitializeConfiguredDatasetBuilder(),
(
parent_builder_cls,
self.BUILDER_CONFIGS,
self.DEFAULT_CONFIG_NAME,
self.dataset_name,
),
self.__dict__.copy(),
)
ConfiguredDatasetBuilder.__name__ = (
f"{builder_cls.__name__.lower().capitalize()}{snakecase_to_camelcase(dataset_name)}"
)
ConfiguredDatasetBuilder.__qualname__ = (
f"{builder_cls.__name__.lower().capitalize()}{snakecase_to_camelcase(dataset_name)}"
)
return ConfiguredDatasetBuilder
def get_dataset_builder_class(
dataset_module: "DatasetModule", dataset_name: Optional[str] = None
) -> Type[DatasetBuilder]:
builder_cls = import_main_class(dataset_module.module_path)
if dataset_module.builder_configs_parameters.builder_configs:
dataset_name = dataset_name or dataset_module.builder_kwargs.get("dataset_name")
if dataset_name is None:
raise ValueError("dataset_name should be specified but got None")
builder_cls = configure_builder_class(
builder_cls,
builder_configs=dataset_module.builder_configs_parameters.builder_configs,
default_config_name=dataset_module.builder_configs_parameters.default_config_name,
dataset_name=dataset_name,
)
return builder_cls
def files_to_hash(file_paths: List[str]) -> str:
"""
Convert a list of scripts or text files provided in file_paths into a hashed filename in a repeatable way.
"""
# List all python files in directories if directories are supplied as part of external imports
to_use_files: List[Union[Path, str]] = []
for file_path in file_paths:
if os.path.isdir(file_path):
to_use_files.extend(list(Path(file_path).rglob("*.[pP][yY]")))
else:
to_use_files.append(file_path)
# Get the code from all these files
lines = []
for file_path in to_use_files:
with open(file_path, encoding="utf-8") as f:
lines.extend(f.readlines())
return _hash_python_lines(lines)
def increase_load_count(name: str, resource_type: str):
"""Update the download count of a dataset or metric."""
if not config.HF_DATASETS_OFFLINE and config.HF_UPDATE_DOWNLOAD_COUNTS:
try:
head_hf_s3(name, filename=name + ".py", dataset=(resource_type == "dataset"))
except Exception:
pass
def _download_additional_modules(
name: str, base_path: str, imports: Tuple[str, str, str, str], download_config: Optional[DownloadConfig]
) -> List[Tuple[str, str]]:
"""
Download additional module for a module <name>.py at URL (or local path) <base_path>/<name>.py
The imports must have been parsed first using ``get_imports``.
If some modules need to be installed with pip, an error is raised showing how to install them.
This function return the list of downloaded modules as tuples (import_name, module_file_path).
The downloaded modules can then be moved into an importable directory with ``_copy_script_and_other_resources_in_importable_dir``.
"""
local_imports = []
library_imports = []
download_config = download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading extra modules"
for import_type, import_name, import_path, sub_directory in imports:
if import_type == "library":
library_imports.append((import_name, import_path)) # Import from a library
continue
if import_name == name:
raise ValueError(
f"Error in the {name} script, importing relative {import_name} module "
f"but {import_name} is the name of the script. "
f"Please change relative import {import_name} to another name and add a '# From: URL_OR_PATH' "
f"comment pointing to the original relative import file path."
)
if import_type == "internal":
url_or_filename = url_or_path_join(base_path, import_path + ".py")
elif import_type == "external":
url_or_filename = import_path
else:
raise ValueError("Wrong import_type")
local_import_path = cached_path(
url_or_filename,
download_config=download_config,
)
if sub_directory is not None:
local_import_path = os.path.join(local_import_path, sub_directory)
local_imports.append((import_name, local_import_path))
# Check library imports
needs_to_be_installed = {}
for library_import_name, library_import_path in library_imports:
try:
lib = importlib.import_module(library_import_name) # noqa F841
except ImportError:
if library_import_name not in needs_to_be_installed or library_import_path != library_import_name:
needs_to_be_installed[library_import_name] = library_import_path
if needs_to_be_installed:
_dependencies_str = "dependencies" if len(needs_to_be_installed) > 1 else "dependency"
_them_str = "them" if len(needs_to_be_installed) > 1 else "it"
if "sklearn" in needs_to_be_installed.keys():
needs_to_be_installed["sklearn"] = "scikit-learn"
raise ImportError(
f"To be able to use {name}, you need to install the following {_dependencies_str}: "
f"{', '.join(needs_to_be_installed)}.\nPlease install {_them_str} using 'pip install "
f"{' '.join(needs_to_be_installed.values())}' for instance."
)
return local_imports
def _copy_script_and_other_resources_in_importable_dir(
name: str,
importable_directory_path: str,
subdirectory_name: str,
original_local_path: str,
local_imports: List[Tuple[str, str]],
additional_files: List[Tuple[str, str]],
download_mode: Optional[Union[DownloadMode, str]],
) -> str:
"""Copy a script and its required imports to an importable directory
Args:
name (str): name of the resource to load
importable_directory_path (str): path to the loadable folder in the dynamic modules directory
subdirectory_name (str): name of the subdirectory in importable_directory_path in which to place the script
original_local_path (str): local path to the resource script
local_imports (List[Tuple[str, str]]): list of (destination_filename, import_file_to_copy)
additional_files (List[Tuple[str, str]]): list of (destination_filename, additional_file_to_copy)
download_mode (Optional[Union[DownloadMode, str]]): download mode
Return:
importable_local_file: path to an importable module with importlib.import_module
"""
# Define a directory with a unique name in our dataset or metric folder
# path is: ./datasets|metrics/dataset|metric_name/hash_from_code/script.py
# we use a hash as subdirectory_name to be able to have multiple versions of a dataset/metric processing file together
importable_subdirectory = os.path.join(importable_directory_path, subdirectory_name)
importable_local_file = os.path.join(importable_subdirectory, name + ".py")
# Prevent parallel disk operations
lock_path = importable_directory_path + ".lock"
with FileLock(lock_path):
# Create main dataset/metrics folder if needed
if download_mode == DownloadMode.FORCE_REDOWNLOAD and os.path.exists(importable_directory_path):
shutil.rmtree(importable_directory_path)
os.makedirs(importable_directory_path, exist_ok=True)
# add an __init__ file to the main dataset folder if needed
init_file_path = os.path.join(importable_directory_path, "__init__.py")
if not os.path.exists(init_file_path):
with open(init_file_path, "w"):
pass
# Create hash dataset folder if needed
os.makedirs(importable_subdirectory, exist_ok=True)
# add an __init__ file to the hash dataset folder if needed
init_file_path = os.path.join(importable_subdirectory, "__init__.py")
if not os.path.exists(init_file_path):
with open(init_file_path, "w"):
pass
# Copy dataset.py file in hash folder if needed
if not os.path.exists(importable_local_file):
shutil.copyfile(original_local_path, importable_local_file)
# Record metadata associating original dataset path with local unique folder
# Use os.path.splitext to split extension from importable_local_file
meta_path = os.path.splitext(importable_local_file)[0] + ".json"
if not os.path.exists(meta_path):
meta = {"original file path": original_local_path, "local file path": importable_local_file}
# the filename is *.py in our case, so better rename to filename.json instead of filename.py.json
with open(meta_path, "w", encoding="utf-8") as meta_file:
json.dump(meta, meta_file)
# Copy all the additional imports
for import_name, import_path in local_imports:
if os.path.isfile(import_path):
full_path_local_import = os.path.join(importable_subdirectory, import_name + ".py")
if not os.path.exists(full_path_local_import):
shutil.copyfile(import_path, full_path_local_import)
elif os.path.isdir(import_path):
full_path_local_import = os.path.join(importable_subdirectory, import_name)
if not os.path.exists(full_path_local_import):
shutil.copytree(import_path, full_path_local_import)
else:
raise ImportError(f"Error with local import at {import_path}")
# Copy additional files like dataset_infos.json file if needed
for file_name, original_path in additional_files:
destination_additional_path = os.path.join(importable_subdirectory, file_name)
if not os.path.exists(destination_additional_path) or not filecmp.cmp(
original_path, destination_additional_path
):
shutil.copyfile(original_path, destination_additional_path)
return importable_local_file
def _get_importable_file_path(
dynamic_modules_path: str,
module_namespace: str,
subdirectory_name: str,
name: str,
) -> str:
importable_directory_path = os.path.join(dynamic_modules_path, module_namespace, name.replace("/", "--"))
return os.path.join(importable_directory_path, subdirectory_name, name + ".py")
def _create_importable_file(
local_path: str,
local_imports: List[Tuple[str, str]],
additional_files: List[Tuple[str, str]],
dynamic_modules_path: str,
module_namespace: str,
subdirectory_name: str,
name: str,
download_mode: DownloadMode,
) -> None:
importable_directory_path = os.path.join(dynamic_modules_path, module_namespace, name.replace("/", "--"))
Path(importable_directory_path).mkdir(parents=True, exist_ok=True)
(Path(importable_directory_path).parent / "__init__.py").touch(exist_ok=True)
importable_local_file = _copy_script_and_other_resources_in_importable_dir(
name=name.split("/")[-1],
importable_directory_path=importable_directory_path,
subdirectory_name=subdirectory_name,
original_local_path=local_path,
local_imports=local_imports,
additional_files=additional_files,
download_mode=download_mode,
)
logger.debug(f"Created importable dataset file at {importable_local_file}")
def _load_importable_file(
dynamic_modules_path: str,
module_namespace: str,
subdirectory_name: str,
name: str,
) -> Tuple[str, str]:
module_path = ".".join(
[
os.path.basename(dynamic_modules_path),
module_namespace,
name.replace("/", "--"),
subdirectory_name,
name.split("/")[-1],
]
)
return module_path, subdirectory_name
def infer_module_for_data_files_list(
data_files_list: DataFilesList, download_config: Optional[DownloadConfig] = None
) -> Tuple[Optional[str], dict]:
"""Infer module (and builder kwargs) from list of data files.
It picks the module based on the most common file extension.
In case of a draw ".parquet" is the favorite, and then alphabetical order.
Args:
data_files_list (DataFilesList): List of data files.
download_config (bool or str, optional): mainly use use_auth_token or storage_options to support different platforms and auth types.
Returns:
tuple[str, dict[str, Any]]: Tuple with
- inferred module name
- dict of builder kwargs
"""
extensions_counter = Counter(
("." + suffix.lower(), xbasename(filepath) in ("metadata.jsonl", "metadata.csv"))
for filepath in data_files_list[: config.DATA_FILES_MAX_NUMBER_FOR_MODULE_INFERENCE]
for suffix in xbasename(filepath).split(".")[1:]
)
if extensions_counter:
def sort_key(ext_count: Tuple[Tuple[str, bool], int]) -> Tuple[int, bool]:
"""Sort by count and set ".parquet" as the favorite in case of a draw, and ignore metadata files"""
(ext, is_metadata), count = ext_count
return (not is_metadata, count, ext == ".parquet", ext)
for (ext, _), _ in sorted(extensions_counter.items(), key=sort_key, reverse=True):
if ext in _EXTENSION_TO_MODULE:
return _EXTENSION_TO_MODULE[ext]
elif ext == ".zip":
return infer_module_for_data_files_list_in_archives(data_files_list, download_config=download_config)
return None, {}
def infer_module_for_data_files_list_in_archives(
data_files_list: DataFilesList, download_config: Optional[DownloadConfig] = None
) -> Tuple[Optional[str], dict]:
"""Infer module (and builder kwargs) from list of archive data files.
Args:
data_files_list (DataFilesList): List of data files.
download_config (bool or str, optional): mainly use use_auth_token or storage_options to support different platforms and auth types.
Returns:
tuple[str, dict[str, Any]]: Tuple with
- inferred module name
- dict of builder kwargs
"""
archived_files = []
archive_files_counter = 0
for filepath in data_files_list:
if str(filepath).endswith(".zip"):
archive_files_counter += 1
if archive_files_counter > config.GLOBBED_DATA_FILES_MAX_NUMBER_FOR_MODULE_INFERENCE:
break
extracted = xjoin(StreamingDownloadManager().extract(filepath), "**")
archived_files += [
f.split("::")[0]
for f in xglob(extracted, recursive=True, download_config=download_config)[
: config.ARCHIVED_DATA_FILES_MAX_NUMBER_FOR_MODULE_INFERENCE
]
]
extensions_counter = Counter(
"." + suffix.lower() for filepath in archived_files for suffix in xbasename(filepath).split(".")[1:]
)
if extensions_counter:
most_common = extensions_counter.most_common(1)[0][0]
if most_common in _EXTENSION_TO_MODULE:
return _EXTENSION_TO_MODULE[most_common]
return None, {}
def infer_module_for_data_files(
data_files: DataFilesDict, path: Optional[str] = None, download_config: Optional[DownloadConfig] = None
) -> Tuple[Optional[str], Dict[str, Any]]:
"""Infer module (and builder kwargs) from data files. Raise if module names for different splits don't match.
Args:
data_files ([`DataFilesDict`]): Dict of list of data files.
path (str, *optional*): Dataset name or path.
download_config ([`DownloadConfig`], *optional*):
Specific download configuration parameters to authenticate on the Hugging Face Hub for private remote files.
Returns:
tuple[str, dict[str, Any]]: Tuple with
- inferred module name
- builder kwargs
"""
split_modules = {
split: infer_module_for_data_files_list(data_files_list, download_config=download_config)
for split, data_files_list in data_files.items()
}
module_name, default_builder_kwargs = next(iter(split_modules.values()))
if any((module_name, default_builder_kwargs) != split_module for split_module in split_modules.values()):
raise ValueError(f"Couldn't infer the same data file format for all splits. Got {split_modules}")
if not module_name:
raise DataFilesNotFoundError("No (supported) data files found" + (f" in {path}" if path else ""))
return module_name, default_builder_kwargs
def create_builder_configs_from_metadata_configs(
module_path: str,
metadata_configs: MetadataConfigs,
supports_metadata: bool,
base_path: Optional[str] = None,
default_builder_kwargs: Dict[str, Any] = None,
download_config: Optional[DownloadConfig] = None,
) -> Tuple[List[BuilderConfig], str]:
builder_cls = import_main_class(module_path)
builder_config_cls = builder_cls.BUILDER_CONFIG_CLASS
default_config_name = metadata_configs.get_default_config_name()
builder_configs = []
default_builder_kwargs = {} if default_builder_kwargs is None else default_builder_kwargs
base_path = base_path if base_path is not None else ""
for config_name, config_params in metadata_configs.items():
config_data_files = config_params.get("data_files")
config_data_dir = config_params.get("data_dir")
config_base_path = xjoin(base_path, config_data_dir) if config_data_dir else base_path
try:
config_patterns = (
sanitize_patterns(config_data_files)
if config_data_files is not None
else get_data_patterns(config_base_path)
)
config_data_files_dict = DataFilesPatternsDict.from_patterns(
config_patterns,
allowed_extensions=ALL_ALLOWED_EXTENSIONS,
)
except EmptyDatasetError as e:
raise EmptyDatasetError(
f"Dataset at '{base_path}' doesn't contain data files matching the patterns for config '{config_name}',"
f" check `data_files` and `data_fir` parameters in the `configs` YAML field in README.md. "
) from e
if config_data_files is None and supports_metadata and config_patterns != DEFAULT_PATTERNS_ALL:
try:
config_metadata_patterns = get_metadata_patterns(base_path, download_config=download_config)
except FileNotFoundError:
config_metadata_patterns = None
if config_metadata_patterns is not None:
config_metadata_data_files_list = DataFilesPatternsList.from_patterns(config_metadata_patterns)
config_data_files_dict = DataFilesPatternsDict(
{
split: data_files_list + config_metadata_data_files_list
for split, data_files_list in config_data_files_dict.items()
}
)
ignored_params = [
param for param in config_params if not hasattr(builder_config_cls, param) and param != "default"
]
if ignored_params:
logger.warning(
f"Some datasets params were ignored: {ignored_params}. "
"Make sure to use only valid params for the dataset builder and to have "
"a up-to-date version of the `datasets` library."
)
builder_configs.append(
builder_config_cls(
name=config_name,
data_files=config_data_files_dict,
data_dir=config_data_dir,
**{
param: value
for param, value in {**default_builder_kwargs, **config_params}.items()
if hasattr(builder_config_cls, param) and param not in ("default", "data_files", "data_dir")
},
)
)
return builder_configs, default_config_name
@dataclass
class BuilderConfigsParameters:
"""Dataclass containing objects related to creation of builder configurations from yaml's metadata content.
Attributes:
metadata_configs (`MetadataConfigs`, *optional*):
Configs parsed from yaml's metadata.
builder_configs (`list[BuilderConfig]`, *optional*):
List of BuilderConfig objects created from metadata_configs above.
default_config_name (`str`):
Name of default config taken from yaml's metadata.
"""
metadata_configs: Optional[MetadataConfigs] = None
builder_configs: Optional[List[BuilderConfig]] = None
default_config_name: Optional[str] = None
@dataclass
class DatasetModule:
module_path: str
hash: str
builder_kwargs: dict
builder_configs_parameters: BuilderConfigsParameters = field(default_factory=BuilderConfigsParameters)
dataset_infos: Optional[DatasetInfosDict] = None
@dataclass
class MetricModule:
module_path: str
hash: str
class _DatasetModuleFactory:
def get_module(self) -> DatasetModule:
raise NotImplementedError
class _MetricModuleFactory:
def get_module(self) -> MetricModule:
raise NotImplementedError
class GithubMetricModuleFactory(_MetricModuleFactory):
"""Get the module of a metric. The metric script is downloaded from GitHub.
<Deprecated version="2.5.0">
Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate
</Deprecated>
"""
@deprecated("Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate")
def __init__(
self,
name: str,
revision: Optional[Union[str, Version]] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
dynamic_modules_path: Optional[str] = None,
trust_remote_code: Optional[str] = None,
):
self.name = name
self.revision = revision
self.download_config = download_config.copy() if download_config else DownloadConfig()
if self.download_config.max_retries < 3:
self.download_config.max_retries = 3
self.download_mode = download_mode
self.dynamic_modules_path = dynamic_modules_path
self.trust_remote_code = trust_remote_code
assert self.name.count("/") == 0
increase_load_count(name, resource_type="metric")
def download_loading_script(self, revision: Optional[str]) -> str:
file_path = hf_github_url(path=self.name, name=self.name + ".py", revision=revision, dataset=False)
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading builder script"
return cached_path(file_path, download_config=download_config)
def get_module(self) -> MetricModule:
if config.HF_DATASETS_TRUST_REMOTE_CODE and self.trust_remote_code is None:
_loading_script_url = hf_github_url(
path=self.name, name=self.name + ".py", revision=self.revision, dataset=False
)
warnings.warn(
f"The repository for {self.name} contains custom code which must be executed to correctly "
f"load the metric. You can inspect the repository content at {_loading_script_url}\n"
f"You can avoid this message in future by passing the argument `trust_remote_code=True`.\n"
f"Passing `trust_remote_code=True` will be mandatory to load this metric from the next major release of `datasets`.",
FutureWarning,
)
# get script and other files
revision = self.revision
try:
local_path = self.download_loading_script(revision)
revision = self.revision
except FileNotFoundError:
if revision is not None:
raise
else:
revision = "main"
local_path = self.download_loading_script(revision)
logger.warning(
f"Couldn't find a directory or a metric named '{self.name}' in this version. "
f"It was picked from the main branch on github instead."
)
imports = get_imports(local_path)
local_imports = _download_additional_modules(
name=self.name,
base_path=hf_github_url(path=self.name, name="", revision=revision, dataset=False),
imports=imports,
download_config=self.download_config,
)
# copy the script and the files in an importable directory
dynamic_modules_path = self.dynamic_modules_path if self.dynamic_modules_path else init_dynamic_modules()
hash = files_to_hash([local_path] + [loc[1] for loc in local_imports])
importable_file_path = _get_importable_file_path(
dynamic_modules_path=dynamic_modules_path,
module_namespace="metrics",
subdirectory_name=hash,
name=self.name,
)
if not os.path.exists(importable_file_path):
trust_remote_code = resolve_trust_remote_code(self.trust_remote_code, self.name)
if trust_remote_code:
_create_importable_file(
local_path=local_path,
local_imports=local_imports,
additional_files=[],
dynamic_modules_path=dynamic_modules_path,
module_namespace="metrics",
subdirectory_name=hash,
name=self.name,
download_mode=self.download_mode,
)
else:
raise ValueError(
f"Loading {self.name} requires you to execute the dataset script in that"
" repo on your local machine. Make sure you have read the code there to avoid malicious use, then"
" set the option `trust_remote_code=True` to remove this error."
)
module_path, hash = _load_importable_file(
dynamic_modules_path=dynamic_modules_path,
module_namespace="metrics",
subdirectory_name=hash,
name=self.name,
)
# make the new module to be noticed by the import system
importlib.invalidate_caches()
return MetricModule(module_path, hash)
class LocalMetricModuleFactory(_MetricModuleFactory):
"""Get the module of a local metric. The metric script is loaded from a local script.
<Deprecated version="2.5.0">
Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate
</Deprecated>
"""
@deprecated("Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate")
def __init__(
self,
path: str,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
dynamic_modules_path: Optional[str] = None,
trust_remote_code: Optional[str] = None,
):
self.path = path
self.name = Path(path).stem
self.download_config = download_config or DownloadConfig()
self.download_mode = download_mode
self.dynamic_modules_path = dynamic_modules_path
self.trust_remote_code = trust_remote_code
def get_module(self) -> MetricModule:
if config.HF_DATASETS_TRUST_REMOTE_CODE and self.trust_remote_code is None:
warnings.warn(
f"The repository for {self.name} contains custom code which must be executed to correctly "
f"load the metric. You can inspect the repository content at {self.path}\n"
f"You can avoid this message in future by passing the argument `trust_remote_code=True`.\n"
f"Passing `trust_remote_code=True` will be mandatory to load this metric from the next major release of `datasets`.",
FutureWarning,
)
# get script and other files
imports = get_imports(self.path)
local_imports = _download_additional_modules(
name=self.name,
base_path=str(Path(self.path).parent),
imports=imports,
download_config=self.download_config,
)
# copy the script and the files in an importable directory
dynamic_modules_path = self.dynamic_modules_path if self.dynamic_modules_path else init_dynamic_modules()
hash = files_to_hash([self.path] + [loc[1] for loc in local_imports])
importable_file_path = _get_importable_file_path(
dynamic_modules_path=dynamic_modules_path,
module_namespace="metrics",
subdirectory_name=hash,
name=self.name,
)
if not os.path.exists(importable_file_path):
trust_remote_code = resolve_trust_remote_code(self.trust_remote_code, self.name)
if trust_remote_code:
_create_importable_file(
local_path=self.path,
local_imports=local_imports,
additional_files=[],
dynamic_modules_path=dynamic_modules_path,
module_namespace="metrics",
subdirectory_name=hash,
name=self.name,
download_mode=self.download_mode,
)
else:
raise ValueError(
f"Loading {self.name} requires you to execute the dataset script in that"
" repo on your local machine. Make sure you have read the code there to avoid malicious use, then"
" set the option `trust_remote_code=True` to remove this error."
)
module_path, hash = _load_importable_file(
dynamic_modules_path=dynamic_modules_path,
module_namespace="metrics",
subdirectory_name=hash,
name=self.name,
)
# make the new module to be noticed by the import system
importlib.invalidate_caches()
return MetricModule(module_path, hash)
class LocalDatasetModuleFactoryWithScript(_DatasetModuleFactory):
"""Get the module of a local dataset. The dataset script is loaded from a local script."""
def __init__(
self,
path: str,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
dynamic_modules_path: Optional[str] = None,
trust_remote_code: Optional[bool] = None,
):
self.path = path
self.name = Path(path).stem
self.download_config = download_config or DownloadConfig()
self.download_mode = download_mode
self.dynamic_modules_path = dynamic_modules_path
self.trust_remote_code = trust_remote_code
def get_module(self) -> DatasetModule:
if config.HF_DATASETS_TRUST_REMOTE_CODE and self.trust_remote_code is None:
warnings.warn(
f"The repository for {self.name} contains custom code which must be executed to correctly "
f"load the dataset. You can inspect the repository content at {self.path}\n"
f"You can avoid this message in future by passing the argument `trust_remote_code=True`.\n"
f"Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.",
FutureWarning,
)
# get script and other files
dataset_infos_path = Path(self.path).parent / config.DATASETDICT_INFOS_FILENAME
dataset_readme_path = Path(self.path).parent / config.REPOCARD_FILENAME
imports = get_imports(self.path)
local_imports = _download_additional_modules(
name=self.name,
base_path=str(Path(self.path).parent),
imports=imports,
download_config=self.download_config,
)
additional_files = []
if dataset_infos_path.is_file():
additional_files.append((config.DATASETDICT_INFOS_FILENAME, str(dataset_infos_path)))
if dataset_readme_path.is_file():
additional_files.append((config.REPOCARD_FILENAME, dataset_readme_path))
# copy the script and the files in an importable directory
dynamic_modules_path = self.dynamic_modules_path if self.dynamic_modules_path else init_dynamic_modules()
hash = files_to_hash([self.path] + [loc[1] for loc in local_imports])
importable_file_path = _get_importable_file_path(
dynamic_modules_path=dynamic_modules_path,
module_namespace="datasets",
subdirectory_name=hash,
name=self.name,
)
if not os.path.exists(importable_file_path):
trust_remote_code = resolve_trust_remote_code(self.trust_remote_code, self.name)
if trust_remote_code:
_create_importable_file(
local_path=self.path,
local_imports=local_imports,
additional_files=additional_files,
dynamic_modules_path=dynamic_modules_path,
module_namespace="datasets",
subdirectory_name=hash,
name=self.name,
download_mode=self.download_mode,
)
else:
raise ValueError(
f"Loading {self.name} requires you to execute the dataset script in that"
" repo on your local machine. Make sure you have read the code there to avoid malicious use, then"
" set the option `trust_remote_code=True` to remove this error."
)
module_path, hash = _load_importable_file(
dynamic_modules_path=dynamic_modules_path,
module_namespace="datasets",
subdirectory_name=hash,
name=self.name,
)
# make the new module to be noticed by the import system
importlib.invalidate_caches()
builder_kwargs = {"base_path": str(Path(self.path).parent)}
return DatasetModule(module_path, hash, builder_kwargs)
class LocalDatasetModuleFactoryWithoutScript(_DatasetModuleFactory):
"""Get the module of a dataset loaded from the user's data files. The dataset builder module to use is inferred
from the data files extensions."""
def __init__(
self,
path: str,
data_dir: Optional[str] = None,
data_files: Optional[Union[str, List, Dict]] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
):
if data_dir and os.path.isabs(data_dir):
raise ValueError(f"`data_dir` must be relative to a dataset directory's root: {path}")
self.path = Path(path).as_posix()
self.name = Path(path).stem
self.data_files = data_files
self.data_dir = data_dir
self.download_mode = download_mode
def get_module(self) -> DatasetModule:
readme_path = os.path.join(self.path, config.REPOCARD_FILENAME)
standalone_yaml_path = os.path.join(self.path, config.REPOYAML_FILENAME)
dataset_card_data = DatasetCard.load(readme_path).data if os.path.isfile(readme_path) else DatasetCardData()
if os.path.exists(standalone_yaml_path):
with open(standalone_yaml_path, "r", encoding="utf-8") as f:
standalone_yaml_data = yaml.safe_load(f.read())
if standalone_yaml_data:
_dataset_card_data_dict = dataset_card_data.to_dict()
_dataset_card_data_dict.update(standalone_yaml_data)
dataset_card_data = DatasetCardData(**_dataset_card_data_dict)
metadata_configs = MetadataConfigs.from_dataset_card_data(dataset_card_data)
dataset_infos = DatasetInfosDict.from_dataset_card_data(dataset_card_data)
# we need a set of data files to find which dataset builder to use
# because we need to infer module name by files extensions
base_path = Path(self.path, self.data_dir or "").expanduser().resolve().as_posix()
if self.data_files is not None:
patterns = sanitize_patterns(self.data_files)
elif metadata_configs and "data_files" in next(iter(metadata_configs.values())):
patterns = sanitize_patterns(next(iter(metadata_configs.values()))["data_files"])
else:
patterns = get_data_patterns(base_path)
data_files = DataFilesDict.from_patterns(
patterns,
base_path=base_path,
allowed_extensions=ALL_ALLOWED_EXTENSIONS,
)
module_name, default_builder_kwargs = infer_module_for_data_files(
data_files=data_files,
path=self.path,
)
data_files = data_files.filter_extensions(_MODULE_TO_EXTENSIONS[module_name])
# Collect metadata files if the module supports them
supports_metadata = module_name in _MODULE_SUPPORTS_METADATA
if self.data_files is None and supports_metadata:
try:
metadata_patterns = get_metadata_patterns(base_path)
except FileNotFoundError:
metadata_patterns = None
if metadata_patterns is not None:
metadata_data_files_list = DataFilesList.from_patterns(metadata_patterns, base_path=base_path)
if metadata_data_files_list:
data_files = DataFilesDict(
{
split: data_files_list + metadata_data_files_list
for split, data_files_list in data_files.items()
}
)
module_path, _ = _PACKAGED_DATASETS_MODULES[module_name]
if metadata_configs:
builder_configs, default_config_name = create_builder_configs_from_metadata_configs(
module_path,
metadata_configs,
base_path=base_path,
supports_metadata=supports_metadata,
default_builder_kwargs=default_builder_kwargs,
)
else:
builder_configs: List[BuilderConfig] = [
import_main_class(module_path).BUILDER_CONFIG_CLASS(
data_files=data_files,
**default_builder_kwargs,
)
]
default_config_name = None
builder_kwargs = {
"base_path": self.path,
"dataset_name": camelcase_to_snakecase(Path(self.path).name),
}
# this file is deprecated and was created automatically in old versions of push_to_hub
if os.path.isfile(os.path.join(self.path, config.DATASETDICT_INFOS_FILENAME)):
with open(os.path.join(self.path, config.DATASETDICT_INFOS_FILENAME), encoding="utf-8") as f:
legacy_dataset_infos = DatasetInfosDict(
{
config_name: DatasetInfo.from_dict(dataset_info_dict)
for config_name, dataset_info_dict in json.load(f).items()
}
)
if len(legacy_dataset_infos) == 1:
# old config e.g. named "username--dataset_name"
legacy_config_name = next(iter(legacy_dataset_infos))
legacy_dataset_infos["default"] = legacy_dataset_infos.pop(legacy_config_name)
legacy_dataset_infos.update(dataset_infos)
dataset_infos = legacy_dataset_infos
if default_config_name is None and len(dataset_infos) == 1:
default_config_name = next(iter(dataset_infos))
hash = Hasher.hash({"dataset_infos": dataset_infos, "builder_configs": builder_configs})
return DatasetModule(
module_path,
hash,
builder_kwargs,
dataset_infos=dataset_infos,
builder_configs_parameters=BuilderConfigsParameters(
metadata_configs=metadata_configs,
builder_configs=builder_configs,
default_config_name=default_config_name,
),
)
class PackagedDatasetModuleFactory(_DatasetModuleFactory):
"""Get the dataset builder module from the ones that are packaged with the library: csv, json, etc."""
def __init__(
self,
name: str,
data_dir: Optional[str] = None,
data_files: Optional[Union[str, List, Dict]] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
):
self.name = name
self.data_files = data_files
self.data_dir = data_dir
self.download_config = download_config
self.download_mode = download_mode
increase_load_count(name, resource_type="dataset")
def get_module(self) -> DatasetModule:
base_path = Path(self.data_dir or "").expanduser().resolve().as_posix()
patterns = sanitize_patterns(self.data_files) if self.data_files is not None else get_data_patterns(base_path)
data_files = DataFilesDict.from_patterns(
patterns,
download_config=self.download_config,
base_path=base_path,
)
supports_metadata = self.name in _MODULE_SUPPORTS_METADATA
if self.data_files is None and supports_metadata and patterns != DEFAULT_PATTERNS_ALL:
try:
metadata_patterns = get_metadata_patterns(base_path, download_config=self.download_config)
except FileNotFoundError:
metadata_patterns = None
if metadata_patterns is not None:
metadata_data_files_list = DataFilesList.from_patterns(
metadata_patterns, download_config=self.download_config, base_path=base_path
)
if metadata_data_files_list:
data_files = DataFilesDict(
{
split: data_files_list + metadata_data_files_list
for split, data_files_list in data_files.items()
}
)
module_path, hash = _PACKAGED_DATASETS_MODULES[self.name]
builder_kwargs = {
"data_files": data_files,
"dataset_name": self.name,
}
return DatasetModule(module_path, hash, builder_kwargs)
class HubDatasetModuleFactoryWithoutScript(_DatasetModuleFactory):
"""
Get the module of a dataset loaded from data files of a dataset repository.
The dataset builder module to use is inferred from the data files extensions.
"""
def __init__(
self,
name: str,
revision: Optional[Union[str, Version]] = None,
data_dir: Optional[str] = None,
data_files: Optional[Union[str, List, Dict]] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
):
self.name = name
self.revision = revision
self.data_files = data_files
self.data_dir = data_dir
self.download_config = download_config or DownloadConfig()
self.download_mode = download_mode
increase_load_count(name, resource_type="dataset")
def get_module(self) -> DatasetModule:
hfh_dataset_info = HfApi(config.HF_ENDPOINT).dataset_info(
self.name,
revision=self.revision,
token=self.download_config.token,
timeout=100.0,
)
# even if metadata_configs is not None (which means that we will resolve files for each config later)
# we cannot skip resolving all files because we need to infer module name by files extensions
revision = hfh_dataset_info.sha # fix the revision in case there are new commits in the meantime
base_path = f"hf://datasets/{self.name}@{revision}/{self.data_dir or ''}".rstrip("/")
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading readme"
try:
dataset_readme_path = cached_path(
hf_hub_url(self.name, config.REPOCARD_FILENAME, revision=revision),
download_config=download_config,
)
dataset_card_data = DatasetCard.load(Path(dataset_readme_path)).data
except FileNotFoundError:
dataset_card_data = DatasetCardData()
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading standalone yaml"
try:
standalone_yaml_path = cached_path(
hf_hub_url(self.name, config.REPOYAML_FILENAME, revision=revision),
download_config=download_config,
)
with open(standalone_yaml_path, "r", encoding="utf-8") as f:
standalone_yaml_data = yaml.safe_load(f.read())
if standalone_yaml_data:
_dataset_card_data_dict = dataset_card_data.to_dict()
_dataset_card_data_dict.update(standalone_yaml_data)
dataset_card_data = DatasetCardData(**_dataset_card_data_dict)
except FileNotFoundError:
pass
metadata_configs = MetadataConfigs.from_dataset_card_data(dataset_card_data)
dataset_infos = DatasetInfosDict.from_dataset_card_data(dataset_card_data)
# we need a set of data files to find which dataset builder to use
# because we need to infer module name by files extensions
if self.data_files is not None:
patterns = sanitize_patterns(self.data_files)
elif metadata_configs and "data_files" in next(iter(metadata_configs.values())):
patterns = sanitize_patterns(next(iter(metadata_configs.values()))["data_files"])
else:
patterns = get_data_patterns(base_path, download_config=self.download_config)
data_files = DataFilesDict.from_patterns(
patterns,
base_path=base_path,
allowed_extensions=ALL_ALLOWED_EXTENSIONS,
download_config=self.download_config,
)
module_name, default_builder_kwargs = infer_module_for_data_files(
data_files=data_files,
path=self.name,
download_config=self.download_config,
)
data_files = data_files.filter_extensions(_MODULE_TO_EXTENSIONS[module_name])
# Collect metadata files if the module supports them
supports_metadata = module_name in _MODULE_SUPPORTS_METADATA
if self.data_files is None and supports_metadata:
try:
metadata_patterns = get_metadata_patterns(base_path, download_config=self.download_config)
except FileNotFoundError:
metadata_patterns = None
if metadata_patterns is not None:
metadata_data_files_list = DataFilesList.from_patterns(
metadata_patterns, download_config=self.download_config, base_path=base_path
)
if metadata_data_files_list:
data_files = DataFilesDict(
{
split: data_files_list + metadata_data_files_list
for split, data_files_list in data_files.items()
}
)
module_path, _ = _PACKAGED_DATASETS_MODULES[module_name]
if metadata_configs:
builder_configs, default_config_name = create_builder_configs_from_metadata_configs(
module_path,
metadata_configs,
base_path=base_path,
supports_metadata=supports_metadata,
default_builder_kwargs=default_builder_kwargs,
download_config=self.download_config,
)
else:
builder_configs: List[BuilderConfig] = [
import_main_class(module_path).BUILDER_CONFIG_CLASS(
data_files=data_files,
**default_builder_kwargs,
)
]
default_config_name = None
builder_kwargs = {
"base_path": hf_hub_url(self.name, "", revision=revision).rstrip("/"),
"repo_id": self.name,
"dataset_name": camelcase_to_snakecase(Path(self.name).name),
}
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading metadata"
try:
# this file is deprecated and was created automatically in old versions of push_to_hub
dataset_infos_path = cached_path(
hf_hub_url(self.name, config.DATASETDICT_INFOS_FILENAME, revision=revision),
download_config=download_config,
)
with open(dataset_infos_path, encoding="utf-8") as f:
legacy_dataset_infos = DatasetInfosDict(
{
config_name: DatasetInfo.from_dict(dataset_info_dict)
for config_name, dataset_info_dict in json.load(f).items()
}
)
if len(legacy_dataset_infos) == 1:
# old config e.g. named "username--dataset_name"
legacy_config_name = next(iter(legacy_dataset_infos))
legacy_dataset_infos["default"] = legacy_dataset_infos.pop(legacy_config_name)
legacy_dataset_infos.update(dataset_infos)
dataset_infos = legacy_dataset_infos
except FileNotFoundError:
pass
if default_config_name is None and len(dataset_infos) == 1:
default_config_name = next(iter(dataset_infos))
hash = revision
return DatasetModule(
module_path,
hash,
builder_kwargs,
dataset_infos=dataset_infos,
builder_configs_parameters=BuilderConfigsParameters(
metadata_configs=metadata_configs,
builder_configs=builder_configs,
default_config_name=default_config_name,
),
)
class HubDatasetModuleFactoryWithParquetExport(_DatasetModuleFactory):
"""
Get the module of a dataset loaded from parquet files of a dataset repository parquet export.
"""
def __init__(
self,
name: str,
revision: Optional[str] = None,
download_config: Optional[DownloadConfig] = None,
):
self.name = name
self.revision = revision
self.download_config = download_config or DownloadConfig()
increase_load_count(name, resource_type="dataset")
def get_module(self) -> DatasetModule:
exported_parquet_files = _datasets_server.get_exported_parquet_files(
dataset=self.name, revision=self.revision, token=self.download_config.token
)
exported_dataset_infos = _datasets_server.get_exported_dataset_infos(
dataset=self.name, revision=self.revision, token=self.download_config.token
)
dataset_infos = DatasetInfosDict(
{
config_name: DatasetInfo.from_dict(exported_dataset_infos[config_name])
for config_name in exported_dataset_infos
}
)
hfh_dataset_info = HfApi(config.HF_ENDPOINT).dataset_info(
self.name,
revision="refs/convert/parquet",
token=self.download_config.token,
timeout=100.0,
)
revision = hfh_dataset_info.sha # fix the revision in case there are new commits in the meantime
metadata_configs = MetadataConfigs._from_exported_parquet_files_and_dataset_infos(
revision=revision, exported_parquet_files=exported_parquet_files, dataset_infos=dataset_infos
)
module_path, _ = _PACKAGED_DATASETS_MODULES["parquet"]
builder_configs, default_config_name = create_builder_configs_from_metadata_configs(
module_path,
metadata_configs,
supports_metadata=False,
download_config=self.download_config,
)
hash = self.revision
builder_kwargs = {
"repo_id": self.name,
"dataset_name": camelcase_to_snakecase(Path(self.name).name),
}
return DatasetModule(
module_path,
hash,
builder_kwargs,
dataset_infos=dataset_infos,
builder_configs_parameters=BuilderConfigsParameters(
metadata_configs=metadata_configs,
builder_configs=builder_configs,
default_config_name=default_config_name,
),
)
class HubDatasetModuleFactoryWithScript(_DatasetModuleFactory):
"""
Get the module of a dataset from a dataset repository.
The dataset script comes from the script inside the dataset repository.
"""
def __init__(
self,
name: str,
revision: Optional[Union[str, Version]] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
dynamic_modules_path: Optional[str] = None,
trust_remote_code: Optional[bool] = None,
):
self.name = name
self.revision = revision
self.download_config = download_config or DownloadConfig()
self.download_mode = download_mode
self.dynamic_modules_path = dynamic_modules_path
self.trust_remote_code = trust_remote_code
increase_load_count(name, resource_type="dataset")
def download_loading_script(self) -> str:
file_path = hf_hub_url(self.name, self.name.split("/")[-1] + ".py", revision=self.revision)
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading builder script"
return cached_path(file_path, download_config=download_config)
def download_dataset_infos_file(self) -> str:
dataset_infos = hf_hub_url(self.name, config.DATASETDICT_INFOS_FILENAME, revision=self.revision)
# Download the dataset infos file if available
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading metadata"
try:
return cached_path(
dataset_infos,
download_config=download_config,
)
except (FileNotFoundError, ConnectionError):
return None
def download_dataset_readme_file(self) -> str:
readme_url = hf_hub_url(self.name, config.REPOCARD_FILENAME, revision=self.revision)
# Download the dataset infos file if available
download_config = self.download_config.copy()
if download_config.download_desc is None:
download_config.download_desc = "Downloading readme"
try:
return cached_path(
readme_url,
download_config=download_config,
)
except (FileNotFoundError, ConnectionError):
return None
def get_module(self) -> DatasetModule:
if config.HF_DATASETS_TRUST_REMOTE_CODE and self.trust_remote_code is None:
warnings.warn(
f"The repository for {self.name} contains custom code which must be executed to correctly "
f"load the dataset. You can inspect the repository content at https://hf.co/datasets/{self.name}\n"
f"You can avoid this message in future by passing the argument `trust_remote_code=True`.\n"
f"Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.",
FutureWarning,
)
# get script and other files
local_path = self.download_loading_script()
dataset_infos_path = self.download_dataset_infos_file()
dataset_readme_path = self.download_dataset_readme_file()
imports = get_imports(local_path)
local_imports = _download_additional_modules(
name=self.name,
base_path=hf_hub_url(self.name, "", revision=self.revision),
imports=imports,
download_config=self.download_config,
)
additional_files = []
if dataset_infos_path:
additional_files.append((config.DATASETDICT_INFOS_FILENAME, dataset_infos_path))
if dataset_readme_path:
additional_files.append((config.REPOCARD_FILENAME, dataset_readme_path))
# copy the script and the files in an importable directory
dynamic_modules_path = self.dynamic_modules_path if self.dynamic_modules_path else init_dynamic_modules()
hash = files_to_hash([local_path] + [loc[1] for loc in local_imports])
importable_file_path = _get_importable_file_path(
dynamic_modules_path=dynamic_modules_path,
module_namespace="datasets",
subdirectory_name=hash,
name=self.name,
)
if not os.path.exists(importable_file_path):
trust_remote_code = resolve_trust_remote_code(self.trust_remote_code, self.name)
if trust_remote_code:
_create_importable_file(
local_path=local_path,
local_imports=local_imports,
additional_files=additional_files,
dynamic_modules_path=dynamic_modules_path,
module_namespace="datasets",
subdirectory_name=hash,
name=self.name,
download_mode=self.download_mode,
)
else:
raise ValueError(
f"Loading {self.name} requires you to execute the dataset script in that"
" repo on your local machine. Make sure you have read the code there to avoid malicious use, then"
" set the option `trust_remote_code=True` to remove this error."
)
module_path, hash = _load_importable_file(
dynamic_modules_path=dynamic_modules_path,
module_namespace="datasets",
subdirectory_name=hash,
name=self.name,
)
# make the new module to be noticed by the import system
importlib.invalidate_caches()
builder_kwargs = {
"base_path": hf_hub_url(self.name, "", revision=self.revision).rstrip("/"),
"repo_id": self.name,
}
return DatasetModule(module_path, hash, builder_kwargs)
class CachedDatasetModuleFactory(_DatasetModuleFactory):
"""
Get the module of a dataset that has been loaded once already and cached.
The script that is loaded from the cache is the most recent one with a matching name.
"""
def __init__(
self,
name: str,
cache_dir: Optional[str] = None,
dynamic_modules_path: Optional[str] = None,
):
self.name = name
self.cache_dir = cache_dir
self.dynamic_modules_path = dynamic_modules_path
assert self.name.count("/") <= 1
def get_module(self) -> DatasetModule:
dynamic_modules_path = self.dynamic_modules_path if self.dynamic_modules_path else init_dynamic_modules()
importable_directory_path = os.path.join(dynamic_modules_path, "datasets", self.name.replace("/", "--"))
hashes = (
[h for h in os.listdir(importable_directory_path) if len(h) == 64]
if os.path.isdir(importable_directory_path)
else None
)
if hashes:
# get most recent
def _get_modification_time(module_hash):
return (
(Path(importable_directory_path) / module_hash / (self.name.split("/")[-1] + ".py"))
.stat()
.st_mtime
)
hash = sorted(hashes, key=_get_modification_time)[-1]
warning_msg = (
f"Using the latest cached version of the module from {os.path.join(importable_directory_path, hash)} "
f"(last modified on {time.ctime(_get_modification_time(hash))}) since it "
f"couldn't be found locally at {self.name}"
)
if not config.HF_DATASETS_OFFLINE:
warning_msg += ", or remotely on the Hugging Face Hub."
logger.warning(warning_msg)
# make the new module to be noticed by the import system
module_path = ".".join(
[
os.path.basename(dynamic_modules_path),
"datasets",
self.name.replace("/", "--"),
hash,
self.name.split("/")[-1],
]
)
importlib.invalidate_caches()
builder_kwargs = {
"repo_id": self.name,
}
return DatasetModule(module_path, hash, builder_kwargs)
cache_dir = os.path.expanduser(str(self.cache_dir or config.HF_DATASETS_CACHE))
cached_datasets_directory_path_root = os.path.join(cache_dir, self.name.replace("/", "___"))
cached_directory_paths = [
cached_directory_path
for cached_directory_path in glob.glob(os.path.join(cached_datasets_directory_path_root, "*", "*", "*"))
if os.path.isdir(cached_directory_path)
]
if cached_directory_paths:
builder_kwargs = {
"repo_id": self.name,
"dataset_name": self.name.split("/")[-1],
}
warning_msg = f"Using the latest cached version of the dataset since {self.name} couldn't be found on the Hugging Face Hub"
if config.HF_DATASETS_OFFLINE:
warning_msg += " (offline mode is enabled)."
logger.warning(warning_msg)
return DatasetModule(
"datasets.packaged_modules.cache.cache",
"auto",
{**builder_kwargs, "version": "auto"},
)
raise FileNotFoundError(f"Dataset {self.name} is not cached in {self.cache_dir}")
class CachedMetricModuleFactory(_MetricModuleFactory):
"""
Get the module of a metric that has been loaded once already and cached.
The script that is loaded from the cache is the most recent one with a matching name.
<Deprecated version="2.5.0">
Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate
</Deprecated>
"""
@deprecated("Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate")
def __init__(
self,
name: str,
dynamic_modules_path: Optional[str] = None,
):
self.name = name
self.dynamic_modules_path = dynamic_modules_path
assert self.name.count("/") == 0
def get_module(self) -> MetricModule:
dynamic_modules_path = self.dynamic_modules_path if self.dynamic_modules_path else init_dynamic_modules()
importable_directory_path = os.path.join(dynamic_modules_path, "metrics", self.name)
hashes = (
[h for h in os.listdir(importable_directory_path) if len(h) == 64]
if os.path.isdir(importable_directory_path)
else None
)
if not hashes:
raise FileNotFoundError(f"Metric {self.name} is not cached in {dynamic_modules_path}")
# get most recent
def _get_modification_time(module_hash):
return (Path(importable_directory_path) / module_hash / (self.name + ".py")).stat().st_mtime
hash = sorted(hashes, key=_get_modification_time)[-1]
logger.warning(
f"Using the latest cached version of the module from {os.path.join(importable_directory_path, hash)} "
f"(last modified on {time.ctime(_get_modification_time(hash))}) since it "
f"couldn't be found locally at {self.name}, or remotely on the Hugging Face Hub."
)
# make the new module to be noticed by the import system
module_path = ".".join([os.path.basename(dynamic_modules_path), "metrics", self.name, hash, self.name])
importlib.invalidate_caches()
return MetricModule(module_path, hash)
def dataset_module_factory(
path: str,
revision: Optional[Union[str, Version]] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
dynamic_modules_path: Optional[str] = None,
data_dir: Optional[str] = None,
data_files: Optional[Union[Dict, List, str, DataFilesDict]] = None,
cache_dir: Optional[str] = None,
trust_remote_code: Optional[bool] = None,
_require_default_config_name=True,
_require_custom_configs=False,
**download_kwargs,
) -> DatasetModule:
"""
Download/extract/cache a dataset module.
Dataset codes are cached inside the dynamic modules cache to allow easy import (avoid ugly sys.path tweaks).
Args:
path (str): Path or name of the dataset.
Depending on ``path``, the dataset builder that is used comes from a generic dataset script (JSON, CSV, Parquet, text etc.) or from the dataset script (a python file) inside the dataset directory.
For local datasets:
- if ``path`` is a local directory (containing data files only)
-> load a generic dataset builder (csv, json, text etc.) based on the content of the directory
e.g. ``'./path/to/directory/with/my/csv/data'``.
- if ``path`` is a local dataset script or a directory containing a local dataset script (if the script has the same name as the directory):
-> load the dataset builder from the dataset script
e.g. ``'./dataset/squad'`` or ``'./dataset/squad/squad.py'``.
For datasets on the Hugging Face Hub (list all available datasets with ``huggingface_hub.list_datasets()``)
- if ``path`` is a dataset repository on the HF hub (containing data files only)
-> load a generic dataset builder (csv, text etc.) based on the content of the repository
e.g. ``'username/dataset_name'``, a dataset repository on the HF hub containing your data files.
- if ``path`` is a dataset repository on the HF hub with a dataset script (if the script has the same name as the directory)
-> load the dataset builder from the dataset script in the dataset repository
e.g. ``glue``, ``squad``, ``'username/dataset_name'``, a dataset repository on the HF hub containing a dataset script `'dataset_name.py'`.
revision (:class:`~utils.Version` or :obj:`str`, optional): Version of the dataset script to load.
As datasets have their own git repository on the Datasets Hub, the default version "main" corresponds to their "main" branch.
You can specify a different version than the default "main" by using a commit SHA or a git tag of the dataset repository.
download_config (:class:`DownloadConfig`, optional): Specific download configuration parameters.
download_mode (:class:`DownloadMode` or :obj:`str`, default ``REUSE_DATASET_IF_EXISTS``): Download/generate mode.
dynamic_modules_path (Optional str, defaults to HF_MODULES_CACHE / "datasets_modules", i.e. ~/.cache/huggingface/modules/datasets_modules):
Optional path to the directory in which the dynamic modules are saved. It must have been initialized with :obj:`init_dynamic_modules`.
By default, the datasets and metrics are stored inside the `datasets_modules` module.
data_dir (:obj:`str`, optional): Directory with the data files. Used only if `data_files` is not specified,
in which case it's equal to pass `os.path.join(data_dir, "**")` as `data_files`.
data_files (:obj:`Union[Dict, List, str]`, optional): Defining the data_files of the dataset configuration.
cache_dir (`str`, *optional*):
Directory to read/write data. Defaults to `"~/.cache/huggingface/datasets"`.
<Added version="2.16.0"/>
trust_remote_code (`bool`, defaults to `True`):
Whether or not to allow for datasets defined on the Hub using a dataset script. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
<Tip warning={true}>
`trust_remote_code` will default to False in the next major release.
</Tip>
<Added version="2.16.0"/>
**download_kwargs (additional keyword arguments): optional attributes for DownloadConfig() which will override
the attributes in download_config if supplied.
Returns:
DatasetModule
"""
if download_config is None:
download_config = DownloadConfig(**download_kwargs)
download_mode = DownloadMode(download_mode or DownloadMode.REUSE_DATASET_IF_EXISTS)
download_config.extract_compressed_file = True
download_config.force_extract = True
download_config.force_download = download_mode == DownloadMode.FORCE_REDOWNLOAD
filename = list(filter(lambda x: x, path.replace(os.sep, "/").split("/")))[-1]
if not filename.endswith(".py"):
filename = filename + ".py"
combined_path = os.path.join(path, filename)
# We have several ways to get a dataset builder:
#
# - if path is the name of a packaged dataset module
# -> use the packaged module (json, csv, etc.)
#
# - if os.path.join(path, name) is a local python file
# -> use the module from the python file
# - if path is a local directory (but no python file)
# -> use a packaged module (csv, text etc.) based on content of the directory
#
# - if path has one "/" and is dataset repository on the HF hub with a python file
# -> the module from the python file in the dataset repository
# - if path has one "/" and is dataset repository on the HF hub without a python file
# -> use a packaged module (csv, text etc.) based on content of the repository
# Try packaged
if path in _PACKAGED_DATASETS_MODULES:
return PackagedDatasetModuleFactory(
path,
data_dir=data_dir,
data_files=data_files,
download_config=download_config,
download_mode=download_mode,
).get_module()
# Try locally
elif path.endswith(filename):
if os.path.isfile(path):
return LocalDatasetModuleFactoryWithScript(
path,
download_mode=download_mode,
dynamic_modules_path=dynamic_modules_path,
trust_remote_code=trust_remote_code,
).get_module()
else:
raise FileNotFoundError(f"Couldn't find a dataset script at {relative_to_absolute_path(path)}")
elif os.path.isfile(combined_path):
return LocalDatasetModuleFactoryWithScript(
combined_path,
download_mode=download_mode,
dynamic_modules_path=dynamic_modules_path,
trust_remote_code=trust_remote_code,
).get_module()
elif os.path.isdir(path):
return LocalDatasetModuleFactoryWithoutScript(
path, data_dir=data_dir, data_files=data_files, download_mode=download_mode
).get_module()
# Try remotely
elif is_relative_path(path) and path.count("/") <= 1:
try:
_raise_if_offline_mode_is_enabled()
hf_api = HfApi(config.HF_ENDPOINT)
try:
dataset_info = hf_api.dataset_info(
repo_id=path,
revision=revision,
token=download_config.token,
timeout=100.0,
)
except Exception as e: # noqa catch any exception of hf_hub and consider that the dataset doesn't exist
if isinstance(
e,
(
OfflineModeIsEnabled,
requests.exceptions.ConnectTimeout,
requests.exceptions.ConnectionError,
),
):
raise ConnectionError(f"Couldn't reach '{path}' on the Hub ({type(e).__name__})")
elif "404" in str(e):
msg = f"Dataset '{path}' doesn't exist on the Hub"
raise DatasetNotFoundError(msg + f" at revision '{revision}'" if revision else msg)
elif "401" in str(e):
msg = f"Dataset '{path}' doesn't exist on the Hub"
msg = msg + f" at revision '{revision}'" if revision else msg
raise DatasetNotFoundError(
msg + ". If the repo is private or gated, make sure to log in with `huggingface-cli login`."
)
else:
raise e
if filename in [sibling.rfilename for sibling in dataset_info.siblings]: # contains a dataset script
fs = HfFileSystem(endpoint=config.HF_ENDPOINT, token=download_config.token)
if _require_custom_configs or (revision and revision != "main"):
can_load_config_from_parquet_export = False
elif _require_default_config_name:
with fs.open(f"datasets/{path}/{filename}", "r", encoding="utf-8") as f:
can_load_config_from_parquet_export = "DEFAULT_CONFIG_NAME" not in f.read()
else:
can_load_config_from_parquet_export = True
if config.USE_PARQUET_EXPORT and can_load_config_from_parquet_export:
# If the parquet export is ready (parquet files + info available for the current sha), we can use it instead
# This fails when the dataset has multiple configs and a default config and
# the user didn't specify a configuration name (_require_default_config_name=True).
try:
return HubDatasetModuleFactoryWithParquetExport(
path, download_config=download_config, revision=dataset_info.sha
).get_module()
except _datasets_server.DatasetsServerError:
pass
# Otherwise we must use the dataset script if the user trusts it
return HubDatasetModuleFactoryWithScript(
path,
revision=revision,
download_config=download_config,
download_mode=download_mode,
dynamic_modules_path=dynamic_modules_path,
trust_remote_code=trust_remote_code,
).get_module()
else:
return HubDatasetModuleFactoryWithoutScript(
path,
revision=revision,
data_dir=data_dir,
data_files=data_files,
download_config=download_config,
download_mode=download_mode,
).get_module()
except Exception as e1:
# All the attempts failed, before raising the error we should check if the module is already cached
try:
return CachedDatasetModuleFactory(
path, dynamic_modules_path=dynamic_modules_path, cache_dir=cache_dir
).get_module()
except Exception:
# If it's not in the cache, then it doesn't exist.
if isinstance(e1, OfflineModeIsEnabled):
raise ConnectionError(f"Couldn't reach the Hugging Face Hub for dataset '{path}': {e1}") from None
if isinstance(e1, (DataFilesNotFoundError, DatasetNotFoundError, EmptyDatasetError)):
raise e1 from None
if isinstance(e1, FileNotFoundError):
raise FileNotFoundError(
f"Couldn't find a dataset script at {relative_to_absolute_path(combined_path)} or any data file in the same directory. "
f"Couldn't find '{path}' on the Hugging Face Hub either: {type(e1).__name__}: {e1}"
) from None
raise e1 from None
else:
raise FileNotFoundError(
f"Couldn't find a dataset script at {relative_to_absolute_path(combined_path)} or any data file in the same directory."
)
@deprecated("Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate")
def metric_module_factory(
path: str,
revision: Optional[Union[str, Version]] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
dynamic_modules_path: Optional[str] = None,
trust_remote_code: Optional[bool] = None,
**download_kwargs,
) -> MetricModule:
"""
Download/extract/cache a metric module.
<Deprecated version="2.5.0">
Use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate
</Deprecated>
Metrics codes are cached inside the dynamic modules cache to allow easy import (avoid ugly sys.path tweaks).
Args:
path (str): Path or name of the metric script.
- if ``path`` is a local metric script or a directory containing a local metric script (if the script has the same name as the directory):
-> load the module from the metric script
e.g. ``'./metrics/accuracy'`` or ``'./metrics/accuracy/accuracy.py'``.
- if ``path`` is a metric on the Hugging Face Hub (ex: `glue`, `squad`)
-> load the module from the metric script in the GitHub repository at huggingface/datasets
e.g. ``'accuracy'`` or ``'rouge'``.
revision (Optional ``Union[str, datasets.Version]``):
If specified, the module will be loaded from the datasets repository at this version.
By default:
- it is set to the local version of the lib.
- it will also try to load it from the main branch if it's not available at the local version of the lib.
Specifying a version that is different from your local version of the lib might cause compatibility issues.
download_config (:class:`DownloadConfig`, optional): Specific download configuration parameters.
download_mode (:class:`DownloadMode` or :obj:`str`, default ``REUSE_DATASET_IF_EXISTS``): Download/generate mode.
dynamic_modules_path (Optional str, defaults to HF_MODULES_CACHE / "datasets_modules", i.e. ~/.cache/huggingface/modules/datasets_modules):
Optional path to the directory in which the dynamic modules are saved. It must have been initialized with :obj:`init_dynamic_modules`.
By default, the datasets and metrics are stored inside the `datasets_modules` module.
trust_remote_code (`bool`, defaults to `True`):
Whether or not to allow for datasets defined on the Hub using a dataset script. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
<Tip warning={true}>
`trust_remote_code` will default to False in the next major release.
</Tip>
<Added version="2.16.0"/>
**download_kwargs (additional keyword arguments): optional attributes for DownloadConfig() which will override
the attributes in download_config if supplied.
Returns:
MetricModule
"""
with warnings.catch_warnings():
# Ignore equivalent warnings to the one already issued
warnings.filterwarnings("ignore", message=".*https://huggingface.co/docs/evaluate$", category=FutureWarning)
if download_config is None:
download_config = DownloadConfig(**download_kwargs)
download_mode = DownloadMode(download_mode or DownloadMode.REUSE_DATASET_IF_EXISTS)
download_config.extract_compressed_file = True
download_config.force_extract = True
filename = list(filter(lambda x: x, path.replace(os.sep, "/").split("/")))[-1]
if not filename.endswith(".py"):
filename = filename + ".py"
combined_path = os.path.join(path, filename)
# Try locally
if path.endswith(filename):
if os.path.isfile(path):
return LocalMetricModuleFactory(
path,
download_mode=download_mode,
dynamic_modules_path=dynamic_modules_path,
trust_remote_code=trust_remote_code,
).get_module()
else:
raise FileNotFoundError(f"Couldn't find a metric script at {relative_to_absolute_path(path)}")
elif os.path.isfile(combined_path):
return LocalMetricModuleFactory(
combined_path, download_mode=download_mode, dynamic_modules_path=dynamic_modules_path
).get_module()
elif is_relative_path(path) and path.count("/") == 0:
try:
return GithubMetricModuleFactory(
path,
revision=revision,
download_config=download_config,
download_mode=download_mode,
dynamic_modules_path=dynamic_modules_path,
trust_remote_code=trust_remote_code,
).get_module()
except Exception as e1: # noqa all the attempts failed, before raising the error we should check if the module is already cached.
try:
return CachedMetricModuleFactory(path, dynamic_modules_path=dynamic_modules_path).get_module()
except Exception: # noqa if it's not in the cache, then it doesn't exist.
if not isinstance(e1, FileNotFoundError):
raise e1 from None
raise FileNotFoundError(
f"Couldn't find a metric script at {relative_to_absolute_path(combined_path)}. "
f"Metric '{path}' doesn't exist on the Hugging Face Hub either."
) from None
else:
raise FileNotFoundError(f"Couldn't find a metric script at {relative_to_absolute_path(combined_path)}.")
@deprecated("Use 'evaluate.load' instead, from the new library 🤗 Evaluate: https://huggingface.co/docs/evaluate")
def load_metric(
path: str,
config_name: Optional[str] = None,
process_id: int = 0,
num_process: int = 1,
cache_dir: Optional[str] = None,
experiment_id: Optional[str] = None,
keep_in_memory: bool = False,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
revision: Optional[Union[str, Version]] = None,
trust_remote_code: Optional[bool] = None,
**metric_init_kwargs,
) -> Metric:
"""Load a `datasets.Metric`.
<Deprecated version="2.5.0">
Use `evaluate.load` instead, from the new library 🤗 Evaluate: https://huggingface.co/docs/evaluate
</Deprecated>
Args:
path (``str``):
path to the metric processing script with the metric builder. Can be either:
- a local path to processing script or the directory containing the script (if the script has the same name as the directory),
e.g. ``'./metrics/rouge'`` or ``'./metrics/rogue/rouge.py'``
- a metric identifier on the HuggingFace datasets repo (list all available metrics with ``datasets.list_metrics()``)
e.g. ``'rouge'`` or ``'bleu'``
config_name (:obj:`str`, optional): selecting a configuration for the metric (e.g. the GLUE metric has a configuration for each subset)
process_id (:obj:`int`, optional): for distributed evaluation: id of the process
num_process (:obj:`int`, optional): for distributed evaluation: total number of processes
cache_dir (Optional str): path to store the temporary predictions and references (default to `~/.cache/huggingface/metrics/`)
experiment_id (``str``): A specific experiment id. This is used if several distributed evaluations share the same file system.
This is useful to compute metrics in distributed setups (in particular non-additive metrics like F1).
keep_in_memory (bool): Whether to store the temporary results in memory (defaults to False)
download_config (Optional ``datasets.DownloadConfig``: specific download configuration parameters.
download_mode (:class:`DownloadMode` or :obj:`str`, default ``REUSE_DATASET_IF_EXISTS``): Download/generate mode.
revision (Optional ``Union[str, datasets.Version]``): if specified, the module will be loaded from the datasets repository
at this version. By default, it is set to the local version of the lib. Specifying a version that is different from
your local version of the lib might cause compatibility issues.
trust_remote_code (`bool`, defaults to `True`):
Whether or not to allow for datasets defined on the Hub using a dataset script. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
<Tip warning={true}>
`trust_remote_code` will default to False in the next major release.
</Tip>
<Added version="2.16.0"/>
Returns:
`datasets.Metric`
Example:
```py
>>> from datasets import load_metric
>>> accuracy = load_metric('accuracy')
>>> accuracy.compute(references=[1, 0], predictions=[1, 1])
{'accuracy': 0.5}
```
"""
with warnings.catch_warnings():
# Ignore equivalent warnings to the one already issued
warnings.filterwarnings("ignore", message=".*https://huggingface.co/docs/evaluate$", category=FutureWarning)
download_mode = DownloadMode(download_mode or DownloadMode.REUSE_DATASET_IF_EXISTS)
metric_module = metric_module_factory(
path,
revision=revision,
download_config=download_config,
download_mode=download_mode,
trust_remote_code=trust_remote_code,
).module_path
metric_cls = import_main_class(metric_module, dataset=False)
metric = metric_cls(
config_name=config_name,
process_id=process_id,
num_process=num_process,
cache_dir=cache_dir,
keep_in_memory=keep_in_memory,
experiment_id=experiment_id,
**metric_init_kwargs,
)
# Download and prepare resources for the metric
metric.download_and_prepare(download_config=download_config)
return metric
def load_dataset_builder(
path: str,
name: Optional[str] = None,
data_dir: Optional[str] = None,
data_files: Optional[Union[str, Sequence[str], Mapping[str, Union[str, Sequence[str]]]]] = None,
cache_dir: Optional[str] = None,
features: Optional[Features] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
revision: Optional[Union[str, Version]] = None,
token: Optional[Union[bool, str]] = None,
use_auth_token="deprecated",
storage_options: Optional[Dict] = None,
trust_remote_code: Optional[bool] = None,
_require_default_config_name=True,
**config_kwargs,
) -> DatasetBuilder:
"""Load a dataset builder from the Hugging Face Hub, or a local dataset. A dataset builder can be used to inspect general information that is required to build a dataset (cache directory, config, dataset info, etc.)
without downloading the dataset itself.
You can find the list of datasets on the [Hub](https://huggingface.co/datasets) or with [`huggingface_hub.list_datasets`].
A dataset is a directory that contains:
- some data files in generic formats (JSON, CSV, Parquet, text, etc.)
- and optionally a dataset script, if it requires some code to read the data files. This is used to load any kind of formats or structures.
Note that dataset scripts can also download and read data files from anywhere - in case your data files already exist online.
Args:
path (`str`):
Path or name of the dataset.
Depending on `path`, the dataset builder that is used comes from a generic dataset script (JSON, CSV, Parquet, text etc.) or from the dataset script (a python file) inside the dataset directory.
For local datasets:
- if `path` is a local directory (containing data files only)
-> load a generic dataset builder (csv, json, text etc.) based on the content of the directory
e.g. `'./path/to/directory/with/my/csv/data'`.
- if `path` is a local dataset script or a directory containing a local dataset script (if the script has the same name as the directory)
-> load the dataset builder from the dataset script
e.g. `'./dataset/squad'` or `'./dataset/squad/squad.py'`.
For datasets on the Hugging Face Hub (list all available datasets with [`huggingface_hub.list_datasets`])
- if `path` is a dataset repository on the HF hub (containing data files only)
-> load a generic dataset builder (csv, text etc.) based on the content of the repository
e.g. `'username/dataset_name'`, a dataset repository on the HF hub containing your data files.
- if `path` is a dataset repository on the HF hub with a dataset script (if the script has the same name as the directory)
-> load the dataset builder from the dataset script in the dataset repository
e.g. `glue`, `squad`, `'username/dataset_name'`, a dataset repository on the HF hub containing a dataset script `'dataset_name.py'`.
name (`str`, *optional*):
Defining the name of the dataset configuration.
data_dir (`str`, *optional*):
Defining the `data_dir` of the dataset configuration. If specified for the generic builders (csv, text etc.) or the Hub datasets and `data_files` is `None`,
the behavior is equal to passing `os.path.join(data_dir, **)` as `data_files` to reference all the files in a directory.
data_files (`str` or `Sequence` or `Mapping`, *optional*):
Path(s) to source data file(s).
cache_dir (`str`, *optional*):
Directory to read/write data. Defaults to `"~/.cache/huggingface/datasets"`.
features ([`Features`], *optional*):
Set the features type to use for this dataset.
download_config ([`DownloadConfig`], *optional*):
Specific download configuration parameters.
download_mode ([`DownloadMode`] or `str`, defaults to `REUSE_DATASET_IF_EXISTS`):
Download/generate mode.
revision ([`Version`] or `str`, *optional*):
Version of the dataset script to load.
As datasets have their own git repository on the Datasets Hub, the default version "main" corresponds to their "main" branch.
You can specify a different version than the default "main" by using a commit SHA or a git tag of the dataset repository.
token (`str` or `bool`, *optional*):
Optional string or boolean to use as Bearer token for remote files on the Datasets Hub.
If `True`, or not specified, will get token from `"~/.huggingface"`.
use_auth_token (`str` or `bool`, *optional*):
Optional string or boolean to use as Bearer token for remote files on the Datasets Hub.
If `True`, or not specified, will get token from `"~/.huggingface"`.
<Deprecated version="2.14.0">
`use_auth_token` was deprecated in favor of `token` in version 2.14.0 and will be removed in 3.0.0.
</Deprecated>
storage_options (`dict`, *optional*, defaults to `None`):
**Experimental**. Key/value pairs to be passed on to the dataset file-system backend, if any.
<Added version="2.11.0"/>
trust_remote_code (`bool`, defaults to `True`):
Whether or not to allow for datasets defined on the Hub using a dataset script. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
<Tip warning={true}>
`trust_remote_code` will default to False in the next major release.
</Tip>
<Added version="2.16.0"/>
**config_kwargs (additional keyword arguments):
Keyword arguments to be passed to the [`BuilderConfig`]
and used in the [`DatasetBuilder`].
Returns:
[`DatasetBuilder`]
Example:
```py
>>> from datasets import load_dataset_builder
>>> ds_builder = load_dataset_builder('rotten_tomatoes')
>>> ds_builder.info.features
{'label': ClassLabel(num_classes=2, names=['neg', 'pos'], id=None),
'text': Value(dtype='string', id=None)}
```
"""
if use_auth_token != "deprecated":
warnings.warn(
"'use_auth_token' was deprecated in favor of 'token' in version 2.14.0 and will be removed in 3.0.0.\n"
"You can remove this warning by passing 'token=<use_auth_token>' instead.",
FutureWarning,
)
token = use_auth_token
download_mode = DownloadMode(download_mode or DownloadMode.REUSE_DATASET_IF_EXISTS)
if token is not None:
download_config = download_config.copy() if download_config else DownloadConfig()
download_config.token = token
if storage_options is not None:
download_config = download_config.copy() if download_config else DownloadConfig()
download_config.storage_options.update(storage_options)
dataset_module = dataset_module_factory(
path,
revision=revision,
download_config=download_config,
download_mode=download_mode,
data_dir=data_dir,
data_files=data_files,
cache_dir=cache_dir,
trust_remote_code=trust_remote_code,
_require_default_config_name=_require_default_config_name,
_require_custom_configs=bool(config_kwargs),
)
# Get dataset builder class from the processing script
builder_kwargs = dataset_module.builder_kwargs
data_dir = builder_kwargs.pop("data_dir", data_dir)
data_files = builder_kwargs.pop("data_files", data_files)
config_name = builder_kwargs.pop(
"config_name", name or dataset_module.builder_configs_parameters.default_config_name
)
dataset_name = builder_kwargs.pop("dataset_name", None)
info = dataset_module.dataset_infos.get(config_name) if dataset_module.dataset_infos else None
if (
path in _PACKAGED_DATASETS_MODULES
and data_files is None
and dataset_module.builder_configs_parameters.builder_configs[0].data_files is None
):
error_msg = f"Please specify the data files or data directory to load for the {path} dataset builder."
example_extensions = [
extension for extension in _EXTENSION_TO_MODULE if _EXTENSION_TO_MODULE[extension] == path
]
if example_extensions:
error_msg += f'\nFor example `data_files={{"train": "path/to/data/train/*.{example_extensions[0]}"}}`'
raise ValueError(error_msg)
builder_cls = get_dataset_builder_class(dataset_module, dataset_name=dataset_name)
# Instantiate the dataset builder
builder_instance: DatasetBuilder = builder_cls(
cache_dir=cache_dir,
dataset_name=dataset_name,
config_name=config_name,
data_dir=data_dir,
data_files=data_files,
hash=dataset_module.hash,
info=info,
features=features,
token=token,
storage_options=storage_options,
**builder_kwargs,
**config_kwargs,
)
builder_instance._use_legacy_cache_dir_if_possible(dataset_module)
return builder_instance
def load_dataset(
path: str,
name: Optional[str] = None,
data_dir: Optional[str] = None,
data_files: Optional[Union[str, Sequence[str], Mapping[str, Union[str, Sequence[str]]]]] = None,
split: Optional[Union[str, Split]] = None,
cache_dir: Optional[str] = None,
features: Optional[Features] = None,
download_config: Optional[DownloadConfig] = None,
download_mode: Optional[Union[DownloadMode, str]] = None,
verification_mode: Optional[Union[VerificationMode, str]] = None,
ignore_verifications="deprecated",
keep_in_memory: Optional[bool] = None,
save_infos: bool = False,
revision: Optional[Union[str, Version]] = None,
token: Optional[Union[bool, str]] = None,
use_auth_token="deprecated",
task="deprecated",
streaming: bool = False,
num_proc: Optional[int] = None,
storage_options: Optional[Dict] = None,
trust_remote_code: bool = None,
**config_kwargs,
) -> Union[DatasetDict, Dataset, IterableDatasetDict, IterableDataset]:
"""Load a dataset from the Hugging Face Hub, or a local dataset.
You can find the list of datasets on the [Hub](https://huggingface.co/datasets) or with [`huggingface_hub.list_datasets`].
A dataset is a directory that contains:
- some data files in generic formats (JSON, CSV, Parquet, text, etc.).
- and optionally a dataset script, if it requires some code to read the data files. This is used to load any kind of formats or structures.
Note that dataset scripts can also download and read data files from anywhere - in case your data files already exist online.
This function does the following under the hood:
1. Download and import in the library the dataset script from `path` if it's not already cached inside the library.
If the dataset has no dataset script, then a generic dataset script is imported instead (JSON, CSV, Parquet, text, etc.)
Dataset scripts are small python scripts that define dataset builders. They define the citation, info and format of the dataset,
contain the path or URL to the original data files and the code to load examples from the original data files.
You can find the complete list of datasets in the Datasets [Hub](https://huggingface.co/datasets).
2. Run the dataset script which will:
* Download the dataset file from the original URL (see the script) if it's not already available locally or cached.
* Process and cache the dataset in typed Arrow tables for caching.
Arrow table are arbitrarily long, typed tables which can store nested objects and be mapped to numpy/pandas/python generic types.
They can be directly accessed from disk, loaded in RAM or even streamed over the web.
3. Return a dataset built from the requested splits in `split` (default: all).
It also allows to load a dataset from a local directory or a dataset repository on the Hugging Face Hub without dataset script.
In this case, it automatically loads all the data files from the directory or the dataset repository.
Args:
path (`str`):
Path or name of the dataset.
Depending on `path`, the dataset builder that is used comes from a generic dataset script (JSON, CSV, Parquet, text etc.) or from the dataset script (a python file) inside the dataset directory.
For local datasets:
- if `path` is a local directory (containing data files only)
-> load a generic dataset builder (csv, json, text etc.) based on the content of the directory
e.g. `'./path/to/directory/with/my/csv/data'`.
- if `path` is a local dataset script or a directory containing a local dataset script (if the script has the same name as the directory)
-> load the dataset builder from the dataset script
e.g. `'./dataset/squad'` or `'./dataset/squad/squad.py'`.
For datasets on the Hugging Face Hub (list all available datasets with [`huggingface_hub.list_datasets`])
- if `path` is a dataset repository on the HF hub (containing data files only)
-> load a generic dataset builder (csv, text etc.) based on the content of the repository
e.g. `'username/dataset_name'`, a dataset repository on the HF hub containing your data files.
- if `path` is a dataset repository on the HF hub with a dataset script (if the script has the same name as the directory)
-> load the dataset builder from the dataset script in the dataset repository
e.g. `glue`, `squad`, `'username/dataset_name'`, a dataset repository on the HF hub containing a dataset script `'dataset_name.py'`.
name (`str`, *optional*):
Defining the name of the dataset configuration.
data_dir (`str`, *optional*):
Defining the `data_dir` of the dataset configuration. If specified for the generic builders (csv, text etc.) or the Hub datasets and `data_files` is `None`,
the behavior is equal to passing `os.path.join(data_dir, **)` as `data_files` to reference all the files in a directory.
data_files (`str` or `Sequence` or `Mapping`, *optional*):
Path(s) to source data file(s).
split (`Split` or `str`):
Which split of the data to load.
If `None`, will return a `dict` with all splits (typically `datasets.Split.TRAIN` and `datasets.Split.TEST`).
If given, will return a single Dataset.
Splits can be combined and specified like in tensorflow-datasets.
cache_dir (`str`, *optional*):
Directory to read/write data. Defaults to `"~/.cache/huggingface/datasets"`.
features (`Features`, *optional*):
Set the features type to use for this dataset.
download_config ([`DownloadConfig`], *optional*):
Specific download configuration parameters.
download_mode ([`DownloadMode`] or `str`, defaults to `REUSE_DATASET_IF_EXISTS`):
Download/generate mode.
verification_mode ([`VerificationMode`] or `str`, defaults to `BASIC_CHECKS`):
Verification mode determining the checks to run on the downloaded/processed dataset information (checksums/size/splits/...).
<Added version="2.9.1"/>
ignore_verifications (`bool`, defaults to `False`):
Ignore the verifications of the downloaded/processed dataset information (checksums/size/splits/...).
<Deprecated version="2.9.1">
`ignore_verifications` was deprecated in version 2.9.1 and will be removed in 3.0.0.
Please use `verification_mode` instead.
</Deprecated>
keep_in_memory (`bool`, defaults to `None`):
Whether to copy the dataset in-memory. If `None`, the dataset
will not be copied in-memory unless explicitly enabled by setting `datasets.config.IN_MEMORY_MAX_SIZE` to
nonzero. See more details in the [improve performance](../cache#improve-performance) section.
save_infos (`bool`, defaults to `False`):
Save the dataset information (checksums/size/splits/...).
revision ([`Version`] or `str`, *optional*):
Version of the dataset script to load.
As datasets have their own git repository on the Datasets Hub, the default version "main" corresponds to their "main" branch.
You can specify a different version than the default "main" by using a commit SHA or a git tag of the dataset repository.
token (`str` or `bool`, *optional*):
Optional string or boolean to use as Bearer token for remote files on the Datasets Hub.
If `True`, or not specified, will get token from `"~/.huggingface"`.
use_auth_token (`str` or `bool`, *optional*):
Optional string or boolean to use as Bearer token for remote files on the Datasets Hub.
If `True`, or not specified, will get token from `"~/.huggingface"`.
<Deprecated version="2.14.0">
`use_auth_token` was deprecated in favor of `token` in version 2.14.0 and will be removed in 3.0.0.
</Deprecated>
task (`str`):
The task to prepare the dataset for during training and evaluation. Casts the dataset's [`Features`] to standardized column names and types as detailed in `datasets.tasks`.
<Deprecated version="2.13.0">
`task` was deprecated in version 2.13.0 and will be removed in 3.0.0.
</Deprecated>
streaming (`bool`, defaults to `False`):
If set to `True`, don't download the data files. Instead, it streams the data progressively while
iterating on the dataset. An [`IterableDataset`] or [`IterableDatasetDict`] is returned instead in this case.
Note that streaming works for datasets that use data formats that support being iterated over like txt, csv, jsonl for example.
Json files may be downloaded completely. Also streaming from remote zip or gzip files is supported but other compressed formats
like rar and xz are not yet supported. The tgz format doesn't allow streaming.
num_proc (`int`, *optional*, defaults to `None`):
Number of processes when downloading and generating the dataset locally.
Multiprocessing is disabled by default.
<Added version="2.7.0"/>
storage_options (`dict`, *optional*, defaults to `None`):
**Experimental**. Key/value pairs to be passed on to the dataset file-system backend, if any.
<Added version="2.11.0"/>
trust_remote_code (`bool`, defaults to `True`):
Whether or not to allow for datasets defined on the Hub using a dataset script. This option
should only be set to `True` for repositories you trust and in which you have read the code, as it will
execute code present on the Hub on your local machine.
<Tip warning={true}>
`trust_remote_code` will default to False in the next major release.
</Tip>
<Added version="2.16.0"/>
**config_kwargs (additional keyword arguments):
Keyword arguments to be passed to the `BuilderConfig`
and used in the [`DatasetBuilder`].
Returns:
[`Dataset`] or [`DatasetDict`]:
- if `split` is not `None`: the dataset requested,
- if `split` is `None`, a [`~datasets.DatasetDict`] with each split.
or [`IterableDataset`] or [`IterableDatasetDict`]: if `streaming=True`
- if `split` is not `None`, the dataset is requested
- if `split` is `None`, a [`~datasets.streaming.IterableDatasetDict`] with each split.
Example:
Load a dataset from the Hugging Face Hub:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset('rotten_tomatoes', split='train')
# Map data files to splits
>>> data_files = {'train': 'train.csv', 'test': 'test.csv'}
>>> ds = load_dataset('namespace/your_dataset_name', data_files=data_files)
```
Load a local dataset:
```py
# Load a CSV file
>>> from datasets import load_dataset
>>> ds = load_dataset('csv', data_files='path/to/local/my_dataset.csv')
# Load a JSON file
>>> from datasets import load_dataset
>>> ds = load_dataset('json', data_files='path/to/local/my_dataset.json')
# Load from a local loading script
>>> from datasets import load_dataset
>>> ds = load_dataset('path/to/local/loading_script/loading_script.py', split='train')
```
Load an [`~datasets.IterableDataset`]:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset('rotten_tomatoes', split='train', streaming=True)
```
Load an image dataset with the `ImageFolder` dataset builder:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset('imagefolder', data_dir='/path/to/images', split='train')
```
"""
if use_auth_token != "deprecated":
warnings.warn(
"'use_auth_token' was deprecated in favor of 'token' in version 2.14.0 and will be removed in 3.0.0.\n"
"You can remove this warning by passing 'token=<use_auth_token>' instead.",
FutureWarning,
)
token = use_auth_token
if ignore_verifications != "deprecated":
verification_mode = VerificationMode.NO_CHECKS if ignore_verifications else VerificationMode.ALL_CHECKS
warnings.warn(
"'ignore_verifications' was deprecated in favor of 'verification_mode' in version 2.9.1 and will be removed in 3.0.0.\n"
f"You can remove this warning by passing 'verification_mode={verification_mode.value}' instead.",
FutureWarning,
)
if task != "deprecated":
warnings.warn(
"'task' was deprecated in version 2.13.0 and will be removed in 3.0.0.\n",
FutureWarning,
)
else:
task = None
if data_files is not None and not data_files:
raise ValueError(f"Empty 'data_files': '{data_files}'. It should be either non-empty or None (default).")
if Path(path, config.DATASET_STATE_JSON_FILENAME).exists():
raise ValueError(
"You are trying to load a dataset that was saved using `save_to_disk`. "
"Please use `load_from_disk` instead."
)
if streaming and num_proc is not None:
raise NotImplementedError(
"Loading a streaming dataset in parallel with `num_proc` is not implemented. "
"To parallelize streaming, you can wrap the dataset with a PyTorch DataLoader using `num_workers` > 1 instead."
)
download_mode = DownloadMode(download_mode or DownloadMode.REUSE_DATASET_IF_EXISTS)
verification_mode = VerificationMode(
(verification_mode or VerificationMode.BASIC_CHECKS) if not save_infos else VerificationMode.ALL_CHECKS
)
# Create a dataset builder
builder_instance = load_dataset_builder(
path=path,
name=name,
data_dir=data_dir,
data_files=data_files,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
revision=revision,
token=token,
storage_options=storage_options,
trust_remote_code=trust_remote_code,
_require_default_config_name=name is None,
**config_kwargs,
)
# Return iterable dataset in case of streaming
if streaming:
return builder_instance.as_streaming_dataset(split=split)
# Some datasets are already processed on the HF google storage
# Don't try downloading from Google storage for the packaged datasets as text, json, csv or pandas
try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
# Download and prepare data
builder_instance.download_and_prepare(
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
try_from_hf_gcs=try_from_hf_gcs,
num_proc=num_proc,
storage_options=storage_options,
)
# Build dataset for splits
keep_in_memory = (
keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
)
ds = builder_instance.as_dataset(split=split, verification_mode=verification_mode, in_memory=keep_in_memory)
# Rename and cast features to match task schema
if task is not None:
# To avoid issuing the same warning twice
with warnings.catch_warnings():
warnings.simplefilter("ignore", FutureWarning)
ds = ds.prepare_for_task(task)
if save_infos:
builder_instance._save_infos()
return ds
def load_from_disk(
dataset_path: str, fs="deprecated", keep_in_memory: Optional[bool] = None, storage_options: Optional[dict] = None
) -> Union[Dataset, DatasetDict]:
"""
Loads a dataset that was previously saved using [`~Dataset.save_to_disk`] from a dataset directory, or
from a filesystem using any implementation of `fsspec.spec.AbstractFileSystem`.
Args:
dataset_path (`str`):
Path (e.g. `"dataset/train"`) or remote URI (e.g.
`"s3://my-bucket/dataset/train"`) of the [`Dataset`] or [`DatasetDict`] directory where the dataset will be
loaded from.
fs (`~filesystems.S3FileSystem` or `fsspec.spec.AbstractFileSystem`, *optional*):
Instance of the remote filesystem used to download the files from.
<Deprecated version="2.9.0">
`fs` was deprecated in version 2.9.0 and will be removed in 3.0.0.
Please use `storage_options` instead, e.g. `storage_options=fs.storage_options`.
</Deprecated>
keep_in_memory (`bool`, defaults to `None`):
Whether to copy the dataset in-memory. If `None`, the dataset
will not be copied in-memory unless explicitly enabled by setting `datasets.config.IN_MEMORY_MAX_SIZE` to
nonzero. See more details in the [improve performance](../cache#improve-performance) section.
storage_options (`dict`, *optional*):
Key/value pairs to be passed on to the file-system backend, if any.
<Added version="2.9.0"/>
Returns:
[`Dataset`] or [`DatasetDict`]:
- If `dataset_path` is a path of a dataset directory: the dataset requested.
- If `dataset_path` is a path of a dataset dict directory, a [`DatasetDict`] with each split.
Example:
```py
>>> from datasets import load_from_disk
>>> ds = load_from_disk('path/to/dataset/directory')
```
"""
if fs != "deprecated":
warnings.warn(
"'fs' was deprecated in favor of 'storage_options' in version 2.9.0 and will be removed in 3.0.0.\n"
"You can remove this warning by passing 'storage_options=fs.storage_options' instead.",
FutureWarning,
)
storage_options = fs.storage_options
fs: fsspec.AbstractFileSystem
fs, _, _ = fsspec.get_fs_token_paths(dataset_path, storage_options=storage_options)
if not fs.exists(dataset_path):
raise FileNotFoundError(f"Directory {dataset_path} not found")
if fs.isfile(posixpath.join(dataset_path, config.DATASET_INFO_FILENAME)) and fs.isfile(
posixpath.join(dataset_path, config.DATASET_STATE_JSON_FILENAME)
):
return Dataset.load_from_disk(dataset_path, keep_in_memory=keep_in_memory, storage_options=storage_options)
elif fs.isfile(posixpath.join(dataset_path, config.DATASETDICT_JSON_FILENAME)):
return DatasetDict.load_from_disk(dataset_path, keep_in_memory=keep_in_memory, storage_options=storage_options)
else:
raise FileNotFoundError(
f"Directory {dataset_path} is neither a `Dataset` directory nor a `DatasetDict` directory."
)
| datasets/src/datasets/load.py/0 | {
"file_path": "datasets/src/datasets/load.py",
"repo_id": "datasets",
"token_count": 52316
} | 72 |
import io
import json
from itertools import islice
from typing import Any, Callable, Dict, List
import numpy as np
import pyarrow as pa
import datasets
logger = datasets.utils.logging.get_logger(__name__)
class WebDataset(datasets.GeneratorBasedBuilder):
DEFAULT_WRITER_BATCH_SIZE = 100
IMAGE_EXTENSIONS: List[str] # definition at the bottom of the script
AUDIO_EXTENSIONS: List[str] # definition at the bottom of the script
DECODERS: Dict[str, Callable[[Any], Any]] # definition at the bottom of the script
NUM_EXAMPLES_FOR_FEATURES_INFERENCE = 5
@classmethod
def _get_pipeline_from_tar(cls, tar_path, tar_iterator):
current_example = {}
for filename, f in tar_iterator:
if "." in filename:
example_key, field_name = filename.split(".", 1)
if current_example and current_example["__key__"] != example_key:
yield current_example
current_example = {}
current_example["__key__"] = example_key
current_example["__url__"] = tar_path
current_example[field_name.lower()] = f.read()
if field_name in cls.DECODERS:
current_example[field_name] = cls.DECODERS[field_name](current_example[field_name])
if current_example:
yield current_example
def _info(self) -> datasets.DatasetInfo:
return datasets.DatasetInfo()
def _split_generators(self, dl_manager):
"""We handle string, list and dicts in datafiles"""
# Download the data files
if not self.config.data_files:
raise ValueError(f"At least one data file must be specified, but got data_files={self.config.data_files}")
data_files = dl_manager.download(self.config.data_files)
if isinstance(data_files, (str, list, tuple)):
tar_paths = data_files
if isinstance(tar_paths, str):
tar_paths = [tar_paths]
tar_iterators = [dl_manager.iter_archive(tar_path) for tar_path in tar_paths]
splits = [
datasets.SplitGenerator(
name=datasets.Split.TRAIN, gen_kwargs={"tar_paths": tar_paths, "tar_iterators": tar_iterators}
)
]
else:
splits = []
for split_name, tar_paths in data_files.items():
if isinstance(tar_paths, str):
tar_paths = [tar_paths]
tar_iterators = [dl_manager.iter_archive(tar_path) for tar_path in tar_paths]
splits.append(
datasets.SplitGenerator(
name=split_name, gen_kwargs={"tar_paths": tar_paths, "tar_iterators": tar_iterators}
)
)
if not self.info.features:
# Get one example to get the feature types
pipeline = self._get_pipeline_from_tar(tar_paths[0], tar_iterators[0])
first_examples = list(islice(pipeline, self.NUM_EXAMPLES_FOR_FEATURES_INFERENCE))
if any(example.keys() != first_examples[0].keys() for example in first_examples):
raise ValueError(
"The TAR archives of the dataset should be in WebDataset format, "
"but the files in the archive don't share the same prefix or the same types."
)
pa_tables = [pa.Table.from_pylist([example]) for example in first_examples]
if datasets.config.PYARROW_VERSION.major < 14:
inferred_arrow_schema = pa.concat_tables(pa_tables, promote=True).schema
else:
inferred_arrow_schema = pa.concat_tables(pa_tables, promote_options="default").schema
features = datasets.Features.from_arrow_schema(inferred_arrow_schema)
# Set Image types
for field_name in first_examples[0]:
extension = field_name.rsplit(".", 1)[-1]
if extension in self.IMAGE_EXTENSIONS:
features[field_name] = datasets.Image()
# Set Audio types
for field_name in first_examples[0]:
extension = field_name.rsplit(".", 1)[-1]
if extension in self.AUDIO_EXTENSIONS:
features[field_name] = datasets.Audio()
self.info.features = features
return splits
def _generate_examples(self, tar_paths, tar_iterators):
image_field_names = [
field_name for field_name, feature in self.info.features.items() if isinstance(feature, datasets.Image)
]
audio_field_names = [
field_name for field_name, feature in self.info.features.items() if isinstance(feature, datasets.Audio)
]
for tar_idx, (tar_path, tar_iterator) in enumerate(zip(tar_paths, tar_iterators)):
for example_idx, example in enumerate(self._get_pipeline_from_tar(tar_path, tar_iterator)):
for field_name in image_field_names + audio_field_names:
example[field_name] = {"path": example["__key__"] + "." + field_name, "bytes": example[field_name]}
yield f"{tar_idx}_{example_idx}", example
# Obtained with:
# ```
# import PIL.Image
# IMAGE_EXTENSIONS = []
# PIL.Image.init()
# for ext, format in PIL.Image.EXTENSION.items():
# if format in PIL.Image.OPEN:
# IMAGE_EXTENSIONS.append(ext[1:])
# ```
# We intentionally do not run this code on launch because:
# (1) Pillow is an optional dependency, so importing Pillow in global namespace is not allowed
# (2) To ensure the list of supported extensions is deterministic
IMAGE_EXTENSIONS = [
"blp",
"bmp",
"dib",
"bufr",
"cur",
"pcx",
"dcx",
"dds",
"ps",
"eps",
"fit",
"fits",
"fli",
"flc",
"ftc",
"ftu",
"gbr",
"gif",
"grib",
"h5",
"hdf",
"png",
"apng",
"jp2",
"j2k",
"jpc",
"jpf",
"jpx",
"j2c",
"icns",
"ico",
"im",
"iim",
"tif",
"tiff",
"jfif",
"jpe",
"jpg",
"jpeg",
"mpg",
"mpeg",
"msp",
"pcd",
"pxr",
"pbm",
"pgm",
"ppm",
"pnm",
"psd",
"bw",
"rgb",
"rgba",
"sgi",
"ras",
"tga",
"icb",
"vda",
"vst",
"webp",
"wmf",
"emf",
"xbm",
"xpm",
]
WebDataset.IMAGE_EXTENSIONS = IMAGE_EXTENSIONS
# Obtained with:
# ```
# import soundfile as sf
#
# AUDIO_EXTENSIONS = [f".{format.lower()}" for format in sf.available_formats().keys()]
#
# # .mp3 is currently decoded via `torchaudio`, .opus decoding is supported if version of `libsndfile` >= 1.0.30:
# AUDIO_EXTENSIONS.extend([".mp3", ".opus"])
# ```
# We intentionally do not run this code on launch because:
# (1) Soundfile is an optional dependency, so importing it in global namespace is not allowed
# (2) To ensure the list of supported extensions is deterministic
AUDIO_EXTENSIONS = [
"aiff",
"au",
"avr",
"caf",
"flac",
"htk",
"svx",
"mat4",
"mat5",
"mpc2k",
"ogg",
"paf",
"pvf",
"raw",
"rf64",
"sd2",
"sds",
"ircam",
"voc",
"w64",
"wav",
"nist",
"wavex",
"wve",
"xi",
"mp3",
"opus",
]
WebDataset.AUDIO_EXTENSIONS = AUDIO_EXTENSIONS
def text_loads(data: bytes):
return data.decode("utf-8")
def tenbin_loads(data: bytes):
from . import _tenbin
return _tenbin.decode_buffer(data)
def msgpack_loads(data: bytes):
import msgpack
return msgpack.unpackb(data)
def npy_loads(data: bytes):
import numpy.lib.format
stream = io.BytesIO(data)
return numpy.lib.format.read_array(stream, allow_pickle=False)
def npz_loads(data: bytes):
return np.load(io.BytesIO(data), allow_pickle=False)
def cbor_loads(data: bytes):
import cbor
return cbor.loads(data)
# Obtained by checking `decoders` in `webdataset.autodecode`
# and removing unsafe extension decoders.
# Removed Pickle decoders:
# - "pyd": lambda data: pickle.loads(data)
# - "pickle": lambda data: pickle.loads(data)
# Removed Torch decoders:
# - "pth": lambda data: torch_loads(data)
# Modified NumPy decoders to fix CVE-2019-6446 (add allow_pickle=False):
# - "npy": npy_loads,
# - "npz": lambda data: np.load(io.BytesIO(data)),
DECODERS = {
"txt": text_loads,
"text": text_loads,
"transcript": text_loads,
"cls": int,
"cls2": int,
"index": int,
"inx": int,
"id": int,
"json": json.loads,
"jsn": json.loads,
"ten": tenbin_loads,
"tb": tenbin_loads,
"mp": msgpack_loads,
"msg": msgpack_loads,
"npy": npy_loads,
"npz": npz_loads,
"cbor": cbor_loads,
}
WebDataset.DECODERS = DECODERS
| datasets/src/datasets/packaged_modules/webdataset/webdataset.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/webdataset/webdataset.py",
"repo_id": "datasets",
"token_count": 4107
} | 73 |
from importlib import import_module
from .logging import get_logger
logger = get_logger(__name__)
class _PatchedModuleObj:
"""Set all the modules components as attributes of the _PatchedModuleObj object."""
def __init__(self, module, attrs=None):
attrs = attrs or []
if module is not None:
for key in module.__dict__:
if key in attrs or not key.startswith("__"):
setattr(self, key, getattr(module, key))
self._original_module = module._original_module if isinstance(module, _PatchedModuleObj) else module
class patch_submodule:
"""
Patch a submodule attribute of an object, by keeping all other submodules intact at all levels.
Example::
>>> import importlib
>>> from datasets.load import dataset_module_factory
>>> from datasets.streaming import patch_submodule, xjoin
>>>
>>> dataset_module = dataset_module_factory("snli")
>>> snli_module = importlib.import_module(dataset_module.module_path)
>>> patcher = patch_submodule(snli_module, "os.path.join", xjoin)
>>> patcher.start()
>>> assert snli_module.os.path.join is xjoin
"""
_active_patches = []
def __init__(self, obj, target: str, new, attrs=None):
self.obj = obj
self.target = target
self.new = new
self.key = target.split(".")[0]
self.original = {}
self.attrs = attrs or []
def __enter__(self):
*submodules, target_attr = self.target.split(".")
# Patch modules:
# it's used to patch attributes of submodules like "os.path.join";
# in this case we need to patch "os" and "os.path"
for i in range(len(submodules)):
try:
submodule = import_module(".".join(submodules[: i + 1]))
except ModuleNotFoundError:
continue
# We iterate over all the globals in self.obj in case we find "os" or "os.path"
for attr in self.obj.__dir__():
obj_attr = getattr(self.obj, attr)
# We don't check for the name of the global, but rather if its value *is* "os" or "os.path".
# This allows to patch renamed modules like "from os import path as ospath".
if obj_attr is submodule or (
isinstance(obj_attr, _PatchedModuleObj) and obj_attr._original_module is submodule
):
self.original[attr] = obj_attr
# patch at top level
setattr(self.obj, attr, _PatchedModuleObj(obj_attr, attrs=self.attrs))
patched = getattr(self.obj, attr)
# construct lower levels patches
for key in submodules[i + 1 :]:
setattr(patched, key, _PatchedModuleObj(getattr(patched, key, None), attrs=self.attrs))
patched = getattr(patched, key)
# finally set the target attribute
setattr(patched, target_attr, self.new)
# Patch attribute itself:
# it's used for builtins like "open",
# and also to patch "os.path.join" we may also need to patch "join"
# itself if it was imported as "from os.path import join".
if submodules: # if it's an attribute of a submodule like "os.path.join"
try:
attr_value = getattr(import_module(".".join(submodules)), target_attr)
except (AttributeError, ModuleNotFoundError):
return
# We iterate over all the globals in self.obj in case we find "os.path.join"
for attr in self.obj.__dir__():
# We don't check for the name of the global, but rather if its value *is* "os.path.join".
# This allows to patch renamed attributes like "from os.path import join as pjoin".
if getattr(self.obj, attr) is attr_value:
self.original[attr] = getattr(self.obj, attr)
setattr(self.obj, attr, self.new)
elif target_attr in globals()["__builtins__"]: # if it'a s builtin like "open"
self.original[target_attr] = globals()["__builtins__"][target_attr]
setattr(self.obj, target_attr, self.new)
else:
raise RuntimeError(f"Tried to patch attribute {target_attr} instead of a submodule.")
def __exit__(self, *exc_info):
for attr in list(self.original):
setattr(self.obj, attr, self.original.pop(attr))
def start(self):
"""Activate a patch."""
self.__enter__()
self._active_patches.append(self)
def stop(self):
"""Stop an active patch."""
try:
self._active_patches.remove(self)
except ValueError:
# If the patch hasn't been started this will fail
return None
return self.__exit__()
| datasets/src/datasets/utils/patching.py/0 | {
"file_path": "datasets/src/datasets/utils/patching.py",
"repo_id": "datasets",
"token_count": 2222
} | 74 |
---
TODO: Add YAML tags here. Copy-paste the tags obtained with the online tagging app: https://huggingface.co/spaces/huggingface/datasets-tagging
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
| datasets/templates/README.md/0 | {
"file_path": "datasets/templates/README.md",
"repo_id": "datasets",
"token_count": 810
} | 75 |
import csv
import os
import pytest
from datasets import Dataset, DatasetDict, Features, NamedSplit, Value
from datasets.io.csv import CsvDatasetReader, CsvDatasetWriter
from ..utils import assert_arrow_memory_doesnt_increase, assert_arrow_memory_increases
def _check_csv_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_csv_keep_in_memory(keep_in_memory, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = CsvDatasetReader(csv_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory).read()
_check_csv_dataset(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_csv_features(features, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
# CSV file loses col_1 string dtype information: default now is "int64" instead of "string"
default_expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = CsvDatasetReader(csv_path, features=features, cache_dir=cache_dir).read()
_check_csv_dataset(dataset, expected_features)
@pytest.mark.parametrize("split", [None, NamedSplit("train"), "train", "test"])
def test_dataset_from_csv_split(split, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
dataset = CsvDatasetReader(csv_path, cache_dir=cache_dir, split=split).read()
_check_csv_dataset(dataset, expected_features)
assert dataset.split == split if split else "train"
@pytest.mark.parametrize("path_type", [str, list])
def test_dataset_from_csv_path_type(path_type, csv_path, tmp_path):
if issubclass(path_type, str):
path = csv_path
elif issubclass(path_type, list):
path = [csv_path]
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
dataset = CsvDatasetReader(path, cache_dir=cache_dir).read()
_check_csv_dataset(dataset, expected_features)
def _check_csv_datasetdict(dataset_dict, expected_features, splits=("train",)):
assert isinstance(dataset_dict, DatasetDict)
for split in splits:
dataset = dataset_dict[split]
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_csv_datasetdict_reader_keep_in_memory(keep_in_memory, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = CsvDatasetReader({"train": csv_path}, cache_dir=cache_dir, keep_in_memory=keep_in_memory).read()
_check_csv_datasetdict(dataset, expected_features)
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_csv_datasetdict_reader_features(features, csv_path, tmp_path):
cache_dir = tmp_path / "cache"
# CSV file loses col_1 string dtype information: default now is "int64" instead of "string"
default_expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = CsvDatasetReader({"train": csv_path}, features=features, cache_dir=cache_dir).read()
_check_csv_datasetdict(dataset, expected_features)
@pytest.mark.parametrize("split", [None, NamedSplit("train"), "train", "test"])
def test_csv_datasetdict_reader_split(split, csv_path, tmp_path):
if split:
path = {split: csv_path}
else:
path = {"train": csv_path, "test": csv_path}
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "int64", "col_2": "int64", "col_3": "float64"}
dataset = CsvDatasetReader(path, cache_dir=cache_dir).read()
_check_csv_datasetdict(dataset, expected_features, splits=list(path.keys()))
assert all(dataset[split].split == split for split in path.keys())
def iter_csv_file(csv_path):
with open(csv_path, encoding="utf-8") as csvfile:
yield from csv.reader(csvfile)
def test_dataset_to_csv(csv_path, tmp_path):
cache_dir = tmp_path / "cache"
output_csv = os.path.join(cache_dir, "tmp.csv")
dataset = CsvDatasetReader({"train": csv_path}, cache_dir=cache_dir).read()
CsvDatasetWriter(dataset["train"], output_csv, num_proc=1).write()
original_csv = iter_csv_file(csv_path)
expected_csv = iter_csv_file(output_csv)
for row1, row2 in zip(original_csv, expected_csv):
assert row1 == row2
def test_dataset_to_csv_multiproc(csv_path, tmp_path):
cache_dir = tmp_path / "cache"
output_csv = os.path.join(cache_dir, "tmp.csv")
dataset = CsvDatasetReader({"train": csv_path}, cache_dir=cache_dir).read()
CsvDatasetWriter(dataset["train"], output_csv, num_proc=2).write()
original_csv = iter_csv_file(csv_path)
expected_csv = iter_csv_file(output_csv)
for row1, row2 in zip(original_csv, expected_csv):
assert row1 == row2
def test_dataset_to_csv_invalidproc(csv_path, tmp_path):
cache_dir = tmp_path / "cache"
output_csv = os.path.join(cache_dir, "tmp.csv")
dataset = CsvDatasetReader({"train": csv_path}, cache_dir=cache_dir).read()
with pytest.raises(ValueError):
CsvDatasetWriter(dataset["train"], output_csv, num_proc=0)
| datasets/tests/io/test_csv.py/0 | {
"file_path": "datasets/tests/io/test_csv.py",
"repo_id": "datasets",
"token_count": 2815
} | 76 |
import os
import tempfile
from pathlib import Path
from unittest import TestCase
import pyarrow as pa
import pytest
from datasets.arrow_dataset import Dataset
from datasets.arrow_reader import ArrowReader, BaseReader, FileInstructions, ReadInstruction, make_file_instructions
from datasets.info import DatasetInfo
from datasets.splits import NamedSplit, Split, SplitDict, SplitInfo
from .utils import assert_arrow_memory_doesnt_increase, assert_arrow_memory_increases
class ReaderTest(BaseReader):
"""
Build a Dataset object out of Instruction instance(s).
This reader is made for testing. It mocks file reads.
"""
def _get_table_from_filename(self, filename_skip_take, in_memory=False):
"""Returns a Dataset instance from given (filename, skip, take)."""
filename, skip, take = (
filename_skip_take["filename"],
filename_skip_take["skip"] if "skip" in filename_skip_take else None,
filename_skip_take["take"] if "take" in filename_skip_take else None,
)
open(os.path.join(filename), "wb").close()
pa_table = pa.Table.from_pydict({"filename": [Path(filename).name] * 100})
if take == -1:
take = len(pa_table) - skip
if skip is not None and take is not None:
pa_table = pa_table.slice(skip, take)
return pa_table
class BaseReaderTest(TestCase):
def test_read(self):
name = "my_name"
train_info = SplitInfo(name="train", num_examples=100)
test_info = SplitInfo(name="test", num_examples=100)
split_infos = [train_info, test_info]
split_dict = SplitDict()
split_dict.add(train_info)
split_dict.add(test_info)
info = DatasetInfo(splits=split_dict)
with tempfile.TemporaryDirectory() as tmp_dir:
reader = ReaderTest(tmp_dir, info)
instructions = "test[:33%]"
dset = Dataset(**reader.read(name, instructions, split_infos))
self.assertEqual(dset["filename"][0], f"{name}-test")
self.assertEqual(dset.num_rows, 33)
self.assertEqual(dset.num_columns, 1)
instructions1 = ["train", "test[:33%]"]
instructions2 = [Split.TRAIN, ReadInstruction.from_spec("test[:33%]")]
for instructions in [instructions1, instructions2]:
datasets_kwargs = [reader.read(name, instr, split_infos) for instr in instructions]
train_dset, test_dset = (Dataset(**dataset_kwargs) for dataset_kwargs in datasets_kwargs)
self.assertEqual(train_dset["filename"][0], f"{name}-train")
self.assertEqual(train_dset.num_rows, 100)
self.assertEqual(train_dset.num_columns, 1)
self.assertIsInstance(train_dset.split, NamedSplit)
self.assertEqual(str(train_dset.split), "train")
self.assertEqual(test_dset["filename"][0], f"{name}-test")
self.assertEqual(test_dset.num_rows, 33)
self.assertEqual(test_dset.num_columns, 1)
self.assertIsInstance(test_dset.split, NamedSplit)
self.assertEqual(str(test_dset.split), "test[:33%]")
del train_dset, test_dset
def test_read_sharded(self):
name = "my_name"
train_info = SplitInfo(name="train", num_examples=1000, shard_lengths=[100] * 10)
split_infos = [train_info]
split_dict = SplitDict()
split_dict.add(train_info)
info = DatasetInfo(splits=split_dict)
with tempfile.TemporaryDirectory() as tmp_dir:
reader = ReaderTest(tmp_dir, info)
instructions = "train[:33%]"
dset = Dataset(**reader.read(name, instructions, split_infos))
self.assertEqual(dset["filename"][0], f"{name}-train-00000-of-00010")
self.assertEqual(dset["filename"][-1], f"{name}-train-00003-of-00010")
self.assertEqual(dset.num_rows, 330)
self.assertEqual(dset.num_columns, 1)
def test_read_files(self):
train_info = SplitInfo(name="train", num_examples=100)
test_info = SplitInfo(name="test", num_examples=100)
split_dict = SplitDict()
split_dict.add(train_info)
split_dict.add(test_info)
info = DatasetInfo(splits=split_dict)
with tempfile.TemporaryDirectory() as tmp_dir:
reader = ReaderTest(tmp_dir, info)
files = [
{"filename": os.path.join(tmp_dir, "train")},
{"filename": os.path.join(tmp_dir, "test"), "skip": 10, "take": 10},
]
dset = Dataset(**reader.read_files(files, original_instructions="train+test[10:20]"))
self.assertEqual(dset.num_rows, 110)
self.assertEqual(dset.num_columns, 1)
del dset
@pytest.mark.parametrize("in_memory", [False, True])
def test_read_table(in_memory, dataset, arrow_file):
filename = arrow_file
with assert_arrow_memory_increases() if in_memory else assert_arrow_memory_doesnt_increase():
table = ArrowReader.read_table(filename, in_memory=in_memory)
assert table.shape == dataset.data.shape
assert set(table.column_names) == set(dataset.data.column_names)
assert dict(table.to_pydict()) == dict(dataset.data.to_pydict()) # to_pydict returns OrderedDict
@pytest.mark.parametrize("in_memory", [False, True])
def test_read_files(in_memory, dataset, arrow_file):
filename = arrow_file
reader = ArrowReader("", None)
with assert_arrow_memory_increases() if in_memory else assert_arrow_memory_doesnt_increase():
dataset_kwargs = reader.read_files([{"filename": filename}], in_memory=in_memory)
assert dataset_kwargs.keys() == {"arrow_table", "info", "split"}
table = dataset_kwargs["arrow_table"]
assert table.shape == dataset.data.shape
assert set(table.column_names) == set(dataset.data.column_names)
assert dict(table.to_pydict()) == dict(dataset.data.to_pydict()) # to_pydict returns OrderedDict
def test_read_instruction_spec():
assert ReadInstruction("train", to=10, unit="abs").to_spec() == "train[:10]"
assert ReadInstruction("train", from_=-80, to=10, unit="%").to_spec() == "train[-80%:10%]"
spec_train_test = "train+test"
assert ReadInstruction.from_spec(spec_train_test).to_spec() == spec_train_test
spec_train_abs = "train[2:10]"
assert ReadInstruction.from_spec(spec_train_abs).to_spec() == spec_train_abs
spec_train_pct = "train[15%:-20%]"
assert ReadInstruction.from_spec(spec_train_pct).to_spec() == spec_train_pct
spec_train_pct_rounding = "train[:10%](closest)"
assert ReadInstruction.from_spec(spec_train_pct_rounding).to_spec() == "train[:10%]"
spec_train_pct_rounding = "train[:10%](pct1_dropremainder)"
assert ReadInstruction.from_spec(spec_train_pct_rounding).to_spec() == spec_train_pct_rounding
spec_train_test_pct_rounding = "train[:10%](pct1_dropremainder)+test[-10%:](pct1_dropremainder)"
assert ReadInstruction.from_spec(spec_train_test_pct_rounding).to_spec() == spec_train_test_pct_rounding
def test_make_file_instructions_basic():
name = "dummy"
split_infos = [SplitInfo(name="train", num_examples=100)]
instruction = "train[:33%]"
filetype_suffix = "arrow"
prefix_path = "prefix"
file_instructions = make_file_instructions(name, split_infos, instruction, filetype_suffix, prefix_path)
assert isinstance(file_instructions, FileInstructions)
assert file_instructions.num_examples == 33
assert file_instructions.file_instructions == [
{"filename": os.path.join(prefix_path, f"{name}-train.arrow"), "skip": 0, "take": 33}
]
split_infos = [SplitInfo(name="train", num_examples=100, shard_lengths=[10] * 10)]
file_instructions = make_file_instructions(name, split_infos, instruction, filetype_suffix, prefix_path)
assert isinstance(file_instructions, FileInstructions)
assert file_instructions.num_examples == 33
assert file_instructions.file_instructions == [
{"filename": os.path.join(prefix_path, f"{name}-train-00000-of-00010.arrow"), "skip": 0, "take": -1},
{"filename": os.path.join(prefix_path, f"{name}-train-00001-of-00010.arrow"), "skip": 0, "take": -1},
{"filename": os.path.join(prefix_path, f"{name}-train-00002-of-00010.arrow"), "skip": 0, "take": -1},
{"filename": os.path.join(prefix_path, f"{name}-train-00003-of-00010.arrow"), "skip": 0, "take": 3},
]
@pytest.mark.parametrize(
"split_name, instruction, shard_lengths, read_range",
[
("train", "train[-20%:]", 100, (80, 100)),
("train", "train[:200]", 100, (0, 100)),
("train", "train[:-200]", 100, None),
("train", "train[-200:]", 100, (0, 100)),
("train", "train[-20%:]", [10] * 10, (80, 100)),
("train", "train[:200]", [10] * 10, (0, 100)),
("train", "train[:-200]", [10] * 10, None),
("train", "train[-200:]", [10] * 10, (0, 100)),
],
)
def test_make_file_instructions(split_name, instruction, shard_lengths, read_range):
name = "dummy"
split_infos = split_infos = [
SplitInfo(
name="train",
num_examples=shard_lengths if not isinstance(shard_lengths, list) else sum(shard_lengths),
shard_lengths=shard_lengths if isinstance(shard_lengths, list) else None,
)
]
filetype_suffix = "arrow"
prefix_path = "prefix"
file_instructions = make_file_instructions(name, split_infos, instruction, filetype_suffix, prefix_path)
assert isinstance(file_instructions, FileInstructions)
assert file_instructions.num_examples == (read_range[1] - read_range[0] if read_range is not None else 0)
if read_range is None:
assert file_instructions.file_instructions == []
else:
if not isinstance(shard_lengths, list):
assert file_instructions.file_instructions == [
{
"filename": os.path.join(prefix_path, f"{name}-{split_name}.arrow"),
"skip": read_range[0],
"take": read_range[1] - read_range[0],
}
]
else:
file_instructions_list = []
shard_offset = 0
for i, shard_length in enumerate(shard_lengths):
filename = os.path.join(prefix_path, f"{name}-{split_name}-{i:05d}-of-{len(shard_lengths):05d}.arrow")
if shard_offset <= read_range[0] < shard_offset + shard_length:
file_instructions_list.append(
{
"filename": filename,
"skip": read_range[0] - shard_offset,
"take": read_range[1] - read_range[0]
if read_range[1] < shard_offset + shard_length
else -1,
}
)
elif shard_offset < read_range[1] <= shard_offset + shard_length:
file_instructions_list.append(
{
"filename": filename,
"skip": 0,
"take": read_range[1] - shard_offset
if read_range[1] < shard_offset + shard_length
else -1,
}
)
elif read_range[0] < shard_offset and read_range[1] > shard_offset + shard_length:
file_instructions_list.append(
{
"filename": filename,
"skip": 0,
"take": -1,
}
)
shard_offset += shard_length
assert file_instructions.file_instructions == file_instructions_list
@pytest.mark.parametrize("name, expected_exception", [(None, TypeError), ("", ValueError)])
def test_make_file_instructions_raises(name, expected_exception):
split_infos = [SplitInfo(name="train", num_examples=100)]
instruction = "train"
filetype_suffix = "arrow"
prefix_path = "prefix_path"
with pytest.raises(expected_exception):
_ = make_file_instructions(name, split_infos, instruction, filetype_suffix, prefix_path)
| datasets/tests/test_arrow_reader.py/0 | {
"file_path": "datasets/tests/test_arrow_reader.py",
"repo_id": "datasets",
"token_count": 5688
} | 77 |
import os
from tempfile import TemporaryDirectory
from unittest import TestCase
import pytest
from absl.testing import parameterized
from datasets import config
from datasets.arrow_reader import HF_GCP_BASE_URL
from datasets.builder import DatasetBuilder
from datasets.dataset_dict import IterableDatasetDict
from datasets.iterable_dataset import IterableDataset
from datasets.load import dataset_module_factory, import_main_class
from datasets.utils.file_utils import cached_path
DATASETS_ON_HF_GCP = [
{"dataset": "wikipedia", "config_name": "20220301.de"},
{"dataset": "wikipedia", "config_name": "20220301.en"},
{"dataset": "wikipedia", "config_name": "20220301.fr"},
{"dataset": "wikipedia", "config_name": "20220301.frr"},
{"dataset": "wikipedia", "config_name": "20220301.it"},
{"dataset": "wikipedia", "config_name": "20220301.simple"},
{"dataset": "wiki40b", "config_name": "en"},
{"dataset": "wiki_dpr", "config_name": "psgs_w100.nq.compressed"},
{"dataset": "wiki_dpr", "config_name": "psgs_w100.nq.no_index"},
{"dataset": "wiki_dpr", "config_name": "psgs_w100.multiset.no_index"},
{"dataset": "natural_questions", "config_name": "default"},
]
def list_datasets_on_hf_gcp_parameters(with_config=True):
if with_config:
return [
{
"testcase_name": d["dataset"] + "/" + d["config_name"],
"dataset": d["dataset"],
"config_name": d["config_name"],
}
for d in DATASETS_ON_HF_GCP
]
else:
return [
{"testcase_name": dataset, "dataset": dataset} for dataset in {d["dataset"] for d in DATASETS_ON_HF_GCP}
]
@parameterized.named_parameters(list_datasets_on_hf_gcp_parameters(with_config=True))
class TestDatasetOnHfGcp(TestCase):
dataset = None
config_name = None
def test_dataset_info_available(self, dataset, config_name):
with TemporaryDirectory() as tmp_dir:
dataset_module = dataset_module_factory(dataset, cache_dir=tmp_dir)
builder_cls = import_main_class(dataset_module.module_path, dataset=True)
builder_instance: DatasetBuilder = builder_cls(
cache_dir=tmp_dir,
config_name=config_name,
hash=dataset_module.hash,
)
dataset_info_url = "/".join(
[
HF_GCP_BASE_URL,
builder_instance._relative_data_dir(with_hash=False).replace(os.sep, "/"),
config.DATASET_INFO_FILENAME,
]
)
datset_info_path = cached_path(dataset_info_url, cache_dir=tmp_dir)
self.assertTrue(os.path.exists(datset_info_path))
@pytest.mark.integration
def test_as_dataset_from_hf_gcs(tmp_path_factory):
tmp_dir = tmp_path_factory.mktemp("test_hf_gcp") / "test_wikipedia_simple"
dataset_module = dataset_module_factory("wikipedia", cache_dir=tmp_dir)
builder_cls = import_main_class(dataset_module.module_path)
builder_instance: DatasetBuilder = builder_cls(
cache_dir=tmp_dir,
config_name="20220301.frr",
hash=dataset_module.hash,
)
# use the HF cloud storage, not the original download_and_prepare that uses apache-beam
builder_instance._download_and_prepare = None
builder_instance.download_and_prepare()
ds = builder_instance.as_dataset()
assert ds
@pytest.mark.integration
def test_as_streaming_dataset_from_hf_gcs(tmp_path):
dataset_module = dataset_module_factory("wikipedia", cache_dir=tmp_path)
builder_cls = import_main_class(dataset_module.module_path, dataset=True)
builder_instance: DatasetBuilder = builder_cls(
cache_dir=tmp_path,
config_name="20220301.frr",
hash=dataset_module.hash,
)
ds = builder_instance.as_streaming_dataset()
assert ds
assert isinstance(ds, IterableDatasetDict)
assert "train" in ds
assert isinstance(ds["train"], IterableDataset)
assert next(iter(ds["train"]))
| datasets/tests/test_hf_gcp.py/0 | {
"file_path": "datasets/tests/test_hf_gcp.py",
"repo_id": "datasets",
"token_count": 1782
} | 78 |
import pytest
from datasets.utils.sharding import _distribute_shards, _number_of_shards_in_gen_kwargs, _split_gen_kwargs
@pytest.mark.parametrize(
"kwargs, expected",
[
({"num_shards": 0, "max_num_jobs": 1}, []),
({"num_shards": 10, "max_num_jobs": 1}, [range(10)]),
({"num_shards": 10, "max_num_jobs": 10}, [range(i, i + 1) for i in range(10)]),
({"num_shards": 1, "max_num_jobs": 10}, [range(1)]),
({"num_shards": 10, "max_num_jobs": 3}, [range(0, 4), range(4, 7), range(7, 10)]),
({"num_shards": 3, "max_num_jobs": 10}, [range(0, 1), range(1, 2), range(2, 3)]),
],
)
def test_distribute_shards(kwargs, expected):
out = _distribute_shards(**kwargs)
assert out == expected
@pytest.mark.parametrize(
"gen_kwargs, max_num_jobs, expected",
[
({"foo": 0}, 10, [{"foo": 0}]),
({"shards": [0, 1, 2, 3]}, 1, [{"shards": [0, 1, 2, 3]}]),
({"shards": [0, 1, 2, 3]}, 4, [{"shards": [0]}, {"shards": [1]}, {"shards": [2]}, {"shards": [3]}]),
({"shards": [0, 1]}, 4, [{"shards": [0]}, {"shards": [1]}]),
({"shards": [0, 1, 2, 3]}, 2, [{"shards": [0, 1]}, {"shards": [2, 3]}]),
],
)
def test_split_gen_kwargs(gen_kwargs, max_num_jobs, expected):
out = _split_gen_kwargs(gen_kwargs, max_num_jobs)
assert out == expected
@pytest.mark.parametrize(
"gen_kwargs, expected",
[
({"foo": 0}, 1),
({"shards": [0]}, 1),
({"shards": [0, 1, 2, 3]}, 4),
({"shards": [0, 1, 2, 3], "foo": 0}, 4),
({"shards": [0, 1, 2, 3], "other": (0, 1)}, 4),
({"shards": [0, 1, 2, 3], "shards2": [0, 1]}, RuntimeError),
],
)
def test_number_of_shards_in_gen_kwargs(gen_kwargs, expected):
if expected is RuntimeError:
with pytest.raises(expected):
_number_of_shards_in_gen_kwargs(gen_kwargs)
else:
out = _number_of_shards_in_gen_kwargs(gen_kwargs)
assert out == expected
| datasets/tests/test_sharding_utils.py/0 | {
"file_path": "datasets/tests/test_sharding_utils.py",
"repo_id": "datasets",
"token_count": 977
} | 79 |
# Discord 101 [[discord-101]]
Hey there! My name is Huggy, the dog 🐕, and I'm looking forward to train with you during this RL Course!
Although I don't know much about fetching sticks (yet), I know one or two things about Discord. So I wrote this guide to help you learn about it!
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/huggy-logo.jpg" alt="Huggy Logo"/>
Discord is a free chat platform. If you've used Slack, **it's quite similar**. There is a Hugging Face Community Discord server with 50000 members you can <a href="https://discord.gg/ydHrjt3WP5">join with a single click here</a>. So many humans to play with!
Starting in Discord can be a bit intimidating, so let me take you through it.
When you [sign-up to our Discord server](http://hf.co/join/discord), you'll choose your interests. Make sure to **click "Reinforcement Learning,"** and you'll get access to the Reinforcement Learning Category containing all the course-related channels. If you feel like joining even more channels, go for it! 🚀
Then click next, you'll then get to **introduce yourself in the `#introduce-yourself` channel**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit0/discord2.jpg" alt="Discord"/>
They are in the reinforcement learning category. **Don't forget to sign up to these channels** by clicking on 🤖 Reinforcement Learning in `role-assigment`.
- `rl-announcements`: where we give the **lastest information about the course**.
- `rl-discussions`: where you can **exchange about RL and share information**.
- `rl-study-group`: where you can **ask questions and exchange with your classmates**.
- `rl-i-made-this`: where you can **share your projects and models**.
The HF Community Server has a thriving community of human beings interested in many areas, so you can also learn from those. There are paper discussions, events, and many other things.
Was this useful? There are a couple of tips I can share with you:
- There are **voice channels** you can use as well, although most people prefer text chat.
- You can **use markdown style** for text chats. So if you're writing code, you can use that style. Sadly this does not work as well for links.
- You can open threads as well! It's a good idea when **it's a long conversation**.
I hope this is useful! And if you have questions, just ask!
See you later!
Huggy 🐶
| deep-rl-class/units/en/unit0/discord101.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit0/discord101.mdx",
"repo_id": "deep-rl-class",
"token_count": 686
} | 80 |
# Additional Readings [[additional-readings]]
These are **optional readings** if you want to go deeper.
## Monte Carlo and TD Learning [[mc-td]]
To dive deeper into Monte Carlo and Temporal Difference Learning:
- <a href="https://stats.stackexchange.com/questions/355820/why-do-temporal-difference-td-methods-have-lower-variance-than-monte-carlo-met">Why do temporal difference (TD) methods have lower variance than Monte Carlo methods?</a>
- <a href="https://stats.stackexchange.com/questions/336974/when-are-monte-carlo-methods-preferred-over-temporal-difference-ones"> When are Monte Carlo methods preferred over temporal difference ones?</a>
## Q-Learning [[q-learning]]
- <a href="http://incompleteideas.net/book/RLbook2020.pdf">Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 5, 6 and 7</a>
- <a href="https://youtu.be/Psrhxy88zww">Foundations of Deep RL Series, L2 Deep Q-Learning by Pieter Abbeel</a>
| deep-rl-class/units/en/unit2/additional-readings.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit2/additional-readings.mdx",
"repo_id": "deep-rl-class",
"token_count": 297
} | 81 |
# Conclusion [[conclusion]]
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep Q-Learning agent and shared it on the Hub 🥳.
Take time to really grasp the material before continuing.
Don't hesitate to train your agent in other environments (Pong, Seaquest, QBert, Ms Pac Man). The **best way to learn is to try things on your own!**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
In the next unit, **we're going to learn about Optuna**. One of the most critical tasks in Deep Reinforcement Learning is to find a good set of training hyperparameters. Optuna is a library that helps you to automate the search.
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
| deep-rl-class/units/en/unit3/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit3/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 291
} | 82 |
# Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: What are the advantages of policy-gradient over value-based methods? (Check all that apply)
<Question
choices={[
{
text: "Policy-gradient methods can learn a stochastic policy",
explain: "",
correct: true,
},
{
text: "Policy-gradient methods are more effective in high-dimensional action spaces and continuous actions spaces",
explain: "",
correct: true,
},
{
text: "Policy-gradient converges most of the time on a global maximum.",
explain: "No, frequently, policy-gradient converges on a local maximum instead of a global optimum.",
},
]}
/>
### Q2: What is the Policy Gradient Theorem?
<details>
<summary>Solution</summary>
*The Policy Gradient Theorem* is a formula that will help us to reformulate the objective function into a differentiable function that does not involve the differentiation of the state distribution.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_gradient_theorem.png" alt="Policy Gradient"/>
</details>
### Q3: What's the difference between policy-based methods and policy-gradient methods? (Check all that apply)
<Question
choices={[
{
text: "Policy-based methods are a subset of policy-gradient methods.",
explain: "",
},
{
text: "Policy-gradient methods are a subset of policy-based methods.",
explain: "",
correct: true,
},
{
text: "In Policy-based methods, we can optimize the parameter θ **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.",
explain: "",
correct: true,
},
{
text: "In Policy-gradient methods, we optimize the parameter θ **directly** by performing the gradient ascent on the performance of the objective function.",
explain: "",
correct: true,
},
]}
/>
### Q4: Why do we use gradient ascent instead of gradient descent to optimize J(θ)?
<Question
choices={[
{
text: "We want to minimize J(θ) and gradient ascent gives us the gives the direction of the steepest increase of J(θ)",
explain: "",
},
{
text: "We want to maximize J(θ) and gradient ascent gives us the gives the direction of the steepest increase of J(θ)",
explain: "",
correct: true
},
]}
/>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
| deep-rl-class/units/en/unit4/quiz.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit4/quiz.mdx",
"repo_id": "deep-rl-class",
"token_count": 878
} | 83 |
# Quiz
The best way to learn and [to avoid the illusion of competence](https://www.coursera.org/lecture/learning-how-to-learn/illusions-of-competence-BuFzf) **is to test yourself.** This will help you to find **where you need to reinforce your knowledge**.
### Q1: Which of the following interpretations of bias-variance tradeoff is the most accurate in the field of Reinforcement Learning?
<Question
choices={[
{
text: "The bias-variance tradeoff reflects how my model is able to generalize the knowledge to previously tagged data we give to the model during training time.",
explain: "This is the traditional bias-variance tradeoff in Machine Learning. In our specific case of Reinforcement Learning, we don't have previously tagged data, but only a reward signal.",
correct: false,
},
{
text: "The bias-variance tradeoff reflects how well the reinforcement signal reflects the true reward the agent should get from the enviromment",
explain: "",
correct: true,
},
]}
/>
### Q2: Which of the following statements are true, when talking about models with bias and/or variance in RL?
<Question
choices={[
{
text: "An unbiased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "",
correct: true,
},
{
text: "A biased reward signal returns rewards similar to the real / expected ones from the environment",
explain: "If a reward signal is biased, it means the reward signal we get differs from the real reward we should be getting from an environment",
correct: false,
},
{
text: "A reward signal with high variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "",
correct: true,
},
{
text: "A reward signal with low variance has much noise in it and gets affected by, for example, stochastic (non constant) elements in the environment",
explain: "If a reward signal has low variance, then it's less affected by the noise of the environment and produce similar values regardless the random elements in the environment",
correct: false,
},
]}
/>
### Q3: Which of the following statements are true about Monte Carlo method?
<Question
choices={[
{
text: "It's a sampling mechanism, which means we don't analyze all the possible states, but a sample of those",
explain: "",
correct: true,
},
{
text: "It's very resistant to stochasticity (random elements in the trajectory)",
explain: "Monte Carlo randomly estimates everytime a sample of trajectories. However, even same trajectories can have different reward values if they contain stochastic elements",
correct: false,
},
{
text: "To reduce the impact of stochastic elements in Monte Carlo, we take `n` strategies and average them, reducing their individual impact",
explain: "",
correct: true,
},
]}
/>
### Q4: How would you describe, with your own words, the Actor-Critic Method (A2C)?
<details>
<summary>Solution</summary>
The idea behind Actor-Critic is that we learn two function approximations:
1. A `policy` that controls how our agent acts (π)
2. A `value` function to assist the policy update by measuring how good the action taken is (q)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step2.jpg" alt="Actor-Critic, step 2"/>
</details>
### Q5: Which of the following statements are true about the Actor-Critic Method?
<Question
choices={[
{
text: "The Critic does not learn any function during the training process",
explain: "Both the Actor and the Critic function parameters are updated during training time",
correct: false,
},
{
text: "The Actor learns a policy function, while the Critic learns a value function",
explain: "",
correct: true,
},
{
text: "It adds resistance to stochasticity and reduces high variance",
explain: "",
correct: true,
},
]}
/>
### Q6: What is `Advantage` in the A2C method?
<details>
<summary>Solution</summary>
Instead of using directly the Action-Value function of the Critic as it is, we could use an `Advantage` function. The idea behind an `Advantage` function is that we calculate the relative advantage of an action compared to the others possible at a state, averaging them.
In other words: how taking that action at a state is better compared to the average value of the state
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/advantage1.jpg" alt="Advantage in A2C"/>
</details>
Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read the chapter again to reinforce (😏) your knowledge.
| deep-rl-class/units/en/unit6/quiz.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit6/quiz.mdx",
"repo_id": "deep-rl-class",
"token_count": 1508
} | 84 |
# Introduction to PPO with Sample-Factory
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/thumbnail2.png" alt="thumbnail"/>
In this second part of Unit 8, we'll get deeper into PPO optimization by using [Sample-Factory](https://samplefactory.dev/), an **asynchronous implementation of the PPO algorithm**, to train our agent to play [vizdoom](https://vizdoom.cs.put.edu.pl/) (an open source version of Doom).
In the notebook, **you'll train your agent to play the Health Gathering level**, where the agent must collect health packs to avoid dying. After that, you can **train your agent to play more complex levels, such as Deathmatch**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/environments.png" alt="Environment"/>
Sound exciting? Let's get started! 🚀
The hands-on is made by [Edward Beeching](https://twitter.com/edwardbeeching), a Machine Learning Research Scientist at Hugging Face. He worked on Godot Reinforcement Learning Agents, an open-source interface for developing environments and agents in the Godot Game Engine.
| deep-rl-class/units/en/unit8/introduction-sf.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit8/introduction-sf.mdx",
"repo_id": "deep-rl-class",
"token_count": 328
} | 85 |
# Godot RL Agents
[Godot RL Agents](https://github.com/edbeeching/godot_rl_agents) is an Open Source package that allows video game creators, AI researchers, and hobbyists the opportunity **to learn complex behaviors for their Non Player Characters or agents**.
The library provides:
- An interface between games created in the [Godot Engine](https://godotengine.org/) and Machine Learning algorithms running in Python
- Wrappers for four well known rl frameworks: [StableBaselines3](https://stable-baselines3.readthedocs.io/en/master/), [CleanRL](https://docs.cleanrl.dev/), [Sample Factory](https://www.samplefactory.dev/) and [Ray RLLib](https://docs.ray.io/en/latest/rllib-algorithms.html)
- Support for memory-based agents with LSTM or attention based interfaces
- Support for *2D and 3D games*
- A suite of *AI sensors* to augment your agent's capacity to observe the game world
- Godot and Godot RL Agents are **completely free and open source under a very permissive MIT license**. No strings attached, no royalties, nothing.
You can find out more about Godot RL agents on their [GitHub page](https://github.com/edbeeching/godot_rl_agents) or their AAAI-2022 Workshop [paper](https://arxiv.org/abs/2112.03636). The library's creator, [Ed Beeching](https://edbeeching.github.io/), is a Research Scientist here at Hugging Face.
Installation of the library is simple: `pip install godot-rl`
## Create a custom RL environment with Godot RL Agents
In this section, you will **learn how to create a custom environment in the Godot Game Engine** and then implement an AI controller that learns to play with Deep Reinforcement Learning.
The example game we create today is simple, **but shows off many of the features of the Godot Engine and the Godot RL Agents library**. You can then dive into the examples for more complex environments and behaviors.
The environment we will be building today is called Ring Pong, the game of pong but the pitch is a ring and the paddle moves around the ring. The **objective is to keep the ball bouncing inside the ring**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/ringpong.gif" alt="Ring Pong">
### Installing the Godot Game Engine
The [Godot game engine](https://godotengine.org/) is an open source tool for the **creation of video games, tools and user interfaces**.
Godot Engine is a feature-packed, cross-platform game engine designed to create 2D and 3D games from a unified interface. It provides a comprehensive set of common tools, so users **can focus on making games without having to reinvent the wheel**. Games can be exported in one click to a number of platforms, including the major desktop platforms (Linux, macOS, Windows) as well as mobile (Android, iOS) and web-based (HTML5) platforms.
While we will guide you through the steps to implement your agent, you may wish to learn more about the Godot Game Engine. Their [documentation](https://docs.godotengine.org/en/latest/index.html) is thorough, and there are many tutorials on YouTube we would also recommend [GDQuest](https://www.gdquest.com/), [KidsCanCode](https://kidscancode.org/godot_recipes/4.x/) and [Bramwell](https://www.youtube.com/channel/UCczi7Aq_dTKrQPF5ZV5J3gg) as sources of information.
In order to create games in Godot, **you must first download the editor**. Godot RL Agents supports the latest version of Godot, Godot 4.0.
Which can be downloaded at the following links:
- [Windows](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_win64.exe.zip)
- [Mac](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_macos.universal.zip)
- [Linux](https://downloads.tuxfamily.org/godotengine/4.0.1/Godot_v4.0.1-stable_linux.x86_64.zip)
### Loading the starter project
We provide two versions of the codebase:
- [A starter project, to download and follow along for this tutorial](https://drive.google.com/file/d/1C7xd3TibJHlxFEJPBgBLpksgxrFZ3D8e/view?usp=share_link)
- [A final version of the project, for comparison and debugging.](https://drive.google.com/file/d/1k-b2Bu7uIA6poApbouX4c3sq98xqogpZ/view?usp=share_link)
To load the project, in the Godot Project Manager click **Import**, navigate to where the files are located and load the **project.godot** file.
If you press F5 or play in the editor, you should be able to play the game in human mode. There are several instances of the game running, this is because we want to speed up training our AI agent with many parallel environments.
### Installing the Godot RL Agents plugin
The Godot RL Agents plugin can be installed from the Github repo or with the Godot Asset Lib in the editor.
First click on the AssetLib and search for “rl”
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot1.png" alt="Godot">
Then click on Godot RL Agents, click Download and unselect the LICENSE and README .md files. Then click install.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot2.png" alt="Godot">
The Godot RL Agents plugin is now downloaded to your machine. Now click on Project → Project settings and enable the addon:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot3.png" alt="Godot">
### Adding the AI controller
We now want to add an AI controller to our game. Open the player.tscn scene, on the left you should see a hierarchy of nodes that looks like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot4.png" alt="Godot">
Right click the **Player** node and click **Add Child Node.** There are many nodes listed here, search for AIController3D and create it.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot5.png" alt="Godot">
The AI Controller Node should have been added to the scene tree, next to it is a scroll. Click on it to open the script that is attached to the AIController. The Godot game engine uses a scripting language called GDScript, which is syntactically similar to python. The script contains methods that need to be implemented in order to get our AI controller working.
```python
#-- Methods that need implementing using the "extend script" option in Godot --#
func get_obs() -> Dictionary:
assert(false, "the get_obs method is not implemented when extending from ai_controller")
return {"obs":[]}
func get_reward() -> float:
assert(false, "the get_reward method is not implemented when extending from ai_controller")
return 0.0
func get_action_space() -> Dictionary:
assert(false, "the get get_action_space method is not implemented when extending from ai_controller")
return {
"example_actions_continous" : {
"size": 2,
"action_type": "continuous"
},
"example_actions_discrete" : {
"size": 2,
"action_type": "discrete"
},
}
func set_action(action) -> void:
assert(false, "the get set_action method is not implemented when extending from ai_controller")
# -----------------------------------------------------------------------------#
```
In order to implement these methods, we will need to create a class that inherits from AIController3D. This is easy to do in Godot, and is called “extending” a class.
Right click the AIController3D Node and click “Extend Script” and call the new script `controller.gd`. You should now have an almost empty script file that looks like this:
```python
extends AIController3D
# Called when the node enters the scene tree for the first time.
func _ready():
pass # Replace with function body.
# Called every frame. 'delta' is the elapsed time since the previous frame.
func _process(delta):
pass
```
We will now implement the 4 missing methods, delete this code, and replace it with the following:
```python
extends AIController3D
# Stores the action sampled for the agent's policy, running in python
var move_action : float = 0.0
func get_obs() -> Dictionary:
# get the balls position and velocity in the paddle's frame of reference
var ball_pos = to_local(_player.ball.global_position)
var ball_vel = to_local(_player.ball.linear_velocity)
var obs = [ball_pos.x, ball_pos.z, ball_vel.x/10.0, ball_vel.z/10.0]
return {"obs":obs}
func get_reward() -> float:
return reward
func get_action_space() -> Dictionary:
return {
"move_action" : {
"size": 1,
"action_type": "continuous"
},
}
func set_action(action) -> void:
move_action = clamp(action["move_action"][0], -1.0, 1.0)
```
We have now defined the agent’s observation, which is the position and velocity of the ball in its local coordinate space. We have also defined the action space of the agent, which is a single continuous value ranging from -1 to +1.
The next step is to update the Player’s script to use the actions from the AIController, edit the Player’s script by clicking on the scroll next to the player node, update the code in `Player.gd` to the following:
```python
extends Node3D
@export var rotation_speed = 3.0
@onready var ball = get_node("../Ball")
@onready var ai_controller = $AIController3D
func _ready():
ai_controller.init(self)
func game_over():
ai_controller.done = true
ai_controller.needs_reset = true
func _physics_process(delta):
if ai_controller.needs_reset:
ai_controller.reset()
ball.reset()
return
var movement : float
if ai_controller.heuristic == "human":
movement = Input.get_axis("rotate_anticlockwise", "rotate_clockwise")
else:
movement = ai_controller.move_action
rotate_y(movement*delta*rotation_speed)
func _on_area_3d_body_entered(body):
ai_controller.reward += 1.0
```
We now need to synchronize between the game running in Godot and the neural network being trained in Python. Godot RL agents provides a node that does just that. Open the train.tscn scene, right click on the root node, and click “Add child node”. Then, search for “sync” and add a Godot RL Agents Sync node. This node handles the communication between Python and Godot over TCP.
You can run training live in the editor, by first launching the python training with `gdrl`.
In this simple example, a reasonable policy is learned in several minutes. You may wish to speed up training, click on the Sync node in the train scene, and you will see there is a “Speed Up” property exposed in the editor:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit9/godot6.png" alt="Godot">
Try setting this property up to 8 to speed up training. This can be a great benefit on more complex environments, like the multi-player FPS we will learn about in the next chapter.
### There’s more!
We have only scratched the surface of what can be achieved with Godot RL Agents, the library includes custom sensors and cameras to enrich the information available to the agent. Take a look at the [examples](https://github.com/edbeeching/godot_rl_agents_examples) to find out more!
For the ability to export the trained model to .onnx so that you can run inference directly from Godot without the Python server, and other useful training options, take a look at the [advanced SB3 tutorial](https://github.com/edbeeching/godot_rl_agents/blob/main/docs/ADV_STABLE_BASELINES_3.md).
## Author
This section was written by <a href="https://twitter.com/edwardbeeching">Edward Beeching</a>
| deep-rl-class/units/en/unitbonus3/godotrl.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus3/godotrl.mdx",
"repo_id": "deep-rl-class",
"token_count": 3416
} | 86 |
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| diffusers/LICENSE/0 | {
"file_path": "diffusers/LICENSE",
"repo_id": "diffusers",
"token_count": 3168
} | 87 |
FROM ubuntu:20.04
LABEL maintainer="Hugging Face"
LABEL repository="diffusers"
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y bash \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
python3.8 \
python3-pip \
python3.8-venv && \
rm -rf /var/lib/apt/lists
# make sure to use venv
RUN python3 -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
# follow the instructions here: https://cloud.google.com/tpu/docs/run-in-container#train_a_jax_model_in_a_docker_container
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
python3 -m pip install --upgrade --no-cache-dir \
clu \
"jax[cpu]>=0.2.16,!=0.3.2" \
"flax>=0.4.1" \
"jaxlib>=0.1.65" && \
python3 -m pip install --no-cache-dir \
accelerate \
datasets \
hf-doc-builder \
huggingface-hub \
Jinja2 \
librosa \
numpy \
scipy \
tensorboard \
transformers
CMD ["/bin/bash"] | diffusers/docker/diffusers-flax-cpu/Dockerfile/0 | {
"file_path": "diffusers/docker/diffusers-flax-cpu/Dockerfile",
"repo_id": "diffusers",
"token_count": 666
} | 88 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
The APIs in this section are more experimental and prone to breaking changes. Most of them are used internally for development, but they may also be useful to you if you're interested in building a diffusion model with some custom parts or if you're interested in some of our helper utilities for working with 🤗 Diffusers.
| diffusers/docs/source/en/api/internal_classes_overview.md/0 | {
"file_path": "diffusers/docs/source/en/api/internal_classes_overview.md",
"repo_id": "diffusers",
"token_count": 212
} | 89 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# K-Diffusion
[k-diffusion](https://github.com/crowsonkb/k-diffusion) is a popular library created by [Katherine Crowson](https://github.com/crowsonkb/). We provide `StableDiffusionKDiffusionPipeline` and `StableDiffusionXLKDiffusionPipeline` that allow you to run Stable DIffusion with samplers from k-diffusion.
Note that most the samplers from k-diffusion are implemented in Diffusers and we recommend using existing schedulers. You can find a mapping between k-diffusion samplers and schedulers in Diffusers [here](https://huggingface.co/docs/diffusers/api/schedulers/overview)
## StableDiffusionKDiffusionPipeline
[[autodoc]] StableDiffusionKDiffusionPipeline
## StableDiffusionXLKDiffusionPipeline
[[autodoc]] StableDiffusionXLKDiffusionPipeline | diffusers/docs/source/en/api/pipelines/stable_diffusion/k_diffusion.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/stable_diffusion/k_diffusion.md",
"repo_id": "diffusers",
"token_count": 380
} | 90 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DPMSolverMultistepScheduler
`DPMSolverMultistep` is a multistep scheduler from [DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps](https://huggingface.co/papers/2206.00927) and [DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models](https://huggingface.co/papers/2211.01095) by Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu.
DPMSolver (and the improved version DPMSolver++) is a fast dedicated high-order solver for diffusion ODEs with convergence order guarantee. Empirically, DPMSolver sampling with only 20 steps can generate high-quality
samples, and it can generate quite good samples even in 10 steps.
## Tips
It is recommended to set `solver_order` to 2 for guide sampling, and `solver_order=3` for unconditional sampling.
Dynamic thresholding from [Imagen](https://huggingface.co/papers/2205.11487) is supported, and for pixel-space
diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
thresholding. This thresholding method is unsuitable for latent-space diffusion models such as
Stable Diffusion.
The SDE variant of DPMSolver and DPM-Solver++ is also supported, but only for the first and second-order solvers. This is a fast SDE solver for the reverse diffusion SDE. It is recommended to use the second-order `sde-dpmsolver++`.
## DPMSolverMultistepScheduler
[[autodoc]] DPMSolverMultistepScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| diffusers/docs/source/en/api/schedulers/multistep_dpm_solver.md/0 | {
"file_path": "diffusers/docs/source/en/api/schedulers/multistep_dpm_solver.md",
"repo_id": "diffusers",
"token_count": 600
} | 91 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
[[open-in-colab]]
# Quicktour
Diffusion models are trained to denoise random Gaussian noise step-by-step to generate a sample of interest, such as an image or audio. This has sparked a tremendous amount of interest in generative AI, and you have probably seen examples of diffusion generated images on the internet. 🧨 Diffusers is a library aimed at making diffusion models widely accessible to everyone.
Whether you're a developer or an everyday user, this quicktour will introduce you to 🧨 Diffusers and help you get up and generating quickly! There are three main components of the library to know about:
* The [`DiffusionPipeline`] is a high-level end-to-end class designed to rapidly generate samples from pretrained diffusion models for inference.
* Popular pretrained [model](./api/models) architectures and modules that can be used as building blocks for creating diffusion systems.
* Many different [schedulers](./api/schedulers/overview) - algorithms that control how noise is added for training, and how to generate denoised images during inference.
The quicktour will show you how to use the [`DiffusionPipeline`] for inference, and then walk you through how to combine a model and scheduler to replicate what's happening inside the [`DiffusionPipeline`].
<Tip>
The quicktour is a simplified version of the introductory 🧨 Diffusers [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) to help you get started quickly. If you want to learn more about 🧨 Diffusers' goal, design philosophy, and additional details about its core API, check out the notebook!
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install --upgrade diffusers accelerate transformers
```
- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) speeds up model loading for inference and training.
- [🤗 Transformers](https://huggingface.co/docs/transformers/index) is required to run the most popular diffusion models, such as [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
## DiffusionPipeline
The [`DiffusionPipeline`] is the easiest way to use a pretrained diffusion system for inference. It is an end-to-end system containing the model and the scheduler. You can use the [`DiffusionPipeline`] out-of-the-box for many tasks. Take a look at the table below for some supported tasks, and for a complete list of supported tasks, check out the [🧨 Diffusers Summary](./api/pipelines/overview#diffusers-summary) table.
| **Task** | **Description** | **Pipeline**
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
| Unconditional Image Generation | generate an image from Gaussian noise | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
| Text-Guided Image Generation | generate an image given a text prompt | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
| Text-Guided Image-to-Image Translation | adapt an image guided by a text prompt | [img2img](./using-diffusers/img2img) |
| Text-Guided Image-Inpainting | fill the masked part of an image given the image, the mask and a text prompt | [inpaint](./using-diffusers/inpaint) |
| Text-Guided Depth-to-Image Translation | adapt parts of an image guided by a text prompt while preserving structure via depth estimation | [depth2img](./using-diffusers/depth2img) |
Start by creating an instance of a [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
You can use the [`DiffusionPipeline`] for any [checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads) stored on the Hugging Face Hub.
In this quicktour, you'll load the [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint for text-to-image generation.
<Tip warning={true}>
For [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) models, please carefully read the [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) first before running the model. 🧨 Diffusers implements a [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) to prevent offensive or harmful content, but the model's improved image generation capabilities can still produce potentially harmful content.
</Tip>
Load the model with the [`~DiffusionPipeline.from_pretrained`] method:
```python
>>> from diffusers import DiffusionPipeline
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
```
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components. You'll see that the Stable Diffusion pipeline is composed of the [`UNet2DConditionModel`] and [`PNDMScheduler`] among other things:
```py
>>> pipeline
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.21.4",
...,
"scheduler": [
"diffusers",
"PNDMScheduler"
],
...,
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
```
We strongly recommend running the pipeline on a GPU because the model consists of roughly 1.4 billion parameters.
You can move the generator object to a GPU, just like you would in PyTorch:
```python
>>> pipeline.to("cuda")
```
Now you can pass a text prompt to the `pipeline` to generate an image, and then access the denoised image. By default, the image output is wrapped in a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) object.
```python
>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png"/>
</div>
Save the image by calling `save`:
```python
>>> image.save("image_of_squirrel_painting.png")
```
### Local pipeline
You can also use the pipeline locally. The only difference is you need to download the weights first:
```bash
!git lfs install
!git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
```
Then load the saved weights into the pipeline:
```python
>>> pipeline = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5", use_safetensors=True)
```
Now, you can run the pipeline as you would in the section above.
### Swapping schedulers
Different schedulers come with different denoising speeds and quality trade-offs. The best way to find out which one works best for you is to try them out! One of the main features of 🧨 Diffusers is to allow you to easily switch between schedulers. For example, to replace the default [`PNDMScheduler`] with the [`EulerDiscreteScheduler`], load it with the [`~diffusers.ConfigMixin.from_config`] method:
```py
>>> from diffusers import EulerDiscreteScheduler
>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
```
Try generating an image with the new scheduler and see if you notice a difference!
In the next section, you'll take a closer look at the components - the model and scheduler - that make up the [`DiffusionPipeline`] and learn how to use these components to generate an image of a cat.
## Models
Most models take a noisy sample, and at each timestep it predicts the *noise residual* (other models learn to predict the previous sample directly or the velocity or [`v-prediction`](https://github.com/huggingface/diffusers/blob/5e5ce13e2f89ac45a0066cb3f369462a3cf1d9ef/src/diffusers/schedulers/scheduling_ddim.py#L110)), the difference between a less noisy image and the input image. You can mix and match models to create other diffusion systems.
Models are initiated with the [`~ModelMixin.from_pretrained`] method which also locally caches the model weights so it is faster the next time you load the model. For the quicktour, you'll load the [`UNet2DModel`], a basic unconditional image generation model with a checkpoint trained on cat images:
```py
>>> from diffusers import UNet2DModel
>>> repo_id = "google/ddpm-cat-256"
>>> model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)
```
To access the model parameters, call `model.config`:
```py
>>> model.config
```
The model configuration is a 🧊 frozen 🧊 dictionary, which means those parameters can't be changed after the model is created. This is intentional and ensures that the parameters used to define the model architecture at the start remain the same, while other parameters can still be adjusted during inference.
Some of the most important parameters are:
* `sample_size`: the height and width dimension of the input sample.
* `in_channels`: the number of input channels of the input sample.
* `down_block_types` and `up_block_types`: the type of down- and upsampling blocks used to create the UNet architecture.
* `block_out_channels`: the number of output channels of the downsampling blocks; also used in reverse order for the number of input channels of the upsampling blocks.
* `layers_per_block`: the number of ResNet blocks present in each UNet block.
To use the model for inference, create the image shape with random Gaussian noise. It should have a `batch` axis because the model can receive multiple random noises, a `channel` axis corresponding to the number of input channels, and a `sample_size` axis for the height and width of the image:
```py
>>> import torch
>>> torch.manual_seed(0)
>>> noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
>>> noisy_sample.shape
torch.Size([1, 3, 256, 256])
```
For inference, pass the noisy image and a `timestep` to the model. The `timestep` indicates how noisy the input image is, with more noise at the beginning and less at the end. This helps the model determine its position in the diffusion process, whether it is closer to the start or the end. Use the `sample` method to get the model output:
```py
>>> with torch.no_grad():
... noisy_residual = model(sample=noisy_sample, timestep=2).sample
```
To generate actual examples though, you'll need a scheduler to guide the denoising process. In the next section, you'll learn how to couple a model with a scheduler.
## Schedulers
Schedulers manage going from a noisy sample to a less noisy sample given the model output - in this case, it is the `noisy_residual`.
<Tip>
🧨 Diffusers is a toolbox for building diffusion systems. While the [`DiffusionPipeline`] is a convenient way to get started with a pre-built diffusion system, you can also choose your own model and scheduler components separately to build a custom diffusion system.
</Tip>
For the quicktour, you'll instantiate the [`DDPMScheduler`] with its [`~diffusers.ConfigMixin.from_config`] method:
```py
>>> from diffusers import DDPMScheduler
>>> scheduler = DDPMScheduler.from_pretrained(repo_id)
>>> scheduler
DDPMScheduler {
"_class_name": "DDPMScheduler",
"_diffusers_version": "0.21.4",
"beta_end": 0.02,
"beta_schedule": "linear",
"beta_start": 0.0001,
"clip_sample": true,
"clip_sample_range": 1.0,
"dynamic_thresholding_ratio": 0.995,
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"sample_max_value": 1.0,
"steps_offset": 0,
"thresholding": false,
"timestep_spacing": "leading",
"trained_betas": null,
"variance_type": "fixed_small"
}
```
<Tip>
💡 Unlike a model, a scheduler does not have trainable weights and is parameter-free!
</Tip>
Some of the most important parameters are:
* `num_train_timesteps`: the length of the denoising process or, in other words, the number of timesteps required to process random Gaussian noise into a data sample.
* `beta_schedule`: the type of noise schedule to use for inference and training.
* `beta_start` and `beta_end`: the start and end noise values for the noise schedule.
To predict a slightly less noisy image, pass the following to the scheduler's [`~diffusers.DDPMScheduler.step`] method: model output, `timestep`, and current `sample`.
```py
>>> less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
>>> less_noisy_sample.shape
torch.Size([1, 3, 256, 256])
```
The `less_noisy_sample` can be passed to the next `timestep` where it'll get even less noisy! Let's bring it all together now and visualize the entire denoising process.
First, create a function that postprocesses and displays the denoised image as a `PIL.Image`:
```py
>>> import PIL.Image
>>> import numpy as np
>>> def display_sample(sample, i):
... image_processed = sample.cpu().permute(0, 2, 3, 1)
... image_processed = (image_processed + 1.0) * 127.5
... image_processed = image_processed.numpy().astype(np.uint8)
... image_pil = PIL.Image.fromarray(image_processed[0])
... display(f"Image at step {i}")
... display(image_pil)
```
To speed up the denoising process, move the input and model to a GPU:
```py
>>> model.to("cuda")
>>> noisy_sample = noisy_sample.to("cuda")
```
Now create a denoising loop that predicts the residual of the less noisy sample, and computes the less noisy sample with the scheduler:
```py
>>> import tqdm
>>> sample = noisy_sample
>>> for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
... # 1. predict noise residual
... with torch.no_grad():
... residual = model(sample, t).sample
... # 2. compute less noisy image and set x_t -> x_t-1
... sample = scheduler.step(residual, t, sample).prev_sample
... # 3. optionally look at image
... if (i + 1) % 50 == 0:
... display_sample(sample, i + 1)
```
Sit back and watch as a cat is generated from nothing but noise! 😻
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusion-quicktour.png"/>
</div>
## Next steps
Hopefully, you generated some cool images with 🧨 Diffusers in this quicktour! For your next steps, you can:
* Train or finetune a model to generate your own images in the [training](./tutorials/basic_training) tutorial.
* See example official and community [training or finetuning scripts](https://github.com/huggingface/diffusers/tree/main/examples#-diffusers-examples) for a variety of use cases.
* Learn more about loading, accessing, changing, and comparing schedulers in the [Using different Schedulers](./using-diffusers/schedulers) guide.
* Explore prompt engineering, speed and memory optimizations, and tips and tricks for generating higher-quality images with the [Stable Diffusion](./stable_diffusion) guide.
* Dive deeper into speeding up 🧨 Diffusers with guides on [optimized PyTorch on a GPU](./optimization/fp16), and inference guides for running [Stable Diffusion on Apple Silicon (M1/M2)](./optimization/mps) and [ONNX Runtime](./optimization/onnx).
| diffusers/docs/source/en/quicktour.md/0 | {
"file_path": "diffusers/docs/source/en/quicktour.md",
"repo_id": "diffusers",
"token_count": 4837
} | 92 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Text-to-image
<Tip warning={true}>
The text-to-image script is experimental, and it's easy to overfit and run into issues like catastrophic forgetting. Try exploring different hyperparameters to get the best results on your dataset.
</Tip>
Text-to-image models like Stable Diffusion are conditioned to generate images given a text prompt.
Training a model can be taxing on your hardware, but if you enable `gradient_checkpointing` and `mixed_precision`, it is possible to train a model on a single 24GB GPU. If you're training with larger batch sizes or want to train faster, it's better to use GPUs with more than 30GB of memory. You can reduce your memory footprint by enabling memory-efficient attention with [xFormers](../optimization/xformers). JAX/Flax training is also supported for efficient training on TPUs and GPUs, but it doesn't support gradient checkpointing, gradient accumulation or xFormers. A GPU with at least 30GB of memory or a TPU v3 is recommended for training with Flax.
This guide will explore the [train_text_to_image.py](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) training script to help you become familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
<hfoptions id="installation">
<hfoption id="PyTorch">
```bash
cd examples/text_to_image
pip install -r requirements.txt
```
</hfoption>
<hfoption id="Flax">
```bash
cd examples/text_to_image
pip install -r requirements_flax.txt
```
</hfoption>
</hfoptions>
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
## Script parameters
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) and let us know if you have any questions or concerns.
</Tip>
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L193) function. This function provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_text_to_image.py \
--mixed_precision="fp16"
```
Some basic and important parameters include:
- `--pretrained_model_name_or_path`: the name of the model on the Hub or a local path to the pretrained model
- `--dataset_name`: the name of the dataset on the Hub or a local path to the dataset to train on
- `--image_column`: the name of the image column in the dataset to train on
- `--caption_column`: the name of the text column in the dataset to train on
- `--output_dir`: where to save the trained model
- `--push_to_hub`: whether to push the trained model to the Hub
- `--checkpointing_steps`: frequency of saving a checkpoint as the model trains; this is useful if for some reason training is interrupted, you can continue training from that checkpoint by adding `--resume_from_checkpoint` to your training command
### Min-SNR weighting
The [Min-SNR](https://huggingface.co/papers/2303.09556) weighting strategy can help with training by rebalancing the loss to achieve faster convergence. The training script supports predicting `epsilon` (noise) or `v_prediction`, but Min-SNR is compatible with both prediction types. This weighting strategy is only supported by PyTorch and is unavailable in the Flax training script.
Add the `--snr_gamma` parameter and set it to the recommended value of 5.0:
```bash
accelerate launch train_text_to_image.py \
--snr_gamma=5.0
```
You can compare the loss surfaces for different `snr_gamma` values in this [Weights and Biases](https://wandb.ai/sayakpaul/text2image-finetune-minsnr) report. For smaller datasets, the effects of Min-SNR may not be as obvious compared to larger datasets.
## Training script
The dataset preprocessing code and training loop are found in the [`main()`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L490) function. If you need to adapt the training script, this is where you'll need to make your changes.
The `train_text_to_image` script starts by [loading a scheduler](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L543) and tokenizer. You can choose to use a different scheduler here if you want:
```py
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
```
Then the script [loads the UNet](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L619) model:
```py
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
```
Next, the text and image columns of the dataset need to be preprocessed. The [`tokenize_captions`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L724) function handles tokenizing the inputs, and the [`train_transforms`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L742) function specifies the type of transforms to apply to the image. Both of these functions are bundled into `preprocess_train`:
```py
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["input_ids"] = tokenize_captions(examples)
return examples
```
Lastly, the [training loop](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L878) handles everything else. It encodes images into latent space, adds noise to the latents, computes the text embeddings to condition on, updates the model parameters, and saves and pushes the model to the Hub. If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Once you've made all your changes or you're okay with the default configuration, you're ready to launch the training script! 🚀
<hfoptions id="training-inference">
<hfoption id="PyTorch">
Let's train on the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset to generate your own Pokémon. Set the environment variables `MODEL_NAME` and `dataset_name` to the model and the dataset (either from the Hub or a local path). If you're training on more than one GPU, add the `--multi_gpu` parameter to the `accelerate launch` command.
<Tip>
To train on a local dataset, set the `TRAIN_DIR` and `OUTPUT_DIR` environment variables to the path of the dataset and where to save the model to.
</Tip>
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export dataset_name="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$dataset_name \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--enable_xformers_memory_efficient_attention
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model" \
--push_to_hub
```
</hfoption>
<hfoption id="Flax">
Training with Flax can be faster on TPUs and GPUs thanks to [@duongna211](https://github.com/duongna21). Flax is more efficient on a TPU, but GPU performance is also great.
Set the environment variables `MODEL_NAME` and `dataset_name` to the model and the dataset (either from the Hub or a local path).
<Tip>
To train on a local dataset, set the `TRAIN_DIR` and `OUTPUT_DIR` environment variables to the path of the dataset and where to save the model to.
</Tip>
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export dataset_name="lambdalabs/pokemon-blip-captions"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$dataset_name \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model" \
--push_to_hub
```
</hfoption>
</hfoptions>
Once training is complete, you can use your newly trained model for inference:
<hfoptions id="training-inference">
<hfoption id="PyTorch">
```py
from diffusers import StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained("path/to/saved_model", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
image = pipeline(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
</hfoption>
<hfoption id="Flax">
```py
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained("path/to/saved_model", dtype=jax.numpy.bfloat16)
prompt = "yoda pokemon"
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 50
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = pipeline.prepare_inputs(prompt)
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
image.save("yoda-pokemon.png")
```
</hfoption>
</hfoptions>
## Next steps
Congratulations on training your own text-to-image model! To learn more about how to use your new model, the following guides may be helpful:
- Learn how to [load LoRA weights](../using-diffusers/loading_adapters#LoRA) for inference if you trained your model with LoRA.
- Learn more about how certain parameters like guidance scale or techniques such as prompt weighting can help you control inference in the [Text-to-image](../using-diffusers/conditional_image_generation) task guide.
| diffusers/docs/source/en/training/text2image.md/0 | {
"file_path": "diffusers/docs/source/en/training/text2image.md",
"repo_id": "diffusers",
"token_count": 4033
} | 93 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Load community pipelines and components
[[open-in-colab]]
## Community pipelines
Community pipelines are any [`DiffusionPipeline`] class that are different from the original implementation as specified in their paper (for example, the [`StableDiffusionControlNetPipeline`] corresponds to the [Text-to-Image Generation with ControlNet Conditioning](https://arxiv.org/abs/2302.05543) paper). They provide additional functionality or extend the original implementation of a pipeline.
There are many cool community pipelines like [Speech to Image](https://github.com/huggingface/diffusers/tree/main/examples/community#speech-to-image) or [Composable Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#composable-stable-diffusion), and you can find all the official community pipelines [here](https://github.com/huggingface/diffusers/tree/main/examples/community).
To load any community pipeline on the Hub, pass the repository id of the community pipeline to the `custom_pipeline` argument and the model repository where you'd like to load the pipeline weights and components from. For example, the example below loads a dummy pipeline from [`hf-internal-testing/diffusers-dummy-pipeline`](https://huggingface.co/hf-internal-testing/diffusers-dummy-pipeline/blob/main/pipeline.py) and the pipeline weights and components from [`google/ddpm-cifar10-32`](https://huggingface.co/google/ddpm-cifar10-32):
<Tip warning={true}>
🔒 By loading a community pipeline from the Hugging Face Hub, you are trusting that the code you are loading is safe. Make sure to inspect the code online before loading and running it automatically!
</Tip>
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline", use_safetensors=True
)
```
Loading an official community pipeline is similar, but you can mix loading weights from an official repository id and pass pipeline components directly. The example below loads the community [CLIP Guided Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#clip-guided-stable-diffusion) pipeline, and you can pass the CLIP model components directly to it:
```py
from diffusers import DiffusionPipeline
from transformers import CLIPImageProcessor, CLIPModel
clip_model_id = "laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
feature_extractor = CLIPImageProcessor.from_pretrained(clip_model_id)
clip_model = CLIPModel.from_pretrained(clip_model_id)
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
custom_pipeline="clip_guided_stable_diffusion",
clip_model=clip_model,
feature_extractor=feature_extractor,
use_safetensors=True,
)
```
For more information about community pipelines, take a look at the [Community pipelines](custom_pipeline_examples) guide for how to use them and if you're interested in adding a community pipeline check out the [How to contribute a community pipeline](contribute_pipeline) guide!
## Community components
Community components allow users to build pipelines that may have customized components that are not a part of Diffusers. If your pipeline has custom components that Diffusers doesn't already support, you need to provide their implementations as Python modules. These customized components could be a VAE, UNet, and scheduler. In most cases, the text encoder is imported from the Transformers library. The pipeline code itself can also be customized.
This section shows how users should use community components to build a community pipeline.
You'll use the [showlab/show-1-base](https://huggingface.co/showlab/show-1-base) pipeline checkpoint as an example. So, let's start loading the components:
1. Import and load the text encoder from Transformers:
```python
from transformers import T5Tokenizer, T5EncoderModel
pipe_id = "showlab/show-1-base"
tokenizer = T5Tokenizer.from_pretrained(pipe_id, subfolder="tokenizer")
text_encoder = T5EncoderModel.from_pretrained(pipe_id, subfolder="text_encoder")
```
2. Load a scheduler:
```python
from diffusers import DPMSolverMultistepScheduler
scheduler = DPMSolverMultistepScheduler.from_pretrained(pipe_id, subfolder="scheduler")
```
3. Load an image processor:
```python
from transformers import CLIPFeatureExtractor
feature_extractor = CLIPFeatureExtractor.from_pretrained(pipe_id, subfolder="feature_extractor")
```
<Tip warning={true}>
In steps 4 and 5, the custom [UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py) and [pipeline](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) implementation must match the format shown in their files for this example to work.
</Tip>
4. Now you'll load a [custom UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py), which in this example, has already been implemented in the `showone_unet_3d_condition.py` [script](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) for your convenience. You'll notice the `UNet3DConditionModel` class name is changed to `ShowOneUNet3DConditionModel` because [`UNet3DConditionModel`] already exists in Diffusers. Any components needed for the `ShowOneUNet3DConditionModel` class should be placed in the `showone_unet_3d_condition.py` script.
Once this is done, you can initialize the UNet:
```python
from showone_unet_3d_condition import ShowOneUNet3DConditionModel
unet = ShowOneUNet3DConditionModel.from_pretrained(pipe_id, subfolder="unet")
```
5. Finally, you'll load the custom pipeline code. For this example, it has already been created for you in the `pipeline_t2v_base_pixel.py` [script](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/pipeline_t2v_base_pixel.py). This script contains a custom `TextToVideoIFPipeline` class for generating videos from text. Just like the custom UNet, any code needed for the custom pipeline to work should go in the `pipeline_t2v_base_pixel.py` script.
Once everything is in place, you can initialize the `TextToVideoIFPipeline` with the `ShowOneUNet3DConditionModel`:
```python
from pipeline_t2v_base_pixel import TextToVideoIFPipeline
import torch
pipeline = TextToVideoIFPipeline(
unet=unet,
text_encoder=text_encoder,
tokenizer=tokenizer,
scheduler=scheduler,
feature_extractor=feature_extractor
)
pipeline = pipeline.to(device="cuda")
pipeline.torch_dtype = torch.float16
```
Push the pipeline to the Hub to share with the community!
```python
pipeline.push_to_hub("custom-t2v-pipeline")
```
After the pipeline is successfully pushed, you need a couple of changes:
1. Change the `_class_name` attribute in [`model_index.json`](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/model_index.json#L2) to `"pipeline_t2v_base_pixel"` and `"TextToVideoIFPipeline"`.
2. Upload `showone_unet_3d_condition.py` to the `unet` [directory](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py).
3. Upload `pipeline_t2v_base_pixel.py` to the pipeline base [directory](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py).
To run inference, simply add the `trust_remote_code` argument while initializing the pipeline to handle all the "magic" behind the scenes.
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"<change-username>/<change-id>", trust_remote_code=True, torch_dtype=torch.float16
).to("cuda")
prompt = "hello"
# Text embeds
prompt_embeds, negative_embeds = pipeline.encode_prompt(prompt)
# Keyframes generation (8x64x40, 2fps)
video_frames = pipeline(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
num_frames=8,
height=40,
width=64,
num_inference_steps=2,
guidance_scale=9.0,
output_type="pt"
).frames
```
As an additional reference example, you can refer to the repository structure of [stabilityai/japanese-stable-diffusion-xl](https://huggingface.co/stabilityai/japanese-stable-diffusion-xl/), that makes use of the `trust_remote_code` feature:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/japanese-stable-diffusion-xl", trust_remote_code=True
)
pipeline.to("cuda")
# if using torch < 2.0
# pipeline.enable_xformers_memory_efficient_attention()
prompt = "柴犬、カラフルアート"
image = pipeline(prompt=prompt).images[0]
``` | diffusers/docs/source/en/using-diffusers/custom_pipeline_overview.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/custom_pipeline_overview.md",
"repo_id": "diffusers",
"token_count": 2927
} | 94 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Push files to the Hub
[[open-in-colab]]
🤗 Diffusers provides a [`~diffusers.utils.PushToHubMixin`] for uploading your model, scheduler, or pipeline to the Hub. It is an easy way to store your files on the Hub, and also allows you to share your work with others. Under the hood, the [`~diffusers.utils.PushToHubMixin`]:
1. creates a repository on the Hub
2. saves your model, scheduler, or pipeline files so they can be reloaded later
3. uploads folder containing these files to the Hub
This guide will show you how to use the [`~diffusers.utils.PushToHubMixin`] to upload your files to the Hub.
You'll need to log in to your Hub account with your access [token](https://huggingface.co/settings/tokens) first:
```py
from huggingface_hub import notebook_login
notebook_login()
```
## Models
To push a model to the Hub, call [`~diffusers.utils.PushToHubMixin.push_to_hub`] and specify the repository id of the model to be stored on the Hub:
```py
from diffusers import ControlNetModel
controlnet = ControlNetModel(
block_out_channels=(32, 64),
layers_per_block=2,
in_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
cross_attention_dim=32,
conditioning_embedding_out_channels=(16, 32),
)
controlnet.push_to_hub("my-controlnet-model")
```
For models, you can also specify the [*variant*](loading#checkpoint-variants) of the weights to push to the Hub. For example, to push `fp16` weights:
```py
controlnet.push_to_hub("my-controlnet-model", variant="fp16")
```
The [`~diffusers.utils.PushToHubMixin.push_to_hub`] function saves the model's `config.json` file and the weights are automatically saved in the `safetensors` format.
Now you can reload the model from your repository on the Hub:
```py
model = ControlNetModel.from_pretrained("your-namespace/my-controlnet-model")
```
## Scheduler
To push a scheduler to the Hub, call [`~diffusers.utils.PushToHubMixin.push_to_hub`] and specify the repository id of the scheduler to be stored on the Hub:
```py
from diffusers import DDIMScheduler
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
scheduler.push_to_hub("my-controlnet-scheduler")
```
The [`~diffusers.utils.PushToHubMixin.push_to_hub`] function saves the scheduler's `scheduler_config.json` file to the specified repository.
Now you can reload the scheduler from your repository on the Hub:
```py
scheduler = DDIMScheduler.from_pretrained("your-namepsace/my-controlnet-scheduler")
```
## Pipeline
You can also push an entire pipeline with all it's components to the Hub. For example, initialize the components of a [`StableDiffusionPipeline`] with the parameters you want:
```py
from diffusers import (
UNet2DConditionModel,
AutoencoderKL,
DDIMScheduler,
StableDiffusionPipeline,
)
from transformers import CLIPTextModel, CLIPTextConfig, CLIPTokenizer
unet = UNet2DConditionModel(
block_out_channels=(32, 64),
layers_per_block=2,
sample_size=32,
in_channels=4,
out_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
cross_attention_dim=32,
)
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
vae = AutoencoderKL(
block_out_channels=[32, 64],
in_channels=3,
out_channels=3,
down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
latent_channels=4,
)
text_encoder_config = CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=32,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
text_encoder = CLIPTextModel(text_encoder_config)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
```
Pass all of the components to the [`StableDiffusionPipeline`] and call [`~diffusers.utils.PushToHubMixin.push_to_hub`] to push the pipeline to the Hub:
```py
components = {
"unet": unet,
"scheduler": scheduler,
"vae": vae,
"text_encoder": text_encoder,
"tokenizer": tokenizer,
"safety_checker": None,
"feature_extractor": None,
}
pipeline = StableDiffusionPipeline(**components)
pipeline.push_to_hub("my-pipeline")
```
The [`~diffusers.utils.PushToHubMixin.push_to_hub`] function saves each component to a subfolder in the repository. Now you can reload the pipeline from your repository on the Hub:
```py
pipeline = StableDiffusionPipeline.from_pretrained("your-namespace/my-pipeline")
```
## Privacy
Set `private=True` in the [`~diffusers.utils.PushToHubMixin.push_to_hub`] function to keep your model, scheduler, or pipeline files private:
```py
controlnet.push_to_hub("my-controlnet-model-private", private=True)
```
Private repositories are only visible to you, and other users won't be able to clone the repository and your repository won't appear in search results. Even if a user has the URL to your private repository, they'll receive a `404 - Sorry, we can't find the page you are looking for`. You must be [logged in](https://huggingface.co/docs/huggingface_hub/quick-start#login) to load a model from a private repository. | diffusers/docs/source/en/using-diffusers/push_to_hub.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/push_to_hub.md",
"repo_id": "diffusers",
"token_count": 2084
} | 95 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# インストール
お使いのディープラーニングライブラリに合わせてDiffusersをインストールできます。
🤗 DiffusersはPython 3.8+、PyTorch 1.7.0+、Flaxでテストされています。使用するディープラーニングライブラリの以下のインストール手順に従ってください:
- [PyTorch](https://pytorch.org/get-started/locally/)のインストール手順。
- [Flax](https://flax.readthedocs.io/en/latest/)のインストール手順。
## pip でインストール
Diffusersは[仮想環境](https://docs.python.org/3/library/venv.html)の中でインストールすることが推奨されています。
Python の仮想環境についてよく知らない場合は、こちらの [ガイド](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/) を参照してください。
仮想環境は異なるプロジェクトの管理を容易にし、依存関係間の互換性の問題を回避します。
ではさっそく、プロジェクトディレクトリに仮想環境を作ってみます:
```bash
python -m venv .env
```
仮想環境をアクティブにします:
```bash
source .env/bin/activate
```
🤗 Diffusers もまた 🤗 Transformers ライブラリに依存しており、以下のコマンドで両方をインストールできます:
<frameworkcontent>
<pt>
```bash
pip install diffusers["torch"] transformers
```
</pt>
<jax>
```bash
pip install diffusers["flax"] transformers
```
</jax>
</frameworkcontent>
## ソースからのインストール
ソースから🤗 Diffusersをインストールする前に、`torch`と🤗 Accelerateがインストールされていることを確認してください。
`torch`のインストールについては、`torch` [インストール](https://pytorch.org/get-started/locally/#start-locally)ガイドを参照してください。
🤗 Accelerateをインストールするには:
```bash
pip install accelerate
```
以下のコマンドでソースから🤗 Diffusersをインストールできます:
```bash
pip install git+https://github.com/huggingface/diffusers
```
このコマンドは最新の `stable` バージョンではなく、最先端の `main` バージョンをインストールします。
`main`バージョンは最新の開発に対応するのに便利です。
例えば、前回の公式リリース以降にバグが修正されたが、新しいリリースがまだリリースされていない場合などには都合がいいです。
しかし、これは `main` バージョンが常に安定しているとは限らないです。
私たちは `main` バージョンを運用し続けるよう努力しており、ほとんどの問題は通常数時間から1日以内に解決されます。
もし問題が発生した場合は、[Issue](https://github.com/huggingface/diffusers/issues/new/choose) を開いてください!
## 編集可能なインストール
以下の場合、編集可能なインストールが必要です:
* ソースコードの `main` バージョンを使用する。
* 🤗 Diffusers に貢献し、コードの変更をテストする必要がある場合。
リポジトリをクローンし、次のコマンドで 🤗 Diffusers をインストールしてください:
```bash
git clone https://github.com/huggingface/diffusers.git
cd diffusers
```
<frameworkcontent>
<pt>
```bash
pip install -e ".[torch]"
```
</pt>
<jax>
```bash
pip install -e ".[flax]"
```
</jax>
</frameworkcontent>
これらのコマンドは、リポジトリをクローンしたフォルダと Python のライブラリパスをリンクします。
Python は通常のライブラリパスに加えて、クローンしたフォルダの中を探すようになります。
例えば、Python パッケージが通常 `~/anaconda3/envs/main/lib/python3.8/site-packages/` にインストールされている場合、Python はクローンした `~/diffusers/` フォルダも同様に参照します。
<Tip warning={true}>
ライブラリを使い続けたい場合は、`diffusers`フォルダを残しておく必要があります。
</Tip>
これで、以下のコマンドで簡単にクローンを最新版の🤗 Diffusersにアップデートできます:
```bash
cd ~/diffusers/
git pull
```
Python環境は次の実行時に `main` バージョンの🤗 Diffusersを見つけます。
## テレメトリー・ロギングに関するお知らせ
このライブラリは `from_pretrained()` リクエスト中にデータを収集します。
このデータには Diffusers と PyTorch/Flax のバージョン、要求されたモデルやパイプラインクラスが含まれます。
また、Hubでホストされている場合は、事前に学習されたチェックポイントへのパスが含まれます。
この使用データは問題のデバッグや新機能の優先順位付けに役立ちます。
テレメトリーはHuggingFace Hubからモデルやパイプラインをロードするときのみ送信されます。ローカルでの使用中は収集されません。
我々は、すべての人が追加情報を共有したくないことを理解し、あなたのプライバシーを尊重します。
そのため、ターミナルから `DISABLE_TELEMETRY` 環境変数を設定することで、データ収集を無効にすることができます:
Linux/MacOSの場合
```bash
export DISABLE_TELEMETRY=YES
```
Windows の場合
```bash
set DISABLE_TELEMETRY=YES
```
| diffusers/docs/source/ja/installation.md/0 | {
"file_path": "diffusers/docs/source/ja/installation.md",
"repo_id": "diffusers",
"token_count": 2494
} | 96 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 개요
노이즈가 많은 출력에서 적은 출력으로 만드는 과정으로 고품질 생성 모델의 출력을 만드는 각각의 반복되는 스텝은 많은 계산이 필요합니다. 🧨 Diffuser의 목표 중 하나는 모든 사람이 이 기술을 널리 이용할 수 있도록 하는 것이며, 여기에는 소비자 및 특수 하드웨어에서 빠른 추론을 가능하게 하는 것을 포함합니다.
이 섹션에서는 추론 속도를 최적화하고 메모리 소비를 줄이기 위한 반정밀(half-precision) 가중치 및 sliced attention과 같은 팁과 요령을 다룹니다. 또한 [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) 또는 [ONNX Runtime](https://onnxruntime.ai/docs/)을 사용하여 PyTorch 코드의 속도를 높이고, [xFormers](https://facebookresearch.github.io/xformers/)를 사용하여 memory-efficient attention을 활성화하는 방법을 배울 수 있습니다. Apple Silicon, Intel 또는 Habana 프로세서와 같은 특정 하드웨어에서 추론을 실행하기 위한 가이드도 있습니다. | diffusers/docs/source/ko/optimization/opt_overview.md/0 | {
"file_path": "diffusers/docs/source/ko/optimization/opt_overview.md",
"repo_id": "diffusers",
"token_count": 943
} | 97 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Textual-Inversion
[[open-in-colab]]
[textual-inversion](https://arxiv.org/abs/2208.01618)은 소수의 예시 이미지에서 새로운 콘셉트를 포착하는 기법입니다. 이 기술은 원래 [Latent Diffusion](https://github.com/CompVis/latent-diffusion)에서 시연되었지만, 이후 [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion)과 같은 유사한 다른 모델에도 적용되었습니다. 학습된 콘셉트는 text-to-image 파이프라인에서 생성된 이미지를 더 잘 제어하는 데 사용할 수 있습니다. 이 모델은 텍스트 인코더의 임베딩 공간에서 새로운 '단어'를 학습하여 개인화된 이미지 생성을 위한 텍스트 프롬프트 내에서 사용됩니다.

<small>By using just 3-5 images you can teach new concepts to a model such as Stable Diffusion for personalized image generation <a href="https://github.com/rinongal/textual_inversion">(image source)</a>.</small>
이 가이드에서는 textual-inversion으로 [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) 모델을 학습하는 방법을 설명합니다. 이 가이드에서 사용된 모든 textual-inversion 학습 스크립트는 [여기](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion)에서 확인할 수 있습니다. 내부적으로 어떻게 작동하는지 자세히 살펴보고 싶으시다면 해당 링크를 참조해주시기 바랍니다.
<Tip>
[Stable Diffusion Textual Inversion Concepts Library](https://huggingface.co/sd-concepts-library)에는 커뮤니티에서 제작한 학습된 textual-inversion 모델들이 있습니다. 시간이 지남에 따라 더 많은 콘셉트들이 추가되어 유용한 리소스로 성장할 것입니다!
</Tip>
시작하기 전에 학습을 위한 의존성 라이브러리들을 설치해야 합니다:
```bash
pip install diffusers accelerate transformers
```
의존성 라이브러리들의 설치가 완료되면, [🤗Accelerate](https://github.com/huggingface/accelerate/) 환경을 초기화시킵니다.
```bash
accelerate config
```
별도의 설정없이, 기본 🤗Accelerate 환경을 설정하려면 다음과 같이 하세요:
```bash
accelerate config default
```
또는 사용 중인 환경이 노트북과 같은 대화형 셸을 지원하지 않는다면, 다음과 같이 사용할 수 있습니다:
```py
from accelerate.utils import write_basic_config
write_basic_config()
```
마지막으로, Memory-Efficient Attention을 통해 메모리 사용량을 줄이기 위해 [xFormers](https://huggingface.co/docs/diffusers/main/en/training/optimization/xformers)를 설치합니다. xFormers를 설치한 후, 학습 스크립트에 `--enable_xformers_memory_efficient_attention` 인자를 추가합니다. xFormers는 Flax에서 지원되지 않습니다.
## 허브에 모델 업로드하기
모델을 허브에 저장하려면, 학습 스크립트에 다음 인자를 추가해야 합니다.
```bash
--push_to_hub
```
## 체크포인트 저장 및 불러오기
학습중에 모델의 체크포인트를 정기적으로 저장하는 것이 좋습니다. 이렇게 하면 어떤 이유로든 학습이 중단된 경우 저장된 체크포인트에서 학습을 다시 시작할 수 있습니다. 학습 스크립트에 다음 인자를 전달하면 500단계마다 전체 학습 상태가 `output_dir`의 하위 폴더에 체크포인트로서 저장됩니다.
```bash
--checkpointing_steps=500
```
저장된 체크포인트에서 학습을 재개하려면, 학습 스크립트와 재개할 특정 체크포인트에 다음 인자를 전달하세요.
```bash
--resume_from_checkpoint="checkpoint-1500"
```
## 파인 튜닝
학습용 데이터셋으로 [고양이 장난감 데이터셋](https://huggingface.co/datasets/diffusers/cat_toy_example)을 다운로드하여 디렉토리에 저장하세요. 여러분만의 고유한 데이터셋을 사용하고자 한다면, [학습용 데이터셋 만들기](https://huggingface.co/docs/diffusers/training/create_dataset) 가이드를 살펴보시기 바랍니다.
```py
from huggingface_hub import snapshot_download
local_dir = "./cat"
snapshot_download(
"diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes"
)
```
모델의 리포지토리 ID(또는 모델 가중치가 포함된 디렉터리 경로)를 `MODEL_NAME` 환경 변수에 할당하고, 해당 값을 [`pretrained_model_name_or_path`](https://huggingface.co/docs/diffusers/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained.pretrained_model_name_or_path) 인자에 전달합니다. 그리고 이미지가 포함된 디렉터리 경로를 `DATA_DIR` 환경 변수에 할당합니다.
이제 [학습 스크립트](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py)를 실행할 수 있습니다. 스크립트는 다음 파일을 생성하고 리포지토리에 저장합니다.
- `learned_embeds.bin`
- `token_identifier.txt`
- `type_of_concept.txt`.
<Tip>
💡V100 GPU 1개를 기준으로 전체 학습에는 최대 1시간이 걸립니다. 학습이 완료되기를 기다리는 동안 궁금한 점이 있으면 아래 섹션에서 [textual-inversion이 어떻게 작동하는지](https://huggingface.co/docs/diffusers/training/text_inversion#how-it-works) 자유롭게 확인하세요 !
</Tip>
<frameworkcontent>
<pt>
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="./cat"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="textual_inversion_cat" \
--push_to_hub
```
<Tip>
💡학습 성능을 올리기 위해, 플레이스홀더 토큰(`<cat-toy>`)을 (단일한 임베딩 벡터가 아닌) 복수의 임베딩 벡터로 표현하는 것 역시 고려할 있습니다. 이러한 트릭이 모델이 보다 복잡한 이미지의 스타일(앞서 말한 콘셉트)을 더 잘 캡처하는 데 도움이 될 수 있습니다. 복수의 임베딩 벡터 학습을 활성화하려면 다음 옵션을 전달하십시오.
```bash
--num_vectors=5
```
</Tip>
</pt>
<jax>
TPU에 액세스할 수 있는 경우, [Flax 학습 스크립트](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion_flax.py)를 사용하여 더 빠르게 모델을 학습시켜보세요. (물론 GPU에서도 작동합니다.) 동일한 설정에서 Flax 학습 스크립트는 PyTorch 학습 스크립트보다 최소 70% 더 빨라야 합니다! ⚡️
시작하기 앞서 Flax에 대한 의존성 라이브러리들을 설치해야 합니다.
```bash
pip install -U -r requirements_flax.txt
```
모델의 리포지토리 ID(또는 모델 가중치가 포함된 디렉터리 경로)를 `MODEL_NAME` 환경 변수에 할당하고, 해당 값을 [`pretrained_model_name_or_path`](https://huggingface.co/docs/diffusers/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained.pretrained_model_name_or_path) 인자에 전달합니다.
그런 다음 [학습 스크립트](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion_flax.py)를 시작할 수 있습니다.
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATA_DIR="./cat"
python textual_inversion_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--output_dir="textual_inversion_cat" \
--push_to_hub
```
</jax>
</frameworkcontent>
### 중간 로깅
모델의 학습 진행 상황을 추적하는 데 관심이 있는 경우, 학습 과정에서 생성된 이미지를 저장할 수 있습니다. 학습 스크립트에 다음 인수를 추가하여 중간 로깅을 활성화합니다.
- `validation_prompt` : 샘플을 생성하는 데 사용되는 프롬프트(기본값은 `None`으로 설정되며, 이 때 중간 로깅은 비활성화됨)
- `num_validation_images` : 생성할 샘플 이미지 수
- `validation_steps` : `validation_prompt`로부터 샘플 이미지를 생성하기 전 스텝의 수
```bash
--validation_prompt="A <cat-toy> backpack"
--num_validation_images=4
--validation_steps=100
```
## 추론
모델을 학습한 후에는, 해당 모델을 [`StableDiffusionPipeline`]을 사용하여 추론에 사용할 수 있습니다.
textual-inversion 스크립트는 기본적으로 textual-inversion을 통해 얻어진 임베딩 벡터만을 저장합니다. 해당 임베딩 벡터들은 텍스트 인코더의 임베딩 행렬에 추가되어 있습습니다.
<frameworkcontent>
<pt>
<Tip>
💡 커뮤니티는 [sd-concepts-library](https://huggingface.co/sd-concepts-library) 라는 대규모의 textual-inversion 임베딩 벡터 라이브러리를 만들었습니다. textual-inversion 임베딩을 밑바닥부터 학습하는 대신, 해당 라이브러리에 본인이 찾는 textual-inversion 임베딩이 이미 추가되어 있지 않은지를 확인하는 것도 좋은 방법이 될 것 같습니다.
</Tip>
textual-inversion 임베딩 벡터을 불러오기 위해서는, 먼저 해당 임베딩 벡터를 학습할 때 사용한 모델을 불러와야 합니다. 여기서는 [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/docs/diffusers/training/runwayml/stable-diffusion-v1-5) 모델이 사용되었다고 가정하고 불러오겠습니다.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
```
다음으로 `TextualInversionLoaderMixin.load_textual_inversion` 함수를 통해, textual-inversion 임베딩 벡터를 불러와야 합니다. 여기서 우리는 이전의 `<cat-toy>` 예제의 임베딩을 불러올 것입니다.
```python
pipe.load_textual_inversion("sd-concepts-library/cat-toy")
```
이제 플레이스홀더 토큰(`<cat-toy>`)이 잘 동작하는지를 확인하는 파이프라인을 실행할 수 있습니다.
```python
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("cat-backpack.png")
```
`TextualInversionLoaderMixin.load_textual_inversion`은 Diffusers 형식으로 저장된 텍스트 임베딩 벡터를 로드할 수 있을 뿐만 아니라, [Automatic1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) 형식으로 저장된 임베딩 벡터도 로드할 수 있습니다. 이렇게 하려면, 먼저 [civitAI](https://civitai.com/models/3036?modelVersionId=8387)에서 임베딩 벡터를 다운로드한 다음 로컬에서 불러와야 합니다.
```python
pipe.load_textual_inversion("./charturnerv2.pt")
```
</pt>
<jax>
현재 Flax에 대한 `load_textual_inversion` 함수는 없습니다. 따라서 학습 후 textual-inversion 임베딩 벡터가 모델의 일부로서 저장되었는지를 확인해야 합니다. 그런 다음은 다른 Flax 모델과 마찬가지로 실행할 수 있습니다.
```python
import jax
import numpy as np
from flax.jax_utils import replicate
from flax.training.common_utils import shard
from diffusers import FlaxStableDiffusionPipeline
model_path = "path-to-your-trained-model"
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(model_path, dtype=jax.numpy.bfloat16)
prompt = "A <cat-toy> backpack"
prng_seed = jax.random.PRNGKey(0)
num_inference_steps = 50
num_samples = jax.device_count()
prompt = num_samples * [prompt]
prompt_ids = pipeline.prepare_inputs(prompt)
# shard inputs and rng
params = replicate(params)
prng_seed = jax.random.split(prng_seed, jax.device_count())
prompt_ids = shard(prompt_ids)
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
image.save("cat-backpack.png")
```
</jax>
</frameworkcontent>
## 작동 방식

<small>Architecture overview from the Textual Inversion <a href="https://textual-inversion.github.io/">blog post.</a></small>
일반적으로 텍스트 프롬프트는 모델에 전달되기 전에 임베딩으로 토큰화됩니다. textual-inversion은 비슷한 작업을 수행하지만, 위 다이어그램의 특수 토큰 `S*`로부터 새로운 토큰 임베딩 `v*`를 학습합니다. 모델의 아웃풋은 디퓨전 모델을 조정하는 데 사용되며, 디퓨전 모델이 단 몇 개의 예제 이미지에서 신속하고 새로운 콘셉트를 이해하는 데 도움을 줍니다.
이를 위해 textual-inversion은 제너레이터 모델과 학습용 이미지의 노이즈 버전을 사용합니다. 제너레이터는 노이즈가 적은 버전의 이미지를 예측하려고 시도하며 토큰 임베딩 `v*`은 제너레이터의 성능에 따라 최적화됩니다. 토큰 임베딩이 새로운 콘셉트를 성공적으로 포착하면 디퓨전 모델에 더 유용한 정보를 제공하고 노이즈가 적은 더 선명한 이미지를 생성하는 데 도움이 됩니다. 이러한 최적화 프로세스는 일반적으로 다양한 프롬프트와 이미지에 수천 번에 노출됨으로써 이루어집니다.
| diffusers/docs/source/ko/training/text_inversion.md/0 | {
"file_path": "diffusers/docs/source/ko/training/text_inversion.md",
"repo_id": "diffusers",
"token_count": 9077
} | 98 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
파이프라인은 독립적으로 훈련된 모델과 스케줄러를 함께 모아서 추론을 위해 diffusion 시스템을 빠르고 쉽게 사용할 수 있는 방법을 제공하는 end-to-end 클래스입니다. 모델과 스케줄러의 특정 조합은 특수한 기능과 함께 [`StableDiffusionPipeline`] 또는 [`StableDiffusionControlNetPipeline`]과 같은 특정 파이프라인 유형을 정의합니다. 모든 파이프라인 유형은 기본 [`DiffusionPipeline`] 클래스에서 상속됩니다. 어느 체크포인트를 전달하면, 파이프라인 유형을 자동으로 감지하고 필요한 구성 요소들을 불러옵니다.
이 섹션에서는 unconditional 이미지 생성, text-to-image 생성의 다양한 테크닉과 변화를 파이프라인에서 지원하는 작업들을 소개합니다. 프롬프트에 있는 특정 단어가 출력에 영향을 미치는 것을 조정하기 위해 재현성을 위한 시드 설정과 프롬프트에 가중치를 부여하는 것으로 생성 프로세스를 더 잘 제어하는 방법에 대해 배울 수 있습니다. 마지막으로 음성에서부터 이미지 생성과 같은 커스텀 작업을 위한 커뮤니티 파이프라인을 만드는 방법을 알 수 있습니다.
| diffusers/docs/source/ko/using-diffusers/pipeline_overview.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/pipeline_overview.md",
"repo_id": "diffusers",
"token_count": 1174
} | 99 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 安装
在你正在使用的任意深度学习框架中安装 🤗 Diffusers 。
🤗 Diffusers已在Python 3.8+、PyTorch 1.7.0+和Flax上进行了测试。按照下面的安装说明,针对你正在使用的深度学习框架进行安装:
- [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
- [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
## 使用pip安装
你需要在[虚拟环境](https://docs.python.org/3/library/venv.html)中安装 🤗 Diffusers 。
如果你对 Python 虚拟环境不熟悉,可以看看这个[教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
在虚拟环境中,你可以轻松管理不同的项目,避免依赖项之间的兼容性问题。
首先,在你的项目目录下创建一个虚拟环境:
```bash
python -m venv .env
```
激活虚拟环境:
```bash
source .env/bin/activate
```
现在,你就可以安装 🤗 Diffusers了!使用下边这个命令:
**PyTorch**
```bash
pip install diffusers["torch"]
```
**Flax**
```bash
pip install diffusers["flax"]
```
## 从源代码安装
在从源代码安装 `diffusers` 之前,确保你已经安装了 `torch` 和 `accelerate`。
`torch`的安装教程可以看 `torch` [文档](https://pytorch.org/get-started/locally/#start-locally).
安装 `accelerate`
```bash
pip install accelerate
```
从源码安装 🤗 Diffusers 需要使用以下命令:
```bash
pip install git+https://github.com/huggingface/diffusers
```
这个命令安装的是最新的 `main`版本,而不是最近的`stable`版。
`main`是一直和最新进展保持一致的。比如,上次发布的正式版中有bug,在`main`中可以看到这个bug被修复了,但是新的正式版此时尚未推出。
但是这也意味着 `main`版本不保证是稳定的。
我们努力保持`main`版本正常运行,大多数问题都能在几个小时或一天之内解决
如果你遇到了问题,可以提 [Issue](https://github.com/huggingface/transformers/issues),这样我们就能更快修复问题了。
## 可修改安装
如果你想做以下两件事,那你可能需要一个可修改代码的安装方式:
* 使用 `main`版本的源代码。
* 为 🤗 Diffusers 贡献,需要测试代码中的变化。
使用以下命令克隆并安装 🤗 Diffusers:
```bash
git clone https://github.com/huggingface/diffusers.git
cd diffusers
```
**PyTorch**
```
pip install -e ".[torch]"
```
**Flax**
```
pip install -e ".[flax]"
```
这些命令将连接到你克隆的版本库和你的 Python 库路径。
现在,不只是在通常的库路径,Python 还会在你克隆的文件夹内寻找包。
例如,如果你的 Python 包通常安装在 `~/anaconda3/envs/main/lib/python3.8/Site-packages/`,Python 也会搜索你克隆到的文件夹。`~/diffusers/`。
<Tip warning={true}>
如果你想继续使用这个库,你必须保留 `diffusers` 文件夹。
</Tip>
现在你可以用下面的命令轻松地将你克隆的 🤗 Diffusers 库更新到最新版本。
```bash
cd ~/diffusers/
git pull
```
你的Python环境将在下次运行时找到`main`版本的 🤗 Diffusers。
## 注意 Telemetry 日志
我们的库会在使用`from_pretrained()`请求期间收集 telemetry 信息。这些数据包括Diffusers和PyTorch/Flax的版本,请求的模型或管道类,以及预训练检查点的路径(如果它被托管在Hub上的话)。
这些使用数据有助于我们调试问题并确定新功能的开发优先级。
Telemetry 数据仅在从 HuggingFace Hub 中加载模型和管道时发送,而不会在本地使用期间收集。
我们知道,并不是每个人都想分享这些的信息,我们尊重您的隐私,
因此您可以通过在终端中设置 `DISABLE_TELEMETRY` 环境变量从而禁用 Telemetry 数据收集:
Linux/MacOS :
```bash
export DISABLE_TELEMETRY=YES
```
Windows :
```bash
set DISABLE_TELEMETRY=YES
``` | diffusers/docs/source/zh/installation.md/0 | {
"file_path": "diffusers/docs/source/zh/installation.md",
"repo_id": "diffusers",
"token_count": 2456
} | 100 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from math import pi
from typing import Callable, List, Optional, Tuple, Union
import numpy as np
import torch
from PIL import Image
from diffusers import DDPMScheduler, DiffusionPipeline, ImagePipelineOutput, UNet2DModel
from diffusers.utils.torch_utils import randn_tensor
class DPSPipeline(DiffusionPipeline):
r"""
Pipeline for Diffusion Posterior Sampling.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
Parameters:
unet ([`UNet2DModel`]):
A `UNet2DModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
[`DDPMScheduler`], or [`DDIMScheduler`].
"""
model_cpu_offload_seq = "unet"
def __init__(self, unet, scheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
measurement: torch.Tensor,
operator: torch.nn.Module,
loss_fn: Callable[[torch.Tensor, torch.Tensor], torch.Tensor],
batch_size: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
num_inference_steps: int = 1000,
output_type: Optional[str] = "pil",
return_dict: bool = True,
zeta: float = 0.3,
) -> Union[ImagePipelineOutput, Tuple]:
r"""
The call function to the pipeline for generation.
Args:
measurement (`torch.Tensor`, *required*):
A 'torch.Tensor', the corrupted image
operator (`torch.nn.Module`, *required*):
A 'torch.nn.Module', the operator generating the corrupted image
loss_fn (`Callable[[torch.Tensor, torch.Tensor], torch.Tensor]`, *required*):
A 'Callable[[torch.Tensor, torch.Tensor], torch.Tensor]', the loss function used
between the measurements, for most of the cases using RMSE is fine.
batch_size (`int`, *optional*, defaults to 1):
The number of images to generate.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
num_inference_steps (`int`, *optional*, defaults to 1000):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Example:
```py
>>> from diffusers import DDPMPipeline
>>> # load model and scheduler
>>> pipe = DDPMPipeline.from_pretrained("google/ddpm-cat-256")
>>> # run pipeline in inference (sample random noise and denoise)
>>> image = pipe().images[0]
>>> # save image
>>> image.save("ddpm_generated_image.png")
```
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.ImagePipelineOutput`] is returned, otherwise a `tuple` is
returned where the first element is a list with the generated images
"""
# Sample gaussian noise to begin loop
if isinstance(self.unet.config.sample_size, int):
image_shape = (
batch_size,
self.unet.config.in_channels,
self.unet.config.sample_size,
self.unet.config.sample_size,
)
else:
image_shape = (batch_size, self.unet.config.in_channels, *self.unet.config.sample_size)
if self.device.type == "mps":
# randn does not work reproducibly on mps
image = randn_tensor(image_shape, generator=generator)
image = image.to(self.device)
else:
image = randn_tensor(image_shape, generator=generator, device=self.device)
# set step values
self.scheduler.set_timesteps(num_inference_steps)
for t in self.progress_bar(self.scheduler.timesteps):
with torch.enable_grad():
# 1. predict noise model_output
image = image.requires_grad_()
model_output = self.unet(image, t).sample
# 2. compute previous image x'_{t-1} and original prediction x0_{t}
scheduler_out = self.scheduler.step(model_output, t, image, generator=generator)
image_pred, origi_pred = scheduler_out.prev_sample, scheduler_out.pred_original_sample
# 3. compute y'_t = f(x0_{t})
measurement_pred = operator(origi_pred)
# 4. compute loss = d(y, y'_t-1)
loss = loss_fn(measurement, measurement_pred)
loss.backward()
print("distance: {0:.4f}".format(loss.item()))
with torch.no_grad():
image_pred = image_pred - zeta * image.grad
image = image_pred.detach()
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
if __name__ == "__main__":
import scipy
from torch import nn
from torchvision.utils import save_image
# defining the operators f(.) of y = f(x)
# super-resolution operator
class SuperResolutionOperator(nn.Module):
def __init__(self, in_shape, scale_factor):
super().__init__()
# Resizer local class, do not use outiside the SR operator class
class Resizer(nn.Module):
def __init__(self, in_shape, scale_factor=None, output_shape=None, kernel=None, antialiasing=True):
super(Resizer, self).__init__()
# First standardize values and fill missing arguments (if needed) by deriving scale from output shape or vice versa
scale_factor, output_shape = self.fix_scale_and_size(in_shape, output_shape, scale_factor)
# Choose interpolation method, each method has the matching kernel size
def cubic(x):
absx = np.abs(x)
absx2 = absx**2
absx3 = absx**3
return (1.5 * absx3 - 2.5 * absx2 + 1) * (absx <= 1) + (
-0.5 * absx3 + 2.5 * absx2 - 4 * absx + 2
) * ((1 < absx) & (absx <= 2))
def lanczos2(x):
return (
(np.sin(pi * x) * np.sin(pi * x / 2) + np.finfo(np.float32).eps)
/ ((pi**2 * x**2 / 2) + np.finfo(np.float32).eps)
) * (abs(x) < 2)
def box(x):
return ((-0.5 <= x) & (x < 0.5)) * 1.0
def lanczos3(x):
return (
(np.sin(pi * x) * np.sin(pi * x / 3) + np.finfo(np.float32).eps)
/ ((pi**2 * x**2 / 3) + np.finfo(np.float32).eps)
) * (abs(x) < 3)
def linear(x):
return (x + 1) * ((-1 <= x) & (x < 0)) + (1 - x) * ((0 <= x) & (x <= 1))
method, kernel_width = {
"cubic": (cubic, 4.0),
"lanczos2": (lanczos2, 4.0),
"lanczos3": (lanczos3, 6.0),
"box": (box, 1.0),
"linear": (linear, 2.0),
None: (cubic, 4.0), # set default interpolation method as cubic
}.get(kernel)
# Antialiasing is only used when downscaling
antialiasing *= np.any(np.array(scale_factor) < 1)
# Sort indices of dimensions according to scale of each dimension. since we are going dim by dim this is efficient
sorted_dims = np.argsort(np.array(scale_factor))
self.sorted_dims = [int(dim) for dim in sorted_dims if scale_factor[dim] != 1]
# Iterate over dimensions to calculate local weights for resizing and resize each time in one direction
field_of_view_list = []
weights_list = []
for dim in self.sorted_dims:
# for each coordinate (along 1 dim), calculate which coordinates in the input image affect its result and the
# weights that multiply the values there to get its result.
weights, field_of_view = self.contributions(
in_shape[dim], output_shape[dim], scale_factor[dim], method, kernel_width, antialiasing
)
# convert to torch tensor
weights = torch.tensor(weights.T, dtype=torch.float32)
# We add singleton dimensions to the weight matrix so we can multiply it with the big tensor we get for
# tmp_im[field_of_view.T], (bsxfun style)
weights_list.append(
nn.Parameter(
torch.reshape(weights, list(weights.shape) + (len(scale_factor) - 1) * [1]),
requires_grad=False,
)
)
field_of_view_list.append(
nn.Parameter(
torch.tensor(field_of_view.T.astype(np.int32), dtype=torch.long), requires_grad=False
)
)
self.field_of_view = nn.ParameterList(field_of_view_list)
self.weights = nn.ParameterList(weights_list)
def forward(self, in_tensor):
x = in_tensor
# Use the affecting position values and the set of weights to calculate the result of resizing along this 1 dim
for dim, fov, w in zip(self.sorted_dims, self.field_of_view, self.weights):
# To be able to act on each dim, we swap so that dim 0 is the wanted dim to resize
x = torch.transpose(x, dim, 0)
# This is a bit of a complicated multiplication: x[field_of_view.T] is a tensor of order image_dims+1.
# for each pixel in the output-image it matches the positions the influence it from the input image (along 1 dim
# only, this is why it only adds 1 dim to 5the shape). We then multiply, for each pixel, its set of positions with
# the matching set of weights. we do this by this big tensor element-wise multiplication (MATLAB bsxfun style:
# matching dims are multiplied element-wise while singletons mean that the matching dim is all multiplied by the
# same number
x = torch.sum(x[fov] * w, dim=0)
# Finally we swap back the axes to the original order
x = torch.transpose(x, dim, 0)
return x
def fix_scale_and_size(self, input_shape, output_shape, scale_factor):
# First fixing the scale-factor (if given) to be standardized the function expects (a list of scale factors in the
# same size as the number of input dimensions)
if scale_factor is not None:
# By default, if scale-factor is a scalar we assume 2d resizing and duplicate it.
if np.isscalar(scale_factor) and len(input_shape) > 1:
scale_factor = [scale_factor, scale_factor]
# We extend the size of scale-factor list to the size of the input by assigning 1 to all the unspecified scales
scale_factor = list(scale_factor)
scale_factor = [1] * (len(input_shape) - len(scale_factor)) + scale_factor
# Fixing output-shape (if given): extending it to the size of the input-shape, by assigning the original input-size
# to all the unspecified dimensions
if output_shape is not None:
output_shape = list(input_shape[len(output_shape) :]) + list(np.uint(np.array(output_shape)))
# Dealing with the case of non-give scale-factor, calculating according to output-shape. note that this is
# sub-optimal, because there can be different scales to the same output-shape.
if scale_factor is None:
scale_factor = 1.0 * np.array(output_shape) / np.array(input_shape)
# Dealing with missing output-shape. calculating according to scale-factor
if output_shape is None:
output_shape = np.uint(np.ceil(np.array(input_shape) * np.array(scale_factor)))
return scale_factor, output_shape
def contributions(self, in_length, out_length, scale, kernel, kernel_width, antialiasing):
# This function calculates a set of 'filters' and a set of field_of_view that will later on be applied
# such that each position from the field_of_view will be multiplied with a matching filter from the
# 'weights' based on the interpolation method and the distance of the sub-pixel location from the pixel centers
# around it. This is only done for one dimension of the image.
# When anti-aliasing is activated (default and only for downscaling) the receptive field is stretched to size of
# 1/sf. this means filtering is more 'low-pass filter'.
fixed_kernel = (lambda arg: scale * kernel(scale * arg)) if antialiasing else kernel
kernel_width *= 1.0 / scale if antialiasing else 1.0
# These are the coordinates of the output image
out_coordinates = np.arange(1, out_length + 1)
# since both scale-factor and output size can be provided simulatneously, perserving the center of the image requires shifting
# the output coordinates. the deviation is because out_length doesn't necesary equal in_length*scale.
# to keep the center we need to subtract half of this deivation so that we get equal margins for boths sides and center is preserved.
shifted_out_coordinates = out_coordinates - (out_length - in_length * scale) / 2
# These are the matching positions of the output-coordinates on the input image coordinates.
# Best explained by example: say we have 4 horizontal pixels for HR and we downscale by SF=2 and get 2 pixels:
# [1,2,3,4] -> [1,2]. Remember each pixel number is the middle of the pixel.
# The scaling is done between the distances and not pixel numbers (the right boundary of pixel 4 is transformed to
# the right boundary of pixel 2. pixel 1 in the small image matches the boundary between pixels 1 and 2 in the big
# one and not to pixel 2. This means the position is not just multiplication of the old pos by scale-factor).
# So if we measure distance from the left border, middle of pixel 1 is at distance d=0.5, border between 1 and 2 is
# at d=1, and so on (d = p - 0.5). we calculate (d_new = d_old / sf) which means:
# (p_new-0.5 = (p_old-0.5) / sf) -> p_new = p_old/sf + 0.5 * (1-1/sf)
match_coordinates = shifted_out_coordinates / scale + 0.5 * (1 - 1 / scale)
# This is the left boundary to start multiplying the filter from, it depends on the size of the filter
left_boundary = np.floor(match_coordinates - kernel_width / 2)
# Kernel width needs to be enlarged because when covering has sub-pixel borders, it must 'see' the pixel centers
# of the pixels it only covered a part from. So we add one pixel at each side to consider (weights can zeroize them)
expanded_kernel_width = np.ceil(kernel_width) + 2
# Determine a set of field_of_view for each each output position, these are the pixels in the input image
# that the pixel in the output image 'sees'. We get a matrix whos horizontal dim is the output pixels (big) and the
# vertical dim is the pixels it 'sees' (kernel_size + 2)
field_of_view = np.squeeze(
np.int16(np.expand_dims(left_boundary, axis=1) + np.arange(expanded_kernel_width) - 1)
)
# Assign weight to each pixel in the field of view. A matrix whos horizontal dim is the output pixels and the
# vertical dim is a list of weights matching to the pixel in the field of view (that are specified in
# 'field_of_view')
weights = fixed_kernel(1.0 * np.expand_dims(match_coordinates, axis=1) - field_of_view - 1)
# Normalize weights to sum up to 1. be careful from dividing by 0
sum_weights = np.sum(weights, axis=1)
sum_weights[sum_weights == 0] = 1.0
weights = 1.0 * weights / np.expand_dims(sum_weights, axis=1)
# We use this mirror structure as a trick for reflection padding at the boundaries
mirror = np.uint(np.concatenate((np.arange(in_length), np.arange(in_length - 1, -1, step=-1))))
field_of_view = mirror[np.mod(field_of_view, mirror.shape[0])]
# Get rid of weights and pixel positions that are of zero weight
non_zero_out_pixels = np.nonzero(np.any(weights, axis=0))
weights = np.squeeze(weights[:, non_zero_out_pixels])
field_of_view = np.squeeze(field_of_view[:, non_zero_out_pixels])
# Final products are the relative positions and the matching weights, both are output_size X fixed_kernel_size
return weights, field_of_view
self.down_sample = Resizer(in_shape, 1 / scale_factor)
for param in self.parameters():
param.requires_grad = False
def forward(self, data, **kwargs):
return self.down_sample(data)
# Gaussian blurring operator
class GaussialBlurOperator(nn.Module):
def __init__(self, kernel_size, intensity):
super().__init__()
class Blurkernel(nn.Module):
def __init__(self, blur_type="gaussian", kernel_size=31, std=3.0):
super().__init__()
self.blur_type = blur_type
self.kernel_size = kernel_size
self.std = std
self.seq = nn.Sequential(
nn.ReflectionPad2d(self.kernel_size // 2),
nn.Conv2d(3, 3, self.kernel_size, stride=1, padding=0, bias=False, groups=3),
)
self.weights_init()
def forward(self, x):
return self.seq(x)
def weights_init(self):
if self.blur_type == "gaussian":
n = np.zeros((self.kernel_size, self.kernel_size))
n[self.kernel_size // 2, self.kernel_size // 2] = 1
k = scipy.ndimage.gaussian_filter(n, sigma=self.std)
k = torch.from_numpy(k)
self.k = k
for name, f in self.named_parameters():
f.data.copy_(k)
def update_weights(self, k):
if not torch.is_tensor(k):
k = torch.from_numpy(k)
for name, f in self.named_parameters():
f.data.copy_(k)
def get_kernel(self):
return self.k
self.kernel_size = kernel_size
self.conv = Blurkernel(blur_type="gaussian", kernel_size=kernel_size, std=intensity)
self.kernel = self.conv.get_kernel()
self.conv.update_weights(self.kernel.type(torch.float32))
for param in self.parameters():
param.requires_grad = False
def forward(self, data, **kwargs):
return self.conv(data)
def transpose(self, data, **kwargs):
return data
def get_kernel(self):
return self.kernel.view(1, 1, self.kernel_size, self.kernel_size)
# assuming the forward process y = f(x) is polluted by Gaussian noise, use l2 norm
def RMSELoss(yhat, y):
return torch.sqrt(torch.sum((yhat - y) ** 2))
# set up source image
src = Image.open("sample.png")
# read image into [1,3,H,W]
src = torch.from_numpy(np.array(src, dtype=np.float32)).permute(2, 0, 1)[None]
# normalize image to [-1,1]
src = (src / 127.5) - 1.0
src = src.to("cuda")
# set up operator and measurement
# operator = SuperResolutionOperator(in_shape=src.shape, scale_factor=4).to("cuda")
operator = GaussialBlurOperator(kernel_size=61, intensity=3.0).to("cuda")
measurement = operator(src)
# set up scheduler
scheduler = DDPMScheduler.from_pretrained("google/ddpm-celebahq-256")
scheduler.set_timesteps(1000)
# set up model
model = UNet2DModel.from_pretrained("google/ddpm-celebahq-256").to("cuda")
save_image((src + 1.0) / 2.0, "dps_src.png")
save_image((measurement + 1.0) / 2.0, "dps_mea.png")
# finally, the pipeline
dpspipe = DPSPipeline(model, scheduler)
image = dpspipe(
measurement=measurement,
operator=operator,
loss_fn=RMSELoss,
zeta=1.0,
).images[0]
image.save("dps_generated_image.png")
| diffusers/examples/community/dps_pipeline.py/0 | {
"file_path": "diffusers/examples/community/dps_pipeline.py",
"repo_id": "diffusers",
"token_count": 11141
} | 101 |
from typing import Union
import torch
from PIL import Image
from torchvision import transforms as tfms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
)
class MagicMixPipeline(DiffusionPipeline):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[PNDMScheduler, LMSDiscreteScheduler, DDIMScheduler],
):
super().__init__()
self.register_modules(vae=vae, text_encoder=text_encoder, tokenizer=tokenizer, unet=unet, scheduler=scheduler)
# convert PIL image to latents
def encode(self, img):
with torch.no_grad():
latent = self.vae.encode(tfms.ToTensor()(img).unsqueeze(0).to(self.device) * 2 - 1)
latent = 0.18215 * latent.latent_dist.sample()
return latent
# convert latents to PIL image
def decode(self, latent):
latent = (1 / 0.18215) * latent
with torch.no_grad():
img = self.vae.decode(latent).sample
img = (img / 2 + 0.5).clamp(0, 1)
img = img.detach().cpu().permute(0, 2, 3, 1).numpy()
img = (img * 255).round().astype("uint8")
return Image.fromarray(img[0])
# convert prompt into text embeddings, also unconditional embeddings
def prep_text(self, prompt):
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embedding = self.text_encoder(text_input.input_ids.to(self.device))[0]
uncond_input = self.tokenizer(
"",
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
uncond_embedding = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
return torch.cat([uncond_embedding, text_embedding])
def __call__(
self,
img: Image.Image,
prompt: str,
kmin: float = 0.3,
kmax: float = 0.6,
mix_factor: float = 0.5,
seed: int = 42,
steps: int = 50,
guidance_scale: float = 7.5,
) -> Image.Image:
tmin = steps - int(kmin * steps)
tmax = steps - int(kmax * steps)
text_embeddings = self.prep_text(prompt)
self.scheduler.set_timesteps(steps)
width, height = img.size
encoded = self.encode(img)
torch.manual_seed(seed)
noise = torch.randn(
(1, self.unet.config.in_channels, height // 8, width // 8),
).to(self.device)
latents = self.scheduler.add_noise(
encoded,
noise,
timesteps=self.scheduler.timesteps[tmax],
)
input = torch.cat([latents] * 2)
input = self.scheduler.scale_model_input(input, self.scheduler.timesteps[tmax])
with torch.no_grad():
pred = self.unet(
input,
self.scheduler.timesteps[tmax],
encoder_hidden_states=text_embeddings,
).sample
pred_uncond, pred_text = pred.chunk(2)
pred = pred_uncond + guidance_scale * (pred_text - pred_uncond)
latents = self.scheduler.step(pred, self.scheduler.timesteps[tmax], latents).prev_sample
for i, t in enumerate(tqdm(self.scheduler.timesteps)):
if i > tmax:
if i < tmin: # layout generation phase
orig_latents = self.scheduler.add_noise(
encoded,
noise,
timesteps=t,
)
input = (
(mix_factor * latents) + (1 - mix_factor) * orig_latents
) # interpolating between layout noise and conditionally generated noise to preserve layout sematics
input = torch.cat([input] * 2)
else: # content generation phase
input = torch.cat([latents] * 2)
input = self.scheduler.scale_model_input(input, t)
with torch.no_grad():
pred = self.unet(
input,
t,
encoder_hidden_states=text_embeddings,
).sample
pred_uncond, pred_text = pred.chunk(2)
pred = pred_uncond + guidance_scale * (pred_text - pred_uncond)
latents = self.scheduler.step(pred, t, latents).prev_sample
return self.decode(latents)
| diffusers/examples/community/magic_mix.py/0 | {
"file_path": "diffusers/examples/community/magic_mix.py",
"repo_id": "diffusers",
"token_count": 2446
} | 102 |
# Copyright 2023 Jake Babbidge, TencentARC and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ignore the entire file for precommit
# type: ignore
import inspect
from collections.abc import Callable
from typing import Any, List, Optional, Union
import numpy as np
import PIL
import torch
import torch.nn.functional as F
from transformers import (
CLIPTextModel,
CLIPTextModelWithProjection,
CLIPTokenizer,
)
from diffusers import DiffusionPipeline
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
from diffusers.loaders import (
FromSingleFileMixin,
LoraLoaderMixin,
StableDiffusionXLLoraLoaderMixin,
TextualInversionLoaderMixin,
)
from diffusers.models import (
AutoencoderKL,
ControlNetModel,
MultiAdapter,
T2IAdapter,
UNet2DConditionModel,
)
from diffusers.models.attention_processor import (
AttnProcessor2_0,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
XFormersAttnProcessor,
)
from diffusers.models.lora import adjust_lora_scale_text_encoder
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
USE_PEFT_BACKEND,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import DiffusionPipeline, T2IAdapter
>>> from diffusers.utils import load_image
>>> from PIL import Image
>>> from controlnet_aux.midas import MidasDetector
>>> adapter = T2IAdapter.from_pretrained(
... "TencentARC/t2i-adapter-sketch-sdxl-1.0", torch_dtype=torch.float16, variant="fp16"
... ).to("cuda")
>>> controlnet = ControlNetModel.from_pretrained(
... "diffusers/controlnet-depth-sdxl-1.0",
... torch_dtype=torch.float16,
... variant="fp16",
... use_safetensors=True
... ).to("cuda")
>>> pipe = DiffusionPipeline.from_pretrained(
... "diffusers/stable-diffusion-xl-1.0-inpainting-0.1",
... torch_dtype=torch.float16,
... variant="fp16",
... use_safetensors=True,
... custom_pipeline="stable_diffusion_xl_adapter_controlnet_inpaint",
... adapter=adapter,
... controlnet=controlnet,
... ).to("cuda")
>>> prompt = "a tiger sitting on a park bench"
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
>>> image = load_image(img_url).resize((1024, 1024))
>>> mask_image = load_image(mask_url).resize((1024, 1024))
>>> midas_depth = MidasDetector.from_pretrained(
... "valhalla/t2iadapter-aux-models", filename="dpt_large_384.pt", model_type="dpt_large"
... ).to("cuda")
>>> depth_image = midas_depth(
... image, detect_resolution=512, image_resolution=1024
... )
>>> strength = 0.4
>>> generator = torch.manual_seed(42)
>>> result_image = pipe(
... image=image,
... mask_image=mask,
... adapter_image=depth_image,
... control_image=depth_image,
... controlnet_conditioning_scale=strength,
... adapter_conditioning_scale=strength,
... strength=0.7,
... generator=generator,
... prompt=prompt,
... negative_prompt="extra digit, fewer digits, cropped, worst quality, low quality",
... num_inference_steps=50
... ).images[0]
```
"""
def _preprocess_adapter_image(image, height, width):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
image = [np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])) for i in image]
image = [
i[None, ..., None] if i.ndim == 2 else i[None, ...] for i in image
] # expand [h, w] or [h, w, c] to [b, h, w, c]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
if image[0].ndim == 3:
image = torch.stack(image, dim=0)
elif image[0].ndim == 4:
image = torch.cat(image, dim=0)
else:
raise ValueError(
f"Invalid image tensor! Expecting image tensor with 3 or 4 dimension, but recive: {image[0].ndim}"
)
return image
def mask_pil_to_torch(mask, height, width):
# preprocess mask
if isinstance(mask, Union[PIL.Image.Image, np.ndarray]):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask = torch.from_numpy(mask)
return mask
def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool = False):
"""
Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
Args:
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
Raises:
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
(ot the other way around).
Returns:
tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
# checkpoint. TOD(Yiyi) - need to clean this up later
if image is None:
raise ValueError("`image` input cannot be undefined.")
if mask is None:
raise ValueError("`mask_image` input cannot be undefined.")
if isinstance(image, torch.Tensor):
if not isinstance(mask, torch.Tensor):
mask = mask_pil_to_torch(mask, height, width)
if image.ndim == 3:
image = image.unsqueeze(0)
# Batch and add channel dim for single mask
if mask.ndim == 2:
mask = mask.unsqueeze(0).unsqueeze(0)
# Batch single mask or add channel dim
if mask.ndim == 3:
# Single batched mask, no channel dim or single mask not batched but channel dim
if mask.shape[0] == 1:
mask = mask.unsqueeze(0)
# Batched masks no channel dim
else:
mask = mask.unsqueeze(1)
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
# assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
# Check image is in [-1, 1]
# if image.min() < -1 or image.max() > 1:
# raise ValueError("Image should be in [-1, 1] range")
# Check mask is in [0, 1]
if mask.min() < 0 or mask.max() > 1:
raise ValueError("Mask should be in [0, 1] range")
# Binarize mask
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
# Image as float32
image = image.to(dtype=torch.float32)
elif isinstance(mask, torch.Tensor):
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
else:
# preprocess image
if isinstance(image, Union[PIL.Image.Image, np.ndarray]):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
# resize all images w.r.t passed height an width
image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
mask = mask_pil_to_torch(mask, height, width)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
if image.shape[1] == 4:
# images are in latent space and thus can't
# be masked set masked_image to None
# we assume that the checkpoint is not an inpainting
# checkpoint. TOD(Yiyi) - need to clean this up later
masked_image = None
else:
masked_image = image * (mask < 0.5)
# n.b. ensure backwards compatibility as old function does not return image
if return_image:
return mask, masked_image, image
return mask, masked_image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class StableDiffusionXLControlNetAdapterInpaintPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
https://arxiv.org/abs/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
adapter ([`T2IAdapter`] or [`MultiAdapter`] or `List[T2IAdapter]`):
Provides additional conditioning to the unet during the denoising process. If you set multiple Adapter as a
list, the outputs from each Adapter are added together to create one combined additional conditioning.
adapter_weights (`List[float]`, *optional*, defaults to None):
List of floats representing the weight which will be multiply to each adapter's output before adding them
together.
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
requires_aesthetics_score (`bool`, *optional*, defaults to `"False"`):
Whether the `unet` requires a aesthetic_score condition to be passed during inference. Also see the config
of `stabilityai/stable-diffusion-xl-refiner-1-0`.
force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
Whether the negative prompt embeddings shall be forced to always be set to 0. Also see the config of
`stabilityai/stable-diffusion-xl-base-1-0`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
tokenizer_2: CLIPTokenizer,
unet: UNet2DConditionModel,
adapter: Union[T2IAdapter, MultiAdapter],
controlnet: Union[ControlNetModel, MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
requires_aesthetics_score: bool = False,
force_zeros_for_empty_prompt: bool = True,
):
super().__init__()
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer,
tokenizer_2=tokenizer_2,
unet=unet,
adapter=adapter,
controlnet=controlnet,
scheduler=scheduler,
)
self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
self.register_to_config(requires_aesthetics_score=requires_aesthetics_score)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
self.default_sample_size = self.unet.config.sample_size
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
processing larger images.
"""
self.vae.enable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(
self,
prompt: str,
prompt_2: Optional[str] = None,
device: Optional[torch.device] = None,
num_images_per_prompt: int = 1,
do_classifier_free_guidance: bool = True,
negative_prompt: Optional[str] = None,
negative_prompt_2: Optional[str] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
lora_scale (`float`, *optional*):
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
device = device or self._execution_device
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, StableDiffusionXLLoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if self.text_encoder is not None:
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if self.text_encoder_2 is not None:
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder_2, lora_scale)
else:
scale_lora_layers(self.text_encoder_2, lora_scale)
prompt = [prompt] if isinstance(prompt, str) else prompt
if prompt is not None:
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# Define tokenizers and text encoders
tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
text_encoders = (
[self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
)
if prompt_embeds is None:
prompt_2 = prompt_2 or prompt
prompt_2 = [prompt_2] if isinstance(prompt_2, str) else prompt_2
# textual inversion: procecss multi-vector tokens if necessary
prompt_embeds_list = []
prompts = [prompt, prompt_2]
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, tokenizer)
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = text_encoder(text_input_ids.to(device), output_hidden_states=True)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
if clip_skip is None:
prompt_embeds = prompt_embeds.hidden_states[-2]
else:
# "2" because SDXL always indexes from the penultimate layer.
prompt_embeds = prompt_embeds.hidden_states[-(clip_skip + 2)]
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
# get unconditional embeddings for classifier free guidance
zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
elif do_classifier_free_guidance and negative_prompt_embeds is None:
negative_prompt = negative_prompt or ""
negative_prompt_2 = negative_prompt_2 or negative_prompt
# normalize str to list
negative_prompt = batch_size * [negative_prompt] if isinstance(negative_prompt, str) else negative_prompt
negative_prompt_2 = (
batch_size * [negative_prompt_2] if isinstance(negative_prompt_2, str) else negative_prompt_2
)
uncond_tokens: List[str]
if prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = [negative_prompt, negative_prompt_2]
negative_prompt_embeds_list = []
for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = tokenizer(
negative_prompt,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = text_encoder(
uncond_input.input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
negative_pooled_prompt_embeds = negative_prompt_embeds[0]
negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
negative_prompt_embeds_list.append(negative_prompt_embeds)
negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
if self.text_encoder_2 is not None:
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
else:
prompt_embeds = prompt_embeds.to(dtype=self.unet.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
if self.text_encoder_2 is not None:
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
else:
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.unet.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if do_classifier_free_guidance:
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if self.text_encoder is not None:
if isinstance(self, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
if self.text_encoder_2 is not None:
if isinstance(self, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder_2, lora_scale)
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.check_inputs
def check_inputs(
self,
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=None,
negative_prompt_2=None,
prompt_embeds=None,
negative_prompt_embeds=None,
pooled_prompt_embeds=None,
negative_pooled_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt_2 is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if prompt_embeds is not None and pooled_prompt_embeds is None:
raise ValueError(
"If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
)
if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
raise ValueError(
"If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
)
def check_conditions(
self,
prompt,
prompt_embeds,
adapter_image,
control_image,
adapter_conditioning_scale,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
):
# controlnet checks
if not isinstance(control_guidance_start, (tuple, list)):
control_guidance_start = [control_guidance_start]
if not isinstance(control_guidance_end, (tuple, list)):
control_guidance_end = [control_guidance_end]
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if isinstance(self.controlnet, MultiControlNetModel):
if len(control_guidance_start) != len(self.controlnet.nets):
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Check controlnet `image`
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
self.controlnet, torch._dynamo.eval_frame.OptimizedModule
)
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
self.check_image(control_image, prompt, prompt_embeds)
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if not isinstance(control_image, list):
raise TypeError("For multiple controlnets: `control_image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in control_image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(control_image) != len(self.controlnet.nets):
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(control_image)} images and {len(self.controlnet.nets)} ControlNets."
)
for image_ in control_image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
# adapter checks
if isinstance(self.adapter, T2IAdapter) or is_compiled and isinstance(self.adapter._orig_mod, T2IAdapter):
self.check_image(adapter_image, prompt, prompt_embeds)
elif (
isinstance(self.adapter, MultiAdapter) or is_compiled and isinstance(self.adapter._orig_mod, MultiAdapter)
):
if not isinstance(adapter_image, list):
raise TypeError("For multiple adapters: `adapter_image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in adapter_image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(adapter_image) != len(self.adapter.adapters):
raise ValueError(
f"For multiple adapters: `image` must have the same length as the number of adapters, but got {len(adapter_image)} images and {len(self.adapters.nets)} Adapters."
)
for image_ in adapter_image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `adapter_conditioning_scale`
if isinstance(self.adapter, T2IAdapter) or is_compiled and isinstance(self.adapter._orig_mod, T2IAdapter):
if not isinstance(adapter_conditioning_scale, float):
raise TypeError("For single adapter: `adapter_conditioning_scale` must be type `float`.")
elif (
isinstance(self.adapter, MultiAdapter) or is_compiled and isinstance(self.adapter._orig_mod, MultiAdapter)
):
if isinstance(adapter_conditioning_scale, list):
if any(isinstance(i, list) for i in adapter_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(adapter_conditioning_scale, list) and len(adapter_conditioning_scale) != len(
self.adapter.adapters
):
raise ValueError(
"For multiple adapters: When `adapter_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of adapters"
)
else:
assert False
def prepare_latents(
self,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
image=None,
timestep=None,
is_strength_max=True,
add_noise=True,
return_noise=False,
return_image_latents=False,
):
shape = (
batch_size,
num_channels_latents,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if (image is None or timestep is None) and not is_strength_max:
raise ValueError(
"Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
"However, either the image or the noise timestep has not been provided."
)
if image.shape[1] == 4:
image_latents = image.to(device=device, dtype=dtype)
elif return_image_latents or (latents is None and not is_strength_max):
image = image.to(device=device, dtype=dtype)
image_latents = self._encode_vae_image(image=image, generator=generator)
image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
if latents is None and add_noise:
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# if strength is 1. then initialise the latents to noise, else initial to image + noise
latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
# if pure noise then scale the initial latents by the Scheduler's init sigma
latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
elif add_noise:
noise = latents.to(device)
latents = noise * self.scheduler.init_noise_sigma
else:
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
latents = image_latents.to(device)
outputs = (latents,)
if return_noise:
outputs += (noise,)
if return_image_latents:
outputs += (image_latents,)
return outputs
def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
dtype = image.dtype
if self.vae.config.force_upcast:
image = image.float()
self.vae.to(dtype=torch.float32)
if isinstance(generator, list):
image_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(image.shape[0])
]
image_latents = torch.cat(image_latents, dim=0)
else:
image_latents = self.vae.encode(image).latent_dist.sample(generator=generator)
if self.vae.config.force_upcast:
self.vae.to(dtype)
image_latents = image_latents.to(dtype)
image_latents = self.vae.config.scaling_factor * image_latents
return image_latents
def prepare_mask_latents(
self,
mask,
masked_image,
batch_size,
height,
width,
dtype,
device,
generator,
do_classifier_free_guidance,
):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask = torch.nn.functional.interpolate(
mask,
size=(
height // self.vae_scale_factor,
width // self.vae_scale_factor,
),
)
mask = mask.to(device=device, dtype=dtype)
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
if mask.shape[0] < batch_size:
if not batch_size % mask.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = None
if masked_image is not None:
masked_image = masked_image.to(device=device, dtype=dtype)
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(
batch_size // masked_image_latents.shape[0], 1, 1, 1
)
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return mask, masked_image_latents
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_img2img.StableDiffusionXLImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device, denoising_start=None):
# get the original timestep using init_timestep
if denoising_start is None:
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
else:
t_start = 0
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
# Strength is irrelevant if we directly request a timestep to start at;
# that is, strength is determined by the denoising_start instead.
if denoising_start is not None:
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_start * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = (timesteps < discrete_timestep_cutoff).sum().item()
if self.scheduler.order == 2 and num_inference_steps % 2 == 0:
# if the scheduler is a 2nd order scheduler we might have to do +1
# because `num_inference_steps` might be even given that every timestep
# (except the highest one) is duplicated. If `num_inference_steps` is even it would
# mean that we cut the timesteps in the middle of the denoising step
# (between 1st and 2nd devirative) which leads to incorrect results. By adding 1
# we ensure that the denoising process always ends after the 2nd derivate step of the scheduler
num_inference_steps = num_inference_steps + 1
# because t_n+1 >= t_n, we slice the timesteps starting from the end
timesteps = timesteps[-num_inference_steps:]
return timesteps, num_inference_steps
return timesteps, num_inference_steps - t_start
def _get_add_time_ids(
self,
original_size,
crops_coords_top_left,
target_size,
aesthetic_score,
negative_aesthetic_score,
dtype,
text_encoder_projection_dim=None,
):
if self.config.requires_aesthetics_score:
add_time_ids = list(original_size + crops_coords_top_left + (aesthetic_score,))
add_neg_time_ids = list(original_size + crops_coords_top_left + (negative_aesthetic_score,))
else:
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_neg_time_ids = list(original_size + crops_coords_top_left + target_size)
passed_add_embed_dim = (
self.unet.config.addition_time_embed_dim * len(add_time_ids) + text_encoder_projection_dim
)
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
if (
expected_add_embed_dim > passed_add_embed_dim
and (expected_add_embed_dim - passed_add_embed_dim) == self.unet.config.addition_time_embed_dim
):
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. Please make sure to enable `requires_aesthetics_score` with `pipe.register_to_config(requires_aesthetics_score=True)` to make sure `aesthetic_score` {aesthetic_score} and `negative_aesthetic_score` {negative_aesthetic_score} is correctly used by the model."
)
elif (
expected_add_embed_dim < passed_add_embed_dim
and (passed_add_embed_dim - expected_add_embed_dim) == self.unet.config.addition_time_embed_dim
):
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. Please make sure to disable `requires_aesthetics_score` with `pipe.register_to_config(requires_aesthetics_score=False)` to make sure `target_size` {target_size} is correctly used by the model."
)
elif expected_add_embed_dim != passed_add_embed_dim:
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
)
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
add_neg_time_ids = torch.tensor([add_neg_time_ids], dtype=dtype)
return add_time_ids, add_neg_time_ids
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
def upcast_vae(self):
dtype = self.vae.dtype
self.vae.to(dtype=torch.float32)
use_torch_2_0_or_xformers = isinstance(
self.vae.decoder.mid_block.attentions[0].processor,
(
AttnProcessor2_0,
XFormersAttnProcessor,
LoRAXFormersAttnProcessor,
LoRAAttnProcessor2_0,
),
)
# if xformers or torch_2_0 is used attention block does not need
# to be in float32 which can save lots of memory
if use_torch_2_0_or_xformers:
self.vae.post_quant_conv.to(dtype)
self.vae.decoder.conv_in.to(dtype)
self.vae.decoder.mid_block.to(dtype)
# Copied from diffusers.pipelines.t2i_adapter.pipeline_stable_diffusion_adapter.StableDiffusionAdapterPipeline._default_height_width
def _default_height_width(self, height, width, image):
# NOTE: It is possible that a list of images have different
# dimensions for each image, so just checking the first image
# is not _exactly_ correct, but it is simple.
while isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[-2]
# round down to nearest multiple of `self.adapter.downscale_factor`
height = (height // self.adapter.downscale_factor) * self.adapter.downscale_factor
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[-1]
# round down to nearest multiple of `self.adapter.downscale_factor`
width = (width // self.adapter.downscale_factor) * self.adapter.downscale_factor
return height, width
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
Args:
s1 (`float`):
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
s2 (`float`):
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
"""
if not hasattr(self, "unet"):
raise ValueError("The pipeline must have `unet` for using FreeU.")
self.unet.enable_freeu(s1=s1, s2=s2, b1=b1, b2=b2)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_freeu
def disable_freeu(self):
"""Disables the FreeU mechanism if enabled."""
self.unet.disable_freeu()
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Optional[Union[str, list[str]]] = None,
prompt_2: Optional[Union[str, list[str]]] = None,
image: Optional[Union[torch.Tensor, PIL.Image.Image]] = None,
mask_image: Optional[Union[torch.Tensor, PIL.Image.Image]] = None,
adapter_image: PipelineImageInput = None,
control_image: PipelineImageInput = None,
height: Optional[int] = None,
width: Optional[int] = None,
strength: float = 0.9999,
num_inference_steps: int = 50,
denoising_start: Optional[float] = None,
denoising_end: Optional[float] = None,
guidance_scale: float = 5.0,
negative_prompt: Optional[Union[str, list[str]]] = None,
negative_prompt_2: Optional[Union[str, list[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, list[torch.Generator]]] = None,
latents: Optional[Union[torch.FloatTensor]] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[dict[str, Any]] = None,
guidance_rescale: float = 0.0,
original_size: Optional[tuple[int, int]] = None,
crops_coords_top_left: Optional[tuple[int, int]] = (0, 0),
target_size: Optional[tuple[int, int]] = None,
adapter_conditioning_scale: Optional[Union[float, list[float]]] = 1.0,
cond_tau: float = 1.0,
aesthetic_score: float = 6.0,
negative_aesthetic_score: float = 2.5,
controlnet_conditioning_scale=1.0,
guess_mode: bool = False,
control_guidance_start=0.0,
control_guidance_end=1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
adapter_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]` or `List[List[PIL.Image.Image]]`):
The Adapter input condition. Adapter uses this input condition to generate guidance to Unet. If the
type is specified as `Torch.FloatTensor`, it is passed to Adapter as is. PIL.Image.Image` can also be
accepted as an image. The control image is automatically resized to fit the output image.
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
`init`, images must be passed as a list such that each element of the list can be correctly batched for
input to a single ControlNet.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
strength (`float`, *optional*, defaults to 1.0):
Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
starting point and more noise is added the higher the `strength`. The number of denoising steps depends
on the amount of noise initially added. When `strength` is 1, added noise is maximum and the denoising
process runs for the full number of iterations specified in `num_inference_steps`. A value of 1
essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
denoising_start (`float`, *optional*):
When specified, indicates the fraction (between 0.0 and 1.0) of the total denoising process to be
bypassed before it is initiated. Consequently, the initial part of the denoising process is skipped and
it is assumed that the passed `image` is a partly denoised image. Note that when this is specified,
strength will be ignored. The `denoising_start` parameter is particularly beneficial when this pipeline
is integrated into a "Mixture of Denoisers" multi-pipeline setup, as detailed in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
denoising_end (`float`, *optional*):
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
completed before it is intentionally prematurely terminated. As a result, the returned sample will
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionAdapterPipelineOutput`]
instead of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
For most cases, `target_size` should be set to the desired height and width of the generated image. If
not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added to the
residual in the original unet. If multiple adapters are specified in init, you can set the
corresponding scale as a list.
adapter_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the adapter are multiplied by `adapter_conditioning_scale` before they are added to the
residual in the original unet. If multiple adapters are specified in init, you can set the
corresponding scale as a list.
aesthetic_score (`float`, *optional*, defaults to 6.0):
Used to simulate an aesthetic score of the generated image by influencing the positive text condition.
Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
negative_aesthetic_score (`float`, *optional*, defaults to 2.5):
Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). Can be used to
simulate an aesthetic score of the generated image by influencing the negative text condition.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput`] if `return_dict` is True, otherwise a
`tuple`. When returning a tuple, the first element is a list with the generated images.
"""
# 0. Default height and width to unet
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
adapter = self.adapter._orig_mod if is_compiled_module(self.adapter) else self.adapter
height, width = self._default_height_width(height, width, adapter_image)
device = self._execution_device
if isinstance(adapter, MultiAdapter):
adapter_input = []
for one_image in adapter_image:
one_image = _preprocess_adapter_image(one_image, height, width)
one_image = one_image.to(device=device, dtype=adapter.dtype)
adapter_input.append(one_image)
else:
adapter_input = _preprocess_adapter_image(adapter_image, height, width)
adapter_input = adapter_input.to(device=device, dtype=adapter.dtype)
original_size = original_size or (height, width)
target_size = target_size or (height, width)
# 0.1 align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
if isinstance(adapter, MultiAdapter) and isinstance(adapter_conditioning_scale, float):
adapter_conditioning_scale = [adapter_conditioning_scale] * len(adapter.nets)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
)
self.check_conditions(
prompt,
prompt_embeds,
adapter_image,
control_image,
adapter_conditioning_scale,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(
prompt=prompt,
prompt_2=prompt_2,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
)
# 4. set timesteps
def denoising_value_valid(dnv):
return isinstance(denoising_end, float) and 0 < dnv < 1
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(
num_inference_steps,
strength,
device,
denoising_start=denoising_start if denoising_value_valid else None,
)
# check that number of inference steps is not < 1 - as this doesn't make sense
if num_inference_steps < 1:
raise ValueError(
f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
)
# at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
is_strength_max = strength == 1.0
# 5. Preprocess mask and image - resizes image and mask w.r.t height and width
mask, masked_image, init_image = prepare_mask_and_masked_image(
image, mask_image, height, width, return_image=True
)
# 6. Prepare latent variables
num_channels_latents = self.vae.config.latent_channels
num_channels_unet = self.unet.config.in_channels
return_image_latents = num_channels_unet == 4
add_noise = denoising_start is None
latents_outputs = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
image=init_image,
timestep=latent_timestep,
is_strength_max=is_strength_max,
add_noise=add_noise,
return_noise=True,
return_image_latents=return_image_latents,
)
if return_image_latents:
latents, noise, image_latents = latents_outputs
else:
latents, noise = latents_outputs
# 7. Prepare mask latent variables
mask, masked_image_latents = self.prepare_mask_latents(
mask,
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 8. Check that sizes of mask, masked image and latents match
if num_channels_unet == 9:
# default case for runwayml/stable-diffusion-inpainting
num_channels_mask = mask.shape[1]
num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
elif num_channels_unet != 4:
raise ValueError(
f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 10. Prepare added time ids & embeddings & adapter features
if isinstance(adapter, MultiAdapter):
adapter_state = adapter(adapter_input, adapter_conditioning_scale)
for k, v in enumerate(adapter_state):
adapter_state[k] = v
else:
adapter_state = adapter(adapter_input)
for k, v in enumerate(adapter_state):
adapter_state[k] = v * adapter_conditioning_scale
if num_images_per_prompt > 1:
for k, v in enumerate(adapter_state):
adapter_state[k] = v.repeat(num_images_per_prompt, 1, 1, 1)
if do_classifier_free_guidance:
for k, v in enumerate(adapter_state):
adapter_state[k] = torch.cat([v] * 2, dim=0)
# 10.2 Prepare control images
if isinstance(controlnet, ControlNetModel):
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif isinstance(controlnet, MultiControlNetModel):
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
raise ValueError(f"{controlnet.__class__} is not supported.")
# 8.2 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
if isinstance(self.controlnet, MultiControlNetModel):
controlnet_keep.append(keeps)
else:
controlnet_keep.append(keeps[0])
# ----------------------------------------------------------------
add_text_embeds = pooled_prompt_embeds
if self.text_encoder_2 is None:
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
else:
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
add_time_ids, add_neg_time_ids = self._get_add_time_ids(
original_size,
crops_coords_top_left,
target_size,
aesthetic_score,
negative_aesthetic_score,
dtype=prompt_embeds.dtype,
text_encoder_projection_dim=text_encoder_projection_dim,
)
add_time_ids = add_time_ids.repeat(batch_size * num_images_per_prompt, 1)
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_neg_time_ids = add_neg_time_ids.repeat(batch_size * num_images_per_prompt, 1)
add_time_ids = torch.cat([add_neg_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device)
# 11. Denoising loop
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
# 11.1 Apply denoising_end
if (
denoising_end is not None
and denoising_start is not None
and denoising_value_valid(denoising_end)
and denoising_value_valid(denoising_start)
and denoising_start >= denoising_end
):
raise ValueError(
f"`denoising_start`: {denoising_start} cannot be larger than or equal to `denoising_end`: "
+ f" {denoising_end} when using type float."
)
elif denoising_end is not None and denoising_value_valid(denoising_end):
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_end * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
timesteps = timesteps[:num_inference_steps]
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if num_channels_unet == 9:
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# predict the noise residual
added_cond_kwargs = {
"text_embeds": add_text_embeds,
"time_ids": add_time_ids,
}
if i < int(num_inference_steps * cond_tau):
down_block_additional_residuals = [state.clone() for state in adapter_state]
else:
down_block_additional_residuals = None
# ----------- ControlNet
# expand the latents if we are doing classifier free guidance
latent_model_input_controlnet = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input_controlnet = self.scheduler.scale_model_input(latent_model_input_controlnet, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
controlnet_added_cond_kwargs = {
"text_embeds": add_text_embeds.chunk(2)[1],
"time_ids": add_time_ids.chunk(2)[1],
}
else:
control_model_input = latent_model_input_controlnet
controlnet_prompt_embeds = prompt_embeds
controlnet_added_cond_kwargs = added_cond_kwargs
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=control_image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
added_cond_kwargs=controlnet_added_cond_kwargs,
return_dict=False,
)
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
down_intrablock_additional_residuals=down_block_additional_residuals, # t2iadapter
down_block_additional_residuals=down_block_res_samples, # controlnet
mid_block_additional_residual=mid_block_res_sample, # controlnet
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(
noise_pred,
noise_pred_text,
guidance_rescale=guidance_rescale,
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
**extra_step_kwargs,
return_dict=False,
)[0]
if num_channels_unet == 4:
init_latents_proper = image_latents
if do_classifier_free_guidance:
init_mask, _ = mask.chunk(2)
else:
init_mask = mask
if i < len(timesteps) - 1:
noise_timestep = timesteps[i + 1]
init_latents_proper = self.scheduler.add_noise(
init_latents_proper,
noise,
torch.tensor([noise_timestep]),
)
latents = (1 - init_mask) * init_latents_proper + init_mask * latents
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
callback(i, t, latents)
# make sure the VAE is in float32 mode, as it overflows in float16
if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
if output_type != "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
else:
image = latents
return StableDiffusionXLPipelineOutput(images=image)
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image,)
return StableDiffusionXLPipelineOutput(images=image)
| diffusers/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py/0 | {
"file_path": "diffusers/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py",
"repo_id": "diffusers",
"token_count": 43133
} | 103 |
# Inspired by: https://github.com/Mikubill/sd-webui-controlnet/discussions/1236 and https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionControlNetPipeline
from diffusers.models import ControlNetModel
from diffusers.models.attention import BasicTransformerBlock
from diffusers.models.unets.unet_2d_blocks import CrossAttnDownBlock2D, CrossAttnUpBlock2D, DownBlock2D, UpBlock2D
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import logging
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import cv2
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> from diffusers import UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
>>> # get canny image
>>> image = cv2.Canny(np.array(input_image), 100, 200)
>>> image = image[:, :, None]
>>> image = np.concatenate([image, image, image], axis=2)
>>> canny_image = Image.fromarray(image)
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetReferencePipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
safety_checker=None,
torch_dtype=torch.float16
).to('cuda:0')
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe_controlnet.scheduler.config)
>>> result_img = pipe(ref_image=input_image,
prompt="1girl",
image=canny_image,
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
>>> result_img.show()
```
"""
def torch_dfs(model: torch.nn.Module):
result = [model]
for child in model.children():
result += torch_dfs(child)
return result
class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeline):
def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance):
refimage = refimage.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
ref_image_latents = [
self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
ref_image_latents = torch.cat(ref_image_latents, dim=0)
else:
ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator)
ref_image_latents = self.vae.config.scaling_factor * ref_image_latents
# duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method
if ref_image_latents.shape[0] < batch_size:
if not batch_size % ref_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1)
ref_image_latents = torch.cat([ref_image_latents] * 2) if do_classifier_free_guidance else ref_image_latents
# aligning device to prevent device errors when concating it with the latent model input
ref_image_latents = ref_image_latents.to(device=device, dtype=dtype)
return ref_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
ref_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
guess_mode: bool = False,
attention_auto_machine_weight: float = 1.0,
gn_auto_machine_weight: float = 1.0,
style_fidelity: float = 0.5,
reference_attn: bool = True,
reference_adain: bool = True,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
specified in init, images must be passed as a list such that each element of the list can be correctly
batched for input to a single controlnet.
ref_image (`torch.FloatTensor`, `PIL.Image.Image`):
The Reference Control input condition. Reference Control uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to Reference Control as is. `PIL.Image.Image` can
also be accepted as an image.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list.
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
attention_auto_machine_weight (`float`):
Weight of using reference query for self attention's context.
If attention_auto_machine_weight=1.0, use reference query for all self attention's context.
gn_auto_machine_weight (`float`):
Weight of using reference adain. If gn_auto_machine_weight=2.0, use all reference adain plugins.
style_fidelity (`float`):
style fidelity of ref_uncond_xt. If style_fidelity=1.0, control more important,
elif style_fidelity=0.0, prompt more important, else balanced.
reference_attn (`bool`):
Whether to use reference query for self attention's context.
reference_adain (`bool`):
Whether to use reference adain.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
assert reference_attn or reference_adain, "`reference_attn` or `reference_adain` must be True."
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
image,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
global_pool_conditions = (
controlnet.config.global_pool_conditions
if isinstance(controlnet, ControlNetModel)
else controlnet.nets[0].config.global_pool_conditions
)
guess_mode = guess_mode or global_pool_conditions
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Prepare image
if isinstance(controlnet, ControlNetModel):
image = self.prepare_image(
image=image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
height, width = image.shape[-2:]
elif isinstance(controlnet, MultiControlNetModel):
images = []
for image_ in image:
image_ = self.prepare_image(
image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
images.append(image_)
image = images
height, width = image[0].shape[-2:]
else:
assert False
# 5. Preprocess reference image
ref_image = self.prepare_image(
image=ref_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=prompt_embeds.dtype,
)
# 6. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 7. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 8. Prepare reference latent variables
ref_image_latents = self.prepare_ref_latents(
ref_image,
batch_size * num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 9. Modify self attention and group norm
MODE = "write"
uc_mask = (
torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt)
.type_as(ref_image_latents)
.bool()
)
def hacked_basic_transformer_inner_forward(
self,
hidden_states: torch.FloatTensor,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
timestep: Optional[torch.LongTensor] = None,
cross_attention_kwargs: Dict[str, Any] = None,
class_labels: Optional[torch.LongTensor] = None,
):
if self.use_ada_layer_norm:
norm_hidden_states = self.norm1(hidden_states, timestep)
elif self.use_ada_layer_norm_zero:
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
)
else:
norm_hidden_states = self.norm1(hidden_states)
# 1. Self-Attention
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if self.only_cross_attention:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
else:
if MODE == "write":
self.bank.append(norm_hidden_states.detach().clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if MODE == "read":
if attention_auto_machine_weight > self.attn_weight:
attn_output_uc = self.attn1(
norm_hidden_states,
encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1),
# attention_mask=attention_mask,
**cross_attention_kwargs,
)
attn_output_c = attn_output_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
attn_output_c[uc_mask] = self.attn1(
norm_hidden_states[uc_mask],
encoder_hidden_states=norm_hidden_states[uc_mask],
**cross_attention_kwargs,
)
attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc
self.bank.clear()
else:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if self.use_ada_layer_norm_zero:
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = attn_output + hidden_states
if self.attn2 is not None:
norm_hidden_states = (
self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
)
# 2. Cross-Attention
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
# 3. Feed-forward
norm_hidden_states = self.norm3(hidden_states)
if self.use_ada_layer_norm_zero:
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
if self.use_ada_layer_norm_zero:
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = ff_output + hidden_states
return hidden_states
def hacked_mid_forward(self, *args, **kwargs):
eps = 1e-6
x = self.original_forward(*args, **kwargs)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append(mean)
self.var_bank.append(var)
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank) / float(len(self.mean_bank))
var_acc = sum(self.var_bank) / float(len(self.var_bank))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
x_uc = (((x - mean) / std) * std_acc) + mean_acc
x_c = x_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
x_c[uc_mask] = x[uc_mask]
x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc
self.mean_bank = []
self.var_bank = []
return x
def hack_CrossAttnDownBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
output_states = ()
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_DownBlock2D_forward(self, hidden_states, temb=None, *args, **kwargs):
eps = 1e-6
output_states = ()
for i, resnet in enumerate(self.resnets):
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_CrossAttnUpBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
def hacked_UpBlock2D_forward(
self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, *args, **kwargs
):
eps = 1e-6
for i, resnet in enumerate(self.resnets):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
if reference_attn:
attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)]
attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0])
for i, module in enumerate(attn_modules):
module._original_inner_forward = module.forward
module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock)
module.bank = []
module.attn_weight = float(i) / float(len(attn_modules))
if reference_adain:
gn_modules = [self.unet.mid_block]
self.unet.mid_block.gn_weight = 0
down_blocks = self.unet.down_blocks
for w, module in enumerate(down_blocks):
module.gn_weight = 1.0 - float(w) / float(len(down_blocks))
gn_modules.append(module)
up_blocks = self.unet.up_blocks
for w, module in enumerate(up_blocks):
module.gn_weight = float(w) / float(len(up_blocks))
gn_modules.append(module)
for i, module in enumerate(gn_modules):
if getattr(module, "original_forward", None) is None:
module.original_forward = module.forward
if i == 0:
# mid_block
module.forward = hacked_mid_forward.__get__(module, torch.nn.Module)
elif isinstance(module, CrossAttnDownBlock2D):
module.forward = hack_CrossAttnDownBlock2D_forward.__get__(module, CrossAttnDownBlock2D)
elif isinstance(module, DownBlock2D):
module.forward = hacked_DownBlock2D_forward.__get__(module, DownBlock2D)
elif isinstance(module, CrossAttnUpBlock2D):
module.forward = hacked_CrossAttnUpBlock2D_forward.__get__(module, CrossAttnUpBlock2D)
elif isinstance(module, UpBlock2D):
module.forward = hacked_UpBlock2D_forward.__get__(module, UpBlock2D)
module.mean_bank = []
module.var_bank = []
module.gn_weight *= 2
# 11. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=image,
conditioning_scale=controlnet_conditioning_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# ref only part
noise = randn_tensor(
ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype
)
ref_xt = self.scheduler.add_noise(
ref_image_latents,
noise,
t.reshape(
1,
),
)
ref_xt = self.scheduler.scale_model_input(ref_xt, t)
MODE = "write"
self.unet(
ref_xt,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)
# predict the noise residual
MODE = "read"
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| diffusers/examples/community/stable_diffusion_controlnet_reference.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_controlnet_reference.py",
"repo_id": "diffusers",
"token_count": 21091
} | 104 |
# Latent Consistency Distillation Example:
[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is a method to distill a latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use latent consistency distillation to distill stable-diffusion-v1.5 for inference with few timesteps.
## Full model distillation
### Running locally with PyTorch
#### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
#### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example, and for illustrative purposes only. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/). You may also need to search the hyperparameter space according to the dataset you use.
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_sd_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--learning_rate=1e-6 --loss_type="huber" --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub
```
## LCM-LoRA
Instead of fine-tuning the full model, we can also just train a LoRA that can be injected into any SDXL model.
### Example
The following uses the [Conceptual Captions 12M (CC12M) dataset](https://github.com/google-research-datasets/conceptual-12m) as an example. For best results you may consider large and high-quality text-image datasets such as [LAION](https://laion.ai/blog/laion-400-open-dataset/).
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_lora_sd_wds.py \
--pretrained_teacher_model=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--lora_rank=64 \
--learning_rate=1e-4 --loss_type="huber" --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
``` | diffusers/examples/consistency_distillation/README.md/0 | {
"file_path": "diffusers/examples/consistency_distillation/README.md",
"repo_id": "diffusers",
"token_count": 1511
} | 105 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import time
from pathlib import Path
import jax
import jax.numpy as jnp
import numpy as np
import optax
import torch
import torch.utils.checkpoint
import transformers
from datasets import load_dataset, load_from_disk
from flax import jax_utils
from flax.core.frozen_dict import unfreeze
from flax.training import train_state
from flax.training.common_utils import shard
from huggingface_hub import create_repo, upload_folder
from PIL import Image, PngImagePlugin
from torch.utils.data import IterableDataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTokenizer, FlaxCLIPTextModel, set_seed
from diffusers import (
FlaxAutoencoderKL,
FlaxControlNetModel,
FlaxDDPMScheduler,
FlaxStableDiffusionControlNetPipeline,
FlaxUNet2DConditionModel,
)
from diffusers.utils import check_min_version, is_wandb_available, make_image_grid
# To prevent an error that occurs when there are abnormally large compressed data chunk in the png image
# see more https://github.com/python-pillow/Pillow/issues/5610
LARGE_ENOUGH_NUMBER = 100
PngImagePlugin.MAX_TEXT_CHUNK = LARGE_ENOUGH_NUMBER * (1024**2)
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.26.0.dev0")
logger = logging.getLogger(__name__)
def log_validation(pipeline, pipeline_params, controlnet_params, tokenizer, args, rng, weight_dtype):
logger.info("Running validation...")
pipeline_params = pipeline_params.copy()
pipeline_params["controlnet"] = controlnet_params
num_samples = jax.device_count()
prng_seed = jax.random.split(rng, jax.device_count())
if len(args.validation_image) == len(args.validation_prompt):
validation_images = args.validation_image
validation_prompts = args.validation_prompt
elif len(args.validation_image) == 1:
validation_images = args.validation_image * len(args.validation_prompt)
validation_prompts = args.validation_prompt
elif len(args.validation_prompt) == 1:
validation_images = args.validation_image
validation_prompts = args.validation_prompt * len(args.validation_image)
else:
raise ValueError(
"number of `args.validation_image` and `args.validation_prompt` should be checked in `parse_args`"
)
image_logs = []
for validation_prompt, validation_image in zip(validation_prompts, validation_images):
prompts = num_samples * [validation_prompt]
prompt_ids = pipeline.prepare_text_inputs(prompts)
prompt_ids = shard(prompt_ids)
validation_image = Image.open(validation_image).convert("RGB")
processed_image = pipeline.prepare_image_inputs(num_samples * [validation_image])
processed_image = shard(processed_image)
images = pipeline(
prompt_ids=prompt_ids,
image=processed_image,
params=pipeline_params,
prng_seed=prng_seed,
num_inference_steps=50,
jit=True,
).images
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
image_logs.append(
{"validation_image": validation_image, "images": images, "validation_prompt": validation_prompt}
)
if args.report_to == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images.append(wandb.Image(validation_image, caption="Controlnet conditioning"))
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
wandb.log({"validation": formatted_images})
else:
logger.warn(f"image logging not implemented for {args.report_to}")
return image_logs
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
img_str = ""
if image_logs is not None:
for i, log in enumerate(image_logs):
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
validation_image.save(os.path.join(repo_folder, "image_control.png"))
img_str += f"prompt: {validation_prompt}\n"
images = [validation_image] + images
make_image_grid(images, 1, len(images)).save(os.path.join(repo_folder, f"images_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
- jax-diffusers-event
inference: true
---
"""
model_card = f"""
# controlnet- {repo_id}
These are controlnet weights trained on {base_model} with new type of conditioning. You can find some example images in the following. \n
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--controlnet_model_name_or_path",
type=str,
default=None,
help="Path to pretrained controlnet model or model identifier from huggingface.co/models."
" If not specified controlnet weights are initialized from unet.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--from_pt",
action="store_true",
help="Load the pretrained model from a PyTorch checkpoint.",
)
parser.add_argument(
"--controlnet_revision",
type=str,
default=None,
help="Revision of controlnet model identifier from huggingface.co/models.",
)
parser.add_argument(
"--profile_steps",
type=int,
default=0,
help="How many training steps to profile in the beginning.",
)
parser.add_argument(
"--profile_validation",
action="store_true",
help="Whether to profile the (last) validation.",
)
parser.add_argument(
"--profile_memory",
action="store_true",
help="Whether to dump an initial (before training loop) and a final (at program end) memory profile.",
)
parser.add_argument(
"--ccache",
type=str,
default=None,
help="Enables compilation cache.",
)
parser.add_argument(
"--controlnet_from_pt",
action="store_true",
help="Load the controlnet model from a PyTorch checkpoint.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--output_dir",
type=str,
default="runs/{timestamp}",
help="The output directory where the model predictions and checkpoints will be written. "
"Can contain placeholders: {timestamp}.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=1, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=5000,
help=("Save a checkpoint of the training state every X updates."),
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_steps",
type=int,
default=100,
help=("log training metric every X steps to `--report_t`"),
)
parser.add_argument(
"--report_to",
type=str,
default="wandb",
help=('The integration to report the results and logs to. Currently only supported platforms are `"wandb"`'),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument("--streaming", action="store_true", help="To stream a large dataset from Hub.")
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training dataset. By default it will use `load_dataset` method to load a custom dataset from the folder."
"Folder must contain a dataset script as described here https://huggingface.co/docs/datasets/dataset_script) ."
"If `--load_from_disk` flag is passed, it will use `load_from_disk` method instead. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--load_from_disk",
action="store_true",
help=(
"If True, will load a dataset that was previously saved using `save_to_disk` from `--train_data_dir`"
"See more https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.load_from_disk"
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing the target image."
)
parser.add_argument(
"--conditioning_image_column",
type=str,
default="conditioning_image",
help="The column of the dataset containing the controlnet conditioning image.",
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set. Needed if `streaming` is set to True."
),
)
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
nargs="+",
help=(
"A set of prompts evaluated every `--validation_steps` and logged to `--report_to`."
" Provide either a matching number of `--validation_image`s, a single `--validation_image`"
" to be used with all prompts, or a single prompt that will be used with all `--validation_image`s."
),
)
parser.add_argument(
"--validation_image",
type=str,
default=None,
nargs="+",
help=(
"A set of paths to the controlnet conditioning image be evaluated every `--validation_steps`"
" and logged to `--report_to`. Provide either a matching number of `--validation_prompt`s, a"
" a single `--validation_prompt` to be used with all `--validation_image`s, or a single"
" `--validation_image` that will be used with all `--validation_prompt`s."
),
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run validation every X steps. Validation consists of running the prompt"
" `args.validation_prompt` and logging the images."
),
)
parser.add_argument("--wandb_entity", type=str, default=None, help=("The wandb entity to use (for teams)."))
parser.add_argument(
"--tracker_project_name",
type=str,
default="train_controlnet_flax",
help=("The `project` argument passed to wandb"),
)
parser.add_argument(
"--gradient_accumulation_steps", type=int, default=1, help="Number of steps to accumulate gradients over"
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
args = parser.parse_args()
args.output_dir = args.output_dir.replace("{timestamp}", time.strftime("%Y%m%d_%H%M%S"))
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
if args.dataset_name is not None and args.train_data_dir is not None:
raise ValueError("Specify only one of `--dataset_name` or `--train_data_dir`")
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
if args.validation_prompt is not None and args.validation_image is None:
raise ValueError("`--validation_image` must be set if `--validation_prompt` is set")
if args.validation_prompt is None and args.validation_image is not None:
raise ValueError("`--validation_prompt` must be set if `--validation_image` is set")
if (
args.validation_image is not None
and args.validation_prompt is not None
and len(args.validation_image) != 1
and len(args.validation_prompt) != 1
and len(args.validation_image) != len(args.validation_prompt)
):
raise ValueError(
"Must provide either 1 `--validation_image`, 1 `--validation_prompt`,"
" or the same number of `--validation_prompt`s and `--validation_image`s"
)
# This idea comes from
# https://github.com/borisdayma/dalle-mini/blob/d2be512d4a6a9cda2d63ba04afc33038f98f705f/src/dalle_mini/data.py#L370
if args.streaming and args.max_train_samples is None:
raise ValueError("You must specify `max_train_samples` when using dataset streaming.")
return args
def make_train_dataset(args, tokenizer, batch_size=None):
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
streaming=args.streaming,
)
else:
if args.train_data_dir is not None:
if args.load_from_disk:
dataset = load_from_disk(
args.train_data_dir,
)
else:
dataset = load_dataset(
args.train_data_dir,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if isinstance(dataset["train"], IterableDataset):
column_names = next(iter(dataset["train"])).keys()
else:
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
if args.image_column is None:
image_column = column_names[0]
logger.info(f"image column defaulting to {image_column}")
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = column_names[1]
logger.info(f"caption column defaulting to {caption_column}")
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.conditioning_image_column is None:
conditioning_image_column = column_names[2]
logger.info(f"conditioning image column defaulting to {caption_column}")
else:
conditioning_image_column = args.conditioning_image_column
if conditioning_image_column not in column_names:
raise ValueError(
f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if random.random() < args.proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
images = [image_transforms(image) for image in images]
conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]
conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]
examples["pixel_values"] = images
examples["conditioning_pixel_values"] = conditioning_images
examples["input_ids"] = tokenize_captions(examples)
return examples
if jax.process_index() == 0:
if args.max_train_samples is not None:
if args.streaming:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).take(args.max_train_samples)
else:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
if args.streaming:
train_dataset = dataset["train"].map(
preprocess_train,
batched=True,
batch_size=batch_size,
remove_columns=list(dataset["train"].features.keys()),
)
else:
train_dataset = dataset["train"].with_transform(preprocess_train)
return train_dataset
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])
conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
batch = {
"pixel_values": pixel_values,
"conditioning_pixel_values": conditioning_pixel_values,
"input_ids": input_ids,
}
batch = {k: v.numpy() for k, v in batch.items()}
return batch
def get_params_to_save(params):
return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
def main():
args = parse_args()
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
transformers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
# wandb init
if jax.process_index() == 0 and args.report_to == "wandb":
wandb.init(
entity=args.wandb_entity,
project=args.tracker_project_name,
job_type="train",
config=args,
)
if args.seed is not None:
set_seed(args.seed)
rng = jax.random.PRNGKey(0)
# Handle the repository creation
if jax.process_index() == 0:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer and add the placeholder token as a additional special token
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
else:
raise NotImplementedError("No tokenizer specified!")
# Get the datasets: you can either provide your own training and evaluation files (see below)
total_train_batch_size = args.train_batch_size * jax.local_device_count() * args.gradient_accumulation_steps
train_dataset = make_train_dataset(args, tokenizer, batch_size=total_train_batch_size)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=not args.streaming,
collate_fn=collate_fn,
batch_size=total_train_batch_size,
num_workers=args.dataloader_num_workers,
drop_last=True,
)
weight_dtype = jnp.float32
if args.mixed_precision == "fp16":
weight_dtype = jnp.float16
elif args.mixed_precision == "bf16":
weight_dtype = jnp.bfloat16
# Load models and create wrapper for stable diffusion
text_encoder = FlaxCLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
vae, vae_params = FlaxAutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path,
revision=args.revision,
subfolder="vae",
dtype=weight_dtype,
from_pt=args.from_pt,
)
unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="unet",
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
args.controlnet_model_name_or_path,
revision=args.controlnet_revision,
from_pt=args.controlnet_from_pt,
dtype=jnp.float32,
)
else:
logger.info("Initializing controlnet weights from unet")
rng, rng_params = jax.random.split(rng)
controlnet = FlaxControlNetModel(
in_channels=unet.config.in_channels,
down_block_types=unet.config.down_block_types,
only_cross_attention=unet.config.only_cross_attention,
block_out_channels=unet.config.block_out_channels,
layers_per_block=unet.config.layers_per_block,
attention_head_dim=unet.config.attention_head_dim,
cross_attention_dim=unet.config.cross_attention_dim,
use_linear_projection=unet.config.use_linear_projection,
flip_sin_to_cos=unet.config.flip_sin_to_cos,
freq_shift=unet.config.freq_shift,
)
controlnet_params = controlnet.init_weights(rng=rng_params)
controlnet_params = unfreeze(controlnet_params)
for key in [
"conv_in",
"time_embedding",
"down_blocks_0",
"down_blocks_1",
"down_blocks_2",
"down_blocks_3",
"mid_block",
]:
controlnet_params[key] = unet_params[key]
pipeline, pipeline_params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
args.pretrained_model_name_or_path,
tokenizer=tokenizer,
controlnet=controlnet,
safety_checker=None,
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
pipeline_params = jax_utils.replicate(pipeline_params)
# Optimization
if args.scale_lr:
args.learning_rate = args.learning_rate * total_train_batch_size
constant_scheduler = optax.constant_schedule(args.learning_rate)
adamw = optax.adamw(
learning_rate=constant_scheduler,
b1=args.adam_beta1,
b2=args.adam_beta2,
eps=args.adam_epsilon,
weight_decay=args.adam_weight_decay,
)
optimizer = optax.chain(
optax.clip_by_global_norm(args.max_grad_norm),
adamw,
)
state = train_state.TrainState.create(apply_fn=controlnet.__call__, params=controlnet_params, tx=optimizer)
noise_scheduler, noise_scheduler_state = FlaxDDPMScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler"
)
# Initialize our training
validation_rng, train_rngs = jax.random.split(rng)
train_rngs = jax.random.split(train_rngs, jax.local_device_count())
def compute_snr(timesteps):
"""
Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
"""
alphas_cumprod = noise_scheduler_state.common.alphas_cumprod
sqrt_alphas_cumprod = alphas_cumprod**0.5
sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
alpha = sqrt_alphas_cumprod[timesteps]
sigma = sqrt_one_minus_alphas_cumprod[timesteps]
# Compute SNR.
snr = (alpha / sigma) ** 2
return snr
def train_step(state, unet_params, text_encoder_params, vae_params, batch, train_rng):
# reshape batch, add grad_step_dim if gradient_accumulation_steps > 1
if args.gradient_accumulation_steps > 1:
grad_steps = args.gradient_accumulation_steps
batch = jax.tree_map(lambda x: x.reshape((grad_steps, x.shape[0] // grad_steps) + x.shape[1:]), batch)
def compute_loss(params, minibatch, sample_rng):
# Convert images to latent space
vae_outputs = vae.apply(
{"params": vae_params}, minibatch["pixel_values"], deterministic=True, method=vae.encode
)
latents = vae_outputs.latent_dist.sample(sample_rng)
# (NHWC) -> (NCHW)
latents = jnp.transpose(latents, (0, 3, 1, 2))
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise_rng, timestep_rng = jax.random.split(sample_rng)
noise = jax.random.normal(noise_rng, latents.shape)
# Sample a random timestep for each image
bsz = latents.shape[0]
timesteps = jax.random.randint(
timestep_rng,
(bsz,),
0,
noise_scheduler.config.num_train_timesteps,
)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(
minibatch["input_ids"],
params=text_encoder_params,
train=False,
)[0]
controlnet_cond = minibatch["conditioning_pixel_values"]
# Predict the noise residual and compute loss
down_block_res_samples, mid_block_res_sample = controlnet.apply(
{"params": params},
noisy_latents,
timesteps,
encoder_hidden_states,
controlnet_cond,
train=True,
return_dict=False,
)
model_pred = unet.apply(
{"params": unet_params},
noisy_latents,
timesteps,
encoder_hidden_states,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = (target - model_pred) ** 2
if args.snr_gamma is not None:
snr = jnp.array(compute_snr(timesteps))
snr_loss_weights = jnp.where(snr < args.snr_gamma, snr, jnp.ones_like(snr) * args.snr_gamma)
if noise_scheduler.config.prediction_type == "epsilon":
snr_loss_weights = snr_loss_weights / snr
elif noise_scheduler.config.prediction_type == "v_prediction":
snr_loss_weights = snr_loss_weights / (snr + 1)
loss = loss * snr_loss_weights
loss = loss.mean()
return loss
grad_fn = jax.value_and_grad(compute_loss)
# get a minibatch (one gradient accumulation slice)
def get_minibatch(batch, grad_idx):
return jax.tree_util.tree_map(
lambda x: jax.lax.dynamic_index_in_dim(x, grad_idx, keepdims=False),
batch,
)
def loss_and_grad(grad_idx, train_rng):
# create minibatch for the grad step
minibatch = get_minibatch(batch, grad_idx) if grad_idx is not None else batch
sample_rng, train_rng = jax.random.split(train_rng, 2)
loss, grad = grad_fn(state.params, minibatch, sample_rng)
return loss, grad, train_rng
if args.gradient_accumulation_steps == 1:
loss, grad, new_train_rng = loss_and_grad(None, train_rng)
else:
init_loss_grad_rng = (
0.0, # initial value for cumul_loss
jax.tree_map(jnp.zeros_like, state.params), # initial value for cumul_grad
train_rng, # initial value for train_rng
)
def cumul_grad_step(grad_idx, loss_grad_rng):
cumul_loss, cumul_grad, train_rng = loss_grad_rng
loss, grad, new_train_rng = loss_and_grad(grad_idx, train_rng)
cumul_loss, cumul_grad = jax.tree_map(jnp.add, (cumul_loss, cumul_grad), (loss, grad))
return cumul_loss, cumul_grad, new_train_rng
loss, grad, new_train_rng = jax.lax.fori_loop(
0,
args.gradient_accumulation_steps,
cumul_grad_step,
init_loss_grad_rng,
)
loss, grad = jax.tree_map(lambda x: x / args.gradient_accumulation_steps, (loss, grad))
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
def l2(xs):
return jnp.sqrt(sum([jnp.vdot(x, x) for x in jax.tree_util.tree_leaves(xs)]))
metrics["l2_grads"] = l2(jax.tree_util.tree_leaves(grad))
return new_state, metrics, new_train_rng
# Create parallel version of the train step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
# Replicate the train state on each device
state = jax_utils.replicate(state)
unet_params = jax_utils.replicate(unet_params)
text_encoder_params = jax_utils.replicate(text_encoder.params)
vae_params = jax_utils.replicate(vae_params)
# Train!
if args.streaming:
dataset_length = args.max_train_samples
else:
dataset_length = len(train_dataloader)
num_update_steps_per_epoch = math.ceil(dataset_length / args.gradient_accumulation_steps)
# Scheduler and math around the number of training steps.
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
logger.info("***** Running training *****")
logger.info(f" Num examples = {args.max_train_samples if args.streaming else len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
logger.info(f" Total optimization steps = {args.num_train_epochs * num_update_steps_per_epoch}")
if jax.process_index() == 0 and args.report_to == "wandb":
wandb.define_metric("*", step_metric="train/step")
wandb.define_metric("train/step", step_metric="walltime")
wandb.config.update(
{
"num_train_examples": args.max_train_samples if args.streaming else len(train_dataset),
"total_train_batch_size": total_train_batch_size,
"total_optimization_step": args.num_train_epochs * num_update_steps_per_epoch,
"num_devices": jax.device_count(),
"controlnet_params": sum(np.prod(x.shape) for x in jax.tree_util.tree_leaves(state.params)),
}
)
global_step = step0 = 0
epochs = tqdm(
range(args.num_train_epochs),
desc="Epoch ... ",
position=0,
disable=jax.process_index() > 0,
)
if args.profile_memory:
jax.profiler.save_device_memory_profile(os.path.join(args.output_dir, "memory_initial.prof"))
t00 = t0 = time.monotonic()
for epoch in epochs:
# ======================== Training ================================
train_metrics = []
train_metric = None
steps_per_epoch = (
args.max_train_samples // total_train_batch_size
if args.streaming or args.max_train_samples
else len(train_dataset) // total_train_batch_size
)
train_step_progress_bar = tqdm(
total=steps_per_epoch,
desc="Training...",
position=1,
leave=False,
disable=jax.process_index() > 0,
)
# train
for batch in train_dataloader:
if args.profile_steps and global_step == 1:
train_metric["loss"].block_until_ready()
jax.profiler.start_trace(args.output_dir)
if args.profile_steps and global_step == 1 + args.profile_steps:
train_metric["loss"].block_until_ready()
jax.profiler.stop_trace()
batch = shard(batch)
with jax.profiler.StepTraceAnnotation("train", step_num=global_step):
state, train_metric, train_rngs = p_train_step(
state, unet_params, text_encoder_params, vae_params, batch, train_rngs
)
train_metrics.append(train_metric)
train_step_progress_bar.update(1)
global_step += 1
if global_step >= args.max_train_steps:
break
if (
args.validation_prompt is not None
and global_step % args.validation_steps == 0
and jax.process_index() == 0
):
_ = log_validation(
pipeline, pipeline_params, state.params, tokenizer, args, validation_rng, weight_dtype
)
if global_step % args.logging_steps == 0 and jax.process_index() == 0:
if args.report_to == "wandb":
train_metrics = jax_utils.unreplicate(train_metrics)
train_metrics = jax.tree_util.tree_map(lambda *m: jnp.array(m).mean(), *train_metrics)
wandb.log(
{
"walltime": time.monotonic() - t00,
"train/step": global_step,
"train/epoch": global_step / dataset_length,
"train/steps_per_sec": (global_step - step0) / (time.monotonic() - t0),
**{f"train/{k}": v for k, v in train_metrics.items()},
}
)
t0, step0 = time.monotonic(), global_step
train_metrics = []
if global_step % args.checkpointing_steps == 0 and jax.process_index() == 0:
controlnet.save_pretrained(
f"{args.output_dir}/{global_step}",
params=get_params_to_save(state.params),
)
train_metric = jax_utils.unreplicate(train_metric)
train_step_progress_bar.close()
epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
# Final validation & store model.
if jax.process_index() == 0:
if args.validation_prompt is not None:
if args.profile_validation:
jax.profiler.start_trace(args.output_dir)
image_logs = log_validation(
pipeline, pipeline_params, state.params, tokenizer, args, validation_rng, weight_dtype
)
if args.profile_validation:
jax.profiler.stop_trace()
else:
image_logs = None
controlnet.save_pretrained(
args.output_dir,
params=get_params_to_save(state.params),
)
if args.push_to_hub:
save_model_card(
repo_id,
image_logs=image_logs,
base_model=args.pretrained_model_name_or_path,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if args.profile_memory:
jax.profiler.save_device_memory_profile(os.path.join(args.output_dir, "memory_final.prof"))
logger.info("Finished training.")
if __name__ == "__main__":
main()
| diffusers/examples/controlnet/train_controlnet_flax.py/0 | {
"file_path": "diffusers/examples/controlnet/train_controlnet_flax.py",
"repo_id": "diffusers",
"token_count": 19822
} | 106 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import copy
import gc
import logging
import math
import os
import shutil
import warnings
from pathlib import Path
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from huggingface_hub import create_repo, upload_folder
from huggingface_hub.utils import insecure_hashlib
from packaging import version
from peft import LoraConfig
from peft.utils import get_peft_model_state_dict, set_peft_model_state_dict
from PIL import Image
from PIL.ImageOps import exif_transpose
from torch.utils.data import Dataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.loaders import LoraLoaderMixin
from diffusers.optimization import get_scheduler
from diffusers.training_utils import _set_state_dict_into_text_encoder, cast_training_params
from diffusers.utils import (
check_min_version,
convert_state_dict_to_diffusers,
convert_unet_state_dict_to_peft,
is_wandb_available,
)
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.torch_utils import is_compiled_module
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.26.0.dev0")
logger = get_logger(__name__)
def save_model_card(
repo_id: str,
images=None,
base_model=str,
train_text_encoder=False,
prompt=str,
repo_folder=None,
pipeline: DiffusionPipeline = None,
):
img_str = ""
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
instance_prompt: {prompt}
tags:
- {'stable-diffusion' if isinstance(pipeline, StableDiffusionPipeline) else 'if'}
- {'stable-diffusion-diffusers' if isinstance(pipeline, StableDiffusionPipeline) else 'if-diffusers'}
- text-to-image
- diffusers
- lora
inference: true
---
"""
model_card = f"""
# LoRA DreamBooth - {repo_id}
These are LoRA adaption weights for {base_model}. The weights were trained on {prompt} using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following. \n
{img_str}
LoRA for the text encoder was enabled: {train_text_encoder}.
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path,
subfolder="text_encoder",
revision=revision,
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "RobertaSeriesModelWithTransformation":
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
return RobertaSeriesModelWithTransformation
elif model_class == "T5EncoderModel":
from transformers import T5EncoderModel
return T5EncoderModel
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args(input_args=None):
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--instance_data_dir",
type=str,
default=None,
required=True,
help="A folder containing the training data of instance images.",
)
parser.add_argument(
"--class_data_dir",
type=str,
default=None,
required=False,
help="A folder containing the training data of class images.",
)
parser.add_argument(
"--instance_prompt",
type=str,
default=None,
required=True,
help="The prompt with identifier specifying the instance",
)
parser.add_argument(
"--class_prompt",
type=str,
default=None,
help="The prompt to specify images in the same class as provided instance images.",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
help="A prompt that is used during validation to verify that the model is learning.",
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=50,
help=(
"Run dreambooth validation every X epochs. Dreambooth validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--with_prior_preservation",
default=False,
action="store_true",
help="Flag to add prior preservation loss.",
)
parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
parser.add_argument(
"--num_class_images",
type=int,
default=100,
help=(
"Minimal class images for prior preservation loss. If there are not enough images already present in"
" class_data_dir, additional images will be sampled with class_prompt."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="lora-dreambooth-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--train_text_encoder",
action="store_true",
help="Whether to train the text encoder. If set, the text encoder should be float32 precision.",
)
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
parser.add_argument(
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
)
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
" checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--lr_num_cycles",
type=int,
default=1,
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
)
parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--prior_generation_precision",
type=str,
default=None,
choices=["no", "fp32", "fp16", "bf16"],
help=(
"Choose prior generation precision between fp32, fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to fp16 if a GPU is available else fp32."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--pre_compute_text_embeddings",
action="store_true",
help="Whether or not to pre-compute text embeddings. If text embeddings are pre-computed, the text encoder will not be kept in memory during training and will leave more GPU memory available for training the rest of the model. This is not compatible with `--train_text_encoder`.",
)
parser.add_argument(
"--tokenizer_max_length",
type=int,
default=None,
required=False,
help="The maximum length of the tokenizer. If not set, will default to the tokenizer's max length.",
)
parser.add_argument(
"--text_encoder_use_attention_mask",
action="store_true",
required=False,
help="Whether to use attention mask for the text encoder",
)
parser.add_argument(
"--validation_images",
required=False,
default=None,
nargs="+",
help="Optional set of images to use for validation. Used when the target pipeline takes an initial image as input such as when training image variation or superresolution.",
)
parser.add_argument(
"--class_labels_conditioning",
required=False,
default=None,
help="The optional `class_label` conditioning to pass to the unet, available values are `timesteps`.",
)
parser.add_argument(
"--rank",
type=int,
default=4,
help=("The dimension of the LoRA update matrices."),
)
if input_args is not None:
args = parser.parse_args(input_args)
else:
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.with_prior_preservation:
if args.class_data_dir is None:
raise ValueError("You must specify a data directory for class images.")
if args.class_prompt is None:
raise ValueError("You must specify prompt for class images.")
else:
# logger is not available yet
if args.class_data_dir is not None:
warnings.warn("You need not use --class_data_dir without --with_prior_preservation.")
if args.class_prompt is not None:
warnings.warn("You need not use --class_prompt without --with_prior_preservation.")
if args.train_text_encoder and args.pre_compute_text_embeddings:
raise ValueError("`--train_text_encoder` cannot be used with `--pre_compute_text_embeddings`")
return args
class DreamBoothDataset(Dataset):
"""
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
It pre-processes the images and the tokenizes prompts.
"""
def __init__(
self,
instance_data_root,
instance_prompt,
tokenizer,
class_data_root=None,
class_prompt=None,
class_num=None,
size=512,
center_crop=False,
encoder_hidden_states=None,
class_prompt_encoder_hidden_states=None,
tokenizer_max_length=None,
):
self.size = size
self.center_crop = center_crop
self.tokenizer = tokenizer
self.encoder_hidden_states = encoder_hidden_states
self.class_prompt_encoder_hidden_states = class_prompt_encoder_hidden_states
self.tokenizer_max_length = tokenizer_max_length
self.instance_data_root = Path(instance_data_root)
if not self.instance_data_root.exists():
raise ValueError("Instance images root doesn't exists.")
self.instance_images_path = list(Path(instance_data_root).iterdir())
self.num_instance_images = len(self.instance_images_path)
self.instance_prompt = instance_prompt
self._length = self.num_instance_images
if class_data_root is not None:
self.class_data_root = Path(class_data_root)
self.class_data_root.mkdir(parents=True, exist_ok=True)
self.class_images_path = list(self.class_data_root.iterdir())
if class_num is not None:
self.num_class_images = min(len(self.class_images_path), class_num)
else:
self.num_class_images = len(self.class_images_path)
self._length = max(self.num_class_images, self.num_instance_images)
self.class_prompt = class_prompt
else:
self.class_data_root = None
self.image_transforms = transforms.Compose(
[
transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def __len__(self):
return self._length
def __getitem__(self, index):
example = {}
instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
instance_image = exif_transpose(instance_image)
if not instance_image.mode == "RGB":
instance_image = instance_image.convert("RGB")
example["instance_images"] = self.image_transforms(instance_image)
if self.encoder_hidden_states is not None:
example["instance_prompt_ids"] = self.encoder_hidden_states
else:
text_inputs = tokenize_prompt(
self.tokenizer, self.instance_prompt, tokenizer_max_length=self.tokenizer_max_length
)
example["instance_prompt_ids"] = text_inputs.input_ids
example["instance_attention_mask"] = text_inputs.attention_mask
if self.class_data_root:
class_image = Image.open(self.class_images_path[index % self.num_class_images])
class_image = exif_transpose(class_image)
if not class_image.mode == "RGB":
class_image = class_image.convert("RGB")
example["class_images"] = self.image_transforms(class_image)
if self.class_prompt_encoder_hidden_states is not None:
example["class_prompt_ids"] = self.class_prompt_encoder_hidden_states
else:
class_text_inputs = tokenize_prompt(
self.tokenizer, self.class_prompt, tokenizer_max_length=self.tokenizer_max_length
)
example["class_prompt_ids"] = class_text_inputs.input_ids
example["class_attention_mask"] = class_text_inputs.attention_mask
return example
def collate_fn(examples, with_prior_preservation=False):
has_attention_mask = "instance_attention_mask" in examples[0]
input_ids = [example["instance_prompt_ids"] for example in examples]
pixel_values = [example["instance_images"] for example in examples]
if has_attention_mask:
attention_mask = [example["instance_attention_mask"] for example in examples]
# Concat class and instance examples for prior preservation.
# We do this to avoid doing two forward passes.
if with_prior_preservation:
input_ids += [example["class_prompt_ids"] for example in examples]
pixel_values += [example["class_images"] for example in examples]
if has_attention_mask:
attention_mask += [example["class_attention_mask"] for example in examples]
pixel_values = torch.stack(pixel_values)
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.cat(input_ids, dim=0)
batch = {
"input_ids": input_ids,
"pixel_values": pixel_values,
}
if has_attention_mask:
batch["attention_mask"] = attention_mask
return batch
class PromptDataset(Dataset):
"A simple dataset to prepare the prompts to generate class images on multiple GPUs."
def __init__(self, prompt, num_samples):
self.prompt = prompt
self.num_samples = num_samples
def __len__(self):
return self.num_samples
def __getitem__(self, index):
example = {}
example["prompt"] = self.prompt
example["index"] = index
return example
def tokenize_prompt(tokenizer, prompt, tokenizer_max_length=None):
if tokenizer_max_length is not None:
max_length = tokenizer_max_length
else:
max_length = tokenizer.model_max_length
text_inputs = tokenizer(
prompt,
truncation=True,
padding="max_length",
max_length=max_length,
return_tensors="pt",
)
return text_inputs
def encode_prompt(text_encoder, input_ids, attention_mask, text_encoder_use_attention_mask=None):
text_input_ids = input_ids.to(text_encoder.device)
if text_encoder_use_attention_mask:
attention_mask = attention_mask.to(text_encoder.device)
else:
attention_mask = None
prompt_embeds = text_encoder(
text_input_ids,
attention_mask=attention_mask,
return_dict=False,
)
prompt_embeds = prompt_embeds[0]
return prompt_embeds
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
# This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
# TODO (sayakpaul): Remove this check when gradient accumulation with two models is enabled in accelerate.
if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
raise ValueError(
"Gradient accumulation is not supported when training the text encoder in distributed training. "
"Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Generate class images if prior preservation is enabled.
if args.with_prior_preservation:
class_images_dir = Path(args.class_data_dir)
if not class_images_dir.exists():
class_images_dir.mkdir(parents=True)
cur_class_images = len(list(class_images_dir.iterdir()))
if cur_class_images < args.num_class_images:
torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
if args.prior_generation_precision == "fp32":
torch_dtype = torch.float32
elif args.prior_generation_precision == "fp16":
torch_dtype = torch.float16
elif args.prior_generation_precision == "bf16":
torch_dtype = torch.bfloat16
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
torch_dtype=torch_dtype,
safety_checker=None,
revision=args.revision,
variant=args.variant,
)
pipeline.set_progress_bar_config(disable=True)
num_new_images = args.num_class_images - cur_class_images
logger.info(f"Number of class images to sample: {num_new_images}.")
sample_dataset = PromptDataset(args.class_prompt, num_new_images)
sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
sample_dataloader = accelerator.prepare(sample_dataloader)
pipeline.to(accelerator.device)
for example in tqdm(
sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
):
images = pipeline(example["prompt"]).images
for i, image in enumerate(images):
hash_image = insecure_hashlib.sha1(image.tobytes()).hexdigest()
image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
image.save(image_filename)
del pipeline
if torch.cuda.is_available():
torch.cuda.empty_cache()
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
elif args.pretrained_model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
use_fast=False,
)
# import correct text encoder class
text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = text_encoder_cls.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
try:
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
except OSError:
# IF does not have a VAE so let's just set it to None
# We don't have to error out here
vae = None
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# We only train the additional adapter LoRA layers
if vae is not None:
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
unet.requires_grad_(False)
# For mixed precision training we cast all non-trainable weights (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
unet.to(accelerator.device, dtype=weight_dtype)
if vae is not None:
vae.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
if args.train_text_encoder:
text_encoder.gradient_checkpointing_enable()
# now we will add new LoRA weights to the attention layers
unet_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0", "add_k_proj", "add_v_proj"],
)
unet.add_adapter(unet_lora_config)
# The text encoder comes from 🤗 transformers, we will also attach adapters to it.
if args.train_text_encoder:
text_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
)
text_encoder.add_adapter(text_lora_config)
def unwrap_model(model):
model = accelerator.unwrap_model(model)
model = model._orig_mod if is_compiled_module(model) else model
return model
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
# there are only two options here. Either are just the unet attn processor layers
# or there are the unet and text encoder atten layers
unet_lora_layers_to_save = None
text_encoder_lora_layers_to_save = None
for model in models:
if isinstance(model, type(unwrap_model(unet))):
unet_lora_layers_to_save = convert_state_dict_to_diffusers(get_peft_model_state_dict(model))
elif isinstance(model, type(unwrap_model(text_encoder))):
text_encoder_lora_layers_to_save = convert_state_dict_to_diffusers(
get_peft_model_state_dict(model)
)
else:
raise ValueError(f"unexpected save model: {model.__class__}")
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
LoraLoaderMixin.save_lora_weights(
output_dir,
unet_lora_layers=unet_lora_layers_to_save,
text_encoder_lora_layers=text_encoder_lora_layers_to_save,
)
def load_model_hook(models, input_dir):
unet_ = None
text_encoder_ = None
while len(models) > 0:
model = models.pop()
if isinstance(model, type(unwrap_model(unet))):
unet_ = model
elif isinstance(model, type(unwrap_model(text_encoder))):
text_encoder_ = model
else:
raise ValueError(f"unexpected save model: {model.__class__}")
lora_state_dict, network_alphas = LoraLoaderMixin.lora_state_dict(input_dir)
unet_state_dict = {f'{k.replace("unet.", "")}': v for k, v in lora_state_dict.items() if k.startswith("unet.")}
unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict)
incompatible_keys = set_peft_model_state_dict(unet_, unet_state_dict, adapter_name="default")
if incompatible_keys is not None:
# check only for unexpected keys
unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
if unexpected_keys:
logger.warning(
f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
f" {unexpected_keys}. "
)
if args.train_text_encoder:
_set_state_dict_into_text_encoder(lora_state_dict, prefix="text_encoder.", text_encoder=text_encoder_)
# Make sure the trainable params are in float32. This is again needed since the base models
# are in `weight_dtype`. More details:
# https://github.com/huggingface/diffusers/pull/6514#discussion_r1449796804
if args.mixed_precision == "fp16":
models = [unet_]
if args.train_text_encoder:
models.append(text_encoder_)
# only upcast trainable parameters (LoRA) into fp32
cast_training_params(models, dtype=torch.float32)
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Make sure the trainable params are in float32.
if args.mixed_precision == "fp16":
models = [unet]
if args.train_text_encoder:
models.append(text_encoder)
# only upcast trainable parameters (LoRA) into fp32
cast_training_params(models, dtype=torch.float32)
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# Optimizer creation
params_to_optimize = list(filter(lambda p: p.requires_grad, unet.parameters()))
if args.train_text_encoder:
params_to_optimize = params_to_optimize + list(filter(lambda p: p.requires_grad, text_encoder.parameters()))
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
if args.pre_compute_text_embeddings:
def compute_text_embeddings(prompt):
with torch.no_grad():
text_inputs = tokenize_prompt(tokenizer, prompt, tokenizer_max_length=args.tokenizer_max_length)
prompt_embeds = encode_prompt(
text_encoder,
text_inputs.input_ids,
text_inputs.attention_mask,
text_encoder_use_attention_mask=args.text_encoder_use_attention_mask,
)
return prompt_embeds
pre_computed_encoder_hidden_states = compute_text_embeddings(args.instance_prompt)
validation_prompt_negative_prompt_embeds = compute_text_embeddings("")
if args.validation_prompt is not None:
validation_prompt_encoder_hidden_states = compute_text_embeddings(args.validation_prompt)
else:
validation_prompt_encoder_hidden_states = None
if args.class_prompt is not None:
pre_computed_class_prompt_encoder_hidden_states = compute_text_embeddings(args.class_prompt)
else:
pre_computed_class_prompt_encoder_hidden_states = None
text_encoder = None
tokenizer = None
gc.collect()
torch.cuda.empty_cache()
else:
pre_computed_encoder_hidden_states = None
validation_prompt_encoder_hidden_states = None
validation_prompt_negative_prompt_embeds = None
pre_computed_class_prompt_encoder_hidden_states = None
# Dataset and DataLoaders creation:
train_dataset = DreamBoothDataset(
instance_data_root=args.instance_data_dir,
instance_prompt=args.instance_prompt,
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
class_prompt=args.class_prompt,
class_num=args.num_class_images,
tokenizer=tokenizer,
size=args.resolution,
center_crop=args.center_crop,
encoder_hidden_states=pre_computed_encoder_hidden_states,
class_prompt_encoder_hidden_states=pre_computed_class_prompt_encoder_hidden_states,
tokenizer_max_length=args.tokenizer_max_length,
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.train_batch_size,
shuffle=True,
collate_fn=lambda examples: collate_fn(examples, args.with_prior_preservation),
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
num_cycles=args.lr_num_cycles,
power=args.lr_power,
)
# Prepare everything with our `accelerator`.
if args.train_text_encoder:
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
)
else:
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = vars(copy.deepcopy(args))
tracker_config.pop("validation_images")
accelerator.init_trackers("dreambooth-lora", config=tracker_config)
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the mos recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
if args.train_text_encoder:
text_encoder.train()
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
pixel_values = batch["pixel_values"].to(dtype=weight_dtype)
if vae is not None:
# Convert images to latent space
model_input = vae.encode(pixel_values).latent_dist.sample()
model_input = model_input * vae.config.scaling_factor
else:
model_input = pixel_values
# Sample noise that we'll add to the latents
noise = torch.randn_like(model_input)
bsz, channels, height, width = model_input.shape
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
)
timesteps = timesteps.long()
# Add noise to the model input according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# Get the text embedding for conditioning
if args.pre_compute_text_embeddings:
encoder_hidden_states = batch["input_ids"]
else:
encoder_hidden_states = encode_prompt(
text_encoder,
batch["input_ids"],
batch["attention_mask"],
text_encoder_use_attention_mask=args.text_encoder_use_attention_mask,
)
if unwrap_model(unet).config.in_channels == channels * 2:
noisy_model_input = torch.cat([noisy_model_input, noisy_model_input], dim=1)
if args.class_labels_conditioning == "timesteps":
class_labels = timesteps
else:
class_labels = None
# Predict the noise residual
model_pred = unet(
noisy_model_input,
timesteps,
encoder_hidden_states,
class_labels=class_labels,
return_dict=False,
)[0]
# if model predicts variance, throw away the prediction. we will only train on the
# simplified training objective. This means that all schedulers using the fine tuned
# model must be configured to use one of the fixed variance variance types.
if model_pred.shape[1] == 6:
model_pred, _ = torch.chunk(model_pred, 2, dim=1)
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(model_input, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
if args.with_prior_preservation:
# Chunk the noise and model_pred into two parts and compute the loss on each part separately.
model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
target, target_prior = torch.chunk(target, 2, dim=0)
# Compute instance loss
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# Compute prior loss
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
# Add the prior loss to the instance loss.
loss = loss + args.prior_loss_weight * prior_loss
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(params_to_optimize, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=unwrap_model(unet),
text_encoder=None if args.pre_compute_text_embeddings else unwrap_model(text_encoder),
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
scheduler_args = {}
if "variance_type" in pipeline.scheduler.config:
variance_type = pipeline.scheduler.config.variance_type
if variance_type in ["learned", "learned_range"]:
variance_type = "fixed_small"
scheduler_args["variance_type"] = variance_type
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
pipeline.scheduler.config, **scheduler_args
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
if args.pre_compute_text_embeddings:
pipeline_args = {
"prompt_embeds": validation_prompt_encoder_hidden_states,
"negative_prompt_embeds": validation_prompt_negative_prompt_embeds,
}
else:
pipeline_args = {"prompt": args.validation_prompt}
if args.validation_images is None:
images = []
for _ in range(args.num_validation_images):
with torch.cuda.amp.autocast():
image = pipeline(**pipeline_args, generator=generator).images[0]
images.append(image)
else:
images = []
for image in args.validation_images:
image = Image.open(image)
with torch.cuda.amp.autocast():
image = pipeline(**pipeline_args, image=image, generator=generator).images[0]
images.append(image)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
# Save the lora layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = unwrap_model(unet)
unet = unet.to(torch.float32)
unet_lora_state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet))
if args.train_text_encoder:
text_encoder = unwrap_model(text_encoder)
text_encoder_state_dict = convert_state_dict_to_diffusers(get_peft_model_state_dict(text_encoder))
else:
text_encoder_state_dict = None
LoraLoaderMixin.save_lora_weights(
save_directory=args.output_dir,
unet_lora_layers=unet_lora_state_dict,
text_encoder_lora_layers=text_encoder_state_dict,
)
# Final inference
# Load previous pipeline
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path, revision=args.revision, variant=args.variant, torch_dtype=weight_dtype
)
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
scheduler_args = {}
if "variance_type" in pipeline.scheduler.config:
variance_type = pipeline.scheduler.config.variance_type
if variance_type in ["learned", "learned_range"]:
variance_type = "fixed_small"
scheduler_args["variance_type"] = variance_type
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config, **scheduler_args)
pipeline = pipeline.to(accelerator.device)
# load attention processors
pipeline.load_lora_weights(args.output_dir, weight_name="pytorch_lora_weights.safetensors")
# run inference
images = []
if args.validation_prompt and args.num_validation_images > 0:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
images = [
pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"test": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
if args.push_to_hub:
save_model_card(
repo_id,
images=images,
base_model=args.pretrained_model_name_or_path,
train_text_encoder=args.train_text_encoder,
prompt=args.instance_prompt,
repo_folder=args.output_dir,
pipeline=pipeline,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| diffusers/examples/dreambooth/train_dreambooth_lora.py/0 | {
"file_path": "diffusers/examples/dreambooth/train_dreambooth_lora.py",
"repo_id": "diffusers",
"token_count": 25751
} | 107 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import shutil
from pathlib import Path
import accelerate
import datasets
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.state import AcceleratorState
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from tqdm import tqdm
from transformers import CLIPImageProcessor, CLIPTextModelWithProjection, CLIPTokenizer, CLIPVisionModelWithProjection
from transformers.utils import ContextManagers
import diffusers
from diffusers import AutoPipelineForText2Image, DDPMScheduler, PriorTransformer
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel, compute_snr
from diffusers.utils import check_min_version, is_wandb_available, make_image_grid
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.26.0.dev0")
logger = get_logger(__name__, log_level="INFO")
DATASET_NAME_MAPPING = {
"lambdalabs/pokemon-blip-captions": ("image", "text"),
}
def save_model_card(
args,
repo_id: str,
images=None,
repo_folder=None,
):
img_str = ""
if len(images) > 0:
image_grid = make_image_grid(images, 1, len(args.validation_prompts))
image_grid.save(os.path.join(repo_folder, "val_imgs_grid.png"))
img_str += "\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {args.pretrained_prior_model_name_or_path}
datasets:
- {args.dataset_name}
tags:
- kandinsky
- text-to-image
- diffusers
inference: true
---
"""
model_card = f"""
# Finetuning - {repo_id}
This pipeline was finetuned from **{args.pretrained_prior_model_name_or_path}** on the **{args.dataset_name}** dataset. Below are some example images generated with the finetuned pipeline using the following prompts: {args.validation_prompts}: \n
{img_str}
## Pipeline usage
You can use the pipeline like so:
```python
from diffusers import DiffusionPipeline
import torch
pipe_prior = DiffusionPipeline.from_pretrained("{repo_id}", torch_dtype=torch.float16)
pipe_t2i = DiffusionPipeline.from_pretrained("{args.pretrained_decoder_model_name_or_path}", torch_dtype=torch.float16)
prompt = "{args.validation_prompts[0]}"
image_embeds, negative_image_embeds = pipe_prior(prompt, guidance_scale=1.0).to_tuple()
image = pipe_t2i(image_embeds=image_embeds, negative_image_embeds=negative_image_embeds).images[0]
image.save("my_image.png")
```
## Training info
These are the key hyperparameters used during training:
* Epochs: {args.num_train_epochs}
* Learning rate: {args.learning_rate}
* Batch size: {args.train_batch_size}
* Gradient accumulation steps: {args.gradient_accumulation_steps}
* Image resolution: {args.resolution}
* Mixed-precision: {args.mixed_precision}
"""
wandb_info = ""
if is_wandb_available():
wandb_run_url = None
if wandb.run is not None:
wandb_run_url = wandb.run.url
if wandb_run_url is not None:
wandb_info = f"""
More information on all the CLI arguments and the environment are available on your [`wandb` run page]({wandb_run_url}).
"""
model_card += wandb_info
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def log_validation(
image_encoder, image_processor, text_encoder, tokenizer, prior, args, accelerator, weight_dtype, epoch
):
logger.info("Running validation... ")
pipeline = AutoPipelineForText2Image.from_pretrained(
args.pretrained_decoder_model_name_or_path,
prior_image_encoder=accelerator.unwrap_model(image_encoder),
prior_image_processor=image_processor,
prior_text_encoder=accelerator.unwrap_model(text_encoder),
prior_tokenizer=tokenizer,
prior_prior=accelerator.unwrap_model(prior),
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
images = []
for i in range(len(args.validation_prompts)):
with torch.autocast("cuda"):
image = pipeline(args.validation_prompts[i], num_inference_steps=20, generator=generator).images[0]
images.append(image)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
elif tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompts[i]}")
for i, image in enumerate(images)
]
}
)
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
torch.cuda.empty_cache()
return images
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of finetuning Kandinsky 2.2.")
parser.add_argument(
"--pretrained_decoder_model_name_or_path",
type=str,
default="kandinsky-community/kandinsky-2-2-decoder",
required=False,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_prior_model_name_or_path",
type=str,
default="kandinsky-community/kandinsky-2-2-prior",
required=False,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--validation_prompts",
type=str,
default=None,
nargs="+",
help=("A set of prompts evaluated every `--validation_epochs` and logged to `--report_to`."),
)
parser.add_argument(
"--output_dir",
type=str,
default="kandi_2_2-model-finetuned",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=1, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="learning rate",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument(
"--adam_weight_decay",
type=float,
default=0.0,
required=False,
help="weight decay_to_use",
)
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--validation_epochs",
type=int,
default=5,
help="Run validation every X epochs.",
)
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
return args
def main():
args = parse_args()
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(
total_limit=args.checkpoints_total_limit, project_dir=args.output_dir, logging_dir=logging_dir
)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load scheduler, image_processor, tokenizer and models.
noise_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", prediction_type="sample")
image_processor = CLIPImageProcessor.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_processor"
)
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="tokenizer")
def deepspeed_zero_init_disabled_context_manager():
"""
returns either a context list that includes one that will disable zero.Init or an empty context list
"""
deepspeed_plugin = AcceleratorState().deepspeed_plugin if accelerate.state.is_initialized() else None
if deepspeed_plugin is None:
return []
return [deepspeed_plugin.zero3_init_context_manager(enable=False)]
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
).eval()
text_encoder = CLIPTextModelWithProjection.from_pretrained(
args.pretrained_prior_model_name_or_path, subfolder="text_encoder", torch_dtype=weight_dtype
).eval()
prior = PriorTransformer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
# Freeze text_encoder and image_encoder
text_encoder.requires_grad_(False)
image_encoder.requires_grad_(False)
# Set prior to trainable.
prior.train()
# Create EMA for the prior.
if args.use_ema:
ema_prior = PriorTransformer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
ema_prior = EMAModel(ema_prior.parameters(), model_cls=PriorTransformer, model_config=ema_prior.config)
ema_prior.to(accelerator.device)
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if args.use_ema:
ema_prior.save_pretrained(os.path.join(output_dir, "prior_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "prior"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "prior_ema"), PriorTransformer)
ema_prior.load_state_dict(load_model.state_dict())
ema_prior.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = PriorTransformer.from_pretrained(input_dir, subfolder="prior")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
prior.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
text_input_ids = inputs.input_ids
text_mask = inputs.attention_mask.bool()
return text_input_ids, text_mask
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
clip_pixel_values = torch.stack([example["clip_pixel_values"] for example in examples])
clip_pixel_values = clip_pixel_values.to(memory_format=torch.contiguous_format).float()
text_input_ids = torch.stack([example["text_input_ids"] for example in examples])
text_mask = torch.stack([example["text_mask"] for example in examples])
return {"clip_pixel_values": clip_pixel_values, "text_input_ids": text_input_ids, "text_mask": text_mask}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
clip_mean = prior.clip_mean.clone()
clip_std = prior.clip_std.clone()
prior, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
prior, optimizer, train_dataloader, lr_scheduler
)
image_encoder.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
tracker_config.pop("validation_prompts")
accelerator.init_trackers(args.tracker_project_name, tracker_config)
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
clip_mean = clip_mean.to(weight_dtype).to(accelerator.device)
clip_std = clip_std.to(weight_dtype).to(accelerator.device)
for epoch in range(first_epoch, args.num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(prior):
# Convert images to latent space
text_input_ids, text_mask, clip_images = (
batch["text_input_ids"],
batch["text_mask"],
batch["clip_pixel_values"].to(weight_dtype),
)
with torch.no_grad():
text_encoder_output = text_encoder(text_input_ids)
prompt_embeds = text_encoder_output.text_embeds
text_encoder_hidden_states = text_encoder_output.last_hidden_state
image_embeds = image_encoder(clip_images).image_embeds
# Sample noise that we'll add to the image_embeds
noise = torch.randn_like(image_embeds)
bsz = image_embeds.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=image_embeds.device
)
timesteps = timesteps.long()
image_embeds = (image_embeds - clip_mean) / clip_std
noisy_latents = noise_scheduler.add_noise(image_embeds, noise, timesteps)
target = image_embeds
# Predict the noise residual and compute loss
model_pred = prior(
noisy_latents,
timestep=timesteps,
proj_embedding=prompt_embeds,
encoder_hidden_states=text_encoder_hidden_states,
attention_mask=text_mask,
).predicted_image_embedding
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
mse_loss_weights = torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(
dim=1
)[0]
if noise_scheduler.config.prediction_type == "epsilon":
mse_loss_weights = mse_loss_weights / snr
elif noise_scheduler.config.prediction_type == "v_prediction":
mse_loss_weights = mse_loss_weights / (snr + 1)
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(prior.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_prior.step(prior.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompts is not None and epoch % args.validation_epochs == 0:
if args.use_ema:
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
ema_prior.store(prior.parameters())
ema_prior.copy_to(prior.parameters())
log_validation(
image_encoder,
image_processor,
text_encoder,
tokenizer,
prior,
args,
accelerator,
weight_dtype,
global_step,
)
if args.use_ema:
# Switch back to the original UNet parameters.
ema_prior.restore(prior.parameters())
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
prior = accelerator.unwrap_model(prior)
if args.use_ema:
ema_prior.copy_to(prior.parameters())
pipeline = AutoPipelineForText2Image.from_pretrained(
args.pretrained_decoder_model_name_or_path,
prior_image_encoder=image_encoder,
prior_text_encoder=text_encoder,
prior_prior=prior,
)
pipeline.prior_pipe.save_pretrained(args.output_dir)
# Run a final round of inference.
images = []
if args.validation_prompts is not None:
logger.info("Running inference for collecting generated images...")
pipeline = pipeline.to(accelerator.device)
pipeline.torch_dtype = weight_dtype
pipeline.set_progress_bar_config(disable=True)
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
for i in range(len(args.validation_prompts)):
with torch.autocast("cuda"):
image = pipeline(args.validation_prompts[i], num_inference_steps=20, generator=generator).images[0]
images.append(image)
if args.push_to_hub:
save_model_card(args, repo_id, images, repo_folder=args.output_dir)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
main()
| diffusers/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py/0 | {
"file_path": "diffusers/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py",
"repo_id": "diffusers",
"token_count": 16895
} | 108 |
# !pip install opencv-python transformers accelerate
import argparse
import cv2
import numpy as np
import torch
from controlnetxs import ControlNetXSModel
from PIL import Image
from pipeline_controlnet_xs import StableDiffusionControlNetXSPipeline
from diffusers.utils import load_image
parser = argparse.ArgumentParser()
parser.add_argument(
"--prompt", type=str, default="aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
)
parser.add_argument("--negative_prompt", type=str, default="low quality, bad quality, sketches")
parser.add_argument("--controlnet_conditioning_scale", type=float, default=0.7)
parser.add_argument(
"--image_path",
type=str,
default="https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png",
)
parser.add_argument("--num_inference_steps", type=int, default=50)
args = parser.parse_args()
prompt = args.prompt
negative_prompt = args.negative_prompt
# download an image
image = load_image(args.image_path)
# initialize the models and pipeline
controlnet_conditioning_scale = args.controlnet_conditioning_scale
controlnet = ControlNetXSModel.from_pretrained("UmerHA/ConrolNetXS-SDXL-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetXSPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
# get canny image
image = np.array(image)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
num_inference_steps = args.num_inference_steps
# generate image
image = pipe(
prompt,
controlnet_conditioning_scale=controlnet_conditioning_scale,
image=canny_image,
num_inference_steps=num_inference_steps,
).images[0]
image.save("cnxs_sdxl.canny.png")
| diffusers/examples/research_projects/controlnetxs/infer_sdxl_controlnetxs.py/0 | {
"file_path": "diffusers/examples/research_projects/controlnetxs/infer_sdxl_controlnetxs.py",
"repo_id": "diffusers",
"token_count": 650
} | 109 |
"""
The main idea for this code is to provide a way for users to not need to bother with the hassle of multiple tokens for a concept by typing
a photo of <concept>_0 <concept>_1 ... and so on
and instead just do
a photo of <concept>
which gets translated to the above. This needs to work for both inference and training.
For inference,
the tokenizer encodes the text. So, we would want logic for our tokenizer to replace the placeholder token with
it's underlying vectors
For training,
we would want to abstract away some logic like
1. Adding tokens
2. Updating gradient mask
3. Saving embeddings
to our Util class here.
so
TODO:
1. have tokenizer keep track of concept, multiconcept pairs and replace during encode call x
2. have mechanism for adding tokens x
3. have mech for saving emebeddings x
4. get mask to update x
5. Loading tokens from embedding x
6. Integrate to training x
7. Test
"""
import copy
import random
from transformers import CLIPTokenizer
class MultiTokenCLIPTokenizer(CLIPTokenizer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.token_map = {}
def try_adding_tokens(self, placeholder_token, *args, **kwargs):
num_added_tokens = super().add_tokens(placeholder_token, *args, **kwargs)
if num_added_tokens == 0:
raise ValueError(
f"The tokenizer already contains the token {placeholder_token}. Please pass a different"
" `placeholder_token` that is not already in the tokenizer."
)
def add_placeholder_tokens(self, placeholder_token, *args, num_vec_per_token=1, **kwargs):
output = []
if num_vec_per_token == 1:
self.try_adding_tokens(placeholder_token, *args, **kwargs)
output.append(placeholder_token)
else:
output = []
for i in range(num_vec_per_token):
ith_token = placeholder_token + f"_{i}"
self.try_adding_tokens(ith_token, *args, **kwargs)
output.append(ith_token)
# handle cases where there is a new placeholder token that contains the current placeholder token but is larger
for token in self.token_map:
if token in placeholder_token:
raise ValueError(
f"The tokenizer already has placeholder token {token} that can get confused with"
f" {placeholder_token}keep placeholder tokens independent"
)
self.token_map[placeholder_token] = output
def replace_placeholder_tokens_in_text(self, text, vector_shuffle=False, prop_tokens_to_load=1.0):
"""
Here, we replace the placeholder tokens in text recorded in token_map so that the text_encoder
can encode them
vector_shuffle was inspired by https://github.com/rinongal/textual_inversion/pull/119
where shuffling tokens were found to force the model to learn the concepts more descriptively.
"""
if isinstance(text, list):
output = []
for i in range(len(text)):
output.append(self.replace_placeholder_tokens_in_text(text[i], vector_shuffle=vector_shuffle))
return output
for placeholder_token in self.token_map:
if placeholder_token in text:
tokens = self.token_map[placeholder_token]
tokens = tokens[: 1 + int(len(tokens) * prop_tokens_to_load)]
if vector_shuffle:
tokens = copy.copy(tokens)
random.shuffle(tokens)
text = text.replace(placeholder_token, " ".join(tokens))
return text
def __call__(self, text, *args, vector_shuffle=False, prop_tokens_to_load=1.0, **kwargs):
return super().__call__(
self.replace_placeholder_tokens_in_text(
text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
),
*args,
**kwargs,
)
def encode(self, text, *args, vector_shuffle=False, prop_tokens_to_load=1.0, **kwargs):
return super().encode(
self.replace_placeholder_tokens_in_text(
text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
),
*args,
**kwargs,
)
| diffusers/examples/research_projects/multi_token_textual_inversion/multi_token_clip.py/0 | {
"file_path": "diffusers/examples/research_projects/multi_token_textual_inversion/multi_token_clip.py",
"repo_id": "diffusers",
"token_count": 1827
} | 110 |
import inspect
from typing import Callable, List, Optional, Union
import torch
from PIL import Image
from retriever import Retriever, normalize_images, preprocess_images
from transformers import CLIPFeatureExtractor, CLIPModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
EulerAncestralDiscreteScheduler,
EulerDiscreteScheduler,
ImagePipelineOutput,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
logging,
)
from diffusers.image_processor import VaeImageProcessor
from diffusers.utils import is_accelerate_available, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class RDMPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Retrieval Augmented Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
clip ([`CLIPModel`]):
Frozen CLIP model. Retrieval Augmented Diffusion uses the CLIP model, specifically the
[clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
clip: CLIPModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[
DDIMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,
EulerAncestralDiscreteScheduler,
DPMSolverMultistepScheduler,
],
feature_extractor: CLIPFeatureExtractor,
retriever: Optional[Retriever] = None,
):
super().__init__()
self.register_modules(
vae=vae,
clip=clip,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
feature_extractor=feature_extractor,
)
# Copy from statement here and all the methods we take from stable_diffusion_pipeline
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.retriever = retriever
def enable_xformers_memory_efficient_attention(self):
r"""
Enable memory efficient attention as implemented in xformers.
When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference
time. Speed up at training time is not guaranteed.
Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention
is used.
"""
self.unet.set_use_memory_efficient_attention_xformers(True)
def disable_xformers_memory_efficient_attention(self):
r"""
Disable memory efficient attention as implemented in xformers.
"""
self.unet.set_use_memory_efficient_attention_xformers(False)
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
"""
self.vae.enable_tiling()
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
if isinstance(self.unet.config.attention_head_dim, int):
slice_size = self.unet.config.attention_head_dim // 2
else:
slice_size = self.unet.config.attention_head_dim[0] // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
def enable_sequential_cpu_offload(self):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device("cuda")
for cpu_offloaded_model in [self.unet, self.clip, self.vae]:
if cpu_offloaded_model is not None:
cpu_offload(cpu_offloaded_model, device)
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(self, prompt):
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
prompt_embeds = self.clip.get_text_features(text_input_ids.to(self.device))
prompt_embeds = prompt_embeds / torch.linalg.norm(prompt_embeds, dim=-1, keepdim=True)
prompt_embeds = prompt_embeds[:, None, :]
return prompt_embeds
def _encode_image(self, retrieved_images, batch_size):
if len(retrieved_images[0]) == 0:
return None
for i in range(len(retrieved_images)):
retrieved_images[i] = normalize_images(retrieved_images[i])
retrieved_images[i] = preprocess_images(retrieved_images[i], self.feature_extractor).to(
self.clip.device, dtype=self.clip.dtype
)
_, c, h, w = retrieved_images[0].shape
retrieved_images = torch.reshape(torch.cat(retrieved_images, dim=0), (-1, c, h, w))
image_embeddings = self.clip.get_image_features(retrieved_images)
image_embeddings = image_embeddings / torch.linalg.norm(image_embeddings, dim=-1, keepdim=True)
_, d = image_embeddings.shape
image_embeddings = torch.reshape(image_embeddings, (batch_size, -1, d))
return image_embeddings
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def retrieve_images(self, retrieved_images, prompt_embeds, knn=10):
if self.retriever is not None:
additional_images = self.retriever.retrieve_imgs_batch(prompt_embeds[:, 0].cpu(), knn).total_examples
for i in range(len(retrieved_images)):
retrieved_images[i] += additional_images[i][self.retriever.config.image_column]
return retrieved_images
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
retrieved_images: Optional[List[Image.Image]] = None,
height: int = 768,
width: int = 768,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: Optional[int] = 1,
knn: Optional[int] = 10,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipeline_utils.ImagePipelineOutput`] instead of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipeline_utils.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if
`return_dict` is True, otherwise a `tuple. When returning a tuple, the first element is a list with the
generated images.
"""
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if retrieved_images is not None:
retrieved_images = [retrieved_images for _ in range(batch_size)]
else:
retrieved_images = [[] for _ in range(batch_size)]
device = self._execution_device
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt_embeds is None:
prompt_embeds = self._encode_prompt(prompt)
retrieved_images = self.retrieve_images(retrieved_images, prompt_embeds, knn=knn)
image_embeddings = self._encode_image(retrieved_images, batch_size)
if image_embeddings is not None:
prompt_embeds = torch.cat([prompt_embeds, image_embeddings], dim=1)
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_embeddings = torch.zeros_like(prompt_embeds).to(prompt_embeds.device)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([uncond_embeddings, prompt_embeds])
# get the initial random noise unless the user supplied it
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
else:
image = latents
image = self.image_processor.postprocess(
image, output_type=output_type, do_denormalize=[True] * image.shape[0]
)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| diffusers/examples/research_projects/rdm/pipeline_rdm.py/0 | {
"file_path": "diffusers/examples/research_projects/rdm/pipeline_rdm.py",
"repo_id": "diffusers",
"token_count": 9068
} | 111 |
# Stable Diffusion XL text-to-image fine-tuning
The `train_text_to_image_sdxl.py` script shows how to fine-tune Stable Diffusion XL (SDXL) on your own dataset.
🚨 This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset. 🚨
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/text_to_image` folder and run
```bash
pip install -r requirements_sdxl.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.6.0` installed in your environment.
### Training
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--enable_xformers_memory_efficient_attention \
--resolution=512 --center_crop --random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--report_to="wandb" \
--validation_prompt="a cute Sundar Pichai creature" --validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="sdxl-pokemon-model" \
--push_to_hub
```
**Notes**:
* The `train_text_to_image_sdxl.py` script pre-computes text embeddings and the VAE encodings and keeps them in memory. While for smaller datasets like [`lambdalabs/pokemon-blip-captions`](https://hf.co/datasets/lambdalabs/pokemon-blip-captions), it might not be a problem, it can definitely lead to memory problems when the script is used on a larger dataset. For those purposes, you would want to serialize these pre-computed representations to disk separately and load them during the fine-tuning process. Refer to [this PR](https://github.com/huggingface/diffusers/pull/4505) for a more in-depth discussion.
* The training script is compute-intensive and may not run on a consumer GPU like Tesla T4.
* The training command shown above performs intermediate quality validation in between the training epochs and logs the results to Weights and Biases. `--report_to`, `--validation_prompt`, and `--validation_epochs` are the relevant CLI arguments here.
* SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
### Inference
```python
from diffusers import DiffusionPipeline
import torch
model_path = "you-model-id-goes-here" # <-- change this
pipe = DiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
### Inference in Pytorch XLA
```python
from diffusers import DiffusionPipeline
import torch
import torch_xla.core.xla_model as xm
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = DiffusionPipeline.from_pretrained(model_id)
device = xm.xla_device()
pipe.to(device)
prompt = "A pokemon with green eyes and red legs."
start = time()
image = pipe(prompt, num_inference_steps=inference_steps).images[0]
print(f'Compilation time is {time()-start} sec')
image.save("pokemon.png")
start = time()
image = pipe(prompt, num_inference_steps=inference_steps).images[0]
print(f'Inference time is {time()-start} sec after compilation')
```
Note: There is a warmup step in PyTorch XLA. This takes longer because of
compilation and optimization. To see the real benefits of Pytorch XLA and
speedup, we need to call the pipe again on the input with the same length
as the original prompt to reuse the optimized graph and get the performance
boost.
## LoRA training example for Stable Diffusion XL (SDXL)
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables and, optionally, the `VAE_NAME` variable. Here, we will use [Stable Diffusion XL 1.0-base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**Notes**:
* SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
### Using DeepSpeed
Using DeepSpeed one can reduce the consumption of GPU memory, enabling the training of models on GPUs with smaller memory sizes. DeepSpeed is capable of offloading model parameters to the machine's memory, or it can distribute parameters, gradients, and optimizer states across multiple GPUs. This allows for the training of larger models under the same hardware configuration.
First, you need to use the `accelerate config` command to choose to use DeepSpeed, or manually use the accelerate config file to set up DeepSpeed.
Here is an example of a config file for using DeepSpeed. For more detailed explanations of the configuration, you can refer to this [link](https://huggingface.co/docs/accelerate/usage_guides/deepspeed).
```yaml
compute_environment: LOCAL_MACHINE
debug: true
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
You need to save the mentioned configuration as an `accelerate_config.yaml` file. Then, you need to input the path of your `accelerate_config.yaml` file into the `ACCELERATE_CONFIG_FILE` parameter. This way you can use DeepSpeed to train your SDXL model in LoRA. Additionally, you can use DeepSpeed to train other SD models in this way.
```shell
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
export ACCELERATE_CONFIG_FILE="your accelerate_config.yaml"
accelerate launch --config_file $ACCELERATE_CONFIG_FILE train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 \
--train_batch_size=1 \
--num_train_epochs=2 \
--checkpointing_steps=2 \
--learning_rate=1e-04 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--mixed_precision="fp16" \
--max_train_steps=20 \
--validation_epochs=20 \
--seed=1234 \
--output_dir="sd-pokemon-model-lora-sdxl" \
--validation_prompt="cute dragon creature"
```
### Finetuning the text encoder and UNet
The script also allows you to finetune the `text_encoder` along with the `unet`.
🚨 Training the text encoder requires additional memory.
Pass the `--train_text_encoder` argument to the training script to enable finetuning the `text_encoder` and `unet`:
```bash
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl-txt" \
--train_text_encoder \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
### Inference
Once you have trained a model using above command, the inference can be done simply using the `DiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora-sdxl`.
```python
from diffusers import DiffusionPipeline
import torch
model_path = "takuoko/sd-pokemon-model-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16)
pipe.to("cuda")
pipe.load_lora_weights(model_path)
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
| diffusers/examples/text_to_image/README_sdxl.md/0 | {
"file_path": "diffusers/examples/text_to_image/README_sdxl.md",
"repo_id": "diffusers",
"token_count": 4086
} | 112 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Conversion script for the LDM checkpoints. """
import argparse
import json
import os
import torch
from transformers.file_utils import has_file
from diffusers import UNet2DConditionModel, UNet2DModel
do_only_config = False
do_only_weights = True
do_only_renaming = False
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--repo_path",
default=None,
type=str,
required=True,
help="The config json file corresponding to the architecture.",
)
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
args = parser.parse_args()
config_parameters_to_change = {
"image_size": "sample_size",
"num_res_blocks": "layers_per_block",
"block_channels": "block_out_channels",
"down_blocks": "down_block_types",
"up_blocks": "up_block_types",
"downscale_freq_shift": "freq_shift",
"resnet_num_groups": "norm_num_groups",
"resnet_act_fn": "act_fn",
"resnet_eps": "norm_eps",
"num_head_channels": "attention_head_dim",
}
key_parameters_to_change = {
"time_steps": "time_proj",
"mid": "mid_block",
"downsample_blocks": "down_blocks",
"upsample_blocks": "up_blocks",
}
subfolder = "" if has_file(args.repo_path, "config.json") else "unet"
with open(os.path.join(args.repo_path, subfolder, "config.json"), "r", encoding="utf-8") as reader:
text = reader.read()
config = json.loads(text)
if do_only_config:
for key in config_parameters_to_change.keys():
config.pop(key, None)
if has_file(args.repo_path, "config.json"):
model = UNet2DModel(**config)
else:
class_name = UNet2DConditionModel if "ldm-text2im-large-256" in args.repo_path else UNet2DModel
model = class_name(**config)
if do_only_config:
model.save_config(os.path.join(args.repo_path, subfolder))
config = dict(model.config)
if do_only_renaming:
for key, value in config_parameters_to_change.items():
if key in config:
config[value] = config[key]
del config[key]
config["down_block_types"] = [k.replace("UNetRes", "") for k in config["down_block_types"]]
config["up_block_types"] = [k.replace("UNetRes", "") for k in config["up_block_types"]]
if do_only_weights:
state_dict = torch.load(os.path.join(args.repo_path, subfolder, "diffusion_pytorch_model.bin"))
new_state_dict = {}
for param_key, param_value in state_dict.items():
if param_key.endswith(".op.bias") or param_key.endswith(".op.weight"):
continue
has_changed = False
for key, new_key in key_parameters_to_change.items():
if not has_changed and param_key.split(".")[0] == key:
new_state_dict[".".join([new_key] + param_key.split(".")[1:])] = param_value
has_changed = True
if not has_changed:
new_state_dict[param_key] = param_value
model.load_state_dict(new_state_dict)
model.save_pretrained(os.path.join(args.repo_path, subfolder))
| diffusers/scripts/change_naming_configs_and_checkpoints.py/0 | {
"file_path": "diffusers/scripts/change_naming_configs_and_checkpoints.py",
"repo_id": "diffusers",
"token_count": 1631
} | 113 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Conversion script for the LDM checkpoints. """
import argparse
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
from diffusers import DDIMScheduler, I2VGenXLPipeline, I2VGenXLUNet, StableDiffusionPipeline
CLIP_ID = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
def assign_to_checkpoint(
paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
):
"""
This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
attention layers, and takes into account additional replacements that may arise.
Assigns the weights to the new checkpoint.
"""
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
# Splits the attention layers into three variables.
if attention_paths_to_split is not None:
for path, path_map in attention_paths_to_split.items():
old_tensor = old_checkpoint[path]
channels = old_tensor.shape[0] // 3
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
query, key, value = old_tensor.split(channels // num_heads, dim=1)
checkpoint[path_map["query"]] = query.reshape(target_shape)
checkpoint[path_map["key"]] = key.reshape(target_shape)
checkpoint[path_map["value"]] = value.reshape(target_shape)
for path in paths:
new_path = path["new"]
# These have already been assigned
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
continue
if additional_replacements is not None:
for replacement in additional_replacements:
new_path = new_path.replace(replacement["old"], replacement["new"])
# proj_attn.weight has to be converted from conv 1D to linear
weight = old_checkpoint[path["old"]]
names = ["proj_attn.weight"]
names_2 = ["proj_out.weight", "proj_in.weight"]
if any(k in new_path for k in names):
checkpoint[new_path] = weight[:, :, 0]
elif any(k in new_path for k in names_2) and len(weight.shape) > 2 and ".attentions." not in new_path:
checkpoint[new_path] = weight[:, :, 0]
else:
checkpoint[new_path] = weight
def renew_attention_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside attentions to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
mapping.append({"old": old_item, "new": new_item})
return mapping
def shave_segments(path, n_shave_prefix_segments=1):
"""
Removes segments. Positive values shave the first segments, negative shave the last segments.
"""
if n_shave_prefix_segments >= 0:
return ".".join(path.split(".")[n_shave_prefix_segments:])
else:
return ".".join(path.split(".")[:n_shave_prefix_segments])
def renew_temp_conv_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
mapping.append({"old": old_item, "new": old_item})
return mapping
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item.replace("in_layers.0", "norm1")
new_item = new_item.replace("in_layers.2", "conv1")
new_item = new_item.replace("out_layers.0", "norm2")
new_item = new_item.replace("out_layers.3", "conv2")
new_item = new_item.replace("emb_layers.1", "time_emb_proj")
new_item = new_item.replace("skip_connection", "conv_shortcut")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
if "temopral_conv" not in old_item:
mapping.append({"old": old_item, "new": new_item})
return mapping
def convert_ldm_unet_checkpoint(checkpoint, config, path=None, extract_ema=False):
"""
Takes a state dict and a config, and returns a converted checkpoint.
"""
# extract state_dict for UNet
unet_state_dict = {}
keys = list(checkpoint.keys())
unet_key = "model.diffusion_model."
# at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
print(f"Checkpoint {path} has both EMA and non-EMA weights.")
print(
"In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
" weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
)
for key in keys:
if key.startswith("model.diffusion_model"):
flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
else:
if sum(k.startswith("model_ema") for k in keys) > 100:
print(
"In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
" weights (usually better for inference), please make sure to add the `--extract_ema` flag."
)
for key in keys:
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
additional_embedding_substrings = [
"local_image_concat",
"context_embedding",
"local_image_embedding",
"fps_embedding",
]
for k in unet_state_dict:
if any(substring in k for substring in additional_embedding_substrings):
diffusers_key = k.replace("local_image_concat", "image_latents_proj_in").replace(
"local_image_embedding", "image_latents_context_embedding"
)
new_checkpoint[diffusers_key] = unet_state_dict[k]
# temporal encoder.
new_checkpoint["image_latents_temporal_encoder.norm1.weight"] = unet_state_dict[
"local_temporal_encoder.layers.0.0.norm.weight"
]
new_checkpoint["image_latents_temporal_encoder.norm1.bias"] = unet_state_dict[
"local_temporal_encoder.layers.0.0.norm.bias"
]
# attention
qkv = unet_state_dict["local_temporal_encoder.layers.0.0.fn.to_qkv.weight"]
q, k, v = torch.chunk(qkv, 3, dim=0)
new_checkpoint["image_latents_temporal_encoder.attn1.to_q.weight"] = q
new_checkpoint["image_latents_temporal_encoder.attn1.to_k.weight"] = k
new_checkpoint["image_latents_temporal_encoder.attn1.to_v.weight"] = v
new_checkpoint["image_latents_temporal_encoder.attn1.to_out.0.weight"] = unet_state_dict[
"local_temporal_encoder.layers.0.0.fn.to_out.0.weight"
]
new_checkpoint["image_latents_temporal_encoder.attn1.to_out.0.bias"] = unet_state_dict[
"local_temporal_encoder.layers.0.0.fn.to_out.0.bias"
]
# feedforward
new_checkpoint["image_latents_temporal_encoder.ff.net.0.proj.weight"] = unet_state_dict[
"local_temporal_encoder.layers.0.1.net.0.0.weight"
]
new_checkpoint["image_latents_temporal_encoder.ff.net.0.proj.bias"] = unet_state_dict[
"local_temporal_encoder.layers.0.1.net.0.0.bias"
]
new_checkpoint["image_latents_temporal_encoder.ff.net.2.weight"] = unet_state_dict[
"local_temporal_encoder.layers.0.1.net.2.weight"
]
new_checkpoint["image_latents_temporal_encoder.ff.net.2.bias"] = unet_state_dict[
"local_temporal_encoder.layers.0.1.net.2.bias"
]
if "class_embed_type" in config:
if config["class_embed_type"] is None:
# No parameters to port
...
elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
else:
raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
first_temp_attention = [v for v in unet_state_dict if v.startswith("input_blocks.0.1")]
paths = renew_attention_paths(first_temp_attention)
meta_path = {"old": "input_blocks.0.1", "new": "transformer_in"}
assign_to_checkpoint(paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config)
new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
# Retrieves the keys for the input blocks only
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
input_blocks = {
layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Retrieves the keys for the middle blocks only
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
middle_blocks = {
layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
# Retrieves the keys for the output blocks only
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
output_blocks = {
layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
for layer_id in range(num_output_blocks)
}
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
temp_attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.2" in key]
if f"input_blocks.{i}.op.weight" in unet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.op.bias"
)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
temporal_convs = [key for key in resnets if "temopral_conv" in key]
paths = renew_temp_conv_paths(temporal_convs)
meta_path = {
"old": f"input_blocks.{i}.0.temopral_conv",
"new": f"down_blocks.{block_id}.temp_convs.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(temp_attentions):
paths = renew_attention_paths(temp_attentions)
meta_path = {
"old": f"input_blocks.{i}.2",
"new": f"down_blocks.{block_id}.temp_attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
resnet_0 = middle_blocks[0]
temporal_convs_0 = [key for key in resnet_0 if "temopral_conv" in key]
attentions = middle_blocks[1]
temp_attentions = middle_blocks[2]
resnet_1 = middle_blocks[3]
temporal_convs_1 = [key for key in resnet_1 if "temopral_conv" in key]
resnet_0_paths = renew_resnet_paths(resnet_0)
meta_path = {"old": "middle_block.0", "new": "mid_block.resnets.0"}
assign_to_checkpoint(
resnet_0_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
temp_conv_0_paths = renew_temp_conv_paths(temporal_convs_0)
meta_path = {"old": "middle_block.0.temopral_conv", "new": "mid_block.temp_convs.0"}
assign_to_checkpoint(
temp_conv_0_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
resnet_1_paths = renew_resnet_paths(resnet_1)
meta_path = {"old": "middle_block.3", "new": "mid_block.resnets.1"}
assign_to_checkpoint(
resnet_1_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
temp_conv_1_paths = renew_temp_conv_paths(temporal_convs_1)
meta_path = {"old": "middle_block.3.temopral_conv", "new": "mid_block.temp_convs.1"}
assign_to_checkpoint(
temp_conv_1_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
)
attentions_paths = renew_attention_paths(attentions)
meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(
attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
temp_attentions_paths = renew_attention_paths(temp_attentions)
meta_path = {"old": "middle_block.2", "new": "mid_block.temp_attentions.0"}
assign_to_checkpoint(
temp_attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
for i in range(num_output_blocks):
block_id = i // (config["layers_per_block"] + 1)
layer_in_block_id = i % (config["layers_per_block"] + 1)
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
output_block_list = {}
for layer in output_block_layers:
layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
if layer_id in output_block_list:
output_block_list[layer_id].append(layer_name)
else:
output_block_list[layer_id] = [layer_name]
if len(output_block_list) > 1:
resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
temp_attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.2" in key]
resnet_0_paths = renew_resnet_paths(resnets)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
temporal_convs = [key for key in resnets if "temopral_conv" in key]
paths = renew_temp_conv_paths(temporal_convs)
meta_path = {
"old": f"output_blocks.{i}.0.temopral_conv",
"new": f"up_blocks.{block_id}.temp_convs.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
if ["conv.bias", "conv.weight"] in output_block_list.values():
index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.bias"
]
# Clear attentions as they have been attributed above.
if len(attentions) == 2:
attentions = []
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {
"old": f"output_blocks.{i}.1",
"new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(temp_attentions):
paths = renew_attention_paths(temp_attentions)
meta_path = {
"old": f"output_blocks.{i}.2",
"new": f"up_blocks.{block_id}.temp_attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
else:
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
for path in resnet_0_paths:
old_path = ".".join(["output_blocks", str(i), path["old"]])
new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
new_checkpoint[new_path] = unet_state_dict[old_path]
temopral_conv_paths = [l for l in output_block_layers if "temopral_conv" in l]
for path in temopral_conv_paths:
pruned_path = path.split("temopral_conv.")[-1]
old_path = ".".join(["output_blocks", str(i), str(block_id), "temopral_conv", pruned_path])
new_path = ".".join(["up_blocks", str(block_id), "temp_convs", str(layer_in_block_id), pruned_path])
new_checkpoint[new_path] = unet_state_dict[old_path]
return new_checkpoint
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--unet_checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
)
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
parser.add_argument("--push_to_hub", action="store_true")
args = parser.parse_args()
# UNet
unet_checkpoint = torch.load(args.unet_checkpoint_path, map_location="cpu")
unet_checkpoint = unet_checkpoint["state_dict"]
unet = I2VGenXLUNet(sample_size=32)
converted_ckpt = convert_ldm_unet_checkpoint(unet_checkpoint, unet.config)
diff_0 = set(unet.state_dict().keys()) - set(converted_ckpt.keys())
diff_1 = set(converted_ckpt.keys()) - set(unet.state_dict().keys())
assert len(diff_0) == len(diff_1) == 0, "Converted weights don't match"
unet.load_state_dict(converted_ckpt, strict=True)
# vae
temp_pipe = StableDiffusionPipeline.from_single_file(
"https://huggingface.co/ali-vilab/i2vgen-xl/blob/main/models/v2-1_512-ema-pruned.ckpt"
)
vae = temp_pipe.vae
del temp_pipe
# text encoder and tokenizer
text_encoder = CLIPTextModel.from_pretrained(CLIP_ID)
tokenizer = CLIPTokenizer.from_pretrained(CLIP_ID)
# image encoder and feature extractor
image_encoder = CLIPVisionModelWithProjection.from_pretrained(CLIP_ID)
feature_extractor = CLIPImageProcessor.from_pretrained(CLIP_ID)
# scheduler
# https://github.com/ali-vilab/i2vgen-xl/blob/main/configs/i2vgen_xl_train.yaml
scheduler = DDIMScheduler(
beta_schedule="squaredcos_cap_v2",
rescale_betas_zero_snr=True,
set_alpha_to_one=True,
clip_sample=False,
steps_offset=1,
timestep_spacing="leading",
prediction_type="v_prediction",
)
# final
pipeline = I2VGenXLPipeline(
unet=unet,
vae=vae,
image_encoder=image_encoder,
feature_extractor=feature_extractor,
text_encoder=text_encoder,
tokenizer=tokenizer,
scheduler=scheduler,
)
pipeline.save_pretrained(args.dump_path, push_to_hub=args.push_to_hub)
| diffusers/scripts/convert_i2vgen_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_i2vgen_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 9968
} | 114 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Conversion script for the LDM checkpoints. """
import argparse
import importlib
import torch
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
)
# !wget https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml
parser.add_argument(
"--original_config_file",
default=None,
type=str,
help="The YAML config file corresponding to the original architecture.",
)
parser.add_argument(
"--config_files",
default=None,
type=str,
help="The YAML config file corresponding to the architecture.",
)
parser.add_argument(
"--num_in_channels",
default=None,
type=int,
help="The number of input channels. If `None` number of input channels will be automatically inferred.",
)
parser.add_argument(
"--scheduler_type",
default="pndm",
type=str,
help="Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']",
)
parser.add_argument(
"--pipeline_type",
default=None,
type=str,
help=(
"The pipeline type. One of 'FrozenOpenCLIPEmbedder', 'FrozenCLIPEmbedder', 'PaintByExample'"
". If `None` pipeline will be automatically inferred."
),
)
parser.add_argument(
"--image_size",
default=None,
type=int,
help=(
"The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Siffusion v2"
" Base. Use 768 for Stable Diffusion v2."
),
)
parser.add_argument(
"--prediction_type",
default=None,
type=str,
help=(
"The prediction type that the model was trained on. Use 'epsilon' for Stable Diffusion v1.X and Stable"
" Diffusion v2 Base. Use 'v_prediction' for Stable Diffusion v2."
),
)
parser.add_argument(
"--extract_ema",
action="store_true",
help=(
"Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
" or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
" higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
),
)
parser.add_argument(
"--upcast_attention",
action="store_true",
help=(
"Whether the attention computation should always be upcasted. This is necessary when running stable"
" diffusion 2.1."
),
)
parser.add_argument(
"--from_safetensors",
action="store_true",
help="If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.",
)
parser.add_argument(
"--to_safetensors",
action="store_true",
help="Whether to store pipeline in safetensors format or not.",
)
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
parser.add_argument(
"--stable_unclip",
type=str,
default=None,
required=False,
help="Set if this is a stable unCLIP model. One of 'txt2img' or 'img2img'.",
)
parser.add_argument(
"--stable_unclip_prior",
type=str,
default=None,
required=False,
help="Set if this is a stable unCLIP txt2img model. Selects which prior to use. If `--stable_unclip` is set to `txt2img`, the karlo prior (https://huggingface.co/kakaobrain/karlo-v1-alpha/tree/main/prior) is selected by default.",
)
parser.add_argument(
"--clip_stats_path",
type=str,
help="Path to the clip stats file. Only required if the stable unclip model's config specifies `model.params.noise_aug_config.params.clip_stats_path`.",
required=False,
)
parser.add_argument(
"--controlnet", action="store_true", default=None, help="Set flag if this is a controlnet checkpoint."
)
parser.add_argument("--half", action="store_true", help="Save weights in half precision.")
parser.add_argument(
"--vae_path",
type=str,
default=None,
required=False,
help="Set to a path, hub id to an already converted vae to not convert it again.",
)
parser.add_argument(
"--pipeline_class_name",
type=str,
default=None,
required=False,
help="Specify the pipeline class name",
)
args = parser.parse_args()
if args.pipeline_class_name is not None:
library = importlib.import_module("diffusers")
class_obj = getattr(library, args.pipeline_class_name)
pipeline_class = class_obj
else:
pipeline_class = None
pipe = download_from_original_stable_diffusion_ckpt(
checkpoint_path_or_dict=args.checkpoint_path,
original_config_file=args.original_config_file,
config_files=args.config_files,
image_size=args.image_size,
prediction_type=args.prediction_type,
model_type=args.pipeline_type,
extract_ema=args.extract_ema,
scheduler_type=args.scheduler_type,
num_in_channels=args.num_in_channels,
upcast_attention=args.upcast_attention,
from_safetensors=args.from_safetensors,
device=args.device,
stable_unclip=args.stable_unclip,
stable_unclip_prior=args.stable_unclip_prior,
clip_stats_path=args.clip_stats_path,
controlnet=args.controlnet,
vae_path=args.vae_path,
pipeline_class=pipeline_class,
)
if args.half:
pipe.to(torch_dtype=torch.float16)
if args.controlnet:
# only save the controlnet model
pipe.controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
else:
pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
| diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 2893
} | 115 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.