
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 22,578 | closed | 🌐 [i18n-KO] Translated `tutorial/proprecssing.mdx` to Korean | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Translated ~partially~ the documentation `tutorial/proprecessing.mdx` to Korean.
- [x] Proprecessing 전처리
- [x] Natural Language Processing 자연어처리
- [x] Pad 패딩
- [x] Trancation 생략
- [x] Build Tensor 텐서 만들기
- [x] Audio 오디오
- [x] Computer Vision 컴퓨터 비전
- [x] Pad 패딩
- [x] Multimodal 멀티모달
Thank you in advance for your review!
Part of #20179
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Team PsedoLab, could you review this PR?
@wonhyeongseo @0525hhgus @kihoon71 @gabrielwithappy, @HanNayeoniee, @jungnerd
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-05-2023 03:29:48 | 04-05-2023 03:29:48 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sim-so keep it up 👍 :-)
<|||||>Some updates!
- Newly translated two parts of this documentation: `Build Tensors` and `Audio`
- Revised the sentence with the feedback as below:
`토크나이저가 두 개의 특수한 토큰(분류 토큰 CLS와 구분 토큰 SEP)을 문장에 추가했습니다.`
- Translated and revised all `feature extractor` to `특징 추출기` based on TTA.
I am going to finish it by this Sunday. Thank you all in advance! :smile:<|||||>I translated all of this document.
Thank you in advance for your review! 😉 <|||||>다른 문서들을 참고하여 일부 단어의 번역어를 모두 변경했습니다.
- argument -> 인수
- feature extractor -> 특성 추출기
- method -> 메소드
- separator([SEP]) -> 분할 토큰<|||||>Could you review this PR?
@sgugger, @ArthurZucker, @eunseojo |
transformers | 22,577 | open | BeitFeatureExtractor no longer works with grayscale images "unsupported number of image dimensions" | ### System Info
```
Python 3.7.13 (default, Mar 29 2022, 02:18:16)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import transformers
>>> transformers.__version__
'4.27.4'
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I recently had to update my transformers version due to a cross dependency issue and my image preprocesssing code stopped working.
```
from PIL import Image
from transformers import BeitFeatureExtractor
pil_image = Image.open('sample_rgb_image.png').convert('L') #RGB image and convert to grayscale
image_feature_extractor = BeitFeatureExtractor.from_pretrained('/opt/ml/configs/beit-config.json')
pixel_input_ids = image_feature_extractor(pil_image, return_tensors="pt")['pixel_values']
```
Produces this error:
```
/opt/conda/lib/python3.7/site-packages/transformers/models/beit/feature_extraction_beit.py:31: FutureWarning: The class BeitFeatureExtractor is deprecated and will be removed in version 5 of Transformers. Please use BeitImageProcessor instead.
FutureWarning,
Traceback (most recent call last):
File "test_beit.py", line 8, in <module>
pixel_input_ids = image_feature_extractor(pil_image, return_tensors="pt")['pixel_values']
File "/opt/conda/lib/python3.7/site-packages/transformers/models/beit/image_processing_beit.py", line 359, in __call__
return super().__call__(images, segmentation_maps=segmentation_maps, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/image_processing_utils.py", line 458, in __call__
return self.preprocess(images, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/beit/image_processing_beit.py", line 481, in preprocess
for img in images
File "/opt/conda/lib/python3.7/site-packages/transformers/models/beit/image_processing_beit.py", line 481, in <listcomp>
for img in images
File "/opt/conda/lib/python3.7/site-packages/transformers/models/beit/image_processing_beit.py", line 314, in _preprocess_image
image_std=image_std,
File "/opt/conda/lib/python3.7/site-packages/transformers/models/beit/image_processing_beit.py", line 271, in _preprocess
image = self.resize(image=image, size=size, resample=resample)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/beit/image_processing_beit.py", line 176, in resize
image, size=(size["height"], size["width"]), resample=resample, data_format=data_format, **kwargs
File "/opt/conda/lib/python3.7/site-packages/transformers/image_transforms.py", line 290, in resize
data_format = infer_channel_dimension_format(image) if data_format is None else data_format
File "/opt/conda/lib/python3.7/site-packages/transformers/image_utils.py", line 159, in infer_channel_dimension_format
raise ValueError(f"Unsupported number of image dimensions: {image.ndim}")
ValueError: Unsupported number of image dimensions: 2
```
### Expected behavior
In the past I was always able to give a grayscale PIL image as input to feature extractor. Is this input type no longer supported? | 04-05-2023 02:54:26 | 04-05-2023 02:54:26 | cc @amyeroberts <|||||>Hi @grantdelozier, thanks for reporting this.
Unfortunately for some of the image transformations, grayscale images aren't currently compatible. Handling the different input formats in a more robust way is something I'm currently working on. Having these issues reported is really useful to know how to prioritise and which test cases that should pass.
At the moment, grayscale images / masks are handled in a bit of a hacky way by adding an axis e.g. [here in mask2former](https://github.com/huggingface/transformers/blob/48706c7178127e7bcd6cccd90d941801e071a4a2/src/transformers/models/mask2former/image_processing_mask2former.py#L611).
To understand the previous behaviour, could you share the feature extractor config and version of transformers which was working? The reason I ask is that when testing on commit `83e5a1060` - which added the BeiT model, the feature extractor also failed with a grayscale image input. <|||||>Hi Amy,
First, thanks for all the awesome work in the transformers project!
My last known version transformers where grayscale worked is `transformers==4.24`
Here is my beit config:
```
{
"architectures": [
"BeitForMaskedImageModeling"
],
"attention_probs_dropout_prob": 0.0,
"drop_path_rate": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"image_size": [512, 512],
"size": [512, 512],
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"layer_scale_init_value": 0.1,
"model_type": "beit",
"num_attention_heads": 12,
"num_channels": 1,
"num_hidden_layers": 12,
"patch_size": 16,
"semantic_loss_ignore_index": 255,
"torch_dtype": "float32",
"use_absolute_position_embeddings": true,
"use_auxiliary_head": true,
"use_mask_token": true,
"use_mean_pooling": true,
"use_relative_position_bias": true,
"use_shared_relative_position_bias": false,
"do_center_crop": false,
"vocab_size": 8192,
"image_mean": [0.5],
"image_std": [0.5]
}
```
<|||||>@grantdelozier Thanks for sharing the config :) I'll use this as reference grayscale config to make sure everything works as expected in the fixes for accepting grayscale images. <|||||>Just ran into this issue today as well, with both `ViTFeatureExtractor` and `MobileViTFeatureExtractor` (but I believe this is an issue with the base class anyway).
@amyeroberts Is there a problem with just expanding the dimensions of the image after converting to a numpy array / tensor?
e.g.,:
```bash
>>> example['image']
<PIL.PngImagePlugin.PngImageFile image mode=L size=28x28 at 0x7F0480FA54B0>
>>> feature_extractor(example['image'], return_tensors='pt')
...
ValueError: Unsupported number of image dimensions: 2
>>> feature_extractor(np.expand_dims(np.array(example['image']), 0), return_tensors='pt')
{'pixel_values': tensor([[[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]]])}
``` |
transformers | 22,576 | closed | Generate: `TextIteratorStreamer` timeout | # What does this PR do?
Learning the hard way: exception in a thread that feeds an iterator = iterator hangs forever.
This PR adds a timeout to the queue so that we can protect ourselves from hanging streaming generation. | 04-04-2023 20:48:59 | 04-04-2023 20:48:59 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,575 | closed | Add GPTBigCode model (Optimized GPT2 with MQA from Santacoder & BigCode) | The GPTBigcode model from BigCode. It is the same model as GPT2, with:
* Added support for Multi-Query Attention (https://arxiv.org/abs/1911.02150)
* A large number of optimizations, mostly targeting inference but also useful in training.
Other than MQA, it's the same model as GPT2, just a new implementation (though it's not numerically equivalent and the checkpoints are not compatible)
The optimizations (I might be missing some):
* Use `gelu_pytorch_tanh` (see #21344 #21345)
* Avoid unnecessary synchronizations (added to GPT2 in #20061, but wasn't in the original santacoder).
* Use Linear layers instead of Conv1D (good speedup but makes the checkpoints incompatible).
* Merge `_attn` and `_upcast_and_reordered_attn`. Always merge the matmul with scaling. Rename `reorder_and_upcast_attn`->`attention_softmax_in_fp32`
* Rename `scale_attn_by_inverse_layer_idx`-> `scale_attention_softmax_in_fp32` and change its behavior to match Megatron-LM (divide by layer_idx in fp16, then multiply in fp32).
* Cache the attention mask value to avoid recreating it every time.
* Use jit to fuse the attention fp32 casting, masking, softmax, and scaling.
* Combine the attention and causal masks into a single one, pre-computed for the whole model instead of every layer.
* Merge the key and value caches into one (this changes the format of `layer_past`/ `present`, does it risk creating problems?)
* Use the memory layout (self.num_heads, 3, self.head_dim) instead of (3, self.num_heads, self.head_dim) for the QKV tensor with MHA. (prevents an overhead with the merged key and values, but makes the checkpoints incompatible).
Excluded from this PR (optional/opt-in features, could be added later):
* CPU optimization for inference, aka InferenceRunner (huge speedup for generation with pre-allocated tensors, pre-computed views and support; faster than Deepspeed, but too experimental to add now)
* KV cache pre-allocation and padding. (Same reason)
* MQA with separate Q and KV (MQA2 in bigcode, a bit faster for training , slower for inference)
* FlashAttention (planning to add support in near future)
* Conversion script for Megatron weights (the MQA part needs the BigCode fork of Megatron)
TODO:
* Update/fix the tests
* Update the docs (should be mostly ok by now)
* Address the remaining circleci issues (mostly related to the tests) | 04-04-2023 20:31:48 | 04-04-2023 20:31:48 | @lvwerra @harm-devries
(Replaces #21253)<|||||>Code on the Hub is fine too and we are adding better support for it every day :-)<|||||>Hi @sgugger, the next generation of the model will also support this architecture so there should also be significantly more usage. Discussed this also with @LysandreJik previously, what do you think?<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>If you prefer @lvwerra and if the architecture is frozen: we won't be able to accommodate changes after it's merged and released in Transformers (no breaking changes in Transformers), whereas it's easier to quickly experiment with code on the Hub. If you feel the model is mature enough and it's time, I'm not opposed :-)<|||||>Thanks a lot for your feedback! Just addressed them all,
Small note that the cpu/disk offload seem to not work on the testing suite, but I think it is related to the corner case issues we faced with tiny T5 models, as the test pass for the `GPTBigCodModelTest` but does not pass for the `GPTBigCodeMQAModelTest`.
I will also make sure doctests pass before merging<|||||>Please wait a bit before merging, I'll do a final check for the latest changes<|||||>I did a few minor tweaks, I'm OK for merging if it works for everyone. (Assuming CI passes)<|||||>any updates on supporting flash attention ? or do we have a different PR to track it<|||||>cc @younesbelkada I think this is supported in [BetterTransformers](https://huggingface.co/docs/optimum/bettertransformer/tutorials/convert) no? <|||||>Indeed this should go into `BetterTransformer` API on optimum library: https://github.com/huggingface/optimum
Once the feature is added there, you can just call `model.to_bettertransformer()` and benefit from flash-attention backend. @bharadwajymg would you mind opening a ticket there and request for BetterTransformer support for GPTBigCode model ? thanks! |
transformers | 22,574 | closed | aml vision benchmark | aml vision benchmark | 04-04-2023 19:55:05 | 04-04-2023 19:55:05 | Thanks for your PR, but we are not interested in this modification of this example.<|||||>The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22574). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,573 | closed | Convert T5x "Scalable T5" models to PyTorch | ### Feature request
Google T5X library has a new model architecture called "scalable_t5" based on T5, the main difference is that it supports giant model training.
It supports Jax Scan and Rematerialization / Checkpointing, allowing it to load and train giant models on TPU or GPU.
Links:
https://github.com/google-research/t5x/tree/main/t5x/examples/scalable_t5
It has the same architecture as T5, but the checkpoints are stored differently, rather than storing each layer in a separate folder. It stores all layers for the encoder or the decoder in a single folder.
This makes the current T5 convertors doesn't work.
### Motivation
Training large models like PaLM on TPU pods requires this specific architecture. Unfortunately, trained models using this architecture are not yet convertible to hugging face. This means the community can't use such models at Hugging Face.
Pinging:
@patrickvonplaten
@stefan-it
@bastings
@ArthurZucker
### Your contribution
None | 04-04-2023 17:12:23 | 04-04-2023 17:12:23 | Hi @agemagician ,
thanks for pinging! Could you confirm that the new umT5 checkpoints have this new scalable format:
https://console.cloud.google.com/storage/browser/t5-data/pretrained_models/t5x/umt5_small/checkpoint_1000000?pageState=(%22StorageObjectListTable%22:(%22f%22:%22%255B%255D%22))&prefix=&forceOnObjectsSortingFiltering=false
(Yeah, they put the wrong link in the [overview table](https://github.com/google-research/t5x/blob/main/docs/models.md#umt5-checkpoints) for umT5, I will also prepare a PR fixing that...)<|||||>Update:
I wrote the umT5X conversion script - and it conversion seems to work.
Here's the initial draft:
https://gist.github.com/stefan-it/5d6a4ec89e7ad97181983881434cb4eb
@agemagician Could you please check if it's working with your checkpoints?
I placed that file in `/home/stefan/Repositories/transformers/src/transformers/models/t5`.
And installed latest `t5x` version (Git main branch) and latest `jaxlib`.
I tried it with umT5 Small checkpoints:
```bash
gsutil -o GSUtil:parallel_composite_upload_threshold=150M -m cp -r gs://t5-data/pretrained_models/t5x/umt5_small/checkpoint_1000000 .
```
Then you can call the script with:
```bash
python3 convert_umt5x_checkpoint_to_flax.py --config_name google/mt5-small --t5x_checkpoint_path ~/Dokumente/umt5/checkpoint_1000000 --flax_dump_folder_path ./exported
```
-> It's important that the `config_name` matches architecture size of the checkpoint.
Caveats: I will of course do some downstream tasks experiments to see if conversion works. If @agemagician has a working evaluation pipeline it would be great to hear some feedback of the performance! I will work on the conversion script later - need some sleep now.<|||||>Hi @stefan-it ,
Thanks a lot for your quick reply.
I have created a small random model based on the new scalable architecture like umT5X to check the conversion script, which was converted successfully.
However, I debugged the code to make sure it was converted correctly, and I think it was converted incorrectly.
I created a small model based on this configuration:
```
{
"_name_or_path": "./",
"architectures": [
"T5ForConditionalGeneration"
],
"d_ff": 16,
"d_kv": 6,
"d_model": 8,
"decoder_start_token_id": 0,
"dense_act_fn": "silu",
"dropout_rate": 0.0,
"eos_token_id": 1,
"feed_forward_proj": "gated-silu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"is_gated_act": true,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"num_decoder_layers": 3,
"num_heads": 4,
"num_layers": 3,
"output_past": true,
"pad_token_id": 0,
"relative_attention_max_distance": 128,
"relative_attention_num_buckets": 64,
"tie_word_embeddings": false,
"torch_dtype": "float32",
"transformers_version": "4.26.0",
"use_cache": true,
"vocab_size": 256
}
```
I also checked the gin file to make sure it is similar :
```
network.T5Config.dropout_rate = %DROPOUT_RATE
network.T5Config.dtype = 'bfloat16'
network.T5Config.emb_dim = 8
network.T5Config.head_dim = 6
network.T5Config.logits_via_embedding = False
network.T5Config.mlp_activations = ('silu', 'linear')
network.T5Config.mlp_dim = 16
network.T5Config.num_decoder_layers = 3
network.T5Config.num_encoder_layers = 3
network.T5Config.num_heads = 4
network.T5Config.remat_policy = 'minimal'
network.T5Config.scan_layers = True
network.T5Config.vocab_size = 256
```
Then I added the following print statement to check the dimensions :
```
config = T5Config.from_pretrained(config_name)
flax_model = FlaxT5ForConditionalGeneration(config=config)
t5x_model = checkpoints.load_t5x_checkpoint(t5x_checkpoint_path)
print(config.num_layers)
print(len(t5x_model["target"]["encoder"]["encoder"]["attention"]["key"]["kernel"]))
print(t5x_model["target"]["encoder"]["encoder"]["attention"]["key"]["kernel"][0].shape)
print(flax_model.params["encoder"]["block"][str(0)]["layer"]["0"]["SelfAttention"]["k"][
"kernel"
].shape)
```
The output is:
```
3
8
(3, 4, 6)
(8, 24)
```
As you can see, the current conversion tries to copy three layers while the checkpoint shows 8.
Also, you can see the dimension of the selected layer doesn't match (3, 4, 6) vs (8, 24).
It seems the new checkpoints are stored based on the following order:
1. emb_dim - > num_layers -> num_heads -> head_dim
So, I think we either need to copy a slice during every iteration or rearrange the parameters.
I think we should also have an assert check to make sure both destination and original parameters have the same size.
<|||||>To make it easy for you to debug it, I have created a repo contains this small model which should accelerate testing and debugging :
[agemagician/scalable_t5x_tiny_test](https://huggingface.co/agemagician/scalable_t5x_tiny_test/tree/main)<|||||>Ah, yeah length/shape checks would be the next thing that I would have tried! Many thanks for your feedback, I will work on it today! Also thanks for uploading your checkpoints!!<|||||>Great, I will wait for your updated version.
Maybe at the end, we could meet and celebrate since we both live in Munich 😉 <|||||>Hey @agemagician ,
yeah really good idea :hugs:
I read through the code and compared the "normal" t5x `layer.py` vs. scaled t5x `layer.py`.
As you already noticed in the (4, 6) vs (24) notation: old t5x used a `joined_kv`, whereas scaled t5 uses `heads` and `kv` in separate variables. This joining stuff is also "explained" in the [readme](https://github.com/google-research/t5x/blob/main/docs/usage/partitioning.md#canonical-logical-axis-names) - markdown in that table is broken, here's a better overview:
```bash
For "heads * kv" fused dimension of attention matrices,
when the kernel is reshaped such that "heads" and "kv"
are packed in the same dimension.
```
So I will try to reshape it to get a `joined_kv`!
**Update**: yes! Transposing and reshaping yields the correct shape now!!<|||||>Hi @agemagician ,
I updated the gist: https://gist.github.com/stefan-it/5d6a4ec89e7ad97181983881434cb4eb
Conversion script has now a shape check (it compares the shape of the init. FLAX model with the shape of read T5X checkpoint model).
I will do some more tests after I got some sleep -> hopefully on downstream tasks to test the performance.
Please also test the new version of the script :hugs: <|||||>Amazing work @stefan-it 👍
I went through the code and tested it, and I believe it should lead to a correct conversion.
It was a smart idea to use transpose to correct the order and then reshape. The only drawback is that we have to store 0.5x additional memory of the model, either encoder or decoder, during the weights copying process. So, this might be a bit problematic with very large models. However, given this is readable code, I think we should stick with it :)
Yes, I agree that the next step should be a downstream task test, before merge this script to HF.<|||||>I think we should definitely support this is the t5x -> pytorch conversion script! Maybe @ArthurZucker here as well <|||||>Great, thanks a lot @patrickvonplaten for joining forces 😄
@stefan-it , I have created a small Colab example to test the model output vs mt5, which should give somehow a similar output:
https://colab.research.google.com/drive/1QrqxNdIK7ugQ3FC8tqxUqZZwP0zdvYE4?usp=sharing
However, the output from the umt5 model is garbage compared to mt5 for the following input:
`"Wikipedia is a <extra_id_0>"`
umt5:
`<pad>xictoarelor nhaulated辙ktör betroffen syntet Undesagrado硼颤oplasm betroffen nhau痍剖 المختلفةrieks`
mt5:
`<pad> <extra_id_0> political encyclopedia</s>`
I have checked the paper in case there is something different, and indeed, there is a difference in the architecture:
```
C ADDITIONAL TRAINING DETAILS
The model architectures used in this study are the same as mT5 models, except that relative position embeddings are not shared across layers. In all of our models, the vocabulary size is 256,000
subwords, and byte-level fallback is enabled, so unknown tokens are broken down into UTF-8 bytes.
We use the T5X library (Roberts et al., 2022) to train the models using Google Cloud TPUs. For
pretraining, we use Adafactor optimizer (Shazeer & Stern, 2018) with a constant learning rate of
0.01 in the first 10,000 steps and inverse square root decay afterwards. For finetuning, we use
Adafactor with a constant learning rate of 5e−5. Unlike mT5, we do not use loss normalization
factor. Instead we use the number of real target tokens as the effective loss normalization.
Finally, we do not factorize the second moment of the Adafactor states and we also use momentum,
neither of which are used in T5 and mT5 studies.
```
So we can't simply use the current HF mt5 model architecture as it is.
@patrickvonplaten, any thoughts on how not to share relative position embeddings across layers on mt5 model script ?<|||||>Many thanks for that Notebook! Make things a bit easier - I've also converted the model to PyTorch incl. vocab and uploaded it on the hub:
https://huggingface.co/stefan-it/umt5-small/tree/main
I noticed one difference - I think it was in `t5x_model["target"]["decoder"]["decoder"]["relpos_bias"]["rel_embedding"]` and yeah... it corresponds to the relative position embeddings, oh no!<|||||>Looking more into "network.py" for both t5 and scalable_t5, I found it is true what is mentioned in the paper.
On t5, they define the relative embedding once, then they call it on each encoder layer:
https://github.com/google-research/t5x/blob/main/t5x/examples/t5/network.py#L56
On scalable_t5, they define the relative embedding on each encoder layer separately:
https://github.com/google-research/t5x/blob/main/t5x/examples/scalable_t5/network.py#L64
The same goes for the decoder.
So the current implementation of mt5 at huggingface can't work directly with the new umt5 because at mt5 we only have a single shared relative bias, while on umt5 we have a separate relative bias for each layer.<|||||>Yeah, this architecture breaking change is really annoying! It means a lot of copying of code from T5 I guess...<|||||>But this issue is a good pointer where to perform some modifications (in a new umT5 model implementation):
https://github.com/huggingface/transformers/issues/13397<|||||>> But this issue is a good pointer where to perform some modifications (in a new umT5 model implementation):
>
> #13397
yes, I am already working on a solution for that :)
I will make a PR today that allows umt5 to work with separate relative bias using mt5 code base without the need of a new model.<|||||>I have made the pull request :
https://github.com/huggingface/transformers/pull/22613
All we need is to set the following parameter in the config :
share_relative_attention_bias = False<|||||>Hi @agemagician ,
do you see the `relative_attention_bias` in all layers? I'm using the PR and it shows:
```
T5Config {
"_name_or_path": "./",
"architectures": [
"T5ForConditionalGeneration"
],
"d_ff": 1024,
"d_kv": 64,
"d_model": 512,
"decoder_start_token_id": 0,
"dense_act_fn": "gelu_new",
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "gated-gelu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"is_gated_act": true,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"num_decoder_layers": 8,
"num_heads": 6,
"num_layers": 8,
"pad_token_id": 0,
"relative_attention_max_distance": 128,
"relative_attention_num_buckets": 32,
"share_relative_attention_bias": false,
"tie_word_embeddings": false,
"tokenizer_class": "T5Tokenizer",
"torch_dtype": "float32",
"transformers_version": "4.28.0.dev0",
"use_cache": true,
"vocab_size": 256384
}
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
Layer: 0
dict_keys(['k', 'o', 'q', 'relative_attention_bias', 'v'])
Layer: 1
dict_keys(['k', 'o', 'q', 'v'])
Layer: 2
dict_keys(['k', 'o', 'q', 'v'])
Layer: 3
dict_keys(['k', 'o', 'q', 'v'])
Layer: 4
dict_keys(['k', 'o', 'q', 'v'])
Layer: 5
dict_keys(['k', 'o', 'q', 'v'])
Layer: 6
dict_keys(['k', 'o', 'q', 'v'])
Layer: 7
dict_keys(['k', 'o', 'q', 'v'])
```<|||||>But it is there when I'm using PyTorch! I can see a difference between `config.share_relative_attention_bias` = `True` or `False`, but not with Flax implementation at the moment!<|||||>> share_relative_attention_bias
hmmm, checking ..<|||||>---- Replied Message ----
| From | Ahmed ***@***.***> |
| Date | 04/06/2023 18:18 |
| To | ***@***.***> |
| Cc | ***@***.***> |
| Subject | Re: [huggingface/transformers] Convert T5x "Scalable T5" models to PyTorch (Issue #22573) |
Great, thanks a lot @patrickvonplaten for joining forces 😄
@stefan-it , I have created a small Colab example to test the model output vs mt5, which should give somehow a similar output:
https://colab.research.google.com/drive/1QrqxNdIK7ugQ3FC8tqxUqZZwP0zdvYE4?usp=sharing
However, the output from the umt5 model is garbage compared to mt5 for the following input:
"Wikipedia is a <extra_id_0>"
umt5:
<pad>xictoarelor nhaulated辙ktör betroffen syntet Undesagrado硼颤oplasm betroffen nhau痍剖 المختلفةrieks
mt5:
<pad> <extra_id_0> political encyclopedia</s>
I have checked the paper in case there is something different and indeed there is a difference in the architecture:
C ADDITIONAL TRAINING DETAILS
The model architectures used in this study are the same as mT5 models, except that relative position embeddings are not shared across layers. In all of our models, the vocabulary size is 256,000
subwords, and byte-level fallback is enabled, so unknown tokens are broken down into UTF-8 bytes.
We use the T5X library (Roberts et al., 2022) to train the models using Google Cloud TPUs. For
pretraining, we use Adafactor optimizer (Shazeer & Stern, 2018) with a constant learning rate of
0.01 in the first 10,000 steps and inverse square root decay afterwards. For finetuning, we use
Adafactor with a constant learning rate of 5e−5. Unlike mT5, we do not use loss normalization
factor. Instead we use the number of real target tokens as the effective loss normalization.
Finally, we do not factorize the second moment of the Adafactor states and we also use momentum,
neither of which are used in T5 and mT5 studies.
So we can't simply use the current HF mt5 model architecture as it is.
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you are subscribed to this thread.Message ID: ***@***.***><|||||>Hmm, so @sgugger asked to create a separate model for that.
I will do it and share a new PR with u.<|||||>@agemagician please let me know if you need some help with that :hugs: <|||||>Closed by #24477 |
transformers | 22,572 | closed | Informer not working on basic example | ### System Info
I am trying minimal example code of Informer specified on HuggingFace website: https://huggingface.co/docs/transformers/model_doc/informer
however I am getting this error while running that:
```
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1536x23 and 22x32)
```
I am using 4.27.4 version of transformers library.
The code from website used:
```
from huggingface_hub import hf_hub_download
import torch
from transformers import InformerModel
file = hf_hub_download(
repo_id="kashif/tourism-monthly-batch", filename="train-batch.pt", repo_type="dataset"
)
batch = torch.load(file)
model = InformerModel.from_pretrained("huggingface/informer-tourism-monthly")
# during training, one provides both past and future values
# as well as possible additional features
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"],
static_real_features=batch["static_real_features"],
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
)
last_hidden_state = outputs.last_hidden_state
```
The full traceback:
```
outputs = model(
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\transformers\models\informer\modeling_informer.py", line 1870, in forward
outputs = self.model(
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\transformers\models\informer\modeling_informer.py", line 1704, in forward
encoder_outputs = self.encoder(
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\transformers\models\informer\modeling_informer.py", line 1178, in forward
hidden_states = self.value_embedding(inputs_embeds)
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\transformers\models\informer\modeling_informer.py", line 305, in forward
return self.value_projection(x)
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\torch\nn\modules\linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1536x23 and 22x32)
```
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from huggingface_hub import hf_hub_download
import torch
from transformers import InformerModel
file = hf_hub_download(
repo_id="kashif/tourism-monthly-batch", filename="train-batch.pt", repo_type="dataset"
)
batch = torch.load(file)
model = InformerModel.from_pretrained("huggingface/informer-tourism-monthly")
# during training, one provides both past and future values
# as well as possible additional features
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"],
static_real_features=batch["static_real_features"],
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
)
last_hidden_state = outputs.last_hidden_state
```
### Expected behavior
no error, `outputs` contains model output | 04-04-2023 17:01:21 | 04-04-2023 17:01:21 | cc @kashif <|||||>thanks @sgugger having a look!<|||||>@SlimakSlimak just to test: the model works if you comment out the `static_real_features` argument to the `model`?
<|||||>Hi, yes that works, thank you!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,571 | closed | seq2seq examples can't handle DataParallel | ### System Info
main
### Who can help?
@sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This was originally reported here: https://github.com/pytorch/pytorch/issues/98102#issuecomment-1496173632
with 2+ gpus:
```
PYTHONPATH=src python examples/pytorch/translation/run_translation.py \
--model_name_or_path t5-base --do_train --do_eval --source_lang en \
--target_lang de --source_prefix 'translate English to German: ' \
--dataset_name stas/wmt14-en-de-pre-processed --output_dir \
/tmp/tst-translation --num_train_epochs 1 --per_device_train_batch_size=1 \
--max_train_samples 10 --overwrite_output_dir --seed 1137 \
--per_device_eval_batch_size 1 --predict_with_generate --fp16 \
--max_eval_samples 10
```
crashes:
```
[INFO|configuration_utils.py:575] 2023-04-04 09:20:48,136 >> Generate config GenerationConfig {
"_from_model_config": true,
"decoder_start_token_id": 0,
"eos_token_id": 1,
"pad_token_id": 0,
"transformers_version": "4.28.0.dev0"
}
Traceback (most recent call last):
File "examples/pytorch/translation/run_translation.py", line 664, in <module>
main()
File "examples/pytorch/translation/run_translation.py", line 605, in main
metrics = trainer.evaluate(max_length=max_length, num_beams=num_beams, metric_key_prefix="eval")
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer_seq2seq.py", line 159, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer.py", line 2990, in evaluate
output = eval_loop(
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer.py", line 3171, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer_seq2seq.py", line 280, in prediction_step
gen_config = model.generation_config
File "/home/stas/anaconda3/envs/py38-pt20/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1614, in __getattr__
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'DataParallel' object has no attribute 'generation_config'
```
Using a workaround `CUDA_VISIBLE_DEVICES=0` overcomes this problem - so we aren't dealing with wrapping properly here.
But then it fails again inside eval:
```
[INFO|trainer.py:3126] 2023-04-04 09:28:07,548 >> ***** Running Evaluation *****
[INFO|trainer.py:3128] 2023-04-04 09:28:07,548 >> Num examples = 10
[INFO|trainer.py:3131] 2023-04-04 09:28:07,548 >> Batch size = 1
[INFO|configuration_utils.py:575] 2023-04-04 09:28:07,552 >> Generate config GenerationConfig {
"_from_model_config": true,
"decoder_start_token_id": 0,
"eos_token_id": 1,
"pad_token_id": 0,
"transformers_version": "4.28.0.dev0"
}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:02<00:00, 3.72it/s]Traceback (most recent call last):
File "examples/pytorch/translation/run_translation.py", line 664, in <module>
main()
File "examples/pytorch/translation/run_translation.py", line 605, in main
metrics = trainer.evaluate(max_length=max_length, num_beams=num_beams, metric_key_prefix="eval")
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer_seq2seq.py", line 159, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer.py", line 2990, in evaluate
output = eval_loop(
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/trainer.py", line 3278, in evaluation_loop
metrics = self.compute_metrics(EvalPrediction(predictions=all_preds, label_ids=all_labels))
File "examples/pytorch/translation/run_translation.py", line 546, in compute_metrics
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/tokenization_utils_base.py", line 3445, in batch_decode
return [
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/tokenization_utils_base.py", line 3446, in <listcomp>
self.decode(
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/tokenization_utils_base.py", line 3485, in decode
return self._decode(
File "/mnt/nvme0/code/huggingface/transformers-master/src/transformers/tokenization_utils_fast.py", line 549, in _decode
text = self._tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
OverflowError: out of range integral type conversion attempted
```
| 04-04-2023 16:32:37 | 04-04-2023 16:32:37 | No, it is a wrapping problem.
@gante The Seq2SeqTrainer might need to do something to use the unwrapped model (which is the `self.model` attribute) instead of the model. I think just changing line 280 to use `self.model.config` instead of `model.config` will be enough.<|||||>and a new test please! Thank you!<|||||>This was caught by the last scheduled test, looking at the reports right now. It's just that Yih-Dar is off so didn't ping anyone on it :-)<|||||>oh, then all is perfect testing-wise!
In the interim perhaps before merging Trainer-related PRs those slow trainer-only tests could be run locally - would require 2 gpus I think.
------------------
and I'd imagine the subsequent crash was not detected by the test and it's not wrapping related it seems. (part 2 of my Issue)<|||||>I split off the 2nd issue into its own Issue https://github.com/huggingface/transformers/issues/22634 as they aren't really related
So closing this one as the first part has been resolved here https://github.com/huggingface/transformers/pull/22584 |
transformers | 22,570 | open | Add MobileViT v2 | ### Model description
[MobileViT](https://openreview.net/forum?id=vh-0sUt8HlG) is a computer vision model that combines CNNs with transformers that has already been added to Transformers.
[MobileViT v2](https://arxiv.org/abs/2206.02680) is the second version; it is constructed by replacing multi-headed self-attention in MobileViT v1 with the proposed separable self-attention.
Does Hugging Face have plan to add MobileViT v2 to Transformers?
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
The official implementation is from Apple at this link: [https://github.com/apple/ml-cvnets](https://github.com/apple/ml-cvnets)
The timm library also implemented it and has pre-trained weights at this link: [https://github.com/huggingface/pytorch-image-models/blob/82cb47bcf360e1974c00c35c2aa9e242e6b5b565/timm/models/mobilevit.py](https://github.com/huggingface/pytorch-image-models/blob/82cb47bcf360e1974c00c35c2aa9e242e6b5b565/timm/models/mobilevit.py)
| 04-04-2023 16:21:37 | 04-04-2023 16:21:37 | Hi @SunHaozhe , I would like to work on implementing this model. |
transformers | 22,569 | closed | AttributeError: 'GPTJModel' object has no attribute 'first_device' | ### System Info
```
transformers.__version__ # 4.28.0.dev0
torch.__version__ # 2.0.0+cu117
python # Python 3.7.12
```
### Who can help?
@sgugger @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
The followig gist uses `model_name = 'facebook/opt-2.7b'`, which seems working as expected.
[Gist-model-parallel](https://gist.github.com/innat/e6c4826382641f640cc91def95026ad3)
But for model like `'EleutherAI/gpt-j-6b'` or `gpt2`, it gives error.
```
AttributeError: 'GPTJModel' object has no attribute 'first_device'
```
Full logs
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[14], line 20
12 trainer = Trainer(
13 model=model,
14 args=training_args,
15 data_collator=data_collator,
16 train_dataset=train_dataset,
17 )
19 model.config.use_cache = False
---> 20 trainer.train()
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/transformers/trainer.py:1639, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1634 self.model_wrapped = self.model
1636 inner_training_loop = find_executable_batch_size(
1637 self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size
1638 )
-> 1639 return inner_training_loop(
1640 args=args,
1641 resume_from_checkpoint=resume_from_checkpoint,
1642 trial=trial,
1643 ignore_keys_for_eval=ignore_keys_for_eval,
1644 )
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/transformers/trainer.py:1906, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1904 tr_loss_step = self.training_step(model, inputs)
1905 else:
-> 1906 tr_loss_step = self.training_step(model, inputs)
1908 if (
1909 args.logging_nan_inf_filter
1910 and not is_torch_tpu_available()
1911 and (torch.isnan(tr_loss_step) or torch.isinf(tr_loss_step))
1912 ):
1913 # if loss is nan or inf simply add the average of previous logged losses
1914 tr_loss += tr_loss / (1 + self.state.global_step - self._globalstep_last_logged)
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/transformers/trainer.py:2652, in Trainer.training_step(self, model, inputs)
2649 return loss_mb.reduce_mean().detach().to(self.args.device)
2651 with self.compute_loss_context_manager():
-> 2652 loss = self.compute_loss(model, inputs)
2654 if self.args.n_gpu > 1:
2655 loss = loss.mean() # mean() to average on multi-gpu parallel training
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/transformers/trainer.py:2684, in Trainer.compute_loss(self, model, inputs, return_outputs)
2682 else:
2683 labels = None
-> 2684 outputs = model(**inputs)
2685 # Save past state if it exists
2686 # TODO: this needs to be fixed and made cleaner later.
2687 if self.args.past_index >= 0:
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/transformers/models/gptj/modeling_gptj.py:869, in GPTJForCausalLM.forward(self, input_ids, past_key_values, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, use_cache, output_attentions, output_hidden_states, return_dict)
867 # Set device for model parallelism
868 if self.model_parallel:
--> 869 torch.cuda.set_device(self.transformer.first_device)
870 hidden_states = hidden_states.to(self.lm_head.weight.device)
872 # make sure sampling in fp16 works correctly and
873 # compute loss in fp32 to match with mesh-tf version
874 # https://github.com/EleutherAI/gpt-neo/blob/89ce74164da2fb16179106f54e2269b5da8db333/models/gpt2/gpt2.py#L179
File /opt/conda/envs/gpt_neox/lib/python3.9/site-packages/torch/nn/modules/module.py:1614, in Module.__getattr__(self, name)
1612 if name in modules:
1613 return modules[name]
-> 1614 raise AttributeError("'{}' object has no attribute '{}'".format(
1615 type(self).__name__, name))
AttributeError: 'GPTJModel' object has no attribute 'first_device'
```
### Expected behavior
Couldn't interpret the problem (`no attribute 'first_device'`), otherwise, it's expected to work same as other model. | 04-04-2023 16:16:58 | 04-04-2023 16:16:58 | This comes from your hack of setting the attributes of the model in cell 6. This then makes the model want to try to use the old model parallel API which crashes since you didn't really use it ;-)<|||||>Ah, I see. Sorry, it was bit confusing. As mentioned, model `fb/opt` worked. Also `abeja/gpt-neox-japanese-2.7b` worked either. Is there any easy fix for the newer API?<|||||>It will work with any model that does not implement the `parallelize` API. As for fixes, the issue you originally psoted on will fix the models with head if needed, and the Trainer has been fixed as @younesbelkada mentioned, so you shouldn't need this hack anymore.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,568 | closed | junk results for int8 for Flan-xl/xxl | ### System Info
- `transformers` version: 4.27.4
- Platform: Linux-5.10.147+-x86_64-with-glibc2.31
- Python version: 3.9.16
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 2.0.0+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.6.8 (gpu)
- Jax version: 0.4.7
- JaxLib version: 0.4.7
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: no
### Who can help?
@younesbelkada and maybe @philschmid ?
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Steps to reproduce the behavior:
1. made a copy of notebook [HuggingFace_bnb_int8_T5](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing)
2. set runtime hardware accelerator to GPU, standard
3.
> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
> import torch
>
> model_name = "t5-3b-sharded" # NB. T5-11B does not fit into a GPU in Colab
> # T5-3b and T5-11B are supported!
> # We need sharded weights otherwise we get CPU OOM errors
> model_id=f"ybelkada/{model_name}"
>
> tokenizer = AutoTokenizer.from_pretrained(model_id)
> model_8bit = AutoModelForSeq2SeqLM.from_pretrained(model_id, device_map="cuda", load_in_8bit=True)
4.
> model_8bit.get_memory_footprint()
5.
> max_new_tokens = 400
>
> text = """
> Summarize: Whether out at a restaurant or buying tickets to a concert, modern life counts on the convenience of a credit card to make daily purchases. It saves us from carrying large amounts of cash and also can advance a full purchase that can be paid over time. How do card issuers know we’ll pay back what we charge? That’s a complex problem with many existing solutions—and even more potential improvements, to be explored in this competition.
>
> Credit default prediction is central to managing risk in a consumer lending business. Credit default prediction allows lenders to optimize lending decisions, which leads to a better customer experience and sound business economics. Current models exist to help manage risk. But it's possible to create better models that can outperform those currently in use.
>
> American Express is a globally integrated payments company. The largest payment card issuer in the world, they provide customers with access to products, insights, and experiences that enrich lives and build business success.
>
> In this competition, you’ll apply your machine learning skills to predict credit default. Specifically, you will leverage an industrial scale data set to build a machine learning model that challenges the current model in production. Training, validation, and testing datasets include time-series behavioral data and anonymized customer profile information. You're free to explore any technique to create the most powerful model, from creating features to using the data in a more organic way within a model.
> """
>
>
> input_ids = tokenizer(
> text, return_tensors="pt"
> ).input_ids
>
> if torch.cuda.is_available():
> input_ids = input_ids.to('cuda')
>
> outputs = model_8bit.generate(input_ids, max_new_tokens=max_new_tokens)
> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Resulting output (note the series of blanks at the beginning of the result between the periods). I also tried other prompts and the results were poor/unexpected.
My goal was to check that the int8 model _reliably_ produces at least similar results as the non-int8, in order to potentially use the int8 for inference. Please see comparison of results in next section from using the Hosted Inference API or spaces API. What am I missing?
> . . You can also use a combination of techniques to create a model that can outperform the current model in production. The goal is to create a model that can outperform the current model in production. The goal is to create a model that can outperform. The
### Expected behavior
something akin to:
a)
> ['Challenge your machine learning skills to predict credit default.']
or b)
> Challenge your machine learning skills to predict credit default.
a) is the result from trying a space API
> response = requests.post("https://awacke1-google-flan-t5-xl.hf.space/run/predict", json={
>
> "data": [
> text,
> ],
> "max_length": 500,
> }).json()
>
> data = response["data"]
> print(data)
b) is the result from your Hosted inference API
Hope you can shed light. | 04-04-2023 16:12:23 | 04-04-2023 16:12:23 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>Hi @i-am-neo
You should upgrade your `transformers` version and re-run your inference script as the recent releases contain a fix for T5 family models for fp16 and in8 inference
https://github.com/huggingface/transformers/pull/20683
#20760<|||||>Thanks @younesbelkada . Still junky. Using your notebook and t5-3b-sharded, compare:
```
text = "Summarize: Hello my name is Younes and I am a Machine Learning Engineer at Hugging Face" # outputs "s.:s. Summarize: Hello my name is Younes."
text = "summarize: Hello my name is Younes and I am a Machine Learning Engineer at Hugging Face" # outputs "Younes is a Machine Learning Engineer at Hugging Face."
```
<|||||>```
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
model_name = "t5-3b-sharded"
# T5-3b and T5-11B are supported!
# We need sharded weights otherwise we get CPU OOM errors
model_id=f"ybelkada/{model_name}"
#model_id='google/flan-t5-xl'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model_8bit = AutoModelForSeq2SeqLM.from_pretrained(model_id, device_map="auto", load_in_8bit=True)
```
```
- `transformers` version: 4.29.2
- Platform: Linux-5.15.107+-x86_64-with-glibc2.31
- Python version: 3.10.11
- Huggingface_hub version: 0.14.1
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.6.9 (gpu)
- Jax version: 0.4.8
- JaxLib version: 0.4.7
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,567 | open | Unable to import VGG16 model transformers | ### Model description
i have recently upload my trained vgg16 model to hugging face.After uploading i have a prompt of instructions to use my model.
Although i have followed the prompt i got errors.
[https://huggingface.co/Nvsai/DeviceClassification](url)
>>> from transformers import VGG16
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'VGG16' from 'transformers' (/mnt/mydrive/ubantu/programming/openvino/lib/python3.9/site-packages/transformers/__init__.py)
>>>
>>> model = VGG16.fro

m_pretrained("Nvsai/DeviceClassification")

### Open source status
- [ ] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
_No response_ | 04-04-2023 15:29:00 | 04-04-2023 15:29:00 | That code sample is plain wrong, there is no VGG16 in Transformers.<|||||>@sgugger Hi, can you please suggest me how to use my vgg16 model using transformers?Also i am new to transformers model i am sorry if i made any mistake in uploading my model.Could please redirect me to some helpful resources for vgg16 with transformers?
|
transformers | 22,566 | closed | Support Streaming to Other Locations Besides STDOUT | ### Feature request
I would like to build a token streaming model that sends the tokens to a web socket or SSE connection. Today I would need to put a redirect from stdout to the other location which is a pain. Instead I would like to receive a raw python generator from the TextStreamer object that I can iterate over in any way I need.
### Motivation
I'd like to emulate something like https://github.com/hyperonym/basaran but in native HF code.
### Your contribution
TBD | 04-04-2023 15:24:21 | 04-04-2023 15:24:21 | cc @gante <|||||>@sam-h-bean an iterator class was merged yesterday, but I haven't communicated about it :)
You can check its implementation [here](https://github.com/huggingface/transformers/blob/fc5b7419d4c8121d8f1fa915504bcc353422559e/src/transformers/generation/streamers.py#L125). This would be what you are looking for, correct?
EDIT: communicated [here](https://twitter.com/joao_gante/status/1643330507093196800)<|||||>@gante Is there going to be an option for using this with the pipelines API? I would like to incorporate this feature into langchain but that currently only supports the pipeline API.<|||||>@sam-h-bean yes, it is in the works! :D <|||||>@gante What about dynamic batching combined with streaming? If I wanted to support dynamic batching for an LLM because I expected a high amount of throughput but I wanted to stream tokens back to each client individually how would I accomplish that?<|||||>@sam-h-bean for now only the [text-generation-inference](https://github.com/huggingface/text-generation-inference) supports it.
I'd like to add it to `transformers` sometime in the future, but it definitely won't happen in the next months.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,565 | closed | VisionEncoderDecoderModel ONNX Conversion - TrOCR | I want to convert my TrOCR model into TFLite version. To do that, based on my understanding, I need to convert it first to ONNX, then to TF, and lastly to TFLite. I stumbled upon [#19604](https://github.com/huggingface/transformers/pull/19254). However, it's a bit different. In my case, I used the `trainer.save` function to save my finetuned TrOCR model. As a result, I got the checkpoint files and also these files:
```
config.json
generation_config.json
preprocessor_config.json
pytorch_model.bin
training_args.bin
```
Command I used:
```
python -m transformers.onnx --model=trocr/base/ --feature=vision2seq-lm onnx/ --atol 1e-3
```
Error that I still got:
```
ValueError: Unrecognized feature extractor in base/. Should have a `feature_extractor_type` key in its preprocessor_config.json of config.json, or one of the following `model_type` keys in its config.json: audio-spectrogram-transformer, beit, chinese_clip, clap, clip, clipseg, conditional_detr, convnext, cvt, data2vec-audio, data2vec-vision, deformable_detr, deit, detr, dinat, donut-swin, dpt, flava, glpn, groupvit, hubert, imagegpt, layoutlmv2, layoutlmv3, levit, maskformer, mctct, mobilenet_v1, mobilenet_v2, mobilevit, nat, owlvit, perceiver, poolformer, regnet, resnet, segformer, sew, sew-d, speech_to_text, speecht5, swin, swinv2, table-transformer, timesformer, tvlt, unispeech, unispeech-sat, van, videomae, vilt, vit, vit_mae, vit_msn, wav2vec2, wav2vec2-conformer, wavlm, whisper, xclip, yolos
```
In the `config.json`, I have both `trocr` and `vision-encoder-decoder` as the model type, which is not included in the list given by the error. Any other way to do this? | 04-04-2023 15:04:59 | 04-04-2023 15:04:59 | cc @Rocketknight1 maybe?<|||||>@sgugger pinging since there's no response<|||||>It looks like this bug is arising in ONNX export of a PyTorch model, which I don't know too much about!<|||||>I'm quite confused on this one. Any other workarounds on this? I did read some ways like JIT or using the export function of Torch, but not quite sure on how to do it, especially the input part.<|||||>Would need help referring this issue to others @Rocketknight1 @sgugger, appreciate it! :D<|||||>@sgugger @Rocketknight1 I'm also facing this same issue. Any help would be much appreciated. Thanks! <|||||>@NielsRogge @michaelbenayoun <|||||>Hi,
Could you try with [Optimum](https://github.com/huggingface/optimum)?
```
optimum-cli export onnx -m trocr/base/ --task vision2seq-lm onnx/ --atol 1e-3
```
Trying to pinpoint if it comes from the exporting tool or really from some information lacking in the `preprocessor_config.json` file.<|||||>Hi @michaelbenayoun, thank you for the response. Yes, I retried using Optimum and it works. I then continued my conversion to TF and TFLite with these commands.
```
optimum-cli export onnx --model base/ onnx/ --task vision2seq-lm
onnx-tf convert -i onnx/encoder_model.onnx -o encoder/
onnx-tf convert -i onnx/decoder_model.onnx -o decoder/
tflite_convert --saved_model_dir=encoder/ --output_file=encoder.tflite
tflite_convert --saved_model_dir=decoder/ --output_file=decoder.tflite
```
When I check the encoder input shape to use it for inference, I got the following:
```
[{'name': 'serving_default_pixel_values:0',
'index': 0,
'shape': array([1, 1, 1, 1], dtype=int32),
'shape_signature': array([-1, -1, -1, -1], dtype=int32),
'dtype': numpy.float32,
'quantization': (0.0, 0),
'quantization_parameters': {'scales': array([], dtype=float32),
'zero_points': array([], dtype=int32),
'quantized_dimension': 0},
'sparsity_parameters': {}}]
```
Any idea on how to fix this? It can't be the correct expected shape right?<|||||>We support also the export to TFLIte directly in Optimum, but not for TrOCR yet, just letting you know.
About your issue, if I understand correctly you convert the ONNX models to a TensorFlow SavedModels.
Once you have done that, I would suggest convert those SavedModels to TFLite programatically, for each SavedModel try:
1. Load the SavedModel
2. Create a `tf.function` with the proper input signature from it:
```python
func = tf.function(loaded_model, input_signature=[tf.TensorSpec([shape here], dtype=torch.float32)])
```
4. Create a concrete function from `func`:
```python
concrete_func = func.get_concrete_function()
```
5. Convert the concrete function to TFLite following this [example](https://www.tensorflow.org/lite/models/convert/convert_models?hl=fr#convert_concrete_functions_)
Tell me if it works!<|||||>Wow, thank you for the heads-up @michaelbenayoun, that Optimum feature is surely awaited!
Anyway, I tried your suggestion. Currently:
```
model = tf.saved_model.load("converted/tf/encoder/")
func = tf.function(model, input_signature=[tf.TensorSpec([1, 384, 384, 3], dtype=tf.float32)])
concrete_func = func.get_concrete_function()
```
However, I got this error from the concrete function getter:
```
ValueError: Could not find matching concrete function to call loaded from the SavedModel. Got:
Positional arguments (1 total):
* <tf.Tensor 'None_0:0' shape=(1, 384, 384, 3) dtype=float32>
Keyword arguments: {}
Expected these arguments to match one of the following 1 option(s):
Option 1:
Positional arguments (0 total):
*
Keyword arguments: {'pixel_values': TensorSpec(shape=(None, None, None, None), dtype=tf.float32, name='pixel_values')}
```
From my research I think this is because the shape is incorrect, but I don't know how to reshape the input. Any other suggestion on this? TIA! :D<|||||>I think it's because it does not recognize the input signature.
Could you try:
```python
func = tf.function(model, input_signature=[tf.TensorSpec([1, 384, 384, 3], dtype=tf.float32, name="pixel_values")])
```<|||||>Nope, still got the same error with that. <|||||>any updates on this,
I am also facing this issue @RichardRivaldo @michaelbenayoun <|||||>no @textyash20 have you found the solution for this?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,564 | closed | a possible bug in function find_mismatched_keys | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
### Issue
When setting ```ignore_mismatched_sizes=True``` in ```Blip2ForConditionalGeneration```, a KeyError is raised.
### Reproduce
* blip2-flan-t5-xl
```
from transformers import Blip2ForConditionalGeneration
model_name = "Salesforce/blip2-flan-t5-xl"
model = Blip2ForConditionalGeneration.from_pretrained(model_name, ignore_mismatched_sizes=True)
```
the output is ```KeyError: 'language_model.decoder.block.0.layer.2.DenseReluDense.wi_1.weight'```
* blip2-opt-2.7b
```
from transformers import Blip2ForConditionalGeneration
model_name = "Salesforce/blip2-opt-2.7b"
model = Blip2ForConditionalGeneration.from_pretrained(model_name, ignore_mismatched_sizes=True)
```
the output is ```KeyError: 'language_model.lm_head.weight'```
Fixes #22563 (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [√ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-04-2023 14:51:51 | 04-04-2023 14:51:51 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22564). All of your documentation changes will be reflected on that endpoint.<|||||>cc @younesbelkada
This is not the right fix as `loaded_keys` should only contain keys that are in the `state_dict` and we are looping other that in this piece of code.<|||||>In line [3054-3061](https://github.com/huggingface/transformers/blob/11fd2c773b11c3fcfe0fa25aa4b92db03c83636c/src/transformers/modeling_utils.py#L3054-L3061), the ```original_loaded_keys``` is input to the inner function ```_find_mismatched_keys```.
By using ```python -m pdb xxx.py```, I found that some keys in ```original_loaded_keys ``` are not in the ```state_dict``` .
So, in the line [2977](https://github.com/huggingface/transformers/blob/11fd2c773b11c3fcfe0fa25aa4b92db03c83636c/src/transformers/modeling_utils.py#L2977) , a ```KeyError``` is raised.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,563 | closed | KeyError when setting ignore_mismatched_sizes=True in Blip2ForConditionalGeneration | ### System Info
### Issue
When setting ```ignore_mismatched_sizes=True``` in ```Blip2ForConditionalGeneration```, a KeyError is raised.
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
### Env
```
transformers==4.28.0.dev0
```
### Reproduction
* blip2-flan-t5-xl
```
from transformers import Blip2ForConditionalGeneration
model_name = "Salesforce/blip2-flan-t5-xl"
model = Blip2ForConditionalGeneration.from_pretrained(model_name, ignore_mismatched_sizes=True)
```
the output is ```KeyError: 'language_model.decoder.block.0.layer.2.DenseReluDense.wi_1.weight'```
* blip2-opt-2.7b
```
from transformers import Blip2ForConditionalGeneration
model_name = "Salesforce/blip2-opt-2.7b"
model = Blip2ForConditionalGeneration.from_pretrained(model_name, ignore_mismatched_sizes=True)
```
the output is ```KeyError: 'language_model.lm_head.weight'```
### Expected behavior
I would like to revised the input resolution, which needs to set ``` ignore_mismatched_sizes=True```. | 04-04-2023 14:50:12 | 04-04-2023 14:50:12 | I fixed this possible issue in #22564, and I would like to know whether there are any other reasons.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,562 | closed | A potential bug in get_class_in_module by using subprocess to copy files among temp dir. | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.16
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 1.13.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no need
- Using distributed or parallel set-up in script?: no need
### Who can help?
@ydshieh @sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
The function in `dynamic_module_utils.py` as below will cause a `No such file or directory` error in parallel env (namely multiple process).
```
def get_class_in_module(class_name, module_path):
"""
Import a module on the cache directory for modules and extract a class from it.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
module_dir = Path(HF_MODULES_CACHE) / os.path.dirname(module_path)
module_file_name = module_path.split(os.path.sep)[-1] + ".py"
# Copy to a temporary directory. We need to do this in another process to avoid strange and flaky error
# `ModuleNotFoundError: No module named 'transformers_modules.[module_dir_name].modeling'`
shutil.copy(f"{module_dir}/{module_file_name}", tmp_dir)
# On Windows, we need this character `r` before the path argument of `os.remove`
cmd = f'import os; os.remove(r"{module_dir}{os.path.sep}{module_file_name}")'
# We don't know which python binary file exists in an environment. For example, if `python3` exists but not
# `python`, the call `subprocess.run(["python", ...])` gives `FileNotFoundError` (about python binary). Notice
# that, if the file to be removed is not found, we also have `FileNotFoundError`, but it is not raised to the
# caller's process.
try:
subprocess.run(["python", "-c", cmd])
except FileNotFoundError:
try:
subprocess.run(["python3", "-c", cmd])
except FileNotFoundError:
pass
# copy back the file that we want to import
shutil.copyfile(f"{tmp_dir}/{module_file_name}", f"{module_dir}/{module_file_name}")
# import the module
module_path = module_path.replace(os.path.sep, ".")
module = importlib.import_module(module_path)
return getattr(module, class_name)
```
The below error can be reproduced by the same code fragment in [issue22555](https://github.com/huggingface/transformers/issues/22555).
```
Process p4:
/var/folders/pv/nyl4rqb54tq1bslm06h34m840000gp/T/tmpebghdmvd/configuration_glm.py
Traceback (most recent call last):
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/Users/mfg/Code/torch_submit/mp_load_model/main.py", line 9, in func
model = AutoModel.from_pretrained(local_dir, trust_remote_code=True)
File "/Users/mfg/Code/transformers/src/transformers/models/auto/auto_factory.py", line 441, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/Users/mfg/Code/transformers/src/transformers/models/auto/configuration_auto.py", line 923, in from_pretrained
config_class = get_class_from_dynamic_module(
File "/Users/mfg/Code/transformers/src/transformers/dynamic_module_utils.py", line 400, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module.replace(".py", ""))
File "/Users/mfg/Code/transformers/src/transformers/dynamic_module_utils.py", line 178, in get_class_in_module
module = importlib.import_module(module_path)
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 839, in exec_module
File "<frozen importlib._bootstrap_external>", line 975, in get_code
File "<frozen importlib._bootstrap_external>", line 1032, in get_data
FileNotFoundError: [Errno 2] No such file or directory: '/Users/mfg/.cache/huggingface/modules/transformers_modules/glm-10b/configuration_glm.py'
```
This error only occurs in single machine for the reason of race condition on a same file or dir.
So I think it is a good way to solve it by using FileLock as below:
```
import fcntl
import os
class FileLock(object):
def __init__(self, file_path):
self.file_path = file_path
self.fd = None
def __enter__(self):
while True:
try:
self.fd = os.open(self.file_path, os.O_RDWR | os.O_CREAT)
fcntl.lockf(self.fd, fcntl.LOCK_EX)
return
except:
pass
def __exit__(self, exc_type, exc_val, exc_tb):
fcntl.lockf(self.fd, fcntl.LOCK_UN)
os.close(self.fd)
```
Usage:
```
def get_class_in_module(class_name, module_path):
"""
Import a module on the cache directory for modules and extract a class from it.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
module_dir = Path(HF_MODULES_CACHE) / os.path.dirname(module_path)
module_file_name = module_path.split(os.path.sep)[-1] + ".py"
lock_file = f"./transformers/{module_file_name}_lockfile"
lock = FileLock(lock_file)
with lock:
# Copy to a temporary directory. We need to do this in another process to avoid strange and flaky error
# `ModuleNotFoundError: No module named 'transformers_modules.[module_dir_name].modeling'`
shutil.copy(f"{module_dir}/{module_file_name}", tmp_dir)
...
```
I have test this solution in my local machine and meet no error any more.
Any comments are welcome~
### Expected behavior
Can work in multiple process. | 04-04-2023 14:26:13 | 04-04-2023 14:26:13 | This has been fixed by #22537 <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,561 | closed | Make all Transformer models compatible with model parallelism | Accelerate makes it easy to load a model on multiple GPUs with `device_map="auto"`. This in turn allows users to train model with naive model parallelism if they have several GPUs.
A problem that happens in Transformers, with model with heads (so not XxxModel but for instance XxxModelForSequenceClassification) is that the labels end up on a different device than the logits and there is a device mistmatch error.
Thankfully, there is an easy fix for that! #22535 shows how to fix this for T5 by just moving the labels to the same device as the logits they are compared to. This is a noop when the devices are the same, and fixes the issue if devices are different.
We would like help from the community to extend this to all models that support model parallelism, which are:
- [x] BART
- [x] BigBirdPegasus
- [x] BLIP2
- [x] BLOOM
- [x] BridgeTower
- [x] CamemBERT
- [x] CLIP
- [x] CLIPSeg
- [x] CodeGen
- [x] Data2Vec Text
- [x] Deit
- [x] ESM
- [x] GPT-2
- [x] GPT-Neo
- [x] GPT-NeoX
- [x] GPT-NeoX Japanese
- [x] GPT-J
- [x] GPT-San
- [x] JukeBox
- [x] Lilt
- [x] LLaMA (`LlamaForSequenceClassification` only)
- [x] Longformer
- [x] LongT5
- [x] Luke
- [x] M2M100
- [x] mBART
- [x] mT5
- [x] NLLB
- [x] OPT
- [x] Owl-ViT
- [x] Pix2Struct
- [x] PLBART
- [x] RoBERTa
- [x] RoBERTa PreLayerNorm
- [x] SwitchTransformer
- [x] T5
- [x] Vilt
- [x] ViT
- [x] ViT-Hybrid
- [x] Whisper
- [x] XLM-RoBERTa
If you would like to grab one of those models and apply the same fix as #22535 to all the model with heads, please leave a comment here! | 04-04-2023 13:58:00 | 04-04-2023 13:58:00 | I think I can help with this Issue :) <|||||>I would like to work on this issue - BART model :)<|||||>Hi, I can take this up 🙌🏻
<|||||>Indeed, this fix is required for BLOOM. https://github.com/huggingface/transformers/compare/main...zsc:transformers:main (my fix is hacky and not PR-ready. Just FYI)<|||||>Just to make sure does `LlamaForCausalLM` supports this feature already?(https://github.com/huggingface/transformers/issues/22546 ) it seems that, still there are some errors when using `device_map="auto"` for this task.<|||||>Hi, I'd like to pick up the GPT-2 model!<|||||>Hi! I am taking this up for `LlamaForSequenceClassification`. <|||||>> Just to make sure does `LlamaForCausalLM` supports this feature already?(#22546 ) it seems that, still there are some errors when using `device_map="auto"` for this task.
It does (#22329). I have started seeing similar errors to #22546, but only after updating my drivers from 525 to 530, similar to https://github.com/huggingface/transformers/issues/22546#issuecomment-1498348442
(which is good news to me, I had no idea why that gpu started disappearing occasionally. It seems it can happen when that gpu is under any load, not just during training)
Edit: seems like the errors I was getting were actually caused by GPU sag. I haven't yet reproduced that exact error, but it has been reported elsewhere. It is certainly not consistent though.<|||||>@younesbelkada @sgugger
Does this fix (moving label/logit to same device) supposed to work (model parallelism) for all models (listed above)? Or, a crucial step toward it? Also, this design fix is only for pytorch model and not for jax or tf?<|||||>I think it is supposed to work for all models listed above, as long as you are loading your model with `device_map=xxx`. And yes this should be for Pytorch only, though I am not really aware of how model parallelism work on TF & Jax<|||||>> I think it is supposed to work for all models listed above, as long as you are loading your model with device_map=xxx
I tried with such fix here https://github.com/huggingface/transformers/pull/22591#issuecomment-1498013324 but sadly it didn't work out. Any catch?<|||||>@sgugger
As the goal of this ticket is to enable model parallelism with easy fix, have the merged PR(s) checked on multi-gpu? I couldn't find any test script here https://github.com/huggingface/transformers/pull/22663/ regarding that .<|||||>I would love to work with BridgeTower<|||||>Hi. I would like to try with "Whisper"<|||||>I'd like to claim OPT model if no one else has picked it up.<|||||>Taking this up for the remaining GPT models<|||||>Hello, I just completed the GPT-J code. Just filling in the PR now.<|||||>Hello! I'd like to work in Whisper model<|||||>Hi, is there any model on which I can work, please? Thanks.<|||||>Is there any remaining model on which I can work ? Thanks .<|||||>@sgugger Hello, can I work on the JukeBox?<|||||>Hello @sgugger , I'd like to work on `m2m100`<|||||>@sgugger I would love to work on CodeGen if it is unclaimed<|||||>Hi @sgugger I can work on `Luke` if it has not been taken<|||||>@sgugger I would like to work on SwitchTransformer, if not taken.<|||||>@sgugger I think all transformers are covered, I have checked for others also...for example, switch transformers have parallelism implemented already. i think we can close this issue. The only pending models are clip,jukebox,owlvit, and Nllb , may be model parallelism is not applicable for some of there models
<|||||>Indeed, all models have been covered. Thanks a lot everyone! |
transformers | 22,560 | closed | [WIP]🌐 [i18n-KO] Translated `tasks/translation.mdx` to Korean | <!-- PR의 제목은 "🌐 [i18n-KO] Translated `<your_file>.mdx` to Korean" 으로 부탁드립니당 -->
# What does this PR do?
Partially translated the `tasks/translation.mdx` file of the documentation to Korean. I will finish off the rest by Thursday if possible. PseudoLab team members will review the quality of the translation by then.
Thank you in advance for your review. ❤️
Part of https://github.com/huggingface/transformers/issues/20179
<!-- 메인 이슈에 기록이 남아요! 가짜연구소 리포를 사용해 연습하실때는 제거해주시면 감사하겠습니다! :smile: -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
<!-- 제출 전 체크리스트로, 가짜연구소만의 체크리스트도 <details>로 감싸서 만들어두면 더 좋을 것 같아요. -->
## Who can review?
<!-- 가짜연구소 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
<!-- @sgugger, @ArthurZucker, @eunseojo May you please review this PR? -->
Team PseudoLab, may you please review this PR?
@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd | 04-04-2023 13:48:20 | 04-04-2023 13:48:20 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Due to WSL compatibility issues causing unreachable commits, I have opened another PR on a different branch.<|||||>Closing in favor of https://github.com/huggingface/transformers/pull/22678 |
transformers | 22,559 | closed | fixing a bug about gradient accumulation in codeparrot_training | # What does this PR do?
The gradient accumulation was not pausing. In order to fix this issue, I modified the training loop in order to incorporate a better use of `Accelerator` to handle gradient accumulation.
I also modified the declaration of accelerator in order to incorporate the argument `gradient_accumulation_steps`.
To be tested.
Fixes #22541
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue #22541 ?
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
@lvwerra @loubnabnl
| 04-04-2023 11:58:59 | 04-04-2023 11:58:59 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22559). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,558 | closed | Add id2label and label2id to model's config in run_xnil | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Models fine-tune via `run_xnil.py` script don't have any labels in their `id2label` and `label2id` fields in config. They are just placeholder like LABEL_0 etc. This is similar to this issue #2487 and is based on this PR #2945
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [X] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@ArthurZucker @younesbelkada
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-04-2023 11:26:53 | 04-04-2023 11:26:53 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,557 | closed | corrected the code comment for the output of find_pruneable_heads_and_indices | # What does this PR do?
This PR improves the doc (code comment), because the code comment of find_pruneable_heads_and_indices was not correct.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@anmolsjoshi @sgugger
| 04-04-2023 11:05:29 | 04-04-2023 11:05:29 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,556 | closed | [`bnb`] Fix typo | # What does this PR do?
Fixes a small typo, in fact the correct argument name is `llm_int8_enable_fp32_cpu_offload`
| 04-04-2023 10:48:01 | 04-04-2023 10:48:01 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,555 | closed | get_class_from_dynamic_module may throw exception in multiple process | ### System Info
- `transformers` version: 4.22.1
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.16
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 1.13.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no need
- Using distributed or parallel set-up in script?: no need
### Who can help?
@ArthurZucker @sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
To simplify the problem, I design a simple code fragment to reproduce the bug:
```
import multiprocessing as mp
def func():
from transformers import AutoTokenizer, AutoModel
local_dir = "/Users/mfg/Code/huggingface/glm-10b" # change to your local dir
tokenizer = AutoTokenizer.from_pretrained(local_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(local_dir, trust_remote_code=True)
print(tokenizer)
if __name__ == '__main__':
procs = []
for i in range(10):
p = mp.Process(target=func)
p.start()
procs.append(p)
for p in procs:
p.join()
print("done")
```
All files in dir "/Users/mfg/Code/huggingface/glm-10b" can be found in https://huggingface.co/THUDM/glm-10b/tree/main .
(no need to download the large file [pytorch_model.bin](https://huggingface.co/THUDM/glm-10b/blob/main/pytorch_model.bin) for that the exception happens before loading model)
After you run, you may meet the exception as below:
```
Process Process-6:
Process Process-5:
Traceback (most recent call last):
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/Users/mfg/Code/torch_submit/mp_load_model/main.py", line 7, in func
tokenizer = AutoTokenizer.from_pretrained("/Users/mfg/Code/huggingface/glm-10b", trust_remote_code=True)
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 594, in from_pretrained
tokenizer_class = get_class_from_dynamic_module(
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 375, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module.replace(".py", ""))
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 148, in get_class_in_module
return getattr(module, class_name)
AttributeError: module 'transformers_modules.local.tokenization_glm' has no attribute 'GLMChineseTokenizer'
Traceback (most recent call last):
copy /Users/mfg/Code/huggingface/glm-10b/tokenization_glm.py /Users/mfg/.cache/huggingface/modules/transformers_modules/local/tokenization_glm.py
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/Users/mfg/Code/torch_submit/mp_load_model/main.py", line 7, in func
tokenizer = AutoTokenizer.from_pretrained("/Users/mfg/Code/huggingface/glm-10b", trust_remote_code=True)
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 594, in from_pretrained
tokenizer_class = get_class_from_dynamic_module(
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 375, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module.replace(".py", ""))
Process Process-10:
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 148, in get_class_in_module
return getattr(module, class_name)
Traceback (most recent call last):
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/Users/mfg/Code/torch_submit/mp_load_model/main.py", line 7, in func
tokenizer = AutoTokenizer.from_pretrained("/Users/mfg/Code/huggingface/glm-10b", trust_remote_code=True)
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py", line 594, in from_pretrained
tokenizer_class = get_class_from_dynamic_module(
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 375, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module.replace(".py", ""))
File "/opt/miniconda3/envs/py38_torch/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 148, in get_class_in_module
return getattr(module, class_name)
AttributeError: module 'transformers_modules.local.tokenization_glm' has no attribute 'GLMChineseTokenizer'
AttributeError: module 'transformers_modules.local.tokenization_glm' has no attribute 'GLMChineseTokenizer'
```
In my opinion, the bug is caused by running `shutil.copy` and `importlib.import_module(module_path)` concurrently.
```
# lib/python3.8/site-packages/transformers/dynamic_module_utils.py #get_cached_module_file
if submodule == "local":
# We always copy local files (we could hash the file to see if there was a change, and give them the name of
# that hash, to only copy when there is a modification but it seems overkill for now).
# The only reason we do the copy is to avoid putting too many folders in sys.path.
shutil.copy(resolved_module_file, submodule_path / module_file)
for module_needed in modules_needed:
module_needed = f"{module_needed}.py"
shutil.copy(os.path.join(pretrained_model_name_or_path, module_needed), submodule_path / module_needed)
```
```
# lib/python3.8/site-packages/transformers/dynamic_module_utils.py
def get_class_in_module(class_name, module_path):
"""
Import a module on the cache directory for modules and extract a class from it.
"""
module_path = module_path.replace(os.path.sep, ".")
module = importlib.import_module(module_path)
return getattr(module, class_name)
```
Looking forward to your reply. Thanks a lot.
### Expected behavior
no exception | 04-04-2023 09:50:51 | 04-04-2023 09:50:51 | I will try to fix this bug and push a commit soon.<|||||>Awesome thanks for reporting this! <|||||>This will be fixed by #22537<|||||>> This will be fixed by #22537
OK~<|||||>
I met the same `AttributeError` issue. But the problem still exist after I update the master branch code with this fix https://github.com/huggingface/transformers/pull/22537. I'm wondering if that pr really fix this issue?
<img width="1140" alt="image" src="https://user-images.githubusercontent.com/17028350/231663726-b80068a8-10f3-44d8-94aa-9a96102aed08.png">
Some information:
I saved glm-10b model files on NFS storage, launch 8 process one node. Add debug code as blow:
```python
# /opt/conda/lib/python3.8/site-packages/transformers/dynamic_module_utils.py
def get_class_in_module(class_name, module_path):
"""
Import a module on the cache directory for modules and extract a class from it.
"""
module_path = module_path.replace(os.path.sep, ".")
module = importlib.import_module(module_path)
try:
return getattr(module, class_name)
except:
with open('/root/.cache/huggingface/modules/transformers_modules/glm-10b-chinese/configuration_glm.py', 'r') as f:
print('print /root/.cache configuration_glm.py')
print(f.read())
raise
```
When the `AttributeError` exception happened, I found this code print `configuration_glm.py` file in `/root/.cache` is empty.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,554 | closed | Add `torch_dtype` attribute | # What does this PR do?
Disclaimer: Maybe there is a more canonical way to retrieve the `torch_dtype` of a loaded model !
I propose to add the attribute `torch_dtype` inside `PreTrainedModel` so that it can be conveniently retrieved. Useful for example for `peft` where I see this solution as one of the possible solution to fix forward pass issues in half-precision for `PrefixTuning` models.
To provide more context, the prefix tuning models feed to the base model [new `past_key_values`](https://github.com/huggingface/peft/blob/main/src/peft/tuners/prefix_tuning.py#L103-L109). Those are computed by default in `float32` (and should always stay in `float32`). However, if the base model is in half-precision, the forward pass would fail (`dtype` mismatch errors). This PR would make the retrieving process of the base model's `dtype` super easy, thus handling this error.
cc @sgugger @pacman100 | 04-04-2023 09:46:09 | 04-04-2023 09:46:09 | The `torch_dtype` in the config can't be used for that? <|||||>I don't think so because sometimes (and very often) you load `fp32` models from the Hub, and not all models on the Hub have the `torch_dtype` attribute<|||||>Also there is this :
```python
@property
def dtype(self) -> torch.dtype:
"""
`torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
"""
return get_parameter_dtype(self)
```
but maybe all the parameters do not have the same dtype?
<|||||>Ah that works! Thanks for the pointer! I should have digged further :D<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,553 | closed | ValueError in finetuning NLLB | ### System Info
- `transformers` version: 4.21.1
- Platform: Linux-5.15.0-56-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 1.10.1+cu113 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
It is surprising why there is still no example of finetuning any of NLLB models (at least, the smallest one) in a huggingface transformers environment. So I have followed [this](https://huggingface.co/docs/transformers/tasks/translation) guide and adapted the code to my case, namely, `nllb-200-distilled-600M`.
My custom train and eval datasets I want to finetune `nllb-200-distilled-600M` on consist of 2 entries each, see my attached code. Running this code gives me `ValueError: You have to specify either decoder_input_ids or decoder_inputs_embeds`.
```
from transformers import AutoModelForSeq2SeqLM, NllbTokenizer, Seq2SeqTrainingArguments, Seq2SeqTrainer, DataCollatorForSeq2Seq
from datasets import Dataset
import numpy as np
import evaluate
trainPart = []
evalPart = []
def buildDataset():
trainPart.append({'id': 0, 'translation': {
'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
'ru': 'Но это высокое плато имело размер всего в несколько саженей, и вскоре мы снова оказались в своей стихии.'}})
trainPart.append({'id': 1, 'translation': {
'en': 'What awakened us was a sound which sent chills of fear down my spine: the howling of the monsters\' sirens, and the reverberations of distant explosions.',
'ru': 'Разбудили нас звуки, от которых у меня по спине побежали мурашки страха, - завывания сирен чудовищ и эхо отдаленных взрывов.'}})
evalPart.append({'id': 0, 'translation': {
'en': 'It could be coming from reverberations, deeper caverns caught in currents.',
'ru': 'Это, наверное, от ревербераций в глубинных полостях, вызванных течениями.'}})
evalPart.append({'id': 1, 'translation': {
'en': 'There’s a four to five second reverberation.',
'ru': 'Реверберация длится от четырех до пяти секунд.'}})
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def run():
modelName = "nllb-200-distilled-600M"
model = AutoModelForSeq2SeqLM.from_pretrained(modelName, use_auth_token=True)
tokenizer = NllbTokenizer.from_pretrained(
modelName, src_lang='eng_Latn', tgt_lang='rus_Cyrl'
)
trainSet = Dataset.from_list(trainPart)
evalSet = Dataset.from_list(evalPart)
def preprocess_function(examples):
inputs = [example['en'] for example in examples["translation"]]
targets = [example['ru'] for example in examples["translation"]]
model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
return model_inputs
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
tokenized_trainset = trainSet.map(preprocess_function, batched=True)
tokenized_evalset = evalSet.map(preprocess_function, batched=True)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model) # или modelName?
metric = evaluate.load("sacrebleu")
training_args = Seq2SeqTrainingArguments(
output_dir="test_ft",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=2,
predict_with_generate=True,
fp16=True,
push_to_hub=False,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_trainset,
eval_dataset=tokenized_evalset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
buildDataset()
run()
```
### Expected behavior
A set of finetuned model's files in my `output_dir` | 04-04-2023 08:50:49 | 04-04-2023 08:50:49 | You should use the [forums](https://discuss.huggingface.co/) to help debug your training code.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>There still was no help from the forums. See https://discuss.huggingface.co/t/valueerror-in-finetuning-nllb/35533 |
transformers | 22,552 | closed | fix bug because of implicit attention_mask argument in generation | # What does this PR do?
Fixes # (issue)
gpt2 prepares generation input with attention mask not in explicit way like beolw, and it conflicts with self._validate_model_kwargs which checks unused arguments and gets error.
```
/usr/local/lib/python3.9/site-packages/torch/utils/_contextlib.py in decorate_context(*args, **kwargs)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
116
117 return decorate_context
/usr/local/lib/python3.9/site-packages/transformers/generation/utils.py in generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, streamer, **kwargs)
1229 model_kwargs = generation_config.update(**kwargs) # All unused kwargs must be model kwargs
1230 generation_config.validate()
-> 1231 self._validate_model_kwargs(model_kwargs.copy())
1232
1233 # 2. Set generation parameters if not already defined
/usr/local/lib/python3.9/site-packages/transformers/generation/utils.py in _validate_model_kwargs(self, model_kwargs)
1107
1108 if unused_model_args:
-> 1109 raise ValueError(
1110 f"The following `model_kwargs` are not used by the model: {unused_model_args} (note: typos in the"
1111 " generate arguments will also show up in this list)"
ValueError: The following `model_kwargs` are not used by the model: ['attention_mask'] (note: typos in the generate arguments will also show up in this list)
```
below is gpt2 ln:1007 https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/modeling_gpt2.py
```
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs):
token_type_ids = kwargs.get("token_type_ids", None)
# only last token for inputs_ids if past is defined in kwargs
if past_key_values:
input_ids = input_ids[:, -1].unsqueeze(-1)
if token_type_ids is not None:
token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
attention_mask = kwargs.get("attention_mask", None)
position_ids = kwargs.get("position_ids", None)
```
## Before submitting
- [v] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [v] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [v] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [v] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@gante
| 04-04-2023 07:53:37 | 04-04-2023 07:53:37 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hey @Soonhwan-Kwon 👋
I am unable to reproduce the issue you describe (see script below). Can you share a reproducer for the exception you're seeing?
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
tok = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
inputs = tok(["This cat is"], return_tensors="pt")
gen_out = model.generate(inputs.input_ids, attention_mask=inputs.attention_mask, do_sample=True)
print(tok.decode(gen_out[0]))
```<|||||>> Hey @Soonhwan-Kwon 👋
>
> I am unable to reproduce the issue you describe (see script below). Can you share a reproducer for the exception you're seeing?
>
> ```python
> from transformers import AutoModelForCausalLM, AutoTokenizer
>
> tok = AutoTokenizer.from_pretrained("gpt2")
> model = AutoModelForCausalLM.from_pretrained("gpt2")
>
> inputs = tok(["This cat is"], return_tensors="pt")
> gen_out = model.generate(inputs.input_ids, attention_mask=inputs.attention_mask, do_sample=True)
> print(tok.decode(gen_out[0]))
> ```
Sure, it occurs in GPT2LMHeadModel and below is the reproduction code.
```
from transformers import AutoModelWithLMHead, AutoTokenizer
tok = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelWithLMHead.from_pretrained("gpt2")
# GPT2LMHeadModel
inputs = tok(["This cat is"], return_tensors="pt")
gen_out = model.generate(inputs.input_ids, attention_mask=inputs.attention_mask, do_sample=True)
print(tok.decode(gen_out[0]))
```<|||||>@Soonhwan-Kwon I can't reproduce the issue with the script you shared. What version of transformers are you using? |
transformers | 22,551 | closed | Extend Transformers Trainer Class to Enable XPU | Rename GPU utils to CUDA
Add XPU backend
Doc on XPU backend
| 04-04-2023 06:28:12 | 04-04-2023 06:28:12 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22551). All of your documentation changes will be reflected on that endpoint.<|||||>Thanks for your PR, but we are not going to rename core utils like this.<|||||>> Thanks for your PR, but we are not going to rename core utils like this.
thanks for the review, if so, I just rolled back the rename. <|||||>@sgugger May you please help review it again? thanks.<|||||>Thanks for your PR. We can leave this branch as is for people who want to use XPUs but:
1. We do not have the ability to test them, so cannot commit to maintain this yet.
2. The Trainer will be rewritten to use Accelerate very soon, so the support should be added in Accelerate (I believe there is already a PR open) and then will come in the Trainer for free.<|||||>> Thanks for your PR. We can leave this branch as is for people who want to use XPUs but:
>
> 1. We do not have the ability to test them, so cannot commit to maintain this yet.
> 2. The Trainer will be rewritten to use Accelerate very soon, so the support should be added in Accelerate (I believe there is already a PR open) and then will come in the Trainer for free.
Yes, my colleague is working with me preparing the PR for accelerate now. But, we still would like to merge this change into transformer since intel-extension-for-pytorch cpu backend is already in transformer, and we expect user can use it directly even without accelerate.<|||||>The Trainer will require a dependency on Accelerate in roughly a month, so that point is moot.<|||||>@sgugger thanks for the info. May you please help explain how transformer depend on Accelerate? Does it will look like below?
first, use accelerate to wrap model,optimizer, data
model, optimizer, data = accelerator.prepare(model, optimizer, input)
second, pass the model/optimizer/data to Trainer of transformer
Trainer(model,args, ...)
Besides, accelerate seems only cover training path, how about inference path when Trainer has dependency on Accelerate?
<|||||>@sgugger sorry for being push, but your reply is quite important to us, thanks in advance.<|||||>@sgugger we are investigating how to provide solution for xpu now, another PR is in https://github.com/huggingface/accelerate/pull/1118, detailed info about how transformer depend on accelerate is important to us, may you please take time to explain it to us? Thanks in advance.<|||||>@mingxiaoh I would appreciate that you stop pinging me on this PR repeatedly. I said migrating the Trainer to use Accelerate for all the boilerplate code is a work in progress that will take roughly a month, so I would appreciate your patience on this and let us do the actual work.
Once the migration is done and the PR on the Accelerate side is merged, there will be no need for this PR or any other kind of PR, XPU will just work out-of-the-box with the Trainer.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>hello, @pacman100
May you please take some time to help explain this issue? Thanks in advance.
I found that transormers Trainer is using Accelerate now, is it the final solution? Why I ask so is because I found that, currently, if a model is wrapped by transformers trainer(e.g., IPEX CPU), it won't use accelerate to prepare model(see https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L1734-L1737), which means, for IPEX cpu, it won't use accelerate to prepare model, for IPEX xpu, it will use accelerate to prepare model, this might make users confused. Besides, for accelerate, it could not tell whether it is inference mode or training mode, currently, in accelerate, IPEX xpu always assumes it is training mode and wrap model into training mode, in this case, we could not run transformers in inference mode for IPEX xpu, any comments for this issue?
<|||||>@pacman100 my colleague told me that you are the owner of integration of traniner & accelerate, if it is not too trouble, may you please take time to help explain it a little bit for us? Thanks.<|||||>Hello @mingxiaoh, we are still in the process of migration. The next steps would involve shifting to Accelerate for ipex and adding the functionality in Accelerate if it isn't available there yet. Gentle ping @muellerzr who will be looking into this. <|||||>@pacman100 hello, may I know the the process of migration? Intel would like to extend it to xpu asap for customers' usge. Thanks in advance.<|||||>@mingxiaoh XPU support is currently happening in Accelerate due to efforts of @abhilash1910 and @sywangyi. It was in the last Accelerate release, so from here we need to look at the specific DDP efforts the Trainer has that need to be handled with XPU specific support that *isn't* already done via the Accelerator object. (aka add an arg to configure the `state` properly if needed, otherwise most of the trainer should work OOTB with the XPU). (v 0.20.0). Related PR here: https://github.com/huggingface/accelerate/pull/1118
As the Trainer is now using Accelerate for all of it's device/compute configuration and specialized code<|||||>@muellerzr Thanks, I know https://github.com/huggingface/accelerate/pull/1118 and xpu is supported in accelerate, we were working together for it before. But the issue is, we would like to know how the process of migration, in accelerate currently, inference is not supported on xpu, but for transformers, we must consider inference case. So, may I know the process of migration? we were told there is some problem about one month ago. |
transformers | 22,550 | closed | OverflowError with device="mps" using dedicated GPU | ### System Info
- 2019 Mac Pro
- AMD Radeon Pro W5700X 16 GB
- macOS Ventura 13.3
`transformers-cli env`:
- `transformers` version: 4.27.4
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.16
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 2.1.0.dev20230403 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Shell:
```
conda create -n transformerstest
conda activate transformerstest
conda install -c huggingface transformers
conda install pytorch torchvision torchaudio -c pytorch-nightly
```
Python:
```
from transformers import pipeline
generator = pipeline("text-generation", device="mps")
generator("In this course, we will teach you how to")
```
The system is then compiling Metal shaders and doing something on the GPU, but the result is:
```
Traceback (most recent call last):
File "/Users/fabian/devel/transformers-course/test.py", line 4, in <module>
generator("In this course, we will teach you how to")
File "/usr/local/Caskroom/miniconda/base/envs/transformerstest/lib/python3.9/site-packages/transformers/pipelines/text_generation.py", line 209, in __call__
return super().__call__(text_inputs, **kwargs)
File "/usr/local/Caskroom/miniconda/base/envs/transformerstest/lib/python3.9/site-packages/transformers/pipelines/base.py", line 1109, in __call__
return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File "/usr/local/Caskroom/miniconda/base/envs/transformerstest/lib/python3.9/site-packages/transformers/pipelines/base.py", line 1117, in run_single
outputs = self.postprocess(model_outputs, **postprocess_params)
File "/usr/local/Caskroom/miniconda/base/envs/transformerstest/lib/python3.9/site-packages/transformers/pipelines/text_generation.py", line 270, in postprocess
text = self.tokenizer.decode(
File "/usr/local/Caskroom/miniconda/base/envs/transformerstest/lib/python3.9/site-packages/transformers/tokenization_utils_base.py", line 3476, in decode
return self._decode(
File "/usr/local/Caskroom/miniconda/base/envs/transformerstest/lib/python3.9/site-packages/transformers/tokenization_utils_fast.py", line 549, in _decode
text = self._tokenizer.decode(token_ids, skip_special_tokens=skip_special_tokens)
OverflowError: out of range integral type conversion attempted
```
### Expected behavior
Generating output. This works on a MacBook Pro M1 with `device="mps"` (utilizing the GPU AFAICT) or on the Mac Pro without it (not utilizing GPU).
Thanks for your support! | 04-04-2023 06:03:15 | 04-04-2023 06:03:15 | This looks similar to #22529 and this is not a bug in Transformers but in PyTorch, so you will have to wait for them to release a fix.<|||||>Thanks for the quick answer!
Not holding my breath for a fix though. It's one out of 10K+ open issues in pytorch...<|||||>> Thanks for the quick answer!
>
> Not holding my breath for a fix though. It's one out of 10K+ open issues in pytorch...
Yeah that's the same issue. It just got marked high priority a few minutes ago so they're definitely looking at it.
In the meantime you can get it working if you make some manual fixes to your local copy of transformers. Not pretty, but it works.
In brief, I worked around it locally by searching `<python-install>/lib/python3.X/site-packages/transformers` for all references to `argmax`, and changing all relevant references such that `X.argmax(...)` is changed to `X.max(...).indices`. I think I changed it in 5 or 6 files total. Which references are relevant will depend on what you're doing. There's a ton of references under `models/` but you'd only need to change the ones you might actually need. I'm currently only looking at Llama models and there were no calls to `argmax` under `models/llama` so I didn't change any files under `models/`.
If you want to try that I can send you a list of files I had to changed, relative to `4.28.0.dev0`
Then you'd also need check your client code to see if it's making any of its own calls to `torch.argmax`, and change those too.
Finally, if you're using an Intel system with AMD GPU, then due to separate issue https://github.com/pytorch/pytorch/issues/92752 you also need to check for calls to `torch.multinomial` and rewrite those. There weren't any in transformers that affected me, but there was one in the client code I was using. I described how I changed that here: https://github.com/jankais3r/LLaMA_MPS/issues/14#issuecomment-1494959026 . Apparently Silicon systems aren't affected by this bug.
It's a bit of a mess at the moment due to those MPS bugs - but it is possible to get it working if you're willing to hack transformers and check your client code.<|||||>> It just got marked high priority a few minutes ago so they're definitely looking at it.
I pinged the PyTorch team on it ;-)<|||||>Much appreciated!<|||||>Actually running LLaMa was my goal, I was just trying something simpler first.
Now I tried LLaMa using the following:
```python
from transformers import AutoTokenizer, LlamaForCausalLM, pipeline
model = LlamaForCausalLM.from_pretrained("/path/to/models/llama-7b/")
tokenizer = AutoTokenizer.from_pretrained("/path/to/models/llama-7b/")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device="mps")
pipe("In this course, we will teach you how to")
```
Result:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/pipelines/text_generation.py", line 209, in __call__
return super().__call__(text_inputs, **kwargs)
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1109, in __call__
return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/pipelines/base.py", line 1117, in run_single
outputs = self.postprocess(model_outputs, **postprocess_params)
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/pipelines/text_generation.py", line 270, in postprocess
text = self.tokenizer.decode(
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/tokenization_utils_base.py", line 3485, in decode
return self._decode(
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/tokenization_utils.py", line 931, in _decode
filtered_tokens = self.convert_ids_to_tokens(token_ids, skip_special_tokens=skip_special_tokens)
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/tokenization_utils.py", line 912, in convert_ids_to_tokens
tokens.append(self._convert_id_to_token(index))
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/transformers/models/llama/tokenization_llama.py", line 119, in _convert_id_to_token
token = self.sp_model.IdToPiece(index)
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/sentencepiece/__init__.py", line 1045, in _batched_func
return _func(self, arg)
File "/usr/local/Caskroom/miniconda/base/envs/textgen/lib/python3.10/site-packages/sentencepiece/__init__.py", line 1038, in _func
raise IndexError('piece id is out of range.')
IndexError: piece id is out of range.
```
Which sounds like "minus nine trillion something" indices happening somewhere again. I didn't find "multinomial" or "argmax" under models/llama, but it's possible of course that those functions are called somewhere else.<|||||>> Which sounds like "minus nine trillion something" indices happening somewhere again. I didn't find "multinomial" or "argmax" under models/llama, but it's possible of course that those functions are called somewhere else.
Yes, it is not referenced anywhere under `models/llama` but is referenced multiple other places throughout `transformers`. In my earlier reply I described the process I followed to change those.
That test code works for me with my locally hacked copy of `transformers`.
Code:
```python
from transformers import LlamaTokenizer, LlamaForCausalLM, pipeline
model = LlamaForCausalLM.from_pretrained("/Users/tomj/src/llama.cpp/models/llama-7b-HF")
tokenizer = LlamaTokenizer.from_pretrained("/Users/tomj/src/llama.cpp/models/llama-7b-HF")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device="mps")
print(pipe("In this course, we will teach you how to"))
```
Output:
```
tomj@Eddie ~/src $ ~/anaconda3/envs/torch21/bin/python ./test_llama.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:20<00:00, 1.61it/s]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
/Users/tomj/anaconda3/envs/torch21/lib/python3.10/site-packages/transformers/generation/utils.py:1219: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation)
warnings.warn(
/Users/tomj/anaconda3/envs/torch21/lib/python3.10/site-packages/transformers/generation/utils.py:1313: UserWarning: Using `max_length`'s default (20) to control the generation length. This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we recommend using `max_new_tokens` to control the maximum length of the generation.
warnings.warn(
[{'generated_text': 'In this course, we will teach you how to use the most popular and powerful tools in the industry'}]
```<|||||>Same error with torch nightly version: 2.1.0.dev20230428 and
'MPS' on a 2020 iMac 27" with an AMD Radeon 5700 XT gpu in
https://github.com/andreamad8/FSB<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,549 | closed | [i18n-KO] fix: docs: ko: sagemaker anchors and `_toctree.yml` | Co-authored-by: Wonhyeong Seo
<[email protected]>
# What does this PR do?
I fixed the anchors and `_toctree.yml`
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Part of #20179 (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
Please review this PR: @sgugger
| 04-04-2023 03:56:28 | 04-04-2023 03:56:28 | _The documentation is not available anymore as the PR was closed or merged._<|||||><img src="https://user-images.githubusercontent.com/29195190/229707009-e1fca054-e464-4b98-af53-809e4c0778db.jpg" width="200px">
We are getting a 500 error (probably due to spacing issues in `_toctree.yml`). Please do not merge until the problem is resolved.<|||||>> I think the error in the doc preview comes from bad yaml syntax in the modified toctree.
Yes, I agree @sgugger . There were two titles for a section on L13-19. Editing `_toctree.yml` like so fixed the issue for me locally.

<|||||>Also when squashing the commits, please fix the typo on `Co-auth*e*red-by` to `Co-auth*o*red-by` and add arrow brackets (`<>`) to the email.
You may also use Github Desktop to ease the process. Thank you for your PR @jungnerd and feel free to ask me any questions.<|||||>Great work, @jungnerd !
You solved the issue; now please squash the commits into one. You can use
- chat-gpt for the commit message and
- Github Desktop to add co-authors
if you want. :raised_hands: Good night!<|||||>@jungnerd we can remove the `_toctree.yml` change completely as we updated it in the upstream `ko: complete toctree` commit. After that and rebasing, this PR should be good to go! Let's try to do this on Thursday.<|||||>May you please review this PR?
@sgugger, @ArthurZucker, @eunseojo |
transformers | 22,548 | open | [HOW TO FINETUNE CLIP OPENAI LAION2B MODELS FOR IMAGE CLASSIFICATION] | I try to finetune CLIP model by using pretrained: https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K
But I met a bug:
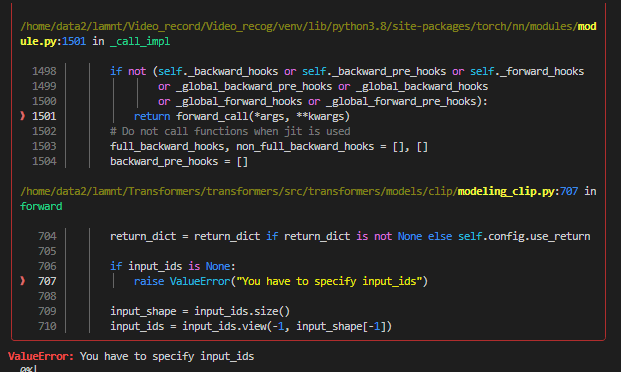
Help me! Thanks | 04-04-2023 03:30:09 | 04-04-2023 03:30:09 | There is no need to yell at us in all caps. No one can do anything without seeing the code you run. |
transformers | 22,547 | closed | Compared OneFormer by transformers with original GitHub code, It's worked bad . Why ? | ### System Info
transformers == 4.26.0
Python == 3.8.8
### Who can help?
@praeclarumjj3 @NielsRogge
### Reproduction
Thanks for your great Work !
I compared OneFormer in transformers with original [ original GitHub code](https://github.com/SHI-Labs/OneFormer), It sometimes worked bad .
OneFormer by transformers:
```
from transformers import OneFormerProcessor, OneFormerForUniversalSegmentation
from collections import defaultdict
import matplotlib.pyplot as plt
from matplotlib import cm
import matplotlib.patches as mpatches
def draw_panoptic_segmentation(segmentation, segments_info):
segmentation= segmentation.to(cpu_device)
# get the used color map
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# for each segment, draw its legend
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model_oneformer.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
plt.savefig('./panoptic.png')
processor = OneFormerProcessor.from_pretrained("shi-labs/oneformer_coco_dinat_large")
model = OneFormerForUniversalSegmentation.from_pretrained("shi-labs/oneformer_coco_dinat_large").to(device)
image = original_image.resize((512, 512))
inputs = processor(image, ["panoptic"], return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
# you can pass them to processor for panoptic postprocessing
panoptic_segmentation = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(panoptic_segmentation.keys())
draw_panoptic_segmentation(**panoptic_segmentation)
```
original GitHub code:
```
from detectron2.config import get_cfg
from detectron2.projects.deeplab import add_deeplab_config
# from detectron2.data import MetadataCatalog
from oneformer import (
add_oneformer_config,
add_common_config,
# add_swin_config,
add_dinat_config,
)
from demo.defaults import DefaultPredictor
def setup_cfg():
# load config from file and command-line arguments
cfg = get_cfg()
add_deeplab_config(cfg)
add_common_config(cfg)
# add_swin_config(cfg)
add_oneformer_config(cfg)
add_dinat_config(cfg)
cfg_path = "OneFormer/configs/coco/oneformer_dinat_large_bs16_100ep.yaml"
cfg.merge_from_file(cfg_path)
if torch.cuda.is_available():
cfg.MODEL.DEVICE = 'cuda'
else:
cfg.MODEL.DEVICE = 'cpu'
# cfg.MODEL.WEIGHTS = hf_hub_download(repo_id="shi-labs/oneformer_coco_dinat_large",
# filename="150_16_dinat_l_oneformer_coco_100ep.pth", local_dir=local_dir)
cfg.MODEL.WEIGHTS = 'OneFormer/oneformer_coco_dinat_large/150_16_dinat_l_oneformer_coco_100ep.pth'
cfg.freeze()
return cfg
predictor = setup_modules()
img = cv2.resize(img.astype(np.uint8), (512, 512),interpolation=cv2.INTER_AREA)
predictions = predictor(img, "panoptic")
panoptic_seg, segments_info = predictions["panoptic_seg"]
```
### Expected behavior
input image:

OneFormer by transformers output:

OneFormer by original GitHub output:

| 04-04-2023 02:58:13 | 04-04-2023 02:58:13 | cc @alaradirik and @amyeroberts <|||||>Hi @onefish51, thanks for reporting this issue! It's definitely not the desired behaviour, and I'm digging into it now.
As a first pass, it seems this is related to specific checkpoints and inputs. For example, for the checkpoint you provided, `shi-labs/oneformer_coco_dinat_large` I also see poor segmentation for the example image:

But good segmentation for a different input image:

And a different oneformer checkpoint `shi-labs/oneformer_coco_swin_large` outputs a reasonable segmentation map:

This indicates to me that the differences are more likely to be coming from the model outputs than the pre/post processing steps, TBC.
To help narrow down the effects, could you share some more information about the environment you're using (run `transformers-cli env` to get the info) and the device the model is being run on e.g. `"cpu"`?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>cc @praeclarumjj3<|||||>> Hi @onefish51, thanks for reporting this issue! It's definitely not the desired behaviour, and I'm digging into it now.
>
> As a first pass, it seems this is related to specific checkpoints and inputs. For example, for the checkpoint you provided, `shi-labs/oneformer_coco_dinat_large` I also see poor segmentation for the example image: 
>
> But good segmentation for a different input image: 
>
> And a different oneformer checkpoint `shi-labs/oneformer_coco_swin_large` outputs a reasonable segmentation map: 
>
> This indicates to me that the differences are more likely to be coming from the model outputs than the pre/post processing steps, TBC.
>
> To help narrow down the effects, could you share some more information about the environment you're using (run `transformers-cli env` to get the info) and the device the model is being run on e.g. `"cpu"`?
hi @amyeroberts thanks for reporting ! I guess it has nothing to do with the env, and I run it by GPU V100
```sh
$ transformers-cli env
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.28.0.dev0
- Platform: Linux-5.4.0-146-generic-x86_64-with-glibc2.17
- Python version: 3.8.16
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 1.10.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
and you said
>the differences are more likely to be coming from the model outputs than the pre/post processing steps, TBC.
may right<|||||>and I will create a colab to compare it , if needed<|||||>@onefish51 it's also worth mentioning that OneFormer was added by the authors themselves. I'd recommend comparing the output logits of models, which should be the same.<|||||>Hi, @onefish51, thanks for your interest in OneFormer and bringing up this issue. I am sorry for not replying earlier. I am currently occupied with a few other things.
This strange case could be image specific for the DiNAT-L OneFormer checkpoint. As @alaradirik suggested, comparing the HF model outputs **for this image** to the model outputs using the official GitHub repo could provide some hints. The tests suggest they should be the same, but it's good to look.
I'll do this myself once I get some time. Please let us know if you compare these on your end.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,546 | closed | RuntimeError: CUDA error: device-side assert triggered when running Llama on multiple gpus | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-3.10.0-1160.81.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.11.2
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger @MKhalusova @ArthurZucker @younesbelkada
I am experiencing an assertion error in ScatterGatherKernel.cu when using LlamaTokenizer and multi-GPU inference with any variant of Llama model. The error occurs during the model.generate() call.
```
import os
# os.environ['TRANSFORMERS_CACHE'] = '/tmp/cache/'
# os.environ['NCCL_P2P_DISABLE'] = '1'
from transformers import AutoModelForCausalLM,AutoConfig,LlamaTokenizer
from accelerate import init_empty_weights, infer_auto_device_map
import torch
def get_device_map(model_path):
with init_empty_weights():
config = AutoConfig.from_pretrained(model_path)
model = AutoModelForCausalLM.from_config(config)
d = {0: "18GiB"}
for i in range(1, 5):
d[i] = "26GiB"
device_map = infer_auto_device_map(
model, max_memory=d,dtype=torch.float16, no_split_module_classes=["BloomBlock", "OPTDecoderLayer", "LLaMADecoderLayer", "LlamaDecoderLayer"]
)
print(device_map)
del model
return device_map
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-13b-hf")
model = AutoModelForCausalLM.from_pretrained("decapoda-research/llama-13b-hf", torch_dtype=torch.float16, device_map=get_device_map("decapoda-research/llama-13b-hf"))
generate_kwargs = {
"max_new_tokens": 200,
"min_new_tokens": 100,
"temperature": 0.1,
"do_sample": False, # The three options below used together leads to contrastive search
"top_k": 4,
"penalty_alpha": 0.6,
}
prompt = "Puma is a "
with torch.no_grad():
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
assert len(input_ids) == 1, len(input_ids)
if input_ids[0][-1] == 2: # 2 is EOS, hack to remove. If the prompt is ending with EOS, often the generation will stop abruptly.
input_ids = input_ids[:, :-1]
input_ids = input_ids.to(0)
#input_ids = tokenizer(prompt, padding=True, truncation=True, return_tensors="pt").input_ids.to(0)
generated_ids = model.generate(
input_ids,
#stopping_criteria=stopping_criteria,
**generate_kwargs
)
result = tokenizer.batch_decode(generated_ids.cpu(), skip_special_tokens=True)
print(result)
```
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
normalizer.cc(51) LOG(INFO) precompiled_charsmap is empty. use identity normalization.
{'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0, 'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0, 'model.layers.9': 0, 'model.layers.10': 0, 'model.layers.11': 0, 'model.layers.12': 0, 'model.layers.13': 0, 'model.layers.14': 0, 'model.layers.15': 0, 'model.layers.16': 0, 'model.layers.17': 0, 'model.layers.18': 0, 'model.layers.19': 0, 'model.layers.20': 0, 'model.layers.21': 0, 'model.layers.22': 0, 'model.layers.23': 0, 'model.layers.24': 0, 'model.layers.25': 0, 'model.layers.26': 0, 'model.layers.27': 0, 'model.layers.28': 0, 'model.layers.29': 1, 'model.layers.30': 1, 'model.layers.31': 1, 'model.layers.32': 1, 'model.layers.33': 1, 'model.layers.34': 1, 'model.layers.35': 1, 'model.layers.36': 1, 'model.layers.37': 1, 'model.layers.38': 1, 'model.layers.39': 1, 'model.layers.40': 1, 'model.layers.41': 1, 'model.layers.42': 1, 'model.layers.43': 1, 'model.layers.44': 1, 'model.layers.45': 1, 'model.layers.46': 1, 'model.layers.47': 1, 'model.layers.48': 1, 'model.layers.49': 1, 'model.layers.50': 1, 'model.layers.51': 1, 'model.layers.52': 1, 'model.layers.53': 1, 'model.layers.54': 1, 'model.layers.55': 1, 'model.layers.56': 1, 'model.layers.57': 1, 'model.layers.58': 1, 'model.layers.59': 2, 'model.norm': 2, 'lm_head': 2}
Loading checkpoint shards: 100%|██████████████████████████| 61/61 [00:25<00:00, 2.43it/s]
/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/generation/utils.py:1219: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation)
warnings.warn(
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [64,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [65,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [66,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [67,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [68,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [69,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [70,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [71,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [72,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [73,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [74,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [75,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [76,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [77,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [78,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [79,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [80,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [81,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [82,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [83,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [84,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [85,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [86,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [87,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [88,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [89,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [90,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [91,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [92,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [93,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [94,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [95,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [96,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [97,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [98,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [99,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [100,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [101,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [102,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [103,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [104,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [105,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [106,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [107,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [108,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [109,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [110,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [111,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [112,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [113,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [114,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [115,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [116,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [117,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [118,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [119,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [120,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [121,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [122,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [123,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [124,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [125,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [126,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [127,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [0,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [1,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [2,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [3,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [4,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [5,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [6,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [7,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [8,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [9,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [10,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [11,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [12,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [13,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [14,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [15,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [16,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [17,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [18,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [19,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [20,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [21,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [22,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [23,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [24,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [25,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [26,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [27,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [28,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [29,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [30,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [31,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [32,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [33,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [34,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [35,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [36,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [37,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [38,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [39,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [40,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [41,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [42,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [43,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [44,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [45,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [46,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [47,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [48,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [49,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [50,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [51,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [52,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [53,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [54,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [55,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [56,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [57,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [58,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [59,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [60,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [61,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [62,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [63,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [64,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [65,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [66,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [67,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [68,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [69,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [70,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [71,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [72,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [73,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [74,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [75,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [76,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [77,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [78,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [79,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [80,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [81,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [82,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [83,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [84,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [85,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [86,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [87,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [88,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [89,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [90,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [91,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [92,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [93,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [94,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [95,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [96,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [97,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [98,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [99,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [100,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [101,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [102,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [103,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [104,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [105,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [106,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [107,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [108,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [109,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [110,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [111,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [112,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [113,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [114,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [115,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [116,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [117,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [118,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [119,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [120,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [121,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [122,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [123,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [124,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [125,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [126,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [127,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [0,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [1,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [2,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [3,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [4,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [5,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [6,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [7,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [8,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [9,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [10,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [11,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [12,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [13,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [14,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [15,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [16,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [17,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [18,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [19,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [20,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [21,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [22,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [23,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [24,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [25,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [26,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [27,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [28,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [29,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [30,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [31,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [32,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [33,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [34,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [35,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [36,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [37,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [38,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [39,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [40,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [41,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [42,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [43,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [44,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [45,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [46,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [47,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [48,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [49,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [50,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [51,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [52,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [53,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [54,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [55,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [56,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [57,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [58,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [59,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [60,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [61,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [62,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
../aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [1,0,0], thread: [63,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
Traceback (most recent call last):
File "/home/u30/terrycruz/chatPaper.py", line 48, in <module>
generated_ids = model.generate(
^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/generation/utils.py", line 1457, in generate
return self.contrastive_search(
^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/generation/utils.py", line 1871, in contrastive_search
outputs = self(
^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 687, in forward
outputs = self.model(
^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 577, in forward
layer_outputs = decoder_layer(
^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 292, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/u30/terrycruz/anaconda3/envs/multiple_gpu/lib/python3.11/site-packages/transformers/models/llama/modeling_llama.py", line 241, in forward
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. run my script: `CUDA_LAUNCH_BLOCKING=1 python script.py`
### Expected behavior
The puma bla bla bla. | 04-03-2023 20:10:58 | 04-03-2023 20:10:58 | This repo is not in sync with the model and tokenizer as implemented in the Transformers library. Sadly, we do not have permission to distribute the weights, so there is no official checkpoint you can use. After you get the official weights from Meta and run the conversion command as documented, you shouldn't have any problem with the model.<|||||>@sgugger I'm experiencing exactly the same error when using official llama weights converted using the huggingface conversion script from the master branch. It happens on the master branch when running inference with accelerate on multiple GPUs (I tried 2x4090 and 4x4090). To reproduce:
```
p=pipeline("text-generation", "path/to/converted-llama-30b-hf", torch_dtype=torch.float16, device_map="auto")
p("hi there")
```
This used to work last week. I don't have the exact branch commit ID, but could do git bisect if it'd help.
I'm using pytorch==2.0.0, cuda 11.7, and recent versions of accelearte and bitsandbytes (yes, it also shows the same error with load_in_8bits=True).
<|||||>@emvw7yf Could you print `pipeline.model.hf_device_map` and report that here? This would help us debug this issue.<|||||>@sgugger I managed to use the official llama weights and still getting the same error, for llama 7B, using the code from https://github.com/huggingface/transformers/issues/22546#issuecomment-1496891148, and printing `pipeline.model.hf_device_map` I'm getting the following:
{'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0, 'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0, 'model.layers.9': 0, 'model.layers.10': 0, 'model.layers.11': 0, 'model.layers.12': 0, 'model.layers.13': 0, 'model.layers.14': 0, 'model.layers.15': 0, 'model.layers.16': 1, 'model.layers.17': 1, 'model.layers.18': 1, 'model.layers.19': 1, 'model.layers.20': 1, 'model.layers.21': 1, 'model.layers.22': 1, 'model.layers.23': 1, 'model.layers.24': 1, 'model.layers.25': 1, 'model.layers.26': 1, 'model.layers.27': 1, 'model.layers.28': 1, 'model.layers.29': 1, 'model.layers.30': 1, 'model.layers.31': 1, 'model.norm': 1, 'lm_head': 1}<|||||>So I skimmed through the existing repos to look for one that has the same weights/tokenizer as what I get after the conversion script is applied. Applying this code:
```
p=pipeline("text-generation", "huggyllama/llama-7b", torch_dtype=torch.float16, device_map="auto")
p("hi there")
```
gives me the exact same device map as you @TerryCM and works without any issue. I am on Transformers main and Accelerate latest version.<|||||>@sgugger I'm also on Transformers main and accelerate version (I used pip install accelerate), could be this a drivers problem? Im using the following drivers

<|||||>Are you using the same repository as me? I'm on CUDA 11.8 and 520 drivers.<|||||>I can reliably reproduce it on both runpod.io and vast.ai. I'm using 2x4090 GPUs and the default docker image on each service (runpod/pytorch:3.10-2.0.0-117 and pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel).
I'm running the following:
```
pip install git+https://github.com/huggingface/transformers.git accelerate sentencepiece
import torch
from transformers import pipeline
p=pipeline("text-generation", "huggyllama/llama-7b", torch_dtype=torch.float16, device_map="auto")
p("hi there")
```
This results in the assertion error above. When I restrict it to a single GPU (using CUDA_VISIBLE_DEVICES), it works without errors.
Versions (taken on vast.ai):
```
[email protected]:/$ nvidia-smi
Wed Apr 5 23:57:43 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:41:00.0 Off | Off |
| 0% 21C P8 18W / 450W | 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce ... On | 00000000:42:00.0 Off | Off |
| 0% 21C P8 24W / 450W | 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
[email protected]:/$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Jun__8_16:49:14_PDT_2022
Cuda compilation tools, release 11.7, V11.7.99
Build cuda_11.7.r11.7/compiler.31442593_0
[email protected]:/$ python -c "import torch; print(torch.version.cuda)"
11.7
```
How could I help debugging this?<|||||>I actually realized that the error I'm getting is slightly different (even though the assertion is the same), pasting it below:
```
/opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:1313: UserWarning: Using `max_length`'s default (20) to control the generation length. This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we recommend using `max_new_tokens` to control the maximum length of the generation.
warnings.warn(
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [64,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [65,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [66,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [67,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [68,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [69,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [70,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [71,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [72,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [73,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [74,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [75,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [76,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [77,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [78,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [79,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [80,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [81,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [82,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [83,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [84,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [85,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [86,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [87,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [88,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [89,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [90,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [91,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [92,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [93,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [94,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [95,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [0,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [1,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [2,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [3,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [4,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [5,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [6,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [7,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [8,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [9,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [10,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [11,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [12,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [13,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [14,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [15,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [16,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [17,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [18,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [19,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [20,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [21,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [22,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [23,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [24,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [25,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [26,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [27,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [28,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [29,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [30,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [31,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [96,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [97,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [98,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [99,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [100,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [101,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [102,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [103,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [104,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [105,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [106,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [107,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [108,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [109,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [110,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [111,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [112,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [113,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [114,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [115,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [116,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [117,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [118,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [119,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [120,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [121,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [122,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [123,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [124,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [125,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [126,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [127,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [32,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [33,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [34,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [35,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [36,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [37,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [38,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [39,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [40,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [41,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [42,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [43,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [44,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [45,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [46,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [47,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [48,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [49,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [50,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [51,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [52,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [53,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [54,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [55,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [56,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [57,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [58,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [59,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [60,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [61,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [62,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1678411187366/work/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:144: operator(): block: [0,0,0], thread: [63,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[2], line 5
2 from transformers import pipeline
4 p=pipeline("text-generation", "huggyllama/llama-7b", torch_dtype=torch.float16, device_map="auto")
----> 5 p("hi there")
File /opt/conda/lib/python3.10/site-packages/transformers/pipelines/text_generation.py:209, in TextGenerationPipeline.__call__(self, text_inputs, **kwargs)
168 def __call__(self, text_inputs, **kwargs):
169 """
170 Complete the prompt(s) given as inputs.
171
(...)
207 ids of the generated text.
208 """
--> 209 return super().__call__(text_inputs, **kwargs)
File /opt/conda/lib/python3.10/site-packages/transformers/pipelines/base.py:1109, in Pipeline.__call__(self, inputs, num_workers, batch_size, *args, **kwargs)
1101 return next(
1102 iter(
1103 self.get_iterator(
(...)
1106 )
1107 )
1108 else:
-> 1109 return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File /opt/conda/lib/python3.10/site-packages/transformers/pipelines/base.py:1116, in Pipeline.run_single(self, inputs, preprocess_params, forward_params, postprocess_params)
1114 def run_single(self, inputs, preprocess_params, forward_params, postprocess_params):
1115 model_inputs = self.preprocess(inputs, **preprocess_params)
-> 1116 model_outputs = self.forward(model_inputs, **forward_params)
1117 outputs = self.postprocess(model_outputs, **postprocess_params)
1118 return outputs
File /opt/conda/lib/python3.10/site-packages/transformers/pipelines/base.py:1015, in Pipeline.forward(self, model_inputs, **forward_params)
1013 with inference_context():
1014 model_inputs = self._ensure_tensor_on_device(model_inputs, device=self.device)
-> 1015 model_outputs = self._forward(model_inputs, **forward_params)
1016 model_outputs = self._ensure_tensor_on_device(model_outputs, device=torch.device("cpu"))
1017 else:
File /opt/conda/lib/python3.10/site-packages/transformers/pipelines/text_generation.py:251, in TextGenerationPipeline._forward(self, model_inputs, **generate_kwargs)
249 prompt_text = model_inputs.pop("prompt_text")
250 # BS x SL
--> 251 generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)
252 out_b = generated_sequence.shape[0]
253 if self.framework == "pt":
File /opt/conda/lib/python3.10/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File /opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:1437, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, streamer, **kwargs)
1431 raise ValueError(
1432 f"num_return_sequences has to be 1, but is {generation_config.num_return_sequences} when doing"
1433 " greedy search."
1434 )
1436 # 11. run greedy search
-> 1437 return self.greedy_search(
1438 input_ids,
1439 logits_processor=logits_processor,
1440 stopping_criteria=stopping_criteria,
1441 pad_token_id=generation_config.pad_token_id,
1442 eos_token_id=generation_config.eos_token_id,
1443 output_scores=generation_config.output_scores,
1444 return_dict_in_generate=generation_config.return_dict_in_generate,
1445 synced_gpus=synced_gpus,
1446 streamer=streamer,
1447 **model_kwargs,
1448 )
1450 elif is_contrastive_search_gen_mode:
1451 if generation_config.num_return_sequences > 1:
File /opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:2248, in GenerationMixin.greedy_search(self, input_ids, logits_processor, stopping_criteria, max_length, pad_token_id, eos_token_id, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, synced_gpus, streamer, **model_kwargs)
2245 model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
2247 # forward pass to get next token
-> 2248 outputs = self(
2249 **model_inputs,
2250 return_dict=True,
2251 output_attentions=output_attentions,
2252 output_hidden_states=output_hidden_states,
2253 )
2255 if synced_gpus and this_peer_finished:
2256 continue # don't waste resources running the code we don't need
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File /opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py:687, in LlamaForCausalLM.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, labels, use_cache, output_attentions, output_hidden_states, return_dict)
684 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
686 # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
--> 687 outputs = self.model(
688 input_ids=input_ids,
689 attention_mask=attention_mask,
690 position_ids=position_ids,
691 past_key_values=past_key_values,
692 inputs_embeds=inputs_embeds,
693 use_cache=use_cache,
694 output_attentions=output_attentions,
695 output_hidden_states=output_hidden_states,
696 return_dict=return_dict,
697 )
699 hidden_states = outputs[0]
700 logits = self.lm_head(hidden_states)
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py:577, in LlamaModel.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, use_cache, output_attentions, output_hidden_states, return_dict)
569 layer_outputs = torch.utils.checkpoint.checkpoint(
570 create_custom_forward(decoder_layer),
571 hidden_states,
(...)
574 None,
575 )
576 else:
--> 577 layer_outputs = decoder_layer(
578 hidden_states,
579 attention_mask=attention_mask,
580 position_ids=position_ids,
581 past_key_value=past_key_value,
582 output_attentions=output_attentions,
583 use_cache=use_cache,
584 )
586 hidden_states = layer_outputs[0]
588 if use_cache:
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File /opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py:292, in LlamaDecoderLayer.forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache)
289 hidden_states = self.input_layernorm(hidden_states)
291 # Self Attention
--> 292 hidden_states, self_attn_weights, present_key_value = self.self_attn(
293 hidden_states=hidden_states,
294 attention_mask=attention_mask,
295 position_ids=position_ids,
296 past_key_value=past_key_value,
297 output_attentions=output_attentions,
298 use_cache=use_cache,
299 )
300 hidden_states = residual + hidden_states
302 # Fully Connected
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File /opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py:243, in LlamaAttention.forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache)
240 attn_output = attn_output.transpose(1, 2)
241 attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
--> 243 attn_output = self.o_proj(attn_output)
245 if not output_attentions:
246 attn_weights = None
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/accelerate/hooks.py:165, in add_hook_to_module.<locals>.new_forward(*args, **kwargs)
163 output = old_forward(*args, **kwargs)
164 else:
--> 165 output = old_forward(*args, **kwargs)
166 return module._hf_hook.post_forward(module, output)
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/linear.py:114, in Linear.forward(self, input)
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasGemmEx( handle, opa, opb, m, n, k, &falpha, a, CUDA_R_16F, lda, b, CUDA_R_16F, ldb, &fbeta, c, CUDA_R_16F, ldc, CUDA_R_32F, CUBLAS_GEMM_DFALT_TENSOR_OP)`
```
<|||||>Interestingly, I'm not getting this error on my home machine. I'm using the same GPUs and the same docker image, so the versions are exactly the same - except the nvidia driver is 525.89.02 instead of 525.78.01.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I encountered the same error, with CUDA Version: 11.7 and Driver Version: 515.86.01 <|||||>>
In "config.json" change "pad_token_id=-1" to "pad_token_id=2". This happens because during batch generation, the model sometimes generates pad_token_id=-1<|||||>> I encountered the same error, with CUDA Version: 11.7 and Driver Version: 515.86.01
how to solve?
<|||||>> pad_token_id
Thanks! This solve my problem.<|||||>same problem<|||||>same error when I load model on multiple gpus eg. 4,which set bu CUDA_VISIBLE_DEVICES=0,1,2,3. but when I load model only in 1 gpu, It can generate result succesfully. my code:
`
tokenizer = LlamaTokenizer.from_pretrained(hf_model_path)
model = LlamaForCausalLM.from_pretrained(
hf_model_path,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
load_in_8bit=True
)
generation_output = model.generate(**inputs,
return_dict_in_generate=True,
output_scores=True,
#max_length=512,
max_new_tokens=512,
do_sample=False,
early_stopping=True,
#top_p = 0.6,
num_beams=3,
#eos_token_id=tokenizer.eos_token_id,
num_return_sequences = 1)
sentence = tokenizer.decode(generation_output.sequences[0])
`
how to explain this problem?
transformer version: 4.30.2
accelerate version: 0.20.3<|||||>> same error when I load model on multiple gpus
I'm experiencing the same issue with two gpus. When I replace `device_map="auto"` to `device_map={"":"cuda:0"}` the model generates as expected.
I'm using two A6000s.
CUDA Version: 12.2
CUDA Driver: 535.54.03
transformer version: 4.28.1
accelerate version: 0.20.3
Python: 3.8.10
torch: 2.0.1
<|||||>same problem when running with multiple gpus<|||||>same problem here<|||||>Please stop commenting with "same problem" without providing a reproducer. We can't do anything about a bug we can't reproduce.<|||||>@sgugger sorry, here's my environment:
Two A6000s.
CUDA Version: 11.7
transformer version: 4.32.0.dev
accelerate version: 0.21.0
Python: 3.9.16
torch: 2.0.1 |
transformers | 22,545 | closed | Model.eval() always returns the same logits for SequenceClassfication models with binary labels | ### System Info
On GoogleColab
- `transformers` version: 4.27.4
- Platform: Linux-5.10.147+-x86_64-with-glibc2.31
- Python version: 3.9.16
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 2.0.0+cu118 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.6.8 (gpu)
- Jax version: 0.4.7
- JaxLib version: 0.4.7
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: not
### Who can help?
@younesbelkada @sgugger
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from sklearn.model_selection import train_test_split
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from evaluate import load
from tqdm import tqdm
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch import cuda
from datasets import load_dataset
from transformers import TrainingArguments, Trainer
device = 'cuda' if cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
dataset = load_dataset("ethos", "binary")
def tokenize_function(examples):
return tokenizer(examples["text"], max_length = 512, padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(0, 898))
small_eval_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(898, 998))
load_accuracy = load("accuracy")
load_f1 = load("f1")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = load_accuracy.compute(predictions=predictions, references=labels)["accuracy"]
f1 = load_f1.compute(predictions=predictions, references=labels)["f1"]
return {"accuracy": accuracy, "f1": f1}
training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch", learning_rate = 1e-03, per_device_train_batch_size =16,
per_device_eval_batch_size=4,
num_train_epochs=1)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
### Expected behavior
```trainer.predict(small_eval_dataset)``` should return different logits but it returns the same for all the test examples
```
PredictionOutput(predictions=array([[ 0.30563816, -0.10853065],
[ 0.30566448, -0.10852079],
[ 0.3056038 , -0.10854296],
[ 0.30563852, -0.10852969],
[ 0.30562696, -0.10853519],
[ 0.3057046 , -0.10850368],
[ 0.3056232 , -0.10853792],
[ 0.3056584 , -0.10852299],
[ 0.30566052, -0.10852136],
[ 0.30566704, -0.10851857],
[ 0.30566064, -0.10852212],
[ 0.30565894, -0.10852377],
[ 0.30565098, -0.10852514],
[ 0.30566713, -0.10852013],
....
````
```python
inputs = torch.tensor(small_eval_dataset['input_ids']).to(device)
mask = torch.tensor(small_eval_dataset['attention_mask']).to(device)
model.train()
model(inputs[0:10], mask[0:10])
```
```
SequenceClassifierOutput(loss=None, logits=tensor([[ 0.2427, -0.2602],
[ 0.2804, -0.2819],
[ 0.0620, -0.1497],
[ 0.6520, -0.3421],
[ 0.5095, -0.1113],
[ 0.3538, 0.0181],
[ 0.2826, 0.1292],
[ 0.4033, 0.0041],
[ 0.4308, -0.1813],
[ 0.3979, -0.2117]], device='cuda:0', grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
```
```python
model.eval()
model(inputs[0:10], mask[0:10])
```
```
SequenceClassifierOutput(loss=None, logits=tensor([[ 0.3056, -0.1085],
[ 0.3057, -0.1085],
[ 0.3056, -0.1085],
[ 0.3056, -0.1085],
[ 0.3056, -0.1085],
[ 0.3057, -0.1085],
[ 0.3056, -0.1085],
[ 0.3057, -0.1085],
[ 0.3057, -0.1085],
[ 0.3057, -0.1085]], device='cuda:0', grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
``` | 04-03-2023 19:35:35 | 04-03-2023 19:35:35 | That's because your model training diverged. It has nothing to do with the Transformers library and is probably due to your very high learning rate. You should go on the [forums](https://discuss.huggingface.co/) if you need help debugging your trainings.<|||||>Yes thanks this was the reason |
transformers | 22,544 | closed | Generate: Add text streamer decoding options | # What does this PR do?
In advance of communicating the iterator streamer with Gradio demos, adds two important options:
1. option to skip the prompt in the streamer (e.g. for chatbots)
2. option to receive `decode()` kwargs (e.g. to skip special tokens)
It also makes use of the changes in #22516 to make the iterator streamer much more compact -- it is now a child class of the stdout streamer, with a few modifications. | 04-03-2023 18:54:36 | 04-03-2023 18:54:36 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,543 | closed | Update test_image_processing_pix2struct.py | # What does this PR do?
This PR should fix the failing test on `main`.
The fix is to replace the previous image with the one I have uploaded on the Hub: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/australia.jpg
cc @sgugger | 04-03-2023 18:27:03 | 04-03-2023 18:27:03 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,542 | closed | Backbone add mixin tests | # What does this PR do?
Adds a set of tests specifically for the Backbone class
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests? | 04-03-2023 17:38:41 | 04-03-2023 17:38:41 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,541 | closed | Issue with gradient accumulation in CodeParrot example | There is a bug in the gradient accumulation that causes the [training script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/codeparrot/scripts/codeparrot_training.py) to run slower than necessary. Currently we have the following:
```python
for step, batch in enumerate(train_dataloader, start=1):
if args.resume_from_checkpoint and step < resume_step:
continue # we need to skip steps until we reach the resumed step
loss = model(batch, labels=batch, use_cache=False).loss
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
loss_tracking += avg_loss.item() / args.gradient_accumulation_steps
log_metrics(step, {"samples": step * samples_per_step,
"loss_per_step/train": loss.item()})
loss = loss / args.gradient_accumulation_steps
if step % args.gradient_accumulation_steps != 0:
# Prevent backward from doing gradient all_reduce in every step
if accelerator.distributed_type == DistributedType.MULTI_GPU:
with model.no_sync():
accelerator.backward(loss)
else:
accelerator.backward(loss)
else:
lr = get_lr()
accelerator.backward(loss)
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
elapsed_time = time.time() - t_start
tflops = compute_tflops(elapsed_time, accelerator, args)
log_metrics(
step,
{
"steps": completed_steps,
"loss/train": loss_tracking,
"lr": lr,
"tflops": tflops,
"time_per_iteration": elapsed_time,
},
)
t_start = time.time()
loss_tracking = 0
completed_steps += 1
```
When it should be something along the lines of this:
```python
for step, batch in enumerate(train_dataloader, start=1):
with accelerator.accumulate(model):
if args.resume_from_checkpoint and step < resume_step:
continue # we need to skip steps until we reach the resumed step
lr = get_lr()
loss = model(batch, labels=batch, use_cache=False).loss
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
loss_tracking += avg_loss.item() / args.gradient_accumulation_steps
log_metrics(step, {"samples": step * samples_per_step,
"loss_per_step/train": loss.item()})
accelerator.clip_grad_norm_(model.parameters(), 1.0)
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if accelerator.gradient_state.sync_gradients:
elapsed_time = time.time() - t_start
tflops = compute_tflops(elapsed_time, accelerator, args)
log_metrics(
step,
{
"steps": completed_steps,
"loss/train": loss_tracking,
"lr": lr,
"tflops": tflops,
"time_per_iteration": elapsed_time,
},
)
t_start = time.time()
loss_tracking = 0
completed_steps += 1
```
We're not actually pausing the gradient accumulation. Here's an example:
https://github.com/huggingface/accelerate/blob/92d072043eb24eddf714edd578bceff07a2d9470/examples/by_feature/gradient_accumulation.py#L171-L183
And here some explanation:
https://huggingface.co/docs/accelerate/concept_guides/gradient_synchronization.
This could speed-up training up to 2x as [reported](https://github.com/muellerzr/timing_experiments) by @muellerzr! Thanks for reporting!

cc @ArmelRandy @loubnabnl
| 04-03-2023 17:09:50 | 04-03-2023 17:09:50 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,540 | closed | Fix inverted conditional in TF common test! | Noticed a rather alarming conditional being backwards in the `test_pt_tf_model_equivalence` common test. This probably resulted in a lot of tests being skipped! | 04-03-2023 16:02:32 | 04-03-2023 16:02:32 | _The documentation is not available anymore as the PR was closed or merged._<|||||>As expected this has raised a few bugs in the cross-test that were silent before - I'll see what I can do in this PR<|||||>Most likely - I'll investigate them all soon!<|||||>Quick summary of the fixes needed:
ESM: `TFEsmForTokenClassification` copied the computation from `TFBertForTokenClassification`, but this has some slightly odd BERT-specific behaviour and doesn't mask -100 in the same way as other models. Replaced it with the loss block from `TFRobertaForTokenClassification` and all tests pass.
GPT2: For model classes that take rank-3 inputs (e.g. `MultipleChoice` or `DoubleHeads`), when `output_hidden_states=True` , inputs have their second two dims flattened internally in the main model stem. This means that the output `hidden_states` are rank 3 `(bsz, seq_len * num_choices, hidden_dim)` and not rank 4 `(bsz, num_choices, seq_len, hidden_dim)`. However, the PT model un-flattens the output for the final `hidden_states`, which means the last hidden state is rank-4, unlike the others which remain rank-3. In the old TF model, all hidden states are rank-3. I modified the TF code to un-flatten the last hidden state in the same way.
HUBERT: Loss computation especially for CTC overflows a lot with the default labels, which creates lots of `inf` values and makes it very hard to compare TF and PT losses. I skipped PT-TF equivalence testing for the losses, but keep it for all non-loss outputs.
Wav2Vec2: Same as HUBERT
XGLM: The PT XGLM model does a weird thing where it shifts labels by 1 and then adds `pad_token_id` as the final label to all samples. I'm not sure this is correct, but I modified the TF code to do the same. It's possible the TF code is the right one here though, in which case we should revert it and change the PT code instead.<|||||>@gante I fixed all the bugs that this surfaced, explained above ^
cc @sgugger for final review too<|||||>Thank you for the fix @Rocketknight1 ❤️ . And I apologize for the mistake I introduced ... |
transformers | 22,539 | closed | [setup] migrate setup script to `pyproject.toml` | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Follows discussion in https://github.com/huggingface/transformers/pull/22531#issuecomment-1494493545
Changes:
- migrate setup script to `pyproject.toml`
- migrate `pytest` configs to `pyproject.toml`
- cleanup `isort` and `flake8` configs
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-03-2023 15:52:38 | 04-03-2023 15:52:38 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,538 | closed | Cross Attention of MarianMT translation model, inconsistent with paper! | ### System Info
When I'm inspecting the cross-attention layers from the pretrained transformer translation model (MarianMT model), It is very strange that the cross attention from layer 0 and 1 provide best alignment between input and output. I used bertviz to visualize all heads from all 6 layers, and tried different language, english to german and english to chinese, it all gives the same results, which does not make sense because the last layers should be more accurate according to the paper _Jointly Learning to Align and Translate with Transformer Models_ [https://arxiv.org/pdf/1909.02074.pdf](url)

But when I'm looking at the cross attention of model _Helsinki-NLP/opus-mt-en-de_ and _Helsinki-NLP/opus-mt-en-zh_ , the layer 1 gives the best alignment. the code is below:
```python
from transformers import AutoTokenizer, AutoModel
import os
os.environ['TRANSFORMERS_CACHE'] = '/data2/hanyings/.cache'
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = AutoModel.from_pretrained("Helsinki-NLP/opus-mt-en-de", output_attentions=True)
encoder_input_ids = tokenizer("She sees the small elephant.", return_tensors="pt", add_special_tokens=True).input_ids
with tokenizer.as_target_tokenizer():
decoder_input_ids = tokenizer("Sie sieht den kleinen Elefanten.", return_tensors="pt", add_special_tokens=True).input_ids
outputs = model(input_ids=encoder_input_ids, decoder_input_ids=decoder_input_ids)
encoder_text = tokenizer.convert_ids_to_tokens(encoder_input_ids[0])
decoder_text = tokenizer.convert_ids_to_tokens(decoder_input_ids[0])
from bertviz import model_view
model_view(
encoder_attention=outputs.encoder_attentions,
decoder_attention=outputs.decoder_attentions,
cross_attention=outputs.cross_attentions,
encoder_tokens= encoder_text,
decoder_tokens = decoder_text
)
```
And the results are:


From the above pictures, I observed that the first 2 layers give the best alignment whereas the last layers do not align the input and output tokens properly. Can you please help me to explain why this happens? and If the alignment of the last layer is not accurate, how does the model provide correct predictions? @ArthurZucker @younesbelkada @gante Please! It is very important for my research project!
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers import AutoTokenizer, AutoModel
import os
os.environ['TRANSFORMERS_CACHE'] = '/data2/hanyings/.cache'
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = AutoModel.from_pretrained("Helsinki-NLP/opus-mt-en-de", output_attentions=True)
encoder_input_ids = tokenizer("She sees the small elephant.", return_tensors="pt", add_special_tokens=True).input_ids
with tokenizer.as_target_tokenizer():
decoder_input_ids = tokenizer("Sie sieht den kleinen Elefanten.", return_tensors="pt", add_special_tokens=True).input_ids
outputs = model(input_ids=encoder_input_ids, decoder_input_ids=decoder_input_ids)
encoder_text = tokenizer.convert_ids_to_tokens(encoder_input_ids[0])
decoder_text = tokenizer.convert_ids_to_tokens(decoder_input_ids[0])
from bertviz import model_view
model_view(
encoder_attention=outputs.encoder_attentions,
decoder_attention=outputs.decoder_attentions,
cross_attention=outputs.cross_attentions,
encoder_tokens= encoder_text,
decoder_tokens = decoder_text
)
```
### Expected behavior
The bottom layers give better alignment (layer0 and 1) | 04-03-2023 15:52:23 | 04-03-2023 15:52:23 | Hey @42694647426 👋
As per our [issues guidelines](https://github.com/huggingface/transformers/blob/main/ISSUES.md), we reserve GitHub issues for bugs in the repository and/or feature requests. For any other matters, we'd like to invite you to use our [forum](https://discuss.huggingface.co/) 🤗
In this case, I'd also advise attempting to reach out to the original authors of the paper you linked, as well as the creators of the Marian models in question (Helsinki-NLP)!<|||||>> Hey @42694647426 👋
>
> As per our [issues guidelines](https://github.com/huggingface/transformers/blob/main/ISSUES.md), we reserve GitHub issues for bugs in the repository and/or feature requests. For any other matters, we'd like to invite you to use our [forum](https://discuss.huggingface.co/) 🤗
>
> In this case, I'd also advise attempting to reach out to the original authors of the paper you linked, as well as the creators of the Marian models in question (Helsinki-NLP)!
Hi @gante, thank you for the quick reply! Since a few papers have proven that the last two encoder-decoder layers should give the best alignment (the second last layer is actually the best from the paper mentioned above) and it also makes sense that the last layer should have gained the most information to generate output.
Is there any possibility that the cross_attention in the output sequence is ordered reversely(layer 0 is actually the last layer i.e. the layer closest to the output)?
Thank you for your help.<|||||>
I don't think the cross_attentions is outputted in reverse. Looking at line 1075 for [marian](https://github.com/huggingface/transformers/blob/main/src/transformers/models/marian/modeling_marian.py) we see that the cross attentions is added one layer at a time with the correct order:
```
for idx, decoder_layer in enumerate(self.layers):
...
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
```
Looking at the generation utils with beam search, I don't see any rearranging of the cross attentions happening either.
But now that you mention it, it is kind of weird how the alignment in the early layers give the best results - but it's not a bug from the looks of it.
Is it possible the model is still providing correct outputs because the positional info is being propagated to the successive layers? [P-Transformer](https://arxiv.org/pdf/2212.05830.pdf) claims this isn't generally the case, but that's document translation.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,537 | closed | Remove hack for dynamic modules and use Python functions instead | # What does this PR do?
#21646 introduced a new way of dealing with dynamic modules locally to avoid a flaky failure in the CI, using a bit of hack with subprocess python commands. This seems to cause problem with distributed runs using this code (#22506 and was also reported internally as failing with big code experiment in the cluster).
It turns out there is a simple way to reset the cache which should be used when copying new modules, this PR uses that solution. I have run the scripts to reproduce the flakiness given in #21646 and didn't get any issue with the changes in this PR.
Fixes #22506 | 04-03-2023 15:48:49 | 04-03-2023 15:48:49 | _The documentation is not available anymore as the PR was closed or merged._<|||||>I confirm that this fixes a race condition discovered today with:
```
from transformers import GPT2Config, GPT2LMHeadModel, AutoModelForCausalLM, AutoConfig
model_name = "bigcode/santacoder"
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
```
which fails randomly when multiple processes run it in parallel.
```
[default0]:Traceback (most recent call last):
[default0]: File "<string>", line 1, in <module>
[default0]:FileNotFoundError: [Errno 2] No such file or directory: '/fsx/m4/modules/transformers_modules/bigcode/santacoder/bb63c0e145ad465df0a97dec285a949c9042523c/configuration_gpt2_mq.py'
```
the problem goes away with this PR.
I suspect a race condition is:
https://github.com/huggingface/transformers/blob/159ff3342c576ccf26cb00fb9510666ed626f42d/src/transformers/dynamic_module_utils.py#L173
which copies from multiple files to the same single target destination. This fails on FSX distributed filesystem with more than 2 dist processes.
Please note that the exception is not trapped and comes from the sub-process.<|||||>> It turns out there is a simple way to reset the cache which should be used when copying new modules, this PR uses that solution. I have run the scripts to reproduce the flakiness given in https://github.com/huggingface/transformers/pull/21646 and didn't get any issue with the changes in this PR.
I did notice that the SHA of the cached entry kept on changing. Why would one need to reset the cache, other than in special cases? Isn't the whole point of a cache is not to do anything but to load the file immediately?
The problem we had was not on CI, so I'm not sure why the reset code was even run. Perhaps there is a need to check the reset isn't performed unless asked explicitly? Since it appears to be happening since we shouldn't have run into this issue in the first place if this code was meant to be run on reset only. Please correct me if I'm missing something.<|||||>> Why would one need to reset the cache, other than in special cases?
If you do not reset the cache after adding a new module, the import system of Python will not find it (see the doc of [`importlib.invalidate_caches()`](https://docs.python.org/3/library/importlib.html#importlib.invalidate_caches).
The function is only called when such a new module is added (new init, or newly copied dynamic code file) as you can see in the PR. It will only happen repeatedly if you keep downloading new models with dynamic code (or make it appear as such by doing save_pretrained then from_pretrained from different temp folders).
In any case, this situation will become even more rare in the near future when we will stop moving around those files with the code in each repo but trust only one source of truth.<|||||>But I'm not adding a new module, I'm rerunning the [same 1 line of code](https://github.com/huggingface/transformers/pull/22537#issuecomment-1495215758).
Is there something special about `"bigcode/santacoder"` that it never gets cached?
There should be 2 different behaviors:
1. first time - when it's downloaded
2. 2nd and onward time when it's already cached.
no?<|||||>I am confused about what sha of the cached entry keeps changing. Could you elaborate? I added a print statement the five times `importlib.invalidate_caches()` is called after this PR and I can confirm it is never called once the model is cached when I run your sample above:
```py
from transformers import GPT2Config, GPT2LMHeadModel, AutoModelForCausalLM, AutoConfig
model_name = "bigcode/santacoder"
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
```<|||||>I'm not exactly sure of the exact behavior, I was using several debug scripts and it seemed to be cycling between `bb63c0e145ad465df0a97dec285a949c9042523c` and `6a4fb77ff71c32c34dc8c61af500c7a7ca17c1a6`
But I wasn't talking about this, I was asking why was re-running this script with 4 processes:
```
from transformers import GPT2Config, GPT2LMHeadModel, AutoModelForCausalLM, AutoConfig
model_name = "bigcode/santacoder"
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
```
kept re-rerunning the reset code - as it was failing most of the time in 1 or 2 out of 4 processes.
My thinking is that with the caching happened, even with the bug in resetting code, that resetting code shouldn't have been run.
e.g. here I reverted to transformers before this PR's fix:
1. run and make sure it's cached:
```
$ python test.py
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
```
it should be cached now for sure, right?
2. now it should just read the cached module
```
$ python -m torch.distributed.run --nproc_per_node=4 --nnodes=1 --tee 3 test.py
[...]
[default0]:Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
[default1]:Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
[default3]:Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
[default2]:Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
[default1]:Traceback (most recent call last):
[default1]: File "<string>", line 1, in <module>
[default1]:FileNotFoundError: [Errno 2] No such file or directory: '/fsx/m4/modules/transformers_modules/bigcode/santacoder/6a4fb77ff71c32c34dc8c61af500c7a7ca17c1a6/configuration_gpt2_mq.py'
[default0]:ModuleNotFoundError: No module named
[default0]:'transformers_modules.bigcode.santacoder.6a4fb77ff71c32c34dc8c61af500c7a7ca17c1a6.configuration_gpt2_mq'
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 2722338) of binary: /fsx/m4/conda/stas-m4/bin/python
```
so that was my concern.<|||||>I am very confused, if you revert before this PR's fix, you will have the issue with the race condition. I don't get what the problem is after this PR?<|||||>there is no problem after this PR. It's OK, Sylvain.<|||||>If your question is why there was a change even with the file cached before this PR, it was because of a hack we implemented instead of using the proper way provided with `importlib.invalidate_cache()` (which we didn't know about), where the file with the code was deleted and recreated before each use. This is obviously bad for race conditions, hence the proper fix in this PR :-)<|||||>Aha! Thank you for clarifying the cause, Sylvain.<|||||>Thank you for removing the ugly hack I added 💯 |
transformers | 22,536 | closed | Fix missing metrics with multiple eval datasets | Fixes #22530
[Issue](https://github.com/huggingface/transformers/issues/22530)
**tl;dr** - `Trainer` only keeps the last metric when using multiple eval datasets. This PR fixes that by merging metrics from all eval datasets into one dict.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
@sgugger
| 04-03-2023 15:25:19 | 04-03-2023 15:25:19 | _The documentation is not available anymore as the PR was closed or merged._<|||||>It seems like the tests failed on an irrelevant "File not found error" in tokenizers, but I can not rerun the tests.
@sgugger would you kindly trigger them again?<|||||>:call_me_hand: |
transformers | 22,535 | closed | [`T5`] Enable naive Pipeline Parallelism training for T5 | # What does this PR do?
Similarly as https://github.com/huggingface/transformers/pull/22329 this PR enables training `T5` models in a "Naive Pipeline Parallelism" setup. What is termed as "Naive Pipeline Parallelism" is simply to spread the model across multiple GPUs and run naively the forward/backward pass by communicating the activations and gradients between each GPU.
Without this fix, users will encounter device mismatch issues when training this model that has been loaded across multiple GPUs. Hence, the fix is to manually set the device of the `labels` to the same device as `lm_logits`.
A simple snippet to reproduce the behaviour below (this needs to be run on a multi-gpu env):
```python
import torch
from transformers import AutoModelForSeq2SeqLM
model_id = "google/flan-t5-base"
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, device_map="balanced")
print(set(model.hf_device_map.values())) # >>> {0, 1}
dummy_input = torch.LongTensor([[1, 2, 3, 4, 5]])
loss = model(input_ids=dummy_input, labels=dummy_input).loss
```
Error trace:
```bash
│ 1746 │ │ loss = None │
│ 1747 │ │ if labels is not None: │
│ 1748 │ │ │ loss_fct = CrossEntropyLoss(ignore_index=-100) │
│ ❱ 1749 │ │ │ loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1)) │
│ 1750 │ │ │ # TODO(thom): Add z_loss https://github.com/tensorflow/mesh/blob/fa19d69eafc │
│ 1751 │ │ │
│ 1752 │ │ if not return_dict: │
│ │
│ /home/younes_huggingface_co/miniconda3/envs/fix-test/lib/python3.9/site-packages/torch/nn/module │
│ s/module.py:1501 in _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
│ │
│ /home/younes_huggingface_co/miniconda3/envs/fix-test/lib/python3.9/site-packages/torch/nn/module │
│ s/loss.py:1174 in forward │
│ │
│ 1171 │ │ self.label_smoothing = label_smoothing │
│ 1172 │ │
│ 1173 │ def forward(self, input: Tensor, target: Tensor) -> Tensor: │
│ ❱ 1174 │ │ return F.cross_entropy(input, target, weight=self.weight, │
│ 1175 │ │ │ │ │ │ │ ignore_index=self.ignore_index, reduction=self.reduction, │
│ 1176 │ │ │ │ │ │ │ label_smoothing=self.label_smoothing) │
│ 1177 │
│ │
│ /home/younes_huggingface_co/miniconda3/envs/fix-test/lib/python3.9/site-packages/torch/nn/functi │
│ onal.py:3029 in cross_entropy │
│ │
│ 3026 │ │ ) │
│ 3027 │ if size_average is not None or reduce is not None: │
│ 3028 │ │ reduction = _Reduction.legacy_get_string(size_average, reduce) │
│ ❱ 3029 │ return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(re │
│ 3030 │
│ 3031 │
│ 3032 def binary_cross_entropy( │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0! (when checking argument for argument target
in method wrapper_CUDA_nll_loss_forward)
```
cc @sgugger
## Related issues:
https://github.com/huggingface/peft/issues/242
https://github.com/huggingface/peft/issues/205
| 04-03-2023 15:17:02 | 04-03-2023 15:17:02 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,534 | closed | 🌐 [i18n-KO] Translated `custom_models.mdx` to Korean | <!-- PR의 제목은 "🌐 [i18n-KO] Translated `<your_file>.mdx` to Korean" 으로 부탁드립니당 -->
# What does this PR do?
Translated the `custom_models.mdx` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
<!-- 메인 이슈에 기록이 남아요! 가짜연구소 리포를 사용해 연습하실때는 제거해주시면 감사하겠습니다! :smile: -->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
<!-- 제출 전 체크리스트로, 가짜연구소만의 체크리스트도 <details>로 감싸서 만들어두면 더 좋을 것 같아요. -->
## Who can review?
<!-- 가짜연구소 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
<!-- @sgugger, @ArthurZucker, @eunseojo May you please review this PR? -->
Team PseudoLab, may you please review this PR?
@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd
May you please review this PR?
@sgugger, @ArthurZucker, @eunseojo | 04-03-2023 15:15:07 | 04-03-2023 15:15:07 | _The documentation is not available anymore as the PR was closed or merged._<|||||>I think we should discuss whether to translate `configuration` to 구성.
Since the configuration is the name of the class, I think it will be misunderstood when translated into Korean to understand that it is a class.
`configuration`이 class의 이름이기 때문에 한국어로 번역 시 class임을 이해하지 못하도록 오해할 것 같습니다.<|||||>> I think we should discuss whether to translate `configuration` to 구성. Since the configuration is the name of the class, I think it will be misunderstood when translated into Korean to understand that it is a class.
>
> `configuration`이 class의 이름이기 때문에 한국어로 번역 시 class임을 이해하지 못하도록 오해할 것 같습니다.
저도 놓친 부분이네요. 클래스를 의미하는 부분은 `configuration`로, 클래스를 의미하지 않는 부분(본문에서 config라고 적힌 경우)은 `구성`으로 번역하는걸 검토해보겠습니다.<|||||>May you please review this PR?
@sgugger, @ArthurZucker, @eunseojo |
transformers | 22,533 | closed | 🌐[i18n-KO] Translate `autoclass_tutorial` to Korean and Fix the typo of `quicktour` | # What does this PR do?
Translated the `autoclass_tutorial.mdx` file of the documentation to Korean and fix the typo of `quicktour`
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
<!-- 가짜연구소 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
<!-- @sgugger, @ArthurZucker, @eunseojo May you please review this PR? -->
Team PseudoLab, may you please review this PR?
@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd
May you please review this PR?
@sgugger, @ArthurZucker, @eunseojo
## Review result
- [x] fix a wrong source code link of functions in the document
> Links for API documents are not activated. I checked other language documents have same problem. I think it will be fixed when API documents are translated. | 04-03-2023 14:33:51 | 04-03-2023 14:33:51 | _The documentation is not available anymore as the PR was closed or merged._<|||||>- need to add the english link of `Load pretrained instances with an AutoClass`
- keep the `AutoClass` as a english<|||||>squashed commit messages and check a final document result.
<|||||>@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd
Please review thie PR.
Thank you in advance.<|||||>[Korean]
음.. 좀 헷갈리네요. 링크가 안되는 이유가 뭔지 좀 알아봐야 될 것 같습니다.
소스코드에 링크가 안걸리는게 문제 같습니다. 좀 더 찾아볼께요
[English]
I will check why the hyperlink does not work.
I think I missed somthing on link code of source codes in the document<|||||>Thank you.
I found my source code links are wrong.
I updated review action items and fix it @HanNayeoniee <|||||>May you please review this PR?
@sgugger, @ArthurZucker, @eunseojo<|||||>Thanks for your contribution! |
transformers | 22,532 | closed | [`Trainer`] Force `is_model_parallel` when model is loaded in multiple GPUs using `accelerate` | # What does this PR do?
When using the Trainer on a multi-GPU environment, users currently apply a patch that leads to some bugs.
Before running a training they [need to call](https://github.com/huggingface/peft/issues/205#issuecomment-1491455711):
```python
setattr(model, 'model_parallel', True)
setattr(model, 'is_parallelizable', True)
```
Which can lead to unexpected bugs on some models, such as T5, that has the `parallelize` API that is still in place, thus when forcing `model_parallel` to be `True`, calls that API, which is deprecated and should not be maintained.
Script to reproduce:
```python
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoModelForSeq2SeqLM, AutoTokenizer, Trainer, TrainingArguments, DataCollatorForLanguageModeling
from peft import prepare_model_for_int8_training,LoraConfig, get_peft_model
causal_lm_model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(
causal_lm_model_id,
load_in_8bit=True,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(causal_lm_model_id)
model = prepare_model_for_int8_training(model)
# setattr(model, 'model_parallel', True)
# setattr(model, 'is_parallelizable', True)
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
trainer = Trainer(
model=model,
train_dataset=data["train"],
args=TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=3,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.is_model_parallel = True
model.config.use_cache = False
trainer.train()
```
cc @sgugger
Related: https://github.com/huggingface/peft/issues/205
| 04-03-2023 14:08:44 | 04-03-2023 14:08:44 | Could you elaborate why is such a patch needed and what is the goal of your PR? Cause all of this seems very hacky.<|||||>These hacks were needed because `self.place_model_on_device` [needs to be set to `True`](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L461-L469) in order for the `Trainer` to work correctly on a multi-GPU environment, i.e. with a model that has been loaded across multiple GPUs (so we're talking about Naive PP here). Otherwise users will encounter device mismatch between model's input/output.
Moreover, modifying `place_model_on_device` directly on `TrainingArguments` seems to not work, as this argument seems to not be on the `__init__` of that class, and also it seems to me that it is better to not touch this attribute as it is a property method: https://github.com/huggingface/transformers/blob/9419f144ad6d5464afc3c9c65a23c6940f8dd9c2/src/transformers/training_args.py#L1801
That is why I preferred to introduce a new argument to avoid modifying what is already in place and modify directly what is needed to be edited, without having to modify the model's internals (forcing `model_parallel` to `True` on T5 models will call the deprecated `parallelize` API that leads to some bugs)<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Or you could just analyze the device map of the model and determine if there are several GPUs used. It would be cleaner and not require the user to learn the 97th training argument.<|||||>Ahh yes good point! |
transformers | 22,531 | closed | [setup] drop deprecated `distutils` usage | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Migrate setup script to `pyproject.toml` ([PEP 517 – A build-system independent format for source trees](https://peps.python.org/pep-0517)).
Changes:
- drop deprecated `distutils` usage
- ~~migrate setup script to `pyproject.toml`~~
- ~~migrate `isort` and `pytest` configs to `pyproject.toml`~~
- ~~migrate `flake8` configs to `.flake8` and remove `setup.cfg` file~~
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-03-2023 13:16:01 | 04-03-2023 13:16:01 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> but we are very happy with the setup as it is.
Thanks for the clarification. The `pyprojct.toml` format is the recommended packaging method in [PEP 517 – A build-system independent format for source trees](https://peps.python.org/pep-0517). I have reverted some of the commits but kept the first one. The `distutils` module is deprecated and will be removed in Python 3.12 (See also [PEP 632 – Deprecate distutils module](https://peps.python.org/pep-0632)). In this PR, I changed `distutils.core.Command` to `setuptools.Command`.<|||||>I think you can suggest the changes thate removed the setup.cfg in a separate PR, it's a good cleanup (but not relevant to this PR anymore)
For migrating the setup.py to the pyproject, let's see with @LysandreJik what he thinks. My first reaction is to keep what's been working for us all these years ;-)<|||||>Thanks for the clarification. Since we have already dropped Python 3.6 support, `setuptools` works very well with `pyproject.toml` based project. We can move the static parts in `setup.py` to `pyproject.toml`. Note that the optional dependencies are too dynamic, so we still need a `setup.py` file.
Most Python utilities support `pyproject.toml` configuration (`black`, `isort`, `ruff`, `pytest`, ...). And some do not even support other config files like `setup.cfg` (e.g., `black`). I think maintaining configurations in a single file is a good practice. If you decide to migrate to `pyproject.toml`, pin me if I can help.<|||||>Yes, moving all configurations to the pyproject.toml is something we would like to clean up. If you want to contribute it, please open a PR :-) Note that we kept the isort and flake8 configurations for a bit after our migration to ruff, but they can now be completely removed, so it would just be pytest if I'm not mistaken. |
transformers | 22,530 | closed | Multiple eval datasets can only use last dataset for best checkpoint | I have a setup where I evaluate the model on several datasets and only the metrics from the last dataset can be used. The [code from Trainer](https://github.com/huggingface/transformers/blob/559a45d1dc1f46d6e9942cdc9ff5eef5a811a59d/src/transformers/trainer.py#L2234) looks like:
```python
if self.control.should_evaluate:
if isinstance(self.eval_dataset, dict):
for eval_dataset_name, eval_dataset in self.eval_dataset.items():
metrics = self.evaluate(
eval_dataset=eval_dataset,
ignore_keys=ignore_keys_for_eval,
metric_key_prefix=f"eval_{eval_dataset_name}",
)
else:
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
self._report_to_hp_search(trial, self.state.global_step, metrics)
if self.control.should_save:
self._save_checkpoint(model, trial, metrics=metrics)
````
Only the last metric is used, when datasets are passed as a `Dict[str, Dataset]`
Is this a bug?
A possible fix:
````python
if self.control.should_evaluate:
if isinstance(self.eval_dataset, dict):
metrics = {}
for eval_dataset_name, eval_dataset in self.eval_dataset.items():
dataset_metrics = self.evaluate(
eval_dataset=eval_dataset,
ignore_keys=ignore_keys_for_eval,
metric_key_prefix=f"eval_{eval_dataset_name}",
)
metrics.update(dataset_metrics)
else:
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
self._report_to_hp_search(trial, self.state.global_step, metrics)
if self.control.should_save:
self._save_checkpoint(model, trial, metrics=metrics)
```
````
Please, close this if this is the intended behavior. If it's not I can submit a pr with fixes. | 04-03-2023 12:27:29 | 04-03-2023 12:27:29 | It's possible there is a bug, so please open a PR if you think you have the right fix! |
transformers | 22,529 | closed | Intel macOS system with AMD 6900XT GPU, using MPS: cannot get any usable result back from any model | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.10.10
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 2.1.0.dev20230402 (False) says false but I am using PyTorch on GPU via `mps`
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
OS: macOS x64 Ventura 13.3
Hardware: Intel system with AMD 6900XT GPU
### Who can help?
@sgugger (possibly PyTorch related?)
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
My goal is to try models like Alpaca and GPT4ALL on my home Intel macOS system using my AMD 6900XT GPU.
I tried and failed to get tloen's Alpaca Lora UI and the LLaMa_MPS project running (details below). In investigating this, I have run this simple test script I wrote to test using MPS to get a result from `t5-small`. As a base for the code I used https://github.com/huggingface/transformers/issues/22122#issuecomment-1475302212 as the discussions in that thread indicated it should work fine:
```
import torch
import transformers
from transformers import T5ForConditionalGeneration, AutoTokenizer
print("PyTorch version: ", torch.__version__)
print("transformers version: ", transformers.__version__)
print()
tokenizer = AutoTokenizer.from_pretrained('t5-small', model_max_length=512)
input_string = 'translate English to German: "The house is wonderful."'
print("Input string:", input_string)
## On CPU
print("Trying CPU")
model_cpu = T5ForConditionalGeneration.from_pretrained('t5-small', device_map='auto')
print("Running on: ", model_cpu.device)
inputs = tokenizer(input_string, return_tensors='pt').input_ids
outputs = model_cpu.generate(inputs, max_length=200)
print("Decoded Output: ", tokenizer.decode(outputs[0]))
print("raw output: ", outputs)
## On MPS
print()
print("Trying mps")
model_mps = T5ForConditionalGeneration.from_pretrained('t5-small')
model_mps = model_mps.to('mps')
print("Running on: ", model_mps.device)
inputs_mps = tokenizer(input_string, return_tensors='pt').input_ids
inputs_mps = inputs_mps.to('mps')
outputs = model_mps.generate(inputs_mps, max_length=200)
try:
print("Decoded Output: ", tokenizer.decode(outputs[0]))
except Exception as e:
print(e)
print("raw output: ", outputs)
```
This produces the following result; CPU works fine, MPS produces a strange, repeating and very long result which throws an exception when being decoded:
```
PyTorch version: 2.1.0.dev20230402
transformers version: 4.28.0.dev0
Input string: translate English to German: "The house is wonderful."
Trying CPU
Running on: cpu
Decoded Output: <pad> "Das Haus ist wunderbar."</s>
raw output: tensor([[ 0, 96, 17266, 4598, 229, 19250, 535, 1]])
Trying mps
Running on: mps:0
out of range integral type conversion attempted
raw output: tensor([[ 0, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808, -9223372036854775808,
-9223372036854775808, -9223372036854775808]], device='mps:0')
```
Before trying this script, I first tried tloen's alpaca-lora GUI which has MPS support (https://huggingface.co/spaces/tloen/alpaca-lora/blob/main/app.py), and LLaMA_MPS (https://github.com/jankais3r/LLaMA_MPS)
Both of these exhibit the same or a very similar problem: the code appears to run fine, it uses my AMD 6900XT GPU (as detected via macOS Activity Manager), but I either get no output at all (alpaca-lora), or the output is corrupted, showing each token as a `??` symbol (LLaMa_MPS).
I am an AI newbie so I'm unsure how to try and debug this but I am pretty sure that all three of these examples are exhibiting the same problem.
I don't know if it's an issue in transformers or in PyTorch which provides the MPS backend, so I thought I'd start here.
Note: I'm running PyTorch 2.1 dev version because trying 2.0.0 with alpaca-lora gave me the error `RuntimeError: MPS does not support cumsum op with int64 input` - this was fixed by updating to 2.1-dev and Ventura 13.3. I have tested LLaMa_MPS with PyTorch 2.0.0 with the same result, so I don't believe it's specific to 2.1-dev.
Thanks in advance for any help.
### Expected behavior
The mps code shown above should output the same result as the CPU code. | 04-03-2023 12:19:23 | 04-03-2023 12:19:23 | I just did some mores searching and realised that -9223372036854775808 is "the smallest value that can be stored in a 64-bit signed integer" and that this issue looks the same as the Pytorch MPS issue reported here: https://github.com/pytorch/pytorch/issues/92311
In that thread, someone reported this workaround:
> Just replace argmax(...) with max(...).indices for instance replace output.argmax(dim=1) with output.max(dim=1).indices
I don't know if this helps me here as I'm not running any PyTorch code directly, but rather calling it through Transformers.
Anyway I guess this likely shows this isn't a transformers issue but is in PyTorch, and has already been reported. In which case, apologies for not noticing this before reporting this. <|||||>yea it looks like this is something that needs to be fixed on the PyTorch side. We can't just change the code of `generate` on our side to accommodate MPS devices and this is clearly a bug in PyTorch. So we just have to wait a bit for them to fix it.<|||||>Understood, thanks for the quick reply. |
transformers | 22,528 | closed | Add DePlot + MatCha on `transformers` | # What does this PR do?
Adds [MatCha](https://arxiv.org/pdf/2303.18223.pdf) and [DePlot](https://arxiv.org/pdf/2212.10505.pdf) on `transformers`.
Those are two different papers from Google AI but fully based on `Pix2Struct`.
Model weights:
- https://huggingface.co/ybelkada/deplot
- https://huggingface.co/ybelkada/matcha-base
- https://huggingface.co/ybelkada/matcha-chart2text-pew
- https://huggingface.co/ybelkada/matcha-chart2text-statista
- https://huggingface.co/ybelkada/matcha-plotqa-v1
- https://huggingface.co/ybelkada/matcha-plotqa-v2
I will move them to Google org once I will double check the model card contents with the authors
EDIT: all the weights have been moved
| 04-03-2023 11:18:45 | 04-03-2023 11:18:45 | _The documentation is not available anymore as the PR was closed or merged._<|||||>All models have been moved to Google org and model cards updated correctly! This PR is ready for review cc @sgugger |
transformers | 22,527 | closed | [Pix2struct] Simplify generation | # What does this PR do?
This PR aims to fix the warning that is currently printed out when generating text with Pix2Struct:
```
A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.
```
I see that all Pix2Struct models have `config.is_encoder_decoder=False`, but as Pix2Struct is an encoder-decoder model it'd be great/more logical to have this argument set to `True` and instead overwrite `prepare_inputs_for_generation` to have a cleaner way of generating text. This also makes us get rid of the warning.
To do:
- [ ] for the moment there're still one integration test failing (`test_batched_inference_image_captioning_conditioned`):
```
AssertionError: 'An photography of the Temple Bar and a collection of other items.' != 'An photography of the Temple Bar and a few other places.'
E - An photography of the Temple Bar and a collection of other items.
E ? ^^^^ ^^^^^^^^ ^^ -
E + An photography of the Temple Bar and a few other places.
``` | 04-03-2023 09:40:36 | 04-03-2023 09:40:36 | _The documentation is not available anymore as the PR was closed or merged._<|||||>PR is ready for review, however checkpoints on the hub will need to be updated (`is_encoder_decoder` = True) for this PR to be merged<|||||>PR is ready, models on the hub don't need to be updated since they don't have `is_encoder_decoder` set on the model config level (i.e. `Pix2StructConfig`. They have set it only in `Pix2StructTextConfig`). cc @younesbelkada |
transformers | 22,526 | closed | Fix convert_opt_original_pytorch_checkpoint_to_pytorch.py typo | # What does this PR do?
`load_checkpoint()` silently fails because `".qkj_proj." in key` is always `False`, but will eventually cause an error at `model.load_state_dict(state_dict)`. This PR fixes the typo that causes this issue.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten | 04-03-2023 08:54:27 | 04-03-2023 08:54:27 | |
transformers | 22,525 | closed | Update convert_llama_weights_to_hf.py | # What does this PR do?
Fix problem mentioned in https://github.com/huggingface/transformers/issues/22287
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@amyeroberts
@ArthurZucker
| 04-03-2023 08:22:30 | 04-03-2023 08:22:30 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Well this was bound to disappear with #22402 😅 |
transformers | 22,524 | closed | I want the 4.28.0.dev0 version of transformers | ### Feature request
I want the 4.28.0.dev0 version of transformers
### Motivation
I want the 4.28.0.dev0 version of transformers
### Your contribution
I want the 4.28.0.dev0 version of transformers | 04-03-2023 07:43:28 | 04-03-2023 07:43:28 | you can pip install with source code |
transformers | 22,523 | closed | Each list in `nested_token_ids` can't be a complete subset of another list, but is | ### Feature request
Enable passing disjunctive constraints (https://github.com/huggingface/transformers/blob/main/src/transformers/generation/beam_constraints.py#L261)
where one is a subset of the other
### Motivation
in the constrainted beam decoding feature, specifically in the case of disjunctive constraints, currently there is no option for one disjunctive constraint to be a subset of the other, as can be seen here:
https://github.com/huggingface/transformers/blob/main/src/transformers/generation/beam_constraints.py#L220
But, in many cases, this is exactly the case.
For example, if I wanted to consider all the inflections of the verb "sentence": ["sentence", "sentences", "sentenced", "sentencing"], then the tokenizer separates "sentenced" into ["sentence", "d"], which means that "sentence" is a subset of "sentenced".
### Your contribution
N/A | 04-03-2023 07:21:31 | 04-03-2023 07:21:31 | cc @gante<|||||>Hey @lovodkin93 👋 the constraints feature in beam search is experimental, so our efforts are currently limited to fixing bugs.
If you'd like to add the feature yourself, go for it :) <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,522 | closed | Update docs for assigning path to all_video_file_paths | # What does this PR do?
Updating a few lines in the video classification tasks guide as the way its written it seems like we are not actually iterating over the file paths, but rather the string.
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
| 04-03-2023 05:47:01 | 04-03-2023 05:47:01 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22522). All of your documentation changes will be reflected on that endpoint.<|||||>@amyeroberts yes you're right, the dataset is downloaded to the .cache directory and extracted into local directory. I have updated accordingly and tested in colab to confirm that its working
<img width="1387" alt="Screenshot 2023-04-05 at 16 06 57" src="https://user-images.githubusercontent.com/8465628/230124560-1eef5951-70f3-4b10-b4a8-4d1766bcb531.png">
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,521 | closed | Codeparrot Humaneval metric error? | Hi~, I tried to reproduce the metrics you reported by running transformers/examples/research_projects/codeparrot/scripts/human_eval.py, and the model is codeparrot-small, but the results have significant deviations. Does anyone could reproduce the results? | 04-03-2023 05:07:12 | 04-03-2023 05:07:12 | cc @lvwerra <|||||>Hi @Keysmis can you report the arguments you used for the script? And what results did you get? We updated some models and maybe we didn't update the reported metrics everywhere. cc @loubnabnl <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,520 | closed | Llama Tokenizer uses incorrect indices for PAD | ### System Info
latest transformer main
### Who can help?
@gante
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
configuration_llama.py sets
```
pad_token_id=0,
bos_token_id=1,
eos_token_id=2
```
but this is wrong. After checking the original tokenizer from FB,
```python
sp_model = SentencePieceProcessor(model_file="/home/ubuntu/llama/tokenizer.model")
print("bos_id: ", sp_model.bos_id())
print("eos_id: ", sp_model.eos_id())
print("pad_id: ", sp_model.pad_id())
```
we see that
```
bos_id: 1
eos_id: 2
pad_id: -1
```
### Expected behavior
```
bos_id: 1
eos_id: 2
pad_id: -1
```
instead of
```
pad_token_id=0,
bos_token_id=1,
eos_token_id=2
``` | 04-03-2023 00:02:46 | 04-03-2023 00:02:46 | cc @ArthurZucker -- is this fixed in #22402 ?<|||||>This is probably not gonna be fixed with regard to the `configuration_llama`.
However note that having the `sp_model` sending `-1` as a pad token means that it does not have any indices. Llama does not use a padding token.
The fix that we provide is that in the `tokenization_llama` the `pad_token` is set to `None`.
The config should be fixed to ensure that `pad_token=None` rather than `pad_token = 0`<|||||>Thanks @gante @ArthurZucker
What about the mismatch between the eos and bos tokens? Or is HF's tokenizer zero-indexed while Meta's native tokenizer is one-indexed?<|||||>As you said and showed using the `sp_model`,
> bos_id: 1
eos_id: 2
If you instantiate the tokenizer using [this](https://huggingface.co/hf-internal-testing/llama-tokenizer/tree/main) for example, it has the same ids so I am not sure I follow the problem? <|||||>@ArthurZucker if I want to batching then I have to manually add a pad_token. In this case how do I ensure that the pad_token_id is actually correct? I.e how do I get the tokenizer to set pad_tokens to 0 instead of 32000 that I am getting now, by using add_special_tokens like `add_special_tokens({'pad_token': '[PAD]'})`<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>The problem is that `0` is already the `unk` token. The easiest way is to set the pad token to the unk token.
|
transformers | 22,519 | closed | Grabbing the output for all Convolution layers in Wav2VecForCTC Model | ### Feature request
I want to be able to grab the output of all 7 convolution blocks from the Wav2VecForCTC model but I cant think of a way to do it. I tried to update the forward function of the Wav2Vec2FeatureEncoder with a new attribute that stores each hidden state of the convolution to a list but the moment I load the default pretrained model, the attribute no longer exists.
### Motivation
I am working on model explainability and the option to grab outputs of each convolution at every step would allow me to do a deeper dive of how the model interprets different phonemes.
### Your contribution
I am happy to help out how I can! Im not really sure where to even being though with this, maybe there is something simple that I am missing? | 04-02-2023 21:56:13 | 04-02-2023 21:56:13 | cc @sanchit-gandhi and @ArthurZucker <|||||>Hey @priyammaz - you can append the hidden-states for each layer to a tuple in the same way that we do for the Wav2Vec2Encoder.
In the forward call of `Wav2Vec2FeatureEncoder`:
```python
def forward(self, input_values, output_hidden_states=False):
all_hidden_states = () if output_hidden_states else None
hidden_states = input_values[:, None]
# make sure hidden_states require grad for gradient_checkpointing
if self._requires_grad and self.training:
hidden_states.requires_grad = True
for conv_layer in self.conv_layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if self._requires_grad and self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(conv_layer),
hidden_states,
)
else:
hidden_states = conv_layer(hidden_states)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states,
)
```
In the forward call of `Wav2Vec2Model`:
```python
def forward(
self,
input_values: Optional[torch.Tensor],
attention_mask: Optional[torch.Tensor] = None,
mask_time_indices: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, Wav2Vec2BaseModelOutput]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
conv_features = self.feature_extractor(input_values, output_hidden_states=output_hidden_states)
extract_features = conv_features[0].transpose(1, 2)
if attention_mask is not None:
# compute reduced attention_mask corresponding to feature vectors
attention_mask = self._get_feature_vector_attention_mask(
extract_features.shape[1], attention_mask, add_adapter=False
)
hidden_states, extract_features = self.feature_projection(extract_features)
hidden_states = self._mask_hidden_states(
hidden_states, mask_time_indices=mask_time_indices, attention_mask=attention_mask
)
encoder_outputs = self.encoder(
hidden_states,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = encoder_outputs[0]
if self.adapter is not None:
hidden_states = self.adapter(hidden_states)
if not return_dict:
return (hidden_states, extract_features) + encoder_outputs[1:]
all_hidden_states = conv_features[1] + encoder_outputs.hidden_states if output_hidden_states else None
return Wav2Vec2BaseModelOutput(
last_hidden_state=hidden_states,
extract_features=extract_features,
hidden_states=all_hidden_states,
attentions=encoder_outputs.attentions,
)
```
All in all, it looks something like this: https://github.com/sanchit-gandhi/codesnippets/blob/main/modeling_wav2vec2_with_conv_states.py
<|||||>ThanK you so much! I will give this a try this weekend and let you know if I am stuck anywhere, I am still learning the HuggingFace platform!<|||||>This worked perfectly thank you so much! <|||||>Cool! Glad to hear that @priyammaz! Thinking about it more, we also apply a feature projection after the last CNN layer:
https://github.com/sanchit-gandhi/codesnippets/blob/cb6a463b2b948a78081b382d51c062ca0ae8de31/modeling_wav2vec2_with_conv_states.py#L1324
This feature projection is essentially just layer norm followed by a linear layer:
https://github.com/sanchit-gandhi/codesnippets/blob/cb6a463b2b948a78081b382d51c062ca0ae8de31/modeling_wav2vec2_with_conv_states.py#L485
You may also want to return the output of this feature projection layer if it's of interest to your research (you can do so simply by appending the outputs to our tuple of `output_hidden_states` as we do for the conv layer outputs:
https://github.com/sanchit-gandhi/codesnippets/blob/cb6a463b2b948a78081b382d51c062ca0ae8de31/modeling_wav2vec2_with_conv_states.py#L1345 <|||||>Thanks for the info! I will definitely give that a try! |
transformers | 22,518 | closed | Add ViViT | # What does this PR do?
Fixes #15666. Reopening #20441, as I have missed the comments provided by @amyeroberts so the issue was closed by the bot.
Add Video Vision Transformer to transformers. This PR implements a spacetime version of the Video Vision Transformer from the original paper.
I have provided the model weights here https://huggingface.co/jegormeister/vivit-b-16x2-kinetics400
I will try to add Factorised Encoder version later on (these are the two versions that authors provide weight for).
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? https://github.com/huggingface/transformers/issues/15666
- [x] Did you make sure to update the documentation with your changes? I have added the documentation, but I have troubles testing it as I couldn't run the preview command of the doc-builder, so if someone has the possibility to run and check it, I will be really grateful!
- [x] Did you write any new necessary tests? WIP
## Who can review?
@amyeroberts provided the last suggestions to the closed PR, so I hope you can review this one. Thanks!
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| 04-02-2023 15:24:49 | 04-02-2023 15:24:49 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@amyeroberts thank you for your comments in the previous PR! I have addressed your suggestions and also added the image processor test.
However, I ran `make style`, however the pipeline was failing at check_code_quality. Therefore I've updated the testing dependencies which lead to black updating. But! When I run `make style` again, it gives the following output:
```sh
reformatted transformers/examples/research_projects/deebert/src/modeling_highway_bert.py
reformatted transformers/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py
reformatted transformers/src/transformers/models/reformer/modeling_reformer.py
reformatted transformers/src/transformers/models/vivit/modeling_vivit.py
reformatted transformers/tests/models/vivit/test_image_processing_vivit.py
```
So it fixes not only the files from this PR, but also the already existing ones. Therefore I have a question: should I only pus reformatted files from this PR or all?
<|||||>@jegork The files listed e.g. `transformers/examples/research_projects/deebert/src/modeling_highway_bert.py` should have the most recent formatting applied and shouldn't need to be updated with this PR.
Could you rebase on main, make sure the most recent formatting packages are installed using `pip install -e .[quality]` and try `make style` again? <|||||>@amyeroberts Thanks for your comments. I have addressed everything. However, I still get the same problems with `make style`
I did `git fetch upstream`, then `git rebase upstream/main`, `pip install -e ".[quality]"` after which I ran `make style`
Which resulted in the following output at the end:
```sh
black examples tests src utils setup.py
Skipping .ipynb files as Jupyter dependencies are not installed.
You can fix this by running ``pip install "black[jupyter]"``
reformatted /Users/jegorkitskerkin/Documents/projects/transformers/examples/research_projects/deebert/src/modeling_highway_bert.py
reformatted /Users/jegorkitskerkin/Documents/projects/transformers/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py
reformatted /Users/jegorkitskerkin/Documents/projects/transformers/src/transformers/models/vivit/modeling_vivit.py
reformatted /Users/jegorkitskerkin/Documents/projects/transformers/src/transformers/models/reformer/modeling_reformer.py
reformatted /Users/jegorkitskerkin/Documents/projects/transformers/tests/models/vivit/test_image_processing_vivit.py
All done! ✨ 🍰 ✨
5 files reformatted, 2380 files left unchanged.
ruff examples tests src utils setup.py --fix
/Library/Developer/CommandLineTools/usr/bin/make autogenerate_code
running deps_table_update
updating src/transformers/dependency_versions_table.py
/Library/Developer/CommandLineTools/usr/bin/make extra_style_checks
python utils/custom_init_isort.py
python utils/sort_auto_mappings.py
doc-builder style src/transformers docs/source --max_len 119 --path_to_docs docs/source
Overwriting content of src/transformers/models/vivit/modeling_vivit.py.
Cleaned 1 files!
python utils/check_doc_toc.py --fix_and_overwrite
```
As you can see, the same unrelated-to-this-PR-files are getting formatted<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>hey @amyeroberts i've managed to fix the formatting-related problems and addressed your comments. However, I seem to be facing some problems with running tests. CI fails with
```
FAILED tests/models/vivit/test_modeling_vivit.py::VivitModelTest::test_model_outputs_equivalence - Failed: Timeout >120.0s
```
and as I see, `test_model_outputs_equivalence` comes from the `ModelTesterMixin` so I am not sure how to handle this <|||||>@jegork Mmmm, indeed that's odd. It's not immediately clear from the CI traceback why that would happen.
Are you able to run the tests locally and do they pass?:
```
RUN_SLOW=1 tests/models/vivit/test_modeling_vivit.py::VivitModelTest::test_model_outputs_equivalence
```
<|||||>@amyeroberts yep, everything works and passes locally<|||||>@jegork Thanks for confirming. I'm going to rerun CircleCI in case there was just some transient issue with the run. If it persists we can dig a bit more into it. <|||||>Thanks @amyeroberts and @jegork for working on this, we look forward to using the ViVit model!<|||||>@jegork Is the PR OK to merge? Or are there any other commits you'd like to push before I press the big green button? 🟢 <|||||>@amyeroberts I think it's ready to be merged. Thanks for your help!
<|||||>Hi @jegork congrats on your amazing contribution!
is it ok if we transfer the ViViT checkpoints to the `google` organization on the hub? (assuming they are officially released checkpoints by Google)<|||||>Hey @NielsRogge, thanks!
Sure |
transformers | 22,517 | closed | LLaMA tokenizer seems to be broken | ### System Info
- huggingface_hub version: 0.13.3
- Platform: Linux-5.19.0-32-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /root/.cache/huggingface/token
- Has saved token ?: True
- Who am I ?: supreethrao
- Configured git credential helpers:
- FastAI: N/A
- Tensorflow: N/A
- Torch: 1.14.0a0+44dac51
- Jinja2: 3.1.2
- Graphviz: N/A
- Pydot: N/A
- Pillow: 9.2.0
- hf_transfer: N/A
- ENDPOINT: https://huggingface.co
- HUGGINGFACE_HUB_CACHE: /root/.cache/huggingface/hub
- HUGGINGFACE_ASSETS_CACHE: /root/.cache/huggingface/assets
- HF_TOKEN_PATH: /root/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I converted the LLaMA weights to the HuggingFace format from the script in the documentation
```
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
When I try and load the tokenizer as follows
```
>>> from transformers import LlamaTokenizer
>>> tokenizer = LlamaTokenizer.from_pretrained('path_to_converted_llama_model')
```
I get the following error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py", line 1811, in from_pretrained
return cls._from_pretrained(
File "/usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py", line 1965, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/models/llama/tokenization_llama.py", line 78, in __init__
self.sp_model.Load(vocab_file)
File "/usr/local/lib/python3.8/dist-packages/sentencepiece/__init__.py", line 905, in Load
return self.LoadFromFile(model_file)
File "/usr/local/lib/python3.8/dist-packages/sentencepiece/__init__.py", line 310, in LoadFromFile
return _sentencepiece.SentencePieceProcessor_LoadFromFile(self, arg)
```
I have the following versions of the library
```
transformers 4.28.0.dev0 (installed from source though pip install git+https://github.com/huggingface/transformers.git)
sentencepiece 0.1.97
```
### Expected behavior
The tokenizer should get loaded be able function properly without the aformentioned errors
### Edit
The tokenizer.model file was corrupted which caused this issue, once that was fixed, conversion and tokenization works.
closing this issue now | 04-02-2023 15:10:14 | 04-02-2023 15:10:14 | |
transformers | 22,516 | closed | Generate: Enable easier TextStreamer customization | # What does this PR do?
Minimally adapts recently integrated (https://github.com/huggingface/transformers/pull/22449) by adding a more obvious API hook for streaming tokens yet retains all the current semantics.
I am excited to use TextStreamer but I found the hook-in API not as intuitive as it could be if one needs to customize token printing. For example, I need to use specific colouring to print arriving tokens, yet achieving this without a complete TextStreamer rewrite is not as easy. We can easily create an obvious hook-in method:
```def on_new_token(self, token: str, stream_end: bool = False):```
This method is called by TextStreamer yet its subclasses can easily customize printing. The default implementation of on_new_token method simply prints tokens to stdout as it currently does.
I don't foresee any major documentation updates as a consequence of this PR.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@gante @sgugger | 04-02-2023 14:17:14 | 04-02-2023 14:17:14 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> I like the structure, but I dislike the name `on_new_token`. It's actually a callback on "new print-ready text". Perhaps `on_finalized_text`? WDYT?
@gante I am completely indifferent regarding the name. Please adjust the name as you like!
On a second look, I'm also not 100% sure whether to put this method into TextStreamer only. Your call. <|||||>Let's keep it in `TextStreamer` for now. It's still early to tell how people will want to use it :) |
transformers | 22,515 | closed | [BLIP] fix cross attentions for BlipTextEncoder | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes a bug in the output of the cross attentions in BlipTextEncoder
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-02-2023 13:04:42 | 04-02-2023 13:04:42 | _The documentation is not available anymore as the PR was closed or merged._<|||||>cc @ArthurZucker and @younesbelkada <|||||>Sure, happy to provide more details. This bug is caused by the all_cross_attentions variable not properly storing the cross-attention produced by each BlipTextLayer. The variable is initialized at line 404 and returned in either line 460 or 469, but it remains unchanged between initialization and return. As a result, the forward function consistently returns an empty tuple for cross-attention.
To address this issue, I have made changes to ensure that all_cross_attentions correctly stores the cross-attention produced by each BlipTextLayer, allowing the forward function to return the appropriate cross-attention.
To reproduce the bug, please run the following snippet (the returned cross attentions will always be an empty tuple):
```python
import torch
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base").to("cuda")
model.text_encoder.config.output_attentions = True
img_path = "path of an image"
raw_image = Image.open(img_path).convert('RGB')
name = "cat"
question = [
"Is there a {} in the view?".format(name),
]
inputs = processor([raw_image]*len(question), question, padding=True, return_tensors="pt").to("cuda")
vision_outputs = model.vision_model(inputs['pixel_values'])
image_embeds = vision_outputs[0]
image_attention_mask = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image_embeds.device)
question_outputs = model.text_encoder(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_attention_mask,
return_dict=True
)
# question_outputs['cross_attentions'] will always be an empty tuple
print(question_outputs['cross_attentions'])
``` |
transformers | 22,514 | closed | llama docs: fix conversion script url | Fixes the link on this page:
https://huggingface.co/docs/transformers/main/model_doc/llama
| 04-02-2023 12:17:07 | 04-02-2023 12:17:07 | _The documentation is not available anymore as the PR was closed or merged._<|||||>hmm, probably should work now<|||||>Could you try pushing an empty commit?<|||||>Thanks again! |
transformers | 22,513 | closed | Generate a pre-training model for GAP Computational Discrete Algebra System. | ### Feature request
I can't find any fine-tuned pre-training models for [GAP Computational Discrete Algebra](https://www.gap-system.org/).
### Motivation
I'm a scholar who conducts research in related fields of mathematical physics based on group theory methods. So, I would like to have a fine-tuned pre-training model for [GAP Computational Discrete Algebra](https://www.gap-system.org/).
### Your contribution
I want to know the possibilities in creating such a model based on the resources provided on huggingface. Any hints/comments will be appreciated. | 04-02-2023 08:57:08 | 04-02-2023 08:57:08 | This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,512 | closed | PyTorch ViTMAEModel output is not deterministic | ### System Info
- `transformers` version: 4.27.4
- Platform: Linux-5.13.0-1023-gcp-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 2.0.0+cu117 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): 0.6.8 (tpu)
- Jax version: 0.4.8
- JaxLib version: 0.4.7
- Using GPU in script?: No.
- Using distributed or parallel set-up in script?: No
### Who can help?
@amyeroberts @sgugger @stevhliu @MKhalusova
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run the [example snippet](https://huggingface.co/docs/transformers/v4.27.2/en/model_doc/vit_mae#transformers.ViTMAEModel) in the documentation. I'll copy & paste it below for your convenience:
```python
from transformers import AutoImageProcessor, ViTMAEModel
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
Put the code in a script, execute it twice, and you will notice that the content in `last_hidden_states` is different.
### Expected behavior
The embeddings should be deterministic across runs. | 04-01-2023 20:48:59 | 04-01-2023 20:48:59 | Hi,
Yes that's expected behaviour, see https://github.com/huggingface/transformers/issues/20431<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,511 | closed | Inconsistent issue in multi gpu training single machine | ### System Info
Environment from `transformers-cli env`:
```
- `transformers` version: 4.26.0
- Platform: Linux-5.15.0-1033-aws-x86_64-with-glibc2.31
- Python version: 3.10.10
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes, 8 GPUs on AWS pd4.24xlarge A100 40GB chips
- Using distributed or parallel set-up in script?: Both FSDP and DeepSpeed
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
See Expected behavior section, script attached with run commands but unable to provide data due to sensitivity concerns
### Expected behavior
I am doing some fine-tuning on a causal LM similar to the code in https://github.com/tatsu-lab/stanford_alpaca but with additional custom data. I notice that when I fire off the multi-gpu training on a single node using a `torchrun` comand similar to:
```
torchrun --nproc_per_node=8 --master_port=8080 train.py \
--seed 1718 \
--model_name_or_path "facebook/opt-6.7b" \
--output_dir "opt-6.7b" \
--overwrite_data True \
--validation_size 0.05 \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "steps" \
--eval_steps 200 \
--save_strategy "steps" \
--save_steps 200 \
--log_level "info" \
--logging_strategy "steps" \
--logging_steps 1 \
--save_total_limit 1 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'OPTDecoderLayer' \
--bf16 True \
--tf32 True
```
I get a bunch of warnings indicating that the local_rank of each process is -1. After stepping through some of the code in `src/trainer.py`, it looks like only data parallel gets kicked off. As such, the behavior I notice is since I requested ```--nproc_per_node=8```, it appears that literally 8 instances of my script are getting fired off per GPU I have on my machine. I can confirm this based on looking at the 8 processes running on each GPU id from the `nvidia-smi` command. Since so many processes are starting on each GPU, I get an OOM error immediately. These OOM errors occur (since the local_rank = -1) whether I use FSDP or DeepSpeed (stage 2, 3 and both with/without CPU/disk offload).
However, when I add the "patch" below before I kicked off the training using the `Trainer` object:
```python
# Update local ranks
training_args.local_rank = int(os.environ["LOCAL_RANK"])
assert training_args.local_rank != -1, "BAD THINGS ARE ABOUT TO HAPPEN!"
LOGGER.info(f"Configuring local ranks: I am local process: {training_args.local_rank}", main_process_only=False)
```
I finally get the single process per GPU and it looks like the GPUs are in fact doing distributed training and the script runs fine. I have attached the entire script in case this helps with debugging -- not sure what could be causing this behavior. When I run the alpaca repo, the training runs fine and no issues with the `torchrun` command.
Any ideas if I'm doing something clearly off here? I tried upgrading to the latest version of `transformers` and the same issue. Again, no issues running the alpaca repo but mine has that local_rank = -1 problem and without the "patch" the scripts errors out right when training starts.
[train.py.zip](https://github.com/huggingface/transformers/files/11130281/train.py.zip)
| 04-01-2023 18:31:20 | 04-01-2023 18:31:20 | Could you confirm if the issue persists with the latest release?<|||||>Hi @sgugger -- just updated to the latest version `4.27.4`. I received this error message last time about the FSDP config not being updated correctly from the command line, slipped my mind. This is why I originally rolled back to `4.26.0` based on the version that worked with the `alpaca` repo.
Either way, with the new transformers version, here are some of the error logs, still the local_rank = -1 warning and also now the `args.fsdp_config["xla"]` error, bc I think the args.fsdp_config is empty before the `Trainer` object fires off training
```
PyTorch: setting up devices
PyTorch: setting up devices
PyTorch: setting up devices
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
PyTorch: setting up devices
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
File "/home/ubuntu/llm/train.py", line 585, in <module>
File "/home/ubuntu/llm/train.py", line 585, in <module>
File "/home/ubuntu/llm/train.py", line 585, in <module>
Traceback (most recent call last):
PyTorch: setting up devices
File "/home/ubuntu/llm/train.py", line 585, in <module>
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
train()train()
train() File "/home/ubuntu/llm/train.py", line 565, in train
File "/home/ubuntu/llm/train.py", line 565, in train
File "/home/ubuntu/llm/train.py", line 565, in train
train()
File "/home/ubuntu/llm/train.py", line 565, in train
trainer = Trainer(
trainer = Trainer( File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
trainer = Trainer(
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
trainer = Trainer(
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
if not args.fsdp_config["xla"] and args.local_rank == -1:
if not args.fsdp_config["xla"] and args.local_rank == -1:
if not args.fsdp_config["xla"] and args.local_rank == -1:
TypeErrorTypeError: : 'NoneType' object is not subscriptable'NoneType' object is not subscriptable
TypeError: 'NoneType' object is not subscriptable
if not args.fsdp_config["xla"] and args.local_rank == -1:
Traceback (most recent call last):
File "/home/ubuntu/llm/train.py", line 585, in <module>
TypeError: 'NoneType' object is not subscriptable
train()
File "/home/ubuntu/llm/train.py", line 565, in train
trainer = Trainer(
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
if not args.fsdp_config["xla"] and args.local_rank == -1:
TypeError: 'NoneType' object is not subscriptable
PyTorch: setting up devices
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
PyTorch: setting up devices
Traceback (most recent call last):
File "/home/ubuntu/llm/train.py", line 585, in <module>
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
train()
File "/home/ubuntu/llm/train.py", line 565, in train
trainer = Trainer(
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
PyTorch: setting up devices
torch.distributed process group is initialized, but local_rank == -1. In order to use Torch DDP, launch your script with `python -m torch.distributed.launch
if not args.fsdp_config["xla"] and args.local_rank == -1:
TypeError: 'NoneType' object is not subscriptable
Traceback (most recent call last):
File "/home/ubuntu/llm/train.py", line 585, in <module>
train()
File "/home/ubuntu/llm/train.py", line 565, in train
Traceback (most recent call last):
File "/home/ubuntu/llm/train.py", line 585, in <module>
trainer = Trainer(
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
train()
File "/home/ubuntu/llm/train.py", line 565, in train
if not args.fsdp_config["xla"] and args.local_rank == -1:
TypeError: 'NoneType' object is not subscriptabletrainer = Trainer(
File "/opt/conda/envs/pytorch/lib/python3.10/site-packages/transformers/trainer.py", line 421, in __init__
if not args.fsdp_config["xla"] and args.local_rank == -1:
TypeError: 'NoneType' object is not subscriptable
```<|||||>cc @pacman100 <|||||>Will look into this in a few days.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>This block of code seems to only allow FSDP with XLA? Can anyone confirm?
https://github.com/huggingface/transformers/blob/v4.30.0/src/transformers/trainer.py#L1490,L1526
When trying to follow this blog https://www.philschmid.de/sagemaker-fsdp-gpt, the entire model gets loaded onto all the gpus causing OOM although the blog tries to demonstrate FSDP (I chose an instance size with GPU mem < model size to test model sharding)
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,510 | closed | [WIP]🌐[i18n-KO] Translate `autoclass_tutorial` to Korean | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Part of #20179
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
@0525hhgus, @KIHOON71, @gabrielwithappy, @jungnerd, @sim-so, @HanNayeoniee, @wonhyeongseo
Pseudo Lab, Please review this PR.
| 04-01-2023 17:32:27 | 04-01-2023 17:32:27 | _The documentation is not available anymore as the PR was closed or merged._<|||||>To update PR commit comment rule, I closed this PR and will update new PR with new template.
Thank you. |
transformers | 22,509 | closed | docs: ko: sagemaker.mdx | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Part of #20179 (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
@wonhyeongseo, @HanNayeoniee, @0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy
Team Pseudo-Lab, please review this PR. | 04-01-2023 14:12:25 | 04-01-2023 14:12:25 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Also please mention @HanNayeoniee instead of your id(@jungnerd) for requesting review on the last 2 lines of your main PR message. Thank you.
Edit: or just add her 😄 your choice really. Thank you so much for participating on Saturday's meeting.<|||||>> Also please mention @HanNayeoniee instead of your id(@jungnerd) for requesting review on the last 2 lines of your main PR message. Thank you.
>
> Edit: or just add her 😄 your choice really. Thank you so much for participating on Saturday's meeting.
Thanks for telling me. I've fixed the commit.🤭<|||||>We should also update `_toctree.yml`, and I can help with this anytime. Please feel free to ping me on KakaoTalk. 🙌<|||||>Great work! First PR of Pseudo-lab team!
I think [WIP] tag needs to be removed since translation is all done and it's been merged. |
transformers | 22,508 | closed | 🌐 [i18n-KO] Translated `pipeline_tutorial.mdx` to Korean | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Part of #20179 (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@wonhyeongseo, @jungnerd, @0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee
Team Pseudo-Lab, please review this PR. | 04-01-2023 13:26:29 | 04-01-2023 13:26:29 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hello Mr. @sgugger , thank you for your patience! May you please review & merge this PR?
The internal review time frame (7 days) has passed since I requested feedback from my colleagues at PseudoLab. |
transformers | 22,507 | closed | Fix NameError `init_empty_weights` when importing Blip2Processor | ## Context
Was trying to run [https://huggingface.co/Salesforce/blip2-flan-t5-xl](https://huggingface.co/Salesforce/blip-image-captioning-base) in a colab notebook (after installing `accelerate`) and was getting an error when importing Blip2Processor:
```
NameError `init_empty_weights` is not defined
```
<img width="1285" alt="Screen Shot 2023-04-01 at 1 31 17 pm" src="https://user-images.githubusercontent.com/3723005/229265367-36eed050-b75b-4d06-b69b-f80a649e2d2e.png">
## Changes
Splitting out the if statements to check for `accelerate` and `bitsandbytes` separately seems to fix this problem, in `load_in_8bit` mode.
Applies a similar fix to the imports in `deepspeed.py`. This fixed the same error as above but in this conditional block, later in the file.
```
if is_deepspeed_zero3_enabled():
import deepspeed
[logger.info](http://logger.info/)("Detected DeepSpeed ZeRO-3: activating zero.init() for this model")
init_contexts = [deepspeed.zero.Init(config_dict_or_path=deepspeed_config())] + init_contexts
```
After these changes, I was able to import, Blip2Processor, Blip2ForConditionalGeneration on Colab :) | 04-01-2023 04:31:36 | 04-01-2023 04:31:36 | @pacman100 Is this something you'd be able to review for me? This my first contribution in this repo but I'm pretty sure it fixes a real issue in loading BLIP2.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Perhaps @NielsRogge, since this is your implementation of BLIP2, you could review for me? I was able to reproduce the error in colab.<|||||>Thanks for the review @sgugger, makes sense now |
transformers | 22,506 | closed | Dynamic module import error when using ddp | ### System Info
- `transformers` version: 4.27.3
- Platform: Linux-5.4.0-72-generic-x86_64-with-glibc2.10
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): 2.11.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Create a file `a.py` with the following content
```python
from transformers import AutoConfig
AutoConfig.from_pretrained("THUDM/glm-10b", trust_remote_code=True)
```
Run it with `torchrun`
```
torchrun --nproc-per-node 8 a.py
```
Then we would get this error sometimes
```
Traceback (most recent call last):
File "a.py", line 5, in <module>
AutoConfig.from_pretrained("THUDM/glm-10b", trust_remote_code=True)
File "/home/linjinzhen/.miniconda3/lib/python3.8/site-packages/transformers/models/auto/configuration_auto.py", line 911, in from_pretrained
config_class = get_class_from_dynamic_module(
File "/home/linjinzhen/.miniconda3/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 399, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module.replace(".py", ""))
File "/home/linjinzhen/.miniconda3/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 157, in get_class_in_module
shutil.copy(f"{module_dir}/{module_file_name}", tmp_dir)
File "/home/linjinzhen/.miniconda3/lib/python3.8/shutil.py", line 418, in copy
copyfile(src, dst, follow_symlinks=follow_symlinks)
File "/home/linjinzhen/.miniconda3/lib/python3.8/shutil.py", line 264, in copyfile
with open(src, 'rb') as fsrc, open(dst, 'wb') as fdst:
FileNotFoundError: [Errno 2] No such file or directory: '/home/linjinzhen/.cache/huggingface/modules/transformers_modules/THUDM/glm-10b/696788d4f82ac96b90823555f547d1e754839ff4/configuration_glm.py'
```
or
```
Traceback (most recent call last):
File "a.py", line 5, in <module>
AutoConfig.from_pretrained("THUDM/glm-10b", trust_remote_code=True)
File "/home/linjinzhen/.miniconda3/lib/python3.8/site-packages/transformers/models/auto/configuration_auto.py", line 911, in from_pretrained
config_class = get_class_from_dynamic_module(
File "/home/linjinzhen/.miniconda3/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 399, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module.replace(".py", ""))
File "/home/linjinzhen/.miniconda3/lib/python3.8/site-packages/transformers/dynamic_module_utils.py", line 177, in get_class_in_module
module = importlib.import_module(module_path)
File "/home/linjinzhen/.miniconda3/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 973, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'transformers_modules.THUDM.glm-10b.696788d4f82ac96b90823555f547d1e754839ff4.configuration_glm'
Traceback (most recent call last):
File "<string>", line 1, in <module>
FileNotFoundError: [Errno 2] No such file or directory: '/home/linjinzhen/.cache/huggingface/modules/transformers_modules/THUDM/glm-10b/696788d4f82ac96b90823555f547d1e754839ff4/configuration_glm.py'
```
It seems that it is a multiprocess-relalted issue.
https://github.com/huggingface/transformers/blob/v4.27.4/src/transformers/dynamic_module_utils.py#L147-L179
### Expected behavior
Dynamic module can be imported successfully when using ddp.
| 04-01-2023 04:05:59 | 04-01-2023 04:05:59 | Thanks for raising this issue. I think this is linked to #21646, I will push a fix shortly. |
transformers | 22,505 | open | HF CLIP image features different from OpenAI CLIP image features | ### System Info
python3.8, CUDA 12.1, Ubuntu20.02, latest clip, transformers==4.26.1
### Who can help?
@amyeroberts
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
url = "https://canary.contestimg.wish.com/api/webimage/61b241a3a4ee2ecaf2f63c77-large.jpg?cache_buster=bbeee1fdb460a1d12bc266824914e030"
# get HF image fearures
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
outputs = model.get_image_features(**inputs)
pooled_output_hf = outputs.detach().cpu().numpy()
# get OpenAI image features
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open(requests.get(url, stream=True).raw)).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
pooled_output_clip = image_features.detach().cpu().numpy()
# check difference
assert np.allclose(pooled_output_hf, pooled_output_clip, atol=0.1), "hf and clip too different"
```
### Expected behavior
HF CLIP should be close to OpenAI CLIP but they differ more than 0.1 | 04-01-2023 03:13:13 | 04-01-2023 03:13:13 | Hi @junwang-wish, thanks for reporting this issue and the detailed reproduction script. I'll dig into this to find where the differences are coming from. <|||||>Thanks @amyeroberts , due to the significant difference would u recommend me to use HF clip or OpenAI clip based on your domain expertise?<|||||>@junwang-wish I managed to track down difference in values down to a slight difference in how the images are cropped during processing. The cropping in the feature extractor changed with #17628 - which resulted in the position of the occasionally being 1 pixel to the left or up from the OpenAI implementation. The PR #22608 aims to address this. Checking this update on the repro example in this issue, I can confirm the OpenAI and HF CLIP models return equivalent outputs again.
In terms of which to use, it depends on what you wish to use the model for. As the difference is arising from preprocessing, rather than the models themselves, provided the same image is passed in there shouldn't be any significant difference in outputs and I'd recommend whichever model fits best within your workflow. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>@amyeroberts @junwang-wish
Hi I have the same issue with transformer==4.30.2.
I found the preprocessing makes the difference. I tried 3 different ways to do the preprocessing and only the 3. from Openai's implementation keep the correct results.
1. Use CLIPFeatureExtractor
2. `tform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(
(224, 224),
interpolation=transforms.InterpolationMode.BICUBIC,
antialias=False,
),
transforms.Normalize(
[0.48145466, 0.4578275, 0.40821073],
[0.26862954, 0.26130258, 0.27577711]),
])`
3. from openai's original preprocessing.
`x = kornia.geometry.resize(x, (224, 224), interpolation='bicubic', align_corners=True, antialias=False)
x = (x + 1.) / 2.
x = kornia.enhance.normalize(x, torch.Tensor([0.48145466, 0.4578275, 0.40821073]), torch.Tensor([0.26862954, 0.26130258, 0.27577711]))`
I'm wondering if this will be fixed in a newer version or the repo isn't trying to keep exact the same results with openai's CLIP. Thanks. |
transformers | 22,504 | closed | Expose callback for download progress | ### Feature request
When using `AutoTokenizer` and `AutoModelForCausalLM`, I would like be able to pass a callback function (or some other solution) that will allow me to report on the status of the download if it's not cached.
```
AutoTokenizer.from_pretrained(
model_name,
download_progress_callback=lambda perc: print(f"Downloading tokenizer: {perc}%")
)
AutoModelForCausalLM.from_pretrained(
model_name,
download_progress_callback=lambda perc: print(f"Downloading model: {perc}%")
)
```
Ideally this would be the **total** download progress (achievable with the `file_metadata` flag of `HfApi.model_info`).
### Motivation
I am building a UI wrapper around hugging face models, and would like to enable a "on click" install for any model. The issue is it can take quite some time to download, and the UI is left spinning sometimes for hours. I would like to provide more feedback to the end user on the status (plus maybe some time estimations eventually)
### Your contribution
Happy to contribute in any way, however I'll need to be pointed in the right direction. I've taken a peruse through the `huggingface_hub` repo, as well as this one, but am a little unsure of how to approach this. In particular, I'm unsure how a model determines _which specific_ files to download from the hub. | 03-31-2023 22:15:01 | 03-31-2023 22:15:01 | This looks like a feature that would need to be implemented in `huggingface_hub` first, then we would use it here and pass along the proper argument.
cc @Wauplin and @LysandreJik <|||||>Hey @tristanMatthias :wave: This is a tricky feature request as I don't want to complexify too much the current API/implementation of the underlying methods to download files. It is quite unknown but in `snapshot_download` there is a [`tqdm_class: Optional[tqdm]`](https://huggingface.co/docs/huggingface_hub/v0.13.3/en/package_reference/file_download#huggingface_hub.snapshot_download.tqdm_class) parameter that can be passed. Instead of providing a callback, you overwrite completely the progress bar that is used. The passed class must inherit from `tqdm.auto.tqdm` or at least mimic its behavior.
What we can do in `huggingface_hub` is to add this parameter to `hf_hub_download` as well. Then `transformers` would have to adapt its API. What do you think about it? If it fits your need, I can point you the code that needs to be updated in `hfh`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,503 | closed | Add copied from statements for image processors | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 03-31-2023 19:33:17 | 03-31-2023 19:33:17 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22503). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,502 | closed | Running LlamaForCausalLM with MPS provokes "RuntimeError: MPS does not support cumsum op with int64 input" | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: macOS-13.2.1-arm64-arm-64bit
- Python version: 3.9.6
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes, I use device='mps'
- Using distributed or parallel set-up in script?: No
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
To reproduce, just run this on a M1/M2 Mac with Apple silicon
```
from transformers import LlamaForCausalLM, LlamaTokenizer
import torch
tokenizer = LlamaTokenizer.from_pretrained('/path/to/weights')
model = LlamaForCausalLM.from_pretrained('/path/to/weights')
device = torch.device('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
print(f'Using device: {device}')
model = model.to(device)
prompt = "Hey, are you consciours? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()} # place on device
input_ids = inputs['input_ids'].to(torch.int32) # doesn't appear to help
attn_masks = inputs['attention_mask'].to(torch.int32) # doesn't appear to help
generate_ids = model.generate(input_ids, max_length=30)
```
### Expected behavior
No error. Will post stack trace. | 03-31-2023 19:20:27 | 03-31-2023 19:20:27 | Relevant stack trace (can provide more if needed):
> File [~/Developer/python39_env/lib/python3.9/site-packages/transformers/generation/utils.py:2245](https://file+.vscode-resource.vscode-cdn.net/Users/kechan/Library/CloudStorage/GoogleDrive-kelvin%40jumptools.com/My%20Drive/LLaMA/notebooks/~/Developer/python39_env/lib/python3.9/site-packages/transformers/generation/utils.py:2245), in GenerationMixin.greedy_search(self, input_ids, logits_processor, stopping_criteria, max_length, pad_token_id, eos_token_id, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, synced_gpus, streamer, **model_kwargs)
> 2242 break
> 2244 # prepare model inputs
> -> 2245 model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
> 2247 # forward pass to get next token
> 2248 outputs = self(
> 2249 **model_inputs,
> 2250 return_dict=True,
> 2251 output_attentions=output_attentions,
> 2252 output_hidden_states=output_hidden_states,
> 2253 )
>
> File [~/Developer/python39_env/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py:736](https://file+.vscode-resource.vscode-cdn.net/Users/kechan/Library/CloudStorage/GoogleDrive-kelvin%40jumptools.com/My%20Drive/LLaMA/notebooks/~/Developer/python39_env/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py:736), in LlamaForCausalLM.prepare_inputs_for_generation(self, input_ids, past_key_values, attention_mask, inputs_embeds, **kwargs)
> 733 position_ids = kwargs.get("position_ids", None)
> 734 if attention_mask is not None and position_ids is None:
> 735 # create position_ids on the fly for batch generation
> --> 736 position_ids = attention_mask.long().cumsum(-1) - 1
> 737 position_ids.masked_fill_(attention_mask == 0, 1)
> 738 if past_key_values:
>
> RuntimeError: MPS does not support cumsum op with int64 input
This seems to happen during greedy search and subsequently precisely at:
`position_ids = attention_mask.long().cumsum(-1) - 1`<|||||>Actually, this could be PyTorch/MPS issue, that the int64 version of cumsum is not implemented. Found the issue there:
https://github.com/pytorch/pytorch/issues/96610
I wonder if long is necessary for attention_mask? should int32 be good enough?
<|||||>According to the issue it should be fixed with a nightly install of PyTorch and MacOS 13.3<|||||>@sgugger thanks for responding. I just updated to 13.3 and the torch nightly, and indeed, no more problem. Closing issue.<|||||>just for fun, increase length to 256
my prompt is "Is facebook a bad company?"
" Is facebook a bad company?\nI'm not sure if this is the right place to post this, but I'm not sure where else to post it.\nI'm not a facebook user, but I've heard a lot of bad things about it. I've heard that it's a bad company, that it's a bad product, that it's a bad service, that it's a bad website, that it's a bad social network, that it's a bad company, that it's a bad product, that it's a bad service, that it's a bad website, that it's a bad social network, that it's a bad company, that it's a bad product, that it's a bad service, that it's a bad website, that it's a bad social network, that it's a bad company, that it's a bad product, that it's a bad service, that it's a bad website, that it's a bad social network, that it's a bad company, that it's a bad product, that it's a bad service, that it's a bad website"
it started repeating things. Maybe this is 7B, and it would behave better for larger one?
This must have not been an encouraging sign for earlier pioneers. So it is amazing openAi stuck at it and arrived all the way to chatGPT level of great. |
transformers | 22,501 | closed | Generate: `TextIteratorStreamer` (streamer for gradio) | # What does this PR do?
Following the previous streamer PR (#22449), this PR adds a streamer that can be used as an iterator. If we want to use the iterator while generate is running, they must be on separate threads (naturally).
The interface looks quite simple, as can be seen in the documentation 🤗 The only kink is the need to call generation on a separate thread, but there is no great way around it (at most we can design an `if` branch inside generate where, if a streamer is used, generate is called in a separate thread... but that seems overkill for now).
A Gradio demo running on this branch can be seen [here](https://huggingface.co/spaces/joaogante/chatbot_transformers_streaming). There is pretty much no slowdown compared to a non-streamer call.
Inspired by @oobabooga's work (see [this comment](https://github.com/huggingface/transformers/pull/22449#issuecomment-1491311486)). | 03-31-2023 18:55:50 | 03-31-2023 18:55:50 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,500 | closed | Make tiny model creation + pipeline testing more robust | (After this, we/I can start to look the current skipped failing pipeline tests. I will also start to write the documentation on how some CIs are performed on Notion)
# What does this PR do?
- make pipeline testing **could also** work against **local** tiny models
- make tiny model creation script work with multi-processes
- A (renamed) workflow to:
- (new steps) create **all** tiny models locally + run pipeline tests against local tiny models
- (steps already on `main`) create + upload tiny models for new model **architecture** to Hub and generate new summary file
### Motivation
- make sure any modification to the tiny model creation script don't break things
- to ease the process of updating the summary file and test new tiny models on Hub) | 03-31-2023 18:28:29 | 03-31-2023 18:28:29 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,499 | closed | Make FlaxPreTrainedModel a Flax Module | ### Feature request
Issue for discussing #22627
As stated the idea is to make `FlaxPreTrainedModel` a `nn.Module` so Flax users can easily integrate it into other Flax networks or systems that expect Flax Modules.
## Requirements
1. Be backward compatible, it is desirable not to brake any existing `transformers` users.
2. When `_do_init=False` the `FlaxPreTrainedModel` should behave like regular Flax Module, this means you cannot use `__call__` directly and must instead use the usual `apply` method.
## Challenges
The main challenge is that Flax Module are dataclasses and use various dataclasses APIs like `dataclasses.replace`. This implies a couple of things:
1. All fields must be specified as class annotations.
2. Most of the current logic in `__init__` has to be done in `__post_init__`.
3. Constructors with `**kwargs` will be tricky to handle.
## Current approach
I've decided solve this problem the following way:
1. `FlaxPreTrainedModel` will define all the needed dataclass fields and to comply with its current signature. `__init__` was refactored into a `__post_init__`.
2. `FlaxPreTrainedModel` sub-classes like `FlaxBertPreTrainedModel` will define its own `__init__` such that they keep their current signature and will then forward everything to `super().__init__`. One thing to note is that sub-classes that inherit from other sub-classes that define `__init__` like `FlaxBertModel(FlaxBertPreTrainedModel)` must define a trivial `__init__` that forwards everything to the parent or else `dataclass` will define one for them according to dataclass semantics.
3. To make `dataclasses.replace` happy, the signature for custom `__init__` functions must accept all the fields names as arguments (i.e. must comply with the dataclass signature) even if it will not use some because e.g. the sub-class will define them on its own before forwarding them to the parent class.
4. I've made the `params` an `Optional` since I'll be expecting it to be `None` when `_do_init=False` (we should not keep the weights aside a Flax Module when its behaving as such).
One thing to note about `3` is that it will require ALL subclasses to define `__init__`, currently some get it for free. We can fix all standard `transformers` models, but user defined sub-classes that reuse `__init__` will break. If this is not good enough we can try to automatically generate a `__inti__` method during `__init_subclass__`.
cc @patrickvonplaten @sanchit-gandhi | 03-31-2023 17:16:16 | 03-31-2023 17:16:16 | One additional note, in the current state of #22479 `dataclasses.replace` still doesn't work, which is why the `test_clone` test is not passing:
https://github.com/huggingface/transformers/pull/22479/files#diff-abf3849ef52688f44671a0752d5a74bf08c861db1eaaab7a4827e52b17cc9dcbR166-R169<|||||>> One thing to note about `3` is that it will require ALL subclasses to define `__init__`, currently some get it for free. We can fix all standard `transformers` models, but user defined sub-classes that reuse `__init__` will break. If this is not good enough we can try to automatically generate a `__inti__` method during `__init_subclass__`.
I think this type of users is more advanced and used to seeing breaking changes from time to time. They would typically just pin `transformers` version or update their methods.<|||||>`test_clone` has been fixed by fully mimicking the dataclass signature from the custom `__init__` methods.<|||||>@sanchit-gandhi do you have some time to look into this? <|||||>Latest PR for the refactor is ongoing: https://github.com/huggingface/transformers/pull/22866<|||||>PR remains ongoing - @cgarciae are you able to see this one through to completion? More than happy to discuss any final design decisions and get you another review on the PR as and when required!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,498 | closed | Implemented safetensors checkpoints save/load for Trainer | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #22478
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 03-31-2023 17:08:42 | 03-31-2023 17:08:42 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Should be fine now. @sgugger can you have a look?<|||||>One test failed:
```
=================================== FAILURES ===================================
_________________ WhisperModelTest.test_equivalence_pt_to_flax _________________
[gw1] linux -- Python 3.8.12 /home/circleci/.pyenv/versions/3.8.12/bin/python
self = <tests.models.whisper.test_modeling_whisper.WhisperModelTest testMethod=test_equivalence_pt_to_flax>
@is_pt_flax_cross_test
def test_equivalence_pt_to_flax(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
init_shape = (1,) + inputs_dict["input_features"].shape[1:]
for model_class in self.all_model_classes:
with self.subTest(model_class.__name__):
fx_model_class_name = "Flax" + model_class.__name__
if not hasattr(transformers, fx_model_class_name):
# no flax model exists for this class
return
# Output all for aggressive testing
config.output_hidden_states = True
config.output_attentions = self.has_attentions
fx_model_class = getattr(transformers, fx_model_class_name)
# load PyTorch class
pt_model = model_class(config).eval()
# Flax models don't use the `use_cache` option and cache is not returned as a default.
# So we disable `use_cache` here for PyTorch model.
pt_model.config.use_cache = False
# load Flax class
fx_model = fx_model_class(config, input_shape=init_shape, dtype=jnp.float32)
# make sure only flax inputs are forward that actually exist in function args
fx_input_keys = inspect.signature(fx_model.__call__).parameters.keys()
# prepare inputs
pt_inputs = self._prepare_for_class(inputs_dict, model_class)
# remove function args that don't exist in Flax
pt_inputs = {k: v for k, v in pt_inputs.items() if k in fx_input_keys}
# send pytorch inputs to the correct device
pt_inputs = {
k: v.to(device=torch_device) if isinstance(v, torch.Tensor) else v for k, v in pt_inputs.items()
}
# convert inputs to Flax
fx_inputs = {k: np.array(v) for k, v in pt_inputs.items() if torch.is_tensor(v)}
fx_state = convert_pytorch_state_dict_to_flax(pt_model.state_dict(), fx_model)
fx_model.params = fx_state
# send pytorch model to the correct device
pt_model.to(torch_device)
with torch.no_grad():
pt_outputs = pt_model(**pt_inputs)
fx_outputs = fx_model(**fx_inputs)
fx_keys = tuple([k for k, v in fx_outputs.items() if v is not None])
pt_keys = tuple([k for k, v in pt_outputs.items() if v is not None])
self.assertEqual(fx_keys, pt_keys)
> self.check_pt_flax_outputs(fx_outputs, pt_outputs, model_class)
tests/models/whisper/test_modeling_whisper.py:865:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
tests/test_modeling_common.py:2098: in check_pt_flax_outputs
self.check_pt_flax_outputs(
tests/test_modeling_common.py:2123: in check_pt_flax_outputs
self.check_pt_flax_outputs(fx_output, pt_output, model_class, tol=tol, name=attr)
tests/test_modeling_common.py:2152: in check_pt_flax_outputs
self.assertLessEqual(
E AssertionError: 1.1086464e-05 not less than or equal to 1e-05 : outputs.encoder_last_hidden_state: Difference between PyTorch and Flax is 1.1086463928222656e-05 (>= 1e-05).
```
But I doubt that it is due to the changes added. @sgugger correct me if I am wrong<|||||>Should be good to merge now<|||||>Thanks again for your contribution! |
transformers | 22,497 | closed | Update Neptune callback docstring | # What does this PR do?
Updates to the `NeptuneCallback` docstring:
- Update links to Neptune docs following migration
- Formatting
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 03-31-2023 16:19:46 | 03-31-2023 16:19:46 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks for your PR! For the formatting, could you apply `make style` on your branch (after a `pip install -e .["quality"]`) so that it's auto-fixed? In particular multi-line argument descriptions need to be all in the indented blocks. |
transformers | 22,496 | closed | feat: Whisper prompting | # What does this PR do?
Closes #22395, thank you @sanchit-gandhi for the descriptive ask!
Note: due to initial scope expansion the commit history includes initial work towards `condition_on_previous_text`, `always_use_initial_prompt`, and pipeline integration, but these efforts have been pushed to a later PR
This this pull request adds 3 new functionalities + tests to support initial prompting functionality within Whisper's `model.generate()` and `tokenizer`:
- `prompt_ids` param for `model.generate()`:
- Optional param of initial prompt ids to provide context for each chunk of text generated by in `model.generate()`
- `get_prompt_ids` Processor method to create initial prompt ids to pass to generate from a passed in string
- Removing the prompt when the tokenizer is decoding if `skip_special_tokens=True`
Example new API usage:
```py
processor = WhisperProcessor.from_pretrained("openai/whisper-tiny")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny")
input_features = processor(input_speech, return_tensors="pt").input_features
# --- Without prompt ---
prompt_ids = processor.get_prompt_ids("Leighton")
output_without_prompt = model.generate(input_features)
print(processor.decode(output_without_prompt[0]))
# "<|startoftranscript|><|en|><|transcribe|><|notimestamps|> He has grave doubts whether Sir Frederick Layton's work is really Greek after all and can discover in it but little of Rocky Ithaca.<|endoftext|>"
# --- With prompt ---
prompt_ids = processor.get_prompt_ids("Leighton")
output_with_prompt = model.generate(input_features, prompt_ids=prompt_ids)
print(processor.decode(output_with_prompt[0]))
# "<|startofprev|> Leighton<|startoftranscript|><|en|><|transcribe|><|notimestamps|> He has grave doubts whether Sir Frederick Leighton's work is really Greek after all and can discover in it but little of Rocky Ithaca.<|endoftext|>"
```
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation). **Haven't added anywhere outside of documenting the new generate() arg directly on the function**
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
@sanchit-gandhi | 03-31-2023 15:54:56 | 03-31-2023 15:54:56 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Hey this PR looks really good (although I'll leave the actual review to Sanchit or Arthur).
I was just wondering whether it also makes sense to support the `condition_on_previous_text` option that the OpenAI repo has, since that uses the same mechanism (using the `<|startofprev|>` token).
In addition, there's [this PR](https://github.com/openai/whisper/pull/1040) that suggests an `always_use_initial_prompt` option that uses the prompt on every segment, not just the first. Might be useful to consider that here as well.
<|||||>> Hey this PR looks really good (although I'll leave the actual review to Sanchit or Arthur).
>
> I was just wondering whether it also makes sense to support the `condition_on_previous_text` option that the OpenAI repo has, since that uses the same mechanism (using the `<|startofprev|>` token).
>
> In addition, there's [this PR](https://github.com/openai/whisper/pull/1040) that suggests an `always_use_initial_prompt` option that uses the prompt on every segment, not just the first. Might be useful to consider that here as well.
Hey Matthijs thanks, I'm happy to add what's wanted. Will look for HF guidance on that and whether it should be added here or in a follow on PR. `temperature` was another factor I saw in the Whisper model, if it was > 0.5 no prompt tokens were added ([link](https://github.com/openai/whisper/blob/b5851c6c40e753606765ac45b85b298e3ae9e00d/whisper/transcribe.py#L311-L313)). <|||||>To-do list before re-requesting review
- [x] **Converting the prompt token to an ID in an instance variable gives an incorrect ID, unlike when its called in decode**
--Given we're only using it in two places and it's an inexpensive op to call `convert_tokens_to_ids` I've left this, at least for now, to focus more on the below
- [x] **Bug I found where if the ending text of the prompt matches the start of the transcribed text, that text will not be included in the transcription output. Example:**
--I'm actually not sure this is a bug now. The model has learned to be penalized for repeating itself and this only happens if the end of the prompt matches the beginning of the transcription almost exactly. It also appears to be happening inside the model itself as opposed to in the logits processing or other modification before / after.
<img width="779" alt="Screenshot 2023-04-05 at 1 14 03 AM" src="https://user-images.githubusercontent.com/78612354/229986962-269e4564-2b01-405a-a510-fab7d82c2915.png">
Added from @hollance's below two comments:
- [x] **Add `always_use_initial_prompt` and `condition_on_previous_text` options** to pipeline and `model.generate()`
- [x] **Add prompting functionality to the `automatic-speech-recognition` pipeline**
<|||||>One more thing we'll need to do, is change the `automatic-speech-recognition` pipeline so that it will actually call `model.generate()` with the prompt, but only for the first chunk (or always if we also decide to support an `always_use_initial_prompt` option). This logic cannot be part of the modeling code, as `model.generate()` has no knowledge of which chunk of audio it's processing.<|||||>I looked a bit more into how this works today, and it turns out that 🤗 Transformers does things a bit differently than the original OpenAI code.
OpenAI does the following:
For the first 30-second chunk of audio, it passes the following token sequence to the model's decoder on the first iteration: `<|startofprev|> initial prompt<|startoftranscript|><|en|><|transcribe|>`. And then it decodes the rest of the sequence autoregressively.
Then for the second chunk of audio, it passes the following sequence to the decoder on the first iteration: `<|startofprev|> initial prompt output of the first chunk<|startoftranscript|><|en|><|transcribe|>`.
For the next chunk, it uses `<|startofprev|> initial prompt output of the first chunk output of the second chunk<|startoftranscript|><|en|><|transcribe|>`
And so on... This list of tokens that it passes in the `<|startofprev|>` section grows longer and longer with each new chunk.
(When you set the `condition_on_previous_text` option to False, it only uses the output from the previous chunk instead of the complete history. In that case the initial prompt text is only used for the very first chunk.)
Our ASR `pipeline` works quite differently. It also splits up the audio in 30-second chunks but they partially overlap, and then it runs the model on these chunks in parallel. That makes it impossible to pass the previous context to these chunks, as each chunk is processed independently. So we have no way of sending `<|startofprev|> initial prompt output of the first chunk<|startoftranscript|><|en|><|transcribe|>` to the second chunk.
The best we can do is send `<|startofprev|> initial prompt<|startoftranscript|><|en|><|transcribe|>` to the very first chunk only, or always send it to all chunks. So we ignore the "previous context" part and always include the prompt. (The latter would do the same as this open [PR on the OpenAI repo](https://github.com/openai/whisper/pull/1040) for always passing the initial prompt inside `<|startofprev|>` instead of the previous context.)
The suggested modifications to `model.generate()` in this PR make it possible to have both `initial_prompt` and the `condition_on_previous_text` options as in OpenAI, but it would require the user to write their own processing loop to get the same results as OpenAI. So we should definitely continue with this PR, but if we also want to support `initial_prompt` in the `pipeline` we'll have to decide on which approach we want. (It's not possible to have `condition_on_previous_text` in the current pipeline.)<|||||>> * We can provide a prompt in the pipeline like the below without modifying the pipeline at all, works for me locally. Is this sufficient / what you had in mind?
You are correct that when you do the following,
```python
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-tiny")
res = pipe(samples, generate_kwargs={ "prompt_ids": prompt_ids })
```
the pipeline will automatically pass the `prompt_ids` to `model.generate()`. However note that this pipeline only processes the first 30 seconds of the audio file. This is fine for audio that is shorter than 30 seconds.
However, to process an audio file that is longer than 30 seconds, we have to do:
```python
res = pipe(example, generate_kwargs={ "prompt_ids": prompt_ids }, chunk_length_s=30, stride_length_s=[6, 0])
```
Now the same `prompt_ids` are passed to `model.generate()` for each 30-second chunk. In effect, this is the `always_use_initial_prompt` option.
To get the regular `initial_prompt` (i.e. `always_use_initial_prompt` disabled) and `condition_on_previous_text` behavior as they work in OpenAI with the current pipeline, we'd have to pass in a `stride_length_s=[0,0]` and `batch_size=1` to make the loop work sequentially rather than in parallel, and somehow keep track of the previous outputs. <|||||>Ok the additional requested features are now added so I believe this is ready for re-review. Thank you for your comments!
> However note that this pipeline only processes the first 30 seconds of the audio file. This is fine for audio that is shorter than 30 seconds... In effect, this is the `always_use_initial_prompt` option.
I think I’m missing something here as I’ve tried this on >1 min of audio in the below example where I also added a debug line to decode the tokens inside of the pipeline as they were generated, and it appears to be properly sequential. In any case, if we don’t want this I’ll remove `condition_on_previous_text` from the pipeline just lmk!
```python
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-tiny")
res = pipe(samples, generate_kwargs={ "condition_on_previous_text": True, "prompt_ids": prompt_ids })
# ['<|startofprev|><|startoftranscript|><|en|><|transcribe|><|notimestamps|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.<|endoftext|>']
# ["<|startofprev|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.<|startoftranscript|><|en|><|transcribe|><|notimestamps|> Nor is Mr. Quilter's manner less interesting than his matter.<|endoftext|>"]
# ["<|startofprev|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter.<|startoftranscript|><|en|><|transcribe|><|notimestamps|> He tells us that at this festive season of the year with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind.<|endoftext|>"]
# ["<|startofprev|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind.<|startoftranscript|><|en|><|transcribe|><|notimestamps|> He has grave doubts whether Sir Frederick Layton's work is really Greek after all and can discover in it but little of Rocky Ithaca.<|endoftext|>"]
# ["<|startofprev|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all and can discover in it but little of Rocky Ithaca.<|startoftranscript|><|en|><|transcribe|><|notimestamps|> Lennils, pictures are a sort of upguards and atom paintings and Mason's exquisite itals are as national as a jingo poem. Mr. Berkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says like a shampoo or a turkish bath. Next man<|endoftext|>"]
# ["<|startofprev|> Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all and can discover in it but little of Rocky Ithaca. Lennils, pictures are a sort of upguards and atom paintings and Mason's exquisite itals are as national as a jingo poem. Mr. Berkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says like a shampoo or a turkish bath. Next man<|startoftranscript|><|en|><|transcribe|><|notimestamps|> it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate and expression.<|endoftext|>"]
# ["<|startofprev|> middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year with Christmas and roast beef looming before us, similarly drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Layton's work is really Greek after all and can discover in it but little of Rocky Ithaca. Lennils, pictures are a sort of upguards and atom paintings and Mason's exquisite itals are as national as a jingo poem. Mr. Berkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says like a shampoo or a turkish bath. Next man it is obviously unnecessary for us to point out how luminous these criticisms are, how delicate and expression.<|startoftranscript|><|en|><|transcribe|><|notimestamps|> On the general principles of art and Mr. Quilter writes with equal lucidity.<|endoftext|>"]
```
<br>
>The suggested modifications to model.generate() in this PR make it possible to have both initial_prompt and the condition_on_previous_text options as in OpenAI, but it would require the user to write their own processing loop to get the same results as OpenAI.
Aimed to address this with the new sequential loop over chunks of the input. Right now this way is incompatible with `return_dict_in_generate`=True as I wasn't sure how / if we'd still want to several ModelOutputs, looking for guidance here.
<br>
Also, there are hacks in a few places related to getting the id of the prompt start token and separating it from the prompt text ids. Would this be something we could add to the model or generation config?<|||||>cc'ing in @gante re `generate` <|||||>>1. Add the prompt_ids to model.generate() as in your earlier version of the PR. All this does is insert the prompt in the <|startofprev|> section. This doesn't give us the OpenAI functionality yet, it only adds <|startofprev|> support to the modeling and tokenizer code.
Thanks @hollance I definitely agree splitting this into >1 PR is ideal, have pushed back up code for number 1 above so this can just address that portion. It now implicitly does `always_use_initial_prompt`.<|||||>Curious if by adding `return_tensors` to `get_prompt_ids` you're setting up effectively doing `condition_on_previous_text` via cleverly feeding batches / prompts to `model.generate()` calls (i.e. the first chunk of a second model.generate call would use the text from the first chunk of the first model.generate call as a prompt and so on for each chunk in the batch), but that's more of a question for subsequent PRs<|||||>The reason I asked for the `return_tensors` argument is that passing the `prompt_ids` into `model.generate()` as a `torch.LongTensor` instead of `List[int]` is more consistent with how we normally pass tokens into Transformers models. I understand that inside the model you might need turn it into a list anyway for the `forced_decoder_ids`, but that's really an internal implementation detail. When we generate, the output token sequence is also a Tensor, and so we can concat this to the previous `prompt_ids` to create the next one, etc. I hope that makes sense. :-)
<|||||>All right, I think this all looks very good. Pinging @sanchit-gandhi for an additional review since he opened the issue.<|||||>Is there an estimation of when this branch will be merged?<|||||>Rebased to include tolerance increase for unrelated flaky flaky PT-FLAX whisper test<|||||>Thanks for the latest round of changes @connor-henderson! Kindly requesting a final review from @amyeroberts!<|||||>Since we're all happy with it, I'm pinging @amyeroberts from the core maintainers team to have a final look.<|||||>@amyeroberts @connor-henderson
Hi All,
Thank you for your great contribution, however I would like a raise a little concern.
We tried to inference the model using this branch and the latest commit and got some weird results.
We provide the audio sample in addition to the prompts for easy reproducing:
[WAV file link](https://drive.google.com/file/d/1kbMEuQv8AmTAyJKkARlwx-wfFhI7uilX/view?usp=sharing)
code:
```python
from transformers import WhisperForConditionalGeneration, WhisperProcessor
import torchaudio
input_speech, sr = torchaudio.load(
"sample.wav"
)
model_name = "openai/whisper-medium"
processor = WhisperProcessor.from_pretrained(model_name, cache_dir="artifacts")
model = WhisperForConditionalGeneration.from_pretrained(model_name, cache_dir="artifacts")
input_features = processor(input_speech.squeeze(), sampling_rate=sr, return_tensors="pt").input_features
# --- Without prompt ---
output_without_prompt = model.generate(input_features)
print(processor.decode(output_without_prompt[0], skip_special_tokens=False))
print(processor.decode(output_without_prompt[0], skip_special_tokens=True))
# --- With prompt ---
prompt_ids = processor.get_prompt_ids("Mexico city")
output_with_prompt = model.generate(input_features, prompt_ids=prompt_ids)
print(processor.decode(output_with_prompt[0], skip_special_tokens=False))
print(processor.decode(output_with_prompt[0], skip_special_tokens=True))
```
and this is the trace:
```
<|startoftranscript|><|en|><|transcribe|><|notimestamps|> San Francisco educators. She was teaching in Mexico City.<|endoftext|>
San Francisco educators. She was teaching in Mexico City.
<|startofprev|> Mexico city<|startoftranscript|><|en|><|transcribe|><|notimestamps|> and<|endoftext|>
and
```
When we don't pass prompts we get the expected output, but when we do pass prompts (that appear in the transcription) we end up with a bad output.
Note that we did not commit any code changes before running this script.
System:
- pytorch 2.0.1
- The test was made on CPU
<|||||>@AvivSham thanks for sharing, I looked at this and I think it may just be that prompting can be finicky. I believe the model perceives the prompt as previous context, so having 'Mexico city' be followed by 'San Francisco' with no grammar in between might've been viewed as unlikely by the model, which could then have led to further model confusion in successive generations.
I tried your example with the tiny model and the prompt actually corrected the output, and trying it with the medium Whisper model I was able to repro your issue but also address it by adding a period to the end of the prompt:
```py
# --- Without prompt ---
output_without_prompt = model.generate(input_features)
print(processor.decode(output_with_prompt[0], skip_special_tokens=False))
# <|startoftranscript|><|en|><|transcribe|><|notimestamps|> San Francisco educators. She was teaching in Mexico City.<|endoftext|>
print(processor.decode(output_with_prompt[0], skip_special_tokens=True))
# San Francisco educators. She was teaching in Mexico City.
# --- With prompt ---
prompt_ids = processor.get_prompt_ids("Mexico city.") # Added a period to the end
output_with_prompt = model.generate(input_features, prompt_ids=prompt_ids)
print(processor.decode(output_with_prompt[0], skip_special_tokens=False))
# <|startofprev|> Mexico city.<|startoftranscript|><|en|><|transcribe|><|notimestamps|> San Francisco educators. She was teaching in Mexico city.<|endoftext|>
print(processor.decode(output_with_prompt[0], skip_special_tokens=True))
# San Francisco educators. She was teaching in Mexico City.
```<|||||>Awesome - thanks for the reviews @amyeroberts and @gante, and for the fast iteration and detailed explanations from you @connor-henderson! Excited to see this PR merged when confirmed as ready 🤗
Regarding prompt engineering, my advice would by to try and emulate a full sentence, complete with punctuation and casing, since really what we're providing as the 'prompt' is just the target transcription from a previous window (see https://github.com/openai/whisper/discussions/963#discussioncomment-4987057)<|||||>Hi all,
Thanks for the great work on adding prompt in 'model.generate'.
Is it possible to add 'initial_prompt' in the Fine-Tune code with a 'prompt_use_rate' to control how often to add prompts to the sentences in training sets?
So that we may improve the performance for some special prompts via prompt-tuning.<|||||>@AvivSham Thanks for reporting and @connor-henderson thanks for investigating!
I think we're good to merge 👍 <|||||>Thank you so much for adding this! I've found that I occasionally get the following:
```
Traceback (most recent call last):
File "G:\Conda\hfwhisper\lib\site-packages\transformers\models\whisper\modeling_whisper.py", line 1662, in generate
return super().generate(
File "G:\Conda\hfwhisper\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "G:\Conda\hfwhisper\lib\site-packages\transformers\generation\utils.py", line 1518, in generate
return self.greedy_search(
File "G:\Conda\hfwhisper\lib\site-packages\transformers\generation\utils.py", line 2345, in greedy_search
next_token_logits = outputs.logits[:, -1, :]
IndexError: index -1 is out of bounds for dimension 1 with size 0
```
My workaround is to catch the exception and try again without the prompt_ids.<|||||>Do you have a reproducible example for this @dgram0? That seems like a serious enough bug that needs investigating further.<|||||>@Johnson-NLP
> Is it possible to add 'initial_prompt' in the Fine-Tune code with a 'prompt_use_rate' to control how often to add prompts to the sentences in training sets?
Sounds like an interesting idea. Would you mind opening a new issue for this? Thanks!
<|||||>To get prompting working with fine-tuning, we probably don't want to explicitly add 'prompted' examples per-se, but rather split longer examples up into shorter ones and feed them sequentially through the model, providing previous passages as 'context' to the model.
For example, if we had a training sample that looked like:
```
This is the first sentence. This is the second sentence. And finally, this is the third.
```
Currently what we do is feed it to the model all at once:
```
<|startoftranscript|> This is the first sentence. This is the second sentence. And finally, this is the third. <|endoftranscript|>
```
What we can do is feed the first sentence in:
```
<|startoftranscript|> This is the first sentence. <|endoftranscript|>
```
Then the second sentence, with the first sentence as context:
```
<|startofprev|> This is the first sentence.<|startoftranscript|> This is the second sentence. <|endoftranscript|>
```
And then the third, with both the first and second sentences as context:
```
<|startofprev|> This is the first sentence. This is the second sentence.<|startoftranscript|> And finally, this is the third.<|endoftranscript|>
```
At inference time, we then just provide the "context" as our prompts:
```
<|startofprev|> This is the prompt.<|startoftranscript|> (model generates the rest)
```
See section 2.3 of the [Whisper paper](https://arxiv.org/pdf/2212.04356.pdf) for an in-depth explanation as to how they achieve this during pre-training. We essentially want to do the same for fine-tuning.
For this to work, ideally we need an original sentence that is >> 30s in duration. That way when we split it up, we don't have super short examples that we feed to the model.<|||||>> Do you have a reproducible example for this @dgram0? That seems like a serious enough bug that needs investigating further.
I'll try reproducing in a small toy example. It's reproducible on my side with the fine-tuned large private model I've been working with.<|||||>> Do you have a reproducible example for this @dgram0? That seems like a serious enough bug that needs investigating further.
The following triggers the bug on the 13th iterations of the loop. (Usually, it takes a lot more iterations.)
```
from datasets import load_dataset, DatasetDict
from transformers import WhisperForConditionalGeneration, WhisperProcessor
it = iter(load_dataset("librispeech_asr", "all", split="test.other", streaming=True))
processor = WhisperProcessor.from_pretrained("openai/whisper-tiny", language="English", task="transcribe")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny")
prompt = 'some text rich in domain specific vocabulary lives here'
past_prompts = ["I am from the cutter lying off the coast"]
while it:
_ = [next(it) for x in range(3)]
clip = next(it)
input_features = processor(clip['audio']['array'], sampling_rate=clip['audio']['sampling_rate'], return_tensors="pt").input_features
prompt_ids = processor.get_prompt_ids(prompt + ' - ' + ' - '.join(past_prompts))
pred_ids = model.generate(input_features, language="english", task="transcribe", max_new_tokens=128, prompt_ids=prompt_ids)
result = processor.batch_decode(pred_ids, skip_special_tokens=True)[0].strip()
result_text = result.removesuffix('.')
print(result_text)
if result_text != '':
past_prompts.append(result_text)
if len(past_prompts) > 12:
past_prompts = past_prompts[1:]
```
<|||||>@dgram0 thanks for sharing, I was able to repro this. As far as its relation to prompting I think this is another case of prompt sensitivity as opposed to a bug, but it may still be of interest with regards to Whisper generally since its the same error message as issue #22682.
I noticed that joining the prompts by `' - '` was causing the model to start predicting chinese characters, and using `'. '` instead did not lead to the error (at least through 30 loops, at that point I stopped testing). I did notice degraded predictions over time though since a period did not necessarily belong after each result, and every now and again a chinese char was still predicted so. I'd just be cautious about how prompts are chained together.<|||||>@connor-henderson It's a bit of a contrived example meant just to recreate the issue without having to loop too much and at the same time show what may be considered a normal use case. Even without it predicting non-English characters or words you'll eventually encounter the issue within a few hundred loops.<|||||>> @dgram0 thanks for sharing, I was able to repro this. As far as its relation to prompting I think this is another case of prompt sensitivity as opposed to a bug, but it may still be of interest with regards to Whisper generally since its the same error message as issue #22682.
>
> I noticed that joining the prompts by `' - '` was causing the model to start predicting chinese characters, and using `'. '` instead did not lead to the error (at least through 30 loops, at that point I stopped testing). I did notice degraded predictions over time though since a period did not necessarily belong after each result, and every now and again a chinese char was still predicted so. I'd just be cautious about how prompts are chained together.
The following still joins the prompts using `' - '`, doesn't allow non-English characters in the prompts, doesn't seem to predict Chinese characters, does a decent job of transcription, and still fails on the 144th loop.
```
from datasets import load_dataset, DatasetDict
from transformers import WhisperForConditionalGeneration, WhisperProcessor
import re
import torch
it = iter(load_dataset("librispeech_asr", "all", split="test.other", streaming=True))
processor = WhisperProcessor.from_pretrained("openai/whisper-tiny", language="English", task="transcribe")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-tiny")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
_ = model.to(device)
prompt = 'Some text rich in domain specific vocabulary and example format lives here.'
past_prompts = ["I am from the cutter lying off the coast."]
while it:
clip = next(it)
input_features = processor(clip['audio']['array'], sampling_rate=clip['audio']['sampling_rate'], return_tensors="pt").input_features
prompt_ids = processor.get_prompt_ids(prompt + ' - ' + ' - '.join(past_prompts))
if device.type == 'cuda':
input_features = input_features.cuda()
pred_ids = model.generate(input_features, language="english", task="transcribe", max_new_tokens=128, prompt_ids=prompt_ids)
result = processor.batch_decode(pred_ids, skip_special_tokens=True)[0].strip()
result_text = re.sub(r"[^\u0000-\u05C0\u2100-\u214F]+$", "", result)
print(result)
if result_text != '':
past_prompts.append(result_text)
if len(past_prompts) > 12:
past_prompts = past_prompts[1:]
```<|||||>Thanks @dgram0 in that case I think this is a bug, I opened an issue #23723 and PR #23724 for both this and another bug this made me realize where `max_new_tokens` isn't properly enforced when the prompt_ids length is too large. I think they both have the same root cause.<|||||>Thanks, @dgram0. Would you have time to look at this bug @connor-henderson, since you're most familiar with this code? If not, I can have a look.
EDIT: LOL, I'm way too slow. Should probably refresh my browser before commenting. Thanks for making these new issues, Connor. 😄 <|||||>@connor-henderson @sanchit-gandhi Hey, did we ever resolve the `add_prefix_space` issue?
If I do the following,
```python
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-tiny")
prompt_ids = pipe.tokenizer.get_prompt_ids("Hello, world!", return_tensors="pt")
```
I get the error,
```python
TypeError: _batch_encode_plus() got an unexpected keyword argument 'add_prefix_space'
```
It works fine if I create a `processor` or `tokenizer` object by hand and call `get_prompt_ids()`.
I seem to recall this issue came up before but not sure if anything was decided for it?
<|||||>@hollance @versae I missed that just looked into it. Appears to be a difference with the slow tokenizer accepting `add_prefix_space` and the fast tokenizer not recognizing or applying it, opened an issue here: #23764 |
transformers | 22,495 | closed | Unable to pre-train Roberta from scratch using example/run_mlm.py script | ### System Info
- `transformers` version: 4.27.0.dev0
- Platform: Linux-4.19.0-23-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.12
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.12.1+cu113 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: NO
- Using distributed or parallel set-up in script?: No
### Who can help?
I trained a custom tokenizer by and tried pre-training Roberta using the official script https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_mlm.py
Using the parameters:
python run_mlm.py \
--model_type roberta \
--tokenizer_name new_gcs/cnn_final/ \
--dataset_name new_gcs/cnn_final/ \
--max_seq_length 512 \
--line_by_line true \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train true\
--do_eval true \
--output_dir ./test-mlm
But I get this error and I checked model.vocab is same as len(token) and max_token in sample is 512 as well.
transformers versions is: '4.27.0.dev0'
File "run_mlm.py", line 632, in <module>
main()
File "run_mlm.py", line 581, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1635, in train
ignore_keys_for_eval=ignore_keys_for_eval,
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1898, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 2640, in training_step
loss = self.compute_loss(model, inputs)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 2672, in compute_loss
outputs = model(**inputs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/roberta/modeling_roberta.py", line 1109, in forward
return_dict=return_dict,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/roberta/modeling_roberta.py", line 850, in forward
past_key_values_length=past_key_values_length,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/roberta/modeling_roberta.py", line 128, in forward
position_embeddings = self.position_embeddings(position_ids)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/sparse.py", line 160, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py", line 2199, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
0%| | 0/8883 [00:00<?, ?it/s]
@sgugger @ArthurZucker @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Running the official scipt: https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_mlm.py
### Expected behavior
Should triain the model | 03-31-2023 15:04:18 | 03-31-2023 15:04:18 | roberta is coded in a hacky way which requires you to set its `max_position_embeddings` to the len of the tokenizer +2 (for instance its 514 for `roberta-base`).<|||||>How can I set that in the script?<|||||>By changing the line creating the config for instance.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,494 | closed | Bump redis from 4.5.3 to 4.5.4 in /examples/research_projects/decision_transformer | Bumps [redis](https://github.com/redis/redis-py) from 4.5.3 to 4.5.4.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/redis/redis-py/releases">redis's releases</a>.</em></p>
<blockquote>
<h2>4.5.4</h2>
<h1>Changes</h1>
<p>Upgrade urgency: SECURITY, contains fixes to security issues.</p>
<ul>
<li>(CVE-2023-28859) - Cancelling an async future does not, properly trigger, leading to a potential data leak in specific cases.</li>
<li>(CVE-2023-28858) - Cancelling an async future does not, properly trigger, leading to a potential data leak in specific cases.</li>
</ul>
<h2>🐛 Bug Fixes</h2>
<ul>
<li>Fixing cancelled async futures (<a href="https://redirect.github.com/redis/redis-py/issues/2666">#2666</a>)</li>
<li>Fix: do not use asyncio's timeout lib before 3.11.2 (<a href="https://redirect.github.com/redis/redis-py/issues/2659">#2659</a>)</li>
<li>Fix UDS in v4.5.2: UnixDomainSocketConnection missing constructor argument (<a href="https://redirect.github.com/redis/redis-py/issues/2630">#2630</a>)</li>
</ul>
<h2>🧰 Maintenance</h2>
<ul>
<li>Minor fixes for <a href="https://redirect.github.com/redis/redis-py/issues/2666">#2666</a> and enhanced async test (<a href="https://redirect.github.com/redis/redis-py/issues/2673">#2673</a>)</li>
<li>Fix issue 2660: PytestUnraisableExceptionWarning from asycio client (<a href="https://redirect.github.com/redis/redis-py/issues/2669">#2669</a>)</li>
<li>Removing accidentally checked in files (<a href="https://redirect.github.com/redis/redis-py/issues/2642">#2642</a>)</li>
</ul>
<h2>Contributors</h2>
<p>We'd like to thank all the contributors who worked on this release!</p>
<p><a href="https://github.com/bellini666"><code>@bellini666</code></a>, <a href="https://github.com/chayim"><code>@chayim</code></a>, <a href="https://github.com/dvora-h"><code>@dvora-h</code></a>, <a href="https://github.com/shacharPash"><code>@shacharPash</code></a> and <a href="https://github.com/woutdenolf"><code>@woutdenolf</code></a></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/redis/redis-py/commit/e1017fd77afd2f56dca90f986fc82e398e518a26"><code>e1017fd</code></a> Version 4.5.4 (<a href="https://redirect.github.com/redis/redis-py/issues/2674">#2674</a>)</li>
<li><a href="https://github.com/redis/redis-py/commit/ef3f086ba95d597b815b41fa382283f62a08b509"><code>ef3f086</code></a> Fix async (<a href="https://redirect.github.com/redis/redis-py/issues/2673">#2673</a>)</li>
<li><a href="https://github.com/redis/redis-py/commit/5acbde355058ab7d9c2f95bcef3993ab4134e342"><code>5acbde3</code></a> Fixing cancelled async futures (<a href="https://redirect.github.com/redis/redis-py/issues/2666">#2666</a>)</li>
<li><a href="https://github.com/redis/redis-py/commit/6d886d7c7b405c0fe5d59ca192c87b438bf080f5"><code>6d886d7</code></a> Fix issue 2660: PytestUnraisableExceptionWarning from asycio client (<a href="https://redirect.github.com/redis/redis-py/issues/2669">#2669</a>)</li>
<li><a href="https://github.com/redis/redis-py/commit/326bb1cf156279919101cc88a696d6cfcd9f3fe9"><code>326bb1c</code></a> removing useless files (<a href="https://redirect.github.com/redis/redis-py/issues/2642">#2642</a>)</li>
<li><a href="https://github.com/redis/redis-py/commit/4856813169f84faa871557dc4e1a98958f5fca6d"><code>4856813</code></a> UnixDomainSocketConnection missing constructor argument (<a href="https://redirect.github.com/redis/redis-py/issues/2630">#2630</a>)</li>
<li><a href="https://github.com/redis/redis-py/commit/480253037afe4c12e38a0f98cadd3019a3724254"><code>4802530</code></a> fix: do not use asyncio's timeout lib before 3.11.2 (<a href="https://redirect.github.com/redis/redis-py/issues/2659">#2659</a>)</li>
<li>See full diff in <a href="https://github.com/redis/redis-py/compare/v4.5.3...v4.5.4">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/huggingface/transformers/network/alerts).
</details> | 03-31-2023 14:39:35 | 03-31-2023 14:39:35 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22494). All of your documentation changes will be reflected on that endpoint. |
transformers | 22,493 | closed | Backbone add out indices | # What does this PR do?
Add out_indices as a way to specify which feature maps are returned in the backbone.
This isn't strictly necessary for cross loading timm backbones and is an optional design choice.
Reasoning:
* Greater compatibility between timm and transformer models when loading with `AutoBackbone`. For the same model e.g. `microsoft/resnet-50` and `resnet50`, the stage names are different, whereas the layer index is the same. `out_indices=(1,)` means the same for both model. whereas selecting features requires knowing one uses `layer1` and the other uses `stage1`.
* `out_features` requires knowing the names of the layers in order select which layers you want and is more prone to errors with typos
* `out_indices` is the param used in timm. Once advantage of `out_indices` is that you can do negative indexing easily. For example, to get the last two feature maps, you need only pass `out_indices=(-2, -1)`.
Outstanding question on whether both `out_features` and `out_indices` should exist at the same time.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 03-31-2023 13:47:23 | 03-31-2023 13:47:23 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,492 | closed | Errror even if offload_dir is provided | ### System Info
Windows 10
16 GB RAM
4GB NVIDIA
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
You need CUDA enabled system.
You also need a version of transofrmers that has no other bugs and one that has the LlamaTokenizer available.
I am using transformers 4.28.0-dev, but not the latest as it has bugs.
Executing the following code:
```
import torch
from peft import PeftModel
import transformers
import os, time
import tempfile
assert ("LlamaTokenizer" in transformers._import_structure["models.llama"]), "LLaMA is now in HuggingFace's main branch.\nPlease reinstall it: pip uninstall transformers && pip install git+https://github.com/huggingface/transformers.git"
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
BASE_MODEL = "decapoda-research/llama-7b-hf"
LORA_WEIGHTS = "tloen/alpaca-lora-7b"
force_cpu = False
if torch.cuda.is_available() and not force_cpu:
device = "cuda"
print("Video memory available:", torch.cuda.get_device_properties(0).total_memory / 1024 / 1024, "MBs")
else:
device = "cpu"
print("Compute device is:", device)
try:
if torch.backends.mps.is_available():
device = "mps"
except:
pass
print("Loading model with selected weights ...")
if device == "cuda":
print("model on cuda")
model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
offload_folder="offload", #required on GPU with not enough memory
)
model = PeftModel.from_pretrained(
model,
LORA_WEIGHTS,
torch_dtype=torch.float16,
device_map="auto",
offload_folder="offload", #required on GPU with not enough memory
)
```
Gives the error:
`ValueError: We need an `offload_dir` to dispatch this model according to this `device_map`, the following `
The offload folder is specified in my code and it works the first time, but not the second. I am forced to hard code the folder like this: `offload_dir = "offload"` to big_modeling.py at line 341 in order to avoid the error.
### Expected behavior
No error. | 03-31-2023 12:25:55 | 03-31-2023 12:25:55 | Actually this is in accelerate. I need to move it there. |
transformers | 22,491 | closed | In one-node multi-GPU setups, the ImageProcessor module in Detr and other object detection models may cause an error in the Trainer. | ### System Info
When training object detection models using multiple GPUs in a single node, I encountered an issue with nn.DataParallel. The nn.DataParallel module splits Tensor data across each GPU before model inference, but it does not split List data. Since all object detection ImageProcessor modules return List objects, the targets will not be split, but the inputs will have already been split. Additionally, inputs are of type Tensor, while targets are of type List.
During loss computation, the shapes of inputs and targets may not match along the 0th dimension.
Is this the best practice for single-node multi-GPU setup? Should I avoid using nn.DataParallel?
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Due to confidentiality reasons, I cannot submit the complete code. I will provide a example later.
### Expected behavior
Training object detection model with multiple GPUs on a single machine as usual. | 03-31-2023 11:37:16 | 03-31-2023 11:37:16 | You should use DistributedDataParallel for multi-GPU setup, which is better supported and the recommended way from the PyTorch team. It is supported by the Trainer, but just launch your training with `torchrun` instead of `python`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,490 | open | Adding a skip_special_tokens Parameter to .encode() in Transformers | ### Feature request
I would like to propose adding a skip_special_tokens parameter to the .encode() method in Transformers. Currently, in order to achieve this behavior, I have to either create two different tokenizers or use a workaround such as inserting a character in the middle of a special token and then removing it to simulate the desired behavior.
### Motivation
The motivation for this feature request is that in real-world scenarios, users may enter any type of textual data, including special tokens used by the tokenizer. If the tokenizer were to tokenize the user's input as is, it would cause confusion for the whole model and impact the performance of the product. The skip_special_tokens parameter is essential for ensuring the correct processing of user inputs, not just for the `decode()` method but also for the `encode()` and `__call__()` methods.
### Your contribution
I have implemented my own tokenizer that inherits from Transformers and simulates this behavior by removing the special tokens from the vocab before encoding. However, I believe this approach **would not be efficient** for scaling up, as it would cause a lot of memory allocations and deallocations.
To address this issue, I suggest implementing **two separate dictionaries**, one for special tokens and one for the vocabulary, and incorporating an if-statement to test for the skip_special_tokens parameter. This would make the implementation performant and efficient.
Thank you for considering this feature request. | 03-31-2023 11:34:32 | 03-31-2023 11:34:32 | cc @ArthurZucker <|||||>Hey, we have to consider whether or not we want to maintain this and add this as a functionality to ALL tokenizers.
If you actually want to `skip` the special tokens, then a simple way to do this in the `slow` tokenizer is to modify the `tokenize` function like the following:
```python
def tokenize(self, text: TextInput, **kwargs) -> List[str]:
......
skip_special_tokens = kwargs.pop("skip_special_tokens", False)
for i, token in enumerate(tokens):
if token in no_split_token:
.........
if isinstance(tok_extended, AddedToken):
if skip_special_tokens:
tokens[i] = None
else:
.....
return tokenized_text
```
This could be added as it is general enough (though might not have a lot of usages) and requires base modifications.
However, if you are looking for something similar to a fallback where the special tokens are not split, I don't really see the need of removing the token from the vocabulary. You have to redefine the `convert_tokens_to_ids` function. Here is a snippet:
```python
def convert_tokens_to_ids(self, tokens: Union[str, List[str]]) -> Union[int, List[int]]:
for token in tokens:
if token in self.all_special_tokens: # ['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
# post process the way you want. Split the string?
for tok in token.split():
ids.append(self._convert_token_to_id_with_added_voc(tok))
ids.append(self._convert_token_to_id_with_added_voc(token))
return ids
```
This is something pretty specific, and I don't see a reason to include it to transformers. |
transformers | 22,489 | closed | fix FSDP version related issues | # What does this PR do?
1. This checks if the arg is available before using it to be backward compatible.
2. Fixes #22446 | 03-31-2023 10:02:53 | 03-31-2023 10:02:53 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks fix! |
transformers | 22,488 | closed | Accelerate support for GLM | ### Feature request
Accelerate support for [GLM](https://github.com/THUDM/GLM).
### Motivation
[GLM](https://github.com/THUDM/GLM) is a SOTA chinese LLM. However, running the following code...
```
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("THUDM/glm-10b", trust_remote_code=True, device_map="auto", load_in_8bit=True)
```
gives error...
```
ValueError: GLMForConditionalGeneration does not support `device_map='auto'` yet.
```
### Your contribution
I would be happy to contribute. However, I can't find a guide on adding other models to `accelerate`. | 03-31-2023 09:48:36 | 03-31-2023 09:48:36 | You just need to add the proper attribute to `GLMPreTrainedModel` so that it knows which layers should not be split across GPUs and then test it works properly. Since this model uses the code on the Hub feature, the code of the model needs to be changed [there](https://huggingface.co/THUDM/glm-10b/blob/main/modeling_glm.py#L627) to add something like in T5 [here](https://github.com/huggingface/transformers/blob/516077b3b09fe4a210525e2b16b1b3f08685c020/src/transformers/models/t5/modeling_t5.py#L785) (since the model seems to look like T5). You can open a PR on their repo with this maybe?<|||||>Thanks @sgugger for the advice! I've added the `_no_split_modules` attributes in this [PR](https://huggingface.co/THUDM/glm-10b-chinese/discussions/2/files).
However, when I tried using `device_map` with the following code...
```
from transformers import AutoModelForSeq2SeqLM
model_name_or_path = "THUDM/glm-10b-chinese"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path,
trust_remote_code=True,
revision="6adb492",
device_map="auto",
load_in_8bit=True,
)
model.eval()
```
I faced the error...
```
Overriding torch_dtype=None with `torch_dtype=torch.float16` due to requirements of `bitsandbytes` to enable model loading in mixed int8. Either pass torch_dtype=torch.float16 or don't pass this argument at all to remove this warning.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[7], line 2
1 # ours
----> 2 model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path,
3 trust_remote_code=True,
4 cache_dir=SHARED_MODEL_DIR,
5 revision="6adb492",
6 device_map="auto",
7 load_in_8bit=True,
8 )
9 model.eval()
File ~/ln/lib/python3.8/site-packages/transformers/models/auto/auto_factory.py:466, in _BaseAutoModelClass.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
462 model_class = get_class_from_dynamic_module(
463 pretrained_model_name_or_path, module_file + ".py", class_name, **hub_kwargs, **kwargs
464 )
465 model_class.register_for_auto_class(cls.__name__)
--> 466 return model_class.from_pretrained(
467 pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
468 )
469 elif type(config) in cls._model_mapping.keys():
470 model_class = _get_model_class(config, cls._model_mapping)
File ~/ln/lib/python3.8/site-packages/transformers/modeling_utils.py:2648, in PreTrainedModel.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
2638 if dtype_orig is not None:
2639 torch.set_default_dtype(dtype_orig)
2641 (
2642 model,
2643 missing_keys,
2644 unexpected_keys,
2645 mismatched_keys,
2646 offload_index,
2647 error_msgs,
-> 2648 ) = cls._load_pretrained_model(
2649 model,
2650 state_dict,
2651 loaded_state_dict_keys, # XXX: rename?
2652 resolved_archive_file,
2653 pretrained_model_name_or_path,
2654 ignore_mismatched_sizes=ignore_mismatched_sizes,
2655 sharded_metadata=sharded_metadata,
2656 _fast_init=_fast_init,
2657 low_cpu_mem_usage=low_cpu_mem_usage,
2658 device_map=device_map,
2659 offload_folder=offload_folder,
2660 offload_state_dict=offload_state_dict,
2661 dtype=torch_dtype,
2662 load_in_8bit=load_in_8bit,
2663 keep_in_fp32_modules=keep_in_fp32_modules,
2664 )
2666 model.is_loaded_in_8bit = load_in_8bit
2668 # make sure token embedding weights are still tied if needed
File ~/ln/lib/python3.8/site-packages/transformers/modeling_utils.py:2971, in PreTrainedModel._load_pretrained_model(cls, model, state_dict, loaded_keys, resolved_archive_file, pretrained_model_name_or_path, ignore_mismatched_sizes, sharded_metadata, _fast_init, low_cpu_mem_usage, device_map, offload_folder, offload_state_dict, dtype, load_in_8bit, keep_in_fp32_modules)
2961 mismatched_keys += _find_mismatched_keys(
2962 state_dict,
2963 model_state_dict,
(...)
2967 ignore_mismatched_sizes,
2968 )
2970 if low_cpu_mem_usage:
-> 2971 new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(
2972 model_to_load,
2973 state_dict,
2974 loaded_keys,
2975 start_prefix,
2976 expected_keys,
2977 device_map=device_map,
2978 offload_folder=offload_folder,
2979 offload_index=offload_index,
2980 state_dict_folder=state_dict_folder,
2981 state_dict_index=state_dict_index,
2982 dtype=dtype,
2983 load_in_8bit=load_in_8bit,
2984 is_safetensors=is_safetensors,
2985 keep_in_fp32_modules=keep_in_fp32_modules,
2986 )
2987 error_msgs += new_error_msgs
2988 else:
File ~/ln/lib/python3.8/site-packages/transformers/modeling_utils.py:665, in _load_state_dict_into_meta_model(model, state_dict, loaded_state_dict_keys, start_prefix, expected_keys, device_map, offload_folder, offload_index, state_dict_folder, state_dict_index, dtype, load_in_8bit, is_safetensors, keep_in_fp32_modules)
662 module_name = ".".join(module_name.split(".")[:-1])
663 if module_name == "" and "" not in device_map:
664 # TODO: group all errors and raise at the end.
--> 665 raise ValueError(f"{param_name} doesn't have any device set.")
666 param_device = device_map[module_name]
667 if param_device == "disk":
ValueError: word_embeddings.weight doesn't have any device set.
```
I managed to fix this by specifying a custom `device_map` (code below). However, `device_map='auto'` should work without the user passing a specific `device_map` right? Is my PR missing something?
```
device_map={'glm.word_embeddings': 0,
'glm.transformer.embedding_dropout': 0,
'glm.transformer.position_embeddings': 0,
'glm.transformer.block_position_embeddings': 0,
'glm.transformer.layers.0': 0,
'glm.transformer.layers.1': 0,
'glm.transformer.layers.2': 0,
'glm.transformer.layers.3': 0,
'glm.transformer.layers.4': 0,
'glm.transformer.layers.5': 0,
'glm.transformer.layers.6': 0,
'glm.transformer.layers.7': 0,
'glm.transformer.layers.8': 0,
'glm.transformer.layers.9': 0,
'glm.transformer.layers.10': 0,
'glm.transformer.layers.11': 0,
'glm.transformer.layers.12': 0,
'glm.transformer.layers.13': 0,
'glm.transformer.layers.14': 0,
'glm.transformer.layers.15': 0,
'glm.transformer.layers.16': 0,
'glm.transformer.layers.17': 0,
'glm.transformer.layers.18': 0,
'glm.transformer.layers.19': 0,
'glm.transformer.layers.20': 0,
'glm.transformer.layers.21': 0,
'glm.transformer.layers.22': 0,
'glm.transformer.layers.23': 0,
'glm.transformer.layers.24': 0,
'glm.transformer.layers.25': 0,
'glm.transformer.layers.26': 0,
'glm.transformer.layers.27': 0,
'glm.transformer.layers.28': 0,
'glm.transformer.layers.29': 0,
'glm.transformer.layers.30': 0,
'glm.transformer.layers.31': 0,
'glm.transformer.layers.32': 0,
'glm.transformer.layers.33': 0,
'glm.transformer.layers.34': 0,
'glm.transformer.layers.35': 0,
'glm.transformer.layers.36': 0,
'glm.transformer.layers.37': 0,
'glm.transformer.layers.38': 0,
'glm.transformer.layers.39': 0,
'glm.transformer.layers.40': 0,
'glm.transformer.layers.41': 0,
'glm.transformer.layers.42': 0,
'glm.transformer.layers.43': 0,
'glm.transformer.layers.44': 0,
'glm.transformer.layers.45': 0,
'glm.transformer.layers.46': 0,
'glm.transformer.layers.47': 0,
'glm.transformer.final_layernorm': 0}
# ours
model_name_or_path = "THUDM/glm-10b-chinese"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path,
trust_remote_code=True,
revision="6adb492",
device_map=device_map,
load_in_8bit=True,
)
model.eval()
```<|||||>Does it work without the load_in_8bit part? Also what is your version of Accelerate?<|||||>Nope, same error. Here's my dependencies:
```
accelerate==0.18.0
aiohttp==3.8.4
aiosignal==1.3.1
anyio==3.6.2
argon2-cffi==21.3.0
argon2-cffi-bindings==21.2.0
arrow==1.2.3
asttokens==2.2.1
async-timeout==4.0.2
attrs==22.2.0
backcall==0.2.0
beautifulsoup4==4.12.0
bitsandbytes==0.37.2
bleach==6.0.0
certifi==2022.12.7
cffi==1.15.1
charset-normalizer==3.1.0
cmake==3.26.1
comm==0.1.3
datasets==2.11.0
debugpy==1.6.6
decorator==5.1.1
defusedxml==0.7.1
dill==0.3.6
evaluate==0.4.0
executing==1.2.0
fastjsonschema==2.16.3
filelock==3.10.7
fqdn==1.5.1
frozenlist==1.3.3
fsspec==2023.3.0
huggingface-hub==0.13.3
idna==3.4
importlib-metadata==6.1.0
importlib-resources==5.12.0
ipykernel==6.22.0
ipython==8.12.0
ipython-genutils==0.2.0
isoduration==20.11.0
jedi==0.18.2
Jinja2==3.1.2
jsonpointer==2.3
jsonschema==4.17.3
jupyter-events==0.6.3
jupyter_client==8.1.0
jupyter_core==5.3.0
jupyter_server==2.5.0
jupyter_server_terminals==0.4.4
jupyterlab-pygments==0.2.2
-e git+https://github.com/larrylawl/prompt-infill-prompt.git@aefd41e421cf30485b2e14b13877cdf1232335c7#egg=lexnorm
lit==16.0.0
MarkupSafe==2.1.2
matplotlib-inline==0.1.6
mistune==2.0.5
mpmath==1.3.0
multidict==6.0.4
multiprocess==0.70.14
nbclassic==0.5.4
nbclient==0.7.3
nbconvert==7.3.0
nbformat==5.8.0
nest-asyncio==1.5.6
networkx==3.1
notebook==6.5.3
notebook_shim==0.2.2
numpy==1.24.2
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-cupti-cu11==11.7.101
nvidia-cuda-nvrtc-cu11==11.7.99
nvidia-cuda-runtime-cu11==11.7.99
nvidia-cudnn-cu11==8.5.0.96
nvidia-cufft-cu11==10.9.0.58
nvidia-curand-cu11==10.2.10.91
nvidia-cusolver-cu11==11.4.0.1
nvidia-cusparse-cu11==11.7.4.91
nvidia-nccl-cu11==2.14.3
nvidia-nvtx-cu11==11.7.91
packaging==23.0
pandas==2.0.0
pandocfilters==1.5.0
parso==0.8.3
pexpect==4.8.0
pickleshare==0.7.5
pkgutil_resolve_name==1.3.10
platformdirs==3.2.0
prometheus-client==0.16.0
prompt-toolkit==3.0.38
psutil==5.9.4
ptyprocess==0.7.0
pure-eval==0.2.2
pyarrow==11.0.0
pycparser==2.21
Pygments==2.14.0
pyrsistent==0.19.3
python-dateutil==2.8.2
python-json-logger==2.0.7
pytz==2023.3
PyYAML==6.0
pyzmq==25.0.2
regex==2023.3.23
requests==2.28.2
responses==0.18.0
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
Send2Trash==1.8.0
sentencepiece==0.1.97
six==1.16.0
sniffio==1.3.0
soupsieve==2.4
stack-data==0.6.2
sympy==1.11.1
terminado==0.17.1
tinycss2==1.2.1
tokenizers==0.13.2
torch==2.0.0
tornado==6.2
tqdm==4.65.0
traitlets==5.9.0
transformers==4.27.4
triton==2.0.0
typing_extensions==4.5.0
tzdata==2023.3
uri-template==1.2.0
urllib3==1.26.15
wcwidth==0.2.6
webcolors==1.13
webencodings==0.5.1
websocket-client==1.5.1
xxhash==3.2.0
yarl==1.8.2
zhon==1.1.5
zipp==3.15.0
```<|||||>I just tried
```py
from transformers import AutoModelForSeq2SeqLM
model_name_or_path = "THUDM/glm-10b-chinese"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path, trust_remote_code=True, revision="6adb492", device_map="auto")
```
and it worked without any issue.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,487 | open | Support `text-to-speech` in `pipeline` function and in Optimum | ### Feature request
SpeechT5 was recently added to Transformers:
* **Blog post**: https://huggingface.co/blog/speecht5
* **Spaces demo**: https://huggingface.co/spaces/Matthijs/speecht5-tts-demo
* **Models**: https://huggingface.co/mechanicalsea/speecht5-tts
It would be great if `text-to-speech` could be supported across the Transformers stack.
### Motivation
@xenova [bumped into this as an issue](https://github.com/xenova/transformers.js/issues/59) when trying to get SpeechT5 working in the browser (Transformers.js).
### Your contribution
Probably unable to help with this at the moment. | 03-31-2023 08:46:37 | 03-31-2023 08:46:37 | cc @sanchit-gandhi <|||||>Indeed, a TTS pipeline would be super helpful to run SpeechT5. We're currently planning on waiting till we have 1-2 more TTS models in the library before pushing ahead with a TTS pipeline, in order to verify that the pipeline is generalisable and gives a benefit over loading a single model + processor.
cc @hollance<|||||>Any viable contenders for the other 1-2 models? https://paperswithcode.com/task/text-to-speech-synthesis<|||||>Hey, I'd be more than happy to take up this task if we can decide on the other 1-2 models<|||||>> Hey, I'd be more than happy to take up this task if we can decide on the other 1-2 models
We can probably just select the most popular models from the hub: https://huggingface.co/models?pipeline_tag=text-to-speech&sort=downloads<|||||>There is an [open PR](https://github.com/huggingface/transformers/pull/15773) for FastSpeech2. I think this is a good new model to add. If anyone is interested in taking that PR to completion, that would be awesome!<|||||>> Hey, I'd be more than happy to take up this task if we can decide on the other 1-2 models
Let me know if you need any help! I’m excited for this to be added 🔥<|||||>Here's another model which could fall into the `text-to-speech` category: https://github.com/huggingface/transformers/issues/23036<|||||>Just added one more https://github.com/huggingface/transformers/issues/23050<|||||>Please add support for the mms-tts model as mentioned in above [issue](https://github.com/xenova/transformers.js/issues/209) to the TTS pipeline.<|||||>Good news! This is currently being worked on: https://github.com/huggingface/transformers/pull/24952 🚀🔥 |
transformers | 22,486 | closed | fix `_no_split_modules` for Whisper model | # What does this PR do?
1. fix `_no_split_modules` for Whisper model | 03-31-2023 08:27:56 | 03-31-2023 08:27:56 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,485 | closed | Add Cross attention to GPTNeo | ### Feature request
I have been working on using GPTNeo as a decoder for an encoder-decoder model, and I was hoping to add cross attention to GPTNeo.
### Motivation
For encoder-decoder model
### Your contribution
I would like to submit a PR for it but anyone is up to taking it | 03-31-2023 06:52:45 | 03-31-2023 06:52:45 | @patil-suraj <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,484 | closed | Load generation config from model config Error! | ### System Info
- `transformers` version: 4.27.4
- Platform: Linux-3.10.0-1160.11.1.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.16
- Huggingface_hub version: 0.13.2
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
This is where I call your generate() method:
`output_sequences = super().**generate**(**batch, pad_token_id=self.tokenizer.pad_token_id, eos_token_id=self.tokenizer.eos_token_id,**input_generation_kwargs)`
**batch** looks like this:
batch
{'input_ids': tensor([[ 259, 661...='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1,...='cuda:0'), 'decoder_input_ids': tensor([[ 0, 3259...='cuda:0'), 'loss_ids': tensor([[0, 1, 1, 0,...='cuda:0'), 'guid': ['0', '1', '2', '3'], 'tgt_text': ['_', '_', '_', '_']}
print(batch)
{'input_ids': tensor([[ 259, 6611, 22933, 267, 259, 2967, 278, 14342, 368, 8183,
2357, 1838, 13663, 5020, 25598, 20782, 7858, 2286, 3726, 5702,
6302, 259, 428, 271, 15597, 10714, 267, 32595, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 259, 6611, 22933, 267, 259, 2967, 278, 14342, 368, 8183,
2357, 1838, 13663, 5020, 25598, 20782, 7858, 2286, 3726, 5702,
6302, 259, 428, 271, 15597, 10714, 267, 32595, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 259, 6611, 22933, 267, 259, 2967, 278, 14342, 368, 8183,
2357, 1838, 13663, 5020, 25598, 20782, 7858, 2286, 3726, 5702,
6302, 259, 428, 271, 15597, 10714, 267, 32595, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 259, 6611, 22933, 267, 259, 2967, 278, 14342, 368, 8183,
2357, 1838, 13663, 5020, 25598, 20782, 7858, 2286, 3726, 5702,
6302, 259, 428, 271, 15597, 10714, 267, 32595, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]],
device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]], device='cuda:0'), 'decoder_input_ids': tensor([[ 0, 32595],
[ 0, 32595],
[ 0, 32595],
[ 0, 32595]], device='cuda:0'), 'loss_ids': tensor([[0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], device='cuda:0'), 'guid': ['0', '1', '2', '3'], 'tgt_text': ['_', '_', '_', '_']}
model config like this:
`T5Config {
"_name_or_path": "IDEA-CCNL/Randeng-T5-784M-MultiTask-Chinese",
"architectures": [
"T5ForConditionalGeneration"
],
"bad_words_ids": [
[
3473,
1837
],
[
3473,
27556
],
[
259,
3473
]
],
"d_ff": 2816,
"d_kv": 64,
"d_model": 1024,
"decoder_start_token_id": 0,
"dense_act_fn": "gelu_new",
"diversity_penalty": 3.0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "gated-gelu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"is_gated_act": true,
"layer_norm_epsilon": 1e-06,
"length_penalty": 3.0,
"max_length": 200,
"max_new_tokens": 4,
"metric": [
"sentence_bleu"
],
"min_length": 5,
"model_type": "t5",
"num_beam_groups": 5,
"num_beams": 5,
"num_decoder_layers": 24,
"num_heads": 16,
"num_layers": 24,
"output_past": true,
"pad_token_id": 0,
"parent_config": "task",
"relative_attention_max_distance": 128,
"relative_attention_num_buckets": 32,
"repetition_penalty": 5.0,
"temperature": 2.0,
"tie_word_embeddings": false,
"tokenizer_class": "T5Tokenizer",
"top_k": 0,
"top_p": 0.9,
"torch_dtype": "float32",
"transformers_version": "4.27.4",
"use_cache": true,
"vocab_size": 32596
}`
### Expected behavior
Hello, @gante, When I evaluate my generation model, I need to load generation config from model config.
You can find the code at [https://github.com/huggingface/transformers/blob/main/src/transformers/generation/utils.py#L1225](url)
It's not working to copy model config, but when I change code like this:
`self.generation_config.update(**new_generation_config.to_dict())`
the copy can work. I think this is a bug you should probably fix.
Thank you for your excellent work! | 03-31-2023 03:47:48 | 03-31-2023 03:47:48 | Hey @CinderellaCc 👋 Thank you for raising the issue!
I'm not sure I follow the exact details if your issue -- would you be able to share a stand-alone short script to reproduce the issue? :)
`from_model_config()` calls `.to_dict()` internally, and it should work with model config objects 🤔 <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,483 | closed | `libssl.so.10' not found but ll exsit | ### System Info
ImportError: /home/aaa/anaconda3/envs/ner/lib/python3.9/site-packages/tokenizers/../../../libssl.so.10: version `libssl.so.10' not found (required by /home/aaa/anaconda3/envs/ner/lib/python3.9/site-packages/tokenizers/tokenizers.cpython-39-x86_64-linux-gnu.so)
(ner) aaa@:lib$ ll /home/aaa/anaconda3/envs/ner/lib/python3.9/site-packages/tokenizers/../../../libssl.so.10
lrwxrwxrwx 1 aaa aaa 15 Mar 30 21:03 /home/aaa/anaconda3/envs/ner/lib/python3.9/site-packages/tokenizers/../../../libssl.so.10 -> libssl.so.1.0.0
Ubuntu 22.04.2 LTS
conda 23.1.0
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. in another environment of conda 'git clone https://github.com/huggingface/transformers.git' and 'pip install -e .'
2. pip uninstall transformers
3. conda remove -n (that conda env in step 1) --all
4. then `libssl.so.10' not found and I copy libssl.so.1.0.0 from other place in my ubuntu
5. ln -s libssl.so.1.0.0 libssl.so.10
### Expected behavior
just found it | 03-31-2023 02:07:49 | 03-31-2023 02:07:49 | it is my mistake:chmod 775 |
transformers | 22,482 | closed | DDP + gloo + gpt2 crashes | ### System Info
- `transformers` version: 4.27.4
- Platform: macOS-12.6-arm64-arm-64bit (also have tested on ubuntu)
- Python version: 3.10.9
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 1.13.1 (False) (also have tested on older torch versions)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: yes, see script
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
import transformers
import multiprocessing as mp
import torch.multiprocessing as mp
import os
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
gpt2 = transformers.AutoModelForCausalLM.from_pretrained('gpt2')
module = DistributedDataParallel(gpt2)
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == '__main__':
world_size = 2
run_demo(demo_basic, world_size)
```
gives
```
Running basic DDP example on rank 1.
Running basic DDP example on rank 0.
NOTE: Redirects are currently not supported in Windows or MacOs.
NOTE: Redirects are currently not supported in Windows or MacOs.
Traceback (most recent call last):
File "/Users/danielking/github/composer/scripts/gpt2-dist.py", line 36, in <module>
run_demo(demo_basic, world_size)
File "/Users/danielking/github/composer/scripts/gpt2-dist.py", line 29, in run_demo
mp.spawn(demo_fn,
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 240, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 198, in start_processes
while not context.join():
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 160, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/Users/danielking/github/composer/scripts/gpt2-dist.py", line 24, in demo_basic
module = DistributedDataParallel(gpt2)
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 657, in __init__
_sync_module_states(
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/distributed/utils.py", line 136, in _sync_module_states
_sync_params_and_buffers(
File "/Users/danielking/miniconda3/envs/composer-dev-3.10/lib/python3.10/site-packages/torch/distributed/utils.py", line 154, in _sync_params_and_buffers
dist._broadcast_coalesced(
RuntimeError: Invalid scalar type
```
It looks like the attention bias was changed from `torch.uint8` in `transformers` version `4.26.1` to `torch.bool` in `transformers` version `4.27.x`. I'm not sure if I'm doing something wrong, torch has a bug, or transformers has a bug. I don't use the gloo backend much, and discovered this error from our unit tests when upgrading `transformers` version. Thanks for your help!
### Expected behavior
DDP wrapping gpt2 works on CPU | 03-31-2023 01:18:32 | 03-31-2023 01:18:32 | We had to change the bias to `torch.bool` especially because the `torch.where` operations are no longer supported with `uint8` in the most recent versions of pytorch.
> Use of uint8 masks in torch.where has been deprecated for couple years, and though it still works in pytorch eager (with a warning), support for this has been removed in torch.compile. It would be good to audit places where uint8 masks are used and replace them with bool masks.
cc @sgugger as I am not sure about the support for DDP<|||||>Interesting. Does the bug persist on PyTorch 2.0? I'll ask in our channels with PyTorch about the support of bool tensors and DDP.<|||||>The issue does persist on torch 2.0<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.<|||||>I believe this remains an issue<|||||>Is there a fix for this issue yet? <|||||>I have pinged the PyTorch team multiple times but got no reply on this. You can try opening an issue on their repo.
They basically told us to move the torch.uint8 to torch.bool because torch.uint8 won't be supported in some operations like `torch.where`.<|||||>Any fix for this issue? I also met in the GPT-J test. I raise one issue in the pytorch github: https://github.com/pytorch/pytorch/issues/103585<|||||>Passing `broadcast_buffers=False` to `DistributedDataParallel` fixed this for me. I've opened a PR at #24326 to surface that argument to the Trainer user.<|||||>I think there's two issues here:
- GLOO doesn't support `bool`. This requires update in `torch.distributed` to get it to work:
```python
import os
import torch
from torch import distributed as dist
def initialize_torch_distributed():
rank = int(os.getenv('RANK', '0'))
world_size = int(os.getenv("WORLD_SIZE", '1'))
backend = "gloo"
# Call the init process.
init_method = 'tcp://'
master_ip = os.getenv('MASTER_ADDR', 'localhost')
master_port = os.getenv('MASTER_PORT', '6000')
init_method += master_ip + ':' + master_port
torch.distributed.init_process_group(
backend=backend,
world_size=world_size,
rank=rank,
init_method=init_method
)
return True
def main():
initialize_torch_distributed()
w = torch.randn(1,3) > 0 # bool tensor
dist.broadcast(w, src=0) # Fails with `RuntimeError: Invalid scalar type`
print(f"Sucess: {dist.get_rank()}/{dist.get_world_size()}")
if __name__ == "__main__":
main()
```
I'm not completely sure, but that can probably be fixed by adding the Scalar::Bool here to cast to uint8 (or bool?): https://github.com/pytorch/pytorch/blame/dbc8eb2a8fd894fbc110bbb9f70037249868afa8/torch/csrc/distributed/c10d/ProcessGroupGloo.cpp#L98
- Once you have the distributed call issues (using nccl for example), you end up with an autograd errors due to DDP broadcasting your buffers. I'm still not super clear as to why it gets triggered.
For both issues, the `broadcast_buffers=False` can be a good workaround. The only issue is if you mix buffers that require DDP syncing, like BatchNorm.<|||||>Although I have passed the `broadcast_buffers=False` to `DistributedDataParallel`, it seems that the issue remains:

Expect your feedback @TevenLeScao <|||||>Hey @tianyil1 , this looks like another issue to me, and I'm not seeing in my case. If you send your file here, it could be easier to run it to debug!<|||||>Thanks for your feedback @TevenLeScao. The running script was the similar to the first post but added the `broadcast_buffers=False` to the `DistributedDataParallel`:
```python
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
import transformers
import multiprocessing as mp
import torch.multiprocessing as mp
import os
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
gptj = transformers.AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
module = DistributedDataParallel(gptj, broadcast_buffers=False)
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == '__main__':
world_size = 2
run_demo(demo_basic, world_size)
```<|||||>Okay there's a hack you can do:
```python
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
import transformers
import multiprocessing as mp
import torch.multiprocessing as mp
import os
import torch
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
gpt2 = transformers.AutoModelForCausalLM.from_pretrained("gpt2")
gpt2._ddp_params_and_buffers_to_ignore = [name for name, buffer in gpt2.named_buffers() if buffer.dtype == torch.bool] # This is the trick, you ask DDP to ignore all buffers that are in torch.bool because GLOO doesn't support bool.
module = DistributedDataParallel(gpt2)
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == '__main__':
world_size = 2
run_demo(demo_basic, world_size)
```
Since you don't need to sync them, it should work for you. Though the best fix would be to support bool in GLOO backend.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,481 | closed | Fix OPTForQuestionAnswering doc string | Fixes OPTForQuestionAnswering doc string for more adequate model answer decoding
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
| 03-30-2023 23:07:08 | 03-30-2023 23:07:08 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger Thanks! Done! (took me two attempts 😅 ) |
transformers | 22,480 | closed | Evaluate QA models using run_qa.py script | null | 03-30-2023 22:31:10 | 03-30-2023 22:31:10 | The same command given in the README without the training prompts works perfectly. Just tried:
```
python examples/pytorch/question-answering/run_qa.py \
--model_name_or_path deepset/deberta-v3-base-squad2 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ~/tmp/debug_squad/
```
And it proceeds without error to an F1 of 92.28 and accuracy of 85% for exact matches.<|||||>You will need to adapt the example (which is just that, an example) to the format of your own data. |
transformers | 22,479 | closed | Make FlaxPreTrainedModel a Flax Module | Moved to #22627 | 03-30-2023 22:07:55 | 03-30-2023 22:07:55 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22479). All of your documentation changes will be reflected on that endpoint.<|||||>Thanks for the review @sanchit-gandhi !
> => perhaps as a start we first make a PR that triggers this warning (advising users that the functinality is going to change in N months / releases time), and then have this PR as a follow-up that makes the changes?
I was planning on entirely deleting the `params` argument from `__call__` 😅. If we want to make the change a bit more gradual then maybe we could do something like this:
```diff
- if self._do_init:
+ if self.scope is None:
```
This would condition on whether the module being called inside `apply` or not.<|||||>Closing in favor of #22627<|||||>Thanks for the clarifications here @cgarciae! 🙌 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.