
repo
stringclasses 1
value | number
int64 1
25.3k
| state
stringclasses 2
values | title
stringlengths 1
487
| body
stringlengths 0
234k
⌀ | created_at
stringlengths 19
19
| closed_at
stringlengths 19
19
| comments
stringlengths 0
293k
|
|---|---|---|---|---|---|---|---|
transformers | 22,778 | closed | LLama RuntimeError: CUDA error: device-side assert triggered | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-4.18.0-372.16.1.el8_6.0.1.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.7
- Huggingface_hub version: 0.13.3
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
`
0%| | 0/1524 [00:00<?, ?it/s]Traceback (most recent call last):
File "alpaca-lora/finetune.py", line 234, in <module>
fire.Fire(train)
File ".local/lib/python3.9/site-packages/fire/core.py", line 141, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/home/c703/c7031420/.local/lib/python3.9/site-packages/fire/core.py", line 475, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File "/home/c703/c7031420/.local/lib/python3.9/site-packages/fire/core.py", line 691, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "alpaca-lora/finetune.py", line 203, in train
trainer.train()
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/trainer.py", line 1639, in train
return inner_training_loop(
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/trainer.py", line 1906, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/trainer.py", line 2652, in training_step
loss = self.compute_loss(model, inputs)
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/trainer.py", line 2684, in compute_loss
outputs = model(**inputs)
File ".conda/envs/llama/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File ".conda/envs/llama/lib/python3.9/site-packages/peft/peft_model.py", line 575, in forward
return self.base_model(
File ".conda/envs/llama/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File ".conda/envs/llama/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 765, in forward
outputs = self.model(
File ".conda/envs/llama/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File ".conda/envs/llama/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 574, in forward
attention_mask = self._prepare_decoder_attention_mask(
File ".conda/envs/llama/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 476, in _prepare_decoder_attention_mask
combined_attention_mask = _make_causal_mask(
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.`
### Description
I am interested in working with the Arabic language. I have tried adding all the tokens to the LLama tokenizer, and the tokenizer seems to work fine. However, during training, I encountered an error. I am looking for a solution to resolve this error. | 04-14-2023 17:41:57 | 04-14-2023 17:41:57 | @abdoelsayed2016 Thanks for raising this issue. Could you share a minimal code snippet to enable us to reproduce the error?
Just from the traceback alone, it seems that the issue is CUDA related, rather than the transformers model. The Llama model has been under active development and was part of the official version release yesterday. I'd also suggest updating to the most version of the code to make sure you have any possible updates which might have been added. <|||||>@abdoelsayed2016 hi, any suggestion? same error here when I want to train llama with lora.<|||||>@j-suyako did you add token to the tokenizer?<|||||>yes, I follow the [alpaca](https://github.com/tatsu-lab/stanford_alpaca/blob/main/train.py) to create the dataset, but I forget to resize the tokenizer length. Thanks for your reply! |
transformers | 22,777 | closed | Remove accelerate from tf test reqs | # What does this PR do?
This PR removes `accelerate` from the tf example test requirements as I believe its unused and causing issues with the `Accelerate` integration
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@Rocketknight1, @sgugger
| 04-14-2023 17:13:18 | 04-14-2023 17:13:18 | While the tests aren't being ran here, I did run it on the branch I'm working on (that doesn't touch tf code) and it still passes (and passes now):

<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Per conversation with @Rocketknight1, not merging this because it actually makes the TF example tests fail. However since they were not run here, we can't test that. (And as a result shows a bug)<|||||>This should work now after you rebase on main! |
transformers | 22,776 | closed | Indexing fix - CLIP checkpoint conversion | # What does this PR do?
In the conversion script, there was an indexing error, where the image and text logits where taken as the 2nd and 3rd outputs of the HF model. However, this is only the case if the model returns a loss.
This PR updates the script to explicitly take the named parameters.
Fixes #22739
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? | 04-14-2023 17:13:03 | 04-14-2023 17:13:03 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,775 | closed | trainer.is_model_parallel seems conflict with deepspeed | ### System Info
accelerate 0.18.0
aiofiles 23.1.0
aiohttp 3.8.4
aiosignal 1.3.1
altair 4.2.2
anyio 3.6.2
asttokens 2.2.1
async-timeout 4.0.2
attrs 22.2.0
backcall 0.2.0
backports.functools-lru-cache 1.6.4
bcrypt 4.0.1
bitsandbytes 0.37.2
certifi 2022.12.7
cfgv 3.3.1
chardet 5.1.0
charset-normalizer 3.0.1
click 8.1.3
colossalai 0.2.5
comm 0.1.3
contexttimer 0.3.3
contourpy 1.0.7
cPython 0.0.6
cycler 0.11.0
datasets 2.11.0
debugpy 1.6.7
decorator 5.1.1
deepspeed 0.9.0
dill 0.3.6
distlib 0.3.6
dnspython 2.3.0
entrypoints 0.4
evaluate 0.4.0
executing 1.2.0
fabric 3.0.0
fastapi 0.95.0
ffmpy 0.3.0
filelock 3.11.0
fonttools 4.39.3
frozenlist 1.3.3
fsspec 2023.4.0
gradio 3.24.1
gradio_client 0.0.8
h11 0.14.0
hjson 3.1.0
httpcore 0.16.3
httpx 0.23.3
huggingface-hub 0.13.4
identify 2.5.18
idna 3.4
importlib-metadata 6.3.0
importlib-resources 5.12.0
invoke 2.0.0
ipykernel 6.22.0
ipython 8.12.0
jedi 0.18.2
Jinja2 3.1.2
joblib 1.2.0
jsonschema 4.17.3
jupyter_client 8.1.0
jupyter_core 5.3.0
kiwisolver 1.4.4
linkify-it-py 2.0.0
loralib 0.1.1
markdown-it-py 2.2.0
MarkupSafe 2.1.2
matplotlib 3.7.1
matplotlib-inline 0.1.6
mdit-py-plugins 0.3.3
mdurl 0.1.2
mpi4py 3.1.4
multidict 6.0.4
multiprocess 0.70.14
nest-asyncio 1.5.6
ninja 1.11.1
nodeenv 1.7.0
numpy 1.24.2
nvidia-cublas-cu11 11.10.3.66
nvidia-cuda-nvrtc-cu11 11.7.99
nvidia-cuda-runtime-cu11 11.7.99
nvidia-cudnn-cu11 8.5.0.96
orjson 3.8.10
packaging 23.1
pandas 2.0.0
paramiko 3.0.0
parso 0.8.3
peft 0.2.0
pexpect 4.8.0
pickleshare 0.7.5
Pillow 9.5.0
pip 23.0.1
platformdirs 3.2.0
pre-commit 3.1.0
prompt-toolkit 3.0.38
psutil 5.9.4
ptyprocess 0.7.0
pure-eval 0.2.2
py-cpuinfo 9.0.0
pyarrow 10.0.0
pydantic 1.10.7
pydub 0.25.1
Pygments 2.15.0
pymongo 4.3.3
PyNaCl 1.5.0
pyparsing 3.0.9
pyrsistent 0.19.3
python-dateutil 2.8.2
python-multipart 0.0.6
pytz 2023.3
PyYAML 6.0
pyzmq 25.0.2
regex 2022.10.31
requests 2.28.2
responses 0.18.0
rfc3986 1.5.0
rich 13.3.1
scikit-learn 1.2.2
scipy 1.10.1
semantic-version 2.10.0
sentencepiece 0.1.97
setuptools 67.6.0
six 1.16.0
sniffio 1.3.0
stack-data 0.6.2
starlette 0.26.1
threadpoolctl 3.1.0
tokenizers 0.13.2
toolz 0.12.0
torch 1.13.1
tornado 6.2
tqdm 4.65.0
traitlets 5.9.0
transformers 4.28.0.dev0
typing_extensions 4.5.0
tzdata 2023.3
uc-micro-py 1.0.1
urllib3 1.26.15
uvicorn 0.21.1
virtualenv 20.19.0
wcwidth 0.2.6
websockets 11.0.1
wheel 0.40.0
xxhash 3.2.0
yarl 1.8.2
zipp 3.15.0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
python -m torch.distributed.launch $DISTRIBUTED_ARGS run_clm.py --model_name_or_path "/mnt/zts-dev-data/llama-7b-hf/" --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --do_train --do_eval --output_dir /mnt/zts-dev-data/tmp/test-clm --tokenizer_name test --logging_steps 50 --save_steps 1000 --overwrite_output_dir --fp16 True --deepspeed deepspeed_test.json
### Expected behavior
It's ok for me when i pretrained a llama 7b model with 2*a100 with no deepspeed(OOM when only 1*a100 training and huggingface would support model parallel by default therefore no OOM occured), but when i configured training script with --deepspeed this error appeared:
```python
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:1 and cuda:0! (when checking argument for argument index in method wrapper__index_select)
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 70758 closing signal SIGTERM
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 70757) of binary:
```
```
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 1,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
zero_optimization with stage 2 also errors | 04-14-2023 16:34:28 | 04-14-2023 16:34:28 | https://huggingface.co/transformers/v4.6.0/_modules/transformers/trainer.html<|||||>and when i test a smaller model which could fit in one gpu memory and does not need model parallel
by running :
deepspeed "script + config" --deepspeed **.json (with num_gpus 2 )
no error occures anymore<|||||>cc @stas00 <|||||>Please provide a reproducible example that I can run to see what the problem is and I would be happy to look at it - I can't do it with what you shared. Thank you.<|||||>@stas00 this problem ocures when i instance model with parameter device_map="auto" and no bug when i do not use device_map,device_map will use model parallel when model size is too big for one gpu to hold in a multigpu-training env。
You can test it just use run_clm.py in transformers and use a large model(one gpu memory could not save the model eg:llama7b)instanced with parameter device_map="auto"
```
model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,torch_dtype=torch.float32,
device_map="auto",
load_in_8bit=False)
```
so previous bug may be a conflict between deepspeed and transformers,transformers build model parallel by default in my setting but deepspeed backend algorithms don't when device_map="auto"<|||||>> @stas00 this problem ocures when i instance model with parameter device_map="auto" and no bug when i do not use device_map,device_map will use model parallel when model size is too big for one gpu to hold in a multigpu-training env。 You can test it just use run_clm.py in transformers and use a large model(one gpu memory could not save the model eg:llama7b)instanced with parameter device_map="auto"
>
> ```
> model = LlamaForCausalLM.from_pretrained(model_args.model_name_or_path,torch_dtype=torch.float32,
> device_map="auto",
> load_in_8bit=False)
> ```
>
> so previous bug may be a conflict between deepspeed and transformers,transformers build model parallel by default in my setting but deepspeed backend algorithms don't when device_map="auto"
Hey, the same situation happend to me, did you solve the problem?<|||||>`device_map="auto"` and DeepSpeed are incompatible. You cannot use them together. |
transformers | 22,774 | closed | Don't use `LayoutLMv2` and `LayoutLMv3` in some pipeline tests | # What does this PR do?
These 2 models require **different input format** than those of usual text models. See the relevant code block at the end.
The offline discussion with @NielsRogge is that **these 2 models are only for DocQA pipeline**, despite they have implementations for different head tasks.
Therefore, this PR **removes these 2 models from being tested (pipeline) in the first place**, instead of skipping them at later point.
**IMO, we should also remove these models being used in the pipeline classes (except DocQA)** if they are not going to work. But I don't do anything on this.
**`LayoutLMv3` with `DocumentQuestionAnsweringPipeline` (and the pipeline test) is still not working due to some issue. We need to discuss with @NielsRogge to see if it could be fixed, but it's out of this PR's scope.**
### relevant code block
https://github.com/huggingface/transformers/blob/daf53241d6276c0cd932ee8ce3e5b0a403f392b7/src/transformers/models/layoutlmv3/tokenization_layoutlmv3.py#L610-L625 | 04-14-2023 15:35:41 | 04-14-2023 15:35:41 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Merge now as this PR only touches tests. Feel free to leave a comment if any @NielsRogge |
transformers | 22,773 | closed | 'transformer_model' object has no attribute 'module' | ### System Info
```shell
Platform: Kaggle
python: 3.7
torch: 1.13.0
transformers: 4.27.4
tensorflow: 2.11.0
pre-trained model used: XLNET
```
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I reproduce others' open-sourced work on Kaggle. Following the partly code:
```
import torch
from torch import nn
from transformers import XLNetConfig, XLNetLMHeadModel, XLNetModel, XLNetTokenizer,AutoTokenizer
class transformer_model(nn.Module):
def __init__(self, model_name, drop_prob = dropout_prob):
super(transformer_model, self).__init__()
configuration = XLNetConfig.from_pretrained(model_name, output_hidden_states=True)
self.xlnet = XLNetModel.from_pretrained(model_name, config = configuration)
...
```
```
def train(model, optimizer, scheduler, tokenizer, max_epochs, save_path, device, val_freq = 10):
bestpoint_dir = os.path.join(save_path)
os.makedirs(bestpoint_dir, exist_ok=True)
...
model.save_pretrained(bestpoint_dir) #here
print("Saving model bestpoint to ", bestpoint_dir)
...
model = transformer_model(model_name).to(device)
...
```
Error messages: 'transformer_model' object has no attribute 'save_pretrained'
```
'transformer_model' object has no attribute 'save_pretrained'
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/tmp/ipykernel_23/1390676391.py in <module>
414 num_training_steps = total_steps)
415
--> 416 train(model, optimizer, scheduler, tokenizer, epochs, save_path, device)
417
418 print(max_accuracy, "\n", max_match)
/tmp/ipykernel_23/1390676391.py in train(model, optimizer, scheduler, tokenizer, max_epochs, save_path, device, val_freq)
385
386 # To save the model, uncomment the following lines
--> 387 model.save_pretrained(bestpoint_dir)
388 print("Saving model bestpoint to ", bestpoint_dir)
389
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in __getattr__(self, name)
1264 return modules[name]
1265 raise AttributeError("'{}' object has no attribute '{}'".format(
-> 1266 type(self).__name__, name))
1267
1268 def __setattr__(self, name: str, value: Union[Tensor, 'Module']) -> None:
AttributeError: 'transformer_model' object has no attribute 'save_pretrained'
```
### Expected behavior
```shell
`model.save_pretrained(...) `should work, I tried to fix the problem by using `model.module.save_pretrained(...)` and `torch.save(...)`, but failed.
How can I fix the problem? Thx!
```
### Checklist
- [X] I have read the migration guide in the readme. ([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers); [pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [X] I checked if a related official extension example runs on my machine. | 04-14-2023 15:28:10 | 04-14-2023 15:28:10 | @sqinghua, this is happening because the class `transformer_model` inherits from PyTorch's nn.Module class, which doesn't have a `save_pretrained` method. `save_pretrained` is a transformers library specific method common to models which inherit from `PreTrainedModel`.
I'm not sure why `torch.save(...)` doesn't work. I would need more information to be able to help e.g. traceback and error message to know if it's a transformers related issue.
It should be possible to save the xlnet model out using `model.xlnet.save_pretrained(checkpoint)`. This won't save out any additional modeling which happens in `transformer_model` e.g. additional layers or steps in the forward pass beyond passing to `self.xlnet`. <|||||>@amyeroberts Thank you for your detailed answer, it was very helpful. :) |
transformers | 22,772 | closed | Seq2SeqTrainer: Evict decoder_input_ids only when it is created from labels | # What does this PR do?
Fixes #22634 (what remains of the issue, the [failing FSMT command in this comment](https://github.com/huggingface/transformers/issues/22634#issuecomment-1500919952))
A previous PR (#22108) expanded the capabilities of the trainer, by delegating input selection to `.generate()`. However, it did manually evict `decoder_input_ids` from the inputs to make the SQUAD test pass, causing the issue seen above.
This PR makes a finer-grained eviction decision -- we only want to evict `decoder_input_ids` when it is built from `labels`. In this particular case, `decoder_input_ids` will likely have right-padding, which is unsupported by `.generate()`. | 04-14-2023 15:24:30 | 04-14-2023 15:24:30 | > Did you confirm the failing test now passes?
Yes :D Both the SQUAD test that made me add the previous eviction and the command that FSMT command that @stas00 shared are passing with this PR<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,771 | open | TF Swiftformer | ### Model description
Add the TensorFlow port of the SwiftFormer model. See related issue: #22685
To be done once the SwiftFormer model has been added: #22686
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
Original repo: https://github.com/amshaker/swiftformer | 04-14-2023 14:53:55 | 04-14-2023 14:53:55 | Hi! I would like to take on this as my first issue if possible. Is that okay?<|||||>@joaocmd Of course! Cool issue to start on 🤗
If you haven't seen it already, there's a detailed guide in the docs on porting a model to TensorFlow: https://huggingface.co/docs/transformers/add_tensorflow_model
It's best to wait until the PyTorch implementation is merged in, which will be at least a day or two away. <|||||>Sounds great @amyeroberts, thank you :)
I'll start looking into it once the PyTorch PR is merged.<|||||>Any news on this tf model? <|||||>Hi @D-Roberts, I haven't started looking into it as the pytorch version has not yet been merged.<|||||>Hi @joaocmd , the PyTorch version of SwiftFormer is now merged so you can continue working the TensorFlow version of it.<|||||>Hi @shehanmunasinghe, I'm on it, thanks!<|||||>Hi @amyeroberts ,
May I proceed to work on this issue if it has not been sorted yet?<|||||>@sqali There is currently an open PR which is actively being worked on by @joaocmd: #23342 <|||||>Hi @amyeroberts ,
Is there any other issue that you are working on in which I can help you with?<|||||>@sqali Here's a page in the docs all about different ways to contribute and how to find issues to work on: https://huggingface.co/docs/transformers/main/contributing. I'd suggest looking at issues marked with the 'Good First Issues' tag and finding one which no-one is currently working on: https://github.com/huggingface/transformers/labels/Good%20First%20Issue
|
transformers | 22,770 | closed | Tweak ESM tokenizer for Nucleotide Transformer | Nucleotide Transformer is a model that takes DNA inputs. It uses the same model architecture as the protein model ESM, but in addition to a different vocabulary it tokenizes inputs without a `<sep>` or `<eos>` token at the end. This PR makes a small tweak to the tokenization code for ESM, so that it doesn't try to add `self.eos_token_id` to sequences when the tokenizer does not have an `eos_token` set. With this change, we can fully support Nucleotide Transformer as an ESM checkpoint. | 04-14-2023 13:48:07 | 04-14-2023 13:48:07 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,769 | open | Error projecting concatenated Fourier Features. | ### System Info
- `transformers` version: 4.27.4
- Platform: macOS-13.3.1-arm64-arm-64bit
- Python version: 3.9.16
- Huggingface_hub version: 0.13.4
- PyTorch version (GPU?): 2.0.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
import torch
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor
input_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="conv",
spatial_downsample=4,
temporal_downsample=1,
position_encoding_type="fourier",
in_channels=4,
out_channels=256,
conv2d_use_batchnorm=True,
concat_or_add_pos="concat",
project_pos_dim=128,
fourier_position_encoding_kwargs = dict(
num_bands=64,
max_resolution=[25,50], # 4x downsample include
)
)
test = torch.randn(1,4,100,200)
inputs, modality_sizes, inputs_without_pos = input_preprocessor(test)
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[4], line 23
21 test = torch.randn(1,4,100,200)
22 # preprocessor outputs a tuple
---> 23 inputs, modality_sizes, inputs_without_pos = input_preprocessor(test)
25 print(inputs.shape)
26 print(inputs_without_pos.shape)
torch/nn/modules/module.py:1501), in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
transformers/models/perceiver/modeling_perceiver.py:3226), in PerceiverImagePreprocessor.forward(self, inputs, pos, network_input_is_1d)
3223 else:
3224 raise ValueError("Unsupported data format for conv1x1.")
-> 3226 inputs, inputs_without_pos = self._build_network_inputs(inputs, network_input_is_1d)
3227 modality_sizes = None # Size for each modality, only needed for multimodal
3229 return inputs, modality_sizes, inputs_without_pos
transformers/models/perceiver/modeling_perceiver.py:3169), in PerceiverImagePreprocessor._build_network_inputs(self, inputs, network_input_is_1d)
3166 pos_enc = self.position_embeddings(index_dims, batch_size, device=inputs.device, dtype=inputs.dtype)
3168 # Optionally project them to a target dimension.
-> 3169 pos_enc = self.positions_projection(pos_enc)
3171 if not network_input_is_1d:
3172 # Reshape pos to match the input feature shape
3173 # if the network takes non-1D inputs
3174 sh = inputs.shape
torch/nn/modules/module.py:1501), in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
torch/nn/modules/linear.py:114), in Linear.forward(self, input)
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1176x258 and 256x128)
### Expected behavior
Linear projection input number of features should equal the number of positional features.
When concatenating Fourier Features the expected number of positional features is: (2 * num_bands * num_dims) + 2.
The build_position_encoding() function takes as input the out_channels which is used to define the input number of features for linear projection. PerceiverImagePreprocessor incorrectly passes in the embedding dimension to out_channels for positional encoding projection.
Possible Fix:
Use the positional encoding class method output_size() to pull number of input features for projection within build_position_encoding() function.
positions_projection = nn.Linear(output_pos_enc.output_size(), project_pos_dim) if project_pos_dim > 0 else nn.Identity() | 04-14-2023 13:45:32 | 04-14-2023 13:45:32 | @sr-ndai Thanks for raising this issue and detailed reproduction.
Could you share the config or checkpoint being used in this example? <|||||>@amyeroberts No problem, here is the configuration I used:
```python
from transformers import PerceiverConfig
config = PerceiverConfig(
num_latents = 128,
d_latents=256,
num_blocks=6,
qk_channels = 256,
num_self_attends_per_block=2,
num_self_attention_heads=8,
num_cross_attention_heads=8,
self_attention_widening_factor=2,
cross_attention_widening_factor=1,
hidden_act='gelu_new',
attention_probs_dropout_prob=0.1,
use_query_residual=True,
num_labels = 128 # For decoder
)
``` |
transformers | 22,768 | closed | How to avoid adding double start of token<s><s> in TrOCR during training ? | **Describe the bug**
The model I am using (TrOCR Model):
The problem arises when using:
* [x] the official example scripts: done by the nice tutorial [(fine_tune)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_Seq2SeqTrainer.ipynb) @NielsRogge
* [x] my own modified scripts: (as the script below )
```
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-large-handwritten")
def compute_metrics(pred):
labels_ids = pred.label_ids
print('labels_ids',len(labels_ids), type(labels_ids),labels_ids)
pred_ids = pred.predictions
print('pred_ids',len(pred_ids), type(pred_ids),pred_ids)
pred_str = processor.batch_decode(pred_ids, skip_special_tokens=True)
print(pred_str)
labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
label_str = processor.batch_decode(labels_ids, skip_special_tokens=True)
print(label_str)
cer = cer_metric.compute(predictions=pred_str, references=label_str)
return {"cer": cer}
class Dataset(Dataset):
def __init__(self, root_dir, df, processor, max_target_length=128):
self.root_dir = root_dir
self.df = df
self.processor = processor
self.max_target_length = max_target_length
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
# get file name + text
file_name = self.df['file_name'][idx]
text = self.df['text'][idx]
# prepare image (i.e. resize + normalize)
image = Image.open(self.root_dir + file_name).convert("RGB")
pixel_values = self.processor(image, return_tensors="pt").pixel_values
# add labels (input_ids) by encoding the text
labels = self.processor.tokenizer(text,
padding="max_length",
truncation=True,
max_length=self.max_target_length).input_ids
# important: make sure that PAD tokens are ignored by the loss function
labels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels]
# encoding
return {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
#Train a model
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-large-handwritten")
# set special tokens used for creating the decoder_input_ids from the labels
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
model.config.pad_token_id = processor.tokenizer.pad_token_id
# make sure vocab size is set correctly
model.config.vocab_size = model.config.decoder.vocab_size
# set beam search parameters
model.config.eos_token_id = processor.tokenizer.sep_token_id
model.config.max_length = 64
model.config.early_stopping = True
model.config.no_repeat_ngram_size = 3
model.config.length_penalty = 2.0
model.config.num_beams = 4
model.config.decoder.is_decoder = True
model.config.decoder.add_cross_attention = True
working_dir = './test/'
training_args = Seq2SeqTrainingArguments(...)
# instantiate trainer
trainer = Seq2SeqTrainer(model=model, args=training_args, train_dataset = train_dataset,
data_collator = default_data_collator, )
trainer.train()
# python3 train.py path/to/labels path/to/images/
```
- Platform: Linux Ubuntu distribution [GCC 9.4.0] on Linux
- PyTorch version (GPU?): 0.8.2+cu110
- transformers: 4.22.2
- Python version:3.8.10
A clear and concise description of what the bug is.
To **Reproduce** Steps to reproduce the behavior:
1. After training the model or during the training phase when evaluating metrics calculate I see the model added the double start of token `<s><s>` or ids `[0,0, ......,2,1,1, 1 ]`
2. here is an example during the training phase showing generated tokens in compute_metrics
Input predictions: `[[0,0,506,4422,8046,2,1,1,1,1,1]]`
Input references: `[[0,597,2747 ...,1,1,1]] `
4. Other examples during testing models [[](https://i.stack.imgur.com/sWzbf.png)]
**Expected behavior** A clear and concise description of what you expected to happen.
In 2 reproduced problems:
I am expecting during `training`Input predictions should be: `[[0,506,4422, ... ,8046,2,1,1,1,1,1 ]] `
In addition during the `testing` phase: generated text without double` **<s><s>** `
`tensor([[0,11867,405,22379,1277,..........,368,2]]) `
`<s>ennyit erről, tőlem fényképezz amennyit akarsz, a véleményem akkor</s>`
cc @ArthurZucker | 04-14-2023 11:15:49 | 04-14-2023 11:15:49 | cc @ArthurZucker <|||||>+1<|||||>Thanks for Natabara for his comment The solution is super easy by just skipping <s> start token `labels= labels[1:] ` coming from the tokenizer because the tokenizer adds start token <s> and the TrOCR adds start token <s> automatically as mentioned in TrOCR paper ``` def __getitem__(self, idx): # get file name + text file_name = self.df['file_name'][idx] text = self.df['text'][idx] # prepare image (i.e. resize + normalize) image = Image.open(self.root_dir + file_name).convert("RGB") pixel_values = self.processor(image, return_tensors="pt").pixel_values # add labels (input_ids) by encoding the text labels = self.processor.tokenizer(text, padding="max_length", truncation=True, max_length=self.max_target_length).input_ids # important: make sure that PAD tokens are ignored by the loss function labels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels] labels= labels[1:] return {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)} ``` |
transformers | 22,767 | closed | Mobilenet_v1 Dropout probability | Hi @amyeroberts [here](https://github.com/huggingface/transformers/pull/17799) is the pull request with some interesting bug. Mobilenetv2 made from tensorflow checkpoint, but in Tensorflow dropout prob is the fraction of **non zero** values, but in PyTorch this is fraction of **zero** values. It should be **1 - prob** for PyTorch.
Load Mobilenetv1 model from 'google/mobilenet_v1_1.0_224'
Dropout prob should be 1 - tf_prob | 04-14-2023 09:43:34 | 04-14-2023 09:43:34 | @andreysher Thanks for raising this issue. The dropout rate `p` or `rate` is defined the same for TensorFlow and PyTorch layers.
From the [TensorFlow documentation](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dropout):
> The Dropout layer randomly sets input units to 0 with a frequency of `rate` at each step during training time
From the [PyTorch documentation](https://pytorch.org/docs/stable/generated/torch.nn.Dropout.html):
> During training, randomly zeroes some of the elements of the input tensor with probability `p`
Is there something specific about the original MobileNet implementation or checkpoints which means this doesn't apply?
<|||||>Thanks for this clarification! But i don't understand why default dropout_prob in the PR is 0.999? If i load model by
```
from transformers import AutoImageProcessor, MobileNetV1ForImageClassification
model = MobileNetV1ForImageClassification.from_pretrained("google/mobilenet_v1_1.0_224")
```
i get model with dropout p = 0.999. This is unexpected. Could you enplane why such value is presented in pretrained model?<|||||>@andreysher Ah, OK, I think I see what the issue is. The reason the dropout value p=0.999 is because it's set in the [model config](https://huggingface.co/google/mobilenet_v1_1.0_224/blob/dd9bc45ff57d9492e00d48547587baf03f0cdade/config.json#L5). This is a mistake as, as you had identified, the probability in the original mobilenet repo is the [keep probability](https://github.com/tensorflow/models/blob/ad32e81e31232675319d5572b78bc196216fd52e/research/slim/nets/mobilenet_v1.py#L306) i.e. `(1 - p)`. I've opened PRs on the hub to update the model configs:
- https://huggingface.co/google/mobilenet_v1_0.75_192/discussions/2
- https://huggingface.co/google/mobilenet_v2_1.0_224/discussions/3
- https://huggingface.co/google/mobilenet_v1_1.0_224/discussions/2
- https://huggingface.co/google/mobilenet_v2_0.35_96/discussions/2
- https://huggingface.co/google/mobilenet_v2_1.4_224/discussions/2
- https://huggingface.co/google/mobilenet_v2_0.75_160/discussions/2
Thanks for flagging and the time take to explain. <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,766 | closed | Fix failing torchscript tests for `CpmAnt` model | # What does this PR do?
The failure is caused by some type issues (dict, tuple, etc) in the outputs. | 04-14-2023 09:21:03 | 04-14-2023 09:21:03 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,765 | closed | Fix word_ids hyperlink | Fixes https://github.com/huggingface/transformers/issues/22729 | 04-14-2023 09:13:29 | 04-14-2023 09:13:29 | CC @amyeroberts <|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,764 | closed | Fix a mistake in Llama weight converter log output. | # What does this PR do?
Fixes a mistake in Llama weight converter log output.
Before: `Saving a {tokenizer_class} to {tokenizer_path}`
After: `Saving a LlamaTokenizerFast to outdir.`
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@ArthurZucker and @younesbelkada
| 04-14-2023 08:55:01 | 04-14-2023 08:55:01 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,763 | closed | Generate: pin number of beams in BART test | # What does this PR do?
A recent change added the `num_beams==1` requirement for contrastive search. One of the tests started failing because of that change -- BART has `num_beams=4` [in its config](https://huggingface.co/facebook/bart-large-cnn/blob/main/config.json#L49), so the test was now triggering beam search, and not contrastive search. This PR corrects it.
(The long-term solution is to add argument validation to detect these cases)
| 04-14-2023 08:28:33 | 04-14-2023 08:28:33 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,762 | closed | RecursionError: maximum recursion depth exceeded while getting the str of an object. | **System Info**
Python 3.8.10
transformers 4.29.0.dev0
sentencepiece 0.1.97
**Information**
- [x] The official example scripts
- [ ] My own modified scripts
**Reproduction**
In https://github.com/CarperAI/trlx/tree/main/examples
```python https://ppo_sentiments_llama.py```
The loops occur as follows:
/usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_fast.py:250 in │
│ convert_tokens_to_ids │
│ │
│ 247 │ │ │ return None │
│ 248 │ │ │
│ 249 │ │ if isinstance(tokens, str): │
│ ❱ 250 │ │ │ return self._convert_token_to_id_with_added_voc(tokens) │
│ 251 │ │ │
│ 252 │ │ ids = [] │
│ 253 │ │ for token in tokens: │
│ │
│ /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_fast.py:260 in │
│ _convert_token_to_id_with_added_voc │
│ │
│ 257 │ def _convert_token_to_id_with_added_voc(self, token: str) -> int: │
│ 258 │ │ index = self._tokenizer.token_to_id(token) │
│ 259 │ │ if index is None: │
│ ❱ 260 │ │ │ return self.unk_token_id │
│ 261 │ │ return index │
│ 262 │ │
│ 263 │ def _convert_id_to_token(self, index: int) -> Optional[str]: │
│ │
│ /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py:1141 in │
│ unk_token_id │
│ │
│ 1138 │ │ """ │
│ 1139 │ │ if self._unk_token is None: │
│ 1140 │ │ │ return None │
│ ❱ 1141 │ │ return self.convert_tokens_to_ids(self.unk_token) │
│ 1142 │ │
│ 1143 │ @property │
│ 1144 │ def sep_token_id(self) -> Optional[int]: │
│ │
│ /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_fast.py:250 in │
│ convert_tokens_to_ids │
│ │
│ 247 │ │ │ return None │
│ 248 │ │ │
│ 249 │ │ if isinstance(tokens, str): │
│ ❱ 250 │ │ │ return self._convert_token_to_id_with_added_voc(tokens) │
│ 251 │ │ │
│ 252 │ │ ids = [] │
│ 253 │ │ for token in tokens:
...
Until
/usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py:1021 in unk_token │
│ │
│ 1018 │ │ │ if self.verbose: │
│ 1019 │ │ │ │ logger.error("Using unk_token, but it is not set yet.") │
│ 1020 │ │ │ return None │
│ ❱ 1021 │ │ return str(self._unk_token) │
│ 1022 │ │
│ 1023 │ @property │
│ 1024 │ def sep_token(self) -> str:
RecursionError: maximum recursion depth exceeded while getting the str of an object
**Expected behavior**
Is the algorithm expected to call the function `convert_tokens_to_ids` in `tokenization_utils.py` instead of `tokenization_utils_fast.py`?
Thanks!
| 04-14-2023 08:22:39 | 04-14-2023 08:22:39 | cc @ArthurZucker <|||||>same problem, is there any progress?<|||||>Hey! The main issue is that they did not update the tokenizer files at `"decapoda-research/llama-7b-hf"` but they are using the latest version of transformers. The tokenizer was fixed see #22402 and corrected. Nothing we can do on our end...<|||||>@ArthurZucker I am facing a similar issue with openllama
```python
save_dir = "../open_llama_7b_preview_300bt/open_llama_7b_preview_300bt_transformers_weights/"
tokenizer = AutoTokenizer.from_pretrained(save_dir)
tokenizer.bos_token_id
```
calling `tokenizer.bos_token_id` this causes max recursion depth error.
```python
tokenizer
LlamaTokenizerFast(name_or_path='../open_llama_7b_preview_300bt/open_llama_7b_preview_300bt_transformers_weights/', vocab_size=32000, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': AddedToken("", rstrip=False, lstrip=False, single_word=False, normalized=True), 'eos_token': AddedToken("", rstrip=False, lstrip=False, single_word=False, normalized=True), 'unk_token': AddedToken("", rstrip=False, lstrip=False, single_word=False, normalized=True)}, clean_up_tokenization_spaces=False)
```
`transformers version = 4.29.1`
`tokenizer_config.json`
```
{
"bos_token": "",
"eos_token": "",
"model_max_length": 1e+30,
"tokenizer_class": "LlamaTokenizer",
"unk_token": ""
}
```
Initializing as following works but I am not sure if this should be needed:
```
tokenizer = AutoTokenizer.from_pretrained(save_dir, unk_token="<unk>",
bos_token="<s>",
eos_token="</s>")
```
<|||||>So.... Again, if you are not using the latest / most recently converted tokenizer, I cannot help you. Checkout [huggyllama/llama-7b](https://huggingface.co/huggyllama/llama-7b) which has a working tokenizer. |
transformers | 22,761 | closed | Pix2struct: doctest fix | # What does this PR do?
Fixes the failing doctest: different machines may produce minor FP32 differences. This PR formats the printed number to a few decimal places. | 04-14-2023 08:02:09 | 04-14-2023 08:02:09 | oops, wrong core maintainer :D<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,760 | closed | WhisperForAudioClassification RuntimeError tensor size doesn't match | ### System Info
- `transformers` version: 4.28.0
- Platform: Linux-5.4.190-107.353.amzn2.x86_64-x86_64-with-glibc2.31
- Python version: 3.9.16
- Huggingface_hub version: 0.13.4
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Multi-GPU on the same machine
### Who can help?
@sanchit-gandhi finetuning WhisperForAudioClassification model and getting this error. The dataset and script works fine when switching to the Wav2Vec2 model.
File "/opt/conda/envs/voice/lib/python3.9/site-packages/torch/nn/parallel/parallel_apply.py", line 64, in _worker
output = module(*input, **kwargs)
File "/opt/conda/envs/voice/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/jovyan/.local/lib/python3.9/site-packages/transformers/models/whisper/modeling_whisper.py", line 1739, in forward
encoder_outputs = self.encoder(
File "/opt/conda/envs/voice/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/jovyan/.local/lib/python3.9/site-packages/transformers/models/whisper/modeling_whisper.py", line 823, in forward
hidden_states = inputs_embeds + embed_pos
RuntimeError: The size of tensor a (750) must match the size of tensor b (1500) at non-singleton dimension 1
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Followed this tutorial, and switched Wav2vec2 to WhisperForAudioClassification model.
Using a dataset with 100K+ wav files.
Training fails with the above error.
### Expected behavior
It would train with no errors. | 04-14-2023 06:51:52 | 04-14-2023 06:51:52 | Hey @xiao1ongbao! I'm hoping that your fine-tuning run was successful! Let me know if you encounter any issues - more than happy to help here 🤗<|||||>Hey! How did you solve that?<|||||>Do you have a reproducible code snippet to trigger the error @lnfin? I didn't encounter this in my experiments! |
transformers | 22,759 | closed | chore: allow protobuf 3.20.3 requirement | Allow latest bugfix release for protobuf (3.20.3)
# What does this PR do?
Change in requirements for python library so it allows the use of latest bugfix release for protobuf (3.20.3) instead of restricting it to the upper bound limit for this dependency to 3.20.2 (<=3.20.2).
| 04-14-2023 06:42:50 | 04-14-2023 06:42:50 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22759). All of your documentation changes will be reflected on that endpoint.<|||||>cc @ydshieh <|||||>Hi @jose-turintech Thank you for this PR ❤️ .
Unfortunately, as you can see in the CI results, the changes cause some errors
```python
FAILED tests/models/albert/test_tokenization_albert.py::AlbertTokenizationTest::test_pickle_subword_regularization_tokenizer
FAILED tests/models/bert_generation/test_tokenization_bert_generation.py::BertGenerationTokenizationTest::test_pickle_subword_regularization_tokenizer
```
(Fatal Python error: Segmentation fault)
So we are not able to merge this PR so far. There might be some way to fix these 2 issues, but I am not sure. Let me know if you want to dive into this.
<|||||>Hey @jose-turintech ,
Thanks for submitting this PR! The latest `tensorflow==2.12` release depends on `protobuf >= 3.20.3`, so this would unblock installing the latest `tensorflow` alongside `transformers`.
After setting up this PR's environment, I just ran this locally and those tests seem to pass. Would it be possible to trigger a re-run @ydshieh? Alternatively, would it be possible to get extra logs on the CI failures? <|||||>> Hey @jose-turintech ,
>
> Thanks for submitting this PR! The latest `tensorflow==2.12` release depends on `protobuf >= 3.20.3`, so this would unblock installing the latest `tensorflow` alongside `transformers`.
>
> After setting up this PR's environment, I just ran this locally and those tests seem to pass. Would it be possible to trigger a re-run @ydshieh? Alternatively, would it be possible to get extra logs on the CI failures?
Hello @adriangonz, just updated my branch with latest changes on origin in order to test if the PR check would retrigger. It seems so; so i guess we'll see if the PR passes all check within some minutes.
Thanks for your comment.<|||||>As you can see in [the latest run](https://app.circleci.com/pipelines/github/huggingface/transformers/63908/workflows/bcaedcfc-54af-42e8-9e9c-a97d9612b185/jobs/789487), the 2 failed tests are still there.
The error (provided at the end below) is some processes crashed, and there is no more informative log being given by the `pytest`.
When I run the two failed tests individually on my local env., they pass.
However, since the latest release of `tensorflow-probaility` broke everything in the CI since we don't support `TensorFlow 2.12` yet and it needs that version, we will take a more deep look to see if we can unblock this situation.
```bash
=================================== FAILURES ===================================
______ tests/models/bert_generation/test_tokenization_bert_generation.py _______
[gw0] linux -- Python 3.8.12 /home/circleci/.pyenv/versions/3.8.12/bin/python
worker 'gw0' crashed while running 'tests/models/bert_generation/test_tokenization_bert_generation.py::BertGenerationTokenizationTest::test_pickle_subword_regularization_tokenizer'
_______________ tests/models/albert/test_tokenization_albert.py ________________
[gw6] linux -- Python 3.8.12 /home/circleci/.pyenv/versions/3.8.12/bin/python
worker 'gw6' crashed while running 'tests/models/albert/test_tokenization_albert.py::AlbertTokenizationTest::test_pickle_subword_regularization_tokenizer'
``` <|||||>@ydshieh i've merged origin into this branch once again to retrigger CI checks just to see if test passed after the downtime of some huggingface transformers yesterday. Tests pass now after your modifications :) .
Only difference with main is the tensorflow-probaility>0.20 restriction is not applied in this CI build.
Thanks for taking the time to take a look into the issue.<|||||>@jose-turintech I accidentally pushed the experimental changes to this PR branch, I am really sorry. The CI is green as I removed some 3rd packages (tensorflow for example), which it should be kept.
I am still looking how to resolve the issue. There is a big problem (at least the desired environment when running inside CircleCI runner). I will keep you update soon.<|||||>In the meantime, let us convert this PR into a draft mode, so it won't be merged by accident. Thank you for your comprehension.<|||||>## Issue
(for the hack to fix, see the next reply)
This PR want to use `protobuf==3.20.3` so we can use `tensorflow==2.12`. However, some tests like `test_pickle_subword_regularization_tokenizer` fails with this environment. The following describes the issue.
- First, setup the env. to have `tensorflow-cpu==2.12` with `potobuf==3.20.3` but `without torch installed`.
- Use a `sentencepiece` tokenizer with `enable_sampling=True`
- `run the code with pytest` --> crash (core dump)
- (run with a script --> no crash)
- (run the code with pytest where torch is also there --> no crash)
Here are 2 code snippets to reproduce (and not): run in python 3.8 will more likely to reproduce
______________________________________________________________________________
- create `tests/test_foo.py` and run `python -m pytest -v tests/test_foo.py` --> crash
```
from transformers import AlbertTokenizer
def test_foo():
fn = "tests/fixtures/spiece.model"
text = "This is a test for subword regularization."
# `encode` works with `False`
sp_model_kwargs = {"enable_sampling": False}
tokenizer = AlbertTokenizer(fn, sp_model_kwargs=sp_model_kwargs)
# test 1 (usage in `transformers`)
# _ = tokenizer.tokenize(text)
# test 2 (direct use in sentencepiece)
pieces = tokenizer.sp_model.encode(text, out_type=str)
# `encode` fails with `True` if torch is not installed and tf==2.12
sp_model_kwargs = {"enable_sampling": True}
tokenizer = AlbertTokenizer(fn, sp_model_kwargs=sp_model_kwargs)
# test 1 (usage in `transformers`)
# _ = tokenizer.tokenize(text)
# This gives `Segmentation fault (core dumped)` under the above mentioned conditions
# test 2 (direct use in sentencepiece)
pieces = tokenizer.sp_model.encode(text, out_type=str)
print(pieces)
```
- create `foo.py` and run `python foo.py` -> no crash
```
from transformers import AlbertTokenizer
fn = "tests/fixtures/spiece.model"
text = "This is a test for subword regularization."
# `encode` works with `False`
sp_model_kwargs = {"enable_sampling": False}
tokenizer = AlbertTokenizer(fn, sp_model_kwargs=sp_model_kwargs)
# test 1 (usage in `transformers`)
# _ = tokenizer.tokenize(text)
# test 2 (direct use in sentencepiece)
pieces = tokenizer.sp_model.encode(text, out_type=str)
# `encode` works with `True` if torch is not installed and tf==2.12
sp_model_kwargs = {"enable_sampling": True}
tokenizer = AlbertTokenizer(fn, sp_model_kwargs=sp_model_kwargs)
# test 1 (usage in `transformers`)
# _ = tokenizer.tokenize(text)
# This works
# test 2 (direct use in sentencepiece)
pieces = tokenizer.sp_model.encode(text, out_type=str)
print(pieces)
```<|||||>## (Hacky) Fix
The relevant failing tests are:
- test_subword_regularization_tokenizer
- test_pickle_subword_regularization_tokenizer
As mentioned above, those failing tests only happen when running with pytest. Furthermore, those test don't actually need `protobuf` in order to run. However, in the TF CI job, `protobuf` is a dependency from TensorFlow.
It turns out that running those 2 problematic tests in a subprocess will avoid the crash. It's unclear what actually happens though.
This PR modify those 2 tests to be run in a subprocess, so we can have `protobuf==3.20.3` along with `tensroflow==2.12`.<|||||>The TF job is successful with the last fix, see this job run
https://app.circleci.com/pipelines/github/huggingface/transformers/64174/workflows/688a1174-8a6f-4599-9479-f51bbc2aacdb/jobs/793536/artifacts
The other jobs should be fine (we will see in 30 minutes) as they already pass before.<|||||>> Thank you again @jose-turintech for this PR, which allows to use TF 2.12!
Thank you very much for taking the time to fix the issues, you did all the work; really appreciate it. |
transformers | 22,758 | closed | GPTNeoX position_ids not defined | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-4.18.0-425.10.1.el8_7.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.13
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: yes
### Who can help?
@ArthurZucker @stas00
Hi, I am performing inference using `GPT-NeoX 20B` model using greedy search. Without deepspeed the text generation works fine. However, when I use deepspeed for inference, I am getting the following error
```bash
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ ~/examplesinference/asqa_inference.py:297 in │
│ <module> │
│ │
│ 294 │
│ 295 │
│ 296 if __name__ == "__main__": │
│ ❱ 297 │ main() │
│ 298 │
│ │
│ ~/examplesinference/asqa_inference.py:271 in main │
│ │
│ 268 │ │ │ │ + "\nQ: " │
│ 269 │ │ │ ) │
│ 270 │ │ new_prompt = prompt + d["question"] + "\nA:" │
│ ❱ 271 │ │ output = predict_text_greedy( │
│ 272 │ │ │ model, │
│ 273 │ │ │ tokenizer, │
│ 274 │ │ │ new_prompt, │
│ │
│ ~/examplesinference/asqa_inference.py:98 in │
│ predict_text_greedy │
│ │
│ 95 │ │
│ 96 │ model.eval() │
│ 97 │ with torch.no_grad(): │
│ ❱ 98 │ │ generated_ids = model.generate( │
│ 97 │ with torch.no_grad(): │ [64/49095]
│ ❱ 98 │ │ generated_ids = model.generate( │
│ 99 │ │ │ input_ids, │
│ 100 │ │ │ max_new_tokens=50, │
│ 101 │ │ │ use_cache=use_cache, │
│ │
│ ~/my_envlib/python3.9/site-packages/deepspeed/inference/engine.py:588 in │
│ _generate │
│ │
│ 585 │ │ │ │ "add your request to: https://github.com/microsoft/DeepSpeed/issues/2506 │
│ 586 │ │ │ ) │
│ 587 │ │ │
│ ❱ 588 │ │ return self.module.generate(*inputs, **kwargs) │
│ 589 │
│ │
│ ~/my_envlib/python3.9/site-packages/torch/utils/_contextlib.py:115 in │
│ decorate_context │
│ │
│ 112 │ @functools.wraps(func) │
│ 113 │ def decorate_context(*args, **kwargs): │
│ 114 │ │ with ctx_factory(): │
│ ❱ 115 │ │ │ return func(*args, **kwargs) │
│ 116 │ │
│ 117 │ return decorate_context │
│ 118 │
│ │
│ ~/my_envlib/python3.9/site-packages/transformers/generation/utils.py:1437 in │
│ generate │
│ │
│ 1434 │ │ │ │ ) │
│ 1435 │ │ │ │
│ 1436 │ │ │ # 11. run greedy search │
│ ❱ 1437 │ │ │ return self.greedy_search( │
│ 1438 │ │ │ │ input_ids, │
│ 1439 │ │ │ │ logits_processor=logits_processor, │
│ 1440 │ │ │ │ stopping_criteria=stopping_criteria, │
│ │
│ ~/my_envlib/python3.9/site-packages/transformers/generation/utils.py:2248 in │
│ greedy_search │
│ │
│ 2245 │ │ │ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs) │
│ 2246 │ │ │ │
│ 2247 │ │ │ # forward pass to get next token │
│ ❱ 2248 │ │ │ outputs = self( │
│ 2249 │ │ │ │ **model_inputs, │
│ 2250 │ │ │ │ return_dict=True, │
│ 2251 │ │ │ │ output_attentions=output_attentions, │
│ │
│ ~/my_envlib/python3.9/site-packages/torch/nn/modules/module.py:1501 in │
│ _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │ [12/49095]
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
│ │
│ ~/my_envlib/python3.9/site-packages/transformers/models/gpt_neox/modeling_gp │
│ t_neox.py:662 in forward │
│ │
│ 659 │ │ ```""" │
│ 660 │ │ return_dict = return_dict if return_dict is not None else self.config.use_return │
│ 661 │ │ │
│ ❱ 662 │ │ outputs = self.gpt_neox( │
│ 663 │ │ │ input_ids, │
│ 664 │ │ │ attention_mask=attention_mask, │
│ 665 │ │ │ position_ids=position_ids, │
│ │
│ ~/my_envlib/python3.9/site-packages/torch/nn/modules/module.py:1501 in │
│ _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
│ │
│ ~/my_envlib/python3.9/site-packages/transformers/models/gpt_neox/modeling_gp │
│ t_neox.py:553 in forward │
│ │
│ 550 │ │ │ │ │ head_mask[i], │
│ 551 │ │ │ │ ) │
│ 552 │ │ │ else: │
│ ❱ 553 │ │ │ │ outputs = layer( │
│ 554 │ │ │ │ │ hidden_states, │
│ 555 │ │ │ │ │ attention_mask=attention_mask, │
│ 556 │ │ │ │ │ position_ids=position_ids, │
│ │
│ ~/my_envlib/python3.9/site-packages/torch/nn/modules/module.py:1501 in │
│ _call_impl │
│ │
│ 1498 │ │ if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks │
│ 1499 │ │ │ │ or _global_backward_pre_hooks or _global_backward_hooks │
│ 1500 │ │ │ │ or _global_forward_hooks or _global_forward_pre_hooks): │
│ ❱ 1501 │ │ │ return forward_call(*args, **kwargs) │
│ 1502 │ │ # Do not call functions when jit is used │
│ 1503 │ │ full_backward_hooks, non_full_backward_hooks = [], [] │
│ 1504 │ │ backward_pre_hooks = [] │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
TypeError: forward() got an unexpected keyword argument 'position_ids'
```
This is how I am wrapping deepspeed around the model
```python
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer.padding_side = "left"
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
reduced_model_name = model_name.split("/")[-1]
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = deepspeed.init_inference(
model, mp_size=world_size, dtype=torch.float32, replace_with_kernel_inject=True
)
```
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import deepspeed
model_name = 'EleutherAI/gpt-neox-20b'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer.padding_side = "left"
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
reduced_model_name = model_name.split("/")[-1]
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = deepspeed.init_inference(
model, mp_size=world_size, dtype=torch.float32, replace_with_kernel_inject=True
)
model.to(device)
model.eval()
input_ids = tokenizer('The quick brown fox jumped over the lazy dog', return_tensors="pt").input_ids.to(
dtype=torch.long, device=device
)
with torch.no_grad():
generated_ids = model.generate(
input_ids,
max_new_tokens=50,
pad_token_id=tokenizer.eos_token_id,
)
preds = [
tokenizer.decode(
g, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
for g in generated_ids
]
```
### Expected behavior
There should be no difference whether I wrap `deepspeed` around the model or not. | 04-14-2023 04:38:05 | 04-14-2023 04:38:05 | `transformers` isn't involved with deepspeed's inference engine, other than being used by it indirectly, so please refile at https://github.com/microsoft/DeepSpeed/issues. Thank you. |
transformers | 22,757 | closed | Huge Num Epochs (9223372036854775807) when using Trainer API with streaming dataset | ### System Info
# System Info
Running on SageMaker Studio g4dn 2xlarge.
```
!cat /etc/os-release
PRETTY_NAME="Debian GNU/Linux 10 (buster)"
```
```
!transformers-cli env
- `transformers` version: 4.28.0
- Platform: Linux-4.14.309-231.529.amzn2.x86_64-x86_64-with-debian-10.6
- Python version: 3.7.10
- Huggingface_hub version: 0.13.4
- Safetensors version: not installed
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: YES
- Using distributed or parallel set-up in script?: <fill in>
```
```
!nvidia-smi
Fri Apr 14 04:32:30 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:1E.0 Off | 0 |
| N/A 32C P0 25W / 70W | 13072MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
```
# Background
Fine tune BLOOM model for summarization.
- Model: [bigscience/bloom-560m](https://huggingface.co/bigscience/bloom-560m)
- Task: Summarization (using PromptSource with ```input_ids``` set to tokenized text and ```labels``` set to tokenized summary.
- Framework: Pytorch
- Training: Trainer API
- Dataset: [xsum](https://huggingface.co/datasets/xsum)
# Problem
When using the streaming huggingface dataset, Trainer API shows huge ```Num Epochs = 9,223,372,036,854,775,807```.
```
trainer.train()
-----
***** Running training *****
Num examples = 6,144
Num Epochs = 9,223,372,036,854,775,807 <-----
Instantaneous batch size per device = 1
Total train batch size (w. parallel, distributed & accumulation) = 1
Gradient Accumulation steps = 1
Total optimization steps = 6,144
Number of trainable parameters = 559,214,592
```
The ```TrainingArguments``` used:
```
DATASET_STREAMING: bool = True
NUM_EPOCHS: int = 3
DATASET_TRAIN_NUM_SELECT: int = 2048
MAX_STEPS: int = NUM_EPOCHS * DATASET_TRAIN_NUM_SELECT if DATASET_STREAMING else -1
training_args = TrainingArguments(
output_dir="bloom_finetuned",
max_steps=MAX_STEPS, # <--- 2048 * 3
num_train_epochs=NUM_EPOCHS,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
learning_rate=2e-5,
weight_decay=0.01,
no_cuda=False,
)
```
When not using streaming ```DATASET_STREAMING=False``` as in the code, the ```Num Epochs``` is displayed as expected.
```
***** Running training *****
Num examples = 2,048
Num Epochs = 3
Instantaneous batch size per device = 1
Total train batch size (w. parallel, distributed & accumulation) = 1
Gradient Accumulation steps = 1
Total optimization steps = 6,144
Number of trainable parameters = 559,214,592
```
### Who can help?
trainer: @sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Run the code below
```
! pip install torch transformers datasets evaluate scikit-learn rouge rouge-score promptsource --quiet
```
```
import multiprocessing
import re
from typing import (
List,
Dict,
Callable,
)
import evaluate
import numpy as np
from datasets import (
load_dataset,
get_dataset_split_names
)
from promptsource.templates import (
DatasetTemplates,
Template
)
from transformers import (
AutoTokenizer,
DataCollatorWithPadding,
DataCollatorForSeq2Seq,
BloomForCausalLM,
TrainingArguments,
Trainer
)
## Huggingface Datasets
DATASET_NAME: str = "xsum"
DATASET_STREAMING: bool = True # If using Dataset streaming
DATASET_TRAIN_NUM_SELECT: int = 2048 # Number of rows to use for training
DATASET_VALIDATE_NUM_SELECT: int = 128
# Huggingface Tokenizer (BLOOM default token length is 2048)
MAX_TOKEN_LENGTH: int = 512 # Max token length to avoid out of memory
PER_DEVICE_BATCH_SIZE: int = 1 # GPU batch size
# Huggingface Model
MODEL = "bigscience/bloom-560m"
# Training
NUM_EPOCHS: int = 3
MAX_STEPS: int = NUM_EPOCHS * DATASET_TRAIN_NUM_SELECT if DATASET_STREAMING else -1
train = load_dataset("xsum", split="train", streaming=DATASET_STREAMING)
prompt_templates = DatasetTemplates( dataset_name=DATASET_NAME)
template: Template = prompt_templates['summarize_DOC']
# # Preprocess
tokenizer = AutoTokenizer.from_pretrained(MODEL, use_fast=True)
def get_convert_to_request_response(template: Template) -> Callable:
def _convert_to_prompt_response(example: Dict[str, str]) -> Dict[str, str]:
"""Generate prompt, response as a dictionary:
{
"prompt": "Summarize: ...",
"response": "..."
}
NOTE: DO NOT use with dataset map function( batched=True). Use batch=False
Args:
example: single {document, summary} pair to be able to apply template
Returns: a dictionary of pro
"""
# assert isinstance(example, dict), f"expected dict but {type(example)}.\n{example}"
assert isinstance(example['document'], str), f"expected str but {type(example['document'])}."
prompt, response = template.apply(example=example, truncate=False)
return {
"prompt": re.sub(r'[\s\'\"]+', ' ', prompt),
"response": re.sub(r'[\s\'\"]+', ' ', response)
}
return _convert_to_prompt_response
convert_to_request_response: Callable = get_convert_to_request_response(template=template)
def tokenize_prompt_response(examples):
"""Generate the model inputs in the dictionary with format:
{
"input_ids": List[int],
"attention_mask": List[int]",
"labels": List[int]
}
Note: Huggngface dataaset map(batched=True, batch_size=n) merges values of
n dictionarys into a values of the key. If you have n instances of {"key", "v"}, then
you will get {"key": ["v", "v", "v", ...] }.
Args:
examples: a dictionary of format {
"prompt": [prompt+],
"response": [respnse+]
} where + means more than one instance because of Dataset.map(batched=True)
"""
inputs: Dict[str, List[int]] = tokenizer(
text_target=examples["prompt"],
max_length=MAX_TOKEN_LENGTH,
truncation=True
)
labels: Dict[str, List[int]] = tokenizer(
text_target=examples["response"],
max_length=MAX_TOKEN_LENGTH,
truncation=True,
padding='max_length',
)
inputs["labels"] = labels["input_ids"]
return inputs
remove_column_names: List[str] = list(train.features.keys())
tokenized_train = train.map(
function=convert_to_request_response,
batched=False,
batch_size=2048,
drop_last_batch=False,
remove_columns=remove_column_names,
).map(
function=tokenize_prompt_response,
batched=True,
batch_size=32,
drop_last_batch=True,
remove_columns=['prompt', 'response']
).shuffle(
seed=42
).with_format(
"torch"
)
if DATASET_STREAMING:
tokenized_train = tokenized_train.take(DATASET_TRAIN_NUM_SELECT)
else:
tokenized_train = tokenized_train.select(
indices=range(DATASET_TRAIN_NUM_SELECT)
)
del train
tokenized_validation = load_dataset(
path="xsum",
split="validation",
streaming=DATASET_STREAMING
).map(
function=convert_to_request_response,
batched=False,
batch_size=2048,
drop_last_batch=False,
remove_columns=remove_column_names,
).map(
function=tokenize_prompt_response,
batched=True,
batch_size=32,
drop_last_batch=True,
remove_columns=['prompt', 'response']
).with_format(
"torch"
)
if DATASET_STREAMING:
tokenized_validation = tokenized_validation.take(DATASET_TRAIN_NUM_SELECT)
else:
tokenized_validation = tokenized_validation.select(
indices=range(DATASET_TRAIN_NUM_SELECT)
)
# # Training
model = BloomForCausalLM.from_pretrained(MODEL)
model.cuda()
def predict(prompt: str) -> str:
inputs = tokenizer(prompt, return_tensors='pt')
print(inputs["input_ids"].shape)
response_tokens = model.generate(
inputs["input_ids"].cuda(),
max_new_tokens=1,
do_sample=False,
top_k=50,
top_p=0.9
)[0]
response = tokenizer.decode(response_tokens, skip_special_tokens=True)
return response
# DataCollatorWithPadding does not pad 'labels' which causes an error at train()
# https://stackoverflow.com/a/74228547/4281353
data_collator = DataCollatorWithPadding(
tokenizer=tokenizer,
padding='max_length',
pad_to_multiple_of=8,
max_length=MAX_TOKEN_LENGTH,
return_tensors='pt'
)
# ## Evaluation
rouge = evaluate.load("rouge")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
result = rouge.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
# ## Trainer API
training_args = TrainingArguments(
output_dir="bloom_finetuned",
max_steps=MAX_STEPS,
num_train_epochs=NUM_EPOCHS,
per_device_train_batch_size=PER_DEVICE_BATCH_SIZE,
per_device_eval_batch_size=PER_DEVICE_BATCH_SIZE,
learning_rate=2e-5,
weight_decay=0.01,
fp16=True,
no_cuda=False,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=3,
log_level="debug",
disable_tqdm=False,
push_to_hub=False,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_validation,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
### Expected behavior
Get the intended epochs 3 or explanation of the Num Epochs (9223372036854775807).
When not using streaming ```DATASET_STREAMING=False``` as in the code, the ```Num Epochs``` is displayed as expected.
```
***** Running training *****
Num examples = 2,048
Num Epochs = 3
Instantaneous batch size per device = 1
Total train batch size (w. parallel, distributed & accumulation) = 1
Gradient Accumulation steps = 1
Total optimization steps = 6,144
Number of trainable parameters = 559,214,592
```
# Related
* [TrainingArguments class - max_steps formula when using streaming dataset](https://discuss.huggingface.co/t/trainingarguments-class-max-steps-formula-when-using-streaming-dataset/36531)
* [Streaming Dataset of Sequence Length 2048](https://discuss.huggingface.co/t/streaming-dataset-of-sequence-length-2048/17649) | 04-14-2023 04:36:11 | 04-14-2023 04:36:11 | That's because the dataset you are using does not have a length, so the Trainer sets the number of epochs to a very high number to make sure it does the number of steps you are asking for.<|||||>@sgugger , thanks for the explanation.
May I suggest updating the document adding the Trainer behavior and requirements for streaming dataset e.g. to use max_steps and what value to set. Otherwise users may keep raising questions on max_steps (there have been at least 3 questions in forum) and epochs?
I am afraid otherwise you may need to spend your time for each time we raise it.
Currently [Datasets - Stream](https://huggingface.co/docs/datasets/stream) and [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer#trainer) documents have no such information as far as I looked at (please correct if there is).<|||||>We welcome any PR making the documentation better :-) |
transformers | 22,756 | open | TypeError: export() got an unexpected keyword argument 'preprocessor' | ### Model description
onnx_inputs, onnx_outputs = export(
preprocessor=tokenizer, model=model, config=onnx_config, opset=10, output=onnx_model_path
)
i got error: TypeError: export() got an unexpected keyword argument 'preprocessor'
### Open source status
- [ ] The model implementation is available
- [ ] The model weights are available
### Provide useful links for the implementation
_No response_ | 04-14-2023 03:42:51 | 04-14-2023 03:42:51 | @susht3, could you please follow the issue template and provide a minimal reproducible code snippet, information about the running environment (found using `transformers-cli env`) and a full trackback of the error? |
transformers | 22,755 | closed | no transformers version 4.29.0.dev0 | https://github.com/huggingface/transformers/blob/bfb3925fcbbb4fda83e023448e36e4d6c6f16a4c/examples/pytorch/language-modeling/run_mlm.py#L56
I try to run script `run_mlm.py`, meet an error: ImportError: This example requires a source install from HuggingFace Transformers (see `https://huggingface.co/transformers/installation.html#installing-from-source`), but the version found is 4.28.0.
Check out https://huggingface.co/transformers/examples.html for the examples corresponding to other versions of HuggingFace Transformers.
There seems no transformers version 4.29.0.dev0. | 04-14-2023 02:25:58 | 04-14-2023 02:25:58 | `pip install git+https://github.com/huggingface/transformers`
The above will install the git/head version which is 4.29.0.dev0.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,754 | closed | 🌐 [i18n-KO] translate `create_a_model` doc to Korean | # What does this PR do?
Translated the `create_a_model.mdx` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Team PseudoLab, may you please review this PR?
@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd
@sgugger, @ArthurZucker, @eunseojo May you please review this PR?
<!-- @sgugger, @ArthurZucker, @eunseojo May you please review this PR? -->
<!-- Team PseudoLab, may you please review this PR?
@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd --> | 04-14-2023 01:27:37 | 04-14-2023 01:27:37 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Team PseudoLab, may you please review this PR?
@0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd
<|||||>리뷰 해주신 내용 확인했습니다.
확인해보고 다시 업데이트 할께요~<|||||>@sgugger, @ArthurZucker, @eunseojo May you please review this PR? <|||||>There are still a couple of comments left to address @gabrielwithappy <|||||>@sgugger oh, I just found! I will chech and change to draft before ready-to-review
:-)<|||||>@sgugger, @ArthurZucker, @eunseojo
May you please review this PR?
I checked anchors of titles in the doc and fixed all reviews
BRs. |
transformers | 22,753 | closed | Add callbacks method to the trainer which are called when the loop starts and when skipping steps ends | ### Feature request
Add callbacks method in the training loop when the loop starts and when the steps skipping end.
### Motivation
When using an iterable dataset, all preprocessing is done on the fly when a batch is requested by the dataloader. As a result, when resuming training from a checkpoint, steps skipping can be extremely long because all the preprocessing steps are done for nothing.
If we have callback(s) that signal when the step skipping starts and ends, we could for instance set an environment variable that we can use in all our processing to signal to not do anything with the current batch.
The callback on_step_begin is only called once the first useful batch is loaded, it is then too late to signal to actually perform the processings.
I'm also open to propostions if you know another way of rapidly skipping batches when using an iterable dataset
### Your contribution
I could contribute to a PR if needed | 04-13-2023 23:01:30 | 04-13-2023 23:01:30 | cc @sgugger <|||||>It sounds like an interesting addition, but the callbacks don't have access to the training dataset, so I'm not sure how you would use that for your use case.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,752 | closed | Introduce `PartialState` as the device handler in the `Trainer` | # What does this PR do?
This PR is the start of the `Trainer` integration of [Accelerate](https://github.com/huggingface/accelerate)
The integration will follow multiple stages to ensure small changes happen iteratively. This first one simply changes the device handler/setter to be the `PartialState` in `Accelerate` and nothing more. In a follow-up PR, I will start to include more utilities utilizing it.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger @pacman100
| 04-13-2023 19:52:32 | 04-13-2023 19:52:32 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@pacman100 I'm starting small with what is minimally needed with the API. E.g. the AcceleratorState isn't needed until we get into parts such as mixed precision. The device handling can be done separately altogether as it doesn't need to rely on an accelerator object the user passes in
This may eventually be the `AcceleratorState`, but for now just starting with the `PartialState` seemed okay to me. <|||||>PR is good for final review, tested on single + multi gpu + deepspeed and seemed to work fine. Ignore the `examples_tensorflow` failure, as that's actually a good failure (if one could exist)<|||||>@muellerzr
I don't know if here is a right place to report but
I think this merge causing error in Seq2SeqTrainingArguments.
before this merge, I was able to run this code
```
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./train_test", # change to a repo name of your choice
per_device_train_batch_size=8,
gradient_accumulation_steps=2, # increase by 2x for every 2x decrease in batch size
learning_rate=1e-5,
warmup_steps=5,
max_steps=40,
gradient_checkpointing=True,
fp16=True,
group_by_length=True,
evaluation_strategy="steps",
per_device_eval_batch_size=8,
predict_with_generate=True,
generation_max_length=225,
save_steps=10,
eval_steps=10,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
push_to_hub=False,
)
```
Error messages
```
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
[<ipython-input-25-7693116680cc>](https://localhost:8080/#) in <cell line: 3>()
1 from transformers import Seq2SeqTrainingArguments
2
----> 3 training_args = Seq2SeqTrainingArguments(
4 output_dir="./whisper-large-ja-7", # change to a repo name of your choice
5 per_device_train_batch_size=8,
usr/local/lib/python3.9/dist-packages/transformers/training_args_seq2seq.py in __init__(self, output_dir, overwrite_output_dir, do_train, do_eval, do_predict, evaluation_strategy, prediction_loss_only, per_device_train_batch_size, per_device_eval_batch_size, per_gpu_train_batch_size, per_gpu_eval_batch_size, gradient_accumulation_steps, eval_accumulation_steps, eval_delay, learning_rate, weight_decay, adam_beta1, adam_beta2, adam_epsilon, max_grad_norm, num_train_epochs, max_steps, lr_scheduler_type, warmup_ratio, warmup_steps, log_level, log_level_replica, log_on_each_node, logging_dir, logging_strategy, logging_first_step, logging_steps, logging_nan_inf_filter, save_strategy, save_steps, save_total_limit, save_safetensors, save_on_each_node, no_cuda, use_mps_device, seed, data_seed, jit_mode_eval, use_ipex, bf16, fp16, fp16_opt_level, half_precision_backend, bf16_full_eval, fp16_full_eval, tf32, local_rank, xpu_backend, tpu_num_cores, tpu_metrics_debug, debug, dataloader_drop_last, eval_steps, dataloader_num_workers, past_index, run_name, disable_tqdm, remove_unused_columns, label_names, load_best_model_at_end, metric_for_best_model, greater_is_better, ignore_data_skip, sharded_ddp, fsdp, fsdp_min_num_params, fsdp_config, fsdp_transformer_layer_cls_to_wrap, deepspeed, label_smoothing_factor, optim, optim_args, adafactor, group_by_length, length_column_name, report_to, ddp_find_unused_parameters, ddp_bucket_cap_mb, dataloader_pin_memory, skip_mem...
[/usr/local/lib/python3.9/dist-packages/transformers/training_args.py](https://localhost:8080/#) in __post_init__(self)
1253 self.framework == "pt"
1254 and is_torch_available()
-> 1255 and (self.device.type != "cuda")
1256 and (get_xla_device_type(self.device) != "GPU")
1257 and (self.fp16 or self.fp16_full_eval)
[/usr/local/lib/python3.9/dist-packages/transformers/training_args.py](https://localhost:8080/#) in device(self)
1613 """
1614 requires_backends(self, ["torch"])
-> 1615 return self._setup_devices
1616
1617 @property
[/usr/local/lib/python3.9/dist-packages/transformers/utils/generic.py](https://localhost:8080/#) in __get__(self, obj, objtype)
52 cached = getattr(obj, attr, None)
53 if cached is None:
---> 54 cached = self.fget(obj)
55 setattr(obj, attr, cached)
56 return cached
[/usr/local/lib/python3.9/dist-packages/transformers/training_args.py](https://localhost:8080/#) in _setup_devices(self)
1547 device = self.distributed_state.device
1548 else:
-> 1549 self.distributed_state = PartialState(backend=self.xpu_backend)
1550 device = self.distributed_state.device
1551 self._n_gpu = 1
NameError: name 'PartialState' is not defined
```<|||||>@rennn2002 Could you try updating your version of accelerate i.e. `pip install --upgrade accelerate`? |
transformers | 22,751 | closed | DeepSpeed integration not respecting `--warmup_steps` in multi-gpu setting | ### System Info
- `transformers` version: 4.26.1
- Platform: Linux-5.15.0-1030-gcp-x86_64-with-debian-bullseye-sid
- Python version: 3.7.16
- Huggingface_hub version: 0.13.4
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Deepspeed version: 0.8.3
### Who can help?
@stas00 @sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. DeepSpeed config file `ds_config_zero2_no_optim.json` (adapted from https://huggingface.co/docs/transformers/main_classes/deepspeed#deepspeed-trainer-integration)
```
{
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": "auto",
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
2. DeepSpeed launch the training script with 4 GPUs (the script is copied from https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py)
```
deepspeed --num_gpus=4 run_clm.py \
--deepspeed $HOME/projects/ds_config_zero2_no_optim.json \
--report_to mlflow \
--evaluation_strategy steps \
--logging_strategy steps \
--logging_steps 20 \
--save_strategy steps \
--save_steps 10000 \
--max_steps 2560 \
--num_train_epochs 2 \
--learning_rate 0.00006 \
--warmup_steps 100 \
--model_name_or_path gpt2-medium \
--do_train \
--do_eval \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--output_dir ./tmp/gpt2_medium-test-mlflow \
--overwrite_output_dir \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--max_train_samples=2560 \
--max_eval_samples=10
```
3. Note that the `--warmup_steps 100` and `--learning_rate 0.00006`, so by default, learning rate should increase linearly to 6e-5 at step 100. But the learning rate curve shows that it took 360 steps, and the slope is not a straight line.
<img width="1036" alt="image" src="https://user-images.githubusercontent.com/47165889/231864162-12f80df5-2827-4bb9-b706-aac66eae5a47.png">
4. Interestingly, if you deepspeed launch with just a single GPU `--num_gpus=1`, the curve seems correct
<img width="927" alt="image" src="https://user-images.githubusercontent.com/47165889/231865235-3d564e5d-4d60-4c5f-ad75-588e35283789.png">
6. The above model is `gpt2-medium`, but training other models such as `gpt2` (with 2 GPUs) also has a similar behavior. For example, note below that `gpt2` at step-100 has a learning rate about `5.82e-05` :
<img width="945" alt="image" src="https://user-images.githubusercontent.com/47165889/231867661-232a017b-d192-490d-822f-0de8d269ba4d.png">
### Expected behavior
The default scheduler should warmup the learning rate linearly, to the specified max learning rate at the specified `warmup_steps`. | 04-13-2023 19:38:46 | 04-13-2023 19:38:46 | Thank you for the detailed report and an easy way to reproduce it, @cchen-dialpad
I'm very much doubting this has anything to do with deepspeed, since you're not using its LR Scheduler, but the default `get_linear_schedule_with_warmup` in HF Trainer. That is you should see the same behavior w/o using deepspeed.
Now I recommend adding: `--logging_steps 1 --logging_strategy steps` and checking the actual LR reports after each step, rather than the graph which most likely extrapolates.
Can you try with the latest `transformers`? I can't repro your report with it. I lowered the number of warm up steps to 10 and you can see that it gets there in 10 steps:
```
$ deepspeed --num_gpus=4 examples/pytorch/language-modeling/run_clm.py --logging_steps 1 --logging_strategy steps --report_to none --evaluation_strategy steps --save_strategy steps --save_steps 10000 --max_steps 200 --num_train_epochs 2 --learning_rate 0.00006 --warmup_steps 10 --model_name_or_path gpt2-medium --do_train --do_eval --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --output_dir ./tmp/gpt2_medium-test-mlflow --overwrite_output_dir --per_device_train_batch_size=1 --per_device_eval_batch_size=1 --max_train_samples=200 --max_eval_samples=10 --evaluation_strategy no --deepspeed ds.json
{'loss': 3.3841, 'learning_rate': 6e-06, 'epoch': 0.02}
{'loss': 3.1834, 'learning_rate': 1.2e-05, 'epoch': 0.04}
{'loss': 3.0764, 'learning_rate': 1.8e-05, 'epoch': 0.06}
{'loss': 3.1638, 'learning_rate': 2.4e-05, 'epoch': 0.08}
{'loss': 3.0197, 'learning_rate': 3e-05, 'epoch': 0.1}
{'loss': 3.3902, 'learning_rate': 3.6e-05, 'epoch': 0.12}
{'loss': 3.0261, 'learning_rate': 4.2e-05, 'epoch': 0.14}
{'loss': 3.1501, 'learning_rate': 4.8e-05, 'epoch': 0.16}
{'loss': 3.1557, 'learning_rate': 5.4000000000000005e-05, 'epoch': 0.18}
{'loss': 3.1952, 'learning_rate': 6e-05, 'epoch': 0.2}
```
Also fyi if you were to run under fp16, you could get optimizer skipping steps while it's tuning up its mixed precision scale factor, so that could also contribute to taking more steps than requested. But you're not using fp16 so this shouldn't be the cause. Just sharing this as FYI.<|||||>@stas00 Ah, it's working properly with transformers `v4.28.0` and `v4.27.0`. Not sure how it was fixed from the release info, but thanks for checking! Closing now.<|||||>> Also fyi if you were to run under fp16, you could get optimizer skipping steps while it's tuning up its mixed precision scale factor, so that could also contribute to taking more steps than requested. But you're not using fp16 so this shouldn't be the cause. Just sharing this as FYI.
Thanks for sharing, I believe I will run into this later :)<|||||>same issues with version 4.29.dev0, the lr is increasing at the first several steps while configured with a warmup scheduler in deepspeed config. |
transformers | 22,750 | closed | Revert (for now) the change on `Deta` in #22437 | # What does this PR do?
See #22656 for some discussion. Basically, the loading of checkpoints for this model is currently not working correctly, and we do want to avoid this situation as early as possible. | 04-13-2023 19:11:40 | 04-13-2023 19:11:40 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,749 | closed | Allow fine-tune wav2vec2 with local path custom dataset | # What does this PR do?
In the examples for fine-tuning Wav2Vec2 it is possible to use a HuggingFace dataset that is ready to be trained. But when we want to use a local/custom dataset, it's easier to create a .tsv that points to the file path. Which doesn't work in current version - returning error: "AttributeError: 'Value' object has no attribute 'sampling_rate'"
So this PR adds a code to check if the "audio_column_name" has an audio format or a path (string), if it is a string, load the file and convert it to audio format.
Below is an example of a .tsv file that does not work with the current version and works with this PR:
path | sentence
-- | --
data/clips/common_voice_tr_21921195.mp3 | Pirin sözleri hâlâ yankılanıyor.
data/clips/common_voice_tr_21921199.mp3 | Müze Gecesi beş yıldır her yıl düzenleniyor.
data/clips/common_voice_tr_21921206.mp3 | Yunanistan'ın Selanik kenti de ilk ona girdi.
## Who can review?
@sanchit-gandhi
| 04-13-2023 18:35:15 | 04-13-2023 18:35:15 | @ProgramadorArtificial Thanks for taking the time to open this PR.
The example scripts are just examples and won't work out-of-the-box for all problems. As you've done here, a few lines of code might be needed to adapt to different use cases. This change is very specific. As such, it's not an addition we'll be merging in.
<|||||>Hey @ProgramadorArtificial! In this case, it might be easier to first load your audio data as a HF datasets object (here's an excellent guide on how to do so: https://huggingface.co/docs/datasets/audio_load). You can then save this data locally and/or push it to the Hub:
```python
# set a save path and HF Hub dataset id
LOCAL_DATASET_DIR = ...
HF_DATASET_ID = ...
dataset.save_to_disk(LOCAL_DATASET_DIR)
# and/or push to hub
dataset.push_to_hub(HF_DATASET_ID)
```
You'll then be able to use the training script directly with your dataset (either from the local path or loading from the Hub, in the same way that we do for Common Voice in the example).<|||||>Hey @ProgramadorArtificial - just re-iterating that the examples script is assumed to work with a HF dataset that has an audio column already present (i.e. one that has an [`Audio` feature](https://huggingface.co/docs/datasets/v2.12.0/en/package_reference/main_classes#datasets.Audio)). If your custom dataset does not have the audio files loaded up, you'll need to perform a round of pre-processing to get your dataset into the right format for this script (expected to have two columns: "audio" and "text"). |
transformers | 22,748 | closed | Generate: handle text conditioning with multimodal encoder-decoder models | # What does this PR do?
Consolidates `decoder_input_ids` preparation changes in a single place, for all future multimodal encoder-decoder models on PT and TF.
In a nutshell, this PR generalizes the following use cases:
1. The user passes `decoder_input_ids`, but it is missing the BOS token (some tokenizers, like the T5 tokenizer, do not prepend a BOS token). In this case, a BOS token is prepended.
2. The user passes `input_ids`, but the encoder has no `input_ids` input. In this case, `input_ids` is handled just like `decoder_input_ids`.
Slow tests were run on T5, Pix2Struct, BLIP, and BLIP2. | 04-13-2023 17:43:23 | 04-13-2023 17:43:23 | cc @younesbelkada @NielsRogge FYI -- this PR consolidates your recent changes regarding text conditioning on multimodal models. The next models should be easier to add :) <|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks a lot @gante! 🙏 |
transformers | 22,747 | closed | [trainer] update url | Fixes: https://github.com/huggingface/transformers/issues/22142
update the link to its stable version now that pt-2.0 is out. | 04-13-2023 15:35:05 | 04-13-2023 15:35:05 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,746 | closed | fix(llama): fix LlamaTokenzier | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #22742
- #22742
This PR removes an extra `sep` token in the sequence length calculation.
Ref:
https://github.com/huggingface/transformers/blob/7df1343292a9d75f1410cb37a99f423dcde15dae/src/transformers/models/llama/tokenization_llama.py#L178-L187
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-13-2023 14:00:54 | 04-13-2023 14:00:54 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks for your quick review, I have re-run the CI tests. 🤗 @amyeroberts @ArthurZucker |
transformers | 22,745 | closed | `DocumentQuestionAnsweringPipeline` only for fast ⚡ tokenizers | # What does this PR do?
So let's make this more clear and explicit. | 04-13-2023 13:54:08 | 04-13-2023 13:54:08 | _The documentation is not available anymore as the PR was closed or merged._<|||||>The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22745). All of your documentation changes will be reflected on that endpoint. |
transformers | 22,744 | closed | Bug in Seq2SeqTrainer? | ### System Info
Transformers version: 4.28.0.dev0
Pytorch version: 2
### Who can help?
@sanchit-gandhi @sgugger
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Finetune Whisper on multiGPU, using Seq2SeqTrainer
During generation step, I am getting an `AttributeError` ('DataParallel' object has no attribute 'generation_config') due to [this line of code](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer_seq2seq.py#L280). Note that `generation_config` is a correct attribute in the model.
I did finetune a modified version of Whisper on 2 GPUs in the past, but I did not experience the same error. I think that previously, generation was done on one GPU, even if the trainer was using data parallel. Not exactly sure if something has changed or if I did something wrong
The model is `openai/whisper-large-v2`
### Expected behavior
Either generation should not use `DataParallel` or `Seq2SeqTrainer` should access `model.model.generation_config` if the model is an instance of `DataParallel`
Happy to write a PR if necessary, let me know
| 04-13-2023 13:50:42 | 04-13-2023 13:50:42 | This has been fixed on main, so make sure to do a source install (or in a couple of hours you can upgrade to v4.28.0 once it's released).<|||||>Shame on me, I did not pull the latest changes
Thank you for your quick answer<|||||>No worries at all! |
transformers | 22,743 | closed | Fix `serving_output` for TF composite models (encoder-decoder like models) | # What does this PR do?
**[If the concept is approved, I will apply the same changes to other TF encoder-decoder family of models]**
The composite models use its components' configurations. See for example
https://github.com/huggingface/transformers/blob/95e7057507c9eca8e997abb98645eee2621a5aea/src/transformers/modeling_tf_utils.py#L426-L430
However, in some places, our codebase still try to access some attributes at the top level of the configuration (i.e. not inside the 2 components), like
https://github.com/huggingface/transformers/blob/95e7057507c9eca8e997abb98645eee2621a5aea/src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py#L664-L669
In particular, `self.config` may not have `use_cache`, for example, for this checkpoint `"nlpconnect/vit-gpt2-image-captioning"`. We should instead look `self.config.deocder.use_cache`.
**This PR try to follow the rule of ` # Encoder Decoder models delegate the application of the configuration options to their inner models. `.**
**This PR is also (another) one necessary step to fix #22731.** | 04-13-2023 12:16:15 | 04-13-2023 12:16:15 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,742 | closed | Bug in LlamaTokenizer when `return_token_type_ids=True` | ### System Info
- `transformers` version: 4.29.0.dev0
- Platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.31
- Python version: 3.10.10
- Huggingface_hub version: 0.13.4
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help?
tokenizers: @ArthurZucker
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
When I use LLama's tokenizer and pass `return_token_type_ids=True`, I found that the length of the return value `token_type_ids` is different from `input_ids` and `attention_mask`.
```python
In [2]: from transformers import AutoTokenizer
In [3]: tok = AutoTokenizer.from_pretrained('/mnt/checkpoint/llama_7B_hf', use_fast=False)
In [4]: inputs = 'I LOVE'
In [5]: outputs = 'huggingface'
In [6]: tok(inputs, outputs, return_token_type_ids=True)
Out[6]: {'input_ids': [1, 306, 11247, 12064, 1, 298, 688, 3460, 2161], 'token_type_ids': [0, 0, 0, 0, 0, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
In [7]: list(map(len, _.values()))
Out[7]: [9, 10, 9]
```
### Expected behavior
```python
In [6]: tok(inputs, outputs, return_token_type_ids=True)
Out[6]: {'input_ids': [1, 306, 11247, 12064, 1, 298, 688, 3460, 2161], 'token_type_ids': [0, 0, 0, 0, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
In [7]: list(map(len, _.values()))
Out[7]: [9, 9, 9]
``` | 04-13-2023 09:29:37 | 04-13-2023 09:29:37 | Hey yep that's indeed a bug thanks for reporting |
transformers | 22,741 | closed | Remove `DS_BUILD_AIO=1` | # What does this PR do?
In order to make
```
PASSED tests/deepspeed/test_deepspeed.py::TrainerIntegrationDeepSpeed::test_stage3_nvme_offload
```
Note it pass, not skipped. I am not sure if this is normal however, but you can see the results in [this job run](https://github.com/huggingface/transformers/actions/runs/4686799372) | 04-13-2023 09:10:27 | 04-13-2023 09:10:27 | _The documentation is not available anymore as the PR was closed or merged._<|||||>funny, it means that it built it at runtime and it worked. So it finds the right library at run time.
So actually if we wanted to skip the test we would need to removed apt install libaio-dev.
But this is a better outcome, so let's keep it the way you proposed. |
transformers | 22,740 | closed | Change `torch_dtype` to str when `saved_model=True` in `save_pretrained` for TF models | # What does this PR do?
One issue in #22731 is: the config contains `torch_type` with a torch dtype class as value. Usually, our `save_pretrained` will take care of it. But when `saved_model=True` in `save_pretrained` for TF models, it is not handled, and TF/Keras complains about it.
See the first part in [this comment](https://github.com/huggingface/transformers/issues/22731#issuecomment-1506538658) | 04-13-2023 08:55:10 | 04-13-2023 08:55:10 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,739 | closed | AssertionError when converting openai clip's weight to hf | ### System Info
- `transformers` version: 4.26.1
- Platform: Linux-4.18.0-305.25.1.el8_4.x86_64-x86_64-with-redhat-8.5-Ootpa
- Python version: 3.7.10
- Huggingface_hub version: 0.12.0
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): 2.8.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.4.1 (gpu)
- Jax version: 0.3.15
- JaxLib version: 0.3.15
### Who can help?
@amyeroberts
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Hi, I'm trying to convert huggingface's clip weight back to openai's because I need to adapt a finetuned model, but it seems there is no such script available. Luckily I found one that converts clip from openai to hugginface here: [https://github.com/huggingface/transformers/blob/main/src/transformers/models/clip/convert_clip_original_pytorch_to_hf.py](url)
So I start with this script. But When I run it:
`python convert_clip_original_pytorch_to_hf.py --checkpoint_path 'path/to/ViT-B-32.pt' --pytorch_dump_folder_path './'`
I got the following error:
╭─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /home/test/convert_clip_original_pytorch_to_hf.py:1 │
│ 48 in <module> │
│ │
│ 145 │ parser.add_argument("--config_path", default=None, type=str, help="Path to hf config │
│ 146 │ args = parser.parse_args() │
│ 147 │ │
│ ❱ 148 │ convert_clip_checkpoint(args.checkpoint_path, args.pytorch_dump_folder_path, args.co │
│ 149 │
│ │
│ /home/anaconda3/envs/hf/lib/python3.7/site-packages/torch/autograd │
│ /grad_mode.py:27 in decorate_context │
│ │
│ 24 │ │ @functools.wraps(func) │
│ 25 │ │ def decorate_context(*args, **kwargs): │
│ 26 │ │ │ with self.clone(): │
│ ❱ 27 │ │ │ │ return func(*args, **kwargs) │
│ 28 │ │ return cast(F, decorate_context) │
│ 29 │ │
│ 30 │ def _wrap_generator(self, func): │
│ │
│ /home/test/convert_clip_original_pytorch_to_hf.py:1 │
│ 36 in convert_clip_checkpoint │
│ │
│ 133 │ pt_logits_per_image, pt_logits_per_text = pt_model(pixel_values, input_ids) │
│ 134 │ │
│ 135 │ assert torch.allclose(hf_logits_per_image, pt_logits_per_image, atol=1e-3) │
│ ❱ 136 │ assert torch.allclose(hf_logits_per_text, pt_logits_per_text, atol=1e-3) │
│ 137 │ │
│ 138 │ hf_model.save_pretrained(pytorch_dump_folder_path) │
│ 139 │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
### Expected behavior
A hf's clip weight should be generated from original openai's by running this script. | 04-13-2023 08:38:43 | 04-13-2023 08:38:43 | Hi @wingvortex, thanks for raising this issue.
~~The trackback in the issue description doesn't contain the error message - could you share that please?~~ Scratch that: I see it's in the `torch.allclose` assert
For the checkpoints being converted, could you confirm which of the ViT-B-32 checkpoints are being used e.g. `('ViT-B-32', 'laion400m_e31'),`<|||||>@amyeroberts It's a checkpoint downloaded by `clip.load('ViT-B/32')`<|||||>@wingvortex Thanks again for reporting and the additional info. I managed to track it down to an indexing error in the conversion script, which should be resolved when #22776 is merged. |
transformers | 22,738 | closed | [LLAMA]: LLAMA tokenizer | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.8.16
- Huggingface_hub version: 0.13.2
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu117 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```py
from transformers import LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained(..., add_eos_token=True)
input_text = "Hello, Huggingface"
tokens = tokenizer(input_text)
# token.input_ids = [0, ..., 0]
```
### Expected behavior
at commit id ``7ade6ef7d``
the ``eos_token_id`` and ``bos_token_id`` is 0 and 0, while those from LLAMA official repo released by META is 2 and 1.
Why there is such kind of distinction? | 04-13-2023 08:33:34 | 04-13-2023 08:33:34 | cc @ArthurZucker <|||||>Hey! This is because:
1. You are not using the correct version of transformers:
2. You are not using the correct checkpoints
Here is the snipper I used to get the expected output:
```python
>>> from transformers import LlamaTokenizer
>>> tokenizer = LlamaTokenizer.from_pretrained("huggyllama/llama-7b", add_eos_token= True)
>>> tokenizer.decode(tokenizer.encode("Hello", add_special_tokens = True))
'<s> Hello</s>'
```
<|||||>> Hey! This is because:
>
> 1. You are not using the correct version of transformers:
> 2. You are not using the correct checkpoints
> Here is the snipper I used to get the expected output:
>
> ```python
> >>> from transformers import LlamaTokenizer
> >>> tokenizer = LlamaTokenizer.from_pretrained("huggyllama/llama-7b", add_eos_token= True)
> >>> tokenizer.decode(tokenizer.encode("Hello", add_special_tokens = True))
> '<s> Hello</s>'
> ```
Which version of transformers do you use?<|||||>`main` but latest release also has these changes<|||||>Faced the same issue. It seems like a mismatch between transformers and llama chkt version.
It appears that in commit c0f99b4d2ec73090595914dde4c16da207e21d73, a major change has been made to llama tokenizer, so you either install an earlier version (commit 9eae4aa57650c1dbe1becd4e0979f6ad1e572ac0 or before), or convert llama weight using the latest commit. <|||||>Or you can just use the tokenizer files from `huggyllama` and save them wherever you want <|||||>> Faced the same issue. It seems like a mismatch between transformers and llama chkt version.
>
> It appears that in commit [c0f99b4](https://github.com/huggingface/transformers/commit/c0f99b4d2ec73090595914dde4c16da207e21d73), a major change has been made to llama tokenizer, so you either install an earlier version (commit [9eae4aa](https://github.com/huggingface/transformers/commit/9eae4aa57650c1dbe1becd4e0979f6ad1e572ac0) or before), or convert llama weight using the latest commit.
Many thanks! Already fix it.<|||||>> Faced the same issue. It seems like a mismatch between transformers and llama chkt version.
>
> It appears that in commit [c0f99b4](https://github.com/huggingface/transformers/commit/c0f99b4d2ec73090595914dde4c16da207e21d73), a major change has been made to llama tokenizer, so you either install an earlier version (commit [9eae4aa](https://github.com/huggingface/transformers/commit/9eae4aa57650c1dbe1becd4e0979f6ad1e572ac0) or before), or convert llama weight using the latest commit.
You have just saved my life! Debugged for days for this weird problem.<|||||>> Or you can just use the tokenizer files from `huggyllama` and save them wherever you want
Hi, how can I convert a llama model trained with older transformers (commit [9eae4aa](https://github.com/huggingface/transformers/commit/9eae4aa57650c1dbe1becd4e0979f6ad1e572ac0) or before) to be compatible with the latest transformer code? |
transformers | 22,737 | closed | Indexing fix for gpt_bigcode | The `past_key_values` is a list of tensors in gpt_bigcode, and not a list of lists like with most models, so we don't want to index twice. The code works either way but it's safer to avoid the unnecessary indexing. I also fixed the associated type hint.
@younesbelkada | 04-13-2023 03:55:41 | 04-13-2023 03:55:41 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,736 | closed | add onnx support for llama | # What does this PR do?
Add ONNX serialization support for Llama models.
Fixes # (issue)
https://github.com/huggingface/optimum/issues/918
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@JingyaHuang @chainyo | 04-12-2023 20:40:28 | 04-12-2023 20:40:28 | _The documentation is not available anymore as the PR was closed or merged._<|||||>cc @michaelbenayoun |
transformers | 22,735 | closed | [Doctest] Add configuration_mvp.py | Adds configuration_mvp.py to utils/documentation_tests.txt
Based on https://github.com/huggingface/transformers/issues/19487
@ydshieh can you please have a look?this passes the test as well, with two warnings.thank you :) | 04-12-2023 20:40:14 | 04-12-2023 20:40:14 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,734 | closed | FSDP hangs before training starts | ### System Info
- `transformers` version: 4.27.4
- Platform: Linux-5.4.0-128-generic-x86_64-with-glibc2.31
- Python version: 3.9.16
- Huggingface_hub version: 0.13.4
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@pacman100 @stas @sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Steps to reproduce the behaviour :
1. I created the FSDP Config file using accelerate config as follows :
```
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: GPTJBlock
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 6
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
2. My bash script looks like this :
```
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5
accelerate launch train_llm.py \
--output_dir /path/to/dir \
--model_name_or_dir "EleutherAI/gpt-j-6B" \
--do_train --per_device_train_batch_size 8 \
--do_eval --per_device_eval_batch_size 8 \
--num_train_epochs 3 \
--evaluation_strategy "steps" \
--eval_steps 1000 \
--save_strategy "steps" \
--save_steps 1000 \
--learning_rate 5e-5 \
--logging_steps 1 \
--bf16 \
--run_name run_fsdp \
--gradient_checkpointing true \
--warmup_ratio 0.03 \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap "GPTJBlock"
```
3. My train_llm.py file look like this this -
```
if __name__ == "__main__":
parser = HfArgumentParser(TrainingArguments)
parser.add_argument("--model_name_or_dir")
training_args, args = parser.parse_args_into_dataclasses()
transformers.logging.set_verbosity_debug()
model = AutoModelForCausalLM.from_pretrained(args.model_name_or_dir, use_cache=True, ignore_mismatched_sizes=True)
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_dir, use_cache=True)
tokenizer.pad_token_id = tokenizer.eos_token_id
train_path = 'path/to/train'
train_data = glob(train_path)
val_path = 'path/to/val'
val_data = glob(val_path)
dataset = load_dataset("json", data_files = {"train": train_data, "validation" : val_data})
dataset = dataset.map(transform, batched=True, remove_columns = ["id" ,"tokens"])
train_dataset = dataset["train"]
val_dataset = dataset["validation"]
trainer = Trainer(
model,
training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForTokenClassification(tokenizer, padding='longest'),
compute_metrics=None,
callbacks = [TensorBoardCallback()]
)
if trainer.is_world_process_zero():
print(dataset)
trainer.pop_callback(MLflowCallback)
if training_args.do_train:
if trainer.is_world_process_zero():
print("Training...")
start = time.time()
trainer.train()
mlflow.log_metric(
"time/epoch", (time.time() - start) / 60 / training_args.num_train_epochs
)
```
4. After running my bash script, I see some amount of GPU being used (10G/80G) on all of the 6 GPU's, but it hangs after logging this --
```
***** Running training *****
Num examples = 364978
Num Epochs = 3
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 48
Gradient Accumulation steps = 1
Total optimization steps = 22812
Number of trainable parameters = 1030852826
0%| | 0/22812
```
### Expected behavior
Expected Behaviour is for the training to start and the processes to not hang. | 04-12-2023 20:39:43 | 04-12-2023 20:39:43 | Ok the issue is not related to FSDP per say. Looks like something related to communication between the GPU's. I fixed it by
modifying an environment variable as follows : `export NCCL_P2P_DISABLE=1`
Closing! |
transformers | 22,733 | closed | [Doctest] Add configuration_m2m_100.py | Add configuration_m2m_100.py to utils/documentation_tests.txt for doctest.
Based on issue https://github.com/huggingface/transformers/issues/19487
@ydshieh can you please have a look? thanks :D
it passes the test with a few warnings. | 04-12-2023 18:12:04 | 04-12-2023 18:12:04 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thank you for your assistance @ydshieh 😃 |
transformers | 22,732 | open | BLIP special additional token self.tokenizer.enc_token_id | ### System Info
Hello,
It seems to me that the Salesforce implementation of BLIP uses a special tokem 'ENC' at the beginning of each text sentence, it is added
https://github.com/salesforce/BLIP/blob/a176f1e9cc5a232d2cc6e21b77d2c7e18ceb3c37/models/blip.py#L190
and used when encoding text conditioned on images e.g. https://github.com/salesforce/BLIP/blob/a176f1e9cc5a232d2cc6e21b77d2c7e18ceb3c37/models/blip.py#L67
or here
https://github.com/salesforce/BLIP/blob/b7bb1eeb6e901044a9eb1016f408ee908b216bc7/models/blip_retrieval.py#L124
Shouldn't we do the same? What is special about that token?
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
N/A
### Expected behavior
When in conditional mode with images, we should add
`encoder_input_ids[:,0] = self.tokenizer.enc_token_id`?
| 04-12-2023 15:49:13 | 04-12-2023 15:49:13 | cc @ArthurZucker <|||||>Hey! Thanks for submitting this issue. I think @younesbelkada is the most familiar with Blip and should be able to answer whether or not the `enc_token_id` should be added. BLIP seems to be using a `BertTokenizer`, and looking at [this](https://huggingface.co/Salesforce/blip-image-captioning-large/blob/main/tokenizer_config.json) I don't think that we are adding it. <|||||>Any news here? <|||||>Hi @DianeBouchacourt
Do you notice any notable qualitative difference when adding that token? When porting the model I got predictions matched with the current approach <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,731 | closed | Saving TFVisionEncoderDecoderModel as SavedModel: `The following keyword arguments are not supported by this model: ['attention_mask', 'token_type_ids'].` | ### System Info
- `transformers` version: 4.27.4
- Platform: Linux-6.2.6-76060206-generic-x86_64-with-debian-bookworm-sid
- Python version: 3.7.16
- Huggingface_hub version: 0.13.4
- PyTorch version (GPU?): 1.13.1 (False)
- Tensorflow version (GPU?): 2.11.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
### Who can help?
@gante Could be related to #16400?
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hello,
I am trying to save a TFVisionEncoderDecoderModel in a SavedModel format. Specifically, I am using the `nlpconnect/vit-gpt2-image-captioning` pretrained model. It seems like the model is able to be intiallised from the PyTorch checkpoint. However, when trying to save it as a SavedModel, it fails with the error.
```
ValueError: The following keyword arguments are not supported by this model: ['attention_mask', 'token_type_ids'].
```
Link to Google Colab Reproduction:
https://colab.research.google.com/drive/1N2TVejxiBT5S7bRJ2LSmJ8IIR45folGA#scrollTo=aIL92KqPDDjf
Thanks for your time!
### Expected behavior
The model should be saved as a SavedModel without problems, similarly to other pretrained models. | 04-12-2023 15:37:21 | 04-12-2023 15:37:21 | cc @ydshieh <|||||>Hi @DevinTDHa Just a quick update: instead of `input_ids` in the signature, we have to use `decoder_input_ids`, as the text inputs are for the decoder.
```python
"pixel_values": tf.TensorSpec((None, None, None, None), tf.float32, name="pixel_values"),
"decoder_input_ids": tf.TensorSpec((None, None), tf.int32, name="decoder_input_ids"),
```
This change will fix the issue you mentioned, but the saving is still not working due to other problems - I am still looking how to fix them. <|||||>Two extra steps to make the saving working are:
- First, after `model = TFVisionEncoderDecoderModel.from_pretrained(MODEL_NAME, from_pt=True)` in your code, add
```python
model.config.torch_dtype = None
```
- Then, in the file `src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py`, for the class `TFVisionEncoderDecoderModel`, change the method from
```python
def serving_output(self, output):
pkv = tf.tuple(output.past_key_values)[1] if self.config.use_cache else None
...
```
to
```python
def serving_output(self, output):
pkv = tf.tuple(output.past_key_values)[1] if self.config.decoder.use_cache else None
...
```
You can do these changes in your own fork if you want to proceed quickly.
I will discuss the team about the fix in our codebase.<|||||>Thanks a lot, especially for the suggested edits!<|||||>@DevinTDHa
In fact, what I did that works is I added the following block for the class `TFVisionEncoderDecoderModel` in the file `src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py`
```python
@tf.function(
input_signature=[
{
"pixel_values": tf.TensorSpec((None, None, None, None), tf.float32, name="pixel_values"),
"decoder_input_ids": tf.TensorSpec((None, None), tf.int32, name="decoder_input_ids"),
}
]
)
def serving(self, inputs):
"""
Method used for serving the model.
Args:
inputs (`Dict[str, tf.Tensor]`):
The input of the saved model as a dictionary of tensors.
"""
output = self.call(inputs)
return self.serving_output(output)
```
I am not sure why using the approach in your notebook doesn't work (i.e. by specifying `serving_fn` explicitly)<|||||>The fixes have been merged to the `main` branch. The only thing to do manually is to add the correct `input_signature` to the proper place as shown in the above comment. However, this could not be done in `transformers` codebase I believe, but you can still do it in your own fork.
I will discuss with our TF experts regarding why specifying `signatures` as you did is not working. But I am going to close this issue. If you still have any related question on this issue, don't hesitate to leave comments 🤗 <|||||>Hi @Rocketknight1 Since you are a TF saving expert 🔥 , could you take a look on the code snippet below, and see why it doesn't work when we specify `signatures` manually, please? (it works if I add `serving` method to `TFVisionEncoderDecoderModel` directly.
(You have to pull `main` branch to incorporate 2 fixes first)
Thank you in advanceeeeeeee ~
```python
import tensorflow as tf
from transformers import TFVisionEncoderDecoderModel
# load a fine-tuned image captioning model and corresponding tokenizer and image processor
MODEL_NAME = "nlpconnect/vit-gpt2-image-captioning"
model = TFVisionEncoderDecoderModel.from_pretrained(MODEL_NAME, from_pt=True)
EXPORT_PATH = f"exports/{MODEL_NAME}"
# ========================================================================================================================
# This works
# Add this block to `TFVisionEncoderDecoderModel` in `src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py`
"""
@tf.function(
input_signature=[
{
"pixel_values": tf.TensorSpec((None, None, None, None), tf.float32, name="pixel_values"),
"decoder_input_ids": tf.TensorSpec((None, None), tf.int32, name="decoder_input_ids"),
}
]
)
def serving(self, inputs):
output = self.call(inputs)
return self.serving_output(output)
"""
#model.save_pretrained(
# EXPORT_PATH,
# saved_model=True,
# # signatures={"serving_default": my_serving_fn},
#)
# ========================================================================================================================
# Not working (without changing `TFVisionEncoderDecoderModel`)
@tf.function(
input_signature=[
{
"pixel_values": tf.TensorSpec((None, None, None, None), tf.float32, name="pixel_values"),
"decoder_input_ids": tf.TensorSpec((None, None), tf.int32, name="decoder_input_ids"),
}
]
)
def my_serving_fn(inputs):
output = model.call(inputs)
return model.serving_output(output)
# This fails
model.save_pretrained(
EXPORT_PATH,
saved_model=True,
signatures={"serving_default": my_serving_fn},
)
# ========================================================================================================================
```<|||||>@ydshieh I have a question regarding this actually:
Currently I'm trying to access the decoder (GPT-2) from the saved model but it seems to my knowledge that it is not possible. The default serving signature you suggested outputs the encoder (ViT) outputs only (or am I wrong in this regard?)
However, trying to create a serving for the `model.generate()` function, seems to cause the same error. The error is the same as with saving the model with a custom signature. Would this be possible in theory (combining encoder and decoder in one serving function)?<|||||>> @ydshieh I have a question regarding this actually:
>
> Currently I'm trying to access the decoder (GPT-2) from the saved model but it seems to my knowledge that it is not possible. The default serving signature you suggested outputs the encoder (ViT) outputs only (or am I wrong in this regard?)
>
I believe it gives the outputs of both the encoder and decoder. But if you find it is not the case, please open a new issue and we are more than happy to look into it 🤗 .
> However, trying to create a serving for the `model.generate()` function, seems to cause the same error. The error is the same as with saving the model with a custom signature.
I have never created a saved model format with `generate` and not sure if it will work in most case(s) - @gante Do you have any knowledge if this is supposed to work (in most cases). cc @Rocketknight1 too.
> Would this be possible in theory (combining encoder and decoder in one serving function)?
See my comment in the first paragraph 😃
|
transformers | 22,730 | closed | About Whisper finetuning on a out-of-vocabulary language datset | ### Feature request
Hello!
I am working on Whisper, and I want to finetune the model on _Amharic_ in OpenASR20 dataset. As far as I know, _Amharic_ is not one of the languages participating in Whisper training. If I want to finetune the model on _Amharic_, what should I do?
Looking forward to your reply! Thank you!
### Motivation
Whisper finetuning on a out-of-vocabulary language datset
### Your contribution
I can do as needed. | 04-12-2023 15:00:36 | 04-12-2023 15:00:36 | Hi @LYPinASR, thanks for raising an issue!
Questions like this are best placed [in the forum](https://discuss.huggingface.co/), as we try to reserve github issues for bug reporting and feature requests. Here's a relevant thread about a previous finetuning event which might help: https://discuss.huggingface.co/t/open-to-the-community-whisper-fine-tuning-event/26681<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,728 | closed | `torch.distributed` group initialization for `torch_neuron` disabled when `optimum-neuron` is installed | As per title. | 04-12-2023 12:08:49 | 04-12-2023 12:08:49 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,727 | closed | Update warning levels | # What does this PR do?
This PR updates the warning levels at 2 places:
- use logger.info instead of logger.warning when an image processor gets loaded based on a preprocessor_config.json file.
- use `logger.warning_once` instead of warnings.warn(..., FutureWarning) for DETR and friends. | 04-12-2023 11:54:36 | 04-12-2023 11:54:36 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,726 | closed | Modify pipeline_tutorial.mdx | generator(model="openai/whisper-large") always returns error. As the error says the generator expects an input, just like the .flac file above. Even the generator object has no parameters called model. While there are parameters which can be passed to generator like 'batch_size' but to pass a model i believe the the parameter has to be passed while instantiating the pipeline and not as a parameter to the instance.
I believe the correct term should be:
generator = pipeline(model="openai/whisper-large", device=0)
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-12-2023 11:46:10 | 04-12-2023 11:46:10 | _The documentation is not available anymore as the PR was closed or merged._<|||||>cc @Narsil <|||||>You are welcome, Happy to help!! |
transformers | 22,725 | closed | [Image processors] Fix warnings | # What does this PR do?
This PR aims to reduce the number of warnings shown to the user for 2 use cases:
- DETR and friends' `max_size` argument which is deprecated => if this gets approved, I'll run fix-copies to fix the other DETR-based models
- the pattern matching warning when a configuration doesn't have an image processor in the config | 04-12-2023 09:21:33 | 04-12-2023 09:21:33 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Thanks for the review! After offline discussion, will close this PR in favor of a new one that just updates the warning levels. The removal of `max_size` can be done in a follow-up PR. |
transformers | 22,724 | closed | add fast support and option | # What does this PR do?
Adresses #22669 | 04-12-2023 09:17:32 | 04-12-2023 09:17:32 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,723 | closed | remove wrong doc in readme | # What does this PR do?
Fixes a typo caught in #22710 | 04-12-2023 09:06:14 | 04-12-2023 09:06:14 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,722 | closed | Inconsistency in Model Output [ Token Classification] | ```
from transformers import AutoTokenizer, AutoModelForTokenClassification
import torch
from transformers import pipeline
```
```
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
```
```
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
```
```
ner_results = nlp(example)
print(ner_results)
```
**Output 1:**
```
[{'entity': 'B-PER', 'score': 0.9990139, 'index': 4, 'word': 'Wolfgang', 'start': 11, 'end': 19},
{'entity': 'B-LOC', 'score': 0.999645, 'index': 9, 'word': 'Berlin', 'start': 34, 'end': 40}]
```
```
inputs = tokenizer.encode_plus(example, return_tensors="pt", add_special_tokens=True, max_length=512, padding="max_length", truncation=True)
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
# Feed the encoded segment into the model to obtain the predicted labels for each token
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs.logits
predicted_labels = torch.argmax(logits, dim=2)[0]
```
`[0, 0, 0, 0, 3, 0, 0, 0, 0, 0]`
```
label_list = [ "O","B-MISC","I-MISC","B-PER","I-PER","B-ORG","I-ORG","B-LOC","I-LOC"]
final_label_names = [label_list[label] for label in predicted_labels]
```
**Output 2:**
`['O','O','O','O', 'B-PER', 'O','O','O','O','O']`
| 04-12-2023 08:51:37 | 04-12-2023 08:51:37 | |
transformers | 22,721 | closed | Error when loading LlamaTokenizer | ### System Info
centos 7
python version is 3.7.12
transformers 4.28.0.dev0
sentencepiece 0.1.97
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
My situation is using a LAN, so I can't using function like tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf", add_eos_token=True) which will download the files.
Becasue of this, I have uploaded the llama-7b-hf files into the LAN, and use the directroy to load, such as tokenizer = LlamaTokenizer.from_pretrained("/home/qilin7/chat/llama-7b-hf", add_eos_token=True)
When I do this, I get the error like below:
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_1357/3612021170.py in
5 tokenizer = LlamaTokenizer.from_pretrained("/home/qilin7/chat/llama-7b-hf", add_eos_token=True)
6 tokenizer.pad_token = tokenizer.eos_token
7 tokenizer.pad_token_id = tokenizer.eos_token_id
/opt/conda/lib/python3.7/site-packages/transformers/tokenization_utils_base.py in from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
1818 local_files_only=local_files_only,
1819 _commit_hash=commit_hash,
-> 1820 **kwargs,
1821 )
1822
/opt/conda/lib/python3.7/site-packages/transformers/tokenization_utils_base.py in _from_pretrained(cls, resolved_vocab_files, pretrained_model_name_or_path, init_configuration, use_auth_token, cache_dir, local_files_only, _commit_hash, *init_inputs, **kwargs)
1963 # Instantiate tokenizer.
1964 try:
-> 1965 tokenizer = cls(*init_inputs, **init_kwargs)
1966 except OSError:
1967 raise OSError(
/opt/conda/lib/python3.7/site-packages/transformers/models/llama/tokenization_llama.py in init(self, vocab_file, unk_token, bos_token, eos_token, pad_token, sp_model_kwargs, add_bos_token, add_eos_token, clean_up_tokenization_spaces, **kwargs)
94 self.add_eos_token = add_eos_token
95 self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
---> 96 self.sp_model.Load(vocab_file)
97
98 def getstate(self):
/media/cfs/.pylib/lib/python3.7/site-packages/sentencepiece/init.py in Load(self, model_file, model_proto)
903 if model_proto:
904 return self.LoadFromSerializedProto(model_proto)
--> 905 return self.LoadFromFile(model_file)
906
907
/media/cfs/.pylib/lib/python3.7/site-packages/sentencepiece/init.py in LoadFromFile(self, arg)
308
309 def LoadFromFile(self, arg):
--> 310 return _sentencepiece.SentencePieceProcessor_LoadFromFile(self, arg)
311
312 def _EncodeAsIds(self, text, enable_sampling, nbest_size, alpha, add_bos, add_eos, reverse, emit_unk_piece):
RuntimeError: Internal: src/sentencepiece_processor.cc(1101) [model_proto->ParseFromArray(serialized.data(), serialized.size())]
### Expected behavior
I had ask the problem on sentencepiece, the had replyed like this
https://github.com/google/sentencepiece/issues/850#issuecomment-1504857453
Thanks. | 04-12-2023 08:30:37 | 04-12-2023 08:30:37 | Given the error, the tokenizer checkpoints that you are using are clearly outdated. Convert the model again using `main` then upload them to your LAN. Also not that you using the fast tokenizer will require to have the latest `tokenizers` library |
transformers | 22,720 | closed | Ko translate fast tokenizer | # What does this PR do?
Translated the fast_tokenizer.mdx file of the documentation to Korean.
Thank you in advance for your review.
Part of [#20179](https://github.com/huggingface/transformers/issues/20179)
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Team PseudoLab, may you please review this PR?
[@0525hhgus](https://github.com/0525hhgus), [@KIHOON71](https://github.com/KIHOON71), [@sim-so](https://github.com/sim-so), [@gabrielwithappy](https://github.com/gabrielwithappy), [@HanNayeoniee](https://github.com/HanNayeoniee), [@wonhyeongseo](https://github.com/wonhyeongseo), [@jungnerd](https://github.com/jungnerd)
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-12-2023 05:26:36 | 04-12-2023 05:26:36 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22720). All of your documentation changes will be reflected on that endpoint. |
transformers | 22,719 | closed | GPT2DoubleHeadsModel Multiple Choice Head Always Has 1 Out Feature | ### System Info
- `transformers` version: 4.27.4
- Platform: Windows-10-10.0.19044-SP0
- Python version: 3.10.0
- Huggingface_hub version: 0.13.4
- PyTorch version (GPU?): 1.13.1+cu116 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am using the GPT2DoubleHeadsModel to label tweets as either bot generated or human generated, and I encountered an issue where no matter what I did, the multiple choice head for the model only ever had 1 out feature (example in second code block below). I wrote some small sample code for a sentiment classifier to demonstrate.
```Python
from transformers import GPT2Tokenizer, GPT2DoubleHeadsModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2', do_lower_case=True, pad_token='0', padding_side='right', truncation_side='right')
model = GPT2DoubleHeadsModel.from_pretrained('gpt2', num_labels=2)
print(model)
example_sequences = ["I love NLP!", "Hello, world!", "I don't like carrots", "This is bad."]
example_labels = torch.LongTensor([1, 1, 0, 0])
nput_ids_and_masks = tokenizer(example_sequences, truncation=True, padding=True, return_tensors='pt')
model(input_ids = input_ids_and_masks['input_ids'], attention_mask=input_ids_and_masks['attention_mask'], mc_labels=example_labels)
```
```
GPT2DoubleHeadsModel(
(transformer): GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=768, out_features=50257, bias=False)
(multiple_choice_head): SequenceSummary(
(summary): Linear(in_features=768, out_features=1, bias=True)
(activation): Identity()
(first_dropout): Dropout(p=0.1, inplace=False)
(last_dropout): Identity()
)
)
```
```
Traceback (most recent call last):
File "C:\Users\...\train.py", line 201, in <module>
model(input_ids = input_ids_and_masks['input_ids'], attention_mask=input_ids_and_masks['attention_mask'], mc_labels=example_labels)
File "C:\Users\_\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\_\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\models\gpt2\modeling_gpt2.py", line 1318, in forward
mc_loss = loss_fct(mc_logits.view(-1, mc_logits.size(-1)), mc_labels.view(-1))
File "C:\Users\_\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\_\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\loss.py", line 1174, in forward
return F.cross_entropy(input, target, weight=self.weight,
File "C:\Users\_\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\functional.py", line 3026, in cross_entropy
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
ValueError: Expected input batch_size (1) to match target batch_size (4).
```
After spending some time debugging, I noticed that the double heads model class in `modeling_gpt2.py` manually sets `config.num_labels = 1` in its `__init__`.
```Python
class GPT2DoubleHeadsModel(GPT2PreTrainedModel):
_keys_to_ignore_on_load_missing = [r"attn.masked_bias", r"attn.bias", r"lm_head.weight"]
def __init__(self, config):
super().__init__(config)
config.num_labels = 1
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.multiple_choice_head = SequenceSummary(config)
# Model parallel
self.model_parallel = False
self.device_map = None
# Initialize weights and apply final processing
self.post_init()
```
After removing that line (`config.num_labels = 1`), my code worked perfectly. I was going to open a pull request for this, but I had trouble installing all the dependencies after I forked the repo :(, so this was the next best thing I could do.
### Expected behavior
Firstly, I would expect the multiple choice head of the model to have the number of out features specified in num_labels, so that it is able to perform multiclass classification tasks.
Secondly, I would expect that when giving the model batched input with the correct dimensions, as specified in the [documentation for the double heads model](https://huggingface.co/docs/transformers/v4.27.2/en/model_doc/gpt2#transformers.GPT2DoubleHeadsModel), the model would properly run the batched input. | 04-12-2023 03:37:43 | 04-12-2023 03:37:43 | Hey! Thanks for opening and issue and reporting this. I'll check if this is expected or not, and if we can open a PR to fix this.
Since gpt2 is a very old model, touching it might be a bit complicated 😓 <|||||>Okay! So it seems that the way you are using the model is a bit different from what [the documentation mentions ](https://huggingface.co/docs/transformers/main/en/model_doc/gpt2#transformers.GPT2DoubleHeadsModel).
Here is a version adapted to your code:
```python
import torch
from transformers import AutoTokenizer, GPT2DoubleHeadsModel
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = GPT2DoubleHeadsModel.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
# Add a [CLS] to the vocabulary (we should train it also!)
num_added_tokens = tokenizer.add_special_tokens({"cls_token": "[CLS]"})
# Update the model embeddings with the new vocabulary size
embedding_layer = model.resize_token_embeddings(len(tokenizer))
choices = ["I love NLP! [CLS]", "Hello, world! [CLS]", "I don't like carrots [CLS]", "This is bad. [CLS]"]
encoded_choices = [tokenizer.encode(s, padding = "max_length") for s in choices]
cls_token_location = [tokens.index(tokenizer.cls_token_id) for tokens in encoded_choices]
input_ids = torch.tensor(encoded_choices).unsqueeze(0) # Batch size: 1, number of choices: 4
mc_token_ids = torch.tensor([cls_token_location]) # Batch size: 1
outputs = model(input_ids, mc_token_ids=mc_token_ids, mc_labels = torch.tensor([0]))
lm_logits = outputs.logits
mc_logits = outputs.mc_logits
mc_loss = outputs.mc_loss
```
this seems to produce a correct output, though I am not sur it follows your intended usage. Closing as it is expected. |
transformers | 22,729 | closed | Report a hyperlink mistake | The website is https://huggingface.co/docs/transformers/tasks/token_classification
And the sentence is: Mapping all tokens to their corresponding word with the [word_ids](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.word_ids) method.
The hyperlink is mistake, it should be the tokenizer in transformers package (https://huggingface.co/docs/transformers/v4.27.2/en/main_classes/tokenizer#transformers.BatchEncoding.word_ids) but the hyperlink given is in tokenizers package. | 04-12-2023 03:05:49 | 04-12-2023 03:05:49 | Thanks for reporting! Would you be interested in opening a PR to fix it? The exact file to be modified is https://github.com/huggingface/transformers/blob/main/docs/source/en/tasks/token_classification.mdx and then you would have the contribution :) Happy to open a PR otherwise.
Transfering to the transformers repo as well as that's the correct one<|||||>Happy to open a PR if needed<|||||>@mayankagarwals Great! Feel free to open a PR and ping me for review :) <|||||>Sure @amyeroberts <|||||>@amyeroberts https://github.com/huggingface/transformers/pull/22765/files . Please review :) |
transformers | 22,718 | closed | Failed to create cublas handle: cublas error | ### System Info
Kaggle with Accelerator **GPU P100**
### Who can help?
@amyeroberts
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Steps to Reproduce the behaviour:
1. Go to Kaggle. Create a new notebook. Switch to **GPU P100** accelerator.
2. Use `TFSegformerForSemanticSegmentation`:
```
from transformers import TFSegformerForSemanticSegmentation
model_checkpoint = "nvidia/mit-b0"
id2label = {0: "outer", 1: "inner", 2: "border"}
label2id = {label: id for id, label in id2label.items()}
num_labels = len(id2label)
model = TFSegformerForSemanticSegmentation.from_pretrained(
model_checkpoint,
num_labels=num_labels,
id2label=id2label,
label2id=label2id,
ignore_mismatched_sizes=True,
)
```
While running this code block, I get this `cublas` error:
```
2023-04-12 02:44:14.603089: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:219] failed to create cublas handle: cublas error
2023-04-12 02:44:14.603208: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:221] Failure to initialize cublas may be due to OOM (cublas needs some free memory when you initialize it, and your deep-learning framework may have preallocated more than its fair share), or may be because this binary was not built with support for the GPU in your machine.
---------------------------------------------------------------------------
NotFoundError Traceback (most recent call last)
/tmp/ipykernel_23/279563332.py in <module>
10 id2label=id2label,
11 label2id=label2id,
---> 12 ignore_mismatched_sizes=True,
13 )
/opt/conda/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
2764 model(model.dummy_inputs) # build the network with dummy inputs
2765 else:
-> 2766 model(model.dummy_inputs) # build the network with dummy inputs
2767
2768 if safetensors_from_pt:
/opt/conda/lib/python3.7/site-packages/keras/utils/traceback_utils.py in error_handler(*args, **kwargs)
68 # To get the full stack trace, call:
69 # `tf.debugging.disable_traceback_filtering()`
---> 70 raise e.with_traceback(filtered_tb) from None
71 finally:
72 del filtered_tb
/opt/conda/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in run_call_with_unpacked_inputs(self, *args, **kwargs)
430
431 unpacked_inputs = input_processing(func, config, **fn_args_and_kwargs)
--> 432 return func(self, **unpacked_inputs)
433
434 # Keras enforces the first layer argument to be passed, and checks it through `inspect.getfullargspec()`. This
/opt/conda/lib/python3.7/site-packages/transformers/models/segformer/modeling_tf_segformer.py in call(self, pixel_values, labels, output_attentions, output_hidden_states, return_dict)
859 output_attentions=output_attentions,
860 output_hidden_states=True, # we need the intermediate hidden states
--> 861 return_dict=return_dict,
862 )
863
/opt/conda/lib/python3.7/site-packages/transformers/modeling_tf_utils.py in run_call_with_unpacked_inputs(self, *args, **kwargs)
430
431 unpacked_inputs = input_processing(func, config, **fn_args_and_kwargs)
--> 432 return func(self, **unpacked_inputs)
433
434 # Keras enforces the first layer argument to be passed, and checks it through `inspect.getfullargspec()`. This
/opt/conda/lib/python3.7/site-packages/transformers/models/segformer/modeling_tf_segformer.py in call(self, pixel_values, output_attentions, output_hidden_states, return_dict, training)
484 output_hidden_states=output_hidden_states,
485 return_dict=return_dict,
--> 486 training=training,
487 )
488 sequence_output = encoder_outputs[0]
/opt/conda/lib/python3.7/site-packages/transformers/models/segformer/modeling_tf_segformer.py in call(self, pixel_values, output_attentions, output_hidden_states, return_dict, training)
414 embedding_layer, block_layer, norm_layer = x
415 # first, obtain patch embeddings
--> 416 hidden_states, height, width = embedding_layer(hidden_states)
417
418 # second, send embeddings through blocks
/opt/conda/lib/python3.7/site-packages/transformers/models/segformer/modeling_tf_segformer.py in call(self, pixel_values)
87
88 def call(self, pixel_values: tf.Tensor) -> Tuple[tf.Tensor, int, int]:
---> 89 embeddings = self.proj(self.padding(pixel_values))
90 height = shape_list(embeddings)[1]
91 width = shape_list(embeddings)[2]
NotFoundError: Exception encountered when calling layer 'proj' (type Conv2D).
{{function_node __wrapped__Conv2D_device_/job:localhost/replica:0/task:0/device:GPU:0}} No algorithm worked! Error messages:
Profiling failure on CUDNN engine 1: UNKNOWN: CUDNN_STATUS_EXECUTION_FAILED
in tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc(4294): 'cudnnConvolutionForward( cudnn.handle(), alpha, input_nd_.handle(), input_data.opaque(), filter_.handle(), filter_data.opaque(), conv_.handle(), ToConvForwardAlgo(algo), scratch_memory.opaque(), scratch_memory.size(), beta, output_nd_.handle(), output_data.opaque())'
Profiling failure on CUDNN engine 0: UNKNOWN: CUDNN_STATUS_EXECUTION_FAILED
in tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc(4294): 'cudnnConvolutionForward( cudnn.handle(), alpha, input_nd_.handle(), input_data.opaque(), filter_.handle(), filter_data.opaque(), conv_.handle(), ToConvForwardAlgo(algo), scratch_memory.opaque(), scratch_memory.size(), beta, output_nd_.handle(), output_data.opaque())'
Profiling failure on CUDNN engine 2: UNKNOWN: CUDNN_STATUS_EXECUTION_FAILED
in tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc(4294): 'cudnnConvolutionForward( cudnn.handle(), alpha, input_nd_.handle(), input_data.opaque(), filter_.handle(), filter_data.opaque(), conv_.handle(), ToConvForwardAlgo(algo), scratch_memory.opaque(), scratch_memory.size(), beta, output_nd_.handle(), output_data.opaque())' [Op:Conv2D]
Call arguments received by layer 'proj' (type Conv2D):
• inputs=tf.Tensor(shape=(3, 518, 518, 3), dtype=float32)
```
### Expected behavior
When I run the PyTorch version of `Segformer`, it loads the model successfully.
```
from transformers import SegformerForSemanticSegmentation
model_checkpoint = "nvidia/mit-b0"
id2label = {0: "outer", 1: "inner", 2: "border"}
label2id = {label: id for id, label in id2label.items()}
num_labels = len(id2label)
model = SegformerForSemanticSegmentation.from_pretrained(
model_checkpoint,
num_labels=num_labels,
id2label=id2label,
label2id=label2id,
ignore_mismatched_sizes=True,
)
``` | 04-12-2023 03:03:49 | 04-12-2023 03:03:49 | Hi @cosmo3769, thanks for reporting this issue. I'll look into it.
p.s. I think you might have tagged the wrong Amy :) <|||||>> Hi @cosmo3769, thanks for reporting this issue. I'll look into it.
Sure.
> p.s. I think you might have tagged the wrong Amy :)
Oh yeah, sorry for that. 😅
<|||||>@cosmo3769 It seems this issue might be coming from the kaggle notebook setup and/or hardware. I'm able to run the snippet loading `TFSegformerForSemanticSegmentation` without issue on a linux machine with 2 GPUs.
Could you share some more information about the running environment: copy-paste the output of running `! transformers-cli env` in a cell.
Looking up the error online, some other users have reported similar issues (e.g. [here](https://stackoverflow.com/questions/53698035/failed-to-get-convolution-algorithm-this-is-probably-because-cudnn-failed-to-in)) which were resolved with setting `os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'` which is simple enough to warrant a try :)
<|||||>Yes, it solves the issue. Thanks. |
transformers | 22,717 | closed | The `xla_device` argument has been deprecated | ### System Info
Transformers v4.4.0 pycharm python3.8
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-question-generation-ap")
model = AutoModelForSeq2SeqLM.from_pretrained("mrm8488/t5-base-finetuned-question-generation-ap")
def get_question(answer, context, max_length=64):
input_text = "answer: %s context: %s </s>" % (answer, context)
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'],
max_length=max_length)
output = tokenizer.decode(output[0])[6:][:-4]
return output
context = "Alan Turing defined AI as the science that enables computers to perform tasks that require human intelligence. Academics at Stanford University consider AI to be the science and engineering of intelligent machines, especially intelligent computer programs. Wikipedia defines AI as the intelligence shown by artificially created systems, and the term also refers to the scientific field that studies whether and how such intelligent systems can be achieved. No matter how it is defined, it cannot be separated from intelligence. However, so far, human beings have not been able to give a unified definition of intelligence, and generally speaking, intelligence only refers to the expression form of human intelligence. Professor Zhong Yixin, former chairman of the Chinese Society for Artificial Intelligence, believes that human intelligence consists of finding problems, defining problems and solving problems, while artificial intelligence is only capable of solving problems. The author believes that intelligence is a kind of order, the embodiment of information, and also the ability to make the world develop in an orderly direction. Sadly, according to the principle of increasing entropy, no matter what the agents do, the universe is always moving in the direction of increasing entropy, which is more and more disorder and chaos. It is not known whether this is God's deliberate arrangement, or human observation of the universe beyond the universe."
answer = "solving problems"
output = get_question(answer, context)
#########[error message]:
The `xla_device` argument has been deprecated in v4.4.0 of Transformers. It is ignored and you can safely remove it from your `config.json` file.
The `xla_device` argument has been deprecated in v4.4.0 of Transformers. It is ignored and you can safely remove it from your `config.json` file.
The `xla_device` argument has been deprecated in v4.4.0 of Transformers. It is ignored and you can safely remove it from your `config.json` file.
The `xla_device` argument has been deprecated in v4.4.0 of Transformers. It is ignored and you can safely remove it from your `config.json` file.
### Expected behavior
The program can run normally. This warning will reduce the previous script loading speed. How to eliminate this warning. Thank you.
| 04-12-2023 02:57:08 | 04-12-2023 02:57:08 | Hi @yqiz-98, thanks for reporting this issue. The warning is being raised, as the [config for the checkpoint mrm8488/t5-base-finetuned-question-generation-ap](https://huggingface.co/mrm8488/t5-base-finetuned-question-generation-ap/blob/5b3fa1afa0bba84b23b2c27eb7b4bc35aae63876/config.json#L51) contains [the argument `xla_device`](https://github.com/huggingface/transformers/blob/370f0ca18c8e4577357df59936e790acdecef4ac/src/transformers/configuration_utils.py#L363). As the error message indicates, this is now deprecated and can be removed from the config.
It would be up to the user [mrm8488](https://huggingface.co/mrm8488) whether they want to make this update to the configuration file. The update would mean that the config file isn't fully compatible with versions of transformers < 4.4.x. I'd suggest opening a discussion [on the repo](https://huggingface.co/mrm8488/t5-base-finetuned-question-generation-ap/discussions) to ask about this.
With this config file, the program can still run normally. I'd be surprised if this caused significant differences to the loading speed. One update we can do on our end, if update `logger.warning` to `logger.warning_once` so that the message is only printed to terminal once.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,716 | closed | Unable to install transformers due to RuntimeError with libssl.so.10 | ### System Info
Runnin gthis code on a red hat linux machine
I tried installing transformers with all the methods mentioned in https://huggingface.co/docs/transformers/installation
I am hitting the same error (related to pipelines):
Traceback (most recent call last):
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/utils/import_utils.py", line 1125, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/home/eng/s/sxc220013/anaconda3/lib/python3.9/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1030, in _gcd_import
File "<frozen importlib._bootstrap>", line 1007, in _find_and_load
File "<frozen importlib._bootstrap>", line 986, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 680, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 850, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/pipelines/__init__.py", line 29, in <module>
from ..models.auto.configuration_auto import AutoConfig
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/models/__init__.py", line 15, in <module>
from . import (
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/models/mt5/__init__.py", line 36, in <module>
from ..t5.tokenization_t5_fast import T5TokenizerFast
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/models/t5/tokenization_t5_fast.py", line 24, in <module>
from ...tokenization_utils_fast import PreTrainedTokenizerFast
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/tokenization_utils_fast.py", line 25, in <module>
import tokenizers.pre_tokenizers as pre_tokenizers_fast
File "/home/eng/s/sxc220013/anaconda3/lib/python3.9/site-packages/tokenizers/__init__.py", line 79, in <module>
from .tokenizers import (
ImportError: libssl.so.10: cannot open shared object file: No such file or directory
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "<frozen importlib._bootstrap>", line 1055, in _handle_fromlist
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/utils/import_utils.py", line 1115, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/home/eng/s/sxc220013/Documents/transformers/src/transformers/utils/import_utils.py", line 1127, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.pipelines because of the following error (look up to see its traceback):
libssl.so.10: cannot open shared object file: No such file or directory
### Who can help?
@Narsil @sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I ran the following commands :
conda install -c huggingface transformers
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
### Expected behavior
I would expect that the following python command prints the output of the sentiment analysis. | 04-12-2023 01:31:49 | 04-12-2023 01:31:49 | Do you have openssl installd in your environment ?
`conda install -c anaconda openssl` ?
This library is missing from your environment and `tokenizers` is looking for it when loading.
Or do you have another version of ssl installed maybe ? You can do `locate libssl` to try and find it.<|||||>@Kodhandarama A similar issue has been raised in #21805. As noted there, this isn't a Transformers issue per se, but appears to arise when installing with `conda`. Other users reported installing with `pip` or running `conda update tokenizers` resolved the issue. <|||||>@ArthurZucker FYI.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,715 | closed | Can't load the model from your tutorial for inference | ### System Info
Linux. Doesn't matter
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https://huggingface.co/docs/transformers/main/tasks/image_captioning
### Expected behavior
I tried this:
`model_trained = AutoModelForCausalLM.from_pretrained("/workspace/git-base-trainer/checkpoint-100")`
But when I ran
```
inputs = processor(images=image, return_tensors="pt").to("cuda")
pixel_values = inputs.pixel_values
generated_ids = model_trained.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
i got this error:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[61], line 4
1 inputs = processor(images=image, return_tensors="pt").to("cuda")
2 pixel_values = inputs.pixel_values
----> 4 generated_ids = model_trained.generate(pixel_values=pixel_values, max_length=50)
5 generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
6 # print(generated_caption)
File /usr/local/lib/python3.10/dist-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File /usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:1406, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, **kwargs)
1400 raise ValueError(
1401 f"num_return_sequences has to be 1, but is {generation_config.num_return_sequences} when doing"
1402 " greedy search."
1403 )
1405 # 11. run greedy search
-> 1406 return self.greedy_search(
1407 input_ids,
1408 logits_processor=logits_processor,
1409 stopping_criteria=stopping_criteria,
1410 pad_token_id=generation_config.pad_token_id,
1411 eos_token_id=generation_config.eos_token_id,
1412 output_scores=generation_config.output_scores,
1413 return_dict_in_generate=generation_config.return_dict_in_generate,
1414 synced_gpus=synced_gpus,
1415 **model_kwargs,
1416 )
1418 elif is_contrastive_search_gen_mode:
1419 if generation_config.num_return_sequences > 1:
File /usr/local/lib/python3.10/dist-packages/transformers/generation/utils.py:2201, in GenerationMixin.greedy_search(self, input_ids, logits_processor, stopping_criteria, max_length, pad_token_id, eos_token_id, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, synced_gpus, **model_kwargs)
2198 model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
2200 # forward pass to get next token
-> 2201 outputs = self(
2202 **model_inputs,
2203 return_dict=True,
2204 output_attentions=output_attentions,
2205 output_hidden_states=output_hidden_states,
2206 )
2208 if synced_gpus and this_peer_finished:
2209 continue # don't waste resources running the code we don't need
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.10/dist-packages/transformers/models/git/modeling_git.py:1496, in GitForCausalLM.forward(self, input_ids, attention_mask, position_ids, pixel_values, head_mask, inputs_embeds, labels, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
1493 if labels is not None:
1494 use_cache = False
-> 1496 outputs = self.git(
1497 input_ids,
1498 attention_mask=attention_mask,
1499 position_ids=position_ids,
1500 pixel_values=pixel_values,
1501 head_mask=head_mask,
1502 inputs_embeds=inputs_embeds,
1503 past_key_values=past_key_values,
1504 use_cache=use_cache,
1505 output_attentions=output_attentions,
1506 output_hidden_states=output_hidden_states,
1507 return_dict=return_dict,
1508 )
1510 sequence_output = outputs[0]
1511 logits = self.output(sequence_output)
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.10/dist-packages/transformers/models/git/modeling_git.py:1236, in GitModel.forward(self, input_ids, attention_mask, position_ids, pixel_values, head_mask, inputs_embeds, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
1233 if pixel_values is not None:
1234 if pixel_values.ndim == 4:
1235 # here we assume pixel_values is of shape (batch_size, num_channels, height, width)
-> 1236 visual_features = self.image_encoder(pixel_values).last_hidden_state
1238 elif pixel_values.ndim == 5:
1239 # here we assume pixel_values is of shape (batch_size, num_frames, num_channels, height, width)
1240 visual_features = []
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.10/dist-packages/transformers/models/git/modeling_git.py:1039, in GitVisionModel.forward(self, pixel_values, output_attentions, output_hidden_states, return_dict)
1016 r"""
1017 Returns:
1018
(...)
1035 >>> last_hidden_state = outputs.last_hidden_state
1036 ```"""
1037 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-> 1039 return self.vision_model(
1040 pixel_values=pixel_values,
1041 output_attentions=output_attentions,
1042 output_hidden_states=output_hidden_states,
1043 return_dict=return_dict,
1044 )
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.10/dist-packages/transformers/models/git/modeling_git.py:965, in GitVisionTransformer.forward(self, pixel_values, output_attentions, output_hidden_states, return_dict)
962 if pixel_values is None:
963 raise ValueError("You have to specify pixel_values")
--> 965 hidden_states = self.embeddings(pixel_values)
966 hidden_states = self.pre_layrnorm(hidden_states)
968 encoder_outputs = self.encoder(
969 inputs_embeds=hidden_states,
970 output_attentions=output_attentions,
971 output_hidden_states=output_hidden_states,
972 return_dict=return_dict,
973 )
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.10/dist-packages/transformers/models/git/modeling_git.py:630, in GitVisionEmbeddings.forward(self, pixel_values)
628 def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
629 batch_size = pixel_values.shape[0]
--> 630 patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
631 patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
633 class_embeds = self.class_embedding.expand(batch_size, 1, -1)
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/conv.py:463, in Conv2d.forward(self, input)
462 def forward(self, input: Tensor) -> Tensor:
--> 463 return self._conv_forward(input, self.weight, self.bias)
File /usr/local/lib/python3.10/dist-packages/torch/nn/modules/conv.py:459, in Conv2d._conv_forward(self, input, weight, bias)
455 if self.padding_mode != 'zeros':
456 return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode),
457 weight, bias, self.stride,
458 _pair(0), self.dilation, self.groups)
--> 459 return F.conv2d(input, weight, bias, self.stride,
460 self.padding, self.dilation, self.groups)
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
```
I tried running this:
`processor_trained = AutoProcessor.from_pretrained("/workspace/git-base-trainer/checkpoint-100")`
But immediately got this error:
```
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[63], line 3
1 # tokenizer = AutoTokenizer.from_pretrained("/workspace/git-base-trainer/checkpoint-50")
----> 3 processor_trained = AutoProcessor.from_pretrained("/workspace/git-base-trainer/checkpoint-100")
4 # model_trained = AutoModelForCausalLM.from_pretrained("/workspace/git-base-trainer/checkpoint-100")
File /usr/local/lib/python3.10/dist-packages/transformers/models/auto/processing_auto.py:276, in AutoProcessor.from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
274 # Last try: we use the PROCESSOR_MAPPING.
275 if type(config) in PROCESSOR_MAPPING:
--> 276 return PROCESSOR_MAPPING[type(config)].from_pretrained(pretrained_model_name_or_path, **kwargs)
278 # At this stage, there doesn't seem to be a `Processor` class available for this model, so let's try a
279 # tokenizer.
280 try:
File /usr/local/lib/python3.10/dist-packages/transformers/processing_utils.py:184, in ProcessorMixin.from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
153 @classmethod
154 def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
155 r"""
156 Instantiate a processor associated with a pretrained model.
157
(...)
182 [`~tokenization_utils_base.PreTrainedTokenizer.from_pretrained`].
183 """
--> 184 args = cls._get_arguments_from_pretrained(pretrained_model_name_or_path, **kwargs)
185 return cls(*args)
File /usr/local/lib/python3.10/dist-packages/transformers/processing_utils.py:228, in ProcessorMixin._get_arguments_from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
225 else:
226 attribute_class = getattr(transformers_module, class_name)
--> 228 args.append(attribute_class.from_pretrained(pretrained_model_name_or_path, **kwargs))
229 return args
File /usr/local/lib/python3.10/dist-packages/transformers/models/auto/image_processing_auto.py:315, in AutoImageProcessor.from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
312 trust_remote_code = kwargs.pop("trust_remote_code", False)
313 kwargs["_from_auto"] = True
--> 315 config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
316 image_processor_class = config_dict.get("image_processor_type", None)
317 image_processor_auto_map = None
File /usr/local/lib/python3.10/dist-packages/transformers/image_processing_utils.py:268, in ImageProcessingMixin.get_image_processor_dict(cls, pretrained_model_name_or_path, **kwargs)
265 image_processor_file = IMAGE_PROCESSOR_NAME
266 try:
267 # Load from local folder or from cache or download from model Hub and cache
--> 268 resolved_image_processor_file = cached_file(
269 pretrained_model_name_or_path,
270 image_processor_file,
271 cache_dir=cache_dir,
272 force_download=force_download,
273 proxies=proxies,
274 resume_download=resume_download,
275 local_files_only=local_files_only,
276 use_auth_token=use_auth_token,
277 user_agent=user_agent,
278 revision=revision,
279 subfolder=subfolder,
280 )
281 except EnvironmentError:
282 # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted to
283 # the original exception.
284 raise
File /usr/local/lib/python3.10/dist-packages/transformers/utils/hub.py:380, in cached_file(path_or_repo_id, filename, cache_dir, force_download, resume_download, proxies, use_auth_token, revision, local_files_only, subfolder, user_agent, _raise_exceptions_for_missing_entries, _raise_exceptions_for_connection_errors, _commit_hash)
378 if not os.path.isfile(resolved_file):
379 if _raise_exceptions_for_missing_entries:
--> 380 raise EnvironmentError(
381 f"{path_or_repo_id} does not appear to have a file named {full_filename}. Checkout "
382 f"'[https://huggingface.co/{path_or_repo_id}/{](https://huggingface.co/%7Bpath_or_repo_id%7D/%7Brevision)[revision](https://huggingface.co/%7Bpath_or_repo_id%7D/%7Brevision)}' for available files."
383 )
384 else:
385 return None
OSError: /workspace/git-base-trainer/checkpoint-100 does not appear to have a file named preprocessor_config.json. Checkout 'https://huggingface.co//workspace/git-base-trainer/checkpoint-100/None' for available files.
```
But when i ran this (with old model):
```
inputs = processor(images=image, return_tensors="pt").to("cuda")
pixel_values = inputs.pixel_values
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```
, i was getting a different caption from raw `microsoft/git-base` model, meaning that it fine-tuned, but for some reason (why the hell?) it overriden a loaded model and stayed in memory.
Meaning you can spend thousand of dollars on training but can't just load the model so it works the same as after training.
Could you please provide a clear tutorial on how to be able to do the inference from the same fine-tuned model after a server was shut down? | 04-12-2023 00:04:25 | 04-12-2023 00:04:25 | Honestly, there is just too much info in docs which does not help.<|||||>@kopyl, the first error due to GPU, you moved input into `.to("cuda")`, but model is still on `cpu`. The second error due to lack of preprocessing [file](https://huggingface.co/microsoft/git-base/blob/main/preprocessor_config.json), so you can download it or
`processor_trained = AutoProcessor.from_pretrained("microsoft/git-base")`<|||||>@Xrenya oh, thanks a lot, this helped ❤️
Are you a maintainer of Transformers? If so, could I please ask you to add this info to the guide?
And also do you know whether I should load a custom processor from training or the `microsoft/git-base` does the same?
Or do I just train only the model and don't interfere with the processor while training and leaving the old one does not have any side effects?<|||||>I think it is already contain that information in the following sections **Preprocess the dataset** and **Load a base model** in [doc](https://huggingface.co/docs/transformers/main/tasks/image_captioning).
```
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
```
```
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
If your custom preprocessing is different (parameters, e.g. image_mean, image_std etc. ) from `microsoft/git-base` then you should your preprocessing for training and inference, otherwise, you can just use their preprocessing. <|||||>@Xrenya thanks :)
Haven't seen this info in the doc :(<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,714 | closed | Adding Cross attention to GPT Neo | # What does this PR do?
This PR adds Cross attention to GPT Neo
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #22485 (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
@ArthurZucker @younesbelkada
| 04-11-2023 23:56:21 | 04-11-2023 23:56:21 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22714). All of your documentation changes will be reflected on that endpoint.<|||||>@patrickvonplaten @patil-suraj <|||||>@gagan3012 Thanks for contributing and opening the feature request and PR.
These changes are for a very specific use-case and not one that we want everyone to have in the GPTNeo: it makes the code too unreadable just for using as a decoder in the EncoderDecoder model. We can leave the fork open if you want to share it with others, and you can also push it in any repo on the Hub using the dynamic code feature.
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,713 | closed | Added parallel device usage for GPT-J | # What does this PR do?
This PR is within the issue [22561](https://github.com/huggingface/transformers/issues/22561), and is related to issue [22535](https://github.com/huggingface/transformers/pull/22535) which concerns model parallelism. Specifically, this PR fixes the issue in GPT-J where tensors might accidentally be moved to different devices, causing a mismatch. The implemented fix ensures that all tensors are on the same device, preventing potential errors.
Test case:
`
#Setting up the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-j-6B")
model = GPTJForSequenceClassification.from_pretrained("EleutherAI/gpt-j-6B")
#Now move the model to the GPU
model.to("cuda:0")
#setting up the text
text = "this is an example of text for device mismatch for GPT-J"
inputs = tokenizer(text,return_tensors = "pt")
#I've already move the model to Cuda:0
for k,v in inputs.items():
inputs[k] = v.to('cuda:0')
labels = torch.tensor([1]).to('cpu')
#Forward pass
outputs = model(**inputs,labels = labels)`
I recreated the issue by running the code without the fix, which resulted in the following error: "RuntimeError: Expected all tensors to be on the same device, ...". After implementing the fix, the error disappeared, and the model now keeps all tensors on the same device, as expected.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # 22561
## Motivation and Context
I worked on helping with the code to make all transformers compatible with model parallelism, specifically GPT-J.
## Who can review?
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-11-2023 22:38:26 | 04-11-2023 22:38:26 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,712 | closed | [tests] switch to torchrun | This PR fixes the following errors in nightly CI tests
```
FAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_run_seq2seq_apex
1422
FAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_run_seq2seq_ddp
1423
FAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_trainer_log_level_replica_0_base
1424
FAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_trainer_log_level_replica_1_low
1425
FAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_trainer_log_level_replica_2_high
1426
FAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_trainer_log_level_replica_3_mixed
```
by switching from deprecated `distributed.launch` to `distributed.run`
```
: File "/workspace/transformers/examples/pytorch/translation/run_translation.py", line 664, in <module>
384
stderr: main()
385
stderr: File "/workspace/transformers/examples/pytorch/translation/run_translation.py", line 262, in main
386
stderr: model_args, data_args, training_args = parser.parse_args_into_dataclasses()
387
stderr: File "/workspace/transformers/src/transformers/hf_argparser.py", line 341, in parse_args_into_dataclasses
388
stderr: raise ValueError(f"Some specified arguments are not used by the HfArgumentParser: {remaining_args}")
389
stderr: ValueError: Some specified arguments are not used by the HfArgumentParser: ['--local-rank=1']
390
stderr: /opt/conda/lib/python3.8/site-packages/torch/distributed/launch.py:181: FutureWarning: The module torch.distributed.launch is deprecated
391
stderr: and will be removed in future. Use torchrun.
392
stderr: Note that --use-env is set by default in torchrun.
393
stderr: If your script expects `--local-rank` argument to be set, please
394
stderr: change it to read from `os.environ['LOCAL_RANK']` instead. See
395
stderr: https://pytorch.org/docs/stable/distributed.html#launch-utility for
396
stderr: further instructions
```
I updated `tests/trainer/test_trainer_distributed.py` while at it. | 04-11-2023 22:15:25 | 04-11-2023 22:15:25 | _The documentation is not available anymore as the PR was closed or merged._<|||||>Unfortunately, conda refuses to install `libstdcxx-ng=12`, and gives a super super long report of conflict packages after 20 or more minutes of examization.
I think we can merge this PR first. And I can try if there is anyway to make to get `GLIBCXX_3.4.30` installed.
@stas00 Does this work for you?<|||||>The `GLIBCXX_3.4.30` is totally unrelated to this issue so let's deal with it separately. |
transformers | 22,711 | closed | Patching clip model to create mask tensor on the device | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-11-2023 18:20:27 | 04-11-2023 18:20:27 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@shanmugamr1992 Thanks for opening this PR!
For the quality tests to pass, you'll need to run `make fixup` locally and commit any formatting changes that were applied. There were some recent updates to our formatting libraries, so you might need to run `pip install -e .["quality"]` to ensure that you have the up-to-date settings.
Could you add this update to the other implementations of `_build_causal_attention_mask` for pytorch models in the repo too please? <|||||>The main idea is to reduce host and device syncs<|||||>@amyeroberts Could you verify and merge it please thanks .<|||||>@shanmugamr1992 Thanks again for your contribution and updating. I think just a final rebase / fix conflicts as there were some recent updates on the docs on `main`, then we're good to merge :) <|||||>@amyeroberts All done. Thanks a lot for the wonderful suggestions. |
transformers | 22,710 | closed | Llama: Generating text token by token removes whitespaces | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.10.10
- Huggingface_hub version: 0.13.4
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help?
@ArthurZucker @sgugger
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Run the following script
```python
import torch
from transformers import (
LlamaForCausalLM,
LlamaTokenizer,
LogitsProcessorList,
RepetitionPenaltyLogitsProcessor,
TemperatureLogitsWarper,
TopPLogitsWarper,
)
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = LlamaTokenizer.from_pretrained("./path/to/llama")
model = LlamaForCausalLM.from_pretrained(
"./models/llama-7b-hf", torch_dtype=torch.float16
).to(device)
@torch.no_grad()
def stream_generate(
prompt: str,
temperature=1.0,
max_new_tokens=512,
top_p=1.0,
repetition_penalty=1.0,
):
global tokenizer, model
if tokenizer is None or model is None:
return {"error": "Model not loaded."}
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
original_size = len(input_ids[0])
logits_processor = LogitsProcessorList(
[
TemperatureLogitsWarper(temperature=temperature),
RepetitionPenaltyLogitsProcessor(penalty=repetition_penalty),
TopPLogitsWarper(top_p=top_p),
]
)
while True:
# Get logits for the next token
logits = model(input_ids).logits[:, -1, :]
logits = logits_processor(input_ids, logits)
probs = torch.nn.functional.softmax(logits, dim=-1)
next_token_id = torch.multinomial(probs, num_samples=1)
next_token = tokenizer.decode(next_token_id[0], skip_special_tokens=True)
print(next_token, end="", flush=True)
input_ids = torch.cat((input_ids, next_token_id), dim=1)
if len(input_ids[0]) >= original_size + max_new_tokens:
break
stream_generate("In a shocking finding, ")
```
### Expected behavior
Text should be printed in a streaming manner, similar to OpenAI's playground, this behaviour properly happens with models like GPT-2 or GPT-J, however, with LLaMA, there are no whitespaces inbetween words.
I believe this is related to this, mentionned in the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/llama)
> The LLaMA tokenizer is based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. “Banana”), the tokenizer does not prepend the prefix space to the string. To have the tokenizer output the prefix space, set decode_with_prefix_space=True in the LlamaTokenizer object or in the tokenizer configuration.
However, it seems that `decode_with_prefix_space` has been removed | 04-11-2023 18:11:25 | 04-11-2023 18:11:25 | cc @gante
Note that the streaming API is new and still experimental :-)<|||||>Also note that we aim to match the original tokenizer 1 to 1, while trying not to add super model specific pieces of code in the more general api 😉 <|||||>> Note that the streaming API is new and still experimental :-)
I may be wrong as I'm not sure what you are mentionning, but I don't believe I am using the streaming API
The example code is something I wrote based on the generate() function in transformers, It's an old piece of code that I attempted to run with LLaMa and that seems to pose issues
<|||||>Oh my bad, I read to fast. I don't know what this `decode_with_prefix_space` mentioned in the documentation is. It does not exist in the codebase at all (not for LLaMA and not for any other sentencepiece model either).<|||||>> I don't know what this decode_with_prefix_space mentioned in the documentation is. It does not exist in the codebase at all (not for LLaMA and not for any other sentencepiece model either).
I haven't had much time to check why , but i noticed that it was removed in the latest commit to LLaMA's tokenizer
https://github.com/huggingface/transformers/commit/c0f99b4d2ec73090595914dde4c16da207e21d73
> Also note that we aim to match the original tokenizer 1 to 1, while trying not to add super model specific pieces of code in the more general api
I understand, is it then normal for the tokenizer to do this as it is based on sentencepiece? <|||||>Not sure I understand your question. Yes it is normal, if you use the sentencepiece tokenizer, you will get the same results when decoding.
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained('huggyllama/llama-30b')
>>> tokenizer.batch_decode(tokenizer.encode("Hey how are you doing?"), skip_special_tokens = True)
['', 'Hey', 'how', 'are', 'you', 'doing', '?']
```
whether you are using the fast or slow tokenizer, both will output the same.
If you use `tokenizer.sp_model.decode` (which is basically the sentencpiece model that the original llama uses) then you have no additional prefix space (see the original codebase [here](https://github.com/facebookresearch/llama/blob/main/llama/tokenizer.py)). However, the doc should be updated to remove the `decode_with_prefix_space` thanks for catching this. <|||||>> Not sure I understand your question. Yes it is normal, if you use the sentencepiece tokenizer, you will get the same results when decoding.
I apologize, my question was meant to ask if it is normal for the tokenizer to not have an option to `decode_with_prefix_space`
As it is the case, I will close this issue, I will find another way to fix my piece of code <|||||>This feature was added on my request so I do not think it is justified that this got closed.
decode_with_prefix_space was meant as a workaround for the fact that the tokenizer is unsuitable for downstream tasks like the one mentioned in this issue. The default behavior was off, but it allowed implementations to turn it on and get proper generations.
I do not know if it ever worked right, but without this my users keep complaining that every generation lacks the space. If this is not added back I will have to do this myself in my own code, but that would be unfortunate for the rest of the ecosystem.<|||||>@henk717 While I can't help with the removal of `decode_with_prefix_space` from the library, here is how I dealt with it, hope this helps
```python
while True:
# Get logits for the next token
logits = model(input_ids).logits[:, -1, :]
# Apply logits processor
next_tokens_scores = logits_processor(input_ids, logits)
probs = torch.nn.functional.softmax(next_tokens_scores, dim=-1)
next_token_id = torch.multinomial(probs, num_samples=1)
# Note: This is done to handle Sentencepiece based tokenizers,
# as they don't preprend the prefix space to the start of a word
tokens_previous = tokenizer.decode(input_ids[0], skip_special_tokens=True)
input_ids = torch.cat((input_ids, next_token_id), dim=1)
tokens = tokenizer.decode(input_ids[0], skip_special_tokens=True)
new_tokens = tokens[len(tokens_previous) :]
```
This is a fairly unclean way to fix the issue, but it works.
<|||||>> @henk717 While I can't help with the removal of `decode_with_prefix_space` from the library, here is how I dealt with it, hope this helps
>
> ```python
> while True:
> # Get logits for the next token
> logits = model(input_ids).logits[:, -1, :]
> # Apply logits processor
> next_tokens_scores = logits_processor(input_ids, logits)
>
> probs = torch.nn.functional.softmax(next_tokens_scores, dim=-1)
> next_token_id = torch.multinomial(probs, num_samples=1)
>
> # Note: This is done to handle Sentencepiece based tokenizers,
> # as they don't preprend the prefix space to the start of a word
> tokens_previous = tokenizer.decode(input_ids[0], skip_special_tokens=True)
> input_ids = torch.cat((input_ids, next_token_id), dim=1)
> tokens = tokenizer.decode(input_ids[0], skip_special_tokens=True)
>
> new_tokens = tokens[len(tokens_previous) :]
> ```
>
> This is a fairly unclean way to fix the issue, but it works.
it works for me, thank you! |
transformers | 22,709 | closed | Fix passing kwargs to the tokenizer in FillMaskPipeline preprocess method | As per title, the kwargs was not passed.
The modification follows https://github.com/huggingface/transformers/blob/fe1f5a639d93c9272856c670cff3b0e1a10d5b2b/src/transformers/pipelines/text_classification.py#L91-L179 | 04-11-2023 16:14:56 | 04-11-2023 16:14:56 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22709). All of your documentation changes will be reflected on that endpoint.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,708 | closed | Fix decorator order | # What does this PR do?
Fix decorator order.
For some tests, like `test_basic_distributed`, we have the following on `main`.
```
@require_torch_multi_gpu
@parameterized.expand(params, name_func=parameterized_custom_name_func)
def test_basic_distributed(self, stage, dtype):
```
but the (generated) tests are actually run even on a single GPU machine.
We need to change the order:
```python
@parameterized.expand(params, name_func=parameterized_custom_name_func)
@require_torch_multi_gpu
```
(PS: it doesn't mean the tests will fail on a single GPU VM. It still passes, but I am not sure if it makes sense.) | 04-11-2023 13:44:18 | 04-11-2023 13:44:18 | cc @sgugger : I think this observation might be interesting to you.<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Yes, this requirement is documented here https://huggingface.co/docs/transformers/testing#to-gpu-or-not-to-gpu but it's not "enforced" so it's easy to miss
Perhaps it can be added to the quality checks? |
transformers | 22,707 | closed | the generated results are different between generating a batch input_ids and a single sequence input_ids | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-4.15.0-142-generic-x86_64-with-glibc2.23
- Python version: 3.9.16
- Huggingface_hub version: 0.13.4
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@ArthurZucker @gante @youne
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I finetuned a pre-trained XGLM model with LoRA, and when I use the model to generate sequences with a same input ( the only diffience between two ways is one sentence is in a list with other sentence and generate them together, the other is a single sentence in a list ),the result is different with the same setting!
the details are following:
```python
tokenizer = XGLMTokenizer.from_pretrained(base_model)
tokenizer.padding_side = "left"
tokenizer.add_special_tokens({'additional_special_tokens': ['=']})
model = XGLMForCausalLM.from_pretrained(base_model,device_map="auto",)
model = PeftModel.from_pretrained(model,lora_weights,)
model.eval()
model = torch.compile(model)
p = ['今年 , 这种 主导作用 依然 非常 突出 。 = ', '国际足联 将 严惩 足球场 上 的 欺骗 行为 = ', '枪手 被 警方 击毙 。 = ']
a = tokenizer(p, padding=True, return_tensors='pt')
ga = model.generate(**a, num_beams=5, max_new_tokens=128)
oa = tokenizer.batch_decode(ga, skip_special_tokens=False)
b = ['今年 , 这种 主导作用 依然 非常 突出 。 = '] # b equals p[0]
b = tokenizer(b, padding=True, return_tensors='pt')
gb = model.generate(**b, num_beams=5, max_new_tokens=128)
ob = tokenizer.batch_decode(gb, skip_special_tokens=False)
### result:
print(oa)
['<pad><pad><pad><pad><pad></s> 今年, 这种 主导作用 依然 非常 突出 。= this year, this dominant role is still very prominent.</s>', '</s> 国际足联 将 严惩 足球场 上 的 欺骗 行为= fifa to punish cheaters in stadiums</s><pad><pad><pad><pad><pad>', '<pad><pad><pad><pad><pad><pad><pad><pad><pad></s> 枪手 被 警方 击<unk> 。= the gunman was killed by police.</s><pad><pad><pad><pad>']
print(ob)
['</s> 今年, 这种 主导作用 依然 非常 突出 。= this year, this dominant role has still been very prominent.</s>']
```
the output following the "=" token is different in the case.
### Expected behavior
the output following the "=" token is different in the case.
I am confused why the same input but different output just because of the additional pad token? But the attention mask of pad is 0.
And I want to know how to change the code to make them be same?
Is it a bug or is there a problem with the code?
Looking forward to a quick response, and thanks very much! | 04-11-2023 12:40:50 | 04-11-2023 12:40:50 | cc @younesbelkada (I am mostly thinking about sampling + beam + randomness) <|||||>> cc @younesbelkada (I am mostly thinking about sampling + beam + randomness)
I don't think so, the default arg do_sample of method `generate` is `False`, and I manually set this arg `False`, the result is same as the issue.
And I generated `a` and decoded `ga` few times, every times the result `oa` is not change; the same as `b`, `gb` and `ob` .<|||||>Hey @ZeroneBo 👋
When an input is passed with padding, the padded tokens are not removed from the input. Instead, they are numerically masked in the attention layer -- they will have a minuscule impact on the output, but it is not exactly the same as the case without padding. This means that slightly different outputs may be observed with `.generate()` between the padded and unpadded cases (and the differences increase when FP16/BF16/INT8 is used).
Nevertheless, these changes should be very infrequent and, when they happen, the difference tends to retain a similar meaning. If you notice that `XGLM` is modifying the outputs frequently in the presence of padding, let us know :)<|||||>Hey @gante , thanks for explaining.
Yes, there is significant difference between this two ways in my case, generating batchs in six test sets getting a avg score 7.398, and generating sequences one by one in the six test sets without padding getting a avg score 14.538. The performance gap is very obvious. Although "one by one" generating gets better score, it costs much more time. I hope "batch" generating can get a same performance.
I have an another question. When training or generating a CLM, the padding side should always be in left? Is there some cases the padding side must be in right? Sometimes the outputs differs because of different padding side with a same model. And how can I know which side I should pad to get a better performance?<|||||>> Yes, there is significant difference between this two ways in my case, generating batchs in six test sets getting a avg score 7.398, and generating sequences one by one in the six test sets without padding getting a avg score 14.538.
@ZeroneBo This large performance drop should not happen at all, it probably means that the code related to batched generation for Donut is incorrect 👀 I've added this to my to do list -- if you'd be able to share some way to reproduce the issue with an open model and dataset, it would speed up the process for me 🙏
> I have an another question. When training or generating a CLM, the padding side should always be in left? Is there some cases the padding side must be in right? Sometimes the outputs differs because of different padding side with a same model. And how can I know which side I should pad to get a better performance?
The rule of thumb is the following: if you expect the model to continue generation from your input text (as in the GPT models), then padding should be on the left. Otherwise, the text will only be used as input (and not as part of the output), in which case you should use right padding.<|||||>@gante Here are a part of data from the original data and the model I used, it may be helpful.
https://github.com/ZeroneBo/xglm-tmp<|||||>@ZeroneBo as a short-term remedy, if you set `model.config.use_cache = False`, your batched results should match the one-by-one results (but it will be slightly slower).
Meanwhile, I'm working on a fix so you can use cache (= faster) while getting the same results :)<|||||>Hello @gante , I have tried to set `model.config.use_cache = False` in both finetuning and generating code, but it did't work. The performance gap exits.<|||||>@ZeroneBo can you try installing from `main` and rerunning your experiments? I couldn't reproduce the problems you described, as left-padding issues were fixed :) <|||||>@gante That' effective, thanks for your work. 👍<|||||>Hi, do we have a recommended way to use `XGLM` to do translation task? Why do we need to add "=" manually?
```python
tokenizer = XGLMTokenizer.from_pretrained(base_model)
tokenizer.padding_side = "left"
tokenizer.add_special_tokens({'additional_special_tokens': ['=']})
model = XGLMForCausalLM.from_pretrained(base_model,device_map="auto",)
model = PeftModel.from_pretrained(model,lora_weights,)
model.eval()
```<|||||>@Hannibal046 Hi, In my impression, the paper used the "=" template to do translation task. You can also use other tokens or symbols in the task.<|||||>I know, but i am just curious about why "=" is not a special token at the first place. |
transformers | 22,706 | closed | transformers trainer llama Trying to resize storage that is not resizable | ### System Info
transformers ==4.28.0.dev0
pytorch==1.13.1
### Who can help?
--
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
--
### Expected behavior

I found that this is a bug with AutoModelForCausalLM, because the code that uses this module is unable to load the checkpoint. | 04-11-2023 11:21:52 | 04-11-2023 11:21:52 | Hi @lw3259111, thanks for raising this issue.
So that we can best try and help, could you provide some more information about how to reproduce this error. Specifically the following:
* The running environment and important dependency versions. This can be found running `transformers-cli env` in your terminal
* A minimal code snippet to reproduce the error. If, for anonymity, it's not possible to share a checkpoint name, it's OK to do something like the example below. This so we know how e.g. the `Trainer` class is being called and the possible code path triggering this issue.
```py
from transformers import AutoModelForCausalLM
checkpoint = "checkpoint-name" # Dummy name
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
<|||||>@amyeroberts
`
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.28.0.dev0
- Platform: Linux-4.15.0-208-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.13.2
- Safetensors version: 0.3.0
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>`
**model_name = "checkpoints-1200"**
The error :
<img width="1438" alt="image" src="https://user-images.githubusercontent.com/12690488/231175851-dbdc50ee-26f4-4f4e-966f-bb3ae06f291f.png">
<img width="1437" alt="image" src="https://user-images.githubusercontent.com/12690488/231176038-4f6d80bb-0e02-45e9-8ce9-f0b3650f615f.png">
<img width="1439" alt="image" src="https://user-images.githubusercontent.com/12690488/231176126-4945d00f-6ced-48af-98cd-35d83daff78c.png">
<|||||>@lw3259111, great, thanks for the additional details. For the checkpoint that's being loaded, which model architecture does it map to i.e. which `XxxForCausalLM` model? <|||||>@amyeroberts
I want to load `LlamaForCausalLM` model
and the same error has beed found in follow link
`
https://github.com/tatsu-lab/stanford_alpaca/issues/61#issuecomment-1504117715
https://github.com/lm-sys/FastChat/issues/351
`<|||||>@lw3259111 Thanks for the additional information. I'm able to load some checkpoints with both of the following:
```py
model = LlamaForCausalLM.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
without this error occurring. So the issue is likely relating to the specific weights being loaded, model configuration or something else in the environment.
A few questions, comments and suggestions:
* Looking at the screenshots shared, in the first one in [this comment](https://github.com/huggingface/transformers/issues/22706#issuecomment-1503343784), I can see there is an error being triggered relating to `git-lfs` not being installed in the environment. Could you try installing or reinstalling `git lfs`? It's worthwhile making sure this work, but I doubt this is the issue.
* [In the linked issues](https://github.com/tatsu-lab/stanford_alpaca/issues/61#issuecomment-1504459664), the version of transformers in your env is different from in this issue. I'm assuming a typo, but can you confirm the version. Note: the transformers library needs to be install from source to use the Llama model.
* When `model = AutoModelForCausalLM.from_pretrained(checkpoint, low_cpu_mem_usage=True, **kwargs)` is called, could you share what the kwargs are?
* Following [this issue](https://github.com/tatsu-lab/stanford_alpaca/issues/61), is the model being loaded one which was saved out after using the `Trainer` class?
<|||||>@amyeroberts Thank you for your reply. I will reply to your questions one by one
- git-lfs has been installed in my compute
<img width="723" alt="image" src="https://user-images.githubusercontent.com/12690488/231516433-e6ff8f1e-3313-4f0c-93ca-95b7c8332a2b.png">
- my transformers version is 4.28.0.dev0, [https://github.com/tatsu-lab/stanford_alpaca/issues/61#issuecomment-1504459664](url). I made a mistake in writing the corresponding Transformers version of this link, and I have made the necessary modifications
- `kwargs` are `{'torch_dtype': torch.float16,
'device_map': 'auto',
'max_memory': {0: '13GiB', 1: '13GiB'}}`
- yes,The checkpoint-1200 was saved out after using the Trainer class<|||||>https://github.com/lm-sys/FastChat/issues/351#issuecomment-1519060027
This is related to https://github.com/lm-sys/FastChat/issues/256#issue-1658116931<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,705 | closed | using Deepspeed zero stage3 finetune sd2, dimension error occurs | ### System Info
Describe the bug
An error is reported when using deepspeed's zero stage3 finetune diffusers/examples/text_to_image/train_text_to_image.py script. My machine's GPU is 2*A100, running on deepspeed zero stage3
```
def train(args):
if args.non_ema_revision is not None:
deprecate(
"non_ema_revision!=None",
"0.15.0",
message=(
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
" use `--variant=non_ema` instead."
),
)
# logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
deepspeed_plugin = DeepSpeedPlugin(zero_stage=3, gradient_accumulation_steps=2)
# deepspeed_plugin.set_mixed_precision("fp16")
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
logging_dir=args.log_dir,
project_config=accelerator_project_config,
deepspeed_plugin=deepspeed_plugin
)
```
error log is
```
04/11/2023 16:59:12 0:INFO: Prepare everything with our accelerator.
[2023-04-11 16:59:12,036] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed info: version=0.6.5, git-hash=unknown, git-branch=unknown
04112023 16:59:13|INFO|torch.distributed.distributed_c10d| Added key: store_based_barrier_key:2 to store for rank: 0
04112023 16:59:13|INFO|torch.distributed.distributed_c10d| Added key: store_based_barrier_key:2 to store for rank: 1
04112023 16:59:13|INFO|torch.distributed.distributed_c10d| Rank 1: Completed store-based barrier for key:store_based_barrier_key:2 with 2 nodes.
/usr/local/conda/lib/python3.9/site-packages/torch/distributed/distributed_c10d.py:429: UserWarning: torch.distributed.distributed_c10d._get_global_rank is deprecated please use torch.distributed.distributed_c10d.get_global_rank instead
warnings.warn(
04112023 16:59:13|INFO|torch.distributed.distributed_c10d| Rank 0: Completed store-based barrier for key:store_based_barrier_key:2 with 2 nodes.
/usr/local/conda/lib/python3.9/site-packages/torch/distributed/distributed_c10d.py:429: UserWarning: torch.distributed.distributed_c10d._get_global_rank is deprecated please use torch.distributed.distributed_c10d.get_global_rank instead
warnings.warn(
[2023-04-11 16:59:13,796] [INFO] [engine.py:278:__init__] DeepSpeed Flops Profiler Enabled: False
[2023-04-11 16:59:13,796] [INFO] [engine.py:1086:_configure_optimizer] Removing param_group that has no 'params' in the client Optimizer
[2023-04-11 16:59:13,796] [INFO] [engine.py:1092:_configure_optimizer] Using client Optimizer as basic optimizer
[2023-04-11 16:59:13,878] [INFO] [engine.py:1108:_configure_optimizer] DeepSpeed Basic Optimizer = AdamW
[2023-04-11 16:59:13,878] [INFO] [utils.py:52:is_zero_supported_optimizer] Checking ZeRO support for optimizer=AdamW type=<class 'torch.optim.adamw.AdamW'>
[2023-04-11 16:59:13,878] [INFO] [logging.py:69:log_dist] [Rank 0] Creating fp16 ZeRO stage 3 optimizer
[2023-04-11 16:59:13,878] [INFO] [engine.py:1410:_configure_zero_optimizer] Initializing ZeRO Stage 3
[2023-04-11 16:59:13,887] [INFO] [stage3.py:275:__init__] Reduce bucket size 500000000
[2023-04-11 16:59:13,887] [INFO] [stage3.py:276:__init__] Prefetch bucket size 50000000
Using /home/hadoop-hmart-waimai-rank/.cache/torch_extensions/py39_cu117 as PyTorch extensions root...
Using /home/hadoop-hmart-waimai-rank/.cache/torch_extensions/py39_cu117 as PyTorch extensions root...
Emitting ninja build file /home/hadoop-hmart-waimai-rank/.cache/torch_extensions/py39_cu117/utils/build.ninja...
Building extension module utils...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
ninja: no work to do.
Loading extension module utils...
Time to load utils op: 0.5212891101837158 seconds
Loading extension module utils...
Time to load utils op: 0.5023727416992188 seconds
[2023-04-11 16:59:16,286] [INFO] [stage3.py:567:_setup_for_real_optimizer] optimizer state initialized
Using /home/hadoop-hmart-waimai-rank/.cache/torch_extensions/py39_cu117 as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0005068778991699219 seconds
[2023-04-11 16:59:16,615] [INFO] [utils.py:828:see_memory_usage] After initializing ZeRO optimizer
[2023-04-11 16:59:16,616] [INFO] [utils.py:829:see_memory_usage] MA 7.45 GB Max_MA 10.52 GB CA 11.47 GB Max_CA 11 GB
[2023-04-11 16:59:16,616] [INFO] [utils.py:837:see_memory_usage] CPU Virtual Memory: used = 5.49 GB, percent = 2.4%
[2023-04-11 16:59:16,616] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed Final Optimizer = AdamW
[2023-04-11 16:59:16,616] [INFO] [engine.py:795:_configure_lr_scheduler] DeepSpeed using client LR scheduler
[2023-04-11 16:59:16,616] [INFO] [logging.py:69:log_dist] [Rank 0] DeepSpeed LR Scheduler = None
[2023-04-11 16:59:16,617] [INFO] [logging.py:69:log_dist] [Rank 0] step=0, skipped=0, lr=[0.0001], mom=[(0.9, 0.999)]
[2023-04-11 16:59:16,618] [INFO] [config.py:1059:print] DeepSpeedEngine configuration:
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] activation_checkpointing_config {
"partition_activations": false,
"contiguous_memory_optimization": false,
"cpu_checkpointing": false,
"number_checkpoints": null,
"synchronize_checkpoint_boundary": false,
"profile": false
}
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] aio_config ................... {'block_size': 1048576, 'queue_depth': 8, 'thread_count': 1, 'single_submit': False, 'overlap_events': True}
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] amp_enabled .................. False
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] amp_params ................... False
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] autotuning_config ............ {
"enabled": false,
"start_step": null,
"end_step": null,
"metric_path": null,
"arg_mappings": null,
"metric": "throughput",
"model_info": null,
"results_dir": null,
"exps_dir": null,
"overwrite": true,
"fast": true,
"start_profile_step": 3,
"end_profile_step": 5,
"tuner_type": "gridsearch",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"model_info_path": null,
"mp_size": 1,
"max_train_batch_size": null,
"min_train_batch_size": 1,
"max_train_micro_batch_size_per_gpu": 1.024000e+03,
"min_train_micro_batch_size_per_gpu": 1,
"num_tuning_micro_batch_sizes": 3
}
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] bfloat16_enabled ............. False
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] checkpoint_tag_validation_enabled True
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] checkpoint_tag_validation_fail False
[2023-04-11 16:59:16,619] [INFO] [config.py:1063:print] communication_data_type ...... None
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] curriculum_enabled ........... False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] curriculum_params ............ False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] dataloader_drop_last ......... False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] disable_allgather ............ False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] dump_state ................... False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] dynamic_loss_scale_args ...... None
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_enabled ........... False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_gas_boundary_resolution 1
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_layer_name ........ bert.encoder.layer
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_layer_num ......... 0
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_max_iter .......... 100
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_stability ......... 1e-06
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_tol ............... 0.01
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] eigenvalue_verbose ........... False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] elasticity_enabled ........... False
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] flops_profiler_config ........ {
"enabled": false,
"profile_step": 1,
"module_depth": -1,
"top_modules": 1,
"detailed": true,
"output_file": null
}
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] fp16_enabled ................. True
[2023-04-11 16:59:16,620] [INFO] [config.py:1063:print] fp16_master_weights_and_gradients False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] fp16_mixed_quantize .......... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] global_rank .................. 0
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] gradient_accumulation_steps .. 1
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] gradient_clipping ............ 0.0
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] gradient_predivide_factor .... 1.0
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] initial_dynamic_scale ........ 4294967296
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] loss_scale ................... 0
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] memory_breakdown ............. False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] optimizer_legacy_fusion ...... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] optimizer_name ............... None
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] optimizer_params ............. None
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] pipeline ..................... {'stages': 'auto', 'partition': 'best', 'seed_layers': False, 'activation_checkpoint_interval': 0}
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] pld_enabled .................. False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] pld_params ................... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] prescale_gradients ........... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_change_rate ......... 0.001
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_groups .............. 1
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_offset .............. 1000
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_period .............. 1000
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_rounding ............ 0
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_start_bits .......... 16
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_target_bits ......... 8
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_training_enabled .... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_type ................ 0
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] quantize_verbose ............. False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] scheduler_name ............... None
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] scheduler_params ............. None
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] sparse_attention ............. None
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] sparse_gradients_enabled ..... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] steps_per_print .............. inf
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] tensorboard_enabled .......... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] tensorboard_job_name ......... DeepSpeedJobName
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] tensorboard_output_path ......
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] train_batch_size ............. 16
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] train_micro_batch_size_per_gpu 8
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] use_quantizer_kernel ......... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] wall_clock_breakdown ......... False
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] world_size ................... 2
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] zero_allow_untested_optimizer True
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] zero_config .................. {
"stage": 3,
"contiguous_gradients": true,
"reduce_scatter": true,
"reduce_bucket_size": 5.000000e+08,
"allgather_partitions": true,
"allgather_bucket_size": 5.000000e+08,
"overlap_comm": true,
"load_from_fp32_weights": true,
"elastic_checkpoint": false,
"offload_param": null,
"offload_optimizer": null,
"sub_group_size": 1.000000e+09,
"prefetch_bucket_size": 5.000000e+07,
"param_persistence_threshold": 1.000000e+05,
"max_live_parameters": 1.000000e+09,
"max_reuse_distance": 1.000000e+09,
"gather_16bit_weights_on_model_save": false,
"ignore_unused_parameters": true,
"round_robin_gradients": false,
"legacy_stage1": false
}
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] zero_enabled ................. True
[2023-04-11 16:59:16,621] [INFO] [config.py:1063:print] zero_optimization_stage ...... 3
[2023-04-11 16:59:16,622] [INFO] [config.py:1065:print] json = {
"train_batch_size": 16,
"train_micro_batch_size_per_gpu": 8,
"gradient_accumulation_steps": 1,
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "none"
},
"offload_param": {
"device": "none"
},
"stage3_gather_16bit_weights_on_model_save": false
},
"steps_per_print": inf,
"fp16": {
"enabled": true,
"auto_cast": true
},
"bf16": {
"enabled": false
},
"zero_allow_untested_optimizer": true
}
Using /home/hadoop-hmart-waimai-rank/.cache/torch_extensions/py39_cu117 as PyTorch extensions root...
No modifications detected for re-loaded extension module utils, skipping build step...
Loading extension module utils...
Time to load utils op: 0.0004420280456542969 seconds
04/11/2023 16:59:16 0:INFO: set weight type
04/11/2023 16:59:16 0:INFO: Move text_encode and vae to gpu and cast to weight_dtype
04/11/2023 16:59:16 0:INFO: [starship] accelerate not support all python data type
04/11/2023 16:59:16 0:INFO: ***** Running training *****
04/11/2023 16:59:16 0:INFO: Num examples = 400
04/11/2023 16:59:16 0:INFO: Num Epochs = 100
04/11/2023 16:59:16 0:INFO: Instantaneous batch size per device = 8
04/11/2023 16:59:16 0:INFO: Total train batch size (w. parallel, distributed & accumulation) = 16
04/11/2023 16:59:16 0:INFO: Gradient Accumulation steps = 1
04/11/2023 16:59:16 0:INFO: Total optimization steps = 2500
Steps: 0%| | 0/2500 [00:00<?, ?it/s]Parameter containing:
tensor([], device='cuda:0', dtype=torch.float16)
Traceback (most recent call last):
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/app/main.py", line 29, in <module>
main()
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/app/main.py", line 21, in main
run_aigc(args)
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/app/task.py", line 61, in run_aigc
train(args)
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/diffuser/train_txt2img.py", line 526, in train
encoder_hidden_states = text_encoder(batch["input_ids"].to(accelerator.device))[0]
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py", line 823, in forward
return self.text_model(
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py", line 719, in forward
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py", line 234, in forward
inputs_embeds = self.token_embedding(input_ids)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/sparse.py", line 160, in forward
return F.embedding(
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/functional.py", line 2210, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: 'weight' must be 2-D
Parameter containing:
tensor([], device='cuda:1', dtype=torch.float16)
Steps: 0%| | 0/2500 [00:05<?, ?it/s]
Traceback (most recent call last):
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/app/main.py", line 29, in <module>
main()
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/app/main.py", line 21, in main
run_aigc(args)
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/app/task.py", line 61, in run_aigc
train(args)
File "/workdir/fengyu05/501587/2924467c592a472aa750166c252e166d/src/diffuser/train_txt2img.py", line 526, in train
encoder_hidden_states = text_encoder(batch["input_ids"].to(accelerator.device))[0]
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py", line 823, in forward
return self.text_model(
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py", line 719, in forward
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py", line 234, in forward
inputs_embeds = self.token_embedding(input_ids)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/modules/sparse.py", line 160, in forward
return F.embedding(
File "/usr/local/conda/lib/python3.9/site-packages/torch/nn/functional.py", line 2210, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: 'weight' must be 2-D
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 32336) of binary: /usr/local/conda/bin/python
Traceback (most recent call last):
File "/usr/local/conda/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/conda/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/launch.py", line 195, in <module>
main()
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/launch.py", line 191, in main
launch(args)
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/launch.py", line 176, in launch
run(args)
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/run.py", line 753, in run
elastic_launch(
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 132, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/usr/local/conda/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 246, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
src/app/main.py FAILED
------------------------------------------------------------
Failures:
[1]:
time : 2023-04-11_16:59:28
host : workbenchxwmx64350ee0-f9ggd
rank : 1 (local_rank: 1)
exitcode : 1 (pid: 32337)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-04-11_16:59:28
host : workbenchxwmx64350ee0-f9ggd
rank : 0 (local_rank: 0)
exitcode : 1 (pid: 32336)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
real 0m26.485s
user 0m23.241s
sys 0m22.802s
```
I read https://github.com/huggingface/diffusers/issues/1865 , https://www.deepspeed.ai/tutorials/zero/#allocating-massive-megatron-lm-models and https://deepspeed.readthedocs.io/en/latest/zero3.html#deepspeed.zero.GatheredParameters
modify /usr/local/conda/lib/python3.9/site-packages/transformers/models/clip/modeling_clip.py as this:
```
209 self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
210 with deepspeed.zero.GatheredParameters(self.token_embedding.weight,
211 modifier_rank=0):
212 # Initialize the position embeddings.
213 nn.init.uniform_(self.token_embedding.weight, -1.0, 1)
214
215 # deepspeed.zero.register_external_parameter(self, self.token_embedding.weight)
```
but it does not work.
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [x] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I am also experiencing the same issue as mentioned in https://github.com/huggingface/diffusers/issues/1865, therefore I have copied the reproduction steps from the original post.
1.
```compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/kas/zero_stage3_offload_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 4
use_cpu: false
```
2.
/home/kas/zero_stage3_offload_config.json
```
{
"train_micro_batch_size_per_gpu": 16,
"gradient_accumulation_steps":2,
"train_batch_size":128,
"steps_per_print": 2,
"gradient_clipping": 1,
"zero_optimization": {
"stage": 3,
"allgather_partitions": false,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"stage3_max_live_parameters" : 2e8,
"stage3_max_reuse_distance" : 2e8,
"stage3_prefetch_bucket_size": 2e8,
"stage3_param_persistence_threshold": 2e8,
"sub_group_size" : 2e8,
"round_robin_gradients": true
},
"bf16": {
"enabled": true
}
}
```
4.
```
git clone https://github.com/huggingface/diffusers.git
cd expamles/text_to_imag
pip install deepspeed
export MODEL_NAME="stabilityai/stable-diffusion-2"
export dataset_name="lambdalabs/pokemon-blip-captions"
accelerate launch --config_file ./accelerate.yaml --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$dataset_name \
--use_ema \
--resolution=224 --center_crop --random_flip \
--train_batch_size=16 \
--gradient_accumulation_steps=2 \
--gradient_checkpointing \
--max_train_steps=500 \
--learning_rate=6e-5 \
--max_grad_norm=1 \
--lr_scheduler="constant_with_warmup" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
5.
```0%| | 0/500 [00:00<?, ?it/s] Steps: 0%| | 0/500 [00:00<?, ?it/s]Traceback (most recent call last):
File "train_text_to_image.py ", line 718, in <module>
main()
File "train_text_to_image.py ", line 648, in main
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
File "/opt/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/lib/python3.7/site-packages/transformers/models/clip/modeling_clip.py", line 739, in forward
return_dict=return_dict,
File "/opt/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/lib/python3.7/site-packages/transformers/models/clip/modeling_clip.py", line 636, in forward
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
File "/opt/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/lib/python3.7/site-packages/transformers/models/clip/modeling_clip.py", line 165, in forward
inputs_embeds = self.token_embedding(input_ids)
File "/opt/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/miniconda3/lib/python3.7/site-packages/torch/nn/modules/sparse.py", line 160, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/opt/miniconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 2183, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: 'weight' must be 2-D
```
### Expected behavior
The goal is to be able to use Zero3 normally. | 04-11-2023 09:21:25 | 04-11-2023 09:21:25 | @stas00
could please help me take a look at this issue?<|||||>See https://github.com/huggingface/diffusers/pull/3076
Please carefully read the OP of the PR for details.<|||||>@uygnef Have you solved this problem?
<|||||>@luochuwei Yes, it works for training one model, but there seems to be an issue with training multiple models. I have submit the issue at https://github.com/microsoft/DeepSpeed/issues/3472<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,704 | closed | Remove mask | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-11-2023 07:04:08 | 04-11-2023 07:04:08 | |
transformers | 22,703 | closed | Make vilt, switch_transformers compatible with model parallelism | # Make vilt, switch_transformers compatible with model parallelism
Fixes https://github.com/huggingface/transformers/issues/22561#issue-1653950092
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
- PyTorch: @sgugger
| 04-11-2023 04:25:05 | 04-11-2023 04:25:05 | _The documentation is not available anymore as the PR was closed or merged._<|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>@sgugger I fixed the issue, but, unfortunately, I have closed and reopened PR to trigger the CircleCI.<|||||>Thanks a lot! |
transformers | 22,702 | closed | Enable naive Pipeline Parallelism training for Gpt neox japanese and san japanese | As suggested in the https://github.com/huggingface/transformers/issues/22561, moved labels to the same device as logits for GPT Neox Japanese and Gpt San Japanese | 04-11-2023 03:50:12 | 04-11-2023 03:50:12 | @sgugger Could you review this once?<|||||>_The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,701 | closed | [test] add CI workflow for VCS installation | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Add a CI test for checking VCS installation (via URL or git repo). This workflow prevents potential breakage for [install from source](https://huggingface.co/docs/transformers/installation#install-from-source) installation method.
Ref:
- #22539
- #22658
- #22599
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-11-2023 03:23:28 | 04-11-2023 03:23:28 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22701). All of your documentation changes will be reflected on that endpoint.<|||||>Or we can just leave the setup as is and there won't be any need for this new check :-)<|||||>> Or we can just leave the setup as is and there won't be any need for this new check :-)
The CI workflows in this PR can also benefit to check the viability of `transformers`' dependencies.
I think the ultimate solution is to ask the user to upgrade their `pip` first in the documentation:
```bash
pip install --upgrade pip setuptools # upgrade to support PEP 660
pip install git+https://github.com/huggingface/transformers
```
<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,700 | open | Add support of output_scores to flax models | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Flax models does not support `output_scores` when generate() method is called, despite the PyTorch models that fully supports this feature.
It is tried to follow naming and format of these parameters as same as PyTorch model codes (utils.py)
## Before submitting
- [x] This PR adds support of `output_scores` to flax models.
- [x] Flax Whisper model handles `output_scores` and `num_beams` parameters to consider during generate().
## Who can review?
@sanchit-gandhi
| 04-10-2023 23:04:15 | 04-10-2023 23:04:15 | The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_22700). All of your documentation changes will be reflected on that endpoint.<|||||>@sanchit-gandhi @ArthurZucker
Could you please review this PR?<|||||>I get a new error on CI for test codes of all models:
```AttributeError: module 'jax' has no attribute 'Array'```
However there was not such error two weeks ago (while my commit all tests passed).
Is there any updates on `Jax` that is not compatible with?
Any ideas @sanchit-gandhi ?
Update: The above mentioned error has been raised from `optax` source codes:
```
examples/flax/test_flax_examples.py:41: in <module>
import run_clm_flax
examples/flax/language-modeling/run_clm_flax.py:40: in <module>
import optax
../.pyenv/versions/3.8.12/lib/python3.8/site-packages/optax/__init__.py:18: in <module>
from optax._src.alias import adabelief
../.pyenv/versions/3.8.12/lib/python3.8/site-packages/optax/_src/alias.py:23: in <module>
from optax._src import clipping
../.pyenv/versions/3.8.12/lib/python3.8/site-packages/optax/_src/clipping.py:130: in <module>
) -> Tuple[List[chex.Array], jax.Array]:
E AttributeError: module 'jax' has no attribute 'Array'
```
Does it have relevance to this recent merge: https://github.com/huggingface/transformers/pull/22895 ?<|||||>> I get a new error on CI for test codes of all models: `AttributeError: module 'jax' has no attribute 'Array'` However there was not such error two weeks ago (while my commit all tests passed). Is there any updates on `Jax` that is not compatible with? Any ideas @sanchit-gandhi ?
>
> Update: The above mentioned error has been raised from `optax` source codes:
>
> ```
> examples/flax/test_flax_examples.py:41: in <module>
> import run_clm_flax
> examples/flax/language-modeling/run_clm_flax.py:40: in <module>
> import optax
> ../.pyenv/versions/3.8.12/lib/python3.8/site-packages/optax/__init__.py:18: in <module>
> from optax._src.alias import adabelief
> ../.pyenv/versions/3.8.12/lib/python3.8/site-packages/optax/_src/alias.py:23: in <module>
> from optax._src import clipping
> ../.pyenv/versions/3.8.12/lib/python3.8/site-packages/optax/_src/clipping.py:130: in <module>
> ) -> Tuple[List[chex.Array], jax.Array]:
> E AttributeError: module 'jax' has no attribute 'Array'
> ```
>
> Does it have relevance to this recent merge: #22895 ?
I've found that this issue was related to the optax version (which installed the 0.1.5). In the updated version of transformer repo, the version to be installed is forced to be 0.1.4<|||||>Good catch regarding the `jax.Array` issue! I need to un-pin JAX on Transformers since new Optax / Chex versions are running ahead https://github.com/huggingface/transformers/issues/19842 Will do this tomorrow 🤗<|||||>Thanks for the review @gante 🙌 See https://github.com/huggingface/transformers/pull/22700#discussion_r1182794360 for the next steps @hannan72 🚀<|||||>Also see related: #22700
This might get merged before this PR, in which case we can rebase to get the beam score fixes from main! Your changes will still be valuable for greedy search @hannan72 🤗<|||||>Hey @hannan72! This PR is looking in good shape - would you like to get it over the line with the last bits of integration?<|||||>> Hey @hannan72! This PR is looking in good shape - would you like to get it over the line with the last bits of integration?
Sorry for late response. I was busy on a product release.
Yes I really want to make it final and put it in the next release of transformers. What is remaining?
Please clarify the remaining steps to finalize the PR and close this issue.<|||||>Awesome! It's more or less as you left it - the major "TODO" is getting the correct vocab size in the first forward pass (see https://github.com/huggingface/transformers/pull/22700#discussion_r1178185868)<|||||>> Awesome! It's more or less as you left it - the major "TODO" is getting the correct vocab size in the first forward pass (see [#22700 (comment)](https://github.com/huggingface/transformers/pull/22700#discussion_r1178185868))
I had made a try on it and posted the result:
I tried to do this. But there was an error stopped me working on it.
I get the `vocab_size` from logits shape in the first step as follows:
```
next_tokens_scores = logits_processor(state.sequences, logits, state.cur_len)
next_token = jnp.argmax(next_tokens_scores, axis=-1)
scores = state.scores
if output_scores and state.scores is None:
vocab_size = next_tokens_scores.shape[-1]
scores = jnp.ones((batch_size, max_length, vocab_size)) * np.array(-1.0e7)
tokens_scores = scores.at[:, state.cur_len, :].set(next_tokens_scores) if output_scores else None
```
But in the line:
https://github.com/huggingface/transformers/blob/312b104ff65514736c0475814fec19e47425b0b5/src/transformers/generation/flax_utils.py#L641
it checks that tensor shapes between runs should be exactly same, which causes the following error :
```
Exception has occurred: TypeError (note: full exception trace is shown but execution is paused at: _run_module_as_main) body_fun output and input must have same type structure, got PyTreeDef(CustomNode(GreedyState[()], [*, *, *, *, *, {'decoder_attention_mask': *, 'decoder_position_ids': *, 'encoder_attention_mask': None, 'encoder_outputs': CustomNode(FlaxBaseModelOutput[()], [*, None, None]),...
```
So it seems the second suggestion is not going to work here. Because in Jax, every tensor shape should be pre-defined before deployment while we get the `vocab_size` during the deployment.<|||||>The idea here would be to run the first pass outside of the lax while loop (which we already do), then get the logits shape, then run the loop with the correct vocab size. Picking up on L730:
https://github.com/huggingface/transformers/blob/9ade58f0555430cec851e307c83c3a56c4a77d0b/src/transformers/generation/flax_utils.py#L730
This would look something like:
```python
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
if input_ids.shape[1] > 1:
state = sample_search_body_fn(state)
# now get the vocab size
vocab_size = state.logits.shape[-1]
# do the other stuff that we need to do to init the state scores
# ...
# now run the main body
if not trace:
state = self._run_loop_in_debug(sample_search_cond_fn, sample_search_body_fn, state)
else:
state = lax.while_loop(sample_search_cond_fn, sample_search_body_fn, state)
```<|||||>> The idea here would be to run the first pass outside of the lax while loop (which we already do), then get the logits shape, then run the loop with the correct vocab size. Picking up on L730:
>
> https://github.com/huggingface/transformers/blob/9ade58f0555430cec851e307c83c3a56c4a77d0b/src/transformers/generation/flax_utils.py#L730
>
> This would look something like:
>
> ```python
> # The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
> if input_ids.shape[1] > 1:
> state = sample_search_body_fn(state)
>
> # now get the vocab size
> vocab_size = state.logits.shape[-1]
>
> # do the other stuff that we need to do to init the state scores
> # ...
>
> # now run the main body
> if not trace:
> state = self._run_loop_in_debug(sample_search_cond_fn, sample_search_body_fn, state)
> else:
> state = lax.while_loop(sample_search_cond_fn, sample_search_body_fn, state)
> ```
I implemented your suggestion by applying following changes in `greedy_search_body_fn` and get the `vocab_size` from the first run as follows:
```
def greedy_search_body_fn(state):
"""state update fn."""
model_outputs = model(state.running_token, params=params, **state.model_kwargs)
logits = model_outputs.logits[:, -1]
# apply min_length, ...
next_tokens_scores = logits_processor(state.sequences, logits, state.cur_len)
next_token = jnp.argmax(next_tokens_scores, axis=-1)
if output_scores:
if state.scores is not None:
tokens_scores = state.scores.at[:, state.cur_len, :].set(next_tokens_scores)
else:
scores = jnp.ones((batch_size, max_length, next_tokens_scores.shape[-1])) * np.array(-1.0e7)
tokens_scores = scores.at[:, state.cur_len, :].set(next_tokens_scores)
else:
tokens_scores = None
next_token = next_token * ~state.is_sent_finished + pad_token_id * state.is_sent_finished
next_is_sent_finished = state.is_sent_finished | (next_token == eos_token_id)
next_token = next_token[:, None]
next_sequences = lax.dynamic_update_slice(state.sequences, next_token, (0, state.cur_len))
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return GreedyState(
cur_len=state.cur_len + 1,
sequences=next_sequences,
scores=tokens_scores,
running_token=next_token,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
)
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
# Besides, when output_scores is true, to return scores vocab_size of the model is got from first run.
if input_ids.shape[1] > 1 or output_scores:
state = greedy_search_body_fn(state)
```<|||||>@sanchit-gandhi
I think this PR is ready to merge. All tests are passed.
Could you please review it again and merge it?<|||||>@sanchit-gandhi
I have checked out to my latest commit (b82ef360c5d819efc10298344d7d2fb4c33e1c47) and run a test as follows:
* Model_name: whisper_medium with flax inference
* GPU: A100-40GB
* Input audio: 5seconds
* transformers: git+https://github.com/huggingface/transformers.git@b82ef360c5d819efc10298344d7d2fb4c33e1c47
* Pytorch: 2.0.0
* jax: [cuda12_local] 0.4.11
A. Normal Inference (while `output_scores=False`):
The model has been deployed for 5 sequence runs. Inference time is ~0.2 seconds:
```
model = FlaxWhisperForConditionalGeneration.from_pretrained(model_id, dtype=jnp.float16, from_pt=True)
jit_generate = jax.jit(model.generate, static_argnames=["max_length", "language", "task"])
runtime=[]
for i in range(5):
start_time = time.time()
input_features = jnp.array(input_features, dtype=jnp.float16)
pred_ids = jit_generate(input_features, max_length=128, language='<|de|>', task ="transcribe")
runtime.append(time.time() - start_time)
print("Inference time: ", runtime)
print("output scores: ", scores)
```
result:
Inference time: [57.01693844795227, 0.22632288932800293, 0.1981194019317627, 0.19892430305480957, 0.19736719131469727]
output scores: None
B. Inference with confidence scores (while `output_scores=True`):
The model has been deployed for 5 sequence runs. Inference time is also ~0.2 seconds:
```
model = FlaxWhisperForConditionalGeneration.from_pretrained(model_id, dtype=jnp.float16, from_pt=True)
jit_generate = jax.jit(model.generate, static_argnames=["max_length", "language", "task", "output_hidden_states", "output_scores", "return_dict_in_generate"])
runtime=[]
for i in range(5):
start_time = time.time()
input_features = jnp.array(input_features, dtype=jnp.float16)
pred_ids = jit_generate(input_features, max_length=128, language='<|de|>', task ="transcribe",
output_scores=True, output_hidden_states=True, return_dict_in_generate=True)
runtime.append(time.time() - start_time)
print("Inference time: ", runtime)
print("output scores: ", scores)
```
result:
Inference time: [82.8741066455841, 0.20504498481750488, 0.19746017456054688, 0.1972200870513916, 0.1973130702972412]
output scores: [[[-10000000. -10000000. -10000000. ... -10000000. -10000000. -10000000.]
[ -inf -inf -inf ... -inf -inf -inf]
[ -inf -inf -inf ... -inf -inf -inf]
...
[-10000000. -10000000. -10000000. ... -10000000. -10000000. -10000000.]
[-10000000. -10000000. -10000000. ... -10000000. -10000000. -10000000.]
[-10000000. -10000000. -10000000. ... -10000000. -10000000. -10000000.]]]
It should be also noted that the result of model inference are exactly the same. The only change is that the first run takes more when `output_score=True` But next inferences are the approximately the same value.
Could you please review and merge this PR? |
transformers | 22,699 | closed | BF16 on AMD MI250x GPU | ### System Info
Hi,
on ROCm, I am seeing the following error with BF16
ValueError: Your setup doesn't support bf16/gpu. You need torch>=1.10, using Ampere GPU with cuda>=11.0
raise ValueError(
Since the error and underlying check is NVIDIA specific and can be ignored on AMD MI250X GPUs, it would be good to turn it into a warning to not have to hack the `utils/import_utils.py` source.
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run any huggingface model with `--bf16` command line option on an AMD MI250X GPU
### Expected behavior
Training works | 04-10-2023 22:25:58 | 04-10-2023 22:25:58 | Ah this is a bit of a tricky situation. Is there a way to get the difference between an Nvidia GPU and an AMD GPU from PyTorch? Most users ignore warnings, so I'd really prefer to keep the error, but of course we can refine the test to ignore the GPUs that are not concerned.<|||||>Perhaps use `torch.cuda.get_device_name()`?
https://stackoverflow.com/questions/48152674/how-do-i-check-if-pytorch-is-using-the-gpu
On NVIDIA V100:
```
>>> torch.cuda.get_device_name()
'Tesla V100-SXM2-16GB'
```
on AMD MI-250x:
```
>>> torch.cuda.get_device_name()
''
```
(empty string)
A simple check could consist of testing for NVIDIA GPU and then erroring out if not finding the right one, otherwise just issuing a warning. In any case, attempting to use BF16 kernels on a non-supported GPU would probable produce pertinent error messages later on.
```
device_name = torch.cuda.get_device_name()
nvidia_models = [ 'GeForce', 'Tesla' ]
if any([ model in device_name for model in nvidia_models ]):
# check for A100 and above
else:
# raise a warning that BF16 may not be supported and may cause exceptions during training or inference, and that the
# user should know what they're doing
```
Alternatively, provide a `Trainer` argument to override this error.
<|||||>The `get_device_name` sounds like a good option. Would you like to suggest this change in a PR?<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,698 | closed | Use code on the Hub from another repo | # What does this PR do?
This makes it easier to maintain only one source of ground truth when using the code on the Hub feature by storing the repo ID on top of the module containing the class inside the config. Thus, when saving and re-pushing a model using code on the Hub, the code is not copied over anymore, but a reference to the original repo containing the code is put.
This might be breaking if some users relied on the code being copied over when `save_pretrained(xxx)` is executed. To enable that old behavior, one only needs to call the `register_for_auto_class` method:
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
model.save_pretrained(some_path)
```
then some_path only contains the config and weights of the model. The config will contain links to the repo where the code of the model is defined (`hf-internal-testing/test_dynamic_model`) so that it can be reloaded via
```py
AutoModel.from_pretrained(some_path)
```
To get the custom code file copied other (behavior before this PR) just do:
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
model.register_for_auto_class("AutoModel")
model.save_pretrained(some_path)
```
| 04-10-2023 20:36:24 | 04-10-2023 20:36:24 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,697 | closed | Make it easier to develop without a dev install | # What does this PR do?
This PR makes the only quality check that failed without all the dev dependencies work without them, then makes it clear in all contributing guides that installing with the quality extra should be enough for most development. | 04-10-2023 20:31:19 | 04-10-2023 20:31:19 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,696 | open | `no_repeat_ngram_size` has no effect for Flax model | ### System Info
transformes = ^4.27.4, macOS, python = ^3.9.6
### Who can help?
@sanchit-gandhi @ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I have been walking through the generation example in [here](https://huggingface.co/blog/how-to-generate), but I am trying to use `FlaxGPT2LMHeadModel` instead of `GPT2LMHeadModel`.
Everything works up to when `no_repeat_ngram_size` is introduced. In the example, setting `no_repeat_ngram_size=2` changes the generated sentence from
```
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll
```
to
```
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break
```
However, when using `FlaxGPT2LMHeadModel` instead of `GPT2LMHeadModel`, the generated sentence with `no_repeat_ngram_size=2` remains exactly the same as the first message.
Here is a reproducing example.
```
from transformers import FlaxGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = FlaxGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='jax')
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print(tokenizer.decode(beam_output.sequences.tolist()[0], skip_special_tokens=True))
# I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
# I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll
```
Perhaps there is a bug in the interplay of `FlaxGPT2LMHeadModel` and `no_repeat_ngram_size`?
### Expected behavior
Everything works fine when `GPT2LMHeadModel` is used instead. Here an example.
```
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='pt')
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
# I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
# I've been thinking about this for a while now, and I think it's time for me to take a break
``` | 04-10-2023 20:30:52 | 04-10-2023 20:30:52 | cc @sanchit-gandhi <|||||>Hey @gianlucadetommaso
You are right. `no_repeat_ngram` is one of the various logit processors used during generation. While I can see it's defined in tensorflow : https://github.com/huggingface/transformers/blob/151425ddb29d4ad1a121e8cce62000a2ac52d3ba/src/transformers/generation/tf_utils.py#L1451
I don't think it's defined in flax:
https://github.com/huggingface/transformers/blob/151425ddb29d4ad1a121e8cce62000a2ac52d3ba/src/transformers/generation/flax_utils.py#L488
@sanchit-gandhi
Let me know if you have your hands full.
Been meaning to get into flax for a while, can take this up. Shouldn't be very problematic. I'll just need to see how to implement the same processor in flax, might need a little guidance
<|||||>@mayankagarwals @sanchit-gandhi It seems also `num_return_sequences` does not work for the Flax model, and indeed it seems missing from [transformers/src/transformers/generation/flax_utils.py](https://github.com/huggingface/transformers/blob/151425ddb29d4ad1a121e8cce62000a2ac52d3ba/src/transformers/generation/flax_utils.py#L488).
Worth doing a more general comparison of functionalities, I guess. 😄 <|||||>Hey, I noticed this issue randomly, so just dropping in to say it looks like #18707.
The implementation was attempted in #18769 (cc @gante) and dropped because it was memory heavy, but I think it should be doable with a XLA `while` loop without allocating huge tensors. I implemented similar logic in Elixir recently (with the same shape restrictions, since we also use XLA), so perhaps [this](https://github.com/elixir-nx/bumblebee/blob/6ae97b2ce2e99a863a658f0730334c0a4984fc3d/lib/bumblebee/text/generation.ex#L745-L779) helps. The code is fairly high-level, but if anything is not clear let me know :)<|||||>@jonatanklosko nice, I had given up on it after spending a few hours on it! I'll keep tabs on your implementation, in case no one picks it up in the near future :)
@gianlucadetommaso @mayankagarwals feel free to pick up the task of adding missing logits processors to FLAX! In general, a close copy of TF's implementations will work on FLAX, since they both rely on XLA and have similar syntax.
<|||||>@gante Got it. I'll take some time out and look into this. Quite interesting!<|||||>@gante
While I was able to understand and reproduce your solution (kudos on the clean code), I had a question.
The following code works as expected
```import tensorflow as tf
batch_size = 5
ngram_size = 4
vocab_size = 52
seq_len = 50
input_ids = tf.convert_to_tensor([[ 40, 28, 35, 36, 37, 14, 15, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51], [ 40, 28, 35, 36, 37, 14, 15, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51],[ 40, 28, 35, 36, 37, 14, 15, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51], [ 40, 28, 35, 36, 37, 14, 15, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51],[ 40, 28, 35, 36, 37, 14, 15, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51]])
transition_tensor = tf.zeros((batch_size, ngram_size - 1, vocab_size, vocab_size), dtype=tf.bool)
# if `input_ids` is padded this will do some useless computations, but that is fine (avoids XLA recompilation)
for i in range(seq_len - (ngram_size - 1)):
ngrams = input_ids[:, i : i + ngram_size]
# creates the indexing for the batch and the n-th member of the ngram
batch_indexing, ngram_indexing = tf.meshgrid(tf.range(ngrams.shape[0]), tf.range(ngrams.shape[1] - 1))
batch_indexing = tf.reshape(tf.transpose(batch_indexing), (-1,))
ngram_indexing = tf.reshape(tf.transpose(ngram_indexing), (-1,))
# creates the indexing for the current -> next token p airs
curr_tokens = ngrams[:, :-1]
next_tokens = ngrams[:, 1:]
current_token_indexing = tf.reshape(curr_tokens, (-1,))
next_token_indexing = tf.reshape(next_tokens, (-1,))
# scatters the observed ngrams into the transition tensor
update_indices = tf.stack(
(batch_indexing, ngram_indexing, current_token_indexing, next_token_indexing), axis=1
)
transition_tensor = tf.tensor_scatter_nd_update(
tensor=transition_tensor,
indices=update_indices,
updates=tf.ones(update_indices.shape[0], dtype=tf.bool),
)
print(transition_tensor)
```
But when done with higher dimensions, gives core dump on CPU. This is just eager evaluation without any xla. Any idea why this might be? Does tensorflow give core dump when it can't do large operations on CPU?
```# batch_size = 5
# ngram_size = 4
# vocab_size = 50257
# seq_len = 50
#
#
# input_ids = tf.convert_to_tensor([[ 40, 2883, 6155, 351, 616, 13779, 3290, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256], [ 40, 2883, 6155, 351, 616, 13779, 3290, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256],[ 40, 2883, 6155, 351, 616, 13779, 3290, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256], [ 40, 2883, 6155, 351, 616, 13779, 3290, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256],[ 40, 2883, 6155, 351, 616, 13779, 3290, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256,
# 50256, 50256, 50256, 50256, 50256]])
```<|||||>@mayankagarwals I believe I got stuck precisely at that point :) Have you had a chance to look at @jonatanklosko's implementation? <|||||>I just had a high-level overview, yet to dig in. I figured I'd first understand why this implementation wasn't working. I'll get to it soon
That is very odd behavior though. If there was an issue with resources, the code should have failed while allocating the transition tensor
`transition_tensor = tf.zeros((batch_size, ngram_size - 1, vocab_size, vocab_size), dtype=tf.bool)
`
But instead, it fails while performing the scatter and update op.
To debug further I broke down the scatter and update it into 15 different operations in a loop. It's failing for some and not failing for others.
```
for j in update_indices:
print(j)
tf.tensor_scatter_nd_update(transition_tensor, tf.expand_dims(j, axis=0), tf.constant([True], dtype=tf.bool))
```
Anyway, if by any chance you figure this out during your stint with TensorFlow. Do let me know, I'd be interested to know
<|||||>Keeping this open in case you want to continue on @mayankagarwals - seems like you were making good progress!<|||||>Thanks, @sanchit-gandhi. I will find time to work on this soon, just got caught up with other things. Will update the thread as I make progress :) <|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,695 | closed | Can't import Mega for causal LM model | ### System Info
ImportError: cannot import name 'MegaForCausalLM' from 'transformers' (/usr/local/lib/python3.9/dist-packages/transformers/__init__.py)
This happens while running the example code here: https://huggingface.co/docs/transformers/main/model_doc/mega
from transformers import AutoTokenizer, MegaForCausalLM, AutoConfig
import torch
tokenizer = AutoTokenizer.from_pretrained("mnaylor/mega-base-wikitext")
config = AutoConfig.from_pretrained("mnaylor/mega-base-wikitext")
config.is_decoder = True
config.bidirectional = False
model = MegaForCausalLM.from_pretrained("mnaylor/mega-base-wikitext", config=config)
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
prediction_logits = outputs.logits
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
!pip install transformers
from transformers import AutoTokenizer, MegaForCausalLM, AutoConfig
### Expected behavior
It should import MegaForCausalLM. | 04-10-2023 19:40:33 | 04-10-2023 19:40:33 | The example you are referring to comes from the documentation of the main branch of Transformers, not the released version. You will thus need a [source install](https://huggingface.co/docs/transformers/installation#install-from-source) to be able to execute it.<|||||>Thank you @sgugger |
transformers | 22,694 | closed | Training Evaluation Display on VSCode | ### System Info
1. OSX Ventura 13.2
1. VSCode 1.77.1
- Chromium 102.0.5005.196
- Jupyter extension v2023.3.1000892223
3. Transformers 4.26.1
### Who can help?
Not sure. Please let me know if it is a VSCode issue
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https://github.com/huggingface/notebooks/blob/main/examples/text_classification.ipynb
Run the notebook (I commented out the parts pushing to hub)
### Expected behavior
The table of metrics during evaluation phase in training fail to show up as html object in VSCode. There seems to be no similar issue on colab or AWS
Currently, the output looks like this (repeated by the number of times evaluation is run during training)
```
0.3564084804084804
{'eval_loss': 1.6524937152862549, 'eval_f1': 0.3564084804084804, 'eval_accuracy': 0.36, 'eval_runtime': 4.6151, 'eval_samples_per_second': 10.834, 'eval_steps_per_second': 1.517, 'epoch': 0.26}
***** Running Evaluation *****
Num examples = 50
Batch size = 8
{'loss': 1.6389, 'learning_rate': 3.611111111111111e-05, 'epoch': 0.28}
```
| 04-10-2023 17:50:23 | 04-10-2023 17:50:23 | We had specifically excluded VSCode in the past as the widgets were not properly working there. Could you try to install from source and see if commenting out those [two lines](https://github.com/huggingface/transformers/blob/151425ddb29d4ad1a121e8cce62000a2ac52d3ba/src/transformers/utils/import_utils.py#L619) result in a nice training?<|||||>What do you mean by install from source?
<|||||>I installed the package from source. I can see the table formatted correctly now, but it stops updating after the first evaluation

I guess that is the widget problem you're referring to. Is there a workaround for people on VSCode so it doesn't print out a thousand lines of evaluation? Like hiding the printout and retrieving evaluation stats after training is done?
<|||||>You can filter the log level of printed informations with `transformers.utils.set_verbosity_warning()` (to avoid all infos like the logs of the evaluation results).<|||||>I have also encountered this problem, and for procedural reasons, I cannot install from source.
It would be very helpful if this issue could be addressed, please :)<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,693 | closed | Replace -100s in predictions by the pad token | # What does this PR do?
This PR fixes the seq2seq examples with the Trainer on datasets with small samples. The problem is that the results on those samples get padded with a -100 by the Trainer, and this in turns gets an index error in the tokenizer decode method.
Fixes part of #22634 | 04-10-2023 17:49:46 | 04-10-2023 17:49:46 | _The documentation is not available anymore as the PR was closed or merged._ |
transformers | 22,692 | closed | Offline mode not working for remote code? | ### System Info
I want to run remote code offline and the revision is in my cache dir. For example,
```python
from transformers import AutoConfig
config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, revision="cde457b39fe0670b10dd293909aab17387ea2c80", local_files_only=True)
```
However, it still reports that connection error.
```
ConnectionError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/THUDM/chatglm-6b/revision/cde457b39fe0670b10dd293909aab17387ea2c80 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x7f6f8f9887f0>: Failed to establish a new connection: [Errno -3] Temporary failure in name resolution'))
```
Is there anything wrong for offline mode with remote code?
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run this piece of code offline:
```python
from transformers import AutoConfig
config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, revision="cde457b39fe0670b10dd293909aab17387ea2c80", local_files_only=True)
```
### Expected behavior
run remote code offline with local cache | 04-10-2023 15:55:58 | 04-10-2023 15:55:58 | This has just been fixed on the main branch (by #22661) so make sure to use the latest!<|||||>It works for normal cases. However, when I set my customized cache dir, it still report error:
```
445 f" cached files and it looks like {path_or_repo_id} is not the path to a directory containing
a file named"
446 f" {full_filename}.\nCheckout your internet connection or see how to run the library in offlin
e mode at"
447 " 'https://huggingface.co/docs/transformers/installation#offline-mode'."
448 )
449 except EntryNotFoundError:
450 if not _raise_exceptions_for_missing_entries:
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached fil
es and it looks like THUDM/chatglm-6b is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
```
I just set `export TRANSFORMERS_CACHE=/my/cache/dir`.<|||||>Please give us a reproducible code example as well as the full traceback.<|||||>First, run the following code to download cache:
```python
from transformers import AutoConfig
config = AutoConfig.from_pretrained('THUDM/chatglm-6b', trust_remote_code=True, revision="aa51e62ddc9c9f334858b0af44cf59b05c70148a")
```
Then, run the same code with `TRANSFORMERS_OFFLINE=1 TRANSFORMERS_CACHE=~/.cache/huggingface` environment variables. Things will go wrong.<|||||>That's probably because you are not using the right folder. The default cache folder is in `~/.cache/huggingface/hub` so executing the lines above with `TRANSFORMERS_OFFLINE=1 TRANSFORMERS_CACHE=~/.cache/huggingface` doesn't work on my side but `TRANSFORMERS_OFFLINE=1 TRANSFORMERS_CACHE=~/.cache/huggingface/hub` does.<|||||>wow, that's cool. It works now. Thank you so much!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,691 | closed | Model parallelism: Moving labels to same devices as the logits are | As suggested in the https://github.com/huggingface/transformers/issues/22561, moving the labels to the same device as the logits are for the Data2Vec Text, ESM, Longformer and LongT5 models.
@sgugger Can you please review? | 04-10-2023 15:54:54 | 04-10-2023 15:54:54 | _The documentation is not available anymore as the PR was closed or merged._<|||||>> Thanks a lot for your contribution!
It's a pleasure. I would love to contribute more and expecting some guidance! |
transformers | 22,690 | closed | Error SIGABRT when running esmfold_v1 on TPU | ### System Info
tpu-vm-pt-2.0 (torch ; torchvision ; torch-xla : 2.0)
accelerator : v2-8
transformers: 4.27.4
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Create a TPUvm and connect to it :
```
gcloud compute tpus tpu-vm create ${TPU_NAME} --project=${PROJECT_ID} --zone=${ZONE} --accelerator-type=v2-8 --version=tpu-vm-pt-2.0
gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE} --project=${PROJECT_ID}
```
Load the model on the TPU :
```
import torch
import torch_xla.core.xla_model as xm
device = xm.xla_device()
from transformers import AutoTokenizer, EsmForProteinFolding
from transformers.models.esm.openfold_utils.protein import to_pdb, Protein as OFProtein
from transformers.models.esm.openfold_utils.feats import atom14_to_atom37
tokenizer = AutoTokenizer.from_pretrained("facebook/esmfold_v1")
model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1")
import gc
gc.collect()
model = model.half()
model = model.to(device)
model.trunk.set_chunk_size(64)
```
Try running the first part of the esmfold_v1 script :
```
def esmfold_prediction(tokenized_sequences , path_out) :
"""
The function takes as an input :
- 'tokenized_sequences', the output of the function tokenize_fasta
- 'path_out', the path of the directory when the pdb files are to be written
The function generates the pdb files in the path_out
"""
for protein in tokenized_sequences :
pdb_files = []
with torch.no_grad():
prot_to_pred = protein[1].to(device)
output = model(prot_to_pred)
```
Error :
```
src/tcmalloc.cc:332] Attempt to free invalid pointer 0x7ffc17c89fc0
https://symbolize.stripped_domain/r/?trace=7f99dc4ff00b,7f99dc4ff08f,fffffffffb6affff,e900000002bffe88&map=
*** SIGABRT received by PID 132988 (TID 132988) on cpu 36 from PID 132988; stack trace: ***
PC: @ 0x7f99dc4ff00b (unknown) raise
@ 0x7f988e574a1a 1152 (unknown)
@ 0x7f99dc4ff090 (unknown) (unknown)
@ 0xfffffffffb6b0000 (unknown) (unknown)
@ 0xe900000002bffe89 (unknown) (unknown)
https://symbolize.stripped_domain/r/?trace=7f99dc4ff00b,7f988e574a19,7f99dc4ff08f,fffffffffb6affff,e900000002bffe88&map=ceee8fa20ddf9c34af43f587221e91de:7f988164c000-7f988e78b840
E0410 13:36:27.439930 132988 coredump_hook.cc:414] RAW: Remote crash data gathering hook invoked.
E0410 13:36:27.439944 132988 coredump_hook.cc:453] RAW: Skipping coredump since rlimit was 0 at process start.
E0410 13:36:27.439952 132988 client.cc:278] RAW: Coroner client retries enabled (b/136286901), will retry for up to 30 sec.
E0410 13:36:27.439956 132988 coredump_hook.cc:512] RAW: Sending fingerprint to remote end.
E0410 13:36:27.439962 132988 coredump_socket.cc:120] RAW: Stat failed errno=2 on socket /var/google/services/logmanagerd/remote_coredump.socket
E0410 13:36:27.439970 132988 coredump_hook.cc:518] RAW: Cannot send fingerprint to Coroner: [NOT_FOUND] Missing crash reporting socket. Is the listener running?
E0410 13:36:27.439974 132988 coredump_hook.cc:580] RAW: Dumping core locally.
E0410 13:36:27.833706 132988 process_state.cc:784] RAW: Raising signal 6 with default behavior
Aborted (core dumped)
```
Disabling tcmalloc that way :
`export LD_PRELOAD=""`
Running the script again returns the error :
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 14, in esmfold_prediction
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/robbyconchaeloko/.local/lib/python3.8/site-packages/transformers/models/esm/modeling_esmfold.py", line 2154, in forward
structure: dict = self.trunk(s_s_0, s_z_0, aa, position_ids, attention_mask, no_recycles=num_recycles)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/robbyconchaeloko/.local/lib/python3.8/site-packages/transformers/models/esm/modeling_esmfold.py", line 1965, in forward
structure = self.structure_module(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/robbyconchaeloko/.local/lib/python3.8/site-packages/transformers/models/esm/modeling_esmfold.py", line 1782, in forward
rigids = rigids.compose_q_update_vec(self.bb_update(s))
File "/home/robbyconchaeloko/.local/lib/python3.8/site-packages/transformers/models/esm/openfold_utils/rigid_utils.py", line 917, in compose_q_update_vec
new_rots = self._rots.compose_q_update_vec(q_vec)
File "/home/robbyconchaeloko/.local/lib/python3.8/site-packages/transformers/models/esm/openfold_utils/rigid_utils.py", line 518, in compose_q_update_vec
return Rotation(
File "/home/robbyconchaeloko/.local/lib/python3.8/site-packages/transformers/models/esm/openfold_utils/rigid_utils.py", line 289, in __init__
quats = quats / torch.linalg.norm(quats, dim=-1, keepdim=True)
RuntimeError: Error while lowering: [] aten::div, xla_shape=f32[1,214,2560]{2,1,0}
Error: /pytorch/xla/torch_xla/csrc/convert_ops.cpp:86 : Unsupported XLA type 10
Frames:
```
### Expected behavior
Generates the input for the next function :
```
def convert_outputs_to_pdb(outputs):
final_atom_positions = atom14_to_atom37(outputs["positions"][-1], outputs)
outputs = {k: v.to("cpu").numpy() for k, v in outputs.items()}
final_atom_positions = final_atom_positions.cpu().numpy()
final_atom_mask = outputs["atom37_atom_exists"]
pdbs = []
for i in range(outputs["aatype"].shape[0]):
aa = outputs["aatype"][i]
pred_pos = final_atom_positions[i]
mask = final_atom_mask[i]
resid = outputs["residue_index"][i] + 1
pred = OFProtein(
aatype=aa,
atom_positions=pred_pos,
atom_mask=mask,
residue_index=resid,
b_factors=outputs["plddt"][i],
chain_index=outputs["chain_index"][i] if "chain_index" in outputs else None,
)
pdbs.append(to_pdb(pred))
return pdbs
```
And writes the pdb file | 04-10-2023 14:08:03 | 04-10-2023 14:08:03 | cc @Rocketknight1 <|||||>I'm not an expert on torch XLA, but I think the problem here is that TPUs do not support `float16`, only `bfloat16`. `model.half()` converts the model parameters to `float16`, and the error you're seeing is caused by TPUs not having a division operation that can work on `float16` inputs.
You could try removing the `model.half()` line, and/or using some of the PyTorch environment variables for downcasting to BF16 on TPU instead, such as `XLA_USE_BF16`. Please see the docs [here](https://pytorch.org/xla/release/2.0/index.html#xla-tensors-and-bfloat16).<|||||>Thank you for your suggestion @Rocketknight1. I got to step further by adding :
```
model = model.half()
model = model.to(dtype=torch.bfloat16)
model = model.to(device)
```
However I run into some memory issues. Two options for me : put my hand on a more powerful accelerator or try model parallelism. Trying my luck, how much have you guys played with model parallelism on TPUs ?
Thanks again for the help<|||||>That's interesting - I admit I haven't tried it on PyTorch + TPU! However, in our testing, we were able to get ESMFold to run on a GPU with 16-24GB of memory. This meant we were able to generate protein folds fine using our [ESMFold Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb), even with the free GPU, and if you want to do longer or batch predictions then the premium GPUs should be more than enough. Have you tried running on Colab already?<|||||>@Rocketknight1, I tried but got issues with GPUs with vram<14GB (free colab and free Kaggle notebooks). I think I'll do it on a GPU V100 32GB.
Thanks again for the help |
transformers | 22,689 | closed | Multiple Node Training Log | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-4.15.0-175-generic-x86_64-with-glibc2.27
- Python version: 3.10.10
- Huggingface_hub version: 0.13.4
- Safetensors version: not installed
- PyTorch version (GPU?): 1.12.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@sgugger @stas00
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I am training GPT on 2 nodes, each with 8 GPUs currently. I used the `Trainer` API provided by huggingface for training. In addition, I used Deepspeed's `ZeRO3` strategy. I have successfully start training, but there are the following issues in the output log:
1. Due to the presence of two nodes, there will be two rows of output at a time, each from a different node. I observed that the output of two nodes is the same, and the following is an example. Do I only need to focus on one line of output?(in other words, one of these two lines is redundant.) Or do these two lines mean that two machines have fed the same data and print the same output?
```shell
node1: {'loss': 1.4406, 'learning_rate': 2e-05, 'epoch': 0.17}
node2: {'loss': 1.4406, 'learning_rate': 2e-05, 'epoch': 0.17}
node1: {'loss': 1.4457, 'learning_rate': 2e-05, 'epoch': 0.18}
node2: {'loss': 1.4457, 'learning_rate': 2e-05, 'epoch': 0.18}
```
2. There will be a progress bar during single node training, which should be performed using `tqdm`. However, there is no progress bar during the training.
3. In the training command, I used `--report_to "tensorboard"`, but I did not find any output in `tensorboard`.
Here is my command to start training.
```shell
deepspeed --num_gpus 8 --num_nodes 2 --hostfile=host.txt train.py \
--model_name_or_path /path/to/model \
--data_path /path/to/data \
--output_dir /path/to/output \
--num_train_epochs 1 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 100 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--logging_steps 1 \
--report_to "tensorboard" \
--gradient_checkpointing True \
--deepspeed configs/deepspeed_config.json \
--fp16 True
```
### Expected behavior
I hope you can provide answers to the above three questions. Thanks! | 04-10-2023 12:10:37 | 04-10-2023 12:10:37 | By default `--log_on_each_node` is `True` but you can set it to `False` to avoid the duplicate logs. I don't know if DeepSpeed does anything to the default log levels, the progress bar should be there on the two main nodes by default (every process that has a log level high enough).<|||||>> By default `--log_on_each_node` is `True` but you can set it to `False` to avoid the duplicate logs. I don't know if DeepSpeed does anything to the default log levels, the progress bar should be there on the two main nodes by default (every process that has a log level high enough).
Thank you for your reply. Your answer made me want to know the answer to the first question. For the second question, when the training was shuted down, the progress bar appeared. I don't know why. In my experiment, all outputs were only on the master node, and non master nodes had no outputs. For the last question, I think @stas00 can help.<|||||>> By default `--log_on_each_node` is `True` but you can set it to `False` to avoid the duplicate logs. I don't know if DeepSpeed does anything to the default log levels, the progress bar should be there on the two main nodes by default (every process that has a log level high enough).
Hi, I tried adding some arguments to the original command to prevent this redundant output. Here are my two ways:
`--log_on_each_node False` `--log_level warning --log_level_replica error --log_on_each_node 0`. It doesn't seem to have much effect because redundant output is still generated on one node.<|||||>For the third question, I found the output in `tensorboard`. I tried to change the master node, so I solved the third problem. For the first two problems, I think the first one still needs to be solved urgently because I have tried various solutions but have not been able to solve them. For the second question, it is possible to estimate the training time in Tensorboard, but I still hope to improve this issue. I guess if the first problem is solved, then the second problem can also be solved.<|||||>As you closed the issue I'm not sure if there is anything remaining to address here.
The integration code does propagate the log-level setting here:
https://github.com/huggingface/transformers/blob/9858195481e0d29e9b720705d359f98620680a06/src/transformers/deepspeed.py#L350
but the outputs you shared in the OP come from HF Trainer and not Deepspeed.<|||||>Thank you for your reply. So does this mean that the first two issues I mentioned are from Huggingface's Trainer and not Deepspeed?<|||||>The first log is coming from HF Trainer - if you're not sure what comes from where it's very simple to test. Turn deepspeed off and see what you get as a baseline. If the model is too big, swap in a tiny model - we have one for each arch here: https://huggingface.co/hf-internal-testing
Wrt tqdm the training progress bar is there with deepspeed, at least on a single node. I have just tested it.
But let's first align so that we are testing the same code, please use this example (from `transformers` git clone top level dir)
```
$ PYTHONPATH=src USE_TF=0 deepspeed --num_gpus 2 --num_nodes 1 \
examples/pytorch/translation/run_translation.py --model_name_or_path \
patrickvonplaten/t5-tiny-random --output_dir /tmp/zero3 --overwrite_output_dir \
--max_train_samples 40 --max_eval_samples 40 --max_source_length 128 \
--max_target_length 128 --val_max_target_length 128 --do_train --do_eval \
--num_train_epochs 1 --per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 --learning_rate 3e-3 --warmup_steps 500 \
--predict_with_generate --save_steps 0 --eval_steps 0 --group_by_length \
--dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro \
--source_prefix 'translate English to Romanian: ' --deepspeed \
tests/deepspeed/ds_config_zero3.json --logging_steps 5 --logging_strategy \
steps
```
and check that it logs correctly
then try with `deepspeed --num_gpus 2 --num_nodes 2` and check again. If something doesn't look right, we will sort it out.
As Sylvain mentioned you will probably need to set `--log_on_each_node 0` in that multi-node experiment.
And to run the same w/o deepspeed, so that you could check the baseline:
```
$ PYTHONPATH=src USE_TF=0 torchrun --nproc-per-node 2 --nnodes 2 \
examples/pytorch/translation/run_translation.py --model_name_or_path \
patrickvonplaten/t5-tiny-random --output_dir /tmp/zero3 --overwrite_output_dir \
--max_train_samples 40 --max_eval_samples 40 --max_source_length 128 \
--max_target_length 128 --val_max_target_length 128 --do_train --do_eval \
--num_train_epochs 1 --per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 --learning_rate 3e-3 --warmup_steps 500 \
--predict_with_generate --save_steps 0 --eval_steps 0 --group_by_length \
--dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro \
--source_prefix 'translate English to Romanian: ' --logging_steps 5 --logging_strategy \
steps
```<|||||>> The first log is coming from HF Trainer - if you're not sure what comes from where it's very simple to test. Turn deepspeed off and see what you get as a baseline. If the model is too big, swap in a tiny model - we have one for each arch here: https://huggingface.co/hf-internal-testing
>
> Wrt tqdm the training progress bar is there with deepspeed, at least on a single node. I have just tested it.
>
> But let's first align so that we are testing the same code, please use this example (from `transformers` git clone top level dir)
>
> ```
> $ PYTHONPATH=src USE_TF=0 deepspeed --num_gpus 2 --num_nodes 1 \
> examples/pytorch/translation/run_translation.py --model_name_or_path \
> patrickvonplaten/t5-tiny-random --output_dir /tmp/zero3 --overwrite_output_dir \
> --max_train_samples 40 --max_eval_samples 40 --max_source_length 128 \
> --max_target_length 128 --val_max_target_length 128 --do_train --do_eval \
> --num_train_epochs 1 --per_device_train_batch_size 1 \
> --per_device_eval_batch_size 1 --learning_rate 3e-3 --warmup_steps 500 \
> --predict_with_generate --save_steps 0 --eval_steps 0 --group_by_length \
> --dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro \
> --source_prefix 'translate English to Romanian: ' --deepspeed \
> tests/deepspeed/ds_config_zero3.json --logging_steps 5 --logging_strategy \
> steps
> ```
>
> and check that it logs correctly
>
> then try with `deepspeed --num_gpus 2 --num_nodes 2` and check again. If something doesn't look right, we will sort it out.
>
> As Sylvain mentioned you will probably need to set `--log_on_each_node 0` in that multi-node experiment.
>
> And to run the same w/o deepspeed, so that you could check the baseline:
>
> ```
> $ PYTHONPATH=src USE_TF=0 torchrun --nproc-per-node 2 --nnodes 2 \
> examples/pytorch/translation/run_translation.py --model_name_or_path \
> patrickvonplaten/t5-tiny-random --output_dir /tmp/zero3 --overwrite_output_dir \
> --max_train_samples 40 --max_eval_samples 40 --max_source_length 128 \
> --max_target_length 128 --val_max_target_length 128 --do_train --do_eval \
> --num_train_epochs 1 --per_device_train_batch_size 1 \
> --per_device_eval_batch_size 1 --learning_rate 3e-3 --warmup_steps 500 \
> --predict_with_generate --save_steps 0 --eval_steps 0 --group_by_length \
> --dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro \
> --source_prefix 'translate English to Romanian: ' --logging_steps 5 --logging_strategy \
> steps
> ```
Thank you for your reply. Our current machine is undergoing model training. This is expected to take 3 days. As I currently do not have any additional machines to test, I will try them in 3 days.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,688 | closed | Reporting a vulnerability | Hello!
I hope you are doing well!
We are a security research team. Our tool automatically detected a vulnerability in this repository. We want to disclose it responsibly. GitHub has a feature called **Private vulnerability reporting**, which enables security research to privately disclose a vulnerability. Unfortunately, it is not enabled for this repository.
Can you enable it, so that we can report it?
Thanks in advance!
PS: you can read about how to enable private vulnerability reporting here: https://docs.github.com/en/code-security/security-advisories/repository-security-advisories/configuring-private-vulnerability-reporting-for-a-repository | 04-10-2023 11:50:02 | 04-10-2023 11:50:02 | We are using another platform for vulnerability reporting. @Michellehbn can tell you more.<|||||>Hi @igibek ! Thanks for reaching out to us! 🤗 We have a bug bounty program with HackerOne and would love for you to submit security vulnerability reports to our private program at https://hackerone.com/hugging_face. Will it be possible to send us your H1 username or email address so that we can invite you to our program please, either here or to [email protected]? Thanks again!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,687 | closed | Vicuna 13B forward method is very slow in FSDP mode. | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.13.3
- Safetensors version: not installed
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@sgugger, @ArthurZucke, @younesbelkada
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from functools import partial
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from transformers import LlamaTokenizer, LlamaForCausalLM
from transformers.models.llama.modeling_llama import LlamaDecoderLayer
torch.distributed.init_process_group("nccl",
rank=WORLD_RANK,
world_size=WORLD_SIZE,
)
llama_auto_wrap_policy = partial(transformer_auto_wrap_policy,
transformer_layer_cls={
LlamaDecoderLayer,
},
)
tokenizer = LlamaTokenizer.from_pretrained(model_dir)
model = LlamaForCausalLM.from_pretrained(model_dir,
torch_dtype=torch.float16,
low_cpu_mem_usage=True)
model = FSDP(model,
auto_wrap_policy=llama_auto_wrap_policy,
device_id=torch.cuda.current_device(),
# sharding_strategy=sharding_strategy,
)
inputs = tokenizer(['Who is Dalai?'])
logits = model.forward(inputs).logits[:, -1, :]
```
The execution time of the forward method is a more than a minute.
### Expected behavior
The execution time of the forward method is a few seconds. | 04-10-2023 11:22:16 | 04-10-2023 11:22:16 | I also want to attach a link to the discussion topic of the [**generate** method in **FSDP** mode.](https://discuss.huggingface.co/t/feature-request-gradient-checkpointing-for-encoderdecodermodel/25278)<|||||>cc @pacman100 <|||||>I forgot to mention that I'm running the model on **two RTX 3090 GPUs**.<|||||>Here is a working example you can try:
```python
from functools import partial
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from transformers import LlamaTokenizer, LlamaForCausalLM
from transformers.models.llama.modeling_llama import LlamaDecoderLayer
model_dir = "<insert your path to model here>"
import os
from time import perf_counter
local_rank = int(os.environ["LOCAL_RANK"])
local_world_size = int(os.environ["LOCAL_WORLD_SIZE"])
torch.cuda.set_device(torch.device(f"cuda:{local_rank}"))
torch.distributed.init_process_group(
"nccl",
rank=local_rank,
world_size=local_world_size,
)
llama_auto_wrap_policy = partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
LlamaDecoderLayer,
},
)
print(torch.cuda.current_device())
tokenizer = LlamaTokenizer.from_pretrained(model_dir)
model = LlamaForCausalLM.from_pretrained(model_dir, torch_dtype=torch.float16, low_cpu_mem_usage=True)
model = FSDP(
model,
auto_wrap_policy=llama_auto_wrap_policy,
device_id=torch.device(f"cuda:{local_rank}"),
# sharding_strategy=sharding_strategy,
)
inputs = tokenizer(["Who is Dalai?"], return_tensors="pt")
print(inputs)
t1_start = perf_counter()
logits = model(**inputs).logits[:, -1, :]
t1_stop = perf_counter()
print("forward time:", t1_stop - t1_start)
print(torch.cuda.max_memory_allocated() / 1e9)
```
Run with `torchrun --nproc_per_node=2 --master_port=56718 run_forward.py`.
For me this prints a forward runtime of ~0.8 sec on 2 A100 gpus and a peak GPU memory of ~14.5 GB (using llama-13b, current transformers main branch). <|||||>I think that you have such good performance because the model is placed on one GPU.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,686 | closed | Add swiftformer | # What does this PR do?
Adds 'SwiftFormer' into huggingface/transformers
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # ([issue](https://github.com/huggingface/transformers/issues/22685))
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case. https://github.com/huggingface/transformers/issues/22685
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@amyeroberts @NielsRogge @alaradirik
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-10-2023 10:14:17 | 04-10-2023 10:14:17 | Are there plans for tensorflow version? I am interested in having the tf model available for use in a downstream task in my work/research<|||||>Hi @shehanmunasinghe, thanks for opening this PR!
Could you make sure to fill out all the necessary documentation for the model in the README and `swiftformer.mdx` file?
Quick question about the modeling code - it seems that all of the model components are copied from ViT i.e. their architecture and forward pass are exactly the same - is this correct?
@D-Roberts I don't know of anyone working on the TensorFlow version of this, looking through the [open PRs](https://github.com/huggingface/transformers/pulls?q=is%3Apr+is%3Aopen+swiftformer) or [issues](https://github.com/huggingface/transformers/issues?q=is%3Aissue+is%3Aopen+swiftformer). @shehanmunasinghe - do you know of anyone who is working on a TF port?
<|||||>Hi @amyeroberts, Thanks for your response.
Please note that this is a Work In Progress (WIP) pull request. The changes to the modeling code and the documentation will be reflected once I push them.
Hi @D-Roberts, currently I'm not aware of anyone working on the TensorFlow version of this.
<|||||>@shehanmunasinghe OK - sounds good :) Let us know when the PR is ready to review. In the meantime, please don't hesitate if there are any questions.
@D-Roberts - would you be interested in porting this model once the pytorch version is merged in? <|||||>@amyeroberts I am still working on porting the Efficientformer; I am interested in having both in tf to train in some downstream tasks / research... I would like to do the port for swiftformer too but can't commit to it right now due to time constraints (I do this in my spare time).. I'll revisit after I am done with the efficientformer and after the swiftformer torch pr here is merged too.<|||||>@D-Roberts Of course, no worries, and thank you for your work on adding EfficientFormer :) I've opened an issue - #22771 - to add the TF version of this model where future discussions on how, who and when can be organised. <|||||>_The documentation is not available anymore as the PR was closed or merged._<|||||>Hi @amyeroberts , this is now ready for your review.<|||||>Hi @amyeroberts ,
There is one test case failing (_examples_torch_). This happened only after I merged recent changes from the main branch. Could you please help me identify what's causing this issue?
https://app.circleci.com/pipelines/github/huggingface/transformers/62802/workflows/2558056a-de51-44b6-9c22-8ba3b67d127a/jobs/774714?invite=true#step-111-2647 <|||||>Hi @amyeroberts , I have resolved the issues that were raised during the code review. Please take a look.<|||||>@shehanmunasinghe Great! I'm away for a few days, but will re-review when I'm back at my computer at the start of next week. <|||||>Hi @amyeroberts, thanks for your time and effort in reviewing this. This is my first pull request on this repo and I'm glad to hear your constructive comments. I have applied the suggestions you made and updated the code again. <|||||>Hi @amyeroberts , I have fixed those issues and pushed the updated code.
However, as indicated [here](https://app.circleci.com/pipelines/github/huggingface/transformers/64108/workflows/8a8e0c78-afcd-44ab-9079-393eb6abc14f/jobs/792496?invite=true#step-113-8379) one test is failing, though this has nothing to do with `tests/models/whisper/test_modeling_whisper.py`.
`
FAILED tests/models/whisper/test_modeling_whisper.py::WhisperModelTest::test_pt_tf_model_equivalence - AssertionError: 1.04904175e-05 not less than or equal to 1e-05 : outputs.encoder_hidden_states_0: Difference between PyTorch and TF is 1.049041748046875e-05 (>= 1e-05).
`
<|||||>> Hi @amyeroberts , I have fixed those issues and pushed the updated code.
>
> However, as indicated [here](https://app.circleci.com/pipelines/github/huggingface/transformers/64108/workflows/8a8e0c78-afcd-44ab-9079-393eb6abc14f/jobs/792496?invite=true#step-113-8379) one test is failing, though this has nothing to do with `tests/models/whisper/test_modeling_whisper.py`.
>
> `FAILED tests/models/whisper/test_modeling_whisper.py::WhisperModelTest::test_pt_tf_model_equivalence - AssertionError: 1.04904175e-05 not less than or equal to 1e-05 : outputs.encoder_hidden_states_0: Difference between PyTorch and TF is 1.049041748046875e-05 (>= 1e-05).`
All checks are passing now.<|||||>Hi @amyeroberts , thanks for approving this PR. I have updated everything and now I think it can be merged. |
transformers | 22,685 | open | Add SwiftFormer | ### Model description
'SwiftFormer' paper introduces a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations in the self-attention computation with linear element-wise multiplications. A series of models called 'SwiftFormer' is built based on this, which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Even their small variant achieves 78.5% top-1 ImageNet1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2× faster compared to MobileViT-v2.
I would like to add this model to Huggingface.
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
Paper: https://arxiv.org/abs/2303.15446
Original code and weights: https://github.com/Amshaker/SwiftFormer
Author: @Amshaker
| 04-10-2023 09:53:10 | 04-10-2023 09:53:10 | |
transformers | 22,684 | closed | Clarify stride option | # What does this PR do?
Clarify the `stride` option which refers to the number of overlapping tokens between chunks.
Fixes #22391
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
| 04-10-2023 09:18:55 | 04-10-2023 09:18:55 | _The documentation is not available anymore as the PR was closed or merged._<|||||>@Narsil, I just added a sentence in the doc to avoid confusion about the naming.
Have a good day |
transformers | 22,683 | closed | Performance Regression from commit 7dcd870 | ### System Info
- `transformers` version: 4.28.0.dev0 (656e869a4523f6a0ce90b3aacbb05cc8fb5794bb)
- Platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.35
- Python version: 3.10.10
- Huggingface_hub version: 0.13.4
- Safetensors version: 0.3.0
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I have a benchmark script which benchmarks the generation speed of different LLaMA models. Before commit 7dcd870 my generation speed averaged around 48 tokens/s in ideal cases, RTX 3090. After that commit the average speed is 43 tokens/s.
The specific issue seems to be the change to `apply_rotary_pos_emb`. My guess is the change from a rather simple slicing of two Tensors to a scatter-gather.
To test my theory I patched `apply_rotary_pos_emb` to its pre 7dcd870 state, and minimally modified `LlamaAttention` accordingly. No other modifications. Speed jumped back to 48 tokens/s.
The problem should apply generally, but the specific script I'm using is: https://github.com/fpgaminer/GPTQ-triton/blob/99ec4a3adb7fad9de33ff026bbfb64cbb3bab2f8/benchmark_generate.py
### Expected behavior
I would not expect a 10% drop in performance. | 04-10-2023 05:26:57 | 04-10-2023 05:26:57 | cc @gante and @ArthurZucker <|||||>@fpgaminer commit 7dcd870 fixes generation when there is padding in the input (which is almost always the case for `batch_size>1`). It's natural that it introduces slowdowns, as the correct behavior implies changing to the tensor gathering you mentioned :)
We don't optimize for performance but rather for correctness. To skip this gathering while remaining correct, `.generate()` would need to be rewritten to dynamically squeeze padding and evict completed rows, which is something we have in our plans for the next months.
Meanwhile, is there anything else we can help you with?<|||||>That's fair, though a 10% performance hit is rather painful.
To that end, here's my attempt to optimize `apply_rotary_pos_emb`:
```
def ref_apply_rotary_pos_emb(q, k, cos, sin, position_ids):
gather_indices = position_ids[:, None, :, None] # [bs, 1, seq_len, 1]
gather_indices = gather_indices.repeat(1, cos.shape[1], 1, cos.shape[3])
cos = torch.gather(cos.repeat(gather_indices.shape[0], 1, 1, 1), 2, gather_indices)
sin = torch.gather(sin.repeat(gather_indices.shape[0], 1, 1, 1), 2, gather_indices)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
def fast_apply_rotary_pos_emb(q, k, cos, sin, position_ids):
cos = cos.squeeze((0, 1)) # [seq_len, dim]
sin = sin.squeeze((0, 1)) # [seq_len, dim]
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
def test_foo(B, L):
cos = torch.randn(1, 1, 2048, 128, dtype=torch.float16, device='cuda')
sin = torch.randn(1, 1, 2048, 128, dtype=torch.float16, device='cuda')
position_ids = torch.randint(0, 2048, (B, L), dtype=torch.int64, device='cuda')
q = torch.randn(B, 32, L, 128, dtype=torch.float16, device='cuda')
k = torch.randn(B, 32, L, 128, dtype=torch.float16, device='cuda')
# Verify
ref = ref_apply_rotary_pos_emb(q, k, cos, sin, position_ids)
fast = fast_apply_rotary_pos_emb(q, k, cos, sin, position_ids)
assert torch.equal(ref[0], fast[0])
assert torch.equal(ref[1], fast[1])
# Benchmark
ref_ms, ref_min_ms, ref_max_ms = triton.testing.do_bench(lambda: ref_apply_rotary_pos_emb(q, k, cos, sin, position_ids))
fast_ms, fast_min_ms, fast_max_ms = triton.testing.do_bench(lambda: fast_apply_rotary_pos_emb(q, k, cos, sin, position_ids))
speedup = ref_ms * 100 / fast_ms
print(f'{B} | {L:3d} | {ref_ms:.6f} | {fast_ms:.6f} | {speedup:.2f}%')
print('B | L | ref | fast | speedup')
for B in [1, 2, 4, 8]:
for L in [1, 2, 4, 8, 10, 100]:
test_foo(B, L)
```
Output:
```
B | L | ref | fast | speedup
1 | 1 | 0.043008 | 0.035840 | 120.00%
1 | 2 | 0.044032 | 0.036864 | 119.44%
1 | 4 | 0.047104 | 0.038912 | 121.05%
1 | 8 | 0.046080 | 0.039936 | 115.38%
1 | 10 | 0.048128 | 0.039936 | 120.51%
1 | 100 | 0.058368 | 0.052224 | 111.76%
2 | 1 | 0.047104 | 0.036864 | 127.78%
2 | 2 | 0.049152 | 0.039936 | 123.08%
2 | 4 | 0.050176 | 0.040960 | 122.50%
2 | 8 | 0.050176 | 0.041984 | 119.51%
2 | 10 | 0.050176 | 0.041984 | 119.51%
2 | 100 | 0.079872 | 0.070656 | 113.04%
4 | 1 | 0.051200 | 0.039936 | 128.21%
4 | 2 | 0.053248 | 0.040960 | 130.00%
4 | 4 | 0.054272 | 0.041984 | 129.27%
4 | 8 | 0.057344 | 0.045056 | 127.27%
4 | 10 | 0.057344 | 0.045056 | 127.27%
4 | 100 | 0.130048 | 0.119808 | 108.55%
8 | 1 | 0.057344 | 0.040960 | 140.00%
8 | 2 | 0.059392 | 0.041984 | 141.46%
8 | 4 | 0.062464 | 0.045056 | 138.64%
```
For reference, the pre 7dc870 function runs in 0.030ms on 1x1, so this isn't quite as fast but gets closer.
Would a pull request with this change be welcome? I've done my best to verify its correctness with the above code.<|||||>@fpgaminer that is great! Absolutely, a PR would be very welcome 🙌
(We'd be happy to integrate other optimization opportunities if you spot them, we rarely have the bandwidth to optimize our modeling code)<|||||>> @fpgaminer commit [7dcd870](https://github.com/huggingface/transformers/commit/7dcd8703ef904adc3ac19b47f769879221c33849) fixes generation when there is padding in the input (which is almost always the case for `batch_size>1`). It's natural that it introduces slowdowns, as the correct behavior implies changing to the tensor gathering you mentioned :)
Maybe there's something I'm not seeing here but Llama uses rotary positional embeddings so left padding should have no effect on the result?
Sure, the intermediate result from `apply_rotary_pos_emb` changes if you shift all tokens left or right, but the whole point of using relative embeddings is that they're invariant to the absolute position in terms of the final attention weight. So you can shift all tokens 50 positions to the right and the attention score between *pairs of tokens* will be the same, modulus any rounding errors.
Or are you saying there are cases when padding is literally inserted *inside* of the sequence, therefore changing the relative distances between tokens, @gante?<|||||>@aljungberg I agree with everything you wrote, rotary positional embeddings should be position-invariant. In practice, the small rounding errors compound over autoregressive text generation, leading greedy decoding (which is normally invariant wrt small fluctuations) to produce different text.
With the right position index, the error becomes much smaller, and the results become more stable regardless of padding. That's why [we also added it to our high-performance text generation repo](https://github.com/huggingface/text-generation-inference/pull/126), despite the difference being quite small.
Out of curiosity, [this test](https://github.com/huggingface/transformers/blob/main/tests/generation/test_utils.py#L1602) was failing on GPTNeoX and Llama before we added this change. In theory, it shouldn't have failed at all!<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,682 | closed | whisper recognition error! | ### System Info
- `transformers` version: 4.28.0.dev0
- Platform: Linux-5.4.0-144-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.16
- Huggingface_hub version: 0.13.2
- PyTorch version (GPU?): 1.13.1+cu116 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@sanchit-gandhi @Narsil @sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
i was fine-tune whisper-base model with wenetspeech datasets,need to verify effectiveness use pipeline:
```
processor = WhisperProcessor.from_pretrained(model_path)
asr_pipeline = pipeline(task="automatic-speech-recognition", model=model_path, device="cpu")
asr_pipeline.model.config.forced_decoder_ids = processor.get_decoder_prompt_ids(language=lang, task="transcribe")
ds = load_dataset("audiofolder", data_dir=wav_path)
ds = ds.cast_column("audio", Audio(sampling_rate=16000))
audio = ds['train'][0]['audio']
inputs = processor(audio["array"], sampling_rate=audio["sampling_rate"], language=lang, task="transcribe", return_tensors="pt")
input_features = inputs.input_features
generated_ids = asr_pipeline.model.generate(inputs=input_features, max_new_tokens=32767)
transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
frist of all ,this script can works,but in some mp3 file it tips error:
> ╭───────────────────── Traceback (most recent call last) ──────────────────────╮
│ │
│ /home/youxixie/008-Whisper-Pro/005-whisper-fineturn-pro/transformers-main/ex │
│ amples/pytorch/speech-recognition/run_whisper_speech_recognition.py:45 in │
│ <module> │
│ │
│ 42 │ print("test model:{} ".format(args.model)) │
│ 43 │ print("test wav path:{} ".format(args.path)) │
│ 44 │ print("test language:{} ".format(args.lang)) │
│ ❱ 45 │ eval_whisper(args.model, args.path, args.lang) │
│ 46 │
│ /home/youxixie/008-Whisper-Pro/005-whisper-fineturn-pro/transformers-main/ex │
│ amples/pytorch/speech-recognition/run_whisper_speech_recognition.py:25 in │
│ eval_whisper │
│ │
│ 22 │ │ audio = ds['train'][i]['audio'] │
│ 23 │ │ inputs = processor(audio["array"], sampling_rate=audio["samplin │
│ 24 │ │ input_features = inputs.input_features │
│ ❱ 25 │ │ generated_ids = asr_pipeline.model.generate(inputs=input_featur │
│ 26 │ │ │
│ 27 │ │ transcription = processor.batch_decode(generated_ids, skip_spec │
│ 28 │ │ #print(transcription) │
│ │
│ /home/youxixie/008-Whisper-Pro/005-whisper-fineturn-pro/transformers-main/sr │
│ c/transformers/models/whisper/modeling_whisper.py:1613 in generate │
│ │
│ 1610 │ │ │ stopping_criteria, │
│ 1611 │ │ │ prefix_allowed_tokens_fn, │
│ 1612 │ │ │ synced_gpus, │
│ ❱ 1613 │ │ │ **kwargs, │
│ 1614 │ │ ) │
│ 1615 │ │
│ 1616 │ def prepare_inputs_for_generation( │
│ │
│ /home/youxixie/anaconda3/envs/Huggingface-Whisper/lib/python3.7/site-package │
│ s/torch/autograd/grad_mode.py:27 in decorate_context │
│ │
│ 24 │ │ @functools.wraps(func) │
│ 25 │ │ def decorate_context(*args, **kwargs): │
│ 26 │ │ │ with self.clone(): │
│ ❱ 27 │ │ │ │ return func(*args, **kwargs) │
│ 28 │ │ return cast(F, decorate_context) │
│ 29 │ │
│ 30 │ def _wrap_generator(self, func): │
│ │
│ /home/youxixie/008-Whisper-Pro/005-whisper-fineturn-pro/transformers-main/sr │
│ c/transformers/generation/utils.py:1415 in generate │
│ │
│ 1412 │ │ │ │ output_scores=generation_config.output_scores, │
│ 1413 │ │ │ │ return_dict_in_generate=generation_config.return_dict │
│ 1414 │ │ │ │ synced_gpus=synced_gpus, │
│ ❱ 1415 │ │ │ │ **model_kwargs, │
│ 1416 │ │ │ ) │
│ 1417 │ │ │
│ 1418 │ │ elif is_contrastive_search_gen_mode: │
│ │
│ /home/youxixie/008-Whisper-Pro/005-whisper-fineturn-pro/transformers-main/sr │
│ c/transformers/generation/utils.py:2211 in greedy_search │
│ │
│ 2208 │ │ │ if synced_gpus and this_peer_finished: │
│ 2209 │ │ │ │ continue # don't waste resources running the code we │
│ 2210 │ │ │ │
│ ❱ 2211 │ │ │ next_token_logits = outputs.logits[:, -1, :] │
│ 2212 │ │ │ │
│ 2213 │ │ │ # pre-process distribution │
│ 2214 │ │ │ next_tokens_scores = logits_processor(input_ids, next_tok │
╰──────────────────────────────────────────────────────────────────────────────╯
IndexError: index -1 is out of bounds for dimension 1 with size 0
### Expected behavior
if some file can't have result, just give empty resulte or special symbols | 04-10-2023 03:42:48 | 04-10-2023 03:42:48 | What is the value of model_path in the above code?<|||||>fine-tune model based on whisper-base use wenetspeech datasets<|||||>use huggingface model “whisper-base”,test file [common_voice_zh-CN_18662117.mp3](https://huggingface.co/corner/whisper-base-zh/blob/main/common_voice_zh-CN_18662117.mp3),got the same error<|||||>When I had this error, limiting the max_new_tokens specified to the amount the model can generate per chunk fixed it for me (see the [generation_config.json](https://huggingface.co/openai/whisper-base/blob/main/generation_config.json)'s max_length). Looks like that might be the case here since the max is 448 for whisper-base and 32767 is given. Maybe a nice error message for when max_new_tokens is > max_length would be wanted?<|||||>Hey @xyx361100238! In this case, you can probably simplify how you're transcribing the audio file to simply:
```python
asr_pipeline = pipeline(task="automatic-speech-recognition", model=model_path, device="cpu")
transcription = processor.batch_decode("path/to/audio/file", generate_kwargs={"language": lang, "task": "transcribe"})
```
This looks like quite a strange error for Whisper - in most cases you can specify `max_new_tokens` as some arbitrary value (e.g. for LLMs this is just the number of new tokens generated, which doesn't depend on our max length).<|||||>` processor = WhisperProcessor.from_pretrained(model_path)
asr_pipeline = pipeline(task="automatic-speech-recognition", model=model_path, device="cpu")
transcription = processor.batch_decode("common_voice_zh-CN_18524189.wav", generate_kwargs={"language": lang, "task": "transcribe"})
`
tips error:

<|||||>Sorry, I rushed my code snippet! It should have been:
```python
from transformers import pipeline
asr_pipeline = pipeline(task="automatic-speech-recognition", model=model_path, device="cpu") # change device to "cuda:0" to run on GPU
transcription = asr_pipeline("path/to/audio/file", chunk_length_s=30, generate_kwargs={"language": "<|zh|>", "task": "transcribe"}) # change language as required - I've set it to Chinese
```<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,681 | closed | Donut model.generate is extremely slow when run inference | I trained a Donut model for document classification using my custom dataset (format similar to RVL-CDIP). However, when I run inference, the model.generate() run extremely slow (5.9s ~ 7s).
Inference device: NVIDIA A100 40GB.
Requirements:
CUDA 11.7
torch==1.13.1+cu117
torchvision==0.14.1+cu117
datasets==2.10.1
transformers==4.26.1
sentencepiece==0.1.97
onnx==1.12.0
protobuf==3.20.0
Here is the GPU when I run inference:
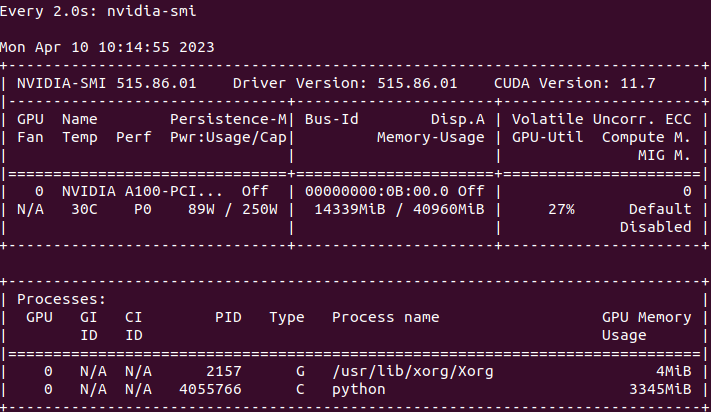
This is my code for inference
```
model = VisionEncoderDecoderModel.from_pretrained(CKPT_PATH, config=config)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
accs = []
model.eval()
for i, sample in tqdm(enumerate(val_ds), total=len(val_ds)):
pixel_values = sample["pixel_values"]
pixel_values = torch.unsqueeze(pixel_values, 0)
pixel_values = pixel_values.to(device)
start = time.time()
task_prompt = "<s_fci>"
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
decoder_input_ids = decoder_input_ids.to(device)
print(f"Tokenize time: {time.time() - start:.4f}s")
start = time.time()
outputs = model.generate(
pixel_values,
decoder_input_ids=decoder_input_ids,
max_length=model.decoder.config.max_position_embeddings,
early_stopping=True,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
num_beams=1,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
print(f"Inference time: {time.time() - start:.4f}s")
# turn into JSON
start = time.time()
seq = processor.batch_decode(outputs.sequences)[0]
seq = seq.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
seq = re.sub(r"<.*?>", "", seq, count=1).strip() # remove first task start token
seq = processor.token2json(seq)
if "class" not in seq.keys():
seq["class"] = "other"
print(f"Decoding time: {time.time() - start:.4f}s")
gt = sample["labels"]
score = float(seq["class"] == gt["class"])
accs.append(score)
acc_score = np.mean(accs)
print(f"Accuracy: {acc_score * 100:.4f}%")
```
Can someone look into this issue? Thank you very much. | 04-10-2023 03:16:12 | 04-10-2023 03:16:12 | cc @gante and @younesbelkada <|||||>@gante and @younesbelkada can you guys look into this issue? Thank you very much.<|||||>Hey @MS1908 👋
Text generation can be quite slow. 6-7s is within the expected time for large-ish models, and the generation time greatly depends on the length of the output. As a reference, [the example in the documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut#inference) takes ~1s on `.generate()` on an nvidia 3090, and the output is very short.
My top recommendation would be to batch your inputs, as opposed to calling `.generate()` with one example at a time. The execution time of generate grows very slowly with the batch size -- the biggest limitation is GPU memory, which you have plenty :D
On the `generate` side, we have some speedup tricks like using smaller variable representation. Sadly, as far as I know, most of them don't work out of the box with multimodal models like Donut (is this correct, @younesbelkada?). The only option that I see is to use [PT2.0+dynamo](https://pytorch.org/docs/stable/dynamo/index.html) to compile `.generate()`.<|||||>This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored. |
transformers | 22,680 | closed | Adding progress-bars to pipelines | ### Feature request
In order to implement https://github.com/huggingface/evaluate/issues/442, in order to provide progress bars while using `evaluator_instance.compute(..., progress_bar=True)`, we would have to update the `base.py` pipeline in order to support this.
Quoting the referenced issue from evaluate:
After doing some digging, It's a matter of if the dataset+pipeline can support progress bars. For example, on the [call](https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/base.py#L1046) pipeline function, we can see that the actual pipeline could be many things, including but not limited to a GeneratorType (which does not advertise a __len__, a Dataset or a list (which typically have __len__), so the worse-case progress bar you can get would be a tqdm "X iterations / s" dialogue.
### Motivation
Progress bars are always nice and they are relatively simple to implement: just wrap an iterator.
It gives us a qualitative sense of what we're doing. If the underlying unit supports `__len__`, it's extra useful for debugging or giving a rough processing estimate without having to run through everything.
### Your contribution
I'm willing to contribute given some guidance from the hf team. | 04-09-2023 09:07:16 | 04-09-2023 09:07:16 | cc @Narsil <|||||>Hey, you can already to that:
```python
import tqdm
for out in tqdm.tqdm(pipe(dataset)):
pass
```
When using an iterating dataset instead of a real dataset you can add (`total=total` to get the "correct" progressbar).
Advantage of having the progressbar in usercode is that we don't have to choose your favorite progress bar or handle colab+jupyter weirdness here.<|||||>@Narsil I am referring to passing in a progress bar argument into the pipeline's `__call__` function, in order to accomplish
https://github.com/huggingface/evaluate/issues/442, not to adding progress bar to dataset iteration.<|||||>This can be done in `evaluate` directly is what I was saying. |
transformers | 22,679 | closed | (feat): Moving labels to same device as logits for Deit | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
Add model parallelism for `Deit`.
<!-- Remove if not applicable -->
Related to #22561
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer: @stas00, Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
--> @sgugger
| 04-09-2023 09:05:20 | 04-09-2023 09:05:20 | _The documentation is not available anymore as the PR was closed or merged._ |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.